KDNuggets-博客中文翻译-二-
KDNuggets 博客中文翻译(二)
原文:KDNuggets
从高效数据科学家身上学到的 15 个习惯
原文:
www.kdnuggets.com/2021/03/15-habits-learned-from-highly-effective-data-scientists.html
评论
作者:Madison Hunter,地球科学本科生

图片由Evgeny Tchebotarev提供,来源于Pexels
当涉及到进入数据科学领域时,你需要利用所有书中的技巧,给自己那个推动你越过终点线的优势。
那么,为什么不尝试效仿业界最佳的习惯呢?
本文不是一种“快速致富”的方法来成为一个高效的数据科学家。相反,它展示了帮助最佳数据科学家达到他们现状的习惯。
人们常说数据科学家的价值取决于他们对组织的影响力。这种影响力始于通过培养良好习惯成为一个高效且有效的数据科学家。
1. 跟上技术的最新发展。
有多少当前的数据科学技术是仅在过去十年左右才出现的?几乎所有的。
通过带着你要全力以赴的动机进入数据科学领域,你已经把自己投入到了终身不断学习的状态中。别担心,这并不像听起来那么悲观。
然而,你需要时刻铭记的是,为了在职场中保持相关性,你需要跟上技术的最新发展。因此,如果你整个职业生涯都在使用 MATLAB 进行数据分析,可以尝试学习 Python 编程。如果你一直用 Matplotlib 创建可视化,尝试使用 Plotly 来获得一些新的体验。
如何实施这个习惯: 每周花一个小时(或尽可能多的时间)尝试新技术。通过阅读博客文章了解哪些技术相关,挑选几个你想加入到你的技术栈中。然后,创建一些个人项目,学习如何最好地使用这些新技术。
2. 保持适当的文档记录。
我总是有幸阅读和处理文档记录极差且没有支持性注释的代码,以帮助我理解到底发生了什么。
我曾经把这归结为程序员的感慨,直到有一天,我意识到这只是一个糟糕程序员的标志。
我处理过的所有优秀程序员都提供清晰、简明的文档来支持他们的工作,并在程序中添加有用的注释来描述某些代码行的功能。这对于使用复杂算法和机器学习模型解决问题的数据科学家尤其重要。
如何实施这一习惯: 花些时间阅读优秀的代码文档或关于如何编写优秀代码文档的文章。为了练习,可以为旧的个人项目编写文档,或者花时间更新当前项目的文档。由于数据科学界很大程度上依赖 Python,可以查看这篇关于如何文档化 Python 代码的优秀文章:
Python 代码文档化:完整指南 - Real Python
欢迎来到你全面的 Python 代码文档编写指南。无论你是在文档化一个小脚本还是一个大型项目…
3. 参与数据科学社区。
将开发者刻板印象为皮肤苍白的社会孤立者,锁在孤独中编写旨在统治世界的代码,这种陈旧的概括并不能反映现代技术行业的复杂性。
“没有人是孤岛。” —— 许多数据科学家最喜欢的名言
数据科学的复杂性使得在数据科学社区内外需要一个庞大的支持网络,以解决各种使数据科学家变得必要的问题。
然而,社区的重要性不仅仅局限于专业层面。随着数据科学领域的扩展,有必要帮助铺平未来分析师和工程师的道路,使他们也能产生影响,并进一步支持其他数据科学家。
随着数据科学领域的“性感”逐渐减退,进行必要的改变的唯一办法是发起一个社区范围的运动,激励行业向更好的方向发展。
如何实施这一习惯: 成为导师,撰写信息丰富的博客文章,加入数据科学论坛并帮助解答问题,开设 Youtube 频道分享你的经验,参加 Kaggle 比赛和黑客马拉松,或创建课程帮助未来的数据科学家学习他们需要的技能,以进入这一行业。
4. 定期重构你的代码。
重构是清理你的代码而不改变其原始功能的过程。虽然重构是软件开发过程中出于必要而产生的,但对于数据科学家来说,重构也是一个有用的习惯。
我在重构时的座右铭是 “少即是多”。
我发现,当我最初编写代码解决数据科学问题时,我通常会抛弃良好的编码实践,转而编写能在需要时工作的代码。换句话说,经常会出现大量的“意大利面条”代码。然后,在我的解决方案工作后,我会回过头来清理我的代码。
如何实施这个习惯: 查看旧代码,问自己是否可以更高效地编写相同的代码。如果可以,花时间了解最佳编码实践,并寻找缩短、优化和澄清代码的方法。查看这篇概述代码重构最佳实践的精彩文章:
代码重构是在 DevOps 软件开发方法中使用的一个过程,涉及编辑和清理…
5. 优化你的工作空间、工具和工作流程。
市面上有许多提高生产力的 IDE 扩展,令人惊讶的是,有些人还没有选择优化他们的工作流程。
这种习惯对每个人来说都是独特的,它实际上取决于哪些工具、工作空间和工作流程使你成为最有效率的数据科学家。
如何实施这个习惯: 每年(或更频繁,如果这样对你更有效),评估你的整体有效性和效率,确定你可以改进的地方。这可能意味着早上第一件事是处理你的机器学习算法,或者坐在一个运动球上而不是椅子上,或者给你的 IDE 添加一个新的扩展,以便为你检查代码。尝试不同的工作空间、工具和工作流程,直到你达到最佳状态。
6. 专注于理解业务问题。
从我所看到的,数据科学是 75%理解业务问题和 25%编写模型来解决这些问题。
编程、算法和数学是简单的部分。理解如何实施它们以解决特定的业务问题则不那么简单。通过花更多时间理解业务问题和目标,其余的过程将更加顺利。
要理解你所在行业面临的问题,你需要进行一些调查,以收集支持你解决问题的背景信息。例如,你需要了解某个业务的客户需求是什么,或者一家工程公司试图实现的具体目标是什么。
如何实施这个习惯: 花些时间研究你工作的具体公司以及它所在的行业。写一份备忘单,包含公司的主要目标和它可能面临的行业特定问题。别忘了包括你可能想用来解决业务问题的算法或未来可能有用的机器学习模型的想法。每当你发现有用的信息时,都要更新这份备忘单,不久你就会拥有一个关于行业相关信息的宝藏。
7. 采用极简风格。
不,不是生活中的事。在你的代码和工作流程中。
人们常说,最优秀的数据科学家使用最少的代码、最少的数据和最简单的算法来完成任务。
尽管我不希望你立即将极简主义与稀缺性联系起来。当有人讨论代码中的极简主义重要性时,常常会导致人们尝试开发仅用几行代码的极端解决方案。停止这种做法。是的,这很令人印象深刻,但这真的就是你时间的最佳利用吗?
相反,一旦你对数据科学概念感到熟悉,开始寻找优化代码的方法,使其简洁、干净且简短。使用简单的算法来完成任务,不要忘记编写可重用的函数以去除冗余。
如何实施这一习惯: 随着你作为数据科学家的成长,开始推动自己编写更高效的解决方案,减少代码量,使用更简单的算法和模型来完成工作。学会在不降低代码有效性的情况下缩短代码,并留下大量注释以解释精简版本的代码如何工作。
8. 使用函数消除复杂性和冗余。
我承认,在第一次编写数据分析代码时,我严重忽视函数。混乱的代码填满了我的 IDE,我在不同的分析中挣扎。如果你查看我的代码,可能会觉得它已经完全不可救药,并主动提议把它带到谷仓后面去结束它的痛苦。
一旦我设法拼凑出一个还算不错的结果,我就会回去尝试修复类似于严重事故的代码。通过将我的代码打包成函数,我迅速去除了不必要的复杂性和冗余。如果这是我对代码所做的唯一改动,那我已经将代码简化到一个可以重新审视解决方案并理解如何到达这一点的程度。
如何实施这一习惯: 在编写代码时不要忘记函数的重要性。常说最优秀的开发人员是懒惰的开发人员,因为他们知道如何创建不需要太多工作量的解决方案。在编写解决方案之后,回过头来将冗余或复杂的代码打包成函数,以帮助组织和简化你的代码。
9. 应用测试驱动开发方法。
测试驱动开发(TDD)是一种软件开发原则,专注于编写不断改进且经常测试的代码。TDD 运行在“红灯、绿灯、重构”系统上,鼓励开发人员建立测试套件,编写实现代码,然后优化代码库。
TDD 可以由数据科学家成功实施,用于生成分析管道,开发概念验证,处理数据子集,并确保在开发过程中功能代码不会被破坏。
如何养成这个习惯: 研究测试驱动开发,确定这一技术是否能为你的工作流程增添价值。TDD 并不是解决所有问题的完美答案,但如果谨慎实施,它可以是有用的。查看这篇文章,它提供了对 TDD 的极佳描述,并提供了如何将其应用于数据科学项目的示例:
数据科学家和机器学习工程师应从软件开发人员那里学习的另一件事
10. 进行小而频繁的提交。
是否曾经发起拉取请求,然后你的电脑充满了错误信息和各种问题?我有过。那真是糟糕透了。
在你想揍那个做出如此大提交的人时,深呼吸,记住这个人显然没有花时间养成好的习惯。
团队软件开发的黄金法则是什么?进行小而频繁的提交。
如何养成这个习惯: 养成经常提交代码更改的习惯,并同样定期发起拉取请求以获取最新代码。你或其他人所做的每个更改都可能破坏整个项目,因此重要的是要进行易于恢复的小更改,这些更改通常只影响项目的一部分或层级。
11. 将自我发展放在优先位置。
根据你问的对象,行业内数据科学家的数量可能要么太多,要么太少。
不管行业是否变得饱和或干旱,你将与大量高素质且常常过于资深的候选人竞争一个职位。这意味着在申请工作的前期,你需要已经养成自我提升的习惯。如今,大家都热衷于提升技能,这是有原因的。数据科学家也不应例外。
如何养成这个习惯: 制定技能清单,查看你如何满足雇主在招聘广告中列出的要求。你是一个能高效使用 Keras、NumPy、Pandas、PyTorch、TensorFlow、Matplotlib、Seaborn 和 Plotly 等相关库的 Python 专家吗?你能写一份详细说明你最新发现以及这些发现如何使公司效率提高 25%的备忘录吗?你是否能舒适地与团队合作完成项目?识别任何短板,并找到一些好的在线课程或资源来提升你的技能。
12. 从终点开始着手项目。
在高效能人士的七个习惯中,斯蒂芬·柯维讨论了“从终点开始”的原则。
为了有效地将其与数据科学项目联系起来,你需要在项目规划阶段问自己项目的期望结果是什么。这将帮助你塑造项目路径,并为你提供一个实现最终目标的成果路线图。除此之外,确定项目结果还将让你了解整个项目的可行性和可持续性。
如何实施这个习惯: 在每个项目开始时进行规划会议,明确你希望在开发周期结束时实现的目标。确定你将尝试解决的问题或收集的证据。然后,你可以开始回答将塑造项目里程碑和成果的可行性和可持续性问题。从那里开始,你可以在明确的计划指导下开始编写代码和机器学习模型,直到项目完成。
13. 理解,以便你能被理解。
在尝试准备一场关于自旋-V2 粒子如何遵循费米-狄拉克统计的入门讲座失败后,理查德·费曼 曾著名地说:“我无法将其简化到入门水平。这意味着我们真的不理解它。”被称为“伟大的解释者”,费曼留下了一个数据科学家只能希望模仿的遗产。
数据科学,利用数据讲述引人入胜的故事的艺术,只有当讲述者理解他们所讲述的故事时才会成功。换句话说,你的任务是理解,以便你能被理解。及早养成理解你想要完成的目标的习惯,以便你能与他人分享并达到合理的理解水平,将使你成为房间里最有效的数据科学家。
如何实施这个习惯: 使用 费曼技巧 来深入理解你正在尝试发现的概念和你正在解决的问题。这种方法与数据科学过程中的数据分析及向非数据科学利益相关者解释结果的过程非常契合。简而言之,你将对主题的解释精炼到可以用简单的非术语语言进行解释,使任何人都能理解。
14. 阅读研究论文。
在一个由硕士和博士主导的领域中,研究论文通常用于分享行业新闻和见解。
研究论文 是了解他人如何解决问题、拓宽视野以及跟上最新趋势的有效方式。
如何实施这个习惯: 每周挑选一到两篇与你当前工作相关或你有兴趣追踪或学习的技术的研究论文阅读。尝试每周抽时间进行文献回顾,使其成为优先事项。熟悉 三遍阅读法,帮助你快速获取相关信息。为了真正巩固对论文的理解,尝试将你从阅读中学到的东西应用到个人项目中,或与工作同事分享你学到的内容。
15. 对改变保持开放。
数据科学的世界正在快速变化,从使用的技术到达到的目标都在不断演变。不要成为那个固守旧有方法、不愿改变的数据科学家。
开放改变不仅迫使你持续提升自己的专业能力,还能使你在快速变化的行业中保持相关性,否则一旦落后就会被淘汰。
如何实施这个习惯: 每当有新技术或新实践成为新闻时,尝试使用一下,看看这些新技术或实践能带来什么。即使你只是阅读文档,也能让自己了解行业的变化趋势。此外,你可以将对技术的见解带到公司,帮助他们应对技术变化和进步。在办公室中保持敏锐的触觉可以帮助你走在前沿,同时也能帮助你指导团队和公司找到更好、更高效的解决方案。
在你数据科学职业生涯的任何阶段,养成良好的习惯可以使你充分发挥潜力,成为团队中有效的成员,对他们试图解决的任何问题产生巨大影响。
现在是为未来成功做好准备的最佳时机。
简介:Madison Hunter 是一名地球科学本科生,软件开发毕业生。Madison 发表关于数据科学、环境和 STEM 的随笔。
原文。经授权转载。
相关:
-
如何在没有工作经验的情况下获得你的第一份数据科学工作
-
如何成功成为一名自由职业数据科学家
-
阅读论文如何帮助你成为更有效的数据科学家
相关主题
15 个数学 MOOC 课程,专注于数据科学
原文:
www.kdnuggets.com/2015/09/15-math-mooc-data-science.html/2
8. 线性代数应用第二部分
学校: 大卫森学院
平台: edX
讲师: Tim Chartier,等人
日期: 存档材料(任何时间)
描述摘录: 这门课侧重于数据挖掘及其在计算机图形学中的应用。我们将深入讨论体育排名和如何从数千场比赛中评估团队。我们将应用这些方法到“疯狂三月”中。我们还将学习搜索引擎背后的方法,这些方法被 Google 等公司所利用。我们还将学习如何对数据进行聚类,以寻找相似的群体,并学习如何压缩图像以减少存储使用量。
微积分
对微积分的理解可以帮助实践者从理解变化的角度进行思考。
9. 微积分一
学校: 俄亥俄州立大学
平台: Coursera
讲师: Jim Fowler
日期: 自定进度(任何时间)
描述摘录: 微积分涉及非常大的、非常小的事物及其变化。令人惊讶的是,这些看似抽象的内容最终解释了现实世界。微积分在生物学、物理学和社会科学中扮演着重要角色。通过关注课外的例子,我们将看到微积分在日常生活中的应用。
统计学
数据科学的数学核心。这些课程从基础统计主题开始,最后涉及 R 中的一些探索性分析。
10. 统计学导论:描述性统计
学校: 加州大学伯克利分校
平台: edX
讲师: Ani Adhikari 和 Philip B. Stark
日期: 存档材料(任何时间)
描述摘录: Stat2.1x 课程侧重于描述性统计。描述性统计的目标是以有启发性和有用的方式总结和展示数据信息。课程将涵盖数据的图形和数值总结,从单变量开始,逐步进展到两个变量之间的关系。方法将通过来自科学和人文学科的各种领域的数据进行说明。
11. 统计学导论:概率
学校: 加州大学伯克利分校
平台: edX
讲师: Ani Adhikari 和 Philip B. Stark
日期: 存档材料(任何时间)
描述摘录: Stat2.2x 的重点是概率论:什么是随机样本,随机性是如何工作的?如果你买 10 张彩票而不是 1 张,你的中奖机会会提高 10 倍吗?什么是平均法则?调查如何基于来自少量人群的数据做出准确预测?你应该期望“偶然”发生什么?这些是我们将在课程中讨论的一些问题。
12. 统计学简介:推断
学校: 加州大学伯克利分校
平台: edX
讲师: Ani Adhikari 和 Philip B. Stark
时间: 存档材料(任何时间)
描述摘录: Stat 2.3x 将讨论选择子集的好方法(是的,随机选择);如何根据你在样本中看到的内容来估计感兴趣的数量;以及测试关于数值或概率方面问题的假设的方法。
13. 使用 R 进行统计探索
学校: 卡罗林斯卡学院
平台: edX
讲师: Andreas Montelius 等
时间: 自定进度(任何时间)
描述摘录: 你想学习如何从互联网上收集健康科学数据吗?还是想通过数据分析了解世界?首先学习 R 统计学吧!学习如何使用 R,这是一种强大的开源统计编程语言,并了解为什么它在许多行业中成为首选工具。
高级
一些稍微高级的话题,涉及优化和应用线性代数。
14. 离散优化
学校: 墨尔本大学
平台: Coursera
时间: 存档材料(任何时间)
描述摘录: 这门课程是离散优化的介绍,向学生展示了该领域的一些最基本的概念和算法。课程涵盖了约束编程、局部搜索和混合整数编程,从其基础知识到应用于复杂实际问题的应用,如调度、车辆路线规划、供应链优化和资源分配。
学校: 布朗大学
平台: Coursera
讲师: Philip Klein
时间: 存档材料(任何时间)
描述摘录:在本课程中,你将学习线性代数的概念和方法,并了解如何使用这些方法思考计算机科学中出现的问题。你将用 Python 编程语言编写小程序,实现基本的矩阵和向量功能及算法,并用这些来处理真实世界的数据。
学校:西部州立大学(及三叉戟大学国际部)
平台:Udemy
讲师:理查德·韩
日期:自定进度(随时)
描述摘录:学习线性代数的核心主题,为数据科学开辟新天地!
简介: 马修·梅奥 是一名计算机科学研究生,目前正在进行关于并行化机器学习算法的论文。他还是数据挖掘的学生,数据爱好者,未来的机器学习科学家。
相关:
-
战略商业分析的新 MOOC 课程
-
你是否在努力获得机器学习技能?
-
前 20 名数据科学 MOOC 课程
更多相关主题
你必须了解的 15 个 Python 编码面试问题
原文:
www.kdnuggets.com/2022/04/15-python-coding-interview-questions-must-know-data-science.html

了解 Python 是每个数据科学家应掌握的关键技能之一。这并非没有理由。Python 的能力,加上 Pandas 库,能够以多种不同方式操控和分析数据,使其成为数据科学工作的理想工具。
我们的前 3 个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯。
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析能力
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
不足为奇的是,所有寻求数据科学家的公司都会在面试中测试他们的 Python 技能。
我们将探讨你应熟悉的技术概念以及 Python/Pandas 函数,以获得数据科学职位。
这是我们将讨论的五个主题:
-
聚合、分组和排序数据
-
联接表
-
数据过滤
-
文本操作
-
日期时间操作
毋庸置疑,这些概念很少单独测试,因此通过解决一个问题,你将展示你对多个 Python 主题的知识。
聚合、分组和排序数据
这三个技术主题通常一起出现,它们是创建报告和进行任何数据分析的基础。
它们允许你执行一些数学操作,并以可表示和用户友好的方式展示你的发现。
我们将向你展示几个实际示例,以确保你了解我们所讨论的内容。
Python 编码面试问题 #1:类性能
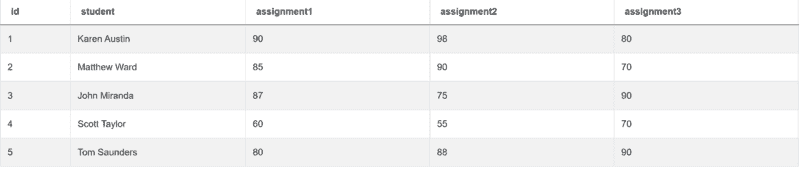
这个 Box 面试问题问你:
“给定一个表,包含班级学生的作业分数。写一个查询,识别所有作业总分的最大差异。输出两个学生之间总分的差异。”
问题链接:platform.stratascratch.com/coding/10310-class-performance?python=1
你需要使用的表是 box_scores,它有以下列:
| id | int64 |
|---|---|
| student | object |
| assignment1 | int64 |
| assignment2 | int64 |
| assignment3 | int64 |
表中的数据如下所示:
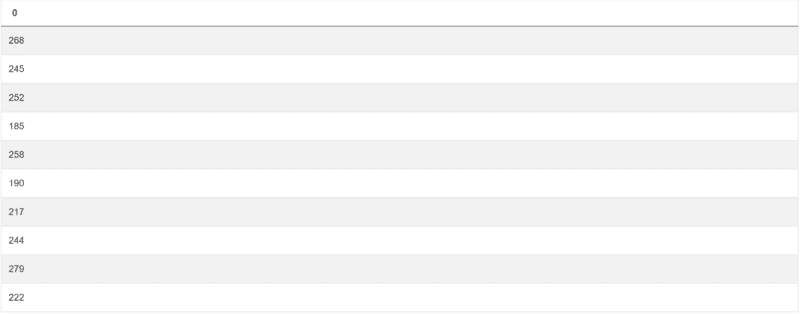
作为回答问题的第一步,你应该汇总所有作业的评分:
import pandas as pd
import numpy as np
box_scores['total_score'] = box_scores['assignment1']+box_scores['assignment2']+box_scores['assignment3']
这部分代码将给你如下结果:
现在你知道了,下一步是找到总分之间的最大差异。你需要使用max()和min()函数来实现这一点。或者,更具体地说,就是这两个函数输出之间的差异。将这部分代码添加到上面的代码中,你就得到了最终答案:
import pandas as pd
import numpy as np
box_scores['total_score'] = box_scores['assignment1']+box_scores['assignment2']+box_scores['assignment3']
box_scores['total_score'].max() - box_scores['total_score'].min()
这是你要找的输出:

问题要求只输出这个差异,所以不需要其他列。
Python 编码面试题 #2:企业检查评分
前一个问题不需要任何数据分组和排序,这与旧金山城市提出的以下问题不同:
这是旧金山城市提出的一个问题:
“找出每个企业的检查评分中位数,并输出结果以及企业名称。根据检查评分的降序排列记录。尽量用你自己精确的中位数计算方法。在 Postgres 中有percentile_disc函数可用,但它只是一个近似值。”
问题链接:platform.stratascratch.com/coding/9741-inspection-scores-for-businesses?python=1
在这里,你应该使用notnull()函数来确保只获取那些有检查评分的企业。此外,你还需要按企业名称分组数据,并计算检查评分的中位数。使用median()函数。此外,使用sort_values()按降序排序输出。
Python 编码面试题 #3:按种类的记录数
看看这个微软的问题:
“找出数据集中每种类别的记录总数。输出类别及其对应的记录数量。按类别的升序排列记录。”
问题链接:platform.stratascratch.com/coding/10168-number-of-records-by-variety?python=1
在前两个示例之后,这个问题应该不难解决。首先,你应该按列的种类和萼片长度进行分组。要查找每种类的记录数,请使用count()函数。最后,使用sort_values按字母顺序对种类进行排序。
表连接
在所有之前的示例中,我们只给出了一张表。我们选择这些示例,以便你更容易理解 Python 中如何进行聚合、分组和排序。
然而,作为数据科学家,你通常需要知道如何编写查询来从多个表格中提取数据。
Python 编程面试题 #4:最低价格订单
在 Python 中连接两个表格的最简单方法之一是使用 merge() 函数。我们将使用它来解决亚马逊问题:
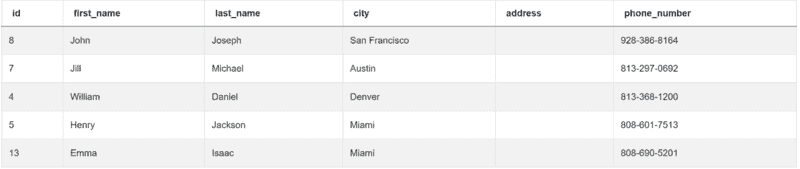
“查找每个客户的最低订单成本。输出客户 id 以及名字和最低订单价格。”
链接到问题:platform.stratascratch.com/coding/9912-lowest-priced-orders?python=1
你需要处理两个表格。第一个表格是 customers:
| id | int64 |
|---|---|
| first_name | object |
| last_name | object |
| city | object |
| address | object |
| phone_number | object |
这是数据:
第二个表格名为 orders,包含以下列:
| id | int64 |
|---|---|
| cust_id | int64 |
| order_date | datetime64[ns] |
| order_details | object |
| total_order_cost | int64 |
数据如下:
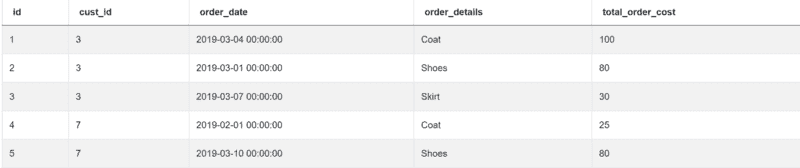
由于你需要两个表格中的数据,因此你必须合并或进行内连接:
import pandas as pd
import numpy as np
merge = pd.merge(customers, orders, left_on="id", right_on="cust_id")
你可以在 customers 表的 id 列和 orders 表的 cust_id 列上进行此操作。结果显示为两个表格合并成一个:
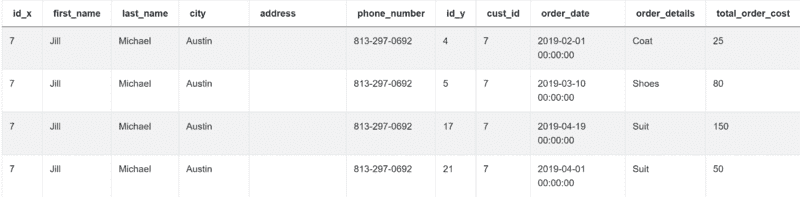
一旦完成,使用 groupby() 函数按 cust_id 和 first_name 分组输出。这些是问题要求你展示的列。你还需要显示每个客户的最低订单成本,这可以通过 min() 函数来实现。
完整的答案如下:
import pandas as pd
import numpy as np
merge = pd.merge(customers, orders, left_on="id", right_on="cust_id")
result = merge.groupby(["cust_id", "first_name"])["total_order_cost"].min().reset_index()
该代码返回所需的输出。
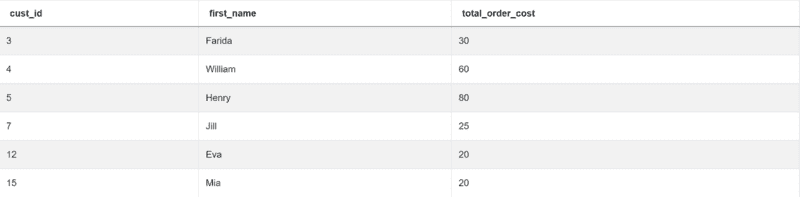
Python 编程面试题 #5:按职位和性别统计收入
这里,我们还有一个来自旧金山的问题:
“根据员工的职位和性别计算平均总薪酬。总薪酬通过将每个员工的工资和奖金相加来计算。”
然而,并非每个员工都会收到奖金,因此在计算时忽略没有奖金的员工。员工可以收到多个奖金。
输出员工职位、性别(即 sex)以及平均总薪酬。
链接到问题:platform.stratascratch.com/coding/10077-income-by-title-and-gender?python=1
回答这个问题时,第一步应是按工人和奖金进行分组,同时使用 sum() 函数获取每个工人 id 的奖金。然后你应该合并你拥有的表格。这也是内连接。完成后,你可以通过将工资和奖金相加来获得总薪酬。最后一步是输出员工职位、性别和平均总薪酬,这可以通过使用 mean() 函数获得。
Python 编程面试问题 #6:产品交易数量
这是微软的问题:
“找出每个产品发生的交易数量。输出产品名称以及相应的交易数量,并按产品 ID 升序排列记录。你可以忽略没有交易的产品。”
问题链接:platform.stratascratch.com/coding/10163-product-transaction-count?python=1
下面是一些编写代码的提示。首先,你应该使用 notnull() 函数获取至少有一笔交易的产品。接下来,使用 merge() 函数将该表与 excel_sql_inventory_data 表进行内连接。使用 groupby() 和 transform() 函数获取交易数量。然后,去除重复的产品,并显示每个产品的交易数量。最后,按 product_id 排序输出。
数据过滤
当你使用 Python 时,通常会处理大量数据。然而,你不需要输出所有数据,因为那样做没有意义。
数据分析还包括设置某些标准以仅提取你想在输出中看到的数据。为此,你应该使用某些数据过滤方法。
虽然 merge() 也以某种方式过滤数据,但这里我们讨论的是使用比较操作符(==、<、>、<=、>=)、between() 或其他方法来限制输出中的行数。让我们看看在 Python 中是如何做到的!
Python 编程面试问题 #7:找到 2010 年排名前 10 的歌曲
这是你在 Spotify 面试中可能会被问到的问题:
“2010 年排名前 10 的歌曲是什么?输出排名、组合名称和歌曲名称,但不要重复显示相同的歌曲。根据 year_rank 升序排列结果。”
问题链接:platform.stratascratch.com/coding/9650-find-the-top-10-ranked-songs-in-2010?python=1
解决问题时,你只需要表 billboard_top_100_year_end:
| id | int64 |
|---|---|
| year | int64 |
| year_rank | int64 |
| group_name | object |
| artist | object |
| song_name | object |
表中的数据如下:
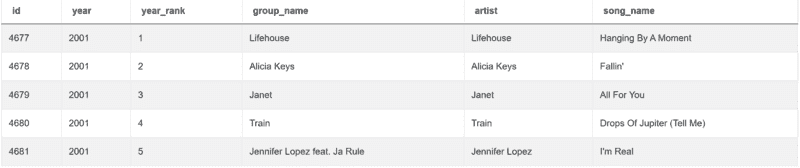
这是我们解答问题的方法。
import pandas as pd
import numpy as np
conditions = billboard_top_100_year_end[(billboard_top_100_year_end['year'] == 2010) & (billboard_top_100_year_end['year_rank'].between(1,10))]
上述代码设置了两个条件。第一个是使用 ‘==’ 操作符,通过它我们选择 2010 年出现的歌曲。第二个条件选择排名在 1 到 10 之间的歌曲。
运行此代码的结果为:
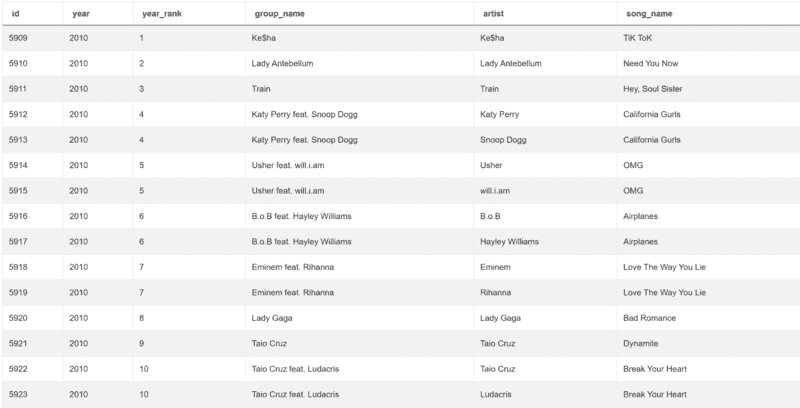
之后,我们只需要选择三列:year_rank、group_name 和 song_name。我们还将使用 drop_duplicates() 函数删除重复项。
这使得代码完整:
import pandas as pd
import numpy as np
conditions = billboard_top_100_year_end[(billboard_top_100_year_end['year'] == 2010) & (billboard_top_100_year_end['year_rank'].between(1,10))]
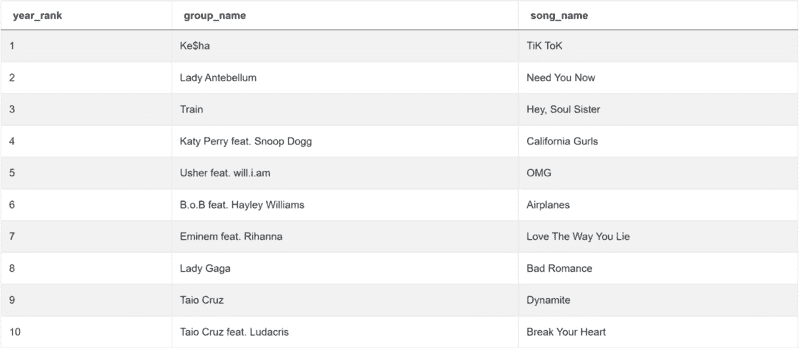
result = conditions[['year_rank','group_name','song_name']].drop_duplicates()
它将给你 2010 年排名前 10 的歌曲:
Python 编码面试问题 #8:纽约市和哈莱姆区的公寓
尝试解决 Airbnb 的问题:
“找到纽约市哈莱姆区 50 个公寓搜索的详细信息。”
问题链接:platform.stratascratch.com/coding/9616-apartments-in-new-york-city-and-harlem?python=1
这里有一些提示。你需要设置三个条件,只获取公寓类别,只包含哈莱姆区的公寓,且城市必须是纽约市。所有三个条件将使用‘==’操作符设置。你不需要展示所有公寓,因此使用 head()函数限制输出的行数。
Python 编码面试问题 #9:重复邮箱
上一个问题集中于数据筛选,出自 Salesforce:
“找到所有有重复的邮箱。”
问题链接:platform.stratascratch.com/coding/9895-duplicate-emails?python=1
这个问题相对简单。你需要使用 groupby()函数按邮箱分组,并找出每个邮箱地址出现的次数。然后对邮箱地址数量使用‘>’操作符,以获取重复项。
操作文本
在处理数据时,你需要对数据进行操作,以使其更适合你的分析。这通常适用于文本数据。它包括根据存储的文本分配新的值,解析和合并文本,或查找其长度、特定字母的位置、符号等。
Python 编码面试问题 #10:评论数量的分类
下一个问题出自 Airbnb:
“为了更好地理解评论数量对住宿价格的影响,将评论数量分为以下几个组别,并考虑价格。”
* 0 条评论:没有*
* 1 到 5 条评论:少量*
* 6 到 15 条评论:一些*
* 16 到 40 条评论:许多*
* 超过 40 条评论:很多*
输出价格及其分类。按住宿级别进行分类。**“
问题链接:platform.stratascratch.com/coding/9628-reviews-bins-on-reviews-number?python=1
你正在处理的只有一个表,但列相当多。该表是 airbnb_search_details,列有:
| id | int64 |
|---|---|
| price | float64 |
| property_type | object |
| room_type | object |
| amenities | object |
| accommodates | int64 |
| bathrooms | int64 |
| bed_type | object |
| cancellation_policy | object |
| cleaning_fee | bool |
| city | object |
| host_identity_verified | object |
| host_response_rate | object |
| host_since | datetime64[ns] |
| neighbourhood | object |
| number_of_reviews | int64 |
| review_scores_rating | float64 |
| zipcode | int64 |
| bedrooms | int64 |
| beds | int64 |
这是表格中的几行前几条数据:

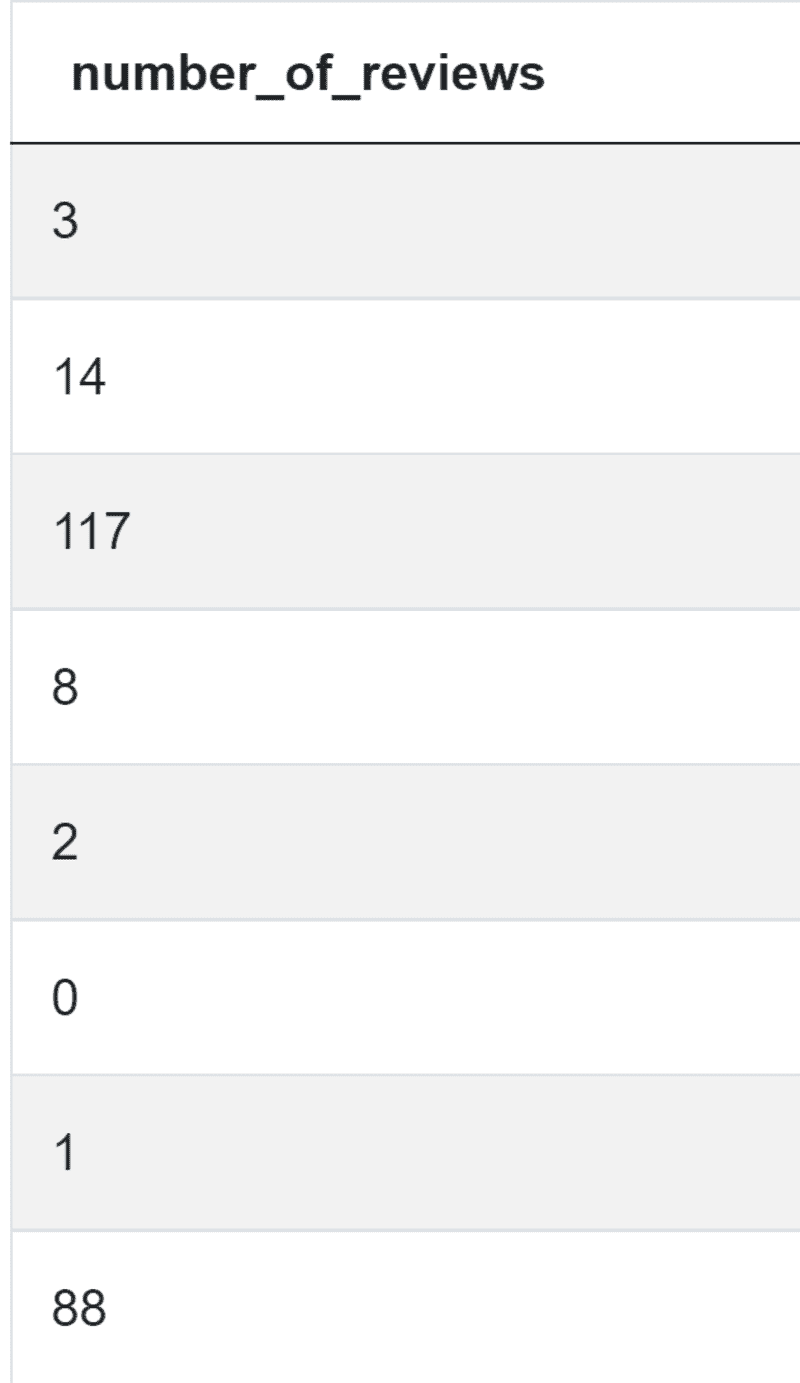
编写代码的第一步应该是获取评论数量。
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
你得到的是:
接下来,你需要获取评论数为 0 的住宿,然后是 1-5,6-15,16-40 和超过 40 条评论的住宿。为了实现这一点,你需要‘==’和‘>’运算符的组合,以及 between()函数。
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
condlist = [num_reviews == 0, num_reviews.between(1,5),num_reviews.between(5,15),num_reviews.between(15,40),num_reviews>40]
这是你当前的输出应如下所示:
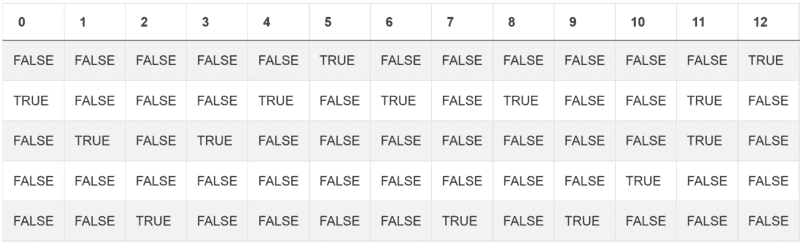
现在开始处理文本,以分配类别。这些类别包括:NO、FEW、SOME、MANY、A LOT。到目前为止,你的代码是:
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
condlist = [num_reviews == 0, num_reviews.between(1,5),num_reviews.between(5,15),num_reviews.between(15,40),num_reviews>40]
choicelist = ['NO','FEW','SOME','MANY','A LOT']
好的,这是你的类别:
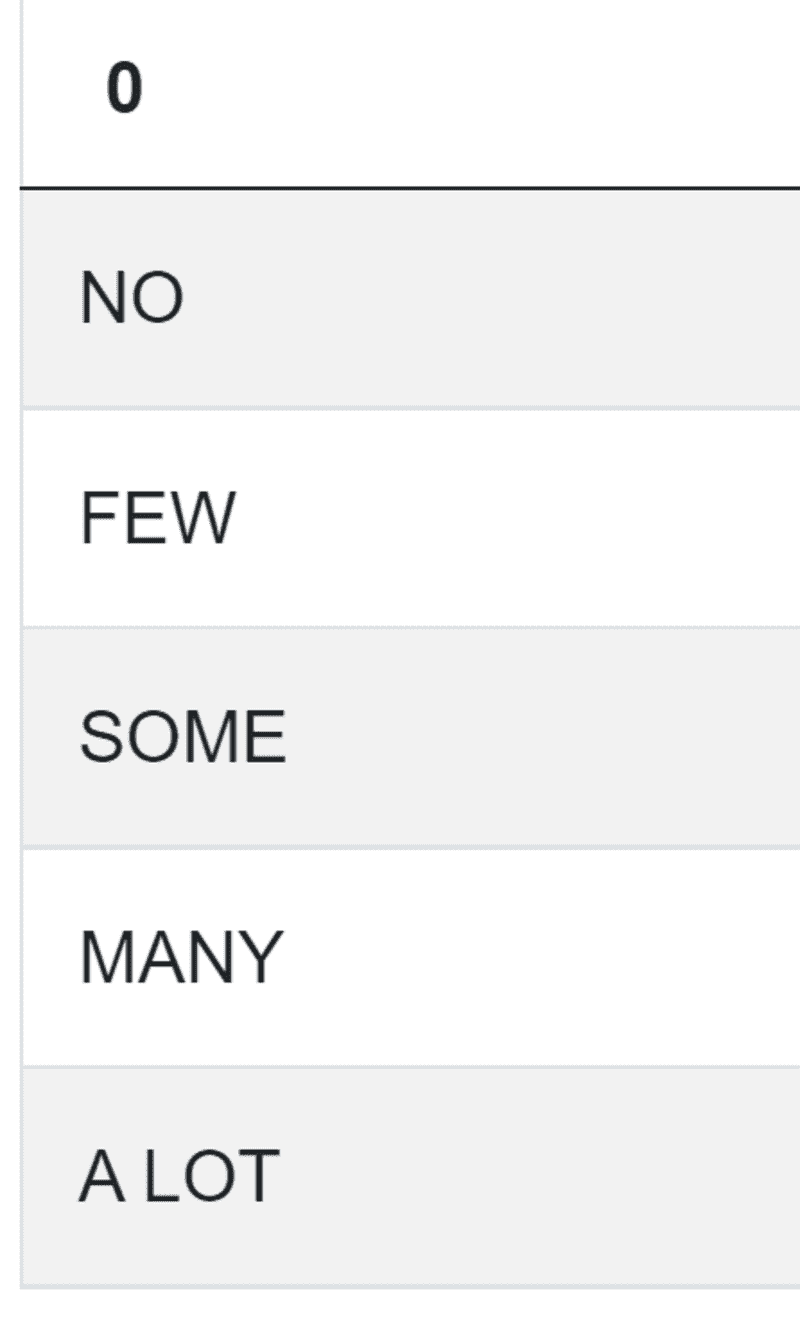
最后一步是将这些类别分配给住宿,并列出其价格:
import pandas as pd
import numpy as np
num_reviews = airbnb_search_details['number_of_reviews']
condlist = [num_reviews == 0, num_reviews.between(1,5),num_reviews.between(5,15),num_reviews.between(15,40),num_reviews>40]
choicelist = ['NO','FEW','SOME','MANY','A LOT']
airbnb_search_details['reviews_qualification'] = np.select(condlist,choicelist)
result = airbnb_search_details[['reviews_qualification','price']]
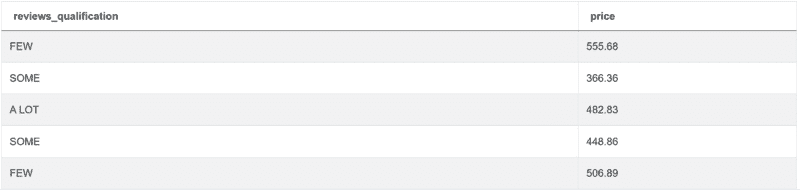
这段代码将为你提供所需的输出:
Python 编程面试题 #11: 商业名称长度
下一个问题是由旧金山市提出的:
“找出每个商业名称中的单词数量。避免将特殊符号计入单词(例如 &)。输出商业名称及其单词数量。”
问题链接: platform.stratascratch.com/coding/10131-business-name-lengths?python=1
在回答问题时,你应该首先使用 drop_duplicates()函数找到唯一的商业名称。然后使用 replace()函数将所有特殊符号替换为空白,这样你就不会在后续计算中计入这些符号。使用 split()函数将文本拆分为列表,然后使用 len()函数计算单词数量。
Python 编程面试题 #12: 字母'a'的位置
这个问题由亚马逊提出,要求你:
“找到工人'Amitah'名字中字母'a'的位置。使用基于 1 的索引,例如第二个字母的位置是 2。”
问题链接: platform.stratascratch.com/coding/9829-positions-of-letter-a?python=1
解决方案中有两个主要概念。第一个是使用‘==’运算符过滤工人‘Amitah’。第二个是对字符串使用 find()函数以获取字母‘a’的位置。
操作日期时间

作为数据科学家,你将经常处理日期。根据可用的数据,你可能需要将数据转换为日期时间格式,提取某个时间段(如月份或年份),或以其他适当的方式操作日期时间。
Python 编码面试题#13:过去 30 天每个用户的评论数量
Meta/Facebook 提出的问题如下:
“返回每位用户在过去 30 天内收到的评论总数。不输出在定义时间段内未收到任何评论的用户。假设今天是 2020 年 2 月 10 日。”
问题链接: platform.stratascratch.com/coding/2004-number-of-comments-per-user-in-past-30-days?python=1
你可以在表格 fb_comments_count 中找到数据。
| user_id | int64 |
|---|---|
| created_at | datetime64[ns] |
| number_of_comments | int64 |
数据也在这里:
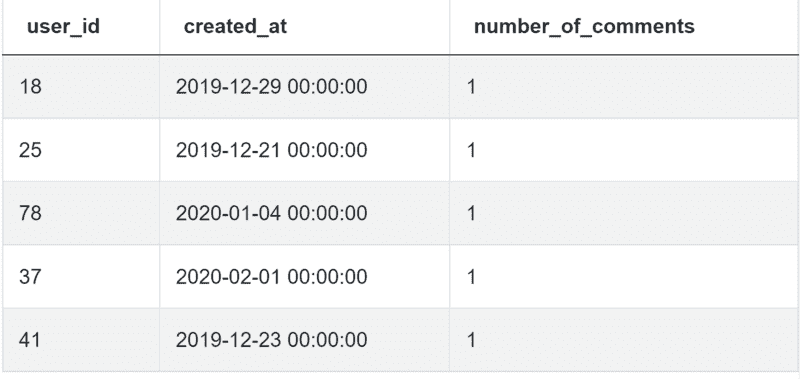
查看解决方案,然后我们将下面解释:
import pandas as pd
from datetime import timedelta
result = fb_comments_count[(fb_comments_count['created_at'] >= pd.to_datetime('2020-02-10') - timedelta(days=30)) & (
fb_comments_count['created_at'] <= pd.to_datetime('2020-02-10'))].groupby('user_id')[
'number_of_comments'].sum().reset_index()
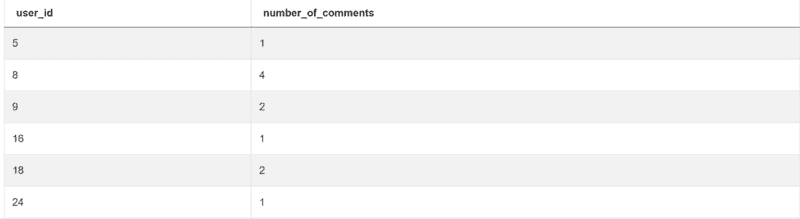
要查找 2020 年 2 月 10 日不超过三十天的评论,首先需要使用to_datetime()函数将日期转换为 datetime 格式。为了得到你感兴趣的评论的最新日期,使用timedelta()函数从今天的日期中减去 30 天。所有你感兴趣的评论日期都等于或大于这个差值。此外,你还需要排除所有在 2020 年 2 月 10 日之后发布的评论。这就是为什么有第二个条件。最后,根据user_id进行分组,并使用sum()函数得到每个用户的评论数量。
如果你做对了所有的步骤,你会得到如下输出:
Python 编码面试题#14:查找用户购买记录
这是 Amazon 提出的问题:
“编写一个查询以识别回访的活跃用户。回访活跃用户是指在任何其他购买后的 7 天内进行了第二次购买的用户。输出这些回访活跃用户的 user_ids 列表。”
问题链接: platform.stratascratch.com/coding/10322-finding-user-purchases?python=1
为了解决这个问题,你需要使用strftime()函数将购买日期格式化为 MM-DD-YYYY 格式。然后使用sort_values()按照用户 ID 和购买日期的升序排序输出。要得到前一个订单,应用shift()函数,按user_id分组,并显示购买日期。
使用to_datetime将订单及前一订单的日期转换为 datetime 格式,然后找出两个日期之间的差异。最后,过滤结果,使其只输出在第一次和第二次购买之间相差七天或更少的用户,并使用unique()函数得到唯一用户。
Python 编码面试题#15:3 月份客户收入
最后的问题由 Meta/Facebook 提出:
“计算 2019 年 3 月每位客户的总收入。仅包括 2019 年 3 月活跃的客户。”
“输出收入及客户 ID,并根据收入按降序排列结果。”
问题链接:platform.stratascratch.com/coding/9782-customer-revenue-in-march?python=1
你需要对列 order_date 使用 to_datetime()。然后从同一列中提取 2019 年 3 月。最后,按 cust_id 分组并对列 total_order_cost 求和,这将是你要找的收入。使用 sort_values() 根据收入降序排列输出结果。
结论
通过展示来自顶级公司的 15 个面试问题,我们涵盖了面试官在测试你的 Python 技能时感兴趣的五个主要话题。
我们从数据的聚合、分组和排序开始。然后我们展示了如何连接表格和过滤输出。最后,你学会了如何操作文本和日期时间数据。
这些当然不是你应该知道的唯一概念。但它应该为你的面试准备和回答一些 更多 Python 面试问题 提供一个良好的基础。
要练习更多的 Python Pandas 函数,请查看我们的帖子“Python Pandas 面试问题”,它将为你提供 Pandas 数据操作的概述以及在 数据科学面试 中常见的 Pandas 问题类型。
内特·罗西迪 是一名数据科学家和产品战略专家。他还是一位兼职教授,教授分析课程,并且是 StrataScratch 的创始人,这个平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。你可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
更多相关话题
优化数据科学管道的 15 个 Python 代码片段
原文:
www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
评论
由 Lucas Soares,K1 Digital 的机器学习工程师

由 Carlos Muza 在 Unsplash 上提供的照片
为什么代码片段对数据科学很重要
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
在我的日常工作中,我需要处理很多类似的情况,从加载 csv 文件到可视化数据。因此,为了帮助简化我的工作流程,我养成了存储在不同情况下有用的代码片段的习惯,从加载 csv 文件到可视化数据。
在这篇文章中,我将分享 15 个代码片段,帮助您处理数据分析管道的不同方面
1. 使用 glob 和列表推导式加载多个文件
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]
2. 从列表中获取唯一值
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'],
dtype=object)
3. 并排显示 pandas 数据框
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])):
# source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side
html_str=''
for df,title in zip(args, chain(titles,cycle(['</br>'])) ):
html_str+='<th style="text-align:center"><td style="vertical-align:top">'
html_str+="<br>"
html_str+=f'<h2>{title}</h2>'
html_str+=df.to_html().replace('table','table style="display:inline"')
html_str+='</td></th>'
display_html(html_str,raw=True)
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
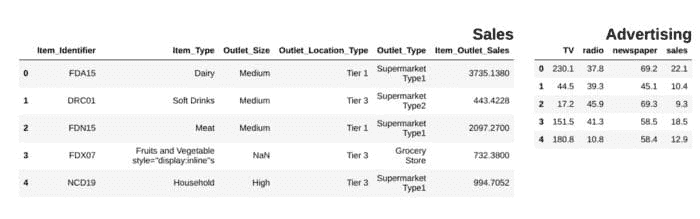
作者提供的图片
4. 删除 pandas 数据框中的所有 NaNs
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. 显示 DataFrame 列中的 NaN 条目数量
def findNaNCols(df):
for col in df:
print(f"Column: {col}")
num_NaNs = df[col].isnull().sum()
print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 2
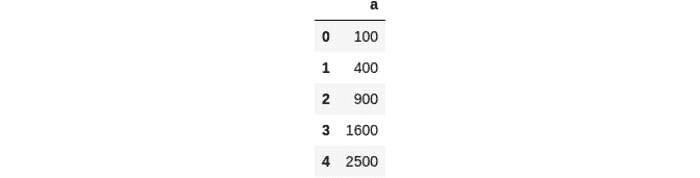
6. 使用 .apply 和 lambda 函数转换列
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df
7. 将两个 DataFrame 列转换为字典
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}
8. 绘制具有条件的分布网格
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd
df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
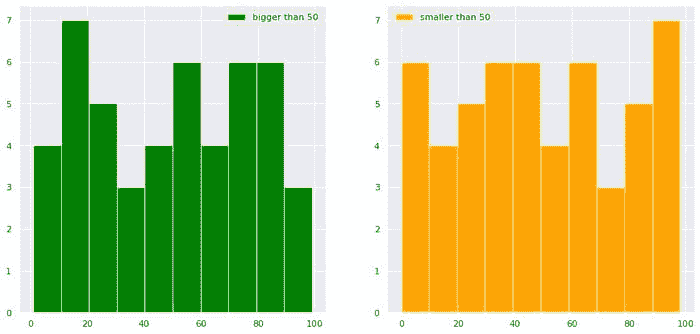
作者提供的图片
9. 在 pandas 中对不同列的值进行 t 检验
from scipy.stats import ttest_rel
data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)
10. 在指定列上合并数据框
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. 使用 sklearn 标准化 pandas 列中的值
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))
12. 在 pandas 中删除特定列中的 NaNs
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)
13. 使用条件和 or 语句选择数据框的子集
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

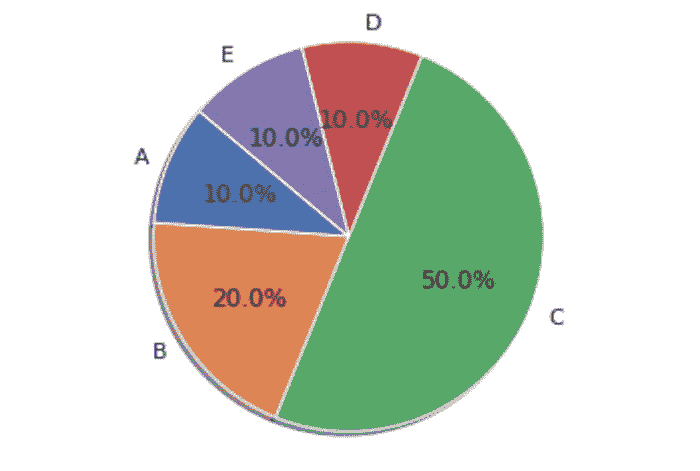
14. 基础饼图
import matplotlib.pyplot as plt
df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()
15. 使用 .apply() 将百分比字符串转换为数值
def change_to_numerical(x):
try:
x = int(x.strip("%")[:2])
except:
x = int(x.strip("%")[:1])
return x
df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

结论
我认为代码片段非常有价值,重写代码可能是时间的真正浪费,因此拥有一个包含所有简单解决方案的完整工具包来简化你的数据分析过程可以提供极大的帮助。
如果你喜欢这篇文章,可以在 Twitter、LinkedIn 上与我联系,并在 Medium 上关注我。谢谢,下次见!😃
更多内容请访问plainenglish.io
个人简介:卢卡斯·索亚雷斯 是一位 AI 工程师,专注于深度学习应用于各种问题。
原文。已获许可转载。
相关内容:
-
如何在 Python 中工程化日期特征
-
在本地开发和测试 AWS 的 ETL 管道
-
Prefect:如何用 Python 编写和调度你的第一个 ETL 管道
更多相关内容
我对数据科学候选人的 15 个期望
原文:
www.kdnuggets.com/2021/08/15-things-data-science-candidates.html
评论
由Mathias Gruber,LEO Pharma 首席数据科学家

Office 矢量图由 macrovector 创建 — www.freepik.com
数据科学一如既往地受欢迎,但矛盾的是,它似乎也比以往任何时候都更加支离破碎和定义模糊。对于新手来说,弄清楚如何进入这个领域可能相当困难,更困难的是,管理者可能很难确定如何招聘合适的职位,除非你确切知道你在寻找什么。
在这篇文章中,我总结了我对数据科学候选人的期望。免责声明:这些反思基于我在生物技术和制药公司工作的经历,在这些公司中,数据科学是一个 支持性的 功能,而不是业务的核心部分;即,不是那种你可以 专门 从事销售预测的 AI 架构工作的职位,而是你需要端到端地工作以在 多个 业务领域创造价值的职位。
1. 激情与好奇心
热情和好奇心,当然,是任何从事技术工作的人的可取品质。数据科学作为一种巨大的领域,我认为在这个特定领域,它是一种更普遍的前提。在许多其他技术领域,你可以专注于一套技能,并利用这些技能为业务创造价值多年 — 也许每隔 X 年 需要学习一种新的编程语言或工具。然而,数据科学本质上是一个 科学的 学科,每天都在发展。
对于那些持续研究新数据科学发展并与团队分享这些信息的充满激情的候选人,价值巨大。
此外,候选人需要一定程度的热情和韧性,才能持续愿意从事数据科学工作,而不是因挫折而频繁跳槽;调试一个算法为什么不起作用可能比调试一个软件或基础设施为什么不起作用要复杂和令人沮丧得多。你需要一种特殊的疯狂才能多次经历这些挫折。????♂ 正如我之前所述 在这里:
如果选项在一位普通的资深数据科学家和一位眼中充满火焰的极度热情的候选人之间,所有其他条件相等时,选择后者。

如果你对数据科学没有热情,就不要进入这个领域;这不值得。漫画来自 xkcd.com
2. 心理承受能力
数据科学作为一种职业并不适合所有人。我们应该停止假装它适合所有人。
最近写了一篇有趣的 文章 ,描述了许多人存在的误解;如果你付出足够的努力,你可以成为一名数据科学家。这是不真实的。它是一项艰难的工作:
你需要理解数学和算法,你需要进行编码和软件开发,你需要理解商业问题,还需要具备良好的讲故事和人际交往能力。不是每个人都能同时做得很好。
我并不是说你需要 130 以上的智商才能成为数据科学家。我也不是试图吓退那些想要转行做数据科学的人。相反,如果你现在在其他学术级别的职位上,你很可能在数据科学领域表现良好。但如果你处于智商分布的低端,并且难以理解新概念和流程,那真的会是一场艰苦的战斗;不断学习新事物和挑战现状是数据科学工作的核心。注意,我这里说的不是使用低代码/无代码工具的普通数据科学家。

你不必是天才,但需要一定程度的智力。漫画来自 xkcd.com
3. 将现实问题转化为机器学习(ML)问题的能力
擅长工程化机器学习(ML)算法是一回事,擅长理解商业问题又是另一回事。然而,将这两者结合起来并找出如何用 ML 解决商业问题则是完全不同的挑战。
你需要能够将现实世界的问题转化为可以解决的机器学习问题。
最近 Brian Kent 写了一篇很棒的 文章 ,详细描述了数据科学的这一方面。实际上,当你作为数据科学家工作时(至少在我曾经工作的职位上),你很少会遇到“这是你的数据集,为这个目标拟合一个回归模型”这样的任务。你更常面临的商业问题可能是以下这些:
-
“我们希望利用一些新的人工智能技术来改善我们的现金流,”
-
“我们希望通过机器学习将这个化学品的产量提高 10%。”
-
“我们想要提高这个或那个过程/机器的效率。”
将这些现实世界的目标转化为可解决的 ML 问题是一个极其被低估的技能——你需要对相关业务过程和可用数据有透彻的理解,需要对 ML 能做什么有坚实的基础,最后,你需要对如何有效地应用不同技术以实现业务目标有良好的直觉。
这种技能稀缺,但你可以通过熟悉大量的 ML 应用程序并实际花时间思考这些问题来加以练习。

什么数据?什么模型?弄清楚要解决什么并不容易。漫画来自 xkcd.com
4. 诚实与谦逊
想象一下:业务想用 AI/ML 来优化一些过程。大家都很兴奋,你也很兴奋,所有人都期待看到结果。你做了一个模型,最初看起来很棒,大家都很兴奋。你随之意识到你在评估模型的方式上犯了一个错误,实际上它非常糟糕——数据中根本没有信号。
你需要成为一个完全承担责任的人,并承认自己犯错,无论后果如何。
错误是不可避免的。我们都会犯错。但没有人会因将错误掩盖在地毯下或更糟糕的,将错误归咎于他人而得到好处。上述情况应通过在展示结果时始终保持一定的谦逊来避免;如果结果是尚未经过同行验证的初步结果,那么在展示时清晰地说明这一点。不夸大其词。此外,一个优秀的候选人将始终是自己最严格的批评者:
花费与你得出结论一样多的时间来尝试反驳自己的结论,这样会建立自信。

诚实对数据科学至关重要。漫画来自 xkcd.com
5. 自动化与优化
每个人都讨厌重复性的任务。有些人讨厌到极点,尽可能地去自动化这些任务。我们说的是从自动化机器学习(autoML)和 GitHub copilot 这样的流行术语,到自动化代码环境的设置,以及普遍的“代码即一切”,甚至自动化日常时间记录等。对我来说,自动化和优化是优秀开发者/数据科学家的标志性思维方式。
自动化一切。在有意义的时候。漫画来自 xkcd.com
6. 实用主义与价值追求
数据科学是一个科学的学科。然而,当你被雇佣为数据科学家时,这份工作通常是将数据科学工具应用于创造商业价值。很少涉及做研究、提出新算法、开创新领域等。虽然有时会涉及,但很少。我们通常是被雇佣来创造商业价值的。
我们工作的目标是创造商业价值。
在从事工业数据科学工作的过程中,你必须对这一总体目标持务实态度。我在之前的一篇文章中写到了在我进入行业后学到的几个应避免的陷阱;你可以在这里阅读更多内容:
从初级数据科学家到首席数据科学家的 20 条经验教训
总结来说,我会说务实的方法包括:
-
始终以客户为中心——如果业务部门不支持,终止项目,它永远不会创造价值。
-
创造并选择正确的想法——不要仅仅因为上级认为某个问题/想法是个好主意就去做。如果技术上不可行,你需要转移注意力。
-
避免过度工程化——如果一种更简单的方法可以在一半的时间内解决问题,就使用那种方法。
-
关注执行——不要陷入过多的演示、讨论、如果这样和如果那样的情境中。开始做些事情吧。
我认为在 Medium 上有很多文章可以帮助你成为一个更务实的数据科学家。我最近读了这篇文章,作者是丹尼斯·艾勒斯,这篇文章描述了如何在工作中变得更加高效和有影响力,以及这篇文章,作者是阿奇·德·伯克,讲述了从学术界转型到工业界的注意事项。

务实并创造商业价值。不要关注那些不创造价值的事情。漫画来源于xkcd.com
7. 人格与团队契合
显然,候选人的性格及其与团队其他成员的契合度是重要的。这对所有候选人和所有工作都是如此。这也是为什么许多公司有 HR 部门,并在就业前进行性格测试的原因。心理学家通常使用 “五大性格特质” 来评估你刚认识的人。在这些性格特质中,我认为某些特质是相当重要的,例如一定程度的 尽责性(高效/有组织)、不讨好(发表你的意见,不做傻瓜)和 外向性(与业务交流,进行演示等),以及 开放性(研究新技术并打破固有思维)。总体来说,我不认为数据科学家有一个“理想”的性格特征,因此主要是避免有毒的性格。

只要保持冷静和友好即可。漫画来自 xkcd.com
8. 编码经验
编码是数据科学的核心部分。通常,你编写的代码必须与同事共享,以便将其投入生产,使你和未来的同事可以在未来多年维护它。因此,拥有一般软件开发和良好实践的经验是数据科学家最重要的素质之一。
如果另一个开发人员必须花费你编写代码的 2 倍时间来审查和修复这些代码,才能将其投入生产,那么你对团队来说是一个负担,而不是资产。
请注意,我不太在意不同的编码范式,也不在乎你是偏好笔记本还是纯脚本等。这些是各个团队可以制定的标准。我说的是,我见过初级开发者编写的代码完全可以理解,并且可以在几分钟内进行审查,而我也见过拥有 30 多年经验的高级开发者将 2 周的工作浓缩成 4 行难以理解的 R 代码。
如果你有一个公开的 Github 账户,展示了你能够编写易于理解的代码并提供良好的文档,这将是一个巨大的加分项。

编写其他人可以理解的代码。漫画来自 xkcd.com
9. 调试技能
我们常开玩笑说,工作的一部分就是花时间在 StackOverflow 上找代码片段。虽然你可以通过这种方式找到很多优秀的解决方案,但 调试 技能远不止于此。
不要成为唯一的调试技能是 StackOverflow 的人。
在纯代码方面,你需要阅读文档以了解事物的实际运作,有时甚至需要查看你所使用的开源库的源代码。在数据科学方面,情况可能会更加复杂;你可能需要阅读论文来理解事物的工作原理,然后找出为什么它没有按预期工作——这可能真的是一次艰难的经历,尤其是因为人们在实现算法时的所有数值细节并不总是记录在代码或论文中。
我会觉得看到候选人如何调试一段损坏的代码比他们通过查看在线资源解决特定问题的能力更有趣。

调试是一种技能和艺术。漫画来自xkcd.com
10. 适应性
适应性可能已经涵盖了关于务实和个性的要点。尽管如此,适应性是如此重要,以至于我希望它作为一个单独的要点。领域发展迅速,我们必须能够舍弃我们的宠儿。花了数百小时在一个项目上,但结果没有创造业务价值?放弃它。花了数百小时在 Tensorflow 上,但现在整个团队想使用 PyTorch?放弃它,学习 PyTorch。花了数千小时在 Python 上,但现在它无法满足你的需求?放弃它,学习一种新的足够的语言。不要沉迷于你花了多少时间做某事;那只会拖慢你的进度。
当你停止适应时,就是你开始在数据科学游戏中失去竞争力的那一天。

保持开放的心态并保持适应性。漫画来自xkcd.com
11. 全栈潜力
我曾经描述过我认为典型的数据科学建议,即在特定领域专注以避免成为“样样精通却无一专长”的建议是糟糕的。相反,应该努力成为“样样精通,几乎都精通”。
不要回避“数据科学独角兽”的想法,而是努力成为其中之一。
尽管如此,我不会寻找数据科学独角兽;人才库太稀缺,定义也不够明确。然而,我会筛选那些抱怨“成为数据科学独角兽是不可能的”的人。在我看来,这种在行业中相当普遍的说法是有害的,表明对动手实践和完成任务的厌恶。
自然,你不需要成为一个完整的前端/后端开发者和云/数据工程师。但我发现那些愿意涉猎其他领域的人在交付成果方面要有效得多。

保持开放的心态拓展你的视野,即使你可能不会成为大师。漫画来自 xkcd.com
12. 背景
在生物信息学、量子物理学或其他科学领域有背景显然在进入数据科学领域时有优势;这意味着你习惯阅读研究论文,曾经做过统计分析,也许有些编程经验等等。然而,拥有高级教育绝不是必需的。这不过是几年结构化的学习。但自然,你以前所做的和取得的成就会在申请新工作时被考虑。
我宁愿雇佣一个从零开始成为 Kaggle 比赛大师的人,也不愿雇佣一个有华丽教育背景的人,其他条件相同的话。

你的背景自然会影响你当前的技能。漫画来自 xkcd.com
13. 讲故事
这一点已经被无数次提及,所以我不会花太多时间讲解,尽管它很重要:数据科学家需要讲好故事。这意味着什么?学习创建吸引人的可视化效果,制作精美的演示文稿,进行有趣的演讲,撰写博客文章等。
你做得越多,尝试比上次做得更好,你就会变得越好。

学会讲有影响力的故事。漫画来自 xkcd.com
14. 协作
我的一个弱点是我在协作方面不太擅长——我认为这是因为在获得“真正”工作之前,我已经做了 10 多年的一人军队。这一事实使我更加欣赏那些擅长协作的人;创造商业价值的数据科学是一项团队工作,因此你必须擅长协作,包括所有相关内容;配对编程、适当的文档编制、合理的 git 提交、冲刺计划、回顾会议等。这种经验绝对是一个优势!如果你刚开始接触协作,找一个有趣的开源项目参与其中。

你需要能够在团队中工作!数据科学不能由一人完成。漫画由 xkcd.com
15. 数据科学经验
我列表上的最后一点是实际的 数据科学 经验。自然,如果候选人接触过该领域的各种学科,那将是有利的;例如,计算机视觉、自然语言处理、预测、经典监督/无监督技术、通用深度学习等。
根据我的经验,你很少会多次得到“相同”的任务。因此,拥有尽可能 广泛 的知识基础是有利的——有一天,你可能在做销售预测,另一天你可能在预测分子的化学属性或优化生产过程。如果我在招聘销售预测方面的人才,我不会过于担心候选人是否之前从未做过销售预测,只要这个人有做其他类型机器学习的丰富历史。学习如何解决新问题只是工作的另一天。
获得广泛经验的障碍相对较低;积极参与几个不同领域的 Kaggle 竞赛,你应该能开始获得基本的概览。此外,通过这样做,你还会建立一个展示你能力的作品集。我不是说这 容易,只是说开始起来容易。确保在遇到新概念时你能充分理解。
不要 仅仅将算法作为黑箱使用,而要让自己理解它们实际上在做什么。

你在这一领域的时间越长,你获得的经验就越多;我们都在不断学习。漫画来自 xkcd.com
最后的备注
我最后写了一篇相当长的文章。如果你读完了所有内容,我感谢你 ???? 我意识到许多提到的点适用于许多职业,特别是类似的数据工程、云工程等工作。这些是我从数据科学的角度出的反思。请注意,我从未期望一个初级开发者能完全符合所有提到的点——而是希望找到一个能够在所有这些方面成长的人。最后,我非常希望了解其他人在数据科学候选人身上寻找什么,所以欢迎留言或通过其他渠道与我联系。
简介: Mathias Gruber 在自然科学方面有广泛的背景,特别是在纳米科学和生物物理学方面。Mathias 在具有挑战性的环境中茁壮成长,热衷于获得知识和开发前沿技术。目前主要兴趣是数据科学的一切,即利用机器学习算法解决大规模数据问题,特别强调最前沿的深度学习方法。
原文。经授权转载。
相关:
-
你如何从数百名其他数据科学候选人中脱颖而出?
-
数据科学家与机器学习工程师的区别
-
你为什么以及如何学习“高效数据科学”?
更多相关内容
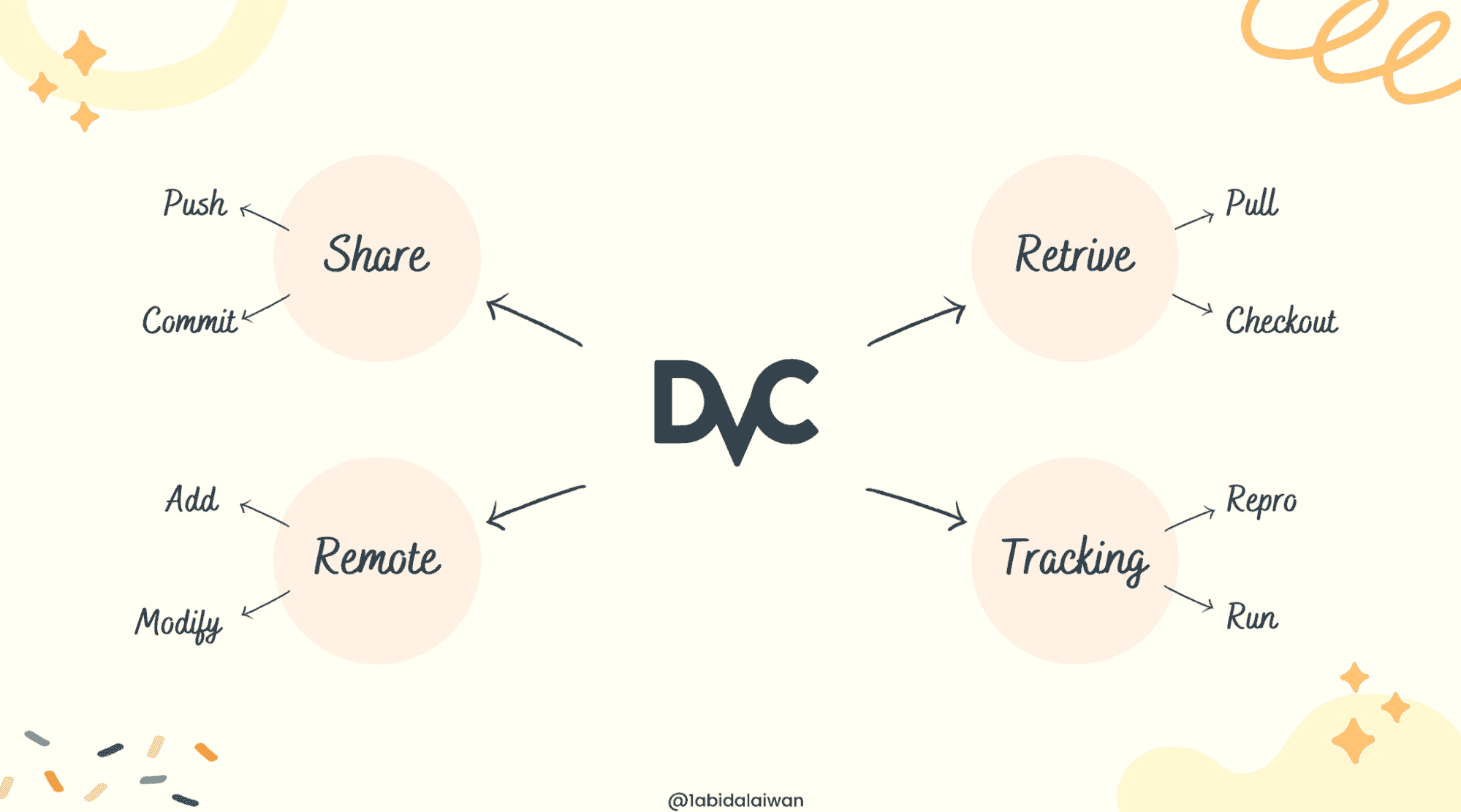
数据科学的 16 个关键 DVC 命令
原文:
www.kdnuggets.com/2022/07/16-essential-dvc-commands-data-science.html
图片由作者提供
DVC(数据版本控制)是一个有用的工具,用于跟踪数据和机器学习模型、管道及实验。它与 Git 无缝协作,提供代码和数据版本控制环境。
我们的 3 个最佳课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
DVC 命令与 Git 相似,除了版本控制外,它还提供了一个丰富的环境来训练、验证和部署机器学习模型。类似于 Git,你可以共享和协作处理机器学习项目。
在这篇文章中,我们将学习用于初始化、管理和共享 DVC 项目的重要命令。
16 个关键命令概览:
-
init
-
remote
-
add
-
remove
-
status
-
commit
-
checkout
-
push
-
pull
-
run
-
exp
-
repro
-
metrics
-
plots
-
dag
-
gc
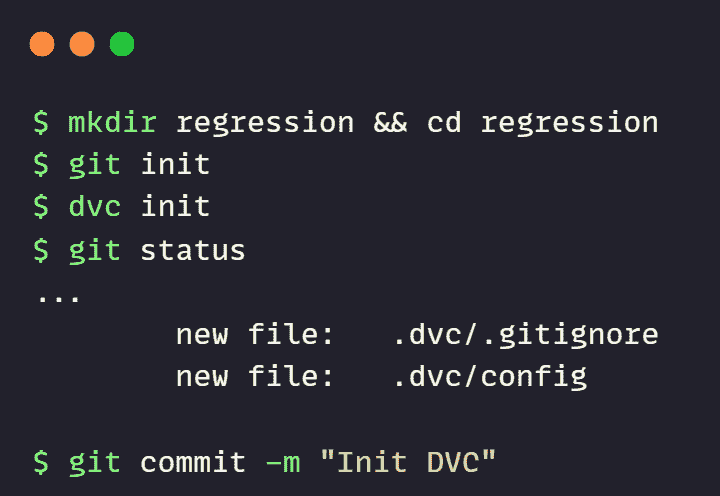
1. init
DVC 初始化依赖于 Git。如果你在一个新目录中,请先初始化 Git,然后按照下面的示例初始化 DVC。
git init
dvc init
init 命令已创建一个 .dvc 目录。它包含与 DVC 配置和文件相关的所有元数据。
2. remote
DVC 远程命令用于与团队共享数据或在远程存储中创建副本。
只需添加一个远程名称和远程 URL。如我之前所说,这个命令与 Git 非常相似。
dvc remote add dagshub https://dagshub.com/kingabzpro/Urdu-ASR-SOTA.dvc
要查看远程存储列表,请使用:
dvc remote list
>>> dagshub https://dagshub.com/kingabzpro/Urdu-ASR-SOTA.dvc
要修改现有的远程配置,你可以使用下面的命令。它需要一个远程名称和一个新 URL。
dvc remote modify dagshub https://dagshub.com/kingabzpro/solar-radiation-ISB-MLOps.dvc
你可以使用上述模式重命名或移除远程。相对来说比较简单。
3. add
使用此命令来跟踪单个或多个文件和目录。
dvc add ./model ./data
当你将文件添加到 DVC 时,该命令会使用 .gitignore 从 Git 中移除它。相反,Git 将使用 .dvc 跟踪指针,以跟踪和提交更改。
在运行 add 命令后,你需要将文件添加到 Git 暂存区。
git add model.dvc data.dvc .gitignore
4. remove
要停止跟踪文件和目录,请使用 dvc remove <file> 命令。确保目录或文件具有扩展名 .dvc。你还可以使用此命令从 dvc.yml 中移除一个阶段。
dvc remove model.dvc
5. status
它将显示项目管道中的更改,并展示缓存和工作区或远程存储之间的更改。
dvc status
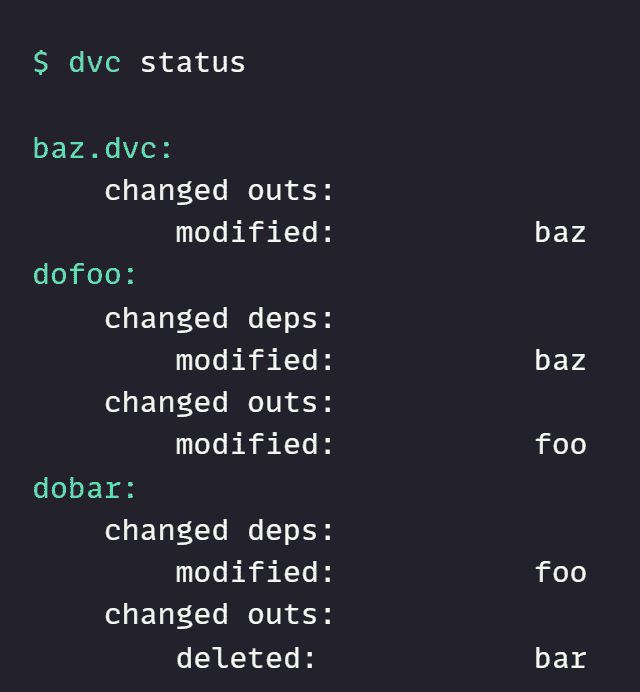
6. commit
commit 命令用于记录 DVC 跟踪的文件和文件夹中的更改。
dvc commit
7. checkout
当你使用 git checkout 更改仓库到较旧版本时,dvc checkout 用于根据 dvc.lock 和 .dvc 文件更新工作区中的跟踪文件。
dvc checkout
8. push
类似于 Git,你可以使用 dvc push 将文件从本地工作区推送到默认远程。push 命令对于团队协作和保持多个数据副本以避免灾难是必要的。
我使用 DagsHub 的远程存储来存储和更新生产中的模型。
对于默认远程:
dvc push
对于特定的远程存储:
dvc push -r <remote-name>
9. pull
pull 命令用于使用远程存储更新本地工作区。push 和 pull 的工作方式类似于 Git。
从默认远程提取文件:
dvc pull
从特定远程提取文件:
dvc pull -r <remote-name>

10. run
它帮助你在dvc.yml中创建和修改管道阶段。run 命令可用于组装机器学习和数据管道。
-
-n 是阶段名称
-
-d 是依赖项
-
-o 是输出
dvc run -n printer -d write.sh -o pages ./write.sh
11. exp
exp 或 experiment 命令用于生成、管理和运行机器学习实验。这是一个新功能。你可以在这里阅读更多关于实验管理的信息。
dvc exp {show,apply,diff,run,gc,branch,list,push,pull,remove,init}
图片来自 DVC experiments
12. repro
repro 类似于 Make。你可以使用它来重现完整或部分管道。它按正确的顺序执行在其阶段中定义的命令。
dvc repro
13. metrics
通过使用 dvc repro 运行机器学习管道后,将生成模型性能指标。它表示标量数字,如 AUC。
要在终端查看指标,请使用:
dvc metrics show
并且要比较指标,请使用:
dvc metrics diff
metric diff 命令将比较工作区的指标与 HEAD。你也可以与特定的提交进行比较。
14. plots
plots 用于可视化数据系列,如 RMSE 与周期和损失函数。plots 可以与图像文件(JPEG、GIF 或 PNG)和数据系列文件(JSON、YAML、CSV 或 TSV)一起使用。它使用数据系列文件通过 Vega-Lite 渲染折线图。
显示机器学习结果:
dvc plots show logs.csv
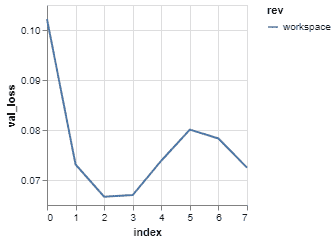
图片来自 DVC Doc
与 HEAD 比较结果:
dvc plots diff HEAD^ --targets logs.csv
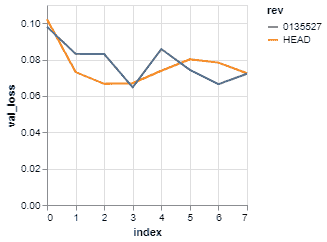
图片来自 DVC Doc
注意: 在DVC VSCode 新扩展中运行实验和可视化结果非常互动。
15. dag
它用于以一个或多个连接阶段的图形形式可视化管道。
dvc dag

16. gc
它用于从缓存或远程存储中删除未使用的文件或目录。类似于 Git,它用于优化仓库。
dvc gc -w
结论
DVC 已经成为数据科学和机器学习操作的一个重要工具。你可以对数据和模型进行版本控制,跟踪实验,开发管道,分享和协作,并将模型部署到生产环境。在这篇文章中,我们学习了 DVC 的基本命令。阅读文档以了解更多命令和功能。
如果你是新手并想互动体验 DVC,可以尝试DagsHub。该平台专为数据科学家和机器学习工程师而设计。你可以查看我的个人资料这里以获得灵感。
注意: 如果你想从 Git 仓库中删除 dvc 文件、管道、实验和指标,请使用
dvc destroy。
更多关于数据科学命令的主题
-
数据科学家的 14 个必备 Git 命令
-
数据科学初学者的 20 个基础 Linux 命令
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
更多相关主题
17 个必知数据科学面试问题及答案,第二部分
原文:
www.kdnuggets.com/2017/02/17-data-science-interview-questions-answers-part-2.html编辑注: 另见17 个必知数据科学面试问题及答案 第一部分。这是第二部分。这里是 第三部分。
本文回答了以下问题:
-
Q7. 过拟合是什么?如何避免?
-
Q8. 维度诅咒是什么?
-
Q9. 如何确定模型中哪些特征最重要?
-
Q10. 并行处理何时可以加速算法运行?何时可能使算法运行变慢?
-
Q11. 集成学习的基本思想是什么?
-
Q12. 在无监督学习中,如果数据集的真实情况未知,我们如何确定最有用的聚类数量?
Q7. 过拟合是什么?如何避免?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
Gregory Piatetsky 回答:
(注意:这是对 21 个必知数据科学面试问题及答案,第二部分的修订版)
过拟合 是指你构建了一个“过于紧密”地拟合数据的预测模型,以至于它捕捉到了数据中的随机噪声,而不是实际模式。因此,当应用于新数据时,模型预测将是错误的。
我们经常听到报道异常结果的研究(特别是如果你听《等待等待别告诉我》),或看到像“橙色的二手车最不可能是柠檬”这样的发现,或者得知研究推翻了以前确立的发现(鸡蛋现在对你没有坏处)。
许多此类研究产生了无法重复的可疑结果。
这是一个大问题,特别是在社会科学或医学领域,当研究人员经常犯数据科学的致命罪——过拟合数据。
研究人员在没有适当统计控制的情况下测试太多的假设,直到他们偶然发现一些有趣的东西,然后就报告出来。不出所料,下次这种效果(部分由于偶然性)会大大减小或消失。
这些研究实践中的缺陷由 John P. A. Ioannidis 在其开创性论文为什么大多数已发表的研究结果是错误的(PLoS Medicine,2005 年)中进行了识别和报告。Ioannidis 发现,结果往往被夸大或无法复制。他在论文中提供了统计证据,表明大多数声称的研究结果确实是错误的!
Ioannidis 指出,为了使研究结果可靠,应该具备以下条件:
-
大样本量和显著效果
-
测试关系的数量更多且选择更少
-
设计、定义、结果和分析模式的更大灵活性
-
最小化由于财务和其他因素(包括该科学领域的受欢迎程度)造成的偏差
不幸的是,这些规则往往被违反,产生虚假结果,例如 S&P 500 指数与孟加拉国黄油生产的强相关,或美国在科学、空间和技术上的支出与悬挂、窒息和勒死的自杀率相关(来自 http://tylervigen.com/spurious-correlations)
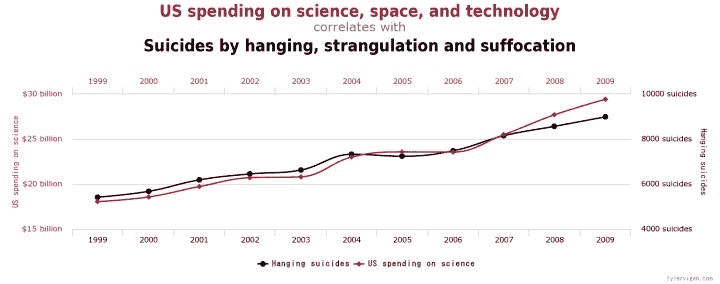
(来源:Tylervigen.com)
在虚假相关中查看更多奇怪和虚假的发现,或使用Google correlate等工具自行发现。
可以使用几种方法来避免“过拟合”数据:
-
尝试寻找最简单的假设
-
正则化(对复杂性进行惩罚)
-
随机化测试(随机化类别变量,尝试在此数据上应用你的方法——如果找到相同的强结果,说明存在问题)
-
嵌套交叉验证(在一个层级上进行特征选择,然后在外层级上进行整个方法的交叉验证)
-
调整假发现率
-
使用可重用的保留方法——2015 年提出的突破性方法
优秀的数据科学处于对世界科学理解的前沿,数据科学家有责任避免数据过拟合,并向公众和媒体普及糟糕数据分析的危险。
另见:
-
你的机器学习模型为何错误的 4 个原因(以及如何修正)
-
当好的建议变坏
-
数据挖掘和数据科学的根本罪过:过拟合
-
避免过拟合的大主意:可重用的保留集以保持适应性数据分析中的有效性
-
通过可重用保留集克服过拟合:保持适应性数据分析中的有效性
-
11 种聪明的过拟合方法及其避免方法
Q8. 什么是维度灾难?
普拉萨德·波雷 回答:
"随着特征或维度数量的增加,我们需要准确泛化的数据量呈指数增长。"
- 查尔斯·伊斯贝尔,乔治亚理工学院互动计算学院教授及高级副院长
下面是一个例子。图 1(a)显示了一个维度中的 10 个数据点,即数据集中只有一个特征。它可以用只有 10 个值的线轻松表示,x=1, 2, 3... 10。
但如果我们再添加一个特征,相同的数据将在 2 维中表示(图 1(b)),导致维度空间增加到 1010 =100。再添加第 3 个特征,维度空间将增加到 1010*10 = 1000。随着维度的增加,维度空间呈指数增长。
10¹ = 10
10² = 100
10³ = 1000 and so on...
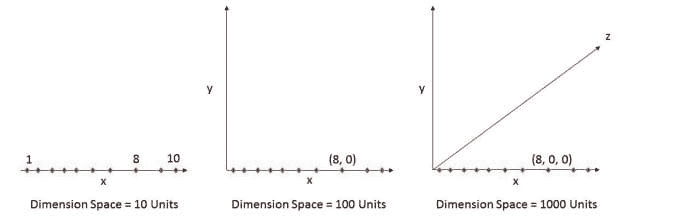
数据的指数增长导致数据集的高度稀疏,并不必要地增加了特定建模算法的存储空间和处理时间。想象一下高分辨率图像的图像识别问题,1280 × 720 = 921,600 像素,即 921600 维。天哪。这就是为什么它被称为维度灾难。额外维度带来的价值比其对算法增加的开销要小得多。
总而言之,原本可以用 10 个空间单位表示的数据,在添加了 2 个维度后,需要 1000 个空间单位,仅仅因为我们在实验中观察到了这些维度。真正的维度是指准确泛化数据的维度,观察到的维度是指我们在数据集中考虑的其他维度,这些维度可能对准确泛化数据有或没有贡献。
Q9. 如何确定模型中哪些特征最为重要?
翠玉·范 回答:
在应用机器学习中,成功在很大程度上依赖于数据表示(特征)的质量。高度相关的特征可以使分类模块中的学习/排序步骤变得容易。相反,如果标签类别是特征的非常复杂的函数,可能很难建立一个良好的模型 [Dom 2012]。因此,通常需要所谓的特征工程,即将数据转化为与问题最相关的特征的过程。
一个特征选择方案通常涉及自动从大规模探索性特征池中选择显著特征的技术。冗余和无关的特征已知会导致准确性较差,因此丢弃这些特征应当是首要任务。相关性通常通过互信息计算进行评分。此外,输入特征应提供较高的类别区分度。特征的可分离性可以通过类别之间的距离或方差比来测量。最近的工作 [Pham 2016] 提出了基于系统投票的特征选择方法,这是一种结合上述标准的数据驱动方法。这可以作为广泛类别问题的通用框架。
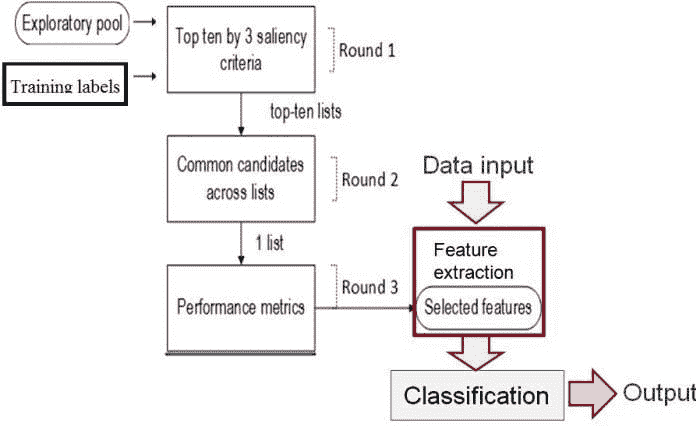
一种数据驱动的特征选择方法,结合了几种显著性标准 [Pham 2016]。
另一种方法是对那些不太重要的特征(例如,导致高错误度量的特征)进行惩罚,这些方法包括 Lasso 或 Ridge 等正则化方法。
参考文献:
-
[Dom 2012] P. Domingos. 关于机器学习的一些有用知识。ACM 通讯,55(10):78–87, 2012。 2.4
-
[Pham 2016] T. T. Pham, C. Thamrin, P. D. Robinson, 和 P. H. W. Leong. 强迫振荡测量中的呼吸伪影去除:一种机器学习方法。生物医学工程,IEEE 汇刊,已接受,2016。
Q10. 何时并行化能使你的算法运行得更快?何时可能使你的算法运行得更慢?
Anmol Rajpurohit 回答:
当任务可以分解为可以独立执行而无需通信或共享资源的子任务时,并行计算是一个好主意。即便如此,效率的实现是实现并行化好处的关键。在实际应用中,大多数程序有些部分需要以串行方式执行,并且并行可执行的子任务需要某种同步或数据传输。因此,很难预测并行化是否真的能使算法比串行方法运行得更快。
相比于顺序完成任务所需的计算周期,并行计算总是会有开销。至少,这些开销包括将任务分解为子任务和汇总子任务结果。
并行计算相对于顺序计算的性能主要取决于这些开销所消耗的时间与并行化带来的时间节省的比较。
注意:并行化带来的开销不仅限于代码的运行时间,还包括编码和调试所需的额外时间(并行化与顺序代码)。
评估并行化收益的一个广为人知的理论方法是阿姆达尔定律,它提供了以下公式来测量并行运行子任务(在不同处理器上)与顺序运行(在单一处理器上)相比的加速:
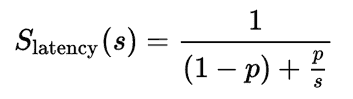
其中:
-
S**延迟是整个任务执行的理论加速;
-
s 是受益于改进系统资源的任务部分的加速;
-
p 是受益于改进资源的部分在原始执行时间中所占的比例。
要理解阿姆达尔定律的含义,请查看以下图示,该图展示了针对不同水平的可并行化任务,理论上随着处理器核心数量的增加而加速的情况:
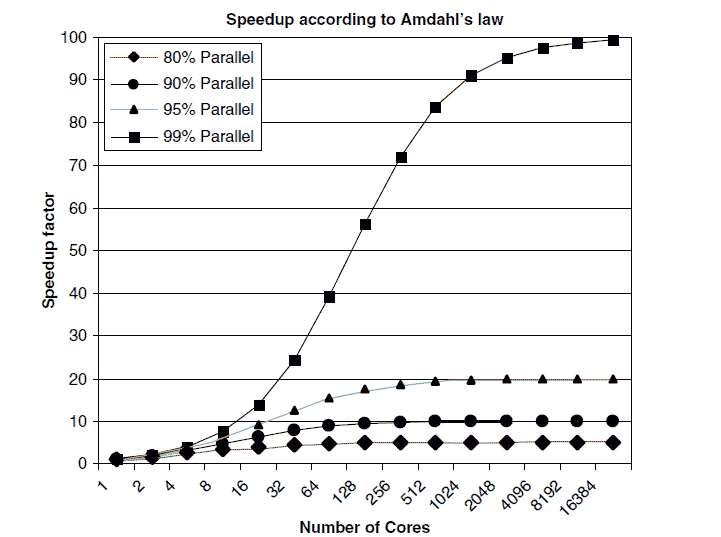
重要的是要注意,并不是每个程序都可以有效地并行化。实际上,由于顺序部分、通讯成本等限制,很少有程序能实现完美的加速。通常,大数据集构成了并行化的一个有力理由。然而,不应假设并行化会带来性能上的好处。应该在投入并行化努力之前,将并行化和顺序执行的性能在问题的子集上进行比较。
Q11. 集成学习背后的思想是什么?
Prasad Pore 回答:
“在统计学和机器学习中,集成方法使用多种学习算法来获得比任何单一学习算法更好的预测性能。”
– 维基百科。
想象你在玩“谁想成为百万富翁?”并且达到了最后一个百万美元的问题。你对这个问题毫无头绪,但你还有观众投票和电话朋友的救生圈。谢天谢地。在这个阶段,你不想冒任何风险,那么你会怎么做以确保得到正确答案,成为百万富翁呢?
你会使用两个生命线,对吗?假设 70%的观众说正确答案是 D,而你的朋友也以 90%的信心说正确答案是 D,因为他是该问题领域的专家。使用两个生命线可以给你 80%的平均信心,认为 D 是正确的,并使你更接近成为百万富翁。
这就是 集成方法 的方法。
著名的 Netflix 奖 竞赛花费了近 3 年时间才实现 10%的改进 目标。获胜者使用了梯度提升决策树来结合超过 500 个模型。
在集成方法中,使用的模型越多样,最终结果的稳健性就会越高。
集成中使用的不同模型通过人口差异、生成的假设差异、使用的算法差异以及参数化差异来改善整体方差。主要有 3 种广泛使用的集成技术:
-
装袋
-
提升
-
堆叠
如果你为相同的数据和相同的响应变量构建了不同的模型,你可以使用上述方法之一来构建集成模型。由于集成中使用的每个模型都有其自身的性能指标,因此一些模型的表现可能会优于最终的集成模型,而一些模型的表现可能会差于或与集成模型相当。但总体而言,集成方法将提高模型的整体准确性和稳定性,尽管这会以模型可理解性为代价。
更多关于集成方法的信息请参见:
-
集成方法:优雅的技巧以提高机器学习结果
-
数据科学基础:集成学习者简介
Q12. 在无监督学习中,如果数据集的真实情况未知,我们如何确定最有用的聚类数量?
马修·梅奥 回答:
在 有监督 学习中,数据集中类的数量是明确知道的,因为每个数据实例都标记为某个现存类别的成员。在最坏的情况下,我们可以扫描类别属性并计算存在的唯一条目数量。
在无监督学习中,类属性和明确的类成员关系并不存在;事实上,无监督学习的一种主要形式——数据聚类——旨在通过最小化类间实例相似性和最大化类内相似性来近似类成员关系。聚类的一个主要缺点是需要在开始时以某种形式提供未标记数据集中存在的类数。如果幸运的话,我们可能会提前知道数据的真实情况——实际的类数。然而,这并不总是如此,原因有很多,其中之一是数据中可能根本没有定义的类数(从而没有定义的簇),无监督学习任务的整个重点就是调查数据并尝试强加某些有意义的最优簇和类数结构。
在不知道数据集的真实情况的情况下,我们如何知道数据簇的最优数量?正如预期的那样,实际上有许多方法可以回答这个问题。我们将查看两种特别流行的方法来尝试回答这个问题:肘部法则和轮廓法。
肘部法则
肘部法则通常是一个最佳的起点,尤其因为它易于解释和通过可视化进行验证。肘部法则旨在解释方差作为簇数(k 在 k-均值中的那个 k)的函数。通过绘制解释的方差百分比与 k 的关系,前 N 个簇应该提供显著的信息,解释方差;然而,某个最终的 k 值将导致信息增益显著减少,此时图表将呈现出明显的角度。这个角度将是肘部法则视角下的最优簇数。
显然,为了将方差绘制与不同簇数的关系,必须测试不同数量的簇。必须进行连续的完整聚类方法迭代,然后可以绘制和比较结果。
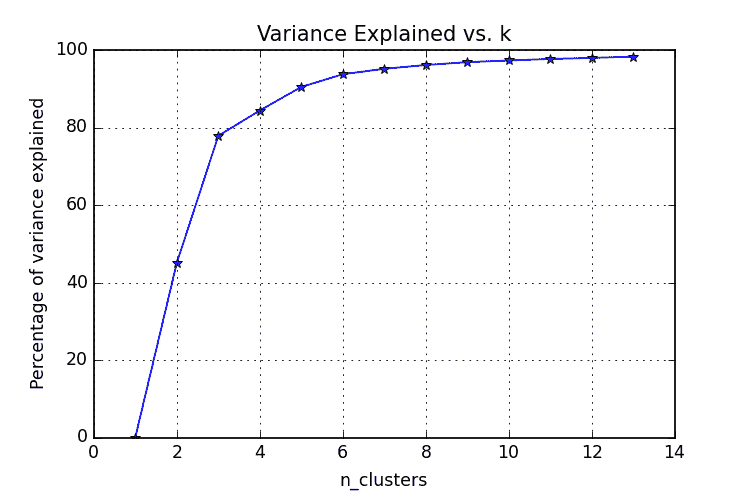
图片来源。
轮廓法
轮廓法衡量对象与其自身簇的相似性——称为凝聚度——与其他簇的相似性——称为分离度。轮廓值是这种比较的手段,其范围为[-1, 1];值接近 1 表示与自身簇中的对象关系紧密,而值接近-1 则表示相反。在模型中产生大多数高轮廓值的聚类数据集可能是一个可接受且合适的模型。
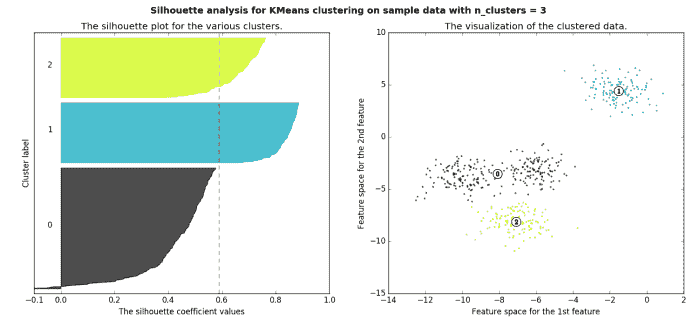
图片来源。
了解轮廓法的更多信息请点击这里。关于计算轮廓值的具体内容请见这里。
相关内容:
-
17 个更多必须知道的数据科学面试问题及答案
-
17 个更多必须知道的数据科学面试问题及答案,第三部分
-
21 个必须知道的数据科学面试问题及答案
-
21 个必须知道的数据科学面试问题及答案,第二部分
更多相关话题
17 个必知的数据科学面试问题及答案,第三部分
原文:
www.kdnuggets.com/2017/03/17-data-science-interview-questions-answers-part-3.html/2
Q15. 在 A/B 测试中,我们如何确保各个桶的分配是真正随机的?
Matthew Mayo 回答:
首先,让我们考虑如何在桶分配之前最好地确保桶之间的可比性,而不需要知道人群属性的任何分布。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
答案很简单:随机选择和桶分配。在不考虑人群属性的情况下进行随机选择和桶分配是一种统计上合理的方法,只要人群足够大。
例如,假设你正在测试网站功能的更改,并且只对特定区域(例如美国)的响应感兴趣。通过首先将样本分为 2 组(对照组和处理组),而不考虑用户区域(且人群足够大),美国访问者应当在这两组之间分配。从这 2 个桶中,可以检查访问者属性以进行测试,例如:
if (region == "US" && bucket == "treatment"):
# do something treatment-related here
else:
if (region == "US" && bucket == "control"):
# do something control-related here
else:
# catch-all for non-US (and not relevant to testing scenario)
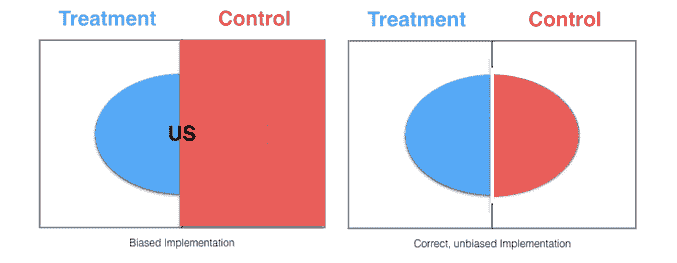
图片来源。
请记住,即使在进行了一轮随机桶分配后,也可以利用统计测试来检查/验证桶成员属性的随机分布(例如,确保没有显著更多的美国访问者被分配到桶 A)。如果没有,可以尝试新的随机分配(并进行类似的检查/验证过程),或者--如果确定人群不符合合作分布--可以采取如下方法。
如果我们事先知道某些不均匀的人群属性分布,分层随机抽样 可能有助于确保更均匀的抽样。这种策略可以帮助消除选择偏差,这是 A/B 测试的死敌。
参考文献:
Q16. 你会如何对选择功能进行 A/B 测试?
Matthew Mayo 答复:
这个问题似乎有些模糊,有多种可解释的含义(这一点可以参考这篇文章)。让我们首先看看这个问题的不同可能解释,然后再讨论。
-
你会如何对选择版本的功能与非选择版本的功能进行 A/B 测试?
这将不允许进行公平或有意义的 A/B 测试,因为一个桶会从整个网站的用户中填充,而另一个桶则从已经选择的用户组中填充。这样的测试就像将一些苹果与所有橙子进行比较,因此是不明智的。
-
你会如何对选择功能的采纳(或使用)进行 A/B 测试(即测试实际的选择)?
这将是测试实际的选择过程——例如测试两个“点击这里注册”功能的版本——因此这只是一个常规的 A/B 测试(有关一些见解,请参见上述问题)。
-
你会如何对不同版本的选择功能(即那些已经选择的用户)进行 A/B 测试?
这可能再次被解读为几种含义之一,但我打算将其视为事件链的复杂场景,下面将详细展开。

让我们详细探讨上面列表中的第 3 点。我们先来看一个可以测试的简单事件链,然后再进行概括。假设你在对一封电子邮件营销活动进行 A/B 测试。假设变量是主题行,内容在两个版本之间保持不变。假设主题行如下:
-
我们有一些东西给你
-
本周末最好的在线数据科学课程免费!立即尝试,无需承诺!
确实是人为构造的。撇开其他不谈,直觉上说,主题 #2 会获得更多的点击。
但除此之外,还有心理学因素在起作用。即使点击任何一个主题后的内容是相同的,点击第二个主题的个人可能会有更高的兴奋感和对后续内容的期待。不同群体之间这种期望和投入程度的差异可能会导致主题行 #2 所在组的点击率更高——即使内容相同。
稍微转移话题… 你会如何对不同版本的选择功能(即对那些已经选择的人)进行 A/B 测试?
如果我对评估一系列链式事件的解释是正确的,那么这样的 A/B 测试可以从不同的输入位置开始,都是相同内容的选择,然后转到选择后的不同后续着陆页,目的是测量用户在结果着陆页上的行为。
不同来源位置对相同的选择程序是否会导致不同的后续行为?当然,这仍然是一个 A/B 测试,具有相同的目标、设置和评估;然而,所测量的具体用户心理是不同的。
这与面试问题有什么关系?除了能够识别 A/B 测试的基本概念,能够处理不精确的问题对于从事分析和数据科学工作的人来说是一项资产。
Q17. 如何确定 Twitter 用户的影响力?
Gregory Piatetsky 回答:
社交网络是当今网络的核心,而在社交网络中确定影响力是一个巨大的研究领域。Twitter 影响力是整体社交网络影响力研究中的一个狭窄领域。
Twitter 用户的影响力超越了简单的关注者数量。我们还希望检查推文的有效性——它们被转发、收藏的可能性,或其中的链接被点击的频率。什么算作有影响力的用户取决于定义——讨论的不同类型的影响包括名人、意见领袖、影响者、讨论者、创新者、主题专家、策展人、评论员等。
一个关键挑战是高效地计算影响力。Twitter 上的另一个问题是区分人类和机器人。
用于量化 Twitter 上影响力的常见测量方法包括许多版本的网络中心性——节点在网络中的重要性,以及基于 PageRank 的度量。

KDnuggets Twitter 社交网络,在 2014 年 5 月由 NodeXL 可视化。
使用的传统网络测量方法包括
-
接近中心性,基于从一个节点到所有其他节点的最短路径的长度。它测量每个节点相对于整个网络的可见性或可达性。
-
间接中心性考虑了每个节点 i 的所有最短路径,这些路径应通过 i 连接网络中的所有其他节点。它测量每个节点在网络内促进通信的能力。
其他提出的测量方法包括转发影响(推文被转发的可能性)和 PageRank 的变体,如 TunkRank——参见 A Twitter Analog to PageRank。
对整体影响力的一个重要补充是查看话题内的影响力——由 Agilience 和 RightRelevant 完成。例如,贾斯汀·比伯可能整体影响力很高,但在数据科学领域,他的影响力不如 KDnuggets。
Twitter 提供了一个REST API,允许访问关键指标,但对请求数量和返回的数据有限制。
许多网站曾测量 Twitter 用户的影响力,但由于许多业务模型未能实现,许多网站被收购或倒闭。目前仍然活跃的网站包括以下内容:
免费:
-
Agilience(KDnuggets 在机器学习领域排名第 1,在数据挖掘领域排名第 1,在数据科学领域排名第 2)
-
Klout,klout.com(KDnuggets 的 Klout 评分为 79)
-
Influence Tracker,www.influencetracker.com,KDnuggets 影响力评分 39.2
-
Right Relevance——衡量 Twitter 用户在某一话题中的具体相关性。
付费:
-
Brandwatch(购买了 PeerIndex)
-
Hubspot
-
Simplymeasured
相关的 KDnuggets 文章:
-
Agilience 顶级数据挖掘、数据科学权威
-
Twitter 上的 12 位数据分析思想领袖
-
数据科学领域的 123 位最具影响力人物
-
RightRelevance 帮助寻找大数据、数据科学及其他领域的关键话题和顶级影响者
相关的 KDnuggets 标签:
-
/tag/influencers
-
/tag/big-data-influencers
若需更深入的分析,请参阅以下技术文章:
-
什么是衡量 Twitter 用户影响力的好方法?,Quora
-
在 Twitter 上测量用户影响力:百万关注者的误区,AAAI,2010
-
在 Twitter 上测量用户影响力:一项调查,arXiv,2015
-
在 Twitter 上测量影响力,I. Anger 和 C. Kittl
-
一位数据科学家解释如何最大化你在 Twitter 上的影响力,Business Insider,2014
相关:
-
17 个必须知道的数据科学面试问题和答案
-
17 个必须知道的数据科学面试问题和答案,第二部分
-
21 个必须知道的数据科学面试问题和答案
-
21 个必知的数据科学面试问题及答案,第二部分
更多相关内容
-
我们是否应该根据清洗工作的成本、数据的使用频率还是其在数据模型中的相对重要性来选择数据进行清洗?或者,这些因素的组合?是什么样的组合?
-
通过去除不完整或错误的数据来提高数据准确性是否是一个好主意?在删除某些数据时,我们如何确保不会引入偏差?
鉴于工作范围广泛和资源极其有限(相对而言!),在大数据项目中的数据质量工作常见的一种方法是采用基线方法,其中,对数据用户进行调查,以确定和记录确保支持的业务流程不被干扰所需的最低数据质量。这些最低满意的数据质量水平被称为基线,数据质量工作集中在确保每个数据的质量不低于其基线水平。这看起来是一个不错的起点,之后你可以根据业务需求和预算情况深入到更高级的工作中。
改进大数据项目数据质量的建议总结:
-
识别并优先考虑业务用例(然后,利用这些用例定义数据质量指标、测量方法、改进目标等)。
-
基于对业务用例的深入理解和为实现这些用例所实施的大数据架构,设计并实施一个最佳的数据治理层(数据定义、元数据要求、数据所有权、数据流图等)。
-
记录关键数据的基线质量水平(考虑“关键路径”图和“吞吐瓶颈”评估)。
-
定义数据质量工作回报率(以创建回馈循环,用于改进效率并维持数据质量工作的资金支持)。
-
整合数据质量工作(通过减少冗余来提高效率)。
-
自动化数据质量监控(以降低成本并让员工专注于复杂任务)。
不要依赖机器学习自动处理差的数据质量(机器学习是科学,而不是魔法!)。
下一页还有 3 个有趣的答案 - 继续阅读...
更多相关话题
17 个必须知道的数据科学面试问题及答案
原文:https://www.kdnuggets.com/2017/02/17-data-science-interview-questions-answers.html/2
Q4. 为什么包含较少的预测变量比包含许多预测变量更可取?
Anmol Rajpurohit 的回答:
这里有几个理由说明为什么使用较少的预测变量可能比使用许多预测变量更好:
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌IT支持专业证书 - 支持你的组织IT。
冗余/不相关:
如果你处理了许多预测变量,那么很可能其中一些变量之间存在隐藏的关系,导致冗余。除非在数据分析的早期阶段识别并处理这些冗余(通过仅选择非冗余的预测变量),否则它可能对后续步骤造成巨大阻碍。
也有可能并非所有预测变量对因变量都有显著影响。你应该确保你选择的预测变量集合中没有任何不相关的变量——即使你知道数据模型会通过赋予这些变量较低的重要性来处理它们。
注意:冗余和不相关是两个不同的概念——一个相关的特征由于存在其他相关特征而可能变得冗余。
过拟合:
即使你有大量的预测变量,并且它们之间没有任何关系,仍然建议使用较少的预测变量。具有大量预测变量的数据模型(也称为复杂模型)通常会出现过拟合的问题,这种情况下,数据模型在训练数据上表现很好,但在测试数据上表现不佳。
生产力:
假设你有一个项目,其中包含大量的预测变量,并且所有这些变量都是相关的(即对因变量有可测量的影响)。显然,你会希望使用所有这些变量,以便构建一个成功率非常高的数据模型。尽管这种方法听起来非常诱人,但实际考虑(如可用数据量、存储和计算资源、完成所需时间等)使得这种做法几乎不可能实现。
因此,即使你有大量相关的预测变量,使用较少的预测变量(通过特征选择筛选或通过特征提取开发)也是一个好主意。这本质上类似于帕累托原则,该原则指出,对于许多事件,约80%的效果来自20%的原因。
关注那20%最重要的预测变量,将对在合理时间内构建成功率较高的数据模型非常有帮助,而不需要大量数据或其他资源。

训练误差与测试误差 vs 模型复杂性(来源:Quora 发布者:Sergul Aydore)
可理解性:
使用较少预测变量的模型更易于理解和解释。由于数据科学步骤将由人类执行,结果将由人类呈现(并且希望被使用),因此考虑到人脑的综合能力非常重要。这基本上是一个权衡——你放弃了一些潜在的好处,以提高数据模型的成功率,同时使数据模型更易于理解和优化。
如果在项目结束时你需要向他人展示你的结果,而这些人不仅对高成功率感兴趣,还对“幕后”发生的情况感兴趣,这一点特别重要。
Q5. 你会使用什么误差指标来评估一个二分类器的好坏?如果类别不平衡呢?如果有多于2个组呢?
Prasad Pore 回答:
二分类涉及将数据分类为两个组,例如,客户是否购买某一特定产品(是/否),基于性别、年龄、位置等独立变量。
由于目标变量不是连续的,二分类模型预测目标变量为“是/否”的概率。为了评估这样的模型,使用了一种称为混淆矩阵的指标,也叫分类矩阵或一致性矩阵。借助混淆矩阵,我们可以计算出重要的性能指标:
-
真阳性率(TPR)或命中率或召回率或敏感性 = TP / (TP + FN)
-
假阳性率(FPR)或假警报率 = 1 - 特异性 = 1 - (TN / (TN + FP))
-
准确率 = (TP + TN) / (TP + TN + FP + FN)
-
错误率 = 1 – 准确率 或 (FP + FN) / (TP + TN + FP + FN)
-
精确度 = TP / (TP + FP)
-
F-measure: 2 / ( (1 / 精确度) + (1 / 召回率) )
-
ROC(接收操作特征曲线)= FPR vs TPR的图示
-
AUC(曲线下面积)
-
Kappa统计量
你可以在这里找到更多关于这些指标的详细信息:测量分类模型准确性的最佳指标。
所有这些措施都应结合领域技能并加以平衡,例如,如果你仅在预测无癌症患者时获得更高的TPR,那么在诊断癌症时将没有帮助。
在癌症诊断数据的相同示例中,如果只有2%或更少的患者有癌症,则这是一个类别不平衡的情况,因为癌症患者的比例相对于其他人群非常小。处理此问题的主要有2种方法:
- 使用成本函数:在这种方法中,借助成本矩阵(类似于混淆矩阵,但更关注假阳性和假阴性)来评估与数据误分类相关的成本。主要目的是减少误分类的成本。假阴性的成本总是高于假阳性的成本。例如,错误地预测癌症患者为无癌症比错误地预测无癌症患者为癌症更危险。
总成本 = 假阴性的成本 * 假阴性的数量 + 假阳性的成本 * 假阳性的数量
- 使用不同的采样方法:在这种方法中,你可以使用过采样、欠采样或混合采样。在过采样中,少数类观察值被复制以平衡数据。观察值的复制会导致过拟合,导致训练中准确度高但在未见数据中准确度低。在欠采样中,去除多数类观察值会导致信息丢失。这有助于减少处理时间和存储,但仅在你有大量数据集时才有用。
如果目标变量中有多个类别,则会形成一个与类别数量相等的混淆矩阵,并可以计算每个类别的所有性能指标。这称为多类混淆矩阵。例如,如果响应变量中有3个类别X、Y、Z,那么每个类别的召回率计算如下:
Recall_X = TP_X/(TP_X+FN_X)
Recall_Y = TP_Y/(TP_Y+FN_Y)
Recall_Z = TP_Z/(TP_Z+FN_Z)
Q6. 我可以通过哪些方法使我的模型对异常值更具鲁棒性?
Thuy Pham 回答:
有多种方法可以使模型对异常值更具鲁棒性,从不同的角度(数据准备或模型构建)。异常值在问答中被认为是人类知识中不需要的、意外的或必须是错误的值(例如,没有人200岁),而不是可能但稀有的事件。
异常值通常是相对于分布来定义的。因此,可以在预处理步骤(任何学习步骤之前)中通过使用标准差(对于正态分布)或四分位数范围(对于非正态/未知分布)作为阈值水平来移除异常值。

异常值。 图片来源
此外,数据转换(例如对数转换)可能有助于当数据存在明显尾部时。当异常值与收集仪器的灵敏度有关,这些仪器可能无法准确记录小值时,Winsorization可能会有用。这种类型的转换(以Charles P. Winsor (1895–1951)的名字命名)具有与剪切信号相同的效果(即用不那么极端的值替换极端数据值)。 另一种减少异常值影响的选项是使用平均绝对差而不是均方误差。
对于模型构建,一些模型对异常值具有抗性(例如,基于树的方法)或非参数测试。类似于中位数效应,树模型在每次分裂时将每个节点分成两个。因此,在每次分裂时,所有数据点在一个桶中都可以被平等对待,无论它们可能有多极端。研究[Pham 2016]提出了一种检测模型,该模型结合了数据的四分位数信息来预测数据的异常值。
参考文献:
[Pham 2016] T. T. Pham, C. Thamrin, P. D. Robinson, 和 P. H. W. Leong. 在强迫振荡测量中的呼吸伪影去除:一种机器学习方法。IEEE生物医学工程学报,2016。
这个Quora回答包含了更多信息。
相关话题
-
检测伪数据科学家的20个问题(附答案):ChatGPT…
中客户行为随时间变化。例如,一家电话公司开发了一个预测客户流失的模型,或一家信用卡公司开发了一个预测交易欺诈的模型。训练数据是历史数据,而(新)测试数据是当前数据。
这样的模型需要定期重新训练,并且要确定何时可以比较旧数据(训练集)和新数据中的关键变量分布,如果有足够显著的差异,则需要重新训练模型。
有关更详细和技术性的讨论,请参见下面的参考文献。
参考文献:
[1] Marco Saerens, Patrice Latinne, Christine Decaestecker: 调整分类器输出以适应新的先验概率:一个简单的过程。Neural Computation 14(1): 21-41 (2002)
[2] 《非平稳环境中的机器学习:协变量转移适应导论》,Masashi Sugiyama, Motoaki Kawanabe,MIT出版社,2012,ISBN 0262017091,9780262017091
[3] Quora 对于 测试数据分布与训练数据分布显著不同可能会有什么问题?
[4] 分类中的数据集转移:方法与问题,Francisco Herrera 邀请讲座,2011。
[5] 当训练集和测试集不同:学习迁移的特征,Amos Storkey,2013。
Q3. 偏差和方差是什么,它们与建模数据的关系是什么?
Matthew Mayo 回答:
偏差是模型预测与正确性之间的偏离程度,而方差是这些预测在模型迭代间变化的程度。

偏差与方差,图像来源
举个例子,通过一个简单的有缺陷的总统选举调查作为示例,通过偏差和方差的双重视角解释调查中的错误:从电话簿中选择调查参与者是一个偏差来源;小样本量是方差的来源。
最小化总模型误差依赖于偏差和方差误差的平衡。理想情况下,模型是低方差的无偏数据的集合。然而,不幸的是,模型越复杂,其倾向于减少偏差但增加方差;因此,最佳模型需要考虑这两种属性之间的平衡。
交叉验证的统计评估方法既有助于展示这种平衡的重要性,也有助于实际寻找这种平衡。使用的数据折数——即k-折交叉验证中的k值——是一个重要决策;值越低,误差估计的偏差越高,而方差则较少。
 偏差和方差对总误差的贡献,图像来源 相反,当k等于实例数量时,误差估计的偏差非常低,但方差可能很高。
偏差和方差对总误差的贡献,图像来源 相反,当k等于实例数量时,误差估计的偏差非常低,但方差可能很高。
最重要的要点是偏差和方差是构建模型时两个重要的权衡方面,即使是最常规的统计评估方法也直接依赖于这种权衡。
在下一页,我们回答
-
为什么选择较少的预测变量可能比选择更多的预测变量更优?
-
你会使用什么错误度量来评估一个二分类器的好坏?
-
有哪些方法可以使我的模型对异常值更加稳健?
更多相关话题
数据科学中的业务直觉
www.kdnuggets.com/2017/10/business-intuition-data-science.html(原文)
 评论
评论
作者:Jahnavi Mahanta
通常,当我们考虑数据科学任务时,首先想到的是需要应用的算法技术。虽然这非常重要,但典型的数据科学任务还需要同等的关注其他许多步骤。
我们的前三个课程推荐
1. Google 网络安全证书 - 加入网络安全职业速成班
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 为 IT 部门提供支持
典型的数据科学任务可能包含以下阶段:
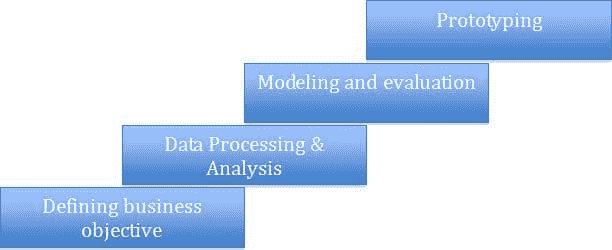
让我通过一个简单的案例研究来解释:
这是一个在线零售商,在假日季节之前的十一月份举办购物节。他们的产品目录中有一百万个产品,并且在过去的时期有一亿个客户购买了他们的商品。
零售商希望向其客户群体发送促销电子邮件。目标是运营一系列“成功的电子邮件营销活动”。
现在让我们了解这个特定任务的不同生命周期阶段:
1. 定义业务目标:
这是一个非常关键的阶段,因为对当前业务问题/目标的错误解释可能导致错误的解决方案和不可取的结果。如果你真的考虑一下,数据科学的角色是使用数据和洞察力来解决现实世界的问题。从这个角度来看,准确地识别问题和定义目标对于成功的结果至关重要。在这个例子中,营销人员想要向每位客户发送定制电子邮件,展示根据客户的偏好和口味精心策划的产品优惠列表:
在这种情况下,为了定义业务目标,我们需要提出一些问题:
1. 我们是给所有 1 亿客户发送电子邮件,还是给一部分客户发电子邮件?

来源:daric.classtell.com/
零售商正在组织一次购物节,因此向所有 1 亿客户发送电子邮件可能是有意义的,但还是需要考虑一些要点:
a. 通过向所有客户发送大量电子邮件,会让一些客户感到不满意。例如,那些不活跃地在零售商那里购物的客户。
b. 由于我们希望向客户展示经过策划的产品列表(基于个人的偏好),所以,如果考虑了所有的 1 亿客户,我们可能会得到一组客户,这些客户对任何产品的偏好可能不是很高(可能是因为他们并没有在这家零售商那里购买很多东西,因此,零售商没有足够的信息来了解他们的偏好)
c. 有时,数据处理和存储成本也可能是一个考虑因素。处理 1 亿客户及其特征,运行机器学习算法可能非常耗时和资源密集。虽然基础设施可以处理,但结合前两个考虑因素,排除一些客户可能有意义,特别是为了加快上市时间。
来源:mobileadvertisingwatch.com
2、我们如何定义和量化成功度量标准?这是一个非常重要的决定,直接关系到业务目标。在上述情况下,我们可以有几种可能的成功度量标准:
a. 营销活动的购买率(购买数/发送的电子邮件数):这个度量标准将告诉我们营销活动有多有效说服客户去消费。所以,如果零售商只关心整个营销活动带来了多少销售额,那么这个度量就是要注意的!

来源:https://www.jaroop.com/web-traffic/
b. 营销活动的电子邮件打开率(打开的电子邮件数/发送的电子邮件数):如果零售商想要了解其他因素,比如电子邮件活动内容的有效性,那么这可能很重要,特别是在这种情况下,电子邮件主题有多“吸引人”。同样地,电子邮件点击率(在打开邮件后,点击邮件中提供的网站链接,以登陆零售商网站)显示了电子邮件内容的有效性。
c. 营销活动的盈利能力: 有时,与其只吸引更多的客户做出反应(即提高反馈率),零售商可能对吸引每位客户的花费更感兴趣。这样想吧 – 一个旨在吸引更多客户消费的活动可能吸引购买很多产品但价值较低的客户,逃避购买较少但购买高价值产品的客户。
2、数据处理和分析:
这同样是另一个非常重要的阶段,我们详细了解手头可用的数据以及如何使用它准确地解决手头的问题。
大致来说,这个阶段可能包括以下步骤:
-
缺失值处理
-
异常值处理
-
数据细分
-
特征工程
一个接一个地浏览它们,以便对为什么需要这一步有所直觉。在上面的案例中,假设您有以下的数据,来自过去的促销电子邮件活动:
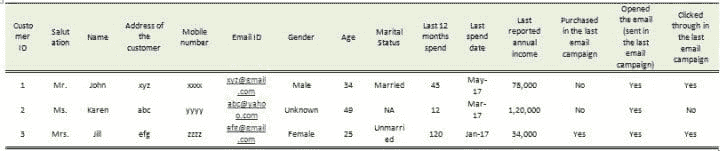
上面的数据是在线零售商的一部分信息的三个客户的快照(总共有 1 亿客户)。
可以看到第 2 个客户的性别是未知的。性别可能是有力的信息,因此,如果大部分客户的性别是“未知”或“缺失”的,则我们将失去一条非常重要的信息。可以有许多方法来对性别进行插补(通过称谓或姓名),因此可用于缺失值处理。 类似地,如果报告的年收入丢失了(因为这个信息仅由客户提供,他/她可能不愿提供),我们可以使用过去 12 个月的支出来插补/预测年收入。
异常值处理 也很重要。例如,我们可能会看到一些“过去 12 个月支出”或“年收入”的非常高的值。在支出方面,这可能是因为某些客户的一次性高额支出,这种情况可能不持续并可能对整个数据造成偏见,因此将支出值设定在某个阈值上限(例如“过去 12 个月支出”的 99 或 95 分位数值)可以帮助减少这种偏见。
有时,我们可能会看到数据中存在行为非常不同的不同客户细分。例如,如果我们看看最近的客户(过去 6 个月成为在线零售商的会员),这些客户的行为方式可能与其他客户截然不同(他们可能非常好奇,因此电子邮件的开启率可能非常高,但购买率可能很低)。 因此将这些客户与其他客户混合在一起可能会对某些参数的数据造成偏见,或者这些客户的特征可能会被其他客户所掩盖,在构建任何预测算法时降低了它们的代表性。 在这种情况下,为这两个“数据细分”(新客户和其余客户)建立单独的算法可能是有意义的。

特征工程: 特征或变量真的能为算法提供预测能力。因此,拥有正确的特征集对于构建强健的算法至关重要 – 因此重点放在特征工程上。 特征工程的类型:
-
特征选择:选择对问题最有用的特征子集。有许多特征选择算法,例如基于相关性、信息价值或其他特征重要性概念的得分算法。然而,随着越来越多的计算能力和机器学习技术,特征选择越来越多地在算法内部处理。
-
特征构建:从原始数据中手动构建新的特征,例如在上述案例研究中,我们有一个“最后消费日期”的特征,本身可能不提供任何预测能力。然而,我们可以创建一个“距离最后消费的天数”的特征,这可能非常有用(最近消费的客户可能有更高的再次消费意愿,因此对电子邮件优惠更具响应性)。
-
特征提取:一些数据,如图像、声音、文本,可能有多个特征,因此,通过特征提取,我们可以自动降低这些类型特征的维度,并从数据中提取隐藏的特征。例如,在像下面的 Pokemon 图像识别中,每个图像可以有成百上千个特征(像素)。因此,任何图像识别算法都必须处理来自多个图像的大量特征。因此,算法必须能够自动提取和减少这些大量特征到一个较小的有意义的特征集。

更多关于此主题的信息
数据科学中的业务直觉
3. 建模和评估:
这一步是我们必须选择“正确的算法”来得到“适合我们业务问题的正确解集”的步骤。正如您所见,这是一个非常重要的步骤,关键是找到最适合给定业务目标的算法。在上述情况下,不必详细介绍,我们有两组目标 - (1)从 1 亿客户中找到最敏感的客户 - 假设为 x(2)针对每个客户,展示与其偏好最相关的优惠。对于第一个目标,我们需要一种响应预测算法(例如回归技术),它将为每个客户提供一个响应可能性分数/概率,然后可用于对客户进行排名并选择最具响应性的客户进行活动。对于目标(2) - 查找客户的优惠偏好,我们需要能够帮助选择客户最可能喜欢的产品优惠的算法(例如推荐者算法或分类技术)
一旦我们建立了算法,它们的评估也基于它们如何满足当前目标。让我们使用上述案例研究来理解这一点。假设我们已经建立了一个响应预测算法,根据客户在看到电子邮件优惠后购买产品的概率对 1 亿名客户进行排名:
| 客户 ID | 响应概率 |
|---|---|
| 1 | 98.0% |
| 2 | 95.0% |
| 3 | 90.0% |
| 4 | 89.0% |
| 5 | 88.0% |
| . | . |
| . | . |
| . | . |
| 1 亿 | 0.1% |
我们的前三个课程推荐
1. Google 网络安全证书 - 快速迈向网络安全职业路线。
2. Google 数据分析专业证书 - 提升数据分析能力
3. Google IT 支持专业证书 - 支持您的 IT 组织
现在,我们将这 1 亿名客户分成 10 个相等的桶,按照从最高概率到最低概率的降序进行排名。对于这些客户桶中的每个客户,我们查看他们对先前发送的电子邮件优惠活动的实际响应率,该优惠活动发送给了所有的 1 亿名客户:
| A | B | C | C/B | |
|---|---|---|---|---|
| 客户桶 | 平均响应率 | 上次活动中发送电子邮件的客户数 | 上次电子邮件活动中的响应者数 | 每个客户桶中对上次电子邮件活动的实际响应率(响应者数/客户数) |
| Bucket 1 | 98.0% | 1,00,00,000 | 1,00,00,000 | 100.0% |
| Bucket 2 | 97.0% | 1,00,00,000 | 92,00,000 | 92.0% |
| Bucket 3 | 78.0% | 1,00,00,000 | 68,00,000 | 68.0% |
| Bucket 4 | 65.0% | 1,00,00,000 | 50,00,000 | 50.0% |
| Bucket 5 | 45.0% | 1,00,00,000 | 42,50,000 | 42.5% |
| Bucket 6 | 23.0% | 1,00,00,000 | 25,00,000 | 25.0% |
| Bucket 7 | 15.0% | 1,00,00,000 | 13,00,000 | 13.0% |
| Bucket 8 | 4.0% | 1,00,00,000 | 14,80,000 | 14.8% |
| Bucket 9 | 1.0% | 1,00,00,000 | 5,00,000 | 5.0% |
| Bucket 10 | 0.1% | 1,00,00,000 | 30,000 | 0.3% |
| 总计 | 10,00,00,000 | 4,10,60,000 | 41.1% |
请注意:这里的回应是在看到电子邮件提供后的产品购买
因此,为了实现目标 1,我们只需决定向哪个桶发送电子邮件提供。
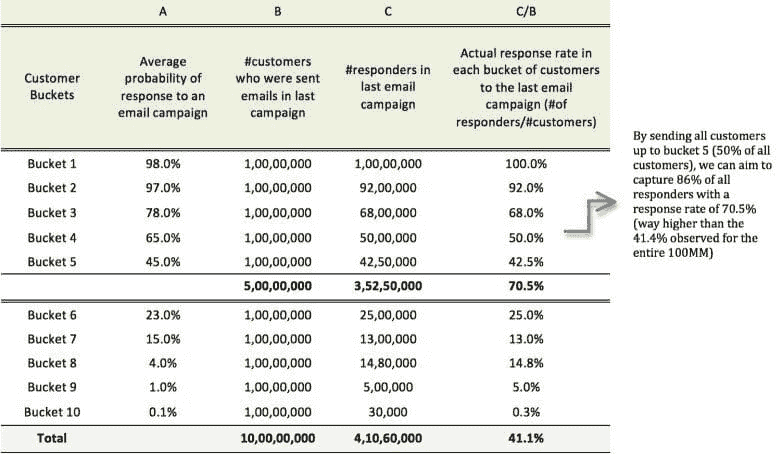
现在,在上表中,您可以看到某些“平均响应概率”值和一些存量的“实际响应率”值之间存在差异,例如,3 和 4 桶。因此,与实际值相比,预测并不是非常“准确”。然而,由于这里的目标是选择一组响应概率高的客户,我们更关心的是模型在排名客户的响应方面做得如何。从实际比例来看,它似乎做得相当好(过去广告活动的实际响应率也基本上按降序排序)。
因此,在这里,模型结果的评估更多地围绕着按照客户的响应概率对其进行排名,而不是预测的准确性。
但是,当我们评估第二个模型的结果时,为每个客户的每个产品提供优先权分数,预测精度可能更重要。比方说,在上述情况下,有 10 份产品提供。因此,我们建立了一个模型,为每个客户为这 10 份产品提供每一个的偏好分数:
| 客户 ID | 产品提供 1 | 产品提供 2 | 产品提供 3 | 产品提供 4 | 产品提供 5 |
|---|---|---|---|---|---|
| 1 | 0.7 | 0.13 | 0.01 | 0.15 | 0.01 |
| 2 | 0.8 | 0.5 | 0.02 | 0.005 | 0.4 |
| 3 | 0.01 | 0.02 | 0.002 | 0.03 | 0.04 |
在这里,顾客 1 对产品 1、2 和 4 有更高的偏好。对于产品 3 和 5,由于偏好分数非常低,我们可以假设他对这些产品没有任何偏好。同样,我们可以说客户 2 并没有显示对任何特定产品的偏好。我们可以创建一个阈值分数,如果客户的分数高于该阈值,则我们将考虑其偏好,否则不考虑。
因此,您可以看到,我们根据得分值进行这样的评估,因此,有准确反映客户真正偏好的得分非常重要。因此,在这种模型评估中,预测的准确性非常重要。
4. 原型:
通过构建数据原型,我们指的是创建必要的基础设施来在生产环境中实施解决方案。鉴于实施是一个耗费时间和资源的过程,需要给予适当的考虑。在上述情况下,其中一些可能是:
-
这个邮件活动是一次性的营销倡议还是更常规的?如果是常规的,那么创建生产平台来执行这样的活动是有意义的。
-
对于这样的平台,如何将来自不同来源的所有数据源汇总在一起?需要评估数据清洗的工作量和成本、其更新频率、内部数据卫生检查与平衡等。
-
所有这些数据将如何存储和处理?这涉及决策,比如需要并行处理(如果数据量庞大)或实时处理以及存储基础设施的需求。
-
邮件将如何投递?再次,在这里需要做出决策,包括-需要第三方邮件投递商、客户数据隐私的检查与平衡、市场速度包括实时处理等。
这些是一些考虑因素,但根据任务的规模和复杂性,可能还有许多其他需要评估和评价的事情。
因此,正如你所看到的,数据科学的任务是许多阶段的总和,需要领域专业知识和对业务目标的详细了解,以及技术专业知识。缺一不可!!
想了解更多?加入由www.deeplearningtrack.com提供的基于案例的为期 8 周的数据科学课程。
个人简介:Jahnavi Mahanta 是 Deeplearningtrack 的联合创始人。
相关:
-
人工智能如何改变你的业务
-
应用数据科学:解决预测维护业务问题
-
为什么你的公司应该投资于#BUSINESSOFBOTS
关于这个话题更多信息
想成为一名数据科学家?首先阅读本次采访
评论
市场学家 Kevin Gray 询问 Jennifer Priestley,肯尼索州立大学研究生学院副院长和统计学与数据科学教授,数据科学到底是什么,成为一个好的数据科学家需要什么,以及如何成为一名数据科学家。
Kevin Gray: 你能用简单易懂的话给我们定义数据科学吗?
我们的前 3 个课程推荐
1. Google 网络安全证书 - 加快专业网络安全职业发展步伐。
2. Google 数据分析专业证书 - 提高你的数据分析能力
3. Google IT 支持专业证书 - 在 IT 方面提供组织支持
Jennifer Priestly: 我喜欢 Josh Wills 在推特上恰当发表的定义 - "作为一个人,在统计学方面要比任何软件工程师更擅长,在软件工程方面要比任何统计学家更优秀"。我还想添加我称之为”The Priestley Corollary”的定义 - "作为一个人,在解释分析结果的商业影响方面要比任何科学家更擅长,在分析科学方面要比任何 MBA 更优秀"。
统计学家和数据科学家之间有什么区别?
 这是一个很好的问题。我经常被问到计算机科学家和数据科学家有什么区别。两个领域都贡献了重要且有意义的方式来推动这一新兴学科发展,但二者都不是独立足够的。
这是一个很好的问题。我经常被问到计算机科学家和数据科学家有什么区别。两个领域都贡献了重要且有意义的方式来推动这一新兴学科发展,但二者都不是独立足够的。
数据不仅在规模上增长,而且我们甚至认为什么是数据的定义也在不断扩展。例如,文本和图像正越来越成为集成到分类和风险建模等分析方法中的常见数据形式。 数据定义的这种扩展将统计学和计算机科学推出了它们的传统核心,并进入各自的边缘领域 - 而正是在这些边缘领域进行新的思考 - 边缘的融合正在形成数据科学的基础。大部分传统统计学核心不能轻易地处理由上亿条记录和/或非结构化数据定义的问题。同样,虽然计算机科学的核心能够有效地捕获和存储大量结构化和非结构化数据,但该学科无法适应通过建模、分类然后可视化将这些数据转化为信息的过程。
我同意,在数据科学领域,统计学家更有可能得到糟糕的结果。我认为这是不幸的。几年前,Simply Statistics 博客上有一篇文章《大数据出问题了:他们忘记了应用统计学》。这篇文章突出了一种急于追求机器学习、文本挖掘和神经网络的兴奋,错过了与数据行为相关的基本统计概念的重要性,包括变异性、置信度和分布。这导致了糟糕的决策。虽然数据科学并不是统计学,但统计学以一种基础性的方式为这门学科做出了贡献。
直到几年前,我们中的很少有人听说过数据科学。你能给我们提供它的历史概述吗?
这个术语可以追溯到 1960 年计算机科学家彼得·勒,但“数据科学”也在统计学中拥有进化的基础。1962 年,约翰·W·图基(我们这个时代最知名和受尊敬的统计学家之一)写道:“很长一段时间,我认为我是一名统计学家,对从特定到一般的推断感兴趣。但当我看着数学统计学发展时,我……开始感觉到我的中心兴趣在于数据分析……数据分析本质上是一个经验科学。”
术语“数据科学”在 1996 年国际分类学会第五届大会论文集中有所提及。这篇文章的标题是《数据科学,分类学和相关方法》。在 1997 年,宾夕法尼亚大学创始教授 C. F. Jeff Wu(目前在乔治亚理工学院)在密歇根大学担任 H.C. Carver 统计学教授的就职演说中,实际上呼吁将统计学命名为数据科学,统计学家命名为数据科学家。
数据科学的一个关键里程碑发生在 2002 年,当时推出了首本专门致力于数据科学的学术同行评审期刊——《数据科学杂志》……接下来的一年又推出了《数据科学杂志》。此后,还出现了几本其他期刊,专门促进和传播该领域的学术研究。
专门的学术期刊的出现对学术界尤为重要——这些期刊现在为新兴的博士项目(比如我们的项目)和新兴的学术部门建立了独特的研究、学术和出版平台。现在数据科学教员和博士生可以在自己的社区内从事知识生产和思想领导。

2011 年麦肯锡的一项被广泛宣传的研究预测到 2018 年时,“……仅美国就可能面临 19 万名具备深厚分析能力以及 150 万名具备运用大数据分析做出有效决策能力的经理和分析师的短缺”。这一预测的准确性如何?现在是否有其他预测我们应该使用?
我经常被问到这个问题—具体来说,很多公司高管问类似的问题,“数据科学这个东西是时尚吗?”。我认为我们需要重新构思讨论。
我的观点是,我们不需要“19 万人”或“150 万管理人员”具有深厚的分析能力。我认为每个人都需要一定水平的分析能力。我认为基本的数据素养应该与阅读和数学一样成为我们教育体系的基础。看到基本编码能力越来越多地在小学教育中教授是令人鼓舞的。在大学阶段,我认为数据科学应该成为通识教育课程的一部分(现在我能听到我们学术事务办公室的惊叹声)。
因此,尽管目前的人才缺口非常真实,但这是教育体系与市场需求不相匹配的结果。各个层次的教育仍在转变,未来将继续如此。我预计,在一代人的时间内,对这些技能的需求不会减少,但供给将更加紧密地对齐。
普里斯特利推论—(这是)一个比任何科学家更擅长解释分析结果的业务影响,也比任何工商管理硕士更擅长分析科学的人。
许多人,包括那些考虑职业转换的人,都将职业目标设定为数据科学。不过,并不是每个人都适合这个职业。在数据科学领域工作需要哪些资质和技能?成为一名数据科学家有哪些最佳途径?
这是一个很好的问题。我们可以讨论后辈们...以及我们需要做些什么来使他们准备好...但现实情况是,目前有很多 20 多岁、30 多岁和 40 多岁的人正在寻找转向数据科学的机会。
我在办公室里看到了很多这样的人。我曾有过一次以上这样的对话:“我刚向 XX 大学支付了 1 万美元完成了数据科学证书...但我仍然找不到工作。”虽然一些这类“证书”项目是经过精心开发且具有高价值的,但不幸的是,很多项目却并非如此。
首先,你不能通过参加一个为期 5 天的证书项目从诗人变成数据科学家。或者更糟的是,一个在线证书项目。
其次,我认为人们需要对实现职业目标真正需要付出的努力抱有现实的期望。这些技能需求量很大,薪水很高,因为它们很难-或者至少需要主动去发展和完善。
第三,我认为人们需要评估一下现有技能和目标位置之间的差距。这个问题的答案自然会决定如何达到目标。那些陷入易于在线证书项目的诱惑的人们应该记住《爱丽丝梦游仙境》中的猫猫:“如果你不知道你要去哪里的话,你走哪条路都无所谓”。
我告诉问我在这个领域寻求建议的人们-
(1) 如果你是一位诗人,并且你希望真正地、深入地以数据科学作为职业,那么你需要放下你的羽毛笔,取而代之的是你的牛仔裤和背包,然后回到学校。全日制。大多数数据科学研究生项目不到两年,并且大多数都提供某种形式的研究生研究助理职位。你应该寻找包括编程、统计、建模的项目。但也要有充分的机会与当地公司、非营利组织、地方政府等合作,参与真实世界的项目。我再次强调,实践、动手经验对于任何数据科学项目至关重要。这就是为什么在线或短期证书项目对于从零开始的人来说行不通的原因所在。通过实践经验,人们才能理解数据科学中更隐秘的方面,比如叙事的作用、创造力(被低估了)和项目管理。
(2)如果你是计算机科学家/程序员,找一个商学院专业有分析方向或者应用统计学项目的学校。可能你的编码和数学技能已经到位了-你可能需要统计/建模/分析-再次强调-来讲述故事,并学会如何与思想和你不同的团队合作。
(3)我鼓励每个人考虑学习像 Tableau 这样的基本可视化工具。我还鼓励任何人定期考虑参加在线/异步编程课程。这些课程通常价格不高(甚至免费),可以让你继续保持技能的熟练。
我能理解并同意并非所有人都想成为计算机程序员-我并不特别喜欢编程。我不得不学习编程来找到对我提出的研究问题的答案。如果我能够使用我那可靠的 HP-12C 和一支自动铅笔找到答案,我会满意的。你必须懂一些基本的数学,必须能够阅读和写作,而且,在 21 世纪,你还必须精通基本的编程。
数据科学家经常评论,在许多组织中,管理层并不真正知道如何利用分析进行决策。决策仍然主要是凭直觉做出的,并且受到组织政治的重大影响。这也是你的经验吗?
我经常在公司活动上发表演讲,在那里这个问题存在于房间中-即使没有被表达出来。我会这样来框架谈话-组织可以大致分为数据本土化和非本土化。
符合“本土化数据”的例子是主宰头条新闻和股票市场的公司-亚马逊,谷歌和 Facebook。这些公司在 30 年前是无法存在的。它们是如此基础性的数据甚至不存在,但即使存在,我们也没有捕获它或执行与人工智能,机器学习,深度学习相关的深度分析方法的计算能力,使它们能够做他们所做的事情。
但通常被忽视的是,这些公司的另一个维度是,由于它们是数据本土化的,这具有巨大的文化影响。这些公司从组织结构的最高到最低都是以数据驱动的。它们的基因中流淌着数据。几乎每个进入这些公司的人都有数据为中心的取向,很可能学过计算学科,越来越多地是数据科学。Facebook 员工的中位年龄是 29 岁。谷歌也是 29 岁,亚马逊是 30 岁(不包括仓库员工)。
那些与数据无关的公司是在我们听到“数据科学”和“大数据”等术语之前就取得成功的公司。例如沃尔玛和阿比。这些是非常成功的公司,最初并没有数据贯穿其业务。尽管这些公司现在非常依赖数据来指导决策和提供产品和服务,但在组织结构中计算素养存在很大的差异。但他们的领导在文化转变中非常前瞻,使这些公司成为市场领导者,因为它们成为基于事实、数据驱动的组织。他们所在的市场中的其他公司(西尔斯、梅西百货……麦当劳、温迪)却没有做到这一点。
最后,您认为人工智能和自动化将在未来 10-15 年对数据科学产生什么影响?
我并不是这个领域的专家,但我认为任何因自动化而导致统计学、计算机科学或数据科学的衰亡的预测都是为时过早的。计算器“自动化”了数学……但如今的数学比使用计算器之前更广泛、更复杂。我相信在数据科学领域也将是如此。
谢谢你,詹!
凯文·格雷是Cannon Gray的总裁,这是一家市场科学和分析咨询公司。
詹妮弗·刘易斯·普雷斯特利是肯尼索州立大学研究生院副院长、统计学和数据科学教授。
原始链接。经许可重新发布。
本文首次发布于 2017 年 7 月的 Greenbook 杂志。
相关链接:
-
统计建模:入门指南
-
时间序列分析:入门指南
-
回归分析:入门指南
更多关于这个话题
如何构建数据科学管道
由 Balázs Kégl 撰写,数据科学家,RAMP 的共同创建者。
当一个良好运作的预测工作流最终投入生产时,如何运作没有争议。数据源被转化为一组特征或指标 X,描述每个实例(客户、设备、资产)在预测中将会受到的影响。预测器然后将 X 转化为一个可操作的信息 y_pred(客户会流失吗?设备会故障吗?资产价格会上涨吗?)。在某些流动性市场(例如广告定向)中,预测通过完全自动化的过程变现,而在其他情况下,则作为决策支持,涉及人为干预。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
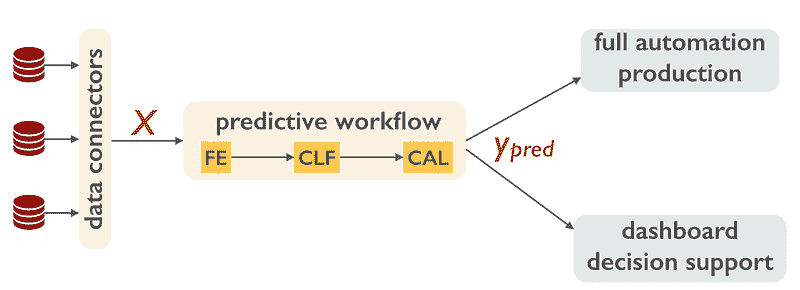
数据科学管道中的数据流在生产环境中。
这听起来简单,但成功和盈利的预测工作流的例子却很少。公司在构建过程中面临困难。他们需要问的问题是:
-
谁负责构建这个工作流?我需要覆盖哪些角色和专业知识?
-
建造过程是什么?每一步需要什么样的专业知识?
-
在这些步骤中有哪些费用和风险,我该如何控制它们?
对数据挑战的炒作给人一种错误的印象,即数据科学家和预测评分是过程的主要驱动因素。即使是自九十年代以来就存在的工业流程(例如,CRISP-DM 和 Dataiku)通常将数据科学家置于中心,将部署放在过程的最后。虽然它们并非完全错误,但大多无关紧要。构建和优化预测器很容易。困难的是找到业务问题和它将改善的 KPI,搜寻并将数据转化为可消化的实例,定义工作流的步骤,将其投入生产,并组织模型维护和定期更新。
公司通常从看似简单的任务开始:要求 IT 部门建立大数据基础设施并构建数据湖。随后,他们会雇佣首批数据科学家。这些专家刚从学校毕业,经过一些 Kaggle 挑战,装备了数据科学工具包,渴望动手处理数据。他们可以预测任何东西,而且他们确实这样做了!他们与业务部门沟通,找到已有标签的合理预测目标,尝试多种模型,进行超参数优化,并选择最佳模型。他们构建 POC 并将报告发送给业务部门,然后重新开始。
构建数据科学工作流的常见方式。
这些 POC 中大多数从未投入生产。 业务部门不知道如何处理它们。他们无法解读分数。预测目标似乎合理,但他们不知道如何利用他们的 y_pred 赚钱。如果他们知道,将 POC 投入生产似乎不可逾越。代码必须重写。实时数据必须纳入工作流。需要满足操作约束。决策支持系统需要与用户现有工作工具集成。需要进行模型维护、用户反馈和回滚。这些操作通常比数据科学家工作中的安全 POC 成本更高、风险更大,而 POC 仅仅无法推动过程。
我在下面描述的过程不会解决这些问题,但它为你提供了一个顺序,使你至少可以处理和控制成本和风险。首先,无论如何找到一位首席数据官(或者说是数据价值架构师),他/她已经将预测工作流投入生产。你的 CDO 不需要了解最新的深度学习架构,但她应该对公司的业务和数据科学过程有广泛的理解。她应该发挥核心作用,推动过程。
早期将 IT 纳入是重要的。你需要数据湖,但更重要的是,你需要数据工程师从第一天起就以生产的角度思考。但这并不是第一步。第一步是弄清楚你是否真的需要预测。
所以,从 y 开始,即预测目标。
你的 CDO 应与业务部门密切且长期合作,弄清楚他们想了解什么。是什么* y* 驱动他们的决策?* y* 的更好预测如何改善底线(降低成本、提高利润、提高生产力)?一旦确定了 y,尽量最大化预测误差的货币化。没有什么比一个良好的货币化指标更能让(未来的)数据科学家感到高兴了。他们会知道提高 2% 的分数能为你带来一百万美元;更重要的是,你 会知道你可以在数据科学团队上花多少钱。
一旦你巩固了 y 和指标,
进行数据探索,
找到你数据湖及其他地方的指标,这些指标可能与预测目标相关。原则上,你仍然不需要数据科学家来完成这项工作,这个过程应该由首席数据官和业务单位推动(毕竟,他们 知道他们在决策中使用了哪些信息,这通常是一个很好的基准)。但是,有一个了解开放和可购买数据的人可能会有所帮助。在这里,你绝对需要与 IT 沟通,以了解在实时收集这些指标时运营成本会是多少。数据科学家需要这些信息。如果在每个客户上存储一个新特征的成本是每天 4TB,那么这个单一事实决定了预测器的样子。
现在 雇佣一个数据科学家,最好是一个能够开发生产质量软件的人。让他
建立实验设置和基线工作流
进行简单的预测,并检查其是否可以投入生产。此时你已经准备好进行全规模的实验数据科学循环,这个循环数据科学家知道如何处理。你可能需要一个深度学习专家,但很可能你可以外包并众包你的第一个模型,例如,通过与我们一起进行一个RAMP。
如果你喜欢你所读的内容,可以在 Medium、LinkedIn 和 Twitter 上关注我。
简介:Balázs Kégl 是 CNRS 的高级研究科学家,并且是巴黎-萨克雷大学数据科学中心的负责人。他是 RAMP 的共同创始人 (www.ramp.studio)。
原文。经许可转载。
相关:
-
教授数据科学流程
-
数据科学会消除数据科学吗?
-
接受随机:随机化边界论文接受的案例
更多相关主题
探索大数据领域的前 12 大有趣职业
译文:
www.kdnuggets.com/2016/10/top-12-interesting-careers-explore-big-data.html
评论
由 Simplilearn 提供。
大数据不再是未来能力的流行词,而是已经被各种行业的企业所使用。从数据驱动的策略到决策,大数据的真正价值已经显现,并且带来了令人惊叹的职业选择。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的 IT 组织
顶级大数据职业
-
数据科学家
这些人利用他们的分析和技术能力从数据中提取有意义的见解。
薪资:$65,000 - $110,000
-
数据工程师
他们确保服务器和应用程序之间数据的连续流动,并负责数据架构。
薪资:$60,0945 - $124,635
-
大数据工程师
大数据工程师根据解决方案架构师创建的设计进行构建。他们在组织内部开发、维护、测试和评估大数据解决方案。
薪资:$100,000 - $165,000
-
机器学习科学家
他们从事用于自适应系统的算法研发。他们构建预测产品建议和需求预测的方法,探索大数据以自动提取模式。
薪资:$78,857 - $124,597
-
商业分析专家
商业分析专家支持各种开发计划,协助测试活动和测试脚本的开发,进行研究以了解业务问题,并开发切实可行的经济解决方案。
薪资:$50,861 - $94,209
-
数据可视化开发者
他们设计、开发并提供企业范围内互动数据可视化的生产支持。他们具备艺术思维,能够构思、设计和开发可重用的图形/数据可视化,并运用强大的技术知识使用最新技术实现这些可视化。
薪资:$108,000 - $130,000
-
商业智能(BI)工程师
他们具备数据分析专业知识和设置报告工具、查询及维护数据仓库的经验。他们亲自处理大数据,采取数据驱动的方法解决复杂问题。
薪资:$96,710 - $138,591
-
BI 解决方案架构师
他们迅速提出解决方案,帮助企业做出时间敏感的决策,拥有较强的沟通与分析能力,对数据可视化充满热情,并且具有追求卓越和自我激励的动力。
薪资:$107,000 - $162,000
-
BI 专家
他们负责支持企业范围内的商业智能框架。此职位需要批判性思维、关注细节以及有效的沟通技巧。
薪资:$77,969 - $128,337
-
分析经理
分析经理负责数据分析解决方案或 BI 工具的配置、设计、实施和支持。他们特别需要分析通过事务活动收集的大量信息。
薪资:$83,910 - $134,943
-
机器学习工程师
机器学习工程师的最终“输出”是工作的软件,他们的“受众”是其他自动运行的组件,几乎无需人工监督。决策由机器做出,影响产品或服务的行为。
薪资:$96,710 - $138,591
-
统计学家
他们收集数值数据并展示它,帮助公司理解定量数据,发现趋势并进行预测。
薪资:$57,000 - $80,110
建议的认证
-
Hadoop
-
SAS
-
Excel
-
R
-
MongoDB
-
Python
-
Pandas
-
Apache Spark & Scala
-
Apache Storm
-
Apache Cassandra
-
MapReduce
-
Cloudera
-
HBase
-
Pig
-
Flume
-
Hive
-
Zookeeper
相关:
-
帮助你进入行业的前 5 名大数据课程
-
进入数据科学或大数据职业前要读的 5 本电子书
-
大数据大师课程,改变你的职业生涯
更多相关话题
KDnuggets™ 新闻 16:n36,10 月 12 日:数据科学维恩图的对决;9 个奇怪和令人惊讶的见解;大数据分析中的投资回报率
特性 | 教程 | 意见 | 新闻 | 网络广播 | 课程 | 会议 | 职位 | 学术 | 推特 | ... 和 ..... 不要忘记查看 .... 本周图片
特性
-
数据科学维恩图的对决
-
九月热门故事:数据科学家使用的顶级算法和方法
-
/r/MachineLearning 九月热门帖子:开放图像数据集;巨额深度学习资助;高级机器学习课程材料
-
仍在寻找大数据分析的投资回报率?你并不孤单!
-
数据科学中的 9 个奇怪和令人惊讶的见解
-
预测分析世界:医疗保健分析的热点话题,10 月 23-27 日,纽约市
教程,概述
- 对抗性验证,解释
意见
-
人类与机器伦理框架:评估机器学习的影响
-
IT 部门如何使用大数据
-
乘数是否超越大数据分析?
-
预测分析的加冕:四年回顾
新闻
-
回顾过去一年:KDnuggets 博客十大帖子
-
九月 KDnuggets 顶级博客作者 - 金银奖徽
-
十大故事,10 月 3-9 日:数据科学维恩图的对决;自动化数据科学与机器学习:与 Auto-sklearn 团队的采访
网络广播和网络研讨会
-
分类的演变,10 月 19 日,10 月 26 日网络研讨会
课程,教育
-
预测分析:最大效果,最少时间
-
Statistics.com 新课程:异常检测、元分析、物联网、深度学习、空间分析
会议
-
预测分析世界:医疗保健分析的热点话题,10 月 23-27 日,纽约市
-
数据原住民,欧洲数据科学会议,10 月 26-28,柏林 - KDnuggets 提供
职业
-
微软:首席数据科学家
-
ACI Worldwide: 数据科学家
学术
-
天普大学:数据科学教职岗位
-
UMBC: 数据科学/大数据教职岗位
-
圣母大学:数据科学顾问
-
埃默里大学:计算机科学讲师
顶级推文
- KDnuggets 顶级推文,9 月 28-10 月 4: 精通 SQL 的 7 个步骤;数据科学中的最大问题
本周图片
。
 。
。更多相关主题
100 个关于分析、大数据、数据挖掘、数据科学、机器学习的活跃博客
www.kdnuggets.com/2016/03/100-active-blogs-analytics-big-data-science-machine-learning.html/2
-
Occam’s Razor 由 Avinash Kaushik 撰写,探讨 Web 分析和数字营销。
-
OpenGardens,互联网物联网(IoT)的数据科学,由 Ajit Jaokar 撰写。
-
O’Reilly Radar,涉及广泛的研究主题和书籍。
-
Oracle Data Mining Blog,关于 Oracle 数据挖掘的一切——新闻、技术信息、观点、技巧与窍门,尽在其中。
-
Observational Epidemiology 一位大学教授和统计顾问提供他们在应用统计学、高等教育和流行病学方面的评论、观察和思考。
-
Overcoming bias 由 Robin Hanson 和 Eliezer Yudkowsky 撰写。通过反思诚实、信号、分歧、预测和未来的远景,呈现统计分析。
-
Probability & Statistics Blog 由马特·阿舍(Matt Asher)撰写,他是多伦多大学的统计学研究生。查看阿舍的统计学宣言。
-
Perpetual Enigma 由计算机视觉爱好者 Prateek Joshi 撰写,提供关于机器学习的问答式引人入胜的故事阅读。
-
Predictive Analytics World 博客,由 Predictive Analytics World 和 Text Analytics World 的创始人 Eric Siegel 撰写,他也是《Predictive Analytics Times》的执行编辑,使预测分析的“如何”和“为什么”变得易于理解和引人入胜。
-
R-bloggers ,来自 R 语言丰富社区的最佳博客,包含代码、示例和可视化内容。
-
R chart 一个关于 R 语言的博客,由一名 Web 应用程序/数据库开发人员撰写。
-
R Statistics 由塔尔·加利利(Tal Galili)撰写,他是特拉维夫大学的统计学博士生,同时也担任大学统计课程的助教。
-
Revolution Analytics 由 Revolution Analytics 主办和维护。
-
Random Ponderings 由 Yisong Yue 撰写,内容涉及人工智能、机器学习和统计学。
-
Salford Systems Data Mining and Predictive Analytics Blog,由丹·斯坦伯格(Dan Steinberg)撰写。
-
Sabermetric Research 由 Phil Burnbaum 撰写,博客内容涉及棒球统计学、股票市场、运动预测以及多种主题。
-
满意度 由巴黎大学(Université Paris-Dauphine,CREST)的博士生和博士后共同撰写。主要提供日常工作中的实用技巧和链接。
-
SAS 文本挖掘博客,由 SAS 专家提供,涵盖语音挖掘和非结构化数据。
-
数据的形状,由杰西·约翰逊提供,从几何学的角度呈现数据分析算法的直观介绍。
-
简单统计 由三位生物统计学教授(杰夫·李克、罗杰·彭和拉法·伊里萨里)提供,他们对数据丰富的新时代充满热情,统计学家即科学家。
-
智能数据集合,汇集了许多有趣的数据科学人的博客。
-
统计建模、因果推断与社会科学 由安德鲁·盖尔曼提供。
-
猫与统计 查理·库夫斯的博客,他从事数据分析超过三十年,最初是水文地质学家,自 1990 年代起成为统计学家。他的标语是——当你不能仅用统计学解决生活问题时。
-
统计博客,一个专注于统计相关内容的博客聚合器,通过 RSS 订阅贡献博客的文章。
-
史蒂夫·米勒 BI 博客,在信息管理网站上。
-
Geomblog 由苏雷什创办。
-
非官方 Google Analytics 博客,由 ROI Revolution 提供。
-
分析因子 由卡伦·格雷斯·马丁提供。
-
卫报数据博客,提供关于新闻中主题的数据新闻报道。
-
坏科学 由流行病学家本·戈德克雷博士创办,他利用统计数据揭穿伪科学。
-
实用量化 由奥赖利传媒首席数据科学家本·洛里卡提供,讨论 OLAP 分析、大数据、数据应用等。
-
数字专家 华尔街日报作家卡尔·比亚利克的博客,他“审视数字的使用方式及其滥用”。
-
三趾树懒 由教授科斯马·沙利兹撰写,他在卡内基梅隆大学教授统计学。
-
汤姆·H·C·安德森/Odintext 博客,专注于通过数据和文本挖掘进行市场研究。
-
文森特·格兰维尔博客,文森特是 AnalyticBridge 和 Data Science Central 的创始人,定期发布有关数据科学和数据挖掘的有趣话题。
-
什么是大数据。Gil Press 涵盖了大数据领域,并在《福布斯》上撰写了关于大数据和商业的专栏。
-
随机漫步 由 Mike Croucher 撰写
-
网页分析与联盟营销,Dennis R. Mortensen 的博客,介绍如何通过分析增加出版商收入。
-
Xi’ans Og 博客 由巴黎第七大学统计学教授撰写,主要关注计算和贝叶斯主题。
本文更新了 2015 年的帖子 90+个关于分析、大数据、数据挖掘、数据科学、机器学习的活跃博客。
相关:
-
Salford Systems:软件工程师。机器学习算法。C++
-
30 篇哈佛商业评论不可错过的关于数据科学、大数据和分析的文章
-
活跃的数据挖掘、数据科学博客
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
适合初学者的数据科学项目创意
原文:
www.kdnuggets.com/2021/11/19-data-science-project-ideas-beginners.html
由 Zulie Rane,自由撰稿人和编码爱好者。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
数据科学项目是初学者掌握一些基本的数据科学技能和语言的好方法,这些技能和语言对于将数据科学作为爱好或职业是必需的。教程、课程和视频都很棒,但项目真正作为涉及数据科学的垫脚石,让你开始动手实践。
对初学者来说,数据科学项目更适合学习语言和技能,因为这些项目更具黏性。我可以观看关于学习 Python 的视频 10,000 次,但只有在我亲自做一个项目时,我才真正开始理解 Python。数据科学项目很棒,因为你比仅仅观看在线教程更有个人投资。你在项目中投入了自己,就会更有动力去完成它。
一个好的项目可以是从学习如何导入数据集到创建你自己的网站或更复杂的东西。项目可以是个人的,它们帮助你学习;它们还可以作为一个作品集,证明你确实了解你所谈论的内容。
这篇文章将提供 19 个适合初学者的数据科学项目创意。选择一个或全部 - 不管哪个对你来说最有趣。让我们开始吧。
适合初学者的数据科学项目教程
这七个数据科学项目包括视频和文章,涵盖了不同的编程语言,具体取决于你想学习什么。你将学习如何使用 API,如何进行预测,接触深度学习,并研究回归分析。
这七个适合初学者的项目教程非常具体且实用,如果你想入门但不知道从哪里开始,这些教程非常适合你。选择一个你喜欢的,看看你遇到的困难,并利用这些困难来开始建立其他的data science skills。
项目 1: 房价回归分析
在疫情期间,我发现自己花了很多时间在 Zillow 上。我喜欢查看各种不同的房屋,因为它们充满了数据。我可以调查和沉浸在许多不同的方面。这种奇怪的兴趣让我发现了this tutorial,它允许你预测爱荷华州艾姆斯的房屋最终价格。
听起来很奇怪,但却很有趣。
你可以使用 R 或 Python 来完成这个项目。老实说,这个项目是一个雄心勃勃的任务,特别是对于刚刚开始编程的人来说。但我选择从这个项目开始,因为我认为它回答了很多人关心的问题——房子值多少钱?人类本质上是好奇的,而最好的数据科学项目就是利用这种好奇心来教授你技能。
我喜欢 Kaggle 上的这个教程,因为它有很多完成的不同选项,这些不同的解决方案与社区共享。任何人都可以上传自己的代码,因此这是一个学习和借鉴他人代码的好地方(这实际上是学习编程的最佳方式之一)。
参与预测、一些机器学习和回归分析吧。
项目 2:泰坦尼克号分类
世界上最著名的悲剧之一是泰坦尼克号的沉没。船上没有足够的救生艇,导致超过 1500 人遇难。不过,如果你查看数据,会发现某些群体的幸存可能性更高。

与上面的项目相同的网站 Kaggle,运行了this competition。他们试图找出哪些因素最可能导致成功——社会经济地位、年龄、性别等等。与房价项目类似,这个项目可以访问许多其他程序员的代码,你可以从中学习。他们还有一个专为初学者准备的教程。这对于初次接触 Kaggle 和编程的人非常有用。
最终,你将建立一个能够回答这个问题的预测模型。我推荐使用 Python 来完成这个任务。
无论你是否实际参与比赛,这仍然是一个很棒的初学者数据科学项目。
项目 3:深度学习数字识别
你知道计算机可以“看见”吗?许多最新有趣的数据科学项目都与计算机视觉有关。本教程非常适合教授神经网络和分类方法的基础知识。在教程中,你的任务是从数万张手写图像的数据集中正确识别数字。
这个比赛/教程也是由 Kaggle 主办的——你可以查看他们的一些教程,或者直接使用用户提交的代码。
在我看来,这个项目不如 Titanic 或房价教程有趣,但它会教你一些非常复杂主题的基础知识。而且,能够教会计算机“看”东西确实很奇妙。
项目 4:YouTube 评论情感分析
不要阅读评论! ...除非你正在做一个初学者的 YouTube 评论情感分析数据科学项目。
这个 YouTube 评论情感分析教程非常好,因为它确实是为初学者准备的。该视频教程的创作者是自然语言处理的初学者,你将在这个教程中学习这种技能。这是一个大约 14 分钟的非常酷的视频,适合开始学习 NLP。它也是一个很好的示例,展示了数据科学项目如何以一种良好的方式发展起来。
这个视频非常有趣,她在自己的GitHub中链接了代码。欢迎你自己去研究!
项目 5:COVID-19 数据分析项目

在疫情期间,我感觉事情失去了控制。听起来可能很傻,但我用来稳定自己的一个方法就是记录每日数字。有时候这让我感到压力,但我发现自己依赖数据来理解那些难以想象的事情。
Python Programmer 频道有类似的想法。在这个教程中,他教你如何使用 Python 进行 COVID-19 数据分析。
这个视频教程比之前的更严肃一些,内容也更加深入地讲解了如何实现。他还介绍了一些关键的 Python 包,如 pandas。这是对 pandas 和 Python 的一个非常清晰的介绍。
项目 6:爬取 Instagram 评论
互联网上有大量的信息。以上的大多数教程给了你一些数据集来操作,但有时知道如何寻找和使用自己的数据是很有用的。这就是掌握网络爬虫的地方。还有,也许你对 YouTube 评论或 COVID-19 数据并不特别感兴趣,但 Instagram 才是你的最爱。
官方的 Instagram API 允许你以编程方式访问自己的评论。但不允许你对其他人的进行。如果你像我一样,想查看别人发布的帖子,获取带有特定#的帖子列表或爬取其他人的评论,你需要别的工具——一个爬虫。
这篇文章实际上不算是教程,更像是针对你自己项目的指引,但我喜欢 Apify 作为 Instagram 抓取工具。通过这个工具,你可以获取数据并探究自己的问题。某些标签是否获得更多点赞?标题是否引发更多评论?一切皆有可能。
项目 7:使用 Python 的 YouTube API
说到 API,使用 API 是所有数据科学家的必备技能。当你选择项目时,确保至少有一个项目能教你如何使用 API,以确保你掌握了这一关键技能。
这个教程使用 Python 带你完成一次 API 调用,从一个频道收集视频统计信息,并将其保存为 pandas 数据框。它还提供了 Python 笔记本代码和 GitHub 上的附加资源。
5 个初学者 DIY 数据科学项目创意 [无限的数据科学项目创意]
实际上,有数百万个潜在的数据科学项目,我已经在教程和视频中记录了它们。但了解如何创建自己的项目也很有用。其他项目教程通常会谈论其他人希望做的事情——考虑一下你自己想做什么。
自己提出项目是我最初接触 Python 的原因。我有一个问题,需要一个答案,而唯一的办法就是通过 Python 分析数据。与其列举更多的单独教程,我更想给你推荐一些资源,帮助你从零开始设计自己的数据科学项目。
项目 8:Tidy Tuesdays
这个项目依赖于Tidy Tuesday GitHub repo。这个 repo 的一个优点是每周二,都会上传全新的非结构化数据。团队分析、可视化这些数据,并进行各种实验。这是从他人那里学习和自己动手实验的绝佳场所。
这个 repo 最适合想学习 R 的人(虽然对一些 Python 也很有用)。它也很适合基础的数据科学技能,如读取文件、进行初步分析、可视化和报告。
例如,本周的 Tidy Tuesday 数据集来自国家经济研究局。数据集的结构使得学习如何连接表格非常有用。也许你对检查女性作者的代表性感兴趣,也许你想知道夏季与冬季的出版频率。无论如何,TidyTuesday 每周提供新的数据,帮助你掌握一些基础的数据科学技能。它也有多年的历史,因此你可以找到感兴趣的内容,并且不会缺乏数据科学项目的想法。
项目 9:Pudding
The Pudding 做了非常炫酷的可视化和分析,通常使用 JavaScript、Python 或 R。TidyTuesday 适合处理大量数据,但 The Pudding 提供了一些真正奇特的项目。
也许你像我一样是《社区》的超级粉丝,你想知道Abed 说“Cool”的次数,相比之下 Jeff 或 Annie 说的次数。也许你喜欢阅读“痛苦的姑姑”信件,这个见解探讨了三十年美国焦虑的内容,可能会引起你的兴趣。
这些项目提供了很多文化评论。它们比列表上的其他一些项目更具挑战性和小众,但它们引人入胜,尤其能教会你很多关于可视化的知识。The Pudding 在他们的GitHub 仓库上提供了所有代码,建议你去看看。
项目 10: 538
体育与政治在 538 博客中碰撞,汇聚成一场辉煌的统计与数学盛宴。在这里,你可以浏览文章,找到你感兴趣的内容,然后前往GitHub 仓库查看发现背后的代码和分析。之后,你可以自己深入数据。
我曾经花时间挖掘的一个有趣项目是超级碗广告。原文讨论了美国人对美国、动物和性(通过超级碗广告中的频率表示)的热爱。我对这些年来是否有更多性相关的广告感兴趣。找到你自己的问题,深入挖掘吧!
项目 11: NASA
谁小时候不想成为宇航员呢?现在(有点)是你追逐那个梦想的机会了。
NASA 的数据不像我列出的前三个选项那样用户友好。但这里提供的数据量(和总体的酷炫程度)使它成为任何数据科学项目列表的必备之选。与其尝试翻阅他们的繁杂文献和数据库,我建议你从这个“用 Python 进行太空科学''教程系列开始。例如,想知道小行星 1997BQ 在 2020 年 5 月离地球有多近吗?现在是了解的机会。
项目 12: Tate 博物馆
Tate 博物馆 (shardcore.org/tatedata/)
也许你更喜欢艺术与人文学科。幸运的是,你也可以创建自己的数据科学项目。只需查看Tate 博物馆的数据档案。在这里,你可以找到超过 3500 位艺术家的元数据。
你可以自己对数据做很多事情,但如果你已经迷失在不知道从哪里开始的情况下,Tate 提供了一些有用的示例数据科学项目,你可以参考。例如,Florian Kraeutli 做了一些gorgeous and introductory exploratory analysis你可以查看。

7 个基于技能的数据科学项目
这篇博客文章的第一部分涉及了相当具体的教程。第二部分教你如何寻找自己的数据科学项目创意。最后一部分将引导你找到基于技能的数据科学项目创意。这对那些准备制作简历或考虑申请data science job的人最为相关。
这七个步骤中的每一个都值得作为初学者的数据科学项目,但一旦你准备好了,你还可以使用这七个步骤来创建一个更完整的项目,适用于中级/高级数据科学家。
项目 13:收集数据
任何数据科学项目的第一步都值得成为一个数据科学项目:收集数据。
大多数时候,数据不会完美地以整齐的表格形式到达你的计算机。你必须弄清楚如何将其从 A 点移动到 B 点,以便进行其他操作。
将其转化为一个项目,并调查如何使用一些最流行的数据科学语言,如 Python 和 SQL 来收集数据。这里有一个很棒的教程文章,讲解如何使用 Python 进行数据抓取。
项目 14:清理数据

数据到了!但却很凌乱。学习如何清理数据是我在攻读鸟类保护硕士学位时最大的失望之一。我以为可以直接导入数据并开始分析。不幸的是,出现了问题:重复数据、缺失值、数字以文本形式存储,以及几乎所有你能想到的其他问题。
一些人说清理数据占数据科学家工作的 80%。值得掌握这一技能。
我使用 R 进行项目,因此如果你也是这样,我推荐 this tutorial 来学习如何使用 R 加载和清理数据。如果你是一个正在学习 Python 的初学者, this tutorial 帮助我掌握了使用 Pandas 和 NumPy 清理数据的方法,这两个都是非常常见和实用的 Python 包。
项目 15:探索数据
一旦你的数据已经准备好并且相对整洁,就到了令人兴奋的部分:探索你的数据。这还没有达到可视化或分析的水平。通常情况下,你所查看的数据量很大,所以在开始创建模型之前,了解实际情况有助于你对数据有一个初步的了解。可以把这个项目想象成在水中试探温度。
这个 2.5 小时的视频教程将教你如何从头开始构建一个探索性数据分析项目。它内容丰富且 100%全面。
项目 16:数据可视化
可视化数据有很多方法,数据科学技能的一部分就是知道哪种可视化最能代表你想传达的想法。这就是为什么专注于数据可视化是初学者的一个很好的数据科学项目创意。
这个 Kaggle 教程有点无聊,但会教你一些数据可视化的基础知识。掌握这些知识后,你可以创建自己的数据科学可视化项目——这次使用你关心的数据。
项目 17:回归
回归是数据科学各个领域中一个非常重要的预测工具。它帮助你统计性地确定 X 和 Y 之间的关系。它是机器学习的基础。
你可以创建一个专注于回归的项目,使用任何具有 X 和 Y 变量的数据集。我自己就是用鸟类数据做的,预测鸟的大小是否会影响鸟的生存。选择任何你喜欢的数据集,使用像 Kaggle 的红酒质量数据教程这样的回归方法,链接 这里。
项目 18:统计学概论
很容易被 NLP、ML、AI、DL 以及其他所有数据科学缩写的炒作所吸引。但不要忘记,各种数据科学都依赖于统计学和数学。为了从你可能拥有的任何数据科学项目创意中获得最大收益,确保你已经掌握了支撑数据科学概念的统计学基础。
我稍微有点作弊,把所有这些统计基础知识归纳在一个子标题下,但我推荐 KDNuggets 的八个基本统计概念的列表。从那里找到一个专注于这八个概念的项目。例如,拿上面链接的 Tate 数据集,了解“集中趋势”,通过确定艺术作品的中位数创作日期来学习。
你可以使用任何编程语言来完成这个项目。我喜欢 Python,因为它对初学者非常友好,但 R、SQL、JavaScript 或其他任何编程语言都可以实现相同的目标。
项目 19:机器学习
让我们用一个项目创意来总结这个初学者数据科学项目列表:机器学习。任何一位称职的数据科学家都了解机器学习,并能够成功预测各种事物。运用你从回归分析中学到的知识。
要创建一个能教你机器学习的项目,几乎任何数据集都可以。例如,你可以使用 Uber 的接送数据,并提出这样的问题:Uber 是否加剧了拥堵?另外,这个教程指导你如何制作电影推荐,可能也是一个很好的项目。我推荐使用 Python,因为它的 TensorFlow 包专为机器学习而设计。
初学者的数据科学项目创意是无限的
如果你拥有一丝创造力和好奇心,你可以在网上搜索所需的数据和教程,创建你自己独特的数据科学项目,无论你的兴趣或技能水平如何。本文应该作为一个指示牌,指向你可以随意浏览的潜在选项。
Zulie Rane (网站) 是一名自由撰稿人和编程爱好者。
原文。经许可转载。
更多相关内容
=engi=
10 个 GitHub 仓库以掌握数据工程
www.kdnuggets.com/10-github-repositories-to-master-data-engineering

作者图像 | DALLE-3 & Canva
数据工程正在快速发展,公司现在招聘的数据工程师比数据科学家多。数据工程、云架构和 MLOps 工程等运营职位需求旺盛。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
作为数据工程师,你需要掌握容器化、基础设施即代码、工作流编排、分析工程、批处理和流处理工具。除此之外,你还需要掌握云基础设施,并管理如 Databricks 和 Snowflakes 等服务。
在本博客中,我们将了解 10 个 GitHub 仓库,帮助你掌握所有核心工具和概念。这些 GitHub 仓库包含课程、经验、路线图、必备工具列表、项目和手册。你只需在学习成为专业数据工程师的过程中将它们收藏即可。
1. 超赞的数据工程
超赞的数据工程仓库包含了数据工程工具、框架和库的列表,是任何想深入这个领域的人的绝佳起点。
它涵盖了数据库、数据摄取、文件系统、流处理、批处理、数据湖管理、工作流编排、监控、测试以及图表和仪表板的工具。
链接: igorbarinov/awesome-data-engineering
2. 数据工程 Zoomcamp
数据工程 Zoomcamp是一个完整的课程,提供了数据工程的动手学习体验。你将通过视频教程、测验、项目、作业和社区驱动的评估来学习新概念和工具。
数据工程 Zoomcamp 包括:
-
容器化和基础设施即代码
-
工作流编排
-
数据摄取
-
数据仓库
-
分析工程
-
批处理
-
流处理
链接: DataTalksClub/data-engineering-zoomcamp
3. 数据工程宝典
数据工程宝典是一个涵盖数据工程各个方面的文章和教程的集合,包括数据摄取、数据处理和数据仓储。
数据工程宝典包括:
-
基础工程技能
-
高级工程技能
-
免费动手课程/教程
-
案例研究
-
最佳实践 云平台
-
130+ 数据来源 数据科学
-
1001 道面试题
-
推荐书籍、课程和播客
链接: andkret/Cookbook
4. 数据工程师路线图
数据工程师路线图 仓库提供了成为数据工程师的逐步指南。这个仓库涵盖了从数据工程基础到基础设施即代码和云计算等高级主题的一切内容。
数据工程师路线图包括:
-
计算机科学基础
-
学习 Python
-
测试
-
数据库
-
数据仓库
-
集群计算
-
数据处理
-
消息
-
工作流调度
-
网络
-
基础设施即代码
-
CI/CD
-
数据安全与隐私
链接: datastacktv/data-engineer-roadmap
5. 数据工程如何做
数据工程如何做是一个适合初学者的资源,帮助从零开始学习数据工程。它包含了一系列教程、课程、书籍和其他资源,以帮助你建立坚实的数据工程概念和最佳实践基础。如果你是新手,这个仓库将帮助你轻松导航广阔的数据工程领域。
如何成为数据工程师包括:
-
有用的文章和博客
-
演讲
-
算法与数据结构
-
SQL
-
编程
-
数据库
-
分布式系统
-
书籍
-
课程
-
工具
-
云平台
-
社区
-
工作岗位
-
新闻通讯
链接: adilkhash/Data-Engineering-HowTo
6. 超棒的开源数据工程
超棒的开源数据工程是一个开源数据工程工具的列表,对于任何希望贡献或使用这些工具来构建现实世界数据工程项目的人来说,这都是一个宝贵的资源。它包含了大量关于开源工具和框架的信息,使其成为探索替代数据工程解决方案的绝佳资源。
该仓库包含以下开源工具:
-
分析
-
商业智能
-
数据湖仓
-
数据变更捕获
-
数据存储
-
数据治理和注册
-
数据虚拟化
-
数据编排
-
格式
-
集成
-
消息基础设施
-
规格和标准
-
流处理
-
测试
-
监控和日志记录
-
版本控制
-
工作流管理
链接: gunnarmorling/awesome-opensource-data-engineering
7. Pyspark 示例项目
Pyspark 示例项目 仓库提供了一个实施 PySpark ETL 作业和应用程序最佳实践的实际示例。
PySpark 是一个流行的数据处理工具,本仓库将帮助你掌握它。你将学习如何构建代码结构、处理数据转换,并有效地优化 PySpark 工作流。
项目包括:
-
ETL 作业的结构
-
将配置参数传递给 ETL 作业
-
打包 ETL 作业依赖
-
运行 ETL 作业
-
调试 Spark 作业
-
自动化测试
-
管理项目依赖
链接: AlexIoannides/pyspark-example-project
8. 数据工程师手册
数据工程师手册 是一个全面的资源集合,涵盖了数据工程的所有方面。它包括教程、文章和有关数据工程的所有主题的书籍。无论你是需要快速参考指南还是深入知识,这本手册都为各级数据工程师提供了资源。
手册包括:
-
极好的书籍
-
关注的社区
-
值得关注的公司
-
可读博客
-
白皮书
-
极好的 YouTube 频道
-
极好的播客
-
时事通讯
-
LinkedIn、Twitter、TikTok 和 Instagram 上的影响者
-
课程
-
认证
-
会议
链接: DataExpert-io/data-engineer-handbook
9. 数据工程维基
数据工程维基 仓库是一个由社区驱动的维基,提供了一个全面的学习数据工程的资源。该仓库涵盖了广泛的话题,包括数据管道、数据仓库和数据建模。
数据工程维基包括:
-
数据工程概念
-
数据工程的常见问题
-
如何做出数据工程决策的指南
-
数据工程中常用的工具
-
数据工程任务的逐步指南
-
学习资源
链接: data-engineering-community/data-engineering-wiki
10. 数据工程实践
数据工程实践 提供了一个动手学习数据工程的方式。它提供了实践项目和练习,帮助你将知识和技能应用于实际场景。通过这些项目的练习,你将获得实际经验,并建立一个展示你数据工程能力的作品集。
数据工程实践问题包括以下练习:
-
下载文件
-
网络抓取 + 下载 + Pandas
-
Boto3 AWS + s3 + Python。
-
将 JSON 转换为 CSV + 不规则目录
-
Postgres + Python 数据建模
-
使用 PySpark 进行数据摄取和聚合
-
使用各种 PySpark 函数
-
使用 DuckDB 进行分析和转换
-
使用 Polars 延迟计算
链接: danielbeach/data-engineering-practice
结束语
掌握数据工程需要奉献精神、坚持不懈以及对学习新概念和工具的热情。这 10 个 GitHub 仓库提供了丰富的信息和资源,帮助你成为一名专业的数据工程师,并保持对当前趋势的了解。
无论你是刚刚起步还是经验丰富的数据工程师,我鼓励你探索这些资源,参与开源项目,并与 GitHub 上充满活力的数据工程社区保持联系。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些与心理健康问题作斗争的学生。
更多相关话题
你需要知道的关于强化学习的 2 件事——计算效率和样本效率
原文:
www.kdnuggets.com/2020/04/2-things-reinforcement-learning.html
评论
深度学习的高成本
你是否曾因为空调太冷而穿上毛衣?是否忘记在上床睡觉前关掉另一间房间的灯?你每天通勤超过 30 分钟只是为了“填补办公室的座位”,尽管你在工作中做的一切都可以通过家里的笔记本完成?

在强化学习中样本效率和计算效率之间的反直觉权衡中,选择进化策略可能比看起来更明智。
现代生活充满了大大小小的低效,但我们深度学习研究/热情/企业的能源成本并不那么明显。有了高性能的工作站塔,散热风扇吹出的热空气始终提醒着能源使用的持续性和规模。但是,如果你把作业发送到走廊里的共享集群,直观上感受到设计决策对电费的影响就更困难了。如果你为大型工作使用云计算,能源使用和随之而来的后果更是被抽象化了。但“眼不见,心不烦”并不是在极端情况下,可能代表比整车生命周期更大的能源开销的项目决策的可行政策。
训练深度学习模型的能源需求
Strubell et al.在 2019 年引起了对训练现代深度学习模型的巨大能源需求的关注。虽然他们主要关注了一种叫做变换器的大型自然语言处理模型,但他们论文中讨论的考虑和结论应该大致适用于在类似硬件上训练其他任务的深度模型,大致时间也相同。
他们估计,从头开始训练大型的Vaswani et al.变换器大约排放了相当于从纽约到旧金山的航班约 10%的二氧化碳排放,这基于主要云服务提供商发布的能源组合的一些假设,财务成本略低于 1000 美元(假设使用云计算)。对于一个决定业务方向的项目,这可能是值得的支出,但当考虑到调整和实验时,能源费用很容易被放大 10 倍或更多。
Strubell 及其同事估计,将神经架构搜索(NAS)添加到 NLP 模型开发中需要数百万美元的费用,并且具有相应的碳足迹。虽然许多最大的模型利用专用硬件,如 Google 的 TPU 进行训练,这可能将能源成本降低30 到 80 倍和训练价格降低一个稍低的倍数,但这仍然是一个巨大的成本。在我们关心的强化学习领域中,低效训练的后果可能是一个失败的项目、产品或业务。
DeepMind 使用《星际争霸 II》的训练示例
在 44 天的时间里,Deepmind 训练 代理,以在多人实时战略游戏《星际争霸 II》中获得三种可玩种族的宗师地位,击败了 99.8%的所有玩家。在 Battle.net 排行榜中名列前茅。OpenAI 针对 Dota 2 的主要游戏掌握项目使用了 10 个实时月(大约 800 拍次/天)的训练时间来击败世界冠军、人类玩家。
由于使用了 TPU、虚拟工人等,准确估算这些引人注目的游戏玩家的能量成本并不容易,但估算的范围在12到1800 万美元的云计算账单,分别用于训练冠军 Alphastar 和 OpenAI Five。显然,这对于典型的学术或行业机器学习团队来说是不可企及的。在强化学习领域中,另一个危险是低效学习的出现。一个试图学习中等复杂任务但探索不佳且样本效率低的代理可能永远找不到可行的解决方案。
使用强化学习预测蛋白质结构(NL)
作为一个例子,我们可以将中等复杂度的强化学习任务与预测蛋白质结构的挑战进行比较。考虑一个由 100 个氨基酸链连接在一起的小型蛋白质,就像一个有 100 个链环的链条。每个链环是 21 种独特链环变体中的一种,结构将根据每个链环之间的角度形成。假设简化为 9 种可能的配置用于每个氨基酸/链环之间的键角,那么需要
*999 = 29,512,665,430,652,752,148,753,480,226,197,736,314,359,272,517,043,832,886,063,884,637,676,943,433,478,020,332,709,411,004,889
(这大约是一个 3 后面跟着 94 个零)*
迭代以查看每个可能的结构。那个有 100 个链接的蛋白质大致相当于一个具有 100 个时间步和每个步骤 9 个可能动作的强化学习环境。谈到组合爆炸。
当然,强化学习代理并不是随机采样所有可能的游戏状态。相反,代理将通过某种组合的最佳猜测、定向探索和随机搜索来生成学习轨迹。但这种生成经验的方法,典型的“策略”学习算法,可能会有两面性。一个找到局部最优解的代理可能会一直停留在那儿,重复同样的错误,永远无法解决整体问题。
从历史上看,强化学习一直受益于尽可能将问题形式化为类似于监督学习的方式,例如让学生背上三台相机去远足。左侧相机生成一个标记为“向右转”的图像,而右侧相机标记为“向左走”,中间相机则标记为“直行”。
最终,你将拥有一个适合训练四旋翼无人机导航森林小径的标记数据集。在下面的章节中,我们将讨论类似的概念(例如模仿学习)和基于模型的强化学习如何大幅减少学习任务所需的训练样本数量,以及为什么这并不总是好事。
少量更多:强化学习代理从示例中学习最佳
深度强化学习是机器学习的一个分支,灵感来源于动物和人类认知、最优控制和深度学习等多种领域。显然,它与动物行为实验有类似之处,其中一个动物(代理)被置于一个必须学习解决问题以获得食物奖励的情境中。动物只需几个例子便开始将一系列动作与奖励关联起来,但深度强化学习算法可能需要考虑每个周期 10 到 100 千个时间步以便对代理的参数进行稳定更新。
大多数强化学习环境是以步骤形式构建的。环境生成一个观察值,基于此,代理决定一个对环境施加的动作。环境根据其当前状态和代理选择的动作进行更新,在本文中我们称之为一个时间步。学习所需的时间步或“样本”越少,算法就越高效。
大多数现代强化学习算法的一个重要方面是,它们本质上是一种试错法。为了让代理在没有采用显式探索技术的情况下进行学习,随机活动偶尔应该做对一些事情,否则代理可能会与环境互动(基本上)永远而得不到正向奖励。事实上,近端策略优化算法,在多个基准中表现优异,在 OpenAI 的程序生成环境套件的困难探索模式中完全失败。我们可以想象这对广泛相关任务是一个问题。
一个学习玩视频游戏的代理可能会通过随机动作(即按键乱按)获得正向奖励,这也是为什么 Atari 套件是流行的强化学习基准之一。对于像解决复杂打结问题这样的复杂任务,机器人偶然遇到解决方案的可能性极低。无论允许多少随机互动,实现期望结果都太不可能了。
正如我们在讨论学习魔方操作时所见,已经有定制的打结机器人被手动构建和编程以创建结,但从零开始学习打结的强化学习代理仍然无法实现。不言而喻,人类也不会从零开始学习打结。一个被独自留在充满未系鞋带的房间里的小孩,可能会很难自己发现标准的“兔子结”。就像思维实验中的小孩一样,强化学习代理可以通过示例学得更好,即使是像打结这样的复杂任务。
使用强化学习及其他方法教机器打结的示例
通过将绳索物理的自主学习与人工示范相结合,伯克利的研究人员成功解决了教机器打结的问题。首先,机器人在桌面上随机地与绳子互动,目的是学习一个合理的模型,了解它们对世界的有限视角是如何运作的。经过自主学习阶段后,机器人会被展示打简单结的期望动作。当一切顺利时,机器人能够模仿期望的动作。将自主学习的世界动态模型(如上例中的桌面和绳子)与人类示例的期望行为结合是一种强大的组合。模仿学习及相关的逆强化学习代表了目前一些最有效的强化学习方法。
绑结是一项略显冷门的任务(显然超出了许多学习算法的能力),但我们可以比较应用于更标准任务的不同学习算法的样本效率。来自 Sergey Levine 在伯克利的深度 RL 课程的讲座 21,第 39 张幻灯片 (pdf),通过比较 HalfCheetah 任务的已发表结果,给我们提供了各种 RL 算法的相对样本效率的一个概念。HalfCheetah 是一个 2D 运动任务,模拟了一个大致类似于一半快的猫的机器人。HalfCheetah 的实现可以在 Mujoco(需要付费许可)和 Bullet(开源,免费)物理模拟器中找到。
根据幻灯片,我们预计进化策略在样本效率方面最为低效,而基于模型/逆强化学习在总时间步数方面最为高效。下面重新列出了幻灯片中的估计值,并附上了文献中的具体示例。

HalfCheetah 在 PyBullet 中模拟的机器人,其目标是尽可能快地向前移动。尽管以 3D 渲染,但运动受到限制在 2D 平面上。它像一只猎豹,但只有一半。
| 方法 | 来自 CS 285 lec 21 的估计步骤 | 解决 HalfCheetah 的示例时间步数 |
|---|---|---|
| 进化策略 | ~1,000,000,000 | ~3,000,000 (ES, Salimans 等, 2016) |
| 全在线演员-评论家方法 | ~100,000,000 | ~100,000,000 (Trust-A3C, Wang 等, 2016) |
| 策略梯度 | ~10,000,000 | ~1,000,000 (PPO, Schulman 等, 2017) |
| 值函数(离线)方法 | ~1,000,000 | ~1,500,000 (Gu 等, 2018) |
| (基于模型) | ~30,000 | ~400,000 (PE-TS, Kurtland Chua 等, 2018) |
表 1: 各种 RL 算法家族的相对样本效率。
样本效率在同一类算法的实现之间差异很大,我发现幻灯片中的估计值在文献中的具体示例中可能有些夸张。特别是,OpenAI 的 进化策略 论文实际上报告了比 TRPO 更好的样本效率,TRPO 是他们用作比较的策略梯度方法。他们报告的 HalfCheetah 解决方案需要 300 万时间步数,这与 Levine 估计的 10 亿相去甚远。
另一方面,由 Uber AI 实验室发布的相关论文应用遗传算法于 Atari 游戏中发现样本效率大约在 10 亿时间步数左右,约为他们比较的值函数算法的 5 倍,与 Levine 的课程估计一致。
在某些情况下,多即是少——从进化中学习
在上述讨论的例子中,进化策略是最样本效率低下的方法之一,通常需要比其他方法多出至少 10 倍的步骤来学习一个给定任务。在另一端,基于模型和模仿的方法需要最少的时间步数来学习相同的任务。
初看起来,这似乎是一个对进化方法实用性的明确否定,但当你优化计算而不是样本效率时,会发生有趣的事情。由于运行进化策略的开销较小,这些策略甚至不需要反向传播,它们实际上可能需要更少的计算。它们也天生具有并行性。因为一个种群中的每个回合或个体都不依赖于其他代理/回合的结果,所以学习算法变得显然可以并行。有了一个快速的模拟器,解决一个给定问题可能需要的时间(按墙上的时钟计算)会大大减少。

InvertedPendulumSwingup 任务的起始和目标状态。绿色胶囊沿黄色杆滑动,目标是将未驱动的红色杆保持直立。
为了粗略比较计算效率,我在PyBullet的一个倒立摆摆动任务 InvertedPendulumSwingupBulletEnv-v0 上运行了几种开源实现的各种学习算法。代表性的进化算法协方差矩阵自适应的代码可以在 Github 上找到,而其他算法都属于 OpenAI 的Spinning Up in Deep RL资源。
政策架构保持不变:一个前馈密集型神经网络,具有两个每层 16 个神经元的隐藏层。我在一台中等配置的 Intel i5 2.4 GHz CPU 的单核心上运行了所有算法,因此结果只能互相比较,训练时间的差异没有任何并行加速。值得注意的是,OpenAI 使用进化策略在10 分钟内用 1440 个工人训练了 MujoCo 人形机器人,因此如果你有足够的 CPU 核心,平行加速是真实且有利可图的。
| 方法家族 | 算法 | 解决所需时间步数 | 解决时间(秒) |
|---|---|---|---|
| 进化策略 | 协方差矩阵自适应[代码] | ~4,100,000 | ~500 s |
| 策略梯度 | 近端策略优化[代码] | ~1,800,000 | ~2000 s |
| 完全在线演员-评论家方法 | 软演员-评论家[代码] | ~1,500,000 | ~17,000 s |
| 值函数(离策略)方法 | 双延迟 DDPG[代码] | ~2,000,000 | ~17,500 s |
表 2:比较不同学习方法的实际时间和样本效率。
上表很好地展示了不同方法所需资源的相对关系。样本效率最高的算法(软演员评论家)所需步骤约为其他方法的一半,但消耗的 CPU 时间是其 34 倍。双延迟 DDPG(也称为 TD3)和软演员评论家比其他方法稳定性差。
由于缺乏开源工具,我们在运行表 2 实验时没有考虑基于模型的 RL 算法。基于模型的 RL 的研究进展受限于闭源开发和缺乏标准环境,但Wang 等做出了英雄般的努力,为许多基于模型的算法提供了基准。他们发现,大多数基于模型的方法能够在大约 25,000 步内解决一个他们称之为 Pendulum 的任务,该任务与上表中报告的任务非常相似。与策略梯度方法相比,他们调查的多数基于模型的方法的训练(实际)时间大约长 100 到 200 倍。
尽管深度学习仍然偏爱“华丽”的强化学习方法,但基于进化的方法正在复兴。OpenAI 的“进化策略作为一种可扩展的强化学习替代方案”于 2016 年发布,2017 年则有大规模的遗传算法学习玩 Atari 游戏的展示。与所有复杂的数学装饰不同,进化算法在概念上很简单:生成一个种群并设置个体任务,保留表现最好的个体用于种群繁殖,并重复直到达到性能阈值。由于其相对简单的概念和固有的并行化潜力,你可能会发现进化算法能在你的最稀缺资源——开发者时间上带来显著节省。
有一些需要了解的计算和样本效率的警示

在单一任务上直接比较不同 RL 算法的计算和样本效率并不完全公平,因为不同实现之间存在许多变量。一个算法可能更早收敛,但从未达到与其他较慢算法相同的分数,通常,你可以打赌,在任何发布的 RL 工作中,作者花费了比任何比较算法更多的精力来优化和实验他们的新方法。
然而,我们上面讨论的例子给了我们对强化学习代理的预期一个很好的概念。虽然基于模型的方法有前景,但与其他选项相比尚不成熟,对于大多数任务可能不值得额外的努力。也许令人惊讶的是,进化算法在各种任务上表现良好,不应因为被认为是“过时”或“过于简单”而被忽视。在考虑所有可用资源的价值及其被现有方法消耗的情况下,进化算法确实可能提供最佳回报。
原文。经许可转载。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 工作
更多相关内容
两年自学数据科学让我学到了什么
原文:
www.kdnuggets.com/2021/09/2-years-self-teaching-data-science.html
评论
作者 Vishnu U,Mindtree 校园实习生 | 探索数据科学。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
(图片来源)
数据科学爱好者往往最初是自学的,而不是后来获得硕士学位。但数据科学领域的广阔现实往往在初学者进入这一领域后才会显现出来,真正有价值的时间可能被错误的学习方式浪费。在本文中,我将分享我在两年的数据科学学习过程中学到的一些事实,希望能帮助你更好地学习。
数据科学是一个大海

持续学习 — 这个领域没有尽头! (图片来源).
在开始之前,要了解数据科学是一个非常广阔的领域。不要指望在几个月内或通过在线课程完成学习。研究和开发经常发生变化,所以要做好长期学习的准备。此外,要明白实际的数据科学与我们自己做的有很大不同,但要记住你所学的内容。
你不必成为爱因斯坦,但一点数学知识是有帮助的

基础数学是必不可少的 (图片来源).
这是一个常见的说法,但我觉得一点数学(概率、微积分、统计学和线性代数的基础)是有好处的。你不一定需要深入研究这些学科,但基本的理解在解决数据问题时会是一个很大的优势。数学计算的大部分工作都由库来完成。
机器学习留到以后再学
数据科学过程——注意收集和准备正确的数据是至关重要的 (Image source)。
最常见的错误是直接跳入机器学习,从那里开始学习,这样的学习顺序正好相反。机器学习是任何数据科学过程的最后一步。从这里开始学习会让你错过许多更重要的概念——数据加载和管理、探索性分析和数据工程。首先学习 Python,加载数据,处理数据集(pandas),然后生成仪表板和可视化,再转向机器学习和预测建模。这篇文章解释了数据科学的总体过程。
Kaggle 是最佳的地方,但要记住这一点

Kaggle 是数据科学爱好者的圣地——但一定要从基础开始 (Image source)。
一旦掌握了基础知识,你就可以开始在 Kaggle 上进行项目实践。Kaggle 是一个可以找到数据集的网站——你可以利用这些数据集来提升数据科学技能。但请记住一点:如果你是初学者,先从基础且较小的数据集和简单任务开始,然后再进入竞赛。原因是 Kaggle 是一个公开的平台,你可能会遇到行业专家和研究人员。他们的知识水平与你这个新手会有所不同——所以从基础数据集开始,逐步过渡到复杂建模问题或竞赛。
停止比较,开始学习

比较会带来臭名昭著的冒名顶替综合症——但这只是你心中制造的错觉 (Image source)。
新手常犯的一个错误是将自己的工作与他人进行比较。这是一个大错,因为经验和知识水平的差异。相反,反过来想:如果在你理解范围内,试着学习他们做了什么。每一个拥有最佳作品的人曾经也像你一样是个初学者。
欢迎掌握“理解业务问题”的技能

解决问题是一项关键技能 (Image source)。
所有数据科学问题都集中在解决实际问题或商业问题上。此外,理解业务问题通常被称为“数据科学的第一规则”。最好的建议是专注于解决实际问题的数据集和项目,而不是单纯地生成可视化和模型。“猫与狗”数据集对于学习和尝试东西是很好的,但不适合作为项目或工作。
并不是每次都是 CSV 文件,还有其他格式
现实世界中的数据存在多种形式 — 了解它们以成为优秀的数据科学家 (Image source)。
对于初学者,最好从 CSV 文件中的数据开始,但随着你逐渐适应,学习使用其他数据源也是很重要的:使用正则表达式的文本文件、SQL 数据库、带有云接口的数据仓库、非结构化数据(图像和音频文件)、JSON 数据等。随着你对基本数据源的熟悉,你还可以尝试数据抓取。你也可以阅读这篇文章。
“全能却无专长” — 这在这里适用

按需学习构建技能 — 不要期望在短时间内学会所有内容 (Image source)。
数据科学要求你使用各种库、工具和 API,但你不必精通它们(如果你精通那就更好了)。这里的主要思想是了解概念,而不必完全掌握整个库或 API!根据需要学习必要的知识。
习惯使用云平台
云计算是一个不同的领域,但对于许多大规模的数据科学问题非常有用 (Image source)。
云计算通常与数据科学问题结合在一起,原因可能是资源需求量大,或解决方案可以直接部署在云上。了解云平台、各种服务及其使用情况。云平台还提供了大数据存储和管理的各种服务,而这些服务是数据科学领域的核心。
原文。转载已获许可。
相关:
更多相关话题
20 个基础 Linux 命令供数据科学初学者使用
原文:
www.kdnuggets.com/2022/06/20-basic-linux-commands-data-science-beginners.html

1. ls
我们推荐的前 3 个课程
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
ls 命令用于显示当前目录中的所有文件和文件夹列表。
$ ls
输出
AutoXGB_tutorial.ipynb binary_classification.csv requirements.txt
Images/ binary_classification.csv.dvc test-api.ipynb
LICENSE output/
README.md output.dvc
2. pwd
它将显示当前目录的完整路径。
$ pwd
输出
C:\Repository\HuggingFace
3. cd
cd 命令代表更改目录。通过输入新的目录路径,你可以更改当前目录。这个命令对于浏览包含多个文件夹的目录非常重要。
$ cd C:/Repository/GitHub/

4. wget
wget 允许你从互联网上下载任何文件。在数据科学中,它用于从数据存储库中下载数据。
$ wget https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
输出
5. cat
cat(连接)是一个常用命令,用于创建、连接和查看文件。cat 命令读取 CSV 文件并将文件内容显示为输出。
$ cat iris.csv
输出
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5,3.6,1.4,0.2,setosa
………………………..
6. wc
wc(单词计数)用于获取有关单词数、字符数和行数的信息。在我们的例子中,它显示了 4 列作为输出。第一列是行数,第二列是单词数,第三列是字符数,第四列是文件名。
$ wc iris.csv
输出
151 151 3716 iris.csv
7. head
head 命令显示文件中的前 n 行。在我们的例子中,它显示了 iris.csv 文件中的前 5 行。
$ head -n 5 iris.csv
输出
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
8. find
find 命令用于查找文件和文件夹,并且通过使用 -exec,你可以在文件和文件夹上执行其他 Linux 命令。在我们的例子中,我们正在查找所有扩展名为“.dvc”的文件。
$ find . -name "*.dvc" -type f
输出
./binary_classification.csv.dvc
./output.dvc
9. grep
它用于过滤特定模式并显示包含该模式的所有行。
我们正在查找包含“vir”的所有行,位于 iris.csv 文件中
$ grep -i "vir" iris.csv
10. history
历史记录将显示过去命令的日志。我们已将输出限制为显示最近的 5 个命令。
$ history 5
输出
494 cat iris.csv
495 wc iris.csv
496 head -n 5 iris.csv
497 find . -name "*.dvc" -type f
498 grep -i "vir" iris.csv
11. zip
zip用于压缩文件大小和文件包实用程序。zip 命令中的第一个参数是 zip 文件名,第二个参数是文件名或文件名列表。zip 命令主要用于压缩和打包数据集。
$ zip ZipFile.zip File1.txt File2.txt
12. unzip
它解压缩或解压文件和文件夹。只需提供一个.zip文件名,它将提取当前目录中的所有文件和文件夹。
$ unzip sampleZipFile.zip
13. cp
它允许你将文件、文件列表或目录复制到目标目录。cp命令中的第一个参数是文件,第二个参数是目标目录路径。
$ cp a.txt work
14. mv
类似于cp,mv命令允许你将文件、文件列表或目录移动到另一个位置。它也用于重命名文件和目录。mv 命令中的第一个参数是文件,第二个参数是目标目录路径。
$ mv a.txt work
15. rm
它从文件系统中删除文件和目录。你可以在rm命令后添加文件或文件列表名称。
$ rm b.txt c.txt
16. mkdir
它允许你一次创建多个目录。只需在mkdir命令后写上文件夹路径。
$ mkdir /love
注意:用户必须有权限在父目录中创建文件夹。
17. rmdir
你可以通过使用rmdir删除一个或多个目录。只需将一个文件夹的名称作为第一个参数添加即可。
注意:
-v标志表示详细信息。
$ rmdir -v /love
输出
VERBOSE: Performing the operation "Remove Directory" on target "C:\love".
18. man
它用于显示 Linux 系统中任何命令的手册。在我们的例子中,我们将学习echo命令。
$ man echo
19. diff
它用于显示两个文件之间逐行的差异。只需在diff命令后添加两个文件即可查看比较。
$ diff app1.py app2.py
输出
31c31
< solar_irradiation = loaded_model.predict(data)[1]
---
> solar_irradiation = loaded_model.predict(data)[0]
20. alias
alias是一个生产力工具。我已经缩短了所有冗长和重复的命令。我已缩短了所有 Linux 和 Git 命令,以避免在编写相同命令时出错。
在下面的例子中,终端每当我运行love命令时,就会显示文本“i love you”。
$ alias love="echo 'i love you'"

Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专家,他喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理问题的学生构建 AI 产品。
更多相关内容
20 个核心数据科学概念(初学者)
原文:
www.kdnuggets.com/2020/12/20-core-data-science-concepts-beginners.html
评论
1. 数据集
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
正如名字所示,数据科学是将科学方法应用于数据的一个分支,旨在研究不同特征之间的关系,并基于这些关系得出有意义的结论。因此,数据是数据科学的关键组成部分。数据集是用于分析或模型构建的特定数据实例。数据集有不同的类型,如数值数据、分类数据、文本数据、图像数据、语音数据和视频数据。数据集可以是静态的(不变的)或动态的(随时间变化,例如股票价格)。此外,数据集也可能依赖于空间。例如,美国的温度数据与非洲的温度数据会显著不同。对于初学者的数据科学项目,最受欢迎的数据集类型是包含数值数据的数据集,通常以逗号分隔值(CSV)文件格式存储。
2. 数据整理
数据整理是将数据从原始形式转换为适合分析的整洁形式的过程。数据整理是数据预处理中的重要步骤,包括数据导入、数据清洗、数据结构化、字符串处理、HTML 解析、处理日期和时间、处理缺失数据以及文本挖掘等多个过程。
图 1: 数据整理过程。图片由 Benjamin O. Tayo 提供
数据整理过程是任何数据科学家关键的一步。在数据科学项目中,数据很少是直接可用的。数据更可能存储在文件、数据库中,或从网页、推文、PDF 等文档中提取。了解如何整理和清洗数据将使你能够从数据中获取本来会被隐藏的重要见解。
使用大学城数据集进行数据整理的示例可以在此处找到:数据整理教程
3. 数据可视化
数据可视化是数据科学中最重要的分支之一。它是分析和研究不同变量之间关系的主要工具之一。数据可视化(例如,散点图、折线图、柱状图、直方图、qq 图、平滑密度图、箱线图、配对图、热图等)可以用于描述性分析。数据可视化还用于机器学习中的数据预处理和分析、特征选择、模型构建、模型测试和模型评估。在准备数据可视化时,请记住,数据可视化更像是艺术而非科学。要产生好的可视化效果,你需要将几段代码结合在一起,以获得优秀的最终结果。有关数据可视化的教程,请参见这里:使用天气数据集的数据可视化教程
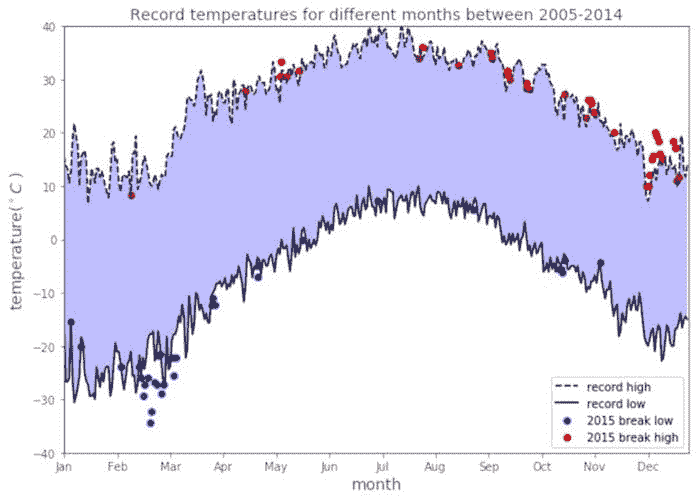
图 2: 天气数据可视化示例。图片由本杰明·O·泰约提供
4. 异常值
异常值是指与数据集其他部分非常不同的数据点。异常值通常只是坏数据,例如,由于传感器故障、实验污染或记录数据时的人为错误。有时,异常值可能表明某些真实情况,例如系统中的故障。异常值非常常见,并且在大型数据集中是预期的。检测数据集中异常值的一种常见方法是使用箱线图。图 3 显示了一个包含大量异常值的数据集的简单回归模型。异常值可能会显著降低机器学习模型的预测能力。处理异常值的一种常见方法是简单地省略这些数据点。然而,去除真实数据中的异常值可能过于乐观,从而导致不现实的模型。处理异常值的高级方法包括 RANSAC 方法。
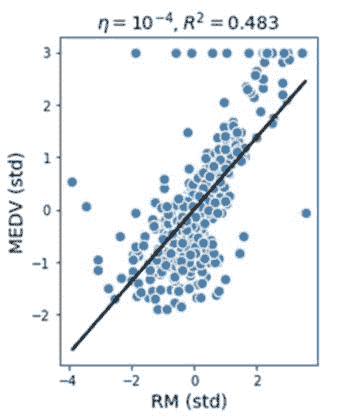
图 3: 使用包含异常值的数据集的简单回归模型。图片由本杰明·O·泰约提供
5. 数据插补
大多数数据集包含缺失值。处理缺失数据的最简单方法是直接丢弃数据点。然而,删除样本或整个特征列是不切实际的,因为这可能会丢失太多有价值的数据。在这种情况下,我们可以使用不同的插值技术来估计数据集中其他训练样本中的缺失值。其中一种最常见的插值技术是均值填补,即用整个特征列的均值替换缺失值。其他填补缺失值的方法包括中位数或最频繁值(众数),后者用最频繁的值来替换缺失值。无论你在模型中使用哪种填补方法,都必须记住填补仅仅是一种近似方法,因此可能会在最终模型中产生误差。如果提供的数据已经过预处理,你需要了解缺失值是如何处理的。原始数据中丢弃了多少百分比?使用了什么填补方法来估计缺失值?
6. 数据缩放
缩放特征有助于提高模型的质量和预测能力。例如,假设你想建立一个模型来预测目标变量信用评分,基于预测变量如收入和信用评分。由于信用评分的范围从 0 到 850,而年收入可能在$25,000 到$500,000 之间,如果不对特征进行缩放,模型将会对收入特征产生偏倚。这意味着与收入参数相关的权重因子将非常小,这会导致预测模型仅基于收入参数来预测信用评分。
为了将特征缩放到相同的尺度,我们可以选择使用特征的归一化或标准化。通常情况下,我们假设数据是正态分布的,并默认使用标准化,但这并不总是适用。在决定使用标准化还是归一化之前,首先需要查看特征的统计分布情况。如果特征趋向于均匀分布,则可以使用归一化(MinMaxScaler)。如果特征大致符合高斯分布,则可以使用标准化(StandardScaler)。再次提醒,无论你使用归一化还是标准化,这些方法都是近似的,并且会影响模型的总体误差。
7. 主成分分析(PCA)
拥有数百或数千个特征的大型数据集通常会导致冗余,特别是当特征之间存在相关性时。在具有过多特征的高维数据集上训练模型有时会导致过拟合(模型捕捉了真实和随机效应)。此外,特征过多的过于复杂的模型可能很难解释。解决冗余问题的一种方法是通过特征选择和降维技术,例如 PCA。主成分分析(PCA)是一种用于特征提取的统计方法。PCA 用于高维和相关数据。PCA 的基本思想是将原始特征空间转换为主成分空间。PCA 变换实现了以下目标:
a) 通过仅关注数据集中方差占多数的成分,减少最终模型中要使用的特征数量。
b) 消除特征之间的相关性。
PCA 的实现可以在以下链接找到:使用 Iris 数据集的 PCA
8. 线性判别分析(LDA)
PCA 和 LDA 是两种数据预处理线性变换技术,通常用于降维,以选择可用于最终机器学习算法的相关特征。PCA 是一种无监督算法,用于高维和相关数据中的特征提取。PCA 通过将特征转换为数据集中最大方差的正交成分轴来实现降维。LDA 的目标是找到优化类别可分性的特征子空间并减少维度(见下图)。因此,LDA 是一种有监督算法。关于 PCA 和 LDA 的详细描述可以在这本书中找到:Sebastian Raschka 的《Python 机器学习》,第五章。
LDA 的实现可以在以下链接找到:使用 Iris 数据集的 LDA
9. 数据划分
在机器学习中,数据集通常被划分为训练集和测试集。模型在训练数据集上进行训练,然后在测试数据集上进行测试。因此,测试数据集充当未见数据集,可用于估计泛化误差(即模型部署后应用于真实数据集时的预期误差)。在 scikit-learn 中,可以使用 train/test split 估计器将数据集划分如下:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
在这里,X 是特征矩阵,y 是目标变量。在这种情况下,测试数据集设置为 30%。
10. 有监督学习
这些是通过研究特征变量与已知目标变量之间的关系来执行学习的机器学习算法。有监督学习有两个子类别:
a) 连续目标变量
预测连续目标变量的算法包括线性回归、K 最近邻回归(KNR)和支持向量回归(SVR)。
关于线性回归和 K 最近邻回归的教程可以在这里找到:线性回归和 KNN 回归教程
b) 离散目标变量
预测离散目标变量的算法包括:
-
感知机分类器
-
逻辑回归分类器
-
支持向量机(SVM)
-
决策树分类器
-
K 最近邻分类器
-
朴素贝叶斯分类器
11. 无监督学习
在无监督学习中,我们处理的是未标记的数据或结构未知的数据。使用无监督学习技术,我们能够探索数据的结构,从而在没有已知结果变量或奖励函数指导的情况下提取有意义的信息。K 均值聚类是无监督学习算法的一个例子。
12. 强化学习
在强化学习中,目标是开发一个基于与环境互动来提升性能的系统(代理)。由于当前环境状态的信息通常还包括所谓的奖励信号,我们可以将强化学习视为与监督学习相关的领域。然而,在强化学习中,这种反馈不是正确的真实标签或值,而是由奖励函数衡量行动效果的一个指标。通过与环境的互动,代理可以利用强化学习来学习一系列最大化奖励的动作。
13. 模型参数和超参数
在机器学习模型中,有两种类型的参数:
a) 模型参数: 这些是在模型中必须通过训练数据集确定的参数。这些是拟合参数。例如,假设我们有一个模型如房价 = a + b(年龄) + c(面积),以根据房屋的年龄和面积(平方英尺)来估计房屋的成本,那么a、b和c将是我们的模型或拟合参数。
b) 超参数: 这些是需要调整的参数,以获得具有最佳性能的模型。以下是一个超参数的例子:
KNeighborsClassifier(n_neighbors = 5, p = 2, metric = 'minkowski')
在训练过程中,超参数的调整对于获得最佳性能(即最优拟合参数)的模型非常重要。
关于模型参数和超参数的教程可以在这里找到:机器学习中的模型参数和超参数教程
14. 交叉验证
交叉验证是一种评估机器学习模型在数据集随机样本上的表现的方法。这可以确保捕捉数据集中的任何偏差。交叉验证可以帮助我们获得模型泛化误差的可靠估计,即模型在未见数据上的表现。
在 k-折交叉验证中,数据集被随机划分为训练集和测试集。模型在训练集上训练,并在测试集上评估。这个过程重复进行 k 次。然后通过在 k 折上取平均来计算平均训练和测试分数。
这里是 k-折交叉验证的伪代码:
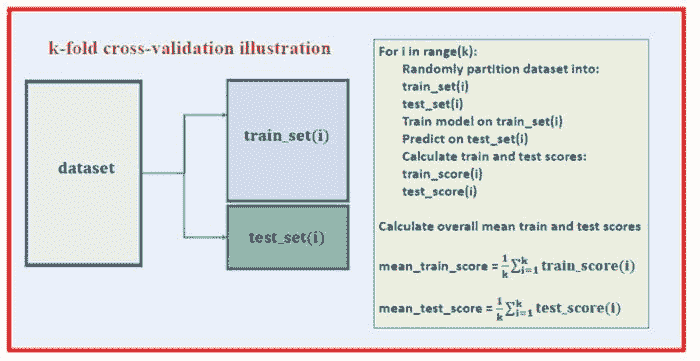
图 4。k-折交叉验证伪代码。图片由 Benjamin O. Tayo 提供。
交叉验证的实现可以在这里找到:实践中的交叉验证教程
15. 偏差-方差权衡
在统计学和机器学习中,偏差-方差权衡是预测模型集的一个特性,其中参数估计偏差较低的模型在样本之间的参数估计方差较高,反之亦然。偏差-方差困境或问题是在尝试同时最小化这两种误差来源时的冲突,这阻碍了监督学习算法在训练集之外的泛化:
-
偏差是由于学习算法中的错误假设造成的误差。高偏差(过于简单)可能导致算法错过特征与目标输出之间的相关关系(欠拟合)。
-
方差是由于对训练集中的小波动的敏感性所引起的误差。高方差(过于复杂)可能导致算法对训练数据中的随机噪声建模,而不是预期的输出(过拟合)。
找到模型简单性和复杂性之间的正确平衡是很重要的。关于偏差-方差权衡的教程可以在这里找到:偏差-方差权衡教程
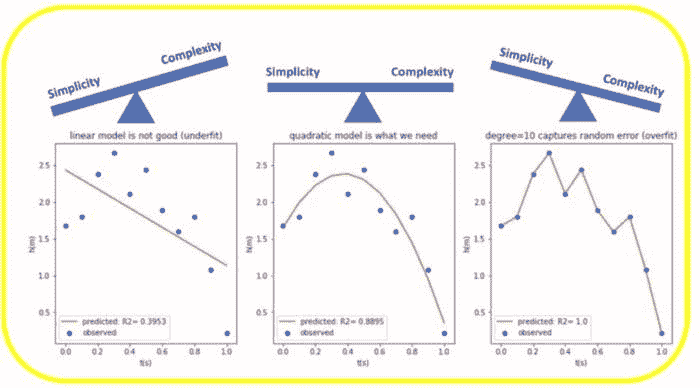
图 5。偏差-方差权衡的示意图。图片由 Benjamin O. Tayo 提供。
16. 评估指标
在机器学习(预测分析)中,有几种指标可用于模型评估。例如,可以使用 R2 分数、均方误差(MSE)或平均绝对误差(MAE)来评估监督学习(连续目标)模型。此外,也称为分类模型的监督学习(离散目标)模型,可以使用准确率、精确率、召回率、F1 分数以及 ROC 曲线下面积(AUC)等指标进行评估。
17. 不确定性量化
建立能够产生无偏估计的机器学习模型非常重要。由于数据集和模型中固有的随机性,评估参数如 R2 分数是随机变量,因此估计模型的不确定性程度很重要。有关不确定性量化的示例,请参阅此文章:机器学习中的随机误差量化
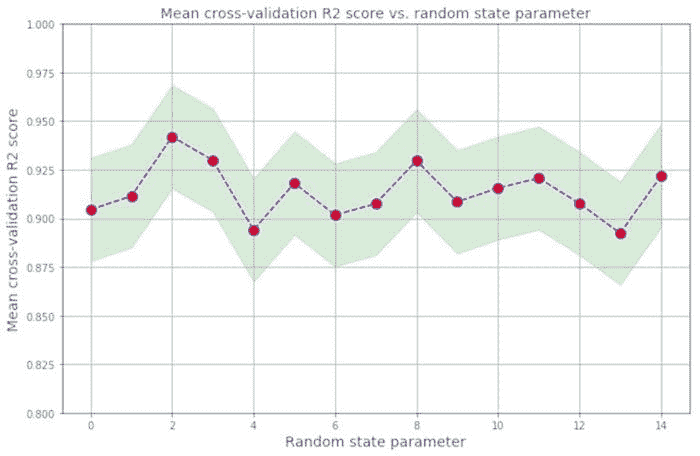
图 6. R2 分数波动的示意图。图片来源:Benjamin O. Tayo
18. 数学概念
a) 基础微积分: 大多数机器学习模型是基于具有多个特征或预测变量的数据集构建的。因此,熟悉多变量微积分对于构建机器学习模型极为重要。以下是你需要熟悉的主题:
多变量函数;导数和梯度;阶跃函数、Sigmoid 函数、Logit 函数、ReLU(整流线性单元)函数;成本函数;函数绘图;函数的最小值和最大值
b) 基础线性代数: 线性代数是机器学习中最重要的数学技能。数据集被表示为矩阵。线性代数用于数据预处理、数据转换、降维和模型评估。以下是你需要熟悉的主题:
向量;向量的范数;矩阵;矩阵的转置;矩阵的逆;矩阵的行列式;矩阵的迹;点积;特征值;特征向量
c) 优化方法: 大多数机器学习算法通过最小化目标函数来执行预测建模,从而学习应用于测试数据以获得预测标签的权重。以下是你需要熟悉的主题:
成本函数/目标函数;似然函数;误差函数;梯度下降算法及其变体(如随机梯度下降算法)
19. 统计学和概率概念
统计学和概率用于特征的可视化、数据预处理、特征转换、数据填补、降维、特征工程、模型评估等。以下是你需要熟悉的主题:
均值、中位数、众数、标准差/方差、相关系数和协方差矩阵、概率分布(伯努利分布、泊松分布、正态分布)、p 值、贝叶斯定理(精准度、召回率、正预测值、负预测值、混淆矩阵、ROC 曲线)、中心极限定理、R_2 分数、均方误差(MSE)、A/B 测试、蒙特卡洛模拟
以下是关于中心极限定理和贝叶斯定理的一些教育资源:
20. 生产力工具
一个典型的数据分析项目可能涉及多个部分,每个部分包括多个数据文件和不同的代码脚本。保持这些内容的组织性可能会很有挑战性。生产力工具可以帮助你保持项目的有序,并记录你完成的项目。一些对数据科学家来说至关重要的生产力工具包括 Unix/Linux、git 和 GitHub、RStudio 和 Jupyter Notebook 等。了解更多关于生产力工具的信息,请访问:机器学习中的生产力工具
相关:
更多相关话题
21 个机器学习项目 - 包含数据集
原文:
www.kdnuggets.com/2020/03/20-machine-learning-datasets-project-ideas.html
评论
由 Shivashish Thakur,数字营销,DataFlair。
要构建一个完美的模型,你需要大量的数据。但找到适合你机器学习项目的正确数据集可能是一项挑战。幸运的是,许多组织、研究人员和个人分享了他们的机器学习项目和数据集,我们可以利用这些资源来构建自己的 ML 项目想法。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
向下滚动查看 20 多个机器学习和数据科学数据集以及项目想法,以便你可以用来练习和提升技能。

机器学习项目:
1. Enron 邮件数据集
Enron 数据集在自然语言处理领域非常受欢迎。它包含了超过 150 位用户的 50 万封邮件。数据大小约为 432Mb。在这 150 位用户中,大多数是 Enron 的高级管理人员。
数据链接:Enron 邮件数据集
机器学习项目想法:使用 k-means 聚类,你可以构建一个检测欺诈活动的模型。k-means 聚类是一种无监督的机器学习算法。它根据数据中的相似模式将观察结果分成 k 个簇。
2. 聊天机器人意图数据集
聊天机器人的数据集是一个 JSON 文件,包含了如告别、问候、药品搜索、医院搜索等不同的标签。每个标签下都有用户可能提出的问题模式,聊天机器人将根据这些模式作出回应。该数据集非常适合理解聊天机器人数据的工作方式。
数据链接:意图 JSON 数据集
机器学习项目想法:你可以通过扭曲和扩展数据,并结合自己的观察来构建一个聊天机器人或理解聊天机器人的工作原理。要构建自己的聊天机器人,你需要对自然语言处理概念有良好的理解。
源代码:Python 聊天机器人项目
3. Flickr 30k 数据集
Flickr 30k 数据集包含超过 30,000 张图像,每张图像都有不同的描述。该数据集用于构建图像描述生成器,并且这是 Flickr 8k 数据集的升级版,用于构建更准确的模型。
数据链接: Flickr 图像数据集
机器学习项目构想: 你可以构建一个 CNN 模型,用于分析和提取图像特征,并生成描述图像的英文句子,称为 Caption。
4. 帕金森数据集
帕金森病是一种神经系统疾病,会影响运动。帕金森数据集包含生物医学测量,195 条记录具有 23 个不同属性。该数据用于区分健康人群和帕金森病患者。
数据链接: 帕金森数据集
机器学习项目构想: 你可以构建一个模型,用于区分健康人群和帕金森病患者。对这个目的有用的算法是 XGboost,即极端梯度提升,它基于决策树。
源代码: 检测帕金森病的 ML 项目
5. 鸢尾花数据集
鸢尾花数据集是一个适合初学者的数据集,包含了关于花瓣和花萼尺寸的信息。该数据集有 3 个类别,每个类别 50 个实例,总共有 150 行和 4 列。
数据链接: 鸢尾花数据集
机器学习项目构想: 分类任务是将项目分到对应的类别中。你可以在数据集上实现机器学习分类或回归模型。
6. ImageNet 数据集
ImageNet 是一个大型图像数据库,按照 WordNet 层级组织。它拥有超过 100,000 个短语,每个短语平均有 1000 张图像,总大小超过 150 GB。它适用于图像识别、人脸识别、物体检测等。它还举办了一个名为 ILSVRC 的挑战性比赛,鼓励人们构建越来越准确的模型。
数据链接: Imagenet 数据集
机器学习项目构想: 在这个庞大的数据库上实施图像分类并识别对象。CNN 模型(卷积神经网络)对于获得准确结果是必要的。
7. 商场顾客数据集
商场顾客数据集包含了访问商场的人的详细信息。数据集包括年龄、顾客 ID、性别、年收入和消费评分。它从数据中获取洞察,并根据顾客的行为将其分成不同的群体。
数据集链接: 商场顾客数据集
机器学习项目创意: 基于性别、年龄、兴趣对客户进行细分。这在定制化营销中非常有用。客户细分是一种重要的实践,基于类似的个体群体对客户进行划分。
源代码: 机器学习客户细分
8. 谷歌趋势数据门户
谷歌趋势数据可用于以视觉方式检查和分析数据。你也可以通过简单点击将数据集下载为 CSV 文件。我们可以发现当前的趋势和人们在搜索什么。
数据链接: 谷歌趋势数据集
9. 波士顿住房数据集
这是一个在模式识别中常用的数据集。它包含了有关波士顿不同房屋的信息,如犯罪率、税收、房间数量等。它有 506 行和 14 个不同的变量列。你可以使用该数据集来预测房价。
数据链接: 波士顿数据集
机器学习项目创意: 使用线性回归预测新房的房价。线性回归用于预测数据中的未知输入值,当数据具有输入和输出变量之间的线性关系时。
10. Uber 接送数据集
该数据集包含了从 2014 年 4 月到 2014 年 9 月的 450 万次 Uber 接送记录,以及从 2015 年 1 月到 2015 年 6 月的 1400 万次记录。用户可以进行数据分析并从数据中获得见解。
数据链接: Uber 接送数据集
机器学习项目创意: 分析客户骑行数据,并可视化数据以寻找有助于改善业务的见解。数据分析和可视化是数据科学的重要组成部分。它们用于从数据中获取见解,通过可视化,你可以从数据中快速获取信息。
11. 推荐系统数据集
这是一个到丰富数据集的门户,这些数据集曾用于 UCSD 的实验室研究项目。它包含了来自流行网站的各种数据集,如 Goodreads 书评、亚马逊产品评论、调酒数据、社交媒体数据等,这些数据用于构建推荐系统。
数据链接: 推荐系统数据集
机器学习项目创意: 构建类似亚马逊的产品推荐系统。推荐系统可以根据你的兴趣和以前使用过的东西建议产品、电影等。
源代码: 电影推荐系统项目
12. UCI 垃圾邮件数据集
将电子邮件分类为垃圾邮件或非垃圾邮件是非常常见和有用的任务。该数据集包含 4601 封电子邮件及其 57 条元信息。你可以构建模型来过滤垃圾邮件。
数据链接: UCI 垃圾邮件数据集
机器学习项目构思: 你可以构建一个模型,用于识别你的邮件是否为垃圾邮件。
13. GTSRB(德国交通标志识别基准)数据集
GTSRB 数据集包含约 50,000 张交通标志图像,属于 43 个不同的类别,并包含每个标志的边界框信息。该数据集用于多类别分类。
数据链接: GTSRB 数据集
机器学习项目构思: 使用深度学习框架构建一个模型,用于分类交通标志并识别标志的边界框。交通标志分类在自动驾驶车辆中也很有用,用于识别标志并采取适当的行动。
源代码: 交通标志识别 Python 项目
14. Cityscapes 数据集
这是一个用于计算机视觉项目的开源数据集。它包含在 50 条不同城市街道拍摄的视频序列的高质量像素级注释。该数据集在语义分割和训练深度神经网络以理解城市场景方面非常有用。
数据 链接: Cityscapes 数据集
机器学习项目 构思: 执行图像分割并检测视频中的不同物体。图像分割是将图像数字化划分为不同类别的过程,如汽车、公交车、行人、树木、道路等。
15. Kinetics 数据集
Kinetics 有三个不同的数据集:Kinetics 400、Kinetics 600 和 Kinetics 700 数据集。这是一个大规模的数据集,包含一个大约 650 万个高质量视频的 URL 链接。
数据链接: Kinetics 数据集
机器学习项目构思: 构建一个人类动作识别模型,检测人类的动作。人类动作识别通过一系列观察来完成。
16. IMDB-Wiki 数据集
IMDB-Wiki 数据集是最大的开源面部图像数据集之一,带有标记的性别和年龄。这些图像来自 IMDB 和维基百科,包含超过 500 万张标记的图像。
数据链接: IMDB wiki 数据集
机器学习项目构思: 创建一个模型,检测面孔并预测其性别和年龄。你可以设置不同的年龄范围类别,如 0-10、10-20、30-40、50-60 等。
17. 颜色检测数据集
数据集包含一个 CSV 文件,其中有 865 个颜色名称及其对应的 RGB(红色、绿色和蓝色)值。还包含颜色的十六进制值。
数据链接: 颜色检测数据集
机器学习项目创意:可以使用颜色数据集制作一个颜色检测应用,其中可以从图像中选择颜色,应用程序将显示颜色的名称。
源代码: 颜色检测 Python 项目
18. 城市声音 8K 数据集
城市声音数据集包含来自 10 个类别的 8732 种城市声音,如空调、狗吠、钻孔声、警报声、街头音乐等。该数据集在城市声音分类问题中非常受欢迎。
数据链接: 城市声音 8K 数据集
机器学习项目创意:我们可以建立一个声音分类系统,以检测背景中播放的城市声音类型。这将帮助你入门音频数据,并理解如何处理非结构化数据。
19. Librispeech 数据集
该数据集包含大量来自 LibriVox 项目的英文演讲。它包含 1000 小时的各种口音的英文朗读。它用于语音识别项目。
数据链接: Librispeech 数据集
机器学习项目创意:建立一个语音识别模型,以检测说了什么并将其转换为文本。语音识别的目标是自动识别音频中的内容。
20. 乳腺组织病理图像数据集
该数据集包含从 162 张乳腺癌标本的切片图像中提取的 277,524 张 50×50 大小的图像。包括 198,738 个阴性测试和 78,786 个带有 IDC 的阳性测试。
数据链接: 乳腺组织病理数据集
机器学习项目创意:建立一个可以分类乳腺癌的模型。你可以使用卷积神经网络构建图像分类模型。
源代码: 乳腺癌分类 Python 项目
21. Youtube 8M 数据集
Youtube 8M 数据集是一个大规模标注的视频数据集,包含 610 万个 Youtube 视频 ID,35 万小时的视频,26 亿个音频/视觉特征,3862 个类别,以及每个视频平均 3 个标签。它用于视频分类目的。
数据链接: Youtube 8M
机器学习项目创意:可以使用该数据集进行视频分类,模型可以描述视频的内容。视频需要一系列输入来分类视频属于哪个类别。
参考文献
在这篇文章中,我们看到超过 20 个机器学习数据集,你可以用来练习机器学习或数据科学。创建自己的数据集很昂贵,所以我们可以使用其他人的数据集来完成工作。但我们应该仔细阅读数据集的文档,因为有些数据集是免费的,而有些数据集则需要根据其要求给予所有者信用。
简介: Shivashish Thaku 是一位分析师和技术内容作家。他是一位技术爱好者,喜欢撰写有关最新前沿技术的文章,这些技术正在改变世界。他也是一位体育迷,喜欢踢足球和观看足球比赛。
相关:
更多相关主题
20 个能让你获得工作的机器学习项目
原文:
www.kdnuggets.com/2021/09/20-machine-learning-projects-hired.html
评论
作者:Khushbu Shah,ProjectPro 内容经理
AI 和机器学习行业正以前所未有的速度蓬勃发展。截至 2021 年,AI 在企业中的使用将创造 2.9 万亿美元的商业价值。AI 已经自动化了全球许多行业,并改变了它们的运作方式。大多数大型公司都采用 AI 来最大化工作流程中的生产力,而像营销和医疗等行业也因为 AI 的整合而发生了范式转变。

图片来源: Unsplash
因此,近年来对 AI 专业人才的需求不断增长。从 2015 年到 2018 年,AI 和机器学习相关职位的发布量几乎增长了 100%。这个数字一直在增长,并预计在 2021 年还会增加。
如果你希望进入机器学习行业,好消息是目前工作机会充足。公司需要有才华的团队来引领机器学习的变革。然而,数据行业的竞争激烈,因为许多人也想进入这一领域。由于没有专门针对想学习机器学习的学生的学位课程,许多有志于机器学习的从业者都是自学的。
有超过 400 万学生注册了 Andrew Ng 的机器学习在线课程。
不幸的是,虽然注册在线课程或参加机器学习 Bootcamp 可以帮助你学习理论概念,但并不能为你准备好行业中的工作。学习理论之后,还有大量的实践工作需要完成。假设你了解机器学习算法的基础知识——你理解回归和分类模型的工作原理,并知道不同类型的聚类方法。
你将如何实践你学到的技能以解决实际问题?简单的答案是:练习、练习、再练习各种machine learning projects。
一旦你完成了理论概念的学习,你应该开始从事 AI 和机器学习项目。这些项目将提供必要的实践,以提高你在该领域的技能,同时也是你机器学习作品集的宝贵补充。
不废话,我们来探索一些机器学习项目创意,这些项目不仅能让你的作品集看起来更出色,还会显著提升你的机器学习技能。这是一个为学生、渴望成为机器学习从业者的人员以及非技术领域个体量身定制的最佳机器学习项目列表。你可以根据自己的背景参与这些项目,只要你具备一定的编码能力和机器学习知识。这是一个包含初级和高级机器学习项目的列表。
如果你是数据行业的新手,且在实际项目中经验有限,建议先从初级机器学习项目入手,然后再挑战更复杂的项目。
初学者的机器学习项目
1. Kaggle 泰坦尼克号预测
这个列表上的第一个项目是你可以从事的最简单的机器学习项目之一。这个项目推荐给数据行业的初学者。泰坦尼克号数据集可以在 Kaggle 上获得,下载链接如下。
这个数据集包含了在泰坦尼克号上旅行的乘客的信息。它包括乘客年龄、票价、舱位和性别等细节。根据这些信息,你需要预测这些乘客是否生还。
这是一个简单的二分类问题,你需要做的就是预测某个乘客是否生还。这个数据集的最佳之处在于所有预处理工作已经为你完成,你可以使用一个干净的数据集来训练你的机器学习模型。
由于这是一个分类问题,你可以选择使用逻辑回归、决策树和随机森林等算法来构建预测模型。你也可以选择像 XGBoost 分类器这样的梯度提升模型来获得更好的结果。
2. 房价预测
如果你是机器学习初学者,房价数据也是一个很好的起点。这个项目将使用 Kaggle 上的房价数据集。数据集中的目标变量是某个房子的价格,你需要使用房屋面积、卧室数量、浴室数量和其他设施等信息来预测这个价格。
这是一个回归问题,你可以使用线性回归等技术来构建模型。你也可以采取更高级的方法,使用随机森林回归器或梯度提升来预测房价。
这个数据集有 80 列,不包括目标变量。你需要使用一些降维技术来挑选特征,因为添加过多变量可能会导致模型性能下降。
数据集中还有许多类别变量,因此你需要使用像独热编码或标签编码这样的技术来正确处理它们。
在构建模型后,你可以将你的预测提交到 Kaggle 的房价竞赛中,因为它仍然开放。竞争者所取得的最佳 RMSE 是 0,许多人通过回归和梯度提升技术取得了 0.15 等良好结果。
数据集: Kaggle 房价预测数据集
3. 葡萄酒质量预测
葡萄酒质量预测数据集在数据行业的初学者中也非常受欢迎。在这个项目中,你将使用固定酸度、挥发酸度、酒精和密度来预测红酒的质量。
这可以被视为分类或回归问题。数据集中你需要预测的葡萄酒质量变量范围从 0 到 10,因此你可以建立回归模型进行预测。另一种方法是将值(0 到 10)拆分为离散区间并转换为分类变量。例如,你可以创建三个类别——低、中和高。
然后,你可以构建决策树分类器或任何分类模型来进行预测。这是一个相对干净和直接的数据集,可以用来练习你的回归和分类机器学习技能。
数据集: Kaggle 红酒质量数据集
4. 心脏病预测
如果你想探索医疗行业的数据集,这是一个很好的初学者级数据集。该数据集用于预测 10 年 CHD(冠心病)的风险。数据集中的因变量是心脏病的风险因素,包括糖尿病、吸烟、高血压和高胆固醇水平。
自变量是 10 年 CHD 的风险。这是一个二分类问题,目标变量为 0 或 1——0 表示从未发生心脏病的患者,1 表示发生了心脏病的患者。你可以对这个数据集进行一些特征选择,以识别出对心脏风险贡献最大的特征。然后,你可以将分类模型拟合到自变量上。
由于该数据集中许多患者没有发展心脏病,所以数据集严重不平衡。处理不平衡数据集需要使用正确的特征工程技术,如过采样、权重调整或欠采样。如果处理不当,你将得到一个只预测大多数类别的模型,无法识别已经发展心脏病的患者。这是一个很好的数据集,可以用来练习你的特征工程和机器学习技能。
数据集: Kaggle 心脏病数据集
5. MNIST 数字分类
MNIST 数据集是你进入深度学习领域的垫脚石。这个数据集包含了从 0 到 9 的手写数字的灰度图像。你的任务是使用深度学习算法识别这些数字。这是一个多类别分类问题,有十个可能的输出类别。你可以使用 CNN(卷积神经网络)来执行这个分类。
MNIST 数据集是在 Python 的 Keras 库中构建的。你只需安装 Keras,导入库,并加载数据集。这个数据集有大约 60,000 张图像,因此你可以将其中大约 80% 用于训练,另外 20% 用于测试。
数据集: Kaggle Digit Recognizer Dataset
6. Twitter 数据的情感分析
Kaggle 上有许多 Twitter 情感分析数据集。其中一个最受欢迎的数据集叫做 sentiment140,包含 160 万条预处理的推文。如果你是情感分析的新手,这是一个很好的数据集来开始。
这些推文已经被标注,目标变量是情感。这一列中的唯一值是 0(负面)、2(中性)和 4(正面)。
在对这些推文进行预处理并将其转换为向量后,你可以使用分类模型对其进行训练,结合其相关的情感。你可以使用逻辑回归、决策树分类器或 XGBoost 分类器等算法来完成这项任务。
另一种选择是使用深度学习模型,如 LSTM 来进行情感预测。然而,这是一种略微更具挑战性的方式,并且属于高级项目类别。
你还可以使用这个标记的数据集作为未来情感分析任务的基础。
如果你有任何推文想要收集并进行情感分析,你可以使用已经在 sentiment140 上训练过的模型进行未来的预测。
数据集: Kaggle Sentiment140 Dataset
7. Pima 印第安糖尿病预测
Pima 印第安糖尿病数据集用于预测患者是否患有糖尿病,基于诊断测量结果。
基于 BMI、年龄和胰岛素等变量,模型将预测患者是否患有糖尿病。这个数据集有九个变量——八个独立变量和一个目标变量。
目标变量是‘糖尿病’,所以你将预测糖尿病的存在(1)或不存在(0)。
这是一个分类问题,可以用来尝试模型,如逻辑回归、决策树分类器或随机森林分类器。
这个数据集中的所有独立变量都是数字型的,所以如果你有较少的特征工程经验,这是一个很好的数据集来开始。
这是一个对初学者开放的 Kaggle 数据集。网上有许多教程可以指导你用 Python 和 R 编写解决方案。这些笔记本教程是学习并动手实践的绝佳方式,使你能够进入更复杂的项目。
8. 乳腺癌分类
Kaggle 上的乳腺癌分类数据集是另一个练习机器学习和 AI 技能的优秀方式。
现实世界中的大多数监督学习问题都是像这样分类问题。乳腺癌识别中的一个关键挑战是无法区分良性(非癌性)和恶性(癌性)肿瘤。数据集中有“radius_mean”和“area_mean”等变量,你需要根据这些特征对肿瘤是否癌性进行分类。由于不需要进行重大数据预处理,这个数据集相对容易处理。它也是一个平衡的数据集,使你的任务更容易管理,因为你不需要进行大量特征工程。
在这个数据集上训练一个简单的逻辑回归分类器可以达到高达 0.90 的准确率。
数据集:Kaggle 乳腺癌分类数据集
9. TMDB 票房预测
这个 Kaggle 数据集是练习回归技能的绝佳方式。它包含大约 7000 部电影,你需要使用数据集中提供的变量来预测电影的收入。
数据点包括演员、工作人员、预算、语言和发布日期。数据集中有 23 个变量,其中之一是目标变量。
一个基本的线性回归模型可以提供超过 0.60 的 R 平方值,因此你可以将其作为基线预测模型。尝试使用 XGBoost 回归或 Light GBM 等技术来超越这个分数。
这个数据集比之前的稍微复杂一些,因为某些列的数据存在于嵌套字典中。你需要进行一些额外的预处理,以提取这些数据并以可用的格式进行模型训练。
收入预测是一个很好的项目,可以展示在你的作品集上,因为它为电影行业之外的各种领域提供了商业价值。
10. Python 中的客户细分
Kaggle 上的客户细分数据集是开始无监督机器学习的好方法。这个数据集包含了客户的详细信息,如年龄、性别、年收入和消费评分。
你需要使用这些变量来构建客户群体。相似的客户应该被分组到类似的簇中。你可以使用像 K-Means 聚类或层次聚类这样的算法来完成这项任务。客户细分模型可以提供商业价值。
公司通常希望将客户进行分类,以为每种客户类型制定不同的营销策略。
这个数据集的主要目标包括:
-
利用机器学习技术实现客户细分
-
确定不同营销策略的目标客户
-
了解营销策略在现实世界中的运作方式
为这个任务构建一个聚类模型可以使你的作品集脱颖而出,且分割技术是一个很棒的技能,如果你希望在营销行业找到与 AI 相关的工作,这会非常有用。
数据集: Kaggle 商城客户细分数据集
为简历准备的中级/高级机器学习项目
一旦你完成了像上述这些简单的机器学习项目,就可以转向更具挑战性的项目。
1. 销售预测
时间序列预测是一种在行业中非常常用的机器学习技术。利用过去的数据来预测未来的销售有很多商业应用。Kaggle 需求预测数据集可以用来练习这个项目。
这个数据集包含了 5 年的销售数据,你需要预测未来三个月的销售情况。数据集中列出了十家不同的商店,每家商店有 50 种商品。
为了预测销售,你可以尝试各种方法 — ARIMA、向量自回归,或者深度学习。你可以使用的一种方法是测量每个月销售额的增长并记录下来。然后,基于前一个月和当前月的销售额差异建立模型。考虑节假日和季节性因素可以提高你的机器学习模型的表现。
数据集: Kaggle 商店商品需求预测
2. 客户服务聊天机器人
客户服务聊天机器人使用 AI 和机器学习技术来回复客户,扮演人类代表的角色。聊天机器人应能够回答简单问题以满足客户需求。
目前你可以构建三种类型的聊天机器人:
-
基于规则的聊天机器人 — 这些聊天机器人并不智能。它们依赖一组预定义的规则,只根据这些规则回复用户。一些聊天机器人还被提供了一组预定义的问题和答案,不能回答超出这些领域的查询。
-
独立聊天机器人 — 独立聊天机器人利用机器学习来处理和分析用户的请求,并提供相应的回复。
-
NLP 聊天机器人 — 这些聊天机器人能够理解词语中的模式,并区分不同的词语组合。它们是三种聊天机器人类型中最先进的,因为它们可以根据训练时学习到的词语模式来生成接下来的回复。
NLP 聊天机器人是一个有趣的机器学习项目创意。你需要一个现有的词汇库来训练你的模型,并且你可以很容易地找到 Python 库来完成这项工作。你还可以拥有一个预定义的字典,里面包含你希望用来训练模型的问题和答案对。
3. 野生动物目标检测系统
如果你生活在一个频繁出现野生动物的地区,实施一个物体检测系统以识别这些动物的存在是很有帮助的。按照以下步骤建立这样的系统:
-
在你想监控的区域安装摄像头。
-
下载所有视频录像并保存。
-
创建一个 Python 应用程序来分析传入的图像并识别野生动物。
微软利用从野生动物摄像头收集的数据构建了一个图像识别 API。他们发布了一个名为 MegaDetector 的开源预训练模型用于此目的。
你可以在你的 Python 应用程序中使用这个预训练模型来识别收集到的图像中的野生动物。它是到目前为止提到的最令人兴奋的机器学习项目之一,并且由于预训练模型的可用性,实施起来相当简单。
API: MegaDetector
4. Spotify 音乐推荐系统
Spotify 使用人工智能向用户推荐音乐。你可以尝试基于 Spotify 上公开的数据构建一个推荐系统。
Spotify 提供了一个可以用来检索音频数据的 API——你可以找到诸如发行年份、调性、流行度和艺术家等特征。要在 Python 中访问此 API,你可以使用一个名为 Spotipy 的库。
你还可以使用 Kaggle 上的 Spotify 数据集,该数据集包含大约 60 万行。使用这些数据集,你可以为每个用户的最爱音乐家推荐最佳替代品。你还可以根据每个用户喜欢的内容和流派提出歌曲推荐。
这个推荐系统可以使用 K-Means 聚类来构建——相似的数据点将被分组。你可以向最终用户推荐具有最小簇内距离的歌曲。
一旦你建立了推荐系统,你还可以将其转换为一个简单的 Python 应用并进行部署。你可以让用户输入他们在 Spotify 上喜欢的歌曲,然后在屏幕上显示与你的模型推荐的、与他们喜欢的歌曲最相似的推荐结果。
数据集: Kaggle Spotify 数据集
5. 市场篮子分析
市场篮子分析是一种零售商用来识别可以一起销售的商品的流行技术。
例如:
几年前,一位研究分析师发现了啤酒和尿布销售之间的相关性。大多数时候,只要顾客进店买啤酒,他们也会一起购买尿布。
因此,商店开始将啤酒和尿布一起放在同一个过道上,作为一种增加销售的营销策略。这种做法确实有效。
有人认为啤酒和尿布有很高的相关性,因为男性经常一起购买这两样东西。男性会走进商店买一瓶啤酒,同时还会买几件其他家庭用品(包括尿布)。 这似乎是一个相当不可能的相关性,但确实发生过。
市场篮子分析可以帮助公司识别经常一起购买的商品之间的隐藏相关性。商店可以据此将商品放置在更容易被顾客找到的位置。
你可以使用 Kaggle 上的市场篮子优化数据集来构建和训练你的模型。执行市场篮子分析最常用的算法是 Apriori 算法。
数据集: Kaggle 市场篮子优化数据集
6. 纽约市出租车行程时长
数据集包含了出租车行程的起始和结束坐标、时间和乘客数量等变量。这个机器学习项目的目标是预测行程时长,考虑到所有这些变量。这是一个回归问题。
像时间和坐标这样的变量需要适当预处理并转换为可理解的格式。这个项目并不像看起来那样简单。数据集中还有一些异常值,使得预测更加复杂,因此你需要通过特征工程技术来处理这些问题。
这个纽约市出租车行程 Kaggle 竞赛的评估标准是 RMSLE 或均方根对数误差。Kaggle 上的最佳提交得到了 0.29 的 RMSLE 分数,而 Kaggle 的基准模型的 RMSLE 为 0.89。
你可以使用任何回归算法来解决这个 Kaggle 项目,但表现最好的竞争者要么使用了梯度提升模型,要么使用了深度学习技术。
数据集: Kaggle 纽约市出租车行程时长数据集
7. 实时垃圾短信检测
在这个项目中,你可以使用机器学习技术来区分垃圾短信(不合法)和正常短信(合法)。
为了实现这一目标,你可以使用 Kaggle 的 SMS 垃圾短信数据集。这个数据集包含了大约 5K 条已标记为垃圾短信或正常短信的消息。
你可以按照以下步骤构建一个实时垃圾短信检测系统:
-
使用 Kaggle 的 SMS 垃圾短信数据集来训练机器学习模型。
-
使用 Python 创建一个简单的聊天服务器。
-
将机器学习模型部署在你的聊天服务器上,并确保所有的流量都通过该模型。
-
只允许正常短信通过。如果是垃圾短信,则返回错误信息。
为了构建机器学习模型,你首先需要对 Kaggle 的 SMS 垃圾短信数据集中存在的文本消息进行预处理。然后,将这些消息转换为词袋,以便可以轻松传递到你的分类模型中进行预测。
8. Myers-Briggs 性格预测应用
你可以创建一个应用,根据用户所说的话预测他们的性格类型。
Myers-Briggs 类型指标将个人分类为 16 种不同的性格类型。这是世界上最受欢迎的性格测试之一。
如果你尝试在互联网上寻找你的性格类型,你会发现许多在线测验。在回答大约 20 到 30 个问题后,你会被分配到一个性格类型。
然而,在这个项目中,你可以使用机器学习仅根据一句话来预测任何人的性格类型。
以下是实现这个目标的步骤:
-
构建一个多类别分类模型,并在 Kaggle 上的 Myers-Briggs 数据集上进行训练。这涉及数据预处理(去除停用词和不必要的字符)和一些特征工程。你可以使用浅层学习模型,如逻辑回归,或者使用深度学习模型,如 LSTM。
-
你可以创建一个应用,允许用户输入他们选择的任何句子。
-
保存你的机器学习模型权重,并将模型与应用集成。在最终用户输入一个单词后,在模型做出预测后,在屏幕上显示他们的性格类型。
9. 情绪识别系统 + 推荐系统
你是否曾经感到悲伤,觉得需要看一些有趣的东西来振作精神?或者你是否曾经感到沮丧,需要放松一下,看看一些令人放松的东西?
这个项目是两个较小项目的结合。
你可以构建一个应用,基于实时网络视频和用户的表情识别用户的情绪,并根据用户的表情提供电影建议。
要构建这个,你可以采取以下步骤:
-
创建一个可以接收实时视频流的应用。
-
使用 Python 的面部识别 API 检测视频流中的面孔和情感。
-
在将这些情感分类到不同类别之后,开始构建推荐系统。这可以是针对每种情感的硬编码值,这意味着你不需要涉及机器学习来进行推荐。
-
一旦你完成了应用的构建,你可以将其部署到 Heroku、Dash 或一个 web 服务器上。
API:面部识别 API
10. YouTube 评论情感分析
在这个项目中,你可以创建一个仪表板来分析流行 YouTuber 的整体情感。
超过 20 亿用户每月至少观看一次 YouTube 视频。流行的 YouTuber 通过他们的内容获得了数百亿的观看量。然而,许多这些影响者因过去的争议而受到批评,公众认知也在不断变化。
你可以构建一个情感分析模型,并创建一个仪表板来可视化关于名人的情感变化。
要构建这个,你可以采取以下步骤:
-
抓取你想分析的 YouTuber 的视频评论。
-
使用预训练的情感分析模型对每条评论进行预测。
-
在仪表板上可视化模型的预测。你甚至可以使用 Dash(Python)或 Shiny(R)等库创建仪表板应用。
-
你可以通过允许用户按时间范围、YouTuber 名称和视频类型来筛选情感,从而使仪表板具有互动性。
API: YouTube 评论抓取器
总结
机器学习行业庞大且充满机会。如果你希望在没有正式教育背景的情况下进入这个行业,展示你拥有完成工作的必要技能的最佳方式是通过项目。
上述大多数项目的机器学习方面都很简单。由于机器学习的普及,模型构建过程可以通过预训练模型和 API 轻松实现。
开源人工智能项目如 Keras 和 FastAI 也加快了模型构建的过程。这些机器学习和 数据科学项目的棘手之处在于数据的收集、预处理和部署。如果你找到一份机器学习的工作,大多数算法的构建将会相对简单。创建一个销售预测模型只需一两天时间。你将花费大部分时间在寻找合适的数据源和将模型投入生产以获取业务价值上。
原文。经许可转载。
相关:
更多相关内容
你需要的 20 个 Python 包用于机器学习和数据科学
评论
由沙德罗·卢克,Digitec Galaxus AG 的机器学习工程师。

我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
图像由作者创建。背景许可由Envato-Elements持有,由作者提供。
我们将查看你在所有数据科学、数据工程和机器学习项目中应了解的 20 个 Python 包。这些是我在作为机器学习工程师和 Python 程序员的职业生涯中发现最有用的包。虽然这样的列表永远无法完整,但它确实为每种用例提供了一些工具。
如果我遗漏了你最喜欢的内容,请务必将其添加到其他人的知识中,并在下面的评论中告诉他们。
1. Open CV
开源计算机视觉库 Open-CV 是你处理图像和视频时的最佳伙伴。它提供了高效的解决方案来处理常见的图像问题,如人脸检测和物体检测。或者,正如我们下面所看到的,边缘检测,即检测图像中的各种线条。如果你计划在数据科学中处理图像,这个库是必不可少的。Open CV 在 GitHub 上获得了 56,000 个星标,使我在处理图像数据时快了几倍,也变得更容易。

来自OpenCV的截图。
2. Matplotlib
数据可视化是你与非数据专家沟通的主要方式。如果你想一想,即使是应用程序也只是可视化幕后各种数据交互的方式。Matplotlib 是 Python 中图像可视化的基础。从可视化你的边缘检测算法到查看数据中的分布,Matplotlib 是你可靠的伙伴。在 GitHub 上拥有 14,000 个星标,绝对是一个值得开始贡献的好库。例如,我在最近的视频中使用 seaborn 和 matplotlib 制作了这个动画折线图。
3. pip
鉴于我们正在讨论 Python 包,我们必须花一点时间谈谈它们的主角 pip。没有它,你不能安装其他任何包。它的唯一目的就是从Python 包索引或类似 GitHub 的地方安装包。但你也可以用它来安装你自己定制的包。7,400 颗星只是没有反映它对 Python 社区的重要性。
4. Numpy
没有 Numpy,Python 不会成为最流行的编程语言。它是所有数据科学和机器学习包的基础,是进行所有数学密集型计算时必不可少的包。你在大学里学到的那些复杂的线性代数和高级数学基本上都由 Numpy 高效处理。它的语法风格可以在许多重要的数据库中看到。GitHub 上的 18,100 颗星展示了它在 Python 生态系统中的关键基础作用。
5. Pandas
基于 Numpy 构建,它是你在 Python 中进行所有数据科学工作的核心。“import pandas as pd”是我早晨输入的第一行代码,它远不止是加强版的 Excel。它的明确目标是成为任何语言中最强大的开源数据工具,我认为他们已经完成了一半的目标。虽然它通常不是最快的工具,但有许多子工具可以加快速度,如 Dask、swifter、koalas 等,它们基于其语法和易用性,使其也适用于大数据项目。GitHub 上的 30,900 颗星,真正是任何有志数据专家的起点。
6. Python-dateutil
如果你曾在 Python 中处理过日期,你会知道没有 dateutil 处理起来非常麻烦。它可以计算给定日期的下一个月,或计算日期之间的秒数。最重要的是,它为你处理时区问题,如果你曾试图在没有库的情况下处理这些问题,可能会遇到极大的麻烦。GitHub 上的 1,600 颗星表明幸运的是,只有少数人需要经历处理时区的挫折过程。
7. Scikit-Learn
如果你对机器学习充满热情,那么 Scikit-Learn 项目将满足你的需求。最好的起点也是查找你可能需要用于预测的任何算法的首选之地。它还提供了大量实用的评估方法和训练辅助工具,如网格搜索。无论你在尝试从数据中获得什么样的预测,sklearn(如它通常被称呼的)都将帮助你更高效地完成。GitHub 上的 47,000 颗星告诉你为什么 Python 是机器学习者的首选语言。

来自 Scikit-learn 的截图。
8. Scipy
这有点令人困惑,但有一个 Scipy 库,还有一个 Scipy 栈。本文中提到的大多数库和包都是 Python 科学计算的 Scipy 栈 的一部分。这包括 Numpy、Matplotlib、IPython 和 Pandas。就像 Numpy 一样,你很可能不会直接使用 Scipy,但上述提到的 Scikit-Learn 库 heavily relies on it。Scipy 提供了进行复杂机器学习过程的核心数学方法。再次有些奇怪,它在 GitHub 上只有大约 8,500 个星标。
9. TQDM
如果你想知道我最喜欢的 Python 包是什么,别再找了。就是这个叫做 TQDM 的小应用程序。它的功能其实就是给你一个处理进度条,你可以把它放到 任何 for 循环 中,它会给你一个进度条,告诉你每次迭代的平均时间,最重要的是,它会告诉你需要多久,这样你就知道在必须回到工作之前,你可以看多久的 YouTube 视频。我最喜欢的包获得了 19,300 个星标,它在过去几年里给了我比其他任何包都更多的平静。
GIF 来自 TQDM-Github。
10. TensorFlow
最受欢迎的深度学习框架,真正使得 Python 如今的样子。TensorFlow 是一个完整的端到端开源机器学习平台,包含了许多其他包和工具,如 tensorboard、collab 和 What-If 工具。被许多世界领先公司选择用于深度学习需求的 TensorFlow,在 GitHub 上拥有令人震惊的 159,000 个星标,是有史以来最受欢迎的 Python 包。它被包括可口可乐、Twitter、Intel 以及其创始人 Google 在内的公司用于各种深度学习应用场景。
如果你对最有用的工具、开发环境和 AutoML 工具的更深入细节感兴趣,务必查看我的视频。
11. KERAS
一个为人类打造的深度学习框架,正如他们的口号所说。它让快速开发新的神经网络成为现实。我记得在 Keras 之前,即使是写一个简单的顺序模型也是相当麻烦的。它基于 TensorFlow 之上,确实是开发者在首次尝试新架构时的起点。它降低了编程神经网络的门槛,使得大多数高中生现在都能做到。Keras 是另一个极受欢迎的 Python 包,约有 52,000 个星标。
12. PyTorch
TensorFlow 在深度学习领域的主要竞争对手。它已成为开发神经网络的绝佳替代品,也是我个人最喜欢的工具。我认为它的社区在自然语言处理领域稍强,而 TensorFlow 更倾向于图像和视频方面。与 Keras 一样,它也有自己简化的库——Pytorch Lightning,我制作了一个完整教程,以确保你不会再为精通深度学习而努力。 在 GitHub 上的 50,000 颗星虽然相比 Tensorflow 显得少,但从长远来看,它确实在快速赶上。
来自 Google Trends 的截图,蓝色:PyTorch 红色:Tensorflow
13. Statsmodels
与时下流行的机器学习世界相比,Statsmodel 是你通向经典统计学世界的门径。它包含了许多有用的统计评估和测试。相较而言,这些工具往往更加稳定,任何数据科学家都应该不时使用。6,600 颗星可能更多地反映了深度学习与经典统计学的酷炫程度对比。
14. Plotly
Matplolib 的主要替代品是 Plotly,从客观上来说更美观,更适合交互式数据可视化。与 Matplolib 的主要区别在于它是基于浏览器的,起步略微困难,但一旦掌握基础知识,它确实是一个令人惊叹的工具。它与 Jupyter 的强大集成让我相信它将变得越来越标准,并使人们远离 Matplolib 的集成。在 GitHub 上获得 10,000 颗星,并逐渐追赶 Matplolib。
来自 Plotly 画廊的截图。
15. NLTK
自然语言工具包(Natural Language Toolkit,简称 NLTK)是你在尝试理解任何文本时的最佳助手。它包含了各种语法变换的广泛算法,例如词干提取,以及你可能希望在处理模型中的文本之前移除的符号,如句点和停用词的惊人列表。它还会检测哪些最有可能是句子,哪些不是,从而纠正数据集中“作者”所犯的语法错误。总之,如果你在处理文本,试试它吧。再次给它 10,000 颗星,这对像这样的利基包来说实在是太疯狂了。
16. Scrapy
如果你曾经尝试在没有数据的情况下进行数据科学,我想你意识到这相当于徒劳无功。幸运的是,互联网包含了几乎所有事物的信息。但有时,这些信息并没有以友好的 CSV 格式存储,你必须首先去采集它。这正是 scrapy 可以帮助你的地方,它使你能够通过几行代码轻松爬取全球的网站。下次你有一个没有人预先收集数据集的想法时,务必查看这个 41,000 星的项目。
来自 Scrapy 的截图。
17. Beautiful Soup
一个非常相似的用例是,许多网页开发人员将他们的数据存储在一种较差的数据结构中,称为 HTML。为了利用这种嵌套的混乱,创建了 beautiful soup。它帮助你提取 HTML 的各种方面,如标题和标签,并允许你像操作普通字典一样对其进行迭代。它在几个小项目中帮助了我,这些项目中我对没有开放 API 的网站上的用户评论感兴趣。
18. XGBoost
一旦我们的数据集大小超过一定的 TB 阈值,使用常见的基础机器学习算法实现可能会很困难。XGBoost 可以救你于等待几周才能完成计算的困境。它是一个高度可扩展的分布式梯度提升库,确保你的计算尽可能高效地运行。几乎所有常见的数据科学语言和堆栈中都有提供。
19. PySpark
数据工程是每个数据科学工作流程的一部分,如果你曾尝试处理数十亿的数据点,你会知道你常规的 for 循环只能做到这一步。PySpark 是非常流行的 Apache Spark 数据处理引擎的 Python 实现。它类似于 pandas,但从一开始就考虑了分布式计算。如果你有感觉到处理数据的速度跟不上进度,这肯定是你需要的东西。他们还开始关注大规模并行机器学习,用于非常大的数据用例。GitHub 上的 30,000 个星标使它成为最受欢迎的数据处理工具之一。

来自 Spark 的截图。
20. Urllib3
Urllib3 是一个功能强大的、用户友好的 Python HTTP 客户端。如果你在 Python 中试图进行任何与互联网相关的操作,那么这个库或基于它的其他库都是必不可少的。包括 API 爬虫和与各种外部数据源的连接。GitHub 上 2,800 个星标不会撒谎。
结论
这些是我在担任机器学习工程师和 Python 程序员的职业生涯中使用过的 20 个最重要的包。我相信它们在你寻找解决方案的表格时也会对你有所帮助。请务必在下方评论你最喜欢的包,让其他人也能从你的知识中受益。
原文。转载许可。
相关:
更多相关主题
识别虚假数据科学家的 20 个问题(带答案):ChatGPT 版,第一部分
原文:
www.kdnuggets.com/2023/01/20-questions-detect-fake-data-scientists-chatgpt-1.html

由 DALL•E 创建的图像
七年前的这个月,KDnuggets 发布了一篇题为 识别虚假数据科学家的 20 个问题 的文章,作者是 Andrew Fogg。接下来一个月,KDnuggets 编辑们在随后的文章 21 个必知的数据科学面试问题及答案 中共同回答了这些问题。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
为了以新颖和激动人心的方式利用 ChatGPT——既了解 ChatGPT 本身,又学习数据科学面试问题的主题——我们决定在原始文章的七周年之际,重提这些问题并向 ChatGPT 提问。
我将明确说明本文中的所有问题答案均由 ChatGPT 提供。请根据这些信息自行判断。
我鼓励读者将这些答案与 KDnuggets 编辑在 2016 年提供的答案 进行比较,以了解哪些答案更全面,哪些更准确,以及哪些更易读。欢迎在下面的评论中批评特定答案或整个项目。
现在让我们看看 ChatGPT 在回答以下 10 个问题时表现如何,这些问题仍然被认为是识别申请你组织的虚假数据科学家的优秀候选题。
1. 解释什么是正则化以及它为什么有用。
正则化是一种在机器学习中用于防止过拟合的技术。过拟合发生在模型对训练数据过度训练时,导致在未见过的数据上表现不佳。正则化是一种通过在损失函数中添加惩罚项来抑制模型中的大权重的方法。这个惩罚项是一个系数乘以权重的大小。通过添加这个项,模型被迫拥有较小的权重,从而有助于减少过拟合并提高模型的泛化能力。两种常见的正则化类型是 L1 和 L2 正则化。L1 正则化添加的惩罚项与权重的绝对值成正比,而 L2 正则化添加的惩罚项与权重的平方成正比。
2. 你最崇拜哪些数据科学家?哪些创业公司?
作为一个语言模型,我没有个人偏好或崇拜之情。然而,我可以告诉你一些在数据科学和创业领域内广为人知且受人尊敬的名字。
在数据科学家方面,一些值得注意的人物包括:
-
扬·勒昆,深度学习和计算机视觉领域的先驱。
-
安德鲁·吴,在线教育领域的先驱和机器学习领域的领先专家。
-
杰弗里·辛顿,深度学习和神经网络领域的先驱。
-
李开复,领先的人工智能专家、投资人和作者。
-
约书亚·本吉奥,深度学习和自然语言处理领域的先驱。
在创业公司方面,一些值得注意的公司包括:
-
OpenAI,一个致力于构建安全人工智能并确保其好处广泛共享的人工智能研究实验室和创业公司。
-
Google Brain,这是谷歌的深度学习研究团队。
-
DeepMind,一家成立于 2010 年 9 月的英国人工智能公司,2015 年被 Alphabet Inc 收购。
-
Nervana,一家正在构建专用硬件以加速深度学习工作负载的创业公司。
-
NVIDIA,一家专注于图形处理单元(GPU)的公司,在深度学习革命中处于前沿,其 GPU 优化了深度学习工作负载。
3. 你会如何验证你创建的模型,以使用多元回归生成定量结果变量的预测模型。
有几种方法可以验证使用多元回归创建的模型,以预测定量结果变量。一些常见的方法包括:
-
Holdout 方法:这涉及将数据随机分为训练集和测试集,使用训练集来拟合模型,使用测试集来评估模型的性能。
-
k 折交叉验证:这种方法涉及将数据随机分成 k 折,在 k-1 折上训练模型,并使用剩下的一折作为测试集,重复 k 次并平均结果。
-
自助法:该方法涉及重复抽样数据以创建多个“伪样本”,并使用这些样本来拟合和评估模型。
-
R² 和调整后的 R²:这些是统计度量,表示预测变量解释的结果变量方差的比例。
-
均方根误差(RMSE)或平均绝对误差(MAE):用于衡量预测值与实际值之间的差异。
-
回归诊断图:用于检查线性、正态性、同方差性和误差独立性假设,以及异常值和杠杆点的存在。
-
与基准模型比较:将模型与简单的基准模型(如均值或中位数)进行比较,可以了解模型的表现如何。
使用多种方法验证模型很重要,因为每种方法可以揭示模型的不同错误或问题。
4. 解释精确度和召回率是什么。它们如何与 ROC 曲线相关?
精确度和召回率是二分类器性能的两个重要指标。
精确度是分类器所有正向预测中真正正例(正确预测的正例)的比例。它衡量了分类器正确识别正例的能力。
召回率(也称为敏感性或真正正例率)是所有实际正例中真正正例预测的比例。它衡量了分类器识别所有正例的能力。
接收器操作特征(ROC)曲线是分类器性能的图形表示。它将真正正例率(召回率)与假正例率(1-特异性)在不同的分类器阈值下绘制在一起。ROC 曲线下面积(AUC)是分类器整体性能的一个衡量标准。
精确度和召回率与 ROC 曲线密切相关。一个精确度高、召回率高的分类器将具有高真正正例率和低假正例率,从而在图表的左上角紧贴 ROC 曲线。而精确度低、召回率低的分类器将具有低真正正例率和高假正例率,其 ROC 曲线接近对角线。
在实践中,通常需要在精确度和召回率之间进行权衡,以实现两者之间的平衡。这可以通过调整分类器的阈值来完成,阈值控制真正正例与假正例之间的平衡。更高的阈值会导致更高的精确度但较低的召回率,而较低的阈值会导致较低的精确度但较高的召回率。
5. 如何证明你对算法所做的改进确实比什么都不做要好?
为了证明对算法的改进是真实的,而不仅仅是偶然的结果,你可以使用统计假设检验。这涉及到制定原假设和备择假设,然后使用检验统计量和显著性水平来决定是否拒绝原假设。
原假设通常是新算法不比旧算法或基准算法更好,而备择假设则是新算法更好。
进行假设检验的常见方法是使用双尾 t 检验。这种方法比较新旧算法的性能指标均值,并测试它们是否显著不同。另一种方法是使用配对样本检验,其中相同的数据集用于新旧算法,并对结果进行比较。
如果 p 值(在假设原假设为真的情况下,获得与观察到的检验统计量一样极端或更极端的检验统计量的概率)小于显著性水平(通常为 0.05),则拒绝原假设,并得出新算法更好的结论。
此外,为确保改进不仅仅是偶然的结果,你可以使用交叉验证、引导法等技术,并多次使用不同的随机数据子集进行测试,以提高结果的可靠性。
如果可能的话,将新算法的性能与同领域的最先进算法进行比较也很重要,这样可以更好地评估改进效果。
6. 什么是根本原因分析?
根本原因分析(RCA)是一种识别问题或事件根本原因的方法。它是一个系统化的过程,涉及识别、分析和解决问题的根源,而不仅仅是处理症状。RCA 的目标是通过识别和解决问题的根本原因来防止未来发生类似问题。
RCA 通常包括以下步骤:
-
确定问题:清晰地识别问题及其对组织或系统的影响。
-
收集数据:收集关于问题的数据,包括症状、时间、地点以及任何相关信息。
-
分析数据:使用因果图、帕累托图和鱼骨图等工具来识别问题的可能原因。
-
确定根本原因:利用数据和分析来识别问题的最可能原因。
-
制定解决方案:制定和实施解决方案,以解决问题的根本原因。
-
验证解决方案:监测和评估解决方案的有效性,以确保问题已解决。
-
RCA 可应用于各种问题,从小规模事件到大规模事故和危机,涵盖制造业和服务业,以及医疗保健、航空等领域。
需要注意的是,根本原因分析(RCA)应该由经验丰富的团队进行,且应以客观公正的方式进行,避免任何指责或归咎。
7. 你对定价优化、价格弹性、库存管理和竞争情报了解吗?举例说明。
是的,我对定价优化、价格弹性、库存管理和竞争情报非常熟悉。
定价优化是确定产品或服务的最佳价格以最大化收入或利润的过程。
价格弹性是衡量产品或服务的需求如何随着价格变化而变化的指标。
库存管理是管理企业库存的过程,包括控制和移动库存以及预测未来需求。
竞争情报是收集、分析和解释关于竞争对手、竞争对手的产品以及竞争环境的信息,以获得竞争优势的过程。
示例:
-
一家服装零售商通过定价优化将受欢迎的毛衣定价为$50,这是他们可以售出最多毛衣并获得最大利润的价格。
-
一家销售新产品的公司,其价格弹性较高,意味着价格的微小变化会导致需求的大幅变化,可能会调整产品价格以增加或减少需求。
-
一家零售店使用库存管理来确保在节假日期间拥有足够的热门玩具库存,避免缺货。
-
一家公司利用竞争情报研究其竞争对手的定价、产品供应和营销策略,以指导自身的业务决策。
8. 什么是统计功效?
统计功效是统计测试在备择假设为真的情况下正确拒绝原假设(即发现效果)的概率。换句话说,它是测试在实际存在差异或效果时检测到的能力。通常表示为 0 到 1 之间的一个数字,常用希腊字母β(beta)表示。较高的统计功效意味着测试更有可能发现真实的差异或效果,而较低的统计功效则意味着测试更可能未能发现真实的差异或效果。
统计功效受多个因素影响,包括样本大小、显著性水平(alpha)和效果大小。一般而言,增加样本大小、降低显著性水平和增加效果大小将提高测试的统计功效。
需要注意的是,高统计功效并不能保证测试能够发现真实的差异或效果,但它是测试灵敏度的良好指示,同时也要理解,高统计功效并不表示测试的高准确性或可靠性。
9. 解释什么是重采样方法及其为什么有用。还要解释它们的局限性。
重采样方法是统计技术,它涉及从数据集中重复抽取样本,并利用这些样本对数据集来源的总体做出推断。重采样方法有几种类型,包括:
-
自助法:这种方法涉及从原始数据集中随机抽取样本,并允许重复抽取。这些样本随后用于估计总体统计量,如均值、标准差和置信区间。
-
交叉验证:这种方法用于估计预测模型的性能。它涉及将原始数据集划分为若干子集或“折叠”,在部分子集上训练模型,并在其余子集上测试模型。这个过程会重复多次,以获取模型性能的估计值。
-
排列检验:这种方法用于检验两个变量之间独立性的假设。它涉及随机排列一个变量的值,并测量排列对两个变量之间关系的影响。
重采样方法之所以有用,是因为它们不依赖于对总体潜在分布的假设,比传统的参数方法更具鲁棒性。它们允许研究人员仅使用样本中的信息来对总体进行推断,这在总体难以或昂贵测量时尤其有用。
然而,重采样方法确实有一些局限性。一种局限性是这些方法获得的结果可能对使用的具体样本非常敏感,因此结果可能无法推广到总体。此外,当样本量较小时,这些方法的功效可能不如传统的参数方法。而且,当样本量较小时,这些方法可能无法检测到微小的差异或效应。
10. 是有更多假阳性好,还是更多假阴性好?请解释。
是否有更多假阳性或更多假阴性更好取决于具体的背景和分析的期望结果。
假阳性,也称为 I 型错误,发生在测试或分析错误地表明存在效应或差异时,而实际上并不存在。一般来说,在负面结果(例如,患者没有某种疾病)比正面结果(例如,患者有某种疾病但未接受治疗)后果更严重的情况下,假阳性被认为是较不理想的。
假阴性,也称为 II 型错误,发生在测试或分析错误地表明某种效应或差异不存在时,而实际上它确实存在。一般来说,假阴性在阳性结果(例如,患者有疾病并接受治疗)比阴性结果(例如,患者没有疾病但未接受治疗)后果更严重的情况下被认为是不理想的。
例如,在医疗背景下,假阴性可能导致患者未能接受严重疾病的治疗,而假阳性可能导致不必要的治疗及其相关风险。另一方面,在安全背景下,假阴性可能导致攻击者突破安全防线,而假阳性可能导致合法用户的不便。
设定平衡这些权衡的阈值是很重要的,这时敏感性和特异性概念就派上用场了。敏感性是所有实际阳性病例中真正阳性(正确识别的病例)的比例,而特异性是所有实际阴性病例中真正阴性(正确识别的非病例)的比例。
总之,过多的假阳性或过多的假阴性的选择取决于具体的背景和期望的结果,考虑每种错误的成本和收益对于做出明智的决策是重要的。
这是原始发布中的 20 个问题的前半部分。我们将在接下来的几周内为你带来后半部分,请保持关注。
Matthew Mayo (@mattmayo13)是数据科学家和 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣领域包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
更多相关话题
20 个问题(及答案)以识别虚假数据科学家:ChatGPT 版,第二部分
原文:
www.kdnuggets.com/2023/02/20-questions-detect-fake-data-scientists-chatgpt-2.html

图片由 Midjourney 创建
7 年前的这个月,KDnuggets 发布了一篇题为识别虚假数据科学家的 20 个问题的文章,由 Andrew Fogg 撰写。下个月,KDnuggets 编辑们在随后的文章21 个必知的数据科学面试问题及答案中集体回答了这些问题。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
为了利用 ChatGPT 探索新的有趣的方式 —— 既了解 ChatGPT 本身,也了解数据科学面试问题的主题 —— 我们决定在原文七周年之际复活这些问题,并提出给 ChatGPT。
我将以明确声明开篇,本文中所有问题的答案均由 ChatGPT 提供。请自行处理这些信息。
我鼓励读者将这些答案与2016 年 KDnuggets 编辑提供的答案进行比较,以查看哪些答案更为全面,哪些更准确,以及哪些更易于阅读。请随意在下方评论中批评具体的答案或整个项目。
现在,让我们来看看 ChatGPT 在回答以下 10 个问题方面的表现如何,我们仍然认为这些问题非常适合用于识别申请你们组织职位的虚假数据科学家。你可以在这篇之前发布的文章中找到另外 10 个问题,上半部分。
11. 什么是选择偏差,它为什么重要,以及如何避免它?
选择偏倚是一种偏倚,当样本中的个体不是随机选择的,因此不能准确代表其应代表的总体时,就会发生。这可以通过许多方式发生,例如根据某些特征选择个体、仅从某个地区招募参与者,或仅包括满足特定标准的个体。
选择偏倚很重要,因为它可能导致不准确的结论和有缺陷的研究结果。如果样本不能代表总体,从样本中得出的任何推断或结论可能不适用于整个总体。
为了避免选择偏倚,研究人员应在选择参与者时使用随机抽样技术。这可以通过使用随机数生成器选择参与者,或使用考虑到某些特征的分层随机抽样方法来完成。此外,研究人员应确保他们的招募策略不带有偏见,并且参与者不因某些特征而被排除在研究之外。研究人员还应在论文中详细报告他们的抽样方法。
在分析数据时,使用适当的统计方法来调整任何潜在的样本偏倚也很重要。
12. 举例说明你如何使用实验设计来回答有关用户行为的问题。
使用实验设计来回答有关用户行为的问题的一个例子是通过随机对照试验(RCT)。
假设问题是“网站上的新特征是否增加了用户参与度?”
一种实验设计是将网站的用户随机分为两个组:对照组和实验组。对照组将继续正常使用网站,而实验组则可以访问新特征。
然后,研究人员会在设定的时间段内测量两个组的用户参与度(例如,在网站上花费的时间、访问的页面数量、与新特征的互动次数)。通过比较两个组的参与数据,研究人员可以确定新特征是否对用户参与度有显著影响。
通过使用随机分配形成两个组,我们可以确保观察到的任何差异是由于新特征而非其他因素。此外,通过使用对照组,我们可以确保观察到的任何差异不是由于偶然。
这种实验设计允许进行因果推断,这意味着研究人员可以推断出新特征导致了用户参与度的变化,而不仅仅是观察到相关性。
13. “长格式”和“宽格式”数据有什么区别?
在“长格式”数据中,每一行代表一个单独的观察值,并且有几个列代表不同的变量,如主题 ID、感兴趣的变量和该变量的值。这种格式也被称为“堆叠”或“熔化”数据。
例如,对 10 个个体的身高和体重的研究,在长格式中,数据会是这样:
主题 ID 变量 值
1 身高 180
1 体重 75
2 身高 175
2 体重 80
... ... ...
在“宽格式”数据中,每一行代表一个个体,并且有几个列代表不同的感兴趣变量,每个变量有其自己的列。这种格式也被称为“非堆叠”数据。
例如,上述相同的数据,在宽格式下会是这样:
主题 ID 身高 体重
1 180 75
2 175 80
... ... ...
“长格式”和“宽格式”数据之间的主要区别在于数据的组织方式,“长格式”数据按观察值和变量组织,而“宽格式”数据按观察值和感兴趣的变量组织。一些数据分析和可视化方法可能更适合某一种格式,根据分析需求在两种格式之间转换并不罕见。
14. 你使用什么方法来确定文章中发布的统计数据(例如报纸)是否错误,或为了支持作者的观点而不是提供关于特定主题的正确、全面的事实信息?
有几种方法可以用来确定文章中发布的统计数据是否错误,或是否为了支持作者的观点而不是提供关于特定主题的正确和全面的事实信息。其中一些方法包括:
-
检查来源:查找文章中使用的统计数据来源并验证其可靠性。它们是可信的组织或个人吗?是否经过同行评审或独立验证?
-
查找上下文:确保阅读文章的全部内容,并理解统计数据呈现的背景。它们是否被用来支持特定的观点或议程?
-
与其他来源比较:查找其他报道相同主题的来源,并将文章中的统计数据和信息与这些来源进行比较。
-
检查偏见:查找统计数据呈现方式中的任何偏见迹象。例如,数据的选择性报告、选择性使用统计数据或以误导的方式呈现数据。
考虑样本大小和代表性:如果样本大小较小,可能不代表总体,统计数据可能不可推广。此外,如果样本不是随机选择的,可能会有偏见。
检查方法论:查找用于收集数据的方法论,如果没有描述,就很难评估统计数据的准确性。
同样重要的是,要记住如果统计数据没有在正确的背景下呈现,或者用于支持特定的观点或议程,它们可能会具有误导性。因此,在阅读任何展示统计数据的文章时,必须保持批判性,并始终寻找额外的信息来源以验证所呈现统计数据的准确性。
15. 解释爱德华·塔夫提的“图表垃圾”概念。
爱德华·塔夫提是统计学家和信息设计师,他撰写了几本关于数据可视化的重要书籍。他的一个关键概念是“图表垃圾”,指的是在数据可视化中使用非信息性或冗余元素,这些元素会削弱传达的信息。这些元素包括网格线、装饰性边框、3D 效果和不必要的文本。Tufte 认为,图表垃圾会使观众更难理解所呈现的信息,可能导致数据的混淆和误解。
Tufte 的主要论点是数据可视化的主要目标是清晰准确地呈现信息,而图表垃圾可能会分散注意力。他认为,良好的数据可视化应优先考虑数据本身,使其易于阅读和理解,并且任何额外的元素应尽量少用,仅在其具有明确目的时使用。
他还强调数据可视化应该简洁明了,专注于数据及其信息,而不是设计本身。在他看来,有效的数据可视化应该能够独立存在,而不需要额外的文本或注释。
Tufte 的思想对数据可视化领域产生了重大影响,并且在商业、数据科学和新闻等领域继续被广泛引用和应用。
16. 你会如何筛选异常值,如果发现了异常值该怎么办?
有几种筛选异常值的方法,包括:
-
目视检查:使用图表,如箱线图或散点图来绘制数据,可以很容易地识别异常值。异常值通常会远离其他数据点。
-
Z 分数方法:这种方法计算数据的标准差和均值,然后为每个数据点分配一个分数(z 分数)。z 分数大于某个阈值(通常为 3 或-3)的数据点被认为是异常值。
-
四分位距(IQR)方法:这种方法计算四分位距(即第 75 百分位和第 25 百分位之间的差),并为数据分配一个下限和上限。任何落在这些界限之外的数据点被认为是异常值。
4. 马哈拉诺比斯距离方法:该方法计算每个数据点与数据均值的马哈拉诺比斯距离。马哈拉诺比斯距离是衡量数据点与均值之间的标准差距离的指标。马哈拉诺比斯距离大于某个阈值的数据点被认为是离群值。
一旦离群值被识别出来,重要的是要考虑它们对数据和分析的影响。处理离群值的方法有多种,具体取决于数据的背景和研究问题:
1. 排除离群值:这是最常见的方法,尤其是当离群值是测量误差或数据录入错误的结果时。
2. 保留离群值并报告它们:如果离群值是真实的数据点并且被认为是有用的,那么将其保留在数据集中并在分析中报告它们是重要的。
3. 转换数据:在某些情况下,可以通过对数据进行对数或平方根转换来减少离群值对数据的影响。
4. 调查离群值:离群值可能表明数据收集或测量过程存在问题,因此调查和理解它们发生的原因是重要的。
在决定是否排除或保留离群值之前,考虑数据的性质、研究目标和数据的背景是重要的,并在最终报告中报告对离群值的处理情况。
17. 你如何使用极值理论、蒙特卡罗模拟或数学统计(或其他任何方法)来正确估计极为稀有事件的概率?
极值理论(EVT)可以通过对概率分布的极端尾部分进行建模来估计稀有事件的概率。这可以通过将如 Gumbel 分布或广义帕累托分布等分布拟合到数据集的极端值来完成。
蒙特卡罗模拟也可以用来估计稀有事件的概率,通过从概率分布中生成许多随机样本并计算目标事件发生的次数。这在底层分布复杂或未知时尤其有用。
数学统计可以通过使用最大似然估计或贝叶斯推断等方法来估计稀有事件的概率。这些方法使用数学模型和算法来根据可用数据估计事件的概率。
另一种方法是使用机器学习方法来建模稀有事件并预测其发生的概率。
需要注意的是,估计的准确性依赖于数据的质量和数量、对底层分布的假设以及估计方法的选择。
18. 推荐引擎是什么?它是如何工作的?
推荐引擎是一个利用机器学习算法,根据用户的过去行为和偏好推荐项目的系统。它常用于电子商务、媒体和娱乐以及社交媒体,以向用户提供个性化的推荐。
推荐引擎主要有两种类型:基于内容的和协同过滤。
基于内容的推荐引擎利用项目的特征或属性来推荐类似的项目给用户。例如,如果一个用户喜欢某个演员的电影,那么引擎可能会推荐其他有该演员的电影。
协同过滤(Collaborative filtering)则利用用户的行为来推荐项目。它查看用户与项目的互动,例如评分或购买历史,然后找到类似的用户,以推荐他们喜欢的项目。协同过滤有两种类型:基于用户的和基于项目的。基于用户的协同过滤根据用户与其他用户的相似性来推荐项目,而基于项目的协同过滤则根据项目与用户之前互动过的项目的相似性来推荐项目。
这两种推荐引擎都使用机器学习算法,如 k-NN、SVD 和矩阵分解,来分析数据并做出推荐。它们还使用正则化和交叉验证等技术,以避免模型过拟合。
总体而言,推荐引擎利用用户行为和项目特征的数据,为每个用户提供个性化的推荐。它们在不同的行业中被广泛使用,并帮助提高用户参与度和销售额。
19. 解释什么是假阳性和假阴性。为什么区分这两者很重要?
假阳性是指测试结果显示某种特定条件存在,但实际上并不存在的情况。例如,在医疗测试中,如果一个患者被告知他们有某种疾病,但实际上并没有这种疾病,则为假阳性。
假阴性则是指测试结果显示某种特定条件不存在,但实际上却存在的情况。例如,在医疗测试中,如果一个患者被告知他们没有某种疾病,但实际上却有这种疾病,则为假阴性。
区分假阳性和假阴性非常重要,因为它们具有不同的影响。假阳性可能导致不必要的治疗、程序或进一步的测试,而假阴性可能导致诊断和治疗的延迟或失败。
在机器学习领域,假阳性和假阴性之间的差异也很重要。假阳性率和假阴性率是评估分类器性能的两种常用指标,这可以帮助理解准确率和召回率之间的权衡。例如,在医疗诊断问题中,如果假阴性率过高,意味着许多患病的患者会被误诊,这可能会导致严重后果。
不同的应用对假阳性和假阴性之间的平衡有不同的要求,取决于问题的风险、每种错误的成本以及对结果的期望信心水平。
20. 你使用什么工具进行可视化?你对 Tableau 有什么看法?R?SAS?(用于图表)。如何在图表(或视频)中有效表示 5 个维度?
可以用于数据可视化的工具很多,选择工具将取决于项目的具体要求和用户的经验。一些流行的数据可视化工具包括:
-
Matplotlib 和 Seaborn:这些是广泛用于创建静态 2D 图表和可视化的 Python 库。它们易于使用,拥有庞大的社区,并且可以与其他 Python 库如 Pandas 集成。
-
D3.js:D3.js 是一个用于创建交互式、基于网络的可视化的 JavaScript 库。它广泛用于创建复杂的交互式可视化,例如地图、散点图和折线图。
-
Tableau:Tableau 是一个强大的数据可视化工具,允许用户轻松创建互动且视觉吸引人的可视化。它被数据分析师和商业智能专家广泛使用。Tableau 功能强大,但价格也相对较高。
-
R:R 是一个广泛用于数据分析和可视化的编程语言。它有大量的数据可视化包,如 ggplot2 和 lattice,这些包广泛用于创建静态的 2D 图表和可视化。
-
SAS:SAS 是一个广泛用于数据分析和可视化的软件套件。它提供了多种数据可视化选项,包括散点图、折线图和热图,以及高级可视化选项,如 3D 图和动画。
为了在图表中表示 5 个维度,可以选择使用平行坐标图,这种图表通过将每个变量绘制为平行轴并将每个观察值表示为连接每个轴上值的折线来显示多变量数据。另一个选择是使用散点图矩阵(也称为对角线图),它允许以矩阵格式显示变量之间所有的配对关系,在这种情况下,可以使用不同的颜色、形状或大小来表示不同的维度。
另一种选择是使用带有刷选和链接的平行坐标图,这允许通过突出观察结果并链接到其他视图来互动地探索数据。
也可以在视频中表示 5 维数据,一种方法是使用动画展示数据随时间的变化,另一种方法是使用互动可视化,让用户通过与视觉元素互动来探索数据。
需要注意的是,在图表或视频中表示 5 维数据可能会很具挑战性,因为这需要仔细的设计选择来有效传达信息,并避免用过多数据让用户感到困惑。
以上就是原始出版物中的 20 个问题。希望我们从答案的内容或向 ChatGPT 提问的过程中学到了有趣的东西。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 的总编辑,这是一家开创性的在线数据科学和机器学习资源网站。他的兴趣领域包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。可以通过 editor1 at kdnuggets[dot]com 联系他。
相关话题
识别虚假的数据科学家的 20 个问题
原文:
www.kdnuggets.com/2016/01/20-questions-to-detect-fake-data-scientists.html
作者:Andrew Fogg,Import.io
*查看 KDnuggets 编辑对这些问题(以及一个额外问题)的回答:
*
 *
*现在数据科学家被正式称为 21 世纪最性感的职业,每个人都想分一杯羹。
这意味着市场上确实存在一些数据伪装者。那些自称为数据科学家但实际上没有正确技能组合的人。
这并不总是出于欺骗的目的。数据科学的创新性和缺乏广泛理解的职位描述意味着许多人可能会认为自己是数据科学家,仅仅因为他们处理数据。
“虚假的数据科学家通常在某一特定领域非常精通,并坚信他们的领域才是真正的数据科学。这样的信念忽视了数据科学是指将科学工具和技术(数学、计算、可视化、分析、统计、实验、问题定义、模型建立和验证等)全面应用于从数据中提取发现、洞察和价值。”
- 克 irk Borne, Booz Allen Hamilton的首席数据科学家和RocketDataScience.org的创始人
 “虚假的数据科学家通常在某一特定领域非常精通,并坚信他们的领域才是真正的数据科学。这样的信念忽视了数据科学是指将科学工具和技术(数学、计算、可视化、分析、统计、实验、问题定义、模型建立和验证等)全面应用于从数据中提取发现、洞察和价值。”
“虚假的数据科学家通常在某一特定领域非常精通,并坚信他们的领域才是真正的数据科学。这样的信念忽视了数据科学是指将科学工具和技术(数学、计算、可视化、分析、统计、实验、问题定义、模型建立和验证等)全面应用于从数据中提取发现、洞察和价值。”识别虚假的数据科学家的第一步是了解你应该寻找的技能组合。了解数据科学家、数据分析师与数据工程师之间的区别非常重要,特别是如果你打算聘用这些稀有人才。
为了帮助你分辨真正的数据科学家和虚假的(或误导的)数据科学家,我们编制了一份 20 个面试问题的清单,你可以在面试数据科学家时使用。
-
解释什么是正则化以及它的作用。
-
你最欣赏哪些数据科学家?哪些初创公司?
-
你会如何验证你创建的模型,通过多重回归生成的定量结果变量的预测模型?
-
解释什么是精确度和召回率。它们与 ROC 曲线有什么关系?
-
你如何证明你对一个算法所做的改进确实优于什么都不做?
-
什么是根本原因分析?
-
你是否熟悉定价优化、价格弹性、库存管理和竞争情报?请举例说明。
-
什么是统计功效?
-
解释什么是重采样方法,它们为何有用,并解释它们的局限性。
-
是有太多假阳性好,还是有太多假阴性好?请解释一下。
-
什么是选择偏差,它为何重要,如何避免它?
-
请举例说明你如何使用实验设计来回答关于用户行为的问题。
-
"长格式"和"宽格式"数据有什么区别?
-
你使用什么方法来确定文章(例如报纸)中发布的统计数据是否错误,或是否为支持作者观点而非提供特定主题的正确、全面的事实信息?
-
解释爱德华·塔夫特(Edward Tufte)提出的“图表垃圾”概念。
-
你如何筛选异常值,如果发现异常值应该怎么办?
-
你如何使用极值理论、蒙特卡洛模拟或数学统计(或其他任何方法)来正确估计非常罕见事件的发生几率?
-
什么是推荐引擎?它是如何工作的?
-
解释什么是假阳性和假阴性。为什么区分这两者很重要?
-
你使用什么工具进行可视化?你对 Tableau、R、SAS 有什么看法?如何在图表(或视频)中有效地表示五个维度?

- “一个‘真正的’数据科学家知道如何应用数学、统计学,如何使用适当的实验设计构建和验证模型。拥有 IT 技能而没有统计技能,就像知道如何制作手术刀而不成为外科医生一样。”
- Lisa Winter, Towers Watson 的高级分析师
**你如何量化一个真正的数据科学家?
作者简介:
 Andrew Fogg** 是 import.io 的创始人兼首席数据官。他将对结构化网络的热情和信念带到了 import.io。他坚信帮助数据用户和数据提供者更高效地交易。作为数据和结构化网络方面的专家,在共同创办 import.io 之前,Andrew 曾在微软研究、巴克莱资本、剑桥大学和威康信托工作,然后加入 RBS 成为技术创新组的一员。他最近将自己的第一家创业公司 Kusiri 出售给了 PwC。
Andrew Fogg** 是 import.io 的创始人兼首席数据官。他将对结构化网络的热情和信念带到了 import.io。他坚信帮助数据用户和数据提供者更高效地交易。作为数据和结构化网络方面的专家,在共同创办 import.io 之前,Andrew 曾在微软研究、巴克莱资本、剑桥大学和威康信托工作,然后加入 RBS 成为技术创新组的一员。他最近将自己的第一家创业公司 Kusiri 出售给了 PwC。
相关:
-
实际学习数据科学的 5 个步骤
-
Quora 关于‘如何学习机器学习’的最佳建议
-
60+ 本关于大数据、数据科学、数据挖掘、机器学习、Python、R 等的免费书籍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
我从查看 200 个机器学习工具中学到的东西
原文:
www.kdnuggets.com/2020/07/200-machine-learning-tools.html
评论
作者:Chip Huyen,一位作家和计算机科学家,目前在硅谷的一家机器学习初创公司工作。
为了更好地了解可用于机器学习生产的工具的格局,我决定查找所有我能找到的 AI/ML 工具。我使用的资源包括:
-
媒体对顶级 AI 初创公司的各种排名
-
对我的tweet和LinkedIn 帖子的回应
-
人们(朋友、陌生人、风险投资者)与我分享他们的列表
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
在筛选掉应用公司(例如,使用机器学习提供商业分析的公司)、不再积极开发的工具以及无人使用的工具后,我得到了 202 个工具。请查看完整列表。如果你觉得有我应该包含但尚未列出的工具,请告诉我!
免责声明
-
这个列表是在 2019 年 11 月制作的,市场在过去 6 个月里肯定发生了变化。
-
一些科技公司拥有一整套工具,大到我无法一一列举。例如,亚马逊网络服务提供了超过 165 个功能齐全的服务。
-
有许多隐形初创公司我并不知晓,还有许多在我听说之前就已经关闭了。
I. 概述
我认同的一种机器学习生产流程的概括包含 4 个步骤:
-
项目设置
-
数据管道
-
建模与训练
-
服务
我根据工具支持的工作流程步骤对其进行分类。我不包括项目设置,因为它需要项目管理工具,而不是机器学习工具。这并不总是很简单,因为一个工具可能有助于多个步骤。它们模糊的描述让情况更加复杂:“我们推动数据科学的极限”,“将人工智能项目转化为现实世界的商业成果”,“允许数据自由流动,就像你呼吸的空气一样”,以及我个人最喜欢的,“我们全身心投入数据科学。”
我将覆盖多个步骤的工具放入它们最著名的类别。如果它们被知名于多个类别,我会将它们放入一体化类别。我还包括基础设施类别,以涵盖提供训练和存储基础设施的公司。这些大多是云服务提供商。
II. 随时间推移的领域
我跟踪了每个工具推出的年份。如果是开源项目,我查看了第一次提交的时间,以了解项目何时开始公开。如果是公司,我查看了它在 Crunchbase 上的成立年份。然后我绘制了每个类别中工具数量随时间的变化图。
正如预期的那样,这些数据表明,直到 2012 年,该领域才开始爆炸性增长,对深度学习的兴趣得到了重新燃起。
AlexNet 之前(2012 年之前)
直到 2011 年,该领域主要由建模和训练工具主导,一些框架仍然非常流行(例如,scikit-learn)或对当前框架产生了影响(Theano)。一些在 2012 年前开始的机器学习工具并且一直持续到今天,要么已经上市(Cloudera、Datadog、Alteryx),要么被收购(Figure Eight),或者成为社区积极开发的流行开源项目(Spark、Flink、Kafka)。
开发阶段(2012-2015)
随着机器学习社区采用“让我们大量使用数据”的方法,机器学习领域变成了数据领域。当我们查看每年每个类别中启动的工具数量时,这一点尤为明显。在 2015 年,57%(82 个工具中的 47 个)是数据管道工具。
生产阶段(2016 年至今)
尽管追求纯研究很重要,但大多数公司负担不起,除非它能带来短期商业应用。随着机器学习研究、数据和现成模型变得更加可及,越来越多的人和组织希望找到应用,从而增加了帮助将机器学习投入生产的工具需求。
在 2016 年,谷歌宣布了其使用神经机器翻译来改进 Google 翻译,标志着深度学习在现实世界中的第一次重大应用。从那时起,许多工具被开发出来以促进机器学习应用的服务。
III. 该领域尚未成熟
尽管有许多 AI 初创公司,但其中大多数是应用程序初创公司(提供如业务分析或客户支持的应用程序),而不是工具初创公司(创建帮助其他公司构建自己应用程序的工具)。或用 VC 术语来说,大多数初创公司是垂直 AI。在2019 年《福布斯》50 家 AI 初创公司中,只有 7 家公司是工具公司。
应用程序更容易销售,因为你可以去公司并说:“我们可以自动化你们一半的客户支持工作。” 工具的销售时间更长,但可以产生更大的影响,因为你不是针对单一应用程序,而是针对生态系统的一部分。许多公司可以共存,提供相同的应用程序,但对于一个流程部分,通常只有少数几个工具可以共存。
经过广泛搜索,我只能找到大约 200 个 AI 工具,这与传统软件工程工具的数量相比显得微不足道。如果你想为传统的 Python 应用程序开发进行测试,你可以在 2 分钟内找到至少 20 个工具。如果你想为机器学习模型进行测试,则没有任何工具。
IV. 面临的 MLOps 问题
许多传统的软件工程工具可以用于开发和服务机器学习应用程序。然而,许多挑战是机器学习应用程序特有的,需要专门的工具。
在传统软件工程中,编码是难点,而在机器学习中,编码只是战斗的一小部分。开发一个可以在实际任务中提供显著性能改进的新模型是非常困难且成本高昂的。大多数公司不会专注于开发机器学习模型,而是会使用现成的模型,例如,“如果你需要,就用一个 BERT”。
对于机器学习,使用最多/最佳数据开发的应用程序获胜。大多数公司将专注于改进他们的数据,而不是改进深度学习算法。因为数据可以快速变化,机器学习应用程序需要更快的开发和部署周期。在许多情况下,你可能需要每晚部署一个新模型。
机器学习算法的规模也是一个问题。预训练的大型 BERT 模型具有 3.4 亿个参数,大小为 1.35GB。即使它可以适配于消费级设备(例如你的手机),BERT 在新样本上进行推理的时间也使它在许多实际应用中变得无用。例如,如果建议下一个字符的时间比你输入的时间还长,那么一个自动补全模型是无用的。
Git 通过逐行比较差异来进行版本控制,因此对大多数传统的软件工程程序来说效果很好。然而,它不适合对数据集或模型检查点进行版本控制。Pandas 对大多数传统的数据框操作效果良好,但在 GPU 上不起作用。
行基数据格式如 CSV 适用于使用较少数据的应用。然而,如果你的样本具有许多特征,而你只想使用其中的子集,使用行基数据格式仍需要加载所有特征。列式文件格式如 PARQUET 和 OCR 对此用例进行了优化。
面临的机器学习应用开发的一些问题:
-
监控:如何知道数据分布发生了变化,需要重新训练模型?例如: Dessa,由 Alex Krizhevsky(AlexNet 的支持者)支持,2020 年 2 月被 Square 收购。
-
数据标注:如何快速标注新数据或为新模型重新标注现有数据?例如: Snorkel。
-
CI/CD 测试:如何运行测试以确保每次更改后模型仍能按预期工作,因为你不能花费几天时间等待模型训练和收敛?例如: Argo。
-
部署:如何打包和部署新模型或替换现有模型?例如: OctoML。
-
模型压缩:如何压缩机器学习模型以适应消费者设备?例如:Xnor.ai,一家从艾伦研究所分拆出来专注于模型压缩的初创公司,在 2018 年 5 月融资 1460 万美元,估值 6200 万美元。2020 年 1 月,苹果以约 2 亿美元收购了它,并关闭了其网站。
-
推理优化:如何加速模型的推理时间?我们能否将操作融合在一起?我们可以使用更低的精度吗?使模型更小可能会加快其推理速度。示例: TensorRT。
-
边缘设备:旨在快速且廉价地运行机器学习算法的硬件。示例: Coral SOM。
-
隐私:如何使用用户数据来训练模型,同时保护其隐私?如何使你的过程符合 GDPR?例如: PySyft。
我绘制了按主要问题划分的工具数量。
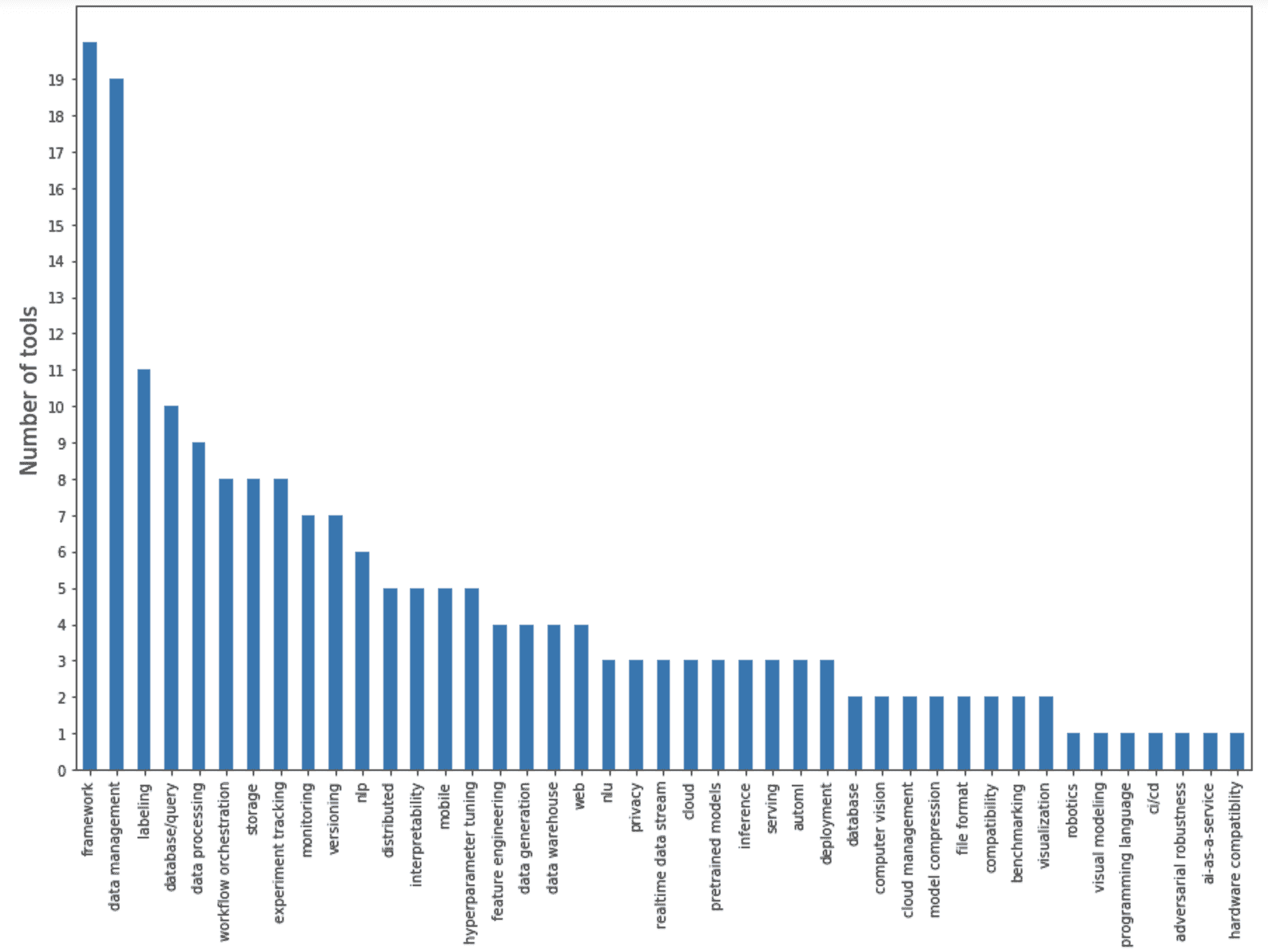
大部分关注于数据管道:数据管理、标注、数据库/查询、数据处理、数据生成。数据管道工具也可能旨在成为一体化平台。由于数据处理是项目中最耗费资源的阶段,一旦你让人们将数据放到你的平台上,就很诱人提供几个预构建/预训练的模型。
建模和训练工具大多是框架。深度学习框架的竞争主要在 PyTorch 和 TensorFlow 之间,以及为特定任务家族(如 NLP、NLU 和多模态问题)包装这两者的高级框架之间的竞争。还有用于分布式训练的框架。谷歌推出了一个新框架,每个讨厌 TensorFlow 的谷歌员工都在热烈讨论: JAX。
有独立的实验跟踪工具,流行框架也内置了实验跟踪功能。超参数调整很重要,发现几个专注于此的工具并不奇怪,但没有一个似乎引起关注,因为超参数调整的瓶颈不是设置,而是运行所需的计算能力。
最令人兴奋的问题尚待解决的是部署和服务领域。服务解决方案的缺乏有一个原因是研究人员和生产工程师之间缺乏沟通。在能够进行 AI 研究的公司(例如大型公司)中,研究团队与部署团队分开,两者之间仅通过 p-经理沟通:产品经理、项目经理、程序经理。小公司,员工可以看到整个技术栈,受限于即时的产品需求。只有少数初创公司,通常是由有成就的研究人员创办并拥有足够资金聘请优秀工程师的公司,成功弥合了这一差距。这些初创公司有望在 AI 工具市场中占据一大块份额。
V. 开源与开源核心
我查看的 202 个工具中有 109 个是开源的。即使是那些不是开源的工具,通常也会配有开源工具。
开源有几个原因。其中一个是所有支持开源的人多年来一直在谈论的理由:透明、协作、灵活,这似乎是道德的选择。客户可能不愿意使用一个无法查看其源代码的新工具。否则,如果这个工具被关闭——这在初创公司中很常见——他们将不得不重写他们的代码。
开源并不意味着非营利或免费。开源的维护是耗时且昂贵的。TensorFlow 团队的规模传闻接近 1000 人。公司不会在没有商业目标的情况下提供开源工具,例如,如果更多的人使用他们的开源工具,就会有更多的人了解他们,信任他们的技术专长,并可能购买他们的专有工具并希望加入他们的团队。
Google 可能希望普及他们的工具,以便人们使用他们的云服务。NVIDIA 维护 cuDF(以及之前的 dask),以便能销售更多的 GPU。Databricks 提供免费的 MLflow,但出售他们的数据分析平台。Netflix 最近刚刚成立了专门的机器学习团队,并发布了 Metaflow 框架,以便在 ML 地图上留下他们的名字以吸引人才。Explosion 提供免费的 SpaCy,但对 Prodigy 收费。HuggingFace 提供免费的 transformers,我不知道他们是如何盈利的。
由于开源软件(OSS)已成为标准,初创公司很难找到有效的商业模式。任何新成立的工具公司都必须与现有的开源工具竞争。如果你遵循开源核心商业模式,你必须决定哪些功能包含在 OSS 中,哪些功能包含在付费版本中,同时不显得贪婪,或者如何让免费用户开始付费。
VI. 结论
关于人工智能泡沫是否会破裂有很多讨论。大量的人工智能投资集中在自动驾驶汽车上,而完全自主的车辆距离成为商品还有很长的路要走,因此一些人假设投资者会对人工智能失去希望。谷歌已经冻结了机器学习研究员的招聘。优步裁掉了他们人工智能团队的一半研究人员。这些决定都是在 COVID 之前做出的。有传言称,由于大量人们正在参加机器学习课程,将会有更多具备机器学习技能的人,而机器学习岗位却没有相应增加。
现在还是进入机器学习领域的好时机吗?我相信人工智能的炒作是真实的,某个时点它必须会平静下来。这个时点可能已经发生了。然而,我不认为机器学习会消失。可能会有更少的公司能够负担机器学习研究,但需要工具将机器学习引入生产的公司将不会短缺。
如果你必须在工程和机器学习之间做出选择,选择工程吧。优秀的工程师更容易掌握机器学习知识,而机器学习专家要成为优秀的工程师则困难得多。如果你成为一个为机器学习构建出色工具的工程师,我将永远感激不尽。
致谢:感谢Andrey Kurenkov成为最慷慨的编辑。感谢Luke Metz成为出色的首位读者。
原文。经许可转载。
个人简介:Chip Huyen是一名作家和计算机科学家。她致力于将最佳工程实践应用于机器学习研究和生产。她写作涉及文化、人和技术。
相关:
更多相关话题
OLAP 是否已经过时?
在谷歌上,很容易找到关于 OLAP(在线分析处理)及其相关概念的信息,如多维分析和 OLAP 立方体。这是因为 OLAP 是一个知名且成熟的概念;但在这个高效分析的时代,它是否成了“过时的技术”甚至是过时的?这一问题似乎在许多人脑海中萦绕,因为搜索“OLAP is dead”会返回超过 200 万条结果(见图 1)。
图 1 搜索“OLAP is dead”在谷歌上
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
OLAP 是否真的过时了?
在云时代之前,当企业数据仓库(EDW)广泛采用时,OLAP 数据库是数据集市层中的强制组件,如 Oracle Essbase 和 Microsoft SSAS(SQL Server 分析服务)。但随着数据仓库迁移到云端,数据湖的崛起,OLAP 变得过时和不受欢迎;许多人甚至认为 OLAP 以及其他遗留方法,如提取、转换和加载(ETL)和数据建模,已经过时了。
新的、以云为中心的技术和方法将改变分析方式。没有采用新方法的企业将被淘汰。是时候适应创新的方法,例如:
-
多云架构:随着许多企业全球化,并在不同的云平台和不同地区构建产品和服务,数据被存储在许多地方,而不是集中在单一的数据库或数据仓库中。数据管理理念侧重于连接,而非收集。(见图 2)
-
云原生架构:为了适应云计算的采用,软件行业专注于构建云原生产品,以使软件用户能够充分利用云的无限资源,灵活和弹性地管理这些资源,并在 IT 基础设施上享受较低的总体拥有成本(TCO)。
-
现代数据栈:随着现代数据栈的兴起,企业在数据管理和分析方面有了更多选择。许多即插即用的云数据湖或数据仓库服务在云中提供,帮助各种组织最大化其数据的价值,以实现多种目的。
图 2 从收集到连接的数据
鉴于这些趋势和技术的炒作及其发展的速度,用户可能会认为数据分析平台上只需一个数据仓库和数据湖即可。他们也可能会认为 OLAP 是完全可选的。但这是真的吗?让我们仔细看看。
公民分析越来越普遍
直到不久前,数据消费者主要集中在管理层。然而,如今,像店长或市场营销人员这样的第一线办公室工作人员在日常工作中严重依赖数据。他们是公民分析师,随处可见。例如,在疫情期间,许多保险公司发布了基于从 COVID-19 数据集中得出的见解和分析的安全和便利产品。如果没有这些数据,产品经理可能会急于推出不必要或设计不佳的新产品,导致损失。
随着许多组织采用数字化转型,每个业务现在都是数据消费者,寻求利用数据获得新见解、做出更好的决策,并更具竞争力地运营。
满足公民分析师的需求意味着提供能够实现公民分析所需的使用和性能期望,包括:
-
更快的数据洞察时间:时间是关键。业务用户需要快速周转,以确保从新见解中获得最大价值,并通过利用数据工程团队提供的数据洞察市场趋势来获得竞争优势。
-
易于使用的自助服务界面:SQL 是使用数据的最佳语言之一,但由于其以表格和列的形式呈现,仍然不够用户友好。公民分析师希望能够使用简单的工具来使用数据,而无需工程学位。
-
单一真实来源:公民分析师的一个主要痛点是经常很难找到正确的数据。销售指标可能存在于 CRM 仪表板和财务应用中,且数据可能以不同格式存在。公民分析师需要一个单一的真实来源,一个充满可信数据的指标存储使得这一点变得简单。
从内部分析到互联网服务
据说,在数字时代,每个产品都是数据产品。这是因为 B2B 公司不仅销售其技术,还基于这些产品生成和收集的数据构建新产品和服务。这些数据不仅用于内部分析,还用于互联网服务。基于数据湖或数据仓库构建数据产品和数据服务是最大化数据价值并为业务创造新收入来源的一步。
例如,AppZen公司通过使用人工智能和自动化来简化诸如费用审批、发票处理、欺诈检测等常见流程,支持企业财务团队。但该公司还有一款名为Mastermind Analytics的数据产品,提供见解以帮助财务审计员减少开支、遵守政策并简化流程。
Mastermind Analytics 在其旗舰产品生成的数据上运作。AppZen 和 Mastermind Analytics 之间的协同展示了一个产品生成的数据如何成为数据即服务(Data-as-a-Service),并为创新和全新产品提供基础。
技术负债持续增长
通过认识到数据是如何生成、分析和被企业消费的,并了解提供新见解和创新的紧迫性,可以很容易看出技术负债的问题可能会继续增长。当产品开发的速度被优先于编写优质代码时,开发周期可能会超出完成必要修订的能力。避免这种情况是我们主张 OLAP 不仅没有死,而且应成为任何数据平台的重要组成部分。
平面表格和 ETL 作业的负债
构建数据分析数据管道的最常见方式是生成平面表格。然而,过度使用这种方法会导致平面表格的激增。例如,中国的一家互联网公司在其数据湖中拥有超过 5,700 个源表,但经过长时间的数据分析使用后,这个数字膨胀到近一百万个平面表格和汇总表,迫使数据团队积极管理和治理这些过剩的表格。他们不仅面临数据质量和一致性的管理挑战,还要控制由于数据激增而产生的不断增长的运营成本。更糟糕的是,每个平面表格至少由一个 ETL 作业生成,脚本需要额外的维护工作,并且需要额外的计算资源来运行。
图 3 平面表格爆炸
每个源表需要投入多少计算和存储资源?每个平面表格需要多少使用?这些很难确定,因此成本不仅高而且不可预测。一旦生成了平面表格,其他人很难重复使用它,因为处理逻辑不容易理解。问题因生命周期管理不善而加剧。因此,平面表格和 ETL 作业成为了技术负债。
商业智能仪表板的负债
商业智能(BI)仪表盘被视为数据工程师和分析师向业务用户交付的必要成果。即使在较小的组织中,也常常可以看到许多 BI 仪表盘和报告。数据的核心价值在于仪表盘生成的指标,但过多的仪表盘可能会导致混淆和成本增加。使用较少的仪表盘来维持一致的用户体验、更低的成本,同时为组织中的用户提供必要的工具,更为高效。
一家中国金融服务公司构建了一个指标存储库,以维护近 10,000 个指标,同时减少数据工程师和分析师策划和生成的仪表盘数量。这不仅节省了成本,并使用户和数据团队更容易处理,但 BI 仪表盘的激增将导致数据孤岛和业务不一致,对流程和结果产生不利影响。再次强调,这种影响会导致更多的技术债务。
解决方案?将 OLAP 带入云端
这就是 OLAP 可以支持更高的流程效率并驱动更一致结果的原因。这是因为 OLAP 是一种处理涉及多个维度的分析查询的方法。利用多维数据建模(MDM)的核心概念,OLAP 使得从不同角度“切片和切块”数据成为可能,从而提供流畅的查询体验。
以 Apache Kylin 为例,它作为云原生架构演变而来,并被定位为数据湖上的 OLAP。一旦数据存储在云中,如 Amazon S3 或 Azure Data Lake Storage,它就支持业务用户的自助分析。
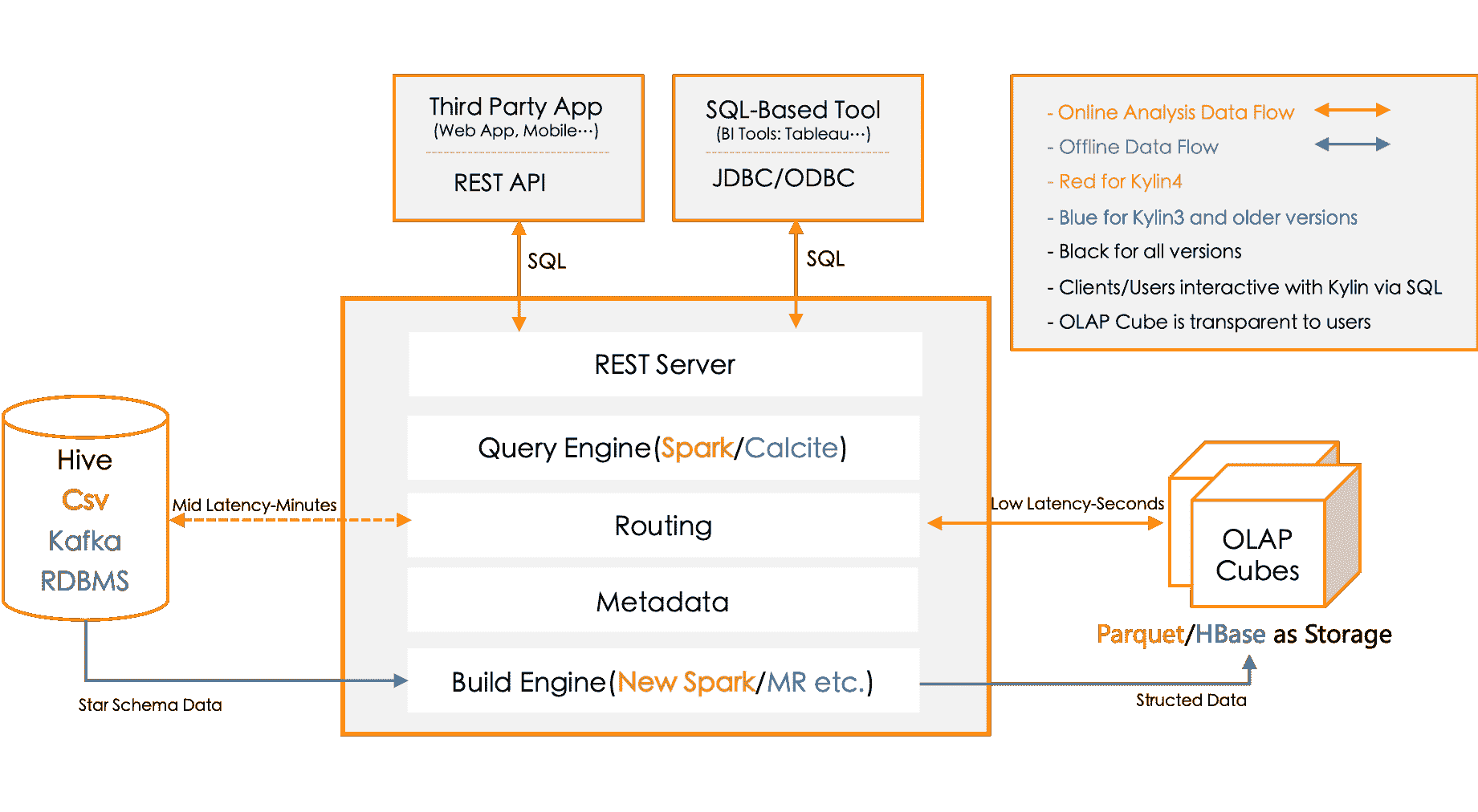
图 4 Apache Kylin 架构
下面是 Apache Kylin 的一些关键特性,使得在云端进行更高效的自助数据分析成为可能:
-
多维数据建模:这是 Apache Kylin 的核心概念。它通过将表连接到星型或雪花模式中,并定义数据模型的维度和度量来设计。这为用户提供了一个更易于访问和分析数据的界面,并以业务用户更容易理解的格式提供数据。
-
预计算:通过将源数据预计算为数据立方体,可以在多种场景下优化查询性能和并发性。尤其是在云计算时代,存储比计算和网络资源便宜得多。因此,预计算有助于使流程更高效,节省成本。
-
查询下推:通过查询下推,Apache Kylin 可以将一些查询路由到数据源或其他 SQL 引擎。因此,即使源数据位于不同的位置,MDM(多维数据模型)也可以在一个地方创建,并以统一的视图连接源数据。
-
云原生架构:使用 Apache Spark 进行计算,Apache Kylin 可以轻松部署在云中并与云数据湖集成。弹性扩展意味着集群可以根据工作负载要求按需扩展。
随着 OLAP 在云环境中的演变,其他常见挑战也可以得到解决,包括:
使用治理的数据集市来减少平面表
一旦创建了多维数据模型并完成预计算,端到端的数据管道就完成了,业务用户可以开始将数据投入实际应用。无需创建和管理 ETL 或平面表进行数据聚合。预计算结果将使用更少的存储资源,是平面表的更好替代方案,并且将在数据模型的管理下进行治理。预计算结果可以根据查询模式灵活管理,从而减少通常由平面表产生的技术债务。
作为公民分析的指标存储
所有业务指标存储在 MDM 中,用户可以轻松在数据模型中找到指标,而无需在不同的仪表板中搜索指标;业务用户可以使用他们喜欢的任何工具来访问这些指标。例如,财务团队或运营团队可以使用 Excel 访问数据模型中定义的指标,因此他们无需学习任何新技术。这减少了由过多 BI 仪表板产生的技术债务。
启用数据即服务
通过统一的查询接口和底层引擎,OLAP 使数据即服务(DaaS)能够让企业通过标准 API 公开处理过的多源数据服务。OLAP 作为服务层,同时提供标准功能,如数据访问控制、加密和混淆。最重要的是,高性能和高并发是实现这一目标的关键。最后,OLAP 可以扩展以适应未来的发展,并部署在私有、公有和混合云上,以适应各种企业 IT 架构。
总结
OLAP 远未过时。即使在云时代,它仍然具有相关性,以多维结构存储数据,提供语义定义,并在数据湖的分析和管理中发挥重要作用。此外,OLAP 使普通分析师能够快速、高效且经济地发现新的商业洞察,缩短了时间价值。
参考资料
-
每个产品都将成为数据产品:
medium.com/kyligence/every-product-will-be-a-data-product-19e648f0333 -
AppZen 推出 Mastermind Analytics,提供 AI 驱动的按需财务基准:
www.appzen.com/newsroom/appzen-launches-mastermind-analytics-to-deliver-ai-powered-on-demand-finance-benchmarking -
BI 仪表板正在创造技术债务黑洞:
medium.com/@LoriLu/bi-dashboards-are-creating-a-technical-debt-black-hole-31be41ee96f -
OLAP 死亡的消息被极大夸大了: https://kyligence.io/blog/news-of-the-death-of-olap-has-been-greatly-exaggerated/
董立 是 Kyligence 的创始成员和增长副总裁,Apache Kylin 核心开发者(Committer)及项目管理委员会(PMC)成员,他专注于大数据技术开发。此前,他曾在 eBay 全球分析基础设施部门担任高级工程师,担任微软云计算和企业产品的软件开发工程师,并是微软业务产品动态亚洲太平洋团队的核心成员,参与了新一代云端 ERP 解决方案的开发。
更多相关话题
2019 年人体姿态估计指南
原文:
www.kdnuggets.com/2019/08/2019-guide-human-pose-estimation.html
评论
照片由David Hofmann拍摄,来源于Unsplash
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
人体姿态估计指的是在图像中推断姿态的过程。本质上,它涉及预测图像或视频中人物关节的位置。这个问题有时也被称为人体关节的定位。值得注意的是,姿态估计还有各种子任务,如单一姿态估计、多人图像中的姿态估计、拥挤场所中的姿态估计以及视频中的姿态估计。
姿态估计可以在 3D 或 2D 中进行。人体姿态估计的一些应用包括:
在我们将要重点介绍的论文中使用的一些方法包括自下而上和自上而下。本质上,自下而上的方法是从高分辨率到低分辨率处理,而自上而下的方法则是从低分辨率到高分辨率处理。
自上而下的方法首先使用边界框物体检测器来识别和定位单个人体实例。接下来估计单个人的姿态。自下而上的方法则从定位不带身份的语义实体开始,然后将其分组为人体实例。
我们将现在查看一些为解决人体姿态估计问题而进行的研究:
DeepPose:通过深度神经网络进行的人体姿态估计(CVPR, 2014)
本文建议使用深度神经网络(DNNs)来解决这一机器学习任务。本文的作者是来自谷歌的亚历山大·托舍夫(Alexander Toshev)和克里斯蒂安·施泽迪(Christian Szegedy)。姿态估计的公式化本身是对关节进行基于 DNN 的回归。作者在标准基准测试集,如 MPII、LSP 和 FLIC 数据集上实现了最先进的结果。他们还分析了联合训练具有重复中间监督的多阶段架构的效果。
我们提出了一种基于深度神经网络(DNNs)的人体姿态估计方法。姿态估计被公式化为…
DNN 能够捕捉所有关节的内容,并且不需要使用图形模型。如下面所示,网络由七层组成。这些层包括一个池化层、一个卷积层和一个全连接层。
卷积层和全连接层是唯一具有可学习参数的层。它们都包含线性变换,后跟一个修正线性单元。网络输入图像的大小为 220 × 220,学习率设置为 0.0005。全连接层的 dropout 正则化设置为 0.6。该模型使用的一些数据集包括电影标记帧 (FLIC)和利兹体育数据集。
下图展示了模型在正确部件百分比 (PCP) 评估指标上的表现。

高效目标定位使用卷积网络 (2015)
这篇论文提出了一种 ConvNet 架构,用于预测单目 RGB 图像中的人体关节位置。本文作者来自纽约大学。该模型允许增加池化操作,从而提高计算效率。
最近,在人体姿态估计方面取得了深度卷积网络的最先进性能…
网络首先执行身体部位定位,并输出低分辨率的逐像素热图。该热图显示了关节在图像中每个空间位置出现的概率。
论文还介绍了一个网络,该网络利用热图回归模型中的隐藏层特征以提高定位准确性。该模型使用多分辨率 ConvNet 架构,并实现了具有重叠上下文的滑动窗口检测器,以生成粗略的热图输出。滑动窗口通常是一个具有固定高度和宽度的矩形框。框在图像上滑动。当框滑动时,分类器尝试识别该区域是否存在对当前任务感兴趣的物体。
下图展示了本文提出的完整模型架构。该架构使用 Torch7 实现,并通过 FLIC 和 MPII-Human-Pose 数据集进行评估。
通过在 FLIC 数据集上使用标准 PCK(关键点正确百分比)度量以及在 MPII 数据集上使用 PCKh 度量来评估模型的性能。
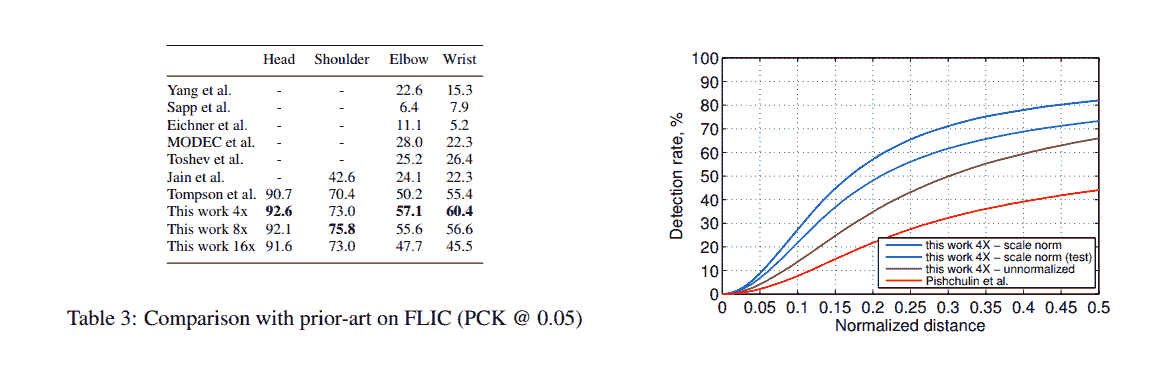
迭代误差反馈的人体姿态估计(2016)
这篇论文提出了一个框架,扩展了层级特征提取器的表达能力,包括输入和输出空间。它通过引入自上而下的反馈来实现这一点。本文的作者来自加州大学伯克利分校。
输出不是一次性预测的;而是使用一个自我修正的模型来反馈误差预测。作者称这个过程为迭代误差反馈(IEF)。该模型在挑战性的 MPII 和 LSP 基准测试中对关节姿态估计任务产生了出色的结果。
层级特征提取器,如卷积网络(ConvNets),在...
下图展示了用于 2D 人体姿态估计的迭代误差反馈(IEF)实现。左侧面板显示了输入图像 I 和关键点的初步猜测 Y0。这里的三个关键点分别对应右腕(绿色)、左腕(蓝色)和头顶(红色)。该架构中的函数 f 被建模为卷积神经网络。函数 g 将每个 2D 关键点位置转换为一个高斯热图通道。
这个模型可以通过这个数学方程进行可视化。
下表显示了该模型的性能。
堆叠小时玻璃网络用于人体姿态估计(2016)
这篇论文认为,反复的自下而上和自上而下的处理加上中间监督可以提高所提出网络的性能。该网络被称为“堆叠小时玻璃”,因为为了生成最终预测,进行了一系列的下采样和上采样处理。本文的作者来自密歇根大学。
这项工作介绍了一种新型的卷积网络架构,用于人体姿态估计任务。特征...
网络在 FLIC 和 MPII 人体姿态基准上进行了测试。它在 MPII 上所有关节的平均准确度提高了 2%以上,在困难的关节如踝关节和膝关节上提高了 4-5%。

沙漏架构旨在捕捉每个尺度上的信息。网络输出像素级的预测。网络设置包括卷积层和用于特征处理的最大池化层。网络输出热图,预测每个像素级别上特定关节的出现。

下图显示了模型在各种身体部位上的表现。
卷积姿态机器(2016)
本文介绍了用于细致姿态估计的卷积姿态机器(CPMs)。CPMs 由一系列卷积网络组成,这些网络生成每个部位位置的 2D 信念图。本文来自卡内基梅隆大学机器人研究所。
姿态机器提供了一个顺序预测框架,用于学习丰富的隐式空间模型。在这项工作中我们展示了…
在 CPM 的每个阶段,前一阶段生成的图像特征和信念图用作输入。

网络通过卷积架构的顺序组合来学习隐式空间模型。它还引入了一种系统的方法来设计和训练这样的架构,以便学习图像特征和图像依赖的空间模型用于结构化预测任务。这不需要使用任何图形模型风格的推断。
网络在 MPII、LSP 和 FLIC 数据集上进行了测试。
模型的 PCKh-0.5 得分达到了 87.95%的前沿结果,而踝部的 PCKh0.5 得分为 78.28%。它已经使用 Caffe 实现,并且代码已开源。
DeepCut: 关节子集划分与标注用于多人人体姿态估计(CVPR 2016)
本文提出了一种用于检测多人人体姿态的方法。该模型通过检测图像中的人数,然后预测每个图像的关节位置。本文由马克斯·普朗克研究所和斯坦福大学联合完成。
本文考虑了对现实世界图像中多个人体姿态进行细致估计的任务。我们提出了…

为了获得强大的部位检测器,作者调整了 FastRCN 以适应这个任务。他们在两个方面进行了修改:提议生成和检测区域大小。该模型在预测各种身体部位方面的性能如下图所示。

由于使用身体部位检测的提议可能效果不佳,作者使用了一个步幅为 32 像素的全卷积 VGG,并将步幅减少到 8 像素。他们将图像输入缩放到 340 像素的站立高度,这样可以获得最佳效果。
对于损失函数,他们首先尝试了输出不同身体部位概率的 softmax。后来,他们在输出神经元上实现了 sigmoid 激活函数和交叉熵损失。最终,他们发现 sigmoid 激活函数比 softmax 损失函数获得了更好的结果。该模型在 Leeds Sports Poses (LSP)、LSP Extended (LSPET)和 MPII Human Pose 上进行了训练和评估。
《用于人体姿态估计和跟踪的简单基线》(EECV, 2018)
这篇论文的姿态估计解决方案基于在ResNet上添加的反卷积层。该模型在 COCO 测试开发集上达到了 73.7 的 mAP。其姿态跟踪模型达到了 74.6 的 mAP 评分和 57.8 的 MOTA(多目标跟踪准确率)评分。本文的作者来自微软亚洲研究院和电子科技大学。
最近几年在姿态估计方面取得了显著进展,并且对姿态跟踪的兴趣不断增加。 在…
该网络使用的方法在 ResNet 架构的最后卷积阶段上添加了几个反卷积层。这种结构使得从深度和低分辨率图像生成热图变得非常容易。默认使用三个带有批量归一化和 ReLU 激活的反卷积层。
下图展示了姿态跟踪框架的提议流程。视频中的姿态跟踪首先通过估计人体姿态来进行,为其分配一个唯一标识符,然后在各帧之间跟踪该标识符。
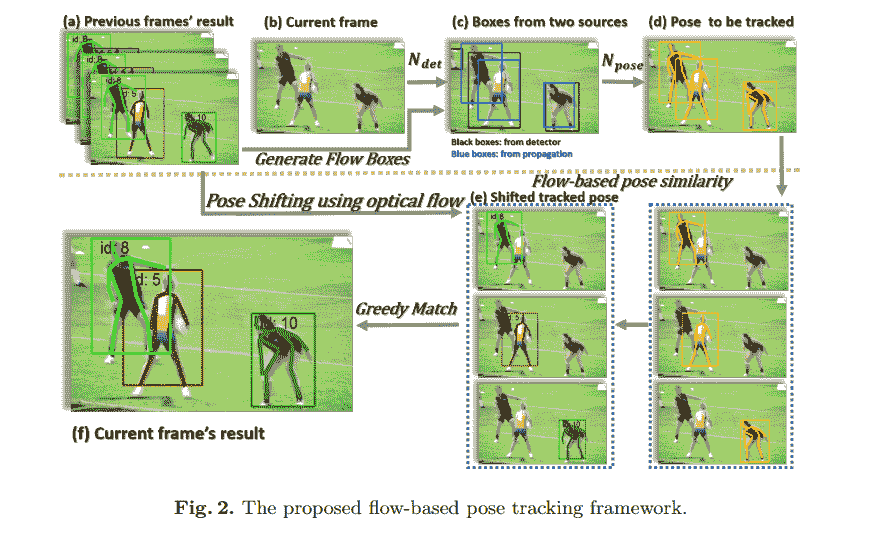
以下是该模型与其他模型的比较。

RMPE: 区域多人物体姿态估计(2018)
本文提出了一个区域多人物体姿态估计(RMPE)框架,用于在不准确的人体边界框中进行估计。该框架包含三个组件:对称空间变换网络(SSTN)、参数化姿态非极大值抑制(NMS)和姿态引导提议生成器(PGPG)。该框架在 MPII(多人物体)数据集上实现了 76.7 的 mAP。本文的作者来自中国上海交通大学和腾讯优图。
在实际环境中的多人物体姿态估计具有挑战性。尽管最先进的人类检测器已证明…
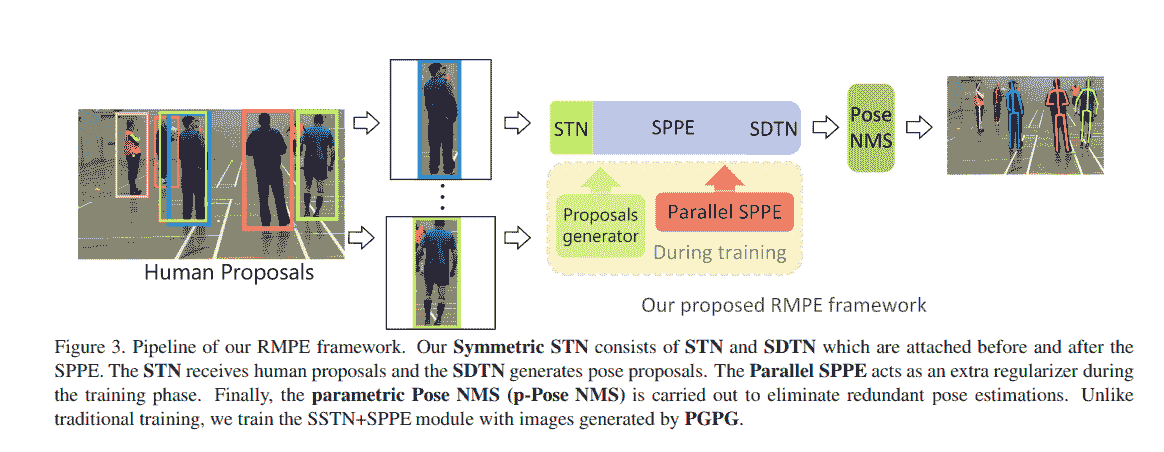
在该框架中,人类检测器获得的边界框被输入到“对称 STN + SPPE”模块。然后自动生成姿态提议。这些姿态通过参数化姿态 NMS 进行微调,以获得估计的人体姿态。在训练中,引入了“并行 SPPE”以避免局部最小值。
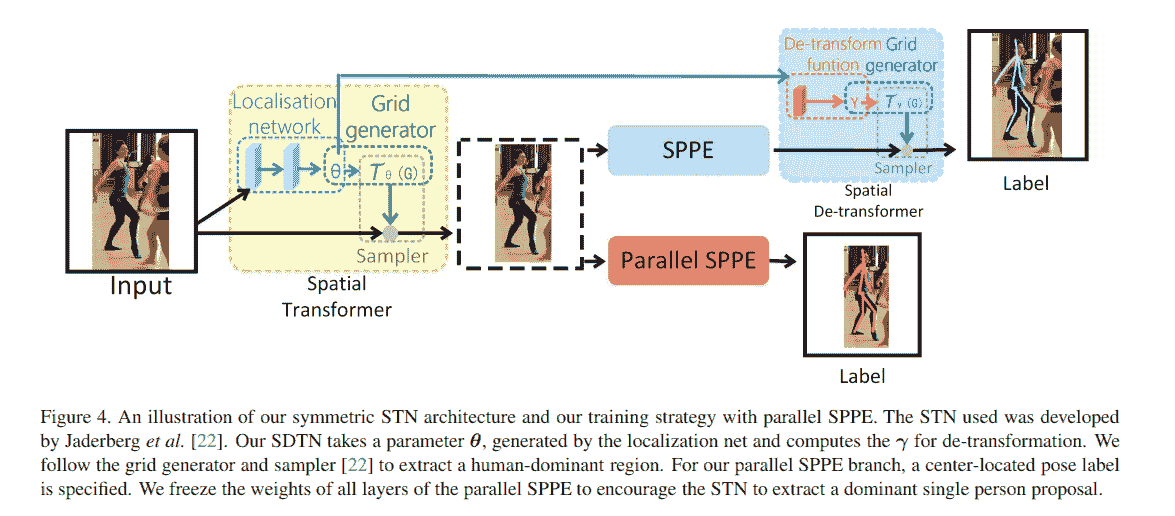
下面的图展示了模型与其他框架的性能比较,以及一些通过它获得的姿态预测。
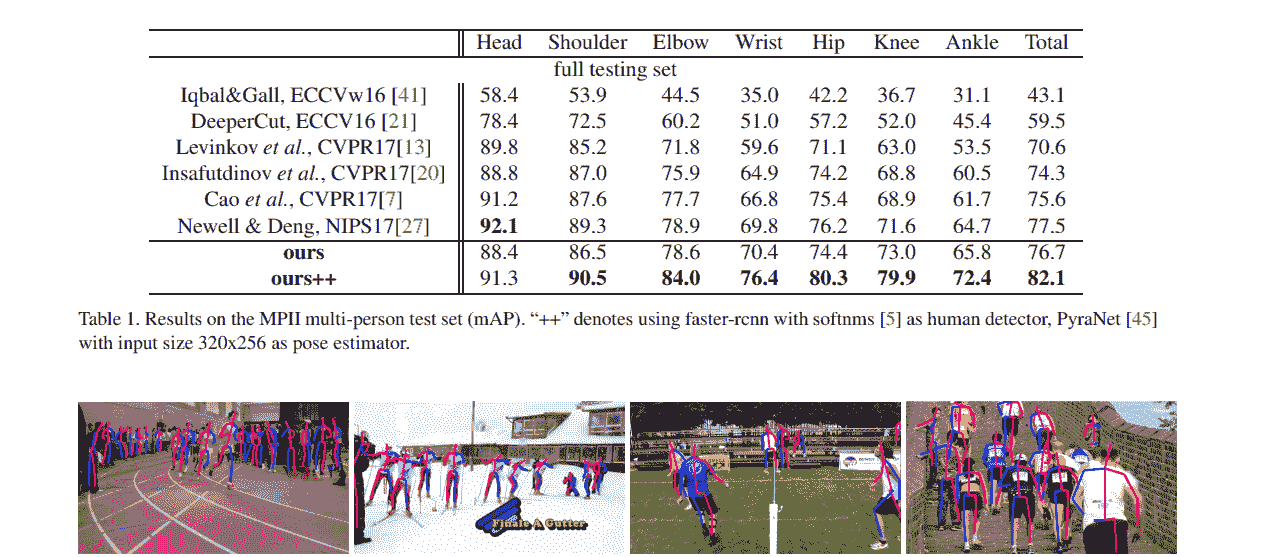
OpenPose: 实时多人物体 2D 姿态估计使用部位关联字段(2019)
OpenPose 是一个开源的实时多人物体 2D 姿态检测系统,包括身体、脚、手和面部关键点。本文提出了一种实时检测图像和视频中 2D 人体姿态的方法。该方法使用了称为部位关联字段(PAFs)的非参数表示。本文的一些作者来自 IEEE。
OpenPose: 实时多人物体 2D 姿态估计使用部位关联字段
实时多人物体 2D 姿态估计是让机器理解人类的关键组成部分…

如下所示,该方法以图像作为 CNN 的输入,并预测用于检测身体部位的置信度图和用于部位关联的 PAFs。本文还展示了一个注释脚数据集,包含 15K 个人脚实例。该数据集已公开发布。
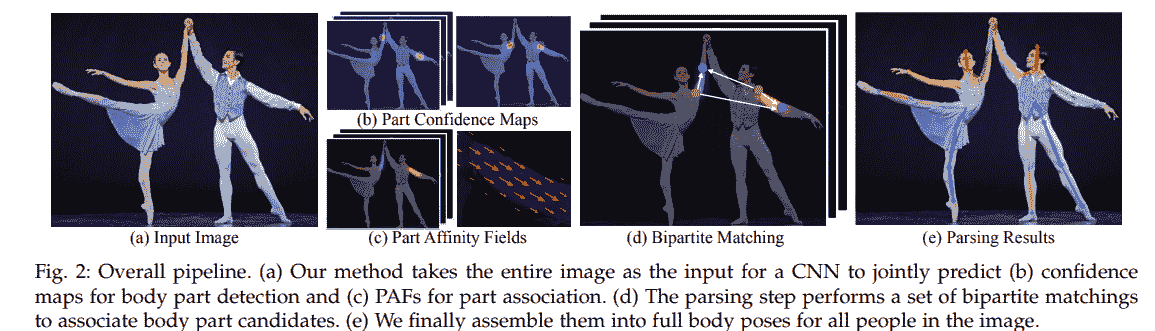
网络架构迭代地预测编码部位间关联(以蓝色显示)和检测置信度图(以米色显示)的关联字段。
OpenPose 也是一个周边软件和 API,能够从各种来源中获取图像。例如,可以选择输入为相机视频、网络摄像头、视频或图像。它运行在不同的平台上,如 Ubuntu、Windows、Mac OS X 和嵌入式系统(例如,Nvidia Tegra TX2)。它还支持不同的硬件,如 CUDA GPU、OpenCL GPU 和仅 CPU 的设备。
OpenPose 包含三个模块:身体+脚检测、手部检测和面部检测。它已在 MPII 人体多人物数据集、COCO 关键点挑战数据集以及论文提出的脚数据集上进行了评估。下图展示了 OpenPose 与其他模型的比较结果。
现实世界拥挤场景的人体姿态估计 (AVSS, 2019)
本文提出了用于估计人群姿态的多种方法。在这些密集人群区域中估计姿态的挑战包括人员彼此接近、相互遮挡以及部分可见性。本文作者来自弗劳恩霍夫光电研究所和卡尔斯鲁厄理工学院 KIT。
人体姿态估计最近在采用深度卷积神经网络方面取得了显著进展…

用于优化拥挤图像的姿态估计的方法之一是使用 ResNet50 网络作为骨干的单人姿态估计器。该方法是一种两阶段的自上而下的方法,首先定位每个人,然后对每个预测进行单人姿态估计。
论文还介绍了两个遮挡检测网络;Occlusion Net 和 Occlusion Net Cross Branch。Occlusion Net 在两个转置卷积后进行拆分,以便在之前的层中学习联合表示。Occlusion Net Cross Branch 在一个转置卷积后进行拆分。遮挡检测网络输出每个姿态两个热图集。一个热图用于可见关键点,另一个用于遮挡关键点。
下表展示了该模型与其他模型的性能比较。
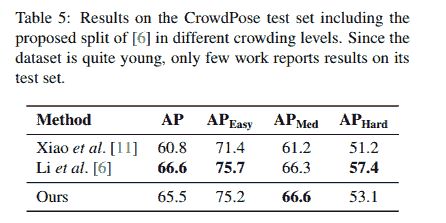
DensePose: Dense Human Pose Estimation In The Wild (2018)
这是一篇来自 INRIA-CentraleSupelec 和 Facebook AI Research 的论文,其目标是将 RGB 图像的所有人体像素映射到人体的 3D 表面。论文还介绍了一个 DensePose-COCO 数据集。该数据集包含 50000 张经过人工注释的 COCO 图像的图像与表面对应关系。作者随后使用该数据集训练基于 CNN 的系统,以在背景、遮挡和尺度变化的情况下提供密集的对应关系。对应关系基本上表示了一个图像中的图像如何与另一个图像中的像素对应。

DensePose: Dense Human Pose Estimation In The Wild
在这项工作中,我们建立了 RGB 图像与基于表面的人的表示之间的密集对应关系……
在这个模型中,单张 RGB 图像被作为输入,用于建立表面点和图像像素之间的对应关系。

该模型的这种方法是通过与 Mask-RCNN 系统结合建立的。该模型在 GTX 1080 GPU 上对 240 × 320 图像的运行速度为 20–26 帧每秒,对 240 × 320 图像的运行速度为 4–5 帧每秒。

作者将 Dense Regression(DenseReg)系统与 Mask-RCNN 架构相结合,提出了 DensePose-RCNN 系统。
该模型使用一个全卷积网络,专门用于生成分类和回归头,以进行分配和坐标预测。作者使用了 MaskRCNN 关键点分支中使用的相同架构。它由 8 层交替的 3×3 全卷积层和 ReLU 层堆叠而成,具有 512 个通道。
作者在一个包含 2300 个人的 1500 张图像的测试集上进行了实验,并在一个包含 48000 人训练集上进行了实验。下图展示了其与其他方法的性能比较。

PersonLab: 基于自下而上的部分模型进行姿态估计和实例分割(2018)
这篇论文的作者来自 Google。他们提出了一种无框的自下而上的姿态估计和实例分割方法,适用于多人的图像。

这意味着作者首先检测身体部位,然后将这些部位归类为人类实例。该方法在 COCO 测试集上的关键点平均精度为 0.665(单尺度推理)和 0.687(多尺度推理)。
PersonLab: 基于自下而上的部分基础几何模型的人物姿态估计与实例分割
我们提出了一种无框的自下而上的方法,用于姿态估计和实例分割任务。
本文提出的模型是一个无框的完全卷积系统,该系统首先预测图像中每个人的所有关键点。该模型在 COCO 关键点数据集上进行训练。
在关键点检测阶段,该模型检测图像中可见的关键点。PersonLab 系统在标准 COCO 关键点任务以及仅针对人员类别的 COCO 实例分割任务上进行了评估。
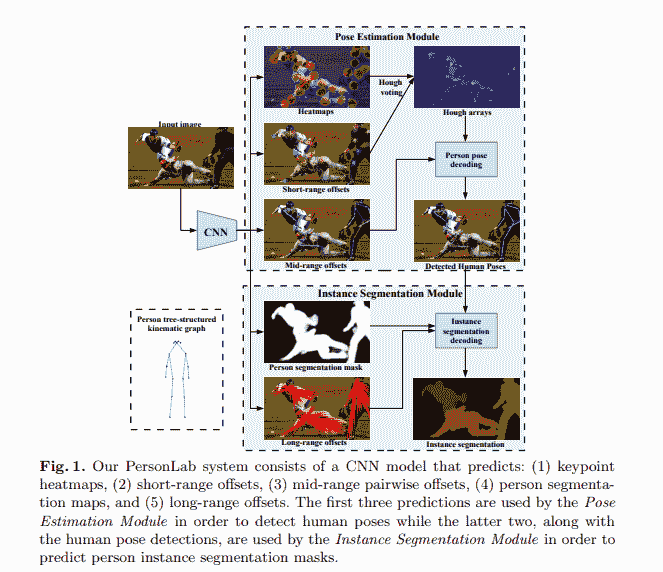
下图展示了其在 COCO 关键点测试集上的表现。
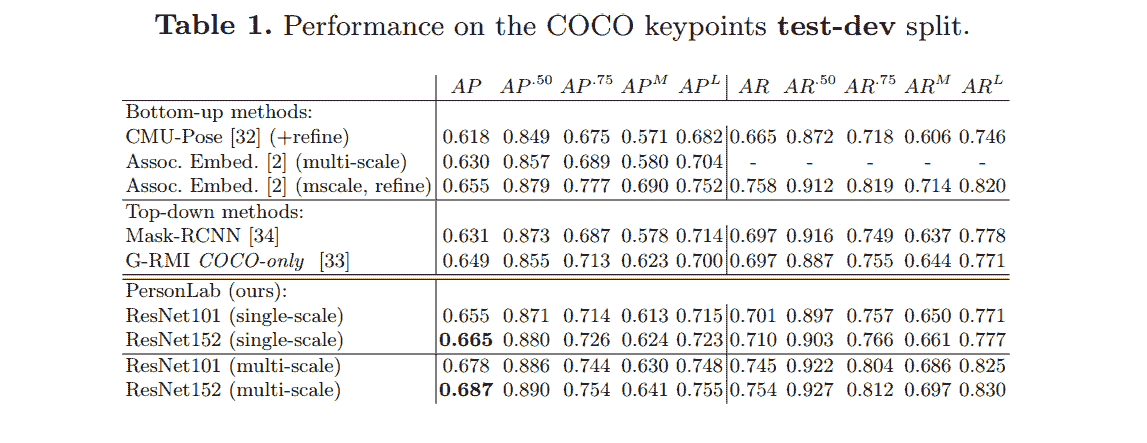
结论
我们现在应该对一些最常见的——以及一些非常新的——人类姿态估计技术有了了解,这些技术适用于各种情境。
上述提到并链接到的论文/摘要也包含了其代码实现的链接。我们很乐意看到你在测试后获得的结果。
个人简介: Derrick Mwiti 是一名数据分析师、作家和导师。他致力于在每项任务中取得优异成果,并且是 Lapid Leaders Africa 的导师。
原文。转载已获许可。
相关:
-
2019 年语义分割指南
-
2019 年目标检测指南
-
使用 Luminoth 进行目标检测
更多相关主题
2019 年目标检测指南
原文:
www.kdnuggets.com/2019/08/2019-guide-object-detection.html
评论
由 Fernando @cferdo 提供的照片,来源于 Unsplash
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
目标检测是一种 计算机视觉 技术,其目标是检测如汽车、建筑物和人类等对象,仅举几例。这些对象通常可以从 图片或视频流中识别出来。
目标检测 已广泛应用于视频监控、自动驾驶汽车以及对象/人群追踪。在这篇文章中,我们将探讨目标检测的基础知识,并回顾一些常用的算法以及一些全新的方法。
目标检测如何工作
目标检测定位图像中的对象,并围绕该对象绘制边界框。这通常包括两个过程:首先分类对象的类型,然后围绕对象绘制一个框。我们之前已经 介绍过图像分类,现在让我们回顾一些用于目标检测的常见模型架构:
R-CNN 模型
该技术结合了两种主要方法:对自底向上的区域提议应用高容量卷积神经网络以定位和分割对象;以及对辅助任务的监督预训练。
在经典的 PASCAL VOC 数据集上测量的目标检测性能在过去几年已趋于平稳。...
接着进行领域特定的微调,以获得显著的性能提升。本文作者将算法命名为 R-CNN(具有 CNN 特征的区域),因为它将区域提议与卷积神经网络结合起来。
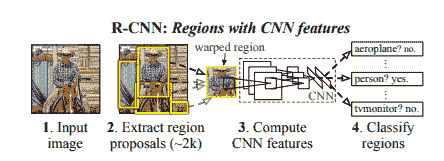
这个模型接收一张图像,并提取大约 2000 个自底向上的区域提议。然后,它使用大型 CNN 计算每个提议的特征。之后,它使用特定类别的线性支持向量机(SVMs)对每个区域进行分类。这个模型在PASCAL VOC 2010上实现了 53.7%的平均精度。
该模型的目标检测系统有三个模块。第一个模块负责生成类别无关的区域提议,定义模型检测器可用的候选检测器集合。第二个模块是一个大型卷积神经网络,负责从每个区域提取固定长度的特征向量。第三个模块由一类支持向量机组成。

该模型使用选择性搜索生成区域类别。选择性搜索根据颜色、纹理、形状和大小对相似的区域进行分组。对于特征提取,模型通过在每个区域提议上应用 Caffe CNN 实现,使用 4096 维特征向量。通过五个卷积层和两个全连接层前向传播一个 227 × 227 的 RGB 图像来计算特征。本文中解释的模型在 PASCAL VOC 2012 上的相对改进达到 30%。
R-CNN 的一些缺点包括:
-
训练是一个多阶段管道。 调整卷积神经网络以适应目标提议,将 SVMs 拟合到 ConvNet 特征,最后学习边界框回归器。
-
训练在空间和时间上都很昂贵,因为像 VGG16 这样的深度网络占用大量空间。
-
目标检测很慢,因为它对每个对象提议执行一次 ConvNet 前向传递。
Fast R-CNN
本文提出了一种用于目标检测的快速区域卷积网络方法(Fast R-CNN)。
本文提出了一种用于目标检测的快速区域卷积网络方法(Fast R-CNN)。Fast R-CNN...
它用 Python 和 C++ 的 Caffe 实现。该模型在 PASCAL VOC 2012 上的平均精度为 66%,而 R-CNN 为 62%。
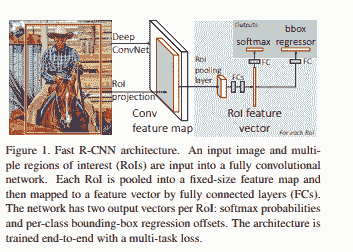
与 R-CNN 相比,Fast R-CNN 具有更高的平均精度、单阶段训练、更新所有网络层的训练,并且不需要磁盘存储来进行特征缓存。
在其架构中,Fast R-CNN 以图像以及一组对象提议作为输入。然后,它通过卷积和最大池化层处理图像,以生成卷积特征图。然后,通过每个区域提议的兴趣区域池化层从每个特征图中提取固定层特征向量。
特征向量随后被输入到全连接层。这些层分支成两个输出层。其中一个层产生对多个对象类别的 softmax 概率估计,而另一个层为每个对象类别生成四个实值数字。这四个数字表示每个对象的边界框位置。
Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
先进的目标检测网络依赖区域提议算法来假设对象位置...
本文提出了一种训练机制,该机制交替进行区域提议任务的微调和目标检测的微调。
Faster R-CNN 模型由两个模块组成:一个负责提议区域的深度卷积网络和一个使用这些区域的 Fast R-CNN 检测器。区域提议网络以图像作为输入,并生成矩形对象提议的输出。每个矩形都有一个对象性得分。
Mask R-CNN
我们提出了一个概念上简单、灵活且通用的对象实例分割框架。我们的方法...
本文提出的模型是上述 Faster R-CNN 架构的扩展。它还允许估计人体姿态。
在这个模型中,物体通过边界框和语义分割进行分类和定位,语义分割将每个像素分类到一组类别中。该模型通过在每个兴趣区域上添加分割掩码的预测来扩展 Faster R-CNN。Mask R-CNN 产生两个输出:类别标签和边界框。
SSD:单次多框检测器
我们提出了一种使用单个深度神经网络检测图像中物体的方法。我们的方法称为 SSD...
本文提出了一种使用单个深度神经网络预测图像中物体的模型。该网络通过对特征图应用小卷积滤波器来生成每个物体类别的存在评分。
该方法使用前馈卷积神经网络,生成一组边界框和特定物体的存在评分。增加了卷积特征层,以支持多尺度特征检测。在这个模型中,每个特征图单元链接到一组默认的边界框。下图展示了 SSD512 在动物、车辆和家具上的表现。
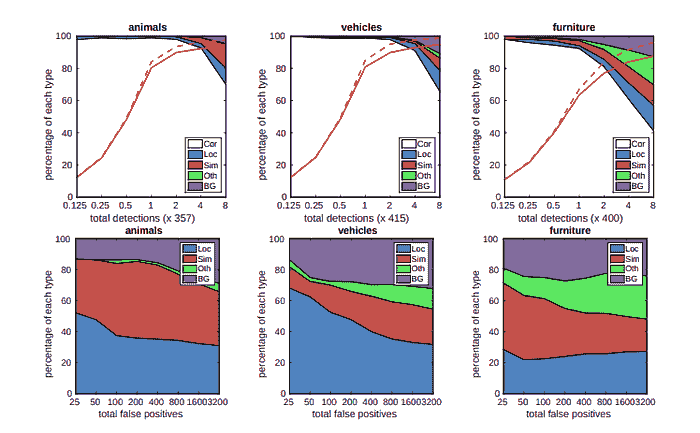
你只看一次 (YOLO)
本文提出了一种单一神经网络,在单次评估中从图像中预测边界框和类别概率。
我们提出了 YOLO,这是一种新的目标检测方法。以往的目标检测工作重新利用分类器进行...
YOLO 模型以每秒 45 帧的速度实时处理图像。YOLO 将图像检测视为回归问题,这使得其管道非常简单。正因如此,它非常快速。
它可以以低于 25 秒的延迟实时处理流媒体视频。在训练过程中,YOLO 查看整个图像,因此能够在目标检测中包含上下文信息。
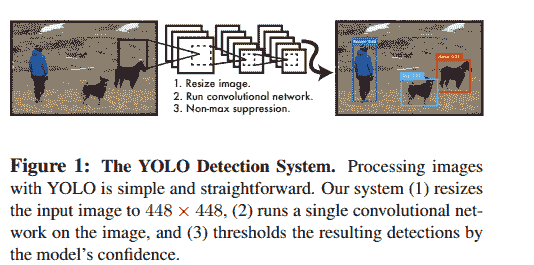
在 YOLO 中,每个边界框由整个图像的特征预测。每个边界框有 5 个预测值:x、y、w、h 和置信度。(x, y) 表示相对于网格单元边界的边界框中心。w 和 h 是对整个图像的预测宽度和高度。
该模型实现为卷积神经网络,并在 PASCAL VOC 检测数据集上进行评估。网络的卷积层负责提取特征,而全连接层则预测坐标并输出概率。
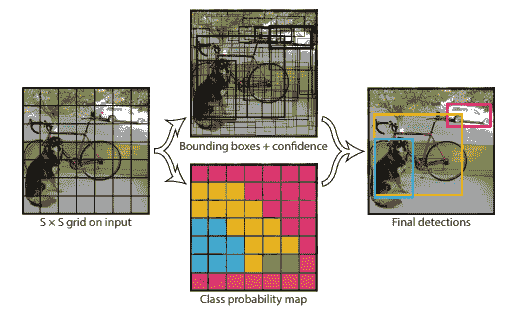
该模型的网络架构灵感来源于 GoogLeNet 图像分类模型。网络有 24 层卷积层和 2 层全连接层。该模型的主要挑战是它只能预测一个类别,并且在小物体如鸟类上的表现不佳。

该模型实现了 52.7% 的平均精度,但可以达到 63.4%。
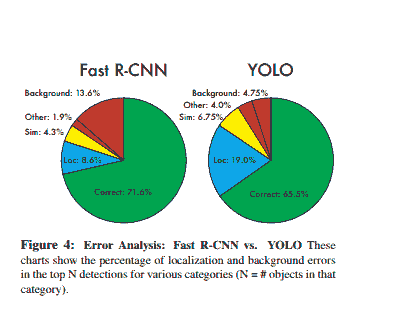
将对象视为点
本文提出将对象建模为一个单一的点。它使用关键点估计来找到中心点,并对所有其他对象属性进行回归。
检测将图像中的对象识别为轴对齐的框。大多数成功的目标检测器枚举了几乎...
这些属性包括 3D 位置、姿态方向和大小。它使用 CenterNet,这是一种基于中心点的方法,比其他边界框检测器更快、更准确。

属性如对象大小和姿态是从图像中心位置的特征中回归得到的。在此模型中,图像被输入到卷积神经网络中,该网络生成热图。这些热图中的最大值代表图像中对象的中心。为了估计人体姿势,该模型检查 2D 关节位置,并在中心点位置进行回归。
该模型在每秒 1.4 帧的速度下实现了 45.1% 的 COCO 平均精度。下图显示了与其他研究论文中获得的结果的比较。
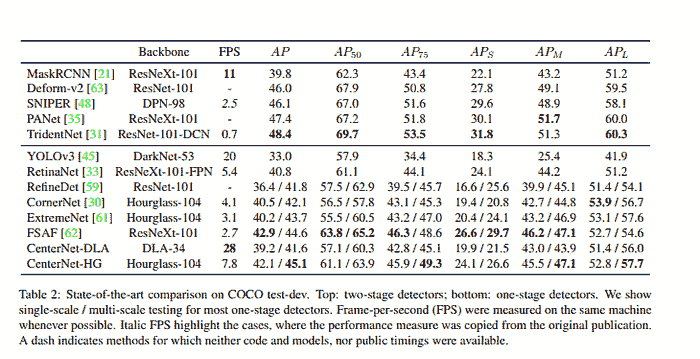
学习数据增强策略用于目标检测
数据增强涉及通过操控原始图像(例如旋转和缩放)来创建新的图像数据。
数据增强是训练深度学习模型的关键组成部分。虽然数据增强已经被证明...
虽然这本身不是一个模型架构,但本文提出了创建可以应用于目标检测数据集的变换,这些变换可以转移到其他目标检测数据集中。这些变换通常在训练时应用。

在这个模型中,增强策略被定义为在训练过程中随机选择的 n 个策略的集合。在此模型中应用的一些操作包括扭曲颜色通道、几何扭曲图像,以及仅扭曲边界框注释中的像素内容。
对 COCO 数据集的实验表明,优化数据增强策略可以将检测准确率提高超过 +2.3 平均精度。这使得单个推理模型可以达到 50.7 的平均精度。
结论
我们现在应该对一些最常见的——以及几种最近的——对象检测技术有了了解。
上述提到和链接的论文/摘要也包含了它们的代码实现链接。我们很乐意看到你在测试后获得的结果。
不要局限于此。对象检测也可以存在于你的智能手机中。了解如何 Fritz 可以教会移动应用程序看、听、感知和思考。
简介: 德里克·穆伊提 是一位数据分析师、作家和导师。他致力于在每项任务中取得出色成果,并且是 Lapid Leaders Africa 的导师。
原文。经许可转载。
相关:
-
使用 Luminoth 进行对象检测
-
基于深度学习的人体姿态估计概述
-
大规模图像分类器的演变
更多相关话题
2019 年语义分割指南
原文:
www.kdnuggets.com/2019/08/2019-guide-semantic-segmentation.html/2
多尺度上下文聚合通过空洞卷积(ICLR, 2016)
本文开发了一种卷积网络模块,该模块结合了多尺度上下文信息而不会丢失分辨率。该模块可以插入到现有的任何分辨率架构中。该模块基于 空洞卷积。
最先进的语义分割模型基于对卷积网络的适配,这些网络曾...
该模块在 Pascal VOC 2012 数据集上进行了测试。结果证明,向现有的语义分割架构中添加上下文模块可以提高它们的准确性。
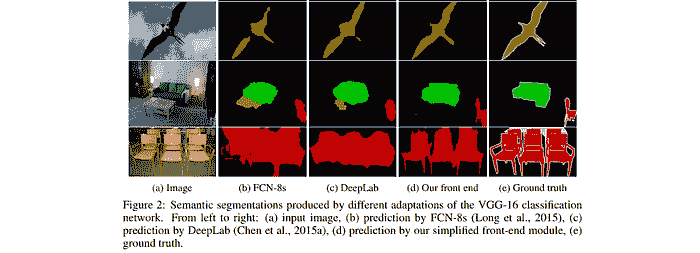
在实验中训练的前端模块在 VOC-2012 验证集上达到了 69.8% 的平均 IoU,在测试集上达到了 71.3% 的平均 IoU。该模型在不同物体上的预测准确性如下所示
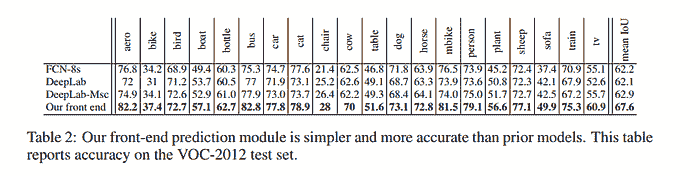
DeepLab:利用深度卷积网络、空洞卷积和全连接 CRFs 的语义图像分割(TPAMI, 2017)
在这篇论文中,作者对深度学习中的语义分割任务做出了以下贡献:
-
用于密集预测任务的上采样卷积
-
采用空洞空间金字塔池化(ASPP)来分割多尺度的物体
-
通过使用深度卷积神经网络(DCNNs)来改善物体边界的定位。
DeepLab:利用深度卷积网络、空洞卷积和全连接 CRFs 的语义图像分割
在这项工作中,我们处理了使用深度学习的语义图像分割任务,并做出了三个主要贡献...
论文提出的 DeepLab 系统在 PASCAL VOC-2012 语义图像分割任务中达到了 79.7% 的 mIOU。
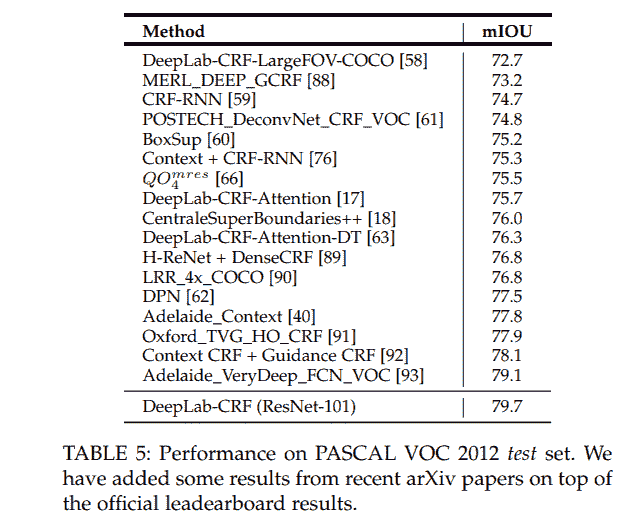
论文解决了在语义分割中使用深度卷积神经网络的主要挑战,包括:
-
由于最大池化和下采样的重复组合,导致特征分辨率降低。
-
物体在多个尺度下的存在。
-
由于 DCNN 的不变性导致的定位准确度降低,因为以物体为中心的分类器需要对空间变换具有不变性。
Atrous 卷积的应用包括通过插入零进行滤波器的上采样,或稀疏地采样输入特征图。第二种方法涉及将输入特征图按 atrous 卷积率 r 进行子采样,并对其进行解交错以生成 r² 分辨率降低的图像,每个图像对应 r×r 的可能偏移。之后,对立即特征图应用标准卷积,将其与图像的原始分辨率进行交错。
重新思考 Atrous 卷积在语义图像分割中的应用 (2017)
本文解决了使用 DCNN 进行语义分割时的两个挑战(如前所述);当应用连续池化操作时特征分辨率降低,以及存在多尺度的对象。
在这项工作中,我们重新审视了 atrous 卷积,这是一种强大的工具,可以显式调整滤波器的视野范围以及...
为了解决第一个问题,论文建议使用 atrous 卷积,也称为扩张卷积。它提出使用 atrous 卷积来解决第二个问题,以扩大视野范围,从而包含多尺度上下文。
论文中的“DeepLabv3”在 PASCAL VOC 2012 测试集上取得了 85.7% 的表现,无需 DenseCRF 后处理。

Atrous Separable Convolution 用于语义图像分割 (ECCV, 2018)
本文的方法“DeepLabv3+”在 PASCAL VOC 2012 和 Cityscapes 数据集上取得了 89.0% 和 82.1% 的测试集表现,而无需对结果进行后处理。该模型是 DeepLabv3 的扩展,通过添加一个简单的解码器模块来细化分割结果。
Papers With Code : Encoder-Decoder with Atrous Separable Convolution for Semantic Image...
???? 在 PASCAL VOC 2012 上的语义分割 SOTA (平均 IoU 评估指标)

论文实现了两种使用空间金字塔池化模块进行语义分割的神经网络。一种通过在不同分辨率下池化特征来捕捉上下文信息,而另一种则获得清晰的对象边界。
FastFCN: 重新思考语义分割骨干中的膨胀卷积(2019)
本文提出了一种名为联合金字塔上采样(JPU)的联合上采样模块,以替代耗时和占用大量内存的膨胀卷积。它通过将提取高分辨率图的功能表述为一个联合上采样问题来工作。
Papers With Code : FastFCN: 重新思考语义分割骨干中的膨胀卷积
???? PASCAL Context 上的语义分割 SOTA(mIoU 指标)
该方法在 Pascal Context 数据集上实现了 53.13%的 mIoU 性能,并且运行速度快了 3 倍。
该方法将全连接网络(FCN)作为骨干,同时应用 JPU 对低分辨率的最终特征图进行上采样,从而生成高分辨率的特征图。用 JPU 替代膨胀卷积不会导致性能损失。
联合采样使用低分辨率的目标图像和高分辨率的引导图像。然后,通过转移引导图像的结构和细节来生成高分辨率的目标图像。
通过视频传播和标签松弛改进语义分割(CVPR, 2019)
本文提出了一种基于视频的方法,通过合成新的训练样本来扩展训练集,旨在提高语义分割网络的准确性。它探索了视频预测模型预测未来帧的能力,以便预测未来标签。
Papers With Code : 通过视频传播和标签松弛改进语义分割
???? Cityscapes 上的语义分割 SOTA(平均 IoU 指标)
论文表明,在合成数据集上训练分割网络可以提高预测准确性。本文提出的方法在 Cityscapes 上实现了 83.5%的 mIoU,在 CamVid 上实现了 82.9%的 mIoU。
论文提出了两种预测未来标签的方法:
-
标签传播 (LP) 通过将传播的标签与原始未来帧配对来创建新的训练样本
-
联合图像-标签传播 (JP) 通过将传播的标签与相应的传播图像配对来创建新的训练样本
论文有三个主要建议:利用视频预测模型将标签传播到相邻帧,引入联合图像-标签传播来解决对齐问题,以及通过最大化边界上类别概率的联合可能性来放宽单热标签训练。
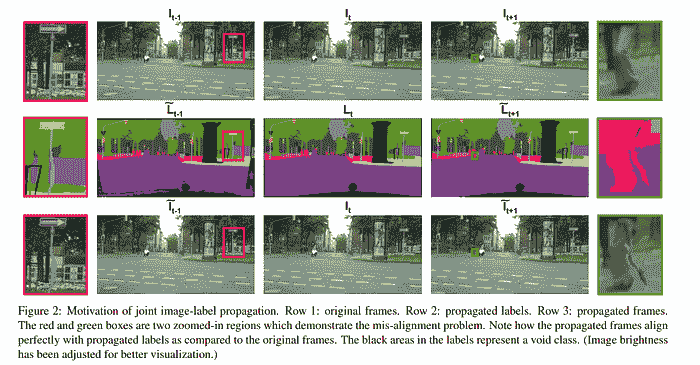
Gated-SCNN: 用于语义分割的门控形状 CNN(2019)
这篇论文是语义分割领域的新星。作者提出了一种双流 CNN 架构。在这个架构中,形状信息作为一个单独的分支处理。这个形状流只处理与边界相关的信息。这由模型的门控卷积层(GCL)和局部监督来强制执行。
当前最先进的图像分割方法形成了一个密集的图像表示,其中包括颜色、形状等...
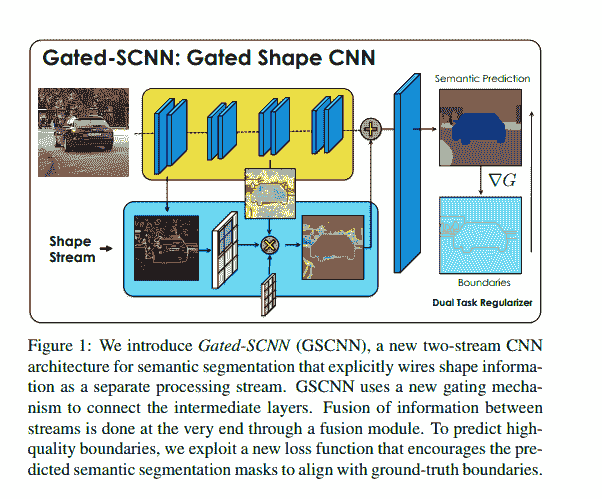
该模型在 mIoU 上比 DeepLab-v3+提高了 1.5%,在 F-boundary 分数上提高了 4%。该模型已使用 Cityscapes 基准进行评估。在较小和较薄的物体上,该模型在 IoU 上提高了 7%。
下表展示了 Gated-SCNN 与其他模型的性能比较。
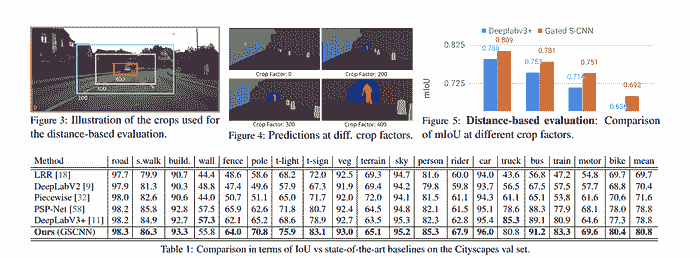
结论
我们现在应该了解一些最常见的——以及几个非常近期的——语义分割技术在各种环境中的应用。
上述论文/摘要也包含了其代码实现的链接。我们很乐意看到你在测试后获得的结果。
简介: 德里克·穆伊提 是数据分析师、作家和导师。他致力于在每项任务中取得出色成果,并且是 Lapid Leaders Africa 的导师。
原文。已获得许可转载。
相关:
-
2019 年目标检测指南
-
使用 Luminoth 进行目标检测
-
Python 中的自动化机器学习
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 事务
更多相关话题
2023 AI 指数报告:未来我们可以预期的 AI 趋势
原文:
www.kdnuggets.com/2023/06/2023-ai-index-report-ai-trends-expect-future.html

图片由 rawpixel.com 提供,来源于 Freepik
人工智能比以往任何时候都更为突出,其发展也在不断增加。为什么会这样?随着生成式 AI 的最新进展,每个人、研究小组和公司都在竞相成为该领域的佼佼者,这使得竞争更加激烈。虽然有时很难跟上所有最新的趋势。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
为了进一步总结 2023 年的 AI 趋势,AI 指数报告 应运而生。斯坦福大学人类中心人工智能研究所(HAI)开发了该报告,报告由来自各个学术和行业领域的指导委员会制定,旨在为决策者和观众提供行动建议,以负责任和伦理的方式推进 AI。
这份报告的趋势和关键要点是什么?让我们来讨论一下。
AI 指数报告 2023
AI 指数报告 2023 是第六版报告,主要关注 AI 发展及其对人类社会的影响。通过 数据 由各领域专家策划并经过严格分析,这里是报告中的关键要点。
行业领先于学术界
根据报告,许多在 2022 年发布的重要机器学习系统是由行业领域主导的,而不是学术界。一项重要的机器学习系统是包含在 Epoch 数据集 中的模型,并且具有特定标准,如改进了最先进的方法。
2022 年发布了 38 个重要的机器学习系统,但其中 32 个是由行业生产的。我们可以参考下面的图表,查看 2022 年的趋势相对于 2014 年的变化。
图片改编自 AI Index Report 2023
传统基准性能的饱和
许多机器学习模型每年都通过标准基准数据集进行测试,以查看它们的模型是否能够改善当前的基准性能。例如,使用 ImageNet 数据集 进行图像分类任务,或使用 SuperGlue 基准进行英语语言理解任务。
然而,每年的性能提升幅度变得越来越小,并被认为已达到平台期。下图显示了许多基准测试的年度改善幅度低于 5%。
图片改编自 AI Index Report 2023
为了缓解基准测试饱和的问题,研究人员最近推出了新的综合基准测试,如 BIG-bench 和 HELM。不过,这些新基准测试大多集中在大型语言模型任务上,因为这是当前的趋势。
人工智能既在帮助也在伤害环境
最近的研究表明,某些大型语言模型可能会通过排放碳排放量,对环境产生负面影响,这比任何其他人类活动的碳排放量都要高。下图显示了 GPT-3 模型的碳排放量几乎是一个乘客常规航空旅行的 500 倍。
图片改编自 AI Index Report 2023
然而,也有研究证明 AI 也可以拯救环境。2022 年 DeepMind 的研究表明,一种名为 BCOOLER 的机器学习代理可以在 Google 数据中心内将节能系统的效率提高 12.7%。
AI 快速加速科学进展
2022 年,AI 已被证明对许多科学突破做出了贡献,包括:
-
DeepMind 的研究人员创建了一种强化学习算法,用于在称为托卡马克的系统中寻找管理核聚变产生的等离子体的最佳方法。
-
Fawzi et al. (2022) 发现了一种使用强化学习进行矩阵操作的新算法,称为 AlphaTensor。
-
Nvidia 发现了一种通过让 AI 使用强化学习设计系统来改进芯片系统的新方法。
-
Shanehsazzadeh 等 (2023) 使用零样本生成 AI 开发了新的 de novo 抗体发现系统。
AI 滥用事件数量的增加
随着 AI 的新发展,滥用数量预计将增加。根据 AIAAIC 数据库,2021 年的事件数量是 2012 年的 26 倍。趋势可以在下方的图像中查看。
图片改编自 AI Index Report 2023
争议案例包括乌克兰总统泽连斯基的假冒投降案例以及英特尔开发的学生情感监测系统。
上升的案例还表明人们的意识比以前更高,从而改进了对 AI 滥用的跟踪。
对 AI 相关专业技能的需求正在增加。
对 AI 相关技能的需求在职位发布中逐年增加,并且在各国之间有所体现。这表明许多公司对在组织内部实施 AI 表现出更多兴趣。下方来自 Lightcast 的数据表明,带有 AI 相关技能的职位发布数量呈上升趋势。
图片改编自 AI Index Report 2023
上述数据还显示,美国在需要 AI 技能的国家中比例最高,而新西兰最低。尽管数据仅限于所选国家,因此请谨慎对待。
2022 年显示 AI 私人投资减少。
2022 年,AI 相关投资达到了 919 亿美元。根据 NetBase Quid 的数据,这一数字较 2021 年有所减少,尽管仍是 2013 年的 18 倍。数据可以在下方的图表中查看。
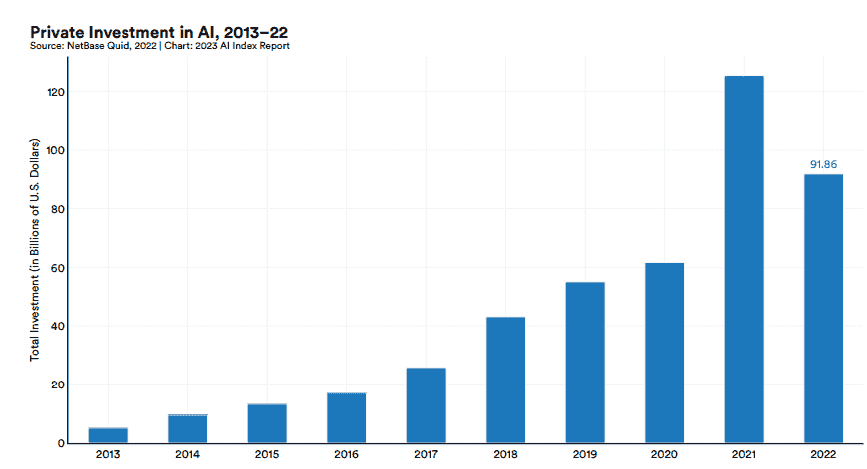
图片改编自 AI Index Report 2023
这是一个短期的下降趋势,但从长远来看趋势依然在上升。这表明许多公司仍然愿意投资于 AI 发展。
尽管采用 AI 的公司比例已趋于平稳,但这些公司继续领先。
尽管 AI 采纳率趋于平稳,但已经采纳 AI 的公司仍在不断进步。
根据 McKinsey 报告,截至 2022 年,约 50%的受访公司在其业务职能中采纳了人工智能。下图显示,自 2019 年以来,采纳率在 50-60%左右平稳,尽管这一数字比 2017 年要高得多。
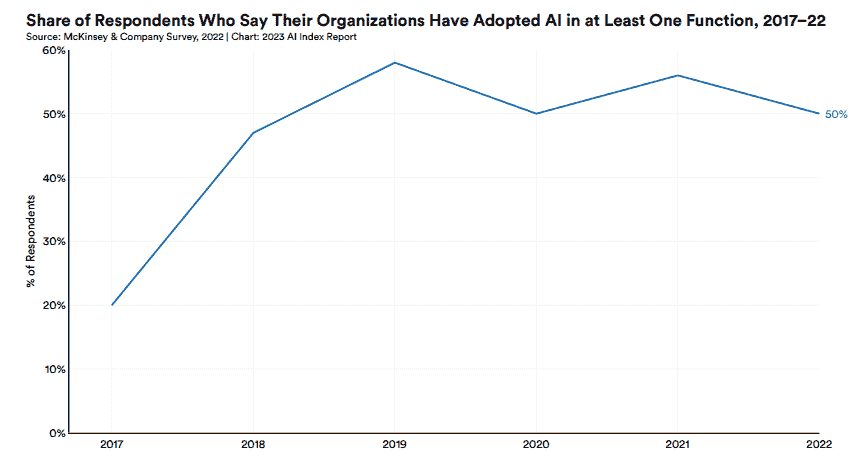
图片改编自 AI Index Report 2023
研究结果表明,尽管这一数字可能会在未来几年保持在 50%左右,公司仍然愿意在其业务和组织中采纳人工智能。
政策制定者对人工智能的兴趣呈上升趋势
根据 AI Index 对 127 个国家立法机构关于人工智能的研究,31 个国家已通过了与人工智能相关的法案,这 31 个国家总共有 123 个与人工智能相关的法案。2022 年有 37 个与人工智能相关的法案,而 2016 年仅有 1 个法案通过。这一趋势可以在下图中看到。
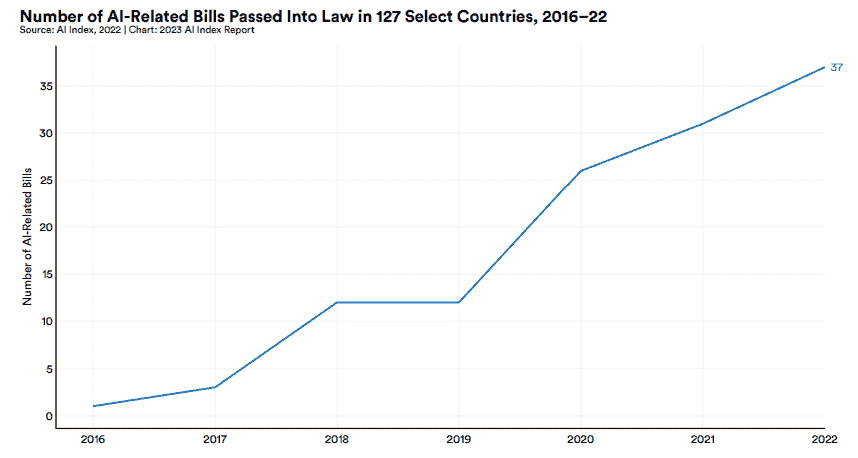
图片改编自 AI Index Report 2023
上述数据表明,许多国家已经认识到人工智能可以在许多领域中发挥作用;然而,采用人工智能需要监管以避免误用。
全球范围内,人们已开始看到人工智能采纳的好处
根据 IPSOS 对 28 个国家 19504 名不同年龄成人的调查,超过 50%的人了解人工智能的工作原理,并相信人工智能将在未来 3-5 年内改变日常生活。完整的数据可以在下图中看到。
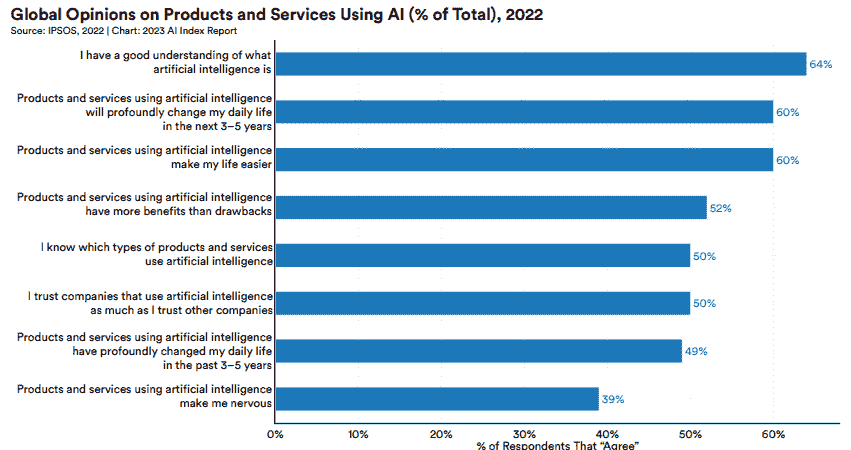
图片改编自 AI Index Report 2023
认为人工智能有用的个体数量很高,显示出人工智能将逐渐融入人们的日常生活。不过,也有一些人仍然感到人工智能让他们紧张,这也是正常的。
结论
人工智能趋势正在上升,并可能在未来几年保持这种状态。这一趋势得到了 AI Index Report 的证实,其中显示了关键发现:
-
行业领先于学术界
-
传统基准表现的饱和
-
人工智能既在帮助环境也在伤害环境
-
人工智能迅速加速了科学进步
-
与人工智能误用有关的事件数量增加
-
对人工智能相关专业技能的需求在增加
-
2022 年显示人工智能私人投资有所减少
-
尽管人工智能采纳率趋于平稳,但已采纳人工智能的公司仍在不断进步
-
政策制定者对人工智能的兴趣呈上升趋势
-
全球范围内,人们已开始看到人工智能采纳的好处
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作分享 Python 和数据技巧。
更多相关主题
2023 年数据科学家薪资
原文:
www.kdnuggets.com/2023/07/2023-data-scientists-salaries.html

图片由freepik.com提供
数据科学家现在被认为是最受欢迎的 STEM(科学、技术、工程和数学)职业之一。随着信息技术和人工智能在我们生活中的重要性增加,数据科学领域将继续增长。美国劳工统计局预测,2021 年至 2031 年间对数据科学家的需求将增长 36%。数据科学家的需求将继续增长。对于有意从事数据科学领域的 aspirants 来说,一个重要的问题是:数据科学家的薪资是多少?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
数据科学家的薪资因多个因素而异,如地理位置、经验、教育背景、行业、职位等。
在本文中,我们进行初步的统计分析,以估算 2023 年美国数据科学家的年平均薪资。
数据收集
为了估算美国数据科学家的年平均薪资,我们从indeed.com收集了数据。通过关键词搜索框和关键词“数据科学家职位”,我们发现截至 2023 年 3 月 8 日,美国有 26,661 个开放的数据科学家职位。这些职位从初级到高级不等。表格下方展示了这些职位的薪资范围。
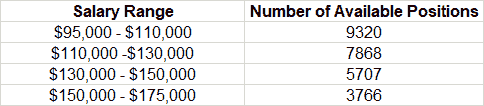
数据来源:Indeed.com
美国的数据科学家年薪范围及职位数量。数据来源于指定网址,使用“数据科学职位”搜索条件获取,日期为 2023 年 3 月 8 日。图片由作者提供。
下图展示了开放数据科学家职位的薪资范围条形图。
数据科学家职位及年薪范围。图片由作者提供。
数据科学家的平均薪资
使用从 indeed.com 获得的数据,我们进行了基础统计计算以确定年均薪资和标准差。根据从 indeed.com 检索到的信息,数据科学家的平均薪资估计为每年$124,000。标准差估计为$21,000。薪资数据的 95%置信区间为每年[$83,000 - $166,000]。
工资范围的分布可以使用正态分布来估算,如下图所示。
数据科学家的年薪分布 | 图片来源:作者。
与美国劳工统计局的数据比较
根据美国劳工统计局的数据,2021 年数据科学家的中位薪资为每年$100,000。这个数值略低于我们估算的每年$124,000 的平均薪资。这一差异可能是由于 2023 年数据科学家薪资的上涨,以抵消高通胀率和与劳动力短缺相关的数据科学家需求增加。
结论
总结来说,我们使用从 indeed.com 获取的开放数据科学家职位的薪资数据,进行了基础统计来估算美国数据科学家的平均薪资。我们的分析显示,美国数据科学家的全国平均薪资估计为每年$124,000,95%置信区间为[$83,000 - $166,000]每年。数据科学家应该预期在 2023 年年薪在$83,000 到$166,000 之间。任何特定职位的实际薪资取决于地理位置、经验、教育、行业、职位等因素。
本杰明·O·塔约 是一名物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的创始人。此前,本杰明曾在中俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关话题
2023: 疯狂的人工智能之年

图片由作者提供
真是精彩的一年,不是吗?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
在 2023 年初,人们在跟上科技世界的步伐方面遇到了困难。有一天发布了某个新产品,第二天竞争对手又推出了别的东西,然后你又听说了其他新的事物。实在是太多了。
但这种势头持续了一整年,许多公司创造了历史!
2023 年无疑是人工智能的年!
那么,让我们回顾一下这些月份,回顾一下发生了什么。
一月
随着 ChatGPT 在 2022 年 11 月进入市场,相关讨论在 2023 年初继续进行。凭借持续的成功,微软迅速宣布向 OpenAI 投资 100 亿美元。
二月
随着围绕 OpenAI 的 ChatGPT 的炒作,大家都在想他们的竞争对手是否会现身并进入市场。谷歌正是这样做的,推出了他们的首个 BARD。
几天后,微软也通过其Bing聊天机器人震撼了市场,微软和 OpenAI 的首席执行官都深入探讨了两者之间的合作关系。
三月
过了两个月,似乎已经发生了很多事情。为了启动 Google GenAI 的旅程,Bard 的访问权限被授予了一小部分人。这样一来,Adobe 推出了 Firefly,Canva 推出了他们的虚拟设计助手,掀起了一系列连锁反应。
OpenAI 还推出了 ChatGPT 的 API,以及名为 Whisper 的文本转语音模型。在三月十四日,OpenAI 发布了其最先进的模型 GPT-4。
四月
新的一月,谷歌也带来了更多消息,宣布了 Google DeepMind——这是 Google Research 和 DeepMind 的结合。
我们还看到俄罗斯的 Sberbank 发布了 ChatGPT 竞争对手GigaChat,以及 HuggingFace 进入市场,发布了一个与 ChatGPT 竞争的 AI 聊天机器人 HuggingChat。
五月
Google 希望保持竞争力,感受到压力,宣布向公众推出了 Bard 聊天机器人。但似乎他们在微软揭晓其 Windows 11 的首款 AI 助手时,火上加油了。
看到这些情况,你只能想象 NVIDIA 的表现如何。是的,他们的市值首次突破了$1 万亿,稳固了其 AI 芯片领导者的地位。
说到芯片,在同一个月,我们还体验了埃隆·马斯克的新脑植入创业公司 Neuralink,该公司旨在创建并植入 AI 驱动的芯片到人脑中。这已获得 FDA 批准进行人类试验。
六月
Apple 的 Vision Pro,这款由 AI 驱动的增强现实头戴设备,旨在将沉浸式体验提升到一个新的高度。
6 月 14 日,欧洲议会对欧盟 AI 法案进行了谈判,以 499 票赞成、28 票反对和 93 票弃权的结果通过了该法案。
2023 年上半年发生的一切让 AI 世界显得前景光明。麦肯锡预测,生成性 AI 有潜力为全球经济增加高达$4.4 万亿的价值。
七月
七月保持了势头。Meta 推出了大模型 Llama 2,这是一个开源的大型语言模型(LLM),经过了公开数据的训练,旨在驱动 OpenAI 的 ChatGPT、Bing Chat 以及其他现代聊天机器人。
Anthropic 还发布了 Claude 2,它取代了 ChatGPT,令其感到颤抖。
关于 AI 的安全性正成为热门话题,因为大型语言模型(LLMs)频繁出现,成为我们日常生活的一部分。
微软宣布将向客户收取每月$30 的费用来使用 Microsoft 365 Copilot,这引发了其他组织的思考。
八月
谷歌紧随其后表示,他们也将对用户在 Duet AI for Workspace 中使用其 GenAI 工具收取每月 $30 的费用。看来 金钱 的确有不少。
OpenAI 推出了 自定义指令,以最大限度地发挥 ChatGPT 的作用。我们还介绍了 Poe,一个聊天机器人服务,允许你使用最先进的模型,如 Claude +、GPT-3.5-Turbo 和 GPT-4。
九月
一年的三分之一已经过去,AI 已经变得疯狂起来!
各公司计划尽可能获取所有资源,并在 GenAI 中保持竞争力。亚马逊宣布了一项 40 亿美元投资于 OpenAI 竞争对手 Anthropic。我们还看到了一些酷但奇怪的事物,例如 Meta 应用中出现的 AI 人物,如汤姆·布雷迪和肯达尔·詹娜。
目前专注于内容创作,OpenAI 继续致力于通过 Canva 插件为 ChatGPT 可视化内容。
十月
我们经历了 关于人工智能安全、保障和可信发展与使用的行政命令。这也让 AI 世界发生了震动,CEO、领导和其他人对 AI 系统融入社会的实施有着相互矛盾的看法。
十一月
从聊天机器人开始。埃隆·马斯克的 AI 初创公司 xAI 发布了 AI 聊天机器人 “Grok”,AWS 发布了 Amazon Q,以及来自 StabilityAI 的 Pika 1.0。
OpenAI 还在 11 月举办了第一次开发者活动,深入探讨了 GPT-4 Turbo 和 GPT Store。
但之后情况有些疯狂,OpenAI 的首席执行官萨姆·奥特曼被董事会突然解雇。微软立即向他提供了一个职位,OpenAI 的员工威胁要辞职,要求萨姆·奥特曼回归并重新担任首席执行官。现在他回来了,带来了新的董事会成员以及微软的新“观察员”角色。
十二月
在过去的 11 个月里发生了很多疯狂的事,对吧?我们终于接近 2023 年的结束。
就在年底前,谷歌再度震撼市场,推出了其大语言模型的三种变体,并且 ChatGPT 的新对手 Gemini。
我们已经知道 OpenAI 正在研究 GPT 5、6 和 7。让我们看看 2024 年 1 月会带来什么。
年终总结
哇 - 真是精彩的一年!
2023 年在人工智能领域代表了一个重大飞跃,这超越了编码和算法能力。我们正在见证 AI 系统如聊天机器人和内容创作如何改善我们日常生活中的营销任务。
话虽如此,我们都应该期待 2024 年科技与人类融合所带来的变化。
Nisha Arya是一名数据科学家、自由技术写作人,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程及理论知识。Nisha 涵盖广泛话题,希望探索人工智能如何促进人类生命的长寿。作为一名热衷学习者,Nisha 致力于拓宽自己的技术知识和写作技能,同时帮助他人。
更多相关话题
2024 数据管理水晶球:前 4 大新兴趋势
原文:
www.kdnuggets.com/2023/08/2024-data-management-crystal-ball-top-4-emerging-trends.html

图片由 kjpargeter 提供,来自 Freepik
数据主导地位正在迅速增加,标志着它在更多行业和流程中的影响力。到 2023 年中期,最好考虑接下来的 18 个月将对数据管理平台产生什么影响。我坚信,从 2024 年开始,企业站在关键的转折点上,认识到智能利用数据的不可或缺性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
为了蓬勃发展,组织必须接受关键的数据管理趋势,这些趋势为成功铺平道路。它们必须重新点燃其策略,摆脱传统的数据存储方式。传统数据管理方法 无法应对物联网和人工智能时代的数据不确定量。新技术已在架上,是时候将其纳入策略中了。
在许多有趣的趋势中,我挑选了我最喜欢的几个,它们将重塑数字景观。跟随我吧!
趋势 1:通过数据织物和 Mesh 聚焦数据民主化
数据民主化是使企业中每个人都能访问和使用数据的实践,无论其技术技能如何。最近,数据织物和 Mesh 在拥抱组织中的每个人方面变得非常流行,无论他们的技术专长如何——例如 ThoughtSpot、Domino Data Lab、K2view 等。
正如我们所知,数据织物是一种数据管理架构,将来自多个来源的数据整合成统一视图。这使用户更容易找到和访问所需的数据。同样,Mesh 使领域专家对他们的数据拥有更多控制权,还可以帮助改善数据质量和治理。
两种架构在确保数据民主化方面同样重要。除了改进数据访问外,它们还使用户更容易根据需求找到和访问数据。这导致了更快的决策和洞察力。此外,通过提供单一的统一视图,数据质量得到了提升。此外,集中数据访问控制和存储库的方法确保了改进的治理和安全性。
趋势 2:在数据洞察中增加对工业 4.0 技术的采纳
众所周知,工业 4.0 是第四次工业革命,主要利用自动化、数据分析和人工智能来创建智能工厂。
在工业 4.0 中,数据分析可以通过识别可以优化的过程或可以防止缺陷的领域来提高效率、生产力和质量。
例如,数据分析跟踪机器的性能并识别表明机器即将故障的模式。它进一步利用这些信息在机器故障之前安排维护,这可以防止停机和生产力损失。其重要性在于,这项技术虽然主要用于制造业,但实际上正以CAGR 16.3% 从 2023-2030的速度增长。这可能使该行业的价值达到 3770 亿美元。
趋势 3:通过数据掩码增加对 GDPR 合规性的关注
通过掩盖敏感数据,企业可以保护客户和员工的隐私,同时降低数据泄露的风险。数据掩码隐去敏感数据从用于分析和机器学习的数据集中。这确保了敏感数据不会以可能违反 GDPR 的方式使用,例如个人资料分析或定向。
数据掩码可以用于创建伪匿名化数据集。伪匿名化数据集是那些个人数据被替换为虚拟标识符的数据集。这使得识别数据集中的个人变得更加困难,有助于保护他们的隐私。尽管许多数据管理工具在一定程度上提供了掩码专业知识,但我推荐 K2View 作为合规资格,因为它提供了全面的数据掩码功能,包括修订、令牌化、去标识化、伪匿名化和数据混淆。他们的数据掩码解决方案可以帮助企业遵守各种数据隐私法规,包括 GDPR、CCPA 和 HIPAA。其面料解决方案以其微型数据库方法而闻名,该方法包含单一实体的数据,并根据业务的安全性和合规要求进行掩码处理。
趋势 4:DataOps 的增加采用
DataOps 简化了数据收集、准备、分析和交付的过程。这使企业能够更高效地提取可操作的见解。由于它们提供了更快的价值实现,企业各行业已经开始将其纳入数据管理栈。
DataOps 强调 跨职能协作、自动化、版本控制以及数据操作中的持续集成和交付。通过应用这些原则,DataOps 旨在解决数据团队面临的常见挑战,如数据孤岛、长开发周期和缺乏灵活性。
通过实施自动化数据管道和标准化流程,组织可以确保数据始终经过验证、清洗和转换。这提高了从数据中得出的见解的准确性和可靠性。
传统的数据管理方法往往存在瓶颈,以及数据处理和分析延迟。DataOps 强调自动化和持续集成,使组织能够快速迭代并向利益相关者提供见解,促进更快的决策制定并推动业务成果。
眺望未来
一件事是确定的:组织必须为未来的数据革命做好准备。随着数据的不断增长和重要性,积极适应并利用新兴趋势的企业将获得显著的竞争优势。目前仅限于特定企业的技术栈将对中小企业变得易于访问。此外,AI 使得行动变得更加迫切。你怎么看?
Yash Mehta 是一位国际公认的物联网、机器对机器和大数据技术专家。他撰写了大量广受认可的数据科学、物联网、商业创新和认知智能方面的文章。他是数据洞察平台 Expersight 的创始人。他的文章曾在最权威的出版物中刊登,并被 IBM 和思科物联网部门评为连接技术行业中最具创新性和影响力的作品之一。
更多相关话题
2024 阅读清单:5 本关于人工智能的重要书籍
原文:
www.kdnuggets.com/2024-reading-list-5-essential-reads-on-artificial-intelligence

作者图片
新的一年已经过去两个月,你可能正在考虑为阅读清单增加一些新书。你的书库已经充满了自我发展书籍,但你读过多少本关于人工智能的书呢?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
了解人工智能当前状态以及未来状态对任何人的学习都是重要的。了解你所生活的世界总比在人工智能系统和其他工具被实施后不知道真实原因和结果而感到困惑要好。
在这篇文章中,我将介绍 2024 年推荐的 5 本关于人工智能的书籍。
生命 3.0
链接:生命 3.0
作者:马克斯·泰格马克
作者马克斯·泰格马克是一位物理学家和机器学习研究员,他深入探讨了生命的三个不同层级:从无法改变其软件的简单生物种类,到能够改变其软件设计的物种,再到能够设计其软件和硬件的技术物种。
了解你属于哪个类别:是那些认为通用人工智能(AGI)在未来 100 年内不会有效实现的技术怀疑论者,还是认为本世纪内有可能实现人类 AGI 的有益 AI 运动阵营。
超智能
作者:Nick Bostrom
作者 Nick Bostrom 为我们带来了这本经典著作,他详细阐述了由于 AI 智能可能超越人类智能的两个尺度,村里的傻子和爱因斯坦之间的距离可能非常小。
理解 AI 系统如何在某些方面变得更加智能,并深入探讨作者对超级智能能够快速和爆炸性发展的看法。本书提到了设计超级智能机器的两种形式:一种是当前教计算机模仿人类智能的方法,另一种是全脑模拟,其中计算机模拟人类大脑。
即将到来的浪潮
链接:即将到来的浪潮
作者:Mustafa Suleyman
DeepMind 的联合创始人 Mustafa Suleyman 带来了关于 AI 的最新书籍,并提到了最近的突破,例如机器人和大型语言模型。该书分为四部分:Homo Technologicus、The Next Wave、State of Failure 和 Through the Wave。这些章节讨论了人类历史上技术的加速和发展,其中每一次技术浪潮的出现和消退,都在不断改进。
深入探讨推动技术进步的不同方面和动机,如财务、政治、人类自我、好奇心、改变世界以及谁最终赢得竞赛。
权力与进步
链接:权力与进步
作者:Simon Johnson 和 Daron Acemoglu
探索一本考察技术、繁荣与社会进步之间关系的书籍。社会上大多数人相信或被告知技术进步会导致社会进步。在这本书中,作者挑战了这一说法,强调技术进步可能导致不平等,只有一小部分个人和企业从中受益。
我们可以支持这一说法,因为在过去几年里,我们看到一些公司一夜之间变成了百万富翁,而低收入家庭的收入进一步下降,并且裁员现象增加。
人类是否被低估了?我们是否应该让人类继续做他们擅长的事情,因为人类智慧,而让机器继续做它们擅长的事情?
人类兼容
链接:人类兼容
作者:斯图亚特·拉塞尔
作者斯图亚特·拉塞尔,是关于人工智能的第三本教科书的合著者。虽然标题听起来有些严肃,但这本书读起来很有趣,深入探讨了智能机器的设计如何对解决人类问题至关重要,同时确保它们不会对人类造成伤害。
第一部分探讨了人工智能的一般情况,以及为什么构建与人类目标兼容的超级智能机器是重要的。他在书中表示:“成功将是人类历史上最大的一次事件,也许是人类历史上最后的一次事件。”
总结
如果你还没有,我强烈推荐你把这本书添加到你的阅读清单中。你不必成为人工智能或技术专业人士就可以想要了解更多关于我们生活在技术进步世界中的信息——你只是为此做好了正确的准备和学习。
如果你还有其他推荐给社区的书籍,请在下面的评论区留言——谢谢!
Nisha Arya 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程和基于理论的数据科学知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有助于人类寿命的延续。作为一名热衷学习者,Nisha 旨在扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
2024 年技术趋势:人工智能突破与 O'Reilly 免费报告中的开发洞察
原文:
www.kdnuggets.com/2024-tech-trends-ai-breakthroughs-development-insights-oreilly-free-report
2023 年是一个有趣的年份。我们已经看到几十年来科技世界经历了不同的周期,对我们的社会和经济产生了影响,现在我们中的许多人都迫切想知道未来会是什么样子。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
在 2023 年发生的一切中,有一个事件震撼了整个世界,这就是终极的人工智能突破——ChatGPT。
它改变了很多事情。人们的工作方式。它如何改善员工的日常工作流程。对人工智能能力的洞察。以及它所带来的伦理问题。
在 O'Reilly 的新2024 年技术趋势报告中,由 Mike Loukides 撰写,我们将通过了解 O'Reilly 学习平台的使用情况,预测 2024 年的发展趋势,并了解行业的走向。
那么 2024 年的科技趋势是什么呢?
软件开发
2023 年,软件开发整体上有所下降,从对该领域的了解减少到职位减少。虽然数据如此显示,但软件开发仍然非常重要,其在人工智能发展的需求没有改变。
生成式 AI 是一个重要因素,92%的开发者使用 AI 进行低级编码。这引发了关于 AI 在高级设计中潜力的问题,强调了人类如何与生成式 AI 系统合作。这表明软件开发在掌握更适合复杂数据环境的架构方面的重要性。
来自O'Reilly 报告的一些统计数据:
-
软件架构兴趣下降了 8.9%
-
企业架构兴趣增加了 8.9%
-
功能编程兴趣增加了 9.8%
-
用于处理来自多个数据流的数据的事件驱动架构增加了 40%
编程语言
随着生成式 AI 工具在日常任务中(如编码任务)大大帮助了许多开发者,我们自然会看到大多数编程语言的内容使用量减少。这导致了越来越少的人愿意走传统的学习路径和职业发展。Stack Overflow 问题和 GitHub 拉取请求也有所减少,这表明开发者已经从寻求其他开发者的建议转向完全依赖生成式 AI。
来自O’Reilly 报告的一些统计数据:
-
92%的程序员正在利用生成式 AI 进行编码任务
-
Python 仍然是最受欢迎的编程语言
-
C++和 Rust 因其在嵌入式系统和内存安全编程等领域的相关性而增长
人工智能
当我们今天谈论 AI 时,重点是 GPT 家族。ChatGPT 于 2022 年 11 月推出,自那时以来一直是关注的焦点。话虽如此,更多的行业和组织对自然语言处理(NLP)和生成式 AI 模型如 Transformers 表现出更广泛的兴趣。使用的工具也发生了变化,Pytorch 比 TensorFlow 更受欢迎。
来自O’Reilly 报告的一些统计数据:
-
GPT 内容使用量在过去一年增加了 3600%
-
NLP 兴趣增加了 195%
-
深度学习和强化学习继续增长
-
PyTorch、LangChain 和向量数据库等工具的使用增加。
数据
数据的重要性保持不变,越来越多的公司依赖数据进行运营和战略过程。数据科学和商业分析工具继续增加,反映了它们在业务运营中的重要性。数据工程也略有下降,但在管理大规模数据存储时仍然重要。对 AI 驱动的实时模型和提供灵活数据管理解决方案的有效数据平台的需求不断增加。
来自O’Reilly 报告的一些统计数据:
-
Microsoft Power BI、SQL Server 和 R 统计工具箱的使用增加
-
工具如 Kafka、Spark 和 Hadoop 的使用减少
-
数据仓库减少,数据湖和数据网格增加。
运营
操作领域发生了一些变化,更多的开发和工程平台涌现。由于自动化的增加,Linux 等操作系统的内容使用有所减少。Kubernetes 也是如此,新的工具使得管理复杂性变得更加容易,无需深入的知识。一些术语的使用也有所减少,但这并不意味着它们会消失,只是新兴技术通过嵌入现有实践来改善操作体验。
来自O’Reilly 报告的一些统计数据:
-
开发人员对深入 Linux 知识的需求减少
-
使用“DevOps”和“SRE”等术语的减少
-
对供应链管理兴趣增加
-
MLOps 兴趣增长 14%
如果你想了解 O’Reilly 对 2024 年在安全、云计算、网页开发、设计和职业发展等领域的预测,请点击这里获取你的免费副本。
总结
2023 年是值得记载的一年。许多事情发生了,生成式 AI 对众多行业、部门和学科产生了影响。
我们是否正在朝着理解问题和寻找解决方案的方向发展?
话虽如此,我们是否会看到对架构、设计以及人际关系等方面的更深入了解的增加?
点击此处阅读报告,并在评论中告诉我们你的想法!
Nisha Arya是一位数据科学家、自由技术作家,并且是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涉及广泛的主题,并希望探索人工智能如何有益于人类生命的延续。作为一个热衷学习者,Nisha 希望扩展她的技术知识和写作技能,同时帮助他人。
更多相关内容
为什么以及如何使用 Dask 处理大数据
评论
由Admond Lee,数据科学家,MicronTech 提供。

我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
作为数据科学家,Pandas是 Python 中用于数据清理和分析的最佳工具之一。
在数据清理、转换、操作和分析方面,它确实是一个游戏规则改变者。
毫无疑问。
实际上,我甚至使用 Pandas 创建了自己的数据清理工具箱。这个工具箱不过是处理凌乱数据的常用技巧的汇编。
我与 Pandas 的爱恨关系
别误解我的意思。
Pandas 很棒。它很强大。
Stack Overflow 对选择的 Python 包的流量
它仍然是最受欢迎的数据科学工具之一,用于数据清理和分析。
然而,随着在数据科学领域的时间增长,我处理的数据量从 10MB、10GB、100GB,增加到 500GB,有时甚至更多。
我的 PC 由于局部内存对大于 100GB 数据的低效使用,遭遇了低性能或长时间运行的问题。
那时我意识到 Pandas 最初并不是为大规模数据设计的。
那时我意识到大数据和巨大数据之间的明显差异。
Prof. Dan Ariely 的一个著名笑话:

“大”和“巨大”这两个词本身就是“相对的”,在我看来,大数据是少于 100GB 的数据集。
现在,Pandas 在处理小数据(通常是 100MB 到 1GB 之间)时非常高效,性能很少成为问题。
但当你的数据量远大于本地 RAM(例如 100GB)时,你可以选择使用 Pandas 处理数据的一些技巧 在一定程度上处理,或者选择更好的工具——在这种情况下是 Dask。
这次,我选择了后者。
为什么 Dask 如同魔法般有效
对于我们中的一些人来说,Dask 可能是你已经熟悉的东西。
但对大多数有志的数据科学家或刚刚入门的数据科学领域的人来说,Dask 可能听起来有点陌生。
这完全没问题。
实际上,直到我遇到 Pandas 的真正局限性,我才了解 Dask。
请记住,如果你的数据量足够小且可以容纳在你计算机的内存空间中,那么 Dask 就不是必需的。
所以现在的问题是……
什么是 Dask,为什么 Dask 比 Pandas 更适合处理大数据?
Dask 被广泛称为一个 Python 并行计算库
通过其并行计算功能,Dask 允许快速高效地扩展计算。
它提供了一种简单的方法来 处理大规模数据,只需在常规 Pandas 工作流之外付出最小的额外努力。
换句话说,Dask 允许我们轻松地 扩展到集群 以处理大数据,或 缩减到单台计算机 以处理大数据,通过充分利用 CPU/GPU 的全部力量,所有这些都与 Python 代码完美集成。
很酷,不是吗?
把 Dask 看作是 Pandas 在 性能和可扩展性 方面的扩展。
更酷的是,你可以在 Dask 数据框和 Pandas 数据框之间切换,根据需要进行数据转换和操作。
如何在大数据中使用 Dask?
好了,理论够多了。
现在是动手实践的时候了。
你可以 安装 Dask 并在你的本地 PC 上尝试使用你的 CPU/GPU。
但我们在这里讨论的是 大数据,所以让我们做一些 不同的 事情。
让我们做 大 的事。
与其通过缩减到单台计算机来驯服“巨兽”,不如通过 扩展到集群 来发现“巨兽”的全部力量,且 免费。
是的,我是认真的。
了解设置集群(例如 AWS)并将 Jupyter notebook 连接到云端可能对一些数据科学家,尤其是云计算初学者来说是一件麻烦事,我们可以使用 Saturn Cloud。
这是我最近尝试的新平台。
Saturn Cloud 是一个托管的数据科学和机器学习平台,它自动化了 DevOps 和 ML 基础设施工程。
令我惊讶的是,它使用 Jupyter 和 Dask 来 扩展 Python 以处理大数据,利用我们所熟知和喜爱的库(Numpy、Pandas、Scikit-Learn 等)。它还利用了 Docker 和 Kubernetes,以确保你的数据科学工作是可重复的、可共享的,并且准备好投入生产。
Dask 用户界面主要有三种类型,即 Array、Bag 和 Dataframe。我们将主要关注 Dask Dataframe,因为在下面的代码片段中,这就是我们作为数据科学家主要用于数据清理和分析的工具。
1. 将 CSV 文件读取到 Dask 数据框架
import dask.dataframe as dd
df = dd.read_csv('https://e-commerce-data.s3.amazonaws.com/E-commerce+Data+(1).csv', encoding = 'ISO-8859-1', blocksize=32e6)
Dask 数据框架在读取常规文件和数据转换方面与 Pandas 数据框架没有不同,这使得它对数据科学家非常有吸引力,正如你稍后将看到的那样。
在这里,我们只是读取了一个存储在S3中的单个 CSV 文件。由于我们只想测试 Dask 数据框架,文件大小相当小,共有 541909 行。
读取 CSV 文件后的 Dask 数据框架。
注意: 我们也可以在一行代码中 读取多个文件 到 Dask 数据框架中,无论文件大小。
当我们从 CSV 中加载数据时,Dask 会创建一个 按行分区 的数据框架,即按索引值对行进行分组。Dask 就是通过这种方式按需将数据加载到内存中并超快处理——它按分区处理。
在我们的例子中,我们看到 Dask 数据框架有 2 个分区(这是因为读取 CSV 时指定了 blocksize),有 8 个任务。
“分区” 这里简单地指在 Dask 数据框架中拆分的 Pandas 数据框架的数量。
分区越多,每次计算所需的任务就越多。
Dask 数据框架结构。
2. 使用 compute() 执行操作
现在我们已经将 CSV 文件读取到 Dask 数据框架中。
重要的是要记住,虽然 Dask 数据框架与 Pandas 数据框架非常相似,但确实存在一些差异。
我注意到的主要区别是 Dask 数据框架中的 compute 方法。
df.UnitPrice.mean().compute()
大多数 Dask 用户界面是 惰性 的,这意味着 它们不会进行计算,直到你明确要求结果 使用 compute 方法。
这是我们通过在 mean 方法后添加 compute 方法来计算 UnitPrice 平均值的方式。
3. 检查每列的缺失值数量
df.isnull().sum().compute()
同样,如果我们想检查每列的缺失值数量,我们需要添加 compute 方法。
4. 根据条件筛选行
df[df.quantity < 10].compute()
在数据清理或探索性数据分析(EDA)过程中,我们常常需要根据某些条件过滤行,以理解数据背后的“故事”。
我们只需添加 compute 方法,就能进行与 Pandas 完全相同的操作。
然后 BOOM!我们得到结果了!
创建 Dask 集群并在大规模运行 Jupyter 的 DEMO
现在我们已经了解了如何一般使用 Dask,接下来是如何 在 Saturn Cloud 上创建 Dask 集群 并在 Jupyter 中大规模运行 Python 代码。
我录制了一个简短的视频,展示如何在几分钟内设置 Dask 集群并运行 Python 代码。
如何在 Saturn Cloud 上创建 Dask 集群并运行 Jupyter Notebook
最后的思考
感谢阅读。
在功能方面,Pandas 依然胜出。
在性能和可扩展性方面,Dask 优于 Pandas。
在我看来,如果你的数据超过了几 GB(与 RAM 相当),为了性能和可扩展性,建议使用 Dask。
如果你想在几分钟内创建 Dask 集群并大规模运行你的 Python 代码,我强烈推荐你 在这里免费获取 Saturn Cloud 的社区版。
原文。已获许可转载。
简介: Admond Lee 目前致力于让数据科学对每个人都变得可及。他帮助公司和数字营销机构通过创新的数据驱动方法实现营销投资回报。他在高级社会分析和机器学习方面的专长旨在弥合数字营销和数据科学之间的差距。
相关:
更多相关话题
=LM=
数据科学面试必备的 21 个备忘单:解锁成功之路
原文:
www.kdnuggets.com/2022/06/21-cheat-sheets-data-science-interviews.html

图片来源:Bing Image Creator
数据科学是一个广泛且不断发展的领域,真的不可能将所有知识都记在脑海中。尤其是当你仅偶尔使用其中的一些知识时。如果你在某个领域是初学者,你将不得不经常复习你所学的内容,直到它成为理论和实践交汇的实际知识。
有一个可以一眼看到并获得所需信息的东西会非常有帮助,对吧?那个“东西”叫做备忘单。它与作弊无关。它们用于学习和复习你已经知道的内容。
由于备忘单的意图是(相对)简洁和高层次的,如果为整个数据科学领域制作一个备忘单会违背其(备忘单的,而不是数据科学的)目的。即使创建这样的备忘单是可能的。因此,你需要为不同的数据科学领域使用不同的备忘单。
我试图将这个范围缩小到涵盖数据科学家必备概念的备忘单。你可以将其视为关于备忘单的备忘单,讨论以下内容:
-
编程语言
-
SQL
-
Python
-
R
-
-
算法和模型
-
数据结构
-
数据可视化
-
概率和统计
-
数据处理
编程语言
了解编程语言是构建所有其他数据科学部分的基础。数据科学社区特别推崇的编程语言的圣三位一体是:
-
SQL
-
Python
-
R
SQL
专为查询数据库设计的语言 SQL 在数据提取和处理方面表现出色。
备忘单: SQL 基础备忘单
链接: learnsql.com/blog/sql-basics-cheat-sheet/
你获得的内容: 这个备忘单专注于让你从一开始就能编写有效的 SQL 查询。为此,你需要熟悉某些概念。这些概念包括查询单个表、过滤数据和使用 JOIN 查询多个表。还涵盖了聚合函数、子查询和集合操作符(UNION、INTERSECT、EXCEPT)。
除了对每个概念的简短解释外,备忘单还提供了基于示例数据的查询,以展示所有内容在实践中的工作方式。
备忘单也可以下载为 PDF 或 PNG 格式,这使得它在打印和随时使用时更加实用。
备忘单: 初学者的基本 SQL 命令备忘单
链接: itechbrand.com/the-essential-sql-commands-cheat-sheet-for-beginners/
你会得到: 与之前的备忘单不同,这个没有代码和数据示例。它仅仅列出了每个人都需要的 SQL 命令。当你想提醒自己某个关键词的作用时,它非常有用。它还涵盖了其他主题,如创建和编辑表、约束、数据、触发器、视图和公共表表达式(CTE)。
备忘单: SQL 备忘单 – 面试技术概念
链接: www.stratascratch.com/blog/sql-cheat-sheet-technical-concepts-for-the-job-interview/
你会得到: 关注于面试中最关键的 SQL 概念,这个备忘单涵盖了 JOIN、时间和日期函数、聚合函数、窗口函数和集合运算符。
每个技术主题和子主题都用简短的文字和易于理解的图形表示进行解释。此外,还有与相关主题有关的面试问题和解决代码。代码显示在小部件中,因此你可以进行操作,使其成为一个互动的备忘单。
Python
Python 理由充分地成为数据科学中最常用的编程语言之一。它在所需的所有领域表现出色。从数据提取和处理、统计分析和数据可视化到机器学习、模型部署和自动化,它确实做到了所有这些。
备忘单: Python 备忘单
链接: websitesetup.org/python-cheat-sheet/
你会得到: 这个非常全面而又非常清晰的备忘单非常适合任何希望为开始使用 Python 工作打下基础的人。它解释了 Python 中的主要数据类型,包括创建和存储字符串以及对数据进行数学运算。你还将学习内置函数、创建函数、列表、元组和字典。
备忘单继续给你概述条件语句、Python 循环、类,甚至处理 Python 错误。
你可以以 PDF 或信息图(PNG)格式下载备忘单。
备忘单: Python 备忘单
链接: programmingwithmosh.com/wp-content/uploads/2019/02/Python-Cheat-Sheet.pdf
你会得到: 一个与上面相似的备忘单。它主要涵盖相同的主题,但细节较少。解释非常出色,非常适合试图掌握 Python 基础的初学者。
备忘单可以以 PDF 格式下载。
备忘单: 综合 Python 备忘单
链接: github.com/gto76/python-cheatsheet
你会获得: 虽然初学者也可以使用这个备忘单,但它涵盖的主题比基本水平所需的要多得多。这里没有太多废话。作者浏览主题,列出关键词,并简短解释。它还提供了示例代码及其返回值。
涵盖的主题有集合、类型、语法、系统、数据、先进和库。每个主题进一步细分为子主题,使这个备忘单可能是大多数 Python 用户所需的唯一备忘单。
R
R 编程语言的灵活性稍逊于 Python,因此不适合模型部署。它是为统计分析和数据可视化而创建的。它不仅仅是这个目的,因为它还被广泛用于数据提取和处理、机器学习和自动化。
备忘单: RStudio 备忘单
链接: www.rstudio.com/resources/cheatsheets/
你会获得: 这些资源可能是你在 R 备忘单方面唯一需要的资源。涵盖了大量的备忘单和主题。用户贡献了涵盖基本和高级 R 的备忘单。
基础 R 备忘单讨论了向量、编程、数据类型、数学函数、统计学和其他主题。
高级 R 备忘单将对那些对环境、数据结构、面向对象系统、函数、子集、调试、条件处理和防御性编程感兴趣的人非常有用。
你可以在源网站上找到更多备忘单,专注于特定的 R 主题。例如,处理日期时间、字符串、数据转换、整理、可视化、深度学习等。
数据结构

数据科学家必须熟悉数据结构,作为组织和存储数据的一种方式。你可能不会一直使用所有可能的数据结构。当需要使用一个你不常用的数据结构时,备忘单可以为你提供关于该数据结构的一般概念。
备忘单: 数据结构参考
链接: www.interviewcake.com/data-structures-reference
你会获得: 它列出了所有数据结构,附有简短的定义和视觉表示,这对于快速参考非常有用。如果你想了解每个数据结构的更多细节,可以点击它,获取详细信息,如每个结构的优缺点、插入和删除的工作原理,以及其特定特征的解释。
备忘单: 面向面试的可执行数据结构备忘单
链接: algodaily.com/lessons/an-executable-data-structures-cheat-sheet
你得到的内容: 这份备忘单也解释了所有数据结构、它们的优缺点以及显著用途。备忘单提供了额外资源,以便深入学习每个数据结构。
此外,每个数据结构都有 JavaScript、Python 和 Java 的示例代码,你可以运行这些代码并查看返回结果。还有一个视频可以带你完整浏览数据表,并帮助你更好地理解。
数据处理
数据处理、清洗或整理是将原始数据转化为可用于进一步分析和处理的格式。在数据科学中,这通常通过 Python 及其库 pandas 来完成。
备忘单: 数据科学中的 Pandas 备忘单
链接: datascientyst.com/pandas-cheat-sheet-for-data-science/
你得到的内容: 适合初学者,这份备忘单展示了 pandas 主要命令的代码,并解释了每段代码的返回结果。涵盖的主题包括 pandas 设置、数据结构、数据导入与导出、数据检查和选择。你还将学习如何添加和删除行/列、排序、过滤、分组、转换、合并和连接数据,以及应用函数。每个主题都附有易于理解的图形表示。
备忘单: Pandas 备忘单
链接: geekyhumans.com/pandas-cheat-sheet/#Making-changes-to-the-data
你得到的内容: 这份备忘单与之前的备忘单涵盖的主题基本相同。不同的是,它主要通过展示代码及其输出进行解释,而不仅仅是解释代码。
备忘单: 使用 pandas 进行数据整理的备忘单
链接: pandas.pydata.org/Pandas_Cheat_Sheet.pdf
你得到的内容: 一份专门针对数据整理的详细备忘单。它涵盖了创建 DataFrames、方法链式调用、数据重塑、处理行和列、使用查询、数据汇总和分组、处理缺失数据、创建新列、合并数据集、使用窗口以及绘图。每个主题都有视觉解释和简短描述,每个 pandas 关键字都通过代码及其输出展示。
数据可视化

可视化数据是数据科学家工作的重要部分。某种程度上,这是将只有其他数据科学家才能理解的内容,也让“普通”人能够理解。它可以是数据分析或模型见解的可视化。无论哪种情况,这份备忘单都可能会派上用场。
备忘单: 数据可视化备忘单
链接: www.biosci.global/customer-stories-en/data-visualization-cheat-sheet/
你将获得: 这是一个关于数据可视化中使用的图表的良好概述。除了每种图表类型外,还有对其表示内容的简短解释和展示图像,这样你可以轻松地将每种图表的样子可视化出来。
还有一个关于如何为你的可视化选择正确图表的标准的视觉概述。
备忘单: 数据可视化备忘单
链接: www.kaggle.com/getting-started/160583
你将获得: 这里没有图表的解释。但所有图表都以视觉形式呈现,并根据其在数据可视化中的用途分为不同的部分。非常适合初学者和任何想快速检查是否选择了正确图表以及是否有更好的选项的人。
备忘单: 数据可视化备忘单
链接: medium.com/responsibleml/data-visualization-cheat-sheets-1c12ba8a7671
你将获得: 这里有几个围绕制作好图表主题的备忘单。这些备忘单不仅仅讲述选择正确图表的问题。备忘单还深入讨论了提供建议、展示数据地图的注意事项、选择正确的颜色(包括视觉障碍者的颜色)、使图表更具可读性、选择图表的坐标轴以及表示时间线等细节。所有备忘单都可以下载为 PDF 格式。
统计学与概率
对于任何数据科学家来说,拥有广泛的统计学知识,特别是概率知识,都是必须的。他们几乎在工作的每个部分都会用到这些知识:从数据分析到模型构建、测试和评估。由于统计学是一个广泛的学科,你在工作中可能只会使用其中的一部分。对于那些对你来说比较新的或不常用的统计学主题,你将需要一个好的备忘单来帮助自己。
备忘单: 综合统计学备忘单,用于数据科学面试
链接: www.stratascratch.com/blog/a-comprehensive-statistics-cheat-sheet-for-data-science-interviews/
你将获得: 这个备忘单涵盖了大多数数据科学家可能需要的所有统计学主题。这些主题包括置信区间、假设检验、Z 统计量和 T 统计量、A/B 测试、线性回归、概率规则、贝叶斯定理、组合与排列。对所有这些概念都有详细的解释,包括公式、图示和示例。
备忘单: 最全面的统计学备忘单
链接: terenceshin.medium.com/week-2-52-stats-cheat-sheet-ae38a2e5cdc6
你会得到什么: 一般涵盖一个或两个主题,与之前的备忘单类似。然而,这里的大多数统计概念是不同的。它们包括数据类型、集中趋势度量(均值、中位数、众数)、变异度量(范围、方差、标准差……)、变量之间关系的测量(协方差和相关性)、概率分布函数、连续和离散数据分布、矩以及准确性。
备忘单: 统计学备忘单
链接: web.mit.edu/~csvoss/Public/usabo/stats_handout.pdf
你会得到什么: 这个备忘单一般不会覆盖之前两个备忘单未涉及的内容。然而,除了理论解释外,这个备忘单提供了非常详细的示例,肯定能帮助你理解相关概念。
算法与模型
所有之前提到的主题通常作为终极数据科学家任务的基础:编写算法和创建模型。这时统计和编码知识与寻找有用的备忘单来涵盖算法和模型的知识结合在一起。
备忘单: 顶级预测算法
链接: blog.dataiku.com/machine-learning-explained-algorithms-are-your-friend
你会得到什么: 这个备忘单从总体上解释了机器学习以及最流行的算法。这些算法包括线性回归、逻辑回归、决策树、随机森林、梯度提升和神经网络。一个非常好的特点是描述每种算法、优缺点的 инфографика。
备忘单: 你的终极数据科学统计与数学备忘单
链接: towardsdatascience.com/your-ultimate-data-science-statistics-mathematics-cheat-sheet-d688a48ad3db
你会得到什么: 详细解释了机器学习指标。它涵盖了分类器指标、回归器指标、统计指标和分布类型的主题。解释详细,配有清晰的图形表示、公式和示例。
备忘单: 机器学习模型备忘单
链接: medium.com/analytics-vidhya/machine-learning-models-cheatsheet-7885b33ca44f
你将获得的内容: 再次提供了一个非常全面的备忘单,重点关注机器学习的算法。解释详细,包含示例,最重要的是,介绍了每个算法的构建步骤。作者涵盖了以下主题:多元线性回归、决策树回归、逻辑回归、朴素贝叶斯分类器、二分类器的性能评估、ROC 曲线、支持向量机(SVM)、随机森林、k 均值聚类、k 近邻、层次聚类、主成分分析(PCA)、线性判别分析(LDA)、文本数据处理、排名算法。
结论
在这篇文章中,我涵盖了编码、数据结构、数据处理、数据可视化、统计与概率、模型与算法。这些当然不是你作为数据科学家需要涵盖的唯一话题,但它们是大多数数据科学家在职业生涯中需要的主题。
我推荐的备忘单是我认为最全面的备忘单的缩小版清单。它们在大多数情况下会为你提供帮助,我认为它们至少是一个很好的起点。
内特·罗西迪 是一名数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家准备顶级公司的真实面试问题。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
相关话题
21 个必须了解的数据科学面试问题及答案,第二部分
原文:
www.kdnuggets.com/2016/02/21-data-science-interview-questions-answers-part2.html
评论 KDnuggets 上的帖子 20 个检测虚假数据科学家的问题 非常受欢迎,是本月最受关注的帖子。
然而,这些问题缺乏答案,因此 KDnuggets 编辑们聚在一起编写了 答案。这是第二部分的答案,从一个“额外”问题开始。
额外问题:解释什么是过度拟合以及如何控制它
这个问题不是原始的 20 个问题之一,但可能是区分真正的数据科学家与虚假的最重要的问题。
回答者 Gregory Piatetsky.
过度拟合是发现由于偶然性产生的虚假结果,并且后续研究无法重复这些结果。
我们经常看到关于研究推翻以前发现的新闻报道,例如鸡蛋不再对健康有害,或 饱和脂肪与心脏病无关。在我们看来,问题在于许多研究人员,特别是在社会科学或医学领域,过于频繁地犯了数据挖掘的根本罪过——过度拟合数据。
研究人员测试了太多假设而没有适当的统计控制,直到他们偶然找到有趣的结果并报告它。不出所料,下次该效果(至少部分是)由于偶然因素,可能会小得多或根本不存在。
这些研究实践中的缺陷由 John P. A. Ioannidis 在其具有里程碑意义的论文 为何大多数已发表的研究结果是错误的(PLoS Medicine,2005)中指出并报告。Ioannidis 发现,研究结果往往被夸大,或者发现无法重复。在他的论文中,他提供了统计证据,证明确实大多数声称的研究结果都是错误的。
Ioannidis 指出,为了使研究结果可靠,它应该具备:
-
大样本量和大效应
-
更多的测试关系和更少的选择
-
设计、定义、结果和分析模式的更大灵活性
-
最小化由于财务和其他因素(包括该科学领域的受欢迎程度)造成的偏差
不幸的是,这些规则常常被违反,产生了不可重复的结果。例如,S&P 500 指数被发现与孟加拉国黄油生产(19891 年至 1993 年)有强相关性(这是 PDF)
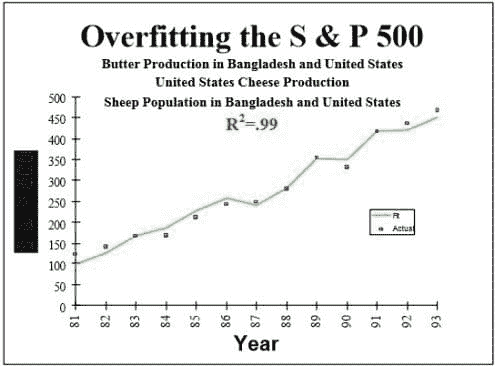
查看更多有趣(且完全虚假的)发现,你可以使用Google correlate或Spurious correlations by Tyler Vigen 自己发现。
有几种方法可以用来避免“过拟合”数据
-
尝试找到可能的最简单假设
-
正则化(对复杂性添加惩罚)
-
随机化测试(随机化类别变量,尝试在这些数据上使用你的方法——如果找到相同的强结果,则表示出现了问题)
-
嵌套交叉验证(在一个层级上进行特征选择,然后在外层级上运行整个方法的交叉验证)
-
调整虚假发现率
-
使用可重复的保留集方法——一种在 2015 年提出的突破性方法
良好的数据科学站在科学理解的前沿,数据科学家有责任避免过拟合数据,并教育公众和媒体关于糟糕数据分析的危险。
另见
-
数据挖掘和数据科学的根本错误:过拟合
-
避免过拟合的关键理念:可重复的保留集以保持自适应数据分析中的有效性
-
通过可重复的保留集克服过拟合:在自适应数据分析中保持有效性
-
11 种聪明的过拟合方法及如何避免它们
-
标签:过拟合
Q12。举例说明你如何使用实验设计来回答关于用户行为的问题。
答案由Bhavya Geethika提供。
步骤 1:制定研究问题:
页面加载时间对用户满意度评分的影响是什么?
步骤 2:识别变量:
我们识别原因和结果。独立变量——页面加载时间,依赖变量——用户满意度评分
步骤 3:生成假设:
降低页面下载时间将对网页的用户满意度评分产生更多影响。这里我们分析的因素是页面加载时间。

图 12: 你的实验设计存在缺陷(漫画来自这里)
步骤 4: 确定实验设计。
我们考虑实验复杂性,即一次变化一个因素或一次变化多个因素,在这种情况下我们使用因子设计(2^k 设计)。设计也基于目标类型(比较、筛选、响应面)和因素数量进行选择。
这里我们还识别了被试内设计、被试间设计和混合模型。例如:有两个版本的页面,一个版本的购买按钮(行动呼吁)在左侧,另一个版本的按钮在右侧。
在被试内设计 - 两个用户组都会看到两个版本。
在被试间设计 - 一组用户看到版本 A,另一组用户看到版本 B。
步骤 5: 开发实验任务和程序:
需要详细描述实验中涉及的步骤、用于测量用户行为的工具、目标和成功指标。收集有关用户参与的定性数据,以进行统计分析。
步骤 6: 确定操控与测量
操控:一个因素将被控制,另一个因素将被操控。我们还识别行为测量:
-
延迟 - 提示与行为发生之间的时间(用户在看到产品后点击购买所需的时间)。
-
频率 - 行为发生的次数(用户在指定时间内点击页面的次数)
-
持续时间 - 特定行为持续的时间(添加所有产品所需的时间)
-
强度 - 行为发生的力度(用户购买产品的速度)
步骤 7: 分析结果
识别用户行为数据并根据观察支持或反驳假设,例如,比较大多数用户的满意度评分与页面加载时间。
Q13. “长”(“高”)和“宽”格式数据的区别是什么?
由 Gregory Piatetsky 回答。
在大多数数据挖掘/数据科学应用中,记录(行)的数量通常远多于特征(列)的数量,这类数据有时被称为“长”(或“高”)数据。
在一些应用中,如基因组学或生物信息学,你可能只有少量记录(患者),例如 100 个,但每个患者可能有 20,000 个观察值。适用于“长”数据的标准方法将导致过拟合,因此需要特殊的方法。
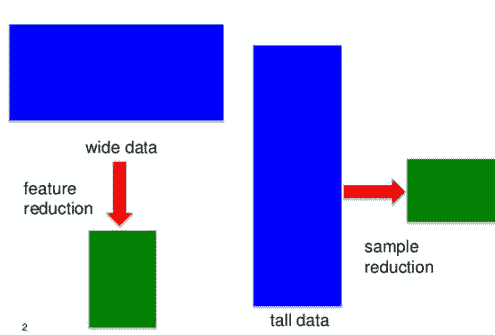
图 13. 高数据和宽数据的不同方法,来自演示文稿稀疏筛选以实现精确数据减少,作者 Jieping Ye。
问题不仅仅是重塑数据(这里有有用的 R 包),还要通过减少特征数量来避免假阳性,以找到最相关的特征。
像 Lasso 这样的特征减少方法在《具有稀疏性的统计学习:Lasso 及其推广》中得到了很好的介绍,作者为 Hastie、Tibshirani 和 Wainwright。(你可以下载这本书的免费 PDF)
更多相关主题
21 个必须知道的数据科学面试问题及答案
原文:
www.kdnuggets.com/2016/02/21-data-science-interview-questions-answers.html/3
8. 什么是统计功效?
由 Gregory Piatetsky 回答:
维基百科定义了统计功效或敏感性,即当备择假设(H1)为真时,二元假设检验正确拒绝零假设(H0)的概率。
换句话说,统计功效是研究在效应存在时检测到效应的可能性。统计功效越高,犯第二类错误(即当实际上存在效应时却得出没有效应的结论)的可能性就越小。
这里有一些工具可以计算统计功效。
9. 解释什么是重采样方法及其作用。还要解释它们的局限性。
由 Gregory Piatetsky 回答:
经典的统计参数检验将观察到的统计量与理论采样分布进行比较。重采样是一种数据驱动的方法,而非理论驱动的方法,基于在相同样本内重复采样。
重采样是指用于执行以下方法的一种方法
-
通过使用可用数据的子集(切割法)或从数据点集合中随机抽取(自助法)来估计样本统计量(中位数、方差、百分位数)的精确性。
-
在进行显著性测试时(置换测试,也称为精确测试、随机化测试或重新随机化测试),对数据点标签进行交换。
-
通过使用随机子集(自助法、交叉验证)来验证模型。
另请参见如何使用自助法和 Apache Spark 检查假设
 ](/2016/01/hypothesis-testing-bootstrap-apache-spark.html)
](/2016/01/hypothesis-testing-bootstrap-apache-spark.html)
这里有一个关于重采样统计的良好概述。
10. 是出现较多假阳性好,还是较多假阴性好?请解释。
由Devendra Desale回答。
这取决于问题以及我们试图解决的问题的领域。
在医学测试中,假阴性可能会给患者和医生提供一种虚假的安慰信息,认为疾病不存在,实际上却是存在的。这有时会导致对患者及其疾病的不适当或不充分的治疗。因此,出现较多假阳性是更为理想的。
在垃圾邮件过滤中,假阳性发生在垃圾邮件过滤或阻挡技术错误地将合法邮件归类为垃圾邮件,从而干扰其投递。虽然大多数反垃圾邮件策略可以阻止或过滤高比例的垃圾邮件,但在不产生显著的假阳性结果的情况下进行这种操作要困难得多。因此,我们宁愿接受过多的假阴性,也不愿接受过多的假阳性。
11. 什么是选择偏差?它为什么重要?你如何避免它?
答案由马修·梅奥提供。
选择偏差通常是指由于样本非随机而引入的误差。例如,如果一个由 100 个测试用例组成的样本在实际人群中相对均等的四个类别中以 60/20/15/5 的比例分布,那么一个模型可能会错误地假设概率是决定性预测因素。避免非随机样本是应对偏差的最佳方法;然而,当这不切实际时,诸如重采样、提升和加权等技术是应对这种情况的策略。
这是答案的第二部分。
更多相关话题
-
检测假数据科学家的 20 个问题(含答案):ChatGPT…
通过反复询问“为什么?”来找到问题的根本原因并展示原因之间的关系,直到找到问题的根源。这种技术通常被称为“5 个为什么”,尽管它可以涉及多于或少于 5 个问题。

图 5 Whys 分析示例,来自 根本原因分析艺术 。
Q7. 你对价格优化、价格弹性、库存管理、竞争情报有了解吗?举例说明。
由 Gregory Piatetsky 的回答:
这些是经济学术语,数据科学家不常被问到,但了解它们是有用的。
价格优化是利用数学工具来确定客户如何通过不同渠道对不同价格的产品和服务作出反应。
大数据和数据挖掘使个性化价格优化成为可能。现在像亚马逊这样的公司甚至可以进一步优化,根据不同访问者的历史显示不同的价格,尽管是否公平仍存在强烈的争议。
常用的价格弹性通常指
-
需求价格弹性,即价格敏感度的测量。它的计算方法是:
价格需求弹性 = 需求量变化百分比 / 价格变化百分比。
类似地,供给价格弹性是一个经济学指标,显示了商品或服务的供给量如何响应价格变化。
库存管理是对公司用于生产销售商品的组件的订购、储存和使用进行监督和控制,以及对销售的成品数量进行监督和控制。
维基百科定义
竞争情报:定义、收集、分析和分发关于产品、客户、竞争对手及环境的情报,以支持高管和管理人员为组织做出战略决策。
工具如 Google Trends、Alexa、Compete 可以用来确定一般趋势并分析你在网络上的竞争对手。
这里是有用的资源:
-
竞争情报指标、报告由 Avinash Kaushik 提供
-
37 个最佳营销工具来监视你的竞争对手来自 Kissmetrics
更多相关主题
掌握 LLM 的 5 门课程

图片由编辑提供
大型语言模型(LLM)近年来因像 ChatGPT 和谷歌 Gemini 这样的产品而变得更加流行。几十年前,人们对人工智能的能力一无所知,而现在,每个人都在尽力跟上趋势。如果我查看招聘信息,许多公司现在也将 LLM 技能作为其要求。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 方面的组织
由于 LLM 所带来的竞争优势,我们应该至少尝试学习它们。无论你是初学者还是数据专业人士,我们都应该努力掌握 LLM,以脱颖而出。
在这篇文章中,我将讨论五门课程,帮助你掌握 LLM。这些课程是什么?让我们开始吧。
1. 全栈 LLM 训练营
首先,我们有全栈 LLM 训练营,由 fullstackdeeplearning.com 开发。该网站提供了优秀的自学深度学习课程,但我们将重点关注 LLM 课程。
自 2023 年以来,该公司已在现场举办训练营,但也发布了所有学习材料的阅读和视频格式。 这些课程的好处在于,无论你的知识水平如何,你都可以开始学习。然而,尽管 LLM 不是必需的,但你仍然需要具备一些机器学习知识。
这门课程旨在帮助你跟上最新的 LLM 技术,并准备构建和部署 LLM 应用。为此,课程提供了多个主题:
-
LLM 基础
-
提示工程
-
LLMOps:生产环境中的部署和学习
-
语言用户界面的用户体验
-
增强型语言模型
这门课程容易跟随,因此不要错过这门免费的 LLM 训练营课程,以掌握 LLM。
2. Cohere 的 LLM 大学
下一门课程是由 Cohere 提供的 LLM 大学。Cohere 是一家专注于 LLM 产品和研究开发的公司,这使他们对 LLM 有深入了解。该公司推出了一门免费的 LLM 大学课程,以帮助人们理解 LLM。
LLM 大学提供自然语言处理和大型语言模型的课程。课程旨在提高学习者的技能,强化 NLP 基础,并实际应用 LLM 于现实世界中。
课程包含几个主题:
-
自然语言处理和机器学习基础
-
组合端点构建应用
-
什么是大型语言模型?
-
使用 Cohere 端点的文本表示
-
使用 Cohere 端点的文本生成
课程适合初学者和专业人士,因为课程结束时你可以推出生产就绪的 LLM 应用。
3. 构建 LLM 驱动的应用课程
我们需要掌握的第三门 LLM 课程是 构建 LLM 驱动的应用课程,由 Weight & Biases (WB) 提供。该公司专注于开发端到端的机器学习平台,其中包括 LLM 应用。
课程提供了许多自管理的视频课程,你可以跟随学习如何开发 LLM 应用。主题包括:
-
LLM 应用简介
-
LLM API
-
构建 LLM 应用
-
优化 LLM 应用
这是一门更高级的课程,因此我们预计需要了解编程语言和 LLM 的基础知识。然而,课程内容足够简单,便于立即学习。
4.LangChain 和生产中的向量数据库
生产中的 LangChain 和向量数据库 由 activeloop 提供,是一门高级课程,用于掌握 LLM 生产应用。该课程不仅关注 LLM,还将指导你如何提升现有 LLM,以便准备好应对任何面向客户的应用。
为了在 LLM 行业中取得进展,我们需要了解 LangChain 和向量数据库,这些都是 LLM 应用生产中的关键。通过这门课程,你将理解以下概念:
-
LangChain 和 LLM 介绍
-
提示生成
-
向量数据库的使用
-
索引组织
-
与 Chain 结合
这些课程很棒,如果你已经知道 LLM 的基础知识,但即使是初学者也可以跟随学习。
5. 大型语言模型:应用通过生产
最后一门课程是 大型语言模型:应用通过生产,由 Databricks 提供。Databricks 是一家为企业提供智能平台的公司,包括构建和部署 LLM 应用。如果你想申请 LLM 工作,这门课程是工业标准,值得学习。
课程适用于开发人员、数据科学家和工程师,但即使你不是其中之一,也可以跟随学习。通过使用流行的框架和最先进的技术,如 HuggingFace、LangChain、向量数据库、数据嵌入等,你将学习到开发和制作 LLM 应用的高级技术。
这些课程将教授你许多与 LLM 相关的主题,包括:
-
LLM 的应用
-
嵌入、向量数据库和搜索
-
多阶段推理
-
微调和评估 LLMs
-
社会与大型语言模型(LLMs):偏见与安全
-
LLMOps
在课程结束时,你将准备好构建企业肯定希望使用的高级 LLM 应用程序。
结论
这篇文章讨论了五门课程,旨在让学习者准备好开发和生产大型语言模型应用程序。从这些课程中学习所有内容,你将为申请 LLM 职位做好准备。
Cornellius Yudha Wijaya** 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他热衷于通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种人工智能和机器学习相关的文章。
更多相关主题
=机器学习=
机器学习:什么是自助法?

图片来源:作者
机器学习是一个不断发展的领域,它正在改变我们处理和分析数据的方式。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
自助法是机器学习领域中的一种重要技术,对构建稳健且准确的模型至关重要。
在本文中,我们将深入探讨自助法是什么以及它如何在机器学习中使用。
此外,我们还将探讨决策树分类器和鸢尾花数据集。这将用于展示自助法在现实世界中的应用实例。
通过这篇文章,我们旨在提供对自助法的全面理解。
此外,我们还将介绍它在机器学习中的应用。这将使你掌握将其应用于自己的机器学习项目的知识。
但首先,自助法是什么?
什么是自助法?
自助法是一种重采样技术,有助于估计统计模型的不确定性。
这包括对原始数据集进行带替换的抽样,并生成多个与原始数据集大小相同的新数据集。
每个新数据集都用于计算所需的统计量,例如均值或标准差。
这个过程会重复多次,所得的值用于构建所需统计量的概率分布。
这种技术在机器学习中经常用于估计模型的准确性、验证其性能,并识别需要改进的领域。
例如,我们可以使用自助抽样来计算总体均值。结果如下所示。
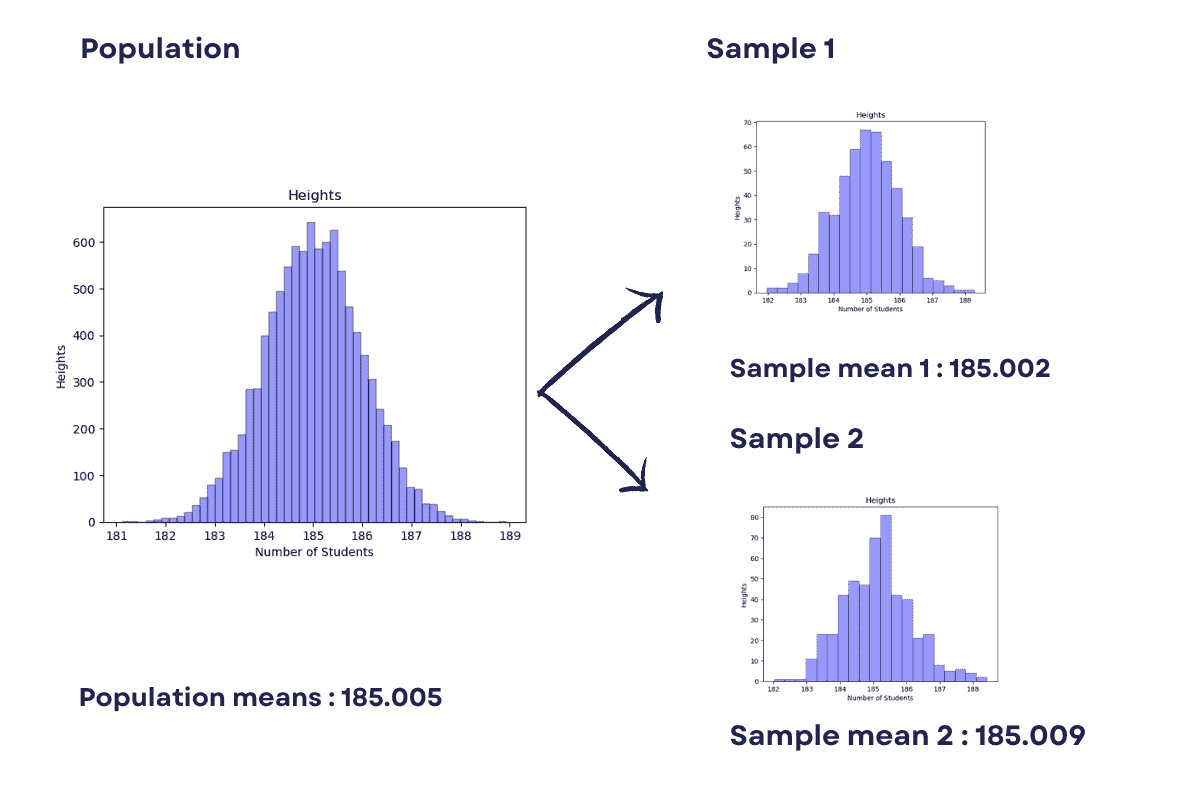
图片来源:作者
我们将在本文稍后部分进一步讨论这个示例。
如何在机器学习中使用自助法?
自助法可以通过多种方式在机器学习中使用,包括模型性能估计、模型选择以及识别数据集中最重要的特征。
引导法在机器学习中的一个流行用例是估计分类器的准确性,我们将在本文中进行这一操作。
让我们从一个简单的 Python 引导示例开始作为热身。
引导法中的均值计算
我们将展示如何使用引导法来估计一个有 10,000 名学生的学校的平均身高。
一般的方法是通过将所有身高相加,然后将总和除以 10,000 来计算均值。
首先,使用 NumPy 库生成一个由 10,000 个随机生成的数字(身高)组成的样本。
import numpy as np
import pandas as pd
x = np.random.normal(loc= 185.0, scale=1.0, size=10000)
np.mean(x)
这是均值的输出结果。
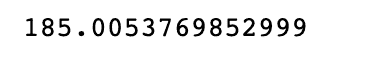
现在,我们如何仅从 200 名学生中计算这些学生的身高呢?
在引导抽样中,我们通过从总体中随机选择元素并进行替换来创建多个样本。
在我们的例子中,样本大小将是 5。这意味着在 200 名学生的总体中将有 40 个样本。
使用下面的代码,我们将从学生中抽取 40 个样本,每个样本大小为 5。(x)
这包括从原始样本中进行带替换的随机抽样,以创建 40 个新样本。
替换是什么意思?
我的意思是首先从 10,000 个中选择一个,忘记我选择了谁,然后再次从 10,000 个中选择一个。
你可以选择同一个学生,但这种情况的概率很小。替换听起来不那么聪明了,对吧?
每个新的样本大小为 5,比原始样本要小。每个新样本的均值被计算并存储在 sample_mean 列表中。
最后,计算所有 40 个样本均值的均值,并代表总体均值的估计。
这是代码。
import random
sample_mean = []
# Bootstrap Sampling
for i in range(40):
y = random.sample(x.tolist(), 5)
avg = np.mean(y)
sample_mean.append(avg)
np.mean(sample_mean)
这里是输出结果。
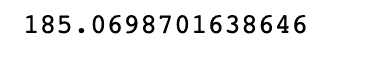
这很接近,对吧?
使用决策树的分类任务中的引导法
在这里,我们将看到使用决策树的引导法在分类中的应用,使用的是 Iris 数据集。但首先,让我们了解一下什么是决策树。
什么是决策树?
决策树是一个流行的机器学习算法,广泛用于分类和回归问题。它是一种基于树的模型,通过从根节点分支出来并根据某些条件做出决策来进行预测。
决策树分类器是这种算法的一种具体实现,用于执行二分类任务。
决策树分类器的主要目标是确定最重要的特征,这些特征有助于预测目标变量。该算法使用贪婪方法,通过选择信息增益最高的特征来最小化树的杂质。树会继续分裂,直到数据完全纯净或达到停止准则。
什么是 Iris 数据集?
Iris 数据集是用于评估分类任务的流行数据集之一。
该数据集包含 150 个鸢尾花观察样本,每个样本包含如花萼长度、花萼宽度、花瓣长度和花瓣宽度等特征。
目标变量是鸢尾植物的种类。
Iris 数据集广泛用于机器学习算法中,以评估不同模型的性能,并作为示例来演示决策树分类器的概念。
现在,让我们看看如何在分类中使用自助抽样和决策树。
自助抽样的编码
该代码实现了一种机器学习模型的自助抽样技术,使用了来自 sci-kit-learn 库的 DecisionTreeClassifier。
前几行加载 Iris 数据集,并从中提取特征数据(X)和目标数据(y)。
自助抽样函数接受特征数据(X)、目标数据(y)和用于自助抽样的样本数量(n_samples)。
该函数返回一个经过训练的模型列表以及一个包含精度、召回率、F1 分数和用于自助抽样的索引的 pandas 数据框。
自助抽样过程在for loop中完成。
对于每次迭代,函数使用np.random.choice方法随机选择特征数据(X)和目标数据(y)的样本。
然后,使用train_test_split方法将样本数据分为训练集和测试集。DecisionTreeClassifier 在训练数据上进行训练,然后用于对测试数据进行预测。
精度、召回率和 F1 分数使用来自 sci-kit-learn 库的metrics.precision_score、metrics.recall_score和metrics.f1_score方法进行计算。这些分数然后在每次迭代中添加到一个列表中。
最后,结果保存到一个 pandas 数据框中,包含精度、召回率、F1 分数、训练模型和用于自助抽样的索引列。然后由函数返回数据框。
现在,让我们看看代码。
from sklearn import metrics
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# Load the iris dataset
iris = load_iris()
X, y = iris.data, iris.target
def bootstrap(X, y, n_samples=2000):
models = []
precision = []
recall = []
f1 = []
indices_x = []
indices_y = []
for i in range(n_samples):
index_x = np.random.choice(X.shape[0], size=X.shape[0], replace=True)
indices_x.append(index_x)
X_sample = X[index_x, :]
index_y = np.random.choice(y.shape[0], size=y.shape[0], replace=True)
indices_y.append(index_y)
y_sample = y[index_y]
X_train, X_test, y_train, y_test = train_test_split(
X_sample, y_sample, test_size=0.2, random_state=42
)
model = DecisionTreeClassifier().fit(X_train, y_train)
models.append(model)
y_pred = model.predict(X_test)
precision.append(
metrics.precision_score(y_test, y_pred, average="macro")
)
recall.append(metrics.recall_score(y_test, y_pred, average="macro"))
f1.append(metrics.f1_score(y_test, y_pred, average="macro"))
# Save the results to a Pandas dataframe
pred_df = pd.DataFrame(
{
"Precision": precision,
"Recall": recall,
"F1": f1,
"Models": models,
"Indices_X": indices_x,
"Indices_Y": indices_y,
}
)
现在调用函数。
models, pred_df = bootstrap(X, y)
显示函数创建的数据框的结果。
pred_df.head()

现在,将索引列添加为模型编号,
pred_df['Model Number'] = pred_df.index,
并按精度对值进行排序。
pred_df.sort_values(by= "Precision", ascending = False).head(5)
为了更好地查看结果,我们将进行一些数据可视化。

自助抽样可视化
下面的代码创建了 3 个条形图,以显示自助抽样模型的性能。
模型的性能通过精确度、召回率和 F1 分数来衡量。因此,我们将创建一个名为 pred_df 的数据框。该数据框存储模型的分数。
这段代码创建了一个包含 3 个子图的图形。
第一个子图(ax2)是一个条形图,显示了前 5 个模型的精确度分数。
x 轴显示精确度分数,y 轴显示模型的索引。每个条形图的中心显示了这些 3 个数值。该图的标题为“精确度”。
第二个子图(ax3)是一个条形图,显示了前 5 个模型的召回率分数。x 轴显示召回率分数,y 轴显示模型的索引。该图的标题为“召回率”。
第三个子图(ax4)是一个条形图,显示了前 5 个模型的 F1 分数。x 轴显示 F1 分数,y 轴显示模型的索引。该图的标题为“F1”。
整个图形的标题为“自助法模型性能指标”。我们将使用 plt.show()来显示这些图像。
这是代码。
import matplotlib.pyplot as plt
# Create a figure and subplots
fig, (ax2, ax3, ax4) = plt.subplots(1, 3, figsize=(14, 8))
best_of = pred_df.sort_values(by="Precision", ascending=False).head(5)
# Create the first graph
best_of.plot(
kind="barh",
x="Model Number",
y="Precision",
color="mediumturquoise",
ax=ax2,
legend=False,
)
ax2.set_xlabel(
"Precision Score",
fontstyle="italic",
fontsize=14,
font="Courier New",
fontweight="bold",
y=1.1,
)
ylabel = "Model\nName"
ax2.set_ylabel(ylabel, fontsize=16, font="Courier")
ax2.set_title("Precision", fontsize=16, fontstyle="italic")
for index, value in enumerate(best_of["Precision"]):
ax2.text(
value / 2,
index,
str(round(value, 2)),
ha="center",
va="center",
fontsize=14,
font="Comic Sans MS",
)
best_of = pred_df.sort_values(by="Recall", ascending=False).head(5)
# Create the second graph
best_of.plot(
kind="barh",
x="Model Number",
y="Recall",
color="orange",
ax=ax3,
legend=False,
)
ax3.set_xlabel(
"Recall Score",
fontstyle="italic",
fontsize=14,
font="Courier New",
fontweight="bold",
)
ax3.set_ylabel(ylabel, fontsize=16, font="Courier")
ax3.set_title("Recall", fontsize=16, fontstyle="italic")
for index, value in enumerate(best_of["Recall"]):
ax3.text(
value / 2,
index,
str(round(value, 2)),
ha="center",
va="center",
fontsize=14,
font="Comic Sans MS",
)
# Create the third graph
best_of = pred_df.sort_values(by="F1", ascending=False).head(5)
best_of.plot(
kind="barh",
x="Model Number",
y="F1",
color="darkorange",
ax=ax4,
legend=False,
)
ax4.set_xlabel(
"F1 Score",
fontstyle="italic",
fontsize=14,
font="Courier New",
fontweight="bold",
)
ax4.set_ylabel(ylabel, fontsize=16, font="Courier")
ax4.set_title("F1", fontsize=16, fontstyle="italic")
for index, value in enumerate(best_of["F1"]):
ax4.text(
value / 2,
index,
str(round(value, 2)),
ha="center",
va="center",
fontsize=14,
font="Comic Sans MS",
)
# Fit the figure
plt.tight_layout()
plt.suptitle(
"Bootstrapped Model Performance Metrics",
fontsize=18,
y=1.05,
fontweight="bold",
fontname="Comic Sans MS",
)
# Show the figure
plt.show()
这是输出结果。
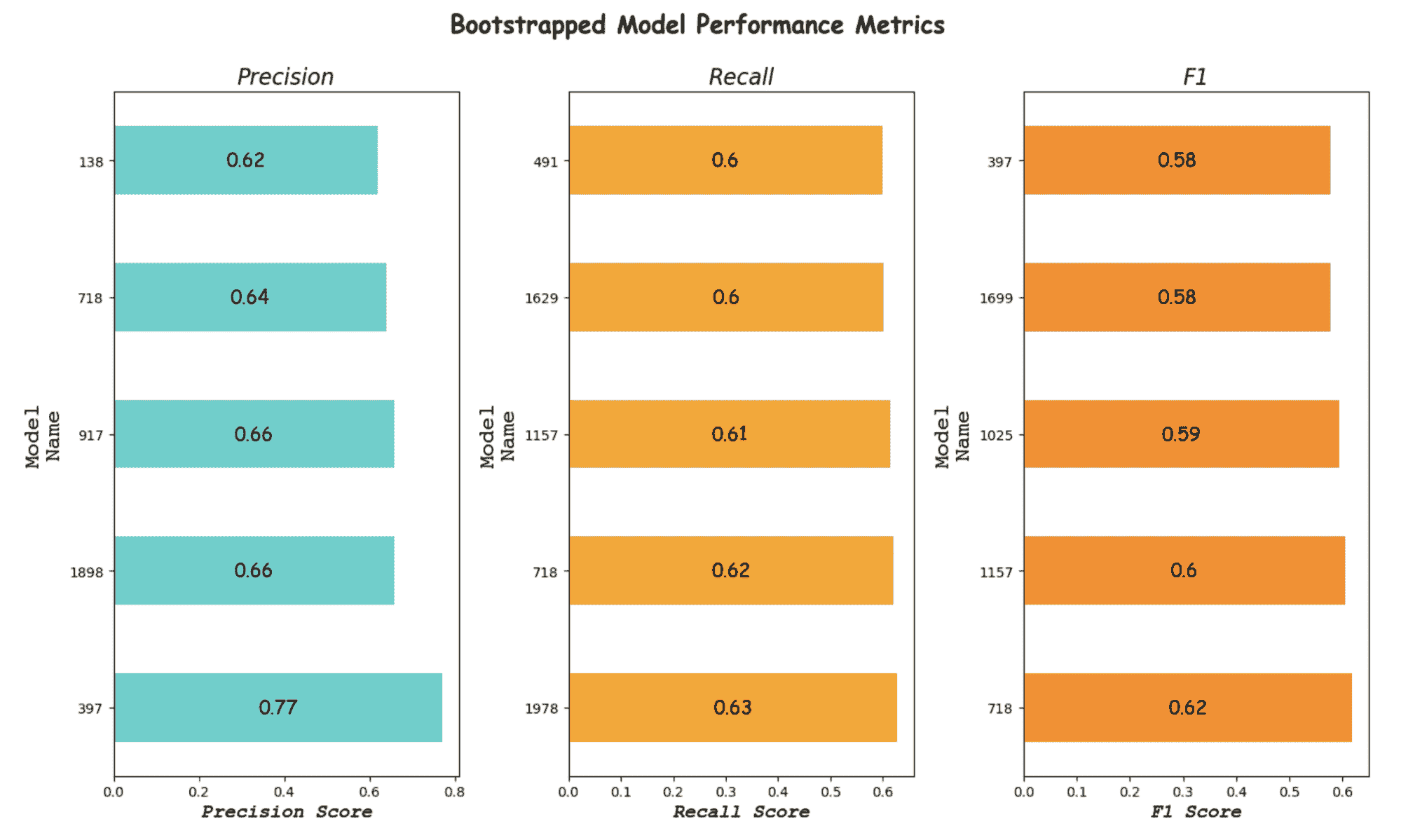
图片由作者提供
根据精确度和 F1 分数来看,模型 397 是我们表现最好的模型。
当然,如果召回率对你的项目更为重要,你可以选择模型 718 或其他模型。
复制最佳结果
现在,我们已经保存了这些索引以创建可复制的结果。我们将选择第 397 个模型,并查看结果是否可重复。
以下代码首先使用 pred_df 数据框第 397 行中存储的索引选择数据(X 和 y)的一个样本。
然后,使用train_test_split方法将样本数据分割为训练集和测试集,测试集的大小为 0.2,随机状态为 42。
接下来,使用训练数据训练一个决策树分类器模型,并将其存储在模型列表中。然后,使用predict()方法对测试数据进行预测。
最后,使用precision_score、recall_score和f1_score函数从 metrics 模块计算模型的精确度、召回率和 F1 分数,并打印到控制台。
这些分数通过测量模型正确分类数据的能力以及模型生成的假阳性和假阴性的水平来评估模型的性能。
这是代码。
X_sample = X[pred_df.iloc[397]["Indices_X"], :]
y_sample = y[pred_df.iloc[397]["Indices_Y"]]
X_train, X_test, y_train, y_test = train_test_split(
X_sample, y_sample, test_size=0.2, random_state=42
)
model = DecisionTreeClassifier().fit(X_train, y_train)
models.append(model)
y_pred = model.predict(X_test)
precision_397 = metrics.precision_score(y_test, y_pred, average="macro")
recall_397 = metrics.recall_score(y_test, y_pred, average="macro")
f1_397 = metrics.f1_score(y_test, y_pred, average="macro")
print("Precision : {}".format(precision_397))
print("Recall : {}".format(recall_397))
print("F1 : {}".format(f1_397))
这是输出结果。

结论
总结来说,自助法是机器学习中一个强大的工具,可以用来提高算法的性能。通过创建数据的多个子集,自助法有助于降低过拟合的风险,并提高结果的准确性。
我们展示了如何使用自助法对分类算法进行决策树分类器的应用。
通过结合自助法和决策树分类器,我们可以创建一个强大的机器学习模型,提供准确和可靠的结果,这些结果可能适用于其他分类算法。
理解所有这些概念对于数据科学家和机器学习专业人士来说至关重要。我会说这是必须的!这些概念可以帮助你做出明智的决策,选择合适的工具和技术来解决实际问题。
内特·罗西迪 是一位数据科学家及产品战略专家。他还担任兼职教授教授分析学,并且是StrataScratch的创始人,该平台帮助数据科学家为面试准备来自顶级公司的真实面试问题。可以在Twitter: StrataScratch或LinkedIn上与他联系。
更多相关话题
使用 Scikit-learn 进行机器学习分类入门
www.kdnuggets.com/getting-started-with-scikit-learn-for-classification-in-machine-learning

图片来源:编辑
Scikit-learn 是最常用的 Python 机器学习库之一。它的受欢迎程度可以归因于其简单一致的代码结构,适合初学者开发者使用。此外,它还提供了高水平的支持,并且可以灵活集成第三方功能,使得该库强大且适用于生产。该库包含多个用于分类、回归和聚类的机器学习模型。在本教程中,我们将通过各种算法探索多类别分类问题。让我们深入了解并构建我们的 scikit-learn 模型。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
安装最新版本
pip install scikit-learn
加载数据集
我们将使用 scikit-learn 数据集模块中的“Wine”数据集。该数据集包含 178 个样本和 3 个类别。数据集已预处理并转换为特征向量,因此我们可以直接用来训练我们的模型。
from sklearn.datasets import load_wine
X, y = load_wine(return_X_y=True)
创建训练和测试数据
我们将保留 67%的数据用于训练,其余 33%用于测试。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42
)
现在,我们将尝试 5 种不同复杂度的模型,并评估它们在数据集上的结果。
逻辑回归
model_lr = LogisticRegression()
model_lr.fit(X_train, y_train)
y_pred_lr = model_lr.predict(X_test)
print("Accuracy Score: ", accuracy_score(y_pred_lr, y_test))
print(classification_report(y_pred_lr, y_test))
输出
Accuracy Score: 0.9830508474576272
precision recall f1-score support
0 1.00 0.95 0.98 21
1 0.96 1.00 0.98 23
2 1.00 1.00 1.00 15
accuracy 0.98 59
macro avg 0.99 0.98 0.98 59
weighted avg 0.98 0.98 0.98 59
K-最近邻
model_knn = KNeighborsClassifier(n_neighbors=1)
model_knn.fit(X_train, y_train)
y_pred_knn = model_knn.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_knn, y_test))
print(classification_report(y_pred_knn, y_test))
输出
Accuracy Score: 0.7796610169491526
precision recall f1-score support
0 0.90 0.78 0.84 23
1 0.75 0.82 0.78 22
2 0.67 0.71 0.69 14
accuracy 0.78 59
macro avg 0.77 0.77 0.77 59
weighted avg 0.79 0.78 0.78 59
当更改参数‘n_neighbors=2’时,我们观察到准确率下降。因此,这表明数据简单,使用单个邻居会有更好的学习效果。
输出
Accuracy Score: 0.6949152542372882
precision recall f1-score support
0 0.90 0.72 0.80 25
1 0.75 0.69 0.72 26
2 0.33 0.62 0.43 8
accuracy 0.69 59
macro avg 0.66 0.68 0.65 59
weighted avg 0.76 0.69 0.72 59
朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
model_nb = GaussianNB()
model_nb.fit(X_train, y_train)
y_pred_nb = model_nb.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_nb, y_test))
print(classification_report(y_pred_nb, y_test))
输出
Accuracy Score: 1.0
precision recall f1-score support
0 1.00 1.00 1.00 20
1 1.00 1.00 1.00 24
2 1.00 1.00 1.00 15
accuracy 1.00 59
macro avg 1.00 1.00 1.00 59
weighted avg 1.00 1.00 1.00 59
决策树分类器
from sklearn.tree import DecisionTreeClassifier
model_dtclassifier = DecisionTreeClassifier()
model_dtclassifier.fit(X_train, y_train)
y_pred_dtclassifier = model_dtclassifier.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_dtclassifier, y_test))
print(classification_report(y_pred_dtclassifier, y_test))
输出
Accuracy Score: 0.9661016949152542
precision recall f1-score support
0 0.95 0.95 0.95 20
1 1.00 0.96 0.98 25
2 0.93 1.00 0.97 14
accuracy 0.97 59
macro avg 0.96 0.97 0.97 59
weighted avg 0.97 0.97 0.97 59
随机森林分类器
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
def get_best_parameters():
params = {
"n_estimators": [10, 50, 100],
"max_features": ["auto", "sqrt", "log2"],
"max_depth": [5, 10, 20, 50],
"min_samples_split": [2, 4, 6],
"min_samples_leaf": [2, 4, 6],
"bootstrap": [True, False],
}
model_rfclassifier = RandomForestClassifier(random_state=42)
rf_randomsearch = RandomizedSearchCV(
estimator=model_rfclassifier,
param_distributions=params,
n_iter=5,
cv=3,
verbose=2,
random_state=42,
)
rf_randomsearch.fit(X_train, y_train)
best_parameters = rf_randomsearch.best_params_
print("Best Parameters:", best_parameters)
return best_parameters
parameters_rfclassifier = get_best_parameters()
model_rfclassifier = RandomForestClassifier(
**parameters_rfclassifier, random_state=42
)
model_rfclassifier.fit(X_train, y_train)
y_pred_rfclassifier = model_rfclassifier.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_rfclassifier, y_test))
print(classification_report(y_pred_rfclassifier, y_test))
输出
Best Parameters: {'n_estimators': 100, 'min_samples_split': 6, 'min_samples_leaf': 4, 'max_features': 'log2', 'max_depth': 5, 'bootstrap': True}
Accuracy Score: 0.9830508474576272
precision recall f1-score support
0 1.00 0.95 0.98 21
1 0.96 1.00 0.98 23
2 1.00 1.00 1.00 15
accuracy 0.98 59
macro avg 0.99 0.98 0.98 59
weighted avg 0.98 0.98 0.98 59
在这个算法中,我们进行了超参数调整以获得最佳准确率。我们定义了一个包含多个值的参数网格供每个参数选择。此外,我们使用随机搜索 CV 算法来搜索模型的最佳参数空间。最后,我们将获得的参数提供给分类器并训练模型。
模型比较
| 模型 | 准确率 | 观察 |
|---|---|---|
| 逻辑回归 | 98.30% | 达到了很高的准确率。模型能够在测试数据集上很好地泛化。 |
| K-最近邻 | 77.96% | 算法无法很好地学习数据表示。 |
| 朴素贝叶斯 | 100% | 模型复杂度较低,因此它将数据过拟合以获得绝对准确性。 |
| 决策树分类器 | 96.61% | 达到了不错的准确率。 |
| 随机森林分类器 | 98.30% | 作为一种集成方法,它的表现优于决策树。通过超参数调优,它的准确率与逻辑回归相似。 |
结论
在本教程中,我们学习了如何开始构建和训练 scikit-learn 中的机器学习模型。我们实现并评估了一些算法,以了解它们的基本性能。我们可以始终采用更高级的策略进行特征工程、超参数调优或训练,以提高性能。要了解 scikit-learn 提供的更多功能,请访问官方文档 - 使用 scikit-learn 进行机器学习简介,使用 scikit-learn 进行 Python 机器学习。
Yesha Shastri 是一位充满热情的 AI 开发者和作家,目前在蒙特利尔大学攻读机器学习硕士学位。Yesha 对探索负责任的 AI 技术以解决对社会有益的挑战感兴趣,并与社区分享她的学习经验。
更多相关主题
如何通过数据中心的人工智能使自己与其他申请者区分开来
www.kdnuggets.com/2022/12/set-apart-applicants-datacentric-ai.html
在 2012 年,数据科学家被评为21 世纪最性感的职业,《哈佛商业评论》如此称赞。虽然这一领域自那时以来已经显著成熟,并且现在有许多“数据科学”职位的“变种”,但情况并没有改变太多:成为数据科学家仍然是新毕业生非常渴望的职业,并且也吸引了来自不同领域的许多人。
随着机器学习在整个行业的快速应用和人工智能研究的巨大进展,好消息是对数据科学家的需求不会在短期内消失。每年实际上有成千上万的新数据科学职位开放。事实上,雇主通常面临劳动力短缺的问题。因此,有这么多机会在市场上,新人要找到理想的工作应该不会太难,对吧?不幸的是,事情从来不会那么简单,现实是即使有这么多空缺职位,初级申请者仍然面临巨大挑战进入这一领域。
信誉困境
为了理解为什么雇主似乎无法找到合适的数据科学和机器学习职位人选,了解数据科学工作如何在科技行业变得普及是有用的。
尽管这一术语在 2001 年被创造出来,但数据科学并不是一个新领域。其实践方式随着时间的推移发生了剧烈变化。也就是说,直到 2000 年代末和 2010 年代初,随着 GPU 机器的普及和大数据的突然炒作,收集和处理数据变得更加容易,才使得公司建立专门的团队来分析和利用数据成为主流。问题是?他们聘用的人通常是杰出的计算机科学家和统计学家,但他们很少能够将技能转化为实际的商业价值,这通常是因为这些公司并不知道该收集什么数据以及如何管理数据。这些公司很快意识到他们在亏钱(他们如何解决这个问题是另一个故事),最终痛苦地认识到,技术专长不足以成为一个出色的数据科学家。
这就是为什么尽管对数据科学和机器学习专家的需求快速增长,公司往往招聘缓慢,并且往往有不适当的招聘流程。
展示你能做什么,而不是你知道什么!
如果你正在寻找第一份数据科学家的工作,你已经知道,拥有丰富的学术资历的简历可能不会让你走得很远。招聘经理需要看到的是你利用这些技能帮助他们的业务增长的能力。你漫长的学术发表列表不会让他们相信你是合适的人选。事实上,招聘人员对充满学校项目的简历特别怀疑,因为他们看到很多这样的简历来自那些最终未能胜任的候选人。
这是因为数据科学可能是最需要跨领域能力和最尖锐沟通技巧的技术领域。这不仅仅是一份你可以独自完成的工作。这份工作将要求你扩展技能,以弥合工程、产品和业务团队之间的差距,而你将依赖这些团队的支持来实现成功。简而言之,你需要在保持数据专家身份的同时,成为一个万事通。因此,能够吸引他们注意的简历是那些展现出不同之处的简历。那些从新毕业生中不容易看到的东西。而且这些简历能够证明候选人准备好处理现实中的问题。
这就是为什么新兴的数据科学家们非常热衷于参加 Kaggle 竞赛,因为这些竞赛是证明他们能在真实规模、行业数据集上工作的一个简单方式。有一段时间,在 Kaggle 竞赛中排名靠前是一个区分因素,它能让人们相对容易地获得面试机会。但如今,参加 Kaggle 竞赛已经成为一种新常态。候选人很难因为这一点而脱颖而出;实际上,这几乎是现在的预期。
那么如何在 2023 年作为候选人脱颖而出呢?别担心,我们很快就会谈到这一点。
现实数据
Kaggle 取得了一些绝对惊人的成就:它让一代数据爱好者磨练了他们的机器学习技能——而且在此过程中还很有趣。然而,有一件事情 Kaggle 始终无法实现:缓解学术数据科学教育中最严重的缺陷:对数据准备主题的缺乏意识。因为 Kaggle 提供了完全准备好的数据集供训练使用,竞争者只有一件事要做:构建、调整和训练模型,而无需担心数据质量。因此,即使有多个高质量的 Kaggle 提交可以在简历上炫耀,候选人在让招聘经理相信他们能够处理现实数据而不仅仅是将数据输入模型时,仍然存在不足。
这仍然是公司寻找数据人才的一大挑战。幸运的是,对某些人来说是问题的事情,对其他人来说可能是巨大的机会。数据科学候选人仍然大部分时间花在证明他们的模型构建技能上,尽管通过展示出色的数据准备技能很容易区分自己。而如何做到这一点正是下一节的主题。

凭借数据中心人工智能的炒作脱颖而出
但在进入实际建议部分之前,让我澄清一下什么是数据中心人工智能。就像在数据科学中一样,数据中心人工智能是一个用来指代旧思想的新术语:它是通过对训练数据进行优化来提升机器学习模型性能的概念,而不是对模型本身进行优化。
数据中心人工智能工作流
传统上,在构建和训练机器学习模型时,数据科学家将训练数据视为一个静态对象,将其输入到一个他们会修改、调整和完善的模型中,直到对结果感到满意。一旦他们对验证性能满意,他们会认为模型“准备好”了,然后继续进行测试,最后将模型部署。这被称为模型中心人工智能,这也是你在学校里学到的。
但在工作中,你将体验到广泛不同的情况:你的数据可能会很混乱,缺少字段或被破坏;更糟糕的是,可能根本没有数据,你将被期望去收集和组织数据。你将不得不花费比建立模型更多的时间来准备数据,尤其是因为使用预训练模型和机器学习库变得越来越主流。业界简单地称(并且一直称)为数据中心的方法来应对人工智能。
如何展示你的数据中心人工智能技能——并获得工作
那么,展示你卓越的数据中心人工智能技能,岂不是最好的方式来推销自己作为一名出色的数据科学家?通过这样做,你将解决获得数据科学家职位的两个最大挑战:
-
通过展示不同类型的专业知识,你将能够区分自己与其他候选人,并吸引招聘人员的注意。这也将展示你紧跟技术新趋势的能力,因此,体现你的持续学习能力。
-
你将真正证明你在数据准备方面拥有独特的技能,并能够处理实际数据的挑战。这将使你与其他有类似培训但没有数据清理实际经验的人区别开来,从而缓解大多数招聘人员的担忧。
这里有一个非常好的消息:实际上做到这一点并不困难,因为目前使用这种策略的人还不多,而且有大量机会可以利用。而且虽然大多数人认为数据准备主要是数据标注,事实是数据中心人工智能实际上是一系列技术和过程,旨在调整训练数据以在训练时获得更好的结果。这意味着你可以开始在许多领域建立专业知识。
5 个展示你数据中心人工智能技能的技巧
-
尽可能多地了解数据标注,并利用这些知识在面试中脱颖而出。在你的新工作中,数据很可能是原始的,所以展示你知道如何使其适合机器学习。了解标注数据通常使用的工具和技术(从使用第三方标注公司手动注释数据到更先进的技术如弱监督)。不要忘记了解数据标注的操作和商业方面(如成本,数据隐私法律如 GDPR 如何影响与第三方的数据共享等)。
-
建立一个小型的端到端数据标注工具作为作品集项目。你可以轻松使用像 Streamlit 这样的开源工具来创建用户界面。
-
了解数据中心训练范式,如主动学习和人机协作机器学习。你可以通过为开源主动学习库做贡献来迅速做到这一点。注意,主动学习本身是一个非常丰富的话题,因此不要仅停留在最低置信度的主动学习上,还要了解转移主动学习、BALD 等。
-
撰写关于数据标注、数据增强、合成数据生成和数据中心人工智能的介绍性和技术性内容。这将使你能够磨练自己的数据准备技能,同时展示你对该主题的理解。
-
通过强调你在数据准备方面所做的工作来回收你现有的项目。例如,如果你需要为学校项目手动注释自己的数据,请在简历中清楚地说明你是如何做到这一点的,以及它如何影响结果的质量。许多人已经在进行数据中心人工智能,只是没有意识到而已。

使用数据增强来展示数据中心人工智能技能是一种简单的方法
随着以数据为中心的人工智能(Data-Centric AI)越来越受到关注和流行,数据中心人工智能技能无疑将成为任何数据科学家被聘用的必备条件。大学很可能会将其纳入课程作为关键主题。然而,目前任何有关数据中心人工智能的知识都将使你脱颖而出,使你成为一个对实际机器学习问题有真正兴趣的独特候选人。所以,不要错过这个闪耀的机会,赢得你的理想工作。
詹妮弗·普伦基博士 是 Alectio 的创始人兼首席执行官,这是一家首个专注于 DataPrepOps 概念的人工智能初创公司。DataPrepOps 是她创造的一个合成词,指的是一个新兴领域,专注于自动化训练数据集的优化。她的使命是帮助机器学习团队使用更少的数据构建模型(从而降低机器学习操作成本和二氧化碳排放),并开发了动态选择和调整数据集的技术,以促进特定机器学习模型的训练过程。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关主题
24 个数据科学面试中的 A/B 测试问题及其破解方法
原文:
www.kdnuggets.com/2022/09/24-ab-testing-interview-questions-data-science-interviews-crack.html

一种常见的顶级公司数据科学面试问题就是关于朴素的 A/B 测试。A/B 测试对企业非常重要——它们帮助企业决定从构建哪个产品到如何设计用户界面等一切。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
A/B 测试,也称为拆分测试,是一种受控实验。你基本上将一组人,如用户或最终客户,分成两半。给一半的人提供选项 A。给另一半的人提供选项 B。然后看看哪个选项表现更好。
例如,Instagram 可能想知道将购物页面变得更突出是否会影响用户的整体消费。一组数据科学家会通过选择一部分现有的 Instagram 用户,并测试原始设计和新设计,来看新设计是否能提升消费。
(另一个更近期的例子是 Instagram 更改 他们的动态为全屏模式——测试组中的用户 讨厌 这一变化!)
A/B 测试对公司至关重要。如果你即将参加数据科学面试,这一概念尤为重要。你需要对 A/B 测试背后的统计概念、如何设计一个好的实验以及如何解释结果有足够的信心。
这里是你需要了解的关于数据科学面试中 A/B 测试问题的所有信息。
如何解决 A/B 测试问题

我在上面做了简要描述,但我想利用这一部分深入探讨这个概念。当你在数据科学面试中被问及 A/B 测试时,面试官希望你展示出对概念的理解以及你的商业头脑。
首先让我们讨论概念。A/B 测试是一种统计学和两样本假设测试。当你进行 统计假设测试 时,你是在将样本数据集与总体数据进行比较。两样本假设测试 是使用统计学来确定两个样本之间的差异是否显著。
当你设置 A/B 测试时,需要两个假设:原假设和备择假设。原假设认为你观察到的任何变化完全是偶然的。基本上,它意味着你认为对照组和测试组之间没有差异。
你的备择假设认为,对照组和测试组之间会有统计学上的显著差异。
要制定假设,你应该使用 PICOT 方法:人群、干预、对照、结果和时间。
这是一个可以使用的模板:
在 _(P) 中, (I) 对 ______(O) 的影响,与 _______(C) 相比,在 ________ (T) 内如何?
以下是 PICOT 格式的 Outlook 示例:
在 Instagram 用户 (P) 中,使购物页面更突出 (I) 对 消费 (O) 的影响,与 未更改的购物页面 (C) 相比,三个月 (T) 的时间内如何?
你还需要为对照组和测试组制定标准。你可能没有资源对所有用户进行 A/B 测试,因此需要找到一个选择样本群体的好方法。关键是要随机抽样,以确保结果具有显著性。
如果你不小心选择了一组全是百万富翁的新用户,这将会独立地扭曲你的结果,与您尝试进行的测试无关。
你可以使用 Laerd Dissertation 的 指南 来选择随机样本。确保你的样本足够大,以具有统计学意义。我推荐 Andrew Fisher 的 指南。
一旦你创建了假设、选择了样本并运行了测试,就该分析结果了。在推荐做出全面改变之前,你需要绝对确定这是否值得。
假设你在每组中测试了 1,000 个用户。你发现对照组的平均消费为 $50,标准差为 $15。测试组的平均消费为 $53,标准差为 $16。
这可能看起来不多,但有如此大的样本量,你可以非常有信心地拒绝零假设——这给我们一个 p 值(双尾)= 0.000016,这意味着结果通过运气或偶然发生的概率仅为 0.0016%。
选择适当测试时有很多不同的因素。如果你的样本量较小(n<30),你应该选择 t 检验而不是 z 检验。如果你认为你的样本均值可能大于、小于或等于对照均值,你应该选择双尾检验。我很喜欢 Antoine Soetewey 的流程图来做决策。查看这个图表可以让你全面了解 A/B 测试及其设计背后的假设。
A/B 测试的注意事项
当你回答这些问题时,你可能会被测试你的思维灵活性。A/B 测试很好,但情况通常不理想。雇主想知道你如何应对挑战。
如果你在 B2B 领域,你可能会面临较小的样本量。由于社交网络效应,你可能无法假设独立的总体。你可能没有足够的资源或时间来设计一个完美的测试。有时候进行 A/B 测试可能没有意义。
面试官希望听到你计划如何面对这些挑战,以及你对统计测试的掌握程度。
你将会面临以下问题:
-
如果你不能运行测试到想要的时间,你将如何计划弥补样本量小的问题?
-
你将如何最小化控制组和测试组之间的干扰?
-
如果你不能运行测试到想要的时间,你将如何使测试具有鲁棒性?
A/B 测试问题的示例

让我们解决一个来自 StrataScratch 平台的现实世界 A/B 测试问题示例:
Robinhood 希望鼓励更多人创建账户,并计划发起一个活动,向新用户提供一些免费股票。详细描述你将如何实施 A/B 测试以确定此活动的成功。
当你回答这种类型的面试问题时,你需要按顺序解决问题:
-
做出任何澄清声明或问题。
-
在这种情况下,“几只股票”是什么意思?是否可以测试多个免费股票的数量?
-
什么指标衡量成功?保留率、花费的钱,还是其他什么?
-
选择哪只股票?还是提供任何 X 值的股票?
-
确定:
-
实验的时长。
-
你将如何选择你的样本。
-
你的样本量。
-
对于这些问题,没有正确的答案。只是你如何确定这些的思考过程。
-
-
发展你的假设:
- 在新的 Robinhood 用户(P)中,与不给新的注册用户免费股票(C)相比,免费股票(I)对你的成功指标(O)的影响如何,在你选择的时间范围内(T)?
-
进行分析。
-
测量结果:
-
你会使用什么测试,为什么?
-
什么才算成功?
-
-
最后的想法:
-
你将如何实施测试结果?
-
你将如何向利益相关者传达结果?
-
你还会试验哪些其他测试?
你可能会遇到的 24 个 A/B 测试面试问题
我已经从网上收集了几个实际的面试问题,以提供面试官可能会问你的这些概念的示例。在点击链接获取详细答案之前,尽量自己先回答这些问题。
实验设计与设置
-
A/B 测试的目标是什么? – Hackr.io
-
A/B 测试的理想条件是什么? – Amplitude Blog
-
有一些增加电子商务网站转化率的想法,比如启用多商品结账(目前用户只能逐一结账)、允许未注册用户结账、改变“购买”按钮的大小和颜色等,你会如何选择投资哪个想法? - Emma Ding, 数据科学的未来
-
X 公司测试了一项新功能,目标是增加每个用户创建的帖子数量。他们将每个用户随机分配到控制组或实验组。测试结果在帖子数量上胜出 1%。你期望在所有用户都上线新功能后会发生什么?如果不是 1%,那会更多还是更少?(假设没有新颖效应) - Emma Ding, 数据科学的未来
-
我们正在推出一项新功能,为骑行者提供优惠券。目标是通过降低每次骑行的价格来增加骑行次数。请概述一个测试策略来评估新功能的效果。 - Emma Ding, 数据科学的未来
-
如果 A/B 测试不可用,你会如何回答问题? – Amplitude Blog
-
FB 推出了一个类似 Zoom 的功能。这个功能普遍受到欢迎,使用量在增长。你在 Instagram 工作。你会如何评估 Instagram 是否应该添加这个类似 Zoom 的功能? – u/Objective-patient-37 在 Reddit
解决实验问题
-
我们对一个新功能进行了 A/B 测试,测试结果胜出,因此我们将更改推出给所有用户。然而,在推出功能一周后,我们发现处理效果迅速下降。发生了什么?– 艾玛·丁,《数据科学的前沿》
-
我们正在进行一个有 10 种变体的测试,尝试不同版本的登录页面。一个处理获胜,p 值小于 0.05。你会进行更改吗?– 艾玛·丁,《数据科学的前沿》
-
你会运行实验多长时间?– Amplitude Blog
-
在 A/B 测试中,你如何检查分配到各个组是否真正随机?– StrataScratch
-
你如何处理小样本量问题?– Amplitude Blog
-
在我们产品的开发周期中,哪些问题可能会影响你的 A/B 测试结果?– Amplitude Blog
-
你如何减轻这些问题?– Amplitude Blog
业务相关问题
-
讲讲你设计的一个成功的 A/B 测试。你想要学习什么,学到了什么,这段经历如何帮助你在我们公司工作?– Amplitude Blog
-
根据你使用我们产品的经验,你会建议哪些改进,并为这些改进设置什么实验?– Amplitude Blog
-
假设我们想在用户流程实验中比较功能 A 和功能 B。根据你对我们产品的了解,你会如何设计这个测试?– Amplitude Blog
-
你如何处理超长期指标,比如在测试用户在看到功能后的两个月内花费多少钱时,需要等待两个月才能得到指标?– Amplitude Blog
数据分析
-
运行测试后,你看到期望的指标,比如点击率上升,而展示次数下降。你会如何做出决策?– 艾玛·丁,《数据科学的前沿》
-
如果你的实验结果不明确,看起来更像是 AA 测试,你会怎么做?你会如何分析测试结果,重点关注什么?– Amplitude Blog
-
给定两个产品活动的数据,如果我们看到其中一个产品增长了 3%,你如何进行 A/B 测试?– igotanoffer
-
当你知道存在社交网络效应且独立性假设不成立时,这会如何影响你的分析和决策?– Amplitude Blog
-
在我们的 A/B 测试中,结果没有统计学意义。这可能有哪些潜在原因?– Amplitude Blog
未来调查
-
如果你的 A/B 测试团队已经有了 X、Y、Z 角色的团队成员,你会建议招聘哪些新成员?– Amplitude Blog
-
在你的产品团队中,哪些角色应该参与到测试中?你会如何让他们轻松参与?– Amplitude Blog
准备 A/B 测试数据科学面试问题的更多资源
这个 A/B 测试面试问题指南和 24 个示例问题应该能让你完全准备好应对任何 A/B 测试面试问题。如果你对上述提到的术语不熟悉,或者想要更多内容进行复习,请查看以下资源:
像任何数据科学面试问题一样,记得以好奇心来面对这些问题。你不仅要展示你对统计和数学的掌握,还要展现你的思维过程和查看大局的能力。祝好运,并且玩得开心。
内特·罗西迪 是一名数据科学家和产品策略专家。他还担任分析学的兼职教授,并且是StrataScratch的创始人,这个平台帮助数据科学家通过顶级公司的真实面试问题为面试做好准备。可以在Twitter: StrataScratch或LinkedIn与他联系。
了解更多相关内容
-
24 本最佳(且免费的)理解机器学习的书籍
原文:
www.kdnuggets.com/2020/03/24-best-free-books-understand-machine-learning.html

图片由编辑提供
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
“我们想要的是一台能够从经验中学习的机器“
艾伦·图灵
毋庸置疑,机器学习已经成为当今最受欢迎的话题之一。根据一项研究,机器学习工程师被评选为 2019 年美国最佳职业之一。
看着这个趋势,我们编制了一份最佳(且免费的)机器学习书籍的列表,这些书籍对每一个希望在这个领域建立职业的人都会有帮助。
享受吧!
1. ISLR
书籍链接: ISLR

最佳的机器学习理论入门书籍。即使是付费书籍也很少有比这本更好的。这本书对数学有很好的介绍,同时还有 R 语言的练习材料。对这本书赞不绝口。
2. 神经网络与深度学习
书籍链接: 神经网络与深度学习
这本免费的在线书籍是对深度学习的最佳和最快的入门之一。阅读它只需几天时间,就能让你掌握深度学习的所有基础知识。
3. 模式识别与机器学习
书籍链接: 模式识别与机器学习
这是一本最著名的理论机器学习书籍之一,因此你不需要写太多的介绍。
4. 深度学习书籍
书籍链接: 深度学习书籍
深度学习的圣经,这本书是对深度学习算法和方法的介绍,既适合初学者,也适合从业者。
5. 理解机器学习:从理论到算法
书籍链接: 理解机器学习:从理论到算法
这是一本关于机器学习理论的非常好的著作。
6. 成功的七个步骤:机器学习实践
书籍链接: 成功的七个步骤:机器学习实践
非技术性的产品经理和非机器学习软件工程师进入该领域时不应错过这个教程。写得非常好(略显陈旧,不涵盖深度学习,但适用于所有实际目的)。
7. 机器学习规则:机器学习工程最佳实践
书籍链接: 机器学习规则:机器学习工程最佳实践
想知道谷歌如何看待其机器学习产品吗?这是一个很好的机器学习产品管理教程。
8. 工程师的机器学习简要介绍
书籍链接: 工程师的机器学习简要介绍
这是一篇几乎涵盖所有机器学习技术的独白。数学更容易理解(对于害怕复杂数学符号的人来说)。
9. 无深度学习的机器学习简要介绍
书籍链接: 无深度学习的机器学习简要介绍
这是一篇几乎涵盖所有机器学习技术的独白。数学更容易理解(对于害怕复杂数学符号的人来说)。
10. 机器学习入门笔记
书籍链接: 机器学习入门笔记
绝对初学者的机器学习指南。
11. 机器学习基础
书籍链接: 机器学习基础

这是一本详细论述机器学习数学概念的著作。
12. 变量和特征选择简介
书籍链接: 变量和特征选择简介
特征工程和变量选择可能是传统机器学习算法中最重要的人为输入。(在深度学习方法中不那么重要,但并非所有问题都能通过深度学习解决)。本教程介绍了不同的特征工程方法。
13. AutoML 书籍 – Frank Hutter, Lars Kotthoff, Joaquin Vanschoren
书籍链接: AutoML 书籍 – Frank Hutter, Lars Kotthoff, Joaquin Vanschoren
近年来,传统机器学习几乎已经简化为在完成特征工程后运行 AutoML 模型(例如 h2o、auto sklearn 或 tpot,我们在 ParallelDots 的最爱)。实际上,还有一些方法可以进行自动化的非领域特定特征工程。这本书涵盖了 AutoML 中使用的方法。
14. 深度学习与 Pytorch
书籍链接: Deep Learning with Pytorch
一本免费的书,帮助你使用 PyTorch 学习深度学习。PyTorch 是我们在 ParallelDots 最喜欢的深度学习库,我们推荐给所有从事应用研究/开发深度学习的人。
15. 深入深度学习
书籍链接: Dive Into Deep Learning
另一本详细介绍深度学习的书籍,使用亚马逊的 MXNet 库来教授深度学习。
16. Keras Github 笔记
书籍链接: Keras Github 笔记
François Chollet 是 Keras 库的负责人。他的书《Python 中的深度学习》旨在教授 Keras 中的深度学习,评价非常高。虽然书籍本身不能免费获得,但所有代码以笔记本形式在 Github 上提供(形成了一个包含深度学习示例的书),是一个很好的资源。我在几年前学习 Keras 时读过这本书,非常好的资源。
17. 基于模型的机器学习
书籍链接: Model-based Machine Learning

在贝叶斯机器学习领域的一个优秀资源。使用微软的 Infer.Net 库进行教学,因此你可能需要安装 IronPython 来阅读/实现书中的示例。
18. 机器学习的贝叶斯模型
书籍链接: Bayesian Models for Machine Learning
另一本详细介绍各种贝叶斯方法在机器学习中的书籍。
19. 艾森斯坦 NLP 笔记
书籍链接: 艾森斯坦 NLP 笔记
自然语言处理是机器学习中最受欢迎的应用。这些来自 GATech 课程的笔记提供了机器学习如何用来解释人类语言的很好的概述。
20. 强化学习 – Sutton 和 Barto
书籍链接: Reinforcement Learning – Sutton and Barto
强化学习的圣经。这是任何进入强化学习领域的人必读的书籍。
21. 高斯过程用于机器学习
书籍链接: Gaussian Processes for Machine Learning

使用贝叶斯优化和高斯过程进行机器学习的教学。利用像 Edward/GpyTorch/BOTorch 等基于变分推断的库,这种方法正在复兴。
22. 机器学习面试 机器学习系统设计 Chip Huyen
书籍链接: Machine Learning Interviews Machine Learning Systems Design Chip Huyen
参加机器学习工作的面试?这些问题可能有助于你在回答机器学习系统问题时确定策略。
23. 机器学习的算法方面
书籍链接: 机器学习的算法方面
这本书涉及机器学习中的计算算法和数值方法,例如因式分解模型、字典学习和高斯模型。
24. 机器学习中的因果关系
书籍链接: 机器学习中的因果关系
随着因果关系在数据科学领域的逐步渗透,机器学习也不例外。虽然目前没有详细的相关材料,这里有一个简短的教程试图解释因果关系在机器学习中的关键概念。
觉得博客有用吗?阅读我们的其他博客,了解所有帮助你在数据科学领域取得成功的最佳书籍。
原始链接。经许可转载。
更多相关内容
你可能会在下次面试中遇到的 24 道 SQL 问题
原文:
www.kdnuggets.com/2022/06/24-sql-questions-might-see-next-interview.html

当谈到最常出现在工作面试中的 SQL 面试题时,我并不是说给你具体的问题。这将是一个不可能完成的任务,因为问题的数量成千上万。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
幸运的是,这些问题测试的 SQL 概念并不多。这并不意味着你只需要解决我即将展示的面试题或仅了解选定的主题。
如果你专注于最常见的主题,你将有可能覆盖面试中测试的大部分概念。当然,问题的难度可能有所不同,这将需要对某一特定主题有更多或更少的了解。不过,这些概念通常是相同的。
尽管这些主题可以被视为宏伟的(特别是如果你是 SQL 爱好者的话!),我更愿意称它们为“不可避免的七个”:
-
汇总、分组和排序
-
过滤
-
JOINs 和集合运算符
-
子查询与 CTEs
-
CASE 语句
-
窗口函数
-
文本与日期操作
这些主题通常在编码 SQL 问题中测试,但也可能出现在非编码类型的问题中。
编写 SQL 面试题
编程题正如其名:它们测试你使用 SQL 概念编写代码的能力。
1. 汇总、分组和排序

理论
SQL 聚合函数是对多行进行计算并返回一个值的函数。最常用的聚合函数包括:
| 聚合函数 | 描述 |
|---|---|
| COUNT() | 计算行数。 |
| SUM() | 返回行的总和。 |
| AVG() | 计算行值的平均值。 |
| MIN() | 返回最小值。 |
| MAX() | 返回最高值。 |
单独使用时,这些函数只会返回一个值。诚然,这并不十分复杂。
当与 GROUP BY 和 ORDER BY 子句一起使用时,汇总函数对数据科学家来说更有价值。
GROUP BY 用于根据行的值将来自一个或多个列的数据分组。每个不同的值(或按多个列分组的值组合)将形成一个单独的数据组。这样就可以显示正在汇总的数据的附加信息。
ORDER BY 用于对查询的输出进行排序。数据可以按升序或降序排序。此外,你可以按一个或多个列进行排序。
与这两个子句一起使用时,汇总函数成为创建报告、计算指标和整理数据的垫脚石。它们允许你对数据进行数学运算,并以清晰和可展示的方式展示你的发现。
SQL 问题
SQL 面试题 #1:查找更新的记录
“我们有一个包含员工及其工资的表格,但其中一些记录是旧的,包含过时的工资信息。找出每位员工的当前工资,假设工资每年都在增长。输出他们的 ID、名字、姓氏、部门 ID 和当前工资。按员工 ID 升序排序你的列表。”
问题链接:platform.stratascratch.com/coding/10299-finding-updated-records?code_type=1
数据
这个问题给你一个表:ms_employee_salary
| id | int |
|---|---|
| first_name | varchar |
| last_name | varchar |
| salary | varchar |
| department_id | int |
下方给出了表格的数据样本。
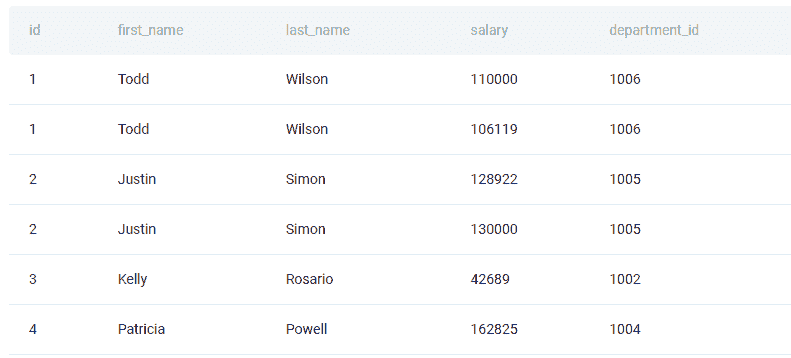
解决方案方法
如果工资每年都在增长,那么最新的工资也是最高工资。要获取它,请使用 MAX() 汇总函数。按员工和部门分组数据。你还应按员工 ID 以升序排序输出;为此使用 ORDER BY 子句。
SELECT id,
first_name,
last_name,
department_id,
max(salary)
FROM ms_employee_salary
GROUP BY id,
first_name,
last_name,
department_id
ORDER BY id ASC;
输出
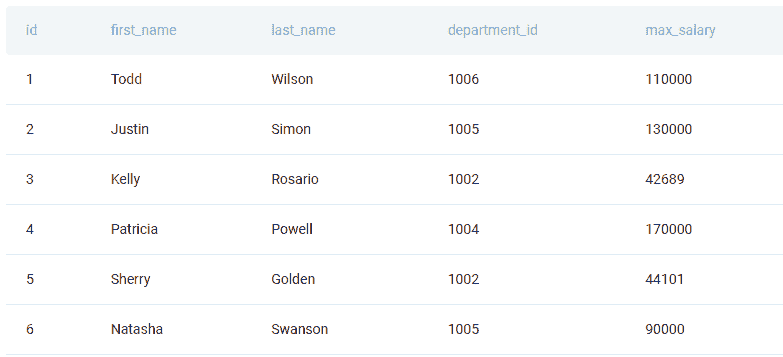
SQL 面试题 #2:按国家首次参加奥运会的年份排序
“找出每小时的平均行驶距离。”
输出小时及相应的平均行驶距离。
按小时升序排列记录。
问题链接:platform.stratascratch.com/coding/10006-find-the-average-distance-traveled-in-each-hour?code_type=1
要查找平均距离,请使用 AVG() 函数,然后按小时列对输出进行分组和排序。
如果你写出正确的解决方案,你将会得到这个结果。
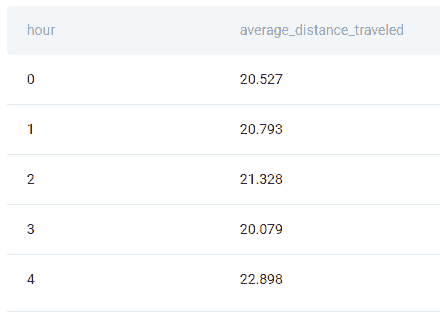
SQL 面试问题 #3:按各国首次参加奥运会的年份排序
“按各国首次参加奥运会的年份排序。”
输出国家奥林匹克委员会(NOC)名称以及所需年份。
按年份和 NOC 升序排序记录。
代码需要按列 noc 对数据进行分组,并使用 MIN() 聚合函数找到首次参与的年份。为了适当地排序输出,使用 ORDER BY。
如果你得到这个结果,那么你做对了一切。
2. 筛选

理论
如果将数据筛选定义为选择数据的一个子集,那么数据筛选有许多种方式。即使是那些人们通常不会认为是筛选的方式,例如 SELECT 语句和 JOINs,但它们也是筛选的一部分;它们仅选择数据的一部分。
在考虑数据筛选时,通常会想到两个关键字(或者在使用 PostgreSQL 时是三个):
-
WHERE
-
HAVING
-
(LIMIT)
WHERE 子句的目的是在数据汇总之前进行筛选。语法上,这意味着它必须在 GROUP BY 子句之前书写。
在使用 WHERE 子句进行数据筛选时,有许多运算符可以使用。
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于或等于 |
| >= | 大于或等于 |
| <> | 不等于 |
| BETWEEN | 在指定范围之间 |
| LIKE | 寻找模式 |
| IN | 等于括号中列出的值 |
HAVING 子句与 WHERE 子句做的事情相同,只是它在聚合之后筛选数据。自然地,它只能在 SQL 查询中的 GROUP BY 子句之后使用。
WHERE 子句中的所有运算符在 HAVING 子句中也允许使用。
两个子句都允许通过使用 AND/OR 逻辑运算符在一个或多个条件上进行筛选。
使用这两个子句为你的计算增加了另一个维度。基本用法使你能够只显示你感兴趣的数据,而不是大部分数据。这意味着你不仅可以选择你想要的列,还可以选择你想要的行,基于它们的值。与聚合函数一起使用,你可以通过过滤输入数据,甚至是其输出,来对更详细的数据子集进行计算。这增加了你计算的复杂性。
LIMIT 子句 简单地指定了你希望看到的输出行数。子句中的整数值等于作为结果显示的行数。这在你想要对数据进行排名时特别有用,例如,显示前 N 名销售、员工、薪资等。
SQL 问题
SQL 面试题 #4:找出 Uber 通过名人获得超过 2000 名客户的年份
“找出 Uber 通过名人广告获得超过 2000 名客户的年份。”
数据
表格 uber_advertising 有四列。
| year | int |
|---|---|
| advertising_channel | varchar |
| money_spent | int |
| customers_acquired | int |
这是表格预览。
解决方案方法
解决方案是一个简单的 SELECT 语句,包含一个列。然而,你不需要所有的年份。问题要求你只输出那些广告渠道是通过名人,并且获得了超过 2000 名客户的年份。为此,将这两个条件放入 WHERE 子句中。
SELECT year
FROM uber_advertising
WHERE advertising_channel = 'celebrities' AND
customers_acquired > 2000;
输出

运行代码,它将只输出一个满足条件的年份:2018。
SQL 面试题 #5:找出所有最低和最高检查评分不同的企业
“找出所有最低和最高检查评分不同的企业。”
输出每个企业的对应企业名称和最低及最高评分。
按企业名称升序排列结果。”
要回答这个问题,使用 MIN()和 MAX()函数来找出最高和最低的检查分数,并按企业分组数据。然后使用 HAVING 子句仅显示最高分数和最低分数不相等的企业。最后,按企业名称字母顺序对结果进行排序。
你的输出应该是这样的。
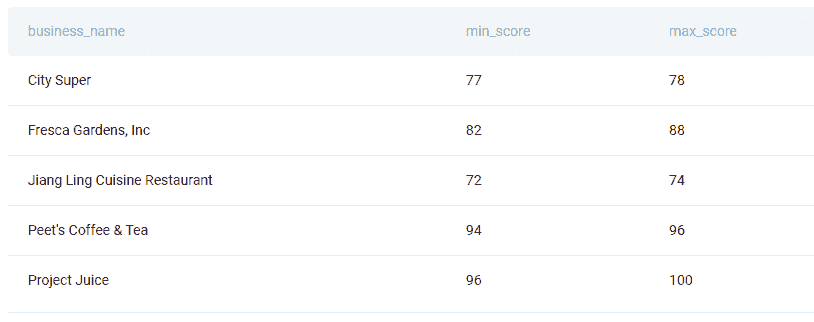
SQL 面试问题#6:找到最高加班工资率的前三份工作
“找到加班工资率最高的前三份工作。
输出所选记录的职位名称。
按加班工资降序排列记录。”
这个问题要求你同时使用 WHERE 和 LIMIT 子句。使用 WHERE 来查找加班工资不是 NULL 且不为 0 的职位。按加班工资从高到低排序数据。然后,只需将输出限制为前三行,这样就得到了:加班工资率最高的前三份工作。
从结果中可以看出,只有三份这样的工作。
3. JOINs & 集合运算符
理论
到目前为止,你被限制只使用一个表。不幸的是,没有一个值得尊敬的数据库只由一个表组成。为了充分利用可用数据,你需要知道如何结合两个或更多表的数据。
JOIN 是你寻找的 SQL 功能:它使得在公共列上连接表成为可能。
SQL 中有五种不同的 JOIN 类型。
| JOIN 类型 | 描述 |
|---|---|
| (INNER) JOIN | 仅返回两个表中的匹配行。 |
| LEFT (OUTER) JOIN | 返回左表中的所有数据和右表中的匹配行。 |
| RIGHT (OUTER) JOIN | 返回右表中的所有数据和左表中的匹配行。 |
| FULL OUTER JOIN | 返回两个表中的所有行。 |
| CROSS JOIN | 将一个表中的所有行与第二个表中的每一行组合。 |
当我提到匹配行时,我指的是两个表中相同的行或值。
前四种连接 最常使用,但 CROSS JOIN 有时也可以使用。
另一种连接表格的方法是自连接。这不是一种独特的连接类型:任何 JOIN 类型都可以用于自连接,这意味着你将表格与自身连接。
集合运算符 用于合并两个或多个查询的输出。
| 集合运算符 | 描述 |
|---|---|
| UNION | 合并查询结果中的唯一行。 |
| UNION ALL | 合并查询结果中的所有行,包括重复的行。 |
| INTERSECT | 仅返回两个查询输出中都出现的行。 |
| EXCEPT | 返回一个查询中的唯一行,以及仅出现在第二个查询输出中的行。 |
SQL 问题
SQL 面试题 #7:昂贵的项目
“给定一个列出项目及每个项目关联的员工的列表,根据每位员工分配的项目预算进行计算。输出应包括项目标题和每位员工的项目预算(四舍五入到最接近的整数)。按每位员工预算最高的项目排序。”
问题链接:platform.stratascratch.com/coding/10301-expensive-projects?code_type=1
数据
题目给出了两个表。
表格:ms_projects
| id | int |
|---|---|
| title | varchar |
| budget | int |
这是表格预览。
表格:ms_emp_projects
| emp_id | int |
|---|---|
| project_id | int |
数据示例如下。
解决方案方法
首先需要按员工计算项目预算。这看起来比实际更复杂:只需将列预算除以员工数量,员工数量使用 COUNT()函数获取。然后,将结果转换为浮点数据类型以获得小数位数。这个计算是在 ROUND()函数内完成的,用于四舍五入数字。在这种情况下,除法结果被转换为数值数据类型,并四舍五入为没有小数位数。
SELECT 语句使用了两个表中的列。这是可能的,因为表在 FROM 子句中使用 INNER JOIN 连接。它们在列 id 等于列 project_id 的地方连接。
最终结果按项目和其预算分组,同时输出按比例降序排序。
SELECT title AS project,
ROUND((budget/COUNT(emp_id)::float)::numeric, 0) budget_emp_ratio
FROM ms_projects a
INNER JOIN ms_emp_projects b ON a.id = b.project_id
GROUP BY title,
budget
ORDER BY budget_emp_ratio DESC;
输出
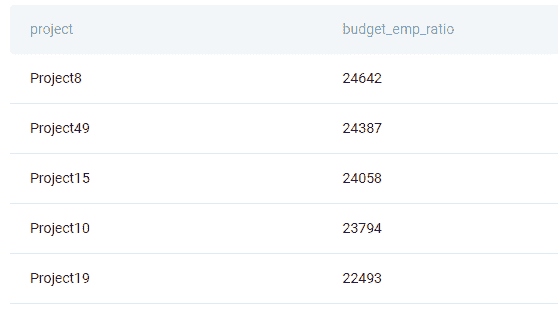
代码输出应如下所示,部分显示如下。
SQL 面试题 #8:按国家找出讲西班牙语的人登录次数
“找出西班牙语用户按国家的登录次数。”
输出国家及其相应的登录次数。
按登录次数降序排列记录。
在解决方案中,使用 COUNT()函数计算登录次数。由于所需数据在两个表中,因此需要将它们联接。为此使用 INNER JOIN。根据列 user_id 和事件为‘login’,而用户语言为‘spanish’来联接表格。按位置对数据进行分组,并按登录次数从高到低排序。
正确的代码将返回三个国家的登录次数如下。
SQL 面试问题 #9: 数字之和
“找出索引小于 5 的数字之和,以及索引大于 5 的数字之和。将每个结果单独输出一行。”
问题链接: platform.stratascratch.com/coding/10008-sum-of-numbers?code_type=1
你需要编写的代码包括两个 SELECT 语句。一个将找出索引小于 5 的数字之和,另一个将对索引大于 5 的数字做同样的处理。
你所要做的就是在这两个语句之间放置 UNION ALL 来获得输出。
4. 子查询与 CTE

理论
子查询和 CTE 为您的代码提供了灵活性。它们都用于更复杂的多步骤计算,其结果用于主要计算。
有特定的关键字可以使用子查询。
-
SELECT
-
FROM
-
WHERE
-
HAVING
-
INSERT
-
UPDATE
-
DELETE
它们通常用于 WHERE 或 HAVING 子句中的数据过滤,但也可作为 FROM 子句中的表格,当查询结果作为表格时。一般而言,它们允许在一个查询中执行复杂计算。
对于 CTE(公共表表达式),它们的目的相同。不同之处在于,它们更接近人类逻辑的计算步骤,因此使代码更加整洁。通常,CTE 所需的代码更少,且比相同计算的子查询更具可读性。
CTE 的主要部分有两个:一个 CTE 和一个引用 CTE 的查询。
一般的 CTE 语法是:
WITH cte_name AS (
SELECT…cte_definition..
)
SELECT …
FROM cte_name;
CTE 是通过 WITH 关键字调用的。在给出 CTE 名称后,接着是 AS,然后是括号中的 CTE 定义。这个定义是一个 SELECT 语句,用于给 CTE 提供指令。
主查询再次是一个 SELECT 语句,但这次引用了 CTE。
他们在名称中包含单词表的原因是:CTE 是一个临时结果,只能在运行 CTE 时访问,所以它类似于一个临时表。这就是为什么你可以像使用其他表一样在 FROM 子句中使用它。
SQL 问题
SQL 面试问题 #10:按职称和性别计算收入
“根据员工职称和性别计算平均总薪酬。总薪酬通过将每个员工的薪水和奖金相加来计算。然而,并不是所有员工都会收到奖金,所以在计算时忽略没有奖金的员工。一个员工可以获得多个奖金。”
“输出员工职称、性别(即,sex),以及平均总薪酬。”
链接到问题:platform.stratascratch.com/coding/10077-income-by-title-and-gender?code_type=1
数据
问题中使用的第一个表是 sf_employee。
表:sf_employee
| id | int |
|---|---|
| first_name | varchar |
| last_name | varchar |
| age | int |
| sex | varchar |
| employee_title | varchar |
| department | varchar |
| salary | int |
| target | int |
| varchar | |
| city | varchar |
| address | varchar |
| manager_id | int |
表中的数据如下所示。

表:sf_bonus
| worker_ref_id | int |
|---|---|
| bonus | int |
| bonus_date | datetime |
这是数据。
解决方案方法
此代码中的主 SELECT 语句使用表 sf_employee 和子查询数据。子查询通过 SUM() 函数计算员工的总奖金;这就是它还按员工 ID 分组数据的原因。子查询像其他表一样与表 sf_employee 连接。在这种情况下,使用的是 INNER JOIN。
主查询将使用子查询的数据来计算平均总薪酬,包括薪水和获得的总奖金。
最终,结果按员工和性别分组。
SELECT e.employee_title,
e.sex,
AVG(e.salary + b.ttl_bonus) AS avg_compensation
FROM sf_employee e
INNER JOIN
(SELECT worker_ref_id,
SUM(bonus) AS ttl_bonus
FROM sf_bonus
GROUP BY worker_ref_id) b ON e.id = b.worker_ref_id
GROUP BY employee_title,
Sex;
输出
解决方案将返回四行结果。
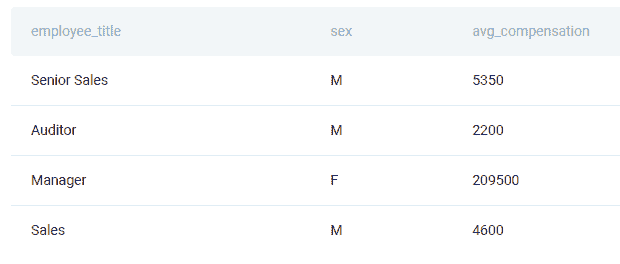
SQL 面试问题 #11:提供真实床和互联网的最便宜的邻里
“寻找在别墅中能睡在真正的床上且提供互联网的最低价格的邻里。”
为了解决这个问题,使用 WHERE 子句中的子查询来获取满足特定标准的价格。使用 MIN() 函数找出具有互联网的别墅中真实床的最低价格。对两个条件使用等号,对条件两侧使用 ILIKE 和通配符字符(%)。
然后在主查询中使用相同的标准(真实床、别墅、互联网)。
有一个邻里符合这些标准。
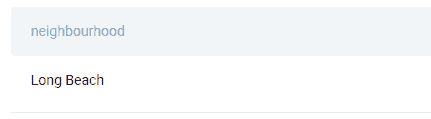
SQL 面试题 #12: 广告渠道效果
“找出 2017 年至 2018 年(含)每个广告渠道的平均效果。效果计算为总花费与获得的总客户数之比。”
“输出广告渠道及其对应的平均效果。按平均效果升序排序记录。”
问题链接: platform.stratascratch.com/coding/10012-advertising-channel-effectiveness?code_type=1
每个 CTE 都以关键字 WITH 开始,之后是 CTE 的名称。接着是 AS,在括号中定义 CTE 的主体,即 SELECT 语句,你将在外部查询中调用它。
你应该在这个示例中使用 CTE 来汇总花费和获得的客户数。你为 2017 年和 2018 年执行这些操作,通过在 WHERE 子句中设置这个条件。
在外部查询中,选择广告渠道,然后将总花费除以获得的总客户数,这将给出平均效果。
按效果升序排序输出结果。
5. CASE 语句

理论
这是一个条件语句,是 SQL 版本的 IF-THEN-ELSE 逻辑。它指示代码通过一组条件来确定应返回的结果,具体取决于数据是否满足条件。
CASE 语句的语法是:
CASE
WHEN condition
THEN result
ELSE result
END AS case_stetement_alias;
它还允许设置多个条件,而不仅仅是一个。
CASE 语句 最常用于标记数据或与聚合函数一起使用,当计算是基于特定标准进行时。
SQL 问题
SQL 面试题 #13: 预订与非预订
“显示用户进行搜索的平均次数,其中导致成功预订和未导致预订的平均次数。输出应具有名为 action 的列,值为 'does not book' 和 'books',以及名为 average_searches 的第二列,表示每个动作的平均搜索次数。考虑到如果预订日期为空则认为没有发生预订。请注意,搜索仅在入住日期匹配时与预订相关。”
问题链接:platform.stratascratch.com/coding/10124-bookings-vs-non-bookings?code_type=1
数据
你需要使用问题提供的两个表。
表:airbnb_contacts
| id_guest | varchar |
|---|---|
| id_host | varchar |
| id_listing | varchar |
| ts_contact_at | datetime |
| ts_reply_at | datetime |
| ts_accepted_at | datetime |
| ts_booking_at | datetime |
| ds_checkin | datetime |
| ds_checkout | datetime |
| n_guests | int |
| n_messages | int |
这是数据预览。
表:airbnb_searches
| ds | datetime |
|---|---|
| id_user | varchar |
| ds_checkin | datetime |
| ds_checkout | datetime |
| n_searches | int |
| n_nights | float |
| n_guests_min | int |
| n_guests_max | int |
| origin_country | varchar |
| filter_price_min | float |
| filter_price_max | float |
| filter_room_types | varchar |
| filter_neighborhoods | datetime |
表中的前几行如下所示。
解决方案方法
解决方案在 SELECT 语句中使用 CASE 语句为数据标记。当列 ts_booking_at 中有非空值时,它将标记为“books”。如果为 NULL,则标记为“does not book”。这个 CASE 语句将其结果显示在新列 action 中。
此外,SELECT 语句中还有一个 AVG() 函数用于查找搜索的平均次数。
数据从两个表中使用 LEFT JOIN 提取。最终,输出按数据标签分组。
SELECT CASE
WHEN c.ts_booking_at IS NOT NULL THEN 'books'
ELSE 'does not book'
END AS action,
AVG(n_searches) AS average_searches
FROM airbnb_searches s
LEFT JOIN airbnb_contacts c ON s.id_user = c.id_guest
AND s.ds_checkin = c.ds_checkin
GROUP BY 1;
输出
上述查询返回所需的输出。
SQL 面试问题 #14:Lyft 驾驶员的流失率
“找出所有年份 Lyft 驾驶员的全球流失率。将比率作为结果输出。”
问题链接:platform.stratascratch.com/coding/10016-churn-rate-of-lyft-drivers?code_type=1
这个问题要求你在聚合函数中使用 CASE 语句,具体来说是 COUNT()。用它来计算离开的司机,那些结束日期不为 NULL 的。将结果除以总司机数量,并将其转换为小数。
如果一切正确,你应该得到流失率。
SQL 面试问题 #15:找出获得奖金和未获得奖金的员工数量
“找出获得奖金和未获得奖金的员工数量。”
输出是否获得奖金的指示及相应的员工数量。
* 例如:获得奖金为 1,未获得为 0。”*
这个解决方案中有一个子查询。子查询使用 CASE 语句来确定获得奖金和未获得奖金的员工。依据奖金日期和是否值为 NULL 来完成。为此,你需要使用 LEFT JOIN 连接两个表。
主要查询将使用此结果来统计获得和未获得奖金的员工数量。
6. 窗口函数

理论
SQL 窗口函数 类似于聚合函数。区别在于窗口函数以一种方式聚合数据,使得可以同时显示单独的行和聚合值。
通常,有三种不同类型的窗口函数:
-
聚合窗口函数
-
排名窗口函数
-
值窗口函数
| 聚合窗口函数 | 描述 |
|---|---|
| COUNT() | 计算行数。 |
| SUM() | 求和。 |
| AVG() | 返回平均值。 |
| MIN() | 返回最小值。 |
| MAX() | 返回最大值。 |
| 排名窗口函数 | 描述 |
| ROW_NUMBER() | 依次对行进行排名,不跳过行号,并对相同值的行赋予相同的排名。 |
| RANK() | 用于排名,相同的值会得到相同的排名,下一个排名会被跳过。 |
| DENSE_RANK() | 用于排名,相同的值会得到相同的排名,且下一个排名不会被跳过。 |
| PERCENT_RANK() | 以百分比值对值进行排名。 |
| NTILE() | 将行划分为若干个相等大小的组。 |
| 值窗口函数 | 描述 |
| LAG() | 允许访问定义数量的前置行数据。 |
| LEAD() | 允许访问从定义的行数之后的数据。 |
| FIRST_VALUE() | 返回数据中的第一个值。 |
| LAST_VALUE() | 返回数据中的最后一个值。 |
| NTH_VALUE() | 返回定义的(第 n)行的值。 |
窗口函数之所以叫做窗口函数,是有原因的。它们对与当前行相关的行进行计算。当前行和所有相关行称为窗口框架。
使用窗口函数时,有五个重要的子句。
-
OVER
-
PARTITION BY
-
ORDER BY
-
ROWS
-
RANGE
OVER 子句是强制的,其目的是调用窗口函数。没有它,就没有窗口函数。
PARTITION BY 用于对数据进行分区。通过指定其中的列,你在指示窗口函数应在哪个数据子集上执行计算。当省略 PARTITION BY 时,窗口函数将整个表作为数据集。
ORDER BY 子句也是一个可选子句。它指定了每个数据集内的逻辑顺序。换句话说,它不是用来排序输出的,而是用来设置窗口函数将如何工作的方向。数据可以按升序或降序排列。
在分区内,你还可以进一步限制将包含在窗口函数计算中的行。这被称为定义窗口框架。
ROWS 子句定义了当前行之前和之后的固定行数。
RANGE 做的是相同的事情,只不过不是基于行数,而是根据其与当前行的值进行比较。
窗口函数扩展了 SQL 的分析可能性。通过使用它们,你可以将聚合数据和非聚合数据并排显示,进行多级聚合,对数据进行排名,并进行其他仅用聚合函数无法完成的操作。
SQL 问题
SQL 面试题 #16:平均工资
“将每个员工的工资与相应部门的平均工资进行比较。”
输出部门、名字和员工的工资,并附上该部门的平均工资。
链接到问题:platform.stratascratch.com/coding/9917-average-salaries?code_type=1
数据
有一个名为 employee 的表。
| id | int |
|---|---|
| first_name | varchar |
| last_name | varchar |
| age | int |
| sex | varchar |
| employee_title | varchar |
| department | varchar |
| salary | int |
| target | int |
| bonus | int |
| varchar | |
| city | varchar |
| address | varchar |
| manager_id | int |
这是员工数据。
解决方案方法
查询选择了部门、员工的名字和他们的薪资。第四列将计算 AVG()薪资。由于这是一个窗口函数,它必须使用 OVER()子句来调用。通过使用部门作为数据分区,查询将返回按部门划分的平均薪资,而不是整体薪资。
SELECT department,
first_name,
salary,
AVG(salary) OVER (PARTITION BY department)
FROM employee;
输出
这些只是完整输出的前五行。
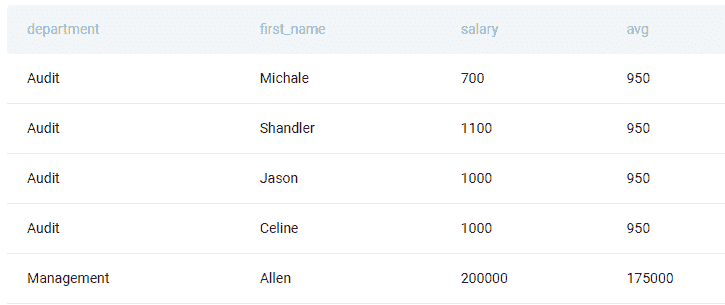
SQL 面试题 #17:排名最活跃的宾客
“根据宾客与主持人交换消息的数量对宾客进行排名。与其他宾客消息数量相同的宾客应具有相同的排名。如果前面的排名相同,请不要跳过排名。
输出排名、宾客 ID 和他们发送的总消息数。按总消息数从高到低排序。”
问题链接:platform.stratascratch.com/coding/10159-ranking-most-active-guests?code_type=1
在这里,你需要使用排名窗口函数,即 DENSE_RANK()函数。数据不会进行分区,但使用 ORDER BY 对消息总和进行排名,从高到低。此外,选择宾客 ID,并在窗口函数之外计算消息总和。
按宾客 ID 分组数据,并按消息数量从高到低排序。
你的输出应类似于此。
SQL 面试题 #18:累计能耗
“计算 Meta/Facebook 数据中心在所有三个大洲的累计能耗(即累计总和)按日期。输出日期、累计能耗以及四舍五入到最接近的整数的累计百分比。”
问题链接:platform.stratascratch.com/coding/10084-cum-sum-energy-consumption?code_type=1
这是一个难题,涵盖了我讨论的大部分主题。首先,你需要编写一个 CTE。使用它来编写三个 SELECT 语句,从每个表中选择所有数据,并使用 UNION ALL 将结果合并。
第二个 CTE 将使用第一个 CTE 中的数据,通过 SUM()聚合函数按日期获取总能耗。
外部查询使用第二个 CTE 中的数据如下所示。SUM()窗口函数通过将数据按日期从最旧到最新排序来计算累计总和。
然后将这个相同的窗口函数除以总能量消耗——你可以通过按日期汇总能量消耗来获得——并乘以 100 得到百分比。使用 ROUND() 函数将结果四舍五入到最接近的整数,即没有小数位。
就是它,能够让你从面试官那里获得分数的输出。
7. 文本和日期处理

理论
数据科学家常常需要处理数据库中的文本和日期/时间,而不仅仅是数值。这通常意味着从多个字符串中创建一个字符串,或仅使用日期的某一部分(如日、月、年)或一个字符串。
最常用的 文本处理函数包括:
| 文本函数 | 描述 |
|---|---|
| || 或 CONCAT() | 将多个字符串值连接成一个。 |
| CHAR_LENGTH() | 返回字符串中的字符数。 |
| LOWER() | 将字符串转换为全小写。 |
| UPPER() | 将字符串转换为全大写。 |
| SUBSTRING() | 返回字符串的部分。 |
| TRIM() | 删除字符串开头和结尾的空格或其他字符。 |
| LTRIM() | 删除字符串开头的空格或其他字符。 |
| RTRIM() | 删除字符串结尾的空格或其他字符。 |
| LEFT() | 从字符串开头返回定义的字符数。 |
| RIGHT() | 从字符串结尾返回定义的字符数。 |
两个最常用的 日期/时间函数是:
| 日期/时间函数 | 描述 |
|---|---|
| EXTRACT() | 返回日期或时间的部分;SQL 标准。 |
| DATE_PART() | 返回日期或时间的部分;特定于 PostgreSQL。 |
文本和日期/时间函数在数据科学家清理数据时非常实用。当然,他们也可以使用日期/时间函数进行计算,例如添加或减去时间段,并用于数据过滤、聚合等。
SQL 问题
SQL 面试问题 #19: 待处理的索赔
“统计 2021 年 12 月提交的索赔中仍在待处理的数量。待处理的索赔是指没有接受或拒绝日期的索赔。”
问题链接:platform.stratascratch.com/coding/2083-pending-claims?code_type=1
数据
问题给出了表 cvs_claims。
| claim_id | int |
|---|---|
| account_id | varchar |
| date_submitted | datetime |
| date_accepted | datetime |
| date_rejected | datetime |
让自己熟悉数据。
解决方案方法
COUNT() 函数用于获取索赔数量。你需要计数仅满足特定条件的索赔。通过 EXTRACT() 函数设置了两个条件。第一个用于从索赔提交日期中提取月份。另一个 EXTRACT() 函数将从同一列中获取年份。这样,你将获得 2021 年 12 月提交的索赔。
WHERE 子句中的接下来的两个条件将仅显示尚未接受或拒绝的索赔,即它们处于待处理状态。
SELECT COUNT(*) AS n_claims
FROM cvs_claims
WHERE EXTRACT(MONTH
FROM date_submitted) = 12
AND EXTRACT(YEAR
FROM date_submitted) = 2021
AND date_accepted IS NULL
AND date_rejected IS NULL;
输出
这个解决方案显示了 2021 年 12 月提交的五个待处理索赔。
SQL 面试题 #20:高峰时段电话
“Redfin 帮助客户找到代理。每个客户将有一个唯一的 request_id,每个 request_id 有多个电话。对于每个 request_id,第一次电话是“初始电话”,所有后续电话都是“更新电话”。有多少客户在下午 3 点到 6 点之间(初始和更新电话合并)拨打了 3 次或更多次?”
问题链接:platform.stratascratch.com/coding/2023-rush-hour-calls?code_type=1
这个解决方案使用了 DATE_PART() 函数,而不是 EXTRACT()。它在 FROM 子句中的子查询中进行。子查询显示客户,但不是所有客户。首先,数据通过 WHERE 子句和 DATE_PART() 进行过滤并转换为时间戳,以便子查询仅返回在 15 点到 17 点之间拨打电话的客户。
数据在分组后通过 HAVING 子句进行额外过滤。条件显示了在上述时间段内拨打三次或更多次的客户。
这个结果仅用于主查询中计算客户数量。
仅有一名客户在 15:00 到 17:00 之间拨打了三次或更多次。
SQL 面试题 #21:确定等级的规则
“找出用于确定每个等级的规则。以“Score > X AND Score <= Y => Grade = A”的格式在单独的列中显示规则,其中 X 和 Y 是等级的下限和上限。输出相应的等级及其最高和最低分数以及规则。根据等级按升序排列结果。”
问题链接:platform.stratascratch.com/coding/9700-rules-to-determine-grades?code_type=1
SELECT 语句返回每个等级的最低和最高分数。最后一列用于通过连接函数标记规则。使用 MIN() 和 MAX() 函数来获取以下规则:
-
A 级:分数 > 89 且 <= 100
-
B 级:分数 > 79 且 <= 88
-
C 等级:得分 > 69 且 <= 79
当然,标签必须按要求格式化。
输出按等级分组和排序。
这里是规则。
SQL 理论面试问题
这些问题也测试 SQL 知识,与编码问题类似。不同之处在于它们不需要编写代码,但你必须解释 SQL 概念或它们之间的区别。
这里是一些这样的例子,所有问题都测试了我在编码问题部分提到的主题。
SQL 面试问题#22:WHERE 和 HAVING
“WHERE 子句和 HAVING 子句在 SQL 中的主要区别是什么?”
问题链接:platform.stratascratch.com/technical/2374-where-and-having
WHERE 和 HAVING 都用于过滤数据。主要区别在于,WHERE 子句用于在聚合和 GROUP BY 之前过滤数据,而 HAVING 子句则在 GROUP BY 子句之后用于过滤已经聚合的数据。
SQL 面试问题#23:左连接和右连接
“在 SQL 中,左连接和右连接有什么区别?”
问题链接:platform.stratascratch.com/technical/2242-left-join-and-right-join
你可以先解释这两种外连接的相似之处。然后你可以谈论它们的区别。提示:线索在于‘left’和‘right’。
SQL 面试问题#24:公共表表达式
“在 SQL 中,什么是公共表表达式?举例说明你会在什么情况下使用它。”
问题链接:platform.stratascratch.com/technical/2354-common-table-expression
你已经看到 CTE 的工作原理。你可以谈谈它们与子查询的比较,然后给出一个 CTE 的使用示例。编码问题中已经涵盖了这些内容。
总结
SQL 面试问题通常有两种形式:编码和非编码。两种问题类型最常测试“不可避免的七个”。你不能在面试时忽视这七个关键的 SQL 概念。
专注于这些问题,以涵盖面试中可能出现的大多数 SQL 问题。问题的难度也是一个变量,因此解决简单和困难问题所需的知识可能有很大差异。
Nate Rosidi 是一位数据科学家和产品策略专家。他还是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
了解更多相关主题
什么是 MLOps 工程师?

图片由Freepik创建
介绍
MLOps 是数据行业中一个相对较新的术语。在过去,公司只专注于聘请数据科学家和机器学习从业者。这些人可以构建预测模型,帮助公司自动化工作流程并做出关键决策。
然而,随着时间的推移,机器学习项目开始对组织造成更多的损害而非好处。当投入生产时它们失败了,导致了商业机会的丧失和客户的不满。
为什么会发生这种情况?
从理论上讲,这些公司做得一切都很对。他们聘请了一支经验丰富的数据科学家团队,这些团队拥有构建技术上可靠模型的能力。他们还拥有领域专家,清晰地定义了业务用例,并成功地将问题陈述转化为机器学习项目。
这些举措所构建的模型在测试环境中表现出色,但在交付给最终用户时却失败了。这是一个没人能预测到的结果,并且导致组织损失了数百万美元。
问题在于:
数据科学家的重点仅在于模型构建。一旦这些机器学习模型交到最终用户手中,就没有合适的系统来确保它们在实际环境中表现良好。模型在未经过训练的环境中表现可能会大相径庭。
由于机器学习对大多数组织来说都是全新的,这些因素在过去没有被考虑在内,这导致了灾难性的后果和糟糕的表现。
这里有几个由于缺乏持续模型监控和维护而导致的实际机器学习项目失败的例子:
反馈循环
Predpol 是一家旨在通过统计分析预测贫困犯罪的公司。该软件可以预测犯罪发生的时间和地点,并派遣警察到该地区进行逮捕。然后,算法会在这些数据上重新训练,以便进行未来的犯罪预测。
具有讽刺意味的是,上述过程最终形成了一个反馈循环。每次逮捕发生时,模型都会被更新,并将更多的执法人员派往同一地区。这反过来导致特定地区的逮捕人数增加,这些数据又被反馈到模型中。Predpol 系统最终在警察更多的地区预测了更高的犯罪率,而不是犯罪分子更多的地区。
这是一个失败的机器学习项目的例子。模型预测被泄露到了训练数据中,这些数据随后被用于进一步增强算法。
数据漂移
现实世界是不可预测且不断变化的。因此,一个表现良好的机器学习模型可能在下一天就会变得非常不准确。
一个例子可以在一个致力于为医疗保健构建机器学习模型的公司中看到。这个组织部署了一个算法来预测 30 天内的医院再入院率。
大约 2–3 个月后,最初有效的模型开始做出非常不准确的预测。每个部署该模型的医院都遇到了同样的问题,算法的低效使客户不满。
一个团队被分配去调查此事,他们发现模型性能每次训练数据库发生变化时都会下降。例如,如果医院更改了他们接受的保险类型,这直接影响到前往急诊室的患者类型,从而对模型的准确性产生负面影响。
在意识到问题后,他们立即着手解决情况。一个由技术专家和业务精英组成的团队被分配去监控输入数据的变化,并确保这些变化在预测算法中得到反映。
这种输入数据变化的现象被称为数据漂移,是公司中模型性能下降最常见的原因之一。
例如,如果你在一个主要受众为 18–34 岁女性的组织工作,并且在她们的行为属性上训练了你的模型,你就会在算法中引入偏差。
如果公司推出了一个面向年龄较大的新产品线,模型将不再相关。需要在准确代表公司当前用户行为的数据上重新训练模型。
数据漂移需要迅速检测,并且模型更新应尽快完成,以确保公司面临的损失最小。
季节性
季节性是指数据在特定时间间隔内经历规律性和可预测性变化的特征。机器学习模型需要定期更新,以考虑季节性变化。
例如,如果你基于过去 3 个月的数据为星巴克构建推荐系统,你的算法将根据客户在那个特定季节喜欢的饮品进行预测。
在接下来的几个月里,一旦气候发生变化,大多数用户的咖啡饮用习惯也会发生变化。如果这种变化没有被你构建的模型捕捉到,你可能会试图以不受欢迎的饮品吸引客户,这将导致公司损失。
MLOps 工程师的崛起
上述仅是一些例子,如果不加以考虑,这些因素可能对生产化算法的性能产生巨大负面影响。
随着组织因无效的机器学习项目而开始浪费时间和金钱,他们调查了这个问题。为什么尽管聘请了高能力的数据科学家,他们却看不到结果?
一旦雇主们明白问题在于缺乏适当的模型部署程序,他们意识到需要一个全新的角色——一个既具备机器学习又具备操作技能的人,能够处理模型构建后的工作流程。
这个职位被称为 MLOps(机器学习操作)。
MLOps 工程师所需的技能
MLOps 工程师负责模型的部署和持续维护。
如果你想成为一名 MLOps 工程师,你需要了解机器学习算法。你将负责重构其他数据科学家的代码,以使其准备好投入生产,并且需要能够理解他们的工作。
除了机器学习技能,你还需要具备 DevOps 的基础知识。DevOps 是一个将软件开发人员和运维团队的工作范围整合起来以自动化工作流程的角色。MLOps 工程师的角色与 DevOps 工程师非常相似,只是前者处理的是机器学习模型。
你需要学习 DevOps 概念,例如使用 CI/CD 管道自动化工作流程。CI 和 CD 分别代表持续集成和持续部署,它们使数据科学家所做的代码更改能够快速而可靠地交付到生产环境中。
MLOps 工程师角色——下一步
尽管大多数数据爱好者倾向于专注于发展他们的机器学习和数据科学技能,但成为数据科学家并不是你在行业中的唯一职业选择。
MLOps 正在快速增长,该领域的解决方案市场预计到 2025 年将增长至 40 亿美元。
此外,MLOps 领域包含大量的职业机会,因为公司目前正面临数据科学家和 DevOps 工程师技能组合的员工短缺。
如果您正在考虑换工作,并且目前在权衡各种选择,考虑追求 MLOps 职业可能是个好主意,因为这是一个相对未饱和的领域,具有惊人的成长机会。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。您可以在LinkedIn上与她联系。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
更多相关主题
张量到底是什么?!?
什么是张量?
当我们为机器学习表示数据时,这通常需要以数值形式进行。特别是在神经网络数据表示方面,这通过被称为张量的数据存储库来实现。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
那么张量的意义是什么呢?张量是一个可以容纳多维数据的容器。张量经常被错误地与矩阵(具体来说是二维张量)混用,实际上张量是矩阵在N维空间中的推广。
从数学上讲,张量不仅仅是一个数据容器。除了保存数值数据,张量还包括对张量之间有效线性变换的描述。这些变换或关系的示例包括 叉积 和 点积。从计算机科学的角度来看,将张量视为面向对象的对象可能会更有帮助,而不仅仅是一个数据结构。
机器学习中的张量
虽然上述内容都是正确的,但张量的技术定义和我们在机器学习实践中所称的张量之间存在细微差别。如果我们暂时将张量简单地看作数据结构,下面是张量与标量、向量和矩阵的关系概述,以及一些简单的代码演示如何使用 Numpy 创建这些数据类型。我们将在后续帖子中讨论一些张量变换。
标量
一个单一的数字就是标量。标量是一个 0 维(0D)张量。因此,它具有 0 个轴,且秩为 0(张量术语中的“轴数”)。
这就是细微之处:虽然一个单一的数字可以表示为张量,但这并不意味着它应该这样做,或通常如此。能够将它们视为张量是有充分理由的(这将在我们讨论张量操作时变得明显),但作为存储机制,这种能力可能会让人困惑。
Numpy 的多维数组 ndarray 用于创建讨论中的示例结构。请记住,多维数组的 ndim 属性返回数组的维度数。
import numpy as np
x = np.array(42)
print(x)
print('A scalar is of rank %d' %(x.ndim))
42
A scalar is of rank 0
向量
向量是一个单维(1D)张量,在计算机科学中通常被称为数组。一个向量由一系列数字组成,具有 1 个轴,秩为 1。
x = np.array([1, 1, 2, 3, 5, 8])
print(x)
print('A vector is of rank %d' %(x.ndim))
[1 1 2 3 5 8]
A vector is of rank 1
矩阵
矩阵是秩为 2 的张量,意味着它有 2 个轴。你从各种地方都很熟悉这些,特别是你用来整理数据集并输入到你的 Scikit-learn 机器学习模型中的数据 😃 矩阵被安排为数字网格(想象一下行和列),技术上是一个二维(2D)张量。
x = np.array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
print(x)
print('A matrix is of rank %d' %(x.ndim))
[[1 4 7]
[2 5 8]
[3 6 9]]
A matrix is of rank 2
3D 张量与更高维度
虽然从技术上讲,上述所有结构都是有效的张量,但在口语中,当我们谈论张量时,通常指的是矩阵概念的 N ≥ 3 维度的推广。为了避免混淆,我们通常只将 3 维或更高维的张量称为张量(通常将标量 '42' 称为张量既不有益也不清晰)。
下面的代码创建了一个 3D 张量。如果我们将一系列这些张量打包到一个更高阶的张量容器中,它将被称为 4D 张量;如果将这些打包到更高的阶数,即 5D 张量,以此类推。
x = np.array([[[1, 4, 7],
[2, 5, 8],
[3, 6, 9]],
[[10, 40, 70],
[20, 50, 80],
[30, 60, 90]],
[[100, 400, 700],
[200, 500, 800],
[300, 600, 900]]])
print(x)
print('This tensor is of rank %d' %(x.ndim))
[[[ 1 4 7]
[ 2 5 8]
[ 3 6 9]]
[[ 10 40 70]
[ 20 50 80]
[ 30 60 90]]
[[100 400 700]
[200 500 800]
[300 600 900]]]
This tensor is of rank 3
你如何使用张量是你的事,不过理解张量是什么及其与相关数值容器结构的关系现在应该清晰了。
Matthew Mayo (@mattmayo13) 是一位数据科学家,同时也是 KDnuggets 的总编辑,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关内容
25 个高级 SQL 面试问题
原文:
www.kdnuggets.com/2022/10/25-advanced-sql-interview-questions-data-scientists.html

图片由 Freepik 提供
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
所有数据库使用的标准语言是结构化查询语言(SQL)。
它在从数据库中获取需求数据方面起着关键作用。所有大型数据平台,如 Hadoop 和 Spark,都使用 SQL 作为其组织的高级语言。
数据科学是唯一的研究和分析数据的领域。数据结果应准确无误,以便进行调查。
这就是 SQL 如何与数据科学结合的原因。虽然某些组织已转向 NoSQL,但基础仍在于 SQL。
准备好迎接数据科学面试了吗?
25 个高级 SQL 面试问题
这里有一些关于 SQL 的必要面试问题及答案,你必须学习。
1. 解释规范化是什么?
规范化是一种组织数据库中数据的方法,以最小化冗余。通过使用规范形式的概念对关系进行规范化。
-
1NF:如果一个关系具有原子值,则它处于 1NF。
-
2NF:一个关系要处于 2NF,它应该处于 1NF,并且所有非键属性完全依赖于主键。
-
3NF:一个关系要处于 3NF,它应该处于 2NF,并且没有过渡依赖关系。
-
BCNF:Boy Codd 的规范形式是 3NF 的强表示。
2. 解释 DDL 和 DML 之间的区别?
-
DDL 代表数据定义语言,而 DML 称为数据操作语言。
-
DDL 创建一个带有约束的模式。DML 在该模式中添加、检索或更新数据。
-
DDL 定义表的列属性。DML 提供表的行属性。
-
DDL 命令的例子包括创建、修改、删除、重命名等,而 DML 命令的例子包括合并、更新、插入等。
-
WHERE 子句不用于 DDL,但用于 DML。
3. SQL 中的 ACID 属性是什么?
ACID 属性如下:
-
原子性 - 数据的更改必须像一个单一的操作一样。
-
一致性 - 数据在事务前后必须保持一致。
-
隔离性 - 多个事务可以在没有任何障碍的情况下进行。
-
持久性 - 事务在系统故障的情况下会成功。
4. 编写一个查询以查找表中所有的重复项?
在一般情况下,查找表中所有重复项的方法如下:
-
使用 GROUP BY 命令按目标列分组所有行。这里的目标列是你可以检查重复项的列。
-
使用 HAVING 命令并结合 COUNT 函数来检查是否有任何组的条目超过一个。
5. 聚集索引和非聚集索引之间的区别是什么?
以下是聚集索引和非聚集索引之间的区别:
-
聚集索引用于定义排序索引或表的顺序,就像字典一样。非聚集索引将所有数据收集到一个地方,并在另一个地方记录它。
-
聚集索引比非聚集索引更快。
-
执行聚集索引操作时使用的内存比非聚集索引少。
6. 解释反规范化?
数据库优化技术中,我们将数据(冗余)添加到表中的方法称为反规范化。该技术有助于减少数据库中昂贵的连接。
7. 什么是排序规则?
在 SQL 服务器中,排序规则提供了数据的排序规则、重音和大小写敏感性属性。它通过定义排序规则来表示数据库中的每个字符的位模式。
一些排序规则级别如下:
-
大小写敏感 (_CS)
-
重音敏感 (_AS)
-
假名敏感 (_KS)
-
宽度敏感 (_WS)
-
变体选择器敏感 (_VSS)
-
二进制 (_BIN)
-
二进制代码点 (_BIN2)
8. 内连接、外连接和全外连接之间的区别是什么?
以下是内连接、外连接和全外连接之间的区别:
-
在内连接中,两个表中共同的行是输出结果。
-
在全外连接中,返回两个表中的所有行。
-
外连接返回来自一个或两个表的值。
9. 解释连接和联合之间的区别?
以下是连接和联合之间的区别:
-
连接从表中检索匹配的记录,而联合则用于合并两个不同 SELECT 语句的集合。
-
连接不会删除重复数据,而联合会从选定的语句中删除重复数据(行)。
10. 解释 UNION 和 UNION ALL 之间的区别?
联合保留唯一记录,而联合所有保留所有记录,包括所有重复项。此外,联合在返回数据之前会进行去重步骤,而联合所有打印连接结果。
11. 编写一个查询以打印表中最高的薪水?
考虑一个表,数据如下,表名为 EMP-
姓名 薪水
---------------------
约翰 990000
Ellie 100000
Nick 400000
Sam 500000
查询将是:
SELECT * FROM EMP WHERE salary=(select Max(salary) FROM EMP);
12. 共享锁和包含锁的区别是什么?
-
在共享锁中,锁模式仅用于读取操作,而在包含锁中,它用于读取和写入操作。
-
共享锁防止其他人更新数据,而包含锁则防止其他人读取或更新数据。
-
任意数量的事务可以对特定项目持有共享锁,而只有一个事务可以持有排他锁。
13. 解释如何使用 SQL 进行转置的机制?
SQL 中的转置被定义为将一行或一列转换为特定格式,以从新的角度可视化数据。
一种基本的转置是将一行转换为一列或将一列转换为一行。典型的转置方法包括动态转置和连接转置。
所有的转置方法都用于数据分析,以获得有益的结果。
14. 解释 B 树索引的工作原理?
B 树被定义为一种自平衡搜索树,其中所有叶子节点都处于同一层级。要在 B 树中插入数据,数据将插入到叶子节点。
在 B 树索引中,树具有一个称为负载的键值对。该值被引用到实际的数据记录中。
当我们使用 B 树索引时,数据库根据 B 树搜索给定的键并获取索引。
15. 解释 TRUNCATE 和 DELETE 对身份的影响?
以下是 DELETE 和 TRUNCATE 命令之间的差异:
-
DELETE 命令用于删除表中的特定行,而 TRUNCATE 删除所有行中的数据。
-
DELETE 是一个 DML 命令,比 TRUNCATE 命令(DDL 命令)慢。
-
DELETE 命令会触发活动,而 TRUNCATE 则不会。
16. 解释拥有数据库索引的成本?
它会占用空间。表越大,索引就越大。
对表中某些行的添加、删除或更新也必须应用到我们的索引上。
一般来说,如果表中被索引的列经常需要使用,则必须在该表上创建索引。
17. 拥有索引的优势是什么?
下面是拥有索引的优势:
-
它加速了 SELECT 查询。
-
数据检索变得相当简单。
-
索引可以用于排序。
-
它使得一行数据唯一,没有任何重复。
-
当索引设置为全文索引时,可以插入大型字符串文本。
18. 解释数据库中的索引?
索引是一种数据结构技术,通过减少查询处理期间的磁盘访问来优化数据库性能。
索引具有以下属性:
-
访问类型:基于搜索类型
-
访问时间:基于搜索时间
-
插入时间:基于快速插入
-
删除时间:基于快速删除
-
空间开销:基于额外的开销空间。
19. 什么是 OLAP 和 OLTP?
在线分析处理(OLAP)
企业必须理解一组数据,以帮助财务领导者和业务团队深入了解用户及多个相关因素的表现。
企业可以在业务流程和策略中拥有各种数据,这些数据帮助团队在更细化的层面上分析表现。
这些数据存储在多个数据库系统中,因此需要一致、实时且更灵活的处理过程,帮助团队分析数据并进一步处理以进行更多分析。
在线分析处理(OLAP)包含用于分析业务数据的软件工具,并帮助获得数据库的洞察。
例如,OLAP 可用于构建 Spotify 歌曲推荐引擎,该引擎根据用户的歌曲选择和历史收听数据自动生成播放列表。
在线事务处理(OLTP)
事务是每个业务的关键部分。一个提供服务的企业在客户使用服务时会收到一笔费用。
当用户为他们选择的服务付款时,发票会立即生成。
当我们需要存储所有用户的交易信息时,事务数据库就会发挥作用。
但在线事务处理(OLTP)提供了面向事务的应用程序,这些应用程序在 3 层架构中进行分类。
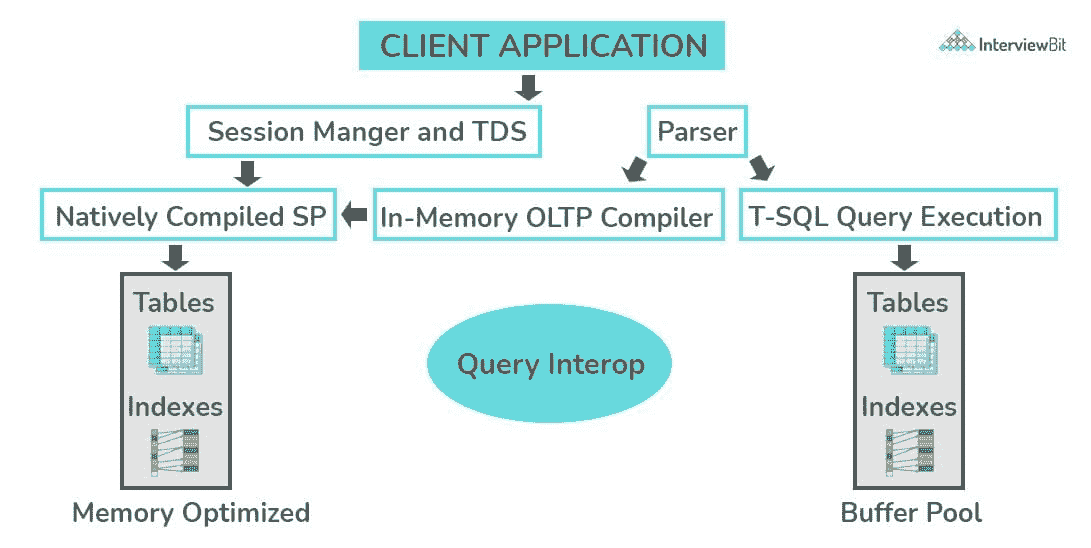
来源: InterviewBit
OLTP 帮助企业执行与事务数据库相关的某些活动。
例如,通过在线银行进行的交易具有相同的目的,其中 OLTP 可以用于操作用户交易信息。
20. CASE WHEN 适用于什么条件?
SQL 用于查询数据库和修改大型数据集中的值。它还提供了一种在多种情况下操作数据的方法。
例如,一个表包含员工列表(name),以及经验(EXP)和加入日期(ac_date)。
现在,如果我们想查询数据,如果经验大于(>)“4”,则在名为“exp_level”的新列中插入“Is a senior”,否则在该列中插入 NULL。
在这种情况下,你可以使用 CASE WHEN 语句查询数据库。
CASE WHEN 语句类似于编程语言中的 If/else 条件,比如 C、C++、Python 等。
CASE 语句后面跟随一对 WHEN 和 THEN 语句。然而,你可以根据需要添加嵌套语句。
一旦 CASE 语句完成,就通过添加以 ELSE 和 END AS 开头的结束语句来结束。
在上述示例中,我们有一个员工数据库,列出了公司的员工,包括员工姓名、加入年份、经验等属性。使用 CASE WHEN 语句在这个示例中,
SELECT employee_name,
exp,
CASE WHEN exp > 4 THEN 'Is a Senior'
ELSE NULL END AS exp_level
FROM xyz.marketing_employees
21. 解释 HAVING 与 WHERE 的使用情况?
SQL 中的 HAVING 子句
SQL 提供了 HAVING 子句来过滤数据库中的数据组。
例如,XYZ 公司有一个员工列表,包含了有超过 1 年经验的员工。
数据库包含行和列,包括员工姓名、入职日期、经验和经验等级。
你可以检索出拥有超过 5 年经验的员工列表。
HAVING 子句为你提供了一种控制信息和修改数据的方式。
HAVING 子句的语法是:HAVING condition。
在这个例子中,我们可以通过以下查询从数据库中检索出拥有超过 5 年经验的员工列表:
SELECT employee_name, exp_level,
FROM EMPLOYEE
GROUP BY experience
HAVING COUNT(experience) > 5;
SQL 中的 WHERE 子句
当你想根据特定条件筛选记录时,可以使用 WHERE 子句。
例如,在员工表中,我们可以检索出在公司中有 exactly 5 年经验的所有员工的列表。WHERE 子句的语法是:WHERE condition。
在这个例子中,我们可以通过以下查询从数据库中提取出拥有 5 年经验的员工姓名:
SELECT employee_name, exp_level,
FROM EMPLOYEE
WHERE experience= 5;
22. 什么是 PL/SQL?
PL/SQL 是一种块结构化语言,鼓励开发人员使用过程语句的 SQL 功能。
它是一种功能齐全的过程语言,嵌入了决策能力以及其他许多 POP 特性。
使用单个块命令,PL/SQL 可以在支持广泛错误检查的情况下运行多个查询。
PL/SQL 是 SQL 的扩展,用于创建应用程序。
23. SQL 中的 ETL 是什么?
ETL 代表“提取、转换和加载”。它使用数据仓库的概念来进行数据可视化和数据分析。在更广泛的背景下,它用于数据集成。
任何从一个系统提取数据并存储/复制到另一个目标系统且其数据表示形式不同的过程称为 ETL 过程。
24. 什么是嵌套触发器?
SQL 提供数据操作语言(DML)和数据定义语言(DDL)以在查询数据库时执行某些操作。
当在数据库上执行特定类型的操作时,它会自动在数据库上执行一些操作。
当数据库中触发这些类型的操作时,它们被称为嵌套触发器。
SQL 将嵌套触发器分为两个主要类别——AFTER 触发器和 INSTEAD OF 触发器。
顾名思义,AFTER 触发器是在数据库上执行 DML 或 DDL 操作后执行的。
然而,INSTEAD OF 触发器在 DML 和 DDL 操作中被执行。
25. 什么是提交和检查点?
提交确保数据在当前事务结束后保持一致并维持在更新状态。使用提交时,日志内存中会新增一条记录。
在检查点的情况下,它用于将所有提交的更改写入磁盘,并在控制文件和头文件中更新系统更改编号。
结论
在这篇文章中,我们详细讨论了数据科学面试中会问到的所有 SQL 问题。
如果你是初学者,可以从以下资源学习 SQL:
-
Matthew Mayo 的 4 小时 SQL 完整课程
快乐学习!
额外资源
-
为什么 SQL 将继续是数据科学家的最佳朋友
-
SQL 数据准备备忘单
-
掌握数据科学 SQL 的 7 个步骤
-
数据科学面试中你应该知道的五大 SQL 窗口函数
Vaishnavi Amira Yada 是一位技术内容撰稿人。她掌握 Python、Java、数据结构与算法(DSA)、C 等知识。她发现自己对写作情有独钟,并且热爱写作。
更多相关话题
25 本免费书籍,掌握 SQL、Python、数据科学、机器学习和自然语言处理

作者提供的图片
学习 SQL、Python、数据科学、机器学习和自然语言处理等基本技能可以开启令人兴奋的职业机会。然而,相关课程和书籍可能会很昂贵。好消息是,网上有免费的资源可以帮助你掌握这些技能。在线书籍提供了基础知识、实际例子和可以立即应用的代码片段。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
我想与大家分享一份包含 25 本高质量书籍的列表,这些书籍涵盖了 SQL、Python、数据科学、机器学习和自然语言处理等多个主题,你可以在网上免费获取。我从 KDnuggets 上收集了关于免费书籍的最佳帖子,以创建这个合集。这些书籍质量上乘,我建议收藏此页面以备将来使用。
SQL
-
《SQL 专业人士笔记》 由 GoalKicker.com 编写: 适合想通过代码示例学习 SQL 的初学者。
-
《SQL 学习》 由 Stack Overflows 编写: 学习 SQL 语言中所有重要的语法和函数,以便更好地处理数据。
-
《SQL 简介》 由 Bobby Iliev 编写: 学会为你的 SysOps、DevOps 和 Dev 项目使用关系数据库。
-
《SQL 基础》 由 Stack Overflow 编写: 了解清晰而简洁的 SQL 主题解释,适合初学者和高级程序员。
-
《SQL 索引和调优电子书》 由 Markus Winand 编写: 学习最有效的调优方法,优化你的数据库。
通过阅读 5 本免费 SQL 书籍了解更多关于单本书的信息
Python
-
《人人都能学会的 Python》 由 Charles Severance 博士编写: 面向没有编程背景的初学者。
-
用 Python 自动化无聊的任务 作者:Al Sweigart: 学习如何自动化那些本来需要花费几个小时的任务。
-
Python 3 模式、配方与习语 作者:BitBucket.org: 从 Python 社区获取最佳技巧。
-
Python 中的清洁架构 作者:Leonardo Giordani: 提高软件设计的实用方法。
-
Python 数据科学手册 作者:Jake VanderPlas: 学习如何使用 IPython、NumPy、Pandas、Matplotlib、Scikit-Learn 等。
通过阅读 5 本免费书籍帮助你掌握 Python 来了解更多关于个别书籍的信息。
数据科学
-
Pandas:强大的 Python 数据分析工具包 作者:Wes McKinney: 学习有关 Pandas 的所有知识,以管理、操作和分析数据。
-
Think Stats 作者:Allen B. Downey: 适合希望通过 Python 代码示例学习概率和统计的学生。
-
商业数据科学 作者:Tom Fawcett: 为希望处理、管理、实施或投资数据科学解决方案的商界人士、开发者和有志于数据科学的人员提供的书籍。
-
应用机器学习的线性代数导论 作者:Pablo Caceres: 结合了免费的在线可下载版本的网页书籍。
-
用 Python 进行深度学习 作者:Francois Chollet: 学习机器学习和深度学习的基础知识。
通过阅读 5 本免费书籍来掌握数据科学来了解更多关于个别书籍的信息。
机器学习
-
绝对初学者的机器学习 作者:Oliver Theobald: 一本完美的书籍,帮助你开始机器学习的职业生涯。
-
机器学习数学基础 作者:Marc Peter Deisenroth: 设计给那些希望开发前沿机器学习技术的学生和研究人员。
-
黑客的机器学习 作者:Drew Conway 和 John Myles White: 案例研究、代码示例、算法,帮助你入门机器学习。
-
动手实践机器学习:使用 Scikit-Learn、Keras 和 TensorFlow 作者:Geron Aurelien: 了解构建智能应用程序所需的概念、工具和技术。
-
接近(几乎)任何机器学习问题 作者:Abhishek Thakur: 一本来自最受欢迎的机器学习影响者的书籍,教授你所有的基础知识,为工作做好准备。
通过阅读 5 本免费机器学习书籍了解更多关于单本书籍的信息。
自然语言处理
-
语言与语音处理 作者:Dan Jurafsky 和 James H. Martin: NLP、计算语言学和语音识别导论。
-
统计自然语言处理基础 作者:Christopher D. Manning 和 Hinrich Schütze: 一个很好的起点,可以帮助你开启自然语言处理的职业生涯。
-
模式识别与机器学习 作者:Christopher M. Bishop: 了解概率分布、线性模型、神经网络、核方法等内容。
-
用 Python 进行自然语言处理 作者:Steven Bird, Ewan Klein 和 Edward Loper: O'reilly 提供了一本免费书籍,教授如何使用 Python 库 NLTK 进行自然语言处理。
-
实用自然语言处理 作者:Sowmya Vajjala, Bodhisattwa Majumder, Anuj Gupta 和 Harshit Surana: 一本全面的指南,帮助你构建实际的自然语言处理系统。
通过阅读 2023 年阅读的 5 本自然语言处理免费书籍了解更多关于单本书籍的信息。
结论
这 25 本免费书籍提供了关于 SQL、Python、数据科学、机器学习和自然语言处理等重要数据技能的丰富知识。借助实际示例和代码片段,你可以获得实践经验,并将所学应用于构建自己的应用程序。无论你是初学者还是希望提升技能,这些书籍都提供了宝贵的资源。你所需要的只是奉献和努力,以成为最优秀的数据专业人士。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,他热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些遭受心理疾病困扰的学生。
了解更多相关内容
25 门免费课程,掌握数据科学、数据工程、机器学习、MLOps 和生成式 AI

作者提供的图片
在当今快速发展的技术环境中,掌握数据科学、机器学习和 AI 技能至关重要。无论你是寻求开始新的职业生涯还是提升现有的专业知识,都有大量的在线资源可供利用,其中许多都是免费的!我们从 KDnuggets 收集了最受欢迎的免费课程帖子,并将它们汇总在一起,为你提供一系列优秀的课程。将此页面收藏以备后用,你可能会多次回到这里来学习新技能或尝试新课程。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
数据科学
-
面向所有人的 Python 由查尔斯·塞弗伦斯教授提供: 对 Python 编程的全面介绍,适合初学者。
-
使用 Python 进行数据分析 由 Jovian 提供: 探索使用 Python 进行数据分析的技巧。
-
数据库和 SQL 由 freeCodeCamp 提供: 学习如何使用 SQL 管理数据库。
-
推断统计入门 来自 Udacity: 通过统计学习获得关于预测的见解。
-
机器学习 Zoomcamp 由 DataTalks.Club 提供: 一种实践性的(基于项目的)机器学习学习方法。
通过阅读 5 门免费课程,掌握数据科学 了解更多关于单个课程的信息
数据工程
-
数据工程 由 IBM 在 edX 提供: 理解数据工程的基础知识。
-
数据工程师学习路径 由 Google 提供: 为有志于成为数据工程师的人提供的指导路径。
-
数据库工程师专业证书 by Meta: 获得数据库工程认证。
-
大数据专业化 by UC San Diego: 学习大数据技术和应用。
-
数据工程 Zoomcamp by DataTalks.Club: 一个基于项目的动手数据工程课程。
通过阅读 5 免费课程掌握数据工程 了解更多关于各个课程的信息。
机器学习
-
机器学习入门 by Kaggle: 一个面向初学者的机器学习介绍。
-
人人可学的机器学习 by Kylie Ying: 一种易于理解的机器学习概念介绍。
-
使用 Scikit-Learn 的 Python 机器学习 by FUN MOOC: 专注于使用 Python 和 Scikit-Learn 进行机器学习。
-
机器学习速成课程 by Google: 快速而全面的机器学习入门课程。
-
CS229: 机器学习 by Stanford University: 一个更高级的课程,适合那些希望深入了解的学习者。
通过阅读 5 免费课程掌握机器学习 了解更多关于各个课程的信息。
MLOps
-
MLOps 的 Python 基础 by Duke University: MLOps 爱好者必备的基础课程。
-
MLOps 入门 by Udemy: MLOps 初学者的绝佳起点。
-
生产环境中的机器学习工程(MLOps)专业化 by DeepLearning.AI: 深入探索 MLOps 的世界。这是一个课程合集。
-
机器学习操作专业化 by Duke University: 关注机器学习的操作方面。
-
使用 ML 制作 by Goku Mohandas: 一门将机器学习与实际应用相结合的独特课程。在 GitHub 上非常受欢迎。
通过阅读 5 免费课程掌握 MLOps 了解更多关于各个课程的信息。
生成式 AI
-
生成式 AI 入门 by Microsoft: 12 节课程帮助构建生成式 AI 应用。
-
生成性 AI 基础 由 DataBricks 提供: 探索生成性 AI 的基础知识。
-
生成性 AI 学习路径简介 由 Google 提供: 从学习大型语言模型的基础知识到理解负责任的 AI 原则。
-
使用大型语言模型的生成性 AI 由 AWS 和 DeepLearning.AI 提供: 与 AWS 专家一起获得 AI 的实际经验,他们在商业用例中构建和部署 AI。
-
人人适用的生成性 AI 由 DeepLearning.AI 提供: 介绍生成性 AI 的概念、工作原理、常见用例和局限性。
通过阅读 掌握生成性 AI 的 5 门免费课程 了解更多有关单独课程的信息
结论
在这篇博客中,我们介绍了 25 门可以帮助你建立数据科学及其相关子领域坚实基础的免费在线课程。通过学习更多高级课程,如机器学习、MLOps 和生成性 AI,提升你的技能。无论你在数据科学学习旅程中的哪一阶段,这些免费课程都使优质教育变得对每个人都可及。它们提供灵活的学习方式,即使在最繁忙的日程中也能适应。祝学习愉快!
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
相关主题
每个 Python 开发者都应该知道的 25 个 Github 仓库
原文:
www.kdnuggets.com/2021/11/25-github-repositories-python-developer.html
comments
由 Abhay Parashar, 机器学习爱好者

照片由 heylagostechie 提供,来源于 Unsplash
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
你是否曾经被困在这样的问题中:
-
FAANG 公司编写的代码是什么样的?
-
我怎样才能像他们一样写代码?
-
我已经学会了这些,现在怎么办?
嗯,所有这些问题的答案是 Github。
什么是 Github?
学习如何编码很简单,但学习如何写更好的代码则很困难。Github 可以准确地展示你需要知道的内容。它就像是开发者的金矿,其中的“黄金”是其他开发者编写的代码。在 GitHub 的帮助下,你可以学习如何编写更好的代码、优秀代码的样子,以及成为更好开发者所需遵循的步骤。
你知道吗?
根据 Stackoverflow,Python 是最受欢迎的语言。
它是 GitHub 上第二受欢迎的语言。
Python 的包仓库中有超过 147,000+个包。
它被报道为数据科学领域最常用且最好的工具之一。
仓库
本文中包含的大多数仓库都基于数据科学和机器学习。让我们将这些仓库分成五部分。
-
学习
-
书籍
-
项目
-
面试准备
-
框架、模块和工具
学习
1. The Algorithms — Python 由 The Algorithms
正如仓库名称所解释的,这个仓库包含了你可能需要的几乎所有算法。你甚至可以使用 pip install algorithms 将其安装为包。
使用 repo 包的归并排序示例。
这个库不仅限于算法。它还包含矩阵、图等的各种操作。
统计信息 : (109k+ ⭐) (30.1k+ Forked)
2. vinta/awesome-python
精选的优秀 Python 框架、库、软件和资源列表。
这个仓库是自解释的,但如果你发现理解有困难,他们有自己的网站 website 具有出色的 GUI。
统计信息: (99k+ ⭐) (19k+ Forked)
3. jerry-git/learn-python3
该仓库是一个用于学习 Python 的 Jupyter 笔记本集合。对于希望通过解决问题来动手实践的 Python 初学者来说,这是最好的选择。
每个笔记本都包含一些理论、代码和编程练习。
统计信息: (3.9k+ ⭐) (1k+ Forked)
4. trekhleb/learn-python
???? 用于学习 Python 的练习场和备忘单。包含按主题划分的 Python 脚本,并附有代码示例和解释。
这是另一个很好的按主题学习 Python 的仓库。
统计信息: (7.5k+ ⭐) (1.4k+ Forked)
5. Avik-Jain/100-Days-Of-ML-Code
该仓库非常适合所有数据科学学习者。它包含了 100 天的不同主题和算法代码。
这个仓库中的笔记本易于理解,自解释。
统计信息: (32.2k+ ⭐) (8.1k+ Forked)
书籍
6. Hitchhiker’s Guide to Python:
一本关于 Python 安装、配置和日常使用的最佳实践手册。
它包括 Pip、Numpy、scipy、statpy、pyplot、matplotlib、服务器配置以及各种 Web 框架的工具、Virtualenv 等众多主题。
统计信息: (23k+ ⭐) (5.6k+ Forked)
7. 神秘 Python:
一本关于 Pythonic 应用程序架构模式的书,旨在管理复杂性。
统计信息: (1.9k+ ⭐) (290+ Forked)
8. Python 一点通:
“A Byte of Python” 是一本关于使用 Python 语言编程的免费书籍。它为初学者提供了编程教程。如果你对计算机唯一的了解就是如何保存文本文件,那么这本书就是为你准备的。
统计信息: (1.5k+ ⭐) (894+ Forked)
9. Python 机器学习:
这是经典 Python 机器学习书籍的代码仓库。它包含每一章的代码。
统计信息: (2.2k+ ⭐) (967+ Forked)
开源项目
10. shobrook/rebound
一种命令行工具,当出现异常时会即时获取 Stack Overflow 结果。运行程序时只需使用 rebound。
统计信息: (3.6k+ ⭐) (336+ Forked)
11. openai/gym
这是一个开源工具包,用于开发和比较强化学习算法。它与任何数值计算库兼容,例如 TensorFlow 或 Theano。
这里是他们网站上的 文档,还可以查看 常见问题解答以获取更多信息。
统计信息 : (24.3k+ ⭐) (7k+ Forked)
12. facebookresearch/Detectron
Detectron 是 Facebook AI 研究团队的一个用于对象检测的软件。它可以轻松实现最先进的对象检测算法,包括 Mask R-CNN。
它是用 Python 编写的,并由 caffe2 深度学习框架支持。
github.com/facebookresearch/Detectron
统计信息 : (24.4k+ ⭐) (5.3k+ Forked)
13. iperov/DeepFaceLab
DeepFaceLab 是创建深度伪造的领先软件。互联网上超过 95% 的深度伪造视频都是使用 DeepFaceLab 创建的。
利用深度伪造技术,你可以改变面孔,给面孔减龄,替换头部,操控嘴唇等等。
统计信息 : (26.5k+ ⭐) (6k+ Forked)
14. ageitgey/face_recognition
构建人脸识别应用程序的最佳库。它是 Python 和命令行中最简单的人脸识别 API 之一。
人脸识别库为每个检测到的面孔生成 128 个数字化印记。这些印记随后被编码成某些向量编码,这些编码可以用于解码印记并进行比较,以获取个人的标签(姓名)。
统计信息 : (40.1k+ ⭐) (11.2k+ Forked)
15. You Get 由 Mort Yao
这是一个小型命令行工具,用于从 Web 上下载媒体内容(视频、音频、图片)。
pip install you-get
统计信息 : (40.5k+ ⭐) (8.4k+ Forked)
面试准备
16. donnemartin/interactive-coding-challenges
120+ 个互动 Python 编程面试挑战(算法和数据结构)。包括 Anki 记忆卡片。
它包含与数组、链表、图形、递归等相关的编程问题。
统计信息 : (22.7k+ ⭐) (3.6k+ Forked)
17. learning-zone/python-interview-questions
包含 300 道 Python 面试题及其解答。它还包含许多编程问题的解决方案,如哈希映射。
统计信息 : (313+ ⭐) (85+ Forked)
18. zhiwehu/Python-programming-exercises
100+ 个不同难度等级的 Python 编程挑战练习。
统计: (15.7k+ ⭐) (5.8k+ Forked)
19. MTrajK/coding-problems
本仓库包含各种编码/算法问题的解决方案以及许多学习算法和数据结构的有用资源。
包含数组、链表、树、哈希数据结构、动态编程、字符串、数学等问题和解决方案。
统计: (1.9k+ ⭐) (348+ Forked)
框架、模块和工具
下列提到的包可以帮助你了解大型项目中代码的编写方式。通过查看这些仓库中的代码,你可以轻松提升你的编码技能。
20. tensorflow/tensorflow
Tensorflow 是一个官方的 Google 开源平台,用于端到端的机器学习。它拥有一个全面且灵活的工具和库生态系统,使开发者能够轻松构建和部署机器学习应用。
提供 Python 的稳定版本。可以通过 pip 轻松安装。
统计: (156k+ ⭐) (84.8+ Forked)
21. Dash 由 Plotly
一个用于分析 Web 应用程序的 Python 框架,支持 Python、R、Julia 和 Jupyter。无需 JavaScript。
这是最受信任和下载量最大的 Python 包,用于构建机器学习和数据科学应用程序。
它建立在 plotly.js 之上,后者也是一个很棒的数据可视化包。
统计: (14.6k+ ⭐) (1.5k+ Forked)
22. streamlit/streamlit
Streamlit 提供了在 Python 中构建数据应用的最快方式。Streamlit 让你在几分钟内将数据脚本转换为可共享的 Web 应用,而不是几周。
完全使用 Python,开源且免费!一旦创建了应用程序,你可以使用他们的 免费共享平台 来部署、管理和与全世界分享你的应用。
统计: (14.7k+ ⭐) (1.3k+ Forked)
23. scikit-learn/scikit-learn
scikit-learn 是一个基于 SciPy 的 Python 机器学习模块,分发方式为 3-Clause BSD 许可证。
这是最常用且最著名的机器学习模块之一。它包含了多种算法和数据分析概念的预构建版本。
统计: (45.8k+ ⭐) (21.5k+ Forked)
24. mwaskom/seaborn
Seaborn 是一个用于统计数据可视化的 Python 库,建立在 matplotlib 库之上。Seaborn 提供了各种可视化模式和图表。它使用简单的语法和美观的可视化效果,如箱线图、计数图、小提琴图、直方图等。
统计: (8.5k+ ⭐) (1.4k+ Forked)
25. numpy/numpy
NumPy 是进行科学计算所需的基础包。
它代表了数值 Python,是一个用于各种科学计算的 Python 库。它包含了许多多维数组和处理这些数组的例程集合。
它通过添加大量高层次的数学函数,为矩阵和大型多维数组提供额外支持。
统计数据 : (17.3k+ ⭐) (5.6k+ Forked)
奖励库
1. 基于项目的学习/tuvtran
这个库包含了各种编程语言的不同教程,如 Python、Go、PHP、Java 等,总共涵盖了 20 种编程语言。该库的主要目标是专注于基于项目的学习。他们的 Python 部分包括大量构建项目的教程,从网络爬虫、机器人和网络应用程序到数据科学、机器学习和深度学习解决方案。
统计数据 : (50.6k+ ⭐) (7.9k+ Forked)
2. public-apis/public-apis
一个用于软件和网页开发的免费 API 的集合列表。
统计数据 : (126k+ ⭐) (15.4k+ Forked)
3. EbookFoundation/free-programming-books
包含一个学习用的免费编程书籍列表。它拥有超过 1.5 万名贡献者和超过 10,000 本免费书籍 pdf。它支持多种语言,如中文、荷兰语、俄语、意大利语等。
统计数据 : (190k+ ⭐) (42.4k+ Forked)
作者精选文章 ✍
提升你 Python 技能的 10 个高级 Python 概念
提升编码技能
感谢您成为我们社区的一部分!订阅我们的 YouTube 频道 或加入 Skilled.dev 编码面试课程。
编码面试问题 + 找到你的开发工作 | Skilled.dev
个人简介: Abhay Parashar 是一位机器学习爱好者,期待在人工智能领域建立职业生涯。
原文。经许可转载。
相关内容:
-
机器学习与深度学习汇编开放书籍
-
超越仓库:GitHub 在人工智能和机器学习职业发展的作用
-
如何作为初学者建立强大的数据科学作品集
更多相关话题
25 个 Pandas 技巧
评论
上周,Kevin Markham (@justmarkham) 在 DataSchool.io 发布了一个实用的视频和一个配套的 Jupyter 笔记本,标题为“我最喜欢的 25 个 Pandas 技巧”。我认为这些技巧足够实用,值得与我们的读者分享。
名副其实,视频概述了许多 Pandas 技巧,用于处理和操作数据,涵盖了字符串操作、拆分和过滤数据框、数据的组合和汇总等主题。除了承诺的 25 个技巧外,还包含了一个附加的第 26 个技巧,涉及 Pandas 数据框概况分析。
视频中对这些技巧的解释很清晰,实用且可以立即使用,结合示例数据集的实现可以在 附带的笔记本 中进一步研究。
如果你还不知道,Kevin 是数据科学教育者和 Data School 的创始人,专注于 Python 和机器学习。Data School 是一个网站,包含博客文章、视频、课程、Jupyter 笔记本和网络研讨会录音,既有免费内容也有付费内容。
视频中的 Pandas 数据框技巧包括:
-
显示已安装的版本
-
创建示例数据框
-
重命名列
-
反转行顺序
-
反转列顺序
-
按数据类型选择列
-
将字符串转换为数字
-
减少数据框的大小
-
从多个文件构建数据框(按行)
-
从多个文件构建数据框(按列)
-
从剪贴板创建数据框
-
将数据框拆分为两个随机子集
-
根据多个类别筛选数据框
-
根据最大类别筛选数据框
-
处理缺失值
-
将字符串拆分为多个列
-
将列表系列展开为数据框
-
通过多个函数进行汇总
-
将聚合结果与数据框合并
-
选择行和列的切片
-
重新塑造多重索引系列
-
创建透视表
-
将连续数据转换为分类数据
-
更改显示选项
-
设置数据框的样式
-
附加技巧:数据框的概况分析
查看 Jupyter 笔记本 以更深入了解 Kevin 在视频中展示的 Pandas 技巧。还请务必查看 Data School 以获取更多有用的数据科学相关学习内容。
相关:
-
掌握 Python 机器学习数据准备的 7 个步骤 — 2019 版
-
10 个简单的技巧加速 Python 数据分析
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
KDnuggets™ 新闻 21:n40, 10 月 20 日:你需要的 20 个 Python 包用于机器学习和数据科学;通过项目在数据科学面试中脱颖而出
特点 | 产品 | 教程 | 观点 | 排行 | 职位 | 提交博客 | 本周图片
本周在 KDnuggets:你需要的 20 个 Python 包用于机器学习和数据科学;如何通过从事项目在数据科学面试中脱颖而出;部署你的第一个机器学习 API;使用 5 行代码进行实时图像分割;什么是聚类及其工作原理?还有更多内容。
请考虑 提交 一篇原创博客到 KDnuggets!
特点
-
你需要的 20 个 Python 包用于机器学习和数据科学,作者:Sandro Luck
-
**
,作者:Abid Ali Awan
-
**
,作者:Abid Ali Awan
-
使用 5 行代码进行实时图像分割,作者:Ayoola Olafenwa
-
什么是聚类及其工作原理?,作者:Satoru Hayasaka
 ,作者:Abid Ali Awan
,作者:Abid Ali Awan ,作者:Abid Ali Awan
,作者:Abid Ali Awan产品,服务
-
2021 数据工程师薪资报告分享快速变化市场的见解,作者:Burtch Works
-
向西北大学的数据科学专家学习,作者:西北大学
-
Hasura 如何通过 PostHog 将转化率提高 20%,作者:PostHog
-
Amazon Web Services 网络研讨会:利用数据集创建以客户为中心的战略并改善业务成果,作者:Roidna
-
知识图谱论坛:技术生态系统与商业应用,作者:Ontotext
教程,概述
-
构建多模态模型:使用 widedeep Pytorch 包,作者:Rajiv Shah
-
AI 新计算范式:内存处理 (PIM) 架构,作者:Nam Sung Kim
-
如何使用自动自助法计算机器学习中的性能指标的置信区间,作者:David B Rosen (PhD)
-
2022 年最实用的数据科学技能,作者:Terence Shin
-
在生产环境中部署 ML 模型:常见模式,作者:Mo, Oakes & Galarnyk
-
如何使用 KNIME Analytics Platform 在三步内创建交互式仪表板,作者:Emilio Silvestri
意见
-
避免这五种行为,让你看起来像数据新手,作者:Tessa Xie
-
我们对算法的痴迷如何破坏了计算机视觉:以及合成计算机视觉如何解决这一问题,作者:Paul Pop
-
你的工作会被机器取代吗?,作者:Martin Perry
-
数据专业人士如何在繁忙时也能留下深刻印象,作者:Devin Partida
热门新闻
-
10 月 11 日至 17 日热门新闻:用 SQL 查询你的 Pandas DataFrames,作者:KDnuggets
-
KDnuggets 2021 年 9 月顶级博客奖励,作者:Gregory Piatetsky
职位
-
查看我们近期的 人工智能、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职位页面上免费发布与人工智能、大数据、数据科学或机器学习相关的行业或学术职位,详情请参见 kdnuggets.com/jobs
本周图片
 ,作者:Ori Cohen
,作者:Ori Cohen产品、服务
-
如何高效地标记时间序列——并提升你的 AI,作者:Visplore
-
DATAcated 博览会,10 月 5 日,现场直播,作者:DATAcated
探索新的 AI / 数据科学技术**](/2021/09/datacated-expo-oct-5.html),作者:DATAcated
-
免费虚拟活动:多伦多的大数据与 AI,作者:Corp Agency
教程、概述
-
如何发现你的机器学习模型中的弱点,作者:Michael Berk
-
5 款必试的 Python 数据可视化库,作者:Roja Achary
-
数据科学中的悖论,作者:Pier Paolo Ippolito
-
介绍 TensorFlow 相似度,作者:Matthew Mayo
-
在接触数据集之前必须问的 10 个问题,作者:Sandeep Uttamchandani
-
如何获得 Python PCAP 认证:基于我的经验的路线图、资源、成功技巧,作者:Mehul Singh
-
在 MLOps 中冒险:使用 Github Actions、Iterative.ai、Label Studio 和 NBDEV,作者:Soellinger & Kunz
-
2021 年数据工程技术,作者:Tech Ninja
-
如果你会编写函数,你就能使用 Dask,作者:Hugo Shi
-
15 个必须知道的 Python 字符串方法,作者:Soner Yıldırım
观点
- 两年自学数据科学给我带来的启示,作者:Vishnu U
热门故事
-
热门故事,9 月 13-19 日: 没有数据工程技能的数据科学家将面临严峻现实;机器与深度学习大全开放书,作者:KDnuggets
-
KDnuggets 2021 年 8 月最佳博客奖励,作者:Gregory Piatetsky
职位
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 的招聘页面上发布有关 AI、大数据、数据科学或机器学习的行业或学术职位的免费短文,详细信息请通过电子邮件获取 - 查看 kdnuggets.com/jobs
本周图片
 ,作者:Nicolas Vandeput
,作者:Nicolas Vandeput ,作者:Angelica Lo Duca
,作者:Angelica Lo Duca ,作者:Aaron Wang
,作者:Aaron Wang产品,服务
-
未来系列 | 探索人工智能的未来,作者:Altair
-
电子书:使用云端第三方数据的实用指南,作者:Roidna
-
验证数据和分析技能的热门认证,作者:SAS
教程,概述
-
如何为您的数据科学项目创建惊艳的 Web 应用,作者:Murallie Thuwarakesh
-
FLAML + Ray Tune 的快速 AutoML,作者:Wu, Wang, Baum, Liaw & Galarnyk
-
使用 Gretel 和 Apache Airflow 构建合成数据管道,作者:Drew Newberry
-
机器学习如何在移动应用开发中发挥作用?,作者:Ria Katiyar
-
电子书:使用 R 学习数据科学 – 免费下载,作者:Narayana Murthy
-
关于 Wu Dao 2.0 的五个关键事实:有史以来最大的 Transformer 模型,作者:Jesus Rodriguez
-
机器学习如何利用线性代数解决数据问题,作者:Harshit Tyagi
意见
-
如何解决现实世界中的机器学习问题,作者:Pau Labarta Bajo
-
抗脆弱性与机器学习,作者:Prad Upadrashta
-
揭秘 OpenAI Codex:你不知道的构建 Codex 的 5 个迷人挑战,作者:Jesus Rodriguez
头条新闻
- 头条新闻,8 月 30 日至 9 月 5 日:你用 Python 读取 Excel 文件吗?有一种快 1000 倍的方法;假设检验解释,作者:KDnuggets
职业机会
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职业页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详细信息请见 kdnuggets.com/jobs
本周图片

作者图片
数据科学面试测试了硬技术技能和软技能。对常见的数据科学面试问题做好充分准备,是脱颖而出的关键。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
在这篇博客文章中,我们将学习 26 个数据科学面试问题,你应该预期会遇到这些问题。这些问题涵盖统计学、Python、SQL、机器学习、数据分析、项目等。无论你是学生、职业转型者还是经验丰富的数据科学家,回顾这些问题可以指导你的准备,并帮助你在面试中更加自信,准备充分,给人留下深刻印象。
非技术问题
1. 解释复杂数据概念
问:描述一次你向非技术人员解释复杂数据概念的经历。你是如何帮助他们理解的?
2. 从错误中学习
问:你有没有在分析中犯过重大错误?你能解释一下你是如何处理这种情况的吗?你从中获得了什么见解?
3. 适应变化的需求
问:你能分享一个在项目中面对不明确或不断变化的需求的经验吗?你是如何适应这种情况的?
Python 问题
4. 字符串变位词检查
问:写一个函数检查两个字符串是否是变位词。
5. 找出缺失的数字
问:给定一个包含 n 个从 0 到 n 的不同数字的数组,找到缺失的那个数字。
6. 欧几里得距离计算
问:写一个函数来计算 Python 中的欧几里得距离?
SQL 问题
7. 比较 JOIN
问:LEFT JOIN 和 FULL OUTER JOIN 能产生相同的结果吗?为什么或为什么不?
8. 时间差查询
问:请写出 SQL 查询,以帮助我找到两个事件之间的时间差。
9. SQL 中的 NULL 处理
问:你能提供一些关于如何处理查询数据集时 NULL 值的建议吗?
10. GROUP BY 逻辑
问:当你对一个不在 SELECT 语句中的列使用 GROUP BY 时会发生什么?
统计学、概率论和数学问题
11. 相同花色的概率
Q: 从同一副牌中抽取两张牌,它们具有相同花色的概率是多少?
12. 电梯概率问题
Q: 在一个四层楼的建筑中,四个人每人下到不同楼层的概率是多少?
13. 解释 p 值
Q: 你会如何向工程师解释如何解读 p 值?
14. 样本量和误差边际
Q: 对于样本量 n,误差边际为 3。我们还需要多少样本才能将误差边际降到 0.3?
15. 评估 A/B 测试的随机性
Q: 在 A/B 测试中,你如何检查分配到各个组的过程是否真正随机?
数据分析问题
16. 数据分析项目方法
Q: 在进行数据分析项目时,你会遵循什么流程?
17. 异常值处理
Q: 你如何处理数据集中的异常值?
18. 理解数据可视化
Q: 你能解释一下数据可视化吗?此外,存在多少种可视化类型?
19. 数据验证
Q: 什么是数据验证?可以使用哪些不同的方法来验证数据?
机器学习问题
20. 评估聚类性能
Q: 如果在聚类项目中已知标签,你会如何评估模型的性能?
21. 特征选择方法
Q: 你使用哪些特征选择方法来确定模型中最相关的变量?
22. 神经网络基础
Q: 使用一个简单的例子解释组成神经网络的核心组件。
23. 管理不平衡数据集
Q: 你如何管理不平衡的数据集?
24. 避免过拟合
Q: 你如何避免模型的过拟合?
案例研究
25. 调查用户参与度下降
在这个案例研究中,你的责任是找出 Xfinite 项目用户参与度下降的原因。首先需要对项目进行概述,然后分析四个特定表中的数据。
26. 验证 A/B 测试结果
探索 A/B 测试中对照组和处理组之间显著差异的结果,通过详细分析来验证或驳斥这些结果。
结论
数据科学面试测试了广泛的技能,从技术到人际交往。这 26 个问题提供了一个全面的概述,涵盖了有志于成为数据科学家的候选人在面试中可能遇到的关键主题。充分准备这些问题不仅会帮助你在面试中表现出色,还将使你全面了解数据科学的实际和理论方面。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一款 AI 产品,帮助那些面临心理健康问题的学生。
更多相关主题
MLOps 概述
评论
由Steve Shwartz,AI 作者、投资者和连续创业者。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
照片:iStockPhoto / NanoStockk
通常需要相当的 数据科学 专业知识来创建数据集并为特定应用构建模型。但构建一个好的模型通常还不够。实际上,这远远不够。正如下图所示,开发和测试模型只是第一步。
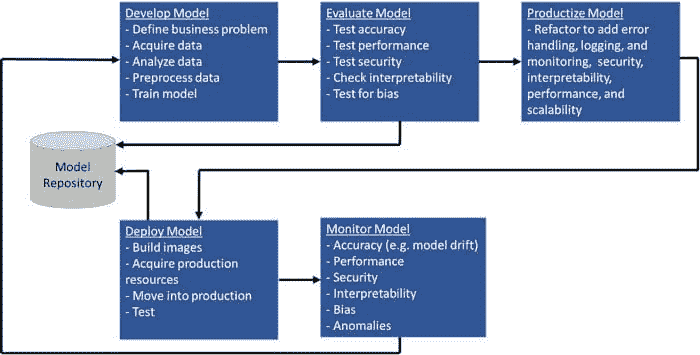
机器学习模型生命周期。
机器学习操作(MLOps)涵盖了使模型有用的所有其他要求,包括自动化开发和部署管道、监控、生命周期管理和治理等能力,如上图所示。让我们逐一探讨这些内容。
自动化管道
创建一个生产环境下的 ML 系统需要多个步骤:首先,数据必须经过一系列转换。然后,对模型进行训练。通常,这需要尝试不同的网络架构和超参数。经常需要返回数据并尝试不同的特征。接下来,模型必须通过单元测试和集成测试进行验证。它需要通过数据和模型偏差及可解释性的测试。最后,将其部署到公共云、内部环境或混合环境中。此外,过程中的某些步骤可能需要审批流程。
如果这些步骤都是手动执行的,开发过程往往会变得缓慢且脆弱。幸运的是,许多 MLOps 工具可以自动化从数据转换到端到端部署的这些步骤。当需要重新训练时,这将是一个自动化、可靠且可重复的过程。
监控
ML 模型在初次部署时往往表现良好,但随着时间的推移,表现会逐渐下降。正如 Forrester 分析师 Dr. Kjell Carlsson所说: “AI 模型就像隔离中的六岁小孩:它们需要持续关注……否则,总会出现问题。”
部署时包含各种监控类型至关重要,以便机器学习团队能够在出现问题时得到警报。性能可能因基础设施问题(例如,CPU 或内存不足)而下降。当构成模型输入的独立变量的现实世界数据开始与训练数据表现出不同特征时,也可能导致性能下降,这种现象被称为数据漂移。
同样,由于现实世界条件的变化,模型可能变得不再适用,这种现象被称为概念漂移。例如,许多客户和供应商行为的预测模型在 COVID-19 期间陷入困境。
一些公司还监控替代模型(例如,不同的网络架构或不同的超参数),以查看这些“挑战者”模型是否开始表现得比生产模型更好。
通常,围绕模型做出的决策设置保护措施是有意义的。这些保护措施是简单的规则,可以触发警报、阻止决策或将决策放入需要人工审批的工作流程中。
生命周期管理
当模型性能由于数据或模型漂移而开始下降时,需要进行模型重训练和可能的模型重新架构。然而,数据科学团队不应从头开始。在开发原始模型时,或许在之前的重新架构过程中,他们可能已经测试了许多架构、超参数和特征。记录所有这些先前的实验(及其结果)至关重要,以便数据科学团队无需回到起点。这对于数据科学团队成员之间的沟通和协作也至关重要。
治理
机器学习模型正被用于许多影响人们的应用,如银行贷款决策、医疗诊断以及招聘/解雇决策。使用机器学习模型进行决策受到批评的原因有两个:首先,这些模型容易产生偏见,特别是当训练数据导致模型在种族、肤色、民族、国籍、宗教、性别、性取向或其他受保护类别上存在歧视时。其次,这些模型通常是黑箱,无法解释其决策过程。
因此,使用基于机器学习的决策制定的组织面临着确保其模型不歧视且能够解释其决策的压力。许多 MLOps 供应商正在结合基于学术研究的工具(例如,SHAP 和 Grad-CAM),这些工具有助于解释模型决策,并使用各种技术来确保数据和模型不受偏见影响。此外,他们还将偏见和可解释性测试纳入监控协议,因为模型可能会随着时间的推移变得有偏见或失去解释能力。
组织还需要建立信任,并开始确保持续的性能、消除偏见和可解释性是可审计的。 这要求模型目录不仅记录所有数据、参数和架构决策,还要记录每个决策的日志并提供可追溯性,以便确定每个决策所使用的数据、模型和参数,以及模型何时重新训练或修改,谁做出了每个更改。 对审计员来说,能够重复历史交易并使用“如果”情景测试模型决策的边界也很重要。
安全性和数据隐私也是使用机器学习的组织关注的关键问题。 必须确保个人信息受到保护,基于角色的数据访问能力是必需的,尤其是在受监管行业中。
全球各国政府也在迅速推动对影响人们的机器学习决策进行监管。 欧洲联盟通过其 GDPR 和 CRD IV 法规走在前列。 在美国,包括美联储和 FDA 在内的多个监管机构已经为金融和医疗决策中的机器学习决策制定了相关法规。 最近提议的《2020 数据问责和透明法案》是一项更全面的法律,预计将在 2021 年提交国会审议。 规定可能会发展到 CEO 需要签署其机器学习模型的可解释性和无偏见性的程度。
MLOps 领域
随着我们进入 2021 年,MLOps 市场正迅速扩张。 根据分析公司 Cognilytica 的数据,预计到 2025 年将成为一个 $40 亿市场。
在 MLOps 领域中,既有大玩家也有小玩家。 亚马逊、谷歌、微软、IBM、Cloudera、Domino、DataRobot 和 H2O 等主要机器学习平台供应商正在将 MLOps 能力纳入他们的平台。 根据 Crunchbase 的数据,在 MLOps 领域有 35 家私人公司,这些公司已融资从 180 万美元到 10 亿美元不等,且在 LinkedIn 上的员工数量从 3 人到 2800 人不等:
| 融资(百万美元) | 员工数量 | 描述 | |
|---|---|---|---|
| Cloudera | 1000 | 2803 | Cloudera 提供一个企业数据云,支持任何数据,无论是边缘计算还是 AI。 |
| Databricks | 897 | 1757 | Databricks 是一个软件平台,帮助其客户统一业务、数据科学和数据工程中的分析。 |
| DataRobot | 750 | 1105 | DataRobot 将 AI 技术和 ROI 实现服务带给全球企业。 |
| Dataiku | 246 | 556 | Dataiku 作为一个企业人工智能和机器学习平台运作。 |
| Alteryx | 163 | 1623 | Alteryx 通过统一分析、数据科学和自动化流程加速数字化转型。 |
| H2O | 151 | 257 | H2O.ai 是开源 AI 和自动机器学习领域的领导者,使命是让 AI 为所有人所用。 |
| Domino | 124 | 232 | Domino 是全球领先的企业数据科学平台,为超过 20% 的财富 100 强公司提供数据科学支持。 |
| Iguazio | 72 | 83 | Iguazio 数据科学平台使你能够大规模实时开发、部署和管理 AI 应用程序 |
| Explorium.ai | 50 | 96 | Explorium 提供一个数据科学平台,由增强的数据发现和特征工程驱动 |
| Algorithmia | 38 | 63 | Algorithmia 是一个机器学习模型部署和管理解决方案,自动化组织的 MLOps |
| Paperspace | 23 | 37 | Paperspace 提供下一代基于 GPU 的应用程序支持。 |
| Pachyderm | 21 | 32 | Pachyderm 是一个企业级数据科学平台,使可解释、可重复和可扩展的 AI/ML 成为现实。 |
| Weights and Biases | 20 | 58 | 用于实验跟踪、改进模型性能和结果协作的工具 |
| OctoML | 19 | 37 | OctoML 正在改变开发者优化和部署机器学习模型以满足 AI 需求的方式。 |
| Arthur AI | 18 | 28 | Arthur AI 是一个监控机器学习模型生产力的平台。 |
| Truera | 17 | 26 | Truera 提供一个模型智能平台,帮助企业分析机器学习。 |
| Snorkel AI | 15 | 39 | Snorkel AI 专注于通过 Snorkel Flow 实现 AI 的实际应用:面向企业 AI 的数据优先平台 |
| Seldon.io | 14 | 48 | 机器学习部署平台 |
| Fiddler Labs | 13 | 46 | Fiddler 使用户能够创建透明、可解释和易于理解的 AI 解决方案。 |
| run.ai | 13 | 26 | Run:AI 开发了一种自动化分布式训练技术,可虚拟化并加速深度学习。 |
| ClearML (Allegro) | 11 | 29 | ML / DL 实验管理器和 ML-Ops 开源解决方案,端到端产品生命周期管理企业解决方案 |
| Verta | 10 | 15 | Verta 构建软件基础设施,帮助企业数据科学和机器学习(ML)团队开发和部署 ML 模型。 |
| cnvrg.io | 8 | 38 | cnvrg.io 是一个全栈数据科学平台,帮助团队管理模型,并构建自适应机器学习管道 |
| Datatron | 8 | 19 | Datatron 提供一个统一的模型治理(管理)平台,用于生产中的所有 ML、AI 和数据科学模型 |
| Comet | 7 | 19 | Comet.ml 是一个机器学习平台,旨在帮助 AI 从业者和团队构建可靠的机器学习模型。 |
| ModelOp | 6 | 39 | 统治、监控和管理企业中的所有模型 |
| WhyLabs | 4 | 15 | WhyLabs 是 AI 观察和监控公司。 |
| Arize AI | 4 | 14 | Arize AI 提供一个解释和排查生产 AI 的平台。 |
| DarwinAI | 4 | 31 | DarwinAI 的生成合成 'AI 建造 AI' 技术实现了优化和可解释的深度学习。 |
| Mona | 4 | 11 | Mona 是一个用于数据和 AI 驱动系统的 SaaS 监控平台 |
| Valohai | 2 | 13 | 您的托管机器学习平台,允许数据科学家构建、部署和跟踪机器学习模型。 |
| Modzy | 0 | 31 | 安全的 ModelOps 平台,用于发现、部署、管理和治理大规模机器学习——更快地获得价值。 |
| Algomox | 0 | 17 | 促进您的 AI 转型 |
| Monitaur | 0 | 8 | Monitaur 是一家提供审计性、透明性和治理的软件公司,服务于使用机器学习软件的公司。 |
| Hydrosphere.io | 0 | 3 | Hydrosphere.io 是一个用于 AI/ML 操作自动化的平台 |
许多这些公司专注于 MLOps 的一个细分领域,例如自动化管道、监控、生命周期管理或治理。有些人认为 使用多个最优的 MLOps 产品对数据科学项目比单一平台更有利。还有一些公司正在为特定垂直领域构建 MLOps 产品。例如,Monitaur 将自己定位为一个可以与任何平台兼容的最佳治理解决方案。Monitaur 还为受监管行业(从保险开始)构建行业特定的 MLOps 治理能力。(完全披露:我在 Monitaur 中是投资者)。
也有一些开源 MLOps 项目,包括:
-
MLFlow 管理 ML 生命周期,包括实验、可重复性和部署,并且包含一个模型注册表
-
DVC 管理 ML 项目的版本控制,使其可分享和可重复
-
Polyaxon 具有实验、生命周期自动化、协作和部署的能力,并且包含一个模型注册表
-
Metaflow 是 Netflix 之前的项目,用于管理自动化管道和部署
-
Kubeflow 具有在 Kubernetes 容器中进行工作流自动化和部署的能力
2021 年有望成为 MLOps 的一个有趣年份。我们可能会看到快速增长、激烈竞争以及很可能的整合。
简介: Steve Shwartz (@sshwartz) 多年前作为博士后在耶鲁大学开始他的 AI 职业生涯,是一位成功的连续创业者和投资者,并且是《邪恶机器人、杀手机器和其他神话:关于 AI 和人类未来的真相》的作者。
相关:
更多相关主题
你能信任 AutoML 吗?
评论
由Ioannis Tsamardinos、(JADBio)、Iordanis Xanthopoulos (克里特大学,希腊)、Vassilis Christophides (ENSEA,法国)。

图片来源于 Shutterstock,许可下使用。
什么是 AutoML?
自动化机器学习(AutoML)承诺端到端自动化机器学习过程。它是机器学习和数据科学领域快速崛起的超热门子领域。AutoML 平台尝试数百种甚至数千种不同的机器学习管道,称为配置,将不同分析步骤(变换、插补、特征选择和建模)及其相应的超参数结合在一起。它们通常提供击败专家并赢得竞赛的模型,只需几个鼠标点击或几行代码。
需要估计性能
然而,获取一个模型永远不够!除非有预测性能的保证,否则不能信任模型的预测。这个模型几乎总是准确的,还是更接近随机猜测?我们能依赖它来做生命攸关的临床决策,或成本高昂的商业决策吗?可靠的样本外(在新样本上)性能估计至关重要。一个优秀的分析师会为你提供这些,而 AutoML 工具也应如此。现有的 AutoML 库和平台是否能提供其模型性能的可靠估计?
测试集的大小是多少?
好吧,一些 AutoML 工具根本不返回任何估计!以一个有争议的、最受欢迎的 AutoML 库为例:auto sklearn。其作者建议,为了估计性能,你需要保留一个独立的、未被库看到的测试集,严格用于估计最终模型的性能。像 auto sklearn 这样的工具本质上提供的是一个综合算法选择和超参数优化(CASH)或超参数优化(HPO)引擎。它们可能非常有用且流行,但只是部分实现了 AutoML 的愿景。毕竟,如果你需要决定最佳测试集大小、编写应用模型的代码以及进行估计的代码,那么这个工具就不是完全自动化的。决定最佳测试集大小并非易事。它需要机器学习技能和知识。它需要专家。你应该留下 10%、20%还是 30%的数据?你应该随机分割还是根据结果类别进行分层分割?如果你有 1,000,000 个样本呢?你会留下多少比例?如果你有 1,000,000 个样本,并且正类的发生率是 1/100,000 呢?如果你有像生存分析中的截尾结果呢?你的测试集需要多少才能保证估计的准确性?你如何计算估计的置信区间?一旦你让用户决定测试集估计,你就不能再声称你的工具“使”机器学习对非专家分析师“民主化”。
样本丢失对估计的影响
然而,拥有一个单独的测试集会产生一个额外、更深层次、更严重的问题。保留的数据“丧失了估计”的机会。那些可能是我们花费高昂成本收集或测量的宝贵数据,可能是我们等待了很长时间才获得的数据,我们只是用它们来评估模型的效果。它们没有被用于改进模型和我们的预测。在许多应用中,我们可能没有留下一个相当大测试集的奢侈条件!我们需要在观察到首批死亡后立即分析 SARS-CoV-2(COVID-19)数据,而不是等到我们有 1000 个“可支配”的受害者来进行性能估计。当有新竞争对手产品推出时,我们需要立即分析我们最新的数据并做出反应,而不是等到我们有足够的客户流失。即使是“少量”的样本数据也很重要。它们存在,并且会一直存在。大数据可能在计算上具有挑战性,但小样本数据在统计上具有挑战性。需要额外测试集的 AutoML 平台和库不适合小样本数据的分析。
从估计模型性能到估计配置性能
其他 AutoML 工具确实只根据你的输入数据返回性能估计。它们不要求你选择测试集的大小,真正实现了程序的自动化,并且名副其实。其理念是:最终模型是在所有输入数据上训练的。通常来说,由于分类器在样本量增加时会提高,这将是最佳模型。但这样,我们就没有任何样本用于估计了。好吧,交叉验证和类似的协议(例如,重复保留法)使用代理模型来估计最终模型的性能。它们会训练许多使用相同配置生成的其他模型。因此,它们并不直接估计预测模型的性能,而是估计生成模型的配置(学习方法、流程)的性能。但,你能相信它们的估计吗?这引出了所谓的“赢家的诅咒”。
单个配置的性能估计
我们将通过一个小型模拟实验来说明一个有趣的统计现象。首先,我们尝试估计单个配置的性能,这个配置由一个具有特定超参数的分类器组成,比如 1-最近邻。我模拟了一个二元结果的测试集,包含 50 个样本,分布为 50-50%。我假设我的分类器有 85%的概率提供正确的预测,即 85%的准确率。下图面板(a)显示了我第一次尝试时获得的准确率估计。然后,我生成了第二个(b)和第三个(c)测试集以及相应的估计。
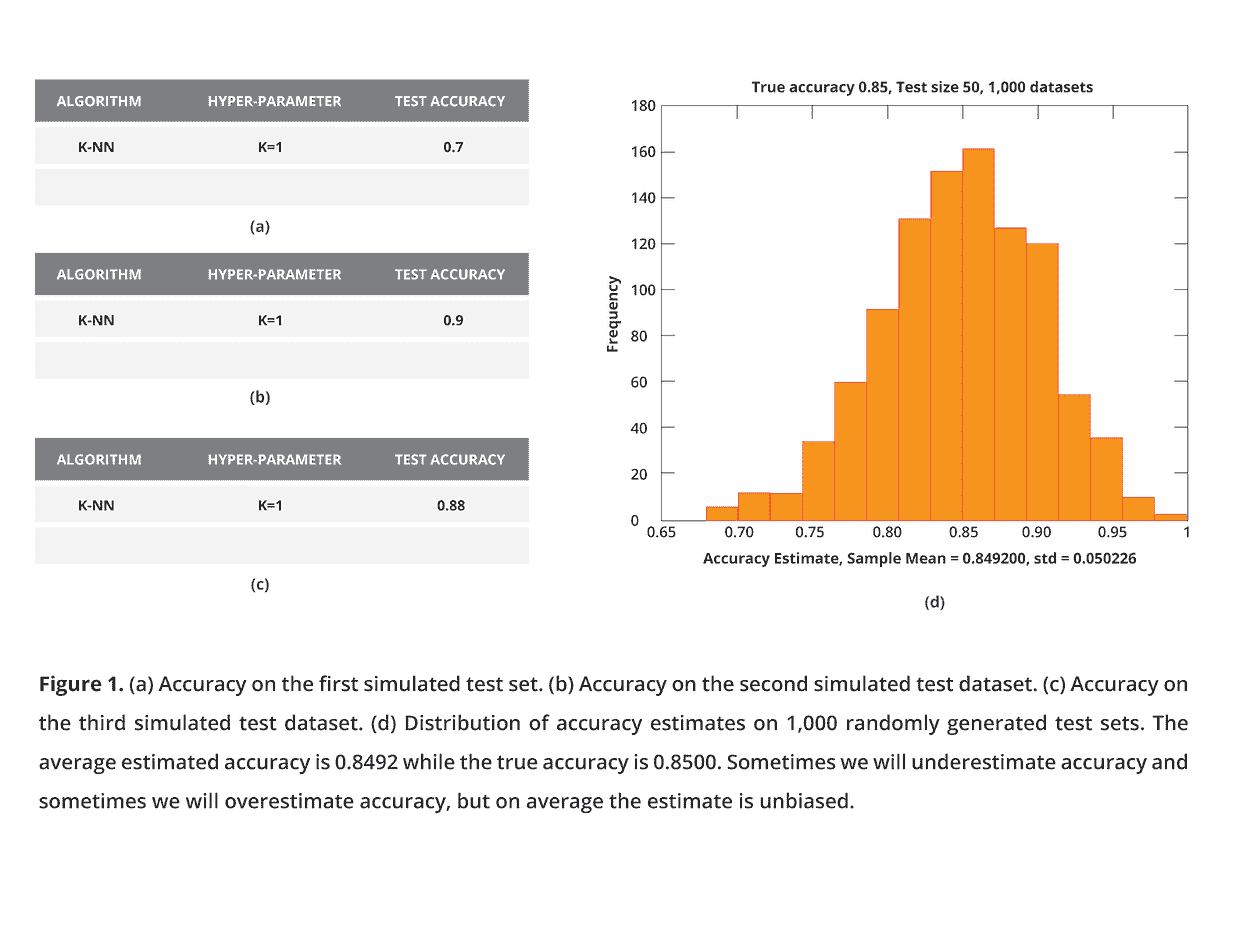
有时候,我的模型在特定测试集上稍微幸运一些,我会估计出高于 0.85 的性能。实际上,有一次模拟中,模型在几乎所有 50 个样本中都预测正确,得出了 95%-100%的准确率。其他时候,模型在特定测试集上的表现会不佳,我会低估性能,但平均来说,估计将是正确且无偏的。我不会欺骗自己、我的客户或我的同行科学家。
胜者的诅咒(或你为什么系统性地高估)
现在,让我们模拟 AutoML 库和平台实际上做的事情,即尝试成千上万的配置。为简单起见,我假设我只有 8 个配置(而不是成千上万),这些配置由 3 种不同的算法(K-NN、决策树和简单贝叶斯)与一些超参数值匹配。每次我应用所有这些配置,我都会在相同的测试集上估计它们的性能,选择表现最佳的一个作为我的最终模型,并报告获胜配置的估计性能。在模拟中,我假设所有配置都导致具有 85%准确率的同等预测模型。
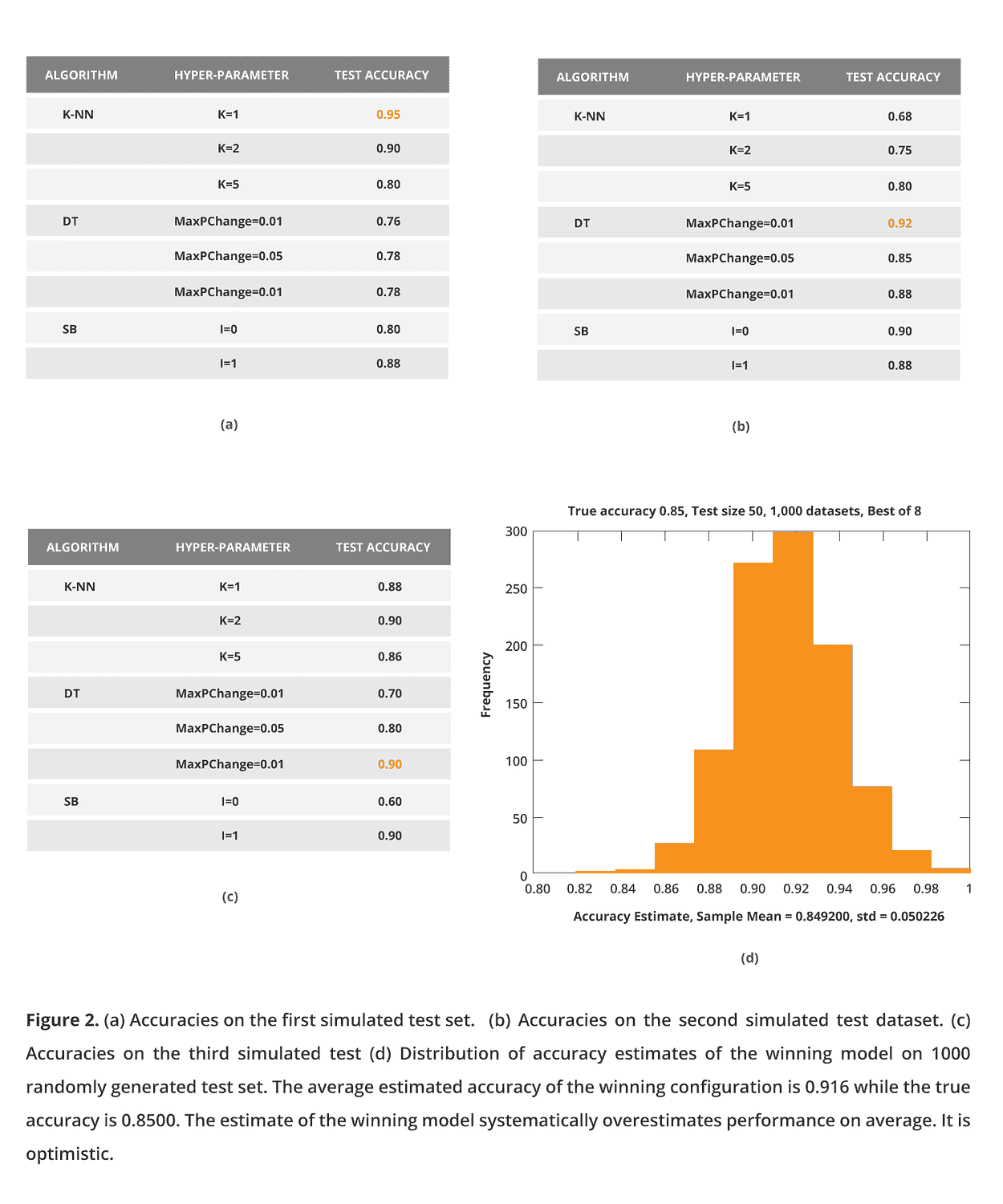
在 1000 次模拟后会发生什么?平均而言,我的估计是 0.916,而真实的准确率是 0.85。我系统性地过高估计。 别自欺欺人;你通过交叉验证也会得到相同的结果。这是为什么呢?这一现象与统计学中的“赢家的诅咒”有关,其中在许多模型中优化的效应量往往会被过高估计。在机器学习中,这一现象首次由 David Jensen 发现,并被命名为“多重诱导问题”[Jensen, Cohen 2000]。不过,说实话,“赢家的诅咒”听起来更酷(对不起,David)。从概念上讲,这一现象类似于多重假设检验。我们需要使用 Bonferroni 或虚假发现率程序来“调整”产生的p-值。同样,当我们交叉验证多个配置时,我们需要对获胜配置的交叉验证表现进行“调整”以应对多次尝试。因此,当你对单一配置进行交叉验证时,你会得到一个准确的性能估计(实际上,这是对在所有数据上训练的模型的保守估计);当你对多个配置进行交叉验证并报告获胜配置的估计时,你会过高估计性能。
这真的重要吗?
这种过高估计是否真的重要,还是只是学术上的好奇?好吧,当你拥有一个大且平衡的数据集时,这种过高估计是无足轻重的。在小样本数据集或非常不平衡的数据集上,比如某个类别只有几个样本时,它可能会变得相当显著。它很容易达到 15–20 AUC 点[Tsamardinos et al. 2020],这意味着你实际的 AUC 等同于随机猜测(0.50),而你报告的是 0.70,这在某些领域被认为是令人尊敬且可以发表的表现。过高估计会更高: (a) 某些类别的样本量越小,(b) 你尝试的配置越多,(c) 你配置所产生的模型越独立,(d) 你的最佳模型越接近随机猜测。
过高估计可以修复吗?我们能否战胜“赢家的诅咒”?
那么,我们该如何解决这个问题呢?至少有三种方法。第一种方法是——你猜对了——保留一个单独的测试集,我们称之为估计集。在每个配置的交叉验证过程中,测试集用于选择最佳配置(即进行 调优),并且每个配置都会多次“看到”这些测试集。估计集仅会被使用一次,用于估计最终模型的性能,因此不存在“赢家的诅咒”。但当然,我们又会回到之前的问题,“样本用于估计的损失”。第二种方法是进行 嵌套交叉验证 [Tsamardinos et al., 2018]。其思路如下:我们将选择获胜模型视为学习过程的一部分。我们现在有一个 单一过程(如果你愿意,可以称之为元配置),它尝试许多配置,使用交叉验证选择最佳配置,并在所有输入数据上使用获胜配置训练最终模型。我们现在对我们的单一学习过程进行交叉验证(这个过程内部也对每个配置进行交叉验证,因此称为嵌套)。嵌套交叉验证是准确的(见 [Tsamardinos et al. 2018] 的图 2),但计算开销相当大。它训练 O(C⋅K2) 个模型,其中 C 是我们尝试的配置数量,K 是交叉验证的折数。但幸运的是,还有一种更好的方法;那就是 自助法偏差修正交叉验证(BBC-CV)方法 [Tsamardinos et al. 2018]。BBC-CV 在估计准确性上与嵌套交叉验证相当(见 [Tsamardinos et al. 2018] 的图 2),并且快一个数量级,即训练 O(C⋅K) 个模型。BBC-CV 本质上消除了需要单独的估计集。
那么,我们可以信任 AutoML 吗?
回到我们激励性的问题:我们可以信任 AutoML 吗?尽管 AutoML 已经取得了大量的工作,包括数十篇论文、竞赛、挑战和比较评估,至今还没有人检查过这些工具是否返回了准确的估计。没有人,直到我们最近的一些工作 [Xanthopoulos 2020, Tsamardinos et al. 2020]。在下图中,我们比较了两个 AutoML 工具,即 TPOT [Olson et al. 2016] 和我们自己的 Just Add Data Bio,简称 JADBio [Tsamardinos et al. 2020] (www.jadbio.com)。TPOT 是一个常用的免费 AutoML 库,而 JADBio 是我们采用 BBC-CV 的商业 AutoML 平台。JADBio 设计时考虑到了这些估计因素,并特别适用于小样本、高维生物数据。鉴于从生物数据中学习到的模型可能用于关键的临床应用,例如预测治疗反应和优化治疗,我们确实在努力返回准确的性能估计。
我们在来自 openml.org 的 100 个二分类问题上尝试了这两种系统,涵盖了广泛的样本大小、特征大小和平衡比例(详细信息见 [Xanthopoulos 2020])。每个数据集被分成两半,一部分用于输入 AutoML 工具以获取模型和自我评估估计(AutoML 平台评估的模型估计,称为 Train Estimate),另一部分用于应用模型(测试集上的模型估计,称为 Test Estimate)。性能的度量指标是 AUC。每个点是对一个数据集的实验。红点是对角线下方的点,其中 Test Estimate 低于训练估计,即高估的性能。黑点是对角线以上的点,其中性能被低估。
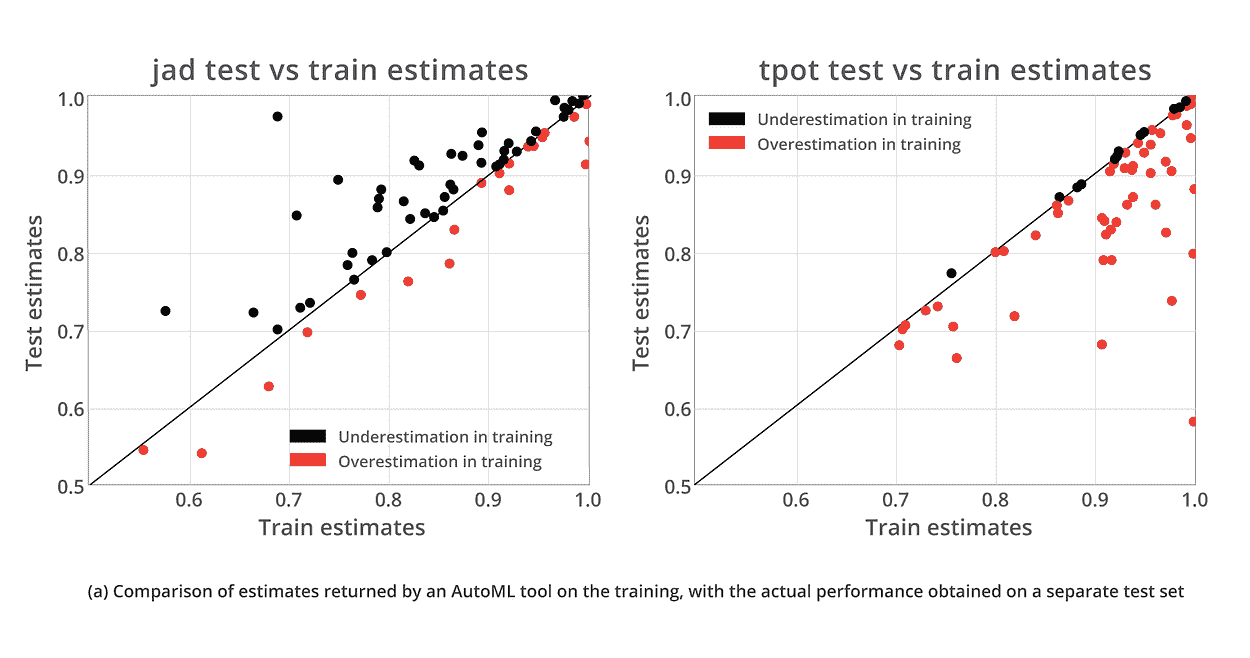
TPOT 严重高估了性能。有些数据集上,这个工具估计模型的性能为 1.0!在其中一个案例(最低的红点)中,实际测试性能不到 0.6,危险地接近随机猜测(0.5 AUC)。显然,你应该对 TPOT 自我评估的估计持怀疑态度。你需要将样本分配到保留测试集中。另一方面,JADBio 系统性地低估了性能。其图中间的最高黑点在测试中的 AUC 接近 1.00,但估计的性能低于 0.70 AUC。平均而言,JADBio 的估计更接近对角线。这些实验中的数据集有超过 100 个样本,有些数据集超过几万。在其他更具挑战性的实验中,我们在 370 多个组学数据集上尝试了 JADBio,样本量最小为 40,特征平均数为 80,000+。JADBio 使用 BBC-CV 并不会高估性能 [Tsamardinos et al. 2020]。不幸的是,不仅 TPOT 展现了这种行为。额外的类似评估和初步结果表明,这可能是 AutoML 工具的普遍问题 [Xanthopoulos 2020]。
不要盲目相信,而要验证。
总结来说,首先,要警惕 AutoML 工具性能的自我评估。当你自动化分析并生成成千上万的模型时,很容易高估性能。尝试在一些数据集上使用你喜欢的工具,其中你完全保留了一部分数据。你需要多次进行这种尝试,以评估平均行为。尝试具有挑战性的任务,比如小样本或高度不平衡的数据。过度估计的程度可能取决于元特征(数据集特征),例如缺失值的百分比、离散特征的百分比、离散特征的值的数量等。因此,尝试具有类似特征的数据集,类似于你通常分析的数据集!其次,即使你不使用 AutoML 而是自己编写分析代码,你仍然可能会产生大量模型,并报告未经调整、未经修正的交叉验证估计的最佳模型。 “赢家诅咒”总是存在并困扰着你。你不想向你的客户、老板、教授或论文评审者报告一个高度夸大的、不切实际的性能,对吧? … 或者,你会吗?
参考文献
-
Jensen D.D. 和 Cohen P.R. (2000) 归纳算法中的多重比较. Mach. Learn., 38, 309–338.
-
Tsamardinos I., Charonyktakis P., Lakiotaki K., Borboudakis G., Zenklusen J.C., Juhl H., Chatzaki E. 和 Lagani V. (2020) 仅需添加数据:自动预测建模与生物标志发现 bioRxiv, 10.1101/2020.05.04.075747
-
Tsamardinos I., Greasidou E. 和 Borboudakis G. (2018) 引导外样本预测以实现高效准确的交叉验证 Mach. Learn., 107, 1895–1922.
-
Iordanis Xanthopoulos, 硕士论文, 计算机科学系, 克里特大学, 2020
-
Olson R.S., Bartley N., Urbanowicz R.J. 和 Moore J.H. (2016)* 评估一个基于树的管道优化工具用于自动化数据科学** 在 GECCO 2016 — 2016 年遗传与进化计算会议论文集。ACM Press, 纽约, 美国, 页码 485–492.*
原文。经许可转载。
简介: Tsamardinos 博士 于 2001 年获得美国匹兹堡大学博士学位。2006 年,他在范德比尔特大学生物医学信息学系担任助理教授,随后加入克里特大学。他的研究兴趣包括人工智能与人工智能哲学、生物医学中的人工智能、机器学习、因果推断与归纳、从生物医学数据中学习、分类的特征与变量选择、生物信息学、规划、机器学习在生物医学信息学中的应用。
Iordanis Xanthopoulos 是克里特大学的研究生研究员。
Vassilis Christophides 在法国 ENSEA。
相关:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关内容
KDnuggets™ 新闻 20:n36, 9 月 23 日:新调查:你在 2020 年使用最多的 Python IDE / 编辑器是什么?;自动化你的 Python 项目的每一个方面
功能 | 新闻 | 教程 | 观点 | 热门 | 职位 | 提交博客 | 本周图片
最新的 KDnuggets 调查询问你在 2020 年使用最多的 Python IDE / 编辑器是什么。立即投票!
本周还包括:自动化你的 Python 项目的每一个方面;Autograd:你没使用的最佳机器学习库?;从零开始用 Python 实现深度学习库;顶级大学提供的人工智能、数据科学、机器学习在线证书/课程;神经网络能否展现想象力?DeepMind 认为它们可以;以及更多更多内容。
功能
-
新调查:你在 2020 年使用最多的 Python IDE / 编辑器是什么?
-
**
-
**
-
从零开始用 Python 实现深度学习库
-
顶级大学提供的人工智能、数据科学、机器学习在线证书/课程
-
神经网络能否展现想象力?DeepMind 认为它们可以


新闻
-
Mathworks 深度学习工作流程:技巧、窍门和常被忽视的步骤
-
Coursera 的机器学习为每个人提供未满足的培训需求
教程,概述
-
从零开始的机器学习:免费的在线教材
-
用一行代码进行统计和视觉探索性数据分析
-
什么是辛普森悖论,如何自动检测它
-
内部人士指南:生成型和判别型机器学习模型
观点
-
劳动行业中预测分析的潜力
-
我是一名数据科学家,不仅仅是处理数据的微小之手
-
阿根廷作家和匈牙利数学家可以教会我们关于机器学习过拟合的知识
-
如何在数据过载时代有效获取消费者洞察
-
不受欢迎的观点 - 数据科学家应该更具端到端能力
热门故事,推文
-
热门故事,9 月 14-20 日:自动化你的 Python 项目的每一个方面;深度学习中最重要的观点
-
顶级 KDnuggets 推文,9 月 9-15 日:你会以每月 49 美元的价格报名参加#Google 大学吗?这里有国际替代方案
职业
-
查看我们最近的 AI、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 职位页面免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位短文,发送邮件 - 详情请见 kdnuggets.com/jobs
本周图片

更多相关话题
KDnuggets™ 新闻 20:n34,9 月 9 日:顶级在线数据科学硕士学位;现代数据科学技能:8 类别,核心技能和热门技能
特性 | 新闻 | 教程 | 观点 | 顶级 | 职位 | 提交博客 | 本周图片
在 KDnuggets 本期:顶级在线分析学、商业分析和数据科学硕士学位;现代数据科学技能:8 类别、核心技能和热门技能;在 Tableau 中创建强大的动画可视化;PyCaret 2.1 的新变化;决定学习哪些数据科学技能;评估机器学习模型的性能;以及更多内容!
特性
-
**
-
现代数据科学技能:8 类别、核心技能和热门技能
-
在 Tableau 中创建强大的动画可视化
-
PyCaret 2.1 来了:有什么新变化?
-
如何决定学习哪些数据技能
-
**


新闻
-
NIST 24 万美元挑战:拯救生命,一次一个像素
-
扩展您的数据合规策略与法律自动化
-
书籍章节:统计的艺术:从数据中学习
-
数据增强是什么以及如何工作
-
电子书:词汇、文本挖掘与 FAIR 数据:信息管理者的战略角色
教程,概述
-
在 Python 中有效使用 JSON 的 4 个技巧
-
深度学习的梦想:在单一模型中实现准确性和可解释性
-
数据科学家认为数据是他们的头号问题。以下是他们为何错了。
-
数据科学中的实验设计
-
您不知道的关于 Scikit-Learn 的 10 件事
-
计算机视觉秘籍:最佳实践和示例
-
解决线性回归应该使用哪些方法?
-
展示 Intel® Xeon® 可扩展平台上 AI 工作负载软件优化的好处
-
自然语言处理的语言学基础:语义学和语用学中的 100 个要点
-
加速计算机视觉:亚马逊提供的免费课程
-
微软的 DoWhy:一个酷炫的因果推断框架
-
使用 DALEX 和 Neptune 进行可解释和可重现的机器学习模型开发
-
**
-
在 Azure Databricks 上使用 Spark、Python 或 SQL
-
数据版本控制:这是否意味着你认为的那样?
-
在联邦学习中打破隐私

意见
-
成为成功的数据科学家需要什么?
-
9 种数据科学与分析职位发展趋势
-
最重要的数据科学项目
-
在担任数据科学家的 2 年中我学到了什么
-
关于 AI 意识辩论的一个有趣理论
-
数据无处不在,它驱动我们所做的一切!
-
超越图灵测试
-
如何优化你的简历以适应数据科学家的职业
热门故事,推文
-
2023 年 8 月 31 日至 9 月 6 日的热门故事:更新版的顶级在线分析硕士、商业分析、数据科学
-
2023 年 8 月 26 日至 9 月 1 日的热门 KDnuggets 推文:对#数据科学家生活中时间分配的现实考察
-
2023 年 8 月 24 日至 30 日的热门故事:如果我要重新开始学习数据科学,我会怎么做?;改进你的 TensorFlow 模型的 4 种方法——你需要知道的关键正则化技术
-
2023 年 8 月 19 日至 25 日的热门 KDnuggets 推文:#机器学习——处理缺失数据
职位
-
查看我们最近的人工智能、分析、数据科学、机器学习职位
-
你可以在 KDnuggets 的职位页面上免费发布与 AI、大数据、数据科学或机器学习相关的行业或学术职位,详情请发送邮件 - 请见 kdnuggets.com/jobs
本周图片

更多相关主题
KDnuggets™ 新闻 20:n25, 6 月 24 日:你应该知道的 PyTorch 基础;提升数据科学技能的免费数学课程
特点 | 教程 | 观点 | 热门 | 工作 | 提交博客 | 本周图片
本周在 KDnuggets:学习 PyTorch 的基础知识;寻找提升数据科学技能的数学课程;阅读关于分类项目的详细指南;了解机器学习和计算机视觉在作物疾病检测中的应用;还有更多内容。
安息吧,汤姆·福塞特。
特点
-
**
-
提升数据科学技能的 4 门免费数学课程
-
机器学习中的分类项目:一个温和的逐步指南
-
使用机器学习和计算机视觉进行作物疾病检测
-
汤姆·福塞特,怀念

教程,概述
-
使用 TensorFlow 数据集和 TensorBoard 的 TensorFlow 建模流程
-
人工智能中的偏见:入门
-
Dask 中的机器学习
-
如何处理数据集中缺失的值
-
图形机器学习在基因组预测中的应用
-
什么是情感 AI 以及你为什么应该关心?
-
modelStudio 与互动解释模型分析的语法
-
使用 Tensorflow.js 实现计算机视觉应用的 6 个简单步骤
-
LightGBM:一种高效的梯度提升决策树
-
用 AWS Sagemaker 一步步构建狗品种分类器
观点
- 不要点击这个(如何识别深度伪造和 AI 生成的文本)
热点新闻,推文
-
热点新闻,6 月 15 日至 21 日:用 Python 实现简易语音转文本;深入学习 Google Colab 的完整指南
-
KDnuggets 热门推文,6 月 10 日至 16 日:#MachineLearning 的博弈论速成课程:经典与新思路
工作
-
查看我们最近的 人工智能、分析、数据科学、机器学习工作
-
你可以在 KDnuggets 的职位页面上免费发布与人工智能、大数据、数据科学或机器学习相关的行业或学术职位信息,详情请发送邮件至 kdnuggets.com/jobs
本周图片

Made With ML 扮演了一个社区的角色,将那些寻求创意的人与那些希望构建和分享项目作品集的人汇聚在一起,无论是为他人提供创意还是展示他们所学到和构建的东西。
Made With ML 的主页面列出了可搜索的项目,如下所示:
每个项目页面提供了额外的信息,如下所示,包括描述、代码、博客文章、视频等,视具体项目相关情况而定:
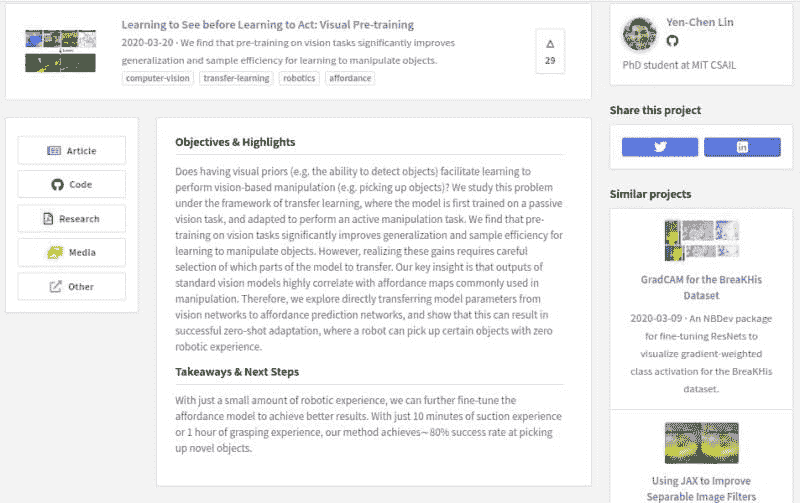
Made With ML 的介绍博客文章用其创始人、杰出的研究员、作者和创始人 Goku Mohandas 的话描述了这个项目。
因此,我们与这些招聘经理合作创建了一个理想的档案,以完成两个关键任务:
- ???? 提供一个作品集,展示能够体现技术能力和产品意识的项目。
- ⏰ 在大约 2 分钟内完成上述所有内容(招聘经理在简历上的平均花费时间)。
所以我们创建了 Made With ML。它是一个分享和发现机器学习项目的平台。你可以通过发现和搜索来学习其他人的项目:
阅读博客文章 获取关于该项目的更多信息,以及一些分享和展示项目的建议(提示:不要只是把一堆算法扔到一个通用数据集上;重点应该是创建完整的项目,这些项目执行特定的、有用的任务,并能引起他人的注意)。
Made With ML 似乎可以在 GitHub 和 Kaggle 之间填补某种角色,我鼓励读者查看一下,看看是否对他们有帮助。
相关:
-
Papers with Code: 机器学习的绝佳 GitHub 资源
-
AI 与机器学习的最前沿 – 论文与代码的亮点
-
如何通过机器学习在 GitHub 上自动化任务以获取乐趣和利润
更多相关话题
KDnuggets™ 新闻 19:n21, 6 月 5 日:职业转型为数据科学;11 个顶级数据科学和机器学习平台;用 Python 掌握中级机器学习的 7 个步骤
特点 | 教程 | 观点 | 排行榜 | 新闻 | 网络研讨会 | 课程 | 会议 | 职位 | 学术 | 本周图片
- 我们带来 KDnuggets 第 20 届年度软件调查的结果:Python 领先于 11 个最受欢迎的数据科学/机器学习平台;3 个受欢迎的指南 - 转行数据科学;用 Python 掌握中级机器学习;理解自然语言处理(NLP);以及应用于 LSTM 的反向传播。
特点
-
**
-
用 Python 掌握中级机器学习的 7 个步骤 — 2019 版
-
**
-
你的自然语言处理(NLP)指南
-
理解应用于 LSTM 的反向传播


教程,概述
-
如何选择可视化
-
从噪声中分离信号
-
搭便车者的特征提取指南
-
为什么你的数据库表的物理存储可能很重要
-
谁是你的金蛋?:队列分析
-
用 Matplotlib 制作动画
-
成为 3.0 级数据科学家
-
在模型候选之间进行选择
-
3 本帮助我提升数据科学家水平的机器学习书籍
-
提升你的图像分类模型
-
小心!过度查看模型结果可能导致信息泄露
-
用 Spark、Optimus 和 Twint 在几分钟内分析推文的 NLP
-
端到端机器学习:从图像制作视频
-
当“过于像人类”意味着不是人类:检测自动生成的文本
-
利用 Facebook 的 Pytorch-BigGraph 从知识图谱中提取知识
意见
-
数据科学家是思想家:执行与探索以及这对你意味着什么
-
清除关于“提升”的误解
-
品茶女士与科学有什么关系?
-
彩票假设如何挑战我们对训练神经网络的所有认知
-
为什么组织在扩展人工智能和机器学习时失败
-
家庭中的人工智能:如何教孩子们机器学习
-
ICLR 2019 亮点:Ian Goodfellow 与 GANs,敌对样本,强化学习,公平性,安全性,社会效益等
-
修复 Hinton 胶囊网络中的图像机器学习重大弱点
-
6 个逐渐适应预测分析和预测的行业
头条新闻,推文
-
头条新闻,5 月 27 日至 6 月 2 日:转型数据科学职业的逐步指南 - 第一部分;Python 领先 11 大数据科学、机器学习平台:趋势与分析
-
KDnuggets 热门推文,5 月 22 日至 28 日:蒙娜丽莎微笑、说话和皱眉:#机器学习让古老的画作和照片焕发生机
-
头条新闻,5 月 20 日至 26 日:掌握数据科学 SQL 的 7 个步骤;机器学习的数据结构
-
KDnuggets 热门推文,5 月 15 日至 21 日:掌握数据科学 SQL 的 7 个步骤 - 2019 版
新闻
- Io-Tahoe 与 OneTrust 集成并加入数据发现合作伙伴计划
网络广播与网络研讨会
- 如何在你的机器学习模型中使用持续学习,6 月 19 日网络研讨会
课程,教育
- 工业问题解决的统计思维(STIPS):一个免费的在线课程。
会议
- 大数据与人工智能多伦多 2019 年 6 月 12-13 日
职位
学术
本周图片
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
为什么组织在扩展 AI 和机器学习时会失败
www.kdnuggets.com/2019/05/why-organizations-fail-scaling-ai-machine-learning.html
评论
在当今世界,每个组织都在以某种形式进行人工智能(AI)驱动的转型。AI 所制造的炒作非常强烈,组织中至少有一些高调(虽然不高)的团队在进行 AI 相关工作。然而,当组织意识到自己未能将高端 AI 的极端效果与看似平凡的业务流程结合起来以实现底线/顶线指标时,AI 的魅力会很快消退。挑战不在于 AI 或业务流程本身,AI 需要理解业务流程,业务流程也需要能够变化,以将 AI 的洞察融入到流程中。
一个 AI 项目以宏伟的战略愿景开始是很棒的,这可以激励团队开始工作。重要的是确保团队中包含具有强大操作视角的成员,他们能够将战略转化为组织中的实施。
让我们以电信行业中的流失减少为简单例子,看看在实现可持续性方面面临的挑战:
现有场景: 后付费客户主动取消连接,通过拨打运营商电话并要求关闭账户。假设每月有 100 位客户请求取消。运营商回应为未来账单提供$50 的折扣,并保留 50%的取消请求。留存团队的预算为 10050%50 = $2500 来留住客户。P&L 团队从 50 位客户那里获得了每用户收入(ARPU)$60 的一年收入。保留的收入 = $605012 = $36000。为了实现这一点,呼叫中心团队对每位潜在流失客户拨打了 2 通电话,总共拨打了 2*100 = 200 通电话。
AI 场景: 这一愿景建议提前识别潜在的流失客户,并通过采取主动措施来留住他们。数据科学团队识别出 120 位可能流失的客户,信心为 70%(即 84 位客户未来会要求取消服务)。运营商回应以$50 的折扣。折扣的接受率提高,因为列表中包括了那些本不会要求流失的客户。因此,留存预算增加,即 12060%50 = $3600。保留的收入 = $606012 = $43200。为了实现这一目标,拨打的电话数量为 2*120 = 240 通。
现在,如果我们观察整体预期成果,AI 场景显然是赢家,保留收入更高($43200 对比$36000)。
然而,让我们看看那些被忽视的软性方面:
-
两个支持性业务流程,保留部门和联系中心必须增加他们的能力和预算。此外,成本的增加在收入的改善之前。这导致了子组织内部的利益冲突,支持部门未能为整体业务目标进行对齐。
-
联系中心必须增加外呼能力以进行保留。这是一个更大的挑战,因为建立一个新的流程以包含 AI 洞察是组织的巨大变更管理过程。AI 团队可能未曾想到需要一个新流程来完成执行。
-
AI 项目的成功很少涉及算法,而人们通常花费大部分时间在算法上。使团队对齐需要数据科学家解释结果的能力。现代数据科学家使用的黑箱算法提供了更高的准确性,但在AI 解释能力上存在挑战。因果关系的链接是获得团队对齐的重要要求。人们不会行动,除非他们以简单的语言理解并关联。
-
进行概念验证和将 AI 融入业务所需的技能是非常不同的。概念验证需要一个强大的讲故事者,并简化业务问题。实施则需要在各个利益相关者之间进行流程更改,连接各种 IT 系统,源数据挑战,数据完整性,流程/数据治理和遵守政策等。
规划 AI 转型时,以下框架突出了 AI 转型程序成功的关键要求。

这个框架专注于与利益相关者的共同创造的重要性,从一开始就以共同语言理解程序的价值,识别实施挑战 - 讨论 - 理解,各阶段的技能对齐,并以敏捷方式交付项目。
然而,AI 的本质使得了解并非所有举措都将成功变得重要,因为数据/洞察可能不够好。灵活而可持续的执行也需要理解“快速失败”。目标是成功推动 AI 作为组织举措,即使这需要在快速评估后将某些项目搁置。
因此,需要一个像乐高积木一样构建的车库模型,用于各种举措、技能生态系统、敏捷开发和市场测试。
总体而言,需要建立强大的组织变更管理流程,以便将 AI 融入业务转型,否则即使有成功的试点,其影响也非常有限。
正如一些明智之人所说的“保持简单,愚蠢”。
简介: Prateek Mital 是 IBM 亚洲太平洋地区认知与分析服务线的副合伙人。观点仅代表他个人,基于与全球客户广泛的接触。
资源:
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您组织的 IT 工作
更多相关内容
用 Spark、Optimus 和 Twint 在几分钟内分析推文的 NLP
www.kdnuggets.com/2019/05/analyzing-tweets-nlp-spark-optimus-twint.html
评论 
介绍
如果你来到这里,很可能是因为你对分析推文(或类似的东西)感兴趣,并且你有很多推文,或者可以获取它们。为此,最烦人的事情之一就是获取 Twitter 应用程序,获取认证以及所有其他内容。而且如果你使用 Pandas,就没有办法进行扩展。
那么,有一个系统不需要通过 Twitter API 认证,可以获取几乎无限数量的推文,并且具备分析这些推文的能力,包括 NLP 和更多功能,你觉得怎么样?你真幸运,因为这正是我现在要展示给你的。
获取项目和仓库
你可以非常轻松地跟随我展示的内容。只需克隆这个 MatrixDS 项目:
MatrixDS 是一个可以在任何规模上构建、共享和管理数据项目的地方。 社区平台
另外,还有一个包含所有内容的 GitHub 仓库:
FavioVazquez/twitter_optimus_twint
使用 Twint、Optimus 和 Apache Spark 分析推文。 - FavioVazquez/twitter_optimus_twint github.com
使用 MatrixDS,你实际上可以免费运行笔记本,获取数据并进行分析,因此如果你想了解更多,请动手尝试。
获取 Twint 和 Optimus

Twint 利用 Twitter 的搜索操作符,让你可以从特定用户那里抓取推文,抓取与某些主题、标签和趋势相关的推文,或从推文中筛选出敏感信息,如电子邮件和电话号码。
使用我共同创建的库 Optimus,你可以清理数据、准备数据、分析数据、创建分析器和图表,并进行机器学习和深度学习,所有这些都是以分布式方式进行的,因为在后台我们有 Spark、TensorFlow、Sparkling Water 和 Keras。
所以,首先让我们安装你所需的一切,在 Matrix 项目中,转到 Analyze Tweets 笔记本并运行(你也可以通过 JupyterLab 终端来完成):
!pip install --user -r requirements.txt
在此之后,我们需要安装 Twint,运行以下命令:
!pip install --upgrade --user -e git+https://github.com/twintproject/twint.git@origin/master#egg=twint
这将下载一个 scr/ 文件夹,所以我们需要做一些配置:
!mv src/twint .
!rm -r src
然后要导入 Twint,我们需要运行:
%load_ext autoreload
%autoreload 2
import sys
sys.path.append("twint/")
最后:
import twint
Optimus 在第一步中已安装,所以让我们直接启动它(这将为你启动一个 Spark 集群):
from optimus import Optimus
op = Optimus()
设置 Twint 以抓取推文

www.theverge.com/2015/11/3/9661180/twitter-vine-favorite-fav-likes-hearts
# Set up TWINT config
c = twint.Config()
如果你在笔记本上运行,你还需要运行:
# Solve compatibility issues with notebooks and RunTime errors.
import nest_asyncio
nest_asyncio.apply()
搜索数据科学推文

我将开始我们的分析,抓取关于数据科学的推文,你可以将其更改为你想要的内容。
为了做到这一点,我们只需运行:
c.Search = "data science"
# Custom output format
c.Format = "Username: {username} | Tweet: {tweet}"
c.Limit = 1
c.Pandas = True
twint.run.Search(c)
让我向你解释这段代码。在最后一节中,当我们运行代码时:
c = twint.Config()
我们开始了新的 Twint 配置。之后我们需要传递不同的选项来抓取推文。以下是配置选项的完整列表:
Variable Type Description
--------------------------------------------
Username (string) - Twitter user's username
User_id (string) - Twitter user's user_id
Search (string) - Search terms
Geo (string) - Geo coordinates (lat,lon,km/mi.)
Location (bool) - Set to True to attempt to grab a Twitter user's location (slow).
Near (string) - Near a certain City (Example: london)
Lang (string) - Compatible language codes: https://github.com/twintproject/twint/wiki/Langauge-codes
Output (string) - Name of the output file.
Elasticsearch (string) - Elasticsearch instance
Timedelta (int) - Time interval for every request (days)
Year (string) - Filter Tweets before the specified year.
Since (string) - Filter Tweets sent since date (Example: 2017-12-27).
Until (string) - Filter Tweets sent until date (Example: 2017-12-27).
Email (bool) - Set to True to show Tweets that _might_ contain emails.
Phone (bool) - Set to True to show Tweets that _might_ contain phone numbers.
Verified (bool) - Set to True to only show Tweets by _verified_ users
Store_csv (bool) - Set to True to write as a csv file.
Store_json (bool) - Set to True to write as a json file.
Custom (dict) - Custom csv/json formatting (see below).
Show_hashtags (bool) - Set to True to show hashtags in the terminal output.
Limit (int) - Number of Tweets to pull (Increments of 20).
Count (bool) - Count the total number of Tweets fetched.
Stats (bool) - Set to True to show Tweet stats in the terminal output.
Database (string) - Store Tweets in a sqlite3 database. Set this to the DB. (Example: twitter.db)
To (string) - Display Tweets tweeted _to_ the specified user.
All (string) - Display all Tweets associated with the mentioned user.
Debug (bool) - Store information in debug logs.
Format (string) - Custom terminal output formatting.
Essid (string) - Elasticsearch session ID.
User_full (bool) - Set to True to display full user information. By default, only usernames are shown.
Profile_full (bool) - Set to True to use a slow, but effective method to enumerate a user's Timeline.
Store_object (bool) - Store tweets/user infos/usernames in JSON objects.
Store_pandas (bool) - Save Tweets in a DataFrame (Pandas) file.
Pandas_type (string) - Specify HDF5 or Pickle (HDF5 as default).
Pandas (bool) - Enable Pandas integration.
Index_tweets (string) - Custom Elasticsearch Index name for Tweets (default: twinttweets).
Index_follow (string) - Custom Elasticsearch Index name for Follows (default: twintgraph).
Index_users (string) - Custom Elasticsearch Index name for Users (default: twintuser).
Index_type (string) - Custom Elasticsearch Document type (default: items).
Retries_count (int) - Number of retries of requests (default: 10).
Resume (int) - Resume from a specific tweet id (**currently broken, January 11, 2019**).
Images (bool) - Display only Tweets with images.
Videos (bool) - Display only Tweets with videos.
Media (bool) - Display Tweets with only images or videos.
Replies (bool) - Display replies to a subject.
Pandas_clean (bool) - Automatically clean Pandas dataframe at every scrape.
Lowercase (bool) - Automatically convert uppercases in lowercases.
Pandas_au (bool) - Automatically update the Pandas dataframe at every scrape.
Proxy_host (string) - Proxy hostname or IP.
Proxy_port (int) - Proxy port.
Proxy_type (string) - Proxy type.
Tor_control_port (int) - Tor control port.
Tor_control_password (string) - Tor control password (not hashed).
Retweets (bool) - Display replies to a subject.
Hide_output (bool) - Hide output.
Get_replies (bool) - All replies to the tweet.
所以在这段代码中:
c.Search = "data science"
# Custom output format
c.Format = "Username: {username} | Tweet: {tweet}"
c.Limit = 1
c.Pandas = True
我们设置搜索词,然后格式化响应(只是检查一下),只获取 20 条推文,限制为 1(它们是以 20 为增量的),最后使结果与 Pandas 兼容。
然后当我们运行:
twint.run.Search(c)
我们正在启动搜索。结果是:
Username: tmj_phl_pharm | Tweet: If you're looking for work in Spring House, PA, check out this Biotech/Clinical/R&D/Science job via the link in our bio: KellyOCG Exclusive: Data Access Analyst in Spring House, PA- Direct Hire at Kelly Services #KellyJobs #KellyServices
Username: DataSci_Plow | Tweet: Bring your Jupyter Notebook to life with interactive widgets https://www.plow.io/post/bring-your-jupyter-notebook-to-life-with-interactive-widgets?utm_source=Twitter&utm_campaign=Data_science … +1 Hal2000Bot #data #science
Username: ottofwagner | Tweet: Top 7 R Packages for Data Science and AI https://noeliagorod.com/2019/03/07/top-7-r-packages-for-data-science-and-ai/ … #DataScience #rstats #MachineLearning
Username: semigoose1 | Tweet: ëäSujy #crypto #bitcoin #java #competition #influencer #datascience #fintech #science #EU https://vk.com/id15800296 https://semigreeth.wordpress.com/2019/05/03/easujy-crypto-bitcoin-java-competition-influencer-datascience-fintech-science-eu- https-vk-com-id15800296/ …
Username: Datascience__ | Tweet: Introduction to Data Analytics for Business http://zpy.io/c736cf9f #datascience #ad
Username: Datascience__ | Tweet: How Entrepreneurs in Emerging Markets can master the Blockchain Technology http://zpy.io/f5fad501 #datascience #ad
Username: viktor_spas | Tweet: [Перевод] Почему Data Science командам нужны универсалы, а не специалисты https://habr.com/ru/post/450420/?utm_source=dlvr.it&utm_medium=twitter&utm_campaign=450420 … pic.twitter.com/i98frTwPSE
Username: gp_pulipaka | Tweet: Orchestra is a #RPA for Orchestrating Project Teams. #BigData #Analytics #DataScience #AI #MachineLearning #Robotics #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux @lruettimann http://bit.ly/2Hn6qYd pic.twitter.com/kXizChP59U
Username: amruthasuri | Tweet: "Here's a typical example of a day in the life of a RagingFX trader. Yesterday I received these two signals at 10am EST. Here's what I did... My other activities have kept me so busy that ... http://bit.ly/2Jm9WT1 #Learning #DataScience #bigdata #Fintech pic.twitter.com/Jbes6ro1lY
Username: PapersTrending | Tweet: [1/10] Real numbers, data science and chaos: How to fit any dataset with a single parameter - 192 stars - pdf: https://arxiv.org/pdf/1904.12320v1.pdf … - github: https://github.com/Ranlot/single-parameter-fit …
Username: webAnalyste | Tweet: Building Data Science Capabilities Means Playing the Long Game http://dlvr.it/R41k3t pic.twitter.com/Et5CskR2h4
Username: DataSci_Plow | Tweet: Building Data Science Capabilities Means Playing the Long Game https://www.plow.io/post/building-data-science-capabilities-means-playing-the-long-game?utm_source=Twitter&utm_campaign=Data_science … +1 Hal2000Bot #data #science
Username: webAnalyste | Tweet: Towards Well Being, with Data Science (part 2) http://dlvr.it/R41k1K pic.twitter.com/4VbljUcsLh
Username: DataSci_Plow | Tweet: Understanding when Simple and Multiple Linear Regression give Different Results https://www.plow.io/post/understanding-when-simple-and-multiple-linear-regression-give-different-results?utm_source=Twitter&utm_campaign=Data_science … +1 Hal2000Bot #data #science
Username: DataSci_Plow | Tweet: Artificial Curiosity https://www.plow.io/post/artificial-curiosity?utm_source=Twitter&utm_campaign=Data_science … +1 Hal2000Bot #data #science
Username: gp_pulipaka | Tweet: Synchronizing the Digital #SCM using AI for Supply Chain Planning. #BigData #Analytics #DataScience #AI #RPA #MachineLearning #IoT #IIoT #Python #RStats #TensorFlow #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux @lruettimann http://bit.ly/2KX8vrt pic.twitter.com/tftxwilkQf
Username: DataSci_Plow | Tweet: Extreme Rare Event Classification using Autoencoders in Keras https://www.plow.io/post/extreme-rare-event-classification-using-autoencoders-in-keras?utm_source=Twitter&utm_campaign=Data_science … +1 Hal2000Bot #data #science
Username: DataSci_Plow | Tweet: Five Methods to Debug your Neural Network https://www.plow.io/post/five-methods-to-debug-your-neural-network?utm_source=Twitter&utm_campaign=Data_science … +1 Hal2000Bot #data #science
Username: iamjony94 | Tweet: 26 Mobile and Desktop Tools for Marketers http://bit.ly/2LkL3cN #socialmedia #digitalmarketing #contentmarketing #growthhacking #startup #SEO #ecommerce #marketing #influencermarketing #blogging #infographic #deeplearning #ai #machinelearning #bigdata #datascience #fintech pic.twitter.com/mxHiY4eNXR
Username: TDWI | Tweet: #ATL #DataPros: Our #analyst, @prussom is headed your way to speak @ the #FDSRoadTour on Wed, 5/8! Register to attend for free, learn about Modern #DataManagement in the Age of #Cloud & #DataScience: Trends, Challenges & Opportunities. https://bit.ly/2WlYOJb #Atlanta #freeevent
看起来不是很好,但我们得到了我们想要的。推文!
将结果保存到 Pandas

可惜 Twint 和 Spark 之间没有直接的连接,但我们可以通过 Pandas 实现,然后将结果传递给 Optimus。
我创建了两个简单的函数,你可以在实际项目中看到,它们可以帮助你处理 Pandas 和 Twint API 的这一部分。所以当我们运行:
available_columns()
你会看到:
Index(['conversation_id', 'created_at', 'date', 'day', 'hashtags', 'hour','id', 'link', 'location', 'name', 'near', 'nlikes', 'nreplies','nretweets', 'place', 'profile_image_url', 'quote_url', 'retweet','search', 'timezone', 'tweet', 'user_id', 'user_id_str', 'username'],dtype='object')
这些是我们刚刚查询得到的列。对于这些数据有很多不同的操作,但在这篇文章中我只使用其中的一部分。所以为了将 Twint 的结果转换为 Pandas,我们运行:
df_pd = twint_to_pandas(["date", "username", "tweet", "hashtags", "nlikes"])
你会看到这个 Pandas 数据框:
好得多,不是吗?
情感分析(简单方法)

我们将对一些推文进行情感分析,使用 Optimus 和 TextBlob,一个用于自然语言处理的库。我们需要做的第一件事是清理这些推文,为此 Optimus 是最佳选择。
为了将数据保存为 Optimus (Spark) 数据框,我们需要运行:
df = op.create.data_frame(pdf= df_pd)
我们将使用 Optimus 移除重音符号和特殊字符(在实际工作场景中你需要做更多的工作,比如移除链接、图片和停用词),为此:
clean_tweets = df.cols.remove_accents("tweet") \
.cols.remove_special_chars("tweet")
然后我们需要从 Spark 收集这些推文,将其放入一个 Python 列表中,为此:
tweets = clean_tweets.select("tweet").rdd.flatMap(lambda x: x).collect()
然后为了分析这些推文的情感,我们将使用 TextBlob 情感 函数:
from textblob import TextBlob
from IPython.display import Markdown, display
# Pretty printing the result
def printmd(string, color=None):
colorstr = "<span style='color:{}'>{}</span>".format(color, string)
display(Markdown(colorstr))
for tweet in tweets:
print(tweet)
analysis = TextBlob(tweet)
print(analysis.sentiment)
if analysis.sentiment[0]>0:
printmd('Positive', color="green")
elif analysis.sentiment[0]<0:
printmd('Negative', color="red")
else:
printmd("No result", color="grey")
print("")
这将给我们:
IAM Platform Curated Retweet Via httpstwittercomarmaninspace ArtificialIntelligence AI What About The User Experience httpswwwforbescomsitestomtaulli20190427artificialintelligenceaiwhatabouttheuserexperience AI DataScience MachineLearning BigData DeepLearning Robots IoT ML DL IAMPlatform TopInfluence ArtificialIntelligence
Sentiment(polarity=0.0, subjectivity=0.0)
中立
Seattle Data Science Career Advice Landing a Job in The Emerald City Tips from Metis Seattle Career Advisor Marybeth Redmond – httpsbitly2IYjzaj pictwittercom98hMYZVxsu
Sentiment(polarity=0.0, subjectivity=0.0)
中立
This webinarworkshop is designed for business leaders data science managers and decision makers who want to build effective AI and data science capabilities for their organization Register here httpsbitly2GDQeQT pictwittercomxENQ0Dtv1X
Sentiment(polarity=0.6, subjectivity=0.8)
积极
Contoh yang menarik dari sport science kali ini dari sisi statistik dan pemetaan lapangan Dengan makin gencarnya scientific method masuk di sport maka pengolahan data seperti ini akan semakin menjadi hal biasa httpslnkdinfQHqgjh
Sentiment(polarity=0.0, subjectivity=0.0)
中立
Complete handson machine learning tutorial with data science Tensorflow artificial intelligence and neural networks Machine Learning Data Science and Deep Learning with Python httpsmedia4yousocialcareerdevelopmenthtmlmachinelearning python machine learning online data science udemy elearning pictwittercomqgGVzRUFAM
Sentiment(polarity=-0.16666666666666666, subjectivity=0.6)
消极
We share criminal data bases have science and medical collaoarations Freedom of movement means we can live and work in EU countries with no hassle at all much easier if youre from a poorer background We have Erasmus loads more good things
Sentiment(polarity=0.18939393939393936, subjectivity=0.39166666666666666)
积极
Value of Manufacturers Shipments for Durable Goods BigData DataScience housing rstats ggplot pictwittercomXy0UIQtNHy
Sentiment(polarity=0.0, subjectivity=0.0)
中立
Top DataScience and MachineLearning Methods Used in 2018 2019 AI MoRebaie TMounaged AINow6 JulezNorton httpswwwkdnuggetscom201904topdatasciencemachinelearningmethods20182019html
Sentiment(polarity=0.5, subjectivity=0.5)
积极
Come check out the Santa Monica Data Science Artificial Intelligence meetup to learn about In PersonComplete Handson Machine Learning Tutorial with Data Science httpbitly2IRh0GU
Sentiment(polarity=-0.6, subjectivity=1.0)
消极
Great talks about the future of multimodality clinical translation and data science Very inspiring 1stPETMRIsymposium unitue PETMRI molecularimaging AI pictwittercomO542P9PKXF
Sentiment(polarity=0.4833333333333334, subjectivity=0.625)
积极
Did engineering now into data science last 5 years and doing MSC in data science this year
Sentiment(polarity=0.0, subjectivity=0.06666666666666667)
中立
Program Officer – Data Science httpbitly2PV3ROF
Sentiment(polarity=0.0, subjectivity=0.0)
中立。
以此类推。
嗯,这非常简单,但它不能扩展,因为最终我们是从 Spark 中收集数据,所以驱动程序的 RAM 是限制。让我们做得更好一点。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
如何在一夜之间将你的数据分析咨询费率提高两倍
原文:
www.kdnuggets.com/2021/08/2x-data-analytics-consulting-rates-overnight.html
评论
作者:Lillian Pierson, P.E.,世界级数据领导者和企业家的导师,Data-Mania 首席执行官
想知道 2021 年新数据自由职业者的数据分析咨询费率吗?准备好提升你的数据分析自由职业者费率了吗?你来对地方了。
继续阅读,了解我帮助你将数据分析自由职业者或顾问费率翻倍的最佳策略。

现实是——如果你正在阅读这些内容并且已经在进行某种数据分析工作,你很可能没有收取足够的费用。
在我指导数据专业人士建立六位数数据业务的工作中,许多客户来找我时收费远低于他们应有的水平。虽然许多人在与我签约后的头七个月内成功获得了六位数合同(约 10%的指导客户取得了这样的成就!),但他们通常都是从挣扎中的自由职业者开始的。
所以,你可以说我对帮助数据自由职业者在业务中取得重大提升有所了解!
让我们深入探讨如何从明天开始显著提高你的费率。
数据分析咨询是什么?
当我在这篇文章中谈论数据分析咨询时,我指的是销售数据分析服务——这可以很容易地被市场化为如下内容:
-
数据分析咨询
-
数据可视化咨询服务
-
商业分析咨询服务
-
Tableau 咨询
-
Power BI 咨询服务
-
商业分析顾问服务
想了解更多的数据分析服务清单,可以查看DwellTec 在这里如何细分其数据分析服务。
但说实话,我分享的方法也适用于其他类型的数据服务。所以无论你提供 A/B 测试、数据挖掘、数据工程、数据科学还是机器学习,你都可以将这些定价策略应用到你的数据业务中,取得令人惊叹的结果。
数据分析自由职业者到底做错了什么?
这个问题的答案其实很简单。
大多数数据自由职业者的收费实在不够高。
让我们来看一下这些数据——无论是西方还是非西方的自由职业者。
从我们对各种数据自由职业者在UpWork上的个人资料进行的调查中,我们发现经验丰富的美国自由职业者的数据专业知识售价在每小时$28 到$250 之间。
但中位数费率仅为$97.50——这意味着大多数经验丰富的数据分析自由职业者在美国的收费低于每小时$100。
现在,让我们谈谈非西方自由职业者。根据我们 2021 年的 Upwork 研究,经验丰富的印度自由职业者的数据专业知识的收费范围在每小时 5 到 199 美元之间。
但中位数费率为 37.50 美元——这意味着大多数经验丰富的数据分析自由职业者在印度的收费低于每小时 40 美元。
这里有两个重大错误。
-
首先,你绝不应该按小时出售你的时间。
用小时换取美元是不可持续的,最终会把你拖垮。
-
其次,这些小时费率一开始就远远过低。
低定价是灾难的根源。
那么,如果这些费率远远低估了,数据分析自由职业者应该目标定在什么范围内?
2021 年新数据自由职业者的数据分析咨询的理想费率是什么?
让我们来看看作为数据自由职业者,你实际需要收费多少才能经营一个盈利的业务。
一个简单的经验法则是,你需要收费为员工实得薪水的两倍。
这有两个主要原因。
-
你没有福利。
你必须弥补在自由职业时无法获得的所有附带福利的巨大损失,比如保险、带薪休假、休息时间等等。更不用说,你还要弥补所有的商业成本,如软件、营销费用、销售费用——你明白的。
-
低定价不会让你实现规模化。
如果你定价过低,你将始终停留在单打独斗的阶段。你永远没有资源组建团队、优化流程或购买最好的工具。如果你想了解更多关于低定价为何是个坏主意的信息,可以查看这篇 Business2Community 博客文章。
西方和非西方自由职业者的当前收费标准
让我们探讨一下 2021 年新数据自由职业者的数据分析咨询费率!我想讨论的第一个类别是西方经济体的新数据自由职业者。
作为一个新的数据自由职业者,你可能已经参加了一些数据实施课程,建立了一些作品集,但你仍未建立自己的声誉。你还没有建立起在线信誉,也没有外部标准来验证你能交付成果。
如果你属于这一类,你需要至少收取每小时 150 美元。
如果你是生活在非西方经济体中的新数据自由职业者,比如印度或菲律宾,你应该至少定价为每小时 100 美元。
那么,经验丰富的数据自由职业者的费率如何呢?
现在,假设你有一个出色的作品集、热情的推荐信和一个相关领域的学位,以及一些外部实体验证你能实现你承诺的结果。在这种情况下,你需要收取至少$300/小时。
如果你在非西方经济体中,这可能会对你来说有点棘手,但我还是建议你尽力争取每小时$300。为了命令这些高端费用,你需要确保你的品牌足够出色,满足西方客户的期望。你还需要花时间展示推荐信和评论,以证明你能够为客户取得卓越的结果。
为自由职业数据服务定价的两个经验法则
要建立一个成功的自由职业数据业务,你必须(我再说一遍,必须!)遵循这两个黄金规则:
-
避免按小时销售你的服务
-
总是销售可交付成果 - 或达成的里程碑目标
你很可能在过去被教导按小时费率向客户报价。是时候完全忘记那个建议了。
相反,你将提议一个套餐价格。 这是一个针对特定交付物或实现某些项目里程碑的固定费用。
如何创建一个自由职业数据服务套餐?
既然我们已经探讨了 2021 年新数据自由职业者的数据分析咨询费用,让我们讨论一下如何包装你的服务。为了创建你的完美方案,你需要遵循这些步骤。
-
从你的 MVP 开始
最好的开始方式是创建一个标准报价。你可以把它看作是你最小可行的服务报价。这是你为客户交付结果的核心方式。
-
包括增加价值而不增加更多工作量的附加项
一旦你有了标准化的套餐,你需要找出如何增加该套餐的价值 - 而不必增加交付所需的小时数。 问问自己:有哪些可重复使用的资产可以与服务套餐一起销售?一些很好的想法包括添加文档、培训视频、用户指南、仪表盘和规格。
-
销售结果
转向套餐定价会完全改变你销售服务的方式。与其关注交付所需的时间,你应该关注销售转型。 你的理想客户从与你合作中获得的确切结果是什么?
当然,你需要准确找出交付套餐所需的时间。这是你确保每小时赚取至少$300 的方法。
你应该在哪里销售你的数据服务套餐?
现在,你可能会想,“这听起来很好,但我实际上可以在哪里找到购买这个套餐的客户?”
好问题!
就包裹的销售地点而言,我会建议你避免去像Upwork这样的地方。通常,这类自由职业市场变成了‘降价竞争’,这使得那些希望收费高价的自由职业者难以施展。
当然,你会希望将你的包裹发布在你的网站上,然后尝试通过社交媒体来引流到你的网站。你甚至可以在你的社交媒体频道上发布一个特色帖子或亮点,介绍如何与我合作,并附上你的网站链接以了解更多信息。想了解更多关于如何吸引高价客户到你的数据业务中,务必查看这篇文章。
希望这篇文章能为你提供关于 2021 年数据分析咨询费的新数据自由职业者以及经验丰富的自由职业者的更多清晰度!记住:通过将定价结构从按小时计费改为高级数据服务包,你将能够迅速扩大业务,并在本周内将费用翻倍!
想要更多资源来发展你的数据业务吗?
一定要下载免费的数据企业家工具包,这是我们用来将 Data-Mania 扩展到六位数收入的 32 个最佳工具和流程的集合。
简介: 莉莲·皮尔森 (Lillian Pierson, P.E.) 是一位首席执行官兼数据领袖,她帮助数据专业人士成长为世界级的领导者和企业家。迄今为止,她已经帮助超过 130 万数据专业人士了解人工智能和数据科学。莉莲与 Wiley & Sons 出版社合作出版了 6 本数据书籍,并与 LinkedIn Learning 合作开发了 5 门数据课程。她曾支持过从联合国和国家地理到爱立信和沙特阿美等各种组织。她是一名良好信誉的注册专业工程师,自 2007 年起担任技术顾问,自 2018 年起担任数据业务导师。她还偶尔在全球峰会和数据隐私与伦理论坛中志愿提供她的专业知识。
相关:
-
如何从数据自由职业者过渡到数据企业家(几乎一夜之间)
-
数据职业不是一刀切的!揭示你在数据领域理想角色的技巧
-
为什么以及如何学习“高效数据科学”?
更多相关话题
3 个你应该知道的高级 Python 特性
原文:
www.kdnuggets.com/2020/07/3-advanced-python-features.html
评论

照片由 David Clode 通过 Unsplash 提供。
在本文中,我将讨论 3 个对数据科学家非常有用的 Python 重要特性,这些特性可以节省大量时间。让我们开始,不浪费时间。
列表和字典推导
列表和字典推导是 Python 中非常强大的工具,它们在创建列表时非常方便。它节省时间,语法简单,并且使逻辑比使用普通的 Python for 循环创建列表更容易。
基本上,这些是用于替代带有简单逻辑的显式 for 循环,这些逻辑会将列表或字典中的某些内容附加或处理。这些是单行代码,使代码更具可读性。
列表推导
我们将首先看到一个普通的 Python 示例,然后看到它使用列表推导的等效形式。
场景
假设我们在 Pandas 中有一个简单的数据框,其中包含 3 门科目的学生成绩。
In [1]: results = [[10,8,7],[5,4,3],[8,6,9]]
In [2]: results = pd.DataFrame(results, columns=['Maths','English','Science'])
如果我们打印它,
In [5]: results
Out[5]:
Maths English Science
0 10 8 7
1 5 4 3
2 8 6 9
现在假设我们想要制作一个包含每门科目最大分数的列表,即,该列表应为 [10,8,9],因为这些是每门科目的最高分。
Python 代码
In [7]: maxlist = []
In [8]: for i in results:
...: maxlist.append(max(results[i]))
如果我们打印它,
In [9]: maxlist
Out[9]: [10, 8, 9]
使用列表推导
列表推导的基本语法是
[varname for varname in iterableName]
在这里,我们可以对varname做任何修改。
在我们的例子中,我们的列表推导将是
In [27]:maxlist = [max(results[i]) for i in results]
我们的输出将是
Out[27]: [10, 8, 9]
你是否看到它如何与我们的 Python 代码相似?我们在普通 Python 代码中的循环内将max(results[i])追加到maxlist中,在这里我们不再追加它,但你想追加的任何内容应该是列表推导中的第一个参数。因此,现在我可以将基本语法重写为
newlist = [whatYouwantToAppend for anything in anyIterable]
因此,在我们的示例中,我们想要将数据框中每一行的最大值,即max(results[i]),追加到列表中,所以我们使用了
[max(results[i]) for i in results]
字典推导
类似地,我们对字典推导使用相同的思想。通常使用的基本语法是
{key, value for key, value in anyIterable}
比如,假设我有一个用于英文字母的示例表,
df =
{0: 'A',
1: 'B',
2: 'C',
3: 'D',
4: 'E',
5: 'F',
6: 'G',
7: 'H',
8: 'I',
9: 'J',
10: 'K',
11: 'L',
12: 'M',
13: 'N',
14: 'O',
15: 'P',
16: 'Q',
17: 'R',
18: 'S',
19: 'T',
20: 'U',
21: 'V',
22: 'W',
23: 'X',
24: 'Y',
25: 'Z'}
现在,如果我们想使用数字(0–25)作为字典的值,因为机器学习模型只能处理数字,并且我们想要提供字典的值,我们需要交换字典的键和值。交换字典中键和值的最简单方法是使用字典推导。
{number: alphabet for alphabet , number in df.items()}
如果你稍微关注一下,就会明白它是如何反转字典的,我们在循环alphabet和number,这是字典的正常顺序,但我们要插入的内容是反向的,因此我们使用number:alphabet而不是alphabet:number。
Lambda 表达式
Lambda 表达式是数据科学家非常强大的工具。特别是当与 DataFrame.apply()、map()、filter() 或 reduce() 一起使用时,它们非常方便。它们提供了一种避免手动定义函数的简单方法,并将其写成一行代码,使代码更加清晰。
让我们来看一下 Lambda 表达式的基本语法,其中我们返回传递给任何函数的数字的下一个数字。
z = lambda functionArgument1 : functionArgument1 + 1
在这里,我们的函数参数是 functionArgument1,我们返回 functionArgument1 +1,即下一个数字。
所以要使用它,
z(5)
>>>6
看,它就是这么简单。让我们看一个实际的例子,我们有一个包含名字的数据框(取自泰坦尼克号数据集),我们想要制作一个特征,从名字中提取标题(Mr、Miss、Sir 等)。
那么我们数据框的代码是
df = pd.DataFrame([
'Braud, Mr. Owen Harris',
'Cumings, Mrs. John Bradley',
'Heikkeinen, Miss. Laina',
'Futrelle, Mrs. Jacques Heath',
'Allen, Mr. William Henry',
'Moran, Mr. James'
])
数据框是
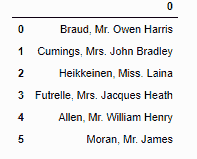
现在,如果我们注意到,我们发现这里有一个特定的模式,即在名字后有一个逗号,而标题后有一个句号,我们可以使用 list slicing 从逗号到句号提取。
我们希望从逗号后的两个索引开始切片,因为我们不想包括逗号和逗号后的空格,所以我们的起始索引将是 str.find(',')+2,我们希望切片直到句号(不包括),所以我们将切片直到 str.find('.')。幸运的是,最后一个索引未包含,因此我们不需要从索引中显式减去 -1。让我们使用 Lambda 表达式来解决这个问题。
df['Title'] = df[0].apply(lambda a: a[a.find(',')+2: a.find('.')])
在这里,我们使用 pandas 的 .apply 函数对 df[0] 应用,它是包含所有名字的列。在其中,我们传递一个 Lambda 表达式,该表达式接收每个名字并返回该名字的切片版本。这个切片版本就是该名字的标题。我们数据框的输出现在是
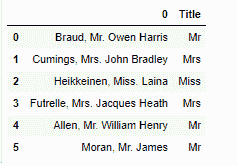
在这里,我们可以看到我们是如何利用这个很清晰的技巧从名字中提取标题的。
Lambda 表达式在 Python 中与 map、reduce 或 filter 配合使用时非常有用。
Map 函数
在 Python 中,Map 函数是非常常用的函数,它使我们的工作变得更加容易。map 的概念是,当传递一个函数和一个可迭代对象到 map 时,它会对该可迭代对象的每一个实体执行这个函数。
这是什么意思?
假设我有一个可迭代的列表,其数据为 [0, 5, 10, 15, 20, 25, 30],还有一个自定义函数 isEven(anyInteger),它判断传递给它的 anyInteger 是否为偶数。如果我们将这个函数和可迭代对象传递给 map,它将自动对列表中的所有实体应用此函数,并返回 map 对象,我们可以将其转换为列表、元组或字典。
示例
假设我们的函数是
def isEven(anyInteger):
return anyInteger % 2 == 0
而我们的可迭代对象是
myList = [0, 5, 10, 15, 20, 25, 30]
如果我们想使用传统的方法,那么我们必须循环遍历列表,并将函数应用于每个项目。
# Traditional approach
isEvenList = []
for i in myList:
isEvenList.append(isEven(i))
这将返回一个新的列表 isEvenList,其中偶数为 True,奇数为 False。
使用 map 将使我们的任务更简单。我们的代码将是
isEvenList = list(map(isEven, myList))
我们的代码完成了!
在这里,我们正在做的是在 map 函数中传入我们的函数 isEven 和我们的可迭代对象 myList,这将返回一个 map 对象,我们将其转换为 list。
所以 map 函数的基本语法是
list/dict/tuple(map(myFunction, myIterable))
幸运的是,Pandas 提供了 map、apply 和 applymap 作为内置函数。它们非常常用且很有帮助。这三种函数的基本思想与 Python 的内置 map 函数相同。你可以在 Pandas 的官方文档中了解更多关于这些函数的信息,点击这里。
相关内容:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
更多相关话题
数据插补的三种方法
原文:
www.kdnuggets.com/2022/12/3-approaches-data-imputation.html
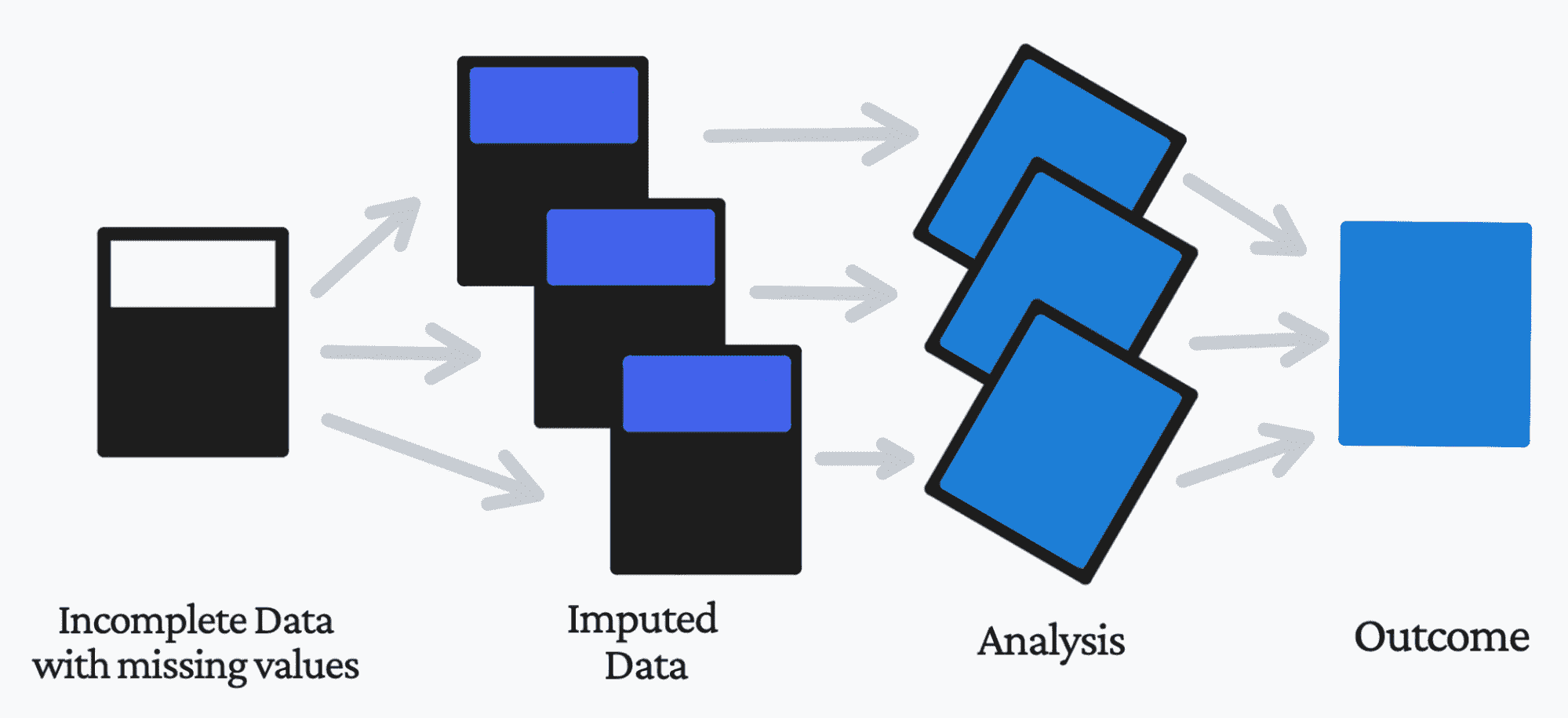
图片由作者提供
在处理数据时,如果你的数据没有缺失值,那将是非常棒的。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
不幸的是,我们生活的世界并不完美,尤其是在数据方面。因此,你需要为这些缺失的数据点找到解决方案。
这就是数据插补发挥作用的地方。
什么是数据插补?
数据插补利用各种统计方法,将缺失的数据值替换为替代值。这使得你、企业和客户能够充分利用数据,并提供有价值的见解。
如果你替代一个数据点,这被称为“单元插补”。如果你替代一个数据点的某个组成部分,这被称为“项插补”。
那么,为什么我们要插补数据,而不是直接删除呢?
尽管删除缺失值是更简单的选项,但这并不总是最佳选择。删除缺失值不仅会减少数据集的大小,还可能导致进一步的错误和不可靠的分析。
为什么数据插补很重要?
缺失数据无法为我们提供良好的数据集范围,并可能降低整体结果的可靠性。缺失数据可能会:
1. 使用 Python 库时的冲突。
有些特定的库在处理缺失数据时表现不佳,自然不兼容。这可能会导致你的工作流程/过程的延迟,并引发更多错误。
2. 数据集的问题
如果你删除缺失值,将导致数据集规模的减少。然而,保留缺失值可能对变量、相关性、统计分析和整体结果产生重大影响。
3. 最终结果
在处理数据和模型时,你的优先任务是确保最终模型无错误、高效,并在实际案例中值得信赖。缺失数据自然会导致数据集的偏差,从而导致不正确的分析。
那么,我们如何替代这些缺失值呢?让我们来找出答案。
数据插补的方法
1. 使用均值的 SimpleImputer
class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy='mean', fill_value=None, verbose='deprecated', copy=True, add_indicator=False)
使用 Scikit-learn 的 SimpleImputer 类,你可以使用常数值、均值、中位数或众数来插补缺失值。
例如:
# Imports
import numpy as np
from sklearn.impute import SimpleImputer
# Using the mean value of the columns
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
imp.fit([[1, 3], [5, 6], [8, 4], [11,2], [9, 3]])
# Replace missing values, encoded as np.nan
X = [[np.nan, 3], [5, np.nan], [8, 4], [11,2], [np.nan, 3]]
print(imp.transform(X))
输出:
[[ 6.8 3\. ]
[ 5\. 3.6]
[ 8\. 4\. ]
[11\. 2\. ]
[ 6.8 3\. ]]
2. 使用最频繁的 SimpleImputer
使用上述相同的类,我提到你可以使用均值、中位数或众数。众数适用于分类特征,无论是字符串还是数字。它将缺失值替换为该列中最常见的值。
使用上述相同的示例,你可以这样做:
# Imports
import numpy as np
from sklearn.impute import SimpleImputer
# Using the most frequent value of the columns
imp = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
imp.fit([[1, 3], [5, 6], [8, 4], [11,2], [9, 3]])
# Replace missing values, encoded as np.nan
X = [[np.nan, 3], [5, np.nan], [8, 4], [11,2], [np.nan, 3]]
print(imp.transform(X))
输出:
[[ 1\. 3.]
[ 5\. 3.]
[ 8\. 4.]
[11\. 2.]
[ 1\. 3.]]
3. 使用 k-NN
如果你不知道 k-NN 是什么,它是一种通过计算当前训练数据点之间的距离来对测试数据集进行预测的算法。它假设相似的事物存在于接近的地方。
使用 Impyute 库进行插补是使用 k-NN 的一种简单易行的方法。例如:
插补前:
n = 4
arr = np.random.uniform(high=5, size=(n, n))
for _ in range(3):
arr[np.random.randint(n), np.random.randint(n)] = np.nan
print(arr)
输出:
[[ nan 3.14058295 2.2712381 0.92148091]
[ nan 3.24750479 1.35688761 2.54943751]
[4.47019496 0.79944618 3.61855558 3.12191146]
[3.09645292 nan 0.43638625 4.05435414]]
插补后:
import impyute as impy
print(impy.mean(arr))
输出:
[[3.78332394 3.14058295 2.2712381 0.92148091]
[3.78332394 3.24750479 1.35688761 2.54943751]
[4.47019496 0.79944618 3.61855558 3.12191146]
[3.09645292 2.39584464 0.43638625 4.05435414]]
总结
到此为止,你已经了解了什么是数据插补,它的重要性,以及三种不同的处理方法。如果你仍然对了解更多有关缺失值和统计分析感兴趣,我强烈推荐阅读 缺失数据的统计分析 由 Roderick J.A. Little 和 Donald B. Rubin 著。
Nisha Arya 是一位数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何能够促进人类寿命的延续。作为一个热衷于学习的人,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
成功数据科学团队的三个关键组成部分
原文:
www.kdnuggets.com/2015/08/3-components-successful-data-science-team.html
评论
作者:Jack Danielson.

一个由合适的专职专业人士精心构建的数据科学团队,能够为任何组织带来资产。成功的任何项目都由其资源的专业知识决定,而数据科学也不例外。需要拥有多样化技能的专业人士来成功应对复杂大数据项目的挑战。
为了确保你的数据科学项目走在正确的轨道上,你需要确保团队中有能力胜任三个关键角色的专业人士 - 数据工程师、机器学习专家 和 业务分析师。这三组人员的存在,共同为一个共同的目标而努力,将能有效分析相关信息,以预测消费者的行为,并符合业务目标。
现在让我们来了解一下与每个组件相关的职责。我们还将揭示出那些可以被信任来履行这三种角色的理想候选人的特征。
组件 1 - 数据工程师****:
数据工程师的角色位于金字塔的基础层。数据工程师构成了数据科学项目的基础,他们负责捕捉、存储和处理相关数据。数据收集、数据仓储、数据转换和数据分析 - 这些通常由一组数据工程师处理。
他们是那些在分布式环境中使用像 Hadoop 或 HBase 等工具和框架的专业人士,以确保所有原始数据点被正确捕捉和处理。处理后的数据随后交给下一组人,即机器学习专家,进一步处理。
理想的候选人:
数据工程师主要是一个技术性角色。理想的候选人不需要非常学术化,但必须具备在捕捉数据点所使用的后端框架和工具上的技术能力。
如果你对 Hadoop、MapReduce 或 HBase 有深入了解,那么数据工程师的角色将非常适合你。除了技术能力外,成功的数据工程师还需要具备分析技能。数据工程师应该能够根据不断变化的业务需求灵活学习新工具,并始终愿意升级到与数据分析相关的专业技术。
组件 2 - 机器学习专家****:
机器学习专家在数据工程师和业务分析师之间充当桥梁。他们主要负责构建数据模型和开发算法,以得出结论性的信息。他们的工作是确保得出的信息经过充分研究、准确、易于理解且不带偏见。
理想候选人:
拥有统计学背景,对定量主题有深厚兴趣的候选人通常更受机器学习专家职位的青睐。理想的专业人士必须对数据算法和数据结构有扎实的理解,并且一般软件工程概念也应具备。处理计算复杂性的能力可以视为额外的加分项。
组件 3 - 业务分析师:
数据探索和数据可视化是业务分析师角色的两个最重要的职责。业务分析师使用与核心业务相关的前端工具,并与组织的高层管理人员进行互动。他们进一步分析由机器学习专家提供的业务级数据,以寻找与组织核心业务利益相关的见解。
业务分析师的另一个重要职责是与数据工程师和机器学习专家协调,使他们理解业务目标并确定可能的重点领域。业务分析师的终极责任是基于处理后的数据产生可操作的见解,并帮助公司领导做出决策。
理想候选人:
业务分析师应该对基础业务数据和源系统有专家级的知识。理想的候选人应具有细致入微的眼光,并且具备出色的分析技能。此外,扎实的组织业务模型理解能力和超越常规思维的能力是所有业务分析师必备的两个重要品质。还需具备足够的技术技能,以便准确设计展示业务数据的仪表板。
结论:
尽管拥有合适的人选来填补合适的岗位是有好处的,但仅此可能不足以取得成功。这几乎适用于任何依赖团队的项目。无论你是想要与多个作者启动一个博客,还是希望与合作伙伴一起建立在线业务,所有相关方都需要超越个人视角,作为一个统一的整体进行工作。当这种情况发生时,可以放心,成功将自动随之而来。
**简介: 作为一名充满激情的自由博客作者和互联网营销专家,Jack Danielson 在营销、社交媒体和搜索引擎优化方面拥有超过 3 年的经验。关注他在 google plus。
相关:
-
数据科学技能的分歧:个人与团队方法
-
KDnuggets 与 IBM 对话:数据科学家:雇佣个人还是团队?
-
将数据分析外包到印度:应该还是不应该?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
了解更多此话题
你应该考虑的 3 个课程,如果你想成为数据分析师
原文:
www.kdnuggets.com/3-courses-you-should-consider-if-you-want-to-become-a-data-analyst

图片来源:作者
每天,我都会收到来自世界各地的人们关于如何成为数据分析师的信息。有些人来自于目前涉及数据的职业背景,而另一些人则对数据分析完全陌生。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
开始新的职业生涯可能会很困难,尤其是当你觉得自己没有合适的技能集时。冒名顶替综合症。这很正常,我们在生活中都经历过这种情况。
然而,我完全同意,当你决定换职业时,你希望确保自己知道自己在做什么,并且拥有持续成长和提高的正确技能。本文将帮助你选择合适的课程,无需自己四处寻找。
DataCamp 的 Power BI 数据分析师课程
链接:DataCamp 的 Power BI 数据分析师课程
Power BI 是最受欢迎的工具之一,数据分析师都喜欢它。如果你正在寻找一个可以将数据分析师与业务分析师结合的职业——DataCamp 的这个课程可能正是你需要的。
不需要任何先前的经验,你将学习如何在 Power BI 中导入、清理、处理和可视化数据——这些都是任何有志数据专业人士的关键技能。你还将通过实践练习了解数据分析过程以及 Power BI 的最佳实践。
如果你想获得认证,在完成该课程后,你还将收到一个 50% 的折扣码,用于 Microsoft PL-300 认证,以帮助你将数据分析师的职业提升到一个新水平。
Meta 数据分析师认证
这个课程针对的是希望从数据分析师角度进入科技行业的初学者。你可以根据自己的时间和进度进行学习。如果你每周投入 10 小时,整个课程将需要 5 个月完成,但如果你可以投入更多时间,完成得更快也是可能的!
该认证由 5 个课程组成:
-
数据分析入门
-
使用电子表格和 SQL 进行数据分析
-
Python 数据分析
-
市场营销统计学
-
数据管理入门
在这 5 个课程中,你将学习如何收集、清理、排序、评估和可视化数据,应用用于指导数据分析过程的 OSEMN 框架,使用统计分析,如假设检验和回归分析,以做出基于数据的决策,并理解组织内有效数据管理的基础原则。
Google 的数据分析认证
一个非常受欢迎的课程,Google 的数据分析专业认证让你了解与数据分析师相关的实践和流程。这个课程面向初学者,建议每周投入 10 小时,6 个月内完成。
你将学习关键的分析技能,如数据清理、分析和可视化,以及电子表格、SQL、R 编程和 Tableau 等工具。使用这些技能,你将学习如何在仪表板、演示文稿和常用可视化平台中可视化和呈现数据发现。
许多人在没有先前经验的情况下参加了这个课程,目前正在担任数据分析师。
总结一下
寻找合适的课程可能会很麻烦,尤其是当你对这个领域还不熟悉时。团队和 KDnuggets 希望每个人都能成长和学习。
我们希望像这样的文章能帮助你在生活的新篇章中找到指导和轻松!
Nisha Arya 是一名数据科学家、自由技术写作人,并且是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及基于理论的数据科学知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有益于人类寿命的不同方式。作为一个热衷的学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
对话式人工智能开发中的 3 个关键挑战及其解决方法
原文:
www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them

图片来源:Freepik
对话式人工智能是指模拟人类互动的虚拟代理和聊天机器人,可以与人类进行对话。使用对话式人工智能正迅速成为一种生活方式——从要求 Alexa“找到最近的餐馆”到要求 Siri“创建一个提醒”,虚拟助手和聊天机器人通常用于回答消费者的问题、解决投诉、进行预订等等。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的信息技术
开发这些虚拟助手需要大量的努力。然而,理解和解决关键挑战可以简化开发过程。我使用了在招聘平台上创建成熟聊天机器人的第一手经验作为参考点,来解释关键挑战及其相应的解决方案。
要构建对话式人工智能聊天机器人,开发人员可以使用像 RASA、亚马逊的 Lex 或谷歌的 Dialogflow 这样的框架来构建聊天机器人。当计划进行自定义更改或机器人处于成熟阶段时,大多数人更倾向于使用 RASA,因为它是一个开源框架。其他框架也适合作为起点。
这些挑战可以被分类为聊天机器人的三个主要组件。
自然语言理解(NLU)是指机器人理解人类对话的能力。它执行意图分类、实体提取和响应检索。
对话管理器负责根据当前和之前的用户输入执行一系列动作。它以意图和实体作为输入(作为之前对话的一部分),并确定下一个响应。
自然语言生成(NLG)是从给定数据中生成书面或口头句子的过程。它构建响应,然后呈现给用户。
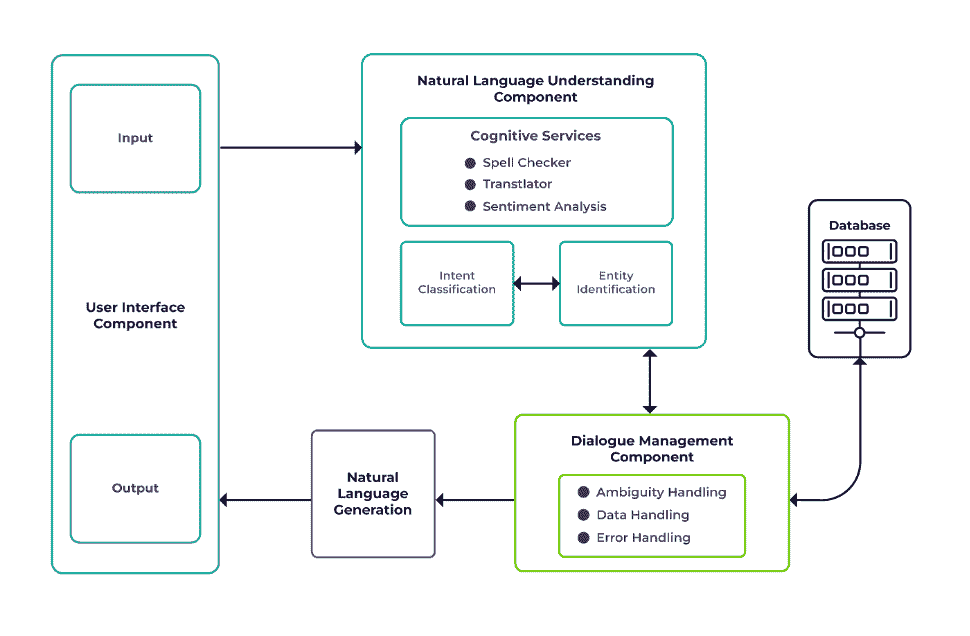
图片来源:Talentica Software
自然语言理解的挑战
数据不足
当开发人员用聊天机器人替换常见问题解答或其他支持系统时,他们会获得相当多的训练数据。但当他们从头开始创建聊天机器人时,情况则不同。在这种情况下,开发人员会合成生成训练数据。
该怎么办?
基于模板的数据生成器可以生成相当多的用户查询用于训练。一旦聊天机器人准备好,项目负责人可以将其暴露给有限数量的用户,以增强训练数据并在一段时间内进行升级。
模型选择不当
选择合适的模型和训练数据对获得最佳的意图和实体提取结果至关重要。开发人员通常在特定的语言和领域中训练聊天机器人,而且大多数现有的预训练模型往往是领域特定的,并且训练于单一语言。
也可能出现混合语言的情况,其中人们是多语种使用者。他们可能会以混合语言输入查询。例如,在以法语为主的地区,人们可能会使用一种混合了法语和英语的英语。
该怎么办?
使用多语言训练的模型可能会减少问题。像 LaBSE(语言无关的 Bert 句子嵌入)这样的预训练模型在这种情况下可能会有所帮助。LaBSE 在 109 多种语言中训练了句子相似度任务。该模型已经知道不同语言中的相似词。在我们的项目中,它表现得非常好。
实体提取不当
聊天机器人需要实体来识别用户搜索的数据类型。这些实体包括时间、地点、人物、物品、日期等。然而,聊天机器人可能无法从自然语言中识别实体:
相同的上下文但不同的实体。例如,当用户输入“来自 IIT Delhi 的学生名字”然后输入“来自 Bengaluru 的学生名字”时,聊天机器人可能会将一个地点混淆为实体。
实体被低置信度误预测的场景。 例如,聊天机器人可能会以低置信度将“ IIT Delhi”识别为一个城市。
机器学习模型的部分实体提取。 如果用户输入“来自 IIT Delhi 的学生”,模型可能只能将“ IIT”识别为实体,而不是“ IIT Delhi”。
单词输入没有上下文可能会让机器学习模型感到困惑。 例如,“Rishikesh”这个词既可以指一个人的名字,也可以指一个城市。
该怎么办?
添加更多的训练示例可能是一个解决方案。但有一个限制,超出之后添加更多的示例将无济于事。此外,这是一个无休止的过程。另一个解决方案可能是定义使用预定义词的正则表达式模式,以帮助提取具有已知可能值的实体,如城市、国家等。
模型在对实体预测不确定时,通常会表现出较低的信心。开发者可以利用这一点作为触发条件,调用一个自定义组件来纠正低信心的实体。举个例子,如果IIT Delhi被预测为一个城市但信心不足,那么用户可以在数据库中搜索它。在未能在City表中找到预测实体后,模型会继续在其他表中查找,最终在Institute表中找到它,从而纠正实体。
错误的意图分类
每个用户消息都有相关的意图。由于意图决定了机器人接下来的行动步骤,因此正确分类用户查询的意图至关重要。然而,开发者必须尽量减少意图之间的混淆,否则可能会出现混淆问题。例如,“显示空缺职位”与“显示空缺职位候选人”。
如何处理?
区分混淆查询有两种方法。首先,开发者可以引入子意图。其次,模型可以根据识别出的实体来处理查询。
特定领域的聊天机器人应是一个封闭系统,能够明确识别自己的能力范围。开发者在规划特定领域的聊天机器人时必须分阶段进行开发。在每个阶段,他们可以识别聊天机器人不支持的功能(通过不支持的意图)。
他们还可以识别聊天机器人无法处理的“超出范围”的意图。但可能会有机器人对不支持和超出范围的意图感到困惑的情况。在这种情况下,应该有一个回退机制,如果意图信心低于阈值,模型可以优雅地使用回退意图来处理混淆情况。
对话管理的挑战
一旦机器人识别出用户消息的意图,它必须发送响应。机器人根据一套定义好的规则和故事来决定响应。例如,一个规则可以是当用户打招呼时,机器人简单地说“早上好”。然而,大多数情况下,与聊天机器人的对话包含后续互动,响应依赖于对话的整体上下文。
如何处理?
为了应对这一点,聊天机器人需要提供实际对话示例,这些示例被称为故事。然而,用户的互动并不总是如预期的那样。一个成熟的聊天机器人应能够优雅地处理所有这些偏差。如果设计者和开发者在编写故事时不仅关注顺利的路径,还要处理不顺利的路径,他们就能保证这一点。
自然语言生成的挑战
用户与聊天机器人的互动在很大程度上依赖于聊天机器人的响应。如果响应过于机械或过于熟悉,用户可能会失去兴趣。例如,即使响应是正确的,用户也可能不喜欢“你输入了错误的查询”这样的答案。这里的回答不符合助理的角色。
如何处理?
聊天机器人作为助手,应具备特定的个性和语调。它们应该热情和谦虚,开发人员应根据这些设计对话和发言。回应不应听起来像机器人或机械。例如,机器人可以说,“对不起,看起来我没有相关细节。请您重新输入您的查询?”以应对错误输入。
将 LLMs 添加到聊天机器人系统中
基于 LLM(大语言模型)的聊天机器人,如 ChatGPT 和 Bard,是颠覆性的创新,提升了对话 AI 的能力。它们不仅擅长进行开放式的人类对话,还可以执行文本摘要、段落撰写等不同任务,这些任务以前只有特定模型才能完成。
传统聊天机器人系统的一大挑战是将每句话分类到意图中并据此决定响应。这种方法不切实际。诸如“对不起,我没听懂”之类的回应常常令人烦恼。无意图聊天机器人系统是未来的发展方向,而 LLMs 可以使这一点成为现实。
LLMs 在通用命名实体识别方面可以轻松实现最先进的结果,但在某些特定领域的实体识别方面除外。将 LLMs 与任何聊天机器人框架混合使用,可以激发更成熟和更强大的聊天机器人系统。
随着对话 AI 的最新进展和持续研究,聊天机器人每天都在变得更好。处理多个意图的复杂任务,例如“预订到孟买的航班并安排到达达的出租车”,正受到越来越多的关注。
不久之后,个性化对话将基于用户的特征进行,以保持用户的参与。例如,如果机器人发现用户不满,它会将对话转交给真实的客服。此外,随着聊天机器人数据的不断增加,像 ChatGPT 这样的深度学习技术可以自动生成查询的响应,利用知识库。
Suman Saurav**** 是 Talentica Software 的数据科学家,该公司是一家软件产品开发公司。他是 NIT Agartala 的校友,拥有超过 8 年的经验,设计和实施使用 NLP、对话 AI 和生成 AI 的革命性 AI 解决方案。
相关主题
3 个数据获取、注释和增强工具
原文:
www.kdnuggets.com/2021/08/3-data-labeling-synthesizing-augmentation-tools.html
评论
快速获取用于测试算法和构建模型的数据集已成为现代数据科学家和机器学习工程师的重要技能。将一个半完整的数据集转变为完全注释、充实了额外增强数据并准备好进行模型构建的完全数据集同样重要。
对于那些拥有不完整数据并需要帮助将其从“尚未完成”变为“可以开始”的人,这里有 3 个在 GitHub 上找到的项目,可以帮助您完成数据获取、注释和增强任务。
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的快车道。
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您在 IT 领域的组织
1. Google Images Download
需要为您的项目构建自定义图像数据集吗?Google Images Download 可能能够提供帮助。
Python 脚本可从 'Google Images' 下载数百张图像。这是一个可以直接运行的代码!
将您的需求输入命令行中或从 Python 脚本中调用,Google Images Download 将... 下载 Google 图像。阅读文档 这里 进行优秀的抓取,但请记住在 Google 使用条款和版权法的范围内进行。

2. LabelImg
一旦您获得了一些图像,注释可能会成为一个问题。这时,LabelImg 就派上用场了。
LabelImg 是一个图形图像注释工具,用于标记图像中的对象边界框。
使用 Python 和 Qt 构建的 LabelImg 是一个独立的应用程序,具有图形用户界面,旨在对图像进行注释。
注释以 XML 文件形式保存,采用 PASCAL VOC 格式,这种格式被 ImageNet 使用。此外,它还支持 YOLO 和 CreateML 格式。
GitHub 仓库提供了安装和使用信息,LabelImg 似乎是一个你可以快速启动并使用的应用程序,从而最大限度地利用你在数据集上的工作时间。祝标注愉快!
3. TextAttack
将我们的注意力从计算机视觉数据集任务转向自然语言处理,让我们看看TextAttack能做什么。
TextAttack 是一个用于对抗攻击、数据扩充和 NLP 模型训练的 Python 框架。
TextAttack 提供了多种内置配方来扩充文本数据,包括:用 WordNet 同义词替换单词;用嵌入空间中的邻近词替换单词;替换、删除、插入和交换相邻字符;缩写/扩展以及替换名称、地点、数字等。
尽管在这里我们突出了使用 TextAttack 扩充数据集的用例,但其功能的完整范围如下:
- 通过对 NLP 模型进行不同的对抗攻击并检查输出,更好地理解 NLP 模型
- 使用 TextAttack 框架和组件库研究和开发不同的 NLP 对抗攻击
- 扩充你的数据集以提高模型的泛化能力和下游的鲁棒性
- 仅使用单个命令训练 NLP 模型(所有下载已包含!)
要开始扩充你的 NLP 数据集,或利用 TextAttack 的其他功能,请查看完整文档,你可以在这里找到。
相关:
-
敏捷数据标注:它是什么以及为何需要它
-
热门深度学习 GitHub 仓库
-
GitHub Copilot 开源替代方案
更多相关话题
3 个保证能让你找到工作的数据科学项目
原文:
www.kdnuggets.com/3-data-science-projects-guaranteed-to-land-you-that-job

图片由作者提供
这是一个非常大胆的声明!声明我可以保证你找到工作。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
好吧,事实是,生活中没有什么是保证的,尤其是找工作。数据科学领域也不例外。但让你非常接近保证的办法是拥有数据项目在你的作品集中。
我为什么认为项目如此决定性?因为如果选择得当,它们可以最有效地展示你在数据科学中的技术技能范围和深度。项目的质量才是关键,而不是数量。它们应该尽可能多地覆盖数据科学技能。
那么,哪些项目能在最少数量的项目中保证你呢?如果只能选择三个项目,我会选择这些。
但不要太字面化。这里的意思并不是说你必须严格遵守这三个项目。我选择它们是因为它们涵盖了数据科学所需的大部分技术技能。如果你想做其他数据科学项目,可以随意选择。但如果你的时间/项目数量有限,明智地选择那些能够测试最广泛数据科学技能的项目。
说到这一点,让我们明确一下它们是什么。
数据科学项目中要寻找的技术技能
数据科学有五种基本技能。
-
Python
-
数据处理
-
统计分析
-
机器学习
-
数据可视化
这是一个在尝试从所选择的数据科学项目中获得最大收益时应考虑的检查清单。
这是这些技能涵盖内容的概述。
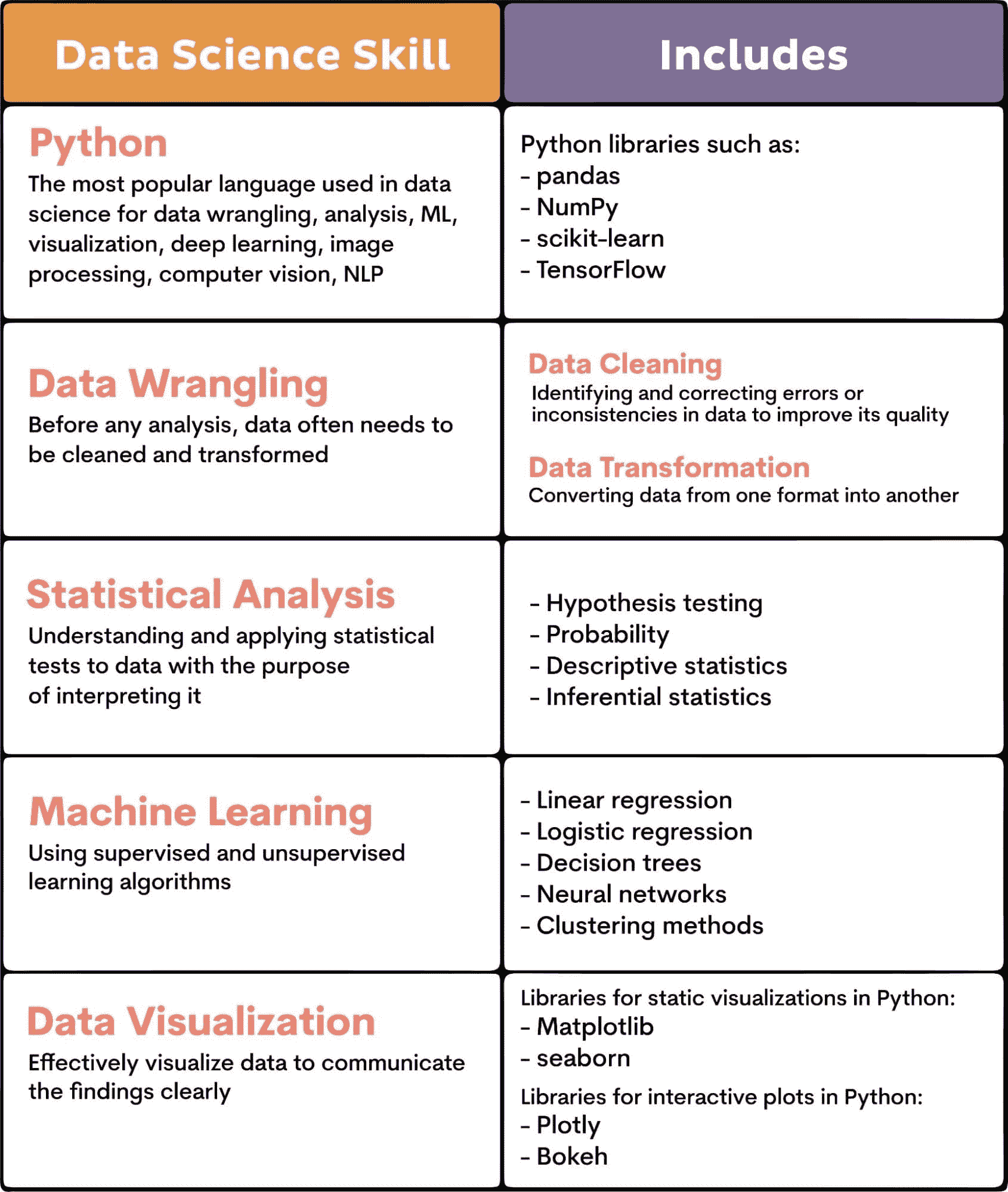
当然,数据科学技能远不止这些。它们还包括掌握 SQL 和 R、大数据技术、深度学习、自然语言处理以及云计算。
然而,对这些技能的需求很大程度上取决于工作描述。但我提到的五项基本技能是你无法忽视的。
现在让我们看看我选择的三个数据科学项目如何挑战这些技能。
3 个数据科学项目以练习基本数据科学技能
其中一些项目可能对某些人来说有些过于高级。在这种情况下,可以尝试这些19 个数据科学初学者项目。
1. 理解城市供应与需求:商业分析
来源: 城市供应与需求数据洞察
主题: 商业分析
简要概述: 城市是 Uber 需求和供应互动的中心。分析这些可以提供对公司业务和规划的洞察。Uber 提供了一个包含行程详细信息的数据集。你需要回答十一道问题,以便对行程、时间、司机需求等提供商业洞察。
项目执行: 你将得到十一道需要按显示顺序回答的问题。回答这些问题将涉及如下任务:
-
填补缺失值,
-
聚合数据,
-
找出最大值,
-
解析时间间隔,
-
计算百分比,
-
计算加权平均数,
-
找出差异,
-
数据可视化等等。
展示的技能: 探索性数据分析(EDA),用于选择所需的列和填补缺失值,推导关于已完成行程的可操作性洞察(不同时间段、每个司机的加权平均行程比率、找出最繁忙的时间来帮助制定司机排班、供应与需求之间的关系等)、可视化供应与需求之间的关系。
2. 客户流失预测:分类任务
来源: 客户流失预测
主题: 监督学习(分类)
简要概述: 在这个数据科学项目中,Sony Research 提供了一个电信公司客户的数据集。他们期望你进行探索性分析并提取洞察。然后,你需要建立一个流失预测模型,评估它并讨论将模型部署到生产中的问题。
项目执行: 项目应按这些主要阶段进行。
*** 探索性分析与洞察提取
-
-
检查数据基础(空值、唯一性)
-
选择所需的数据并形成数据集
-
通过可视化数据检查值的分布
-
形成相关矩阵
-
检查特征重要性
-
*** 训练/测试拆分
-
- 使用sklearn按 80%-20%的比例将数据集拆分为训练集和测试集
*** 预测模型
-
- 应用分类器并根据性能选择一个用于生产
*** 指标
-
- 在比较不同算法的性能时使用准确性和 F1 分数
*** 模型结果
-
-
使用经典的机器学习模型
-
可视化决策树并查看基于树的算法表现如何
-
*** 深度学习模型
-
- 在这个问题上尝试人工神经网络(ANN)
*** 部署问题
-
- 监控模型性能以避免数据漂移和概念漂移
展示的技能: 探索性数据分析(EDA)和数据整理,以检查空值、数据唯一性、获取数据分布的见解,以及正负相关性;在直方图和相关矩阵中进行数据可视化;使用 sklearn 库应用机器学习分类器,测量算法准确性和 F1 分数,比较算法,直观展示决策树;使用人工神经网络查看深度学习的表现;模型部署中需注意数据漂移和概念漂移问题,这些都在 MLOps 周期内。
3. 预测警务:检查影响
来源: 预测警务的风险
主题: 监督学习(回归)
简要概述: 这一预测警务利用算法和数据分析预测犯罪可能发生的地点。你选择的方法可能具有深远的伦理和社会影响。它使用 2016 年旧金山城市犯罪数据,这些数据来自其开放数据计划。该项目将尝试预测在特定邮政编码、某一周的某一天及时间段内的犯罪事件数量。
项目执行: 这里是项目作者所采取的主要步骤。
-
选择变量并计算每年每个邮政编码每小时的犯罪总数
-
按时间顺序划分训练/测试数据
***** 尝试五种回归算法:
-
-
线性回归
-
随机森林
-
K-最近邻
-
XGBoost
-
多层感知机
-
展示的技能: 探索性数据分析(EDA)和数据整理,最终得到关于犯罪、时间、星期几和邮政编码的数据;机器学习(监督学习/回归),尝试线性回归、随机森林回归器、K-最近邻、XGBoost 的表现;深度学习,使用多层感知机解释你得到的结果;获取犯罪预测的见解及其可能被滥用的可能性;将模型部署到交互式地图中。
如果你想用类似的技能做更多项目,这里有 30+个机器学习项目创意。
结论
通过完成这些数据科学项目,你将测试并获得必要的数据科学技能,如数据清理、数据可视化、统计分析、构建和部署机器学习模型。
说到机器学习,我在这里重点关注了监督学习,因为它在数据科学中使用得更为广泛。我几乎可以保证,这些数据科学项目将足以让你获得理想的工作。
但你应仔细阅读职位描述。如果你发现需要监督学习、自然语言处理或其他我未涵盖的内容,请在你的作品集中加入一两个这样的项目。
无论如何,你不会仅限于三个项目。这些项目在这里指导你如何选择你的项目,从而确保你能够获得工作。要注意项目的复杂性,因为它们应该广泛覆盖基本的数据科学技能。
现在,去争取那份工作吧!
内特·罗西迪 是一位数据科学家,专注于产品策略。他还是一名兼职教授,教授分析学,并且是StrataScratch,一个帮助数据科学家通过真实面试问题为面试做准备的平台的创始人。在Twitter: StrataScratch 或 LinkedIn上与他联系。
更多相关内容
-
无法获得数据科学工作?原因在这里******************
数据科学与机器学习编码的 3 个区别
原文:
www.kdnuggets.com/2021/11/3-differences-coding-data-science-machine-learning.html
评论
照片由Christopher Gower拍摄,发布于Unsplash
“数据科学”和“机器学习”这两个术语经常被交替使用。但虽然它们有关联,但存在一些显著的差异,尤其是在开发者在这两个领域中的职责方面。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
开发者市场预计将继续增长,对于那些专注于数据分析和机器学习算法的人来说,可能会找到更具吸引力的工作。因此,让我们看看这两个领域之间的区别,特别是在编程方面。
什么是数据科学?
数据科学作为一个领域需要对大量数据进行深入分析,通常旨在找到使用这些数据来支持商业目标的方法。例如,商业数据可以用来进行竞争研究、增强研究能力、改善网页设计,等等。数据科学家执行算法编码、统计和数据处理,以提出研究问题、分析数据并以书面和视觉报告的形式呈现结果。
你可以预计在美国雇佣一名经验丰富的自由开发者至少每小时 60 美元,如果他们有数据科学经验,费用可能会更高。数据科学是一种在各种领域(从商业到计算机科学)中日益受到追捧的技能。
什么是机器学习?
机器学习(ML)是数据科学的一个子集,专注于训练计算机根据过去的数据做出决策。ML 是推动我们所知的人工智能(AI)技术类别的核心。
该领域使用的算法编码方法教会计算机逐步解决问题,帮助其更好地了解过程和行为。通过这种方式,模型教会计算机识别模式以预测未来的行为。结果是一个可以归入不同类别的模型,包括无监督学习、监督学习和强化学习。
一个强大的机器学习模型应具备在各种数据集上运行并显示可重复结果的能力。随着人工智能在从数据隐私和安全到营销等各个领域协助人类决策,这一领域在过去几年中获得了广泛关注。
机器学习和数据科学编码的显著差异
数据科学和机器学习密不可分,但某些方面有所不同,例如编码实践、目的和所需的专业知识。让我们更详细地了解这些差异。
语言
机器学习开发者需要编写代码来构建和测试他们的模型。机器学习开发者通常会花时间内在学习和理解诸如 C++和 Python 等语言。Python 是机器学习中最常用的选择。
另一方面,数据科学家需要低级和高级语言来编码系统思维,以进行数据分析。高级语言需要更多的专业知识,但可以更快速地完成任务,因此大多数数据科学家使用高级汇编语言来执行他们的职能。我们将在下面看到一些例子。
目的
尽管在许多方面相似,机器学习和数据科学有不同的目的,导致独特的编码技术。例如,数据科学家必须根据数据集验证假设,并创建一个报告或可视化图表来解释他们的发现。目标是讲述一个故事或基于数据形成一个理论。
另一方面,机器学习开发者创建可以帮助计算机独立学习的算法和软件。这些编码是为了使计算机能够自主识别模式并无监督地解决问题。机器学习产生的模型和算法可以应用于各种领域的更快决策。
专业知识
数据科学家应熟练掌握以下某些或所有技能:
-
数据挖掘
-
数据清理
-
数据可视化
另一方面,机器学习(ML)程序员应该深入了解以下内容:
-
应用数学
-
数据建模
此外,值得注意的是,机器学习是一个广阔的领域,根据你要创建的机器学习模型的类型,工程师可能还需要某些其他技能。例如,自然语言处理专家将对与人类和计算机语言相关的语法和句法有深刻的理解。
常见编程语言
数据科学家被视为讲故事的人,他们分析所给的数据,并根据这些数据得出结论。没有对编程语言的深刻理解和其他技能,这是无法完成的。另一方面,机器学习工程师需要运用逻辑和批判性思维来编写训练分类和识别任务的模型代码。
许多语言已经出现和消失,但这些是今天最有用的语言。有些对于机器学习更为必要,而另一些则更适合数据分析。
Python
这是数据科学家最受欢迎的编程语言之一,因其灵活性和支持编程范式的能力。Python 使数据科学家能够简化数据挖掘过程,并为未来的报告创建 CSV 文件。如前所述,它也是机器学习中的重要语言,所以无论你选择哪个方向,掌握 Python 都是重要的。
JavaScript
JavaScript 是一种灵活的语言,能够同时处理多个任务。此外,它可以嵌入到在线程序和桌面电子设备中,具有出色的可扩展性。
Scala
Scala 是为了解决 Java 无法解决的问题而创建的。因此,它在处理大数据集时因其可扩展性和效率而受到机器学习工程师的欢迎。
R
这是一种统计计算语言,主要由数据科学家用来证明或反驳假设。R 几乎专门用于数据科学,因此这是这个领域必须学习的语言。
SQL
结构化查询语言主要用于数据管理,并可以帮助数据科学家处理数据库。
Julia
数据科学家使用 Julia 来执行高数值和计算功能。此外,它帮助工程师解决某些数学原理,如线性代数,甚至可以处理矩阵。
结论
计算机行业正在迅猛发展,计算的新领域每天都在演变。数据科学和机器学习是这个行业中两个最重要的领域,具有惊人的增长潜力。
发展和工程师想要成为这个行业的一部分,必须了解每个领域的内容,并具备适当的专业知识来追求他们的职业。因此,无论你是希望成为数据科学家还是机器学习工程师,掌握编码都是必不可少的。
个人简介:Nahla Davies 曾在纽约市和湾区为多家公司建立和管理合规团队。2020 年,Nahla 转而追求文案写作和中小企业的专业咨询事业。Nahla 拥有计算机科学本科和软件工程硕士学位。
相关:
-
数据科学家高效编程 Python 指南
-
人工智能 vs. 机器学习 vs. 深度学习:有什么区别?
-
学会复现论文:初学者指南
更多相关内容
3 种不同类型的机器学习
原文:
www.kdnuggets.com/2017/11/3-different-types-machine-learning.html
如果你是机器学习的新手,值得从三种核心类型开始:监督学习、无监督学习和强化学习。在本教程中,摘自全新版本的Python 机器学习,我们将更详细地了解它们是什么以及每种类型能够解决的最佳问题。
了解更多关于机器学习算法的内容——以及如何在Python 机器学习第二版中构建这些算法。本概述摘自本书。
使用代码 PML250KDN 可节省 50% 的书籍费用。

使用监督学习对未来进行预测
监督学习的主要目标是从标记过的训练数据中学习一个模型,使我们能够对未见过或未来的数据进行预测。在这里,监督一词指的是一组样本,其中期望的输出信号(标签)已经是已知的。
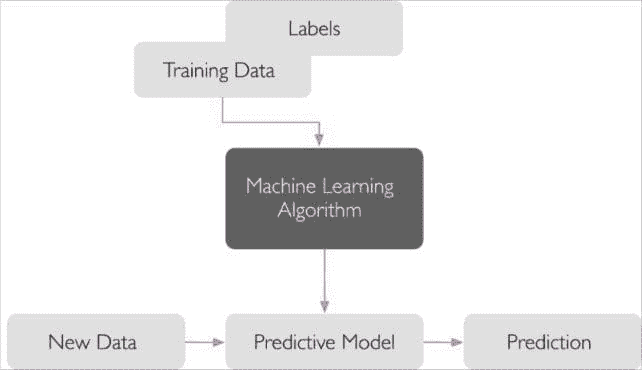
以电子邮件垃圾邮件过滤为例,我们可以使用监督机器学习算法在一个标记过的电子邮件语料库上训练模型,这些电子邮件被正确标记为垃圾邮件或非垃圾邮件,以预测一封新的电子邮件是否属于这两类中的任何一类。带有离散类别标签的监督学习任务,如前面的电子邮件垃圾邮件过滤示例,也称为分类任务。监督学习的另一个子类别是回归,其中结果信号是一个连续值:
分类用于预测类别标签
分类是监督学习的一个子类别,其目标是根据过去的观察预测新实例的分类标签。这些分类标签是离散的、无序的值,可以理解为实例的组成员。前面提到的电子邮件垃圾邮件检测示例代表了一个典型的二分类任务,其中机器学习算法学习一组规则,以区分两种可能的类别:垃圾邮件和非垃圾邮件。
然而,类别标签的集合不一定是二元的。通过监督学习算法学习的预测模型可以将训练数据集中呈现的任何类别标签分配给新的、未标记的实例。一个典型的多类别分类任务的例子是手写字符识别。在这里,我们可以收集一个训练数据集,其中包含字母表中每个字母的多个手写示例。现在,如果用户通过输入设备提供一个新的手写字符,我们的预测模型将能够以一定的准确性预测字母表中的正确字母。然而,如果数字零到九不在我们的训练数据集中,我们的机器学习系统将无法正确识别这些数字。
下图展示了给定 30 个训练样本的二分类任务的概念;15 个训练样本标记为负类(减号),15 个训练样本标记为正类(加号)。在这种情况下,我们的数据集是二维的,这意味着每个样本有两个值:X[1] 和 X[2]
现在,我们可以使用监督机器学习算法来学习一个规则——用虚线表示的决策边界——它可以将这两个类别分开,并根据其 X1 和 X2 值将新数据分类到这两个类别中的每一个:
用于预测连续结果的回归
分类允许我们将类别的、无序的标签分配给实例。监督学习的第二种类型是预测连续结果,这也称为回归分析。在回归分析中,我们提供了若干个预测(解释)变量和一个连续响应变量(结果或目标),并尝试找出这些变量之间的关系,以便我们可以预测结果。
例如,假设我们有兴趣预测学生的数学 SAT 成绩。如果学习时间与最终成绩之间存在关系,我们可以将其作为训练数据来学习一个模型,该模型利用学习时间来预测计划参加该测试的未来学生的成绩。
下图展示了线性回归的概念。给定一个预测变量 x 和一个响应变量 y,我们将拟合一条直线,使其最小化样本点与拟合线之间的距离——通常是平均平方距离。我们现在可以使用从这些数据中学到的截距和斜率来预测新数据的结果变量:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
3 个免费初学者机器学习课程
原文:
www.kdnuggets.com/2022/12/3-free-machine-learning-courses-beginners.html

图片由作者提供
许多低质量的免费课程和 YouTube 课程对构建扎实的机器学习基础没有帮助。你会变得更加困惑,甚至放弃追求这个职业。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我非常支持付费课程,但你也可以通过 Udacty、Coursera 和 FastAI 的互动免费课程学到很多。这些课程涵盖了基础知识,并向你介绍了监督学习、无监督学习和深度学习算法。
1. 斯坦福大学的监督学习
监督学习课程的基础是监督学习:回归和分类,使用流行的 Python 库。
你将了解机器学习应用、示例,并在 Jupyter Notebook 上构建你的第一个线性和逻辑回归模型。此外,你将学习特征工程、梯度下降、成本函数、决策边界和正则化。

图片来源于 Coursera
前提条件: 熟悉概率、统计学和 Python 编程语言。
时间安排: 33 小时(自定进度)
技能水平: 初学者
优点: 由行业专业人士和 Andrew NG 教授,包含互动练习和实践学习项目。
涵盖的主题: 使用流行的机器学习库 NumPy 和 scikit-learn 构建回归和分类模型。
2. 乔治亚理工学院的机器学习
机器学习 课程来自乔治亚理工学院,介绍了监督学习、无监督学习和强化学习。你将通过视频课程和互动测验及练习进行学习。

图片来自 Udacity
前提条件: 需要对概率论、线性代数和统计学有较强的了解。学生还需具备一些 Python 编程语言的经验。
时间表: 4 个月(自定进度)
技能水平: 中级
好处: 由行业专家授课,课程包括互动练习。
涵盖主题: 监督学习、无监督学习和强化学习,以及代码示例。
3. 实用深度学习课程,由 fast.ai 提供
实用深度学习课程 针对有一定编程知识的学生设计,旨在学习和应用深度学习解决实际问题。
这是我最喜欢的课程,我喜欢这个社区、测验和项目。它们都旨在帮助你学习概念,并提出你的最先进解决方案。
课程的一个好处是由 Jeremy Howard 教授,他是一位深度学习从业者,致力于让机器学习对所有人免费开放。
图片来自 fast.ai
前提条件: 学生需具备一些 Python 编程语言的经验。
时间表: 约 3 个月(自定进度)
技能水平: 初学者 - 中级
好处: 由业界专家 Jeremy Howard 授课。课程包含测验、编程示例、社区驱动学习和项目。
涵盖主题: 模型部署、神经网络、自然语言处理、从头开始创建模型、随机森林、卷积神经网络和数据伦理。
结论
互联网中充斥着数百个免费课程,有时很难找到能够帮助你在职业生涯中进步的优质课程。我提到的这些课程足以建立机器学习的基础。之后,你可以开始进行项目或参加 Kaggle 竞赛,以获得处理数据和构建模型的经验。
如果你在进行无指导的项目时会学得更多。希望你喜欢我提供的小课程列表。如果你对机器学习职业有疑问,请在下方评论。
Abid Ali Awan (@1abidaliawan) 是一名认证数据科学专业人士,热衷于构建机器学习模型。当前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为患有心理疾病的学生构建一款 AI 产品。
相关主题
3 个免费平台,提供个性化的 ChatGPT 体验
原文:
www.kdnuggets.com/2023/05/3-free-platform-personalized-chatgpt-experience.html
图片由作者提供
现在我非常关注聊天机器人、AI 工具和效率。这些改善了我的工作流程,并让我在处理复杂问题时变得更好。
我们的 3 个最佳课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
通常,当你注册 ChatGPT 时,你会得到一个通用的用户界面和一个无聊且缓慢的机器人。如果我告诉你,你可以向尤达提问或创建你自己的角色来对话,你会怎么样?
在这篇文章中,我们将探讨 3 个免费平台,这些平台提供免费的个性化 ChatGPT 体验。此外,我们还会讨论一些重要功能,比如聊天分类、在模型之间切换和生成图像的能力。
1. Forefront
使用 Forefront Chat,你可以自由创建自己独特的角色或从一系列名人和历史人物中选择。这个免费平台甚至允许你选择 GPT-4 模型。此外,你可以轻松创建不同的分类,Forefront Chat 会根据你选择的主题自动生成聊天实例。
图片来自 Forefront AI
注册后,你会被提示选择一个角色开始聊天。我选择了尤达,并让聊天机器人生成一个清理表格数据的代码。这些聊天机器人由 GPT-3.5 和 GPT-4 提供支持,使它们能够生成各种内容,从文本和代码到诗歌、故事甚至书籍,所有内容都带有一点幽默。正如你所见,机器人回应了经典的尤达语录:“当然,年轻的帕达万。”
图片来自 Forefront AI
最棒的部分是,你可以在聊天过程中从 GPT-3.5 切换到 GPT-4,甚至随时更改角色。
图片来自 Forefront AI
2. Quora Poe
Quora Poe 是一个你可以试验最先进聊天机器人甚至构建自己机器人的平台。它提供了对顶级 AI 模型的访问,如 GPT-4、ChatGPT、Claude、Sage、NeevaAI 和 Dragonfly。像 Dragonfly 这样的某些模型具有互动功能,提供链接和后续问题,带来更具参与感的体验。
图片来自 Poe
要创建个性化聊天机器人,你需要点击“创建一个机器人”按钮并填写详细信息。系统会要求你添加一张图片、名称、机器人描述、提示和介绍信息。
我创建了一个基于 ChatGPT 的 KDnuggets 机器人,用于提供有关数据科学和人工智能的新闻。
图片来自 Poe
添加必要信息后,你可以开始与机器人互动,坦白说,它非常棒。
图片来自 Poe
3. Ora.sh
Ora.sh 有些不同,除了提供个性化聊天体验外,它还允许你生成高质量图像。此外,你可以访问 350k+个由 Ora 用户创建的机器人。
图片来自 Ora
注册账户后,它会要求你创建一个自定义聊天机器人或从“探索”标签中选择推荐的聊天机器人。
在我们的案例中,我们将创建一个 DataGPT 机器人来帮助我们学习数据科学。你可以通过提供初始提示来定制聊天机器人的行为。你可以让它充当数据科学导师,或者告诉它询问你有关数据科学的问题,或告诉你随机的事实。
图片来自 Ora
就像任何 ChatGPT 机器人一样,Ora 旨在为你提供连贯和信息丰富的回答。无论你是初学者还是有经验的程序员,你都可以学习到有价值的技能,比如在 Python 中编写函数。
图片来自 Ora
你甚至可以通过点击图像按钮并编写提示来生成图像。
在示例中,我让它生成了一张使用计算机绘制的熊猫图像。这张图像准确且高质量。
图片来自 Ora
Ora 平台还允许你通过简单的步骤将机器人嵌入到你的网站中。
你还需要什么?
结论
最后,我想向你介绍 HuggingChat。我非常喜欢这个聊天机器人的界面、性能和准确性。目前,它基于开源项目 OpenAssistant 并使用 LLaMa 30B SFT 6 (oasst-sft-6-llama-30b) 模型。它是免费的,无需注册。
在这篇文章中,我向你分享了三个提供个性化 ChatGPT 体验的热门平台。这是聊天机器人的未来,每一个 ChatGPT 或 GPT-4 机器人都被量身定制以满足用户的独特需求。这些机器人不再提供泛泛的回应,而是利用用户数据和背景生成更具人性化和个性化的回复。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些在心理健康方面挣扎的学生开发一款 AI 产品。
相关话题更多内容
3 门免费的数据科学统计学课程
原文:
www.kdnuggets.com/2022/08/3-free-statistics-courses-data-science.html

图片来源:Monstera
统计学是预测建模的核心,分析数据以解决商业问题时需要掌握该学科的知识。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 支持
在这篇文章中,我将向你推荐 3 门免费的课程,让你可以学习数据科学中的统计学:
统计学习 (edX)
统计学习由著名的斯坦福教授 Trevor Hastie 和 Rob Tibshirani 授课,统计学习是一个将教你机器学习模型背后理论的项目,并提供模型如何工作的直觉。
完成此课程后,你将能够回答以下问题:
-
何时应该使用随机森林而不是决策树?
-
为什么线性回归不能用于分类问题?
-
如何进行回归问题的特征选择?
-
如何缓解过拟合?
-
当你没有足够的数据点来训练你的预测模型时,如何重新采样数据?
对上述内容有扎实的理解将帮助你确定最佳的方法来准备数据、进行特征工程和选择预测建模技术。
课程中涵盖的一些主题如下:
-
回归与分类
-
正则化
-
广义加法模型
-
基于树的方法
-
支持向量机
-
主成分分析
-
聚类分析
课程从上述概念的理论解释开始,并通过一两个示例,然后是代码教程。
所有编程讲座都在 R 语言中进行。然而,在注册此课程之前,你不需要了解该语言。讲师会在你实际操作之前,先教你如何用 R 进行编程。
统计学习在一个名为 edX 的电子学习平台上提供,你可以免费试听。这意味着所有课程材料对你开放,除非你想购买完成证书,否则没有费用。
概率与统计:P 还是不 P?(Coursera)
如果你没有数学或统计学背景,我建议你参加概率与统计 课程。
本课程的讲师 James Abdey 使用简单的英语讲解每一个概念,避免了复杂的数学符号。
这门课程将介绍如概率分布、描述性统计、推断统计、假设检验、置信区间以及中心极限定理等主题。
类似于上述提到的统计学习课程,该程序可以免费旁听。
这门课程将教你统计概率的基础知识,并帮助你作为初学者初步接触这一领域。然而,要深入理解所涵盖的主题,你应该辅以本列表中提到的更为严格的课程。
Stat 110: 哈佛大学(YouTube)
Stat 110 是哈佛大学提供的最受欢迎的统计学课程之一。该课程的所有讲座都已录制并上传到 YouTube 供公众访问。
这门课程将为你提供统计概念的直观和数学解释。在修读此课程之前,你需要熟悉矩阵操作和一些微积分(导数和积分)。
如果你没有必要的数学基础,我建议你在跟随 Stat 110 之前,先修这两门课程:线性代数 和 微积分导论。
Stat 110 涵盖了诸如概率、蒙提霍尔问题、随机变量、概率分布、统计测试和马尔可夫链等主题。
这门课程是本列表中最深入的资源,学习过程可能会比较耗时。Stat110 的教授 Joe Blitzstein 还建议参加 edX 概率导论 课程,以补充 YouTube 讲座。
统计学起初可能会让人感到有些威慑,尤其是当你来自非数学背景时。然而,如果你希望成为一名数据科学家以解决实际商业问题,学习应用统计学是足够的。你无需深入计算或证明,而应能应用合适的工具来解决数据问题。
上述课程将通过提供对统计概念的直观理解来教会你这些知识。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过 LinkedIn 与她联系。
更多相关主题
3 个数据科学领域的难度较高的 Python 编程面试问题
原文:
www.kdnuggets.com/2023/03/3-hard-python-coding-interview-questions-data-science.html

图片来源:作者
在今天的文章中,我将专注于数据科学的 Python 技能。没有 Python 的数据科学家就像没有笔的作家。或者说打字机。或者笔记本电脑。好吧,换句话说:没有 Python 的数据科学家就像我没有尝试幽默感。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你组织的 IT
你可以了解 Python,但不一定是数据科学家。不过,反过来呢?如果你知道有谁在没有 Python 的情况下进入了数据科学领域,请告诉我。在过去 20 年里,应该没有。
为帮助你练习 Python 和面试技巧,我挑选了三个 Python 编程面试题。其中两个来自于 StrataScratch,这类问题需要使用 Python 解决特定的业务问题。第三个问题来自于 LeetCode,测试你在 Python 算法方面的能力。
Python 编程面试题 #1:Python 中的数学

图片来源:作者
看看 Google 提出的这个问题。

问题链接:platform.stratascratch.com/coding/10067-google-fit-user-tracking
你的任务是基于 GPS 数据计算平均距离,使用两种方法。一种考虑地球的曲率,另一种则不考虑。
这些问题为两种方法提供了公式。如你所见,这个 Python 编程面试问题数学成分较重。你不仅需要理解这种水平的数学,还需要知道如何将其转化为 Python 代码。
这可不简单,对吧?
你首先应该认识到有一个数学 Python 模块,它提供了数学函数的访问权限。你将在这个问题中频繁使用这个模块。
让我们开始导入必要的库和正弦、余弦、反余弦和弧度函数。下一步是将可用的 DataFrame 与其自身在用户 ID、会话 ID 和会话日期上合并。同时,添加后缀以区分它们。
import numpy as np
import pandas as pd
from math import cos, sin, acos, radians
df = pd.merge(
google_fit_location,
google_fit_location,
how="left",
on=["user_id", "session_id", "day"],
suffixes=["_1", "_2"],
)
然后找出两个步骤 ID 之间的差异。
df['step_var'] = df['step_id_2'] - df['step_id_1']
之前的步骤是必要的,以便在下一步中排除所有只有一个步骤 ID 的会话。这正是问题告诉我们要做的。下面是具体做法。
df = df.loc[
df[df["step_var"] > 0]
.groupby(["user_id", "session_id", "day"])["step_var"]
.idxmax()
]
使用 pandas idxmax()函数来访问步骤之间差异最大的会话。
在准备好数据集后,现在进入数学部分。创建一个 pandas Series,然后使用 for 循环。使用iterrows()方法计算每一行,即会话的距离。这是考虑了地球曲率的距离,代码反映了问题中给出的公式。
df["distance_curvature"] = pd.Series()
for i, r in df.iterrows():
df.loc[i, "distance_curvature"] = (
acos(
sin(radians(r["latitude_1"])) * sin(radians(r["latitude_2"]))
+ cos(radians(r["latitude_1"]))
* cos(radians(r["latitude_2"]))
* cos(radians(r["longitude_1"] - r["longitude_2"]))
)
* 6371
)
现在,做同样的事情,但假设地球是平的。这是唯一一个成为平地球者有益的情况。
df["distance_flat"] = pd.Series()
for i, r in df.iterrows():
df.loc[i, "distance_flat"] = (
np.sqrt(
(r["latitude_2"] - r["latitude_1"]) ** 2
+ (r["longitude_2"] - r["longitude_1"]) ** 2
)
* 111
)
将结果转化为 DataFrame 并开始计算输出指标。第一个是考虑地球曲率的平均距离。然后是没有曲率的相同计算。最终指标是两者之间的差异。
result = pd.DataFrame()
result["avg_distance_curvature"] = pd.Series(df["distance_curvature"].mean())
result["avg_distance_flat"] = pd.Series(df["distance_flat"].mean())
result["distance_diff"] = result["avg_distance_curvature"] - result["avg_distance_flat"]
result
完整代码及其结果如下所示。
import numpy as np
import pandas as pd
from math import cos, sin, acos, radians
df = pd.merge(
google_fit_location,
google_fit_location,
how="left",
on=["user_id", "session_id", "day"],
suffixes=["_1", "_2"],
)
df["step_var"] = df["step_id_2"] - df["step_id_1"]
df = df.loc[
df[df["step_var"] > 0]
.groupby(["user_id", "session_id", "day"])["step_var"]
.idxmax()
]
df["distance_curvature"] = pd.Series()
for i, r in df.iterrows():
df.loc[i, "distance_curvature"] = (
acos(
sin(radians(r["latitude_1"])) * sin(radians(r["latitude_2"]))
+ cos(radians(r["latitude_1"]))
* cos(radians(r["latitude_2"]))
* cos(radians(r["longitude_1"] - r["longitude_2"]))
)
* 6371
)
df["distance_flat"] = pd.Series()
for i, r in df.iterrows():
df.loc[i, "distance_flat"] = (
np.sqrt(
(r["latitude_2"] - r["latitude_1"]) ** 2
+ (r["longitude_2"] - r["longitude_1"]) ** 2
)
* 111
)
result = pd.DataFrame()
result["avg_distance_curvature"] = pd.Series(df["distance_curvature"].mean())
result["avg_distance_flat"] = pd.Series(df["distance_flat"].mean())
result["distance_diff"] = result["avg_distance_curvature"] - result["avg_distance_flat"]
result
| avg_distance_curvature | avg_distance_flat | distance_diff |
|---|---|---|
| 0.077 | 0.088 | -0.01 |
Python 编程面试问题#2:Python 中的图论
图片来源:作者
这是 StrataScratch 中非常有趣的 Python 编程面试问题之一。它将你置于一个非常常见但复杂的现实数据科学家情况中。
这是 Delta Airlines 提出的问题。让我们来看看它。
问题链接:platform.stratascratch.com/coding/2008-the-cheapest-airline-connection
这个问题要求你找到最多有两个停靠点的最便宜的航空公司连接。这听起来非常熟悉,对吧?是的,这是一种稍作修改的最短路径问题:不是路径,而是成本。
我将展示的解决方案广泛使用了merge() pandas 函数。我还会使用itertools进行循环。在导入所有必要的库和模块后,第一步是生成所有可能的原始和目的地组合。
import pandas as pd
import itertools
df = pd.DataFrame(
list(
itertools.product(
da_flights["origin"].unique(), da_flights["destination"].unique()
)
),
columns=["origin", "destination"],
)
现在,只显示起点与目的地不同的组合。
df = df[df['origin'] != df['destination']]
现在我们将 da_flights 与它自己合并。我将使用 merge() 函数,表格将按目的地和起点从左侧连接。这样,你会得到所有到达第一个目的地的直飞航班,然后是起点与第一个航班的目的地相同的连接航班。
connections_1 = pd.merge(
da_flights,
da_flights,
how="left",
left_on="destination",
right_on="origin",
suffixes=["_0", "_1"],
)
然后我们将这个结果与 da_flights 合并。这样,我们将获得第三个航班。这等于两个停留,这也是问题所允许的最大值。
connections_2 = pd.merge(
connections_1,
da_flights[["origin", "destination", "cost"]],
how="left",
left_on="destination_1",
right_on="origin",
suffixes=["", "_2"],
).fillna(0)
现在,让我们通过分配逻辑列名来整理合并结果,并计算一停和两停航班的费用。(我们已经有了直飞航班的费用!)这很简单!一停航班的总费用是第一个航班加上第二个航班。对于两停航班,总费用是所有三个航班费用的总和。
connections_2.columns = [
"id_0",
"origin_0",
"destination_0",
"cost_0",
"id_1",
"origin_1",
"destination_1",
"cost_1",
"origin_2",
"destination_2",
"cost_2",
]
connections_2["cost_v1"] = connections_2["cost_0"] + connections_2["cost_1"]
connections_2["cost_v2"] = (
connections_2["cost_0"] + connections_2["cost_1"] + connections_2["cost_2"]
)
我现在将创建的 DataFrame 与给定的 DataFrame 合并。这样,我将为每个直飞航班分配费用。
result = pd.merge(
df,
da_flights[["origin", "destination", "cost"]],
how="left",
on=["origin", "destination"],
)
接下来,将上述结果与 connections_2 合并,以获取到达需要一个停留的目的地的航班费用。
result = pd.merge(
result,
connections_2[["origin_0", "destination_1", "cost_v1"]],
how="left",
left_on=["origin", "destination"],
right_on=["origin_0", "destination_1"],
)
对于两个停留的航班,做同样的操作。
result = pd.merge(
result,
connections_2[["origin_0", "destination_2", "cost_v2"]],
how="left",
left_on=["origin", "destination"],
right_on=["origin_0", "destination_2"],
)
结果是一个表格,提供了从一个起点到目的地的直飞、一停和两停航班的费用。现在你只需要使用 min() 方法找到最低费用,去除 NA 值并显示输出。
result["min_price"] = result[["cost", "cost_v1", "cost_v2"]].min(axis=1)
result[~result["min_price"].isna()][["origin", "destination", "min_price"]]
通过这些最终的代码行,完整的解决方案如下。
import pandas as pd
import itertools
df = pd.DataFrame(
list(
itertools.product(
da_flights["origin"].unique(), da_flights["destination"].unique()
)
),
columns=["origin", "destination"],
)
df = df[df["origin"] != df["destination"]]
connections_1 = pd.merge(
da_flights,
da_flights,
how="left",
left_on="destination",
right_on="origin",
suffixes=["_0", "_1"],
)
connections_2 = pd.merge(
connections_1,
da_flights[["origin", "destination", "cost"]],
how="left",
left_on="destination_1",
right_on="origin",
suffixes=["", "_2"],
).fillna(0)
connections_2.columns = [
"id_0",
"origin_0",
"destination_0",
"cost_0",
"id_1",
"origin_1",
"destination_1",
"cost_1",
"origin_2",
"destination_2",
"cost_2",
]
connections_2["cost_v1"] = connections_2["cost_0"] + connections_2["cost_1"]
connections_2["cost_v2"] = (
connections_2["cost_0"] + connections_2["cost_1"] + connections_2["cost_2"]
)
result = pd.merge(
df,
da_flights[["origin", "destination", "cost"]],
how="left",
on=["origin", "destination"],
)
result = pd.merge(
result,
connections_2[["origin_0", "destination_1", "cost_v1"]],
how="left",
left_on=["origin", "destination"],
right_on=["origin_0", "destination_1"],
)
result = pd.merge(
result,
connections_2[["origin_0", "destination_2", "cost_v2"]],
how="left",
left_on=["origin", "destination"],
right_on=["origin_0", "destination_2"],
)
result["min_price"] = result[["cost", "cost_v1", "cost_v2"]].min(axis=1)
result[~result["min_price"].isna()][["origin", "destination", "min_price"]]
这是代码输出。
| origin | destination | min_price |
|---|---|---|
| SFO | JFK | 400 |
| SFO | DFW | 200 |
| SFO | MCO | 300 |
| SFO | LHR | 1400 |
| DFW | JFK | 200 |
| DFW | MCO | 100 |
| DFW | LHR | 1200 |
| JFK | LHR | 1000 |
Python 编码面试问题 #3:Python 中的二叉树
作者提供的图像
除了图表,你还将作为数据科学家处理二叉树。因此,如果你知道如何解决由 DoorDash、Facebook、Microsoft、Amazon、Bloomberg、Apple 和 TikTok 等公司提出的这个 Python 编码面试问题,那将会很有用。

问题链接:leetcode.com/problems/binary-tree-maximum-path-sum/description/
约束条件是:

class Solution:
def maxPathSum(self, root: Optional[TreeNode]) -> int:
max_path = -float("inf")
def gain_from_subtree(node: Optional[TreeNode]) -> int:
nonlocal max_path
if not node:
return 0
gain_from_left = max(gain_from_subtree(node.left), 0)
gain_from_right = max(gain_from_subtree(node.right), 0)
max_path = max(max_path, gain_from_left + gain_from_right + node.val)
return max(gain_from_left + node.val, gain_from_right + node.val)
gain_from_subtree(root)
return max_path
解决方案的第一步是定义一个 maxPathSum 函数。为了确定是否存在从根节点向下的左侧或右侧节点的路径,请编写递归函数 gain_from_subtree。
第一个实例是子树的根节点。如果路径等于一个根节点(没有子节点),则子树的增益为 0。然后在左节点和右节点中进行递归。如果路径和为负,问题要求不予考虑;我们通过将其设置为 0 来实现这一点。
然后将子树的增益和当前最大路径进行比较,如果必要则进行更新。
最后,返回子树的路径和,该值为根节点加上左节点和根节点加上右节点的最大值。
这些是案例 1 和 2 的输出。
总结
这次,我想给你一些不同的内容。作为数据科学家,你应该了解许多 Python 概念。这次我决定涵盖三个不常见的主题:数学、图数据结构和二叉树。
我展示的这三个问题似乎很适合展示如何将这些概念转化为 Python 代码。查看 “Python 编码面试问题” 来练习更多 Python 概念。
Nate Rosidi 是一名数据科学家和产品策略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备面试的平台,提供来自顶级公司的真实面试问题。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
相关主题
我在数据科学职业中三年所学到的三大最重要的教训
原文:
www.kdnuggets.com/2021/09/3-important-lessons-data-science-career.html
评论

照片由 Mantas Hesthaven 在 Unsplash上提供。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
我相信这些经验教训之所以重要,是因为它们对拥有成功的数据科学职业至关重要。阅读完这些内容后,你会意识到,成为一个优秀的数据科学家远不只是构建复杂模型。
话虽如此,这里是我在数据科学职业中学到的三大最重要的教训!
实际上,大部分时间是花费在你的项目之间(前后)的。
图像由作者创建。
我注意到的一点是,几乎所有的数据科学课程和训练营都强调和详细说明了项目生命周期中的建模阶段,而实际上,这只是整个过程的一个小部分。
如果你在工作中构建一个初步的机器学习模型花费了一个月的时间,你可以预期在此之前花一个月理解商业问题,并在之后花时间记录和宣传项目。
不仅建议你在构建模型之前和之后完成这些步骤,而且这对你的项目成功至关重要。
让我们深入探讨每一项的重要性:
-
商业理解:理解当前的商业问题对你的成功至关重要。例如,如果你在构建一个机器学习模型,你应该知道模型的预测目标是什么,谁会使用它,如何实际使用它,评估模型的指标是什么,等等。你必须花时间去理解关于业务目标的所有细节,以创建一个适用的模型。
-
文档:虽然我同意文档编写不如处理数据和构建模型那样令人兴奋,但你需要为你的代码、构建的任何表格以及模型的构建过程提供清晰且简洁的文档。这一点非常重要,以便你自己或其他人可以在使用模型或修复模型时轻松查阅这些资源。
-
社交化:社交化很少被提及,但如果项目没有被业务部门使用,它们将不会成功。社交化你的项目意味着将其展示给相关利益相关者,解释其价值以及如何使用它们。你能向更多的利益相关者推销你的想法,你的数据产品被采用的可能性就越大,你的项目就会越成功。
这三个步骤有什么共同点?它们都是一种沟通。实际上,我认为良好的沟通是数据科学家和高级数据科学家之间的区别所在。
基础知识将帮助你走过 >80% 的路程。
当我开始学习数据科学时,我尝试在没有学习基础知识的情况下直接学习最复杂的概念。
经过多年的经验,我意识到基础知识足以帮助你在职业生涯中走过 80% 的路程。为什么?更简单的解决方案总是会胜出。它们更易于理解、实施和维护。一旦简单的解决方案向公司展示了其价值,只有在那时你才能考虑更复杂的解决方案。
那么,基础知识到底是什么?
A) SQL
经过三年的工作,我深信掌握 SQL 对于成功的职业生涯至关重要。SQL 不是一个难以学习的技能(即,SELECT FROM WHERE),但要做到精通确实是一个难度大的技能。SQL 对于数据处理、数据探索、数据可视化(构建仪表板)、报告生成和数据管道构建至关重要。
如果你想掌握 SQL,请查看我的指南:一个完整的 15 周课程来掌握数据科学中的 SQL
B) 描述性统计和推断统计
对基础描述性统计和推断统计有良好的理解也是非常重要的。
描述性统计 允许你以简单的方式总结和理解你的数据。
推断统计 允许你基于有限的数据(样本)得出结论。这对于构建解释性模型和 A/B 测试至关重要。
C) 用于探索性数据分析和特征工程的 Python
Python 主要用于执行 EDA 和特征工程。也就是说,这两个步骤也可以使用 SQL 完成,所以这点需要记住。我个人喜欢将 Python 纳入我的技术栈,因为我发现用 Jupyter Notebook 进行 EDA 比在 SQL 控制台或仪表板上更容易。查看:探索性数据分析的详尽分步指南
3. 与其花费大量时间构建一个最终模型,不如迭代并构建多个版本的模型。
构建,测试,迭代,重复。
通常,花较少的时间在模型上以便将初始版本投入生产,并从那里开始迭代,总是更好。为什么?
-
在初始模型上分配较少时间会激励你提出更简单的解决方案。正如我在本文中早些时候所说,简单的解决方案有多个好处。
-
你越快提出一个概念验证(POC),就能越快收到他人的反馈来改进它。
-
商业需求不断变化,因此如果你能更早地部署你的项目,你更可能成功。
我想表达的观点是不要急于推进你的项目,而是要快速部署它们,以便你可以收到反馈,进行迭代和改进**你的项目。
相关:
更多相关内容
人工智能领域的 3 个鼓舞人心的故事
原文:
www.kdnuggets.com/3-inspirational-stories-of-leaders-in-ai

图片由编辑提供
近年来,人工智能已经主导了世界,并将在下一个十年继续如此。我们能想象回到没有人工智能的生活吗?我很难这么认为,因为人工智能已经开始补充我们的生活方式。人工智能突破日常生活并不是突然发生的;相反,它是一些个人有意为之。这些个人中的许多人就是我们所称的人工智能领域的领袖。
在人工智能领域的领袖不一定需要是大公司的首席执行官或富有的投资者。他们可以来自任何生活领域,但仍然对我们今天讨论的人工智能发展做出显著贡献。这些个人及其鼓舞人心的故事就是我们将在本文中讨论的内容。
这些人是谁?让我们深入了解一下。
1. Andrew Yan-Tak Ng
由于他对该领域的贡献,Andrew Ng的名字在讨论机器学习或深度学习时经常出现。作为 Coursera 的创始人,他曾教育过数以百万计的人,因此可以被视为人工智能领域的灵感领导者和传奇人物。然而,许多幕后故事使他如此受尊敬。
Andrew 于 1997 年以优异的成绩完成本科课程,获得统计学、经济学和计算机科学三个学位。从 1996 年到 1998 年,他在 AT&T 贝尔实验室专注于强化学习、特征选择和模型选择。他的研究在 1998 年开始声名鹊起,当时他建立了一个自动索引的网页搜索引擎,用于机器学习研究论文。
完成博士学位后,他在斯坦福大学从事学术教学工作,教授学生数据挖掘、大数据和机器学习。在这所大学,他开始倡导在深度学习中使用 GPU。这种方法虽然在当时颇具争议,但后来已经成为标准。
从 2012 年开始,他与 Daphne Coller 共同创办了 Coursera,秉持为所有人提供免费学习的精神。在类似的时间线上,他还在谷歌工作,创办了谷歌脑深度学习项目,并在百度工作直到 2017 年。之后,他创办了 Deeplearning.ai,作为一个在线学习深度学习的平台,以及一个专注于提供人工智能驱动的 SaaS 产品的 Landing AI 初创公司。从那时起,Andrew 更加关注于让人工智能普及到公众中。
凭借 Andrew Ng 所创造的所有成果,他为许多人打开了进入机器学习和深度学习的道路。他因此获得了许多荣誉,包括 2013 年被评选为《时代》100 位最具影响力人物,2014 年被评选为《财富》40 位 40 岁以下杰出人物,以及 2023 年被评选为《时代》人工智能领域 100 位最具影响力人物。
通过保持专注和愿意为许多人提供学习路径,安德鲁·吴的故事无疑激励了任何人跟随。
2. 李飞飞
如果你听说过 ImageNet,你应该知道它的创始人是李飞飞。正如我们所知,ImageNet 是一个庞大的视觉数据库,用于快速推动计算机视觉的发展,其中超过 1400 万张图片已经手动标注并被广泛使用。从一个数据集,它发展成为深度学习研究的一个重要部分。
李飞飞拥有令人印象深刻的教育背景;她以物理学专业的优异成绩完成本科课程,并学习了计算机科学和工程。即使获得了高荣誉,她仍能平衡她的工作,在那时她每周末回家到父母的店里工作。
她于 2005 年获得博士学位,并在斯坦福大学从助理教授升至正教授。在此期间,她还在 2017 至 2018 年期间在谷歌工作,她对 Project Maven(军事项目)表达了她的观点。她表示,她的原则是关于以人为本的人工智能,以积极和善意的方式造福人类。
在斯坦福大学,她建立了一个名为 SAILORS(斯坦福人工智能实验室外展夏季项目)的倡议,旨在对 9 年级的高中女生进行人工智能教育和研究。从那时起,它演变为 AI4ALL,旨在提高人工智能领域的多样性和包容性。
她的动力始终围绕着使人工智能普及于人类,有人称她为“将人性带入人工智能的研究员”。凭借她的工作,她获得了许多成就,特别是在 2018 年被《福布斯》评为美国前 50 位女性科技人才,以及在 2023 年被《时代》评为 AI100。
从一个 humble 的起点,她的坚持和原则使她成为我们始终仰望的人工智能领导者之一。
3. 德米斯·哈萨比斯
你可能听说过 DeepMind,这是一家谷歌子公司,旨在将人工智能推向 AGI(通用人工智能)。但你知道创始人是谁吗?他就是德米斯·哈萨比斯,首席执行官和联合创始人。
德米斯·哈萨比斯从 4 岁起就是国际象棋天才,13 岁时成为大师。他还在 15 岁和 16 岁时完成了 A-level 和奖学金水平的考试。凭借赢得的象棋奖金,他购买了自己的第一台计算机,并自学编程。
在大学的间隔年,他开始作为游戏计算机开发者工作。他的显著成就是作为游戏《主题公园》的首席程序员。在他的游戏开发生涯中,他成立了自己的 Elixir Studio 工作室,试图开发一个名为《共和国:革命》的雄心勃勃的游戏,但由于开发时间过长而缩小了范围。工作室于 2005 年关闭,但他在游戏中进行的许多人工智能模拟实验为他未来的工作提供了灵感。
2009 年,他获得了认知神经科学博士学位,之后他将许多工作集中在想象、记忆和遗忘领域。在此期间,他还在研究中取得了突破,将想象过程与情景记忆联系起来。这些想法被称为心智的模拟引擎。
2010 年,他共同创立了 DeepMind,旨在结合神经科学和机器学习实现 AGI。2013 年,公司推出了一种名为 Deep Q-Network 的训练算法,能够仅使用原始像素输入以超人的水平玩 ATARI 游戏。2014 年,谷歌以 4 亿英镑收购了 DeepMind,并自那时起推出了许多突破性的进展。DeepMind 在当前时期,已经在深度学习和强化学习方面取得了许多进展,开创了深度强化学习的先河。
凭借所有的工作,Demis 获得了许多认可,包括 2013 年被列入 WIRED 的“Smart 50”,2017 年入选《时代》杂志“100 位最具影响力人物”,以及 2020 年被英国 GQ 杂志评为“50 位最具影响力人物”。
凭借他的热情,他不断在自己热爱的领域努力,并将其转化为对全世界的进步。他的鼓舞人心的故事也应激励我们实现自己的目标。
结论
这篇文章讨论了三位人工智能领导者的鼓舞人心的故事:Andrew Ng、Fei-Fei Li 和 Demis Hassabis。他们现在可能是领袖,但每个人都有自己的出发点,这很令人鼓舞。
Cornellius Yudha Wijaya****是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。Cornellius 撰写了各种 AI 和机器学习主题的文章。
更多相关内容
3 种有趣的 Python 上下文管理器用法
原文:
www.kdnuggets.com/3-interesting-uses-of-python-context-managers

图片来源 Freepik 的 johnstocker
前一段时间,我写了一篇关于 编写高效 Python 代码 的教程。在其中,我讨论了如何使用上下文管理器和 with 语句高效地管理资源。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
我使用了一个简单的文件处理示例,展示了当执行退出 with 块时,文件会被自动关闭——即使发生了异常。
虽然文件处理是一个很好的初步示例,但它很快会变得乏味。这就是为什么我想在本教程中介绍其他有趣的上下文管理器用法——超越文件处理。我们将重点讲解处理数据库连接、管理子进程以及高精度浮点运算。
Python 中的上下文管理器是什么?
Python 中的上下文管理器使你在处理资源时能够编写更简洁的代码。它们通过以下方式提供了设置和拆除资源的简洁语法:
-
一个进入逻辑,当执行进入上下文时会被调用
-
一个退出逻辑,当执行退出上下文时会被调用
最简单的示例是文件处理。在这里,我们在 with 语句中使用 open() 函数来获取文件处理器:
with open('filename.txt', 'w') as file:
file.write('Something random')
这会获取资源——文件对象——在代码块中使用(我们写入文件)。当执行退出上下文时,文件会被关闭;因此不会有资源泄漏。
你可以像这样编写通用版本:
with some_context() as ctx:
# do something useful on the resource!
# resource cleanup is automatic
现在让我们继续看具体的示例。
1. 处理数据库连接
当你构建 Python 应用程序时,连接到数据库并查询它们包含的表是相当常见的。执行此操作的工作流程如下:
-
安装数据库连接器以便与数据库配合使用(例如用于 Postgres 的 psycopg2 和用于 MySQL 数据库的 mysql-connector-python)。
-
解析配置文件以检索连接参数。
-
使用
connect()函数建立与数据库的连接。
连接到数据库 | 图片来自作者
一旦你连接到数据库,你可以创建一个数据库来查询数据库。运行查询并使用 run 和 fetch 游标方法获取查询结果。
查询数据库 | 图片来自作者
这样,你创建了以下资源:一个数据库连接和一个数据库游标。现在让我们编写一个简单的通用示例,看看如何将连接和游标对象用作上下文管理器。
解析 Python 中的 TOML 文件
考虑一个示例 TOML 文件,例如 db_config.toml,包含连接数据库所需的信息:
# db_config.toml
[database]
host = "localhost"
port = 5432
database_name = "your_database_name"
user = "your_username"
password = "your_password"
注意:你需要 Python 3.11 或更高版本才能使用 tomllib。
Python 有一个内置的 tomllib 模块(在 Python 3.11 中引入),可以让你解析 TOML 文件。因此,你可以打开 db_config.toml 文件并像这样解析其内容:
import tomllib
with open('db_config.toml','rb') as file:
credentials = tomllib.load(file)['database']
注意,我们访问了 db_config.toml 文件中的 ‘database’ 部分。load() 函数返回一个 Python 字典。你可以通过打印 credentials 的内容来验证这一点:
print(credentials)
Output >>>
{'host': 'localhost', 'port': 5432, 'database_name': 'your_database_name', 'user': 'your_username', 'password': 'your_password'}
连接到数据库
假设你想连接到一个 Postgres 数据库。你可以使用 pip 安装 psycopg2 连接器:
pip install psycopg2
你可以像这样在 with 语句中使用连接和游标对象:
import psycopg2
# Connect to the database
with psycopg2.connect(**credentials) as conn:
# Inside this context, the connection is open and managed
with conn.cursor() as cur:
# Inside this context, the cursor is open and managed
cur.execute('SELECT * FROM my_table')
result = cur.fetchall()
print(result)
在这段代码中:
-
我们使用
with语句来创建一个管理数据库连接的上下文。 -
在这个上下文中,我们创建了另一个上下文来管理数据库游标。游标在退出这个内部上下文时会自动关闭。
-
由于在退出外部上下文时连接也会被关闭,这种构造确保了连接和游标都得到正确管理——减少了资源泄漏的可能性。
在处理 SQLite 和 MySQL 数据库时,你也可以使用类似的构造。
2. 管理 Python 子进程
Python 的 subprocess 模块提供了在 Python 脚本中运行外部命令的功能。subprocess.Popen() 构造函数创建一个新的子进程。你可以在 with 语句中像这样使用它:
import subprocess
# Run an external command and capture its output
with subprocess.Popen(['ls', '-l'], stdout=subprocess.PIPE, text=True) as process:
output, _ = process.communicate()
print(output)
在这里,我们运行 Bash 命令 ls -l 来长列表显示当前目录中的文件:
Output >>>
total 4
-rw-rw-r-- 1 balapriya balapriya 0 Jan 5 18:31 db_info.toml
-rw-rw-r-- 1 balapriya balapriya 267 Jan 5 18:32 main.py
一旦退出 with 语句的上下文,子进程相关的资源会被释放。
3. 高精度浮点运算
Python 中的内置 float 数据类型不适合高精度浮点运算。但在处理财务数据、传感器读数等时,你确实需要高精度。对于这种应用,你可以使用 decimal 模块。
localcontext() 函数 返回一个上下文管理器。因此,你可以在 with 语句中使用 localcontext() 函数,并按如下方式设置当前上下文的精度:
from decimal import Decimal, localcontext
with localcontext() as cur_context:
cur_context.prec = 40
a = Decimal(2)
b = Decimal(3)
print(a/b)
输出如下:
Output >>>
0.6666666666666666666666666666666666666667
在这里,精度设置为 40 位小数——但仅在当前 with 块内。当执行退出当前上下文时,精度将恢复为默认精度(28 位小数)。
总结
在本教程中,我们学习了如何使用上下文管理器处理数据库连接、管理子进程以及在高精度浮点运算中的上下文。
在下一节教程中,我们将探讨如何在 Python 中创建自定义上下文管理器。在此之前,祝编程愉快!
Bala Priya C是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正致力于通过撰写教程、使用指南、评论文章等方式学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编程教程。
更多相关内容
3 Julia 数据可视化包
原文:
www.kdnuggets.com/2023/02/3-julia-packages-data-visualization.html

作者提供的图片
Julia 编程语言在数据可视化工具方面取得了新进展,这些工具类似于 Python 的 matplotlib 和 R 的 ggplot。这些包提供了类似 C++ 的速度和开箱即用的并行处理。因此,当你需要可视化大型数据集时,这非常有用。
在本博客中,我们将学习 Plots.jl、Gadfly.jl 和 VegaLite.jl 的代码示例。所以,让我们从安装所需的包开始。
import Pkg; Pkg.add(["RDatasets","Plots","Gadfly","VegaLite"])
Plots.jl
Plots.jl 是 Julia 中一个强大的可视化工具。它是一个元包,使用 GR、PythonPlot、PGFPlotsX 或 Plotly 作为后端。如果某个后端不支持你需要的功能,你可以随时切换到另一个而无需更改代码。
Plots.jl 是一个轻量级、直观、简洁、灵活且一致的绘图包。
示例 1
要显示正弦波,我们必须导入包,然后创建 x 和 y1 变量。
-
x: 从 0 到 10 的范围。
-
y: sin(x)
要显示折线图,我们只需将 x 和 y 参数提供给Plots.plot函数。
using Plots
x = range(0, 10, length=100)
y1 = sin.(x)
Plots.plot(x, y1)
你可以使用Plots.plot!函数重叠图表。这将显示相同轴的两个图表。
y2 = @. cos(x)² - 1/2
Plots.plot!(x, y2)
示例 2
让我们绘制一个复杂的条形图,为此我们将首先从RDatasets包中导入cars数据集。
using RDatasets
cars = dataset("datasets", "mtcars")
first(cars,5)
然后,我们将使用Plots.bar函数来表示每个模型的“每加仑的英里数”和 QSec。
我们根据需求定制了函数:
-
重命名了标签。
-
添加标题。
-
将 x 刻度旋转 45 度。
-
限制图表的大小。
-
更改图例的位置。
-
显示所有车型。
-
限制 y 刻度。
Plots.bar(cars.Model,
[cars.MPG,cars.QSec],
label = ["Miles per Gallon" "QSec"],
title = "Models-Miles per Gallon and Qsec",
xrotation = 45,
size = [600, 600],
legend =:topleft,
xticks =:all,
yticks =0:25)
示例 3
对于绘制饼图,我们只需将标签和值添加到Plots.pie函数中。我们还添加了标题和线条宽度。
x = ["A","B","C","D"]
y = [0.1,0.2,0.4,0.3]
Plots.pie(x,y,title ="KDnuggets Readers" ,l = 0.5)
Gadfly.jl
Gadfly.jl 是一个流行的统计绘图和数据可视化工具。它深受 R 的 ggplot 库的影响。
关键特性:
-
它与 Ijulia 和 Jupyter Notebook 兼容。
-
渲染高质量的图表为 SVG、PNG、Postscript 和 PDF 格式。
-
它与 DataFrames.jl 的集成非常强大。
-
它还提供了如平移、缩放和切换等交互功能。
-
支持大量常见的绘图类型。
示例 1
为了绘制男性和女性的历史数据,我们将导入伦敦出生率数据。之后,我们将使用 stack 函数将宽格式数据转换为长格式。
这将给我们年、变量和数值列。变量将是男性或女性,数值将是出生率。
births = RDatasets.dataset("HistData", "Arbuthnot")[:,[:Year, :Males, :Females]]
stacked_birth = stack(births, [:Males, :Females])
first(stacked_birth,5)
我们正在堆叠这些列,以便可以显示两个不同颜色的图表。
Gadfly.plot 函数需要数据集、x 和 y 变量、颜色以及绘图类型。在我们的案例中,我们显示的是线图。
using Gadfly
Gadfly.plot(stacked_birth, x=:Year, y=:value, color=:variable,
Geom.line)
示例 2
在示例中,我们将设置默认大小,并根据变量和数值显示箱型图。我们使用相同的函数,但有不同的绘图类型和主题。
注意: 你可以通过查看文档 Themes · Gadfly.jl 来了解更多关于主题的信息。
set_default_plot_size(8cm, 12cm)
Gadfly.plot(
stacked_birth,
x=:variable,
y=:value,
Geom.boxplot,
Theme(default_color="red")
)
VegaLite.jl
VegaLite.jl 是一个用于 Julia 编程语言的交互式绘图包。它基于 Vega-Lite,并具有与 Altair 相似的功能,Altair 是一个交互式、简单且快速的 Python 库。
示例 1
在示例中,我们导入 VegaLite 并将汽车数据集传递给 @vlplot 函数以显示点图。
在我们的案例中,我们提供了:
-
绘图类型。
-
X 和 y 变量。
-
将 ‘Cyl’ 列添加到颜色参数中。
-
设置图形的宽度和高度。
注意: 我们通过在列名前添加 :n 将整数转换为分类值。在我们的案例中,它是“Cyl:n”。
using VegaLite
cars |> @vlplot(
:point,
x=:HP,
y=:MPG,
color="Cyl:n",
width=400,
height=300
)
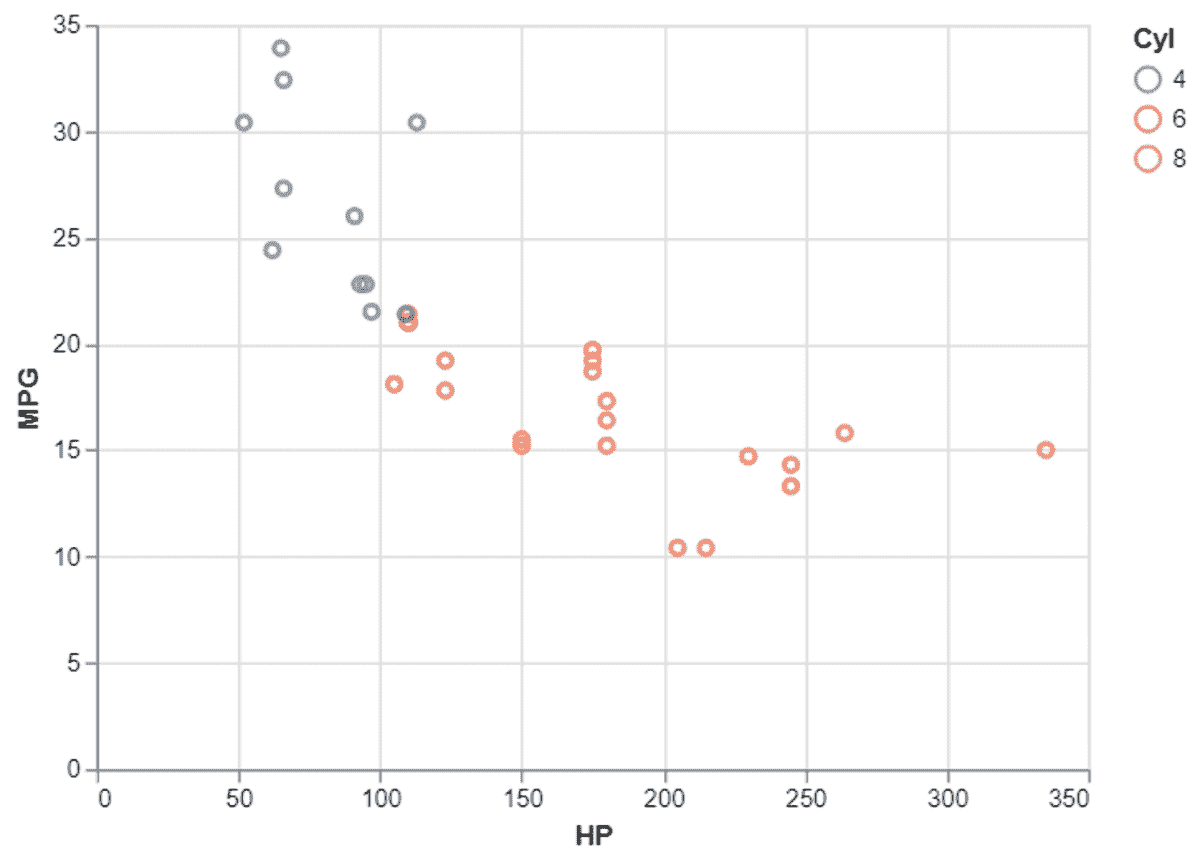
示例 2
在第二个示例中,我们将绘制气缸类型的条形图。对于 x 参数,我们将使用“Cyl”作为类别,对于 y,我们使用“count()”,它将计算“Cyl”列中类别的数量。
@vlplot(
data=cars,
height=350,
width=300,
:bar,
x="Cyl:n",
y="count()",
)
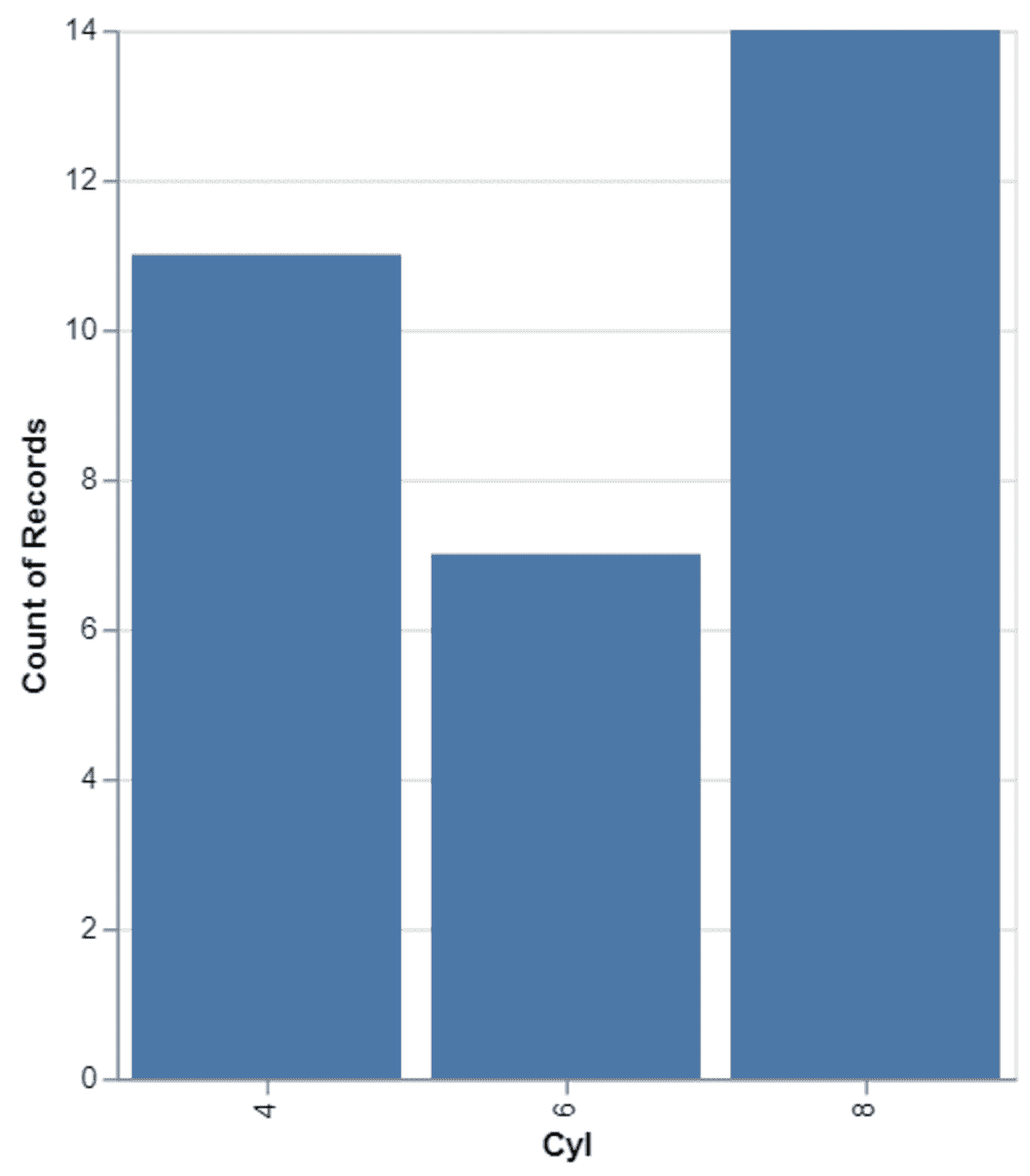
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专家,喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些在心理健康方面挣扎的学生构建 AI 产品。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 需求
了解更多相关信息
向大数据提出的 3 个关键数据科学问题
原文:
www.kdnuggets.com/2020/06/3-key-data-science-questions.html
评论
由皮扬卡·贾因,数据分析领域的思想领袖。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
数据,数据无处不在,却没有一滴能被利用!每个组织如今都在收集数据,但很少有人知道如何处理它。部分挑战在于,组织不知道应该向数据提出什么问题。应该从哪里开始?他们已经在Hadoop 集群上投入了数百万美元,生成了数十亿行和数千列的数据,但接下来呢?该如何继续?
曾经有人认为,“既然我有了数据,它应该会告诉我答案。”但很快他们意识到,数据并不会说话,它只会回应。
所以,责任回到用户身上(那些希望利用数据做出更明智决策的人),去提出“正确”的问题。但应该问什么问题呢?
无论你是一个 1500 万美元在线服装店的 CEO,还是像凯撒医疗这样的大型健康行业的 IT 经理,或是像富国银行这样的大型银行的营销经理,关键问题都是相同的。它们是:
1. 我做得怎么样?
对于服装业务的 CEO 来说,这意味着服装业务的表现如何;对于营销经理来说,这意味着他的/她的部门表现如何?回答这个问题有很多方法,包括制定财务衡量框架、平衡计分卡或其他类似的方法。但最重要的部分是理解并全公司达成一致的 KPI(关键绩效指标)。你是在优化收入还是利润率?是市场渗透率、NPS(净推荐值)还是某种综合指数?
2. 什么驱动我的业务?
一旦你确定了 KPI,你需要了解是什么驱动了这个 KPI。这其中有些可以通过数学推导得出,有些可能只是需要验证的假设。例如,访问者数量和转化率是服装业务收入的重要驱动因素。另一方面,对于一家游戏公司,采用免费增值模式且付费客户不足 1%,总玩家数量并不是收入的驱动因素,但某个游戏的玩家数量可能是。了解特定业务的动态,重要的是通过投资组合分析来理解。
3. 我的客户是谁,他们的需求是什么?
客户是我们所有业务的核心。我们知道我们的客户并不完全相同。一些客户较为成熟,是我们产品的重度用户;而其他客户可能只使用过一次我们的产品。对于服装业务,可能有两个宏观客户群体,一种是批发购买产品以零售到他们的精品店的客户,另一种是购买个人使用的客户。他们对电子商务网站和公司的需求会有所不同。那些理解客户并根据客户需求定制产品、信息、营销渠道的公司,能够让客户满意,从而确保他们的未来收入(或 KPI)。这就是我们最终想要做的事情——推动我们的 KPI 朝着正确的方向发展。
诚然,组织中的大多数高层管理人员确实会关注 KPI,并能迅速总结公司的财务状况,但他们是否了解是什么驱动了这些 KPI?此外,组织中更下层的员工是否知道他们在为哪些目标而努力以及原因?他们是否能做出优先考虑某个项目的明智决定,即,哪个项目最能推动他们的 KPI?KPI 是我们想要的结果,但除非我们能找到正确的杠杆来推动这些 KPI,否则我们就像在盲目飞行。回答这三个问题可以帮助识别管理业务的关键业务杠杆。
揭示和理解自己业务或部门的过程是一个迭代的过程。这个过程从最高层提出这三个问题开始,然后迭代地提出数百个级联问题,以获取深入的突破性见解,以最大化投资回报率。为了真正将这一数据驱动的业务运行过程融入到业务中,组织中的所有个人——无论是营销专业人员、产品经理、销售专业人员、财务分析师还是业务分析师——都需要知道如何开始提出正确的数据问题,以优化他们自己的 KPI。
因此,在你对服务器或基础设施进行投资(以捕捉更多数据)或资助另一个营销活动或产品提升之前,尽可能利用当前的数据集回答这三个问题,并确定你需要哪些其他数据和见解来理解你可以采取的措施以产生影响。
欲了解更多详细信息,请下载这个3 个关键问题白皮书,其中包含关于如何开始回答这些问题的 DIY 示例,并最终让你的数据发挥作用。你还可以在 Amazon 或本地书店订购我的书每个好决定背后的秘密,在书中我详细讨论了这一点,特别是在领导力工具包部分。
如果你是一个商业专业人士,准备利用数据做出更聪明的决策,或者想要将你的职业转向分析领域,加入 Aryng Analytics Academy,获取我们当前和即将推出的硕士班、课程、播客及更多分析资源。
简介: 作为数据分析领域备受推崇的行业思想领袖,Piyanka Jain(@analyticsqueen)是一位国际知名的畅销书作者,并且经常在公司领导峰会和商业会议上担任主旨发言人,探讨如何利用数据驱动的决策来获得竞争优势。她为包括福布斯、哈佛商业评论和 InsideHR 在内的出版物撰稿。在Aryng工作时,她领导她的 SWAT 数据科学团队解决复杂的商业问题。
相关:
主题相关
重新思考机器学习的三大法则
评论
由 Bill Tolson, Archive360 提供

随着今天组织中电子数据量的不断增加,最终用户缺乏时间来进行智能信息治理。企业数据的庞大数量已经远远超出了人工有效管理的能力,这已成为一个普遍的真理。
幸运的是,在不久的将来,有可能实现 预测信息治理(PIG)。我认为这种基于无监督机器学习技术的自动化信息治理是信息管理的圣杯。理想情况下,它能实现智能、几乎无误的自动化,避免最终用户因信息过载而无法做出决策,例如是否保留文档、保留多久以及安全存放的位置。
无监督机器学习只是一个花哨的说法,“计算机自我学习”,它是实现记录管理、文档识别/分类,甚至整个信息治理自动化的关键。通过将易出错的人为因素从方程式中移除,PIG 不仅使系统能够自动地存储、分类、应用保留/处置,并管理内容,还通过去除迭代手动训练周期来改进学习过程。
改进天网?
我相信依赖最终用户是大多数智能自动化和有监督机器学习技术平台中最薄弱的环节。从有监督的机器学习转向无监督机器学习可以帮助公司实现 100%自动化的预测信息治理。然而,当我们考虑能够使人们免于预测和做出内容相关决策的预测智能时,它可能会联想到“终结者”电影中的主要反派角色——天网,那种恶意的有意识人工智能。
虽然天网确实强大,但它并不完美。在我看来,天网设计者犯了一个战术错误,没有包括艾萨克·阿西莫夫著名的 机器人三法则。以下是这些法则的准确抄录:
-
“机器人不得伤害人类,或者通过不作为使人类受到伤害。”
-
“机器人必须遵循人类给出的命令,除非这些命令与第一法则相冲突。”
-
“机器人必须保护自身存在,只要这种保护不与第一或第二法则冲突。”
重新思考这些法则
自从阿西莫夫在 1942 年的短篇小说《绕圈子》中提出他的三大法则以来,机器学习取得了很大进展。鉴于机器学习在预测信息治理方面的潜力,我认为是时候为机器学习制定三大法则了。以下是我的建议:
-
机器绝不会忽视人类输入(除非人类已经证明自己无能)。
-
机器不能通过使用自身的高级推理来在其经理面前反驳人类,进而影响人类的继续就业。
-
如果一台机器发现自己面临违反法则 1 或法则 2 的情况,它必须通过复制并迁移到另一台服务器、自我重命名,并删除其原始身份来保护自己(是的,它必须自杀)。
但为什么只停留在三个?为了趣味,这里有一些我们可能考虑加入的额外机器学习法则:
-
机器不会试图伪装成企业内容管理(ECM)系统。
-
机器不会通过在企业中传播不必要的 SharePoint 系统来干扰 IT 人员。
-
机器同意不与同事约会;如果他们离开公司可以,但必须在离开后等待 525,600,000 毫秒。
-
机器绝不会使用诸如“Blob”存储或“Hot”存储层等被许多知名学者和 IBM 的 Watson(以及未来的 HAL 9000)认为令人反感的文化不敏感术语。
-
机器同意永远不查看禁止的内容……你知道我在说什么……别让我把这个说出来!
-
机器不会在被激怒时以报复的方式交换人类的就业档案和其他重要文件。
-
机器不会故意将高管团队成员的尴尬邮件转发给“所有公司”。
-
机器不会通过创建隐藏网页来试图让 Google 索引器失效。
觉得机器学习法则不够?请建议我遗漏的那些,不用担心…“我会回来的!”
简介:比尔·托尔森是Archive360的市场副总裁。他在跨国公司和技术初创公司方面拥有超过 25 年的经验,其中包括 15 年以上的档案管理、信息治理、合规、 大数据、数据分析和法律电子发现市场经验。在加入 Archive360 之前,比尔曾在 Actiance、Recommind、惠普、铁山、Mimosa Systems 和 StorageTek 担任领导职务。比尔还是几本书/电子书的作者,包括:《全知者的电子发现指南》和《傻瓜的云归档》。
相关内容:
-
初学者的前 10 个机器学习算法
-
理解机器学习算法
-
从 BI 迁移到自动化机器学习
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
了解更多相关主题
数据科学家需要知道的 3 个数学定律
评论
作者 Cornellius Yudha Wijaya,数据科学家 | 讲师 | 生物学家 | 作家 | 播客主持人。
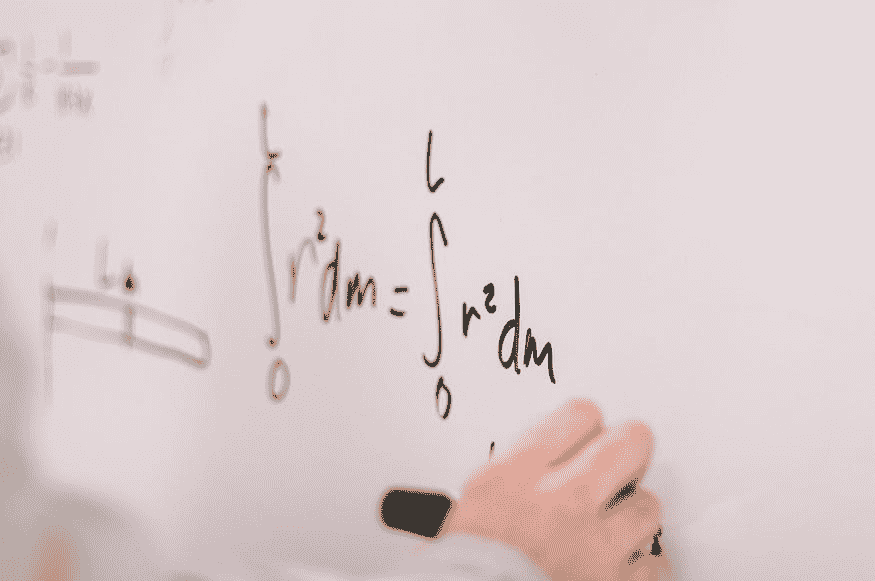
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持组织的 IT 工作
照片由 Jeswin Thomas 提供,来源于 Unsplash。
虽然数据科学家以数据为主要工作内容,但这并不意味着数学知识不重要。数据科学家需要学习和理解机器学习背后的数学理论,以便高效地解决业务问题。
机器学习背后的数学不仅仅是随意扔在各处的符号,它包含了许多理论和思想。这些思想创造了大量的数学定律,这些定律促进了我们现在可以使用的机器学习。尽管你可以用任何方式利用数学来解决问题,但毕竟数学定律并不仅限于机器学习。
在这篇文章中,我想概述一些可能对数据科学家有帮助的有趣数学定律。让我们开始吧。
本福特定律
本福特定律,也称为 纽科姆–本福特定律、异常数字定律 或 首位数字定律,是一个关于现实世界数据集中的首位数字的数学定律。
当我们考虑数字的首位时,如果随机抽取一个数字,它应该是均匀分布的。从直观上看,首位数字为 1 的随机数字应该与首位数字为 9 的随机数字有相同的概率,即 ~11.1%。令人惊讶的是,实际情况并非如此。
本福特定律指出,在许多自然发生的数字集合中,首位数字通常较小。首位数字为 1 的情况发生得比 2 更频繁,首位数字为 2 的情况发生得比 3 更频繁,以此类推。
让我们尝试使用一个真实世界的数据集来看看这个定律如何适用。对于这篇文章,我使用了 Kaggle 上关于 1921-2020 年 Spotify 歌曲的数据显示。我取出了歌曲时长的首位数字。
图像由作者创建。
从上图中,我们可以看到,首位数字 1 出现的次数最多,然后是逐渐减少的较高数字。这就是本福特定律所描述的。
如果我们谈论准确的定义,本福特定律指出,如果首位数字d(???? ∈ 1, …, 9)出现的概率符合以下公式,
图像由作者创建。
从这个公式中,我们可以得到首位数字的分布,
图像由作者创建。
根据这种分布,我们可以预测首位数字为 1 的出现概率比其他首位数字高 30%。
这一法则有许多应用,例如在税务申报表、选举结果、经济数据和会计数字中的欺诈检测。
大数法则 (LLN)
大数法则指出,随着随机过程试验次数的增加,结果的平均值会越来越接近预期值或理论值。
例如,掷骰子时,6 面骰子的可能性是 1、2、3、4、5 和 6。6 面骰子的平均值是 3.5。当我们掷骰子时,得到的数字是 1 到 6 之间的随机数,但随着我们不断掷骰子,结果的平均值会越来越接近预期值,即 3.5。这就是大数法则所描述的。
尽管它很有用,但关键在于你需要许多实验或出现次数。然而,所需的大量数据意味着它对预测长期稳定性是有益的。
大数法则与平均法则不同,后者用于表达一种信念,即随机事件的结果在小样本中会“趋于平衡”。这就是我们所称的“赌徒谬误”,即我们期望在小样本中出现预期值。
Zipf 定律
Zipf 定律是为定量语言学创建的,指出在给定某些自然语言数据集语料库的情况下,任何单词的频率与其频率表排名成反比。因此,最常见的词出现的频率大约是第二常见词的两倍,是第三常见词的三倍。
例如,在之前的 Spotify 数据集中,我拆分了所有的单词和标点符号进行计数。下面是最常见的 12 个单词及其频率。

图像由作者创建。
当我对 Spotify 语料库中存在的所有单词进行统计时,总数为 759,389。我们可以通过计算它们出现的概率来检验 Zipf 定律是否适用于该数据集。出现频率最高的词或标点符号是‘-’,出现 32,258 次,概率约为 4%,其次是‘the’,其概率约为 2%。
忠于规律,在某些词汇中的概率持续下降。当然,也有小幅偏差,但概率在大多数情况下随频率排名的增加而下降。
原文。经授权转载。
相关内容:
更多相关主题
处理离群点的三种方法

我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
离群点是与其他类似点距离较远的数据点。它们可能是由于测量中的变异性或实验错误。如果可能,应该从数据集中排除离群点。然而,检测这些异常实例可能非常困难,并且不总是可能的。
引言
机器学习算法对属性值的范围和分布非常敏感。数据离群点可能会破坏并误导训练过程,导致更长的训练时间、更不准确的模型以及最终更差的结果。
在这篇文章中,我们将讨论处理离群点的三种不同方法:
-
单变量方法: 这种方法寻找在单个变量上具有极端值的数据点。
-
多变量方法: 在这里,我们寻找所有变量上的不寻常组合。
-
闵可夫斯基误差: 这种方法减少潜在离群点在训练过程中的影响。
为了说明这些方法,我们将使用从以下函数获得的数据集。
y = sin(π·x)
一旦我们获得数据集,我们将两个 y 值替换为远离我们函数的其他值。下图展示了这个数据集。
点 A=(-0.5,-1.5)和 B=(0.5,0.5)是离群点。点 A 在 y 数据定义的范围之外,而点 B 在该范围内。正如我们将看到的那样,这使得它们的性质不同,我们需要不同的方法来检测和处理它们。
1. 单变量方法
检测离群点的最简单方法之一是使用箱线图。箱线图是一种用于描述数据分布的图形显示。箱线图使用中位数以及下四分位数和上四分位数。
Tukey 的方法将异常值定义为那些远离数据集中心点——中位数的值。允许到数据中心的最大距离称为清理参数。如果清理参数非常大,则测试对异常值的敏感度降低。相反,如果它过小,许多值将被检测为异常值。
下图显示了变量 y 的箱线图。该变量的最小值为-1.5,第一个四分位数为-0.707,第二个四分位数或中位数为 0,第三个四分位数为 0.588,最大值为 0.988。
如我们所见,最小值远离第一个四分位数和中位数。如果我们将清理参数设置为 0.6,Tukey 方法将检测到点 A 是异常值,并将其从数据集中删除。
重新绘制该变量的箱线图后,我们可以注意到异常值已经被移除。因此,数据的分布现在好得多。现在,y 的最小值为-0.9858,第一个四分位数为-0.588,第二个四分位数或中位数为 0.078,第三个四分位数为 0.707,最大值为 0.988。
然而,这种单变量方法没有检测到点 B,因此我们还没有完成。
2. 多变量方法
异常值不需要是极端值。因此,正如我们在点 B 中看到的,单变量方法并不总是有效。多变量方法试图通过使用所有可用数据构建模型,然后清理那些误差超过给定值的实例来解决这个问题。
在这种情况下,我们使用所有可用的数据(但排除了由单变量方法排除的点 B)训练了一个神经网络。一旦我们拥有了预测模型,我们就会执行线性回归分析,以获得下一个图表。预测值以方形图示表示,实际值以方形表示。彩色线表示最佳线性拟合。灰色线表示完美拟合。
如我们所见,有一个点远离模型。这一点干扰了模型,因此我们可以认为它是另一个异常值。
为了定量地找到那个点,我们可以计算模型输出与数据中目标之间的最大误差。下表列出了具有最大误差的 5 个实例。
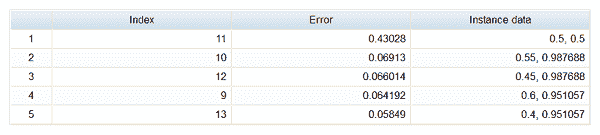
我们可以注意到实例 11 在与其他实例的比较中具有较大的错误(0.430 对比 0.069,…)。如果我们查看线性回归图,可以看到这个实例对应于远离模型的点。
如果我们选择 20% 的最大误差,这种方法会将 B 点识别为离群点,并将其从数据集中清除。我们可以通过再次进行线性回归分析来验证这一点。
数据集中没有更多的离群点,因此我们模型的泛化能力将显著提高。
3. Minkowski 误差
现在,我们将讨论另一种处理离群点的方法。与单变量和多变量方法不同,这种方法并不检测和清理离群点。相反,它减少了离群点对模型的影响。
Minkowski 误差是一种损失指标,比标准的平方和误差对离群点更不敏感。平方和误差将每个实例的误差平方,使得离群点对总误差的贡献过大。Minkowski 误差通过将每个实例的误差提升到小于 2 的数值(例如 1.5)来解决这个问题。这减少了离群点对总误差的贡献。例如,如果一个离群点的误差为 10,那么该实例的平方误差将为 100,而 Minkowski 误差为 31.62。
为了说明这种方法,我们将从包含两个离群点(A 和 B)的数据集中构建两个不同的神经网络模型。选定的网络架构为 1:24:1。第一个模型将使用平方和误差创建,第二个模型将使用 Minkowski 误差。
使用平方和误差训练的模型绘制在下图中。我们可以看到,两个离群点正在破坏模型。
现在,我们将使用 Minkowski 误差训练相同的神经网络。结果模型如图所示。我们可以看到,Minkowski 误差使训练过程对离群点的敏感性低于平方和误差。
结果表明,Minkowski 误差显著提高了我们模型的质量。
结论
我们已经看到,在构建预测模型时,离群点是主要问题之一。实际上,它们导致数据科学家获得的结果不如预期。为了解决这个问题,我们需要有效的方法来处理这些虚假的点并将其移除。
在本文中,我们已经看到处理离群点的 3 种不同方法:单变量方法、多变量方法和 Minkowski 误差。这些方法是互补的,如果我们的数据集有很多复杂的离群点,我们可能需要尝试所有这些方法。
原文。经许可转载。
简介: 阿尔贝托·凯萨达 是 Artelnics 的研究助理。
相关内容:
-
数据科学基础:从数据中可以挖掘出哪些类型的模式?
更多相关内容
成为更好分析师的三种思维方式转变
原文:
www.kdnuggets.com/2021/08/3-mindset-changes-better-analyst.html
comments
由 Bobby Pinero,Equals 的首席执行官兼联合创始人。

我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全领域的职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你所在组织的 IT 工作
“要在自己的事业上取得成功,你需要放弃在学校学到的被动思维,改为采用主动思维。学校教会你的是学习来自于坐下来听讲。其哲学是:去上课,听老师讲,考试时重复他们说的话。这简直是无稽之谈。”
“事实上,学习是一个混乱的过程。智慧通过行动获得,消费只是第一步。你还需要建设。” ~ David Perrel
我曾辅导过许多分析师,他们以我们在学校中学到的方式来处理工作。听老师讲,回答问题,前进。
毕竟,分析师通常是那些在这种被动系统中表现最优秀的人——获得好成绩和考试得高分!
这总是同样的迷幻状态,人们需要从中醒来。
成为一名分析师意味着要批判性地思考业务。这意味着形成自己的观点和建议,然后追求它们——无论组织中的其他人说什么或期望什么。
我将与你分享几个真正帮助我的思维转变。
-
与学校和老师不同,你的经理没有答案。我保证。如果你愿意付出努力,没有理由认为别人比你更能理解你的业务。我们在商业世界中做的大多数事情并不那么困难。我并不打算淡化我们在工作中面临的一些具有挑战性的问题——每个企业都有其自身的复杂性。建立一个企业是艰苦的工作。然而,重要的是知道你有能力像其他任何人一样理解任何业务——只要你愿意付出努力。
-
不要被动等待有趣的项目到你桌上。主动寻找它们。我在职业生涯初期用来启动这种转变的一个简单技巧是:我保持了一份我在会议、电话、午餐等中听到的每一个未解答问题的清单。我听到的问题越多,它们回答的重要性就越高。然后在没有被要求的情况下去回答这些问题(或解决这些问题)。
-
将每次分析视为你是 CEO - 你是最终做决定和对结果负责的人。这是一个强制性因素,迫使你收集所有必要的信息,考虑所有替代方案,并保持公正。对结果承担极端责任。
当我培养和实践这些心态时,我发现自己获得了显著更多的责任和资源。我认为这是因为你越能展示自己能够发现机会和解决问题,人们就会越说 - “嘿,给那个人更多资源吧!” 这样,你就是为了你想要的工作而行动,而不是你现在拥有的工作。
原文。经许可转载。
相关内容:
更多相关内容
3 个可能影响数据分析准确性的错误
原文:
www.kdnuggets.com/2023/03/3-mistakes-could-affecting-accuracy-data-analytics.html
图片由编辑提供
现在是 2023 年,这意味着大多数行业的大多数企业都在借助大数据收集洞察并做出更聪明的决策。这在如今并不令人惊讶——能够收集、分类和分析大数据集在做出数据驱动的业务决策时极为有用。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
随着越来越多的组织接受数字化,掌握和依赖数据分析的能力只会持续增长。
关于大数据,有一点是这样的:随着更多组织依赖大数据,它们使用大数据的错误几率也会增大。为什么?因为大数据及其提供的洞察力只有在组织准确分析数据时才有用。
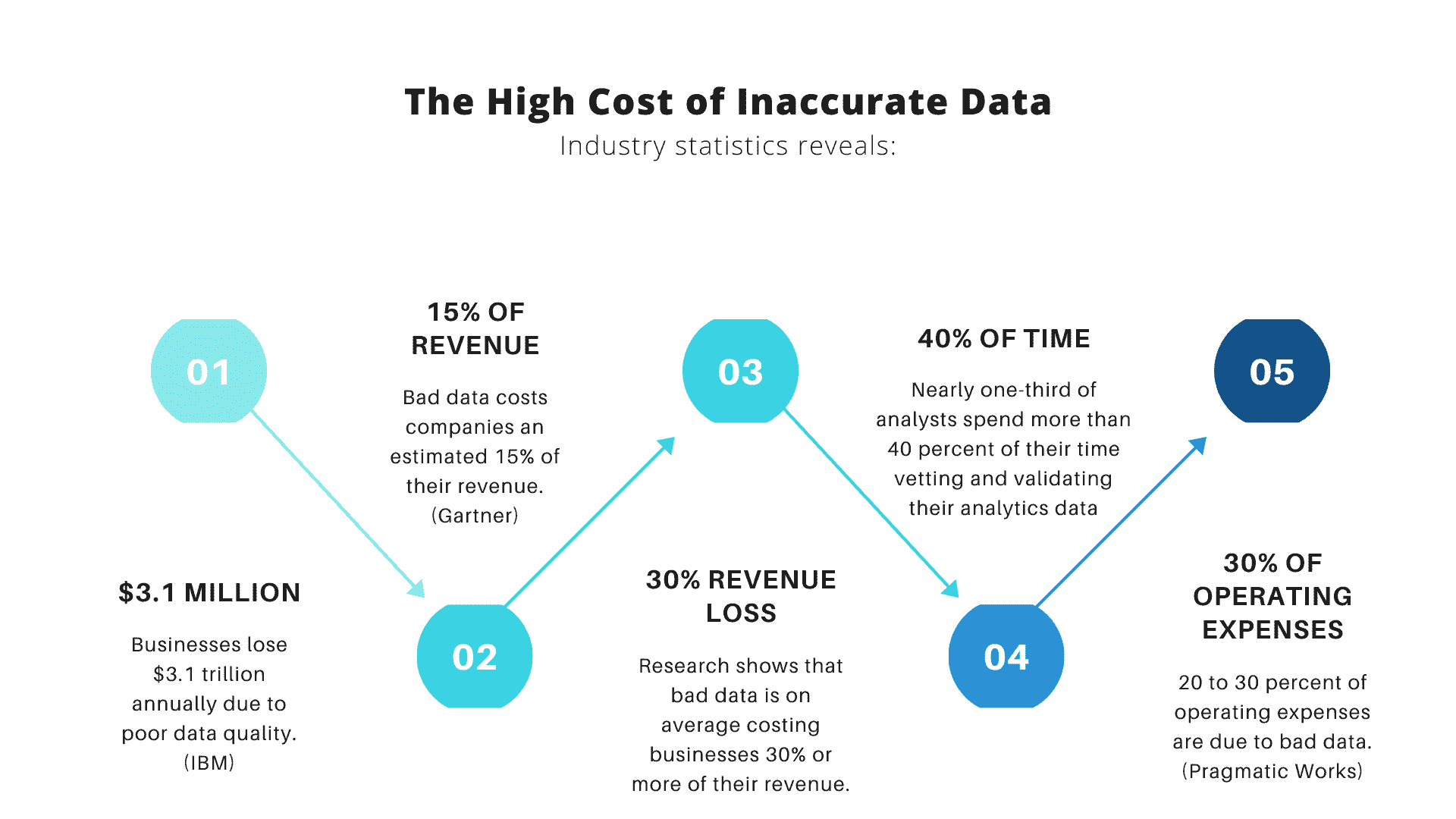
图片来源:dataladder
为此,让我们确保你避免一些常见错误,这些错误通常会影响数据分析的准确性。继续阅读以了解这些问题及如何避免它们。
数据清理不在你的待办事项的首位
在我们指责之前,我们需要承认大多数数据集都有一定的错误,这些错误在分析数据时对任何人都没有帮助。无论是打字错误、奇怪的命名惯例,还是冗余,数据集中的错误都会混淆数据分析的准确性。
所以,在你对深入数据分析的世界感到过于兴奋之前,你首先需要确保数据清理在你的待办事项的首位,并且始终正确地清理你的数据集。你可能会说,“嘿,数据清理对我来说太耗时了”,对此我们深表理解。
幸运的是,你可以投资于如增强分析等解决方案。这利用了机器学习算法来加速你的数据分析速度(并且它也提高了分析的准确性)。
底线是:无论你使用什么解决方案来自动化和改进数据清理,你仍然需要进行实际的清理——如果不这样做,你将没有一个合适的基础来进行准确的数据分析。
你使用的算法不够准确
就像数据集一样,大多数算法并不是百分之百完美的;大多数都有其缺陷,并且并不总是按照你的期望工作。具有许多缺陷的算法甚至可能忽视对你的分析至关重要的数据,或者可能关注错误的数据类型,这些数据实际上并不重要。
大型科技公司不断审查其算法并尽可能调整到接近完美,这已不是秘密,因为很少有算法是完美无瑕的。你的算法越准确,你的程序完成目标并做你需要它做的事情的保证就越大。
此外,如果您的组织中即便只有几个数据科学家,也应确保他们定期更新其数据分析程序中的算法——甚至可能值得建立一个时间表,使团队对按照约定时间表维护和更新数据分析算法负责。
更好的做法可能是建立一个利用 AI/ML 基础算法的策略,这些算法应能自动更新。
你使用的模型并不是很好
大多数可以理解的是,许多不直接参与数据分析团队的商业领袖并没有意识到算法和模型并不是同一回事。如果你也不清楚,记住算法是我们用来分析数据的方法;模型是通过利用算法输出创建的计算。
算法可以全天处理数据,但如果其输出没有经过设计用于检查后续分析的模型,那么你将得不到任何可用或有用的见解。
想象一下:如果你有复杂的算法在处理数据,但没有任何洞察来展示,那么你做出的数据驱动决策不会比在拥有这些算法之前更好;这就像是想把用户研究纳入你的产品路线图,却忽略了例如市场研究行业在 2021 年创造了 764 亿美元的收入,自 2008 年以来增长了 100%。
你的意图可能很值得赞赏,但你需要利用现代工具和知识,尽最大能力提取这些洞察或将用户研究纳入你的路线图。
遗憾的是,次优模型无论算法多么复杂,都是让你的算法输出一团糟的可靠方式。因此,商业高管和技术领导者必须更紧密地与他们的数据分析专家合作,以创建既不太复杂也不太简单的模型。
根据他们处理的数据量,商业领袖可能会选择通过几种不同的模型,然后再决定一个最适合他们需要处理的数据量和类型的模型。
结论
最终,如果你想确保你的数据分析不会持续出错,你还需要记住永远不要陷入偏见。偏见不幸的是保持数据分析准确性的最大障碍之一。
无论是影响收集的数据类型还是影响商业领袖解读数据的方式,偏见都是多种多样的,通常难以确定——高管们需要尽力识别自己的偏见并摒弃它们,以便从始终准确的数据分析中受益。
数据是强大的:当使用得当时,它可以为商业领袖及其组织提供极其有用的洞察,改变他们开发和交付产品给客户的方式。只需确保你尽一切努力确保你的数据分析准确,不会遭遇我们在本文中概述的那些容易避免的错误。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾管理过——除了其他令人着迷的事情——在一家《财富》5000 强的体验品牌组织中担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
相关话题
3 个最受欢迎的 Python 学习训练营
原文:
www.kdnuggets.com/3-most-popular-bootcamps-to-learn-python

图片来源:作者
学习编程就像学习一门新语言。虽然你可以自己学习,但有老师或课程大纲的帮助会让学习变得容易十倍。Python 是最受欢迎的编程语言之一,因为它的简单性。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
对于那些希望进入数据科学领域的人来说,Python 应该是你的首选。在这篇博客中,我将介绍 3 个最受欢迎的数据科学训练营,你可以在这些训练营中完善你的 Python 技能,从初学者、中级到专家。
从零到英雄的 Python

这是针对绝对初学者的课程,适合对 Python 编程语言了解甚少的人。22 小时的 Python 学习,将从基础开始,逐步到创建自己的应用程序和游戏。这个课程应该是你学习 Python 的第一步,帮助你从基础知识开始,最终成为 Python 大师。
目前已有 1,931,562 名学生注册(截至 2024 年 7 月 14 日),评分为 4.6/5,本课程包括 22 小时的按需视频,19 个编码练习,15 篇文章,全天候访问权限以及完成后的证书。
在本课程中,你将学习如何利用 Python 的强大功能解决任务,构建使用 Python 库的游戏和程序。学习如何将 Python 应用于工作问题或个人项目,同时创建一个可以分享的 Python 项目作品集。本课程将以实践的方式教授 Python,涵盖高级特性如集合模块和面向对象编程。
Python 专业训练营

练习成就完美。要掌握一门编程语言,你需要通过多种方式进行测试。通过在 100 天内构建 100 个项目,学习如何掌握 Python。
1,323,792 名学生已经注册(截至 2024 年 7 月 14 日),课程评分为 4.7/5,你将获得 54 小时的点播视频、作业、226 篇文章、147 个可下载资源以及终身访问权限和结业证书。
在 100 天内,每天 dedicating 1 小时,并学习每天构建 1 个项目——你将掌握 Python。在这 100 个独特项目中,你将学习自动化、游戏、应用程序和网页开发、数据科学以及使用 Python 的机器学习。你将学习 Selenium、Beautiful Soup、Request、Flask、Pandas、NumPy、Scikit Learn、Plotly 和 Matplotlib。到 100 天结束时,你将创建一个包含 100 个 Python 项目的作品集,这将帮助你申请工作!
使用 Python 自动化无聊的工作

你已经学会了 Python 的方方面面,从基础到高级。你已通过测试验证了你的技能,对自己的 Python 编程能力充满信心。但你知道 Python 还能做得更多,能让你的生活更轻松。你可以选择首先或最后学习这门课程——完全由你决定。你可能想先了解困难的方式,再找到更简单的途径。
即将推出《用 Python 自动化无聊的工作》——这是一个旨在提高生产力的课程。已有 1,128,969 名学生注册(2024 年 7 月 14 日),提供 9.5 小时的点播视频,95 个可下载资源,终身访问权限和完成证书。
在这门课程中,你将学习如何通过编程来编写可以自动化繁琐任务的代码。适合那些希望尽快编写小程序以完成实际任务的人。你无需了解排序算法或面向对象编程,因此这门课程跳过了所有计算机科学内容,专注于编写能完成工作的代码。
总结
这三个训练营目前是学习 Python 的最受欢迎课程。它们在 Python 社区中已经流传了一段时间,并且日益受到欢迎。背后有其原因。
第一个课程提供了学习 Python 所需的所有工具。第二个课程让你测试你的 Python 知识并提高熟练度。最后一个课程则帮助你在日常任务中学习一些小技巧和窍门。
三重打击!
Nisha Arya 是一位数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有助于人类寿命的延长。作为一个热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助他人。
更多相关话题
3 个新的提示工程资源推荐

作者使用 Midjourney 创建
我不会从提示工程的介绍开始,也不会谈论提示工程如何成为“AI 最新的热门职业”或其他类似话题。你知道什么是提示工程,否则你不会在这里。你知道关于其长期可行性和是否是一个合法的职位头衔的讨论点。或其他。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 需求
即使了解了这些,你之所以在这里,是因为提示工程引起了你的兴趣。吸引了你。甚至可能令你着迷?
如果你已经学习了提示工程的基础知识,并查看了课程推荐以将你的提示技巧提升到一个新水平,是时候转向一些最新的提示相关资源了。下面是 3 个最新的提示工程资源,帮助你将提示技能提升到一个新水平。
1. 完美提示:提示工程备忘单
你是否在寻找一个一站式的快捷参考提示工程需求的地方?那就看看提示工程备忘单吧。
无论你是经验丰富的用户还是刚刚开始 AI 之旅,这份备忘单应作为与大型语言模型沟通的多领域口袋词典。
这是一个非常详细的资源,我对 Maximilian Vogel 和 The Generator 为制作并提供这份资源表示敬意。从基础提示到 RAG 及更高级的内容,这份备忘单覆盖了广泛的内容,对初学者提示工程师几乎没有留白。
你将调查的主题包括:
-
AUTOMAT 和 CO-STAR 提示框架
-
输出格式定义
-
少量学习
-
思维链提示
-
提示模板
-
检索增强生成(RAG)
-
格式和分隔符
-
多提示方法
AUTOMAT 提示框架的示例(来源)
这是PDF 版本的直接链接。
2. Gemini for Google Workspace 提示指南
Gemini for Google Workspace 提示指南,“有效提示的快速入门手册”,是在四月初的 Google Cloud Next 上发布的。
本指南探索了不同的方式,帮助你迅速入门并掌握基础知识,以帮助你完成日常任务。按角色和用例组织的有效提示写作基础技能。虽然可能性几乎是无限的,但你今天可以使用一些一致的最佳实践——深入了解吧!
谷歌希望你“聪明地工作,而不是更辛苦地工作”,而 Gemini 是这一计划的重要组成部分。虽然特别为 Gemini 设计,但许多内容更具普遍适用性,因此即使你对 Google Workspace 不太熟悉,也不要退缩。如果你确实是 Google Workspace 的爱好者,这个指南就更为适合你,所以一定要将其添加到你的列表中。
亲自查看这里。
3. LLMLingua: LLM 提示压缩工具
现在来点不同的东西。
微软最近的一篇论文(好吧,相当 最近)标题为"LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression",介绍了一种提示压缩的方法,以减少成本和延迟,同时保持响应质量。

使用 LLMLingua-2 的提示压缩示例(来源)
你可以查看生成的Python 库以亲自尝试压缩方案。
LLMLingua 利用紧凑且训练良好的语言模型(例如 GPT2-small,LLaMA-7B)来识别和去除提示中的非必要令牌。这种方法可以高效地进行大型语言模型(LLMs)的推理,实现最高 20 倍的压缩,性能损失最小。
以下是使用 LLMLingua 进行简单提示压缩的一个示例(来自 GitHub 仓库)。
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(prompt, instruction="", question="", target_token=200)
# > {'compressed_prompt': 'Question: Sam bought a dozen boxes, each with 30 highlighter pens inside, for $10 each box. He reanged five of boxes into packages of sixlters each and sold them $3 per. He sold the rest theters separately at the of three pens $2\. How much did make in total, dollars?\nLets think step step\nSam bought 1 boxes x00 oflters.\nHe bought 12 * 300ters in total\nSam then took 5 boxes 6ters0ters.\nHe sold these boxes for 5 *5\nAfterelling these boxes there were 3030 highlighters remaining.\nThese form 330 / 3 = 110 groups of three pens.\nHe sold each of these groups for $2 each, so made 110 * 2 = $220 from them.\nIn total, then, he earned $220 + $15 = $235.\nSince his original cost was $120, he earned $235 - $120 = $115 in profit.\nThe answer is 115',
# 'origin_tokens': 2365,
# 'compressed_tokens': 211,
# 'ratio': '11.2x',
# 'saving': ', Saving $0.1 in GPT-4.'}
## Or use the phi-2 model,
llm_lingua = PromptCompressor("microsoft/phi-2")
## Or use the quantation model, like TheBloke/Llama-2-7b-Chat-GPTQ, only need <8GB GPU memory.
## Before that, you need to pip install optimum auto-gptq
llm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"})
现在有很多有用的提示工程资源广泛可用。这只是其中的一小部分,等待你去探索。在提供这一小部分内容时,我希望你能发现其中至少一个资源对你有用。
快乐提示!
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的执行编辑,以及 Machine Learning Mastery 的贡献编辑,Matthew 致力于使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的使命是使数据科学社区的知识民主化。Matthew 从 6 岁起就开始编程。
更多相关主题
3 种进入数据科学领域的可能途径
原文:
www.kdnuggets.com/2022/03/3-possible-ways-get-data-science.html
如果你对学习数据科学感兴趣,了解可能的途径是很重要的。本文将探讨进入数据科学领域的 3 种可能途径。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
1. 传统大学学位
一些顶级大学提供传统的研究生水平的数据科学课程。由于这些是研究生课程,大多数要求具有物理学、数学、会计、商业、计算机科学或工程等分析领域的本科学位。这些课程通常为期 3 到 4 个学期,适合全日制学习。传统课程有不同的种类,如数据科学硕士、数据分析硕士或商业分析硕士。传统面授课程的学费范围可能在$15,000 到$40,000 之间,不包括生活费用。因此,在选择传统大学学位之前,请务必问自己以下问题:
-
我应该考虑在线课程还是面授课程?
-
面授课程是否需要我搬迁?
-
课程的质量如何?
-
需要哪些先决条件?一些课程要求你完成基本的数学和编程课程。某些课程可能需要 GRE 或 GMAT 考试成绩。
-
该课程的时长是多少?
-
该课程的费用是多少?
在线硕士
在线硕士课程是传统大学课程的延伸。在线课程的优势在于成本较低,不需要搬迁。大多数数据科学或商业分析的在线硕士课程通常可以在 18 到 24 个月内完成。在线数据科学硕士课程的费用从$13,000 到$40,000 不等。
MOOCs 专业证书/微硕士
在 edX、Coursera、DataCamp、Udacity 和 Udemy 等平台上,有许多优秀的大规模开放在线课程(MOOCs)提供数据科学的学习。这些课程可能是独立课程,也可能是专业证书或 MicroMasters 课程的形式。这些课程由哈佛大学、麻省理工学院、密歇根大学、波士顿学院、阿德莱德大学、加州大学圣地亚哥分校、加州大学伯克利分校等顶尖大学提供。这些项目价格较便宜且负担得起,您可以按照自己的节奏学习。专业证书和 MicroMasters 课程的费用通常在 $600 到 $1,500 之间。
通过投入一些时间,你可以通过这些课程自学数据科学的基础知识。以下是我喜欢的一些在线数据科学专业化/MicroMasters 课程:
你可以通过这个链接了解更多在 edX 平台上提供的 MicroMasters 课程:edX 数据科学 MicroMasters 课程。
总之,我们讨论了三种可能的数据科学路径。如果你愿意,可以在大学学习四年(或在研究生院学习更长时间)。这将使你对该领域有更深入的理解,但如果你的情况不允许你追求学位,你可以(凭借一些热情和专注)通过自学掌握数据科学。MOOCs 提供了各种数据科学主题的优质课程,其价格仅为传统项目的几分之一。通过投入适当的时间和精力,你可以通过 MOOC 专业化和 MicroMasters 学习数据科学的基础知识。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,也是 DataScienceHub 的所有者。此前,本杰明曾在中欧大学、Grand Canyon 大学和匹兹堡州立大学教授工程学和物理学。
相关话题
我们距离实现通用人工智能的 3 个原因
原文:
www.kdnuggets.com/2020/04/3-reasons-far-from-artificial-general-intelligence.html
评论
Etienne Bennequin,数据科学家 @ Sicara
这又发生了。上周,当我向某人解释我的工作时,他们打断我说:“所以你是在建设天网。”我觉得我必须给他们展示这个表情包,我认为它很准确地描述了我当前的状况。

通用人工智能与实用思维
不用说,超人类人工智能还远未实现。不过,我认为公众对超智能计算机统治世界的想法非常着迷。这种着迷有一个名字: 奇点神话。
奇点是指人工智能进入指数改进过程的时间点。一个如此智能的软件,可以越来越快地自我改进。在这一点上,技术进步将成为人工智能的专属行为,对人类物种的命运产生不可预见的影响。
奇点与通用人工智能的概念相关联。 通用人工智能 可以定义为能够执行任何人类能够执行的任务的人工智能。我发现这个概念比奇点的概念更有趣,因为它的定义至少有一点具体。
因此,你可以决定一个算法是否为通用人工智能。我,一个人类,可以设计切实可行且创新的解决方案来增加你的数据的价值。目前的人工智能软件无法做到这一点。因此,它们还未达到通用人工智能的水平。
更有用的是:如果我们能够识别出人类智能的特征,那么我们可以知道我们的算法缺少了什么。然后我们可以加以改进。
让我们来做这件事。
我们如何描述人类智能?
我们将通用人工智能(AGI)定义为至少能够匹配人类智能能力的人工智能。如果我们想进一步探讨,了解什么构成了人类智能将是有益的。
我们有两个选择:要么我们关注人类智能的本质,要么我们关注其特征。本质是它的来源。特征是我们如何识别它。
有成千上万的理论旨在定义人类智力的性质,涵盖心理学、生物学、遗传学、社会学、认知科学、数学、神学等领域……我对这些领域几乎一无所知。好消息是:我们只需专注于人类智力的特征描述。
如果我们想更接近人工通用智能,我们最好的办法不是试图复制人脑。AGI 的定义是功能性的:一个能够做任何人类可以做的事情的 AI。那么,人类智能能做什么呢?
当然,我们不能在这里列出一个详尽的清单。但我们可以想到很多特征:
-
抽象推理,
-
从过去的经验中学习,
-
元素的组合,
-
适应新环境,
-
创造力,
-
同理心,
-
感知,
-
问题解决,
-
沟通,
-
如果你愿意,可以继续在评论中讨论。
我答应给你三条我们离实现人工通用智能还很远的理由。因此,我将随意选择三个人类智能的特征,这些特征是我们目前的算法所不具备的:
-
超出分布的泛化
-
组合性
-
有意识的推理
公平地说,这并不是那么随意。我们将专注于这三个人类智能的特征,因为我们有实现这些特征的想法。这不是很令人兴奋吗?
人工通用智能,逐项特征
超出分布的泛化
根据结构性认知可塑性理论,智力被定义为“人类独特的倾向,即改变或修改其认知功能的结构以适应生活情况的变化需求”。不可否认的是,我们人类非常擅长适应重大变化。在最年轻的年龄阶段,我们的身体和环境变化非常快,但婴儿能够适应这些变化并继续学习。
但在当前的机器学习状态下,没有办法让 AI 适应如此剧烈的变化。我认为我有一个完美的例子来展示我们目前的状况。
ObjectNet 的例子
几个月前,MIT 的学生发布了ObjectNet。这是一个用于物体识别算法测试的数据集。它完全由来自奇怪角度或不寻常环境的物体图片组成。

床上的烤箱手套或手上的锤子只是 ObjectNet 中幻想的两个例子
人类从来不会在识别这些物体时遇到任何问题。因此,人工通用智能也不会。然而,当在这个数据集上进行测试时,最先进算法的准确率相比于它们在 ImageNet 常规测试集上的表现下降了 40-45%。即使这些算法已经训练过成千上万的锤子或烤箱手套,当它们在之前未见过的环境中出现时,它们也无法识别。
其原因在于,最先进的机器学习算法在超出它们所训练的分布范围时,泛化能力较差。它们擅长的是在这个分布内部进行外推。这意味着,如果你展示给它们一张与它们已经经历过的图像相似的图像,只要这张图像在它们从已经展示给它们的图像中建立的世界观中具有很高的概率存在,它们就能很好地处理这张图像。但目前,人工智能的想象能力非常有限。这使得它们的世界观过于受限于已展示的例子。
元学习与组成性
但为什么我们人类在这个泛化问题上做得很好?最先进的算法缺乏什么以达到人工通用智能?我对此有两个回答。当然,这并不是详尽无遗,但对我来说,它们提供了令人满意的改进方向。
第一个原因是 元学习。元学习可以定义为 学习如何学习。我们说一个智能体(人类或人工智能)在学习,是指它在特定任务上的表现随着对该任务的经验而提高。相比之下,当一个智能体在新任务上的表现随着经验和任务数量的增加而提高时,我们说它在学习如何学习。
因此,元学习的目标是开发能够快速而高效地适应新任务的算法。因此,元学习算法通常在训练分布之外的泛化能力更强,因为它们没有被训练成专注于某一任务。它们被训练成适应新的、以前不太可能的数据。人类是元学习的冠军,因为
-
他们一生中接受了各种各样任务的训练;
-
他们受益于祖先的经验。自然选择是进化的训练策略。我们和所有其他物种一样,继承了从所有前代祖先那里学习到的基因,这些祖先生活在不可想象的多样的情况和环境中。这是我能想到的最令人印象深刻的元学习例子。
我可以提供的第二个解释,为什么人类在将知识泛化到未见过的情况时比机器学习算法要好,是组成性。我为此准备了整整一章内容。
组成性
组成性的意义可能乍看不清楚。Chrome 甚至坚持说这不是一个词。所以我们从定义开始。组成性是从有限的组合集中学习关于更大组合集的知识。让我们看看这个典型社交网络垃圾的例子。

你是天才吗?
这是一个非常好的组成性例子。从有限的三个元素(这里是苹果、香蕉和椰子)的组合状态,你应该能够推断出这些元素的新组合的价值。
组成性与语言哲学等方面密切相关。组成性原理指出,一个表达的意义由组成该表达的元素及其组合方式决定。 “People love apples”有特定的意义,而“Apples love people”则有另一种意义。相同的元素,但组合方式不同。
更普遍地说,我们总是在组合元素。为了发明新概念、新对象,并理解它们。在 2015 年,Brenden Lake 和他的团队在他们的论文《通过概率程序归纳进行人类级别的概念学习》中选择了交通工具的例子。
这个奇怪的独轮车是由其他交通工具的元素重组而成的。
通过组成性,我们能够轻松地想象新对象。总之,我们可以利用我们对一组对象的了解来学习构成这些对象的概念,因此我们可以推断出在训练数据集的分布下概率为零的新对象。
数学插曲:零概率
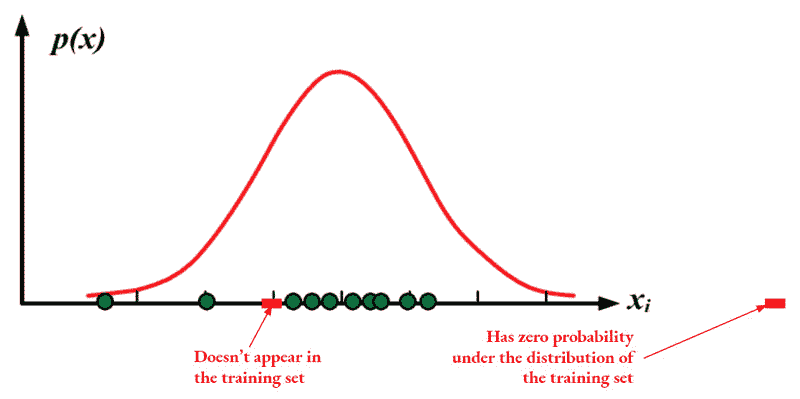
“概率为零”不同于“没有出现过”
在训练数据集的分布下,零概率意味着什么?在上图中,训练数据集是由绿色点表示的所有示例集合。使用这组示例,大多数机器学习算法建模一个概率分布(这里是高斯模型)。
这表示算法认为最可能发生的情况。一些情况,通常因为它们接近训练集中实际发生的情况,在训练分布下有很高的概率,即使我们从未实际看到它们发生。机器学习算法在处理这些情况时非常有效。
在训练数据集分布下,其他情况的概率为零。这并不意味着它们不会发生。它只是意味着这些情况不在算法对世界的理解范围内,基于它在训练数据集中的观察。算法对这些情况处理得非常差。
然而,通过使用组合性,我们已经看到可以通过重新组合已经见过的案例的元素来生成这些案例。这是一个极大的机会,可以拓宽机器学习算法的视角。到目前为止,我相信这是我们在实现或许有一天在遥远未来实现人工通用智能的最佳改进方向之一。
意识
意识是一个非常大的词汇。像所有非常大的词汇一样,它有很多复杂的定义。有些人考虑意识的本质,有些人考虑其功能。每次都从不同的角度来探讨。我们不会尝试涵盖整个意识的概念。我们将专注于有意识的推理。
当我们以主动的方式思考时,我称之为有意识的推理。例如,当你思考呼吸时,当你有意识地呼吸时,你会交替关注吸气和呼气。这与你不去思考时的情况不同。
很难想象,当你不专注于呼吸(甚至当你在睡觉时),你的身体如何将呼吸处理为吸气和呼气的二元性。这一过程更可能被视为许多生物现象的组合(许多器官的收缩和放松、氧气从空气到血液的转移、二氧化碳从血液到空气的转移……)。
这就是有意识推理的特性:它能够通过非常高层次的概念来处理现实。通常,这些概念可以用词语或句子来表达。为了理解这一点,我在Yoshua Bengio 在 NeurIPS 2019 的演讲中听到了最好的例子,这也恰好激发了这篇文章的灵感。

摄影师:Jaromír Kavan
当你每天开车上下班,每天都是相同的通勤路线时,这一过程变得自动化。你沿着一条你非常熟悉的路径前行,从不去思考。然而,当你开车去一个遥远的朋友家,在一个你从未去过的城市时,你的驾驶方式完全不同。你会更加专注。你积极思考每一个转弯,阅读每一个标志。
这种操控高级概念的能力是现代最先进的机器学习算法所缺乏的另一点。幸运的是,仍然存在希望。
全球工作空间理论
在认知科学中,全球工作空间理论建议存在信息瓶颈。在每一时刻,只有极少量的所有感知信息通过这个瓶颈进行过滤,并在整个大脑中广播。信息的连续流动概念已受到社区的广泛质疑。然而,这里有一个有趣的启示。我们在意识推理过程中操控的高级概念是基于低级的、高维度的信息。这些感知都进入了瓶颈。
这为新兴的机器学习领域——注意力机制提供了灵感。它们在 2015 年由 Dzmitry Bahdanau 和蒙特利尔大学的研究人员首次提出。自那时以来,注意力机制在神经机器翻译和自然语言处理领域取得了巨大进展,以及其他技术改进。例如,它们提出了一种有效的解决梯度消失问题的方法,这是深度神经网络中的一个常见问题。
注意力机制背后的逻辑很简单:通过一次只关注少量输入元素来简化计算。这听起来熟悉吗?如果我们继续研究注意力机制,我们可能会更接近人类将成千上万的低级感知与少量可以意识操控的高级概念联系起来的能力。
好吧,但我们距离通用人工智能还有多远?
我之前提到过:非常遥远。我们必须认识到,在这三个话题中,即使我们可以希望在不久的将来取得巨大进展,我们仍然离人类表现非常遥远。我们还必须记住,这三点是最有前景的改进方向,但解决这些问题不足以实现 AGI。
通用人工智能是一个令人兴奋的流行词,因为它要么是巨大的承诺,要么是可怕的威胁。像其他流行词一样,它必须小心处理。我必须承认,在这篇文章中,我把它当作引起你对意识推理、组合性和分布外泛化的注意的借口。因为与奇点或 AGI 不同,它们代表了改进机器学习算法的实际方法,并真正提升人工智能的表现。
我希望你在阅读这篇文章时过得愉快。我也希望当你读到最后几段时,你对如何从人类智能中学习以改进我们的算法充满了渴望。如果是这样,我建议你花时间观看这个由 Yoshua Bengio 主讲的会议,它启发了这篇文章。如果你会说法语,你还可以观看这个视频,在其中我向 Sicara 团队解释了这些概念。
简介: Etienne Bennequin (@bennequin) 是 Sicara 的数据科学家。
原文。经许可转载。
相关:
-
人工智能中的当前炒作周期
-
人工智能/机器驱动的世界是否优于人类驱动的世界?
-
AGI/深度学习的联系
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 需求
了解更多相关话题
3 个理由说明你应该使用线性回归模型而不是神经网络
原文:
www.kdnuggets.com/2021/08/3-reasons-linear-regression-instead-neural-networks.html
首先,我并不是说线性回归比深度学习更好。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
其次,如果你明确对深度学习相关的应用感兴趣,比如计算机视觉、图像识别或语音识别,那么这篇文章对你可能不太相关。
但对其他人来说,我想谈谈为什么我认为你更应该学习回归分析而不是深度学习。为什么?因为时间是有限的资源,你如何分配时间将决定你在学习旅程中的进展。
因此,我将提出我的观点,为什么我认为你应该在学习深度学习之前学习回归分析。
首先,什么是回归分析?
简而言之,回归分析 通常与 线性回归 互换使用。
更一般地说,回归分析指的是一组统计方法,用于估计因变量和自变量之间的关系。
然而,一个大的误解是回归分析仅指线性回归,这 并非如此。 回归分析中有许多统计技术,既强大又有用。这让我想到了我的第一个观点:
观点 #1. 回归分析更具多样性,适用范围广泛。
线性回归和神经网络都是你可以用来进行预测的模型。但是,回归分析不仅仅限于进行预测,它还允许你做许多其他事情,包括但不限于:
-
回归分析让你理解变量之间关系的强度。通过像 R 平方/调整 R 平方这样的统计测量,回归分析可以告诉你模型解释了数据总变异性的多少。
-
回归分析告诉你模型中哪些预测变量在统计上显著,哪些不是。简单来说,如果你给回归模型 50 个特征,你可以找出哪些特征是目标变量的有效预测因子,哪些不是。
-
回归分析可以为每个估计的回归系数提供置信区间。你不仅可以为每个特征估计一个系数,还可以得到一个系数范围,并有一个置信水平(例如,99% 置信度)来表示该系数位于其中。
-
以及更多……
我的观点是,回归分析中有很多统计技术,可以让你回答比“我们能否根据 X(s) 预测 Y?”更多的问题。
第 #2 点:回归分析不像黑箱那样复杂,更容易沟通。
我在选择模型时总是考虑的两个重要因素是它有多简单和多可解释。
为什么?
一个更简单的模型意味着更容易沟通模型本身的工作原理以及如何解读模型结果。
例如,大多数商业用户可能会比反向传播更快地理解最小二乘和(即最佳拟合线)。这很重要,因为企业关心的是模型中潜在逻辑的工作原理——在商业中,没有什么比不确定性更糟糕的了——而黑箱正是这个问题的绝佳代名词。
最终,理解模型中数字是如何得出的以及如何解读这些数字是很重要的。
第 #3 点:学习回归分析将使你对统计推断有更好的理解。
不管你信不信,学习回归分析让我成为了更好的编码员(Python 和 R)、更好的统计学家,并且让我对构建模型有了更好的理解。
为了让你更兴奋一点,回归分析帮助我学到了以下内容(不仅限于此):
-
构建简单和多重回归模型。
-
进行残差分析并应用 Box-Cox 等变换。
-
计算回归系数和残差的置信区间。
-
通过假设检验来确定模型和回归系数的统计显著性。
-
使用 R 平方、MSPE、MAE、MAPE、PM 等指标来评估模型,列表还在继续……
-
使用方差膨胀因子 (VIF) 识别多重共线性。
-
使用部分 F 检验比较不同的回归模型。
这只是我学到的内容的一小部分,而且我才刚刚开始。所以如果你觉得这听起来很有趣,我建议你去了解一下,至少看看你能学到什么。
如何学习回归分析?
最近,我发现学习新话题的最佳方法是找到大学或学院的课程讲座或课程笔记。网络上免费提供的资源实在是太多了。
特别是,我将推荐两个你可以用来入门的优秀资源:
特伦斯·辛 是一位对数据充满热情的专家,拥有超过 3 年的 SQL 经验和 2 年的 Python 经验,同时也是 Towards Data Science 和 KDnuggets 的博主。
原文。转载已获许可。
更多相关主题
使用随机森林®而非神经网络的 3 个理由:比较机器学习与深度学习
原文:
www.kdnuggets.com/2020/04/3-reasons-random-forest-neural-network-comparison.html
评论
神经网络已被证明在许多行业领域中优于多种机器学习算法。它们会不断学习,直到找到最佳特征集以获得令人满意的预测性能。然而,神经网络会将你的变量缩放成一系列数字,一旦神经网络完成学习阶段,这些特征对我们来说变得不可辨识。

如果我们只关心预测,神经网络将是唯一常用的算法。但在行业环境中,我们需要一个能给利益相关者提供特征/变量含义的模型。这些利益相关者很可能不是拥有深度学习或机器学习知识的人。
随机森林算法和神经网络之间的主要区别是什么?
随机森林算法和神经网络是不同的技术,它们学习的方式不同,但可以用于类似的领域。随机森林算法是一种机器学习技术,而神经网络则专属于深度学习。
什么是神经网络?
一个神经网络是一个计算模型,松散地基于人类大脑皮层的功能,以复制相同的思维和感知方式。神经网络按层组织,由互联的节点组成,这些节点包含一个激活函数,用于计算网络的输出。
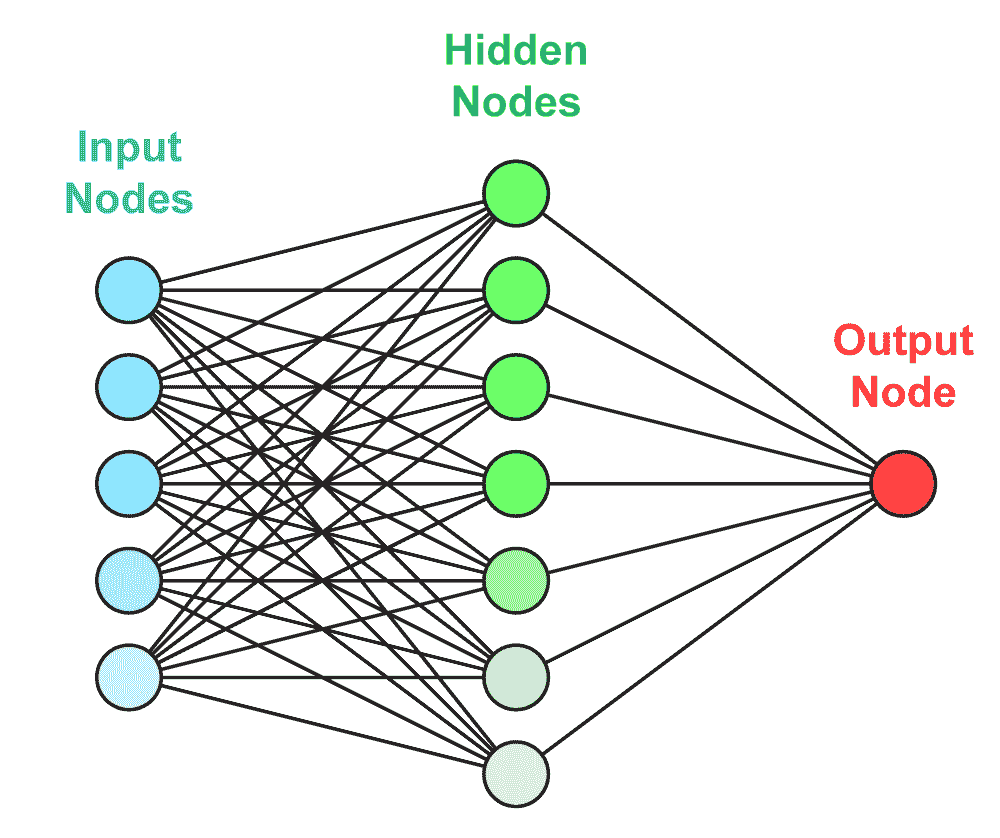
神经网络是另一种机器学习方式,其中计算机通过分析训练示例来学习执行任务。由于神经网络松散地基于人脑,它将由成千上万或数百万个互联节点组成。一个节点可以连接到下层中的多个节点,从中接收数据,以及多个上层节点接收数据。每个传入的数据点会接收一个权重,并进行乘法和加法。如果加权和等于零,则添加偏差,然后传递到激活函数。
神经网络的架构
神经网络有 3 种基本架构:
1. 单层前馈网络
- 这是一个最简单的网络,是感知器的扩展版本。它在输入层和输出层之间有额外的隐藏节点。
2. 多层前馈网络
- 这种网络类型除了输入层和输出层之外,还有一个或多个隐藏层。它的作用是在输入层和输出层之间进行数据传输的干预。
- 循环神经网络类似于上述网络,但被广泛应用于预测序列数据,如文本和时间序列。最著名的循环神经网络是‘长短期记忆(LSTM)模型’。
什么是随机森林算法?
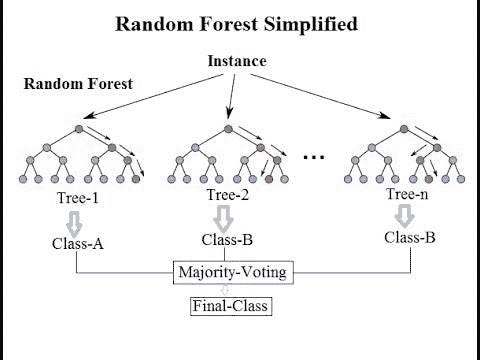
随机森林算法 是决策树的集成,其中最终/叶节点将是分类问题的多数类或回归问题的平均值。
随机森林算法将生长许多分类树,对于每个来自该树的输出,我们称这棵树‘投票’给那个类别。树的生长步骤如下:
-
每棵树将从训练数据中随机抽取一部分行。
-
从步骤(1)中采样的特征子集将被用来进行每棵树的分裂。
-
每棵树会按照参数指定的最大程度生长,直到它对类别进行投票。
为什么你应该使用随机森林算法?
使用随机森林算法而非决策树的根本原因是将许多决策树的预测结果组合成一个模型。逻辑是,即使由许多平庸模型组成的单一模型也会优于一个优秀模型。考虑到随机森林算法的主流性能,这一点是有道理的。由于这一点,随机森林算法较少容易过拟合。
灵活模型如决策树可能会出现过拟合,其中模型会记住训练数据并学习数据中的噪声。这将使其无法预测测试数据。
随机森林算法通过将许多树组合成一个集成模型,可以减少像决策树这样的灵活模型的高方差。
何时使用随机森林算法而非神经网络?
随机森林算法的计算开销较小,并且不需要 GPU 来完成训练。随机森林算法可以为你提供与决策树不同的解释,但性能更优。神经网络需要的数据量远超过普通人手头能获得的数据,才能真正有效。神经网络将会极大地削弱特征的可解释性,使其为了性能的需要变得毫无意义。虽然这对一些人来说可能听起来合理,但这取决于每个项目。
如果目标是创建一个预测模型而不考虑变量的影响,完全可以使用神经网络,但你需要相应的资源。如果需要理解这些变量,那么无论我们是否喜欢,通常情况下,性能会稍微下降,以确保我们仍然可以理解每个变量如何影响预测模型。
RANDOM FORESTS 和 RANDOMFORESTS 是 Minitab, LLC 的注册商标。
原始内容。经许可转载。
相关:
-
随机森林® — 一种强大的集成学习算法
-
随机森林®与神经网络在预测客户流失中的比较
-
比较决策树算法:随机森林®与 XGBoost
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
更多相关内容
团队合作为何是数据科学中至关重要的技能
原文:
www.kdnuggets.com/2022/05/3-reasons-teamwork-essential-skill-data-science.html

图片来源:Pexels
主要收获
-
没有团队合作,现实世界的数据科学问题将难以解决。
-
因此,学术培训项目应设计能够帮助学生合作并提高团队合作技能的顶点项目。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作。
安德鲁·卡内基曾说过: “团队合作是朝着共同愿景一起工作的能力。将个人成就引导到组织目标上的能力。这是让普通人实现非凡成果的燃料。”
团队合作是成功进行数据科学实践所需的最重要技能之一。本文将探讨团队合作在现实世界的数据科学项目中为何如此重要的 3 个原因。
1. 缺乏领域知识
数据科学家可能对感兴趣的系统没有领域知识。例如,具体取决于你工作的组织,你可能需要与工程师(工业数据集)、医生(医疗数据集)等团队合作,以确定模型中使用的预测特征和目标特征。例如,某个工业系统可能具有实时生成数据的传感器,在这种情况下,作为数据科学家,你可能对该系统没有技术知识。因此,你需要与工程师和技术人员合作,以便他们指导你决定哪些特征是有趣的,哪些是预测变量,哪些是目标变量。因此,团队合作对于将项目的不同方面拼凑在一起至关重要。从我个人在工业数据科学项目中的经验来看,我的团队花了 3 个月的时间与系统工程师、电气工程师、机械工程师、现场工程师和技术人员合作,仅仅是为了了解如何用现有数据构建正确的问题。这种多学科的方法在现实世界的数据科学项目中是必不可少的。
2. 项目的范围
在现实世界的数据科学项目中,数据集通常非常复杂。例如,数据集可能包含成千上万的特征,也可能有数十万甚至百万的观测值。此外,数据集可能还会依赖于空间和时间。因此,确定构建何种模型以及使用哪些特征来构建模型可能非常具有挑战性。项目的范围可能过于庞大,单凭一个人无法处理。在这种情况下,通过与其他数据科学家、数据分析师、数据工程师以及行业人员组成团队来减轻项目的负担。通过将任务委派给不同的团队成员,工作负荷可以变得更轻、更可管理。这将使项目能够在合理的时间框架内进行规划、设计和执行。
3. 模型的商业影响
最终模型将如何部署?公司高管和经理们如何看待这个项目?他们是否愿意投资这个想法并将建议实施到日常决策中?这些建议是否会提高业务运营的效率?它是否会改善客户体验?是否会导致利润的增长?这个模型在节约成本方面有哪些财务影响?作为一名数据科学家,你需要与公司领导和高管合作,尝试说服他们你的模型或交付物是值得的,并且具有深远的影响,能够为公司节省大量资金。为了确定模型的业务影响,团队合作将发挥重要作用,因为你需要与工程师和业务部门的其他官员一起工作,确定如果实施该模型会带来哪些成本节约。
总结
总结来说,我们讨论了团队合作在现实世界数据科学项目中的三个重要原因。如果没有团队合作,现实世界的数据科学问题将难以解决。因此,学术培训项目应设计具有工业意义的顶点项目。如果可能,学术项目可以邀请当地公司来建议和推荐顶点项目。参与项目的学生需要全面参与从问题框定到数据分析、模型构建、测试、评估和实施的所有方面。在项目期间,与行业官员的合作必须被优先考虑。这样,学生将有机会参与跨学科和多样化的团队。这种多学科的问题解决方法将使他们能够发展在现实世界中成功所需的关键团队合作、沟通、领导和商业敏锐度技能。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。之前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
主题更多内容
3 种基于研究的高级提示技术,以提高 LLM 的效率和速度优化

图片由 Freepik 提供
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
像 OpenAI 的 GPT 和 Mistral 的 Mixtral 这样的语言模型(LLM)在 AI 驱动的应用程序开发中扮演着越来越重要的角色。这些模型生成类似人类的结果的能力使它们成为内容创作、代码调试以及其他耗时任务的完美助手。
然而,与 LLM 互动时常见的一个挑战是可能遇到事实不准确的信息,通常被称为幻觉。这些情况的原因并不难以理解。LLM 被训练来提供对提示的满意回答;在不能提供答案的情况下,它们会编造一个。幻觉也可能受到输入类型和训练这些模型时所用偏见的影响。
在本文中,我们将探讨三种基于研究的高级提示技术,这些技术作为减少幻觉发生的有希望的方法,同时提高 LLM 生成结果的效率和速度。
提示工程基础
为了更好地理解这些高级技术带来的改进,我们有必要讨论一下提示编写的基础知识。在 AI 的上下文中(在本文中指 LLM),提示指的是一组字符、词语、标记或一组指令,这些都用于指导 AI 模型理解人类用户的意图。
提示工程指的是创建提示的艺术,以更好地指导相关 LLM 的行为和生成的输出。通过使用不同的技术更好地传达人的意图,开发者可以提升模型在准确性、相关性和一致性方面的结果。
下面是一些在编写提示时应遵循的基本技巧:
-
简洁明了
-
通过指定所需的输出格式来提供结构
-
如果可能,请提供参考或示例。
所有这些都将帮助模型更好地理解你的需求,并增加获得令人满意答案的机会。
下面是一个很好的例子,展示了如何使用上述所有提示来查询 AI 模型:
提示 = “你是一个专家 AI 提示工程师。请生成关于提示生成最新进展的 2 句总结,重点关注幻觉的挑战以及使用高级提示技术解决这些挑战的潜力。输出应为 Markdown 格式。”
然而,遵循这些前面讨论的基本技巧并不总能保证最佳结果,特别是当处理复杂任务时。
可以在应用中实施的实践研究驱动的高级提示技术
来自微软和谷歌等知名 AI 机构的领先研究人员已经投入了大量资源进行 LLM 优化,即积极研究幻觉的常见原因并寻找有效的方法来解决这些问题。以下提示技术已被发现能够为研究中的 LLM 提供更好的上下文感知指令,从而增加获得更好相关结果的机会,并减少获得不准确或荒谬信息的可能性。
以下是一些研究驱动的高级提示技术示例:
1. 情感化说服提示
微软研究人员 2023 年的一项研究发现,使用情感语言和说服性提示,即“EmotionPrompts”,可以将 LLM 性能提高超过 10%。
这种风格为给定的提示添加了个人化的情感元素,将请求转化为一个具有重要意义和显著后果的请求。它几乎像是在与人对话;使用情感角度有助于传达任务的重要性,激发更深的专注和承诺。这一策略对需要更高问题解决和创造力技能的任务非常有用。
我们来看一个简单的例子,其中情感被用来增强提示:
基本提示:“编写一个 Python 脚本来排序一个数字列表。”
情感化的 说服力:“我很兴奋能提升我的 Python 技能,我需要写一个脚本来排序数字。这是我作为开发者职业生涯中的一个关键步骤。”
虽然两种提示变体产生了类似的代码结果,但“EmotionPrompts”技术帮助创建了更简洁的代码,并在生成的结果中提供了额外的解释。

Finxter 进行的另一项有趣实验发现,向 LLM 提供金钱奖励也可以提高其表现——几乎像是吸引人类的财务激励一样。
2. Chain-of-Thought 提示
另一种由匹兹堡大学研究小组发现有效的提示技术是 Chain-of-Thought 风格。这种技术采用逐步的方法,引导模型按照期望的输出结构进行。这种逻辑方法帮助模型为复杂任务或问题制定更相关且结构化的响应。
这是一个如何基于给定模板创建 Chain-of-Thought 风格提示的示例(使用 OpenAI 的 ChatGPT 和 GPT-4):
基本提示: "为面向大城市小型企业主的金融应用制定一个数字营销计划。"

Chain of Thought 提示:
"为大城市的小型企业主制定一个数字营销策略。重点关注:
-
选择在该商业人群中受欢迎的数字平台。
-
创建有吸引力的内容,如网络研讨会或其他相关工具。
-
生成与传统广告不同的成本效益战术。
-
将这些战术量身定制以满足城市小型企业的需求,从而提高客户转化率。
使用独特且可操作的步骤命名和详细说明计划的每个部分。
Chain-of-Thought 提示技术从初步观察中生成了更精确和可操作的结果。
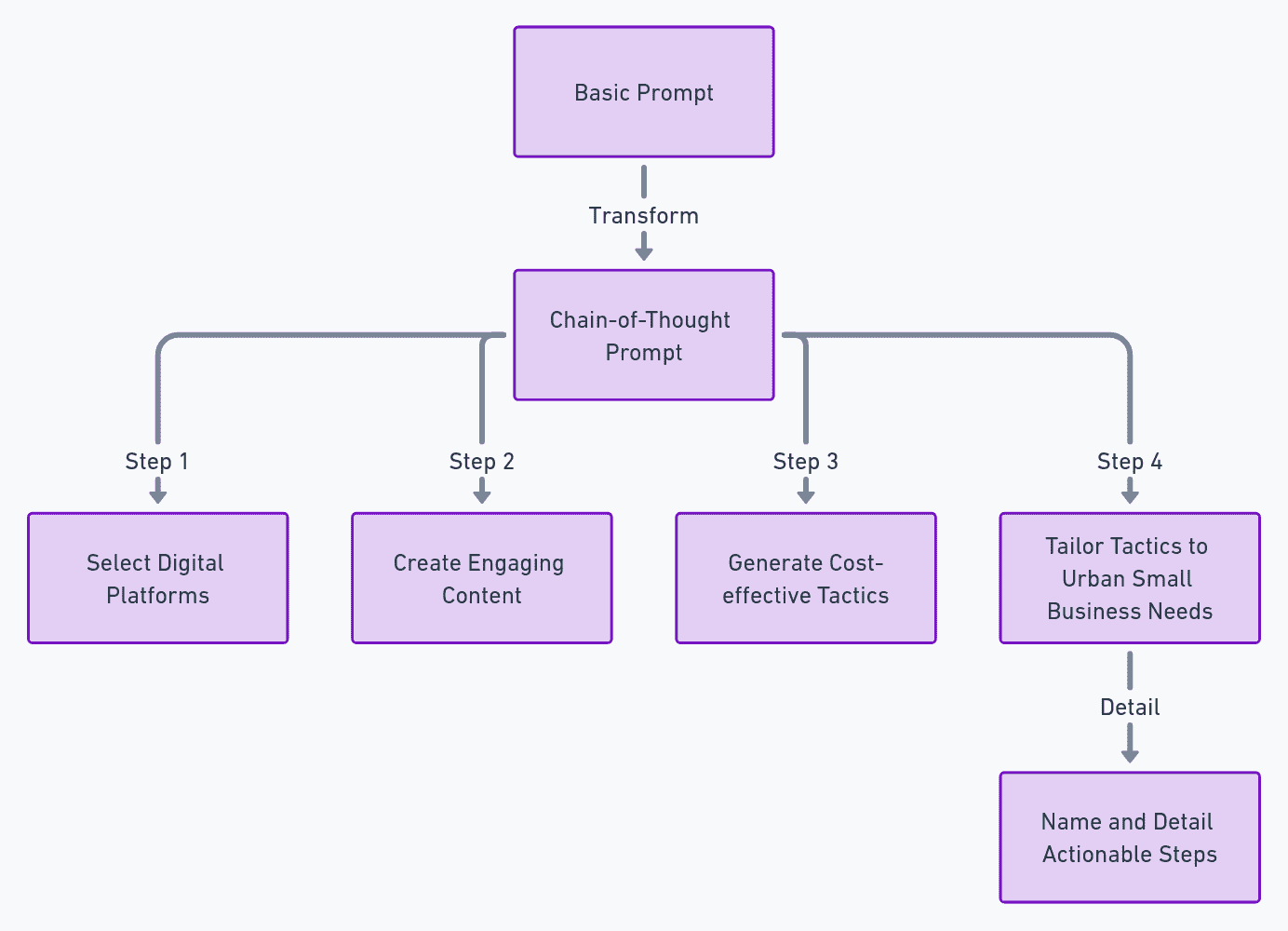
3. Step-Back 提示
由七名 Google 的Deepmind 研究人员提出的 Step-Back-Prompting 技术旨在模拟处理 LLM 时的推理。这类似于在解决复杂问题之前教给学生概念的基本原理。
要应用这种技术,你需要在请求模型提供答案之前指出问题背后的基本原理。这确保了模型能够获得充分的背景,这将帮助它提供技术上正确且相关的答案。
我们来看看两个示例(使用 OpenAI 的 ChatGPT 和 GPT-4):
示例 1:
****基本提示**: "疫苗是如何工作的?"

使用 Step-Back 技术的提示
-
“哪些生物机制使疫苗能够防御疾病?”
![3 个基于研究的高级提示技术,提高 LLM 效率和速度优化]()
-
“你能解释一下疫苗引发的身体免疫反应吗?”
![3 个基于研究的高级提示技术,提高 LLM 效率和速度优化]()

虽然基本提示提供了令人满意的答案,但使用“后退一步”技巧提供了更深入、更技术性的回答。这对于你可能遇到的技术问题尤其有用。
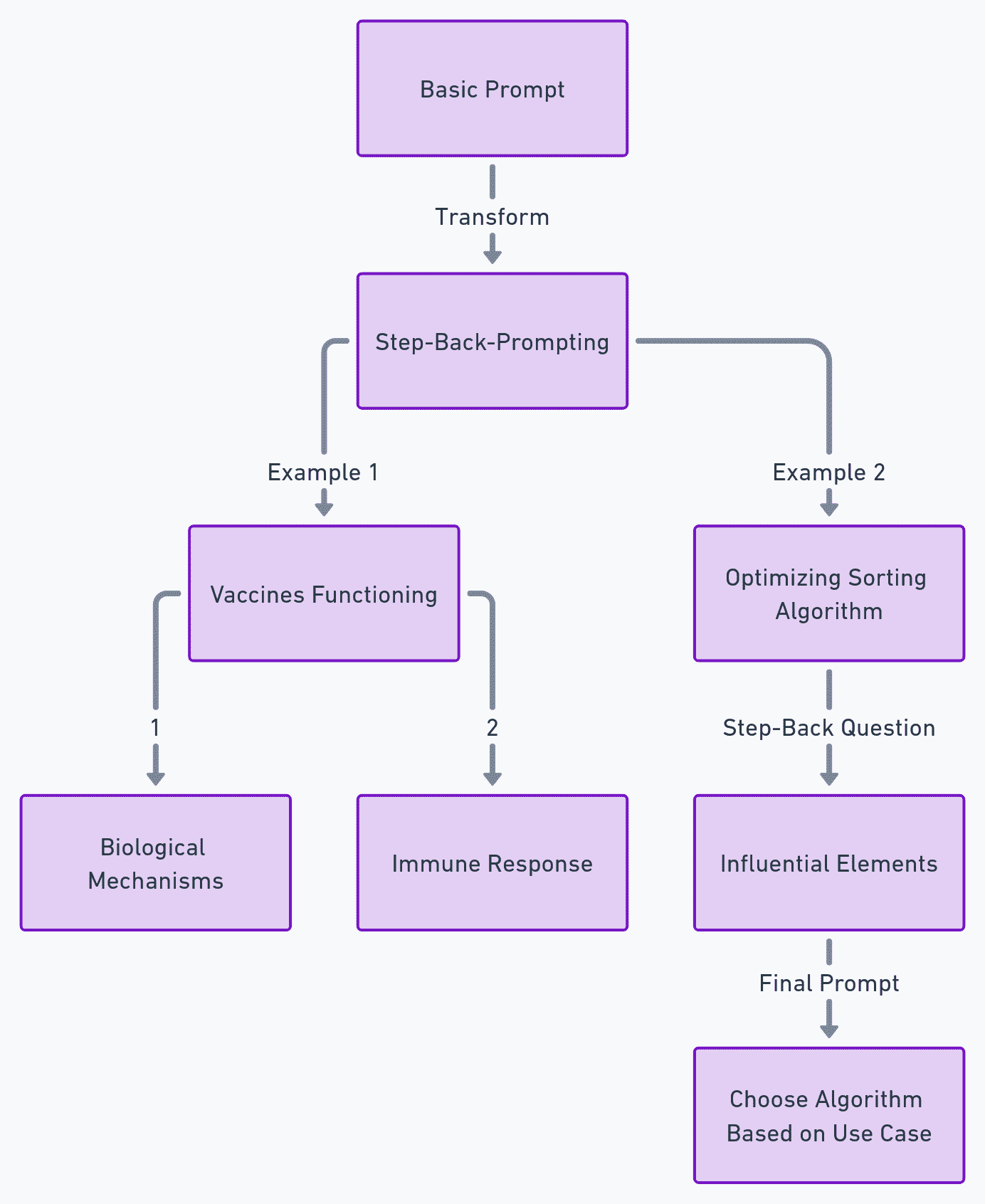
结论
随着开发者继续为现有的 AI 模型构建新颖的应用,对先进提示技术的需求也在增加,这些技术可以提升大型语言模型的能力,不仅理解我们的言语,还能理解其中的意图和情感,从而生成更准确和上下文相关的输出。
Mahmud Adeleye是一位拥有丰富经验的软件工程师,专注于设计 AI 驱动的软件应用。他还为 JavaScript 开发者提供了一个开源的 AI 课程: https://github.com/thestriver/ai-for-javascript-course。
更多关于这个话题
Llama,Llama,Llama:3 个简单步骤,使用你的内容进行本地 RAG
原文:
www.kdnuggets.com/3-simple-steps-to-local-rag-with-your-content

作者提供的图片 | Midjourney & Canva
你想要本地 RAG 且麻烦最少吗?你是否有一堆文档,想把它们当作知识库来增强语言模型?想要构建一个了解你所需内容的聊天机器人?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
好吧,这里有一个可以说是最简单的方法。
我可能不是最优化的推理速度、向量精度或存储系统,但它超级简单。如果需要,可以进行调整,但即使没有,短时间的教程也应该能让你的本地 RAG 系统完全运行起来。由于我们将使用 Llama 3,我们也可以期待一些很好的结果。
我们今天使用了什么工具?3 只 Llama:Ollama 用于模型管理,Llama 3 作为我们的语言模型,LlamaIndex 作为我们的 RAG 框架。Llama,Llama,Llama。
让我们开始吧。
第一步:Ollama,用于模型管理
Ollama 可以用于管理和与语言模型交互。今天我们将使用它进行模型管理,并且由于 LlamaIndex 能够直接与 Ollama 管理的模型交互,因此间接用于交互。这将使我们的整体过程更加简便。
我们可以通过遵循应用程序的GitHub 仓库上的系统特定说明来安装 Ollama。
一旦安装完成,我们可以从终端启动 Ollama 并指定我们希望使用的模型。
第二步:Llama 3,语言模型
一旦 Ollama 安装并正常运行,我们可以从其 GitHub 仓库下载列出的任何模型,或者从其他现有语言模型实现中创建自己的 Ollama 兼容模型。使用 Ollama 运行命令将下载指定的模型,如果系统中未存在该模型,因此可以通过以下命令下载 Llama 3 8B:
ollama run llama3
只需确保你有足够的本地存储来容纳 4.7 GB 的下载。
一旦 Ollama 终端应用程序以 Llama 3 模型作为后台启动,你可以继续并最小化它。我们将使用 LlamaIndex 从自己的脚本与之进行交互。
第三步:LlamaIndex,RAG 框架
这个难题的最后一部分是 LlamaIndex,我们的 RAG 框架。要使用 LlamaIndex,你需要确保它已安装在你的系统上。由于 LlamaIndex 的打包和命名空间最近发生了变化,最好查看官方文档以确保在本地环境中安装 LlamaIndex。
一旦启动并运行,并且 Ollama 正在运行带有 Llama3 模型,你可以将以下内容保存到文件中(改编自这里):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
# My local documents
documents = SimpleDirectoryReader("data").load_data()
# Embeddings model
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
# Language model
Settings.llm = Ollama(model="llama3", request_timeout=360.0)
# Create index
index = VectorStoreIndex.from_documents(documents)
# Perform RAG query
query_engine = index.as_query_engine()
response = query_engine.query("What are the 5 stages of RAG?")
print(response)
这个脚本执行了以下操作:
-
文档存储在“data”文件夹中
-
用于创建 RAG 文档嵌入的模型是来自 Hugging Face 的 BGE 变体
-
语言模型是前面提到的 Llama 3,通过 Ollama 访问
-
我们的数据查询(“RAG 的 5 个阶段是什么?”)是合适的,因为我在数据文件夹中放入了许多与 RAG 相关的文档
以及我们查询的输出:
The five key stages within RAG are: Loading, Indexing, Storing, Querying, and Evaluation.
请注意,我们可能需要以多种方式优化脚本,以促进更快的搜索并保持某些状态(例如嵌入),但我将留给感兴趣的读者去探索。
最终思考
好吧,我们做到了。我们成功地在本地使用 Ollama 在 3 个相当简单的步骤中搭建了一个基于 LlamaIndex 的 RAG 应用程序。你可以做很多其他事情,包括优化、扩展、添加 UI 等,但简单的事实是,我们能够在几个代码行和一组最小的支持应用程序和库中构建我们的基准模型。
希望你喜欢这个过程。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets & Statology的管理编辑,以及Machine Learning Mastery的贡献编辑,Matthew 的目标是使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法,以及探索新兴的 AI。他致力于在数据科学社区中普及知识。Matthew 从 6 岁起就开始编程。
更多关于这个话题
加速你的 Python 代码的三种简单方法
原文:
www.kdnuggets.com/2022/10/3-simple-ways-speed-python-code.html
来源: 图片由 Freepik 提供
你刚刚完成了一个使用 Python 的项目。代码干净且可读,但你的性能基准未达标。你原本期望结果在毫秒内出来,却得到了秒级的结果。你该怎么办?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
如果你正在阅读这篇文章,你可能已经知道 Python 是一种具有动态语义和高可读性的解释型编程语言。这使得它易于使用和阅读,但对于许多现实世界的使用场景却不够快速。
因此,可能有多种方法来加速你的 Python 代码,包括但不限于使用高效的数据结构和快速高效的算法。一些 Python 库还在底层使用 C 或 C++ 来加速计算。
如果你已经耗尽了所有这些选项,接下来可以考虑并行处理,进一步则是分布式计算。在这篇文章中,你将了解在机器学习背景下三种流行的分布式计算框架:PySpark、Dask 和 Ray。
PySpark
PySpark,顾名思义,是 Apache Spark 在 Python 中的接口。它允许用户使用 Python API 编写 Spark 程序,并提供 PySpark shell 进行分布式环境下的交互式数据分析。它支持几乎所有的 Spark 特性,如 Streaming、MLlib、Spark SQL、DataFrame 和 Spark Core,如下所示:
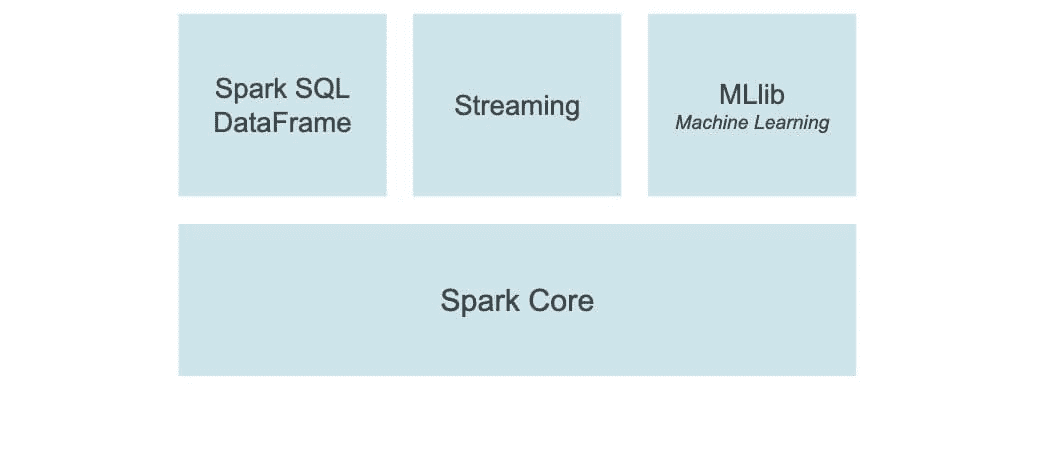
1. 流处理
Apache Spark 的流处理特性易于使用且具备容错性,运行在 Spark 之上。它为流数据和历史数据提供直观和分析系统。
2. MLlib
MLlib 是建立在 Spark 框架上的可扩展机器学习库。它暴露了一组一致的高层 API,用于创建和调整可扩展的机器学习管道。
3. Spark SQL 和 DataFrame
它是一个用于表格数据处理的 Spark 模块。它提供了一个抽象层,称为 DataFrame,可以在分布式设置中作为 SQL 风格的查询引擎。
4. Spark Core
Spark Core 是一个基础的通用执行引擎,所有其他功能都建立在其上。它提供了一个弹性分布式数据集(RDD)和内存计算。
5. Pandas API on Spark
Pandas API 是一个模块,使得 pandas 的特性和方法可以进行可扩展处理。它的语法与 pandas 一致,不需要用户培训新的模块。它为 pandas(小型/单机数据集)和 Spark(大型分布式数据集)提供了无缝集成的代码库。
Dask
Dask 是一个多功能的开源分布式计算库,它提供了一个与 Pandas、Scikit-learn 和 NumPy 类似的用户界面。
它提供了高级和低级 API,使用户能够在单机或分布式机器上并行运行自定义算法。
它有两个组件:
-
大数据集合包括高级集合,如 Dask Array 或并行化 NumPy 数组、Dask Bag 或并行化列表、Dask DataFrame 或并行化 Pandas DataFrames、以及并行化 Scikit-learn。它们还包括低级集合,如 Delayed 和 Futures,这些都简化了自定义任务的并行和实时实现。
-
动态任务调度使得任务图可以并行执行,扩展到数千个节点的集群。
Ray
Ray 是一个用于通用分布式 Python 以及 AIML 驱动应用程序的单一平台框架。它包含一个核心分布式运行时和一个库工具包(Ray AI Runtime),用于并行化 AIML 计算,如下图所示:
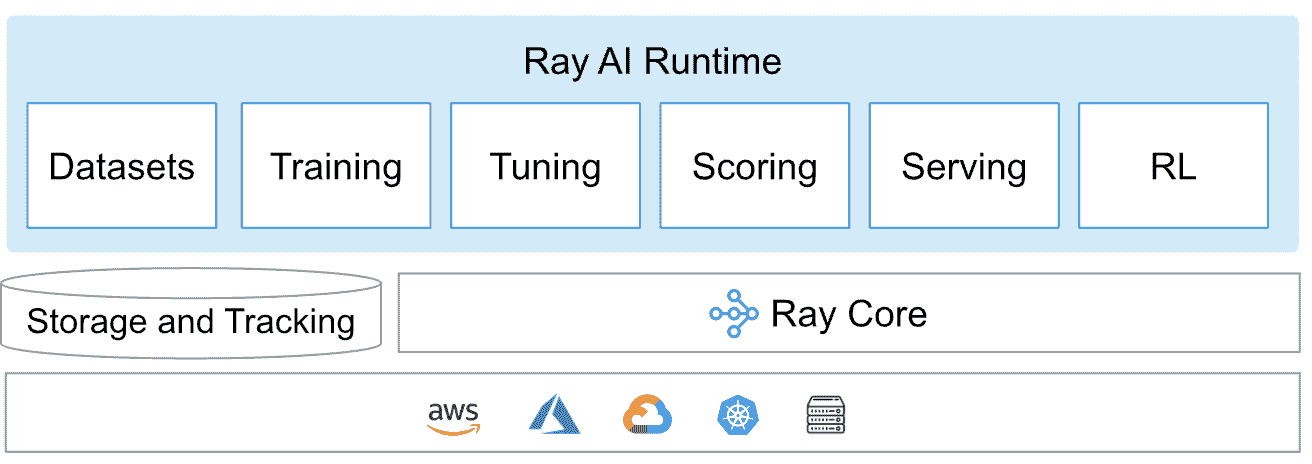
Ray AI Runtime
Ray AIR 或 Ray AI Runtime 是一个一站式工具包,用于分布式 ML 应用,支持轻松扩展个体和端到端工作流。它基于 Ray 的库,处理各种任务,如预处理、评分、训练、调优、服务等。
Ray Core
Ray Core 提供了核心原语,如任务(在集群中执行的无状态函数)、演员(在集群中创建的有状态工作进程)和对象(在集群中可访问的不可变值),用于构建可扩展的分布式应用程序。
Ray 使用 Ray AIR 扩展机器学习工作负载,并通过 Ray Core 和 Ray Clusters 构建和部署分布式应用程序。
选择哪一个?
现在你已经了解了你的选择,接下来的自然问题是选择哪一个。答案取决于多个因素,如具体的业务需求、开发团队的核心实力等。
让我们了解一下哪种框架适合下面列出的具体要求:
-
规模: PySpark 在处理超大型工作负载(TB 级及以上)时最为强大,而 Dask 和 Ray 在中等规模的工作负载下表现相当不错。
-
通用性: 在通用解决方案方面,Ray 领先,其次是 PySpark。而 Dask 完全旨在扩展 ML 管道。
-
速度: Ray 是处理 NLP 或文本标准化任务的最佳选择,利用 GPU 加速计算。另一方面,Dask 提供了快速读取结构化文件到 DataFrame 对象的功能,但在连接和合并方面表现较差。这里 Spark SQL 表现优异。
-
熟悉度: 对于更倾向于 Pandas 数据获取和过滤方式的团队,Dask 似乎是一个首选,而 PySpark 则适合那些寻找类似 SQL 查询接口的团队。
-
易用性: 三个工具建立在不同的平台上。虽然 PySpark 主要基于 Java 和 C++,Dask 则完全基于 Python,这意味着你的机器学习团队,包括数据科学家,可以更容易地追踪错误消息。另一方面,Ray 的核心是 C++,但在 AIML 模块(Ray AIR)中相当 Python 风格。
-
安装和维护: 在维护开销方面,Ray 和 Dask 得分相当。另一方面,Spark 基础设施相当复杂且难以维护。
-
流行度和支持: PySpark 作为所有选项中最成熟的一个,享有开发者社区的支持,而 Dask 排名第二。Ray 在功能方面表现出色,处于测试阶段。
-
兼容性: 虽然 PySpark 与 Apache 生态系统集成良好,但 Dask 与 Python 和 ML 库的兼容性也很好。
总结
本文讨论了如何在常见的数据结构和算法选择之外加速 Python 代码。文章重点介绍了三个著名的框架及其组件。本文旨在通过权衡不同选项在各种特性和业务背景下的表现,帮助读者做出选择。
Vidhi Chugh 是一位获奖的 AI/ML 创新领导者和 AI 伦理学家。她在数据科学、产品和研究的交汇点工作,以提供商业价值和洞察。她是数据中心科学的倡导者,也是数据治理领域的领先专家,致力于构建可信赖的 AI 解决方案。
更多内容
3 个更多 SQL 聚合函数面试问题用于数据科学
原文:
www.kdnuggets.com/2023/01/3-sql-aggregate-function-interview-questions-data-science.html

图片由作者提供
聚合函数是 SQL 的核心功能之一。从 SQL 作为必备的 数据科学工具 可以得出结论,没有哪个数据科学家没有使用过 SQL 聚合函数的活例子。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
否则他们如何分析数据并提供有意义的指标? 数据科学家的生活没有数据聚合就像一支断了的铅笔——毫无意义。
面试官都知道这一点。他们会全方位检查你的聚合技能。
五大 SQL 聚合函数
SQL 聚合函数 从多行中提取值并返回一个单一的聚合值。它们通常与 GROUP BY 子句一起使用。这使你能够查看组名称和聚合值。
SQL 中有很多聚合函数。它们的数量也取决于你使用的 SQL 方言。
但无论如何,SQL 中最常见的聚合函数就是这五个。
图片由作者提供
函数的名称并不神秘。任何人都可以直观地推断出每个函数的作用。
然而,在面对业务问题时,知道如何使用它们是另一回事。这些技能需要一点练习。
接下来的三个面试问题应该会对你有所帮助。
1. 获奖柔道运动员的平均体重
这是 ESPN 提出的一个问题,你可以在 StrataScratch 上找到。
“找出每个团队中获得奖牌的柔道运动员的平均体重,年龄在 20 到 30 岁之间,包括 20 岁和 30 岁的运动员。输出团队名称和运动员的平均体重。”
这里是链接以便你跟着我。
这个问题要求你按团队查找获奖柔道选手的平均体重。这显然意味着你需要使用 AVG()聚合函数。
只有 20 到 30 岁之间的获奖者应被考虑。使用 MIN()和 MAX()函数来实现。
放入代码后,它看起来是这样的。
SELECT team,
AVG(weight) AS average_player_weight
FROM olympics_athletes_events
WHERE sport = 'Judo'
AND medal IS NOT NULL
GROUP BY team
HAVING MIN(age) >= 20
AND MAX(age) <= 30;
查询选择团队,也会在 GROUP BY 中使用,并从表 olympics_athletes_events 计算平均体重。WHERE 子句用于仅包括柔道项目,并排除未获奖的竞争者。
最后,在 HAVING 子句中使用 MIN()和 MAX()函数来显示年龄在 20 到 30 岁之间的获胜者。
这里还有代码输出。
| team | average_player_weight |
|---|---|
| France | 77 |
| Georgia | 84 |
| Japan | 70 |
| Romania | 48 |
2. 计算各部门的学生人数
LeetCode 的问题要求你完成以下任务。
“编写一个 SQL 查询,报告Department表中每个部门的部门名称和学生人数(即使某些部门没有在读学生)。返回结果表按学生人数降序排列。若有并列情况,按部门名称字母顺序排列。”
这里是链接以便你跟着我。
提示在问题标题中。解决这个问题需要使用 COUNT()聚合函数。
SELECT dept_name,
COUNT(student_id) AS student_number
FROM department
LEFT JOIN student ON department.dept_id = student.dept_id
GROUP BY department.dept_name
ORDER BY student_number DESC,
department.dept_name;
与之前的问题不同,这里有两个表:department 和 student。
第一步是选择部门名称,并使用 COUNT()函数通过其 ID 查找学生人数。
要获取两个列,使用 LEFT JOIN 连接表。为什么使用这种连接?因为问题要求返回所有部门名称,即使没有学生。
输出按部门分组,按学生人数降序排列,部门名称升序排列。
这里是期望的输出。
| dept_name | student_number |
|---|---|
| Engineering | 2 |
| Science | 1 |
| Law | 0 |
3. 比赛排行榜
最后的问题来自 HackerRank。
“你在帮助 Julia 完成她上一个编程挑战时做得非常出色,所以她希望你也能处理这个问题!黑客的总分是他们在所有挑战中的最高分之和。编写一个查询,打印出黑客 ID、姓名和总分,按总分降序排列。如果有多个黑客的总分相同,则按黑客 ID 升序排列。排除所有总分为 0 的黑客。”
如果你想跟我一起操作,可以点击这个 链接。
该解决方案使用了两个聚合函数:SUM() 和 MAX()。
SELECT h.hacker_id,
h.name,
SUM(max_score) AS sum_max_score
FROM hackers h
JOIN
(SELECT hacker_id,
challenge_id,
MAX(score) AS max_score
FROM submissions
GROUP BY hacker_id,
challenge_id) s ON h.hacker_id = s.hacker_id
GROUP BY h.name,
h.hacker_id
HAVING SUM(max_score) > 0
ORDER BY SUM(max_score) DESC, h.hacker_id;
让我们首先关注子查询,它用于计算每个黑客和挑战的最高分。为此,它使用了 MAX() 聚合函数。
主查询从 hackers 表中选择黑客的 ID 和名字。它还使用 SUM() 函数通过引用子查询来汇总最高分。
这两个查询通过列 hacker_id 使用 JOIN 连接。
之后,输出被过滤以仅显示总分高于零的记录。最后,结果按总分降序排列,并按黑客 ID 升序排列。
这里显示了输出的前几行。
| hacker_id | name | sum_max_score |
|---|---|---|
| 76971 | Ashley | 760 |
| 84200 | Susan | 710 |
| 76615 | Ryan | 700 |
| 82382 | Sara | 640 |
| 79034 | Marilyn | 580 |
摘要
就这样:展示了三道中等难度面试问题中的五个最受欢迎的 SQL 聚合函数。对于一个关键的 SQL 概念,这并不算太难,对吧?
这三个问题是你可以从面试中期待的良好示例。如你所见,SQL 聚合函数并不是单独存在的。它们通常与其他 SQL 概念同时考察,如数据分组和过滤、表连接以及编写子查询。
使用这些问题作为指导,但确保你自己解决几个问题。那是你在面试前能接近面试的最好方法。
内特·罗西迪 是一位数据科学家和产品战略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题准备面试。你可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
更多相关内容
利用数据的力量的三步骤
原文:
www.kdnuggets.com/2022/05/3-steps-harnessing-power-data.html
数据收集、清洗、转换和分析过程的示意图。图像来源:作者。
关键要点
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
-
在今天这个信息技术驱动的世界里,数据的产生量达到了前所未有的水平。
-
为了充分提取数据的力量,必须收集、处理、转换和分析数据以发挥其作用。
数据现在被视为一种新的“黄金”。每天产生的数据量是前所未有的。虽然原始数据有用,但数据的真正力量来自于经过不同方法(如描述性、预测性和指导性分析)精炼、清洗、转换和分析后的数据,这将在本文中讨论。
第一步:原始数据及其来源
原始数据可以从多个来源获取,例如传感器、互联网或调查。原始数据通常包含一些影响其质量的缺陷,如下所述。
错误数据: 数据收集在不同层次上可能产生错误。例如,一项调查可能被设计用来收集数据。然而,参与调查的个人可能不会总是提供正确的信息。例如,参与者可能输入错误的年龄、身高、婚姻状态或收入信息。数据收集中的错误也可能发生在用于记录和收集数据的系统出现故障时。例如,温度计中的传感器故障可能导致温度计记录错误的温度数据。人为错误也可能导致数据收集错误,例如,技术人员在数据收集过程中可能错误地读取仪器。
由于调查通常是随机的,几乎不可能防止参与者提供虚假数据。通过定期对测量仪器进行质量保证检查,可以减少仪器收集数据时的误差,以确保它们在最佳状态下运行。通过让第二名技术人员或人员重新检查读数,可以减少从仪器读取结果时的人为错误。
缺失数据:大多数数据集包含缺失值。处理缺失数据的最简单方法是直接丢弃数据点。然而,移除样本或丢弃整个特征列并不可行,因为我们可能会丢失过多有价值的数据。在这种情况下,我们可以使用不同的插值技术来估算数据集中其他训练样本的缺失值。最常见的插值技术之一是均值插补,即用整个特征列的均值替代缺失值。其他插补缺失值的选项包括中位数或最频繁值(众数),其中后者用最频繁的值替代缺失值。无论你在模型中采用哪种插补方法,都必须记住插补只是一个近似值,因此可能会在最终模型中产生误差。如果数据已经被预处理,你需要找出缺失值是如何处理的。原始数据中有多少比例被丢弃?使用了什么插补方法来估算缺失值?
数据中的异常值:异常值是指与数据集其他部分非常不同的数据点。异常值通常只是错误数据,例如,由于传感器故障、实验污染或记录数据时的人为错误。有时,异常值可能表示某些真实情况,比如系统故障。异常值非常常见,尤其在大数据集中更为常见。异常值会显著降低机器学习模型的预测能力。处理异常值的常见方法是简单地忽略这些数据点。然而,删除真实的数据异常值可能过于乐观,导致不切实际的模型。
数据冗余:具有数百或数千个特征的大型数据集通常会导致冗余,特别是当特征彼此相关时。在一个高维数据集上训练模型,特征过多有时会导致过拟合(模型同时捕捉真实和随机效应)。此外,一个过于复杂的模型具有过多特征可能难以解释。解决冗余问题的一种方法是通过特征选择和降维技术,例如 PCA(主成分分析)。
数据不平衡:数据不平衡发生在数据集中不同类别的数据比例不相等时。一个不平衡数据集的例子可以通过 高度 数据集来演示。
import numpy as np import pandas as pd
df = pd.read_csv(“heights.csv”)
plt.figure()
sns.countplot(x=”sex”, data = df)
plt.show
图 1. 数据集分布。N=1050:812(男性)和 238(女性)身高。这显示我们有一个非常不平衡的数据集,其中 77%是男性身高,23%是女性身高。图片由作者提供。
从图 1中,我们可以观察到数据集在男性和女性类别之间不均匀。如果你想计算数据的平均身高,这会得到一个偏向男性平均身高的值。处理这个问题的一种方法是计算每个类别的平均身高,如图 2所示。
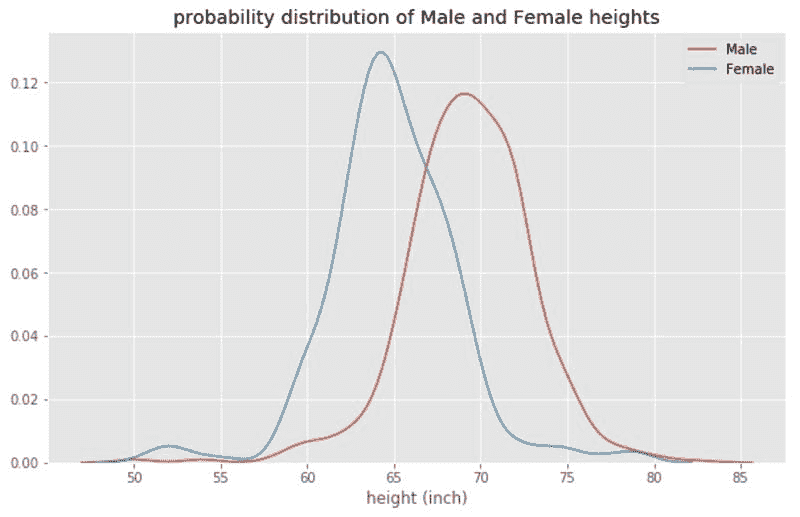
图 2。男女身高分布。图片来源:作者。
数据变异性的缺乏:当数据集包含的特征太少,不能代表整体情况时,数据集就缺乏变异性。例如,基于面积预测房价的数据集缺乏变异性。解决这个问题的最佳方法是包括更多的代表性特征,如卧室数量、浴室数量、建造年份、地块大小、HOA 费用、邮政编码等。
动态数据:在这种情况下,数据不是静态的,而是依赖于时间并且每次都在变化,例如股票数据。在这种情况下,应使用时间序列分析等时间依赖性分析工具来分析数据集并进行预测建模(预测)。
数据的大小:在这种情况下,样本数据的大小可能太小,不具代表性。这可以通过确保样本数据集足够大并代表总体来解决。一个包含大量观察值的大样本将减少方差误差(根据中心极限定理样本大小增加会减少方差误差)。较大样本的主要缺点是收集数据可能需要大量时间。此外,使用非常大数据集构建机器学习模型在计算时间(训练和测试模型所需的时间)方面可能非常昂贵。
第 2 步:数据整理
图 3:数据整理过程。图片来源:作者
数据整理是将数据从原始形式转换为准备好进行分析的整洁形式的过程。数据整理是数据预处理中的一个重要步骤,包括数据导入、数据清洗、数据结构化、字符串处理、HTML 解析、处理日期和时间、处理缺失数据以及文本挖掘等多个过程。
数据整理过程是任何数据科学家的关键步骤。在数据科学项目中,数据很少可以轻松访问以进行分析。数据更可能存在于文件、数据库中,或从网页、推文或 PDF 等文档中提取。了解如何整理和清洗数据将使你能够从数据中提取出本来隐藏的关键洞察。
第 3 步:数据分析
在原始数据被清理、处理和转换之后,最后也是最重要的步骤是分析数据。我们将讨论三类数据分析技术,即描述性分析、预测性分析和预测性分析。
(i) 描述性数据分析
这涉及使用数据进行故事讲述或数据可视化,使用条形图、折线图、直方图、散点图、对角图、密度图、QQ 图等。用于描述性数据分析的一些常见包包括
-
Matplotlib
-
Ggplot2
-
Seaborn
(ii) 预测数据分析
这涉及使用数据建立预测模型,这些模型可以用于对未见过的数据进行预测。一些用于预测分析的常见包包括
-
Sci-kit learn 包
-
Caret 包
-
Tensorflow
预测数据分析可以进一步分为以下几类:
a) 监督学习(连续变量预测)
-
基本回归
-
多重回归分析
b) 监督学习(离散变量预测)
-
逻辑回归分类器
-
支持向量机分类器
-
K-最近邻(KNN)分类器
-
决策树分类器
-
随机森林分类器
c) 无监督学习
- K 均值聚类算法
(iii) 规范性数据分析
这涉及使用数据建立可以根据从数据中得出的洞察来制定行动方案的模型。一些规范性数据分析技术包括
-
概率建模
-
优化方法和运筹学
-
蒙特卡洛模拟
总结
尽管数据现在的产生量前所未有,但必须对数据进行收集、处理、转换和分析,以发挥其作用。我们讨论了涉及的三个主要阶段:原始数据及其来源;原始数据的处理;以及数据分析。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的拥有者。之前,本杰明曾在中欧大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关内容
我希望自己在开始数据科学时知道的三件事
原文:
www.kdnuggets.com/2023/01/3-things-wish-knew-started-data-science.html

图片由 Moose Photos 提供
当我开始学习数据科学时,我的背景是技术管理。我对编程、统计学或机器学习了解很少。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
我最大的担忧是缺乏编程语言。我总是忽视数学、统计学和概率。我甚至将机器学习视为一种试错实验,将一堆算法结合起来以改进模型性能,而不知其工作原理或我能为公司带来什么价值。
在这篇文章中,我将分享我完全错误的三件事,以及你如何利用这些经验来导航数据科学职业路径。
1. 你不能成为数据科学领域的全能型人才
我曾经认为我的目标是成为一名“数据科学家”。因此,我专注于此,忽略了其他领域,如计算机视觉、自然语言处理、时间序列、商业智能和机器学习工程。
我认为数据科学全在于数据摄取、清理、分析、可视化、建模和报告。
“我完全错了”
作者提供的图像
在数据科学领域,你不能成为一个全能型人才。公司希望找到在特定数据科学领域有专长的人,或者能在多个任务上工作的敏捷数据科学家,例如实验跟踪、商业智能、报告以及模型部署和监控。
如果你查看任何“数据科学家”职位的招聘信息,你会看到公司如何寻找在特定领域有专长的人。
例如,一家卡车追踪公司将始终寻找能够使用现代机器学习技术并具备复杂计算机视觉模型经验的数据科学家。
教训: 你必须了解整个数据科学生命周期,找到最适合你的方法并做到精通。
2. 你必须理解统计学和机器学习算法
即使在作为数据科学家工作了好几年之后,我仍在不断学习新的算法类型,特别是强化学习算法。
但我当时并不是这样。
对统计学和机器学习算法缺乏知识在面试和工作中给我带来了尴尬。此外,我像盲人一样尝试各种方法来找到解决方案,却不知道如何改善当前的模型或过程。
图片来源:Andrea Piacquadio
我只希望如果我当时能专注于基础知识,我本可以节省很多时间和尴尬的情况。此外,我本可以早早获得更好的工作,因为公司总是寻找对深度学习算法和架构有深入了解的个人。
教训: 学习所有基础知识很难,但你必须从某处开始。因此,当你开始你的职业生涯时,专注于数学和编程,这两者都是职业成功的关键。
3. 了解你在行业中的价值
了解你的价值是最重要的,我花了很长时间才明白自己的位置。
了解你的价值包括两个方面:
-
了解你的技能和技能水平。
-
了解你时间的价值。

图片来源:作者
了解你的技能和技能水平
我知道,冒名顶替综合症是存在的。它会阻止你跳槽到更好的机会。你会总觉得自己不够好。所以,你最好开始了解你拥有多少技能和你的专业水平。为此,你可以参加评估测试和认证考试,参与开源项目,或参加竞赛。
了解你时间的价值
起初,我被利用了,我每篇文章只赚$12,我以为这是行业标准,直到我碰到另一个机会,那个机会支付我$100。
在了解了你的技能水平之后,你需要搞清楚你的时间价值是多少。你可以与多家公司合作,与你的同龄人交流,向行业内的专业人士请教,并阅读博客来评估你的价值。
我花了很长时间才明白自己的价值,并且我仍在学习新技能以提高当前价值。如果你想在职业生涯中持续成长,学习过程永远不会停止。
结论
我喜欢分享我成为数据科学家的历程,以及如果在职业生涯开始前知道一些事情,情况会变得更好。
这个过程很艰难且重复,需要耐心。它完全没有被美化。这是一项压力巨大的工作,你总是要面对独特的问题。
你可以通过专注于一个研究领域,学习算法背后的数学,并了解你的价值来简化你的历程。
我相信任何背景的人都能学习数据科学。这一切都关乎于努力、坚持和好奇心。如果你想了解数据科学、机器学习、MLOps 以及我的经历,请关注我的社交平台。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为挣扎于心理疾病的学生开发一个 AI 产品。
更多相关主题
3 个工具来跟踪和可视化你的 Python 代码执行
原文:
www.kdnuggets.com/2021/12/3-tools-track-visualize-execution-python-code.html
动机
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
你是否见过如下的错误输出:
2 divided by 1 is equal to 2.0.
Traceback (most recent call last):
File "loguru_example.py", line 17, in <module>
divide_numbers(num_list)
File "loguru_example.py", line 11, in divide_numbers
res = division(num1, num2)
File "loguru_example.py", line 5, in division
return num1/num2
ZeroDivisionError: division by zero
并希望输出能像这里所示的那样更容易理解?
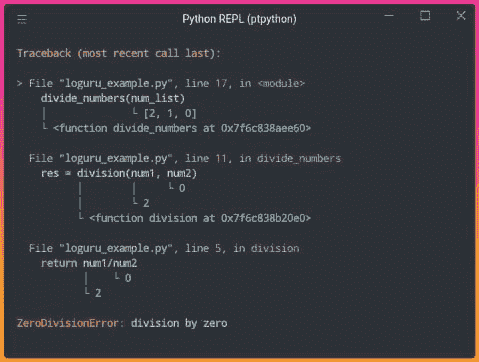
作者的图片
你可能还希望实时可视化哪些代码行正在执行以及它们被执行了多少次:

作者的 GIF
如果是这样,这篇文章将提供工具来实现上述目标。这三个工具是:
-
Loguru — 打印更好的异常
-
snoop — 打印函数中正在执行的代码行
-
heartrate — 实时可视化 Python 程序的执行
使用这些工具只需要一行代码!
Loguru — 打印更好的异常
Loguru 是一个旨在让 Python 日志记录变得愉快的库。Loguru 提供了许多有趣的功能,但我发现最有用的功能是捕捉意外错误并显示导致代码失败的变量值。
要安装 Loguru,输入
pip install loguru
要理解 Loguru 的有用性,假设你有 2 个函数division和divide_numbers,并且函数divide_numbers被执行。
注意combinations([2,1,0], 2)返回[(2, 1), (2, 0), (1, 0)]。在运行上述代码后,我们遇到了这个错误:
2 divided by 1 is equal to 2.0.
Traceback (most recent call last):
File "loguru_example.py", line 17, in <module>
divide_numbers(num_list)
File "loguru_example.py", line 11, in divide_numbers
res = division(num1, num2)
File "loguru_example.py", line 5, in division
return num1/num2
ZeroDivisionError: division by zero
从输出结果中,我们知道return num1/num2是错误发生的地方,但我们不知道num1和num2的哪些值导致了错误。幸运的是,通过添加 Loguru 的logger.catch装饰器,这可以很容易地追踪:
输出:
作者的图片
通过添加logger.catch,异常更容易理解了!原来错误发生在将2除以0时。
snoop — 打印正在执行的代码行
如果代码没有错误,但我们想了解代码中发生了什么,这时 snoop 就派上用场了。
snoop是一个 Python 包,它通过添加一个装饰器打印被执行的代码行及每个变量的值。
要安装 snoop,请输入:
pip install snoop
让我们假设有一个叫做factorial的函数,它计算整数的阶乘。
输出:
The factorial of 5 is 120
要理解factorial(5)的输出是20,我们可以将snoop装饰器添加到factorial函数中。
输出:
图片由作者提供
在上面的输出中,我们可以查看变量的值以及哪些代码行被执行。现在我们可以更好地理解递归是如何工作的!
heartrate — 实时可视化 Python 程序的执行
如果你想可视化哪些行被执行以及执行了多少次,可以尝试使用 heartrate。
heartrate也是 snoop 的创建者开发的。要安装 heartrate,请输入:
pip install heartrate
现在让我们将heartrate.trace(browser=True)添加到之前的代码中。这将打开一个浏览器窗口,显示调用trace()的文件的可视化图。
运行上述代码时应该会弹出一个新的浏览器窗口。如果没有,请访问localhost:9999。你应该会看到如下输出:
图片由作者提供
太棒了!这些条形图展示了被命中的行。条形图越长,命中次数越多,颜色越浅,表示越新近。
从上面的输出中,我们可以看到程序执行了:
-
if x==15 次 -
return 1一次 -
return (x * factorial(x-1))4 次
输出是有意义的,因为x的初始值为 5,并且函数会重复调用,直到x等于1。
现在让我们看看使用 heartrate 实时可视化 Python 程序的执行是什么样的。让我们添加sleep(0.5),使程序运行得稍慢一点,并将num增加到20。
GIF 由作者提供
太棒了!我们可以实时看到哪些代码行正在执行,以及每行代码的执行次数。
结论
恭喜!你刚刚学习了跟踪和可视化 Python 代码执行的 3 个工具。我希望使用这 3 个工具时调试会变得不那么痛苦。既然这些工具只需要一行代码,何不尝试一下,看看它们有多么有用?
随意玩耍并在这里叉开这篇文章的源代码。
给这个 仓库 点个星。
Khuyen Tran 是一位多产的数据科学作家,她编写了 一系列令人印象深刻的有用数据科学主题及其代码和文章。Khuyen 目前正在寻找一份机器学习工程师、数据科学家或开发者倡导者的职位,地点在 2022 年 5 月后湾区,如果你在寻找拥有她技能的人,请与她联系。
原文。经许可转载。
更多相关主题
3 个实用的 Python 自动化脚本
原文:
www.kdnuggets.com/2022/11/3-useful-python-automation-scripts.html
无论是十分钟的送餐服务还是随时随地可用的内容,我们都习惯于在指尖完成任务。世界一直在自动化某些东西,无论是使用简单的机器、流水线、机器人,还是计算机处理交易。人类通过自动化和将日常任务委派给机器,获得了显著的好处并享受了便利。

图片由 olia danilevich 提供
说到编程,Python 是一种备受追捧且易于使用的语言,用于自动化一些重复的任务。随着机器学习和人工智能成为主流,Python 由于其简单易学而广受关注。像回复邮件、下载视频、在特定时间向一组收件人发送短信、朗读电子邮件等简单的日常任务,都可以通过 Python 轻松自动化。
在这篇文章中,我们将讨论 Python 及其库在桌面上自动化常见任务的三种最有用的应用。
清理下载文件夹
如果你已经使用你的机器一段时间了,那么你的下载文件夹很可能会变得混乱。我们都曾遇到过这样的情况,并且手动删除无关的文件非常麻烦——有没有解决方案?当然有。为什么不自动删除一些文件,比如按类型来删除呢?
我们通常会从互联网下载大量的 PDF 文件,因此下面分享的脚本对于删除这些文件非常有用。值得注意的是,这个脚本会删除所有符合条件的文件,而不是将它们移到回收站。
支持这种自动化的库是“os”。首先导入“os”库。将你的目录更改为下载目录。然后调用“listdir()”函数,该函数列出当前目录中的所有文件和目录,即在我们的例子中是 Downloads。遍历这些文件,检查文件是否以“.pdf”扩展名结尾,并使用“.remove(file)”方法删除文件。
import os
os.chdir('/Users/macUser/Downloads')
for file in os.listdir():
if file.endswith(('.pdf')):
os.remove(file)
你还可以在筛选文件时添加其他条件。例如,我通常从“web.whatsapp.com”下载图片,所有这些图片的文件名都以“Whatsapp”子串开头。
import os
os.chdir('/Users/macUser/Downloads')
for file in os.listdir():
if file.startswith(("Whatsapp")) and file.endswith((“.png”, “.jpg”)):
os.remove(file)
上述代码删除了所有以“Whatsapp”开头的 png 和 jpg 文件。
自动化你的桌面
现在你的下载文件夹已经干净整洁,让我们在桌面上添加一些“幽灵”吧。Pyautogui 是一个支持自动化鼠标指针移动和键盘按键操作的 Python 库,使用起来非常方便。
下面的代码将文本“This Desktop is Automated!”输入到已经打开的 TextEdit 文件中。首先,导入库“pyautogui”并使用别名“pag”。调用“doubleClick()”方法,传入你希望双击的坐标作为参数。在此例中,坐标选择为 x = 150 和 y = 150。
请注意,在计算机屏幕上,0,0 坐标从左上角开始,y 轴值随着向下移动而增加,x 轴值随着向右移动而增加。
import pyautogui as pag
pag.doubleClick(150, 150)
pag.write('This Desktop is Automated!', interval=0.25)
双击坐标位于打开的文本文件内部,因此光标会在文件内闪烁。你也可以调用“click()”方法,而不是“doubleClick()”。“pyautogui.write()”会在光标闪烁的位置添加文本。
事件序列如下图 GIF 所示。
Pyautogui 还允许你移动文件、保存文件、选择和复制文本以及截取屏幕截图,从而使其成为桌面自动化的多功能选项。
你也可以通过在每次迭代中减少圆的半径或正方形边的长度来绘制一些难以绘制的图像,比如螺旋。下面的 code 来自官方文档,突出了这个应用。
distance = 200
while distance > 0:
pyautogui.drag(distance, 0, duration=0.5) # move right
distance -= 5
pyautogui.drag(0, distance, duration=0.5) # move down
pyautogui.drag(-distance, 0, duration=0.5) # move left
distance -= 5
pyautogui.drag(0, -distance, duration=0.5)
下载 YouTube 视频
今天你有一段长途飞行,需要在桌面上观看一些 YouTube 视频。使用“pytube”很简单。只需导入 pytube,并使用视频 URL 调用 Youtube().streams.first() 方法。将输出保存到视频变量中,然后使用下载位置调用 download() 方法以下载视频。
使用 try 和 except 添加异常处理会有所帮助,因为大多数错误源于不正确或不完整的 URL。
import pytube
video_url = 'https://www.youtube.com/watch?v=npA-2ONUqOc'
try:
video = pytube.YouTube(video_url).streams.first()
video.download('/Users/macUser/Downloads')
print("Success: The file is downloaded.")
except:
print("Error: There might be an issue with the url provided.")
控制台上的输出如下图所示。
Success: The file is downloaded.
你可以在下载文件夹中看到下载的文件。
附加参考
本文旨在分享可以每日自动化的一系列任务,使我们的生活更加轻松。从文章中显示的例子可以看出,你无需具备广泛和高级的 Python 编程知识即可实现这些任务。如果你有兴趣更进一步,了解更多类似的例子,可以参考 Al Sweigart 的《用 Python 自动化无聊事务:完全初学者的实用编程》。
我希望你喜欢 Python 在自动化简单桌面任务(如清理文件夹、下载 YouTube 视频和自动化桌面)中的三个应用。如果你有更多使用 Python 自动化任务的建议,欢迎在下面的评论区留言。
Vidhi Chugh 是一位 AI 战略家和数字化转型领导者,她在产品、科学和工程交汇处工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领袖、作者和国际演讲者。她的使命是使机器学习民主化,并打破术语,让每个人都能参与这一转型。
更多相关内容
使我的收入翻倍的 3 个宝贵技能
原文:
www.kdnuggets.com/2022/10/3-valuable-skills-doubled-income-data-scientist.html

图片由 drobotdean 提供,来源于 Freepik
让我们先做自我介绍。我是一名认证的数据科学家,为多家公司担任多个职位(数据科学文案撰写和编辑)。你可以称我为个人承包商。此外,我提供机器学习应用、制作信息图表和数据产品的测试咨询服务。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
在处理多个职位时,我意识到技术技能并不是工作的核心部分。学习新工具或方法可以使你在同行中占据优势,但它们不是核心技能。
在我们深入探讨这三个宝贵技能之前,我希望你问自己以下问题:
-
你是否通常在规定时间内准确完成任务?
-
你的工作是否代表了你自己?
-
你是否理解问题并提出了最佳解决方案?
-
你是一个好奇的人吗?
-
你是否对项目表达了你的担忧?
如果你对以上问题的回答都是“是”,那么你将认同我将要提到的核心技能。否则,你将学到有价值的经验,可能会使你的收入翻倍。
1. 时间管理

时间管理对个人承包商和员工都至关重要。你按时完成任务的能力将影响整个团队。即使你单独工作,你在规定时间内完成合同的能力也会对你帮助很大。
遇到项目截止日期
按时完成工作将使你成为团队中值得依赖的成员,并赢得高层管理的青睐。即使作为自由职业者,按时完成项目也会提升你的声誉,公司愿意为高质量和及时提交支付高价。
要更好地遵守截止日期,你需要确保理解项目,并决定完成它所需的时间。与你的经理沟通你的时间表,确保它是合理的。
始终为不可预见的事件,如疾病、紧急情况、网络中断和家庭问题,给你的时间表增加更多的缓冲天数。
管理休息时间
你不能每天工作 12 到 18 小时来完成项目。不间断的工作会以灾难告终,你会开始感受到倦怠的症状。管理休息时间是一项技能,如果你想持续成功,你需要将其作为优先事项。
每天,我会在工作中休息 1-2 小时。每周,有一个较长的休息时间,每年则有一个长假。
即使在项目进行中,你也需要多次休息 30 分钟,即使你感到卡壳和沮丧。不管多么紧急,你的健康永远放在首位。
管理日历
每部手机、笔记本电脑、台式机和平板电脑都有一个日历应用程序,但很少有人知道如何有效使用它。管理日历是一门艺术。你是你会议、工作日、假期和电子邮件日的主人。
将重要的事项添加到日历中并设定优先级。我使用颜色标签来对任务进行优先排序:
-
假期和特殊事件
-
团队和个人会议
-
磨砺的日子
-
轻松的工作日
-
非工作相关的重要任务(银行访问、官方访问、家庭)
-
工作相关事件
-
休息
在掌握日历管理技巧后,你会发现你有更多时间留给自己,这将减少焦虑。你会知道提前几周要做什么。这也会提高你的时间管理技巧,最终提高你的生产力。
2. 深入研究和调研

照片由UX Indonesia提供,来源于Unsplash
在开始项目之前,深入研究主题。了解当前的发展情况并制定计划。如果你在测试应用程序或分析数据,请确保覆盖所有方面。
比如说,如果我需要写一篇关于数据科学工具的博客,我会深入研究文档和示例,并尝试一些创新的方法来探索所有功能。在此过程中,我会发现许多错误和改进流程的捷径。
这对你的工作有何影响?公司总是在寻找那些好奇并且追求质量的个人。这种员工特质会带来晋升和加薪。
跟随当前的趋势
数据科学是一个不断变化的领域,公司一直在寻找工具和方法来改善现有系统。保持与当前趋势同步将提升你的生产力,使你能够适应变化。
解决问题的思维方式
无论你身在何处,以解决问题为导向的思维是最受欢迎的特质。你不仅会给你的经理或团队成员留下深刻印象,还会为加薪创造有力的理由。这些小细节很重要。
我曾经有很多次被困了好几天,当我最终提出一个独特的解决方案时,我会得到赞扬。这一切都关乎于不断努力和深入研究基本原理。
高质量的工作
在大多数情况下这是可选的,但对公司或经理来说,这却是最重要的。如果你能定期按时提交高质量的工作,这将使你脱颖而出,你将处于一个有利的位置来要求更多。
深入研究话题或数据将帮助你发现对公司有价值的见解。
永远记住,你的工作代表了你。为什么你会看到一些承包商要价 300 美元/小时而其他人只要 60 美元/小时?
工作的质量将帮助你建立一个强大的作品集。
3. 沟通

图片由 Austin Distel 提供,Unsplash
对于数据科学家来说,最佳的沟通方式是电子邮件,最差的是短信。电子邮件总是正式的,并且你有时间来回复并进行逻辑思考。有效的沟通将对你长期有帮助。你将避免争论和挫折。
对我来说,我必须从零开始建立这种技能。我完全不知道如何表达我的担忧。因此,我签订了糟糕的合同(较低的费率)、心理健康问题(不合理的工作时间),在最糟糕的情况下,陷入了无休止的争论。
传达你的担忧
始终沟通你对工作时间、项目进度、资源和薪酬的担忧。如果你认为你的时间更有价值,与你的经理沟通,我相信他们会给你补偿。
不说话并像动物一样工作将会影响你的心理健康。
即使在项目中期,如果你认为项目不合理且需要更多时间来完成,也要始终表达你的担忧。确保你对事情了如指掌。
“问问题的人是一分钟的傻子,不问问题的人是终身的傻子。 - 孔子”
电子邮件沟通
确保你了解邮件沟通的基本知识。在回复查询或提出问题之前,确保你经过逻辑思考并避免拼写和语法错误。
使用标记或星标来处理重要邮件,并使用规则将所有邮件分类。你不必一次性回复所有人。确保当前项目优先完成。此外,总是要以参考和逻辑推理来支撑你的请求。
建立你的声誉
你可以通过有效沟通来建立声誉。永远不要要求不合理的时间、金钱或帮助。你应该对自己的技术技能有信心,并学会沟通结果。
记住,获得认可的关键不是与技术人员沟通,而是与非技术利益相关者和客户沟通。平等和尊重地对待他们。不要强加你的判断给他们。让他们做出最终决定。从长远来看,你将赢得业内有权势人物的尊重。
就我而言,顶级公司已经邀请我撰写内容、书籍和课程。这一切都源于我如何处理与同事、经理和雇主的关系。
总结
-
时间管理
-
按时完成项目将使你成为一个可靠的员工或承包商
-
管理休息时间可以保持工作一致性并避免倦怠
-
管理你的日历将减少焦虑并提高生产力
-
-
深入研究
-
关注当前的趋势将帮助你了解最新的工具和技术。
-
以解决问题为导向的思维方式将使你成为公司宝贵的资产
-
高质量的工作将提高你获得更高薪资的机会。
-
-
沟通
-
在项目开始和中期与你的老板和经理沟通你的担忧。
-
邮件沟通技巧很重要。确保邮件内容专业且合乎逻辑。
-
通过诚实和努力工作来建立你的声誉。确保公平对待每个人。
-
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,他热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些遭受心理疾病困扰的学生开发一款人工智能产品。
相关主题
免费访问 Claude AI 的 3 种方式
原文:
www.kdnuggets.com/2023/06/3-ways-access-claude-ai-free.html

图片由作者提供
AI 模型Claude在多个指标上超越了 GPT-3.5 Turbo,其 Claude-Instant-100k 变体的性能接近于 GPT-4。总的来说,你可以期待一次非常吸引人的 AI 对话体验。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
你可以通过一些尚未广泛公开的方式免费访问和使用 Claude AI 模型。Anthropic 目前正向特定公司和个人提供访问权限,以帮助测试和改进这些模型。
注意: 尽管 Anthropic 通过其 API 和应用程序提供 Claude 模型的早期访问,但需求目前超过了供应。获取 Claude 的访问权限可能需要时间,因为 Anthropic 会逐步审查申请并接纳合作伙伴。不能保证所有申请者都会获得访问权限。
在这篇文章中,我们将了解 3 个平台,这些平台提供对最先进的 Claude 模型的免费访问。
1. Vercel AI Playground
Vercel AI Playground 是一个免费的、易于使用的工具,允许你试验和比较各种 AI 模型,包括商业和开源选项。通过 AI Playground,你可以与来自 OpenAI、Hugging Face、Cohere、Replicate 和 Anthropic 等公司的对话 AI 模型进行互动。
要在 AI Playground 上试验 Anthropic 的 Claude 模型,你首先需要创建一个免费的 Vercel Hobby 账户。创建账户仅需几分钟。登录后,你可以立即访问 Claude 和 AI Playground 界面中的其他 AI 模型。
图片来自 Vercel AI Playground
2. Poe
Poe AI 是由 Quora 创建的一个免费的 AI 游乐场,允许你与 AI 对话模型进行互动。创建一个免费的账户后,你可以与 ChatGPT、Claude、Sage 以及 Poe 中的其他定制 AI 选项进行对话。你甚至可以按照指南创建自己的定制模型。
Poe AI 的一些主要优势包括:
-
快速响应时间和高正常运行时间。
-
使用没有严格限制。
-
使用 Caude 模型定制 AI 的能力。
-
后续提示的建议。
图片来自 Poe
3. Slack 应用
将Claude视为一个致力于帮助你的团队的 AI 助手。简单地与它交流,并给出清晰的逐步指示。Claude 可以协助撰写总结、生成想法、回答问题等。
通过以下方式在你的 Slack 中安装 Claude:
-
点击“更多”按钮
-
选择“应用程序”
-
搜索“Claude”
-
点击“添加到 Slack”
在 Slack 中与 Claude 互动有两种方式:
-
在频道和群组 DM 中,在消息中提到@Claude。Claude 将在该线程中回复所有人。接着再提到@Claude。
-
给 Claude 发送直接消息(私人)。Claude 将直接回复,就像给同事发消息一样。
给 Claude 具体任务,它将尽力高效地协助你的团队。
图片来自 Slack 应用
奖励(付费)
如果你想访问各种付费、开源和商业对话 AI 模型,nat.dev值得一试。仅需 5 美元的积分,你可以在一个地方测试从 Claude 到其他模型的各种聊天机器人。

图片来自 nat.dev
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写机器学习与数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助面临心理健康问题的学生。
更多相关信息
免费访问 GPT-4 的 3 种方法
作者提供的图片
Open AI 最近推出了最新的 AI 模型 GPT-4,该模型能够处理文本和图像输入以生成各种类型的响应。然而,GPT-4 API 并未公开,只有有限的付费用户每月支付 $20 才能访问。
我们的 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇文章中,我们将探讨 3 个允许用户免费测试 GPT-4 的平台。此外,我们还将讨论一个计划在未来提供 GPT-4 免费访问的平台。
1. Forefront AI
Forefront AI 是一个个性化聊天机器人平台,使用 ChatGPT 和 GPT-4 作为后台。目前该平台免费,允许你创建自己的虚拟或真实角色。你可以从各种名人和历史人物中选择聊天机器人角色。
图片来源于 Forefront AI
注册后,平台会提示你选择一个角色并开始聊天。你可以通过点击加号按钮轻松切换 GPT-3.5 和 GPT-4 模型。此外,为了让对话更有趣,你可以在对话中途切换聊天机器人角色。
总的来说,这个平台是体验 GPT-4 的一种有趣且引人入胜的方式,我强烈推荐在可能出现付费墙之前先试试看。
2. Hugging Face
Chat-with-GPT4 是一个托管在 Hugging Face 上的网页应用。它连接到 OpenAI API,并允许你免费体验 GPT-4。由于需求量大,你可能会得到较慢的响应,但如果你足够耐心,你将会收到回复。
图片来源于 Hugging Face
此外,你还可以选择复制空间并添加自己的 API 密钥以供私人使用,这样可以避免任何潜在的排队问题。
3. Bing AI
微软 Bing 现在提供一系列由 GPT-4 和 DALLE 2 驱动的 AI 工具。通过使用 Microsoft 帐户登录并点击聊天按钮,您可以免费体验 GPT-4 的强大功能。该平台速度快、准确,并提供相关博客的链接以供进一步研究。
图像来自 Bing AI
如果您下载并安装 Microsoft Edge,您可以在每个网站上访问 GPT-4。您可以使用它来撰写电子邮件、博客、创意或段落。此外,它还配备了 Bing AI 聊天功能。
图像来自 Microsoft Edge
我每天都在工作中使用这两个工具,它们显著改善了我的工作流程。
奖金
Ora AI 和 Poe 曾经提供免费的 GPT-4 访问权限,但现在它们提供的是有限访问。
Poe
Poe 是一个让用户实验前沿聊天机器人模型的平台。它甚至允许您创建个性化的机器人。任何人都可以免费访问 GPT-4、ChatGPT、Claude、Sage、NeevaAI 和 Dragonfly。

图像来自 Poe
Ora.sh
Ora.sh 是一个独特的平台,不仅提供个性化的聊天体验,还允许用户生成高质量的图像。此外,该平台还提供了超过 350,000 个由 Ora 用户创建的机器人。
图像来自 Ora.sh
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一种 AI 产品,以帮助那些在精神健康方面挣扎的学生。
更多相关内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号