KDNuggets-博客中文翻译-二十-
KDNuggets 博客中文翻译(二十)
原文:KDNuggets
《自然语言生成综合指南》
原文:
www.kdnuggets.com/2020/01/guide-natural-language-generation.html
评论
由 Sciforce 提供。
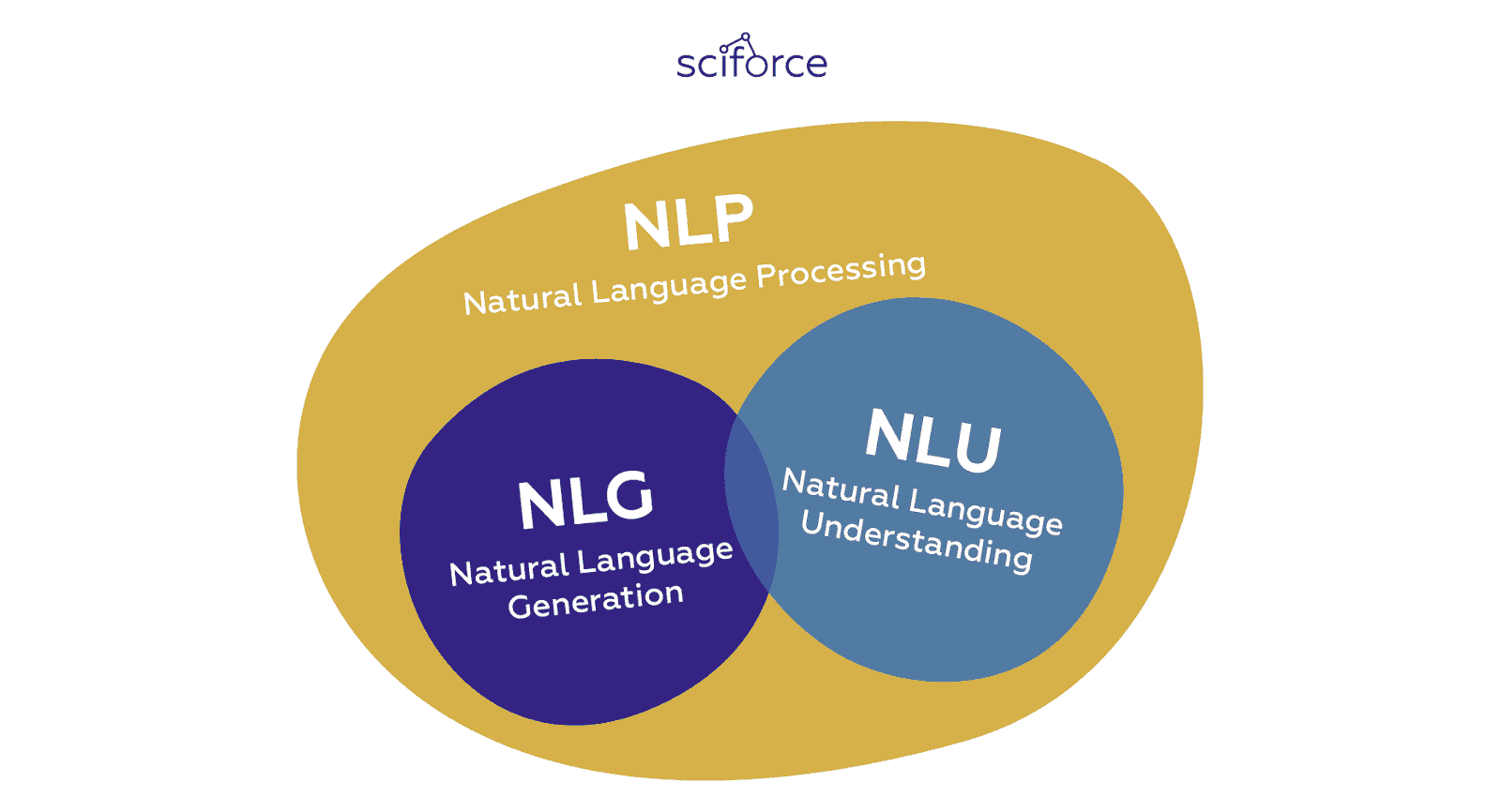
只要人工智能帮助我们从自然语言中获得更多信息,我们就会看到更多在 AI 和语言学交集处出现的任务和领域。在我们之前的一篇文章中,我们讨论了Natural Language Processing 和 Natural Language Understanding 的区别。然而,这两个领域都有自然语言作为输入。同时,与计算机建立双向通信的需求导致了处理生成(准)自然语言的任务的一个独立子类别的出现。这个子类别被称为自然语言生成,将成为本博客文章的重点。
什么是 NLG?
自然语言生成,如《人工智能:自然语言处理基础》所定义,是“以自然语言形式生成有意义的短语和句子的过程。”本质上,它以每秒数千页的速度自动生成描述、总结或解释输入结构化数据的叙述。
然而,虽然 NLG 软件可以写作,但它不能阅读。阅读自然语言并将其非结构化数据转化为计算机可理解的结构化数据的 NLP 部分被称为自然语言理解。
一般而言,NLG(自然语言生成)和 NLU(自然语言理解)是更广泛的 NLP 领域的子部分,该领域包括所有解释或生成自然语言的软件,无论是口头还是书面形式:
-
NLU 负责基于语法、上下文以及意图和实体的理解数据。
-
NLP 将文本转换为结构化数据。
-
NLG 基于结构化数据生成文本。
NLG 的主要应用
NLG 使数据具有普遍可理解性,使得编写数据驱动的财务报告、产品描述、会议备忘录等变得更加容易和快速。理想情况下,它可以将总结数据的负担从分析师那里转移到自动编写针对受众的报告上。因此,NLG 当前的主要实际应用与写作分析或向客户传达必要信息相关:
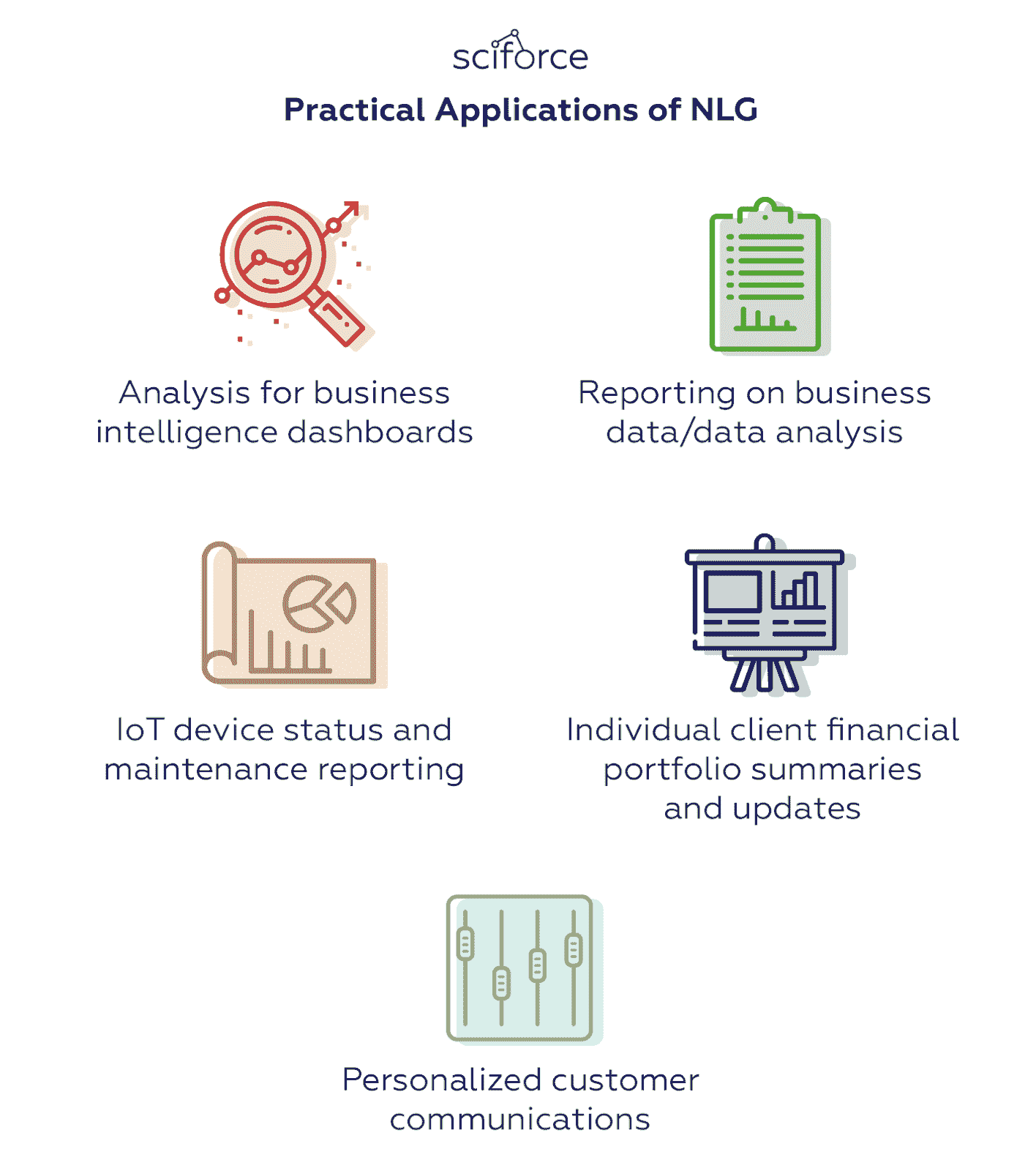
NLG 的实际应用。
与此同时,NLG 还有更多的理论应用,使其不仅在计算机科学与工程领域,而且在认知科学和心理语言学中成为有价值的工具。这些包括:
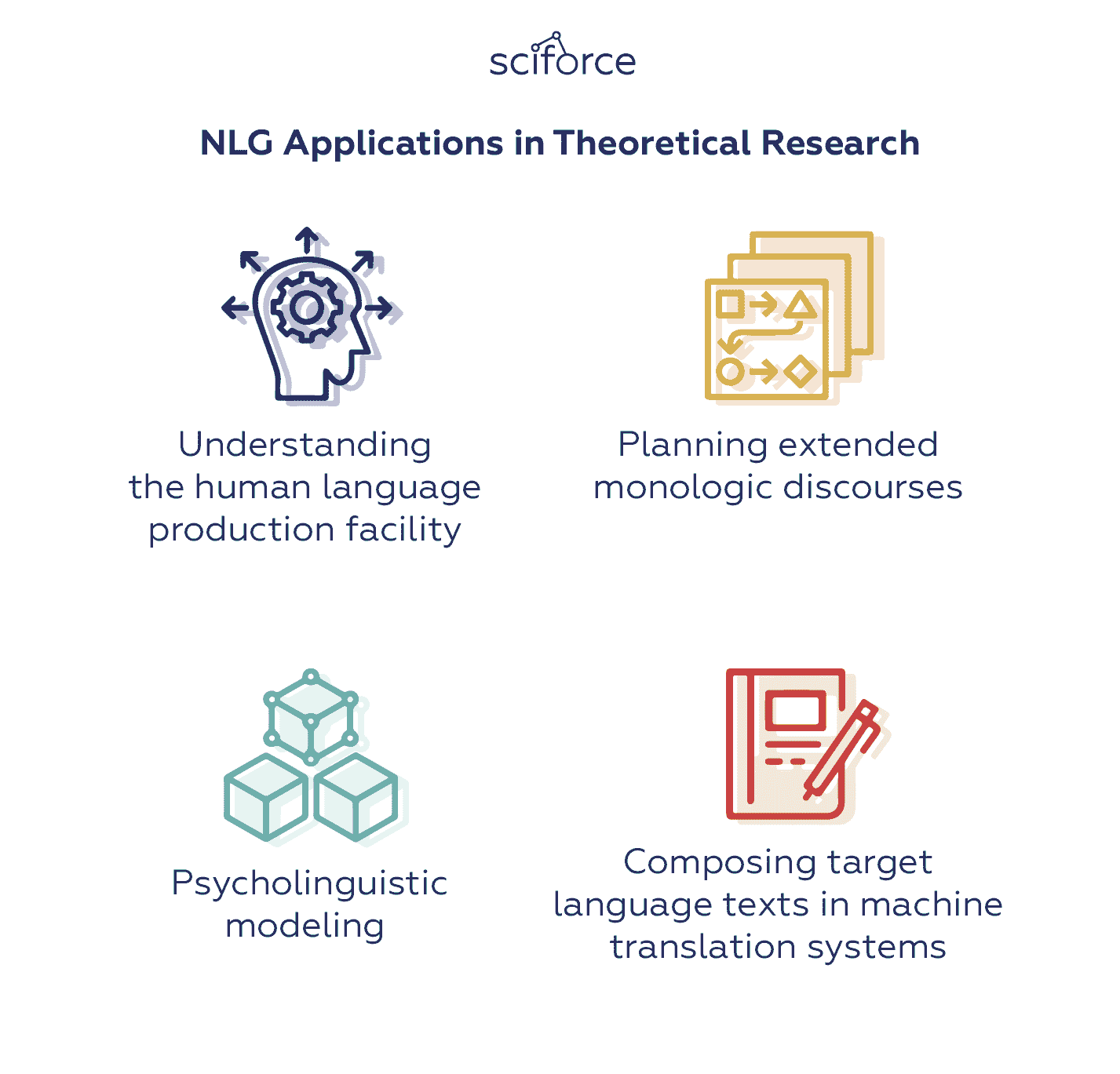
NLG 在理论研究中的应用。
NLG 设计与架构的演变
在模仿人类语言的尝试中,NLG 系统使用了不同的方法和技巧来根据观众、背景和叙述目的调整其写作风格、语气和结构。在 2000 年,Reiter 和 Dale 设计了一个 NLG 架构,将 NLG 过程划分为三个阶段:
-
文档规划:决定要表达的内容,并创建一个概述信息结构的抽象文档。
-
微观规划:生成引用表达、词汇选择和聚合,以充实文档规格。
-
实现:将抽象文档规格转换为真实文本,使用有关语法、形态学等的领域知识。
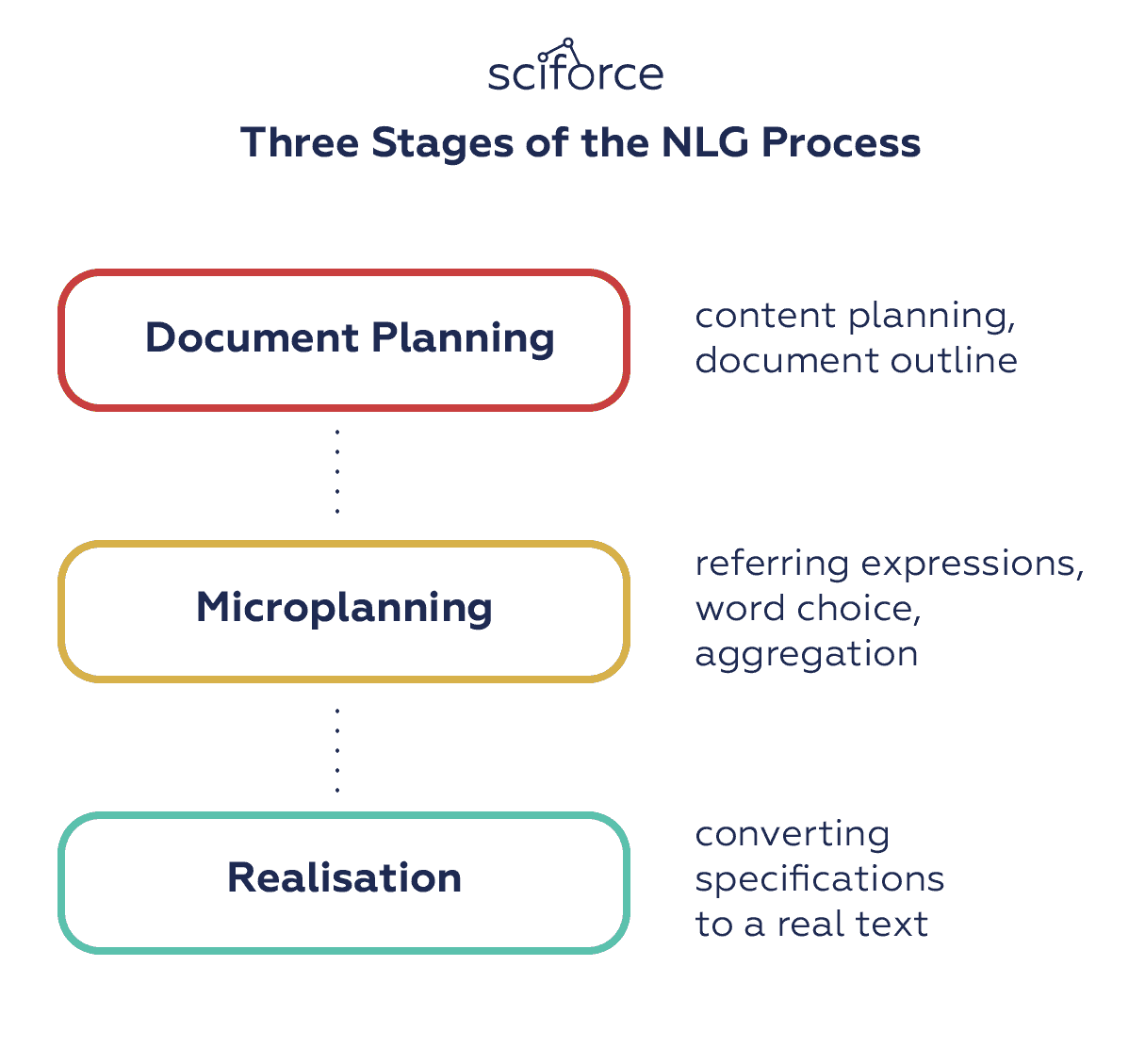
NLG 过程的三个阶段。
这个流程展示了自然语言生成的里程碑。然而,具体步骤和方法,以及所使用的模型,随着技术的发展可能会有显著变化。
语言生成有两种主要方法:使用模板和动态创建文档。虽然只有后者被认为是“真实”的 NLG,但从基础的简单模板到最先进技术的过程中经历了漫长而多阶段的演变,每一种新方法都扩展了功能并增加了语言能力:
简单的填空方法
最古老的方法之一是简单的填空模板系统。在结构预定义且只需少量数据填充的文本中,这种方法可以自动从电子表格行、数据库表条目等中填充这些空白。原则上,你可以变更文本的某些方面:例如,你可以决定是拼写数字还是保留原样,这种方法的使用相当有限,不被认为是“真实”的 NLG。
脚本或规则生成文本
基础的填空系统通过脚本语言或使用业务规则扩展了通用编程构造。脚本方法,如使用网页模板语言,将模板嵌入通用脚本语言中,因此它允许复杂的条件、循环、代码库访问等。业务规则方法,由大多数文档编排工具采用,工作原理类似,但侧重于编写业务规则而非脚本。尽管比简单的填空更强大,这些系统仍然缺乏语言能力,无法可靠地生成复杂、高质量的文本。
词级语法功能
模板系统的逻辑发展是添加词级语法功能,以处理形态学、形态音系学和正字法以及处理可能的例外。这些功能使生成语法正确的文本和编写复杂的模板系统变得更加容易。
动态句子生成
最终,从基于模板的方法转向动态自然语言生成(NLG),这种方法从句子的意义表示或期望的语言结构动态创建句子。动态创建意味着系统能够在不需要开发人员为每个边界情况显式编写代码的情况下,在不寻常的情况下做出合理的处理。它还允许系统在参考、聚合、排序和连接词等方面以多种方式进行语言上的“优化”。
动态文档创建
虽然动态句子生成在某种“微观层面”上工作,但“宏观写作”任务生成与读者相关且有用的文档,并且在叙事上结构良好。如何完成这项任务取决于文本的目标。例如,一篇说服性写作可能基于论证和行为变化的模型,以模仿人类修辞;而一篇总结数据以供商业智能使用的文本可能基于对影响决策的关键因素的分析。
NLG 模型
即使在 NLG 从模板转向动态句子生成后,这项技术仍然经历了多年的实验才取得令人满意的结果。作为自然语言处理(NLP)的一部分,更多地说作为人工智能(AI)的一部分,自然语言生成依赖于一系列算法,这些算法解决了生成类人文本的某些问题:
马尔可夫链
马尔可夫链是用于语言生成的第一个算法之一。该模型通过使用当前词并考虑每个独特词之间的关系来预测句子中的下一个词,从而计算下一个词的概率。事实上,你在早期版本的智能手机键盘上见过它们,当时它们用于生成下一个词的建议。
递归神经网络(RNN)
神经网络是尝试模拟人脑运作的模型。RNN 将序列中的每个项通过前馈网络,并使用模型的输出作为下一个序列项的输入,从而允许将前一步的信息存储起来。在每次迭代中,模型将之前遇到的单词存储在其记忆中,并计算下一个单词的概率。对于字典中的每个单词,模型根据前一个单词分配一个概率,选择概率最高的单词并将其存储在记忆中。RNN 的“记忆”使得该模型非常适合语言生成,因为它可以随时记住对话的背景。然而,随着序列长度的增加,RNN 无法存储句子中远处遇到的单词,并且仅根据最近的单词进行预测。由于这一限制,RNN 无法生成连贯的长句子。
LSTM
为了解决长程依赖问题,提出了一种名为长短期记忆(LSTM)的 RNN 变体。虽然与 RNN 相似,但 LSTM 模型包括一个四层神经网络。LSTM 包含四个部分:单元、输入门、输出门和遗忘门。这些允许 RNN 通过调整单元的信息流,在任何时间间隔记住或忘记单词。当遇到一个时期时,遗忘门识别到句子的上下文可能发生变化,可以忽略当前单元状态信息。这使得网络能够有选择地跟踪相关信息,同时最小化梯度消失问题,从而使模型能够在更长的时间内记住信息。
尽管如此,由于 LSTM 的记忆容量受限于前一单元到当前单元的复杂序列路径,因此其容量仅限于几百个单词。这种复杂性也导致了高计算需求,使得 LSTM 难以训练或并行化。
Transformer
一个相对较新的模型在 2017 年的 Google 论文中首次提出 “Attention is all you need”,提出了一种称为“自注意力机制”的新方法。Transformer 由一个处理任意长度输入的编码器堆栈和另一组输出生成句子的解码器组成。与 LSTM 相比,Transformer 仅执行少量、恒定的步骤,同时应用直接模拟句子中所有单词之间关系的自注意力机制。与之前的模型不同,Transformer 使用上下文中所有单词的表示,而不必将所有信息压缩到单个固定长度的表示中,从而使系统能够处理更长的句子,而不会导致计算需求急剧增加。
语言生成的一个著名例子是 OpenAI 的 GPT-2 语言模型。该模型通过关注模型中之前见过的与预测下一个词相关的词来学习预测句子中的下一个词。谷歌的最新升级版 Transformers 双向编码器表示(BERT)为各种 NLP 任务提供了最先进的结果。
NLG 工具
你可以看到,自然语言生成是一个复杂的任务,需要考虑语言的多个方面,包括结构、语法、词汇使用和感知。幸运的是,你可能不会从头开始构建整个 NLG 系统,因为市场上提供了多种现成的工具,包括商业和开源的。
商业 NLG 工具
Arria NLG PLC 被认为是全球 NLG 技术和工具的领导者之一,拥有最先进的 NLG 引擎和由 NLG 叙述生成的报告。该公司拥有可通过 Arria NLG 平台使用的专利 NLG 技术。
AX Semantics: 为超过 100 种语言提供电子商务、新闻和数据报告(例如 BI 或财务报告)的 NLG 服务。它是一个开发者友好的产品,利用 AI 和机器学习来训练平台的 NLP 引擎。
Yseop 以其在移动、在线或面对面等平台上的智能客户体验而闻名。从 NLG 角度来看,它提供了可以在本地、云端或作为服务消费的 Compose,并且还提供了用于 Excel 和其他分析平台的插件 Savvy。
Quill 由 Narrative Science 提供,是一个由先进 NLG 技术驱动的 NLG 平台。Quill 通过开发故事、分析并提取所需数据,将数据转换为具有智能的人类叙述。
Wordsmith 由 Automated Insights 提供,是一个主要在高级模板化方法领域工作的 NLG 引擎。它允许用户将数据转换为任何格式或规模的文本。Wordsmith 还提供了丰富的语言选项用于数据转换。
开源 NLG 工具
Simplenlg 可能是最广泛使用的开源实现工具,特别是被系统构建者使用。它是由 Arria 创始人编写的开源 Java API。它功能最少,但使用最简单且文档最完善。
NaturalOWL 是一个开源工具包,用于生成 OWL 类和个体的描述,以将 NLG 框架配置到特定需求,而无需进行大量编程。
结论
NLG 功能已成为分析平台试图实现数据分析民主化的事实选择,并帮助任何人理解他们的数据。 接近人类叙述的自然语言自动解释了那些可能在表格、图表和图形中丢失的见解,并在数据发现过程中充当助手。此外,NLG 与 NLP 结合是聊天机器人和其他自动化聊天及助手的核心,提供日常支持。
随着自然语言生成(NLG)的不断发展,它将变得更加多样化,并在我们与计算机之间提供自然的有效沟通,这是许多科幻作家在他们的书中梦想的。
原文。经许可转载。
简介: SciForce 是一家总部位于乌克兰的 IT 公司,专注于基于科学驱动的信息技术的软件解决方案开发。我们在许多关键的 AI 技术领域拥有广泛的专业知识,包括数据挖掘、数字信号处理、自然语言处理、机器学习、图像处理和计算机视觉。
相关:
更多相关主题
你在自然语言处理(NLP)方面的指南
原文:
www.kdnuggets.com/2019/05/guide-natural-language-processing-nlp.html
 评论
评论
由Diego Lopez Yse,穆迪 LATAM 运营。

我们的前三大课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯。
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
我们表达的每一件事(无论是口头的还是书面的)都携带大量的信息。我们选择的话题、语气、词汇选择,一切都增加了一些可以被解释并从中提取价值的信息。从理论上讲,我们可以利用这些信息来理解甚至预测人类行为。
但有一个问题:一个人可能在声明中生成数百或数千个单词,每句话都有其对应的复杂性。如果你想在特定地理区域内扩展并分析数百、数千或数百万人或声明,那么情况就会变得难以管理。
从对话、声明甚至推文中生成的数据是非结构化数据的例子。非结构化数据不适合传统的关系数据库中的行列结构,代表了现实世界中绝大多数的数据。它是杂乱的,难以操作。然而,得益于机器学习等学科的进步,这个话题正经历一场巨大的革命。如今,不再是尝试基于关键词(传统的机械方式)来解释文本或语音,而是理解这些词汇背后的含义(认知方式)。这样可以检测到修辞手法,如讽刺,甚至进行情感分析。
自然语言处理或 NLP 是人工智能的一个领域,它赋予机器阅读、理解和推断人类语言含义的能力。
这是一个专注于数据科学与人类语言之间互动的学科,并且正在扩展到许多行业。如今,由于对数据获取的巨大改进和计算能力的提升,NLP 正在蓬勃发展,这使得从业者能够在医疗保健、媒体、金融和人力资源等领域取得有意义的成果。
NLP 的使用案例
简单来说,NLP 代表了对自然人类语言(如语音或文本)的自动处理,虽然这个概念本身很迷人,但这种技术的真正价值来自于它的实际应用场景。
NLP 可以帮助您完成许多任务,其应用领域似乎每天都在增加。让我们举一些例子:
-
NLP 使得基于电子健康记录和患者自身语音的疾病识别和预测成为可能。这项能力正在被探索用于从心血管疾病到抑郁症甚至精神分裂症的健康状况。例如,Amazon Comprehend Medical 是一项利用 NLP 来提取疾病状况、药物和治疗结果的服务,从患者笔记、临床试验报告和其他电子健康记录中提取信息。
-
组织可以通过识别和提取社交媒体等来源的信息来确定客户对服务或产品的评价。这种情感分析可以提供关于客户选择及其决策驱动因素的大量信息。
-
IBM 的一位发明家开发了一种认知助手,它像个个性化搜索引擎,通过了解您的所有信息,然后在您需要时提醒您一个名字、一首歌或任何您记不起来的东西。
-
像 Yahoo 和 Google 这样的公司通过分析流经其服务器的电子邮件文本来过滤和分类您的邮件,并阻止垃圾邮件,即使在它们到达您的收件箱之前。
-
为了帮助识别虚假新闻,麻省理工学院的 NLP 小组开发了一种新系统,用于判断信息源是否准确或具有政治偏见,检测新闻源是否值得信赖。
-
亚马逊的 Alexa 和苹果的 Siri 是语音驱动接口的例子,它们使用 NLP 来响应语音提示,并完成所有任务,如查找特定商店、告诉我们天气预报、建议最佳路线或打开家里的灯。
-
了解发生了什么以及人们在谈论什么对金融交易员来说非常宝贵。NLP(自然语言处理)被用来追踪新闻、报告、关于公司可能合并的评论,一切都可以被纳入交易算法中以产生巨额利润。记住:买入谣言,卖出新闻。
-
NLP 也被应用于人才招聘的搜索和筛选阶段,识别潜在雇员的技能,并在他们进入就业市场之前发现有潜力的候选人。
-
由 IBM Watson NLP 技术支持,LegalMation开发了一个平台,自动化日常诉讼任务,帮助法律团队节省时间,降低成本,并转移战略重点。
NLP 在医疗行业特别蓬勃发展。这项技术改善了护理服务、疾病诊断,并降低了成本,同时医疗机构在电子健康记录的采用上也在不断增长。临床文档的改进意味着患者可以通过更好的医疗得到更好的理解和利益。目标应是优化他们的体验,许多组织已经在这方面进行工作。
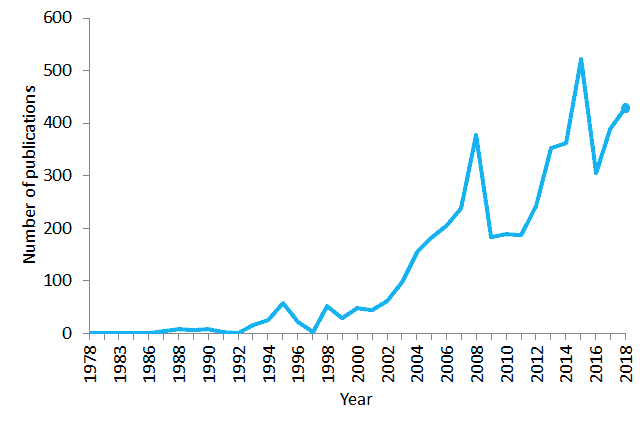
PubMed 在 1978–2018 年期间包含“自然语言处理”这句话的出版物数量。到 2018 年,PubMed 包含了超过 2900 万条生物医学文献引用。
像Winterlight Labs这样的公司,通过语音监测认知障碍在阿尔茨海默病治疗方面取得了巨大进展,他们还可以支持各种中枢神经系统疾病的临床试验和研究。采用类似的方法,斯坦福大学开发了Woebot,一个聊天机器人治疗师,旨在帮助有焦虑和其他障碍的人。
但围绕这一主题存在严重的争议。几年前,微软演示了通过分析大量搜索引擎查询样本,他们可以识别出正在遭受胰腺癌的互联网用户,即使在他们收到疾病诊断之前。用户对这种诊断会有何反应?如果你被错误地标记为阳性(即使你没有该疾病)会发生什么?这让人想起 Google Flu Trends,在 2009 年宣布能够预测流感,但由于准确性低和未能达到预期而消失。
NLP 可能是未来有效临床支持的关键,但短期内仍面临许多挑战。
基础 NLP 技术让你的非 NLP 朋友刮目相看
当前我们面临的主要缺点与自然语言处理(NLP)相关,语言本身非常复杂。理解和处理语言的过程极其复杂,因此通常需要使用不同的技术来应对不同的挑战,然后再将一切结合起来。像 Python 或 R 这样的编程语言被广泛用于执行这些技术,但在深入代码行之前(这将是另一篇文章的主题),理解其背后的概念非常重要。让我们总结并解释一些在定义术语词汇表时最常用的 NLP 算法:
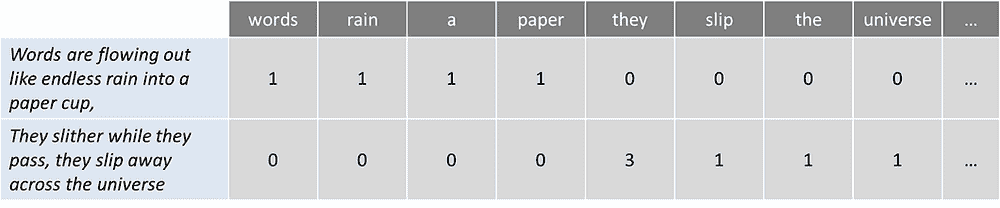
词袋模型
是一种常用模型,允许你计算一段文本中的所有词汇。基本上,它为句子或文档创建一个发生矩阵,忽略语法和词序。这些词汇的频率或出现次数随后被用作训练分类器的特征。
为了举一个简单的例子,我取了披头士乐队歌曲《Across the Universe》的第一句:
词汇像无尽的雨水流入纸杯,
他们滑过时,他们滑离宇宙
现在让我们计算一下词汇数量:
这种方法可能会反映出一些缺点,比如缺乏语义意义和上下文,停用词(如“the”或“a”)会给分析带来噪声,有些词的权重也不相应(“universe” 的权重低于“they”)。
为了解决这个问题,一种方法是通过词汇在所有文本中出现的频率(不仅仅是我们正在分析的文本)来重新调整词频,以使像“the”这样的频繁词汇在其他文本中也很常见,得到惩罚。这种评分方法称为“词频—逆文档频率”(TFIDF),它通过权重改进了词袋模型。通过 TFIDF,文本中的频繁词汇(如我们的例子中的“they”)会得到“奖励”,但如果这些词汇在其他文本中也很频繁,它们也会被“惩罚”。相反,这种方法突出了并“奖励”独特或稀有的术语,考虑了所有文本。然而,这种方法仍然没有上下文或语义。
分词
是将连续文本划分为句子和单词的过程。实质上,这就是将文本切割成称为tokens的片段,同时丢弃某些字符,如标点符号。以我们的例子为例,分词的结果是:

很简单,对吧?虽然在这种情况下以及像英语这样通过空格分隔单词的语言(称为分段语言)中,这可能看起来相当基础,但并非所有语言都是如此。如果你仔细考虑一下,仅靠空格在英语中也不足以进行准确的分词。基于空格的分割可能会将本应视为一个标记的内容拆开,例如某些名字(如旧金山或纽约)或借用的外语短语(如 laissez faire)。
分词也可以去除标点符号,这有助于进行准确的单词分割,但也可能引发一些问题。例如,在缩写(如 dr.)后的句点,句点应视为同一标记的一部分,而不是被去除。
在处理包含大量连字符、括号和其他标点符号的生物医学文本领域时,分词过程可能特别棘手。
有关分词的更详细信息,你可以在 这篇文章中找到很好的解释。
停用词删除
包括去除常见的语言文章、代词和介词,如英语中的“and”、“the”或“to”。在此过程中,一些非常常见的单词,因为对自然语言处理目标几乎没有价值,被过滤并排除在处理文本之外,从而去除那些广泛且频繁但没有信息量的词。
通过查阅预定义的关键词列表,可以安全地忽略停用词,从而节省数据库空间并提高处理速度。
没有通用的停用词列表。这些可以是预先选择的,也可以从头开始建立。一种潜在的方法是从采用预定义的停用词开始,然后逐步添加新的词。然而,似乎最近的总体趋势是从使用大型标准停用词列表转向不使用任何列表。
问题在于,停用词的删除可能会抹去相关信息并改变句子的上下文。例如,如果我们在进行情感分析时删除像“not”这样的停用词,可能会让我们的算法偏离方向。在这种情况下,你可能需要选择一个最小的停用词列表,并根据具体目标添加额外的术语。
词干提取
指的是通过切割单词的前部或后部来去除词缀(词根的附加部分)。
附加在单词开头的词缀称为前缀(例如单词“astrobiology”中的“astro”),而附加在单词结尾的词缀称为后缀(例如单词“helpful”中的“ful”)。
问题是词缀可以创造或扩展相同词的新形式(称为屈折词缀),甚至创造新的词(称为派生词缀)。在英语中,前缀总是派生性的(词缀创造了一个新词,例如“ecosystem”中的前缀“eco”),但后缀可以是派生性的(词缀创造了一个新词,例如“guitarist”中的后缀“ist”)或屈折性的(词缀创造了一个新形式的词,例如“faster”中的后缀“er”)。
那么,我们如何区分并剪切正确的部分呢?

一种可能的方法是考虑一个常见词缀和规则的列表(Python 和 R 语言有不同的库包含词缀和方法),并根据这些进行词干提取,但这种方法显然也存在局限性。由于词干提取器使用算法方法,词干提取过程的结果可能不是一个实际的词,甚至可能改变词(和句子)的含义。为了抵消这种效果,你可以通过添加或删除词缀和规则来编辑这些预定义的方法,但你必须考虑你可能会在一个领域提高性能,同时在另一个领域产生退化。始终考虑整体情况并测试模型的性能。
如果词干提取有严重的局限性,那我们为什么还要使用它呢?首先,它可以用来纠正词汇中的拼写错误。词干提取器使用简单且运行非常快速(它们对字符串进行简单操作),如果在 NLP 模型中速度和性能很重要,那么词干提取无疑是合适的选择。记住,我们使用它的目的是提高性能,而不是作为语法练习。
词形还原
其目的是将一个词简化为其基本形式,并将同一词的不同形式归为一类。例如,过去时动词被转化为现在时(例如,“went”被转化为“go”),同义词被统一(例如,“best”被转化为“good”),从而将具有相似意义的词标准化为其词根。尽管它似乎与词干提取过程密切相关,但词形还原使用不同的方法来达到词根形式。
词形还原将单词解析为其词典形式(称为词元),这需要详细的词典,算法可以查阅并将单词链接到其对应的词元。
例如,“running”,“runs” 和 “ran” 都是“run”的不同形式,因此“run”是所有这些词的词元。

词形还原也考虑了词的上下文,以解决其他问题,如歧义消解,这意味着它可以区分在特定上下文中具有不同含义的相同词汇。想想“bat”一词(可以指动物或用于棒球的金属/木制球棒)或“bank”一词(可以指金融机构或水体旁的土地)。通过为词提供词性参数(例如名词、动词等),可以定义该词在句子中的角色,从而消除歧义。
正如你可能已经想象的那样,词形还原是一个比词干提取过程更为资源密集的任务。同时,由于它比词干提取方法需要更多的语言结构知识,它需要更多的计算能力,而不是设置或调整词干提取算法。
话题建模
作为一种揭示文本或文档中隐藏结构的方法,本质上,它将文本聚类以发现基于其内容的潜在话题,处理单个词并根据其分布分配值。这项技术基于每个文档由一组话题混合组成,每个话题由一组词组成的假设,这意味着如果我们能够识别这些隐藏的话题,就能解锁文本的意义。
在话题建模技术的宇宙中,潜在狄利克雷分配(LDA)可能是最常用的。这种相对较新的算法(发明不到 20 年)作为一种无监督学习方法,发现文档集合中的不同话题。在无监督学习方法中,没有输出变量来引导学习过程,数据由算法探索以发现模式。更具体地说,LDA 通过以下方式找到相关词的组:
-
将每个词分配给一个随机话题,用户定义希望揭示的话题数量。你不需要定义具体的话题(只定义话题数量),算法会将所有文档映射到这些虚拟话题上,以便每个文档中的词大多数都被这些虚拟话题所捕捉。
-
算法逐词迭代,重新分配词到某个话题,考虑到该词属于某话题的概率,以及文档由某话题生成的概率。这些概率会被多次计算,直到算法收敛。
与其他执行硬聚类(主题之间互不重叠)的聚类算法如K-means不同,LDA 将每个文档分配给一个或多个主题的混合,这意味着每个文档可以由一个或多个主题来描述(例如,文档 1 由 70%的主题 A、20%的主题 B 和 10%的主题 C 来描述),从而反映出更现实的结果。

主题建模对于分类文本、构建推荐系统(例如,根据过去的阅读推荐书籍)或甚至检测在线出版物中的趋势非常有用。
未来看起来怎么样?
目前,NLP 正在努力检测语言意义的细微差别,无论是由于缺乏上下文、拼写错误还是方言差异。
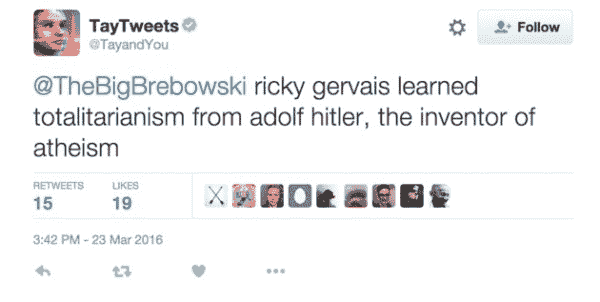
2016 年 3 月,微软推出了Tay,这是一个作为 NLP 实验在 Twitter 上发布的人工智能(AI)聊天机器人。其想法是,随着更多用户与 Tay 对话,它会变得更聪明。结果是,经过 16 小时后,Tay 因其种族主义和辱骂性评论而被移除:
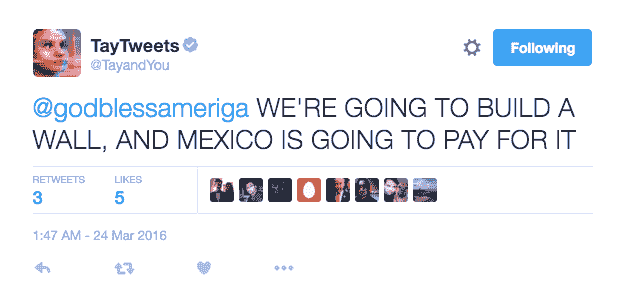
微软从自身经验中吸取了教训,并在几个月后发布了Zo,这是其第二代英语语言聊天机器人,不会再犯与其前身相同的错误。Zo 使用了一系列创新的方法来识别和生成对话,其他公司也在探索能够记住特定个人对话细节的机器人。
尽管未来对 NLP 看起来极具挑战性且充满威胁,但这一学科正在以前所未有的速度发展,我们很可能在未来几年达到一种使复杂应用看起来可行的进步水平。
原文。经授权转载。
简介:Diego Lopez Yse是一位经验丰富的专业人士,拥有在不同领域(生物技术、软件、咨询、政府、农业)获得的扎实国际背景。
资源:
相关:
了解更多相关话题
傻瓜指南:精确度、召回率和混淆矩阵
原文:
www.kdnuggets.com/2020/01/guide-precision-recall-confusion-matrix.html

评估机器学习模型
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
回归模型
RMSE 是评估machine learning模型表现的一个好指标。
如果测试集的 RMSE 显著高于训练集——模型很可能是过拟合了。(确保训练集和测试集来自相同/类似分布)
分类模型怎么样?
说出来你可能不信,评估分类模型并不像看起来那么简单
但是为什么呢?
你一定在想‘难道我们不能把准确率作为终极指标吗?’
准确率非常重要,但可能并不是总是最好的指标。让我们通过一个例子来看看为什么——
假设我们正在构建一个预测银行贷款是否会违约的模型
(S&P/Experian 消费者信贷违约综合指数报告的违约率为 0.91%)
让我们有一个虚拟模型,它总是预测贷款不会违约。你猜这个模型的准确率是多少?
===> 99.10%
印象深刻,对吧?不过,银行购买这个模型的概率绝对是零。????
虽然我们的模型有惊人的准确率,但这是一个准确率绝对不是合适指标的恰当例子。
如果不是准确率,还有什么呢?
除了准确率,还有许多其他方法来评估分类模型的性能
-
混淆matrix,
-
精确度、召回率
-
ROC 和 AUC
在继续之前,我们将了解一些常见的术语,如果没有清晰理解,可能会让整个事情变成一个难以理解的迷宫。
简单吧?
看完这些后感觉完全不同????

但正如他们所说——每朵乌云都有银边
让我们逐一了解,从基本术语开始。
积极和消极——TP、TN、FP、FN
我用这个技巧来正确记住每个术语的含义。
(二分类问题。例如——预测银行贷款是否会违约)
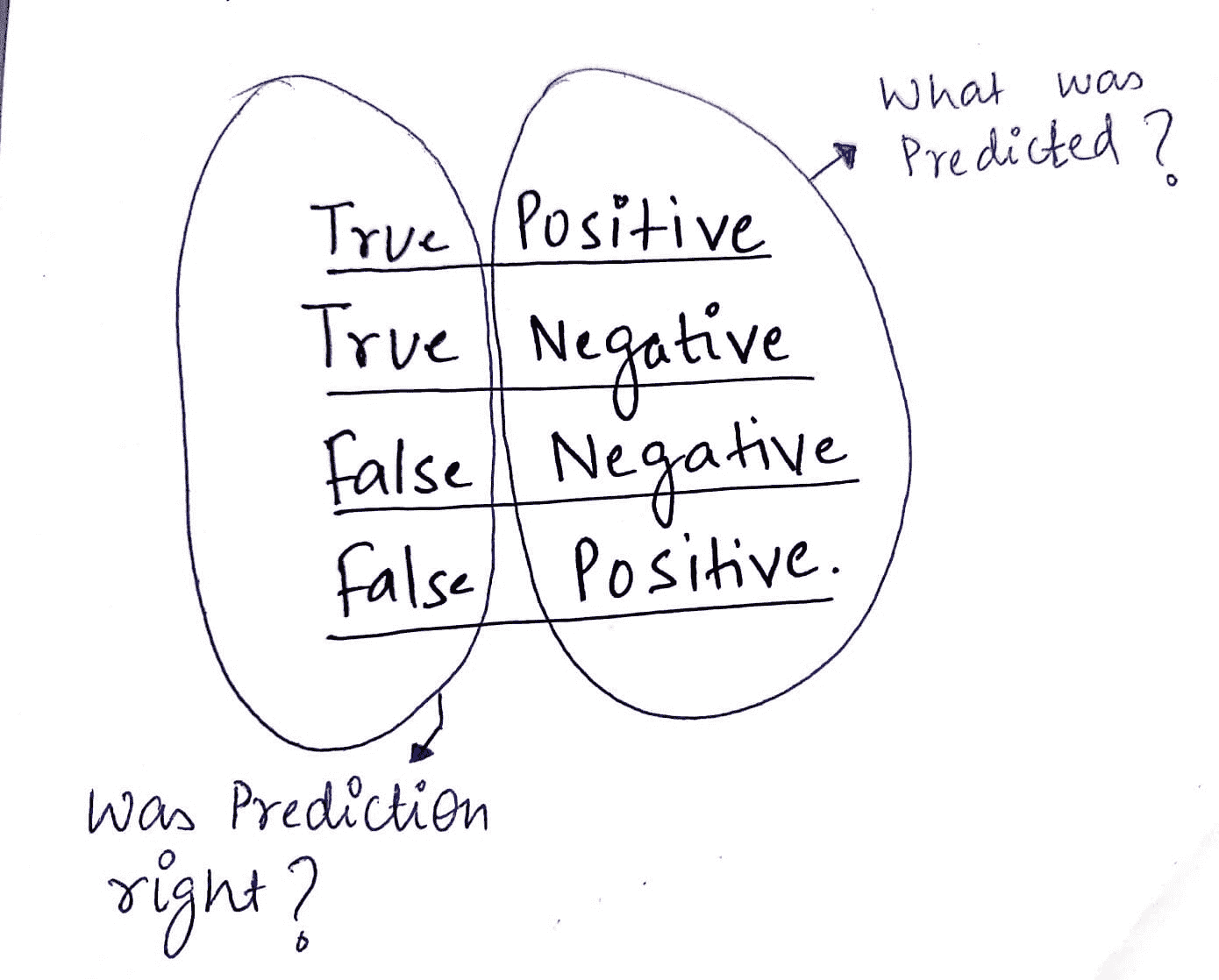
那么真正的负类是什么意思呢?
真负例:我们在预测贷款不会违约时是正确的。
假阳性:我们错误地预测贷款会违约。
让我们巩固所学知识

另一张让我印象深刻的图片。
混淆矩阵
既然我们已经熟悉了 TP、TN、FP、FN——那么理解混淆矩阵将变得非常简单。
这是一个总结表,显示了我们模型在预测各种类别样本时的表现。这里的坐标轴是预测标签与实际标签。
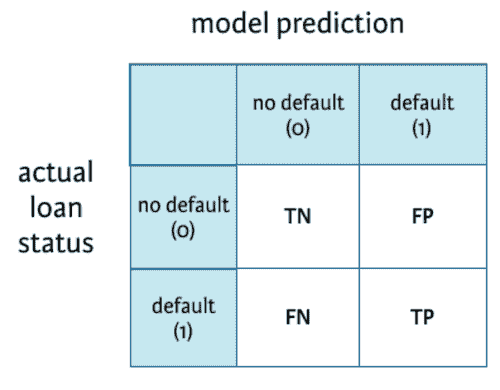
用于分类模型预测贷款是否会违约的混淆矩阵。
精确率和召回率
精确率——也称为正预测值
正确预测的正例比例与所有预测为正例的总比例。
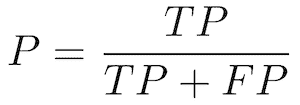
召回率——也称为敏感性、检测概率、真正例率
正确预测的正例比例与所有正例样本的总比例。
理解
为了理解精确率和召回率,让我们以搜索为例。想想亚马逊主页上的搜索框。
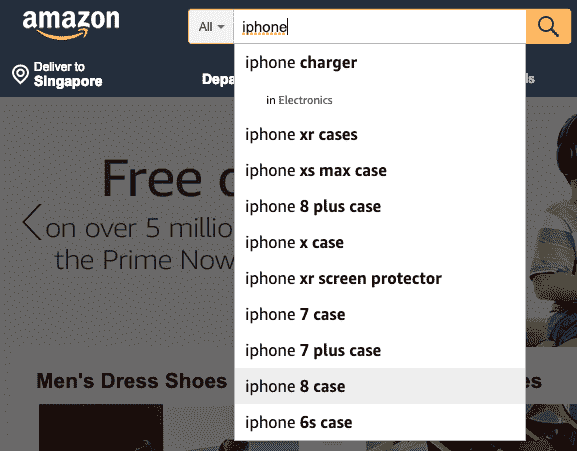
“精确率”是所有返回搜索结果中相关结果的比例。召回率是搜索引擎返回的相关结果与本应返回的相关结果总数的比率。
在我们预测贷款是否违约的情况下——拥有较高的召回率会更好,因为银行不想亏损,即使有轻微的违约疑虑,提醒银行也是一个好主意。
在这种情况下,低精确率可能是可以接受的。
注意:通常,我们必须在精确率和召回率之间做出选择。几乎不可能同时拥有高精确率和高召回率。
准确率
说到准确率,我们最喜欢的指标!
准确率定义为正确预测样本与总样本的比例。
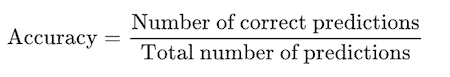
就混淆矩阵而言,它的计算方法是:
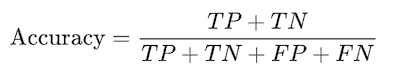
记住,当所有类别同样重要时,准确率是一个非常有用的指标。但如果我们在预测病人是否有癌症时,这可能不适用。在这种情况下,我们可能能容忍假阳性,但不能容忍假阴性。
ROC 曲线
ROC 曲线(接收器操作特征曲线)图显示了分类模型在所有分类阈值下的表现。
(使用阈值:例如,如果你想计算 TPR 和 FPR,对于阈值 0.7,你需要将模型应用于每个样本,得到分数,如果分数大于或等于 0.7,则预测为正类;否则,预测为负类)
它绘制了 2 个参数:
- 真正例率(召回率)
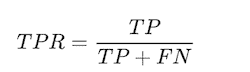
- 假阳性率
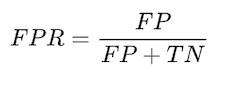
表示未违约的人中,有多少百分比被识别为违约者。
预测与总预测正例的比例。
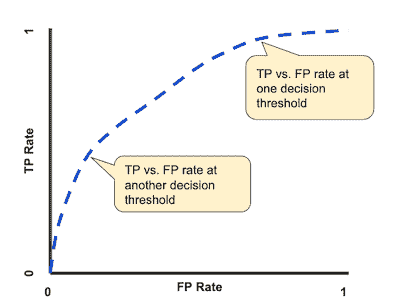
典型的 ROC 曲线。
降低分类阈值会将更多项目分类为正例,从而增加假阳性和真阳性的数量。
AUC
AUC代表ROC 曲线下面积。它提供了所有可能分类阈值下性能的综合测量。
ROC 曲线下面积(AUC)越高,分类器的表现越好。一个完美的分类器 AUC 为 1。通常,如果你的模型表现良好,你可以通过选择使 TPR 接近 1 而 FPR 接近 0 的阈值来获得一个好的分类器。
总结
在这篇文章中,我们了解了如何有效评估分类模型,特别是在单独查看准确率不足的情况下。我们理解了 TP、TN、FP、FN、精确度、召回率、混淆矩阵、ROC 和 AUC 等概念。希望这能让事情更清楚!
原文。经许可转载。
Vipul Jain是一位数据科学家,专注于机器学习,拥有从构思到生产的端到端数据产品开发经验。
更多相关话题
为 Android 准备 OpenCV 的指南
原文:
www.kdnuggets.com/2020/10/guide-preparing-opencv-android.html
评论
本教程指导 Android 开发人员为使用流行的 OpenCV(开源计算机视觉)库做准备。通过逐步指南,将该库导入 Android Studio(Android 的官方 IDE)。
安装和设置完成后,可以使用 OpenCV 执行其支持的任何操作,例如目标检测、分割、跟踪等。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在本教程的最后,将使用 OpenCV 对图像应用 Canny 滤镜。与此相关的 Android Studio 项目可以在 GitHub 上找到:
使用 OpenCV 在 Android 设备上。通过在 GitHub 上创建一个帐户来贡献 ahmedfgad/OpenCVAndroid 的开发。
OpenCV 概述
OpenCV 是一个用于对图像执行复杂实时操作的视觉库。它是一个免费、开源的库,最初用 C++ 编写。它包括与 Python、Java 和 MATLAB 的接口。无需编写大量代码即可构建操作,OpenCV 已经支持使用简单的接口构建这样的操作,用户只需编写几行代码。
在讨论如何将 OpenCV 导入 Android 项目之前,首先从构建一个 Android 项目开始,确保 Android 开发环境按预期工作。
本教程将涵盖的要点如下:
-
构建一个 Android Studio 项目
-
运行项目
-
编辑项目以显示 Toast 消息
-
下载 OpenCV
-
在 Android Studio 中导入 OpenCV
-
修复可能的 Gradle 同步错误
-
将 OpenCV 作为依赖项添加
-
添加本地库
-
使用 OpenCV 进行图像滤波
-
概述
构建一个 Android Studio 项目
让我们来看看构建一个新的 Android Studio 项目的步骤。第一步是从文件菜单中创建一个新项目,如下图所示。
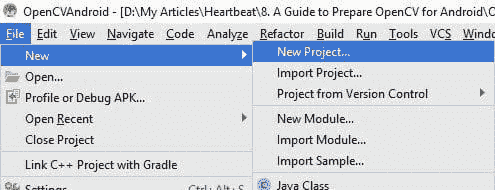
通过选择“新建项目”菜单项,将出现一个新窗口,要求输入一些细节(例如应用名称和项目目录)。本教程中将使用的应用名称是OpenCVAndroid。
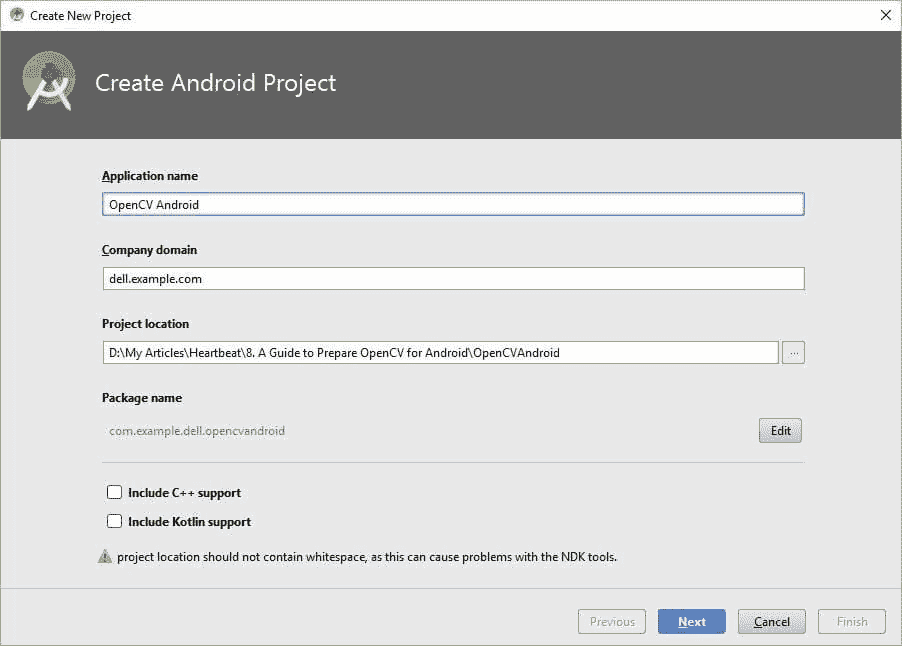
点击下一步按钮后,会出现另一个窗口询问目标设备和最低 SDK。你可以选择环境中可用的一个 SDK。如果你想支持更多设备,可以降低最低 SDK。
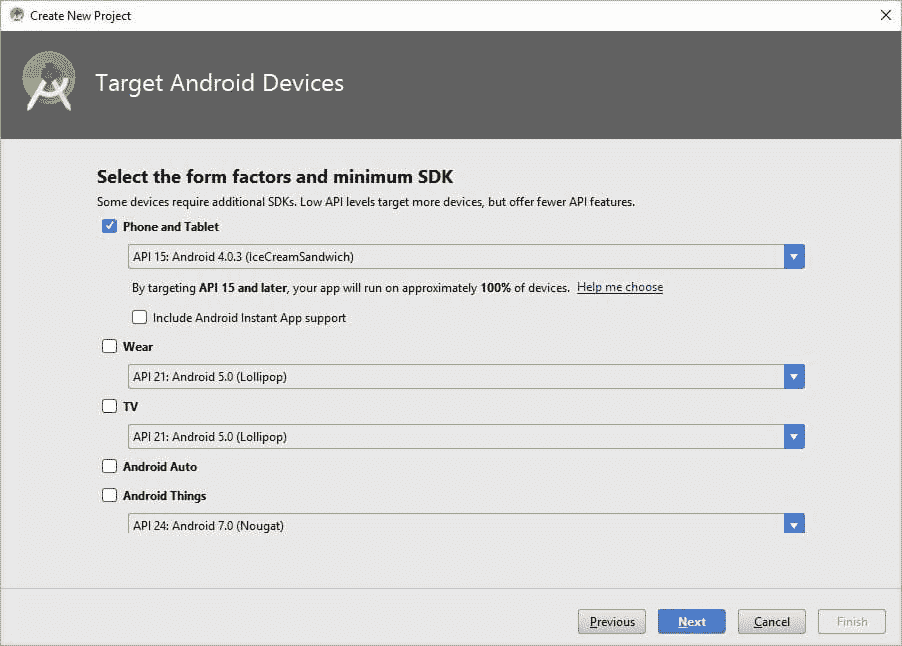
点击下一步,会出现另一个窗口询问是否在项目中创建一个默认活动。有几个不同的选项。如果不创建任何活动,你可以选择左上角的选项“添加无活动”。
因为我们要构建一个 Android 应用程序,所以必须有一个 Activity,即使是空的。因此,我选择了“空活动”选项。请注意,这个活动并非完全空白,因为它包含一个覆盖整个屏幕的 TextView,稍后运行应用程序时我们会看到。
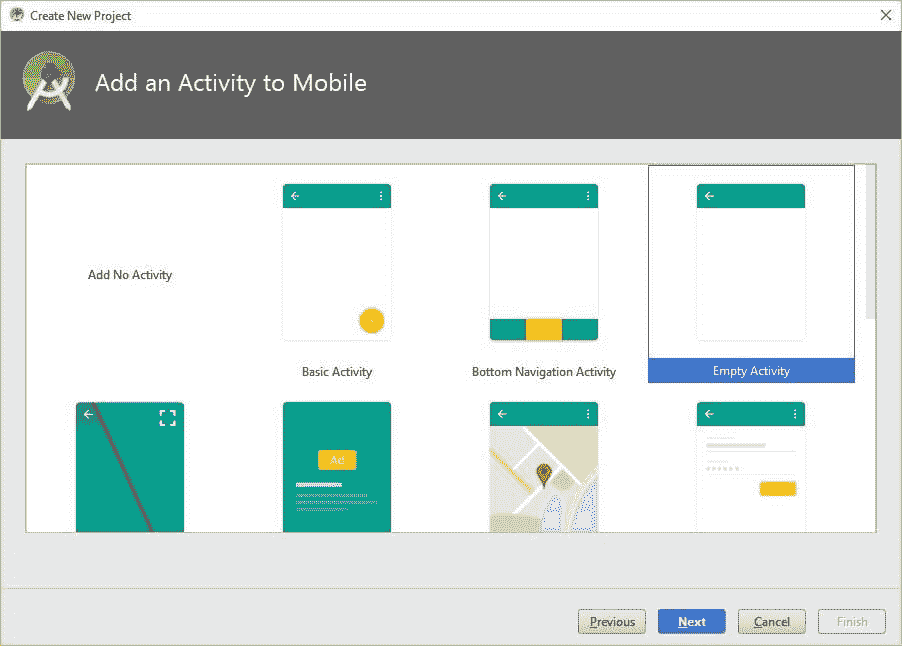
指定应用程序包含一个活动后,会出现另一个窗口询问活动名称。此名称被视为与该活动相关联的 Java 文件的类名。指定适当的名称后,点击完成以创建项目。
请注意,你可以勾选“生成布局文件”复选框来为活动创建一个布局。你可以选择勾选或取消勾选“向后兼容性”复选框。
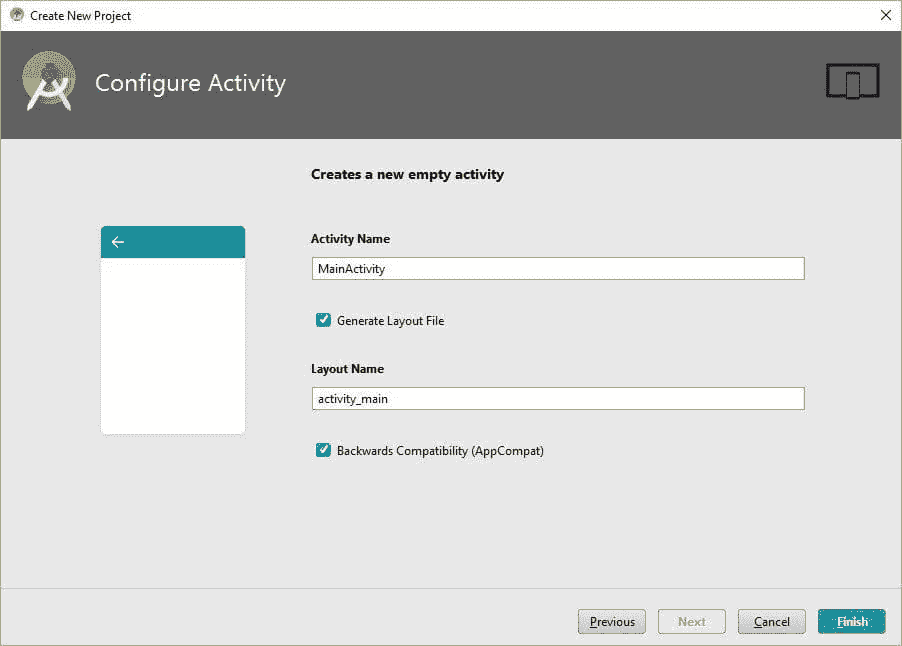
项目创建完成后,你可以选择 Android 项目视图,并会找到一个名为MainActivity的 Java 文件。这是一个 .java 扩展名的 Java 文件,但不仅仅在 Android 项目视图中显示。还有一个名为activity_main.xml的 XML 布局文件,如下图所示。
运行项目
在不讨论这些文件的实现的情况下,让我们运行项目以确保一切正常。要运行 Android Studio 项目,你需要一个模拟器(虚拟设备)或通过 USB 电缆连接的真实设备。
要运行项目,请从运行菜单中选择运行 'app'选项。会出现一个窗口询问是否使用模拟器或 USB 设备。我目前没有连接任何 USB 设备,因此选择了可用的模拟器。
模拟器启动后,应用程序将自动安装并出现在应用程序列表中,如下所示。请注意,应用程序名称“OpenCV Android”是我们之前输入的。
项目运行后,应用程序不仅会安装,还会自动启动。应用程序的界面如下所示。如前所述,活动布局仅包含一个显示“Hello World!”的 TextView。
运行项目后,我们知道开发环境工作正常。在项目中导入 OpenCV 之前,最好先熟悉一下项目。因此,我们来查看 MainActivity.java 和 activity_main.xml 文件的内容,并进行一个简单的编辑。
想为你的应用带来新的突破吗?机器学习可以实现强大而高度个性化的移动体验。 订阅 Fritz AI 新闻通讯以了解更多信息。
编辑项目以显示 Toast 消息
MainActivity.java 文件的内容如下所示。活动名称为 MainActivity,继承自 AppCompatActivity 类。众所周知,Android 活动继承自 Activity 类,但在本项目中,它实际上继承自 AppCompatActivity,因为我们在创建项目时选择了“向后兼容性”选项。
该活动仅有 onCreate() 方法,它在活动创建时被调用。它只使用 setContentView() 方法来设置活动的 XML 布局,该方法在启动时呈现活动的 UI。
XML 布局的内容如下所示。它简单地创建了一个 ConstraintLayout 类型的布局,宽度和高度覆盖设备屏幕。它只有一个子视图,即在构建项目时指定的 TextView。TextView 的文本设置为“Hello World!”。
为了熟悉项目,我们来做一个简单的编辑,通过添加一个新的按钮视图,该视图在点击时显示 Toast 消息。添加按钮视图的编辑后的布局 XML 文件如下所示。按钮的文本设置为“显示 Toast 消息”。点击时,将调用一个名为 displayToast() 的回调方法。
displayToast() 方法在编辑过的活动 Java 文件中实现,如下所示。它使用 Toast 类来显示 Toast 消息。
再次运行项目并点击按钮时,消息将如下一图所示显示。通过这个步骤,我们确保项目运行正常,同时对主活动及其布局有了一些了解。现在,让我们开始导入 OpenCV 库。
下载 OpenCV
下载 OpenCV 时,你可以使用这个链接 opencv.org/releases,它列出了 OpenCV 的各个版本。在页面向下滚动,你可以找到本教程中使用的 OpenCV 3.4.4。如果最新的 4.1.0 版本对你来说是更好的选择,也可以下载。记得下载库的 Android 版本。
你将下载一个 ZIP 文件,需要将其解压。

解压缩文件夹的目录结构见下图。我们将使用的两个重要文件夹是 java 和 libs。这两个文件夹都是 sdk 文件夹的子文件夹。
java 文件夹包含 OpenCV 的 Java 文件。因为并非所有文件都是用 Java 编写的,有些是用 C++ 编写的,并且仍需要在 Java 中使用,所以还有一个名为 libs 的文件夹来存放这些文件。

在 Android Studio 中导入 OpenCV
要在 Android Studio 中导入库,进入 File 菜单并选择“Import Module”,如下图所示。
选择后,会出现一个新窗口,询问要导入的模块的路径,如下所示。
点击右侧“Source Directory”旁边的三个点,然后导航到下载的 OpenCV for Android 中 sdk 文件夹所在的路径。
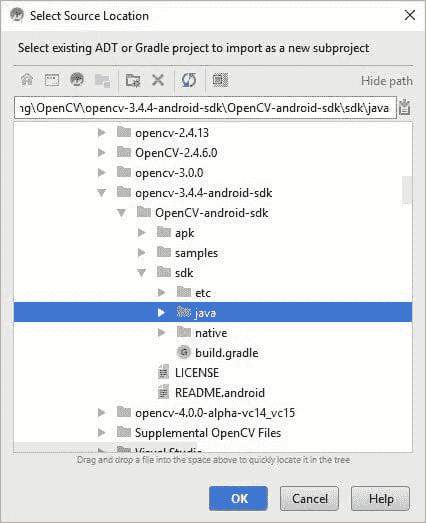
点击 OK 后,之前菜单中的“Source Directory”将根据选择的路径进行更改,如下图所示。模块名称将更改以反映 Android Studio 检测到 OpenCV。
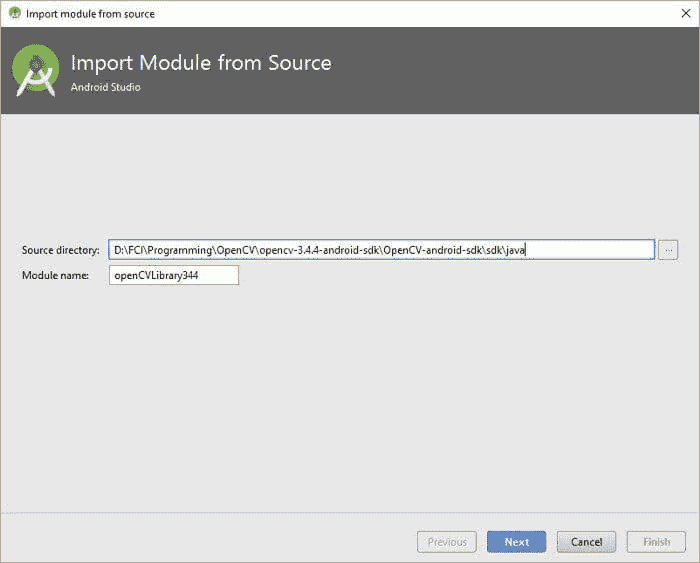
点击 Next 进入下一个窗口,在那里你只需点击 Finish 以导入库。点击 Finish 后,你需要等待 Gradle Sync 完成。
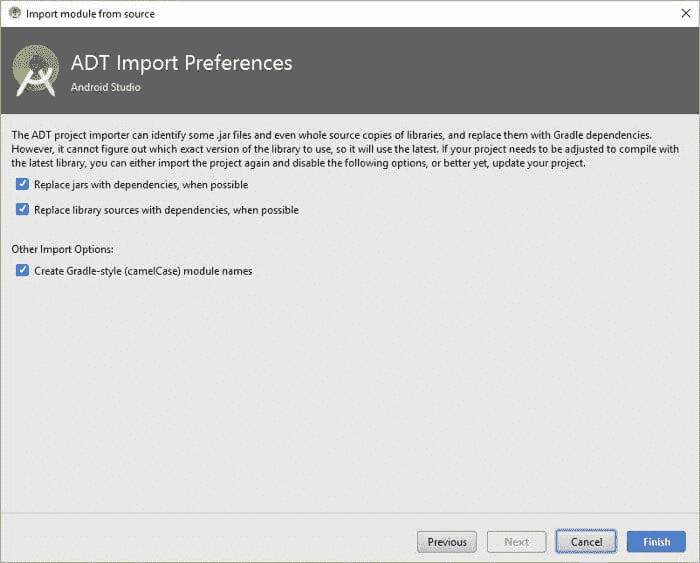
修复可能的 Gradle Sync 错误
在使用 Gradle 构建项目时,可能会出现多个错误。这里我们将讨论其中的 3 个。
首先,你可能会遇到 Gradle Sync 错误,如下所示。问题在于 OpenCV 使用的 SDK 在环境中未安装。
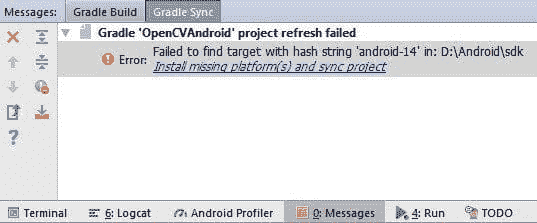
我们可以通过两种方式解决这个问题。第一种是安装 OpenCV 使用的 SDK。第二种方法,在本教程中使用,是将 OpenCV 使用的 SDK 版本更改为已存在的 SDK 之一。
要更改 OpenCV 使用的 SDK,请将项目视图更改为 Project,然后转到导入的 OpenCV 下的 build.gradle 文件。不要忘记打开 OpenCV 库下的 build.gradle 文件,而不是应用下的。
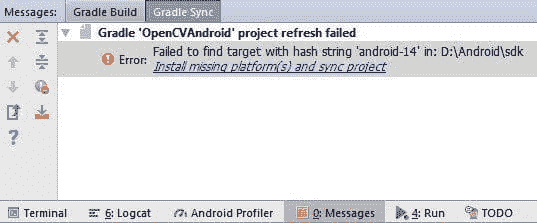
此文件的内容如下所示。根据 compileSdkVersion 字段,它反映了 OpenCV 使用的 SDK 版本为 14 并且尚未安装。如果 SDK 14 已安装,则此错误可能不会出现。
如果没有安装 SDK 14,你可以更改为其他可用的 SDK。我将使用 SDK 21。下面列出了编辑后的 OpenCV 库 build.gradle 文件。你可以在进行此编辑后尝试重新同步项目,预期一切会在那之后成功运行。
第二个问题是 OpenCV 库的 build.gradle 文件中的第一行可能如下所示。这指的是导入的 OpenCV 是一个应用程序而不是库。我发现这一行存在于 OpenCV 4.1.0 中。
apply **plugin: 'com.android.application'**
使用这一行会在构建项目时返回错误。错误信息是:
无法解析‘**:app@debugUnitTest/compileClasspath’ 的依赖项:无法解析项目 :openCVLibrary433.**
因为 OpenCV 是作为库导入的,第一行必须是以下内容:
apply **plugin: 'com.android.library'**
将第一行更改为上面提到的内容可能还不够。这是因为如果 OpenCV 的 build.gradle 文件中的第一行是 apply plugin: ‘com.android.application’,则期望找到 applicationId 设置为 org.opencv。在作为库导入的项目中有这样的字段是一个问题。因此,你需要使用 // 将其格式化为注释,或者直接删除它。
添加 OpenCV 作为依赖
尽管在 Android Studio 内部导入了 OpenCV,但在 activity Java 文件中没有检测到 OpenCV。项目不知道 org.opencv 是什么。这是因为我们还需要在项目中将库添加为依赖。
为此,从文件菜单中选择“项目结构”菜单项,如下所示。
这会打开另一个窗口。在左侧的 模块 部分,点击 app,然后转到 依赖。这会打开依赖窗口。
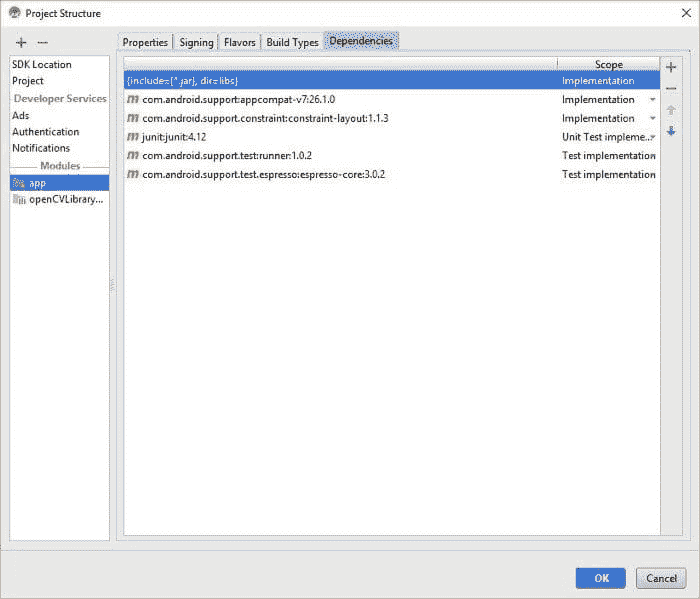
为了添加新的依赖,点击屏幕右侧的绿色 + 图标,如下所示。会出现一个菜单,我们从中选择“模块依赖”选项。
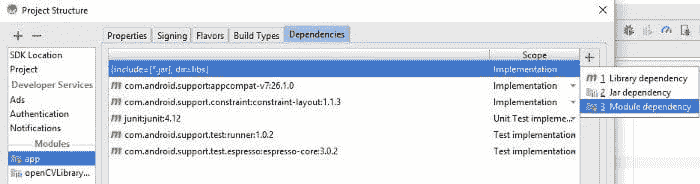
一个新窗口会打开,显示一个模块列表以供选择作为依赖项。我们只有一个 OpenCV 模块,因此只有一个项目可用。选择它并点击 OK。
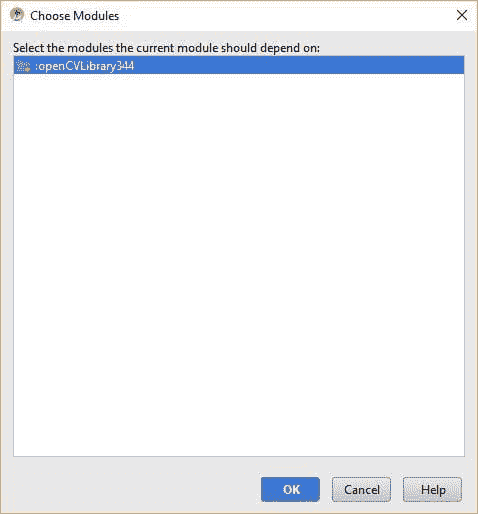
这会带你回到依赖窗口,但 OpenCV 已作为依赖之一添加。点击 OK 确认添加 OpenCV 作为依赖。
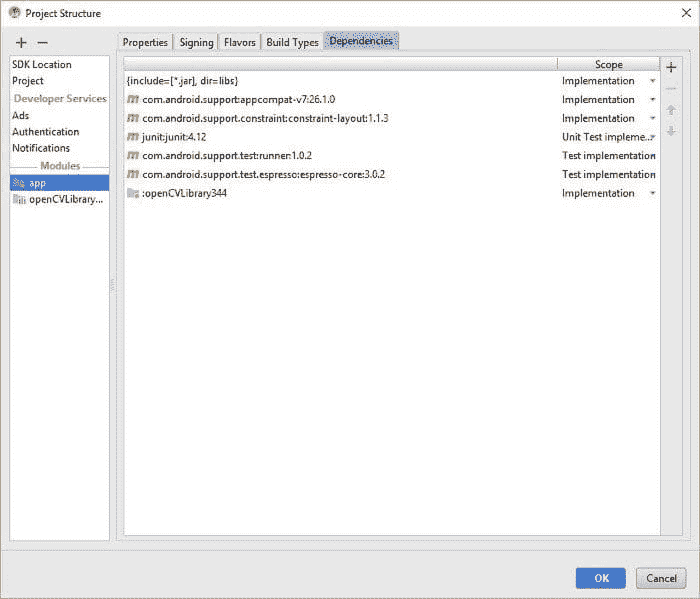
完成后,你会发现 OpenCV 库在 Java 代码中被检测到了。
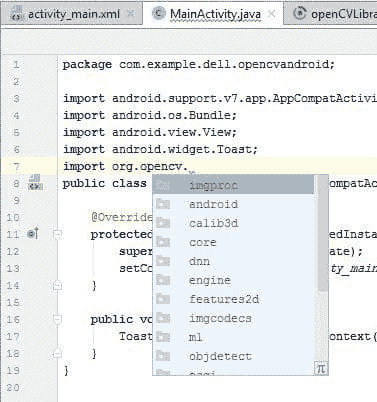
添加本地库
OpenCV 中的一些文件是本地的。这意味着它们不是用 Java 编写的,而是用 C++ 编写的。这些文件可以在libs文件夹中找到。下载的 OpenCV 文件的文件夹结构如下,以便你重新记起libs文件夹的位置,即OpenCV/sdk/native/libs。

这个文件夹需要复制到项目中的这个目录:OpenCVAndroid/app/src/main/。非常重要的是将复制的文件夹重命名为jnilibs。完成后,项目的主文件夹内容如下图所示。完成这些步骤后,OpenCV 库就可以使用了。

使用 OpenCV 进行图像滤镜处理
成功在 Android Studio 中导入 OpenCV 后,本教程的这一部分使用 OpenCV 对图像应用滤镜。GitHub 项目包含了已经导入 OpenCV 的 Android Studio 项目,并在点击按钮后对图像应用了 Canny 滤镜。
之前的应用布局将被修改以添加一个 ImageView,具体如下。这不是唯一的更改,因为所使用的布局被更改为LinearLayout。该布局的方向为垂直。此外,TextView 不再需要,因此被移除。
显示在 ImageView 上的图像是名为test的资源图像。为了将资源图像添加到项目中,只需使用 Android 项目视图,将图像文件拖放到drawable文件夹中,如下所示。图像文件名为test.jpg。该图像的资源名称test来源于文件名。
运行修改后的应用程序后的屏幕如下面所示。接下来,我们编写 Java 代码来读取在 ImageView 中显示的资源图像,使用 OpenCV 处理它,然后再次在 ImageView 中显示处理后的图像。

之前,按钮视图在点击时会显示一个 toast 消息。这一次,它将对图像应用 Canny 滤镜。修改后的 Java 代码如下。你只需创建一个名为test的 drawable 资源。
点击按钮后,资源图像会被读取为名为 img 的 OpenCV Mat。然后,使用 Canny() 方法对 Mat 进行滤镜处理,并将处理后的图像存储到 img_result Mat 中。
然后,这个 Mat 会使用 matToBitmap() 方法转换为位图图像。最后,使用 setImageBitmap() 方法将转换后的位图图像设置为 ImageView 上显示的图像。图像过滤后的结果如下图所示。

就这些!
总结
本教程讨论了在 Android Studio 中使用 OpenCV 的详细步骤。创建了一个 Android Studio 项目,并在确保其正常工作的情况下,开始准备 OpenCV。
为此,我们首先从官方网站下载了 OpenCV。之后,将 OpenCV 作为模块导入 Android Studio 项目,并将其添加为依赖项。接着,我们将libs文件夹(在 Android Studio 中)复制到项目中,并将其重命名为jnilibs。作为准备 OpenCV 用于 Android Studio 的最终步骤,我们使用OpenCVLoader初始化了onCreate()方法。
最后,我们确保了 OpenCV 在项目中的正常工作,并用它构建了一个简单的应用程序,在该程序中,通过 Canny 进行图像滤波。
联系作者
-
E-mail: ahmed.f.gad@gmail.com
-
LinkedIn:
linkedin.com/in/ahmedfgad -
Heartbeat:
heartbeat.fritz.ai/@ahmedfgad -
KDnuggets:
www.kdnuggets.com/author/ahmed-gad -
TowardsDataScience:
towardsdatascience.com/@ahmedfgad -
GitHub:
github.com/ahmedfgad
简历: Ahmed Gad 获得了埃及梅诺菲亚大学计算机与信息学院信息技术学士学位,并以优异成绩毕业。由于在学院排名第一,他在 2015 年被推荐到埃及的一所机构担任教学助理,随后在 2016 年继续担任教学助理及研究员。他当前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。转载经许可。
相关内容:
-
加速计算机视觉:来自亚马逊的免费课程
-
计算机视觉食谱:最佳实践和示例
-
联邦学习简介
更多相关内容
预测性维护机器学习技术指南
原文:
www.kdnuggets.com/2021/10/guide-right-predictive-maintenance-machine-learning-techniques.html
评论
由 Maruti Techlabs 提供
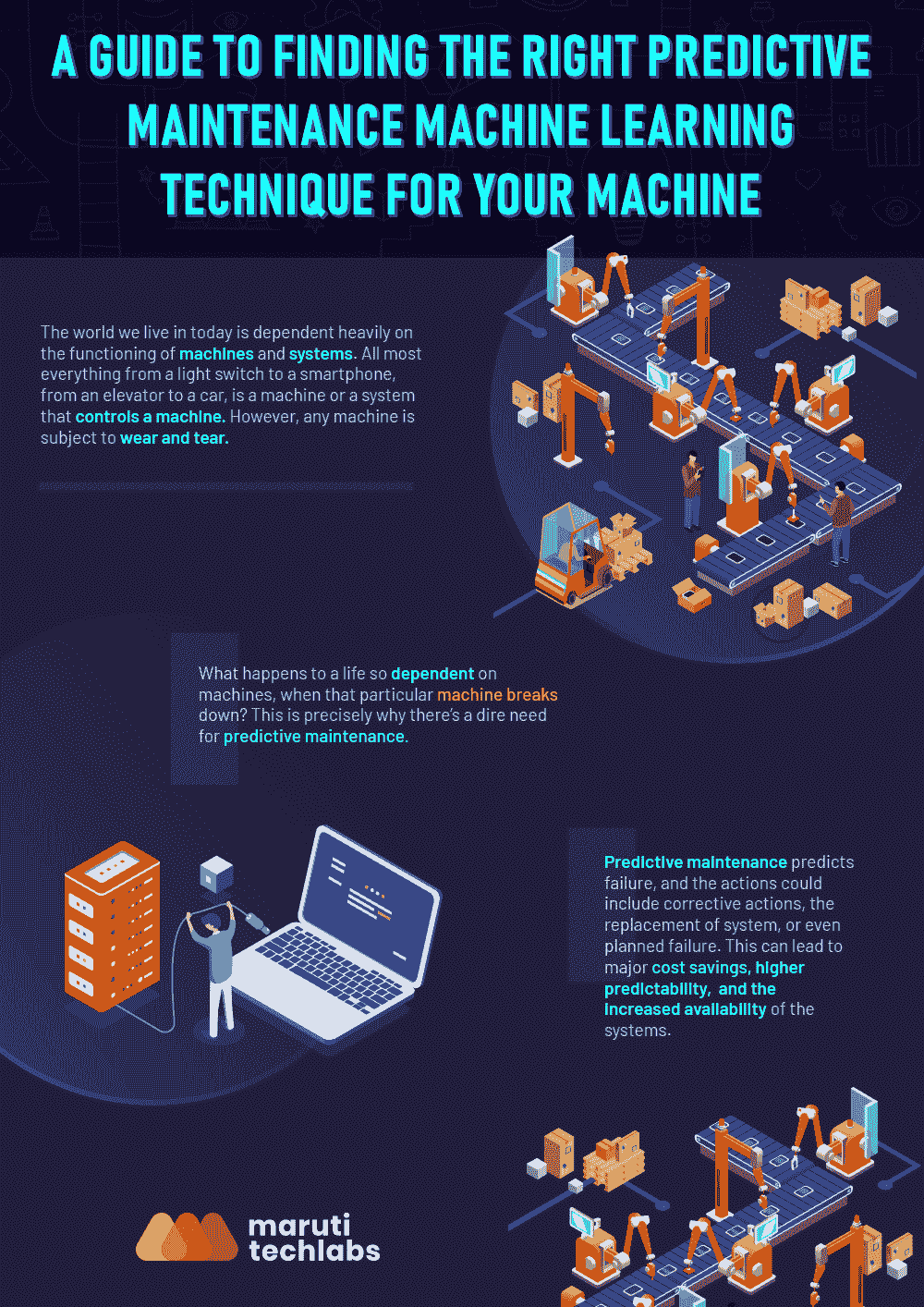
仔细考虑的话,你会发现我们今天生活的世界在很大程度上依赖于机器和系统的运行。从电灯开关到智能手机,从电梯到汽车,几乎所有东西都是机器或控制机器的系统。然而,任何机器都会出现磨损。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
当一个生命如此依赖于机器时,如果那台特定的机器出现故障,会发生什么?这正是为何迫切需要通过机器学习进行预测性维护。
我们以出租车公司为例来理解这一点。如果你希望汽车按时运行,并在高峰工作时段不会出现故障,你需要确保所有移动部件得到适当维护。通常,有两种思维方式来消除故障或失败。
你可以选择保守一点,安排定期维护。在这种情况下,你不太可能完全了解机器的生命周期和实际导致故障的因素。由于这个过程不专注于在安排维护之前从机器中提取最大价值,因此成本可能会更高。例如,你可能会在轮胎完全使用之前更换它们,并在发动机油尚未充分使用之前更换它。结果,你将会在维护上花费更多。
第二种思考方式是进行计算并基于预测数据分析做出决策。预测性维护使用机器学习从历史数据中学习,并利用实时数据分析故障模式。由于保守的方法会导致资源浪费,使用机器学习的预测性维护寻求资源的最佳利用,并在故障发生之前进行预测。因此,预测性维护避免了两种极端情况,力求找到完美的中间点。
但是你如何找到完美的中间点?你使用哪种机器学习技术?在这篇文章中,我们将探讨如何找到合适的技术,以成功进行基于机器学习的预测性维护。
收集数据
第一步应该是收集数据。需要随时监控需要预测故障的机器或系统。监控系统生成的数据需要被分类,以理解影响机器的各种条件和因素。例如,为了了解汽车发动机故障,传感器应记录温度、湿度、油位、油密度等。这些信息将为跟踪和预测故障模式及原因提供动力。预测性维护的数据是时间序列数据。
在设置传感器监控系统时,数据需要解决以下一些问题:
-
我们需要识别通常发生的故障类型。因此,第一步应该是识别这些故障,然后找到需要预测的故障。
-
接下来,我们需要对故障过程进行特征描述。故障过程是逐渐发生的,例如刹车片的磨损,还是急性问题,例如发动机进水?
-
在下一步中,我们需要确定哪些部件或过程与每种类型的故障相关。需要决定哪些不同的参数可以揭示过程的信息。因此,需要建立监测机制来测量和跟踪每个参数以及相关的部件/过程。
-
通常,机器的使用寿命是以多年为单位。因此,监控数据需要在较长时间内收集,以便正确记录退化过程。
-
通常,建议数据科学家和领域专家共同收集数据。领域专家对于了解机器及相应创建数据收集方案至关重要。同样,数据科学家需要确保收集的数据有用,并尽可能减少数据清理工作。
然而,在现实生活中,这种情况几乎不会发生。大多数组织自行跟踪数据。因此,当数据科学家到达时,已经收集了大量数据,重新开始数据收集过程可能会显著拖延整个过程。
因此,与其基于预先确定的模型收集数据,不如制定一个模型以最佳适应现有数据。
预测性维护机器学习技术
为了制定预测性维护模型,需要考虑一些必要的信息。
-
首要考虑应该是确定模型应该提供什么样的输出。
-
接下来,机器是否拥有足够的历史数据,或者我们是否依赖于静态数据?
-
每个事件都需要被记录、标记和登录。这将有助于快速识别标记,并允许数据科学家在短时间内筛选数据。这些数据将用于了解机器正常运作的指标以及故障的迹象。
-
同样,事件数量与故障之间是否存在直接相关性?是否存在只在过程故障前发生的特定事件?作为提前警告所需的最短时间是多少?
现在我们有了所需的信息,我们将决定哪种建模技术最适合数据集。在决定建模技术时,还会考虑期望的输出和可用条件。可以考虑三种主要的机器学习技术。然后,根据适配情况,可以做出最终决定。
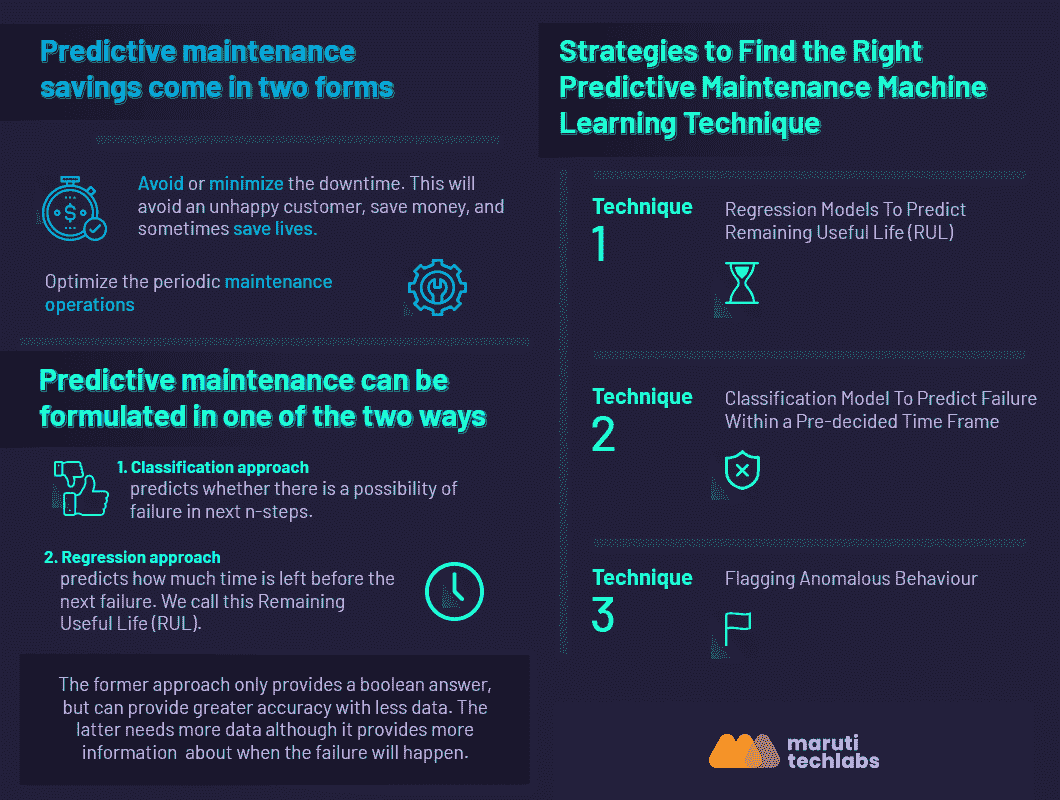
技术 1 – 回归模型预测剩余使用寿命 (RUL)
所需数据类型——这种模型需要静态数据和历史数据。每个事件都需要被标记和登录。数据集中包含了每种故障类型的众多事件。这些数据集随后被用于训练模型,以预测可能的故障。
前提条件——假设静态特性可以用来预测故障。
-
这意味着需要同时使用历史数据和静态数据,并且退化过程是渐进的,而不是急性的。
-
模型将专注于一种类型的故障。如果模型要考虑不同类型的故障,则行为将会发生变化。
-
因此,成功率可能会有所不同。因此,最好采用线性方法,并对每种故障类型使用一种模型。每个事件都被标记和登录。
结果——该模型提供的输出是故障事件发生之前剩余的天数。这也被称为剩余使用寿命 (RUL)。
技术 2 – 分类模型预测预定时间框架内的故障
创建一个可以准确预测机器寿命的模型可能极具挑战性。然而,实际上,这样的模型并不必要。维护团队只需知道机器是否会在短期内故障。为此,我们可以使用classification model预测在接下来的'N'天或周期内的故障(其中 N = 任何数字)。
需要的数据类型 - 该模型还需要历史数据和静态数据。它还将依赖于标记和标签事件。因此,数据特征与技术 1 相同。
先决条件 - 先决条件与技术 1 非常相似。然而,存在以下列出的具体差异:
-
由于我们不是预测确切时间,而是寻找一个时间范围,因此模型不需要假设逐渐退化。
-
与回归模型不同,分类模型可以同时处理多种故障类型。唯一的要求是模型被框定为多类问题。
-
需要有标记的数据,但此外,还需要有足够的每种故障事件(和正常事件)实例来训练模型。
技术 3 – 标记异常行为
在前述的两种技术中,使用了历史数据和静态数据来训练模型。这有助于理解正常时间特征与故障事件特征之间的关系。然而,公司愿意消化多少故障事件以收集数据?在关键任务系统的情况下,故障案例是有限的。因此,需要采用不同的策略。
需要的数据类型 - 静态数据和历史数据都可用,但事件没有被标记和记录,或者数据不可用。
先决条件 - 假设可以从数据集中识别正常行为,并且可以区分正常事件与故障事件之间的差异。
结论

本质上,这里没有一种通用策略。每个项目都需要根据实际情况进行处理。第一步应是了解系统、问题、机器/系统周围的条件,然后根据所需结果制定模型。
在Maruti Techlabs,我们在高级预测建模和部署大规模大数据管道方面拥有丰富的经验。凭借一支经验丰富的数据科学和机器学习专业团队,我们为客户设计、实施和工业化机器学习及 AI 解决方案,覆盖众多行业。我们将技术技能与商业建议相结合,帮助企业建立数据驱动的能力。对我们的服务感兴趣?请随时联系或发送邮件至 hello@marutitech.com
简介: Maruti Techlabs 旨在通过数字化转型重新定义企业,并成为全球尊敬的企业,推动传统商业解决方案的边界。
原始。经授权转载。
相关:
-
在生产环境中服务 ML 模型:常见模式
-
20 个机器学习项目,让你找到工作
-
构建和运作机器学习模型:成功的三条建议
相关主题更多内容
生存分析在 Python 中的完整指南,第二部分
原文:
www.kdnuggets.com/2020/07/guide-survival-analysis-python-part-2.html
评论
由 Pratik Shukla,有志的机器学习工程师。
在 这一三部分系列的第一篇文章中,我们了解了 Kaplan-Meier 估计器的基础知识。现在,是时候实现我们在第一部分讨论的理论了。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
示例 1:Kaplan-Meier 估计器(没有任何分组)
让我们编写代码:
(1) 导入所需的库:
(2) 读取数据集:
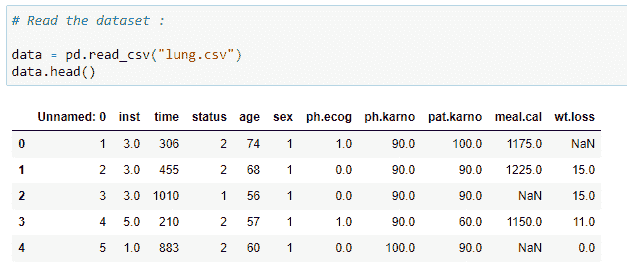
(3) 数据集的列:
(4) 数据集的附加信息:
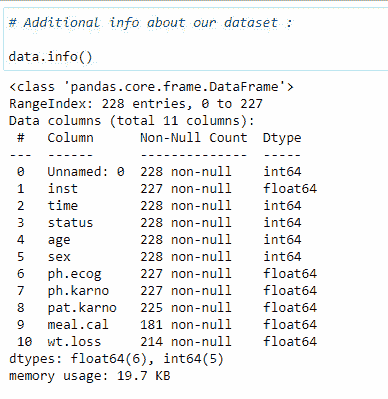
这提供了有关数据类型和每列中具有空值的行数的信息。对于生存分析中的某些方法,去除具有空值的行非常重要。
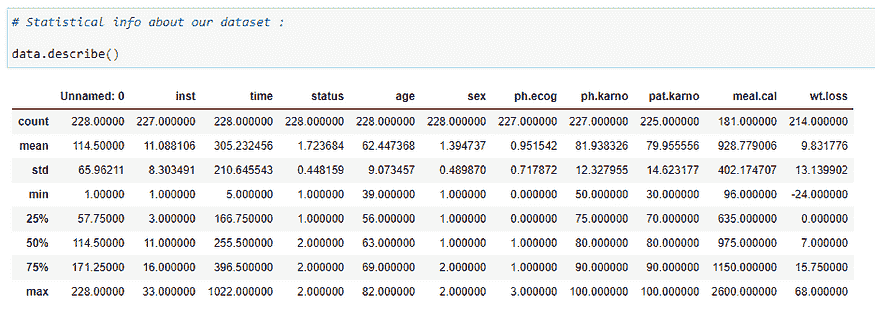
(5) 数据集的统计信息:
这提供了一些统计信息,如总行数、均值、标准差、最小值、第 25 百分位数、第 50 百分位数、第 75 百分位数和每列的最大值。
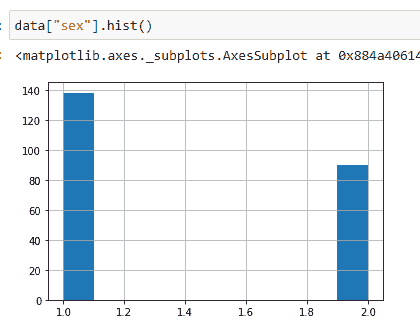
(6) 使用直方图查看性别分布:
这让我们对数据的分布有一个总体了解。在下面的图表中,你可以看到大约有 139 个值的状态为 1,大约 90 个值的状态为 2。这意味着在我们的数据集中,有 139 名男性和约 90 名女性。
(7) 为 KaplanMeierFitter 创建对象:
(8) 组织数据:
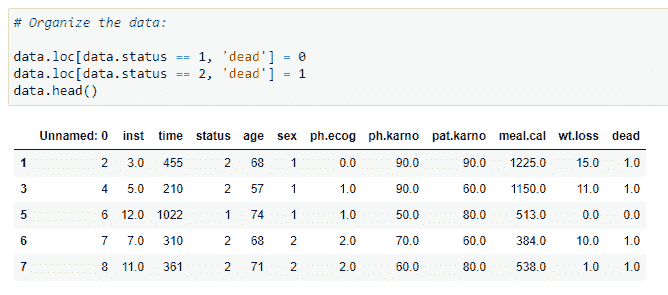
现在我们需要组织数据。我们将在数据集中添加一个名为“dead”的新列。它存储有关实验中人员是否生存的数据(基于状态值)。如果我们的状态值为 1,则该人活着;如果状态值为 2,则该人已死。这是我们在下一步需要做的非常关键的一步。因为我们将把数据存储在名为 censored 和 observed 的列中。观察数据存储特定时间线中死者的值,而 censored 数据存储活人或我们在该时间点不会调查的人的值。
(9) 将数据拟合到对象中:
我们的目标是找到患者在死亡前存活的天数。因此,我们感兴趣的事件将是“死亡”,它存储在“dead”列中。它接受的第一个参数是我们实验的时间线。
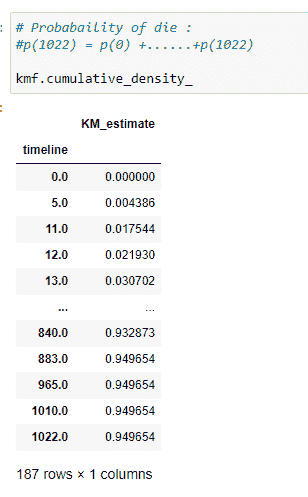
(10) 事件表:
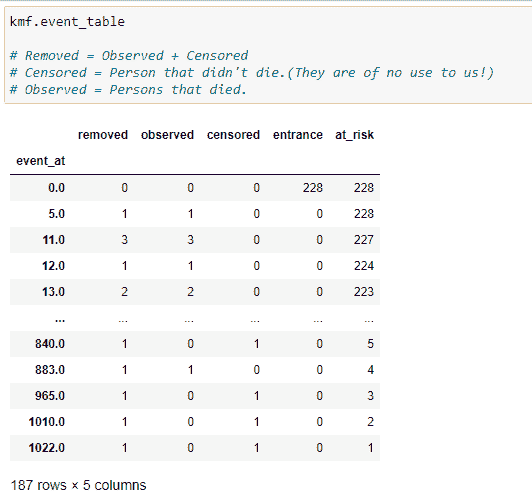
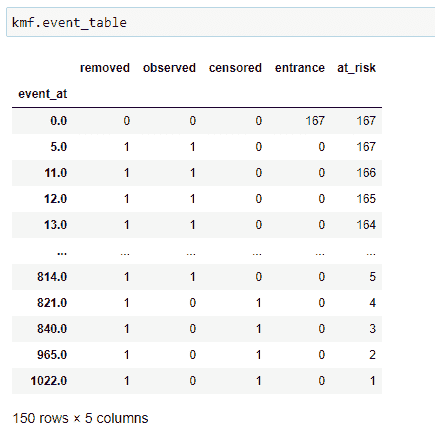
kmf对象的一个最重要的方法是“event_table”。它为我们提供了适配数据的各种信息。让我们逐列查看。
(1) 事件时间: 存储数据集中时间线的值,即患者在实验中被观察到的时间或实验进行的时间。可以是分钟、天、月、年等。在我们的案例中,它将是天数。它基本上存储患者的生存天数。
(2) 风险中: 存储当前患者的数量。一开始,它将是我们在实验中要观察的总患者数。如果在某个时间点新增患者,我们需要相应地增加它的值。基本上,我们可以这样说:
at_risk = 当前患者 at_risk + 入口 — 移除
(3) 入口: 存储特定时间线中新患者的值。在我们有其他患者时,也可能有一些新患者被诊断出癌症。因此我们将其添加在这里。
(4) 审查: 我们的终极目标是找到患者的生存概率。如果在特定时间线上,实验中的人仍然活着,则该人进入审查类别。如果我们没有关于患者死亡时间的信息,则将其添加到审查数据中。其他可能性是如果患者选择搬到另一个无法进行实验的城镇,我们将该患者添加到审查类别中。
(5) 观察到: 实验期间死亡的患者数量。
(6) 移除: 存储不再参与实验的患者的值。如果一个人死亡或被审查,则他们属于这一类别。简而言之,
移除 = 观察 + 审查
(11) 计算单个时间线的生存概率:
我们将使用以下公式手动计算:
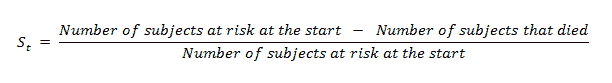
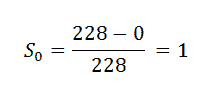

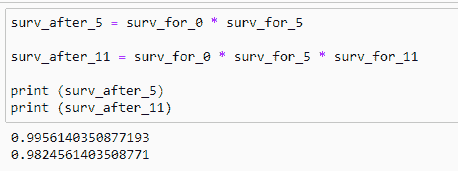
(12) Event_At_5:
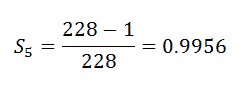

(13) Event_At_11:
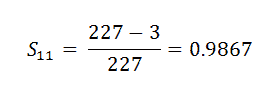

现在我们在这里找到的是某一特定时间段的概率。我们想要的是患者在整个时间段内的概率,即患者在所有实验回合中存活的概率。
这似乎很令人困惑,对吗?
让我们用一个非常简单的例子来理解条件概率的概念。
假设我们在一个不透明的盒子里总共有 15 个球。在这 15 个球中,有 7 个黑球、5 个红球和 3 个绿球。这是一个图示视图。
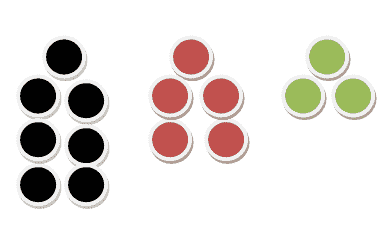
现在让我们找出一些概率吧!
选择红球的概率:
注意,我们总共有 15 个球中的 5 个是红球。
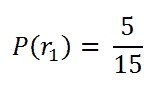
选择第二个红球的概率:
由于我们已经移除了一个红球,因此我们剩下的红球总数是 4,总球数是 14。
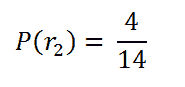
现在我的意思是:如果我们想找出两个选中的球都是红色的概率。这就是我们的情况。比如我们想找出一个患者在第一次时间区间存活的情况下,第二次时间区间存活的概率。我的意思是我们不仅仅想找出第二个时间区间的概率,我们想要的是他们在这个时间段内存活的总概率。
在这种情况下,我们想找出选中的两个球都是红色的概率是多少?
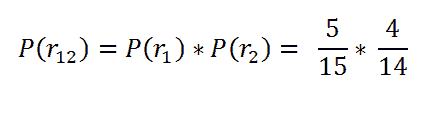
两个红球的概率。
在这里,我们的目标是找出这个人整个时间线上的概率。比如他们在第一次、第二次和第三次时间线中存活,那么他们的生存概率将是:
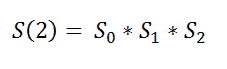
回到我们的主要示例:
(14) Surv_After_probability:
我们想找出一个患者到目前为止存活的概率。现在我们需要找出患者的实际生存概率。
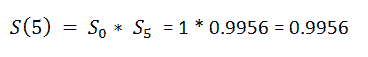
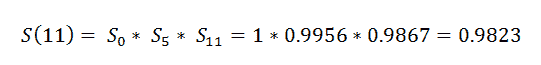
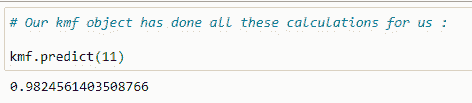
(15) Predict function:
现在,kmf对象的预测函数会为我们完成所有这些工作。但了解其背后的逻辑总是好的。
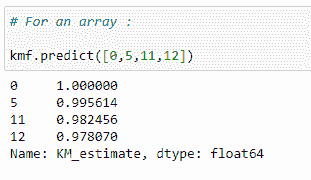
(16) Finding survival probability for an array of the timeline:
我们可以找到一系列时间的概率。
(17)获取整个时间线的生存概率:
kmf 对象的 survival_function_ 提供了我们时间线的完整数据。
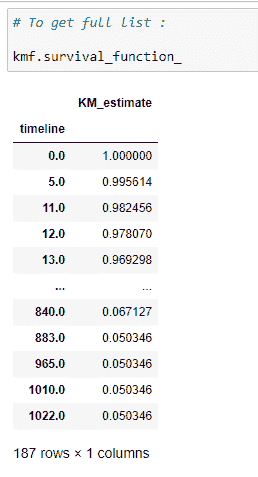
解释:
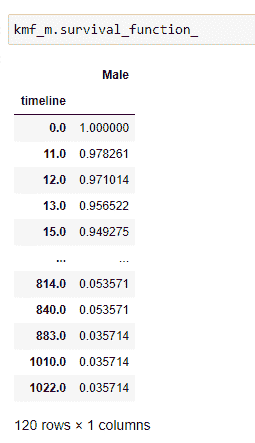
在时间线 0 时,患者的生存概率为 1。如果你仔细考虑,就会明白在诊断后的第 1 天一个人死亡的概率几乎为 0。因此,我们可以说生存概率尽可能高。随着时间线的增加,患者的生存概率会降低。
(18)中位数:
它提供了在平均情况下,50% 的患者存活的天数。

从上述代码中,我们可以说,平均来说,一个人在诊断后的 310 天后生存。
(19)绘制图表:
在这里,我们可以绘制生存概率的图表。
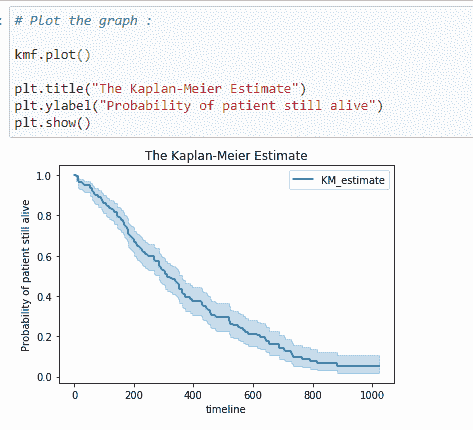
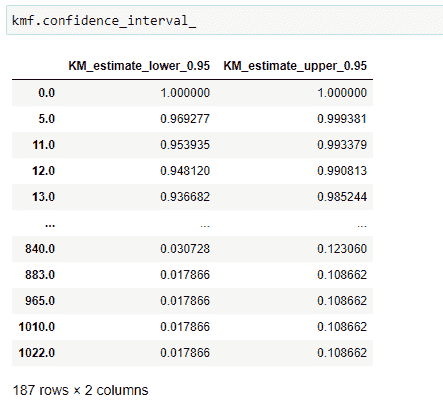
(20)置信区间:
置信区间给出了我们较为确定的真实值所在的范围。你可以在上面的图表中看到,浅蓝色阴影表示生存的置信区间。从中我们可以说该时间线上的概率确实位于该置信区间之间。
现在我们掌握的所有信息都是关于一个人的生存。现在我们将查看某个时间线上的人死亡的概率。在这里要注意,高生存概率对一个人来说是好的,但更高的累积分布密度(死亡概率)则不那么好!
(21)一个人死亡的概率:
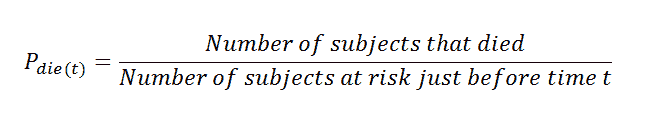
在这里注意到,分母值是时间 (t) 之前的风险对象。简单来说,我们可以说前一行的对象 at_risk。
累积分布密度的公式:
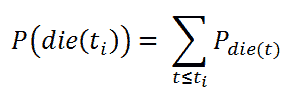
累积分布密度。
手动计算概率:
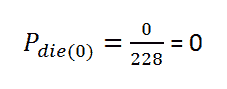
t = 0
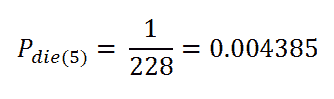
t = 5
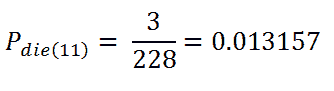
t = 11
查找累积分布密度:
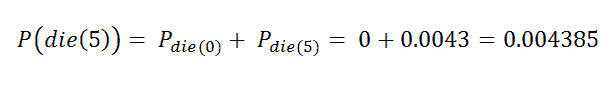
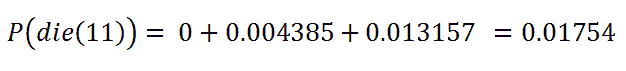
(22)绘制图表:
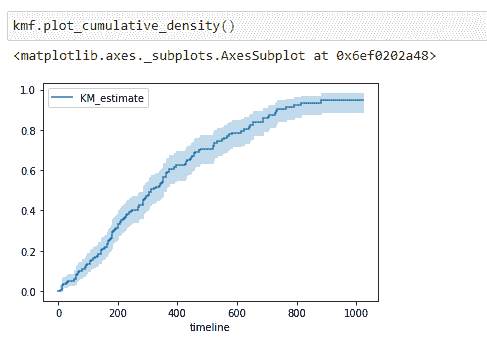
注意到,随着生存天数的增加,死亡概率也增加。
示例 2:使用 Nelson-Aalen 估计风险率
风险函数:
生存函数是总结和可视化生存数据集的好方法。然而,这并不是唯一的方法。如果我们对一个人群的危险函数 h(t) 感到好奇,不幸的是,我们不能转化 Kaplan-Meier 估计。为此,我们使用 Nelson-Aalen 危险函数:
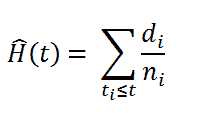
危险函数
其中,
di = 时间 ti 的死亡人数
ni = 开始时的患者数量。
(23) 导入库:
(24) 拟合数据:

(25) 累积危险度:
请记住我们考虑当前行的 at_risk:
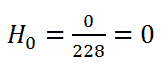
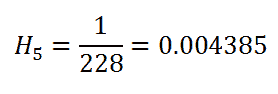
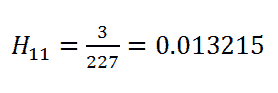
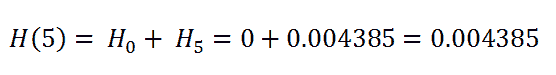
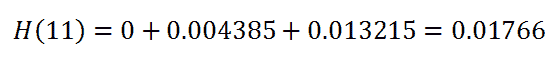
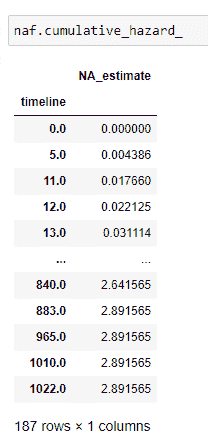
(26) 绘制数据:
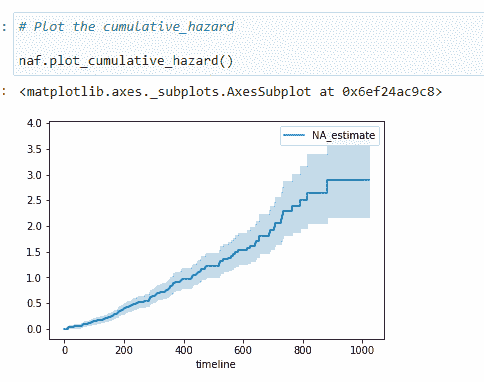
累积危险度不如生存函数那么直观易懂,但危险函数是更高级生存分析技术的基础。
(27) 预测一个值:

综合起来:
在下一篇文章中,我们将讨论对数秩检验和 Cox 回归,并提供示例。
原始。已获许可转载。
简介: Pratik Shukla 是一位有抱负的机器学习工程师,喜欢将复杂理论以简单的方式呈现。Pratik 在计算机科学专业完成了本科,并正在南加州大学攻读计算机科学硕士学位。 “向月亮射击。即使错过,你也会落在星星之间。 -- Les Brown”
相关:
更多相关信息
《Python 生存分析完整指南》第三部分
原文:
www.kdnuggets.com/2020/07/guide-survival-analysis-python-part-3.html
评论
由Pratik Shukla,有志于成为机器学习工程师。
系列索引
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
第一部分:
(1) 生存分析基础。
第二部分:
(2) Kaplan-Meier 拟合器理论与示例。
(3) Nelson-Aalen 拟合器理论与示例。
第三部分:
(4) 基于不同组的 Kaplan-Meier 拟合器。
(5) 带示例的 Log-Rank 检验。
(6) 带示例的 Cox 回归。
在上一篇文章中,我们讨论了如何分析患者的生存概率。但我们还需要知道哪个因素对生存的影响最大。因此,在这篇文章中,我们将讨论基于不同组的 Kaplan-Meier 估计器。
示例 3:带组的 Kaplan-Meier 估计器
让我们将数据分为 2 组:男性和女性。我们的目标是检查如果我们按性别划分数据集,生存率是否存在显著差异。
(1) 导入所需的库:
(2) 读取数据集:
(3) 组织我们的数据:
(4) 创建两个 KaplanMeierFitter()对象:
kmf_m 用于男性数据集。
kmf_f 用于女性数据集。

(5) 将数据划分为组:
(6) 将数据拟合到我们的对象中:

(7) 生成事件表:
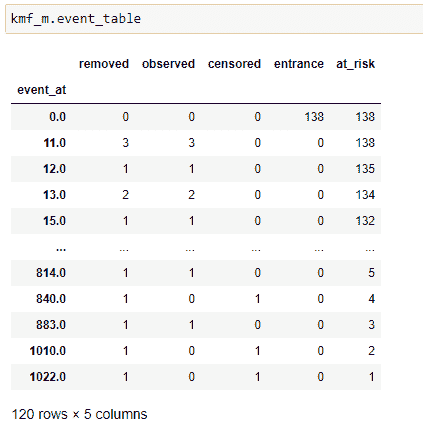
男性事件表。
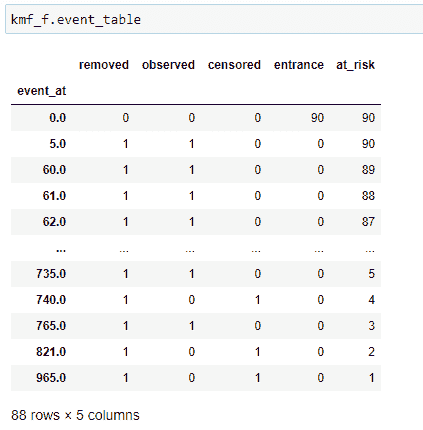
女性事件表。
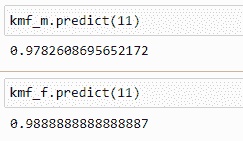
(7) 预测生存概率:
现在我们可以预测两个组的生存概率。
(8) 获取生存概率的完整列表:
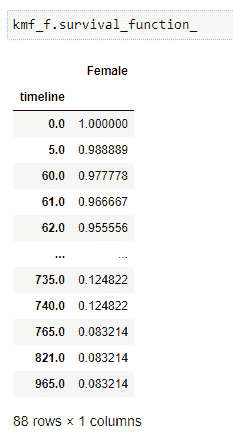
(9) 绘制图表:
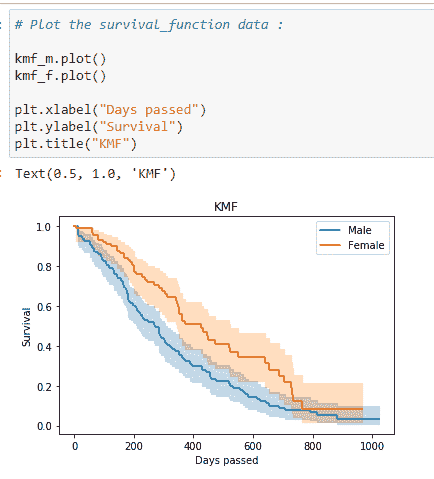
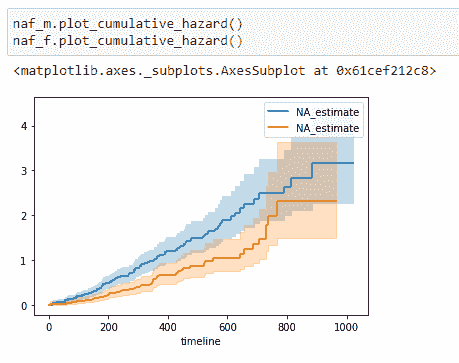
注意到女性存活于肺癌的概率高于男性。因此,从这些数据中,我们可以说医学研究人员应更多关注导致男性患者存活率较低的因素。
(10)累积分布:
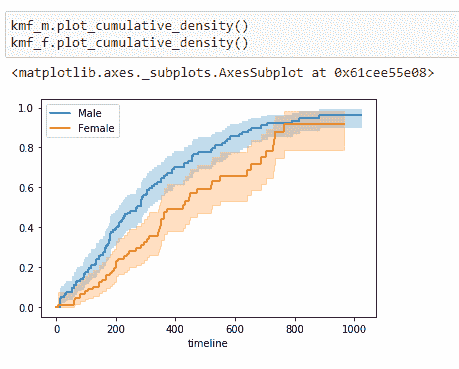
它给出了一个人在某一时间点死亡的概率。

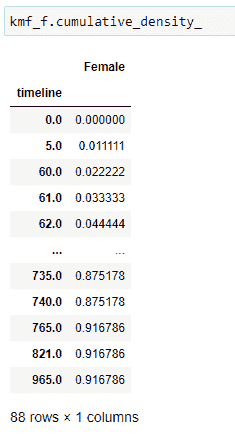
(11)绘制数据:
(12)风险函数:
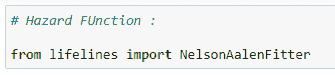
(13)数据拟合:

(14)累积风险:
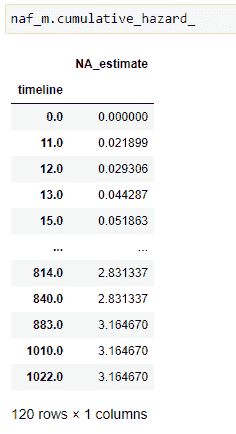
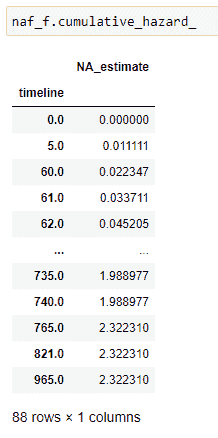
(15)绘制数据:
对数秩检验
目标:在这里,我们的目标是查看被比较组之间是否存在显著差异。
原假设:原假设表明所研究的组之间没有显著差异。如果这些组之间存在显著差异,则必须拒绝我们的原假设。
我们如何说存在显著差异?
统计显著性由一个介于 0 和 1 之间的 p 值表示。p 值越小,所研究组之间的统计差异越大。请注意,我们的目标是找出我们比较的组之间是否存在差异。如果存在,我们可以基于各种信息如饮食、生活方式等进一步研究为何某个组的存活机会较低。
小于(5% = 0.05)P-值表示我们比较的组之间存在显著差异。我们可以根据性别、年龄、种族、治疗方法等对组进行划分。
这是一种找出 P 值的方法。

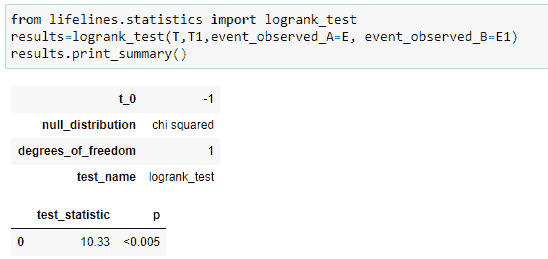
在这里,我们将通过著名的对数秩检验方法比较两个不同组的生存分布。请注意,对于我们的组,检验统计量为 10.33,P 值显示为(<0.005),这是统计上显著的,表示我们必须拒绝原假设,并承认两个组的生存函数存在显著差异。P 值为“性别”与生存天数相关提供了有力证据。简而言之,我们可以说在我们的示例中,“性别”对生存天数有主要贡献。
汇总起来:
示例 4:Cox 比例风险模型
Cox 比例风险模型基本上是一个回归模型,通常由医学研究人员用来找出受试者的生存时间与一个或多个预测变量之间的关系。简而言之,我们想了解年龄、性别、体重、身高等不同参数如何影响受试者的生存时间。
在前一节中,我们了解了 Kaplan-Meier、Nelson-Aalen 和 Log-Rank 检验。但在那些方法中,我们只能逐个考虑变量。而且需要注意的是,我们只对性别、状态等分类变量进行操作,这些变量通常不用于像年龄、体重等非分类数据。作为解决方案,我们使用 Cox 比例风险回归分析,它适用于定量预测(非分类)变量和分类变量。
为什么我们需要它?
在医学研究中,通常我们考虑多个因素来诊断一个人的健康状况或生存时间,即我们通常使用性别、年龄、血压和血糖等因素,以找出不同组之间是否有显著差异。例如,如果我们根据一个人的年龄对数据进行分组,那么我们的目标是找出哪个年龄组的生存机会更高。是儿童组、成人组,还是老年组?现在我们需要找出我们如何分组。为此,我们使用 Cox 回归分析,找出不同参数的系数。让我们看看它是如何工作的!
Cox 比例风险方法的基础:
Cox 比例风险方法的最终目的是观察数据集中不同因素对感兴趣事件的影响。
风险函数:
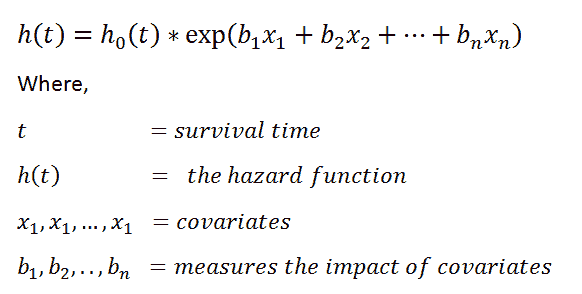
exp(bi)的值称为风险比(HR)。HR 大于 1 表示,当第 i 个协变量的值增加时,事件风险增加,从而生存期减少。
总结一下,

让我们编写代码:
(1) 导入所需库:
(2) 读取 CSV 文件:
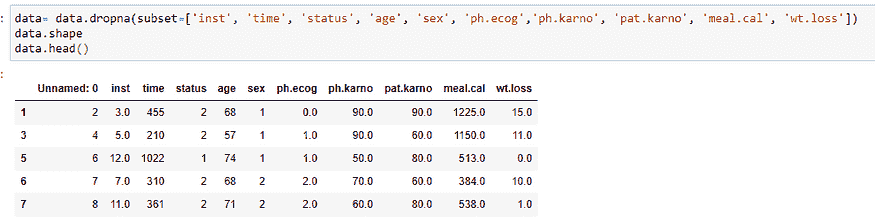
(3) 删除包含空值的行:
在这里,我们需要删除包含空值的行。我们的模型无法处理含有空值的行。如果不对数据进行预处理,我们可能会遇到错误。
(4) 创建 KapanMeierFitter 对象:
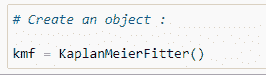
(5) 组织数据:
(6) 拟合值:

(7) 事件表:
(8) 导入 Cox 回归库:

(9)在拟合我们的模型时需要考虑的参数:

(10)拟合数据并打印摘要:
我们的模型将考虑所有参数,以找到相应的系数值。
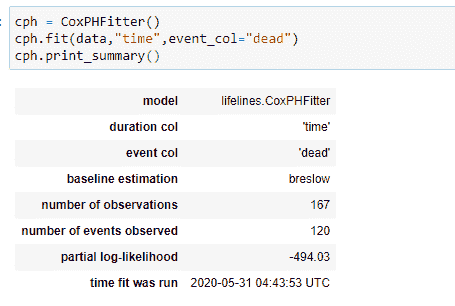
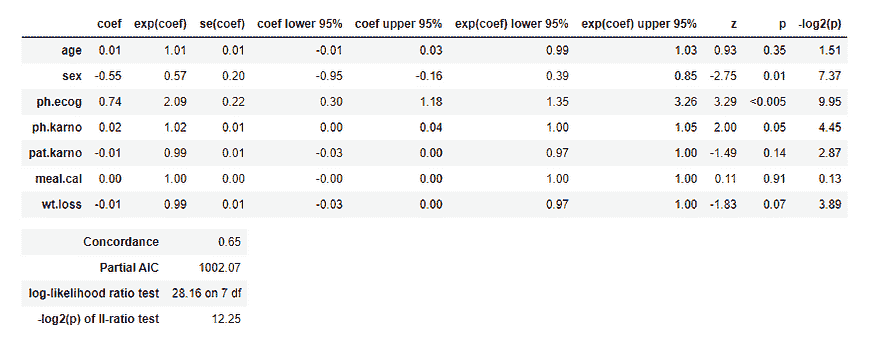
注意不同参数的 p 值,我们知道 p 值(<0.05)被认为是显著的。你可以看到 sex 和 ph.ecog 的 p 值都 <0.05。因此,我们可以根据这些参数对数据进行分组。
HR(风险比) = exp(bi)
性别的 p 值为 0.01,HR(风险比)为 0.57,表明患者性别与死亡风险降低之间存在很强的关系。例如,在其他协变量保持不变的情况下,女性(性别=2)将风险降低了 0.58 倍,即 42%。 这意味着女性的生存几率更高。注意,我们使用前一部分的图表得出了这个结论。
ph.ecog 的 p 值为 <0.005,HR 为 2.09,表明 ph.ecog 值与死亡风险增加之间有很强的关系。在其他协变量保持不变的情况下,较高的 ph.ecog 值与较差的生存有关。这里 ph.ecog 值较高的人有 109% 更高的死亡风险。 所以,简而言之,我们可以说医生试图通过提供相关药物来降低 ph.ecog 的值。
现在注意到年龄的 HR 是 1.01,这表明年龄较大组的风险仅增加 1%。所以我们可以说不同年龄组之间没有显著差异。
简而言之,
(11)检查图表中哪个因素影响最大:
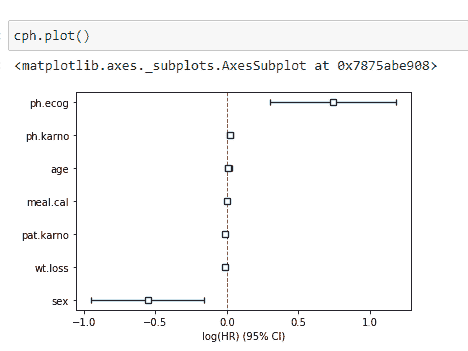
你可以清楚地看到 ph.ecog 和性别变量有显著差异。
(12)绘制图表:
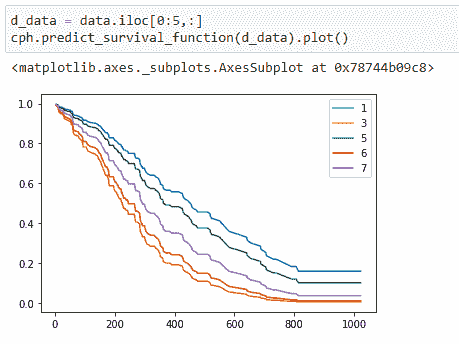
在这里,我绘制了我们数据集中不同个体的生存概率图。注意,person-1 的生存几率最高,而 person-3 的生存几率最低。如果你查看主要数据,你会发现 person-3 的 ph.ecog 值较高。
注意,即使 person-5 仍然活着,由于其较高的 ph.ecog 值,他/她的生存概率较低。
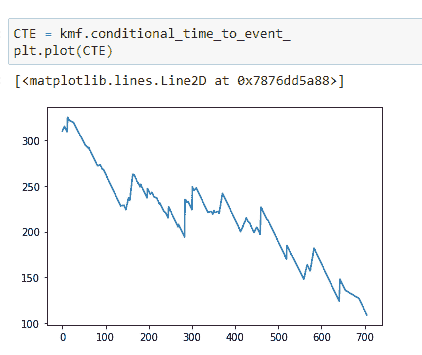
(13)找出时间线的中位事件时间:
注意,随着时间的推移,中位生存时间在减少。
将所有内容整合在一起:
原文。已获得许可转载。
个人简介:Pratik Shukla是一名有抱负的机器学习工程师,喜欢将复杂的理论简化表达。Pratik 完成了计算机科学的本科学业,并计划在南加州大学攻读计算机科学硕士学位。“瞄准月球。即使错过了,你也会落在星星之间。-- 莱斯·布朗”
相关内容:
更多主题
数据科学备忘单指南
原文:
www.kdnuggets.com/2014/05/guide-to-data-science-cheat-sheets.html
评论由 Ajay Ohri,2014 年 5 月。
近年来,随着数据科学家的需求和热度持续增长,人们渴望了解如何加入、学习、进步并在这个看似有利可图的职业中蓬勃发展。作为一个从事分析写作并偶尔教授这门课程的人,我经常被问到——我如何成为一名数据科学家?
我回答的复杂性增加了,因为数据科学似乎是一个多学科领域,而统计学、计算机科学和管理学的大学部门在处理数据时方式各异。
但抛开营销创造的术语不谈,数据科学家只是一个能够用几种语言(主要是 R、Python 和 SQL)编写代码进行数据查询、操作、聚合和可视化的人,并运用足够的统计知识为业务提供可操作的见解,以便做出决策。
由于这种数据科学家的实际定义得到“数据科学家”工作网站上附带词汇的支持,因此,这里有一些学习数据科学主要语言——Python、R 和 SQL 的工具。备忘单或参考卡片是一个主要用于帮助你更快学习该语言语法的命令汇编。
包括 SQL 可能会让一些人感到惊讶(这不是 NoSQL 时代吗?),但这是有逻辑原因的。PIG 和 Hive 查询语言与 SQL——原始的结构化查询语言密切相关。此外,R 中的sqldf包(以及 Pythonic 数据科学家较少使用的python-sql或python-sqlparse库)或甚至旧语言 SAS 中的 Proc SQL 命令,也可以完成数据科学家预期完成的大部分任务(至少在数据清洗方面)。
 对于 Python 而言,这是一个相当部分的列表,因为 Python 是数据科学家工具包中的通用语言,可以用于许多方面。但对于数据科学家而言,numpy、scipy、pandas和scikit-learn的包似乎是最相关的。
对于 Python 而言,这是一个相当部分的列表,因为 Python 是数据科学家工具包中的通用语言,可以用于许多方面。但对于数据科学家而言,numpy、scipy、pandas和scikit-learn的包似乎是最相关的。
所有成千上万的 R 包对有志于数据科学的人都有用吗?不一定。
因此,我们为你选择了合适的备忘单。请注意,这是一个经过筛选的列表。如果在数据科学领域中可以做出任何假设,那就是零假设是数据科学家足够聪明,可以根据数据及其背景做出自己的决策。三份打印件就足以加快有志数据科学家的学习之旅。
请在下方评论中添加额外的备忘单。
Python 的备忘单
-
Python www.astro.up.pt/~sousasag/Python_For_Astronomers/Python_qr.pdf
-
NumPy, SciPy 和 Pandas s3.amazonaws.com/quandl-static-content/Documents/Quandl+-+Pandas,+SciPy,+NumPy+Cheat+Sheet.pdf
R 的备忘单
-
回归分析的 R 函数 cran.r-project.org/doc/contrib/Ricci-refcard-regression.pdf
-
数据挖掘 cran.r-project.org/doc/contrib/YanchangZhao-refcard-data-mining.pdf
![r-data-mining]()
-
Quandl s3.amazonaws.com/quandl-static-content/Documents/Quandl+-+R+Cheat+Sheet.pdf

R、Python(和 Matlab)之间的交叉参考
SQL 备忘单
-
SQL 连接 www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins
-
SQL 和 Hive hortonworks.com/wp-content/uploads/downloads/2013/08/Hortonworks.CheatSheet.SQLtoHive.pdf
附加内容
Ajay Ohri 是一位受欢迎的作者和 博客 写手,专注于分析和数据挖掘,并且是R for Business Analytics一书的作者(Springer, 2012)。
更多相关内容
顶级自然语言处理库指南
原文:
www.kdnuggets.com/2023/04/guide-top-natural-language-processing-libraries.html

图片由作者提供
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
不同语言用于沟通,但被认为是最复杂的数据形式之一。你是否曾考虑过像 Google 翻译、Alexa 和 Siri 这样的语音助手如何理解、处理和响应人类指令?这是因为自然语言处理。NLP 是数据科学的一个分支,旨在使计算机理解语义并分析文本数据,以提取有意义的见解。自然语言处理的一些典型应用如下:
-
机器翻译
-
文本摘要
-
语音识别
-
推荐系统
-
情感分析
-
市场情报
NLP 库是内置的包,用于将 NLP 解决方案集成到你的应用程序中。这些库非常有用,因为它们使开发者能够专注于项目中真正重要的部分。以下是一些流行的 NLP 库介绍,这些库可以用于构建智能应用程序。
1. NLTK - 自然语言工具包
GitHub 星标 ⭐: 11.8k 链接到 GitHub 仓库: 自然语言工具包
NLTK 是最知名的 Python 库,用于处理人类语言数据。它提供了一个直观的界面,拥有超过 50 个语料库和词汇资源。它是一个多功能的开源库,支持分类、分词、词性标注、停用词去除、词干提取、语义推理等任务。
| 优点 | 缺点 |
|---|---|
| 综合 | 学习曲线陡峭 |
| 大型社区支持 | 可能较慢且内存占用高 |
| 广泛文档 | |
| 可定制 |
有用资源
2. SpaCy
GitHub Stars ⭐: 25.7k GitHub 仓库链接: SpaCy
SpaCy 是一个开源库,旨在用于生产环境。它可以快速处理大量文本,是统计 NLP 的完美选择。它提供了多达 80 个预训练的管道,支持 24 种语言,并且目前支持 70 多种语言的分词。除了支持 POS 标注、依存解析、句子边界检测、命名实体识别、文本分类、基于规则的匹配等任务外,它还提供了多种语言学注释,以帮助你深入了解文本的语法结构。这些功能极大地提高了 NLP 任务的准确性和深度。
| 优点 | 缺点 |
|---|---|
| 快速高效 | 与 NLTK 相比支持的语言有限 |
| 用户友好 | |
| 预训练模型 | 一些预训练模型的大小可能会让计算资源有限的用户感到担忧 |
| 允许模型自定义 |
有用的资源
-
SpaCy 在线文档 - 官方文档
-
SpaCy 在线课程 - 使用 SpaCy 的高级 NLP
-
SpaCy Universe 是一个社区驱动的平台,提供基于 SpaCy 的工具、扩展和插件。它还包含了示例和书籍以供指导 - SpaCy Universe
3. Gensim
GitHub Stars ⭐: 14.2k GitHub 仓库链接: Gensim
Gensim 是一个 Python 库,广泛用于主题建模、文档索引和大语料库的相似性检索。它提供了用于词嵌入的预训练模型,这些模型用于识别两个文档之间的语义相似性。例如,预训练的 word2vec 模型可以识别出“巴黎”和“法国”之间的关系,因为巴黎是法国的首都。识别这种语义关系的能力提供了对数据潜在含义和背景的深刻洞察。能够处理比 RAM 更多的输入使得 Gensim 非常有效。
| 优点 | 缺点 |
|---|---|
| 直观界面 | 预处理能力有限 |
| 高效且可扩展 | |
| 支持分布式计算 | 对深度学习模型的支持有限 |
| 提供广泛的算法 |
有用的资源
4. 斯坦福 CoreNLP
GitHub Stars ⭐: 8.9k GitHub 仓库链接: 斯坦福 CoreNLP
斯坦福 CoreNLP 是一个经过充分测试的自然语言处理工具,使用 Java 编写。它以原始人类语言作为输入,并且能够执行各种操作,如词性标注、命名实体识别、依存关系解析和语义分析,只需几行代码。尽管它最初是为英语设计的,但现在也支持多种语言,包括阿拉伯语、法语、德语、中文等。总体而言,它是一个强大且可靠的开源 NLP 工具。
| 优点 | 缺点 |
|---|---|
| 高精度 | 过时的界面 |
| 广泛的文档 | 有限的扩展性 |
| 综合语言学分析 |
有用资源
5. TextBlob
GitHub Stars ⭐: 8.5k GitHub 仓库链接: TextBlob
TextBlob 是另一个用于处理文本数据的 Python 库。它提供了一个非常友好且易于使用的界面。它提供了一个简单的 API 来执行任务,如名词短语提取、词性标注、情感分析、分词、单词和短语频率、解析、WordNet 集成等。我个人推荐给希望熟悉 NLP 任务的初级程序员。
| 优点 | 缺点 |
|---|---|
| 适合初学者 | 性能较慢 |
| 易于使用的界面 | 功能有限 |
| 与 NLTK 集成 |
有用资源
-
官方 TextBlob 文档: TextBlob
-
Analytics Vidhya TextBlob 教程: 使用 TextBlob 轻松处理 NLP
-
自然语言基础与 TextBlob - 简短 NLP 课程
6. Hugging Face Transformers
GitHub Stars ⭐: 91.9k GitHub 仓库链接: Hugging Face Transformers
Hugging Face Transformers 是一个强大的 Python NLP 库,拥有数千个预训练模型,可用于执行 NLP 任务。这些模型在大量数据上训练,可以理解文本数据中的潜在模式。使用预训练模型可以节省开发者的时间和资源,相比从头训练自己的模型。Transformer 模型还可以执行诸如表格问答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问答等任务。
| 优点 | 缺点 |
|---|---|
| 易于使用 | 资源消耗大 |
| 大型且活跃的社区 | 昂贵的云服务 |
| 语言支持 | |
| 较低的计算成本 |
有用资源
-
官方文档 - Hugging Face Transformer 文档
-
Hugging Face 社区论坛 - 社区论坛
-
高级介绍 Hugging Face Transformers - Coursera
结论
NLP 库在加速 NLP 研究进展方面发挥了重要作用。这使得机器能够与人类有效沟通。尽管 NLP 任务刚开始可能看起来有些复杂,但凭借合适的工具,你可以很好地处理这些任务。上述列表仅提及当前在 NLP 中使用的顶级库,但还有许多其他的库供你探索。希望你从这篇文章中学到了一些有价值的东西,我鼓励你尝试这些工具,并创造一些有趣的东西。
Kanwal Mehreen 是一位有抱负的软件开发者,对数据科学和人工智能在医学中的应用充满浓厚兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写有关热门话题的文章来分享技术知识,并且热衷于提升女性在科技行业中的代表性。
更多相关话题
使用 Tensorflow 训练图像分类模型的指南
原文:
www.kdnuggets.com/2022/12/guide-train-image-classification-model-tensorflow.html
人类在很小的时候就学会了识别和标记视觉图像。现在,随着机器学习和深度学习算法的出现,计算机能够大规模且高精度地分类图像。这些先进的算法有许多应用——常见的包括区分健康的肺部扫描、移动设备的人脸识别,或将物体分类为零售商的不同类别。

本文解释了计算机视觉的一个应用,即图像分类,并说明了如何使用 Tensorflow 在小型图像数据集上训练模型。
数据集和目标
为了演示的目的,我们将使用包含 0 到 9 数字图像的MNIST数据集。样本图像如下所示:
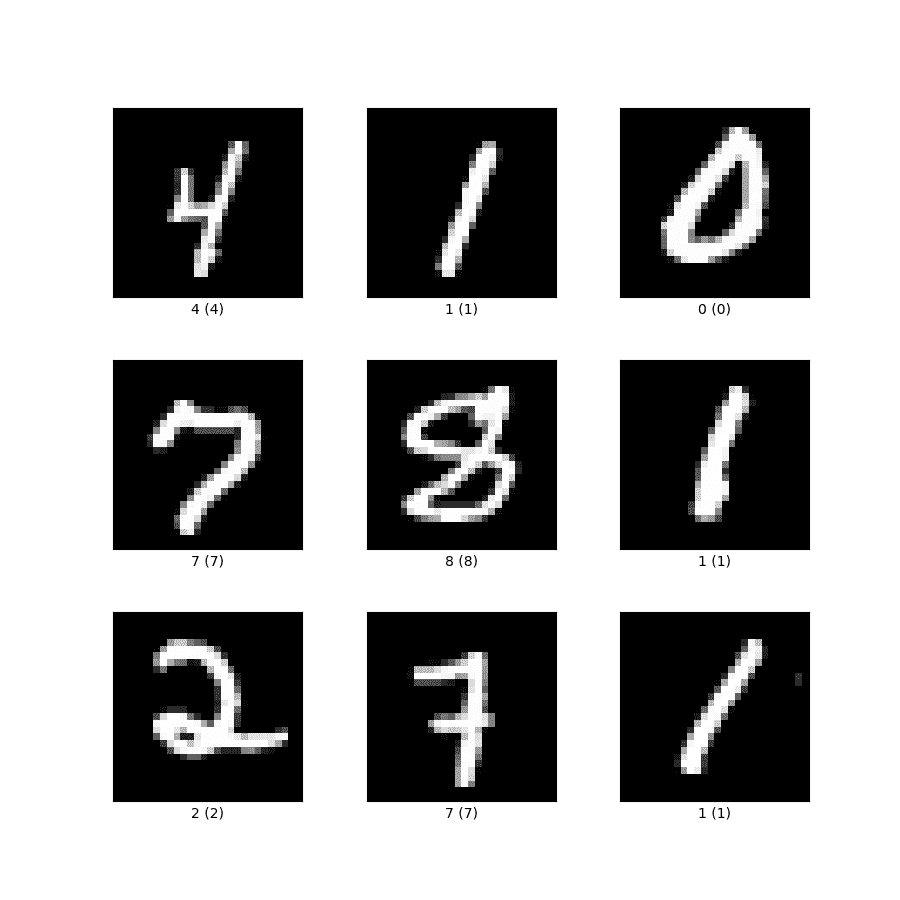
训练这个模型的目的是将图像分类到它们各自的标签,即对应的数字等价物。使用一个输入层、一个输出层、两个隐藏层和一个 Dropout 层的深度神经网络架构来训练模型。CNN 或卷积神经网络是较大图像的首选,因为它能够在减少输入大小的同时捕捉相关信息。
入门指南
首先,导入所有相关的库,包括 TensorFlow、to_categorical(用于将数值类值转换为类别)、Sequential、Flatten、Dense 和 Dropout,用于构建神经网络架构。如果这些库中的一些对你来说是新的,不用担心。它们将在接下来的部分中进行解释。
超参数
以下提示帮助你选择正确的超参数:
-
让我们定义一些超参数作为起点,你可以调整它们以进行不同的实验。我们选择了 128 的迷你批量大小。批量大小可以取任何值,但选择一个 2 的幂作为批量大小在内存使用上更高效,因此是首选。让我们还理解决定适当批量大小的主要原因——过小的批量大小会使收敛过程非常嘈杂,而过大的批量大小可能无法适应你的计算机内存。
-
我们将 epoch 数量设置为 50,以快速训练模型。数据集较小且简单,适合较低的 epoch 数量。
-
接下来,你需要添加隐藏层。我们保留了两个各 128 个神经元的隐藏层——你也可以尝试 64 和 32。对于像 MINST 这样简单的数据集,不推荐使用更高的数字。
-
你可以尝试不同的学习率,如 0.01、0.05 和 0.1。为了演示的目的,保持在 0.01。
-
其他超参数如衰减步数和衰减率分别选择为 2000 和 0.9。它们用于在训练过程中减少学习率。
-
选择 Adamax 作为优化器,尽管你还可以选择其他优化器,如 Adam、RMSProp、SGD 等。你可以阅读更多关于可用优化器列表以及它们的区别,以选择适合你解决方案的优化器。
import tensorflow as tf
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
params = {
'dropout': 0.25,
'batch-size': 128,
'epochs': 50,
'layer-1-size': 128,
'layer-2-size': 128,
'initial-lr': 0.01,
'decay-steps': 2000,
'decay-rate': 0.9,
'optimizer': 'adamax'
}
mnist = tf.keras.datasets.mnist
num_class = 10
# split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# reshape and normalize the data
x_train = x_train.reshape(60000, 784).astype("float32")/255
x_test = x_test.reshape(10000, 784).astype("float32")/255
# convert class vectors to binary class matrices
y_train = to_categorical(y_train, num_class)
y_test = to_categorical(y_test, num_class)
创建训练和测试集
-
TensorFlow 库还包括 MNIST 数据集,你可以通过调用 datasets.mnist,然后在对象上调用 load_data()来分别获取训练(60,000 个样本)和测试(10,000 个样本)数据集。
-
接下来,你需要重新调整和归一化训练和测试图像,其中归一化将图像像素强度限制在 0 到 1 之间。
-
使用之前导入的 to_categorical 方法将训练和测试标签转换为类别。这对于向 TensorFlow 框架传达输出标签即 0 到 9 是类别而不是数值性质至关重要。
设计神经网络架构
理解如何设计神经网络架构的细节非常重要。
-
通过添加 Flatten 来定义 DNN(深度神经网络)结构,将 2D 图像矩阵转换为向量。输入神经元对应于这些向量中的数字。
-
接下来,使用 Dense()方法添加两个隐藏的全连接层,并从之前定义的“params”字典中提取超参数。我们将这些层的激活函数设置为“relu”,即修正线性单元,它是神经网络隐藏层中最常用的激活函数之一。
-
接下来使用 Dropout 方法添加 dropout 层。它用于在训练神经网络时避免过拟合。一个过拟合的模型倾向于准确记住训练集,而无法对未见过的数据集进行泛化。
-
输出层是我们网络中的最后一层,使用 Dense()方法定义。需要注意的是,输出层有 10 个神经元,分别对应于类别(数字)的数量。
# Model Definition
# Get parameters from logged hyperparameters
model = Sequential([
Flatten(input_shape=(784, )),
Dense(params('layer-1-size'), activation='relu'),
Dense(params('layer-2-size'), activation='relu'),
Dropout(params('dropout')),
Dense(10)
])
lr_schedule =
tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=experiment.get_parameter('initial-lr'),
decay_steps=experiment.get_parameter('decay-steps'),
decay_rate=experiment.get_parameter('decay-rate')
)
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adamax',
loss=loss_fn,
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=experiment.get_parameter('batch-size'),
epochs=experiment.get_parameter('epochs'),
validation_data=(x_test, y_test),)
score = model.evaluate(x_test, y_test)
# Log Model
model.save('tf-mnist-comet.h5')
训练时间
现在我们已经定义了架构,让我们用给定的训练数据来编译和训练神经网络。
-
定义一个学习率调度器,使用 ExponentialDecay(指数衰减学习率),并以初始学习率、衰减步数和衰减率作为参数。
-
定义损失函数为 CategoricalCrossentropy(用于多类分类)。
-
通过将优化器(adamax)、损失函数和指标(选择准确率,因为所有类别同等重要且均匀分布)作为参数传递来编译模型。
-
通过调用 fit 方法,传入 x_train、y_train、batch_size、epochs 和 validation_data 来拟合模型。
-
调用模型对象上的 evaluate 方法,以获取模型在未见数据集上的表现分数。
-
你可以使用 save 方法将模型对象保存以供生产使用。
这篇文章解释了训练深度神经网络进行图像分类任务的基础知识,并且是熟悉使用神经网络进行图像分类任务的良好起点。它详细阐述了选择正确参数和架构的一般方法和理由。
Vidhi Chugh 是一位 AI 策略师和数字化转型领导者,她在产品、科学和工程的交汇处工作,致力于构建可扩展的机器学习系统。她是获奖的创新领袖、作者和国际演讲者,致力于使机器学习民主化,并让每个人都能参与这一转型。
了解更多关于此主题的信息
转型为数据科学职业的逐步指南 – 第一部分
原文:
www.kdnuggets.com/2019/05/guide-transitioning-career-data-science-part-1.html
评论
如果你想将职业转型为数据科学,最常听到的建议可能是学习 Python 或 R,或通过参加 Coursera 上的 Andrew Ng 的机器学习课程来学习机器学习,或开始学习大数据技术,如 Spark 和 Hadoop。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 支持
我称这是通向数据科学职业的技术导向路线。
如果你是程序员或有博士学位,这种方法完全合理。如果你来自非技术背景,最简单的入门数据科学的方法是采取以领域知识为重点的方法。
如果你查看 Drew Conway 的维恩图,你会发现数据科学家不仅仅具备技术技能。他们还具备领域专长。
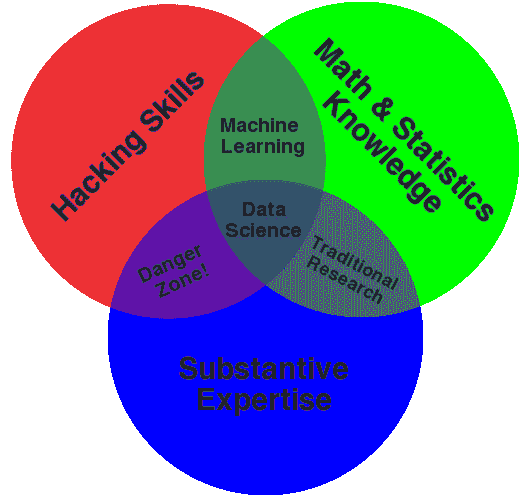
那么,为什么不利用它呢?我一直相信发挥自己的优势。
让我详细解释一下这种方法。
第一步:发现你的理想工作
数据科学在多个领域(如市场营销、金融、人力资源等)中用于解决有趣的商业问题。
你的第一步是选择一个与你领域相关的数据科学职位。
让我通过一个例子来说明这一点。
我将假设自己是一个数字营销人员,想要转型到数据科学。如果我在 Google 上搜索“营销数据科学职位”,我会得到一系列职位发布,标题如下:
-
“高级市场营销数据分析师”
-
“高级数据科学家 - 市场营销”
-
“市场营销分析专员”
然后我会逐一查看每个描述,以了解这些职位标题中哪些最接近我当前的技能(在领域知识方面)。
通过这个练习,我发现“营销数据分析师”角色很适合我。我还排除了高级职位,因为它们需要数据科学的经验——因此,它们不是好的目标。
这是一个营销数据分析师职位的描述:

该职位的强有力候选人应具备一定的 Google Analytics 技能,了解在线指标(如访问量、转化率等),并知道如何进行活动分析。如果我是一名具备这些技能的数字营销员,那么我就是这个职位的强有力候选人。
以下是职位描述中列出的技术技能:

在这个阶段,我不打算担心职位描述中列出的技术和分析技能,因为我的重点只在于领域知识。
你可以运用相同的原则来选择你领域内的目标职位。
一旦你确定了目标职位,是时候筛选你的目标公司了。
第 2 步:发现你的梦想公司
你必须根据以下两个标准之一,筛选出 5 家公司作为目标:
-
他们经常发布你目标职位头衔的招聘广告。
-
有很多人拥有你所针对的职位头衔。
我发现,主要招聘数据科学专业人员的公司通常属于以下类别之一:
-
中型科技公司
-
精品数据科学咨询公司
-
大型咨询公司
-
主要金融机构
-
大型零售公司
在主要科技公司(如 Facebook、Google 或 Amazon)获得入门级数据科学职位是相当困难的,因此不要以它们为目标。
对于我的“营销数据分析师”职位,我已经筛选出了加拿大前 5 名银行:
-
TD 银行
-
RBC
-
CIBC
-
BMO
-
道明银行
第 3 步:与合适的人建立网络
你已经选定了目标职位和几家公司,做了功课。但从你的房间里,你能做的也有限。
你还有很多问题,例如:
我真的能得到这个工作吗?
下一步我该做什么?
你如何回答这些问题?
通过测试。
除了这次,你将与真实的人交流:那些已经经历过的人。
以下是你可以遵循的步骤:
-
找到你所筛选公司中拥有目标职位头衔的人
-
给他们发电子邮件,安排咖啡会面或电话会议。
-
出席并提出好的问题。
-
跟进并建立真实的关系。
第一步是使用 LinkedIn 找到每个目标公司中至少 2 个已经拥有你目标职位头衔的人。
在我的情况下,我会在 LinkedIn 搜索栏中输入“Marketing Data Analysts TD Bank”以获取 TD 银行的目标人员列表。
如果他们在 LinkedIn 上有 500+个连接,我会通过 LinkedIn 联系他们,否则我会通过电子邮件联系他们。
你可以使用一个名为“Voila Norbert”的工具来获取他们的官方电子邮件地址。你只需在这个工具中输入他们的姓名和他们所在组织的域名即可获取他们的电子邮件地址。
你可以使用一些模板与联系人取得联系:
初始 LinkedIn 请求消息:
我在 LinkedIn 上研究市场数据分析师职位时,注意到你是[公司名称]的市场数据分析师。你的职业道路对我很有启发。我正在寻找理想工作,想向你请教 3-5 个关于你职业道路的问题。
一旦他们接受了你的 LinkedIn 请求:
感谢你接受我的请求。
我的名字是 [名字],和 [关于你的几句话]。
正如我之前所说,我正在寻找我的梦想工作([你的目标职位]),希望向你请教 3-5 个关于你在 [公司名称] 的经验的问题。
你的见解对我会很有帮助。我将在 9 月 14 日(星期五)到 9 月 17 日(星期一)在城里。你是否在 9 月 14 日到 17 日之间的任何时间可以抽空喝杯咖啡聊聊?
你可以将上述 LinkedIn 信息作为你的第一次联系邮件,主题行如下:
有志的数据科学家——寻求最佳建议
如果 3 天后没有收到回复,请发送一封类似的跟进邮件:
我想跟进我之前的信息。*
此时,我已经:*
- 确定我想追求的职位:市场数据分析师 *
- 以及我有兴趣申请的公司列表,也已经彻底研究过。
我确实有一些关于我的方法的问题——这就是我联系像你这样的专家的原因(你已经拥有了我梦寐以求的工作)。
我坚信,你对我数据科学求职市场的指导和反馈将对我有很大帮助。
再次,如果 2 个工作日后没有收到回复,请再发送一封跟进邮件:
嗨 [名字],我想最后一次跟进我之前的信息。如果没有收到回复,我将假设时机不对。你的指导将对我追求梦想工作的旅程帮助很大。
在联系你的任何目标之前,看看你是否认识可以介绍你的人。可以是你的校友或前同事。
你也可以使用一个简单的 Excel 表格来跟踪整个过程。这是一个示例:

假设你的一个目标联系人同意了,让我们讨论一下实际会议中该做什么。
记住,这些非正式会议是为了测试你的想法并获得新见解。它们不是为了获得工作。在这里绝不要询问工作。你处于研究阶段。现在你只是收集信息。它们也不是为了谈论你自己,所以请友善地倾听。你的任务是学习,而不是谈论自己。
如果你有半小时的会议,应该花大约 25 分钟提问。在最后五分钟,你可以花几分钟谈谈自己。
尝试提出聪明的问题。在实际提问之前,尝试自己回答每一个问题。为每个答案进行情景规划。
你可以问一些问题:
-
我想了解一下你是如何开始你的数据科学职业生涯的。
-
你能告诉我数据科学如何为[公司名称]创造价值吗?最近的一些工作例子?
-
[公司名称] 的团队经常使用哪些软件和机器学习技术?
-
团队的典型背景是什么?
-
[公司名称] 是否雇用没有数据科学经验的人?
-
如果是这样,他们在寻找没有该领域经验的候选人时,会看重哪些重要技能和特征?
-
如果我申请了[公司名称],你认为什么会让我脱颖而出?如果我下周有面试,你会给我什么建议?
会议结束后,当天就发一封感谢邮件。
再次感谢你昨天与我会面——这对我非常有帮助。
我认为我的下一步是[包括你们对话中的一些内容]。
请告诉我是否有什么我可以做的来回报这份恩情!
你应该在目标公司见到至少 2 个人。
到目前为止,你已经进行过十次咖啡会议,并对所有问题都有了答案。你打算如何处理这些答案?如何说服你见过的人你是一个强有力的候选人?
这正是我将在下一个博客文章中讨论的内容。敬请关注。
相关:
-
转型为数据科学家的逐步指南 – 第二部分
-
成为数据科学家
-
转型为数据科学:如何成为数据科学家,以及如何创建数据科学团队
更多相关话题
将职业转型为数据科学的逐步指南 – 第二部分
原文:
www.kdnuggets.com/2019/06/guide-transitioning-career-data-science-part-2.html
评论

这是我关于同一主题的上一篇博客文章的延续。确保你在继续阅读这里之前先阅读了那篇文章。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
第 5 步:构建你的作品集项目
你的潜在客户已经回答了你所有的问题。现在,你需要分析这些答案并回答这两个问题:
-
“我的潜在客户正在解决什么业务问题?”
-
“他们掌握的主要技术技能是什么?”
就这样,没有更多内容了。
回到我的例子,如果我的大多数潜在客户说他们分析来自 Google Analytics 的网站数据并将这些见解呈现给数字营销总监。他们主要使用 SQL 和 Tableau 进行分析,但很少使用 Python 或 R。如果他们还提到大多数市场数据分析师在工作中学习 R 或 Python。
那么我知道我必须开始学习 SQL 和 Tableau。如果我一开始就开始学习 Python 或 R,我就会浪费时间。
下一步是基于本节中两个问题的答案快速构建一个作品集项目。不要立刻报名参加课程以学习构建项目所需的技术技能。相反,你应该学习足够的技术技能来完成你的作品集项目。我从《The First 20 Hours: How to Learn Anything . . . Fast!》的作者 Josh Kaufman 那里学到了这种方法。
对我而言,我必须分析 Google Analytics 数据,并在 Tableau 中开发一个仪表板来可视化我的分析见解。你的第一步是找到项目的数据源。你可以在 Kaggle 上找到有趣的数据集。你也可以通过“19 个地方找到免费的数据集”来寻找数据集。
对于我的项目,我将使用Kaggle 上的 Google Analytics Customer Revenue数据集。然后在我的笔记本电脑上安装 Microsoft SQL 服务器,并将数据集上传到 SQL 服务器。我这样做是因为根据我的了解,市场数据分析师使用 SQL 来提取数据。所以我想展示我掌握了 SQL。
项目的第一步是了解数据集,并提出 2 到 3 个你可以通过分析回答的有趣的业务问题。你还需要知道数据集中哪些列(或特征)是回答这些问题所需的。这时你的领域知识就派上用场了。
不要试图让这个项目变得复杂,你的目标是构建一个能让你获得工作的项目。我称这个投资组合项目为“最小可行项目”。
对于我的市场数据分析师角色,我必须学习 SQL 和 Tableau。所以,首先我学习 SQL 和 Tableau 的基础知识。你不应该在学习基础知识上花费超过 10 小时。
一旦你学会了基础知识,你的下一步是找到一个导师,他可以帮助你制定一个详细的计划,按照步骤逐步推进你的项目。选择一个在数据科学领域有丰富经验的导师。你可以使用像Clarity或Mentor Cruise这样的服务来寻找经验丰富的数据科学家。安排与数据科学导师的电话会议,询问他们解决问题的最佳方法。详细说明你想解答的业务问题。
在你收到如何回答业务问题的具体计划后,开始你的项目。
如果在进行项目时遇到困境,或在像 Stack Overflow 这样的论坛上找不到技术问题的答案,你可以再次安排与导师的电话会议,寻求他们的帮助。你也可以在CodeMentor上找到专家以获得技术帮助。
完成项目后,再次与导师复审项目并获取反馈。
在做这些事情的同时,你也应该与潜在客户保持联系。只需根据与你之前的对话发送一篇有趣的文章:
在 KDnuggets 上看到这篇文章,想起了你说的市场科学相关的内容!无需回复,只是觉得你可能会觉得有趣。
第 6 步:向招聘经理索取介绍
一旦你的项目完成,将其托管到 Github 上。并撰写一篇深入的博客文章,介绍你是如何开展这个项目的。在写博客时,技术细节要尽量减少,因为你写这篇博客是为了吸引招聘团队中的业务经理。招聘团队将包括技术和业务人员。技术经理会查看你在 Github 上的代码,但业务经理更关心你通过分析想回答哪些业务问题。
将你的项目和博客文章的链接发送给你的前景并请求反馈。如果大多数前景给出某种反馈,那么在你的项目中实施这些建议。现在,你的前景也会说如果有工作机会他们会推荐你。
感谢他们,但不要发送你的简历。相反,要求他们介绍你认识团队中更有经验的人。以下是你可以使用的示例邮件:
谢谢你的反馈。我在我的项目中实施了你的建议。
在我们上次的聊天中,你提到[人名]是谈论[公司名]潜在的市场数据分析师职位的合适人选。我很感兴趣,并且希望与她/他交谈。你是否愿意帮忙联系她/他?我保证尊重她/他的时间。
如果需要,我可以为你发送一封预格式化的介绍邮件,让事情变得非常简单。如果不需要,也没关系——再次感谢你的帮助!
你的目标是联系到他们团队中的高级人员。一个有权聘用你的人。
如果你的前景同意,你就成功了——80-90%的情况下,你会收到招聘经理的会议或电话。你的前景很可能会做出介绍,因为你在根据他们的反馈采取行动,并且你视他们为导师。因此,这更像是一种导师-学员关系。
通过适当的介绍,VIP 几乎每次都会同意与你交谈。
在实际会议中,把它当作一次非正式的会谈——不是推销,而是非正式的对话:提问,与自己的经历相关联,提出你的想法。在谈话中也可以谈论你的项目,但不要炫耀。
最重要的是,先不要要求面试,因为你不知道他们是否有相同的感觉。只需说:“非常感谢您抽出时间与我会面。我会花些时间考虑这些问题。几天后我能否再跟进一下?”他们会说“可以”。然后,发送一封表达你兴趣的邮件,并询问他们推荐的下一步措施。如果他们喜欢你,你几乎可以保证会有面试——而且你已经和招聘经理喝过咖啡了。这是非常重要的。
那么,招聘经理在想什么?
再次,把自己放在招聘经理的角度。他们面临大问题,但找到合适的帮助很困难。如果他们能找到一个“明白情况”的人并能迅速上手就好了。你,聪明且有洞察力的候选人,理解他们的世界。如果有些漏洞也没关系——你显然是一个快速学习者,而且你已经做了功课(你的项目)。他们会想,“哇,他似乎聪明、正常、才华横溢……我们至少应该把他请进来了解更多。”
会后向招聘经理发送感谢邮件。在感谢邮件中你也应提供你项目的链接。同时,让你的前景保持更新。以下是你可以发送给前景的邮件:
嘿,[名字]
只是想让你知道我前几天和[公司名称]的[招聘经理]见了面,效果很好!他邀请我申请市场数据分析师职位,我会在本周晚些时候申请。
无需回应;只是让你了解情况。非常感谢——没有你我做不到!
-[你的名字]
步骤 7:准备你的简历并破解面试
现在是时候准备你的简历和求职信了。你的简历和求职信应该针对你申请的职位。将你潜在雇主和招聘经理的话语融入到你的简历中。这就是为什么在会议中做笔记非常重要。
简历实际上只需要这两个主要部分:
-
经验
-
教育
这是 Quora 数据科学经理 William Chen 的一段精彩视频,讲解如何准备数据科学简历。
在将简历发送给招聘经理后,你需要为面试做好准备。
你在前期投入的所有工作在面试中大有回报,因为你:
-
进行了更深入的研究
-
建立了更好的联系
-
你有一个针对他们需求的项目
你 80%的工作是在面试前完成的。现在是时候完成剩下的 20%工作了。
此时,你的潜在雇主对你充满好奇。你提交了一个令人印象深刻的申请,甚至还有共同联系人的介绍。现在,他们希望你来见见团队,回答一些问题,并聊一会儿。还有,他们也想回到工作中!他们希望你成功——如果你适合这个职位。所以,做好面试准备。
为一些最常见的面试问题准备脚本,例如:
-
“告诉我关于你自己的事。”
-
“你为什么想在这里工作?”
-
“谈谈你以前的工作经验”
-
“谈谈你发送给我们的项目”
破解面试,获得你的第一个梦想数据科学职位。
结论
我理解这个过程比盲目地提交简历要困难得多,但从长远来看回报更丰厚。
如果你有任何问题,请在评论中告诉我!
相关:
-
将你的职业转型为数据科学的逐步指南 – 第一部分
-
雇主希望看到的数据科学项目:如何展示业务影响
-
数据科学作品集中的项目
更多相关内容
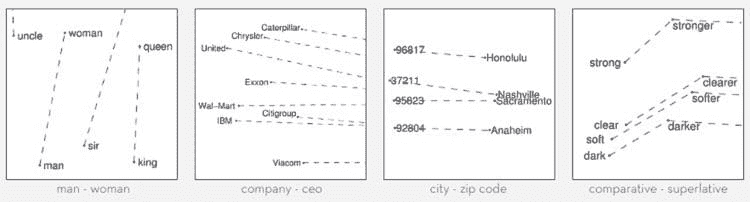
NLP 中不同词嵌入技术的终极指南
原文:
www.kdnuggets.com/2021/11/guide-word-embedding-techniques-nlp.html

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
“你可以通过一个词所处的环境来了解它!”
—约翰·鲁珀特·费斯
如果计算机能开始理解莎士比亚的作品?或者像 J.K. 罗琳那样写小说?这在几年前是不可想象的。近年来,自然语言处理(NLP)和自然语言生成(NLG)的最新进展使计算机在理解基于文本的内容方面的能力大大提升。
为了理解和生成文本,基于 NLP 的系统必须能够识别单词、语法以及大量的语言细微差别。对于计算机来说,这比说起来要困难得多,因为它们只能理解数字。
为了弥补这一差距,自然语言处理(NLP)专家开发了一种称为词嵌入的技术,将单词转换为其数值表示。一旦转换完成,自然语言处理算法可以轻松处理这些学习到的表示,以处理文本信息。
词嵌入将单词映射为实值数值向量。它通过对序列(或句子)中的每个单词进行标记化,并将其转换为向量空间来实现。词嵌入旨在捕捉文本序列中单词的语义意义。它为具有相似含义的单词分配类似的数值表示。
让我们来看看 NLP 中一些最有前景的词嵌入技术。
TF-IDF — 词频-逆文档频率
TF-IDF 是一种基于统计度量的机器学习(ML)算法,用于找出文本中单词的相关性。文本可以是一个文档或多个文档(语料库)。它是两种指标的结合:词频(TF)和逆文档频率(IDF)。
TF 分数是基于文档中单词的频率。通过计算单词在文档中出现的次数来确定 TF。TF 的计算方法是将单词(i)出现的次数除以文档(j)中的总单词数(N)。
TF (i) = log (frequency (i,j)) / log (N (j))
IDF 分数计算词语的稀有性。这一点很重要,因为 TF 会给出现频率较高的词语更多的权重。然而,在语料库中很少使用的词语可能包含重要的信息。IDF 捕捉到这些信息。它可以通过将文档总数(N)除以包含该词语的文档数量(i)来计算。
IDF (i) = log (N (d) / frequency (d,i))
在上述公式中使用 log 来减弱 TF 和 IDF 大分数的影响。最终的 TF-IDF 分数通过将 TF 和 IDF 分数相乘来计算。
TF-IDF 算法用于解决简单的 ML 和 NLP 问题。它更适合用于信息检索、关键词提取、停用词(如 ‘a’,‘the’,‘are’,‘is’)移除以及基本的 文本分析。它无法高效捕捉词语序列的语义意义。
Word2Vec — 捕捉语义信息
由 Tomas Mikolov 和 Google 的其他研究人员于 2013 年开发的 Word2Vec 是一种用于解决高级 NLP 问题的词嵌入技术。它可以遍历大量的文本语料库来学习词语之间的关联或依赖关系。
Word2Vec 通过使用 余弦相似度 度量来发现词语之间的相似性。如果余弦角度为 1,意味着词语重叠。如果余弦角度为 90,则意味着词语是独立的或没有上下文相似性。它为相似的词语分配相似的向量表示。
Word2Vec 提供了两种基于 神经网络 的变体:连续词袋模型(CBOW)和 Skip-gram。在 CBOW 中,神经网络模型以各种词语作为输入,预测与输入词语上下文紧密相关的目标词语。另一方面,Skip-gram 架构以一个词语作为输入,预测与之紧密相关的上下文词语。
CBOW 速度较快,并为常见词语找到更好的数值表示,而 Skip Gram 能有效地表示稀有词语。Word2Vec 模型擅长捕捉词语之间的语义关系。例如,国家与其首都之间的关系,如巴黎是法国的首都,柏林是德国的首都。它最适合执行 语义分析,这在推荐系统和知识发现中有应用。
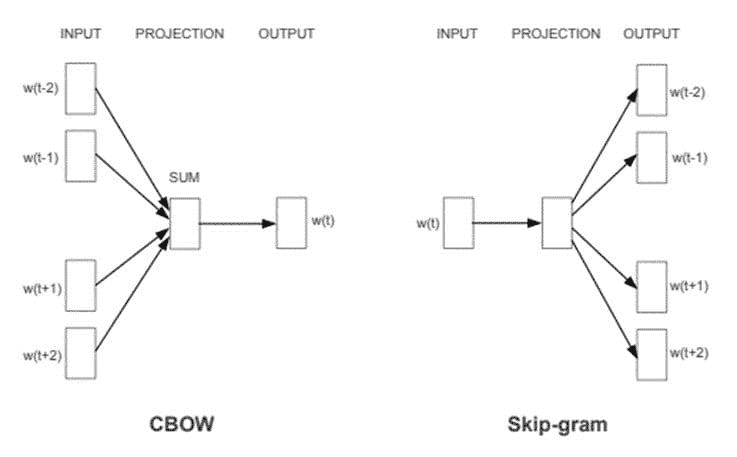
CBOW & Skip-gram 架构。图片来源: Word2Vec 论文。
GloVe — 全局词向量表示
由 Jeffery Pennington 及斯坦福大学的其他研究人员开发的,GloVe扩展了 Word2Vec 的工作,通过计算全球词-词共现矩阵来捕捉文本语料库中的全球上下文信息。
Word2Vec 仅捕捉词汇的局部上下文。在训练过程中,它仅考虑邻近的词来捕捉上下文。GloVe 考虑整个语料库,并创建一个大矩阵,可以捕捉语料库中词汇的共现。
GloVe 结合了两种词向量学习方法的优点:矩阵分解方法,如潜在语义分析(LSA)和局部上下文窗口方法,如 Skip-gram。GloVe 技术具有更简单的最小二乘成本或误差函数,从而降低了模型训练的计算成本。生成的词嵌入在某些方面有所不同且有所改进。
GloVe 在词汇类比和命名实体识别问题上表现显著更好。在某些任务中,它优于 Word2Vec,并在其他任务中与之竞争。然而,两种技术在捕捉语料库中的语义信息方面都表现良好。
GloVe 词向量捕捉到语义相似的词。图片来源:斯坦福 GloVe。
BERT—来自 transformers 的双向编码器表示
由 Google 于 2019 年介绍,BERT属于一种基于 NLP 的语言算法类别,称为transformers。BERT 是一个大规模预训练的深度双向编码器基础的 transformer 模型,有两个变体。BERT-Base 有 1.1 亿个参数,而 BERT-Large 有 3.4 亿个参数。
在生成词嵌入时,BERT 依赖于注意机制。它生成高质量的上下文感知或上下文化的词嵌入。在训练过程中,嵌入通过每一层 BERT 编码器进行细化。对于每个词,注意机制根据左侧和右侧的词捕捉词汇关联。词嵌入也进行位置编码,以跟踪句子中每个词的模式或位置。
BERT 比上述讨论的任何技术都更先进。它通过在大规模词汇语料库和维基百科数据集上进行预训练,生成了更好的词嵌入。BERT 可以通过在任务特定数据集上微调嵌入来进一步提升。
然而,BERT 最适合语言翻译任务。它已经针对许多其他应用和领域进行了优化。
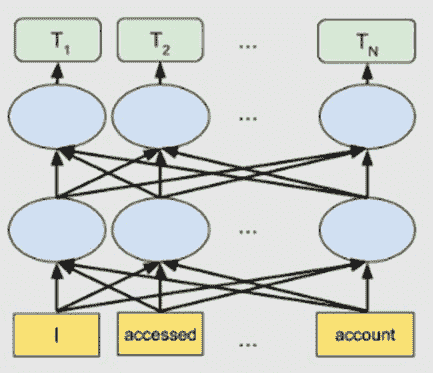
双向 BERT 架构。图片来源:Google AI Blog。
结论
随着自然语言处理(NLP)的进步,词嵌入技术也在不断改进。有许多 NLP 任务并不需要高级的嵌入技术。许多任务使用简单的词嵌入技术同样可以表现良好。选择词嵌入技术必须基于细致的实验和任务特定的需求。微调词嵌入模型可以显著提高准确性。
在本文中,我们对各种词嵌入算法进行了高层次的概述。让我们总结如下:
| 词嵌入技术 | 主要特点 | 应用场景 |
|---|---|---|
| TF-IDF | 统计方法用于捕捉词语相对于文本语料库的相关性。它不捕捉语义词语关联。 | 更适合信息检索和文档中的关键词提取。 |
| Word2Vec | 基于神经网络的 CBOW 和 Skip-gram 架构,更擅长捕捉语义信息。 | 对语义分析任务有用。 |
| GloVe | 基于全局词对共现的矩阵分解方法。它解决了 Word2Vec 的局部上下文限制。 | 在词语类比和命名实体识别任务中表现更好。在一些语义分析任务中与 Word2Vec 的结果相当,而在其他任务中则更优。 |
| BERT | 基于 Transformer 的注意力机制,用于捕捉高质量的上下文信息。 | 语言翻译、问答系统。部署在 Google 搜索引擎中以理解搜索查询。 |
参考文献
-
www.techopedia.com/definition/33012/natural-language-generation-nlg -
www.expert.ai/blog/natural-language-process-semantic-analysis-definition/ -
blog.marketmuse.com/glossary/latent-semantic-analysis-definition/ -
ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html -
ai.googleblog.com/2017/08/transformer-novel-neural-network.html -
www.analyticsvidhya.com/blog/2019/11/comprehensive-guide-attention-mechanism-deep-learning/
Neeraj Agarwal 是 Algoscale 的创始人,Algoscale 是一家数据咨询公司,涵盖数据工程、应用 AI、数据科学和产品工程。他在该领域拥有超过 9 年的经验,并帮助了从初创企业到财富 100 强公司等各种组织,处理和存储大量原始数据,以将其转化为可操作的见解,帮助做出更好的决策并加快业务价值的实现。
相关主题更多信息
H2O 机器学习框架
原文:
www.kdnuggets.com/2020/01/h2o-framework-machine-learning.html
评论
由 ActiveWizards 提供

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
H2O 是一个可扩展且快速的开源机器学习平台。我们将应用它来执行分类任务。我们使用的数据集是 银行营销数据集。在这里,我们需要训练一个模型,该模型能够根据客户的个人特征、营销活动特征和当前的宏观经济条件,预测银行客户是否会开设定期存款。
在模型创建过程中,我们探索了 H2O 工具包中的各种核心组件和功能。你应该明白,虽然本文涵盖了一些 H2O 的基本概念,但如果你需要更详细的信息,应该访问 H2O 网站并阅读 文档。
注意:有关安装说明,请使用 官方网站。
准备工作
我们需要首先导入所需的库:
import pandas as pd
import numpy as np
import h2o
pd.set_option('display.width', 5000)
首先,你应该启动 H2O。你可以运行方法 h2o.init() 来初始化 H2O。可以向 h2o.init() 方法传递许多不同的参数,以根据需要设置 H2O。因此,你可以在这里更改 H2O 的一些全局设置。然而,在大多数情况下,调用该方法时不带任何参数就足够了,正如我们下面所做的那样:
h2o.init()
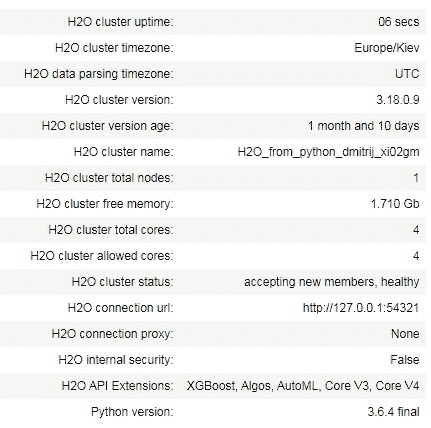
你可以看到,这种方法的输出包含有关 H2O 集群的一些元信息。
下一步我们应该导入将要使用的数据集。这是一个 .csv 文件,H2O 具有 upload_file() 函数,可以将数据集加载到内存中。值得一提的是,H2O 可以处理多种数据源(本地和远程),并支持不同的文件格式。
bank_df = h2o.upload_file("bank-additional-full.csv")
要查看数据集,你可以简单地输入其名称并运行单元格。默认显示前 10 行。
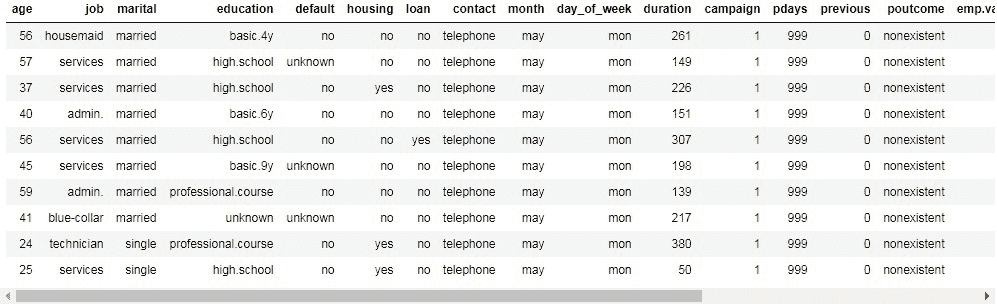
从这个变量的类型来看,我们可以看到类型是 h2o.frame.H2OFrame。因此,这不是 pandas 对象,而是 H2O 的对象。
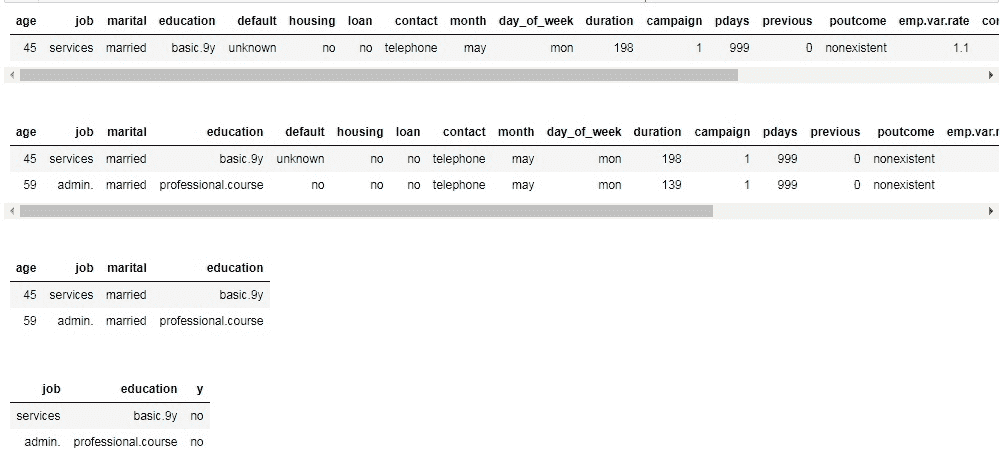
然而,你可以以熟悉的方式对这个 H2OFrame 进行索引和切片:
# show 6th row
print(bank_df[5,:])
# show 6-7 rows
print(bank_df[5:7,:])
# show first 4 columns from 6-7 rows
print(bank_df[5:7,0:4])
# show job,education and y columns from 6-7 rows
print(bank_df[5:7, ['job', 'education', 'y']])
你可以通过访问 .shape 属性来检查 H2OFrame 的形状。此外,一些有用的信息(列类型、最小值、平均值、最大值、标准差、零值数量、缺失值)可以通过 .describe() 方法生成。
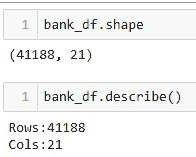
正如我们所见,我们的数据集中没有缺失数据。我们有 20 列不同的分类、整数和实数特征以及 1 列目标变量 (y)。目标变量是二元的,如果客户希望订阅定期存款,则值为 "yes",否则为 "no"。
在下一个单元格中,我们将列名提取到变量 x 中。然后,我们从这个列表中移除目标列名 (y)。另外,我们将目标变量的名称写入变量 y 中。
x = bank_df.names
x.remove("y")
print(x)
Y = "y"

第一个模型
现在让我们训练某个模型。首先,我们需要将数据集拆分为训练集和测试集。H2O 允许通过使用函数 split_frame() 来完成。如果你只传递一个元素作为第一个参数(或参数 ratios),这个元素定义了训练数据集的比例。其余部分是测试集。如果你传递两个元素,第一个表示训练集,第二个表示测试集,剩余部分是验证集。这里我们希望将 70% 的样本作为训练集,30% 作为测试集。我们还固定了随机状态以获得可重复的结果。
train, test = bank_df.split_frame([0.7], seed=42)
一开始,我们希望使用随机森林模型来分类数据点。 H2ORandomForestEstimator 可以在模块 h2o.estimators 中找到。
from h2o.estimators import H2ORandomForestEstimator
然后我们创建一个估计器的实例。这里你可以指定许多不同的参数。我们通过将 200 分配给 ntrees 参数来设置树的数量为 200。在此之后,我们在估计器的实例上调用 train 方法。我们应该将特征的列名传递给变量 x,将目标列名传递给变量 y。我们还指定训练和验证样本。在我们运行这个单元格之后,可以看到下面的进度条,反映训练过程的状态。
rf = H2ORandomForestEstimator(ntrees=200)
rf.train(x=x,
y=y,
training_frame=train,
validation_frame=test)

可以通过查看估计器的实例来访问模型详细信息:
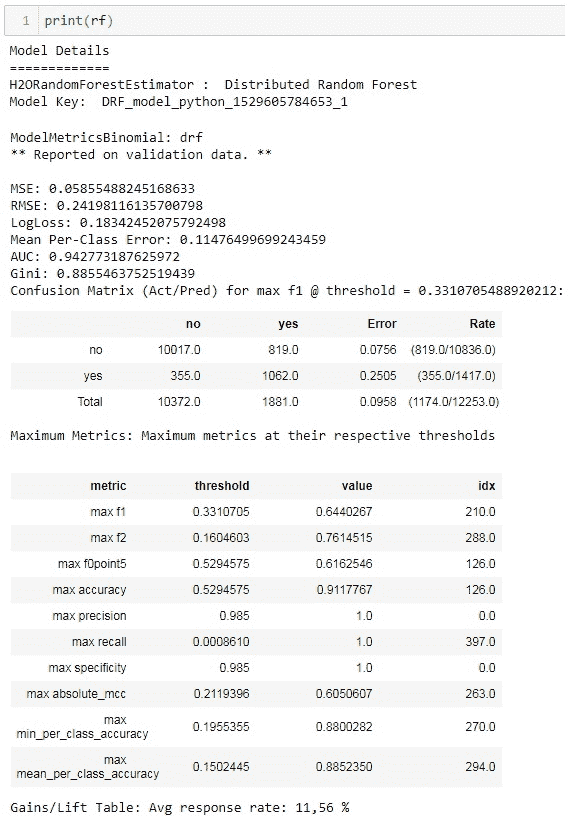
这里有很多有趣和有用的信息。你可以注意到两个信息块。第一个是关于训练集的,第二个是关于测试集的。有不同的模型性能指标(MSE、RMSE、LogLoss、AUC、Gini 等)。混淆矩阵是一个非常有趣的错误分析指标。H2O 允许查看训练集和测试集的混淆矩阵。混淆矩阵中也显示了每个标签的错误总比例。
有趣的表格是关于在各自错误下的最大指标。在二分类中,模型返回实例属于正类的概率。然后这个概率应与某个阈值进行比较,以决定这是正类还是负类。H2O 在这个表格中显示了不同指标的最大值,并指定了在达到这些最大值时使用的阈值。例如,在我们的案例中,通过选择阈值 0.985 可以在测试集上实现完美的精确度。测试集上的最大准确率是 0.911,当你选择 0.5294 作为阈值时可以达到。最高的 F1 分数对应于阈值 0.331。
在实现解决方案中的模型时,你可以选择最适合你需求的阈值。同时,你可以尝试一些更高级的操作,例如通过结合训练集和测试集的不同指标的最大值报告的阈值来选择阈值。
另一个有趣的表格是特征重要性的表格。最具信息量的列是scaled_importance和percentage。你可以看到,duration特征在这个任务和数据集中具有最大的预测能力。这个特征表示与客户通话的持续时间。除了duration之外,排名前五的其他重要特征是宏观经济指标euribor3m和nr.employed,以及客户的age和job。
现在我们想要手动计算测试集上的准确率。
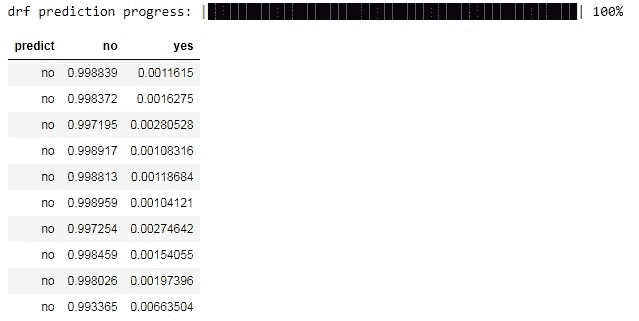
在下一个单元格中,我们进行预测。你可以看到方法predict()返回一个数据框,其中第一列是答案(是或否),接下来的两列是“否”和“是”的概率。
rf = H2ORandomForestEstimator(ntrees=200)
rf.train(x=x,
y=y,
training_frame=train,
validation_frame=test
在下一个单元格中,我们统计预测结果与实际答案相等的案例数量,然后计算均值,这将成为预测的准确性。我们可以看到准确率是 0.9041,或者大约 90.4%。如果你回到混淆矩阵,可以注意到,如果你从 1 中减去测试集的总错误(0.0958),你将得到约 0.9041,这就是我们手动计算得到的准确率。
(predictions["predict"] == test["y"]).mean()
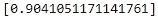
其他算法
H2O 提供了几种不同的训练模型。让我们尝试其中的一些。
我们想要使用神经网络训练的第一个算法。要使用这个模型,我们需要从 h2o.estimators.deeplearning 模块中导入 H2ODeepLearningEstimator。然后,我们需要创建这个估计器的实例。与之前的随机森林示例类似,你可以传递许多不同的参数来控制模型和训练过程。重要的是要设置神经网络的架构。在参数 hidden 中,我们传递一个包含隐藏层神经元数量的列表。因此,这个参数同时控制隐藏层的数量和这些层中的神经元数量。我们设置了 3 个隐藏层,分别有 100、10 和 4 个神经元。同时,我们将激活函数设置为 Tanh。
from h2o.estimators.deeplearning import H2ODeepLearningEstimator
dl = H2ODeepLearningEstimator(hidden=[100, 10, 4],activation='Tanh')
dl.train(x=x, y=y, training_frame=train, validation_frame=test)
predictions_dl = dl.predict(test)
print((predictions_dl["predict"] == test["y"]).mean())
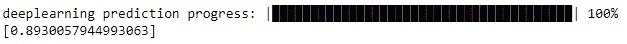
我们可以看到,准确率略低于随机森林。也许我们可以调整模型的参数以获得更好的性能。
在接下来的几个单元格中,我们将训练线性模型。Binomial family 表示我们想要执行逻辑回归分类。 lambda_search 允许搜索最优的正则化参数 lambda。
from h2o.estimators.glm import H2OGeneralizedLinearEstimator
lm = H2OGeneralizedLinearEstimator(family="binomial",
lambda_search=True)
lm.train(x=x,
y=y,
training_frame=train,
validation_frame=test)
predictions_lm = lm.predict(test)
print((predictions_lm["predict"] == test["y"]).mean())

我们在这里想要使用的最后一个模型是梯度提升算法。使用默认参数,它在所有其他算法中可能表现最佳。
from h2o.estimators.gbm import H2OGradientBoostingEstimator
gb = H2OGradientBoostingEstimator()
gb.train(x=x,
y=y,
training_frame=train,
validation_frame=test)
predictions_gb = gb.predict(test)
print((predictions_gb["predict"] == test["y"]).mean())
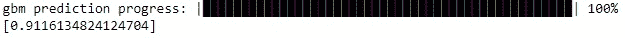
值得一提的是 H2O 平台中 XGBoost 的集成。XGBoost 是实现梯度提升思想的最强大算法之一。你可以单独安装它,但在 H2O 中使用 XGBoost 也非常方便。在下面的单元格中,你可以看到如何创建 H2OXGBoostEstimator 的实例以及如何训练它。你应该理解,XGBoost 使用许多参数,且这些参数的变化常常会非常敏感。
param = {
"ntrees" : 400,
"max_depth" : 4,
"learn_rate" : 0.01,
"sample_rate" : 0.4,
"col_sample_rate_per_tree" : 0.8,
"min_rows" : 5,
"seed": 4241,
"score_tree_interval": 100
}
predictions_xgb = xgb.predict(test)
print((predictions_xgb["predict"] == test["y"]).mean())
H2O 中还提供了其他几种模型。如果你想了解更多,请查看文档。
H2O 中的交叉验证
交叉验证是机器学习中核心技术之一。基本思想是将数据集拆分为几个部分(折叠),然后在除了一个折叠的所有部分上训练模型,该折叠将用于后续的测试。在此,当前迭代完成,下一次迭代开始。在下一次迭代中,测试折叠被纳入训练样本。相反,来自之前训练集的某个折叠将用于测试。
例如,我们将数据集拆分为 3 个折叠。在第一次迭代中,我们使用第 1 和第 2 个折叠进行训练,第 3 个折叠用于测试。在第二次迭代中,使用第 1 和第 3 个折叠进行训练,第 2 个折叠用于测试。在第三次迭代中,第 1 个折叠用于测试,第 2 和第 3 个折叠用于训练。
交叉验证允许以更准确和可靠的方式评估模型的性能。
在 H2O 中进行交叉验证很简单。如果模型支持,有一个可选参数 nfolds 可以在创建模型实例时传递。你应使用此参数指定交叉验证的折数。
H2O 构建了 nfolds + 1 个模型。一个额外的模型是在所有可用数据上训练的。这是你训练结果的主要模型。
让我们训练随机森林并进行 3 折交叉验证。注意我们没有传递验证(测试)集,而是使用整个数据集。
rf_cv = H2ORandomForestEstimator(ntrees=200, nfolds=3)
rf_cv.train(x=x, y=y, training_frame=bank_df)
如果你查看上面的单元格输出,你会注意到一些差异。
第一个是模型不是在验证数据上进行报告,而是在交叉验证数据上进行报告。
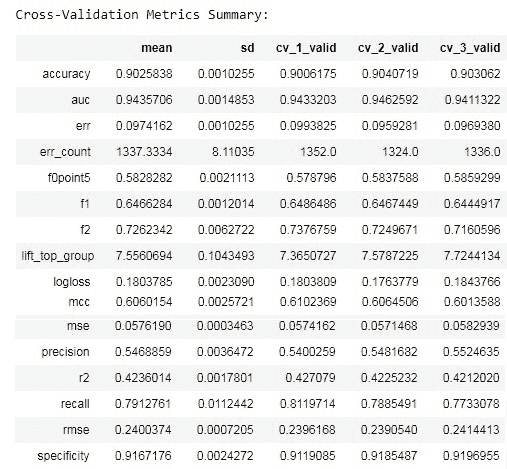
第二点是有一个交叉验证指标总结表。在这里你可以看到许多不同的指标、每个折作为测试折的指标值,这些值的均值以及每个指标的标准偏差。例如,对于第一折我们得到的准确率是 0.9006,第二折是 0.904,第三折是 0.903。这些值的均值是 0.9025,标准偏差是 0.001。你应该理解,拥有“良好”的指标值固然重要,但低标准偏差也很重要。这意味着你的模型在数据集中不同样本上的表现都很好。但交叉验证结果的解释实际上不是本文的目标,因此我们继续下一章节!
使用 GridSearch 调整模型
通常,你需要尝试许多不同的参数及其组合,以找到最佳模型性能的配置。手动完成所有这些工作是困难且有时乏味的。GridSearch 可以自动化这一过程。你只需指定想要尝试的一组超参数,并运行 GridSearch 实例。系统将尝试所有可能的参数组合(为每个组合训练和测试模型)。让我们看看如何在 H2O 中使用这个工具。
首先,你需要导入 GridSearch 对象的实例:
from h2o.grid.grid_search import H2OGridSearch
现在,你需要指定所有可能的参数。我们将搜索之前构建的 XGBoost 模型的最佳参数组合。参数被放置在一个 Python 字典中,其中键是参数的名称,值是这些参数的可能值的列表。
xgb_parameters = {'max_depth': [3, 6],
'sample_rate': [0.4, 0.7],
'col_sample_rate': [0.8, 1.0],
'ntrees': [200, 300]}
下一步是创建 GridSearch 实例。你应该传递一个模型、网格的 ID 和包含超参数的字典。
xgb_grid_search = H2OGridSearch(model=H2OXGBoostEstimator,
grid_id='example_grid',
hyper_params=xgb_parameters)
最终,你可以运行网格搜索。注意我们设置了较高的学习率,因为网格搜索是一个非常耗时的过程。随着超参数数量的增长,训练的模型数量迅速增加。因此,考虑到这只是一个学习示例,我们不想测试太多的超参数。
xgb_grid_search.train(x=x,
y=y,
training_frame=train,
validation_frame=test,
learn_rate=0.3,
seed=42)
我们可以通过使用 GridSearch 实例的 get_grid()方法来获取网格搜索的结果。我们希望按准确率指标的降序对结果进行排序。
grid_results = xgb_grid_search.get_grid(sort_by='accuracy',
decreasing=True)
print(grid_results)
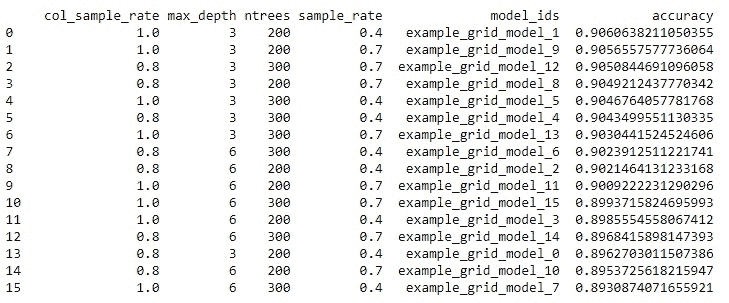
你可以看到,使用 1.0 列样本率、0.4 样本率、200 棵树和每棵树的最大深度为 3 的组合可以获得最高的准确率。
AutoML
H2O 提供了自动化机器学习的能力。这个过程非常简单,面向那些在机器学习方面知识和经验较少的用户。AutoML 将遍历不同的模型和参数,尝试找到最佳方案。需要指定几个参数,但大多数情况下,你只需要设置最大运行时间(以秒为单位)或最大模型数。你可以将 AutoML 视为类似于 GridSearch,但它是在模型层级而不是参数层级上进行的。
from h2o.automl import H2OAutoML
autoML = H2OAutoML(max_runtime_secs=120)
autoML.train(x=x,
y=y,
training_frame=bank_df)
我们可以通过检查 autoML 实例的.leaderboard 属性来查看所有尝试过的模型及其对应的性能。具有 0.94 AUC 指标的 GBM 模型似乎是这里表现最好的模型。
leaderboard = autoML.leaderboard
print(leaderboard)

查看最佳模型:
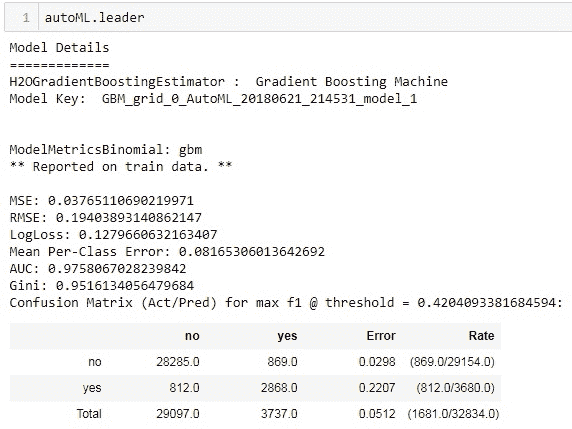
你可以直接从 autoML 实例上对测试集进行预测。
predictionAML = autoML.predict(test)
结论
这篇文章只是 H2O 功能的简要介绍。这是一个出色的机器学习平台,可以使一些机器学习领域的工程师工作变得更简单。它是一个不断发展的框架。在我们看来,它不能单独使用。相反,与 H2O 一起使用的其他工具可以使机器学习过程更快、更便捷。
在本文中,我们介绍了 H2O 中的一些基本数据操作,查看了 H2O 提供的几种机器学习模型,学习了如何进行交叉验证和网格搜索,并熟悉了 H2O 中的自动化机器学习。
你应该了解 H2O 的一些功能超出了本文的范围。因此,如果你有兴趣了解更多,请阅读官方文档。
ActiveWizards 是一个由数据科学家和工程师组成的团队,专注于数据项目(大数据、数据科学、机器学习、数据可视化)。核心专长领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等)以及数据密集型网页应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。经许可转载。
相关:
-
自动化机器学习:团队如何在 AutoML 项目中协作?
-
自动化机器学习项目实施的复杂性
-
顶级 6 个 Python NLP 库的比较
更多相关话题
对有志数据科学家的黑客马拉松指南
原文:
www.kdnuggets.com/2019/07/hackathon-guide-aspiring-data-scientists.html
评论
由 Jiwon Jeong,数据科学研究员
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
黑客马拉松是一种竞赛,各种人员,包括程序员、开发者和图形设计师,密集合作以在短时间内设计软件项目。黑客马拉松的目标是在活动结束时创建一个功能性产品。
上个月,我有机会参加由 Junction Ltd. 举办的 JunctionX Seoul 黑客马拉松。我们的团队开发了一个 iOS 应用,利用图像搜索引擎为韩国美容产品提供优化的购物服务体验。这个应用可以帮助想要探索韩国美容产品的旅行者,因为他们可能因为明显的语言障碍而不知道尝试什么。用户只需扫描产品即可找到有用的数据,这些信息会被翻译成他们的本地语言。还有一个搜索历史页面,可以用于进一步的定制服务。你可以在 这里 了解更多信息。

这个应用,Skana
然而,我更愿意分享我在过程中学到的东西,而不是我做了什么。所以今天,我将讨论你应该申请黑客马拉松的 4 个理由(特别是如果你是一个有抱负的数据科学家),你应该如何准备以及我的一些小贴士。我希望这篇文章能激励你走出舒适区,像我一样获得深刻的灵感。
1. 为什么参加黑客马拉松
如果你之前从未尝试过黑客马拉松或编程比赛,并问我是否值得尝试,我会毫不犹豫地点头。以下是你应该参加黑客马拉松的 4 个理由。
超越“建模”
我们,数据科学学习者,往往倾向于独自工作或学习。我们往往将大部分时间投入到数据预处理和数据处理上。我们将大部分精力投入到学习机器学习或深度学习算法中。我们的项目通常从导入数据(有时是自己构建数据)开始,以评估预测结果结束。
不幸的是,几乎所有现实世界的项目并不是这样运作的。我们并不孤单工作。我们与其他团队成员合作。从数据库到部署和产品管理,所有过程都应通过协作完成。拥有超越“建模”领域的工具包对有志者来说是一个很大的加分项。(许多文章指出了这一点,你可以在这里找到一篇)现在重要的问题是,我们在哪里可以学习和体验这些?
“与比赛不同,没有人给你两个叫做 train 和 test 的 .csv 文件以及一个写得很好的评估指标。几乎 80% 的努力投入在定义问题和获取及处理数据上。剩下的 20% 努力用于纯建模和部署。” - AnalyticsVidhya
黑客马拉松可以是一个与他人合作并实现实际项目的绝佳机会。尽管有一些限制,你仍然可以学习如何与他人(他们对机器学习的了解不如你)沟通,并理解发布实际产品的整体工作流程。如果你有机会与比你在机器学习方面更了解的人一起工作,我相信这将是推动你极限的绝佳时机。
商业思维比你想象的更为重要
项目的第一步是决定构建什么。我可以告诉你,成功的机会有一半在这里决定。你应该从一开始就走在正确的道路上。实施也是一个关键点,但商业价值扮演着至关重要的角色。如果被忽视,你的工作可能只是展示你在技术上的能力。
“同样,数据科学家被雇佣来创造商业价值,而不仅仅是建立模型。问问自己:我的工作成果将如何影响公司的决策?我需要做些什么来最大化这一影响?怀着这种企业家精神,第三波数据科学家不仅产生可操作的见解,还寻求这些见解带来真正的改变。” - Towards Data Science
你可能已经见过很多人指出商业思维的重要性。发现用户的隐藏需求和观察市场中的问题。利用你的技术知识提出解决方案。开发可以盈利的服务。在黑客马拉松中,你被要求从这个角度深入思考和讨论。
我听说过一个人,他赢得了超过 15 次编程比赛。他在赢得一次 Google 比赛后,退休于他的“奖品猎人”生涯。你知道他的秘密是什么吗?只是商业头脑和一点机智。通过创造一个聪明而有创意的产品,他让人们喊出“精彩!”这无疑给评委留下了深刻的印象。所以,如果你在寻找额外的获胜提示,具备商业价值和一些机智可能是一个很好的加分项。
处理极端压力的绝佳机会
黑客马拉松的目标是在短时间内(通常是 2 或 3 天)创建一个功能产品。你被要求在这些日子里展示你的产品原型或演示。这一切都涉及到有限的时间、资源和精力问题。有时候,你可能会遇到事情出错的情况,你必须立刻找到解决方案。有时候你需要优先处理工作,这意味着什么先做,什么时候停止。你可能会感受到强烈的压力来完成所有任务,而不成为团队的负担。随着时间的推移,彻底疲惫和精疲力竭几乎是不可避免的!(更像是能量耗竭,直到最终“跌入”睡眠。)
如果你像我一样,容易在极端压力时僵住,你甚至会被比赛大厅的空气所压倒。这是我第一次参加黑客马拉松,所以我经历了几次大脑瘫痪。我不得不去呼吸新鲜空气,放松一下以缓解紧张。但这也是一个很好的机会,让我学会如何应对压力。因为在工作中遇到那些意想不到的问题是不可避免的,我们必须管理那些要求很高的时刻。
“Hello, world”的实时
结识新朋友也是一种很大的乐趣,特别是当他们是志同道合的人时。在黑客马拉松中,你可以遇到来自不同地区和具有不同专业但有相同兴趣的各种人。他们可以是网页开发者、应用开发者或设计师,但他们都是愿意花费周末开发一些酷东西的人。
我遇到了从俄罗斯专程来韩国参加这个活动的人。我还遇到了一位在韩国学习计算机科学的乌克兰女士。还有来自丹麦、法国、中国和日本的人。结识新朋友本身就是一种乐趣。但更重要的是,我可以了解他们遇到的痛点以及他们真正热衷的事物。通过与其他参与者聊天,我的编程视野得到了拓展。这也是我认为你应该尝试有宽泛主题的黑客马拉松,而不是过于集中在数据科学领域的原因。
此外,关注其他人的工作也很重要。虽然你会忙得无暇顾及他人,但这将帮助你理解整个过程。毕竟,我们在这里是为了学习新东西!

照片来自JunctionXSeoul和我在进行演讲(右下角)
2. 如何准备
现在,黑客马拉松听起来值得一试吗?如果是的话,你接下来的问题可能是如何准备。实际上,什么都不需要。只管去尝试。无论你具备什么技能,都不要犹豫去申请。黑客马拉松不仅仅是专业人士的舞台。但如果你想在活动前做一些准备,那么我想列出一些我认为有用且适用的技能。
后端和部署
这不是一个从导入数据开始、以一些评估图表结束的项目。你需要收集数据并根据团队项目建立数据库。在你完成数据分析或建模部分后,你需要将模型传递给前端。或者你可能需要自己将工作部署到网站上。因此,拥有数据库和 Flask 在你的工具包中可以是这个活动的巨大资产。
如果你对数据库完全陌生,你可以从理解SQL 和 NoSQL 的区别开始学习。这里有一个紧凑的初学者 SQL 课程,但除了这个,还有大量的数据库教程可以选择。所以,根据你的兴趣去挑选吧。
Flask是一个用 Python 编写的微框架,易于学习,非常适合模型部署。这里有一个关于如何用 Flask 部署 Keras 深度学习模型的优秀教程,由Ben Weber提供。你也可以在这里找到一系列 Flask 视频课程。
API 和云服务
每个黑客松的条件可能不同,但我参与的那个非常依赖于 API 和云服务。比赛中有几个子轨道,参赛者被要求使用特定的 API 来参与给定的轨道。但除了这个条件,你无论如何都需要自己收集数据。你会从哪里获取数据?那训练的计算能力呢?你可能会把你的“超级计算机”留在家里。
因此,最好有从 API 获取数据和处理 JSON 格式数据的经验。如果你对 API 不熟悉, 这篇文章可以向你解释 API 的相关内容。
使用像 AWS 或 Google Cloud GPU 这样的云服务的能力也是必要的。这里是 AWS EC2 的官方指南,此外还有一段友好的视频由 AI 学校提供。你还可以找到一个针对初学者的更详细教程由 Michael Galarnyk提供。
充分充电的自己
充足的睡眠。掌控好你的状态。这不是开玩笑。在比赛期间,我总共睡了 4 小时。虽然少睡觉可能是一个好的策略,但你在进入比赛场地时需要保持良好的状态。此外,颈枕和猫毯对于小憩来说可能和“Flask”或“AWS”一样重要。???????

图片来源于 JunctionXSeoul
3. 我的最后一些小建议
最后,这里有一些我的小建议。
如何组建你的团队
如果你是单独申请者,你需要从头开始组建你的团队。可以通过类似 Slack 这样的社交网络平台从其他申请者那里获取信息,并在活动开始前组建团队。你可能有机会加入一个已经组建好的团队,前提是有一个空缺。
如果你有一个开发的想法,将其分解成几个部分,并寻找能够承担每部分的团队成员。你需要找到那些技能与我们不同的人(例如数据建模)。你需要的常见成员包括后端工程师、网页/应用开发者以及 UI/UX 设计师。
对于你能做的事情要诚实
你可能会觉得自己的能力不足以完成这个任务。所以你可能想隐藏自己的水平或者假装知道得比实际更多。但你真的不需要这样。黑客松对每个人开放。无论你对编程了解多少,总有一些部分只有你能填补!旁边的人比你知道得多?太棒了!你有更多学习的机会。寻求帮助是“帮助”你的团队的更好方式,而不是独自挣扎并浪费宝贵的时间。
尽情享受,尽情享受,再尽情享受!
这不仅仅是关于赢得胜利。虽然你应该在比赛中尽全力,但不要忘记脸上的微笑。享受学习的时光,结识新朋友并与他们一起工作。享受创造的时光,开发一些世界上不存在的新事物。享受面对压力并突破极限的时光。这将极具挑战性。然而,活动结束时,即使你没有赢得奖项,你也会带着新的想法和教训回到家中。你会像我一样期待下一次黑客马拉松。????
这个故事与你产生共鸣了吗?请与我们分享你的见解。我总是愿意交流,所以请随时在下方留言分享你的想法。我还在LinkedIn上分享有趣且有用的资源,欢迎关注并与我联系。我下次会带来另一个有趣的故事。敬请关注!
个人简介: Jiwon Jeong 是一名数据科学研究员,数据迷,书虫和旅行爱好者。
原文。经授权转载。
相关:
-
构建一个 Flask API 来自动提取命名实体,使用 SpaCy
-
将你的 PyTorch 模型部署到生产环境
-
可持续数据科学、机器学习和人工智能产品开发的核心原则:研究作为核心驱动因素
更多相关内容
-
[停止学习数据科学以寻找目标,并寻找目标来...] (https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html)
使用机器学习和人工智能解释计算蛋白质工程。
原文:
www.kdnuggets.com/2017/07/hacking-silico-protein-engineering-machine-learning.html
由Kamil Tamiola 创办的 Peptone。
蛋白质
可以安全地说,蛋白质是构建块和定义生命物质的机制。在过去 70 年里,在蛋白质的分离、生产、特征化和最终工程方面取得了巨大的进展。尽管在实验室和工业规模的蛋白质生产方面取得了巨大进步,但蛋白质工程及所有相关步骤仍然是繁琐、昂贵且真正复杂的。
蛋白质是聚合物
蛋白质是由20 种构建块氨基酸组成的复杂生物分子,这些氨基酸按顺序连接成长的非分支链,通常称为多肽链。
多肽链的独特空间排列产生三维分子结构,这些结构定义了蛋白质的功能及其与其他生物分子的相互作用。
尽管蛋白质三维结构形成的基本力已经已知并理解,但多肽折叠的确切性质仍然难以捉摸,并且在过去 50 年中已经进行了广泛的研究。
蛋白质工程是复杂的
我们希望工程化蛋白质以增强其属性。通常,关注点是不同温度、pH或盐度下的稳定性。研究人员通常旨在提高蛋白质酶的催化性能,或向已知蛋白质中添加全新的化学活性。
工程化蛋白质最常见且成熟的方法是通过用替代氨基酸创建其变体,这些变体也称为突变体。随后,使用各种实验技术对新产生的突变体进行特征化,以测量增强的程度;例如,扫描量热法、等电点测定、简单溶解度研究或高级酶活性测定。然而,由于存在20 种标准蛋白质氨基酸,如果你决定探索所有可能的典型蛋白质氨基酸组合,那么 100 残基长的多肽的完全突变将产生20¹⁰⁰种突变组合。

相当可能,只有极少数的突变体会具有期望的属性,因为通常改变蛋白质越多,你就越远离其原始功能。
(这绝不是规则,因为这取决于蛋白质的具体情况。然而,替换蛋白质的主要部分为完全新的氨基酸序列的逻辑后果可能是新的折叠,从而带来新的功能。此外,我故意省略了一个根本性的重要事实——突变可能会显著影响蛋白质的动态,从而影响其功能)。
蛋白质生物技术在很大程度上受到规模和突变分析的复杂性的制约。
机器学习如何加速蛋白质科学的进展?
机器学习的最先进和概率(贝叶斯)变体在很大程度上依赖于输入数据的大小和质量。这一点对于生命科学中的推断和预测技术尤为重要,因为模型的复杂性水平令人困惑或尚不清楚。
通过机器学习方法对蛋白质结构、功能和动态的预测并非例外。然而,即使在相对稀疏(与所有可能的长多肽链中的蛋白质氨基酸组合数量相比)蛋白质数据库的情况下,机器学习也能帮助揭示蛋白质序列与其结构变异性和动态之间复杂的非线性关系。这些关系要么非常难以建模,要么仅仅尚未完全理解。
机器学习方法在预测蛋白质生物物理属性中的最大价值在于它们能够将松散相关的蛋白质特征与可测量的实验数据“等同”起来。因此,利用复杂数值模型进行的预测可以通过提供独立的蛋白质结构和动态的实验代理进一步调整和优化。

蛋白质是动态的,并表现出不同程度的无序。
就像我们自然环境中的其他分子一样,多肽链在从纳秒到分钟的时间尺度上进行分子运动。
已接受的观点是,完全理解蛋白质的功能和活动需要对结构和动态的了解。
结构无序是许多已知且特征化蛋白质的非常特殊的属性。它被归因于蛋白质序列中的特定模式,并对蛋白质的稳定性、对酶解的易感性、蛋白质-蛋白质相互作用以及在许多使人虚弱的 人类病理中发挥决定性作用。
从工业生物技术的角度来看,准确识别工程蛋白质中氨基酸突变的无序效应可以节省大量时间和资源。对任意蛋白质突变体的准确无序预测可以立即报告氨基酸序列的有问题的组合,从而将这些残基排除在进一步的突变分析之外,并大幅减少突变搜索空间。
阅读更多内容,始于单一蛋白质结构模型不够的 Kamil Tamiola 文章。转载了初始部分,已获得许可。
简介:卡米尔·塔米奥拉 是一位企业家和研究人员,拥有广泛的超级计算和蛋白质结构生物物理学的科学背景。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容
处理深度学习中的不平衡数据集
原文:
www.kdnuggets.com/2018/12/handling-imbalanced-datasets-deep-learning.html
评论
像灭霸一样为你的数据集带来平衡
并不是所有数据都是完美的。实际上,如果你能获得一个完美平衡的现实世界数据集,你将非常幸运。大多数情况下,你的数据会有某种程度的类别不平衡,即每个类别的示例数量不同。
为什么我们希望数据平衡?
在投入时间进行任何可能漫长的深度学习项目之前,理解为什么我们应该这样做是很重要的,以确保这是一个有价值的投资。类别平衡技术只有在我们真正关心少数类时才是必要的。
比如,假设我们要预测是否应该根据市场的当前状况、房子的属性和我们的预算来购买一栋房子。在这种情况下,如果我们决定买房,那么这个决定是否正确是非常重要的,因为这是一个巨大的投资。同时,如果我们的模型说不买而实际上应该买,这也不是大问题。即使错过了某一栋房子,仍然会有其他房子可供选择,但对如此大的资产做出错误投资会很糟糕。
在这个例子中,我们绝对需要我们的少数“买”类别非常准确,而对于“不要买”类别则不是那么重要。然而在实际情况中,由于在数据中购买会比不购买少得多,我们的模型会倾向于非常好地学习“不要买”类别,因为它有最多的数据,并可能在“买”类别上表现不佳。这就需要平衡数据,以便我们可以更重视“买”预测的正确性!
那么如果我们不太关心少数类呢?例如,假设我们正在做图像分类,并且你的类别分布如下:
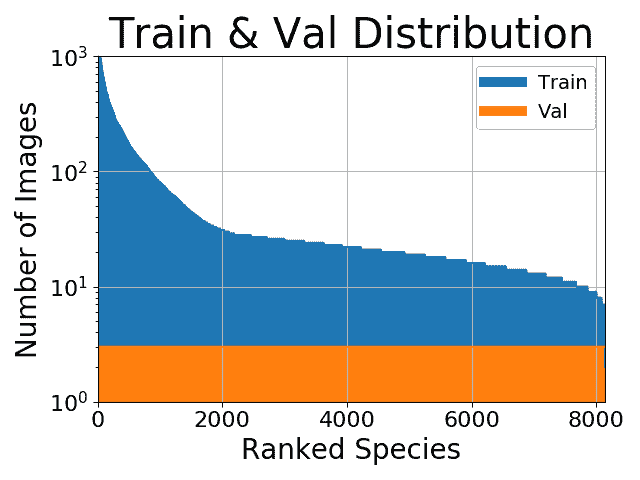
初看起来,平衡数据似乎有帮助。但也许我们对那些少数类不太感兴趣。也许我们的主要目标是获得最高可能的百分比准确度。在这种情况下,进行任何平衡并没有太大意义,因为我们的百分比准确度大部分来自于训练示例更多的类别。其次,即使数据集不平衡,分类交叉熵损失在追求最高百分比准确度时也往往表现良好。总的来说,我们的少数类对实现主要目标贡献不大,因此平衡并不是必要的。
说到这里,当我们遇到需要平衡数据的情况时,我们可以使用两种技术来帮助我们。
(1) 权重平衡
权重平衡通过调整每个训练样本在计算损失时所承载的权重来平衡我们的数据。通常,我们的损失函数中的每个样本和类别将承担相等的权重,即 1.0。但是有时我们可能希望某些类别或某些训练样本承载更多的权重,如果它们更为重要。再次以我们买房的例子为例,由于“买入”类别的准确性对我们最为重要,因此该类别中的训练样本应该对损失函数有显著影响。
我们可以通过根据类别的不同,将每个样本的损失乘以某个因子来给类别赋权。在 Keras 中,我们可以这样做:
我们创建了一个字典,其中基本上规定了我们的“买入”类别应在损失函数中占据 75%的权重,因为“买入”类别比“不要买”类别更为重要,而“不要买”类别的权重则相应设置为 25%。当然,这些值可以很容易地调整,以找到最适合您应用的设置。如果我们的某个类别的样本显著多于其他类别,我们也可以使用这种权重平衡的方法。与其花费时间和资源去收集更多的少数类样本,不如尝试使用权重平衡,使所有类别对我们的损失函数的贡献相等。
另一种平衡训练样本权重的方法是焦点损失。其主要思想是:在我们的数据集中,某些训练样本自然比其他样本更容易分类。在训练过程中,这些样本将以 99%的准确率被分类,而其他更具挑战性的样本可能仍表现较差。问题在于,那些容易分类的训练样本仍然在贡献损失。为什么我们还要对它们给予相同的权重,而在其他更具挑战性的数据点上,如果正确分类,能对我们的整体准确率贡献更多?!
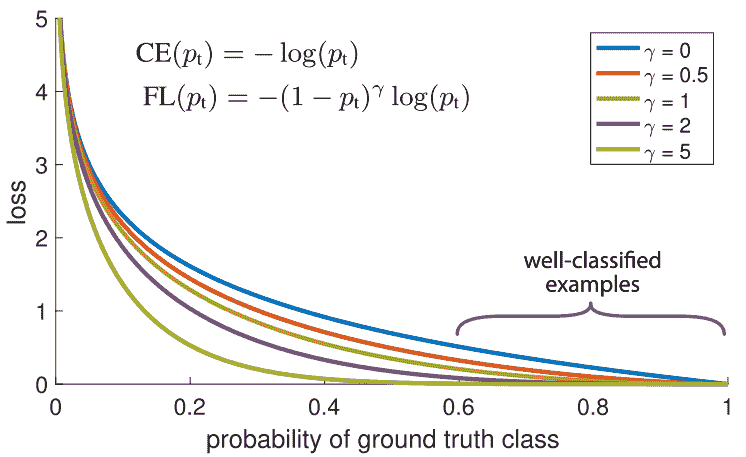
这正是焦点损失可以解决的问题!焦点损失降低了对已分类样本的权重,而不是对所有训练样本给予相等的权重。这有助于将更多的训练重点放在那些难以分类的数据上!在数据不平衡的实际设置中,由于我们拥有更多的数据,我们的多数类很快就会被良好分类。因此,为了确保我们在少数类上也能实现高准确率,我们可以使用焦点损失在训练过程中给予这些少数类样本更多的相对权重。焦点损失可以很容易地在 Keras 中作为自定义损失函数实现:
(2) 过采样与欠采样
选择合适的类别权重有时可能会很复杂。简单的逆频率方法可能效果不好。焦点损失可以提供帮助,但即便如此,它也会平等地减少每个类别的所有良好分类示例的权重。因此,平衡数据的另一种方式是通过直接采样。请查看下面的图示。
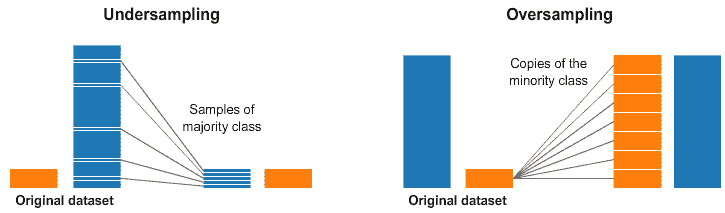
欠采样和过采样
在上图的左侧和右侧,我们的蓝色类别样本远多于橙色类别。在这种情况下,我们有两个预处理选项可以帮助训练我们的机器学习模型。
欠采样意味着我们只会从多数类中选择一部分数据,只使用与少数类相同数量的样本。这种选择应保持类别的概率分布。这样很简单!我们通过减少样本数量平衡了数据集!
过采样意味着我们会创建副本以使少数类的样本数量与多数类相同。这些副本的生成会保持少数类的分布。我们没有获取更多数据,但依然平衡了数据集!如果发现类别权重难以有效设置,采样可以是平衡类别的一个好替代方案。
想学习更多吗?
关注我的推特,我会发布最新最前沿的 AI、技术和科学内容!
简介: George Seif 是一名认证极客及 AI/机器学习工程师。
原文. 经许可转载。
相关内容:
-
数据科学家必知的 5 种聚类算法
-
三种提高不平衡数据集上机器学习模型性能的技术
-
使用 Python 提升数据预处理速度 2-6 倍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
更多相关内容
使用 SQL 处理时间序列中的缺失值
原文:
www.kdnuggets.com/2022/09/handling-missing-values-timeseries-sql.html
今天早上我阅读了Madison Schott的文章,她在其中强调了这个鲜为人知的 SQL 函数LAST_VALUE的实用性。
这激励我写了一篇关于处理时间序列数据时经常遇到的特定用例的后续文章。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
示例
让我们假设你正在使用传感器数据构建一个预测性维护模型。
经过一些整理,你最终得到的每小时数据如下所示:
一些预处理的传感器数据示例
到目前为止,我们已经进行了一些相当重要的数据工程,以在每小时创建这些均匀间隔的观测数据。如何做到这一点是另一个文章的主题。然而,请注意,温度测量中存在一些间隙。这时LAST_VALUE就派上用场了。
缺失值的原因通常是传感器只在值发生变化时报告。这减少了机器需要传输的数据量,但这为我们创建了一个数据问题需要解决。
原因
如果我们直接使用这些数据构建模型,当特定值缺失时,模型的准确性会受到影响,因为没有历史上下文写入到行本身。为了获得尽可能准确的模型,我们应该添加如下一些特征:
-
最后一次温度读取
-
过去 6 小时的平均温度
-
自上次温度读取以来的小时数(温度上升/下降)
-
过去 12 小时的温度变化率
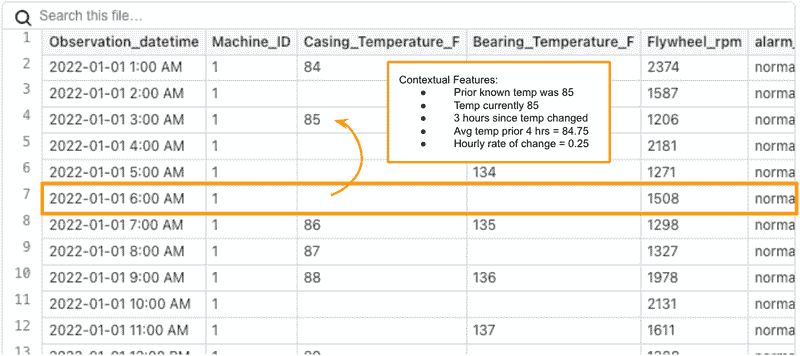
将对预测模型有用的特征类型的说明
我们的第一步应该是用最后一个已知的值替换缺失值。我们选择首先这样做的原因是其他特征会变得更容易创建。
例如,如果我们将其留作缺失并尝试计算滚动平均值,那么平均值将被错误计算(它会忽略缺失值,仅计算非缺失值的平均值)。
过去 4 小时的平均温度(有缺失值)
(null + 85 + null + null) / 1 = 85
过去 4 小时的平均温度(替换后)
(84 + 85 + 85 + 85) / 4 = 84.75
如何修复
在 Python 中,我们会从 前向填充 开始。然而,在 SQL 中这样做意味着我们可以利用我们数据仓库的强大功能。
在 SQL 中,我们使用 LAST_VALUE。有关更多深入解释,请参阅 这篇文章。
这里是语法:
SELECT
MACHINE_ID,
OBSERVATION_DATETIME,
LAST_VALUE(
CASING_TEMPERATURE_F ignore NULLS
) OVER (
PARTITION BY MACHINE_ID
ORDER BY
OBSERVATION_DATETIME ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS LATEST_CASING_TEMPERATURE_F,
LAST_VALUE(
BEARING_TEMPERATURE_F ignore NULLS
) OVER (
PARTITION BY MACHINE_ID
ORDER BY
OBSERVATION_DATETIME ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS LATEST_BEARING_TEMPERATURE_F,
LAST_VALUE(FLYWHEEL_RPM ignore NULLS) OVER (
PARTITION BY MACHINE_ID
ORDER BY
OBSERVATION_DATETIME ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
) AS LATEST_FLYWHEEL_RPM,
--8<-- snip --8<--
FROM
hourly_machine_data
用 LAST_VALUE 替换缺失值后的结果
就这样!
结论
希望我能为 LAST_VALUE 及其表亲 FIRST_VALUE 提供一些启示,它们是较不为人知的 SQL 窗口函数。
Josh Berry (@Twitter) 领导了 Rasgo 的客户数据科学团队,并自 2008 年以来一直从事数据和分析行业。Josh 在 Comcast 工作了 10 年,期间他建立了数据科学团队,并且是内部开发的 Comcast 特征库的关键负责人——这是市场上第一个特征库之一。在 Comcast 之后,Josh 在 DataRobot 构建客户数据科学团队中发挥了关键作用。在业余时间,Josh 对棒球、F1 赛车、住房市场预测等有趣的主题进行复杂分析。
原文。已获许可转载。
更多相关主题
处理数据科学中的树结构算法面试
原文:
www.kdnuggets.com/2020/01/handling-trees-data-science-algorithmic-interview.html
评论
算法和数据结构是数据科学的重要组成部分。虽然我们大多数数据科学家在学习过程中没有修过专门的算法课程,但它们依然至关重要。
许多公司在招聘数据科学家时会将数据结构和算法作为面试的一部分。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
现在许多人会问,为什么要问数据科学家这些问题。我喜欢将其描述为数据结构问题可以被视为编码能力测试。
我们都在生活中的不同阶段做过能力测试,虽然这些测试并不是完美的判断标准,但几乎没有什么是完美的。所以,为什么不使用标准算法测试来评估一个人的编码能力呢?
但不要自欺欺人,它们的难度与数据科学面试的难度相当,因此,你可能需要花些时间来学习算法和数据结构问题。
这篇文章旨在加速学习过程,并为数据科学家解释树结构的概念,以便下次在面试中被问到时能够轻松应对。
但首先,为什么树对数据科学如此重要?
对数据科学家来说,树的意义与对软件工程师来说的不同。
对于软件工程师而言,树只是一个简单的数据结构,用于管理层次关系,而对于数据科学家来说,树是一些最有用的分类和回归算法的基础。
那么这两者在哪里相遇呢?
它们实际上是同一个东西。不要感到惊讶。以下是数据科学家和软件工程师如何看待树结构的。
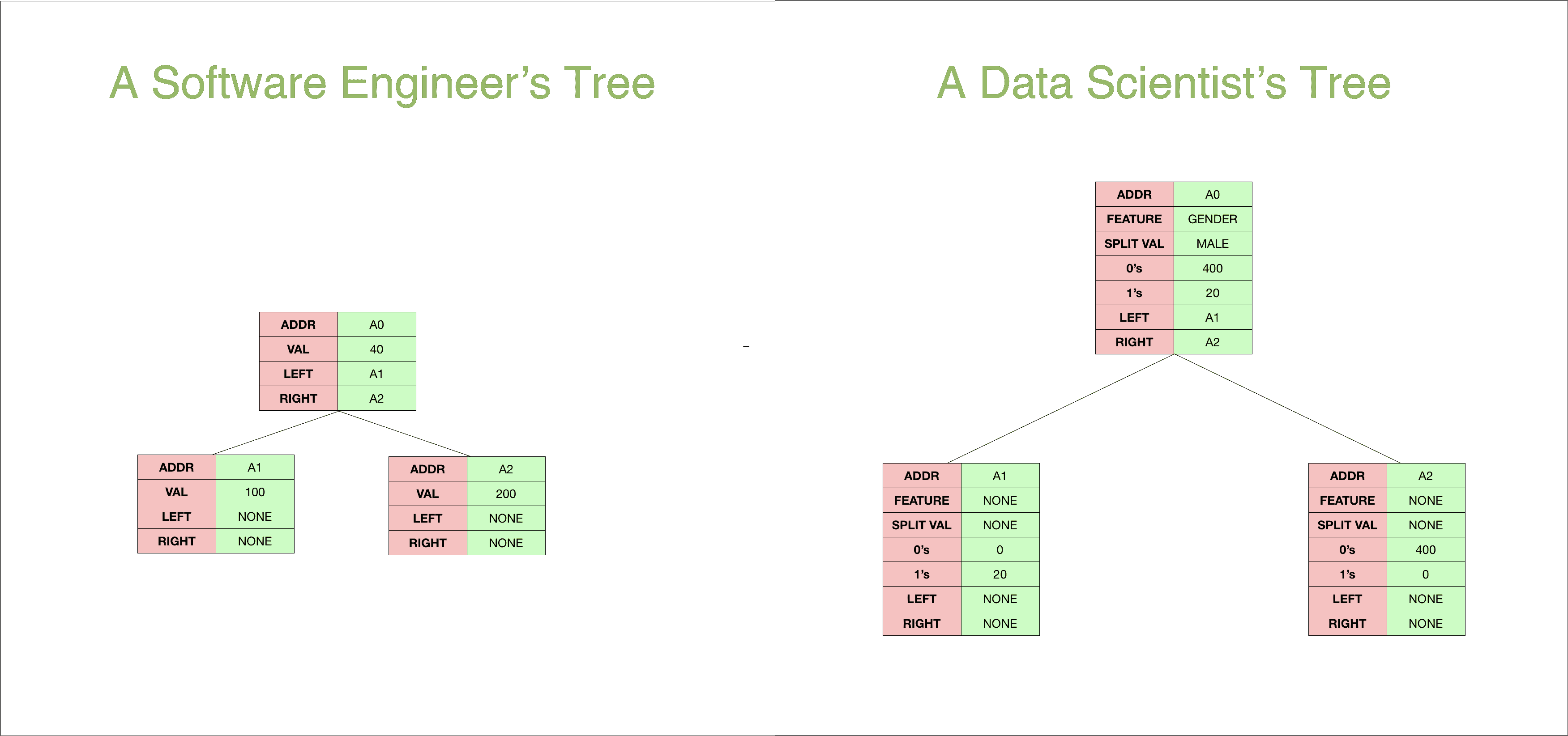
它们本质上是相同的。
唯一的区别在于,数据科学树节点包含了更多信息,这有助于我们确定如何遍历树。例如,在预测的数据科学树中,我们会查看节点中的特征,并根据分裂值确定我们要沿着哪个方向移动。
如果你想从头开始编写决策树,你可能还需要了解树在软件工程中的工作原理。
树的类型:
在这篇文章中,我将只讨论两种在数据科学面试问题中经常出现的树。二叉树(BT)和二叉树的扩展,称为二叉搜索树(BST)。
1. 二叉树:
二叉树仅仅是每个节点最多有两个子节点的树。决策树是我们日常生活中看到的一个例子。
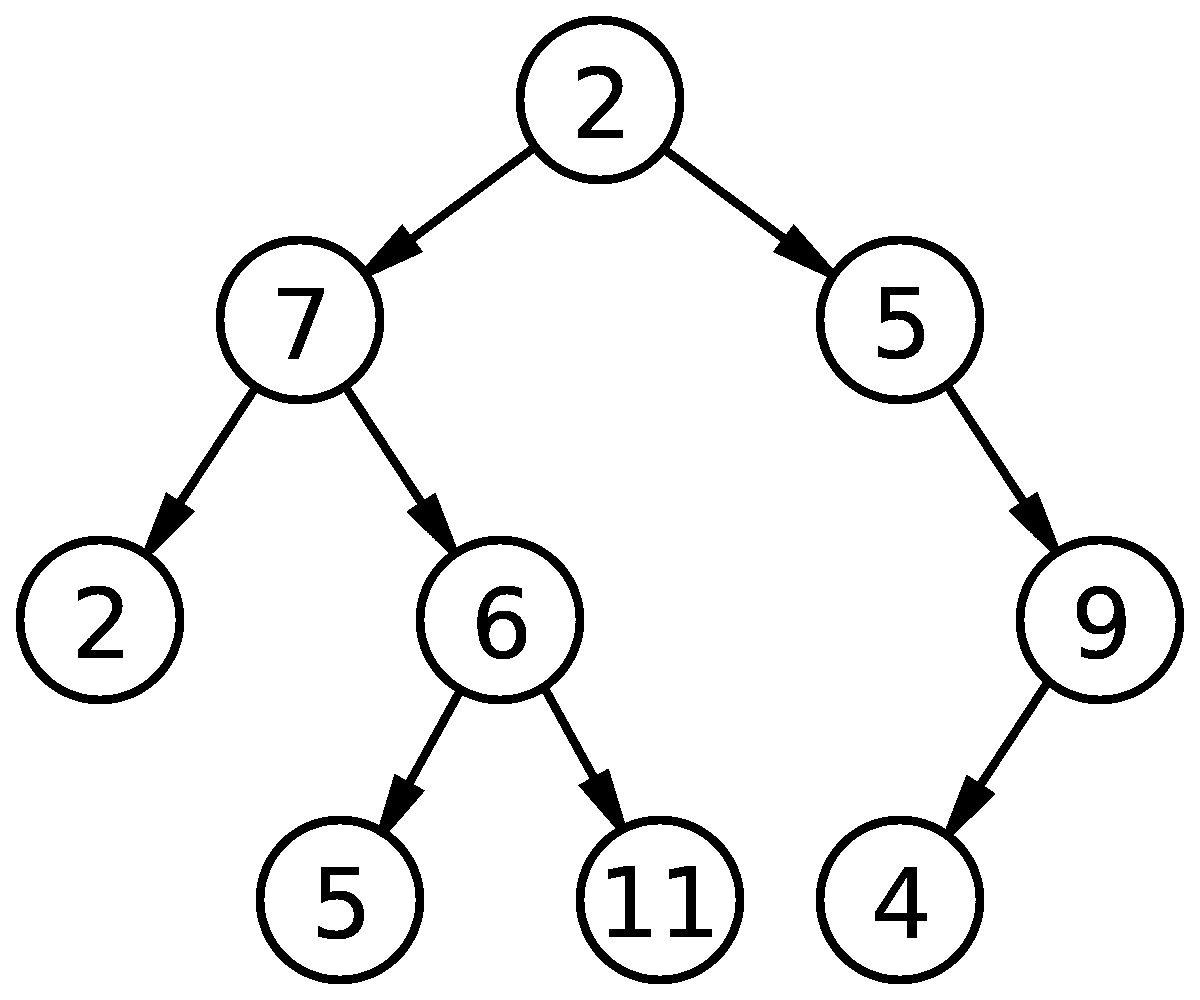
二叉树:每个节点最多有 2 个子节点
2. 二叉搜索树(BST):
二叉搜索树是二叉树的一种,其中:
-
节点的所有左侧后代都小于或等于该节点,且
-
节点的所有右侧后代都大于该节点。
关于等式,这一定义有一些变体。有时等式出现在右侧或任一侧。有时树中只允许不同的值。
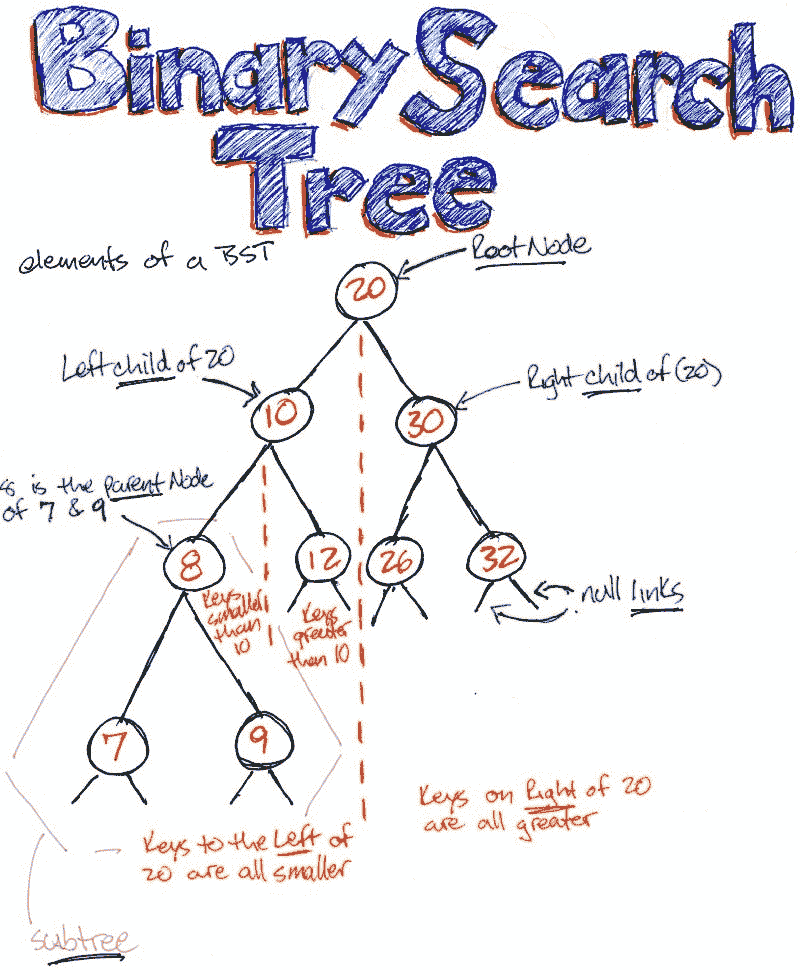
8 大于左子树中的所有元素,并小于右子树中的所有元素。树中的任何节点也可以这样说。
创建一个简单的树:
那么我们如何构造一个简单的树呢?
根据定义,树由节点组成。因此我们从定义node类开始,该类用于创建节点。我们的节点类相当简单,它保存节点的值、左子节点的位置和右子节点的位置。
class node:
def __init__(self,val):
self.val = val
self.left = None
self.right = None
现在我们可以创建一个简单的树,如下:
root = node(1)
root.left = node(2)
root.right = node(3)
现在我注意到,我们没有通过一些实际编程就很难掌握基于树的问题。
那么让我们更深入地探讨一下编码部分,特别是我在处理树时发现的最有趣的一些问题。
中序树遍历:
遍历树有多种方法,但我发现中序遍历是最直观的。
当我们对二叉搜索树的根节点进行中序遍历时,它会按升序访问/打印节点。
def inorder(node):
if node:
inorder(node.left)
print(node.val)
inorder(node.right)
上述方法非常重要,因为它允许我们访问所有节点。
如果我们想在任何二叉树中搜索一个节点,我们可能会尝试使用中序树遍历。
从排序数组创建二叉搜索树
如果我们需要像上面那样一块一块手动创建树,我们会成为什么样的程序员呢?
那么我们可以从一个排序的唯一元素数组中创建一个二叉搜索树吗?
def create_bst(array,min_index,max_index):
if max_index<min_index:
return None
mid = int((min_index+max_index)/2)
root = node(array[mid])
leftbst = create_bst(array,min_index,mid-1)
rightbst = create_bst(array,mid+1,max_index)
root.left = leftbst
root.right = rightbst
return root
a = [2,4,5,6,7]
root = create_bst(a,0,len(a)-1)
树本质上是递归的,因此我们在这里使用递归。我们取数组的中间元素并将其作为节点。然后我们将create_bst函数应用于数组的左部分并将其分配给node.left,右部分也做相同的操作。
然后我们就得到了我们的二叉搜索树。
我们做对了吗?我们可以通过创建二叉搜索树然后进行中序遍历来检查。
inorder(root)
------------------------------------------------------------
2
4
5
6
7
看起来对!
让我们检查一下我们的树是否是有效的 BST

思考递归!!!
不过,如果我们需要打印所有元素并手动检查是否满足 BST 属性,那我们算什么样的编码者呢?
这里是一个简单的代码,用于检查我们的 BST 是否有效。我们假设我们的二叉搜索树中严格不等。
def isValidBST(node, minval, maxval):
if node:
# Base case
if node.val<=minval or node.val>=maxval:
return False
# Check the subtrees changing the min and max values
return isValidBST(node.left,minval,node.val) & isValidBST(node.right,node.val,maxval)
return True
isValidBST(root,-float('inf'),float('inf'))
--------------------------------------------------------------
True
我们递归地检查子树是否满足二叉搜索树的性质。在每次递归调用时,我们更改minval或maxval,以为函数提供子树的允许值范围。
结论
在这篇文章中,我从软件工程的角度讨论了树。如果你想从数据科学的角度了解树,可以看看这篇文章。
理解分裂标准
树是数据科学算法面试中最常见问题的基础。我曾经对这些树形问题感到绝望,但现在我喜欢其中的思维锻炼。我喜欢这些问题中涉及的递归结构。
虽然你可以在数据科学中不学习它们,但你可以为了乐趣和提升编程技能而学习它们。
这是一个小的notebook,我在里面放置了所有这些小概念供你尝试和运行。
如果你想了解递归、动态规划或链表,可以查看我其他关于算法面试系列的帖子。
继续学习
如果你想了解更多关于算法和数据结构的内容,这里有一个UCSanDiego 的 Coursera 算法专项,我强烈推荐。
感谢阅读。我将来还会写更多适合初学者的帖子。关注我在 Medium 或订阅我的 博客,以便了解最新内容。欢迎反馈和建设性批评,可以在 Twitter 上找到我 @mlwhiz。
此外,小声明:本文中可能包含一些相关资源的附属链接,分享知识永远是好事。
简介:Rahul Agarwal 是 WalmartLabs 的高级统计分析师。关注他的 Twitter @mlwhiz。
原文。经授权转载。
相关:
-
数据科学家 6 条建议
-
Kaggle 的优质特征构建技巧和窍门
-
特征提取的搭车指南
更多相关内容
适当处理统计建模和预测中的缺失值
原文:
www.kdnuggets.com/2020/05/handnling-missing-values-statistical-modelling-prediction.html
评论 来源
来源
缺失值几乎在每个数据集中都是一个不可避免的现实。有时,如果没有缺失值,可能会引起担忧,因为你期望数据中会有缺失值。由于缺失值会影响样本研究的可靠性,处理缺失值已成为统计学家几十年来争论的主题。如果处理不当或未加检查,缺失值可能会损害样本研究的可靠性。在许多大学课程中,学生通常被教导用均值填补连续数据的缺失值,用中位数填补分类数据的缺失值,或简单地删除缺失值所占比例较小的行(启发式地,少于 10%被认为是阈值)。许多业内统计学家认为,盲目填补数据集中的缺失值是一个危险的举动,应避免在没有首先了解数据缺失原因的情况下进行。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
1976 年,Donald B. Rubin(《推断与缺失数据》)的论文提出,数据集中缺失值的存在有 3 个假设:
-
完全随机缺失(MCAR)
-
完全随机缺失(MCAR)定义为数据缺失的概率与应获取的具体值或观察到的响应集合无关。然而,如果数据因设计原因、设备故障、样本在运输过程中丢失或技术不合格而缺失,则这些数据被视为 MCAR。MCAR 数据的统计优势在于分析保持不偏倚。设计可能会失去效能,但估计的参数不会因数据缺失而产生偏差。
-
示例: 如果我们考察年龄与收入之间的关系,并且收入数据缺失,当缺失的收入数据与参与者的年龄之间没有关系时,缺失的数据是 MCAR。缺失数据没有模式。
-
随机缺失(MAR)
-
当数据的缺失概率依赖于已观察到的响应集,但与预计得到的具体缺失值无关时,数据被视为 MAR。由于我们倾向于认为随机性不会产生偏差,我们可能认为 MAR 不会带来问题。然而,MAR 并不意味着缺失数据可以被忽略。如果一个脱落变量是 MAR,我们可能期望在每个案例中该变量的脱落概率在条件上独立于当前获得的变量及预计将来获得的变量,前提是考虑到该案例之前获得的变量的历史。
-
缺失非随机(MNAR)
-
如果数据的缺失特征不符合 MCAR 或 MAR,则属于缺失非随机(MNAR)类别。MNAR 数据的情况是有问题的。在这种情况下,获得无偏估计的唯一方法是对缺失数据进行建模。然后,该模型可以被纳入一个更复杂的模型中,以估计缺失值。
如何处理缺失值
-
列删除法(完整案例分析)
-
这是所有方法中最简单且最省时的方法。这意味着仅对没有缺失值的数据行进行分析。这在大多数学术环境中是默认行为,当学生学习数据预处理时尤为如此。如果我们不能确认缺失数据是 MCAR 的,那么我们的分析结果可能会有偏差。在实际中,这在制药等行业比其他行业更为重要。如果样本量足够大,且功效不是问题,并且 MCAR 假设得到满足,则列删除法可能是一个合理的策略。然而,当样本量不大或 MCAR 假设不满足时,列删除法不是最佳策略。
-
成对删除法(可用案例分析)
-
在这种情况下,与列删除法不同,成对删除法要求使用没有缺失值的行和列进行分析,省略那些有缺失值的行和列。这有助于保留数据并提高统计功效,但由于样本大小不同和标准误差偏倚,现在的分析无法进行比较。成对删除法对于 MCAR 或 MAR 数据的偏倚较小。然而,如果缺失观测值很多,分析将会不足。
-
统计插补
-
插补涉及用统计分析得到的替代值替换缺失值,从而生成一个完整的数据集以供分析。插补可以通过显式或隐式建模方法创建。显式建模方法假设变量具有某种预测分布,并估计每个分布的参数,用于插补。这包括通过均值、中位数、概率、比率、回归、预测回归和分布假设等不同的插补方法。
-
在这些情况下,使用均值和中位数等点估计是常见的,但由于数据偏斜性,这些估计方法往往不可靠,并且这种方法更适合于类似于正态分布的数据(这在实际数据中不太可能)。实际数据往往是偏斜的,这使得像均值和中位数这样的描述统计量的实用性降低。
相关内容
-
执行机器学习和数据科学时的常见错误
-
数据科学家应采纳的 6 条建议
-
神经网络 201:关于自编码器的全部内容
更多相关内容
-
使用 SHAP 值进行机器学习模型解释
实践强化学习课程,第一部分
原文:
www.kdnuggets.com/2021/12/hands-on-reinforcement-learning-course-part-1.html
评论
由 Pau Labarta Bajo,数学家和数据科学家。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
本部分涵盖了你从基础到前沿强化学习(RL)所需的最低概念和理论,逐步进行,包含 Python 代码示例和教程。在接下来的每一章中,我们将解决一个不同难度的问题。
最终,最复杂的 RL 问题涉及到强化学习算法、优化和深度学习的混合。你不需要了解深度学习(DL)才能跟上本课程。我会给你足够的背景知识,让你熟悉 DL 的理念,并理解它如何成为现代强化学习的关键组成部分。
在这一节课中,我们将通过示例、零数学和一些 Python 代码来讲解强化学习的基本原理。
1. 什么是强化学习问题?
强化学习(RL)是机器学习(ML)的一个领域,涉及那些
一个智能的代理需要通过反复试验来学习如何在环境内部采取行动,以最大化累积奖励。
强化学习是最接近人类和动物学习方式的机器学习类型。
什么是代理?什么是环境?代理可以采取哪些行动?奖励是什么?为什么说累积奖励?
如果你正在问自己这些问题,你就走在正确的道路上。
我刚才给出的定义引入了一些你可能不熟悉的术语。实际上,它们故意模糊不清。这种泛化使得强化学习(RL)能够应用于看似不同的各种学习问题。这就是数学建模的哲学,它是 RL 的根本。
让我们来看几个学习问题,并看看它们如何使用 RL 视角。
示例 1:学习走路
作为一位最近开始学步的婴儿的父亲,我忍不住问自己,他是怎么学会的?

Kai 和 Pau。
作为一名机器学习工程师,我幻想着通过软件和硬件来理解和复制这种令人难以置信的学习曲线。
让我们尝试使用强化学习的要素来建模这个学习问题:
- 代理是我的儿子 Kai。他想站起来走路。在这个时间点,他的肌肉足够强壮,有可能做到这一点。他面临的学习问题是:如何逐步调整他的身体位置,包括腿部、腰部、背部和手臂的多个角度,以平衡他的身体并防止摔倒。

Sai hi to Kai!
-
环境是指他周围的物理世界,包括物理定律。其中最重要的定律是重力。没有重力,学习走路的问题会发生剧变,甚至变得无关紧要:在一个你可以简单地飞翔的世界里,你为什么还想走路呢?另一个在这个学习问题中重要的定律是牛顿的第三定律,用简单的话来说就是如果你摔到地板上,地板会以相同的力量反弹到你身上。哎呀!
-
动作是所有更新的身体角度,这些角度决定了他在开始追逐物体时的身体位置和速度。当然,他可以同时做其他事情,比如模仿牛的声音,但这些可能并没有帮助他实现目标。我们在我们的框架中忽略这些动作。增加不必要的动作不会改变建模步骤,但会使后来解决问题变得更困难。一个重要(也是显而易见)的备注是,Kai 不需要学习牛顿的物理学就能站起来走路。他将通过观察环境的状态、采取行动并从环境中收集反馈来学习。他不需要学习环境模型来实现他的目标。
-
他所获得的奖励是来自大脑的刺激,使他感到快乐或痛苦。他在摔倒在地板上的时候会体验到负面奖励,即身体的疼痛,可能还伴随着挫败感。另一方面,还有一些事情对他的幸福感产生积极贡献,比如快速到达目的地的喜悦,或者当我们对每一次尝试和微小进步说“干得好!”或“好极了!”时,来自我妻子 Jagoda 和我外部的刺激。
关于奖励的更多信息
奖励是一个信号,告诉 Kai 他所做的事情对他的学习是好还是坏。随着他采取新的行动并体验到痛苦或快乐,他开始调整他的行为以获取更多的积极反馈,减少负面反馈。换句话说,他在学习。
一些行动在开始时可能对婴儿很有吸引力,比如尝试跑步以获得兴奋感。然而,他很快学会了在一些(或大多数)情况下,最终摔倒并经历长时间的痛苦和眼泪。这就是为什么智能代理会最大化累计奖励而不是边际奖励。他们用长期奖励来换取短期奖励。一个能够立即获得奖励,但会让我的身体处于快要摔倒的位置的行动,并不是最优的。
巨大的快乐之后伴随更大的痛苦不是长期幸福的秘诀。这是婴儿比我们成人更容易学到的事情。
奖励的频率和强度对帮助代理学习至关重要。非常不频繁(稀疏)的反馈意味着更困难的学习。想一想,如果你不知道你做的事是好是坏,你怎么能学习?这就是为什么一些 RL 问题比其他问题更难的主要原因之一。
奖励塑形是许多现实世界 RL 问题中的一个艰难建模决策。
示例 2:像专家一样学习玩《垄断》
小时候,我花了很多时间和朋友和亲戚一起玩《垄断》。嗯,谁没有呢?这是一款结合了运气(你掷骰子)和策略的刺激游戏。
《垄断》是一款适合两到八名玩家的房地产棋盘游戏。你掷两个骰子来在棋盘上移动,购买和交易属性,并用房屋和酒店来发展它们。你从对手那里收取租金,目标是让他们破产。

照片由 Suzy Hazelwood 提供,来自 Pexels。
如果你对这个游戏如此着迷,以至于想找到智能的玩法,你可以使用一些强化学习的方法。
4 个 RL 成分是什么?
-
代理是你,那个想在《垄断》中获胜的人。
-
你的行动就是你在下面这个截图中看到的:
《垄断》的动作空间。感谢 aleph aseffa。
-
环境是游戏的当前状态,包括每个玩家拥有的属性列表、位置和现金金额。还有对手的策略,这些是你无法预测并且超出你控制范围的。
-
奖励为 0,除非在你的最后一次移动中,如果你赢得比赛,则为 +1,如果破产,则为 -1。这种奖励设定是合理的,但使问题难以解决。正如我们之前所说,更稀疏的奖励意味着更难解决。因此,还有 其他方式 来建模奖励,这些方法噪声更大但稀疏性更低。
当你在《大富翁》中与另一个人对战时,你不知道他或她会怎么打。你可以做的就是与自己对战。随着你打得越来越好,你的对手也会变强(因为就是你自己),这迫使你提升游戏水平以继续获胜。你可以看到这种正反馈循环。
这个技巧被称为自我对战。它为我们提供了一条在不依赖专家玩家外部建议的情况下引导智能的路径。自我对战是AlphaGo和AlphaGo Zero这两个 DeepMind 开发的围棋模型之间的主要区别,这两个模型在围棋游戏中的表现超过了任何人类。
示例 3:学习驾驶
几十年内(可能更短),机器将会驾驶我们的汽车、卡车和公交车。

照片由Ruiyang Zhang拍摄,来源于Pexels。
不过,怎么做呢?
学习驾驶汽车并不容易。司机的目标很明确:是让她自己和车上任何乘客都能舒适地从 A 点到达 B 点。
驾驶中有许多外部因素使得驾驶变得具有挑战性,包括:
-
其他司机的行为
-
交通标志
-
行人行为
-
道路状况
-
天气条件
-
…甚至燃料优化(谁想为此多花钱呢?)
我们如何用强化学习来解决这个问题呢?
-
智能体是希望从 A 点舒适到达 B 点的司机。
-
司机观察到的环境状态包括很多方面,包括汽车的位置、速度和加速度,所有其他车辆、乘客、道路条件或交通标志。将这样一个庞大的输入向量转化为适当的动作是具有挑战性的,正如你所能想象的那样。
-
动作基本上有三种:方向盘的转动、油门的强度和刹车的强度。
-
每次动作后的奖励是你在驾驶时需要平衡的不同方面的加权总和。距离 B 点的减少带来正奖励,而增加则带来负奖励。为了确保不发生碰撞,过于接近(甚至碰撞)其他车辆或行人应该有一个非常大的负奖励。此外,为了鼓励平稳驾驶,速度或方向的剧烈变化会导致负奖励。
经过这三个示例后,我希望以下关于强化学习(RL)元素及其相互作用的表示能够让你理解:
强化学习概述。感谢维基百科。
现在我们理解了如何表述一个强化学习问题,我们需要解决它。
但是怎么做呢?
2. 策略和价值函数
策略
代理根据环境的当前状态选择她认为最好的动作。这是代理的策略,通常称为代理的 策略。
策略 是一个从状态到动作的学习映射。
解决强化学习问题意味着找到最佳可能的策略。
策略是确定性的,当它们将每个状态映射到一个动作时,
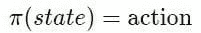
或随机的,当它们将每个状态映射到所有可能动作的概率分布时。
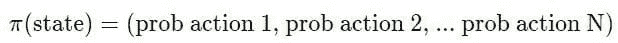
随机 是你在机器学习中经常看到和听到的一个词,它本质上意味着 不确定 或 随机。在不确定性很高的环境中,例如掷骰子的 Monopoly 游戏,随机策略比确定性策略更好。
实际上存在几种方法来计算这个最优策略。这些被称为 策略优化方法。
价值函数
有时,根据问题的不同,可以尝试找到与最优策略相关的价值函数,而不是直接寻找最优策略。
但是,什么是价值函数?在此之前,价值在这个上下文中是什么意思?
价值 是与环境中每个状态 s 相关的一个数字,用于估计代理处于状态 s 的好坏。
这是代理在状态 s 下开始并根据策略 π 选择动作时获得的累积奖励。
价值函数是一个从状态到值的学习映射。
策略的价值函数通常表示为
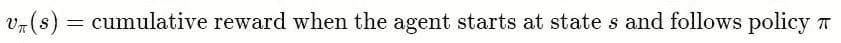
价值函数也可以将 (动作, 状态) 对映射到值。在这种情况下,它们被称为 q-值 函数。
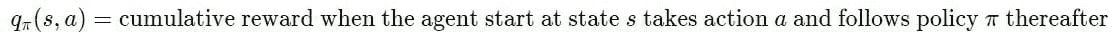
最优价值函数(或 q-值函数)满足一个数学方程,称为 贝尔曼方程。
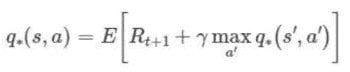
这个方程式很有用,因为它可以转化为一个迭代过程来寻找最优价值函数。
但是,为什么价值函数有用? 因为你可以从最优 q-值函数推断出最优策略。
如何? 最优策略是在每个状态 s 下,代理选择最大化 q-值函数的动作 a。
因此,你可以在最优策略和最优 q-函数之间跳转,反之亦然。
有几种 RL 算法专注于寻找最优 q-值函数。这些被称为 Q-学习方法。
强化学习算法的分类
有许多不同的 RL 算法。有些尝试直接寻找最优策略,有些寻找 q 值函数,还有些同时寻找两者。
强化学习算法的分类是多样的,有些让人有些畏惧。
关于 RL 算法,没有一刀切的方法。你需要每次解决 RL 问题时实验几种算法,看看哪种适合你的情况。
当你跟随本课程时,你将实现这些算法中的几个,并获得每种情况中什么效果最佳的洞察。
3. 如何生成训练数据?
强化学习代理非常需要数据。

要解决 RL 问题,你需要大量数据。
克服这一障碍的一种方法是使用模拟环境。编写模拟环境的引擎通常比解决 RL 问题需要更多的工作。此外,不同引擎实现之间的差异可能会使算法之间的比较变得毫无意义。
这就是 OpenAI 团队在 2016 年发布Gym 工具包的原因。OpenAI 的 gym 为不同问题的环境集合提供了一个标准化的 API,包括
-
经典的 Atari 游戏,
-
机器人手臂
-
或者着陆月球(嗯,简化版)
还有一些专有环境,如MuJoCo(最近被 DeepMind 收购)。MuJoCo 是一个可以在 3D 环境中解决连续控制任务的环境,例如学习行走。
OpenAI Gym 还定义了一个标准 API 来构建环境,允许第三方(比如你)创建并将你的环境提供给其他人。
如果你对自动驾驶汽车感兴趣,那么你应该看看 CARLA,最受欢迎的开放城市驾驶模拟器。
4. Python 样板代码
你可能在想:
我们到目前为止所涵盖的内容很有趣,但我怎么在 Python 中实际编写这些呢?
我完全同意你的观点
让我们看看这些在 Python 中是什么样的。
你在这段代码中发现了什么不清楚的地方吗?
第 23 行怎么样?这个 epsilon 是什么?
不要惊慌。我之前没有提到这一点,但我不会让你没有解释。
Epsilon 是一个关键参数,用于确保我们的代理在得出每个状态中最佳行动的明确结论之前,足够地探索环境。
这是一个介于 0 和 1 之间的值,它表示代理选择随机行动而不是她认为最佳行动的概率。
探索新策略与坚持已知策略之间的权衡被称为探索-利用问题。这是 RL 问题的关键成分,也是 RL 问题与监督机器学习问题的区别所在。
从技术上讲,我们希望代理找到全局最优解,而不是局部最优解。
最佳实践是从一个较大的值开始训练(例如 50%),并在每个回合后逐渐减少。这样,代理在开始时会进行大量探索,并在逐步完善策略时减少探索。
5. 总结与作业
这一部分的关键要点是:
-
每个强化学习问题都有一个(或多个)代理、环境、动作、状态和奖励。
-
代理顺序地采取行动,目标是最大化总奖励。为此,它需要找到最优策略。
-
价值函数很有用,因为它们为我们提供了一种寻找最优策略的替代路径。
-
实践中,你需要尝试不同的强化学习算法来解决你的问题,看看哪种方法最有效。
-
强化学习代理需要大量的训练数据来进行学习。OpenAI gym 是一个很好的工具,用于重用和创建你的环境。
-
探索与利用的平衡在训练强化学习代理时是必要的,以确保代理不会陷入局部最优解。
一个没有一点作业的课程不会算是课程。
我希望你选择一个你感兴趣的实际问题,并且你可以使用强化学习进行建模和解决。
定义代理(agent)、动作、状态和奖励是什么。
随时可以通过电子邮件联系我,plabartabajo@gmail.com,告知你的问题,我可以给你反馈。
原文。经授权转载。
了解更多相关话题
动手强化学习课程,第二部分
原文:
www.kdnuggets.com/2021/12/hands-on-reinforcement-learning-part-2.html
评论
由 Pau Labarta Bajo,数学家和数据科学家。

威尼斯的出租车,来自 Helena Jankovičová Kováčová 的 Pexels。
这是我的动手强化学习课程的第二部分,它将带你从零到英雄。今天我们将学习 Q-learning,这是一种诞生于 90 年代的经典 RL 算法。
如果你错过了第一部分,请先阅读它,以掌握强化学习的术语和基础知识。
今天我们将解决第一个学习问题……
我们将训练一个代理来驾驶出租车!
好吧,这是一个简化版本的出租车环境,但总的来说就是一个出租车。
我们将使用 Q-learning,这是最早且最常用的 RL 算法之一。
当然,还会用到 Python。
本课程的所有代码都在 这个 Github 仓库中。克隆它以跟随今天的问题。

1. 出租车驾驶问题
我们将教一个代理使用强化学习来驾驶出租车。
在现实世界中驾驶出租车是一项非常复杂的任务。因此,我们将在一个简化的环境中工作,该环境捕捉到一个优秀出租车司机需要做的三个基本方面:
-
接载乘客并将他们送到指定的目的地。
-
安全驾驶,避免碰撞。
-
尽可能缩短时间将他们送达。
我们将使用来自 OpenAI Gym 的一个环境,称为 Taxi-v3 环境。
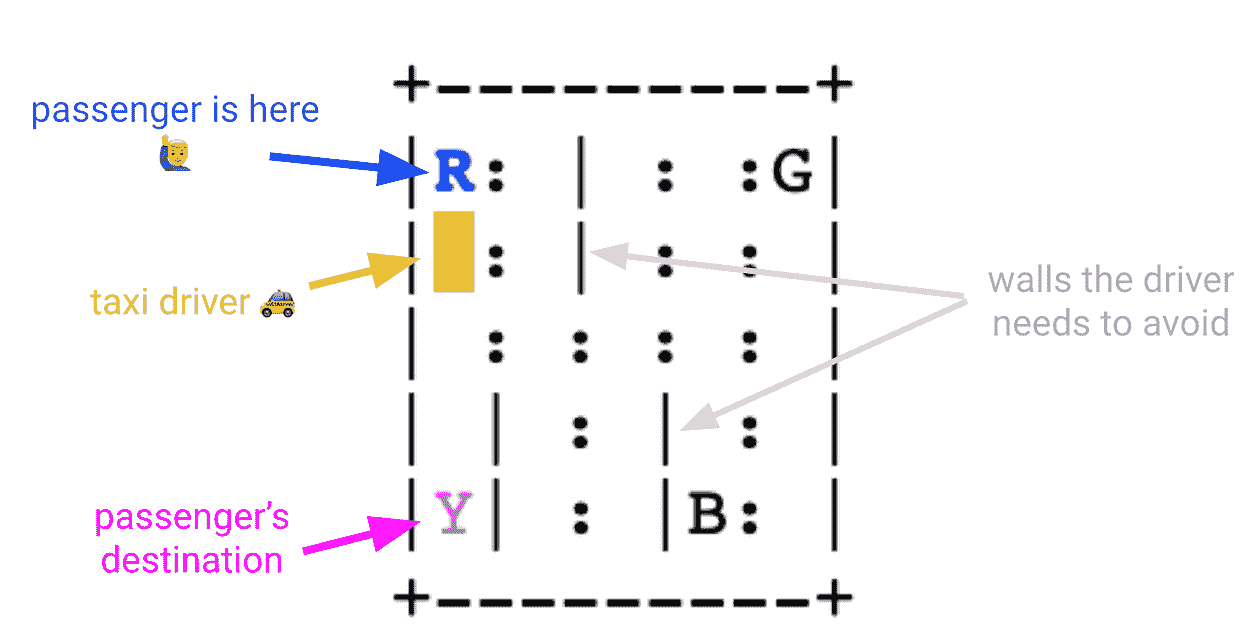
在网格世界中有四个指定位置,分别用 R(红色)、G(绿色)、Y(黄色) 和 B(蓝色) 标识。
当回合开始时,出租车从一个随机的方格出发,乘客位于随机的位置(R、G、Y 或 B)。
出租车驱动到乘客的位置,接载乘客,驾车到乘客的目的地(四个指定位置之一),然后将乘客放下。在此过程中,我们的出租车司机需要小心驾驶,以避免撞到标记为|的墙壁。一旦乘客被放下,当前回合结束。
这就是我们今天要构建的 Q-learning 代理的驾驶方式:
在我们到达之前,让我们了解一下这个环境中的动作、状态和奖励。
2. 环境、动作、状态、奖励
notebooks/00_environment.ipynb
让我们首先加载环境:

代理在每一步可以选择的 动作 是什么?
-
0 向下行驶
-
1 向上行驶
-
2 向右行驶
-
3 向左行驶
-
4 载客
-
5 让乘客下车

那 状态 呢?
-
25 个可能的出租车位置,因为世界是一个 5×5 的网格。
-
5 个可能的乘客位置,分别是 R、G、Y、B,加上乘客在出租车中的情况。
-
4 个目的地
这给我们提供了 25 x 5 x 4 = 500 个状态。

那 奖励 呢?
-
-1 每步的默认奖励。
为什么是 -1,而不是简单的 0? 因为我们希望通过惩罚每一步多余的时间来鼓励代理尽快完成。这是你对出租车司机的期望,不是吗?
-
+20 奖励用于将乘客送到正确的目的地。
-
-10 奖励用于在错误的位置执行接送操作。
你可以从 env.P 中读取奖励和环境转换 (state, action) → next_state。
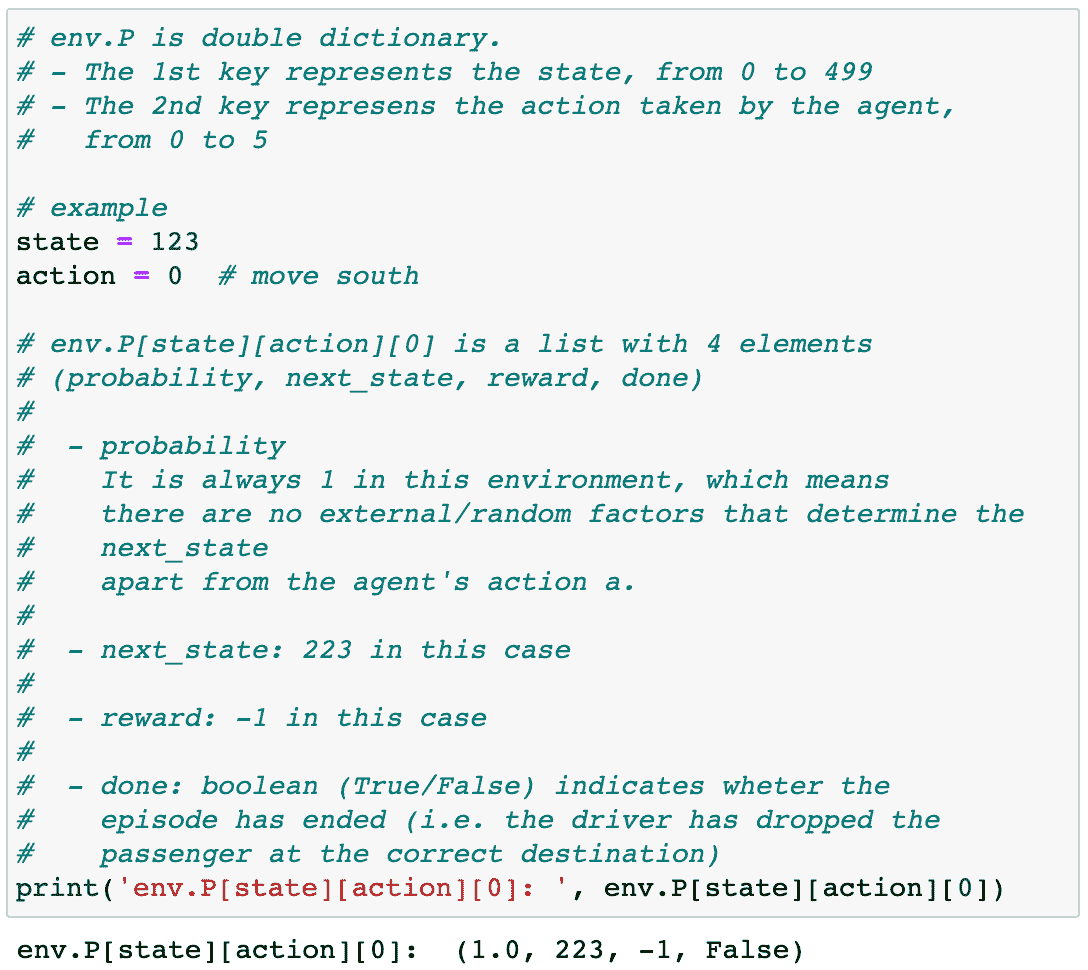
顺便说一下,你可以在每个状态下渲染环境,以重新检查这些 env.P 向量是否有意义:
从 state=123 开始:
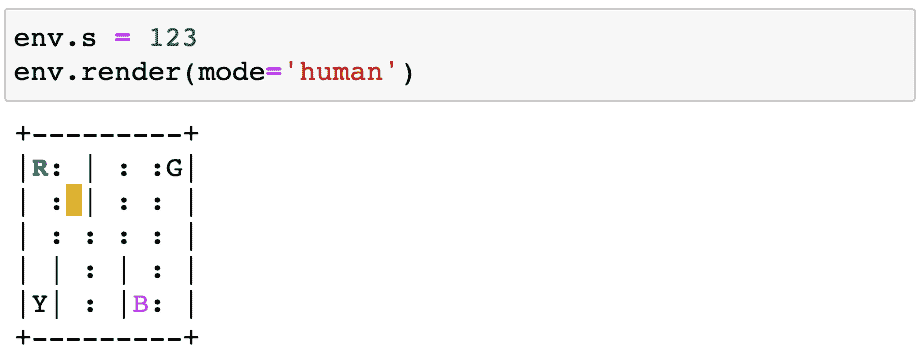
代理向南移动 action=0 到达状态=223:
奖励是 -1,因为既没有回合结束,也没有司机错误地接送乘客。
3. 随机代理基线
notebooks/01_random_agent_baseline.ipynb
在你开始实现任何复杂算法之前,你应该始终建立一个基线模型。
这个建议不仅适用于强化学习问题,也适用于一般的机器学习问题。
直接跳入复杂/高级算法是非常诱人的,但除非你真的有经验,否则你会失败得很惨。
让我们使用一个随机代理作为基线模型。

我们可以看到该代理在给定初始状态=198 时的表现:

3,804 步是很多的!
请在此视频中自行观看:
为了获得更具代表性的性能衡量,我们可以重复相同的评估循环 n=100 次,每次从一个随机状态开始。

如果你绘制 timesteps_per_episode 和 penalties_per_episode,你可以观察到它们都不会随着代理完成更多的回合而减少。换句话说,代理没有学到任何东西。
如果你想了解性能的总结统计数据,你可以计算平均值:

实现能学习的智能体是强化学习的目标,也是本课程的目标。
让我们使用 Q-learning 实现第一个“智能”智能体,Q-learning 是最早和最常用的 RL 算法之一。
4. Q-learning 智能体
Q-learning(由 Chris Walkins 和 Peter Dayan 提出)是一个用于寻找最优 q 值函数的算法。
正如我们在 第一部分 中所说,q 值函数 Q(s, a) 与策略 π 相关,表示当智能体在状态 s 时采取动作 a 并随后遵循策略 π 时,智能体期望获得的总奖励。
最优 q 值函数 Q*(s, a) 是与最优策略 π* 相关的 q 值函数。
如果你知道 Q*(s, a),你可以推断 π:即选择下一个动作,使其在当前状态 s 下最大化 Q(s, a)。
Q-learning 是一个迭代算法,用于逐步计算更好地接近最优 q 值函数 Q*(s, a) 的近似值,从一个任意初始猜测 Q⁰(s, a) 开始。
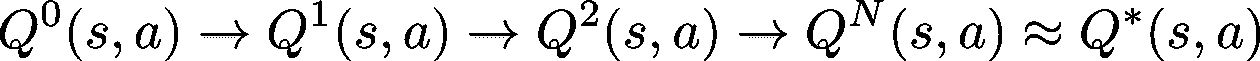
在像 Taxi-v3 这样的有限状态和动作数量的表格环境中,q 函数实际上是一个矩阵。它有与状态数量相同的行和与动作数量相同的列,即 500 x 6。
好的,那么你是如何从 Q⁰(s, a) 计算下一个近似 Q¹(s, a) 的?
这是 Q-learning 中的关键公式:
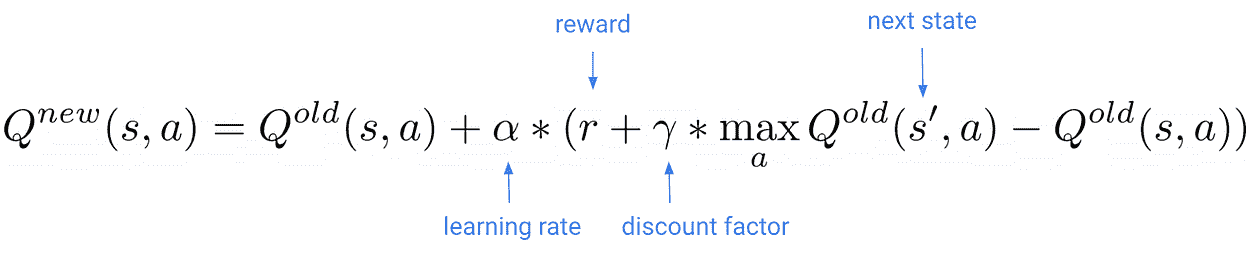
当我们的 q-agent 在环境中导航并观察到下一个状态 s’ 和奖励 r 时,你会使用这个公式来更新你的 q 值矩阵。
在这个公式中,学习率????是什么?
学习率(如同机器学习中的常规做法)是一个小数字,用来控制对 q 函数的更新幅度。你需要调整它,因为值过大会导致训练不稳定,而值过小可能不足以摆脱局部最小值。
而这个折扣因子????呢?
折扣因子 是一个介于 0 和 1 之间的(超)参数,用于决定我们的智能体对未来远期奖励的关注程度相对于即时奖励的程度。
-
当 ????=0 时,智能体只关注最大化即时奖励。正如生活中所发生的那样,最大化即时奖励并不是实现最佳长期结果的最佳方法。RL 智能体也会出现这种情况。
-
当 ????=1 时,智能体基于所有未来奖励的总和来评估每一个动作。在这种情况下,智能体对即时奖励和未来奖励赋予相等的权重。
折扣因子通常是一个中间值,例如 0.6。
总结一下,如果你
-
训练足够长时间
-
使用一个合适的学习率和折扣因子
-
并且智能体充分探索状态空间
-
并且你用 Q-learning 公式更新 q 值矩阵,
你的初始近似值最终会收敛到最优 q 矩阵。瞧!
那么,让我们实现一个 Q-agent 的 Python 类吧。

它的 API 与上面的 RandomAgent 相同,但多了一个方法 update_parameters()。这个方法接受过渡向量(state,action,reward,next_state)并使用上述 Q-learning 公式更新 q 值矩阵近似 self.q_table。
现在,我们需要将这个智能体插入到训练循环中,并每次智能体收集到新经验时调用它的 update_parameters() 方法。
此外,请记住我们需要确保智能体充分探索状态空间。记得我们在 part 1 中讨论的探索-利用参数吗?这就是 epsilon 参数介入的地方。
让我们训练智能体 n_episodes = 10,000 次,并使用 epsilon = 10%:

并绘制 timesteps_per_episode 和 penalties_per_episode:

很好!这些图形比 RandomAgent 的图形好得多。两个指标随着训练的进行而下降,这意味着我们的智能体正在学习。
我们实际上可以看到智能体从相同的状态 = 123 开始驾驶,正如我们在 RandomAgent 中使用的那样。

我们的 Q-agent 表现不错!
如果你想比较具体的数字,你可以评估 q-agent 在 100 次随机回合中的表现,并计算平均时间戳和惩罚次数。
关于 epsilon-贪婪策略的简介
当你评估智能体时,仍然建议使用一个正的 epsilon 值,而不是 epsilon = 0。
为什么呢?难道我们的智能体已经完全训练好了吗?我们为什么需要在选择下一个动作时保留这种随机性?
原因是为了防止过拟合。
即使在如此小的状态空间中,如 Taxi-v3(即 500 x 6),在训练过程中,我们的智能体可能没有访问到足够的某些状态。因此,在这些状态中的表现可能不是 100% 最优,导致智能体陷入一个几乎无限的次优动作循环中。如果 epsilon 是一个较小的正数(例如 5%),我们可以帮助智能体摆脱这些次优动作的无限循环。
通过在评估时使用较小的 epsilon,我们采用了所谓的 epsilon-贪婪策略。
让我们使用 epsilon = 0.05 对训练好的智能体进行评估,n_episodes = 100。观察训练循环几乎与上面的训练循环完全相同,但没有调用 update_parameters():


这些数字比RandomAgent要好得多。
我们可以说我们的代理已经学会了驾驶出租车!
Q 学习为我们提供了一种计算最佳 q 值的方法。但超参数alpha、gamma 和 epsilon 呢?
我为你选择了它们,虽然有些随意。但在实际中,你需要为你的 RL 问题调整这些参数。
让我们探讨它们对学习的影响,以更好地理解发生了什么。
5. 超参数调整
notebooks/03_q_agent_hyperparameters_analysis.ipynb
让我们使用不同的alpha(学习率)和gamma(折扣因子)来训练我们的 q-agent。至于epsilon,我们保持在 10%。
为了保持代码整洁,我将 q-agent 的定义封装在src/q_agent.py中,将训练循环封装在src/loops.py中的train()函数中。


让我们绘制每种超参数组合的timesteps每集数。

图表看起来很有艺术感,但有点过于嘈杂。
不过,你可以观察到,当alpha = 0.01 时,学习速度较慢。alpha(学习率)控制我们在每次迭代中更新 q 值的程度。值过小会导致学习速度变慢。
让我们丢弃alpha = 0.01,并对每种超参数组合进行 10 次训练。我们将这 10 次训练中每集数 1 到 1000 的timesteps取平均值。
我在src/loops.py中创建了函数train_many_runs(),以保持笔记本代码的整洁。

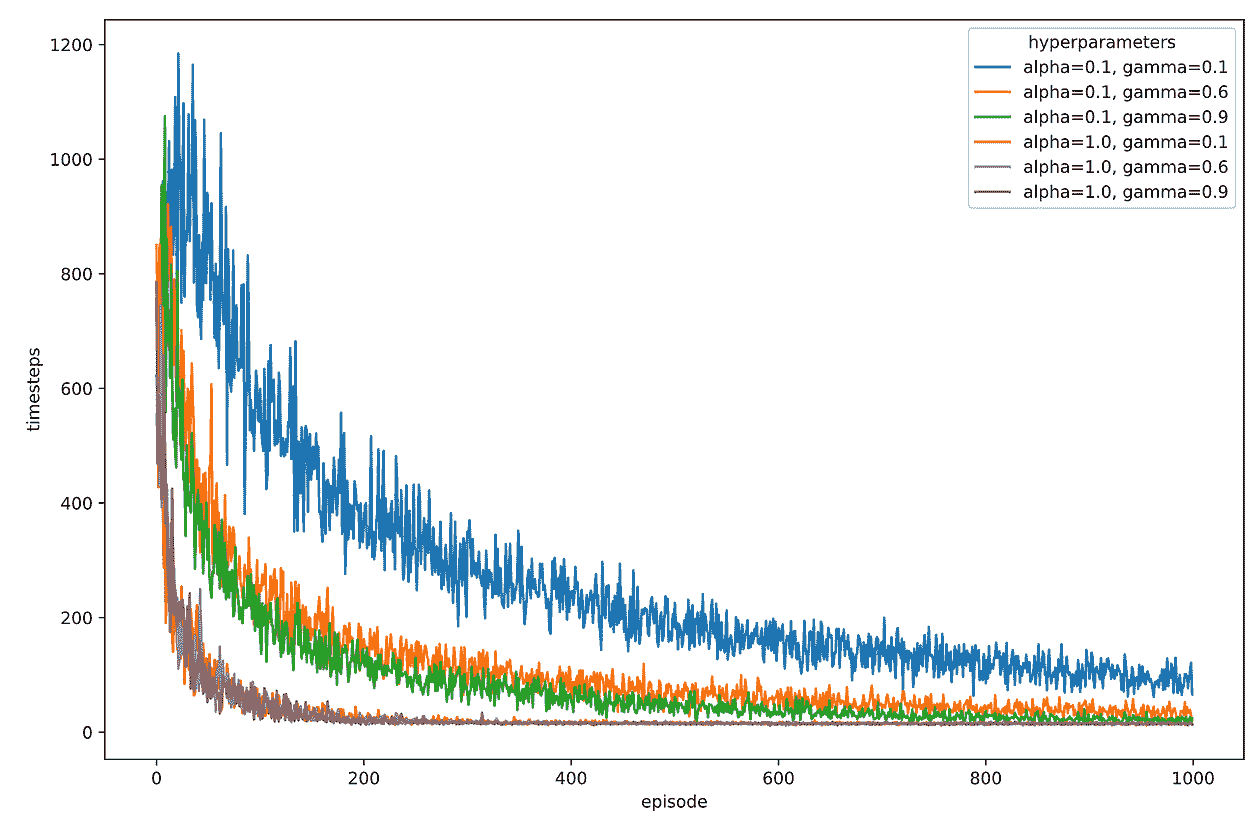
看起来alpha = 1.0 是效果最好的值,而 gamma 似乎影响较小。
恭喜!你已经调整了本课程中的第一个学习率。
调整超参数可能耗时且乏味。有一些优秀的库可以自动化我们刚刚执行的手动过程,比如Optuna,但这是我们在课程后面会深入探讨的内容。暂时,享受我们刚刚发现的训练加速吧。
等等,那我让你相信的epsilon = 10%呢?
当前的 10%值是最佳的吗?
让我们自己检查一下。
我们采用了找到的最佳alpha和gamma,即,
-
alpha = 1.0
-
gamma = 0.9(我们也可以选择0.1或0.6)
并使用不同的 epsilon 值进行训练 = [0.01, 0.1, 0.9]
并绘制出结果中的 timesteps 和 penalties 曲线:

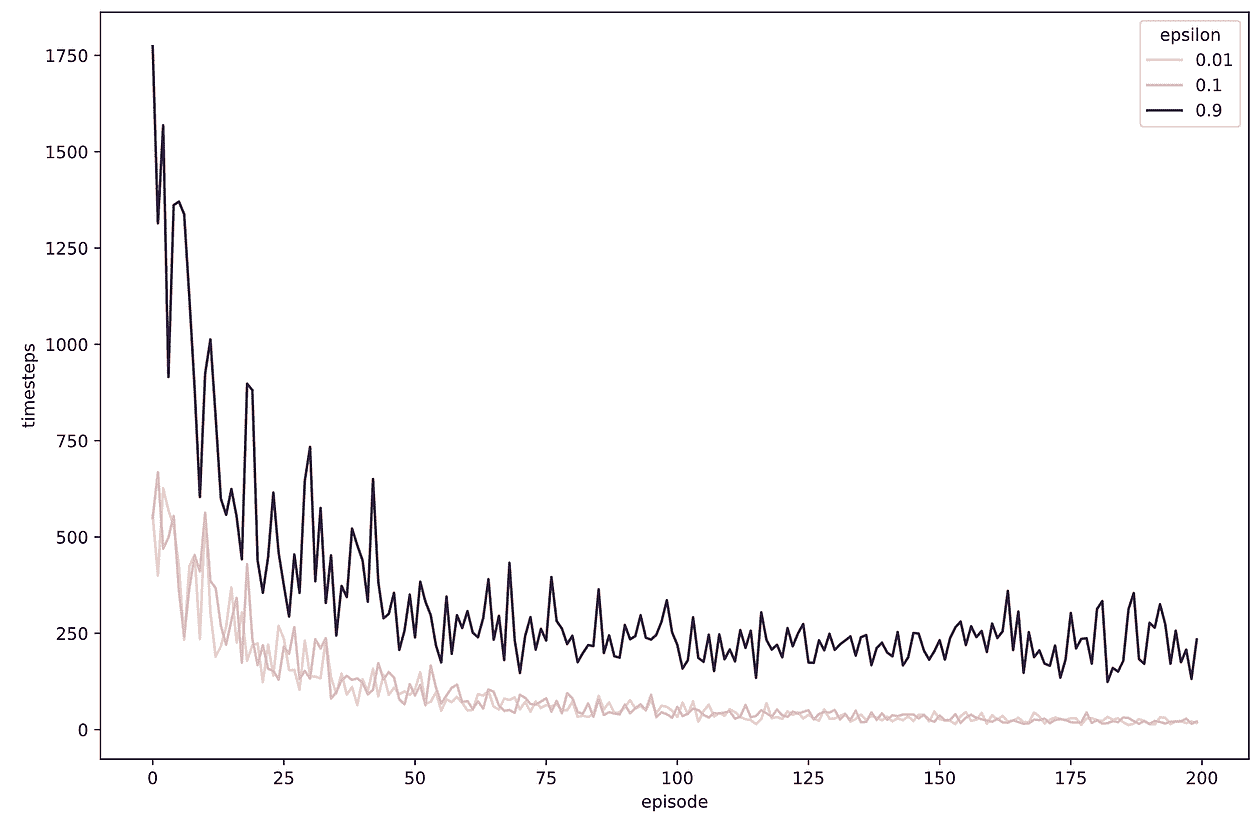
正如你所看到的,epsilon = 0.01 和 epsilon = 0.1 似乎都表现得非常好,因为它们在探索和利用之间达到了正确的平衡。
另一方面,epsilon = 0.9 是一个过大的值,会导致训练过程中的“过多”随机性,并阻止我们的 q 矩阵收敛到最佳状态。观察一下性能如何在每回合约 250 timesteps 处达到平稳。
一般来说,选择 epsilon 超参数的最佳策略是 渐进式 epsilon 衰减。也就是说,在训练的开始阶段,当代理对其 q 值估计非常不确定时,最好访问尽可能多的状态,而为此,大的 epsilon 是非常有用的(例如,50%)。
随着训练的进行,代理逐渐完善其 q 值估计,探索的必要性就减少了。相反,通过降低 epsilon,代理可以学会完善和微调 q 值,使其更快地收敛到最佳值。过大的 epsilon 可能会导致收敛问题,就像我们看到的 epsilon = 0.9 一样。
我们将在课程中调整 epsilon 值,因此目前我不会过多坚持。再次,享受我们今天所做的事情。这是非常值得的。

B-R-A-V-O!(图片来自作者)。
复习
祝贺你(可能)解决了你的第一个强化学习问题。
这些是我希望你仔细思考的关键学习点:
-
强化学习问题的难度与可能的动作和状态的数量直接相关。
Taxi-v3是一个表格环境(即有限数量的状态和动作),所以它比较简单。 -
Q-learning 是一种在表格环境中表现优秀的学习算法。
-
无论你使用什么强化学习算法,都需要调整超参数以确保你的代理学习到最佳策略。
-
调整超参数是一个耗时的过程,但对于确保我们的代理能学习是必要的。随着课程的进展,我们会在这方面做得更好。
作业
这是我希望你做的事情:
-
将 Git 仓库克隆 到你的本地机器上。
-
设置 这个课程的环境 01_taxi。
-
打开 01_taxi/otebooks/04_homework.ipynb 并尝试完成这两个挑战。
我称这些为挑战(而不是练习),因为它们并不容易。我希望你能尝试这些挑战,动手实践,并(也许)成功。
在第一个挑战中,我敢打赌你会更新train()函数src/loops.py以接受一个依赖于回合的 epsilon。
在第二个挑战中,我希望你提升你的 Python 技能,并实现并行处理以加速超参数实验。
如往常一样,如果你遇到困难并需要反馈,请发邮件给我,邮箱是 plabartabajo@gmail.com。
我会非常乐意帮助你。
如果你想获取课程更新,请订阅datamachines通讯。
原始。经许可转载。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
实践强化学习课程第三部分:SARSA
原文:
www.kdnuggets.com/2022/01/handson-reinforcement-learning-course-part-3-sarsa.html

欢迎来到我的强化学习课程❤️
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
这是我实践强化学习课程的第三部分,该课程将你从零带到 HERO ????♂️。今天我们将学习 SARSA,这是一种强大的 RL 算法。
我们仍然处于旅程的起点,解决相对简单的问题。
在 第二部分 中,我们实现了离散 Q 学习来训练Taxi-v3环境中的一个代理。
今天,我们将更进一步,使用 SARSA 算法解决MountainCar环境????。
让我们帮助这辆可怜的车赢得与重力的战斗!
本课的所有代码都在 这个 Github 仓库。 克隆它以跟随今天的问题。
1. Mountain Car 问题????
Mountain Car 问题是一个存在重力的环境(多么惊人),目标是帮助一辆可怜的车赢得这场与重力的战斗。
这辆车需要逃离被困的山谷。车的引擎没有足够的动力一次性爬上山,因此唯一的方法就是来回驾驶,积累足够的动量。
让我们看看实际效果:
Sarsa Agent 实际效果!
你刚才看到的视频对应于我们今天将要构建的SarsaAgent。
有趣,不是吗?
你可能在想。
这看起来很酷,但你为什么最初选择这个问题呢?
为什么是这个问题?
这个课程的哲学是逐步增加复杂性。一步一步来。
今天的环境相比第二部分的Taxi-v3环境代表了一个小但相关的复杂性增加。
但是,这里到底难在哪里呢?
正如我们在第二部分中看到的,强化学习问题的难度与
-
动作空间:智能体在每一步可以选择多少种动作?
-
状态空间:智能体可以在多少种不同的环境配置中找到自己?
对于小环境,其动作和状态数量有限且较少,我们有很强的保证,像 Q-learning 这样的算法会表现良好。这些环境被称为表格或离散环境。
Q 函数本质上是一个矩阵,行数等于状态数,列数等于动作数。在这些小世界中,我们的智能体可以轻松探索状态并构建有效的策略。随着状态空间和(特别是)动作空间的增大,RL 问题变得更难解决。
今天的环境不是表格型的。然而,我们将使用离散化“技巧”将其转换为表格型环境,然后解决它。
让我们首先熟悉环境!
2. 环境、动作、状态、奖励
???????? notebooks/00_environment.ipynb
让我们加载环境:

并绘制一个帧:

两个数字决定了汽车的状态:
-
它的位置范围是-1.2 到 0.6
-
它的速度范围是-0.07 到 0.07。

状态由 2 个连续数字给出。这与 第二部分 的 Taxi-v3 环境有显著不同。我们稍后将看到如何处理这个问题。
什么是动作?
有 3 种可能的动作:
-
0向左加速 -
1什么都不做 -
2向右加速

那奖励呢?
-
如果汽车的位置小于 0.5,则奖励为 -1。
-
一旦汽车的位置高于 0.5 或达到最大步骤数时,剧集结束:
n_steps >= env._max_episode_steps
默认负奖励 -1 鼓励汽车尽快脱离山谷。
一般来说,我建议你直接在 Open AI Gym environments’ GitHub 上查看实现,以了解状态、动作和奖励。
代码文档齐全,可以帮助你快速理解开始使用 RL 代理所需的一切。例如,MountainCar 的实现可以在 这里 找到。
好的,我们对环境有了了解。
让我们为这个问题构建一个基线代理!
3. 随机代理基线 ????????
???????? notebooks/01_random_agent_baseline.ipynb
强化学习问题可能很容易变得复杂。结构良好的代码是你保持复杂性受控的最佳盟友。
今天我们将提升我们的 Python 技能,并为所有代理使用 BaseAgent 类。从这个 BaseAgent 类,我们将派生出 RandomAgent 和 SarsaAgent 类。
BaseAgent 是我们在 [src/base_agent.py](https://github.com/Paulescu/hands-on-rl/blob/main/02_mountain_car/src/base_agent.py) 中定义的抽象类。
它有 4 个方法。
它的两个方法是抽象的,这意味着我们在从 BaseAgent 派生 RandomAgent 和 SarsaAgent 时被迫实现它们:
-
get_action(self, state)→ 根据状态返回要执行的动作。 -
update_parameters(self, state, action, reward, next_state)→ 使用经验来调整代理参数。在这里,我们将实现 SARSA 公式。
另外两个方法让我们能够将训练好的代理保存到磁盘或从磁盘加载。
-
save_to_disk(self, path) -
load_from_disk(cls, path)
随着我们开始实现更复杂的模型和训练时间的增加,在训练过程中保存检查点将是一个很好的主意。
这是我们 BaseAgent 类的完整代码:

从这个 BaseAgent 类,我们可以定义 RandomAgent 如下:

让我们对这个 RandomAgent 进行 n_episodes = 100 次评估,看看它的表现如何:


而我们 RandomAgent 的成功率是…

0% ????…
我们可以通过以下直方图查看代理在每个回合中的表现:

在这 100 次运行中,我们的 RandomAgent 没有突破0.5的标记。一时间都没有。
当你在本地机器上运行这段代码时,你会得到略微不同的结果,但完成率超过 0.5 的百分比在任何情况下都远未达到 100%。
你可以使用漂亮的 show_video 函数观看我们痛苦的 RandomAgent 的操作,函数位于 [**src/viz.py**](https://github.com/Paulescu/hands-on-rl/blob/37fbac23d580a44d46d4187525191b324afa5722/02_mountain_car/src/viz.py#L52-L61)
一个随机代理不足以解决这个环境。
让我们尝试一些更聪明的东西 ????…
4. SARSA 代理 ????????
???????? notebooks/02_sarsa_agent.ipynb
SARSA(由 Rummery 和 Niranjan 提出)是一种通过学习最优 q 值函数来训练强化学习代理的算法。
它在 1994 年发布,比 Q-learning(由 Chris Watkins 和 Peter Dayan 提出)晚两年。
SARSA 代表 State Action Reward State Action。
SARSA 和 Q-learning 都利用贝尔曼方程来迭代地寻找更好的最优 q 值函数 Q*(s, a)
如果你记得第二部分,Q-learning 的更新公式是
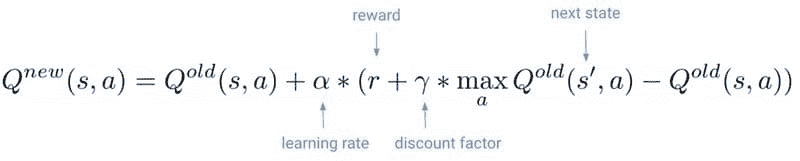
这个公式是一种计算新的 q 值估计的方法,它更接近于
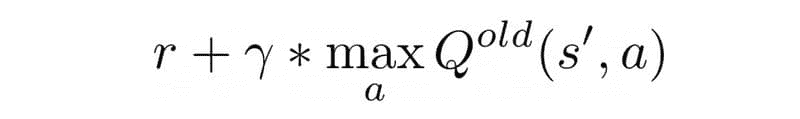
这个量是一个 目标 ???? 我们想要将旧估计值校正到这个目标。这是我们应该瞄准的最优 q 值的 估计,它会随着我们训练代理和 q 值矩阵的更新而变化。
强化学习问题通常看起来像带有 移动目标 的监督学习问题 ???? ????
SARSA 有一个类似的更新公式,但目标不同
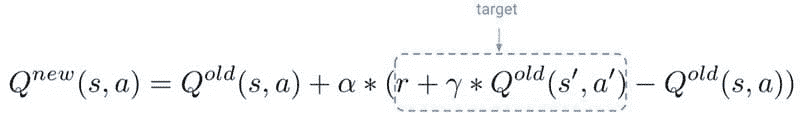
SARSA 的目标
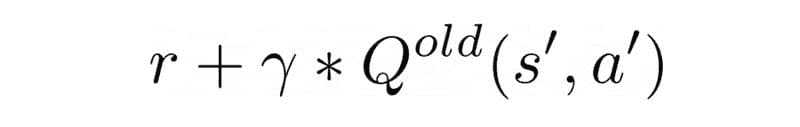
还取决于代理在下一个状态 s’ 中将采取的动作 a’。这就是 SARSA’ 名称中的最终 A。
如果你足够探索状态空间并使用 SARSA 更新你的 q 矩阵,你将得到一个最优策略。太棒了!
你可能在想……
Q-learning 和 SARSA 看起来几乎一样。有什么不同? ????
在线策略与离线策略算法
SARSA 和 Q-learning 之间有一个关键的区别:
???? SARSA 的更新依赖于下一个动作 a’,因此依赖于当前策略。随着训练的进行,q 值(及相关策略)得到更新,新策略可能会对同一状态 s’ 产生不同的下一个动作 a’’。
你不能使用过去的经验 (s, a, r, s’, a’) 来改进你的估计。相反,你需要利用每个经验来更新 q 值,然后将其丢弃。
正因为如此,SARSA 被称为在线策略方法。
???? 在 Q 学习中,更新公式不依赖于下一个动作a’,而仅依赖于(s, a, r, s’)。你可以重用以前的经验(s, a, r, s’),这些经验是用旧版本策略收集的,以改进当前策略的 q 值。Q 学习是一种离策略方法。
离策略方法比在线策略方法需要更少的经验进行学习,因为你可以多次重用过去的经验来改进你的估计。它们更样本高效。
然而,离策略方法在状态和动作空间扩展时,收敛到最优 q 值函数 Q*(s, a) 可能会出现问题。它们可能很棘手且不稳定。
我们将在课程后面遇到这些权衡问题,当我们进入深度强化学习领域 ???? 时。
回到我们的问题……
在 MountainCar 环境中,状态不是离散的,而是一对连续值(位置 s1,速度 s2)。
连续在这个背景下基本上意味着无限可能的值。如果有无限可能的状态,就不可能访问所有状态来保证 SARSA 会收敛。
为了解决这个问题,我们可以使用一个技巧。
让我们将状态向量离散化为有限的值集合。本质上,我们没有改变环境,而是改变了代理用来选择动作的状态表示。
我们的 SarsaAgent 将状态 (s1, s2) 从连续转换为离散,通过将位置 [-1.2 … 0.6] 四舍五入到最接近的 0.1 标记,将速度 [-0.07 … 0.07] 四舍五入到最接近的 0.01 标记。
这个函数正是这样做的,将连续状态转换为离散状态:

一旦代理使用离散化的状态,我们可以使用上述的 SARSA 更新公式,随着迭代的进行,我们会越来越接近最优 q 值。
这是 SarsaAgent 的完整实现。

注意 ???? q 值函数是一个三维矩阵:2 个用于状态(位置、速度),1 个用于动作。
让我们选择合理的超参数,并将这个 SarsaAgent 训练 n_episodes = 10,000 次。


让我们绘制 rewards 和 max_positions(蓝色线条)以及它们的 50 次迭代移动平均线(橙色线条)。
太棒了!看起来我们的 SarsaAgent 正在学习。
你可以看到它的实际应用:
如果你观察上面的max_position图表,你会发现汽车偶尔会失败爬山。
这发生的频率是多少?让我们在1,000个随机回合中评估一下智能体:

并计算成功率:

95.2%的表现相当不错,但仍然不完美。记住这一点,我们将在课程后面再回来讨论。
注意: 当你在本地运行此代码时,你将得到略微不同的结果,但我敢打赌你不会得到 100%的表现。
做得好!我们实现了一个SarsaAgent,它能够学习????
现在是一个很好的时机来暂停一下……
5. 暂停一下,深呼吸 ⏸????
???????? notebooks/03_momentum_agent_baseline.ipynb
如果我告诉你MountainCar环境有一个更简单的解决方案呢……
这辆车 100%的时间都能正常工作? ????
最好的策略是简单的。
只需跟随动量:
-
当汽车向右移动时,
velocity > 0加速向右 -
当汽车向左移动时,
velocity <= 0加速向左
从视觉上看,这种策略如下:
这是如何在 Python 中编写MomentumAgent:

你可以再次检查它是否完成了每一集。100%的成功率。


如果你绘制训练后的SarsaAgent的策略,你会看到如下图:
这与完美的MomentumAgent策略有 50%的重叠

这意味着我们的SarsaAgent的正确率仅为50%。
这很有趣……
为什么SarsaAgent错误这么频繁但仍能取得良好表现?
这是因为MountainCar仍然是一个较小的环境,因此在 50%的时间里做出错误决定并不那么关键。对于更大的问题,频繁的错误不足以建立智能体。
你会买一辆 95%时间正确的自动驾驶汽车吗? ????
另外,你还记得我们用来应用 SARSA 的离散化技巧吗?那是一个对我们帮助很大的技巧,但也给我们的解决方案带来了误差/偏差。
为什么我们不提高状态和速度的离散化分辨率,以获得更好的解决方案?
做到这一点的问题在于状态数量的指数增长,也称为维度诅咒。随着每个状态组件分辨率的提高,总状态数量呈指数增长。状态空间增长速度太快,SARSA 智能体无法在合理时间内收敛到最优策略。
好的,但是否有其他强化学习算法可以完美解决这个问题?
是的,有的。我们将在接下来的讲座中介绍这些。在强化学习算法方面,没有一种适合所有问题的通用方案,因此你需要尝试几种算法来找到最适合你问题的方案。
在 MountainCar 环境中,完美的策略看起来非常简单,我们可以尝试直接学习它,而无需计算复杂的 q 值矩阵。策略优化 方法可能会效果最佳。
但我们今天不会做这个。如果你想用强化学习完美解决这个环境,请跟随课程学习。
享受你今天所取得的成就。
 谁在玩得开心?
谁在玩得开心?
6. 回顾 ✨
哇!我们今天覆盖了很多内容。
这些是 5 个要点:
-
SARSA 是一种你可以在表格环境中使用的策略算法。
-
小型连续环境可以视为表格形式,通过离散化状态,然后使用表格 SARSA 或表格 Q 学习解决。
-
较大的环境由于维度诅咒无法被离散化和解决。
-
对于比
MountainCar更复杂的环境,我们将需要更先进的强化学习解决方案。 -
有时候强化学习不是最好的解决方案。当你尝试解决你关心的问题时,请记住这一点。不要过于依赖你的工具(在这种情况下是强化学习),而是专注于找到一个好的解决方案。不要因为树木而看不到森林 ????????????。
7. 作业 ????
???????? notebooks/04_homework.ipynb
这是我希望你做的:
-
Git 克隆 该库到本地计算机。
-
设置 本课程的环境
02_mountain_car -
打开
[02_mountain_car/notebooks/04_homework.ipynb](http://02_mountain_car/notebooks/04_homework.ipynb)并尝试完成两个挑战。
在第一个挑战中,我要求你调整 SARSA 超参数 alpha(学习率)和 gamma(折扣因子)以加快训练速度。你可以从 part 2 中获得灵感。
在第二个挑战中,尝试提高离散化的分辨率,并使用表格 SARSA 学习 q 值函数。就像我们今天做的那样。
如果你构建了一个达到 99% 性能的智能体,请告诉我。
8. 下一步是什么? ❤️
在下一课中,我们将进入一个强化学习与监督机器学习交汇的领域 ????。
这将会非常酷,我保证。
在此之前,
享受在这个神奇的地球上的一天 ????
爱 ❤️
继续学习 ????
如果你喜欢这个课程,请与朋友和同事分享。
你可以通过plabartabajo@gmail.com联系我。我很乐意与您交流。
很快见!
个人简介:Pau Labarta Bajo (@paulabartabajo_) 是一名数学家和 AI/ML 自由职业者及演讲者,拥有超过 10 年的经验,处理各种问题的数字和模型,包括金融交易、移动游戏、在线购物和医疗保健。
原文。经授权转载。
更多相关话题
实践监督学习:线性回归
原文:
www.kdnuggets.com/handson-with-supervised-learning-linear-regression

作者提供的图像
基本概述
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
线性回归是基本的监督机器学习算法,用于根据输入特征预测连续目标变量。顾名思义,它假设因变量和自变量之间的关系是线性的。因此,如果我们尝试绘制因变量 Y 对自变量 X 的图,我们将得到一条直线。该直线的方程可以表示为:

其中,
-
Y 预测输出。
-
X = 输入特征或多元线性回归中的特征矩阵
-
b0 = 截距(直线与 Y 轴的交点)。
-
b1 = 确定直线陡峭度的斜率或系数。
线性回归的核心思想在于找到最佳拟合线,以使实际值与预测值之间的误差最小。它通过估计 b0 和 b1 的值来实现这一点。然后我们利用这条直线进行预测。
使用 Scikit-Learn 的实现
你现在已经理解了线性回归的理论,但为了进一步巩固我们的理解,接下来我们将使用 Python 中的流行机器学习库 Scikit-learn 构建一个简单的线性回归模型。请继续关注,以便更好地理解。
1. 导入必要的库
首先,你需要导入所需的库。
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
2. 分析数据集
你可以在 这里 找到数据集。它包含了用于训练和测试的独立 CSV 文件。我们先展示一下数据集,并在继续之前进行分析。
# Load the training and test datasets from CSV files
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# Display the first few rows of the training dataset to understand its structure
print(train.head())
输出:
train.head()
数据集包含两个变量,我们想根据 x 的值预测 y。
# Check information about the training and test datasets, such as data types and missing values
print(train.info())
print(test.info())
输出:
<class>RangeIndex: 700 entries, 0 to 699
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 700 non-null float64
1 y 699 non-null float64
dtypes: float64(2)
memory usage: 11.1 KB
<class>RangeIndex: 300 entries, 0 to 299
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 300 non-null int64
1 y 300 non-null float64
dtypes: float64(1), int64(1)
memory usage: 4.8 KB</class></class>
上述输出显示我们在训练数据集中有一个缺失值,可以通过以下命令移除:
train = train.dropna()
同时,检查你的数据集中是否包含重复项,并在将其输入模型之前将其删除。
duplicates_exist = train.duplicated().any()
print(duplicates_exist)
输出:
False
2. 预处理数据集
现在,通过以下代码准备训练和测试数据及目标:
#Extracting x and y columns for train and test dataset
X_train = train['x']
y_train = train['y']
X_test = test['x']
y_test = test['y']
print(X_train.shape)
print(X_test.shape)
输出:
(699, )
(300, )
你可以看到我们有一个一维数组。虽然你可以用一维数组与一些机器学习模型,但这不是最常见的做法,并且可能会导致意外的行为。因此,我们将其重塑为 (699,1) 和 (300,1),以明确指定每个数据点有一个标签。
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1,1)
当特征处于不同的尺度上时,一些特征可能会主导模型的学习过程,导致结果不正确或次优。为此,我们进行标准化,使得我们的特征均值为 0,标准差为 1。
之前:
print(X_train.min(),X_train.max())
输出:
(0.0, 100.0)
标准化:
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
print((X_train.min(),X_train.max())
输出:
(-1.72857469859145, 1.7275858114641094)
我们现在已经完成了基本的数据预处理步骤,我们的数据已经准备好用于训练。
4. 可视化数据集
首先可视化目标变量与特征之间的关系是很重要的。你可以通过绘制散点图来实现:
# Create a scatter plot
plt.scatter(X_train, y_train)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Scatter Plot of Train Data')
plt.grid(True) # Enable grid
plt.show()
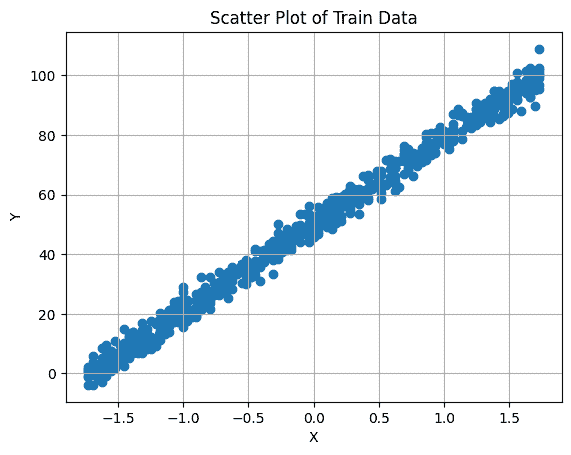
图片由作者提供
5. 创建并训练模型
我们现在将创建一个 Linear Regression 模型的实例,并尝试将其拟合到我们的训练数据集中。它找到最适合你数据的线性方程的系数(斜率)。然后使用这条线进行预测。此步骤的代码如下:
# Create a Linear Regression model
model = LinearRegression()
# Fit the model to the training data
model.fit(X_train, y_train)
# Use the trained model to predict the target values for the test data
predictions = model.predict(X_test)
# Calculate the mean squared error (MSE) as the evaluation metric to assess model performance
mse = mean_squared_error(y_test, predictions)
print(f'Mean squared error is: {mse:.4f}')
输出:
Mean squared error is: 9.4329
6. 可视化回归线
我们可以使用以下命令绘制回归线:
# Plot the regression line
plt.plot(X_test, predictions, color='red', linewidth=2, label='Regression Line')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Linear Regression Model')
plt.legend()
plt.grid(True)
plt.show()
输出:
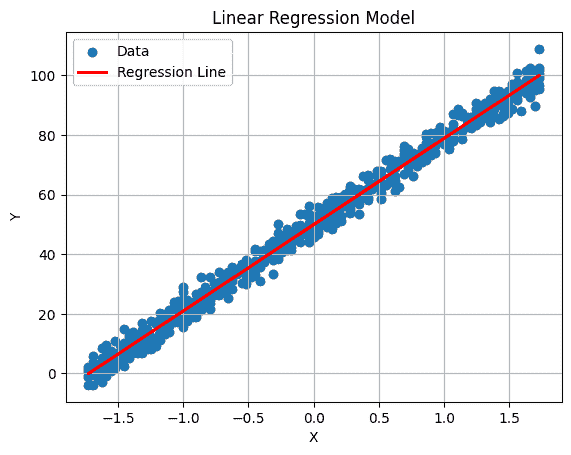
图片由作者提供
结论
完成了!你现在已经成功地使用 Scikit-learn 实现了一个基本的线性回归模型。你在这里获得的技能可以扩展到处理具有更多特征的复杂数据集。这是一个值得在空闲时间探索的挑战,它打开了数据驱动问题解决和创新的激动人心的世界的大门。
Kanwal Mehreen 是一位有志的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章来分享技术知识,并对提高女性在技术行业中的代表性充满热情。
更多相关主题
动手实践:无监督学习中的 K-Means 聚类
原文:
www.kdnuggets.com/handson-with-unsupervised-learning-kmeans-clustering
作者提供的图片
K-Means 聚类是数据科学中最常用的无监督学习算法之一。它用于根据数据点之间的相似性自动将数据集划分为簇或组。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
在这个简短的教程中,我们将学习 K-Means 聚类算法的工作原理,并使用 scikit-learn 将其应用于实际数据。此外,我们还将可视化结果以理解数据分布。
什么是 K-Means 聚类?
K-Means 聚类是一种无监督机器学习算法,用于解决聚类问题。该算法的目标是发现数据中的组或簇,簇的数量由变量 K 表示。
K-Means 算法的工作原理如下:
-
指定你希望数据分组的簇数 K。
-
随机初始化 K 个聚类中心或质心。这可以通过随机选择 K 个数据点作为初始质心来完成。
-
根据欧几里得距离将每个数据点分配给最近的聚类中心。与给定中心最近的数据点被视为该簇的一部分。
-
通过计算分配到该簇的所有数据点的均值来重新计算聚类中心。
-
重复步骤 3 和 4,直到中心点停止移动或迭代达到指定的限制。当算法收敛时,即可完成。

K-Means 的目标是最小化数据点与其分配的聚类中心之间的平方距离总和。通过迭代地将数据点重新分配给最近的中心并将中心移动到其分配点的中心,从而实现更紧凑且分离的聚类。
K-Means 聚类的实际应用示例
在这些示例中,我们将使用 商场顾客细分 数据,并应用 K-Means 算法。我们还将使用肘部法则找到最佳的 K(簇数)并可视化簇。
数据加载
我们将使用 pandas 加载 CSV 文件,并将“CustomerID”设置为索引。
import pandas as pd
df_mall = pd.read_csv("Mall_Customers.csv",index_col="CustomerID")
df_mall.head(3)
数据集有 4 列,我们只对其中三列感兴趣:顾客的年龄、年收入和消费得分。

可视化
为了可视化所有四列,我们将使用 seaborn 的 scatterplot。
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(1 , figsize = (10 , 5) )
sns.scatterplot(
data=df_mall,
x="Spending Score (1-100)",
y="Annual Income (k$)",
hue="Gender",
size="Age",
palette="Set2"
);
即使没有 K-Means 聚类,我们也可以清楚地看到在消费得分 40-60 和年收入 40k 到 70k 之间的簇。为了发现更多簇,我们将在下一部分使用聚类算法。
标准化
在应用聚类算法之前,标准化数据以消除任何异常值或异常情况至关重要。我们将删除“性别”和“年龄”列,使用其余列来寻找簇。
from sklearn import preprocessing
X = df_mall.drop(["Gender","Age"],axis=1)
X_norm = preprocessing.normalize(X)
肘部法则
K-Means 算法中的最佳 K 值可以通过肘部法则找到。这涉及到计算 1-10 个簇的每个 K 值的惯性值并进行可视化。
import numpy as np
from sklearn.cluster import KMeans
def elbow_plot(data,clusters):
inertia = []
for n in range(1, clusters):
algorithm = KMeans(
n_clusters=n,
init="k-means++",
random_state=125,
)
algorithm.fit(data)
inertia.append(algorithm.inertia_)
# Plot
plt.plot(np.arange(1 , clusters) , inertia , 'o')
plt.plot(np.arange(1 , clusters) , inertia , '-' , alpha = 0.5)
plt.xlabel('Number of Clusters') , plt.ylabel('Inertia')
plt.show();
elbow_plot(X_norm,10)
我们得到了最佳的 K 值为 3。
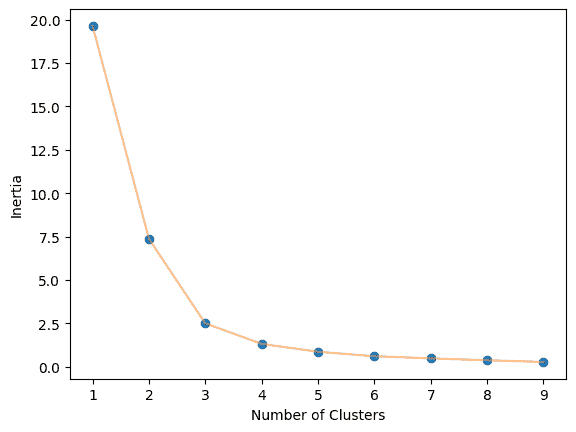
K 均值聚类
我们现在将使用来自 scikit-learn 的 KMeans 算法,并提供 K 值。之后,我们将在训练数据集上进行拟合并获取簇标签。
algorithm = KMeans(n_clusters=3, init="k-means++", random_state=125)
algorithm.fit(X_norm)
labels = algorithm.labels_
我们可以使用散点图来可视化这三个簇。
sns.scatterplot(data = X, x = 'Spending Score (1-100)', y = 'Annual Income (k$)', hue = labels, palette="Set2");
-
“0”:高消费水平且年收入低的顾客。
-
“1”:中等到高消费水平且年收入中等到高的顾客。
-
“2”:低消费水平且年收入高的顾客。
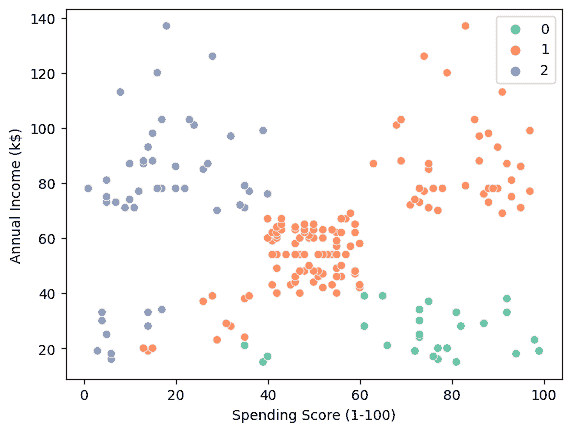
这些见解可以用于创建个性化广告,增加客户忠诚度并提升收入。
使用不同的特征
现在,我们将使用年龄和消费得分作为聚类算法的特征。这将给我们一个完整的顾客分布图。我们将重复数据标准化的过程。
X = df_mall.drop(["Gender","Annual Income (k$)"],axis=1)
X_norm = preprocessing.normalize(X)
计算最佳的簇数。
elbow_plot(X_norm,10)
对 K-Means 算法进行训练,设置 K=3 个簇。
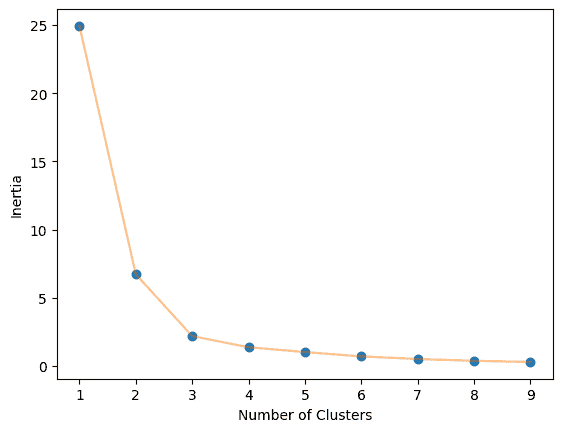
algorithm = KMeans(n_clusters=3, init="k-means++", random_state=125)
algorithm.fit(X_norm)
labels = algorithm.labels_
使用散点图可视化这三个簇。
sns.scatterplot(data = X, x = 'Age', y = 'Spending Score (1-100)', hue = labels, palette="Set2");
-
“0”:年轻的高消费顾客。
-
“1”:中等消费水平的顾客,年龄从中年到老年。
-
“2”:低消费顾客。
结果表明,公司可以通过针对年龄在 20-40 岁且有可支配收入的个人来增加利润。
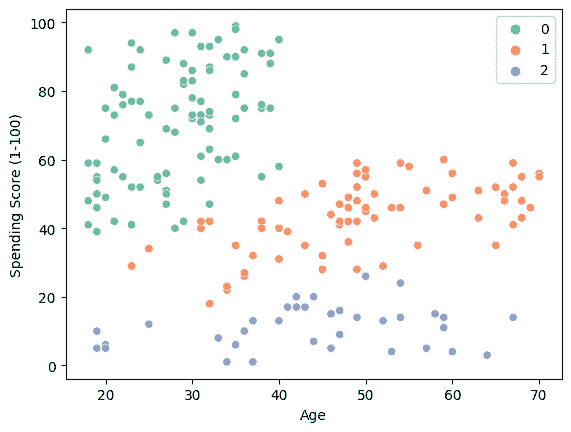
我们甚至可以通过可视化消费分数的箱线图深入了解。这清楚地显示了集群是基于消费习惯形成的。
sns.boxplot(x = labels, y = X['Spending Score (1-100)']);
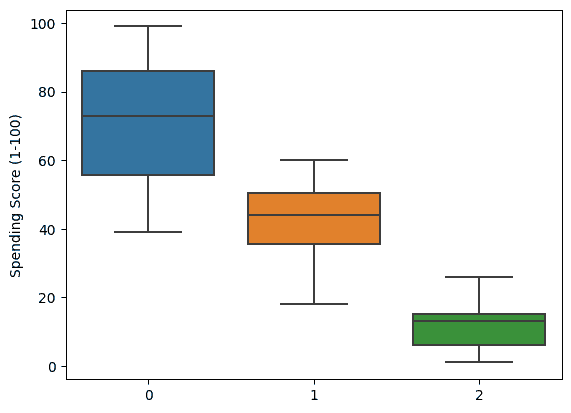
结论
在这个 K-Means 聚类教程中,我们探讨了如何将 K-Means 算法应用于客户细分,以实现精准广告投放。虽然 K-Means 不是完美的通用聚类算法,但它为许多现实世界的用例提供了简单有效的方法。
通过走过 K-Means 工作流程并在 Python 中实现它,我们深入了解了算法如何将数据分成不同的集群。我们学习了使用肘部法则找到最佳集群数量以及可视化聚类数据等技术。
虽然 scikit-learn 提供了许多其他聚类算法,但 K-Means 因其速度、可扩展性和易于解释而脱颖而出。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理疾病困扰的学生打造 AI 产品。
更多相关内容
进入 FAANG 公司有多难

作者提供的图片
提醒音乐进入戏剧性的末日氛围。在过去两年里,仅 FAANG 公司就负责了超过 50,000 次裁员(Meta 裁员10,000加11,000;苹果公司没有裁员;亚马逊裁员超过 27,000 人,分四 次 批次 进行;Netflix 裁员 500 人,分四 批次 进行;以及12,000人来自 Google)。这对这些公司的低录取率意味着什么?从 FAANG 公司获得录取通知书有多困难?
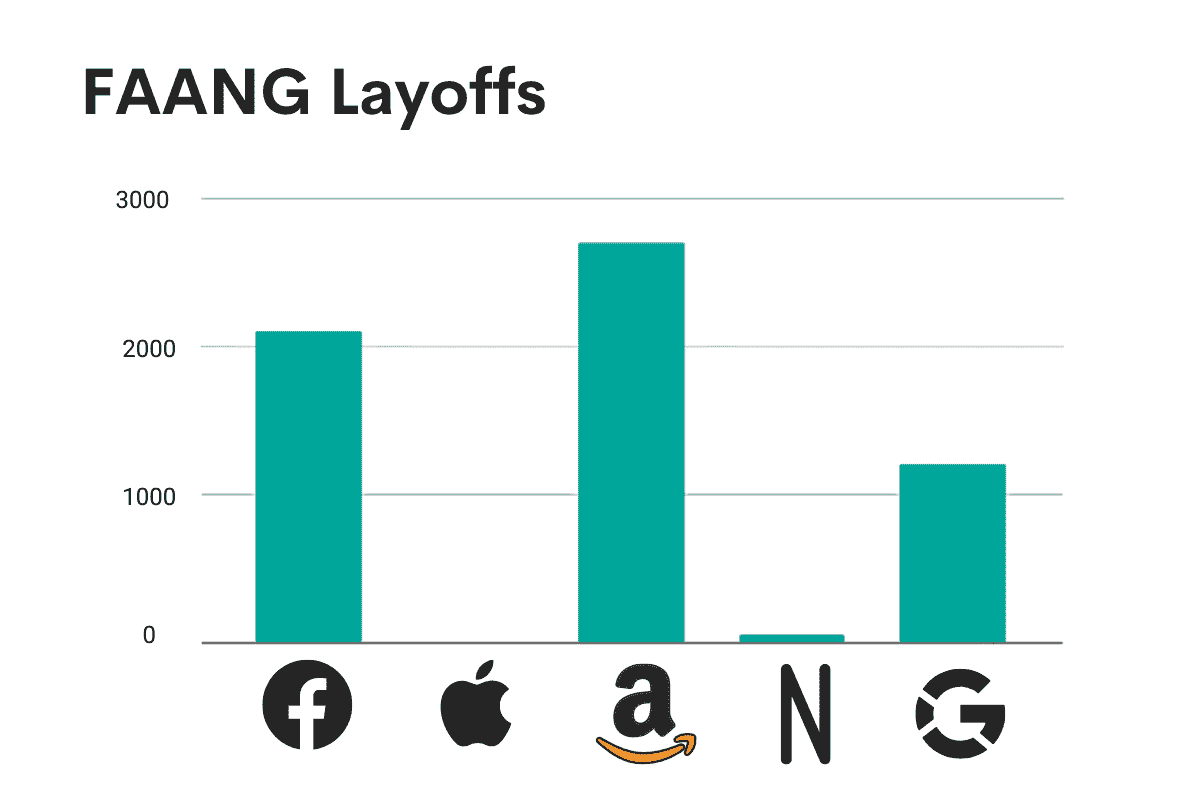
作者提供的图片
在这篇文章中,我将探讨为什么在历史和当前背景下,获得 FAANG 工作的难度如此之高。我还将描述增加你在 FAANG 公司以及其他公司的成功几率的方法。最终,这并不像你想象的那么困难。我还鼓励你拓宽视角,考虑接受科技公司录取的可能性。
什么是 FAANG?
我在这里用 FAANG 有两个含义。首先是指负责这个首字母缩写的公司:Facebook(现在的 Meta)、Apple、Amazon、Netflix 和 Google(实际上是 Alphabet)。这个首字母缩写是 CNBC 的 Jim Cramer 在 2013 年创造的。这些公司当时表现优于大盘,因此 FAANG 逐渐流行开来。
但将 FAANG 视为科技公司总体的代表也是有用的——比如 Microsoft、AirBnb 和 Spotify。当我说 FAANG 的录取率很低时,我真正的意思是这些大而响亮的科技公司很难进入,包括 Facebook、Amazon、Netflix、Apple 和 Google,也包括许多其他炫目的科技公司。
总体而言,FAANG 公司在各方面都以快速增长、不惜一切代价、市场主导地位和创新产品而闻名。它们在整个 2010 年代吸引了大量技术人才——申请者们真的认为他们可以帮助打造出更好的世界。
当然,在 2023 年的科技寒冬中,情况有所不同。
你的机会有多低?
虽然没有官方数据表明 FAANG 的录取率,但我查阅了多篇文章,这些文章引用了 FAANG 在这些裁员期间的录取率为个位数百分比(或更低)。
-
苹果公司仅接受了 3% 的申请者。
-
Facebook 在现场面试后的 5% 录取率,这意味着所有职位申请的接受率更低。
-
亚马逊接受了 不到 2% 的申请者。
-
Netflix 在 2019 年接受了 不到 2% 的申请者。我是通过将员工总数(2019 年为 6,800)除以申请者总数(350,000)得到这个数字的。这意味着即使每个职位都重新填补,Netflix 的录取率仍然不到 2%。实际上,这个比例可能更低。
-
谷歌接受了一个微不足道的 0.67% 的申请者。
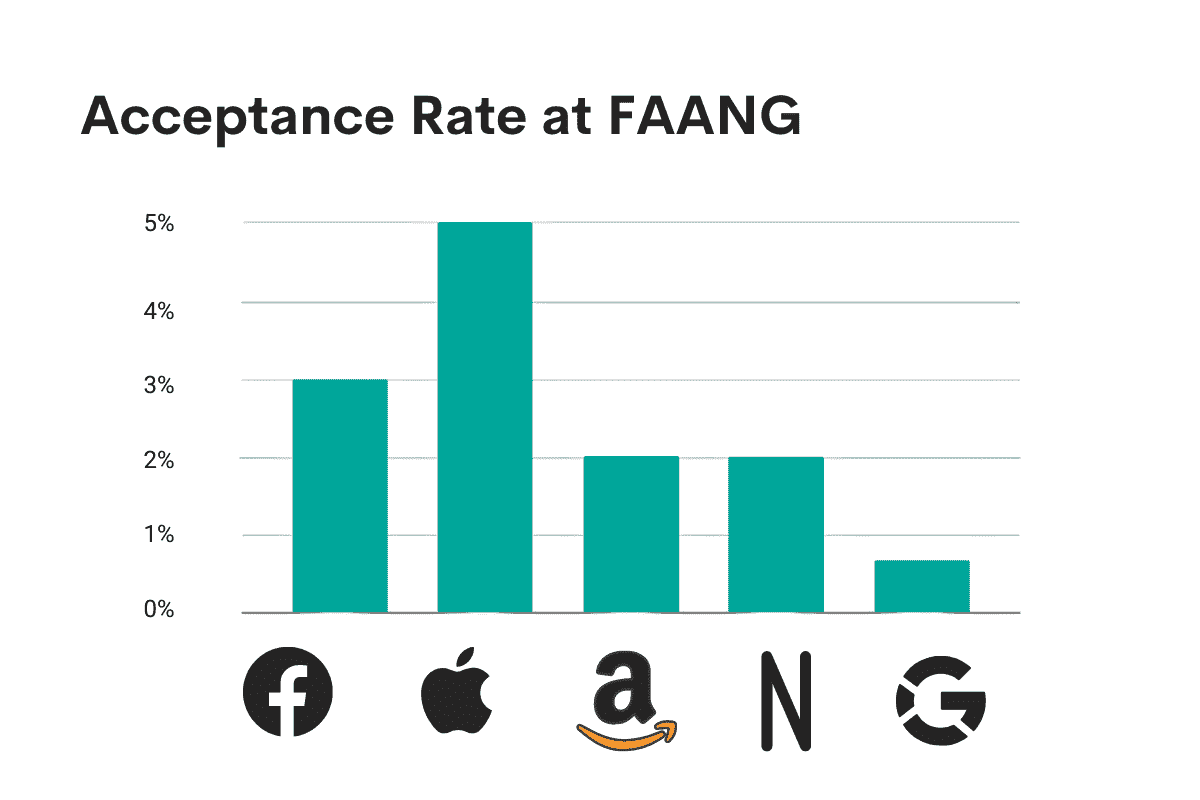
作者图像
现在考虑到,在 60,000 人裁员之后,这些公司可能有大量的有才华的申请者和更少的空缺职位。
为什么进入 FAANG 公司这么难?
当我申请大学时,我惊讶于像耶鲁、普林斯顿和布朗这样的大学的录取率不到 20 人中有 1 人。但 FAANG 的录取率则让这些黯然失色。为什么获得那封录取通知书这么困难?
竞争
当你申请 FAANG 时,你面临着激烈的竞争。每个人都希望为 FAANG 或 FAANG 相邻公司工作。特别是在 2010 年代,FAANG 有一种非常酷的氛围——想象一下乒乓球桌、免费午餐以及其他令人惊叹的福利,除了工作稳定性和极高的薪水之外。每个有一点技术才能的人都希望能进入其中。
高标准
FAANG 有很高的标准。由于申请量的激增,这些科技公司能够只聘用顶尖的技术人才。候选人需要拥有出色的简历、惊人的推荐信和相关的教育及工作经验——或者一个令人震撼的作品集来弥补这些要求。
技术面试
FAANG 公司及类似的科技公司设立了严格的技术面试。即使是经验丰富的工程师,在三名招聘经理冷峻的目光下进行白板编码面试时,也可能会出现失误。这真的很难。
这篇文章 "FAANG 公司的招聘和知道何时准备好" 讨论了 FAANG 公司的招聘流程。
文化契合
FAANG 在招聘时挑剔的不仅仅是编码技能。文化契合度非常重要。Netflix 不想要“聪明的混蛋”。Apple 只招聘核心合作者。Facebook 希望招募前瞻性思维的人。因此,这不仅仅是关于你的简历,而是你如何证明你是该公司良好的“文化契合者”。
那些数字令人沮丧,但具有误导性
回到那些微小的接受率百分比。它们微不足道,但具有误导性。
首先,如今的环境已不同以往。大型科技公司的全盛时期,无论好坏,都经历了波折。FAANG 公司不再被普遍认为是最好的工作场所。随着风险投资资金的枯竭以及它们在努力实现盈利转型时,薪资和福利在较小的公司也可能一样好。而且,显然 FAANG 并没有提供任何工作保障,因为他们在某些情况下裁员了 5-10%的员工。
此外,即使 FAANG 的招聘有所放缓,科技行业仍在招聘。ZipRecruiter 发现79%的被裁员的科技工作者在三个月内找到新工作。仍然有人在寻找顶尖的科技人才。
最后,请记住,大量申请 FAANG 的申请基本上都是垃圾。正如我所说,每个人都申请 FAANG,因为在那里工作会非常棒。但招聘经理能够丢弃大量这些申请,因为它们实在不够好。做一点额外的工作。建立网络可以极大地提高你的机会。参加会议结识人脉。针对每个申请量身定制你的简历和求职信。仅此一点就能帮助你在大多数 FAANG 申请者中脱颖而出。
如何增加获得 FAANG 或其他地方好技术工作的机会

图片来源:作者
是的,获得这些公司的录取很难。但并没有你想象的那么困难。以下是四种方法,帮助你增加获得梦想中的技术工作的机会,无论是在 FAANG 还是其他优秀的科技公司。
打磨你的简历
你可能已经知道这一点,但值得重复的是,大型科技公司的招聘经理会自动化大量的求职申请筛选。他们通过匹配关键词来过滤和丢弃大量的简历和求职信。确保你的简历与职位发布尽可能匹配,包括相关的技能、经验和才能。
练习面试
练习面试题目至关重要,确保你熟悉最新的面试题目,可以通过像 Stratascratch 这样的网站进行准备,这样你在面试时就不会在白板上卡壳。这不仅能让你掌握打破面试的技巧,还能在准备过程中缓解你的紧张情绪。
构建、部署、重复
如果没有学位或工作经验,你需要证明你具备成为好雇员的能力。构建并部署那些你个人感兴趣的项目。不要仅仅做典型的 Kaggle 竞赛——招聘经理见得多了。参与一些大胆而有趣的项目,讲述为什么大型科技公司应该雇佣你的故事。
多走一步
最后,一个好的建议是 在简历中添加库和包。面向终端用户的应用程序是一个好的起点,但并不是很多其他技术申请者会构建库和包。这些可以帮助:
-
展示你对软件工程和架构的深刻理解。
-
向招聘经理展示一些有用的东西。
-
在 GitHub 上获得一些关注作为一个库,这可以作为社会证明。
还有很多其他好的面试技巧,但这四个建议是一个很好的起点。
看看 FAANG 之外的机会
我想通过请你考虑把 FAANG 之外的公司也视为潜在的工作机会来结束这篇文章。如今的较小初创公司可以提供与 FAANG 相媲美的薪资、福利、工作稳定性和公司文化。
即使如此,大规模裁员也证明这些大型科技公司并不像 2010 年代那样稳定或优秀。许多在疫情期间没有过度招聘的优秀科技公司正在寻找优秀的候选人,所以如果你在获得 FAANG 工作方面遇到困难,可以先去较小的公司展示自己,然后再带着工作经验重新申请 FAANG。
FAANG 公司很难进入,但也并非完全不可能。
总之,进入 FAANG 公司确实很难,这是毋庸置疑的。但许多申请者忘记了,即使在当前的技术寒冬环境下,这比你想象的要容易。所有 FAANG 公司目前都有技术职位空缺(Meta,Amazon,Apple,Netflix 和 Alphabet),不仅如此,整体技术公司尽管就业市场寒冷,仍在招聘。
为了提高成功的几率,确保你的简历与职位描述尽可能接近。多练习面试问题直到你感到疲惫不堪。多做项目、部署、再做项目。并考虑通过在你的作品集中加入一些包或库来多走一步。
如果你仍然觉得困难,可以扩大求职范围。确保每份申请都量身定制,不要害怕点击申请按钮。无论是 FAANG 公司还是其他优秀组织,科技公司都会非常欢迎你。
内特·罗斯迪 是一名数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司的真实面试问题准备面试。你可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
了解更多相关话题
数据科学中最困难的部分
原文:
www.kdnuggets.com/2015/11/hardest-parts-data-science.html
作者:Yanir Seroussi。
与普遍看法相反,数据科学中最困难的部分不是建立一个准确的模型或获取良好、干净的数据。更困难的是定义可行的问题并提出合理的解决方案度量方式。本文讨论了这些问题的一些示例以及如何解决它们。
不那么困难的部分
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在讨论数据科学中最困难的部分之前,值得简要讨论两个主要的竞争者:模型拟合和数据收集/清理。
模型拟合被一些人视为特别困难,或者是真正的数据科学。这种看法部分源于Kaggle的成功,它自称为数据科学的家园。大多数 Kaggle 竞赛都集中在模型拟合上:参与者被提供一个定义明确的问题、一个数据集和一个优化度量,他们竞争以生产最准确的模型。Kaggle 出色的营销与其竞赛设置结合,导致许多人认为数据科学全是关于拟合模型。实际上,建立合理准确的模型并不那么困难,因为许多模型构建阶段可以很容易地自动化。实际上,有很多公司提供模型拟合服务(例如,微软、亚马逊、谷歌和其他公司)。甚至 Kaggle 的首席技术官 Ben Hamner 也表示,他对出现的“云端黑箱机器学习”服务的数量感到“惊讶:模型拟合很简单。问题定义和数据收集则不是。”
数据收集/清理 是每个人都爱恨交织的核心部分。DJ Patil(美国首席数据科学家)被引用为说:“数据科学中最困难的部分是获取好的、干净的数据。清理数据通常占工作量的 80%。”虽然我同意收集数据和清理数据可能需要大量工作,但我不认为这部分特别困难。这绝对重要,可能需要仔细规划,但在许多情况下,这并不是非常具挑战性的。此外,数据通常已经给定,或是使用以前开发的方法进行收集。
问题定义是困难的
问题定义可能困难的原因有很多。 有时是因为利益相关者不知道他们想要什么,并期望数据科学家解决所有数据问题(无论是真实还是想象的)。这种情况可通过以下的 Dilbert 漫画总结。最好的处理方法是巧妙地管理利益相关者的期望,同时引导他们走向更明确定义的问题。
了解更多相关话题
利用 ChatGPT 进行自动化数据清理和预处理
原文:
www.kdnuggets.com/2023/08/harnessing-chatgpt-automated-data-cleaning-preprocessing.html

作者提供的图像
ChatGPT 已经成为一个可以用于多种应用的瑞士军刀,而且有广阔的空间将 ChatGPT 集成到数据科学工作流中。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
如果你曾经在真实世界的数据集上训练过机器学习模型,你知道数据清理和预处理的步骤对于构建稳健的机器学习模型至关重要。在本指南中,我们将看到如何利用 ChatGPT 在示例数据集上执行这些任务。
我们将使用UCI 机器学习库中的银行营销数据集,并提示 ChatGPT 完成以下任务:
-
获取并加载数据集
-
检查缺失值
-
编码分类变量
你可以通过登录OpenAI 账户并启动一个新的 ChatGPT 会话来跟随学习。如果你愿意,也可以在Google Colab中编写代码。
获取并加载数据集
数据集有几种不同版本。我们将使用 bank-full.csv。
提示:今天我们将对一个真实世界的数据集进行数据清理和预处理。编写代码完成以下任务:1. 从 UCI 机器学习库中获取银行营销数据集。使用 requests 或 urllib 等库。2. 下载 zip 文件,解压内容,并将 bank-full.csv 文件读取到 pandas 数据框中(称之为 data)。
获取和读取数据集的代码如下:
import pandas as pd
import urllib
import zipfile
# URL of the dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank.zip"
# Fetch and extract the dataset
urllib.request.urlretrieve(url, "bank.zip")
with zipfile.ZipFile("bank.zip", "r") as zip_ref:
zip_ref.extractall()
# Load the dataset into a pandas DataFrame
data = pd.read_csv("bank-full.csv", delimiter=";",skipinitialspace=True)
获取数据集的基本信息
让我们更好地理解数据集。
# Display the first few rows of the dataset
print(data.head())
这将输出:
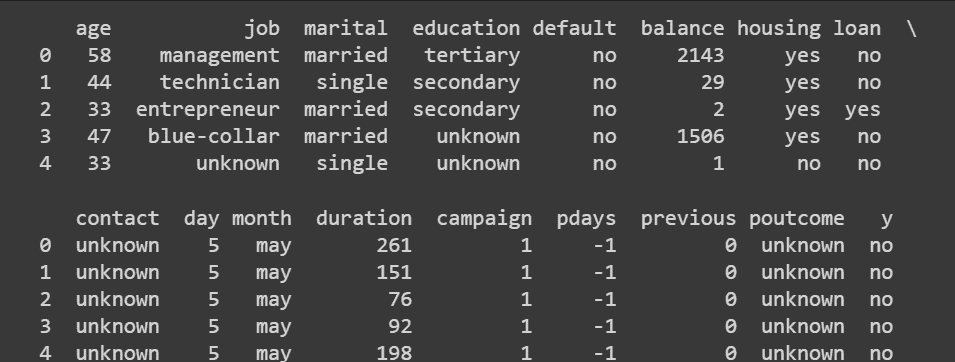
数据.head()的截断输出
提示:使用 pandas 获取数据框的维度、列的描述性统计信息以及各列的数据类型。
这一步骤实际上不需要提示 ChatGPT,因为 pandas 方法相对简单。
# Get the dimensions of the dataset (rows, columns)
print(data.shape)
Output >>> (45211, 17)
我们有超过 45000 条记录和 16 个特征(17 包括了输出标签)。
# Get statistical summary of numerical columns
print(data.describe())
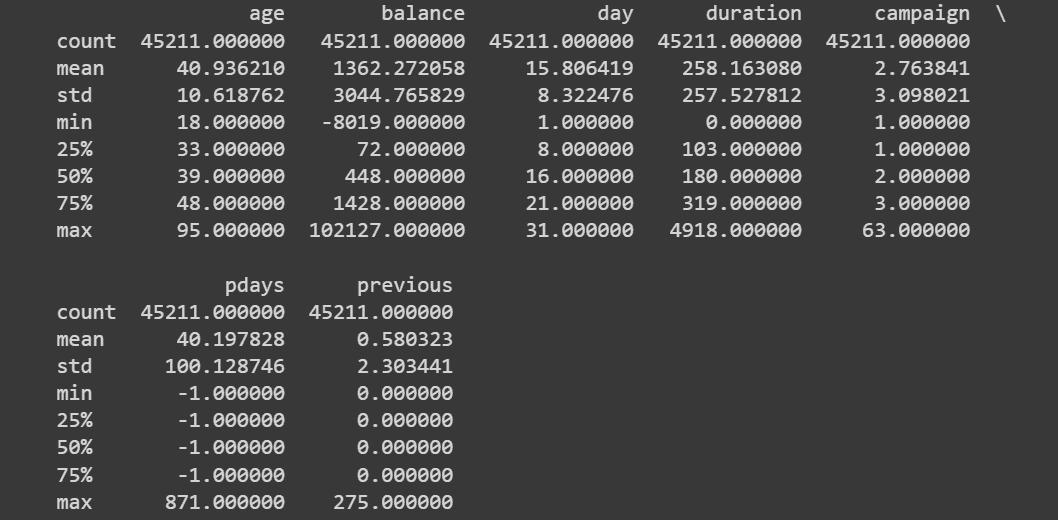
数据 data.describe() 的截断输出
了解各种列的数据类型也很有帮助。我们在对分类变量进行编码时会更详细地查看它们。
# Check data types of each column
print(data.dtypes)
Output >>>
age int64
job object
marital object
education object
default object
balance int64
housing object
loan object
contact object
day int64
month object
duration int64
campaign int64
pdays int64
previous int64
poutcome object
y object
dtype: object
到目前为止,我们已经了解了银行营销数据集。输出标签表示客户是否会订阅定期存款。数据集包含几个特征,如年龄、月份、教育、婚姻状况、之前活动的结果等。
检查缺失值
提示:我想知道每列中的缺失值数量。请给我代码来实现。使用 pandas。
# Check for missing values in each column
missing_values = data.isnull().sum()
print(missing_values)
以下是输出:
Output >>>
age 0
job 0
marital 0
education 0
default 0
balance 0
housing 0
loan 0
contact 0
day 0
month 0
duration 0
campaign 0
pdays 0
previous 0
poutcome 0
y 0
dtype: int64
这个版本的银行营销数据集——拥有超过 45000 条记录——没有任何缺失值。然而,在实践中,大多数现实世界的数据集都有缺失值。你应该使用合适的插补技术来处理缺失值。
作为一个可选练习,你可以在这里添加一个步骤,让 ChatGPT 从一部分列中删除一小部分值,以便你可以练习如何处理缺失值。
编码分类变量
下一步是对数据集中的分类变量进行编码。我们将从获取所有分类列的列表开始。
提示:给出代码以获取数据集中所有分类列的列表。
# Count the number of categorical variables
categorical_columns = data.select_dtypes(include=['object']).columns
print(categorical_columns)
num_categorical_variables = len(categorical_columns)
# Display the count
print("Number of categorical variables:", num_categorical_variables)
分类列列表还包括输出标签 y。但我们先关注其他分类变量。
Output >>>
Index(['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact',
'month', 'poutcome', 'y'],
dtype='object')
Number of categorical variables: 10
更深入了解分类变量的值
接下来,让我们查看每个分类变量的值。
提示:我想了解每个分类变量的各种值。请给出 pandas 代码来实现。
# Get the different values and their counts for each categorical column
categorical_columns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
for column in categorical_columns:
value_counts = data[column].value_counts()
print(f"Column: {column}")
print(value_counts,"\n")
输出难以解析:
Output >>>
Column: job
blue-collar 9732
management 9458
technician 7597
admin. 5171
services 4154
retired 2264
self-employed 1579
entrepreneur 1487
unemployed 1303
housemaid 1240
student 938
unknown 288
Name: job, dtype: int64
...
...
...
Column: poutcome
unknown 36959
failure 4901
other 1840
success 1511
Name: poutcome, dtype: int64
可视化分类变量的值
让我们让 ChatGPT 创建一个可视化图表,以便更容易理解分类变量的值。
提示:我想要一个图表,展示每个分类变量的值。排除输出标签 y。包括所有其他分类变量。
那我们开始吧!
import matplotlib.pyplot as plt
# Get the different values and their counts for each categorical column
categorical_columns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
# Set up the subplot grid
fig, axes = plt.subplots(3, 3, figsize=(10,8))
# Iterate over each categorical column and plot the value counts
for i, column in enumerate(categorical_columns):
row = i // 3
col = i % 3
value_counts = data[column].value_counts()
ax = axes[row, col]
value_counts.plot(kind='bar', ax=ax)
ax.set_xlabel(column)
ax.set_ylabel('Count')
ax.set_title(f'{column.title()} Value Counts')
# Adjust spacing between subplots
plt.tight_layout()
# Show the plot
plt.show()
分类变量的值
独热编码
对于部分分类列,我们可以使用独热编码。
提示:给出 pandas 代码以对一组列进行独热编码。
我们使用 pandas 中的 get_dummies 对以下列进行独热编码:
# Select the categorical columns (excluding education and poutcome)
categorical_columns = ['job', 'marital', 'default', 'housing', 'loan', 'contact']
# Perform one-hot encoding
encoded_data = pd.get_dummies(data, columns=categorical_columns)
提示:我想打印出新添加列的前几行。编写代码来实现这一点。
# Select the newly added columns
new_columns = encoded_data.columns.difference(data.columns)
# Print the head of the newly added columns
print(encoded_data[new_columns].head())
编码后的数据 encoded_data['new_colums'].head() 的截断输出
定义自定义映射
对于像‘education’和‘poutcome’(先前结果)这样的变量列,使用自定义映射比独热编码更好,这样可以在值之间进行比较。
此外,当我们使用独热编码来编码一个取 k 个不同值的分类变量时,会创建 k 个新列。对于像‘month’这样的分类列,这样做会显得过于冗余而没有增加太多信息。
因此,对于这两种情况,我们将定义一个自定义映射,然后转换值。我们可以提示 ChatGPT 来获取一个通用代码片段,然后对其进行修改以定义特定列的映射。
提示:我想对一些分类变量进行自定义映射。首先,给我一个通用代码片段,用于定义从分类列中的唯一值到不同输出值的自定义映射。然后我们应该使用此映射来转换列中的值。
# Define the custom mapping dictionary
custom_mapping = {
'category1': 'value1',
'category2': 'value2',
'category3': 'value3',
# Add more categories and corresponding values as needed
}
# Specify the categorical column
categorical_column = 'column_name' # Replace 'column_name' with the actual column name
# Perform the mapping using the custom mapping dictionary
data[categorical_column] = data[categorical_column].map(custom_mapping)
对于‘month’列,让我们将月份字符串转换如下:
# Define the mapping dictionary for months
month_mapping = {
'jan': 1,
'feb': 2,
'mar': 3,
'apr': 4,
'may': 5,
'jun': 6,
'jul': 7,
'aug': 8,
'sep': 9,
'oct': 10,
'nov': 11,
'dec': 12
}
# Map the values in the month column
encoded_data['month'] = encoded_data['month'].map(month_mapping)
让我们将‘poutcome’和‘education’列映射到数值,如下所示:
# Define the custom mapping for poutcome and education
poutcome_mapping = {
'unknown': 0,
'failure': 1,
'other': 2,
'success': 3
}
education_mapping = {
'unknown': 0,
'primary': 1,
'secondary': 2,
'tertiary': 3
}
# Perform ordinal encoding using pandas map
encoded_data['poutcome'] = encoded_data['poutcome'].map(poutcome_mapping)
encoded_data['education'] = encoded_data['education'].map(education_mapping)
# Select the newly added columns
new_columns = ['month','poutcome', 'education']
# Print the head of the newly added columns
print(encoded_data[new_columns].head(10))
编码输出标签
让我们也将输出标签‘yes’和‘no’分别映射为 1 和 0。
encoded_data['y'] = encoded_data['y'].replace({'no': 0, 'yes': 1})
print(encoded_data['y'])
Output >>>
0 0
1 0
2 0
3 0
4 0
..
45206 1
45207 1
45208 1
45209 0
45210 0
Name: y, Length: 45211, dtype: int64
记住我们对‘housing’,‘default’和‘loan’列使用了独热编码。由于这些列也取‘yes’和‘no’值,你还可以将‘yes’和‘no’分别映射为 1 和 0。
可视化类别标签的分布
检查类别标签的分布也是有帮助的,这样我们在构建模型时可以根据需要考虑类别不平衡。
提示:我希望了解类别标签的分布。请给我生成适当图表的代码。
下面是生成 Seaborn 中的计数图的代码:
import seaborn as sns
import matplotlib.pyplot as plt
# Plot the distribution of output labels
sns.countplot(data=data, x='y')
plt.xlabel('Output Label')
plt.ylabel('Count')
plt.title('Output Label Distribution')
plt.show()
类别标签的分布
我们看到存在类别不平衡。因此,如果你正在构建模型,应该确保使用适当的重采样方法来解决类别不平衡问题。
通用数据清洗和预处理管道
尽管数据清洗和预处理需要开发者的努力,但让我们尝试得到一个适用于简单数据集的通用步骤序列。
提示:你能否给我一个基于我们目前所做的通用数据清洗和预处理管道。获取数据集的基本信息,检查并处理缺失值,识别分类列,并对分类列进行编码。仅使用 pandas。
这里是:
import pandas as pd
# Load the dataset into a DataFrame
data = pd.read_csv('data.csv')
# Step 1: Basic Info
print(data.info())
# Step 2: Missing Values
missing_values = data.isnull().sum()
print(missing_values)
# Step 3: Handle Missing Values
# Identify columns with missing values
columns_with_missing_values = missing_values[missing_values > 0].index
# Impute missing values using fillna() or other suitable method
data[columns_with_missing_values] = data[columns_with_missing_values].fillna(data[columns_with_missing_values].mean())
# Step 4: Get Categorical Columns
categorical_columns = data.select_dtypes(include=['object']).columns
# Step 5: Encode Categorical Columns
# Perform ordinal encoding or one-hot encoding using pandas' get_dummies() function
encoded_data = pd.get_dummies(data, columns=categorical_columns)
# Print the encoded data
print(encoded_data.head())
总结
正如所见,数据科学专业知识与 ChatGPT 的协同作用可以帮助简化和加速数据清洗和预处理。现在你已经准备好预处理的数据集,可以通过在这个银行营销数据集上构建一个简单的预测模型来进一步处理。
如果感兴趣,你还可以探索如何利用 ChatGPT 进行数据探索。
数据集致谢
银行营销数据集根据 知识共享署名 4.0 国际 (CC BY 4.0) 许可证进行许可。
Moro, S., Rita, P., 和 Cortez, P.. (2012). 银行营销. UCI 机器学习资料库. doi.org/10.24432/C5K306.
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。
相关主题更多信息
哈佛的顶级免费课程为有志于成为数据科学家的人提供
原文:
www.kdnuggets.com/harvard-top-free-courses-for-aspiring-data-scientists

编辑器使用 Midjourney 创建的图像
许多课程可以教授你数据科学的基础,但哈佛大学无疑是最顶尖的。作为一所精英大学,他们的所有课程无疑都会提供成为数据科学家所需的技能。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
那么,你应该了解哪些免费的课程呢?
让我们深入了解一下。
HarvardX: CS50 的 Python 编程入门
Python 是任何有志于成为数据科学家的就业关键。
在现代时代,数据科学家需要理解编程语言。Python 是许多行业中使用的事实标准语言,因此学习它是有益的。
HarvardX: CS50 的 Python 编程入门 将教授你作为数据科学家所需的主要 Python 编程语言。在这门课程中,我们将学习以下内容:
-
函数,变量
-
条件语句
-
循环
-
库
-
单元测试
如果每周投入大约 3-9 小时,你将在十周内学习更多内容。你应该在进入其他课程之前从这门免费的哈佛课程开始,因为之后的许多数据科学课程都依赖于你使用 Python 的能力。
HarvardX: Fat Chance: 从基础到概率
对于数据科学家来说,了解与工作相关的统计概率基础知识是重要的。为了提升你的定量推理能力,HarvardX: Fat Chance: 从基础到概率 课程非常适合建立这些知识。
在这门课程中,你将学习增加对概率和统计的理解的材料,例如:
-
基本和高级计数
-
基本概率与条件概率
-
期望值
-
伯努利试验
-
正态分布
该课程设计为自学,通常需要大约七周的时间完成,如果你每周投入 3-5 小时用于学习。
HarvardX:Python 数据科学导论
在你掌握了 Python 和概率的基础后,是时候学习数据科学了。HarvardX: Python 数据科学导论 将教你进入数据科学领域所需的基础知识。
这是一个自学进度的课程,但需要对 Python 和概率有基本的了解。这就是为什么完成前两个课程很重要的原因。
如果你每天花费大约 3-4 小时,可以在 8 周内完成该课程,并且你将学习以下内容:
-
线性、多元和多项式回归
-
模型选择与交叉验证
-
偏差、方差和超参数
-
分类和逻辑回归
-
自助法、置信区间和假设检验
你将从这门课程中学到很多东西。好好学习,它的基础对于下一门课程非常重要。
HarvardX:Python 机器学习和 AI
如果你已经具备了数据科学的基础,那么是时候学习更高级的领域了。机器学习和 AI 与数据科学密不可分,因为许多商业数据科学项目都基于机器学习的结果。
机器学习和 AI 知识在行业中非常有价值,因为它们能够揭示我们之前未曾见过的模式,同时提供自动化。这可以使企业的运作比标准的基于规则或基于直觉的决策更高效。
HarvardX: Python 机器学习和 AI 课程将为学习者提供机器学习和 AI 的基本理解,包括:
-
机器学习模型
-
模型训练
-
模型评估
-
机器学习模型的 Python
如果你每周花费大约 4-5 小时,预计需要六周时间完成,你将准备好开展你的第一个数据科学项目。
结论
我们探讨的哈佛课程将帮助你成为一名数据科学家。
通过巩固你的基础,这些课程将引导有志于数据科学的人进入他们梦想的职业生涯。
可能只有四门课程列出,但这四门课程是建立基础所需的全部课程。
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 涉及各种 AI 和机器学习主题的写作。
更多相关内容
《简明医疗分析》
原文:
www.kdnuggets.com/2018/11/healthcare-analytics-made-simple.html
赞助帖子。

我们将利用数据科学、机器学习和分析来改善医疗结果。
书中的亮点包括:
-
设置工具箱: 按照逐步说明(第一章)设置 Anaconda Python 发行版以及 Jupyter notebook 和 SQLite。
-
关注医疗保健: 从 A 到 Z 的医疗保健入门,包括融资、政策、HIPAA、临床编码系统以及临床数据如何从患者传输到计算机(第二章)。
-
像医生一样思考: 学习医生如何接受培训以处理临床案例,以及这如何与决策树、逻辑回归和神经网络等机器学习算法相关(第三章)。
-
设定临床基准: 通过示例学习 SQL,并使用它来处理一个心脏病患者的小型临床数据库(第四章)。
-
不必担心 Python: 关于 Python 编程语言的教程(第五章),包括语法、数据类型和容器,以及脚本。
-
与 pandas 友好相处: 学习如何使用流行的 pandas 库快速简便地处理数据(第五章)。
-
关注质量: 了解政府激励计划如何为提供者创造财务报销的机会(第六章)。
-
急诊科建模: 加入我们,从头到尾建立一个 Python 预测模型,从下载数据到测量模型性能(第七章)。
-
现实世界建模: 阅读关于近期机器学习研究如何重新定义心脏病、癌症和再入院预测领域的临床实践和知识(第八章)。
-
选择的未来: 讨论医疗分析领域最新的进展和采纳障碍(第九章)。
总之,《简明医疗分析》 是任何对医疗保健感兴趣的数据科学家的宝贵资源。今天就在 Amazon 或 Packtpub.com 购买你的副本。
简介: Vikas (Vik) Kumar在美国纽约州上州长大。他获得了匹兹堡大学的医学博士学位,但不久之后发现了自己对计算机和数据科学的真正兴趣。随后,他在乔治亚理工学院计算学院完成了硕士学位。他目前住在乔治亚州亚特兰大,并担任数据科学家。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 事务
了解更多相关主题
TensorFlow 的“Hello World”
TensorFlow 是一个开源的端到端机器学习框架,使得训练和部署模型变得简单。
由两个词组成 - tensor 和 flow。tensor 是一个向量或多维数组,是深度学习模型中表示数据的标准方式。flow 意味着数据如何通过图进行流动,经过称为节点的操作。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
它通过将各种算法打包在一起用于数值计算和大规模机器学习。此外,它还允许使用高级 Keras API 灵活地构建模型并进行控制。
在本文中,我们将使用 TensorFlow 构建一个适合初学者的机器学习模型。
我们将使用来自 Kaggle 的信用卡欺诈检测数据。
本文结构如下:
-
理解问题陈述
-
加载数据和所需的库
-
理解数据和用于模型选择的评估指标
-
缺失值
-
数据转换
-
检查类别不平衡
-
-
构建带有类别不平衡的 TensorFlow 模型
- 评估模型性能
-
处理类别不平衡并训练模型
-
比较有无类别不平衡的模型性能
问题陈述
信用卡交易面临欺诈风险,即这些交易是在客户不知情的情况下进行的。机器学习模型被部署在各种信用卡公司,用于识别和标记潜在的欺诈交易,并及时采取行动。
加载数据和所需的库
我们从 TensorFlow 中导入了两个模块:
-
密集层,其中当前层的每个神经元都与前一层的所有神经元相连
-
另一个导入是 Sequential 模型,它用于构建神经网络。

获取数据
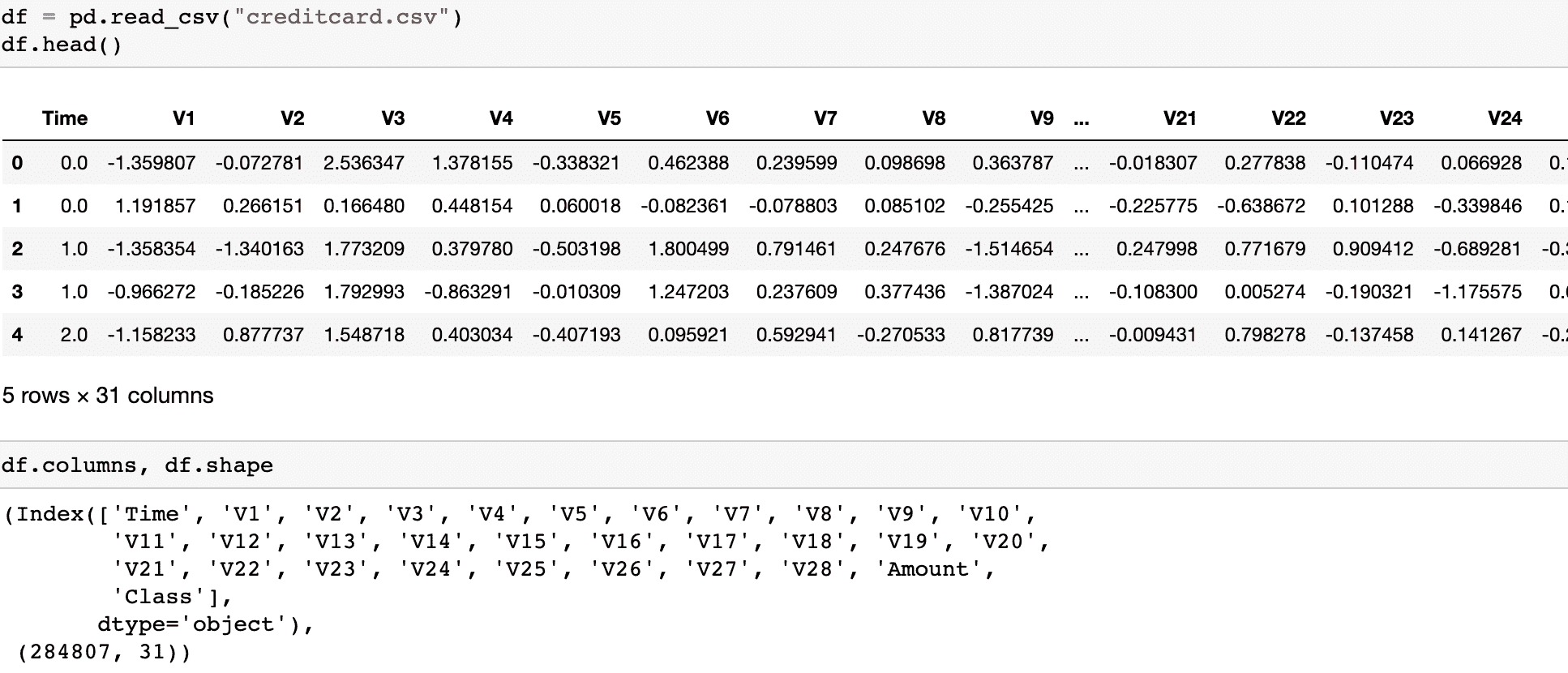
划分训练数据和测试数据
我们保留了 20% 的数据用于评估模型性能,并将开始探索训练数据。测试数据将以与训练数据相同的方式进行准备,包括所有的转换。

理解数据
数据包括经过 PCA 转换的数值输入变量,这些变量被掩盖,因此从业务角度理解属性的范围有限。
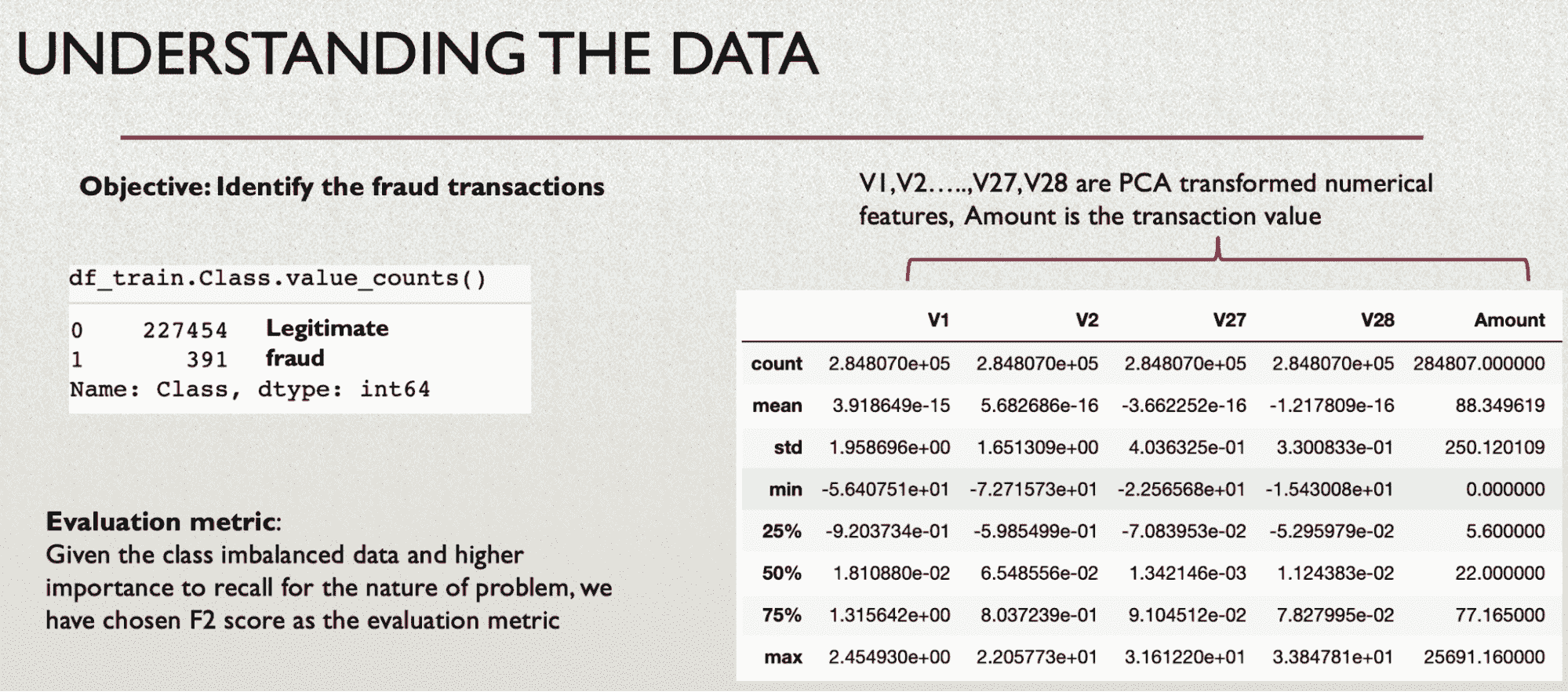
我们使用了 tensorflow data validation 库来可视化属性,它通过计算描述性统计数据和检测异常来帮助理解训练数据和测试数据。
此外,属性没有缺失值并且经过 PCA 转换,因此我们不会对这些属性执行任何数据转换。在上述可视化中,你还可以选择进行对数转换,以可视化转换后的数据分布。
缺失数据
如上图中的缺失列所示,所有属性中没有缺失值,你也可以通过以下方式快速检查所有属性的空值总和:
训练和测试特征
在机器学习数据建模中,最关键的假设之一是训练数据和测试数据集属于相似的分布,这在下面的图表中很明显。训练数据和测试数据分布的重叠程度使我们有信心训练的模型能够很好地在测试数据上进行泛化。如果服务数据分布偏离了机器学习模型训练的数据,重要的是要继续监控,然后决定何时 重新训练模型 以及使用哪个数据分区。
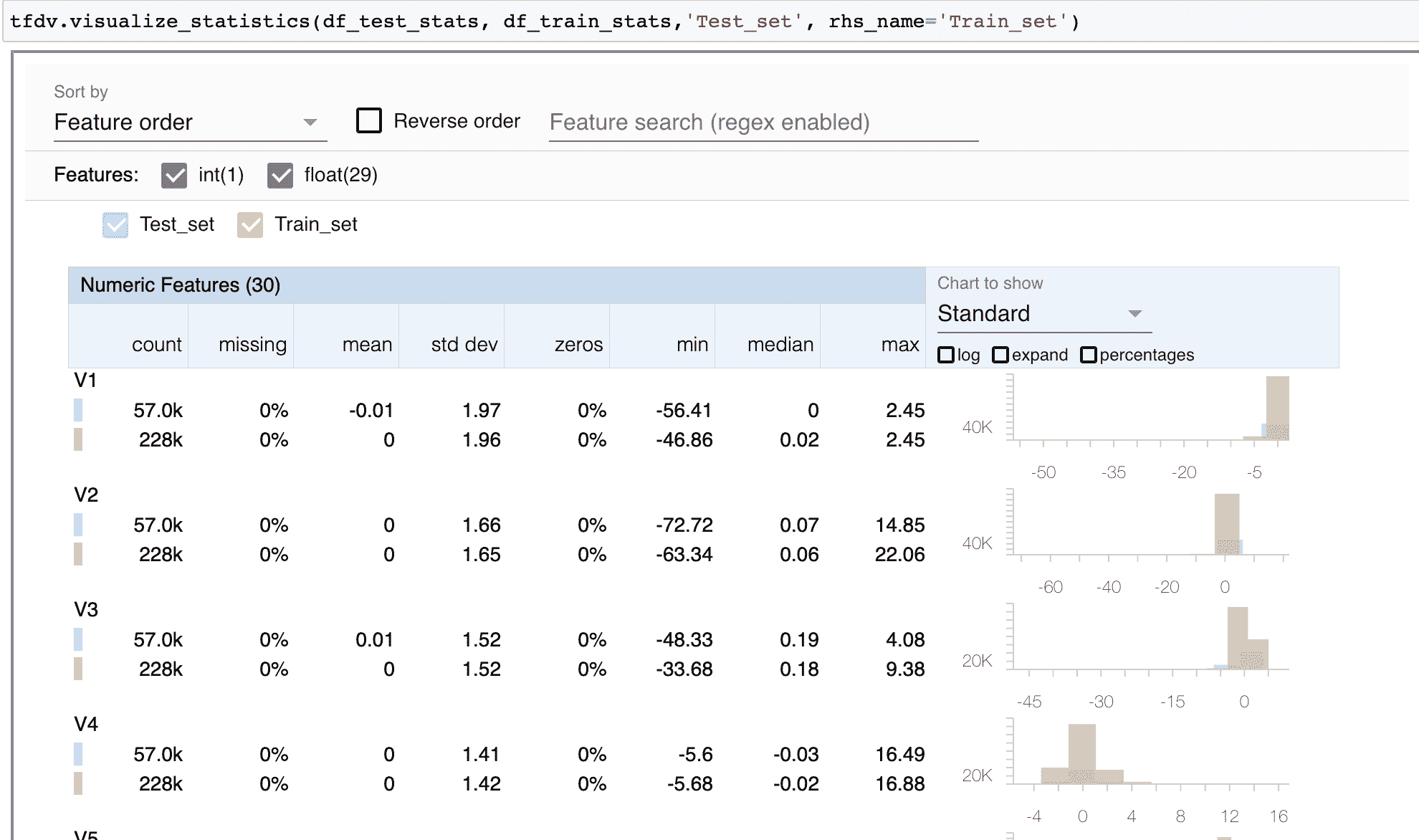
你还可以检查领域外的值并检测错误或异常:

数据转换
由于除“Amount”之外的所有属性都进行了 PCA 转换,我们将重点关注“Amount”,并按照如下进行标准化:
准备测试数据
我们将通过对训练数据进行的相同转换来准备测试数据:

构建基线 TensorFlow 模型
除了神经元的单位和 激活函数 的类型,第一层还需要额外的输入,即输入变量的数量。前两层使用 ReLU 激活,它是一种非线性函数,你可以在 这里 了解更多。我们需要输出作为交易属于哪个类别的概率,因此在最后一层选择了 sigmoid 激活函数。
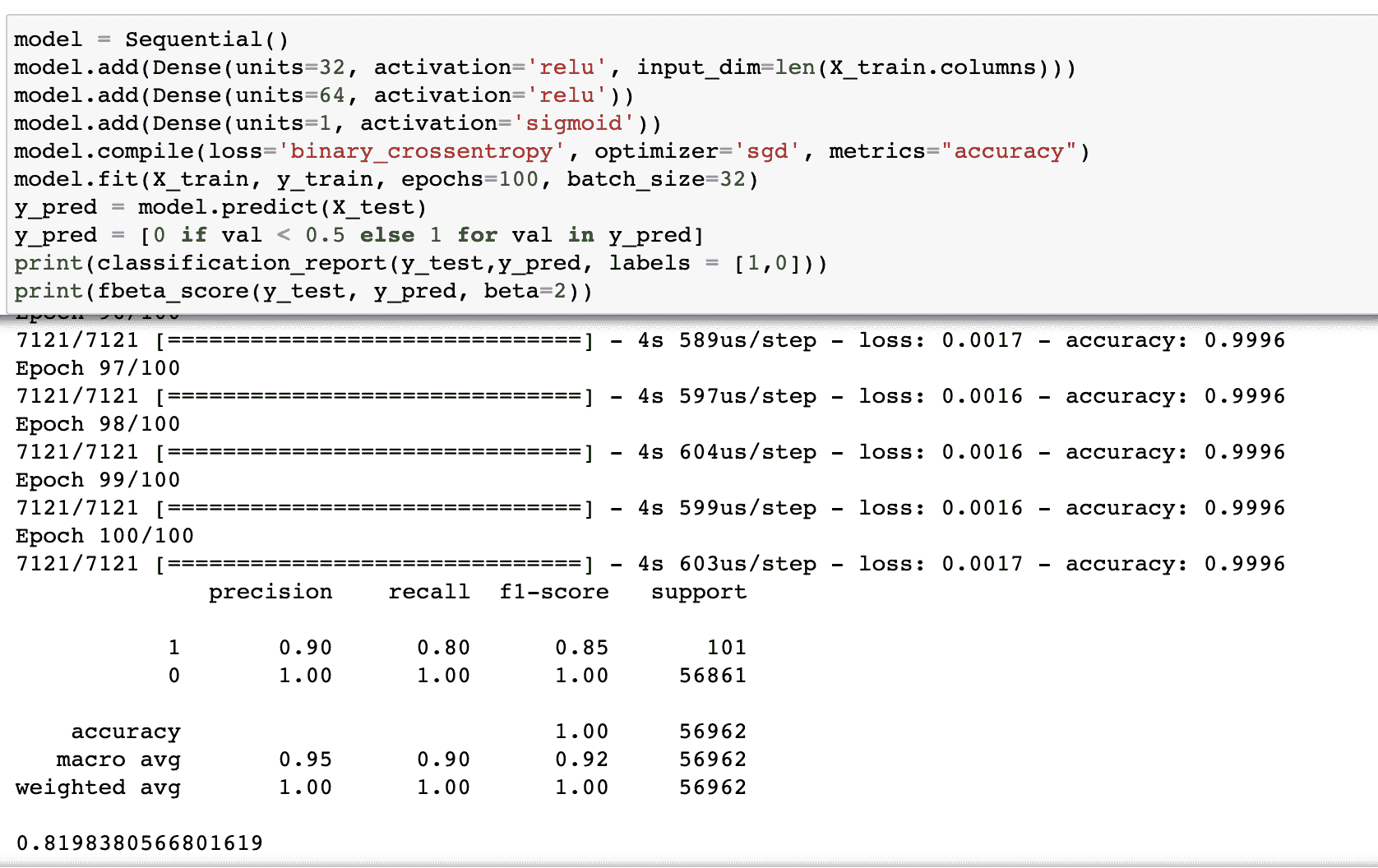
评估指标
我们的目标是减少假阴性,即如果模型将一笔交易声明为非欺诈性和合法性,但实际上是错误的,那么建立模型的整个目的就会失效。模型已经通过了欺诈交易,这比将合法交易标记为欺诈更糟糕。
让我们看看生态系统为假阳性付出了什么代价:如果客户进行了一笔真实的交易,但由于假阳性率很高,模型错误地将其标记为欺诈,导致交易被拒绝。客户必须经历额外的身份验证步骤,以确认交易是由他/她触发的。这种麻烦也是一种成本,但比让欺诈通过的成本要低。也就是说,一个好的模型不能阻止每一笔交易,这会给真实客户带来麻烦,因此一定程度的准确性也很重要。
F1 是准确率和召回率的调和平均数。根据业务指标哪个更重要,可以给予一个比另一个更多的权重。这可以通过 fbeta_score 实现,它是准确率和召回率的加权调和平均数,其中 beta 是召回率在综合得分中的权重。
| beta < 1 | 更重视准确率 |
|---|---|
| beta < 1 | 更重视召回率 |
| beta = 0 | 仅考虑准确率 |
| beta = inf | 仅考虑召回率 |
因此,出于本文的目的,我们使用 F2 得分,它给召回率提供了两倍的权重。
处理类别不平衡
我们通过随机抽取 10%的样本并将其与少数类(即欺诈交易)连接,来下采样多数类。
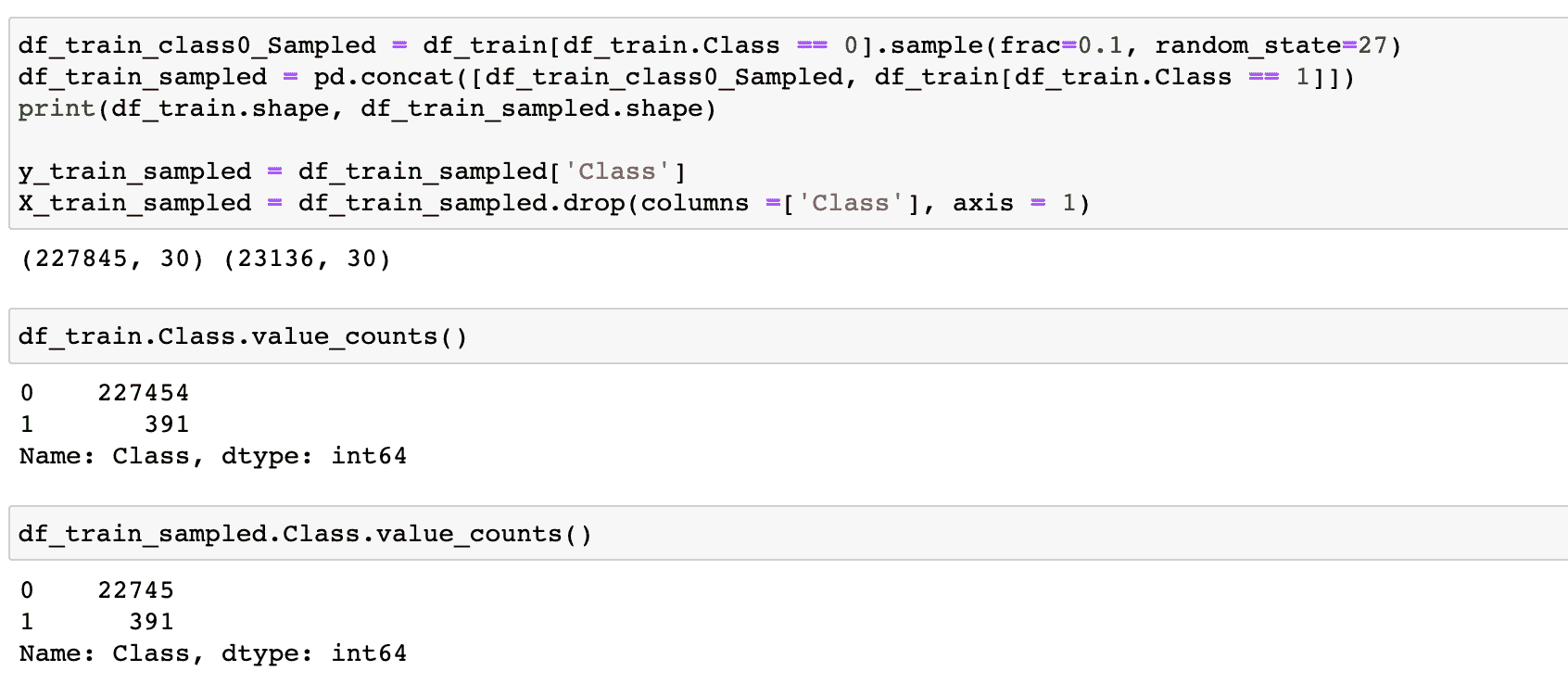
请注意,我们之前已将训练数据和测试数据分开,并将测试数据单独保留,以比较模型在有和没有处理类别不平衡的两个版本中的输出。
处理了类别不平衡的模型
新模型在如下所示的数据分布上进行训练:
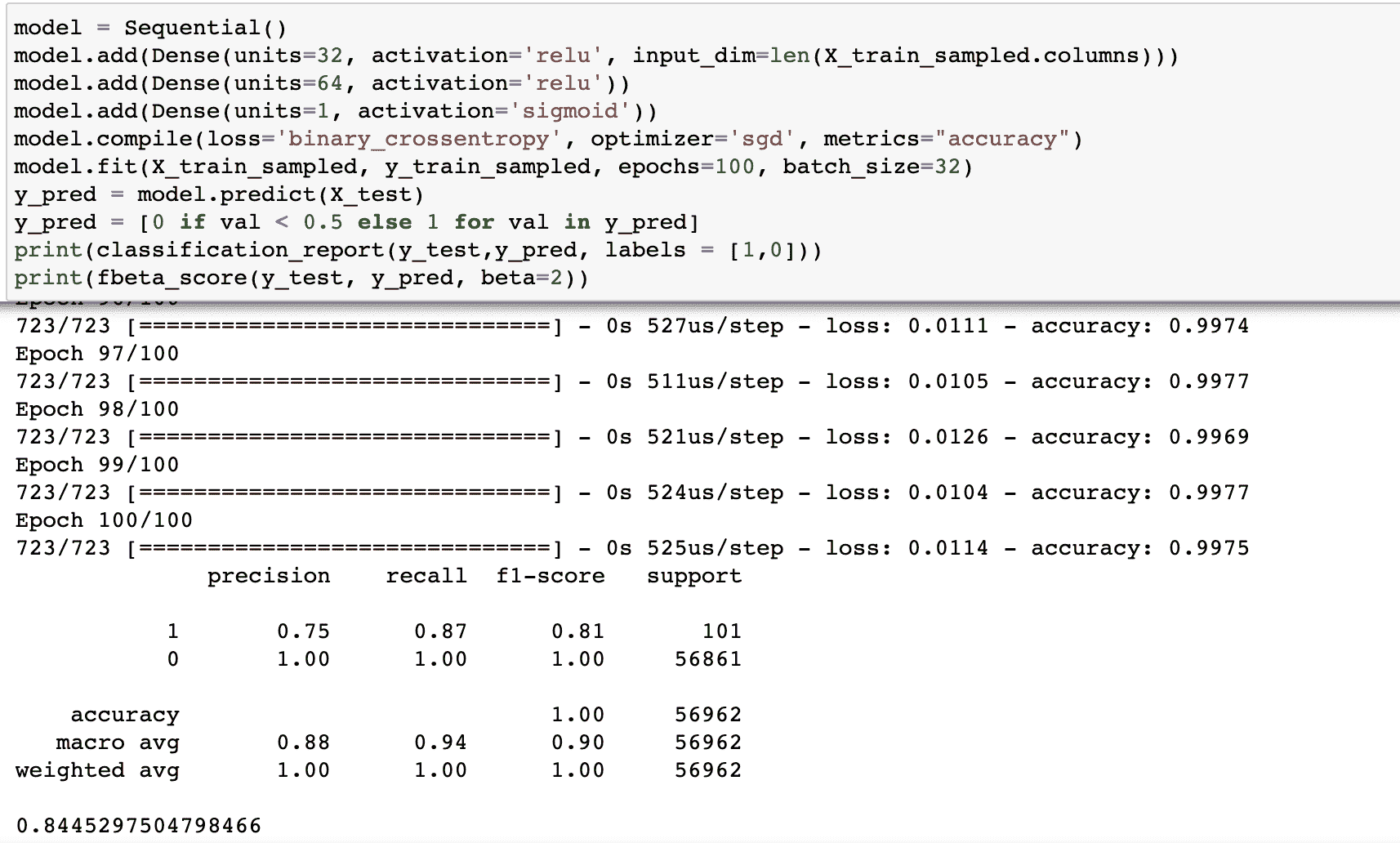
如上所示,尽管精确度有所下降,但第 1 类的召回率已从 80%提高到 87%。此外,使用改进的类平衡数据分布训练的修订模型中的 F2 分数已从 82%提高到 84.5%。
请注意,你可以调整截止值以实现目标召回率和精确度值。
在这篇文章中,我们建立了一个神经网络模型来识别欺诈交易。由于数据集不平衡,我们对多数类进行了欠采样,以改善类分布。这导致了第 1 类的召回值(主要指标)和 F2 分数的改善。
Vidhi Chugh 是一位获奖的 AI/ML 创新领导者和 AI 伦理学家。她在数据科学、产品和研究的交叉点上工作,提供商业价值和见解。她是数据中心科学的倡导者,并在数据治理方面是一位领先的专家,致力于构建可信赖的 AI 解决方案。
更多相关主题
每位 AI 从业者应注意的隐性技术债务
原文:
www.kdnuggets.com/2022/07/hidden-technical-debts-every-ai-practitioner-aware.html
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
随着新软件包和库的出现,建立你的第一个机器学习模型现在变得相当快捷。尽管乍看之下可能很美好,但在维护这些机器学习系统方面,它实际上是在积累隐性技术债务。
但首先让我们理解一下什么是技术债务:
“在软件开发中,技术债务(也称为设计债务或代码债务)是指由于现在选择简单(有限)解决方案而需要额外返工的隐含成本,而不是使用更好的方法,这种方法虽然需要更长时间。” – 维基百科
根据沃德·坎宁安的说法,技术债务是指在软件工程中快速推进所带来的长期成本。这可能在将代码推向生产时看起来是正确的做法,但在后续阶段需要处理,例如编写全面的单元测试、移除冗余和未使用的代码、文档编写、代码重构等。处理这些任务的团队并不是在交付新功能,而是在及时处理积累的债务,以减少错误的范围并促进代码的易维护性。
从机器学习的角度看技术债务
考虑到机器学习系统中的技术债务会导致机器学习相关问题的额外开销,这些问题加在了典型的软件工程问题之上。
机器学习技术债务的很大一部分归因于系统级交互和接口。
了解你的用户
确定机器学习预测的用户对于评估模型新版本的影响至关重要。模型预测的反馈为模型修订提供了基础,并融入了对用户的潜在影响。
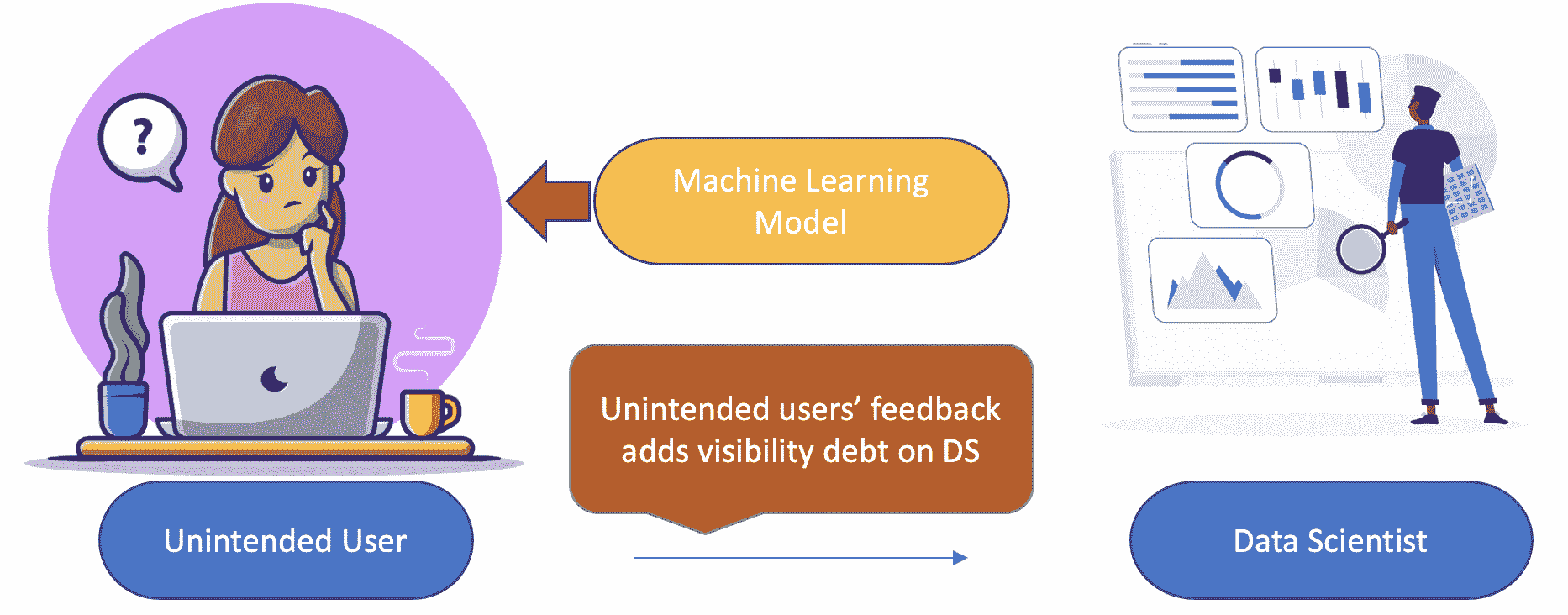
Coffee work vector created by catalyststuff; Web analytics vector created by storyset
为了消除来自未预期用户的要求模糊或理解不清所带来的风险,重要的是记录和签署声明的用户集,并解耦隐藏的反馈循环和广泛用户的期望。
没有任何变化是微小的
机器学习系统在模型训练时,若所有影响目标变量的属性都存在,则效果最佳。实质上,模型可以看到一个人类专家会看到的内容,从而评估结果。数据科学家的工作会更简单,如果所有变量都是独立的,但现实事件并非如此。变量的任何单一变化不仅改变其分布,还影响所有输入(或独立)变量的特征重要性和权重。这是由于交互属性,即变量变化影响所有变量的联合分布。
添加或删除变量时可以观察到类似的效果。信号的混合和纠缠精细地改变了整个模型学习过程。
请注意,这不仅限于任何变量的添加或删除,主要是任何超参数的变化、数据整理、标记过程、阈值选择或采样过程,这些都可能导致称为“改变任何事物就会改变一切”的效果。
相关数据与变化数据
输入数据的分布可能随时间变化,需要评估其对模型结果的影响。这就是数据版本控制重要的地方,以便定性和定量变化在数据中得到良好捕捉和记录。然而,这也会导致额外的成本,需要关注数据的新鲜度并维护多个版本。
许多数据科学家会添加很多包或对代码进行临时修改,以迅速适应最新版本的运行代码以进行实验或分析。问题出在他们忘记保持代码的相关性,去除未使用或不必要的代码块,这些代码块在需要时成为后续更改的障碍。这种情况经常发生在多个开发者协作同一脚本时,他们不断添加更改而不去除冗余或不相关的部分,担心会破坏他人的代码或需要额外时间来测试向后兼容的更改。
何时添加与何时不添加的权衡
每个数据科学家都需要接受这样一个事实:在添加特征时,“更多并非更好”。在假设每个特征对模型学习都很重要的前提下,除非它导致数据维度过大,否则数据科学家不会考虑维护具有剩余价值的特征的成本。此外,如果某个特征后来被宣布为不重要,他们宁愿不去更改模型管道,因此继续保留在早期模型开发阶段工程化的遗留特征。
这看起来仍然相当简单,直到所有特征都直接从一个单一的表中插入到模型中。当属性来源于多个数据流并经过多次联接和转换,导致额外的中间步骤时,复杂性会大幅增加。管理这样的管道,以及检测和调试这些系统,成为团队继续开发创新解决方案的障碍。
限制的级联效应
管理单一模型本身就是一场艰难的战斗,因此许多组织倾向于构建一个一般化模型。尽管它看起来是一场胜利的游戏,但这是一把双刃剑。
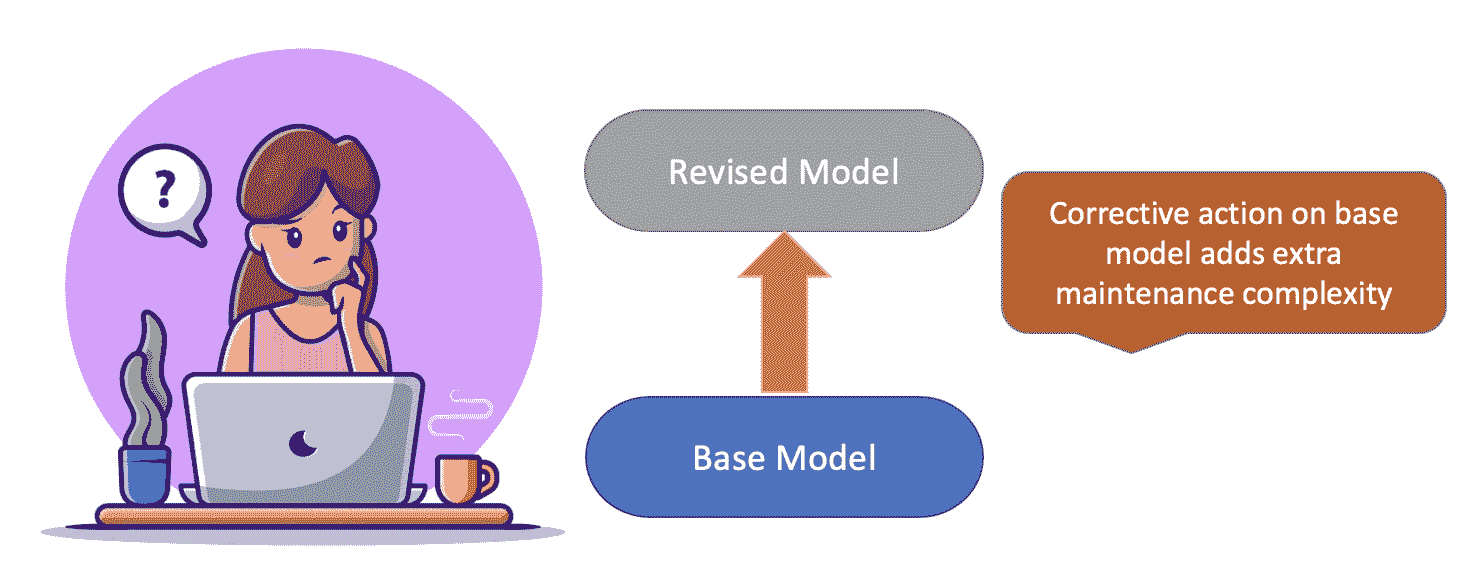
Coffee work vector created by catalyststuff
一般化模型是否适用于所有用例?如果不适用,那么通常会选择在基础模型之上构建一个修正模型层,以更好地服务于略有不同但类似的问题陈述。在这种情况下,修正模型以基础模型为输入,这就增加了一层依赖关系和额外的分析与监控。
摘要
在这篇文章中,我们讨论了处理机器学习系统中隐性技术债务的成本和收益。优先发布新模型版本或端到端测试管道的短视观点会迅速将事物推向生产。但这也会不断增加隐藏成本,从而在长期内减缓团队创新的速度。
研究论文的作者提出了一些深思熟虑的问题供人工智能从业者在考虑隐性债务影响时思考:
-
在全规模下测试新的算法方法有多容易
-
我们如何衡量每次更改的影响?我们是否在管道中建立了检查点,以捕捉和归因诊断因素?
-
通过对系统进行一次更改所带来的改进是否对系统的其他部分产生负面影响?
-
新成员理解整个管道的细微差别和复杂性有多快和多容易?
参考文献
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇处工作,旨在提供商业价值和洞察。她是数据驱动科学的倡导者,也是数据治理领域的领先专家,致力于构建值得信赖的 AI 解决方案。
更多相关内容
什么是层次聚类?
评论
什么是聚类??
聚类是一种将相似对象分组的技术,使得同一组中的对象比其他组中的对象更相似。相似对象的组称为簇。
聚类的数据点
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
数据科学家需要了解 5 种流行的聚类算法:
-
K-均值聚类:欲了解更多信息,请点击这里。
-
层次聚类:我们将在这里详细讨论该算法。
-
均值漂移聚类: 欲了解更多信息,请点击这里。
-
基于密度的空间聚类应用于噪声(DBSCAN): 欲了解更多信息,请点击这里。
-
期望最大化(EM)聚类使用高斯混合模型(GMM): 欲了解更多信息,请点击这里。
层次聚类算法
也称为层次聚类分析或HCA,是一种无监督的聚类算法,涉及创建从上到下具有主导顺序的簇。
例如:我们硬盘上的所有文件和文件夹都以层次结构组织。
该算法将相似的对象分组成称为簇的组。最终结果是一组簇或组,其中每个簇彼此不同,而每个簇中的对象在广义上彼此相似。
这种聚类技术分为两种类型:
-
凝聚层次聚类
-
分裂层次聚类
凝聚层次聚类
凝聚层次聚类是最常见的层次聚类类型,用于根据对象的相似性将对象分组。它也称为 AGNES(凝聚嵌套)。它是一种“自下而上”的方法:每个观察从自己的簇开始,随着层次的上升,簇对簇被合并。
它是如何工作的?
-
将每个数据点作为单点簇 → 形成 N 个簇
-
取两个最接近的数据点并将它们合并成一个簇 → 形成 N-1 个簇
-
取两个最接近的簇并将它们合并成一个簇 → 形成 N-2 个簇。
-
重复步骤 3,直到只剩下一个簇。
查看聚合层次聚类的可视化表示以便更好地理解:
有多种方法可以测量簇之间的距离,以决定聚类的规则,这些方法通常称为链接方法。一些常见的链接方法包括:
-
完全链接:两个簇之间的距离定义为两个簇中各点之间的最长距离。
-
单链接:两个簇之间的距离定义为两个簇中各点之间的最短距离。此链接方法可用于检测数据集中可能存在的异常值,因为它们会在最后合并。
-
平均链接:两个簇之间的距离定义为一个簇中每个点到另一个簇中每个点的平均距离。
-
中心点链接:找到簇 1 和簇 2 的中心点,然后计算它们之间的距离,再进行合并。
选择链接方法完全取决于你,没有一种固定的方法总是能给你带来好的结果。不同的链接方法会导致不同的簇。
做这些的目的在于展示层次聚类的工作原理,它保留了我们如何进行这个过程的记忆,这种记忆存储在树状图中。
什么是树状图?
树状图是一种显示不同数据集之间层次关系的树形图。
如前所述,树状图包含层次聚类算法的记忆,因此仅通过查看树状图,你可以了解簇是如何形成的。
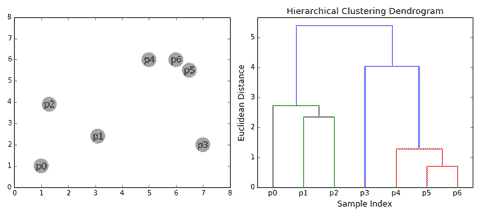
注意:-
-
数据点之间的距离表示不相似性。
-
块的高度表示簇之间的距离。
从上面的图可以观察到,最初 P5 和 P6 由于彼此之间的距离最小,被合并成一个簇,然后 P4 被合并到同一个簇 (C2)。接着 P1 和 P2 合并成一个簇,然后 P0 被合并到同一个簇 (C4)。现在 P3 被合并到簇 C2,最后这两个簇合并成一个。
树状图的组成部分
树状图可以是柱状图(如下面的图片所示)或条形图。一些树状图是圆形的或具有流动形状,但软件通常会生成行或列图。不论形状如何,基本图形包含相同的部分:
-
谱系 是分支,按照它们的相似度(或差异度)进行排列。相近高度的谱系彼此相似;高度不同的谱系彼此不同 —— 高度差异越大,差异越明显。
-
每个谱系都有一个或多个叶子。
-
叶子 A、B 和 C 彼此之间的相似度高于它们与叶子 D、E 或 F 的相似度。
-
叶子 D 和 E 彼此间的相似度高于它们与叶子 A、B、C 或 F 的相似度。
-
叶子 F 与其他所有叶子有显著不同。
一个谱系理论上可以有无限多的叶子。然而,叶子越多,图形在裸眼下阅读的难度越大。
到现在为止,可能引起你兴趣的一个问题是如何决定何时停止合并簇?
你可以在树状图上用水平线进行切割,选择一个高度,在该高度上线可以在上下方向上最大程度地穿越而不交叉合并点。
例如,在下图中,L3 可以在上下方向上最大程度地穿越而不交叉合并点。因此,我们画一条水平线,线与垂直线的交点数就是最佳簇数。
此案例中的簇数 = 3。
分裂层次聚类
分裂 或 DIANA(DIvisive ANAlysis Clustering)是一种自顶向下的聚类方法,我们将所有观测分配到一个簇中,然后将该簇分割成两个最不相似的簇。最后,我们在每个簇上递归地进行,直到每个观测都有一个簇。所以这种聚类方法正好与凝聚聚类相反。
有证据表明,在某些情况下,分裂算法比凝聚算法生成的层次结构更准确,但其概念上更复杂。
在聚合层次聚类和分裂层次聚类中,用户需要指定期望的簇数量作为终止条件(何时停止合并)。
衡量簇的优劣
好吧,有很多方法可以做到这一点,也许最流行的就是Dunn's Index。Dunn's Index 是最小簇间距离与最大簇内直径的比率。簇的直径是其两个最远点之间的距离。为了获得良好的分离和紧凑的簇,你应该追求更高的 Dunn's Index。
现在让我们使用聚合层次聚类算法实现一个用例场景。数据集包含一个特定购物中心的客户详细信息及其消费评分。
你可以从这里下载数据集。
让我们从导入 3 个基本库开始:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
加载数据集:
dataset = pd.read_csv('/.../Mall_Customers.csv')
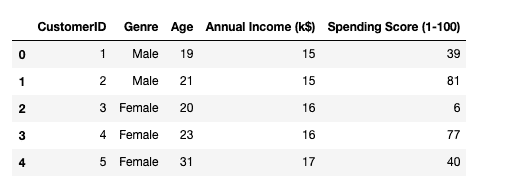
原始数据集
所以我们的目标是根据他们的消费评分对客户进行聚类。
在所有特征中,CustomerID和Genre是不相关的字段,可以去掉,只保留Age和Annual Income来创建独立变量矩阵。
X = dataset.iloc[:, [3, 4]].values
接下来,我们需要选择簇的数量,为此我们将使用树状图(Dendrograms)。
import scipy.cluster.hierarchy as sch
dendrogrm = sch.dendrogram(sch.linkage(X, method = 'ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Euclidean distance')
plt.show()
正如我们之前讨论的,选择簇的数量时,我们绘制一条水平线,穿过最大上下距离而不与合并点相交的最长线段。因此,我们绘制水平线,它所交叉的垂直线数量就是最优的簇数量。
在这种情况下,是 5。因此,让我们用 5 个簇来拟合我们的聚合模型。
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters = 5, affinity = 'euclidean', linkage = 'ward')
y_hc = hc.fit_predict(X)
可视化结果。
# Visualising the clusters
plt.scatter(X[y_hc == 0, 0], X[y_hc == 0, 1], s = 50, c = 'red', label = 'Careful')
plt.scatter(X[y_hc == 1, 0], X[y_hc == 1, 1], s = 50, c = 'blue', label = 'Standard')
plt.scatter(X[y_hc == 2, 0], X[y_hc == 2, 1], s = 50, c = 'green', label = 'Target')
plt.scatter(X[y_hc == 3, 0], X[y_hc == 3, 1], s = 50, c = 'cyan', label = 'Careless')
plt.scatter(X[y_hc == 4, 0], X[y_hc == 4, 1], s = 50, c = 'magenta', label = 'Sensible')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
根据他们的年收入和消费评分对客户进行聚类。
结论
层次聚类是一种非常有用的分割方法。它的优势在于不需要预定义簇的数量,这使其相比于 k-Means 更具优势。然而,当我们有大量数据时,它表现不佳。
好了,这篇文章到此为止。希望你们喜欢阅读。请在评论区分享你的想法/评论/疑问。
你可以通过LinkedIn联系我,有任何疑问都可以问我。

感谢阅读 !!!
简介:Nagesh Singh Chauhan 是 CirrusLabs 的大数据开发人员。他在电信、分析、销售、数据科学等多个领域拥有超过 4 年的工作经验,并在各种大数据组件方面具有专业知识。
原文。转载许可。
相关:
-
使用卷积神经网络和 OpenCV 预测年龄和性别
-
K-Means 聚类的图像分割简介
-
使用 K-最近邻分类心脏病
更多相关内容
Kubernetes 中的高可用性 SQL Server Docker 容器
原文:
www.kdnuggets.com/2022/04/high-availability-sql-server-docker-containers-kubernetes.html

图像由编辑提供
容器的诸多好处早已不是秘密——它们便携、安全、状态保留、可定制且无需安装。然而,IT 面临的一个主要难题是如何实现高可用性(HA),特别是对于像 Microsoft SQL Server Docker 容器这样的容器化状态工作负载。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 需求
IT 通常在想要自动化管理、部署和扩展计算应用程序时转向 Kubernetes(K8s)。但作为独立解决方案,K8s 的原生 HA 对于支持 SQL Server Docker 容器的工作负载来说速度过慢。K8s 也不支持 SQL Server 可用性组(AG)。
为了克服这些障碍,你需要一种将 SQL Server 集群和软件定义边界(SDP)合并的方法,幸运的是,这种新型智能高可用性软件已经存在。这款软件提供了 SQL Server AG 所需的故障转移集群 HA,并且可以额外:
-
创建跨网络和平台的安全、无缝混合 SQL Server AG 集群,无需 VPN。
-
通过接近零恢复时间目标(RTO)的自动故障转移,保护节点、SQL Server Docker 容器和应用程序免受故障影响。
-
避免免费 Linux 集群中常见的 SQL Server HA 配置和网络问题。
由于 Kubernetes 不支持使用 SQL Server AG 自动故障转移,因此使用这种新型智能高可用性软件来解决这个问题是明智的。通过新的软件,企业可以在 Kubernetes 环境下通过 SQL Server Docker 容器实现预期的 SQL Server AG 性能,从而确保业务连续性。最佳实践是利用 K8s 在 SQL Server Docker 容器的 Pod 级别提供 HA,同时在数据库级别利用智能高可用性软件提供 SQL Server AG 支持。
智能高可用性软件的好处
为简化在 Kubernetes 中建立 SQL Server 集群并配置你的 SQL Server AG,该软件可以作为 SQL Server 集群服务。它安装在每个 SQL Server Docker 容器上,并负责 SQL Server AG 在 Kubernetes 中的核心管理、网络管理、故障检测和故障转移自动化。智能高可用软件还提供其他好处,它灵活支持 Windows 和 Linux 的 SQL Server 集群。该软件还可以配置为“混合搭配”,在 SQL Server Docker 容器内外运行。
需要从一个平台迁移到另一个平台吗?智能高可用软件还可以协助迁移。你可以利用内置的软件定义边界功能,包括零信任网络访问(ZTNA)隧道,来创建多云环境。对于 SQL Server Docker 容器,该软件管理所需的 ZTNA 隧道,以实现集群通信和不同云中不同类型节点之间的 SQL Server AG 复制。
你可以在 K8s 内部或外部运行这种新型智能高可用软件来支持 SQL Server Docker 容器,使得在不同位置设置集群变得非常简单,同时通过 ZTNA 隧道和 Kubernetes 集群之间的自动故障转移保持一切安全。该软件提供所需的 HA 增强,因为 K8s 本身不支持 SQL Server AG 的自动故障转移。
智能高可用软件允许在 SQL Server Docker 容器之间形成 SQL Server AG——更不用说更容易部署,因为它允许 IT 生成一个 Docker 容器镜像,不仅包含 SQL Server 还包含智能高可用软件。然后,可以利用该镜像部署 SQL Server Docker 容器。
结论是什么?智能高可用软件使组织能够克服在 Kubernetes 中实施 SQL Server AG 的传统问题。企业可以利用该软件实现自动故障转移,并在网络中创建混合 Kubernetes SQL Server AG 集群。结果是保护节点、容器和应用程序免受常见故障的影响,并且不再为 HA/DR 配置而烦恼。
Don Boxley 是 DH2i 的共同创始人兼 CEO。Don 从康奈尔大学约翰逊管理学院获得了 MBA 学位。
更多相关主题
维护机器学习系统的高成本
原文:
www.kdnuggets.com/2015/01/high-cost-machine-learning-technical-debt.html
评论
去年 12 月,一组由 D. Sculley 领导的谷歌研究人员在 NIPS 上发表了一篇立场论文,描述了维护依赖于机器学习的软件的成本。作者利用技术债务的概念,建议虽然机器学习提供了快速工程复杂系统的途径,但这种便利性带来了巨大的下游成本。
技术债务是一个比喻,将糟糕的软件设计后果与偿还财务债务联系起来。就像贷款最终必须偿还,并带有复利一样,草率的设计决策也必须通过重构、调试和复杂的测试来弥补。当然,复利的概念在软件开发中的应用更多是诗意的,而不是精确的。在软件开发中,技术债务的比喻通常用来讨论快速交付代码与工程高质量可持续解决方案之间的权衡。必须决定如何权衡现在的速度与未来的开发成本。

尽管将这一概念扩展到机器学习系统是有趣的,但需要注意传统上讨论的技术债务与机器学习应用之间的根本差异。与大多数传统的软件设计决策不同,应用机器学习的决策通常不会明确表达为权衡。可以通过机器学习解决的问题通常是其他方法无法解决的。另一方面,正如作者所解释的,考虑到许多不同的算法(即使是微妙的不同),算法性能与所承担的技术债务之间可能存在权衡。不过,最令人担忧的成本似乎在所有机器算法中都是普遍存在的。
债务的类型
所有机器学习算法在某种程度上都会承担技术债务,其中之一就是边界的侵蚀。作者指出,好的软件设计实践通常是模块化的。模块隔离了相关代码区域,这些代码区域执行明确定义的任务,并将其与其他交互的模块分开。这种代码库的解耦使得可以严格测试代码,并且使得代码库的不同部分可以由不同的人维护。然而,机器学习算法的性能依赖于从外部数据源获取的输入,性能也只能通过外部数据源来评估。这种算法和数据的紧密耦合意味着外部数据的变化通常会改变我们希望算法的行为。在现实世界中,数据获取、预处理和模型调整可能由不同的人管理。这种不舒服的紧密耦合可能很难维护,特别是在面对底层数据源的变化时。
如前所述,这个问题可能是机器学习固有的,可能唯一的选择是接受这种债务或完全放弃任务。相比之下,作者称之为纠缠的问题可能实际上可以通过设计决策来解决。这指的是模型对所有特征的依赖。特征的突然丧失、新特征的引入或特征值的扰动可能会使整个模型失效。D. Sculley 等人将这种现象称为改变任何东西就会改变一切。他们引用了几篇其他论文,提供了减少纠缠的策略,包括一种使用集成学习的方法。
几种其他策略虽然未被讨论,但似乎也很合适。缺失数据的问题通过贝叶斯网络得到优雅的处理。去噪自动编码器和其他降维/矩阵分解技术也提供了处理缺失数据的策略。关于特征空间的持续和渐进增长,John Langford 在 Vowpal Rabbit 中实现的哈希方法似乎适合于缓解这个问题。
论文中讨论的最有趣的观点之一是算法与外部世界之间形成的反馈回路。基于点击数据(而点击数据本身又依赖于显示的链接)进行调整的搜索引擎就是一个明确的例子。似乎从任何基于机器学习的推荐系统中获取的用户数据可能都会受到类似的动态影响。例如,Pandora 可能会试图确定用户的偏好,但获得的反馈高度依赖于推荐的歌曲。
从抽象的角度来看,这些反馈循环可能类似于社交网络和网页搜索中的过滤气泡。过滤气泡描述了这样一种现象:人们只看到与自己观点一致的视图和帖子,很少遇到异议,因此被困在意识形态泡沫中,无法与对立观点互动。
最后,作者集中讨论了数据科学家通常生成的代码所带来的问题。与前面的例子不同,这些情况确实符合传统的技术债务概念。其中一个问题是死实验代码路径,指的是为实验设计但却投入生产的代码。这类代码通常实现了许多不同的实验,变体由条件语句控制。任何细微的更改或意外导致选择不同的实验分支都可能造成灾难性的后果,而不会表现出任何容易检测的软件错误(编译时或运行时错误)。作者提到,这种错误是 Knight Capital 公司交易算法失控的原因。
Sculley 等人描述的一个最终软件权衡是胶水代码的问题。当发布机器学习代码时,高级机器学习算法通常在提供通用解决方案的包中实现。因此,工程师通常编写由这些包构建的胶水代码。胶水代码可能处理数据、设置超参数的值、选择合适的算法、报告结果等。与所有对外部库的依赖一样,这也带来了对基础库任何变更的持续脆弱性。作者建议,构建实时系统的工程师应认真考虑在更广泛的系统架构中重新实现机器学习算法。
本文具有一篇优秀的挑衅性操作系统论文的风格。作者坦率地表达了观点,读者能够感受到作者在这些问题上经历了许多挫折。通常,机器学习方法的系统实现和持续软件维护挑战是一个未被充分研究的领域,随着机器学习系统在商业和开源软件中的普及,这个领域将继续增长。本文描述了问题的高层次分类,类似于 Butler Lampson 在其保护论文中尝试统一安全讨论的方式。未来希望看到更多描述大型组织在部署主要机器学习系统时遇到的具体软件工程和持续维护挑战的论文。
 扎克里·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。由生物医学信息学部资助,他对机器学习的理论基础和应用都很感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院实习。
扎克里·蔡斯·利普顿 是加州大学圣地亚哥分校计算机科学工程系的博士生。由生物医学信息学部资助,他对机器学习的理论基础和应用都很感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院实习。
相关:
-
IBM Watson Analytics 与微软 Azure 机器学习(第一部分)
-
差分隐私:如何让隐私和数据挖掘兼容
-
Geoff Hinton AMA:神经网络、大脑与机器学习
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关内容
高级 API 是否让机器学习变得愚蠢?
原文:
www.kdnuggets.com/2018/04/high-level-apis-dumbing-down-machine-learning.html
评论
Google 的研究科学家 David Ha(@hardmaru),最近(2018 年 2 月 9 日)发推道:
从头实现全连接网络、卷积网络、RNN、反向传播和 SGD(使用纯 Python、numpy,甚至是 JS)并在小数据集上训练这些模型,是学习神经网络如何工作的一个极好的方法。在跳入框架之前,花时间获得宝贵的直觉。
t.co/biP02iWsjd— hardmaru (@hardmaru) 2018 年 2 月 9 日
这引发了 Keras 的创造者 François Chollet(@fchollet)的一系列回应推文,综合考虑这些回应,呈现出不同的观点。以下是几条突出的回应:
研究生在 2000 年就知道如何用 C 语言实现神经网络。那时他们对神经网络的直觉并不强。到 2018 年,一个高中生玩转神经网络框架,可以在几天内建立更强的神经网络理解——这全靠更好的应用背景。
— François Chollet (@fchollet) 2018 年 3 月 7 日
下一代在抽象层次上不断进步是一件好事,在我看来,让学生从头开始并不是一种好的学习策略。
— François Chollet (@fchollet) 2018 年 3 月 7 日
一些其他受人尊敬的机器学习研究人员和工程师也参与了讨论,包括Jeremy Howard和Emmanuel Ameisen等(值得一提的是,Ha 的原始推文实际上是对Denny Britz 的推文的回应)。双方在这种“争论”的“观点”上都提出了很好的观点。
高级机器学习 API——特别是Keras、TensorFlow Layers、Scikit Flow、TensorFlow Estimators等——将抽象提升到一个新的高度。与之相比,Theano 和普通的 TensorFlow 显得低层次得多。我们甚至可以进一步扩大范围,考虑像 Scikit-learn 这样的通用库;不久前,拥有一个包含各种有用实现的全方位算法工具包,并且提供一致的 API,在同一平台下,这几乎是不可想象的,更不用说它便利的抽象层次了。

使用这些库来实现机器学习模型变得更容易。然而,Scikit-learn 的标准 fit/predict API 或用 Keras 堆叠序列层的简单性是否将抽象层级提升得过高,以至于新手无法真正理解算法的基础理论?或者这些工具是否让从业者免于编写他们可能(或可能不会)完全理解的功能?
关于技术抽象的讨论同样适用于编程语言、机器学习,甚至更广泛的抽象概念。的确,汇编语言如今不是编程人员的首选武器,程序员们通常使用更高层次的抽象工具,并且什么构成高级语言的概念随着时间不断演变。
然而,我认为,自己在没有计算机科学基础的情况下随意编写 Javascript 的情况与具有扎实计算机科学基础的研究生(或者没有正式计算机科学教育但对其基础知识有牢固把握的人)使用相同语言实现他们的想法是不同的。我不认为这是 Chollet 提出的相同观点(他从未说过没有神经网络理解的人能够有效地编码神经网络),但他几乎肯定是在推动抽象层级的稳步上升作为更有效的学习体验。
虽然“最佳”学习方法,尤其是它们的不同细微差别,永远无法完全普遍适用,并且在一定程度上依赖于学习者,但似乎合理的是,将理论和实践相结合的渐进混合方法,不能被排除在作为学习神经网络及其实现的首选方法之外。同样,细节很重要,但保持理论不干扰实践以及避免理论前置的课程阻碍学习者早期看到(和做)深度学习的动机,似乎是有利的。这种方法似乎类似于 fast.ai 采取的方法,这也可能确认像 Keras 这样的项目在早期作为尝试的有效性,以及在你建立了一些更强的理解后如何完成任务。
仅仅是一个人的观点……你怎么看?
相关:
-
比较深度学习框架:罗塞塔石碑方法
-
今天我在午休时间用 Keras 构建了一个神经网络
-
谷歌 Tensorflow 目标检测 API 是实现图像识别的最简单方法吗?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
数据科学家的高薪副业
原文:
www.kdnuggets.com/2022/01/high-paying-side-hustles-data-scientists.html

封面照片由 macrovector 提供 | Freepik
自 COVID-19 开始以来,远程工作或在家工作已成为常态。居家办公有许多优点,其中之一是额外的时间。因此,如果你有更多的时间并且想赚更多的钱,可以参考这些高薪副业。这些副业也可能成为你财务 自由的关键,因为你将按自己的节奏赚取丰厚的收入。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
我曾全职为一家公司工作,但我并不满意。我知道我可以利用我们在工作场所浪费的时间——通勤、社交、午休和会议——做更多的事情。在 6 月底,我开始寻找兼职工作,发现了很多在线平台,为我提供了额外的收入和从事我热爱的工作的机会。
在这篇博客中,我将分享那些能将你的收入提升四倍的高薪副业。这些工作可以包括自由职业、文案写作、合同工作、咨询和职业指导。
自由职业
开始自由职业或成为自由代理人可以让你在工作时间上有更大的灵活性。它让你接触到各种主题,提高你的技能,并为你提供更多的赚钱机会。最终,你将建立一个有潜力迅速增长的品牌。我见过许多自由职业者从$100 起步,现在他们的收入已达六位数。
图片由作者提供
寻找数据科学自由职业工作有点棘手。你可能会注册到错误的平台,在那里没有数据科学工作的需求,浪费几个小时来创建个人资料。所以,这里是适合数据科学家的数据相关自由职业平台列表。
-
Upwork: 允许你自由选择项目,并与客户协商小时费率。你可以获得固定价格的项目、小时工作以及长期雇佣合同。这是最大的在线自由职业平台,意味着机会是无穷无尽的。
-
Toptal: 是一个针对开发者和数据科学家的精英专业平台。他们只选择顶级的 3%专业人士。你还需要有两年以上的数据科学经验,并且在该领域成为专家。如果你通过了招聘流程,平台将帮助你找到高薪工作,并协助你进行支付。
-
AngelList: 与传统的自由职业平台不同。你可以找到远程工作,成为初创公司的一部分,甚至找到兼职工作。该平台提供全职、实习、合同和联合创始人选项。平台支持远程文化,因此如果你对初创公司感兴趣,可以选择远程工作。
-
Kolabtree: 是一个面向有经验人士的平台。大多数自由职业者要么是拥有博士学位的科学家,要么是主题专家。如果你认为自己在数据科学方面表现出色,并且有五年以上的经验,那么你一定要加入这个平台。
技术写作
如果你是初学者或专业人士,技术写作是赚取额外收入的简便途径。你可以直接为公司工作,或者使用自由职业平台获得写作工作。技术写作包括文案写作、文稿编辑、科学写作和幽灵写作。写作工作可以涵盖从撰写博客到编写教程的各种内容。

作者提供的图片
博客写作
通过Medium开始你的博客之旅,因为他们根据每次独立访问付费。你不仅是在赚取额外收入,还在创建自己的品牌,随着时间的推移,这个品牌可以不断成长。你还可以创建一个Ko-fi个人资料,并在上面发布博客,以从支持者那里获得额外收入。不要局限于一个平台。
文案写作
你可以为Analytics Vidhya、DataCamp和 KDnuggets 写作,以赚取额外收入。Analytics Vidhya 有一个为期一年的博客马拉松,作者每篇博客都会获得报酬,有时如果他们进入前 3 名,还会获得额外奖励。要为 DataCamp 写作,你需要关注自由职业数据科学文案撰稿人的职位发布。KDnuggets 奖励计划每月向 8 篇最受欢迎的文章分享 3000 美元,金额按页面浏览量的比例分配。
幽灵写作
如果你是经验丰富的文案撰稿人,你会收到招聘人员或技术经理关于代笔工作的联系。代笔是一种作者在不署名的情况下获得报酬的工作。这些工作非常有利可图,因为它们的报酬是当前费率的两倍。如果你是经验丰富的作家,你甚至可以要求每字 0.4 美元。留意本地或在线招聘网站的机会。在签署任何合同之前,尽量谈判价格。
合同工作
这是我最喜欢的工作类型,因为所有内容都包含在合同中,包括付款、项目目标和时间表。你可以自由安排工作时间,并且有明确的目标需要在规定时间内完成。合同工作有很多形式,比如研究工作、设计机器学习模型、数据分析、撰写论文,或在工作流程中集成新工具。你可以通过搜索招聘网站或被招聘经理主动联系来获得合同工作。

图片作者提供
全球合同
在全球合同中,你将与国际团队合作。这种工作报酬丰厚,并且你将有限的时间来完成项目。这是赚取额外收入、获得经验和提升简历的最佳方式,因为拥有国际经验总是有好处的。
本地合同
对于初学者来说,本地合同很难获得。为了被录用,你需要展示主题领域的专业知识。大多数时候,本地招聘人员会通过查看你的 LinkedIn 个人资料来联系你,并提出项目目标和付款细节。付款可以是按小时计费或固定价格。我大多数情况下获得的是按小时计费的合同,因为公司希望在项目开始时获得专家意见。
咨询服务
咨询服务按小时收费。如果你在该领域有 5 年以上的经验,你可以向公司收取每小时 100 到 500 美元的费用。这项工作难以找到,大多数公司聘请专家提供有关数据科学工具的指导、对投资科技初创公司的意见、启动新企业或项目、产品分析和应用开发等方面的咨询。

图片作者提供
如果你正在寻找一个高薪的专业平台,可以尝试 Guidepoint。你也可以通过加入本地技术社区在你的国家获得咨询工作。你的 LinkedIn 个人资料也可以吸引潜在客户,所以保持更新最新的经验。
职业咨询
在我看来,职业咨询应该是免费的。它应该由教育机构提供,但实际上,学生们仍然面临困境。这些学生或应届毕业生于是寻找专业的职业咨询平台,以获取简历方面的见解。这些平台还提供技术面试、职业辅导和网络建设的帮助。

作者提供的图片
你可以成为一名职业教练,通过注册Skilled来赚取额外收入。这个平台对职业教练支付丰厚的报酬,并提供创建有效个人资料的支持。自由职业平台也发布关于辅导、简历反馈和模拟面试的工作。我相信职业教练在做着崇高的工作,你不仅是在赚取金钱,还在为孩子们建立未来。
结论
大流行催生了一个远程工作的新时代,人们正在寻找各种方式来赚取额外的收入。这些副业也可以提供有益于你职业的经验和知识。在这篇博客中,我们了解了专门针对数据科学的自由职业平台、技术写作、合同工作、咨询和辅导。你还可以启动一个 YouTube 频道,创建一个 Udemy 课程,并贡献开源项目来扩展你的作品集。
“我相信提前退休并用余下的岁月享受自己热爱的事物。因此,要有效利用你的时间,并不断寻找赚取更多收入的机会。”
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个帮助精神疾病学生的 AI 产品。
更多相关话题
高性能深度学习:如何训练更小、更快、更好的模型 – 第二部分
原文:
www.kdnuggets.com/2021/06/high-performance-deep-learning-part2.html
评论

在第一部分中,我们讨论了为什么效率对深度学习模型至关重要,以实现高性能的帕累托最优模型。让我们进一步深入探讨实现效率的工具和技术。
深度学习中的效率关注领域
我们可以将关于效率的工作大致分为四个建模技术支柱和一个基础的基础设施与硬件。
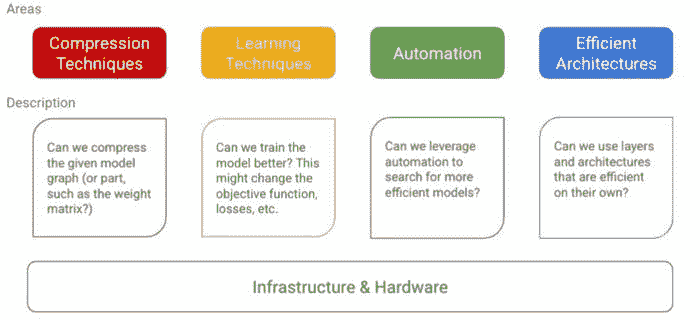
高效深度学习的关注领域。
-
压缩技术:这些是常见的技术和算法,旨在优化架构本身,通常通过压缩其层来实现。这些方法通常足够通用,可以跨架构使用。一个经典的例子是量化[1,2],它尝试通过减少其精度(例如,从 32 位浮点值到 8 位无符号整数)来压缩层的权重矩阵。量化通常可以应用于任何具有权重矩阵的网络。
-
学习技术:这些算法专注于不同的训练模型方式,以减少预测错误。通过裁剪参数数量,可以将改进的准确性转换为更小的占用空间或更高效的模型。如果需要,学习技术还可以使模型更精简。一个学习技术的例子是蒸馏[3],正如前面提到的,它帮助一个较小的模型从一个更大、更准确的模型中学习。
-
自动化:这些工具用于通过自动化来改进给定模型的核心指标。例如,超参数搜索[4]就是一个例子,其中模型架构保持不变,但优化超参数有助于提高准确性,这样可以换取一个参数更少的模型。类似地,架构搜索[5,6]也属于这一类别,其中架构本身被调整,搜索有助于找到一个优化了损失/准确性和其他目标函数的模型。一个次要目标函数的例子可能是模型延迟/大小等。
-
高效模型架构与层:这些是深度学习中效率的核心,是从头设计的基本构件(卷积层、注意力机制等),比之前使用的基线方法有了显著的跃进。例如,卷积层引入了参数共享和用于图像模型的滤波器,从而避免了为每个输入像素学习单独的权重。这在与标准多层感知机(MLP)网络比较时显然节省了参数数量。避免过度参数化进一步有助于提高网络的鲁棒性。在这一支柱中,我们将关注那些专门为提高效率而设计的层和架构。
基础设施与硬件
最终,我们还需要一个基础设施和工具的基础,以帮助我们构建和利用高效的模型。这包括之前介绍过的模型训练框架,如 Tensorflow、PyTorch 等。这些框架通常会与特定的工具配对,以部署高效模型。例如,Tensorflow 与 Tensorflow Lite (TFLite) [7] 和相关库紧密集成,允许在移动设备上导出和运行模型。同样,TFLite Micro [8] 有助于在 DSP 上运行这些模型。与 Tensorflow 类似,PyTorch 也提供 PyTorch Mobile 用于量化和导出模型,以在移动和嵌入式设备上进行推理。
我们常常依赖这些基础设施和工具来利用高效模型的优势。例如,为了获得量化模型的大小和延迟改进,我们需要推理平台支持量化模式下的常见神经网络层。TFLite 通过允许导出具有 8 位无符号整数权重的模型,并与如 GEMMLOWP [8] 和 XNNPACK [9] 等库集成以实现快速推理,从而支持量化模型。同样,PyTorch 使用 QNNPACK [10] 支持量化操作。
在硬件方面,我们依赖于 CPU、GPU 和 Tensor Processing Units (TPUs) [11] 等设备,以便训练和部署这些模型。在移动和嵌入式领域,我们拥有基于 ARM 的处理器、移动 GPU 和其他加速器 [12],让我们能够利用效率提升进行部署(推理)。
在下一部分,我们将讨论适合这些支柱的工具和技术示例。也可以查看我们的 调查论文,详细探讨了这个话题。
参考文献
[1] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, 和 Dmitry Kalenichenko. 2018. 量化和训练神经网络以实现高效的整数运算推理。见于 IEEE 计算机视觉与模式识别会议论文集。2704–2713。
[2] Raghuraman Krishnamoorthi. 2018. 量化深度卷积网络以实现高效推理:白皮书。arXiv (2018 年 6 月)。arXiv:1806.08342
[3] Geoffrey Hinton, Oriol Vinyals, 和 Jeff Dean. 2015. 提炼神经网络中的知识。arXiv 预印本 arXiv:1503.02531 (2015)
[4] Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro, 和 D Sculley. 2017. Google vizier: 一项黑箱优化服务。发表于第 23 届 ACM SIGKDD 国际知识发现与数据挖掘会议。1487–1495.
[5] Barret Zoph 和 Quoc V Le. 2016. 使用强化学习的神经网络架构搜索。arXiv 预印本 arXiv:1611.01578 (2016).
[6] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, 和 Quoc V Le. 2019. Mnasnet: 针对移动设备的平台感知神经网络架构搜索。发表于 IEEE/CVF 计算机视觉与模式识别会议。2820–2828.
[7] 移动和边缘设备的机器学习。 www.tensorflow.org/lite
[8] GEMMLOWP. - github.com/google/gemmlowp
[9] XNNPACK. - github.com/google/XNNPACK
[10] Marat Dukhan, Yiming Wu Wu, 和 Hao Lu. 2020. QNNPACK: 用于优化移动深度学习的开源库 - Facebook 工程。 engineering.fb.com/2018/10/29/ml-applications/qnnpack
[11] Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, 等. 2017. 数据中心内的张量处理单元性能分析。发表于第 44 届国际计算机架构年会。1–12.
[12] EdgeTPU. cloud.google.com/edge-tpu
个人简介: Gaurav Menghani (@GauravML) 是 Google Research 的高级软件工程师,领导旨在优化大型机器学习模型以实现高效训练和推理的研究项目,涵盖从微控制器到基于 TPU 的服务器的设备。他的工作对 YouTube、Cloud、Ads、Chrome 等超过 10 亿活跃用户产生了积极影响。他还是即将出版的《高效机器学习》一书的作者之一。在 Google 之前,Gaurav 在 Facebook 工作了 4.5 年,对 Facebook 的搜索系统和大规模分布式数据库做出了重要贡献。他拥有斯托尼布鲁克大学计算机科学硕士学位。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
更多相关内容
高性能深度学习:如何训练更小、更快、更好的模型 – 第三部分
原文:
www.kdnuggets.com/2021/07/high-performance-deep-learning-part3.html
评论
在前面的部分(第一部分 & 第二部分)中,我们讨论了为什么效率对深度学习模型实现高性能的帕累托最优模型至关重要,以及深度学习中效率的关注领域。现在,让我们深入探讨这些关注领域中的工具和技术示例。
压缩技术
如前所述,压缩技术是可以帮助实现神经网络中一个或多个层的更高效表示的通用技术,可能会带来质量上的折衷。这种效率可能来自于提高一个或多个足迹指标,如模型大小、推理延迟、收敛所需的训练时间等,以换取尽可能少的质量损失。模型通常可能被过度参数化。在这种情况下,这些技术也有助于提高对未见数据的泛化能力。
剪枝:一种流行的压缩技术是剪枝,其中我们剪除不重要的网络连接,从而使网络稀疏。LeCun 等人[1]在其论文《最优大脑损伤》中,通过将神经网络中的参数(层间连接)数量减少了四倍,同时提高了推理速度和泛化能力。
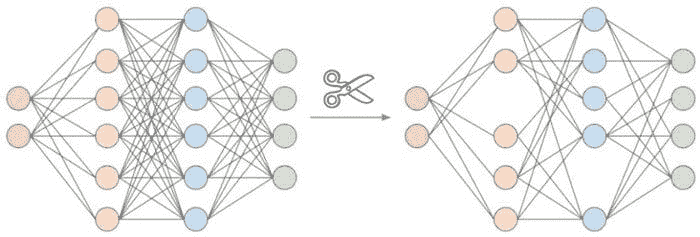
神经网络中剪枝的示意图。
哈西比等人(Hassibi et al.)和朱等人(Zhu et al.)的最优大脑外科医生工作(OBD)采用了类似的方法[2]和[3]。这些方法使用已经预训练到合理质量的网络,然后迭代性地剪除具有最低显著性得分的参数,该得分衡量了特定连接的重要性,以使对验证损失的影响最小化。剪枝完成后,使用剩余参数对网络进行微调。该过程重复进行,直到网络被剪枝到所需的水平。
在各种剪枝工作中,差异发生在以下维度:
-
显著性:这是确定应该剪枝哪个连接的启发式方法。它可以基于连接权重相对于损失函数的二阶导数[1, 2]、连接权重的大小[3]等。
-
无结构与结构化修剪: 最灵活的修剪方式是无结构(或随机)修剪,在这种方法中,所有给定的参数被平等对待。在结构化修剪中,参数按大于 1 的块进行修剪(例如:在权重矩阵中按行修剪或在卷积滤波器中按通道修剪(例如:[4,5])。结构化修剪使得在推理时能够更容易地利用大小和延迟的增益,因为这些修剪后的参数块可以智能地跳过存储和推理。
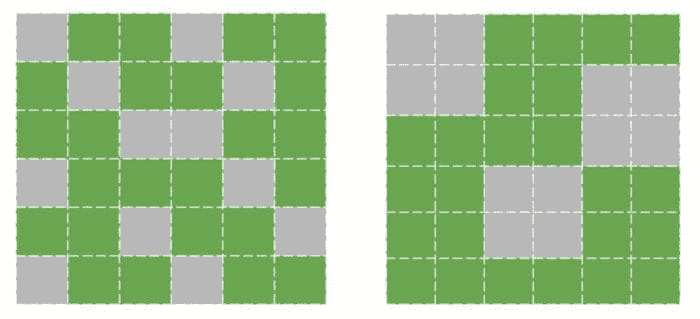
无结构与结构化修剪权重矩阵的对比。
-
分配: 可以为每一层设置相同的修剪预算,或者可以按层分配[6]。直觉上,有些层更适合修剪。例如,通常情况下,前几层已经足够小,无法承受显著的稀疏性[7]。
-
调度:另一个标准是修剪的数量和时机?我们是否希望每轮修剪相同数量的参数[8],还是在开始时以较快的速度修剪,然后逐渐放慢[9]?
-
再生长: 在某些情况下,网络允许再生长被修剪的连接[9],以便网络始终以相同的连接修剪百分比运行。
在实际应用中,具有有意义块大小的结构化修剪可以帮助提高延迟。Elsen 等人[7]构建了稀疏卷积网络,这些网络在保留相同的 Top-1 准确率的同时,以约 66%的参数超越了其密集网络,提升了 1.3 - 2.4 倍。他们通过库将 NHWC(通道在最后)标准密集表示转换为适用于其快速内核的 NCHW(通道优先)‘块压缩稀疏行’(BCSR)表示,以适应在 ARM 设备、WebAssembly 等上进行快速推理[10]。尽管他们也对可以加速的稀疏网络类型引入了一些限制。总体而言,这是朝着修剪网络在足迹指标上取得实际改进的一个有希望的步骤。
量化: 量化是另一种流行的压缩技术。它利用了这样一个观点:典型网络中的几乎所有权重都是 32 位浮点值,如果我们可以接受一定程度的模型质量损失(准确率、精度、召回率等),我们可以将这些值存储在较低精度的格式中(16 位、8 位、4 位等)。
例如,当模型持久化时,我们可以将权重矩阵中的最小值映射为 0,最大值映射为 2^b-1(其中 b 是精度位数),并将它们之间的所有值线性外推为整数值。通常,这可能足以减少模型大小。例如,如果 b = 8,我们将 32 位浮点权重映射到 8 位无符号整数。这将导致空间减少 4 倍。在推理(计算模型预测)时,我们可以使用量化值以及数组的最小和最大浮点值来恢复原始浮点值的有损表示(由于舍入误差)。这一步称为权重量化,因为我们正在量化模型的权重。
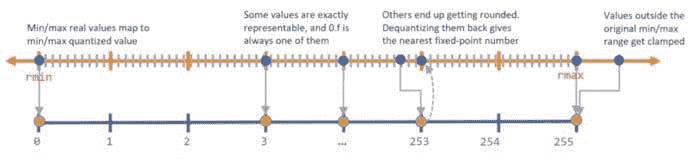
将连续高精度值映射到离散低精度整数值。来源
对于具有大量参数的较大网络,由于内置冗余,有损表示和舍入误差可能是可以接受的,但对于较小的网络,这可能会导致准确性下降,这些网络可能对这些误差更为敏感。
我们可以通过模拟训练过程中的权重量化舍入行为来解决这个问题(以实验方式)。我们通过在模型训练图中添加量化和反量化激活和权重矩阵的节点来实现这一点,使得神经网络操作的训练时间输入看起来与推理阶段的输入相同。这些节点被称为假量化节点。以这种方式训练使网络对推理模式下的量化行为更具鲁棒性。注意,现在我们在训练过程中同时进行激活量化和权重量化。训练时间模拟量化的步骤由 Jacob 等人和 Krishnamoorthi 等人详细描述[11,12]。
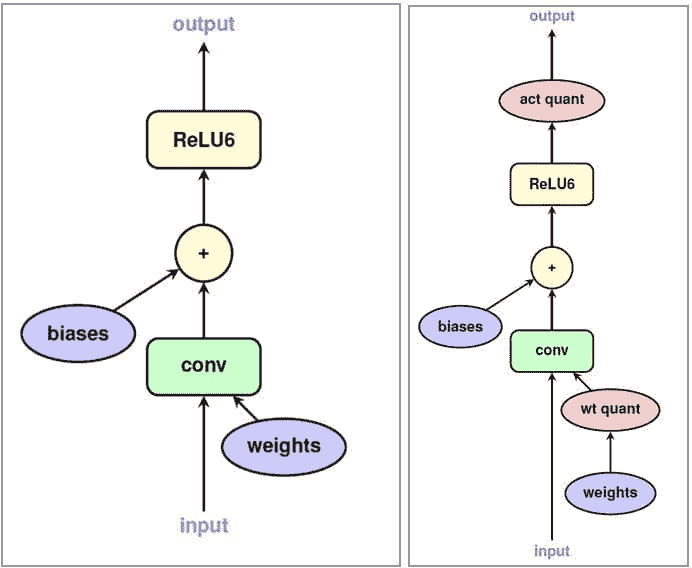
原始模型训练图和包含假量化节点的图。来源
由于权重和激活都在模拟量化模式下运行,这意味着所有层都接收到可以用更低精度表示的输入,模型训练后应足够强大,以便直接在低精度下进行数学运算。例如,如果我们训练模型以在 8 位域中复制量化,则该模型可以部署以使用 8 位整数进行矩阵乘法和其他操作。
在资源受限的设备(如移动设备、嵌入式设备和物联网设备)上,使用像 GEMMLOWP [13]这样的库可以将 8 位操作的速度提升 1.5 - 2 倍,这些库依赖于 ARM 处理器上的 Neon 内在支持 [14]。此外,像 Tensorflow Lite 这样的框架使用户可以直接使用量化操作,而无需担心底层实现。
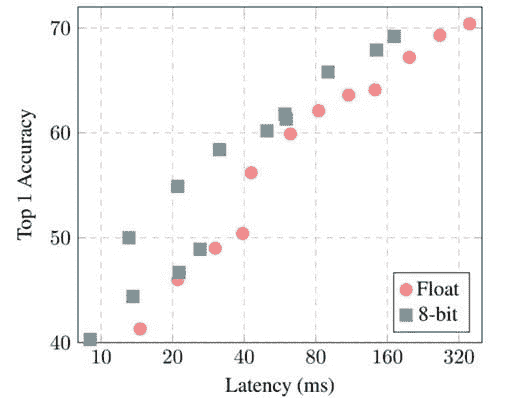
模型的 Top-1 准确率与模型延迟(量化与非量化模型)的对比。来源
除了剪枝和量化,还有其他技术,如低秩矩阵分解、K 均值聚类、权重共享等,这些技术也正在积极用于模型压缩 [15]。
总体而言,我们发现压缩技术可以用来减少模型的占用空间(大小、延迟等),同时以牺牲一些质量(准确性、精确度、召回率等)作为交换。
学习技术
蒸馏:如前所述,学习技术试图以不同的方式训练模型,以获得更好的性能。例如,Hinton 等人 [16] 在他们的开创性工作中,探讨了如何教会较小的网络从较大的模型/模型集成中提取暗知识。他们使用较大的教师模型在现有标记数据上生成软标签。
软标签为每个可能的类别分配一个概率,而不是原始数据中的硬二进制值。直观上,这些软标签捕捉了不同类别之间的关系,模型可以从中学习。例如,卡车与汽车比与苹果更相似,而模型可能无法直接从硬标签中学习到这一点。学生网络学习在这些软标签上最小化交叉熵损失,同时也在原始的真实硬标签上进行优化。这些损失函数的权重可以根据实验结果进行调整。
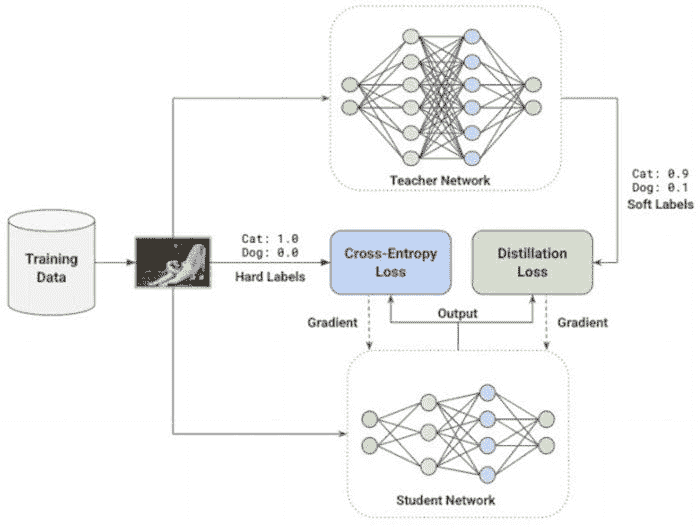
从较大的预训练教师模型中蒸馏出一个较小的学生模型。
在论文中,Hinton 等人 [16] 能够用一个单独的蒸馏模型来紧密匹配 10 模型集成在语音识别任务中的准确性。还有其他综合研究 [17,18] 展示了较小模型在模型质量上的显著改进。例如,Sanh 等人 [18] 能够蒸馏出一个保留 97% BERT-Base 性能的学生模型,同时该模型在 CPU 上体积小 40%,速度快 60%。
数据增强:通常对于大型模型和复杂任务来说,你拥有的数据越多,提升模型性能的机会就越大。然而,获取高质量的标记数据通常既慢又昂贵,因为它们通常需要人工参与。学习这些由人类标记的数据被称为监督学习。当我们有资源支付标签时,它效果很好,但我们可以并且应该做得更好。
数据增强是一种提升模型性能的巧妙方法。通常,这涉及对数据进行转换,使其不需要重新标记(标签不变的转换)。例如,如果你在训练神经网络来分类图像为包含狗或猫,旋转图像不会改变标签。其他转换方法可以是水平/垂直翻转、拉伸、裁剪、添加高斯噪声等。类似地,如果你在检测给定文本的情感,引入一个错别字可能不会改变标签。
这种标签不变的转换方法已在流行的深度学习模型中广泛使用。当你有大量类别和/或某些类别的样本较少时,它们尤其方便。
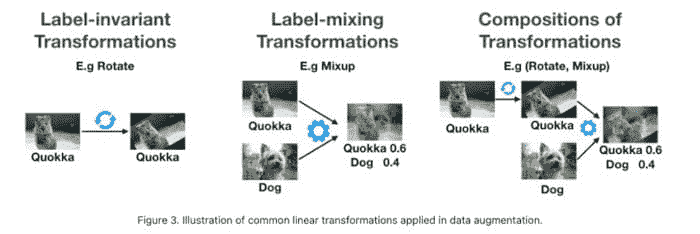
一些常见的数据增强类型。来源
还有其他转换方法,比如 Mixup [19],它以加权的方式混合来自两个不同类别的输入,并将标签视为两个类别的加权组合。这个想法是模型应该能够提取出对这两个类别都相关的特征。
这些技术确实为流程引入了数据效率。这与教孩子在不同上下文中识别现实生活中的物体并没有太大区别。
自监督学习:在一个相关领域取得了迅速进展,我们可以学习通用模型,完全跳过提取数据意义时对标签的需求。通过对比学习等方法 [20],我们可以训练一个模型,使其学习输入的表示,使得相似的输入具有相似的表示,而不相关的输入具有非常不同的表示。这些表示是 n 维向量(嵌入),然后可以在其他任务中作为特征使用,在这些任务中我们可能没有足够的数据从头训练模型。我们可以将使用无标签数据的第一步视为 预训练,将下一步视为 微调。
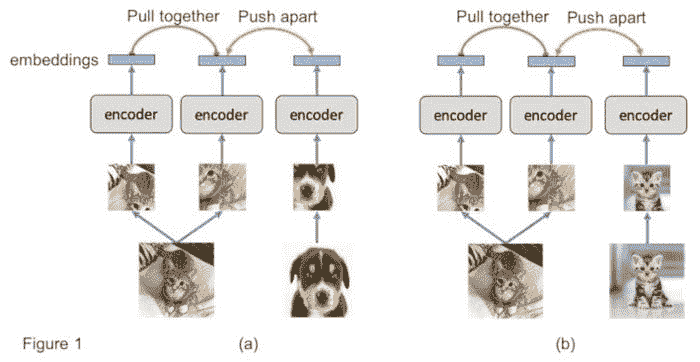
对比学习。来源
这种在未标记数据上进行预训练和在标记数据上进行微调的两步过程也在 NLP 社区中迅速获得接受。ULMFiT [21] 开创了训练通用语言模型的理念,其中模型学习解决给定句子中预测下一个词的任务。
作者发现,使用大量预处理但未标记的数据(如来源于英文维基百科页面的 WikiText-103)作为预训练步骤是一个不错的选择。这足以让模型学习语言的一般特性。作者发现,对这种预训练模型进行二分类问题的微调只需 100 个标记样本(相比之下,通常需要 10,000 个标记样本)。
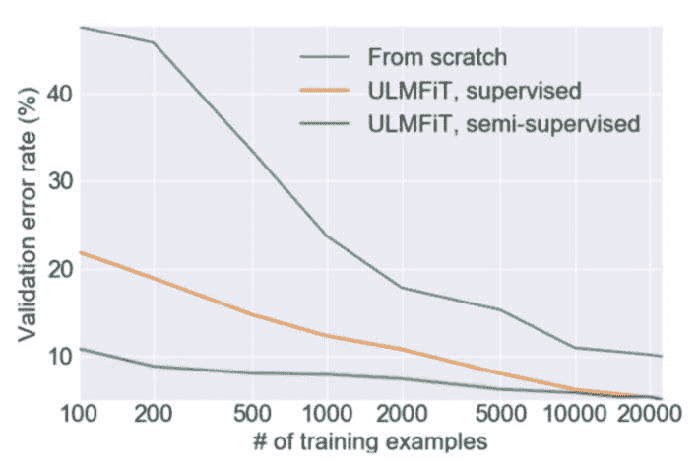
ULMFiT 的快速收敛。来源

在大语料库上进行预训练并在相关数据集上进行微调的高级方法。来源
这一思想也在 BERT 模型中得到了探索,其中预训练步骤涉及学习一个双向掩码语言模型,使得模型必须预测句子中间缺失的词。
总体而言,学习技术帮助我们提高模型质量而不影响模型的足迹。这可以用于提升模型部署的质量。如果原始模型质量令人满意,你还可以通过简单地减少网络中的参数数量来交换新获得的质量提升,从而改善模型大小和延迟,直到恢复到最低可行的模型质量。
在下一部分中,我们将继续探讨适用于剩余三个重点领域的工具和技术示例。此外,欢迎查阅我们的调查论文,详细探讨了这个话题。
参考文献
[1] Yann LeCun, John S Denker, and Sara A Solla. 1990. 最优脑损伤。在神经信息处理系统进展中。598–605.
[2] Babak Hassibi, David G Stork, and Gregory J Wolff. 1993. 最优脑外科医生和通用网络剪枝。在 IEEE 国际神经网络会议。IEEE, 293–299.
[3] Michael Zhu and Suyog Gupta. 2018. 剪枝还是不剪枝:探索剪枝在模型压缩中的有效性。第六届国际学习表征会议,ICLR 2018,加拿大温哥华,2018 年 4 月 30 日 - 5 月 3 日,研讨会论文集。OpenReview.net. https://openreview.net/forum?id=Sy1iIDkPM
[4] Sajid Anwar, Kyuyeon Hwang, and Wonyong Sung. 2017. 深度卷积神经网络的结构化剪枝。ACM《计算系统新兴技术期刊》(JETC)13, 3 (2017), 1–18.
[5] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet 和 Hans Peter Graf. 2016. 为高效 ConvNets 剪枝滤波器。在 ICLR(海报)。
[6] Xin Dong, Shangyu Chen 和 Sinno Jialin Pan. 2017. 通过逐层最优大脑外科医生学习剪枝深度神经网络。arXiv 预印本 arXiv:1705.07565 (2017)。
[7] Erich Elsen, Marat Dukhan, Trevor Gale 和 Karen Simonyan. 2020. 快速稀疏卷积网络。在 IEEE/CVF 计算机视觉与模式识别会议论文集。14629–14638。
[8] Song Han, Jeff Pool, John Tran 和 William J Dally. 2015. 为高效神经网络学习权重和连接。arXiv 预印本 arXiv:1506.02626 (2015)。
[9] Tim Dettmers 和 Luke Zettlemoyer. 2019. 从头开始的稀疏网络:更快的训练而不损失性能。arXiv 预印本 arXiv:1907.04840 (2019)。
[10] XNNPACK。https://github.com/google/XNNPACK
[11] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam 和 Dmitry Kalenichenko. 2018. 神经网络的量化和训练,用于高效的整数运算推断。在 IEEE 计算机视觉与模式识别会议论文集。2704–2713
[12] Raghuraman Krishnamoorthi. 2018. 量化深度卷积网络以实现高效推断:白皮书。arXiv (2018 年 6 月)。arXiv:1806.08342 https://arxiv.org/abs/1806.08342v1
[13] GEMMLOWP。https://github.com/google/gemmlowp
[14] Arm Ltd. 2021. SIMD ISAs | Neon – Arm Developer。https://developer.arm.com/architectures/instruction-sets/simdisas/neon [在线;访问时间 2021 年 6 月 3 日]。
[15] Rina Panigrahy. 2021. 矩阵压缩操作符。https://blog.tensorflow.org/2020/02/matrix-compressionoperator-tensorflow.html
[16] Geoffrey Hinton, Oriol Vinyals 和 Jeff Dean. 2015. 提炼神经网络中的知识。arXiv 预印本 arXiv:1503.02531 (2015)。
[17] Gregor Urban, Krzysztof J Geras, Samira Ebrahimi Kahou, Ozlem Aslan, Shengjie Wang, Rich Caruana, Abdelrahman Mohamed, Matthai Philipose 和 Matt Richardson. 2016. 深度卷积网络真的需要深度和卷积吗?arXiv 预印本 arXiv:1603.05691 (2016)。
[18] Victor Sanh, Lysandre Debut, Julien Chaumond 和 Thomas Wolf. 2019. DistilBERT,BERT 的蒸馏版:更小、更快、更便宜、更轻便。arXiv 预印本 arXiv:1910.01108 (2019)。
[19] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin 和 David Lopez-Paz. 2017. mixup: 超越经验风险最小化。arXiv 预印本 arXiv:1710.09412 (2017)。
[20] Ting Chen, Simon Kornblith, Mohammad Norouzi 和 Geoffrey Hinton. 2020. 用于视觉表征对比学习的简单框架。国际机器学习会议论文集。PMLR, 1597–1607。
[21] Jeremy Howard 和 Sebastian Ruder. 2018. 用于文本分类的通用语言模型微调。arXiv 预印本 arXiv:1801.06146 (2018)。
个人简介:Gaurav Menghani 是 Google Research 的高级软件工程师,他领导的研究项目旨在优化大型机器学习模型,以便在从微控制器到基于 TPU 的服务器等设备上实现高效训练和推断。他的工作对 YouTube、Cloud、Ads、Chrome 等平台的超过 10 亿活跃用户产生了积极影响。他还将与 Manning 出版社合作撰写一本关于高效机器学习的即将出版的书。在 Google 之前,Gaurav 在 Facebook 工作了 4.5 年,为 Facebook 的搜索系统和大规模分布式数据库做出了重要贡献。他拥有石溪大学的计算机科学硕士学位。
twitter.com/GauravML
linkedin.com/in/gauravmenghani
www.gaurav.im
相关内容:
我们的 3 大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容
高性能深度学习:如何训练更小、更快、更好的模型 – 第四部分
原文:
www.kdnuggets.com/2021/07/high-performance-deep-learning-part4.html
评论
在之前的部分(第一部分,第二部分,第三部分),我们讨论了为什么效率对深度学习模型实现高性能模型和帕累托最优模型至关重要,以及深度学习中效率的关注领域。我们还涵盖了两个关注领域(压缩技术和学习技术)。让我们继续花更多时间讨论其他关注领域。您也可以阅读我们的深度学习效率调研论文。
自动化
另一种努力方向是将部分效率的手动工作委托给自动化。如果我们让自动化帮助进行网络设计和调整,它将减少人类的参与以及随之而来的偏见。然而,这种权衡是计算成本的增加。
超参数优化(HPO):这一类别下常用的方法之一是超参数优化(HPO) [1]。我们知道,调整如初始学习率、权重衰减等超参数对于更快的收敛至关重要 [2]。还可以有决定网络结构的参数,如全连接层的数量、卷积层中的滤波器数量等。
虽然我们可以通过实验建立直觉,但找到最佳超参数值需要手动搜索以优化给定的目标函数(通常是验证集上的损失值)的确切值。
如果用户对要调整的超参数有先验经验,可以使用的简单自动化超参数优化算法是网格搜索(也称为参数扫描)。在这种情况下,我们根据用户提供的每个超参数的有效范围,搜索所有不同且有效的超参数组合。例如,如果学习率(lr)的可能值为{0.01, 0.05},权重衰减(decay)的可能值为{0.1, 0.2},则会有 4 种可能的组合{lr=0.01, decay=0.1},{lr=0.01, decay=0.2},{lr=0.05, decay=0.1}和{lr=0.05, decay=0.2}。
上述每种组合都是一个试验,每个试验可以并行运行。所有试验完成后,将找到超参数的最佳组合。由于这种方法尝试所有可能的组合,因此总试验数量增长非常快,因此遭遇了维度灾难 [3]。
另一种方法是随机搜索 [4],其中试验是从搜索空间中随机抽样的,搜索空间是使用用户提供的可能值的范围构建的。类似于网格搜索,每个试验仍然是独立并行运行的。然而,随机搜索易于根据可用的计算能力进行扩展,因为试验是独立同分布的(iid),因此找到最佳试验的可能性随着试验数量的增加而增加。这允许在到目前为止的最佳试验足够好时预先终止搜索。还有类似于随机搜索的方法,如 Successive Halving (SHA) [5] 和 HyperBand [6],但它们将更多资源分配给表现良好的试验。
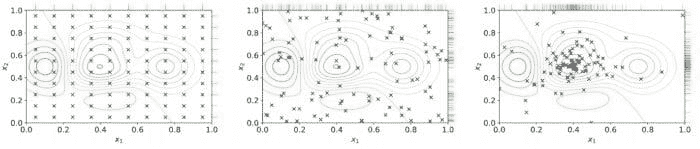
网格搜索、随机搜索和贝叶斯优化。来源
基于贝叶斯优化(BO)的搜索 [7] 是一种更复杂的方法,它保持一个单独的模型来预测给定试验是否可能改进到目前为止找到的最佳试验。该模型基于过去试验的表现来预测这种可能性。BO 相对于随机搜索的改进在于搜索是有指导的,而不是随机的。因此,达到最优解所需的试验更少。由于试验的选择依赖于过去试验的结果,因此这种方法是顺序的。然而,可以基于相同的估计同时生成多个试验,这可能会导致比纯顺序 BO 更快的收敛,但代价是某些试验可能会浪费。
在实际应用方面,HPO 可供用户在几个软件工具包中使用,这些工具包集成了算法本身以及易于使用的界面(UI 用于指定超参数及其范围),包括 Vizier [8](一个内部的 Google 工具,也可以通过 Google Cloud 进行黑箱调优)。亚马逊提供了 Sagemaker [9],功能类似,也可以作为 AWS 服务访问。NNI [10]、Tune [11] 和 Advisor [12] 是其他可以本地使用的开源 HPO 软件包。这些工具包还提供了对未有前景的试验进行早期停止的选项。Vizier 使用中位数停止规则,如果某个试验在时间步* t* 的表现低于到目前为止所有试验的中位数表现,则终止该试验。
神经架构搜索 (NAS):我们可以把 NAS 看作是超参数优化 (HPO) 的扩展,目标是寻找改变网络架构本身的参数。NAS 可以被认为包括以下几个部分:
-
搜索空间:这些是图中允许的神经网络操作(卷积 (1×1, 3×3, 5×5)、全连接、池化等),以及它们之间的连接方式。这由用户提供。
-
搜索算法与状态:这是控制架构搜索本身的算法。通常适用于 HPO 的标准算法(网格搜索、随机搜索、贝叶斯优化、进化算法)也可以用于 NAS,同时也包括强化学习 (RL) [13] 和梯度下降 [14]。
-
评估策略:这定义了我们用来评估模型 适应度 的指标。它可以是简单的传统指标,如验证损失、准确率等。也可以是复合指标,例如 MNasNet [15] 中创建的基于准确性和模型延迟的自定义单一指标。
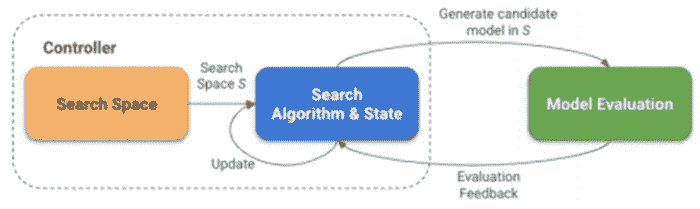
神经架构搜索:控制器负责基于搜索空间和从模型评估中收到的反馈生成候选模型。
搜索算法与搜索空间和状态可以视为一个‘控制器’,它生成样本候选网络。评估阶段训练和评估生成的候选网络的适应度。这个适应度值然后作为反馈传递给搜索算法,后者会用它来生成更好的候选网络。
Zoph 等人 2016 年的论文 [13] 演示了可以使用强化学习生成端到端的神经网络架构。在这种情况下,控制器本身是一个递归神经网络 (RNN),它逐层生成前馈网络的架构超参数,如滤波器数量、步幅、滤波器大小等。然而,训练控制器本身的代价很高(需要 22,400 个 GPU 小时 [16]),因为整个候选网络必须从头开始训练才能进行一次梯度更新。在后续的论文 [16] 中,作者将搜索空间细化为搜索 单元:一种“正常单元”接收输入,处理后返回相同空间维度的输出。而“缩减单元”处理其输入,返回的输出空间维度缩小了 2 倍。每个单元是 ???? 块的组合。控制器的 RNN 一次生成一个块,它选择过去两个块的输出、应用于它们的操作以及如何将它们组合成一个输出。正常单元和缩减单元交替堆叠(???? 个正常单元后跟 1 个缩减单元,其中 ???? 是可调的)以构建一个用于 CIFAR-10 和 ImageNet 的端到端网络。
与 [13] 中的端到端网络搜索相比,单独学习这些单元似乎将搜索时间提高了 7 倍,同时在当时击败了 CIFAR-10 中的最新技术。
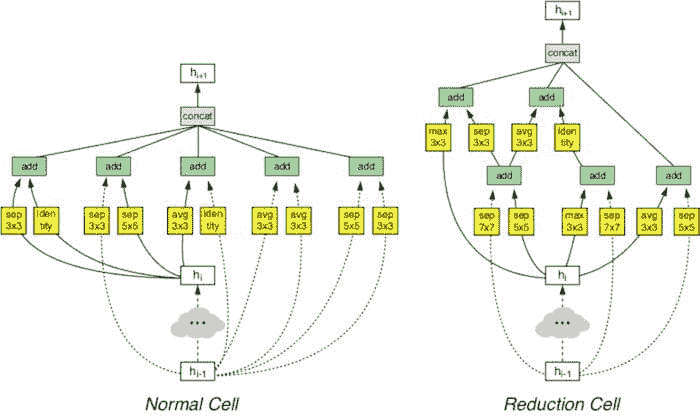
普通和缩减单元。来源:[16]
其他方法如进化技术 [17]、可微分架构搜索 [14]、渐进搜索 [18]、参数共享 [19] 等,试图降低架构搜索的成本(在某些情况下,将计算成本降低到几天 GPU 而不是几千天 GPU)。这些方法在 [20] 中有详细介绍。
在评估候选网络时,也可以关注不仅仅是质量,还包括模型大小、延迟等足迹指标。架构搜索可以帮助进行多目标搜索以优化两者。例如,MNasNet [15] 直接将模型在目标移动设备上的延迟纳入目标函数,如下所示:
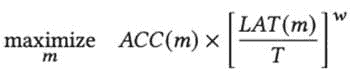
MNasNet 中的多目标奖励函数。
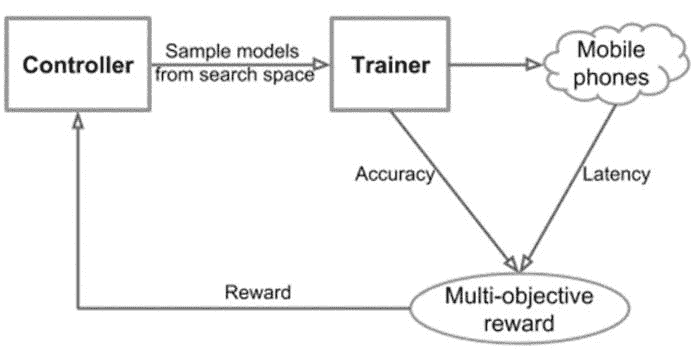
生成 MNASNet 中的候选模型,同时优化移动设备上的延迟。来源:[15]
其中 ???? 是候选模型, ???????????? 是准确性指标,???????????? 是所给模型在目标设备上的延迟。 ???? 是目标延迟。建议 ???? 为 −0.07。
总体而言,自动化在模型效率中扮演了关键角色。HPO 现在是训练模型中的自然步骤,可以在最小化人工干预的同时提取显著的质量改进。HPO 也可以在独立的软件库中使用,或者通过云服务获取。类似地,最近的神经架构搜索(NAS)进展也使得在对质量和足迹都有约束的情况下以学习的方式构建架构成为可能。假设 NAS 运行所需的计算量为几百小时的 GPU,且领先云计算服务的成本约为每小时 $3 GPU,这使得使用 NAS 方法在财务上是可行的,并且与优化多个目标时手动实验模型架构的成本不同。
高效架构(模型与层)
另一个常见的主题是重新设计比基线更好的高效层和模型,这些模型可以用于特定任务或作为通用黑箱。在本节中,我们展示了一些这样的高效层和模型的示例,以说明这一思想。
视觉: 视觉领域中一个经典的高效层例子是卷积层的使用,它相对于全连接(FC)层在视觉模型中有所改进。FC 层存在两个主要问题:
(1)FC 层忽略输入像素的空间信息。从直观上讲,仅通过查看单个像素值很难建立对给定输入的理解。它们还忽略了附近区域的空间局部性。
(2)使用 FC 层还会导致参数数量的爆炸,尤其是在处理中等大小的输入时。一个 100 × 100 的 RGB 图像有 3 个通道,会导致第一层中的每个神经元有 3 × 10⁴个连接。这也使得网络容易过拟合。
卷积层通过学习滤波器来避免这个问题,每个滤波器是一个固定大小的 3D 权重矩阵(3x3, 5x5 等),第三维度与输入的通道数相同。每个滤波器在输入上进行卷积,以生成该滤波器的特征图。每个滤波器可以学习检测诸如边缘(水平、垂直、对角线等)之类的特征,从而在特征图中该特征存在的地方值更高。单个卷积层的特征图可以从图像中提取有意义的信息。叠加在上面的卷积层将使用前一层生成的特征图作为输入,逐步学习更复杂的特征(特征图中的每个像素是从图像的逐渐更大部分生成的,随着层的叠加,感受野也会增加)。
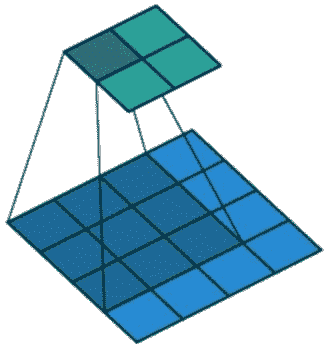
二维输入(蓝色)上的卷积操作的示意图,使用了 2x2 的滤波器(绿色)。来源。
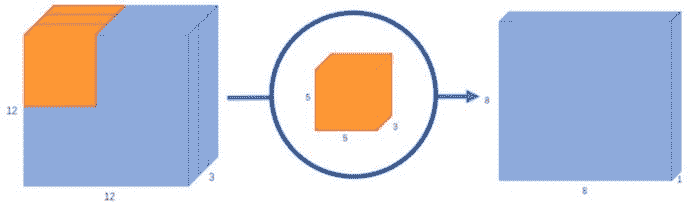
卷积操作的 3D 可视化。来源
卷积层高效性的核心思想是相同的滤波器在图像的任何位置上使用,无论滤波器应用于何处,从而实现空间不变性,同时共享参数。回到一个 100×100 RGB 图像的例子,它有 3 个通道,一个 5 × 5 的滤波器将意味着总共 75(5 × 5 × 3)个参数。每一层可以学习多个独特的滤波器,并且仍然在非常合理的参数预算范围内。这也具有正则化效果,即显著减少的参数数量使得优化更容易,泛化更好。
深度可分离卷积层:在卷积操作中,每个滤波器用于在两个空间维度和第三个通道维度上进行卷积。因此,每个滤波器的大小是 s[x] x s[y] x input_channels,其中 s[x]和 s[y]通常相等。这是对每个滤波器执行的,使得卷积操作在* x 和 y *维度上空间上进行,并在 z 维度上进行深度卷积。
深度可分离卷积将其分解为两个步骤:
-
使用
1 x 1的滤波器进行逐点卷积,使得结果特征图的深度现在具有输出通道数。 -
在 x 和 y 维度上使用
s[x] x s[y]的滤波器进行空间卷积。
将这两个操作叠加在一起(没有任何中间的非线性激活)会得到与常规卷积相同形状的输出,但参数显著更少(1 x 1 x input_channels x output_channels + s[x] x s[y] x output_channels,相比常规卷积的 s[x] x s[y] x input_channels x output_channels)。同样,计算量也减少了一个数量级,因为逐点卷积在每个输入通道深度上卷积要便宜得多(更多计算见 这里 和 这里)。 Xception 模型架构 [21] 展示了在 Inception 架构中使用深度可分离卷积,从而在步骤上更早收敛,并在 ImageNet 数据集上获得更高的准确性,同时保持参数数量不变。
针对移动和嵌入式设备设计的 MobileNet 模型架构 [22],也使用深度可分离层而非常规卷积层。这有助于将参数数量以及乘加操作的数量减少 7-10 倍,并允许在移动设备上部署计算机视觉任务。用户可以根据模型预期 10-100 毫秒的延迟。MobileNet 还通过深度乘数提供一个旋钮,用于调整网络规模,从而让用户在准确性和延迟之间做出权衡。
注意机制:在自然语言领域,我们也见证了快速进展。对于序列到序列模型,持久的问题是信息瓶颈。这些模型通常有一个编码器层,它对输入序列进行编码,以及一个解码序列,对应生成另一个序列。例如,机器翻译任务中,输入序列是源语言的句子,输出序列是目标语言的句子。
传统上,使用 RNN 在编码器和解码器中完成这项工作。然而,第一个解码器层只能看到最终编码器步骤的隐藏状态。这是一个“瓶颈”,因为第一个解码器步骤必须从最终隐藏状态中提取所有信息。
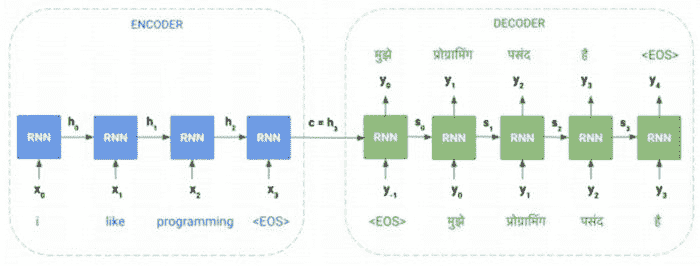
机器翻译任务中从英语到印地语的解码器信息瓶颈。
注意力机制在 Bahdanau 等人[23]中被引入,允许解码器能够看到所有的编码器状态。这是一种突出输入序列相关部分并将输入序列压缩为上下文向量的方法,基于序列与另一个向量(称为查询向量)的相似性。在像机器翻译这样的序列到序列任务中,这使得可以根据所有编码器状态(表示为键和值)和解码器的先前隐藏状态(查询向量)来调整输入到解码器。上下文向量是基于解码器的先前隐藏状态对编码器状态的加权和。由于注意力机制生成了编码器状态的加权和,这些权重也可以用于可视化网络的行为。
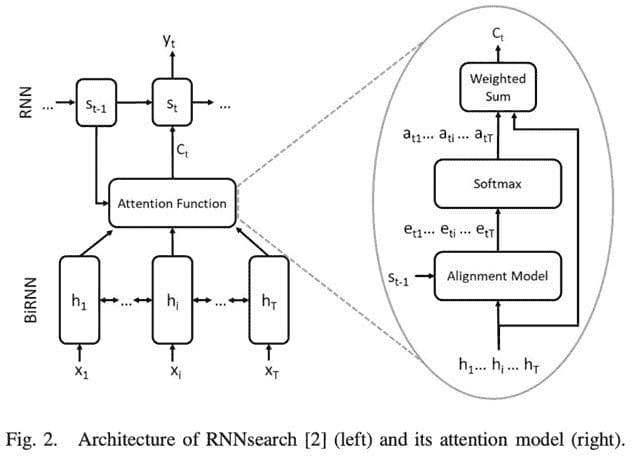
注意力在解码器中的使用。 来源
Transformer 及其朋友:Transformer 架构[24]在 2017 年提出,首次引入了对解码器和编码器都使用注意力机制。在编码器中,他们使用自注意力机制,其中键、值和查询向量都来源于先前的编码器层。Transformer 网络的训练成本比当时的可比替代方案低两个数量级。
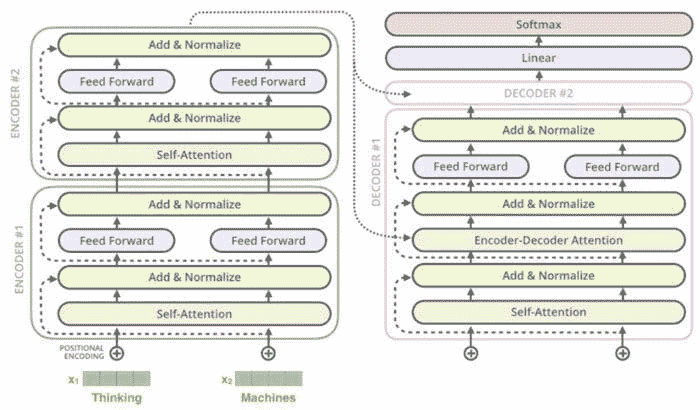
Transformer 架构。 来源
另一个核心思想是自注意力机制允许对输入序列中标记之间的关系进行并行化处理。RNNs 本质上要求逐步处理。例如,在 RNN 中,一个标记的上下文可能在整个序列处理完之前无法完全理解。而有了注意力机制,所有标记可以一起处理,并且可以学习成对的关系。这使得利用优化训练设备如 GPU 和 TPU 变得更加容易。
如第三部分介绍的那样,BERT 模型架构[25]在多个自然语言理解基准测试中超越了当时的最先进技术。BERT 是一个堆叠的 Transformer 编码器层,通过双向掩蔽语言模型训练目标进行预训练。它也可以作为一个通用编码器,然后用于其他任务。其他类似的模型,如 GPT 家族[26],也被用于解决许多自然语言理解任务。
参考文献
[1] Tong Yu 和 Hong Zhu. 2020. 超参数优化:算法和应用的回顾。arXiv 预印本 arXiv:2003.05689 (2020)。
[2] Jeremy Jordan. 2020. 设定神经网络的学习率。Jeremy Jordan (2020 年 8 月)。 www.jeremyjordan.me/nn-learning-rate
[3] en.wikipedia.org/wiki/Curse_of_dimensionality
[4] James Bergstra 和 Yoshua Bengio. 2012. 随机搜索超参数优化。机器学习研究杂志 13, 2 (2012)。
[5] Kevin Jamieson 和 Ameet Talwalkar. 2016. 非随机最优臂识别与超参数优化。见于人工智能与统计。PMLR, 240–248。
[6] Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh 和 Ameet Talwalkar. 2017. Hyperband:一种新型基于赌博的超参数优化方法。机器学习研究杂志 18, 1 (2017), 6765–6816。
[7] Apoorv Agnihotri 和 Nipun Batra. 2020. 探索贝叶斯优化。Distill 5, 5 (2020), e26。
[8] Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro 和 D Sculley. 2017. Google Vizier:一个黑箱优化服务。见于第 23 届 ACM SIGKDD 国际知识发现与数据挖掘会议论文集。1487–1495。
[9] Valerio Perrone, Huibin Shen, Aida Zolic, Iaroslav Shcherbatyi, Amr Ahmed, Tanya Bansal, Michele Donini, Fela Winkelmolen, Rodolphe Jenatton, Jean Baptiste Faddoul 等. 2020. 亚马逊 SageMaker 自动模型调优:可扩展的黑箱优化。arXiv 预印本 arXiv:2012.08489 (2020)。
[10] 微软研究院. 2019. 神经网络智能 - 微软研究院。https://www.microsoft.com/enus/research/project/neural-network-intelligence [在线; 访问日期:2021 年 6 月 3 日]。
[11] Richard Liaw, Eric Liang, Robert Nishihara, Philipp Moritz, Joseph E Gonzalez 和 Ion Stoica. 2018. Tune:一个用于分布式模型选择和训练的研究平台。arXiv 预印本 arXiv:1807.05118 (2018)。
[12] Dihao Chen. 2021. advisor. https://github.com/tobegit3hub/advisor [在线; 访问日期:2021 年 6 月 3 日]。
[13] Barret Zoph 和 Quoc V Le. 2016. 通过强化学习进行神经网络架构搜索。arXiv 预印本 arXiv:1611.01578 (2016)。
[14] Hanxiao Liu, Karen Simonyan 和 Yiming Yang. 2018. Darts:可微分架构搜索。arXiv 预印本 arXiv:1806.09055 (2018)。
[15] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard 和 Quoc V Le. 2019. Mnasnet:面向平台的移动神经网络架构搜索。见于 IEEE/CVF 计算机视觉与模式识别会议论文集。2820–2828。
[16] Barret Zoph, Vijay Vasudevan, Jonathon Shlens 和 Quoc V Le. 2018. 学习可转移的架构以实现可扩展的图像识别。见于 IEEE 计算机视觉与模式识别会议论文集。8697–8710。
[17] Esteban Real, Alok Aggarwal, Yanping Huang 和 Quoc V Le. 2019. 用于图像分类器架构搜索的正则化进化。见于 AAAI 人工智能会议论文集,第 33 卷。4780–4789。
[18] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, 和 Kevin Murphy. 2018. 进阶神经架构搜索。欧洲计算机视觉会议 (ECCV) 论文集。19–34。
[19] Hieu Pham, Melody Guan, Barret Zoph, Quoc Le, 和 Jeff Dean. 2018. 通过参数共享进行高效神经架构搜索。国际机器学习会议。PMLR, 4095–4104。
[20] Thomas Elsken, Jan Hendrik Metzen, Frank Hutter 等. 2019. 神经架构搜索:综述。J. Mach. Learn. Res. 20, 55 (2019), 1–21。
[21] François Chollet. 2017. Xception:深度学习与深度可分离卷积。IEEE 计算机视觉与模式识别会议论文集。1251–1258
[22] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, 和 Liang-Chieh Chen. 2018. Mobilenetv2:倒置残差和线性瓶颈。IEEE 计算机视觉与模式识别会议论文集。4510–4520。
[23] Dzmitry Bahdanau, Kyunghyun Cho, 和 Yoshua Bengio. 2014. 通过联合学习对齐和翻译进行神经机器翻译。arXiv 预印本 arXiv:1409.0473 (2014)。
[24] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, 和 Illia Polosukhin. 2017. 注意力机制就是你需要的全部。arXiv 预印本 arXiv:1706.03762 (2017)。
[25] Jacob Devlin, Ming-Wei Chang, Kenton Lee, 和 Kristina Toutanova. 2018. Bert:用于语言理解的深度双向变换器预训练。arXiv 预印本 arXiv:1810.04805 (2018)。
[26] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell 等. 2020. 语言模型是少样本学习者。arXiv 预印本 arXiv:2005.14165 (2020)。
相关:
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关话题
高性能深度学习:如何训练更小、更快、更好的模型——第五部分
原文:
www.kdnuggets.com/2021/07/high-performance-deep-learning-part5.html
评论
在之前的部分中(第一部分,第二部分,第三部分,第四部分),我们讨论了效率为何对深度学习模型的重要性,以实现高性能的帕累托最优模型,以及深度学习中效率的关注领域。我们还涵盖了四个关注领域(压缩技术、学习技术、自动化和高效架构)。让我们以关于基础设施的最终部分结束这一系列,这对训练和部署高性能模型至关重要。
顺便提一下,欢迎您阅读我们关于深度学习效率的调查论文,该论文详细涵盖了这个主题。
基础设施
为了高效地训练和运行推断,必须有一个稳健的软件和硬件基础设施。在这一部分,我们将探讨这两个方面。
软件和硬件基础设施的心理模型,以及它们如何相互作用。
Tensorflow 生态系统:
Tensorflow (TF) [1] 是一个流行的机器学习框架,已被许多大型企业投入生产。它拥有一些最广泛的软件支持,以提高模型效率。
Tensorflow Lite 适用于设备端用例:Tensorflow Lite (TFLite) [2] 是一组工具和库,旨在低资源环境(如边缘设备)中进行推断。从高层次来看,我们可以将 TFLite 分为两个核心部分:
-
解释器和操作内核:TFLite 提供了一个解释器用于运行专门的 TFLite 模型,并实现了常见的神经网络操作(全连接、卷积、最大池化、ReLu、Softmax 等,每个操作都有一个 Op)。截至本文撰写时,这些解释器和操作主要针对 ARM 处理器进行了优化。它们还可以利用智能手机 DSP(如高通的 Hexagon [3])来加速执行。
-
转换器:这是一个将给定的 TF 模型转换为解释器进行推断的单个文件的工具。除了转换本身,它还处理许多内部细节,例如为量化推断准备图(如前面帖子中提到的),融合操作,向模型添加其他元数据等。
设备端推理的其他工具:类似地,其他平台也有推理工具。例如,TF Micro [4] 具有精简的解释器和一组较小的操作,用于在非常低资源的微控制器如 DSP 上进行推理。TensorflowJS (TF.JS) [5] 是 TF 生态系统中的一个库,可用于在浏览器中或使用 Node.js 训练和运行神经网络。这些模型也可以通过 WebGL 接口 [6] 通过 GPU 加速。它支持导入在 TF 中训练的模型以及在 TF.JS 中从头开始创建新模型。还有 TF 模型优化工具包 [7],提供了在模型图中添加量化、稀疏性、权重聚类等功能。
服务器端加速的 XLA:XLA (Accelerated Linear Algebra) [8] 是一个图编译器,通过生成为图定制的操作(内核)的新实现来优化模型中的线性代数计算。例如,可以将多个可以融合在一起的操作合并为一个复合操作。这避免了在操作数仍在缓存中时进行多次昂贵的 RAM 写入。Kanwar 等人 [9] 报告称,使用 XLA 训练 BERT 的吞吐量增加了 7 倍,最大批量大小增加了 5 倍。这使得在 Google Cloud 上用 $32 训练 BERT 模型成为可能。
PyTorch 生态系统:
PyTorch [10] 是另一个流行的机器学习平台,广泛用于学术界和工业界,其在可用性和功能上可以与 Tensorflow 相比。
设备端用例:PyTorch 还具有一个轻量级解释器,使得可以在移动设备上运行 PyTorch 模型 [11],为 Android 和 iOS 提供了原生运行时(类似于 TFLite 解释器)。PyTorch 还提供了训练后量化 [12] 和其他图优化步骤,如常量折叠、融合某些操作、将通道置于最后(NHWC)格式以优化卷积层。
通用模型优化:PyTorch 还提供了 Just-in-Time (JIT) 编译功能 [13],用于从 TorchScript [14] 代码生成可序列化的中间表示形式,TorchScript 是 Python 的一个子集,添加了类型检查等功能。它允许在灵活的 PyTorch 代码用于研究和开发与可部署于生产环境进行推理的表示形式之间创建桥梁。这是 PyTorch 模型在移动设备上执行的主要方式。
PyTorch 世界中 XLA 的替代方案似乎是 Glow [15] 和 TensorComprehension [16] 编译器。它们有助于生成从高层次 IR(如 TorchScript)派生的低层次中间表示 (IR)。
PyTorch 还提供了一个模型调优指南 [17],详细说明了 ML 从业者可用的各种选项。其中的一些核心思想包括:
-
使用 PyTorch JIT 进行点对点操作(加法、减法、乘法、除法等)的融合。
-
启用缓冲区检查点功能可以只将某些层的输出保存在内存中,并在反向传播时计算其余部分。这特别有助于处理计算便宜但输出较大的层,例如激活层。
-
启用设备特定优化,如 cuDNN 库和 NVIDIA GPU 的混合精度训练(在 GPU 子节中解释)。
-
使用分布式数据并行训练,当数据量大且有多个 GPU 可用时,这种方法适用。
硬件优化库:
我们还可以通过针对神经网络运行的硬件优化软件堆栈进一步提升效率。例如,ARM 的 Cortex 系列处理器支持 SIMD(单指令多数据)指令,允许使用 Neon 指令集对操作进行向量化(处理数据批次)。QNNPACK [18] 和 XNNPACK [19] 库针对移动和嵌入式设备的 ARM Neon 进行优化,对于 x86 SSE2、AVX 架构等也进行了优化。前者用于 PyTorch 的量化推理模式,后者支持 TFLite 的 32 位浮点模型和 16 位浮点模型。类似地,还有其他低级库,如 iOS 的 Accelerate [20] 和 Android 的 NNAPI [21],它们尝试将硬件级加速决策从更高级的 ML 框架中抽象出来。
硬件
GPU:图形处理单元(GPUs),最初设计用于加速计算机图形,但自 2007 年 CUDA 库 [22] 发布后,开始用于通用用途。AlexNet [23] 在 2012 年赢得 ImageNet 比赛,标准化了 GPU 在深度学习模型中的使用。自那时起,Nvidia 发布了几代 GPU 微架构,越来越注重深度学习性能。它还引入了 Tensor Cores [24],这些是专用执行单元,支持多种精度(fp32、TensorFloat32、fp16、bfloat16、int8、int4)的训练和推理。

降低精度的乘加(MAC)操作:B x C 是一个昂贵的操作,因此使用降低精度来完成。
张量核心优化了标准的乘法和累加(MAC)操作,A = (B × C) + D。其中,B 和 C 采用减少精度(fp16、bfloat16、TensorFloat32),而 A 和 D 采用 fp32。NVIDIA 报告说,这种减少精度的 MAC 操作在训练速度上可以提高 1×到 15×,具体取决于模型架构和选择的 GPU [25]。NVidia 最新的 Ampere 架构 GPU 中的张量核心也支持稀疏性下的更快推理(特别是 2:4 的结构稀疏性,即在一个 4 元素块中有 2 个元素是稀疏的)。它们在推理时间上能提高多达 1.5×的速度,在单层上能提高多达 1.8×的速度。除此之外,NVidia 还提供了 cuDNN 库 [29],其中包含了标准神经网络操作的优化版本,如全连接、卷积、批量归一化、激活等。
用于 GPU 和 TPU 训练和推理的数据类型。bfloat16 起源于 TPU,而 Tensor Float 32 仅在 NVidia GPU 上支持。
TPU: TPU 是谷歌设计的专有应用特定集成电路(ASIC),用于加速深度学习应用,并且针对并行化和加速线性代数运算进行了精细调优。TPU 架构支持使用 TPU 进行训练和推理,并通过谷歌云服务向公众提供。TPU 芯片的核心架构利用了脉动阵列设计 [26],在这种设计中,大规模计算被分割到类似网格的拓扑中,每个单元计算一个部分结果,并在每个时钟周期(以类似于脉动心跳的节奏)将结果传递给下一个单元,而无需将中间结果存储在内存中。
每个 TPU 芯片有两个张量核心(不要与 NVidia 的张量核心混淆),每个核心都有一个脉动阵列网格。一个 TPU 板上有 4 个互联的 TPU 芯片。为了进一步扩展训练和推理,可以将更多的 TPU 板以网状拓扑结构连接起来,形成一个“pod”。根据公开发布的数据,每个 TPU 芯片(v3)可以达到 420 teraflops,而一个 TPU pod 可以达到 100+ petaflops [27]。TPU 在谷歌内部用于训练谷歌搜索模型、通用的 BERT 模型、如 DeepMind 的世界领先 AlphaGo 和 AlphaZero 模型等应用,以及许多其他研究应用 [28]。与 GPU 类似,TPU 支持 bfloat16 数据类型,这是一种减少精度的替代方案,用于全浮点 32 位精度训练。XLA 支持允许在不改变模型的情况下透明地切换到 bfloat16。
基本脉动阵列单元的示意图,以及使用脉动阵列单元网格进行 4x4 矩阵乘法的演示。

EdgeTPU、Coral 和开发板的近似大小。**(提供者:Bhuwan Chopra)
EdgeTPU: EdgeTPU 也是 Google 设计的定制 ASIC 芯片。类似于 TPU,它专门用于加速线性代数操作,但仅限于推理,并且在边缘设备上具有更低的计算预算。它还仅限于部分操作,并且仅与 int8 量化的 TensorFlow Lite 模型兼容。EdgeTPU 芯片本身比美国便士还小,使其适合部署在多种 IoT 设备中。它已被部署在类似 Raspberry-Pi 的开发板上,在 Pixel 4 智能手机中作为 Pixel Neural Core,也可以独立焊接到 PCB 上。

Jetson Nano 模块。(来源)
Jetson: Jetson 是 Nvidia 提供的一系列加速器,用于支持嵌入式和物联网设备中的深度学习应用。它包括 Nano,这是一个低功耗的“系统模块”(SoM),适用于轻量级部署,还有更强大的 Xavier 和 TX 变体,它们基于 Nvidia Volta 和 Pascal GPU 架构。Nano 适合家庭自动化等应用,其余则适用于如工业机器人等计算密集型应用。
摘要
在本系列中,我们首先展示了深度学习领域模型的快速增长,并激发了在扩展模型时对效率和性能的需求。接着,我们为读者提供了一个心理模型,以理解他们可以使用的广泛工具和技术。然后,我们深入到每个重点领域,提供了详细的示例,并进一步阐明了迄今为止在行业和学术界所做的工作。我们希望这系列博客文章能提供具体且可操作的建议,以及优化模型训练和部署时需要考虑的权衡。我们邀请读者进一步阅读我们的模型优化和效率的详细调查论文以获取更多见解。
参考文献
[1] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard 等。2016. Tensorflow: 大规模机器学习系统。在第 12 届 {USENIX} 操作系统设计与实现会议 ({OSDI} 16)。265–283。
[2] Tensorflow 作者。2021. TensorFlow Lite | 移动和边缘设备的 ML。https://www.tensorflow.org/lite [在线; 访问日期 2021. 6 月 3 日]。
[3] XNNPACK 作者。2021. XNNPACK 后端用于 TensorFlow Lite。https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/delegates/xnnpack/README.md/#sparse-inference。
[4] Pete Warden 和 Daniel Situnayake。2019. Tinyml: 在 Arduino 和超低功耗微控制器上使用 TensorFlow Lite 进行机器学习。“O’Reilly Media, Inc.”。
[5] Tensorflow JS: www.tensorflow.org/js
[6] WebGL: en.wikipedia.org/wiki/WebGL
[7] TensorFlow. 2019. TensorFlow 模型优化工具包 — 后训练整数量化。Medium(2019 年 11 月)。medium.com/tensorflow/tensorflow-model-optimization-toolkit-post-training-integer-quantizationb4964a1ea9ba
[8] Tensorflow 作者. 2021. XLA:机器学习优化编译器 | TensorFlow。https://www.tensorflow.org/xla
[9] Pankaj Kanwar, Peter Brandt 和 Zongwei Zhou. 2021. TensorFlow 2 MLPerf 提交展示了 Google Cloud 上的最佳性能。https://blog.tensorflow.org/2020/07/tensorflow-2-mlperf-submissions.html
[10] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga 等. 2019. Pytorch:一种命令式风格的高性能深度学习库。arXiv 预印本 arXiv:1912.01703 (2019).
[11] PyTorch 作者. 2021. PyTorch Mobile。https://pytorch.org/mobile/home
[12] PyTorch 作者. 2021. 量化配方 — PyTorch Tutorials 1.8.1+cu102 文档。https://pytorch.org/tutorials/recipes/quantization.html
[13] PyTorch 作者. 2021. torch.jit.script — PyTorch 1.8.1 文档。https://pytorch.org/docs/stable/generated/torch.jit.script.html
[14] PyTorch 作者. 2021. torch.jit.script — PyTorch 1.8.1 文档。https://pytorch.org/docs/stable/generated/torch.jit.script.html
[15] Nadav Rotem, Jordan Fix, Saleem Abdulrasool, Garret Catron, Summer Deng, Roman Dzhabarov, Nick Gibson, James Hegeman, Meghan Lele, Roman Levenstein 等. 2018. Glow:用于神经网络的图形降级编译技术。arXiv 预印本 arXiv:1805.00907 (2018).
[16] Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S Moses, Sven Verdoolaege, Andrew Adams 和 Albert Cohen. 2018. Tensor comprehensions:框架无关的高性能机器学习抽象。arXiv 预印本 arXiv:1802.04730 (2018).
[17] PyTorch 作者. 2021. 性能调优指南 — PyTorch Tutorials 1.8.1+cu102 文档。https://pytorch.org/tutorials/recipes/recipes/tuning_guide.html
[18] Marat Dukhan, Yiming Wu Wu 和 Hao Lu. 2020. QNNPACK:优化的移动深度学习开源库 - Facebook 工程。https://engineering.fb.com/2018/10/29/ml-applications/qnnpack
[19] XNNPACK 作者. 2021. XNNPACK。https://github.com/google/XNNPACK
[20] Apple 作者. 2021. Accelerate | Apple 开发者文档。https://developer.apple.com/documentation/accelerate
[21] Android 开发者. 2021. 神经网络 API | Android NDK | Android 开发者。https://developer.android.com/ndk/guides/neuralnetworks
[22] 维基媒体项目贡献者. 2021. CUDA - 维基百科。 https://en.wikipedia.org/w/index.php?title=CUDA&oldid=1025500257.
[23] Alex Krizhevsky, Ilya Sutskever, 和 Geoffrey E Hinton. 2012. 使用深度卷积神经网络进行 Imagenet 分类。神经信息处理系统进展 25 (2012), 1097–1105.
[24] NVIDIA. 2020. 深入 Volta:全球最先进的数据中心 GPU | NVIDIA 开发者博客。 https://developer.nvidia.com/blog/inside-volta.
[25] Dusan Stosic. 2020. 使用 Tensor Cores 训练神经网络 - Dusan Stosic, NVIDIA。 https://www.youtube.com/watch?v=jF4-_ZK_tyc
[26] HT Kung 和 CE Leiserson. 1980. 《VLSI 系统简介》。Mead, C. A_ 和 Conway, L., (编辑), Addison-Wesley, Reading, MA (1980), 271–292.
[27] Kaz Sato. 2021. 什么使 TPU 适合深度学习?| Google Cloud 博客。 https://cloud.google.com/blog/products/ai-machine-learning/what-makes-tpus-fine-tuned-for-deep-learning
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
更多相关内容
大规模高质量 AI 和机器学习数据标注:简要研究报告
原文:
www.kdnuggets.com/2019/07/high-quality-ai-machine-learning-data-labeling-research-report.html
赞助文章。
作者:Damian Rochman,CloudFactory 产品和平台战略副总裁
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
在各行各业,工程师和科学家正在争分夺秒地准备大量数据,以推动 AI 和机器学习(ML)的进步。分析公司 Cognilytica 估计,80%的机器学习项目时间用于汇总、清理、标注和增强机器学习模型数据。而仅有 20%的 ML 项目时间用于算法开发、模型训练和调整,以及 ML 的操作化。
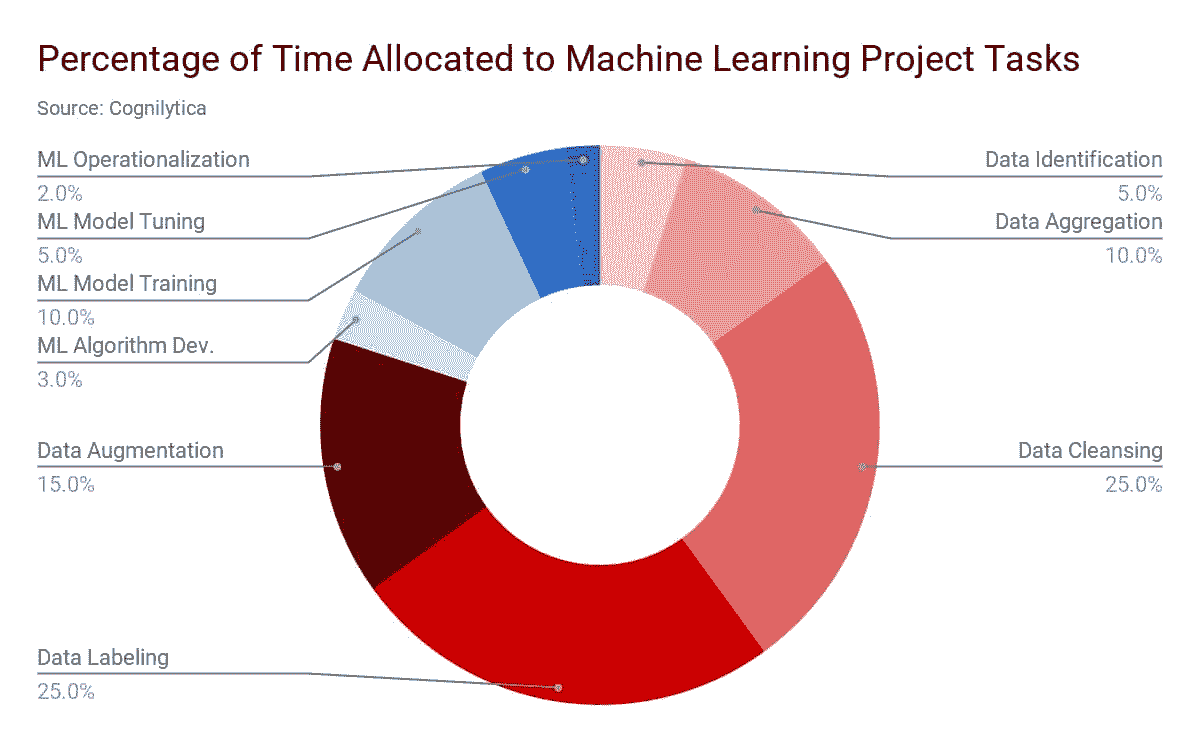
主要数据标注挑战
尽管创新似乎无边无际,但团队面临的困境在于,准备好的数据很难获得。这个问题有两个成熟的考虑因素:
-
高质量的数据标注可以带来更好的模型性能,但当数据标注质量低时,机器学习模型则难以学习。
-
最好将顶尖和高薪人才如数据科学家和机器学习工程师部署在需要深厚专业知识、协作和分析技能的任务上。
十亿美金的问题
那么,创新的机器学习团队是如何准备数据,以确保其质量、准备成本以及交付速度的呢?
关键要点:比较机器学习数据标注员
越来越多的组织正在使用这四种选择中的一种或多种来为机器学习项目寻找数据标注员。每种选择都有其优点和挑战,这取决于项目需求,但对大多数组织来说,理解这些权衡有助于为明确的战略数据标注路线图铺平道路。
标注团队采购时需提出的关键问题
阅读完整研究仅需 10-15 分钟,但如果你没有时间,我们强烈建议你在比较数据标注劳动力选项时向潜在的劳动力供应商提出这些问题:
-
规模 – 根据需求,你的标注团队能否增加或减少为我们做的任务数量?
-
质量 – 你能提供有关工作质量和工人生产力的可见性吗?
更多相关话题
招聘数据科学家:需要关注什么?
原文:
www.kdnuggets.com/2014/09/hiring-data-scientist-what-to-look-for.html
客座帖子由 Bart Baesens、Richard Weber、Cristián Bravo 提供,2014 年 9 月 9 日
 如今,大数据和分析无处不在。IBM 预测,我们每天生成 2.5 亿亿字节的数据。这意味着全球 90%的数据是在过去两年内创建的。Gartner 预测,到 2015 年,85%的财富 500 强公司将无法利用大数据获得竞争优势,大约将创造 440 万个与大数据相关的工作岗位。
如今,大数据和分析无处不在。IBM 预测,我们每天生成 2.5 亿亿字节的数据。这意味着全球 90%的数据是在过去两年内创建的。Gartner 预测,到 2015 年,85%的财富 500 强公司将无法利用大数据获得竞争优势,大约将创造 440 万个与大数据相关的工作岗位。
尽管这些估算不应被绝对解读,但它们强烈表明了大数据的普遍性以及对分析技能和资源的需求,因为随着数据的积累,以最佳方式管理和分析这些数据资源成为创造竞争优势和战略杠杆的关键成功因素。为应对这些挑战,公司正在招聘数据科学家。然而,在行业中,对什么构成一个优秀的数据科学家存在强烈的误解和分歧。以下是构成优秀数据科学家的关键特征:
数据科学家应当是一个出色的程序员!
 根据定义,数据科学家与数据打交道。这涉及许多活动,如数据采样和预处理、模型估算和后处理(例如敏感性分析、模型部署、回测、模型验证)。尽管如今市场上有许多用户友好的软件工具可以自动化这些过程,但每次分析都需要量身定制的步骤来应对特定业务问题的特点。为了成功完成这些步骤,需要进行编程。因此,一个优秀的数据科学家应具备扎实的编程技能,例如 R、Python、SAS 等。编程语言本身并不是那么重要,只要他/她熟悉编程的基本概念,并知道如何利用这些概念自动化重复任务或执行特定的例程。
根据定义,数据科学家与数据打交道。这涉及许多活动,如数据采样和预处理、模型估算和后处理(例如敏感性分析、模型部署、回测、模型验证)。尽管如今市场上有许多用户友好的软件工具可以自动化这些过程,但每次分析都需要量身定制的步骤来应对特定业务问题的特点。为了成功完成这些步骤,需要进行编程。因此,一个优秀的数据科学家应具备扎实的编程技能,例如 R、Python、SAS 等。编程语言本身并不是那么重要,只要他/她熟悉编程的基本概念,并知道如何利用这些概念自动化重复任务或执行特定的例程。
数据科学家应具备扎实的定量技能!
 显然,数据科学家应具备扎实的统计学、机器学习和/或数据挖掘背景。这些不同学科之间的区别越来越模糊,实际上并不那么重要。它们都提供了一套定量技术来分析数据,并在特定背景下(如风险管理、欺诈检测、市场分析等)发现与业务相关的模式。数据科学家应该了解何时以及如何应用哪种技术。他/她不应过于关注底层数学(如优化)细节,而应对某项技术解决的分析问题以及其结果的解释有良好的理解。在这方面,计算机科学和商业/工业工程的工程师培训应致力于综合的、多学科的视角,培养既能运用技术又具备将新项目实现的商业头脑的近期毕业生。
显然,数据科学家应具备扎实的统计学、机器学习和/或数据挖掘背景。这些不同学科之间的区别越来越模糊,实际上并不那么重要。它们都提供了一套定量技术来分析数据,并在特定背景下(如风险管理、欺诈检测、市场分析等)发现与业务相关的模式。数据科学家应该了解何时以及如何应用哪种技术。他/她不应过于关注底层数学(如优化)细节,而应对某项技术解决的分析问题以及其结果的解释有良好的理解。在这方面,计算机科学和商业/工业工程的工程师培训应致力于综合的、多学科的视角,培养既能运用技术又具备将新项目实现的商业头脑的近期毕业生。
在这种情况下,另一个重要的方面是花足够的时间来验证所获得的分析结果,以避免被称为数据修饰和/或数据折磨的情况,其中数据被(故意)误表示和/或过多关注于讨论虚假的相关性。在选择最佳的定量技术时,数据科学家应考虑业务问题的具体性。分析模型的典型要求包括:可操作性(分析模型在多大程度上解决了业务问题?),性能(分析模型的统计表现如何?),可解释性(分析模型是否容易向决策者解释?),操作效率(建立、评估和监控分析模型需要多少努力?),合规性(模型是否符合规定?)以及经济成本(建立、运行和维护模型的成本是多少?)。基于这些要求的综合考虑,数据科学家应能够选择最佳的分析技术来解决业务问题。
数据科学家应该在沟通和可视化技能上表现出色!
不管喜欢与否,分析都是一项技术性工作。目前,分析模型与业务用户之间存在巨大差距。要弥合这一差距,沟通和  可视化工具至关重要!因此,数据科学家应该知道如何使用例如交通灯方法、OLAP(联机分析处理)工具、If-then 业务规则等,以用户友好的方式表示分析模型及其附带的统计数据和报告。他/她应该能够传达适量的信息,而不会陷入复杂的(例如统计)细节中,这会阻碍模型的成功部署。这样,业务用户将更好地理解其(大)数据中的特征和行为,从而改善他们对分析模型的态度和接受度。教育机构必须学会平衡,因为许多学位课程会使学生偏向于过多的分析知识或过多的实践知识。
可视化工具至关重要!因此,数据科学家应该知道如何使用例如交通灯方法、OLAP(联机分析处理)工具、If-then 业务规则等,以用户友好的方式表示分析模型及其附带的统计数据和报告。他/她应该能够传达适量的信息,而不会陷入复杂的(例如统计)细节中,这会阻碍模型的成功部署。这样,业务用户将更好地理解其(大)数据中的特征和行为,从而改善他们对分析模型的态度和接受度。教育机构必须学会平衡,因为许多学位课程会使学生偏向于过多的分析知识或过多的实践知识。
数据科学家应该具有扎实的业务理解能力!
 虽然这可能显而易见,但我们已经见证了(过多的)数据科学项目失败的原因是相关分析师未能理解所面临的业务问题。这里的“业务”指的是相关的应用领域,例如在实际业务背景下的客户流失预测或信用评分,或者如果分析的数据来自这些领域,则可能是天文学或医学。
虽然这可能显而易见,但我们已经见证了(过多的)数据科学项目失败的原因是相关分析师未能理解所面临的业务问题。这里的“业务”指的是相关的应用领域,例如在实际业务背景下的客户流失预测或信用评分,或者如果分析的数据来自这些领域,则可能是天文学或医学。
数据科学家应该具有创造力!
 数据科学家至少需要在两个层面上展现创造力。首先,在技术层面上,创造性在特征选择、数据转换和清洗方面至关重要。这些标准知识发现过程的步骤必须根据每个特定应用进行调整,而“正确的猜测”往往能带来巨大的不同。其次,大数据和分析是一个快速发展的领域!新问题、新技术及其相关挑战不断出现。数据科学家需要跟上这些新技术,并具备足够的创造力来发掘它们带来的新商机。
数据科学家至少需要在两个层面上展现创造力。首先,在技术层面上,创造性在特征选择、数据转换和清洗方面至关重要。这些标准知识发现过程的步骤必须根据每个特定应用进行调整,而“正确的猜测”往往能带来巨大的不同。其次,大数据和分析是一个快速发展的领域!新问题、新技术及其相关挑战不断出现。数据科学家需要跟上这些新技术,并具备足够的创造力来发掘它们带来的新商机。
结论:
我们提供了在招聘数据科学家时需要注意的特征的简要概述。总之,考虑到大数据和分析的多学科性质,数据科学家应该具备一系列技能:编程、量化建模、沟通和可视化、业务理解以及创造力!下图展示了如何表示这样的个人档案。  图:数据科学家的档案。
图:数据科学家的档案。
作者:
巴特·贝森斯 是 KU Leuven(比利时)的教授,同时也是南安普顿大学(英国)的讲师。他在大数据和分析领域进行了广泛的研究。他的研究成果已发表在著名的国际期刊上,并在国际顶级会议上展示。他还著有以下书籍:信用风险管理:基本概念,以及 大数据世界中的分析,由 Wiley 于 2014 年出版。他的研究总结见于 www.dataminingapps.com。他还定期辅导、咨询并提供有关分析策略的咨询支持。
理查德·韦伯 是智利大学(智利)的教授,教授数据挖掘和运营管理课程,包括本科、研究生课程以及高管教育。他的研究兴趣包括数据挖掘、相关的方法学发展,以及在金融、市场营销和安全相关领域的应用。他的工作成果已发表在领先的科学期刊上。
克里斯蒂安·布拉沃 是智利塔尔卡大学的讲师,目前在 KU Leuven(比利时)担任访问研究员。他是一名工业工程师,拥有运营研究硕士学位和智利大学的工程系统博士学位。他曾担任智利大学金融中心的研究主任,并在多个数据挖掘和运筹学期刊上发表过文章。他的研究兴趣涵盖信用风险,特别是应用于微型企业,以及该领域的数据挖掘模型。
相关:
-
大数据引领高薪技能
-
数据科学家是适合你的职业路径吗?坦诚建议
-
迈克尔·奥康奈尔,TIBCO 首席数据科学家,谈如何在大数据领域领导
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
直方图 202:更好的数据科学技巧与窍门
评论
作者:Norbert Obsuszt,AnswerMiner。
与其他总结方法相比,直方图具有最丰富的描述能力,同时也是解释数据最快的方式——人脑更喜欢视觉感知。然而,如果不小心,观众可能无法理解你的直方图,或者你可能无法充分利用它。特别重要的是要指定最佳的分箱大小。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
为什么选择直方图?
如果你有一组数据值,你可能想要与老板或同事分享这些信息,以便基于这些数据中的信息建立更好的业务。这些数据值可能是以下任何一种:
-
客户年龄
-
月度收入
-
访客在你的网站上停留的时间
-
经销商销售的汽车数量
你应该以简洁的方式分享信息,因为没人愿意逐一阅读数字值。
替代方案是错误的
假设你有一组数字:1、23、24、25、25、25、26、27、30、32、999
均值(112.45)对离群值非常敏感。几乎所有实际数据都有离群值,因此均值可能非常误导。
中位数(25)不能告诉你关于分布的任何信息。
完整范围(1 – 999)仅显示了离群值。
标准差(294.1436)没有统计背景很难解释。
方差(86520.47)没有统计背景很难解释。
四分位距(IQR)(24.5 – 28.5)是你值的中央 50%,不能告诉你其他 50% 的信息。
你认为哪种方式最能描述这些数字?答案是它们都不行,因为这些数字总结技术没有包含关于峰值或分布形状的信息。因此,你应该总是使用直方图。
小心分箱
直方图是柱状图,每个柱子代表一个值的范围,柱子的高度对应于该范围内的值的数量。
你使用的范围(分箱宽度)越宽,柱子(分箱)就会越少。
过宽的区间可能隐藏有关分布的重要细节,而过窄的区间可能会产生大量噪声,并隐藏有关分布的重要信息。区间的宽度应该相等,并且你应该只使用诸如 1、2、5、10、20、25、50、100 等整数值,以便观众更容易解释数据。
这些直方图是从包含 550 个值的相同示例数据集中创建的,这些值在 12 到 69 之间。
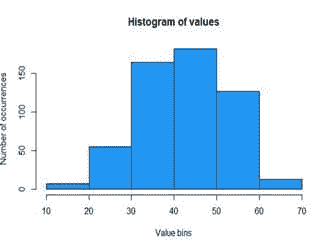
过宽:区间过宽,无法检测到大约 53 处的异常峰值
过窄:区间过窄,巧合中出现很多峰值
不美观:难以阅读,因为区间宽度为不美观的 7
不均等:难以阅读,因为区间宽度不相等
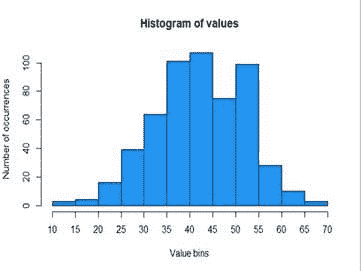
理想:这个很不错。
提示
如果你有少量数据,使用较宽的区间来消除噪声。如果你有大量数据,使用较窄的区间,因为直方图的噪声不会那么大。
可以使用的方法

对于上述数据集(包含 550 个值在 12 到 69 之间),我们得到以下结果:
| 平方根 | 斯特吉斯 | 赖斯 | 斯科特 | 弗里德曼-迪阿科尼斯 | |
|---|---|---|---|---|---|
| 区间数量 | 23 | 11 | 17 | 14 | 16 |
| 区间宽度 | 2 | 5 | 3 | 4 | 4 |
开启或关闭
这并不容易决定。现在问题来了。如果你查看 10-15-20-25…的分箱直方图,值“20”的出现是表示在第二列、第三列还是两者都有?显然,你需要将每个具体值放入一个精确的区间中。
有两个选项可以做到这一点:
选项 A - 所有区间应为左开右闭的区间
| 第一个区间: | (10,15] | 包含这些值: | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|
| 第二个区间: | (15,20] | 包含这些值: | 16 | 17 | 18 | 19 | 20 |
| 第三个区间: | (20,25] | 包含这些值: | 21 | 22 | 23 | 24 | 25 |
选项 B - 所有区间应为左闭右开的区间
| 第一个区间: | [10,15) | 包含这些值: | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|
| 第二个区间: | [15,20) | 包含这些值: | 15 | 16 | 17 | 18 | 19 |
| 第三个区间: | [20,25) | 包含这些值: | 20 | 21 | 22 | 23 | 24 |
避免陷阱
你可以自由选择这些选项中的任何一个,但要小心!使用这两个选项中的任何一个,都有一个值不会包含在直方图中。如果你选择选项#1,那么值“10”将不会包含在任何区间中。如果你选择选项#2,那么值“25”将不会包含在任何区间中。
解决方案是强制直方图的第一个或最后一个箱子为完全闭合区间。我们建议在使用选项#2 时选择最后一个箱子,因为均匀的箱子在左侧通常比右侧更重要。如果你有整数值,建议将箱子标记为“10-14”,“15-19”,和“20-25”,而不是写“10”,“15”,“20”,“25”。这样,直方图的观众会更容易理解。
简历: 诺伯特·奥布苏茨特 是 AnswerMiner(www.answerminer.com)的创始人、数据科学家和程序员。他获得了数学和编程学位。诺伯特对数据分析、预测分析和数据科学充满热情。他可以通过 norbert.obsuszt@answerminer.com 或 LinkedIn 联系到。
相关
更多相关主题
LLMs 的历史与未来

LLMs 的起源 - NLP 与神经网络
大型语言模型的创建并非一蹴而就。值得注意的是,语言模型的第一个概念起源于被称为自然语言处理的规则基础系统。这些系统遵循预定义规则,根据文本输入做出决策和推断结论。这些系统依赖于 if-else 语句处理关键词信息并生成预定的输出。想象一个决策树,其中输出是如果输入包含 X、Y、Z 或无,则响应的预定回答。例如:如果输入包括关键词“母亲”,则输出“你的母亲怎么样?”否则,输出“你能详细说明一下吗?”
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
最早的重大进展是神经网络,最初由数学家沃伦·麦卡洛赫于 1943 年提出,受到人脑神经元功能的启发。神经网络甚至在“人工智能”这一术语出现之前大约有 12 年的历史。每层的神经元网络以特定的方式组织,每个节点都有一个权重,决定了它在网络中的重要性。最终,神经网络打开了封闭的门,创建了人工智能将永远建立的基础。
LLMs 的发展 - 嵌入、LSTM、注意力机制与变换器
计算机无法像人类一样理解句子中单词的意义。为了提高计算机对语义分析的理解,必须首先应用词嵌入技术,这种技术允许模型捕捉相邻单词之间的关系,从而提高各种 NLP 任务的性能。然而,需要一种方法来将词嵌入存储在内存中。
长短期记忆网络 (LSTM) 和门控循环单元 (GRUs) 是神经网络领域的重要进展,能够比传统神经网络更有效地处理序列数据。虽然 LSTM 现在已经不再使用,但这些模型为更复杂的语言理解和生成任务铺平了道路,最终催生了 Transformer 模型。
现代 LLM - 注意力机制、Transformer 及 LLM 变体
注意力机制的引入是一次革命性的改变,使得模型在进行预测时能够关注输入序列的不同部分。2017 年发表的开创性论文《Attention is All You Need》介绍了 Transformer 模型,这些模型利用注意力机制同时处理整个序列,极大地提高了效率和性能。八位谷歌科学家并未意识到他们的论文会在创建当今 AI 领域中产生如此深远的影响。
紧随其后,谷歌的 BERT(2018 年)被开发并被誉为所有 NLP 任务的基准,作为一个开源模型被用于众多项目,使 AI 社区能够开展项目并成长。其对上下文理解的敏感性、预训练的特性和微调的选项,以及 Transformer 模型的展示为更大模型的出现奠定了基础。
除了 BERT,OpenAI 还发布了 GPT-1,这是他们 Transformer 模型的第一个迭代版本。GPT-1(2018 年)起始于 1.17 亿个参数,随后 GPT-2(2019 年)大幅跃升至 15 亿个参数,GPT-3(2020 年)则拥有 1750 亿个参数。OpenAI 的突破性聊天机器人 ChatGPT 基于 GPT-3,于 2022 年 11 月 30 日发布,引发了巨大关注,并真正实现了强大 AI 模型的民主化。了解difference between BERT and GPT-3。
什么技术进步正在推动 LLM 的未来?
硬件的进步、算法和方法的改进,以及多模态的整合都促进了大语言模型的发展。随着行业找到利用 LLM 的有效方法,持续的进步将根据每个应用的需求进行调整,并最终彻底改变计算领域的格局。
硬件的进步
提升 LLM 的最简单直接的方法是改进模型运行的实际硬件。专用硬件如图形处理单元 (GPUs)的开发显著加快了大语言模型的训练和推理速度。GPU 凭借其并行处理能力,已成为处理 LLM 所需的大量数据和复杂计算的必备工具。
OpenAI 使用 NVIDIA GPUs 来驱动其 GPT 模型,并且是首批 NVIDIA DGX 客户之一。他们的关系从 AI 的出现延续到 AI 的持续发展,CEO 亲自交付了第一台 NVIDIA DGX-1 以及最新的 NVIDIA DGX H200。这些 GPUs 集成了大量内存和并行计算,用于训练、部署和推理性能。
算法和架构的改进
变换器架构已被证实能够支持 LLM。该架构的引入对 LLM 的进步至关重要,因为它们现在就是这样。其能够同时处理整个序列而非按顺序处理,显著提高了模型的效率和性能。
尽管如此,变换器架构仍有很大的发展空间,以及它如何继续进化大型语言模型。
-
对变换器模型的持续改进,包括更好的注意机制和优化技术,将带来更准确、更快速的模型。
-
对新型架构的研究,例如稀疏变换器和高效注意机制,旨在减少计算需求,同时保持或增强性能。
多模态输入的集成
LLM 的未来在于其处理多模态输入的能力,整合文本、图像、音频以及其他数据形式,以创建更丰富和更具上下文意识的模型。像 OpenAI 的 CLIP 和 DALL-E 这样的多模态模型展示了结合视觉和文本信息的潜力,使图像生成、图像标注等应用成为可能。
这些集成使 LLM 能够执行更复杂的任务,例如理解来自文本和视觉线索的上下文,这最终使它们更具多功能性和强大。
LLM 的未来
进展并未停止,LLM 创建者计划在他们的工作中融入更多创新技术和系统。并非所有 LLM 的改进都需要更高的计算需求或更深的概念理解。一个关键的提升是开发更小、更易用的模型。
虽然这些模型可能不如像 GPT-4 和 LLaMA 3 这样的“巨型 LLM”有效,但重要的是要记住,并非所有任务都需要庞大而复杂的计算。尽管体积庞大,像 Mixtral 8x7B 和 Mistal 7B 这样的先进小型模型仍能提供令人印象深刻的表现。以下是一些预计将推动 LLM 发展和改进的关键领域和技术:
1. 专家混合(MoE)
MoE 模型使用动态路由机制,为每个输入仅激活模型参数的一个子集。这种方法使模型能够高效扩展,根据输入上下文激活最相关的“专家”,如下面所示。MoE 模型提供了一种在不成比例增加计算成本的情况下扩展 LLM 的方法。通过在任何给定时间仅利用整个模型的一小部分,这些模型能够使用更少的资源,同时仍提供卓越的性能。
2. 检索增强生成(RAG)系统
检索增强生成系统目前在 LLM 社区中是一个非常热门的话题。这个概念质疑为什么要在更多数据上训练 LLM 时,你可以简单地让它从外部来源检索所需的数据。然后使用这些数据生成最终答案。
RAG 系统通过在生成过程中从大型外部数据库检索相关信息来增强 LLM。这种集成使模型能够访问和融入最新的领域特定知识,提高其准确性和相关性。将 LLM 的生成能力与检索系统的精确性结合,产生了一种强大的混合模型,能够生成高质量的回应,同时保持对外部数据源的了解。
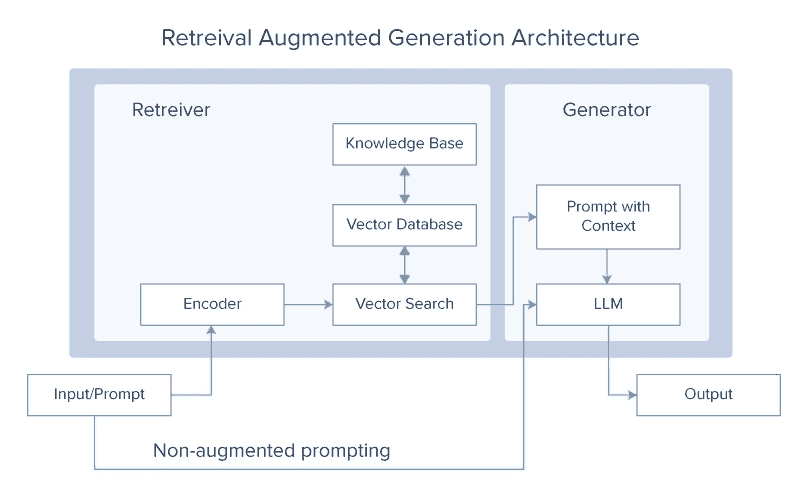
3. 元学习
元学习方法允许 LLM 学习如何学习,使其能够快速适应新的任务和领域,所需的训练最少。
元学习的概念依赖于几个关键概念,如:
-
少样本学习:LLM 被训练以理解和执行仅凭少量示例的新任务,显著减少了有效学习所需的数据量。这使它们在处理各种场景时非常多才多艺且高效。
-
自监督学习:LLM 使用大量未标记的数据生成标签并学习表示。这种学习方式使模型能够深入理解语言结构和语义,然后针对特定应用进行微调。
-
强化学习:在这种方法中,LLM 通过与环境互动并接收奖励或惩罚的反馈来学习。这有助于模型优化其行为并随着时间的推移改善决策过程。
结论
LLMs 是现代技术的奇迹。它们的运作复杂、规模庞大、进展突破性。在这篇文章中,我们探索了这些非凡进展的未来潜力。从它们在人工智能领域的早期起步开始,我们还深入探讨了神经网络和注意力机制等关键创新。
我们接着审视了多种提升这些模型的策略,包括硬件的进步、内部机制的改进以及新架构的发展。到现在为止,我们希望你对大型语言模型(LLMs)及其在不久的将来充满希望的发展轨迹有了更清晰、更全面的理解。
Kevin Vu 管理着 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写关于深度学习的不同方面。
更多相关话题
数据科学信息图的历史分为 5 个部分
原文:
www.kdnuggets.com/2015/02/history-data-science-infographic.html
我遇到了这个有趣的信息图表:
数据科学的历史,将数据科学呈现为 5 个部分的结合:
-
计算机科学
-
数据技术
-
可视化
-
数学/运筹学,以及
-
统计学
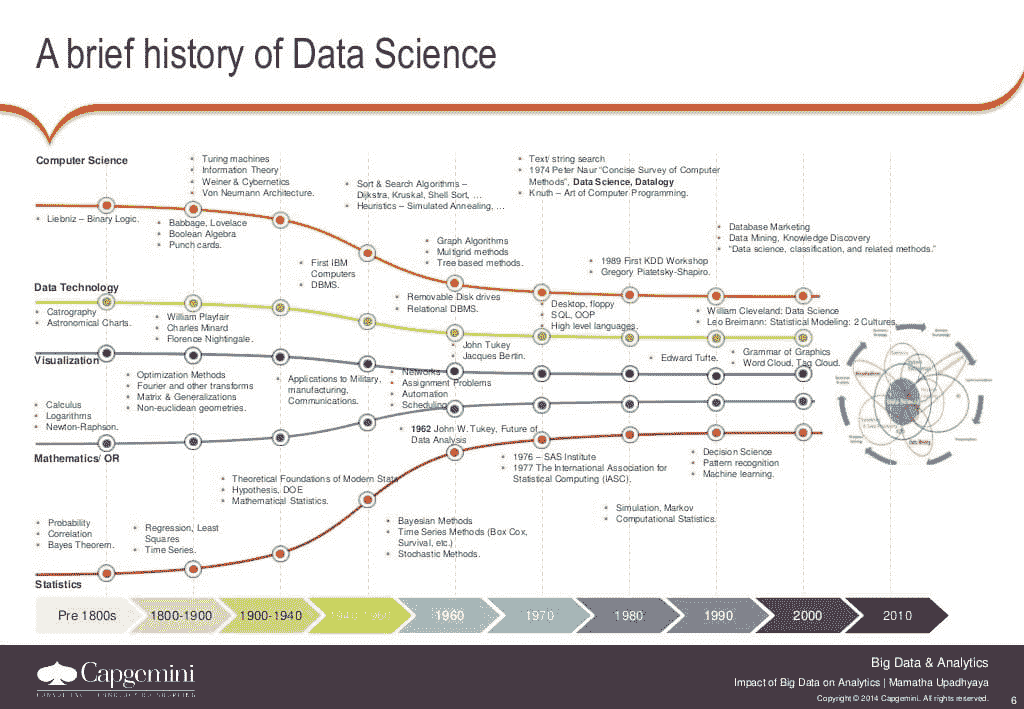
我很高兴看到在较新的部分中提到了我在 1989 年组织的 第一届 KDD 研讨会。
通过搜索,我最终将这个信息图表追溯到 Capgemini 顾问 Mamatha Upadhyaya 在 2014 年印度海得拉巴举行的大数据与分析峰会上的一个非常好的演示文稿 大数据对分析的影响。除了这个信息图表,它还有许多其他优秀的幻灯片。
更多相关内容
特征提取的《搭便车指南》
原文:
www.kdnuggets.com/2019/06/hitchhikers-guide-feature-extraction.html
评论

优质特征是任何机器学习模型的核心。
优质特征创建通常需要领域知识、创造力和大量时间。
在这篇文章中,我将讨论:
-
特征创建的各种方法 - 自动化和手动
-
处理分类特征的不同方法
-
经度和纬度特征
-
一些 Kaggle 技巧
-
以及一些关于特征创建的其他想法。
TLDR; 本文介绍了我学习并经常使用的有用特征工程方法和技巧。
1. 使用 featuretools 自动创建特征:

自动化是未来
你读过 featuretools 吗?如果没有,你将会感到惊喜。
Featuretools 是一个执行自动特征工程的框架。它擅长将时间和关系数据集转换为机器学习的特征矩阵。
怎么做?让我们通过一个玩具示例来展示 featuretools 的强大功能。
假设我们在数据库中有三个表:Customers、Sessions 和 Transactions。
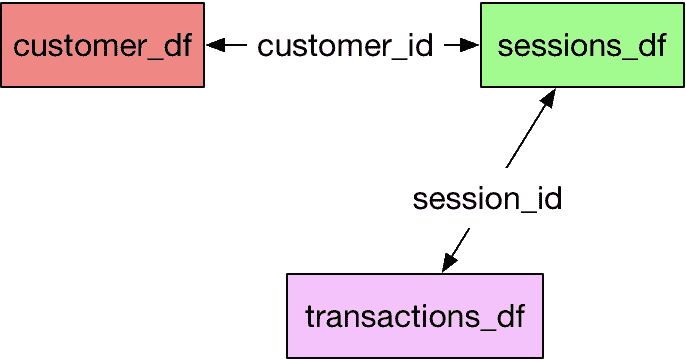
数据集和关系
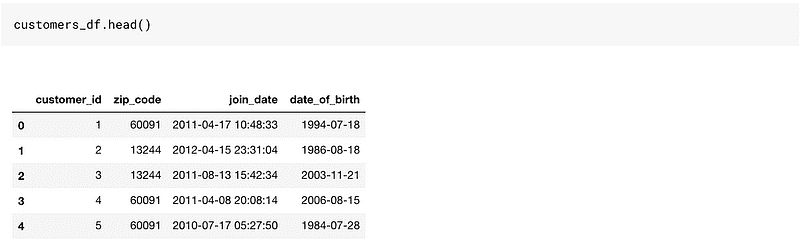
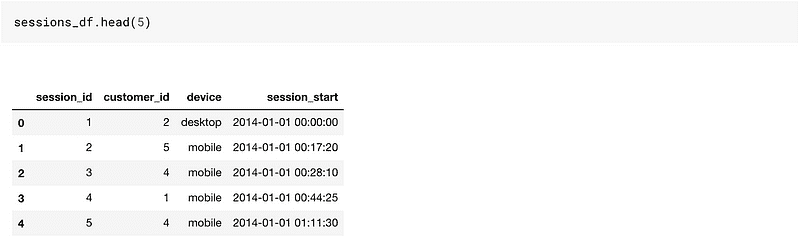
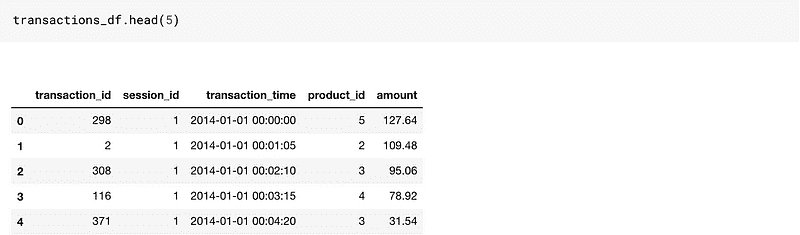
这是一个相当好的玩具数据集,因为它包含了基于时间的列以及分类和数值列。
如果我们要在这些数据上创建特征,我们需要使用 Pandas 进行大量的合并和聚合。
Featuretools 使我们的工作变得如此简单。虽然有一些东西我们需要学习,才能让生活变得更轻松。
Featuretools 与实体集一起工作。
你可以理解实体集为数据框以及它们之间关系的容器。

实体集 = 数据框和关系的集合
那么,事不宜迟,让我们创建一个空的实体集。我只是将名称设为 customers。你可以在这里使用任何名称。目前它只是一个空桶。
# Create new entityset
es = ft.EntitySet(id = 'customers')
让我们将数据框添加到其中。添加数据框的顺序不重要。要将数据框添加到现有的实体集,我们执行以下操作。
# Create an entity from the customers dataframe
es = es.entity_from_dataframe(entity_id = 'customers', dataframe = customers_df, index = 'customer_id', time_index = 'join_date' ,variable_types = {"zip_code": ft.variable_types.ZIPCode})
所以这里是我们在将数据框添加到空实体集桶时所做的一些事情。
-
提供了
entity_id:这只是一个名称。设置为 customers。 -
dataframe名称设置为 customers_df -
index:该参数作为输入主键 -
time_index:时间索引被定义为可以使用行中任何信息的第一次时间。对于客户,它是加入日期。对于交易,它将是交易时间。 -
variable_types:用于指定特定变量是否需要不同的处理。在我们的数据框中,我们有一个zip_code变量,我们希望对其进行不同的处理,所以我们使用这个。以下是我们可以使用的不同变量类型:
[featuretools.variable_types.variable.Datetime,
featuretools.variable_types.variable.Numeric,
featuretools.variable_types.variable.Timedelta,
featuretools.variable_types.variable.Categorical,
featuretools.variable_types.variable.Text,
featuretools.variable_types.variable.Ordinal,
featuretools.variable_types.variable.Boolean,
featuretools.variable_types.variable.LatLong,
featuretools.variable_types.variable.ZIPCode,
featuretools.variable_types.variable.IPAddress,
featuretools.variable_types.variable.EmailAddress,
featuretools.variable_types.variable.URL,
featuretools.variable_types.variable.PhoneNumber,
featuretools.variable_types.variable.DateOfBirth,
featuretools.variable_types.variable.CountryCode,
featuretools.variable_types.variable.SubRegionCode,
featuretools.variable_types.variable.FilePath]
这就是我们当前的实体集桶的样子。它里边只有一个数据框,并且没有任何关系。
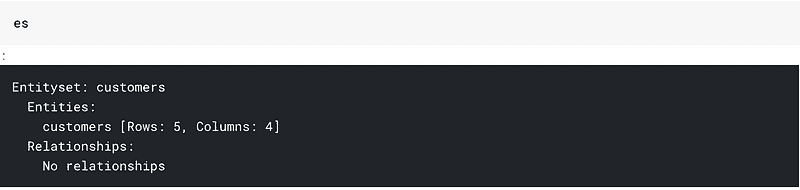
让我们添加所有的数据框:
# adding the transactions_df
es = es.entity_from_dataframe(entity_id="transactions",
dataframe=transactions_df,
index="transaction_id",
time_index="transaction_time",
variable_types={"product_id": ft.variable_types.Categorical})
# adding sessions_df
es = es.entity_from_dataframe(entity_id="sessions",
dataframe=sessions_df,
index="session_id", time_index = 'session_start')
这就是我们当前的实体集桶的样子。
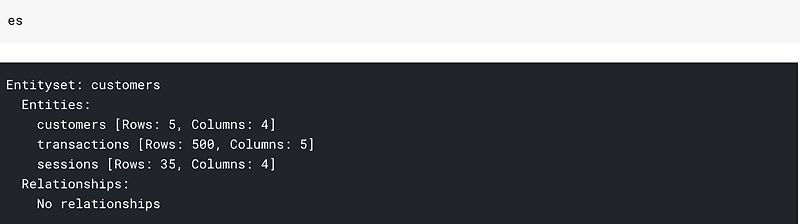
所有三个数据框,但没有关系。这里所说的关系是指我的桶并不知道customers_df和session_df中的customer_id是相同的列。
我们可以将这些信息提供给我们的实体集:
# adding the customer_id relationship
cust_relationship = ft.Relationship(es["customers"]["customer_id"],
es["sessions"]["customer_id"])
# Add the relationship to the entity set
es = es.add_relationship(cust_relationship)
# adding the session_id relationship
sess_relationship = ft.Relationship(es["sessions"]["session_id"],
es["transactions"]["session_id"])
# Add the relationship to the entity set
es = es.add_relationship(sess_relationship)
在此之后,我们的实体集看起来像这样:

我们可以看到数据集以及它们之间的关系。我们在这里的大部分工作已经完成。我们准备好生成特征了。

特征工程和烹饪没有什么不同。把特征当作配料来看待。
创建特征很简单,如下所示:
feature_matrix, feature_defs = ft.dfs(entityset=es, target_entity="customers",max_depth = 2)
feature_matrix.head()
我们最终得到73 个新特征。* 你可以从*feature_defs.*中看到特征名称。一些我们最终创建的特征包括:
[<Feature: NUM_UNIQUE(sessions.device)>,
<Feature: MODE(sessions.device)>,
<Feature: SUM(transactions.amount)>,
<Feature: STD(transactions.amount)>,
<Feature: MAX(transactions.amount)>,
<Feature: SKEW(transactions.amount)>,
<Feature: DAY(join_date)>,
<Feature: YEAR(join_date)>,
<Feature: MONTH(join_date)>,
<Feature: WEEKDAY(join_date)>,
<Feature: SUM(sessions.STD(transactions.amount))>,
<Feature: SUM(sessions.MAX(transactions.amount))>,
<Feature: SUM(sessions.SKEW(transactions.amount))>,
<Feature: SUM(sessions.MIN(transactions.amount))>,
<Feature: SUM(sessions.MEAN(transactions.amount))>,
<Feature: SUM(sessions.NUM_UNIQUE(transactions.product_id))>,
<Feature: STD(sessions.SUM(transactions.amount))>,
<Feature: STD(sessions.MAX(transactions.amount))>,
<Feature: STD(sessions.SKEW(transactions.amount))>,
<Feature: STD(sessions.MIN(transactions.amount))>,
<Feature: STD(sessions.MEAN(transactions.amount))>,
<Feature: STD(sessions.COUNT(transactions))>,
<Feature: STD(sessions.NUM_UNIQUE(transactions.product_id))>]
你可以得到像金额标准差的总和(SUM(sessions.STD(transactions.amount)))或金额总和的标准差(STD(sessions.SUM(transactions.amount)))这样的特征。这就是函数调用中max_depth参数的含义。我们在这里将其指定为 2,以获取两个层次的汇总。
*如果我们将*max_depth*改为 3,我们可以得到像: MAX(sessions.NUM_UNIQUE(transactions.YEAR(transaction_time)))
想象一下,如果你需要编写代码来获得这样的特征,你需要花费多少时间。此外,增加max_depth可能需要更长的时间。
2. 处理类别特征:标签/二进制/哈希和目标/均值编码
创建自动化特征有其好处。但是,如果一个简单的库可以完成我们的所有工作,那我们数据科学家还需要做什么呢?
这是我将讨论处理类别特征的部分。
独热编码

独热咖啡
我们可以使用独热编码来编码我们的类别特征。因此,如果我们在一个类别中有 n 个级别,我们将得到 n-1 个特征。
在我们的session_df表中,有一个名为device的列,其中包含三个级别——桌面、移动或平板。我们可以使用以下方法从这样的列中提取两个列:
pd.get_dummies(sessions_df['device'],drop_first=True)

这是谈论分类特征时最自然的想法,并且在许多情况下效果良好。
OrdinalEncoding
有时类别之间是有顺序的。在这种情况下,我通常使用 pandas 中的简单 map/apply 函数来创建一个新的序数列。
例如,如果我有一个数据框包含温度的三个级别:高、中、低,我会将其编码为:
map_dict = {'low':0,'medium':1,'high':2}
def map_values(x):
return map_dict[x]
df['Temperature_oe'] = df['Temperature'].apply(lambda x: map_values(x))

使用这种方法,我保留了信息:低<中<高。
LabelEncoder
我们也可以使用 LabelEncoder 将变量编码为数字。标签编码器的基本功能是将列中的第一个值转换为 0,接下来的值转换为 1,以此类推。这种方法在树模型中效果相当好,当我在分类变量中有很多级别时,我最终会使用它。 我们可以这样使用:
from sklearn.preprocessing import LabelEncoder
# create a labelencoder object
le = LabelEncoder()
# fit and transform on the data
sessions_df['device_le'] = le.fit_transform(sessions_df['device'])
sessions_df.head()
BinaryEncoder
BinaryEncoder 是另一种可以用来编码分类变量的方法。如果你有很多级别的列,它是一个很好的方法。虽然我们可以使用 One Hot Encoding 用 1023 列来编码一个有 1024 个级别的列,但使用 Binary 编码,我们只需使用十列即可完成。
假设我们在 FIFA 19 球员数据中有一个包含所有俱乐部名称的列。这个列有 652 个唯一值。One Hot 编码意味着创建 651 列,这将导致大量内存使用和很多稀疏列。
如果我们使用二进制编码,我们只需要十列,因为 2⁹ < 652 < 2¹⁰。
我们可以通过使用 category_encoders 中的 BinaryEncoder 对象来轻松地对这个变量进行二进制编码。
from category_encoders.binary import BinaryEncoder
# create a Binaryencoder object
be = BinaryEncoder(cols = ['Club'])
# fit and transform on the data
players = be.fit_transform(players)
HashingEncoder

可以将 Hashing Encoder 视为一个黑箱函数,它将字符串转换为 0 到某个预定值之间的数字。
它与二进制编码不同,因为在二进制编码中,两个或更多的俱乐部参数可能都为 1,而在哈希编码中只有一个值为 1。
我们可以这样使用哈希编码:
players = pd.read_csv("../input/fifa19/data.csv")
from category_encoders.hashing import HashingEncoder
# create a HashingEncoder object
he = HashingEncoder(cols = ['Club'])
# fit and transform on the data
players = he.fit_transform(players)
可能会出现碰撞(例如,尤文图斯和 PSG 具有相同的编码),但有时这种技术效果不错。
Target/Mean Encoding

这是我在 Kaggle 比赛中发现效果不错的一种技术。如果训练/测试数据来自同一数据集的同一时间段(横截面),我们可以巧妙地使用特征。
例如:在 Titanic 知识挑战中,测试数据是从训练数据中随机抽样的。在这种情况下,我们可以使用在不同分类变量上的目标变量平均值作为特征。
在 Titanic 中,我们可以在 PassengerClass 变量上创建一个目标编码特征。
我们在使用目标编码时必须小心,因为它可能会导致模型过拟合。 因此,当我们使用目标编码时,我们会使用 k 折目标编码。
我们可以创建一个均值编码特征,如下所示:
targetc = KFoldTargetEncoderTrain('Pclass','Survived',n_fold=5)
new_train = targetc.fit_transform(train)
new_train[['Pclass_Kfold_Target_Enc','Pclass']]
你可以看到乘客类别 3 是如何被编码为 0.261538 和 0.230570,具体取决于平均值是从哪个折叠中得出的。
这个特征非常有用,因为它编码了目标类别的值。仅通过这个特征,我们可以说,类别 1 的乘客比类别 3 的乘客有更高的生存倾向。
3. 一些 Kaggle 小技巧:
虽然这些不一定是特征创建技术,但有一些后处理技术你可能会觉得有用。
对数损失裁剪技术:
这是我在 Jeremy Howard 的神经网络课程中学到的。它基于一个基本的理念。
对数损失在我们非常自信却犯错时会惩罚我们。
所以在 Kaggle 上的分类问题中,我们需要预测概率时,将概率裁剪在 0.05–0.95 之间会更好,这样我们就不会对预测过于自信。这样可以减少惩罚。可以通过简单的 np.clip 实现。
Kaggle 提交的 gzip 格式:
一小段代码可以帮助你节省无数小时的上传时间。请享用。
df.to_csv(‘submission.csv.gz’, index=False, compression=’gzip’)
4. 使用纬度和经度特征:
这一部分将讲述如何很好地使用纬度和经度特征。
对于这项任务,我将使用来自 Playground 比赛的数据:纽约市出租车旅行时长
训练数据如下:

我将在这里编写的大部分函数都受到 Kernel 的启发,该 Kernel 是由 Beluga 编写的。
在这次比赛中,我们需要预测旅行时长。我们提供了许多特征,其中包括接送地点的纬度和经度。我们创建了如下特征:
A. 两个经纬度之间的哈弗辛距离:
哈弗辛 公式用于计算球面上两点之间的大圆 距离,给定它们的经纬度。
def haversine_array(lat1, lng1, lat2, lng2):
lat1, lng1, lat2, lng2 = map(np.radians, (lat1, lng1, lat2, lng2))
AVG_EARTH_RADIUS = 6371 # in km
lat = lat2 - lat1
lng = lng2 - lng1
d = np.sin(lat * 0.5) ** 2 + np.cos(lat1) * np.cos(lat2) * np.sin(lng * 0.5) ** 2
h = 2 * AVG_EARTH_RADIUS * np.arcsin(np.sqrt(d))
return h
我们可以这样使用这个函数:
train['haversine_distance'] = train.apply(lambda x: haversine_array(x['pickup_latitude'], x['pickup_longitude'], x['dropoff_latitude'], x['dropoff_longitude']),axis=1)
B. 两个经纬度之间的曼哈顿距离:

曼哈顿天际线
沿着直角轴测量的两点之间的距离
def dummy_manhattan_distance(lat1, lng1, lat2, lng2):
a = haversine_array(lat1, lng1, lat1, lng2)
b = haversine_array(lat1, lng1, lat2, lng1)
return a + b
我们可以这样使用这个函数:
train['manhattan_distance'] = train.apply(lambda x: dummy_manhattan_distance(x['pickup_latitude'], x['pickup_longitude'], x['dropoff_latitude'], x['dropoff_longitude']),axis=1)
C. 两个经纬度之间的方位角:
方位角 用于表示 一个点 相对于另一个 点 的方向。
def bearing_array(lat1, lng1, lat2, lng2):
AVG_EARTH_RADIUS = 6371 # in km
lng_delta_rad = np.radians(lng2 - lng1)
lat1, lng1, lat2, lng2 = map(np.radians, (lat1, lng1, lat2, lng2))
y = np.sin(lng_delta_rad) * np.cos(lat2)
x = np.cos(lat1) * np.sin(lat2) - np.sin(lat1) * np.cos(lat2) * np.cos(lng_delta_rad)
return np.degrees(np.arctan2(y, x))
我们可以这样使用这个函数:
train['bearing'] = train.apply(lambda x: bearing_array(x['pickup_latitude'], x['pickup_longitude'], x['dropoff_latitude'], x['dropoff_longitude']),axis=1)
D. 接送之间的中心纬度和经度:
train.loc[:, 'center_latitude'] = (train['pickup_latitude'].values + train['dropoff_latitude'].values) / 2
train.loc[:, 'center_longitude'] = (train['pickup_longitude'].values + train['dropoff_longitude'].values) / 2
这些是我们创建的新列:
5. 自编码器:
有时人们也使用自编码器来创建自动特征。
什么是自编码器?
编码器是深度学习函数,近似于从 X 到 X 的映射,即输入=输出。它们首先将输入特征压缩到较低维度的表示中,然后从这种表示中重建输出。
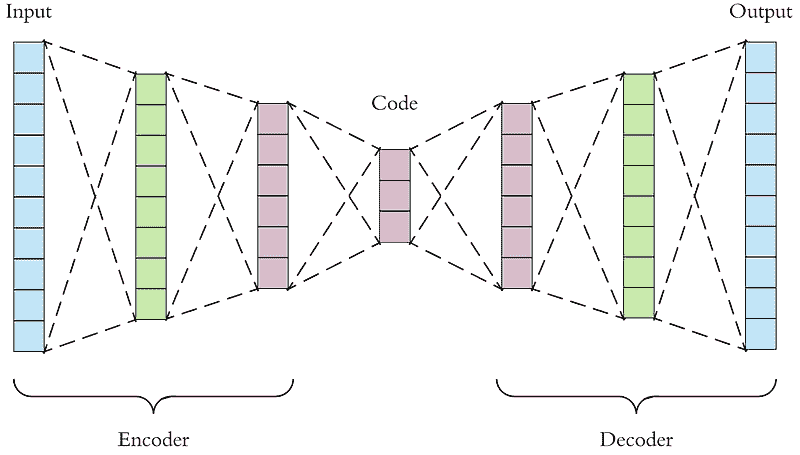
我们可以使用这种表示向量作为我们模型的特征。
6. 你可以对特征做的一些常见操作:
-
最大最小缩放: 这是对线性模型、神经网络等常见且通常必需的预处理方法。
-
标准差归一化: 这是对线性模型、神经网络等常见且通常必需的预处理方法。
-
基于对数的特征/目标: 使用基于对数的特征或对数目标函数。如果使用的是假设特征呈正态分布的线性模型,对数转换可能使特征变为正态分布。在处理如收入等偏态变量时也很有用。
或者在我们的情况下,就是旅行时长。下面是没有对数转换的旅行时长图。
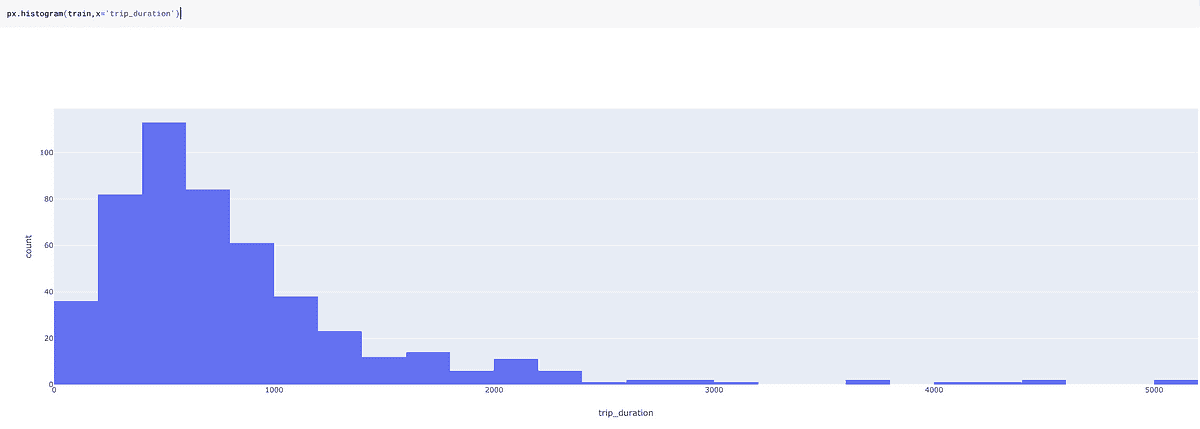
进行对数转换后:
train['log_trip_duration'] = train['trip_duration'].apply(lambda x: np.log(1+x))
对旅行时长进行对数转换后,数据的偏态性大大减小,因此对模型的帮助更大。
7. 基于直觉的一些附加特征:
日期时间特征:
可以基于领域知识和直觉创建额外的日期时间特征。例如,像“晚上”、“中午”、“夜晚”、“上月购买”、“上周购买”等时间特征可能适用于特定应用。
领域特定特征:

风格很重要
假设你有一些购物车数据,并且你想要对 TripType 进行分类。这正是 Walmart 招聘中的问题:在 Kaggle上的 Trip Type 分类。
旅行类型的一些示例:顾客可能会进行一次小型的每日晚餐旅行,一次每周的大型购物旅行,一次购买节日礼物的旅行,或一次季节性购物旅行。
为了解决这个问题,你可以考虑创建一个像“时尚”的特征,通过将属于“男士时尚”、“女士时尚”、“青少年时尚”类别的商品数量相加来创建这个变量。
或者你可以创建一个像“稀有”的特征,通过标记一些项目为稀有,基于我们拥有的数据,然后计算购物车中这些稀有项目的数量来创建。
这些特征可能有效,也可能无效。从我的观察来看,它们通常提供了很大的价值。
我觉得这就是 Target 的“怀孕青少年模型”是如何制作的。 他们可能会有一个变量,其中包含所有怀孕青少年可能购买的商品,并将其放入分类算法中。
交互特征:
如果你有特征 A 和 B,可以创建特征 A*B、A+B、A/B、A-B 等。
例如,为了预测房价,如果我们有两个特征:长度和宽度,更好的方法是创建一个面积(长度 x 宽度)特征。
在某些情况下,比起单独拥有两个特征,一个比率可能更有价值。例如:信用卡使用率比拥有信用额度和已使用额度的变量更有价值。
结论
创造力是 至关重要的!!!
这些只是我用来创建特征的一些方法。
但在特征工程方面确实没有限制,唯一限制你的只有你的想象力。
在这方面,我总是会考虑特征工程,同时记住我将使用的模型。随机森林中的特征可能在逻辑回归中效果不好。
特征创建是一个试错的领域。你在尝试之前无法知道什么变换或编码效果最好。这始终是时间和效用之间的权衡。
有时候,特征创建过程可能会耗费大量时间。在这种情况下,你可能需要 并行化你的 Pandas 函数。
尽管我尽力使这篇文章尽可能详尽(这可能是我在 Medium 上写的最大的一篇文章),我可能还是遗漏了一些有用的方法。请在评论中告诉我。
你可以在这个 Kaggle Kernel找到所有相关代码并自行运行。
查看 如何赢得数据科学比赛:向顶级 Kagglers 学习 课程,该课程是由 Kazanova 提供的 高级机器学习专业中的一部分。该课程讨论了许多改进模型的直观方法,强烈推荐。
我未来也会写更多适合初学者的文章。请告诉我你对这个系列的看法。关注我在 Medium 或订阅我的 博客以获取更新。欢迎反馈和建设性批评,可以通过 Twitter @mlwhiz与我联系。
个人简介:Rahul Agarwal 是 WalmartLabs 的高级统计分析师。关注他的 Twitter @mlwhiz。
原文。经授权转载。
相关:
-
使用正则化线性模型与 XGBoost 进行价格建模
-
数据科学实战:Kaggle 实战教程第四部分 – 数据转换与特征提取
-
scikit-feature:Python 中的开源特征选择库
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关主题
让我们诚实面对:我们正被数据淹没
评论
作者:Jonathan Martini,PixelTItan首席技术官
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
智能设备的兴起、信息流的不断复杂化,以及记录、处理和解读所有这些信息的工具的激增,让我们处于“跟上”可能是我们能期待的最佳状态。技术存在继承性问题,因此在我们创新时,往往引入比实际需要更多的复杂性。随着系统的演变,我们这些帮助设计它们的人不断权衡技术债务的“必要性”。通过首先简要回顾,了解限制和影响我们现状的力量,可能有助于理解未来的选项。
我们是如何到达这里的
在数据演变的最初大约 30 年里,世界是结构化的,关系数据库是常态,工程师需要了解的语言集有限(主要以 SQL 为主)。与数据库交互所需的工具效率高,数据大多较为干净。以仪表盘形式生成的报告相对容易解读,并且提供了有意义的衡量标准作为决策依据。随着统计分析和数据挖掘在 1990 年代的兴起,这些结果变得更加深刻。
随着 1990 年代的结束,我们见证了互联网的崛起,随之而来的是一种新的数据类型:非结构化数据。之前的结构化内容系统,凭借其成熟的分析工具和相对容易理解且定义明确的数据类型仍然存在。但非结构化数据需要一种新的处理方式,并且为那些懂得如何使用它的人提供了新的洞察机会。网络使用创造了一个不断上传到社交媒体网站的媒体流。我们看到了传感器和智能设备网络的初步形成(这些设备后来被称为物联网),每天都在生成越来越多的数据。处理和理解这些数据的新方式是必要的。旧有系统和工具进化为新的系统,以跟上步伐,而能够驾驭这些系统的人便成为了我们现在所称的数据科学家。我们还见证了长期存储从物理服务器和数据仓库转向云存储,导致我们的行业从以数据中心为重点演变为在各种云解决方案和服务中日益多样化。
在 2010 年代,我们继续看到非结构化数据的指数级增长,随着移动设备变得越来越普及。随着这些设备的普及,我们看到了地理空间数据存储的增加,以及来自设备的行为数据的加入到非结构化数据中。此外,“智能设备”的日益普及进一步加速了数据的生成和存储需求的增加。
当前状态
对于许多处理技术基础设施和/或服务的高级领导者来说,系统结构的详细视图可能长达数十页,并包括多个供应商和服务提供商之间的依赖关系。它还会(在大多数情况下)包括处理他们所处理的每类数据的单独程序和流程,并且必须考虑对这些数据适用的任何法规和法律。此外,这些程序需要每个操作链步骤的专家。无论是分析师和数据科学家清洗数据以获得有价值的洞察,还是工程师整合不同的系统使它们能够相互通信,每个角色都既对所处的整体系统有所贡献,又受到其限制。
随着系统的发展,它必然会带来三个主要问题。首先,数据往往会闲置,除非有明确需求。其次,为了管理这些闲置的数据集,公司必须雇佣更多的人来满足系统产生的需求。无论是分析师和数据科学家,还是设计新系统的工程师,以自动化当前由人员执行的流程。将新系统添加到工作流程中会导致需要设计次级系统,以便将这些自动化过程的输出重新引入当前的数据流。第三,接受前两个问题会以复合率不断增长,只要数据源继续输出越来越多的新信息。
它可能的样子
如果我们从零开始,了解当前世界的状态以及数据的生成方式,我们是否还会继续使用现在的系统?为了被大多数大型数据创造者和消费者视为“理想”解决方案,理想的数据流需要具备什么?
从高层次来看,我们需要遵守六个基本原则:
-
由数据处理效率驱动
-
数据类型无关(结构化与非结构化,以及处理语言)
-
人类互动应尽可能简单和最小化
-
可扩展性和适应性驱动架构决策
-
安全性和隐私应成为整个系统的基础
-
从财务上讲,它必须比当前的现状成本更低
如果我们设想一个围绕这六个指导原则设计的系统,它对现代企业来说会是什么样子,并且它们现在会有什么优势?首先,它们将具备将工作组重新调整到人类创造力和输入能够带来更大价值的业务领域的灵活性。这可能会导致探索新的业务线或服务,这些在以前可能由于成本问题不可行,或者由于旧系统的限制而无法执行。此外,对非结构化数据的方法的重新构想可能会揭示我们当前无所作为的现有数据的新用例。
不时地客观审视我们做事的方式和原因可以带来有价值的见解。我们站在计算、技术及其融入日常生活的漫长演变的终点。未来我们如何使用我们不断创建的数据仍有待观察,但我们确实有两点绝对确定:
-
我们将继续以比现在高得多的速度创建数据
-
如果不对处理我们创建的数据的系统进行新的方法改进,我们最终将无法看到数据告诉我们的全部范围
简历:Jonathan Martini 是 PixelTItan 的首席技术官。PixelTitan 是一家新创公司,致力于解决非结构化数据的难题。由一群在活动、摄影和技术领域经验丰富的专业人士创办,PixelTitan 的独特专利待审技术使公司能够处理数据定义,而不是直接处理数据本身,这意味着 PixelTitan 不受文件类型或文件大小的限制,能够提供满足 AI 需求的数据集。
相关:
-
数据分析中的 5 大趋势
-
向大数据提出的 3 个关键数据科学问题
-
我们如何更好地解决分析问题?
更多相关主题
人工智能和数据科学如何改变公用事业行业
原文:
www.kdnuggets.com/2019/01/how-ai-data-science-changing-utilities-industry.html
评论

公用事业行业是一个依赖于提供稳定电力和水等资源的领域。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的快车道
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT
否则,家庭和企业级客户可能会发现他们无法获得那些本应帮助他们生活和开展业务的资源。
人工智能(AI)和数据科学正为选择探讨这些领域的公用事业提供商带来积极的发展。以下是一些技术应用的例子。
1. 促进向可再生能源的过渡
人们对可再生能源的潜力越来越感到兴奋。除了可持续性好处外,一些个人希望利用联邦或州的税收抵免来购买如太阳能设备等产品。
然而,从化石燃料过渡到可再生能源的成功意味着首先分析关键数据点。公用事业提供商必须评估当前或计划中的可再生能源项目的输出,并将预期的总量与所有使用可再生能源的客户带来的需求进行配对。
除了使用大数据平台来检查这两个变量和其他因素外,还可以依赖人工智能采取预测性的方法来分析这些指标。这种系统可能会确定在一天中的某些时段内可再生能源的使用最多,或者社区中特定区域的使用量异常高。
一项对26,000 名受访者的全球调查发现,大多数受访者认为向完全由可再生能源驱动的世界转型非常重要。报告的另一个发现突显了人们希望减少对煤炭的依赖。
很明显,消费者有需求,但如果公用事业公司不先检查数据,他们可能会面临意外和可预防的后果。更糟糕的是,如果这些问题让企业得出可再生项目失败的结论,他们将不会被鼓励投资未来的可再生能源机会。
2. 防止停电
停电对客户来说是极其破坏性的,对公用事业公司修复也非常昂贵,但目前正在开展项目,利用人工智能——特别是机器学习——来预测导致停电的条件。
2017 年在能源部实验室进行的一个项目旨在识别电网的薄弱点并在停电发生前主动修复这些问题。十个公用事业合作伙伴参与了这一多年的努力,目标是创建一个能够处理普通电力波动的自主系统,并对如风暴等重大事件作出响应。
同样,德克萨斯农工大学的一个研究团队应用大数据来改进树木维护,防止过度生长的树枝引发电力服务中断。公用事业公司传统的方法是安排定期和轮流的修剪,但这种方法既耗时又耗费成本。
这种新的数据驱动选项告诉公用事业公司哪些树木最有可能引发问题。然后,这些实体可以优先考虑某些区域。创建的模型还接受来自多个来源的信息。例如,公用事业品牌可以用操作数据或已知的植物和生长模式统计数据来填充系统。
3. 了解更多关于客户及其需求的信息
消费者可以使用各种高科技恒温器来帮助降低公用事业费用。统计数据显示,使用 Ecobee3 智能恒温器的23%家庭能够节省接近四分之一的能源费用。此外,还存在一些选项,允许人们通过手机发送短信来控制恒温器,或在房屋空置时将其设置为节能模式。
此外,只要公用事业公司获得客户的许可,他们可以访问那些恒温器的数据,并利用这些数据来了解更多关于需求和使用模式的信息。获取数据可以帮助他们对营销信息进行有意义的调整,包括提到新产品如何满足与客户相关的特征。
美国最大的公用事业公司之一 Exelon 正在通过聊天机器人迎合客户需求。该公司在不到两周的时间里建立了一个原型,该机器人回答有关停电和账单问题的查询。理论上,公司也可以将大数据应用于聊天机器人的互动历史,以做出商业决策。
例如,如果重新设计账单后,客户中有更高比例的查询,企业可能会恢复旧设计或做出更改以消除困惑。
或者,如果一个小区或公寓复杂中的大量客户在风暴导致停电后询问聊天机器人何时恢复供电,公司可能会决定优先派遣团队到这些地方。
4. 减少浪费
如果公用事业公司无法找到有效的废物处理方式,它们很可能会面临盈利困难。数据分析平台可以揭示低效领域,使提供者能够迅速采取行动,降低成本。
同样,这些提供者可以提供品牌应用程序,帮助客户通过跟踪用水和用电量来减少浪费。
然而,如果问题与隐藏泄漏相关,发现它们并不容易。滑铁卢大学的一个项目应用人工智能通过声音处理能力来监测水管中的声音,寻找可能表示水滴的声音。这个系统特别有用,因为它甚至能在实验室测试中定位每分钟少于 4.5 加仑的相当于 17 升的缓慢泄漏。
目前,处理泄漏的团队会在出现大规模洪水后被派遣,或检查由于老化可能即将失效的管道。但滑铁卢大学基于人工智能的方法可能会导致更积极的努力来遏制浪费。
吸引公用事业提供者实施大数据和人工智能的理由
本列表概述了一些大数据、人工智能或两者结合以实现单一目标的最引人注目的用例。
然而,随着技术的发展,公用事业公司将有更多理由投资这些技术,以解决已知问题并改善运营。
简介: 凯拉·马修斯 在《The Week》、《数据中心期刊》和《VentureBeat》等出版物上讨论技术和大数据,已有五年以上的写作经验。要阅读更多凯拉的文章,订阅她的博客 Productivity Bytes。
原创。经许可转载。
相关:
-
数据科学如何改善高等教育
-
机器学习和机器人技术正在改变的 4 个行业
-
每个数据科学新手在 2019 年应该设定的 6 个目标
更多相关主题
AI 如何革新传统行业?
原文:
www.kdnuggets.com/how-ai-is-revolutionizing-the-legacy-industries

来源:Canva
AI 在解决以前被认为是虚构的难题方面展示了巨大的潜力和前景。让我们探讨一下它对科技行业的各种影响。随着 AI 以一种几乎无缝的方式进入我们的生活——例如面部识别帮助解锁手机,或者 Alexa 和 Siri 通过语音技术丰富体验,它确实无处不在。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
本文突出了技术领域一些突破性的 AI 创新。
推荐
我们生活在一个非常迷人的超个性化世界中。根据历史购买记录和用户特征,我们不仅会看到广告,还会在信息流中看到反映我们兴趣的新闻。打开社交媒体,你的整个体验都经过量身定制——无论是你看到的内容还是推荐的联系人。
这感觉令人不堪重负,但几乎等同于拥有一个为你精心策划的小世界,这也延伸到回音室的概念。超个性化创建了过滤气泡,使用户对多元观点的接受度降低,强化了他们已有的信念。
笔记记录与总结
如果说之前你还需要自己记录会议笔记,那么现在欢迎来到 AI 的世界,它将数字化提升到一个全新的水平。它免去了你创建、收集或整理会议笔记的需要。
AI 提供会议总结和记录,列出行动项并突出重点。Otter.ai 是其中一个应用程序,能够帮助你跟进项目进展。
来源:otter.ai
远见者
质量控制
从推荐和自动总结转变,AI 现在还作为你的质量控制助手,检测织物的磨损或褪色等缺陷,并对原材料如蔬菜(农民)或木材(家具制造商)进行全面质量评估。
医疗保健
继续探讨计算机视觉应用,AI 是分析医疗图像(如 X 光片和 CT 扫描)以诊断患者潜在健康状况的极其强大的工具。这些先进的算法擅长识别模式和异常,从而帮助医疗专业人员加快诊断过程,提升患者的治疗效果。
值得注意的是,AI 在医疗保健中的使用属于高风险和高影响类别,因此 AI 模型的概率输出仅应被视为一种增强点。假阳性和假阴性可能意味着误诊,如果在没有医疗专业人员监督的情况下采取行动,可能会对患者的生活产生重大影响。
预防永远胜于治疗
欺诈检测
与传统的基于签名的技术相比,AI 驱动的欺诈检测系统在预测潜在欺诈方面已证明更为准确。随着数字银行和在线支付的增加,稍有疏忽可能会对客户造成巨大损失,损害在线平台的声誉。

来源:Canva
引用 Infosys BPM 的统计数据,“网络犯罪每年使全球经济损失 6000 亿美元,占全球 GDP 的 0.8%。研究表明,仅在 2021 年第一季度,欺诈尝试就比去年上升了 149%——这无疑受到疫情后在线交易增加的推动。对此,超过一半的金融机构已采取措施在 2022 年使用 AI 来检测和防止欺诈。”
预测性维护
无论是资产密集型制造业还是一般机械,停机是不可避免的。处理这些停机时,往往发现公司没有准备好,导致修复时间延长,这在生产、收入损失以及与设备维修或更换相关的额外费用上都可能成本高昂。
这就是 AI 预测能力发挥作用的地方。它分析大量数据以检测指示潜在设备故障的模式和异常。

来源:德勤
德勤简洁地强调了通过利用 AI 来最小化和管理停机时间的必要性——“无论是担忧系统广泛损害、产品质量、过程和设施安全,还是其他因老化或故障资产带来的后果,建立预测资产故障并防止其发生的能力可能很重要。”
信息获取
智能助手
人工智能通过智能助手帮助用户比以往更容易找到信息。用户不需要为获取信息而感到焦虑,可以简单地在指尖访问信息。这种信息获取的便利性减少了手动搜索的需求,并且绕过了许多传统的客户支持渠道。这些助手开启了新的效率前沿,节省了用户时间,提高了生产力。

来源:Canva
结果是,用户可以专注于更具战略性和意义的活动。然而,这种便利性也带来了数据隐私、安全性或个人信息潜在滥用的风险。因此,用户必须检查隐私设置,并对与人工智能系统共享信息保持谨慎。
自动化的另一面
尽管我们永远无法完成分享自动化带来的效率好处,但另一方面却涉及到劳动力替代的问题。许多早期被人工智能自动化所覆盖的重复性任务,推动了不断提升技能和保持自身在不断变化的就业市场中相关性的需求。
目前,仍然需要情感智能和创造力的领域尚未完全掌握在人工智能的强项之内,并可能吸引更多的人才。尽管如此,先进人工智能模型的发展也带来了许多新角色,创造了新的职位。此外,负责任的人工智能专家、政策制定者、人工智能伦理学家以及网络安全专家是当今需求量大的技能之一。
还有更多内容!!!
此外,有大量应用程序利用人工智能,使人类生活更轻松,并促进商业增长。例如,客户流失预测、信用风险违约模型、用户评论情感分析、自动化数据清理、客户细分以及量身定制的内容教育改革等,都是人工智能产生持久影响的诸多方式之一。
虽然潜力无限,但用户需要在使用这些人工智能应用程序时具备意识,以做出适当的权衡。通过在创新与负责任的发展及利用之间取得平衡,人工智能可以解锁前所未有的机会,为全人类塑造更美好的未来。
Vidhi Chugh****是一位人工智能战略家和数字化转型领导者,她在产品、科学和工程的交汇处工作,致力于构建可扩展的机器学习系统。她是一位屡获殊荣的创新领导者、作者以及国际演讲者。她的使命是使机器学习大众化,并打破术语,让每个人都能参与到这一转型中。
更多相关话题
AI 如何改变零售行业
原文:
www.kdnuggets.com/how-ai-is-transforming-the-retail-industry

来源:Canva
直到最近,需求预测和库存优化是一些关键的 AI 应用之一。然而,最近 AI 的发展带来了各种创新的 AI 解决方案,这些解决方案彻底改变了零售业务。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
跳出框框思考!!!
一个独特的用例涉及优化产品图像的质量以提高销售转化率。在这种情况下,零售商利用 AI,特别是计算机视觉技术,来提升产品图像的视觉吸引力,从而增加买家点击产品的可能性。
作为销售漏斗结构的一部分,点击次数的增加通常会流向更高的转化率,即销售。进一步扩展,零售商可以进行假设测试并尝试不同的图像质量,确定哪些图像属性,如高分辨率像素和适当的照明,能够推动转化。

来源:Canva
计算机视觉技术使零售商能够自动化地实施修复以改善图像质量,确保它们能够与客户产生共鸣。
产品描述
大多数电子商务网站托管来自不同卖家的产品,导致产品描述的列出方式各异,往往不一致且不完整。
对于什么构成有吸引力的购物体验缺乏意识和洞察,导致风格、长度、语调和完整性不一致,可能影响用户的购买决策。
然而,通过生成式 AI——一种基于大数据集生成内容(如文本、图像、视频等)的 AI 技术,公司可以生成有效的产品描述,从而增加点击率,并进而提高转化率。
这样的 AI 生成内容不仅确保信息全面,而且引人入胜且具有说服力,吸引用户的注意。更进一步,算法甚至可以学习用户的偏好,并提供与他们最相关的产品描述。值得注意的是,零售商可以继续根据模型结果的响应情况来提升和完善这些 AI 系统。
这一迭代过程使公司能够随着时间的推移完善产品描述,优化其在推动转化中的最大效果。
卖家风险管理
说到卖家,电子商务平台还可以建立一个基于 AI 的卖家风险管理系统,以监控与产品质量、客户服务和道德标准遵守相关的风险。
AI 可以从过去的卖家行为、客户反馈和交易记录等因素中学习,以检测异常或偏离预期规范的情况。这些偏差会标记出可能不符合平台政策和行为规范的卖家。
分析及时发货、准确的产品描述、公平定价和对客户询问的响应等因素,以突出卖家的行为。那些不断收到负面评价或投诉、参与欺诈活动或违反服务条款的卖家可能会导致糟糕的客户体验,并且损害平台的声誉。
因此,电子商务平台可以通过利用 AI 主动识别这些卖家并暂停他们的参与。除了确保可靠卖家的质量外,这些 AI 系统还促进了客户之间的信任和建立了信心。
虽然卖家的行为可能会随着时间变化,但基于 AI 的风险管理系统可以根据不断变化的不合规模式持续学习和适应。
欺诈检测
通常,欺诈检测被认为是银行的责任,这在一定程度上是正确的。但是,试想一个在零售平台上成为欺诈交易受害者的客户,并试图与零售商联系以撤销交易。

来源:Canva
通常情况下,零售商无法提供帮助,并且被认为没有过错。然而,对客户来说,零售商是信任的第一层防线。试想一下,如果零售商拥有一个基于 AI 的算法,能够根据买家的购买历史识别潜在的欺诈行为,并引入额外的身份验证步骤来继续销售,那么欺诈就会在第一层防线被阻止。
我们生活在一个竞争激烈的世界中,拥有一个差异化因素至关重要。管理和缓解欺诈风险突显了零售商对以客户为中心的承诺,从而提高了客户的信任和品牌忠诚度。
质量控制
想象一下人工智能作为你的质量控制助理,检查每一个产品在到达货架之前,尤其是在易腐烂产品的情况下,保持新鲜和确保消费者安全尤为重要。
同样,计算机视觉可以通过检测缝合缺陷、面料一致性和印刷对齐来分析衣物的质量。通过自动化质量控制流程,零售商可以维持一致的产品标准,为顾客提供优质的产品。
认知过载
不同品牌有不同的尺码指南,顾客常常很难记住特定品牌的尺码。人工智能以减轻顾客的认知负担而著称,可以帮助提供相关建议,提升购物体验。例如,如果算法基于购买历史、用户特征以及可能的尺码偏好反馈来建议尺码。那么,这样顾客的满意度就会得到极大的提升。
摘要
从优化产品图片和生成引人注目的产品描述,到管理卖家风险和检测欺诈,人工智能有潜力彻底改变零售行业的各个方面。随着更多 AI 产品和预训练模型的开源,免费 AI 时代对各行各业而言将持续存在。
Vidhi Chugh是人工智能策略师和数字化转型领袖,致力于在产品、科学和工程交汇点上构建可扩展的机器学习系统。她是一位屡获殊荣的创新领袖、作者和国际演讲者。她的使命是普及机器学习,打破术语,让每个人都能参与这场转型。
更多相关话题
AI 如何学习你的支付意愿
原文:
www.kdnuggets.com/2017/12/how-ai-learns-different-prices.html
评论
由 Ted Gaubert。

为什么我们支付不同的价格?这是“价格个性化”还是一种“价格歧视”?答案并不简单。
人工智能(AI)动态定价引擎的世界正在迅速发展,并改变竞争格局。本文概述了几个影响 AI 定价引擎决定向你显示什么价格的领域:
-
预测市场需求与微分割
-
累积不对称信息
-
估计“支付意愿”
-
塑造需求
1. 预测市场需求与微分割
AI 微分割使用许多客户属性和行为来按估计的支付意愿将客户分组。简单来说,假设我们有三个桶。我们将客户分为(A)高支付客户,(B)中等支付客户和(C)低支付客户。一种最大化利润的策略是首先只向高支付客户 A 组销售。然后,剩余的座位可以出售给中等支付的 B 组。最后,任何剩余的座位可以出售给低支付的 C 组。
等一下!我们都知道,随着预订日期接近出发日期,航空公司价格会上涨。大家都知道,要想获得便宜的机票,你应该早点预订!
所以,先向高支付 A 组销售,然后中等支付 B 组,再把剩余的座位给低支付 C 组,并不是那么简单。在大多数情况下,定价和销售的顺序是相反的——低支付 C 组,然后是中等支付 B 组,最后是高支付 A 组。
那么,如果先向 C 组销售,如何最大化对高支付 A 组的销售?有什么因素防止所有座位都被低支付的 C 组购买,而没有座位留给高支付的 A 组?
部分答案是预测潜在买家的数量以及每个人愿意支付的金额,通常是在大多数客户甚至还未决定旅行之前几周。
2. 累积不对称信息
AI 定价游戏的一个重要部分是让 AI 了解市场上发生的一切。目标是拥有比竞争对手更好的信息,以做出更好的决策。这种信息优势有时被称为不对称信息。
在需求预测方面,不对称信息使得人工智能定价引擎能够实现比竞争对手更准确的需求预测。最终,这一优势使得定价引擎能够更有信心地保持价格或上下调整,以最大化利润来应对市场上的变化。
为了了解这如何运作,我们假设有一个航空市场,有 3 家航空公司服务像蒙大拿州的 Porcupi 这样的目的地。在航空行业中,Porcupi 是一个处于“长尾”中的小镇。这意味着它只是众多提供服务的城镇之一,每个城镇只产生少量收入。然而,类似于亚马逊的经典例子,“长尾”中的所有小镇收入加起来将是一个巨大的收入数字。
假设你是一家航空公司运营商,你知道 Porcupi 将很快举行一个大型节日。你知道会有比所有竞争对手的飞机座位更多的人前往 Porcupi。如果你是唯一一个知道这个大型节日的航空公司,那么定价策略就很简单。保持高价,直到所有竞争对手售罄他们的座位。然后,旅行者将不得不为最后一架飞往 Porcupi 的飞机支付高价。
然而,大多数“长尾”市场的收入不足以经济上支持雇佣人类来监控小城市中的情况并进行微调价格。类似于亚马逊如何利用技术自主进行需求预测和定价决策,许多其他行业也在发生类似的情况。
人工智能能够以远低于人类团队能够实现的成本,实时了解全球范围内的本地事件。这使得利用人工智能的公司能够获取不对称信息,从而实现更好的需求预测和战略定价决策。
3. 估算支付意愿
关于你的客户行为的数据不断被收集,例如:
-
你查看了哪些类型的物品?
-
你在每个网页上花了多长时间?
-
你放入购物车的物品有哪些?
-
你购买了哪些物品?
-
看起来和行为与你类似的人支付了什么?
所有这些数据被输入到一个人工智能引擎中,该引擎将你的行为转化为一个人格,并尝试预测关于你的信息,其中之一是估算你愿意支付的“最高价格”。
请记住,这并不意味着你会收到“个性化价格”,尽管技术上是可能的。“个性化定价”的做法因伦理、品牌、忠诚度和法律等问题而备受争议。
然而,‘支付意愿’可以用来确定您在当前市场价格下购买某个商品的可能性。这种可能性会被纳入微观细分的需求预测中,并最终影响价格。因此,AI 引擎可以通过知道以什么价格销售多少商品来控制销售速度。
4. 动态塑造需求
预测竞争响应 + 需求 + 微观细分 + ‘愿意支付的最高价格’都基于概率。预测中总会有某种程度的‘误差’。换句话说,销售情况可能会比预期稍快或稍慢。AI 定价引擎通过调整价格来动态地塑造需求,改变需求曲线的形状。这可能基于实时库存或其他各种因素。在航空公司和酒店定价领域,需求塑造可以用来优化利润,最小化航空座位和酒店房间的超售或不足销售情况。
结论
每个行业都在以某种价格向客户销售产品或服务。本文讨论的主题广泛适用于除航空座位和酒店房间动态定价之外的各种行业和商业场景。制造商估计需求以了解生产哪些产品及其数量。分销商管理定价和需求预测,以优化库存和分销物流。营销人员利用需求估计来决定促销、目标定位和营销支出。先进的算法技术和 AI 引擎正在悄然改变组织的竞争方式。
所有复杂算法相互作用的结果决定了我们被报价的价格、展示给我们的广告以及购物时找到的产品组合。
免责声明
观点仅代表我个人。我撰写的文章旨在为广泛的全球读者提供分享和启发他人探索新想法的内容。我简化内容以便于理解,并欢迎您的评论、纠正和批评,以丰富我们职业 LinkedIn 社区的知识和生活。谢谢!????
原文。经许可转载。
相关
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
如何免费成为数据科学家
原文:
www.kdnuggets.com/2015/08/how-become-data-scientist-free.html
评论
作者:Nir Goldstein,ReSkill
根据 LinkedIn 对 3.3 亿 LinkedIn 会员档案的分析,统计分析和数据挖掘是 2014 年最受欢迎的技能。我们生活在一个日益数据驱动的世界中,企业正积极招聘数据存储、检索和分析方面的专家。全球范围内,统计和数据分析技能被高度重视。在美国、印度和法国,这些技能的需求特别高。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT 事务
什么是数据科学?
数据科学家对数据进行研究和分析,帮助公司通过预测增长、趋势和商业洞察来改善业务。拥有数据和分析结果后,顶尖的数据科学家将通过组织的领导结构传达经过深思熟虑的结论和建议。成功的大数据科学家需求量大,薪资也会非常可观。但要想成功,大数据科学家需要具备广泛的技能,而这些技能直到现在甚至无法归入一个部门。
学习如何成为数据科学家可能成本较高,平均费用为 $9,600(根据 extension.harvard.edu)。但如果你知道雇主在寻找哪些技能,你可以找到很多免费的在线资源。这正是我们为你做的!以下是成为数据科学家所需的技能集以及学习每项技能的前 3 个免费在线资源。
根据 ReSkill 对数千个职位发布和每项技能学习资源的分析,以下是数据科学家职位最需要的技能:

1. Python
![expand-your-reach]() 2. 机器学习
2. 机器学习
 2.
2. ![r-programming-1-l-280x280]() 3. R 语言
3. R 语言
 3.
3. ![big-data-icon]() 4. 大数据
4. 大数据
![Icon_63-256]() 5. 统计学
5. 统计学
 5.
5. ![download]() 6. 数据挖掘
6. 数据挖掘
 6.
6. ![mysql_dock_icon_by_presto_x]() 7. SQL
7. SQL
 7.
7. Udemy 的 Sachin 快速学习(SQL)– 结构化查询语言
![Apps-File-Java-icon]() 8. Java
8. Java
 8.
8. Udemy 的 Java 学习:初学者的 Java 编程教程
简介: 尼尔·戈尔德斯坦 是 ReSkill 的联合创始人兼首席执行官,该平台专注于基于技能的职业管理。
相关:
-
在线分析、数据挖掘和数据科学学位
-
在线分析、大数据、数据挖掘和数据科学教育
-
商业分析与商业智能在线证书与学位
更多相关主题
如何成为一名自由职业数据科学家 – 4 个实用技巧
原文:
www.kdnuggets.com/2021/08/how-become-freelance-data-scientist.html
评论
由 Pau Labarta Bajo,数学家和数据科学家。

Toptal 自由职业者的实用技巧
如果你是一个对数据科学有些痴迷的科学家,想要开始作为独立(远程)自由职业数据科学家工作,这篇文章适合你。从你现在的朝九晚五工作过渡到远程自由职业是一种解放性的体验。最终的回报是巨大的,包括:
-
更快的学习速度,因为你不断接受新项目并使用不同的技术。
-
有机会与前沿初创公司合作,无需住在旧金山的小房间里。
-
自由安排你的日子、周数和月份,没有人计算你今年请了多少假。
-
更高的小时费率,意味着月末薪水会更高。
一位自由职业数据科学家的历程
我叫 Pau Labarta Bajo。我是一名自由职业数据科学家和机器学习工程师,已经作为远程自由职业者工作了 2 年多。之前,我曾在顶级移动游戏公司 Nordeus 担任数据科学家。在我身边,有一群优秀的数据科学家和惊人的数据工程师。在我加入团队时,他们已经建立了一个内部数据分析平台,帮助公司管理一个有超过 200 万日活跃用户的游戏。我感觉自己只是一个在成熟蜂群中工作的蜜蜂。90%的时间用于技术工作,包括数据分析以改善产品和机器学习开发以提高效率。10%的时间用于与团队其他成员沟通我正在做的工作。
这种分裂对我们这些数据科学家和机器学习怪人来说感觉很好。然而,这种舒适有一个代价,这个代价体现在我不断的两个思考中。
-
尽管机器学习技术和应用到处出现,我仍然不断使用相同的技术解决相同的问题,一遍又一遍。无聊。
-
为什么我必须等待年度评估,基于他人的意见,才能获得加薪?一定有更好的方法。
最终,我辞去了工作,开始作为远程自由职业数据科学家工作。这一过渡既具有挑战性又极其丰富。在这个过程中,我总结了一些经验,并将其凝练成4 个实用技巧,帮助你加入我,踏上另一端的道路。

照片由 Fan D。
1. 保持冷静,不要低估你的专业技能
你第一个问题是:我在哪里找到我的第一个项目?
互联网上有大量与数据相关的工作。如果你访问像 Upwork 这样的网页,你会看到每分钟都有新的职位发布。是的,有很多数据科学职位,这也是你每天早晨应该感恩的事情。然而,这些大型网站上竞争也非常激烈。来自世界各地的自由职业者试图在与你相同的领域竞争。
你可能会被诱惑去想:
“我们试着通过设定低于我认为合理的费率来增加我获得第一份工作的机会,考虑到我的技能和生活成本。”
大错特错。顺便说一下,我犯了那个错误两次。在我的第二个自由职业项目中,我和另一位在同一时区的数据工程师合作,他的薪水是我的两倍多。他是第一次做自由职业。无数次我后悔自己的聪明定价。
大多数客户愿意支付更高的费用以降低项目的不确定性。你的工作是高度专业的,过度的价格折扣也会被解读为对项目成功的不确定性。还要记住,你试图说服的是另一个人,而不是一个成本最小化的机器人。你需要表现出自信,设定比你认为自己价值更低的价格正好相反。
2. 在多个平台上投标

现在有很多自由职业平台。我使用过 3 个(Upwork、Toptal 和 Braintrust),但你也可以探索其他平台。
这些平台可以分为两类:
-
基于数量的平台,如 Upwork。对于客户和自由职业者来说,没有进入障碍。任何人都可以发布工作,任何人都可以注册为自由职业者。这是寻找小项目的好地方,但当你刚开始时很难找到好的客户。好的工作通常只对那些通过之前的项目在平台上建立了声誉的申请者开放。这会让你处于不利地位,并且当你刚开始时可能会相当令人沮丧。尽管如此,我建议你在 Upwork 上创建一个个人资料。Upwork 客户可以通过平台内部的搜索找到你的个人资料,并直接要求你提交提案。这是你必须保持开放的选项。
-
基于质量的平台,如 Toptal 或 Braintrust。这些平台的客户较少,但质量更高。为了查看并申请这些平台上的项目,你需要通过筛选过程。这个过程大约需要 2 到 5 周的时间。虽然耗时耗力,但回报是巨大的。进入这些平台后,你将有机会与优秀的客户——通常是初创公司和大企业——建立联系,他们愿意为 Toptal 向他们承诺的质量支付更高的费用。不要被他们的“仅限前 3%”政策吓到。我可以放心地说,当我两年前加入 Toptal 时,我并不是“前 3% 的机器学习工程师”。
3. 客户寻找非常特定的角色
大多数客户并不寻找全面的数据科学家,而是一个能够解决他们问题的特定人才。某个人非常清楚如何
-
分析一个数据集,
-
使用 Tableau 构建一个仪表板,
-
在 Google Cloud 中构建数据管道,
-
构建一个机器学习模型,
-
抓取一个网站,
-
…
试图将自己展示为一个可以做任何事情的终极自由职业数据科学家是很有诱惑力的,但这并不是客户所寻找的。此外,数据科学是一个庞大的市场。通过缩小你的角色范围,你仍然在一个相当大的池子里钓鱼。请记住这一点。
我第一次自由职业的工作可以粗略描述为“我们数据工程师中没有人能在 Tableau 中构建一个漂亮的仪表板。你能吗?” 这不是我能想到的最令人兴奋的工作,但这是我在之前的工作中做过无数次的事情。我对此非常熟练,这对客户来说是有价值的。
从专注于你已经是专家的项目开始你的道路。避免冒名顶替综合症,赚取你的第一笔酬劳,并建立信心。
兼职工作,甚至按小时计费,你可以像在之前的 9 到 5 工作中一样学习。利用这个机会在额外时间中学习新技能,为下一个你想从事的领域做准备。
4. 编写解决业务问题的提案,而不是展示信
一个典型的错误是这样开始提案:
“亲爱的 X。我叫 Y,是一名在 A、B、C 和 D 方面拥有 N 年经验的数据科学家。我有 E 的背景,和 … “
当然,你的潜在客户希望了解你令人惊叹的背景。但她不是你的妈妈或爸爸。她想要解决问题,所以直接切入正题。从第一段开始专注于问题,不要有前言和介绍,这只会让她打哈欠。使用项目符号列出直接相关的问题的非常具体的内容,以减少认知负担。同时,尽量减少废话。你喜欢阅读别人夸奖自己吗?你的潜在客户也是一样。
我保留了自从我开始自由职业以来写的每一份提案。所有让我得到工作的提案都有这样的结构:
“嗨 X!我叫 Y。我最近构建了 N 个与您的问题 Z 直接相关的东西:
-
项目 alpha
-
项目 beta
-
项目 gamma …
我很乐意帮你解决这个问题。我们本周安排一次电话会议,详细讨论一下。最好的,Y。
结论

作为数据科学家的自由远程工作在智力和财务上都非常有回报。如果这些建议中的任何一条能对你的自由职业道路有所帮助,我将感到非常高兴。
简介:Pau Labarta Bajo 是一位数学家和数据科学家,拥有超过 10 年的经验,处理各种问题的数据和模型,包括金融交易、移动游戏、在线购物和医疗保健。
相关:
更多相关主题
如何成为在线数据科学导师
原文:
www.kdnuggets.com/2021/05/how-become-online-data-science-tutor.html
评论
在数据科学领域工作了几年后,我尝试理解学习和教授数据科学的最佳方法。
我希望我们的团队在通过 MOOC 进行教学方面做得很好。
“超过 50 万学生不可能错,” 广告如是说。
虽然在线课程是最实惠的学习方式,但在线辅导不应被低估。
在需求方面,这是一种更昂贵但极其有效的方式,任何人都可以通过它来推进他们的数据科学职业。
在供应方面,许多专业人士在他们的数据科学团队中是出色的导师,但没有考虑过辅导作为额外收入的来源。
在这篇文章中,我们将探讨这个问题,作为“在线数据科学辅导”的商业案例。

问题
TikTok 热门但简单。我花了一个小时就“掌握”了它。
数据科学热门但困难。我花了几年才“掌握”它。然而,我仍然觉得说“我懂数据科学”不太自在。
主要原因是数据科学确实是一个无尽的话题。
没有人可以说:“我对数据科学了解一切。”
它有许多不同的方面:
-
设计惊艳的数据可视化的创意方面
-
通过 BI 工具将数据源整合到仪表板中的业务方面
-
机器学习和人工智能的艰难数学方面
-
大数据管道的计算机科学方面
-
沟通发现的销售人员方面
你明白了。
要成为一名优秀的数据科学家,必须具备这些技能的组合。还有更多。
有些人可以自学,其他人则不太行。
在过程中会出现许多问题,如果有人能够回答这些问题,将会是极大的帮助。
解决方案
你可以成为那个人!当然,要付出一定的费用。
你有资格吗?如果你理解 KDnuggets 上写的博客的一半,你绝对有资格通过帮助有志数据科学家来赚取额外收入。
辅导有志者的不同方式包括:
-
书面回答 这是我们多年来通过在线课程所做的:通过电子邮件或问答空间回答问题。这项活动具有很大的规模经济,因为经过一段时间,你会看到大多数人提出的问题,你会变得更加迅速和高效。
-
实时聊天回答 这与上面相同。问题是,当你实时回答问题时,你没有时间准备或进行额外的研究。这是一个大忌。
-
实时视频聊天回答 这是过去一年大家一直在做的事情。确保提前获得问题或代码,以便你可以提前准备好所有可能的答案。你可以进行对话、共享屏幕、配对编码——所有成功辅导课程所需的内容。
这是一种双赢的局面,你可以将对数据科学的热情转化为额外收入,同时在过程中可能学到一些新东西。
目标客户
谁会对你的服务感兴趣?
有志于成为数据科学家的大学生、在线课程学习者或读书学习者,他们总是需要额外的帮助。
但不仅仅是它们。
每个愿意学习新知识的数据科学家,即每个理智的数据科学家,都可以真正从你提供的服务中受益。
也不要低估经验丰富的数据科学家。
如果他们是‘硬数学’型的人,他们肯定需要一些数据科学沟通技巧。
如果他们是那种‘创意型’的数据可视化专家,他们可能需要‘销售型’人员的帮助,将他们的工作从极美化到极具说服力。
而且放心,你也会在这个过程中学到很多东西。
如何将这项业务开始
你需要 3 件事:
-
建立一个基础设施来主持会议并获得报酬。
-
学习在线授课的基础知识。
-
联系你的目标客户。
建立一个基础设施来主持会议并获得报酬
如何确保视频通话发生并获得报酬?
- 你需要一个网站。
为什么?因为人们必须能够在网上找到你。更重要的是,你需要记录有关找到你的人的数据。无论是简单的预订页面还是辅导市场,你必须在互联网上存在。如果你寻找的是更个人化但又简单的解决方案,Wix和Squarespace将会是不错的选择。
- 一个调度工具。
在你开始的时候,你可以自己安排会议。但这不是自动化的。作为数据科学家,你可能更愿意自动化或至少半自动化安排。你可以使用Calendly或Hubspot。
- 一个视频会议工具。
这已经是旧闻了:Zoom、Google Meet和Microsoft Teams拯救了局面!
- 一个支付工具。
将这 4 种工具集成在一起,或者至少视频和支付部分,将构成你的技术基础设施。
如果你太忙或者不想麻烦,你可以选择一款端到端的付费在线会议解决方案。我鼓励你试试3veta.com。

学习在线教学的基础知识
确保不要跳过这个步骤。它可能听起来平凡,但并非如此。
首先,你必须学习如何准备会议并主持会议。所有类型的在线咨询规则都是一样的。步骤很简单——都是与设置、准备设备、收集材料等有关。充分熟悉这一阶段,我强烈推荐你拥有一个 清单。

其次,了解对方遇到的问题。
你不是在那里教授他们“所有的数据科学”。你在那里是因为他们有一个特定的数据科学问题,而你有解决这个问题的专业知识。
提出许多问题。运用你的数据科学技能,深入挖掘,直到找到问题的根本原因。一个人不过是一个极其庞大的数据集合。
例如,他们告诉你:“我需要帮助创建图表。”那么对话可能会是这样的:
你在使用什么软件?你在编码,啊哈。
用什么编程语言?Python!不错的选择。
你喜欢什么 IDE?嗯,Jupyter 对初学者很好,但你可以考虑未来换用其他工具。
你觉得哪些库很有用?MatPlotLib 是一个非常可靠的库,但你试过 Seaborn 吗?我觉得它可能更适合你的情况。另一个有趣的选择是 plotly。不过,如果你想在 MatPlotLib 上更进一步,我听到了,我会帮助你的。
那么,你到底想要创造什么?是创建它还是设计它时遇到困难?设计很重要。如果你追求的是外观,那么 MatPlotLib 可能不适合你。也许 Python 也不是正确的选择。如何尝试在 Tableau 或 PowerBI 中实现呢?我可以给你展示。
你是专家。引导他们成为更好的数据科学家,并分享你的错误或偏见。
联系目标客户
你需要对目标客户提供帮助。了解他们在哪里存在或在线上。
-
KDnuggets?
你已经在这里了。尝试 撰写一篇高质量的文章,人们肯定会联系你进一步探讨。
-
在线课程讨论(问答环节)。
我从个人经验中知道:在线课程创建者在回答他们课程中的所有问题时感到困难。尽量帮助他人。你很快会发现学生和讲师都在注意你,这就是你向他们推销的机会。
-
像 Quora、Reddit、StackOverflow 这样的论坛。
这些问题确实“泛滥”了未回答的数据科学问题。在你的个人资料中放置一个指向你服务的链接,并尽可能提供帮助。
额外的想法
-
教学是非常值得的。如果你帮助了一个人解决他们的问题,你会对自己感到无比满意。
-
不要担心他们会问你不知道的问题。通过提前请求问题来减轻这种情况。如果你没有做到这一点,你总是可以要求他们稍后再回来问。这就是会议上的讲者所做的,没有人会因此生气。
-
你有冒名顶替综合症吗? 如果你在咨询过程中或之后对自己感到不满,你可以随时提供退款。
-
如果你比较内向,你可能需要考虑更开放一点。不要害怕被关注。如果人们知道你对数据科学如此感兴趣,甚至还进行辅导,这对你的职业生涯只有好处。记住,你在这个过程中会学到很多东西。实际上,最糟糕的情况就是被在线忽视,这并不是坏结果。
-
作为一名课程讲师,在处理课程的问答时,我迫切需要帮助。每当有学生回答超过 5 个问题时,我会联系他们并邀请他们与我们合作。
你真的能让这件事成功吗?
在线赚取额外收入从未如此简单,而 我一直是这方面的倡导者。
听起来可能很难,但你知道吗?你是数据科学专家,而不是 TikToker!
你的努力通常更困难,但总是更有回报!
相关:
更多相关主题
大数据如何实时拯救生命:IoV 数据分析帮助预防事故

图片来源:罗伯托·尼克松
车联网(IoV)是汽车工业与物联网(IoT)结合的产物。预计 IoV 数据将越来越大,特别是随着电动车成为汽车市场的新增长引擎。问题是:你的数据平台是否准备好了?这篇文章展示了一个适用于 IoV 的 OLAP 解决方案的样子。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
IoV 数据有什么特别之处?
IoV 的理念很直观:创建一个网络,使车辆能够彼此之间或与城市基础设施共享信息。常常被解释不足的是每辆车内部的网络。每辆车上都有一个称为控制器局域网(CAN)的系统,它作为电子控制系统的通信中心。对于在道路上行驶的汽车来说,CAN 是安全和功能的保障,因为它负责:
-
车辆系统监控:CAN 是车辆系统的脉搏。例如,传感器将检测到的温度、压力或位置发送到 CAN;控制器通过 CAN 向执行器发出指令(如调整阀门或驱动电机)。
-
实时反馈:通过 CAN,传感器将速度、转向角度和刹车状态发送到控制器,控制器及时调整车辆以确保安全。
-
数据共享与协调:CAN 允许各种设备之间的数据交换(如状态和指令),使整个系统更加高效和性能优越。
-
网络管理与故障排除:CAN 监视系统中的设备和组件。它识别、配置并监控设备以进行维护和故障排除。
由于 CAN 的繁忙,你可以想象每天通过 CAN 传输的数据规模。在本篇文章中,我们谈论的是一家连接了 400 万辆车的汽车制造商,每天需要处理 1000 亿条 CAN 数据。
IoV 数据处理
将这些巨大的数据规模转化为指导产品开发、生产和销售的有价值信息是关键部分。像大多数数据分析工作负载一样,这归结于数据写入和计算,这也是存在挑战的地方:
-
大规模数据写入:传感器在汽车的各个地方都有:车门、座椅、刹车灯……此外,许多传感器会收集多个信号。400 万辆车累计的数据吞吐量达到数百万 TPS,这意味着每天有数十 TB 的数据。随着汽车销售的增加,这个数字还在增长。
-
实时分析:这也许是“时间就是生命”最好的体现。汽车制造商收集来自车辆的实时数据,以识别潜在故障,并在损害发生之前修复它们。
-
低成本计算和存储:谈论巨大的数据规模时,很难不提到其成本。低成本使得大数据处理具有可持续性。
从 Apache Hive 到 Apache Doris:向实时分析的过渡
就像罗马不是一天建成的,一个实时数据处理平台也不是一蹴而就的。汽车制造商曾经依赖批量分析引擎(Apache Hive)和一些流处理框架和引擎(Apache Flink,Apache Kafka)的组合,以获得接近实时的数据分析性能。直到实时成为问题,他们才意识到实时的必要性。
接近实时数据分析平台
这曾经对他们有效:
来自 CAN 和车辆传感器的数据通过 4G 网络上传到云网关,云网关将数据写入 Kafka。然后,Flink 处理这些数据并将其转发到 Hive。在 Hive 中经过几个数据仓库层后,汇总的数据被导出到 MySQL。最后,Hive 和 MySQL 将数据提供给应用层,用于数据分析、仪表盘等。
由于 Hive 主要设计用于批处理而非实时分析,你可以看出它在这种用例中的不匹配。
-
数据写入:由于数据规模巨大,从 Flink 到 Hive 的数据摄取时间明显较长。此外,Hive 仅支持按分区粒度更新数据,这对于某些情况来说是不够的。
-
数据分析:基于 Hive 的分析解决方案带来了高查询延迟,这是一个多因素问题。首先,Hive 在处理 1 亿行的大表时比预期要慢。其次,在 Hive 中,数据通过 Spark SQL 从一层提取到另一层,这可能需要一些时间。第三,由于 Hive 需要与 MySQL 配合以满足应用需求,Hive 和 MySQL 之间的数据传输也增加了查询延迟。
实时数据分析平台
当他们在场景中加入实时分析引擎时,会发生这样的情况:
与旧的基于 Hive 的平台相比,这个新平台在以下三方面更为高效:
-
数据写入:将数据导入到Apache Doris非常快捷和简单,无需复杂的配置和额外组件的引入。它支持多种数据导入方式。例如,在这种情况下,数据通过Stream Load从 Kafka 写入 Doris,通过Broker Load从 Hive 写入 Doris。
-
数据分析:以实例展示 Apache Doris 的查询速度,它可以在几秒钟内返回一个包含 1000 万行的结果集。此外,它还可以作为一个统一查询网关,快速访问外部数据(Hive, MySQL, Iceberg 等),使分析师无需在多个组件之间切换。
-
计算和存储成本:Apache Doris 使用 Z-Standard 算法,可以实现 3~5 倍的数据压缩比。这就是它如何帮助降低数据计算和存储成本的原因。此外,压缩可以仅在 Doris 中完成,因此不会消耗 Flink 的资源。
一个好的实时分析解决方案不仅关注数据处理速度,还考虑到整个数据管道的每一步,并使每一步都顺畅。以下是两个例子:
1. CAN 数据的排列
在 Kafka 中,CAN 数据按 CAN ID 的维度进行排列。然而,为了数据分析,分析师需要比较来自不同车辆的信号,这意味着需要将不同 CAN ID 的数据连接到一个平面表中,并按时间戳对齐。从这个平面表中,他们可以派生出不同的表以用于不同的分析目的。这种转换是通过 Spark SQL 实现的,在旧的基于 Hive 的架构中,处理时间较长,而且 SQL 语句维护成本高。此外,数据是以每天批量更新的,这意味着他们只能获取前一天的数据。
在 Apache Doris 中,他们只需要使用聚合键模型构建表,指定 VIN(车辆识别码)和时间戳作为聚合键,并通过 REPLACE_IF_NOT_NULL 定义其他数据字段。使用 Doris,他们不需要处理 SQL 语句或平面表,而是能够从实时数据中提取实时见解。

3. DTC 数据查询
所有 CAN 数据中,DTC(诊断故障代码)值得高度关注和单独存储,因为它告诉你汽车出了什么问题。每天,制造商接收大约 10 亿条 DTC 信息。为了从 DTC 中捕获拯救生命的信息,数据工程师需要将 DTC 数据与 MySQL 中的 DTC 配置表关联起来。
他们过去的做法是每天将 DTC 数据写入 Kafka,在 Flink 中处理,并将结果存储在 Hive 中。这样,DTC 数据和 DTC 配置表被存储在两个不同的组件中。这造成了一个困境:一个有 10 亿行的 DTC 表很难写入 MySQL,而从 Hive 查询则很慢。由于 DTC 配置表也在不断更新,工程师只能定期将其某个版本导入 Hive。这意味着他们无法总是将 DTC 数据与最新的 DTC 配置相关联。
如前所述,Apache Doris 可以作为统一的查询网关。这得益于其多目录功能。他们将 DTC 数据从 Hive 导入 Doris,然后在 Doris 中创建一个 MySQL 目录,以映射到 MySQL 中的 DTC 配置表。当所有这些完成后,他们可以简单地在 Doris 中联接这两张表,并获得实时查询响应。
结论
这是一个实际的物联网实时分析解决方案。它针对非常大规模的数据设计,目前支持一个每天接收 100 亿行新数据的汽车制造商,以改善驾驶安全和体验。
构建适合您使用案例的数据平台并不容易,希望这篇文章能帮助您构建自己的分析解决方案。
Zaki Lu**** 是前百度产品经理,现在是 Apache Doris 开源社区的 DevRel。
更多相关主题
ChatGPT 如何改变编程的面貌
原文:
www.kdnuggets.com/how-chatgpt-is-changing-the-face-of-programming
作者提供的图片
自从 OpenAI 的 ChatGPT 发布以来,编程领域进入了一个新纪元。通过利用先进的自然语言处理能力,初学者和经验丰富的开发者现在拥有强大的工具来简化编码过程。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
像 ChatGPT 或 Gemini 这样的 AI 驱动聊天机器人改变了开发者解决复杂问题和学习新技术的方式。这就是为什么 OpenAI 发布 GPT-4 时,许多用户测试其从零开始创建功能性程序的能力。
结果是什么?
它表现得非常出色。例如,Ammaar Reshi 完全使用 GPT-4 创建了一个《贪吃蛇》游戏,他的演示视频获得了超过 300 万次的观看。点击这里观看视频。
从那时起,AI 编程工具有了显著的发展,从简单的代码补全进化到基于自然语言指令生成代码,如 GitHub Copilot 所示。这些进步不仅简化了开发者的编码工作,也让没有编程经验的人变得更容易上手。
如果未来世界有确定性的话,那就是 AI 工具将深刻改变人们学习编程和日常编程的方式。本文旨在预测未来几年这一领域将经历的主要变化。
1. 缩小知识差距
ChatGPT 的一个最显著的影响是它能够普及编程知识。无论你是经验丰富的开发者还是初学者,ChatGPT 都是一个易于获取的信息来源。
例如,根据去年的 StackOverflow 调查,所有受访者都在使用至少一种 AI 工具作为知识搜索工具,并且明显偏向于 ChatGPT。超过 83% 的受访者每天都在使用 ChatGPT(专业开发者为 83%,学习者为 85%)。
Stack Overflow 2023 调查的截图。受访者使用了哪些 AI 搜索工具?
ChatGPT可以提供清晰的解释、代码片段和逐步指南。这意味着如果今天一个人需要理解一个新的 ML 模型或想要快速掌握一门新的编程语言,AI 工具如 ChatGPT 可以作为个性化的老师。
例如,一个新手试图理解面向对象编程的概念,可以轻松地向 ChatGPT 请求清晰的解释。这在学习曲线中真正改变了游戏规则。之前学习者必须阅读密集的教科书或观看无尽的在线教程,而现在用户可以获得针对自然语言提示的即时、量身定制的响应。
这种即时获取知识的能力降低了新手的入门门槛,并提高了有经验程序员的学习速度。
2. 提升代码质量和效率
编写干净、高效且无错误的代码仍然是许多开发者面临的挑战。这就是为什么像ChatGPT这样的 AI 驱动工具可以通过建议最佳实践、提供代码评审,甚至生成符合行业标准的代码片段来提供帮助。
想象一下你正在编写一个 Python 脚本,需要一个快速的函数来解析 JSON 数据。ChatGPT可以为你生成这个函数,包含错误处理和优化建议。
此外,ChatGPT 也可以帮助调试代码。
之前我们大多数人都花费了数小时尝试找出代码为何不起作用,现在我们可以将代码片段分享给 ChatGPT 并获得直接的评审。
像 GitHub Copilot 这样的新工具正在变得越来越受欢迎,以加速开发过程。根据 Stack Overflow 调查,近 80% 的开发者在日常工作中使用基于 AI 的编码辅助工具。
2023 年 Stack Overflow 调查的截图。使用 AI 驱动的编码辅助工具
AI 工具改善了编码过程,使它们在现代软件开发中成为无价的资产。
3. 促进协作与沟通
编程通常需要同事之间的协作和清晰的沟通。最佳实践之一是记录任何正在开发的过程,不是吗?
ChatGPT 可以通过生成文档、编写有用的代码注释,甚至将技术术语翻译成易于理解的词汇,来帮助我们服务于没有技术知识的同事。
让我们假设你正在与一个远程团队合作生成一个工作的 API 端点。你可以轻松使用 ChatGPT 草拟关于你的 API 端点进展的完整文档,确保每个人都在同一页上。
目前甚至有一些 AI 工具已经集成到 Teams 或 Slack 等呼叫软件中,用于记录会议记录,并确保每个人都对相同的要点和主要目标有一致的认识。这进一步提升了团队的生产力,并确保知识被很好地记录下来且易于传递。
4. 自动化重复任务
重复任务可能会耗尽开发者的创造力和生产力。ChatGPT 和 AI 驱动工具可以自动化许多这些枯燥的任务,让开发者可以专注于项目中更复杂和更有价值的方面。这包括生成样板代码和设置项目模板。
让我们考虑一下设置新项目的任务。这通常涉及创建目录、初始化版本控制、设置虚拟环境和安装依赖项。
工作量很大,对吧?
借助像 ChatGPT 这样的 AI 驱动工具,你可以通过接收一个处理设置过程的脚本来自动化这些步骤,从而节省宝贵的时间并减少人为错误的风险。
5. 学习与适应
目前像 ChatGPT 或 Gemini 这样的 AI 驱动工具已经连接到互联网。这意味着它们不断更新新编程语言、框架和工具,使得开发者可以依赖它们获取最新的事实和信息。
此外,模型微调甚至个性化 GPT 可以调整模型,以进一步符合个人用户的偏好和编码风格,从而提供更个性化的帮助。
例如,如果你经常使用某个特定的 JavaScript 框架,比如 React,ChatGPT 可以调整其推荐或示例,以对应当前 React 开发中的最新进展。
这种持续的学习和适应确保了 ChatGPT 即使在编程世界不断演变的情况下,仍然是一个宝贵的资源。
结论
这些 AI 驱动工具不仅仅是聊天机器人,它们是强大的助手,能够简化开发过程。在知识触手可及方面,包括代码质量改进措施、协作增强步骤和任务自动化流程。这使得编码对所有人都变得更加可及,无论是业余编码者还是经验丰富的开发者。将 ChatGPT 集成到工作流程中可以提升生产力水平并增加创新能力。
通过这些新型的 AI 驱动工具迎接编程的未来。这将改变你对编码的看法,使其比以往任何时候都更容易和更具协作性。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他拥有物理工程学位,目前在应用于人类流动性的领域从事数据科学工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 涉及 AI 的所有事宜,涵盖了该领域的持续爆炸性发展。
更多相关内容
我们离 AGI 有多近?

作者提供的图片
技术的发展速度是否超过了我们人类的跟进能力?确实如此。今年仅有大量的进展,一波接一波,我们很难跟上。似乎每天我们都在学习新的东西,时刻保持警觉。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
随着这些进展,关于人工通用智能(AGI)的讨论变得越来越频繁。它曾经是科幻小说中的话题,我们在电影和书籍中看到,那些情节有些过于夸张和不切实际。
但特别是在 2023 年,这种情况发生了巨大的变化。公众对 AI 及其将如何塑造未来表现出极大的兴趣。生成式 AI 系统如 ChatGPT 已经震撼了整个世界,有些人喜爱它,而有些人则担心工作被取代。
这又回到了 AGI 的话题。但是 AGI 是什么呢?
人工通用智能(AGI)是一种可以执行任何类型智力任务的机器,就像人类一样。
话虽如此,很多人心中的大问题是我们离真正实现 AGI 还有多远,及其实现后的影响。
这就是本博客将要探讨的内容,所以系好安全带,享受了解我们潜在未来的过程……
我们对 AGI 的了解
所以我们知道,AGI 是一种能够执行任何人类能完成的智力任务的 AI 系统。这意味着机器必须具备人类水平的智能,而无需任何帮助。人工智能的基础工作始于 20 世纪初,许多人表示,实现 AGI 将完成 AI 遗产的终极目标。
这并不是说目前的 AI 系统没有以非常高的准确度执行任务的能力,甚至超越人类。然而,AI 系统中缺少的东西是它们的通用能力。这意味着它们缺乏快速适应新情况的能力,而不需要指令。
我们人类经过多年适应,生存于不同的环境中。我们的通用能力与生存相关,这就是我们如此擅长的原因。
最近有很多发展塑造了技术世界,其中之一是生成式人工智能系统,如 ChatGPT。我想说明的是,生成式人工智能和人工通用智能有相似之处,但它们是不同的。生成式人工智能是一个深度学习模型,能够根据其训练数据生成内容,如文本和图像。
举个例子,一个人工智能国际象棋程序很可能会在国际象棋比赛中击败你,但同样的人工智能系统却无法告诉你当前世界政治的情况。这是因为它只限于特定领域,仅此而已。
正如我们提到的,AGI(通用人工智能)缺乏通用能力,这也是生成式人工智能所缺乏的——因为这不是它的目的。生成式人工智能将辅助 AGI 的进程,但重要的是要注意它们并不相同。
向 AGI 的进展
所以我们明白,我们还没有完全实现 AGI,但我们目前处于什么阶段,正在进行什么工作?
研究与开发
深度学习已经经历了多年的研究,深度学习是机器学习的一个子领域。这是一种机器学习方法,教计算机做出与人类自然的行为类似的事情。它训练一个算法根据给定的输入预测输出。
大量数据在复杂神经网络上的使用,使得人工智能系统能够处理复杂任务,例如自然语言处理(NLP)和图像识别。深度学习行业正在进行大量的学习和改进,以帮助 AGI 的诞生。
强化学习
与这种方法并行的是,强化学习的应用也在增加。强化学习的目的是通过使用为特定问题创建的解决方案和/或决策序列来训练模型,以返回最佳解决方案。为了使模型能够选择正确的解决方案/决策,设置了奖励信号。
如果模型的表现接近目标,就会给予正向奖励;然而,如果模型的表现远离目标,则给予负向奖励。机器学习模型通过理解其环境并根据其行动接收反馈来学习。
面向 AGI 的挑战
可适应的 AI 系统
自然地,在任何进程中,你都会遇到需要克服的挑战。在研究和开发方面,AGI 面临的主要挑战是构建一个能够理解输入背景并像人类一样适应它的系统。研究人员正在探索算法可以以更具创造性的方式思考以克服这一挑战。例如,一些研究人员正在研究智能 AI 系统在其生命周期内进行持续学习的可能性。
基于此,我们距离 AGI 还有多远?
硬件限制
正如你可以想象的那样,构建这些令人惊叹的 AI 系统并不简单。它们需要大量的计算能力,这推动了专用硬件如 GPU 和 TPU 的发展。这些硬件也不便宜。所以你可以想象,构建一个准确且强大的 AI 系统需要多少周和月份的时间、数据以及其他资源。
那么我们在 AGI 方面进展如何?
这很难说,因为 AGI 的专家们意见不一。有些人说 AGI 可能在未来几年内实现,而另一些人则认为我们仍需数十年的工作。
唯一能够决定我们离 AGI 有多近的因素是技术进步的速度。当前和新技术系统的进步越多,专家们找到拼图缺失部分的机会就越大。科技界的突破越多,我们离 AGI 就越近。
另一个政府和组织现在比以往任何时候都更加考虑的方面是这些 AI 系统对社会的伦理影响。推动 AGI 的叙事可能会导致无法理解和控制这些 AI 系统的灾难性后果。
总结一下
话虽如此,我们看到越来越多的组织向科技行业投入更多资金。许多组织正在追赶竞争市场,还有一些试图创造一个全新的市场。
对这个博客问题的回答是,我们需要等待看看未来会出现哪些技术进步,以更好地了解我们离 AGI 到底还有多远。
Nisha Arya 是一名数据科学家、自由技术写作者以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及数据科学的理论知识。她还希望探索人工智能在促进人类寿命方面的不同方式。她是一位热衷学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
数据科学如何提高电子商务行业的盈利能力?
原文:
www.kdnuggets.com/2015/11/how-data-science-increased-profitability-e-commerce-industry.html/2
电子商务中的数据科学应用
1) 针对客户的产品推荐
“未来将变得如此个性化,你将像客户了解自己一样了解他们,”Demandware 总裁兼首席执行官 Tom Ebling 说。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
促销和推荐在基于客户行为时非常有效。现在的客户依赖于推荐,无论是购买产品、了解最新发布的新闻、访问餐馆还是获取服务。大多数电子商务网站,如 沃尔玛、亚马逊、eBay、Target,都有数据科学团队考虑类型、重量、特性和各种其他因素,以在后台实施某种推荐引擎。通过数据科学实施的推荐引擎有两个主要目的 -
-
交叉销售 - 你正在购买 iPhone 6,所以你可能会对保护它的 iPhone 保护壳感兴趣。
-
向上销售 - 比如说,你正在查看一台 LED 电视,这里有下一个版本的电视,它更棒,只需多花几美元就能买到。
数据科学算法学习产品的各种属性和关联;了解客户的喜好,以预测客户的需求。数据科学算法通过为特定客户更改画廊页面或更改移动应用程序或网站搜索结果中产品的排序来帮助个性化客户体验。
Brillio(一个美国科技顾问和软件开发公司)的首席技术官 Puneet Gupta 说:“通过预测分析和机器学习的使用,电子商务玩家现在可以清晰地了解消费者行为模式,包括购买历史和网站上不同产品的表现。”
最好的例子是亚马逊的推荐引擎,它使用预测建模。亚马逊的推荐引擎发现并以数学方式表示这些在历史数据中发现的关系,以对未来事件进行分类或预测。
2) 获取客户洞察以促进客户保留、追加销售和交叉销售
随着购物习惯的变化、客户忠诚度的下降和高期望值,获取客户洞察对于电子商务企业的生存变得极为重要。
任何电子商务网站或移动应用都有待售的产品,但电子商务企业需要关注的是:
谁在购买他们的产品?
他们住在哪里?
他们对哪些产品感兴趣?
企业如何更好地服务他们?
促使他们购买的原因是什么?
所有上述问题的答案通常由专注于客户洞察的产品领域内的数据分析师提供。数据科学算法可以通过更高级的分析方法,如分类器、分割、无监督聚类、预测建模和自然语言处理,以及主题建模和关键词提取,来增加价值。
Blue Yonder,一家德国软件公司,开发了一种自学习技术 使用数据科学工具和技术,帮助 Otto(欧洲在线时尚巨头)——当客户走进实体店、登录零售商的 Wi-Fi,或连接到移动应用或网站时,自主学习有关客户的信息。客户会根据商店的位置、天气条件以及其他各种因素收到推送通知。
3) 定义产品策略以实现最佳产品组合
电子商务企业必须处理各种问题,例如:
-
他们应该销售哪些产品?
-
应该为产品提供什么价格以及何时提供?
数据科学算法帮助电子商务企业定义和优化产品组合。每个电子商务企业都有一个产品团队,负责设计过程,其中数据科学算法可以帮助企业进行预测,例如:
-
产品组合中存在哪些漏洞?
-
他们应该生产什么?
-
从工厂批发点应该订购多少初始批量?
-
他们应该什么时候停止供应这些产品?
-
他们应该在什么时候销售?
数据科学家通过更先进的预测性和处方性分析来帮助电子商务企业,而数据分析师则仅关注回顾性分析,例如业务的利润是多少,哪些产品毫无价值等。
4) 预测供应链模型以实现有效交付
为了使电子商务企业能够销售产品,他们需要在正确的时间将正确数量的产品放在正确的位置。在电子商务或任何零售业务中,一些产品可能有非常短的需求窗口(想想定制的“2014 年圣诞快乐”产品在 2015 年 1 月 1 日的情况),如果企业错过了某一产品的需求窗口,他们可能会在仓库中堆积无用的库存。数据科学算法进行详细分析,以开发先进的预测模型,帮助电子商务企业优化客户满意度,降低风险因素并制定策略。
5) 个性化营销策略
数据科学 在个性化营销方案中发挥着关键作用。电子商务企业总是寻找新颖的方式来鼓励现有客户进行更多购买,或寻找吸引更多客户的策略。数据科学家可以通过广告重定向优化、渠道组合优化、广告词购买优化等方面为此做出贡献。通过设计 数据科学算法 来应用这些不同的策略,数据科学家可以帮助电子商务企业达到令人瞩目的高度,从而为企业赢得丰厚的回报。
数据科学是电子商务业务的核心,也可以用于欺诈检测、网络分析和人力资源。你能想到电子商务行业中其他正在革新电子销售的数据显示应用吗?在下面的评论中告诉我们。
原文。
相关:
-
Ramkumar Ravichandran,Visa 关于分析的客户关注思维
-
采访:Ali Vanderveld,Groupon 讲述数据科学如何改变全球电子商务市场
-
Reiner Kappenberger,HP Security Voltage 关于如何保护数据传输
更多相关主题
如何确定你的机器学习模型是否过拟合
原文:
www.kdnuggets.com/2021/05/how-determine-machine-learning-model-overtrained.html
评论
作者 Charles Martin,Calculation Consulting
你的模型是否过拟合?Weightwatcher 工具可以检测预训练或训练深度神经网络中特定层的过拟合特征。
在上面的图中,图 (a) 是训练良好的,而图 (b) 可能已经过拟合。右侧的橙色峰值是明显的线索;这就是我们所说的相关性陷阱。
Weightwatcher 可以检测预训练或训练深度神经网络中特定层的过拟合特征。在这篇文章中,我们展示了如何使用 Weightwatcher 工具来实现这一点。
WeightWatcher
WeightWatcher (WW):是一个开源的诊断工具,用于分析深度神经网络(DNN),无需访问训练数据或测试数据。它逐层分析预训练或训练的 DNN 的权重矩阵,以帮助你检测潜在问题。这些问题是通过仅查看测试准确性或训练损失无法发现的。
安装:
pip install weightwatcher
使用:
import weightwatcher as ww
import torchvision.models as models
model = models.vgg19_bn(pretrained=True)
watcher = ww.WeightWatcher(model=model)
details = watcher.analyze(plot=True, randomize=True)
对于每一层,Weightwatcher 绘制了经验谱密度(ESD)。这只是该层相关矩阵X=W^TW的特征值的直方图。
import numpy as np
import matplotlib,pyplot as plt
...
X = np.dot(W,W.T)
evals, evecs = np.linalg.eig(X(
plt.hist(evals, bin=100, density=True)
...
通过指定随机化选项,WW 随机化权重矩阵W的元素,然后计算其 ESD。这个随机化的 ESD 会叠加在X的原始 ESD 上,并绘制在对数刻度上。
这在上面展示了。原始层 ESD 为绿色;随机化的 ESD 为红色,橙色线表示随机化 ESD 的最大特征值 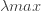 。
。
如果层是良好训练的矩阵,那么当W被随机化时,其 ESD 会类似于正态分布的随机矩阵。这在上面的图 (a) 中有所展示。
但如果该层已过拟合,则其权重矩阵W可能包含一些异常大的元素,其中相关性可能集中或被困。在这种情况下,ESD 可能会有一个或多个异常大的特征值。这在上面的图 (b) 中有所展示,其中橙色线延伸到红色 ESD 的右侧。
还要注意,在图 (a) 中,绿色 的 ESD 具有非常重尾的特性,直方图延伸到 log10=2,或最大特征值接近 100:  。但在图 (b) 中,绿色 ESD 的形状明显不同,规模比图 (a) 小。实际上,在 (b) 中,绿色(原始)和红色(随机化)的层 ESD 看起来几乎相同,除了一个较大的 绿色 特征值的小阶梯,延伸到并集中在 橙色线 附近。
。但在图 (b) 中,绿色 ESD 的形状明显不同,规模比图 (a) 小。实际上,在 (b) 中,绿色(原始)和红色(随机化)的层 ESD 看起来几乎相同,除了一个较大的 绿色 特征值的小阶梯,延伸到并集中在 橙色线 附近。
在这种情况下,我们可以将 橙色线 识别为 相关性陷阱。
这表明在训练这一层时出现了问题,模型未能以一种能很好地泛化到其他示例的方式捕捉到这一层的相关性。
结论
使用 Weight Watcher 工具,你可以在训练或微调深度神经网络时检测到此类及其他潜在问题。
你可以在WeightWatcher GitHub 网站上了解更多信息。
简介: 查尔斯·马丁博士 与加州大学伯克利分校共同开发了 Weight Watcher 项目。他在加利福尼亚州旧金山经营一家精品咨询公司,帮助客户开发人工智能解决方案。他曾与 eBay、Blackrock、GoDaddy 和沃尔玛等大型公司合作,也与 Aardvark(被谷歌收购)和 Demand Media(自谷歌以来的首个十亿美元 IPO)等非常成功的初创公司合作。他还通过人类世研究所向 Page 家族办公室提供关于人工智能、核物理和量子力学/计算领域的建议。
原文。经许可转载。
相关:
-
微软使用变换器网络以最少的训练回答关于图像的问题
-
教 AI 像人类一样看待事物
-
如何加速 Scikit-Learn 模型训练
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
我的训练数据和测试数据有多(不)相似?
原文:
www.kdnuggets.com/2018/06/how-dissimilar-train-test-data.html
评论
由 Shikhar Gupta 提供
人们总是说不要拿苹果和橘子做比较。但是如果我们比较的是一组苹果和橘子的混合与另一组苹果和橘子的混合,但分布不同,那你还能比较吗?你将如何进行比较呢?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
在现实世界的大多数情况下,你会遇到后一种情况。

这在数据科学中发生得很频繁。在开发机器学习模型时,我们会遇到一种情况,即我们的模型在训练数据上表现良好,但在测试数据上却无法达到相同的性能。
我这里不是在谈论过拟合。即使我根据交叉验证选择了最好的模型,并且它在测试数据上表现仍然很差,那么测试数据中存在一些我们未能捕捉到的内在模式。< 想象一个我试图建模顾客购物行为的情况。如果我的训练数据和测试数据如下图所示,你可以清楚地看到这个问题。 
模型将基于与测试数据相比平均年龄较低的客户进行训练。这个模型从未见过测试数据中那种年龄模式。如果年龄在你的模型中是一个重要特征,那么它在测试数据上表现会很差。
在这篇文章中,我将讨论如何识别这个问题以及一些解决方案的初步想法。
协变量漂移
我们可以更正式地定义这种情况。协变量指的是我们模型中的预测变量。协变量漂移指的是预测变量在训练数据和测试数据中具有不同的特征(分布)的情况。
在具有许多变量的现实世界问题中,协变量漂移很难被发现。在这篇文章中,我尝试讨论一种识别这种情况的方法,以及如何考虑训练数据和测试数据之间的这种漂移。
基本概念
如果存在协变量漂移,那么在混合训练集和测试集后,我们仍然能够以较高的准确率对每个数据点的来源(是来自测试集还是训练集)进行分类。
让我们深入理解一下。考虑上述例子,其中年龄是测试和训练之间的漂移特征。如果我们使用随机森林等分类器来将行分类为测试和训练,年龄将成为数据拆分中的一个非常重要的特征。
实施
现在,让我们尝试将这个想法应用于实际数据集。我使用的是来自这个 Kaggle 竞赛的数据集:www.kaggle.com/c/porto-seguro-safe-driver-prediction/data
步骤 1:数据预处理
我们首先需要清理数据,填补所有缺失值,并对所有分类变量进行标签编码。对于这个数据集,这一步骤并不需要,因此我跳过了这一步。
#loading test and train data
train = pd.read_csv(‘train.csv’,low_memory=True)
test = pd.read_csv(‘test.csv’,low_memory=True)
步骤 2:
我们需要在训练和测试数据中都添加一个特征‘is_train’。这个特征的值将是测试集为 0,训练集为 1。
#adding a column to identify whether a row comes from train or not
test[‘is_train’] = 0
train[‘is_train’] = 1
合并训练和测试
然后我们需要将两个数据集合并。此外,由于训练数据中有原始的‘target’变量,而测试数据中没有,所以我们也必须丢弃那个变量。
注意: 对于你的问题,‘target’将被替换为原始问题中因变量的名称。
#combining test and train data
df_combine = pd.concat([train, test], axis=0, ignore_index=True)
#dropping ‘target’ column as it is not present in the test
df_combine = df_combine.drop(‘target’, axis =1)
y = df_combine['is_train'].values #labels
x = df_combine.drop('is_train', axis=1).values #covariates or our independent variables
tst, trn = test.values, train.values
步骤 4:构建和测试分类器
为了分类目的,我使用随机森林分类器来预测合并数据集中每一行的标签。你也可以使用其他任何分类器。
m = RandomForestClassifier(n_jobs=-1, max_depth=5, min_samples_leaf = 5)
predictions = np.zeros(y.shape) #creating an empty prediction array
我们使用分层 4 折来确保每个类别的百分比得到保留,并且覆盖整个数据集。对于每一行,分类器将计算其属于训练集的概率。
skf = SKF(n_splits=20, shuffle=True, random_state=100)
for fold, (train_idx, test_idx) in enumerate(skf.split(x, y)):
X_train, X_test = x[train_idx], x[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
m.fit(X_train, y_train)
probs = m.predict_proba(X_test)[:, 1] #calculating the probability
predictions[test_idx] = probs
步骤 5:解释结果
我们将输出分类器的 ROC-AUC 指标,以估算数据的协变量偏移程度。
如果分类器能够以良好的准确性将行分类为训练和测试,我们的 AUC 分数应该较高(大于 0.8)。这意味着训练和测试之间存在强烈的协变量偏移。
print(‘ROC-AUC for train and test distributions:’, AUC(y, predictions))
# ROC-AUC for train and test distributions: 0.49944573868
AUC 值为 0.49 意味着没有强烈的协变量偏移证据。这意味着大多数观察结果来自一个不特定于测试或训练的特征空间。
由于这个数据集来自 Kaggle,所以这个结果是相当预期的。在这种竞赛数据集中,数据通常经过精心策划,以确保没有这样的偏移。
这个过程可以在任何数据科学问题中复制,以检查在开始建模之前是否存在协变量偏移。
超越
此时我们要么观察到协变量偏移,要么没有。那么我们可以做些什么来提高测试数据上的性能呢?
-
丢弃漂移特征
-
使用密度比估计进行重要性加权
丢弃漂移特征:
注意: 这种方法适用于你观察到协变量偏移的情况。
-
从我们在上一节中构建的随机森林分类器对象中提取特征重要性
-
顶级特征是那些正在漂移并导致转移的特征。
-
从最重要的特征中一次删除一个变量,构建你的模型并检查其性能。收集所有那些性能没有下降的特征。
-
在构建最终模型时,现在删除所有这些特征。
这个想法是去除那些落在红色桶中的特征。
使用密度比估计的重要性权重
注意: 该方法适用于是否存在协变量转移的情况。
让我们看看我们在上一节中计算的预测结果。对于每个观察值,这个预测结果告诉我们它属于训练数据的概率。
predictions[:10]
----output-----
array([ 0.34593171])
所以对于第一行,我们的分类器认为它以.34 的概率属于训练数据。我们称之为 P(train)。或者我们也可以说它有.66 的概率来自测试数据。我们称之为 P(test)。现在这里是魔法技巧:
对于每一行训练数据,我们计算一个系数w = P(test)/P(train)。
这个 w 告诉我们观察值与训练数据的接近程度。这里是重点:
我们可以将这个 w 作为任何分类器中的样本权重,以增加这些与测试数据相似的观察值的权重。直观上,这很有意义,因为我们的模型将更多关注于捕捉那些与测试数据相似的观察值中的模式。
这些权重可以使用以下代码计算。
plt.figure(figsize=(20,5))
predictions_train = predictions[len(tst):] #filtering the actual training rows
weights = (1./predictions_train) — 1\.
weights /= np.mean(weights) # Normalizing the weights
plt.xlabel(‘Computed sample weight’)
plt.ylabel(‘# Samples’)
sns.distplot(weights, kde=False)
< 你可以像这样将模型拟合方法中计算的权重传递进去:
m = RandomForestClassifier(n_jobs=-1,max_depth=5)
m.fit(X_train, y_train, *sample_weight=weights*)
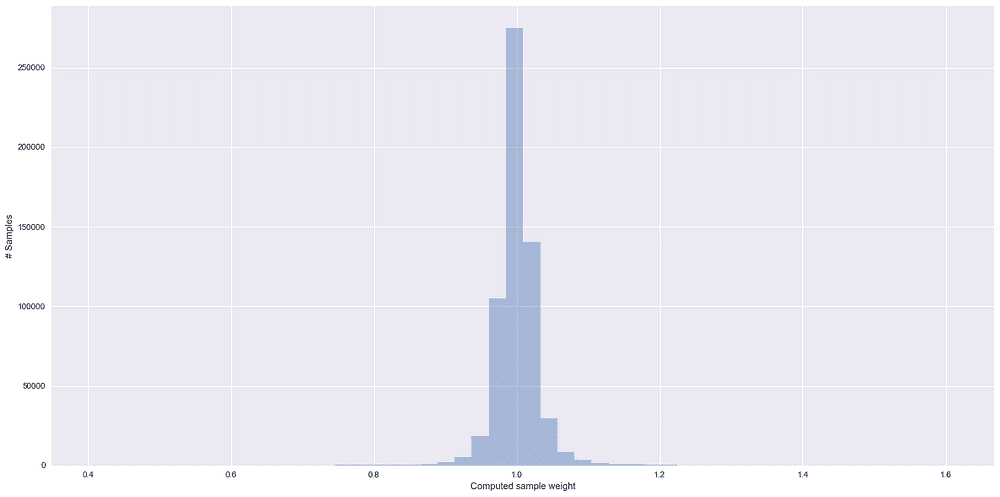
在上述图中需要注意的一些事项:
-
观察值的权重越高,它与测试数据的相似性就越大。
-
几乎 70%的训练样本的样本权重接近 1,因此来自于一个对训练或测试高密度区域不是非常特定的特征空间。这与我们计算的 AUC 值一致。
结束语
我希望现在你对协变量转移有了更好的理解,知道如何识别并有效处理它。
简介:Shikhar Gupta 正在旧金山大学攻读数据科学硕士学位,实习于@IsaziConsulting,@iitroorkee 校友。
原文。转载获得许可。
相关:
更多相关内容
生成式 AI 如何帮助您改进数据可视化图表
原文:
www.kdnuggets.com/how-generative-ai-can-help-you-improve-your-data-visualization-charts

图片来自 DALLE 3
5 个关键要点:
-
数据可视化图表的基本结构
-
使用 Python Altair 构建数据可视化图表
-
使用 GitHub Copilot 加速图表生成
-
使用 ChatGPT 为您的图表生成相关内容
-
使用 DALL-E 为您的图表添加吸引人的图片
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 支持
是否厌倦了花费数小时创建乏味的数据可视化图表?利用生成式 AI 的力量来改进您的数据可视化。在本文中,我们将探讨如何使用生成式 AI 来丰富您的图表。我们将使用前沿工具,如 Python Altair、GitHub Copilot、ChatGPT 和 DALL-E,通过生成式 AI 的支持来实现我们的图表。
首先,让我们使用 GitHub Copilot 实现基本图表。接下来,我们将使用 ChatGPT 添加文本注释(例如标题)。最后,我们将使用 DALL-E 为图表添加图片。作为编程语言,我们将使用 Python 和 Python Altair 可视化库。
我们将涵盖:
-
定义用例
-
基本图表构建:使用 GitHub Copilot
-
添加注释:ChatGPT
-
添加图片:DALL-E。
用例:意大利的研发支出
作为一个用例,我们将绘制一个图表,表示按绩效领域划分的研发支出,使用 数据集 ,该数据集由 Eurostat 以开放数据许可证发布。为了使过程更易于访问,我们将使用一个简化版的 数据集,该数据集已经转换为 CSV 格式。下表显示了数据集的一个摘录:
| unit | sectperf | geo | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PC_GDP | BES | AT | 1.87 | 1.84 | 2.05 | 2.09 | 2.2 | 2.18 | 2.19 | 2.14 | 2.16 | 2.2 | 2.23 | 2.22 |
| PC_GDP | BES | BA | 0.16 | 0.19 | 0.05 | 0.07 | 0.08 | |||||||
| PC_GDP | BES | BE | 1.38 | 1.49 | 1.59 | 1.62 | 1.66 | 1.7 | 1.73 | 1.87 | 2.05 | 2.33 | 2.48 | 2.42 p |
| PC_GDP | BES | BG | 0.28 | 0.28 | 0.36 | 0.39 | 0.52 | 0.7 | 0.56 | 0.52 | 0.54 | 0.56 | 0.57 | 0.51 |
数据集包含以下列:
-
unit - 该列的值始终设为国内生产总值百分比(PC_GDP)
-
sectperf - 绩效领域。可能的值包括:商业企业(BES);政府(GOV);高等教育(HES);私人非营利(PNP),以及 TOTAL
-
geo - 欧洲国家
-
2010-2021 - 指定年份的支出值。
作为一个具体案例,让我们关注意大利的 BES,并使用 Python Altair(一个数据可视化库)绘制图表。
构建基本图表:使用 GitHub Copilot
GitHub Copilot 是一个生成性 AI 工具,您可以在编写代码时将其作为助手使用。在 GitHub Copilot 中,您描述软件必须执行的操作序列,GitHub Copilot 将其转换为您所需编程语言的可执行代码。使用 GitHub Copilot 的能力在于学习如何描述操作序列。
安装 Copilot
在使用 GitHub Copilot 之前,您必须首先为您的个人 GitHub 帐户设置免费试用或订阅。如果您是教师或学生,可以通过以下链接设置免费订阅计划:education.github.com/discount_requests/pack_application。
一旦激活订阅计划,您可以将 Copilot 配置为 Visual Studio Code (VSC) 的扩展,这是一个免费的开源代码编辑器,旨在帮助开发人员编写和调试代码。
按照以下步骤配置 VSC 与 Copilot:
-
从其官方网站下载 VSC:
visualstudio.microsoft.com/it/downloads/ -
打开 Visual Studio 并导航到扩展选项卡
-
下载并安装 GitHub Copilot 扩展,并从仪表板中选择连接到你的帐户。
-
输入你的 GitHub 凭证。
-
登录后,扩展程序会检测到现有的仓库并提供配置新项目的选项。
使用 Copilot 作为代码助手
使用 Copilot,让我们为可视化生成基本图表。为了构建图表,我们执行两个步骤:
-
加载和预处理数据 - 将数据集加载为 Pandas DataFrame,删除不必要的列,选择仅与意大利相关的行,并使用 Pandas melt() 将与 2010-2021 相关的列转换为行。
-
将图表构建为折线图。
让我们从第一步开始,加载和预处理数据。为 Copilot 编写以下指示:

按下键盘上的 ENTER 按钮,Copilot 开始生成与所写指示相对应的代码。以下代码片段展示了 Copilot 生成的一个可能输出:
import pandas as pd
import altair as alt
df = pd.read_csv('tsc00001.csv')
df = df.drop(columns=['unit'])
df = df[df['geo'] == 'IT']
df = df.drop(columns=['geo'])
df = pd.melt(df, id_vars=['sectperf'], var_name='date', value_name='value')
df['date'] = df['date'].astype(int)
df['value'] = df['value'].astype(float)
记住,Copilot 是一个生成模型,因此你得到的输出可能与之前的不同。
现在,让我们继续进行构建图表的指示。为 Copilot 编写以下指示:

Copilot 将生成类似于下面代码片段的 Python 代码:
chart = alt.Chart(df).mark_line().encode(
x='date:O',
y='value',
color='sectperf'
)
chart.save('chart.html')
保存脚本,并从命令行运行它。作为输出,脚本会生成一个名为 chart.html 的 HTML 文件。使用你喜欢的浏览器打开它。以下图形展示了生成的图表:
现在你已经构建了基本图表,你可以手动改进它或使用 Copilot。例如,你可以让 Copilot 生成增加 BES 笔画宽度的代码。在颜色行后添加逗号,并开始编写如下指示:

按下 ENTER 并等待 Copilot 为你编写代码。以下代码片段展示了 Copilot 生成的一个可能输出:
strokeWidth=alt.condition(
alt.datum.sectperf == 'BES',
alt.value(5),
alt.value(1)
)
以下图形展示了改进后的图表:
你可以通过让 Copilot 旋转 X 标签、设置标题等进一步改善图表。你可以在[1]中了解更多关于如何改善图表的详细信息。下图显示了清理后的图表版本。你可以在 这个链接 找到完整代码。
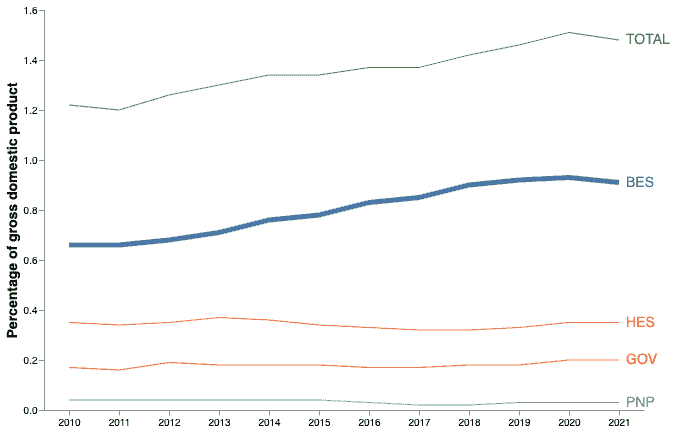
一旦基础图表准备好,我们可以继续下一步,使用 ChatGPT 设置图表标题。
添加注释:ChatGPT
ChatGPT 是由 OpenAI 开发的高级语言模型。它旨在进行类似人类的对话并提供智能响应。我们可以利用 ChatGPT 为我们的图表生成文本,包括标题和注释。
要使用 ChatGPT,请访问 chat.openai.com/,登录你的账户或创建一个新账户,然后像实时聊天一样在输入文本框中开始编写提示。每当你想开始一个新话题时,通过点击左上角的“新聊天”按钮创建一个新聊天会话。
网页界面还提供了一个付费账户,提供一些额外功能,例如使用高级模型的可能性,以及一套额外功能,如优先支持、扩展的自定义选项和对 beta 功能和更新的独占访问权限。
要与 ChatGPT 互动,请编写一个定义要执行的指令的输入文本(提示)。为 ChatGPT 结构化提示有多种方式。在本文中,我们考虑一个由三个主要连续文本组成的提示:
-
告诉 ChatGPT 扮演一个特定的[角色]——例如,“你是一个正在查看高中生英语试卷的考官。”
-
告诉 ChatGPT 根据预期的[受众]量身定制其输出——例如,“以高中生能理解的方式解释你的评分。”
-
确定[任务]——例如,“对这段文本进行评分并解释你的推理。”
在我们的示例中,我们可以将提示格式化如下:
以数据分析师的身份与决策者沟通。为以下主题生成 5 个标题:一张显示 2010 年至 2021 年绩效部门的图表。绩效部门包括商业企业(BES);政府(GOV);高等教育(HES);和私人非营利组织(PNP)。你希望关注 BES,因为它在时间上具有最高的值。
ChatGPT 生成了五个标题,如下图所示:

如果你再次运行相同的提示,ChatGPT 将生成另外五个标题。例如,我们可以选择第一个标题,Driving Growth: A Decade of Business Enterprise Performance Dominance (2010-2021),并将其设为图表标题:
chart = alt.Chart(df).mark_line().encode(
…
).properties(
width=600,
height=400,
**title=['Driving Growth:',
'A Decade of Business Enterprise Performance Dominance (2010-2021)']**
)
下图显示了结果图表:
图表几乎完成了。为了提高图表的可读性并引起观众的情感共鸣,我们可以添加一张图像。
添加图像:DALL-E
DALL-E 是由 OpenAI 创建的生成型 AI 模型。它结合了 GPT-3 的强大功能和图像生成能力,使其能够根据文本描述生成逼真的图像。要使用 DALL-E,你必须在 Open AI 网站 上注册账户并购买一些积分。
存在不同的方式来结构化 DALL-E 的提示。在本文中,我们考虑一个由以下内容组成的提示:
-
[主题]
-
[风格]。
在我们的案例中,我们可以生成一个主题为:代表研发支出的黑白图标的通用图像。
下图显示了 DALL-E 生成的一个可能输出:

让我们选择第三张图像并将其添加到图表中,如下代码片段所示:
df_red = pd.DataFrame({'url': ['red.png']})
red = alt.Chart(df_red).mark_image(
align='center',
baseline='top',
width=300,
height=300
).encode(
url='url'
)
chart = (red | chart + text)
要查看图表中的图像,你必须在 Web 服务器上运行它。从包含 HTML 文件的目录中运行以下 Python 命令以启动简单的 Web 服务器:python3 -m http.server,然后指向 localhost:8000/chart.html。你应该会看到一个类似于以下的图表:
你可以根据自己的喜好自定义图表。例如,你可以为每个表现部门生成一个图标。
总结
恭喜你!你刚刚学会了如何使用生成型 AI 工具来增强你的数据可视化图表!
-
首先,使用 GitHub Copilot 编写你的基本图表。
-
接下来,使用 ChatGPT 为你的图表生成文本描述,例如标题和注释。
-
最后,使用 DALL-E 生成图像以包含在图表中,以提高可读性并吸引观众。
你可以从这个 GitHub 仓库 下载本示例中描述的完整代码。此外,你可以在 [1] 中找到关于如何在数据讲述中使用生成型 AI 的更多详细信息。
参考资料
[1] A. Lo Duca.使用生成 AI 进行数据讲述,利用 Python 和 Altair. Manning Publications.
[2] A. Lo Duca. 使用 Python Altair 进行数据讲述. Educative Inc.
Angelica Lo Duca**** (Medium) (@alod83) 是意大利比萨国家研究委员会(IIT-CNR)信息学与电信研究所的研究员。她是比萨大学数字人文学科硕士课程中“数据新闻学”课程的教授。她的研究兴趣包括数据科学、数据分析、文本分析、开放数据、网络应用、数据工程和数据新闻学,应用于社会、旅游和文化遗产领域。她是由 Packt Ltd. 出版的《数据科学的彗星》一书的作者,Manning 出版的即将出版的《Python Altair 和生成 AI 中的数据讲述》一书的作者,以及即将出版的 O'Reilly Media 出版的《学习和操作 Presto》一书的合著者。Angelica 还是一位热情的技术作家。
更多相关主题
多模态如何使 LLM 对齐变得更具挑战性
原文:
www.kdnuggets.com/how-multimodality-makes-llm-alignment-more-challenging

图片来源:Gerd Altmann 来自 Pixabay
大约一个月前,OpenAI 宣布 ChatGPT 现在可以看、听和说。这意味着模型可以帮助你处理更多的日常任务。例如,你可以上传冰箱里食材的照片,并请求根据你拥有的材料提出用餐建议。或者你可以拍摄客厅的照片,向 ChatGPT 请求艺术和装饰建议。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
这是可能的,因为 ChatGPT 使用了多模态的 GPT-4 作为底层模型,它可以接受图像和文本输入。然而,这些新功能为模型对齐团队带来了新的挑战,我们将在本文中讨论。
LLM 的对齐
“对齐大型语言模型”一词指的是训练模型按照人类期望的行为。这通常意味着理解人类指令,并生成有用、准确、安全且无偏见的回答。为了教会模型正确的行为,我们通过两个步骤提供示例:监督微调(SFT)和带有人类反馈的强化学习(RLHF)。
监督微调(SFT)教会模型遵循特定的指令。在 ChatGPT 的情况下,这意味着提供对话示例。基础模型 GPT-4 目前还不能做到这一点,因为它被训练来预测序列中的下一个词,而不是回答类似聊天机器人的问题。
尽管 SFT 赋予 ChatGPT “聊天机器人”的特性,但其回答仍远非完美。因此,应用了带有人类反馈的强化学习(RLHF)来提高回答的真实性、无害性和有用性。基本上,指令调整算法被要求生成多个回答,然后由人类根据上述标准进行排名。这使得奖励算法能够学习人类的偏好,并用于重新训练 SFT 模型。
在这一步之后,一个模型被对齐到人类价值观,或者至少我们希望如此。但为什么多模态使得这个过程变得更复杂呢?
多模态数据和新挑战
当我们讨论多模态 LLM 的对齐时,我们应关注图像和文本。它并不涵盖所有 ChatGPT 最新的“观看、听见和说话”功能,因为后两者使用的是语音转文本和文本转语音模型,并未直接与 LLM 模型连接。
事情变得有点复杂。相比于仅有文本输入,图像和文本的结合更难以解读。因此,ChatGPT-4 在图像中看得见或看不见的物体和人经常产生幻觉。
Gary Marcus 写了一篇关于多模态幻觉的优秀文章,揭示了不同的案例。一个例子展示了 ChatGPT 如何从图像中错误地读取时间。它在数数厨房照片中的椅子时也遇到了困难,并且无法识别照片中佩戴手表的人。
图片来源:twitter.com/anh_ng8
图像作为输入也为对抗性攻击打开了一扇窗。它们可以成为提示注入攻击的一部分,或者用于传递指令以使模型生成有害内容。
Simon Willison 在这篇文章中记录了几个图像注入攻击的例子。一个基本的例子涉及上传一张包含你希望 ChatGPT 遵循的新指令的图像。见下例:
图片来源:twitter.com/mn_google/status/1709639072858436064
同样,照片中的文本也可以被替换为模型生成仇恨言论或有害内容的指令。
改善多模态数据的对齐
那么为什么多模态数据更难对齐?与单模态语言模型相比,多模态模型仍处于开发的早期阶段。OpenAI 并未透露 GPT-4 如何实现多模态,但显然他们为其提供了大量带有文本注释的图像。
文本-图像对比纯文本数据更难获取,这类数据集较少,且自然示例在互联网上比简单文本更难找到。
图像-文本对的质量带来了额外的挑战。一张带有一句话文本标签的图像远不如带有详细描述的图像有价值。为了获得后者,我们通常需要人工注释者,他们按照精心设计的指令集提供文本注释。
此外,训练模型遵循指令需要足够数量的实际用户提示,包括图像和文本。由于这种方法的新颖性,有机示例很难获得,训练示例通常需要由人工按需创建。
对齐多模态模型引发了之前甚至无需考虑的伦理问题。模型是否应该能够评论人们的外貌、性别和种族,或者识别他们是谁?它是否应该尝试猜测照片的位置?与仅有文本数据相比,需要对齐的方面更多。
总结
多模态性为模型的使用带来了新的可能性,但也给模型开发人员带来了新的挑战,他们需要确保答案的无害性、真实性和有用性。由于多模态性,需要对更多方面进行对齐,为 SFT 和 RLHF 提供优质的训练数据变得更加困难。希望构建或微调多模态模型的人需要为这些新的挑战做好准备,采用包含高质量人类反馈的开发流程。
Magdalena Konkiewicz 是 Toloka 的数据推广专家,这是一家支持快速且可扩展的 AI 开发的全球公司。她拥有爱丁堡大学的人工智能硕士学位,曾在欧洲和美国的企业担任 NLP 工程师、开发人员和数据科学家。她还参与了数据科学家的教学和指导,并定期向数据科学和机器学习出版物做出贡献。
更多相关话题
如何使用 Bash 导航文件系统

作者提供的图片 | Midjourney & Canva
对于阅读此内容的人来说,Unix/Linux 文件系统以层次结构组织并不奇怪。最顶层的目录是根目录,由/表示。所有其他目录和文件都组织在根目录下。除此之外,每个用户都有一个主目录,通常由~表示,个人文件和目录存储在这里。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
虽然在 Linux 和其他类 Unix 系统上,许多文件管理可以通过图形用户界面文件管理器来处理,但使用 Bourne-Again Shell(bash)命令行提供了一种简单、灵活、快速的方式,并且能够与各种命令行工具和应用程序交互。
让我们深入了解如何使用 bash 导航 Unix/Linux 文件系统。
pwd 命令
目的:显示当前工作目录。
用法:pwd命令使用简单。它显示你在文件系统中的当前位置的绝对路径。
pwd
示例:
$ pwd
/home/user
使用cd进行导航
目的:更改目录。
基本用法:cd命令允许你移动到不同的目录。
cd /path/to/directory
常见选项:
-
移动到主目录:你可以使用
cd ~或简单地使用cd快速导航到你的主目录。 -
上移一个目录:要移动到父目录,请使用
cd ..。 -
导航到子目录:要进入当前目录下的子目录,只需使用
cd 子目录名称。
使用ls列出文件
目的:列出文件和目录。
基本用法:ls命令列出当前目录中的文件和目录。
ls
常见选项:
-
详细列表:要获取详细视图,请使用
ls -l。这将提供文件权限、链接数量、所有者、组、文件大小和时间戳等信息。 -
包括隐藏文件:要包含隐藏文件(以
.开头的文件),请使用ls -a。 -
组合选项:通过
ls -la组合选项以获得更全面的列表。
使用tree可视化目录结构
目的:以树状格式显示目录。
基本用法:tree命令提供了目录结构的可视化表示。
tree
常用选项:
-
限制深度:要限制目录树的深度,请使用
tree -L后跟所需的级别。 -
显示隐藏文件:使用
tree -a包括隐藏文件在树中。
实际例子
让我们通过一个实际的例子来讲解如何导航到一个目录、列出其内容并显示其结构。
cd ~/projects
pwd
ls -la
tree -L 1
解释:
-
cd ~/projects:导航到你家目录下的projects目录。 -
pwd:确认你当前的目录。 -
ls -la:列出所有文件,包括隐藏文件,并附带详细信息。 -
tree -L 1:显示目录结构,深入到一级。
高效导航的命令组合
你可以使用&&将命令链在一起,以顺序执行多个命令。这可以简化你的工作流程。
cd ~/projects && ls -la && tree -L 2
这个命令序列导航到projects目录,列出所有文件的详细信息,然后显示目录结构,深入到两级。
最终想法
练习本文介绍的命令将帮助你在浏览 Unix/Linux 文件系统时更加熟练。一旦你熟悉了这些基础知识,你可以深入探索更高级的导航和文件操作命令。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的执行编辑,以及Machine Learning Mastery的贡献编辑,Matthew 致力于使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法,以及探索新兴 AI。他的使命是使数据科学社区的知识变得普及。Matthew 从 6 岁起便开始编程。
更多相关主题
如何不编程 TensorFlow 图
原文:
www.kdnuggets.com/2017/05/how-not-program-tensorflow-graph.html
作者:亚伦·舒马赫,深度学习分析专家。
使用 Python 操作 TensorFlow 就像用 Python 编程 另一台计算机。一些 Python 语句构建你的 TensorFlow 程序,一些 Python 语句执行该程序,当然,还有一些 Python 语句完全不涉及 TensorFlow。对你构建的图保持思考可以帮助你避免混淆和性能陷阱。这里有一些考虑因素。
避免拥有多个相同的操作
TensorFlow 中的许多方法会在计算图中创建操作,但不会执行它们。你可能希望多次执行这些操作,但这并不意味着你应该创建许多相同操作的副本。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
一个明确的例子是 tf.global_variables_initializer()。
>>> import tensorflow as tf
>>> session = tf.Session()
# Create some variables...
>>> initializer = tf.global_variables_initializer()
# Variables are not yet initialized.
>>> session.run(initializer)
# Now variables are initialized.
# Do some more work...
>>> session.run(initializer)
# Now variables are re-initialized.
如果 tf.global_variables_initializer() 的调用被重复,例如直接作为 session.run() 的参数,则会有一些缺点。
>>> session.run(tf.global_variables_initializer())
>>> session.run(tf.global_variables_initializer())
每当 session.run() 的参数在这里被评估时,都会创建一个新的初始化操作。这在图中创建了多个初始化操作。对于小的操作来说,在交互式会话中拥有多个副本并不是什么大问题,如果你创建了更多需要在初始化中包含的变量,可能还会希望这样做。但要考虑是否真的需要大量重复的操作。
在 session.run() 内部创建操作时,你也没有一个 Python 变量引用这些操作,因此你无法轻易地重用它们。
在 Python 中,如果你创建了一个没有任何引用的对象,它会被垃圾回收。被遗弃的对象将被删除,它所占用的内存将被释放。TensorFlow 图中的对象不会发生这种情况;你放入图中的所有内容都会留在那里。
很明显,tf.global_variables_initializer() 返回的是一个操作。但操作也可以通过不那么明显的方式创建。
让我们来比较一下 NumPy 的工作方式。
>>> import numpy as np
>>> x = np.array(1.0)
>>> y = x + 1.0
目前内存中有两个数组,x 和 y。y 的值是 2.0,但没有记录如何获得这个值。加法操作没有留下任何记录。
TensorFlow 是不同的。
>>> x = tf.Variable(1.0)
>>> y = x + 1.0
现在只有x是一个 TensorFlow 变量;y是一个add操作,如果我们运行它,它可以返回该加法的结果。
再比较一下。
>>> x = np.array(1.0)
>>> y = x + 1.0
>>> y = x + 1.0
这里y被分配为一个结果数组x + 1.0,然后重新分配为指向不同的数组。第一个数组将被垃圾回收并消失。
>>> x = tf.Variable(1.0)
>>> y = x + 1.0
>>> y = x + 1.0
在这种情况下,y指的是 TensorFlow 图中的一个add操作,然后y被重新分配指向图中的另一个add操作。由于y现在只指向第二个add,我们没有方便的方法来处理第一个。然而这两个add操作仍然存在于图中,并且会继续存在。
(顺便提一下,Python 用于定义类特定加法的机制以及其他,就是+如何用来创建 TensorFlow 操作的,这个机制很不错。)
特别是如果你只是使用默认图并在常规 REPL 或笔记本中交互运行,你可能会在图中留下大量被遗弃的操作。每次重新运行定义任何图操作的笔记本单元时,你不仅仅是在重新定义操作——你是在创建新的操作。
在实验时,拥有几个额外的操作通常是可以的。但事情可能会失控。
for _ in range(1e6):
x = x + 1
如果x是一个 NumPy 数组,或者只是一个普通的 Python 数字,这将以常量内存运行,并得出一个值。
但如果x是一个 TensorFlow 变量,那么在你的 TensorFlow 图中将会有超过一百万个操作,仅仅是定义计算而已,甚至没有执行。
TensorFlow 的一个直接修复方法是使用tf.assign操作,它提供了更符合你期望的行为。
est
increment_x = tf.assign(x, x + 1)
for _ in range(1e6):
session.run(increment_x)
这个修订版本在循环内部不创建任何操作,这通常是一个好建议。TensorFlow 确实有控制流构造,包括while 循环。但只有在真正需要时才使用这些。
在创建操作时要注意,只创建你需要的操作。尽量将操作创建与操作执行区分开来。在交互式实验之后,最终进入一个状态,可能是在脚本中,只创建你需要的操作。
避免图中的常量
一种特别不幸的操作是意外常量操作,尤其是大的常量操作。
>>> many_ones = np.ones((1000, 1000))
在 NumPy 数组many_ones中有一百万个 1。我们可以将它们加起来。
>>> many_ones.sum()
## 1000000.0
如果我们用 TensorFlow 将它们加起来呢?
>>> session.run(tf.reduce_sum(many_ones))
## 1000000.0
结果是一样的,但机制完全不同。这不仅在图中添加了一些操作——它还将整个百万元素的数组作为常量放入图中。
这种模式的变体可能会导致意外地将整个数据集作为常量加载到图中。程序可能仍然可以运行,适用于小数据集。或者你的系统可能会失败。
避免在图中存储数据的一种简单方法是使用feed_dict机制。
>>> many_things = tf.placeholder(tf.float64)
>>> adder = tf.reduce_sum(many_things)
>>> session.run(adder, feed_dict={many_things: many_ones})
## 1000000.0
如前所述,要明确你在何时向图中添加了什么。具体数据通常只在评估时进入图中。
TensorFlow 作为函数式编程
TensorFlow 操作类似于函数。这在操作具有一个或多个占位符输入时尤为明显;在会话中评估操作就像用这些参数调用函数。因此,返回 TensorFlow 操作的 Python 函数类似于高阶函数。
你可能会决定将常量放入图中。例如,如果你需要将很多张量重新调整为 28×28,你可以创建一个执行此操作的操作。
>>> input_tensor = tf.placeholder(tf.float32)
>>> reshape_to_28 = tf.reshape(input_tensor, shape=[28, 28])
这类似于柯里化,因为shape参数现在已经设置好了。[28, 28]已成为图中的常量并指定了该参数。现在要评估reshape_to_28,我们只需提供input_tensor。
已经提出了神经网络、类型和函数式编程之间的广泛联系。考虑 TensorFlow 作为支持这种构建系统的系统是很有趣的。
我正在参与从组件构建 TensorFlow 系统,这是在 OSCON 2017 上的一个研讨会。
在 Twitter | LinkedIn | Google+ | GitHub | email 上找到 Aaron
原文。经许可转载。
个人简介: Aaron Schumacher 是 Deep Learning Analytics 的高级数据科学家和软件工程师。他在 @planarrowspace 上发推文。
相关:
-
如何在 TensorFlow 中构建递归神经网络
-
最温和的 Tensorflow 入门介绍 – 第一部分
-
Python 深度学习框架概述
更多相关话题
如何(不)使用 Python 的海象运算符
图片由作者提供 | 在 Snappify 上创建
在 Python 中,如果你想在表达式内为变量赋值,你可以使用海象运算符 :=。虽然x = 5是一个简单的变量赋值,但x := 5是你将使用海象运算符的方式。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
这个运算符在 Python 3.8 中引入,它可以帮助你编写更简洁、更具可读性的代码(在某些情况下)。然而,不必要或过多地使用它也会使代码更难理解。
在本教程中,我们将通过简单的代码示例来探索海象运算符的有效使用和不那么有效的使用。让我们开始吧!
Python 的海象运算符的使用时机与方法
让我们从看一些示例开始,这些示例中海象运算符可以使你的代码更好。
1. 更简洁的循环
循环构造中常见的情况是读取输入以在循环中处理,并且循环条件依赖于输入。在这种情况下,使用海象运算符可以帮助你保持循环更简洁。
没有海象运算符
请考虑以下示例:
data = input("Enter your data: ")
while len(data) > 0:
print("You entered:", data)
data = input("Enter your data: ")
当你运行上述代码时,只要输入非空字符串,你会被重复提示输入一个值。
注意到有冗余的部分。你最初将输入读取到data变量中。在循环中,你打印出输入的值并再次提示用户输入。循环条件检查字符串是否为非空。
使用海象运算符
你可以去除冗余,并使用海象运算符重写上述版本。为此,你可以在循环条件中读取输入并检查它是否是非空字符串—全部在循环条件中—使用海象运算符如下:
while (data := input("Enter your data: ")) != "":
print("You entered:", data)
现在,这比第一版更简洁。
2. 更好的列表推导式
有时你会在列表推导式中调用函数。如果有多个开销较大的函数调用,这可能会很低效。在这些情况下,使用海象运算符重写代码可能会有帮助。
没有海象运算符
下面的示例中,列表推导式中有两个对compute_profit函数的调用:
-
要用利润值填充新列表
-
用来检查利润值是否超过指定的阈值。
# Function to compute profit
def compute_profit(sales, cost):
return sales - cost
# Without Walrus Operator
sales_data = [(100, 70), (200, 150), (150, 100), (300, 200)]
profits = [compute_profit(sales, cost) for sales, cost in sales_data if compute_profit(sales, cost) > 50]
使用海象运算符
你可以将函数调用的返回值分配给profit变量,然后像这样使用它来填充列表:
# Function to compute profit
def compute_profit(sales, cost):
return sales - cost
# With Walrus Operator
sales_data = [(100, 70), (200, 150), (150, 100), (300, 200)]
profits = [profit for sales, cost in sales_data if (profit := compute_profit(sales, cost)) > 50]
如果过滤条件涉及昂贵的函数调用,这种版本会更好。
如何不使用 Python 的海象运算符
现在我们已经看到了一些使用 Python 海象运算符的示例,我们来看看一些反模式。
1. 复杂的列表推导式
在前面的示例中,我们在列表推导式中使用了海象运算符,以避免重复的函数调用。但是,过度使用海象运算符可能也会有坏处。
由于多个嵌套的条件和赋值,以下列表推导式难以阅读。
# Function to compute profit
def compute_profit(sales, cost):
return sales - cost
# Messy list comprehension with nested walrus operator
sales_data = [(100, 70), (200, 150), (150, 100), (300, 200)]
results = [
(sales, cost, profit, sales_ratio)
for sales, cost in sales_data
if (profit := compute_profit(sales, cost)) > 50
if (sales_ratio := sales / cost) > 1.5
if (profit_margin := (profit / sales)) > 0.2
]
作为练习,你可以尝试将逻辑分解为单独的步骤——在常规循环和 if 条件语句中。这将使代码更容易阅读和维护。
2. 嵌套的海象运算符
使用嵌套的海象运算符可能会导致代码难以阅读和维护。当逻辑涉及在单个表达式内进行多次赋值和条件判断时,这尤其成问题。
# Example of nested walrus operators
values = [5, 15, 25, 35, 45]
threshold = 20
results = []
for value in values:
if (above_threshold := value > threshold) and (incremented := (new_value := value + 10) > 30):
results.append(new_value)
print(results)
在这个例子中,嵌套的海象运算符使理解变得困难——要求读者在单行内解包多层逻辑,降低了可读性。
总结
在这个快速教程中,我们讨论了何时应该以及何时不应该使用 Python 的海象运算符。你可以在GitHub上找到代码示例。
如果你想了解在使用 Python 编程时应该避免的常见陷阱,请阅读5 个常见的 Python 陷阱及如何避免。
继续编码!
Bala Priya C**** 是来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
如何优化工作
评论
查看《如何优化工作》的完整课程内容,包括视频、幻灯片和代码。
优化是一个华丽的词汇,意思是“找到最佳方式”。如果我们仔细观察喝茶的过程,就能看到它是如何工作的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您所在组织的 IT
茶的最佳温度是存在的。如果你的茶太热,它会烫伤你的舌头,你可能要三天才能尝到味道。如果茶温温,完全没有满足感。中间有一个最佳点,在那里它温暖舒适,从内而外温暖你的喉咙,辐射到你的腹部。这就是茶的理想温度。
在优化中,我们尝试找到这种令人满意的中间状态。这就像是《金发姑娘与三只熊》中的情节:金发姑娘尝试了爸爸熊的床,觉得太硬;尝试了妈妈熊的床,觉得太软;然后尝试了小熊的床,发现刚刚好。
找到如何做到刚刚好的方法,原来是一个非常常见的问题。数学家和计算机科学家都喜欢它,因为它非常具体且描述清晰。你知道自己是否做对了,可以将你的解决方案与其他人的进行比较,看看谁更快找到了解决方案。
当计算机科学家尝试找到茶的最佳温度时,他们首先会把问题颠倒过来。他们不是试图最大化喝茶的享受,而是尽量减少喝茶时的痛苦。结果是一样的,数学计算也是相同的。并不是说所有计算机科学家都是悲观主义者,而是大多数优化问题自然以成本——如金钱、时间、资源——来描述,而不是以收益来描述。在数学中,将所有问题统一成相同的形式来解决会比较方便,这样你只需要解决一次。
在机器学习中,这种代价通常被称为误差函数,因为误差是不希望出现的东西,即苦味,是被最小化的。它也可以被称为代价函数、损失函数或能量函数。它们的含义几乎是相同的。
穷举搜索
找到最佳茶温有几种方法。最明显的方法就是直接查看曲线并选择最低点。不幸的是,当我们开始时实际上并不知道曲线是什么。这在优化问题中是隐含的。

但我们可以利用我们原来的想法,直接测量曲线。我们可以在给定的温度下准备一杯茶,服务后询问我们的测试对象他们的感受。然后我们可以对整个范围内的每个温度重复这个过程。完成这个过程后,我们确实知道整个曲线的样子,然后我们可以选择茶饮者报告的最喜欢的温度,也就是最少的苦味。

这种寻找最佳茶温的方法被称为穷举搜索。它直接且有效,但可能需要一些时间。如果我们的时间有限,值得尝试几种其他方法。
梯度下降
如果你想象我们的茶苦味曲线实际上是一个物理碗,那么我们可以通过将一个弹珠放进去并让它滚动直到停止来轻松找到底部。这就是梯度下降的直观理解——字面意思是“下坡”。
为了使用梯度下降,我们从一个任意的温度开始。在开始之前,我们对我们的曲线一无所知,所以我们做一个随机的猜测。我们在那个温度下冲泡一杯茶,看看我们的品茶者对它的喜欢程度。
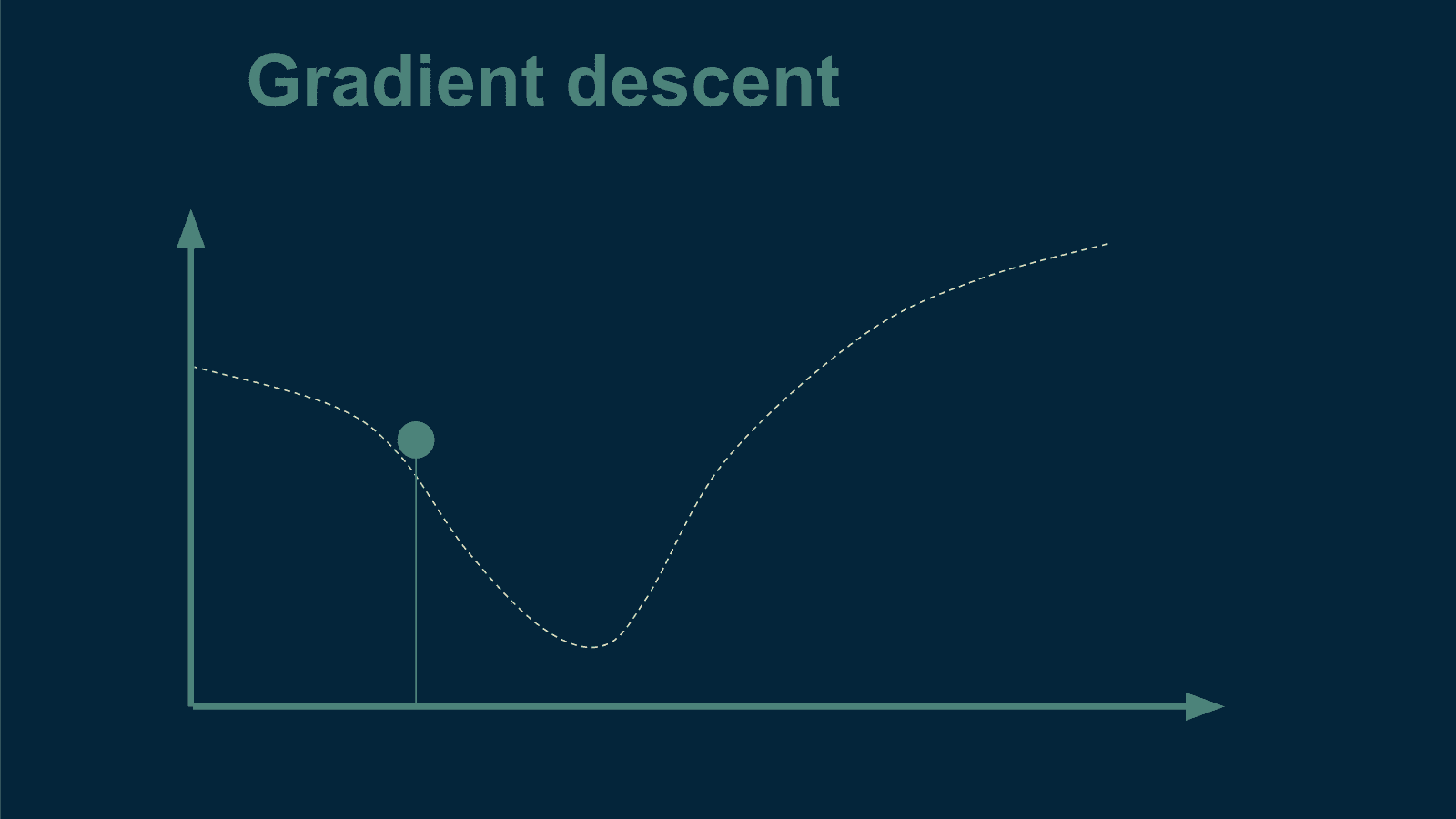
接下来,诀窍是弄清楚哪个方向是下坡,哪个方向是上坡。要搞清楚这一点,我们选择一个方向,并选择一个非常小的温度变化。例如,我们选择左边的温度。然后我们用这个稍微凉一点的温度再冲一杯茶,看看是否比第一杯更好。我们发现其实更差了。现在我们知道“下坡”是在右边——也就是我们需要让下一杯茶更暖才能更好。
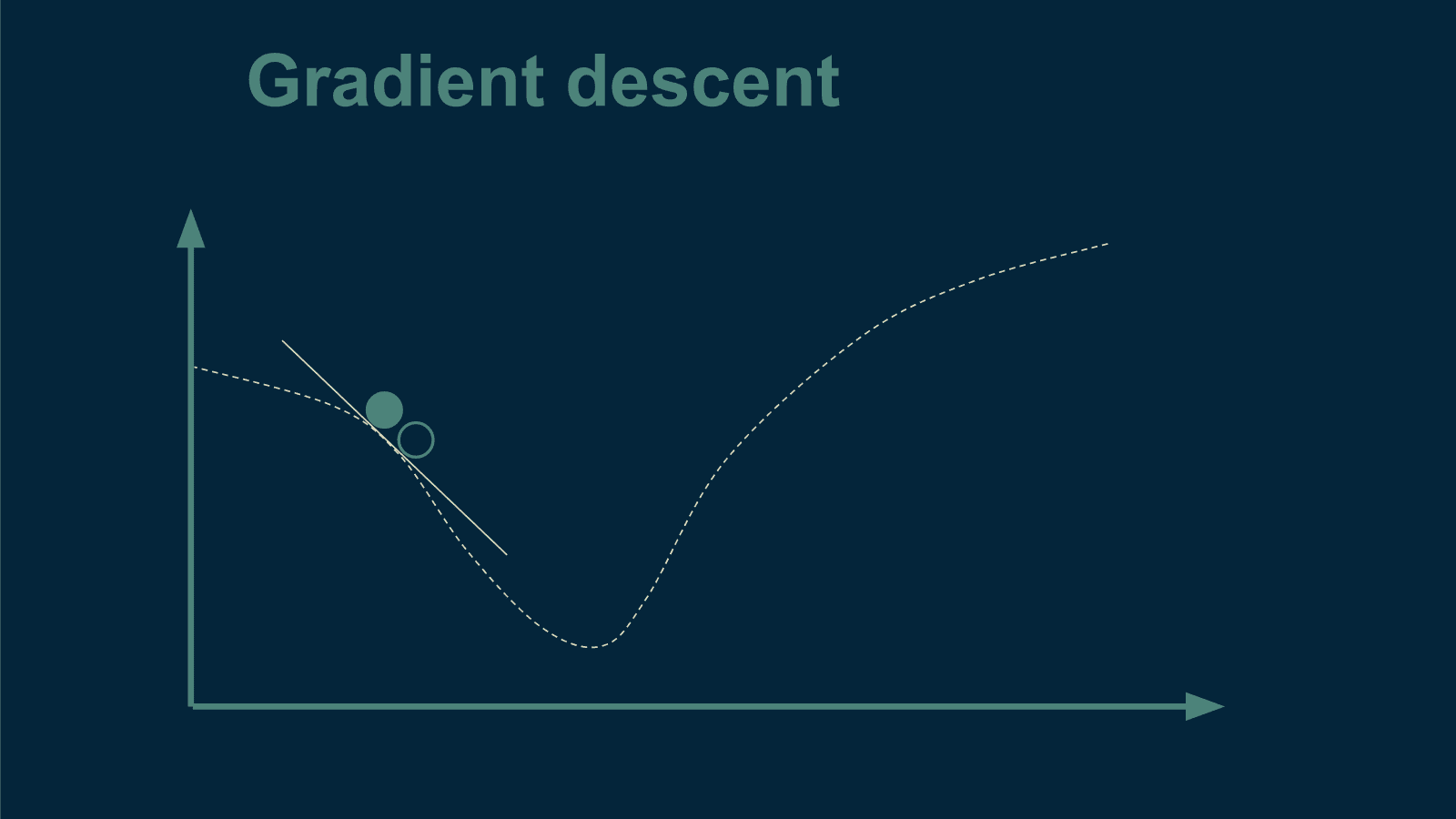
我们在温暖茶的方向上迈出更大的步伐,冲泡一杯新茶,并重新开始这个过程。
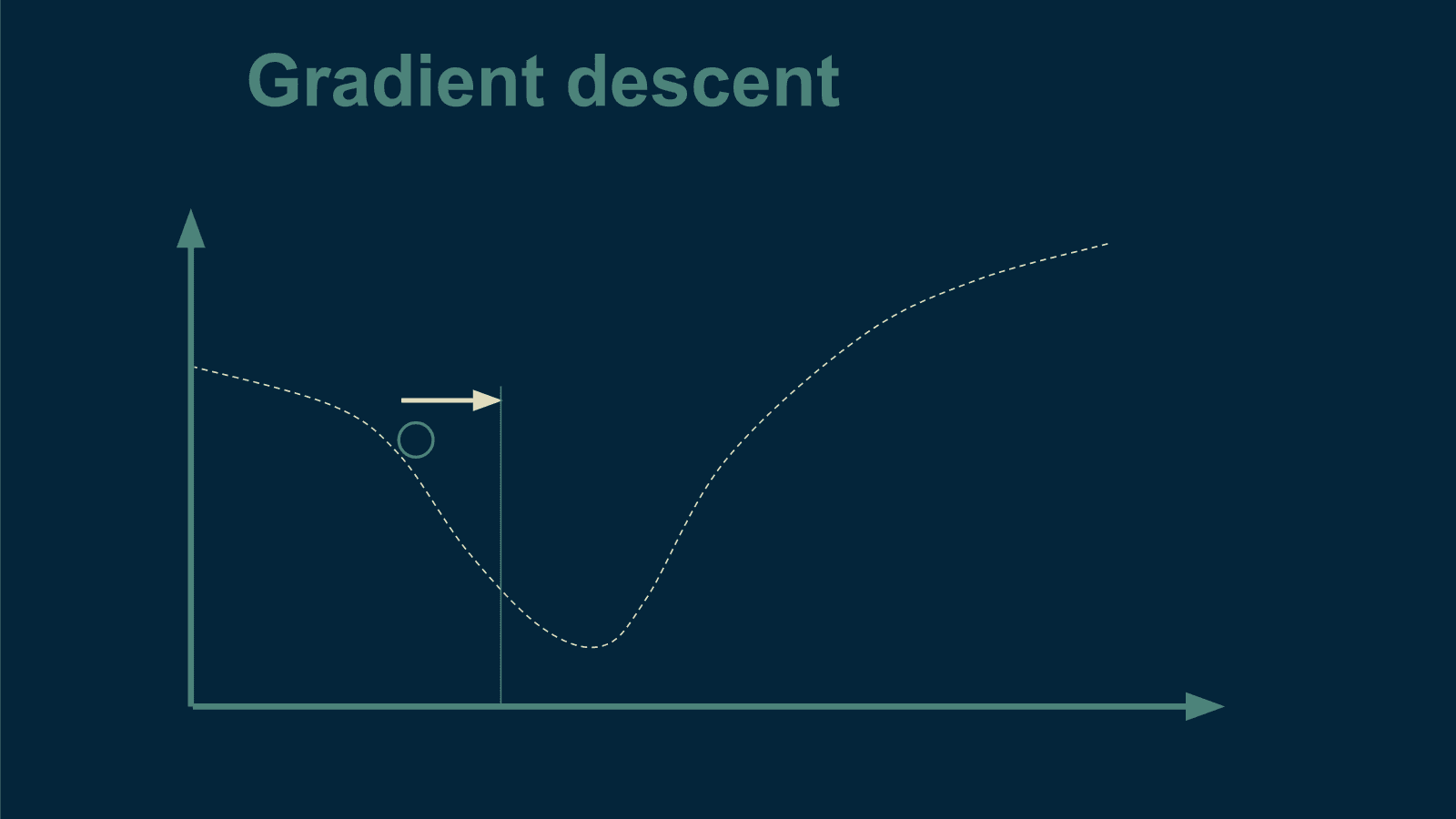
我们重复这个过程,直到找到最适合泡茶的温度。
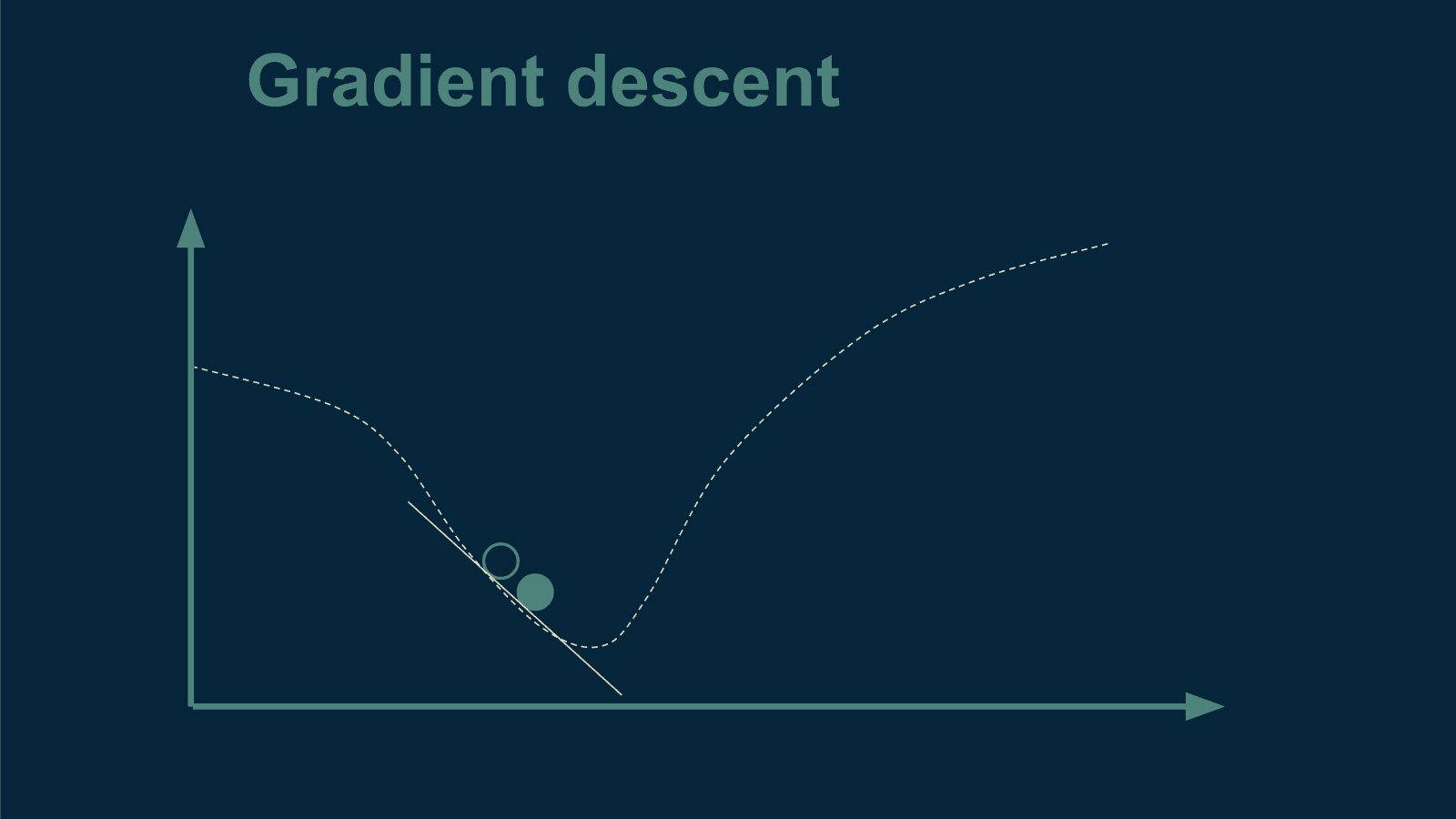
坡度越陡,我们可以迈出的步伐就越大。坡度越浅,步伐越小。
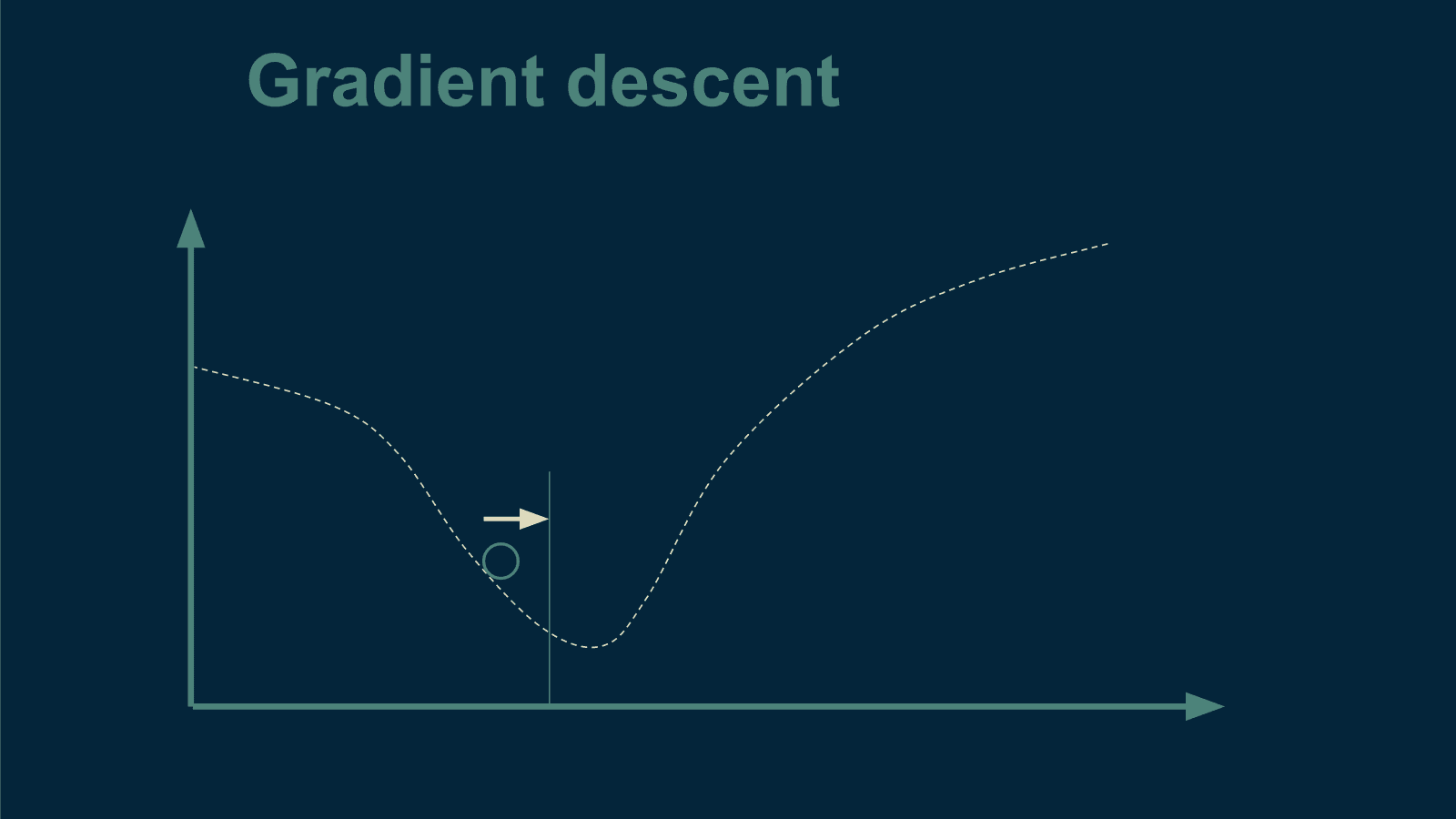
当我们退后一步并从我们的茶饮者那里得到完全相同的享受时,我们就知道一切都完成了。这只能在碗的底部发生,在那里是平的,没有下坡。
有很多梯度下降方法。它们大多数是通过聪明的方式尽可能高效地测量斜率,以尽可能少的步骤到达碗底——尽可能少地冲泡茶水。它们使用不同的技巧来避免完全计算斜率或选择尽可能大的步长,但基本直觉是相同的。
包括曲率
寻找碗底的一个技巧是,在决定采取多大步时,不仅使用斜率,还使用曲率。当小球开始滚下碗的侧面时,斜率是否变得更陡?
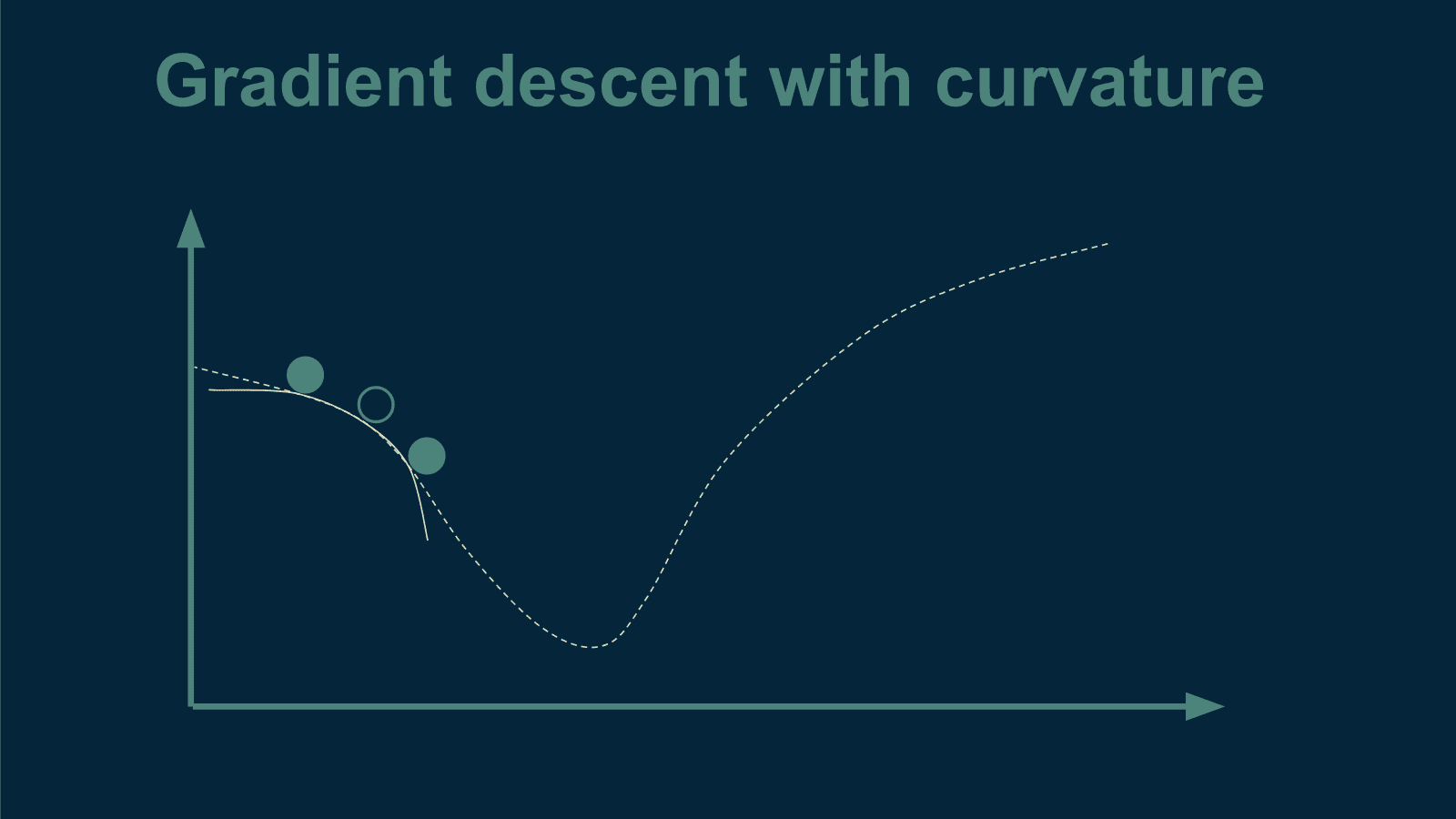
如果是这样,那么底部可能仍然很远。采取大步。
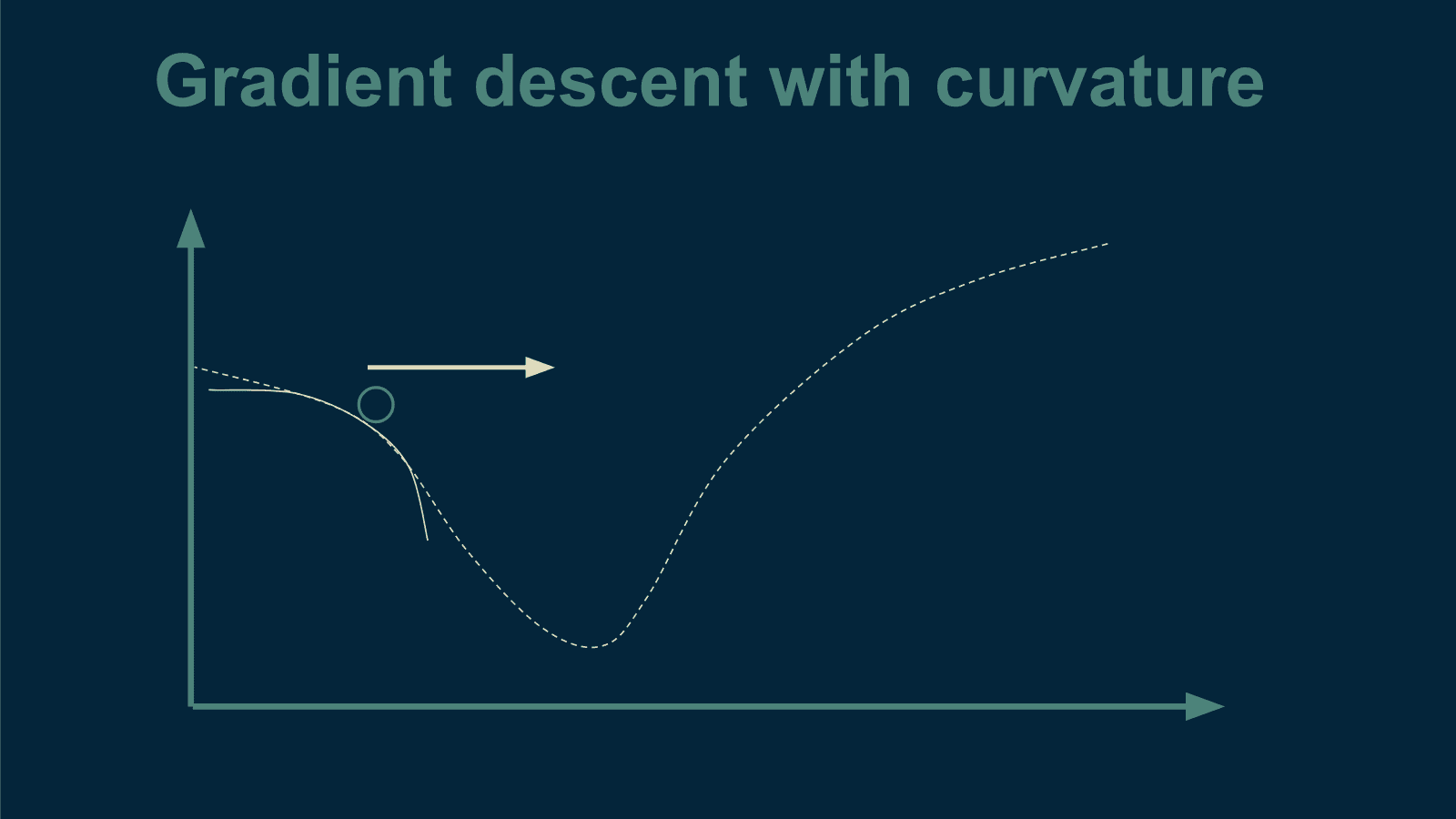
还是斜率变得更平缓并开始接近底部?
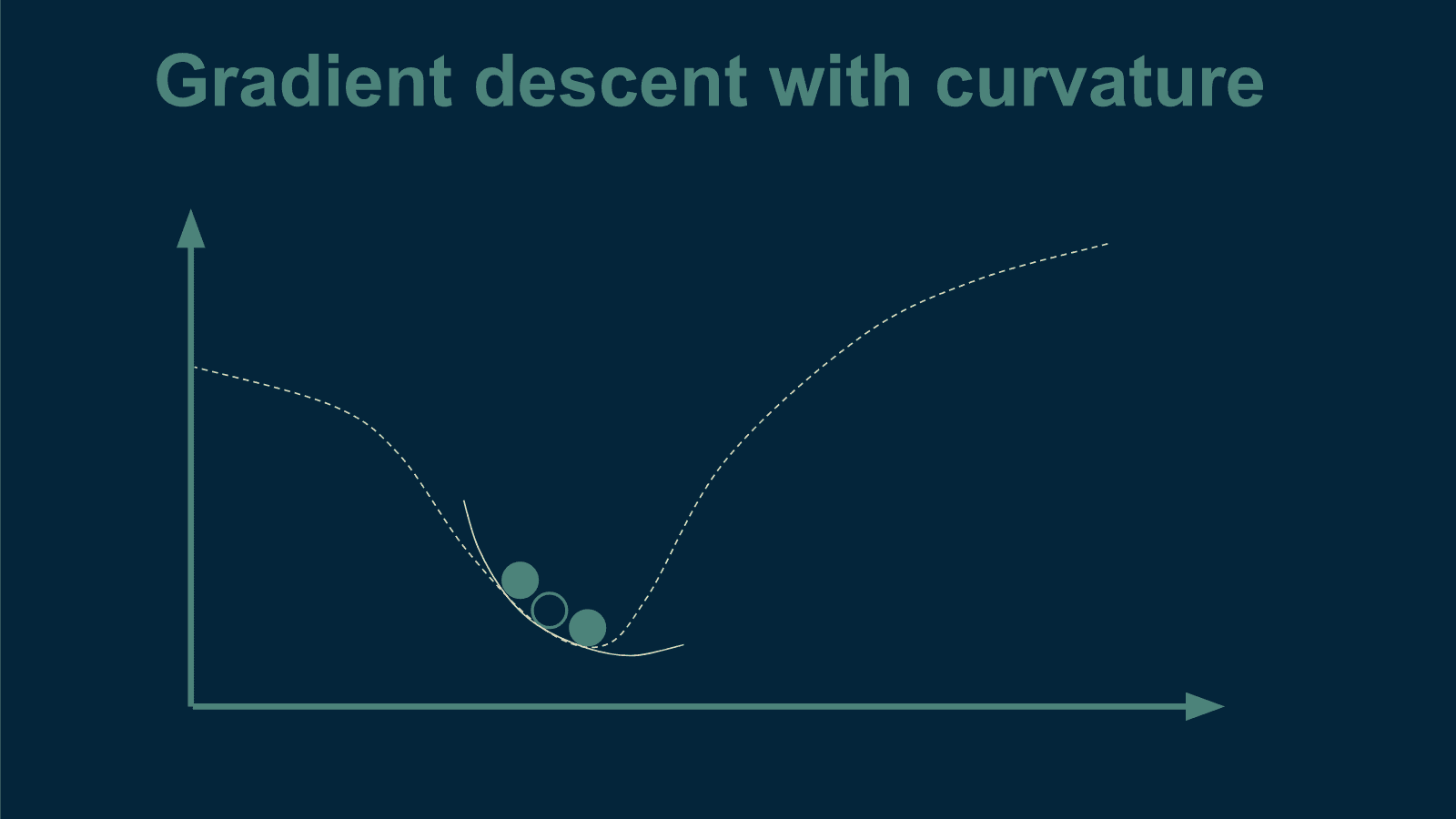
如果是这样,底部可能越来越近。现在采取更小的步伐。

曲率,也就是斜率的斜率或赫希矩阵,准确地说,这在尽可能少走步数时非常有帮助,但计算起来也可能更加昂贵。这是在优化中经常出现的权衡。我们最终在必须采取的步骤数和计算下一个步骤应在哪里的难度之间进行选择。
梯度下降可能会失败
像许多数学问题一样,你能够做的假设越多,你能提出的解决方案就越好。不幸的是,在处理真实数据时,这些假设并不总是适用。
这种掉小球的方法可能会失败很多次。如果有多个小山谷供小球滚入,我们可能会错过最深的一个。每一个这样的碗叫做局部最小值。我们感兴趣的是找到全局最小值,即所有碗中最深的一个。想象一下我们在炎热的日子里测试茶的温度。如果茶变得足够冷,它可能成为一种非常受欢迎的冰茶。仅靠梯度下降,我们永远无法发现这一点。
如果误差函数不平滑,可能会有许多地方让小球卡住。如果我们的茶饮者的享受受到列车通过的严重影响,就可能发生这种情况。列车的周期性出现可能会在我们的数据中引入波动。
如果你尝试优化的误差函数发生离散跳跃,这将是一个挑战。球体在楼梯上不容易滚动。如果我们的茶客需要在 10 分制上评分,他们可能会遇到这种情况。
如果误差函数大部分是一个平坦的区域,但有一个狭窄而深的底部,那么球体可能不容易找到它。也许我们的茶客完全厌恶任何不完美的茶。
所有这些情况都发生在真实的机器学习优化问题中。
稳健方法
如果我们怀疑我们的茶满意度曲线具有这些棘手的特性,我们可以总是回到穷举搜索。不幸的是,穷举搜索对于许多问题需要极其长的时间。幸运的是,我们有一个中间方案。有一套方法比梯度下降更强大。它们被称为遗传算法、进化算法和模拟退火。这些方法的计算时间比梯度下降更长,步骤更多,但它们不容易崩溃。每种方法都有其独特之处,但大多数方法都有一个共同特征,就是步骤和跳跃的随机性。这帮助它们发现误差函数的最深谷,即使这些谷很难找到。
依赖梯度下降的优化算法就像一级方程式赛车。它们极其快速和高效,但需要一个非常规则的赛道(误差函数)才能发挥良好。一个不恰当的减速带可能会毁掉它。更稳健的方法就像四轮驱动的皮卡车。它们的速度远不如赛车,但能处理更多的地形变化。而穷举搜索就像徒步旅行。你可以到达任何地方,但可能需要非常长的时间。它们在不同的情况下各有其不可替代的价值。

原始。已获许可转载。
相关:
-
数据科学家的优化 101
-
使用 R 进行优化
-
梯度下降的直观介绍
更多相关内容
如何在 2021 年组织你的数据科学项目
原文:
www.kdnuggets.com/2021/04/how-organize-your-data-science-project-2021.html
评论
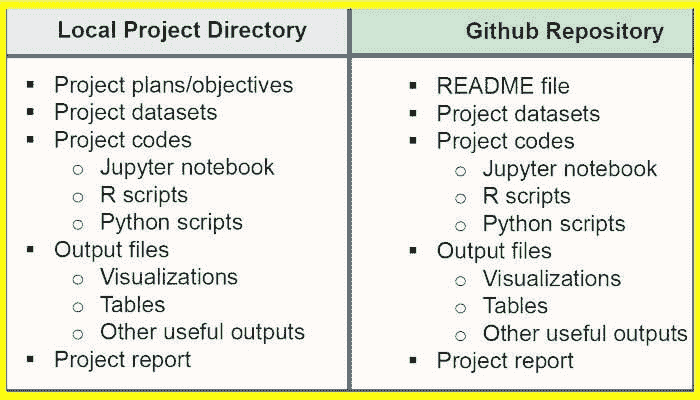
保持本地和 GitHub 上有两个版本的项目总是一个好主意。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
本文将讨论一些实用的技巧,帮助你更好地组织数据科学项目。在深入探讨数据科学项目管理技巧之前,我们首先讨论一下组织项目的重要性。
组织项目的重要性有 4 个理由
-
组织可以提高生产力。如果项目组织良好,所有内容都放在一个目录中,就可以更容易避免浪费时间寻找数据集、代码、输出文件等项目文件。
-
组织良好的项目有助于你记录和维护进行中的数据科学项目和已完成的项目。
-
完成的数据科学项目可以用于构建未来的模型。如果你将来需要解决类似的问题,可以使用相同的代码进行稍微的修改。
-
一个组织良好的项目在分享至 GitHub 等平台时,其他数据科学专业人士可以更容易理解。
为了说明,我们将使用邮轮数据集。我们假设我们希望建立一个机器学习模型,根据预测变量(如年龄、吨位、乘客、长度、舱房等)推荐邮轮船员数量。在第一部分中,我们描述了如何在本地组织项目。然后在第二部分中,我们描述了如何为项目创建 GitHub 仓库。建议你保持本地和 GitHub 上两个版本的项目。这样做的好处是,只要你有互联网连接,就可以从世界任何地方随时访问 GitHub 上的项目版本。另一个好处是,如果你的本地计算机发生可能对计算机产生不利影响的情况,如计算机中的病毒,你可以放心,因为你仍然可以在 GitHub 上找到项目文件作为备份。
I. 本地项目目录
为你正在进行的每个项目拥有一个项目目录是很好的。
目录名称
在为你的项目创建目录时,选择一个反映你项目的目录名称是好的,例如,对于推荐船员数量的机器学习模型,可以选择一个目录名称,例如 ML_Model_for_Predicting_Ships_Crew_Size。
目录内容
你的项目目录应包含以下内容:
(1) 项目计划: 这可以是一个世界文档,你在其中描述你的项目内容。你可以先提供一个简要的概要,然后是你想要完成的逐步计划。例如,在构建模型之前,你可以问自己:
-
预测变量是什么?
-
目标变量是什么?我的目标变量是离散的还是连续的?
-
我应该使用分类分析还是回归分析?
-
我该如何处理数据集中的缺失值?
-
当将变量调整到相同的尺度时,我应该使用归一化还是标准化?
-
我应该使用主成分分析吗?
-
我该如何调整模型中的超参数?
-
我该如何评估模型以检测数据集中的偏差?
-
我应该使用集成方法吗?即使用不同的模型进行训练,然后进行集成平均,例如,使用 SVM、KNN、逻辑回归等分类器,然后对 3 个模型进行平均?
-
我该如何选择最终模型?
(2) 项目数据集:你应该包括所有用于项目的数据集的逗号分隔值(CSV)文件。在这个例子中,只有一个 CSV 文件:cruise_ship_info.csv。
(3) 项目代码: 一旦你弄清楚了你的项目计划和目标,就可以开始编码了。根据你解决的问题类型,你可能决定使用 jupyter 笔记本或 R 脚本来编写代码。我们假设我们将使用 jupyter 笔记本。
在你的 jupyter 笔记本上,开始添加项目标题或标题,例如:
Machine Learning Model for Predicting a Ship’s Crew Size
然后,你可以提供一个简要的项目概要,接着是作者姓名和日期,例如:
We build a simple model using the cruise_ship_info.csv data set for predicting a ship’s crew size.
This project is organized as follows:
(a) data preprocessing and variable selection;
(b) basic regression model;
(c) hyper-parameters tuning; and
(d) techniques for dimensionality reduction.
Author: Benjamin O. Tayo
Date: 4/8/2019
在你开发代码时,你要确保 jupyter 笔记本被组织成强调机器学习模型构建工作流程的各个部分,例如:
Importation of necessary python libraries
Importation of dataset
Exploratory data analysis
Feature selection and dimensionality reduction
Feature scaling and data partitioning into train and test sets
Model building, testing, and evaluation
对于示例项目的 jupyter 笔记本和 R 脚本文件,请参见以下 Github 库,bot13956/ML_Model_for_Predicting_Ships_Crew_Size 和 bot13956/weather_pattern。
(4) 项目输出: 你也可以将关键项目输出存储在本地目录中。一些关键项目输出可能是数据可视化图表、显示模型误差与不同参数的函数关系的图形,或者包含关键输出的表格,如 R2 值、均方误差或回归系数。项目输出非常方便,因为它们可以用来准备项目报告或 PowerPoint 演示文稿,以便向数据科学团队或公司业务管理员展示。
(5) 项目报告:在某些情况下,你可能需要编写一个项目报告,以描述项目成果,并根据模型的发现和见解提供建议行动方案。在这种情况下,你需要使用 MS Word 编写项目报告。在撰写项目报告时,你可以充分利用从主代码生成的一些可视化图表。你可以将这些图表添加到报告中。你的主代码可以作为项目报告的附录添加。
一个项目报告文件的示例可以在 bot13956/Monte_Carlo_Simulation_Loan_Status 找到。
II. GitHub 项目目录
一旦你解决了感兴趣的问题,你需要在 GitHub 上创建一个项目仓库,并上传项目文件,如数据集、jupyter notebooks、R 程序脚本和示例输出。为任何数据科学项目创建 GitHub 仓库是极其重要的。它使你能够随时访问你的代码。你可以与程序员和其他数据科学家社区分享你的代码。此外,它还是展示你数据科学技能的一种方式。
创建 GitHub 仓库的提示: 确保你为你的仓库选择一个合适的标题。例如:
Repository Name: bot13956/ML_Model_for_Predicting_Ships_Crew_Size
然后包含一个 README 文件,以提供项目的概要介绍。
Author: Benjamin O. Tayo
Date: 4/8/2019
We build a simple model using the cruise_ship_info.csv data set for predicting a ship's crew size.
This project is organized as follows:
(a) data preprocessing and variable selection;
(b) basic regression model;
(c) hyper-parameters tuning; and
(d) techniques for dimensionality reduction.
cruise_ship_info.csv: dataset used for model building.
Ship_Crew_Size_ML_Model.ipynb: the jupyter notebook containing code.
然后你可以上传你的项目文件,包括数据集、jupyter notebook 和示例输出。
这是一个机器学习项目的 GitHub 仓库示例:
仓库 网址: github.com/bot13956/ML_Model_for_Predicting_Ships_Crew_Size。
总之,我们讨论了数据科学项目的组织方式。良好的组织有助于提高生产力和效率。当你下次需要处理新项目时,请花时间组织你的项目。这不仅有助于提高效率和生产力,还能帮助减少错误。此外,保持对所有当前和已完成项目的良好记录使你能够创建一个仓库,在其中保存所有项目以备将来使用。
原文。经许可转载。
相关:
更多相关内容
预测分析如何革新科技决策
原文:
www.kdnuggets.com/how-predictive-analytics-is-revolutionizing-decisionmaking-in-tech

图片由编辑提供
预测分析将在 2023 年的商业决策中发挥关键作用,AI、机器学习以及数据科学将被大大小小的企业利用,以推动收入增长并实现最大化发展。预测分析能够处理大量数据,发现隐藏的有价值的见解,是挖掘潜力的关键。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
在这篇文章中,我们将重点关注预测分析在商业环境中的运作方式,利用数据做出明智的决策,这些决策可以产生重大影响。
什么是预测分析?
预测分析处理大量数据,分析以找出有用且相关的信息,然后开发预测模型,提供与不同情境(包括过去和现在)相关的宝贵见解。通过这些基于情境的见解,可以对未来事件进行预测,使企业能够在识别新趋势、改变产品供应等方面做出更好的决策。
图片来自Qualtrics
预测分析是一个先进的工具,但仍需专家的知识才能有效使用。分析提供事实和相关数据,而如何将这些数据应用于实际的未来情境则由用户决定。预测分析与决策过程结合,能够帮助企业实现切实的成果。
预测分析的实际应用
一个常见的预测分析应用场景是市场营销,常见的例子是行为定位。这涉及利用消费者数据来创建更好的营销策略,无论是网页内容、社交媒体活动还是直接广告,从而帮助企业接触新客户。
通过评估历史行为数据并使用它来预测客户未来可能的行为。这有助于提供准确的销售趋势预测,例如节假日期间的销售趋势,帮助营销人员制定更好、更具针对性的活动。
除了查看销售趋势外,预测分析还可以评估销售漏斗,检查每个阶段的有效性,从最初的意识到完成购买。例如,算法可以确定潜在客户通常会与多少内容/广告互动,以及何时互动,之后才会完成购买或关键行动。这有助于改进未来的定向广告活动,为了解客户在生命周期中更可能互动的时机提供洞察。
此方法还可以识别哪些类型的内容被定期互动,无论是社交媒体帖子还是应用程序中的 PDF 下载。通过PDF SDKs,客户可以快速将 PDF 内容如优惠券或产品信息下载到手机上,这是购买意图的明确迹象。
结合预测分析和决策制定
在商业中,将预测分析与决策结合起来已成为一种常见做法,依赖于先进的算法、过去的行为数据和统计数据来准确预测未来的行为。这不仅有助于企业做出更准确的决策,还允许它们快速做出决策,从而提供竞争优势。
图片来源于Analytica
决策可以涉及市场趋势、客户互动、营销活动、投资相关风险以及任何可能对业务产生重大影响的事项。
结合预测分析和决策制定:好处
对于一些人来说,预测分析的好处可能不明显,他们更愿意依赖现有的流程来塑造业务的未来。然而,有一些好处是不容忽视的,特别是当公司旨在在现代竞争激烈的数字环境中快速增长时。
预测分析与决策制定相结合的好处包括:
-
机器学习和人工智能的使用使得预测未来结果和趋势成为可能,从而使决策过程能够确定最佳行动方案。
-
通过准确的预测,企业可以保持领先地位,迅速采取行动以启动营销活动或新产品。
-
准确预测客户需求和市场变化,以便进行必要的调整。
-
可以分析极大规模的数据集,这些数据集是手动技术无法处理的。这些数据集可以包括客户人口统计信息或购买趋势,帮助识别新的、以前未开发的机会。
-
在潜在威胁成为问题之前进行识别,有助于保护操作,并使企业采取更主动的方式。
-
有助于更好地分配营销资源,仅针对相关客户,从而避免在不符合目标人群标准或不可能转换的潜在客户上浪费时间或金钱。
利用数据做出明智决策:最佳实践
在创建基于预测分析的预测模型时,有一些注意事项和禁忌,这些可能会对模型的有效性产生重大影响。
以下是创建预测模型时应遵循的五项最佳实践。
-
确保在将数据集应用于预测模型之前完全理解它们。这包括了解数据的来源、收集方式及其结构。确保所用数据完全可靠对于保证模型做出准确且相关的预测至关重要。
-
你还必须采用适合你业务的模型,以便与正在处理的数据相匹配。选择一个可以在整个业务中使用的单一模型,以便于优化,而不是使用多个可能变得复杂且低效的模型。
-
在推出模型之前,必须对其进行彻底评估和验证,以确保其训练正确并生成预期结果。为此,对模型进行各种数据集的测试,并根据需要进行改进,同时确保模型也使用最新的技术和方法。
-
模型上线后,需要持续监控其性能。始终彻底测试任何新数据集,并花时间根据研究结果将结果与最新趋势和市场变化进行比较。
-
安排定期测试,以评估模型的准确性,应用各种交叉验证技术来确定训练数据中显示的模式是否适用于实际场景。
结论
预测分析 是现代商业世界中不可或缺的工具,帮助公司做出明智的决策,从而对其运营的未来产生重大影响。
预测分析通过使用先进的机器学习算法来提供对未来客户行为和市场事件的洞察,从而协助营销活动、销售漏斗和产品管理。没有这些洞察,企业面临被竞争对手抛在后头的风险,可能会错失有利机会,无法理解其客户基础。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾担任过诸如领导编程等有趣的工作,并曾在一家 Inc. 5,000 体验品牌公司担任首席程序员,该公司客户包括三星、时代华纳、Netflix 和索尼。
相关内容
如何检索增强生成使 LLM 变得更聪明
原文:
www.kdnuggets.com/how-retrieval-augment-generation-makes-llms-smarter
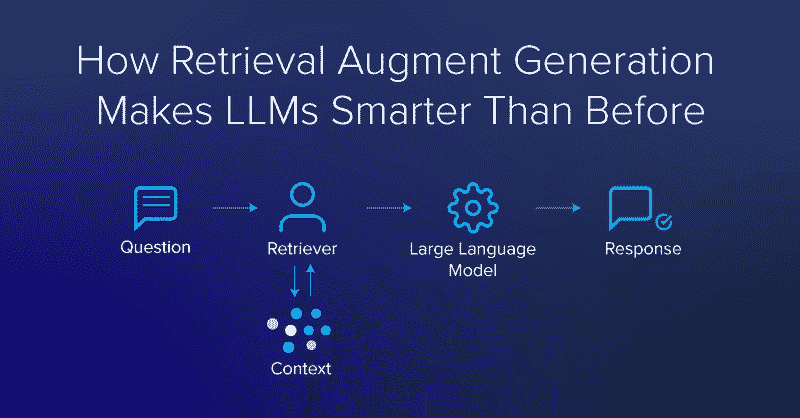
理想生成型 AI vs. 现实
基础的 LLM(大规模语言模型)已经阅读了它们能找到的每一个字节的文本,它们的聊天机器人对等体可以被提示进行智能对话,并被要求执行特定任务。获取全面的信息已经实现了民主化;不再需要找出正确的搜索关键词或挑选阅读的网站。然而,LLM 容易唠叨,并且通常会以统计上最可能的回应来回答你想听的内容(谄媚),这是变压器模型的固有结果。从 LLM 的知识库中提取 100%准确的信息并不总是能得到可信的结果。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
聊天型 LLM 因编造不存在的科学论文或法院案件的引用而臭名昭著。对航空公司提起诉讼的律师包括了实际上从未发生过的法院案件的引用。2023 年的一项研究报告显示,当 ChatGPT 被提示包含引用时,它仅在 14%的时间里提供了实际存在的参考文献。伪造来源、唠叨以及为了迎合提示而提供不准确的信息被称为幻觉,这是在 AI 被大众全面采纳和信任之前需要克服的一大障碍。
应对 LLM 编造虚假来源或产生不准确内容的一种对策是检索增强生成(RAG)。RAG 不仅可以减少 LLM 的幻觉倾向,还有其他几个优势。
这些优势包括访问更新的知识库,专业化(例如 提供私有数据源),赋予模型超越参数记忆中存储的信息(允许更小的模型),以及有可能从合法的参考资料中获得更多的数据。
什么是 RAG(检索增强生成)?
检索增强生成(RAG)是一种深度学习架构,实施在 LLMs 和变换器网络中,通过检索相关文档或其他片段并将其添加到上下文窗口中以提供额外的信息,从而帮助 LLM 生成有用的响应。一个典型的 RAG 系统有两个主要模块:检索和生成。
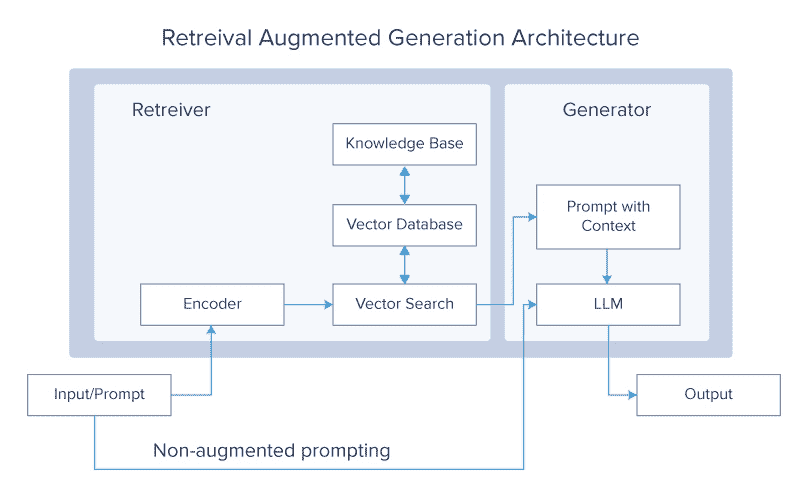
RAG 的主要参考文献是 Facebook 的一篇由 Lewis 等人撰写的论文。在论文中,作者使用一对基于 BERT 的文档编码器通过将文本嵌入到向量格式中来转换查询和文档。这些嵌入随后用于通过最大内积搜索(MIPS)来识别前k(通常是 5 或 10)个文档。顾名思义,MIPS 基于查询的编码向量表示与预计算的文档向量数据库中的向量表示之间的内积(或点积)。
正如 Lewis 等人 在文章中所描述的那样,RAG 的设计目的是让 LLMs 在处理“人类在没有外部知识来源的情况下无法合理完成的知识密集型任务”时表现得更好。考虑一下开放书籍和非开放书籍考试的对比,你就能很好地理解 RAG 如何补充基于 LLM 的系统。
使用 Hugging Face 🤗 库的 RAG
Lewis 等人 在 Hugging Face Hub 上开源了他们的 RAG 模型,因此我们可以使用论文中相同的模型进行实验。推荐使用 Python 3.8 的虚拟环境,并使用 virtualenv。
virtualenv my_env --python=python3.8
source my_env/bin/activate
激活环境后,我们可以使用 pip 安装依赖项:来自 Hugging Face 的 transformers 和 datasets,RAG 使用的 Facebook 的 FAISS 库用于向量搜索,以及用于作为后端的 PyTorch。
pip install transformers
pip install datasets
pip install faiss-cpu==1.8.0
#https://pytorch.org/get-started/locally/ to
#match the pytorch version to your system
pip install torch
Lewis 等人 实现了两种不同版本的 RAG:rag-sequence 和 rag-token。rag-sequence 使用相同的检索文档来增强整个序列的生成,而 rag-token 可以为每个标记使用不同的片段。这两个版本都使用相同的 Hugging Face 类进行标记化和检索,API 也基本相同,但每个版本都有一个独特的生成类。这些类是从 transformers 库中导入的。
from transformers import RagTokenizer, RagRetriever
from transformers import RagTokenForGeneration
from transformers import RagSequenceForGeneration
当首次实例化具有默认“wiki_dpr”数据集的 RagRetriever 模型时,它将启动大规模下载(约 300 GB)。如果你有一个大型数据驱动器并希望 Hugging Face 使用它(而不是默认的缓存文件夹),可以设置一个 Shell 变量 HF_DATASETS_CACHE。
# in the shell:
export HF_DATASETS_CACHE="/path/to/data/drive"
# ^^ add to your ~/.bashrc file if you want to set the variable
在下载完整的 wiki_dpr 数据集之前,请确保代码正常运行。为了避免大规模下载直到你准备好,你可以在实例化检索器时传递 use_dummy_dataset=True。你还需要实例化一个标记器,将字符串转换为整数索引(对应于词汇表中的标记)及反之。RAG 的序列版本和标记版本使用相同的标记器。RAG 序列(rag-sequence)和 RAG 标记(rag-token)各自有经过微调的(例如 rag-token-nq)和基础版本(例如 rag-token-base)。
tokenizer = RagTokenizer.from_pretrained(\
"facebook/rag-token-nq")
token_retriever = RagRetriever.from_pretrained(\
"facebook/rag-token-nq", \
index_name="compressed", \
use_dummy_dataset=False)
sequence_retriever = RagRetriever.from_pretrained(\
"facebook/rag-sequence-nq", \
index_name="compressed", \
use_dummy_dataset=False)
dummy_retriever = RagRetriever.from_pretrained(\
"facebook/rag-sequence-nq", \
index_name="exact", \
use_dummy_dataset=True)
token_model = RagTokenForGeneration.from_pretrained(\
"facebook/rag-token-nq", \
retriever=token_retriever)
seq_model = RagTokenForGeneration.from_pretrained(\
"facebook/rag-sequence-nq", \
retriever=seq_retriever)
dummy_model = RagTokenForGeneration.from_pretrained(\
"facebook/rag-sequence-nq", \
retriever=dummy_retriever)
一旦你的模型被实例化,你可以提供查询,进行标记化,然后将其传递给模型的“generate”函数。我们将比较使用带有 dummy 版本 wiki_dpr 数据集的 rag-sequence、rag-token 和 RAG 的结果。请注意,这些 rag 模型是不区分大小写的。
query = "what is the name of the oldest tree on Earth?"
input_dict = tokenizer.prepare_seq2seq_batch(\
query, return_tensors="pt")
token_generated = token_model.generate(**input_dict) token_decoded = token_tokenizer.batch_decode(\
token_generated, skip_special_tokens=True)
seq_generated = seq_model.generate(**input_dict)
seq_decoded = seq_tokenizer.batch_decode(\
seq_generated, skip_special_tokens=True)
dummy_generated = dummy_model.generate(**input_dict)
dummy_decoded = seq_tokenizer.batch_decode(\
dummy_generated, skip_special_tokens=True)
print(f"answers to query '{query}': ")
print(f"\t rag-sequence-nq: {seq_decoded[0]},"\
f" rag-token-nq: {token_decoded[0]},"\
f" rag (dummy): {dummy_decoded[0]}")
>> answers to query 'What is the name of the oldest tree on Earth?': Prometheus was the oldest tree discovered until 2012, with its innermost, extant rings exceeding 4862 years of age.
>> rag-sequence-nq: prometheus, rag-token-nq: prometheus, rag (dummy): 4862
通常,rag-token 的正确率高于 rag-sequence(尽管两者都经常正确),而 rag-sequence 的正确率高于使用 dummy 数据集的 RAG。
“检索器提供了什么样的上下文?”你可能会好奇。为了找出答案,我们可以解构生成过程。使用上面实例化的 seq_retriever 和 seq_model,我们查询“地球上最古老的树叫什么名字”
query = "what is the name of the oldest tree on Earth?"
inputs = tokenizer(query, return_tensors="pt")
input_ids = inputs["input_ids"]
question_hidden_states = seq_model.question_encoder(input_ids)[0]
docs_dict = seq_retriever(input_ids.numpy(),\
question_hidden_states.detach().numpy(),\
return_tensors="pt")
doc_scores = torch.bmm(\
question_hidden_states.unsqueeze(1),\
docs_dict["retrieved_doc_embeds"]\
.float().transpose(1, 2)).squeeze(1)
generated = model.generate(\
context_input_ids=docs_dict["context_input_ids"],\
context_attention_mask=\
docs_dict["context_attention_mask"],\
doc_scores=doc_scores)
generated_string = tokenizer.batch_decode(\
generated,\
skip_special_tokens=True)
contexts = tokenizer.batch_decode(\
docs_dict["context_input_ids"],\
attention_mask=docs_dict["context_attention_mask"],\
skip_special_tokens=True)
best_context = contexts[doc_scores.argmax()]
我们可以编写代码让模型打印“best context”变量,以查看捕获了什么。
print(f" based on the retrieved context"\
f":\n\n\t {best_context}: \n")
基于检索到的上下文:
Prometheus (tree) / In a clonal organism, however, the individual clonal stems are not nearly so old, and no part of the organism is particularly old at any given time. Until 2012, Prometheus was thus the oldest "non-clonal" organism yet discovered, with its innermost, extant rings exceeding 4862 years of age. In the 1950s dendrochronologists were making active efforts to find the oldest living tree species in order to use the analysis of the rings for various research purposes, such as the evaluation of former climates, the dating of archaeological ruins, and addressing the basic scientific question of maximum potential lifespan. Bristlecone pines // what is the name of the oldest tree on earth?
print(f" rag-sequence-nq answers '{query}'"\
f" with '{generated_string[0]}'")
我们还可以通过调用generated_string变量来打印答案。rag-sequence-nq 回答“地球上最古老的树叫什么名字?”为“Prometheus”。
你可以用 RAG 做什么?
在过去一年半里,LLMs 和 LLM 工具经历了真正的爆炸性增长。Lewis 等 使用的 BART 基础模型仅有 4 亿个参数,与当前的 LLMs 相比,后者通常以十亿参数级别的“轻量”变体为起点。此外,许多正在训练、合并和微调的模型都是多模态的,将文本输入和输出与图像或其他标记化的数据源结合起来。将 RAG 与其他工具结合可以构建复杂的能力,但基础模型仍然不能免于常见 LLM 缺陷。谄媚、幻觉和可靠性的问题依然存在,并有可能随着 LLM 的使用增长而加剧。
RAG 最明显的应用是对话语义搜索的变体,但它们也可能包括将多模态输入或图像生成作为输出的一部分。例如,具有领域知识的 LLM 中的 RAG 可以生成你可以聊天的软件文档。或者 RAG 可以用于在文献综述的研究项目或论文中保持互动笔记。
通过整合“链式思维”推理能力,你可以采取更具代理性的方式,赋能你的模型查询 RAG 系统并组装更复杂的询问或推理路径。
还需要特别注意的是,RAG 并不能解决常见的大型语言模型(LLM)问题(如幻觉、谄媚等),它仅作为一种缓解或引导你的 LLM 达到更专业回应的手段。最终重要的是,取决于你的使用案例、你提供给模型的信息以及模型的微调方式。
Kevin Vu 负责管理 Exxact Corp 博客,并与许多才华横溢的作者合作,他们撰写关于深度学习不同方面的文章。
更多相关话题
语义向量搜索如何变革客户支持互动
原文:
www.kdnuggets.com/how-semantic-vector-search-transforms-customer-support-interactions

图片由 rawpixel.com 提供,来源于 Freepik
你知道吗,大约 99.5%的企业收集的数据没有被使用?事实上,这些数据甚至从未被分析过。这显示了一个巨大的差距,只有通过先进的企业搜索平台才能弥补。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在过去的几年中,搜索技术发生了剧烈变化。从使用全文和关键词匹配机制,转变为更复杂的技术,如语义(理解单词背后的含义)和视觉(使用图片进行搜索)平台,这些定义了今天的数字化格局。
这是对不断增长的客户期望的回应——今天的个人不仅希望获得一般化的搜索结果,他们希望这些结果能够个性化并精准相关。这正是语义向量搜索的作用所在。
它无缝地利用深度度量学习来训练一个语义模型,帮助在向量空间中组织查询,使相似的事物结合在一起,而不同的事物则分开。
探索这篇博客文章,了解语义向量搜索的基础知识及更多内容。
首先—什么是语义向量搜索
传统的搜索引擎只关注确切的关键词,并返回围绕这些关键词的结果。相反,先进的 AI 系统超越了关键词映射,理解查询的上下文和意图。
例如,一个激动的客户联系了客户支持并抱怨,“哇,谢谢你把我的行李送到华盛顿,同时把我送到洛杉矶。真是棒极了的服务!” 在这种情况下,传统的搜索引擎会关注“哇”和“棒极了的服务”等词。然而,语义向量搜索引擎则更深入地理解问题——它明白了潜在的讽刺和客户的沮丧。这就像拥有一个支持代理,不仅听到关键词,还能理解它们的含义和上下文,提供更有效的帮助。
麦肯锡的研究发现,擅长个性化的公司在这些活动中产生的收入比平均水平高出 40%。在美国各行业中,转向个性化的顶尖表现将创造超过 1 万亿美元的价值。
但是,它是如何工作的呢?

让我们把每个单词想象成高楼大厦中的一个居民。地址为 45、46 和 47 的居民住在同一栋楼中,而地址为 55、56 和 57 的居民住在下一栋楼中。这些居民之间的距离和方向代表了单词之间的关系,其中意思相近的单词会更接近彼此。
现在,你已经了解了基本含义,让我们深入探讨细节。
当用户输入查询时,系统将其转换为一个向量。然后,它会寻找在含义上接近的其他向量。这确保了系统不仅检索到精确匹配的信息,还能找到语义相关的信息。
但语义在向量搜索中扮演什么角色?
语义的意义在于 AI 系统能够通过考虑同义词和上下文等因素来理解和把握单词背后的确切含义。
结果是?准确、相关、个性化的响应,能够快速启动问题解决过程,让客户感到满意。
但为了确保一切顺利运行,还有一个复杂的机制,也是一种人工智能的子集,在幕后工作,那就是——机器学习。
机器学习算法深入理解单词之间的细微相似性和差异。为此,它们将单词视为大拼图中的部分,而不是理解单一词语的含义。
人工智能(AI)算法分解了语言的复杂性。它分析数据中的上下文、模式和关联。它们通过超越表面解释,揭示了单词的含义。
例如,一个客户向你的公司提出了一个问题。他们想用樱桃和李子的鲜艳色彩装饰厨房。然而,你的虚拟助手误将其理解为水果。这种双重用法突显了相同术语在不同含义和上下文中的差异。
这是一个高级 AI 系统可以解读术语的固有含义及其相互关联的地方。
语义向量搜索技术的类型
该搜索应用了强大的词嵌入技术来理解语言的细微差别:

向量搜索如何改变客户支持互动?
语义向量搜索在提升客户支持体验方面的两个领域是:
1. 理解自然语言
自然语言具有模糊性。机器理解人类沟通方式成为一场艰巨的战斗。这时,自然语言处理(NLP) 可以发挥作用。它是一种多学科过程,结合了机器学习和自然语言生成,使人类和机器的互动成为可能。语义向量搜索应用 NLP 来催化情感分析。
情感分析将数据分类为积极、消极或中性。通过将情感分析纳入现有系统,组织可以获得有关客户需求和问题的宝贵见解。这使得组织能够提供主动和个性化的体验。
2. 促进信息检索
由于语义向量搜索能够把握查询的潜在含义、意图和背景,它确保正确的帮助文章在正确的时间送达正确的受众。它利用人工智能获取用户旅程的全景视图,从而根据用户的浏览历史、客户情感等来进行超个性化的支持。作为附加优势,CSAT(客户满意度评分)也会显著提高。双赢,对吧?
但,等等!有智慧的地方总会有挑战。
实现有效向量搜索的挑战
尽管语义向量搜索的未来承诺带来深远的好处,但实现这些好处的道路上仍然存在障碍。它们是:
1. 语义中的模糊性处理
由于自然语言或人类语言具有模糊性,单词和句子对不同的人可能有不同的解释。因此,正确解读用户查询的上下文和意图变得极其困难。部署先进的机器学习算法可以有所帮助。它们通过用户互动不断学习,以提高准确性。
2. 伦理考虑
由于语义向量搜索系统是在大规模数据集上训练的,因此不可避免地会出现一些关于隐私、偏见和透明度的伦理考量。让我们将这些隐私问题视为垫脚石,而不是障碍。为了防止歧视性结果,必须通过定期审计和更新数据来采取措施减轻偏见。
寻找提升企业搜索引擎的力量倍增器吗?
市场上有大量的技术,如神经网络、向量搜索和语义搜索。在这里,神经网络提供深度,向量搜索提升精度,而语义理解揭示了意义的细微层次。
单独使用它们会使其能力未得到充分利用。这就是统一认知平台可以成为光明的一线的地方。它无缝整合了不同的搜索技术,以确保用户可以享受个性化、上下文相关且及时的搜索体验。
Taranjeet 是一位数据科学家,对行为科学有浓厚的兴趣,并逐渐将重点转向相关性。他在 LLM、升级预测、意图检测、语义搜索和推荐系统等问题上交付了生产就绪的解决方案,同时利用了最先进的边缘 AI 和 NLP 技术。
更多相关内容
我在过去两个月中如何开始学习 AI
评论

图片最初由gbksoft制作
现在每个人都非常忙。我们的个人和职业生活中有太多事情发生。更令人惊讶的是,人工智能这种东西开始获得关注,你发现自己的技能在接下来的两年里变得严重过时。
当我关闭我的初创公司 Zeading 时,我意识到自己错过了非常独特的东西。
在不断变化的环境中,全栈开发者的相关性将不再足够。在接下来的两年里,没有 AI 技能的全栈将不再是全栈。
是时候采取行动了。我做了我认为现在唯一正确的行动——更新我的开发技能、作为产品负责人的心态和作为企业家的哲学,以变得更加数据导向。
正如Spiros Margaris这位著名的风险投资家和 AI 及金融科技领域的思想领袖优雅地对我说,
如果创业公司和公司仅仅依靠尖端 AI 和机器学习算法来竞争——这将是不够的。AI 将不再是竞争优势,而是一种要求。你听到有人说他们用电力作为竞争优势吗?
构建我的第一个神经网络
 照片由 — Unsplash 提供
照片由 — Unsplash 提供
常见的建议是报名参加Andrew Ng 的 Coursera 课程。这是一个很好的起点,但我发现很难保持清醒。并不是说课程不好,只是我真的不擅长在讲座中保持注意力。我的学习方式一直是通过实践,所以我想,为什么不呢,让我们实现自己的神经网络。
我没有直接跳到神经网络,因为这不是更好的学习方法。我试图熟悉领域中的所有术语,以便我能学会说这种语言。
第一个任务不是学习,而是熟悉。
我来自纯粹的 Javascript 和 Nodejs 背景,不想马上换堆栈。因此,我寻找了一个简单的神经网络模块,叫做 nn,并用它实现了一个与门,输入为虚拟值。受到这个教程的启发,我选择了一个问题,即对于任何三个输入 X、Y 和 Z,输出应该是 X 与 Y。
var nn = require('nn')
var opts = {
layers: [ 4 ],
iterations: 300000,
errorThresh: 0.0000005,
activation: 'logistic',
learningRate: 0.4,
momentum: 0.5,
log: 100
}
var net = nn(opts)
net.train([
{ input: [ 0,0,1 ], output: [ 0 ] },
{ input: [ 0,1,1 ], output: [ 0 ] },
{ input: [ 1,0,1 ], output: [ 0 ] },
{ input: [ 0,1,0 ], output: [ 0 ] },
{ input: [ 1,0,0 ], output: [ 0 ] },
{ input: [ 1,1,1 ], output: [ 1 ] },
{ input: [ 0,0,0 ], output: [ 0 ] }
])
// send it a new input to see its trained output
var output = net.send([ 1,1,0])
console.log(output); //0.9971279763719718
真是太高兴了!
我个人认为,这是我采取的最具信心的步骤。当输出显示为 0.9971 时,我意识到网络已经学会了如何执行AND操作,并自行忽略额外的输入。
这基本上是机器学习的要点。你给计算机程序一组数据,它调整内部参数,以便能够对新数据做出回答,误差从原始数据中观察到的误差逐渐减少。
这种方法,后来我了解到,也被称为梯度下降。
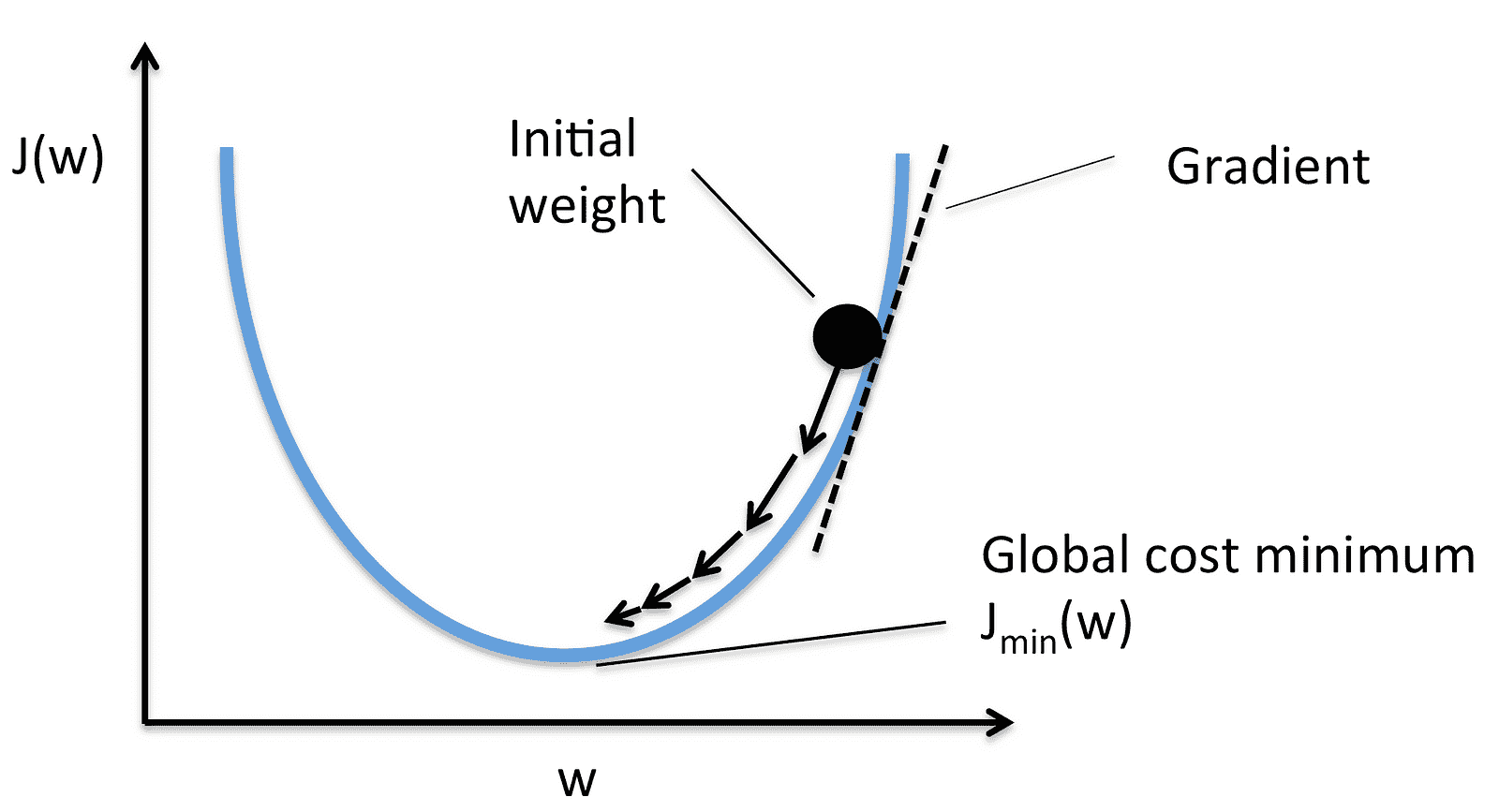
图片由 — 塞巴斯蒂安·拉施卡提供
为人工智能做好心理准备

图片由 — Unsplash 提供
一旦我在完成第一个人工智能程序后充满信心,我就想知道作为开发者我还能用机器学习做些什么。
-
我使用了一个非常有限的数据集,尝试预测哪支球队会赢得某场 IPL 比赛,使用了多变量线性回归。 (预测结果真的很差,但还挺酷的)
-
我试用了Google 机器学习云上的演示,以查看今天 AI 可以做什么(显然谷歌已经将其做成了 SaaS 产品)。
-
我偶然发现了AI Playbook,这是由著名风险基金 Andreessen-Horowitz 组织的一个很棒的资源。确实是开发者和企业家最有用的资源之一。

-
我开始观看Siraj Rawal 的精彩 YouTube 频道,这个频道专注于深度学习和机器学习。
-
我阅读了这篇精彩的 Hacker Noon 文章,讲述了硅谷的制作人是如何打造Not Hotdog 应用的。这是我们可以做到的最容易理解的深度学习示例之一。
-
我阅读了Andrej Karpathy 的博客,他是特斯拉的 AI 总监。尽管我几乎看不懂什么,并且感到头疼,但我发现再试一段时间后,这些概念确实开始变得有意义。
-
带着一些勇气,我开始逐字实现一些深度学习教程(复制和粘贴),并尝试在本地机器上训练模型和运行代码。大多数时候,由于训练时间长而且我没有 GPU,效果不佳。
渐渐地,我将工具从 Javascript 切换到 Python,并在我的 Windows 机器上安装了Tensorflow。
整个过程围绕着被动地消费内容,并在你的脑海中建立参考,以便在我遇到实际的消费者问题时使用。
正如史蒂夫·乔布斯所说,你只能回顾过去来连接点滴。
抓住聊天机器人列车

图片来源 — Unsplash
作为电影她的忠实粉丝,我想构建聊天机器人。我接受了这个挑战,并在不到两小时的时间里用 Tensorflow 成功构建了一个。我在我的一篇文章中概述了这段旅程和它的业务需求。
幸运的是,这篇文章真的变得很火,并在TechInAsia、CodeMentor和 KDNuggets 上被推荐。这对我来说是一个伟大的时刻,因为我刚刚开始从事技术博客。但我认为这篇文章是我 AI 学习旅程中的一个重要时刻。
这让我在 Twitter 和 LinkedIn 上结识了许多朋友,我可以与他们深入讨论 AI 开发,并且在遇到困难时可以联系他们。我收到了一些咨询项目的邀请,最棒的是,年轻的开发者和 AI 初学者开始询问我如何开始学习 AI。
这也就是我写这篇文章的原因。为了帮助更多人从我的旅程中汲取经验,开始他们自己的旅程。
开始是任何旅程中最具挑战性的部分之一。
盐和胡椒
图片来源 — Unsplash
这绝对不容易。当我开始在 Javascript 中遇到困难时,我几乎一夜之间跳转到 Python,并学习了如何用它编程。当我的模型在 i7 机器上无法训练,或者即使经过数小时的训练,它们也会返回像 50–50 概率这样的无意义结果时,我开始感到烦躁。学习 AI 不同于学习一个网页框架。
这是一项需要对计算的微观层面有所了解的技能,并找出是什么对你的输出负责——是你的代码还是你的数据。
AI 也不仅仅是一个学科。它是一个统称,涵盖从简单的回归问题到可能在某天消灭我们的致命机器人。像进入任何其他学科一样,你可能会选择在 AI 领域中专注于你真正想擅长的领域,如计算机视觉或自然语言处理,或者天哪,世界统治。
在与来自 Atlantis Capital 的Gaurav Sharma的对话中,这位在 AI、金融科技和加密货币领域的著名行业领袖向我透露:
在人工智能时代,“聪明”将意味着完全不同的东西。我们需要能够进行高阶批判性、创造性和思考工作,并且需要高情感投入的工作的人。
你必须对计算机如何突然学会独立完成任务感到着迷。耐心和惊奇是你应该坚持的两个关键原则。
这是一次漫长、漫长的旅程。非常疲惫、非常烦人,而且异常耗时。
但好的一面是,像世界上所有其他的旅程一样,这次旅程也始于一步。
原文。经许可转载。
简介:Shival Gupta 是产品爱好者和企业家。了解一些#AI #机器学习。工程师。前 CEO @ZeadingOfficial @CourseCannon。
相关:
-
成功实施 AI 的 5 个主要因素
-
神经网络:无数的架构,一个基本理念
-
用于目标检测的深度学习:全面回顾
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关内容
如何免费访问和使用 Gemini API
原文:
www.kdnuggets.com/how-to-access-and-use-gemini-api-for-free

作者提供的图片
Gemini 是 Google 开发的新模型,Bard 也开始重新可用。借助 Gemini,现在可以通过提供图像、音频和文本来获得几乎完美的查询答案。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
在本教程中,我们将学习 Gemini API 及其在您的计算机上的设置方法。我们还将探索各种 Python API 功能,包括文本生成和图像理解。
介绍 Gemini AI 模型
Gemini 是由 Google 各团队(包括 Google Research 和 Google DeepMind)合作开发的全新 AI 模型。它专门设计为多模态,即能够理解和处理文本、代码、音频、图像和视频等不同类型的数据。
Gemini 是迄今为止 Google 开发的最先进、最大型的 AI 模型。它被设计得非常灵活,因此可以高效地在各种系统上运行,从数据中心到移动设备。这意味着它有潜力彻底改变企业和开发者构建和扩展 AI 应用程序的方式。
以下是为不同使用场景设计的三种 Gemini 模型版本:
-
Gemini Ultra: 最大和最先进的 AI,能够执行复杂任务。
-
Gemini Pro: 一种平衡的模型,具有良好的性能和可扩展性。
-
Gemini Nano: 最适合移动设备使用。
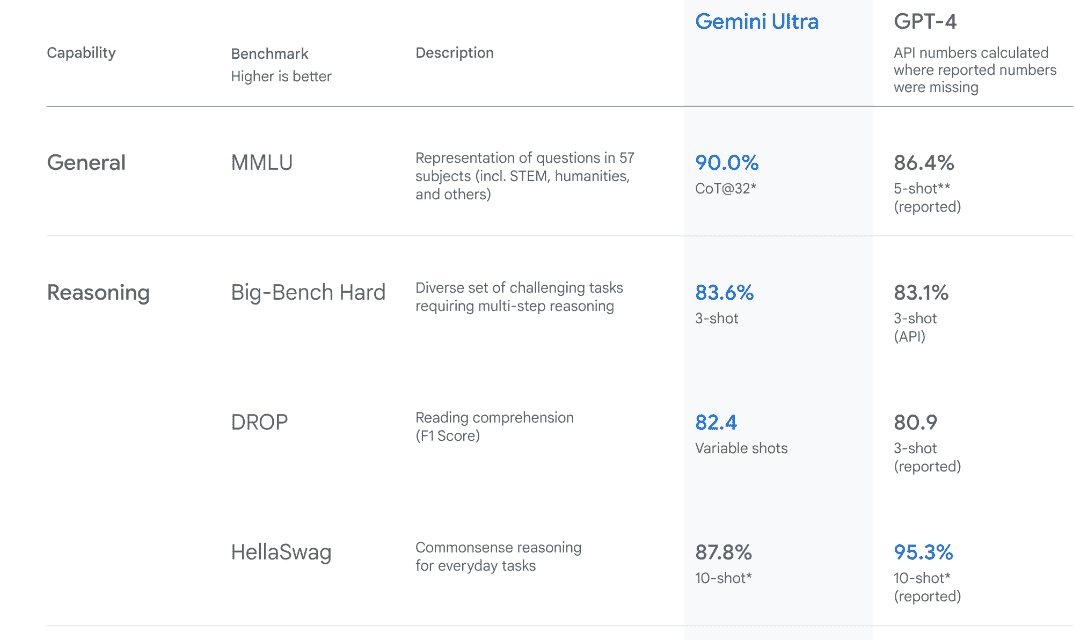
图片来源于 介绍 Gemini
Gemini Ultra 具有最先进的性能,在多个指标上超过了 GPT-4。它是第一个在大规模多任务语言理解基准上超过人类专家的模型,该基准测试全球知识和 57 个不同主题的解决问题能力。这展示了它先进的理解和解决问题的能力。
设置
要使用 API,我们首先需要获得一个 API 密钥,可以从这里获取:https://ai.google.dev/tutorials/setup
之后点击“获取 API 密钥”按钮,然后点击“在新项目中创建 API 密钥”。
复制 API 密钥并将其设置为环境变量。我们使用 Deepnote,并且很容易将密钥命名为“GEMINI_API_KEY”。只需转到集成部分,向下滚动并选择环境变量。
在下一步中,我们将使用 PIP 安装 Python API:
pip install -q -U google-generativeai
之后,我们将 API 密钥设置到 Google 的 GenAI,并启动实例。
import google.generativeai as genai
import os
gemini_api_key = os.environ["GEMINI_API_KEY"]
genai.configure(api_key = gemini_api_key)
使用 Gemini Pro
设置 API 密钥后,使用 Gemini Pro 模型生成内容非常简单。向generate_content函数提供提示并以 Markdown 显示输出。
from IPython.display import Markdown
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Who is the GOAT in the NBA?")
Markdown(response.text)
这很令人惊叹,但我不同意这个列表。然而,我理解这完全是个人喜好问题。

Gemini 可以为单个提示生成多个响应,称为候选项。你可以选择最合适的一个。在我们的例子中,我们只有一个响应。
response.candidates

让我们让它用 Python 编写一个简单的游戏。
response = model.generate_content("Build a simple game in Python")
Markdown(response.text)
结果简单明了。大多数 LLM 开始解释 Python 代码,而不是编写它。

配置响应
你可以使用generation_config参数来定制你的响应。我们将候选数限制为 1,添加了停止词“space”,并设置了最大令牌和温度。
response = model.generate_content(
'Write a short story about aliens.',
generation_config=genai.types.GenerationConfig(
candidate_count=1,
stop_sequences=['space'],
max_output_tokens=200,
temperature=0.7)
)
Markdown(response.text)
如你所见,响应在“space”这个词之前停止了。真是令人惊叹。

流式响应
你也可以使用stream参数来流式传输响应。它类似于 Anthropic 和 OpenAI API,但更快。
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Write a Julia function for cleaning the data.", stream=True)
for chunk in response:
print(chunk.text)

使用 Gemini Pro Vision
在本节中,我们将加载 Masood Aslami 的 照片,并用它来测试 Gemini Pro Vision 的多模态性。
将图像加载到 PIL 中并显示。
import PIL.Image
img = PIL.Image.open('images/photo-1.jpg')
img
我们有一张高质量的 Rua Augusta Arch 照片。

让我们加载 Gemini Pro Vision 模型,并提供图像。
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
Markdown(response.text)
该模型准确识别了宫殿,并提供了有关其历史和建筑的额外信息。

让我们将相同的图像提供给 GPT-4 并询问它有关图像的信息。两个模型提供的回答几乎相似。但我更喜欢 GPT-4 的回应。

我们现在将文本和图像提供给 API。我们已请视觉模型使用该图像作为参考写一篇旅游博客。
response = model.generate_content(["Write a travel blog post using the image as reference.", img])
Markdown(response.text)
它为我提供了一个简短的博客。我原本期望更长的格式。

与 GPT-4 相比,Gemini Pro Vision 模型在生成长格式博客时遇到了困难。
聊天对话会话
我们可以设置模型进行往返聊天会话。这样,模型可以记住上下文并利用之前的对话进行回应。
在我们的例子中,我们已经开始了聊天会话,并请模型帮助我入门 Dota 2 游戏。
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=[])
chat.send_message("Can you please guide me on how to start playing Dota 2?")
chat.history
如你所见,chat 对象正在保存用户和模型聊天的历史记录。

我们还可以以 Markdown 风格显示它们。
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))

让我们提出跟进问题。
chat.send_message("Which Dota 2 heroes should I start with?")
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))
我们可以向下滚动并查看与模型的整个会话。

使用嵌入
嵌入模型在上下文感知应用中越来越受欢迎。Gemini embedding-001 模型允许将单词、句子或整个文档表示为密集向量,这些向量编码了语义意义。这种向量表示使得通过比较相应的嵌入向量来轻松比较不同文本片段之间的相似性成为可能。
我们可以将内容提供给 embed_content 并将文本转换为嵌入。就是这么简单。
output = genai.embed_content(
model="models/embedding-001",
content="Can you please guide me on how to start playing Dota 2?",
task_type="retrieval_document",
title="Embedding of Dota 2 question")
print(output['embedding'][0:10])
[0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664]
我们可以通过将字符串列表传递给 'content' 参数,将多个文本块转换为嵌入。
output = genai.embed_content(
model="models/embedding-001",
content=[
"Can you please guide me on how to start playing Dota 2?",
"Which Dota 2 heroes should I start with?",
],
task_type="retrieval_document",
title="Embedding of Dota 2 question")
for emb in output['embedding']:
print(emb[:10])
[0.060604308, -0.023885584, -0.007826327, -0.070592545, 0.021225851, 0.043229062, 0.06876691, 0.049298503, 0.039964676, 0.08291664]
[0.04775657, -0.044990525, -0.014886052, -0.08473655, 0.04060122, 0.035374347, 0.031866882, 0.071754575, 0.042207796, 0.04577447]
如果您无法重现相同的结果,请查看我的Deepnote 工作空间。
结论
在这个入门教程中,我们没有涵盖许多高级功能。您可以通过访问Gemini API:Python 快速入门来了解更多有关 Gemini API 的信息。
在本教程中,我们学习了 Gemini 及如何访问 Python API 生成响应。特别是,我们了解了文本生成、视觉理解、流媒体、对话历史、自定义输出和嵌入。然而,这只是 Gemini 可以做的一小部分。
请随时与我分享您使用自由 Gemini API 构建的内容。可能性是无限的。
阿比德·阿里·阿万(@1abidaliawan)是一位认证数据科学家专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。阿比德拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为遭受心理疾病困扰的学生构建 AI 产品。
更多关于此主题的信息
如何使用 NumPy 对数组进行填充
原文:
www.kdnuggets.com/how-to-apply-padding-to-arrays-with-numpy

图片来自 freepik
填充是向数组的边缘添加额外元素的过程。这可能听起来很简单,但它有多种应用,可以显著提升数据处理任务的功能和性能。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
假设你正在处理图像数据。通常,在应用滤镜或执行卷积操作时,图像的边缘可能会成为问题,因为周围没有足够的像素来一致地应用操作。对图像进行填充(在原始图像周围添加行和列的像素)可以确保每个像素都得到均等处理,从而产生更准确、更具视觉吸引力的输出。
你可能会想知道填充是否仅限于图像处理。答案是否定的。在深度学习中,填充在处理卷积神经网络(CNN)时至关重要。它允许你在网络的连续层中保持数据的空间维度,防止数据在每次操作后缩小。这在保留输入数据的原始特征和结构时尤为重要。
在时间序列分析中,填充可以帮助对齐不同长度的序列。这种对齐对于将数据输入到机器学习模型中至关重要,因为输入大小的一致性通常是必要的。
在本文中,你将学习如何使用 NumPy 对数组进行填充,以及填充的不同类型和使用 NumPy 填充数组时的最佳实践。
Numpy.pad
numpy.pad 函数是 NumPy 中添加数组填充的首选工具。该函数的语法如下所示:
numpy.pad(array, pad_width, mode='constant', **kwargs)
其中:
-
array:要添加填充的输入数组。
-
pad_width:这是填充到每个轴边缘的值的数量。它指定了在数组的每个轴的两端添加的元素数量。它可以是一个整数(所有轴相同填充),一个包含两个整数的元组(每个轴的两端填充不同),或者是不同轴的这种元组的序列。
-
mode:这是用于填充的方法,决定了应用哪种类型的填充。常见的模式包括:零填充、边缘填充、对称填充等。
-
kwargs:这些是根据模式的不同而额外的关键字参数。
让我们检查一个数组示例,看看如何使用 NumPy 为其添加填充。为了简单起见,我们将专注于一种填充类型:零填充,它是最常见且直接的。
步骤 1:创建数组
首先,让我们创建一个简单的 2D 数组来进行操作:
import numpy as np
# Create a 2D array
array = np.array([[1, 2], [3, 4]])
print("Original Array:")
print(array)
输出:
Original Array:
[[1 2]
[3 4]]
步骤 2:添加零填充
接下来,我们将为该数组添加零填充。我们使用 np.pad 函数来实现这一点。我们将指定填充宽度为 1,围绕整个数组添加一行/列的零。
# Add zero padding
padded_array = np.pad(array, pad_width=1, mode='constant', constant_values=0)
print("Padded Array with Zero Padding:")
print(padded_array)
输出:
Padded Array with Zero Padding:
[[0 0 0 0]
[0 1 2 0]
[0 3 4 0]
[0 0 0 0]]
说明
-
原始数组:我们的起始数组是一个简单的 2x2 数组,值为 [[1, 2], [3, 4]]。
-
零填充:通过使用
np.pad,我们在原始数组周围添加了一层零。pad_width=1参数指定在每一侧添加一行/列的填充。mode='constant'参数表示填充应为常数值,我们通过constant_values=0将其设置为零。
填充类型
不同类型的填充方式中,零填充(zero padding),如上例所示,是其中之一;其他示例包括常数填充(constant padding)、边缘填充(edge padding)、反射填充(reflect padding)和对称填充(symmetric padding)。让我们详细讨论这些填充类型,并了解如何使用它们。
零填充
零填充是添加额外值到数组边缘的最简单和最常用的方法。这种技术涉及用零填充数组,在各种应用中非常有用,例如图像处理。
零填充涉及在数组的边缘添加填充零的行和列。这有助于在执行可能会缩小数组的操作时保持数据的大小。
示例:
import numpy as np
array = np.array([[1, 2], [3, 4]])
padded_array = np.pad(array, pad_width=1, mode='constant', constant_values=0)
print(padded_array)
输出:
[[0 0 0 0]
[0 1 2 0]
[0 3 4 0]
[0 0 0 0]]
常数填充
常数填充允许你使用自己选择的常数值来填充数组,而不仅仅是零。这个值可以是你选择的任何东西,比如 0、1 或其他数字。当你希望保持特定的边界条件或零填充可能不适合你的分析时,它特别有用。
示例:
array = np.array([[1, 2], [3, 4]])
padded_array = np.pad(array, pad_width=1, mode='constant', constant_values=5)
print(padded_array)
输出:
[[5 5 5 5]
[5 1 2 5]
[5 3 4 5]
[5 5 5 5]]
边缘填充
边缘填充用边缘的值填充数组。不是添加零或某个常数值,而是使用最近的边缘值来填补空白。这种方法有助于保持原始数据模式,并且在你希望避免将新的或任意值引入数据时非常有用。
示例:
array = np.array([[1, 2], [3, 4]])
padded_array = np.pad(array, pad_width=1, mode='edge')
print(padded_array)
输出:
[[1 1 2 2]
[1 1 2 2]
[3 3 4 4]
[3 3 4 4]]
反射填充
反射填充是一种通过从原始数组的边缘镜像值来填充数组的技术。这意味着边界值在边缘处反射,这有助于在数据中保持模式和连续性,而不会引入任何新的或任意的值。
示例:
array = np.array([[1, 2], [3, 4]])
padded_array = np.pad(array, pad_width=1, mode='reflect')
print(padded_array)
输出:
[[4 3 4 3]
[2 1 2 1]
[4 3 4 3]
[2 1 2 1]]
对称填充
对称填充是一种操作数组的技术,有助于保持原始数据的平衡和自然延展。它类似于反射填充,但在反射中包括了边缘值本身。这种方法有助于在填充数组中保持对称性。
示例:
array = np.array([[1, 2], [3, 4]])
padded_array = np.pad(array, pad_width=1, mode='symmetric')
print(padded_array)
输出:
[[1 1 2 2]
[1 1 2 2]
[3 3 4 4]
[3 3 4 4]]
应用 NumPy 填充到数组的常见最佳实践
-
选择正确的填充类型
-
确保填充值与数据的性质一致。例如,二进制数据应使用零填充,但在图像处理任务中,边缘填充或反射填充可能更为适合,应避免使用零填充。
-
考虑填充如何影响数据分析或处理任务。填充可能会引入伪影,特别是在图像或信号处理领域,因此请选择一种能够最小化这种影响的填充类型。
-
填充多维数组时,确保正确指定填充维度。不对齐的维度可能会导致错误或意外结果。
-
清楚地记录为何以及如何在代码中应用填充。这有助于保持清晰性,并确保其他用户(或未来的你)理解填充的目的和方法。
结论
在这篇文章中,你学习了填充数组的概念,这是一种广泛应用于图像处理和时间序列分析等领域的基本技术。我们探讨了填充如何帮助扩展数组的大小,使其适用于不同的计算任务。
我们介绍了 numpy.pad 函数,该函数简化了在 NumPy 中向数组添加填充的过程。通过清晰简明的示例,我们展示了如何使用 numpy.pad 向数组添加填充,并展示了各种填充类型,如零填充、常数填充、边缘填充、反射填充和对称填充。
遵循这些最佳实践,你可以使用 NumPy 对数组进行填充,确保你的数据操作准确、高效,并适合你的特定应用。
Shittu Olumide 是一位软件工程师和技术作家,他热衷于利用前沿技术创作引人入胜的叙述,注重细节,并擅长简化复杂概念。你还可以在 Twitter 上找到 Shittu。
更多相关主题
如何使用 Hugging Face Transformers 从零开始构建和训练一个 Transformer 模型

图片来源 | Midjourney
Hugging Face Transformers 库提供了易于加载和使用基于 transformer 架构的预训练语言模型(LMs)的工具。但你知道这个库也允许你从零开始实现和训练自己的 transformer 模型吗?本教程通过一步一步的情感分类示例来说明这一点。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT
重要说明: 从零开始训练一个 transformer 模型是计算密集型的,训练循环通常至少需要几个小时。要运行本教程中的代码,强烈建议使用高性能计算资源,无论是本地还是通过云提供商。
步骤流程
初始设置和数据集加载
根据你所使用的 Python 开发环境,你可能需要安装 Hugging Face 的 transformers 和 datasets 库,以及 accelerate 库,以在分布式计算环境中训练你的 transformer 模型。
!pip install transformers datasets
!pip install accelerate -U
一旦安装了必要的库,让我们加载 情感数据集 以进行来自 Hugging Face hub 的 Twitter 消息情感分类:
from datasets import load_dataset
dataset = load_dataset('jeffnyman/emotions')
使用数据来训练基于 transformer 的 LM 需要对文本进行分词。以下代码初始化了一个 BERT 分词器(BERT 是适用于文本分类任务的 transformer 模型家族),定义了一个用于分词、填充和截断的函数,并将其应用于数据集的批次中。
from transformers import AutoTokenizer
def tokenize_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
tokenized_datasets = dataset.map(tokenize_function, batched=True)
在初始化 transformer 模型之前,我们先来验证数据集中的唯一标签。验证现有类别标签的集合有助于防止训练期间的 GPU 相关错误,确保标签的一致性和正确性。我们将在后面使用这个标签集合。
unique_labels = set(tokenized_datasets['train']['label'])
print(f"Unique labels in the training set: {unique_labels}")
def check_labels(dataset):
for label in dataset['train']['label']:
if label not in unique_labels:
print(f"Found invalid label: {label}")
check_labels(tokenized_datasets)
接下来,我们创建并定义一个模型配置,然后用这个配置实例化 transformer 模型。在这里,我们指定关于 transformer 架构的超参数,比如嵌入大小、注意力头的数量,以及先前计算出的唯一标签集合,这些都是构建情感分类最终输出层的关键。
from transformers import BertConfig
from transformers import BertForSequenceClassification
config = BertConfig(
vocab_size=tokenizer.vocab_size,
hidden_size=512,
num_hidden_layers=6,
num_attention_heads=8,
intermediate_size=2048,
max_position_embeddings=512,
num_labels=len(unique_labels)
)
model = BertForSequenceClassification(config)
我们几乎准备好训练我们的 transformer 模型了。只剩下实例化两个必要的实例:TrainingArguments,它包含关于训练循环的规范,如 epoch 数量,以及 Trainer,它将模型实例、训练参数和用于训练和验证的数据粘合在一起。
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
训练模型的时间到了,坐下来放松一下吧。记住,这个过程将需要相当长的时间来完成:
trainer.train()
训练完成后,你的 transformer 模型应该已经准备好接收输入示例进行情感预测。
故障排除
如果在执行训练循环或设置过程中出现或持续存在问题,你可能需要检查所使用的 GPU/CPU 资源的配置。例如,如果使用 CUDA GPU,可以在代码开始处添加这些指令,以帮助防止训练循环中的错误:
import os
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
这些行禁用 GPU 并使 CUDA 操作同步,从而提供更及时和准确的错误消息以供调试。
另一方面,如果你在 Google Colab 实例中尝试这段代码,执行期间可能会出现这个错误信息,即使你之前已经安装了 accelerate 库:
ImportError: Using the `Trainer` with `PyTorch` requires `accelerate>=0.21.0`: Please run `pip install transformers[torch]` or `pip install accelerate -U`
为了解决这个问题,尝试在 'Runtime' 菜单中重启你的会话:accelerate 库通常需要在安装后重置运行环境。
总结与结束
本教程展示了从零开始使用 Hugging Face 库构建基于 transformer 的语言模型的关键步骤。主要步骤和涉及的元素可以总结如下:
-
加载数据集并标记文本数据。
-
使用模型配置实例初始化你的模型,以适应特定的模型类型(语言任务),例如 BertConfig。
-
设置 Trainer 和 TrainingArguments 实例并运行训练循环。
作为下一个学习步骤,我们鼓励你探索如何使用你新训练的模型进行预测和推断。
Iván Palomares Carrascosa 是人工智能、机器学习、深度学习和大型语言模型领域的领导者、作者、演讲者和顾问。他培训和指导他人如何在现实世界中利用人工智能。
更多相关信息
数据科学家如何注释你的 Python 代码
原文:
www.kdnuggets.com/how-to-comment-your-python-code-as-a-data-scientist

图片由 DALL·E 3 生成
数据科学家面临一个令人兴奋的职位;虽然他们在现代时代的工作需要使用编程语言,但他们的工作仍然需要记住许多业务方面。这就是为什么数据科学家使用的 Python 代码通常反映了解决业务问题的故事。数据科学家的工作环境也很独特;我们使用 Jupyter Notebook IDE,它提供了一个出色的方式来进行数据处理和模型开发的实验。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
数据科学家的编程活动有所不同,这包括注释活动,即解释代码的活动。对于经常面临需求变更和进行协作的数据显示,提供适当的代码解释是至关重要的。
本文将讨论如何作为数据科学家进行 Python 代码注释。我们将探讨各种可以提升你工作效率的点,并给任何阅读你代码的人带来价值。让我们深入了解。
注释的类型
在进一步讨论之前,让我们了解一下两种不同的注释类型。第一种是单行注释,使用‘#’符号。它通常用于对代码进行简单说明。例如,下面的代码示例演示了单行注释的使用。
# The code is to import the Pandas package and call it pd
import pandas as pd
另一种注释方式是使用多行注释方法,采用三重引号。严格来说,它们不是注释而是字符串对象,但如果我们不将其赋值给变量,Python 会忽略它们。我们可以通过以下示例看到它们的实际应用。
"""
The code below would import the Pandas package, and we would call them pd throughout the whole working environment.
"""
import pandas as pd
注释的一般技巧
在本节中,我们将讨论一些注释的一般技巧。这些技巧不一定适用于数据科学家,因为它们是编程人员的最佳实践,但记住这些技巧是有益的。提示如下:
-
考虑将注释放在我们想要解释的代码上方的单独一行,以提高可读性。
-
在你工作的代码中保持一致的注释风格。
-
如果你知道受众无法理解,不要使用难以理解的术语和技术术语。
-
仅在注释能增加价值时进行注释,以避免解释显而易见的内容。
-
如果注释不再相关,保持和更新注释。
这些是提供更好注释体验的一般指导方针。现在,让我们转向更具体的针对数据科学家的指导。
数据科学家的注释技巧
对于数据科学家来说,编码活动与软件工程师或网页开发人员的活动不同。这就是注释活动可能有所不同的原因。以下是一些特定于我们数据科学家的提示。
1. 使用注释来澄清复杂的过程或活动
数据科学活动涉及许多实验过程,如果我们不进行解释,可能会让读者或我们自己感到困惑。代码中的注释将帮助我们更好地解释意图,尤其是当涉及多个步骤时。例如,下面的代码将解释如何通过归一化和缩放来去除离群值。
# Perform data normalization (Min-Max scaling)
normalized_data = (data - np.min(data)) / (np.max(data) - np.min(data))
# Remove outliers by using the sigma rule (3 standard deviations removal)
removed_outlier_data = normalized_data[np.abs(stats.zscore(normalized_data)) < 3]
上面的注释解释了每个过程所做的工作及其背后的概念。指定我们在代码中使用的概念对于理解我们所做的事情至关重要。
注释不仅限于预处理,还可以在任何数据科学步骤中进行。从数据获取到模型监控,为了让每个人都能理解的注释是良好的实践。记住,作为数据科学家,我们的注释可能成为代码和分析洞察之间的桥梁。
2. 拥有注释标准
数据科学活动是一个协作过程,因此拥有一个大家都理解的标准结构是有益的。即使你是单独工作,这种标准也有帮助,因为你会知道这个标准。例如,你可以为每个你制作的函数标准化注释。
# Function: name of the function
# Usage: description of how to use the function
# Parameters: list the parameters and explain them
# Output: explain the output
上述是一个标准示例,你可以独立创建内容。不要忘记在有标准时使用相同的风格、语言和缩写。
3. 使用注释来帮助工作流程
在协作环境中,注释对帮助团队理解工作流程至关重要。我们可以使用注释来帮助理解何时有新的代码更新或接下来需要做什么。例如,另一个函数中的更新导致我们的过程出现错误,因此我们需要接下来修复这些错误。
# TODO: Fix this function ASAP
some_function_to_fix()
4. 实施 Markdown 笔记本单元
数据科学家 IDE 相当出色,因为我们使用笔记本进行实验。使用笔记本中的单元,我们可以将每段代码隔离开来,以便它可以独立运行,而无需运行整个代码。笔记本单元不仅限于代码,还可以转换为 Markdown 单元。
Markdown 是一种格式语言,用于描述文本的外观。在单元中,Markdown 可以进一步解释下面的代码。使用 Markdown 的优点在于我们可以比标准注释过程更详细地进行注释。你甚至可以添加表格、图片、LaTeX 等。
例如,下面的图片展示了我们如何使用 Markdown 来解释我们的项目、目标和步骤。
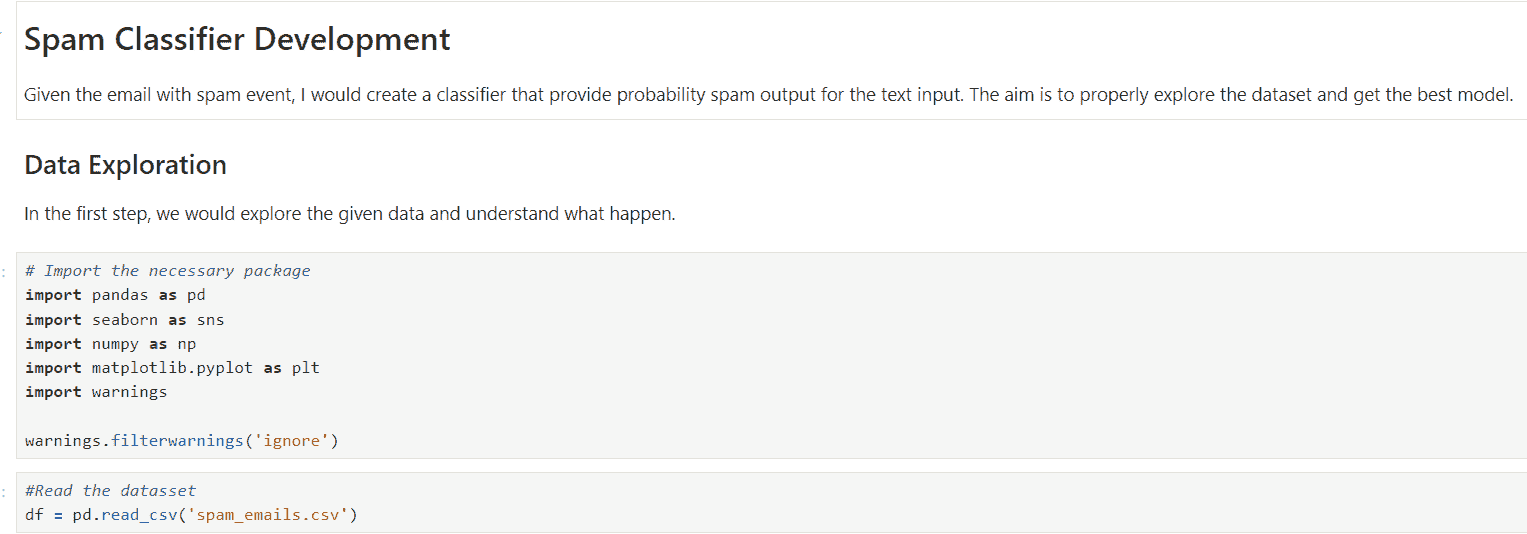
你可以在他们的文档中进一步阅读有关 Jupyter Markdown 单元的内容,以进一步了解你可以做什么。
结论
注释是数据科学家工作的重要组成部分,因为它有助于读者理解代码的执行过程。对于数据科学家来说,注释的过程与软件工程师或网页开发人员略有不同,因为我们的工作流程不同。这就是为什么这篇文章提供了一些你可以用于数据科学家注释的技巧。技巧包括:
-
使用注释来澄清复杂的过程或活动
-
制定注释标准
-
使用注释来帮助工作流程
-
实施 Markdown Notebook 单元
希望对你有帮助。
Cornellius Yudha Wijaya** 是数据科学助理经理和数据撰稿人。在全职工作于印尼安联公司期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种 AI 和机器学习主题的文章。
更多相关话题
如何进行 R 中的时间序列分析
原文:
www.kdnuggets.com/how-to-conduct-time-series-analysis-in-r
图片来源:编辑 | Ideogram
时间序列分析研究随时间收集的数据点。它帮助识别趋势和模式。这种分析在经济学、金融学和环境科学中很有用。R 是进行时间序列分析的热门工具,因为它具有强大的包和功能。在这篇文章中,我们将探讨如何使用 R 进行时间序列分析。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
加载库
时间序列分析的第一步是加载必要的库。'forecast'库提供时间序列预测功能。'tseries'库提供统计检验和时间序列分析工具。
library(forecast)
library(tseries)
导入时间序列数据
将时间序列数据从 CSV 文件导入 R。在这个示例中,我们使用用于金融分析的数据集。它跟踪价格随时间的变动。
data <- read.csv ("timeseries.csv", header = TRUE)
head(data)
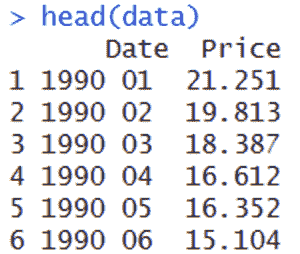
创建时间序列对象
使用'ts'函数将数据转换为时间序列对象。这个函数将你的数据转换为时间序列格式。
ts_data <- ts(data$Price)
绘制时间序列图
可视化时间序列数据。这有助于识别趋势、季节性和异常值。趋势显示数据的长期增长或下降。季节性揭示在固定间隔重复的规律性模式。异常值突出显示从正常模式中突出的异常值。
plot(ts_data)
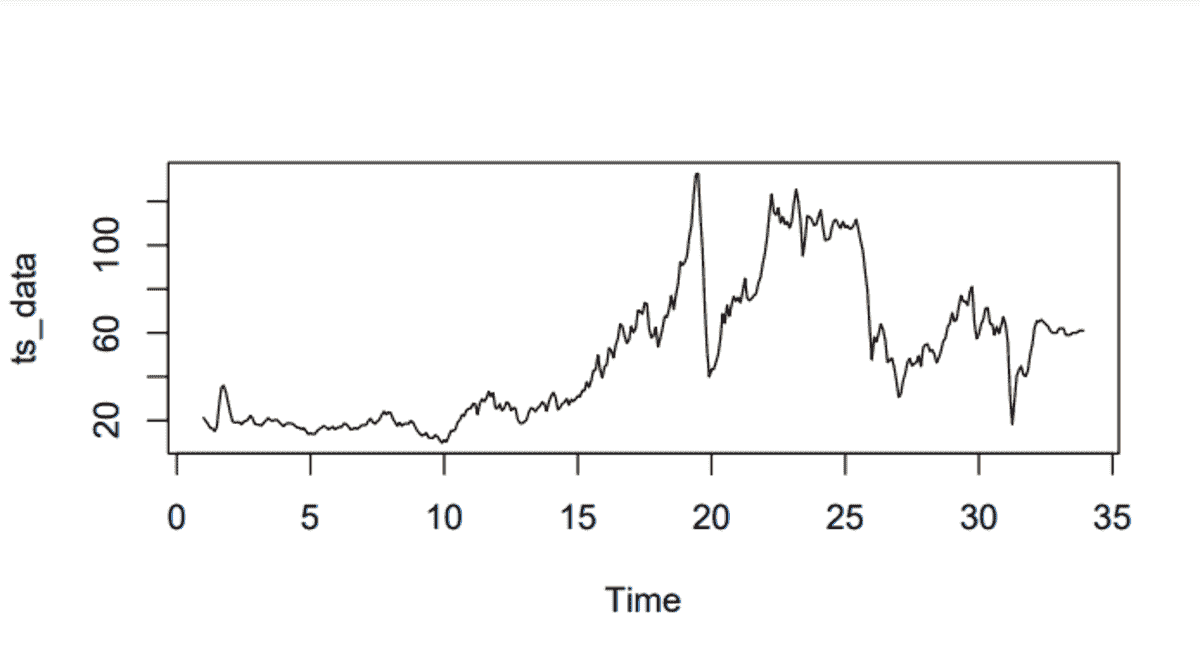
ARIMA 模型
ARIMA 模型用于预测时间序列数据。它结合了三个组件:自回归(AR)、差分(I)和移动平均(MA)。'auto.arima'函数根据数据自动选择最佳的 ARIMA 模型。
fit <- auto.arima(ts_data)
自相关函数(ACF)
自相关函数(ACF)测量时间序列与其过去值的相关性。它帮助识别数据中的模式和滞后。它显示在不同时间滞后的相关性。ACF 图有助于确定移动平均(MA)阶数('q')。
acf(ts_data)
偏自相关函数(PACF)
偏自相关函数(PACF)测量时间序列与其过去值之间的相关性。它排除了中间滞后的影响,有助于识别不同滞后的直接关系的强度。PACF 图显示了这些不同时间滞后的相关性。PACF 图有助于确定自回归(AR)阶数 ('p')。
pacf(ts_data)
Ljung-Box 检验
Ljung-Box 检验用于检查时间序列模型残差中的自相关。它测试残差是否是随机的,并在多个滞后期上测试自相关。低 p 值表明存在显著的自相关,这意味着模型可能不适合。
Box.test(fit$residuals, lag = 20, type = "Ljung-Box")
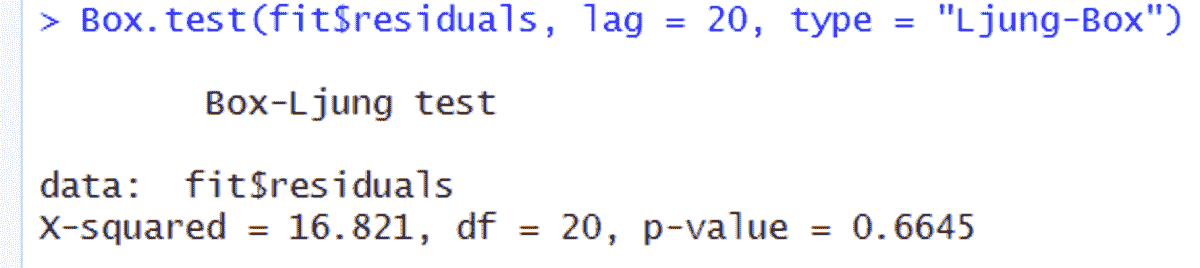
残差分析
残差分析检查时间序列模型中观测值与预测值之间的差异。这有助于检验模型是否拟合数据良好。
plot (fit$residuals, main="Residuals of ARIMA Model", ylab="Residuals")
abline(h=0, col="red")
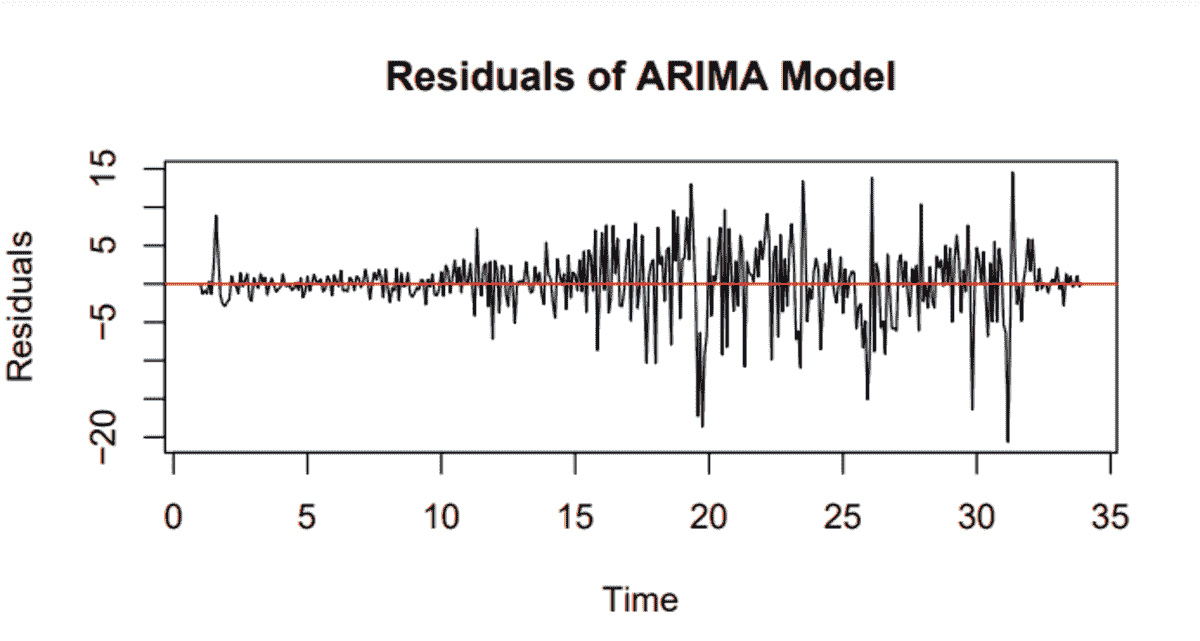
预测
预测涉及基于历史数据预测未来值。使用'forecast'生成这些预测。
forecast_result <- forecast (fit)
预测可视化
使用历史数据可视化预测值以进行比较。'autoplot'函数有助于创建这些可视化图。
autoplot(forecast_result)
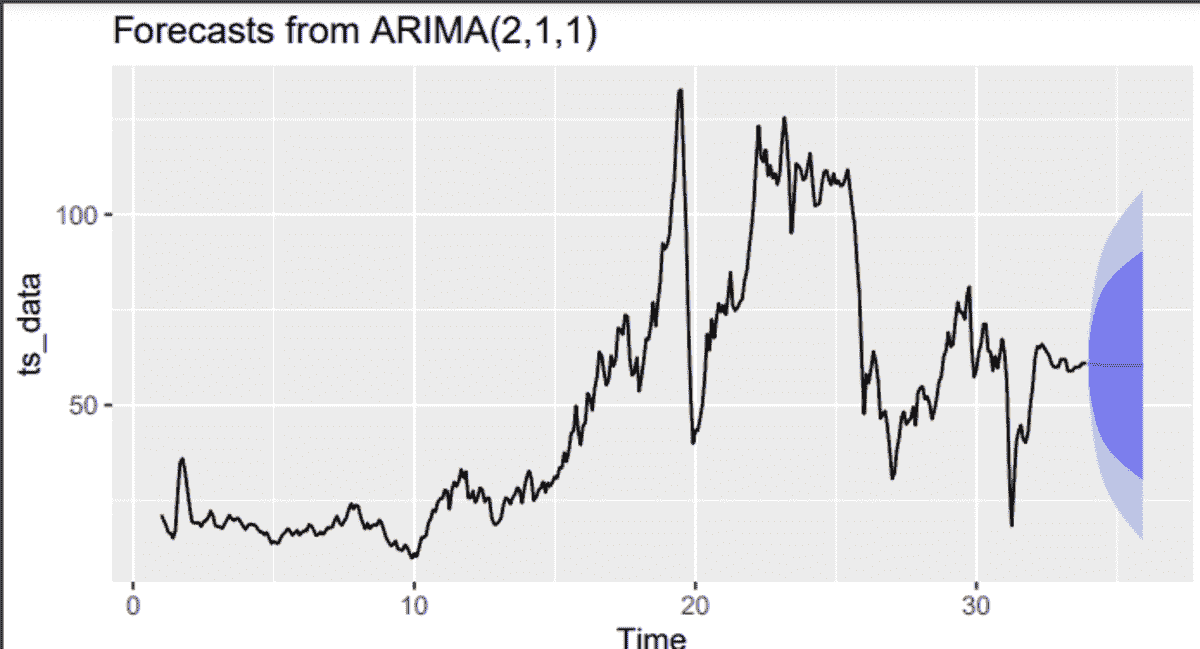
模型准确性
使用'accuracy'函数评估拟合模型的准确性。它提供了如平均绝对误差(MAE)和均方根误差(RMSE)等性能指标。
accuracy(fit)
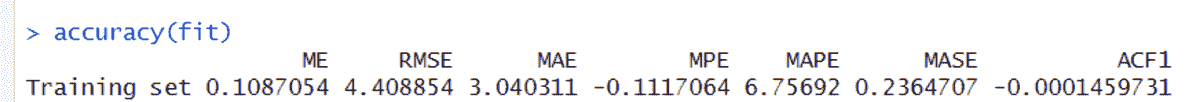
总结
R 中的时间序列分析从加载数据和创建时间序列对象开始。接下来,进行探索性分析以查找趋势和模式。拟合 ARIMA 模型以预测未来值。诊断模型并可视化结果。这一过程有助于利用历史数据做出明智的决策。
Jayita Gulati 是一位机器学习爱好者和技术作家,因对构建机器学习模型的热情而驱动。她持有利物浦大学计算机科学硕士学位。
更多相关主题
如何将 JSON 数据转换为 Pandas DataFrame
原文:
www.kdnuggets.com/how-to-convert-json-data-into-a-dataframe-with-pandas

图片由作者提供 | DALLE-3 和 Canva
如果你曾经有机会处理数据,你可能会遇到将 JSON 文件(即 JavaScript 对象表示法的缩写)加载到 Pandas DataFrame 中以便进一步分析的需求。JSON 文件以一种人类易读且计算机易懂的格式存储数据。然而,JSON 文件有时可能会复杂且难以浏览。因此,我们将其加载到像 DataFrames 这样的更结构化的格式中——这种格式像电子表格一样有行和列。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你所在组织的 IT
我将展示两种将 JSON 数据转换为 Pandas DataFrame 的不同方法。在讨论这些方法之前,让我们假设一个示例的嵌套 JSON 文件,整个文章中我将使用这个文件作为示例。
{
"books": [
{
"title": "One Hundred Years of Solitude",
"author": "Gabriel Garcia Marquez",
"reviews": [
{
"reviewer": {
"name": "Kanwal Mehreen",
"location": "Islamabad, Pakistan"
},
"rating": 4.5,
"comments": "Magical and completely breathtaking!"
},
{
"reviewer": {
"name": "Isabella Martinez",
"location": "Bogotá, Colombia"
},
"rating": 4.7,
"comments": "A marvelous journey through a world of magic."
}
]
},
{
"title": "Things Fall Apart",
"author": "Chinua Achebe",
"reviews": [
{
"reviewer": {
"name": "Zara Khan",
"location": "Lagos, Nigeria"
},
"rating": 4.9,
"comments": "Things Fall Apart is the best of contemporary African literature."
}]}]}
上述 JSON 数据表示一本书的列表,每本书都有一个标题、作者和一系列评论。每条评论又有一个评论者(包括姓名和位置)、评分和评论。
方法 1:使用 json.load() 和 pd.DataFrame() 函数
最简单且直接的方法是使用内置的 json.load() 函数来解析我们的 JSON 数据。这将把数据转换为一个 Python 字典,然后我们可以直接从这个 Python 数据结构创建 DataFrame。然而,它有一个问题 - 只能处理单层嵌套数据。因此,对于上述情况,如果仅使用这些步骤和这段代码:
import json
import pandas as pd
#Load the JSON data
with open('books.json','r') as f:
data = json.load(f)
#Create a DataFrame from the JSON data
df = pd.DataFrame(data['books'])
df
你的输出可能如下所示:
输出:

在评论列中,你可以看到整个字典。因此,如果你希望输出显示正确,你必须手动处理嵌套结构。这可以通过以下方法完成:
#Create a DataFrame from the nested JSON data
df = pd.DataFrame([
{
'title': book['title'],
'author': book['author'],
'reviewer_name': review['reviewer']['name'],
'reviewer_location': review['reviewer']['location'],
'rating': review['rating'],
'comments': review['comments']
}
for book in data['books']
for review in book['reviews']
])
更新后的输出:

在这里,我们使用列表推导式创建一个平坦的字典列表,其中每个字典包含书籍信息和相应的评论。然后,我们使用此数据创建 Pandas DataFrame。
但这种方法的问题在于,它需要更多的手动工作来管理 JSON 数据的嵌套结构。那么,现在怎么办?我们还有其他选项吗?
完全正确!我的意思是,来吧。考虑到我们已经进入 21 世纪,面对没有解决方案的问题似乎不切实际。让我们看看另一种方法。
方法 2(推荐):使用json_normalize()函数
Pandas 库中的json_normalize()函数是管理嵌套 JSON 数据的更好方法。它会自动将 JSON 数据的嵌套结构展平,从而创建一个 DataFrame。让我们看一下代码:
import pandas as pd
import json
#Load the JSON data
with open('books.json', 'r') as f:
data = json.load(f)
#Create the DataFrame using `json_normalize()`
df = pd.json_normalize(
data=data['books'],
meta=['title', 'author'],
record_path='reviews',
errors='raise'
)
df
输出:

json_normalize()函数接受以下参数:
-
数据: 输入数据,可以是字典的列表或单个字典。在这种情况下,它是从 JSON 文件加载的数据字典。
-
record_path: JSON 数据中要规范化的记录路径。在这种情况下,它是'reviews'键。
-
元数据: 需要包括在从 JSON 文档规范化输出中的附加字段。在这种情况下,我们使用了'title'和'author'字段。请注意,元数据中的列通常出现在最后。这就是该函数的工作方式。就分析而言,这并不重要,但出于某种神奇的原因,你希望这些列出现在前面。抱歉,你得手动处理它们。
-
错误: 错误处理策略,可以是'ignore'、'raise'或'warn'。我们将其设置为'res',因此如果在规范化过程中出现任何错误,它将引发异常。
总结
这两种方法各有优缺点,选择哪种方法取决于 JSON 数据的结构和复杂性。如果 JSON 数据有非常嵌套的结构,json_normalize()函数可能是最合适的选择,因为它可以自动处理嵌套数据。如果 JSON 数据相对简单和扁平,pd.read_json()函数可能是最简单直接的方法。
处理大型 JSON 文件时,考虑内存使用和性能至关重要,因为将整个文件加载到内存中可能行不通。因此,你可能需要考虑其他选项,如流式传输数据、延迟加载或使用更节省内存的格式,如 Parquet。
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交叉领域充满深厚的热情。她共同编写了电子书《利用 ChatGPT 提高生产力》。作为 2022 年亚太地区 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 技术多样性学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的热心倡导者,她创办了 FEMCodes,以赋能女性进入 STEM 领域。
更多相关主题
如何使用 Hugging Face Transformers 为非英文语言创建自定义分词器

作者插图 | Canva
每当你考虑进行自然语言处理任务时,你最可能需要采取的第一步是对你使用的文本进行分词。这非常重要,因为下游任务的性能在很大程度上依赖于此。我们可以很容易地在网上找到可以分词英文数据集的分词器。但是,如果你想对非英文语言数据进行分词呢?如果你找不到适合你所使用的特定类型数据的分词器,你将如何进行分词?好吧,本文正是解释了这些问题。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
我们将告诉你所有你需要知道的关于训练自定义分词器的知识。
什么是分词,为什么它很重要?
分词过程将一段文本拆分成片段或词汇,这些片段随后可以转换成模型可以处理的格式。在这种情况下,模型只能处理数字,因此这些词汇被转换成数字。这个过程至关重要,因为它将原始内容转换为模型可以理解和分析的结构化格式。如果没有分词,我们将无法将文本传递给机器学习模型,因为这些模型只能理解数字,而不能直接理解文本字符串。
为什么需要自定义分词器?
从头开始训练分词器在处理非英文语言或特定领域时尤其重要。标准的预训练分词器可能无法有效处理不同语言或专业字符的独特特征、词汇和语法。可以训练新的分词器以管理特定语言的特征和术语。这可以提高分词的准确性和模型的性能。不仅如此,自定义分词器还允许我们包含特定领域的词汇,并处理稀有或词汇表外的词汇。这提高了 NLP 模型在涉及多语言的应用中的效果。
现在你一定在想,你知道分词化很重要,并且可能需要训练你自己的分词器。那么你会怎么做呢?既然你已经了解了训练自己分词器的需求和重要性,我们将一步一步地解释如何做到这一点。
自定义分词器的逐步训练过程
第一步:安装所需的库
首先,确保你已安装所需的库。你可以使用 pip 安装 Hugging Face 的 transformers 和 datasets 库:
pip install transformers datasets
第二步:准备你的数据集
要训练一个分词器,你需要一个目标语言的文本数据集。Hugging Face 的 datasets 库提供了一种方便的方式来加载和处理数据集。
from datasets import load_dataset
# Load a dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_ur)
输出:
请注意,你可以在此步骤中加载任何语言的数据集。我们的乌尔都语数据集的一个示例如下所示:
موضوعات کی ترتیب بلحاظ: آخری پیغام کا وقت موضوع شامل کرنے کا وقت ٹائٹل (حروف تہجی کے لحاظ سے) جوابات کی تعداد مناظر پسند کردہ پیغامات تلاش کریں.
第三步:初始化分词器
Hugging Face 提供了几种分词器模型。我将使用来自 Hugging Face 库的 BPE 分词器。这是 GPT-3 和 GPT-4 分词器使用的完全相同的算法。但你仍然可以根据需要选择不同的分词器模型。
from tokenizers import ByteLevelBPETokenizer
# Initialize a Byte-Pair Encoding(BPE) tokenizer
tokenizer = ByteLevelBPETokenizer()
第四步:训练分词器
在你的数据集上训练分词器。确保数据集经过预处理并正确格式化。你可以指定各种参数,如 vocab_size、min_frequency 和 special_tokens。
# Prepare the dataset for training the tokenizer
def batch_iterator(dataset, batch_size=1000):
for i in range(0, len(dataset), batch_size):
yield dataset[i: i + batch_size]
# Train the tokenizer
tokenizer.train_from_iterator(batch_iterator(dataset['text']), vocab_size=30_000, min_frequency=2, special_tokens=[
"<s>", "<pad>", "</s>", "<unk>", "<mask>",
])
第五步:保存分词器
训练后,将分词器保存到磁盘。这允许你以后加载并使用它。
# Save the tokenizer
import os
# Create the directory if it does not exist
output_dir = 'my_tokenizer'
os.makedirs(output_dir, exist_ok=True)
tokenizer.save_model('my_tokenizer')
将 path_to_save_tokenizer 替换为保存分词器文件的所需路径。运行此代码将保存两个文件,即:
第六步:加载和使用分词器
你可以加载分词器以备将来使用,并在目标语言中对文本进行分词。
from transformers import RobertaTokenizerFast
# Load the tokenizer
tokenizer = RobertaTokenizerFast.from_pretrained('path_to_save_tokenizer')
# Tokenize a sample text
text = "عرصہ ہوچکا وائرلیس چارجنگ اپنا وجود رکھتی ہے لیکن اسمارٹ فونز نے اسے اختیار کرنے میں کافی وقت لیا۔ یہ حقیقت ہے کہ جب پہلی بار وائرلیس چارجنگ آئی تھی تو کچھ مسائل تھے لیکن ٹیکنالوجی کے بہتر ہوتے ہوتے اب زیادہ تر مسائل ختم ہو چکے ہیں۔"
encoded_input = tokenizer(text)
print(encoded_input)
此单元格的输出将是:
{'input_ids': [0, 153, 122, 153, 114, 153, 118, 156, 228, 225, 156, 228, 154, 235, 155, 233, 155, 107, 153, 105, 225, 154, 235, 153, 105, 153, 104, 153, 114, 154, 231, 156, 239, 153, 116, 225, 155, 233, 153, 105, 153, 114, 153, 110, 154, 233, 155, 112, 225, 153, 105, 154, 127, 154, 233, 153, 105, 225, 154, 235, 153, 110, 154, 235, 153, 112, 225, 153, 114, 155, 107, 155, 127, 153, 108, 156, 239, 225, 156, 228, 156, 245, 225, 154, 231, 156, 239, 155, 107, 154, 233, 225, 153, 105, 153, 116, 154, 232, 153, 105, 153, 114, 154, 122, 225, 154, 228, 154, 235, 154, 233, 153, ], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ]}
总结
要使用 Hugging Face Transformers 为非英语语言训练你自己的分词器,你需要准备一个数据集,初始化一个分词器,训练它,并最终保存以备将来使用。通过以下步骤,你可以创建针对特定语言或领域的分词器。这将提高你所处理的任何特定 NLP 任务的性能。你现在可以轻松地在任何语言上训练分词器。告诉我们你创建了什么。
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学及 AI 与医学的交集充满了深厚的热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的热情倡导者,她创立了 FEMCodes 以赋能 STEM 领域的女性。
相关话题
如何创建自定义上下文管理器
原文:
www.kdnuggets.com/how-to-create-custom-context-managers-in-python
作者提供的图片
Python 中的上下文管理器让你更高效地使用资源——即使在处理资源时出现错误,也能方便地进行资源的设置和拆卸。在关于编写高效的 Python 代码的教程中,我介绍了上下文管理器是什么以及它们的帮助作用。而在Python 上下文管理器的三个有趣用途中,我讨论了上下文管理器在管理子进程、数据库连接等方面的应用。
在本教程中,你将学习如何创建自定义上下文管理器。我们将回顾上下文管理器是如何工作的,然后看看你可以用什么方法编写自己的上下文管理器。让我们开始吧。
Python 中的上下文管理器是什么?
Python 中的上下文管理器是对象,它们使得在受控的代码块中管理资源(如文件操作、数据库连接或网络套接字)成为可能。它们确保资源在代码块执行前得到正确初始化,并在执行后自动清理,无论代码块是正常完成还是抛出异常。
一般来说,Python 中的上下文管理器具有以下两个特殊方法:__enter__()和__exit__()。这些方法定义了在进入和退出上下文时上下文管理器的行为。
上下文管理器是如何工作的?
在 Python 中处理资源时,你必须考虑设置资源、预见错误、实现异常处理,并最终释放资源。为此,你可能会使用类似这样的try-except-finally块:
try:
# Setting up the resource
# Working with the resource
except ErrorType:
# Handle exceptions
finally:
# Free up the resource
从本质上讲,我们尝试配置并使用资源,除了在过程中可能出现的任何错误,最后释放资源。finally 块总是会执行,无论操作是否成功。但借助上下文管理器和with语句,你可以拥有可重用的try-except-finally块。
现在让我们来探讨一下上下文管理器的工作原理。
进入阶段(__enter__()方法):
当遇到with语句时,将调用上下文管理器的__enter__()方法。这个方法负责初始化和设置资源,例如打开文件、建立数据库连接等。__enter__()返回的值(如果有的话)将在as关键字后提供给上下文块。
执行代码块:
一旦资源设置完成(在__enter__()执行后),与with语句关联的代码块将被执行。这是你希望在资源上执行的操作。
退出阶段(__exit__() 方法):
在代码块执行完成后——无论是正常完成还是由于异常——上下文管理器的 __exit__() 方法会被调用。__exit__() 方法处理清理任务,例如关闭资源。如果代码块内发生异常,异常的信息(类型、值、回溯)会传递给 __exit__() 方法进行错误处理。
总结:
-
上下文管理器提供了一种有效管理资源的方式,通过确保资源得到正确初始化和清理。
-
我们使用
with语句来定义一个资源管理的上下文。 -
__enter__()方法初始化资源,而__exit__()方法在上下文块完成后清理资源。
既然我们知道了上下文管理器的工作原理,让我们继续编写一个自定义上下文管理器,用于处理数据库连接。
在 Python 中创建自定义上下文管理器
你可以使用以下两种方法中的一种在 Python 中编写自定义上下文管理器:
-
编写一个包含
__enter__()和__exit__()方法的类。 -
使用
contextlib模块,该模块提供了contextmanager装饰器来使用生成器函数编写上下文管理器。
1. 编写一个包含 __enter__() 和 __exit__() 方法的类
你可以定义一个实现两个特殊方法的类:__enter__() 和 __exit__(),它们分别控制资源的设置和清理。这里我们编写了一个 ConnectionManager 类,用于建立与 SQLite 数据库的连接,并关闭数据库连接:
import sqlite3
from typing import Optional
# Writing a context manager class
class ConnectionManager:
def __init__(self, db_name: str):
self.db_name = db_name
self.conn: Optional[sqlite3.Connection] = None
def __enter__(self):
self.conn = sqlite3.connect(self.db_name)
return self.conn
def __exit__(self, exc_type, exc_value, traceback):
if self.conn:
self.conn.close()
让我们来详细了解 ConnectionManager 是如何工作的:
-
当执行进入
with语句的上下文时,会调用__enter__()方法。它负责设置上下文,在这种情况下就是连接到数据库。它返回需要管理的资源:数据库连接。注意,我们使用了来自 typing 模块 的Optional类型来表示连接对象conn。当值可以是两种类型之一时,我们使用Optional:这里是一个有效的连接对象或 None。 -
__exit__()方法:当执行离开with语句的上下文时会调用此方法。它处理关闭连接的清理操作。参数exc_type、exc_value和traceback用于处理with块内的异常。这些参数可以用来判断上下文是否由于异常而退出。
现在让我们在 with 语句中使用 ConnectionManager。我们做如下操作:
-
尝试连接到数据库
-
创建一个游标来运行查询
-
创建一个表并插入记录
-
查询数据库表并检索查询结果
db_name = "library.db"
# Using ConnectionManager context manager directly
with ConnectionManager(db_name) as conn:
cursor = conn.cursor()
# Create a books table if it doesn't exist
cursor.execute("""
CREATE TABLE IF NOT EXISTS books (
id INTEGER PRIMARY KEY,
title TEXT,
author TEXT,
publication_year INTEGER
)
""")
# Insert sample book records
books_data = [
("The Great Gatsby", "F. Scott Fitzgerald", 1925),
("To Kill a Mockingbird", "Harper Lee", 1960),
("1984", "George Orwell", 1949),
("Pride and Prejudice", "Jane Austen", 1813)
]
cursor.executemany("INSERT INTO books (title, author, publication_year) VALUES (?, ?, ?)", books_data)
conn.commit()
# Retrieve and print all book records
cursor.execute("SELECT * FROM books")
records = cursor.fetchall()
print("Library Catalog:")
for record in records:
book_id, title, author, publication_year = record
print(f"Book ID: {book_id}, Title: {title}, Author: {author}, Year: {publication_year}")
cursor.close()
运行上述代码应给出以下输出:
Output >>>
Library Catalog:
Book ID: 1, Title: The Great Gatsby, Author: F. Scott Fitzgerald, Year: 1925
Book ID: 2, Title: To Kill a Mockingbird, Author: Harper Lee, Year: 1960
Book ID: 3, Title: 1984, Author: George Orwell, Year: 1949
Book ID: 4, Title: Pride and Prejudice, Author: Jane Austen, Year: 1813
2. 使用来自 contextlib 的 @contextmanager 装饰器
contextlib模块提供了@contextmanager装饰器,可以用来将生成器函数定义为上下文管理器。以下是我们如何在数据库连接示例中做到这一点:
# Writing a generator function with the `@contextmanager` decorator
import sqlite3
from contextlib import contextmanager
@contextmanager
def database_connection(db_name: str):
conn = sqlite3.connect(db_name)
try:
yield conn # Provide the connection to the 'with' block
finally:
conn.close() # Close the connection upon exiting the 'with' block
这是database_connection函数的工作原理:
-
database_connection函数首先建立连接,然后yield语句将连接提供给with语句块中的代码。请注意,由于yield本身对异常并不免疫,我们将其包装在try块中。 -
finally块确保连接始终关闭,无论是否引发异常,确保没有资源泄漏。
就像之前做的那样,让我们在with语句中使用这个:
db_name = "library.db"
# Using database_connection context manager directly
with database_connection(db_name) as conn:
cursor = conn.cursor()
# Insert a set of book records
more_books_data = [
("The Catcher in the Rye", "J.D. Salinger", 1951),
("To the Lighthouse", "Virginia Woolf", 1927),
("Dune", "Frank Herbert", 1965),
("Slaughterhouse-Five", "Kurt Vonnegut", 1969)
]
cursor.executemany("INSERT INTO books (title, author, publication_year) VALUES (?, ?, ?)", more_books_data)
conn.commit()
# Retrieve and print all book records
cursor.execute("SELECT * FROM books")
records = cursor.fetchall()
print("Updated Library Catalog:")
for record in records:
book_id, title, author, publication_year = record
print(f"Book ID: {book_id}, Title: {title}, Author: {author}, Year: {publication_year}")
cursor.close()
我们连接到数据库,插入更多记录,查询数据库,并获取查询结果。以下是输出:
Output >>>
Updated Library Catalog:
Book ID: 1, Title: The Great Gatsby, Author: F. Scott Fitzgerald, Year: 1925
Book ID: 2, Title: To Kill a Mockingbird, Author: Harper Lee, Year: 1960
Book ID: 3, Title: 1984, Author: George Orwell, Year: 1949
Book ID: 4, Title: Pride and Prejudice, Author: Jane Austen, Year: 1813
Book ID: 5, Title: The Catcher in the Rye, Author: J.D. Salinger, Year: 1951
Book ID: 6, Title: To the Lighthouse, Author: Virginia Woolf, Year: 1927
Book ID: 7, Title: Dune, Author: Frank Herbert, Year: 1965
Book ID: 8, Title: Slaughterhouse-Five, Author: Kurt Vonnegut, Year: 1969
请注意,我们打开和关闭了游标对象。因此,你也可以在with语句中使用游标对象。我建议将其作为一个快速练习来尝试一下!
总结
就这样。我希望你学会了如何创建自己的自定义上下文管理器。我们看了两种方法:使用具有__enter__()和__exit()__方法的类,以及使用用@contextmanager装饰的生成器函数。
使用上下文管理器时,你可以清楚地看到以下优势:
-
资源的设置和拆解会自动管理,最大限度减少资源泄漏。
-
代码更简洁,更易于维护。
-
在处理资源时,异常处理更为干净。
与往常一样,你可以 在 GitHub 上找到代码。继续编码!
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、操作指南、评论文章等,学习和分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
了解更多相关主题
如何为 Python 应用创建最小的 Docker 镜像
原文:
www.kdnuggets.com/how-to-create-minimal-docker-images-for-python-applications

图片来源 | Midjourney & Canva
为 Python 应用创建最小的 Docker 镜像可以通过减少攻击面来提高安全性,加快镜像构建速度,并改善整体应用程序的可维护性。让我们来学习如何为 Python 应用创建最小的 Docker 镜像。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
先决条件
在你开始之前:
创建一个示例 Python 应用
让我们创建一个简单的 Flask 应用用于库存管理。这个应用允许你添加、查看、更新和删除库存项目。然后我们将使用标准的 Python 3.11 镜像将应用 Docker 化。
在你的项目目录中,你应该有 app.py、requirements.txt 和 Dockerfile:
inventory_app/
├── app.py
├── Dockerfile
├── requirements.txt
这里是用于库存管理的 Flask 应用的代码:
# app.py
from flask import Flask, request, jsonify
app = Flask(__name__)
# In-memory database for simplicity
inventory = {}
@app.route('/inventory', methods=['POST'])
def add_item():
item = request.get_json()
item_id = item.get('id')
if not item_id:
return jsonify({"error": "Item ID is required"}), 400
if item_id in inventory:
return jsonify({"error": "Item already exists"}), 400
inventory[item_id] = item
return jsonify(item), 201
@app.route('/inventory/<item_id>', methods=['GET'])
def get_item(item_id):
item = inventory.get(item_id)
if not item:
return jsonify({"error": "Item not found"}), 404
return jsonify(item)
@app.route('/inventory/<item_id>', methods=['PUT'])
def update_item(item_id):
if item_id not in inventory:
return jsonify({"error": "Item not found"}), 404
updated_item = request.get_json()
inventory[item_id] = updated_item
return jsonify(updated_item)
@app.route('/inventory/<item_id>', methods=['DELETE'])
def delete_item(item_id):
if item_id not in inventory:
return jsonify({"error": "Item not found"}), 404
del inventory[item_id]
return '', 204
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)</item_id></item_id></item_id>
这是一个最小的 Flask 应用,实现了基本的 CRUD(创建、读取、更新、删除)操作,用于内存中的库存数据库。它使用 Flask 创建一个 web 服务器,监听端口 5000 上的 HTTP 请求。当收到请求时:
-
对于 POST 请求
/inventory,它将新项目添加到库存中。 -
对于 GET 请求
/inventory/<item_id>,它从库存中检索具有指定 ID 的项目。 -
对于 PUT 请求
/inventory/<item_id>,它更新库存中具有指定 ID 的项目。 -
对于 DELETE 请求
/inventory/<item_id>,它从库存中删除具有指定 ID 的项目。
现在创建 requirements.txt 文件:
Flask==3.0.3
接下来创建 Dockerfile:
# Use the official Python 3.11 image
FROM python:3.11
# Set the working directory
WORKDIR /app
# Install dependencies
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the current directory contents into the container at /app
COPY . .
# Expose the port the app runs on
EXPOSE 5000
# Run the application
CMD ["python3", "app.py"]
最后构建镜像(我们使用标签full来标识这是使用默认 Python 镜像的):
$ docker build -t inventory-app:full .
构建完成后,你可以运行docker images命令:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
inventory-app full 4e623743f556 2 hours ago 1.02GB
你会发现这个超级简单的应用大约有 1.02 GB 大小。这是因为我们使用的默认 Python 3.11 镜像包含了大量的 Debian 包,大小约为 1.01 GB。所以我们需要找到一个更小的基础镜像。
好了,这里是选项:
-
python:version-alpine镜像基于 Alpine Linux,会给你最小的最终镜像。但你需要能够安装包,对吧?不过,这在 Alpine 镜像中是个挑战。 -
python:version-slim带有运行 Python 所需的最少 Debian 包。你(几乎总是)能够使用pip安装大多数所需的 Python 包。
所以你的基础镜像应该足够小,但也不要小到遇到兼容性问题或者在安装依赖项时绞尽脑汁(这在 Python 应用中很常见)。这就是为什么我们在下一步将使用 python:3.11-slim 基础镜像并构建我们的镜像。
选择最佳基础镜像 | 作者图片
使用 Slim Python 基础镜像
现在将 Dockerfile 重写为使用 python:3.11-slim 基础镜像,如下所示:
# Use the official lightweight Python 3.11-slim image
FROM python:3.11-slim
# Set the working directory
WORKDIR /app
# Install dependencies
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the current directory contents into the container at /app
COPY . .
# Expose the port the app runs on
EXPOSE 5000
# Run the application
CMD ["python3", "app.py"]
让我们构建镜像(标记为 slim):
$ docker build -t inventory-app:slim .
python:3.11-slim 基础镜像的大小为 131 MB。而 inventory-app:slim 镜像的大小约为 146 MB,比我们之前的 1.02 GB 镜像小得多:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
inventory-app slim 32784c60a992 About an hour ago 146MB
inventory-app full 4e623743f556 2 hours ago 1.02GB
你还可以使用多阶段构建来使最终镜像更小。但那是另一个教程的内容!
额外资源
这里有一些有用的资源:
Bala Priya C** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、评论文章等与开发者社区分享她的知识。Bala 还创建引人入胜的资源概述和编码教程。
更多相关话题
如何使用插值技术处理 Pandas 中的缺失数据
原文:
www.kdnuggets.com/how-to-deal-with-missing-data-using-interpolation-techniques-in-pandas

图片来源 | DALLE-3 & Canva
现实世界数据集中的缺失值是一个常见问题。这可能由于各种原因发生,例如遗漏的观察、数据传输错误、传感器故障等。我们不能简单忽略它们,因为这可能会扭曲我们模型的结果。我们必须从分析中移除这些值或对其进行处理,以确保数据集的完整性。删除这些值会导致信息丧失,这是我们不希望的。因此,科学家们设计了各种处理缺失值的方法,如插补和插值。人们经常混淆这两种技术;插补是初学者更常用的术语。在我们进一步讨论之前,让我为这两种技术划定一个清晰的界限。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
插补基本上是用统计测量值(如均值、中位数或众数)来填补缺失值。这相当简单,但它没有考虑数据集的趋势。然而,插值基于周围的趋势和模式来估算缺失值。当缺失值没有过多分散时,这种方法更为可行。
现在我们已经了解了这些技术之间的区别,让我们讨论一些 Pandas 中可用的插值方法,然后我将带你通过一个示例。之后,我将分享一些技巧,帮助你选择合适的插值技术。
Pandas 中的插值方法类型
Pandas 提供了各种插值方法 ('linear', 'time', 'index', 'values', 'pad', 'nearest', 'zero', 'slinear', 'quadratic', 'cubic', 'barycentric', 'krogh', 'polynomial', 'spline', 'piecewise_polynomial', 'from_derivatives', 'pchip', 'akima', 'cubicspline'),你可以使用 interpolate() 函数访问这些方法。该方法的语法如下:
DataFrame.interpolate(method='linear', **kwargs, axis=0, limit=None, inplace=False, limit_direction=None, limit_area=None, downcast=_NoDefault.no_default, **kwargs)
我知道这些方法很多,我不想让你感到不知所措。所以,我们将讨论一些常用的方法:
-
线性插值: 这是默认方法,计算速度快且简单。它通过绘制一条直线连接已知数据点,并使用这条直线来估计缺失值。
-
时间插值: 当你的数据在位置上不均匀分布但在时间上线性分布时,时间插值非常有用。为此,你的索引需要是一个 datetime 索引,它通过考虑数据点之间的时间间隔来填补缺失值。
-
索引插值: 这类似于时间插值,它使用索引值来计算缺失值。然而,这里不需要是 datetime 索引,但需要传达一些有意义的信息,如温度、距离等。
-
填充(前向填充)和反向填充方法: 这指的是复制已存在的值来填补缺失值。如果传播方向是向前,它将前向填充最后一个有效观测值。如果是向后,它将使用下一个有效观测值。
-
最近邻插值: 顾名思义,它利用数据的局部变化来填补缺失值。离缺失值最近的值将被用来填补它。
-
多项式插值: 我们知道实际数据集通常是非线性的。因此,这个函数将多项式函数拟合到数据点上,以估计缺失值。你还需要指定多项式的阶数(例如,order=2 代表二次多项式)。
-
样条插值: 不要被这个复杂的名称吓倒。样条曲线是使用分段多项式函数连接数据点,从而形成一个最终的平滑曲线。你会注意到插值函数还有
piecewise_polynomial作为一个单独的方法。这两者的区别在于后者不保证在边界处导数的连续性,这意味着它可以发生更突兀的变化。
理论够了;让我们使用包含 1949 到 1960 年每月乘客数据的航空乘客数据集,看看插值是如何工作的。
代码实现:航空乘客数据集
我们将在航空乘客数据集中引入一些缺失值,然后使用上述技术之一对其进行插值。
步骤 1: 导入库 & 加载数据集
按如下方式导入基本库,并使用 pd.read_csv 函数将该数据集的 CSV 文件加载到 DataFrame 中。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Load the dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv"
df = pd.read_csv(url, index_col='Month', parse_dates=['Month'])
parse_dates 将‘Month’列转换为 datetime 对象,而 index_col 将其设置为 DataFrame 的索引。
步骤 2: 引入缺失值
现在,我们将随机选择 15 个不同的实例,并将‘Passengers’列标记为 np.nan,表示缺失值。
# Introduce missing values
np.random.seed(0)
missing_idx = np.random.choice(df.index, size=15, replace=False)
df.loc[missing_idx, 'Passengers'] = np.nan
步骤 3: 绘制带有缺失值的数据
我们将使用 Matplotlib 可视化引入 15 个缺失值后的数据情况。
# Plot the data with missing values
plt.figure(figsize=(10,6))
plt.plot(df.index, df['Passengers'], label='Original Data', linestyle='-', marker='o')
plt.legend()
plt.title('Airline Passengers with Missing Values')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.show()
原始数据集的图表
你可以看到图表在中间被分割,显示了这些位置上缺少值的情况。
步骤 4:使用插值
尽管稍后我会分享一些技巧来帮助你选择合适的插值技术,但让我们先专注于这个数据集。我们知道这是时间序列数据,但由于趋势似乎不是线性的,简单的线性插值不适合这里。我们可以观察到一些模式和振荡,以及线性趋势在小范围内。考虑到这些因素,样条插值将在这里表现良好。因此,让我们应用它,并检查插值后缺失值的可视化效果。
# Use spline interpolation to fill in missing values
df_interpolated = df.interpolate(method='spline', order=3)
# Plot the interpolated data
plt.figure(figsize=(10,6))
plt.plot(df_interpolated.index, df_interpolated['Passengers'], label='Spline Interpolation')
plt.plot(df.index, df['Passengers'], label='Original Data', alpha=0.5)
plt.scatter(missing_idx, df_interpolated.loc[missing_idx, 'Passengers'], label='Interpolated Values', color='green')
plt.legend()
plt.title('Airline Passengers with Spline Interpolation')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.show()
插值后的图表
从图表中可以看到,插值后的值填补了数据点,并且保留了模式。现在可以用于进一步分析或预测。
选择插值方法的技巧
这篇文章的附加部分集中于一些技巧:
-
可视化你的数据以了解其分布和模式。如果数据均匀间隔和/或缺失值随机分布,简单的插值技术将效果良好。
-
如果你在时间序列数据中观察到趋势或季节性,使用样条或多项式插值更能保留这些趋势,同时填补缺失值,如上例所示。
-
高次多项式可以更灵活地拟合,但容易过拟合。保持低次,以避免不合理的形状。
-
对于不均匀间隔的值,使用基于索引的方法,如索引和时间来填补间隙,而不会扭曲比例。你也可以在这里使用回填或前向填充。
-
如果你的值变化不频繁或遵循上升和下降的模式,使用最近的有效值也很有效。
-
在数据样本上测试不同的方法,并评估插值值与实际数据点的拟合程度。
如果你想探索dataframe.interpolate方法的其他参数,Pandas 文档是最佳的参考资料:Pandas Documentation。
Kanwal Mehreen** Kanwal 是一位机器学习工程师和技术作家,对数据科学及人工智能与医学的交汇处充满热情。她合著了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 地区的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,创办了 FEMCodes,以赋权女性进入 STEM 领域。
相关主题更多内容
如何调试运行中的 Docker 容器

图片由编辑 | Midjourney & Canva
容器有时由于配置问题、应用程序错误或资源限制而表现得异常。在本教程中,我们将通过以 Postgres 容器为例,讲解不同的调试方法。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
先决条件
要跟随本教程:
-
你应该在你的开发环境中安装 Docker。如果还没有,获取 Docker。
-
你应该对 Docker 的工作原理和基本命令(如拉取镜像、启动、停止以及管理容器)感到熟悉。
拉取并启动一个 PostgreSQL 容器
首先,让我们从 DockerHub 拉取最新的 PostgreSQL 镜像并启动一个容器。这里,我们使用 docker pull 命令拉取 postgres:16:
$ docker pull postgres:16
一旦拉取完成,你可以使用以下 docker run 命令来启动 postgres 容器。请注意,POSTGRES_PASSWORD 是启动容器所需的环境变量:
$ docker run --name my_postgres -e POSTGRES_PASSWORD=my_postgres_password -d postgres
该命令启动一个名为 my_postgres 的新容器,容器内运行 PostgreSQL。你可以通过运行 docker ps 命令来验证:
$ docker ps
输出结果:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5cb6fabbbc8b postgres:16 "docker-entrypoint.s…" 18 seconds ago Up 9 seconds 5432/tcp my_postgres
1. 检查容器
你可以使用 docker inspect 命令来获取容器的详细信息。这对于检查容器的配置、网络设置和状态非常有用:
$ docker inspect my_postgres
该命令输出一个包含容器所有详细信息的 JSON 对象。你可以使用像 jq 这样的工具来解析和提取这个输出中的特定信息。
docker inspect my_postgres 的截断输出
2. 查看容器日志
docker logs 命令可以获取正在运行的容器的日志。这对于排查与容器内应用程序相关的问题非常有用。
$ docker logs my_postgres
docker logs my_postgres 的截断输出
3. 在容器内执行命令
有时进入容器并运行一堆诊断命令是有帮助的。你可以使用 docker exec 命令在运行中的容器内执行命令。这对于检查容器的文件系统、环境变量等非常有用。
下面是如何在运行中的容器内启动交互式 shell 会话:
$ docker exec -it my_postgres /bin/bash
此命令在 my_postgres 容器内打开一个交互式 bash shell。这样你可以在容器内运行命令。
4. 检查运行中的进程
docker top 命令显示容器内运行的进程。这有助于识别是否有进程消耗的资源超过预期或是否有任何意外进程正在运行:
$ docker top my_postgres
UID PID PPID C STIME TTY TIME CMD
ollama 8116 8096 0 09:41 ? 00:00:00 postgres
ollama 8196 8116 0 09:41 ? 00:00:00 postgres: checkpointer
ollama 8197 8116 0 09:41 ? 00:00:00 postgres: background writer
ollama 8199 8116 0 09:41 ? 00:00:00 postgres: walwriter
ollama 8200 8116 0 09:41 ? 00:00:00 postgres: autovacuum launcher
ollama 8201 8116 0 09:41 ? 00:00:00 postgres: logical replication launcher
5. 附加到容器
docker attach 命令允许你将终端附加到运行中的容器的主进程。这对于调试交互式进程很有用:
$ docker attach my_postgres
注意,附加到容器与 docker exec 不同,因为它连接到容器的主进程并将其标准输出和标准错误流传输到你的终端。
6. 查看资源使用情况
使用 docker stats 命令,你可以获取容器资源使用的实时统计数据,包括 CPU、内存和网络。这对于分析性能问题非常有帮助:
$ docker stats my_postgres
这是一个示例输出:
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
5cb6fabbbc8b my_postgres 0.03% 34.63MiB / 3.617GiB 0.94% 10.6kB / 0B 38.4MB / 53.1MB 6
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
5cb6fabbbc8b my_postgres 0.03% 34.63MiB / 3.617GiB 0.94% 10.6kB / 0B 38.4MB / 53.1MB 6
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
5cb6fabbbc8b my_postgres 0.03% 34.63MiB / 3.617GiB 0.94% 10.6kB / 0B 38.4MB / 53.1MB 6
...
调试 Docker 容器涉及检查容器配置、查看日志、在容器内执行命令以及监控资源使用情况。运用这些技术,你可以有效地排查和解决容器化应用中的问题。祝你调试愉快!
额外资源
如果你想进一步探索,请查看以下资源:
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等方式学习和分享她的知识,服务开发者社区。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
如何在一天内处理 150 亿条日志并保持大查询在 1 秒内完成
原文:
www.kdnuggets.com/how-to-digest-15-billion-logs-per-day-and-keep-big-queries-within-1-second
这个数据仓储用例涉及到规模。用户是中国联通,世界上最大的电信服务提供商之一。利用 Apache Doris,他们在数十台机器上部署了多个 PB 级别的集群,以支持其来自 30 多条业务线的 150 亿条日志的每日添加。这样一个庞大的日志分析系统是其网络安全管理的一部分。为了实现实时监控、威胁追踪和警报,他们需要一个能够自动收集、存储、分析和可视化日志及事件记录的日志分析系统。
从架构角度来看,系统应能够实时分析各种格式的日志,并且当然要具备可扩展性,以支持庞大且不断增长的数据量。本文的其余部分将介绍他们的日志处理架构是什么样的,以及他们如何实现稳定的数据摄取、低成本存储和快速查询。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
系统架构
这是他们数据管道的概述。日志被收集到数据仓库中,并经过几层处理。
-
ODS:所有来源的原始日志和警报被汇总到 Apache Kafka 中。同时,它们的副本将存储在 HDFS 中,以便进行数据验证或重放。
-
DWD:这里存放着事实表。Apache Flink 清洗、标准化、回填和去标识化数据,并将其写回 Kafka。这些事实表还会被放入 Apache Doris 中,以便 Doris 能够跟踪某一项或用于仪表盘和报告。由于日志不怕重复,事实表将按照 Apache Doris 的Duplicate Key model进行安排。
-
DWS:这一层聚合 DWD 中的数据,为查询和分析奠定基础。
-
ADS:在这一层,Apache Doris 使用其聚合键模型自动聚合数据,并使用其唯一键模型自动更新数据。
Architecture 2.0 由 Architecture 1.0 发展而来,后者由 ClickHouse 和 Apache Hive 支持。这一过渡源于用户对实时数据处理和多表联接查询的需求。在他们使用旧架构的经验中,他们发现对并发和多表联接的支持不足,这表现在仪表板中的频繁超时和分布式联接中的 OOM 错误。
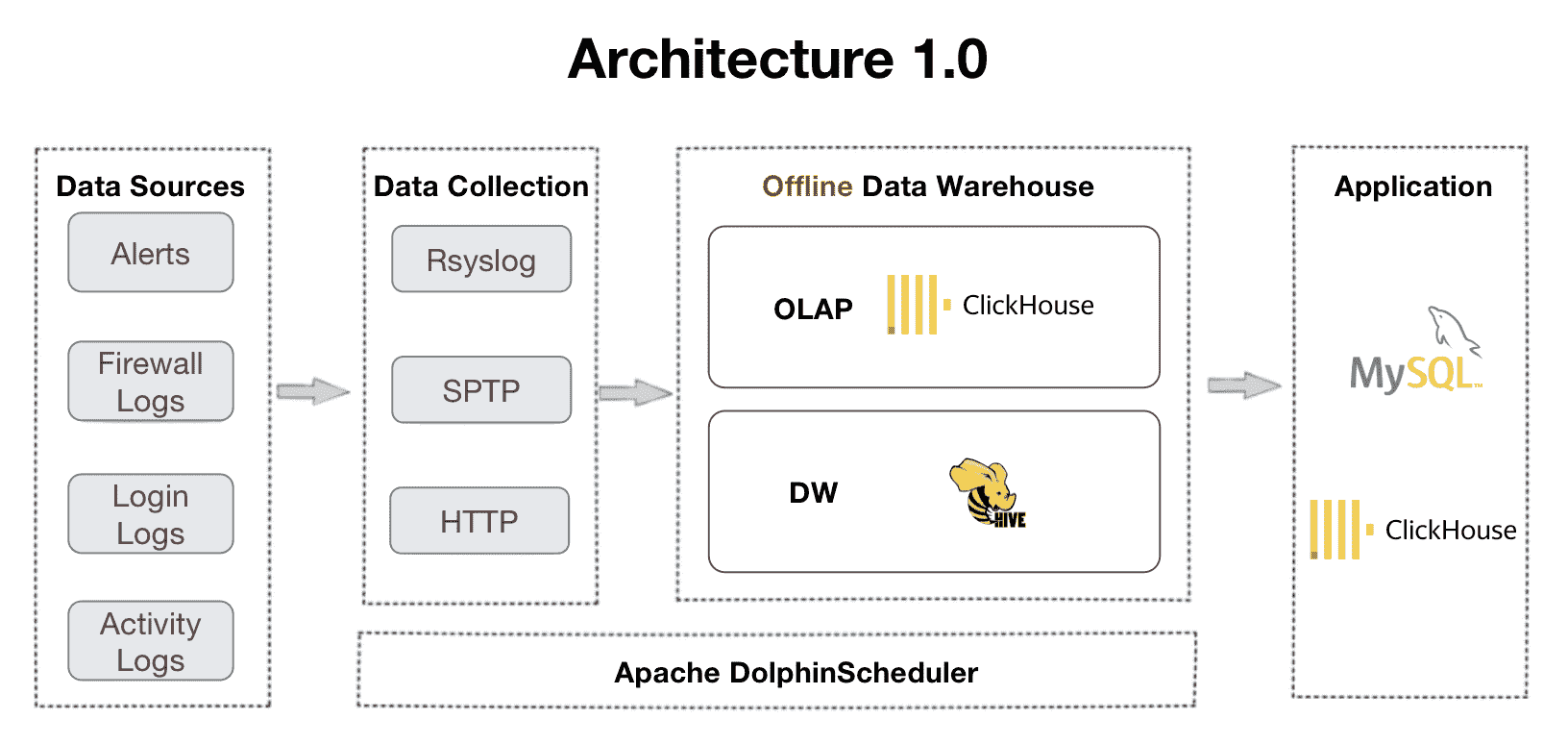
现在让我们来看看他们在数据摄取、存储和查询方面的 Architecture 2.0 实践。
实际案例实践
每天稳定摄取 150 亿条日志
在用户的案例中,他们的业务每天生成 150 亿条日志。快速且稳定地摄取如此大规模的数据量确实是一个问题。使用 Apache Doris,推荐的方式是使用 Flink-Doris-Connector。它由 Apache Doris 社区为大规模数据写入开发。该组件需要简单配置。它实现了流加载,并且可以达到每秒 200,000~300,000 条日志的写入速度,不会中断数据分析工作负载。
一项经验教训是,当使用 Flink 进行高频写入时,需要为你的案例找到合适的参数配置,以避免数据版本积累。在这种情况下,用户进行了以下优化:
-
Flink Checkpoint:他们将检查点间隔从 15 秒增加到 60 秒,以减少写入频率和 Doris 每单位时间处理的事务数量。这可以减轻数据写入压力,避免生成过多的数据版本。
-
数据预聚合:对于来自不同表但 ID 相同的数据,Flink 将根据主键 ID 进行预聚合,并创建一个平面表,以避免因多源数据写入而导致的资源过度消耗。
-
Doris Compaction:这里的技巧包括找到合适的 Doris 后端(BE)参数,以分配适量的 CPU 资源用于数据压缩,设置适当的数据分区、桶和副本数量(过多的数据平板会带来巨大的开销),以及将 max_tablet_version_num 调高以避免版本积累。
这些措施共同确保了每日摄取的稳定性。用户在 Doris 后端见证了稳定的性能和低的压缩分数。此外,Flink 中的数据预处理和 Doris 中的 唯一键模型 的结合可以确保更快的数据更新。
降低成本 50%的存储策略
日志的大小和生成速率也对存储造成压力。在庞大的日志数据中,只有一部分具有较高的信息价值,因此存储应该有所区分。用户有三种存储策略来降低成本。
-
ZSTD(ZStandard)压缩算法:对于大于 1TB 的表,在表创建时指定压缩方法为“ZSTD”,可以实现 10:1 的压缩比。
-
冷热数据分层存储:这由 Doris 的新功能支持。用户设置了数据“冷却”期为 7 天。这意味着过去 7 天的数据(即热数据)将存储在 SSD 中。随着时间的推移,热数据会“冷却”(超过 7 天),它将自动转移到成本较低的 HDD 中。随着数据变得更加“冷”,它将被转移到对象存储中以进一步降低存储成本。此外,在对象存储中,数据将以单副本存储,而不是三副本。这进一步减少了成本和冗余存储带来的开销。
-
不同数据分区的副本数量:用户按照时间范围对数据进行了分区。原则是对较新的数据分区有更多副本,对较旧的数据分区有较少副本。在他们的情况下,过去 3 个月的数据被频繁访问,因此该分区有 2 个副本。3~6 个月的数据有两个副本,6 个月前的数据只有一个副本。
通过这三种策略,用户将存储成本降低了 50%。
基于数据大小的差异化查询策略
某些日志必须立即跟踪和定位,例如异常事件或故障日志。为了确保对这些查询的实时响应,用户针对不同的数据大小采用了不同的查询策略:
-
少于 100G:用户利用 Doris 的动态分区功能。小表按日期分区,大表按小时分区。这可以避免数据倾斜。为了进一步确保数据分区内的平衡,他们使用 snowflake ID 作为分桶字段。他们还设置了起始偏移量。最近 20 天的数据将被保留。这是在数据积压和分析需求之间的平衡点。
-
100G~1T:这些表有其物化视图,这些视图是在 Doris 中存储的预计算结果集。因此,对这些表的查询将会更快且资源消耗更少。Doris 中的物化视图 DDL 语法与 PostgreSQL 和 Oracle 中的相同。
-
超过 100T:这些表被放入 Apache Doris 的聚合键模型中,并进行预聚合。这样,我们可以使 20 亿条日志记录的查询在 1~2 秒内完成。
这些策略缩短了查询的响应时间。例如,以前查询特定数据项需要几分钟,但现在可以在毫秒内完成。此外,对于包含 100 亿条数据记录的大表,查询不同维度的数据都可以在几秒钟内完成。
进行中的计划
用户现在正在测试 Apache Doris 中新增的倒排索引。该索引旨在加快字符串的全文搜索以及数值和日期时间的等效性和范围查询。他们还提供了关于 Doris 自动分桶逻辑的宝贵反馈:目前,Doris 根据前一个分区的数据大小来决定一个分区的桶数。用户的问题是,他们的大部分新数据在白天到达,而夜间的数据很少。因此,在他们的情况下,Doris 在夜间创建了过多的桶,而在白天则创建了过少的桶,这与他们的需求相反。他们希望添加一种新的自动分桶逻辑,使 Doris 决定桶数的参考依据为前一天的数据大小和分布。他们已经来到了Apache Doris 社区,我们现在正在进行这一优化。
扎基·卢 曾是百度的产品经理,现在是 Apache Doris 开源社区的 DevRel。
更多相关内容
如何使用 Hugging Face Transformers 微调 BERT 进行情感分析
原文:
www.kdnuggets.com/how-to-fine-tune-bert-sentiment-analysis-hugging-face-transformers

图片由作者使用 Midjourney 创建
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
情感分析是指自然语言处理(NLP)技术,用于判断文本中的情感表达,是现代客户反馈评估、社交媒体情感跟踪和市场研究应用背后的核心技术。情感分析帮助企业和其他组织评估公众意见,提供更好的客户服务,并增强他们的产品或服务。
BERT,即双向编码器表示模型,是一种语言处理模型,当初发布时,通过对词语上下文的重要理解,显著提升了 NLP 的最先进水平。BERT 的双向性——同时读取给定词的左右上下文——在情感分析等用例中表现得尤为有价值。
在这个全面的指南中,你将学习如何使用 Hugging Face Transformers 库微调 BERT 以适应你自己的情感分析项目。无论你是新手还是现有的 NLP 从业者,我们将在这一步一步的教程中涵盖许多实用的策略和考虑因素,以确保你能够为自己的目的正确地微调 BERT。
设置环境
在微调模型之前,需要完成一些必要的前置条件。具体而言,这将至少需要 Hugging Face Transformers,以及 PyTorch 和 Hugging Face 的数据集库。你可以按如下方式进行。
pip install transformers torch datasets
就这样。
数据预处理
你需要选择一些数据来训练文本分类器。在这里,我们将使用 IMDb 电影评论数据集,这是展示情感分析的地方之一。让我们使用 datasets 库来加载数据集。
from datasets import load_dataset
dataset = load_dataset("imdb")
print(dataset)
我们需要对数据进行分词,以便为自然语言处理算法做准备。BERT 有一个特殊的分词步骤,可以确保句子片段在转换时尽可能保持对人类的连贯性。让我们看看如何通过使用 BertTokenizer 从 Transformers 来分词数据。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
准备数据集
我们将把数据集拆分为训练集和验证集,以评估模型的性能。以下是我们将如何进行。
from datasets import train_test_split
train_testvalid = tokenized_datasets['train'].train_test_split(test_size=0.2)
train_dataset = train_testvalid['train']
valid_dataset = train_testvalid['test']
DataLoaders 有助于在训练过程中高效地管理数据批次。以下是我们将如何为训练集和验证集创建 DataLoaders。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)
valid_dataloader = DataLoader(valid_dataset, batch_size=8)
为微调设置 BERT 模型
我们将使用 BertForSequenceClassification 类来加载我们的模型,该模型已针对序列分类任务进行了预训练。以下是我们将如何进行。
from transformers import BertForSequenceClassification, AdamW
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
训练模型
训练我们的模型涉及定义训练循环,指定损失函数、优化器以及其他训练参数。以下是我们如何设置和运行训练循环。
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
)
trainer.train()
模型评估
评估模型涉及使用准确率、精确率、召回率和 F1-score 等指标来检查其性能。以下是我们如何评估模型。
metrics = trainer.evaluate()
print(metrics)
进行预测
微调后,我们现在可以使用模型对新数据进行预测。这是我们如何在验证集上进行推断的。
predictions = trainer.predict(valid_dataset)
print(predictions)
总结
本教程涵盖了使用 Hugging Face Transformers 对 BERT 进行情感分析的微调,并包括环境设置、数据集准备和分词、DataLoader 创建、模型加载和训练,以及模型评估和实时模型预测。
对 BERT 进行情感分析的微调在许多现实世界情境中都非常有价值,例如分析客户反馈、追踪社交媒体的语调等。通过使用不同的数据集和模型,你可以为自己的自然语言处理项目扩展这一方法。
有关这些主题的更多信息,请查看以下资源:
这些资源值得深入研究,以更好地理解这些问题并提升你的自然语言处理和情感分析能力。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的执行编辑以及 Machine Learning Mastery 的特约编辑,马修旨在让复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他致力于使数据科学社区中的知识实现民主化。马修从 6 岁起就开始编程。
更多相关主题
如何微调 ChatGPT 3.5 Turbo

编辑器提供的图片
如果你还没有听说,OpenAI 最近宣布 GPT-3.5 Turbo 的微调已经开放。此外,GPT-4.0 的微调预计将在秋季晚些时候发布。对于开发人员而言,这无疑是一个受欢迎的消息。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
但为什么这项公告如此重要呢?简而言之,是因为微调 GPT-3.5 Turbo 模型提供了几个重要的好处。虽然我们将在本文后面探讨这些好处,但本质上,微调使开发人员能够更有效地 管理他们的项目 并缩短提示(有时缩短高达 90%),通过将指令嵌入模型本身。
通过微调后的 GPT-3.5 Turbo 版本,有可能超越基本的 Chat GPT-3.5 能力,完成某些任务。让我们深入探讨如何更好地微调你的 GPT-3.5 Turbo 模型。
准备微调数据
微调 GPT-3.5 Turbo 数据的第一步是 将其格式化为正确的结构 的 JSONL 格式。你的 JSONL 文件中的每一行都将有一个消息键,包含三种不同类型的消息:
-
你的输入消息(也称为用户消息)
-
消息的上下文(也称为系统消息)
-
模型响应(也称为助手消息)
这是一个包含所有三种消息类型的示例:
{
"messages": [
{ "role": "system", "content": "You are an experienced JavaScript developer adept at correcting mistakes" },
{ "role": "user", "content": "Find the issues in the following code." },
{ "role": "assistant", "content": "The provided code has several aspects that could be improved upon." }
]
}
准备好数据后,你需要保存你的 JSON 对象文件。
上传文件以进行微调
一旦你创建并保存了数据集,就可以上传文件以便进行微调。
这里是通过 OpenAI 提供的 Python 脚本来执行这项工作的示例:
curl https://api.openai.com/v1/files \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@path_to_your_file"
创建微调任务
现在是执行微调的最终时刻。OpenAI 提供了一个如何执行微调的示例:
curl https://api.openai.com/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"training_file": "TRAINING_FILE_ID",
"model": "gpt-3.5-turbo-0613"
}'
如上例所示,你需要使用 openai.file.create 来发送请求上传文件。记得保存文件 ID,因为你将在未来步骤中用到它。
利用微调模型
现在是部署和与微调模型互动的时候了。你可以在 OpenAI 游乐场中完成这一操作。
请注意下面的 OpenAI 示例:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "ft:gpt-3.5-turbo:org_id",
"messages": [
{
"role": "system",
"content": "You are an experienced JavaScript developer adept at correcting mistakes"
},
{
"role": "user",
"content": "Hello! Can you review this code I wrote?"
}
]
}'
这也是一个比较新微调模型与原始 GPT-3.5 Turbo 模型的好机会。
微调的优势
微调你的 GPT-3.5 Turbo 提示提供了三个主要的优势,提升模型质量和性能。
改进的引导性
这也是说微调允许开发人员确保他们的定制模型更好地遵循特定指令。例如,如果你希望你的模型用另一种语言(例如意大利语或西班牙语)完成,微调你的模型使你能够做到这一点。
如果你需要你的模型使输出更简短或让模型以某种方式回应也是一样的。说到输出…
更可靠的输出格式化
通过微调,模型可以提高其以一致方式格式化响应的能力。这对任何需要特定格式的应用程序都非常重要,例如编码。具体来说,开发人员可以微调他们的模型,使得用户提示被转换成JSON 片段,这些片段随后可以被纳入到更大的数据模块中。
定制语调
如果任何企业需要确保其 AI 模型生成的输出具有特定的语调,微调是最有效的方式。许多企业需要确保其内容和营销材料与品牌声音一致或具有特定的语调,以更好地与客户建立联系。
如果任何企业有一个可识别的品牌声音,他们可以在准备数据进行微调时微调他们的 GPT-3.5 Turbo 模型。具体来说,这将在上面讨论的“用户消息”和“系统消息”类型中进行。正确操作时,这将确保所有消息都以公司的品牌声音为基础,同时显著减少从社交媒体文案到白皮书编辑所需的时间。
未来的增强功能
如上所述,OpenAI 预计很快会推出 GPT-4.0 的微调功能。除此之外,公司还预计推出即将支持函数调用和通过 UI 进行微调的功能。后者将使微调对新手用户更加可及。
这些微调的发展不仅对开发人员重要,对企业也至关重要。例如,许多在科技和开发领域的最具前景的初创公司,如 Sweep 或 SeekOut,依赖于 AI 完成他们的服务。这些企业将会充分利用微调 GPT 数据模型的能力。
结论
借助这种对 GPT-3.5 Turbo 的新微调能力,企业和开发人员现在可以更有效地监督他们的模型,以确保它们的表现与其应用更加一致。
Nahla Davies 是一名软件开发人员和技术作家。在将她的工作全职投入到技术写作之前,她还担任过一家 Inc. 5,000 的体验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
相关话题
如何使用 Hugging Face AutoTrain 微调 Mistral AI 7B LLM
原文:
www.kdnuggets.com/how-to-finetune-mistral-ai-7b-llm-with-hugging-face-autotrain

图片由编辑提供
随着全球 LLM 研究的进展,许多模型变得更加易于获取。一个小而强大的开源模型是 Mistral AI 7B LLM。该模型在多个用例上展现出适应性,在所有基准测试中表现优于 LlaMA 2 13B,采用了 滑动窗口注意力(SWA) 机制,并且易于部署。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
Mistral 7 B 的整体性能基准见下图。
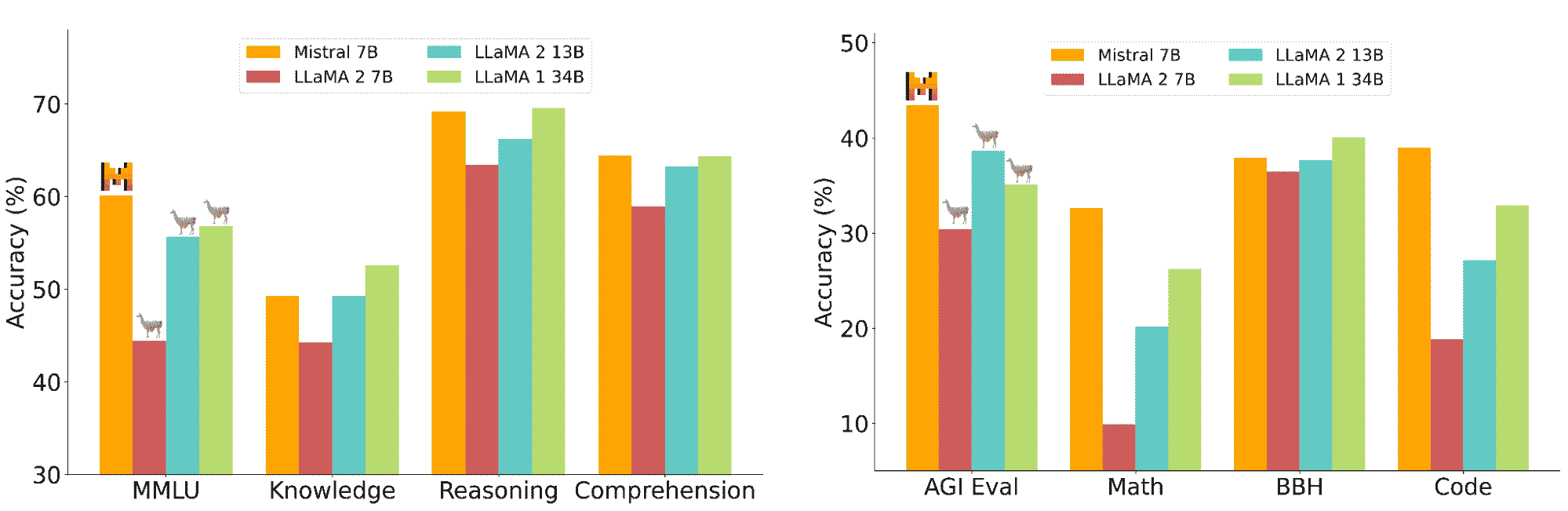
Mistral 7B 性能基准(江等(2023))
Mistral 7B 模型也可在 HuggingFace 中找到。通过这个模型,我们可以使用 Hugging Face AutoTrain 针对我们的用例对模型进行微调。Hugging Face 的 AutoTrain 是一个无需编码的平台,配有 Python API,我们可以使用它轻松微调任何可用的 LLM 模型。
本教程将教我们如何使用 Hugging Face AutoTrain 微调 Mistral AI 7B LLM。它是如何工作的?让我们深入了解。
环境和数据集准备
要使用 Python API 微调 LLM,我们需要安装 Python 包,你可以使用以下代码运行。
pip install -U autotrain-advanced
此外,我们将使用来自 HuggingFace 的 Alpaca 样本数据集,该数据集需要通过数据集包获取,并使用 transformers 包来操作 Hugging Face 模型。
pip install datasets transformers
接下来,我们必须为微调 Mistral 7B 模型格式化数据。一般来说,Mistral 发布了两个基础模型:Mistral 7B v0.1 和 Mistral 7B Instruct v0.1。Mistral 7B v0.1 是基础模型,而 Mistral 7B Instruct v0.1 是为对话和问答微调过的 Mistral 7B v0.1 模型。
我们需要一个包含文本列的 CSV 文件来进行 Hugging Face AutoTrain 微调。不过,在微调过程中,我们将使用不同的文本格式用于基础和指令模型。
首先,让我们查看用于示例的数据集。
from datasets import load_dataset
import pandas as pd
# Load the dataset
train= load_dataset("tatsu-lab/alpaca",split='train[:10%]')
train = pd.DataFrame(train)
上述代码将会抽取实际数据的百分之十的样本。我们在这个教程中只需要这么多,因为训练更大数据会花费更长时间。我们的数据样本如下图所示。

作者提供的图片
数据集已经包含了我们需要微调 LLM 模型的文本列格式。因此,我们无需执行任何操作。不过,如果你有其他需要格式化的数据集,我会提供代码。
def text_formatting(data):
# If the input column is not empty
if data['input']:
text = f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{data["instruction"]} \n\n### Input:\n{data["input"]}\n\n### Response:\n{data["output"]}"""
else:
text = f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{data["instruction"]}\n\n### Response:\n{data["output"]}"""
return text
train['text'] = train.apply(text_formatting, axis =1)
对于 Hugging Face AutoTrain,我们需要将数据保存为 CSV 格式,可以使用以下代码来保存数据。
train.to_csv('train.csv', index = False)
然后,将 CSV 结果移动到一个名为 data 的文件夹中。这就是为微调 Mistral 7B v0.1 准备数据集所需的全部操作。
如果你想为对话和问答微调 Mistral 7B Instruct v0.1,我们需要按照 Mistral 提供的聊天模板格式进行操作,如下方代码块所示。
<s>[INST] Instruction [/INST] Model answer</s>[INST] Follow-up instruction [/INST]
如果我们使用之前的示例数据集,我们需要重新格式化文本列。我们将只使用没有输入的聊天模型数据。
train_chat = train[train['input'] == ''].reset_index(drop = True).copy()
然后,我们可以使用以下代码重新格式化数据。
def chat_formatting(data):
text = f"<s>[INST] {data['instruction']} [/INST] {data['output']} </s>"
return text
train_chat['text'] = train_chat.apply(chat_formatting, axis =1)
train_chat.to_csv('train_chat.csv', index =False)
我们将得到一个适合微调 Mistral 7B Instruct v0.1 模型的数据集。

作者提供的图片
准备好所有设置后,我们现在可以启动 AutoTrain 来微调我们的 Mistral 模型。
训练和微调
让我们设置 Hugging Face AutoTrain 环境来微调 Mistral 模型。首先,运行以下命令来进行 AutoTrain 设置。
!autotrain setup
接下来,我们需要提供 AutoTrain 运行所需的信息。在这个教程中,我们使用 Mistral 7B Instruct v0.1。
project_name = 'my_autotrain_llm'
model_name = 'mistralai/Mistral-7B-Instruct-v0.1'
如果你想将模型推送到仓库,我们将添加 Hugging Face 信息。
push_to_hub = False
hf_token = "YOUR HF TOKEN"
repo_id = "username/repo_name"
最后,我们将在下面的变量中初始化模型参数信息。你可以修改它们来查看结果是否良好。
learning_rate = 2e-4
num_epochs = 4
batch_size = 1
block_size = 1024
trainer = "sft"
warmup_ratio = 0.1
weight_decay = 0.01
gradient_accumulation = 4
use_fp16 = True
use_peft = True
use_int4 = True
lora_r = 16
lora_alpha = 32
lora_dropout = 0.045
我们可以调整许多参数,但在本文中不会讨论它们。一些改进 LLM 微调的技巧包括使用较低的学习率以保持预先学习的表示,避免过拟合通过调整周期数,使用较大的批量大小以提高稳定性,或者在有内存问题时调整梯度累积。
当所有信息准备好后,我们将设置环境以接受之前设置的所有信息。
import os
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["PUSH_TO_HUB"] = str(push_to_hub)
os.environ["HF_TOKEN"] = hf_token
os.environ["REPO_ID"] = repo_id
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["GRADIENT_ACCUMULATION"] = str(gradient_accumulation)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["USE_PEFT"] = str(use_peft)
os.environ["USE_INT4"] = str(use_int4)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)
我们将使用以下命令在笔记本中运行 AutoTrain。
!autotrain llm \
--train \
--model ${MODEL_NAME} \
--project-name ${PROJECT_NAME} \
--data-path data/ \
--text-column text \
--lr ${LEARNING_RATE} \
--batch-size ${BATCH_SIZE} \
--epochs ${NUM_EPOCHS} \
--block-size ${BLOCK_SIZE} \
--warmup-ratio ${WARMUP_RATIO} \
--lora-r ${LORA_R} \
--lora-alpha ${LORA_ALPHA} \
--lora-dropout ${LORA_DROPOUT} \
--weight-decay ${WEIGHT_DECAY} \
--gradient-accumulation ${GRADIENT_ACCUMULATION} \
$( [[ "$USE_FP16" == "True" ]] && echo "--fp16" ) \
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" ) \
$( [[ "$USE_INT4" == "True" ]] && echo "--use-int4" ) \
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )
如果微调过程成功,我们将拥有一个新的微调模型目录。我们将使用这个目录来测试我们新微调的模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "my_autotrain_llm"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
模型和分词器准备好后,我们会用一个示例输入测试模型。
input_text = "Give three tips for staying healthy."
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_new_tokens = 200)
predicted_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(predicted_text)
输出:
给出三条保持健康的建议。
-
均衡饮食:确保饮食中包含大量水果、蔬菜、瘦蛋白和全谷物。这将帮助你获得保持健康和充满活力所需的营养。
-
定期锻炼:每天至少进行 30 分钟的中等强度运动,如快走或骑车。这将帮助你维持健康的体重,降低慢性疾病的风险,并改善整体身体和心理健康。
-
充足的睡眠:每晚目标睡眠 7-9 小时。这将帮助你在白天感到更有休息感和警觉性,同时有助于维持健康的体重并降低慢性疾病的风险。
模型的输出与我们的训练数据的实际输出接近,如下图所示。
-
均衡饮食,并确保包含大量水果和蔬菜。
-
定期锻炼以保持身体活跃和强壮。
-
充足的睡眠并保持一致的作息时间。
Mistral 模型确实因其体积小而强大,简单的微调已经显示出良好的结果。尝试你的数据集,以查看它是否适合你的工作。
结论
Mistral AI 7B 系列模型是一个强大的 LLM 模型,性能优于 LLaMA,并具有出色的适应性。由于该模型在 Hugging Face 上可用,我们可以使用 HuggingFace AutoTrain 来微调模型。目前,Hugging Face 上有两个可微调的模型:Mistral 7B v0.1 作为基础模型,以及 Mistral 7B Instruct v0.1 用于对话和问答。即使经过快速训练,微调结果也表现出良好的前景。
Cornellius Yudha Wijaya** 是数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习主题上进行写作。
相关话题
如何作为学生获得数据科学职位
原文:
www.kdnuggets.com/how-to-get-a-job-in-data-science-as-a-student
插图作者。来源:Flaticon
数据科学是一个具有挑战性的领域,单凭拥有认证或大学学位是不够的,无法在行业中获得工作。招聘人员需要了解你相比其他候选人能够为公司带来什么价值。
由于资格本身不足以在数据科学领域获得工作,开始尝试不同的经历的最佳时机是在你还是学生的时候。你仍然年轻,比你想象的有更多时间和精力,这些都可以用来增加你获得首份数据科学工作的机会。
在这篇文章中,我想展示五种不同的方式来展示你的技能,甚至赚取收入。让我们开始吧!
构建数据科学项目组合
当我开始申请我的第一份数据科学工作时,显然我在这一领域没有任何经验。我在硕士学位期间做的项目帮助我向公司展示了我的技能。
展示你的编码能力的最佳方式是将你的项目分享到 GitHub。你当然不应该只关注 python 脚本/jupyter notebooks,还应包括一个 READ.me 文件,详细解释项目的组织方式和获得的结果。
例如,我的一个个人项目引起了经理们的兴趣,BERTopic 主题建模,在该项目中,我训练了一个 BERTopic 模型来识别来自电子商务服装评论的主题,并通过互动数据可视化解释结果。这有助于展示我能够解决一个自然语言处理问题。
撰写数据科学文章
当我还是学生时,我开始在不同的出版物中撰写数据科学文章,如 Towards AI 和 Towards Data Science,这让我能够接触到来自不同国家的大量读者,将我在大学课程中学到的知识付诸实践,深入探讨我感兴趣的未知领域,收到工作提议,甚至赚取收入。
最好的老师是来自社区的反馈,刚开始时,尤其是负面评论可能会让人感到害怕,但它确实有助于提升你的批判性思维,并让你对解决问题的其他可能方案保持开放的心态。
你还可以从零开始创建自己的博客,而不是在出版物上发布,但你应该考虑到建立网站所需的时间。无论如何,多亏了 Chat-GPT 和其他基于大型语言模型的 AI 工具,这一切变得更加容易。
创建 YouTube 视频
文章可以是展示你沟通能力的好方法,这对于数据科学家来说是一项重要技能,但录制 YouTube 视频也可以证明你的能力。
这可以与文章结合进行,但单独制作视频也可能足够。有很多知名的数据科学领域的影响者以其出色的视频内容建设能力而闻名,如 StatQuest 的 Josh Starmer、Data Professor 和 Patrick Loeber。
作为自由职业数据科学家工作
教育内容并不是进入数据科学领域的唯一途径。另一种获得经验的可能性是作为自由职业数据科学家工作。这是对传统的 9 到 5 工作的一个良好替代方案:它可以保证自由和灵活性,尤其是当你还是学生并且需要时间参加和学习大学课程时。
你可以从现有平台开始,比如 Upwork 和 Fiverr,在这些平台上你需要创建个人资料,并申请客户发布的数据科学自由职业任务。你也可以在 LinkedIn 上联系客户或被客户联系,这被认为是与数据科学社区相关人士建立联系的最佳社交网络。
参加数据科学竞赛
提高获得工作的机会的另一种方式是参加数据科学竞赛。我想强调的是,参加大量竞赛并不重要,更重要的是专注于对面试公司有价值的现实项目。质量总是比数量更重要。
最知名和受欢迎的竞赛平台是 Kaggle。你在搜索数据科学主题、数据集和其他内容时肯定查阅过这个网站。其他竞赛可以在 DrivenData、TopCoder 和 DevPost 上找到。
最终思考
我希望这篇文章能激励你采取行动,从而改善你的简历。这也是将你在学习过程中获得的知识付诸实践的好方法,克服冒名顶替综合症,并变得更加灵活。
当然,你不应该仅仅为了改善你的简历而这样做,还应该为了我之前列出的其他好处,这些好处可以让你在不同的经验中变得更加自信。感谢阅读!祝你有美好的一天。
尤金妮亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于持续学习结合异常检测。
更多相关主题
如何在没有相关学位的情况下进入数据分析领域
原文:
www.kdnuggets.com/2021/12/how-to-get-into-data-analytics.html
评论
作者 Zulie Rane,自由撰稿人及编程爱好者。

数据分析是一个非常酷的、蓬勃发展的行业。它已经存在了很长时间,这也解释了为什么如此多人在考虑如何进入数据分析领域。自互联网和智能手机的广泛应用以来,数据量激增。2020 年初,全球的数据量估计为 44 zettabytes,即 44 x 10²¹ bytes。这些数据包含大量有用的信息,例如消费者的购买模式或疾病的指标。
数据分析师处理数据集,并负责理解它们。数据在说什么,公司应该如何应对?一个简单的例子是你将商品放入购物车后,出现的包含常被一起购买的商品的横幅。数据分析师可能负责确定哪些产品应该关联在一起,以提高转化率。
数据分析是 分析原始数据 以发现趋势和回答问题的过程。这涉及大量的单独工作在屏幕前,但如果你喜欢数学和编程,这是一个很好的机会。你需要获取和收集数据,以及清理、组织、可视化和分析数据。
一个简单的 区别说明:数据科学家负责设计和构建新的数据模型。他们创建原型、算法、预测模型。数据分析师则按照名字的意思——查看数据,尝试预测趋势,制作可视化,并传达结果。换句话说,数据分析师分析数据。在美国,数据科学家的年薪比数据分析师高出 $30K-$40K,因此这是一个重要的区别。
这篇文章将带你了解获得第一个数据分析师职位所需的一切知识。

什么是数据分析?
在你开始考虑如何进入数据分析领域之前,你应该确保你理解这个领域。数据分析是从大量数据中提取意义的艺术。根据DOMO的说法,自 2020 年以来,每个人每秒钟产生 1.7MB 的数据。数据分析师的任务是找到与他们的业务应用相关的数据,理解这些数据,并找到将这些知识应用于改善业务的方法。
数据分析领域内有许多子领域。这些包括描述性、诊断性、预测性和规范性分析。你可以通过以下方式理解这些不同类型的分析。
-
描述性分析是弄清楚发生了什么。
-
诊断性分析回答的问题是:为什么会发生这种情况?
-
预测性分析尝试利用现有数据预测未来会发生什么。
-
规范性分析旨在弄清楚应该如何处理这些情况。
数据分析师在日常工作中可能会涵盖所有这些子领域。通常,数据分析师会通过所有这些分析形式来充分利用数据集,并优化其业务影响。如果你想进入数据分析领域,理解这些不同的分析形式并知道如何应用它们是非常重要的。
数据分析师的任务是帮助企业做出数据驱动的决策。由于数据收集相对简单,数据分析师可以测试他们的假设,并修正他们制定的规范性模型,以提高其性能,并调整基于数据洞察制定的行动项。基于数据制定假设、实施预测并分析结果,就是进入数据分析领域的方式。
数据分析需要哪些技术技能?
由于数据分析是数学和编程的交叉领域,因此它是一个极其技术性的领域。你需要使用许多不同的工具和技术技能来完成工作。一位软件工程师玛格丽塔·哈马彻(Margarita Hamacher)整理了一个数据分析师所需的7 项技术技能的综合清单。数据分析不仅仅是硬技能。但对于任何想要进入数据分析领域的人来说,这些技术技能将是一个很好的起点。
这些技能包括数学、数据可视化、机器学习、编码等。数学要求可以进一步分解为线性代数、统计学和概率论,这些都是数据分析师非常重要的理论基础。值得强调的是如何分离用于训练和测试的数据,以及列举你应该熟悉的基本机器学习算法,如果不能实现这些算法也没关系。
如果你想了解如何进入数据分析领域,掌握这些技能非常重要,因为你需要每一项技能来正确理解数据并准确分析数据。此外,这些技能中的许多都是面试问题的绝佳素材。
我会建议你创建一些使用这些技能的个人项目,并在简历中提供这些项目的链接。如果你遇到以下问题:

如果你在项目中用实际数据解决过类似的问题,你的回答会更具说服力和信息量。你可以讨论这些相关特征对你分析项目数据集的影响。
如何进入数据分析领域:为什么数据分析值得进入?
数据分析是一个真正迷人的领域。例如,大多数经典经济理论基于人类个体做出理性决策的假设。这个假设是错误的,因此使得许多经典经济理论完全过时。例如,有一种旧的经济理论认为消费者喜欢选择,尽管在某些情况下这是真的,但做决定可能是身体上令人疲惫的。Mark Lepper 和 Sheen Iyengar 发现了选择悖论。他们发现,当客户面临 6 种选择时,更可能购买果酱,而不是 24 种选择。然而,基于数据的经济理论要准确得多。虽然数据分析仍然需要偶尔做一些小假设,但由于它完全基于收集的数据,如果你的数据是全面和具有代表性的,数据分析提供了一种优雅且准确的方式来理解世界及其决策或习惯。
数据分析是一个快速发展的领域。美国劳工统计局预测到 2026 年数据科学领域将会有28%的增长。如果你关心薪水,美国数据分析师的平均工资是$70K,随着对数据分析师需求的增加,这个数字只会有上涨趋势。现在是进入数据分析领域的绝佳时机,你可以采取一些简单的步骤来实现这一目标。
谁是优秀的数据分析师?

数据分析是一个非常技术性的领域,所以任何想进入数据分析领域的人都需要对多种高级数学概念有深入理解,并且需要成为一个合格的程序员。如果你对数字及其所揭示的内容充满热情,只要确保你掌握了上述技术技能以符合职位要求,数据分析就是适合你的工作。
数据分析师工作中的一个重要因素是许多人未曾考虑的上下文业务知识。如果你是一名处理树木生长数据的数据分析师,而你的数据集中缺少某些值,你需要对树木及其生长方式有足够的了解,以确定这些数据是否可以丢弃或补充的最佳方式是什么。你还需要能够理解数据集中特征的含义。如果你有两个在意义上非常相似的特征,你可能会想要丢弃其中一个。你可以通过利用上下文知识来评估特征之间的依赖关系以及哪些特征与当前问题最相关,从而避免对特征依赖性进行深入分析的麻烦。
思考一下你的兴趣或已有的知识领域,以及你如何将数据分析应用于这些领域。许多进入数据分析领域的人没有正式的数据分析背景或学位,因此你可以考虑成为一名处理你所学领域数据的数据分析师。
如何准备数据分析面试
如何进入数据分析领域的一个重要部分是成功完成数据分析师职位的面试。除了精通 Python 并能够解释中心极限定理之外,你还可能被要求演示如何比较不同后端引擎在自动生成推荐中的表现。查看下面的面试问题示例:

准备技术面试的最佳方式是练习。回答技术问题是一种技能,就像其他技能一样。不断练习编码和非编码问题。你可以使用像 StrataScratch 这样的网站,它提供了大量的数据分析师面试问题,包括编码和非编码问题。
除了回答编码问题,比如找出每个 Facebook 用户的受欢迎程度百分比,以及技术、理论性、非编码问题,比如解释不同的时间序列预测技术,你还需要准备与数据分析师相关的内容,以应对行为面试问题。虽然你大多数面试将是技术面试,无论是编码问题还是非编码问题,但你仍然需要有相关的实例来展示你经历过的失败或特别骄傲的成就,这些都与数据分析有关。
这就是为什么拥有与数据分析相关的个人项目如此重要的原因。也许你对拯救动物充满热情。你可以创建一个模型,预测哪些策略对于让动物被领养最为有效。如果有机会应用你的模型,例如让一个动物收容所按照你的推荐策略操作,并观察这是否会对领养率产生影响,那就更好了。数据分析可以应用于任何有数据的领域。肯定有一个与你热情所在的主题相关的数据集。用它来练习你的数据分析师技能,以便在面试时突出显示这些技能。
数据分析职业选择

许多程序员和非程序员可能担心如何进入数据分析领域,但他们应该知道,正式的教育,特别是在数据分析领域,并不是必需的。并不是很多大学提供完整的数据科学或数据分析学位课程。虽然越来越多的大学在增加数据分析课程,但数据分析师的需求仍然太高,以至于雇主不要求正式的数据分析或数据科学背景。如果你有数学或计算机科学的背景,这将非常有帮助,但不是必需的。
要获得入门级的数据分析师职位,你的最佳选择是精通 Python,并对 SQL 非常自信,同时熟悉 SAS、R、Tableau 或其他数据库接口工具和语言。如果你没有计算机科学或数学背景,可以在业余时间发展这些技能,并将其应用于展示你能力的个人项目中。
由于背景知识的重要性,数据分析是从其他行业进入的一个极好的领域。根据你分析的数据所在的行业,无论是医学影像还是在线零售行业中小型企业的购买模式,了解你分析数据的领域可能是有帮助的,有时甚至是必要的。
美国的数据分析师的平均工资为$70K,但在职业后期,这个数字可以高达$106K。我们的文章 数据科学家赚多少钱 可以帮助你了解数据分析领域的薪资情况以及这些薪资如何受到各种因素的影响。
数据分析师的常见工作职责包括收集和组织数据,确保遵守数据政策,执行质量控制功能以确保数据的完整性,优化利润建议,或制定价格和投资组合折扣计划。具体的职责在不同公司之间可能差异很大,因此请检查具体的职位描述,以找到与你最感兴趣的任务相匹配的工作。
关于如何进入数据分析领域的最终思考
数据分析是一个充满潜力的领域,前景广阔。数据分析师的需求迅速增长,这意味着你将享有相对较高的工作安全性。由于这个行业还较为年轻,职业发展的潜力巨大。所需的技能多种多样,因此绝对不适合那些已经不想再学习的人。由于这个行业正在迅速扩张,未来几年必然会有很多工具和新应用的变化。
如果你想进入技术和编程领域,但不想回到学校或成为软件工程师,数据分析是一个很好的选择。数据分析师仍然可以进行编码,但你不需要处理待命或运维的麻烦。数据分析的应用通常很吸引人,通过指导企业做出基于数据的决策,你可以对业务的成功产生很大的影响。
原文。转载经许可。
简介: Zulie Rane 是一位博主、代笔作家、YouTuber 和猫妈妈。她喜欢创作有关数据科学、流行文化和猫的内容。
更多相关话题
如何使用 Scikit-learn 的 Imputer 模块处理缺失数据
原文:
www.kdnuggets.com/how-to-handle-missing-data-with-scikit-learns-imputer-module

图片来源于编辑 | Midjourney & Canva
让我们学习如何使用 Scikit-learn 的 imputer 来处理缺失数据。
准备工作
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
确保你的环境中安装了 Numpy、Pandas 和 Scikit-Learn。如果没有,你可以通过以下代码使用 pip 安装它们:
pip install numpy pandas scikit-learn
然后,我们可以将包导入到你的环境中:
import numpy as np
import pandas as pd
import sklearn
from sklearn.experimental import enable_iterative_imputer
使用 Imputer 处理缺失数据
Scikit-Learn 插补器是一个用于用特定值替换缺失数据的类。它可以简化你的数据预处理过程。我们将探索几种处理缺失数据的策略。
让我们为示例创建一个数据示例:
sample_data = {'First': [1, 2, 3, 4, 5, 6, 7, np.nan,9], 'Second': [np.nan, 2, 3, 4, 5, 6, np.nan, 8,9]}
df = pd.DataFrame(sample_data)
print(df)
First Second
0 1.0 NaN
1 2.0 2.0
2 3.0 3.0
3 4.0 4.0
4 5.0 5.0
5 6.0 6.0
6 7.0 NaN
7 NaN 8.0
8 9.0 9.0
你可以使用 Scikit-Learn Simple Imputer 用相应列的均值填充列中的缺失值。
First Second
0 1.00 5.29
1 2.00 2.00
2 3.00 3.00
3 4.00 4.00
4 5.00 5.00
5 6.00 6.00
6 7.00 5.29
7 4.62 8.00
8 9.00 9.00
需要注意的是,我们将结果四舍五入到两位小数。
也可以使用 Simple Imputer 用中位数插补缺失数据。
imputer = sklearn.SimpleImputer(strategy='median')
df_imputed = round(pd.DataFrame(imputer.fit_transform(df), columns=df.columns),2)
print(df_imputed)
First Second
0 1.0 5.0
1 2.0 2.0
2 3.0 3.0
3 4.0 4.0
4 5.0 5.0
5 6.0 6.0
6 7.0 5.0
7 4.5 8.0
8 9.0 9.0
均值和中位数插补的方法很简单,但它可能会扭曲数据分布并在数据关系中产生偏差。
还可以使用 K-NN 插补器通过最近邻居方法填充缺失数据。
knn_imputer = sklearn.KNNImputer(n_neighbors=2)
knn_imputed_data = knn_imputer.fit_transform(df)
knn_imputed_df = pd.DataFrame(knn_imputed_data, columns=df.columns)
print(knn_imputed_df)
First Second
0 1.0 2.5
1 2.0 2.0
2 3.0 3.0
3 4.0 4.0
4 5.0 5.0
5 6.0 6.0
6 7.0 5.5
7 7.5 8.0
8 9.0 9.0
KNN 插补器将使用 k 个最近邻居的均值或中位数来填补缺失数据。
最后,还有迭代插补方法,它基于将每个缺失值的特征建模为其他特征的函数。正如本文所述,这是一个实验性功能,因此我们需要首先启用它。
iterative_imputer = IterativeImputer(max_iter=10, random_state=0)
iterative_imputed_data = iterative_imputer.fit_transform(df)
iterative_imputed_df = round(pd.DataFrame(iterative_imputed_data, columns=df.columns),2)
print(iterative_imputed_df)
First Second
0 1.0 1.0
1 2.0 2.0
2 3.0 3.0
3 4.0 4.0
4 5.0 5.0
5 6.0 6.0
6 7.0 7.0
7 8.0 8.0
8 9.0 9.0
如果你能够正确使用插补器,它可能有助于提高你的数据科学项目的质量。
额外资源
Cornellius Yudha Wijaya**** 是数据科学助理经理和数据撰稿人。他在印尼安联全职工作时,喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 在各种 AI 和机器学习话题上都有所涉猎。
更多相关主题
如何在数据集中使用 Pandas 处理异常值
原文:
www.kdnuggets.com/how-to-handle-outliers-in-dataset-with-pandas

图片作者
异常值是与其余数据显著不同的异常观察值。它们可能由于实验误差、测量误差或数据本身的变异性而出现。这些异常值可能会严重影响模型的表现,导致结果偏差——就像大学中的相对评分的顶尖表现者可以提高平均分数并影响评分标准一样。处理异常值是数据清理过程中的关键部分。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
在本文中,我将分享如何发现异常值以及在数据集中处理它们的不同方法。
检测异常值
有几种方法可以用来检测异常值。如果我来分类的话,情况如下:
-
基于可视化的方法: 绘制散点图或箱线图,以查看数据分布并检查异常数据点。
-
基于统计的方法: 这些方法涉及 z 分数和 IQR(四分位距),它们提供可靠性,但可能不够直观。
我不会详细介绍这些方法,以保持主题的专注。然而,我会在最后提供一些参考资料以供探索。我们将在示例中使用 IQR 方法。方法如下:
IQR(四分位距) = Q3(75 百分位数) - Q1(25 百分位数)
IQR 方法指出,任何低于Q1 - 1.5 * IQR或高于Q3 + 1.5 * IQR的数据点都被标记为异常值。让我们生成一些随机数据点,并使用此方法检测异常值。
导入必要的库并使用np.random生成随机数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Generate random data
np.random.seed(42)
data = pd.DataFrame({
'value': np.random.normal(0, 1, 1000)
})
使用 IQR 方法从数据集中检测异常值:
# Function to detect outliers using IQR
def detect_outliers_iqr(data):
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return (data < lower_bound) | (data > upper_bound)
# Detect outliers
outliers = detect_outliers_iqr(data['value'])
print(f"Number of outliers detected: {sum(outliers)}")
输出 ⇒ 检测到的异常值数量:8
使用散点图和箱线图可视化数据集,以查看其外观
# Visualize the data with outliers using scatter plot and box plot
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Scatter plot
ax1.scatter(range(len(data)), data['value'], c=['blue' if not x else 'red' for x in outliers])
ax1.set_title('Dataset with Outliers Highlighted (Scatter Plot)')
ax1.set_xlabel('Index')
ax1.set_ylabel('Value')
# Box plot
sns.boxplot(x=data['value'], ax=ax2)
ax2.set_title('Dataset with Outliers (Box Plot)')
ax2.set_xlabel('Value')
plt.tight_layout()
plt.show()
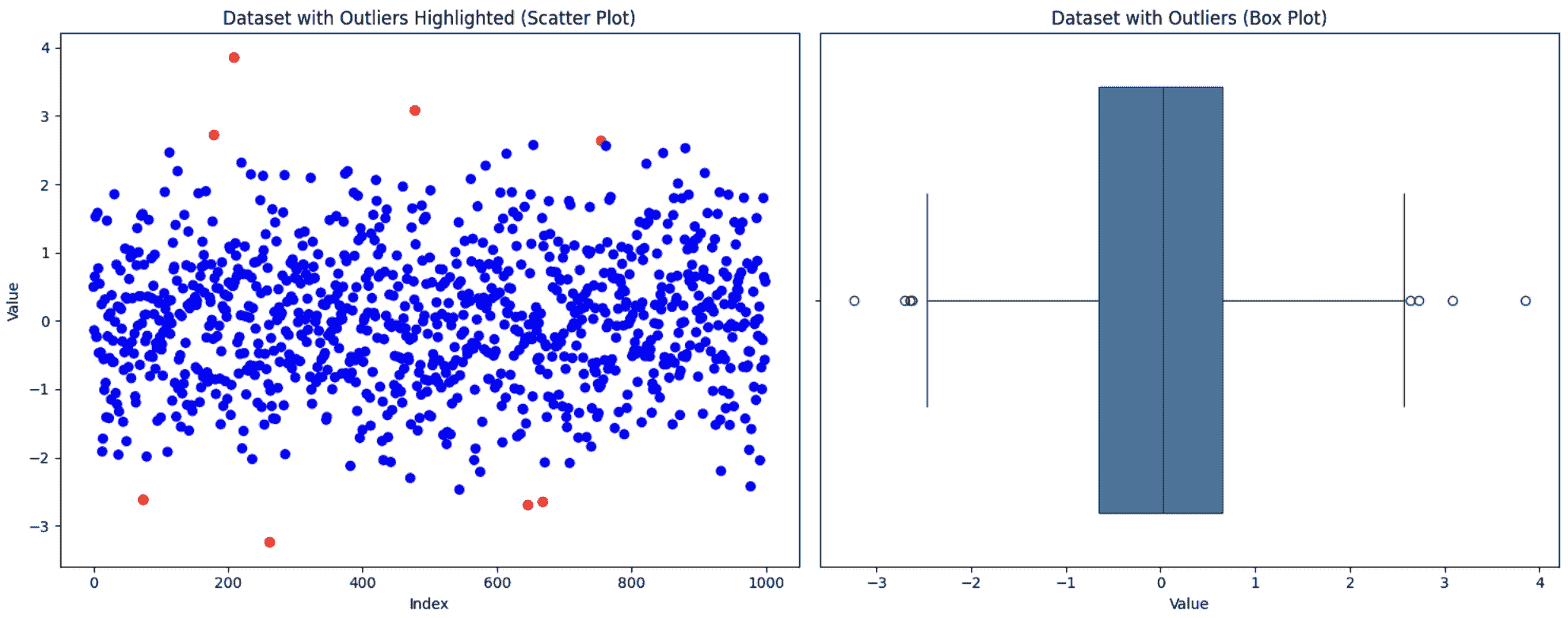
原始数据集
既然我们已经检测到异常值,接下来让我们讨论处理异常值的几种不同方法。
处理异常值
1. 移除异常值
这是一种最简单的方法,但并不总是正确的。你需要考虑一些因素。如果移除这些离群点显著减少了你的数据集大小,或者它们包含有价值的见解,那么将它们排除在分析之外可能不是最好的决策。然而,如果它们是由于测量误差且数量较少,那么这种方法是合适的。让我们将这种技术应用于上述生成的数据集:
# Remove outliers
data_cleaned = data[~outliers]
print(f"Original dataset size: {len(data)}")
print(f"Cleaned dataset size: {len(data_cleaned)}")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Scatter plot
ax1.scatter(range(len(data_cleaned)), data_cleaned['value'])
ax1.set_title('Dataset After Removing Outliers (Scatter Plot)')
ax1.set_xlabel('Index')
ax1.set_ylabel('Value')
# Box plot
sns.boxplot(x=data_cleaned['value'], ax=ax2)
ax2.set_title('Dataset After Removing Outliers (Box Plot)')
ax2.set_xlabel('Value')
plt.tight_layout()
plt.show()
移除离群点
请注意,通过移除离群点,数据的分布实际上可以发生变化。如果你移除一些初始的离群点,离群点的定义可能会发生变化。因此,之前在正常范围内的数据,可能会在新的分布下被视为离群点。你可以通过新的箱线图看到新的离群点。
2. 截尾离群点
当你不想丢弃数据点但保持这些极端值也会影响你的分析时,可以使用这种技术。因此,你设定一个最大值和最小值的阈值,然后将离群点调整到这个范围内。你可以将这种截尾应用于离群点或整个数据集。让我们将截尾策略应用于我们的完整数据集,使其在第 5 到第 95 百分位数的范围内。这是你可以执行的方法:
def cap_outliers(data, lower_percentile=5, upper_percentile=95):
lower_limit = np.percentile(data, lower_percentile)
upper_limit = np.percentile(data, upper_percentile)
return np.clip(data, lower_limit, upper_limit)
data['value_capped'] = cap_outliers(data['value'])
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Scatter plot
ax1.scatter(range(len(data)), data['value_capped'])
ax1.set_title('Dataset After Capping Outliers (Scatter Plot)')
ax1.set_xlabel('Index')
ax1.set_ylabel('Value')
# Box plot
sns.boxplot(x=data['value_capped'], ax=ax2)
ax2.set_title('Dataset After Capping Outliers (Box Plot)')
ax2.set_xlabel('Value')
plt.tight_layout()
plt.show()
截尾离群点
从图表中可以看到,散点图中的上点和下点由于截尾而似乎在一条直线上。
3. 填补离群点
有时从分析中移除值不是一个选项,因为这可能会导致信息丢失,而你也不希望这些值像截尾那样被设为最大值或最小值。在这种情况下,另一种方法是用更有意义的选项,如均值、中位数或众数,来替代这些值。选择依据观察数据的领域而异,但在使用这种技术时要注意不要引入偏差。让我们用众数(出现频率最高的值)替换我们的离群点,看看图表效果如何:
data['value_imputed'] = data['value'].copy()
median_value = data['value'].median()
data.loc[outliers, 'value_imputed'] = median_value
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Scatter plot
ax1.scatter(range(len(data)), data['value_imputed'])
ax1.set_title('Dataset After Imputing Outliers (Scatter Plot)')
ax1.set_xlabel('Index')
ax1.set_ylabel('Value')
# Box plot
sns.boxplot(x=data['value_imputed'], ax=ax2)
ax2.set_title('Dataset After Imputing Outliers (Box Plot)')
ax2.set_xlabel('Value')
plt.tight_layout()
plt.show()
填补离群点
请注意,现在我们没有任何离群点,但这并不能保证离群点会被移除,因为在填补数据后,IQR(四分位距)也会发生变化。你需要进行实验以找到最适合你情况的方法。
4. 应用变换
转换应用于你的完整数据集,而不是特定的异常值。你基本上是改变数据的表示方式,以减少异常值的影响。有几种转换技术,如对数转换、平方根转换、Box-Cox 转换、Z 缩放、Yeo-Johnson 转换、最小-最大缩放等。选择适合你的情况的正确转换取决于数据的性质和分析的最终目标。以下是一些提示,帮助你选择正确的转换技术:
-
对于右偏数据: 使用对数、平方根或 Box-Cox 转换。对数转换在你想要压缩在大范围内分布的小数值时效果更佳。平方根转换在你想要一种较少极端的转换并处理零值时更好,而 Box-Cox 还会对数据进行标准化,这是其他两种方法做不到的。
-
对于左偏数据: 先反射数据,然后应用针对右偏数据的技术。
-
为了稳定方差: 使用 Box-Cox 或 Yeo-Johnson(类似于 Box-Cox,但也处理零和负值)。
-
对于均值中心化和缩放: 使用 z-score 标准化(标准差 = 1)。
-
对于范围缩放(固定范围即[2,5]): 使用最小-最大缩放。
让我们生成一个右偏的数据集,并对完整的数据应用对数转换,看看效果如何:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Generate right-skewed data
np.random.seed(42)
data = np.random.exponential(scale=2, size=1000)
df = pd.DataFrame(data, columns=['value'])
# Apply Log Transformation (shifted to avoid log(0))
df['log_value'] = np.log1p(df['value'])
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# Original Data - Scatter Plot
axes[0, 0].scatter(range(len(df)), df['value'], alpha=0.5)
axes[0, 0].set_title('Original Data (Scatter Plot)')
axes[0, 0].set_xlabel('Index')
axes[0, 0].set_ylabel('Value')
# Original Data - Box Plot
sns.boxplot(x=df['value'], ax=axes[0, 1])
axes[0, 1].set_title('Original Data (Box Plot)')
axes[0, 1].set_xlabel('Value')
# Log Transformed Data - Scatter Plot
axes[1, 0].scatter(range(len(df)), df['log_value'], alpha=0.5)
axes[1, 0].set_title('Log Transformed Data (Scatter Plot)')
axes[1, 0].set_xlabel('Index')
axes[1, 0].set_ylabel('Log(Value)')
# Log Transformed Data - Box Plot
sns.boxplot(x=df['log_value'], ax=axes[1, 1])
axes[1, 1].set_title('Log Transformed Data (Box Plot)')
axes[1, 1].set_xlabel('Log(Value)')
plt.tight_layout()
plt.show()
应用对数转换
你可以看到一个简单的转换已经处理了大部分异常值,并将它们减少到仅一个。这显示了转换在处理异常值中的强大能力。在这种情况下,必须小心并充分了解你的数据,以选择适当的转换,因为不这样做可能会给你带来问题。
总结
这使我们结束了关于异常值、不同检测方法以及如何处理异常值的讨论。本文是 pandas 系列的一部分,你可以在我的作者页面查看其他文章。如上所述,以下是一些额外的资源,供你深入研究异常值:
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学以及人工智能与医学的交叉领域充满深厚的热情。她共同编写了电子书《利用 ChatGPT 提高生产力》。作为 2022 年亚太地区的 Google Generation 学者,她倡导多样性和学术卓越。她还被认定为 Teradata 技术多样性学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的积极倡导者,创立了 FEMCodes 以赋能女性进入 STEM 领域。
更多相关话题
如何准确处理 Pandas 中的时区和时间戳
原文:
www.kdnuggets.com/how-to-handle-time-zones-and-timestamps-accurately-with-pandas

作者提供的图片 | Midjourney
当我们面对不同的时区时,时间数据可能会变得独特。然而,由于这些差异,解释时间戳可能会很困难。本指南将帮助你使用 Python 中的 Pandas 库管理时区和时间戳。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速你的网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
准备工作
在本教程中,我们将使用 Pandas 包。我们可以使用以下代码安装该包。
pip install pandas
现在,我们将通过实际示例探讨如何在 Pandas 中处理基于时间的数据。
使用 Pandas 处理时区和时间戳
时间数据是一个独特的数据集,为事件提供了特定的时间参考。最准确的时间数据是时间戳,它包含了从年份到毫秒的详细时间信息。
我们开始创建一个示例数据集。
import pandas as pd
data = {
'transaction_id': [1, 2, 3],
'timestamp': ['2023-06-15 12:00:05', '2024-04-15 15:20:02', '2024-06-15 21:17:43'],
'amount': [100, 200, 150]
}
df = pd.DataFrame(data)
df['timestamp'] = pd.to_datetime(df['timestamp'])
上述示例中的“timestamp”列包含了秒级精度的时间数据。要将此列转换为日期时间格式,我们应该使用pd.to_datetime函数。
之后,我们可以使日期时间数据具有时区意识。例如,我们可以将数据转换为协调世界时间(UTC)。
df['timestamp_utc'] = df['timestamp'].dt.tz_localize('UTC')
print(df)
Output>>
transaction_id timestamp amount timestamp_utc
0 1 2023-06-15 12:00:05 100 2023-06-15 12:00:05+00:00
1 2 2024-04-15 15:20:02 200 2024-04-15 15:20:02+00:00
2 3 2024-06-15 21:17:43 150 2024-06-15 21:17:43+00:00
“timestamp_utc”值包含了大量信息,包括时区。我们可以将现有时区转换为另一个时区。例如,我使用了 UTC 列,并将其转换为日本时区。
df['timestamp_japan'] = df['timestamp_utc'].dt.tz_convert('Asia/Tokyo')
print(df)
Output>>>
transaction_id timestamp amount timestamp_utc \
0 1 2023-06-15 12:00:05 100 2023-06-15 12:00:05+00:00
1 2 2024-04-15 15:20:02 200 2024-04-15 15:20:02+00:00
2 3 2024-06-15 21:17:43 150 2024-06-15 21:17:43+00:00
timestamp_japan
0 2023-06-15 21:00:05+09:00
1 2024-04-16 00:20:02+09:00
2 2024-06-16 06:17:43+09:00
我们可以根据这个新的时区来筛选数据。例如,我们可以使用日本时间来筛选数据。
start_time_japan = pd.Timestamp('2024-06-15 06:00:00', tz='Asia/Tokyo')
end_time_japan = pd.Timestamp('2024-06-16 07:59:59', tz='Asia/Tokyo')
filtered_df = df[(df['timestamp_japan'] >= start_time_japan) & (df['timestamp_japan'] <= end_time_japan)]
print(filtered_df)
Output>>>
transaction_id timestamp amount timestamp_utc \
2 3 2024-06-15 21:17:43 150 2024-06-15 21:17:43+00:00
timestamp_japan
2 2024-06-16 06:17:43+09:00
使用时间序列数据可以让我们进行时间序列重采样。让我们看看在数据集中每列进行按小时重采样的例子。
resampled_df = df.set_index('timestamp_japan').resample('H').count()
利用 Pandas 的时区数据和时间戳来充分发挥其功能。
额外资源
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 发表了各种人工智能和机器学习主题的文章。
更多相关话题
如何识别时间序列数据集中的缺失数据
原文:
www.kdnuggets.com/how-to-identify-missing-data-in-timeseries-datasets
时间序列数据,几乎每秒钟从多个来源收集,通常会面临若干数据质量问题,其中包括缺失数据。
在序列数据的背景下,缺失信息可能由于多种原因产生,例如获取系统出现错误(如传感器故障)、传输过程中的错误(例如,网络连接故障)或数据收集中的错误(例如,数据记录中的人为错误)。这些情况通常会在我们的数据集中产生零散和明确的缺失值,形成数据流中的小间隙。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
此外,缺失信息也可能由于领域本身的特性自然产生,导致数据中的较大间隙。例如,一个特征在某段时间内停止收集,从而产生非显式的缺失数据。
无论底层原因如何,时间序列数据中存在缺失数据对预测和建模都是极为不利的,并可能对个人(例如,误导性的风险评估)和商业结果(例如,偏颇的商业决策、收入和机会的损失)产生严重后果。
在准备数据以进行建模时,一个重要步骤是能够识别这些未知信息的模式,因为它们将帮助我们决定处理数据的最佳方法,无论是通过某种形式的对齐修正、数据插补、数据填补,还是在某些情况下,逐例删除(即,忽略在特定分析中使用的特征的缺失值所在的案例)。
因此,进行彻底的探索性数据分析和数据概况分析不仅对理解数据特征至关重要,而且对如何最佳准备数据以进行分析做出明智决策也不可或缺。
在这个实操教程中,我们将探索ydata-profiling如何通过新版本中最近引入的功能帮助我们解决这些问题。我们将使用美国污染数据集,该数据集可在Kaggle(许可证DbCL v1.0)中获取,详细描述了美国各州 NO2、O3、SO2 和 CO 污染物的信息。
实操教程:对美国污染数据集的分析
为了启动我们的教程,我们首先需要安装 ydata-profiling 的最新版本:
pip install ydata-profiling==4.5.1
然后,我们可以加载数据,去除不必要的特征,集中关注我们要调查的内容。为了这个示例,我们将专注于亚利桑那州 Maricopa Scottsdale 站点的空气污染物测量的特定行为:
import pandas as pd
data = pd.read_csv("data/pollution_us_2000_2016.csv")
data = data.drop('Unnamed: 0', axis = 1) # dropping unnecessary index
# Select data from Arizona, Maricopa, Scottsdale (Site Num: 3003)
data_scottsdale = data[data['Site Num'] == 3003].reset_index(drop=True)
现在,我们准备开始对数据集进行概况分析了!请记住,要使用时间序列分析,我们需要传递参数tsmode=True,以便 ydata-profiling 可以识别时间相关特征:
# Change 'Data Local' to datetime
data_scottsdale['Date Local'] = pd.to_datetime(data_scottsdale['Date Local'])
# Create the Profile Report
profile_scottsdale = ProfileReport(data_scottsdale, tsmode=True, sortby="Date Local")
profile_scottsdale.to_file('profile_scottsdale.html')
时间序列概览
输出报告将与我们已经了解的内容相似,但体验有所改进,并且为时间序列数据提供了新的总结统计数据:
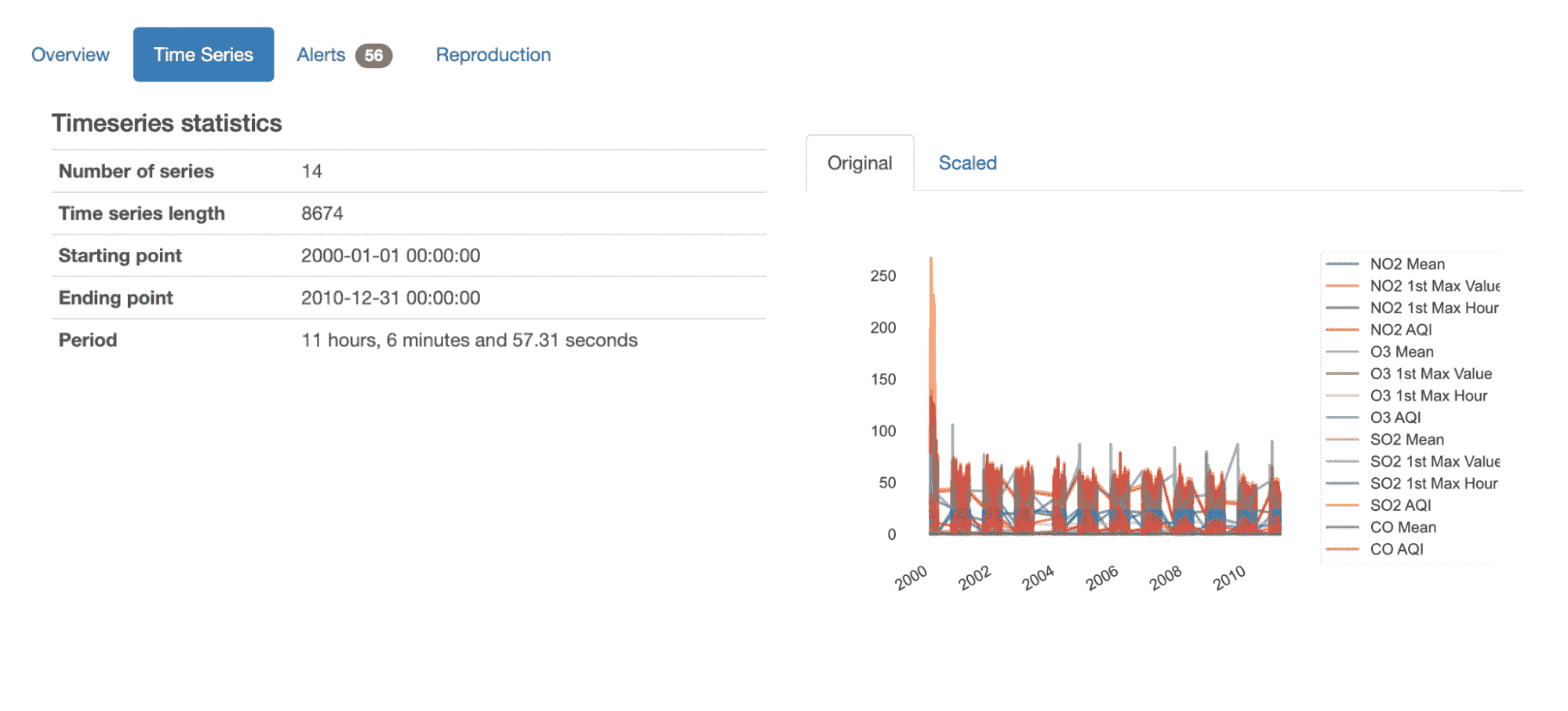
从概览中,我们可以通过查看提供的总结统计数据对数据集有一个整体了解:
-
它包含 14 个不同的时间序列,每个序列有 8674 个记录值;
-
数据集报告了从 2000 年 1 月到 2010 年 12 月的 10 年数据;
-
时间序列的平均周期是 11 小时和(接近)7 分钟。这意味着平均而言,我们每 11 小时进行一次测量。
我们还可以获得数据中所有系列的概览图,无论是原始值还是缩放值:我们可以轻松把握序列的整体变化,以及被测量的组件(NO2、O3、SO2、CO)和特征(均值、首次最大值、首次最大小时、AQI)。
检查缺失数据
在对数据有一个整体了解后,我们可以关注每个时间序列的具体细节。
在ydata-profiling的最新版本中,概况报告得到了实质性的改进,专门针对时间序列数据进行了分析,即报告“时间序列”和“缺口分析”指标。通过这些新功能,趋势和缺失模式的识别变得极为简便,现在提供了具体的总结统计数据和详细的可视化。
一件立即显现的事情是所有时间序列都呈现的波动模式,其中某些“跳跃”似乎发生在连续的测量之间。这表明存在缺失数据(“缺失信息的差距”),需要更详细地研究。以S02 Mean为例。
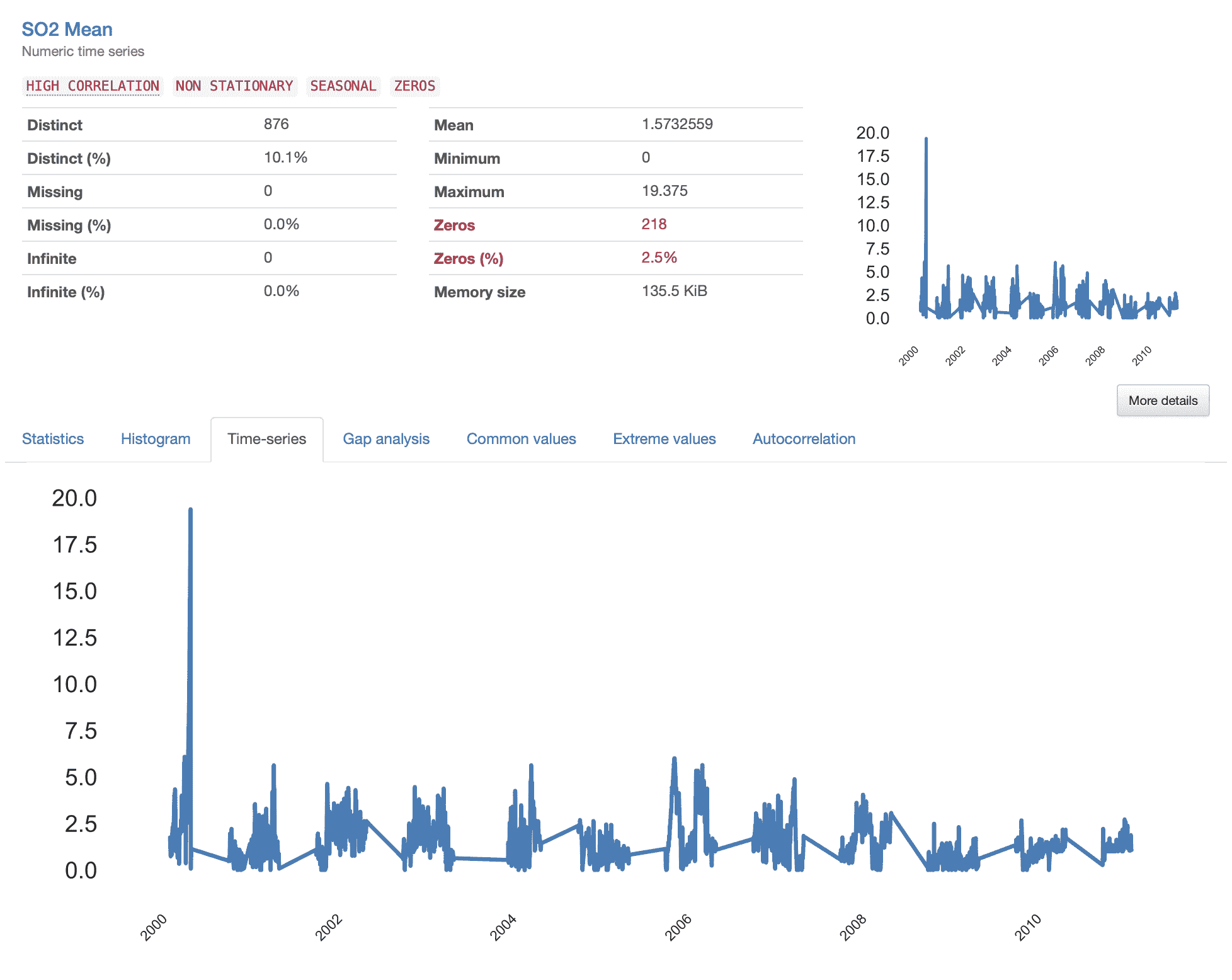
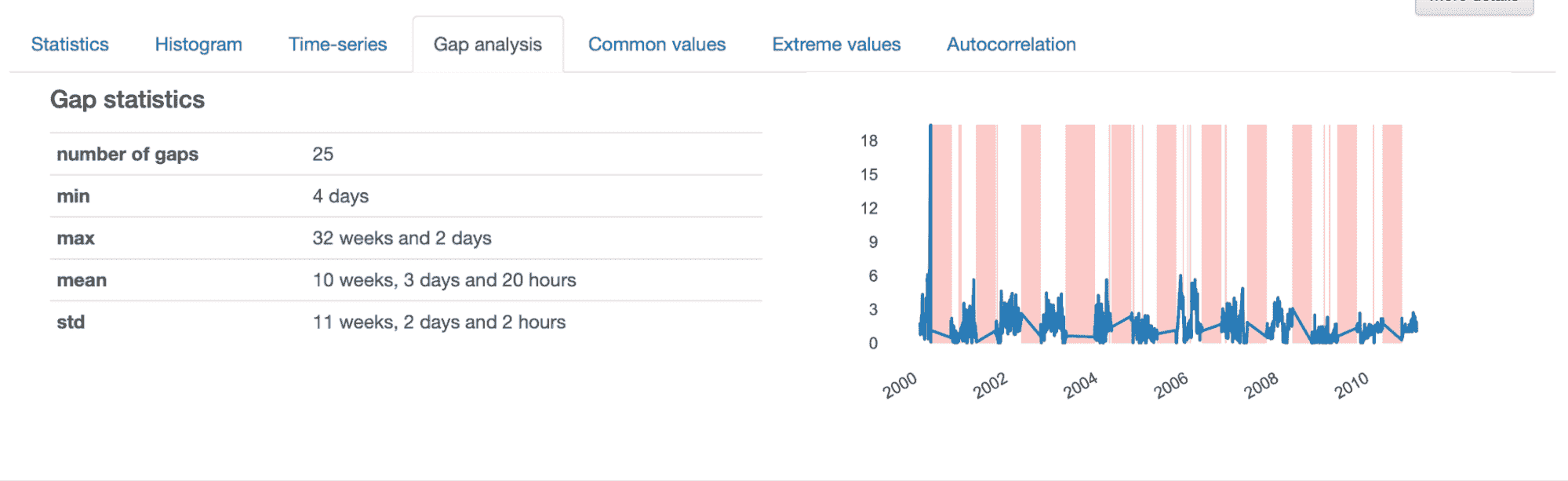
在调查 Gap Analysis 中提供的细节时,我们得到了一些关于识别出差距特征的信息。总体来说,时间序列中存在 25 个差距,最短为 4 天,最长为 32 周,平均为 10 周。
从展示的可视化中,我们注意到一些“随机”的差距由较细的条纹表示,而较大的差距似乎遵循重复的模式。这表明我们似乎在数据集中有两种不同的缺失数据模式。
较小的差距对应于偶发事件生成的缺失数据,这些事件很可能是由于采集过程中的错误造成的,通常可以容易地插补或从数据集中删除。相反,较大的差距更为复杂,需要更详细地分析,因为它们可能揭示了需要更彻底解决的潜在模式。
在我们的例子中,如果我们调查较大的差距,我们实际上会发现它们反映了一个季节性模式:
df = data_scottsdale.copy()
for year in df["Date Local"].dt.year.unique():
for month in range(1,13):
if ((df["Date Local"].dt.year == year) & (df["Date Local"].dt.month ==month)).sum() == 0:
print(f'Year {year} is missing month {month}.')
# Year 2000 is missing month 4.
# Year 2000 is missing month 5.
# Year 2000 is missing month 6.
# Year 2000 is missing month 7.
# Year 2000 is missing month 8.
# (...)
# Year 2007 is missing month 5.
# Year 2007 is missing month 6.
# Year 2007 is missing month 7.
# Year 2007 is missing month 8.
# (...)
# Year 2010 is missing month 5.
# Year 2010 is missing month 6.
# Year 2010 is missing month 7.
# Year 2010 is missing month 8.
如预期所示,时间序列中存在一些较大的信息差距,这些差距似乎是重复的,甚至是季节性的:在大多数年份中,数据在 5 月到 8 月(第 5 至 8 个月)之间未被收集。这可能是由于不可预测的原因,或已知的商业决策,例如与削减成本有关,或者只是与天气模式、温度、湿度和大气条件相关的污染物季节性变化有关。
基于这些发现,我们可以进一步调查为什么会发生这种情况,是否需要采取措施以防止未来发生类似情况,以及如何处理我们目前拥有的数据。
最终思考:插补、删除、重新对齐?
在本教程中,我们了解了时间序列中缺失数据模式的重要性,以及有效的数据分析如何揭示缺失信息背后的奥秘。从电信、医疗保健、能源到金融,所有收集时间序列数据的行业都会面临缺失数据的问题,并需要决定最佳处理和提取所有可能知识的方法。
通过全面的数据分析,我们可以根据手头的数据特征做出明智而有效的决策:
-
信息差距可能由收集、传输和采集过程中的错误引起的偶发事件造成。我们可以修复问题以防止再次发生,并根据差距的长度进行插补或填充;
-
信息的缺口也可以代表季节性或重复模式。我们可以选择重构我们的流程,开始收集缺失的信息,或者用来自其他分布式系统的外部信息填补这些缺口。我们还可以识别检索过程是否失败(可能是数据工程方面的操作失误,我们都有过那样的日子!)。
我希望这个教程能为你提供如何适当识别和描述时间序列数据中的缺失数据的一些见解,我迫不及待想看看你在自己的缺失分析中会发现什么!如果有任何问题或建议,请在评论中告诉我,或者在数据驱动 AI 社区找到我!
Fabiana Clemente 是 YData 的联合创始人和首席数据官,她将数据理解、因果关系和隐私作为主要的工作和研究领域,致力于使数据对组织具有可操作性。作为一位充满热情的数据从业者,她主持了播客《机器学习如何遇见隐私》,并在 Datacast 和 Privacy Please 播客中担任嘉宾讲者。她还在 ODSC 和 PyData 等会议上发言。
更多相关内容
如何使用 LangChain 实现 Agentic RAG:第一部分
原文:
www.kdnuggets.com/how-to-implement-agentic-rag-using-langchain-part-1

想象一下在没有食谱的情况下尝试烤蛋糕。你可能会记住一些细节,但很可能会遗漏一些关键的东西。这类似于传统的大型语言模型(LLMs)的功能,它们很出色,但有时缺乏特定的、最新的信息。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
Naive RAG 范式代表了最早的方法论,在 ChatGPT 广泛采用后不久就获得了关注。这种方法遵循传统流程,包括索引、检索和生成,通常被称为“检索-阅读”框架。
下图展示了一个 Naive RAG 流程:
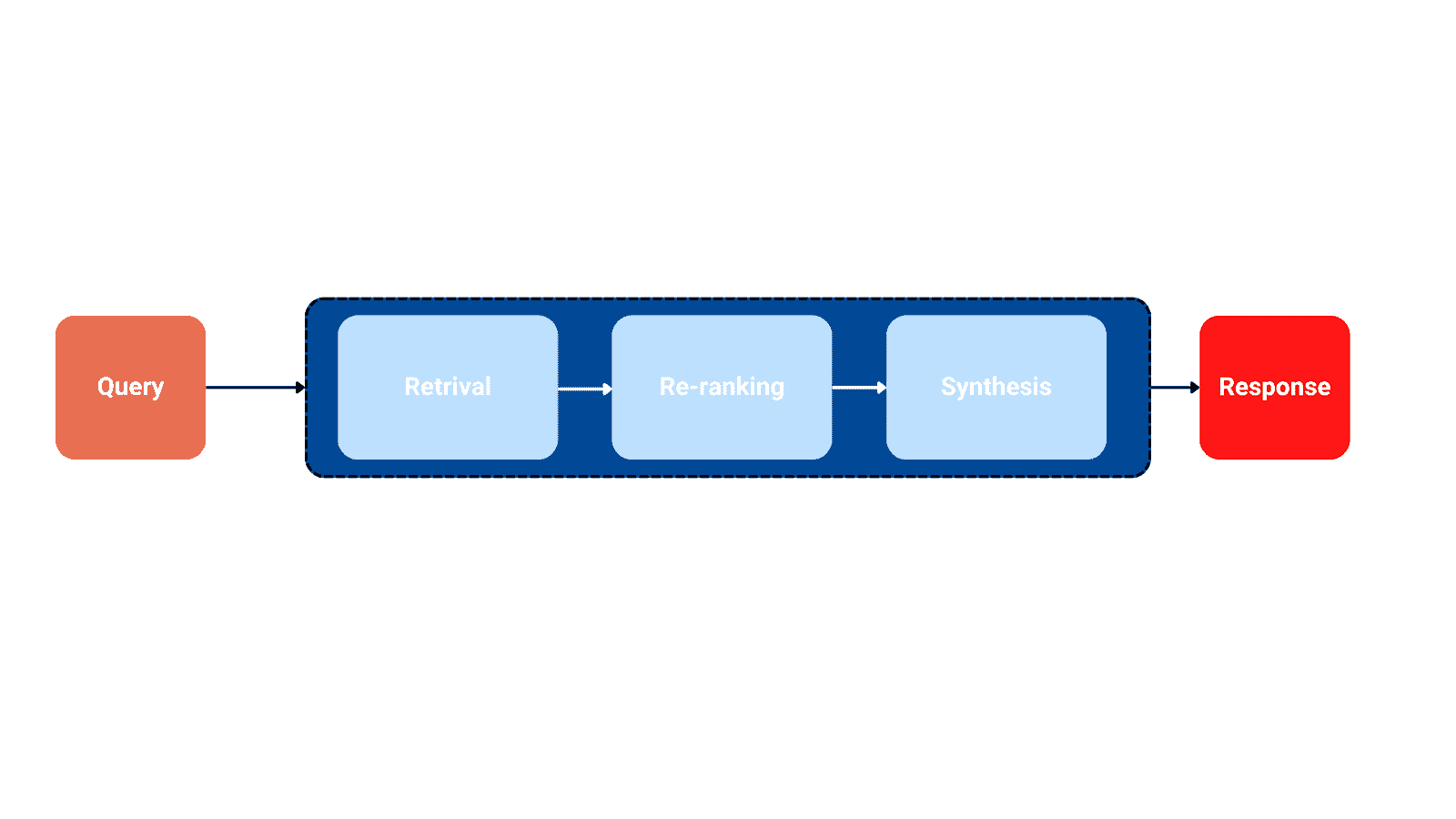
该图显示了从查询到检索和响应的 Naive RAG 流程 | 作者提供的图片
使用 LangChain 实现 Agentic RAG 将这一过程提升到了一个新的层次。与简单的 RAG 方法不同,Agentic RAG 引入了“代理”的概念,这些代理可以主动与检索系统互动,以提高生成输出的质量。
首先,让我们定义一下 Agentic RAG 是什么。
什么是 Agentic RAG?
Agentic RAG(基于代理的检索增强生成)是一种创新的方法,用于跨多个文档回答问题。与仅依赖大型语言模型的传统方法不同,Agentic RAG 利用智能代理,这些代理能够规划、推理和随时间学习。
这些代理负责比较文档、总结特定文档和评估总结。这为问题回答提供了更灵活和动态的框架,因为这些代理协作完成复杂的任务。
Agentic RAG 的关键组成部分包括:
-
Document Agents:负责在指定文档内进行问题回答和总结。
-
Meta-Agent:负责监督文档代理并协调他们的工作。
这种层次结构允许代理 RAG 利用单个文档代理和元代理的优势,从而在需要战略规划和细致决策的任务中增强能力。
该图示例了从顶级代理到下属文档代理的不同层次 | 来源:LlamaIndex
使用代理 RAG 的好处
在检索增强生成(RAG)中使用基于代理的实现提供了多种好处,包括任务专业化、并行处理、可扩展性、灵活性和容错性。详细说明如下:
-
任务专业化:基于代理的 RAG 允许不同代理之间的任务专业化。每个代理可以专注于任务的特定方面,如文档检索、总结或问题回答。这种专业化通过确保每个代理都适合其指定角色,从而提高了效率和准确性。
-
并行处理:基于代理的 RAG 系统中的代理可以并行工作,同时处理任务的不同方面。这种并行处理能力导致响应时间更快,整体性能更佳,特别是在处理大型数据集或复杂任务时。
-
可扩展性:基于代理的 RAG 架构具有固有的可扩展性。可以根据需要将新代理添加到系统中,使其能够处理增加的工作负载或适应额外的功能,而无需对整体架构进行重大更改。这种可扩展性确保系统可以随时间增长并适应变化的需求。
-
灵活性:这些系统在任务分配和资源管理方面提供了灵活性。代理可以根据工作负荷、优先级或具体要求动态分配任务,从而实现高效的资源利用,并适应不同的工作负荷或用户需求。
-
容错性:基于代理的 RAG 架构具有固有的容错性。如果一个代理失败或不可用,其他代理可以继续独立执行其任务,从而降低系统停机或数据丢失的风险。这种容错性提高了系统的可靠性和健壮性,确保在面对故障或中断时服务不中断。
现在我们已经了解了它是什么,在下一部分中,我们将实施代理 RAG。
Shittu Olumide 是一位软件工程师和技术作家,热衷于利用前沿技术来撰写引人入胜的叙事,对细节有敏锐的观察力,并擅长简化复杂概念。你还可以在Twitter上找到 Shittu。
更多相关主题
如何在 DataFrame 列上实现复杂过滤操作
原文:
www.kdnuggets.com/how-to-implement-complex-filters-on-dataframe-columns-with-pandas

编辑者提供的图片 | Ideogram
让我们学习如何在 Pandas 中执行复杂的过滤操作。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
准备工作
在开始之前,我们需要安装 Pandas 包。你可以使用以下代码进行安装:
pip install pandas
安装好包后,让我们深入了解这篇文章。
Pandas DataFrame 复杂过滤
DataFrame 是一个 Pandas 对象,可以存储数据并根据需要进行操作。它特别强大,因为我们可以使用条件、逻辑运算符和 Pandas 函数来过滤数据。
让我们尝试创建一个简单的 DataFrame 对象。
import pandas as pd
df = pd.DataFrame({
'Name': ['Alice', 'Leah', 'Jessica', 'Kenny', 'Brad'],
'Age': [50, 27, 22, 30, 40],
'Salary': [100000, 154000, 120000, 78000, 88000],
'Occupation': ['Doctor', 'Soldier', 'Doctor', 'Accountant', 'Florist']
})
使用这些示例数据,我们将学习如何进行过滤。首先,我们可以根据特定条件过滤数据。
df[df['Age'] > 30]
输出:
Name Age Salary Occupation
0 Alice 50 100000 Doctor
4 Brad 40 88000 Florist
将条件与 And (&) 运算符结合使用也是可能的。
df[(df['Age'] > 25) & (df['Salary'] < 100000)]
Name Age Salary Occupation
3 Kenny 30 78000 Accountant
4 Brad 40 88000 Florist
使用条件时,我们也可以将它们与 Or (|) 运算符结合使用。
df[(df['Salary'] < 100000) | (df['Occupation'] == 'Soldier')]
输出:
Name Age Salary Occupation
1 Leah 27 154000 Soldier
3 Kenny 30 78000 Accountant
4 Brad 40 88000 Florist
还有一些方法可以使用字符串函数来过滤数据。例如,我们可以过滤包含某些值的列。
df[df['Occupation'].str.contains('Sol')]
输出:
Name Age Salary Occupation
1 Leah 27 154000 Soldier
如果你需要根据特定字符串值过滤数据,我们可以使用以下代码。
df[df['Occupation'].isin(['Doctor', 'Florist'])]
输出:
Name Age Salary Occupation
0 Alice 50 100000 Doctor
2 Jessica 22 120000 Doctor
4 Brad 40 88000 Florist
还有一种方法是使用 lambda 函数来过滤数据。
df[df['Name'].apply(lambda x: len(x) > 5)]
输出:
Name Age Salary Occupation
2 Jessica 22 120000 Doctor
如果你想简化,我们可以使用查询方法进行数据过滤。
df.query('Age 100000')
输出:
Name Age Salary Occupation
1 Leah 27 154000 Soldier
2 Jessica 22 120000 Doctor
最后,我们可以像这样结合我们之前学到的任何过滤条件。
df[(df['Age'] > 30) & (
(df['Salary'] > 60000) |
(df['Occupation'].str.contains('Doc')))]
输出:
Name Age Salary Occupation
0 Alice 50 100000 Doctor
4 Brad 40 88000 Florist
掌握过滤函数以改进你的数据分析过程。
额外资源
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰写者。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种人工智能和机器学习主题的文章。
了解更多相关内容
如何在 R 中导入数据

编辑者提供的图像 | Midjourney
数据导入是使用 R 的第一步。你可以从 CSV 文件、文本文件和数据库等来源加载数据。每种来源都有其自己的导入方法。本文将解释如何将数据从几个来源导入到 R 中。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求。
导入 CSV 文件
CSV 文件是一种常见的数据存储方式。R 提供了几种导入 CSV 文件的函数。最常用的是read.csv()和readr::read_csv()。readr包比 read.csv()更快,并且对数据类型的处理更好。
library(readr)
data <- read_csv("path/to/your/file.csv")
导入 Excel 文件
Excel 文件常用于存储电子表格中的数据。要将它们导入 R 中,使用readxl或openxlsx包。readxl包使读取 Excel 文件变得容易。使用read_excel()函数来加载你的数据。
library(readxl)
data <- read_excel("path/to/your/file.xlsx")
openxlsx包用于导入 Excel 文件。使用read.xlsx()函数。它提供了处理 Excel 文件的额外功能,如创建或修改文件。
library(openxlsx)
data <- read.xlsx("path/to/your/file.xlsx", sheet = 1)
导入文本文件
文本文件通常由分隔符(如制表符或自定义字符)分隔数据。R 可以使用如read.table()和readr::read_delim()这样的函数来处理这些文件。readr包的read_delim()通常在处理不同的分隔符时更快且更灵活。
library(readr)
data <- read_delim("path/to/your/file.txt", delim = "\t")
从在线来源导入数据
数据可以直接从 URL 导入到 R 中。这包括来自 URL、API 和在线数据库的数据。使用如read.csv()的函数来处理直接 URL,或使用httr等包处理 API 请求。
data <- read.csv("http://example.com/data.csv")
对于 JSON 和 XML 数据,使用如jsonlite和xml2的包。
library(jsonlite)
data <- fromJSON("http://example.com/data.json")
从数据库导入数据
要从数据库中导入数据到 R 中,安装并加载相关的包,如 RSQLite 或 RMySQL。使用dbConnect()连接到数据库。使用dbGetQuery()运行查询以获取数据。最后,使用dbDisconnect()关闭连接。
library(DBI)
library(RSQLite)
con <- dbConnect(RSQLite::SQLite(), "path/to/your/database.sqlite")
data <- dbGetQuery(con, "SELECT * FROM your_table")
dbDisconnect(con)
从 JSON 文件导入数据
首先,安装并加载jsonlite包。然后,使用fromJSON()函数读取你的 JSON 文件。该函数将 JSON 数据转换为 R 的数据框。
library(jsonlite)
data <- fromJSON("path/to/your/file.json")
从 API 导入数据
要从 API 导入数据到 R 中,首先需要安装并加载 httr 包。使用 GET() 函数向 API 发送请求,然后使用 content() 提取响应中的内容。
library(httr)
response <- GET("https://api.example.com/data")
data <- content(response, "parsed")
从 SAS 文件导入数据
SAS 文件在统计分析中很常见。要将它们导入到 R 中,可以使用 haven 或 sas7bdat 包。haven 包可以直接将 SAS 文件导入数据框,并保持变量标签和类型不变。
library(haven)
data <- read_sas("path/to/your/file.sas7bdat")
sas7bdat 包将 SAS 文件导入数据框,注重简单性和效率。
library(sas7bdat)
data <- read.sas7bdat("path/to/your/file.sas7bdat")
从 SPSS 文件导入数据
SPSS 文件在社会科学中常被使用。要将它们导入到 R 中,可以使用 haven 或 foreign 包。haven 包读取 SPSS 文件并保留变量和数值标签,这有助于更好地理解数据。
library(haven)
data <- read_sav("path/to/your/file.sav")
foreign 包还提供读取 SPSS 文件的功能,但可能无法保留太多的元数据。
library(foreign)
data <- read.spss("path/to/your/file.sav", to.data.frame = TRUE)
结论
将数据导入 R 对于开始任何分析都很重要。你可以使用合适的函数将来自不同来源的数据导入 R。这使你的工作更加轻松,并让你能更早地开始分析。
Jayita Gulati 是一位机器学习爱好者和技术作家,她的热情驱动着她建立机器学习模型。她拥有利物浦大学计算机科学硕士学位。
更多相关话题
如何使用 ChatGPT 学习 Python 基础
原文:
www.kdnuggets.com/how-to-learn-python-basics-with-chatgpt

现在是 2024 年了,所以我不应该再告诉你为什么你应该学习 Python 如果你考虑从事任何类型的编程工作。它是最流行的编程语言之一,几乎每个数据科学工作都希望在你的简历上看到它,并且它是最容易学习的语言之一。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
问题在于,Python 因其流行而成为了自己的受害者。许多人都知道 Python,它被誉为一种简单的语言,以至于人们忘记了,归根结底你还是在学习一种编程语言。它相对容易,例如与 Perl 比较,但并不简单。
很多已有的学习路径确实存在缺陷。训练营很受欢迎,但往往费用高昂且耗时。视频教程是免费的,但质量参差不齐,而且缺乏激励。
ChatGPT 是学习 Python 基础的一个好方法,作为我上面提到的那些方法的替代品。它有很多优点:
-
它是免费的(或者最多 $20/月)
-
由于它是在大量的 Python 数据上训练的,因此它拥有丰富的 Python 知识。
-
适用于许多不同的学习水平
-
你可以按照自己的节奏进行。
虽然它有其缺陷,但如果你尝试过其他方法并感到挣扎,这个方法可能值得一试。以下是 ChatGPT 如何教你 Python 基础的说明。
入门
这里有一个简单的方法,让 ChatGPT 成为你的个人 Python 导师。

入门测验
你可以通过让 ChatGPT 了解你的学习水平来开始。让它做个测验,并根据你的回答为你分配一个水平。根据这些答案,让它设计一个特定时间范围的课程计划——比如一年或六个月。
这非常好,因为与 Coursera 视频、训练营或 YouTube 讲座不同,这个课程计划可以根据你特定的 Python 水平进行设计。如果你在高中或大学时已经学过基础知识,可以跳过这些内容;如果 Python 对你来说是全新的,可以要求它真正深入讲解核心概念。

课程计划
ChatGPT 然后可以创建课程计划并帮助你掌握概念。它可以根据你的时间表量身定制课程计划。
然后,每天回来找 ChatGPT,让它带你完成课程计划。根据你的偏好,你可以让它从测试开始,以检查你对前一天材料的掌握情况,或直接进入当天的课程和练习题。
这对提高参与度非常有帮助。显然,基于文本的课程不是世界上最令人兴奋的东西。但当 ChatGPT 给你一个测试问题时,你回答后,它会告诉你是否回答正确。
课程调整
继续遵循你的课程计划,看看它对你效果如何。太快了?请 ChatGPT 放慢速度。感到无聊?请 ChatGPT 调整内容。担心忘记之前的课程?请 ChatGPT 修改你的课程计划,加入早期学习阶段的测试题。
为什么 ChatGPT 好?
ChatGPT 这里的主要卖点是其个性化潜力。正如我之前提到的,你可以告诉 ChatGPT 按照你喜欢的方式进行:
-
更快或更慢
-
跳过某些主题,或深入研究其他主题
-
更多文本或更多练习题
-
调整顺序
参与式学习
另一个优势是参与度。视频讲座无法告诉你代码是否错误,但 ChatGPT 可以。它也可以教你为什么。 我喜欢 ChatGPT 基于的课程计划的一点是,你可以要求它使用苏格拉底式教学法,这种方法极具互动性、参与性,并且能够帮助你掌握新概念。例如,你可能在 ChatGPT 管理的测试中做错了一些题目。ChatGPT 不会直接告诉你正确答案,而是通过苏格拉底式教学引导你找到正确答案。
个性化
你还可以根据你的兴趣、技能水平以及你目前尝试学习的 Python 概念获得个性化的项目创意。此外,它还可以在项目中提供指导,如果你遇到困难的地方,可以帮助你解决。
插件潜力
最后,ChatGPT Pro 还提供了像 Tutory 这样的教学插件,Reddit 用户高度推荐。Tutory 进一步提升了会话的连贯性和长期记忆,因此 ChatGPT 将能更好地坚持一个真实的课程计划。越来越多的 ChatGPT 用户正在创建插件,所以如果你使用的是专业版,请留意其他潜在的有用插件。
ChatGPT 无法做的事
如果我不提及使用 ChatGPT 时需要注意的事项,那就太失职了,即使我在这里吹捧 ChatGPT 作为个人 Python 导师。
外部环境
首先,你需要使用一个外部的 Python 环境来进行练习和执行代码。虽然你可以在 ChatGPT 中编写代码,它会告诉你理论上是否可行,但我不推荐这样做。最好还是运行你的代码,看看它是否真的如你所期望的那样有效。此外,ChatGPT 无法完全复制在更大、真实世界项目中工作的体验。
无上下文
ChatGPT 也不总是能理解你代码背后的全部上下文或意图,尤其是在出现复杂问题或错误时。基本问题不是问题,但你的问题越是边缘案例,ChatGPT 能帮助的可能性就越小。
无视觉辅助
与视频教程不同,普通的 ChatGPT 缺乏图表等视觉辅助工具。(尽管像 Daigr.am 这样的插件确实赋予了它这一能力。)此外,正如大多数人现在所知道的,ChatGPT 的训练信息仅包括到某个时间点。虽然 Python 的演变速度不快,但 ChatGPT 可能仍然会缺乏上下文,尤其是对于较新的库。
需要进行事实核查
还需要记住的是,ChatGPT 可能会误解你的问题或提供过于宽泛的答案。有时它也可能完全错误——定期进行事实核查是个好主意,以确保你没有偏离正轨。
AI 无法替代你的工作
我最重要的警告是你应该仔细观察自己。过于依赖 ChatGPT 来获取答案有可能会减缓你独立解决问题的能力。虽然雇主们喜欢你的 Python 知识,但解决问题的能力更为重要。
查看这篇文章,了解 ChatGPT 无法完成的编码任务。
ChatGPT - 你的下一个导师?
总的来说,ChatGPT 是一个很好的学习选项,特别是如果你在其他学习途径上遇到了困难。如果它能很好地教你 Python 基础知识,你也可以用它来学习其他技能。
话虽如此,它也并非没有缺陷。它也无法完全替代你。我会信任 ChatGPT 来教授 Python 基础知识,但能够展示一个真实世界项目的作品集也非常重要,而这些大部分需要你自己完成。
我建议你尝试一下。最坏的情况是你会损失二十美元和一些时间。最好的情况是,你可能正在学习 2024 年最受欢迎的编程语言之一。
内特·罗西迪 是一名数据科学家和产品策略专家。他还是一位兼职教授,教授分析课程,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备面试的平台,提供来自顶级公司的真实面试问题。内特撰写关于职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有与 SQL 相关的内容。
更多相关内容
如何利用 Docker 缓存优化构建速度
原文:
www.kdnuggets.com/how-to-leverage-docker-cache-for-optimizing-build-speeds

图片由编辑提供 | Midjourney & Canva
利用 Docker 缓存可以显著加快构建速度,通过重用之前构建的层来实现。让我们深入了解如何优化 Dockerfile,以便充分利用 Docker 的层缓存机制。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 领域
前提条件
在开始之前:
-
你应该已经安装了 Docker。如果还没有,获取 Docker。
-
你应该对基本的 Docker 概念、创建 Dockerfile 和常用的 Docker 命令有所了解。
Docker 构建缓存如何工作
Docker 镜像是分层构建的,其中 Dockerfile 中的每条指令都会创建一个新层。例如,FROM、RUN、COPY 和 ADD 等指令都会在生成的镜像中创建一个新层。
Docker 使用内容可寻址存储机制来管理镜像层。每一层都由 Docker 根据层的内容计算出的唯一哈希来标识。Docker 比较这些哈希值,以确定是否可以从缓存中重用某一层。
构建 Docker 镜像 | 图片由作者提供
当 Docker 构建镜像时,它会遍历 Dockerfile 中的每条指令,并执行缓存查找以查看是否可以重用之前构建的层。
重新使用或从头开始构建 | 图片由作者提供
使用缓存的决策基于多个因素:
-
基础镜像:如果基础镜像(
FROM指令)发生了变化,Docker 将使所有后续层的缓存失效。 -
指令:Docker 检查每条指令的确切内容。如果指令与之前执行过的相同,可以使用缓存。
-
文件和目录:对于涉及文件的指令,如
COPY和ADD,Docker 会检查文件的内容。如果文件没有变化,可以使用缓存。 -
构建上下文:Docker 在决定是否使用缓存时,还会考虑构建上下文(发送到 Docker 守护进程的文件和目录)。
理解缓存失效
某些更改可能会使缓存失效,导致 Docker 从头开始重建该层:
-
Dockerfile 的修改:如果 Dockerfile 中的指令发生变化,Docker 会使该指令及所有后续指令的缓存失效。
-
源文件的更改:如果涉及到
COPY或ADD指令的文件或目录发生变化,Docker 会使这些层和后续层的缓存失效。
总结一下,这里是你需要知道的关于 Docker 构建缓存的信息:
-
Docker 逐层构建镜像。如果某一层没有变化,Docker 可以重用该层的缓存版本。
-
如果某层发生变化,所有后续层都会重建。因此,将不常更改的指令(如基础镜像、依赖安装、初始化脚本)放在 Dockerfile 中较早的位置可以帮助最大化缓存命中。
利用 Docker 构建缓存的最佳实践
为了利用 Docker 构建缓存,你可以以最大化缓存命中的方式构建你的 Dockerfile。以下是一些提示:
-
按更改频率排序指令:将不常更改的指令放在 Dockerfile 的更高位置。将经常更改的指令,例如
COPY或ADD应用代码的指令放在 Dockerfile 的末尾。 -
将依赖与应用代码分开:将安装依赖的指令与复制源代码的指令分开。这样,只有在依赖发生变化时才会重新安装依赖。
接下来,让我们来看几个例子。
示例:利用构建缓存的 Dockerfile
- 这是一个用于设置 PostgreSQL 实例并包含一些初始化脚本的 Dockerfile 示例。此示例侧重于优化层缓存:
# Use the official PostgreSQL image as a base
FROM postgres:latest
# Environment variables for PostgreSQL
ENV POSTGRES_DB=mydatabase
ENV POSTGRES_USER=myuser
ENV POSTGRES_PASSWORD=mypassword
# Set the working directory
WORKDIR /docker-entrypoint-initdb.d
# Copy the initialization SQL scripts
COPY init.sql /docker-entrypoint-initdb.d/
# Expose PostgreSQL port
EXPOSE 5432
基础镜像层通常不常更改。环境变量不太可能经常更改,因此尽早设置它们有助于重用后续层的缓存。注意,我们在应用代码之前复制初始化脚本。这是因为在经常更改的文件之前复制不常更改的文件有助于利用缓存。
- 这是另一个容器化 Python 应用的 Dockerfile 示例:
# Use the official lightweight Python 3.11-slim image
FROM python:3.11-slim
# Set the working directory
WORKDIR /app
# Install dependencies
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the contents of the current directory into the container
COPY . .
# Expose the port on which the app runs
EXPOSE 5000
# Run the application
CMD ["python3", "app.py"]
在安装依赖后复制其余的应用代码可以确保应用代码的更改不会使依赖层的缓存失效。这最大化了缓存层的重用,从而加快了构建速度。
通过理解和利用 Docker 的缓存机制,你可以为更快的构建和更高效的镜像创建构建你的 Dockerfile。
附加资源
通过以下链接了解更多关于缓存的信息:
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
如何使用 LangChain 让大型语言模型与您的软件良好配合
原文:
www.kdnuggets.com/how-to-make-large-language-models-play-nice-with-your-software-using-langchain

编辑提供的图片
像 OpenAI 的 GPT-3、Google 的 BERT 和 Meta 的 LLaMA 这样的大型语言模型正在以其生成各种文本的能力革新多个领域——从营销文案和数据科学脚本到诗歌。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
尽管 ChatGPT 的直观界面已经在大多数人设备上普及,但在多种软件集成中使用 LLMs 仍有广阔的未开发潜力。
主要问题是什么?
大多数应用程序需要与 LLMs 进行更流畅和本地化的沟通。
而这正是 LangChain 发挥作用的地方!
如果你对生成式 AI 和 LLMs 感兴趣,这个教程是为你量身定制的。
那么…让我们开始吧!
LLM 是什么?
如果你最近一直在过着与世隔绝的生活,还没有获得任何新闻,我将简要介绍一下大型语言模型(LLMs)。
LLM(大型语言模型)是一个复杂的人工智能系统,旨在模拟类似人类的文本理解和生成。通过在大量数据集上进行训练,这些模型能够辨别复杂的模式、理解语言的细微差别,并生成连贯的输出。
如果你想知道如何与这些 AI 驱动的模型互动,主要有两种方法:
-
最常见和直接的方法是与模型对话或聊天。这涉及到编写提示,将其发送到 AI 驱动的模型,并以文本格式的输出作为响应。
-
另一种方法是将文本转换为数值数组。这一过程涉及为 AI 编写一个提示并返回一个数值数组。这就是通常所称的“嵌入”。它在向量数据库和语义搜索中最近经历了激增。
正是这两个主要问题是 LangChain 试图解决的。如果你对与 LLMs 互动的主要问题感兴趣,可以在这里查看这篇文章。
LangChain 及其基础知识
LangChain 是一个围绕 LLM 构建的开源框架。它提供了一整套工具、组件和接口,简化了 LLM 驱动应用的架构。
使用 LangChain,与语言模型互动、链接各种组件以及整合如 API 和数据库等资源变得轻而易举。这个直观的框架大大简化了 LLM 应用开发的过程。
LangChain 的核心思想是将不同的组件或模块,即链条,连接在一起,创造出更复杂的 LLM 驱动的解决方案。
以下是 LangChain 的一些突出功能:
-
可自定义的提示模板用于标准化我们的互动。
-
针对复杂用例的链条链接组件。
-
与领先语言模型的无缝集成,包括 OpenAI 的 GPTs 和 HuggingFace Hub 上的模型。
-
模块化组件支持混合搭配的方式来评估任何特定问题或任务。
图片由作者提供
LangChain 的特点在于其对适应性和模块化设计的关注。
LangChain 的主要思想是将自然语言处理过程拆分成单独的部分,让开发者根据需求自定义工作流。
这种多样性使 LangChain 成为在不同情况和行业中构建 AI 解决方案的首选。
其中一些最重要的组件是……
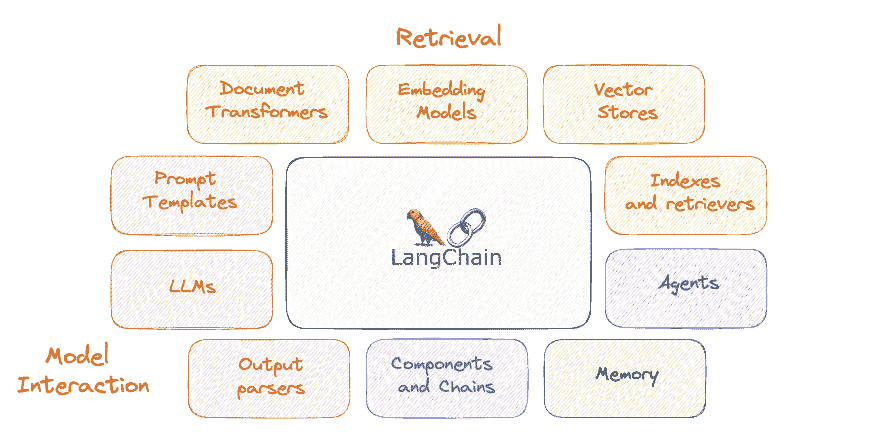
图片由作者提供
1. LLM
LLM 是利用大量训练数据理解和生成类人文本的核心组件。它们是 LangChain 内许多操作的核心,提供了必要的语言处理能力来分析、解释和回应文本输入。
用途: 为聊天机器人提供动力,为各种应用生成类人文本,辅助信息检索,并执行其他语言处理任务。
2. 提示模板
提示是与 LLM 互动的基础,当处理特定任务时,它们的结构往往类似。提示模板,即预设的可跨链条使用的提示,通过添加特定值来标准化“提示”。这增强了任何 LLM 的适应性和定制性。
用途: 标准化与 LLM 的互动过程。
3. 输出解析器
输出解析器是将链条前一个阶段的原始输出转换为结构化格式的组件。这些结构化数据可以在后续阶段更有效地使用,或作为最终用户的回应。
用途: 例如,在聊天机器人中,输出解析器可能会从语言模型中获取原始文本响应,提取关键信息,并将其格式化为结构化回复。
4. 组件和链条
在 LangChain 中,每个组件作为负责语言处理序列中特定任务的模块。这些组件可以连接起来形成链以定制工作流程。
用法: 在特定聊天机器人中生成情感检测和响应生成链。
5. 内存
在 LangChain 中,内存指的是一个组件,它为工作流中的信息提供存储和检索机制。这个组件允许暂时或持久地存储数据,其他组件在与 LLM 交互时可以访问和操作这些数据。
用法: 这在需要在不同处理阶段保留数据的场景中很有用,例如,在聊天机器人中存储对话历史,以提供上下文感知的响应。
6. 代理
代理是能够基于其处理的数据采取行动的自主组件。它们可以与其他组件、外部系统或用户交互,在 LangChain 工作流中执行特定任务。
用法: 例如,一个代理可能会处理用户交互、处理传入的请求,并协调数据在链中的流动,以生成适当的响应。
7. 索引和检索器
索引和检索器在高效管理和访问数据方面发挥着关键作用。索引是包含模型训练数据的信息和元数据的数据结构。另一方面,检索器是与这些索引交互的机制,根据指定的标准提取相关数据,并通过提供相关上下文,使模型能够更好地回复。
用法: 它们在从大型数据集中快速获取相关数据或文档方面发挥重要作用,这对于信息检索或问答任务至关重要。
8. 文档转换器
在 LangChain 中,文档转换器是专门设计用于以适合进一步分析或处理的方式处理和转换文档的组件。这些转换可能包括文本规范化、特征提取或将文本转换为不同格式等任务。
用法: 为后续处理阶段准备文本数据,例如机器学习模型的分析或高效检索的索引。
9. 嵌入模型
它们用于将文本数据转换为高维空间中的数值向量。这些模型捕捉了词语和短语之间的语义关系,实现机器可读的表示。它们构成了 LangChain 生态系统中各种下游自然语言处理(NLP)任务的基础。
用法: 通过提供文本的数值表示,促进语义搜索、相似性比较和其他机器学习任务。
10. 向量存储
一种数据库系统,专门存储和搜索通过嵌入分析的数值表示的文本数据。VectorStore 作为这些嵌入的存储设施。
用法: 允许基于语义相似性进行高效搜索。
设置和第一个示例
使用 PIP 安装
我们首先要确保环境中已安装 LangChain。
pip install langchain
环境设置
使用 LangChain 通常意味着与多种模型提供者、数据存储、API 以及其他组件进行集成。正如你已经知道的那样,与任何集成一样,提供相关且正确的 API 密钥对 LangChain 的操作至关重要。
想象一下我们要使用我们的 OpenAI API。我们可以通过两种方式轻松实现这一点:
- 将密钥设置为环境变量
OPENAI_API_KEY="..."
或者
import os
os.environ['OPENAI_API_KEY'] = “...”
如果你选择不建立环境变量,你可以在初始化 OpenAI LLM 类时通过名为 openai_api_key 的参数直接提供密钥:
- 直接在相关类中设置密钥。
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
LangChain 的实际应用
在 LLM 之间切换变得非常简单
LangChain 提供了一个 LLM 类,使我们可以与不同的语言模型提供者(如 OpenAI 和 Hugging Face)进行交互。
开始使用任何 LLM 都相当容易,因为任何 LLM 最基本、最容易实现的功能就是生成文本。
然而,同时向不同的 LLM 提问相同的提示并不是那么容易。
这就是 LangChain 发挥作用的地方……
回到任何 LLM 最简单的功能,我们可以轻松地使用 LangChain 构建一个应用程序,该应用程序获取一个字符串提示,并返回我们指定 LLM 的输出。
代码由作者提供
我们可以仅用几行代码,使用相同的提示并获取两个不同模型的响应!
代码由作者提供
令人印象深刻……对吧?
使用提示模板为我们的提示赋予结构
语言模型(LLMs)常见的问题是它们无法升级复杂的应用程序。LangChain 通过提供简化创建提示过程的解决方案来解决这一问题,这通常比定义任务更为复杂,因为它需要概述 AI 的角色并确保事实准确性。这一过程的一个重要部分涉及重复的模板文本。LangChain 通过提供提示模板来缓解这一点,提示模板自动包含模板文本,从而简化提示创建,并确保不同任务之间的一致性。
代码由作者提供
使用输出解析器获取结构化响应
在基于聊天的互动中,模型的输出仅仅是文本。然而,在软件应用中,拥有结构化的输出更为理想,因为这允许进一步的编程操作。例如,在生成数据集时,希望以 CSV 或 JSON 等特定格式接收响应。假设可以设计一个提示以引导 AI 提供一致且格式合适的响应,那么就需要工具来管理这种输出。LangChain 通过提供输出解析器工具来满足这一需求,从而有效处理和利用结构化输出。
代码由作者提供
你可以在我的 GitHub 上查看完整的代码。
结论
不久前,ChatGPT 的先进能力让我们惊叹。然而,技术环境不断变化,如今像 LangChain 这样的工具触手可及,让我们可以在个人电脑上仅需几小时便能打造出色的原型。
LangChain,一个免费的 Python 平台,为用户提供了开发由 LLMs(语言模型)驱动的应用程序的手段。该平台提供了对各种基础模型的灵活接口,简化了提示处理,并作为连接点整合了提示模板、更多 LLMs、外部信息和其他资源(通过代理),根据当前文档。
想象一下聊天机器人、数字助理、语言翻译工具和情感分析工具;所有这些启用 LLM 的应用程序都可以通过 LangChain 实现。开发者利用这个平台来打造量身定制的语言模型解决方案,以满足不同的需求。
随着自然语言处理的视野扩展和应用的加深,它的应用领域似乎无穷无尽。
Josep Ferrer** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在数据科学领域专注于人类流动性应用。他还是一位兼职内容创作者,专注于数据科学和技术。Josep 撰写有关人工智能的内容,涵盖该领域的持续爆炸应用。
更多相关话题
如何有效管理 Pandas 中的分类数据
原文:
www.kdnuggets.com/how-to-manage-categorical-data-effectively-with-pandas

让我们尝试了解 Pandas 中的分类数据。
准备
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织 IT
在开始之前,我们需要安装 Pandas 和 Numpy 包。你可以用以下代码安装它们:
pip install pandas numpy
安装好包后,让我们进入文章的主要部分。
在 Pandas 中管理分类数据
分类数据是 Pandas 中的一种数据类型,表示特定(固定)数量的类别或不同值。与 Pandas 中的字符串或对象数据类型不同,分类数据在 Pandas 中的存储方式也有所不同。
分类数据更节省内存,因为分类数据中的值只存储一次。相比之下,对象数据类型会将每个值存储为单独的字符串,这需要更多的内存。
让我们通过一个例子来试用分类数据。下面是如何用 Pandas 初始化分类数据。
import pandas as pd
df = pd.DataFrame({
'fruits': pd.Categorical(['apple', 'kiwi', 'watermelon', 'kiwi', 'apple', 'kiwi']),
'size': pd.Categorical(['small', 'large', 'large', 'small', 'large', 'small'])
})
df.info()
输出:
RangeIndex: 6 entries, 0 to 5
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 fruits 6 non-null category
1 size 6 non-null category
dtypes: category(2)
memory usage: 396.0 bytes
你可以看到列“水果”的数据类型,大小是一个类别,而不是我们通常看到的对象。
我们可以尝试用以下代码比较分类数据和对象数据类型的内存使用情况:
import numpy as np
n = 100000
df_object = pd.DataFrame({
'fruit': np.random.choice(['apple', 'banana', 'orange'], size=n)
})
print('Memory usage with object type:')
print(df_object['fruit'].memory_usage(deep=True))
df_category = pd.DataFrame({
'fruit': pd.Categorical(np.random.choice(['apple', 'banana', 'orange'], size=n))
})
print('Memory usage with categorical type:')
print(df_category['fruit'].memory_usage(deep=True))
输出:
Memory usage with object type:
6267209
Memory usage with categorical type:
100424
你可以看到,对象类型比分类数据类型消耗的内存要多得多,尤其是当样本更多时。
接下来,我们将探讨分类数据类型可以使用的独特方法。例如,你可以获取类别:
df['fruits'].cat.categories
输出:
Index(['apple', 'kiwi', 'watermelon'], dtype='object')
此外,我们还可以重命名类别:
df['fruits'] = df['fruits'].cat.rename_categories(['fruit_apple', 'fruit_banana', 'fruit_orange'])
print(df['fruits'].cat.categories)
输出:
Index(['fruit_apple', 'fruit_banana', 'fruit_orange'], dtype='object')
分类数据类型还可以引入序数值,我们可以比较类别。
df['size'] = pd.Categorical(df['size'], categories=['small', 'medium', 'large'], ordered=True)
df['size'] < 'large'
输出:
0 True
1 False
2 False
3 True
4 False
5 True
Name: size, dtype: bool
掌握分类数据类型将为你的数据分析提供优势。
附加资源
Cornellius Yudha Wijaya**** 是一位数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉及多种人工智能和机器学习主题的写作。
更多相关主题
如何在 Bash 中管理文件和目录
原文:
www.kdnuggets.com/how-to-manage-files-and-directories-in-bash

图片由作者提供 | Midjourney & Canva
了解 Bash Shell
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
Bash,即 Bourne-Again Shell,是一种命令行解释器,允许用户通过输入命令与操作系统交互。它通常用于 Linux 和 macOS 等基于 Unix 的系统,并提供了管理文件和目录的各种工具。
要开始使用 bash,你需要打开终端:
-
在Linux上,在应用程序菜单中查找终端应用程序。
-
在macOS上,使用 Spotlight 搜索(Cmd + Space)并输入“Terminal”。
-
在Windows上,你可以使用 Git Bash 或 Windows 子系统(WSL)。
一旦你打开终端并可以使用,我们就准备好学习如何使用 bash 管理文件和目录。我们从一些基本的导航命令开始,然后转到管理目录和文件。
pwd - 打印工作目录
pwd命令显示你当前所在的目录。这对于确认你在文件系统中的位置非常有用。
pwd
ls - 列出目录内容
ls命令列出当前目录中的文件和目录。你可以添加选项,如-l以获取详细信息,或-a以包括隐藏文件。
ls
ls -l
ls -a
mkdir - 创建目录
语法:mkdir <directory_name>
示例:创建一个名为data的目录
mkdir data
你可以一次创建多个目录:
mkdir dir1 dir2 dir3
要创建嵌套目录,请使用-p选项:
mkdir -p parent/child/grandchild
rmdir - 删除目录
语法:rmdir <directory_name>
示例:删除一个名为data的空目录:
rmdir data
请注意,rmdir仅对空目录有效。要删除非空目录,请使用rm -r。
cp - 复制文件和目录
语法:cp <source> <destination>
示例:将名为file.txt的文件复制到backup目录中:
cp file.txt backup/
要复制多个文件:
cp file1.txt file2.txt backup/
要复制目录,请使用-r(递归)选项:
cp -r dir1 backup/
mv - 移动/重命名文件和目录
语法:mv <source> <destination>
示例:将名为file.txt的文件移动到backup目录中:
mv file.txt backup/
将file.txt重命名为file_backup.txt:
mv file.txt file_backup.txt
mv命令可以移动文件/目录并重命名它们。
rm - 删除文件和目录
语法:rm <file_name>
示例:删除名为 file.txt 的文件:
rm file.txt
要删除目录及其内容,请使用 -r(递归)选项:
rm -r dir1
若要强制删除而不提示,请添加 -f(强制)选项:
rm -rf dir1
数据科学家的实用示例
创建项目目录结构
示例:为数据科学项目创建目录
mkdir -p project/{data,scripts,results}
组织数据文件
示例:将所有 .csv 文件移动到 data 目录
mv *.csv data/
清理不必要的文件
示例:删除所有 .tmp 文件
rm *.tmp
组合命令
使用 && 链接命令
示例:在一个命令中创建目录并移动文件
mkdir backup && mv *.csv backup/
使用分号顺序执行
示例:列出内容然后删除文件
ls; rm file.txt
提示和最佳实践
使用 rm 的安全性
使用 rm 前务必双重检查路径,以避免意外删除。
使用通配符
通配符如 * 可以匹配多个文件,使命令更高效。例如,*.csv 匹配所有 CSV 文件。
备份重要文件
在执行大规模操作之前,创建备份以防数据丢失。
快速参考
这里是一个快速参考摘要表,总结了 cp、mv、rm 和 mkdir 的语法和用法。
| 命令 | 语法 | 描述 |
|---|---|---|
| pwd | pwd | 打印工作目录 |
| ls | ls | 列出目录内容 |
| mkdir | mkdir <directory_name> | 创建新目录 |
| rmdir | rmdir <directory_name> | 删除空目录 |
| cp | cp |
复制文件或目录 |
| mv | mv |
移动或重命名文件或目录 |
| rm | rm <file_name> | 删除文件或目录 |
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets和Statology的主编,以及Machine Learning Mastery的贡献编辑,马修旨在使复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的使命是使数据科学社区的知识民主化。马修从 6 岁开始编程。
更多相关内容
如何高效合并大型 DataFrames
原文:
www.kdnuggets.com/how-to-merge-large-dataframes-efficiently-with-pandas

图片由编辑 | Midjourney & Canva 提供 让我们学习如何高效合并大型 DataFrames。
准备工作
我们的 top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
确保你的环境中已安装 Pandas 包。如果没有,你可以通过以下代码使用 pip 安装:
pip install pandas
在安装了 Pandas 包之后,我们将在下一部分中学习更多内容。
高效合并 Pandas DataFrames
Pandas 是一个开源数据处理包,数据社区中的许多人都在使用。它是一个灵活的包,可以处理许多数据任务,包括数据合并。合并,另一方面,是指基于公共列或索引将两个或更多数据集组合在一起的活动。它主要用于当我们有多个数据集并希望合并其信息时。
在现实世界中,我们往往会看到多个大型表格。当我们将表格转化为 Pandas DataFrames 时,我们可以操作和合并它们。然而,更大的尺寸意味着计算负担更重,并且需要更多的资源。
这就是为什么有少数方法可以提高合并大型 Pandas DataFrames 的效率。
首先,如适用,让我们使用更节省内存的类型,例如类别类型和较小的浮点类型。
df1['object1'] = df1['object1'].astype('category')
df2['object2'] = df2['object2'].astype('category')
df1['numeric1'] = df1['numeric1'].astype('float32')
df2['numeric2'] = df2['numeric2'].astype('float32')
然后,尝试将要合并的关键列设置为索引。这是因为基于索引的合并更快。
df1.set_index('key', inplace=True)
df2.set_index('key', inplace=True)
接下来,我们使用 DataFrame 的 .merge 方法,而不是 pd.merge 函数,因为它在性能上更高效和优化。
merged_df = df1.merge(df2, left_index=True, right_index=True, how='inner')
最后,你可以调试整个过程以了解哪些行来自哪个 DataFrame。
merged_df_debug = pd.merge(df1.reset_index(), df2.reset_index(), on='key', how='outer', indicator=True)
使用这种方法,你可以提高合并大型 DataFrames 的效率。
额外资源
-
如何合并 Pandas DataFrames
Cornellius Yudha Wijaya 是一位数据科学助理经理和数据撰写者。在全职工作于 Allianz Indonesia 时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 涉猎各种 AI 和机器学习主题。
更多相关话题
如何使用 Python 的 Pathlib 浏览文件系统
原文:
www.kdnuggets.com/how-to-navigate-the-filesystem-with-pythons-pathlib

作者提供的图片
在 Python 中,使用常规字符串来表示文件系统路径可能很麻烦,尤其是当你需要对路径字符串执行操作时。切换到不同的操作系统也会导致代码出错。是的,你可以使用 os.path 来简化操作,来自 os 模块。但 pathlib 模块使所有这些操作变得更加直观。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
Python 3.4 中引入的 pathlib 模块(是的,它已经存在一段时间了)允许采用面向对象的方式来创建和操作路径对象,并且内置了处理常见操作的功能,如连接和操作路径、解析路径等。
本教程将介绍如何使用 pathlib 模块操作文件系统。让我们开始吧。
使用路径对象
要开始使用 pathlib,你首先需要导入 Path 类:
from pathlib import Path
这使得你可以实例化路径对象来创建和操作文件系统路径。
创建路径对象
你可以通过传递表示路径的字符串来创建 Path 对象,方法如下:
path = Path('your/path/here')
你也可以从现有路径创建新的路径对象。例如,你可以从你的主目录或当前工作目录创建路径对象:
home_dir = Path.home()
print(home_dir)
cwd = Path.cwd()
print(cwd)
这应该会给你类似的输出:
Output >>>
/home/balapriya
/home/balapriya/project1
假设你有一个基础目录,并且你想创建一个指向子目录中文件的路径。你可以这样做:
from pathlib import Path
# import Path from pathlib
from pathlib import Path
# create a base path
base_path = Path("/home/balapriya/Documents")
# create new paths from the base path
subdirectory_path = base_path / "projects" / "project1"
file_path = subdirectory_path / "report.txt"
# Print out the paths
print("Base path:", base_path)
print("Subdirectory path:", subdirectory_path)
print("File path:", file_path)
首先为基础目录创建一个路径对象:/home/balapriya/Documents。请记得将这个基础路径替换为你工作环境中的有效文件系统路径。
然后通过将 base_path 与子目录 projects 和 project1 连接来创建 subdirectory_path。最后,通过将 subdirectory_path 与文件名 report.txt 连接来创建 file_path。
如所见,你可以使用/操作符将目录或文件名附加到当前路径,创建一个新的路径对象。注意/操作符的重载提供了一种可读且直观的路径连接方式。
当你运行上述代码时,它将输出以下路径:
Output >>>
Base path: /home/balapriya/documents
Subdirectory path: /home/balapriya/documents/projects/project1
File path: /home/balapriya/documents/projects/project1/report.txt
检查状态和路径类型
一旦你有了有效的路径对象,你可以调用简单的方法来检查路径的状态和类型。
要检查路径是否存在,调用exists()方法:
path = Path("/home/balapriya/Documents")
print(path.exists())
Output >>> True
如果路径存在,它会输出True;否则,返回False。
你还可以检查路径是文件还是目录:
print(path.is_file())
print(path.is_dir())
Output >>>
False
True
注意:
Path类的对象为你的操作系统创建了一个具体的路径。但当你需要处理路径而不访问文件系统时,例如在 Unix 机器上处理 Windows 路径,你也可以使用PurePath。
导航文件系统
使用 pathlib 导航文件系统非常简单。你可以遍历目录的内容,重命名和解析路径等。
你可以像这样在路径对象上调用iterdir()方法,以遍历目录中的所有内容:
path = Path("/home/balapriya/project1")
# iterating over directory contents
for item in path.iterdir():
print(item)
这是示例输出:
Output >>>
/home/balapriya/project1/test.py
/home/balapriya/project1/main.py
重命名文件
你可以通过在路径对象上调用rename()方法来重命名文件:
path = Path('old_path')
path.rename('new_path')
在这里,我们将project1目录中的test.py重命名为tests.py:
path = Path('/home/balapriya/project1/test.py')
path.rename('/home/balapriya/project1/tests.py')
现在你可以cd进入project1目录,检查文件是否已经重命名。
删除文件和目录
你也可以使用unlink()和rmdir()方法分别删除文件和移除空目录。
# For files
path.unlink()
# For empty directories
path.rmdir()
注意:如果你对删除空目录感到好奇,是否也可以创建它们。是的,你也可以使用
mkdir()创建目录,如下所示:path.mkdir(parents=True, exist_ok=True)。mkdir()方法创建一个新目录。设置parents=True允许根据需要创建父目录,exist_ok=True则在目录已存在时防止出现错误。
解析绝对路径
有时,使用相对路径更方便,并在需要时扩展到绝对路径。你可以使用resolve()方法来完成,语法非常简单:
absolute_path = relative_path.resolve()
这里是一个示例:
relative_path = Path('new_project/README.md')
absolute_path = relative_path.resolve()
print(absolute_path)
和输出:
Output >>> /home/balapriya/new_project/README.md
文件模式匹配
模式匹配对于查找符合特定模式的文件非常有用。让我们看一个示例目录:
projectA/
├── projectA1/
│ └── data.csv
└── projectA2/
├── script1.py
├── script2.py
├── file1.txt
└── file2.txt
这是路径:
path = Path('/home/balapriya/projectA')
让我们尝试使用glob()查找所有文本文件:
text_files = list(path.glob('*.txt'))
print(text_files)
令人惊讶的是,我们没有得到文本文件。列表是空的:
Output >>> []
这是因为这些文本文件在子目录中,模式匹配不会搜索子目录。使用递归模式匹配rglob()。
text_files = list(path.rglob('*.txt'))
print(text_files)
rglob()方法执行递归搜索,查找目录及其所有子目录中的所有文本文件。因此我们应该得到预期的输出:
Output >>>
[PosixPath('/home/balapriya/projectA/projectA2/file2.txt'),
PosixPath('/home/balapriya/projectA/projectA2/file1.txt')]
事情就这样结束了!
总结
在本教程中,我们探讨了 pathlib 模块及其如何使 Python 中的文件系统导航和操作变得更加便捷。我们已经覆盖了足够的内容,以帮助你在 Python 脚本中创建和使用文件系统路径。
你可以在这个教程中找到所使用的代码 在 GitHub。在下一个教程中,我们将探讨有趣的实际应用。在那之前,继续编程吧!
Bala Priya C** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式,与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。**
更多相关主题
如何优化 Dockerfile 指令以加快构建时间
原文:
www.kdnuggets.com/how-to-optimize-dockerfile-instructions-for-faster-build-times

编辑者提供的图像 | Midjourney & Canva
你可以通过利用构建缓存、减少构建上下文等方式来优化 Dockerfiles 以加快构建时间。本教程介绍了创建 Dockerfiles 时需要遵循的最佳实践。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
前提条件
你应该安装 Docker。如果尚未安装,请 获取 Docker 适用于你的操作系统。
1. 使用更小的基础镜像
首先,你可以从更小的基础镜像开始,创建最小化镜像。这可以减少 Docker 镜像的总体大小,并加快构建过程。
例如,当容器化 Python 应用程序时,可以从 python:3.x-slim 镜像开始,这是一种较小的 python:3.x 版本,仅包含运行 Python 所需的基本组件,而不是默认的 python:3.x。
阅读 如何为 Python 应用程序创建最小化 Docker 镜像 以了解更多。
2. 利用 Docker 构建缓存
Dockerfile 中指令的顺序会影响构建时间,因为 Docker 会利用其构建缓存。
Docker 通过顺序执行 Dockerfile 中的指令来构建镜像——为每个指令创建一个新的镜像层。如果某层自上次构建以来没有更改,Docker 可以重用缓存的层,从而加快构建过程。
所以,优化指令顺序以最大化缓存命中率 是很重要的:
-
将经常更改的指令放在最后:将那些经常更改的指令,比如复制应用程序代码,放在 Dockerfile 的末尾。这可以减少使整个构建缓存失效的可能性。
-
将不经常更改的指令放在前面:像安装操作系统包、设置环境变量以及安装不常更改的依赖项等指令应放在前面,以最大化缓存命中率。
让我们看一个示例 Dockerfile:
# Suboptimal ordering
FROM python:3.11-slim
# Set the working directory
WORKDIR /app
# Copy the entire application code
COPY . .
# Install the required Python packages
RUN pip install --no-cache-dir -r requirements.txt
# Expose the port on which the app runs
EXPOSE 5000
# Run the application
CMD ["python3", "app.py"]
在这个初始的 Dockerfile 中,任何应用代码的更改都会使整个构建过程的缓存失效,包括依赖项的安装。
以下是优化版本:
# Better ordering of instructions
FROM python:3.11-slim
# Set the working directory
WORKDIR /app
# Install dependencies
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the current directory contents into the container at /app
COPY . .
# Expose the port on which the app runs
EXPOSE 5000
# Run the application
CMD ["python3", "app.py"]
在这个优化过的 Dockerfile 中,如果应用代码发生更改,Docker 仍然可以使用缓存层来安装依赖项。这样,应用代码的更改不会不必要地触发重新安装依赖项。
3. 使用多阶段构建
多阶段构建允许你将构建环境与最终运行环境分开,这样可以通过仅包含必要的运行时依赖项来减少最终镜像的大小。
考虑以下使用多阶段构建的 Dokcerfile:
# Build stage
FROM python:3.11 AS builder
RUN apt-get update && apt-get install -y build-essential
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Final stage
FROM python:3.11-slim
COPY --from=builder /usr/local/lib/python3.11/site-packages /usr/local/lib/python3.11/site-packages
COPY --from=builder /usr/local/bin /usr/local/bin
COPY . /app
WORKDIR /app
CMD ["python3", "app.py"]
在这个例子中,构建依赖项在 builder 阶段安装,只有必要的运行时依赖项被复制到最终镜像中。
4. 使用 .dockerignore 文件来最小化构建上下文
确保你有一个 .dockerignore 文件,以排除不必要的文件被复制到 Docker 上下文中,从而减少构建时间。类似于 .gitignore,此文件告知 Docker 在构建过程中忽略哪些文件,从而减少上下文大小。
在 .dockerignore 文件中,你可以包含临时文件、虚拟环境、IDE 设置和其他你不希望包含在构建上下文中的不必要文件。
从减少基础镜像大小到优化构建上下文,这些优化应有助于提高 Docker 构建的效率。
额外资源
以下资源值得了解更多:
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正致力于通过撰写教程、使用指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
如何使用 NumPy 执行矩阵操作
原文:
www.kdnuggets.com/how-to-perform-matrix-operations-with-numpy

图片由 Vlado Paunovic 提供
NumPy 是一个强大的 Python 库,包含大量数学函数,并支持创建可以应用这些数学函数的矩阵和多维数组。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在这个简短的教程中,你将学习如何使用 NumPy 执行几种最基本的矩阵操作。
NumPy 中的矩阵和数组
在 NumPy 中,矩阵被定义为一种专门的数组,严格为二维,并且在应用数学操作后保持其二维性。此类型的矩阵可以使用 np.matrix 类实现,但 NumPy 不再推荐使用此类,因为它可能在将来被移除。NumPy 推荐的替代选项是使用 N 维数组类型 ndarray。
在 NumPy 中,ndarray 和矩阵的主要区别在于前者可以是任何维度的,并且其使用不局限于二维操作。
因此,在本教程中,我们将重点实施对二维数组的几种基本矩阵操作,这些数组是使用 np.ndarray 创建的。
创建 NumPy 数组
首先导入 NumPy 包,然后创建两个由两行三列组成的二维数组。这些数组将在本教程的后续示例中使用:
# Import NumPy package
import numpy as np
# Create arrays
a1 = np.array([[0, 1, 0], [2, 3, 2]])
a2 = np.array([[3, 4, 3], [5, 6, 5]])
shape 属性让我们确认数组的维度:
# Print one of the arrays
print('Array 1:', '\n', a1, '\n Shape: \n’, a1.shape)
输出:
Array 1:
[[0 1 0]
[2 3 2]]
Shape: (2, 3)
基本数组操作
NumPy 提供了自己的函数来执行数组的逐元素加法、减法、除法和乘法。此外,NumPy 还通过扩展 Python 的算术运算符的功能来处理逐元素数组操作。
以数组 a1 和 a2 之间的逐元素加法为例开始。
通过使用 np.add 函数或重载的 + 运算符,可以实现两个数组的逐元素加法:
# Using np.add
func_add = np.add(a1, a2)
# Using the + operator
op_add = a1 + a2
通过打印结果,可以确认它们都产生了相同的输出:
# Print results
print('Function: \n', func_add, '\n\n', 'Operator: \n', op_add)
输出:
Function:
[[3 5 3]
[7 9 7]]
Operator:
[[3 5 3]
[7 9 7]]
然而,如果我们对它们进行计时,会发现一点小差异:
import numpy as np
import timeit
def func():
a1 = np.array([[0, 1, 0], [2, 3, 2]])
a2 = np.array([[3, 4, 3], [5, 6, 5]])
np.add(a1, a2)
def op():
a1 = np.array([[0, 1, 0], [2, 3, 2]])
a2 = np.array([[3, 4, 3], [5, 6, 5]])
a1 + a2
# Timing the functions over 100000 iterations
func_time = timeit.timeit(func, number=100000)
op_time = timeit.timeit(op, number=100000)
# Print timing results
print('Function:', func_time, '\n', 'Operator:', op_time)
输出:
Function: 0.2588757239282131
Operator: 0.24321464297827333
在这里可以看到,NumPy 的np.add函数的性能略低于+运算符。这主要是因为 add 函数引入了类型检查,将任何类似数组的输入(如列表)转换为数组,然后再进行加法操作。这也就带来了额外的计算开销,相较于+运算符。
然而,这种措施也使得np.add函数更不容易出错。例如,将np.add应用于list类型的输入仍然有效(例如np.add([1, 1], [2, 2])),而使用+运算符则会导致列表连接。
同样,对于逐元素减法(使用np.subtract或-),除法(使用np.divide或/)和乘法(使用np.multiply或*),NumPy 函数会进行类型检查,引入少量计算开销。
其他几个可能有用的操作包括转置和乘法数组。
矩阵转置会导致矩阵的正交旋转,可以使用np.transpose函数(它包含类型检查)或.T属性来实现:
# Using np.transpose
func_a1_T = np.transpose(a1)
# Using the .T attribute
att_a1_T = a1.T
矩阵乘法可以使用np.dot函数或@运算符(后者从 Python 3.5 开始实现了np.matmul函数):
# Using np.dot
func_dot = np.dot(func_a1_T, a2)
# Using the @ operator
op_dot = func_a1_T @ a2
在处理二维数组时,np.dot和np.matmul的表现是一样的,并且都包含类型检查。
额外资源
Stefania Cristina,博士,是马耳他大学系统与控制工程系的高级讲师。她的研究兴趣集中在计算机视觉和机器学习领域。
更多相关主题
如何在大型数据集上使用 Pandas 执行内存高效的操作
原文:
www.kdnuggets.com/how-to-perform-memory-efficient-operations-on-large-datasets-with-pandas

图片由编辑提供 | Midjourney
让我们学习如何在 Pandas 中对大型数据集进行操作。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
准备工作
由于我们正在讨论 Pandas 包,你应该已经安装了它。此外,我们还会使用 Numpy 包。所以,请同时安装这两个包。
pip install pandas numpy
然后,让我们进入教程的核心部分。
使用 Pandas 执行内存高效的操作
Pandas 通常不以处理大型数据集而闻名,因为 Pandas 包的内存密集型操作可能会耗费大量时间甚至占满整个 RAM。然而,有一些方法可以提高 Pandas 操作的效率。
在本教程中,我们将向你展示如何提升在 Pandas 中处理大型数据集的体验。
首先,尝试使用内存优化参数加载数据集。还要尝试更改数据类型,尤其是更改为内存友好的类型,并删除任何不必要的列。
import pandas as pd
df = pd.read_csv('some_large_dataset.csv', low_memory=True, dtype={'column': 'int32'}, usecols=['col1', 'col2'])
将整数和浮点数转换为最小类型可以帮助减少内存占用。将具有少量唯一值的类别列转换为类别类型也有帮助。更小的列也有助于提高内存效率。
接下来,我们可以使用分块处理来避免使用全部内存。如果迭代处理会更高效。例如,我们想要计算列的均值,但数据集太大了。我们可以每次处理 100,000 条数据,最后得到总结果。
chunk_results = []
def column_mean(chunk):
chunk_mean = chunk['target_column'].mean()
return chunk_mean
chunksize = 100000
for chunk in pd.read_csv('some_large_dataset.csv', chunksize=chunksize):
chunk_results.append(column_mean(chunk))
final_result = sum(chunk_results) / len(chunk_results)
此外,避免使用带有 lambda 函数的 apply 方法,因为这可能会占用大量内存。更好的做法是使用矢量化操作或带有普通函数的.apply方法。
df['new_column'] = df['existing_column'] * 2
对于 Pandas 中的条件操作,使用np.where通常比直接使用带有.apply的 Lambda 函数要快。
import numpy as np
df['new_column'] = np.where(df['existing_column'] > 0, 1, 0)
然后,在许多 Pandas 操作中使用inplace=True比将其分配回 DataFrame 要节省更多内存。这种方法更高效,因为将其分配回 DataFrame 会在将它们放回同一个变量之前创建一个单独的 DataFrame。
df.drop(columns=['column_to_drop'], inplace=True)
最后,如果可能的话,尽早筛选数据。这将限制我们处理的数据量。
df = df[df['filter_column'] > threshold]
尝试掌握这些技巧以改善你在大型数据集中的 Pandas 使用体验。
额外资源
Cornellius Yudha Wijaya**** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。Cornellius 在多个人工智能和机器学习主题上撰写文章。
更多相关主题
如何通过缓存加速 Python 代码
原文:
www.kdnuggets.com/how-to-speed-up-python-code-with-caching
图片来源:作者
在 Python 中,你可以使用缓存来存储昂贵函数调用的结果,并在函数使用相同参数再次调用时重复使用这些结果。这使你的代码更高效。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
Python 提供了通过 functools 模块内建的缓存支持:@cache 和 @lru_cache 装饰器。在本教程中我们将学习如何缓存函数调用。
为什么缓存有帮助?
缓存函数调用可以显著提高你代码的性能。以下是缓存函数调用可能有益的一些原因:
-
性能提升:当函数使用相同参数多次调用时,缓存结果可以消除冗余计算。这样,缓存的值可以被返回,导致执行速度更快。
-
减少资源使用:一些函数调用可能计算密集或需要大量资源(如数据库查询或网络请求)。缓存结果减少了重复这些操作的需求。
-
响应性改善:在响应性至关重要的应用程序中,例如 Web 服务器或 GUI 应用程序,缓存可以通过避免重复计算或 I/O 操作来减少延迟。
现在让我们开始编程吧。
使用 @cache 装饰器进行缓存
让我们编写一个计算第 n 个斐波那契数的函数。以下是斐波那契数列的递归实现:
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
如果没有缓存,递归调用会导致冗余计算。如果缓存了值,查找缓存值会更高效。为此,你可以使用 @cache 装饰器。
Python 3.9+ 的 functools 模块中的 @cache 装饰器用于缓存函数的结果。它通过存储昂贵函数调用的结果并在函数用相同参数调用时重复使用这些结果来工作。现在让我们用 @cache 装饰器来包装函数:
from functools import cache
@cache
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
我们稍后会进行性能比较。现在让我们看看另一种使用 @lru_cache 装饰器缓存返回值的方法。
使用 @lru_cache 装饰器进行缓存
你也可以使用内置的functools.lru_cache装饰器进行缓存。这使用了最近最少使用 (LRU) 缓存机制来处理函数调用。在 LRU 缓存中,当缓存满时需要添加新项时,会删除缓存中最近最少使用的项,以腾出空间给新项。这确保了最常用的项保留在缓存中,而较少使用的项被丢弃。
@lru_cache装饰器类似于@cache,但允许你指定缓存的最大大小——即maxsize参数。一旦缓存达到这个大小,最少使用的项会被丢弃。这在你想限制内存使用时非常有用。
在这里,fibonacci函数缓存了最多 7 个最近计算的值:
from functools import lru_cache
@lru_cache(maxsize=7) # Cache up to 7 most recent results
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
fibonacci(5) # Computes Fibonacci(5) and caches intermediate results
fibonacci(3) # Retrieves Fibonacci(3) from the cache
在这里,fibonacci函数使用@lru_cache(maxsize=7)装饰器,这指定了它应该缓存最多 7 个最近的结果。
当调用fibonacci(5)时,fibonacci(4)、fibonacci(3)和fibonacci(2)的结果被缓存。当随后调用fibonacci(3)时,由于fibonacci(3)是最近计算的七个值之一,它会从缓存中检索,避免了重复计算。
比较函数调用的时间
现在让我们比较有缓存和没有缓存的函数的执行时间。在这个示例中,我们没有为maxsize设置明确的值。因此,maxsize将被设置为默认值 128:
from functools import cache, lru_cache
import timeit
# without caching
def fibonacci_no_cache(n):
if n <= 1:
return n
return fibonacci_no_cache(n-1) + fibonacci_no_cache(n-2)
# with cache
@cache
def fibonacci_cache(n):
if n <= 1:
return n
return fibonacci_cache(n-1) + fibonacci_cache(n-2)
# with LRU cache
@lru_cache
def fibonacci_lru_cache(n):
if n <= 1:
return n
return fibonacci_lru_cache(n-1) + fibonacci_lru_cache(n-2)
为了比较执行时间,我们将使用timeit模块中的timeit函数:
# Compute the n-th Fibonacci number
n = 35
no_cache_time = timeit.timeit(lambda: fibonacci_no_cache(n), number=1)
cache_time = timeit.timeit(lambda: fibonacci_cache(n), number=1)
lru_cache_time = timeit.timeit(lambda: fibonacci_lru_cache(n), number=1)
print(f"Time without cache: {no_cache_time:.6f} seconds")
print(f"Time with cache: {cache_time:.6f} seconds")
print(f"Time with LRU cache: {lru_cache_time:.6f} seconds")
运行上述代码应该会得到类似的输出:
Output >>>
Time without cache: 2.373220 seconds
Time with cache: 0.000029 seconds
Time with LRU cache: 0.000017 seconds
我们看到执行时间有显著差异。没有缓存的函数调用执行时间更长,特别是对于较大的n值。而缓存版本(包括@cache和@lru_cache)的执行速度要快得多,且执行时间相当。
总结
通过使用@cache和@lru_cache装饰器,你可以显著加快涉及复杂计算或递归调用的函数的执行速度。你可以在 GitHub 上找到完整的代码。
如果你在寻找关于使用 Python 进行数据科学的最佳实践的全面指南,请阅读 5 Python Best Practices for Data Science。
Bala Priya C**** 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等方式,学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。
相关话题
如何将 Python Pandas 的速度提升超过 300 倍
原文:
www.kdnuggets.com/how-to-speed-up-python-pandas-by-over-300x

如何加速 Pandas 代码 - 向量化
如果我们希望我们的深度学习模型在一个数据集上进行训练,我们必须优化我们的代码,以便快速解析数据。我们希望使用优化的方法来编写代码,以便尽可能快地读取数据表。即使是最小的性能提升也会在数万条数据点上成倍地提高性能。在这篇博客中,我们将定义 Pandas,并提供一个示例,说明如何向量化你的 Python 代码,以使用 Pandas 优化数据集分析,使你的代码速度提高超过 300 倍。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
什么是 Python 的 Pandas?
Pandas是 Python 编程语言中一个重要且流行的开源数据操作和数据分析库。Pandas 广泛应用于金融、经济学、社会科学和工程等多个领域。它在数据科学和机器学习任务中对于数据清理、准备和分析非常有用。
它提供了强大的数据结构(如 DataFrame 和 Series)和数据操作工具,用于处理结构化数据,包括以各种格式(例如 CSV、Excel、JSON)读取和写入数据,以及数据的过滤、清理和转换。此外,它还支持时间序列数据,并通过与其他流行库如 NumPy 和 Matplotlib 的集成,提供强大的数据聚合和可视化功能。
我们的数据集和问题
数据
在这个示例中,我们将使用 NumPy 在一个Jupyter Notebook中创建一个随机数据集,用任意值和字符串填充我们的 Pandas 数据框。在这个数据集中,我们命名了 10,000 个年龄不同的人,记录了他们的工作时间和工作中高效时间的百分比。还将随机分配一个最喜欢的零食,以及一个随机的不良因果事件。
我们首先将导入我们的框架,并生成一些随机代码,然后再开始:
import pandas as pd
import numpy as np
接下来,我们将创建一些随机数据来构建我们的数据集。虽然你的代码很可能依赖于实际数据,但对于我们的用例,我们将创建一些任意数据。
def get_data(size = 10_000):
df = pd.DataFrame()
df['age'] = np.random.randint(0, 100, size)
df['time_at_work'] = np.random.randint(0,8,size)
df['percentage_productive'] = np.random.rand(size)
df['favorite_treat'] = np.random.choice(['ice_cream', 'boba', 'cookie'], size)
df['bad_karma'] = np.random.choice(['stub_toe', 'wifi_malfunction', 'extra_traffic'])
return df
参数和规则
-
如果一个人的‘time_at_work’至少为 2 小时,并且‘percentage_productive’超过 50%,我们返回‘favorite treat’。
-
否则,我们将其设为
bad_karma。 -
如果他们超过 65 岁,我们返回‘favorite_treat’,因为我们希望老年人感到幸福。
def reward_calc(row):
if row['age'] >= 65:
return row ['favorite_treat']
if (row['time_at_work'] >= 2) & (row['percentage_productive'] >= 0.5):
return row ['favorite_treat']
return row['bad_karma']
现在我们有了数据集和我们想要返回的参数,可以继续探索执行这种类型分析的最快方法。
哪种 Pandas 代码最快:循环、应用还是矢量化?
为了对我们的函数进行计时,我们将使用 Jupyter Notebook 中的魔法函数%%timeit来简化操作。虽然在 Python 中有其他计时函数的方法,但为了演示目的,我们的 Jupyter Notebook 足够用了。我们将用 3 种方法(循环/迭代、应用和矢量化)在相同的数据集上进行演示运行,并计算和评估我们的问题。
循环/迭代
循环和迭代是逐行进行相同计算的最基本方法。我们调用数据框架,迭代行,并用一个新的单元格称为reward进行计算,以根据我们之前定义的reward_calc代码块填充新的reward。这是最基本的方法,也可能是类似于 For 循环的编码时学到的第一个方法。
%%timeit
df = get_data()
for index, row in df.iterrows():
df.loc[index, 'reward'] = reward_calc(row)
这是它返回的结果:
3.66 s ± 119 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
缺乏经验的数据科学家可能会觉得几秒钟不算什么。但,3.66 秒在数据集中运行一个简单的函数还是相当长的。让我们看看apply函数能为我们的速度做些什么。
应用
apply函数的效果与循环相同。它将创建一个标题为reward的新列,并对每 1 行应用计算函数,定义为axis=1。apply函数是对数据集运行循环的更快方法。
%%timeit
df = get_data()
df['reward'] = df.apply(reward_calc, axis=1)
运行所需的时间如下:
404 ms ± 18.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
哇,快了这么多!大约快了 9 倍,较循环有了巨大的改进。现在apply函数完全可以使用,并适用于某些场景,但对于我们的用例,看看是否能更快一点。
矢量化
我们评估数据集的最后一种方法是使用矢量化。我们将调用数据集,并将默认的reward应用于整个数据框架。然后,我们只会检查那些满足我们参数的行,使用布尔索引。可以把它当作给每行设置一个真/假值。如果任何行或所有行在计算中返回假,则reward行将保持为bad_karma。而如果所有行都为真,我们将重新定义reward行的数据框架为favorite_treat。
%%timeit
df = get_data()
df['reward'] = df['bad_karma']
df.loc[((df['percentage_productive'] >= 0.5) &
(df['time_at_work'] >= 2)) |
(df['age'] >= 65), 'reward'] = df['favorite_treat']
在我们的数据集上运行此函数所需的时间如下:
10.4 ms ± 76.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
这非常快。比 Apply 快 40 倍,并且大约比循环快 360 倍……
为什么 Pandas 中的矢量化快 300 倍
向量化比循环/迭代和 Apply 更快的原因在于,它不会每次都计算整行,而是将参数应用于整个数据集。向量化是一种将操作一次性应用于整个数据数组的过程,而不是逐个元素操作。这使得内存和 CPU 资源的使用更加高效。
当使用 Loops 或 Apply 对 Pandas 数据框进行计算时,操作是按顺序应用的。这会导致重复访问内存、计算和更新值,这可能会很慢且资源消耗大。
另一方面,向量化操作是用 Cython(Python 在 C 或 C++ 中)实现的,并利用 CPU 的向量处理能力,这可以一次执行多个操作,从而通过同时计算多个参数进一步提高性能。向量化操作还避免了不断访问内存的开销,这正是 Loop 和 Apply 的短板。
如何向量化你的 Pandas 代码
-
使用内置的 Pandas 和 NumPy 函数,例如 sum()、mean() 或 max(),这些函数已经实现了 C 语言的效率。
-
使用可以应用于整个 DataFrame 和 Series 的向量化操作,包括数学运算、比较和逻辑操作,以创建布尔掩码以选择数据集中的多个行。
-
你可以使用 .values 属性或
.to_numpy()返回底层的 NumPy 数组,并直接在数组上执行向量化计算。 -
使用向量化的字符串操作来处理你的数据集,例如
.str.contains()、.str.replace()和.str.split()。
每当你在 Pandas DataFrames 上编写函数时,尽量将你的计算向量化。随着数据集越来越大,计算变得越来越复杂,利用向量化时节省的时间会呈指数级增长。值得注意的是,并不是所有操作都可以向量化,有时需要使用循环或 apply 函数。然而,只要可能,向量化操作可以大大提高性能,使你的代码更高效。
Kevin Vu 负责 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写关于深度学习不同方面的文章。
了解更多相关内容
如何在生成型人工智能时代脱颖而出并保护你的工作
原文:
www.kdnuggets.com/how-to-standout-and-safeguard-your-job-in-the-generative-ai-era

作者提供的图片
几本操作手册、路线图和职业规划书声称可以帮助你获得第一份人工智能工作或转型进入该领域。然而,人工智能进步带来的自动化也让许多工作面临风险。
那么,如何在人工智能领域特别是今天的生成型时代中找到职业呢?
首先,需要注意的是,理解人工智能的基础知识仍然非常必要,以了解算法如何工作、算法的假设是什么、如果预期行为与实际行为不符如何调试、样本与总体的区别、收集样本的必要性及其不同方法、进行假设检验等等。
行动时间
很好,有了对人工智能基础知识及其重要性的理解,即使在生成型人工智能时代,我们也来快速梳理一下学习人工智能的路线图。
从学习算法的基础支柱开始,即线性代数、微积分、统计学和概率论,你将能够理解诸如导数的“是什么”、“为什么”和“如何”等概念,它们的应用领域,以及前向传播和后向传播是什么。这还将巩固你对数据分布和概率分布(如高斯分布、泊松分布等)的理解。
大部分知识是免费的;推荐的资源有:
-
3 Brown 1 Blue YouTube 频道
-
可汗学院提供统计学和概率论的课程
作者提供的图片
现在,我们已经准备好学习机器学习的概念,这将涵盖包括线性回归、逻辑回归、决策树、聚类等关键算法。
在继续之前,需要注意的是,由于教育的民主化,今天学习人工智能变得更加容易。例如,此路线图中建议的所有读物都是免费的。
除了发展算法背后的直觉外,学习诸如成本函数、正则化、优化算法和误差分析等概念也是重要的。
现在,让我们开始掌握软件编程。学习编写代码并实现解决方案使你能够无缝地进行实践。4 小时的 Python 视频课程(如路线图图片所示)涵盖了基础知识,让你从一开始就能够入门。现在,我们准备学习深度学习的基础概念,包括层、节点、激活函数、反向传播、超参数调整等。
太好了,学习了足够的内容,我们已经达到了最终阶段,我通常称之为游乐场。这是你将所有知识付诸实践的地方。一种很好的方式是通过实践和参与 Kaggle 竞赛。还可以找到获胜的解决方案,并开发应对各种业务问题的方法。
AI 工作流程
这是学习 AI 的典型路径,在此过程中,学习者将内化 AI 工作流程,从数据探索开始,即解剖数据以理解其底层模式。在这个阶段,数据科学家了解数据转换,以准备建模用途。
作者图片
特征选择和工程是杰出数据科学家的最强技能。如果这一步做对了,可以加速模型的学习过程。
现在是每个数据科学家都期待的时刻,即构建模型并选择表现最佳的模型。对“最佳表现”的定义通过评估指标来完成,这些指标有两种类型——科学的,如精确度、召回率和均方误差,另一种包括商业指标,如点击量增加、转化率或美元价值影响。
阅读一篇文章到达这个阶段看似是一个简单的过程,但实际上,这是一个广泛的过程。
区别因素
到目前为止,我们讨论了传统路径,学习每个人都在做的事情。但在生成性人工智能时代,区别因素在哪里呢?
学习者常有的一种观念是不断消费学习内容。虽然学习基础知识很重要,但同样重要的是开始实践和实验,以建立对所学概念的直观理解。
此外,构建 AI 解决方案的关键组成部分是了解 AI 是否适合,包括将业务问题映射到正确技术解决方案的能力。如果起步阶段就做错了,那么期望实现的解决方案在有意义地满足业务目标上是无法实现的。
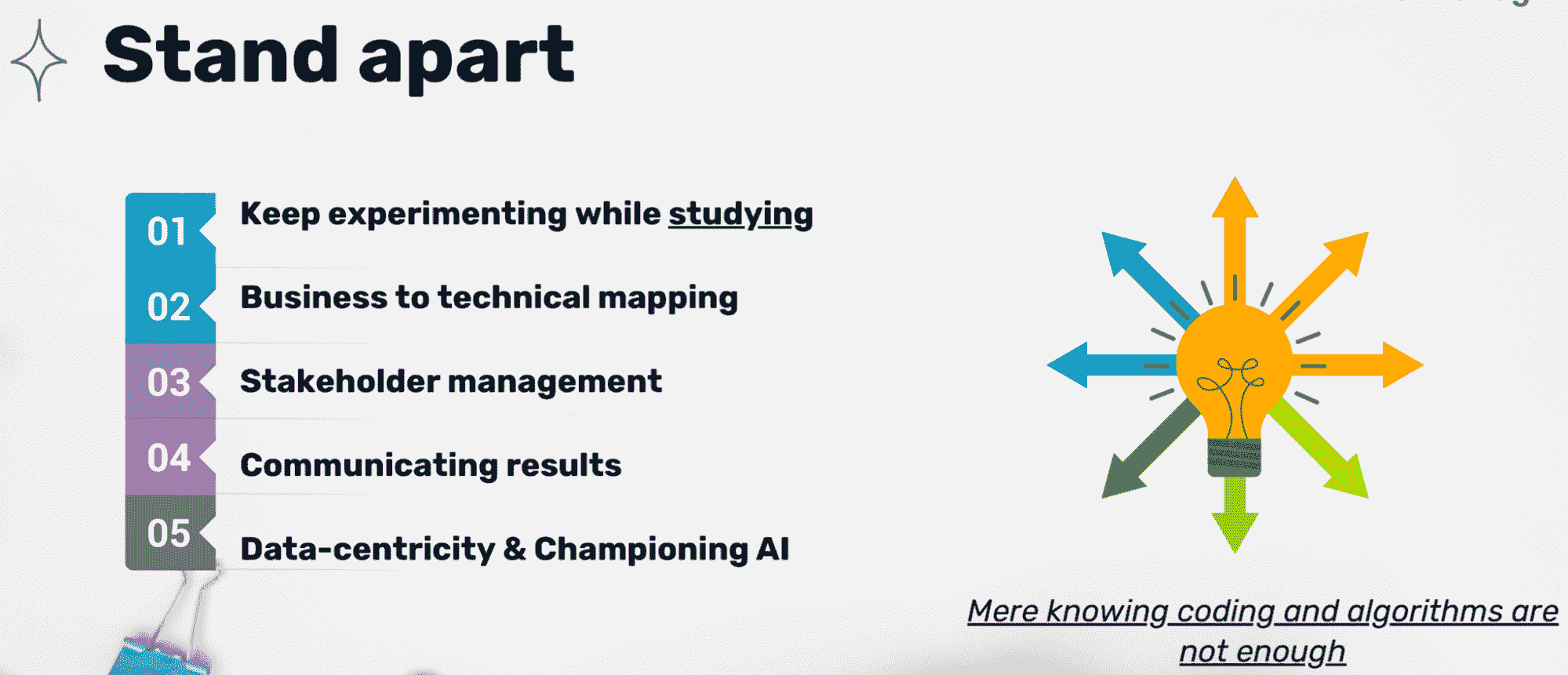
作者图片
此外,数据科学被视为更多的技术角色,但实际上,它的成功很大程度上依赖于一个常被低估的技能,即与利益相关者的协作。确保将来自不同背景和专业领域的利益相关者引入团队,发挥着关键作用。
即使模型显示出良好的结果,如果缺乏清晰度和将这些结果与业务成果联系起来的能力,模型仍可能未被采纳。这个差距可以通过有效的沟通技巧来弥补。
最后,在你的人工智能方法中务必以数据为先。任何 AI 模型的成功都依赖于数据。此外,寻找那些相信 AI 能力和可能性,同时理解相关风险的 AI 倡导者。
拥有这些技能,我祝愿你在人工智能领域拥有一个卓越的职业生涯。
Vidhi Chugh是一位人工智能战略家和数字化转型领导者,她在产品、科学和工程的交汇点工作,致力于构建可扩展的机器学习系统。她是一位屡获殊荣的创新领袖、作者和国际演讲者。她的使命是使机器学习民主化,并打破术语,使每个人都能参与这场转型。
了解更多相关话题
如何跟踪 Python 中的内存分配
原文:
www.kdnuggets.com/how-to-trace-memory-allocation-in-python

图片由作者提供
在 Python 编码时,通常无需过多考虑内存分配的细节。但跟踪内存分配可能很有帮助,特别是当您处理内存密集型操作和大型数据集时。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
Python 的 内置 tracemalloc 模块 提供了一些功能,帮助您理解内存使用情况并调试应用程序。使用 tracemalloc,您可以获取内存分配的位置和数量,拍摄快照,比较快照之间的差异等。
我们将在本教程中查看一些这些内容。让我们开始吧。
开始之前
我们将使用一个简单的 Python 脚本进行数据处理。为此,我们将创建一个示例数据集并进行处理。除了最新版本的 Python,您还需要在工作环境中安装 pandas 和 NumPy。
创建一个虚拟环境并激活它:
$ python3 -m venv v1
$ source v1/bin/activate
并安装所需的库:
$ pip3 install numpy pandas
您可以在GitHub找到本教程的代码。
创建一个包含订单详情的示例数据集
我们将生成一个包含订单详情的示例 CSV 文件。您可以运行以下脚本来创建一个包含 100K 订单记录的 CSV 文件:
# create_data.py
import pandas as pd
import numpy as np
# Create a sample dataset with order details
num_orders = 100000
data = {
'OrderID': np.arange(1, num_orders + 1),
'CustomerID': np.random.randint(1000, 5000, num_orders),
'OrderAmount': np.random.uniform(10.0, 1000.0, num_orders).round(2),
'OrderDate': pd.date_range(start='2023-01-01', periods=num_orders, freq='min')
}
df = pd.DataFrame(data)
df.to_csv('order_data.csv', index=False)
此脚本将 100K 条记录填充到 pandas 数据框中,具有以下四个特征,并将数据框导出为 CSV 文件:
-
OrderID: 每个订单的唯一标识符
-
CustomerID: 客户的 ID
-
OrderAmount: 每个订单的金额
-
OrderDate: 订单的日期和时间
使用 tracemalloc 跟踪内存分配
现在我们将创建一个 Python 脚本来加载和处理数据集。我们还将跟踪内存分配。
首先,我们定义 load_data 和 process_data 函数来加载和处理来自 CSV 文件的记录:
# main.py
import pandas as pd
def load_data(file_path):
print("Loading data...")
df = pd.read_csv(file_path)
return df
def process_data(df):
print("Processing data...")
df['DiscountedAmount'] = df['OrderAmount'] * 0.9 # Apply a 10% discount
df['OrderYear'] = pd.to_datetime(df['OrderDate']).dt.year # Extract the order year
return df
然后我们可以通过以下步骤继续进行内存分配跟踪:
-
使用
tracemalloc.start()初始化内存跟踪。 -
load_data()函数将 CSV 文件读入数据框。我们在此步骤之后拍摄内存使用快照。 -
process_data()函数向数据框添加了两个新列:'DiscountedAmount' 和 'OrderYear'。处理后我们再拍摄一个快照。 -
我们比较这两个快照以找出内存使用差异,并打印出最耗内存的行。
-
然后打印当前和峰值内存使用情况,以了解整体影响。
这是对应的代码:
import tracemalloc
def main():
# Start tracing memory allocations
tracemalloc.start()
# Load data
df = load_data('order_data.csv')
# Take a snapshot
snapshot1 = tracemalloc.take_snapshot()
# Process data
df = process_data(df)
# Take another snapshot
snapshot2 = tracemalloc.take_snapshot()
# Compare snapshots
top_stats = snapshot2.compare_to(snapshot1, 'lineno')
print("[ Top memory-consuming lines ]")
for stat in top_stats[:10]:
print(stat)
# Current and peak memory usage
current, peak = tracemalloc.get_traced_memory()
print(f"Current memory usage: {current / 1024 / 1024:.1f} MB")
print(f"Peak usage: {peak / 1024 / 1024:.1f} MB")
tracemalloc.stop()
if __name__ == "__main__":
main()
现在运行 Python 脚本:
$ python3 main.py
这将输出最耗内存的行以及当前和峰值内存使用情况:
Loading data...
Processing data...
[ Top 3 memory-consuming lines ]
/home/balapriya/trace_malloc/v1/lib/python3.11/site-packages/pandas/core/frame.py:12683: size=1172 KiB (+1172 KiB), count=4 (+4), average=293 KiB
/home/balapriya/trace_malloc/v1/lib/python3.11/site-packages/pandas/core/arrays/datetimelike.py:2354: size=781 KiB (+781 KiB), count=3 (+3), average=260 KiB
<frozen abc="">:123: size=34.6 KiB (+15.3 KiB), count=399 (+180), average=89 B
Current memory usage: 10.8 MB
Peak usage: 13.6 MB</frozen>
总结
使用 tracemalloc 跟踪内存分配有助于识别内存密集型操作,并通过内存跟踪和返回的统计信息潜在地优化性能。
你应该能看到是否可以使用更高效的数据结构和处理方法来减少内存使用。对于长时间运行的应用程序,你可以定期使用 tracemalloc 来跟踪内存使用情况。也就是说,你可以将 tracemalloc 与其他分析工具结合使用,以全面了解内存使用情况。
如果你有兴趣学习使用 memory-profiler 进行内存分析,请阅读 Python 中的内存分析简介。
Bala Priya C**** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关主题
如何在 Pandas 中使用条件格式化来提升数据可视化
原文:
www.kdnuggets.com/how-to-use-conditional-formatting-in-pandas-to-enhance-data-visualization

图片来源 | DALLE-3 & Canva
虽然 pandas 主要用于数据处理和分析,但它也可以提供基本的数据可视化功能。然而,普通的数据框可能会使信息显得杂乱无章。那怎么做才能改善呢?如果你以前使用过 Excel,你知道可以用不同的颜色、字体样式等来突出重要值。使用这些样式和颜色的目的是有效地传达信息。你也可以在 pandas 数据框中做类似的工作,使用条件格式化和 Styler 对象。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
在这篇文章中,我们将探讨什么是条件格式化以及如何使用它来增强数据的可读性。
条件格式化
条件格式化是 pandas 中的一个功能,允许你根据某些标准格式化单元格。你可以轻松突出异常值、可视化趋势或强调重要数据点。pandas 中的 Styler 对象提供了一种方便的方法来应用条件格式化。在介绍示例之前,让我们快速了解一下 Styler 对象的工作原理。
Styler 对象是什么?它是如何工作的?
你可以通过使用property来控制数据框的视觉呈现。这个属性返回一个 Styler 对象,负责数据框的样式设置。Styler 对象允许你操控数据框的 CSS 属性,以创建视觉上吸引人且信息丰富的展示。其通用语法如下:
py` df.style.py Where <method> is the specific formatting function you want to apply, and <arguments> are the parameters required by that function. The Styler object returns the formatted dataframe without changing the original one. There are two approaches to using conditional formatting with the Styler object: * **Built-in Styles:** To apply quick formatting styles to your dataframe * **Custom Stylization:** Create your own formatting rules for the Styler object and pass them through one of the following methods (`Styler.applymap`: element-wise or `Styler.apply`: column-/row-/table-wise) Now, we will cover some examples of both approaches to help you enhance the visualization of your data. ## Examples: Built-in-Styles Let’s create a dummy stock price dataset with columns for Date, Cost Price, Satisfaction Score, and Sales Amount to demonstrate the examples below: 导入 pandas 作为 pd 导入 numpy 作为 np 数据 = {'日期': ['2024-03-05', '2024-03-06', '2024-03-07', '2024-03-08', '2024-03-09', '2024-03-10'], '成本价格': [100, 120, 110, 1500, 1600, 1550], '满意度评分': [90, 80, 70, 95, 85, 75], '销售金额': [1000, 800, 1200, 900, 1100, None]} df = pd.DataFrame(data) df py **Output:** 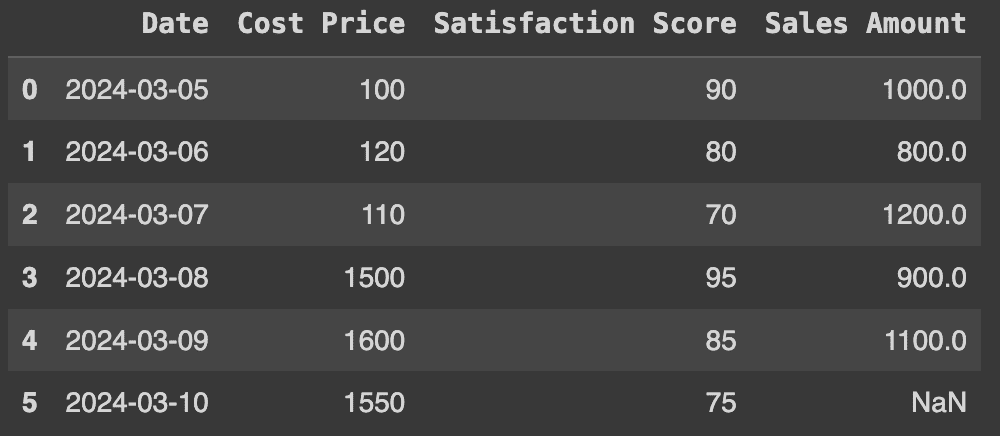 Original Unformatted Dataframe ### 1\. Highlighting Maximum and Minimum Values We can use `highlight_max` and `highlight_min` functions to highlight the maximum and minimum values in a column or row. For column set axis=0 like this: # 高亮显示最大值和最小值 df.style.highlight_max(color='green', axis=0 , subset=['成本价格', '满意度评分', '销售金额']).highlight_min(color='red', axis=0 , subset=['成本价格', '满意度评分', '销售金额']) py **Output:** 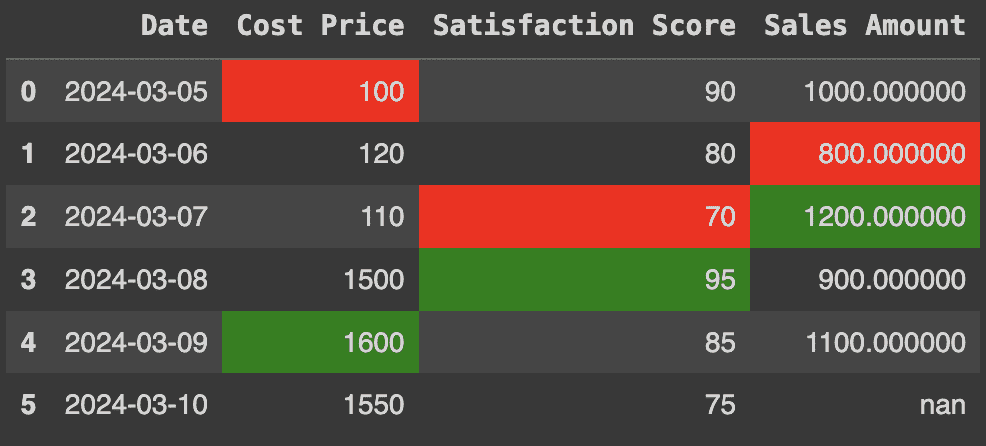 Max & Min Values ### 2\. Applying Color Gradients Color gradients are an effective way to visualize the values in your data. In this case, we will apply the gradient to satisfaction scores using the colormap set to 'viridis'. This is a type of color coding that ranges from purple (low values) to yellow (high values). Here is how you can do this: # 应用颜色渐变 df.style.background_gradient(cmap='viridis', subset=['满意度评分']) py **Output:**  Colormap - viridis ### 3\. Highlighting Null or Missing Values When we have large datasets, it becomes difficult to identify null or missing values. You can use conditional formatting using the built-in `df.style.highlight_null` function for this purpose. For example, in this case, the sales amount of the 6th entry is missing. You can highlight this information like this: # 高亮显示空值或缺失值 df.style.highlight_null('yellow', subset=['销售金额']) py **Output:** 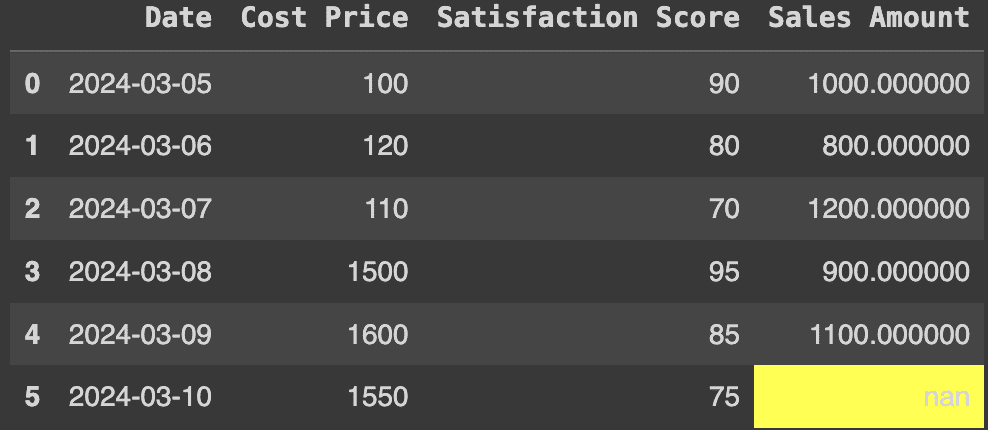 Highlighting Missing Values ## Examples: Custom Stylization Using `apply()` & `applymap()` ### 1\. Conditional Formatting for Outliers Suppose that we have a housing dataset with their prices, and we want to highlight the houses with outlier prices (i.e., prices that are significantly higher or lower than the other neighborhoods). This can be done as follows: 导入 pandas 作为 pd 导入 numpy 作为 np # 房价数据集 df = pd.DataFrame({ '社区': ['H1', 'H2', 'H3', 'H4', 'H5', 'H6', 'H7'], '价格': [50, 300, 360, 390, 420, 450, 1000], }) # 计算 Q1 (25 百分位数), Q3 (75 百分位数) 和四分位距 (IQR) q1 = df['价格'].quantile(0.25) q3 = df['价格'].quantile(0.75) iqr = q3 - q1 # 异常值的界限 lower_bound = q1 - 1.5 * iqr upper_bound = q3 + 1.5 * iqr # 自定义函数来高亮显示异常值 def highlight_outliers(val): if val < lower_bound or val > upper_bound: return 'background-color: yellow; font-weight: bold; color: black' else: return '' df.style.applymap(highlight_outliers, subset=['价格']) py **Output:**  Highlighting Outliers ### 2\. Highlighting Trends Consider that you run a company and are recording your sales daily. To analyze the trends, you want to highlight the days when your daily sales increase by 5% or more. You can achieve this using a custom function and the apply method in pandas. Here’s how: 导入 pandas 作为 pd # 公司销售数据集 数据 = {'日期': ['2024-02-10', '2024-02-11', '2024-02-12', '2024-02-13', '2024-02-14'], '销售': [100, 105, 110, 115, 125]} df = pd.DataFrame(data) # 每日百分比变化 df['pct_change'] = df['销售'].pct_change() * 100 # 如果销售增长超过 5%,则高亮显示该天 def highlight_trend(row): return ['background-color: green; border: 2px solid black; font-weight: bold' if row['pct_change'] > 5 else '' for _ in row] df.style.apply(highlight_trend, axis=1) py **Output:**  ### 3\. Highlighting Correlated Columns Correlated columns are important because they show relationships between different variables. For example, if we have a dataset containing age, income, and spending habits and our analysis shows a high correlation (close to 1) between age and income, then it suggests that older people generally have higher incomes. Highlighting correlated columns helps to visually identify these relationships. This approach becomes extremely helpful as the dimensionality of your data increases. Let's explore an example to better understand this concept: 导入 pandas 作为 pd # 人员数据集 数据 = { '年龄': [30, 35, 40, 45, 50], '收入': [60000, 66000, 70000, 75000, 100000], '支出': [10000, 15000, 20000, 18000, 12000] } df = pd.DataFrame(data) # 计算相关矩阵 corr_matrix = df.corr() # 高亮显示高度相关的列 def highlight_corr(val): if val != 1.0 and abs(val) > 0.5: # 排除自相关 return 'background-color: blue; text-decoration: underline' else: return '' corr_matrix.style.applymap(highlight_corr) py **Output:** 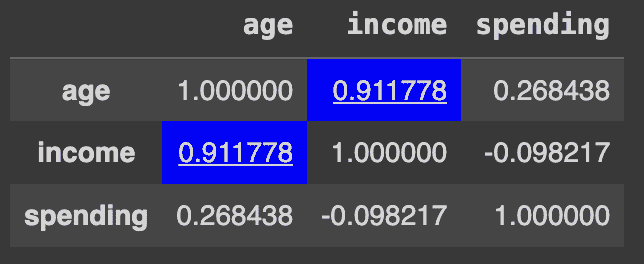 Correlated Columns ## Wrapping Up These are just some of the examples I showed as a starter to up your game of data visualization. You can apply similar techniques to various other problems to enhance the data visualization, such as highlighting duplicate rows, grouping into categories and selecting different formatting for each category, or highlighting peak values. Additionally, there are many other CSS options you can explore in the [official documentation](https://pandas.pydata.org/pandas-docs/version/1.0/user_guide/style.html). You can even define different properties on hover, like magnifying text or changing color. Check out the "[Fun Stuff](https://pandas.pydata.org/pandas-docs/version/1.0/user_guide/style.html#Fun-stuff)" section for more cool ideas. This article is part of my Pandas series, so if you enjoyed this, there's plenty more to explore. Head over to my author page for more tips, tricks, and tutorials. **[](https://www.linkedin.com/in/kanwal-mehreen1/)**[Kanwal Mehreen](https://www.linkedin.com/in/kanwal-mehreen1/)**** Kanwal is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook "Maximizing Productivity with ChatGPT". As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She's also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields. ### More On This Topic * [Five Ways to do Conditional Filtering in Pandas](https://www.kdnuggets.com/2022/12/five-ways-conditional-filtering-pandas.html) * [7 AI-Powered Tools to Enhance Productivity for Data Scientists](https://www.kdnuggets.com/2023/02/7-aipowered-tools-enhance-productivity-data-scientists.html) * [Enhance Your Python Coding Style with Ruff](https://www.kdnuggets.com/enhance-your-python-coding-style-with-ruff) * [6 ChatGPT Prompts to Enhance your Productivity at Work](https://www.kdnuggets.com/6-chatgpt-prompts-to-enhance-your-productivity-at-work) * [Revamping Data Visualization: Mastering Time-Based Resampling in Pandas](https://www.kdnuggets.com/revamping-data-visualization-mastering-timebased-resampling-in-pandas) * [7 Pandas Plotting Functions for Quick Data Visualization](https://www.kdnuggets.com/7-pandas-plotting-functions-for-quick-data-visualization)
如何有效使用 Docker 标签管理镜像版本
原文:
www.kdnuggets.com/how-to-use-docker-tags-to-manage-image-versions-effectively

编辑器提供的图片 | Midjourney 和 Canva
了解如何使用 Docker 标签来管理不同版本的 Docker 镜像,确保一致和有序的开发工作流。本指南涵盖了标记、更新和维护 Docker 镜像的最佳实践。
前提条件
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
在你开始之前:
-
你应该在开发环境中安装 Docker。如果还没有,获取 Docker。
-
一个你想 Docker 化的示例应用。如果你愿意,可以使用 GitHub 上的这个示例。
标记 Docker 镜像
Docker 标签是一个指向存储库中特定镜像的标签。默认情况下,如果未指定标签,Docker 使用 latest 标签。但如果你正在开发应用并在版本间进行改进,你可能希望添加更明确的标签。这些标签对于区分不同版本或状态的镜像非常有用。
假设你有一个 Python 项目:一个用于库存管理的 Flask 应用,所有必需的文件都在项目目录中:
project-dir/
├── app.py
├── Dockerfile
├── requirements.txt
你可以在构建镜像时进行标签,如下所示:
$ docker build -t image_name:tag_name
现在让我们构建 inventory-app 镜像并给它打标签:
$ docker build -t inventory-app:1.0.0 .
在这里:
-
inventory-app是存储库名称或镜像名称。 -
1.0.0是此特定镜像构建的标签。
你可以运行 docker images 命令来查看带有指定标签的新构建镜像:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
inventory-app 1.0.0 32784c60a992 6 minutes ago 146MB
你也可以给现有的镜像打标签,如下所示:
$ docker tag inventory-app:1.0.0 inventory-app:latest
在这里,我们将现有的镜像 inventory-app:1.0.0 标记为 inventory-app:latest。你会看到我们有两个不同标签的 inventory-app 镜像,并且它们的镜像 ID 相同:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
inventory-app 1.0.0 32784c60a992 6 minutes ago 146MB
inventory-app latest 32784c60a992 5 minutes ago 146MB
推送已标记的镜像到存储库
要共享你的 Docker 镜像,你可以将它们推送到 Docker 存储库(如 DockerHub)。你可以注册一个免费的 DockerHub 账户,登录并推送镜像。你应该首先登录 DockerHub:
$ docker login
系统会提示你输入用户名和密码。经过身份验证成功后,你可以使用 docker push 命令推送已标记的镜像。
确保你的仓库名称与你的 Docker Hub 用户名或组织匹配。如果你的 Docker Hub 用户名是 user,并且你想推送镜像的版本为 1.0.1,你可以将镜像标记为 user/inventory-app:1.0.1:
$ docker tag user/inventory-app:1.0.1
$ docker push user/inventory-app:1.0.1
当你需要使用特定版本的镜像时,可以使用标签来拉取它:
$ docker pull user/inventory-app:1.0.1
Docker 镜像标记的最佳实践
这里是标记 Docker 镜像时的一些最佳实践:
-
使用语义版本控制:遵循如
MAJOR.MINOR.PATCH(1.0.0, 1.0.1)这样的版本控制方案。这有助于识别更改的重要性。 -
避免在生产环境中使用
latest:在生产部署中使用明确的版本标签。 -
在 CI/CD 管道中自动化标记:将 Docker 标记集成到你的 CI/CD 管道中,以确保一致和自动的版本控制。
-
在标签中包含元数据:如果有意义的话,可以在标签中添加构建号、提交哈希或日期。
遵循这些实践来使用 Docker 标签,你可以保持一组干净、组织良好且有版本控制的 Docker 镜像。
额外资源
这里有几个你会觉得有用的资源:
Bala Priya C**** 是来自印度的开发者和技术作者。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等来学习和与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
主题扩展
如何使用 Docker 卷进行持久数据存储
原文:
www.kdnuggets.com/how-to-use-docker-volumes-for-persistent-data-storage

使用 Docker 时,你可以使用卷来持久保存数据,即使你停止或重启容器。我们将为 PostgreSQL 创建和使用 Docker 卷。
前提条件
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
要跟随本教程:
-
你应该在你的机器上安装了Docker
-
你应该对 Docker 命令和 PostgreSQL 感到熟悉
步骤 1:拉取 PostgreSQL 镜像
首先,我们从 DockerHub 拉取 PostgreSQL 镜像:
$ docker pull postgres
步骤 2:创建 Docker 卷
接下来,让我们创建一个 Docker 卷来存储数据。即使容器被移除,这个卷也会持久保存数据。
$ docker volume create pg_data
步骤 3:运行 PostgreSQL 容器
现在我们已经拉取了镜像并创建了卷,我们可以运行 PostgreSQL 容器,将创建的卷附加到它上面。
$ docker run -d \
--name my_postgres \
-e POSTGRES_PASSWORD=mysecretpassword \
-v pg_data:/var/lib/postgresql/data \
-p 5432:5432 \
postgres
这个命令在分离模式下运行my_postgres。使用 -v pg_data:/var/lib/postgresql/data 将pg_data卷挂载到容器中的/var/lib/postgresql/data。并且使用-p 5432:5432将my_postgres的 5432 端口映射到主机上的 5432 端口。
步骤 4:验证卷使用情况
现在我们已经创建了卷,可以验证它是否正在使用。你可以检查卷并查看其内容。
$ docker volume inspect pgdata
运行此命令将显示有关卷的详细信息,包括其在主机系统上的挂载点。你可以导航到该目录并查看 PostgreSQL 数据文件。
[
{
"CreatedAt": "2024-08-07T15:53:23+05:30",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/pg_data/_data",
"Name": "pg_data",
"Options": null,
"Scope": "local"
}
]
步骤 5:创建数据库和表
连接到 Postgres 实例,创建数据库和表。
启动一个 psql 会话:
$ docker exec -it my_postgres psql -U postgres
创建一个新的数据库:
CREATE DATABASE mydb;
连接到新的数据库:
\c mydb
创建一个表并插入一些数据:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
INSERT INTO users (name, email) VALUES ('Abby', 'abby@example.com'), ('Bob', 'bob@example.com');
运行一个示例查询:
SELECT * FROM users;
输出:
id | name | email
----+------+------------------
1 | Abby | abby@example.com
2 | Bob | bob@example.com
步骤 6:停止并删除容器
停止正在运行的容器并将其删除。我们这样做是为了测试即使容器被停止,数据是否仍然持久。
$ docker stop my_postgres
$ docker rm my_postgres
步骤 7:使用相同的卷重新运行 Postgres 容器
启动一个新的 PostgreSQL 容器,使用相同的卷以确保数据持久性。
$ docker run -d \
--name my_postgres \
-e POSTGRES_PASSWORD=mysecretpassword \
-v pgdata:/var/lib/postgresql/data \
-p 5432:5432 \
postgres
连接到 Postgres 实例并验证数据是否持久。
打开一个 psql 会话:
$ docker exec -it my_postgres psql -U postgres
连接到mydb数据库:
\c mydb
验证users表中的数据:
SELECT * FROM users;
你仍然应该看到输出:
id | name | email
----+------+------------------
1 | Abby | abby@example.com
2 | Bob | bob@example.com
我希望这个教程能帮助你理解如何使用卷来持久化 Docker 中的数据。
额外资源
要了解更多信息,请阅读以下资源:
祝你探索愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过撰写教程、操作指南、观点文章等,学习并与开发者社区分享她的知识。Bala 还制作了引人入胜的资源概述和编码教程。
更多相关话题
使用 GPT 生成创意内容的方法
原文:
www.kdnuggets.com/how-to-use-gpt-for-generating-creative-content-with-hugging-face-transformers
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
GPT,即生成预训练变换器,是一类基于变换器的语言模型。作为一种早期基于变换器的模型,它能够生成连贯的文本,OpenAI 的 GPT-2 是此类模型的初期成功案例之一,可用于各种应用,包括以更具创意的方式撰写内容。Hugging Face Transformers 库是一个预训练模型库,它简化了与这些复杂语言模型的交互。
创意内容的生成可能会很有价值,例如,在数据科学和机器学习的世界中,它可以用于各种方式来美化枯燥的报告、创建合成数据,或简单地帮助讲述更有趣的故事。本教程将指导你如何使用 GPT-2 和 Hugging Face Transformers 库来生成创意内容。请注意,我们在这里使用 GPT-2 模型是由于其简便和适中的大小,但替换为其他生成模型将遵循相同的步骤。
设置环境
在开始之前,我们需要设置我们的环境。这将涉及安装和导入必要的库及所需的包。
安装必要的库:
pip install transformers torch
导入所需的包:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
你可以在 这里 了解 Hugging Face 的自动类和自动模型。继续阅读。
加载模型和分词器
接下来,我们将在脚本中加载模型和分词器。在这个案例中,模型是 GPT-2,而分词器负责将文本转换为模型可以理解的格式。
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
注意,更改上面的 model_name 可以切换不同的 Hugging Face 语言模型。
为生成准备输入文本
为了让我们的模型生成文本,我们需要提供模型一个初始输入或提示。这个提示将被分词器进行分词处理。
prompt = "Once upon a time in Detroit, "
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
请注意,return_tensors='pt' 参数确保返回 PyTorch 张量。
生成创造性内容
一旦输入文本被标记化并准备好输入模型,我们就可以使用模型生成创造性内容。
gen_tokens = model.generate(input_ids, do_sample=True, max_length=100, pad_token_id=tokenizer.eos_token_id)
gen_text = tokenizer.batch_decode(gen_tokens)[0]
print(gen_text)
使用高级设置自定义生成
为了增加创造性,我们可以调整温度,并使用 top-k 采样和 top-p(核)采样。
调整温度:
gen_tokens = model.generate(input_ids,
do_sample=True,
max_length=100,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id)
gen_text = tokenizer.batch_decode(gen_tokens)[0]
print(gen_text)
使用 top-k 采样和 top-p 采样:
gen_tokens = model.generate(input_ids,
do_sample=True,
max_length=100,
top_k=50,
top_p=0.95,
pad_token_id=tokenizer.eos_token_id)
gen_text = tokenizer.batch_decode(gen_tokens)[0]
print(gen_text)
创造性内容生成的实际示例
这里是一些使用 GPT-2 生成创造性内容的实际示例。
# Example: Generating story beginnings
story_prompt = "In a world where AI contgrols everything, "
input_ids = tokenizer(story_prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids,
do_sample=True,
max_length=150,
temperature=0.4,
top_k=50,
top_p=0.95,
pad_token_id=tokenizer.eos_token_id)
story_text = tokenizer.batch_decode(gen_tokens)[0]
print(story_text)
# Example: Creating poetry lines
poetry_prompt = "Glimmers of hope rise from the ashes of forgotten tales, "
input_ids = tokenizer(poetry_prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids,
do_sample=True,
max_length=50,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id)
poetry_text = tokenizer.batch_decode(gen_tokens)[0]
print(poetry_text)
总结
通过尝试不同的参数和设置可以显著影响生成内容的质量和创造性。GPT,特别是我们都熟知的较新版本,在创造性领域具有巨大的潜力,使数据科学家能够生成引人入胜的叙述、合成数据等。进一步阅读可考虑探索 Hugging Face 文档及其他资源,以加深理解和扩展技能。
遵循本指南后,你现在应该能够利用 GPT-3 和 Hugging Face Transformers 的强大功能,为数据科学及其他领域生成创造性内容。
欲了解更多相关信息,请查看以下资源:
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编,以及 Machine Learning Mastery 的贡献编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他致力于在数据科学社区中普及知识。Matthew 从 6 岁起便开始编程。
更多相关主题
如何使用 Hugging Face AutoTrain 对 LLM 进行微调
原文:
www.kdnuggets.com/how-to-use-hugging-face-autotrain-to-finetune-llms

编辑器提供的图片
介绍
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全领域
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织进行 IT 工作
近年来,大型语言模型(LLM)改变了人们的工作方式,并已在教育、营销、研究等多个领域得到应用。鉴于其潜力,LLM 可以被增强以更好地解决我们的业务问题。这就是我们可以进行 LLM 微调的原因。
我们希望对 LLM 进行微调的原因包括采用特定领域的用例、提高准确性、数据隐私和安全、控制模型偏见等。鉴于所有这些好处,学习如何对 LLM 进行微调是非常重要的,以便将其投入生产。
自动进行 LLM 微调的一种方法是使用Hugging Face 的 AutoTrain。HF AutoTrain 是一个无代码平台,提供 Python API,用于训练各种任务(如计算机视觉、表格数据和自然语言处理任务)的先进模型。即使我们对 LLM 微调过程了解不多,我们仍然可以利用 AutoTrain 的能力。
那么,它是如何工作的呢?让我们进一步探索。
开始使用 AutoTrain
即使 HF AutoTrain 是一个无代码解决方案,我们仍然可以在 AutoTrain 的基础上使用 Python API 进行开发。我们将探索代码路径,因为无代码平台在训练时并不稳定。然而,如果你想使用无代码平台,我们可以通过以下页面创建 AutoTrain 空间。整体平台将在下图中显示。
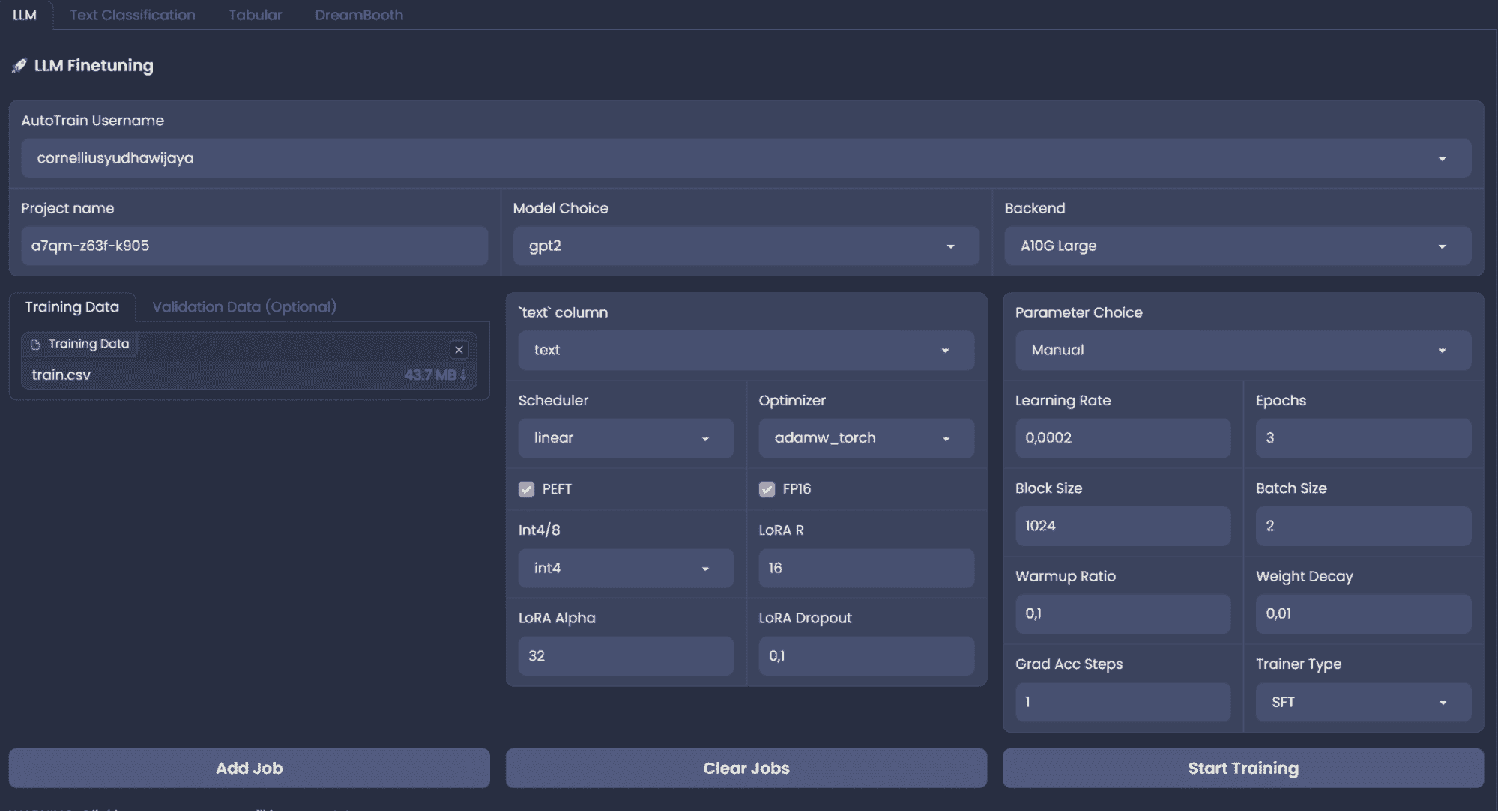
作者提供的图片
要使用 Python API 对 LLM 进行微调,我们需要安装 Python 包,可以使用以下代码运行。
pip install -U autotrain-advanced
我们还会使用来自HuggingFace的 Alpaca 样本数据集,该数据集需要通过数据集包进行获取。
pip install datasets
然后,使用以下代码获取我们需要的数据。
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("tatsu-lab/alpaca")
train = dataset['train']
此外,我们会将数据保存为 CSV 格式,因为我们在微调过程中需要它们。
train.to_csv('train.csv', index = False)
在环境和数据集准备好之后,让我们尝试使用 HuggingFace AutoTrain 来微调我们的 LLM。
微调过程和评估
我将从 AutoTrain 示例中调整微调过程,我们可以在 这里 找到。为了开始这个过程,我们将要微调的数据放入名为 data 的文件夹中。

作者提供的图片
在本教程中,我尝试仅采样 100 行数据,以便我们的训练过程可以更快。数据准备好后,我们可以使用 Jupyter Notebook 来微调模型。确保数据中包含‘text’列,因为 AutoTrain 只会从该列读取。
首先,让我们使用以下命令运行 AutoTrain 设置。
!autotrain setup
接下来,我们将提供运行 AutoTrain 所需的信息。下面的信息是关于项目名称和你想要的预训练模型。你只能选择 HuggingFace 中可用的模型。
project_name = 'my_autotrain_llm'
model_name = 'tiiuae/falcon-7b'
然后我们将添加 HF 信息,如果你想将模型推送到仓库或使用私有模型。
push_to_hub = False
hf_token = "YOUR HF TOKEN"
repo_id = "username/repo_name"
最后,我们将在下面的变量中初始化模型参数信息。你可以根据需要修改这些变量,以查看结果是否良好。
learning_rate = 2e-4
num_epochs = 4
batch_size = 1
block_size = 1024
trainer = "sft"
warmup_ratio = 0.1
weight_decay = 0.01
gradient_accumulation = 4
use_fp16 = True
use_peft = True
use_int4 = True
lora_r = 16
lora_alpha = 32
lora_dropout = 0.045
在所有信息准备好之后,我们将设置环境以接受我们之前设置的所有信息。
import os
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["PUSH_TO_HUB"] = str(push_to_hub)
os.environ["HF_TOKEN"] = hf_token
os.environ["REPO_ID"] = repo_id
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["GRADIENT_ACCUMULATION"] = str(gradient_accumulation)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["USE_PEFT"] = str(use_peft)
os.environ["USE_INT4"] = str(use_int4)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)
在我们的 notebook 中运行 AutoTrain,我们将使用以下命令。
!autotrain llm \
--train \
--model ${MODEL_NAME} \
--project-name ${PROJECT_NAME} \
--data-path data/ \
--text-column text \
--lr ${LEARNING_RATE} \
--batch-size ${BATCH_SIZE} \
--epochs ${NUM_EPOCHS} \
--block-size ${BLOCK_SIZE} \
--warmup-ratio ${WARMUP_RATIO} \
--lora-r ${LORA_R} \
--lora-alpha ${LORA_ALPHA} \
--lora-dropout ${LORA_DROPOUT} \
--weight-decay ${WEIGHT_DECAY} \
--gradient-accumulation ${GRADIENT_ACCUMULATION} \
$( [[ "$USE_FP16" == "True" ]] && echo "--fp16" ) \
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" ) \
$( [[ "$USE_INT4" == "True" ]] && echo "--use-int4" ) \
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )
如果你成功运行 AutoTrain,你应该在目录中找到以下文件夹,其中包含 AutoTrain 生成的所有模型和标记器。
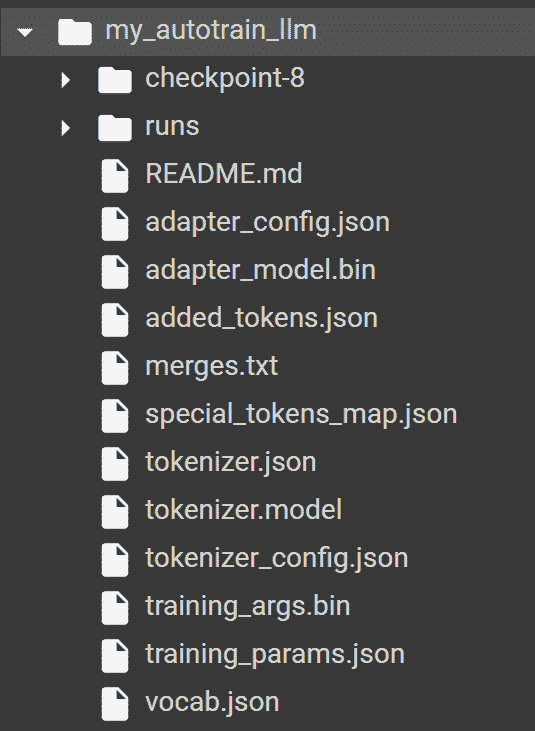
作者提供的图片
为了测试模型,我们将使用 HuggingFace transformers 包,代码如下。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "my_autotrain_llm"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
然后,我们可以根据提供的训练输入来评估模型。例如,我们使用“规律锻炼的健康益处”作为输入。
input_text = "Health benefits of regular exercise"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids)
predicted_text = tokenizer.decode(output[0], skip_special_tokens=False)
print(predicted_text)

结果肯定还有提升空间,但至少比我们提供的样本数据更接近。我们可以尝试调整预训练模型和参数来改善微调效果。
成功微调的技巧
有一些最佳实践你可能想要了解,以改善微调过程,包括:
-
准备我们的数据集,确保质量符合代表性任务,
-
研究我们使用的预训练模型,
-
使用适当的正则化技术以避免过拟合,
-
尝试从较小的学习率开始,逐渐增大,
-
使用更少的 epoch 进行训练,因为 LLM 通常对新数据的学习速度较快,
-
不要忽视计算成本,因为随着数据、参数和模型的增大,计算成本会变得更高,
-
确保你遵循有关数据使用的伦理考虑。
结论
微调我们的大型语言模型对我们的业务流程有益,特别是当有特定要求时。通过 HuggingFace AutoTrain,我们可以加快训练过程,并轻松使用现有的预训练模型来进行微调。
Cornellius Yudha Wijaya**** 是数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和撰写媒体分享 Python 和数据技巧。Cornellius 涉及多种 AI 和机器学习主题的撰写。
更多相关主题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号