KDNuggets-博客中文翻译-八-
KDNuggets 博客中文翻译(八)
原文:KDNuggets
数据科学工作流程中的自动化
原文:
www.kdnuggets.com/2023/03/automation-data-science-workflows.html
机器学习解决方案已经自动化了世界上大部分的操作方式,并且现在也在处理自身的低效问题。所以,数据科学领域也不例外,正在经历核心机器学习工程过程的自动化,以实现更顺畅、更快速的开发。

图片由 RODNAE Productions 提供
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯。
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析水平
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
想象一下以前那些步骤繁琐的过程——从数据集成到模型训练、选择和部署——都是手动完成的。每个步骤都非常严格,需要数据科学家付出大量的努力。无可否认,自动化在帮助数据科学家完成端到端建模和部署过程中变得极为重要。
自动化机器学习(AutoML)显著提高了开发者的生产力,使他们能够专注于需要时间和注意力的关键建模领域。
在评估 AutoML 的优缺点之前,让我们首先了解数据科学世界在机器学习过程自动化之前的运作方式,以更好地理解其价值主张。
自动化胜过人工努力——对组织和数据科学社区的双赢
AutoML 常被视为复制数据科学家的工作,但实际上它是一种加速构建更好模型的工具。数据科学家仍然有许多工作需要手动完成,这给机器学习实施带来了挑战。 dotData 的首席执行官藤卷良平如下解释。
对于组织来说,至关重要的是不要将自动化视为对数据科学家的“替代”,而应将其视为一种工具。我们发现许多企业现在将特征工程过程从数据科学组织中分离出来,交给专注于特征发现的专门团队。无论设置如何,提供使数据科学家工作更轻松的自动化工具和平台应成为重点。
– Ryohei Fujimaki,dotData的首席执行官
机器学习流程中最重要但非常关键且耗时的步骤之一是数据分析和验证数据的良好质量。在这一环节的任何失败或细节偏差都可能代价高昂,因此需要一位熟练的数据分析师来奠定基础。
除了数据分析,数据清洗和特征工程还大大加速了模型学习现象的速度。但问题在于这些技能需要时间来培养。因此,与其等待建立合适的团队和技能来筛选海量数据集中的模式并生成有价值的见解,不如通过自动化机器学习工作流来消除建立模型的障碍。
简而言之,它帮助企业快速扩展其机器学习计划,使非技术专家也能利用这些复杂算法的力量。不仅自动化有助于提高模型准确性,还带来了行业最佳实践,因此没有人需要在已经解决的重复问题上重新发明轮子。
让数据科学家免于花费在可以轻松自动化的无尽琐碎任务上的时间,从而赋予他们用脑力将创新变为现实的能力。
根据微软对 AutoML 的观点,它是通过自动化耗时的迭代任务来构建大规模、高效且富有生产力的机器学习模型的过程,同时保持模型质量。
这需要思维方式的转变,以通过自动化手动任务(如特征工程、特征发现、模型选择等)来改进流程和构建系统。
数据科学过程仍然是一个主要依赖人工的工作。若应用得当,自动化可以大大帮助数据科学家,而不必担心“失业”。当 AutoML 首次流行时,数据科学社区的讨论主要集中在自动化整个数据科学流程生命周期的利弊上。在 dotData,我们发现这种“全有或全无”的方法低估了数据科学流程的复杂性——尤其是在大型组织中。因此,我们认为公司应该更关注提供自动化,以简化数据科学家的工作并提高工作效率。一个这样的领域是特征工程。数据科学家花费大量时间与数据工程师和主题专家合作,发现、开发和优化他们模型的最佳特征。通过自动化大量特征发现过程,数据科学家可以专注于他们真正擅长的任务:构建最佳的机器学习模型。
– Ryohei Fujimaki,dotData的首席执行官
除了提升生产力和效率外,它还减轻了人为错误和偏见的风险,从而增加了模型的可靠性。但正如专家所说,过犹不及。因此,自动化在一定程度的人类监督下最佳,可以结合实时信息和领域专业知识。
自动化的重点领域
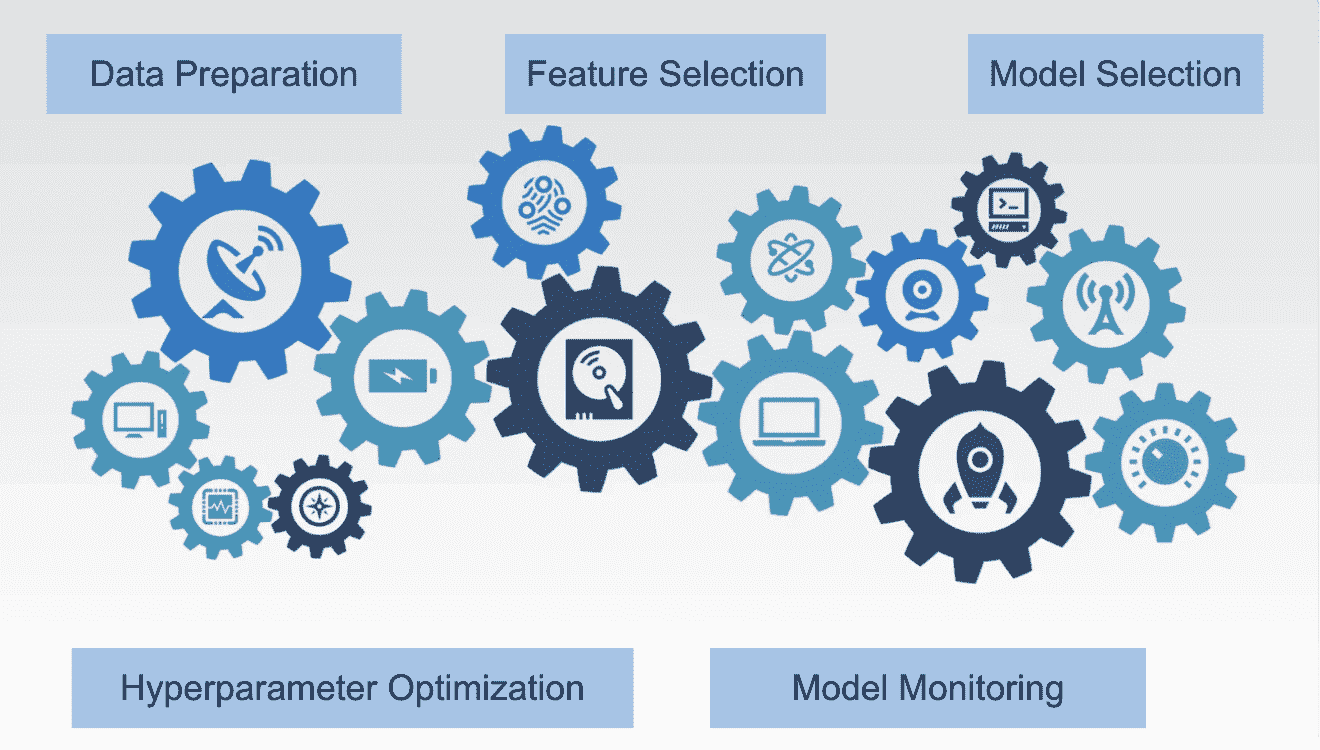
现在我们了解了自动化的好处,让我们重点关注最值得投入时间和精力的具体步骤和流程。以下列出的领域的自动化有可能显著提高效率和准确性:
-
数据准备:来自不同来源的数据使得数据科学家将其准备成适合输入模型训练阶段的格式变得具有挑战性。这涉及诸多步骤,如数据收集、清理和预处理等。
-
特征选择和特征工程:向模型选择和呈现正确的特征是学习正确现象的基础。自动化不仅有助于找到正确的特征,还用于工程化新特征,以加速学习过程。
-
模型选择:这是在候选模型集合中找到最佳表现模型的过程,它决定了模型开发流程的准确性和稳健性。AutoML 在迭代和识别适合特定任务的模型方面非常有用。
-
超参数优化:选择正确的模型是不够的,你还需要为给定的机器学习算法找到合适的超参数,如学习率、层数和迭代次数。这些模型设置需要机器学习工程师调整这些参数,以最优地解决机器学习问题。自动化的超参数优化是一个不可或缺的工具,通过评估各种组合来找到最适合你模型的架构。
-
模型监控:没有哪个机器学习模型能够持续提供准确的预测而无需定期重新训练。自动化工具监控并触发模型流程,以便在部署的模型偏离预期性能时采取纠正措施。
图片来自 Canva
结束语
一般来说,自动化被视为“技术抢走工作”,然而,它实质上有助于简化重复和单调的任务。数据科学中的自动化是数据科学家的一大助力,通过减少人工操作,从而实现改进和高效的建模过程。必须用公平的人类专业知识和监督来补充 AutoML,以充分发挥自动化处理数据科学工作流中挑战性部分的好处。
Vidhi Chugh 是一位人工智能战略家和数字化转型领导者,致力于在产品、科学与工程的交汇处构建可扩展的机器学习系统。她是一位获奖的创新领袖、作者和国际演讲者。她的使命是让机器学习民主化,打破术语,使每个人都能参与到这场转型中。
更多相关主题
自动化工具将如何改变数据科学?
 评论
评论
作者:藤巻良平博士,dotData 的首席执行官和创始人
数据科学现在是技术投资的一个主要领域,鉴于其对客户体验、收入、运营、供应链、风险管理以及许多其他业务功能的影响。数据科学使组织能够实现数据驱动的决策过程,加速数字化转型和人工智能计划。根据 Gartner, Inc,只有 4%的首席信息官已经实施了人工智能,只有 46%的人有计划这么做。虽然投资持续增长,但许多企业发现实施和加速数据科学实践越来越具有挑战性。本文概述了机器学习和数据科学自动化工具的最新趋势,并讨论了这些工具将如何改变数据科学。
传统的数据科学过程
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
那么,是什么阻碍了企业中数据科学的采用和加速呢?一个典型的企业数据科学项目非常复杂,涉及多个步骤,包括数据收集、最后一公里的 ETL*(数据整理)、特征工程、机器学习、可视化和生产(见下图)。即使对于经验丰富的团队,传统的数据科学项目也需要几个月才能完成。这是一个高度参与和协作的过程,需要各种专业技能,如领域专家、数据工程师、数据科学家、商业智能工程师和软件架构师。此外,大多数企业数据科学项目的结果难以解释,这使得业务用户很难实施这些结果。
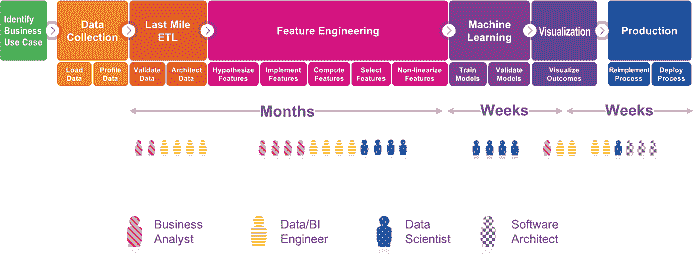
传统的数据科学过程
数据科学为什么这么难?
玩转机器学习(ML)模型被认为是有趣的部分,但任何数据科学项目的真正痛点通常是最后一公里的 ETL 和特征工程。如下面所示,机器学习需要一个称为特征表的单一扁平表。给定一个特征表,数据科学家可以使用 ML 算法进行操作。但实际的企业数据从来不是一个单一的扁平表,而是一组具有复杂关系的数据表。
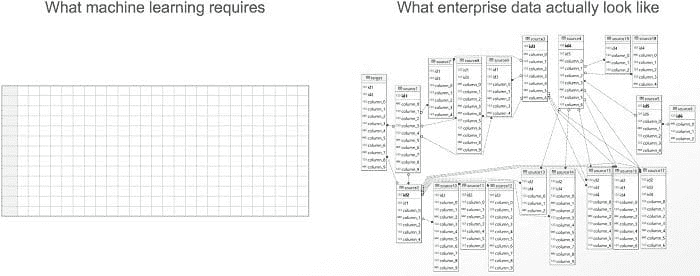
机器学习所需的数据(左)与实际企业源数据(右)
最后一公里的 ETL 和特征工程是将多个表转换为特征表的必要步骤。这些是数据科学项目中最具挑战性和耗时的步骤,需由高技能的数据科学家和领域专家完成——这些资源既昂贵又稀缺。
“……特征工程通常是机器学习项目中大部分努力投入的地方……在这里,直觉、创造力和‘黑艺’与技术内容一样重要……” - Pedro Domingos 博士
数据科学与机器学习自动化工具
自动化机器学习的尝试始于 2010 年代初(例如 2013 年的AutoWEKA),并且变得非常流行。DataRobot和H2O.ai是机器学习自动化领域的领先初创公司。
机器学习自动化的基本理念是使用不同的算法(包括缺失值填充等预处理)和不同的超参数训练评分模型,并验证其准确性以选择最佳模型。最近,像微软这样的公司也开始支持机器学习自动化工具(更多细节可以在这里或这里找到)。这些优秀的工具显著简化了机器学习模型的构建。另一方面,最后一公里的 ETL 和特征工程仍然是一个手动过程,需要领域专家和数据科学家的大量参与。
尽管已有努力自动化特征工程,但大多数关注于给定特征表的非线性转换,这只是特征工程过程中的一个小组成部分,并且依赖于手动创建特征表。dotData发布了一个平台,它不仅自动化了从源数据中生成特征工程,还自动化了机器学习。dotData 称之为“数据科学自动化”。其人工智能驱动的特征工程自动设计和生成重要且可解释的特征,无需领域知识。该平台涵盖了与数据科学过程相关的广泛任务,使构建和实施数据科学项目变得更容易、更快捷。
自动化工具将如何改变数据科学?
数据科学家或领域专家会被自动化工具取代吗?显然不会。没有任何工具可以真正取代熟练的专家。相反,它使他们更高效。自动化将从三个主要方面影响数据科学:
-
敏捷性: 传统的数据科学过程通常遵循“瀑布”方法,这涉及大量前期工作,如数据清洗、ETL 和特征工程,因为每个单独步骤都需要大量的人工和耗时的工作。自动化工具使得尝试想法变得更容易、更快捷,从而使数据科学家能够探索高影响力的用例。
-
民主化: 大型企业中有数百种潜在的分析用例(甚至可能更多)。自动化工具使具有不同技能的人能够执行数据科学任务,并使难以招聘的成熟数据科学团队能够专注于高价值创造的用例。
-
操作化: 如本博客开头所述,大多数企业尚未实施人工智能和数据科学。许多企业级自动化工具,如 dotData,可以自动生成 API 或可执行包,立即在生产中操作。这显著缩短了在企业中实施数据科学的时间和障碍(上图的最后一步)。
随着企业转向数据驱动文化,数据科学变得越来越重要。自动化工具有助于加速数据科学和商业创新。
注释:
- 企业中有两种类型的 ETL(包括数据清洗)。一种是“主数据 ETL”,用于准备组织中通用的数据。有许多出色的工具来支持这个过程,如 informatica。另一方面,即使主数据准备得很好,我们仍然需要针对每个分析用例的定制 ETL 工作,这被称为“最后一公里 ETL”。
ACM 通讯,第 55 卷第 10 期,2012 年 10 月
简介: 藤卷良平博士 是 dotData 的创始人兼首席执行官。在创立 dotData 之前,他曾是 NEC 公司 119 年历史上最年轻的研究员,这一荣誉仅授予了 1000 多名研究人员中的六位。在 NEC 任职期间,良平积极参与开发许多前沿的数据科学解决方案,并在多个高-profile 分析解决方案的成功交付中发挥了重要作用,这些解决方案现在在行业中被广泛使用。
资源:
相关:
更多相关话题
自动化如何改善数据科学家的角色
原文:
www.kdnuggets.com/2020/10/automation-improving-data-scientists.html
评论 
来源: 数据科学中的自动化
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
很多人担心自动化是否会最终取代数据科学家的工作。更可能的结果——而且这种情况已经在发生——是数据自动化将增强科学家们花费时间的方式,并改善他们的成果。以下是五种方式它可以提供帮助。
1. 加速项目完成时间
从数据中获取洞察是决策者最常关注的方面。然而,虽然不那么令人兴奋但却至关重要的任务,比如整理、清理和格式化信息,可能会占据比人们最初意识到的更多项目时间。投资于自动化可以让数据科学团队更高效、更灵活。
举例来说,一家利用数据科学的银行领导发现获取关键洞察所需的时间超过了预期。他们通过自动化补充了工作。在做出这个改变之前,公司每三个月完成一到两个项目。引入自动化让他们在相同的时间框架内完成了十倍的项目。
2. 为有价值的任务提供更多时间
即使数据自动化越来越受欢迎,它也不会取代公司雇佣科学家的需求。相反,自动化工具将提供更多时间用于那些对公司最有价值的职责。
例如,与其将大量工作时间用于将信息整理成正确的格式,数据专业人员可以利用他们的判断分析结果,或专注于创建帮助企业追踪趋势的算法。
最聪明的技术工具不能替代人类的智慧和经验。它们也可能无法检测到可能导致不可靠结果的错误。数据科学自动化在不需要人类知识的重复任务中表现优异。这种方法使人们能够以个人有益的方式运用他们的技能,同时也造福于雇主。
3. 允许数据科学家在任何地方工作
回顾与数据自动化相关的近期历史,可以看到它如何改善了几乎所有使用它的行业。
在一个例子中,制药专家探索了一个自动发送全球通知的系统,关于基于某一国家法规的药物安全事件。云计算的兴起也推动了自动化系统在数据处理中的采用。
根据 2016-2022 年全球自动化即服务市场的市场研究报告,该行业将增长到 62.3 亿美元,到期末实现 28.1%的年均增长率。分析师指出,云计算是增长的重要推动因素。例如,如果数据科学家使用自动化即服务工具来减少手动任务,他们可能会通过云完成工作,并在任何地方进行工作。
4. 帮助更多的数据科学项目成功
广泛引用的研究表明大多数数据科学项目失败。这发生的原因多种多样,包括数据孤岛和技能短缺。
然而,自动化可以为专业人士提供他们所需的资源,使即将到来或当前的项目每一个都获得成功的机会。例如,它可以帮助人们更快地测试假设,从而更有效地排除错误的假设。
数据科学自动化还使与信息打交道的专家能够追求持续改进。正如之前提到的,自动化技术有助于加快项目完成速度。
然而,它也可能带来整体更好的结果。当工具处理最重复的任务时,数据科学家可以利用他们的脑力和经验在项目可能失败时采取纠正措施。
5. 促进更准确的结果
在数据领域,一个经常被提到的警告是算法的聪明程度仅仅取决于构建它的人类。
一些人倾向于让自动化工具尽可能多地完成任务,但这种方法往往会导致错误。因此,一些专家提倡所谓的增强智能。它结合了人工智能(AI)与人类知识。
一家公司利用 AI 对成千上万 的客户评论进行分类,用于年度调查。算法的平均准确率为 90%,但在一些类别中降至 60%。公司通过引入人工专业知识来处理置信度较低的分组,从而弥补了这一差距。这种方法提高了准确性,并产生了可信的结果。
数据科学自动化展现潜力
人类的专业知识无疑将数据科学的努力提升到了极致。然而,公司不应忽视数据科学自动化产品如何帮助熟练人员以最有效、最有用的方式处理信息。
个人简介:德文·帕蒂达 是一位大数据和技术作家,同时也是 ReHack.com 的总编辑。
相关内容:
-
AutoML 何时会取代数据科学家?调查结果与分析
-
预测分析在劳动行业中的潜力
-
数据科学家开发出更快速的污染减少和温室气体排放削减方法
相关话题
自动化机器学习项目实施复杂性
原文:
www.kdnuggets.com/2019/11/automl-implementation-complexities.html
评论 
图片由 Soroush Zargar 提供,来源于 Unsplash
自动化机器学习(AutoML)涵盖了一个相当广泛的任务范围,这些任务可以合理地被认为是机器学习流程的一部分。
一个 AutoML “解决方案”可能包括数据预处理、特征工程、算法选择、算法架构搜索和超参数调整等任务,或者这些任务的某些子集或变体。因此,自动化机器学习现在可以被视为从仅执行单一任务(如自动化特征工程),到完全自动化的流程(从数据预处理、特征工程到算法选择等)的任何事物。
然而,实际的 AutoML 还有一个重要维度,即其实施复杂性。这一维度决定了实现和配置 AutoML 项目所需的配置和工程努力。有些解决方案可以轻松集成到现有的软件 API 中;有些是现有 API 的封装;还有些则进一步远离现有 API,通过命令行或单行代码调用。
为了展示 AutoML 之路上实施复杂性的差异,让我们看看 3 个具体的软件项目如何处理这样的 AutoML “解决方案”,即 Keras Tuner、AutoKeras 和 automl-gs。我们将看到这些项目在哲学上彼此间的差异,并了解实现这些方法所需或适合的不同级别的机器学习知识。
请注意,这些项目中的前两个直接与 Keras 和 TensorFlow 相关,因此它们特定于神经网络。然而,其他 AutoML 软件在这些相对实施复杂性下并不一定特定于神经网络;这两个工具仅提供了一种在实施复杂性之间进行比较的简便方法。
还需要注意的是,所评估的复杂性是解决方案的实际代码实现复杂性。还有许多其他的 AutoML 相关复杂性会影响其整体复杂性,包括数据集的大小、维度等。
Keras Tuner
让我们从Keras Tuner开始,我将其称为“需要一些组装”的自动化机器学习项目。为了成功实施该项目的解决方案,您需要对神经网络、其架构和使用 Keras 库编写代码有一定了解。因此,这比本文讨论的其他库更为“深入”。
本质上,Keras Tuner 为 Keras 提供自动化的超参数调优。您定义一个 Keras 模型,并注明希望包含在自动化调优中的超参数以及搜索空间,然后 Keras Tuner 执行繁重的工作。这些超参数可以包括条件参数,搜索空间可以限制到您喜欢的程度,但本质上这是一个超参数调优应用程序。
回想一下,本文提到的复杂性不是指特定项目执行的 AutoML 任务数量,而是实现这些任务的代码的复杂性。在这方面,鉴于我们可以称之为底层基础库代码的部分必须编写并与我们的 AutoML 库集成,Keras Tuner 代表了 AutoML 实现复杂性谱系中更复杂的一端。
Keras Tuner 最可能的用户是机器学习工程师或数据科学家。您不太可能发现具有少量或没有编码或机器学习专业知识的特定领域专家直接跳转到 Keras Tuner,而不是下面的其他项目之一。要了解原因,这里是如何实现一些非常基础的 Keras Tuner 代码的快速概述(示例来自Keras Tuner 文档网站)。
首先,您需要一个函数来返回一个编译好的 Keras 模型。它接受一个参数,从中采样超参数:
from tensorflow import keras
from tensorflow.keras import layers
from kerastuner.tuners import RandomSearch
def build_model(hp):
model = keras.Sequential()
model.add(layers.Dense(units=hp.Int('units',
min_value=32,
max_value=512,
step=32),
activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(
optimizer=keras.optimizers.Adam(
hp.Choice('learning_rate',
values=[1e-2, 1e-3, 1e-4])),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
然后,您需要一个调优器,它指定了模型构建函数、优化目标、试验次数等内容。
tuner = RandomSearch(
build_model,
objective='val_accuracy',
max_trials=5,
executions_per_trial=3,
directory='my_dir',
project_name='helloworld')
然后开始搜索最佳超参数配置:
tuner.search(x, y,
epochs=5,
validation_data=(val_x, val_y))
最后,要么检查最佳模型,要么打印结果总结:
# Best model(s)
models = tuner.get_best_models(num_models=2)
# Summary of results
tuner.results_summary()
您可能会犹豫是否将此实现的代码称为极其复杂,但当您与以下项目进行比较时,我希望您改变主意。
要查看上述代码的更多细节、Keras Tuner 的一般过程以及您可以对该项目做的更多工作,请参见其网站。
AutoKeras
接下来是AutoKeras,我将其称为“现成的”解决方案,这是一种预打包的、或多或少已经准备好的解决方案,使用更为限制性的代码模板。AutoKeras 自我描述为:
AutoML 的终极目标是为具有有限数据科学或机器学习背景的领域专家提供易于访问的深度学习工具。
为了实现这一点,AutoKeras 执行了 Keras 神经网络模型的架构搜索和超参数调整。
这是使用 AutoKeras 的基本代码足迹:
import autokeras as ak
clf = ak.ImageClassifier()
clf.fit(x_train, y_train)
results = clf.predict(x_test)
如果你使用过 Scikit-learn,这种语法应该很熟悉。上述代码使用了task API;不过,还有其他更复杂的 API。你可以在项目文档网站上找到这些附加 API 的更多信息和更详细的教程。
显然,上述 AutoKeras 代码的复杂性相比 Keras Tuner 显著降低。然而,当你降低复杂性时,确实会牺牲一些精度,这是明显的权衡。对于具有有限机器学习专业知识的领域专家来说,这可能是一个不错的平衡点。
automl-gs
我们要查看的第三种解决方案是automl-gs,它从 30,000 英尺的高度审视 AutoML 实现。这超越了“现成”实现的复杂性,提供了一种有点类似 Staples 简易按钮的方法。
automl-gs 提供了一个“零代码/模型定义接口”。你只需将其指向一个 CSV 文件,确定要预测的目标字段,然后让它自动运行。它生成的 Python 代码可以集成到现有的机器学习工作流中,类似于流行的 AutoML 工具 TPOT的功能。automl-gs 还宣称它不是黑箱,因为你可以看到数据是如何处理的,模型是如何构建的,从而在事后进行调整。
automl-gs 执行数据预处理,并目前使用神经网络(通过 Keras)和 XGBoost 构建模型,同时计划实现 CatBoost 和 LightGBM。
这里是调用 automl-gs 的两种方法的比较,通过命令行和通过一行代码。请注意,你可以在项目网站上找到关于配置选项的更多信息以及检查输出的内容。
命令行:
automl_gs titanic.csv Survived
Python 代码:
from automl_gs import automl_grid_search
automl_grid_search('titanic.csv', 'Survived')
现在应该很容易比较这三种级别的 AutoML 项目复杂性。
automl-gs 可以通过单个命令行命令或单行 Python 代码 API 调用执行。因此,这个项目可能被任何人使用,从寻找项目基准的专业数据科学家,到具有有限编码技能或没有统计知识的业余爱好者,寻求数据科学的入门(在这里插入关于操控你不理解的力量的标准警告)。虽然一个业余项目基于预测做出一些重要决策可能会有问题(在我看来不太可能),但将机器学习和 AutoML 开放给任何想要了解更多的人确实具有价值。
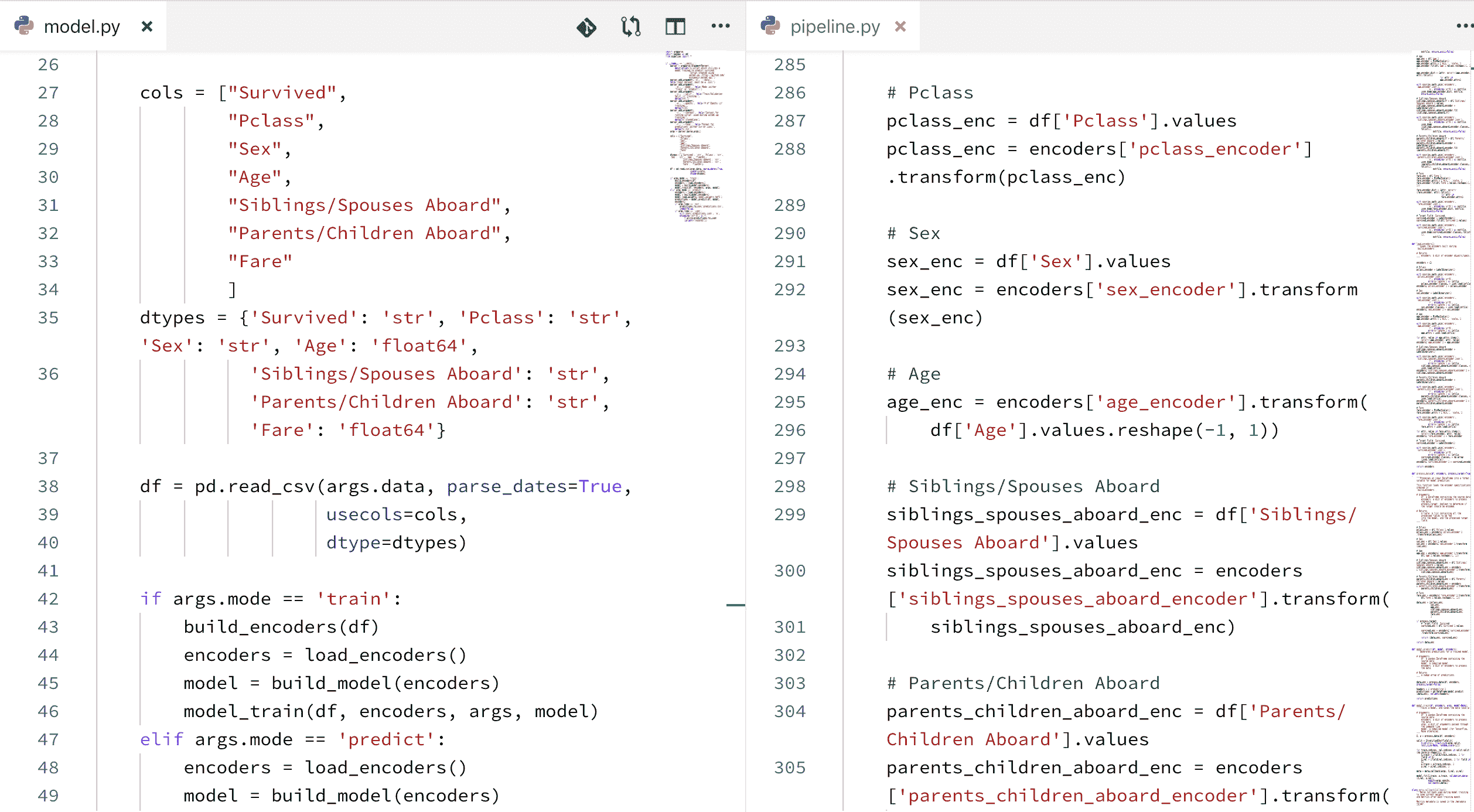
automl-gs 输出代码示例 (来源)
类似于 TPOT,我认为这里的价值在于创建项目基准的潜在低门槛。可以将 automl-gs 指向一个 CSV,让它并行地进行操作,同时手动制作竞争解决方案,并比较结果。这也可以通过其他 AutoML 工具完成,但这种低复杂度工具的绝对简单性依赖于几乎无需设置和考虑的特性,使得它能够非常快速地启动。能够在之后审查模型并进行编辑也很有吸引力,可以作为这种并行 AutoML/手动模型构建过程的另一层添加。
重点内容
机器学习呈现出一系列可以以不同程度自动化的任务,以帮助简化流程并提高成功率。自动化机器学习项目在自动化任务的方式以及对这些任务的配置、执行和后续操作的控制精度上采取不同的方法。希望这里突出介绍的 3 个项目能提供一些关于 AutoML 工具的实际代码复杂度差异的具体示例,以及它们如何以及对谁有用。
相关:
-
GitHub 仓库劫掠者与机器学习的自动化
-
自动化超参数调整您的模型
-
自动化机器学习:究竟多少?
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关主题
AutoML:使用 Auto-Sklearn 和 Auto-PyTorch 的介绍
原文:
www.kdnuggets.com/2021/10/automl-introduction-auto-sklearn-auto-pytorch.html
评论

让计算机自动完成你想要的任务
机器学习 (ML)现在影响着广泛的商业、工程和研究领域,以至于很难找到一个完全未涉及机器学习的领域。机器学习的进展伴随着软件和自动化的广泛趋势:只要人类活动依赖于可以以计算机可以处理的方式描述的重复任务,通常编写一个计算机可以遵循的配方(或程序)是很有用的。
现在使用机器学习意味着对于许多有用的任务,已经不再需要手动编写程序,甚至不需要准确知道如何解决问题。相反,我们可以通过定义一个搜索空间和一个学习算法来解决许多问题,然后让机器来解决。
现代机器学习有时被称为“软件 2.0”,这一趋势受到深度学习效果以及随之而来的研究和开发兴趣的推动。显而易见,这种方法非常适合一些应用:例如,拟合统计模型到数据上;但也有一些更深奥和令人印象深刻的例子,在统计学或旧式机器学习时代并不明显。
在过去几年中,我们看到机器学习比其他任何方法更好地预测蛋白质折叠,在围棋、Dota II、星际争霸 II 等游戏中击败了顶级人类玩家,并创造出相对连贯的文本和语音回应(尽管最后的成就有时可能会有偏差)。
尽管如此,这些项目几乎总是需要大量世界级工程和研究人才的应用。这并不完全令人惊讶,因为即使是配备了先进最尖端机器学习算法的计算机程序,要实现全新的目标仍然需要人类的创新。这种情况可能会在未来发生变化,当人工智能研究人员创造出突破人类专家级别的人工智能研究者门槛的新机器学习代理时。
目前,尽管突破性的人工智能科学仍然难以实现自动化,但有越来越多的机器学习应用场景中,不一定需要人工工程师来优化模型以完成特定任务。实际上,在某些任务中,将选择具体模型和调整学习超参数的任务交给人工判断,实际上可能会拖慢进度或导致结果不佳。人类可能在探索超参数空间时表现不佳,可能因为错误的原因偏向自己喜欢的模型类型,或者可能比实际训练模型所需的更频繁地开始和停止训练(这对他们的心理状态也不好)。
相反,一个好的机器学习从业者应该充分利用所有可用的工具,现在这些工具包括开源现成工具和应用机器学习的最佳实践。换句话说,AutoML。
什么是 AutoML?
AutoML 是一个广泛的技术和工具类别,用于将自动化搜索应用于您的自动化搜索,并将学习应用于您的学习。这些技术从对统计学习算法的超参数应用贝叶斯优化,到对深度学习模型进行神经网络结构搜索。
这个领域非常活跃且多样化,拥有健康的竞赛生态系统,其中许多竞赛都在automl.ai上进行了记录。事实上,最著名的 AutoML 包之一,Auto-SciKit-Learn(Auto-Sklearn),起初是 2014 年至 2016 年 ChaLearn AutoML 挑战赛的获胜者。
Auto-Sklearn 由德国著名的AutoML 超级组织中追求自动化机器学习的最著名研究小组之一开发。这个合作组织由弗赖堡大学和汉诺威大学的实验室组成。其他在这一领域有显著贡献的研究者包括Auto-WEKA背后的科学家,Auto-WEKA 是最早的流行 AutoML 工具包之一,以及其继任者 Auto-WEKA 2.0。这些研究人员主要分布在北美,但以加拿大的不列颠哥伦比亚大学为中心。而 Auto-WEKA 与开源 WEKA 软件和 Java 一起工作,Auto-Sklearn 是一个 Python 包,并且旨在紧密遵循 SciKit-Learn 的使用模式(因此得名“Auto-SciKit-Learn”)。
除了 Auto-Sklearn,弗赖堡-汉诺威 AutoML 小组还开发了一个Auto-PyTorch库。我们将在接下来的简单教程中使用这两个库作为我们进入 AutoML 的起点。
AutoML 教程演示
首先,我们将设置所需的包和依赖项。我们使用 Python3 的 virtualenv 来管理项目的虚拟环境,但如果你更喜欢 Anaconda(特别是如果你在 Anaconda 中使用 pip),你会发现类似的说明应该也能奏效。
以下是从基于 Unix 的系统(如 Ubuntu)或类似 Anaconda 提示符的 Windows 系统的命令行设置环境的命令。Auto-Sklearn 文档建议首先从其 requirements.txt 依赖文件安装,但我们发现对于本教程中使用的代码没有必要这样做。
# create and activate a new virtual environment
virtualenv automl --python=python3
source automl/bin/activate
# install auto-sklearn
pip install auto-sklearn
如果你在同一环境中同时使用 AutoML 库,可能会遇到冲突,因此请为 Auto-PyTorch 创建第二个环境。请注意,此环境需要使用版本大于或等于 3.7 的 Python。
deactivate
virtualenv autopt –-python=python3.7
source autopt/bin/activate
# install auto-pytorch from the github repo
git clone https://github.com/automl/Auto-PyTorch.git
cd Auto-PyTorch
pip install -e .
pip install numpy==1.20.0
pip install ipython
请注意,在 pip install -e . 后还有额外的两个安装语句。在我们的操作中,将 NumPy 版本升级到 1.20.0 解决了一个奇怪的错误,下面重现了该错误。
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
如果你想为项目做贡献,或只是想查看最新的进行中的代码,请查看开发分支。
# (optional)
git checkout development
# make sure to switch back to the primary branch for the tutorial
git checkout master
本教程的其余代码是 Python 代码,因此请启动你的 Python 提示符、Jupyter notebook 或文本编辑器。
本教程将包含使用标准 SciKit-Learn、Auto-Sklearn 和 Auto-PyTorch 分类器进行分类的最少演示。我们将为每种情况使用 SciKit-Learn 提供的内置数据集,每个演示都共享一些代码以导入公共依赖项、加载和拆分数据集。
import time
import sklearn
import sklearn.datasets
#** load and split data **
data, target = sklearn.datasets.load_iris(return_X_y=True)
# split
n = int(data.shape[0] * 0.8)
train_x = data[:n]
train_y = target[:n]
test_x = data[n:]
test_y = target[n:]
上述设置数据集的代码将用于本教程中的每个演示。
我们使用了小型的“iris”数据集(150 个样本,4 个特征和 3 个标签类别),以节省时间,但在完成示例后,你可能会想尝试更复杂的数据集。
其他可以尝试的 sklearn.datasets 中的分类数据集包括糖尿病 (load_diabetes) 数据集和手写数字数据集 (load_digits)。糖尿病数据集有 569 个样本,每个样本有 30 个特征和 2 个标签类别,而手写数字数据集有 1797 个样本,每个样本有 64 个特征(对应 8x8 的图像)和 10 个标签类别。
在开始使用 sklearn 的 AutoML 分类器之前,让我们先使用 vanilla sklearn 的默认设置训练几个标准分类器。可以选择很多,但我们将坚持使用 k-最近邻分类器、支持向量机分类器和多层感知器。
# import classifiers
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
# instantiate with default parameters
knn = KNeighborsClassifier()
mlp = MLPClassifier()
svm = SVC()
SciKit-Learn 使用友好的 fit/predict API,使得训练模型变得非常简单,Auto-Sklearn 和 Auto-PyTorch 也保留了相同的 API。这是易用性的一个重要因素,因为在这三个包中训练模型的体验非常相似。
t0 = time.time()
knn.fit(train_x, train_y)
mlp.fit(train_x, train_y)
svm.fit(train_x, train_y)
t1 = time.time()
同样,评估你的模型也很简单。SciKit-Learn 分类模型有一个 predict 方法,该方法接收输入数据并预测标签,然后可以将结果传递给 sklearn.metrics.accuracy_score 以计算准确率。
以下代码可以用来计算预测和在保留的测试集上的预测准确率,使用的是在上一段代码中训练的 k 最近邻、支持向量机和多层感知器分类器。
knn_predict = knn.predict(test_x)
train_knn_predict = knn.predict(train_x)
svm_predict = svm.predict(test_x)
train_svm_predict = svm.predict(train_x)
mlp_predict = mlp.predict(test_x)
train_mlp_predict = mlp.predict(train_x)
knn_accuracy = sklearn.metrics.accuracy_score(test_y, knn_predict)
train_knn_accuracy = sklearn.metrics.accuracy_score(train_y,train_knn_predict)
svm_accuracy = sklearn.metrics.accuracy_score(test_y, svm_predict)
train_svm_accuracy = sklearn.metrics.accuracy_score(train_y,train_svm_predict)
mlp_accuracy = sklearn.metrics.accuracy_score(test_y, mlp_predict)
train_mlp_accuracy = sklearn.metrics.accuracy_score(train_y,train_mlp_predict)
print(f"svm, knn, mlp test accuracy: {svm_accuracy:.4f}," \
f"{knn_accuracy:.4}, {mlp_accuracy:.4}")
print(f"svm, knn, mlp train accuracy: {train_svm_accuracy:.4f}," \
f"{train_knn_accuracy:.4}, {train_mlp_accuracy:.4}")
print(f"time to fit: {t1-t0}")
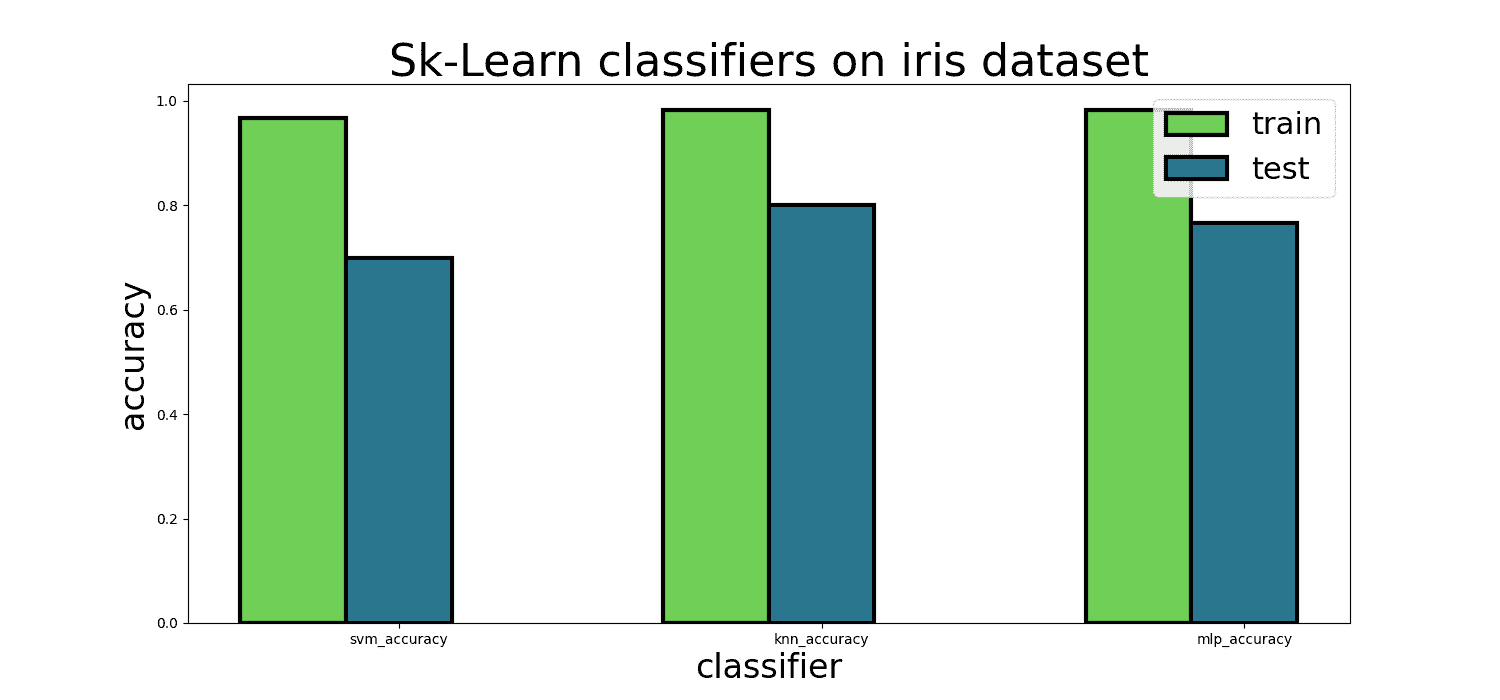
Sklearn 分类器在鸢尾花数据集上的图像
这些模型在鸢尾花训练数据集上相当有效,但训练集和测试集之间存在显著差距。
接下来,让我们使用这个类
AutoSKlearnClassifier
来源于
autosklearn.classification
使用这个基本 AutoML 类的代码看起来和上面示例中训练单个模型的代码完全相同,但实际上它会对多种机器学习模型进行超参数搜索,并保留最佳模型作为集成。
在引入常用库并设置好训练和测试数据集分割后,我们需要导入并实例化 AutoML 分类器。
import autosklearn
from autosklearn.classification import AutoSklearnClassifier as ASC
classifier = ASC()
classifier.time_left_for_this_task = 300
t0 = time.time()
classifier.fit(train_x, train_y)
t1 = time.time()
autosk_predict = classifier.predict(test_x)
train_autosk_predict = classifier.predict(train_x)
autosk_accuracy = sklearn.metrics.accuracy_score( \
test_y, autosk_predict \
)
train_autosk_accuracy = sklearn.metrics.accuracy_score( \
Train_y,train_autosk_predict \
)
print(f"test accuracy {autosk_2_accuracy:.4f}")
print(f"train accuracy {train_autosk_2_accuracy:.4f}")
print(f"time to fit: {t1-t0}")
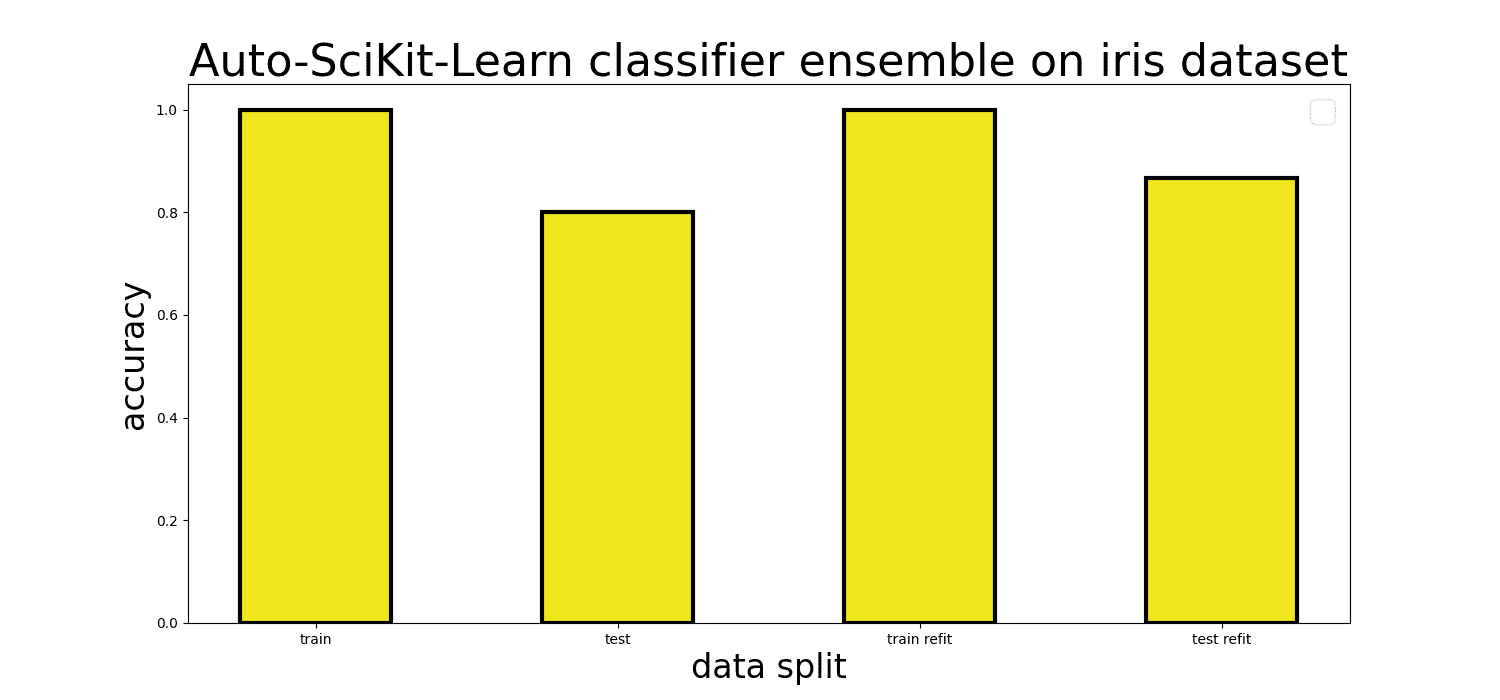
Auto-Sklearn 分类器集成在鸢尾花数据集上的图示
如果你不重置time_left_for_this_task,使用AutoSklearnClassifier运行fit方法将会花费大量时间,因为默认值是 3600 秒(一小时)。对于我们简单的鸢尾花数据集来说,这是过度的。从包文档来看,时间限制应该可以作为初始化分类器对象时的输入参数设置,但在我们的经验(版本 0.13.0)中并非如此。
你还可以尝试启用交叉验证来运行 fit 方法,如果选择这样做,你需要再次使用该方法进行训练。
refit
用最佳模型和超参数训练整个训练数据集。我们发现,当使用交叉验证和重训练相比于默认设置时,测试集准确率从 80%提高到了 86.67%。
请记住,当你在使用predict方法对AutoSklearnClassifier对象进行推断时,你实际上是在利用在 AutoML 超参数搜索过程中找到的最佳模型的集成。
| 方法 | 训练准确率 | 测试准确率 | 运行时间 |
|---|---|---|---|
| 默认 KNN | 0.9833 | 0.8000 | 0.6 ms 总计 |
| 默认 SVM | 0.9667 | 0.7000 | 0.6 ms 总计 |
| 默认 MLP | 0.9833 | 0.7667 | 0.6 ms 总计 |
| Auto-Sklearn | 1.000 | 0.8000 | 291.390 s |
| Auto-Sklearn (含 cv + refit) | 1.000 | 0.8667 | 918.658 s |
| Auto-PyTorch | 0.9917 | 0.9667 | 302.236 s |
最后,让我们尝试一个适合深度学习爱好者的 AutoML 包。
与 Auto-Sklearn 一样,Auto-PyTorch 也旨在极其简单易用。要运行下一段代码,请记得切换到你的 Auto-PyTorch 环境,以确保正确的依赖项可用。在导入常用库并拆分数据之后:
import autoPyTorch
from autoPyTorch import AutoNetClassification as ANC
model = ANC(max_runtime=300, min_budget=30, max_budget=90, cuda=False)
t0 = time.time()
model.fit(train_x, train_y, validation_split=0.1)
t1 = time.time()
auto_predict = model.predict(test_x)
train_auto_predict = model.predict(train_x)
auto_accuracy = sklearn.metrics.accuracy_score(test_y, auto_predict)
train_auto_accuracy = sklearn.metrics.accuracy_score(train_y, train_auto_predict)
print(f"auto-pytorch test accuracy {auto_accuracy:.4}")
print(f"auto-pytorch train accuracy {train_auto_accuracy:.4}")
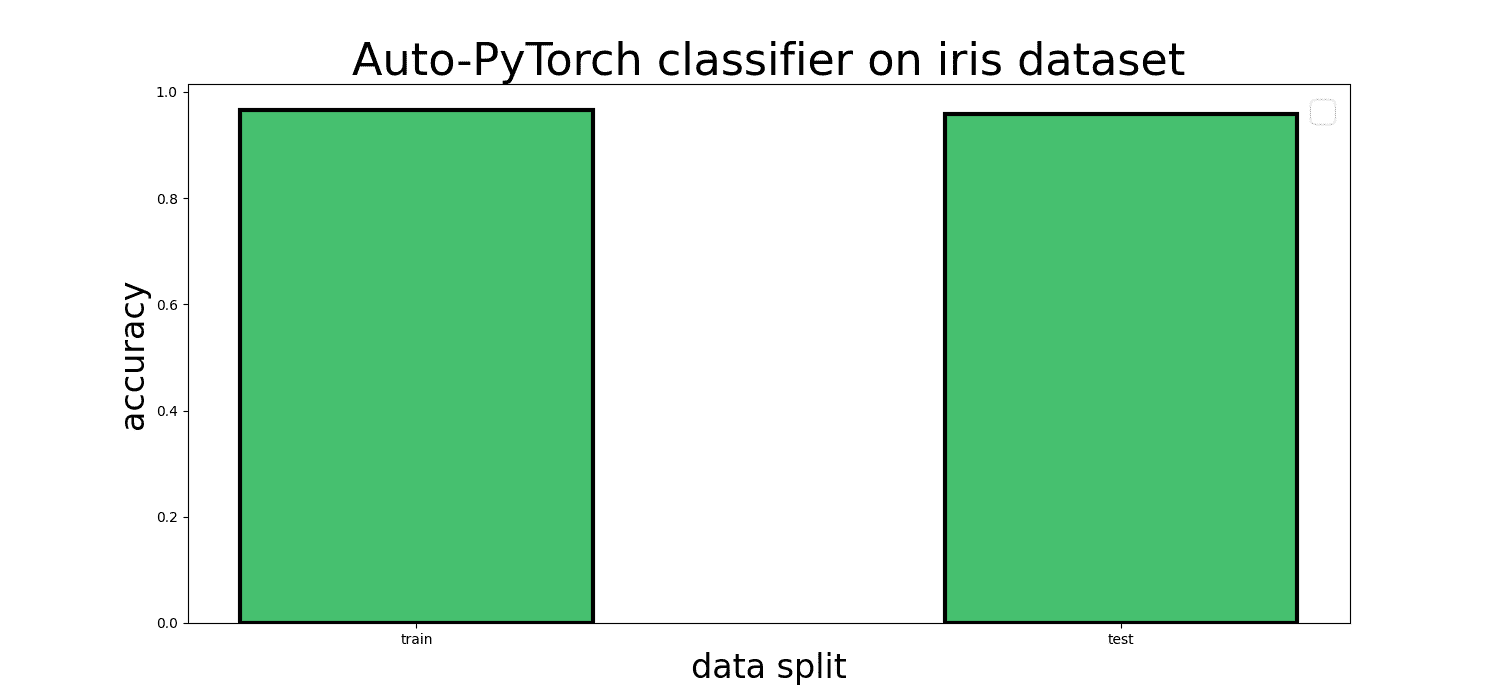
Auto-PyTorch 分类器在鸢尾花数据集上的图示
正如你在结果表中看到的,Auto-PyTorch 在拟合鸢尾花数据集时非常高效和有效,训练和测试准确率达到了 90 多%。这比我们之前训练的自动 SciKit-Learn 分类器稍微好一点,比使用默认参数的标准 sklearn 分类器要好得多。
AutoML 会取代数据科学家吗?
不,未必。AutoML 承诺改善典型数据科学和机器学习工作流的实用性、性能和效率。额外的抽象层和自动化的最佳实践超参数搜索,如果使用得当,确实可以带来显著的不同。对于我们在今天教程中实验的这些软件包,我们将其准备程度描述为正在进行的研究原型。
我们需要进行许多小修小补才能使一切正常工作,例如将 NumPy 升级到 1.20.0 以修复模糊的错误消息,无法将运行时间限制设置为输入参数(如 Auto-Sklearn 文档所建议),以及由于一些模糊的冲突而无法使用单个虚拟环境同时支持两个软件包。此外,AutoML 的价值在于自动化超参数搜索,但自动分类器本身有许多参数,这些参数对最终结果有很大影响,这也让人忍俊不禁。
尽管如此,我们认为 AutoML 是任何机器学习或数据科学从业者工具箱中有价值的补充,无论他们使用 Auto-Sklearn/Auto-PyTorch、Auto-WEKA、其他软件包,还是自行开发解决方案。当 AutoML 工具适合时,它不仅能提升项目的性能,还能减少经济和能源(包括环境)成本,从而避免长时间的超参数和架构搜索。
即使一些工具仍有许多粗糙的地方,这也只是一个很好的理由和动力,让你自己参与到这些项目中。Auto-PyTorch 在 Apache 2.0 许可证下提供,而 Auto-Sklearn 使用 BSD 3-Clause 许可证。
简介:Kevin Vu 负责管理 Exxact Corp 博客,并与许多才华横溢的作者合作,他们撰写有关深度学习不同方面的文章。
原文。经授权转载。
相关内容:
-
自动化机器学习简介
-
如何创建 AutoML 管道优化沙盒
-
使用 TPOT 进行机器学习管道优化
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关内容
如何创建一个 AutoML 管道优化沙箱
原文:
www.kdnuggets.com/2021/09/automl-pipeline-optimization-sandbox.html
评论
你可能了解自动化机器学习(AutoML)。你很可能听说过开源的 AutoML 工具 TPOT,也就是你的 数据科学助手。你甚至可能看过我最近的文章,介绍了如何使用 TPOT 优化机器学习管道(你可能还没看过,所以这是你去看看它的机会... 我会等你)。
无论如何,当这些调节按钮可见且易于调整时,探索 AutoML 和机器学习优化的各种调节按钮将更具意义。在本文中,我们将实现一个版本的 TPOT 示例,我们在上一篇文章中查看过,将其作为一个 Streamlit 应用程序。
如果你不熟悉 Streamlit,这是 30,000 英尺的概述:
Streamlit 可以在几分钟内将数据脚本转化为可分享的网页应用程序。
全部使用 Python。完全免费。不需要前端经验。
概述
除了本文中使用的内容,我不会进一步详细介绍 Streamlit,但你可以在这里找到这个很棒的介绍,以及 Streamlit 备忘单,基本覆盖了在了解其工作原理后你需要知道的一切,点击这里。
除了快速了解实现 Streamlit 项目外,你还将获得一个沙箱网页应用程序,允许使用一对著名数据集进行管道优化实验。通过一些修改,你还应该能够让沙箱与其他数据集一起运行,并扩展功能以包括更多调节按钮。
我们使用 Streamlit 和 TPOT 构建的“AutoML 管道优化沙箱”网页应用程序
我不会重新讲述原始博客文章(请随意现在阅读),但简而言之,我们正在创建一个脚本来自动化预处理和建模的优化——包括有限数量的预处理转换以及算法选择——用于对鸢尾花和数字数据集的分类任务。确实,数据集比较无聊,但使用知名数据来设置应用程序并不是一个坏主意,正如我上面所说,修改几行代码后,你可以尝试任何其他数据集。
关于这个优化过程的一些注意事项,除了上述内容,还有:
-
用于模型评估的交叉验证
-
对建模进行多次迭代(由于 TPOT 内部使用遗传算法)— 对如此小的数据集可能没有用,但随着进展可能会有帮助
-
比较这些多次迭代的结果管道——它们都是相同的吗?
-
你知道 TPOT 现在在后台使用 PyTorch 来构建神经网络进行预测吗?
最后一点今天我们不考虑,但请记住以备未来使用。
让我们看一下创建这个简单 Streamlit 应用所需的代码。
代码
首先,导入:
import streamlit as st
import timeit
import pandas as pd
import matplotlib.pyplot as plt
from tpot import TPOTClassifier
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits, load_iris
from sklearn import metrics
from stqdm import stqdm
一切应该都相当直接。最后一个导入,stqdm,是一个 tqdm 风格的进度条,专门为 Streamlit 编写。
接下来,这是数据加载器函数:
@st.cache
def load_data(dataset, train_size, test_size, random_state):
"""Load data"""
ds = ''
if dataset == 'digits':
ds = load_digits()
df = load_digits(as_frame=True)
if dataset == 'iris':
ds = load_iris()
df = load_iris(as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(ds.data, ds.target, train_size=train_size, test_size=test_size, random_state=random_state)
return X_train, X_test, y_train, y_test, df['frame']
我们使用 Scikit-learn 的 load_iris() 和 load_digits() 函数(TPOT 与之紧密集成)来提取相应的数据集。请注意,这里将数据集分为训练集和测试集,训练/测试特征/标签都分别返回,并提供一个完整的数据集数据框以供展示给用户,因为这样看起来更好,尤其是在 Streamlit 上展示时(Streamlit 能够使用其 write() 方法解释和正确显示各种对象)。还有其他方法可以实现,但对于如此小的数据集,这种方式简单而且没有问题。注意 @st.cache 装饰器,它缓存了函数的结果以便未来应用运行时使用,而不是每次都重新加载数据。
现在我们设置一些全局 Streamlit 配置,设置侧边栏,分配一些变量,并使用上述函数加载数据:
# Set title and description
st.title("AutoML Pipeline Optimization Sandbox")
st.write("Experiment with using open source automated machine learning tool TPOT for building fully-automated prediction pipelines")
# Create sidebar
sidebar = st.sidebar
dataset = sidebar.selectbox('Dataset', ['iris','digits'])
train_display = sidebar.checkbox('Display training data', value=True)
search_iters = sidebar.slider('Number of search iterations', min_value=1, max_value=5)
generations = sidebar.slider('Number of generations', min_value=1, max_value=10)
population_size = sidebar.select_slider('Population size', options=[10,20,30,40,50,60,70,80,90,100])
random_state = 42
train_size = 0.75
test_size = 1.0 - train_size
checkpoint_folder = './tpot_checkpoints'
output_folder = './tpot_output'
verbosity = 0
n_jobs = -1
times = []
best_pipes = []
scores = []
# Load (and display?) data
X_train, X_test, y_train, y_test, df = load_data(dataset)
if train_display:
st.write(df)
将上面的代码与先前作为独立脚本实现的文章或 Streamlit 快捷参考进行比较,相关内容应该都相当直接。
注意到设置交互式用户配置变量的简易性,这些变量随后被用于我们的代码中,以及设置侧边栏的简易性。我们可以使用滑块、复选框和下拉框来选择和显示数据集,并设置遗传算法 TPOT 内部用于优化过程的搜索迭代次数、代数和种群大小。应该越来越容易看出,如何在不费太多力气的情况下将其开放给自定义数据集。
接下来,让我们定义评分方法、模型评估方法和实际的搜索方法。之后,显示优化循环,其中包括一些特定于迭代的输出以便用户参考。
# Define scoring metric and model evaluation method
scoring = 'accuracy'
cv = ('stratified k-fold cross-validation',
StratifiedKFold(n_splits=10,
shuffle=True,
random_state=random_state))
# Define search
tpot = TPOTClassifier(cv=cv[1],
scoring=scoring,
verbosity=verbosity,
random_state=random_state,
n_jobs=n_jobs,
generations=generations,
population_size=population_size,
periodic_checkpoint_folder=checkpoint_folder)
# Pipeline optimization iterations
with st.spinner(text='Pipeline optimization in progress'):
for i in stqdm(range(search_iters)):
start_time = timeit.default_timer()
tpot.fit(X_train, y_train)
elapsed = timeit.default_timer() - start_time
score = tpot.score(X_test, y_test)
best_pipes.append(tpot.fitted_pipeline_)
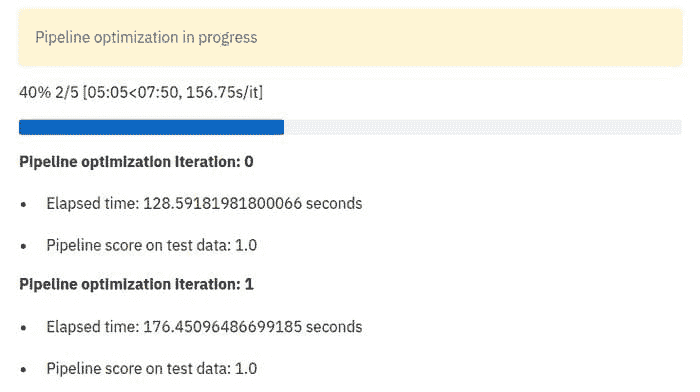
st.write(f'\n__Pipeline optimization iteration: {i}__\n')
st.write(f'* Elapsed time: {elapsed} seconds')
st.write(f'* Pipeline score on test data: {score}')
tpot.export(f'{output_folder}/tpot_{dataset}_pipeline_{i}.py')
此时,你应该将 write()、spinner()、success() 和 Streamlit 快捷参考中的其他显示功能进行比较。
一旦运行,上述优化循环将输出类似以下内容的结果:
最后,我们需要评估我们的结果:
# check if pipelines are the same
result = True
first_pipe = str(best_pipes[0])
for pipe in best_pipes:
if first_pipe != str(pipe):
result = False
if (result):
st.write("\n__All best pipelines were the same:__\n")
st.write(best_pipes[0])
else:
st.write('\nBest pipelines:\n')
st.write(*best_pipes, sep='\n\n')
st.write('__Saved to file:__\n')
st.write(f'```{output_folder}/tpot_{dataset}_pipeline_{i}.py```py')
st.success("Pipeline optimization complete!")

...并输出最佳管道的代码(也保存到文件中):
# Output contents of best pipe file
with open (f'{output_folder}/tpot_{dataset}_pipeline_{i}.py', 'r') as best_file:
code = best_file.read()
st.write(f'```{code}```py')

这是完整的 Streamlit 应用程序代码(请注意,除了这个简短的 Python 脚本之外不需要其他任何东西来完成所有工作):
这就是如何快速构建由 Streamlit 和 TPOT 提供支持的 AutoML 管道优化沙箱,只需使用 Python 代码即可。请注意我们在成功实现这一目标时所需的网络编程技能的缺乏。
非常好。成功!

相关:
-
使用 TPOT 的机器学习管道优化
-
Python 中的简单 AutoML
-
使用 FLAML + Ray Tune 的快速 AutoML
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
LinkedIn 供稿排名的多目标优化的自动调节
原文:
www.kdnuggets.com/2020/08/autotuning-multi-objective-optimization-linkedin-feed-ranking.html
评论
由 Marco Varela 和 Mavis Li,LinkedIn
LinkedIn 主页上的供稿使命是使会员能够建立一个积极的专业社区,促进他们的职业发展。为了在供稿上提供最佳体验,我们利用人工智能(AI)向会员展示最相关的内容。这是具有挑战性的,因为我们需要从数百个选项中选择要展示的内容。这些内容类型可以包括其他会员分享的文章、职位推荐、课程推荐等,每种类型以不同的方式丰富我们的生态系统,这些共同的目标是实现 LinkedIn 的使命,即“连接全球专业人士,让他们更高效、更成功”。鉴于我们希望为会员提供多样化且丰富的体验,我们不能仅仅追求点击量的增加。
为了在内容上实现最佳的平衡以优化会员体验,我们采用了 多目标优化 方法。我们有不同的机器学习模型来优化不同的目标,比如反应、评论、行动的下游影响。然而,这些不同目标的平衡是通过机器学习工程师手动调整参数来实现的,这非常低效。
在这篇文章中,我们分享了如何开发一个自动化系统来调整我们机器学习模型中的一个主要参数,该模型推荐 LinkedIn 供稿中的内容,这只是 以社区为中心的架构 的一部分。我们的目标是实现成员指标的适当平衡,同时考虑到工程师的生产力和满足我们生态系统中的约束。有关 LinkedIn 供稿的更多背景信息,请参考 这篇博客文章。
在供稿上管理指标权衡的方法
为了应对我们生态系统中的复杂性和权衡,我们在优化一组度量标准的同时保持另一组标准不变。优化部分来自我们希望最大化会员的“贡献”。我们所说的“贡献”主要指点赞、评论和分享,这些行为更有可能在我们的生态系统中驱动对话,而不是简单的文章点击。贡献通过几种方式推动更多对话:分享会在 Feed 上创建新的帖子,评论使会员能够与帖子作者开始对话,点赞则在会员网络中生成下游更新。这些行为可以被视为“主动”的,因为会员通过为生态系统做出贡献而主动消费内容。
然而,我们也希望为那些不那么以对话为驱动的内容留下空间,这些内容可以被视为更“被动”的内容。特别是,Feed 上的不频繁访客更可能参与被动消费。基于这些原因,我们决定保持“被动”消费不变。
将度量权衡转化为评分函数
鉴于我们需要在 LinkedIn Feed 上管理内容和目标的多样性,我们决定采用 多目标优化 方法对我们的 Feed 内容进行排序。从高层次来看(略过许多细节),我们用以下方程粗略地对每个更新进行评分:
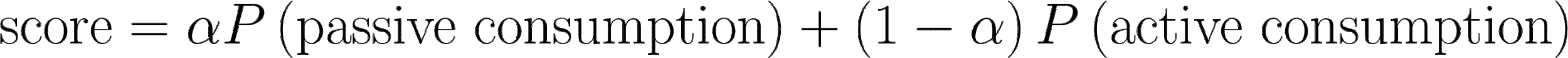
你可以将每个 P(x) 视为模型对特定目标的概率评分。我们使用一种称为点击权重(????)的杠杆来选择更偏向被动消费的内容(例如,可能会驱动点击的工作或文章推荐)与更偏向社区驱动的内容(例如,可能会鼓励评论的帖子)。不同类型的内容在某些使用场景下表现更佳,因此在被动消费和主动消费之间存在权衡。即使在特定类型的内容中,也可能有鼓励更多被动行为而非主动行为的条目。例如,热门文章可能只会鼓励点击,而来自密切联系人的文章可能会引发讨论。
为什么我们需要不断管理权衡
既然我们已经提供了足够的关于 LinkedIn Feed 的背景信息,我们想分享一些我们在选择合适的 ????(点击权重)以平衡被动消费(即点击)与主动消费(即点赞、评论、分享)过程中的经历。在接下来的内容中,我们将把点赞、评论和分享的动作集合称为“贡献”。
???? 参数决定了主动和被动消费之间的平衡,不能保持静态,原因有几个。我们不断改进我们的机器学习模型,以提供最佳的会员体验,这可能会影响两个指标之间的平衡。例如,我们可能会加入新功能或尝试新的建模方法。这会以多种方式影响平衡。一种方式是某个特定的特征变化(例如,会员对文章帖子的偏好)或模型变化可能在推荐主动消费内容时比被动消费更有效,反之亦然。另一种方式是我们的训练过程中存在随机成分,这可能会在重新训练模型后改变最佳权重。
在多目标环境中维持平衡的挑战
我们最初管理正确平衡的方法是基于历史数据建立离线模拟器,运行我们的模型,然后获取不同 ???? 值的模拟指标。这使我们能够通过查看如下输出图表来感知正确的 ????, 其中每个点表示一个不同的 ????:
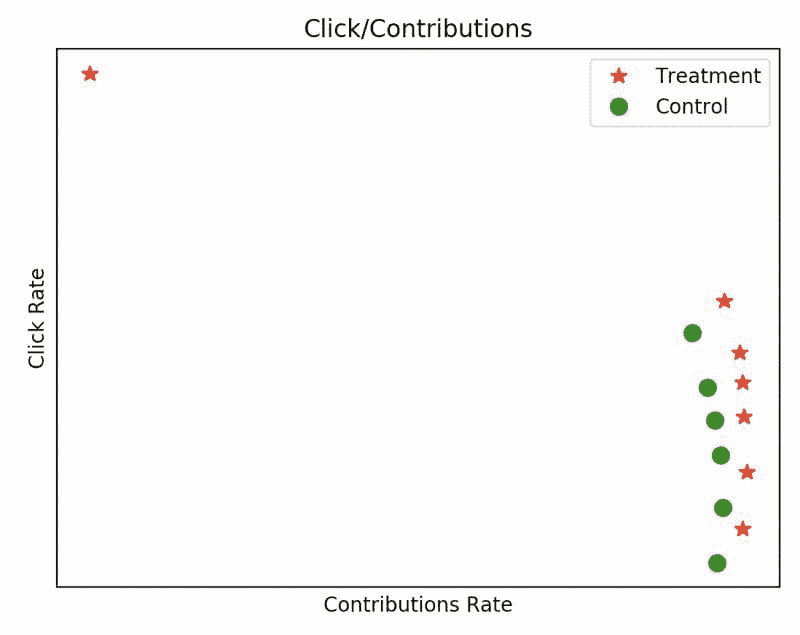
图 1:模拟结果(点击率和贡献率的实际值被排除,因为它们与此帖不相关)。对照组是我们会员的标准体验,而处理组是正在评估的标准体验的变体。
然而,这种方法证明还不够。由于几个原因,我们的模拟器方法在预测在线世界中的效果时固有的存在局限性:
-
LinkedIn 生态系统随时间变化。也许会引入影响会员行为的 UI 变化,或者我们可能会向信息流中引入之前没有的新内容,如投票。这些变化很难在离线环境中复制,因为模拟器仅限于历史数据,可能无法完全反映当前的生态系统状态。
-
会员可能采取的行动顺序可能会根据显示的内容而有所不同。例如,如果他们首先看到一篇他们非常喜欢的文章,他们可能更有可能继续与其他更新进行互动。
-
生态系统中有一些 强化学习 组件,在模拟器环境中特别难以体现。
结果,机器学习工程师不得不在线上发布多个版本的模型以测试不同的 ???? 值,这带来了两个主要痛点。首先,对于工程师来说,创建具有不同 ???? 值的模型变体变得耗时,特别是因为这一过程涉及反复试验。其次,由于我们依赖 A/B 实验来评估每个变体,我们会耗尽在线流量,无法进行我们希望进行的实验。
选择权衡的新方法:在线自适应调优
鉴于手动调优????在线上存在的困难,我们决定自动化这个过程,以减少人工工程工作和在线流量负担。我们确定了几个要求,以便我们的团队能够轻松利用该工具,并在尊重在线流量需求的情况下允许同时进行足够多的实验:
-
该工具需要易于使用,因为我们试图减少工程师的人工工作,并且它应该能够被数十名机器学习工程师轻松采用。
-
该工具只需占用总流量的一小部分。例如,如果工具占用 50% 的流量,那就没有用处。
-
该工具应该在相对较短的时间内得出????的最佳值。例如,如果该工具需要一个月才能找到最佳权重,那就没有用处。
需求 2 和 3 是必要的,以确保我们可以最大化同时进行的实验数量。
在线自动调优的实施:初步策略概述
考虑到这些要求,我们决定在 LinkedIn 中利用TALOS(调优所有大规模在线系统)库,该库旨在在线环境中学习参数。我们的目标是自动调整点击权重(????),以最大化贡献的同时保持被动消费水平。正式地,我们的问题可以写成如下:
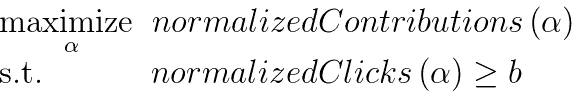 ,
,
其中b是等于基线模型的归一化点击数的常数,????是点击权重。我们根据 Feed 加载的次数以及相关的 alpha(即贡献/加载的 Feed)对贡献和点击进行了归一化。
我们解决这个问题的初步尝试是使用探索-利用策略与 TALOS。探索阶段将成员分配到不同的点击权重桶中,并收集相关指标(即贡献,归一化点击)几天。在利用阶段,算法将聚焦于一个点击权重范围内,收集该范围内更接近解决方案的额外数据。
在线自动调优的实施:指标理解
在我们实施解决方案之前,首先集中精力理解我们的指标。这涉及确定探索的网格点和搜索范围。我们根据历史模型迭代中手动选择的点击权重 [0.0, 0.005] 选择了探索的搜索范围。选择网格点数存在权衡。增加点数可以为点击权重提供更多的细粒度,但也使每个点的流量减少,从而增加了指标中的噪声。当我们用 31 个网格点收集指标时,我们在归一化贡献指标中看到主要是噪声,而在归一化点击指标中看到上升趋势。这在图 2a 和 2b 中得到了说明,这些图显示了对桌面(非应用程序)用户的实验结果。
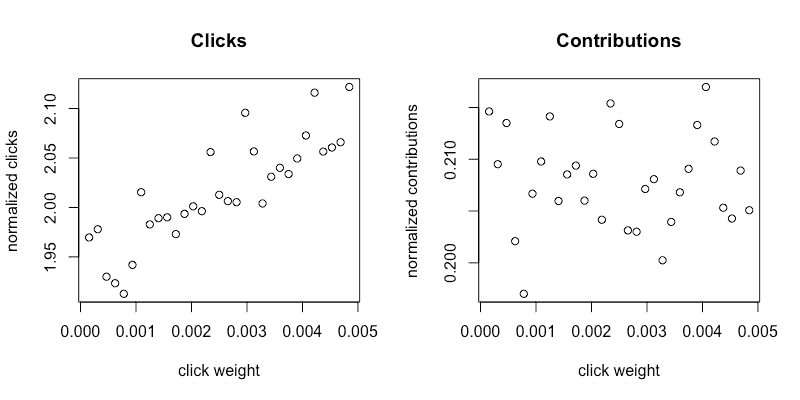
图 2a, 2b: 小搜索范围,31 个点
为了改善这种情况,我们做了两件事:
-
将点数从 31 减少到 15,以在每个点击权重下收集更多数据。
-
扩大了我们的搜索范围,以便更清楚地看到贡献与点击权重之间的关系。
从图 3a 和 3b 中可以看到,经过更改后,点击和贡献都有明显的趋势。
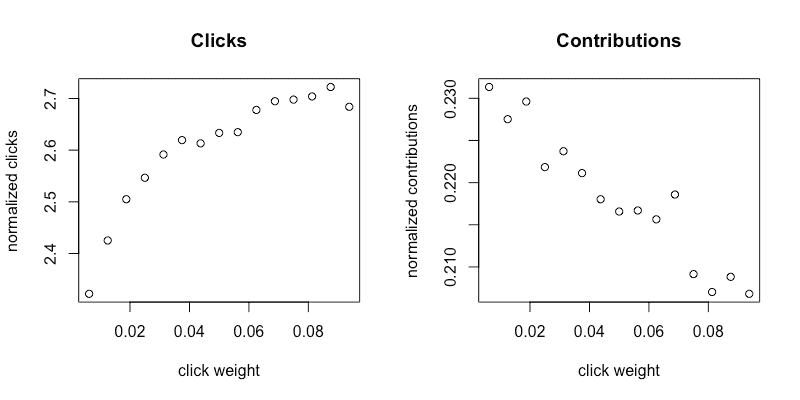
图 3a, 3b: 大搜索范围,15 个点
图 3a 和 3b 是减少点数并增加搜索范围的结果。
在线自动调优的实施:初步策略经验
一旦确定了可靠捕捉指标的正确参数,我们进行了利用阶段的实验,如下图所示。由于这一部分示例了不同平台(移动设备)上的不同模型,因此搜索范围不同。
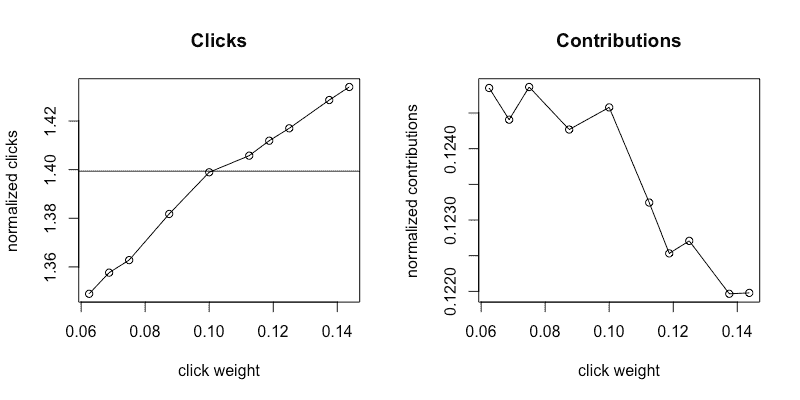
图 4a, 4b: 探索结果
图 4a 和 4b 显示了在探索阶段收集的指标。我们可以在归一化点击指标(4a)中看到明显的正向趋势,而在归一化贡献指标(4b)中看到下降但嘈杂的趋势。黑色水平线表示常数 b,即我们控制模型的归一化点击量。
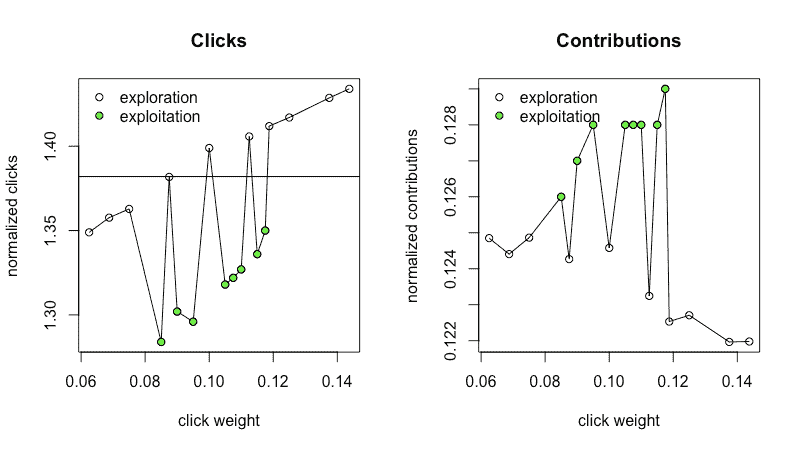
图 5a, 5b: 探索和利用结果
图 5a 和 5b 显示了在探索阶段之后和利用阶段的指标汇总。白色点来自探索阶段(数据与图 4a 和 4b 相同)。探索阶段之后,算法决定解决方案位于缩小的搜索范围内,并选择了新的点(绿色点)以收集利用阶段的指标。
绿色的利用点给我们的指标增加了过多的噪音,使得实际可行的点击权重变得不清晰。这很让人惊讶,因此我们更仔细地查看了我们的指标。我们首先查看了从前一天起标准化点击的变化。如图 6 所示,在某些日子中,变化幅度可以达到 12%。
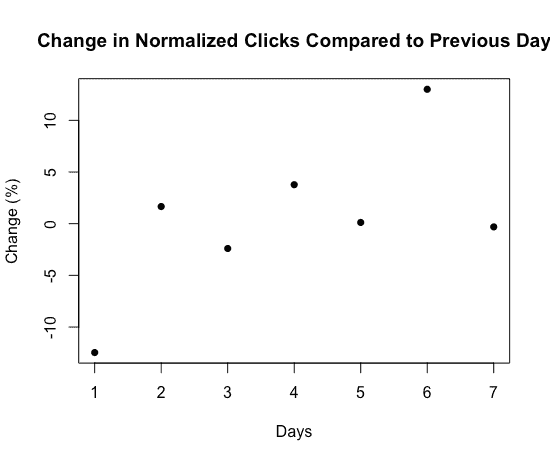
图 6:标准化点击的日间变化
这表明我们的指标存在显著的日间变化,并解释了为什么我们的利用点与探索相比具有如此不同的趋势,这扰乱了算法,因为我们的指标可能受到点击权重和一天中的时间的类似影响。
LinkedIn 应用的使用在每周的不同日期变化显著(例如,专业人士在星期五和星期三的使用模式不同),因此看到这种变异性并不完全令人惊讶。
这尤其具有挑战性,因为我们的工具期望探索和利用的数据趋势相似;然而,一旦我们将探索和利用数据放在一起(如工具要求的那样),趋势就丢失了。由于这些原因,我们决定跳过利用阶段,以在我们工作所限的时间和提升约束下保持合理的趋势。
在线自调节的实施:优化问题的修订
我们随后专注于仅对探索数据应用优化问题,如下所示。我们最初收集了我们在项目开始时设定的两倍在线流量需求的数据(即需求 2),以更好地理解我们的指标。图 7a 和 7b 总结了收集的数据。图 7b 中的蓝色点对应于图 7a 中的蓝色区域,即我们的约束定义的可行区域。
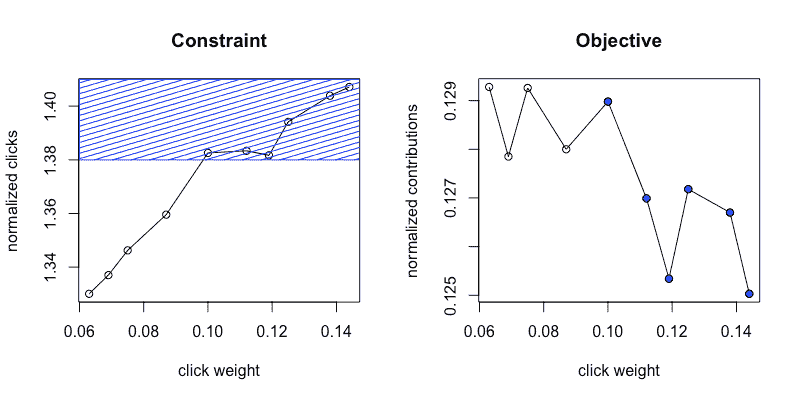
图 7a,7b:带约束的可行区域
我们最大的挑战是弄清楚如何处理贡献指标的噪音问题。正如我们从公共贡献的图表中看到的,即使在所需的提升百分比的两倍下,贡献指标仍然非常嘈杂。由于我们 A/B 实验的流量有限,我们无法信任贡献(????)指标。
为了应对这一挑战,我们更仔细地查看了我们指标的模式。由于贡献指标是????的递减函数,而我们的约束是????的递增函数,因此问题的解决方案在于活动约束集,即 normalizedClicks(????) = b。这是有用的,因为 normalizedClicks(????)是一个更稳定的指标。因此,我们可以将原始问题重新表述为基于原始约束的最小化问题,其中我们仅尝试保持标准化点击与基线相同,避免依赖 normalizedContribuons 指标。
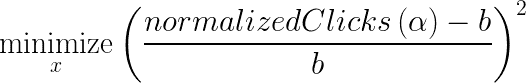
重新表述的问题涉及在没有约束的情况下最小化 normalizedClicksDelta。
在线自动调优的实施:最终策略和结果
在图 6a 中,我们观察了在 5%流量下,经过 2 天的点击权重范围内的新指标。图 6b 显示了点击权重 ????(在 x 轴上显示)成为优化问题中最优点的概率。这个概率是通过首先从后验高斯过程重复抽样函数,然后确定优化(最大化或最小化)这些抽样函数的点来计算的。获得的点的经验分布给出了图 6b。
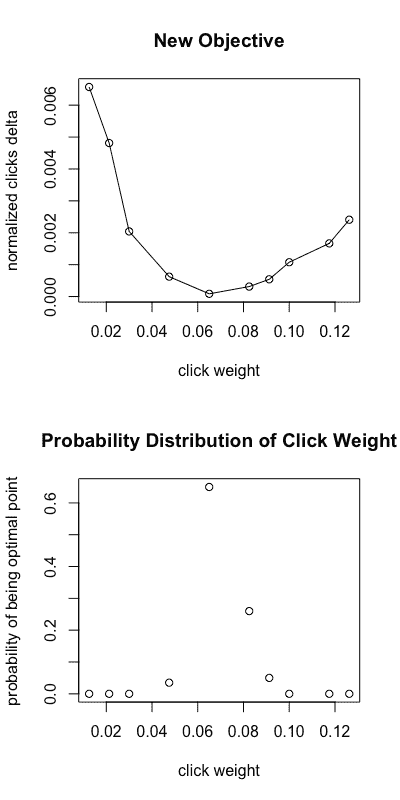
图 8a, 8b:使用新目标的收敛情况
以前,工程师会使用不同的点击权重来测试多个模型,以尝试找到一个调整得当的点击权重模型。如果第一组点击权重中没有理想的点击权重候选项,这可能涉及到几天后重新启动不同的点击权重。实际模型的一个示例时间表可能涉及在 5%流量下收集 4 种不同的点击权重,经过 2 天后选择一个“最优”点击权重。图 9 是引入点击自动调优之前的调试计划示例。图 10 是使用自动调优工具的新调试计划示例。
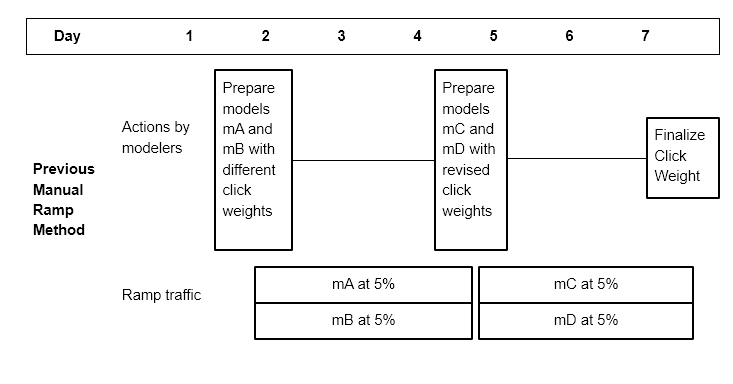
图 9:自动调优工具之前的调试过程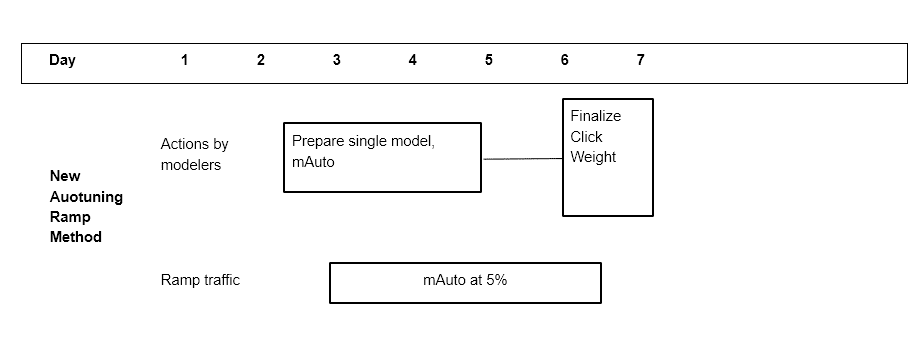
图 10:自动调优工具后的调试过程
旧的调试时间表可能需要在 5 天内完成 10%流量(4 天收集指标,1 天进行流量变化)。现在,通过自动选择参数 ???? 的过程,我们可以将这个部分的过程减少到在 5%流量下的 2 天。在模型调试到 5%后,工程师可以使用脚本启动点击自动调优,并在 2 天内提供一个单一的收敛点击权重。在这两天内,我们会考虑 10 种不同的点击权重,并选择一个可能位于这些点之间的解决方案。这种新工具通过以下三个方面的成本降低提高了我们的效率:
-
调试时长
-
调试量
-
工程师的人工努力
此外,新工具通过在选择 ???? 时更加精准,帮助我们找到更优的点击权重,相比于以前的人工努力。
经验教训
在这段旅程中,我们学到了一些经验教训。首先,我们发现,在这个特定的优化问题中,将问题公式化为尽可能简单是有益的。在花时间理解我们想要目标的指标以及它们如何与我们特定的机器学习模型相关之后,我们意识到我们可以将问题定义从一个带约束的最大化问题转变为一个最小化问题。这使我们能够只处理在较低 ramp 百分比下更可靠的约束指标,同时仍然满足我们的总体目标,即在模型之间保持被动消费恒定,同时减少工程师所需的手动工作量和在线流量需求。
此外,重要的是要意识到解决方案需要解决的约束条件。在我们的案例中,我们只能允许工具使用有限的 ramp 体积,并在有限的时间内最大化同时进行的实验数量。一旦约束条件定义清晰,就更容易识别适合的解决方案。在我们的案例中,所处理的指标存在显著的日间波动,因此在我们的约束下,我们发现探索-开发算法并不适用,因为这些算法需要更长时间和更大的 ramp 来适应我们的难题。
感谢 Kinjal Basu、Viral Gupta、Yunbo Ouyang 构建参数调整库及提供建议,以及我们的经理 Ying Xuan 和 Zheng Li 的支持。
Marco Varela是 Linkedin 的高级软件工程师,他是 Feed AI 团队的一员,专注于通过自动化和特征新鲜度提高 Feed 更新的排名。
Mavis Li是 Linkedin Feed AI 团队的一个软件工程师,负责 Feed 的个性化和排名。她参与了多个项目,包括将下游模型作为目标、将网络外的群组更新整合到 Feed 中,以及点击权重自动调整。
相关:
-
查看这份全面的模型优化技术指南。
-
自动化机器学习:免费的电子书
-
数据科学家的灭亡 – AutoML 会取代他们吗?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关内容
如何避免分析兔子洞:避免调查循环及其陷阱
原文:
www.kdnuggets.com/2017/04/avoid-analytic-rabbit-holes-investigation-loops.html
评论

“如果我们添加这些变量会怎样?..”是一个致命的问题类型,可能会毁掉你的分析项目。虽然好奇心是数据科学家的最佳朋友,但随之而来的诅咒也是不可避免的——有些人称之为分析瘫痪,有些人则称之为过度分析,但我称这些情况为“分析兔子洞”。在你开始任何数据科学项目时——无论是深入的统计研究、机器学习模型,还是简单的业务分析——总会涉及某些步骤。有些来源将它们分解得更细致,有些则更为概括,但从实际业务的角度来看,这种观点最为合理。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
过程如下:数据科学家定义一个假设,然后探索数据,获得帮助解释假设的数据洞察。完成这一步后,循环开始了——新的信息使得假设得到改进,进入“更深入挖掘”的阶段,同时重复数据探索、洞察生成和……再次重新定义假设。这里就是循环的开始,重要的是从一开始就要意识到。如果没有明确一件事——一个有支持的决策——就会陷入分析兔子洞。
如果决定未被明确或不是分析调查的主要目标——项目就会陷入“分析兔子洞”。为什么?因为当数据科学家开始关注假设而不是决策时,就会开始过度分析。虽然这两者看起来非常相似,但实际上它们之间的差异对数据科学项目的成功与否至关重要。我将描述这两种方法以及它们如何导致成功或注定失败。
以假设为中心。 在数据探索的过程中,假设不断被修正,新的见解不断被发现。这个过程的诅咒在于,由于目标是找到完美的答案或假设的解决方案,数据科学家会陷入许多陷阱,比如发现不相关但相关的变量之间的虚假相关性。最终,分析和切分数据的广度开始产生副作用——假设被拆分为子段,每个子段都有一系列的数据点、假设和相互冲突的结论。这个项目的典型结局是一个快乐的数据科学家向一个非技术团队展示这些巨大的发现,而这个团队比数据科学家开始解释第二个要点的速度更快地迷失在细节中。一个能够击垮这一努力的问题是——“我们能对此做点什么吗?”就是这样。几周的工作和一个问题就会使整个努力偏离轨道。
以决策为中心。 探索的重点是寻找影响和改善决策的方法,并尽快测试它是否能有所变化。然后,只有在那时,假设才能被修正。这并没有结束分析的循环,但它确保了数据科学家的重点是发现可以改善基本决策影响的见解。在这种情况下,重点是项目的输出如何影响环境,数据科学家和企业都可以从环境对数据优化行动的响应中学习。没有实际干预的假设测试是分析兔子洞的完美例子。
那又怎样?
尽管这听起来可能非常琐碎,但数据科学家在以假设为中心的项目上浪费的时间非常多。如果这种以假设为中心的理念得不到挑战,可能会毁掉他们的职业生涯,同时也会使其他人对数据科学部门失去信任。相信我——每当你被交付一个非常酷且有趣的假设时,唤醒你内心的极客并陷入分析的兔子洞陷阱是非常诱人的。
数据科学家内心的直觉告诉他们,工作的主要任务是回答复杂问题并获得深刻见解。而实际上,这一切都关乎解决问题——解决问题的唯一方法就是付诸行动。作为数据科学家的目标是通过可操作的数据驱动的建议来支持艰难而复杂的决策。我们是驱动行动的终极内部顾问。有些见解带来的行动总比有全部见解但没有行动要好。因此,永远不要忘记问自己一个问题——“这项分析支持的决策是什么?”这可能会挽救项目,甚至可能挽救你作为数据科学家的职业生涯。
简介: Karolis Urbonas,是亚马逊数据科学部门负责人,是一位充满活力的数据高管,拥有建立高绩效数据科学团队和交付战略分析项目的丰富经验。他在cyborgus.com上博客。
相关:
-
警惕两种数据模糊化策略
-
什么使数据科学家出色?
-
使用 CRISP-DM 时的四个问题及其解决方法
了解更多此主题
避免这五种让你看起来像数据新手的行为
原文:
www.kdnuggets.com/2021/10/avoid-five-behaviors-data-novice.html
评论
由 Tessa Xie,Cruise 高级数据科学家,Medium 撰稿人。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
照片由 Isaiah Rustad 提供,来自 Unsplash。
随着每天收集的数据越来越多,几乎每家公司都以做出数据驱动的决策为荣,数据已经触手可及。数据科学正变得越来越热门。你之所以阅读这篇文章,可能是因为你对数据充满热情,想在这个领域获得专业知识。如今有许多训练营和在线课程,每个人在几个月甚至几周内都可以感到 像 一个数据专家;但要成为真正有用、受欢迎且可信的“数据伙伴”,不仅仅是对 SQL 和 Python 以及基本统计知识的熟悉。
新手和真正懂得如何处理数据并成为有用数据伙伴的人之间存在明显差异。我观察到一些人表现出的行为无异于在空中挥舞双手并大喊:“我对这完全陌生,我不知道自己在做什么……”我自己在刚开始做数据科学家时也做过大部分这些事情。这些行为会迅速降低你作为数据伙伴的信誉,让人怀疑你对主题的理解。所以,希望我能提供一些避免做这些事的建议,以及应该做些什么,以免你成为那种数据新手。
#1 过度解读结果,试图从虚无中编造故事。
“我们已经推断出 X 和 Y 之间有正相关……基于 30 个数据点,我们相信这是因为……”每当我听到类似上述的陈述时,我都会略感不安。在趋势分析和生成洞察时,样本量始终是首要考虑的因素。除非是一个具有代表性的客户群体的焦点小组(我甚至对焦点小组的调查结果存有疑虑,但那是另一个话题),否则 30 个数据点通常不会给你任何可靠的洞察。
有没有比从极小的数据集中推测“趋势”更尴尬的事情?有的,就是为这些“趋势”出现的原因提出理论。我见过人们提出各种荒谬的理论来解释为什么来自微小数据集的结果是“违反直觉”的;当真正的解释很简单……那就是噪声时,他们会失去可信度以及大部分听众。
试试这个: 与其在样本量小的时候急于进行趋势分析,不如专注于建立结构,以便未来能收集到更多高质量的数据,从而进行这些分析。如果你真的希望从小样本中获得一些洞察,请注明样本量的不足,并在报告的指标中添加置信区间。
#2 未在使用数据/查询之前进行质量检查(QC)。
没有完美的数据集;任何告诉你其他情况的人要么在撒谎,要么是无知。因此,作为数据专家,你应该比仅凭数据质量表面现象更了解。你查询和分析的每一份数据都需要经过质量检查——确保表格实际去重,检查时间戳是否在你认为的时区等等。在使用数据之前不进行质量检查可能会导致意外结果和误导性的洞察,并使人们对你处理复杂数据的能力产生怀疑。
试试这个: 制定一个质量检查框架(即你执行的测试列表),每次处理新数据集时都要遵循。例如,检查(意外的)重复项;如果你预计数据集中每个订单只有一行,写一个快速查询按订单 ID 分组并统计行数——你会惊讶于有多少“订单级”表在某些订单 ID 下有 1,000 条记录。始终,始终,始终检查你的工作,并与利益相关者和主题专家双重检查。
#3. 过度工程化。
我仍然记得当我学到像随机森林或 XGBoost 这样的复杂模型后的兴奋;当你有了锤子,尤其是一个闪亮的酷锤子时,所有东西都像钉子。但实际上,除非你是机器学习工程师,否则你在日常数据工作中很少需要 10 层神经网络。使用复杂的机器学习模型,而简单的线性回归足矣,不仅效率低下,还适得其反。正如我在关于data science lessons I learned from working at McKinsey的文章中提到的,作为行业中的数据科学家,产生商业影响是首要目标,而不是炫耀你掌握了多少机器学习知识。
过度工程化模型和分析是一种让自己成为人们不愿意合作的、效果不佳的数据合作伙伴的可靠方法。
试试这个方法:从简单开始,只有在确实必要时才使用更复杂的方法。对你在分析中使用的方法要做出非常明确的决策,并应用 80/20 原则,以避免那些带来边际效益的、不必要的努力。
#4. 使用流行词汇。
这种情况在刚进入数据领域的人中很常见。类似于因为对新建模技能的兴奋而倾向于过度工程化,很多新的数据从业者喜欢在可能的情况下使用他们学到的所有新概念和新词汇。在沟通时,我们往往用复杂性来弥补对事物的理解不足——一个人谈论机器学习和分析时使用的流行词汇越多,通常他/她的分析知识就越少。一个经验丰富的数据从业者应该能够用简单的英语解释方法论和分析细节;如果某人的数据工作解释难以理解,就像阅读维基百科页面一样,很可能是因为他们也是刚从维基百科上读到的。
试试这个方法:当学习一个新的分析概念时,真正努力理解到你能够用简单的英语轻松地向不懂数据科学的朋友解释它。这样的理解水平也将帮助你决定何时应用复杂的高级方法,何时使用传统的线性回归。
#5. 忽视利益相关者在创建数据产品时的需求。
我偶尔遇到一些新的数据从业者,他们不仅仅遭受上述症状 3 和 4 的困扰,还过度热衷于在工作中创建没人欣赏的“数据宠物项目”。别误会,我认为所有的数据热情都应该受到鼓励,宠物项目对技能发展有帮助……只是在你的日常工作中,商业对你使用数据产品来推动影响有很高的期望。
数据产品(例如,仪表盘)就像任何其他产品一样,其设计的首要规则应该是以用户为中心。它们应该基于需求而生……而不是仅仅基于激情。
试试这个方法:在构建任何数据产品之前,与利益相关者沟通。了解当前阶段业务的需求:如果是初创公司,我敢打赌你的利益相关者不会过于关心你构建的数据可视化的格式和颜色,而是更关注可视化背后的数据准确性及其洞察。同样,真正了解受众和使用场景;例如,如果数据产品是打算由非技术受众定期使用的,你可能会花更多时间在打磨和简化用户界面上。
发展你自己的副项目,也许有一天会派上用场;只要不让它们妨碍你成为一个高效且受欢迎的数据合作伙伴。
关键要点
-
不要把事情搞得过于复杂或过度工程化;这不会让你显得聪明,反而会让你看起来不知道做事的最有效方式。
-
确保对数据进行质量检查并审查你的见解,并在数据质量或样本大小存在疑虑时总是要说明发现结果的局限性。
-
在创建数据产品时要考虑利益相关者的需求。
原文。经授权转载。
简介:Tessa Xie 是一名从事 AV 行业的数据科学家,曾在麦肯锡工作,且是三次顶级中等作家。Tessa 白天是数据领域的先锋,晚上是作家,周末则是画家、潜水员,还有更多身份。
相关:
更多相关话题
避免时间序列预测中的这些错误
原文:
www.kdnuggets.com/2021/12/avoid-mistakes-time-series-forecasting.html
评论
作者:Roman Orac,高级数据科学家

图片来源:Photoholgic 在 Unsplash
时间序列预测是数据科学的一个子领域,涉及预测 COVID 的传播、股票价格、每日电力消费……我们可以继续列举下去。
数据科学是一个广泛的研究领域,几乎没有“全才”
数据科学领域是一个广泛的研究领域。许多数据科学家在整个职业生涯中处理的是非顺序数据(经典分类和回归机器学习),他们在职业生涯中从未训练过时间序列预测模型。
这是可以预期的,因为数据科学领域的快速发展。跟上所有子领域变得越来越困难。
计划转入时间序列领域的数据科学家可以做好迎接有趣挑战的准备,因为处理这种数据需要不同的专业方法。
在本文中,我们将深入探讨几个容易陷入的常见时间序列预测陷阱。我基于金融股票数据进行示例,但这些方法也可以应用于其他时间序列数据。
通过阅读本文,你将学到:
-
如何使用 pandas 下载金融时间序列数据
-
如何在时间序列信号中找到峰值和谷值
-
什么是(以及如何使用)自相关图
-
如何检查时间序列是否具有统计显著信号
全才,什么都懂,精通的却没有
我们只需要收集数据

图片来源:Hans Eiskonen 在 Unsplash
一个谬误(以及从一开始就是注定要失败的项目)是,当软件工程师认为他们可以简单地收集股票市场数据,然后将其放入深度神经网络中找到有利可图的模式时。
深度神经网络会自动找到有利可图的模式,对吗?
别误会我,拥有数据是有用的,但最难的部分在于建模。
有数据服务网站,如 EOD Historical Data,提供各种金融数据,并提供免费计划。首先识别有利可图的模式更有意义,因为你可以通过单个 pandas 命令下载历史数据。
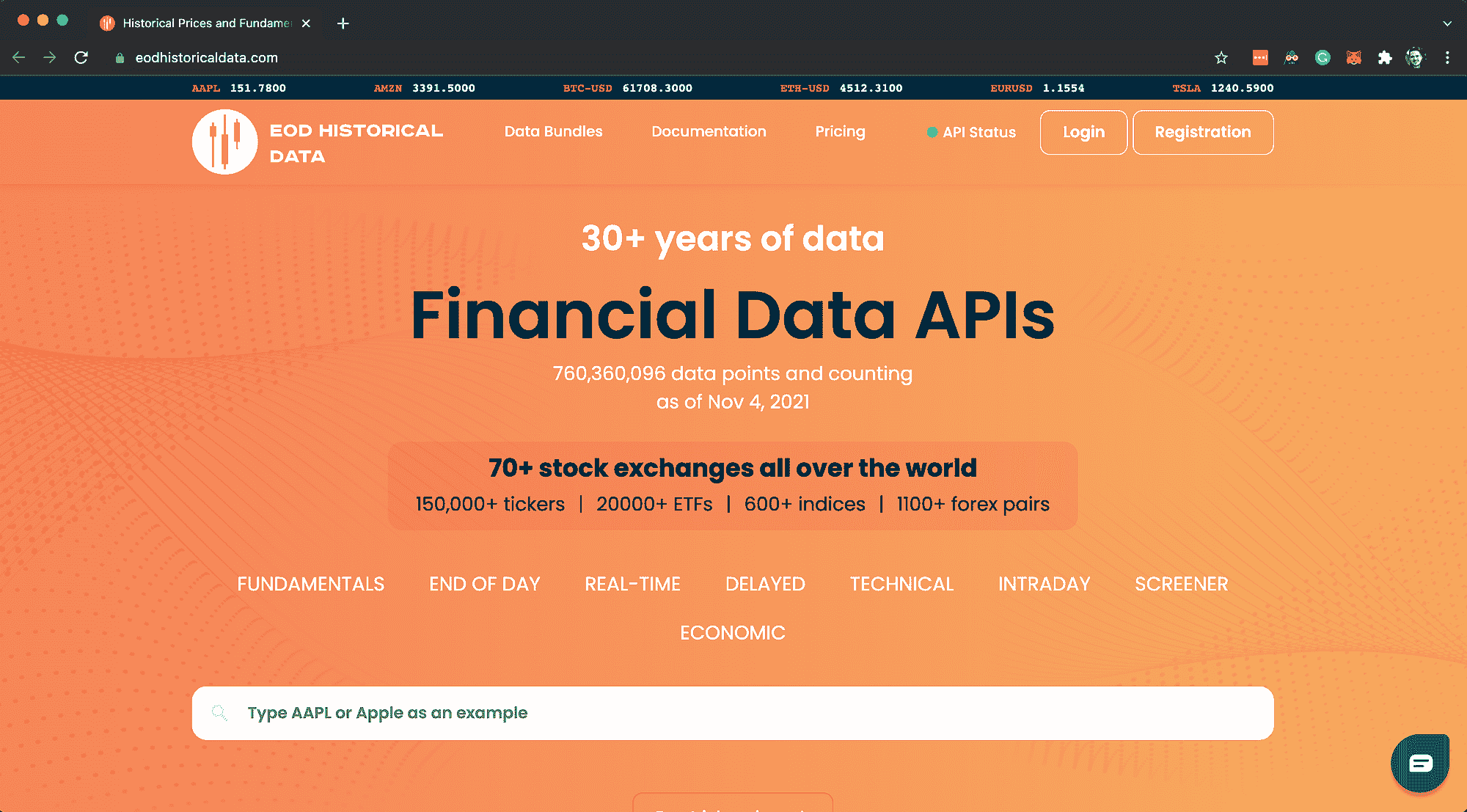
EOD Historical Data 提供各种金融数据,并有一个免费的计划(作者制作的截图)
下载数据的 pandas 命令是什么?
让我们看看下面的例子,我从 2018 年 1 月 1 日起下载了苹果股票的每日价格:
import pandas as pdstock = "AAPL.US"
from_date = "2018-01-01"
to_date = "2021-10-29"
period = "d"eon_url = f"[`eodhistoricaldata.com/api/eod/{stock}?api_token=OeAFFmMliFG5orCUuwAKQ8l4WWFQ67YX&from={from_date}&to={to_date}&period={period}&fmt=json`](https://eodhistoricaldata.com/api/eod/%7Bstock%7D?api_token=OeAFFmMliFG5orCUuwAKQ8l4WWFQ67YX&from={from_date}&to={to_date}&period={period}&fmt=json)"df = pd.read_json(eon_url)
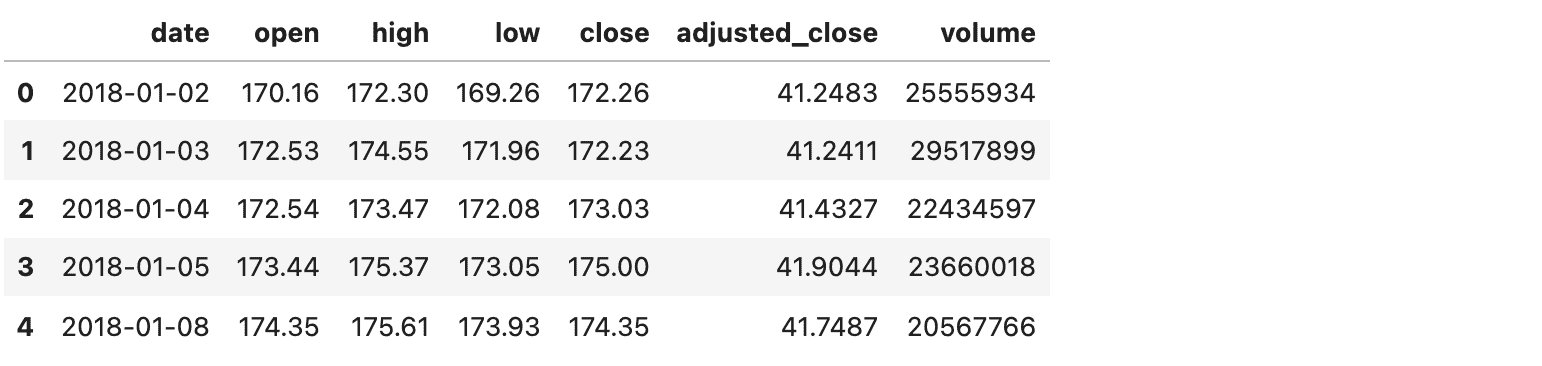
从 2018 年 1 月 1 日起的苹果股票每日价格(作者提供的图片)
然后我们可以通过以下方式可视化苹果股票的调整收盘价和价格分布:
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 7))col = "adjusted_close"
df.plot(x="date", y=col, ax=axes[0])
df[col].hist(ax=axes[1])
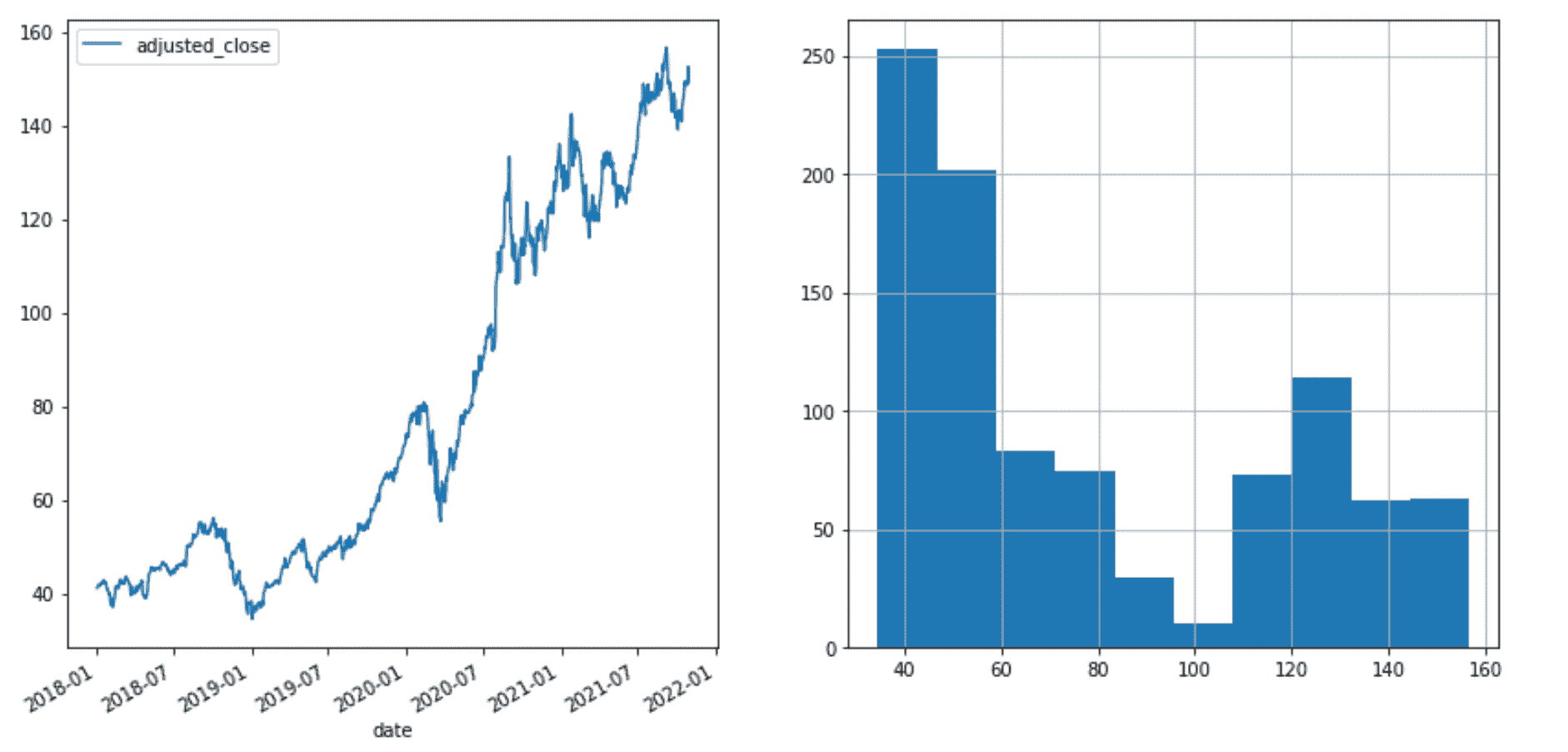
苹果股票调整收盘价和价格分布(作者提供的图片)
寻找峰值和低谷

图片由 Claudel Rheault 提供,来源于 Unsplash
时间序列预测学习问题的一个常见定义是,在时间序列信号上找到峰值和低谷,这些作为机器学习算法的目标变量。
让我们首先减少数据规模,以便更容易可视化:
df_sub = df[df["date"] > "2020-01-01"].copy().reset_index(drop=True)
然后找到峰值:
from scipy.signal import find_peakspeaks = find_peaks(df_sub["adjusted_close"])

包含峰值索引的数组(作者提供的图片)
然后找到低谷:
troughs = find_peaks(-df_sub["adjusted_close"])
然后我们可以进行可视化
ax = df_sub.plot(x="date", y="adjusted_close", figsize=(14, 7))df_sub.iloc[peaks[0]].plot.scatter(x="date", y="adjusted_close", ax=ax, color="green")df_sub.iloc[troughs[0]].plot.scatter(x="date", y="adjusted_close", ax=ax, color="red")
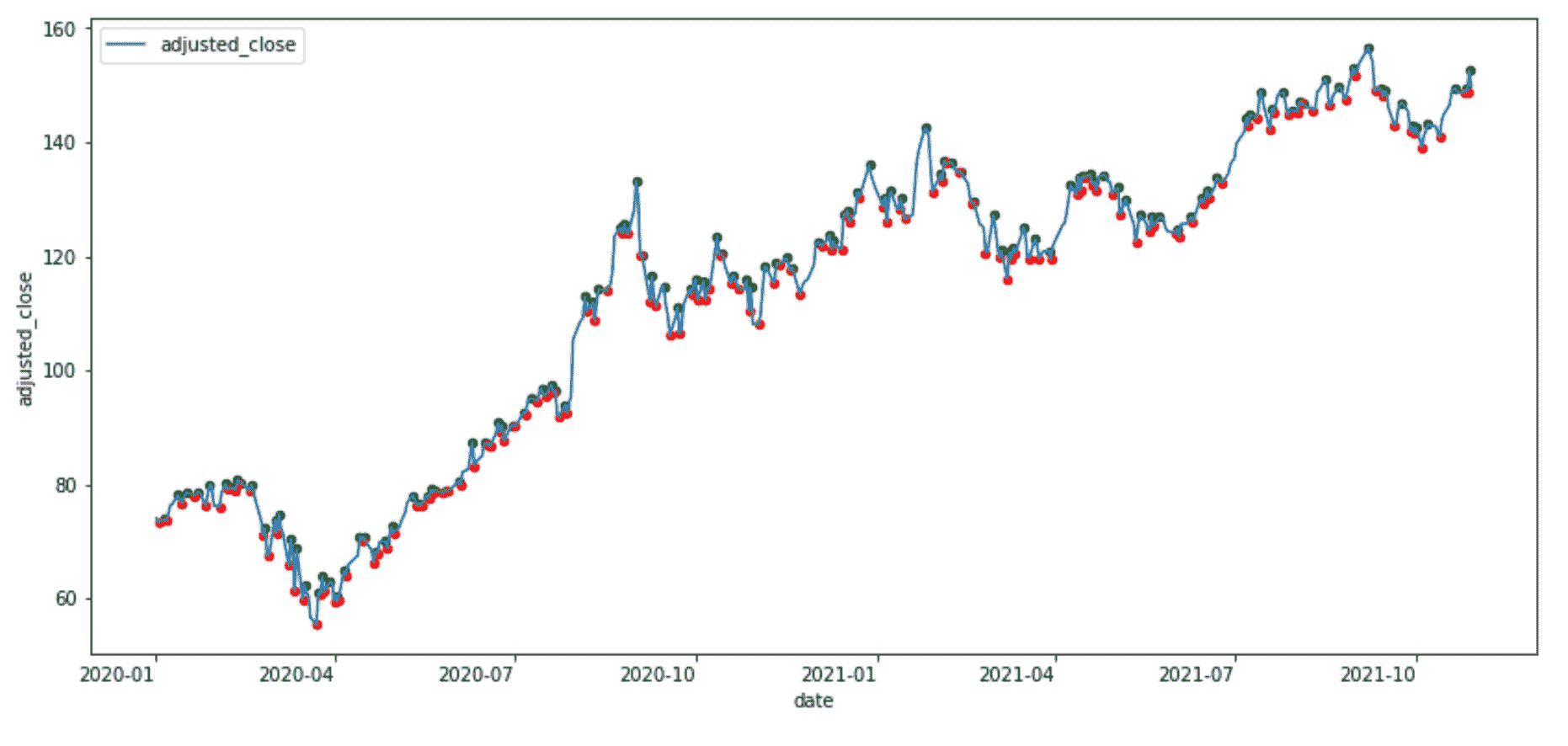
苹果股票时间序列的峰值和低谷(作者提供的图片)
现在数据集已经标记了进出信号,我们只需将神经网络拿出来,坐下来放松一下,对吧?
不完全正确!
技术分析师可能会指出上述例子中的前瞻性偏差。
为什么?
因为
find peaks函数一次性处理整个信号。如果我们基于滞后指标在其基础上定义决策逻辑,它将遭受前瞻性偏差。在金融领域,技术分析是一种通过研究过去市场数据,主要是价格和成交量,来预测价格方向的方法。
但这只是一个问题,如果我们依赖于技术分析的话。
让我们回到机器学习。
从机器学习的角度来看,上述定义是可以的,如果我们将信号分为 3 部分。例如:
-
第一部分用于训练(前 60%)
-
第二部分用于验证(第二 10%)
-
最后一部分用于样本外测试(最后 30%)
find peaks函数的输出仅用于目标,并且不会泄露到特征中。
那么这个学习问题定义有什么问题呢?
我们在对数据应用机器学习算法之前需要回答的百万美元问题:
时间序列中是否存在信号,还是只是随机噪声?
时间序列中是否存在信号?

照片由 Clarisse Meyer 提供,来自 Unsplash
让我们将从高斯分布中生成的随机数与苹果股票时间序列进行比较。
使用下面的命令,我从均值为零、标准差为 1 的高斯分布(也称为正态分布)中生成了 1000 个随机数:
np.random.seed(42)normal_dist = pd.DataFrame(np.random.normal(size=1000), columns=["value"])

从正态分布中提取的随机数(图像由作者提供)
现在,让我们可视化生成的数字并将其与苹果股票时间序列进行比较:
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 7))normal_dist["value"].plot(
ax=axes[0],
title="Random samples drawn from a normal (Gaussian) distribution",
)df.plot(x="date", y="adjusted_close", ax=axes[1], title="Apple stock time series")
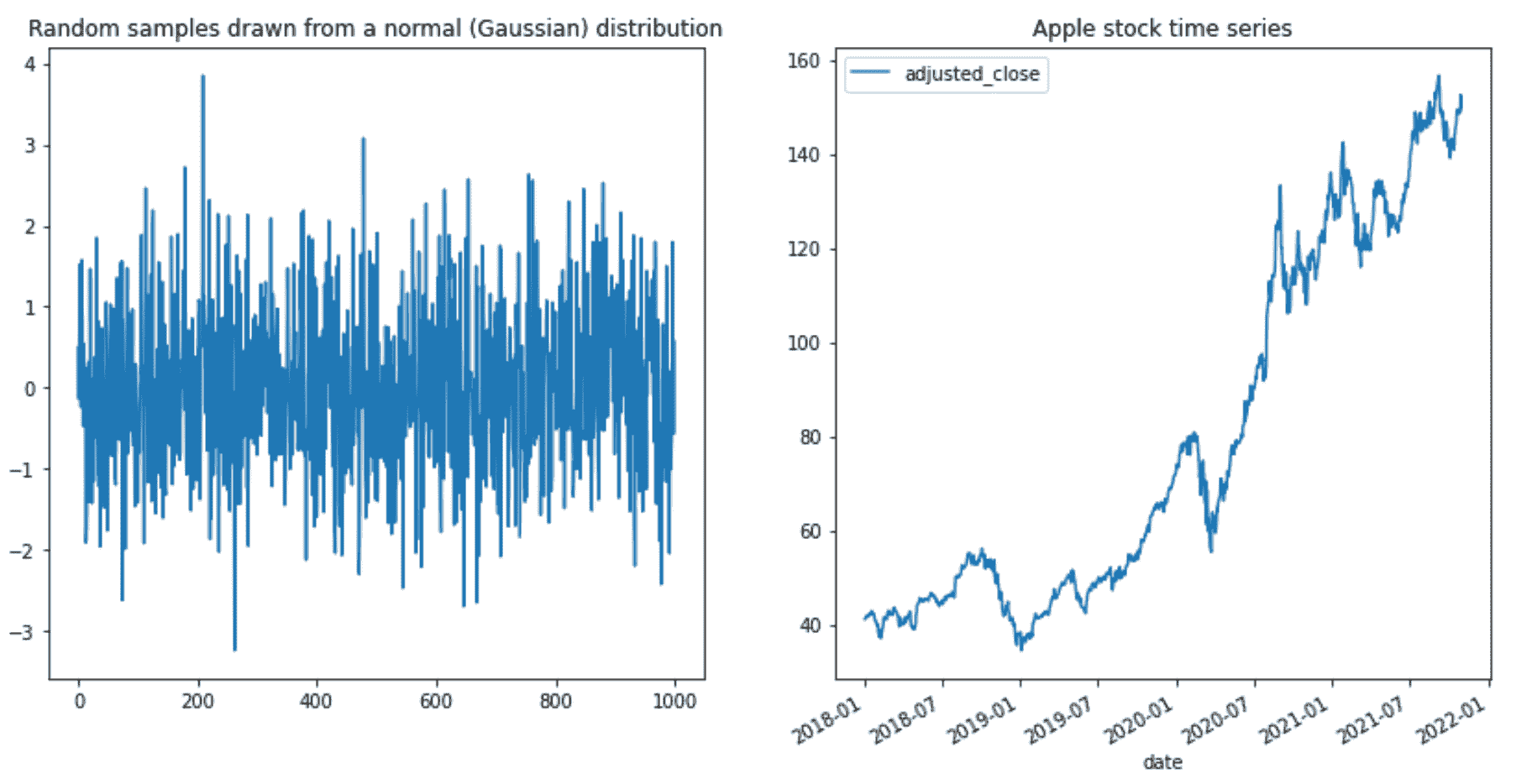
将高斯分布的随机样本与苹果股票时间序列进行比较(图像由作者提供)
你不需要是科学家就能注意到,苹果股票时间序列具有递增的模式,而高斯数值则只是随机上下波动。
苹果股票时间序列真的有一个机器学习算法可以学习的模式吗?
让我带你去进行一次(随机的)游走

照片由 Jonas Weckschmied 提供,来自 Unsplash
随机游走是一种统计工具,它生成-1 和 1 的随机数,下一个数字依赖于前一个状态。这提供了一些一致性,与独立的随机数字不同。随机游走可以帮助我们确定我们的时间序列是否可预测。
让我们看下面的例子。
在第一步中,我们生成了一个包含 1000 个随机选择的-1 和 1 的数字列表。
np.random.seed(42)random_walk = pd.DataFrame()
random_walk.loc[:, "random_number"] = np.random.choice([-1, 1], size=1000, replace=True)
然后,我们将生成的随机值累积总结,以增加对前一个状态的依赖:
random_walk.loc[:, "random_walk"] = random_walk["random_number"].cumsum()
苹果股票的初始调整后收盘价为 34.55。让我们将这个数字添加到 random_walk 中,以便我们使用相同的尺度:
random_walk.loc[:, "random_walk_apple"] = random_walk["random_walk"] + 34.55
最终结果是一个包含生成的随机游走的 pandas Dataframe:
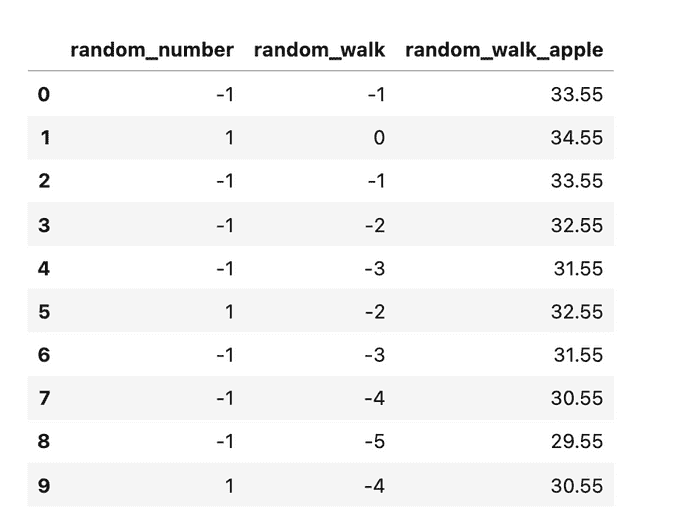
生成的随机游走的 Dataframe(图像由作者提供)
现在,让我们将随机生成的游走与实际的苹果股票时间序列进行比较:
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(14, 14))df["adjusted_close"].plot(ax=axes[0])
random_walk["random_walk_apple"].plot(ax=axes[1])
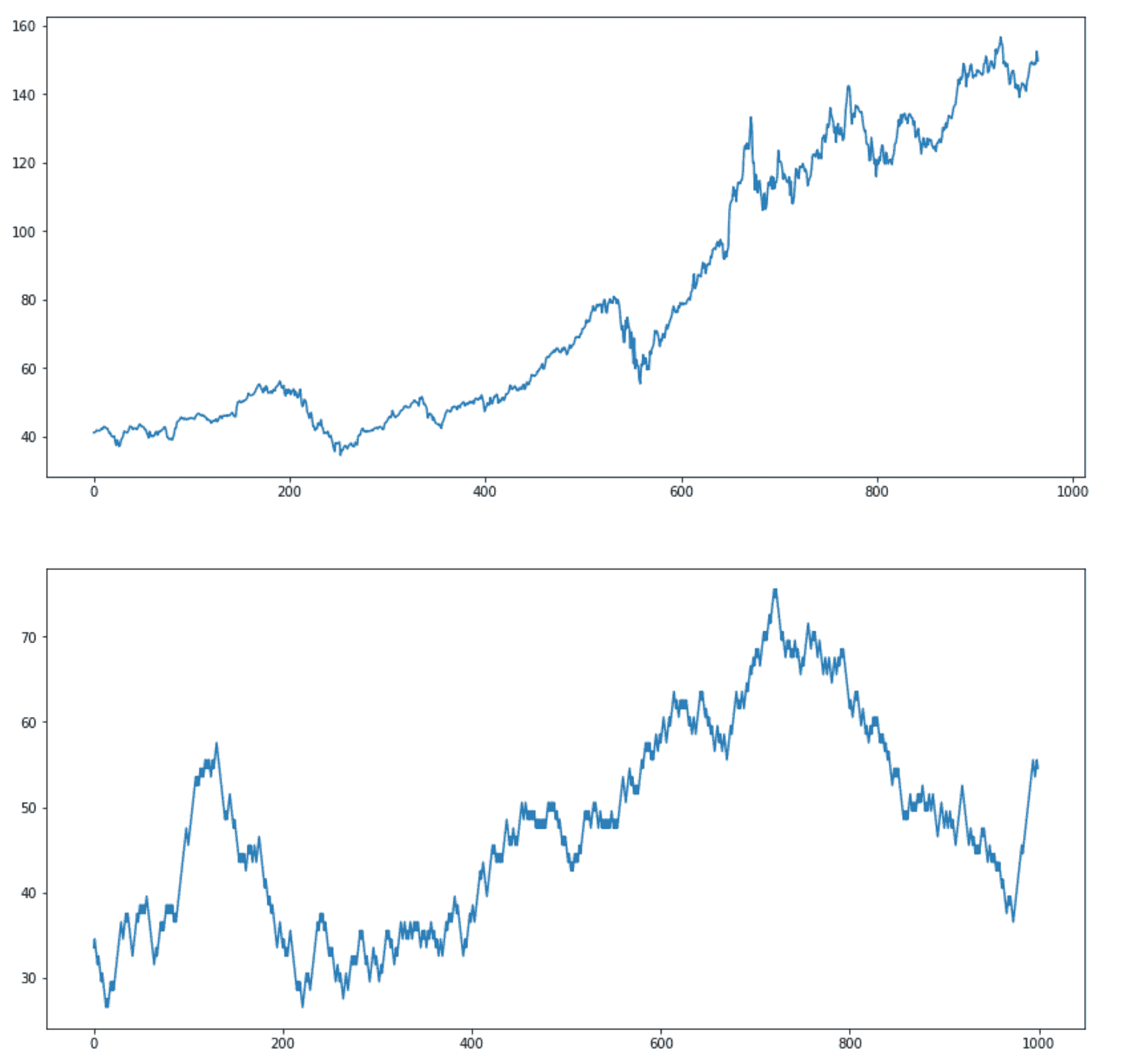
苹果股票时间序列和随机游走(图像由作者提供)
我故意没有在上述图表中包含标题。你能告诉我哪个是随机的,哪个是实际的苹果股票时间序列吗?
我们的时间序列是可以预测的吗,还是随机的?

照片由 Universal Eye 提供,来自 Unsplash
为了回答这个问题,我们需要将随机生成的序列的属性与苹果股票时间序列的属性进行比较。
一个有用的工具是自相关图,它展示了每个观察值与前几个时间步的观察值的相关性。
自相关是信号与其延迟副本的相关性,作为延迟的函数。非正式地说,它是观察值之间的相似性,作为它们之间时间滞后的函数。
随机游走的构造方式(当前状态是从前一个状态计算得出的+1 或-1——对前一个状态的高度依赖),我们可以预期在最初的几个时间步中会有很高的自相关性,随着滞后的增加而线性下降。
Pandas 有一个 autocorrelation_plot 函数,它计算自相关并在自相关图上进行可视化。
让我们可视化随机游走和苹果股票时间序列的自相关图。
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(14, 14))axes[0].set_title("Autocorrelation plot for Apple stock time series")
pd.plotting.autocorrelation_plot(df["adjusted_close"], ax=axes[0])axes[1].set_title("Autocorrelation plot for random walk time series")
pd.plotting.autocorrelation_plot(random_walk["random_walk_apple"], ax=axes[1])
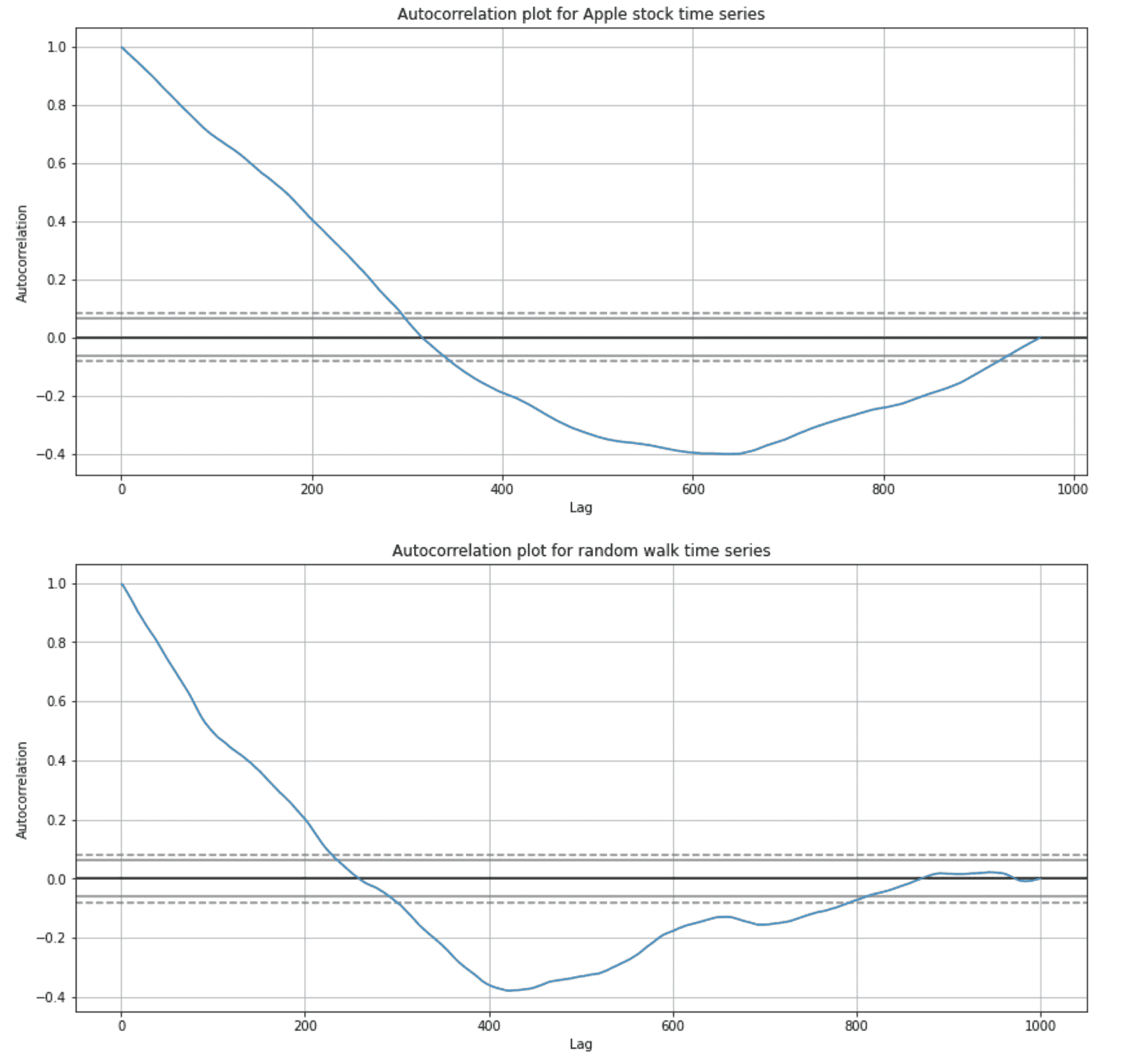
随机游走和苹果股票时间序列的自相关图(图像由作者提供)
图中的 x 轴显示自相关,y 轴显示滞后。图中的水平线对应于 95%和 99%置信区间。虚线是 99%置信区间。高于这些线的值在统计上是显著的。
正如我们对随机游走序列的预期一样,前 100 个时间步中有很高的自相关性,随着滞后的增加而线性下降。
令人惊讶的是(或者对一些人来说不惊讶),苹果股票时间序列的自相关性类似于随机游走自相关图。
让深度神经网络回到休眠状态……

图片由 Pierre Bamin 提供,来源于 Unsplash
让我们通过从当前观察值中移除前一个观察值的值来使两个时间序列平稳——差分。通过应用差分操作,我们去除了时间的函数。
以下命令对苹果股票和随机游走时间序列应用差分操作:
# applying differencing operation
# [1:] is used to remove the first value which is nullapple_stationary = df["adjusted_close"].diff()[1:]
random_walk_stationary = random_walk["random_walk_apple"].diff()[1:]

差分的苹果股票时间序列(图像由作者提供)
现在,让我们可视化差分时间序列:
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(14, 14))apple_stationary.plot(ax=axes[0], title="Differenced time series of Apple stock")random_walk_stationary.plot(ax=axes[1], title="Differenced time series of Random walk")
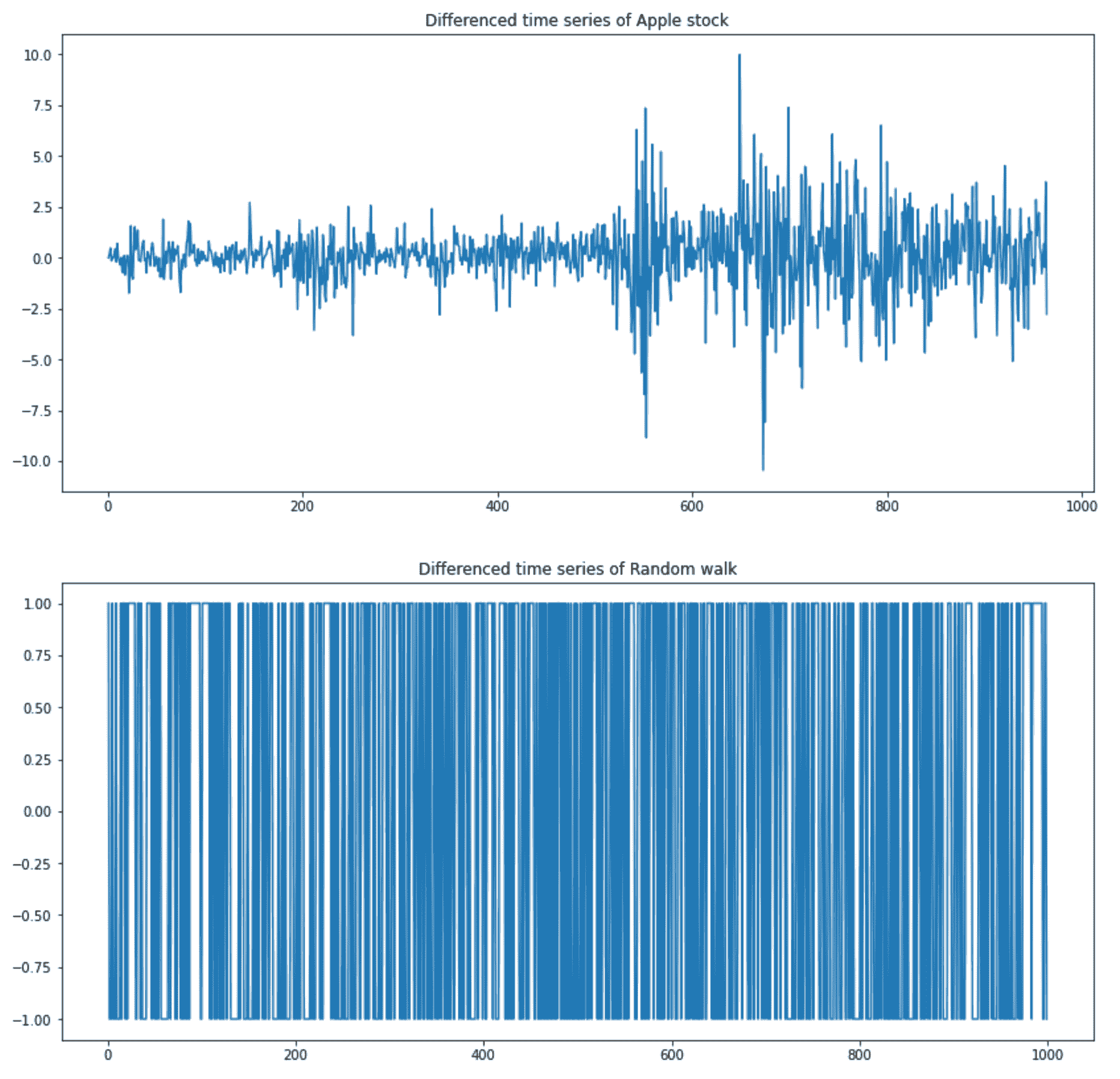
苹果股票和随机游走的差分时间序列(图像由作者提供)
差分的随机游走时间序列只有-1 和+1,正如预期的那样。差分的苹果股票时间序列有更多的波动,但这些波动是否显著?
我们可以通过差分时间序列上的自相关图来检查这一点:
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(14, 14))pd.plotting.autocorrelation_plot(apple_stationary, ax=axes[0])
pd.plotting.autocorrelation_plot(random_walk_stationary, ax=axes[1])
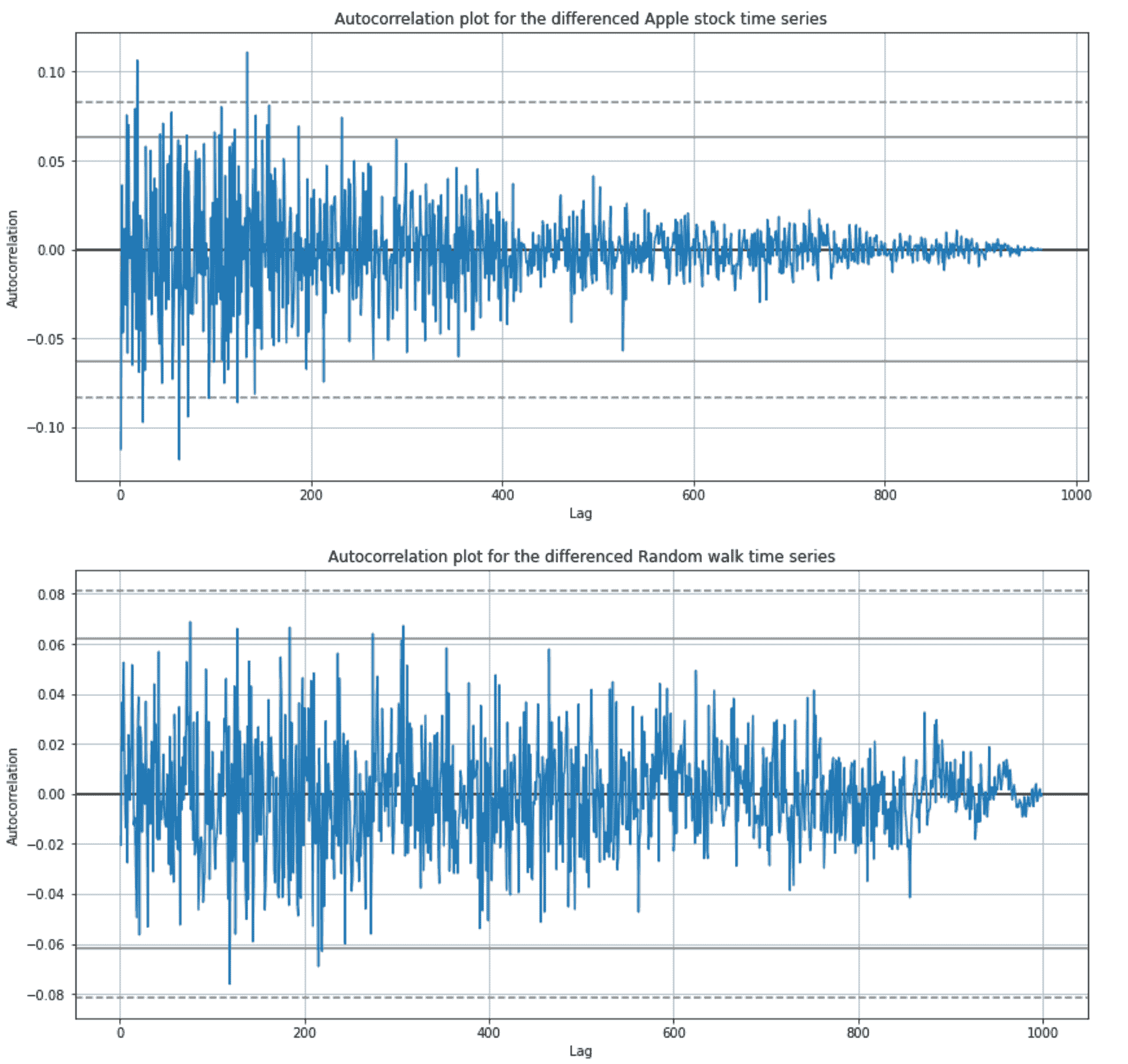
差分的随机游走和苹果股票时间序列的自相关图(图像由作者提供)
请记住,超出水平线的自相关值具有统计显著性。
差分后的苹果股票时间序列有几个自相关值超出 99%的置信区间,但差分后的随机游走时间序列也有几个值超出 95%的置信区间,我们知道信号是随机的,因此我们可以将这些归因于统计错误。
结论

图片来源于 Ferdinand Stöhr 在 Unsplash
在文章中,我们对真实世界的时间序列数据进行了几个统计检查,我们确定其信号是随机的。
我对此的看法是什么?
你可能会感到惊讶(就像我一样),我们在苹果股票时间序列中没有发现任何统计显著的信号。
当我们不断听到关于机器学习算法如何在股市上做出自动决策的故事时,这怎么可能呢?
好吧,虽然我确信机器学习算法被用于做出这样的决策——Marcos López de Prado 为此写了一整本书——但我也确信它们使用了更多的数据。我指的不是更多的价格数据,而是一种不同类型的数据,这种数据影响了股票价格的变动。
你可以阅读维基百科上的随机游走假设,该假设认为股市价格按照随机游走演变(即价格变化是随机的),因此无法预测。
对此你有什么想法?请在下方评论中告诉我。
简介: Roman Orac 是一名机器学习工程师,在改进文档分类和项目推荐系统方面取得了显著成功。Roman 拥有管理团队、指导初学者和向非工程师解释复杂概念的经验。
原文。经允许转载。
相关内容:
-
前 5 名时间序列方法
-
对有志成为数据科学家的建议——你最常见的问题解答
-
基于 LSTM 的 RNN 的多变量时间序列分析
我们的前三名课程推荐
1. Google 网络安全证书 - 加入网络安全职业的快速通道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关主题
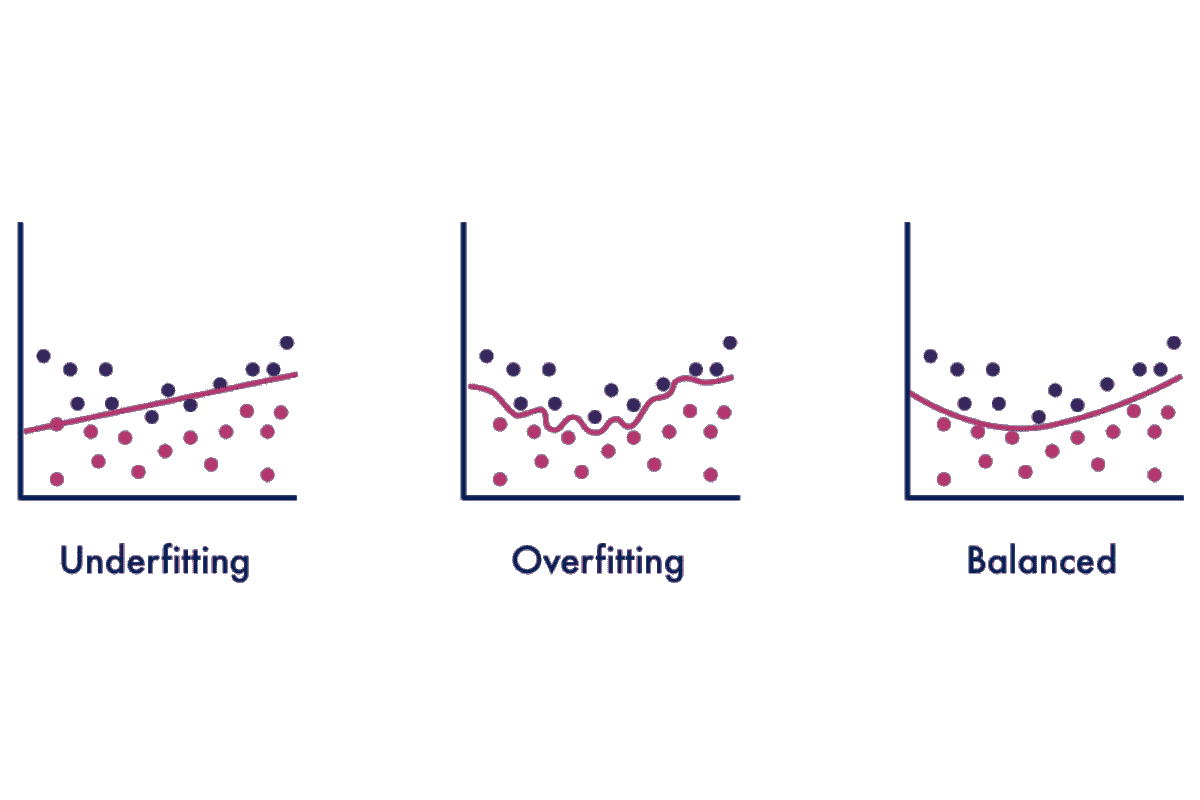
如何避免过拟合
编辑器提供的图片
过拟合是许多数据科学家常犯的一个常规错误。它可能会使你数小时的编码工作付诸东流。你的模型可能会产生不准确的输出,并导致决策过程中的进一步问题。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在我们讨论如何避免过拟合之前,先来了解一下什么是过拟合。
什么是过拟合?
过拟合是指统计模型完全贴合其训练数据。这是一种建模错误,表明你的函数过于紧密地贴合有限的数据点。这是因为模型仅专注于它知道的变量,并自动假设这些预测将适用于测试或未见过的数据。这导致模型无法准确预测未来的观察值。
过拟合发生的原因之一是模型或数据集的复杂性。如果模型过于复杂,或者模型在一个非常大的样本数据集上进行训练——模型开始记住数据集中无关的信息。当信息被记住时,模型对训练集的拟合过于紧密,无法很好地对新数据进行泛化。
尽管在处理训练数据时,这种情况会产生低误差,但在处理测试数据时却变得非常无用,因为它会产生高误差。判断你的模型是否过拟合的一种方法是查看其是否具有低误差率但高方差。
什么是欠拟合?
过拟合的对立面是欠拟合。欠拟合是指模型无法准确识别输入和输出变量之间的关系。这可能是由于模型过于简单,可以通过增加更多输入特征或使用高方差模型如决策树来解决。
欠拟合最糟糕的地方在于它既不能建模训练数据,也不能对新数据进行泛化——在训练集和未见过的数据上都会产生高误差率。
信号和噪声
在我们了解如何避免过拟合之前,我们需要理解信号和噪声。
信号是帮助模型学习数据的真实潜在模式。例如,青少年年龄与身高之间的关系就是一个明确的关系。
噪声是数据集中随机且无关的数据。以信号的示例来说,如果我们采样一所以体育专业闻名的学校——这将导致离群值。由于身体特征,如篮球的身高,学校的学生人数会更高。这将导致模型中的随机性——显示噪声如何干扰信号。
如果你产生一个高效的机器学习模型,能够区分信号和噪声,它将表现良好。
拟合优度是一个统计术语,指的是模型预测值与观察值的匹配程度。当模型学习噪声而不是学习信号时,就会导致过拟合。模型过于复杂或过于简单会提高学习噪声的可能性。
防止过拟合的技术
训练更多数据
我将从你可以使用的最简单技术开始。在训练阶段增加数据量不仅可以提高模型的准确性,还能减少过拟合。这使得你的模型能够识别更多的信号,学习模式并减少错误。
这将帮助模型更好地推广到新数据,因为模型有更多机会理解输入与输出变量之间的关系。然而,你需要确保所使用的额外训练数据是干净的——否则,你可能会做反向操作,增加更多复杂性。
特征选择
减少过拟合的下一个简单技术是特征选择。这是通过仅选择相关特征来减少输入变量数量的过程,从而确保你的模型表现良好。
根据你的任务,有些特征与其他特征没有相关性或关联。因此,这些特征可以被移除,因为它们使你的模型学习不需要的东西。为了找出与任务直接相关的特征,你可以通过在单独的模型上训练不同的特征来测试它们。
你不仅会提高模型性能,还会减少建模的计算成本。
数据增强
数据增强是一组通过从现有数据生成新数据点来人工增加数据量的技术。
虽然增加更多干净数据是一种选择,但这也是一种非常昂贵的选择。数据增强通过使数据看起来更为多样化来降低成本,因为样本数据每次被模型处理时略有不同。每个数据集对模型来说都显得独特——提高了学习速率和性能。
噪声也可以在这个技术中使用,以提高模型的稳定性。向数据中添加噪声使数据更加多样化,而不会降低数据质量。然而,添加噪声的选择应该谨慎进行,以防止过拟合。
提前停止
在训练阶段通过每次迭代测量模型性能是一种有效的防止过拟合的技术。你可以通过在模型开始学习噪声之前暂停训练来实现这一点。然而,需要考虑的是,当使用“提前停止”技术时,有暂停训练过程过早的风险——这可能导致欠拟合。
正则化
正则化是强制你的模型变得更简单,以最小化损失函数并防止过拟合或欠拟合。它不鼓励模型学习非常复杂的东西。
这种技术旨在惩罚系数,这有助于减少过拟合,因为过拟合的模型通常具有膨胀的系数。如果系数膨胀,其效果是成本函数将增加。
正则化也是像交叉验证这样的技术的一个超参数——使得过程更简单。
交叉验证
交叉验证是用于衡量过拟合的最知名技术之一。它用于评估统计分析的结果对未见数据的泛化能力。
交叉验证的过程是从你的训练数据中生成多个训练-测试拆分——这些拆分用于调整你的模型。然后,参数将经历交叉验证,以选择最佳参数并将其反馈到模型中进行再训练。这将提高模型的整体性能和准确性,并帮助模型更好地泛化到未见数据。
交叉验证技术的示例包括 Hold-out、K-folds、Leave-one-out 和 Leave-p-out。
交叉验证的好处在于它简单易懂,易于实现,并且与其他方法相比,通常具有较低的偏差。
如果你想了解更多关于最常用的交叉验证技术 K-fold 的信息,可以阅读这篇文章:为什么使用 k-fold 交叉验证?
集成
我将要讲的最后一种技术是集成。集成方法创建多个模型,然后结合这些模型产生的预测以改善结果。最流行的集成方法包括提升和 Bagging。
Bagging
Bagging 是“Bootstrap Aggregation”的缩写,是一种用于减少预测模型方差的集成方法。Bagging 旨在通过关注“强学习者”来减少过拟合复杂模型的可能性。
它并行训练大量强学习者,然后将这些强学习者组合在一起,以优化和产生准确的预测。决策树,例如分类和回归树(CART),通常以高方差而闻名。
提升算法
提升算法专注于通过提高简单模型的预测灵活性,将“弱学习者”转变为更强的学习者。它通过构建和改进简单模型为强预测模型,从而减少偏差错误。
弱学习者按顺序训练,以便它们能够专注于学习之前的错误。完成这些后,所有的弱学习者将合并成一个强学习者。
如果你想了解更多关于集成技术的信息,可以阅读这篇文章:集成技术何时是一个好的选择?
结论
你已经读到了最后。在这篇文章中,我们已经探讨了:
-
什么是过拟合?
-
什么是欠拟合?
-
信号与噪声
-
防止过拟合的技术
敬请关注更多深入探讨此主题的文章,例如《方差-偏差权衡》等。
Nisha Arya 是一位数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类生命方面的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
避免这 5 个人工智能新手常犯的错误
原文:
www.kdnuggets.com/avoid-these-5-common-mistakes-every-novice-in-ai-makes

图片由作者提供
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速迈入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
你听过爱因斯坦的以下名言吗?
疯狂就是一遍遍地做同样的事情却期待不同的结果。
对于那些刚开始人工智能之旅的人来说,这是一个完美的提醒。作为初学者,面对大量的信息和资源容易感到不知所措。你可能会发现自己犯了许多人之前犯过的相同错误。但为什么要浪费时间和精力重复这些错误,为什么不从他们的经验中学习呢?
作为一个曾与该领域经验丰富的从业者交谈的人,我一直好奇他们的人工智能之旅。我很快发现,他们中的许多人在早期遇到了类似的挑战和陷阱。这就是我写这篇文章的原因——分享新手在人工智能领域常犯的 5 个错误,以便你可以避免它们。
所以,让我们开始吧:
1. 忽视基础知识
作为一个人工智能初学者,容易被炫目的算法和强大的框架所吸引。然而,就像一棵树需要强大的根基才能成长一样,你对人工智能的理解也需要坚实的基础。忽视这些构建块背后的数学可能会阻碍你。框架是为了帮助计算机进行计算,但学习基础概念比仅仅依赖黑箱库和框架更为重要。许多初学者开始使用像 scikit-learn 这样的工具,虽然他们可能会得到结果,但通常会在分析性能或解释发现时遇到困难。这通常是因为他们跳过了理论。要成为成功的人工智能开发者,学习这些核心概念是至关重要的。
确定区分优秀 AI 开发者与新手的技能组合并没有一个简单的“一刀切”答案。这是多个因素的结合。然而,为了讨论基础内容,强调解决问题、数据结构和算法的重要性是必要的。大多数机器学习公司在招聘过程中会评估这些技能,掌握它们将使你成为一个更强的候选人。
2. 万能型人才谬论
你可能见过 LinkedIn 上的个人资料声称在 AI、机器学习、深度学习、计算机视觉、自然语言处理等方面有专长。这就像一长串技能,可能会让人感到头晕。也许是因为社交媒体或“全栈开发者”这一趋势,人们将 AI 与之进行比较。但现实是,生活在幻想世界里并没有帮助。AI 是一个非常广阔的领域。知道所有内容是不现实的,试图做到这一点可能会导致沮丧和倦怠。这样想吧:这就像尝试一口气吃下整个比萨饼——不太实际,对吧?相反,专注于某个特定领域,真正做到精通。通过缩小焦点并将时间投入到掌握 AI 的某个部分,你将能够产生有意义的影响,并在竞争激烈的 AI 领域中脱颖而出。因此,让我们避免分散精力,专注于一次成为一个领域的专家。
3. 陷入教程陷阱
我认为初学者常犯的最大错误就是被大量的在线教程、课程、书籍和文章压倒。学习和参与这些课程并不是负面的事情。然而,我担心的是,他们可能无法在理论和实践之间找到正确的平衡。花太多时间在教程上而不实际应用所学内容,可能会导致被称为“教程地狱”的挫败感。为了避免这种情况,重要的是通过实际项目来检验你的知识,尝试不同的数据集,并不断提高你的结果。此外,你会发现课程中教的一些概念可能并不总是对特定数据集或问题最有效。例如,我最近观看了DeepLearning.ai 的 LLM 对直接偏好优化的对齐讲座,其中 Huggingface 的研究科学家ED Beeching提到,尽管原始的直接偏好优化论文使用了 RMSProp 作为优化器,但他们发现 Adam 在实验中更为有效。你只有通过实际操作和深入实践才能学到这些东西。
4. 数量优于质量的项目
当初学者想展示他们的 AI 技能时,他们常常会被诱惑去创建大量项目以展示他们的专业知识。然而,优先考虑质量而不是数量至关重要。我观察到,在大型科技公司工作的人往往简历上有 2-3 个强有力的项目,而不是像许多人那样有 6-10 个小而平庸的项目。这种方法不仅对求职有利,而且对学习也有帮助。你可以更好地理解主题。与其跟随 YouTube 教程或做一堆普通项目,不如花费一个月左右的时间和精力投入到那些具有长期价值的项目中。这种方法会让你的学习曲线更陡峭,并真正突出你的理解。这也可以让你的简历从其他人中脱颖而出。即使在找到工作后,你也不会在过渡到实际工作时遇到太多困难。
5. 孤狼综合症
我理解不同的人有不同的工作偏好。有些人可能喜欢独自工作,而其他人则寻求支持。对于机器学习的初学者来说,面对这些可能会感到不知所措,孤立工作可能会阻碍你的成长。我强烈推荐你参与 Reddit、Discord、Slack、LinkedIn 和 Facebook 等平台上的 AI 社区。如果你对社区不太舒服,可以考虑找一个 AI 导师进行指导和支持。与他们讨论你的项目,寻求建议,并学习更好的方法。这不仅使学习过程变得愉快,而且节省时间。虽然我不鼓励你在遇到问题时立即发布问题或联系导师,但你应该始终先尝试自己解决。但在某些时候,寻求帮助是可以的。这种方法可以避免倦怠,增强你的学习能力,最终,你会为自己尝试并获得对失败的了解而感到满意。
50 天挑战:敢于接受挑战,提升你的 AI 技能
在本文中,我们讨论了初学者应该避免的 5 个最常见的错误。
我为大家准备了一个令人兴奋的挑战。作为这个社区的负责任成员,我想鼓励你采取行动,将这些技巧应用到自己的 AI 旅程中。以下是“50 天挑战”:
1. 在下方评论区写下“挑战接受”。(如果你无法看到评论区,请刷新页面——可能需要一些时间才能出现。)
2. 在接下来的 50 天里,专注于这 5 个技巧,并将它们应用到你的 AI 学习中。
3. 在 50 天后,返回本文并在评论中分享你的经验。告诉我们这些技巧给你的生活带来了哪些变化,以及它们如何帮助你成长为 AI 从业者。
我迫不及待想听听你的故事,并了解你的进展。此外,如果你有任何建议或额外的提示,可以分享给其他读者,请尽管说出来!让我们互相帮助,共同成长。
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交集充满了深厚的热情。她共同撰写了电子书《利用 ChatGPT 提高生产力》。作为 2022 年亚太地区 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 多样性科技奖学者、Mitacs Globalink 研究奖学者和哈佛 WeCode 学者。Kanwal 是变革的坚定倡导者,创立了 FEMCodes 以赋能 STEM 领域的女性。
更多相关话题
超棒的 100+ 类别的数据集列表
评论
由 Etienne D. Noumen,高级软件工程师。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 部门
数据科学是一个跨学科领域,它使用科学方法、过程、算法和系统从结构化和非结构化数据中提取知识和洞察,并将这些知识和可操作的洞察应用于广泛的应用领域。
在本博客中,我们提供了流行的开源和公共数据集、数据可视化、数据分析资源和数据湖的链接。
目录
-
最新完整的 Netflix 电影数据集
-
通用爬虫
-
蛋白质价格数据集
-
CPOST 数据集:四十年来的自杀攻击
-
信用卡数据集 – 消费者金融调查 (SCF) 综合提取数据 1989-2019 综合提取数据 1989-2019")
-
带注释的无人机图像用于小物体检测和跟踪数据集
-
NOAA 高分辨率快速刷新 (HRRR) 模型 模型")
-
AWS 上的开放数据注册表
-
教科书问答 (TQA)")
-
协调癌症数据集:基因组数据公共门户
-
癌症基因组图谱
-
治疗性应用研究以生成有效治疗方法 (TARGET)")
-
基因组聚合数据库 (gnomAD)")
-
SQuAD (斯坦福问答数据集)")
-
PubMed 糖尿病数据集
-
药物-靶标互动数据集
-
药物基因组数据集
-
胰腺癌类器官分析
-
非洲土壤信息服务 (AfSIS) 土壤化学 Soil Chemistry")
-
E 环境中的情感状态数据集
-
NatureServe Explorer 数据集
-
美国航班记录
-
全球航班数据
-
2019 年美国犯罪统计数据
-
雅虎问答数据集
-
美洲历史 1400-2021
-
波斯语词汇发音数据集
-
历史空气质量数据集
-
Stack Exchange 数据集
-
精彩公共数据集
-
农业数据集
-
生物数据集
-
气候和天气数据集
-
复杂网络数据集
-
计算机网络数据集
-
网络安全数据集
-
数据挑战数据集
-
地球科学数据集
-
经济数据集
-
教育数据集
-
能源数据集
-
娱乐数据集
-
金融数据集
-
地理信息系统数据集
-
政府数据集
-
医疗数据集
-
图像处理数据集
-
机器学习数据集
-
博物馆数据集
-
自然语言数据集
-
神经科学数据集
-
物理数据集
-
前列腺癌数据集
-
心理学和认知数据集
-
公共领域数据集
-
搜索引擎数据集
-
社交网络数据集
-
社会科学数据集
-
软件数据集
-
体育数据集
-
时间序列数据集
-
交通数据集
-
电子竞技数据集
-
补充集合
-
分类公共数据集列表:Sindre Sorhus /awesome List
-
平台
-
编程语言
-
前端开发
-
后端开发
-
计算机科学
-
大数据
-
理论
-
书籍
-
编辑器
-
游戏
-
开发环境
-
娱乐
-
数据库
-
媒体
-
学习
-
安全
-
内容管理系统
-
硬件
-
商业
-
工作
-
网络
-
去中心化系统
-
高等教育
-
事件
-
测试
-
其他
-
相关
-
美国教育部 CRDC 数据集
-
NASA 数据集:从细菌的空间前后测序数据
-
2015 年至 2021 年所有特朗普的推特侮辱记录 CSV 格式
-
数据是复数
-
全球恐怖主义数据库
-
海豚社交网络
-
20 万笑话的数据集
-
百万歌曲数据集
-
康奈尔大学的 eBird 数据集
-
UFO 报告数据集
-
CDC 的趋势药物数据
-
健康与退休研究:公众调查数据
这是一个庞大的列表,这里有100+个更多的类别
最新完整的 Netflix 电影数据集
从 4 个 API 创建。包含 11K+行和 30+属性的 Netflix 数据(评级、收入、演员、语言、可用性、电影预告片等等)
使用FlixGem.com探索这个数据集(这个数据集驱动了这个 web 应用)
Common Crawl
一个由超过 500 亿个网页组成的网络爬虫数据语料库。Common Crawl 语料库包含自 2008 年以来收集的 PB 级数据。它包含原始网页数据、提取的元数据和文本提取。
AWS CLI 访问(无需 AWS 账户)
aws s3 ls s3://commoncrawl/ --no-sign-request
s3://commoncrawl/crawl-data/
蛋白质价格数据集
关于主要商品价格的数据每月更新,基于 IMF 的主要商品价格系统。
CPOST 数据集:四十年来的自杀攻击
芝加哥大学安全与威胁项目展示了更新和扩展后的自杀攻击数据库(DSAT),该数据库现在链接到乌普萨拉冲突数据计划的武装冲突数据,并包括一个新的数据集,用于衡量与自杀攻击组织相关的武装组织之间的联盟和对立关系。在这里访问
信用卡数据集 – 消费者金融调查(SCF)1989-2019 年合并提取数据
你可以在这里以非常简单的方式进行大量汇总分析。
附带小物体检测和跟踪的无人机图像数据集
11 TB 无人机图像数据集附带小物体检测和跟踪的注释
下载和更多信息请访问这里
数据集许可证:CDLA-Sharing-1.0
访问数据集的辅助脚本:DATASET.md
数据集探索:Colab
NOAA 高分辨率快速更新(HRRR)模型
HRRR 是 NOAA 的实时 3 公里分辨率、每小时更新、云解析、允许对流的气象模型,由 3 公里网格和 3 公里雷达同化初始化。雷达数据每 15 分钟同化到 HRRR 中,持续 1 小时,进一步增加了由 13 公里雷达增强的快速刷新每小时数据同化提供的细节。
AWS 开放数据注册表
本注册表旨在帮助人们发现和共享通过 AWS 资源提供的数据集。了解更多关于在 AWS 上共享数据的信息。
查看来自数字地球非洲、Facebook 数据公益、NASA 空间法案协议、NIH STRIDES、NOAA 大数据计划、空间望远镜科学研究所和亚马逊可持续数据计划的数据集。
教科书问答(TQA)
1,076 节教科书课文,26,260 个问题,6229 张图片
协调癌症数据集:基因组数据公共门户
GDC 数据门户是一个强大的数据驱动平台,允许癌症研究人员和生物信息学家搜索和下载癌症数据进行分析。
基因组数据公共门户
癌症基因组图谱
癌症基因组图谱(TCGA),是国家癌症研究所(NCI)和国家人类基因组研究所(NHGRI)之间的合作,旨在生成主要癌症类型和亚型中关键基因组变化的全面、多维度图谱。
AWS CLI 访问(无需 AWS 账户)
aws s3 ls s3://tcga-2-open/ --no-sign-request
临床应用研究以生成有效治疗(TARGET)
临床应用研究以生成有效治疗(TARGET)计划采用全面的基因组方法来确定驱动儿童癌症的分子变化。该计划的目标是利用数据指导开发有效且毒性较小的治疗方案。TARGET 组织为一个疾病特定项目团队的协作网络。TARGET 项目提供全面的分子表征,以确定驱动儿童癌症起始和进展的遗传变化。数据集包含来自基因组数据公共数据库(GDC)的开放临床补充、样本补充、RNA-Seq 基因表达定量、miRNA-Seq 亚型表达定量、miRNA-Seq miRNA 表达定量数据以及来自 GDC 遗留档案的开放数据。点击这里访问。
基因组聚合数据库(gnomAD)
基因组聚合数据库(gnomAD)是由国际研究人员联盟开发的资源,汇总和协调来自各种大规模人类测序项目的外显子组和基因组数据。这里提供的总结数据为科学界提供便利,无使用限制。下载
SQuAD(斯坦福问题回答数据集)
斯坦福问答数据集(SQuAD)是一个阅读理解数据集,由众包工作者在一组维基百科文章上提出问题,每个问题的答案都是来自相应阅读段落的文本片段或范围,或者问题可能没有答案。在这里访问
PubMed 糖尿病数据集
Pubmed 糖尿病数据集包含 19717 篇来自 PubMed 数据库的关于糖尿病的科学出版物,分类为三类之一。引用网络包含 44338 条链接。数据集中的每篇出版物由一个 TF/IDF 加权词向量描述,该词典由 500 个唯一单词组成。数据集中的 README 文件提供了更多细节。
药物-靶标互动数据集
此数据集包含从 DrugBank、KEGG Drug、DCDB 和 Matador 收集的药物与靶标之间的互动。最初由Perlman 等收集。数据集包含 315 种药物、250 个靶标、1306 个药物-靶标互动、5 种药物-药物相似性和 3 种靶标-靶标相似性。药物-药物相似性包括基于化学的、基于配体的、基于表达的、基于副作用的和基于注释的相似性。靶标-靶标相似性包括基于序列的、基于蛋白质-蛋白质相互作用网络的和基于基因本体论的相似性。数据集的原始任务是基于网络中的不同相似性预测药物和靶标之间的新互动。下载链接
药物基因组学数据集
PharmGKB 数据和知识可供下载。通常在使用这些数据进行大规模项目之前,检查与其策展人联系 feedback@pharmgkb.org 是至关重要的,以确保所提供的文件和数据被正确解释。PharmGKB 通常不需要成为这些分析的共同作者;他们只希望确保在投入大量资源之前对数据有正确的理解。
胰腺癌类器官分析
数据集包含开放的 RNA-Seq 基因表达定量数据以及受控的 WGS/WXS/RNA-Seq 对齐读取、WXS 注释体突变、WXS 原始体突变和 RNA-Seq 剪接位点定量。文档
AWS CLI 访问(无需 AWS 账户)
aws s3 ls s3://gdc-organoid-pancreatic-phs001611-2-open/ --no-sign-request
非洲土壤信息服务(AfSIS)土壤化学
该数据集包含通过非洲土壤信息服务(AfSIS)项目收集的土壤红外光谱数据及配对的土壤性质参考测量,这些样本在 2009 年至 2018 年期间进行了地理参考。文档
AWS CLI 访问(无需 AWS 账户)
aws s3 ls s3://afsis/ --no-sign-request
情感状态数据集(E-Environments)
DAiSEE 是第一个多标签视频分类数据集,包含 9068 个视频片段,捕捉自 112 位用户,用于识别用户的无聊、困惑、参与和挫折等情感状态。数据集包含四个标签级别,即非常低、低、高和非常高,每种情感状态都由人群标注,并与使用专家心理学家团队创建的黄金标准标注相关。 在这里下载
NatureServe Explorer 数据集
NatureServe Explorer 提供了超过 95,000 种植物和动物在美国和加拿大的保护状态、分类学、分布和生活历史信息,以及西半球超过 10,000 种植被群落和生态系统的信息。
通过 NatureServe Explorer 提供的数据代表了在 NatureServe 中央数据库中管理的数据。这些数据库是动态的,通过数百名自然遗产项目科学家和其他合作伙伴的输入不断增强和完善。NatureServe Explorer 从这些中央数据库中更新,以反映新的实地调查、最新的分类处理、其他科学出版物以及新的保护状态评估。在这里探索数据
美国航班记录
航空公司准时表现及航班延误原因 – On_Time 数据。
该数据库包含由认证的美国航空承运人报告的计划和实际出发及到达时间、延误原因,这些承运人占国内计划客运收入的至少 1%。数据由运输统计局(BTS)航空信息办公室收集。
FlightAware.com 有数据,但你需要付费才能获得完整的数据集。
anyflights 包提供了一组函数,用于生成类似于nycflights13的航空旅行数据(和数据包!)。通过用户定义的年份和机场,anyflights函数将抓取以下数据:
-
flights: 指某年某月从特定机场起飞的所有航班 -
weather: 某年某月特定机场的每小时气象数据 -
airports: 机场名称、FAA 代码和位置 -
airlines: 两字母航空公司代码与名称的转换 -
planes: 关于flights中每架飞机的建造信息
美国交通部(DOT)的运输统计局(BTS)跟踪大型航空公司运营的国内航班的准时表现。关于准时、延误、取消和改道航班数量的汇总信息会出现在 DOT 的每月航空旅行消费者报告中,该报告在每月结束后约 30 天发布,并在该网站上发布汇总表。BTS 从 2003 年 6 月开始收集航班延误原因的详细信息。汇总统计数据和原始数据在航空旅行消费者报告发布时公开。在此访问
全球航班数据
开放航班:截至 2017 年 1 月,OpenFlights 机场数据库包含超过 10,000个机场、火车站和渡轮码头,遍布全球
下载: airports.dat(仅机场,高质量)
下载: airports-extended.dat(机场、火车站和渡轮码头,包括用户贡献)
Flightera.net 似乎提供了大量免费的优质数据。它提供了深入的航班数据,并且似乎没有日期限制。不过,我无法评论数据的有效性。
flightradar24.com 拥有大量数据,包括历史数据,他们可能会愿意帮助你以良好的格式获取这些数据。
2019 年美国犯罪统计数据
包含按种族和各州分开的美国逮捕数据集。在这里下载 Excel
Yahoo Answers 数据集
Yahoo 将于 2021 年关闭。这是来自 2015 年的 Yahoo Answers 数据集(300MB gzip),相当广泛,大约有 140 万行。这个数据集包含了最佳的问题答案,我指的是所有的答案,包括最荒谬糟糕的答案和最糟糕的问题。在这里下载。
另一个选项在这里:根据跟踪器,已完成 7700 万,还有 2000 万未完成(?),还有 4000 万待完成:
wiki.archiveteam.org/index.php/Yahoo!_Answers
美国历史 1400-2021
来源:
www.ggdc.net/maddison/oriindex.htm
www.globalfirepower.com/countries-comparison.asp
波斯词汇发音数据集
这是一个包含约 55K 个波斯词汇及其发音的数据集。每个词汇占一行,并通过制表符与其发音分开。
历史空气质量数据集
美国户外监测器收集的空气质量数据。这是一个 BigQuery 数据集。没有下载文件,但可以通过 Kernels 使用 BigQuery API 查询。AQS 数据库包含所有来自 AQS 的信息。它记录了 EPA 通过国家环境空气监测计划收集的每一个测量值,还包括 EPA 计算的相关汇总值(8 小时、每日、年度等)。AQS 数据库是每周制作一次的 AQS 副本,通过基于网络的应用程序向公众开放。数据集的预期用户是监管、学术和健康研究领域的空气质量数据分析师。它旨在为那些需要下载大量详细技术数据的人提供,而不提供任何互动分析工具。它作为几个机构互动工具的后端数据库,这些工具无法完全运作:AirData、AirCompare、The Remote Sensing Information Gateway、地图监测站点 KML 页面等。
Stack Exchange 数据集
精彩公共数据集
这个列表包含了高质量的以主题为中心的公共数据源。它们是从博客、回答和用户回应中收集和整理的。下面列出的多数数据集是免费的,但有些则不是。
农业
生物学
气候和 气候和天气
复杂 复杂网络
计算机网络
网络安全
数据挑战
地球科学数据集
经济学数据集
教育数据集
能源数据集
娱乐数据集
金融数据集
GIS 数据集
政府数据集
-
加拿大安大略省多伦多 [修复]
医疗数据集
图像处理数据集
机器学习数据集
博物馆数据集
自然语言数据集
神经科学数据集
物理学数据集
前列腺癌数据集
心理学与认知数据集
公共领域数据集
-
Infochimps [修正]
-
KDNuggets 数据集合
搜索引擎数据集
社交网络数据集
社会科学数据集
软件数据集
体育数据集
时间序列 Datas****ets
交通运输
电子竞技数据集
补充集合
-
一个不断增长的公共数据集集合: CoolDatasets.
-
DataWrangling: 网上可用的一些数据集
-
Inside-r: 在互联网上寻找数据
-
OpenDataMonitor: 欧洲可用开放数据资源概览
-
Quora: 我可以在哪里找到公开的大型数据集?
-
RS.io: 100+ 有趣的统计数据集
-
StaTrek: 利用开放数据理解城市生活
-
CV Papers: 网络上的计算机视觉数据集
-
CVonline: 图像数据库
分类的公共数据集列表: Sindre Sorhus /awesome 列表
平台
-
Node.js – 基于 Chrome 的 V8 JavaScript 引擎构建的异步非阻塞事件驱动 JavaScript 运行时。
- 跨平台 – 在 Node.js 上编写跨平台代码。
-
iOS – 适用于苹果手机和平板的移动操作系统。
-
Android – 由 Google 开发的移动操作系统。
-
Electron – 使用 JavaScript/HTML/CSS 的跨平台原生桌面应用。
-
Cordova – 用于混合应用的 JavaScript API。
-
React Native – 用于编写 iOS 和 Android 原生渲染移动应用的 JavaScript 框架。
-
Xamarin – 移动应用程序开发集成开发环境(IDE)、测试和分发。
-
-
eBPF – 一个虚拟机,使您能够编写更高效和强大的 Linux 系统跟踪和监控代码。
-
基于 Arch 的项目 – 基于 Arch Linux 的 Linux 发行版和项目。
-
macOS – 苹果 Mac 计算机的操作系统。
-
watchOS – 苹果手表的操作系统。
-
IPFS – 点对点超媒体协议。
-
Fuse – 移动开发工具。
-
Heroku – 云平台即服务。
-
树莓派 – 一种信用卡大小的计算机,旨在教授孩子们编程,但能做更多事情。
-
Qt – 跨平台图形用户界面应用程序框架。
-
WebExtensions – 跨浏览器扩展系统。
-
RubyMotion – 使用 Ruby 为 iOS、Android、macOS、tvOS 和 watchOS 编写跨平台原生应用。
-
智能电视 – 为不同的电视平台创建应用。
-
GNOME – 适用于 Linux 的简洁且无干扰的桌面环境。
-
KDE – 一个致力于创建开放且用户友好的计算体验的自由软件社区。
-
Amazon Alexa – 虚拟家庭助理。
-
DigitalOcean – 专为开发人员设计的云计算平台。
-
Flutter – Google 的移动 SDK,用于从一个用 Dart 编写的代码库构建原生 iOS 和 Android 应用。
-
Home Assistant – 开源家居自动化系统,优先考虑本地控制和隐私。
-
IBM 云 – 面向开发者和公司的云平台。
-
Firebase – 基于 Google Cloud Platform 的应用开发平台。
-
机器人操作系统 2.0 – 一套帮助你构建机器人应用的软件库和工具。
-
Adafruit IO – 可视化和存储来自任何设备的数据。
-
Cloudflare – 为你的站点提供 CDN、DNS、DDoS 保护和安全性。
-
Google Actions – Google Assistant 的开发平台。
-
ESP – 低成本的微控制器,具备 WiFi 和广泛的物联网应用。
-
Deno – 一种安全的 JavaScript 和 TypeScript 运行时,使用 V8,构建于 Rust 上。
-
DOS – 一种用于 x86 个人计算机的操作系统,曾在 1980 年代和 1990 年代初期流行。
-
Nix – 用于 Linux 和其他 Unix 系统的包管理器,使包管理可靠且可重现。
编程语言
-
Swift – 苹果的编译编程语言,安全、现代、对程序员友好且快速。
-
Python – 旨在提高可读性的通用编程语言。
-
Asyncio – Python 3 的异步 I/O。
-
科学音频 – 音频/音乐方面的科学研究。
-
CircuitPython – 为微控制器提供的 Python 版本。
-
数据科学 – 数据分析和机器学习。
-
类型检查 – Python 的可选静态类型检查。
-
MicroPython – 为微控制器提供的精简高效的 Python 3 实现。
-
-
- Scala Native – 基于 LLVM 的 Scala 提前优化编译器。
-
Julia – 高级动态编程语言,旨在满足高性能数值分析和计算科学的需求。
-
C/C++ – 通用语言,偏向系统编程和嵌入式、资源受限的软件。
-
R – 用于统计计算和图形的函数式编程语言和环境。
-
Common Lisp – 强大的动态多范式语言,便于迭代和互动开发。
-
Java – 设计为灵活的流行安全面向对象语言,实现“一次编写,到处运行”。
-
PHP – 服务器端脚本语言。
- Composer – 包管理器。
-
Frege – 用于 JVM 的 Haskell。
-
CMake – 构建、测试和打包软件。
-
ActionScript 3 – 面向 Adobe AIR 的面向对象语言。
-
Eta – JVM 的函数式编程语言。
-
Idris – 一种通用的纯函数式编程语言,具有受 Haskell 和 ML 影响的依赖类型。
-
Ada/SPARK – 现代编程语言,适用于需要可靠性和效率的大型、长期运行的应用程序。
-
Q# – 用于表达量子算法的领域特定编程语言。
-
Imba – 受 Ruby 和 Python 启发的编程语言,编译为高效的 JavaScript。
-
Vala – 设计用来充分利用 GLib 和 GNOME 生态系统的编程语言,同时保留 C 代码的速度。
-
Coq – 用于编程和规范的形式化语言和环境,支持交互式机器检查证明的开发。
-
V – 简单、快速、安全的编译语言,用于开发可维护的软件。
前端开发
-
CSS – 用于指定 HTML 元素在屏幕上显示方式的样式表语言。
-
React – 应用框架。
-
Relay – 用于构建数据驱动的 React 应用的框架。
-
React Hooks – 一项新特性,让你在不编写类的情况下使用状态和其他 React 特性。
-
-
Polymer – 用于开发 Web 组件的 JavaScript 库。
-
Angular – 应用框架。
-
Backbone – 应用框架。
-
HTML5 – 用于网站和 Web 应用的标记语言。
-
SVG – 基于 XML 的矢量图像格式。
-
KnockoutJS – JavaScript 库。
-
Dojo Toolkit – JavaScript 工具包。
-
Ember – 应用框架。
-
D3 – 用于制作动态、交互式数据可视化的库。
-
jQuery – 易于使用的 JavaScript 库,用于 DOM 操作。
-
Cycle.js – 函数式和响应式 JavaScript 框架。
-
Vue.js – 应用框架。
-
Marionette.js – 应用框架。
-
Aurelia – 应用框架。
-
PostCSS – CSS 工具。
-
Draft.js – React 的富文本编辑器框架。
-
choo – 应用框架。
-
Redux – JavaScript 应用的状态容器。
-
webpack – 模块打包器。
-
Browserify – 模块打包器。
-
Sass – CSS 预处理器。
-
Ant Design – 企业级 UI 设计语言。
-
Less – CSS 预处理器。
-
WebGL – 用于渲染 3D 图形的 JavaScript API。
-
Preact – 应用框架。
-
Next.js – 用于服务器渲染的 React 应用的框架。
-
lit-html – 用于 JavaScript 的 HTML 模板库。
-
JAMstack – 基于客户端 JavaScript、可重用的 API 和预构建标记的现代 Web 开发架构。
-
WordPress-Gatsby – 以 WordPress 为后端,Gatsby 为前端的 Web 开发技术栈。
-
Mobile Web Development – 创建出色的移动 Web 体验。
-
Storybook – UI 组件的开发环境。
-
Blazor – 使用 C#/Razor 和 HTML 的 .NET 网络框架,通过 WebAssembly 在浏览器中运行。
-
PageSpeed 指标 – 帮助理解页面速度和用户体验的指标。
-
Tailwind CSS – 以实用程序为先的 CSS 框架,用于快速 UI 开发。
-
Seed – 用于创建运行在 WebAssembly 中的网页应用的 Rust 框架。
-
网页性能预算 – 确保网站性能指标的技术。
-
网页动画 – 浏览器中的动画,使用 JavaScript、CSS、SVG 等。
-
Yew – 受 Elm 和 React 启发的 Rust 框架,用于创建多线程前端网页应用与 WebAssembly。
-
Material-UI – 用于更快更容易网页开发的 Material Design React 组件。
-
构建网页应用的模块 – 独立功能模块,可集成到网页应用中。
-
Svelte – 应用框架。
-
设计系统 – 可重用组件的集合,由规则指导,确保一致性和速度。
后端开发
-
Flask – Python 框架。
-
Vagrant – 自动化虚拟机环境。
-
Pyramid – Python 框架。
-
CakePHP – PHP 框架。
-
Symfony – PHP 框架。
-
Laravel – PHP 框架。
-
TALL Stack – 全栈开发解决方案,包含 Laravel 社区构建的库。
-
Rails – Ruby 的网页应用框架。
- Gems – 软件包。
-
Phalcon – PHP 框架。
-
nginx – 网络服务器。
-
Dropwizard – Java 框架。
-
Kubernetes – 自动化 Linux 容器操作的开源平台。
-
Lumen – PHP 微框架。
-
Serverless Framework – 无服务器计算和无服务器架构。
-
Apache Wicket – Java web 应用框架。
-
Vert.x – 用于在 JVM 上构建响应式应用的工具包。
-
Terraform – 用于构建、修改和版本化基础设施的工具。
-
Vapor – Swift 中的服务器端开发。
-
Dash – Python web 应用框架。
-
FastAPI – Python web 应用框架。
-
CDK – 用于在代码中定义云基础设施的开源软件开发框架。
-
IAM – 用户帐户、身份验证和授权。
-
Chalice – 用于在 AWS Lambda 上开发无服务器应用的 Python 框架。
计算机科学
-
-
ML with Ruby – 使用 Ruby 学习、实施和应用机器学习。
-
Core ML Models – Apple 机器学习框架的模型。
-
H3O – 用 Java 编写的开源分布式机器学习平台,提供 R、Python 和 Scala 的 API。
-
Software Engineering for Machine Learning – 从实验到生产级机器学习。
-
AI in Finance – 使用机器学习解决金融中的问题。
-
JAX – 自动微分和 XLA 编译结合用于高性能机器学习研究。
-
Speech and Natural Language Processing
-
Question Answering – 用机器进行自然语言问答的科学。
-
自然语言生成 – 用于数据到文本、对话代理和叙事生成应用的文本生成。
-
- 论文 – 非密码学家使用密码学的理论基础。
-
深度学习 – 神经网络。
-
TensorFlow – 机器智能库。
-
TensorFlow.js – 用于训练和部署模型的 WebGL 加速机器学习 JavaScript 库。
-
TensorFlow Lite – 优化 TensorFlow 模型以便在设备上进行机器学习的框架。
-
论文 – 被引用最多的深度学习论文。
-
-
经验软件工程 – 基于证据的软件系统研究。
-
信息检索 – 学习开发你自己的搜索引擎。
-
量子计算 – 利用量子力学和量子计算机上的量子比特进行计算。
大数据
-
Hadoop – 用于分布式存储和处理超大数据集的框架。
-
Apache Spark – 大规模数据处理的统一引擎。
-
Qlik – 用于数据可视化、分析和报告应用的商业智能平台。
-
Splunk – 用于实时搜索、监控和分析结构化和非结构化机器生成大数据的平台。
理论
书籍
编辑器
-
Atom – 开源且可黑客化的文本编辑器。
-
Visual Studio Code – 跨平台开源文本编辑器。
游戏
-
Godot – 游戏引擎。
-
Unity – 游戏引擎。
-
LÖVE – 游戏引擎。
-
PICO-8 – 幻想控制台。
-
Construct 2 – 游戏引擎。
-
Gideros – 游戏引擎。
-
Minecraft – 沙盒视频游戏。
-
游戏数据集 – 用于游戏中人工智能的材料和数据集。
-
Haxe 游戏开发 – 一种高层次的强类型编程语言,用于生成跨平台的本地代码。
-
libGDX – Java 游戏框架。
-
PlayCanvas – 游戏引擎。
-
游戏重制 – 积极维护的开源游戏重制版。
-
Flame – 用于 Flutter 的游戏引擎。
-
Discord 社区 – 与朋友和社区聊天。
-
CHIP-8 – 70 年代的虚拟计算机游戏机。
-
编程游戏 – 通过制作游戏来学习编程语言。
开发环境
-
快速查看插件 – 适用于 macOS。
-
Fish – 用户友好的 shell。
-
GitHub – Git 仓库的托管服务。
-
Git 插件 – 增强
gitCLI。 -
Git 钩子 – 用于
git工作流中的任务自动化脚本。 -
Hyper – 基于 Web 技术的跨平台终端应用。
-
PowerShell – 跨平台面向对象的 shell。
-
Alfred 工作流 – 适用于 macOS 的生产力应用。
-
GitHub Actions – 创建任务来自动化工作流,并与 GitHub 上的其他人共享。
娱乐
数据库
-
MongoDB – NoSQL 数据库。
-
TinkerPop – 图计算框架。
-
PostgreSQL – 对象关系型数据库。
-
CouchDB – 面向文档的 NoSQL 数据库。
-
HBase – 分布式、可扩展的大数据存储。
-
NoSQL Guides – 使用非关系型、分布式、开源和水平可扩展数据库的帮助。
-
Contexture – 从不同的数据存储如 ElasticSearch 和 MongoDB 中抽象查询/过滤器和结果/聚合。
-
Database Tools – 使数据库操作更简便的工具。
-
Grakn – 逻辑数据库,用于组织大型复杂的数据网络作为一个知识体系。
媒体
-
Codeface – 文本编辑器字体。
-
GIF – 以动画图像著称的图像格式。
-
Pixel Art – 像素级数字艺术。
-
FFmpeg – 跨平台的音视频录制、转换和流媒体解决方案。
-
Icons – 可下载的 SVG/PNG/字体图标项目。
-
Audiovisual – 专业环境中的灯光、音频和视频。
学习
-
CLI Workshoppers – 互动教程。
-
教育游戏 – 在游戏中学习。
-
CSS 学习 – 主要关于 CSS——语言和模块。
-
产品管理 – 学习如何成为更好的产品经理。
-
路线图 – 为提高你的知识和技能提供清晰的路线图。
-
YouTuber – 观看 YouTuber 教授技术的视频教程。
安全
-
CTF – Capture The Flag(夺旗赛)。
-
蜜罐 – 诱捕攻击者尝试入侵组织信息系统的陷阱。
-
网络安全 – 网络应用和服务的安全。
-
开锁 – 不使用钥匙而通过操控锁的组件来解锁的艺术。
-
网络安全蓝队 – 识别信息技术系统安全漏洞的团队。
-
模糊测试 – 一种自动化的软件测试技术,涉及输入伪随机生成的数据。
-
GDPR – 欧盟内所有个人的数据保护和隐私条例。
内容管理系统
-
Refinery CMS – Ruby on Rails 的内容管理系统。
-
Wagtail – 以灵活性和用户体验为重点的 Django CMS。
-
Textpattern – 轻量级 PHP 基础的 CMS。
-
Drupal – 可扩展的 PHP 基础 CMS。
-
Craft CMS – 内容优先的 CMS。
-
Sitecore – .NET 数字营销平台,将 CMS 与管理多个网站的工具结合起来。
-
Silverstripe CMS – PHP MVC 框架,可作为经典或无头 CMS。
硬件
-
电子学 – 面向电子工程师和爱好者。
-
电吉他规格 – 自制电吉他的检查清单。
-
绘图仪 – 计算机控制的绘图机和其他视觉艺术机器人。
-
机器人工具 – 面向专业机器人开发的免费和开源工具。
-
LIDAR – 通过激光光照射目标来测量距离的传感器。
商业
-
OKR 方法论 – 目标设定与沟通最佳实践。
-
领导与管理 – 在科技公司/环境中领导和管理。
-
独立 – 独立开发者业务。
-
交易工具 – Hacker News 上公司使用的工具。
-
清洁技术 – 利用技术应对气候变化。
-
Wardley 图 – 提供高情境感知,帮助改进战略规划和决策。
-
社会企业 – 建立一个主要关注社会影响的组织,该组织至少部分自筹资金。
-
工程团队管理 – 如何从软件开发过渡到工程管理。
-
开发者优先产品 – 针对开发者作为用户的产品。
工作
网络
去中心化系统
-
比特币 – 为软件开发者提供的比特币服务和工具。
-
瑞波 – 开源分布式结算网络。
-
非金融区块链 – 非金融区块链应用。
-
Mastodon – 开源去中心化微博网络。
-
以太坊 – 用于智能合约开发的分布式计算平台。
-
区块链人工智能 – 面向人工智能和机器学习的区块链项目。
-
EOSIO – 支持工业规模应用的去中心化操作系统。
-
Corda – 面向商业的开源区块链平台。
-
Waves – 开源区块链平台和用于 Web 3.0 应用及去中心化解决方案的开发工具包。
-
Substrate – 用于用 Rust 编写可扩展、可升级区块链的框架。
高等教育
-
计算神经科学 – 一门使用计算方法研究神经系统的跨学科科学。
-
数字历史 – 计算机辅助的历史科学研究。
-
科学写作 – 使用 Markdown、reStructuredText 和 Jupyter notebooks 进行无干扰的科学写作。
事件
测试
-
测试 – 软件测试。
-
视觉回归测试 – 确保更改未破坏功能或样式。
-
Selenium – 开源浏览器自动化框架和生态系统。
-
Appium – 应用程序测试自动化工具。
-
TAP – 测试任何协议。
-
JMeter – 负载测试和性能测量工具。
-
k6 – 开源、面向开发者的性能监控和负载测试解决方案。
-
Playwright – 一个 Node.js 库,用于通过单一 API 自动化 Chromium、Firefox 和 WebKit。
-
质量保证路线图 – 如何开始并建立软件测试职业。
杂项
-
JSON – 基于文本的数据交换格式。
-
CSV – 一种文本文件格式,用于存储表格数据,并使用逗号分隔值。
-
Awesome – 递归示意图。
-
回答 – Stack Overflow、Quora 等。
-
Sketch – macOS 的设计应用程序。
-
Gulp – 任务运行器。
-
AMA – 随便问我什么。
-
OpenGL – 跨平台的 2D 和 3D 图形渲染 API。
-
Unicode – Unicode 标准、特性、软件包和资源。
-
公民科学 – 面向社区基础和非机构科学家的资源。
-
MQTT – “物联网”连接协议。
-
Vorpal – Node.js CLI 框架。
-
Vulkan – 低开销的跨平台 3D 图形和计算 API。
-
LaTeX – 排版语言。
-
经济学 – 经济学家的入门工具包。
-
化学信息学 – 应用于化学问题的信息学技术。
-
Colorful – 选择你的下一个配色方案。
-
Steam – 数字分发平台。
-
机器人 – 构建机器人。
-
工程中的同理心 – 构建和推广更具同情心的工程文化。
-
DTrace – 动态追踪框架。
-
用户脚本 – 提升浏览体验。
-
宝可梦 – 宝可梦及宝可梦 GO。
-
ChatOps – 通过聊天管理技术和业务操作。
-
虚假信息 – 程序员信奉的虚假信息。
-
领域驱动设计 – 通过将实施与不断发展的模型连接的复杂需求的软件开发方法。
-
量化自我 – 通过技术进行自我追踪。
-
SaltStack – 基于 Python 的配置管理系统。
-
网页设计 – 针对数字设计师。
-
创意编码 – 编写有表现力的代码而非功能性代码。
-
无登录网页应用 – 无需登录即可使用的网页应用。
-
自由软件 – 自由如同自由。
-
Framer – 原型设计交互式用户界面。
-
Markdown – 标记语言。
-
开发乐趣 – 有趣的开发者项目。
-
医疗保健 – 面向设施、提供者、开发者、政策专家和研究人员的开源医疗软件。
-
Magento 2 – 基于 PHP 的开源电子商务。
-
TikZ – TeX/LaTeX/ConTeXt 图形绘制包。
-
神经科学 – 研究神经系统和大脑。
-
无广告 – 无广告的替代方案。
-
Esolangs – 设计用于实验或作为笑话的编程语言,而非实际使用。
-
普罗米修斯 – 开源监控系统。
-
Homematic – 智能家居设备。
-
账本 – 命令行下的复式记账。
-
网页货币化 – 一种免费的开放网页标准服务,允许你直接在浏览器中发送资金。
-
非版权作品 – 公有领域的作品。
-
加密货币工具与算法 – 使用加密技术调节单位生成和验证交易的数字货币。
-
多样性 – 创建一个更加包容和多样化的技术社区。
-
开源支持者 – 为开源项目提供免费工具和服务的公司。
-
设计原则 – 创造更好、更一致的设计和体验。
-
上座部佛教 – 上座部佛教传统的教义。
-
inspectIT – 开源的 Java 应用性能管理工具。
-
开源维护者 – 成为开源维护者的经验。
-
计算器 – 适用于各种平台的计算器。
-
验证码 – 一种计算机测试,判断用户是否为人类。
-
Jupyter – 创建和分享包含代码、方程、可视化和叙述文本的文档。
-
FIRST 机器人竞赛 – 国际高中机器人锦标赛。
-
人文科技 – 改善社会的开源项目。
-
演讲者 – 编程和设计社区的会议和聚会演讲者。
-
桌面游戏 – 适合所有人的桌面游戏乐趣。
-
软件 Patreon – 资助个人程序员或开源项目的开发。
-
寄生虫 – 寄生虫及宿主-病原体相互作用。
-
食品 – GitHub 上与食品相关的项目。
-
心理健康 – 软件行业中的心理健康意识和自我关怀。
-
比特币支付处理器 – 开始接受比特币。
-
科学计算 – 利用计算机解决复杂的科学问题。
-
农业 – 农业和园艺的开源技术。
-
产品设计 – 从初步概念到生产设计一个产品。
-
Prisma – 将数据库转换为 GraphQL API。
-
软件架构 – 设计和构建软件的学科。
-
连接数据与报告 – 更好地理解谁有权访问电信和互联网基础设施,以及这些访问的条款。
-
技术栈 – 用于构建不同应用和功能的技术栈。
-
细胞数据 – 针对计算生物学家的基于图像的生物学表型分析。
-
IRC – 开源消息传递协议。
-
广告 – 针对网站的广告和程序化媒体。
-
地球 – 寻找解决气候危机的方法。
-
命名 – 计算机科学中的正确命名方式。
-
生物医学信息提取 – 从非结构化生物医学数据和文本中提取信息。
-
网页归档 – 为了未来的世代而努力保存网络。
-
WP-CLI – WordPress 的命令行界面。
-
信用建模 – 将信用申请人分类为风险等级的方法。
-
Ansible – 基于 Python 的开源 IT 配置管理和自动化平台。
-
生物学可视化 – 在网络上交互式地可视化生物数据。
-
二维码 – 一种矩阵条形码,用于存储和分享少量信息。
-
素食主义 – 让植物性生活方式变得简单和可及。
-
翻译 – 将文本的含义从一种语言转移到另一种语言。
相关
-
所有精彩列表 – GitHub 上的所有精彩列表。
-
精彩索引 – 搜索精彩数据集。
-
精彩搜索 – 快速搜索精彩列表。
-
StumbleUponAwesome – 使用浏览器扩展从 Awesome 数据集中发现随机页面。
-
超棒 CLI 工具 – 一个简单的命令行工具,用于深入了解 Awesome 列表。
-
超棒查看器 – 用于可视化上述所有 Awesome 列表的工具。
美国教育部 CRDC 数据集
美国教育部有一个叫做 CRDC 的数据集,收集了所有美国公立学校的数据,包括人口统计、学术、财务和各种其他有趣的数据点。他们还有使用相同标识符的附属数据集——可以视作扩展包。每 2-3 年更新一次。点击这里访问.
NASA 数据集:细菌在被送入太空前后的测序数据
NASA 拥有一些细菌的测序数据,这些细菌在被送入太空前后被采样,用于观察由于缺乏重力、辐射等因素造成的基因差异。如果你想尝试一些生物数据科学,这非常有趣。点击这里访问。
特朗普 2015 至 2021 年的所有推特侮辱记录(CSV 格式)
从 NYT 故事中提取:这里
数据是复数
Data is Plural 是由 Jeremy Singer-Vine 出版的一个非常好的通讯。数据集非常随机,但非常有趣。点击这里访问。
全球恐怖主义数据库
大量来自美国及其他国家的恐怖事件列表。每个条目包含事件的日期和地点、动机、是否有人或财产损失、袭击规模、袭击类型等信息。点击这里访问.
恐怖袭击数据集:该数据集包含 1293 起恐怖袭击,每起袭击被分配一个 6 种标签中的一种,指示袭击类型。每次袭击通过一个 0/1 值的属性向量描述,该向量的条目表示特征的缺失/存在。共有 106 个不同的特征。数据集中的文件可用于创建两个不同的图表。数据集中的 README 文件提供了更多细节。下载链接
恐怖分子: 该数据集包含有关恐怖分子及其关系的信息。此数据集旨在进行分类实验,目的是分类恐怖分子之间的关系。数据集包含 851 个关系,每个关系由一个 0/1 值向量描述,其中每个条目表示一个特征的缺失/存在。共有 1224 个不同的特征。每个关系可以被分配一个或多个标签,最多可达四个标签,使得该数据集适用于多标签分类任务。README 文件提供了更多详细信息。下载链接
海豚社交网络
该网络数据集属于社交网络类别。瓶鼻海豚的社交网络。数据集包含所有链接的列表,其中一个链接代表海豚之间的频繁关联。点击这里访问
200,000 条笑话数据集
该数据库中大约有 208,000 条笑话,来自三个来源。
百万首歌曲数据集
百万首歌曲数据集是一个免费提供的现代流行音乐轨迹的音频特征和元数据集合。
其目的如下:
-
鼓励研究适用于商业规模的算法
-
提供一个参考数据集以评估研究
-
作为创建大型数据集的快捷替代方案(例如 Echo Nest 的)
-
帮助新研究人员入门 MIR 领域
康奈尔大学的 eBird数据集
通过对全球鸟类的几十年观察,真正是利用公民科学的一种令人印象深刻的方式。点击这里访问。
UFO 报告数据集
NUFORC 的地理定位和时间标准化的 UFO 报告,数据覆盖近一个世纪。超过 80,000 份报告。点击这里访问
CDC 的趋势药物数据
CDC 拥有一个名为 NAMCS/NHAMCS 的公共数据库,允许你跟踪药物数据。它还有很多其他的数据点,因此可以用于各种其他用途。点击这里访问。
健康与退休研究:公共调查数据
一份列出了公开可用的双年度、非年度和跨年度数据产品的清单。
示例: COVID-19 数据
| 年份 | 产品 |
|---|---|
| 2020 | 2020 HRS COVID-19 项目 |
原始内容。经许可转载。
相关:
更多相关内容
极好的机器学习和 AI 课程
原文:
www.kdnuggets.com/2020/07/awesome-machine-learning-ai-courses.html
评论
作者:Lukas Spranger,数据科学家和软件工程师
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
编辑说明: 请注意,这是一份不断增长的课程合集,你可以通过简单地提交拉取请求来贡献内容。
这是一个精心策划的,免费机器学习和人工智能课程列表,包含视频讲座。所有课程均由一些顶级 AI 研究人员和教师提供高质量的视频讲座。
除了视频讲座,我还链接了包含讲义、额外阅读和作业的课程网站。
入门讲座
这些课程是入门机器学习和 AI 的绝佳选择。不需要先前的 ML 和 AI 经验。你应该具备一些线性代数、基础微积分和概率知识。建议有一定的编程经验。
-
这本现代经典机器学习课程是理解机器学习概念和技术的绝佳起点。课程涵盖了许多广泛使用的技术,讲义详细且回顾了必要的数学概念。
-
这是开始深度学习的绝佳方式。课程重点讲解卷积神经网络和计算机视觉,同时也概述了递归网络和强化学习。
-
人工智能导论(加州大学伯克利分校 CS188) | 课程网站
涵盖了整个人工智能领域。从搜索方法、博弈树和机器学习到贝叶斯网络和强化学习。
-
作为斯坦福 CS229 的替代课程,顾名思义,这门课程比 Andrew Ng 在斯坦福的机器学习讲座更具应用视角。你会看到更多的代码而不是数学。概念和算法使用流行的 Python 库 scikit-learn 和 Keras。
-
强化学习入门与 David Silver(DeepMind) | 课程网站
由 AlphaGo 和 AlphaZero 背后的领先研究者之一介绍的强化学习入门。
-
自然语言处理与深度学习(斯坦福 CS224N) | 课程网站
现代自然语言处理技术,从递归神经网络和词嵌入到变换器和自注意力。涵盖了诸如问答和文本生成等应用主题。
高级讲座
需要具备机器学习和人工智能基础知识的高级课程。
简介:卢卡斯·斯普兰格 (@sprangerlukas) 是一名数据科学家和软件工程师。目前,他在西门子工作,专注于数据驱动和 AI 驱动的软件解决方案。他拥有计算机科学硕士学位,对通过技术构建更美好未来充满热情。
原文。经许可转载。
相关内容:
-
免费学习顶级大学的数据科学
-
另外 10 个必看的机器学习和数据科学免费课程
-
免费数据分析课程
更多相关主题
GitHub 上的精彩公共数据集
原文:
www.kdnuggets.com/2015/04/awesome-public-datasets-github.html
 无论你阅读多少关于技术的书籍,有些知识只能通过经验获得。这在大数据领域尤为真实。尽管网上有很多资源(包括 KDnuggets 数据集)可以用于大型数据集,但许多有抱负的从业者(主要是新手)往往对尝试将数据科学技能应用于现实生活中的大型数据集时的无限选项知之甚少。因此,我们始终在寻找更多更好的可供公众使用的数据集。
无论你阅读多少关于技术的书籍,有些知识只能通过经验获得。这在大数据领域尤为真实。尽管网上有很多资源(包括 KDnuggets 数据集)可以用于大型数据集,但许多有抱负的从业者(主要是新手)往往对尝试将数据科学技能应用于现实生活中的大型数据集时的无限选项知之甚少。因此,我们始终在寻找更多更好的可供公众使用的数据集。
在我们这一旅程的下一个努力中,我们在这里分享了一份由 Xia Ming(简历见文末)整理的精彩公共数据源列表,这些数据源来自博客、回答和用户反馈。下面列出的多数数据集是免费的,但有些则不是。
农业
生物学
气候/天气
复杂网络
计算机网络
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
来自 Kaggle 的精彩技巧和最佳实践
原文:
www.kdnuggets.com/2021/04/awesome-tricks-best-practices-kaggle.html
评论
由 Bex T.,AI 顶级写手

每周精彩技巧和来自 Kaggle 的最佳实践
关于此项目
Kaggle 是一个很棒的地方。它是数据科学家和机器学习工程师的知识宝库。没有很多平台能在同一个地方找到由领域专家提供的高质量、高效、可重复的优秀代码。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
自推出以来,它已经举办了超过 164 场比赛。这些比赛吸引了来自世界各地的专家和专业人士。结果,每个比赛和 Kaggle 提供的大量开源数据集上都有许多高质量的笔记本和脚本。
在我数据科学旅程的开始,我会去 Kaggle 寻找数据集来练习我的技能。每当我查看其他的 kernels 时,我都会被代码的复杂性所压倒,并立即退缩。
但现在,我发现自己花了大量时间阅读他人的笔记本并参加比赛。有时,有些内容值得你整个周末投入其中。有时,我会发现简单却极其有效的代码技巧和最佳实践,这些只能通过观察其他专家来学习。
剩下的很简单,我的强迫症几乎迫使我把每一条数据科学知识都倾囊相授。所以,我在这里,写下我的“每周精彩技巧和来自 Kaggle 的最佳实践”第一版。在这个系列中,你会发现我写的任何在典型数据科学工作流程中有用的东西,包括与常见库相关的代码快捷方式、Kaggle 上顶级行业专家遵循的最佳实践等等,都是我在过去一周里学到的。请享用!
1. 绘制相关矩阵的下半部分
一个好的相关矩阵可以提供大量有关数据集的信息。通常会绘制它以查看特征与目标变量之间的成对相关性。根据你的需求,你可以决定保留哪些特征并将其输入到你的机器学习算法中。
但今天,数据集包含了如此多的特征,以至于查看这样的相关矩阵可能会让人感到不知所措:

每周 Kaggle 的绝妙技巧和最佳实践
尽管很好,但信息量太大,难以消化。相关矩阵通常沿主对角线对称,因此包含重复数据。此外,对角线本身没有用处。让我们看看如何仅绘制有用的一半:
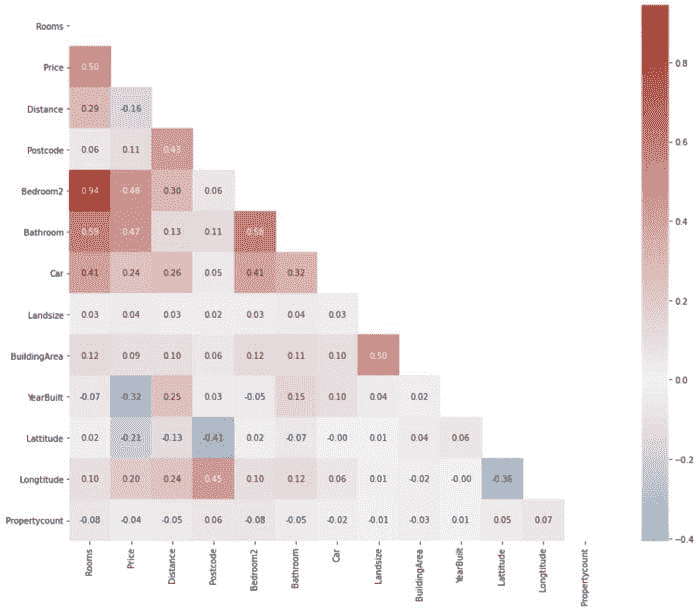
结果图表更容易解读,没有干扰。首先,我们使用 DataFrame 的 .corr 方法构建相关矩阵。然后,我们使用np.ones_like函数,并将dtype设置为bool,创建一个与 DataFrame 形状相同的 True 值矩阵:
然后,我们将其传递给 Numpy 的.triu函数,该函数返回一个包含矩阵下三角部分 False 值的 2D 布尔掩码。然后,我们可以将其传递给 Seaborn 的热图函数,以根据此掩码对子集矩阵:
我还做了一些调整,让图表更美观,比如添加自定义颜色调色板。
2. 在 value_counts 中包含缺失值
使用 value_counts 的一个实用技巧是,你可以通过将dropna设置为 False 来查看任何列中缺失值的比例:
通过确定缺失值的比例,你可以决定是删除还是填补它们。然而,如果你想查看所有列中缺失值的比例,value_counts并不是最佳选择。相反,你可以这样做:
首先,通过将缺失值的数量除以 DataFrame 的长度来找出比例。然后,你可以过滤掉 0% 的列,即仅选择有缺失值的列。
3. 使用 Pandas DataFrame Styler
我们中的许多人从未意识到 pandas 的巨大未开发潜力。pandas 的一个被低估且经常被忽视的功能是其 DataFrame 的样式化。使用 pandas DataFrames 的.style属性,你可以为它们应用条件设计和样式。作为第一个示例,让我们看看如何根据每个单元格的值更改背景颜色:
这几乎是一个没有使用 Seaborn 的热图函数的热图。在这里,我们使用pd.crosstab计算每个钻石切割和净度的组合。使用.style.background_gradient和颜色调色板,你可以轻松找出最常见的组合。从上述 DataFrame 中,我们可以看到大多数钻石为理想切割,最大组合为‘VS2’类型的净度。
我们甚至可以进一步,通过在交叉表中查找每个钻石切割和净度组合的平均价格:

这一次,我们对每个切割和清晰度组合的钻石价格进行汇总。从样式化的 DataFrame 中,我们可以看到最贵的钻石具有 ‘VS2’ 清晰度或高级切割。但如果我们能够通过四舍五入显示汇总价格,那会更好。我们也可以通过 .style 来更改这一点:

通过将 .format 方法与格式字符串 {:.2f} 链接,我们指定了 2 位小数的精度。
使用 .style,你的想象力就是限制。只需了解一点 CSS,你就可以为你的需求构建自定义样式函数。有关更多信息,请查看官方 pandas 指南。
4. 使用 Matplotlib 配置全局绘图设置
在进行 EDA 时,你会发现自己会对所有图形保持一些 Matplotlib 设置不变。例如,你可能想为所有图形应用自定义调色板,使用更大的字体进行刻度标签,改变图例的位置,使用固定的图形大小等。
指定每个自定义图形更改可能是一项相当枯燥、重复且耗时的任务。幸运的是,你可以使用 Matplotlib 的 rcParams 来为你的图形设置全局配置:
from matplotlib import rcParams
rcParams 只是一个包含 Matplotlib 默认设置的普通 Python 字典:

你可以调整每个图形的几乎所有方面。我通常做的事情也是我看到其他人做的事情是设置固定的图形大小、刻度标签字体大小以及其他一些:
你可以在导入 Matplotlib 后立即设置这些选项来避免大量重复。通过调用 rcParams.keys() 查看所有其他可用的设置。
5. 配置 pandas 的全局设置
就像 Matplotlib 一样,pandas 也有可以调整的全局设置。当然,它们大多与显示选项有关。官方用户指南指出,pandas 的整个选项系统可以通过 pandas 命名空间直接访问的 5 个函数来控制:
-
get_option() / set_option() — 获取/设置单个选项的值。
-
reset_option() — 将一个或多个选项重置为默认值。
-
describe_option() — 打印一个或多个选项的描述。
-
option_context() — 使用一组选项执行代码块,执行后还原为先前设置。
所有选项的名称都是不区分大小写的,并且在底层通过正则表达式查找。你可以使用 pd.get_option 来查看默认行为,并使用 set_option 根据自己的喜好进行更改:
>>> pd.get_option(‘display.max_columns’)
20
例如,上述选项控制当 DataFrame 中有很多列时显示的列数。如今,大多数数据集包含超过 20 个变量,每当你调用 .head 或其他显示函数时,pandas 会烦人地添加省略号以截断结果:
>>> houses.head()

我宁愿通过滚动查看所有列。让我们改变这种行为:
>>> pd.set_option(‘display.max_columns’, None)
上述,我完全移除了限制:
>>> houses.head()

你可以使用以下命令恢复到默认设置:
pd.reset_option(‘display.max_columns’)
就像列一样,你可以调整显示的默认行数。如果将 display.max_rows 设置为 5,你就不必总是调用.head():
>>> pd.set_option(‘display.max_rows’, 5)>>> houses

如今,plotly 正变得非常流行,因此将其设置为 pandas 的默认绘图后端是不错的选择。这样,每当你在 pandas DataFrames 上调用.plot 时,你将获得交互式的 plotly 图表:
pd.set_option(‘plotting.backend’, ‘plotly’)
请注意,你需要安装 plotly 才能进行此操作。
如果你不想更改默认行为或者只是想暂时更改某些设置,你可以使用pd.option_context作为上下文管理器。临时行为更改只会应用于紧随其后的代码块。例如,如果数据量很大,pandas 有一个烦人的习惯,会将它们转换为标准记数法。你可以暂时避免这个问题,方法是:
你可以在官方 pandas 用户指南中查看可用选项的列表。
简介:Bex T. 是 AI 领域的顶级作者,撰写有关数据科学和机器学习的“我希望我早一点找到这些”帖子。
原文。转载已获许可。
相关:
-
数据专业人士寻找数据集的 8 个地方
-
数据科学自学的 10 个资源
-
初学者的 10 个 Python 技能
更多相关话题
-
[停止学习数据科学以寻找目标,并找到目标...] (https://www.kdnuggets.com/2021/12/stop-learning-data-science-find-purpose.html)
AWS AI & ML 奖学金计划概述
原文:
www.kdnuggets.com/2022/09/aws-ai-ml-scholarship-program-overview.html

来源:着陆页截图
启动人工智能、机器学习等职业生涯可能很困难。你通常认为你必须上大学学习计算机科学、统计学或数学。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
大学费用昂贵,在线课程费用高,自学也很困难。随着该领域对人才的需求增加,企业正在使人们更顺利地过渡到该领域。
该计划是什么?
AWS 与英特尔和 Udacity 合作,邀请新生进入人工智能(AI)和机器学习(ML)奖学金计划。此奖学金计划旨在帮助那些在高中和大学期间未得到充分服务和代表的人,帮助他们学习机器学习的基础和概念,并在 AI 和 ML 领域建立职业生涯。
该计划提供什么?
当选择人工智能(AI)和机器学习(ML)奖学金计划时,学生可以获得最多两个 2500 个奖学金,以帮助他们启动 AI 和 ML 领域的职业生涯。
这是该计划提供的内容:
使用 AWS DeepRacer Student 学习机器学习
对于此奖学金计划,你将使用 AWS DeepRacer Student,这是一个全新的免费服务,旨在帮助希望学习和实践 ML 技能的学生,然后他们将进一步参加自主 AI/ML 赛车联赛,争取赢得奖品和奖学金。
学生可以访问 20 小时的 ML 教育资源和额外的 10 小时每月模型训练计算资源,帮助他们提升 ML 技能。
你将能够通过每月的比赛检验你的技能,并赢得如奖学金、设备等奖品,还能获得成为全球竞赛顶级赛车手的经验。
通过奖学金更快达到目标
通过奖学金接近你的职业目标总是更好的。这样你财务负担较轻,这自然会提高你的动力和驱动力。
每年,将有 2000 名学生获得 Udacity AI Programming with Python Nanodegree 课程的奖学金,该课程价值 4,000 美元。这个为期 4 个月的虚拟课程将教授你机器学习的基础知识、编程工具等。你还将获得 Udacity 教师在每周小组会议中的支持。
如果你是首个 Udacity Nanodegree 课程中的前 500 名表现最佳的学生,你将有机会获得第二个、更高级的 Udacity Nanodegree。这是一个为期六个月的课程,深入研究其他领域,如深度学习、机器学习工程概念等。
来自 AWS 和 Intel ML 专家的指导
所有 2000 名已注册奖学金计划的学生将获得指导和职业建议。每月都有与顶级行业专家的“问我任何问题”研讨会,允许学生开放且自由地提出问题。
你可以询问有关职业发展、网络建立、技术工作环境、多样性等更多问题。
如果你是第一个项目中的前 500 名表现最佳的学生,并且进入了第二个 Nanodegree 课程,你将获得来自 AWS 或 Intel 员工的一整年的一对一指导,他们将亲自指导你,帮助你在技术职业中达到最佳状态。
我怎么才能成为该计划的一部分?
如果你对 AWS 在人工智能(AI)和机器学习(ML)奖学金计划中提供的内容感兴趣,你可以选择加入 AWS DeepRacer Student 计划。
为了符合 AWS AI & ML 奖学金计划的资格,学生需要完成 AWS DeepRacer Student 上的学习模块和测验。他们还必须年满 16 岁,并且注册了全球范围内的高中或高等教育机构。
结论
如果你对开始技术职业感到犹豫,但又不完全准备好财务上承诺回到大学、参加训练营或支付在线课程费用——我相信这个奖学金计划适合你。
该计划为你提供了一种有趣且免费的方式来学习机器学习,同时成为社区的一部分,并能够参与竞争,赢取奖品以进一步发展你的职业。
尼莎·阿雅 是一位数据科学家和自由技术写作员。她特别感兴趣于提供数据科学职业建议或教程及理论知识。她还希望探索人工智能如何有助于人类寿命的不同方式。作为一名热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
拓扑分析与机器学习:朋友还是敌人?
原文:
www.kdnuggets.com/2015/09/ayasdi-topological-analysis-machine-learning.html
作者:哈兰·塞克斯顿(Ayasdi)。
对拓扑数据分析(TDA)不太熟悉的人常常问我类似的问题:“机器学习和 TDA 之间有什么区别?”这是一个很难回答的问题,部分原因在于这取决于你对机器学习(ML)的定义。
维基百科对机器学习(ML)的描述如下:
“机器学习探索能够从数据中学习并做出预测的算法的研究与构建。这些算法通过从示例输入中构建模型来做出数据驱动的预测或决策,而不是严格遵循静态程序指令。”
在这种广泛性层面上,人们可以争辩说 TDA 是一种机器学习(ML),但我认为大多数在这两个领域工作的人会不同意。
机器学习的具体实例彼此之间的相似性要大于与任何 TDA 示例的相似性。TDA 也是如此,其示例更像 TDA 而不是 ML。
为了说明 TDA 和 ML 之间的区别,也许更重要的是演示 TDA 和 ML 如何及为何能够很好地结合,我将给出两个过于简单的定义,然后通过一个实际例子来说明这一点。
一个简单的定义机器学习(ML)的方法是任何假设了一个参数化数据模型并从数据中学习这些参数的方法。
同样,我们可以将 TDA 定义为任何只使用“相似性”概念作为数据模型的方法。
从这个角度来看,机器学习(ML)模型要具体得多,详细得多,模型的成功取决于它如何与基础数据相契合。优势在于,当数据与模型相符时,结果可能会非常显著——明显的混乱被几乎完美的理解所取代。
TDA 的优势在于其广泛性。
使用拓扑数据分析(TDA)时,任何相似性的概念都足以使用该方法论。相比之下,机器学习(ML)则需要对相似性有强烈的理解(以及更多),才能对任何方法取得进展。
例如,从一个很长的名字列表中,可靠地预测身高和体重是不可能的。你需要更多的信息。
这里的一个关键要素是,源自拓扑学的算法通常对小错误非常宽容——即使你的相似性概念有些缺陷,只要它“基本正确”,TDA 方法通常也能产生有用的结果。
TDA 方法的广泛性比 ML 技术具有额外的优势,即使当 ML 方法很适用时,ML 方法通常会创建详细的内部状态,这些状态生成相似性概念,从而使得将 TDA 与 ML 结合起来,可以对数据集获得更多的洞见。
这一切听起来很棒,但它足够笼统(或者如果你不太宽容的话,足够模糊),可能意味着任何事情。
所以,让我们具体谈谈。
随机森林^(TM) 分类器是一种集成学习方法,通过在训练过程中构建大量决策树,并对这些“森林”(决策树的集合)应用“多数规则”来对非训练数据进行分类。
尽管构建的细节非常有趣和巧妙,但目前并不相关。你只需要记住随机森林的操作方式是:对每个数据点应用一组决策树,并返回一系列“叶节点”(输入“落入”的决策树中的叶子)。
在正常操作中,每棵树中的每个叶子都有一个与之相关联的类别 C,这被解释为“当一个数据点到达树中的这个节点时,我知道它极有可能属于类别 C。”随机森林通过计算每棵树的“叶节点类别投票”并选择赢家来进行分类。虽然这种方法在广泛的数据类型上非常有效,但也丢失了大量的信息。
如果你关心的是数据点类别的最佳猜测,那么你不需要看到那些额外的信息,但有时你需要更多。这些“额外”的信息可以通过定义两个数据点之间的距离为其各自“叶节点”不同的次数来转化为距离函数。
两个数据点之间的距离函数是一个完全有效的度量(实际上,它是数据集变换上的汉明度量),因此我们可以将 TDA 应用于它。
例如,我们来看一个随机抽取的 5000 点样本:
archive.ics.uci.edu/ml/datasets/Dataset+for+Sensorless+Drive+Diagnosis
数据集相对复杂,包含 48 个连续特征,这些特征似乎是硬盘电流信号的未解释测量值。数据还包括一个分类列,有 11 个可能的值,描述了磁盘驱动组件的不同状态(可能是故障模式?)。一个显而易见的尝试是对特征列应用欧几里得度量,然后通过类别对图表进行着色。由于我们对特征列一无所知,首先要尝试的是邻域透镜。结果是一个没有特征的斑点:

这令人失望。
利用一些内部调试能力,我查看了邻域透镜的散点图,明白了为什么效果如此糟糕——它看起来像一棵圣诞树:

显然,在欧几里得度量下,类别没有局部化。
然而,如果你在数据集上构建一个随机森林,分类器的袋外误差非常小,这强烈表明分类器非常可靠。
所以我尝试使用随机森林赫明度量和该度量的邻域镜头来绘制一个图表:

这看起来非常好。为了确认,我们还查看了邻域镜头的散点图,结果与上图所示一致:

从图表和散点图中明显可以看出,随机森林在分类水平以下“看到”的强结构被 TDA 揭示出来了。原因是随机森林未能有效使用“额外”数据,而 TDA 使用了这些数据并从中受益颇丰。
然而,有人可能会问,这种结构是否是虚幻的——或许是我们在系统中使用的算法的某种伪影?在这个数据集的情况下,我们无法确定,因为我们对这些组没有更多了解。
尽管如此,我们仍然使用随机森林度量对客户数据进行了分析,以识别数千种复杂设备可能的故障模式,这些数据是在设备烧机期间收集的。类别是基于对设备进行返厂后的尸检(并非所有都涉及故障)。
我们发现,在这种情况下,随机森林度量在分类故障方面做得很好,而且我们获得的图像特征与上述类似。更重要的是,我们发现特定故障模式下的不同组有时具有不同的原因。
在这两个案例中的要点是,这些原因如果没有使用 TDA 与随机森林进一步分解空间,就会更难找到。
我们刚才看到的例子展示了 TDA 如何与机器学习方法结合,以获得比单独使用任一技术更好的结果。
这就是我们所说的 机器学习与 TDA:更好地结合 的意思。
原文。
相关:
-
世界经济论坛技术先锋与分析获奖者
-
机器学习课程。学习构建解决方案,荷兰代尔夫特,11 月 16-20 日
-
大师算法 – 顶级机器学习研究员 Pedro Domingos 的新书
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
Baby AGI: 完全自主 AI 的诞生
原文:
www.kdnuggets.com/2023/04/baby-agi-birth-fully-autonomous-ai.html

图片由作者提供
任务管理是每个企业中非常重要的一个元素。它在营销管道、技术和时尚等领域都有应用。它是从项目开始到结束监控任务的过程。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
随着人工智能的持续繁荣,我们看到越来越多的应用程序被发布,以帮助特定的过程,例如任务管理。
什么是 Baby AGI?
Baby AGI 是一个使用 OpenAI 和 Pinecone API,以及 LangChain 框架的 Python 脚本,用于创建、组织、优先排序以及执行任务。Baby AGI 的过程是,它将使用基于前一个任务结果的预定义目标创建任务。
这是通过使用 OpenAI 的自然语言处理(NLP)功能来实现的,这允许系统根据目标创建新任务。它使用 Pinecone 来存储特定任务的结果并检索上下文,以及 LangChain 框架来处理决策过程。
例如,您向系统提出一个目标,系统将持续优先排序需要实现或完成的任务,以达到目标。一旦这些任务完成,它们将被存储在记忆中。
系统在无限循环中运行,并通过 4 个步骤执行:
-
第一个任务从任务列表中提取
-
任务被发送到执行代理,并根据上下文使用 OpenAI API 完成任务
-
结果被存储到 Pinecone 中
-
新任务根据目标和前一个任务的结果进行创建和优先排序。
执行代理
execution_agent
执行代理是系统的核心,它利用 OpenAI 的 API 来处理任务。该功能接受两个参数:目标和任务,用于向 OpenAI 的 API 发送提示。这将返回任务的结果作为字符串。
任务创建代理
task_creation_agent()
任务创建代理功能使用 OpenAI 的 API 根据当前对象和之前任务的结果创建新任务。该功能接受四个参数:目标、前一个任务的结果、任务描述和当前任务列表。
然后向 OpenAI 的 API 发送一个提示,该 API 将返回一个新的任务列表作为字符串。该功能将这些新任务作为字典列表返回,每个字典包含任务的名称。
优先级代理
prioritization_agent()
最后一步是任务列表的排序和优先级排序。这是优先级代理功能参与的地方,它使用 OpenAI 的 API 对任务列表进行重新排序。该功能接受一个参数,即当前任务的 ID。然后,它会向 OpenAI 的 API 发送一个提示,并返回一个重新排序的新的任务列表,以编号列表的形式呈现。
图片来源 Yohei(Baby AGI 的创作者)
上述流程展示了 Baby AGI 系统的工作原理。它基于我们讨论的三个代理:执行、创建和优先级排序。
你根据已有的目标开始任务,然后转到从记忆中获取上下文的查询。这将其发送给创建代理,该代理接收数据并将其发送到记忆中。然后,它会经过一个队列,这个队列经过任务的优先级排序。
Baby AGI 具有完成任务、根据先前结果生成新任务以及实时优先排序任务的能力。该系统正在探索并展示大型语言模型的潜力,例如 GPT,以及它如何自主地执行任务。
如何使用 Baby AGI?
使用 Baby AGI 的步骤如下:
-
首先,你需要通过 git clone https://github.com/yoheinakajima/babyagi.git 克隆仓库,并进入克隆的仓库。
-
第二步是安装所需的包:pip install -r requirements.txt
-
第三步是将 .env.example 文件复制到 .env:cp .env.example .env。在这里你将设置所需的变量。
-
第四步是将你的 API 密钥设置到各自的变量中,例如 OpenAI 的 OPENAI_API_KEY 和 OPENAPI_API_MODEL,Pinecone 的 PINECONE_API_KEY 变量中。
-
第五步是设置 PINECONE_ENVIRONMENT 变量中的 Pinecone 环境。
-
第六步是设置 TABLE_NAME 变量中的表名。这是任务结果将被存储的地方。
-
如果你已经有了一个目标,你可以在 OBJECTIVE 变量中设置任务管理系统的目标。(可选)
-
如果你已经有了第一个任务,你可以在 INITIAL_TASK 变量中设置它。(可选)
-
运行脚本。
Baby AGI 是一个任务管理系统,因此脚本被设计为持续运行。这可能导致高 API 使用、内存和资金消耗。监控系统的行为以及确保应用程序的有效性是重要的。
Baby AGI 的未来
Yohei(BabyAGI 的创造者)表示,他们计划在系统中进行未来的改进,包括集成的安全/保障代理、并行任务等。
下面的图片定义了这些未来计划:
图片来自 Yohei(Baby AGI 的创造者)
总结
单独的自主 AI 可以提供诸如数据录入、项目管理等琐碎任务的协助。这将使员工能够更多地关注需要更多时间和精力的任务,而无需担心可以通过 Baby AGI 等系统完成的小任务。
如果你想查看 Baby AGI 的安装和测试过程,请查看 Matthew Berman 的这个视频:NEW BabyAGI
Nisha Arya 是 KDnuggets 的数据科学家、自由职业技术作家和社区经理。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何能够有利于人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
再回首… RAPIDS 故事
由Kris Manohar和Kevin Baboolal撰写

图片由编辑提供
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT
编辑备注: 我们很高兴宣布这篇文章被选为 KDnuggets & NVIDIA 博客写作比赛的获奖者。
介绍
机器学习通过利用大量数据彻底改变了各个领域。然而,在数据获取因成本或稀缺而变得困难的情况下,传统方法往往难以提供准确的预测。本文探讨了小数据集带来的限制,并揭示了 TTLAB 提出的一种创新解决方案,该方案利用了最近邻方法和专门的核函数。我们将深入探讨他们的算法、其优势以及 GPU 优化如何加速其执行。
有限数据的挑战
在机器学习中,拥有大量数据对于训练准确的模型至关重要。然而,当面临只有几百行的小数据集时,其不足之处变得显而易见。一个常见的问题是某些分类算法(如朴素贝叶斯分类器)中遇到的零频率问题。这发生在算法在测试期间遇到未见过的类别值时,导致该案例的概率估计为零。类似地,回归任务在测试集包含训练集中不存在的值时也面临挑战。你可能会发现,当这些缺失特征被排除时,你选择的算法虽然次优但有所改进。这些问题在具有高度不平衡类别的大型数据集中也会显现。
克服数据稀缺
尽管训练-测试拆分通常能缓解这些问题,但在处理较小数据集时仍然存在隐性问题。强迫算法根据较少的样本进行泛化可能会导致次优预测。即使算法能够运行,其预测也可能缺乏稳健性和准确性。由于成本或可用性限制,获取更多数据的简单解决方案并不总是可行。在这种情况下,TTLAB 提出的创新方法被证明是稳健且准确的。
TTLAB 算法
TTLAB 的算法应对了偏倚和有限数据集带来的挑战。他们的方法包括对训练数据集中的所有行进行加权平均,以预测测试样本中目标变量的值。关键在于根据参数化的非线性函数调整每个训练行的权重,这个函数计算特征空间中两个点之间的距离。虽然使用的加权函数有一个单一参数(训练样本与测试样本距离增加时影响衰减率),但优化这个参数的计算工作量可能很大。通过考虑整个训练数据集,该算法提供了稳健的预测。这种方法在提高随机森林和朴素贝叶斯等流行模型的性能方面取得了显著成功。随着算法的普及,正在努力进一步提升其效率。目前的实现涉及调整超参数 kappa,这需要网格搜索。为了加快这一过程,正在探索连续二次近似法,这有望实现更快的参数优化。此外,正在进行的同行评审旨在验证和完善该算法,以便更广泛地采用。
实现 TTLAG 算法时,使用循环和 numpy 进行分类证明效率低下,导致运行时间非常长。展示在链接出版物中的 CPU 实现专注于分类问题,展示了方法的多功能性和有效性。 arxiv.org/pdf/2205.14779.pdf。出版物还显示该算法从向量化中获益良多,暗示了通过使用 CuPy 进行 GPU 加速可以获得进一步的速度提升。事实上,对超参数调优和随机 K 折交叉验证的执行在测试的多个数据集上需要几周时间。通过利用 GPU 的强大计算能力,计算任务得到了有效分配,从而提升了性能。
使用 GPU 加速执行
即使有了像矢量化和 .apply 重构这样的优化,执行时间对于实际应用仍然不切实际。然而,通过 GPU 优化,运行时间显著减少,将执行时间从小时缩短到分钟。这种显著的加速打开了在需要快速结果的场景中使用算法的可能性。
根据从 CPU 实现中获得的经验教训,我们尝试进一步优化我们的实现。为此,我们将层级上移至 CuDF 数据框。将计算矢量化到 GPU 上对于 CuDF 来说是轻而易举的。对我们来说,就像将 import pandas 改为 import CuDF 一样简单(你必须在 pandas 中正确进行矢量化。)
train_df["sum_diffs"] = 0
train_df["sum_diffs"] = train_df[diff_cols].sum(axis=1).values
train_df["d"] = train_df["sum_diffs"] ** 0.5
train_df["frac"] = 1 / (1 + train_df["d"]) ** kappa
train_df["part"] = train_df[target_col] * train_df["frac"]
test_df.loc[index, "pred"] = train_df["part"].sum() / train_df["frac"].sum()
在我们的探索中,我们需要依赖 NumPy 内核。这时,事情变得棘手。回顾一下为什么算法的预测如此可靠,因为每个预测都使用了训练数据框中的所有行。然而,NumPy 内核不支持传递 CuDF 数据框。目前,我们正在尝试一些在 Github 上建议的技巧来处理这种情况。 (github.com/rapidsai/cudf/issues/13375)
现在,我们至少可以通过 .apply_rows 将原始计算传递给 NumPy 内核
def predict_kernel(F, T, numer, denom, kappa):
for i, (x, t) in enumerate(zip(F, T)):
d = abs(x - t) # the distance measure
w = 1 / pow(d, kappa) # parameterize non-linear scaling
numer[i] = w
denom[i] = d
_tdf = train_df[[att, target_col]].apply_rows(
predict_kernel,
incols={att: "F", "G3": "T"},
outcols={"numer": np.float64, "denom": np.float64},
kwargs={"kappa": kappa},
)
p = _tdf["numer"].sum() / _tdf["denom"].sum() # prediction - weighted average
目前,我们没有消除所有的 for 循环,但将大部分计算推送到 NumPy 内核使 CuDF 运行时间减少了超过 50%,标准的 80-20 训练测试拆分的时间约为 2 到 4 秒。
总结
探索 RAPIDS、CuPy 和 CuDF 库在各种机器学习任务中的能力是一次令人振奋和愉快的旅程。这些库证明了它们用户友好且易于理解,使大多数用户都能轻松使用。库的设计和维护值得称赞,使得用户在必要时可以深入了解其复杂性。在一周的时间里,每天只需几个小时,我们就能够从新手进展到通过实现一个高度定制的预测算法来推动库的边界。我们的下一个目标是实现前所未有的速度,力争突破微秒级别的障碍,处理从 20K 到 30K 的大数据集。一旦达成这一里程碑,我们计划将该算法作为一个由 RAPIDS 提供支持的 pip 包发布,以便更广泛地采用和使用。
Kris Manohar 是 ICPC, Trinidad 和 Tobago 的执行董事。
更多相关信息
回到基础,第二部分:梯度下降
原文:
www.kdnuggets.com/2023/03/back-basics-part-dos-gradient-descent.html
欢迎来到我们回到基础系列的第二部分。在 第一部分中,我们介绍了如何使用线性回归和成本函数来找到适合我们房价数据的最佳拟合线。然而,我们也发现测试多个截距值可能是繁琐且低效的。在这一部分中,我们将深入探讨梯度下降,这是一种强大的技术,可以帮助我们找到完美的截距并优化我们的模型。我们将探讨其背后的数学原理,并了解如何将其应用于我们的线性回归问题。
梯度下降是一种强大的优化算法,旨在快速而高效地找到曲线的最小点。最好的可视化方式是想象你站在山顶,山谷中等着你的是一个装满黄金的宝箱。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
然而,山谷的确切位置未知,因为外面非常黑暗,你什么也看不见。此外,你希望在其他人之前到达山谷(因为你想独占所有的宝藏)。梯度下降帮助你在地形中导航,并高效而快速地到达这个最优点。在每个点,它会告诉你该走多少步以及需要朝哪个方向走。
同样,梯度下降可以通过使用算法中规定的步骤应用于我们的线性回归问题。为了可视化寻找最小值的过程,让我们绘制MSE曲线。我们已经知道曲线的方程是:
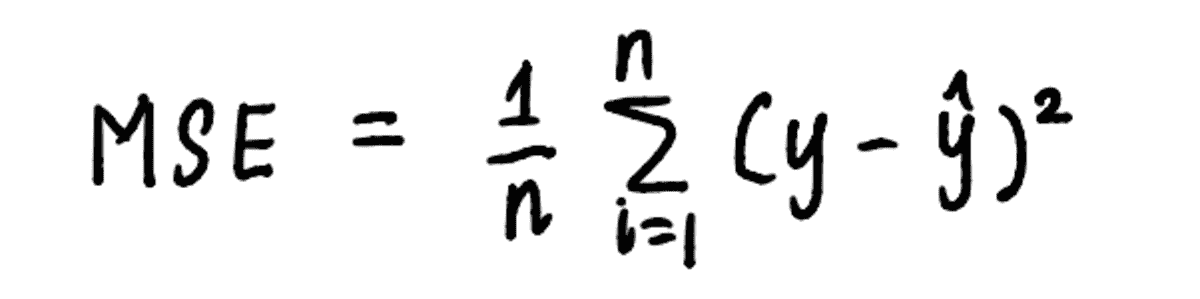
曲线的方程是用来计算 MSE 的方程
从上一篇文章中,我们知道我们问题中的MSE方程是:

如果我们放大,可以看到通过在上述方程中代入大量的截距值,可以找到一条类似我们山谷的MSE曲线。所以我们可以代入 10,000 个截距值,以获得如下曲线:
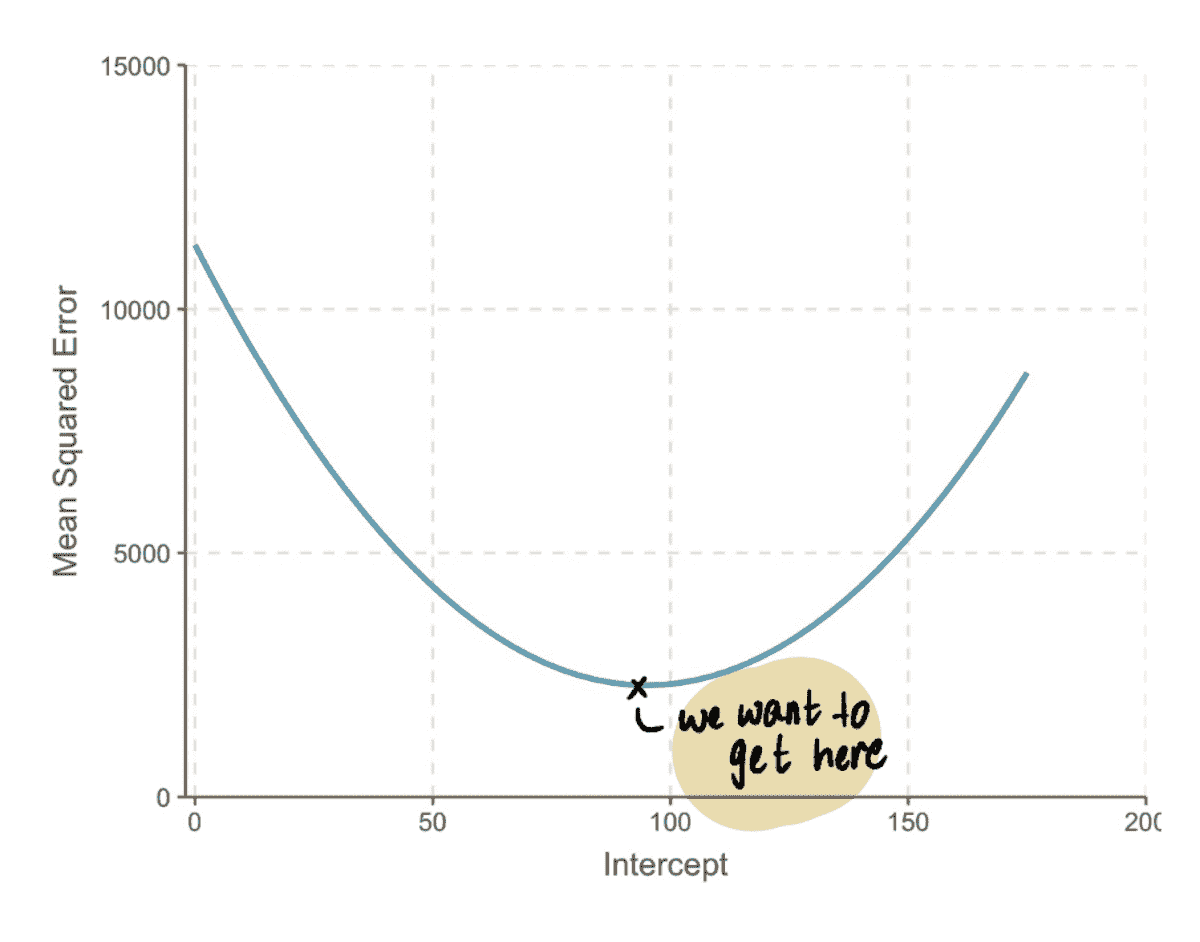
实际上,我们无法知道 MSE 曲线的具体样子
目标是达到这个MSE曲线的底部,我们可以通过以下步骤实现:
步骤 1:从截距值的随机初始猜测开始
在这种情况下,我们假设对截距值的初始猜测是 0。
步骤 2:计算此点的 MSE 曲线的梯度
曲线在某一点的梯度由该点的切线(即线仅在该点触及曲线的另一种说法)表示。例如,在点 A,MSE 曲线的梯度可以用红色切线表示,当截距等于 0 时。
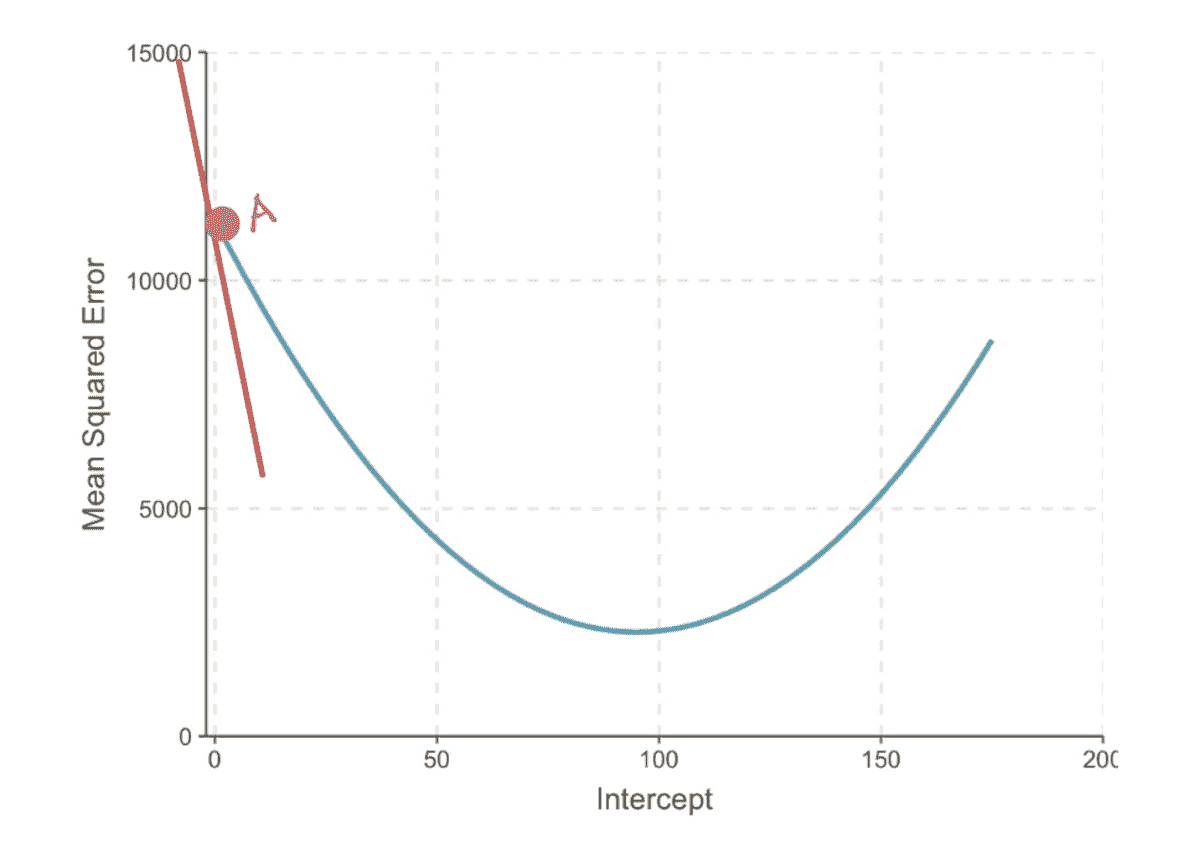
截距 = 0 时 MSE 曲线的梯度
为了确定梯度的值,我们应用微积分知识。具体来说,梯度等于在给定点上曲线相对于截距的导数。这表示为:
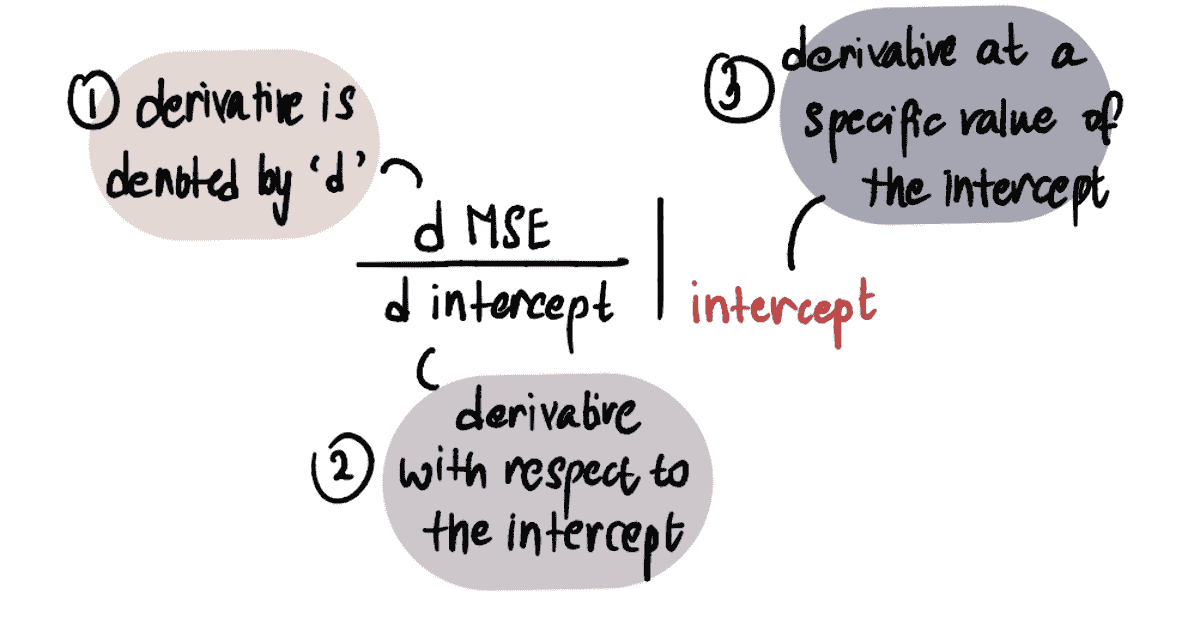
注意:如果你对导数不熟悉,我推荐观看这个Khan Academy 视频以供参考。否则,你可以略过下一部分,仍然能跟上文章的其余部分。
我们计算MSE 曲线的导数如下:
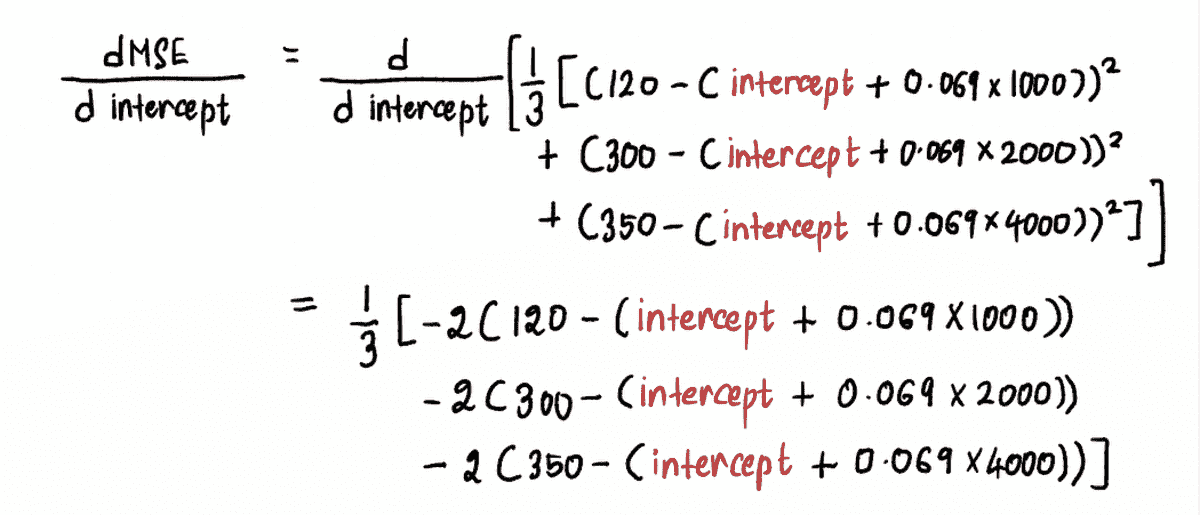
现在,为了找到点 A 的梯度,我们将点 A 处的截距值代入上面的方程中。由于截距 = 0,点 A 处的导数为:
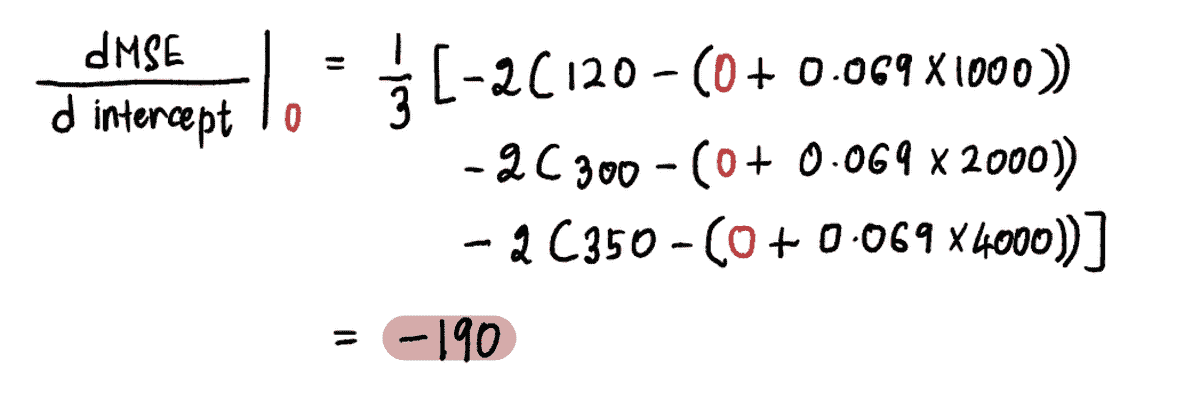
所以当截距 = 0 时,梯度 = -190
注意: 当我们接近最优值时,梯度值接近于零。在最优值处,梯度等于零。相反,离最优值越远,梯度就越大。
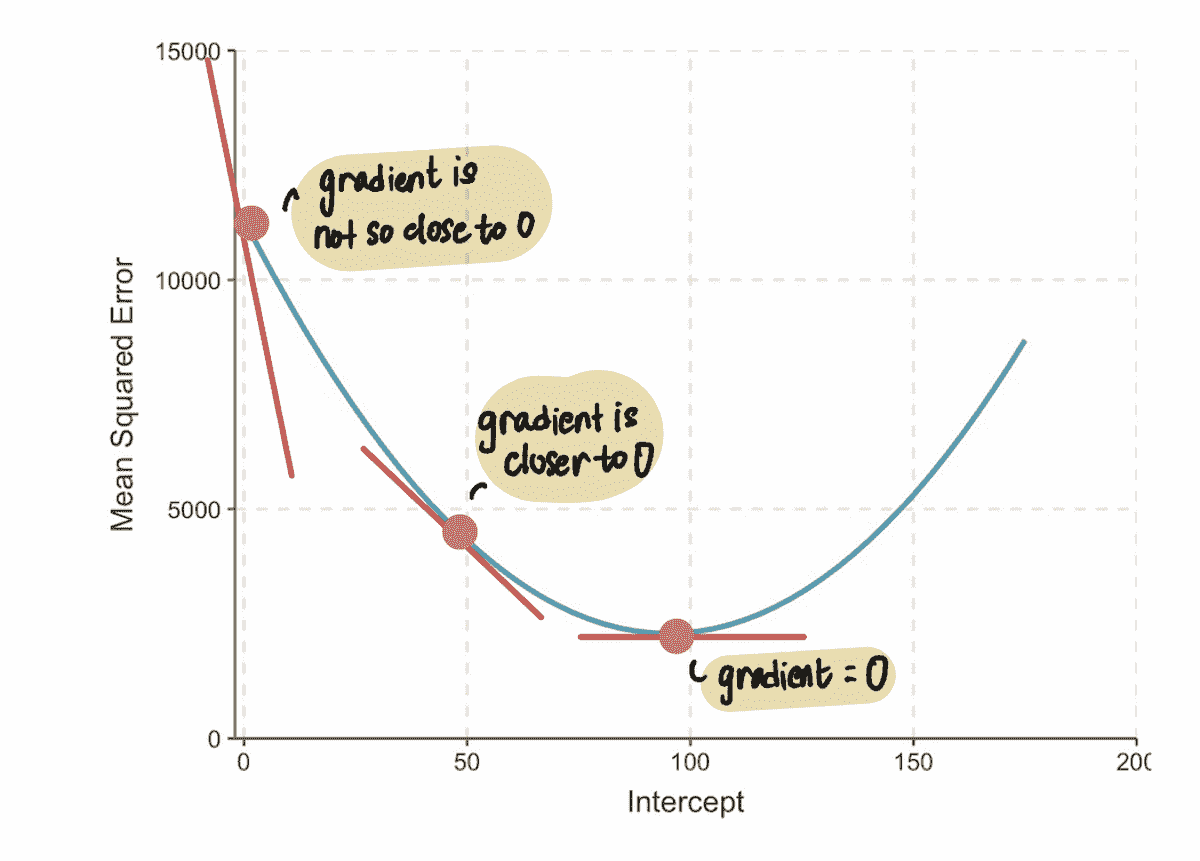
从中我们可以推断,步长应该与梯度有关,因为它告诉我们是采取小步还是大步。这意味着当曲线的梯度接近 0 时,我们应该采取小步,因为我们接近最优值。而当梯度较大时,我们应该采取更大的步伐,以更快地达到最优值。
注意: 然而,如果我们采取一个非常大的步骤,可能会跳过最优点。因此我们需要小心。
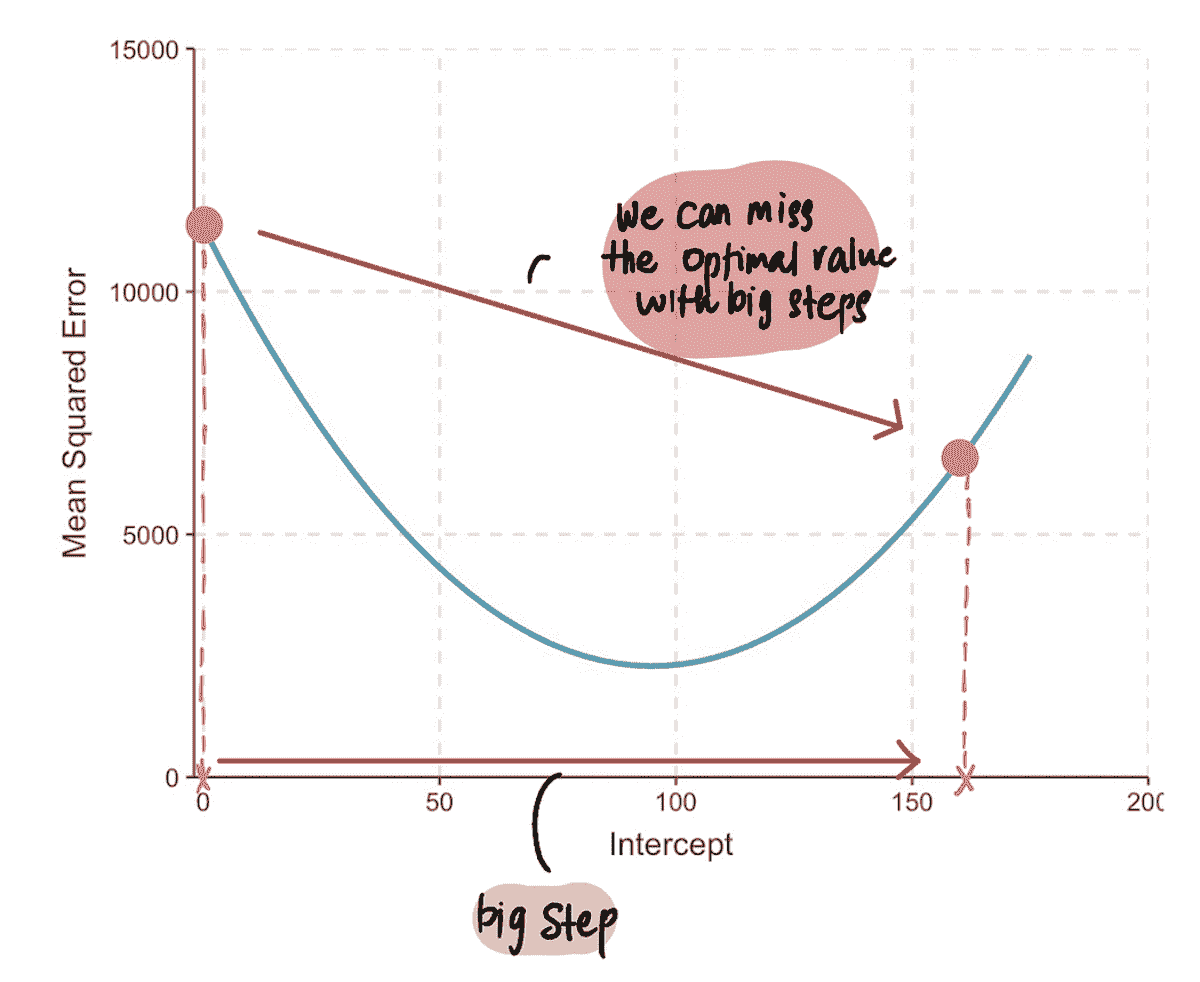
步骤 3:使用梯度和学习率计算步长并更新截距值
由于我们看到步长和梯度是成比例的,因此步长由将梯度乘以一个预定的常数值——即学习率——来确定。

学习率控制步长的大小,并确保所采取的步骤既不过大也不过小。
实际上,学习率通常是一个小的正数,大约是 0.001。但对于我们的问题,让我们将其设置为 0.1。
因此,当截距为 0 时,步长 = 梯度 * x * 学习率 = -1900.1 = -19。
根据我们上面计算的步长,我们使用以下等效公式中的任何一个来更新截距(即改变我们当前位置):

要在此步骤中找到新的截距,我们代入相关值…
…并且发现新的截距 = 19。
现在将这个值代入均方误差(MSE)方程中,我们发现当截距为 19 时,MSE为 8064.095。我们注意到,通过一步大的调整,我们更接近了最优值,并减少了MSE。
即使我们查看图表,也可以看到新的截距为 19 的直线比旧的截距为 0 的直线更好地拟合了我们的数据:
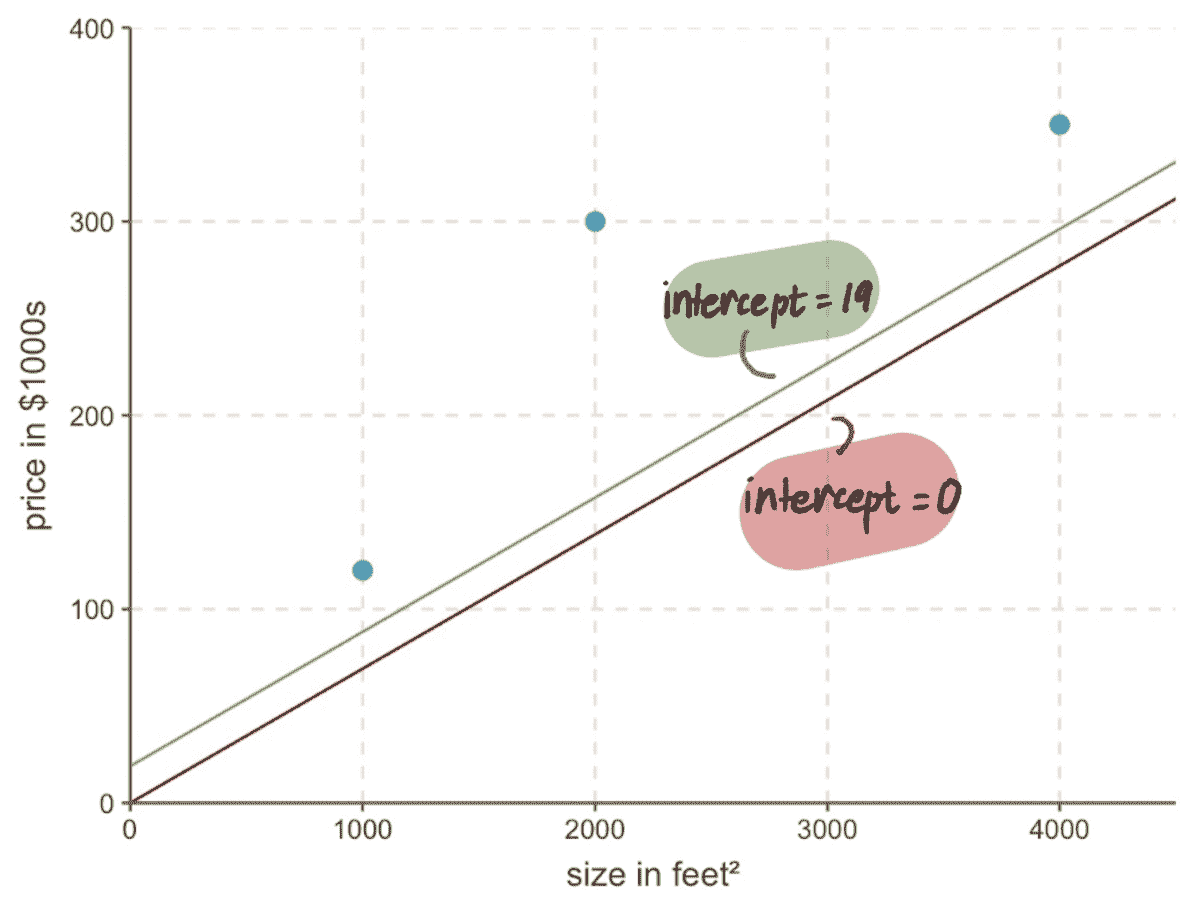
步骤 4:重复步骤 2–3
我们使用更新后的截距值重复步骤 2 和 3。
例如,由于此迭代中新截距值为 19,根据步骤 2,我们将计算这个新点的梯度:
我们发现MSE曲线在截距值 19 处的梯度是 -152(如下面插图中的红色切线所示)。
接下来,根据步骤 3,我们来计算步长:
随后,更新截距值:
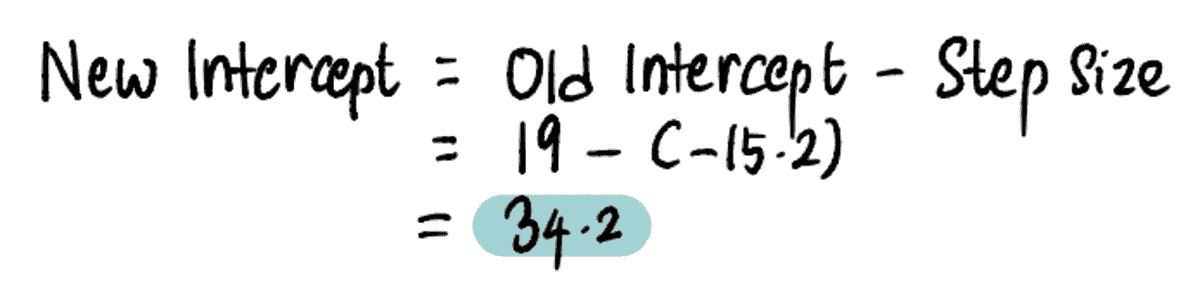
现在我们可以将具有 19 的旧截距的线与具有新截距 34.2 的新线进行比较…
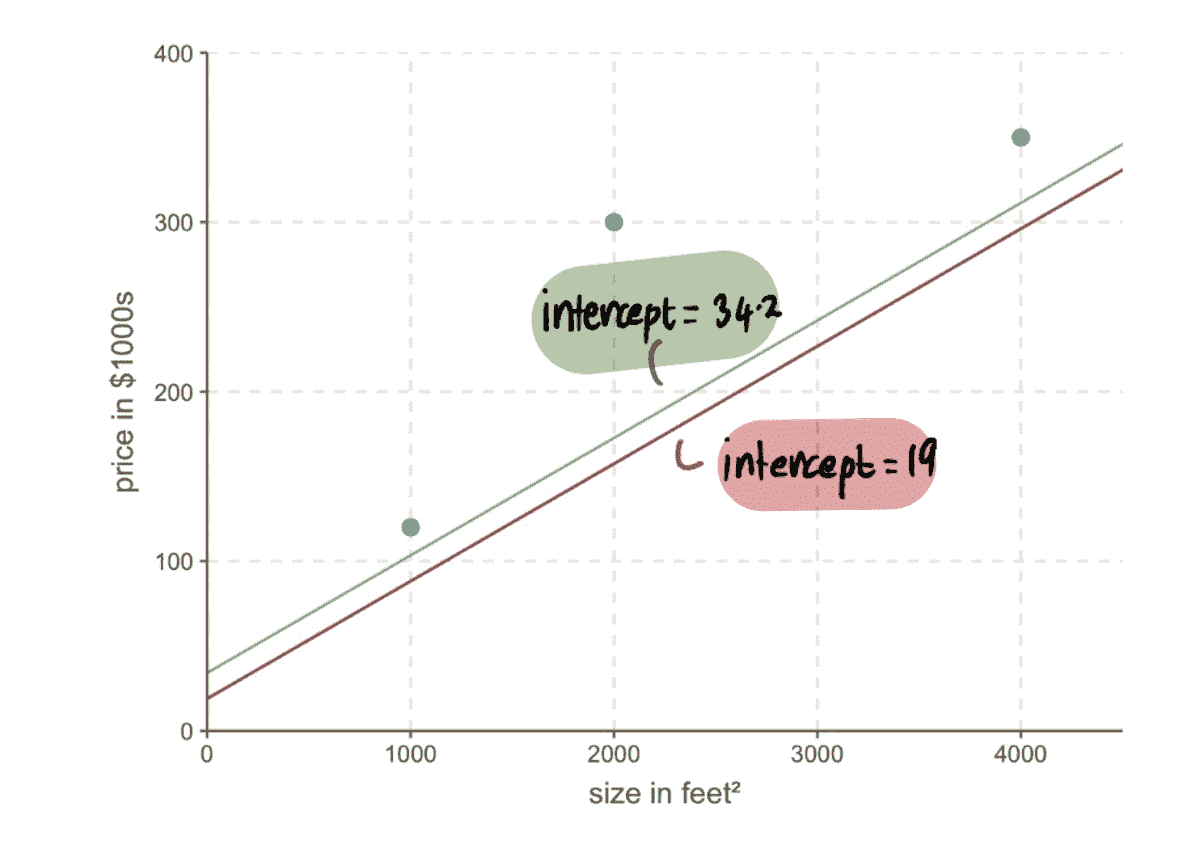
…我们可以看到新线更好地拟合了数据。
总体而言,MSE正在变小…
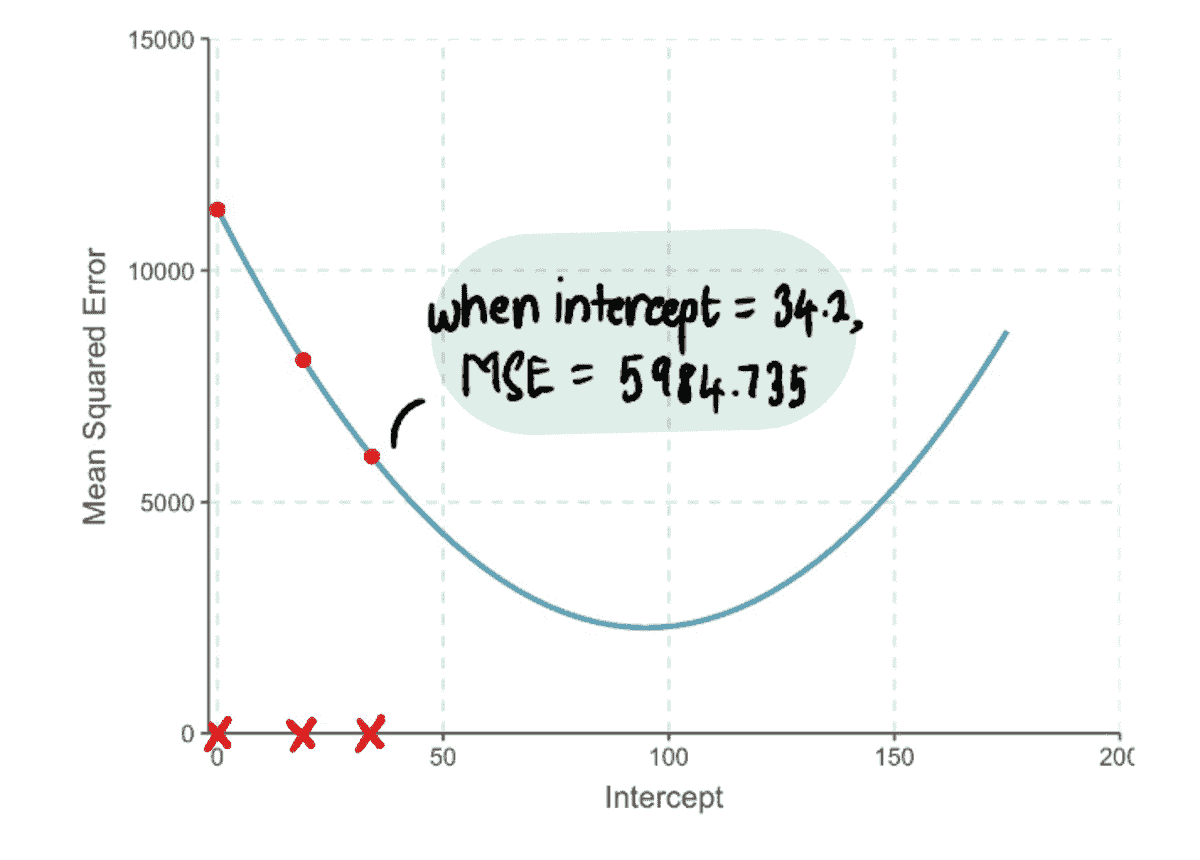
…我们的步长正在变小:
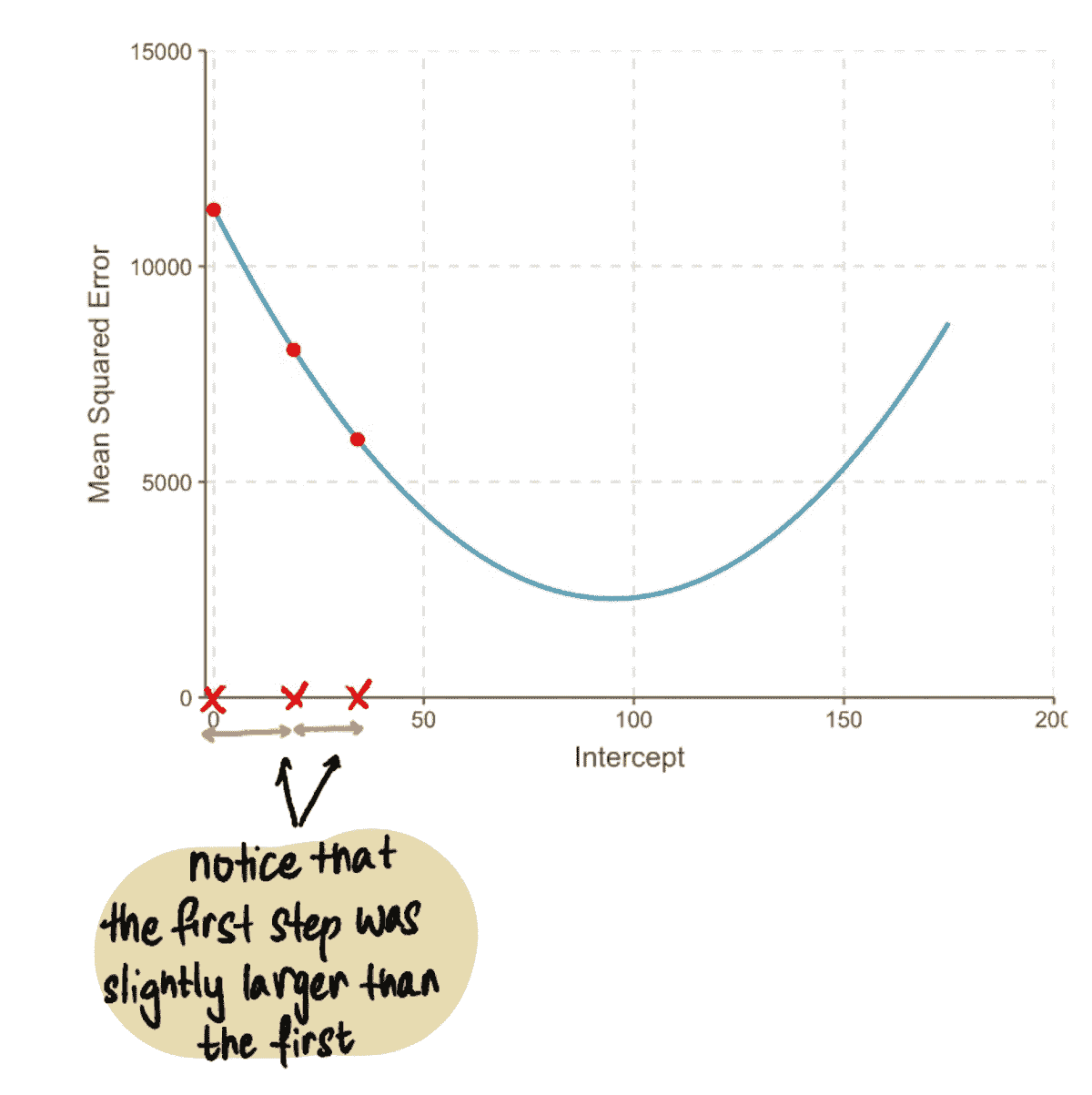
我们重复这个过程,直到我们收敛到最优解:
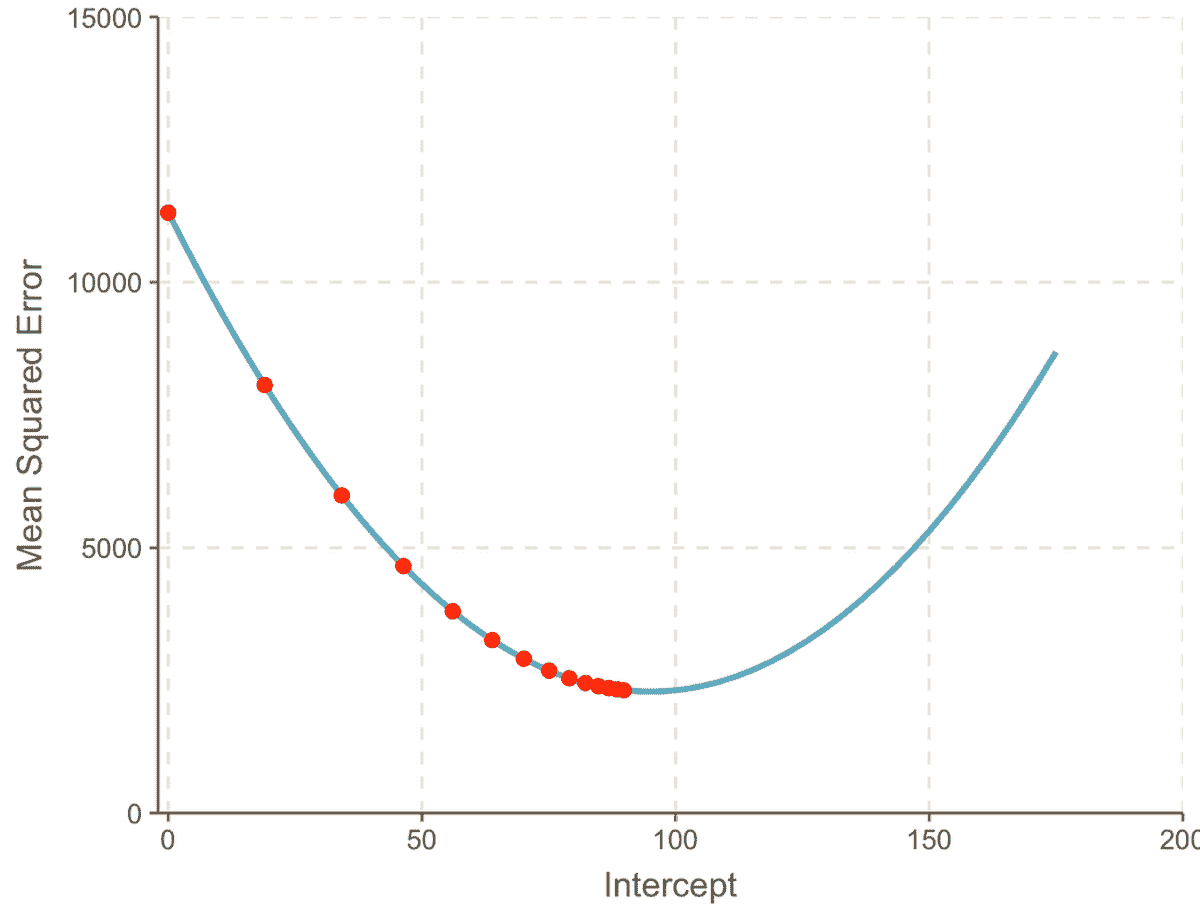
随着我们接近曲线的最小点,我们观察到步长变得越来越小。经过 13 步,梯度下降算法估计截距值为 95。如果我们有一只水晶球,这将被确认是MSE曲线的最小点。显然,这种方法相比于我们在上一篇文章中看到的蛮力方法更加高效。
现在我们拥有了截距的最优值,线性回归模型是:

线性回归线看起来是这样的:
最佳拟合线的截距为 95,斜率为 0.069。
最后,回到我们朋友马克的问题——他应该以多少价格出售他的 2400 平方英尺的房子?

将房屋面积 2400 平方英尺代入上述方程…
…然后就完成了。我们可以告诉我们那位过度担忧的朋友马克,基于他邻里的 3 栋房子,他应该将房子售价定在大约$260,600。
现在我们对这些概念有了充分的理解,让我们快速进行问答环节,解答任何悬而未决的问题。
为什么找到梯度实际上有效?
为了说明这一点,考虑一个场景,我们试图达到曲线 C 的最小点x**。我们当前位于x*左侧的点 A:
如果我们对点 A 处的曲线相对于x求导,得到的值为负(这意味着梯度向下倾斜)。我们还观察到,我们需要向右移动才能到达x**。因此,我们需要增加x以到达最小值x*。
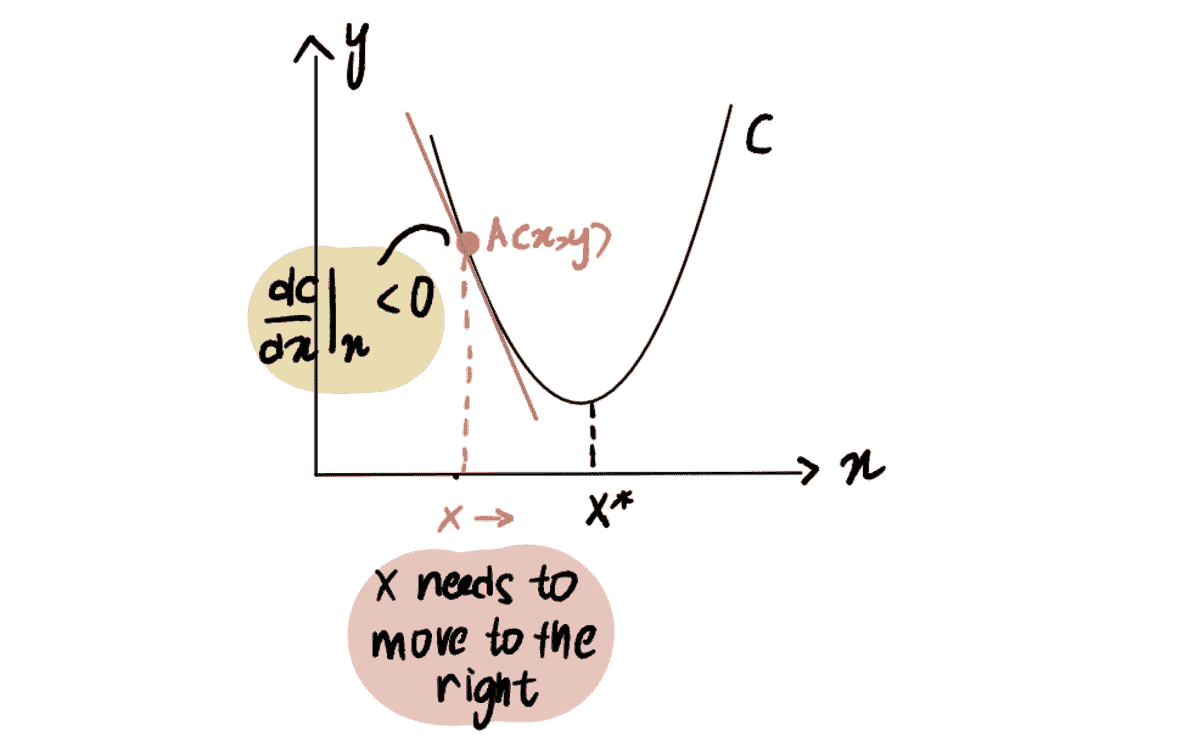
红线,即梯度,向下倾斜 => 负梯度
由于dC(x)/dx是负的,x-??dC(x)/dx将大于x,因此向x*方向移动。
类似地,如果我们在最小点 x右侧的点 A,那么我们得到一个**正的梯度(梯度向上倾斜),dC(x)/dx*。
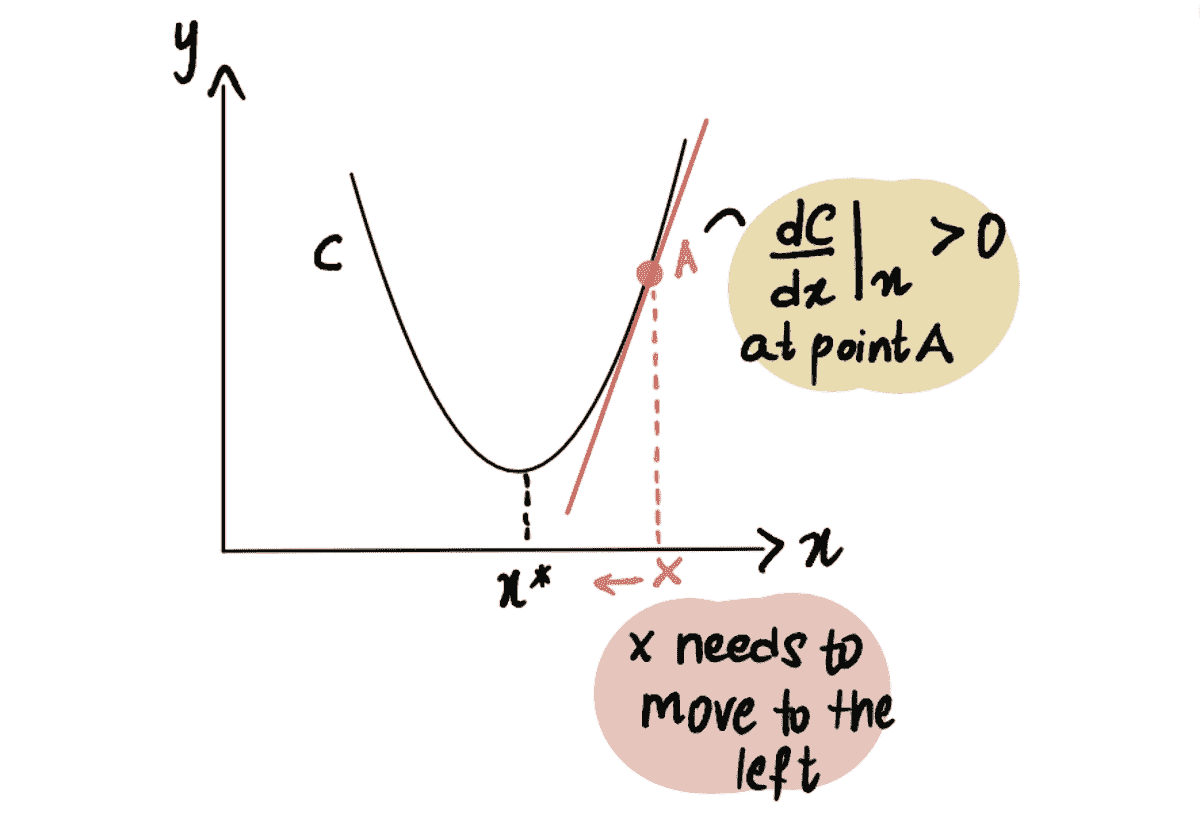
红线,即梯度,向上倾斜 => 正梯度
所以x-??dC(x)/dx将小于x,因此向x*方向移动。
梯度下降如何知道何时停止?
梯度下降在步长(Step Size)非常接近 0 时停止。正如之前讨论的那样,在最小值点,梯度为 0,当我们接近最小值时,梯度也接近 0。因此,当某一点的梯度接近 0 或接近最小值点时,步长也会接近 0,这表明算法已经达到了最优解。
当我们接近最小值点时,梯度接近 0,随之步长(Step Size)也接近 0。
实际中,最小步长 = 0.001 或更小
也就是说,梯度下降还包括一个在放弃之前的步数限制,称为最大步数。
实际中,最大步数 = 1000 或更多
即使步长大于最小步长,如果已经超过了最大步数,梯度下降仍然会停止。
如果最小点更难识别会怎样?
到目前为止,我们一直在处理易于识别最小点的曲线(这些曲线被称为凸性)。但如果我们有一条不那么漂亮的曲线(技术上称为非凸性)并且看起来像这样:
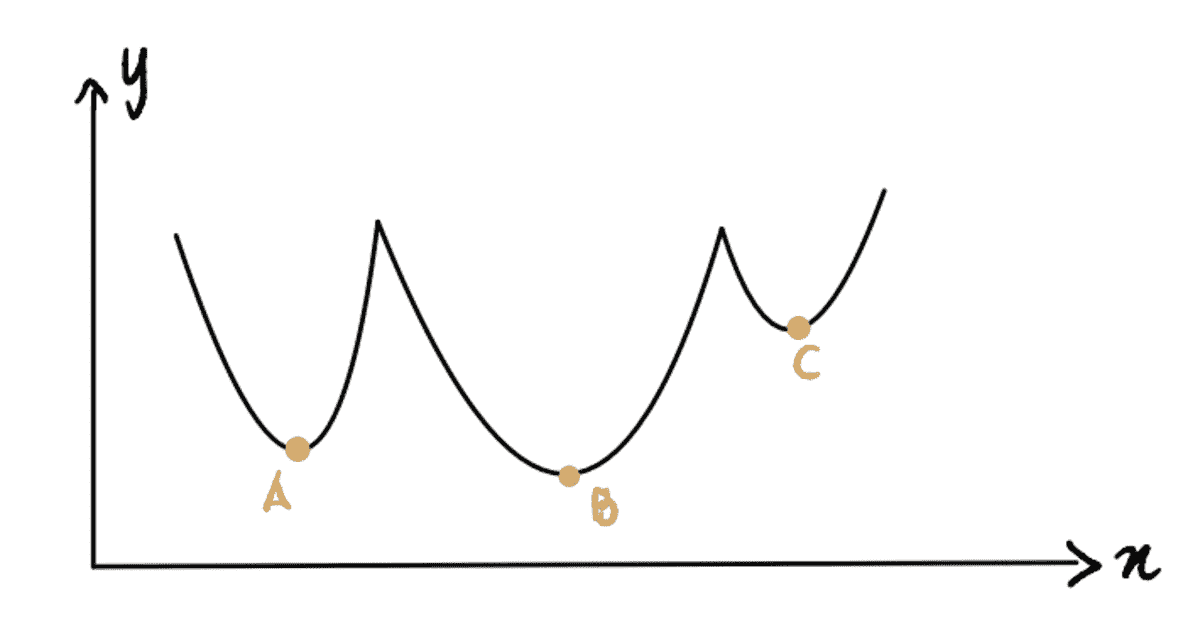
在这里,我们可以看到点 B 是全局最小值(实际最小值),而点 A 和 C 是局部最小值(可能被误认为是全局最小值但实际上不是)。因此,如果一个函数有多个局部最小值和一个全局最小值,并不能保证梯度下降会找到全局最小值。此外,找到哪个局部最小值将取决于初始猜测的位置(如在第 1 步的梯度下降中所示)。
以上面的非凸曲线为例,如果初始猜测在区块 A 或区块 C,梯度下降将分别宣称最小点在局部最小值 A 或 C,而实际上在 B。只有当初始猜测在区块 B 时,算法才能找到全局最小值 B。
现在的问题是——我们如何做出一个好的初始猜测?
简单的回答:试错法。可以算是。
复杂的回答:从上图可以看出,如果我们对x的最小猜测为 0,因为它位于区块 A,将会导致局部最小值 A。因此,如你所见,0 在大多数情况下可能不是一个好的初始猜测。一个常见的做法是基于 x 所有可能值范围的均匀分布应用一个随机函数。此外,如果可行,可以运行算法使用不同的初始猜测并比较它们的结果,这可以提供有关猜测是否存在显著差异的见解。这有助于更高效地识别全局最小值。
好的,我们快到了。最后一个问题。
如果我们尝试找到多个最优值会怎样?
到目前为止,我们只关注于找到最佳的截距值,因为我们神奇地知道线性回归的slope值为 0.069。但如果没有水晶球,不知道最佳的slope值该怎么办?这时我们需要同时优化斜率和截距值,分别表示为x? 和 x?。
为此,我们必须利用偏导数,而不仅仅是导数。
注意:偏导数的计算方式与普通导数相同,但由于我们需要优化多个变量,因此表示方式不同。要了解更多,请阅读这篇文章或观看这个视频。
然而,这个过程仍然与优化单一值的过程相似。成本函数(如 MSE)仍需定义,并且必须应用梯度下降算法,但需要额外的一步,即找到 x? 和 x? 的偏导数。
步骤 1:对 x₀ 和 x₁ 进行初始猜测
步骤 2:在这些点上找到相对于 x₀ 和 x₁ 的偏导数
步骤 3:根据偏导数和学习率同时更新 x₀ 和 x₁
步骤 4:重复步骤 2-3,直到达到最大步骤数或步骤大小小于最小步骤大小
我们可以将这些步骤推广到 3、4 甚至 100 个值进行优化。
总结来说,梯度下降是一种强大的优化算法,能有效帮助我们达到最佳值。梯度下降算法可以应用于许多其他优化问题,使其成为数据科学家工具箱中的基础工具。现在进入更大更好的算法吧!
Shreya Rao 用通俗易懂的语言讲解和说明机器学习算法。
原文。已获得许可转载。
更多相关话题
回到基础奖励周: 部署到云端
原文:
www.kdnuggets.com/back-to-basics-bonus-week-deploying-to-the-cloud
图片由作者提供
KDnuggets 团队希望您享受‘回到基础’系列课程。为了结束这一系列,我们为那些愿意额外努力、扩展知识的人准备了一个奖励周。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
如果您还没看过,请查看:
-
第 1 周: Python 编程与数据科学基础
-
第 2 周: 数据库、SQL、数据管理和统计概念
-
第 3 周: 回到基础第 3 周: 机器学习入门
-
第 4 周: 高级主题与部署
进入奖励周,
-
奖励 1: 5 步入门 Google Platform
-
奖励 2: 将您的机器学习模型部署到 AWS 云端生产环境
5 步入门 Google Platform
奖励周 - 第一部分: 5 步入门 Google Cloud Platform
探索 Google Cloud Platform 的基础知识,从账户设置到模型部署,结合实际项目示例。
本文旨在提供一个逐步概述,帮助您入门 Google Cloud Platform (GCP) 以进行数据科学和机器学习。我们将概述 GCP 及其关键分析功能,演示账户设置,探索诸如 BigQuery 和 Cloud Storage 等重要服务,构建一个示例数据项目,并使用 GCP 进行机器学习。
无论您是 GCP 新手还是需要快速复习,请继续阅读,了解基础知识,迅速上手 Google Cloud。
将您的机器学习模型部署到 AWS 云端生产环境
奖励周 - 第二部分: 将您的机器学习模型部署到云端生产环境
学习一种简单的方法,将模型实时托管在 AWS 上。
AWS,即亚马逊网络服务,是许多企业用于存储、分析、应用、部署服务等的云计算服务平台。它利用多个服务以无服务器的方式支持业务,并采用按需付费方案。
机器学习建模活动也是 AWS 支持的活动之一。借助多个服务,建模活动可以得到支持,例如从开发模型到将其投入生产。AWS 展现了多功能性,这对需要扩展性和速度的业务至关重要。
本文将讨论如何将机器学习模型部署到 AWS 云中并投入生产。我们该如何做到这一点?让我们深入探讨。
总结
就这些内容!
恭喜你完成《回到基础》系列的额外周。
KDnuggets 团队希望《回到基础》路径能为读者提供全面且结构化的数据科学基础掌握方法。
如果你喜欢《回到基础》系列,请在评论中告知我们,以便团队可以制作另一系列。也请提出建议!
尼莎·阿亚 是数据科学家、自由技术写作人、以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程以及理论知识。尼莎涉及广泛的话题,希望探索人工智能如何有益于人类生命的延续。作为一个热心的学习者,尼莎致力于拓宽她的技术知识和写作技能,同时帮助他人。
相关主题
回到基础路径
图片由作者提供
2023 年发生了很多事情,你们中的一些人可能正在考虑转行进入数据科学职业。你可能会想从哪里开始?我应该选择哪个课程?我需要提前了解什么吗?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
这是 KDnuggets 帮助解答所有这些问题的地方!
KDnuggets 团队为所有读者创建了一个数据科学路径,无论他们的生活背景如何,都可以受益。
想了解更多?
第 1 周:Python 编程与数据科学基础
链接: Python 编程与数据科学基础
在第一周,我们将学习 Python、数据处理和可视化。
第 1 天到第 3 天:数据科学新手的 Python 基础
-
介绍 Python 在数据科学中的作用。
-
针对初学者的 Python 语法、数据类型和控制结构指南。
-
互动编码练习以巩固你的理解。
第 4 天:揭开 Python 数据结构的神秘面纱
- 通过我们的逐步指南了解 Python 的核心数据结构。你将学习列表、元组、字典和集合,每种都有实际的例子及其在数据处理中的重要性。
第 5 天到第 6 天:使用 NumPy 和 Pandas 进行实用的数值计算
- 探索 NumPy 和 Pandas 在数值分析和数据处理中的强大功能,包括实际应用和动手练习。
第 7 天:使用 Pandas 的数据清理技巧
- 使用 Pandas 掌握基本的数据清理技能。
第 2 周:数据库、SQL、数据管理和统计概念
链接: 数据库、SQL、数据管理和统计概念
进入第二周,我们将学习数据库、SQL、数据管理和统计概念。
-
第 1 天:数据科学中的数据库简介
-
第 2 天:5 步入门 SQL
-
第 3 天:数据科学的数据管理原则
-
第 4 天:处理大数据:工具和技术
-
第 5 天:数据科学中的统计学:理论与概述
-
第 6 天:在 Python 中应用描述性和推断性统计
-
第 7 天: 假设检验与 A/B 测试
第 3 周: 机器学习简介
链接: 机器学习简介
进入第三周,我们将深入探讨机器学习。
-
第 1 天: 破解机器学习的神秘面纱
-
第 2 天: 5 步骤开始使用 Scikit-learn
-
第 3 天: 理解监督学习: 理论与概述
-
第 4 天: 监督学习实操: 线性回归
-
第 5 天: 揭示无监督学习
-
第 6 天: 无监督学习实操: K-Means 聚类
-
第 7 天: 机器学习评估指标: 理论与概述
第 4 周: 高级话题与部署
链接: 高级话题与部署
进入第三周,我们将深入探讨高级话题与部署。
-
第 1 天: 探索神经网络
-
第 2 天: 深度学习库简介: PyTorch 和 Lightening AI
-
第 3 天: 5 步骤开始使用 PyTorch
-
第 4 天: 使用 PyTorch 构建卷积神经网络
-
第 5 天: 自然语言处理简介
-
第 6 天: 部署你的第一个机器学习模型
-
第 7 天: 数据科学中的云计算简介
奖励周: 部署到云端
链接: 部署到云端
进入奖励周:
-
奖励 1: 5 步骤开始使用 Google 平台
-
奖励 2: 将你的机器学习模型部署到 AWS 云
完成了!
就这样,你已经完成了为期 5 周的路径,启动了你的数据科学职业生涯!KDnuggets 团队希望我们为你提供了推进数据科学职业所需的知识和工具!
在评论中告诉我们你喜欢什么!
Nisha Arya 是一名数据科学家、自由技术作家以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何促进人类生命的持久性。作为一名热心的学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助引导他人。
更多相关主题
回到基础 第 1 周:Python 编程与数据科学基础
原文:
www.kdnuggets.com/back-to-basics-week-1-python-programming-data-science-foundations

图片由作者提供
加入 KDnuggets 的回到基础路径,帮助你启动新职业或刷新数据科学技能。回到基础路径分为 4 周加 1 周附加内容。希望你能将这些博客作为课程指南。
在第一周,我们将学习 Python、数据处理和可视化的所有内容。
-
第 1 到 3 天:有志数据科学家的 Python 必备知识
-
介绍 Python 在数据科学中的角色。
-
适合初学者的 Python 语法、数据类型和控制结构指南。
-
互动编码练习以巩固你的理解。
-
-
第 4 天:Python 数据结构揭秘
- 通过我们的逐步指南了解 Python 的核心数据结构。你将学习列表、元组、字典和集合——每种结构都有实际示例以及它们在数据处理中的重要性。
-
第 5 到 6 天:使用 NumPy 和 Pandas 进行实际数值计算
- 探索 NumPy 和 Pandas 在数值分析和数据处理中的强大功能,包括实际应用和动手练习。
-
第 7 天:使用 Pandas 进行数据清洗技术
- 使用 Pandas 掌握必备的数据清洗技能。
让我们开始吧。
从数据科学入门 Python
第 1 周 - 第一部分:从数据科学入门 Python
初学者指南:设置 Python 并理解其在数据科学中的作用。
生成式 AI、ChatGPT、Google Bard——这些可能是你过去几个月听到的很多术语。随着这种轰动效应,许多人正在考虑进入技术领域,比如数据科学。
不同角色的人希望保住他们的工作,因此他们将致力于提升技能以适应当前的市场。这是一个竞争激烈的市场,我们看到越来越多的人对数据科学产生兴趣,那里有成千上万的在线课程、训练营和硕士(MSc)课程可供选择。
Python 基础:语法、数据类型和控制结构
第 1 周 - 第二部分:Python 基础:语法、数据类型和控制结构
想学 Python 吗?今天就开始学习 Python 的语法、支持的数据类型和控制结构。
你是一个想要学习 Python 编程的初学者吗?如果是的话,这个适合初学者的教程将帮助你熟悉语言的基础。这个教程将介绍 Python 的—相对友好的—语法。你还将学习如何使用不同的数据类型、条件语句和循环。
如果你已经在开发环境中安装了 Python,可以启动 Python REPL 并开始编码。或者,如果你想跳过安装—直接开始编码—我建议你前往Google Colab并开始编程。
从 5 个步骤开始学习 Python 数据结构
第 1 周 - 第三部分: 从 5 个步骤开始学习 Python 数据结构
本教程涵盖了 Python 的基础数据结构——列表、元组、字典和集合。了解它们的特征、使用案例和实际示例,全部在 5 个步骤中完成。
如果你想通过将一系列命令拼凑成算法步骤来实现问题的解决方案,在某些时候,数据需要被处理,数据结构将变得至关重要。
这样的数据结构提供了一种有效组织和存储数据的方法,对于创建快速、模块化的代码,能够执行有用的功能并良好扩展至关重要。Python 作为一种特定编程语言,拥有一系列内置的数据结构。
Numpy 和 Pandas 简介
第 1 周 - 第四部分: Numpy 和 Pandas 简介
使用 Numpy 和 Pandas 进行数值计算和数据处理的入门。
如果你正在进行数据科学项目,Python 包将使你的生活更轻松,因为你只需几行代码即可完成复杂操作,比如数据处理和应用机器学习/深度学习模型。
当你开始数据科学之旅时,建议首先学习两个最有用的 Python 包:NumPy 和 Pandas。在这篇文章中,我们将介绍这两个库。让我们开始吧!
使用 Pandas 进行数据清理
第 1 周 - 第五部分: 使用 Pandas 进行数据清理
这个逐步教程适合初学者,旨在指导他们通过强大的 Pandas 库进行数据清理和预处理。
我们的数据通常来自多个资源,并且不干净。它可能包含缺失值、重复项、错误或不期望的格式等。在这些混乱的数据上运行实验会导致不正确的结果。
因此,在将数据输入模型之前,有必要准备好数据。这种通过识别和解决潜在错误、不准确和不一致性来准备数据的过程称为数据清理。
数据可视化:理论与技术
第 1 周 - 第六部分: 数据可视化:理论与技术
解锁观察我们数据驱动世界的秘密。
在一个由大数据和复杂算法主导的数字化环境中,人们会认为普通人在数据和数字的海洋中迷失了方向。不是吗?
然而,原始数据与可理解洞察之间的桥梁在于数据可视化的艺术。它是指引我们的指南针,是引导我们的地图,也是解码我们每天遇到的大量数据的翻译器。
但一个好的可视化背后的魔力是什么?为什么一个可视化会让人豁然开朗,而另一个却让人困惑?
使用 Matplotlib 和 Seaborn 创建可视化
第 1 周 - 第七部分: 使用 Matplotlib 和 Seaborn 创建可视化
学习用于工作中的基础 Python 包可视化。
数据可视化在数据工作中至关重要,因为它帮助人们理解我们数据的动态。直接以原始形式摄取数据很难,但可视化会激发人们的兴趣和参与度。这就是为什么学习数据可视化对成功从事数据领域至关重要。
Matplotlib 是 Python 中最受欢迎的数据可视化库之一,因为它非常灵活,你可以从头开始可视化几乎所有内容。你可以使用这个包控制你可视化的许多方面。
另一方面,Seaborn 是一个建立在 Matplotlib 之上的 Python 数据可视化包。它提供了更简单的高级代码和各种内置主题。这个包非常适合你想要快速得到外观良好的数据可视化时使用。
总结
恭喜你完成了第 1 周的课程! ??
KDnuggets 团队希望《基础回顾》路径为读者提供了一个全面且结构化的方式来掌握数据科学的基础知识。
第 2 周的内容将在下周一发布,请继续关注!
Nisha Arya 是一位数据科学家、自由技术作家,同时也是 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一名热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助引导他人。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持组织中的 IT 需求
更多相关主题
回到基础第 2 周:数据库、SQL、数据管理和统计概念
原文:
www.kdnuggets.com/back-to-basics-week-2-database-sql-data-management-and-statistical-concepts
作者提供的图片
加入 KDnuggets,通过我们的回到基础路径来启动你的新职业或刷新你的数据科学技能。回到基础路径分为 4 周加 1 周的额外周。我们希望你可以将这些博客作为课程指南。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
如果你还没有,看看第 1 周:回到基础第 1 周:Python 编程与数据科学基础
进入第二周,我们将学习数据库、SQL、数据管理和统计概念。
-
第 1 天:数据科学中的数据库介绍
-
第 2 天:通过 5 个步骤开始 SQL 学习
-
第 3 天:数据科学的数据管理原则
-
第 4 天:处理大数据:工具和技术
-
第 5 天:数据科学中的统计学:理论与概述
-
第 6 天:在 Python 中应用描述性统计和推断统计
-
第 7 天:假设检验和 A/B 测试
数据科学中的数据库介绍
第 2 周 - 第一部分:数据科学中的数据库介绍
理解数据库在数据科学中的相关性。同时学习关系数据库的基本知识、NoSQL 数据库类别等。
数据科学涉及从大量数据中提取价值和洞察以驱动业务决策。它还涉及使用历史数据建立预测模型。数据库促进了大量数据的有效存储、管理、检索和分析。
因此,作为数据科学家,你应该理解数据库的基本知识。因为它们能够存储和管理大量复杂的数据集,从而允许高效的数据探索、建模和洞察分析。
开始 SQL 学习的 5 个步骤
第 2 周 - 第二部分:通过 5 个步骤开始 SQL 学习
在处理和操作关系型数据库中的数据时,结构化查询语言(SQL)是最重要的名字。SQL 是一个主要的领域特定语言,是数据库管理的基石,提供了与数据库交互的标准化方式。
随着数据成为决策和创新的驱动力,SQL 仍然是一项关键技术,要求数据分析师、开发者和数据科学家给予高度关注。
本综合 SQL 教程涵盖了从设置 SQL 环境到掌握高级概念如联接、子查询和优化查询性能的一切内容。通过逐步示例,这个指南非常适合希望提升数据管理技能的初学者。
数据科学的数据管理原则
第 2 周 - 第三部分: 数据科学的数据管理原则
理解数据科学家应了解的关键数据管理原则。
在你作为数据科学家的旅程中,你会遇到挫折,并克服它们。你将学习如何选择不同的过程来处理不同的任务。
这些过程将相辅相成,以确保你的数据科学项目尽可能高效,并在决策过程中发挥关键作用。
处理大数据: 工具和技术
第 2 周 - 第四部分: 处理大数据: 工具和技术
在如此广阔的大数据领域,你从哪里开始?使用哪些工具和技术?我们探讨了这一点,并讨论了大数据中最常用的工具。
商业领域早已不再是所有所需数据都在你的“黑色小本子”里。在数字革命的时代,连传统数据库也不再足够。
处理大数据已成为企业以及数据科学家的关键技能。大数据的特点是其体量、速度和多样性,提供了对模式和趋势的前所未有的洞察。
要有效处理这些数据,需要使用专门的工具和技术。
数据科学中的统计学: 理论与概述
第 2 周 - 第五部分: 数据科学中的统计学: 理论与概述
对统计学在数据科学中作用的高层次探索。
你是否有兴趣掌握统计学,以在数据科学面试中脱颖而出?如果是,你不应该仅仅为了面试而学习。理解统计学可以帮助你从数据中获得更深入、更细致的洞察。
在这篇文章中,我将展示需要掌握的最关键的统计学概念,以便更好地解决数据科学问题。
在 Python 中应用描述性和推断性统计
第 2 周 - 第六部分: 在 Python 中应用描述性和推断性统计
在你的数据科学之旅中,以下是你应该了解的基本统计学知识。
统计学是一个涵盖从数据收集、数据分析到数据解释的领域。它是一个帮助相关方在面对不确定性时做出决策的学科。
统计学领域的两个主要分支是描述统计学和推断统计学。描述统计学是一个涉及使用各种方式总结数据的分支,例如总结统计、可视化和表格。而推断统计学则更多地基于数据样本对总体进行概括。
假设检验和 A/B 测试
第 2 周 - 第七部分:假设检验和 A/B 测试
数据驱动决策的支柱。
在数据主导的时代,企业和组织不断寻找利用数据力量的方法。
从你在 Amazon 上收到的推荐产品到你在社交媒体上看到的内容,背后都有一套精细的方法。
这些决策的核心是什么?A/B 测试和假设检验。
但它们是什么,为什么在我们的数据中心化世界中如此关键?让我们一起发现吧!
总结
恭喜你完成了第 2 周的课程!!
KDnuggets 团队希望“回到基础”路径为读者提供了全面而结构化的方式来掌握数据科学的基础。
第 3 周的内容将于下周一发布 - 敬请关注!
Nisha Arya是一名数据科学家、自由技术写作人员,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有助于人类生命的持久性。作为一个热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
基础回顾 第 3 周: 机器学习介绍
原文:
www.kdnuggets.com/back-to-basics-week-3-introduction-to-machine-learning

图片由作者提供
加入 KDnuggets 的基础回顾课程,帮助你启动新职业或巩固数据科学技能。基础回顾课程分为 4 周,还有一周的额外内容。希望你能将这些博客作为课程指南使用。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
如果你还没有看过,请查看:
-
第 1 周: Python 编程与数据科学基础
-
第 2 周: 数据库、SQL、数据管理和统计概念
进入第三周,我们将深入探讨机器学习。
-
第 1 天: 揭开机器学习的面纱
-
第 2 天: 5 步入门 Scikit-learn
-
第 3 天: 理解监督学习:理论与概述
-
第 4 天: 实操监督学习:线性回归
-
第 5 天: 揭示无监督学习
-
第 6 天: 实操无监督学习:K 均值聚类
-
第 7 天: 机器学习评估指标:理论与概述
揭开机器学习的面纱
第 3 周 - 第一部分: 揭开机器学习的面纱
传统上,计算机会遵循一套明确的指令。例如,如果你希望计算机执行一个简单的加法任务,你必须逐步列出每一步。然而,随着数据变得越来越复杂,这种逐步指令的手动方法变得不够用。
这是机器学习作为游戏规则改变者的起点。我们希望计算机能够从示例中学习,就像我们从经验中学习一样。想象一下教孩子骑自行车,先让他看几次,然后让他摔倒、摸索并自学。这就是机器学习背后的想法。这项创新不仅改变了行业,而且在今天的世界中成为了不可或缺的需求。
5 步入门 Scikit-learn
第 3 周 - 第二部分: 5 步入门 Scikit-learn
本教程提供了一个全面的机器学习 Scikit-learn 实操 walkthrough。读者将学习包括数据预处理、模型训练和评估、超参数调整以及编译集成模型以增强性能的关键概念和技术。
在学习如何使用Scikit-learn时,我们显然需要对机器学习的基本概念有一定的理解,因为 Scikit-learn 只是实现机器学习原理和相关任务的实际工具。机器学习是人工智能的一个子集,使计算机能够通过经验学习和改进,而无需明确编程。算法使用训练数据通过揭示模式和洞察来做出预测或决策。
理解监督学习:理论与概述
第三周 - 第三部分:理解监督学习:理论与概述
监督学习是机器学习的一个子类别,其中计算机从包含输入和正确输出的标记数据集中学习。它试图找到将输入 (x) 与输出 (y) 相关联的映射函数。你可以将其看作是教你的弟弟或妹妹如何识别不同的动物。你会给他们看一些图片 (x) 并告诉他们每种动物的名称 (y)。
经过一段时间,他们将学习到差异,并能够正确识别新的图片。这是监督学习的基本直觉。
监督学习实操:线性回归
第三周 - 第四部分:监督学习实操:线性回归
如果你在寻找一个详细且适合初学者的关于使用 Scikit-learn 实现线性回归的实操教程,你将迎来一段引人入胜的旅程。
线性回归是预测连续目标变量的基础监督机器学习算法,基于输入特征。顾名思义,它假设因变量和自变量之间的关系是线性的。
所以如果我们尝试将因变量 Y 与自变量 X 绘制在一起,我们会得到一条直线。
揭示无监督学习
第三周 - 第五部分:揭示无监督学习
探索无监督学习范式。熟悉关键概念、技术和流行的无监督学习算法。
在机器学习中,无监督学习是一种涉及在未标记数据集上训练算法的范式。因此,没有监督或标记输出。
在无监督学习中,目标是发现数据自身的模式、结构或关系,而不是基于标记的示例进行预测或分类。它涉及探索数据的内在结构,以获得见解并理解复杂信息。
无监督学习实操:K-Means 聚类
第三周 - 第六部分:无监督学习实操:K-Means 聚类
本教程提供了对 K-Means 聚类这一流行的无监督学习算法的关键概念和实现的实践经验,适用于客户细分和目标广告应用。
K-means 聚类是数据科学中最常用的无监督学习算法之一。它用于根据数据点之间的相似性将数据集自动划分为多个簇或组。
在这个简短的教程中,我们将学习 K-Means 聚类算法的工作原理,并使用 scikit-learn 将其应用于真实数据。此外,我们将可视化结果,以理解数据分布。
机器学习评估指标:理论与概述
第三周 - 第七部分:机器学习评估指标:理论与概述
对机器学习中评估指标的高级探索及其重要性。
构建一个对新数据具有良好泛化能力的机器学习模型非常具有挑战性。需要进行评估以了解模型是否足够好,或是否需要进行一些修改以提升性能。
如果模型没有从训练集中学习到足够的模式,它将在训练集和测试集上表现不佳。这就是所谓的欠拟合问题。
过多地学习训练数据的模式,甚至是噪声,将导致模型在训练集上表现非常好,但在测试集上表现较差。这种情况称为过拟合。如果在训练集和测试集上的性能相似,则可以获得模型的泛化能力。
总结
恭喜你完成了第三周!!
KDnuggets 团队希望“回到基础”路径能为读者提供一种全面且有结构的方法,以掌握数据科学的基础知识。
第四周将于下周一发布 - 敬请关注!
Nisha Arya 是一位数据科学家、自由技术写作人,同时也是 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及基于理论的数据科学知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有利于人类寿命的不同方式。作为一个热衷学习者,Nisha 希望拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
回到基础 第四周:高级主题与部署
原文:
www.kdnuggets.com/back-to-basics-week-4-advanced-topics-and-deployment
作者提供的图片
加入 KDnuggets,通过我们的回到基础路径,帮助您启动新职业或提升数据科学技能。回到基础路径分为 4 周,加上一周额外的内容。我们希望您能将这些博客作为课程指南。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
如果您还没有,看看:
-
第一周:Python 编程与数据科学基础
-
第二周:数据库、SQL、数据管理和统计概念
-
第三周:回到基础 第三周:机器学习介绍
进入第三周,我们将深入探讨高级主题和部署。
-
第一天:探索神经网络
-
第二天:深度学习库介绍:PyTorch 和 Lightening AI
-
第三天:通过 5 个步骤开始使用 PyTorch
-
第四天:使用 PyTorch 构建卷积神经网络
-
第五天:自然语言处理介绍
-
第六天:部署您的第一个机器学习模型
-
第七天:数据科学中的云计算介绍
探索神经网络
第四周 - 第一部分:探索神经网络
解锁 AI 的力量:神经网络及其应用指南。
想象一下,一台机器像人脑一样思考、学习和适应,并发现数据中的隐藏模式。
这项技术,即神经网络(NN),其算法模仿认知。我们稍后将探讨 NN 是什么以及它们如何运作。
在这篇文章中,我将向您解释神经网络(NN)的基本方面——结构、类型、实际应用和定义操作的关键术语。
深度学习库介绍:PyTorch 和 Lightening AI
第四周 - 第二部分:深度学习库介绍:PyTorch 和 Lightning AI
对 PyTorch 和 Lightning AI 的简单解释。
深度学习是基于 神经网络 的机器学习模型的一部分。在其他机器模型中,数据处理以寻找有意义的特征通常是手动完成的或依赖于领域专长;然而,深度学习可以模仿人脑发现重要特征,从而提高模型性能。
深度学习模型有许多应用,包括面部识别、欺诈检测、语音转文本、文本生成等。深度学习已成为许多高级机器学习应用的标准方法,我们学习这些内容不会有什么损失。
为了开发这个深度学习模型,我们可以依靠各种库框架,而不是从头开始。在本文中,我们将讨论两个可以用来开发深度学习模型的不同库:PyTorch 和 Lighting AI。
开始使用 PyTorch 的 5 个步骤
第 4 周 - 第三部分: 5 步骤开始使用 PyTorch
本教程提供了一个关于使用 PyTorch 及其高级封装 PyTorch Lightning 的机器学习深度介绍。文章涵盖了从安装到高级主题的基本步骤,提供了构建和训练神经网络的实践方法,并强调了使用 Lightning 的好处。
PyTorch 是一个流行的开源机器学习框架,基于 Python 并针对 GPU 加速计算进行了优化。最初由 Meta AI 于 2016 年开发,并且现在是 Linux 基金会的一部分,PyTorch 已迅速成为深度学习研究和应用中最广泛使用的框架之一。
PyTorch Lightning 是一个建立在 PyTorch 之上的轻量级封装,它进一步简化了研究人员的工作流程和模型开发过程。使用 Lightning,数据科学家可以更多地专注于设计模型,而不是处理样板代码。
使用 PyTorch 构建卷积神经网络
第 4 周 - 第四部分: 使用 PyTorch 构建卷积神经网络
本博客文章提供了一个关于在 PyTorch 中构建用于图像分类的卷积神经网络的教程,利用卷积层和池化层进行特征提取,以及全连接层进行预测。
卷积神经网络 (CNN 或 ConvNet) 是一种深度学习算法,专门设计用于对象识别至关重要的任务——如图像分类、检测和分割。CNN 能够在复杂的视觉任务中实现最先进的准确度,推动了许多现实生活中的应用,如监控系统、仓库管理等。
作为人类,我们可以通过分析模式、形状和颜色轻松识别图像中的物体。卷积神经网络(CNN)也可以通过学习哪些模式对区分很重要来执行这种识别。例如,当试图区分猫和狗的照片时,我们的大脑会关注独特的形状、纹理和面部特征。CNN 学会捕捉这些相同的区分特征。即使是非常细粒度的分类任务,CNN 也能直接从像素中学习复杂的特征表示。
自然语言处理简介
第四周 - 第五部分:自然语言处理简介
自然语言处理(NLP)及其应用的概述。
我们正在学习有关 ChatGPT 和大型语言模型(LLMs)的大量内容。自然语言处理是一个有趣的话题,目前在人工智能和科技界引起了轰动。是的,像 ChatGPT 这样的 LLMs 促进了它们的发展,但了解一切的起源不是很好吗?所以让我们回到基础 - NLP。
自然语言处理(NLP)是人工智能的一个子领域,它是计算机检测和理解人类语言的能力,通过语音和文本就像我们人类一样。NLP 帮助模型处理、理解和输出人类语言。
NLP 的目标是弥合人类和计算机之间的沟通鸿沟。NLP 模型通常在下一个单词预测等任务上进行训练,这使得它们能够建立上下文依赖关系,并生成相关的输出。
部署你的第一个机器学习模型
第四周 - 第六部分:部署你的第一个机器学习模型
只需 3 个简单步骤,你就能比说“玻璃分类模型”还快地构建和部署一个玻璃分类模型!
在本教程中,我们将学习如何使用 玻璃分类 数据集构建一个简单的多分类模型。我们的目标是开发和部署一个可以预测各种类型玻璃的网页应用程序,例如:
-
玻璃窗户浮动处理
-
玻璃窗户非浮动处理
-
车辆窗户浮动处理
-
车辆窗户非浮动处理(数据集中缺失)
-
容器
-
餐具
-
头灯
此外,我们还将学习:
-
Skops:分享你的基于 scikit-learn 的模型并将其投入生产。
-
Gradio:机器学习网页应用程序框架。
-
HuggingFace Spaces:免费机器学习模型和应用程序托管平台。
到本教程结束时,你将获得构建、训练和部署一个基本机器学习模型作为网页应用程序的实际经验。
数据科学的云计算介绍
第四周 - 第七部分:数据科学的云计算介绍
现代科技的强大组合。
在今天的世界中,两个主要力量已经成为改变游戏规则的因素:数据科学和云计算。
想象一个每秒生成巨大数据量的世界。其实,你不必想象……这就是我们的世界!
从社交媒体互动到金融交易,从医疗记录到电子商务偏好,数据无处不在。
但如果我们无法获得价值,这些数据有什么用呢?这正是数据科学的作用所在。
那么我们在哪里存储、处理和分析这些数据呢?这正是云计算的强项所在。
让我们开始探索这两种技术奇迹之间错综复杂的关系吧。让我们(尝试)一起发现一切!
总结一下
恭喜你完成了第 4 周!!
KDnuggets 团队希望“基础回顾”路径为读者提供了一个全面且结构化的方法,以掌握数据科学的基础。
奖励周将在下周一发布——敬请期待!
Nisha Arya 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议、教程和基于理论的知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有利于人类生命的持久性。作为一个热衷学习者,Nisha 致力于拓宽她的技术知识和写作技能,同时帮助他人。
相关主题
使用 Python 进行数据科学的网络爬虫
原文:
www.kdnuggets.com/2017/12/baesens-web-scraping-data-science-python.html
由 Seppe vanden Broucke 和 Bart Baesens 赞助的帖子。
对于那些不熟悉编程或网络深层工作原理的人来说,网络爬虫常常看起来像是一种黑魔法:能够编写一个独立探索互联网并收集数据的程序被视为一种神奇而令人兴奋的能力。在
中,我们提供了一个简洁但全面且现代的网络爬虫指南,以 Python 作为编程语言。此外,这本书还考虑了数据科学受众的需求。
我们自己也是数据科学家,发现网络爬虫常常是你工具箱中的一项强大工具,因为许多数据科学项目的第一步是获得合适的数据集,为什么不利用网络提供的信息宝藏呢?这本书采用了“优先编码”的方法,让你迅速上手,没有太多的样板文本,展示了如何处理现代网络,包括 JavaScript、cookies 和常见的网络爬虫对策,并包括了关于网络爬虫的详细管理和法律讨论。我们还提供了大量的进一步阅读和学习的指引,并包含了十四个现实生活中的完整示例。有关更多细节,请点击这里。
 中,我们提供了一个简洁但全面且现代的网络爬虫指南,以 Python 作为编程语言。此外,这本书还考虑了数据科学受众的需求。
中,我们提供了一个简洁但全面且现代的网络爬虫指南,以 Python 作为编程语言。此外,这本书还考虑了数据科学受众的需求。在这篇文章中,我们简要探讨了网络爬虫在数据科学项目中的实用性。网络“爬虫”(也称为“网络采集”、“网络数据提取”或甚至“网络数据挖掘”)可以定义为“构建一个代理程序以自动方式从网络下载、解析和组织数据”。换句话说:与其让人类最终用户在浏览器中点击并将感兴趣的部分复制粘贴到电子表格中,不如将这项任务交给计算机程序,后者可以比人类更快、更准确地执行这项任务。
从互联网自动收集数据的做法可能和互联网本身一样久远,甚至“抓取”("scraping")这个术语早在网络出现之前就已经存在。在“网页抓取”("web scraping")这一术语流行之前,一种被称为“屏幕抓取”("screen scraping")的做法已经作为一种从视觉表现中提取数据的方式被广泛采用——在计算机的早期(想象一下 1960 年代至 1980 年代),这通常涉及到简单的文本型“终端”。正如今天一样,那时的人们已经对从这些终端中抓取大量文本以备后用感兴趣。当你使用普通的网页浏览器浏览网页时,可能会遇到多个你考虑过收集、存储和分析页面上数据的网站。对于数据科学家来说,数据是他们的“原材料”,网络展示了很多有趣的机会。在这种情况下,使用网页抓取可能会派上用场。如果你能在网页浏览器中查看某些数据,你就能够通过程序访问和提取这些数据。如果你能通过程序访问这些数据,那么数据可以被存储、清理,并以任何方式使用。无论你的兴趣领域是什么,总是有几乎总能利用数据改进或丰富你的实践的应用场景。俗话说“数据是新石油”,网络上有大量的数据。
在这篇文章中,我们的目标是构建一个 S&P 500 公司及其通过董事会成员互联的社交图谱。我们将从 路透社的 S&P 500 页面 开始,获取一个符号列表:
from bs4 import BeautifulSoup
import requests
import re
session = requests.Session()
sp500 = 'https://www.reuters.com/finance/markets/index/.SPX'
page = 1
regex = re.compile(r'/finance/stocks/overview/.*')
symbols = []
while True:
print('Scraping page:', page)
params = params={'sortBy': '', 'sortDir' :'', 'pn': page}
html = session.get(sp500, params=params).text
soup = BeautifulSoup(html, "html.parser")
pagenav = soup.find(class_='pageNavigation')
if not pagenav:
break
companies = pagenav.find_next('table', class_='dataTable')
for link in companies.find_all('a', href=regex):
symbols.append(link.get('href').split('/')[-1])
page += 1
print(symbols)
一旦获得了符号列表,我们可以访问每个符号的董事会成员页面(例如 www.reuters.com/finance/stocks/company-officers/MMM.N),提取出董事会成员的表格,并将其存储为 pandas 数据框:
from bs4 import BeautifulSoup
import requests
import pandas as pd
session = requests.Session()
officers = 'https://www.reuters.com/finance/stocks/company-officers/{symbol}'
symbols = ['MMM.N', [...], 'ZTS.N']
dfs = []
for symbol in symbols:
print('Scraping symbol:', symbol)
html = session.get(officers.format(symbol=symbol)).text
soup = BeautifulSoup(html, "html.parser")
officer_table = soup.find('table', {"class" : "dataTable"})
df = pd.read_html(str(officer_table), header=0)[0]
df.insert(0, 'symbol', symbol)
dfs.append(df)
df = pd.concat(dfs)
df.to_pickle('data.pkl')
这种信息可以引发许多有趣的应用场景,尤其是在图形和社交网络分析领域。例如,我们可以利用收集到的信息导出一个图形,并使用 Gephi 这款流行的图形可视化工具进行可视化:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 方面的工作
import pandas as pd
import networkx as nx
from networkx.readwrite.gexf import write_gexf
df = pd.read_pickle('data.pkl')
G = nx.Graph()
for row in df.itertuples():
G.add_node(row.symbol, type='company')
G.add_node(row.Name,type='officer')
G.add_edge(row.symbol, row.Name)
write_gexf(G, 'graph.gexf')
输出文件可以在 Gephi 中打开、过滤和修改。下图展示了苹果、谷歌和亚马逊的 3 阶自网络的快照,显示它们确实是相互连接的:
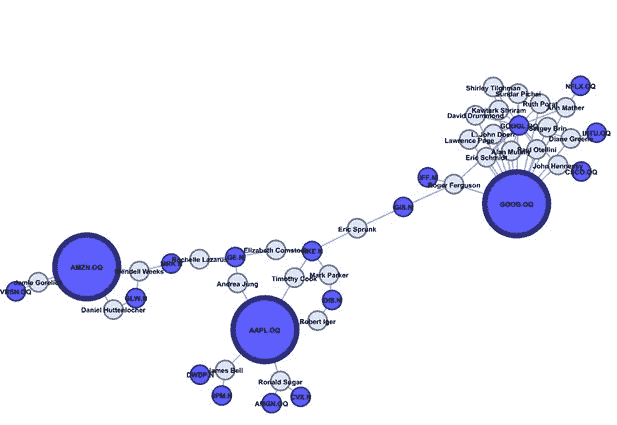
进一步阅读
我们的书《"Python 数据科学中的网页抓取"》即将发布,旨在帮助希望在工作流程中采用网页抓取技术的数据科学家。请关注www.webscrapingfordatascience.com/以获取更多信息。
图表也可以在预测设置中以多种方式使用。有关此主题的更多阅读资料,请参见:
-
Node2Vec 是一种强大的特征化技术,将图中的节点转换为特征向量:
snap.stanford.edu/node2vec/ -
个性化 Pagerank 在例如流失和欺诈分析的背景中非常常用作为特征化方法:
www.r-bloggers.com/from-random-walks-to-personalized-pagerank/ -
Van Vlasselaer, V., Akoglu, L., Eliassi-Rad, T., Snoeck, M., Baesens, B. (2015). Guilt-by-constellation: fraud detection by suspicious clique memberships. 48 届夏威夷国际系统科学会议论文集:第接受卷。HICSS-48。考艾岛(夏威夷),2015 年 1 月 5-8 日
-
Van Vlasselaer, V., Akoglu, L., Eliassi-Rad, T., Snoeck, M., Baesens, B. (2014). 在大型欺诈网络中寻找团体:理论与见解。国际运筹学学会会议(IFORS 2014)。巴塞罗那(西班牙),2014 年 7 月 13-18 日。
-
Van Vlasselaer, V., Akoglu, L., Eliassi-Rad, T., Snoeck, M., Baesens, B. (2014). Gotch'all! 先进的网络分析用于检测欺诈团体。PAW(预测分析世界)。伦敦(英国),2014 年 10 月 29-30 日
-
Van Vlasselaer, V., Van Dromme, D., Baesens, B. (2013). 社会网络分析用于检测社会保障欺诈中的蜘蛛构造:新见解和挑战:第接受卷。欧洲运筹学会议。罗马(意大利),2013 年 7 月 1-4 日
-
Van Vlasselaer, V., Meskens, J., Van Dromme, D., Baesens, B. (2013). 使用社会网络知识检测社会保障欺诈中的蜘蛛构造。2013 IEEE/ACM 国际社交网络分析与挖掘会议论文集。ASONAM。尼亚加拉大瀑布(加拿大),2013 年 8 月 25-28 日(第 813-820 页)。445 Hoes Lane, PO Box 1331, Piscataway, NJ 08855-1331, USA: IEEE 计算机协会
个人简介:塞佩·范登·布鲁克是比利时鲁汶大学经济与商学院的助理教授。他的研究兴趣包括商业数据挖掘与分析、机器学习、流程管理和流程挖掘。他的研究成果已发表在知名国际期刊上,并在顶级会议上展示。塞佩的教学内容包括高级分析、大数据和信息管理课程。他也经常为行业和商业观众授课。
巴特·贝森斯是比利时鲁汶大学(KU Leuven)的大数据与分析教授,同时也是英国南安普顿大学的讲师。他在大数据与分析、信用风险建模、欺诈检测和市场分析方面进行了广泛的研究。他著有 8 本书和 200 多篇科学论文,其中一些发表在知名国际期刊上,并在顶级国际会议上展示。他曾获得各种最佳论文和最佳演讲奖项。他的研究总结可以在 www.dataminingapps.com 找到。
相关话题
YouTube 上关于数据库管理、SQL、数据仓库、商业智能、OLAP、大数据、NoSQL 数据库、数据质量、数据治理和分析的视频 – 免费
由 Prof. Dr. Bart Baesens 提供,KU Leuven。 赞助帖子。
查看播放列表 这里 或如下
包含了超过 20 小时的 YouTube 视频,内容涉及数据库及其设计、物理数据存储、事务管理与数据库访问、数据仓库、数据治理和(大)数据分析。 YouTube 播放列表附带我们的书籍 《数据库管理原理:大数据与小数据存储、管理和分析的实用指南》。 这本全面的教科书教授了数据库设计、建模、系统、数据存储的基础知识,以及不断发展的数据仓库、治理等领域。 由经验丰富的教育者和大数据、分析、数据质量以及数据整合领域的专家撰写,为数据库管理提供了最新的方法。 这本全彩插图文本具有平衡的理论与实践焦点,涵盖了从成熟的数据库技术到近期趋势如大数据、NoSQL 等的基本主题。 基本概念通过现实世界的例子、查询和代码演示、以及图表得到了支持,非常适合高级本科生和信息系统或计算机科学研究生的入门课程。
Bart Baesens 是比利时鲁汶大学(KU Leuven)的大数据和分析教授,并且是英国南安普顿大学的讲师。他在大数据与分析、信用风险建模、欺诈检测和营销分析方面进行了广泛的研究。 他撰写了 200 多篇科学论文,并获得了各种最佳论文和最佳演讲奖。 Bart 是 6 本书的作者:《信用风险管理:基本概念》(牛津大学出版社,2009 年)、《大数据世界中的分析》(Wiley,2014 年)、《Java 编程入门》(Wiley,2015 年)、《使用描述性、预测性和社交网络技术的欺诈分析》(Wiley,2015 年)、《信用风险分析》(Wiley,2016 年)和《以盈利为驱动的商业分析》(Wiley,2017 年)。 他的书籍在全球销售超过 20,000 册,其中一些已被翻译成中文、俄语和韩语。 他的研究总结见 www.dataminingapps.com。
Wilfried Lemahieu 是 KU Leuven 经济与商业学院的教授,同时担任院长职务。他的教学获得了“最佳教师认可”,包括数据库管理、企业信息管理和管理信息学。他的研究专注于大数据存储与集成、数据质量、业务流程管理和面向服务的架构。在此背景下,他与各种行业合作伙伴广泛合作,包括本地和国际。他的研究成果发表在著名国际期刊中,并且他频繁为学术界和行业观众讲座。有关更多详情,请访问 feb.kuleuven.be/wilfried.lemahieu。
Seppe vanden Broucke 在比利时 KU Leuven 经济与商业学院担任助理教授。他的研究兴趣包括商业数据挖掘与分析、机器学习、流程管理和过程挖掘。他的工作已发表在知名国际期刊,并在顶级会议上展示。他还著有《Java 编程基础》(Wiley, 2015),销量超过 4000 本,并翻译成俄文。Seppe 的教学包括高级分析、大数据和信息管理课程。他还经常为行业和商业观众授课。有关更多详情,请访问 seppe.net。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
Baize: 一个开源聊天模型(但有所不同?)
原文:
www.kdnuggets.com/2023/04/baize-opensource-chat-model-different.html

图片由作者提供
我认为可以说 2023 年是大型语言模型(LLMs)的年份。从基于 GPT-3 家族的 ChatGPT 的广泛应用,到具备增强推理能力的 GPT-4 的发布,这一年在生成式 AI 领域取得了许多里程碑。而我们每天醒来时都会看到新应用的发布,这些应用利用 ChatGPT 的能力来解决新问题。
在这篇文章中,我们将了解Baize,一个最近发布的开源聊天模型。
什么是 Baize?
Baize 是一个开源聊天模型。很酷。但为什么还需要另一个聊天模型?
好吧,在与聊天机器人进行的典型会话中,你并不是只提出一个问题来寻求答案。相反,你会问一系列问题,聊天机器人会逐一回答。这种对话链会持续——直到你获得答案或问题的可接受解决方案——在这种多轮对话中。
所以,如果你想开始构建自己的聊天模型,这种多轮对话语料库并不常见。Baize 旨在利用 ChatGPT 生成这样的语料库,并用它来微调 LLaMA 模型。这有助于你构建更好的聊天机器人,并减少训练时间。
Project Baize由 UC San Diego 的 McAuley 实验室资助,并且是 UC San Diego、孙中山大学和微软亚洲研究院研究人员合作的结果。
Baize 的名字来源于中国神话中的白泽,白泽能够理解人类语言[1]。理解人类语言是我们都希望聊天模型具备的能力,对吧?Baize 的研究论文首次上传至 arxiv 是在 2023 年 4 月 3 日。该模型的权重和代码已全部在 GitHub 上公开,仅供研究使用。所以现在是探索这个新开源聊天模型的好时机。
是的,让我们更多地了解 Baize。
Baize 是如何工作的?
Baize 的工作可以(几乎)总结为两个关键点:
-
通过利用 ChatGPT 生成大量的多轮对话数据
-
使用生成的语料库来微调 LLaMA
训练 Baize 的流程 | 图片来源
使用 ChatGPT 自我对话进行数据收集
我们提到过,Baize 使用 ChatGPT 来构建聊天语料库。它使用一种叫做自我对话的过程,其中ChatGPT 与自己对话。
一个典型的聊天会话需要一个人类和一个 AI。数据收集管道中的自聊天过程设计为 ChatGPT 与自己对话——以提供对话的双方。对于自聊天过程,提供了一个模板以及相关要求。
ChatGPT 生成的对话质量非常高(我们在社交媒体上看到的更多,而不是在我们自己的 ChatGPT 会话中)。因此,我们获得了高质量的对话语料库。
让我们来看看 Baize 使用的数据:
-
有一个种子,设置话题以进行聊天会话。它可以是一个问题或一个提供对话中心思想的短语。在 Baize 的训练中,来自 StackOverflow 和 Quora 的问题被用作种子。
-
在 Baize 的训练中,ChatGPT(gpt-turbo-3.5)模型用于自聊天数据收集管道。生成的语料库大约有115K个对话——其中约 55K 个对话来自上述每个来源。
-
此外,还使用了来自斯坦福 Alpaca 的数据。
-
目前已经发布了三个版本的模型:Baize-7B、Baize-13B 和 Baize-30B。(在 Baize-XB 中,XB 表示 X 十亿参数。)
-
种子也可以从特定领域进行抽样。这意味着我们可以运行数据收集过程以构建特定领域的聊天语料库。在这个方向上,Baize-Healthcare 模型已经发布,基于公开的MedQuAD 数据集进行训练,创建了大约 47K 个对话的语料库。
低资源设置中的微调
下一部分是对生成语料库的 LLaMA 模型进行微调。模型微调通常是一个资源密集型的任务。由于在资源限制下调整大型语言模型的所有参数不可行,Baize使用低秩适应(LoRA)来微调 LLaMA 模型。
此外,在推理时,有一个提示指示 Baize 不要进行不道德和敏感的对话。这减少了对人工干预审查的需求。
功能应用从 HuggingFace 中心获取 LLaMA 模型和 LoRA 权重。
Baize 的优点和局限性
接下来,让我们回顾一下 Baize 的一些优点和局限性。
优点
让我们开始列举一些 Baize 的优点:
-
高可用性:你可以尝试Baize-7B on HuggingFaces spaces或本地运行。Baize 不受 API 调用次数的限制,缓解了高需求时期的可用性问题。
-
内置的审核支持:在推理时的提示可以防止对敏感和不道德话题的讨论,这有利于减少需要审查对话的工作量。
-
聊天语料库生成:如前所述,Baize 可以帮助构建大规模的多轮对话语料库。这在大规模训练聊天模型时非常有用。
-
低资源环境中的可访问性:正如[1]中提到的,我们可以在单个 GPU 机器上运行 Baize,这使得在计算资源有限的低资源环境中也能使用它。
-
领域特定的应用:通过精心从特定领域采样种子,我们可以拥有用于领域特定应用(如医疗、农业、金融等)的聊天机器人。
-
可重复性和定制化:代码是公开的,数据收集和训练流程是可重复的。如果你想从各种特定来源收集数据以构建自定义语料库,你可以修改项目代码库中的
collection.py脚本。
局限性
与所有 LLM 驱动的聊天应用一样,Baize 存在以下局限性:
-
不准确的信息:正如 ChatGPT 的回答有时可能因过时的训练数据和语境差异而出现不准确的情况,Baize 的回答也可能在某些时候技术上不准确。
-
实时信息的挑战:LLaMA 模型没有在最新数据上进行训练。这使得需要实时信息以提供准确且有用回答的任务变得具有挑战性。
-
偏见和毒性:通过改变推理提示,可以操控模型拒绝参与敏感、不道德的对话。
总结
今天就到这里!要了解更多关于 Baize 的信息,请务必在 HuggingFace spaces 上尝试演示版或在本地运行。ChatGPT 和 GPT-4 启发了自然语言处理领域的广泛应用。
随着新颖的 OpenAI 包装几乎每天都出现在开发者领域,跟上这些快速的进展和发布可能会让人感到不知所措。与此同时,我们很兴奋地期待生成式 AI 的未来会带来什么。
参考文献和进一步学习的资源
[1] C Xu, D Guo, N Duan, J McAuley, Baize: 一种在自聊天数据上进行参数高效调整的开源模型, arXiv, 2023.
Bala Priya C 是一位技术作家,她喜欢创作长篇内容。她的兴趣领域包括数学、编程和数据科学。她通过撰写教程、操作指南等,向开发者社区分享她的学习经验。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
相关话题
想加入银行吗?数据科学家在金融科技领域工作所需了解的一切
原文:
www.kdnuggets.com/2021/10/bank-data-scientists-working-fintech.html
评论
由Shameek Kundu(金融服务部门负责人,首席战略官)、Divya Gopinath(研究工程师)和Arridhana Ciptadi(机器学习工程师)共同撰写,均为 TruEra 公司成员。

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
除了技术行业,银行和保险业可能是数据科学家的最大雇主。鉴于金融服务一直依赖数据和模型——例如,用于贷款审批或保险承保——这并不令人惊讶。然而,作为数据科学家,你如何决定这是否适合你?你将解决哪些实际问题?你可以预期哪些挑战?成功需要具备什么条件?
加入的五个好理由……
数据科学家在金融服务领域工作的最大优势之一是用例的丰富性和数据科学家能够产生的实际世界影响。当然,还有所有在任何面向客户的业务中常见的应用,例如个性化体验、针对性的交叉销售优惠或预防客户流失的主动策略。但银行、保险公司以及它们的金融科技挑战者以许多其他有趣且有影响力的方式使用数据和分析。
示例包括:
-
使用替代数据,从卫星图像、电信提供商、物联网网络或社交媒体等来源提取,以改善保险风险定价、将贷款扩展到传统上被排除的客户群体或生成投资创意
-
网络分析创建客户生态系统的详细图像——客户、供应商、员工和所有者——这些图像有助于检测和调查恐怖融资、洗钱或人口贩运的案例
-
自然语言处理算法检测投资银行中的潜在内幕交易
-
图像识别算法自动处理大多数汽车保险索赔
-
计算拟议金融投资的环境足迹,例如新的工业设施或甚至个人抵押贷款
许多数据科学家第二个吸引力将是数据集的广度和深度,这些数据集可以用来生成有意义的见解。银行和保险公司通常能够获取大量数据,如人口统计、交易和关系,涵盖宏观层面以及个人客户层面。尽管使用这些数据存在一些限制,但高质量的数据集通常可以追溯多年,这对于构建预测模型来说是数据科学家的梦想。
金融服务公司在数据和技术上的开支规模以及数据生态系统的相对成熟度也可以使其对数据科学家具有吸引力。例如,大多数银行在技术上的年度收入支出超过 10%。数据和分析的支出是其中越来越重要的组成部分,并且对于许多大型公司来说,每年的支出很容易达到或超过数亿美元——这一数字仅次于科技行业中最大的公司。因此,多年的数据支出也使许多公司拥有相对成熟的数据团队。因此,数据科学家可能会发现现有的支持系统,而无需独自管理从数据管道到数据治理的一切。
最后,在大多数地区,银行、保险公司和金融科技公司通常是数据科学家的高薪雇主。尽管这本身很有吸引力,但它也是对这些公司重视数据科学的价值和其对长期职业发展的影响的有用指标。在至少一家主要的全球银行中,首席数据和分析官现在直接向集团首席执行官汇报。
… 以及一些挑战
当然,有一个陷阱。使数据科学家在银行和保险公司工作有趣的一切,特别是大公司,也可能使其在某些时候变得繁琐和令人沮丧。一些数据科学家可能纯粹将这些视为挑战;其他人可能还将其视为自我发展的机会,并产生更大的影响。
鉴于行业中数据和分析的高风险使用,存在高标准的信任要求,以证明数据和模型足够适用于现实生活中的使用。例如,如果数据科学家正在构建一个预测模型,该模型可能被用来拒绝某人贷款或保险,或将某人标记为潜在的洗钱者,那么他们应该预计会受到大量审查。
类似地,鉴于客户经常将生活中最隐私的方面——例如他们的收入或医疗历史——托付给银行和保险公司,数据科学家可以发现复杂的数据可用性和可用性控制。数据隐私、主权、伦理和安全问题存在于各个行业,但很少有其他行业在管理这些问题上投入如此多的时间和精力。
对数据及相关技术的大量投资,以及资源充足的数据工程师、分析师和风险专家团队,可以为数据科学家提供良好的成长环境。然而,相同的因素也可能导致日常工作的灵活性丧失。在许多情况下,这可能意味着数据科学家需要面对限制性的技术选择或多步骤流程,带有复杂的控制和交接程序,才能让他们的工作最终在生产中见光。一个特别让银行新员工感到惊讶的领域是需要由独立团队对所有重要模型进行正式验证——这一步骤可能会使正常的模型生命周期增加几周甚至几个月。
所有这些挑战的根本原因是金融服务是全球最受监管的行业之一。对此,大多数银行和保险公司建立了风险与合规的 DNA,特别是在 2008 年金融危机之后。在许多地区,银行和保险公司的高级经理对其雇主的行为承担个人责任,因此任何可能破坏客户信任或违反监管要求的行为都受到特别谨慎的对待。数据和算法的使用符合所有这些标准。毫不奇怪,金融监管机构已成为首批发布有关负责任使用数据和人工智能的指导方针的机构——例如,在新加坡、香港、欧盟、英国和美国。
那么对你来说呢?
显然,并不是每个数据科学家都喜欢在银行、保险公司或甚至受监管的金融科技公司工作。然而,如果你符合以下条件,你应该积极考虑在该行业的发展:
-
你对在如此广泛的现实世界应用中运用你的技能并通过更大的金融包容性或更好地将金融资源用于全球气候议程等举措产生深远影响感到兴奋。
-
你认为你的工作不仅仅是建立出色的模型,还包括教育他人了解数据科学的“魔力”,以及赢得非数据科学家的信任。你可能是专家,但你公司中还有许多人不是专家,但仍然必须支持你的工作。
-
你接受在“工作方式”中一定程度的标准化和纪律性是为了实现你工作的广泛影响而必须付出的代价。
-
你将数据使用方面的限制,如隐私、伦理和主权等问题,不仅视为挑战或麻烦,而是作为做正确的事情和个人发展的机会。例如,银行和保险公司是隐私增强技术的早期采纳者之一。大多数也走在算法透明度和公平性倡议的前沿。在这些公司工作可以为你作为数据科学家提供实际机会,建立高性能的同时值得信赖的模型。
简历:Shameek Kundu是一位在技术和商业战略方面都具有领先地位的 AI 专家,并且在金融服务行业推动数据分析/AI 负责任应用的职业生涯中大部分时间都致力于此。他是 TruEra 的首席战略官和金融服务部负责人。他还在英格兰银行 AI 公私论坛和 OECD 全球 AI 伙伴关系中担任职务,并曾参与新加坡金融管理局的AI 公平、伦理、问责与透明度指导委员会。最近,Shameek 在渣打银行担任集团首席数据官,帮助银行在多个领域探索和采用 AI(例如,信贷、金融犯罪合规、客户分析、监控)。
Divya Gopinath是 TruEra 的研究工程师,该公司专注于使 AI 值得信赖和透明。在加入之前,Divya 在 MIT 完成了本科和硕士学位,她的研究集中在为医疗领域构建机器学习算法。Divya 是《Towards Data Science》中有关值得信赖 AI 的主要贡献者,专注于公平性和解决机器学习模型中的偏见问题。
Arridhana Ciptadi 是 TruEra 工程团队的成员。他曾是 Blue Hexagon 的创始团队成员,并担任公司所有机器学习工作的技术负责人。在此之前,他在 Amazon Lab126 担任机器学习科学家,负责为各种 Amazon 产品开发机器学习和计算机视觉技术。Ciptadi 拥有乔治亚理工学院计算机科学博士学位。
相关内容:
更多此类话题
Bard 数据科学备忘单
原文:
www.kdnuggets.com/2023/05/bard-data-science-cheat-sheet.html
全部都是 A-Bard!
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
OpenAI 可能是第一个推出 ChatGPT 的,但不要完全排除 Google 的可能性。Bard 在今年 2 月推出,并通过渐进式的推广,已在全球范围内向越来越多的用户和各种场景开放。
Bard 具有与 ChatGPT 和过去 6 个月出现的其他知名 LLM 相似的能力。
Bard 是由 Google AI 开发的大型语言模型(LLM)聊天机器人。它在大量文本和代码数据集上进行了训练,能够生成文本、翻译语言、编写不同类型的创意内容,并以信息丰富的方式回答你的问题。新版 Bard 正在运行 PaLM 2 模型。它在编码、推理和创意写作问题上远胜于 LaMDA。
KDnuggets 的 Bard 数据科学备忘单(点击图片下载 PDF)
说实话:Bard 在 LLM 革命的使用领域中,确实是在赶超 ChatGPT……但又怎么样呢?OpenAI 是最早出现的,并享受了早期进入的优势。这种优势会持续吗?而且,相对的背书分布并不等同于质量(Beta 与 VHS,大家还记得吗?)。
Bard 与 ChatGPT 的全球 Google 趋势搜索对比,数据截取于 2023 年 5 月 29 日
(Bard 以蓝色表示,ChatGPT 以红色表示)
所以,如果你正在使用 ChatGPT,你可能会觉得有必要查看一下其他选项,即使只是为了确保自己决定继续使用它是合适的。为了帮助你做到这一点,查看我们的最新备忘单,以便了解最新信息,并为使用 Google 的 LLM 聊天工具提供一个实用的参考。
使用这份备忘单,你将深入了解以下与 Bard 在数据科学中的使用相关的方面:
-
头脑风暴
-
编程
-
SQL
-
电子表格
-
数据分析
-
机器学习
-
以及更多!
想了解更多关于 Bard 的信息以及如何将其用于数据科学,请查看我们最新的备忘单。
更多相关话题
Bark: 终极音频生成模型
原文:
www.kdnuggets.com/2023/05/bark-ultimate-audio-generation-model.html

图片由作者提供 | Canva Pro | Bing 图片创建者
我们正在见证文本到语音模型的快速进展,这些模型在实现更自然的输出方面表现出了显著的改进。这个领域的进步不仅限于语音生成;在音乐和环境声音生成以及语音克隆的发展上也取得了重大突破,进展迅速。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
在这篇文章中,我们将学习 Bark,这个终极音频生成模型,能够生成各种语言的语音、环境声音、音乐和多讲者提示。我们将深入了解它的功能和关键特性,并提供入门指南。
什么是 Bark?
Bark,由Suno开发,是一种基于变换器的文本到音频模型,擅长生成高度逼真的多语言语音、音乐、背景噪音,甚至简单的声音效果。此外,该模型还可以产生各种非语言交流,如笑声、叹息和哭声。你可以访问已准备好的预训练模型检查点。
图片来源于Bark by suno
Bark 如何工作?
Bark,像Vall-E以及该领域其他令人印象深刻的作品一样,采用 GPT 风格的模型从头生成音频。然而,与 Vall-E 不同,Bark 使用高级语义令牌来嵌入初始文本提示,而不依赖于音素。这使得 Bark 能够广泛适应超越语音的各种任意指令,包括音乐歌词、声音效果以及训练数据中的非语音声音。
生成的语义令牌随后由第二个模型处理,将其转换为音频编解码器令牌,从而生成完整的波形。为了通过公开代码让 Bark 对社区开放,我们将 Facebook 的卓越EnCodec 编解码器作为音频表示进行了集成。
Bark 使用了 nanoGPT 来快速实现 GPT 风格的模型,使用 EnCodec 实现了出色的音频编解码器,使用 AudioLM 进行训练和推理代码,并使用 Vall-E, AudioLM 以及类似论文来开发 Bark 项目。
Bark 功能
多语言
Bark 支持多种语言,且能够自动检测输入文本的语言。即使文本中包含多种语言的混合,称为代码切换,Bark 也能准确识别并应用每种语言的本地口音。
尝试提示:
Hallo, wie geht es dir?. ¿Qué haces aquí? Are you looking **for** someone?
非语音声音
Bark 可以添加非语音声音,如笑声、喘息声和清喉咙声。
只需添加标签或更改文本以使其听起来自然。
-
[笑声]
-
[叹气]
-
[音乐]
-
[喘息声]
-
[清喉咙]
-
… 用于犹豫
-
♪ 用于歌词
-
用于强调单词的大写
-
MAN/WOMAN:用于倾向于说话者
尝试提示:
" [clears throat] Hello, my name is Abid. And, uh -- and I like cheeseburgers. [laughs] But I also have other interests such as [music]... ♪ singing ♪."
音乐
Bark 可以生成所有类型的音频,并且不区分语音和音乐。虽然 Bark 有时可能会将文本生成音乐,但你可以通过在歌词周围添加音乐符号来提高其性能,以帮助它区分这两者。
尝试提示:
♪ Almost heaven, West Virginia. Blue Ridge Mountains, Shenandoah River. Life is old there, older than the trees. Younger than the mountains, growin' like a breeze ♪
语音克隆
Bark 能够完全克隆声音。它可以准确复制说话者的语调、音高、情感和韵律,同时保留其他音频特征,如音乐和环境噪声。然而,为了防止这一先进技术的误用,他们实施了限制。用户只能从 Suno 提供的一组完全合成的选项中进行选择。
说话者提示
虽然你可以提供具体的说话者提示,例如“NARRATOR”,“MAN”,“WOMAN”等,但重要的是要注意,这些提示可能并不总是被遵守,特别是在存在冲突的音频历史提示时。
尝试提示:
MAN: Can you buy me the coffee from starbucks?
WOMAN: Sure, what type of coffee do you want?
入门指南
你可以通过在 Bark by suno 上测试演示,或使用 Google Colab Notebook 进行自己的推理,来开始实验。
如果你想在本地运行,你需要使用下面的命令在终端中安装 bark 包。
pip install git+https://github.com/suno-ai/bark.git
之后,在 Jupyter Notebook 中运行下面的代码。该代码将下载所有模型,然后将文本提示转换为音频。
from bark import SAMPLE_RATE, generate_audio, preload_models
from IPython.display import Audio
# download and load all models
preload_models()
# generate audio from text
text_prompt = """
Hello, my name is Abid Ali. And, uh -- and I like cheeseburgers. [laughs]
But I also have other interests such as playing online games like Dota 2.
"""
audio_array = generate_audio(text_prompt)
# play text in notebook
Audio(audio_array, rate=SAMPLE_RATE)
你可以使用 scipy.io.wavfile 将音频保存为 wav 格式。
from scipy.io.wavfile import write as write_wav
write_wav("/project/sample_audio.wav", SAMPLE_RATE, audio_array)
查看其他资源,学习如何将 Bark 集成到你的应用程序中。
资源:
-
GitHub: suno-ai/bark
-
Spaces 演示: Bark by suno
-
Colab Notebook: Bark Google Colab Demo
-
模型卡片:Bark
-
许可证:CC-BY 4.0 NC。Suno 模型本身可以用于商业用途
-
Suno Studio(早期访问):Suno Studio(typeform.com)
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些在心理健康上遇到困难的学生打造 AI 产品。
更多相关内容
基础率谬误及其对数据科学的影响
原文:
www.kdnuggets.com/2023/04/base-rate-fallacy-impact-data-science.html

作者提供的图片
在处理数据和不同变量时,将一个变量或值指定为比另一个变量或值更大是很容易的。我们可能假设某个特定变量或数据点对结果的影响更大,但我们怎么能确定其他变量是否有相同的影响呢?
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织的 IT 工作
什么是基础率?
在统计学中,基础率可以视为与“特征证据”无关的类别概率。你可以将基础率视为你的先验概率假设。
基础率是研究中的重要工具。例如,如果我们是一家制药公司,并且正在开发和推出一种新疫苗,我们希望了解这种治疗的成功率。如果我们有 4000 人愿意接种这种疫苗,而我们的基础率是 1/25。
这意味着在 4000 人中只有 160 人会通过这种治疗获得成功。在制药界,这是一个非常低的成功率。这就是基础率如何用于提高研究的准确性,并确保产品能够表现良好。
什么是基础率谬误?
如果我们将这些词分开,它将帮助我们更好地理解。谬误意味着错误的信念或有缺陷的推理。如果我们现在将其与上述基础率的定义结合起来。
基础率谬误,也称为基础率偏见和基础率忽视,是指在评估特定情况时,没有考虑所有相关数据的可能性。
基础率谬误涉及基础率信息以及其他相关信息。这可能由于多种原因,如没有彻底检查和分析数据,或忽视以偏袒数据的某个特定部分。
基础率谬误描述了一个人倾向于忽视现有的基础率信息,而偏向于新的信息。这违背了基于证据的推理的基本规则。
你通常会听到这种情况发生在金融行业。例如,投资者会根据不理性的消息来决定买入或出售策略,这会导致市场波动——尽管他们对基础率有所了解。
基础率谬误与数据科学
现在我们对基础率和基础率谬误有了更好的理解。它在数据科学中的相关性和影响是什么?
我们讨论了“类别的概率”和“考虑所有相关数据”。如果你是数据科学家、机器学习工程师,或者刚入门,你会知道概率和相关数据对产生准确输出、机器学习模型的学习过程以及高性能模型的重要性。
为了分析数据和对数据进行预测,或让你的机器学习模型产生准确输出,你需要考虑每一条数据。在你第一次浏览数据时,你可能会认为一些部分相关,而其他部分无关。然而,这只是你的判断,直到进行适当的分析之前并不算事实。
如上所述,初始基础率帮助你确保准确性并产生高性能模型。那么我们在数据科学中如何做到这一点呢?
混淆矩阵
混淆矩阵是一种性能测量工具,它提供了分类问题预测结果的总结。混淆矩阵基于结果:真、假、正、负。
混淆矩阵表示我们模型在测试阶段的预测。混淆矩阵中的假阴性和假阳性是基础率谬误的示例。
-
真阳性(TP) - 你的模型预测为阳性且实际为阳性
-
真阴性(TN) - 你的模型预测为阴性且实际为阴性
-
假阳性(FP) - 你的模型预测为阳性且实际为阴性
-
假阴性(FN) - 你的模型预测为阴性且实际为阳性
混淆矩阵可以计算 5 个不同的指标,以帮助我们衡量模型的有效性:
-
错误分类 = (FP + FN) / (TP + TN + FP + FN)
-
精确率 = TP / (TP + FP)
-
准确率 = (TP + TN) / (TP + TN + FP + FN)
-
特异性 = TN / (TN + FP)
-
灵敏度即召回率 = TP / (TP + FN)
为了更好地理解混淆矩阵,最好查看一个可视化图:
作者提供的图片
基础率谬误的原因
在你阅读这篇文章时,你可能会想到各种基础率谬误的原因,如没有考虑所有相关数据、人为错误或缺乏精确度。
尽管这些都是正确的并且增加了基本率谬误的原因,但它们都与最初忽视基本率信息的最大问题相关。基本率信息常被忽视,因为被认为不相关,但基本率信息可以为人们节省大量时间和金钱。利用可用的基本率信息,可以更精确地预测某个事件是否会发生。
使用基本率信息将帮助你避免基本率谬误。
了解意见、自动化过程等谬误将帮助你解决基本率谬误问题并减少潜在错误。当你在测量某个事件发生的概率时,贝叶斯方法可以帮助减少基本率谬误。
结论
基本率在数据科学中很重要,因为它为你提供了评估研究或项目的基本理解,并优化你的模型,从而整体提升准确性和性能。
如果你想观看关于医学领域基本率谬误的视频,可以查看这个视频:医学测试悖论
Nisha Arya 是一名数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程和围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷学习者,她希望拓宽自己的技术知识和写作技能,同时帮助他人。
相关主题
5 个真正有用的 Bash 脚本用于数据科学
作者提供的图片
Python、R 和 SQL 通常被认为是处理、建模和探索数据的最常用语言。虽然这可能是真的,但并没有理由其他语言不能或没有被用来做这些工作。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
Bash shell 是一种 Unix 及类 Unix 操作系统的 shell,以及与之配套的命令和编程语言。Bash 脚本是使用 Bash shell 脚本语言编写的程序。这些脚本由 Bash 解释器按顺序执行,可以包括其他编程语言中常见的所有构造,包括条件语句、循环和变量。
常见的 Bash 脚本用途包括:
-
自动化系统管理任务
-
执行备份和维护
-
解析日志文件和其他数据
-
创建命令行工具和实用程序
Bash 脚本还用于协调复杂分布式系统的部署和管理,使其成为数据工程、云计算环境和 DevOps 领域极为有用的技能。
在这篇文章中,我们将深入探讨五种与数据科学相关的脚本任务,看看 Bash 可以有多么灵活和有用。
Bash 脚本
清理和格式化原始数据
这是一个用于清理和格式化原始数据文件的 bash 脚本示例:
#!/bin/bash
# Set the input and output file paths
input_file="raw_data.csv"
output_file="clean_data.csv"
# Remove any leading or trailing whitespace from each line
sed 's/^[ \t]*//;s/[ \t]*$//' $input_file > $output_file
# Replace any commas within quoted fields with a placeholder
sed -i 's/","/,/g' $output_file
# Replace any newlines within quoted fields with a placeholder
sed -i 's/","/ /g' $output_file
# Remove the quotes around each field
sed -i 's/"//g' $output_file
# Replace the placeholder with the original comma separator
sed -i 's/,/","/g' $output_file
echo "Data cleaning and formatting complete. Output file: $output_file"
这个脚本:
-
假设你的原始数据文件是一个名为
raw_data.csv的 CSV 文件 -
将清理后的数据保存为
clean_data.csv -
使用
sed命令来:-
从每一行中移除前后空白,并将引用字段中的逗号替换为占位符
-
将引用字段中的换行符替换为占位符
-
移除每个字段周围的引号
-
将占位符替换为原始的逗号分隔符
-
-
打印一条消息,指示数据清理和格式化已完成,并提供输出文件的位置
自动化数据可视化
这是一个用于自动化数据可视化任务的 bash 脚本示例:
#!/bin/bash
# Set the input file path
input_file="data.csv"
# Create a line chart of column 1 vs column 2
gnuplot -e "set datafile separator ','; set term png; set output 'line_chart.png'; plot '$input_file' using 1:2 with lines"
# Create a bar chart of column 3
gnuplot -e "set datafile separator ','; set term png; set output 'bar_chart.png'; plot '$input_file' using 3:xtic(1) with boxes"
# Create a scatter plot of column 4 vs column 5
gnuplot -e "set datafile separator ','; set term png; set output 'scatter_plot.png'; plot '$input_file' using 4:5 with points"
echo "Data visualization complete. Output files: line_chart.png, bar_chart.png, scatter_plot.png"
上述脚本:
-
假设你的数据在一个名为
data.csv的 CSV 文件中 -
使用
gnuplot命令创建三种不同类型的图表:-
绘制第 1 列与第 2 列的折线图。
-
绘制第 3 列的条形图。
-
绘制第 4 列与第 5 列的散点图。
-
-
以 PNG 格式输出图表,并分别保存为
line_chart.png、bar_chart.png和scatter_plot.png。 -
打印一条消息,指示数据可视化已完成以及输出文件的位置。
请注意,为了使此脚本正常工作,需要根据您的数据和需求调整列号和图表类型。
统计分析
这里是一个示例 Bash 脚本,用于对数据集进行统计分析:
#!/bin/bash
# Set the input file path
input_file="data.csv"
# Set the output file path
output_file="statistics.txt"
# Use awk to calculate the mean of column 1
mean=$(awk -F',' '{sum+=$1} END {print sum/NR}' $input_file)
# Use awk to calculate the standard deviation of column 1
stddev=$(awk -F',' '{sum+=$1; sumsq+=$1*$1} END {print sqrt(sumsq/NR - (sum/NR)**2)}' $input_file)
# Append the results to the output file
echo "Mean of column 1: $mean" >> $output_file
echo "Standard deviation of column 1: $stddev" >> $output_file
# Use awk to calculate the mean of column 2
mean=$(awk -F',' '{sum+=$2} END {print sum/NR}' $input_file)
# Use awk to calculate the standard deviation of column 2
stddev=$(awk -F',' '{sum+=$2; sumsq+=$2*$2} END {print sqrt(sumsq/NR - (sum/NR)**2)}' $input_file)
# Append the results to the output file
echo "Mean of column 2: $mean" >> $output_file
echo "Standard deviation of column 2: $stddev" >> $output_file
echo "Statistical analysis complete. Output file: $output_file"
此脚本:
-
假设您的数据在名为
data.csv的 CSV 文件中。 -
使用
awk命令计算 2 列的均值和标准差。 -
使用逗号分隔数据。
-
将结果保存到文本文件
statistics.txt中。 -
打印一条消息,指示统计分析已完成以及输出文件的位置。
请注意,您可以添加更多的awk命令来计算其他统计值或处理更多列。
管理 Python 包依赖关系
这里是一个示例 Bash 脚本,用于管理和更新数据科学项目所需的依赖项和包:
#!/bin/bash
# Set the path of the virtual environment
venv_path="venv"
# Activate the virtual environment
source $venv_path/bin/activate
# Update pip
pip install --upgrade pip
# Install required packages from requirements.txt
pip install -r requirements.txt
# Deactivate the virtual environment
deactivate
echo "Dependency and package management complete."
此脚本:
-
假设您已设置虚拟环境,并且有一个名为
requirements.txt的文件,包含您要安装的包名称和版本。 -
使用
source命令激活由路径venv_path指定的虚拟环境。 -
使用
pip升级pip到最新版本。 -
安装
requirements.txt文件中指定的包。 -
使用
deactivate命令在安装包后停用虚拟环境。 -
打印一条消息,指示依赖项和包管理已完成。
每次更新您的依赖项或为数据科学项目安装新包时,都应运行此脚本。
管理 Jupyter Notebook 执行
这里是一个示例 Bash 脚本,用于自动化执行 Jupyter Notebook 或其他交互式数据科学环境:
#!/bin/bash
# Set the path of the notebook file
notebook_file="analysis.ipynb"
# Set the path of the virtual environment
venv_path="venv"
# Activate the virtual environment
source $venv_path/bin/activate
# Start Jupyter Notebook
jupyter-notebook $notebook_file
# Deactivate the virtual environment
deactivate
echo "Jupyter Notebook execution complete."
上述脚本:
-
假设您已设置虚拟环境,并在其中安装了 Jupyter Notebook。
-
使用
source命令激活虚拟环境,指定路径为venv_path。 -
使用
jupyter-notebook命令启动 Jupyter Notebook 并打开指定的notebook_file。 -
在执行 Jupyter Notebook 后,使用
deactivate命令停用虚拟环境。 -
打印一条消息,指示 Jupyter Notebook 执行已完成。
每次执行 Jupyter Notebook 或其他交互式数据科学环境时,都应运行此脚本。
我希望这些简单的脚本能展示 Bash 脚本的简便性和强大功能。它可能不是您每种情况的首选解决方案,但它确实有其存在的价值。祝您的脚本编写好运。
马修·梅奥 (@mattmayo13) 是一位数据科学家,同时也是 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣领域包括自然语言处理、算法设计与优化、无监督学习、神经网络,以及自动化机器学习方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
主题相关信息
使用 Python 的基础图像数据分析 – 第四部分
原文:
www.kdnuggets.com/2018/10/basic-image-analysis-python-p4.html
评论
之前,我们已经看到了一些 Python 中非常基础的图像分析操作。在这最后一部分基础图像分析中,我们将探讨以下内容。
我们的三大推荐课程
1. Google 网络安全证书 - 快速通道进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
以下内容是我在上一学期完成的学术图像处理课程的反映。因此,我不打算将其应用于生产领域。相反,本文的目的是尝试实现一些基本图像处理技术的基础知识。为此,我将主要使用 SciKit-Image 和 numpy 来执行大部分操作,尽管我会不时使用其他库,而不是使用像 OpenCV 这样的最受欢迎的工具:
我原本计划将这个系列分成两部分,但由于内容的吸引力及其各种结果,我不得不将其分为四部分。你可以在这里找到前三部分:
现在,让我们开始吧!
阈值处理
大津法
阈值处理是图像处理中的一种非常基础的操作。将灰度图像转换为单色图像是常见的图像处理任务。而且,一个好的算法总是以良好的基础开始!
大津阈值处理是一种简单而有效的全局自动阈值方法,用于将灰度图像(如前景和背景)二值化。在图像处理领域,大津阈值处理方法(1979 年)用于基于直方图的形状进行自动二值化水平决策。它完全基于对图像直方图的计算。
该算法假设图像由两类基本类别组成:前景和背景。然后计算一个最佳阈值,以最小化这两类的加权类内方差。
Otsu 阈值在从医学成像到低级计算机视觉的许多应用中被使用。它有许多优点和假设。
Otsu 方法的数学公式。这将引导你到我的主页,在那里我们解释了 Otsu 方法背后的数学。
算法
如果我们在这个简单的逐步算法中加入一点数学,这样的解释就会演变:
-
计算每个强度级别的直方图和概率。
-
设置初始 wi 和 μi。
-
从阈值 t = 0 到 t = L-1 步进:
-
更新: wi 和 μi
-
计算: σ2b(t)
-
期望的阈值对应于 σ2b(t)的最大值。
import numpy as np
import imageio
import matplotlib.pyplot as plt
pic = imageio.imread('img/potato.jpeg')
plt.figure(figsize=(7,7))
plt.axis('off')
plt.imshow(pic);

def otsu_threshold(im):
# Compute histogram and probabilities of each intensity level
pixel_counts = [np.sum(im == i) for i in range(256)]
# Initialization
s_max = (0,0)
for threshold in range(256):
# update
w_0 = sum(pixel_counts[:threshold])
w_1 = sum(pixel_counts[threshold:])
mu_0 = sum([i * pixel_counts[i] for i in range(0,threshold)]) / w_0 if w_0 > 0 else 0
mu_1 = sum([i * pixel_counts[i] for i in range(threshold, 256)]) / w_1 if w_1 > 0 else 0
# calculate - inter class variance
s = w_0 * w_1 * (mu_0 - mu_1) ** 2
if s > s_max[1]:
s_max = (threshold, s)
return s_max[0]
def threshold(pic, threshold):
return ((pic > threshold) * 255).astype('uint8')
gray = lambda rgb : np.dot(rgb[... , :3] , [0.21 , 0.72, 0.07])
plt.figure(figsize=(7,7))
plt.imshow(threshold(gray(pic), otsu_threshold(pic)), cmap='Greys')
plt.axis('off');

好,但不完美。如果直方图可以假设具有双峰分布并假设在两个峰之间具有深且尖锐的谷,则 Otsu 方法表现相对较好。
因此,如果物体区域相对于背景区域较小,则直方图不再表现出双峰性,并且如果物体和背景强度的方差与均值差异相比较大,或者图像被加性噪声严重污染,灰度直方图的尖锐谷值会被退化。
结果是,Otsu 方法确定的可能不正确的阈值会导致分割错误。但我们可以进一步 改进 Otsu 方法。
KMeans 聚类
k-means 聚类是一种 向量量化方法,源自信号处理,在 聚类分析 和 数据挖掘中广受欢迎。
在 Otsu 阈值处理中,我们找到最小化类内像素方差的阈值。因此,我们可以在色彩空间中寻找聚类,而不是从灰度图像中寻找阈值,这样我们就得到了 K-means 聚类 技术。
from sklearn import cluster
import matplotlib.pyplot as plt
# load image
pic = imageio.imread('img/purple.jpg')
plt.figure(figsize=(7,7))
plt.imshow(pic)
plt.axis('off');

为了对图像进行聚类,我们需要将其转换为二维数组。
x, y, z = pic.shape
pic_2d = pic.reshape(x*y, z)
接下来,我们使用 scikit-learn 的 cluster 方法来创建聚类。我们将 n_clusters 设为 5 以形成五个聚类。结果图像中会出现这些聚类,将其分成五个具有不同颜色的部分。
聚类数 5 是通过启发式选择的用于演示。可以更改簇的数量,以视觉验证不同颜色的图像,并确定最接近所需簇数的设置。
%%time
# fit on the image with cluster five
kmeans_cluster = cluster.KMeans(n_clusters=5)
kmeans_cluster.fit(pic_2d)
cluster_centers = kmeans_cluster.cluster_centers_
cluster_labels = kmeans_cluster.labels_
Wall time: 16.2 s
一旦簇形成后,我们可以使用簇中心和标签重建图像,以显示具有分组模式的图像。
plt.figure(figsize=(7,7))
plt.imshow(cluster_centers[cluster_labels].reshape(x, y, z))
plt.axis('off');

线检测
霍夫变换
霍夫变换是一种流行的技术,用于检测任何形状,只要我们能够将该形状表示为数学形式。即使形状稍微破损或扭曲,它也能检测到。我们不会深入分析霍夫变换的机制,而是提供直观的数学描述,然后在代码中实现,并提供一些资源以便更详细地理解它。
霍夫变换的数学公式。这将会重定向到我的主页,在那里我们解释了霍夫变换方法背后的数学。
where
ρ = distance from origin to the line. [-Dmax, Dmax]
Dmax is the diagonal length of the image.
θ = angle from origin to the line. [-90° to 90°]
算法
-
角点或边缘检测
-
ρ范围和θ范围的创建
-
ρ:-Dmax 到 Dmax
-
θ:-90 到 90
-
-
霍夫累加器
- 2D 数组,其中行数等于ρ值的数量,列数等于θ的数量。
-
在累加器中进行投票
- 对于每个边缘点和每个θ值,找到最近的ρ值,并在累加器中递增该索引。
-
峰值寻找
- 累加器中的局部最大值表示输入图像中最突出的线条的参数。
def hough_line(img):
# Rho and Theta ranges
thetas = np.deg2rad(np.arange(-90.0, 90.0))
width, height = img.shape
diag_len = int(np.ceil(np.sqrt(width * width + height * height))) # Dmax
rhos = np.linspace(-diag_len, diag_len, diag_len * 2.0)
# Cache some resuable values
cos_t = np.cos(thetas)
sin_t = np.sin(thetas)
num_thetas = len(thetas)
# Hough accumulator array of theta vs rho
accumulator = np.zeros((2 * diag_len, num_thetas), dtype=np.uint64)
y_idxs, x_idxs = np.nonzero(img) # (row, col) indexes to edges
# Vote in the hough accumulator
for i in range(len(x_idxs)):
x = x_idxs[i]
y = y_idxs[i]
for t_idx in range(num_thetas):
# Calculate rho. diag_len is added for a positive index
rho = round(x * cos_t[t_idx] + y * sin_t[t_idx]) + diag_len
accumulator[rho, t_idx] += 1
return accumulator, thetas, rhos
边缘检测
边缘检测是一种图像处理技术,用于找到图像中对象的边界。它通过检测亮度的不连续性来工作。常见的边缘检测算法包括:
-
Sobel
-
Canny
-
Prewitt
-
Roberts 和
-
模糊逻辑方法。
在这里,我们将介绍最流行的方法之一,即Canny 边缘检测。
一种多阶段边缘检测操作,能够检测图像中各种边缘。现在,Canny 边缘检测算法的过程可以分解为 5 个不同的步骤:
-
应用高斯滤波器
-
找到强度梯度
-
应用非最大抑制
-
应用双重阈值
-
通过滞后跟踪边缘。
让我们直观地理解其中的每一个。有关更全面的概述,请查看本文末尾提供的链接。然而,本文已经变得很长,因此我们决定不在此处提供完整的代码实现,而是给出该代码算法的直观概述。但可以跳到代码库查看代码 😃
Canny 边缘检测的过程。这将重定向到我的主页,我们在其中解释了 Canny 边缘检测方法背后的数学原理。
这标志着 Python 中基础图像处理的 4 部分系列的结束。我希望大家能够跟上,如果你觉得我犯了重要错误,请在评论中告诉我!
完整的源代码可以在:GitHub.
相关内容:
更多相关主题
使用 Numpy 和 OpenCV 的基础图像数据分析 – 第一部分
原文:
www.kdnuggets.com/2018/07/basic-image-data-analysis-numpy-opencv-p1.html
评论
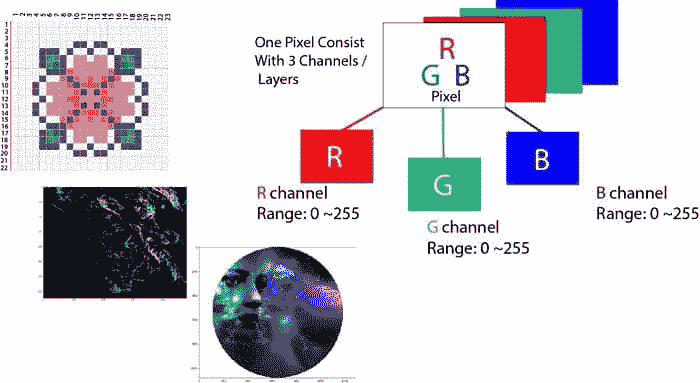
简介:关于像素的一点点信息
计算机将图像存储为微小方块的马赛克。这类似于古老的马赛克艺术形式,或今天孩子们玩耍的熔化珠子套件。如果这些方块瓷砖太大,就很难制作平滑的边缘和曲线。我们使用的方块越多且越小,图像就会越平滑,或者说像素化程度越低。这有时被称为图像的分辨率。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
矢量图形是一种不同的图像存储方法,旨在避免像素相关问题。但即便是矢量图像,最终也是作为像素的马赛克显示。像素这个词意味着图像元素。描述每个像素的一种简单方法是使用三种颜色,即红色、绿色、蓝色。这就是我们所称的RGB图像。
在 RGB 图像中,每个像素由三个8 位数字表示,分别对应红色、绿色、蓝色的值。最终,通过放大镜查看,如果我们放大一张图片,我们会看到这张图片由微小的光点组成,或者更具体地说,就是这些像素,而更有趣的是看到这些微小的光点实际上是不同颜色的小光点,这些颜色无非就是红色、绿色、蓝色通道。
像素从远处来看,组成一幅图像,而近看它们只是开和关的小光点。这些光点的组合创建了图像,基本上就是我们每天在屏幕上看到的。
每一张数字照片都由像素组成。它们是构成图像的最小信息单元。通常是圆形或方形,通常排列在二维网格中。
现在,如果所有三个值都是最大强度,即 255,它们显示为白色;如果所有三个颜色都被抑制,或值为 0,颜色则显示为黑色。这三者的组合将产生特定的像素颜色的阴影。由于每个数字是一个8 位数字,其值范围从 0 到 255。
这三种颜色的组合将趋向于它们之间的最高值。由于每个值可以有 256 种不同的强度或亮度值,因此总共形成了1680万种色调。
在这里,我们将观察一些基本的图像数据分析内容,使用 Numpy 和一些相关的 Python 包,如imageio、matplotlib等。
-
导入图像并观察其属性
-
分离层
-
灰度图
-
对像素值使用逻辑运算符
-
使用逻辑运算符进行掩膜处理
-
卫星图像数据分析
导入图像
现在让我们加载一张图像,并观察其各种属性。
if__name__=='__main__':
import imageio
import matplotlib.pyplotasplt
%matplotlibinline
pic=imageio.imread('F:/demo_2.jpg')
plt.figure(figsize=(15,15))
plt.imshow(pic)

观察图像的基本属性
print('Type of the image : ',type(pic))
print()
print('Shape of the image : {}'.format(pic.shape))
print('Image Hight {}'.format(pic.shape[0]))
print('Image Width {}'.format(pic.shape[1]))
print('Dimension of Image {}'.format(pic.ndim))
-Output:
Type of the image :<class 'imageio.core.util.Image'>
Shape of the image : (562, 960, 3)
Image Height 562
Image Width 960
Dimension of Image 3
ndarray 的形状是一个三层矩阵。这里的前两个数字是长度和宽度,第三个数字(即 3)代表三层:红色、绿色、蓝色。因此,如果我们计算 RGB 图像的大小,总大小将被计算为高度 x 宽度 x 3
print('Image size {}'.format(pic.size))
print('Maximum RGB value in this image {}'.format(pic.max()))
print('Minimum RGB value in this image {}'.format(pic.min()))
Image size 1618560
Maximum RGB value in this image 255
Minimum RGB value in this image 0
这些值很重要,因为八位色彩强度不能超出 0 到 255 的范围。
现在,使用分配给图片的变量,我们还可以访问图像中的任何特定像素值,并进一步分别访问每个RGB通道。
'''
Let's pick a specific pixel located at 100 th Rows and 50 th Column.
And view the RGB value gradually.
'''
pic[100, 50 ]
Image([109, 143, 46], dtype=uint8)
在这些情况下:R = 109;G = 143;B = 46,我们可以看出这个特定的像素中有很多绿色。现在,我们也可以通过提供这三个通道的索引值来专门选择其中一个。现在我们知道了
-
0索引值对应于红色通道
-
1索引值对应于绿色通道
-
2索引值对应于蓝色通道
但值得注意的是,在 OpenCV 中,图像采用的是 BGR 而不是 RGB。imageio.imread加载图像为 RGB(或 RGBA),但 OpenCV 假设图像为BGR 或 BGRA(BGR 是 OpenCV 的默认颜色格式)。
*# A specific pixel located at Row : 100 ; Column : 50*
*# Each channel's value of it, gradually R , G , B*
print('Value of only R channel {}'.format(pic[ 100, 50, 0]))
print('Value of only G channel {}'.format(pic[ 100, 50, 1]))
print('Value of only B channel {}'.format(pic[ 100, 50, 2]))
Value of only R channel 109
Value of only G channel 143
Value of only B channel 46
好的,现在让我们快速查看整张图像中的每个通道。
plt.title('R channel')
plt.ylabel('Height {}'.format(pic.shape[0]))
plt.xlabel('Width {}'.format(pic.shape[1]))
plt.imshow(pic[ : , : , 0])
plt.show()
plt.title('G channel')
plt.ylabel('Height {}'.format(pic.shape[0]))
plt.xlabel('Width {}'.format(pic.shape[1]))
plt.imshow(pic[ : , : , 1])
plt.show()
plt.title('B channel')
plt.ylabel('Height {}'.format(pic.shape[0]))
plt.xlabel('Width {}'.format(pic.shape[1]))
plt.imshow(pic[ : , : , 2])
plt.show()
现在,我们还可以更改 RGB 值的数量。例如,让我们将以下行的红色、绿色、蓝色层设置为完全强度。
-
R 通道:行- 100 到 110
-
G 通道:行- 200 到 210
-
B 通道:行- 300 到 310
我们将加载图像一次,以便我们可以同时可视化每个变化。
pic =imageio.imread('F:/demo_2.jpg')
pic[50:150 , : , 0] =255*# full intensity to those pixel's R channel*
plt.figure( figsize= (10,10))
plt.imshow(pic)
plt.show()
pic[200:300 , : , 1] =255*# full intensity to those pixel's G channel*
plt.figure( figsize= (10,10))
plt.imshow(pic)
plt.show()
pic[350:450 , : , 2] =255*# full intensity to those pixel's B channel*
plt.figure( figsize= (10,10))
plt.imshow(pic)
plt.show()
为了更清楚,我们还会更改列部分,这次我们将同时更改 RGB 通道。
*# set value 200 of all channels to those pixels which turns them to white*
pic[50:450 , 400:600 , [0,1,2] ] =200
plt.figure( figsize= (10,10))
plt.imshow(pic)
plt.show()
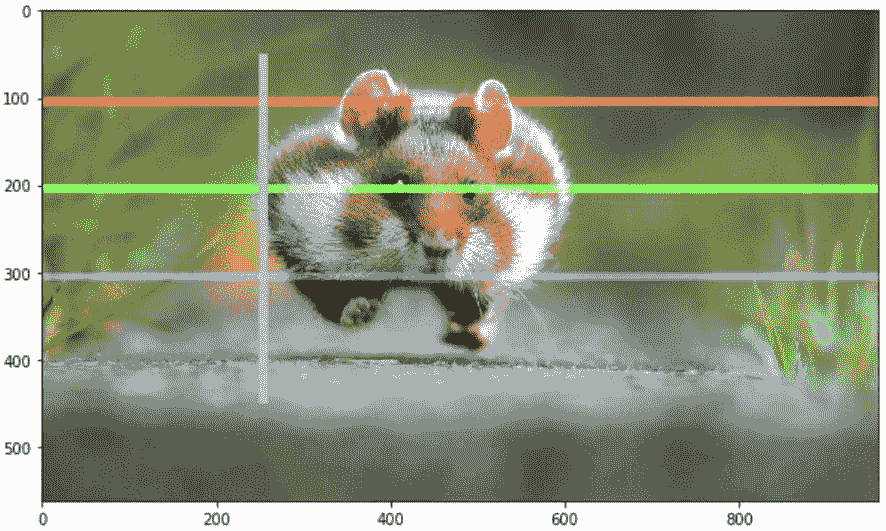
分离层
现在,我们知道每个像素由三个整数表示。将图像分成单独的颜色组件只是提取图像数组中正确切片的问题。
importnumpyasnp
pic=imageio.imread('F:/demo_2.jpg')
fig,ax=plt.subplots(nrows=1,ncols=3,figsize=(15,5))
forc,axinzip(range(3),ax):
*# create zero matrix*
split_img=np.zeros(pic.shape,dtype="uint8")*# 'dtype' by default: 'numpy.float64'*
*# assing each channel* split_img[:,:,c]=pic[:,:,c]
*# display each channel*ax.imshow(split_img)
灰度
黑白图像存储在二维数组中。黑白图像有两种类型:
-
灰度:灰度范围:0~ 255
-
二值化:像素要么是黑色,要么是白色:0 或 255
现在,灰度化是将图像从全色彩转换为灰度阴影的过程。在图像处理工具中,例如:在 OpenCV 中,许多函数在处理之前使用灰度图像,这是因为它简化了图像,几乎起到噪声减少的作用,并且由于图像中的信息较少而增加了处理时间。
有几种方法可以在 Python 中 将图像转换为灰度。但使用 matplotlib 的直接方法是使用 这个 公式计算原始图像的 RGB 值的加权平均值。
Y' = 0.299 R + 0.587 G + 0.114 B
pic=imageio.imread('F:/demo_2.jpg')
gray=lambdargb:np.dot(rgb[...,:3],[0.299,0.587,0.114])
gray=gray(pic)
plt.figure(figsize=(10,10))
plt.imshow(gray,cmap=plt.get_cmap(name='gray'))
plt.show()

不过,GIMP 将颜色转换为灰度图像的软件有三种算法来完成这个任务。
明度 灰度将被计算为
Lightness = ½ × (max(R,G,B) + min(R,G,B))
亮度 灰度将被计算为
Luminosity = 0.21 × R + 0.72 × G + 0.07 × B
平均值 灰度将被计算为
Average Brightness = (R + G + B) ÷ 3
让我们尝试一下他们的一个算法,比如亮度。
pic=imageio.imread('F:/demo_2.jpg')
gray=lambdargb:np.dot(rgb[...,:3],[0.21,0.72,0.07])
gray=gray(pic)
plt.figure(figsize=(10,10))
plt.imshow(gray,cmap=plt.get_cmap(name='gray'))
plt.show()
'''Let's take a quick overview some the changed properties now the color image.
Like we observe some properties of color image,
same statements are applying now for gray scaled image.'''
print('Type of the image : ',type(gray))
print()
print('Shape of the image : {}'.format(gray.shape))
print('Image Hight {}'.format(gray.shape[0]))
print('Image Width {}'.format(gray.shape[1]))
print('Dimension of Image {}'.format(gray.ndim))
print()
print('Image size {}'.format(gray.size))
print('Maximum RGB value in this image {}'.format(gray.max()))
print('Minimum RGB value in this image {}'.format(gray.min()))
print('Random indexes [X,Y] : {}'.format(gray[100,50]))

Type of the image :<class 'imageio.core.util.Image'>
Shape of the image : (562,960)
Image Height 562
Image Width 960
Dimension of Image 2
Image size 539520
Maximum RGB value in this image 254.9999999997
Minimum RGB value in this image 0.0
Random indexes [X,Y] : 129.07
这里是 第二部分。
简介:Mohammed Innat 目前是电子与通信专业的四年级本科生。他热衷于将自己的机器学习和数据科学知识应用于医疗保健和犯罪预测领域,以便在医疗行业和安全部门工程更好的解决方案。
相关内容:
更多相关内容
构建一个基本的 Keras 神经网络 Sequential 模型
原文:
www.kdnuggets.com/2018/06/basic-keras-neural-network-sequential-model.html
评论
正如标题所示,本篇文章介绍了如何使用 Sequential 模型 API 构建一个基本的 Keras 神经网络。这里的具体任务是一个常见任务(在 MNIST 数据集上训练分类器),但这可以被视为处理任何类似任务的模板示例。
这种方法基本上与 Chollet 的 Keras 4 步工作流程 相符,他在他的书 "Python 深度学习" 中概述了这一流程,实际上无非就是在书的早期章节或官方 Keras 教程中可以找到的示例。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织进行 IT
制作这样一篇文章的动机是将其作为一系列即将发布的文章的基础参考,这些文章将以不同的方式配置 Keras。这似乎比在每篇文章开头一遍又一遍地覆盖相同的内容要更好。对于那些没有在 Keras 中构建神经网络经验的人来说,内容应该本身就很有用。

图片来自 Keras 文档网站 的截图
使用的数据集是 MNIST,构建的模型是一个密集层的 Sequential 网络,暂时故意避免使用 CNN。
首先是导入库和一些超参数以及数据调整大小的变量。
from keras import models
from keras.layers import Dense, Dropout
from keras.utils import to_categorical
from keras.datasets import mnist
from keras.utils.vis_utils import model_to_dot
from IPython.display import SVG
import livelossplot
plot_losses = livelossplot.PlotLossesKeras()
NUM_ROWS = 28
NUM_COLS = 28
NUM_CLASSES = 10
BATCH_SIZE = 128
EPOCHS = 10
接下来是一个用于输出我们数据集的简单(但有用的)元数据的函数。由于我们会使用几次,将这些几行代码放在一个可调用的函数中是有意义的。可重用的代码本身就是一个目标 😃
def data_summary(X_train, y_train, X_test, y_test):
"""Summarize current state of dataset"""
print('Train images shape:', X_train.shape)
print('Train labels shape:', y_train.shape)
print('Test images shape:', X_test.shape)
print('Test labels shape:', y_test.shape)
print('Train labels:', y_train)
print('Test labels:', y_test)
接下来我们加载我们的数据集(MNIST,使用 Keras 的数据集工具),然后使用上述函数获取一些数据集元数据。
# Load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Check state of dataset
data_summary(X_train, y_train, X_test, y_test)
Train images shape: (60000, 28, 28)
Train labels shape: (60000,)
Test images shape: (10000, 28, 28)
Test labels shape: (10000,)
Train labels: [5 0 4 ... 5 6 8]
Test labels: [7 2 1 ... 4 5 6]
为了将 MNIST 实例输入神经网络,它们需要从二维图像表示转换为一维序列。我们还将类向量转换为二进制矩阵(使用 to_categorical)。下面完成了这一转换,然后再次调用之前定义的相同函数以展示数据重塑的效果。
# Reshape data
X_train = X_train.reshape((X_train.shape[0], NUM_ROWS * NUM_COLS))
X_train = X_train.astype('float32') / 255
X_test = X_test.reshape((X_test.shape[0], NUM_ROWS * NUM_COLS))
X_test = X_test.astype('float32') / 255
# Categorically encode labels
y_train = to_categorical(y_train, NUM_CLASSES)
y_test = to_categorical(y_test, NUM_CLASSES)
# Check state of dataset
data_summary(X_train, y_train, X_test, y_test)
Train images shape: (60000, 784)
Train labels shape: (60000, 10)
Test images shape: (10000, 784)
Test labels shape: (10000, 10)
Train labels: [[0\. 0\. 0\. ... 0\. 0\. 0.]
[1\. 0\. 0\. ... 0\. 0\. 0.]
[0\. 0\. 0\. ... 0\. 0\. 0.]
...
[0\. 0\. 0\. ... 0\. 0\. 0.]
[0\. 0\. 0\. ... 0\. 0\. 0.]
[0\. 0\. 0\. ... 0\. 1\. 0.]]
Test labels: [[0\. 0\. 0\. ... 1\. 0\. 0.]
[0\. 0\. 1\. ... 0\. 0\. 0.]
[0\. 1\. 0\. ... 0\. 0\. 0.]
...
[0\. 0\. 0\. ... 0\. 0\. 0.]
[0\. 0\. 0\. ... 0\. 0\. 0.]
[0\. 0\. 0\. ... 0\. 0\. 0.]]
所有所需的数据转换都已完成。现在是时候构建、编译和训练神经网络了。你可以在 这篇文章 中查看更多关于此过程的内容。
# Build neural network
model = models.Sequential()
model.add(Dense(512, activation='relu', input_shape=(NUM_ROWS * NUM_COLS,)))
model.add(Dropout(0.5))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(10, activation='softmax'))
# Compile model
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train model
model.fit(X_train, y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
callbacks=[plot_losses],
verbose=1,
validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
唯一的不传统步骤(就使用 Keras 库而言)是使用 Live Loss Plot 回调,该回调在每个训练周期结束时输出逐周期的损失函数和准确率。确保在运行上述代码之前已安装 Live Loss Plot。我们还给出了测试数据集上的最终损失和准确率。
Test loss: 0.09116139834111646
Test accuracy: 0.9803
几乎完成了,但首先让我们输出我们构建的神经网络的总结。
# Summary of neural network
model.summary()
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 256) 131328
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 2570
=================================================================
Total params: 535,818
Trainable params: 535,818
Non-trainable params: 0
最后,视觉化模型:
# Output network visualization
SVG(model_to_dot(model).create(prog='dot', format='svg'))
完整代码如下:
如前所述,这篇文章并没有涉及任何创新内容,但我们将发布一系列使用 Keras 的后续文章,希望能更吸引读者,并且这个常见的起点对参考应该是有益的。
此外,对于那些寻找使用 Keras Sequential 模型构建神经网络的简化方法的读者,这篇文章应该能作为一个基础指南,涵盖沿途所有重要的点。训练后的工作由你决定(目前),但我们未来也会再次讨论这个话题。
相关:
-
Keras 4 步工作流
-
掌握 Keras 深度学习的 7 个步骤
-
今天我在午休时使用 Keras 构建了一个神经网络
更多相关主题
Python 中的基础统计学:描述性统计
原文:
www.kdnuggets.com/2018/08/basic-statistics-python-descriptive-statistics.html
评论
作者:Christian Pascual,Dataquest
统计学领域常常被误解,但它在我们日常生活中扮演着重要角色。正确进行统计学分析可以让我们从模糊、复杂和困难的现实世界中提取知识。如果使用不当,统计学也可能被用来伤害和误导。清楚地理解统计学和各种统计度量的含义对于区分真相和误导至关重要。
我们将在本文中覆盖以下内容:
-
定义统计学
-
描述性统计
-
集中趋势的度量
-
离散度的度量
-
前提条件:
本文假设没有统计学的先验知识,但需要至少具备一般的 Python 知识。如果你对for循环和列表感到不舒服,我建议在继续之前简要了解这些内容。
加载我们的数据
我们将把统计学讨论的根基建立在现实世界的数据上,这些数据来自 Kaggle 的Wine Reviews数据集。数据本身来源于一个抓取程序,该程序扫描了Wine Enthusiast 网站。
为了这篇文章的目的,假设你是一名正在培训中的侍酒师,还是一名新的品酒师。你发现了一个有趣的葡萄酒数据集,你希望比较和对比不同的葡萄酒。你将使用统计学来描述数据集中的葡萄酒,并为自己得出一些见解。也许我们可以从一组便宜的葡萄酒开始培训,或者从评分最高的葡萄酒开始?
下面的代码将数据集wine-data.csv加载到一个名为wines的变量中,作为列表的列表。我们将在整个文章中对wines进行统计。你可以使用这段代码在自己的计算机上跟随操作。
import csv
with open("wine-data.csv", "r", encoding="latin-1") as f:
wines = list(csv.reader(f))
我们简要查看数据表的前五行,以便了解我们正在处理的值类型。
| index | 国家 | 描述 | 指定 | 分数 | 价格 | 省份 | 区域 _1 | 区域 _2 | 品种 | 酒庄 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 美国 | "这款 100%..." | Martha's Vineyard | 96 | 235 | 加利福尼亚 | 纳帕谷 | 纳帕 | 赤霞珠 | Heitz |
| 1 | 西班牙 | "成熟的无花果香气..." | Carodorum Selecci Especial Reserva | 96 | 110 | 西北西班牙 | 托罗 | Tinta de Toro | Bodega Carmen Rodriguez | |
| 2 | 美国 | "Mac Watson honors... | 特选晚收 | 96 | 90 | 加利福尼亚 | 骑士谷 | 索诺玛 | 长相思 | Macauley |
| 3 | 美国 | "这款酒陈放了 20 个月..." | Reserve | 96 | 65 | 俄勒冈 | 威拉米特谷 | 威拉米特谷 | 黑比诺 | Ponzi |
| 4 | 法国 | "这是顶级的葡萄酒..." | La Brelade | 95 | 66 | 普罗旺斯 | 邦多尔 | 普罗旺斯红葡萄酒混合 | Domaine de la Begude |
统计学究竟是什么?
这个问题非常复杂。统计学是许许多多的东西,因此试图将其压缩成简短的总结无疑会掩盖一些细节,但我们必须从某个地方开始。
作为一个整体领域,统计学可以被视为一个科学的数据处理框架。这一定义包括了与数据的收集、分析和解释相关的所有任务。统计学也可以指代表数据本身的总结或方面的个别测量。贯穿整篇文章,我们将尽力区分这一领域和实际的测量。
这自然引出了一个问题:什么是数据?幸运的是,数据的定义相对简单。数据是对世界的观察的广泛集合,性质可以是定性的也可以是定量的。研究人员通过实验收集数据,企业家通过用户收集数据,游戏公司则收集玩家行为的数据。
这些例子指出了数据的另一个重要方面:观察通常涉及一个感兴趣的总体。回到之前的例子,研究人员可能在研究一组具有特定病症的患者。对于我们的数据来说,涉及的总体是一组葡萄酒评论。术语总体有意含糊。通过清晰定义我们的总体,我们能够对数据进行统计分析,并从中提取知识。
那么,我们为什么要关注总体呢?能够比较和对比总体对于测试我们对世界的观点是非常有用的。我们希望知道接受新治疗的患者是否真的比接受安慰剂的患者表现更好,但我们也希望定量证明这一点。这就是统计学的作用:提供一种严格的方法来处理数据,并根据现实世界中的实际事件而非抽象的猜测做出决策。
关键要点:
-
统计学是数据的科学。
-
数据是对感兴趣的总体的任何观察集合。
-
统计学为我们提供了一种具体的方式,通过数字而非模糊的描述来比较总体。
描述统计学
当我们拥有一组观察数据时,将数据特征总结成一个单一的陈述,即描述统计量,是很有用的。正如其名称所示,描述统计量描述了它们所总结的数据的特定特征。这些统计量分为两个主要类别:中心趋势的测量和分布的测量。
中心趋势的测量
中心趋势的度量是表示以下问题答案的指标:“我们的数据中间部分是什么样的?”“中间”这个词比较模糊,因为我们可以用多种定义来表示中间。我们将探讨每种新的度量如何改变我们对中间的定义。
均值
均值 是一个描述统计量,用于查看数据集的平均值。虽然均值是技术术语,但大多数人会理解为平均值。
这个均值是如何计算的?下面的图片展示了实际的方程式,并将计算组件分解为更简单的术语。

对于均值来说,数据集的“中间”指的是这个典型值。均值代表一个典型的观察值。如果我们随机选择一个观察值,那么很可能得到一个接近均值的值。
在 Python 中计算均值是一个简单的任务。我们来找出数据集中葡萄酒评分的平均值。
# Extract all of the scores from the data set
scores = [float(w[4]) for w in wines]
# Sum up all of the scores
sum_score = sum(scores)
# Get the number of observations
num_score = len(scores)
# Now calculate the average
avg_score = sum_score/num_score
avg_score
>>> 87.8884184721394
数据集中葡萄酒的平均评分告诉我们,数据集中“典型”的评分大约是 87.8。这个结果表明,大多数葡萄酒的评分很高,假设评分范围是 0 到 100。然而,我们必须注意到 Wine Enthusiast 网站选择不发布评分低于 80 的评论。
均值有多种类型,但这种形式是最常见的。这个均值被称为算术均值,因为我们是在对感兴趣的值进行求和。
中位数
我们接下来要讨论的中心趋势度量是中位数。中位数也试图定义数据集中的典型值,但与均值不同,它不需要计算。
要找到中位数,我们首先需要将数据集按升序重新排序。然后,中位数是与数据集中的中间部分相一致的值。如果有偶数个项,我们则取“包围”中间的两个值的平均值。

虽然 Python 的标准库不支持中位数函数,但我们仍然可以使用我们描述的过程来找到中位数。我们来尝试找出葡萄酒价格的中位数值。
# Isolate prices from the data set
prices = [float(w[5]) for w in wines if w[5] != ""]
# Find the number of wine prices
num_wines = len(prices)
# We'll sort the wine prices into ascending order
sorted_prices = sorted(prices)
# We'll calculate the middle index
middle = (num_wines / 2) + 0.5
# Now we can return the median
sorted_prices[middle]
>>> 24
数据集中一瓶葡萄酒的中位数价格是 $24。这一发现表明,数据集中至少有一半的葡萄酒售价为 $24 或更少。这相当不错!如果我们试图找到均值会怎样呢?考虑到它们都代表典型值,我们会期望它们大致相同。
sum(prices)/len(prices)
>>> 33.13
平均价格 $33.13 显然与我们的中位数价格相差很远,那么这里发生了什么?均值和中位数之间的差异是由于鲁棒性。
异常值的问题
记住,均值是通过将我们想要的所有值相加并除以项目数量来计算的,而中位数则是通过简单地重新排列项目来找到的。如果我们的数据中有异常值,即比其他值高或低得多的项目,它可能对均值产生不利影响。也就是说,均值对异常值不稳健。中位数由于不考虑异常值,因此对异常值是稳健的。
让我们来看一下数据中的最高价和最低价。
min_price = min(prices)
max_price = max(prices)
print(min_price, max_price)
4.0, 2300.0
我们现在知道数据中存在异常值。异常值可以代表数据收集中的有趣事件或错误,因此识别它们何时存在是很重要的。中位数和众数的比较只是检测异常值存在的众多方法之一,尽管可视化通常是检测它们的更快方法。
众数
我们将讨论的最后一个中心趋势测量是众数。众数定义为在数据中出现最频繁的值。众数作为“中间”的直觉不像均值或中位数那样直接,但有明确的理由。如果一个值在数据中反复出现,我们也知道它将影响均值朝向众数值。值出现的越多,它对均值的影响也越大。因此,众数代表了对我们均值贡献最大的因素。
与中位数一样,Python 中没有内置的众数函数,但我们可以通过计算价格的出现次数并寻找最大值来确定众数。
# Initialize an empty dictionary to count our price appearances
price_counts = {}
for p in prices:
if p not in price_counts:
counts[p] = 1
else:
counts[p] += 1
# Run through our new price_counts dictionary and log the highest value
maxp = 0
mode_price = None
for k, v in counts.items():
if maxp < v:
maxp = v
mode_price = k
print(mode_price, maxp)
>>> 20.0, 7860
众数与中位数相当接近,因此我们可以有信心地认为中位数和众数都代表了我们葡萄酒价格的中间值。
中心趋势的测量有助于总结我们数据中的平均观测值是什么样的。然而,它们并不能告诉我们数据的扩散程度。这些扩散的总结就是扩散测量所帮助描述的内容。
扩散测量
扩散测量(也称为离散度)回答了“我的数据有多变?”的问题。世界上很少有事物在我们观察每次都保持不变。我们都知道有人会因自然波动而抱怨体重的微小变化,而不是明显的体重增加。这种变异使世界变得模糊和不确定,因此拥有总结这种“模糊性”的度量是有用的。
范围和四分位差
我们将讨论的第一个扩散测量是范围。范围是我们看到的测量中最简单的计算方法:只需从数据集中最大的值中减去最小的值即可。
我们在调查中位数时发现了葡萄酒价格的最小值和最大值,因此我们将使用这些来找到范围。
price_range = max_price - min_price
print(price_range)
>>> 2296.0
我们发现了一个范围为 2296,但这具体是什么意思?当我们查看各种度量时,重要的是要将所有这些信息放在数据的背景下。我们的中位数价格为 24 美元,而范围是 2296 美元。范围是中位数的两个数量级,因此这表明我们的数据非常分散。也许如果我们有另一个酒的数据集,我们可以比较这两个数据集的范围,从而了解它们的差异。否则,仅凭范围并不太有帮助。
更常见的是,我们希望查看数据与典型值的偏差程度。这个总结属于标准差和方差的范畴。
标准差
标准差也是观察值分布的一种度量,但它表明了数据偏离典型数据点的程度。也就是说,标准差总结了数据与均值的差异。这种与均值的关系在标准差的计算中很明显。

方程的结构值得讨论。回忆一下,均值是通过将所有观察值相加并除以观察值的数量来计算的。标准差方程类似,但试图计算平均偏差,还包括一个额外的平方根操作。
你可能会在其他地方看到n作为分母而不是n-1。这些细节的具体情况超出了本文的范围,但要知道使用n-1通常被认为更为准确。有关解释的链接在本文末尾。
我们希望计算标准差以更好地描述我们的酒价格和分数,因此我们将创建一个专门的函数来实现这一点。手动计算数字的累积和很麻烦,但 Python 的for循环使这变得简单。我们正在制作自己的函数,以展示 Python 使这些统计计算变得容易,但也值得知道numpy库在std下实现了标准差。
def stdev(nums):
diffs = 0
avg = sum(nums)/len(nums)
for n in nums:
diffs += (n - avg)**(2)
return (diffs/(len(nums)-1))**(0.5)
print(stdev(scores))
>>> 3.2223917589832167
print(stdev(prices))
>>> 36.32240385925089
这些结果是预期的。分数仅在 80 到 100 之间,因此我们知道标准差会很小。相比之下,价格数据及其异常值产生了更高的标准差。标准差越大,数据围绕均值的分布越广,反之亦然。
我们将看到方差与标准差密切相关。
方差
通常,标准差和方差被一起提及是有充分理由的。以下是方差的方程式,你觉得它看起来熟悉吗?

方差和标准差几乎是完全一样的!方差只是标准差的平方。同样,方差和标准差代表了相同的东西——一个分散程度的测量——但值得注意的是它们的单位不同。无论你的数据单位是什么,标准差都会保持不变,而方差的单位则是单位的平方。
许多统计学初学者会问一个问题:"但为什么我们要平方偏差?绝对值不是可以消除和中的麻烦负数吗?"虽然消除负数是平方操作的一个原因,但这并不是唯一的原因。与均值一样,方差和标准差也受到异常值的影响。许多时候,异常值也是我们数据集中的兴趣点,因此平方与均值的差异使我们能够指出这一重要性。如果你熟悉微积分,你会发现有一个指数项可以帮助我们找到最小偏差点的位置。
通常情况下,你所做的任何统计分析都只需要均值和标准差,但方差在其他学术领域中仍然具有重要意义。集中趋势和分散度的度量允许我们总结数据集的关键方面,我们可以在这些总结的基础上从数据中获得更多洞见。
关键要点
-
描述性统计提供了我们数据的简单总结。
-
(算术)均值计算的是我们数据集的典型值。它不是稳健的。
-
中位数是我们数据集中确切的中间值。它是稳健的。
-
众数是出现次数最多的值。
-
范围是我们数据集中最大值和最小值之间的差异。
-
方差和标准差是平均距离均值的度量。
结论
容易被统计方程和细节所困扰,但理解这些概念所代表的含义很重要。在本文中,我们探讨了一些基本描述性统计的细节,同时通过查看一些葡萄酒数据来使我们的概念更为具体。
在下一部分中,我们将讨论统计学与概率的关系。我们在这里学习的描述性统计在理解这种联系中起着关键作用,因此在继续之前,记住这些概念所代表的含义很重要。
进一步阅读:
在文章早些时候,我们略过了为什么标准差的公式中有一个n-1项而不是n。使用n-1项被称为贝塞尔修正。
原文。经许可转载。
相关内容:
-
描述性统计关键术语解析
-
解释正态分布的 68-95-99.7 规则
-
为什么数据科学家喜欢高斯分布
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关主题
Python 中的基本统计学:概率
原文:
www.kdnuggets.com/2018/08/basic-statistics-python-probability.html
评论
作者:Christian Pascual,Dataquest
学习统计学时,你不可避免地需要了解概率论。虽然容易陷入概率的公式和理论中,但它在工作和日常生活中都有重要的应用。我们已经讨论过一些描述性统计的基本概念;现在我们将探讨统计学如何与概率论相关联。
前提条件:
类似于之前的帖子,本文假设没有统计学的先验知识,但需要至少具备基本的 Python 知识。如果你对for 循环和列表感到不熟悉,我建议你在继续之前简单学习一下它们。
什么是概率?
在最基本的层面上,概率试图回答这个问题:“事件发生的机会有多大?”一个事件是指感兴趣的某个结果。为了计算事件发生的机会,我们还需要考虑所有可能发生的其他事件。
概率的典型表示就是简单的掷硬币。在掷硬币中,唯一可能发生的事件是:
-
翻到正面
-
翻到反面
这两个事件形成了样本空间,即所有可能发生的事件的集合。要计算事件发生的概率,我们需要计算感兴趣的事件(比如掷出正面)的发生次数,并将其除以样本空间。因此,概率告诉我们理想的硬币正面或反面的机会是 1/2。通过观察可能发生的事件,概率为我们提供了一个框架,用于做出预测,即事件发生的频率。
然而,即使看起来很明显,如果我们真的尝试掷一些硬币,我们可能会偶尔得到异常高或低的正面次数。如果我们不想假设硬币是公平的,我们该怎么办?我们可以收集数据!我们可以使用统计学根据现实世界的观察来计算概率,并检查它与理想情况的比较。
从统计学到概率论
我们的数据将通过掷硬币 10 次并计算获得多少次正面来生成。我们将一组 10 次掷硬币称为试验。我们的数据点将是我们观察到的正面次数。我们可能得不到“理想的”5 次正面,但我们不会太担心,因为一次试验只是一个数据点。
如果我们进行很多次试验,我们期望所有试验中的平均正面朝上的次数接近 50%。下面的代码模拟了 10 次、100 次、1000 次和 1000000 次试验,并计算了观察到的正面比例的平均值。我们的过程也在下面的图像中总结了。

import random
def coin_trial():
heads = 0
for i in range(100):
if random.random() <= 0.5:
heads +=1
return heads
def simulate(n):
trials = []
for i in range(n):
trials.append(coin_trial())
return(sum(trials)/n)
simulate(10)
>> 5.4
simulate(100)
>>> 4.83
simulate(1000)
>>> 5.055
simulate(1000000)
>>> 4.999781
coin_trial函数表示对 10 次抛硬币的模拟。它使用random()函数生成 0 到 1 之间的浮点数,如果该数在这个范围的一半内,则增加heads计数。然后,simulate根据你希望的次数重复这些试验,返回所有试验中的正面平均次数。
硬币抛掷模拟给我们一些有趣的结果。首先,数据证实我们的平均正面次数确实接近概率所预测的值。此外,这个平均值在更多试验中改善。在 10 次试验中,存在一些轻微的误差,但这种误差在 1,000,000 次试验中几乎完全消失。随着试验次数的增加,偏差从平均值中减少。听起来熟悉吗?
当然,我们可以自己抛硬币,但 Python 通过允许我们在代码中建模这一过程节省了很多时间。随着数据的增加,现实世界开始接近理想情况。因此,给定足够的数据,统计学使我们能够通过现实世界的观察来计算概率。概率提供理论,而统计学提供了使用数据测试该理论的工具。描述性统计,特别是均值和标准差,成为理论的代理。
你可能会问,“如果我可以直接计算理论概率,那我为什么需要一个代理?”硬币抛掷是一个简单的玩具示例,但更有趣的概率并不是那么容易计算的。有人在一段时间内发展某种疾病的机会是多少?在驾驶时,关键汽车部件失败的概率是多少?
计算概率没有简单的方法,因此我们必须依靠数据和统计来进行计算。随着数据量的增加,我们可以对计算结果代表这些重要事件发生的真实概率更加自信。
也就是说,请记住从我们之前的统计帖子中你是一个正在接受培训的侍酒师。在你开始购买葡萄酒之前,你需要弄清楚哪些葡萄酒比其他葡萄酒更好。你手头有很多数据,所以我们将利用统计来指导我们的决策。
数据和分布
在我们处理“哪种酒比平均水平更好”的问题之前,我们需要考虑数据的性质。直观上,我们希望使用酒的评分来比较不同组别,但这里会有一个问题:评分通常在一个范围内。我们如何在不同类型的酒之间比较评分组,并且以某种程度的确定性知道哪一种更好呢?
进入正态分布。正态分布指的是概率与统计领域中一个特别重要的现象。正态分布的形状如下:

关于正态分布,最重要的特点是它的对称性和形状。我们称之为分布,但到底是什么被分布?这取决于背景。
在概率中,正态分布是一种特别的概率分布。x 轴表示我们想知道概率的事件值。y 轴是与每个事件相关的概率,从 0 到 1。虽然我们还没有深入讨论概率分布,但要知道正态分布是特别重要的一种概率分布。
在统计学中,我们的数据值是被分布的。这里,x 轴是我们的数据值,y 轴是这些值的计数。以下是正态分布的相同图示,但根据概率和统计背景进行了标注:

在概率的背景下,正态分布中的高点代表发生概率最高的事件。当你从这个事件的两侧远离时,概率迅速下降,形成熟悉的钟形曲线。在统计背景下,高点实际上代表的是均值。与概率一样,当你远离均值时,频率也迅速下降。也就是说,极高或极低的偏差存在,但极为罕见。
如果你怀疑正态分布在概率和统计之间存在其他关系,那么你的猜测是正确的!我们将在文章后面深入探讨这一重要关系,请稍等。
由于我们将使用评分分布来比较不同的酒,我们需要进行一些设置以捕获我们感兴趣的酒。我们将引入酒的数据,然后分开一些我们感兴趣的酒的评分。
要恢复数据,我们需要以下代码:
import csv
with open("wine-data.csv", "r", encoding="latin-1") as f:
wines = list(csv.reader(f))
数据如下表格所示。我们需要points列,因此我们将其提取到自己的列表中。我们听说过一位酒类专家说匈牙利 Tokaji 酒非常优秀,而一位朋友建议我们从意大利 Lambrusco 开始。我们有数据来比较这些酒!
如果你不记得数据的样子,这里有一个快速的表格供参考和重新熟悉。
| N | 国家 | 描述 | 评级 | 分数 | 价格 | 省份 | 区域 1 | 区域 2 | 品种 | 酒庄 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 美国 | "这瓶酒的绝对 100%..." | 玛莎葡萄园 | 96 | 235 | 加利福尼亚州 | 纳帕谷 | 纳帕 | 赤霞珠 | 海茨 |
| 1 | 西班牙 | "成熟的无花果香... | Carodorum Selecci Especial Reserva | 96 | 110 | 西北西班牙 | 托罗 | 托罗红葡萄 | 卡门·罗德里格斯酒庄 | |
| 2 | 美国 | "Mac Watson honors... | 特别挑选晚收 | 96 | 90 | 加利福尼亚州 | 骑士谷 | 索诺玛 | 长相思 | 澳门利 |
| 3 | 美国 | "这瓶酒经过了 20 个月... | 储备酒 | 96 | 65 | 俄勒冈州 | 威拉米特谷 | 威拉米特谷 | 黑皮诺 | 潘齐 |
| 4 | 法国 | "这是顶级葡萄酒... | La Brelade | 95 | 66 | 普罗旺斯 | 邦多尔 | 普罗旺斯红葡萄酒混合 | 德拉贝古酒庄 |
# Extract the Tokaji scores
tokaji = []
non_tokaji = []
for wine in wines:
if points != '':
points = wine[4]
if wine[9] == "Tokaji":
tokaji.append(float(points))
else:
non_tokaji.append(points)
# Extract the Lambrusco scores
lambrusco = []
non_lambrusco = []
for wine in wines:
if points != '':
points = wine[4]
if wine[9] == "Lambrusco":
lambrusco.append(float(points))
else:
non_lambrusco.append(float(points))
如果我们将每组评分可视化为正态分布,我们可以立即判断两个分布是否不同,基于它们的位置。但这种方法很快会遇到问题,如下所示。我们假设评分会呈正态分布,因为我们有a ton的数据。虽然这个假设在这里是可以接受的,但稍后我们将讨论在什么情况下这样做可能会有危险。

当两个评分分布重叠过多时,最好假设它们实际上来自同一分布,而不是不同的分布。另一方面,如果完全没有重叠,则可以安全地假设这些分布不是相同的。我们的难点在于一些重叠的情况。鉴于一个分布的极高值可能与另一个分布的极低值相交,我们如何判断这些组是否不同?
在这里,我们必须再次利用正态分布来为我们提供答案,并搭建统计学与概率论之间的桥梁。
再次审视正态分布
正态分布对概率和统计学的重要性在于两个因素:中心极限定理和三西格玛法则。
中心极限定理
在上一节中,我们演示了如果我们多次重复 10 次掷硬币的试验,那么所有这些试验的平均正面出现次数将接近我们期望的理想硬币的 50%。随着试验次数的增加,这些试验的平均值将更接近真实概率,即使个别试验本身是不完美的。这一思想是中心极限定理的一个关键原则。
在我们的抛硬币示例中,一次 10 次抛掷的试验产生了一个估计值,即概率所建议的应该发生的情况(5 个正面)。我们称之为估计值,因为我们知道它不会是完美的(即我们不会每次都得到 5 个正面)。如果我们进行许多估计,中心极限定理规定这些估计值的分布将呈现正态分布。这种分布的峰值将与估计值应当取得的真实值对齐。在统计学中,正态分布的峰值与均值对齐,这正是我们观察到的。因此,给定多个“试验”作为我们的数据,中心极限定理建议,即使我们不知道真实概率,我们也可以接近概率所给出的理论理想。
中心极限定理让我们知道,许多试验的平均值将接近真实均值,三西格玛规则将告诉我们数据在这个均值周围的分布情况。
三西格玛规则
三西格玛规则,也称为经验规则或 68-95-99.7 规则,是关于我们观察值落在均值的某个距离内的表达。请记住,标准差(也称为“σ”)是数据集中一个观察值距离均值的平均距离。
三西格玛规则规定在正态分布下,68%的观察值将落在均值一个标准差范围内。95%将落在两个标准差范围内,99.7%将落在三个标准差范围内。推导这些值需要很多复杂的数学运算,因此超出了本文的范围。关键是要知道,三西格玛规则使我们能够了解在正态分布的不同区间内包含的数据量。下图是三西格玛规则的一个很好的总结。

我们将这些概念应用到我们的葡萄酒数据中。作为一名侍酒师,我们希望能够高度自信地知道查尔多内和黑比诺比普通葡萄酒更受欢迎。我们有成千上万条葡萄酒评论,因此根据中心极限定理,这些评论的平均分数应该与所谓的葡萄酒质量的“真实”表现(由评论者判断)一致。
尽管三西格玛规则是关于数据中有多少数据落在已知值范围内的陈述,但它也表明了极端值的稀有性。任何与均值相差超过三倍标准差的值都应当谨慎对待。通过利用三西格玛规则和Z 分数,我们将能够最终为查尔多内和黑比诺与普通葡萄酒的差异的可能性指定一个值。
Z 分数
Z 分数是一个简单的计算,回答了“给定一个数据点,它离均值有多少个标准差?”这个问题。下面的方程式是 Z 分数方程式。

Z-score 本身并没有提供太多信息。它的最大价值在于与Z 表进行比较,Z 表列出了标准正态分布在给定 Z-score 下的累积概率。标准正态分布是均值为 0,标准差为 1 的正态分布。Z-score 使我们能够参考 Z 表,即使我们的正态分布不是标准的。
累积概率是所有值发生的概率之和,直到某一点为止。一个简单的例子是均值本身。均值是正态分布的正中间,因此我们知道,从左侧到均值的所有概率之和是 50%。如果你尝试计算标准差之间的累积概率,实际上会得到“三个西格玛规则”的值。下面的图片提供了累积概率的可视化。

我们知道所有概率的总和必须等于 100%,因此我们可以使用 Z 表来计算正态分布下 Z-score 两侧的概率。

计算超过某个 Z-score 的概率对我们来说非常有用。它让我们从“一个值离均值有多远”转到“一个值离均值这么远在同一组观察中有多可能?”因此,从 Z-score 和 Z 表得出的概率将回答我们关于葡萄酒的问题。
import numpy as np
tokaji_avg = np.average(tokaji)
lambrusco_avg = np.average(lambrusco)
tokaji_std = np.std(tokaji)
lambrusco = np.std(lambrusco)
# Let's see what the results are
print("Tokaji: ", tokaji_avg, tokaji_std)
print("Lambrusco: ", lambrusco_avg, lambrusco_std)
>>> Tokaji: 90.9 2.65015722804
>>> Lambrusco: 84.4047619048 1.61922267961
这对我们朋友的推荐看起来不太好!为了本文的目的,我们将 Tokaji 和 Lambrusco 的评分视为正态分布。因此,每种葡萄酒的平均评分将代表它们在质量上的“真实”评分。我们将计算 Z-score,看看 Tokaji 的平均值离 Lambrusco 有多远。
z = (tokaji_avg - lambrusco_avg) / lambrusco_std
>>> 4.0113309781438229
# We'll bring in scipy to do the calculation of probability from the Z-table
import scipy.stats as st
st.norm.cdf(z)
>>> 0.99996981130231266
# We need the probability from the right side, so we'll flip it!
1 - st.norm.cdf(z)
>>> 3.0188697687338895e-05
答案相当小,但这究竟意味着什么?这种概率的极小需要一些细致的解释。
假设我们相信朋友的 Lambrusco 和葡萄酒专家的 Tokaji 没有区别。也就是说,我们认为 Lambrusco 和 Tokaji 的质量大致相同。同样,由于不同葡萄酒之间的个体差异,这些葡萄酒的评分会有一些分散。如果我们绘制 Tokaji 和 Lambrusco 葡萄酒的直方图,由于中心极限定理,这将产生正态分布的评分。
现在,我们有一些数据可以计算这两种葡萄酒的均值和标准差。这些值使我们能够实际检验我们对 Lambrusco 和 Tokaji 质量相似的信念。我们使用 Lambrusco 的评分作为基础,并比较 Tokaji 的平均值,但我们也可以反过来做,唯一的区别只是 Z-score 会是负值。
Z 分数为 4.01!请记住,三西格玛规则告诉我们,99.7%的数据应落在3 个标准差之内,假设托卡伊和兰布鲁斯科是相似的。在一个假设托卡伊和兰布鲁斯科酒相同的世界里,像托卡伊那样极端的评分平均值的概率非常非常小。如此之小,以至于我们不得不考虑相反的情况:托卡伊酒与兰布鲁斯科酒不同,将产生不同的评分分布。
我们在这里仔细选择了措辞:我特意避免说“托卡伊酒比兰布鲁斯科酒更好”。它们很可能是这样。这是因为我们计算了一个概率,虽然微观上很小,但不为零。为了准确起见,我们可以说兰布鲁斯科酒和托卡伊酒确实不是来自同一评分分布,但我们不能说其中一个比另一个更好或更差。
这种推理属于推断统计学的范畴,本文仅旨在简要介绍其背后的理由。我们在本文中涵盖了许多概念,因此如果你发现自己迷失了方向,请返回并慢慢阅读。拥有这种思维框架是极其强大的,但容易被误用和误解。
结论
我们从描述性统计学开始,然后将其与概率联系起来。从概率出发,我们开发了一种量化方法来显示两个组是否来自同一分布。在这种情况下,我们比较了两种酒的推荐,并发现它们很可能不来自同一评分分布。换句话说,一种酒很可能比另一种更好。
统计学不必仅限于统计学家这个领域。作为数据科学家,对常见统计指标的直观理解将为你提供制定自己理论的优势,并随后测试这些理论的能力。我们在这里只是略微触及了推断统计学的表面,但这些基本思想将有助于指导你在统计学之旅中的直觉。我们的文章讨论了正态分布的优势,但统计学家们也开发了调整非正态分布的技术。
进一步阅读
本文围绕正态分布及其与统计学和概率的关系展开。如果你有兴趣阅读其他相关分布或学习更多关于推断统计学的内容,请参考下面的资源。
原文。已获授权转载。
相关:
-
描述性统计关键术语解释
-
解释正态分布中的 68-95-99.7 规则
-
为什么数据科学家喜欢高斯分布
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关话题
数据科学家的 GPU 计算基础
原文:
www.kdnuggets.com/2016/04/basics-gpu-computing-data-scientists.html
作者:Taposh Dutta-Roy。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 部门
数据科学家的 GPU 计算基础
GPU 已成为图像分析的新核心。越来越多的数据科学家开始考虑使用 GPU 进行图像处理。在这篇文章中,我回顾了数据科学家需要的 GPU 基础知识,并列出了 文献 中讨论的 GPU 在算法中的适用性框架。
我们先来了解什么是 GPU?
图形处理单元(GPU)最初是为了渲染图像而创建的。然而,由于其高性能和低成本,它们已成为图像处理的新标准。它们的应用领域包括图像修复、分割(标记)、去噪、过滤、插值和重建。对 GPU 的网络搜索结果是:“图形处理单元(GPU)是一个计算机芯片,执行快速的数学计算,主要用于渲染图像。”
什么是 GPU 计算?
Nvidia 的博客 定义了 GPU 计算是指使用图形处理单元(GPU)与 CPU 一起加速科学、分析、工程、消费者和企业应用程序。他们还说如果 CPU 是大脑,那么 GPU 是计算机的灵魂。
用于通用计算的 GPU 具有高度的数据并行架构。它们由多个核心组成。每个核心都有多个功能单元,例如算术和逻辑单元(ALUs)等。这些功能单元中的一个或多个用于处理每个执行线程。帮助线程的这些功能单元组称为“线程处理器”。GPU 中的所有线程处理器都执行相同的指令,因为它们共享相同的控制单元。这意味着 GPU 可以对图像的每个像素并行执行相同的指令。GPU 架构复杂且因制造商而异。GPU 市场的两个主要玩家是 Nvidia 和 AMD。Nvidia 将线程处理器称为 CUDA(计算统一设备架构)核心,AMD 称之为流处理器(SP)。
线程处理器与 CPU 核心之间的主要区别在于每个 CPU 核心可以在并行的情况下对不同的数据执行不同的指令,因为每个 CPU 核心有独立的控制单元。研究人员 将核心定义为具有独立控制流的处理单元。根据这个定义,科学家们 将共享相同控制单元的线程处理器组称为核心。GPU 设计为在一个芯片上适配多个线程处理器,而 CPU 则专注于高级控制单元和大缓存。
GPU 编程有两个主要框架——OpenCL 和 CUDA。CUDA 编程语言只能用于 Nvidia 显卡,而 OpenCL 是一个用于不同设备(包括 GPU、CPU 和 FPGA)的开放标准。几种图像处理库提供了 GPU 实现——OpenCV、ArrayFire、Nvidia Performance Primitives (NPP)、CUVLIB、Intel Integrated Performance Primitives、OpenCL Integrated Performance Primitives 和 Insight Took Kit (ITK)。其中较大的库有 OpenCV(支持 CUDA 和 OpenCL)和 ITK(仅支持 OpenCL)。
算法适用于 GPU 使用的标准
Erik Smistad 等 讨论了定义算法适用于 GPU 实现的 5 个因素。这些因素包括——数据并行性、线程数量、分支分歧、内存使用和同步。我创建了这个映射表以便于参考。
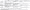
GPU 适用性决定您的算法
作为数据科学家,了解这些信息将帮助你选择适合你算法的 GPU。Nvidia CUDA 更为流行,因为大多数苹果笔记本电脑都配备了它,但其他品牌的 GPU 也在逐渐获得关注。如果你有任何问题或评论,请告诉我。
原文。
相关内容:
-
流行的深度学习工具 – 评测
-
在哪里学习深度学习 – 课程、教程、软件
-
CuDNN – 一个新的深度学习库
更多相关话题
-
[生成式 AI 游乐场:Camel-5b 和 Open LLaMA 3B 的 LLMs](https://www.kdnuggets.com/2024/02/intel-generative-ai-playground-llms-with-camel-5b-and-open-llama-3b)
-
[生成式 AI 游乐场:Text-to-Image 稳定扩散](https://www.kdnuggets.com/2024/02/intel-generative-ai-playground-text-to-image-stable-diffusion)
数据科学维恩图的战斗
原文:
www.kdnuggets.com/2016/10/battle-data-science-venn-diagrams.html/2
评论
7. 在 2014 年 2 月,Michael Malak 添加了一个第四个圆圈,声称 Conway 提到的实质性专业知识并不是指领域知识。

我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
根据 Malak 的说法,在实质性专业知识方面,他是 Inigo Montoya,而我们都是 Vizzini:“你一直在用那个词。我认为它的意思与你认为的不同。” Malak 将其分为领域专业知识,以及……呃,对某个领域的知识,比如社会科学。也许我理解力差,但我不明白这一区别。我也不确定他对整体传统研究的理解,与传统研究不同,根据其位置,它似乎不包括你正在研究的科学知识?我理解错了吗?整体科学 确实存在,但不是那种。总之,数据科学再次回到了独角兽的位置,还有三个危险区(其中一个是双重危险)。每个人都在讨厌黑客。
8. 我的下一个例子 来自 Vincent Granville 在 2014 年 4 月,但他转发了 Gartner 的内容;我不知道原始内容的日期。

这是一个数据科学解决方案的维恩图,而不是数据科学本身。因此,数据科学是其中一个圆圈,其他的专业领域(通常不在同一个人身上,但希望在同一个团队中)包括IT 技能和业务技能。文本标签指向每个切片中的非常具体的位置,这让我有点不安,但实际位置是任意的。这就是商业信息图的特点。
9. Shelly Palmer 在 2015 年为赫芬顿邮报撰写了客座博客,包括了他所写书籍中的这个图示:

完全是 Conway 的标准计算机-数学-领域三合一图示,但有一个革命性的元素:没有危险区域。现在,没有统计学知识的计算机和领域爱好者也能进行数据处理而不会搞得一团糟。这看起来很合理。编辑:对不起 Shelly,Geringer 比你早一步,你现在已经不那么引人注目了。
10. 在 2015 年 11 月,StackExchange 数据科学用户 Stephan Kolassa 提出了我个人最喜欢的图示,将通信添加到 Conway 的图示中,并将他的实质性专长改为商业:

尽管付出了很多努力,他在这个 beta 发布论坛中只获得了 21 个(我也是其中之一)赞。虽然他的分类也非常不错。我认为我属于优秀顾问。或者可能是平庸顾问。努力尝试的顾问? 是的,这就是四集维恩图的样子,而不是 Malak 上面的四个圆圈,这些圆圈并未包含所有交集的组合。
11. 在 2016 年,Matthew Mayo 博客中分享了 Gregory Piatetsky-Shapiro 的图示:

好吧,这图示借鉴了四年前 Tierney 的作品,尽管它声称是数据科学的维恩图,(a)它并不是一个维恩图,(b)数据科学在其中一个圆圈内。这倒是让人看到大数据被认可了。但是...Calibri?真的?你选择了默认字体吗?
12. 最后(我确信我没有列举全;如果你知道我遗漏了什么维恩图,请告诉我!),2016 年晚些时候,Gartner 重新设计了他们繁忙的数据解决方案图示,让它更漂亮,且只限于数据科学,正如 Christi Eubanks 在博客中所述:

我们回到了 Conway 的图示,只不过这次危险区域被数据工程师所取代。我也喜欢这些指向边缘的标记,比他们之前的混乱图示要好。
13. 未来的数据科学维恩图:
维基百科关于数据科学的页面包含了以下这个完全不是维恩图的图示:

说实话,我认为这才是看待数据科学的方式。也许不是这些具体的技能,但它确实是不同学科的协同作用。不幸的是,一项技能有时会掩盖其他技能的严重不足,从而给数据科学带来坏名声。(我可能在去年年轻的时候也为这种现象做出了一些贡献。)
当然,你还需要一个非常复杂的韦恩图。这些图确实存在:这是一个包含七个集合的图:

有人想试试吗?
原文。经许可转载。
相关:
-
(不是很)新的数据科学韦恩图
-
数据科学家是否意味着你认为的那样?
-
数据科学难题解析
了解更多相关内容
《贝叶斯定理在机器学习中的应用》
原文:
www.kdnuggets.com/2019/10/bayes-theorem-applied-machine-learning.html
评论
由Jaime Zornoza提供,马德里理工大学
在上一篇文章中,我们了解了贝叶斯定理是什么,并通过一个简单直观的例子讲解了它的工作原理。你可以在这里找到这篇文章。如果你还不知道贝叶斯定理是什么,且尚未阅读过,我建议你阅读它,这将使你更容易理解本文。
在这篇文章中,我们将探讨该定理在机器学习中的用途。
准备好了吗?那我们开始吧!
机器学习中的贝叶斯定理
正如上一篇文章所提到的,贝叶斯定理告诉我们如何逐渐更新我们的知识,随着我们获得更多关于某事的证据。
一般来说,在监督机器学习中,当我们想要训练一个模型时,主要构建块是包含特征(定义数据点的属性)、标签(我们想要在新数据点上预测的数值或分类标签)和一个假设函数或模型(将这些特征与对应标签关联起来)。我们还需要一个损失函数,它是模型预测值与实际标签之间的差异,我们希望将其减少,以获得最佳结果。
监督学习问题的主要元素
这些监督机器学习问题可以分为两大类:回归,其中我们希望计算一个与数据相关的数值(例如房价),和分类,其中我们希望将数据点分配到某个类别(例如判断图像中是狗还是猫)。
贝叶斯定理可以用于回归和分类。
我们来看看吧!
回归中的贝叶斯定理
假设我们有一组非常简单的数据,表示某个小镇地区每一天的气温(数据点的特征),以及该地区每一天售出的水瓶数量(数据点的标签)。
通过建立一个非常简单的模型,我们可以查看这两者是否相关,如果相关,就可以使用该模型进行预测,以便根据温度储备水瓶,避免库存短缺或过剩。
我们可以尝试一个非常简单的线性回归模型来查看这些变量之间的关系。在描述这个线性模型的以下公式中,y 是目标标签(在我们的例子中是水瓶的数量),每个θs 都是模型的参数(斜率和与 y 轴的截距),x 是我们的特征(在我们的例子中是温度)。
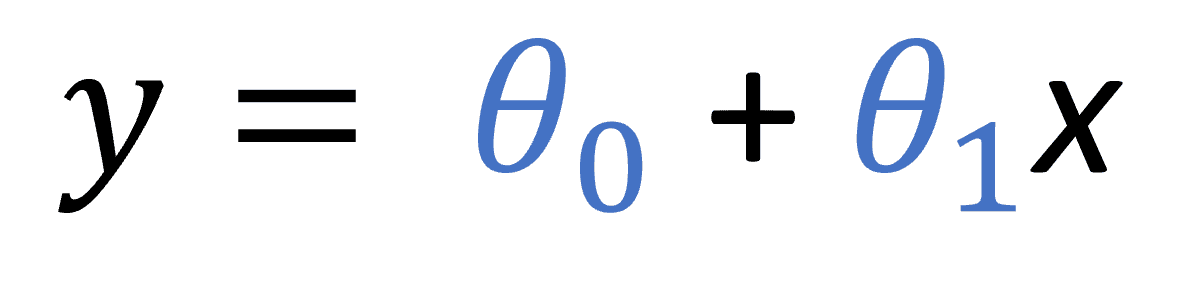
描述线性模型的方程
这次训练的目标是减少提到的损失函数,使模型对已知数据点的预测接近这些数据点的实际标签值。
在用可用数据训练模型后,我们将得到两个θs的值。这种训练可以通过使用迭代过程(如梯度下降)或其他概率方法(如最大似然法)来完成。无论如何,我们只会为每个参数得到一个单一的值。
这样,当我们获得没有标签的新数据(新的温度预测)时,由于我们知道θs 的值,我们可以仅使用这个简单的方程来获得所需的 Ys(每天所需的水瓶数量)。
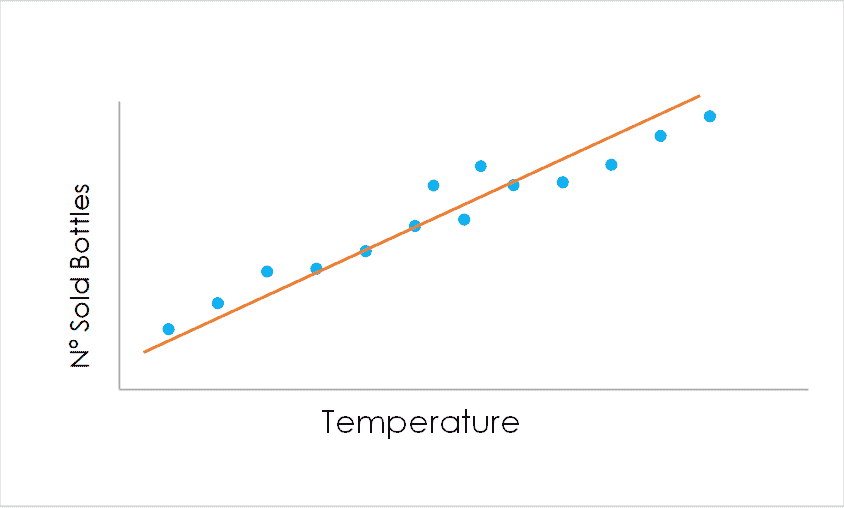
单变量线性回归的图示。使用最初的蓝色数据点,我们计算出最佳拟合这些点的直线,然后当我们获得新的温度时,我们可以轻松计算出当天销售的瓶数。
当我们使用贝叶斯定理进行回归时,我们不是将模型的参数(θs)视为唯一的单一值,而是将其表示为具有某种分布的参数:参数的先验分布。以下图示展示了通用贝叶斯公式,以及如何将其应用于机器学习模型。
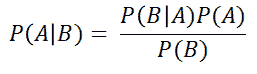
贝叶斯公式 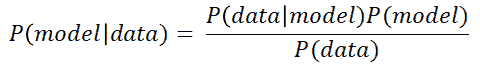
贝叶斯公式应用于机器学习模型
这个想法的基础是,在我们拥有实际数据之前,我们对模型参数有一些先验知识:P(model) 就是这个先验概率。然后,当我们获得一些新数据时,我们会更新模型参数的分布,使其成为后验概率 P(model|data)。
这意味着我们的参数集(模型的θs)不是恒定的,而是有其自己的分布。基于先前的知识(例如来自专家或其他研究)我们对模型参数的分布做出初步假设。然后随着我们用更多的数据训练模型,这个分布会更新并变得更加精确(实际上,方差变小)。
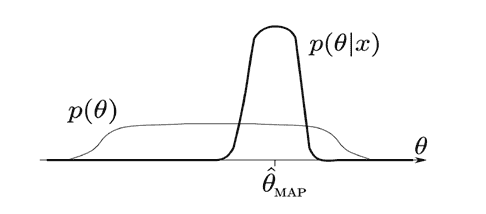
关于先验和后验参数分布的图。θMap 是最大后验估计,我们将其用于我们的模型中。
这个图展示了模型参数的初始分布p(θ),以及随着我们添加更多数据,这个分布如何被更新,使其变得更准确地接近p(θ|x),其中 x 表示这些新数据。这里的θ相当于上述公式中的模型,而这里的x相当于该公式中的数据。
贝叶斯公式,如往常一样,告诉我们如何从先验概率转换为后验概率。我们在迭代过程中进行此操作,随着数据的不断增加,后验概率成为下一次迭代的先验概率。一旦我们用足够的数据训练了模型,为了选择最终的参数集,我们会寻找最大后验(MAP)估计,以使用一组具体的模型参数值。
这种分析的优势来自于初始的先验分布:如果我们没有任何先前的信息,且无法对其做出任何假设,其他概率方法如最大似然估计可能更合适。
然而,如果我们对参数的分布有一些先验信息,贝叶斯方法证明非常强大,特别是在面对不可靠的训练数据的情况下。在这种情况下,由于我们不是从头开始构建模型并计算其参数,而是使用某种先前的知识来推断这些参数的初始分布,这种先验分布使得参数更为稳健,并且不容易受到不准确数据的影响。
我不想在这一部分过于技术化,但这一推理背后的数学是非常美妙的;如果你想了解更多,随时发邮件至 jaimezorno@gmail.com 或在 LinkedIn 上联系我。
贝叶斯定理在分类中的应用
我们已经看到贝叶斯定理如何用于回归,通过估计线性模型的参数。相同的推理也可以应用于其他类型的回归算法。
现在我们将了解如何使用贝叶斯定理进行分类。这被称为贝叶斯最优分类器。现在的推理与之前的非常相似。
想象一下我们有一个分类问题,具有** i 个不同的类别。我们关注的是每个类别的概率** wi。如同之前的回归情况,我们也区分先验概率和后验概率,但现在我们有先验类别概率 p(wi) 以及在使用数据或观测后得到的后验类别概率 p(wi|x)。
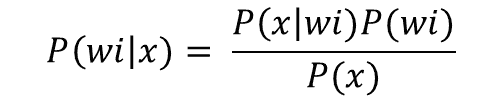
贝叶斯公式用于贝叶斯最优分类器
在这里,P(x) 是与所有数据点共同的密度函数,P(x|wi) 是属于类别wi的数据点的密度函数,而P(wi) 是类别wi的先验分布。P(x|wi) 是从训练数据中计算的,假设某种分布,并计算每个类别的均值向量以及属于该类别的数据点的特征协方差。先验类别分布P(wi) 是基于领域知识、专家建议或以前的工作来估计的,如回归示例中所示。
让我们看一个例子来说明这是如何工作的:假设我们测量了 34 个人的身高:25 名男性(蓝色)和9 名女性(红色),然后我们得到一个新的身高观测值172 厘米,我们想将其分类为男性或女性。下图表示了使用最大似然分类器和贝叶斯最优分类器获得的预测结果。
左侧是两个类别的训练数据及其估计的正态分布。右侧是贝叶斯最优分类器,其中男性的先验类别概率 p(wA)为 25/34,女性的 p(wB)为 9/34。
在这种情况下,我们使用了训练数据中的样本数量作为类别分布的先验知识,但例如,如果我们在特定国家对身高和性别进行相同的区分,并且知道那里女性特别高,同时也知道男性的平均身高,我们可以利用这些信息来构建我们的先验类别分布。
从这个例子中可以看出,使用这些先验知识会导致不同的结果,而不是不使用它们。假设这些先验知识的质量很高(否则我们不会使用它),这些预测应该比不包含这些信息的类似试验更准确。
在这种情况下,随着我们获得更多数据,这些分布会被更新以反映从这些数据中获得的知识。
和之前的情况一样,我不想过于技术化,或过多延伸文章,所以我不会深入数学细节,但如果你对这些细节感到好奇,欢迎随时联系我。
结论
我们已经看到贝叶斯定理在机器学习中的应用;无论是在回归还是分类中,都是将先前的知识纳入我们的模型并加以改进。
在接下来的文章中,我们将看到贝叶斯定理的简化是自然语言处理中最常用的技术之一,以及它们如何应用于许多实际用例,如垃圾邮件过滤器或情感分析工具。要了解更多,请关注我的 Medium](https://medium.com/@jaimezornoza),敬请期待!
贝叶斯分类的另一个示例
以上就是所有内容,希望你喜欢这篇文章。随时可以在 LinkedIn 上联系我,或者在 Twitter 上关注我 @jaimezorno。你也可以查看我在数据科学和机器学习方面的其他文章 这里。阅读愉快!
额外资源
如果你想深入了解贝叶斯和机器学习,请查看以下资源:
如往常一样,有任何问题请随时联系我。祝你有个美好的一天,继续学习。
个人简介:Jaime Zornoza 是一位工业工程师,拥有电子学学士学位和计算机科学硕士学位。
原文。经许可转载。
相关:
-
概率学习 I:贝叶斯定理
-
贝叶斯推断如何工作
-
深度学习 NLP:ANNs、RNNs 和 LSTMs 解析!
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
贝叶斯深度学习与近期量子计算机:量子机器学习中的警示故事
原文:
www.kdnuggets.com/2019/07/bayesian-deep-learning-near-term-quantum-computers.html
评论
由彼得·维特克(阿米尔·费兹普尔和尼克·莫里森编辑)
这篇博客文章是由《量子计算机上的贝叶斯深度学习》一文的作者撰写的量子机器学习概述。文章探讨了量子计算领域中的机器学习应用。本文的作者希望实验结果能够影响量子机器学习的未来发展。
由于研究问题、教育项目和人才需求不断增加,机器学习成为当今技术领域最热门的话题之一。与学习算法的成功相并行的是,量子计算硬件的发展在过去几年中加速了。实际上,我们正处于实现量子优势的门槛上,也就是在某些特定应用领域(例如机器学习)相较于经典算法获得速度或其他性能提升。这听起来很令人兴奋,但不要急于丢弃你的 GPU 集群;量子计算机和你的并行处理单元解决的是不同类别的问题。
如果你查看下图,你将快速了解如何思考量子计算在机器学习中的角色。随着待解决问题复杂性的增长,人工智能堆栈已经开始包含越来越多不同的硬件后端,包括从现成的 CPU 到张量处理单元(TPUs)和神经形态芯片。然而,仍然存在一些问题过于复杂而难以解决,其中一些问题适合用量子计算解决。换句话说,量子计算机可以像过去的 GPU 一样,使创建更复杂的机器学习和深度学习模型成为可能。
图 1。 人工智能已经使用了异构的硬件后端组合。在未来,这种组合将包括量子技术,这些技术能够支持某些学习算法。基于斯蒂夫·朱尔维特森在机器学习与智能市场会议上的讲座。
量子计算机使用“量子比特”(qubits):量子比特是 0 和 1 之间的特殊概率分布。量子比特的数量和我们可以执行的操作的质量(保真度)是衡量量子计算机优劣的最重要指标。量子机器学习使用量子计算机来运行学习算法的某些部分。各种量子机器学习提案的近期可行性各不相同。一些量子算法已经可以在当前量子硬件上运行(例如,需要少量量子比特和量子门的算法,称为变分算法),其他算法则需要更好的量子计算机,具有更多且质量更高的量子比特(如最著名的算法如 Shor 算法的因式分解或 Grover 算法的无结构搜索)。到目前为止,仅有少数基准结果可用于在真实硬件上运行实际的量子机器学习算法。
所有这些基准测试都专注于那些为这些嘈杂、早期量子设备设计的更明显的算法类别。我们则关注另一个极端:让我们选择一个最困难的算法原语(所有步骤都是基本操作,并且不调用其他算法),看看我们能得到什么结果。为什么?一个著名的算法是量子矩阵求逆算法(简称 HHL,取自原始文章的作者),它在矩阵求逆方面相比经典算法提供了指数级的加速,是量子机器学习中最常见的算法原语之一。我们相信使用量子计算机有其优势,但我们也认为必须考虑当前量子硬件的能力。因此,我们开始了一项展示情况可能变得多么糟糕的任务。
量子矩阵求逆算法存在无数的警告:它需要数千个错误校正量子比特和更多的量子门。换句话说,它需要一个完美的大规模通用量子计算机。这与我们今天拥有的少量嘈杂量子比特和由于量子比特只能维持短时间的叠加状态(也称为相干时间)而能够构建的浅层电路形成鲜明对比。叠加状态是我们前面提到的 0 和 1 之间的特殊概率分布。如果相干时间不好,概率分布不在我们的控制之下:我们无法对其进行变换以表达计算。
鉴于量子矩阵反演是量子机器学习中的常见子程序,并且它需要非常高质量的量子计算机,我们想要讲述一个警示故事。我们发现了一个机会:在 2017 年末出现了two papers ,它们将深度学习与高斯过程联系了起来。这是一个重要的成就,因为将深度学习与贝叶斯技术(其中高斯过程是一个例子)结合起来,可以从网络中获取更多信息。特别是,它提供了了解预测不确定性的简便方法。不幸的是,贝叶斯学习是困难的,即使在最好的经典硬件上也是如此。这就是为什么利用这一新发现的联系,我们提出了一种新的量子贝叶斯深度学习协议,该协议内部使用量子矩阵反演来实现加速。从表面上看,新协议看起来不错:这是一个在经典计算中很难解决的问题,我们应用了一些数学技巧,通过使用量子算法使其速度显著提升!不幸的是,这种加速需要非常非常高质量的量子计算机。
我们利用这个机会实现了量子矩阵反演算法,并在现代量子计算机上进行了基准测试。相关的论文刚刚发表(开放版可以在arXiv上找到),还有一个匹配的git 仓库。下图概述了我们提出的内容。
图 2. 量子贝叶斯深度学习的示意图。在某些条件下,神经网络中的一层神经元可以被视为等同于高斯过程。最近的研究表明,如果我们考虑许多层,这种等价关系仍然成立。为了快速训练高斯过程,我们使用了量子辅助协议,并在量子处理单元上运行它。图像来源:Alejandro Pozas-Kerstjens。
结果证实了尽管量子矩阵反演被广泛使用,但它并不是实现实际量子优势的首选目标。任何门噪声都会立即破坏计算,这很直观,因为即使是一个小的矩阵反演也需要几十个门。量子计算结果的读取是通过对设备的测量来完成的。测量量子比特的设备中的故障也会影响算法的性能,不过,由于需要进行的测量较少,这种误差源的影响较小。
图 3. 反转 4x4 矩阵后的最终状态的保真度。使用不同噪声水平和噪声模型进行的模拟。
为了在真实硬件上运行,我们需要简化,因为完整算法即使对 2x2 矩阵来说也过于深奥。幸运的是,我们找到了所需的解决方案:一个专门为求逆 2x2 矩阵设计的浅层电路。虽然这对任何实际应用无关,但这个电路有略多于十二个门(包括状态准备)和有趣的结果。我们使用了16 量子比特的 IBM 芯片和8 量子比特的 Agave 芯片。Agave 芯片具有特定的线性拓扑,增加了一些额外的门来按需操作量子状态。IBM QPU 在测量后成功率为 89%,相当于 0.78 的保真度。Agave QPU 的成功率为 50%,相当于零保真度,但我们认为这主要是由于线性拓扑和需要插入的额外门。这些并不多,但足以使算法的执行时间超过量子比特的相干时间。
为了量子机器学习(QML)算法而创建的内容,如果在 GPU 集群上可以有效完成,则没有意义。由于贝叶斯深度学习在使用经典资源时很难执行,我们通过量子协议进行了攻击。凭借这一理论,我们在允许量子计算机训练深度神经网络方面取得了非平凡的进展。
在实现方面,我们建立了量子矩阵求逆算法的完整实现,这可以作为未来量子计算机的一个严格基准。我们得出结论,最好远离这些抽象算法,更多关注今天量子硬件的局限性。我们希望经典和量子机器学习社区能发现这些结果具有趣味性,并且希望下一代量子编码者能够从这次实验中学习。
原文。经许可转载。
相关内容:
-
预训练、变压器和双向性
-
生成对抗网络也需要关注
-
大规模图像分类器的演变
我们的前 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
更多相关话题
贝叶斯与频率统计学在数据科学中的对比
原文:
www.kdnuggets.com/2023/05/bayesian-frequentist-statistics-data-science.html
作者提供的图片
在深入探讨贝叶斯统计和频率统计的区别之前,让我们先从它们的定义开始。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
什么是贝叶斯方法?
使用统计推断时,你是在根据数据对总体参数做出判断。
贝叶斯推断考虑了先验知识,并且参数被视为随机变量。这意味着事件发生的概率是存在的。例如,如果我们掷一枚硬币,贝叶斯推断将会说明没有对错之分,硬币落在正面或反面的概率取决于他们的观点。
贝叶斯观点基于贝叶斯定理,这是一种基于先验知识计算事件概率的公式。公式如下:
-
P(A):事件 A 发生的概率
-
P(B):事件 B 发生的概率
-
P(A|B):在事件 B 发生的情况下 A 的概率
-
P(B|A):在事件 A 发生的情况下 B 的概率
-
Pr(A|B):后验概率,即在给定数据的情况下参数的概率。
图片来源:维基百科
拥有贝叶斯思维的人会使用概率来衡量事件发生的可能性。这是他们的信念。假设的概率是通过先验意见和知识计算得出的,并且在新数据随时可用的情况下被认为是正确的。这称为先验概率,在项目开始之前得出。
这个先验概率随后转化为后验概率,即项目开始后所持的信念。
先验 + 可能性 = 后验
什么是频率主义方法?
频率主义推断有所不同。它假设事件基于频率,参数不是随机变量——意味着没有概率。使用上述相同的例子,如果你抛硬币,频率主义推断将表明根据频率有一个正确答案。如果你抛硬币并且一半时间都是反面,那么得到反面的概率是 50%。
设有停止标准。停止规则决定了样本空间,因此对它的了解对频率主义推断至关重要。例如,对于抛硬币,频率主义方法可能会重复测试 2000 次,或者直到出现 300 次反面。研究人员通常不会重复测试这么多次。
拥有频率主义思维的人将概率视为频率。他们的概率取决于某个事件在无限次重复中发生的情况。
从频率主义者的角度来看,你用来估计总体的参数被认为是固定的。你将估计一个单一的真实参数,而不是将其建模为概率分布。当有新数据可用时,你将使用它来进行统计测试,并对数据进行概率预测。
在频率主义统计中,最常见的计算是 p 值,这是用来验证假设的统计测量。它描述了如果原假设(即没有统计关系)是正确的,你找到特定观察结果的可能性有多大。
下图中的阴影蓝色区域表示 p 值,即观察结果因随机性发生的概率。
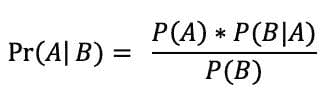
图片由作者提供
它如何应用于数据科学?
统计学是数据科学的重要组成部分,如果你是这个领域的一部分,你一定遇到过贝叶斯定理、p 值和其他统计测试。作为数据科学家或数据工作者,了解统计分析和现有工具对你是有益的。你可能会在某个时候需要这些知识。
在你的团队中,当你讨论项目和下一步计划时,你会开始看到谁拥有贝叶斯思维,谁拥有频率主义思维。数据科学家将从事概率预测,这结合了残差方差和估计的不确定性。这是一个专门的贝叶斯框架。然而,这并不排除一些专家希望使用频率主义方法。
你采取的方法会反映在你选择的统计方法上。数据科学的许多基础是建立在贝叶斯统计上的,有些人甚至将频率主义的方法视为贝叶斯理论的一个子集。
然而,当涉及到数据科学时,你的重点是当前的问题。许多数据科学家根据他们要解决的问题选择模型。贝叶斯方法的优势在于,在数据科学领域,拥有关于问题的具体知识始终是一个优势。
贝叶斯方法被认为更快、可解释、以用户为中心,并且具有更直观的分析方法。
我将在下面进一步探讨这些以及它们之间的区别。
更快的学习
贝叶斯方法从最初的信念开始,这一信念通过收集证据得到支持。这导致更快的学习,因为你有证据来支持你的观点。
频率学方法基于从数据中获得的事实。尽管他们已经查看了数据,但没有进行分析以确保这是证据。没有计算概率来支持假设。
可解释的
贝叶斯方法拥有多种灵活的模型,使其能够应用于复杂的统计问题。这使得贝叶斯方法更易于解释。
不幸的是,频率学方法并不那么灵活,通常会失败。
以用户为中心
这两种方法有不同的途径。贝叶斯方法允许在项目讨论中纳入不同的研究和问题。重点关注可能的效应大小。
而频率学方法限制了这种可能性,因为它专注于不确定的显著性。
贝叶斯与频率学总结
| 属性: | 贝叶斯: | 频率学: |
|---|---|---|
| 是什么? | 参数周围的概率分布 | 参数是固定的且为单点 |
| 质疑什么? | 给定数据,假设的概率是多少? | 假设是真的还是假的? |
| 需要什么? | 先验知识/信息和任何数据集。 | 停止标准 |
| 输出什么? | 关于假设的支持或反对概率。 | 点估计(p 值) |
| 主要优点 | 有证据支持,并且可以应用新信息 | 简单易用,不需要先验知识 |
| 主要缺点 | 需要高级统计学 | 高度依赖样本大小,仅给出“是”或“否”的结果 |
| 何时使用? | 有先验知识时限制数据,使用更多计算资源 | 大量数据时 |
结论
我希望这篇博客能让你更好地理解贝叶斯方法和频率学方法之间的区别。两者之间的争论颇多,甚至是否存在彼此。我的建议是坚持让你感到舒适的方式,以及你如何通过个人逻辑解析问题。
如果你想深入了解,应用你的技能和知识,我推荐:初学者统计学速成课程:使用 Python 的频率学派和贝叶斯统计的理论与应用
尼莎·阿雅 是一位数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何有助于延长人类寿命。作为一个热衷于学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
使用 PyCaret 中的 tune-sklearn 进行贝叶斯超参数优化
原文:
www.kdnuggets.com/2021/03/bayesian-hyperparameter-optimization-tune-sklearn-pycaret.html
评论
由Antoni Baum,PyCaret 的核心贡献者及 Ray Tune 的贡献者

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
这里有一个每个PyCaret用户都熟悉的情况:在从compare_models()中选择了一个或两个有前景的模型后,是时候使用tune_model()调整其超参数,以充分发挥模型的潜力了。
from pycaret.datasets import get_data
from pycaret.classification import *
data = get_data("juice")
exp = setup(
data,
target = "Purchase",
)
best_model = compare_models()
tuned_best_model = tune_model(best_model)
(如果你想了解更多关于 PyCaret 的信息——这是一个开源的低代码 Python 机器学习库,这个指南是一个很好的起点。)
默认情况下,tune_model()使用的是经过验证的RandomizedSearchCV,来自 scikit-learn。然而,并非所有人都知道tune_model()提供的各种高级选项。
在这篇文章中,我将向你展示如何利用tune-sklearn,这是一个用于 scikit-learn 模型选择模块的替代品,提供了前沿的超参数调优技术,来轻松使用其他最先进的算法。我还将报告一系列基准测试结果,展示 tune-sklearn 如何轻松提升分类模型的性能。
随机搜索与贝叶斯优化
超参数优化算法的效率差异可能很大。
随机搜索一直是机器学习的主流方法,这有充分的理由:它易于实现和理解,并且在合理的时间内能给出良好的结果。然而,正如名称所示,它是完全随机的——大量时间可能花在评估不良配置上。考虑到迭代次数是有限的,优化算法专注于它认为有前景的配置,并考虑到已评估的配置,似乎更有意义。
本质上,这就是贝叶斯优化(BO)的核心思想。BO 算法跟踪所有评估,并利用数据构建一个“替代概率模型”,该模型的评估速度比 ML 模型快得多。评估的配置越多,算法的知识越丰富,替代模型就越接近实际的目标函数。这样,算法可以做出明智的选择,决定接下来评估哪些配置,而不仅仅是随机采样。如果你想了解更多关于贝叶斯优化的知识,可以查看Will Koehrsen 的这篇精彩文章。
幸运的是,PyCaret 内置了多个优化库的封装器,在本文中,我们将重点关注tune-sklearn。
PyCaret 中的 tune-sklearn
tune-sklearn是 scikit-learn 模型选择模块的替代品。tune-sklearn 提供了一个基于 scikit-learn 的统一 API,让你可以访问各种流行的先进优化算法和库,包括 Optuna 和 scikit-optimize。这个统一的 API 允许你通过一个参数在多种超参数优化库之间切换。
tune-sklearn 由Ray Tune驱动,它是一个用于实验执行和超参数调优的 Python 库,支持任何规模的调优。这意味着你可以在多台机器上扩展调优,而无需更改代码。
为了更简单,从版本 2.2.0 开始,tune-sklearn 已集成到 PyCaret 中。你只需执行pip install "pycaret[full]",所有可选依赖项将自动处理。
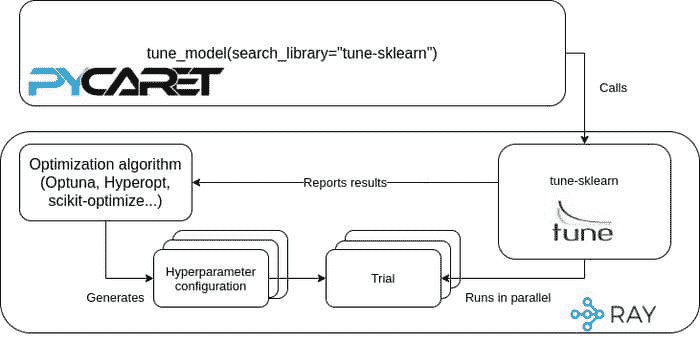
如何协同工作
!pip install "pycaret[full]"
from pycaret.datasets import get_data
from pycaret.classification import *
data = get_data("juice")
exp = setup(
data,
target = "Purchase",
)
best_model = compare_models()
tuned_best_model_hyperopt = tune_model(
best_model,
search_library="tune-sklearn",
search_algorithm="hyperopt",
n_iter=20
)
tuned_best_model_optuna = tune_model(
best_model,
search_library="tune-sklearn",
search_algorithm="optuna",
n_iter=20
)
只需向tune_model()添加两个参数,你就可以通过Hyperopt或Optuna将随机搜索切换为 tune-sklearn 驱动的贝叶斯优化。请记住,PyCaret 内置了所有包含模型的搜索空间,但你始终可以传递自己的搜索空间(如果你愿意的话)。
但是,它们与随机搜索相比效果如何呢?
一个简单的实验
为了比较贝叶斯优化与随机搜索的效果,我进行了一个非常简单的实验。使用 Kaggle 房价数据集,我创建了两个流行的回归模型,分别是 随机森林 和 弹性网络。然后,我使用 scikit-learn 的随机搜索以及 tune-sklearn 的 Hyperopt 和 Optuna 搜索器对它们进行了调优(所有方法进行 20 次迭代,最小化 RMSLE)。该过程重复三次,使用不同的种子,并对结果进行了平均。下面是代码的简化版本——你可以在 这里 找到完整代码。
from pycaret.datasets import get_data
from pycaret.regression import *
data = get_data("house")
exp = setup(
data,
target = "SalePrice",
test_data=data, # so that the entire dataset is used for cross validation - do not normally do this!
session_id=42,
fold=5
)
rf = create_model("rf")
en = create_model("en")
tune_model(rf, search_library = "scikit-learn", optimize="RMSLE", n_iter=20)
tune_model(rf, search_library = "tune-sklearn", search_algorithm="hyperopt", n_iter=20)
tune_model(rf, search_library = "tune-sklearn", search_algorithm="optuna", optimize="RMSLE", n_iter=20)
tune_model(en, search_library = "scikit-learn", optimize="RMSLE", n_iter=20)
tune_model(en, search_library = "tune-sklearn", search_algorithm="hyperopt", n_iter=20)
tune_model(en, search_library = "tune-sklearn", search_algorithm="optuna", optimize="RMSLE", n_iter=20)
PyCaret 让事情变得如此简单,难道不是很棒吗?无论如何,这里是我在我的机器上获得的 RMSLE 分数:
实验的 RMSLE 分数
为了更好地理解,下面是相较于随机搜索的百分比改进:
相较于随机搜索的百分比改进
所有这些操作都使用了相同的迭代次数,在相近的时间内完成。请记住,由于过程的随机性,你的效果可能会有所不同。如果你的改进不明显,可以尝试将迭代次数(n_iter)从默认的 10 增加到 20–30,这通常是一个明智的选择。
Ray 的优点在于你可以轻松地将计算从单台机器扩展到由数十、数百或更多节点组成的集群。虽然 PyCaret 目前尚不完全支持 Ray 集成,但可以在调整之前初始化一个 Ray 集群——并且 tune-sklearn 将自动使用它。
exp = setup(
data,
target = "SalePrice",
session_id=42,
fold=5
)
rf = create_model("rf")
tune_model(rf, search_library = "tune-sklearn", search_algorithm="optuna", optimize="RMSLE", n_iter=20) # Will run on Ray cluster!
只要所有必要的配置就位(RAY_ADDRESS 环境变量),就无需其他操作即可利用 Ray 的分布式计算进行超参数调整。由于超参数优化通常是创建 ML 模型中性能最密集的部分,使用 Ray 进行分布式调整可以为你节省大量时间。
结论
为了加快 PyCaret 中的超参数优化,你只需安装所需的库并更改 tune_model() 中的两个参数——多亏了内置的 tune-sklearn 支持,你可以轻松利用 Ray 的分布式计算,超越本地机器的限制。
请务必查看PyCaret、Ray Tune和tune-sklearn的文档,以及PyCaret和tune-sklearn的 GitHub 仓库。最后,如果你有任何问题或想与社区联系,请加入PyCaret 的 Slack和Ray 的 Discourse。
感谢 Richard Liaw 和 Moez Ali 的校对和建议。
个人简介: Antoni Baum 是计算机科学与计量经济学硕士生,同时也是 PyCaret 的核心贡献者和 Ray Tune 的贡献者。
原文。经许可转载。
相关:
-
高级超参数优化/调优算法
-
轻松的数据科学的 5 种工具
-
你在 PyCaret 中做错的 5 件事
更多相关内容
贝叶斯机器学习的解释
原文:
www.kdnuggets.com/2016/07/bayesian-machine-learning-explained.html
由 Zygmunt Zając, FastML。
所以你知道贝叶斯规则了。它与机器学习有什么关系呢?很难掌握这些拼图如何组合在一起——我们知道这花费了我们一段时间。这篇文章是我们当时希望有的介绍。
虽然我们对这个问题有一些了解,但我们不是专家,因此以下内容可能包含不准确之处甚至明显错误。如有发现,请在评论中或私下指出。
贝叶斯主义者与频率主义者
从本质上讲,贝叶斯意味着概率性。这个特定的术语存在是因为概率有两种方法。贝叶斯主义者认为它是信念的度量,因此概率是主观的并且指向未来。
频率主义者有不同的看法:他们使用概率来指代过去的事件——这样它是客观的,不依赖于个人的信仰。这个名字来源于方法——例如:我们抛硬币 100 次,出现正面 53 次,所以正面的频率/概率是 0.53。
要深入探讨此主题及更多内容,请参阅 Jake VanderPlas 的 Frequentism and Bayesianism 系列文章。
先验、更新和后验
作为贝叶斯主义者,我们从一个称为先验的信念开始。然后我们获得一些数据并用它来更新我们的信念。结果称为后验。如果我们获得更多数据,旧的后验成为新的先验,循环重复。
这个过程使用了 贝叶斯规则:
P( A | B ) = P( B | A ) * P( A ) / P( B )
P( A | B ),读作“在 B 的条件下 A 的概率”,表示条件概率:如果 B 发生,那么 A 的可能性有多大。
从数据中推断模型参数
在贝叶斯机器学习中,我们使用贝叶斯规则从数据(D)中推断模型参数(theta):
P( theta | D ) = P( D | theta ) * P( theta ) / P( data )
这些所有组件都是概率分布。
P( data ) 是我们通常无法计算的,但由于它只是一个标准化常数,因此不是那么重要。在比较模型时,我们主要关心包含 theta 的表达式,因为 P( data ) 对每个模型都是相同的。
P( theta ) 是先验,或者说我们对模型参数可能是什么的信念。我们对此的意见通常比较模糊,如果我们有足够的数据,我们根本不在意。推断应趋于可能的 theta,只要它在先验中不是零。先验是通过参数化的分布来指定的——请参见 Where priors come from。
P( D | theta ) 被称为给定模型参数的数据的似然。似然的公式是特定于模型的。人们经常使用似然来评估模型:一个对真实数据提供更高似然的模型更好。
最终,P( theta | D ),一个后验,是我们追求的目标。它是一个通过先验信念和数据获得的模型参数的概率分布。
当使用似然来获取模型参数的点估计时,这叫做最大似然估计,或 MLE。如果还考虑先验,那么就是最大后验估计(MAP)。如果先验是均匀的,MLE 和 MAP 是相同的。
注意,选择模型可以看作与选择模型(超)参数是分开的。然而,在实践中,它们通常通过验证一起进行。
模型与推断
推断指的是你如何学习模型的参数。模型与训练它的方式是分开的,尤其是在贝叶斯世界中。
考虑深度学习:你可以使用 Adam、RMSProp 或其他一些优化器来训练网络。然而,它们往往彼此相似,都是随机梯度下降的变体。相比之下,贝叶斯推断的方法之间的差异更为深刻。
两种最重要的方法是蒙特卡罗采样和变分推断。采样是黄金标准,但速度较慢。《大师算法》摘录中有更多关于 MCMC 的内容。
变分推断是一种明确设计用来在准确性和速度之间进行权衡的方法。它的缺点是模型特定,但隧道尽头有曙光——见下文的软件部分和变分推断:统计学家的综述。
统计建模
在贝叶斯方法的谱系中,有两种主要的风格。我们称第一种为统计建模,第二种为概率机器学习。后者包含了所谓的非参数方法。
建模发生在数据稀缺、珍贵且难以获得的情况下,例如在社会科学和其他难以进行大规模受控实验的环境中。想象一个统计学家用他所拥有的少量数据精心构建和调整模型。在这种情况下,你不遗余力地充分利用可用输入。
同时,在小数据情况下,量化不确定性非常重要,而这正是贝叶斯方法擅长的。
贝叶斯方法——特别是 MCMC——通常计算成本高。这与小数据密切相关。
为了体验一下,可以参考示例来了解回归分析与多级/层次模型一书。这是一本关于线性模型的书。它们从一个简单的线性模型开始,然后经过一个预测变量、两个预测变量、六个预测变量,直到十一种预测变量的多个线性模型。
这种劳动密集型的模式与当前机器学习的趋势相悖,后者使用数据让计算机自动从中学习。
概率机器学习
让我们尝试将“贝叶斯的”替换为“概率的”。从这个角度来看,它与其他方法的区别不大。就分类而言,大多数分类器能够输出概率预测。即使是支持向量机(SVM),它们在某种程度上是贝叶斯的对立面。
顺便说一下,这些概率只是分类器的信念声明。它们是否对应于真实的概率则是另一回事,这被称为校准。
LDA,一种生成模型
潜在狄利克雷分配是一种将数据投入并让它自动排序的方法(与手动建模相对)。它类似于矩阵因式分解模型,特别是非负矩阵分解。你从一个矩阵开始,其中行是文档,列是词,每个元素是给定文档中给定词的计数。LDA 将大小为n x d的矩阵“因式分解”为两个矩阵,文档/主题(n x k)和主题/词(k x d)。
与因式分解的区别在于,你不能通过相乘这两个矩阵来得到原始矩阵,但由于适当的行/列之和为一,你可以“生成”一份文档。为了得到第一个词,你从一个主题中抽样,然后从这个主题中抽取一个词(第二个矩阵)。对你想要的词数重复这个过程。请注意,这是一种词袋表示,而不是词语的正确顺序。
上述是一个生成模型的例子,这意味着可以从中抽样或生成示例。与通常根据x区分类别的分类器不同,它们通常建模P( y | x )。生成模型关注的是y和x的联合分布P( y, x )。估计这个分布更困难,但它允许抽样,当然也可以从P( y, x )得到P( y | x )。
贝叶斯非参数方法
虽然没有确切的定义,但这个名称意味着模型中的参数数量可以随着数据的增加而增长。这类似于支持向量机(Support Vector Machines),例如,该算法从训练点中选择支持向量。非参数方法包括 LDA 的层次狄利克雷过程版本,其中主题的数量会自动选择,以及高斯过程。
高斯过程
高斯过程与支持向量机有些相似——两者都使用核函数并具有类似的可扩展性(这一点通过使用近似方法在这些年里得到了极大改善)。GP 的自然公式是回归,分类则是次要的。对于 SVM 则正好相反。
另一个区别是 GP 从根本上是概率性的(提供误差条),而 SVM 则不是。你可以在回归中观察到这一点。大多数“常规”方法只提供点估计。贝叶斯对应物,如高斯过程,也会输出不确定性估计。
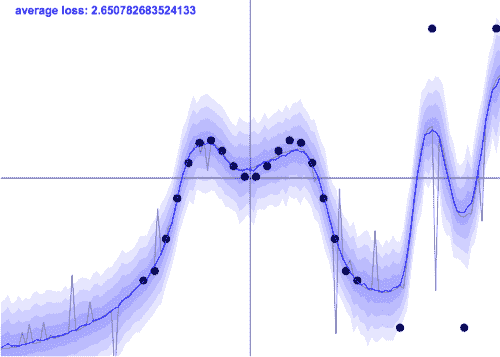
致谢:Yarin Gal 的异方差丢弃不确定性和我的深度模型不知道的东西
不幸的是,这并不是故事的结尾。即使像 GP 这样复杂的方法通常也基于同方差性假设,即均匀的噪声水平。实际上,噪声可能在输入空间中不同(具有异方差性)——见下图。
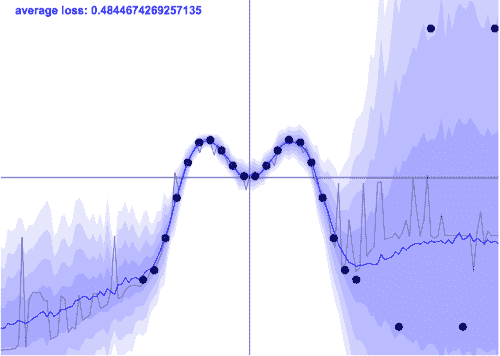
高斯过程的一个相对流行的应用是机器学习算法的超参数优化。数据量很小,无论是维度——通常只有几个需要调整的参数,还是样本数量。每个样本代表目标算法的一次运行,可能需要几个小时或几天。因此,我们希望以尽可能少的样本获取重要信息。
大多数关于 GP 的研究似乎发生在欧洲。英语国家在简化 GP 使用方面做了一些有趣的工作,最终形成了由 Zoubin Ghahramani 领导的自动化统计学家项目。
观看这个视频的前 10 分钟,获得关于高斯过程的简明介绍。
软件
目前最显眼的贝叶斯软件可能是Stan。Stan 是一种概率编程语言,意味着它允许你指定和训练你想要的任何贝叶斯模型。它可以在 Python、R 等语言中运行。Stan 有一个现代的采样器叫做NUTS:
Stan中的大部分计算是通过哈密尔顿蒙特卡洛(HMC)完成的。HMC 需要一些调整,因此 Matt Hoffman 编写了一种新的算法 Nuts(“No-U-Turn Sampler”),它自适应地优化 HMC。在许多情况下,Nuts 实际上比最优的静态 HMC 更具计算效率!
Stan 的一个特别有趣的功能是它具有自动变分推断:
变分推断是一种可扩展的近似贝叶斯推断技术。推导变分推断算法需要繁琐的特定模型计算;这使得自动化变得困难。我们提出了一种自动变分推断算法,即自动微分变分推断(ADVI)。用户只需提供一个贝叶斯模型和一个数据集;别无其他要求。
这种技术为将小规模建模应用于至少中等规模数据铺平了道路。
在 Python 中,最受欢迎的包是 PyMC。它不像 Stan 那样先进或精致(开发者似乎在追赶 Stan),但仍然不错。PyMC 具有 NUTS 和 ADVI——这是一个带有 minibatch ADVI 示例 的笔记本。该软件使用 Theano 作为后端,因此比纯 Python 更快。
Infer.NET 是微软的概率编程库。它主要从 C# 和 F# 等语言中获得,但显然也可以从 .NET 的 IronPython 中调用。Infer.net 默认使用 期望传播。
除此之外,还有大量的包实现了各种贝叶斯计算的变体,从其他概率编程语言到专门的 LDA 实现。其中一个有趣的例子是 CrossCat:
CrossCat 是一种通用的贝叶斯方法,用于分析高维数据表。CrossCat 通过在分层的非参数贝叶斯模型中进行近似推断,从数据中估计表中变量的完整联合分布,并为每个条件分布提供高效的采样器。CrossCat 结合了非参数混合建模和贝叶斯网络结构学习的优势:它可以通过假设潜在变量来建模任何联合分布,只要数据足够,但也能发现可观察变量之间的独立性。
资源
为了巩固你的理解,你可以阅读 Radford Neal 的 Bayesian Methods for Machine Learning 教程。它与本文的主题一一对应。
我们发现 Kruschke 的 Doing Bayesian Data Analysis(被称为小狗书)最为易读。作者详尽地解释了建模的所有细节。
Statistical rethinking似乎是类似的,但更新了。它包含了 R + Stan 的示例。作者 Richard McElreath 在 YouTube 上发布了一系列讲座。
在机器学习方面,这两本书都只涉及到线性模型。同样,Cam Davidson-Pilon 的Probabilistic Programming & Bayesian Methods for Hackers涵盖了贝叶斯部分,但没有涉及机器学习部分。
Alex Etz 关于理解贝叶斯的系列文章也是如此。
对于那些数学爱好者,Kevin Murphy 的Machine Learning: a Probabilistic Perspective可能是一本不错的书。如果你喜欢高难度的内容,那没问题,Bishop 的Pattern Recognition and Machine Learning可以满足你的需求。最近有一个Reddit 帖子简要讨论了这两本书。
David Barber 的Bayesian Reasoning and Machine Learning也很受欢迎,并且在网上免费提供,另外,Gaussian Processes for Machine Learning这本经典书籍也是如此。
据我们所知,目前没有关于贝叶斯机器学习的 MOOC 课程,但mathematicalmonk 从贝叶斯的角度解释了machine learning。
Stan 有一个详尽的手册,PyMC 有一个教程以及相当多的示例。
个人简介: Zygmunt Zając 喜欢新鲜空气、牵手以及海滩上的长途散步。他运营着FastML.com,这是全球最受欢迎的机器学习博客。除了各种有趣的文章,FastML 现在还提供了一个机器学习职位板块和一个3D 数据集可视化工具。
原文。经许可转载。
相关内容:
-
机器学习关键术语解读
-
十大数据挖掘算法解读
-
数据科学难题解读
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
更多相关主题
现代数据科学中的贝叶斯思维
原文:
www.kdnuggets.com/bayesian-thinking-in-modern-data-science

编辑图片 | Midjourney
贝叶斯思维是一种利用概率做决策的方法。它从初始信念(先验)开始,当新的证据出现时进行调整(后验)。这有助于根据数据做出更好的预测和决策。它在人工智能和统计学等领域至关重要,其中准确推理非常重要。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
贝叶斯理论基础
关键术语
-
先验概率(Prior):表示对假设的初始信念。
-
似然性:衡量假设对证据的解释程度。
-
后验概率(Posterior):将先验概率和似然性结合起来。
-
证据:更新假设的概率。
贝叶斯定理
该定理描述了如何根据新信息更新假设的概率。它的数学表达式为:
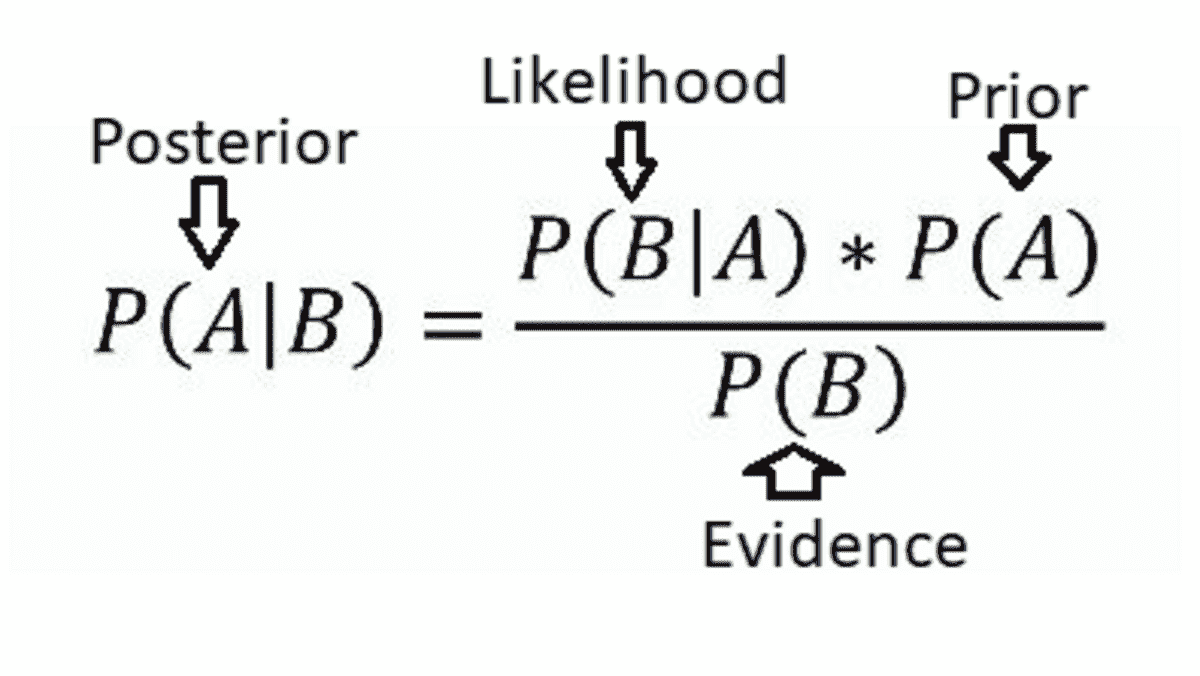 贝叶斯定理(来源:Eric Castellanos 博客) 其中:
贝叶斯定理(来源:Eric Castellanos 博客) 其中:
P(A|B) 是假设的后验概率。
P(B|A) 是给定假设的证据的可能性。
P(A) 是假设的先验概率。
P(B) 是证据的总概率。
贝叶斯方法在数据科学中的应用
贝叶斯推断
贝叶斯推断在不确定时更新信念。它使用贝叶斯定理根据新信息调整初始信念。这种方法有效地将已知信息与新数据结合起来。这种方法量化了不确定性,并相应地调整概率。通过这种方式,它随着更多证据的收集不断改进预测和理解。在需要有效管理不确定性的决策过程中非常有用。
例子:在临床试验中,贝叶斯方法估计新治疗的有效性。它们将过去研究或当前数据中的先验信念结合起来。这更新了治疗效果的概率。研究人员可以利用旧信息和新信息做出更好的决策。
预测建模和不确定性量化
预测建模和不确定性量化涉及做出预测并了解我们对这些预测的信心。它使用如贝叶斯方法等技术来考虑不确定性并提供概率性预测。贝叶斯建模在预测方面有效,因为它管理不确定性。它不仅预测结果,还指示我们对这些预测的信心。这是通过后验分布来实现的,后验分布量化了不确定性。
示例:贝叶斯回归通过提供一系列可能的价格来预测股票价格,而不是单一预测。交易者利用这个价格范围来规避风险并做出投资决策。
贝叶斯神经网络
贝叶斯神经网络(BNNs)是提供概率性输出的神经网络。它们提供预测结果以及不确定性度量。与固定参数不同,BNNs 使用权重和偏置的概率分布。这使得 BNNs 能够捕捉并在网络中传播不确定性。它们对需要不确定性测量和决策的任务非常有用。它们被用于分类和回归任务。
示例:在欺诈检测中,贝叶斯网络分析诸如交易历史和用户行为等变量之间的关系,以发现与欺诈相关的异常模式。与传统方法相比,它们提高了欺诈检测系统的准确性。
贝叶斯分析的工具和库
有多种工具和库可以有效地实现贝叶斯方法。让我们了解一些流行的工具。
PyMC4
这是一个用于 Python 的概率编程库。它有助于贝叶斯建模和推断。它建立在其前身 PyMC3 的优势基础上,通过与 JAX 的集成引入了显著改进。JAX 提供了自动微分和 GPU 加速。这使得贝叶斯模型更快且更具可扩展性。
Stan
一种用 C++ 实现的概率编程语言,通过各种接口(RStan、PyStan、CmdStan 等)提供。Stan 擅长高效地执行 HMC 和 NUTS 采样,并以其速度和准确性著称。它还包括广泛的诊断工具和模型检查工具。
TensorFlow Probability
这是一个用于在 TensorFlow 中进行概率推理和统计分析的库。TFP 提供了多种分布、双射函数和 MCMC 算法。与 TensorFlow 的集成确保了在各种硬件上高效执行。它允许用户将概率模型与深度学习架构无缝结合。本文有助于进行稳健且基于数据的决策。
让我们看一个使用 PyMC4 的贝叶斯统计示例。我们将看到如何实现贝叶斯线性回归。
import pymc as pm
import numpy as np
# Generate synthetic data
np.random.seed(42)
X = np.linspace(0, 1, 100)
true_intercept = 1
true_slope = 2
y = true_intercept + true_slope * X + np.random.normal(scale=0.5, size=len(X))
# Define the model
with pm.Model() as model:
# Priors for unknown model parameters
intercept = pm.Normal("intercept", mu=0, sigma=10)
slope = pm.Normal("slope", mu=0, sigma=10)
sigma = pm.HalfNormal("sigma", sigma=1)
# Likelihood (sampling distribution) of observations
mu = intercept + slope * X
likelihood = pm.Normal("y", mu=mu, sigma=sigma, observed=y)
# Inference
trace = pm.sample(2000, return_inferencedata=True)
# Summarize the results
print(pm.summary(trace))
现在,让我们逐步理解上面的代码。
-
它为截距、斜率和噪声设置初始信念(先验)。
-
它根据这些先验和观测数据定义了一个似然函数。
-
该代码使用马尔科夫链蒙特卡洛(MCMC)采样从后验分布中生成样本。
-
最后,它总结了结果,以展示估计的参数值和不确定性。
总结
贝叶斯方法将先验信念与新证据结合,以进行信息化决策。它们在多个领域提高预测准确性并管理不确定性。工具如 PyMC4、Stan 和 TensorFlow Probability 提供了强大的贝叶斯分析支持。这些工具帮助从复杂数据中做出概率预测。
Jayita Gulati 是一位机器学习爱好者和技术作者,因对构建机器学习模型的热情而驱动。她拥有利物浦大学计算机科学硕士学位。
更多相关主题
使用机器学习战胜博彩公司
原文:
www.kdnuggets.com/2019/03/beating-bookies-machine-learning.html
评论
作者: Richard Bartels, Vantage AI 的数据科学家。
“庄家总是赢”是赌博中的一句俗语。它反映了在大多数运气游戏中,赌场(例如赌场或博彩公司)具有统计上的优势。换句话说,假设下注金额为 1,赌场的预期回报高于 1,而赌徒的预期回报低于 1。因此,如果你去赌场,长期来看,你很可能会遭遇净亏损。
体育博彩也不例外。投注者和博彩公司都可以在预测比赛结果上具备同等的技能,但博彩公司设定了投注规则,从而确保长期获利。他们这样做的方式是控制所谓的支付率。
这里有一个简单的例子。假设有两个水平相当的飞镖运动员,因此在一场对决中他们都有 50%的获胜机会。博彩公司可以设定赔率,我们将其定义为 O₁和 O₂分别对应于运动员 1 和 2。在这个特定的比赛中,O₁ = O₂ = 1.90 是合理的赔率。这意味着每下注 1 美元,如果你赢了,就能得到 1.90 美元的回报。那么你的预期回报 X 是什么呢?如果你对运动员 1 下注 1 美元,你的预期回报为(记住每个运动员的获胜概率是 50%):

所以从长远来看,每花费 1 美元会得到 95 美分的回报,你将会亏损!也就是说,博彩公司为这个游戏设置的“支付率”是 95%,这意味着博彩公司预计会从所有投注中获得 5%的利润,前提是他们准确评估了获胜概率。所以我们看到,博彩公司设定的赔率是不公平的,公平的赔率应该是 O₁ = O₂ = 2.0。注意,这些赔率也对应于每个运动员的相等获胜概率,即 P₁ = O₂/(O₁ + O₂)=0.5 和 P₂ = O₁/(O₁ + O₂)=0.5。
在本博客的其余部分,我们将专注于飞镖这种特定的游戏,其中比赛是对决的,结果在很大程度上取决于运动员的技能。然而,这个讨论也可以推广到其他体育运动。

图片来源: www.1zoom.me/en/wallpaper/517285/z7641.3/.
如何战胜博彩公司
我们上面看到的情况是,博彩公司通过控制赔付来获利。为了做到这一点,他们必须相应地设置赔率。为此,他们需要知道概率。一个能准确获取所有概率的全知博彩公司在长期内是无法被击败的。但博彩公司并非全知,因此有两种方法可以在纯粹基于概率估算上击败他们。
-
如果你 consistently 评估概率比博彩公司更准确,并且这个差距足以弥补他们在赔付中预留的余地。
-
如果你只投注那些你知道博彩公司犯了错误且赔率“公平”的比赛。
实际上,策略 1 只是策略 2 的一个特定版本。尽管如此,即使你能够比博彩公司更准确地预测每场比赛,也不太可能获利,因为博彩公司对概率的估算非常接近正确。从图 1 可以看出,博彩公司在准确估算飞镖赔率方面做得相当好。
图 1:从博彩公司赔率得出的胜率与观察到的胜率(蓝线)对比,涵盖了将近 3700 场飞镖比赛。虚线黑线对应于能够在无限场比赛中完美预测概率。深灰(浅灰)带是由于有限样本量的固有噪声所产生的 68%(95%)区间。由于蓝线在灰色带内保持得相当好,似乎博彩公司知道他们在做什么。
图 1 说明博彩公司在大量比赛中正确评估了概率。但他们在一些个别比赛中仍可能出错。上述提到的策略 2 依赖于识别博彩公司对实际概率的误判。例如,在博彩公司提供相等赔率的非现实事件中,例如 O₁ = O₂ = 1.90,在现任世界冠军迈克尔·范·格尔文与世界第 94 名对手的比赛中,我们的直觉已经告诉我们通过投注范·格尔文可能会获利。目标是识别所有这样的比赛。然而,由于大多数时候很难判断博彩公司何时出错,我们可以尝试让机器学习(ML)算法为我们完成这项工作。
利用 ML 进行飞镖投注
为了这个项目,我们使用了飞镖统计数据,包括平均值、结算百分比、180 分(用 3 支飞镖的最高分)和交锋统计等特征。此外,我们使用了历史赔率来评估这个模型是否能够获利。
首先,为了进一步激励我们仅在一部分比赛中下注的策略,我们来看一下基准准确率。如果我们总是根据博彩公司给出的最高获胜概率的选手下注,我们能达到 70%的准确率。仅基于比赛结果构建的技能评级在相同数据上也能达到 69%的准确率。当训练一个机器学习模型,如随机森林、提升树或经过精心构建特征优化的全连接神经网络,并使用二元交叉熵损失函数进行优化时,我们也达到了 70%的准确率。显然,我们没有超越博彩公司,因此获利的机会很小。
自定义损失函数
二元交叉熵损失函数优化了我们正确预测比赛结果的能力,即优化了我们预测比赛的准确性。然而,这并不是我们的最终目标。我们想要的是识别博彩公司误判真实概率的比赛,从而提供有利的赔率。即,我们想要优化投资回报率。以下是一个精确实现这一点的损失函数。

自定义损失函数包含两个元素,方括号中的项是我们分别在玩家 1 或 2 上下注$1 的回报。请注意,这取决于比赛结果(yᵢ),如果我们预测错误,我们会损失资金。 ReLu 函数包含了我们的下注策略。它的特性是当 x ≤ 0 时,Relu(x) = 0,否则 Relu(x) = x。参数是我们的预期回报:赔率乘以我们估计的获胜概率减去 1。鉴于 ReLu 函数的特性,这意味着只有在我们认为赔率对我们有利时,它才会大于 0。换句话说,如果我们的模型认为赔率不公平,它不会下注任何资金。另一方面,赔率越有利,模型下注的金额就会越高。
这个损失函数确保我们优化的不是预测比赛结果的准确性,而是我们的赢利。注意,由于我们的自定义损失函数,预测的概率并不代表真实的概率,因为当模型认为博彩公司给出的赔率不准确时,它会将概率推向极端(0 或 1),以便下注更多。
那么它的表现如何?
为了测试我们的模型性能,我们构建了一个具有两个隐藏层的密集连接神经网络。最终层是一个 sigmoid 层,用于预测玩家 1 获胜的概率。然后,我们使用博彩公司赔率和比赛结果来计算使用上述自定义损失函数的损失。所有这些都在PyTorch中实现。
由于这是一个时间序列模型,该模型在给定时间点之前的历史数据上进行训练,然后应用于接下来的 50 场比赛。这个过程会对接下来的 50 场比赛重复进行,依此类推。结果如图 2 所示。
图 2:两种不同投注策略的累计收益随时间的变化。红点表示我们始终对博彩公司赔率中获胜概率最高的玩家下注的策略。从长远来看,这导致了约 5%的损失,对应于博彩公司支付方案。绿点是由我们的机器学习模型进行的投注。它只在预计会获得利润时才下注。总体收益波动在 0 附近。然而,也有一些重大收益,能够弥补较大的损失。在这种情况下,我们的利润约为~10%。
我们的模型成功地实现了盈利,尽管随着时间的推移波动较大。它经历了一些重大损失,但也取得了一些主要的收益来弥补这些损失。最终的投资回报率约为 10%。作为基准,我们采用了一种策略,即始终对博彩公司认为最有可能获胜的玩家进行投注(这与我们使用二元交叉熵优化预测赢家的模型不会有太大不同)。由于赔率不公平,我们在长期内会损失约 5%。
总结
-
博彩公司通过控制支付金额来获得利润。
-
对于飞镖比赛,它们通常能够很好地评估获胜概率。这使得仅仅通过预测飞镖比赛结果来获利变得困难。
-
一种具有自定义损失函数的机器学习模型——其目标是识别博彩公司赔率中的不足并获取利润,而不是优化正确预测赢家的准确性——可以提供一种有利可图的投注策略。
-
在任何给定时间点的投资回报率会受到较大波动的影响,只有在较长的时间段内才能期望获得利润。
-
所提出的模型绝不是一个保证盈利的机器。相反,它作为一个概念验证,描述了如何设置你的机器学习模型以击败博彩公司。
致谢
感谢Guido Tournois与我在这个项目中的合作。
个人简介:Richard Bartels是荷兰数据科学咨询公司 Vantage AI 的数据科学家。如果你需要帮助创建适用于数据的机器学习模型,请随时通过info@vantage-ai.com与我们联系。
原文。转载时经许可。
资源:
相关:
我们的 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
了解更多内容
使用 dtreeviz 创建美丽的决策树可视化
原文:
www.kdnuggets.com/2021/03/beautiful-decision-tree-visualizations-dtreeviz.html
评论
由埃里克·刘文森,高级数据科学家
决策树是机器学习模型中非常重要的一类,它们也是许多更高级算法的构建模块,例如随机森林或著名的 XGBoost。这些树也是基准模型的良好起点,我们随后尝试通过更复杂的算法来改进。
决策树最大的优点之一是它们的可解释性——在拟合模型后,它实际上是一组可以用来预测目标变量的规则。这也是为什么可以轻松绘制规则并向利益相关者展示它们,以便他们能轻松理解模型的基本逻辑。当然,前提是树不太深。
使用scikit-learn和matplotlib的组合可以非常简单地可视化决策树。然而,还有一个很棒的库叫做dtreeviz,它提供了更多功能,创建的可视化不仅更美观,还能传达更多有关决策过程的信息。
在本文中,我将首先展示“旧方式”绘制决策树,然后介绍使用dtreeviz的改进方法。
设置
一如既往,我们需要首先导入所需的库。
然后,我们从scikit-learn加载 Iris 数据集。我们还会讨论一个回归示例,但稍后我们会加载波士顿住房数据集。
“旧方式”
下一步是创建训练/测试集,并将决策树分类器拟合到 Iris 数据集上。在本文中,我们纯粹关注于决策树的可视化。因此,我们不会关注模型拟合或寻找合适的超参数(这些主题有很多文章)。我们将“调整”的唯一内容是树的最大深度——我们将其限制为 3,以便树可以适应图像并保持可读。
现在我们已经有了一个拟合的决策树模型,可以继续可视化这棵树。我们从最简单的方法开始——使用scikit-learn中的plot_tree函数。
tree.plot_tree(clf);
图片由作者提供
好吧,对于一行代码来说还不错。但它不是很易读,例如,没有特征名称(只有它们的列索引)或类别标签。我们可以通过运行以下代码轻松改进这一点。
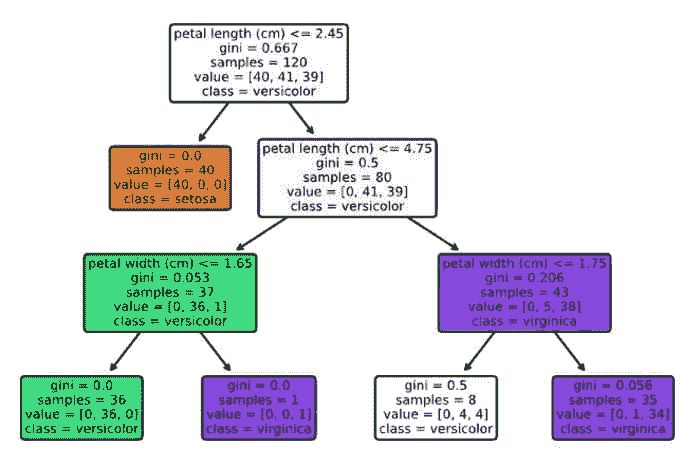
图片由作者提供
好多了!现在,我们可以相对容易地解读决策树。也可以使用graphviz库来可视化决策树,不过,结果非常相似,包含与上图相同的元素。因此,我们在这里跳过这部分,但你可以在GitHub 上的 Notebook中找到实现。
dtreeviz 的实际应用
既然已经看到旧的决策树绘制方法,现在让我们直接进入dtreeviz的方法。
代码片段几乎可以自我解释,因此我们可以继续讨论结果。首先,让我们花一点时间来承认这是一项多么巨大的改进,尤其是考虑到函数调用非常相似。
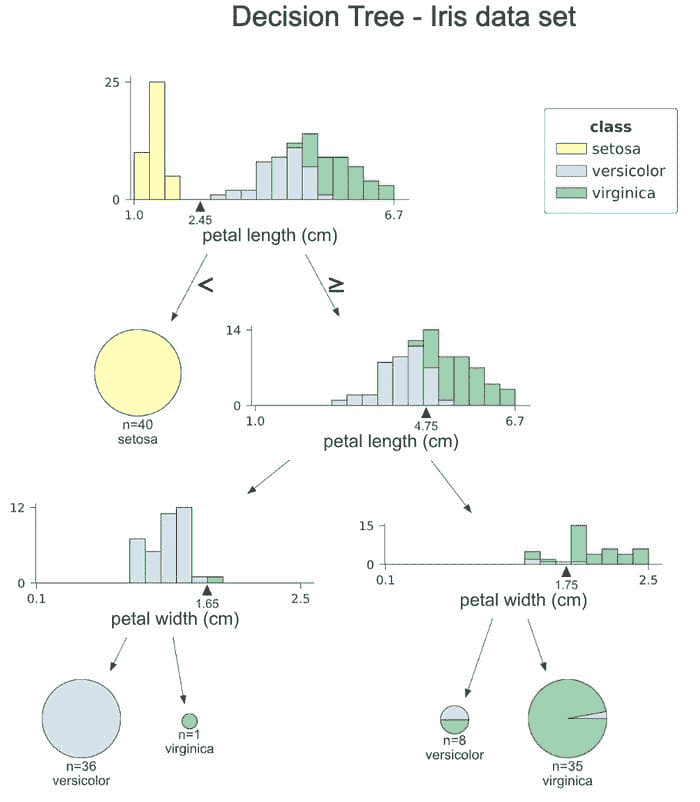
作者提供的图片
让我们逐步查看这个图表。在每个节点,我们可以看到用于分裂观察结果的特征的堆叠直方图,以类别颜色标记。这样,我们可以看到各个类别是如何通过每次分裂进行分隔的。x 轴上的值和小三角形是分裂点。在第一个直方图中,我们可以清楚地看到所有setosa类别的观察数据的花瓣长度小于 2.45 cm。
树的右侧分支表示选择大于或等于分裂值的值,而左侧分支则表示小于分裂值的值。叶节点用饼图表示,显示叶节点内观察结果属于哪个类别的比例。这样,我们可以轻松看出哪个类别是多数,从而也能了解模型的预测。
在这个图表中,我们没有看到每个节点的基尼系数值。在我看来,直方图提供了更多关于分裂的直观信息,而系数的值在向利益相关者展示时可能也并不是那么重要。
注意:我们还可以为测试集创建类似的可视化,只需在调用函数时替换x_data和y_data参数即可。
如果你不喜欢直方图并且想简化图表,可以指定fancy=False来获得以下简化的图表。
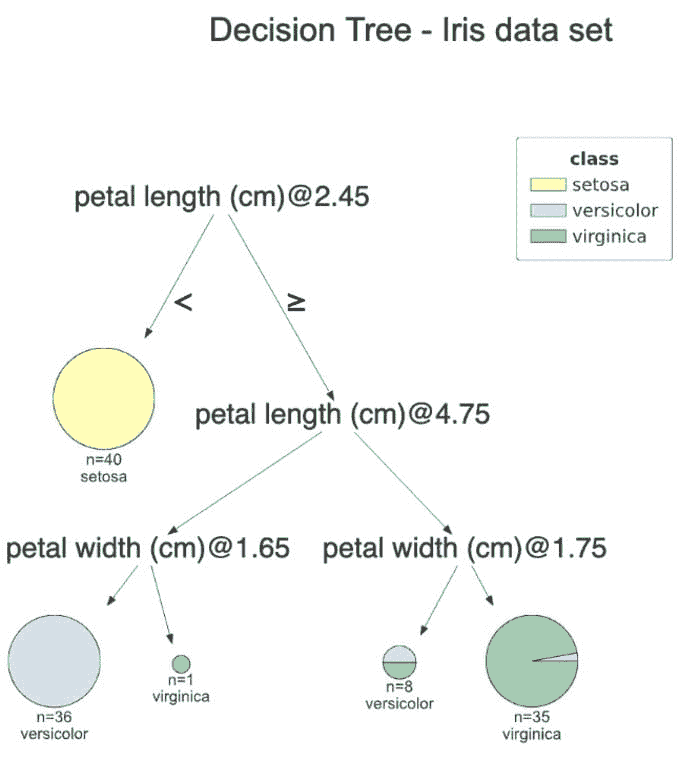
作者提供的图片
dtreeviz的另一个有用功能是对图中的特定观察结果进行路径高亮显示,从而提高模型的可解释性。这样,我们可以清楚地看到哪些特征对类别预测有贡献。
使用下面的代码片段,我们高亮显示了测试集第一条观察数据的路径。
该图与之前的非常相似,但橙色高亮清楚地显示了观察值遵循的路径。此外,我们可以在每个直方图中看到橙色三角形。它代表了所示观察值的特征值。在最后,我们看到该观察值的所有特征值,其中用于决策的特征用橙色突出显示。在这种情况下,只有两个特征被用来预测该观察值属于versicolor类别。
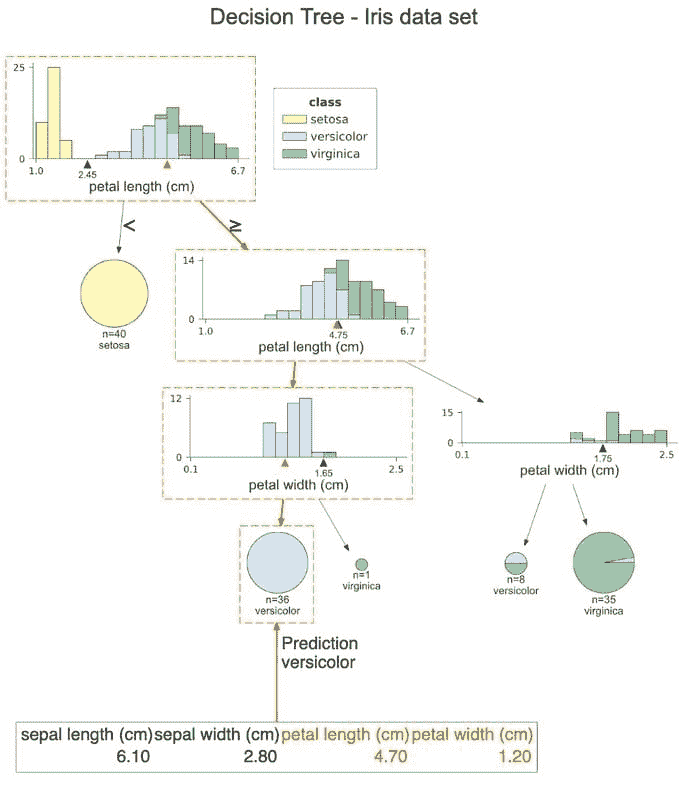
图片由作者提供
提示: 我们还可以通过设置orientation=”LR”将图表的方向从自上而下更改为自左而右。由于图表在较窄屏幕的设备上显示效果不佳,因此本文未展示此选项。
最后,我们可以用简单的英语打印出用于该观察值预测的决策。为此,我们运行以下命令。
这样,我们可以清楚地看到该观察值满足的条件。
回归示例
我们已经介绍了一个分类示例,这展示了库的大多数有趣功能。但为了完整性,我们还讨论了回归问题的示例,以展示图表的不同。我们使用了另一个流行的数据集——波士顿住房数据集。这是一个问题,其中我们使用一组不同的区域来预测波士顿某些区域的中位数房价。
代码已经相似。唯一的变化是我们添加了show_node_labels = True。这对于较大的决策树特别有用。因此,在与小组讨论图表时,很容易通过节点编号来指示我们讨论的分割。
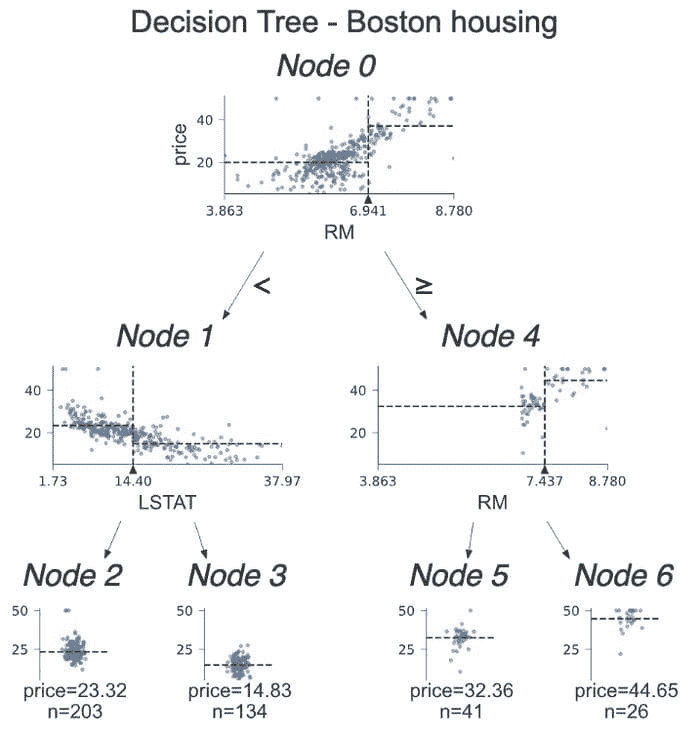
图片由作者提供
让我们深入探讨分类树和回归树之间的差异。这一次,我们不看直方图,而是检查用于分割的特征与目标的散点图。在这些散点图上,我们看到了一些虚线。它们的解释如下:
-
水平线是决策节点中左侧和右侧桶的目标均值。
-
垂直线是分割点。这与黑色三角形表示的信息完全相同,但它使得比较水平线更容易 -> 便于分隔两侧。
在叶子节点中,虚线表示叶子中的目标均值,这也是模型的预测。
我们已经展示了如何突出显示某个观察值的决策路径。我们可以更进一步,只绘制用于该预测的节点。我们通过指定show_just_path=True来实现这一点。以下图只显示了上面树中的选定节点。
图片由作者提供
结论
在这篇文章中,我展示了如何使用dtreeviz库来创建优雅且富有洞察力的决策树可视化。经过一段时间的使用,我将继续把它作为可视化决策树的首选工具。我确实相信,使用这个库创建的图表对于那些不日常从事机器学习的人来说更容易理解,并且有助于向利益相关者传达模型的逻辑。
还值得一提的是,dtreeviz支持一些 XGBoost 和 Spark MLlib 树的可视化。
你可以在我的GitHub上找到这篇文章中使用的代码。像往常一样,欢迎任何建设性的反馈。你可以在Twitter上或在评论中联系我。
如果你喜欢这篇文章,你也许会对以下内容感兴趣:
确保在更新数据集时训练集和测试集从未混合的最佳方法
Lazy Predict:用一行代码拟合和评估 scikit-learn 中的所有模型
最简单的方法来查看哪些模型最适合你的数据集!
学习在 Python 中确定特征重要性的最流行方法
参考文献
个人简介:Eryk Lewinson 目前在荷兰最大的电子商务平台担任高级数据科学家。在他的职业生涯中,他在为两家四大会计师事务所和一家荷兰金融科技初创公司工作时获得了数据科学方法的实际应用经验。在工作中,他专注于使用机器学习为公司提供商业价值。
原始文章。经许可转载。
相关:
-
2021 年你应该知道的所有机器学习算法
-
11 个完整 EDA(探索性数据分析)的必要代码块
-
讲述精彩的数据故事:可视化决策树
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
了解更多相关主题
如何成为 10 倍数据科学家,第一部分
原文:
www.kdnuggets.com/2017/09/become-10x-data-scientist-part1.html
评论
由 Stephanie Kim, Algorithmia。
最近我在PyData Seattle上进行了一个讲座,讨论如何通过借鉴开发者社区的技巧来提升你的数据科学技能。这些建议将帮助你成为一个受团队成员和利益相关者喜爱、更高效的数据科学家。
本文分为五部分,包括:
-
10 倍开发者的历史与争议。
-
项目设计。
-
代码设计。
-
工作所需的工具。
-
模型生产化。
如果你想观看完整的原始讲座,请点击这里。

10 倍开发者是指生产力比普通开发者高 10 倍的人。
10 倍开发者不仅每小时编写的代码比平均开发者多,而且调试能力强,测试代码减少了错误,指导初级开发者,撰写自己的文档,还具备许多超越编程知识的广泛技能。

1968 年,由H. Sackman、W. J. Erikson和E. E. Grant进行的实验“探索性实验研究比较了在线和离线编程性能”发现程序员完成编码任务的时间差异很大。
研究聚焦于平均有 7 年经验的程序员,并发现程序员之间存在 20:1 的差异。
尽管实验中发现了缺陷(如将使用低级语言的程序员与使用高级语言的程序员混合),但后来有更多研究得出了类似的结果。
虽然关于 10 倍开发者是否存在的辩论广泛,但本文将重点介绍如何通过借鉴经验丰富的开发者的技巧和窍门,成为更高效的数据科学家,这些开发者被认为比同行显著更快。

了解业务
无论你是为教育、生物技术还是金融公司工作,你都应该至少对你所解决问题的业务有一个高层次的理解。
为了有效地传达数据分析背后的故事,你应该找出推动业务发展的因素,并了解业务的目标。
例如,如果你专注于优化食品车的位置,你需要了解人流量、竞争、区域内发生的事件,甚至是天气。你需要了解为什么业务要优化位置,可能是为了增加现有食品车的销售额,或者他们可能正在考虑增加食品车。
即使你今天可能是求职网站的数据科学家,明天可能是在金融公司,你也应该知道是什么让业务运转,以使你的分析对利益相关者相关。
你还应该了解你项目的业务流程,例如谁需要对最终结果进行签署,数据模型在你的部分完成后将传递给谁,以及预期的时间框架是什么。
最后,你应该确保知道谁是利益相关者,并向非技术利益相关者介绍现实的期望。你需要做好教育者的角色,教导非技术利益相关者为什么实现他们的目标可能需要比他们预期更多的时间或资源。
当你理解了利益相关者的目标,并确保你传达了实现他们解决方案所需的技术、专业知识和时间时,你将成为公司更有价值的资产。

了解数据
尽管理解业务很重要,但理解数据更为重要。你需要知道数据是如何提取的,何时提取的,谁负责质量控制,为什么数据中可能会有缺口(例如供应商更换或提取方法更改),可能缺少什么以及还有哪些其他数据源可以添加以创建更准确的模型。
关键在于与不同团队沟通并提出大量问题。不要害怕询问别人正在做什么,并讨论你自己正在做的工作,因为你永远不知道别人是否在做重复工作,或者他们是否有你需要访问的更清洁的数据版本。例如,能够查询数据库将节省你大量时间,而不是对 SiteCatalyst 进行多次 API 调用。

为什么在项目设计中花时间和精力会让你成为一个 10 倍的数据科学家?
-
你只会做需要做的工作(在编码之前考虑一下),因此你会更快地完成项目,因为你会做更少的工作!
-
通过发现客户/用户认为他们需要的东西与他们真正需要的东西之间的误解,你将能够将自己定位为专家和共识的建立者。
-
你将加深对需求的理解,从而避免犯下昂贵的错误。
代码设计
尽管在设计代码时有许多最佳实践,但有一些特别突出的做法可以显著提高你的 x 值。
我第一次听到“清晰度胜过巧妙”这个想法是在大学的写作课程中。很容易被自己的巧妙性所吸引,使用最新的流行词来表达你的想法,但就像编程一样,你不仅可能会让自己困惑,还会让他人困惑。

在上面的 Scala 示例中,第一行展示了 sortBy 方法的简写语法。虽然它很简洁,但很难理解下划线代表什么。尽管这是许多人在匿名函数中作为参数名称使用的常见模式,对于较少经验的开发者(或当你有一段时间没有查看你的代码时),理解代码的功能会变得繁琐。
在第二个示例中,我们至少使用了一个参数名,并且它展示了赋值,我们可以看到它是按序列 x 中倒数第二个元素进行排序的。
当代码的抽象程度较低时,后续调试会更容易,因此在第三个示例中,我将明确命名我的参数,使其代表数据。
当你的大脑必须经过每一步,并查找或回忆简写代码的功能时,调试的时间会更长,添加新功能也会更费时。因此,即使使用如上例中的简写最初更简洁、打字更快,但从长远来看,避免过于巧妙会对你和其他人都有好处。

虽然我们不会深入探讨缓存,但我们会讨论命名的重要性。想象一下你在查看一些旧代码时,你看到一个像 Scala 示例中的序列被排序:
py` .sortBy(x => -x._2) ```py ````
使用单个字母来命名序列完全没有提供有用的信息,因为你可能是从 API、数据库或 Spark 中的数据流中提取数据,在这种情况下,你需要运行代码才能知道“x”是什么。
所以继续之前的 Scala 示例:
py` sortBy(clothesCount => -clothesCount._2) ```py ````
你可以在不运行代码的情况下了解我们正在排序的内容。
然而,有时使用 X 作为变量名是完全有理由的。例如,X 经常在机器学习库中使用,其中 X 通常表示观察到的数据,而 y 是尝试预测的变量。在这种情况下,最好使用你所在领域的惯例,其中“model”、“fit”、“predicted”,以及“x”和“y”对该领域的每个人来说都有相同的含义。
在数据科学之外,你需要遵循所使用编程语言的规范。例如,我建议你查看 Python 的 PEP 文档,以了解最佳实践,或者
通过注意命名规范,并且在编码时保持清晰而不是聪明,这将使重构和调试变得更简单、更快捷。遵循这两条编码设计原则,你将更接近成为一个 10 倍的数据科学家。
这里是 如何成为 10 倍数据科学家,第二部分。
原文。经授权转载。
简介: Stephanie Kim 是 Algorithmia 的开发者倡导者。
相关:
-
机器学习项目中最重要的步骤是什么?
-
深度学习从零到一:初学者的 5 个令人惊叹的演示及代码,第二部分
-
数据版本控制:迭代机器学习
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织进行 IT 工作
相关话题
在不到 6 个月内成为商业智能分析师
原文:
www.kdnuggets.com/become-a-business-intelligence-analyst-in-less-than-6-months

作者提供的图像
许多从事技术行业的人会转向不同的领域。商业智能就是其中之一。没有软件开发或编码经验的人喜欢分析数据,以帮助企业做出正确的决策。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
你找到这篇文章是有原因的,这可能是上述两个原因之一。
在商业智能分析方面,主要的是学习基础知识并成为使用工具的专家。这就是为什么我创建了一个顶级提供商的课程列表,其中一些甚至所有课程目前主导了商业智能市场。
本文的目的是让你可以根据想学习的工具选择适合你的证书。例如,是选择 Looker 还是 Tableau?
Google 商业智能证书
链接: Google 商业智能专业证书
Google 以其全面的证书课程而闻名,这些课程帮助了许多人获得高薪职位,而无需回到大学。
由 3 门课程组成,面向寻求高级知识的人,如果每周投入 10 小时,可以在 2 个月内完成。
在这个商业智能证书课程中,你将探讨商业智能专业人员的角色,学习和实践数据建模、提取、转换和加载 (ETL)。然后你将深入挖掘数据发现,并创建数据可视化和仪表盘,以回答可以有效传达给利益相关者的业务问题。
IBM 商业智能 (BI) 分析师证书
IBM 也是一个以多种证书著称的组织。这个证书针对初学者,由 10 门课程组成,可以按照自己的节奏完成。
在这个全面的 10 门课程认证中,你将掌握 SQL 查询和关系数据库的技能,学习数据收集和清洗,并了解数据仓库。你将应用统计分析方法来识别趋势,创建数据可视化,并使用流行的工具如 Tableau、Excel、Cognos 和 Looker 构建仪表板。通过这些工具,你将生成有价值的见解,帮助决策过程。
微软 Power BI 数据分析师证书
另一个了不起的提供者——微软!这门专业证书面向初学者,由 8 门课程组成,如果每周投入 10 小时,可以在 5 个月内完成。
专门针对微软,在这门课程中你将学习如何使用 Power BI 连接数据源,并将其转化为有价值的见解。你将从准备 Excel 数据开始,通过学习常用公式和函数的最佳实践,为分析过程做好准备。接着,你将学习 Power BI 的功能,创建数据可视化、报告和仪表板。
如果你想做好准备,可以通过项目和微软 PL-300 认证考试来展示你的技能。
Tableau 商业智能分析师证书
一门来自最优秀商业智能工具之一的课程!这门课程面向初学者,由 8 门课程组成,如果每周投入 10 小时,可以在 8 个月内完成。
在这门专注于 Tableau 的课程中,你将获得每个初级商业智能分析师所需的基本技能。你将学习如何使用 Tableau Public 准备和处理数据进行分析,然后创建数据可视化,以揭示有意义和可操作的见解。
总结一下
这就是你所需的一切。这 4 门课程将为你提供成为成功商业智能分析师所需的技能和经验。你只需要确定想要成为哪种工具的专家。
祝学习愉快!
Nisha Arya是一名数据科学家、自由技术作家、以及 KDnuggets 的编辑和社区经理。她特别感兴趣于提供数据科学职业建议或教程,并讲解数据科学的理论知识。Nisha 涉及广泛的主题,希望探索人工智能如何有益于人类寿命的不同方式。作为一个积极学习者,Nisha 寻求拓展她的技术知识和写作技能,同时帮助指导他人。
了解更多相关话题
使用 Phraser 和 Stable Diffusion 成为 AI 艺术家
原文:
www.kdnuggets.com/2022/09/become-ai-artist-phraser-stable-diffusion.html
图片由作者提供 | DreamStudio | Phraser | Stable Diffusion
我们生活在一个激动人心的时代,每周都有关于前沿技术的公告。几个月前,OpenAI 推出了最先进的文本到图像模型DALL·E 2。只有少数人获得了早期访问体验这个新 AI 系统,它可以根据描述使用自然语言创建逼真的图像。它仍然对公众关闭。
几周后,Stability AI 推出了名为 Stable Diffusion 模型的开源版本 DALLE2。这次发布改变了一切。因为互联网上的人们纷纷发布提示结果,对逼真的艺术作品感到惊叹。
模型的权重可以在 Hugging Face 的CompVis/stable-diffusion-v1-4上获得。你还可以查看源代码和模型卡。它在The CreativeML OpenRAIL M许可证下对公众开放。
在这篇文章中,我们将了解 Stable Diffusion,并理解一个优秀提示生成器的必要性。
Stable Diffusion
Stable Diffusion 模型是一个开源的最先进文本到图像模型,用于使用自然语言生成艺术作品。它使用潜在扩散来识别形状和噪声,并将与提示同步的所有元素集中到核心焦点上。
该模型在一个LAION-5B图像集上进行了训练,该图像集包含了互联网上 50 亿张公开可用的图像。这些图像附带有标题和标签。
训练该模型花费了数百个高端 GPU(Nvidia A100),Stable Diffusion 的训练成本约为$660,000。在训练过程中,模型使用CLIP(对比语言–图像预训练)将词汇与图像相关联。
你不必自己训练模型。你可以在 Hugging Face Spaces 和 DreamStudio 上免费体验它。你甚至可以下载模型权重并在本地运行。
Hugging Face Spaces
Hugging Face - Stable Diffusion非常棒。只需写一个简单的描述,然后点击生成图像按钮。几秒钟后,你将看到 4 张与你的提示相关的生成图像。
图片由作者提供 | StableDiffusion | Hugging Face Spaces
有时,图像生成可能需要几分钟,甚至因需求量大而排队。这对于无限制的免费试用是可以接受的,但你始终可以查看名为 DreamStudio 的官方 Demo 应用程序。
DreamStudio
注册一个免费的 DreamStudio 账户后,你会获得 2 美元或 200 次生成机会。生成速度很快,你可以玩转其他选项,如尺寸、Cfg 规模、种子、步骤和图像数量。你生成的图像始终保存在历史记录中,你可以使用 API 将其集成到现有应用程序中。
如你所见,使用提示生成完全新图像只需几秒钟。

DreamStudio | 作者
这是另一个示例。我是《魔戒》和霍比特人的忠实粉丝,所以我想,为什么不生成一张 3D 渲染的图像呢?

DreamStudio | 提示:3D 哈比特人的世界
你可以在提示中添加风格甚至平台名称。你可以尝试生成特定图像的许多方法。你甚至可以编写详细描述所有细节的长提示。

DreamStudio | 提示:Artstation HQ 上红发女孩的梦
但如何像下面这样创建详细和高质量的图像呢?真正的艺术家现在是那些想象新角色和新世界的推广者。他们使用关键词生成逼真的生成艺术。

图片来自 nearcyan | 假设的 Marvel 超级反派
使用 Phraser 生成提示
如果你想成为一名 AI 艺术家并出名,锻炼你的想象力并编写创意提示至关重要。你还需要工具来引导你,并允许你探索各种风格、纹理、颜色、内容、感觉和时代。
Phraser 是最好的提示生成器。你将从各种不同的部分中选择多样的选项,如风格和内容类型,而不是尝试不同的词汇。
开始时,它会要求你选择神经网络,如 DALLE2、midjourney 和 Stable Diffusion。之后是内容类型、描述、风格、颜色、纹理、分辨率、相机设置、感觉和时代。选择选项后,你将获得一个提示。
图片由作者提供 | 获取提示的步骤
你可以将提示复制粘贴到 Hugging Face Spaces,或者通过 API 连接 DreamStudio。
连接非常简单,API 连接指南在提示的末尾提供。
图像来自 Phraser | API 密钥指南
连接 API 的主要优势是你可以在 Phrase Web 应用程序中体验稳定扩散的结果,从而节省复制和粘贴提示的时间。
使用 Phraser 生成的提示
结论
我们正进入生成艺术的新时代,每周我们都看到社区带来了稳定扩散模型的新变体。例如,nateraw/stable-diffusion-videos通过插值稳定扩散的潜在空间生成视频。
“请关注 Twitter 和 LinkedIn 上展示技能的专家图像和视频提示员。”
在这篇文章中,我们了解了稳定扩散模型以及如何使用 Hugging Face 和 DreamStudio 等免费平台创建 AI 生成的图像。此外,我们还了解了 Phraser,它帮助你为模型编写创意提示/描述。
参考
Abid Ali Awan(@1abidaliawan)是一位认证数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为在精神疾病中挣扎的学生构建 AI 产品。
更多相关内容
在 90 天内成为 Analytics Engineer
原文:
www.kdnuggets.com/2021/07/become-analytics-engineer-90-days.html
评论
作者:Tuan Nguyen,Joon Solutions 的首席技术官及董事会成员。

Analytics Engineer 是一个由 dbt 创造的全新职位。如果一个数据工程师(DE)和一个数据分析师(DA)结婚,他们有一个女儿,那么这个女儿将会是一个 Analytics Engineer(AE)。嗯,虽然实际上并不是这样,但你明白我的意思。
背景
一名 AE 通常从 DA 开始,制作仪表盘并进行临时查询。她希望做更多的工作,因为那个 DE 家伙工作得像蜗牛一样。她对自己的数据非常了解,因为她每天花几个小时用她高超的 SQL 技能来浏览数据。她也非常了解业务,因为她每天都要与他们互动。但她面临着巨大的挑战,想要接手 DE 家伙的工作。以下是一些挑战:
-
管道是用 Python 构建的,而她不知道如何编程(除了 SQL 以外)。
-
DE 家伙提到过使用 git 来跟踪源代码的变化。她把 SQL 代码存储在 Word 文件中……
-
她对产生数据的系统了解甚少。
-
团队使用各种工具,而她并不熟悉所有这些工具。
-
那个 DE 家伙认为这超出了她的能力,这让她更加生气。
解决方案
如果我们的 DA 女孩能够完成那个傲慢 DE 的工作而不变成他就好了……来看看dbt(数据构建工具)吧!你问一个这样的工具如何在这个领域创造一个全新的职位?让我们看看。
-
她可以用 SQL 而不是 Python 编写转换代码。什么?
-
她可以用编程方式测试连接语句中的重复项。真的吗?
-
她可以编写数据文档,以便业务人员减少对她的打扰。很好!
-
她可以使用 for 循环和变量,使用 SQL 模板进行数据透视。太棒了!
-
她可以展示数据血缘,以便人们知道数据的来源以及对数据所做的处理。太棒了!
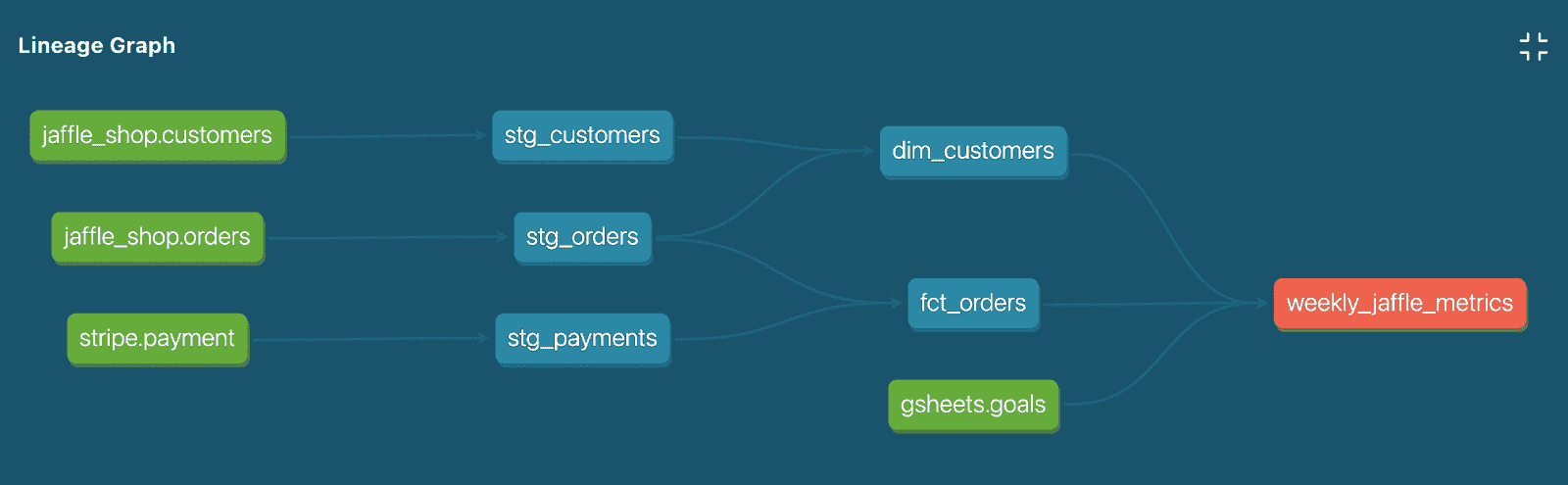
进化
就这样,我们的 DA 女孩变成了 AE。

我在开玩笑。实际上不是这样的。这需要时间、精力和对学习新事物的承诺。如果你能与我们 DA 女孩的故事产生共鸣,我认为这篇文章对你会有帮助。
这是我认为成为 AE 高手所需的技能和技术的有见解的清单。
-
SQL 忍者:如果你是一个士兵,那么 SQL 就像你的武器。SQL 已成为数据提取和转换的标准。作为 AE 或 DA,你必须尽可能熟练掌握 SQL。
-
Git 战士:Git 是团队协作中的一个强大工具。你需要像使用手臂一样使用这个工具。
-
dbt 专家: dbt 是一种技术,使 AE 和 DA 能够完成 DE 的工作。借助 dbt,你可以轻松参与以前只有 DE 才能做的工作,并对数据进行大量操作。
-
BI 工具专家:仪表板不仅仅是数字和图表,它们是讲述故事的强大工具。
-
云计算冠军:云计算是我们拥有第四次工业革命的原因之一。成为云计算冠军只会对你的职业发展有所帮助。
-
Scrum 主任:Scrum 是一种利用敏捷思维来开发、交付和维持复杂项目的框架。
-
文档倡导者:作为人类,我们之所以能走到今天,全靠集体学习。写作是一个强大的沟通工具,你将从练习写作中受益匪浅。
资源
以下是我们在 Joon Solutions 用于培训新分析工程师的资源。它更像是一个清单,也许你可以将这些复制到你喜欢的记笔记应用中。
我不能保证按照此方法,你就能成为 AE。但我确信你可以通过这条路径学到很多东西,并且在正确的环境和团队下,你将发展成为一个分析工程师忍者。
祝学习愉快!
我已经成为了 SQL 忍者
-
我已完成 W3School SQL 课程。
-
我已完成 SQLBolt 课程。
-
我已经浏览了 BigQuery 语法文档 并提出了我需要的所有问题。
-
我已经探索了至少一个 BigQuery 公共数据集 并进行了有趣的查询。
-
我知道什么是 窗口函数 以及如何使用它们。
-
我承认 SQL 是强大的。
我已经成为了 Git 战士
-
我知道什么是 git。
-
我知道一个典型的 git 工作流程 是什么样的。
-
我创建了一个测试仓库、一个提交,并提交了一个拉取请求。
-
我知道什么是 SSH 密钥,在哪里找到它,以及如何将其添加到我的 GitHub 账户。
我已经成为 dbt 大师。
-
我知道什么是 dbt,以及它为什么强大。
-
我阅读了分析工程师指南。
-
我参加了 dbt 的按需课程。
-
我从零开始设置了一个 dbt 项目,并建立了一些很棒的模型。
-
我已阅读并理解了dbt 项目检查表。
-
我已阅读并理解了dbt 最佳实践。
-
我已阅读并理解了dbt 编码规范。
-
我已经准备好并兴奋地想用 dbt 构建实际项目。
我已经成为 BI 工具专家。
-
我查看了 BI 工具的全景,并了解了有哪些工具。
-
我尝试并建立了一个使用Power BI的仪表盘。
-
我尝试并建立了一个使用Metabase的仪表盘。
-
我尝试并建立了一个使用Holistics的仪表盘。
-
我尝试并建立了一个使用Data Studio的仪表盘。
-
我可以自信地说,我知道哪种 BI 工具适合不同的需求。
我已经成为云计算冠军。
-
我了解过一个主要云服务提供商的many services。
-
我了解使用云计算的many benefits。
-
我尝试创建了一个 BigQuery 数据集,并加载了数据。
-
我尝试过BigQuery ML,并了解到用 SQL 创建 ML 模型有多么简单。
我已经成为 Scrum 大师。
-
我了解scrum 开发过程。
-
我阅读过关于scrum 开发的内容。
-
我了解 CI/CD 以及为什么数据团队也应该使用它
我已成为一名文档推广者
原文。经授权转载。
简介: Tuan Nguyen 是 Joon Solutions 的首席技术官,该公司提供数据即服务。他的专业经验包括构建和管理数据科学团队、分析基础设施和分析用例。他热衷于将数据分析和云计算的激情结合起来,帮助企业在数字时代保持竞争力。他的兴趣广泛,包括天文学、阅读、音乐和物联网。
相关:
更多相关主题
成为数据科学专业人士的五个步骤
原文:
www.kdnuggets.com/2022/03/become-data-science-professional-five-steps.html

图片由作者提供
一个典型的初学者会花几个小时在谷歌上搜索数据科学课程,大多数人最终放弃。这是为什么呢?因为我们有多个开始的选项,我们无法确定哪个最适合自己。在我看来,我们都迷失在大量内容中,不知道从哪里开始。在这篇博客中,我将指导你什么对我有效,也许对你也有帮助。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
指南包括:
-
学习数据科学基础
-
提高编程语言水平
-
完整的数据科学学习路径
-
获取数据科学项目的实践经验
-
获取数据科学认证
1. 学习基础知识
学习数据科学基础是你旅程中最重要的部分,因为它将为你迎接学习挑战做好准备。大多数初学者会在不知道自己想要什么的情况下开始课程。最终,90%的人甚至未能完成课程,因为随着时间的推移,课程变得越来越难。因此,如果你正在跟随趋势,请了解数据科学和职业道路。

图片由 Karolina Grabowska 提供,来自 pexels
从观看初学者友好的视频教程开始学习统计学和数据科学基础。这些非技术性视频将帮助你理解数据科学的各个组成部分:数据采集、数据清理、数据分析、建模和应用。如果你不喜欢观看视频,也可以尝试阅读博客和书籍。学习数据科学基础将帮助你理解职业道路,并介绍数据分析和机器学习中使用的最常见工具。
学习资源:
2. 学习编程
学习基础知识后,是时候掌握Python了,因为你在工作中大部分时间都会编写代码。你也可以从R或Julia开始,因为它们本身就是为了统计和科学研究而开发的。掌握 Python 将帮助你进行研究、数据可视化、设计最先进的应用程序以及通过技术面试。

图片由作者提供
我开始我的旅程时学习了 R 和 Python。这帮助我更快地掌握了数据分析的核心概念。之后,我开始学习SQL,它是数据摄取和分析最重要的工具。几乎所有的数据科学面试都会包括 SQL 问题,因此,最好在早期阶段就学习它,以提高被聘用的机会。
学习资源:
-
Codecademy: Python 课程与教程
-
Youtube: 1 小时学会 Python
-
Udemy: Python 训练营
-
Udacity: 免费 Python 入门课程
额外内容:
-
对于 Julia: Julia 科学编程
-
对于 R: 统计学与 R
-
对于 SQL: 学习 SQL
3. 应用数据科学轨道
数据科学轨道包含你需要掌握的所有必要课程;数据管理、探索性分析、统计实验、模型开发、编程和报告。职业轨道还为你提供了一个结构和互动编程练习。这些课程将帮助你理解统计学、机器学习和自然语言处理的核心概念。

图片由作者提供
我的旅程始于 Python 数据科学职业路径,这帮助我理解了数据分析和机器学习。互动课程提高了我的编码技能。在我看来,带有互动练习、编码挑战、作业和项目的职业路径是最好的。它们将帮助你跟踪进展,并随着时间的推移不断提高。
互动职业路径:
-
DataCamp
-
R: R 数据科学家路径
-
Python: Python 数据科学家路径
-
SQL: SQL Server 数据分析师路径
-
-
Udacity: 在线学习成为数据科学家
-
Coursera: 数据科学 | Coursera
-
Codecademy: 数据科学家
4. 实践经验
是时候将你的技能应用到现实世界中,但如果没有一定的经验,找到工作会很困难。如何获得经验?通过参加数据科学竞赛、在 NGO 项目中志愿服务或申请实习来获得经验。

图片由作者提供
参与竞赛
参加数据分析或机器学习竞赛将帮助你建立数据科学作品集。这也将帮助你理解各种现实问题,如预测、医疗保健中的机器学习、机器人技术和计算机视觉。数据科学路径向我展示了数据的世界,Kaggle 竞赛将我塑造为一名数据科学专业人士。我强烈推荐大家参与竞赛并从其他参与者那里学习。
竞赛平台:
进行项目实践
你也可以为 NGO 项目做志愿者,这些项目的入门门槛较低。如果你在寻找合作经验,我建议你查看Omdena项目。为了提升你的数据科学作品集,尝试寻找适合初学者的项目。不要仅仅局限于工作机会,你也可以通过参与开源项目来获得经验。
实习
最后但同样重要的是实习选项。你可以在 LinkedIn 或本地招聘网站上找到学徒岗位、夏令营邀请或实习机会。实习是你进入职业世界的第一步,也是获得全职工作的快捷方式。如果你在寻找实习机会时遇到困难,可以询问朋友或在 LinkedIn 上发布信息。获得专业经验对你在该领域的成功至关重要。
5. 认证
获得数据科学认证会让你在就业市场中占据优势。认证考试难度较大,会考察你的编程、数据管理、建模和报告知识。最好在参加认证考试前,先积累一些数据科学项目的初级经验。

作者提供的图片
我花了两周时间完成所有挑战。第一个挑战是定时评估,测试了我对 SQL、Python 和统计学的知识。随后,我进入了编码挑战,这花费了我整整一天的时间。最后部分是案例研究,包括撰写技术报告和非技术演示。在获得认证后,我从DataCamp免费获得了职业服务,这帮助我通过了多次求职面试。如果你想了解更多关于我的经历,请查看我的博客:如何获得数据科学认证。
顶级数据科学认证列表:
下一步是什么
下一步是寻找数据科学的全职工作。在等待被聘用的同时,最好继续学习新工具并参与项目。你也可以加入数据科学社区或撰写有关你所学内容的博客。
注册自由职业平台,参加竞赛,阅读最新研究话题,在 GitHub、Deepnote、DAGsHub 和 Kaggle 上创建你的作品集。如果你想被 Meta 和 Google 等顶尖公司注意到,持续学习和成长是非常重要的。
如果你正在寻找项目灵感,可以查看我在 Deepnote、Kaggle、GitHub 和 DAGsHub 上的个人资料。你还可以关注我在 LinkedIn 上,了解更多适合初学者的项目,阅读博客和教程。如果你对数据科学职业路径有任何疑问,请在下方评论,我会尽力回答你的问题。
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生构建一个 AI 产品。
更多相关话题
如何成为数据科学家——第一部分
原文:
www.kdnuggets.com/2016/08/become-data-scientist-part-1.html/4
计算机科学 / 软件工程
如果你已经在人工智能/计算机科学领域达到了较高水平,那么你很可能已经处于 B 类数据科学的良好位置。但也有另一条行之有效的路径需要考虑:有经验的软件工程师希望转向数据科学。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面

软件工程师可能有,也可能没有机器学习经验——这要看具体情况。但无论如何,这种背景显然更适合 B 类数据科学,它需要扎实的软件工程基础。我与澳大利亚联邦银行的高级数据科学家詹姆斯·佩特森(James Petterson,曾为软件工程师)讨论了这个问题,他对此的看法如下:
“很多数据科学工作是软件工程。并不总是指设计健壮的系统,而是简单地编写软件。很多任务可以自动化,如果你想进行实验,你必须编写代码,如果你能做到这一点又快又好,差别会很大。当我攻读博士学位时,我每天必须运行数万次实验,在这种规模下,手动完成是不可能的。拥有工程背景意味着我可以快速完成这项工作,而其他背景的学生在基本软件问题上遇到困难:他们数学很好,但实现他们的想法需要很长时间。”
迪伦补充道:
“良好的软件工程实践在你想要在生产环境中创建一个健壮的机器学习算法实现时是非常有价值的。这包括可维护的代码、共享的代码库以便多人协作、日志记录、能够在生产环境中调试问题、可扩展性等——你需要知道一旦工作量增加,你已经以这种方式架构它,以便在需要时可以进行并行处理或添加更多的 CPU。所以如果你在寻找那些需要将这些东西整合到平台中的角色,而不是进行探索性研究或回答临时业务问题,那么软件工程是非常宝贵的。”
我认为这已经说得很清楚了,但总结一下:如果你是一个对数学有良好兴趣的软件工程师,你有很好的条件成为(B 型)数据科学家,前提是你愿意投入工作来掌握统计/机器学习。
数学
显而易见:数学是所有数据科学领域的基础。因此,合理预期许多数学家现在正在作为数据科学家施展他们的才华。然而,直接从数学领域过渡的人相对较少,这种特殊情况引起了我的兴趣。
一个解释是,数学(包括纯数学和应用数学)的毕业生相比其他相关学科较少,但这并没有讲述全部故事。因此,为了深入了解,我找到了 Boris Savkovic,他是 BuildingIQ 的首席数据科学家(这是一家利用先进算法优化商业建筑能源使用的初创公司)。Boris 拥有电气工程和应用数学背景,并且与许多数学家合作过,他提供了以下见解:
“许多数学家喜欢理论问题、美丽的方程式以及在定理中发现深刻含义,而商业数据科学则是经验性的、混乱而肮脏的。虽然一些数学家喜欢这种情况,但许多人讨厌它。现实世界是复杂的,你不能对一切进行沙盒测试,你必须优先考虑,理解他人的激励,为短期、中期和长期的需求妥协数学和技术,关注递减收益(80/20 原则),并处理深度理论和深度实践之间的一切。简而言之:你必须灵活适应以应对现实世界。这就是商业数据科学的终极目标:寻找更快更好的实际解决方案来赚钱。对于那些有着深厚数学/理论背景并希望把一切理解到最后一度的人来说,这可能非常困难,我看到不少数学博士在从研究/学术界过渡到商业数据科学时遇到了严重困难。”
需要注意的是,Boris 更多地指的是纯数学家,他还补充说他在职业生涯中也与许多优秀的应用数学家合作过。这似乎很有逻辑,因为纯数学更有可能吸引那些对理论充满热爱的人,而不是现实世界的问题。而理论工作不会涉及太多的数据,这对于数据科学来说是相当重要的。
当然也有例外,最终还是取决于个人性格,而不仅仅是一个人所学的内容。显然,许多数学毕业生所学的知识具有高度可转移性,因此掌握特定的统计/机器学习技术应该不会太困难(如果尚未了解的话)。
就适用性而言,大多数数学家可能最适合学习 A 类数据科学的工具和理论。然而,也有数学家研究计算机科学(理论计算机科学本质上是数学的一个分支),因此拥有这种背景的人可能更适合 B 类数据科学。
从这些内容中可以得到一个重要的教训,那就是了解商业数据科学的现实。如果你真正理解这些挑战并且这是你所追求的,那么就去做吧。但是,如果你更喜欢理论而非实际应用,你可能需要重新考虑你的想法。
空白画布
如果你刚刚开始,可能你还在学校,喜欢数学、科学和计算,并且对这个叫做数据科学的领域感兴趣,好消息是:你可以在没有先前背景的情况下选择你的道路。而且现在有很多具体的数据科学课程,涵盖计算机科学和数学/统计学。只是要做好长期奋斗的准备;你不会一夜之间成为数据科学家,正如我们将在第二部分中看到的,我们将探讨:如何学习。
简历: Alec Smith 是数据科学和工程领域的专业招聘人员。作为一家招聘机构的招聘人员,他提供了商业分析的独特跨部门视角,并利用这种观点撰写有关数据科学、技术和招聘的各种话题。原籍英国,他目前在澳大利亚悉尼工作。关注 Alec 的 Twitter @dataramblings。
这篇文章最初发表于 Experfy 的博客。
相关:
-
数据科学家的意义是否如你所想?
-
构建数据科学投资组合:机器学习项目第一部分
-
2016 年数据科学家职位最佳地点
更多相关主题
如何成为一名机器学习工程师
原文:
www.kdnuggets.com/2022/05/become-machine-learning-engineer.html

图片来自 rawpixel
机器学习工程在迅速增长,超过了数据科学。这个职位需求量很大,许多数据科学职业的人转型成为机器学习工程师。根据 glassdoor,它目前位列美国前 50 名最佳职业的第 6 位。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
机器学习(ML)工程师是一个精通构建和设计软件以自动化预测模型的程序员。他们的计算机科学背景相较于数据科学家更为深入。
大多数机器学习工程师来自两个背景之一。第一个是拥有数据科学、软件工程、计算机科学和/或人工智能博士学位的人。另一个是那些有过数据科学家或软件工程师经验并转型到这一角色的人。
机器学习工程师的工作是什么?
数据科学家和机器学习工程师都处理动态数据集,进行复杂建模,并具备卓越的数据管理技能。
机器学习工程师的主要职责是设计软件来自动化预测模型,这些模型有助于进行未来预测。这就是‘机器’如何从‘工程’中‘学习’的过程。
执行此操作的子任务包括:
-
研究机器学习算法和工具及其实施方式。
-
选择适当的数据集
-
选择数据表示方法
-
验证数据的质量
-
识别数据中的分布以及它如何影响模型性能。
-
对机器学习系统和模型进行迭代训练
-
执行统计分析
-
微调模型
-
改进现有的机器学习框架和库
成为成功的机器学习工程师需要哪些技能?
成为机器学习工程师需要多种技能。
编程技能
你需要掌握多种编程语言,如 C++、Python 和 Java,以及 R 和 Prolog 等在机器学习中变得重要的编程语言。你掌握的编程语言越多越好;然而,这可能需要大量的学习。
统计学
机器学习更侧重于计算机科学,利用概率和其他统计工具来构建和验证模型。机器学习算法是统计建模程序的延伸,因此理解统计学和数学的基础是重要的。
问题解决者
模型失败的情况是常有的,这可能变得非常复杂,因此 ML 工程师需要具备良好的问题解决能力。不要轻易放弃,通过理解问题并开发相应的方法来高效解决问题,这样可以节省时间并更快地实现目标。
理解数据
ML 工程师能够迅速浏览大型数据集,识别模式,帮助他们了解下一步采取哪些措施以产生有意义的结果。使用 Excel、Tableau 和 Plotly 等工具也可以提供更深入的数据洞察。
如何开始你的 ML 工程师职业生涯

David Iskander via Unsplash
传统途径:大学
对 ML 工程师来说,理想的学位包括数学、数据科学、计算机科学、统计学和物理学。这些学位为 ML 工程师提供了基础知识以及编程、统计工具和分析技能。
如果你想更好地了解大学课程内容,可以阅读这篇文章:免费大学数据科学资源。
一旦完成学位,你需要在软件工程、数据科学等领域积累技能和经验。ML 工程师需要几年高水平的编程经验才能获得成功。
你可以通过获得数据科学、软件工程的硕士学位,或在机器学习领域攻读博士学位来进一步增加知识。
现代技术途径:电子学习
在当今对技术专家需求量大的情况下,另一种可能性是独立学习和/或电子学习。这可以通过 BootCamps、在线课程、YouTube 等途径实现。
如果你想通过 YouTube 学习,有很多 YouTube 频道可以帮助你实现目标。像 John Starmer、Krish Naik 等 YouTuber 都可以提供帮助。如果你想了解更多,可以阅读这篇文章:学习数据科学的顶级 YouTube 频道。
还有各种在线课程,其中一些是由大学提供的。这显示了对技术专家的需求,因为大学已经投入时间创建课程来满足这一需求。随着新的远程生活方式的出现,在线课程变得越来越受欢迎,有助于加速人们的职业发展。
最近令我感兴趣的一个优秀平台是 Great Learning,提供数据科学与商业分析、人工智能与机器学习、云计算、软件开发等课程。他们最受欢迎的机器学习课程之一是:数据科学与机器学习:数据驱动决策课程。
机器学习工程师需要掌握大量与机器学习相关的知识以及不同类型的算法。如果你想了解更多关于你将在机器学习中学习的算法类型,可以阅读这篇文章:流行的机器学习算法。
书籍
尽管许多东西已经转移到在线,但越来越少的人阅读书籍。书籍是学习的绝佳方式,然而,选择哪本书可能很困难。我强烈推荐 Oliver Theobald 的书籍 机器学习入门。
如果你想要更多针对不同学习水平的机器学习书籍推荐;初学者、中级和专家,可以阅读这篇文章:2022 年你需要阅读的机器学习书籍
这不是一条容易的道路,但值得付出
成为机器学习工程师不会一蹴而就,但一旦你获得了正确的资格、技能和经验,你将进入一个为你提供稳固未来的领域。这需要大量的努力和决心,你需要做的就是付出努力。
Nisha Arya 是一位数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何或能如何有益于人类寿命。她是一位热衷学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
如何在 2022 年成为成功的数据科学自由职业者
原文:
www.kdnuggets.com/2022/02/become-successful-data-science-freelancer-2022.html

Andrew Neel的照片,来源于 Unsplash
对大多数人来说,从事自由职业是一种梦想成真。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
自由职业让你能够在家工作。无需每天打卡。你可以挑选要做的任务,拒绝那些你不感兴趣的工作。你可以按自己的节奏工作,也可以选择偶尔休息放松。
如果你是一名有抱负的数据科学家,好消息是全职工作并不是你唯一的职业选择。许多公司和个人都在寻找自由职业的数据科学家。
在这篇文章中,我将带你了解如何运用你的数据科学技能来获得自由职业机会。我将涵盖以下主题:
-
成为自由职业数据科学家的利与弊
-
你可以从事的自由职业数据科学工作类型
-
如何获得你的第一个自由职业机会
-
如何建立一个强大的作品集,以吸引多个工作机会
数据科学自由职业的利与弊
在任何领域从事自由职业可以让你自由选择工作地点和时间。你可以节省许多如汽油和餐饮的费用,因为你不需要每天去办公室。如果你发现自己在做重复和无聊的任务,你有机会改变这种情况,只接受让你兴奋的项目。
如果你全职为一家公司工作,你会受到公司内部工作范围的限制。你无法在不同领域的任务中进行工作。
然而,如果你从事自由职业,你将接触到各种行业。这对你的作品集非常有帮助,并使你有资格申请更广泛的职位。
然而,自由职业也有其自身的缺点。
首先,你将缺乏工作保障。没有很多雇主雇佣自由职业的数据科学家。
一般来说,个人或小型公司/创业公司选择雇佣自由职业者。他们通常不需要数据科学家,也没有完善的数据管道。
较大的公司如果需要数据科学家,通常会有固定职位。他们更倾向于全职雇佣员工,几乎不会聘请自由职业者。
这就是为什么你会看到更多的网页开发者、写作者和设计师的自由职业工作机会,而数据科学家的机会则仅有少数。
成为自由职业数据科学家的最大劣势是你需要不断寻找工作,而这个领域的机会并不多,且供给往往超过需求。
尽管如此,你可以在作为自由职业数据科学家时发挥创造力。你不必仅限于为组织构建机器学习模型。还有许多其他与数据科学家技能集交叉的领域,你可以利用这些领域来争取更多自由职业机会。
这里是我过去做过的一些自由职业工作的例子:
数据收集
这是许多小型组织和个人雇佣数据专业人士进行的任务。
我曾与一个希望收集五年社交媒体数据的人合作,以了解用户对某些股票的情绪趋势。这将帮助他改进一个现有的模型,该模型预测哪些股票值得投资。
许多公司还需要大量数据来辅助决策。我曾经抓取过定价信息、用户评论数据、社交媒体帖子和职位列表,以帮助组织制定有关产品供应和品牌定位的关键决策。
数据分析
这是我帮助组织决定品牌定位、目标受众和广告类型的最常见任务之一。
尽管数据科学中对模型构建的重视很多,但大多数小型到中型组织在初期阶段没有足够的数据来进行这一工作。
这些公司依赖外部数据,然后分析这些数据以识别趋势。这些模式可以告诉你这些公司应该瞄准谁,应该推广哪些类型的产品,这些产品应该什么时候发布,以及如何向不同的人群进行广告宣传。
写作
许多技术出版物和学习平台需要数据科学家撰写与此主题相关的文章,包括观点文章、技巧和数据科学教程。
这些平台中的许多需要能够将高度技术性的主题简化为初学者易于理解的内容的人。
一个很好的例子是 DataCamp 的 博客。他们提供几乎涵盖数据科学每一个主题的教程。这些教程非常易于理解,即使你是该领域的初学者也不例外。每一步都被清晰地列出,代码示例总是包括了为什么要这样做的解释。
这使得最终用户很容易跟随,因为他们不会盲目地复制粘贴自己不理解的代码。实际上,他们在完成教程时对主题有了了解,下次想学习新知识时肯定会回到同一个网站。
将高度技术性的内容简化成一个简单的格式并不是一项容易的任务。如果你能在这方面下功夫,你会在数据科学博客领域发现许多机会。
如果你想成为数据科学作家但不确定如何开始,你可以阅读 这篇文章 来入门。
教学
在学习数据科学主题后,你可以开展研讨会和培训课程,将这些知识分解给行业中的初学者。
许多在线数据科学学习平台正在寻找讲师来讲授特定主题,他们会与你进行一次性或合同性的合作。
你可以为学生举办现场讲座,或创建录制的视频,这些视频会上传到平台上,任何人都可以访问。
我上面列出的角色是基于我过去从事的自由职业任务。除了这些,我还为公司建立了机器学习模型。这比我预期的要复杂,因为这些组织规模较小,他们的数据没有经过清理或正确存储。
我不得不花费大量时间弄清楚不同表之间的关系,如何自动化数据库访问以便模型每次都能运行,以及清理数据以便于查询。
我花了很多时间处理数据并尝试理解它,而在模型构建上花费的精力要少得多。
虽然这些项目占用了我大量的时间,但我学到了很多东西,也掌握了许多可以用于处理大量数据的不同工具。
如何获得自由职业数据科学工作?
现在你知道了作为自由职业数据科学家可以承担的任务类型,你可能会想知道如何获得这些职位。你如何找到并与那些寻找这些职位的雇主联系呢?
你可以在像 Upwork 和 Fiverr 这样的平台上注册为自由职业者。积极在 LinkedIn 上发布内容。
学到一个有趣的新话题?在 LinkedIn 上发布。
创建了一个数据科学项目?写一篇关于它的文章。将你的代码分享到 GitHub 上。
如果你想持续获得自由职业工作,你的工作需要达到正确的受众。你需要对自己所做的事情大声宣传,并持续推广自己。
我几乎每一份自由职业任务都是因为雇主偶然发现了我在社交媒体上的一篇文章或帖子。
另外,记住许多雇主选择招聘基于信任。如果你得到了他们熟悉的人推荐,他们更可能雇佣你,而不是冒险招聘一个在招聘门户网站上传简历的申请者。
一旦你获得了前几份自由职业工作,获取更多工作将变得更容易。你成功完成的工作越多,你在如 Upwork 等平台上的个人资料排名就会越高。
完成雇主的任务后,向他们请求推荐。这将给未来的雇主提供信心,表明你能够完成工作,并增加被聘用的机会。
最后,确保根据你的专业水平设定合理的费用。刚开始时,略低的收费有助于建立你的作品集。随着你开始获得更多的经验和工作,你可以逐渐提高你的费用。
然而,确保进行适当的研究以了解市场费用。我在刚开始自由职业时并不知道这一点,做了很多工作的报酬却远低于市场价格。
我曾经向一家公司收取约$35 来撰写一篇 2500 字的文章。在与他们合作一个月后,我询问是否可以将费用增加到$70. 他们进行了讨价还价,最后定在了$60。
我为他们写了另一篇文章,然后离开了。报酬根本不值得我付出的努力,我决定将精力转向更有价值的任务。
之后如果工作不符合我报价的金额,我就会拒绝多个工作机会。
了解自己的价值是很重要的。你花费了大量的时间和资源来获得你现在的技能。你不断地努力提升技能并获得更多知识,而在线课程/学习材料并不便宜。
这段时间和精力应该得到公平的回报,你需要相应地设定你的自由职业费用。
如果你打算成为一名自由职业数据科学家,希望这篇文章提供的建议对你有帮助。
记住,立即辞掉全职工作并开始自由职业并不明智。我建议先建立一个作品集,兼职接自由职业角色。一旦你不断有稳定的工作流并建立了一定的稳定性,你可以逐渐过渡到全职自由职业者的角色。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在LinkedIn上与她联系。
了解更多相关话题
如何成为一名成功的医疗数据分析师
原文:
www.kdnuggets.com/2019/11/become-successful-healthcare-data-analyst.html
评论
作者:Ritesh Patil,Mobisoft Infotech 的联合创始人
你是否有兴趣开始你的数据分析职业生涯?作为一名医疗数据分析师可能是你最好的选择!查看这篇文章,以获取有关健康数据分析师及其如何成为一名详细的信息。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 方面支持你的组织
随着新技术的出现,医疗行业不断进步。数据分析就是一种技术,它被应用于医院中,以改善患者结果并降低提供医疗服务的成本。因此,医院正在招聘熟练的数据分析师,以有效执行医疗活动。
候选人被健康数据分析师角色的高需求、职业发展和薪资吸引,并且对在这一领域取得卓越成绩表现出兴趣。
什么是健康数据分析师?
数据分析是从大量信息中筛选出重要数据并获得关键见解的过程。这些关键见解主要提供给需要做出某些决策的医疗机构。
那些利用数据采集、分析、解释和数据维护等专业知识,并向专业人员提供重要医疗数据的人被称为医疗数据分析师。
医疗数据分析师的工作是什么?
医疗数据分析师也被称为管理分析师,因为他们维护大量数据,并提供支持以提升医疗保健的效率。医疗分析师还利用大数据和数据科学为医疗保健领域提供最佳解决方案。医疗保健领域包括医生、药物、诊断、医院等多个实体。
数据分析师的主要目标是为管理者提供建议,以在不影响治疗成本的情况下增加利润。此外,数据科学在医疗保健中的应用还有很多。医疗分析师的主要角色包括:
-
利用大数据及其应用,收集和解释来自多个来源的数据,如成本报告、电子健康记录(EHR)等。
-
理解医院功能和系统,以支持决策过程
-
从收集、存储、检索到保护医疗保健数据的端到端数据库管理
-
创建报告和仪表板,以向医疗保健领域的利益相关者传达所需的信息
健康数据分析师将会在哪里就业?
医疗保健数据分析师可以在不同领域开始他们的职业生涯,例如:
-
政府医疗部门
-
私立医院或公共部门医院
-
跨国公司的分析团队
-
诊断中心
-
健康保险公司
如何成为医疗保健数据分析师?
教育资格
成为医疗保健数据分析师,你必须至少拥有学士学位。如果你拥有统计学、数据科学、信息技术或健康信息管理的学位更好。否则,你必须在声誉良好的学院学习这些课程之一。
另一方面,顶级公司寻找那些拥有工商管理硕士(MBA)学位的候选人。
候选人应具备一定的许可证和认证才能成为数据分析师。这些认证和许可证因国家而异,因此找到必要的注册信息非常重要。
大多数公司倾向于让有经验的候选人进行组织的数据分析。你必须在如人力资源、管理和信息技术等领域获得经验。
所需技能
希望成为医疗保健数据分析师的候选人必须具备以下技能。重要点包括:
-
分析技能
-
解决问题的技能
-
决策技能
-
沟通技能
-
时间管理技能
-
人际交往技能
最终思考
这是你在计划成为医疗保健数据分析师时需要了解的基本信息。请通过所提供的信息,确定你是否有资格成为健康数据分析师。提升与健康数据分析师相关的技能和知识,并寻找提供良好工作机会的最佳公司。祝你的职业生涯好运!
简介: Ritesh Patil (@ritesh_patil) 是 Mobisoft Infotech 的联合创始人,该公司是印度和美国领先的医疗保健软件开发公司。他是一位热衷的博主,热爱创新,撰写多种医疗保健应用领域的文章。他与经验丰富的数字健康应用开发人员合作,推出了创新的移动应用程序。他相信知识共享,并专注于初创企业。
相关:
-
人工智能如何改变医疗保健(它能否解决美国医疗保健系统的问题?)
-
数据科学很无聊(第二部分)
-
乳腺癌分类的卷积神经网络
了解更多此主题的信息
如何成为(A 型)数据科学家
原文:
www.kdnuggets.com/2016/08/become-type-a-data-scientist.html

在 Quora 上有一篇由 Michael Hochster 撰写的有趣文章,关于数据科学是什么,讨论了两种类型的数据科学家:A 型数据科学家和 B 型数据科学家(强调的是我个人的观点)

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织 IT
数据科学家是那些拥有编程和统计技能混合的人,他们以各种方式使数据变得有用。在我的领域,有两种主要类型:
A 型数据科学家:A 代表分析。这种类型的数据科学家主要关注于对数据进行理解或以相对静态的方式处理数据。A 型数据科学家与统计学家非常相似(甚至可能是统计学家),但掌握所有统计课程中未教授的实际数据处理细节:数据清洗、处理非常大数据集的方法、可视化、特定领域的深厚知识、写作技巧等。
A 型数据科学家能够很好地编程以处理数据,但不一定是专家。A 型数据科学家可能在实验设计、预测、建模、统计推断或其他统计部门通常教授的领域中是专家。然而,通常来说,数据科学家的工作产品不是“p 值和置信区间”,虽然学术统计学有时会这么暗示(比如传统统计学家在制药行业工作的情况)。在谷歌,A 型数据科学家有时被称为统计学家、定量分析师、决策支持工程分析师或数据科学家,还有可能有更多的称谓。
Type B 数据科学家:B 代表构建。Type B 数据科学家在统计背景方面与 Type A 有一些共同之处,但他们也是非常强的编码员,可能是受过培训的软件工程师。Type B 数据科学家主要对在“生产环境”中使用数据感兴趣。他们构建与用户互动的模型,通常提供推荐(产品、可能认识的人、广告、电影、搜索结果)。
在这篇文章中,我们讨论了将你的职业生涯转型为(Type A)数据科学家的策略。
我在这里讨论的观点是基于我与物联网数据科学课程参与者的合作。
当我第一次读到 Type A 和 Type B 数据科学家的概念时,我觉得它非常解放。
这让你意识到,‘独角兽’数据科学家(无所不知!)——就像他们的骑马同行——也在很大程度上是虚构的。
承认这一点后,你就可以开始朝着将你的职业生涯转向数据科学的策略取得实际进展。
在这里,我讨论了基于我与课程参与者合作的经验,如何从 Type A 数据科学家转型的十二种不常见策略。
但首先,让我们讨论一个共同的主题。是的,你必须构建一个应用程序来学习数据科学。但仅仅构建是不够的。当你从有限的资源开始,尝试构建一个严肃的数据科学应用时,你会很快发现最大的限制是缺乏严肃的数据。因此,像其他人一样,你最终也会选择基于UCI 数据集(或类似的)来构建你的应用。因此,除了构建之外,你还需要考虑更广泛的策略。以下是我们在教学中遵循的一些策略:
注意事项:
-
这里的受众是那些自己探索数据科学的人。
-
我将 Type A 分类为那些利用数据科学解决许多复杂问题的人——但不负责在生产环境中处理高性能模型。
-
从你所知道的开始:这看起来很明显,但经常被忽视。例如,假设你在 Oracle 工作了很长时间,现在你想成为一名数据科学家。为什么不从 Oracle 开始呢?有一整套Oracle BI 工具。这些工具涵盖了从可视化到高级分析的整个范围。它们使用 Pl/SQL 或 R。这可以帮助你更快地入门,而不是学习完全新的东西。我也会对微软(Azure 和 Power BI)和亚马逊(AWS IoT)使用相同的策略——这两个平台都很先进。
-
专注于统计学:存在将数据科学(分析和算法应用)与大数据(基于 Hadoop 的分布式基础设施)混淆的倾向。要掌握前者,你必须具备一些统计学背景,并理解预测背后的数学。我认为你不可能在早期阶段同时掌握两者。但人们仍然尝试!而且他们在这两个方面都不会走得很远。因此,我在教学中的建议是专注于使用统计学(算法)来解决问题。值得阅读这篇深刻的文章 - 为什么大数据陷入困境?因为他们忘记了应用统计学。同时请记住,一些当今最著名的数据科学家,如格雷戈里·皮亚泰斯基-夏皮罗和柯克·D·博恩都有强大的数学/统计学背景。
-
关注处理大量数据的问题:这不一定与大数据相同(因为它可能不是分布式数据处理)——但关注非常大的数据集可以让你获得更丰富的经验。即使这些数据集与未来你可能涉及的应用程序无直接关系,这也是有效的。换句话说,处理大数据集的经验本身就是有价值的。这也解释了为什么许多数据科学家喜欢柯克·D·博恩有 NASA(或太空研究)的背景——因为数据的丰富性。此外,许多优秀的数据科学家来自天气预测背景(出于同样的原因)。在我们的业务中(物联网的数据科学),数据量很重要。你可以使用简单的 Raspberry Pi/Arduino 进行物联网分析,或者你可以分析整个航空公司或油井的数据。这两者完全不同。我最喜欢的一本数据科学书籍是《统计学、数据挖掘与天文学中的机器学习:调查数据分析的实用 Python 指南》 Željko Ivezić, Andrew J. Connolly, Jacob T. VanderPlas & Alexander Gray。即使有 550 页,它也非常易读。但更重要的是,它处理非常大数据集。
-
使用 Zulu 原则:Zulu 原则基于成为某一主题明确且狭窄子集的专家的想法:我自己在物联网数据科学中使用过这个原则,即识别一个利基并在其上深入工作以展示专业知识。
-
系统思维 - 解决行业范围的问题:与微小利基策略相反的是系统思维方法。这需要广泛的理解和经验,以识别行业中的相互联系或缺口。同样,我与 Jean Jacques Bernard 合作使用的策略是创建 用于 IoT 分析的开放方法。
-
Kaggle 算法:如果你关注 Kaggle 竞赛,它们往往使用一些算法多于其他算法——例如 Xgboost。最好从一开始就牢记这些,因为你可能很快就会使用这些算法。
-
SQL 和 NoSQL——关注 SQL 和 NoSQL:使用 SQL 和 NoSQL 可以实现很多目标。查看这些步骤来开始学习 SQL 和 NoSQL。
-
垂直领域的分析知识:这显而易见,但常被忽视。业务知识将变得越来越重要,在每个垂直领域都有特定的指标需要预测或分析。
-
人工智能和深度学习:人工智能和深度学习在许多数据科学领域确实适用,应成为重点关注对象。但需谨慎,如Yann Le Cun 的文章所示。
-
关注工具:有许多工具可以使数据科学家的工作更轻松。在大多数情况下,它们有与编程语言如 R 的接口。我们在课程中使用的完整生命周期工具包括:h2o.ai、dataiku、Tibco Spotfire 和 Pentaho。
-
关注 R:无论你对 R 与 Python 的争论持何种看法,R 在企业层面正获得越来越多的关注,例如针对企业的供应商。Oracle、Microsoft、HPE(Vertica)、SAP(Hana)、Hitachi(Pentaho)等。
-
最后,关注新兴领域——物联网(IoT)仍然是一个新兴领域,还有数据科学。物联网具有独特的特点,如更强调时间序列、传感器融合等。即使在物联网内部,也会出现新的领域——例如,我们目前正在探索用于 Apache NiFi 的 IoT 分析。区块链也将是当前分析的新兴领域。
总结:
-
不试图成为‘独角兽’可能会令人解脱。这可以帮助你专注于掌握数据科学的实际步骤。
-
有许多可能的途径。如果你想成为数据科学家,理想情况下,你应该在某一领域取得卓越成就,同时对其他领域也有足够的了解。
-
你必须知道编程——但如果你想从成为 A 类数据科学家开始,你不必成为狭义的专家。
-
你必须进行实际构建——构建服务是不可替代的——但你需要考虑一下你到底想要构建什么,如上所述。
-
理解并应用统计学。
-
记住,数据科学家是一个通才角色。
-
数据科学是一个快速扩展的领域,许多机会在纵向、新领域、新工具等方面仍待发掘。
-
从 A 类数据科学家开始,随后进阶到 B 类(生产)可能会相对容易。
我在物联网数据科学课程中探讨了许多这些想法。
相关:
-
物联网关键术语解释
-
35 个物联网开源工具
-
强化学习与物联网
更多相关话题
成为 3.0 级数据科学家
原文:
www.kdnuggets.com/2019/05/becoming-a-level-3-data-scientist.html
评论
由 Jan Zawadzki, Carmeq GmbH 的数据与人工智能项目负责人
公司招聘数据科学家分为三个级别:初级、高级或首席。不论您是刚刚入门数据科学还是希望转行,您不可避免地会发现自己处于这些级别之一。
 图片来源:Kelly Sikkema 在 Unsplash
图片来源:Kelly Sikkema 在 Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速迈入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 在 IT 方面支持您的组织
本文旨在阐明每个数据科学职业级别的期望与范围之外的内容。虽然公司可能有不同的职位名称,但本文提供了一个通用的基准。此外,文章最后提供了有关如何为转向人工智能或获得应得晋升的职业准备的一些实用建议。
让我们升级一下。
数据科学技能矩阵
数据科学家应在三个领域具有知识:统计学、工程学和商业。然而,您不必一开始就精通这三个领域。在寻求入门级职位时,应该关注哪些技能?随着职业发展的推进,哪些技能变得更加重要?
以下图表展示了从 1.0 到 3.0 级别的数据科学市场期望。这些结果基于我在该领域的个人经验以及与 斯坦福、eBay、Axel Springer 和 Xing 的专家和影响者的对话。为了避免混淆,我们将职位称为 1.0 级到 3.0 级。
让我们详细分析这些职位的期望。
初级数据科学家 — 进入 1.0 级
原型初级数据科学家是年轻的毕业生。热门的学习领域包括计算机科学、数学或工程。初级数据科学家有 0–2 年的工作经验,熟悉使用 Python 或 R 创建结构化数据集的原型。她参加过 kaggle 比赛,并有一个 GitHub 个人资料。

初级数据科学家可以为公司提供巨大的价值。他们刚刚完成在线课程,可以立即提供帮助。他们通常是自学成才,因为很少有大学提供数据科学学位,因此展现了巨大的承诺和好奇心。他们对自己选择的领域充满热情,渴望学习更多。初级数据科学家擅长原型设计,但在工程和商业思维方面仍然欠缺熟练度。
初级数据科学家应该对机器学习有强烈的热情。你可以通过参与开源项目或参加 kaggle 挑战来展示你的热情。 — Dat Tran,Axel Springer AI 负责人
他们的工作
如果公司正在招聘初级数据科学家,通常数据科学团队已经到位。公司希望得到帮助,以便让更有经验的同事的工作变得更轻松。这包括快速测试新想法、调试和重构现有模型。你将作为团队的对手讨论想法。你会提出改进的方法。你对自己的代码负责,不断努力提高代码质量和影响力。你是一个出色的团队成员,始终寻求支持你的队友,帮助他们构建出色的数据产品。
他们不做的事情
初级数据科学家没有复杂产品解决方案的工程经验。因此,她在团队中工作,将数据科学模型投入生产。由于初级数据科学家刚加入公司,她尚未深入了解公司的业务。因此,她不被期望提出新的产品来影响基础商业方程。然而,始终期望的是对学习的渴望和提升技能的愿望。
我对初级数据科学家完成非平凡项目的能力很感兴趣。完成的意思是这个项目是由个人 — 或团队 — 从头到尾完成的,并最终成为一个完善的产品。我发现这与数据科学家在工作中领导项目的能力相关。 — Kian Katanforoosh,deeplearning.ai 创始成员,斯坦福计算机科学讲师
如果你在担任初级数据科学家时表现出色,你对数据科学模型有着深厚的理解背景。你展示了对学习工程和公司业务的强烈好奇心,以提升你的技能。
下一个级别是什么样的?让我们接下来了解一下高级数据科学家。
高级数据科学家——达到 Level 2.0
高级数据科学家已经曾担任过初级数据科学家、软件工程师,或完成了博士学位。他在该领域有 3–5 年的相关经验,编写可重用的代码,并在云环境中构建弹性的 数据管道。

高级数据科学家应该能够框定数据科学问题。优秀的候选人具有来自过去数据科学经验的深刻洞察。我还会深入了解他们编写生产代码的能力。 — 基安·卡坦福鲁什
公司更愿意聘用高级数据科学家,因为他们在合理的薪水下提供了巨大的价值。他们比初级数据科学家更有经验,从而避免了昂贵的新手错误。他们的成本也低于首席数据科学家,但仍然期望能够交付生产中的数据科学模型。这是一个非常有趣的阶段,已经超过了 Level 1.0,同时还有成长到 Level 3.0 的空间。
他们做的事情
高级数据科学家掌握了将数学模型投入生产的艺术。虽然首席数据科学家或业务经理分配任务,但高级数据科学家以构建架构良好的产品为荣。他们避免模型中的逻辑缺陷,对表现过于优异的系统保持怀疑,并以正确准备数据为荣。高级数据科学家指导初级数据科学家,并向管理层解答业务问题。
他们不做的事情
高级数据科学家不需要领导整个团队。高级数据科学家的职责不是提出新产品的想法,因为这些想法是由经验更丰富的同事和经理产生的。虽然高级数据科学家了解他们所构建产品的细节,但不要求他们了解所有数据驱动产品的整体架构。Level 2.0 的数据科学家在统计学方面很有造诣,并且在工程方面比 Level 1.0 的数据科学家更强,但避开了 Level 3.0 中的不那么有趣的业务部分。
高级数据科学家必须能够将他们的代码投入生产(在数据工程师的支持下)。高级数据科学家应该能够独立完成他们所承担的项目。 — 塞巴斯蒂安·福考德,Xing 数据科学副总裁
高级数据科学家的表现取决于他们模型所产生的影响。他对统计模型的内部工作原理及其实施有很好的直觉。他正在进一步了解公司业务,但尚未被期望提供商业问题的解决方案。
 照片由
照片由 现在我们已经探讨了 2.0 级别,让我们看看最终的 3.0 级别是什么样的。
首席数据科学家 — 最终关卡 3.0
首席数据科学家是数据科学团队中经验最丰富的成员。她拥有 5 年以上的经验,对各种数据科学模型非常熟悉。她了解将模型投入实际使用的最佳实践。她知道如何编写计算效率高的代码,并且时刻关注高影响力的商业项目。

除了她无可挑剔的工程技能和对使用的科学模型的深刻理解外,她还深刻理解公司所处的业务。她在数据科学方面对业务基线产生了显著影响。
首席数据科学家需要在编写任何代码之前,对所解决的业务问题有非常好的理解。这意味着他们需要具备在实施之前验证想法的能力。这种方法能提高数据科学项目的成功率。 — Adnan Boz,eBay 的 AI 产品负责人
他们做的事情
首席数据科学家负责创建高影响力的数据科学项目。她需要与利益相关者紧密协调,领导一个可能的跨职能团队,为特定问题提供最佳解决方案。因此,她的领导能力在 1.0 和 2.0 级别中不断提升。首席数据科学家还充当不同部门产品经理的技术顾问。凭借她在主要数据科学类别中的丰富经验和技能,她成为任何项目中极具价值的资产。
他们不做的事情
虽然在讨论所需技能时,首席数据科学家不负责招聘新团队成员。尽管她了解公司业务并建议具有影响力的新产品,但市场采纳仍由产品经理负责。她也会领导团队,但职业发展决策仍由团队领导做出。
首席数据科学家应能独立地推动项目,而无需依赖数据科学主管。此人应具备初步的领导技能,因此沟通清晰、富有同理心以及对人才有敏锐的眼光非常重要。 — Dat Tran
首席数据科学家已经了解了产品失败的原因,因此她能够成功推动新项目。她在产品讨论中是重要的贡献者,并且喜欢向公司普及数据科学知识。凭借她在交付有影响力的数据科学解决方案方面的经验,她是数据科学部门最宝贵的资产。
 照片由
照片由现在你已经了解了从数据科学家 1.0 到 2.0 再到 3.0 的不同期望,让我们来探讨如何利用这些知识提升你的职业生涯。
提升你的数据科学职业
无论你是希望进入数据科学职业游戏的 1.0 级别,还是希望晋升到更高的级别,采取以下步骤来进行你的下一步职业发展。
1. 评估你的技能
首先,将你的技能与数据科学技能矩阵进行比较。你的统计技能有多扎实?你的工程技能如何?你的商业敏感度如何?
2. 规划你的晋升
许多公司有年度晋升周期来推动员工的晋升。朱莉·卓,Facebook 的产品设计副总裁,建议作为晋升的第一步,让你的晋升愿望公开。在晋升周期开始时,向你的经理表明你希望提升职业发展。询问你的经理如何评估你目前的技能水平以及达到下一个数据科学职业水平的期望是什么。
3. 提升你的技能
一旦你分析了自己的技能并表明了晋升的愿望,就该提升自己的技能了。
 照片由Samuel Zeller拍摄,Unsplash
照片由Samuel Zeller拍摄,Unsplash
你想进入人工智能领域吗?那么就要对统计模型有深入的了解,并学习如何使用结构化数据集解决问题。你想进入 3.0 级别吗?确保你的数学、工程和商业技能都掌握了。掌握这些要点,你就能为与经理谈判升职做好充分准备。
关键要点
探索数据科学职业等级是有趣的。请记住以下关键要点:
-
初级数据科学家具备良好的统计技能。
-
高级数据科学家擅长将模型投入生产。
-
首席数据科学家知道如何创造商业价值。
-
要提升水平,评估你的技能,宣布你想要进步的愿望,并致力于提高突出的技能。
数据科学职业等级之间存在细微差别。例如,Séb Foucaud 更看重初级数据科学家的工程技能而非数学技能。一些高级数据科学家可能会发现自己对构建可扩展的数据管道充满热情,并转型为数据工程师角色。一些首席数据科学家倾向于发展技术专长,而其他人则更愿意专注于商业技能。无论你选择哪条职业路径,围绕数据科学三大主要领域提升你的技能将会使你走得更远。
本文继续教育数据科学家成为商业精英的系列。该系列旨在帮助你提升整体数据科学技能。如果你喜欢这种格式,请关注我在LinkedIn或Medium,以获取最新文章。
 照片来自Mirko Blicke于Unsplash
照片来自Mirko Blicke于Unsplash
个人简介:Jan Zawadzki拥有 5 年的全球咨询和数据科学家经验。Jan 目前在 Carmeq GmbH 担任自驾车领域的项目负责人,Carmeq GmbH 是大众汽车集团的创新车队。Jan 热衷于通过机器学习推动汽车行业的发展,并分享他在商业和数据科学领域的知识。他是 Medium 上“Towards Data Science”刊物的月度贡献者,也是 Deep Learning.ai 的大使,支持深度学习大师 Andrew Ng 的团队。
原文。经许可转载。
相关:
-
第三波数据科学家
-
接受数据科学家工作邀请前需审视的 5 件事
-
数据科学面试问题——三个案例面试示例
更多相关话题
如何开始你的 NLP 之旅
评论
由 Diego Lopez Yse,数据科学家

图片由PNG Design在Unsplash提供
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
自然语言处理(NLP)是人工智能领域中最令人兴奋的领域之一。它允许机器以多种方式处理和理解人类语言,并引发了我们与系统和技术互动方式的革命。
在上一篇文章中,我讲述了 NLP、它的实际应用和一些核心概念。现在我想向你展示 NLP 有多真实,任何人都可以开始学习它。怎么做呢?让我们从一个简单的文本开始,使用一些 NLP 技术进行一些探索性数据分析(EDA)。这样,我们可以使用简单而强大的工具理解数据,然后再忙于模型或更复杂的任务。
定义你的文本
史蒂芬·霍金曾说:
“人工智能(AI)可能是人类发生的最好或最糟糕的事情”
我完全同意他的观点,时间会证明实际发生的事情。然而,这句话是测试一些 NLP 技术的合适句子。为此,让我们首先将这句话保存为一个名为“text”的变量:
text = “Artificial Intelligence (AI) is likely to be either the best or the worst thing to happen to humanity.”
使用langdetect库,我们可以检查其语言,并找出其用该语言写的概率:
import langdetect
from langdetect import detect_langs
print(detect_langs(text))

我们可以以超过 99.9%的确定性声明,这句话是用英语写的。你还应该考虑使用拼写检查功能来纠正任何语法错误。
那么字符的数量呢?
len(text)

我们有 102 个字符,包括空格。不同字符的数量是多少?
len(set(text))

让我们来看看这些:
print(sorted(set(text)))
这里有一些有趣的地方。我们不仅在计算像‘(’和‘.’这样的非字母数字字符,还包括空格,更重要的是,大小写字母被视为不同的字符。
词汇化
词汇化是将连续文本分割成句子和单词的过程。实质上,这是将文本切割成称为tokens的片段的任务。我们使用NLTK库来执行此任务:
import nltk
from nltk.tokenize import word_tokenize
tokenized_word = word_tokenize(text)
print(tokenized_word)

我们可以看到,词汇化产生了一个词汇列表:
type(tokenized_word)

这意味着我们可以调用其中的元素。
tokenized_word[2:9]
我们有多少个 token?
len(tokenized_word)

那么独特的 tokens 呢?
len(set(tokenized_word))

现在我们可以计算一个与文本的词汇丰富性相关的指标:
len(set(tokenized_word)) / len(tokenized_word)

这表明不同词汇的数量占总词汇数量的 85.7%。
小写和标点
现在,让我们将文本转换为小写,以标准化字符,并为未来的停用词移除做准备:
tk_low = [w.lower() for w in tokenized_word]
print(tk_low)

接下来,我们去除非字母数字字符:
nltk.download(“punkt”)
tk_low_np = remove_punct(tk_low)
print(tk_low_np)

让我们可视化词汇的累积频率分布:
from nltk.probability import FreqDist
fdist = FreqDist(tk_low_np)
fdist.plot(title = ‘Word frequency distribution’, cumulative = True)
我们可以看到,“to”和“the”这些词出现得最频繁,但它们实际上并未向文本添加信息。它们被称为停用词。
停用词移除
这一过程包括去除常见的语言文章、代词和介词,如英语中的“and”、“the”或“to”。在此过程中,一些非常常见的词被认为对 NLP 目标贡献甚微或没有价值,因此从待处理的文本中被过滤和排除,从而去除那些没有提供有用信息的广泛和频繁出现的术语。
首先,我们需要创建一个停用词列表,并将其从我们的词汇列表中过滤掉:
from nltk.corpus import stopwords
stop_words = set(stopwords.words(“english”))
print(stop_words)
我们将使用 NLTK 库中的这个列表,但请记住,你可以创建自己的停用词集。让我们在列表中查找“the”这个词:
print(‘the’ in stop_words)

现在,让我们从这些停用词中清理文本:
filtered_text = []
for w in tk_low_np:
if w not in stop_words:
filtered_text.append(w)
print(filtered_text)

我们可以看到,词汇“is”、“to”、“be”、“the”和“or”已从文本中删除。让我们更新词汇的累积频率分布:
停用词移除应以非常谨慎的方式进行,因为它可能在执行其他任务时带来巨大问题,例如情感分析。如果一个词的上下文受到影响(例如,去除“not”这样的词,这是一种否定成分),这种操作可能会改变段落的意义。
除了这个例子,可能还需要处理其他类型的特征,例如 缩写(如“doesn’t”,应展开)或 重音和变音符号(如“cliché”或“naïve”,应通过去除变音符号来规范化)。
正则表达式
正则表达式(简称 REs 或 RegExes)是嵌入在 Python 中的一个微小且高度专业化的编程语言,通过re模块提供。使用它们,你可以指定要匹配的字符串集的规则。你可以提出诸如“这个字符串是否符合模式?”或“这个字符串中是否有符合模式的匹配项?”等问题。
例如,让我们搜索以“st”结尾的单词:
import re
[w for w in filtered_text if re.search(‘st$’, w)]

或计算第一个单词(“artificial”)中的元音字母数量:
len(re.findall(r’[aeiou]’, filtered_text[0]))

你甚至可以根据条件修改文本。例如,将第二个单词(“intelligence”)中的字母“ce”替换为字母“t”:
x = re.sub('ce', 't', filtered_text[1])
print(x)

你可以通过 这个链接 找到更多正则表达式的例子。
结论
我们仅仅触及了所有可能和更复杂的 NLP 技术的表面。你可能不仅想分析结构化文本,还要处理从对话、声明甚至推文中生成的所有数据,这些都是非结构化数据的例子。非结构化数据无法 neatly 放入传统的行列结构的关系数据库中,代表了现实世界中绝大多数的数据。它是混乱的且难以操作。
NLP 因数据访问的巨大改进和计算能力的提升而迅速发展,这使我们能够在医疗、媒体、金融和人力资源等领域取得有意义的成果。
我的建议是:学习 NLP。 尝试不同的数据源和技术。实验、失败并提升自己。这一学科将影响所有可能的行业,我们很可能在未来几年达到一种令人惊叹的进展水平。
个人简介:Diego Lopez Yse 是一位经验丰富的专业人士,拥有在不同领域(资本市场、生物技术、软件、咨询、政府、农业)获得的国际背景。始终是团队成员。擅长商业管理、分析、金融、风险、项目管理和商业运营。拥有数据科学和公司金融硕士学位。
原文。经许可转载。
相关内容:
-
强化版探索性数据分析
-
开始使用 5 个必备的自然语言处理库
-
自然语言处理管道解析
更多相关内容
初学者友好的有趣 Python 项目!
原文:
www.kdnuggets.com/2022/10/beginner-friendly-python-projects-fun.html

Andrey Metelev 通过 Unsplash
我最近做了一篇关于在不到 5 分钟内构建 Python 项目的文章。所以我决定再做一篇,提供更多供初学者玩耍和测试技能的项目。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
如果你在职业生涯中没有乐趣,你很快会失去激情并开始讨厌它。像这样的项目不仅适合初学者,还能为你的学习或职业增添一点乐趣。
现在我们开始吧。
猜数字
在这个第一个项目中,我们将生成一个特定范围内的随机数字,用户需要通过提示来猜测。
用户猜错的次数越多,给出的提示就会越多——但这会减少他们的得分。
代码:
""" Guess The Number """
import random
attempts_list = []
def show_score():
if len(attempts_list) <= 0:
print("There is currently no high score, it's yours for the taking!")
else:
print("The current high score is {} attempts".format(min(attempts_list)))
def start_game():
random_number = int(random.randint(1, 10))
print("Hello traveler! Welcome to the game of guesses!")
player_name = input("What is your name? ")
wanna_play = input("Hi, {}, would you like to play the guessing game? (Enter Yes/No) ".format(player_name))
#Where the show_score function USED to be
attempts = 0
show_score()
while wanna_play.lower() == "yes":
try:
guess = input("Pick a number between 1 and 10 ")
if int(guess) < 1 or int(guess) > 10:
raise ValueError("Please guess a number within the given range")
if int(guess) == random_number:
print("Nice! You got it!")
attempts += 1
attempts_list.append(attempts)
print("It took you {} attempts".format(attempts))
play_again = input("Would you like to play again? (Enter Yes/No) ")
attempts = 0
show_score()
random_number = int(random.randint(1, 10))
if play_again.lower() == "no":
print("That's cool, have a good one!")
break
elif int(guess) > random_number:
print("It's lower")
attempts += 1
elif int(guess) < random_number:
print("It's higher")
attempts += 1
except ValueError as err:
print("Oh no!, that is not a valid value. Try again...")
print("({})".format(err))
else:
print("That's cool, have a good one!")
if __name__ == '__main__':
start_game()
猜字谜
猜字谜的重点是选择一个单词,所以首先我们需要找到一个单词列表。在 StackOverflow 上,有一个包含 2400 多个单词的 JSON 文件。你可以在这里找到它:randomlist。
使用这个 JSON 文件,将这些单词复制到一个 .py 文件中,并将其分配给变量 ‘words’。像这样:
words = "aback","abaft","abandoned","abashed","aberrant","abhorrent"...
代码:
创建一个第二个 .py 文件,命名为 hangman.py,它将包含这些内容:
""" Hangman """
#Imports
import random
from words import words
from hangman_visual import lives_visual_dict
import string
def get_valid_word(words):
word = random.choice(words) # randomly chooses something from the list
while '-' in word or ' ' in word:
word = random.choice(words)
return word.upper()
def hangman():
word = get_valid_word(words)
word_letters = set(word) # letters in the word
alphabet = set(string.ascii_uppercase)
used_letters = set() # what the user has guessed
lives = 7
# getting user input
while len(word_letters) > 0 and lives > 0:
# letters used
# ' '.join(['a', 'b', 'cd']) --> 'a b cd'
print('You have', lives, 'lives left and you have used these letters: ', ' '.join(used_letters))
# what current word is (ie W - R D)
word_list = [letter if letter in used_letters else '-' for letter in word]
print(lives_visual_dict[lives])
print('Current word: ', ' '.join(word_list))
user_letter = input('Guess a letter: ').upper()
if user_letter in alphabet - used_letters:
used_letters.add(user_letter)
if user_letter in word_letters:
word_letters.remove(user_letter)
print('')
else:
lives = lives - 1 # takes away a life if wrong
print('\nYour letter,', user_letter, 'is not in the word.')
elif user_letter in used_letters:
print('\nYou have already used that letter. Guess another letter.')
else:
print('\nThat is not a valid letter.')
# gets here when len(word_letters) == 0 OR when lives == 0
if lives == 0:
print(lives_visual_dict[lives])
print('You died, sorry. The word was', word)
else:
print('YAY! You guessed the word', word, '!!')
if __name__ == '__main__':
hangman()
运行你的 hangman.py 文件,开始游戏吧!
石头、剪刀、布
石头、剪刀、布游戏使用了 random.choice()、if 语句和获取用户输入与这些函数配合:
-
用于生成石头、剪刀或布的随机函数。
-
验证函数用于检查你的动作是否有效
-
结果函数用于检查谁赢得了这一轮
-
记分员用于跟踪得分。
代码:
# if not re.match("^[a-z]*$", input_str):
import random
import os
import re
os.system("cls" if os.name == "nt" else "clear")
while 1 < 2:
print("\n")
print("Rock, Paper, Scissors - Shoot!")
userChoice = input("Choose your weapon [R]ock, [P]aper, or [S]cissors, [E]xit: ")
if userChoice == "E":
break
if not re.match("[SsRrPp]", userChoice):
print("Please choose a letter:")
print("[R]ock, [S]cissors or [P]paper.")
continue
# Echo the user's choice
print("You chose: " + userChoice)
choices = ["R", "P", "S"]
opponenetChoice = random.choice(choices)
print("I chose: " + opponenetChoice)
if opponenetChoice == str.upper(userChoice):
print("Tie!")
# if opponenetChoice == str("R") and str.upper(userChoice) == "P"
elif opponenetChoice == "R" and userChoice.upper() == "S":
print("Scissors beats rock, I win!")
continue
elif opponenetChoice == "S" and userChoice.upper() == "P":
print("Scissors beats paper! I win!")
continue
elif opponenetChoice == "P" and userChoice.upper() == "R":
print("Paper beat rock, I win! ")
continue
else:
print("You win!")
结论
我希望这能帮助你走出舒适区,花 30 分钟来测试你的 Python 技能。我将创建另一篇文章,提供更多来自 YouTuber 的项目教程内容!
尼莎·阿里亚 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及数据科学相关理论知识。她还希望探索人工智能如何及将如何有利于人类寿命的不同方式。她是一名热衷于学习的人员,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题

获取免费电子书《伟大的自然语言处理入门》以及《数据科学备忘单全集》和领先的关于数据科学、机器学习、人工智能与分析的新闻通讯,直接发送到您的邮箱。
订阅即表示您接受 KDnuggets 的 隐私政策
最新文章
|
热门文章
|
© 2024 Guiding Tech Media | 关于 | 联系 | 广告 | 隐私 | 服务条款
由 Nisha Arya 于 2022 年 10 月 3 日 发布
数据科学中的异常检测技术初学者指南
原文:
www.kdnuggets.com/2023/05/beginner-guide-anomaly-detection-techniques-data-science.html
作者提供的图片
异常检测是一个非常重要的任务,如果你处理数据,你会遇到或者最终会遇到它。它在许多领域中被广泛应用,如制造业、金融和网络安全。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
第一次开始这个话题可能会很有挑战性,特别是没有逐步指导的情况下。作为数据科学家的第一次经历,我记得我为了掌握这一学科而奋斗了很久。
首先,异常检测涉及识别那些与其他数据点明显偏离的稀有观测值。这些异常,通常称为离群点,是少数,而大多数项目属于正常类别。这意味着我们正在处理一个不平衡的数据集。
另一个挑战是,在行业中大多数时候没有标记数据,解释预测结果没有目标是很困难的。这意味着你不能使用通常用于分类模型的评估指标,需要采取其他方法来解释和信任模型的输出。让我们开始吧!
什么是异常检测?
异常检测指的是发现数据中不符合预期行为的模式的问题。这些不符合模式的情况通常被称为异常、离群点、不一致的观测值、例外、偏差、惊讶、特异性或污染物,具体取决于应用领域。 异常检测:综述
这是对异常检测的一个很好的简要定义。异常通常与数据收集过程中获得的错误相关,然后这些异常会被消除。但也有一些情况是新的数据项与其他数据具有完全不同的变异性,这时需要合适的方法来识别这种观察。识别这些观察对在许多行业(如金融和制造业)运营的公司决策非常有用。
异常的类型有哪些?
异常主要有三种类型:点异常、上下文异常和集体异常。
点异常的示例。作者插图。
如你所推测,点异常是最简单的情况。当单个观察值与其他数据相比异常时,它会被识别为离群点/异常。例如,假设我们想在银行客户的交易中进行信用卡欺诈检测。在这种情况下,点异常可以被视为客户的欺诈活动。
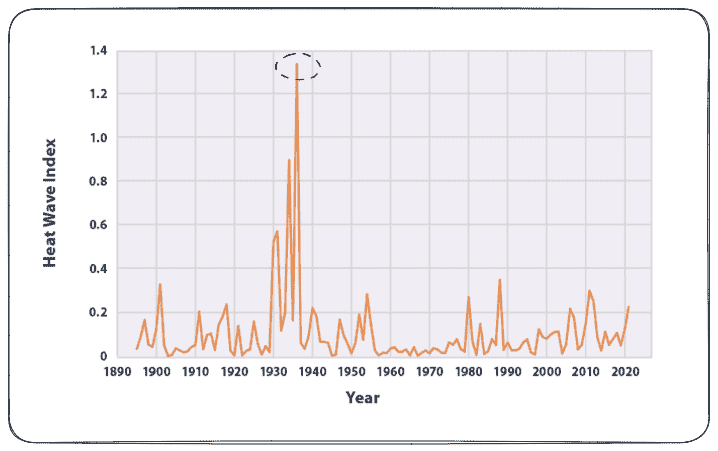
上下文异常的示例。来源 EPA。作者修改。
另一种异常情况可能是上下文异常。这种异常只有在特定的上下文中才会出现。例如,美国的夏季热浪。你会发现 1930 年有一个巨大峰值,这代表了一个极端事件,称为尘土碗。之所以叫这个名字,是因为这是一个尘暴时期,破坏了美国南中部。
集体异常的示例。作者插图。
第三种也是最后一种异常是集体异常。最直观的例子是考虑意大利今年几个月来的降水缺乏。如果我们将数据与过去 50 年进行比较,就会发现没有类似的情况。单个数据点在异常集体中可能不会被识别为离群点,但所有这些数据点一起表明了一个集体异常。在这种情况下,单一天没有降水本身并不异常,而很多天没有降水则相对于前几年的数据可以被认为是异常的。
机器学习模型可以用于异常检测吗?
可以应用于异常检测的几种方法:
-
孤立森林是一种无监督且非参数的技术,由 Fey Tony Liu 于 2012 年引入。与随机森林类似,它是一种集成学习方法,通过并行训练决策树。但不同于其他集成方法,它专注于将异常值与其他项隔离开来。这种方法背后的假设构成了其有效性的原因:(1)异常值是与正常数据相比的少数类;(2)异常值倾向于以最短的平均路径迅速找到。
-
局部离群因子是一种基于密度的聚类算法,由 Markus M. Breuning 于 2000 年提出,它通过计算特定项相对于其邻居的局部密度偏差来检测异常。它假设异常值周围的密度应该与邻居周围的密度显著不同。此外,离群点应该具有较低的密度。
-
自编码器是由两个神经网络组成的无监督模型,分别是编码器和解码器。在训练过程中,只有正常数据会被传递给模型。通过这种方式,它学习正常数据的压缩表示,这与异常值的表示应该有所不同。还假设异常数据不会被模型很好地重建,因为它完全不同于正常数据,因此应该具有较高的重建误差。
如何在无监督环境下评估异常检测模型?
在无监督设置中,没有评估指标可以帮助你了解正确的正预测率(精度)或实际正例的比率(召回率)。
在无法评估模型性能的情况下,提供模型预测的解释比以往任何时候都重要。这可以通过使用可解释性方法,如 SHAP 和 LIME 来实现。
有两种可能的解释:全局和局部。全局可解释性的目标是提供对模型整体的解释,而局部可解释性则旨在解释单个实例的模型预测。
最终想法
希望这个关于异常检测技术的快速概述对你有帮助。正如你所注意到的,这是一项具有挑战性的任务,适用的技术会根据上下文的不同而有所变化。我还应该强调,在应用任何异常检测模型之前,进行一些探索性分析是重要的,比如使用 PCA 将数据可视化到较低的维度空间和箱线图。如果你想深入了解,可以查看下面的资源。感谢阅读!祝你有美好的一天!
资源
尤金尼亚·阿内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中在结合异常检测的持续学习上。
更多相关话题
云计算初学者指南
原文:
www.kdnuggets.com/2023/01/beginner-guide-cloud-computing.html
什么是云计算
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT
云计算通过互联网(“云”)提供计算服务,包括服务器、存储、数据库、网络、软件、分析和智能,以实现更快的创新、灵活的资源和规模经济。通过云计算,组织可以更好地将 IT 资源与业务目标和计划对齐。云服务通常通过按需付费或订阅定价模式提供,使其比传统的本地 IT 解决方案更具成本效益和灵活性。

图片由 storyset 提供
云计算的历史
“云计算”这一术语出现不过几年,但其概念存在的时间更久。利用远程服务器存储和处理数据的想法可以追溯到 1950 年代,当时科学家们在 SAGE 空中防御系统上使用了一种早期形式的云计算来共享数据和资源。在 1980 年代和 1990 年代,像 CompuServe 和 AOL 这样的公司开始为客户提供基本的基于云的服务,如电子邮件和文件存储。
直到 2000 年代初,“云计算”这一术语才被广泛使用。2006 年,亚马逊推出了其 EC2 服务,允许企业在公司的数据中心租用虚拟服务器。这是云计算行业的一个重要转折点,展示了云计算不仅可以用于简单的基于网页的服务。
图片由 cloudcomputing521 提供
云计算是如何工作的
基于互联网的云计算按需向计算机和其他设备提供数据和共享计算资源。这是一种设计,使任何人、任何地方都可以通过网络(例如网络、服务器、存储、应用程序和服务)轻松随时访问可调整的计算资源。无需大量管理工作或服务提供商联系,这些资源可以迅速提供和释放。类似于公共事业,云计算依赖于资源共享来实现一致性和规模经济。
特点
-
按需自助服务: 客户可以自动独立地提供必要的计算资源,如服务器时间和网络存储,而无需单独联系每个服务提供商。
-
广泛的网络访问: 功能通过网络可用,并通过标准程序访问,以促进各种瘦客户端或厚客户端平台(例如手机、笔记本电脑和个人数字助理)的使用。
-
资源池化: 通过多租户方式,将提供商的计算资源组合起来,以服务多个客户。根据客户需求,各种物理和虚拟资源会不断分配和重新分配。
-
可扩展性: 这是云计算最显著的优势之一。通过按需资源,企业可以快速根据需要进行扩展或缩减,无需进行任何前期投资。
-
灵活性: 云计算在付款选项上非常灵活。采用按需付费模式,企业只需为他们使用的资源付费。这是一种节省成本的好方法,因为公司可以避免为不需要的帮助支付过多费用。
-
成本效益: 相比传统 IT 基础设施,你可以通过只支付你使用的资源节省大量资金。此外,许多云服务提供商提供长期合同折扣,使其更加实惠。
图片来源:guru99
云计算服务
云计算服务有各种形式和规模。以下是一些最受欢迎的服务类型:
1. 基础设施即服务(IaaS)
基础设施即服务(IaaS)是一种云计算模型,其中第三方提供商提供计算基础设施——通常是一个平台虚拟化环境——作为服务。IaaS 是云服务的三大主要类别之一,另外两类是软件即服务(SaaS)和平台即服务(PaaS)。
IaaS 提供商为客户提供按需付费模式,用于使用、管理和扩展基础设施资源,包括存储、网络和计算能力。客户可以按需访问这些资源,并仅为他们使用的资源付费。
IaaS 是企业希望获得云的灵活性和可扩展性,而无需管理和维护基础设施的热门选择。IaaS 提供商通常提供广泛的服务,可以根据每个客户的需求进行定制。
2. 平台即服务(PaaS)
在云计算中,平台即服务(PaaS)是一种提供开发、运行和管理应用程序的平台的服务类型。该平台可以用于创建或运行新的应用程序。开发人员通常使用 PaaS 服务来构建和测试应用程序,然后将其部署到生产环境中。
PaaS 解决方案通常以云服务的形式交付,这意味着它们可以通过互联网访问,用户可以从任何地方访问。PaaS 提供商通常为客户管理基础设施和平台,开发人员可以专注于构建和管理应用程序。
PaaS 解决方案可以包括许多功能和服务,从开发工具和框架到应用管理和监控。一些 PaaS 解决方案还提供应用扩展和与其他云服务集成的功能。
PaaS 服务可以用于开发和部署各种应用程序,从简单的网站到复杂的数据驱动应用。
3. 软件即服务(SaaS)
软件即服务(SaaS)是一种通过互联网提供软件的云计算类型。SaaS 使企业可以在云端访问软件,而无需在其计算机上安装和运行它。
SaaS 应用通常通过网页浏览器访问,而软件和数据存储在云服务提供商的服务器上。SaaS 是一种基于订阅的模式,允许企业按月或按年支付他们使用的软件费用。
SaaS 应用通常比传统的本地软件更易于使用,因为它们设计面向广泛的用户,并且不需要广泛的培训。它们也更经济,因为企业只需支付其使用的部分。
SaaS 应用可以用于各种任务,如 CRM、项目管理、开票和会计。
4. 存储即服务(STaaS)
存储即服务(SaaS)是一种云存储模型,提供用户通过互联网访问其数据和文件的功能。SaaS 提供商通常提供各种存储计划和定价选项,使用户能够找到适合其需求的存储解决方案。虽然 STaaS 提供商通常管理和维护存储基础设施,但用户对其数据和文件负责。STaaS 提供商通常提供各种功能和工具,以帮助用户管理其数据和文件,包括访问控制、数据加密和版本控制。
5. 备份即服务(BaaS)
备份即服务(BaaS)是一种基于云的备份解决方案,帮助组织保护数据并确保业务连续性。它提供了一种灵活可扩展的按需付费模型,非常适合各种规模的企业。
BaaS 提供了几个好处,包括:
-
降低成本: BaaS 是一种经济高效的解决方案,因为它消除了昂贵的本地备份基础设施的需求。
-
提高灵活性: BaaS 使组织能够更加灵活,因为他们可以根据需要快速扩展或缩减备份存储容量。
-
增强安全性: BaaS 提供了增强的安全性,因为数据存储在安全的云环境中。
-
增强可靠性: BaaS 是一种可靠的解决方案,由领先的云服务提供商如亚马逊网络服务和微软 Azure 提供。
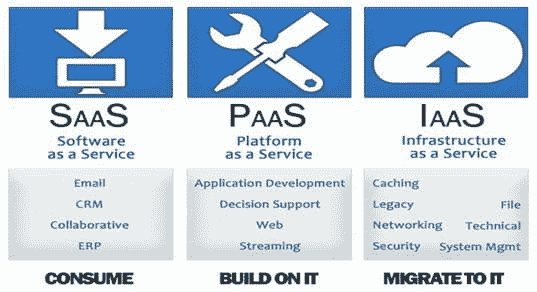
图片由 includehelp 提供
云计算模型
云计算模型有三种类型:私有、公共和混合。每种都有其优点和缺点,应在实施前进行考虑。
公共云
公共云计算是通过互联网按需提供 IT 资源和应用程序,并采用按需付费定价模式。公共云服务由第三方提供商提供,并通过互联网传送。
各种规模的企业都能从公共云计算中受益,因为它可以帮助节省 IT 基础设施和维护成本。此外,公共云计算可以帮助企业提高灵活性和可扩展性。
有几个公共云提供商,例如亚马逊网络服务、微软 Azure 和谷歌云平台。企业可以选择最适合其需求的提供商。
有几个公共云计算的缺点值得提及。
-
公共云通常比私有云安全性差。这是因为公共云在多个用户之间共享,这可能使控制访问和防止数据泄露变得困难。
-
公共云可能比私有云更不可靠,因为它们受制于互联网的波动。如果互联网出现故障,你的公共云也会随之中断。
私有云
私有云是一种云计算类型,提供类似于公共云的优势,包括可扩展性和自服务,但通过专有架构实现。私有云可以部署在本地、外部或两者的混合环境中。
优势
-
增加控制和安全: 由于私有云部署在公司场所,它们比公共云提供更大的控制和安全性。私有云可以根据公司的具体需求进行定制,并与公司的安全基础设施集成。
-
更大的可扩展性和灵活性: 私有云可以轻松地根据变化的需求进行扩展或缩减。与公共云相比,它们还可以更具灵活性,因为它们可以根据公司的具体需求进行定制。
-
较低的成本: 私有云的成本效益可能优于公共云,因为它们不需要相同程度的基础设施投资。
缺点
企业在切换之前应了解私有云计算的一些缺点。最显著的缺点之一是成本。私有云的建立和维护可能非常昂贵,特别是如果需要聘请专家来管理它们。另一个缺点是,私有云的设置和使用可能比较复杂,找到符合具体需求的功能和服务组合可能会很具挑战性。最后,私有云的灵活性可能不如公共云,你可能需要在功能和服务上做出一些妥协,以充分发挥私有云的优势。
混合云
计算中的混合云由两个或更多的云(私有、公有或社区)组成,这些云仍然是分开的,但连接在一起以提供各种部署类型的优势。混合云服务超越了供应商和隔离障碍,使其无法锁定在单一云供应商内部。
混合云的基本特征是能够连接不同的云服务,通常通过基于网络的集成,使其作为一个整体进行工作。集成可以通过几种方式完成,但最常见的是通过虚拟私人网络(VPN)或专用网络连接。
混合云的主要好处是结合了两者的优点:公共云的可扩展性和成本效益与私有云的安全性和控制能力。这可以为你的组织提供应对市场变化的敏捷性和灵活性,而不会牺牲最敏感数据的安全性和合规性。
缺点
在为你的企业实施这种解决方案之前,需要考虑混合云计算的一些缺点。一个缺点是管理本地和云端资源的复杂性增加。这可能使得解决问题和跟踪环境变化变得更加困难。
另一个潜在的缺点是成本。虽然混合云可以通过利用公共云的规模经济提供一些成本节约,但你可能仍会产生额外的费用来管理和集成本地和云端资源。
最后,混合云可能会带来安全隐患。至关重要的是要仔细考虑如何保护数据和访问本地以及云端资源。
尽管存在这些潜在缺点,混合云对于许多企业来说仍然可能是一个非常有效的解决方案。仔细权衡利弊,以确定混合云是否是你组织的正确解决方案。
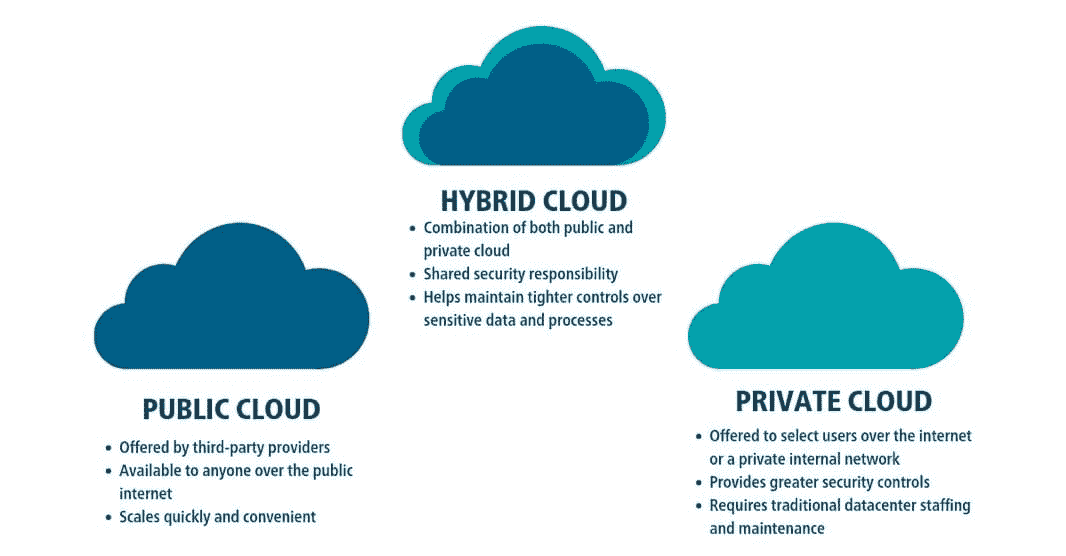
图片由karansinghreen提供
知名的云计算平台
虽然有许多知名的云计算平台,但一些最受欢迎的是 Amazon Web Services (AWS)、Google Cloud Platform (GCP) 和 Microsoft Azure。这些平台都提供了各种服务,可用于构建、部署和扩展应用程序。它们还提供不同的定价选项,以选择最适合您需求的服务。
1. Amazon Web Services (AWS)
AWS 提供各种服务,帮助企业更快地发展,降低 IT 成本,并进行扩展。以下是 AWS 提供的一些最受欢迎的服务:
-
Amazon Elastic Compute Cloud (EC2): EC2 是一个基于网络的服务,允许企业租用虚拟机(VM),用于运行应用程序和存储数据。
-
Amazon Simple Storage Service (S3): S3 是一个对象存储服务,企业可以用来存储和检索互联网上的任何数量的数据。
-
Amazon Relational Database Service (RDS): RDS 是一个托管的关系数据库服务,简化了在云中设置、操作和扩展关系数据库的过程。
-
Amazon CloudFront: CloudFront 是一个内容分发网络(CDN),加快了静态和动态网页内容在全球用户中的传递速度。
2. Google Cloud Platform (GCP)
Google Cloud Platform 提供了多种服务,帮助企业成功。从计算和存储到大数据和机器学习,应有尽有。但哪些服务适合您的企业?
这是 Google Cloud Platform 提供的一些最受欢迎服务的快速概览:
-
Compute Engine: 一个强大且可扩展的云计算平台,可以处理任何工作负载。
-
Storage: 一种可靠且具有成本效益的数据存储解决方案,提供块存储和对象存储选项。
-
BigQuery: 一个快速、强大且具有成本效益的大数据分析平台。
-
Cloud SQL: 一个完全托管的关系数据库服务,用于存储数据。
-
Cloud Spanner: 一个全球分布式的数据库服务,用于处理关键任务工作负载。
-
Machine Learning: 一套强大的机器学习服务,帮助您训练模型和进行预测。
这些仅仅是 Google Cloud Platform 提供的众多服务中的一部分。
3. Microsoft Azure
Microsoft Azure 提供了多种服务,用于构建、部署和管理应用程序。这些服务包括:
-
Azure Compute: 该服务提供了创建和管理虚拟机的能力,并且可以部署和管理容器。
-
Azure Storage: 该服务提供了创建和管理存储账户的能力,以及 Blob、队列和表存储。
-
Azure Networking: 该服务可以创建和管理虚拟网络、负载均衡器和 DNS。
-
Azure Security: 该服务可以创建和管理安全组及访问控制列表。
-
Azure Monitor:该服务可以收集和分析诊断数据。
-
Azure Active Directory:该服务可以创建和管理 Azure Active Directory 帐户。

图片来源于 allcode
云计算的应用
云计算有很多不同的应用,这也是为什么近年来这一技术变得如此受欢迎。以下是一些最常见的云计算应用:
1. 存储
云存储是将数据存储在异地并随时访问的绝佳方式。这对那些希望在灾难发生时保留数据备份的企业或希望安全地在线存储照片和视频的个人来说非常有用。
2. 计算
云计算可以用于从运行网站到驱动复杂应用程序的任何事物。企业通过使用云资源可以节省昂贵的硬件和软件许可证费用。
3. 协作
基于云的应用程序使团队成员可以在全球任何地方协作项目。这对于有远程工作的员工的企业来说,可以节省大量时间和金钱。
4. 电子商务
云计算正在革新电子商务行业。通过使得连接互联网和在云中存储数据成为可能,企业可以更高效地运营并更快速地扩展。
云计算在电子商务中有很多应用方式。其中最受欢迎的之一是使用基于云的平台来构建和托管在线商店。这对那些希望快速启动电子商务商店且不需要大量前期投资的企业来说是一个绝佳的选择。
云计算在电子商务中的另一个应用方式是通过基于云的应用程序。这些应用程序可以简化在线商店的各个方面,例如库存管理、订单处理和客户服务。
最终,云计算还可以存储和管理客户数据。这对于希望更好地了解客户并提供个性化服务的企业来说是一个宝贵的工具。
5. 教育
云计算正在改变教育领域。它为教学、学习和研究提供了新的可能性。它提供了访问大量资源和服务的机会。并且它允许教育工作者和学习者以新的方式连接和合作。
云计算在教育中的应用仍处于初期阶段,但其潜力已经显现。以下是云计算在教育中的一些应用方式:
-
在线学习:云计算在在线学习的增长中扮演了重要角色。在线课程和项目现在比以往任何时候都更易于访问。而且,使用基于云的学习管理系统(LMS)使教育工作者更容易创建和提供在线课程。
-
协作学习:云计算使学生更容易在项目和作业上进行协作。通过基于云的工具,学生可以实时共同处理文档、演示文稿和其他文件。
6. 防病毒
云计算的一个最令人兴奋的应用是防病毒领域。传统上,防病毒软件安装在单个计算机上,每台计算机都需要更新最新的病毒定义才能得到保护。
使用基于云的防病毒软件,病毒定义存储在云端,每台连接到互联网的计算机都可以访问这些定义。这意味着所有计算机都可以得到保护,而无需担心逐一更新。
基于云的防病毒软件在检测和移除病毒方面也更为有效,因为云系统可以分析更多的样本,并能快速识别新的威胁。
7. GPS(全球定位系统)
GPS 追踪是一种基于位置的服务,利用卫星导航来追踪资产和人员的位置。它通常被企业用于追踪车辆、车队和其他设备的位置。GPS 追踪也可以用于个人追踪应用,比如监控儿童或年长的家庭成员。
将 GPS 追踪与云计算结合使用是一种强大的组合,可以提供许多好处。基于云的 GPS 追踪系统可以提供实时追踪数据,可通过任何连接互联网的设备访问。这使企业能够实时追踪其资产和人员,无论他们在哪里。
基于云的 GPS 追踪系统还可以提供传统 GPS 追踪系统无法实现的功能。例如,一些基于云的系统允许企业在资产周围设置虚拟围栏。如果资产越过虚拟围墙,公司会立即收到通知。这可以是一个有价值的安全功能,帮助企业保护投资。
图片来自 guru99
结论
随着世界日益数字化,对云计算服务的需求只会增加。以下是对未来云计算的一些预测:
-
云将变得更加普及:越来越多的企业和个人将依赖基于云的服务来完成工作。
-
云将变得更智能:借助人工智能,云将更好地满足用户需求。
-
云将变得更加安全:随着安全担忧的增加,云提供商将投入更多的安全功能和技术。
-
云将变得更加实惠:随着对云服务需求的增长,服务提供商将竞相降低价格,使云服务对所有人都更加实惠。
-
云计算将变得更加灵活:随着容器化和无服务器计算的兴起,云计算将变得更加灵活和可扩展。
云计算的未来市场规模预计将会很庞大。根据 Grand View Research 的报告,到 2025 年,全球云计算市场预计将达到 6233 亿美元。这一增长由中小企业对云服务的日益采用、对成本效益高且可扩展计算解决方案的不断需求以及云应用程序的日益普及推动。
本文的关键要点
-
首先,我们讨论了云计算及其历史。还讨论了其显著特点,如成本效益、可扩展性等。
-
之后,我们讨论了提供的各种服务,如(PaaS、IaaS、SaaS 等)
-
接着我们讨论了各种云计算模型的优缺点,如私有云、公共云和混合云。
-
最后,我们讨论了像 Google 和 Microsoft 这样的公司,它们提供云计算资源。然后通过讨论云计算的未来来总结文章。
目前就这些了。我相信你喜欢阅读这篇文章。如果你有任何问题或想法,请在下面留言。
Aryan Garg 是一名 B.Tech 电气工程学生,目前处于本科最后一年。他对网页开发和机器学习领域感兴趣。已经追求了这一兴趣,并渴望在这些方向上进一步工作。
更多相关内容
数据工程初学者指南
原文:
www.kdnuggets.com/2023/07/beginner-guide-data-engineering.html

作者提供的图片
随着来自多种来源的大量数据涌入,数据工程已成为数据生态系统中不可或缺的一部分。组织正在寻求建立和扩展他们的数据工程师团队。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
一些数据角色,比如分析师,并不一定需要在该领域的先前经验,只要你有强大的 SQL 和编程技能即可。然而,要进入数据工程领域,之前在数据分析或软件工程方面的经验通常是有帮助的。
如果你想在数据工程领域发展职业生涯,本指南适合你:
-
了解更多关于数据工程及数据工程师的角色,并且
-
熟悉数据工程的基本概念。
什么是数据工程?
在我们讨论数据工程是什么之前,了解数据工程的需求是有帮助的。如果你在数据领域待了很久,你会熟练于使用 SQL 查询关系数据库以及使用类似 SQL 的语言查询 NoSQL 数据库。
但是数据是如何到达那里——准备好进一步分析和报告的?这就涉及到数据工程。
我们知道数据来自各种来源,形式各异:从传统数据库到用户对话和物联网设备。原始数据必须被提取到数据仓库中。进一步扩展:来自各种资源的数据——应当被提取和处理——然后以准备好使用的形式在数据仓库中提供。
数据工程涵盖了所有收集和整合来自各种资源的原始数据的过程——将其整合到一个统一且可访问的数据仓库中——以供分析和其他应用使用。
数据工程师做什么?
了解数据工程的定义应该会帮助你猜测数据工程师在日常工作中的职责。数据工程师的职责包括但不限于以下内容:
-
从各种来源提取和整合数据——数据收集。
-
为分析准备数据:通过应用合适的转换来处理数据,以准备分析和其他下游任务。包括数据清理、验证和转换。
-
设计、构建和维护涵盖从源头到目标的数据流的数据管道。
-
设计和维护数据收集、处理和存储的基础设施——基础设施管理。
数据工程概念
现在我们了解了数据工程的重要性以及数据工程师在组织中的角色,是时候回顾一些基本概念了。
数据源和类型
如前所述,我们从各种资源获得数据:从关系型数据库和网页抓取到新闻源和用户聊天。这些来源的数据可以被分类为三大类之一:
-
结构化数据
-
半结构化数据
-
非结构化数据
下面是概述:
| 类型 | 特征 | 示例 |
|---|---|---|
| 结构化数据 | 具有明确定义的模式。 | 关系型数据库中的数据、电子表格等 |
| 半结构化数据 | 有一定结构但没有严格的模式。通常具有提供附加信息的元数据标签。 | 包括 JSON 和 XML 数据、电子邮件、压缩文件等 |
| 非结构化数据 | 缺乏明确定义的模式。 | 图像、视频及其他多媒体文件、网站数据 |
数据存储库:数据仓库、数据湖和数据集市
从各种来源收集的原始数据应存储在一个合适的存储库中。你应该已经对数据库有所了解——包括关系型和非关系型数据库。但也有其他的数据存储库。
在我们讨论之前,了解两个数据处理系统,即 OLTP 和 OLAP 系统,会有所帮助:
-
OLTP 或 在线事务处理 系统用于存储日常操作数据,例如库存管理。OLTP 系统包括存储数据的关系型数据库,这些数据可以用于分析和得出业务见解。
-
OLAP 或 在线分析处理 系统用于存储大量的历史数据,以进行复杂的分析。除了数据库,OLAP 系统还包括数据仓库和数据湖(稍后会详细介绍)。
数据存储库的选择通常由数据的来源和类型决定。让我们了解常见的数据存储库:
-
数据仓库:数据仓库指的是一个综合性的单一数据存储库。
-
数据湖:数据湖允许以原始格式存储所有数据类型——包括半结构化和非结构化数据,而无需处理这些数据。数据湖通常是 ELT 过程的最终目的地(我们稍后会讨论)。
-
数据集市:你可以把数据集市看作是数据仓库的一个较小子集——为特定的业务用例量身定制。
-
数据湖仓:最近,数据湖仓也变得流行,因为它们既允许数据湖的灵活性,又提供了数据仓库的结构和组织。
数据管道:ETL 和 ELT 过程
数据管道涵盖了数据的整个旅程——从源到目标系统——通过 ETL 和 ELT 过程。
ETL—提取、转换和加载—过程包括以下步骤:
-
从各种来源提取数据
-
转换数据—清理、验证和标准化数据
-
将数据加载到数据仓库或目标应用程序中
ETL 过程通常以数据仓库作为目标。
ELT—提取、加载和转换—是 ETL 过程的一种变体,其中步骤的顺序是:提取、加载和转换,而不是提取、转换和加载。
意思是从源头收集的原始数据被加载到数据仓库中——在应用任何转换之前。这使我们能够应用特定于某一应用程序的转换。ELT 过程的目标是数据湖。
数据工程师应了解的工具
数据工程师应了解的工具清单可能会让人感到不知所措。

图片由作者提供
但不用担心,你不需要精通所有这些工具才能获得数据工程师的职位。在列出数据工程师应了解的各种工具之前,重要的是要注意数据工程需要广泛的基础技能,包括以下内容:
-
编程语言:中级到高级的编程语言能力,最好是 Python、Scala 或 Java 之一
-
数据库和 SQL:对数据库设计有良好的理解,并能够处理关系数据库(如 MySQL 和 PostgreSQL)和非关系数据库(如 MongoDB)
-
命令行基础:熟悉 Shell 脚本和数据处理及命令行
-
操作系统和网络知识
-
数据仓库基础
-
分布式系统基础
即使在学习基础技能时,也要确保构建项目来展示你的熟练程度。没有什么比学习、在项目中应用所学,并在工作中继续学习更有效的了!
此外,数据工程还需要强大的软件工程技能,包括版本控制、日志记录和应用程序监控。你还应了解如何使用容器化工具如 Docker 和容器编排工具如 Kubernetes。
尽管实际使用的工具可能因组织而异,但学习以下内容会有所帮助:
-
dbt(数据构建工具)用于分析工程
-
Apache Spark 用于大数据分析和分布式数据处理
-
Airflow 用于数据管道编排
-
云计算基础及与至少一个云服务提供商如 AWS 或 Microsoft Azure 的合作。
了解更多关于工程工具,包括数据仓库和流处理工具,请阅读:10 种现代数据工程工具。
总结
希望你觉得这篇数据工程介绍信息丰富!如果你对设计、构建和维护大规模数据系统感到兴奋,绝对可以尝试一下数据工程。
数据工程速成班是一个很好的起点——如果你在寻找一个基于项目的课程来学习数据工程的话。你也可以阅读常见的 数据工程师面试问题列表,以了解你需要掌握的内容。
Bala Priya C 是一位来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正致力于通过撰写教程、操作指南、意见文章等来学习和分享她的知识。
更多相关主题
初学者的端到端机器学习指南
原文:
www.kdnuggets.com/2021/12/beginner-guide-end-end-machine-learning.html
评论
作者 Rebecca Vickery,数据科学家

照片由 Modestas Urbonas 贡献,来源于 Unsplash
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
监督学习是一种将一系列输入(X)映射到某些已知输出(y)而无需明确编程的技术。训练机器学习模型指的是机器学习 X 和 y 之间的映射的过程。训练完成后,模型可以用于对新输入进行预测,其中输出未知。
机器学习模型的训练只是端到端机器学习生命周期中的一个环节。为了使模型真正有用,这个映射需要被存储和部署以供使用。这通常被称为将模型投入生产。此外,一旦模型投入生产,需要监控模型的预测和整体性能,以确保预测质量不会随时间下降。
为了介绍端到端机器学习工作流中的基本概念,我将使用 python 库 Pycaret。 Pycaret 是一个低代码机器学习库,旨在通过提供高级编程接口和自动化一些重复的机器学习任务,简化和加快整体机器学习工作流。
该库正在快速发展,最近增加了涵盖整个端到端机器学习工作流的功能。从模型开发到部署和监控。在以下文章中,我将使用这个包来简单介绍端到端机器学习生命周期。
数据
在本教程中,我将使用 Pycaret 内置的数据集之一,称为“employee”。该数据集包含有关某家不特定公司的员工的一组特征,以及一个目标变量,表示该员工是否离开了公司。这是机器学习中的经典分类任务,目标是训练一个能够预测员工是否可能离开的模型。
数据可以通过 Pycaret API 轻松导入。在以下代码中,我们读取数据并保留一个验证样本,以备后续工作流使用。
数据的前几行如下所示:

“employee”数据集的前几行。 图片由作者提供。
预处理
Pycaret 拥有一套模块,包含针对特定机器学习任务的一系列函数。我们使用的数据集包含一个分类问题,因此我们将主要使用classification模块。
第一步是导入 setup 函数。此函数在执行其他步骤之前运行。它初始化了 Pycaret 环境,并创建了一个用于预处理数据以准备建模的转换管道。运行时,Pycaret 会推断所有特征和目标列的数据类型。
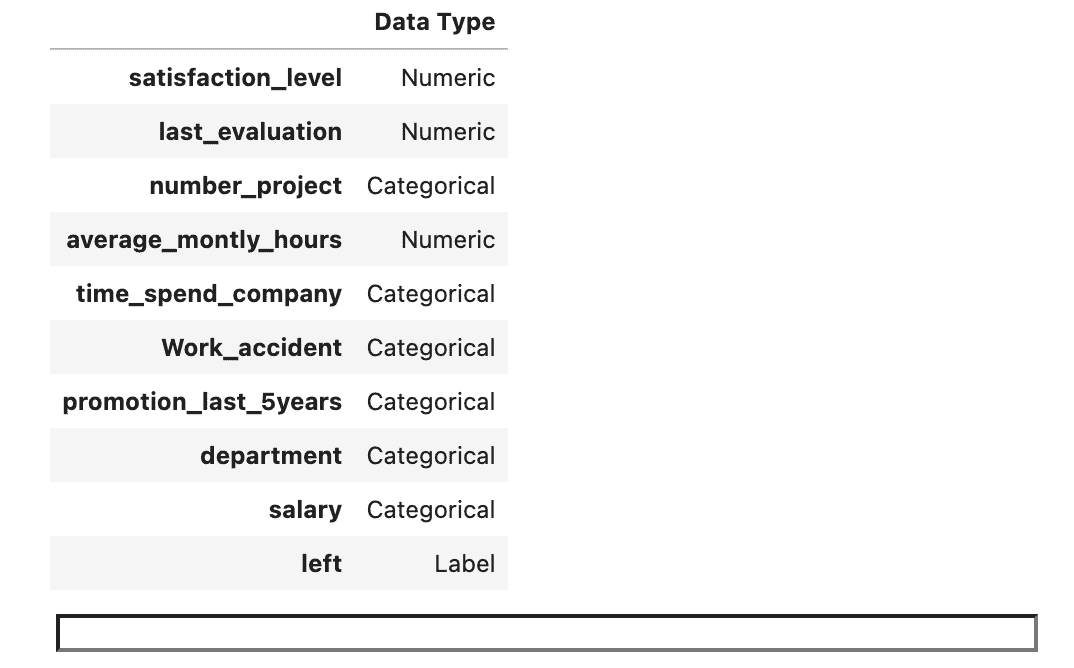
Pycaret 已经推断了特征和目标变量的数据类型。 图片由作者提供
如果我们确认这些数据类型是正确的,并且也愿意依赖 Pycaret 的默认预处理方法,那么我们只需按下回车键,Pycaret 将准备好数据以进行建模,并打印出描述所采取步骤的报告。
以下是该 59 行报告的前 15 行。setup 函数具有大量可选参数,可用于创建自定义预处理。例如,参数 categorical_features 可用于手动指定未正确推断的数据类型的分类列。可用参数的完整列表可以在这里找到。
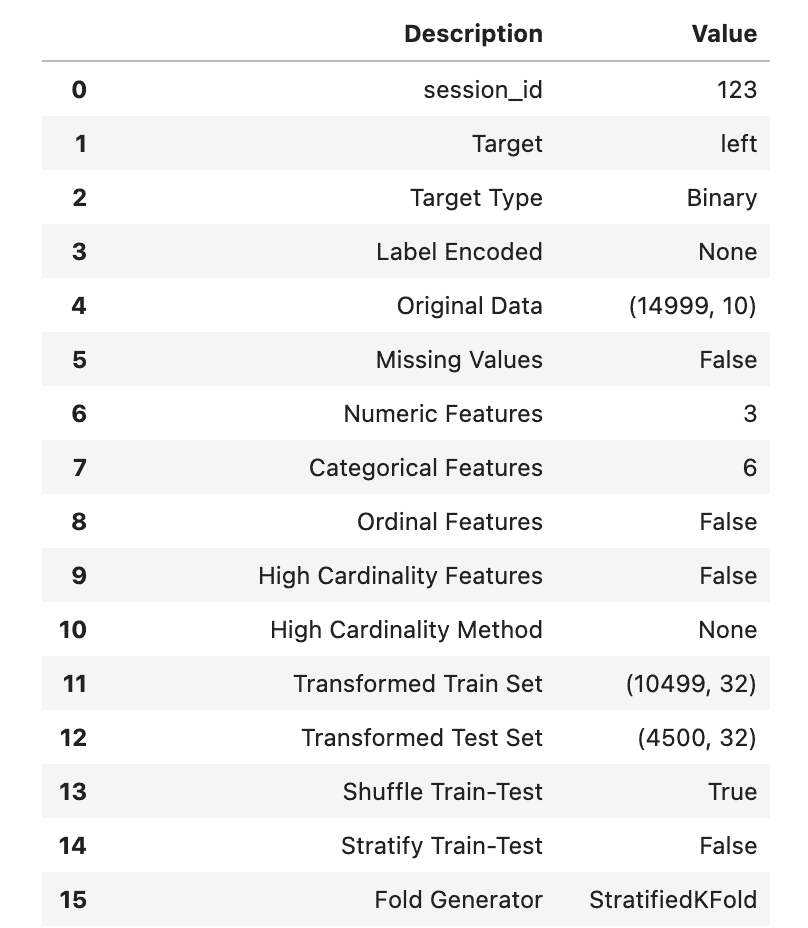
预处理报告的前 15 行。 图片由作者提供。
在真实世界的机器学习项目中,我们很可能会进行更深入的探索性分析和自定义预处理。然而,为了本教程的目的,我们将继续使用默认的预处理方法。
基准模型
通常在机器学习工作流中,首先训练一个简单模型以建立性能基准,然后再转向更复杂的算法是明智的选择。
在撰写时,Pycaret 支持 18 种不同的分类算法。完整的列表可以在这里找到。对于基线模型,我们将使用逻辑回归,并使用create_model函数进行训练。要选择算法,我们传入在文档中找到的缩写字符串。训练后,Pycaret 将打印一份详细说明模型性能的报告。
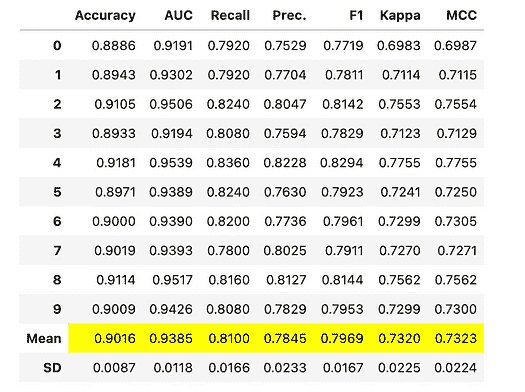
create_model报告。图片由作者提供。
比较模型
通过建立基线模型,我们已经确定了预处理和设置足以构建分类模型。
下一步是比较不同的分类算法,以确定哪一个最适合我们的数据集和问题。Pycaret 有一个叫做compare_models()的函数,可以让我们用一行代码比较所有可用算法的性能。
这个函数将尝试所有算法,并输出按准确度排名的列表。你可以通过sort参数更改目标指标。

比较模型。图片由作者提供。
从中我们可以看出,随机森林是总体上最好的模型。我们将在接下来的工作流程中使用这个模型。
我们再次运行create_model(),这次选择随机森林算法。
调整模型
当我们运行create_model时,它会自动使用默认参数。这些参数不一定是最优的,所以我们需要调整模型以找到最佳选择。运行tune_model()函数使用随机网格搜索来调整模型的超参数。
默认情况下,函数将使用预定义的参数网格,但可以通过将自定义网格传递给custom_grid参数来进行自定义。默认情况下,函数还会优化准确度评分,但也可以使用optimize参数进行自定义。
在下面的代码中,我们使用默认参数网格来调整模型,并优化 MCC 评分。
该函数返回一个包含 k 折验证分数的表格,默认情况下折数为 10。
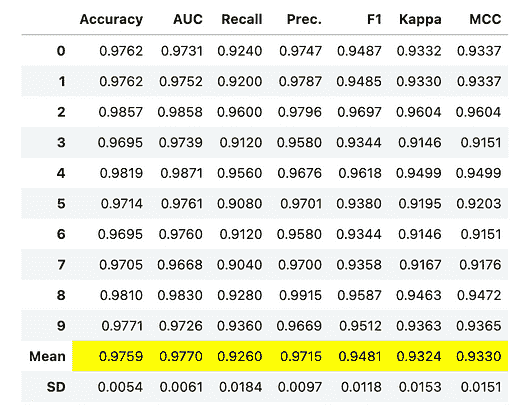
模型调整。图片由作者提供。
解释结果
Pycaret 提供了一系列内置图表来解释模型结果,可以使用plot_model()函数访问这些图表。
下面我们使用这个函数检查特征重要性。
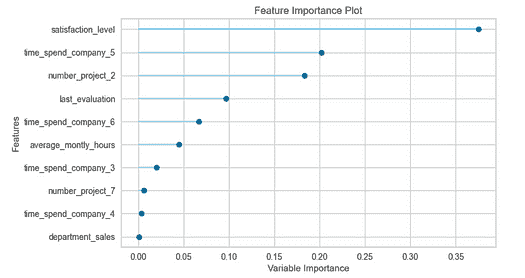
特征重要性。图片由作者提供。
让我们也可视化混淆矩阵。
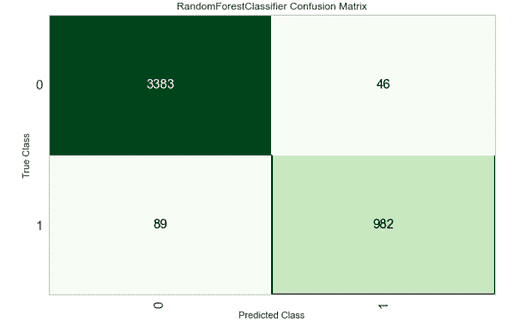
混淆矩阵。图片由作者提供。
部署模型
Pycaret 还具有将模型部署到 AWS 云的附加功能。
要在 AWS 上部署模型,你必须首先在 aws.amazon.com 上创建一个账户。创建后,你需要生成一个访问密钥,以便允许 Pycaret 函数写入你的账户。按以下步骤操作。
-
登录到你的 AWS 账户。
-
悬停在右上角的用户名上。
-
从出现的列表中选择安全凭证。
4. 在这里展开访问密钥部分,并点击“创建新的访问密钥”。
5. 在此阶段,当提示时,你需要下载凭证文件。稍后你需要使用此文件中的凭证。
6. 为了允许 Pycaret 与你的 AWS 账户交互,你还需要安装并配置 AWS CLI。首先运行以下命令。
curl "[`awscli.amazonaws.com/AWSCLIV2.pkg`](https://awscli.amazonaws.com/AWSCLIV2.pkg)" -o "AWSCLIV2.pkg"
然后运行:
sudo installer -pkg ./AWSCLIV2.pkg -target /
现在输入 aws --version 以确认一切已正确安装。你应该看到类似这样的内容。
现在已安装,我们可以使用你的账户详情配置 AWS CLI。运行下面显示的命令,它会要求你输入以下信息。
AWS Access Key ID: 可以在我们之前下载的凭证文件中找到。
AWS Secret Access Key: 也可以在凭证文件中找到。
默认区域名称: 可以在 AWS 控制台中找到。
默认输出格式: 应留空。
接下来,我们创建一个 S3 存储桶以存储部署的模型。从 AWS 控制台选择 S3,然后创建一个你选择名称的存储桶。
现在我们准备使用 Pycaret 部署我们选择的模型。
如果模型已经部署,你将看到以下消息。
生成预测
为了使用模型,我们在之前保留的验证数据上生成预测。
下面显示的代码从 S3 加载模型,并在去除了标签的验证数据上生成预测。
通过运行 predictions[:5] 来查看前 5 个预测结果。

前 5 个预测。图片来自作者
监控
生产机器学习工作流的一个重要方面是跟踪和监控执行的实验。Pycaret 与 MLflow 集成,后者是一个用于管理端到端机器学习生命周期的开源平台。
要通过 Pycaret 使用 MLflow,我们需要导入 MLflow(这应该已经随 Pycaret 一起安装)并设置跟踪 URI。然后,我们在调用 setup 函数时添加几个额外的参数,如下所示。
现在,如果我们将跟踪 URI 复制到浏览器中,你应该能看到 mlflow UI 和它跟踪的实验。

mlflow UI。图片来自作者
我们可以点击查看每个实验的度量指标、工件和参数。
实验跟踪。图片来自作者
这是一个简单的教程,用于学习端到端机器学习项目的基本步骤。在现实世界中,大多数机器学习问题、数据和部署解决方案需要更复杂的处理。然而,为了本教程的目的,我使用了一个简单的数据集和 Python 库,以帮助你开始了解端到端机器学习生命周期。
Pycaret 是一个低代码机器学习库的例子。目前有很多工具正在开发,旨在以不同方式简化机器学习开发。要了解更多关于这些低成本机器学习库的信息,请参见我之前的文章。
有关现实世界中机器学习的更多信息,请参见下面的文章。
感谢阅读!
简介: Rebecca Vickery 是一位数据科学家,拥有丰富的数据分析、机器学习和数据工程经验。12 年 SQL 经验,4 年以上 Python、R、Apache Airflow 和 Google Analytics 经验。
相关:
-
你不知道的关于 Scikit-Learn 的 10 件事
-
数据科学中的五个命令行工具
-
可解释的机器学习 Python 库
更多相关主题
Pandas Melt 函数初学者指南
原文:
www.kdnuggets.com/2023/03/beginner-guide-pandas-melt-function.html

图片来自 catalyststuff 在 Freepik
在处理现实生活中的数据集时,我们不能期望数据集完全符合我们的需求。有时,数据需要转换成另一种格式以便更容易处理。一种方法是将宽格式数据框转换成长格式。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我们经常遇到宽格式数据;每行是数据,每列是数据特征。让我用数据集示例给你一个例子。我们将使用来自 Kaggle 的 产品销售数据(许可证:CC BY-NC-SA 4.0)由 Soumyadipta Das 提供。
import pandas as pd
df = pd.read_csv('time series data.csv')
df.head()
在上述数据集中,每行表示销售发生的时间。另一方面,列是产品类型和其他支持类别(价格、温度)。
上面的数据集很好,但如果我们想在产品级别进行聚合可能会很困难。这就是为什么我们可以将数据转换成长格式以简化分析。为此,我们可以依靠 Pandas 的 melt 函数。
Pandas Melt 函数
Pandas melt 函数用于将数据集从宽格式转换成长格式。什么是长格式数据集?它是一个每行包含变量及其值的数据集。技术上来说,我们是将数据集进行反透视,以获取具有较少列和较长行的数据集。让我们尝试 melt 函数以更好地理解。
pd.melt(df)
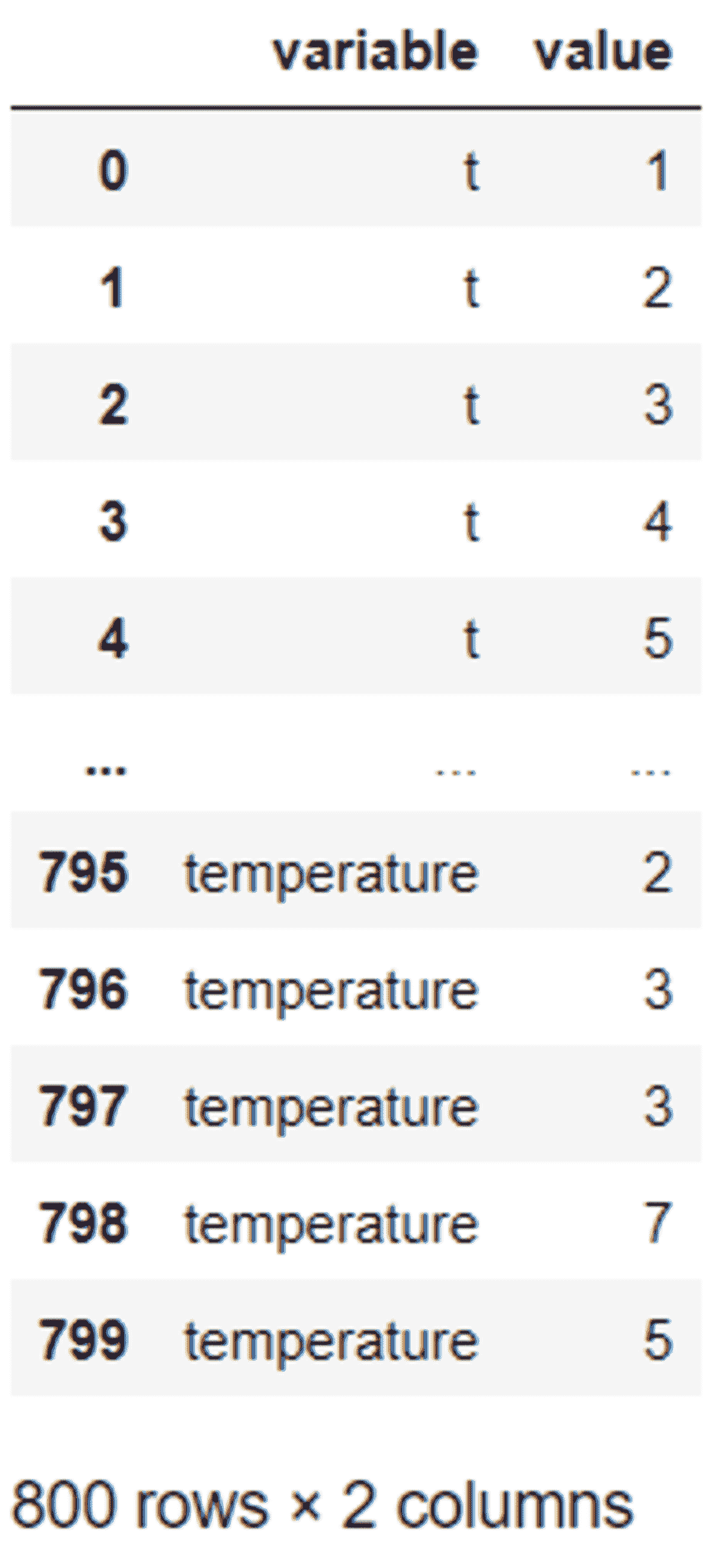
我们从上面的输出中得到长格式数据集。数据集仅包含两列;‘variable’,它是宽格式数据集中的列名,以及‘value’,它是宽格式数据集中每行的数据值。
例如,‘t’列现在被视为数据观测,与原始数据集的行数相匹配,并带有相应的值。基本上,melt 函数从宽格式数据提供了键值对。
与宽格式相比,我们现在可以基于产品级别创建类别,而在宽格式数据中这并不可行,因为产品是列名。让我们尝试使用 melt 函数来做到这一点。
pd.melt(
df,
id_vars=["t"],
value_vars=["ProductP1", "ProductP2"],
var_name="Product",
value_name="Sales",
)

在上述代码中,我们将‘t’列指定为数据标识符,将‘ProductP1’和‘ProductP2’指定为类别。为了便于阅读,我们将变量名称更改为‘Product’,值更改为‘Sales’。
现在,使用上述代码,对于每个时间框架(‘t’),我们获得了两个不同的产品类别及其值。这使得数据集的分析更加直观,因为组比较更为明确。
我们也可以使用 DataFrame 方法来融化数据集。当前代码的工作方式与上述示例完全相同。
df.melt(
id_vars=["t"],
value_vars=["ProductP1", "ProductP2"],
var_name="Product",
value_name="Sales",
)
根据你的数据处理流程,你可以选择不同的数据融化方法。两种方法的结果完全相同。
我们也可以向融化后的数据集中添加更多标识符。为此,我们只需在‘id_vars’参数中指定所有预期的标识符。例如,我会将‘price’列作为额外的标识符。
pd.melt(
df,
id_vars=["t", "price"],
value_vars=["ProductP1", "ProductP2"],
var_name="Product",
value_name="Sales",
)
结果将会是‘t’和‘price’列作为数据集标识符。上述方法在你的宽格式数据集中有多个键时尤其有用,而这些键你不想删除。
要进一步了解 Pandas melt 函数,你可以访问 Pandas 文档。
结论
相比宽格式数据,有时长格式数据更为受欢迎。有时,我们需要分析的正是列,而唯一的方法是将数据反透视。通过使用 Pandas melt 函数,我们成功将宽格式数据转换为包含列名称和原始数据值的键值组合的长格式数据。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
Q 学习初学者指南

亚历山大·安德鲁斯 通过 Unsplash
为了理解 Q 学习,你需要一些强化学习的知识。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
强化学习 源于机器学习,它旨在通过一系列为特定问题创建的解决方案来训练一个返回最佳解决方案的模型。
模型会有多种解决方案,当选择正确的方案时,会生成奖励信号。如果模型的表现接近目标,则生成正奖励;如果模型的表现远离目标,则生成负奖励。
强化学习包括两种算法
-
无模型的: 这排除环境的动态性来估计最佳策略
-
基于模型的: 这包括环境的动态性来估计最佳策略。
什么是 Q-Learning?
Q-Learning 是一种无模型的强化学习算法。它尝试随机找出可以最大化奖励的最佳行动。该算法基于一个方程更新价值函数,使其成为一种基于价值的学习算法。
就像当你试图找到当前情况的解决方案,以确保你获得最大的利益一样。模型可以生成自己的规则,甚至在提供的策略之外运行。这意味着不需要策略,使其成为一种离策略学习者。
离策略学习者 是指模型学习最佳策略的价值而不管代理的行动。而 在策略学习者 是指模型学习代理所执行的策略的价值,找到最佳策略。
让我们来看看基于推荐系统的广告。如今的广告基于你的搜索历史或之前的观看记录。然而,Q-Learning 可以更进一步,通过优化广告推荐系统来推荐那些经常被一起购买的产品。奖励信号是用户是否购买或点击了推荐的产品。
Q 学习中的‘Q’代表质量。它表示给定动作在获得奖励方面的有效性。
贝尔曼方程
贝尔曼方程以理查德·E·贝尔曼的名字命名,他被称为动态规划的奠基人。动态规划旨在通过将复杂问题/任务分解成更小的问题,然后递归解决这些小问题,从而简化复杂问题。
贝尔曼方程确定特定状态的值,并得出该状态的价值。Q 函数使用贝尔曼方程,并使用两个输入:状态(s)和动作(a)。
如果我们知道每个动作的所有期望奖励,怎么知道选择哪个动作?你可以选择生成最佳奖励的动作序列,我们可以将其表示为 Q 值。使用这个方程:
-
Q(s, a)代表在状态‘s’下执行动作‘a’所得到的 Q 值。
-
这通过 r(s, a)计算,其中 r(s, a)代表立即获得的奖励 + 状态‘s’的最佳 Q 值。
-
![方程]() 是折扣因子,控制和决定当前状态的重要性
是折扣因子,控制和决定当前状态的重要性
 是折扣因子,控制和决定当前状态的重要性
是折扣因子,控制和决定当前状态的重要性该方程包括当前状态、学习率、折扣因子、与特定状态相关的奖励以及最大期望奖励。这些用于确定代理的下一个状态。
什么是 Q 表?
你可以想象 Q 学习所提供的不同路径和解决方案。因此,为了管理和确定哪个是最好的,我们使用 Q 表。
Q 表只是一个简单的查找表。它的创建是为了便于计算和管理最大期望的未来奖励。我们可以轻松识别环境中每个状态的最佳动作。通过在每个状态下使用贝尔曼方程,我们获得期望的未来状态和奖励,然后将其保存在表中,以便与其他状态进行比较。
例如:
| 状态: | 动作: |
|---|---|
 |
|
| 0 | 0 |
| .. | |
| 250 | -2.07469 |
| .. | |
| 500 | 11.47930 |
Q 学习过程
1. 初始化 Q 表
第一步是创建 Q 表
-
n = 动作数量
-
m = 状态数量
例如,n 可以是左、右、上或下,而 m 可以是在游戏中的开始、空闲、正确动作、错误动作和结束。
2. 选择并执行一个动作
我们的 Q 表应该全部为 0,因为尚未执行任何动作。然后,我们选择一个动作并在 Q 表中正确的部分更新它。这表示动作已被执行。
3. 使用贝尔曼方程计算 Q 值
使用贝尔曼方程,计算实际奖励的值以及刚刚执行的动作的 Q 值。
4. 继续步骤 2 和 3
重复步骤 2 和 3 直到一个回合结束或 Q 表被填满。
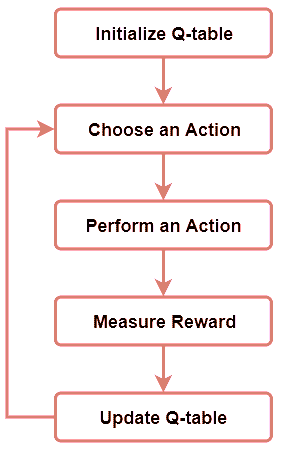
来源:作者图片
结论
这是一个简单的初学者指南,如果你想更好地理解 Q 学习和强化学习,可以阅读这本书:强化学习:导论(第 2 版) 作者为 Richard S. Sutton 和 Andrew G. Barto。
尼莎·阿里亚 是一名数据科学家和自由技术写作人。她特别感兴趣于提供数据科学职业建议或教程,以及数据科学相关的理论知识。她还希望探索人工智能如何对人类寿命产生好处。作为一个渴望学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
Python 网页抓取初学者指南
原文:
www.kdnuggets.com/2022/10/beginner-guide-web-scraping-python.html

图片来自 jemastock 来自 Freepik
有时需要从网站上收集大量信息,以便用于各种目的。这就是网页抓取,可以通过多种方式实现。一个有效的网页抓取方法是使用一种名为 Python 的编程语言。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 需求
本文作为使用 Python 进行网页抓取的初学者指南,介绍了可以使用的不同框架和方法,内容简单明了。
什么是网页抓取?
网页抓取是从网站提取数据(主要是非结构化数据),通常是大量的数据。收集后,这些信息被导出为可用的结构化格式,如电子表格或应用程序编程接口(API)。
对于小型数据集,可以手动完成;然而,处理大量数据最好使用自动化系统,因为这更快且成本更低。
对于网页抓取没有一刀切的方法,因为所有网站的规模和形式各不相同。每个网站可能会提供各种需要克服的障碍,如验证码挑战测试,这就是为什么网页抓取工具需要非常多才多艺的原因。
网页抓取的目的是什么?
网页抓取器可以用于多种用途。以下是一些最受欢迎的用途:
-
比价购物网站
-
房地产列表
-
潜在客户生成
-
显示行业特定的统计数据和见解
-
当前股票价格、加密货币价格和其他财务数据
-
来自 eBay 和 Amazon 等网站的产品数据
-
赌博网站和幻想联盟的体育统计数据
与任何网络项目一样,遵守法律法规非常重要。这不仅可以避免任何法律行动,还可以确保你的系统更好地防范黑客和网络犯罪。务必确保你遵循良好的数字公民实践,如保护隐私、定期更换密码以及报告你在网上遇到的任何非法活动。
什么是 Python,为什么它用于网络爬虫?
Python 是一种通用计算机编程语言,可以用于各种任务,从构建网站和软件到自动化特定任务甚至机器学习。它与几乎任何类型的程序兼容,并不是为了单一目标而开发的。
为什么 Python 是网络爬虫的良好选择?
你应该选择 Python 进行网络爬虫项目的原因有五个。
1. Python 拥有广泛的库选择
Python 拥有大量可以用于你项目的库(库是任何人都可以用来包含在自己程序中的代码段)。Python 库包括 pandas、Matplotlib、Numpy 等等。
这些库可以用于许多不同的功能,非常适合数据处理和网络爬虫项目。
2. Python 相对简单
Python 是最简单的编程语言之一,因为它不使用分号和大括号等符号,使代码不那么复杂。
3. Python 是动态的
Python 可以是动态类型的,这意味着你不需要为 Python 中的变量定义任何数据类型。相反,你可以在需要时插入它们,使过程更加快捷。
4. Python 只需少量代码即可完成复杂任务
网络爬虫的目标是节省时间并快速收集数据,但如果编写代码的过程很长,这个目标也没多大意义。然而,Python 是精简的,只需少量代码即可实现用户的目标。
5. Python 语法可以快速学习
与其他编程语言相比,Python 语法(决定代码如何编写的规则)非常简单易学。每个范围或块在代码中都很容易区分,这使得即使是初学者也能轻松跟随。
初学者 Python 网络爬虫指南
在本节中,我们将讨论一些可以帮助构建网络爬虫程序的框架。接下来,我们将展示如何抓取一个电子商务网站的示例方法。
Python 网络爬虫框架
当使用 Python 进行网络爬虫时,程序可以使用三个框架。这些框架是 Beautiful Soup、Scrapy 和 Selenium。
-
Beautiful Soup - Beautiful Soup 框架用于解析 XML 和 HTML 文件以提取数据。在抓取网站时,必须使用 requests 库发送网站请求并接收响应。然后提取 HTML 并传递给 Beautiful Soup 对象进行解析。
-
Scrapy - Scrapy 是 Python 使用的顶级 网络爬虫和抓取框架之一,能够有效地爬取网站并提取结构化数据。它可用于许多任务,包括数据挖掘、网站监控和自动化测试。Scrapy 专注于 HTML,通过简单地指定一个 URL 来工作。
-
Selenium - Selenium 框架抓取加载动态内容的网站(例如 Facebook、Twitter 和其他社交媒体网站)。它也可以抓取需要登录或注册的网站。
注意!除了上述框架外,你还应该了解数据分析和处理库 Pandas。这个库用于提取数据并将其保存为用户首选的格式。
抓取在线购物网站 - 一个示例
对于这种方法,你需要:
-
Ubuntu 操作系统
-
Google Chrome 浏览器
-
安装了 Selenium、Pandas 和 Beautiful Soup 库的 Python 2+ 或 3+。
第一步
第一步是找到你想抓取的页面/页面的 URL。在这个例子中,我们将抓取一个最大的电子商务网站,以提取智能手机的价格、名称和评级。
第二步
接下来,你应该检查你选择的页面并查看其页面源代码。你寻找的数据通常会在标签内,因此你必须首先确定你想抓取的信息在页面代码中的位置。
在 Google Chrome 中,右键点击网页中的任何元素并点击检查。然后你可以查看页面元素。要查找你的 数据位置,通过右键点击图像或价格然后选择‘查看页面源代码’。
第三步
搜索页面源代码以提取你想要的数据。在这种情况下,评级、名称和价格信息将嵌套在“div”标签中。
第四步
现在,是时候使用 Python 开发代码了。为此,首先打开 Ubuntu 终端并输入:gedit your file name> 的 .py 扩展名。我们将文件命名为‘web scrape’;因此,命令是:
1. 现在,是时候使用 Python 开发代码了。为此,首先打开 Ubuntu 终端并输入:gedit your file name> 的 .py 扩展名。我们将文件命名为‘web scrape’;因此,命令是:
gedit web-scrape.py
2. 使用以下命令提取所需的库:
from selenium import webdriver
from BeautifulSoup import BeautifulSoup
import pandas as pd
3. 确保你安装了 Python 3+ 和 Beautiful Soup
4. 设置 Chrome 驱动程序的路径以使用 Chrome 浏览器:
driver = webdriver.Chrome("/usr/lib/chromium-browser/chromedriver")
5. 接下来,我们需要打开网页并将收集的信息存储为列表:
products = []# store name of the product
prices = []# store price of the product
ratings = []# store rating of the product
driver.get(insert URL)
6. 现在,您已准备好提取数据。输入数据嵌套的 div 标签:
content = driver.page_source
soup = BeautifulSoup(content)
for a in soup.findAll('a', href = True, attrs = {
'class': '_31qSD5'
}):
name = a.find('div', attrs = {
'class': '_3wU53n'
})
price = a.find('div', attrs = {
'class': '_1vC4OE _2rQ-NK'
})
rating = a.find('div', attrs = {
'class': 'hGSR34 _2beYZw'
})
products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
7. 运行代码:
python web-scrape.py
8. 将收集的信息以您喜欢的格式保存;在本例中,我们将其保存为 CSV 文件。
df = pd.DataFrame({
'Product Name': products,
'Price': prices,
'Rating': ratings
})
df.to_csv('products.csv', index = False, encoding = 'utf-8')
9. 然后,再次运行程序以完成过程。
正如您所见,通过安装正确的工具并了解简单的命令,网站可以轻松地使用 Python 进行抓取。我们希望您觉得这份指南有用,并能够将上述一些技巧应用到您的下一个网页抓取项目中。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她在一家 Inc. 5,000 的体验品牌组织中担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
了解更多相关主题
CLIP 模型初学者指南
原文:
www.kdnuggets.com/2021/03/beginners-guide-clip-model.html
评论
作者:Matthew Brems,Roboflow 增长经理
你可能听说过 OpenAI 的 CLIP 模型。如果你查过,它表示 CLIP 是“对比语言-图像预训练”的缩写。这对我来说并不立即清晰,所以我 阅读了论文 来了解他们如何开发 CLIP 模型 —— 以及相应的博客文章。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 部门
我在这里为你分解 CLIP,力求做到——希望——易于理解和有趣!在这篇文章中,我将涵盖:
-
CLIP 是什么,
-
CLIP 是如何工作的,以及
-
为什么 CLIP 很酷。
什么是 CLIP?
CLIP 是第一个多模态(在这种情况下是视觉和文本)模型,旨在解决计算机视觉问题,并于 2021 年 1 月 5 日由 OpenAI 发布。从 OpenAI CLIP 仓库 中,“CLIP(对比语言-图像预训练)是一个在各种(图像,文本)对上训练的神经网络。它可以用自然语言指令来预测给定图像的最相关文本片段,而无需直接优化任务,类似于 GPT-2 和 GPT-3 的零样本能力。”
根据你的背景,这 可能 有意义——但这里有很多可能对你来说不熟悉的内容。让我们深入探讨一下。
-
CLIP 是一个神经网络模型。
-
它的训练数据包含 400,000,000 个(图像,文本)对。一个(图像,文本)对可能是一张图片及其说明。这意味着有 400,000,000 张图片及其说明被匹配在一起,这些数据用于训练 CLIP 模型。
-
“它可以根据给定图像预测最相关的文本片段。” 你可以将一张图片输入到 CLIP 模型中,它会返回最可能的说明或摘要。
-
“无需直接针对任务进行优化,与 GPT-2 和 GPT-3 的零样本能力类似。” 大多数机器学习模型学习一个特定任务。例如,一个经过训练来分类狗和猫的图像分类器被期望在我们给它的任务上表现良好:分类狗和猫。我们通常不期望一个经过训练来识别狗和猫的机器学习模型在检测浣熊方面表现得很好。然而,一些模型——包括 CLIP、GPT-2 和 GPT-3——在它们没有直接训练的任务上表现得很好,这被称为“零样本学习”。
-
“零样本学习”是指模型尝试预测在训练数据中出现零次的类别。因此,将一个只训练过猫和狗的模型用于检测浣熊。像 CLIP 这样的模型,由于它如何利用(图像,文本)对中的文本信息,通常在零样本学习方面表现非常好——即使你查看的图像与训练图像非常不同,你的 CLIP 模型也很可能能为该图像提供一个好的标题。
综合来看,CLIP 模型是:
-
一个基于数亿张图像和标题构建的神经网络模型,
-
可以根据给定的图像返回最佳标题,并且
-
具有令人印象深刻的“零样本”能力,使其能够准确预测从未见过的整个类别!
当我撰写我的计算机视觉简介文章时,我将计算机视觉描述为“计算机以类似于人类的方式看见和理解其所见的能力。”
当我教授自然语言处理时,我以类似的方式描述 NLP:“计算机以类似于人类的方式理解语言的能力。”
CLIP 是计算机视觉与自然语言处理之间的桥梁。
它不仅仅是计算机视觉和自然语言处理之间的桥梁——它是一个非常强大的桥梁,在两者之间具有很大的灵活性和广泛的应用。
CLIP 是如何工作的?
为了使图像和文本相互关联,它们必须都被嵌入。即使你没有这样想过,你之前也曾经使用过嵌入。让我们通过一个例子来说明。假设你有一只猫和两只狗。你可以将其表示为图表上的一个点,如下所示:
“1 只猫,2 只狗。”的嵌入(来源)
这可能看起来不是很令人兴奋,但我们刚刚将这些信息嵌入到你可能在初中学过的 X-Y 坐标系中(正式称为欧几里得空间)。你还可以在同一个图上嵌入你朋友的宠物信息,或者选择多种不同的方式来表示这些信息(例如,将狗放在猫前面,或添加一个用于浣熊的第三维度)。
我喜欢将嵌入理解为一种将信息压缩到数学空间的方式。我们刚刚将关于狗和猫的信息压缩到数学空间中。我们也可以对文本和图像进行同样的操作!
CLIP 模型由两个称为编码器的子模型组成:
-
一个将文本嵌入(压缩)到数学空间中的文本编码器。
-
一个将图像嵌入(压缩)到数学空间中的图像编码器。
每当你训练一个监督学习模型时,你必须找到某种方法来衡量该模型的“好坏”——目标是拟合一个“最好”和“最不差”的模型。
CLIP 模型也不例外:文本编码器和图像编码器都被调整以最大化好坏并最小化坏。
那么,我们如何衡量“好坏”?
在下图中,你会看到一组紫色文本卡片进入文本编码器。每张卡片的输出将是一系列数字。例如,顶部的卡片,pepper the aussie pup,将进入文本编码器——即将其压缩到数学空间中的工具——并以类似(0, 0.2, 0.8)的数字系列输出。
对于图像也会发生完全相同的情况:每张图像将进入图像编码器,每张图像的输出也将是一系列数字。图片中的,可能是 Pepper 这只澳大利亚小狗的图像,将输出类似(0.05, 0.25, 0.7)的数字。
预训练阶段。 (Source.)
我们模型的“好坏”
在理想的情况下,文本“pepper the aussie pup”的数字系列将与对应图像的数字系列非常接近(相同)。事实上,这应该在所有地方都是如此:文本的数字系列应该非常接近对应图像的数字系列。我们衡量模型“好坏”的一种方法是看每个文本的嵌入表示(数字系列)与每个图像的嵌入表示的接近程度。
计算两组数字之间相似性的便捷方法是:余弦相似度。我们在这里不会深入探讨这个公式的内部运作,但可以放心,它是一个经过验证的查看两个向量或数字序列相似性的方法。(虽然这并不是唯一的方法!)
在上图中,浅蓝色方块表示文本和图像重合的部分。例如,T1 是第一个文本的嵌入表示;I1 是第一个图像的嵌入表示。我们希望 I1 和 T1 的余弦相似度尽可能高。对于 I2 和 T2 也是如此,所有浅蓝色方块都应如此。这些余弦相似度越高,我们的模型的“好”就越多!
我们模型的“坏”
与此同时,尽管我们希望最大化每一个蓝色方块的余弦相似度,但还有很多灰色方块表示文本和图像之间的不匹配。例如,T1 是文本“pepper the aussie pup”,但可能 I2 是一张浣熊的图片。

带有边界框注释的浣熊图片。 (来源.)
尽管这只浣熊很可爱,但我们希望这张图片(I2)与文本pepper the aussie pup之间的余弦相似度很小,因为这不是 Pepper the Aussie 小狗!
尽管我们希望所有蓝色方块之间具有较高的余弦相似度(因为这衡量了“好”),但我们希望所有灰色方块之间具有较低的余弦相似度,因为这衡量了“坏”。
最大化蓝色方块的余弦相似度;最小化灰色方块的余弦相似度。 (来源.)
文本和图像编码器如何进行训练?
文本编码器和图像编码器同时进行训练,通过同时最大化这些蓝色方块的余弦相似度,并最小化灰色方块的余弦相似度,来对所有文本+图像对进行优化。
注意:根据数据的大小,这可能需要很长时间。CLIP 模型在 400,000,000 张标记图像上进行了训练。训练过程花费了 30 天,使用了592 个 V100 GPU。在 AWS 按需实例上训练这些模型的费用将达到 1,000,000 美元!
一旦模型训练完成,你可以将一张图片传递给图像编码器,以获取最符合该图片的文本描述——或者,反过来,你也可以将文本描述传递给模型,以获取图像,就像你在下面的一些应用中看到的那样!
CLIP 是计算机视觉与自然语言处理之间的桥梁。
CLIP 为什么很酷?
通过计算机视觉与自然语言处理之间的桥梁,CLIP 具有很多优势和酷炫的应用。我们将重点关注这些应用,但也有一些优势需要指出:
-
泛化能力:模型通常非常脆弱,只能知道你训练它们做的非常具体的事情。CLIP 通过利用文本中的语义信息,扩展了分类模型的知识范围。标准分类模型完全丢弃了类别标签的语义含义,后台仅是列举的数字类别;CLIP 通过理解类别的意义来工作。
-
比以往更好地连接文本/图像:考虑到速度和准确性,CLIP 可能真的是“世界上最好的字幕写手”。
-
已标记的数据:CLIP 是基于已经创建的图像和字幕构建的;其他最先进的计算机视觉算法需要大量额外的人力来进行标记。
为什么 @OpenAI 的 CLIP 模型很重要?
t.co/X7bnSgZ0or— Joseph Nelson (@josephofiowa) 2021 年 1 月 6 日
到目前为止,CLIP 的一些用途:
-
一位 Twitter 用户将包括 Elvis Presley、Beyoncé 和 Billie Eilish 的名人,并使用 CLIP 和 StyleGAN 生成了“我的小马”风格的肖像。
-
你玩过 Pictionary 吗?现在你可以在 paint.wtf 上在线玩游戏,在那里你会被 CLIP 评判。
-
CLIP 可以用来轻松改善 NSFW 过滤器!
-
OpenAI 还创建了 DALL-E,它可以从文本生成图像。
我们希望你能查看上述一些内容——或创建你自己的!我们有一个 CLIP 教程 供你跟随。如果你用它做了什么,告诉我们,以便我们将其添加到上述列表中!
值得注意的是,CLIP 是计算机视觉与自然语言处理之间的 一个 桥梁。CLIP 并不是唯一的桥梁。你可以以非常不同的方式构建这些文本和图像编码器,或者找到其他连接这两者的方法。然而,CLIP 迄今为止是一个异常创新的技术,促进了显著的额外创新。
我们迫不及待地想看到你用 CLIP 创建的内容,以及在其基础上取得的进展!
个人简介:Matthew Brems 是 Roboflow 的增长经理。
原始内容。经许可转载。
相关内容:
-
OpenAI 发布了两个 Transformer 模型,神奇地链接了语言和计算机视觉
-
评估目标检测模型使用平均精度
-
使用 SRU+ 降低训练 NLP 模型的高成本
更多相关话题
数据工程入门指南 - 第二部分
原文:
www.kdnuggets.com/2018/03/beginners-guide-data-engineering-part-2.html/2
评论
Airflow 管道的结构

现在我们已经了解了事实表、维度表、日期分区的概念,以及数据回填的含义,让我们进一步明确这些概念,并将其应用于实际的 Airflow ETL 作业中。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
定义有向无环图 (DAG)
正如我们在早期文章中提到的,任何 ETL 作业本质上都是建立在三个构建块之上的:提取、转换和加载。尽管从概念上讲这可能听起来很简单,但实际中的 ETL 作业往往很复杂,由许多 E、T 和 L 任务的组合组成。因此,使用图形可视化复杂的数据流通常很有用。从视觉上看,图中的节点代表一个任务,而箭头代表一个任务对另一个任务的依赖关系。由于数据只需要在给定任务上计算一次,然后计算结果会继续传递,图是有向的和无环的。这就是为什么 Airflow 作业通常被称为“DAG”(有向 无环 图)的原因。

来源:Airbnb 实验报告框架 DAG 的截图
Airflow UI 的一个巧妙设计是它允许用户以图形视图可视化 DAG,使用代码作为配置。数据管道的作者必须定义任务之间的依赖结构才能进行可视化。这个规范通常写在一个叫做DAG 定义文件的文件中,这个文件展示了 Airflow 作业的结构。
操作符:传感器、操作符和传输
虽然 DAG 描述了如何运行数据管道,但操作符描述了在数据管道中做什么。通常,操作符分为三大类:
-
传感器:等待一定时间、外部文件或上游数据源
-
操作符:触发某种操作(例如运行一个 bash 命令、执行一个 python 函数,或执行一个 Hive 查询等)。
-
传输:将数据从一个位置移动到另一个位置
精明的读者可能会看到这些操作符如何对应于 Extract,
Transform 和 Load 步骤是我们之前讨论过的。
传感器在经过一定时间或当上游数据源的数据可用时,解除数据流的阻塞。在 Airbnb,由于我们的大多数 ETL 作业涉及 Hive 查询,我们经常使用[NamedHivePartitionSensors](https://github.com/apache/incubator-airflow/blob/master/airflow/sensors/named_hive_partition_sensor.py)来检查 Hive 表的最新分区是否已准备好进行下游处理。
操作符触发数据转换,这对应于 Transform 步骤。由于 Airflow 是开源的,贡献者可以扩展 BaseOperator 类以创建自定义操作符。 在 Airbnb,我们最常使用的操作符是[HiveOperator](https://github.com/apache/incubator-airflow/blob/master/airflow/operators/hive_operator.py#L22)(执行 hive 查询),但我们也经常使用[PythonOperator](https://github.com/apache/incubator-airflow/blob/master/airflow/operators/python_operator.py)(例如运行 Python 脚本)和[BashOperator](https://github.com/apache/incubator-airflow/blob/master/airflow/operators/bash_operator.py)(例如运行 bash 脚本,或甚至是一个 fancy Spark 作业)。这里的可能性是无限的!
最后,我们还拥有专门的操作符,传输数据从一个地方到另一个地方,这通常对应于 ETL 中的 Load 步骤。在 Airbnb,我们经常使用[MySqlToHiveTransfer](https://github.com/apache/incubator-airflow/blob/master/airflow/operators/mysql_to_hive.py)或[S3ToHiveTransfer](https://github.com/apache/incubator-airflow/blob/master/airflow/operators/s3_to_hive_operator.py),但这在很大程度上取决于数据基础设施和数据仓库的位置。
一个简单的例子
下面是一个简单的例子,展示了如何定义一个 DAG 定义文件、实例化一个 Airflow DAG,并使用我们之前描述的各种操作符来定义相应的 DAG 结构。
当 DAG 被渲染时,我们看到以下图形视图:
玩具示例 DAG 的图形视图
ETL 最佳实践

图片来源:打造你的工艺需要实践,因此遵循最佳实践是明智的
像任何工艺一样,编写简洁、可读且可扩展的 Airflow 作业需要实践。在我第一次工作时,ETL 对我而言只是一些我必须完成的平凡机械任务。我没有将其视为一种工艺,也不知道最佳实践。在 Airbnb,我学到了很多关于最佳实践的知识,并开始欣赏优秀的 ETL 以及它们的美妙。下面,我列出了一些好的 ETL 管道应遵循的原则,但并非详尽无遗:
-
分区数据表:如前所述,当处理大规模的长历史表时,数据分区特别有用。当数据使用日期戳进行分区时,我们可以利用动态分区来并行化回填。
-
增量加载数据:这一原则使你的 ETL 更加模块化和易于管理,特别是在从事实表构建维度表时。在每次运行中,我们只需将新事务追加到之前日期分区的维度表中,而不是扫描整个事实历史。
-
强制幂等性:许多数据科学家依赖时间点快照进行历史分析。这意味着随着时间的推移,基础源表不应被修改,否则我们将得到不同的结果。管道应构建成这样,即相同的查询在相同的业务逻辑和时间范围内运行时返回相同的结果。这一属性有一个 Fancy 名称叫做幂等性。
-
参数化工作流:就像模板极大地简化了 HTML 页面的组织一样,Jinja 可以与 SQL 结合使用。正如我们之前提到的,Jinja 模板的一个常见用法是将回填逻辑纳入典型的 Hive 查询中。Stitch Fix有一篇很好的文章总结了他们如何在 ETL 中使用这一技术。
-
尽早并频繁地添加数据检查:在处理数据时,将数据写入暂存表中,检查数据质量,然后再用最终生产表交换暂存表是很有用的。在 Airbnb,我们称之为stage-check-exchange范式。这个 3 步范式中的检查是重要的防御机制——它们可以是简单的检查,例如统计记录总数是否大于 0,或者复杂的异常检测系统,用于检查未见过的类别或异常值。
stage-check-exchange 操作的骨架(即数据管道的“单元测试”)
- 构建有用的警报和监控系统:由于 ETL 作业通常需要很长时间才能运行,因此添加警报和监控是很有用的,这样我们就不需要不断关注 DAG 的进度。不同的公司以多种创造性的方法来监控 DAG——在 Airbnb,我们经常使用 EmailOperators 发送缺失 SLA 的作业的警报邮件。其他团队则使用警报来标记实验失衡。还有一个有趣的例子来自 Zymergen,他们通过 SlackOperator 报告模型性能指标,如 R 平方。
这些原则很多灵感来自于与经验丰富的数据工程师的对话、我自己构建 Airflow DAGs 的经验,以及对 Gerard Toonstra 的ETL 最佳实践与 Airflow的阅读。对于感兴趣的读者,我强烈推荐 Maxime 的以下演讲:
来源:Airflow 的原创作者 Maxime 谈论 ETL 最佳实践
第二部分回顾
在这一系列的第二篇文章中,我们更详细地讨论了星型模式和数据建模。我们了解了事实表和维度表之间的区别,并看到了使用日期戳作为分区键的优势,尤其是在回填时。此外,我们剖析了 Airflow 作业的结构,并明确了 Airflow 中不同操作符的功能。我们还强调了构建 ETL 的最佳实践,并展示了 Airflow 作业在与 Jinja 和 SlackOperators 结合使用时的灵活性。可能性无穷无尽!
在系列的最后一篇文章中,我将讨论一些高级数据工程模式——具体来说,从构建管道到构建框架的过程。我将再次使用我们在 Airbnb 使用的一些示例框架作为激励示例。
如果你觉得这篇文章有用,请访问第一部分,并关注第三部分。
我想感谢Jason Goodman和 Michael Musson 对我的宝贵反馈
简介:Robert Chang 是 Airbnb 的一个数据科学家,专注于机器学习、机器学习基础设施和房东增长。在加入 Airbnb 之前,他曾是 Twitter 的数据科学家,并拥有斯坦福大学的统计学学位和加州大学伯克利分校的运筹学学位。
原文。经许可转载。
相关内容:
-
数据工程初学者指南——第一部分
-
对新手和初级数据科学家的建议
-
如何构建数据科学管道
更多相关话题
数据科学流程初学者指南
原文:
www.kdnuggets.com/2018/05/beginners-guide-data-science-pipeline.html
评论
Randy Lao,机器学习助教
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
“信不信由你,你和数据没有什么不同。把自己置于数据的角度,你会看到原因。”
从前有一个名叫数据的男孩。在他的生活中,他总是试图理解他的目的是什么。我有哪些价值? 我能对这个世界产生什么影响? 数据的来源是什么? 你和数据有任何相似之处吗?这些问题一直萦绕在他的脑海中,幸运的是,通过运气的眷顾,数据终于找到了一个解决方案,并经历了巨大的转变。
一切都始于数据在走过一排排时,发现了一个奇怪但有趣的管道。管道一端是入口,另一端是出口。管道上还标有五个不同的字母:“O.S.E.M.N.”。出于好奇,数据决定进入管道。长话短说…… 数据进去了,见解出来了。

提醒: 本文将简要介绍典型数据科学流程的高级概述。从框定业务问题到创建可操作的见解。别担心,这将是一次轻松的阅读!
数据科学是 OSEMN
你很棒。我很棒。数据科学是 OSEMN。你可能会问,为什么数据科学是“棒”的?好吧,作为一个有抱负的数据科学家,你有机会锻炼你作为巫师和侦探的能力。所谓巫师,是指拥有自动预测的能力!而侦探则是指发现数据中未知模式和趋势的能力!

了解数据科学流程的典型工作流程是商业理解和解决问题的重要步骤。如果你对数据科学流程感到困惑,那就别再担心了。本文正是为你准备的! 我找到一个非常简单的缩写,来自希拉里·梅森和克里斯·威金斯,你可以在整个数据科学流程中使用。那个缩写就是O.S.E.M.N.
OSEMN 流程
-
**O — **获取我们的数据
-
**S **— 清理/清洗我们的数据
-
**E — **探索/可视化我们的数据将帮助我们发现模式和趋势
-
**M — **建模我们的数据将赋予我们作为专家的预测能力
-
**N — **解读我们的数据
业务问题
因此,在我们开始OSEMN流程之前,我们必须首先考虑的是我们要解决的问题。再说一遍。在我们开始做“数据科学”之前,我们必须首先考虑我们要解决的问题。如果你有一个小问题要解决,那么你最多只能得到一个小解决方案。如果你有一个大问题要解决,那么你就有可能得到一个大解决方案。
问问自己:
-
我们如何将数据转化为美元?
-
我希望通过这些数据产生什么影响?
-
我们的模型为业务带来了什么价值?
-
什么能为我们节省大量资金?
-
我们可以做些什么来提高业务效率?
“给我钱!”

了解这个基本概念会让你走得更远,并在成为“数据科学家”之路上取得更大成功(这是我认为的…对不起我不是!)不过,这仍然是你必须做的重要一步!无论你的模型预测得多么准确,无论你获得了多少数据,无论你的流程有多么OSEMN…你的解决方案或可操作的见解仅仅取决于你设定的问题。
“优秀的数据科学更关乎你提出的数据问题,而不是数据清洗和分析” — 莱利·纽曼
获取你的数据
作为数据科学家,你无法在没有数据的情况下进行任何操作。通常来说,在获取数据时需要考虑一些因素。你必须识别所有可用的数据集(这些数据集可以来自互联网或外部/内部数据库)。你还必须将数据提取到可用格式(.csv、json、xml 等)。
所需技能:
-
数据库管理:MySQL, PostgresSQL, MongoDB
-
查询关系型数据库
-
检索非结构化数据:文本、视频、音频文件、文档
-
分布式存储:Hadoop、Apache Spark/Flink
数据的清理/清洗
清理第 5 列!这个阶段应该需要最多的时间和精力。 因为你的机器学习模型的结果和输出只与输入的数据质量相关。基本上,垃圾进垃圾出。

目标:
-
检查数据:理解你正在处理的每个特征,识别错误、缺失值和损坏记录
-
清理数据: 丢弃、替换和/或填补缺失值/错误
所需技能:
-
脚本语言: Python,R,SAS
-
数据处理工具: Python Pandas,R
-
分布式处理:Hadoop,Map Reduce / Spark
“准备好的人已经赢得了一半的战斗。”——米格尔·德·塞万提斯
探索(探索性数据分析)
现在在探索阶段,我们尝试理解数据中有哪些模式和值。我们将使用不同类型的可视化和统计测试来支持我们的发现。这是我们通过各种图表和分析来揭示数据背后的隐藏含义的地方。出去探索吧!
“停泊在港湾的船是安全的——但那不是船只建造的目的。”——约翰·A·谢德

目标:
-
通过可视化和图表在数据中查找模式
-
通过使用统计方法识别和测试重要变量来提取特征
所需技能:
-
Python: Numpy,Matplotlib,Pandas,Scipy
-
R: GGplot2,Dplyr
-
推论统计
-
实验设计
-
数据可视化
提示: 在进行分析时,让你的“蛛丝马迹”感知敏锐。要有发现奇怪模式或趋势的敏感性。时刻留意有趣的发现!
设计考虑: 大多数时候,人们直接进入可视化“让我们完成它”。一切都与最终用户有关,他们将解读这些内容。关注你的受众。
建模(机器学习)
现在进入有趣的部分。模型在统计学上是一般规则。把机器学习模型看作是工具箱中的工具。你将有机会使用许多算法来实现不同的业务目标。你使用的特征越好,你的预测能力就会越强。在清理数据并找出最重要的特征后,将模型作为预测工具使用,只会增强你的业务决策能力。
预测分析正逐渐成为变革者。它不仅仅是回顾分析“发生了什么?”,而是帮助高管回答“接下来会发生什么?”以及“我们应该怎么做?”(《福布斯杂志》,2010 年 4 月 1 日)

预测能力示例:一个很好的例子可以在沃尔玛的供应链中看到。沃尔玛能够预测在某个店铺位置在飓风季节期间会售罄所有的草莓口味的 Pop-tarts。通过数据挖掘,他们的历史数据表明,在飓风事件发生前,最受欢迎的商品是Pop-tarts。尽管听起来很疯狂,这是真实的故事,并强调了不要低估预测分析的力量。
目标:
-
深入分析:创建预测模型/算法
-
评估和完善模型
所需技能:
-
机器学习:监督/无监督算法
-
评估方法
-
机器学习库:Python(Sci-kit Learn)/ R(CARET)
-
线性代数与多变量微积分
“模型是嵌入数学中的观点” — 凯西·奥尼尔
解释(数据讲述)
讲故事时间到了!数据管道中最重要的步骤是理解并学习如何通过沟通解释你的发现。讲述故事是关键,不要低估它。这关乎于与人们建立联系、说服他们和帮助他们。理解你的观众并与他们建立联系是数据讲述的最佳部分之一。
“我相信讲故事的力量。故事让我们的心灵打开到一个新的地方,从而开启我们的思维,这通常会导致行动” — 梅琳达·盖茨
情感在数据讲述中扮演着重要角色。人们不会自动理解你的发现。产生影响的最佳方式是通过情感讲述你的故事。作为人类,我们天生受到情感的影响。如果你能触动你观众的情感,那么你,我的朋友,就是掌控者。在展示数据时,请记住心理学的力量。理解你的观众并与他们建立联系是数据讲述的最佳部分之一。
最佳实践:我强烈建议的一个好的实践是反复排练你的数据故事。如果你是家长,那么有好消息给你。与其在孩子睡前读那些典型的苏斯博士的书,不如尝试用你的数据分析结果让他们入睡!因为如果一个孩子能理解你的解释,那么任何人,尤其是你的老板,也都能理解!

“如果你不能向一个六岁孩子解释它,你自己也不理解它。” — 阿尔伯特·爱因斯坦
目标:
-
识别业务洞察:回到业务问题
-
根据你的发现进行可视化:保持简单并以优先级驱动
-
讲述清晰且可操作的故事:有效地与非技术观众沟通
所需技能:
-
业务领域知识
-
数据可视化工具:Tableau、D3.JS、Matplotlib、GGplot、Seaborn
-
沟通:展示/演讲 & 报告/写作
更新你的模型
不要担心你的故事不会在这里结束。随着你的模型投入生产,定期更新模型是很重要的,这取决于你收到新数据的频率。收到的数据越多,更新的频率就越高。假设你是 亚马逊,并且你引入了一个新的“鞋类特性”供客户购买。你的旧模型没有这个特性,因此你必须更新包含该特性的模型。如果不这样做,你的模型会随着时间的推移而退化,性能也会变差,从而导致你的业务也会退化。引入新特性会通过不同的变化或可能与其他特性的相关性改变模型的性能。
结论
总结:
-
确定你的业务问题
-
获取你的数据
获取你的数据,清理你的数据,用可视化探索你的数据,用不同的机器学习算法建模你的数据,通过评估解释你的数据,并更新你的模型。
记住,我们与数据并无不同。我们都有价值、目标,以及在这个世界上存在的理由。
你将面临的大多数问题实际上是工程问题。即使拥有伟大的机器学习大神的所有资源,大多数影响也将来自优秀的特性,而不是优秀的机器学习算法。所以,基本的方法是:
-
确保你的管道端到端都很稳固
-
从一个合理的目标开始
-
直观地理解你的数据
-
确保你的管道保持稳固
这种方法希望能带来大量的收入和/或让许多人长时间感到满意。
所以……下次有人问你什么是数据科学时,告诉他们:
“数据科学即 OSEMN”
希望大家今天学到了一些东西!如果你们想在这篇文章中添加任何内容,请随时留言,不要犹豫!任何形式的反馈都非常感谢。不要害怕分享!谢谢!
在 LinkedIn 上与我联系:
www.linkedin.com/in/randylaosat
简介:Randy Lao 是一名机器学习教学助理。如果机会不敲门,就自己造一扇门!
原文。经许可转载。
相关内容:
-
使用 Scikit-learn 管道管理机器学习工作流 第一部分:温和的介绍
-
命令行中的数据科学:探索数据
-
一小时内开始机器学习!
更多相关内容
Python 中的线性回归初学者指南,使用 Scikit-Learn
原文:
www.kdnuggets.com/2019/03/beginners-guide-linear-regression-python-scikit-learn.html
评论
监督学习算法有两种类型:回归和分类。前者预测连续值输出,而后者预测离散输出。例如,预测房价是一个回归问题,而预测肿瘤是恶性还是良性是一个分类问题。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
在本文中,我们将简要研究什么是线性回归,以及如何使用Scikit-Learn(这是 Python 中最受欢迎的机器学习库之一)来实现两个变量和多个变量的线性回归。
线性回归理论
在代数中,“线性”一词指的是两个或更多变量之间的线性关系。如果我们在二维空间(两个变量之间)绘制这种关系,我们会得到一条直线。
线性回归的任务是基于给定的自变量(x)预测因变量(y)的值。因此,这种回归技术找出 x(输入)和 y(输出)之间的线性关系。因此,称之为线性回归。如果我们将自变量(x)绘制在 x 轴上,将因变量(y)绘制在 y 轴上,线性回归将给我们一条最佳拟合数据点的直线,如下图所示。
我们知道直线的方程基本上是:
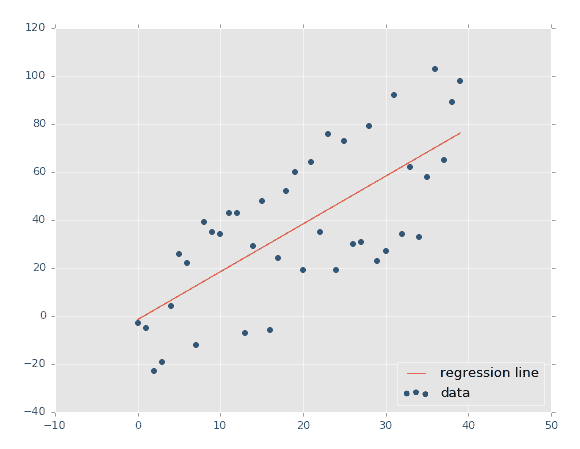
上述直线的方程是:
Y = mx + b
其中 b 是截距,m 是直线的斜率。所以基本上,线性回归算法给出的是截距和斜率(在二维中)的最优值。y 和 x 变量保持不变,因为它们是数据特征,不能改变。我们可以控制的值是截距(b)和斜率(m)。根据截距和斜率的不同,可以有多条直线。线性回归算法的基本原理是,它在数据点上拟合多条直线,并返回误差最小的那一条。
同样的概念可以扩展到变量多于两个的情况。这被称为多元线性回归。例如,考虑一个场景,你需要根据房子的面积、卧室数量、该地区居民的平均收入、房子的年龄等因素来预测房价。在这种情况下,因变量(目标变量)依赖于几个自变量。涉及多个变量的回归模型可以表示为:
y = b[0] + m[1]b[1] + m[2]b[2] + m[3]b[3] + ... m[n]b[n]
这是一个超平面的方程。请记住,在二维中,线性回归模型是直线;在三维中是平面,而在三维以上则是超平面。
在本节中,我们将学习如何使用 Python 的 Scikit-Learn 库来实现回归函数。我们将从涉及两个变量的简单线性回归开始,然后逐步过渡到涉及多个变量的线性回归。
简单线性回归
线性回归
在探索二战空袭行动数据集时,回忆起诺曼底登陆几乎因恶劣天气而被推迟,我下载了这些时期的天气报告,以便与轰炸行动数据集中的任务进行比较。
你可以从这里下载数据集。
数据集包含全球各个气象站记录的天气条件信息。信息包括降水量、降雪量、气温、风速,以及当天是否有雷暴或其他恶劣天气条件。
因此,我们的任务是以最低气温作为输入特征来预测最高气温。
让我们开始编码:
导入所有需要的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as seabornInstance
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
%matplotlib inline
以下命令使用 pandas 导入 CSV 数据集:
dataset = pd.read_csv('/Users/nageshsinghchauhan/Documents/projects/ML/ML_BLOG_LInearRegression/Weather.csv')
让我们通过检查数据集中的行数和列数来稍微探索一下数据。
dataset.shape
你应该会收到输出为 (119040, 31),这意味着数据包含 119040 行和 31 列。
要查看数据集的统计细节,我们可以使用 describe():
dataset.describe()
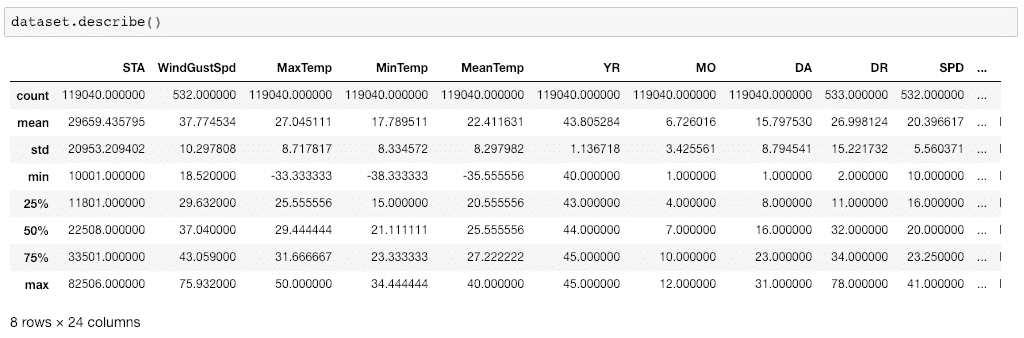
数据集的统计视图
最后,让我们将数据点绘制在二维图上,以直观地查看数据集,并查看我们是否可以手动找到数据之间的关系,使用以下脚本:
dataset.plot(x='MinTemp', y='MaxTemp', style='o')
plt.title('MinTemp vs MaxTemp')
plt.xlabel('MinTemp')
plt.ylabel('MaxTemp')
plt.show()
我们选择了 MinTemp 和 MaxTemp 进行分析。以下是 MinTemp 和 MaxTemp 之间的二维图。
我们来查看一下平均最高温度,一旦我们绘制出来,就可以观察到平均最高温度介于 25 到 35 之间。
plt.figure(figsize=(15,10))
plt.tight_layout()
seabornInstance.distplot(dataset['MaxTemp'])
平均最高温度介于 25 到 35 之间。
我们的下一步是将数据分为“属性”和“标签”。
属性是独立变量,而标签是依赖变量,其值需要预测。在我们的数据集中,我们只有两列。我们希望根据记录的最低温度(MinTemp)预测最高温度(MaxTemp)。因此,我们的属性集将包括存储在 X 变量中的“MinTemp”列,标签将是存储在 y 变量中的“MaxTemp”列。
X = dataset['MinTemp'].values.reshape(-1,1)
y = dataset['MaxTemp'].values.reshape(-1,1)
接下来,我们使用以下代码将 80%的数据分配给训练集,将 20%的数据分配给测试集。
test_size 变量是我们实际指定测试集比例的地方。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
在将数据分为训练集和测试集之后,最后是训练我们的算法。为此,我们需要导入 LinearRegression 类,实例化它,并调用fit()方法,使用我们的训练数据。
regressor = LinearRegression()
regressor.fit(X_train, y_train) #training the algorithm
正如我们讨论的那样,线性回归模型基本上找到截距和斜率的最佳值,从而得出最符合数据的直线。要查看线性回归算法为我们的数据集计算的截距和斜率值,请执行以下代码。
#To retrieve the intercept:
print(regressor.intercept_)
#For retrieving the slope:
print(regressor.coef_)
结果应分别为约 10.66185201 和 0.92033997。
这意味着最低温度每变化一个单位,最高温度的变化约为 0.92%。
现在我们已经训练了我们的算法,是时候做一些预测了。为此,我们将使用我们的测试数据,看看算法预测的百分比分数有多准确。要对测试数据进行预测,请执行以下脚本:
y_pred = regressor.predict(X_test)
现在将X_test的实际输出值与预测值进行比较,执行以下脚本:
df = pd.DataFrame({'Actual': y_test.flatten(), 'Predicted': y_pred.flatten()})
df
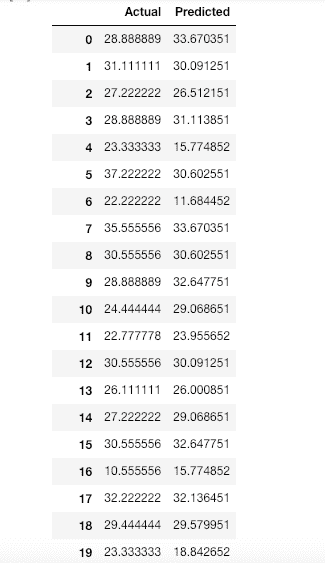
实际值与预测值的比较
我们还可以使用以下脚本将比较结果可视化为条形图:
注意:由于记录数量庞大,为了表示目的,我只取了 25 条记录。
df1 = df.head(25)
df1.plot(kind='bar',figsize=(16,10))
plt.grid(which='major', linestyle='-', linewidth='0.5', color='green')
plt.grid(which='minor', linestyle=':', linewidth='0.5', color='black')
plt.show()
显示实际值与预测值比较的条形图。
虽然我们的模型不是非常精确,但预测的百分比接近实际值。
让我们将直线与测试数据一起绘制:
plt.scatter(X_test, y_test, color='gray')
plt.plot(X_test, y_pred, color='red', linewidth=2)
plt.show()
预测与测试数据
上图中的直线显示我们的算法是正确的。
最后的步骤是评估算法的性能。这个步骤特别重要,用于比较不同算法在特定数据集上的表现。对于回归算法,通常使用三个评估指标:
1. 平均绝对误差(MAE)是绝对误差的均值。计算公式为:
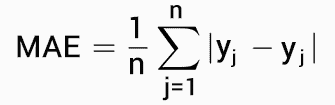
2. 均方误差(MSE)是平方误差的均值,计算公式为:
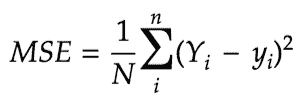
3. 均方根误差(RMSE)是平方误差均值的平方根:
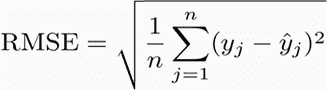
幸运的是,我们不需要手动执行这些计算。Scikit-Learn 库提供了预先构建的函数,可以用来为我们找出这些值。
让我们使用测试数据找到这些指标的值。
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
你应该会收到类似这样的输出(但可能会略有不同):
('Mean Absolute Error:', 3.19932917837853)
('Mean Squared Error:', 17.631568097568447)
('Root Mean Squared Error:', 4.198996082109204)
你可以看到均方根误差的值为 4.19,超过了所有温度百分比均值(即 22.41)的 10%。这意味着我们的算法并不是非常准确,但仍能做出相当不错的预测。
相关话题
Python 和 SciKit Learn 0.18 的神经网络初学者指南!
原文:
www.kdnuggets.com/2016/10/beginners-guide-neural-networks-python-scikit-learn.html/2
数据预处理
如果数据未归一化,神经网络可能在允许的最大迭代次数之前就无法收敛。多层感知器对特征缩放很敏感,因此强烈建议对数据进行缩放。请注意,必须对测试集应用相同的缩放,以获得有意义的结果。有很多不同的数据归一化方法,我们将使用内置的 StandardScaler 进行标准化。
py` StandardScaler(copy=True, with_mean=True, with_std=True) ```py ````
训练模型
现在是时候训练我们的模型了。SciKit Learn 使这一过程非常简单,通过使用估算器对象。在这个例子中,我们将从 SciKit-Learn 的 neural_network 库中导入我们的估算器(多层感知器分类器模型)!
接下来,我们创建模型的一个实例,这里有很多参数可以选择定义和自定义,我们只会定义 hidden_layer_sizes。对于这个参数,你需要传入一个元组,其中包含每一层所需的神经元数量,元组中的第 n 个条目表示 MLP 模型中第 n 层的神经元数量。选择这些数字有很多方法,但为了简单起见,我们将选择 3 层,每层的神经元数量与数据集中的特征数相同:
既然模型已经建立,我们可以将训练数据拟合到模型中,记住这些数据已经过处理和缩放:
py` MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9, beta_2=0.999, early_stopping=False, epsilon=1e-08, hidden_layer_sizes=(30, 30, 30), learning_rate='constant', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True, power_t=0.5, random_state=None, shuffle=True, solver='adam', tol=0.0001, validation_fraction=0.1, verbose=False, warm_start=False) ```py ````
你可以看到输出显示了模型中其他参数的默认值。我鼓励你尝试不同的参数值,发现它们对模型的影响!
预测与评估
现在我们有了一个模型,是时候使用它来获取预测了!我们可以通过对拟合模型调用 predict()方法来轻松完成这一任务:
现在我们可以使用 SciKit-Learn 内置的指标,如分类报告和混淆矩阵来评估我们的模型表现如何:
py`` [[50 3] [ 0 90]] py ```` py precision recall f1-score support 0 1.00 0.94 0.97 53 1 0.97 1.00 0.98 90 avg / total 0.98 0.98 0.98 143 py Looks like we only misclassified 3 tumors, leaving us with a 98% accuracy rate (as well as 98% precision and recall). This is pretty good considering how few lines of code we had to write! The downside however to using a Multi-Layer Preceptron model is how difficult it is to interpret the model itself. The weights and biases won't be easily interpretable in relation to which features are important to the model itself. However, if you do want to extract the MLP weights and biases after training your model, you use its public attributes coefs_ and intercepts_. **coefs_** is a list of weight matrices, where weight matrix at index i represents the weights between layer i and layer i+1. **intercepts_** is a list of bias vectors, where the vector at index i represents the bias values added to layer i+1. 4 30 30` ### Conclusion Hopefully you've enjoyed this brief discussion on Neural Networks! Try playing around with the number of hidden layers and neurons and see how they effect the results! Want to learn more? You can check out my Python for Data Science and Machine Learning on Udemy! Get it for 90% off at this link: www.udemy.com/python-for-data-science-and-machine-learning-bootcamp/?couponCode=KDNUGGETSPY  If you are looking for corporate in-person training, feel free to contact me at: training AT pieriandata.com Bio: Jose Portilla is a Data Science consultant and trainer who currently teaches online courses on Udemy. He also conducts training as the Head of Data Science for Pierian Data Inc. Related: * Deep Learning Key Terms, Explained * A Beginner’s Guide to Neural Networks with R! * Why Do Deep Learning Networks Scale? * * * ## Our Top 3 Course Recommendations 1. Google Cybersecurity Certificate - Get on the fast track to a career in cybersecurity. 2. Google Data Analytics Professional Certificate - Up your data analytics game 3. Google IT Support Professional Certificate - Support your organization in IT * * * ### More On This Topic * Stop Learning Data Science to Find Purpose and Find Purpose to… * What Makes Python An Ideal Programming Language For Startups * Three R Libraries Every Data Scientist Should Know (Even if You Use Python) * A $9B AI Failure, Examined * Top Resources for Learning Statistics for Data Science * The 5 Characteristics of a Successful Data Scientist `````
If you are looking for corporate in-person training, feel free to contact me at: training AT pieriandata.com Bio: Jose Portilla is a Data Science consultant and trainer who currently teaches online courses on Udemy. He also conducts training as the Head of Data Science for Pierian Data Inc. Related: * Deep Learning Key Terms, Explained * A Beginner’s Guide to Neural Networks with R! * Why Do Deep Learning Networks Scale? * * * ## Our Top 3 Course Recommendations 1. Google Cybersecurity Certificate - Get on the fast track to a career in cybersecurity. 2. Google Data Analytics Professional Certificate - Up your data analytics game 3. Google IT Support Professional Certificate - Support your organization in IT * * * ### More On This Topic * Stop Learning Data Science to Find Purpose and Find Purpose to… * What Makes Python An Ideal Programming Language For Startups * Three R Libraries Every Data Scientist Should Know (Even if You Use Python) * A $9B AI Failure, Examined * Top Resources for Learning Statistics for Data Science * The 5 Characteristics of a Successful Data Scientist `````
机器学习的三种类型入门指南
原文:
www.kdnuggets.com/2019/11/beginners-guide-three-types-machine-learning.html
评论
作者:Rebecca Vickery,数据科学家
使用Yellowbrick可视化 KMeans 性能
机器学习问题通常可以分为三种类型。分类和回归被称为监督学习,无监督学习在机器学习应用的上下文中通常指的是聚类。
在接下来的文章中,我将简要介绍这三种问题,并将包括在流行的 Python 库scikit-learn中的演示。
在开始之前,我将简要解释监督学习和无监督学习的含义。
监督学习: 在监督学习中,你有一组已知的输入(特征)和一组已知的输出(标签)。传统上这些被称为 X 和 y。算法的目标是学习将输入映射到输出的映射函数。这样,当给出新的 X 示例时,机器可以正确预测相应的 y 标签。
无监督学习: 在无监督学习中,你只有一组输入(X),没有对应的标签(y)。算法的目标是发现数据中之前未知的模式。这些算法通常用于发现相似样本 X 的有意义的簇,从而在数据中找到固有的类别。
分类
在分类中,输出(y)是类别。这些类别可以是二元的,例如,如果我们将垃圾邮件与非垃圾邮件进行分类。它们也可以是多个类别,比如对花卉的分类,这被称为多类分类。
让我们通过一个使用 scikit-learn 的简单分类示例来演示。如果你还没有安装,可以通过 pip 或 conda 进行安装,安装方法详见这里。
Scikit-learn 有多个可以通过库直接访问的数据集。为了方便起见,在本文中我将使用这些示例数据集。为了说明分类,我将使用葡萄酒数据集,这是一个多类分类问题。在数据集中,输入(X)包括与每种葡萄酒类型相关的 13 个特征。已知的输出(y)是葡萄酒类型,在数据集中被赋予了数字 0、1 或 2。
我在本文中使用的所有代码的导入如下所示。
import pandas as pd
import numpy as npfrom sklearn.datasets import load_wine
from sklearn.datasets import load_bostonfrom sklearn.model_selection import train_test_split
from sklearn import preprocessingfrom sklearn.metrics import f1_score
from sklearn.metrics import mean_squared_error
from math import sqrtfrom sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn import linear_model
from sklearn.linear_model import ElasticNetCV
from sklearn.svm import SVRfrom sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
from yellowbrick.cluster import SilhouetteVisualizer
在下面的代码中,我正在下载数据并转换为 pandas 数据框。
wine = load_wine()
wine_df = pd.DataFrame(wine.data, columns=wine.feature_names)
wine_df['TARGET'] = pd.Series(wine.target)
监督学习问题的下一阶段是将数据拆分为测试集和训练集。训练集可以被算法用来学习输入和输出之间的映射,然后保留的测试集可以用来评估模型学习这个映射的效果。在下面的代码中,我使用了 scikit-learn 的 model_selection 函数 train_test_split 来完成这一任务。
X_w = wine_df.drop(['TARGET'], axis=1)
y_w = wine_df['TARGET']
X_train_w, X_test_w, y_train_w, y_test_w = train_test_split(X_w, y_w, test_size=0.2)
在下一步中,我们需要选择最适合学习你所选数据集映射的算法。在 scikit-learn 中,有许多不同的算法可以选择,这些算法使用不同的函数和方法来学习映射,你可以在 这里 查看完整列表。
为了确定最佳模型,我运行了以下代码。我使用一组选定的算法训练模型,并为每个算法获取 F1 分数。F1 分数是分类器总体准确性的良好指标。我已经详细描述了用于评估分类器的各种度量标准 这里。
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="rbf", C=0.025, probability=True),
NuSVC(probability=True),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GradientBoostingClassifier()
]
for classifier in classifiers:
model = classifier
model.fit(X_train_w, y_train_w)
y_pred_w = model.predict(X_test_w)
print(classifier)
print("model score: %.3f" % f1_score(y_test_w, y_pred_w, average='weighted'))

完美的 F1 分数是 1.0,因此,数值越接近 1.0,模型性能越好。以上结果表明,随机森林分类器是这个数据集的最佳模型。
回归
在回归中,输出(y)是连续值而不是类别。回归的一个例子是预测商店下个月的销售额,或预测你房子的未来价格。
为了说明回归,我将使用一个来自 scikit-learn 的数据集,即波士顿房价数据集。该数据集包含 13 个特征(X),这些特征是房子的各种属性,例如房间数量、房龄和位置的犯罪率。输出(y)是房价。
我正在使用下面的代码加载数据,并使用与我对葡萄酒数据集相同的方法将其拆分为测试集和训练集。
boston = load_boston()
boston_df = pd.DataFrame(boston.data, columns=boston.feature_names)
boston_df['TARGET'] = pd.Series(boston.target)X_b = boston_df.drop(['TARGET'], axis=1)
y_b = boston_df['TARGET']
X_train_b, X_test_b, y_train_b, y_test_b = train_test_split(X_b, y_b, test_size=0.2)
我们可以使用这个 备忘单 查看适用于回归问题的 scikit-learn 可用算法。我们将使用类似的代码来处理分类问题,遍历选择并打印出每个算法的得分。
有多种不同的度量标准用于评估回归模型。这些本质上都是误差度量,衡量模型预测值与实际值之间的差异。我使用了均方根误差(RMSE)。对于这个度量标准,数值越接近零,模型的性能越好。这个 文章 对回归问题的误差度量进行了很好的解释。
regressors = [
linear_model.Lasso(alpha=0.1),
linear_model.LinearRegression(),
ElasticNetCV(alphas=None, copy_X=True, cv=5, eps=0.001, fit_intercept=True,
l1_ratio=0.5, max_iter=1000, n_alphas=100, n_jobs=None,
normalize=False, positive=False, precompute='auto', random_state=0,
selection='cyclic', tol=0.0001, verbose=0),
SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1,
gamma='auto_deprecated', kernel='rbf', max_iter=-1, shrinking=True,
tol=0.001, verbose=False),
linear_model.Ridge(alpha=.5)
]for regressor in regressors:
model = regressor
model.fit(X_train_b, y_train_b)
y_pred_b = model.predict(X_test_b)
print(regressor)
print("mean squared error: %.3f" % sqrt(mean_squared_error(y_test_b, y_pred_b)))

RMSE 分数表明线性回归和岭回归算法在这个数据集中表现最好。
无监督学习
无监督学习有许多不同类型,但为了简化,这里我将重点关注聚类方法。有许多不同的聚类算法,它们使用略微不同的技术来寻找输入的簇。
可能最广泛使用的方法之一是 K 均值(Kmeans)。该算法执行一个迭代过程,其中启动了指定数量的随机生成的均值。计算每个数据点到质心的距离度量,欧几里得距离,从而创建相似值的簇。每个簇的质心随后成为新的均值,这个过程会重复进行,直到达到最佳结果。
让我们使用我们在分类任务中使用的葡萄酒数据集,去掉 y 标签,看看 K 均值算法能多好地从输入中识别出葡萄酒类型。
由于我们仅使用输入来建立此模型,我将使用稍微不同的方法将数据拆分为测试集和训练集。
np.random.seed(0)
msk = np.random.rand(len(X_w)) < 0.8
train_w = X_w[msk]
test_w = X_w[~msk]
由于 K 均值依赖于距离度量来确定簇,因此通常在训练模型之前需要进行特征缩放(确保所有特征具有相同的尺度)。在下面的代码中,我使用 MinMaxScaler 对特征进行缩放,使所有值落在 0 和 1 之间。
x = train_w.values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x)
X_scaled = pd.DataFrame(x_scaled,columns=train_w.columns)
使用 K 均值时,你必须指定算法应使用的簇数量。因此,第一步之一是确定最佳簇数量。这是通过迭代不同的 k 值并将结果绘制在图表上来实现的。这被称为肘部法则,因为它通常生成一个看起来有点像肘部曲线的图。黄砖(yellowbrick)库(这是一个非常适合可视化 scikit-learn 模型的库,可以通过 pip 安装)对此有一个非常好的图。下面的代码生成了这个可视化。
model = KMeans()
visualizer = KElbowVisualizer(model, k=(1,8))
visualizer.fit(X_scaled)
visualizer.show()
通常,我们不会知道数据集中使用聚类技术时有多少类别。然而,在这种情况下,我们知道数据中有三种葡萄酒类型——曲线正确地选择了三作为模型中使用的最佳簇数量。
下一步是初始化 K 均值算法,并将模型拟合到训练数据中,并评估算法对数据的聚类效果。
一种用于此的办法称为 轮廓系数。它衡量集群内部值的一致性。换句话说,它测量每个集群内的值彼此有多相似,以及集群之间的分离程度。轮廓系数是对每个值进行计算的,范围从 -1 到 +1。这些值然后被绘制成轮廓图。再次,yellowbrick 提供了一种简单的方式来构建这种图。下面的代码为酒类数据集创建了这个可视化。
model = KMeans(3, random_state=42)
visualizer = SilhouetteVisualizer(model, colors='yellowbrick')visualizer.fit(X_scaled)
visualizer.show()
轮廓图可以按以下方式解读:
-
平均分数(上图中的红色虚线)越接近 +1,数据点在集群内的匹配度越好。
-
分数为 0 的数据点非常接近另一个集群的决策边界(因此分离度较低)。
-
负值表示数据点可能被分配到了错误的集群。
-
如果每个集群的宽度不均匀,那么可能使用了错误的 k 值。
上面的酒类数据集的图表显示,集群 0 可能不如其他集群一致,因为大多数数据点低于平均分,而且有少数数据点的分数低于 0。
轮廓系数在比较一个算法与另一个算法或不同的 k 值时特别有用。
在这篇文章中,我想简要介绍三种机器学习类型。所有这些过程都涉及许多其他步骤,包括特征工程、数据处理和超参数优化,以确定最佳的数据预处理技术和模型。
感谢阅读!
简介:Rebecca Vickery 通过自学数据科学。数据科学家 @ Holiday Extras。alGo 的联合创始人。
原文。经授权转载。
相关:
-
机器学习分类:基于数据集的图解
-
可解释的机器学习的 Python 库
-
数据科学的五个命令行工具
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
更多相关话题
初学者构建 LLM 应用的指南
原文:
www.kdnuggets.com/beginners-guide-to-building-llm-apps-with-python

图片来源:编辑 | Midjourney & Canva
罗宾·夏尔马说过,“每一个大师曾经都是初学者。每一个专家曾经都是业余爱好者。” 你可能已经听说过大型语言模型(LLMs)、人工智能(AI)和变换器模型(GPT)在 AI 领域掀起的波澜,并且你对如何入门感到困惑。我可以向你保证,今天你看到的每一个正在构建复杂应用程序的人曾经也经历过这种阶段。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
这就是为什么在本文中,你将获得开始使用 Python 编程语言构建 LLM 应用所需的知识。这篇文章完全适合初学者,你可以一边阅读一边进行编码。
你将在本文中构建什么?你将创建一个简单的 AI 个人助手,根据用户的提示生成回应,并将其部署以便全球访问。下面的图片展示了完成后的应用程序的样子。
这张图片展示了本文将构建的 AI 个人助手的用户界面
先决条件
为了跟随本文,你需要具备几个条件。这包括:
-
Python (3.5+),以及编写 Python 脚本的背景。
-
OpenAI: OpenAI 是一个研究组织和技术公司,致力于确保人工通用智能(AGI)造福全人类。它的一个重要贡献是开发了先进的 LLM,例如 GPT-3 和 GPT-4。这些模型能够理解和生成类人文本,使其成为各种应用的强大工具,如聊天机器人、内容创作等。
注册 OpenAI,并从你的账户 API 部分复制你的 API 密钥,以便你可以访问模型。使用下面的命令在你的计算机上安装 OpenAI:
pip install openai
- LangChain: LangChain 是一个框架,旨在简化利用 LLM 的应用程序开发。它提供了管理和简化处理 LLM 各个方面的工具和实用程序,使得构建复杂且强大的应用程序变得更容易。
使用下面的命令在你的计算机上安装 LangChain:
pip install langchain
-
Streamlit: Streamlit 是一个强大且易于使用的 Python 库,用于创建 Web 应用程序。Streamlit 允许你仅使用 Python 创建交互式 Web 应用程序。你不需要具备 Web 开发(HTML、CSS、JavaScript)方面的专业知识,就能构建功能齐全且视觉吸引人的 Web 应用。
这对于构建机器学习和数据科学应用程序很有益,包括那些利用 LLM 的应用程序。使用下面的命令在你的计算机上安装 Streamlit:
pip install streamlit
代码演示
安装所有必需的包和库后,是时候开始构建 LLM 应用程序了。在你的工作目录的根目录中创建一个 requirement.txt 文件,并保存依赖项。
streamlit
openai
langchain
创建一个 app.py 文件,并添加下面的代码。
# Importing the necessary modules from the Streamlit and LangChain packages
import streamlit as st
from langchain.llms import OpenAI
-
导入 Streamlit 库,该库用于创建交互式 Web 应用程序。
-
from langchain.llms import OpenAI从langchain.llms模块中导入 OpenAI 类,该类用于与 OpenAI 的语言模型进行交互。
# Setting the title of the Streamlit application
st.title('Simple LLM-App 🤖')
st.title('Simple LLM-App 🤖')设置 Streamlit Web 的标题。
# Creating a sidebar input widget for the OpenAI API key, input type is password for security
openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')
openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')在侧边栏创建一个文本输入小部件,供用户输入其 OpenAI API 密钥。输入类型设置为 'password' 以隐藏输入的文本以提高安全性。
# Defining a function to generate a response using the OpenAI language model
def generate_response(input_text):
# Initializing the OpenAI language model with a specified temperature and API key
llm = OpenAI(temperature=0.7, openai_api_key=openai_api_key)
# Displaying the generated response as an informational message in the Streamlit app
st.info(llm(input_text))
-
def generate_response(input_text)定义一个名为generate_response的函数,该函数以input_text作为参数。 -
llm = OpenAI(temperature=0.7, openai_api_key=openai_api_key)使用温度设置 0.7 和提供的 API 密钥初始化 OpenAI 类。
Temperature 是一个参数,用于控制语言模型生成文本的随机性或创造力。它决定了模型在预测中引入的变异程度。
-
低温度 (0.0 - 0.5): 使模型更具确定性和专注性。
-
中等温度 (0.5 - 1.0): 在随机性和确定性之间提供平衡。
-
高温度 (1.0 及以上): 增加输出的随机性。较高的值使模型在响应中更具创造性和多样性,但也可能导致输出不连贯,产生更多无意义或离题的内容。
-
st.info(llm(input_text))调用语言模型并用提供的input_text生成响应,然后将其作为信息消息显示在 Streamlit 应用中。
# Creating a form in the Streamlit app for user input
with st.form('my_form'):
# Adding a text area for user input
text = st.text_area('Enter text:', '')
# Adding a submit button for the form
submitted = st.form_submit_button('Submit')
# Displaying a warning if the entered API key does not start with 'sk-'
if not openai_api_key.startswith('sk-'):
st.warning('Please enter your OpenAI API key!', icon='⚠')
# If the form is submitted and the API key is valid, generate a response
if submitted and openai_api_key.startswith('sk-'):
generate_response(text)
-
with st.form('my_form')创建一个名为my_form的表单容器。 -
text = st.text_area('Enter text:', '')在表单中添加一个文本区域输入小部件,供用户输入文本。 -
submitted = st.form_submit_button('Submit')向表单添加一个提交按钮。 -
if not openai_api_key.startswith('sk-') 检查输入的 API 密钥是否不以 sk- 开头。
-
st.warning('Please enter your OpenAI API key!', icon='⚠')如果 API 密钥无效,则显示警告消息。 -
if submitted and openai_api_key.startswith('sk-')检查表单是否已提交以及 API 密钥是否有效。
-
generate_response(text)调用generate_response函数,使用输入的文本生成并显示响应。
综合起来,你现在拥有的是:
# Importing the necessary modules from the Streamlit and LangChain packages
import streamlit as st
from langchain.llms import OpenAI
# Setting the title of the Streamlit application
st.title('Simple LLM-App 🤖')
# Creating a sidebar input widget for the OpenAI API key, input type is password for security
openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')
# Defining a function to generate a response using the OpenAI model
def generate_response(input_text):
# Initializing the OpenAI model with a specified temperature and API key
llm = OpenAI(temperature=0.7, openai_api_key=openai_api_key)
# Displaying the generated response as an informational message in the Streamlit app
st.info(llm(input_text))
# Creating a form in the Streamlit app for user input
with st.form('my_form'):
# Adding a text area for user input with a default prompt
text = st.text_area('Enter text:', '')
# Adding a submit button for the form
submitted = st.form_submit_button('Submit')
# Displaying a warning if the entered API key does not start with 'sk-'
if not openai_api_key.startswith('sk-'):
st.warning('Please enter your OpenAI API key!', icon='⚠')
# If the form is submitted and the API key is valid, generate a response
if submitted and openai_api_key.startswith('sk-'):
generate_response(text)
运行应用程序
应用程序已准备好;你需要使用适合你所用框架的命令来执行应用程序脚本。
streamlit run app.py
通过运行此代码streamlit run app.py,你可以创建一个交互式 Web 应用程序,用户可以输入提示并接收 LLM 生成的文本响应。
当你执行streamlit run app.py时,以下情况会发生:
-
Streamlit 服务器启动:Streamlit 在你的机器上启动一个本地网络服务器,通常默认情况下可以通过
http://localhost:8501访问。 -
代码执行:Streamlit 读取并执行
app.py中的代码,根据脚本定义渲染应用程序。 -
Web 界面:你的 Web 浏览器会自动打开(或者你可以手动导航)到 Streamlit 提供的 URL(通常是http://localhost:8501),你可以在这里与 LLM 应用程序进行交互。
部署你的 LLM 应用程序
部署 LLM 应用程序意味着使其通过互联网可访问,以便其他人可以使用和测试,而无需访问你的本地计算机。这对协作、用户反馈和现实世界的测试很重要,确保应用程序在不同环境中表现良好。
要将应用程序部署到 Streamlit Cloud,请按照以下步骤操作:
-
为你的应用程序创建一个 GitHub 仓库。确保你的仓库包括两个文件:app.py 和 requirements.txt
-
访问 Streamlit Community Cloud,点击工作区中的“新应用”按钮,指定仓库、分支和主文件路径。
-
点击部署按钮,你的 LLM 应用程序将被部署到 Streamlit Community Cloud,并可以全球访问。
结论
恭喜!你已迈出构建和部署 Python LLM 应用程序的第一步。从了解前提条件、安装必要的库到编写核心应用程序代码,你现在已经创建了一个功能齐全的 AI 个人助手。通过使用 Streamlit,你使应用程序具有交互性和易用性,并通过将其部署到 Streamlit Community Cloud,你使其对全球用户可访问。
利用你在本指南中学到的技能,你可以进一步深入探讨 LLMs 和 AI,探索更高级的功能,并构建更复杂的应用。不断实验、学习,并与社区分享你的知识。LLMs 的可能性巨大,你的旅程才刚刚开始。编码愉快!
Shittu Olumide是一位软件工程师和技术作家,热衷于利用前沿技术编写引人入胜的叙述,具有敏锐的细节观察力和简化复杂概念的能力。你还可以在Twitter上找到 Shittu。
相关话题
AI 和机器学习职业入门指南
原文:
www.kdnuggets.com/beginners-guide-to-careers-in-ai-and-machine-learning

图片由作者提供
我们的前三大课程推荐
1. Google 网络安全证书 – 快速进入网络安全职业道路。
2. Google 数据分析专业证书 – 提升你的数据分析能力
3. Google IT 支持专业证书 – 支持你所在组织的 IT 工作
人工智能(AI)和机器学习(ML)的广泛发展迫使就业市场进行调整。AI 和 ML 通才的时代已经结束,我们进入了专家时代。
即使是更有经验的人也可能难以找到合适的方向,更不用说初学者了。
这就是我创建这个小指南来帮助理解不同 AI 和 ML 职位的原因。
什么是 AI 和 ML?
AI 是计算机科学的一个领域,旨在创建表现出类似人类智能的计算机系统。
ML 是 AI 的一个子领域,使用算法来构建和部署可以从数据中学习并在没有明确指令的情况下做出决策的模型。
AI 和 ML 的职位
AI 和 ML 的复杂性及其各种目的导致了各种工作对它们的不同应用。
这里是我将要讨论的十个职位。

尽管它们都需要 AI 和 ML,虽然技能和工具有时会重叠,但每个职位都需要 AI 和 ML 专业知识的某些独特方面。
这里是这些差异的概述。
1. AI 工程师
这个角色专注于开发、实施、测试和维护 AI 系统。
技术技能
核心 AI 工程师技能围绕构建 AI 模型,因此编程语言和 ML 技术至关重要。
工具
主要使用的工具包括 Python 库、大数据工具和数据库。
-
TensorFlow、PyTorch——使用动态图和静态图计算创建神经网络和 ML 应用
-
scikit-learn、Keras——实现监督和无监督 ML 算法并构建模型,包括深度学习模型
-
SQL(例如,PostgreSQL、MySQL、SQL Server、Oracle)、NoSQL 数据库,如 MongoDB(用于文档导向数据,例如,JSON 类似文档)和 Cassandra(列族数据模型,适用于时间序列数据)——存储和管理结构化及非结构化数据
项目
AI 工程师致力于自动化项目和 AI 系统,如:
-
自动驾驶车辆
-
虚拟助手
-
医疗机器人
-
生产线机器人
-
智能家居系统
面试问题类型
面试问题反映了所需技能,因此预计会涉及以下主题:
2. ML 工程师
ML 工程师开发、部署和维护 ML 模型。他们的重点是部署和生产环境中的模型调优。
技术技能
除了机器学习的常规技能,ML 工程师的主要技能还有软件工程和高级数学。
-
高级数学与统计 – 理解数据、构建算法、ML 模型优化和 评估
-
ML 算法 – 与 AI 工程师相同
工具
ML 工程师的工具与 AI 工程师的工具类似。
-
TensorFlow、PyTorch – 开发、训练和部署 ML 和 深度学习模型
-
Jupyter Notebooks – 互动编码、数据可视化、文档编写
-
Docker、Kubernetes – ML 应用的容器化 和管理
-
SQL 和 NoSQL 数据库 – 与 AI 工程师相同
项目
ML 工程师的知识应用于这些项目:
面试问题类型
ML 是每个 ML 工程师工作中的核心,因此也是面试的重点。
-
ML 算法
-
编程问题
-
数据处理 – 准备数据进行建模的基础
-
模型评估 – 模型评估技术和指标,包括准确率、精确度、召回率、F1 分数和 ROC 曲线
-
问题解决问题
3. 数据科学家
数据科学家收集和清洗数据,进行探索性数据分析(EDA)以更好地理解数据。他们创建统计模型、机器学习算法和可视化,以了解数据中的模式并做出预测。
与 ML 工程师不同,数据科学家更涉及机器学习模型的初始阶段;他们专注于发现数据模式并从中提取洞察。
技术技能
数据科学家使用的技能集中在提供可操作的洞察。
工具
-
TensorFlow,scikit-learn,Keras,PyTorch – 开发、训练、部署 ML 和 DL 模型
-
Jupyter Notebooks – 交互式编码、数据可视化、文档编制
-
SQL 和 NoSQL 数据库 – 与 ML 工程师相同
项目
数据科学家从事与 ML 工程师相同的项目,只是在部署前阶段。
面试问题类型
4. 数据工程师
他们开发和维护数据处理系统,并构建数据管道以确保数据的可用性。机器学习不是他们的核心工作。然而,他们与 ML 工程师和数据科学家合作,以确保 ML 模型的数据可用性,因此必须了解 ML 基础。此外,他们有时会将 ML 算法集成到数据管道中,例如用于数据分类或异常检测。
技术技能
-
编程语言 (Python, Scala, Java, Bash) – 数据处理、大数据处理、脚本编写、自动化、构建 数据管道、管理系统进程和文件
-
数据仓库 – 集成数据存储
-
ETL(提取、转换、加载)流程 – 构建 ETL 管道
-
数据库管理 – 数据存储、安全性和可用性
-
ML – 用于 ML 驱动的数据管道
工具
-
SQL 和 NoSQL 数据库 – 与数据科学家相同
-
Informatica, Talend – 数据集成、ETL 和数据管理
-
AWS, Google Cloud Platform – 云计算
项目
数据工程师从事使数据对其他角色可用的项目。
-
构建 ETL 管道
-
构建数据流系统
-
协助部署 ML 模型
面试问题类型
数据工程师必须展示对数据架构和基础设施的知识。
5. AI 研究科学家
这些科学家进行研究,专注于开发新算法和 AI 原理。
技术技能
-
研究方法论 – 实验设计、假设制定与测试、结果分析
-
高级 ML – 开发和完善算法
-
NLP – 提升 NLP 系统的能力
-
DL – 提升 DL 系统的能力
工具
-
TensorFlow,PyTorch – 开发、训练和部署机器学习和深度学习模型
-
Jupyter Notebooks – 互动编码、数据可视化和记录研究工作流程
-
LaTeX – 科学写作
项目
他们负责创建和改进用于:
面试问题类型
人工智能研究科学家必须展示实际的以及非常强的理论人工智能和机器学习知识。
-
人工智能与机器学习的理论基础
-
人工智能的实际应用
-
机器学习算法 – 各种机器学习算法的理论与应用
-
方法论基础
6. 商业智能分析师
BI 分析师分析数据,揭示可操作的见解,并通过数据可视化、报告和仪表板向利益相关者展示。商业智能中的人工智能通常用于自动化数据处理、识别数据中的趋势和模式,以及预测分析。
技术技能
-
编程语言(Python) – 数据查询、处理、分析、报告、可视化
-
数据分析 – 提供可操作的见解以支持决策
-
商业分析 – 识别机会和优化业务流程
-
数据可视化 – 以视觉方式呈现见解
-
机器学习 – 预测分析、异常检测、增强的数据见解
工具
-
Excel – 数据处理、分析和可视化
-
SQL 和 NoSQL 数据库 – 与数据工程师相同
项目
他们所从事的项目集中于分析和报告:
-
流失分析
-
销售分析
-
成本分析
-
客户细分
-
流程改进,例如库存管理
面试问题类型
BI 分析师的面试问题侧重于编码和数据分析技能。
-
编码问题
-
数据和数据库基础
-
数据分析基础
-
问题解决问题
结论
AI 和 ML 是广泛且不断发展的领域。随着它们的发展,要求 AI 和 ML 技能的职位也在不断变化。几乎每天都有新的职位描述和专业化,反映出企业对利用 AI 和 ML 潜力的需求不断增长。
我讨论了六个你可能最感兴趣的职位。然而,这些并不是唯一的 AI 和 ML 职位。还有很多其他职位,并且这些职位会不断涌现,所以尽量保持更新。
Nate Rosidi 是一位数据科学家,专注于产品策略。他也是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。Nate 撰写关于职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
更多相关主题
Pyjanitor 数据清理初学者指南
原文:
www.kdnuggets.com/beginners-guide-to-data-cleaning-with-pyjanitor

图片由作者提供 | DALLE-3 & Canva
你是否曾处理过混乱的数据集?它们是任何数据科学项目中最大的障碍之一。这些数据集可能包含不一致、缺失值或不规则性,妨碍分析。数据清理是打下准确可靠洞察基础的必要第一步,但它既漫长又耗时。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加入网络安全职业的快速通道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 支持
不用担心!让我向你介绍 Pyjanitor,一个可以拯救你的出色 Python 库。它是一个方便的 Python 包,提供了一个简单的解决方案来应对这些数据清理挑战。在这篇文章中,我将讨论 Pyjanitor 的重要性以及它的功能和实际使用。
在本文结束时,你将清楚了解 Pyjanitor 如何简化数据清理及其在日常数据相关任务中的应用。
什么是 Pyjanitor?
Pyjanitor 是一个扩展的 R 包,基于 pandas 构建,简化了数据清理和预处理任务。它通过提供各种有用的功能来扩展其功能,优化数据清理、转换和准备的过程。可以把它看作是你数据清理工具包的升级版。你是否迫不及待想了解 Pyjanitor 了?我也是。让我们开始吧。
入门指南
首先,你需要安装 Pyjanitor。打开你的终端或命令提示符并运行以下命令:
pip install pyjanitor
下一步是将 Pyjanitor 和 Pandas 导入你的 Python 脚本。可以通过以下方式完成:
import janitor
import pandas as pd
现在,你已经准备好使用 Pyjanitor 进行数据清理任务。接下来,我将介绍 Pyjanitor 一些最有用的功能,包括:
1. 清理列名称
举手如果你曾因列名称不一致而感到沮丧。没错,我也是。使用 Pyjanitor 的 clean_names() 函数,你可以迅速标准化列名称,使其统一且一致,只需简单调用即可。这个强大的函数将空格替换为下划线,将所有字符转换为小写,去除前后空格,甚至将点替换为下划线。让我们通过一个基本的例子来理解它。
#Create a data frame with inconsistent column names
student_df = pd.DataFrame({
'Student.ID': [1, 2, 3],
'Student Name': ['Sara', 'Hanna', 'Mathew'],
'Student Gender': ['Female', 'Female', 'Male'],
'Course': ['Algebra', 'Data Science', 'Geometry'],
'Grade': ['A', 'B', 'C']
})
#Clean the column names
clean_df = student_df.clean_names()
print(clean_df)
输出:
student_id student_name student_gender course grade
0 1 Sara Female Algebra A
1 2 Hanna Female Data Science B
2 3 Mathew Male Geometry C
2. 重命名列
有时,重命名列不仅能提升我们对数据的理解,还能改善数据的可读性和一致性。感谢 rename_column() 函数,这项任务变得轻而易举。一个展示该函数实用性的简单例子如下:
student_df = pd.DataFrame({
'stu_id': [1, 2],
'stu_name': ['Ryan', 'James'],
})
# Renaming the columns
student_df = student_df.rename_column('stu_id', 'Student_ID')
student_df =student_df.rename_column('stu_name', 'Student_Name')
print(student_df.columns)
输出:
Index(['Student_ID', 'Student_Name'], dtype='object')
3. 处理缺失值
处理缺失值确实是处理数据集时的一个难题。幸运的是,fill_empty() 函数可以用来解决这些问题。让我们通过一个实际例子来探索如何使用 Pyjanitor 处理缺失值。首先,我们将创建一个虚拟数据框,并填充一些缺失值。
# Create a data frame with missing values
employee_df = pd.DataFrame({
'employee_id': [1, 2, 3],
'name': [None, 'James', 'Alicia'],
'department': ['HR', None, 'Engineering'],
'salary': [60000, 55000, None]
})
现在,让我们看看 Pyjanitor 如何帮助填补这些缺失值:
# Fill missing values in 'department' and 'name' with 'Unknown' and 'salary' with the mean salary
employee_df = employee_df.fill_empty(column_names=['name', 'department'], value='Unknown')
employee_df = employee_df.fill_empty(column_names='salary', value=employee_df['salary'].mean())
print(employee_df)
输出:
employee_id name department salary
0 1 Unknown HR 60000.0
1 2 James Unknown 55000.0
2 3 Alicia Engineering 57500.0
在这个例子中,员工‘詹姆斯’的部门被替换为‘未知’,‘艾莉西亚’的工资则被替换为‘未知’和‘詹姆斯’工资的平均值。你可以使用各种策略来处理缺失值,如前向填充、后向填充或填入特定值。
4. 过滤行和选择列
过滤行和列是数据分析中的一个关键任务。Pyjanitor 通过提供允许你根据特定条件选择列和过滤行的函数,简化了这一过程。假设你有一个包含学生记录的数据框,你想要过滤出成绩低于 60 分的学生(行)。让我们探索 Pyjanitor 如何帮助实现这一点。
# Create a data frame with student data
students_df = pd.DataFrame({
'student_id': [1, 2, 3, 4, 5],
'name': ['John', 'Julia', 'Ali', 'Sara', 'Sam'],
'subject': ['Maths', 'General Science', 'English', 'History','Biology'],
'marks': [85, 58, 92, 45, 75],
'grade': ['A', 'C', 'A+', 'D', 'B']
})
# Filter rows where marks are less than 60
filtered_students_df = students_df.query('marks >= 60')
print(filtered_students_df)
输出:
student_id name subject marks grade
0 1 John Maths 85 A
2 3 Ali English 92 A+
4 5 Sam Biology 75 B
现在假设你还希望只输出特定的列,比如仅输出姓名和 ID,而不是所有数据。Pyjanitor 也可以通过以下方式来实现这一点:
# Select specific columns
selected_columns_df = filtered_students_df.loc[:,['student_id', 'name']]
输出:
student_id name
0 1 John
2 3 Ali
4 5 Sam
5. 方法链
利用 Pyjanitor 的方法链功能,你可以在一行中执行多个操作。这一能力被认为是其最优秀的特性之一。举例来说,假设有一个包含汽车数据的数据框:
# Create a data frame with sample car data
cars_df = pd.DataFrame({
'Car ID': [101, None, 103, 104, 105],
'Car Model': ['Toyota', 'Honda', 'BMW', 'Mercedes', 'Tesla'],
'Price': [25000, 30000, None, 40000, 45000],
'Year': [2018, 2019, 2017, 2020, None]
})
print("Cars Data Before Applying Method Chaining:")
print(cars_df)
输出:
Cars Data Before Applying Method Chaining:
Car ID Car Model Price Year
0 101.0 Toyota 25000.0 2018.0
1 NaN Honda 30000.0 2019.0
2 103.0 BMW NaN 2017.0
3 104.0 Mercedes 40000.0 2020.0
4 105.0 Tesla 45000.0 NaN
现在我们看到数据框包含缺失值和不一致的列名。我们可以通过按顺序执行操作来解决这个问题,例如 clean_names()、rename_column() 和 dropna() 等。或者,我们可以将这些方法链在一起——在一行中执行多个操作——以获得流畅的工作流程和更简洁的代码。
# Chain methods to clean column names, drop rows with missing values, select specific columns, and rename columns
cleaned_cars_df = (
cars_df
.clean_names() # Clean column names
.dropna() # Drop rows with missing values
.select_columns(['car_id', 'car_model', 'price']) # Select columns
.rename_column('price', 'price_usd') # Rename column
)
print("Cars Data After Applying Method Chaining:")
print(cleaned_cars_df)
输出:
Cars Data After Applying Method Chaining:
car_id car_model price_usd
0 101.0 Toyota 25000.0
3 104.0 Mercedes 40000.0
在这个流程中,执行了以下操作:
-
clean_names()函数清理列名。 -
dropna()函数丢弃缺失值所在的行。 -
select_columns()函数选择特定的列,即 ‘car_id’、‘car_model’ 和 ‘price’。 -
rename_column()函数将列名 ‘price’ 重命名为 ‘price_usd’。
总结
因此,总结来说,Pyjanitor 证明了它是一个对任何数据工作者来说都很神奇的库。它提供了比本文中讨论的更多功能,如编码分类变量、获取特征和标签、识别重复行等等。所有这些高级功能和方法都可以在其文档中进行探索。你对其功能的了解越深入,你会对它强大的功能感到越惊讶。最后,享受使用 Pyjanitor 操作数据的乐趣吧。
Kanwal Mehreen**** Kanwal 是一位机器学习工程师和技术作家,对数据科学及人工智能与医学的交叉领域充满热情。她共同编写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 地区的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的热心倡导者,她创立了 FEMCodes,旨在赋能 STEM 领域的女性。
相关主题
机器学习测试初学者指南
原文:
www.kdnuggets.com/beginners-guide-to-machine-learning-testing-with-deepchecks

作者提供的图像 | Canva
DeepChecks是一个 Python 包,提供各种内置检查,以测试模型性能、数据分布、数据完整性等问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
在本教程中,我们将学习 DeepChecks,并使用它来验证数据集和测试训练过的机器学习模型,以生成全面的报告。我们还将学习如何在特定测试上测试模型,而不是生成完整的报告。
我们为什么需要机器学习测试?
机器学习测试对于确保 AI 模型的可靠性、公平性和安全性至关重要。它有助于验证模型性能、检测偏见、增强对抗攻击的安全性,尤其是在大型语言模型(LLMs)中,确保符合监管要求,并实现持续改进。像 Deepchecks 这样的工具提供了一个全面的测试解决方案,涵盖了从研究到生产的 AI 和 ML 验证的所有方面,使其在开发稳健、值得信赖的 AI 系统中变得不可或缺。
使用 DeepChecks 入门
在本入门指南中,我们将加载数据集并执行数据完整性测试。这个关键步骤确保我们的数据集是可靠和准确的,为成功的模型训练铺平道路。
- 我们将通过使用
pip命令安装 DeepChecks Python 包来开始。
!pip install deepchecks --upgrade
-
导入必要的 Python 包。
-
使用 pandas 库加载数据集,该数据集包含 569 个样本和 30 个特征。癌症分类数据集来源于乳腺肿块的细针抽取(FNA)数字化图像,每个特征代表图像中细胞核的一个特征。这些特征使我们能够预测癌症是良性还是恶性。
-
使用目标列‘benign_0__mal_1’将数据集拆分为训练集和测试集。
import pandas as pd
from sklearn.model_selection import train_test_split
# Load Data
cancer_data = pd.read_csv("/kaggle/input/cancer-classification/cancer_classification.csv")
label_col = 'benign_0__mal_1'
df_train, df_test = train_test_split(cancer_data, stratify=cancer_data[label_col], random_state=0)
- 通过提供额外的元数据创建 DeepChecks 数据集。由于我们的数据集没有类别特征,因此我们将参数留空。
from deepchecks.tabular import Dataset
ds_train = Dataset(df_train, label=label_col, cat_features=[])
ds_test = Dataset(df_test, label=label_col, cat_features=[])
- 对训练数据集运行数据完整性测试。
from deepchecks.tabular.suites import data_integrity
integ_suite = data_integrity()
integ_suite.run(ds_train)
生成报告将需要几秒钟。
数据完整性报告包含以下测试结果:
-
特征-特征相关性
-
特征-标签相关性
-
列中的单一值
-
特殊字符
-
混合空值
-
混合数据类型
-
字符串不匹配
-
数据重复
-
字符串长度超出范围
-
冲突标签
-
异常值样本检测
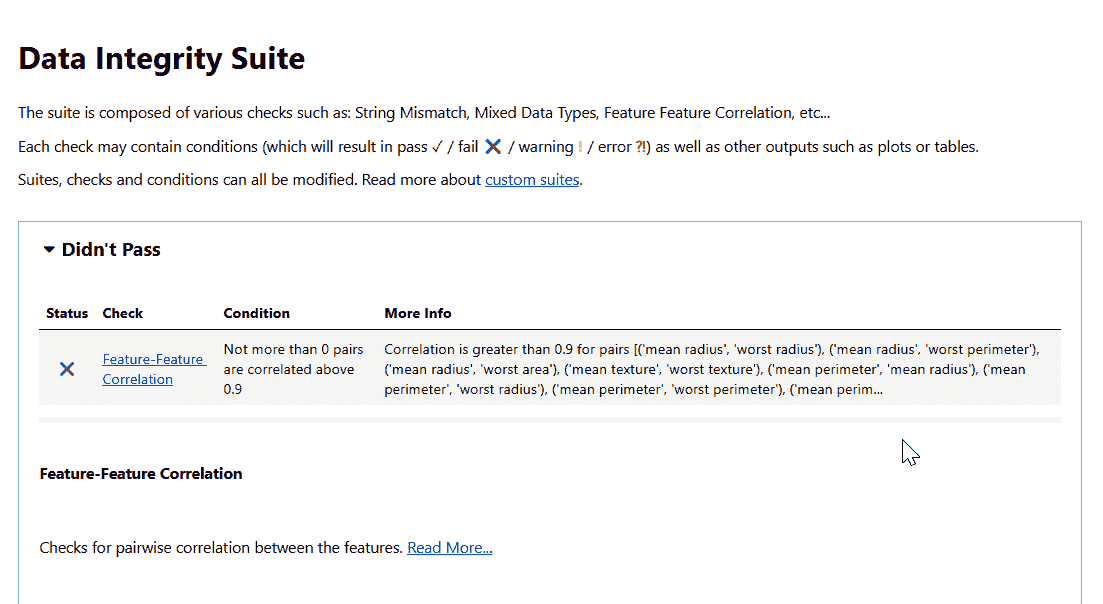
机器学习模型测试
让我们训练我们的模型,然后运行一个模型评估套件,以了解更多关于模型性能的信息。
-
加载必要的 Python 包。
-
构建三个机器学习模型(逻辑回归、随机森林分类器和高斯朴素贝叶斯)。
-
使用投票分类器将它们集成起来。
-
在训练数据集上拟合集成模型。
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
# Train Model
clf1 = LogisticRegression(random_state=1,max_iter=10000)
clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
clf3 = GaussianNB()
V_clf = VotingClassifier(
estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
voting='hard')
V_clf.fit(df_train.drop(label_col, axis=1), df_train[label_col]);
- 训练阶段完成后,使用训练和测试数据集以及模型运行 DeepChecks 模型评估套件。
from deepchecks.tabular.suites import model_evaluation
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(ds_train, ds_test, V_clf)
suite_result.show()
模型评估报告包含以下测试结果:
-
未使用的特征 - 训练数据集
-
未使用的特征 - 测试数据集
-
训练测试性能
-
预测漂移
-
简单模型比较
-
模型推理时间 - 训练数据集
-
模型推理时间 - 测试数据集
-
混淆矩阵报告 - 训练数据集
-
混淆矩阵报告 - 测试数据集
套件中还有其他测试未运行,这是由于模型的集成类型。如果你运行了一个简单模型,如逻辑回归,你可能会得到完整的报告。
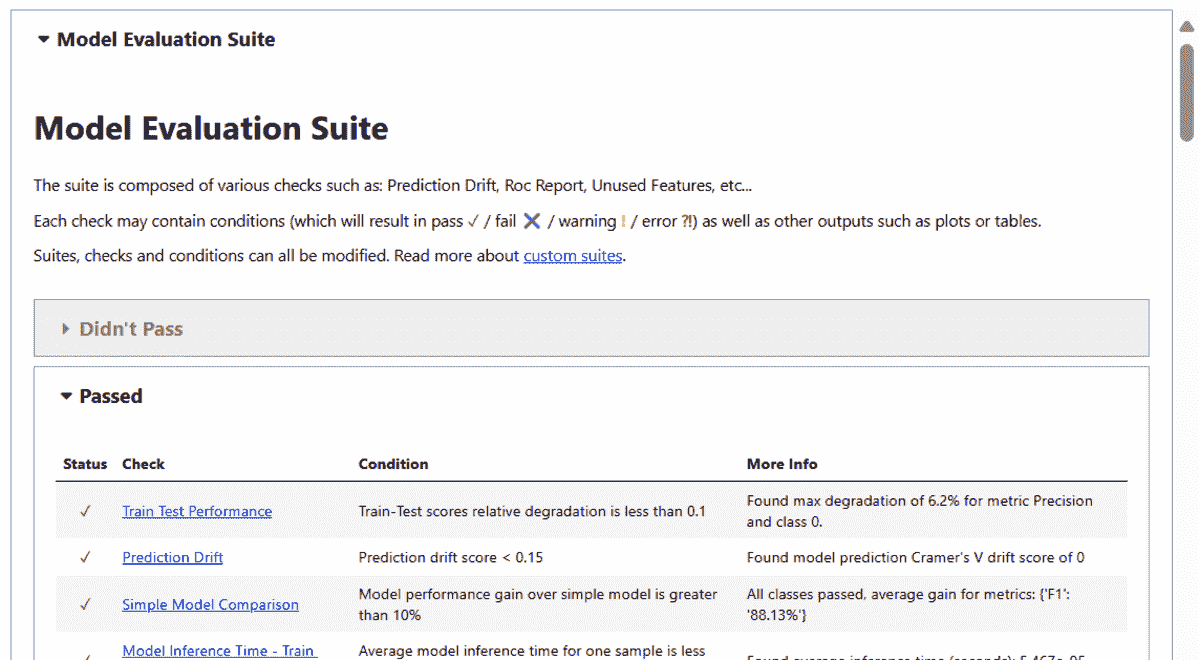
- 如果你想以结构化格式使用模型评估报告,你可以始终使用
.to_json()函数将报告转换为 JSON 格式。
suite_result.to_json()

- 此外,你还可以使用
.save_as_html()函数将此交互式报告保存为网页。
运行单项检查
如果你不想运行整个模型评估测试套件,你也可以在单项检查上测试你的模型。
例如,你可以通过提供训练和测试数据集来检查标签漂移。
from deepchecks.tabular.checks import LabelDrift
check = LabelDrift()
result = check.run(ds_train, ds_test)
result
结果将得到一个分布图和漂移分数。

你甚至可以提取漂移分数的值和方法论。
result.value
{'Drift score': 0.0, 'Method': "Cramer's V"}
结论
你学习旅程的下一步是自动化机器学习测试过程并跟踪性能。你可以通过遵循Deepchecks In CI/CD指南来实现这一点。
在这篇适合初学者的文章中,我们学习了如何使用 DeepChecks 生成数据验证和机器学习评估报告。如果你在运行代码时遇到困难,我建议你查看一下Kaggle Notebook 上的机器学习测试与 DeepChecks并自行运行。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个人工智能产品,帮助那些在心理健康方面挣扎的学生。
更多相关内容
初学者的 Python 机器学习指南
原文:
www.kdnuggets.com/beginners-guide-to-machine-learning-with-python

作者提供的图片
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
预测未来并不是魔法;它是人工智能。
当我们站在 AI 革命的边缘时,Python 让我们能够参与其中。
在这篇文章中,我们将探索如何利用 Python 和机器学习来进行预测。
我们将从基本原理开始,然后应用算法于数据进行预测。让我们开始吧!
什么是机器学习?
机器学习是赋予计算机预测能力的一种方式。它现在非常流行;你可能在日常生活中不经意间使用了它。以下是一些受益于机器学习的技术:
-
自动驾驶汽车
-
人脸检测系统
-
Netflix 电影推荐系统
但有时,AI、机器学习和深度学习之间的区别并不明显。这里有一个宏大的方案,最好地代表了这些术语。
初学者如何分类机器学习
机器学习算法可以通过两种不同的方法进行聚类。其中一种方法涉及确定数据点是否关联了“标签”。在这个上下文中,“标签”指的是你想要预测的数据点的特定属性或特征。
如果有标签,你的算法被归类为监督算法;否则,它是无监督算法。
另一种对机器学习算法进行分类的方法是对算法本身进行分类。如果这样做,机器学习算法可以被分类如下:
就像 Sci-kit Learn 一样,这里。
图片来源:scikit-learn.org
什么是 Sci-kit Learn?
Sci-kit learn 是 Python 中最著名的机器学习库;我们将在本文中使用它。使用 Sci-kit Learn,你将跳过从头定义算法的步骤,直接使用 Sci-kit Learn 的内置函数,这将简化你的机器学习构建过程。
在这篇文章中,我们将使用 Sci-kit Learn 中的不同回归算法构建一个机器学习模型。首先,让我们解释一下回归。
什么是回归?
回归是一种机器学习算法,用于预测连续值。以下是一些回归的现实生活示例,
现在,在应用回归模型之前,让我们看一下三种不同的回归算法及其简单解释;
-
多元线性回归:通过多个预测变量的线性组合进行预测。
-
决策树回归器:创建一个树状模型,通过多个输入特征预测目标变量的值。
-
支持向量回归:找到最佳拟合线(或在高维度中的超平面),使得在某个距离内的点的数量最大。
在应用机器学习之前,你需要遵循特定的步骤。有时,这些步骤可能会有所不同;然而,大多数情况下,它们包括;
-
数据探索与分析
-
数据处理
-
训练-测试拆分
-
构建机器学习模型
-
数据可视化
在这里,让我们使用我们平台上的数据项目来预测价格 这里。

数据探索与分析
在 Python 中,我们有几个函数。通过使用这些函数,你可以熟悉你所使用的数据。
但首先,你应该加载这些函数所需的库。
import pandas as pd
import sklearn
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
很好,让我们加载数据并稍微探索一下。
data = pd.read_csv('path')
输入你目录中文件的路径。Python 有三个函数可以帮助你探索数据。让我们逐个应用它们并查看结果。
这里是查看数据集中前五行的代码。
data.head()
这里是输出结果。
现在,让我们检查第二个函数:查看有关数据集列的信息。
data.info()
这里是输出结果。
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
- - - - - - - - - - - - - - - - - - -
0 loc1 10000 non-null object
1 loc2 10000 non-null object
2 para1 10000 non-null int64
3 dow 10000 non-null object
4 para2 10000 non-null int64
5 para3 10000 non-null float64
6 para4 10000 non-null float64
7 price 10000 non-null float64
dtypes: float64(3), int64(2), object(3)
memory usage: 625.1+ KB
这是最后一个函数,它将以统计方式总结我们的数据。这里是代码。
data.describe()
这里是输出结果。
现在,你对我们的数据更熟悉了。在机器学习中,所有预测变量,也就是你打算用于预测的列,应该是数字型的。
在下一部分,我们将确认这一点。
数据 操作
现在,我们都知道应该将“dow”列转换为数字,但在此之前,让我们检查其他列是否仅包含数字,以便于我们的机器学习模型。
我们有两个可疑的列,loc1 和 loc2,因为从 info() 函数的输出中可以看出,我们只有两列是对象数据类型,这些列可能包含数值和字符串。
让我们使用这段代码来检查;
data["loc1"].value_counts()
这是输出结果。
loc1
2 1607
0 1486
1 1223
7 1081
3 945
5 846
4 773
8 727
9 690
6 620
S 1
T 1
Name: count, dtype: int64
现在,通过使用以下代码,你可以删除那些行。
data = data[(data["loc1"] != "S") & (data["loc1"] != "T")]
但是,我们必须确保另一个列 loc2 不包含字符串值。让我们使用以下代码来确保所有值都是数字。
data["loc2"] = pd.to_numeric(data["loc2"], errors='coerce')
data["loc1"] = pd.to_numeric(data["loc1"], errors='coerce')
data.dropna(inplace=True)
在上面的代码末尾,我们使用了 dropna() 函数,因为 pandas 的转换函数会将“na”转换为非数值型值。
很好。我们可以解决这个问题;让我们将工作日列转换为数字。这里是执行此操作的代码;
# Assuming data is already loaded and 'dow' column contains day names
# Map 'dow' to numeric codes
days_of_week = {'Mon': 1, 'Tue': 2, 'Wed': 3, 'Thu': 4, 'Fri': 5, 'Sat': 6, 'Sun': 7}
data['dow'] = data['dow'].map(days_of_week)
# Invert the days_of_week dictionary
week_days = {v: k for k, v in days_of_week.items()}
# Convert dummy variable columns to integer type
dow_dummies = pd.get_dummies(data['dow']).rename(columns=week_days).astype(int)
# Drop the original 'dow' column
data.drop('dow', axis=1, inplace=True)
# Concatenate the dummy variables
data = pd.concat([data, dow_dummies], axis=1)
data.head()
在这段代码中,我们通过在字典中为每一天定义一个数字,然后简单地用这些数字替换日期名称来定义工作日。这里是输出结果。
现在,我们快完成了。
训练-测试划分
在应用机器学习模型之前,你必须将数据分成训练集和测试集。这允许你通过在训练集上训练模型并在模型未见过的测试集上评估其性能,客观地评估模型的效率。
X = data.drop('price', axis=1) # Assuming 'price' is the target variable
y = data['price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
构建机器学习模型
现在一切准备好了。在这个阶段,我们将一次性应用以下算法。
-
多元线性回归
-
决策树回归
-
支持向量回归
如果你是初学者,这段代码可能看起来很复杂,但请放心,它并不复杂。在代码中,我们首先将模型名称及其相应的 scikit-learn 函数分配给模型的字典。
接下来,我们创建一个名为 results 的空字典来存储这些结果。在第一次循环中,我们同时应用所有机器学习模型,并使用 R² 和 MSE 等指标评估它们,这些指标评估算法的表现。
在最终的循环中,我们打印出我们保存的结果。这是代码
# Initialize the models
models = {
"Multiple Linear Regression": LinearRegression(),
"Decision Tree Regression": DecisionTreeRegressor(random_state=42),
"Support Vector Regression": SVR()
}
# Dictionary to store the results
results = {}
# Fit the models and evaluate
for name, model in models.items():
model.fit(X_train, y_train) # Train the model
y_pred = model.predict(X_test) # Predict on the test set
# Calculate performance metrics
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# Store results
results[name] = {'MSE': mse, 'R² Score': r2}
# Print the results
for model_name, metrics in results.items():
print(f"{model_name} - MSE: {metrics['MSE']}, R² Score: {metrics['R² Score']}")
这是输出结果。
Multiple Linear Regression - MSE: 35143.23011545407, R² Score: 0.5825954700994046
Decision Tree Regression - MSE: 44552.00644904675, R² Score: 0.4708451884787034
Support Vector Regression - MSE: 73965.02477382126, R² Score: 0.12149975134965318
数据可视化
为了更好地查看结果,让我们可视化输出。
这是我们首先计算 RMSE(均方根误差)并可视化输出的代码。
import matplotlib.pyplot as plt
from math import sqrt
# Calculate RMSE for each model from the stored MSE and prepare for plotting
rmse_values = [sqrt(metrics['MSE']) for metrics in results.values()]
model_names = list(results.keys())
# Create a horizontal bar graph for RMSE
plt.figure(figsize=(10, 5))
plt.barh(model_names, rmse_values, color='skyblue')
plt.xlabel('Root Mean Squared Error (RMSE)')
plt.title('Comparison of RMSE Across Regression Models')
plt.show()
这是输出结果。
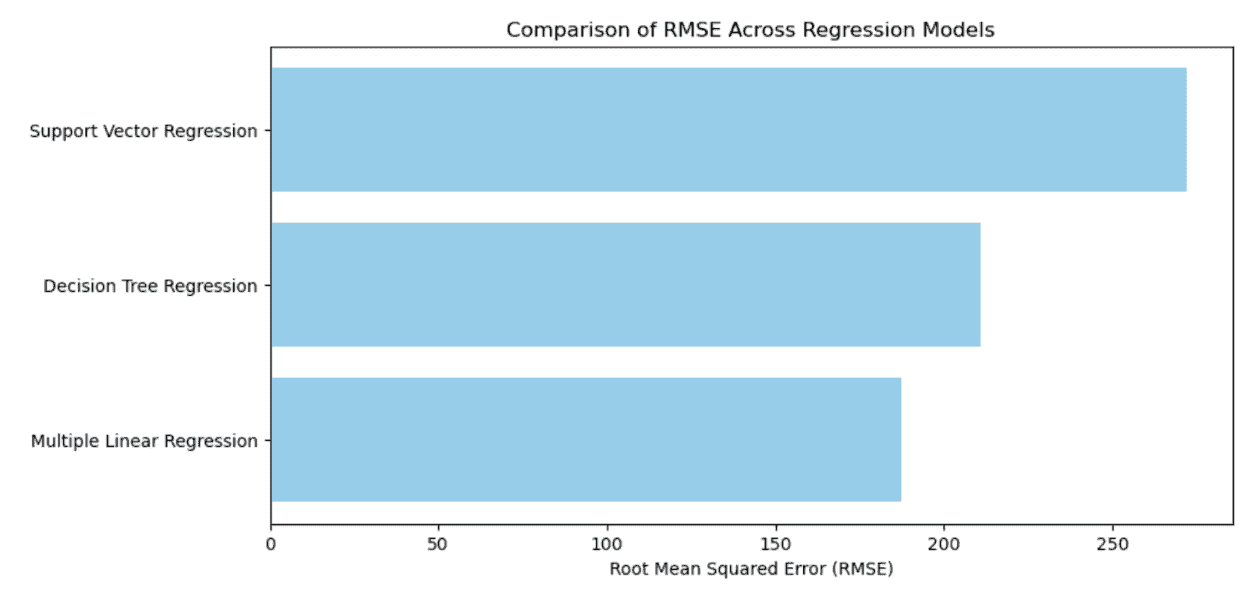
数据项目
在结束之前,这里有一些数据项目可以开始。
-
2024 年数据工程师薪资 - 分析了 2024 年数据工程师薪资趋势
-
2018-2019 英超联赛- 分析了曼联 2018-2019 赛季的统计数据
-
交付时间预测- 分析了 Doordash 的交付时间
-
客户流失预测- 分析了索尼的客户流失情况
此外,如果你想做一些有趣的数据项目,这里有几个可能会引起你兴趣的数据集;
-
心脏病 - 你可以根据给定的特征预测心脏病。
-
使用智能手机进行人类活动识别 - 你可以预测步数。
-
森林火灾 - 你可以预测火灾烧毁的面积。
结论
我们的结果本可以更好,因为还有很多步骤可以提高模型的效率,但我们在这里已经取得了一个很好的开始。查看Sci-kit Learn 的官方文档了解你还能做些什么。
当然,学习后,你需要反复做数据项目来提高你的能力,并学习更多内容。
内特·罗西迪是一位数据科学家,专注于产品战略。他还是一位兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家准备面试,通过顶级公司的真实面试问题。内特撰写关于职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有关于 SQL 的内容。
更多相关内容
使用 Pandas 的推文分析初学者指南
原文:
www.kdnuggets.com/2017/03/beginners-guide-tweet-analytics-pandas.html
Twitter 为所有用户提供了分析访问权限,但我假设相对较少的普通用户会关注其存在。还有各种其他服务可以帮助进行推文和受众分析,以及与地理和自然语言处理相关的进一步分析,但与一些简单的 Python 配合使用时,Twitter 提供的数据可以非常有用。
这是一个简单的指南,帮助你在 Python 中亲自进行一些分析。与许多其他教程通常从实时 Twitter API 中提取数据不同,我们将使用可下载的 Twitter Analytics 数据,我们的大部分工作将在 Pandas 中完成。
在我们开始之前,先处理必要的导入部分。
获取并检查数据
首先我们需要数据。这部分非常简单;前往 Twitter,点击右上角的菜单(你的头像),选择分析,在顶部选择推文选项卡,使用日期范围选择器选择时间段,然后选择导出数据。你使用的数据量无所谓;我们的简单示例适用于任何数量的数据。我选择了默认的过去 28 天。

获取 Twitter 分析数据。
一旦我们有了 CSV 文件,我们将需要将其加载到 Pandas DataFrame 中进行分析。
不用在意所有被丢弃的列;虽然其中很多数据对我们的分析很有用——推文文本、时间、印象、转发等——但许多数据并不有用——所有推广的内容——因此我们将从一开始就省略它们。
正如我们在任何数据分析项目中一样,接下来我们查看数据。

运行:
告诉我们我在过去 4 周内发推了可怜的 95 次。数据集不是很大,我们可能不想根据我们的发现做出任何推断,但这是一个足够好的玩具数据集,可以作为起点。
让我们看看我们可以从中提取出哪些有用的分析数据。
基本推文统计
因此,考虑到在上述数据集中运行head()的输出中显示的数据,并对哪些推文指标可能有用有一个大致的直觉,我们将获取以下统计数据:
-
转发 - 每条推文的平均转发数和前 5 条转发最多的推文
-
点赞 - 每条推文的平均点赞数和前 5 条最受欢迎的推文
-
印象 - 每条推文的平均印象数和前 5 条印象最多的推文
Total tweets this period: 95
Mean retweets: 1.72
Top 5 RTed tweets:
------------------
A PyTorch IPython Notebook tutorial on #deeplearning, with an emphasis on #NaturalLanguageProcessing https://t.co/bxiBD42T7E https://t.co/awTsZA8R9v - 26
On the Origin of #DeepLearning https://t.co/oe7r43HHVS #NeuralNetworks #arxiv https://t.co/BIcba61FR9 - 25
7 MORE Steps to Mastering #MachineLearning With #Python https://t.co/5yAjeUpCfS https://t.co/juWH0rQaNR - 16
Every Intro to #DataScience Course on the Internet, Ranked https://t.co/rQG7Higk6b https://t.co/b6VveKfJxD - 8
Pandas & Seaborn - A guide to handle & visualize #data elegantly @tryolabs https://t.co/LPq2q8k1i1 #Python #dataviz https://t.co/k2IoWsttXM - 7
Mean likes: 3.17
Top 5 liked tweets:
-------------------
A PyTorch IPython Notebook tutorial on #deeplearning, with an emphasis on #NaturalLanguageProcessing https://t.co/bxiBD42T7E https://t.co/awTsZA8R9v - 52
7 MORE Steps to Mastering #MachineLearning With #Python https://t.co/5yAjeUpCfS https://t.co/juWH0rQaNR - 37
On the Origin of #DeepLearning https://t.co/oe7r43HHVS #NeuralNetworks #arxiv https://t.co/BIcba61FR9 - 37
Pandas & Seaborn - A guide to handle & visualize #data elegantly @tryolabs https://t.co/LPq2q8k1i1 #Python #dataviz https://t.co/k2IoWsttXM - 16
I've been reposted on @YhatHQ - The Current State of Automated #MachineLearning https://t.co/ggAW1Hrmxk https://t.co/8030HhAMMA - 14
Mean impressions: 674.39
Top 5 tweets with most impressions:
-----------------------------------
On the Origin of #DeepLearning https://t.co/oe7r43HHVS #NeuralNetworks #arxiv https://t.co/BIcba61FR9 - 6409
A PyTorch IPython Notebook tutorial on #deeplearning, with an emphasis on #NaturalLanguageProcessing https://t.co/bxiBD42T7E https://t.co/awTsZA8R9v - 5684
7 MORE Steps to Mastering #MachineLearning With #Python https://t.co/5yAjeUpCfS https://t.co/juWH0rQaNR - 4374
I've been reposted on @YhatHQ - The Current State of Automated #MachineLearning https://t.co/ggAW1Hrmxk https://t.co/8030HhAMMA - 2270
Pandas & Seaborn - A guide to handle & visualize #data elegantly @tryolabs https://t.co/LPq2q8k1i1 #Python #dataviz https://t.co/k2IoWsttXM - 1818
我不会对这些指标进行任何分析。不用说,我应该提升我的社交媒体表现。
前 #标签 和 @提及
毫无疑问,标签在 Twitter 中扮演着重要角色,提及也有助于扩展你的网络和影响力。它们共同帮助将“社交”融入社交网络,将像 Twitter 这样的平台从被动体验转变为非常活跃的体验。了解这个社交网络最社交的方面将是一个有帮助的努力。
Top 10 hashtags:
----------------
machinelearning - 21
deeplearning - 16
python - 15
datascience - 10
neuralnetworks - 10
ai - 5
data - 4
datascientist - 3
tensorflow - 3
rstats - 3
Top 10 mentions:
----------------
kdnuggets - 3
francescoai - 2
jakevdp - 2
quora - 2
yhathq - 2
noahmp - 1
udacity - 1
clavitolo - 1
monkeylearn - 1
nicholashould - 1
把一些明显的问题,比如推文文本中的标点在检查 Twitter 句柄之前被移除(如果你有名为 Francesco_AI 和 FrancescoAI 的用户,这可能是个问题),这方法有效,至少相对 Pythonic(虽然我相信可以做得更好)。
时间序列分析
最后,我们来看看一些非常基础的时间数据。我们将检查基于推文的小时和星期几的平均印象。我再次警告,这基于很少的数据,因此可能得不到有用的信息。然而,考虑到大量的推文数据,可以计划整个社交媒体活动。
虽然这基于印象,但同样可以(并且容易地)基于互动、转发或其他你喜欢的内容。做广告和推广推文?也许你对我们最初从数据集中剥离的一些推广指标更感兴趣。
我们必须将 Twitter 提供的日期字段转换为合法的 Python datetime 对象,根据其所属的小时段对数据进行分组,识别星期几,然后在 DataFrame 中捕捉这些数据的几个附加列,我们将在之后用来提取统计信息。
Average impressions per tweet by hour tweeted:
----------------------------------------------
0 - 1 : 141 => 1 tweets
9 - 10 : 445 => 10 tweets
10 - 11 : 611 => 9 tweets
11 - 12 : 1319 => 10 tweets
12 - 13 : 528 => 10 tweets
13 - 14 : 448 => 11 tweets
14 - 15 : 464 => 16 tweets
15 - 16 : 763 => 8 tweets
17 - 18 : 634 => 9 tweets
18 - 19 : 1306 => 8 tweets
19 - 20 : 454 => 1 tweets
21 - 22 : 186 => 1 tweets
23 - 24 : 208 => 1 tweets
Average impressions per tweet by day of week tweeted:
-----------------------------------------------------
Mon : 475 => 20 tweets
Tue : 568 => 18 tweets
Wed : 1418 => 18 tweets
Thu : 545 => 17 tweets
Fri : 432 => 22 tweets
看起来我在一天中的时间比较一致地发推。我还发现我的星期三推文、上午 11 点推文和下午 6 点推文是我的主要推文。当然,这基于 95 条推文,因此意义不大且结论不确切。然而,在对一些相当大数据集执行这些相同步骤后,观察到了一些有趣的趋势,这可能有助于商业决策。都是从一些简单的 Python 开始的。
虽然不是惊天动地,我们基于 Pandas 的简单 Twitter 分析代码足以让我们思考如何更好地利用社交媒体。应用于正确的数据,基础脚本可以相当强大。
相关内容:
-
使用 Python 挖掘 Twitter 数据第一部分:收集数据
-
Pandas 备忘单:Python 中的数据科学和数据清理
-
在 Python 中清理数据
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
了解更多相关主题
机器学习的初学者学习路径
原文:
www.kdnuggets.com/2020/05/beginners-learning-path-machine-learning.html
评论

我们的前三大课程推荐
1. Google 网络安全证书 - 加入网络安全职业的快速通道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
对于机器学习感到下定决心,但对从哪里开始感到困惑?我曾经面临过同样的困惑,不知道该如何开始?应该学习 Python 还是选择 R?数学对我来说总是令人害怕的部分,我总是担心从哪里学习数学?我也担心如何为机器学习打下坚实的基础。无论如何,你应该为自己感到庆幸,至少你已经下定了决心。
在这篇文章中,我将告诉你在开始实际机器学习之前应该采取的一些基本步骤和课程。
机器学习的第一步(基础编程)
第一步是你应该学习编程,最可能是 Python。如果你从未写过一行代码,那么我推荐你学习哈佛大学的 CS50,这是一门针对编程初学者的最佳课程,它会从零开始教你所有的 C 语言,以及很多 Python 和 JavaScript 的基础知识,还包括 SQL 和 JSON 的基础。这门非常激动人心的课程在 edx.org 上免费,你可以在这里找到它。关于 CS50 的文章可以在这里阅读。
如果你想直接从 Python 开始,那么我建议你参加 MIT 的《Python 计算机科学导论》,它在 edX 上提供免费课程。请注意,这门课程的先决条件是高中代数,因为你需要解决许多现实世界的数学问题。
如果你觉得自己的计算逻辑不好,且编程中的问题解决能力不强,我推荐微软的这门课程,它与计算思维相关,且在 edx 上完全是免费。这门课程非常棒,教授了很多计算逻辑和批判性思维。
如果你对编程基础很熟练但对面向对象编程没有了解,我建议你学习面向对象编程。虽然它在机器学习(基础级别)中使用不多,但确实很有帮助。我会推荐这门课程,它讲授了 OOP 和 Python 中的算法基础。你可以在 edx.org 上找到这门免费的课程。
下一步是熟悉数据结构和算法。一个好的程序员必须了解一些基本算法,比如链表、二叉树等。微软的这门课程将教你这些:
-
算法分析
-
算法的排序和搜索
-
数据结构:链表、栈、队列
这门课程可以在 edx.org 上免费获得。
如果你想深入了解数据结构和算法,UC San Diego 的专业化是一个杰作。它包含 6 门课程,将你从零基础带到数据结构和算法的高手级别。你可以点击每门课程并免费审阅其材料,但如果你想获得证书,价格为 50$/月,取决于你完成的速度。可以在 Coursera.org 上找到这个专业化或点击这里。
机器学习的第 2 步
是的,你猜对了,大多数初学者最危险的部分,数学。
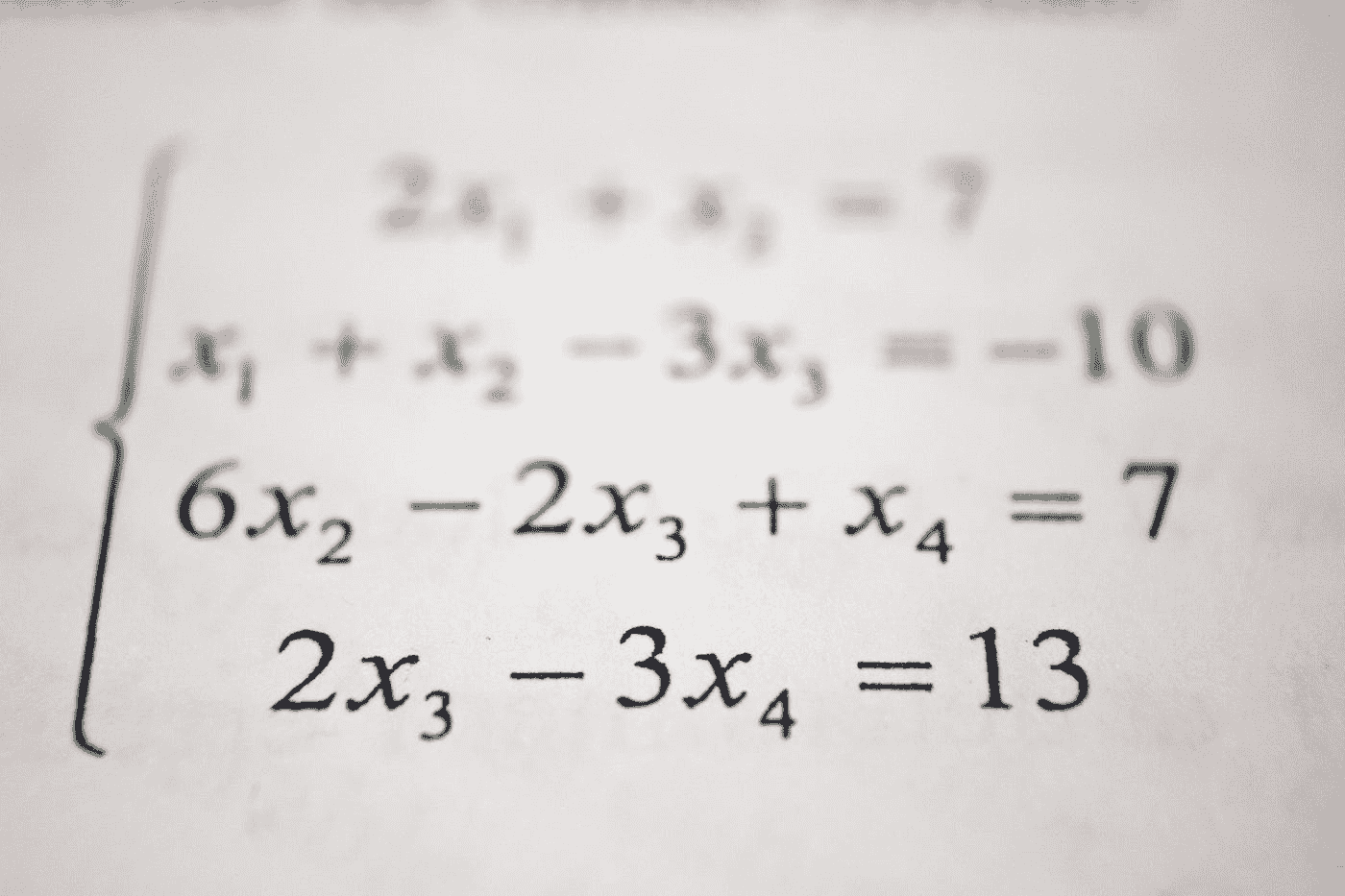
照片由 Antoine Dautry 提供,发布于 Unsplash。
但不用担心,它并不像我们想象的那么困难。如果你认为自己在高中数学(向量、矩阵、微积分、概率和统计)方面有良好的基础,你可以简单地参加一个复习课程。如果你觉得自己不够好,那么学习数学的最佳地方是KHAN ACADEMY。Khan Academy 的内容非常丰富且有帮助,一切都可以免费获得。你可以在这里找到所有线性代数、概率和统计以及多变量微积分的课程。
另一个不错的课程是来自 Imperial College London 的 Coursera 机器学习数学专业化。这是一门很棒的课程,讲解基础并复习概念,但不会深入探讨。练习和测验非常具有挑战性,共有 3 门课程。
麻省理工学院有一门优秀的统计学课程,该课程讲授
-
使用矩量法和最大似然法构造估计量,并决定如何在它们之间进行选择
-
使用置信区间和假设检验来量化不确定性
-
使用拟合优度测试在不同模型之间进行选择
-
使用线性、非线性和广义线性模型进行预测
-
使用主成分分析(PCA)进行降维
在 edx.org 上免费提供。
如果你想在编程的同时学习数学,微软有一门很好的课程,“机器学习的基础数学:Python 版”。这是一门互动课程,使用 Python 的著名库 Numpy、pandas 和 matplotlib 进行图形化数学教学,这些库是该课程的先决条件。可以在 edx.org 上免费找到这门课程。
Udacity 提供了 3 门很棒的免费统计学课程。
你还可以在学习实际机器学习的同时学习数学,遇到不懂的内容,可以在可汗学院或 YouTube 上搜索,有许多相关的优秀视频。
机器学习的第三步
既然你已经熟悉了线性代数、多变量微积分和统计学,现在你需要学习 Python 著名的数据可视化库,包括 Numpy、Pandas、Matplotlib 和 Scipy,它们帮助你分析和操作各种数据,并以图形方式展示。虽然还有很多其他的数据可视化库,但这些是最重要的。将你的线性代数和微积分概念以图形方式实现并可视化。
在这方面的杰作之一是密歇根大学的“Python 统计学专业化”课程,详细讲授数据可视化及其操作。当然,可以在 coursera.org 上免费(点击每门课程进行免费旁听)。
另一门由密歇根大学提供的适合数据分析初学者的课程是“Introduction to Data Science in Python”,它以非常好的方式从 numpy 的基础知识开始教授 pandas。在 coursera.org 上免费提供。该课程的下一部分是颠覆性的。名为“Applied Plotting, Charting, and Data Representation in Python”,它教授所有图形可视化及其技巧和方法。
另一个好的课程是哈佛大学的“Python for Research”,该课程教授这些库以及一些著名的案例研究,其最终项目非常令人兴奋,并且学到很多新东西。在 edx.org 上免费提供。
另一个非常全面的课程是由加州大学圣地亚哥分校提供的“Python for Data Science”,该课程教授
-
Python
-
Jupyter notebooks
-
pandas
-
NumPy
-
Matplotlib
-
git
-
sci kit-learn
-
NLTK
虽然这门课程也会教你机器学习的基础知识,但更重要的是教授数据科学库。在 edx.org 上免费提供(不要忘记阅读其前提条件)。
第四步 实用机器学习

到目前为止,你已经学习了线性代数、多变量微积分、概率统计和 Python 及其数据可视化库,因此你现在准备进入最激动人心的部分——机器学习。第一门课程可能意义重大。如果它不好,你可能会因为不喜欢这门课程而改变领域。因此,这里所有的课程都将是高质量的,在你开始第一门机器学习课程之前做些研究。
这门入门课程不会教你机器学习,而是会给你一个关于机器学习的概念,机器学习术语的含义,人工智能策略及其伦理。这门课程将提供对机器学习是什么以及如何运作的概述,以及其工作流程和如何在公司中构建人工智能。它为你提供了一个很好的人工智能介绍和概述。课程由著名的机器学习讲师Andrew Ng教授,在 coursera.org 上免费提供。
不管你是谷歌搜索还是查看任何博客,大家推荐的第一门课程都是斯坦福大学的机器学习课程,由 Andrew Ng 主讲,这真是一门美妙的课程。已有超过 250 万名学生注册了这门课程,超过 20 万名学生给出了评分(4.9*)。它从最基本的概念讲到高级概念,是一门非常全面的初学者课程。该课程总长度超过 56 小时。想要阅读这门课程的评价吗?这里 是你可以去的地方。另一个 评价在这里。这里 是 Quora 上关于这门课程的另一个评价。以下是课程内容的列表。
-
线性回归
-
多项式回归
-
逻辑回归
-
多类别分类
-
神经网络
-
支持向量机(SVM)
-
K-means 聚类
-
主成分分析(PCA)
-
异常检测
-
推荐系统
唯一的问题(根据一些人的说法)是它是用 octave/Matlab 教授的,但对我来说这不是什么大问题,因为它将澄清所有机器学习的基础和深层概念,实现这些概念在任何其他语言中都不会有任何问题,而且 Matlab 也是一项额外的技能。此课程在斯坦福大学的官方网站上免费提供(这里)和 coursera.org (这里)。
这门课程是每个人都必须上的,因为它好得无法用言语表达。
这门课程之后,你需要将你所学的所有内容在 Python 中实现,并在学习的基础上进一步深入。因此,由 deeplearning.ai 提供的由 Andrew Ng、Kian Katanfrosh 和 Younes Bensouda 主讲的 Coursera 上的进阶专门化课程也是必修的。这个专门化课程包括 5 门课程,分别是
-
神经网络和深度学习
-
改进深度神经网络:超参数调整、正则化和优化
-
结构化机器学习项目
-
卷积神经网络
-
序列模型
你将获得的主要技能包括
-
TensorFlow
-
卷积神经网络
-
人工神经网络
-
深度学习
现在你对 TensorFlow 和机器学习有了很好的掌握。你可能不喜欢 TensorFlow,或者你只是想测试 TensorFlow 的著名对手 PyTorch(由 Facebook 提供),那么为什么不开始这门由 Udacity 提供的 Facebook 与 Amazon Web Services 合作的免费深度学习课程呢?这也是 Udacity 著名的深度学习 Nano Degree,价值 1400 美元。
当然,这只是一个开始,还有很多东西需要学习和发现,但如果你做这些事情,希望你能对自己的现状和下一步要做的事有个了解。
一些建议和推荐
这里有一些推荐。
-
现在就开始收听 OC Devel 的“机器学习指南”播客吧。这将给你提供一个关于机器学习的全面概述,以及一名安卓和网络应用开发者转向机器学习道路的经历。可在Apple Podcasts/iTunes、Google Podcasts 及其官网收听。
-
获取《动手学机器学习:Scikit-Learn 和 TensorFlow 实践》(或其 2019 年 10 月发布的新版本,名为《动手学机器学习:Scikit-Learn、Keras 和 TensorFlow 实践》)。本书作者是Aurélien Géron。本书第一版在人工智能(图书)、自然语言处理(图书)和计算机神经网络类别中均排名第一。这本书内容非常全面,值得推荐。
-
不要忘了阅读这篇。其中有很多有用的信息。
-
在Kaggle上多加练习(你一旦开始机器学习,就会了解它)。
-
保持专注,相信自己能够做到。你只需要保持一致性。
祝好运,祝你在学习如何让机器更智能时有愉快的时光。
原文。已获得授权转载。
相关:
相关话题
行为分析与机器学习和 R:免费电子书
原文:
www.kdnuggets.com/2020/10/behavior-analysis-machine-learning-r-free-ebook.html
评论
由Enrique Garcia-Ceja撰写,SINTEFdigital 研究员,R + 行为分析 + 传感器 + 机器学习。

自动行为监测技术正因传感器和机器学习的进步成为我们日常生活的一部分。自动分析和理解行为被应用于解决多个领域的问题,包括医疗保健、体育、市场营销、生态学、安全和心理学等。行为分析与机器学习和 R旨在介绍应用于多样化行为分析问题的机器学习概念和算法。它侧重于基于从传感器收集或存储在数据库中的数据解决这些问题的实际方面。
本书涵盖了整个数据分析流程中的主题——从数据收集、可视化、预处理、编码到模型训练和评估。不需要事先了解机器学习。一些主题包括:
-
如何构建监督学习模型,以预测基于 Wi-Fi 信号的室内位置,从智能手机传感器和 3D 骨架数据中识别物理活动,从加速度计信号中检测手势等等。
-
了解如何利用无监督学习算法发现犯罪行为模式,并了解 Miss Karlene 如何利用关联规则挖掘帮助这个可怜的女孩找回她被盗的玩偶:

-
编写自己的集成学习方法,并使用多视角堆叠融合来自异质数据源的信号。
-
使用 Keras 和 TensorFlow 训练深度学习模型,包括神经网络以从肌电图信号中分类肌肉活动,以及卷积神经网络以检测图像中的微笑。
这本书可以在免费的enriquegit.github.io/behavior-free获得。
目录:
-
第一章. 引言
-
第二章. 使用分类模型预测行为
-
第三章. 使用集成学习预测行为
-
第四章. 探索和可视化行为数据
-
第五章. 行为数据预处理
-
第六章. 使用无监督学习发现行为
-
第七章. 编码行为数据
-
第八章. 使用深度学习预测行为
-
第九章. 多用户验证
-
附录 A: 设置你的环境
-
附录 B: 数据集
简介:Enrique Garcia Ceja是挪威 SINTEF 的研究科学家。过去 10 年来,他一直在研究利用机器学习和可穿戴设备进行行为监测和分析。
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
更多相关主题
使用 Apache Spark 与 PySpark 的好处与示例
原文:
www.kdnuggets.com/2020/04/benefits-apache-spark-pyspark.html
评论
什么是 Apache Spark?
Apache Spark是技术领域中最热门的新趋势之一。它可能是实现大数据与机器学习结合成果的最有潜力的框架。
它运行速度很快(比传统的Hadoop MapReduce快多达 100 倍),由于内存操作,提供强大、分布式、容错的数据对象(称为RDD),并通过诸如Mlib和GraphX等补充包与机器学习和图形分析领域完美集成。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作

Spark 是基于Hadoop/HDFS实现的,主要用Scala编写,这是一种类似于 Java 的函数式编程语言。实际上,Scala 需要系统上最新的 Java 安装并在 JVM 上运行。然而,对于大多数初学者来说,Scala 并不是他们在进入数据科学领域时首先学习的语言。幸运的是,Spark 提供了一个出色的 Python 集成,称为PySpark,它允许 Python 程序员与 Spark 框架进行接口,学习如何大规模操作数据,并在分布式文件系统上处理对象和算法。
在本文中,我们将学习 PySpark 的基础知识。由于有许多不断发展的概念,因此我们只关注基础知识,并通过一些简单的示例进行介绍。鼓励读者在此基础上进行拓展并自主探索。
Apache Spark 的简短历史
Apache Spark 起初是 2009 年在 UC Berkeley AMPLab 的一个研究项目,并于 2010 年初开源。它最初是 UC Berkeley 的一个课程项目,目的是建立一个集群管理框架,支持不同类型的集群计算系统。多年来,系统背后的许多理念在各种研究论文中提出。发布后,Spark 成长为一个广泛的开发者社区,并于 2013 年迁移到 Apache 软件基金会。如今,该项目由来自数百个组织的数百名开发者共同开发。
Spark 不是一种编程语言
需要记住的一点是,Spark 不是像 Python 或 Java 那样的编程语言。它是一个通用的分布式数据处理引擎,适用于广泛的场景。它特别适合大规模和高速度的大数据处理。
应用开发者和数据科学家通常将 Spark 集成到他们的应用程序中,以快速查询、分析和转换大规模数据。一些最常与 Spark 相关联的任务包括:– 跨大型数据集(通常为 TB 级别)的 ETL 和 SQL 批处理作业,– 处理来自 IoT 设备和节点的流数据、各种传感器的数据、各种金融和事务系统的数据,以及 – 电子商务或 IT 应用的机器学习任务。
从本质上讲,Spark 建立在处理分布式文件的 Hadoop/HDFS 框架之上。它主要用 Scala 实现,Scala 是 Java 的一种函数式语言变体。虽然有一个核心的 Spark 数据处理引擎,但在其之上,还有许多用于 SQL 类型查询分析、分布式机器学习、大规模图计算和流数据处理的库。Spark 支持多种编程语言,以易于使用的接口库形式提供:Java、Python、Scala 和 R。
Spark 使用 MapReduce 范式进行分布式处理
分布式处理的基本思想是将数据块分割成小的可管理的部分(包括一些过滤和排序),将计算任务接近数据,即在大型集群的各个小节点上执行特定任务,然后再将它们重新组合。分割部分称为“Map”操作,重新组合部分称为“Reduce”操作。它们共同构成了著名的“MapReduce”范式,该范式由 Google 于 2004 年左右引入(见原始论文)。
例如,如果一个文件有 100 条记录需要处理,100 个映射器可以一起运行,每个处理一条记录。或者,也许 50 个映射器可以一起运行,每个处理两条记录。所有映射器完成处理后,框架会在将结果传递给减少器之前进行洗牌和排序。一个减少器在映射器仍在进行时不能开始。所有具有相同键的映射输出值会被分配给一个减少器,减少器然后对该键的值进行聚合。
如何设置 PySpark
如果你已经熟悉 Python 及 Pandas 和 Numpy 等库,那么 PySpark 是一个很好的扩展/框架,利用 Spark 的强大功能,你可以创建更具可扩展性、数据密集型的分析和管道。
安装和设置 PySpark 环境(在独立机器上)的确切过程有些复杂,并且可能会根据你的系统和环境略有不同。目标是使你的常规 Jupyter 数据科学环境在后台使用 PySpark 包与 Spark 一起工作。
这篇文章 在 Medium 上提供了关于逐步设置过程的更多细节。

另外,你可以使用 Databricks 设置来练习 Spark。这家公司由 Spark 的原始创建者创建,并提供了一个出色的即用环境来进行分布式分析。
但想法总是一样的。你将大型数据集分布(并复制)到许多节点上的小固定块中。然后你将计算引擎靠近它们,使整个操作实现并行化、容错和可扩展。
通过使用 PySpark 和 Jupyter notebook,你可以在不花费 AWS 或 Databricks 平台费用的情况下学习所有这些概念。你还可以轻松与 SparkSQL 和 MLlib 接口,用于数据库操作和机器学习。如果你事先掌握了这些概念,那么开始使用真实的大型集群将会容易得多!
弹性分布式数据集(RDD)和 SparkContext
许多 Spark 程序围绕弹性分布式数据集(RDD)的概念展开,RDD 是一个可以并行操作的容错元素集合。SparkContext 存在于 Driver 程序中,通过集群管理器在工作节点上管理分布式数据。使用 PySpark 的好处是所有这些数据分区和任务管理的复杂性在后台自动处理,程序员可以专注于具体的分析或机器学习任务。

rdd-1
创建 RDD 有两种方式——在你的驱动程序中并行化现有集合,或者引用外部存储系统中的数据集,如共享文件系统、HDFS、HBase,或任何提供 Hadoop InputFormat 的数据源。
为了使用基于 Python 的方法进行说明,我们将在这里提供第一种类型的示例。我们可以使用 Numpy 的 random.randint() 创建一个包含 20 个随机整数(范围在 0 到 10 之间)的简单 Python 数组,然后按以下方式创建 RDD 对象,
from pyspark import SparkContext
import numpy as np
sc=SparkContext(master="local[4]")
lst=np.random.randint(0,10,20)
A=sc.parallelize(lst)
注意参数中的 ‘4’。它表示要为这个 SparkContext 对象使用的 4 个计算核心(在你的本地机器上)。如果我们检查 RDD 对象的类型,我们会得到以下结果,
type(A)
>> pyspark.rdd.RDD
与并行化相对的是收集(使用 collect()),它将所有分布的元素带回头节点。
A.collect()
>> [4, 8, 2, 2, 4, 7, 0, 3, 3, 9, 2, 6, 0, 0, 1, 7, 5, 1, 9, 7]
但是 A 不再是一个简单的 Numpy 数组。我们可以使用 glom() 方法来检查如何创建分区。
A.glom().collect()
>> [[4, 8, 2, 2, 4], [7, 0, 3, 3, 9], [2, 6, 0, 0, 1], [7, 5, 1, 9, 7]]
现在停止 SC,并用 2 个核心重新初始化它,看看当你重复这个过程时会发生什么。
sc.stop()
sc=SparkContext(master="local[2]")
A = sc.parallelize(lst)
A.glom().collect()
>> [[4, 8, 2, 2, 4, 7, 0, 3, 3, 9], [2, 6, 0, 0, 1, 7, 5, 1, 9, 7]]
RDD 现在分布在两个块中,而不是四个!
你已经了解了分布式数据分析的第一步,即控制数据如何分配到较小的块中以便进一步处理
一些 RDD 和 PySpark 的基本操作示例
计算元素数量
>> 20
第一个元素(first)和前几个元素(take)
A.first()
>> 4
A.take(3)
>> [4, 8, 2]
使用 distinct 移除重复项
注意:这个操作需要进行 shuffle,以便检测跨分区的重复。因此,这个操作较慢。不要过度使用。
A_distinct=A.distinct()
A_distinct.collect()
>> [4, 8, 0, 9, 1, 5, 2, 6, 7, 3]
要对所有元素求和,请使用 reduce 方法
注意这其中使用了 lambda 函数,
A.reduce(lambda x,y:x+y)
>> 80
或者直接使用 sum() 方法
A.sum()
>> 80
通过 reduce 查找最大元素
A.reduce(lambda x,y: x if x > y else y)
>> 9
在一段文本中查找最长的单词
words = 'These are some of the best Macintosh computers ever'.split(' ')
wordRDD = sc.parallelize(words)
wordRDD.reduce(lambda w,v: w if len(w)>len(v) else v)
>> 'computers'
使用 filter 进行基于逻辑的过滤
# Return RDD with elements (greater than zero) divisible by 3
A.filter(lambda x:x%3==0 and x!=0).collect()
>> [3, 3, 9, 6, 9]
编写常规的 Python 函数以配合 reduce() 使用
def largerThan(x,y):
"""
Returns the last word among the longest words in a list
"""
if len(x)> len(y):
return x
elif len(y) > len(x):
return y
else:
if x < y: return x
else: return y
wordRDD.reduce(largerThan)
>> 'Macintosh'
注意这里的 x < y 进行的是字典序比较,确定 Macintosh 比 computers 大!
在 PySpark 中使用 lambda 函数进行映射操作
B=A.map(lambda x:x*x)
B.collect()
>> [16, 64, 4, 4, 16, 49, 0, 9, 9, 81, 4, 36, 0, 0, 1, 49, 25, 1, 81, 49]
在 PySpark 中使用常规 Python 函数进行映射
def square_if_odd(x):
"""
Squares if odd, otherwise keeps the argument unchanged
"""
if x%2==1:
return x*x
else:
return x
A.map(square_if_odd).collect()
>> [4, 8, 2, 2, 4, 49, 0, 9, 9, 81, 2, 6, 0, 0, 1, 49, 25, 1, 81, 49]
groupby** 返回一个根据给定分组操作的分组元素(可迭代)的 RDD**
在以下示例中,我们使用列表推导式与 groupby 一起创建一个包含两个元素的列表,每个元素都有一个标题(这里是 lambda 函数的结果,简单的模 2 运算),以及一个排序的元素列表,这些元素产生了该结果。你可以很容易地想象,这种分离特别适合于处理需要根据对其执行的特定操作进行分箱/整理的数据。
result=A.groupBy(lambda x:x%2).collect()
sorted([(x, sorted(y)) for (x, y) in result])
>> [(0, [0, 0, 0, 2, 2, 2, 4, 4, 6, 8]), (1, [1, 1, 3, 3, 5, 7, 7, 7, 9, 9])]
**使用 histogram
histogram() 方法接受一个桶/区间的列表,并返回一个包含直方图结果(分桶)的元组,
B.histogram([x for x in range(0,100,10)])
>> ([0, 10, 20, 30, 40, 50, 60, 70, 80, 90], [10, 2, 1, 1, 3, 0, 1, 0, 2])
集合操作
你还可以对 RDD 进行常规的集合操作,比如 union()、 intersection()、 subtract(),或 cartesian()。
查看这个 Jupyter 笔记本获取更多示例。
使用 PySpark 的惰性计算(和缓存)
惰性计算是一种评估/计算策略,它为计算任务准备了详细的逐步内部执行管道图,但将最终执行延迟到绝对需要的时候。这种策略是 Spark 加速许多并行化大数据操作的核心。
让我们使用两个 CPU 核心作为这个例子的说明,
sc = SparkContext(master="local[2]")
创建一个包含 100 万个元素的 RDD
%%time
rdd1 = sc.parallelize(range(1000000))
>> CPU times: user 316 µs, sys: 5.13 ms, total: 5.45 ms, Wall time: 24.6 ms
**某些计算函数 – taketime
from math import cos
def taketime(x):
[cos(j) for j in range(100)]
return cos(x)
检查 taketime 函数所花费的时间
%%time
taketime(2)
>> CPU times: user 21 µs, sys: 7 µs, total: 28 µs, Wall time: 31.5 µs
>> -0.4161468365471424
记住这个结果,taketime()函数的实际时间为 31.5 微秒。当然,确切的数字将取决于你使用的机器。
现在对函数进行 map 操作
%%time
interim = rdd1.map(lambda x: taketime(x))
>> CPU times: user 23 µs, sys: 8 µs, total: 31 µs, Wall time: 34.8 µs
为什么每个taketime函数花费 45.8 微秒,但处理 100 万个元素的 RDD 的 map 操作也花费了类似的时间?
由于惰性计算,即在之前的步骤中没有计算任何内容,只是制定了执行计划。变量interim并不指向数据结构,而是指向一个执行计划,表示为依赖关系图。依赖关系图定义了 RDD 如何从彼此之间计算。
通过reduce方法的实际执行
%%time
print('output =',interim.reduce(lambda x,y:x+y))
>> output = -0.28870546796843666
>> CPU times: user 11.6 ms, sys: 5.56 ms, total: 17.2 ms, Wall time: 15.6 s
所以,这里的实际时间是 15.6 秒。记住,taketime()函数的时间是 31.5 微秒吗?因此,我们期望对于一个 100 万的数组,总时间约为 31 秒。由于在两个核心上并行操作,它花费了大约 15 秒。
现在,我们没有在interim中保存(具体化)任何中间结果,所以另一个简单操作(例如计数元素 > 0)将花费几乎相同的时间。
%%time
print(interim.filter(lambda x:x>0).count())
>> 500000
>> CPU times: user 10.6 ms, sys: 8.55 ms, total: 19.2 ms, Wall time: 12.1 s
缓存以减少类似操作的计算时间(消耗内存)
记住我们在前一步中构建的依赖关系图吗?我们可以使用缓存方法运行相同的计算,告诉依赖关系图规划缓存。
%%time
interim = rdd1.map(lambda x: taketime(x)).cache()
第一次计算不会改善,但它缓存了中间结果,
%%time
print('output =',interim.reduce(lambda x,y:x+y))
>> output = -0.28870546796843666
>> CPU times: user 16.4 ms, sys: 2.24 ms, total: 18.7 ms, Wall time: 15.3 s
现在使用缓存结果运行相同的过滤方法,
%%time
print(interim.filter(lambda x:x>0).count())
>> 500000
>> CPU times: user 14.2 ms, sys: 3.27 ms, total: 17.4 ms, Wall time: 811 ms
哇!计算时间从之前的 12 秒降到了不到 1 秒!这就是使用 Spark 编程的核心特性:缓存和并行化以及惰性执行。
DataFrame 和 SparkSQL
除了 RDD,Spark 框架中的第二个关键数据结构是DataFrame。如果你做过 Python Pandas 或 R DataFrame 的工作,这个概念可能会很熟悉。
DataFrame 是在命名列下的分布式行集合。它在概念上等同于关系数据库中的表、带列标题的 Excel 表格或 R/Python 中的数据框,但具有更丰富的底层优化。DataFrames 可以从各种来源构建,如结构化数据文件、Hive 中的表、外部数据库或现有的 RDD。它还与 RDD 共享一些共同特征:
-
本质上是不可变的:我们可以创建 DataFrame / RDD,但不能更改它。我们可以在应用转换后对 DataFrame / RDD 进行变换。
-
惰性计算:意味着任务不会执行,直到进行某个操作。分布式:RDD 和 DataFrame 本质上都是分布式的。

DataFrame 的优点
-
DataFrames 设计用于处理大量结构化或半结构化数据。
-
Spark DataFrame 中的观察数据在命名列下组织,这帮助 Apache Spark 理解 DataFrame 的模式。这有助于 Spark 优化这些查询的执行计划。
-
Apache Spark 中的 DataFrame 具有处理 PB 级数据的能力。
-
DataFrame 支持多种数据格式和来源。
-
它支持 Python、R、Scala、Java 等多种语言的 API。
DataFrame 基础示例
有关 DataFrames 的基本原理和典型使用示例,请参阅以下 Jupyter Notebooks,
SparkSQL 帮助弥合 PySpark 的差距
关系型数据存储容易构建和查询。用户和开发者通常更喜欢使用易于理解的声明性查询语言,如 SQL。然而,随着数据量和种类的增加,关系型方法在构建大数据应用程序和分析系统时扩展性不够好。
我们在大数据分析领域通过 Hadoop 和 MapReduce 范式取得了成功。这虽然强大,但往往速度较慢,并且为用户提供了一个低级的过程编程接口,要求人们即使对非常简单的数据转换也需要编写大量代码。然而,一旦 Spark 发布,它真正革新了大数据分析的方式,专注于内存计算、容错、高级抽象以及易用性。
Spark SQL 本质上试图弥合我们之前提到的两种模型——关系模型和过程模型之间的差距。Spark SQL 通过 DataFrame API 执行关系操作,可以在外部数据源和 Spark 内置的分布式集合上进行大规模操作!

为什么 Spark SQL 这么快且经过优化?原因在于一种新的可扩展优化器Catalyst,基于 Scala 中的函数式编程构造。Catalyst 支持基于规则和基于成本的优化。虽然过去也提出过可扩展的优化器,但通常需要复杂的领域特定语言来指定规则。这通常会导致显著的学习曲线和维护负担。相比之下,Catalyst 使用 Scala 编程语言的标准特性,如模式匹配,使开发人员可以使用完整的编程语言,同时仍然使规则易于指定。
你可以参考以下 Jupyter 笔记本来了解 SparkSQL 的数据库操作:
你打算在你的项目中如何使用 PySpark?
我们介绍了 Apache Spark 生态系统的基础知识及其工作原理,并提供了一些关于核心数据结构 RDD 使用的基本示例,使用的是 Python 接口 PySpark。此外,还讨论了 DataFrame 和 SparkSQL,并提供了示例代码笔记本的参考链接。
使用 Python 的 Apache Spark 还有很多内容可以学习和实验。PySpark 网站是一个很好的参考,它们会定期更新和改进——所以请保持关注。
如果你对使用 Apache Spark 进行大规模分布式机器学习感兴趣,可以查看 PySpark 生态系统的 MLLib 部分。
原文。经许可转载。
相关内容:
-
学习如何在 5 分钟内使用 PySpark(安装 + 教程)
-
时间序列分析:使用 KNIME 和 Spark 的简单示例
-
Spark NLP 101:LightPipeline
更多相关主题
成为数据优先企业的好处
原文:
www.kdnuggets.com/2022/07/benefits-becoming-datafirst-enterprise.html
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
数据是新的石油,但如今并不是区分竞争力的因素。许多组织拥有大量的数据,需要了解如何组织、访问和管理这些数据。因此,速度,即访问数据的敏捷性和处理优质数据,已成为使组织领先于竞争对手的关键因素。

我们将讨论以数据驱动洞察为中心的工具的好处。进一步地,我们将学习这些工具如何在与商业智能(BI)和人工智能(AI)解决方案结合后,得出更有意义的洞察。
但在深入讨论我们的主要议题之前,让我们首先了解什么是商业智能,以及传统智能和现代智能之间的区别。此外,本文还简要介绍了 BI 与 AI 的不同之处,然后详细阐述了成为数据优先组织的各种好处。
什么是商业智能?
这是通过管理和分析原始数据来获得的智能,并能够生成可操作的洞察,帮助企业做出关键决策。简单来说,它是一系列数据分析工具,帮助领导者做出明智的商业决策。
那么,哪些商业决策是由数据驱动的呢?如果你的组织采纳了数据文化,那么几乎所有的决策都是由数据驱动的。数据驱动型组织不依赖于直觉或多年经验。在快速数字化转型的过程中,了解客户的变化动态,通过直接学习从数据中得出的偏好变得至关重要。
传统与现代智能
现代智能解决方案的采用正在增加。这为商业用户提供了一种更无缝的方式来可视化数据并回答他们的问题。
传统的 BI 解决方案更倾向于自上而下,即静态报告回答业务的某些问题。如果出现后续问题,则需要重复这一过程,并经过多个令人不满的迭代步骤,从分析师那里获取回应后再反馈给业务领导者。这种缓慢的迭代报告周期阻碍并削弱了业务做出及时决策的能力。正如我们在本文开头强调的速度重要性,这些排队的后续查询请求导致数据陈旧,并给企业带来竞争劣势。
因此,数据民主化是实现快速访问数据、新数据发现与探索以及有效信息共享的首选解决方案。现代智能使企业能够使用分析工具应对不断变化的期望,快速定制仪表盘和生成报告。虽然 IT 团队继续管理和保护数据访问,但业务用户与 IT 团队之间的无缝协作将推动关键业务决策的速度,实现双赢。
BI 与 AI 的区别
BI(商业智能)由一系列流程、工具和技术组成,这些流程、工具和技术将原始数据转化为有意义的信息,并支持有效的决策制定。
目前,许多组织拥有数据分析和数据科学团队来推动与数据相关的项目,因此理解 BI 和 AI 解决方案的好处非常重要。
广义上,数据分析分为 4 类:
-
描述性:它专注于回答有关发生了什么的具体问题。
-
诊断性:它回答“为什么”部分,即为什么会发生特定事件?
-
预测性:随着企业致力于从历史数据中学习,预测分析帮助他们回答未来可能发生的事情。
-
处方性:根据对可能未来事件的预测,处方分析为组织提供最佳行动方案或对该事件的回应。
尽管 BI 主要处理结构化数据并生成报告和分析,但 AI 解决方案还可以将非结构化数据作为输入,并将其转化为机器可理解的数据格式。
BI 大多是回顾性的,即帮助回答有关已经发生的事情和原因的高层问题。AI 则超越过去,具有前瞻性,即回答未来可能发生的事情以及企业下一步应该怎么做。
数据的好处持续增加
不言而喻,数据对组织的成功至关重要,并提供了多种好处。让我们了解几个使用案例,看看高质量的数据如何为您的业务指明正确的方向:
-
数据不仅限于分析,还包括了解哪些数据资源将带来最大价值。当领导者需要识别具有最大投资回报率或高影响力和价值的项目时,数据驱动的洞察帮助他们优先考虑项目,从而有效利用时间和资源。
-
数据还提供了对组织中不同部门和地区的全面视图。洞察可以在汇总级别生成,也可以缩小到特定的兴趣部门。它帮助企业识别自己的优势和劣势,并最终据此设计其路线图。
-
高质量的数据使员工能够利用闲暇时间从潜在的数据模式中发现创新。这种创新最终开启了推动业务价值的新途径。
-
数据帮助组织回答如何吸引和引导新客户、为什么客户应该选择他们的产品,以及如何进一步改进以保留客户基础等问题。值得注意的是,成功的商业关键在于建立一个快乐的客户基础,即回头客。
-
本质上,组织只有在将数据作为文化的一部分来推广时才能获得数据的好处,即每位员工(包括高层管理人员和开发人员)都参与数据驱动决策。高质量的数据带来高信心的决策和有效的业务成果。总之,智能使用数据为业务成功奠定了基础。
开发数据驱动的洞察
许多组织正在致力于开发一种洞察工具,《福布斯》也引用了它的好处。
“根据 福布斯,利用大数据洞察的公司平均收入增长约为 44%。“
让我们了解投资建立这种工具的其他有机理由:
-
它帮助企业更快、更及时地了解客户需求。
-
它通过识别如何吸引和引导新客户,同时建立一个快乐的客户基础,来协助业务增长模型。
-
该工具通过关注特定客户群体,帮助建立业务价值主张,以了解他们对哪些服务和产品最感兴趣。
-
它揭示了客户的购买模式、他们对特定产品的实用性认知,并可能为业务带来显著的投资回报率。
-
总结来说,这样的工具使企业通过更深入地了解客户生命周期,从而设计合适的营销活动,利用这些洞察更好地满足客户需求。
在这篇文章中,我们了解了传统智能与现代智能的区别,以及商业智能(BI)与人工智能(AI)的不同。接着,我们探讨了组织如何从优质数据中获得好处的各个维度。最后,我们还讨论了构建数据驱动洞察工具的必要性,以及它如何作为业务增长的推动者。
参考资料
-
careerfoundry.com/en/blog/data-analytics/business-intelligence-vs-data-analytics/ -
www.tableau.com/learn/articles/business-intelligence/enterprise-business-intelligence/benefits
Vidhi Chugh 是一位获奖的人工智能/机器学习创新领袖和人工智能伦理学家。她在数据科学、产品和研究的交叉点工作,以提供商业价值和洞察。她提倡以数据为中心的科学,是数据治理领域的领先专家,致力于构建可信赖的人工智能解决方案。
更多相关内容
自然语言 AI 对内容创作者的好处
原文:
www.kdnuggets.com/2022/08/benefits-natural-language-ai-content-creators.html

图片来自 Freepik
内容创作可能很有挑战性,有时很难设计出高效的工作流程,以确保按时完成任务,同时保持内容的新鲜和吸引力。这就是为什么探索新的工具和流程,以便在不降低标准的情况下让你的生活变得更轻松是始终重要的。自然语言处理就是一个可以带来巨大改变的工具。
在这篇文章中,我们将讨论 自然语言 AI 对内容创作者的好处,强调你为什么应该考虑使用它来改善你的内容输出。
什么是自然语言 AI 内容写作?
自然语言处理(NLP)或自然语言理解(NLU)是人工智能和数据科学的结合,用于提供多种功能的工具,包括内容写作。它使计算机能够强烈理解人类语言,将其转化为各种软件和设备(如智能手机)可以使用的数据。
这项技术允许用户发出语音和基于文本的命令和查询以完成不同的操作。聊天机器人是一个 很好的例子,通过智能 AI 对关键词的反应,生成连贯的回答。查询由一个算法处理,该算法提供最合适的回答以解决客户的问题。
其他例子包括智能家居技术、高级家庭安全系统和气候控制设备。
大量数据可以通过自然语言 AI 进行分析,这种强大的技术现在被应用于内容创作。改变内容世界的一个自然语言理解模型是 OpenAI 的 GPT-3。我们将在文章后面详细讨论 GPT-3 的好处。
人工智能内容写作的快速介绍
AI 内容创作通过自然语言理解/处理来理解用户提交文本的含义,以便编译可以用来生成连贯且引人入胜的内容的数据。这是通过处理书面和口头语言,包括地方方言、缩写、口语和甚至拼写错误来完成的。
该文本被分为三个部分:
-
语义信息 - 特定词汇的含义。
-
句法信息 - 句子的结构。
-
上下文信息 - 词语、短语和句子之间的关系。
自然语言 AI 对内容创作者的好处是什么
我们已经简要介绍了用于内容创作的自然语言 AI。现在,让我们看看自然语言理解模型 GPT-3 的关键优势。这是许多市场领先工具所使用的工具,这些工具旨在协助内容创作者。
使用自然语言 AI 创建主题列表
内容创作者喜欢GPT-3 的一个功能是其能够根据简短句子或简单提示编制出可写作的主题列表。作为内容创作者,在制定内容计划时,有时很难想到足够有趣的主题。这尤其适用于你正在扩展到你知之甚少的新领域时。
使用 GPT-3,你可以输入一个提示,例如“我是一名食品博客作者,想推广意大利美食,这里是我将要写的主题”,然后在下一行使用破折号符号来表示这是一个列表。基于这个提示,GPT-3 将返回几个建议的主题,深入探讨其收集的最新数据。
合并多个主题
如果你已经用尽了单一主题或话题的所有潜力,你可以考虑将这些内容与另一个主题领域结合起来,创造出有趣而独特的东西。这是 GPT-3 可以帮助完成的任务。
要合并不同的主题,你必须输入一个详细的提示,指示工具合并这些主题。首先,你必须输入一个短语或句子,告诉 GPT-3 你的目标是什么(合并主题),然后需要跟随这些单独的主题和一个简短的总结(见下例)。
#### 将这些不同的主题结合成一个全新的主题
## 主题 1:最佳意大利美食
(摘要)
## 主题 2:有趣的罗马历史事实
(摘要)
一旦你点击提交,工具将为你提供一个结合了意大利美食和与罗马帝国相关的历史事实的建议主题。每个主题必须广泛相关以保证结果有用;将两个完全无关的主题结合起来可能会导致一些非常奇怪的建议。
将自由形式写作转化为结构化内容
头脑风暴可能是一项繁琐的工作,尤其是在整理你的粗略想法以将其转化为结构化内容时。GPT-3 可以整理你的自由形式写作,并以结构化的方式将其拼接在一起,将粗糙和无序的内容转化为可用的模板。巧妙的算法将分析自由形式写作,并突出任何具有概念意义的内容以创建文章结构,这意味着你不需要手动起草。
自然语言 AI 在文章规划阶段可以大大提高组织效率。这在成立新业务时尤为重要,以确保你能够跟上甚至超越竞争对手。AI 可以成为新成立的内容创作公司最强有力的武器之一。
总结文章并提取关键词
对于专注于更技术性主题的内容创作者来说,GPT-3 特别有用,它可以帮助总结复杂的文章并提取可以用于创作相关内容的关键词。关键词研究有时可能需要花费大量时间,因此使用 AI 来完成这项任务可以帮助提高工作效率。
只需用简短的提示请求 AI 总结文章,如下所示。
#### 为我总结这篇技术文章
## 文章
(文章内容)
## 总结
自然语言 AI 内容写作是否有任何缺点?
作为一种新技术,自然语言处理及其理解确实有一些缺点。然而,从内容创作的角度来看,其好处远远超过这些缺点。
自然语言处理的一些缺点包括:
-
新用户可能需要大量培训
-
数据可能需要较长时间才能汇编完毕,工具才会完全有效
-
定义不清的提示可能导致无用的结果
-
AI 不是 100%可靠的,且难以预测
最佳 AI 内容写作工具有哪些?
Open AI 的 GPT-3 被认为是最好的自然语言处理 AI 内容写作模型,已经有多个工具基于它。这些工具包括 Jasper、ChibiAI、Copysmith 和 Frase。
结论
对于内容创作者来说,自然语言 AI 是一个极好的新工具,可以显著提高工作效率。它可以帮助你进行更有组织的规划、减少关键词研究所需的时间,以及通过合并主题生成更有趣的文章。
GPT-3 是一个自然语言理解模型,被 Jasper 等内容工具使用,内容创作者可以通过输入简单的提示来执行各种功能。GPT-3 的高级算法随后返回的结果可以用来创建更好、更结构化的内容。
Nahla Davies是软件开发者和技术作家。在全职投入技术写作之前,她曾在一家 Inc. 5,000 的体验品牌组织担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关内容
伯克森-杰克尔悖论及其对数据科学的重要性
原文:
www.kdnuggets.com/2023/03/berksonjekel-paradox-importance-data-science.html

作者提供的图片
如果你是数据科学家或有意成为数据科学家,你将知道统计在这个领域中的重要性。统计帮助数据科学家收集、分析和解释数据,通过识别模式和趋势,进而做出未来的预测。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
什么是统计悖论?
统计悖论是指统计结果与预期相矛盾的情况。由于很难在没有进一步方法的情况下理解数据,因此确切原因可能很难确定。然而,这些悖论对于数据科学家来说是重要的,因为它们提供了可能导致误导性结果的线索。
以下是与数据科学相关的统计悖论列表:
-
辛普森悖论
-
伯克森悖论
-
假阳性悖论
-
精确度悖论
-
可学习性-哥德尔悖论
在这篇文章中,我们将重点关注伯克森-杰克尔悖论及其对数据科学的相关性。
伯克森-杰克尔悖论是什么?
伯克森-杰克尔悖论是指当两个变量在数据中相关时,当数据被分组或子集化时,相关性不会被识别。通俗来说,这种相关性在数据的不同子组中是不同的。
伯克森-杰克尔悖论以最早描述这一悖论的统计学家约瑟夫·伯克森和约翰·杰克尔的名字命名。伯克森-杰克尔悖论的发现是在这两位统计学家研究吸烟与肺癌之间的关联时进行的。在他们的研究中,他们发现,住院治疗肺炎的患者与肺癌之间存在关联,而这种关联与一般人群相比。然而,他们进一步的研究表明,这种关联是由于吸烟者更频繁地因肺炎住院,而非吸烟者则较少。
为什么会发生这种情况?
根据统计学家对伯克森-杰克尔悖论的首次研究,你可能会说需要更多研究来弄清楚相关性的确切原因。然而,也有其他原因解释伯克森-杰克尔悖论的发生。
-
隐藏变量:数据集可能包含影响结果的隐藏变量。因此,当研究两个变量的相关性时,数据科学家和研究人员可能未考虑所有潜在因素。
-
样本偏差:数据样本可能无法代表总体,这可能导致误导性的相关性。
-
相关性与因果性:在数据科学中,重要的是要记住相关性并不意味着因果性。两个变量可能相关,但这并不意味着一个变量导致了另一个变量。
为什么伯克森-杰克尔悖论在数据科学中很重要?
统计推理在数据科学中非常重要,主要问题在于处理误导性结果。作为数据科学家,你希望确保生成准确的结果,以用于决策过程和未来预测。做出错误的预测或产生误导性结果是最不希望发生的情况。
如何避免伯克森-杰克尔悖论
有几种方法可以用来避免伯克森-杰克尔悖论:
使用统计方法控制隐藏变量
-
统计建模:你可以使用统计建模来更好地理解两个或多个变量之间的关系。这样,你可以识别可能影响结果的隐藏变量。
-
随机对照试验:这是一种将参与者随机分配到治疗组或对照组的方法。这可以帮助数据科学家控制可能影响研究结果的隐藏变量。
-
结合结果:你可以将多个研究结果结合起来,以帮助你更好地理解研究。这样,数据科学家对每个研究中的隐藏变量有了更好的理解和控制。
数据来源的多样性
如果你在处理由于样本数据不代表总体而导致的误导性结果,可以考虑使用来自不同来源的数据。这将帮助你获得更具代表性的总体样本,更深入地研究变量,并获得更好的理解。
总结
误导性的结果可能会阻碍公司发展。因此,在处理数据时,数据专业人员需要了解数据的局限性、不同变量及其之间的关系,以及如何减少误导性结果的发生。
如果你想了解更多关于辛普森悖论的内容,可以阅读这个:辛普森悖论及其在数据科学中的影响
如果你想了解更多关于其他统计悖论的内容,可以阅读这个:5 个数据科学家应该知道的统计悖论
尼莎·阿亚 是一名数据科学家、自由技术撰稿人以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程及基于理论的知识。她还希望探索人工智能如何/可以促进人类寿命的不同方式。她是一位渴望学习者,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关主题
适合你文本分类任务的最佳架构:对比你的选择
原文:
www.kdnuggets.com/2023/04/best-architecture-text-classification-task-benchmarking-options.html

图片来源于编辑
在我们之前的文章中,我们介绍了基于现代自然语言处理技术的文本分类模型的各种方法。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
在选择传统的 TF-IDF 方法、预训练嵌入模型和各种形状和大小的变换器时,我们希望根据自己的经验提供一些实用建议。哪些模型最适合不同的情况?你自己工作领域中可以找到哪些使用案例?
为了增加趣味性,我们想展示一个实际的基准测试示例,并使用我们为这篇快速跟进文章选择的数据集进行比较。
描述数据集和任务
为了说明我们的观点,我们选择了Twitter 金融新闻,这是一个包含金融相关推文的英文数据集,并且附有注释。它通常用于构建金融相关内容分类模型,将推文分类到多个主题中。
这是一个中等规模的数据集,非常适合用来展示不同模型的表现。同时也相当多样化,这个规模让我们可以相对快速地训练和评估模型。
这个领域有趣的地方在于金融语言通常简练且简洁。存在大量描述品牌、术语和相关实体的专有名词,模型需要学会将它们与含义完全不同的普通名词区分开来。直观地,微调预训练的通用语言模型在这个领域应该能提升整体性能和准确性。
该数据集包含大约 21,000 条记录。既不太小也不太大,非常适合展示每种模型和方法的优缺点。等我们得到结果后再来回顾一下。
最终,数据集有 20 个类别。这不是一个常见的分类任务,你需要区分少数几个情感类别和情感色调。还有一个不平衡的问题。最频繁和最少见的类别之间有 60 倍以上的差异,一些方法可能表现不佳。
让我们看看不同模型在我们的基准测试中的表现如何。
描述方法
基于我们之前的文章,FastText、BERT、RoBERTa(经过二阶段调整)和 GPT-3 是我们用来评估其性能和效率的选择。数据集被拆分为训练集和测试集,分别包含 16,500 和 4,500 个项目。在对前者进行模型训练后,我们在后者上测量了模型的性能和效率(推理时间)。
为了训练一个 FastText 模型,我们使用了fastText 库及相应的命令行工具。我们通过在文本中插入带有正确前缀的标签来准备数据集,运行 fasttext 监督命令以训练分类器,并在仅有 CPU 的机器上等待几分钟以生成模型。接下来的命令 fasttext predict 给出了测试集的预测结果和模型性能。
对于变换器模型,我们选择了三种稍有不同的模型进行比较:BERT(更正式,best-base-uncased)、RoBERTa-large,以及后者的一个改编版本,该版本针对几个金融相关数据集的情感分类进行了调整(在HuggingFace 网站查看)。我们在实验中使用了变换器库,尽管这需要编写一些代码来实际运行训练和评估程序。一台配备 A100 GPU 的单机进行了训练,直到每个模型满足早期停止条件,这一过程耗时 20 到 28 分钟。训练好的模型被存储在 MLFlow 注册表中。
为了训练基于 GPT-3 模型的分类器,我们参考了官方文档并使用相应的命令行工具提交数据进行训练,跟踪其进展,并为测试集进行预测(更正式地说,生成模型的“补全”)。由于工作本身发生在 OpenAI 的服务器上,我们没有使用任何特定的硬件。只需一台普通的笔记本电脑即可创建基于云的模型。我们训练了两个 GPT-3 变体,Ada 和 Babbage,以查看它们是否表现不同。在我们的场景中,训练一个分类器需要 40 到 50 分钟。
训练完成后,我们在测试集上评估了所有模型以建立分类指标。我们选择了宏平均 F1 和加权平均 F1 来进行比较,因为这让我们可以估计精度和召回率,并查看数据集不平衡是否影响了指标。我们还比较了模型的推理速度,单位为每个项目的毫秒,批处理大小为一。在 RoBERTa 模型中,我们还包括了一个 ONNX 优化版本以及使用 A100 GPU 加速器的推理。从我们调优后的 Babbage 模型测得的平均响应时间给出了 GPT-3 的速度(注意,OpenAI 应用了一些速率限制器,因此实际速度可能会因使用条款而有所不同)。
结果
训练效果如何?我们将结果整理在几个表格中,以展示最终产品以及我们观察到的效果。
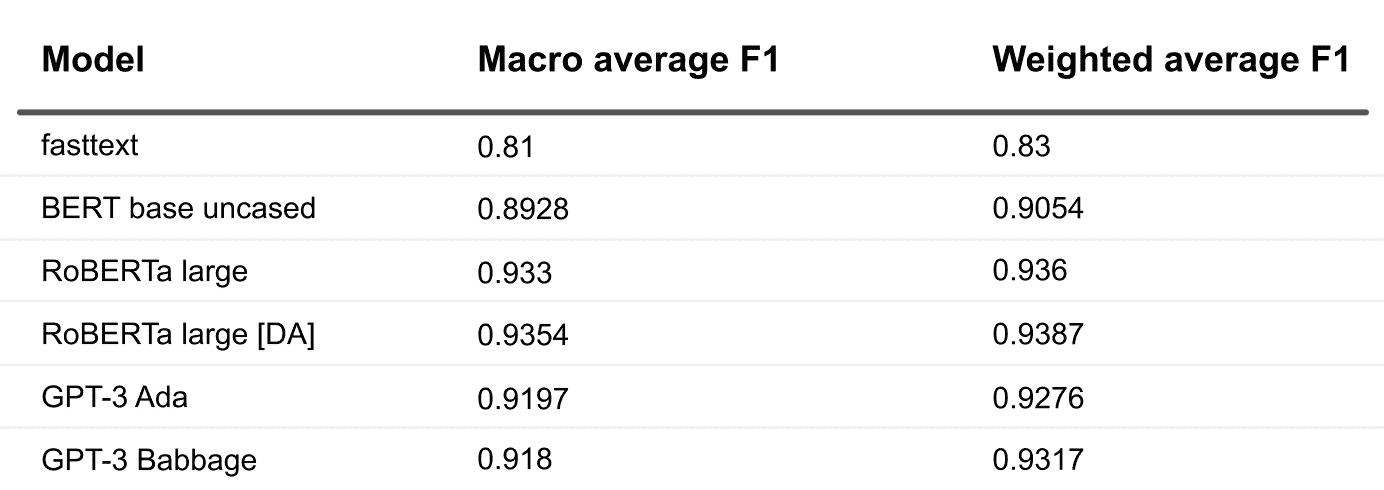
作者照片
首先引起我们注意的是 fasttext 的表现远远落后。尽管如此,它在计算、时间和训练方面所需的资源极少,为我们提供了一个低标准的基准。
变换器的表现如何?正如预期的那样,RoBERTa 的结果优于 BERT,这可以很容易归因于其规模优势。RoBERTa 在特定领域的分类任务中通常表现更好。公平起见,我们为这次比较特别选择了一个大型的 RoBERTa 架构,而基础的 RoBERTa 模型可能与 BERT 的表现相当,尽管在底层语料库和训练方法上有所不同。
BERT 和 RoBERTa 之间 F1 指标的明显差距可能也与我们处理的类别数量相当大有关。数据集存在的不平衡往往会被较大的模型更好地捕捉。但这只是我们的猜测,验证这一点需要更多的实验。你还可以看到,领域预训练的 RoBERTa 提供了一个微小的准确性提升,但这一提升并不显著。很难说预训练的领域调整模型是否对我们的实验真正有价值。
接下来是 GPT-3。我们选择了 Ada 和 Babbage 模型,以便与 BERT 和 RoBERTa-large 进行公平比较,因为它们具有出色的参数规模,这些参数规模逐步增长(从 BERT 的 1.65 亿参数和 RoBERTa-large 的 3.55 亿参数到 Ada 的 27 亿参数和 Babbage 的 67 亿参数),并可以展示模型大小是否确实带来了比例性能提升。令人惊讶的是,Ada 和 Babbage 提供的指标几乎相同,而且即使没有领域特定的预训练,它们实际上也不如 RoBERTa。然而,这其中有原因。请记住,GPT-3 API 可访问的模型实际上为用户提供了生成性推理接口,因此它们试图预测一个标记来对分类任务中的每个示例进行分类。另一方面,RoBERTa 和其他变换器模型的架构的最后一层已正确配置用于分类。想象一下,在最后的 Logit 或 Softmax 中,返回你传递给它的任何数据项的所有类别的可能性。虽然巨大的 GPT-3 足以通过生成正确的标记类别来处理 20 个类别中的一个,但在这里显得有些过剩。我们不要忘记,GPT-3 模型经过微调,并且只需三行代码即可访问,而 RoBERTa 则需要在你的架构上进行工作。
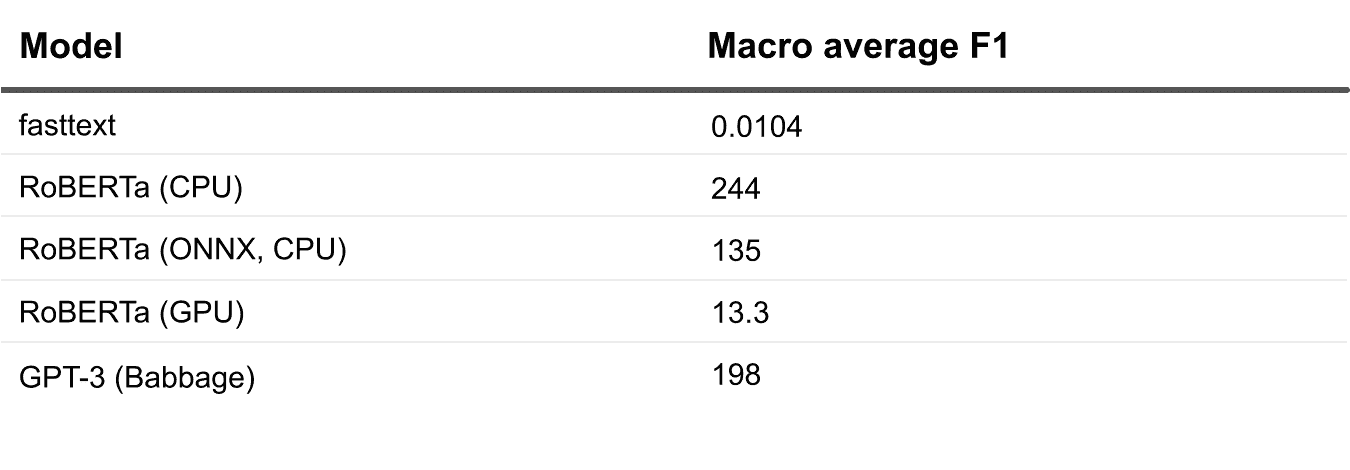
作者提供的照片
现在,让我们最终比较这些模型及其推理设置在请求执行速度方面的表现。由于我们不仅仅是在训练它们以提高性能和准确性,我们还需要考虑它们为新数据返回推理结果的速度。我们记录了对模型的在线同步请求,并尝试了解每个模型的最佳定位。
这里的赢家是 fasttext。然而,它的准确性迫使我们继续往下看。
在 RoBERTa 和 GPT-3 设置之间,我们可以看到,尽管 GPT-3 是最大的,但它的速度相对较快,特别是考虑到它的响应时间包括了到 API 端点的双向网络通信。这里的实际推理很小。这显然是好的,尤其是因为这是一个相对简单的解决方案,可以设置、微调并实现模型调用。虽然它可能很昂贵,特别是如果你计划频繁发送大量数据,但成本效益的决策还是取决于你自己。
GPU 托管版本在 RoBERTa 设置中是赢家。GPU 大大提升了推理计算的性能,但将模型服务器托管在 GPU 机器上可能会超出你的预算。推出基于 GPU 的模型服务器也可能很棘手,特别是如果你之前没有做过这种事情的话。
你还需要记住,尽管这些基准测试在返回模型请求结果方面都很快速,但你不应忘记进行一些规划,细化你计划如何在项目中使用这些模型。实时推理还是异步批量请求?通过互联网访问还是在本地网络内?你是否在模型响应之上还有业务逻辑操作的开销?所有这些都会在每次请求中增加比实际模型推理计算本身更多的时间开销。
结论与后续想法
我们学到了什么?我们尝试展示一个实际例子,平衡运行各种模型的难度、其准确性指标以及它们准备使用时的响应速度。显然,根据你的项目确定何时使用什么以及如何使用是一个挑战。但我们希望能给你一些指导?—— 在 GPT 模型方面没有万灵药。尤其是在机器学习中,我们都必须精打细算。
在 Toloka,我们正在努力开发一个平台,使用户能够使用与 GPT-3 API 相同的三个 API 调用来训练、部署和使用像 RoBERTa 这样的转换器。
在我们的下一篇文章中,我们将进行更多的实验,研究如何缓解数据集不平衡的影响,并进行上采样或下采样以实现平衡。我们怀疑 GPT-3 生成模型的表现会优于 RoBERTa-large。我们还将讨论如果使用一个更小的数据集,这些结果可能会如何变化,并指出 GPT-3+模型在分类任务中何时何地会超越其他模型。敬请关注,并查看我们在 Toloka ML 团队博客上的更多工作。
亚历山大·马卡罗夫 是 Toloka.ai 的高级产品经理,负责 Toloka.ai ML 平台的产品开发,曾是健康科技创业者和 Droice Labs 的共同创始人。
更多相关内容
2023 年你应该考虑的顶级 AutoML 框架
原文:
www.kdnuggets.com/2023/05/best-automl-frameworks-2023.html

图片来源于 Bing 图片创作工具
人工智能(AI)将在未来改变我们的社会。对 AI 专家、数据分析师和数据专家的巨大需求意味着那些希望在竞争激烈的技术环境中取得成功的组织,必须在资源分配上尽可能高效。由于 AI 专业人士 缺乏,数据的探索和预测必须尽可能自动化,以便专家能够专注于更重要的任务。
自动机器学习(AutoML)框架正是实现这一目标的工具。通过自动化数据模型的选择、构建和参数化,AutoML 框架可以为数据专家腾出时间,以便他们专注于更复杂的分析方面。本文将讨论 AutoML 框架的基本知识,它们如何帮助开发 AI 项目,以及在 2023 年最值得使用的 AutoML 框架。
为什么使用 AutoML 框架?
数据集使分析师能够创建预测模型。尽管机器学习可以处理数据并形成预测模型,但这一过程通常繁琐且耗时。传统的机器学习涉及数据处理、确定目标数据特征、寻找最准确的学习模型、调整必要的超参数,以及使用最佳参数训练学习模型。当这一过程中的某些或全部步骤可以自动化时,结果可以更快获得。
AutoML 和 AI 可以开启新的可能性,但在不当使用的情况下,它们也可能成为危险的武器。自动机器学习和 AI 正日益成为一种威胁。网络攻击、身份盗窃和 信用卡诈骗 都可能借助 AI 或自动机器学习的帮助进行,因为它们能够快速处理大量数据并寻找匹配。
AutoML 框架通过处理常规序列和消除手动测试模型来消除数据分析师工作的繁琐方面。AutoML 可以自动化数据的收集和组织过程,并帮助测试模型的超参数。以下是一些最好的 AutoML 框架,可以帮助数据专家在项目中取得更大的成就。
1. TransmogrifAI
使用 Scala 语言创建,并基于 SparkML 框架的 TransmogrifAI 自动化了机器学习的五个最重要功能。优化超参数、检查函数、选择模型、推导函数和变形(因此得名)都是该框架可以自动化的功能。这对于数据清洗、模型选择和特征工程非常有用。
2. AutoGluon
AutoGluon 是 AWS 提供的一个开源库,主要面向机器学习应用开发人员。这是一个理想的 AutoML 框架,适合那些不是专家的人,因为它非常用户友好,同时提供强大的深度学习方法。可以迅速且高精度地实现预测。它也可以成为那些希望探索给定数据集所能实现的内容的良好起点。
AutoGluon 在自动对象识别、表格预测以及以文本和图像形式组织数据方面表现出色。对于更专业的用户,AutoGluon AutoML 框架通过其开源库提供了对模型参数编程的深入了解。
3. MLJAR
MLJAR 可以通过浏览器访问,并可用作快速创建和测试 AutoML 模型的平台。与 NVIDIA 的 CUDA、Python 和 Tensorflow 兼容,还提供了易于使用的 Hyperfeit 搜索功能。数据集可以轻松下载到网站,机器学习算法可以被尝试和测试以确定最佳算法。通过 MLJAR AutoML 框架,识别和部署最佳预测模型变得更加简单,甚至可以分享你的结果。
这显然是更好的 AutoML 框架之一,但它确实需要付费。用户必须支付订阅费用才能使用所有功能,或者只能使用免费的版本,数据限制为 0.25 GB。
4. DataRobot
也许是列表中最容易识别的名称,DataRobot 是数据分析师使用的流行 AutoML 框架。预测分析可以用于没有编程、软件开发或机器学习知识的业务人员。在一个简单的过程中,组织可以创建实时预测模型,通过自动化机器学习提高准确性。
这个机器学习框架的工作流程可以被调整以满足用户的需求。商业专业人士可以轻松使用它根据输入的数据获得准确的预测,而经验丰富的数据科学家则可以调整参数以完善他们自己的预测模型。
5. Google Cloud AutoML
Google AutoML 使得拥有较少机器学习知识的开发人员能够创建高度准确的自定义模型。它支持大量的算法和机器学习技术。利用神经网络架构,Google AutoML 简化了整个过程,并提供了易于使用的界面。
然而,Google AutoML 的价格不菲,除非你打算仅用于研究目的,否则公司不提供免费或演示版本,在这种情况下,可以使用限制版本。
结论
自动化机器学习正在逐渐流行,对这一领域专家的需求正在快速增长。有很多重要的任务只能由数据科学家和分析师完成,例如管理模型性能和分析预测模型产生的数据。
自动化这些日常任务可以节省数据分析师的大量时间,使他们能够专注于更关键的职责。这就是为什么 AutoML 框架如此有价值,并且未来仍将继续如此的原因。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾担任过诸多有趣的职位,其中包括在一家《Inc. 5000》体验式品牌化组织担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
来自大学的最佳 AI 课程与 YouTube 播放列表
原文:
www.kdnuggets.com/2023/08/best-courses-ai-universities-youtube-playlists.html

由作者提供的图片
当你想开始新的事物时,确实很难找到最佳选择。在线有大量的 AI 课程,筛选不同的课程并尝试确定哪个最适合会非常费劲。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
制定学习计划可能会让你感到精疲力竭并导致决策疲劳。因此,我决定减轻你的负担,并创建了一份最佳机器学习和人工智能课程的列表,包括 YouTube 播放列表。
这个列表包括了由可信赖的大学创建的课程。你可能会发现一些课程有相似之处,这很正常。我提供了一个范围,因为我理解每个人的学习方式不同,有些人喜欢演示文稿,有些人对学习的声音很挑剔。为了满足每个人的需求,希望你觉得这个列表有用。
让我们直接进入主题!
斯坦福大学课程
斯坦福大学以其在全球领先的研究和教学机构之一而闻名,并提供富有洞察力的课程。以下是课程列表及其相应的 YouTube 播放列表。
-
CS221 - 人工智能:原理与技术 - YouTube 播放列表
-
CS224U:自然语言理解 - YouTube 播放列表
-
CS224n - 深度学习的自然语言处理 - YouTube 播放列表
-
CS224w - 图形化机器学习 - YouTube 播放列表
-
CS229 - 机器学习 - YouTube 播放列表
-
CS230 - 深度学习 - YouTube 播放列表
-
CS231n - 用于视觉识别的卷积神经网络 - YouTube 播放列表
-
CS234 - 强化学习 - YouTube 播放列表
-
CS330 - 深度多任务与元学习 - YouTube 播放列表
-
CS25 - 变压器联合 - YouTube 播放列表
卡内基梅隆大学课程
卡内基梅隆大学致力于培养解决问题的能力、创新驱动者以及技术和艺术的先驱。他们提供了良好的课程,以帮助你启动和提升人工智能职业生涯。随着大语言模型(LLMs)和自然语言处理(NLP)作用的发展,以下是帮助你更好理解 LLMs 理论和构建的课程列表。
-
CS 10-708: 概率图模型 - YouTube 播放列表
-
CS/LTI 11-711: 高级自然语言处理 - YouTube 播放列表
-
CS/LTI 11-737: 多语言自然语言处理 - YouTube 播放列表
-
CS/LTI 11-747: 自然语言处理的神经网络 - YouTube 播放列表
-
CS/LTI 11-777: 多模态机器学习 - YouTube 播放列表
-
CS/LTI 11-785: 深度学习导论 - YouTube 播放列表
-
CS/LTI 11-785: 神经网络 - YouTube 播放列表
-
CS/LTI 低资源自然语言处理训练营 2020 - YouTube 播放列表
麻省理工学院课程
另一所著名的大学专注于私立研究和科学技术等领域的知识和教育进步。这些课程更侧重于深度学习。
-
6.006 - 算法导论 - YouTube 播放列表
-
6.S191 - 深度学习导论 - YouTube 播放列表
-
6.S094 - 深度学习 - YouTube 播放列表
-
6.S192 - 艺术、美学与创造力的深度学习 - YouTube 播放列表
DeepMind x UCL
DeepMind 研究人员与伦敦大学学院(UCL)合作,为学生提供全面课程,以更好地理解人工智能。
-
COMP M050 - 强化学习导论 - YouTube 播放列表
-
深度学习系列 - YouTube 播放列表
总结
这个列表旨在满足各种不同水平和理解能力的需求。你可能对人工智能完全陌生,这可能是你第一次接触许多新术语。你也可能是一个希望了解更多关于大型语言模型(LLMs)和自然语言处理(NLP)的机器学习工程师。
我希望这个列表能减轻你的负担,为你提供一个更轻松的学习计划和人工智能学习指南。
尼莎·阿亚 是一名数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议、教程和理论知识,并希望探索人工智能如何有益于人类寿命的不同方式。她是一个热衷学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
适合初学者的数据科学书籍
原文:
www.kdnuggets.com/2022/03/best-data-science-books-beginners.html

图片由 Kimberly Farmer 提供,来源于 Unsplash
随着播客和 YouTuber 在社交媒体世界的兴起,向人们传达发生了什么、有什么新鲜事等,最好的知识仍然存在于图书馆的书籍中。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
在网上学习已成为一种新的学习方式。然而,大多数这些研究曾经都是记录下来的。许多人对进入数据科学领域感兴趣,但选择合适的路径和资源可能会很困难。
有成百上千的训练营、备忘单和 PDF 报告可供选择;但是,你如何知道哪个才是适合你的,而不会感到不知所措呢?
我将介绍一些推荐的适合初学者的数据科学书籍。
数据科学实用统计学
作者:Peter Bruce 和 Andrew Bruce
 当你首次考虑进入数据科学领域时,很多人会忽略该领域的基础知识:统计学。统计方法是数据科学的一个关键概念,但只有少数数据科学家对统计学有深入的理解和知识。
当你首次考虑进入数据科学领域时,很多人会忽略该领域的基础知识:统计学。统计方法是数据科学的一个关键概念,但只有少数数据科学家对统计学有深入的理解和知识。
网上有许多关于统计学的课程和书籍可供购买,但很少有资源从数据科学的角度涵盖统计学。
如果你希望成为一名成功的数据科学家,你必须经历不同的层次,并以良好的标准理解每一层。这本书可以让你从理解数据科学到掌握数据科学。
在这本书中,你将学习随机抽样及其如何减少偏差并产生更高质量的数据集,以及使用回归来估计结果和检测异常。
Python 速成教程
作者:Eric Matthes
 如果你选择了 Python 作为你的编程语言学习,这本《Python 速成教程》非常适合你。这本书是全球最畅销的 Python 编程语言学习指南。
如果你选择了 Python 作为你的编程语言学习,这本《Python 速成教程》非常适合你。这本书是全球最畅销的 Python 编程语言学习指南。
你将学习编程的基础知识,如类和循环,同时学习如何编写干净的代码,书中有练习以指导和测试你的技能。
当你完成书的简介部分并对 Python 有了良好的理解后,你将进入项目实现、数据可视化和简单的 Web 应用程序开发。
很多数据科学项目需要 Python 的基础知识,因此学习这些是至关重要的,它们将帮助你提高数据科学技能,并为你在这一领域的发展奠定基础。
Python 机器学习简介:数据科学家的指南
作者:Andreas C. Müller 和 Sarah Guido
 机器学习是数据科学中非常热门的元素,越来越多的人尝试从数据科学家转型为机器学习工程师。
机器学习是数据科学中非常热门的元素,越来越多的人尝试从数据科学家转型为机器学习工程师。
这本书是为 Python 用户准备的,但如果你没有 Python 的基础知识,这本书也能帮助你在学习过程中掌握这门语言。
这本书将涵盖机器学习的基础知识,提供实际示例,帮助你逐步构建一个机器学习模型。适合需要了解 Python 和机器学习基础的初学者。
一旦你理解了概念,建议你继续阅读高级书籍。
Python 数据科学手册
作者:Jake VanderPlas
 当你对编程和数据科学的概念有了更多的信心后,你将准备好探索 Python 库。
当你对编程和数据科学的概念有了更多的信心后,你将准备好探索 Python 库。
这本书深入讲解了 Python 库,如 Pandas、Numpy、Matplotlib、Scikit-learn 等。掌握这些技能后,你将能够提高数据技能,进行更好的分析,并制作数据可视化以展示你的发现。
这是数据科学领域中的一个重要步骤,许多当前的数据科学家日常工作都围绕这些库展开。
Python 数据分析
作者:Wes McKinney
 尽管机器学习目前正如火如荼,但数据科学的其他方面也被广泛使用。数据分析就是其中之一。
尽管机器学习目前正如火如荼,但数据科学的其他方面也被广泛使用。数据分析就是其中之一。
本书提供了使用 Python 处理、处理、清理和分析数据集的完整指导。你将学习到 pandas、NumPy、IPython 等的最新版本,并能够处理实际案例研究。
学会解决现实世界的数据分析问题是作为数据科学家的一个重要技能,强烈推荐。作为数据科学家,你的大部分时间都用于数据整理,不过如果你对库和工具有很好的了解,可以减少这方面的时间。
Nisha Arya 是一名数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何/能如何有利于人类寿命的不同方式。作为一个热衷于学习的者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
了解更多相关内容
哪个最好:数据科学训练营 vs 学位 vs 在线课程
原文:
www.kdnuggets.com/2022/09/best-data-science-bootcamp-degree-online-course.html
| 类型 | 成本 | 时长 | 学习方式 |
|---|---|---|---|
| 数据科学训练营 | $13,500 | 通常 12-16 周 | 指导 |
| 数据科学学位 | $32,000-$200,000 | 两到四年 | 指导 |
| 数据科学在线课程 | $0-$50 | 从几天到几周 | 自学 |
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
世界上有大量的信息供任何想学习数据科学的人使用。困难在于选择合适的格式。你是选择数据科学训练营?还是争取获得学位?或者尝试在线课程呢?
答案归结为:这要看情况。取决于你有多少时间和金钱,你是否喜欢自学,以及你是否有任何关于数据科学的先前知识。你想成为自由职业者吗?数据科学只是一个爱好吗?你想进入数据科学工作吗?
数据科学训练营通常持续 3-6 个月。这是一个对数据科学的深入训练。一些训练营仅覆盖一种语言,而其他的则包括所有基础知识。虽然有兼职选项,但你应该预计每周至少要花费大约 40 小时在此上面。
数据科学学位是一个更全面、更慢、更昂贵的选项。你可以选择从认证大学获得两年或四年的学位,虽然现在大多数人选择像 EdX 或 Coursera 这样的平台从大学提供的课程中学习。
在线课程是最灵活的选项。有大量不同的选择,从初学者到高级,从 Ruby 到 Python 到 Perl,视频课程、基于小组的课程、免费到几千美元,以及你能想象到的各种学习方式。
即使你想在最后获得一份工作,任何选择都能奏效。大多数雇主不太在意你的资质,他们想要证明你能做你所说的事。
让我们详细分析这三种选择:优缺点、成本,以及最终你可以期望从中获得什么。
数据科学训练营

数据科学训练营通常由一个组织以整批学生的形式同时进行。他们大约在十年前开始变得受欢迎,如今你可以找到几乎任何类型的数据科学学习训练营。
数据科学训练营的优点
数据科学训练营最大的好处——也是最大的缺点,不过我们稍后会讨论——就是其极高的强度。
想要完全沉浸在学习环境中,直到你可以吃、睡、呼吸代码?训练营是你的正确选择。这是大量的工作,但很有回报。这些训练营会像全职工作一样花费时间,还加上作业。它是快速学习的好方法。
训练营是一种系统化的学习体验。它就像是强化版的大学教育。你会有讲座、办公时间、作业,甚至职业指导课程。它们是完整的套餐。许多训练营甚至在结束时提供工作保证,因为他们对自己教授可就业技能的能力非常有信心。
由于这些训练营是按小组进行的,它们保持了很高的灵活性。与大学不同,大学在融入新语言和技术时变化缓慢,而训练营会教授最前沿的技术,这有助于你在求职时具有竞争力。
数据科学训练营的缺点
数据科学训练营的缺点,正如我之前提到的,类似于优点。它很密集。你会花费大量金钱。2020 年,数据科学训练营的平均费用约为 13,500 美元。
除了金钱,你还会花费大量的另一种宝贵资源:时间。许多训练营要求每周工作 40 小时,还不包括完成作业和做家庭作业所需的时间。如果你有工作,除非你的老板非常理解,否则这不是你可以轻松应对的事情。
简而言之?它是不灵活的——如果它不适合你的情况,你也无能为力。
另一个优点也转变成了缺点:由于训练营的重点是就业能力,而不是教授数据科学,许多训练营跳过了数据科学的基础知识。大多数训练营不会教授你很多数据科学所需的基本数学和统计学知识。
当然,你将能够像巫师一样编写代码,但你将缺乏可能变得重要的关键知识。此外,如果缺乏基础知识,以后很难扩展你的知识。你可能能记住 Python 语法,但如果你不理解双尾 T 检验是什么,你可能会遇到困难。面试中总有可能会被问到这种问题——雇主不仅希望你能写出代码,还希望知道你是否理解它。如果你不能证明这一点,你可能会发现自己找不到工作。
数据科学学位

数据科学学位是指你在大学里花费几年时间学习如何从事数据科学。对于本文来说,我不会包括 Coursera 或 EdX 的选项,因为这些属于数据科学在线课程。我说的是选择专业、住在宿舍以及坐在讲座厅里学习数据科学学位的情况。
数据科学学位的优点
数据科学学位课程与数据科学训练营形成了完美的对比。它几乎是完全相反的。数据科学学位的最佳部分是你能够全面、深入理解数据科学。而且不仅仅是数据科学——你还会学习到密码学。你将理解算法背后的数学原理。你会知道如何进行统计分析。此外,虽然大多数雇主并不需要数据科学学位,但有这个学位也不会有什么坏处!
你将接触到更多的主题,因为学位课程不像训练营那样范围狭窄。而且,你还会获得更多的软技能。训练营试图以最快的速度灌输尽可能多的可就业信息。数据科学学位课程也教会你如何学习。
最后,你将接受严格的测试。学位要求你通过考试——这就是文凭的价值所在,因为它证明你掌握了足够的知识以在考试中得分。这个考试将准确显示你的强项和弱项,这有助于你进一步巩固知识。
数据科学学位的缺点
缺点与数据科学训练营非常相似,只是更糟糕:如果你觉得训练营花费$13.5k 很贵,那么你可能不愿意知道数据科学学位更为昂贵。除了教育费用外,你还要支付两到四年的住宿和膳食费。公立大学的学位——最便宜的选择——如果你住在校外,每年的费用大约为$14.9k。如果选择在私立非营利大学的校园内,最昂贵的选择每年的费用为$54.4k。
还有时间因素的问题,你需要花费两到四年的时间。虽然这是优质的教育,但你会用自己生命中的数年时间来获得它。
最后,虽然学位课程侧重于基础方面,但它们缺乏实际就业方面的内容。目标是教会你知识,而不是雇佣你。这意味着你在数据科学的基础知识上会有更扎实的理解,但也可能在就业优势方面不如其他选择。
数据科学在线课程

数据科学在线课程是第三种选择。它无疑是最灵活和实惠的。正如我之前提到的,你可以选择任何数据科学主题的在线课程。这也是需要最多内部自律的选项。
数据科学在线课程的优点
数据科学在线课程的主要好处在于你如何利用它。你可以找到在 YouTube 上运行的惊人的免费数据科学在线课程。你还可以获得谷歌认证。如果你想熟练掌握Ruby on Rails,有课程可以选择。如果你更愿意学习密码学,也可以朝这个方向发展。如果你想为像 FAANG 这样的特定大公司做准备,有一个平台“StrataScratch”可以帮助你为面试做好准备。
这里的另一个优点也是一个缺点:它是自定进度的。如果你在工作,还要照顾两个孩子,那么训练营或学位可能不适合你。在线课程会是一个更好的解决方案。它更容易融入你现有的生活方式。
在线课程通常也更便宜。因为它既不会试图在接下来的 12 周内让你找到工作,也不会尝试教你所有的数据科学知识,所以它通常更实惠。
数据科学在线课程的缺点
数据科学在线课程的缺点?
如上所述,它是自定进度的。如果你想学习数据科学,你必须自己掌控进度——没有人会牵着你的手。
找到一个全面的课程也更难。虽然你可以通过一点谷歌搜索来创建自己的数据科学课程,但你必须自己整理信息,而不是将信息一 spoon-fed。再者,你总有可能遗漏某些内容。
你可能会面临动力不足的问题,因为社区支持较少(虽然一些在线课程正在通过 Discord 和社区活动来解决这个问题)。无论是训练营还是学位课程都会提供同行和陪伴。而在课程中,你是孤身一人。
最终,你会错过学位所提供的基础知识和训练营给予的就业技巧。
最终思考:数据科学训练营 vs 学位 vs 在线课程
说哪个选项最好是不可能的,因为这完全取决于你的情况。在许多情况下,使用组合方案是最好的。例如,毕业后,你可能想通过课程或训练营来提升你的知识。
这里是一个快速回顾,帮助你做出自己的决定:
数据科学训练营:大约$13,500,三个月,侧重就业且强度大。
数据科学学位:介于$32,000-$200,000 之间,两到四年,基础知识,强度大。
数据科学课程:许多免费选项,还有许多便宜的选项,大约$100 或更少。这些课程可能需要一周或几个月完成,涵盖从就业相关话题到基础知识的内容。大多数课程为自定进度和自我激励。
Nate Rosidi 是一名数据科学家,从事产品策略工作。他还是一位兼职教授,教授分析课程,并且是 StrataScratch 的创始人,这是一个帮助数据科学家通过顶级公司真实面试问题准备面试的平台。你可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关话题
2022 年最佳数据科学职业轨迹
原文:
www.kdnuggets.com/2022/04/best-data-science-career-tracks-2022.html

作者提供的图片
从随机的数据科学课程中学习会导致对职业道路的很多困惑。这也会让你感到沮丧,因为你投入的时间和精力学到的东西没有实际价值。因此,如果你想在一年内了解数据世界的一切并获得认证,那么我建议你报名参加一个数据科学职业轨迹。一个简单的数据科学轨迹包括几个课程,这些课程将为你准备真实的挑战。它还将帮助你建立数据科学作品集项目,并提供职业支持。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我是数据科学课程的坚定支持者,因为它们在过去帮助了我。我写过几篇关于职业轨迹如何帮助我获得数据科学专业认证的博客:五步成为数据科学专业人士 和 如何获得数据科学家认证。在这篇博客中,我将帮助你选择最具性价比、互动学习平台和认证的数据科学职业轨迹。
Python 数据科学家轨迹
图片来源于 DataCamp
Python 数据科学家轨迹 是一个准备你参加认证考试的职业轨迹。你将学习如何导入、清理、操作和可视化数据。它还将教你自然语言处理(NLP)和机器学习的基础知识。数据科学职业轨迹在理论、实时编码、评估测试、指导项目和教程方面都得到了完美的平衡。完成数据科学轨迹后,该平台将指导你参加认证考试,并在获得证书后,DataCamp 将帮助你找到下一个梦想数据职位。
月度订阅费用不时会有所变化,因为他们总是有某种促销活动,这非常好。你还可以通过GitHub Education获得 2 个月的免费高级订阅,或者如果你是非政府组织的一部分,你可以申请获得免费的年度订阅。内容和互动练习使其对非技术专业人士非常有吸引力。数据科学专业证书难以获得,并且逐渐成为行业标准。
MIT 应用数据科学项目

图片来源于 Great Learning
MIT 应用数据科学项目 是最好的职业认证项目之一。它提供由 MIT 教职员工进行的实时虚拟教学、个性化的指导和支持,以及在行业专家指导下的实践培训。你不仅仅是获得了世界顶级大学的认证,还通过与专家合作项目获得了专业经验。数据科学课程包括数据科学基础、数据分析和可视化、机器学习、推荐系统以及为期 3 周的结业项目。
MIT 应用数据科学项目提供高价值,如果你想快速提升你的职业生涯,我建议你报名参加该项目,并在12 周内完成它。 Great Learning 平台提供专门的支持和职业咨询。如果你对支付该项目费用有疑虑,可以查看 Great Learning 上的庞大数据科学课程库。这个库包含短期课程、证书项目、职业路径和免费课程。
IBM 数据科学专业证书
图片来源于 Coursera
通过参加12 个月的IBM 数据科学专业证书项目,启动你的数据科学和机器学习职业生涯。该项目包含10 门课程,涵盖数据科学、Python 和 SQL 的基础知识。课程没有先决条件,因此即使是非技术专业人士也可以开始数据科学职业生涯。
该项目将教你有关数据科学工具、方法论、人工智能与开发、数据科学项目的处理、数据库与 SQL、数据分析与可视化以及机器学习的知识。完成课程后,你将获得IBM 证书和职场技能。你可以获得经济援助,或者如果你是学生,可以免费获得,前提是你的大学已经注册。我是Coursera学习平台的忠实粉丝,它彻底改变了我的远程学习体验。我相信你一旦开始探索这个平台的隐藏功能,也会爱上它。
成为数据科学家
图片来源于Udacity
通过参加Udacity 数据科学家纳米学位项目,成为一名数据科学家。Udacity的课程让我学到了很多关于生产级Python 编程的知识,并帮助我理解了机器学习的关键概念。在处理最新技术时,你会感到投入和激励。
纳米学位项目为期 4 个月,涵盖了所有重要的主题,如编程(Python、SQL、终端)、概率与统计、数据处理、使用 matplotlib 的数据可视化和机器学习。除了这些基本主题,你还将学习撰写数据科学博客文章,为灾难响应构建数据管道,以及参与各种数据科学和机器学习项目。
该课程价格昂贵,但我向你保证,这些花费是值得的。你还可以获得个人折扣或经济援助,这将使其对来自发展中国家的学生更为实惠。
HarvardX 数据科学专业证书

图片来源于edX
HarvardX 数据科学专业证书是一个基于 R 语言的项目,它将向你介绍 RStudio、tidyverse、GitHub 和机器学习算法。为期一年的证书项目涵盖了 R 编程基础、数据可视化、统计与概率、建模、开发工具、数据处理和机器学习。你将获得哈佛大学的认证,并拥有一种高需求的编程语言的经验。该项目包括 9 门课程,每年运行两次,分别在1 月和7 月。
结论
在最近的博客中,Natassha Selvaraj 解释了如何避免教程陷阱。关键在于为你的未来做出合理选择,而不是浪费时间在随机教程上。她解释了每个教程都在教你相同的内容,而你却没有进展。如果你想避免教程陷阱并走上通向成功的正道,那么从我提到的任何职业路径开始吧。职业路径会按完美的顺序教会你所有内容,并为你提供参与热门作品项目的机会。
Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为有心理问题的学生开发一个 AI 产品。
更多相关话题
你从未听说过的最佳数据科学认证
原文:
www.kdnuggets.com/2020/11/best-data-science-certification-never-heard.html
评论
逆流而上以解决数据质量问题。照片由 alleksana 提供,来源于 Pexels。
更新 10/12:我现在在通过基础考试后被认可为 CDMP 助理。有问题?在评论中提问或加入学习小组。**
更新 8/15:我最近了解到,认证考试是开放书籍,这非常令人兴奋,因为这意味着减少了记忆时间,更多时间可以在现实世界环境中处理数据。此外,我还开设了一个Facebook 学习小组——加入以获得考试准备帮助。**
八年前,数据科学被誉为“21 世纪最性感的职业”。然而,经过数小时的数据清洗,依然感觉确实是不性感的。事实上,数据科学职业的传奇崛起展示了大多数组织在数据管理方面做得有多么糟糕。
进入认证数据管理专业人士(CDMP),由数据管理协会国际(DAMA)颁发。CDMP 是你从未听说过的最佳数据战略认证。(说实话,当你考虑到你现在可能从事的工作是十年前不存在的,这个认证还不普及也就不足为奇了。)
数据战略是一个关键领域,涉及到数据生命周期的端到端管理以及数据治理和数据伦理的关键考虑因素。
本文概述了获得 CDMP 的方法和理由,这为有效的数据战略思想领导奠定了基础。文章还包括了一项调查——你可以提供你对数据科学中数据管理最重要方面的看法,并查看社区的共识。
在本指南中:
-
关于 CDMP 考试
-
如何准备 CDMP
-
CDMP 考试内容
-
调查——数据管理最重要的方面
-
为什么数据科学家应该获得 CDMP 认证
免责声明:此帖并未得到 DAMA 国际的赞助——所表达的观点仅代表我个人。我在亚马逊上提供了一个DMBOK 的附属链接,这是考试所需的参考书,因为这是一本开放书籍考试。通过此链接购买考试有助于支持我关于数据科学和数据战略的写作——提前感谢支持。
关于 CDMP 考试
CDMP 培训涵盖了 14 个与数据战略相关的领域(我将在后面详细介绍)。考试为开卷考试,但100 道题目必须在90 分钟内完成——没有太多时间查找资料。因此,熟悉参考材料是非常重要的。
当你安排考试($300)时,DAMA 会提供 40 个模拟题,这些题目很能反映实际考试的难度。作为进一步的资源,查看这篇关于认证学习过程的文章。
可以通过网络考试并通过摄像头监控($11 监考费)。考试形式为选择题——从五个选项中选择唯一正确答案。你可以标记问题并回过头来再做。考试结束时,你会立即得到你的成绩反馈。
超过 60%被视为及格。如果你对获得 CDMP 助理认证并继续前进感兴趣,这就足够了。如果你对 CDMP 认证的高级层级感兴趣,你需要在 CDMP 实践者考试中达到 70%或在 CDMP 大师考试中达到 80%。要获得最高级别的 CDMP Fellow 认证,你需要获得大师认证,并且还需要展示行业经验和对领域的贡献。这些高级认证还需要通过两个专家考试。
这让我提到最后一点,即为什么——纯粹从职业发展的角度来看——你应该选择通过 CDMP 的学习和考试过程:DAMA 认证与高端职位的领导力、管理和数据架构相关联。(把 CDMP 视为加入一个半秘密的数据高手社团。)越来越多的企业角色和联邦合同与数据管理相关的都要求 CDMP 认证。阅读更多。

通过CDMP。
优点:
-
提供有关数据战略主题的全面知识基础。
-
开卷考试意味着减少了死记硬背的时间。
-
为不同级别的数据管理专业人士提供四个层级。
-
通过最低级别认证的成绩要求为 60%。
-
与精英角色相关。
-
提供 3 年的 DAMA 国际会员资格。
-
$311 的考试费用比微软和开放集团的其他数据相关认证便宜。
缺点:
-
DAMA 没有大型科技公司(如亚马逊、谷歌、微软)的支持,这些公司积极推进市场营销并提升 CDMP 认证的品牌认知度——这意味着 CDMP 主要在已经熟悉数据管理的个人中被认可。
-
$311 的考试费用相对较高,相比之下,AWS 云从业者认证($100)或GPC 认证($200)要便宜得多。
替代方案:
-
微软认证解决方案助理(MCSA)——专注于各种微软产品的模块化认证($330+)
-
微软认证解决方案专家(MCSE)——基于 MCSA,包含关于核心基础设施、数据管理与分析和生产力的集成认证($495+)
-
开放组架构框架(TOGAF)——针对软件开发和企业架构方法论的高层框架的各种认证级别($550+)
-
缩放敏捷框架(SAFe)——针对软件工程团队的角色认证($995)
如何准备 CDMP
由于 CDMP 是开放书籍考试,备考所需的只是 DAMA 知识体系书籍(DMBOK $55)。它大约600 页,但如果你主要把学习时间集中在第一章(数据管理)、图表和图示、角色与职责以及定义上,那么这应该能让你在通过考试的路上走 80%。
关于如何使用DMBOK,一位考生建议每周末花费 4 到 6 小时,持续 8 到 10 周。另一种方法是每天早晚各读几页。不论你采用哪种方式,确保将间隔重复纳入你的学习方法中。
除了作为考试的学习指南外,DMBOK当然也可作为参考书,你可以把它放在同事的桌子上,如果他们需要学习数据策略或在网络研讨会中打瞌睡的话。
CDMP 考试内容
CDMP 涵盖 14 个主题——我按它们在考试中出现的频率排序,并为每个主题提供了简要定义。
数据治理(11%)— 确保数据资产正式管理的实践和流程。 阅读更多.
数据质量(11%)— 确保数据适合使用的标准,包括准确性、完整性、一致性、完整性、合理性、时效性、唯一性/去重、有效性和可访问性。 阅读更多.
数据建模与设计(11%)— 将业务需求转换为技术规格。 阅读更多.
元数据管理(11%)— 收集的数据相关信息。 阅读更多.
主数据与参考数据管理(10%)— 参考数据用于对数据库中其他数据进行分类,或将数据库中的数据与组织外部的信息关联。主参考数据指在组织内多个系统间共享的信息。 阅读更多.
数据仓储与商业智能(10%)— 数据仓库以优化的方式存储来自操作系统的信息(以及其他数据资源),以支持决策过程。商业智能指利用技术收集和分析数据,并将其转化为有用的信息。 阅读更多.
文档与内容管理(6%)— 组织和存储组织文档的技术、方法和工具。 阅读更多.
数据整合与互操作性(6%)— 使用技术和业务流程合并来自不同来源的数据,目标是方便高效地提供有价值的信息。 阅读更多.
数据架构(6%)— 描述现有状态、定义数据需求、指导数据整合和控制数据资产的规格,依据组织的数据策略。 阅读更多.
数据安全(6%)— 实施政策和程序,以确保在恶意输入存在的情况下,人员和系统对数据和信息资产采取正确的行动。 阅读更多.
数据存储与操作(6%)— 描述持有、删除、备份、组织和保护组织信息的硬件或软件。 阅读更多.
数据管理流程 (2%) — 从数据收集、控制、保护、传递到增强的全程管理。了解更多。
大数据 (2%) — 极其庞大的数据集,通常由各种结构化、非结构化和半结构化的数据类型组成。了解更多。
数据伦理 (2%) — 包括数据处理、算法及其他实践的行为准则,以确保数据在道德背景下得到适当使用。了解更多。
为什么数据科学家应该获得 CDMP 认证
仍然不相信数据战略的重要性?让我们从一个希望提升知识和收入潜力的数据科学家的角度来看看。

图片由 Franki Chamaki 提供,来源于 Unsplash。该标识是 Hivery 的商标,该公司利用 AI 为零售行业提供解决方案。
有人说过 数据科学家处于统计学、计算机科学和领域知识的交汇点。你为什么还想在你的盘子上再加一件事?
从成功的角度来看,你掌握两个互补的技能要比精通一个技能更有优势
斯科特·亚当斯,《迪尔伯特》漫画的作者和创作者,提出了一个 观点:“你获得的每一项技能都会将成功的几率加倍。” 他承认这可能有些过于简化 — “显然,有些技能比其他技能更有价值,第十二项技能的价值可能低于前十一项” — 但重点是,有时广度****比深度更好。
抛开利益的相对大小(因为我严重怀疑它是否每项技能增加 2 倍……谢谢,边际效益递减法则),显然,拓宽技能集相较于专注于学习一项具体技能可以带来更显著的收益。简而言之,这就是我认为数据科学家学习数据战略的重要原因。
一般来说,拥有多样化的技能集可以让你:
-
通过跨学科的学习 更有效地解决问题
-
更好地与来自其他专业的团队成员沟通
-
打开新项目的大门,获得新机会
理解数据策略将你从数据消费者转变为你组织中的数据倡导者。值得忍受所有绕口令式的缩写(DMBOK — 真的?他们不能直接叫它数据管理书吗?)*以加深你对端到端知识生成过程的理解。
其他文章以丰富你的技能
通过了解这门广泛使用的编程语言的基础知识,快速获取优质数据。
了解数据仓库作为分析准备数据集的主存储的作用。
如何在最小的努力下掌握 AWS Cloud Practitioner 认证
预测:多云,第一次尝试就能通过的机会为 100%。
如果你喜欢阅读这篇文章,请在Medium、LinkedIn和Twitter上关注我,以获取更多提升数据科学技能的想法。加入 CDMP 考试学习小组。购买 DMBOK。
简介: Nicole Janeway Bills 是一名数据科学家,拥有商业和联邦咨询经验。她帮助组织利用他们的核心资产:简单而强大的数据策略。注册获取她更多的文章。
原文。经许可转载。
相关内容:
-
10 个被低估的 Python 技能
-
作为数据科学家六个月的六个教训
-
5 篇必读的数据科学论文(及其使用方法)
更多相关话题
最佳数据科学项目在你的投资组合中
原文:
www.kdnuggets.com/2021/02/best-data-science-project-portfolio.html
评论

图片由 Jon Tyson 提供,来源于 Unsplash。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
数据科学近年来经历了巨大的增长。将数据转化为价值的潜力吸引了许多企业,从而推动了该领域的新投资。
数据科学的受欢迎程度和潜力,加上对数据科学家的需求不断增加,导致许多人转行从事这一领域的工作。
对于有志成为数据科学家的求职者来说,最大的挑战是迈出第一步。我认为,迈出第一步的困难在于以下几个原因:
-
数据科学是一个跨学科的领域,因此很难获得和评估所需的技能。
-
数据科学仍在发展中,因此在传统教育系统中尚未得到很好的确立。
-
如果你没有之前的工作经验,就没有简单的方法来展示你的技能。
在这篇文章中,我将详细阐述第三个理由,并提供我的建议。
如果你关注数据科学的 Medium 文章,你一定见过列出数据科学项目以放入简历或投资组合中的文章。
这些都非常适合练习硬技能,如编码、数据处理、数据科学库和框架、机器学习算法等。然而,它们缺乏一项重要的技能。
图片由 Azazello BQ 提供,来源于 Unsplash。
我们能否将创造魔方的技能与解决它的技能进行比较?
数据科学家识别一个问题并提出建议解决方案。这些文章中列出的项目为你展示了问题和解决方案。此外,获取所需数据的格式相对整洁。
由于这些项目非常常见,解决方案或实现方法可以很容易在网上找到。因此,把它们当作练习技能的项目。遗憾的是,它们不足以说服招聘经理你是数据科学家职位的好候选人。
我们应该做的是找到一个可以通过数据解决的问题并设计我们的解决方案。问题不一定要复杂,我们也不必提供最佳和最有效的解决方案。我们甚至可能无法妥善解决这个问题。
然而,能够框定一个可以通过数据解决的问题,比完成那些普通项目更有价值。它证明了你的分析思维能力,并清晰地展示了你对数据科学的全面理解。
拥有一两个从零开始构建的项目对于说服未来的雇主非常有帮助。你可能还会获得一个新的商业创意。拥有独特项目的另一个优势是它们能吸引招聘人员和招聘经理。他们很可能主动联系你,而不是你申请大量职位。
你可能会争辩说,提出一个新的项目创意是一项极具挑战性的任务。我完全同意你这一点。这也是我称之为在你作品集中拥有的最佳项目的原因。
我知道,提出一个独特的项目创意需要大量的时间、精力和思考。此外,你将花费长时间来尝试实现你的想法。重要的是要指出,你可能会遇到一个失败的项目。然而,你在这个过程中学到的技能,可能是你无法通过 MOOC 课程或任何教程学习到的。
你还将提高处理问题的技能。你将学会从不同角度评估任务。在某些情况下,你想到的解决方案可能不适合你习惯使用的库或框架。因此,这也会激励你学习新工具。
结论
作品集中的 10 个项目听起来很吸引人。我也做过其中的一些项目。然而,记住,你与之竞争的数据科学家职位的许多人也在做这些 10 个项目。你不会落后,但做同样的事情也不会让你更进一步。
招聘经理或招聘人员会知道你在项目中投入了多少。一些流行的普通项目可以在一两天内完成。因此,你很难通过这些项目来展示你的技能。
我绝对不是反对做这些普通项目。它们在练习和提高硬技能方面是有价值的,但这就是它们的全部贡献。
另一方面,如果你展示一个由你设计和实施的项目,将使你成为一个出色的候选人。
原文。经许可转载。
相关:
更多相关话题
最佳免费数据科学电子书:2020 年更新
原文:
www.kdnuggets.com/2020/09/best-free-data-science-ebooks-2020-update.html
评论
由布伦达·哈利,营销数据专家

图片来源:作者(布伦达·哈利)
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
我们处在一个不断进步的行业中,学习资源是无限的。
去年我整理了一份帮助我在数据科学学习路径上有帮助的电子书汇编,并且得到了导师和教授的推荐,用于解决特定项目或深入理解概念。
当我花时间深入学习时,我发现了一些之前未推荐的新书,或找到所有我推荐书籍的更新。所有电子书都合法免费或采用‘你愿意支付多少就付多少’的概念,最低为 $0。
如果你喜欢一本书,并且有条件的话,我建议你寻找支持作者的方式,例如购买纸质版、在 Patreon 上支持他们,或是请他们喝杯咖啡。
让我们让优质教育内容为大众所用。
免责声明:Python 和有时的 R 是我首选的编程语言,这也是为什么大多数书籍基于这些语言。如果你有其他语言书籍的推荐,请在评论中分享或发送我一条推文,我会将其添加到推荐中。
概率与统计
OpenIntro Statistics (2019) 由 David Diez、Mine Cetinkaya-Rundel、Christopher Barr 和 OpenIntro 合著
描述:一个完整的统计学基础,也为数据科学打下基础。OpenIntro Statistics 提供了大学水平的传统统计学介绍。这本教科书在大学水平广泛使用,为从社区学院到常春藤联盟的学生提供了卓越且易于接触的入门教材。
概率论导论 — 2019 年哈佛大学 Stats 110 官方书籍,Joseph K. Blitzstein 和 Jessica Hwang 著
描述:这本书提供了理解统计学、随机性和不确定性的基本语言和工具。书中探讨了各种应用和示例,从巧合和悖论到 Google PageRank 和马尔可夫链蒙特卡洛(MCMC)。其他探讨的应用领域还包括遗传学、医学、计算机科学和信息理论。
作者以易于理解的风格呈现材料,并通过现实世界的例子来激发概念。要做好准备,这本书很厚重!
同时,查看他们的 很棒的概率速查表。
黑客的概率编程与贝叶斯方法(2020) 由 Cam Davidson-Pilon 著
描述:《黑客的贝叶斯方法》旨在从计算/理解优先、数学其次的角度介绍贝叶斯推断。当然,作为一本入门书籍,我们只能停留在这个层次:一本入门书。对于数学训练有素的人,他们可以通过其他专门设计的数学分析文本来解答这本书引发的好奇心。对于数学背景较少或不感兴趣于数学但仅仅对贝叶斯方法的实践感兴趣的爱好者,这本书应该足够且有趣。
请查看他们的 使用 TensorFlow 的神奇 Github 仓库。
数据科学的实用统计学(2017) 由 Peter Bruce 和 Andrew Bruce 著
描述:这本书面向已经对 R 编程语言有一定了解,并且有一定(可能是不稳定或短暂的)统计学基础的数据科学家。我们两个人都来自统计学领域,因此我们对统计学对数据科学艺术的贡献有一定的理解。同时,我们也深知传统统计教学的局限性:统计学作为一门学科已有一个半世纪的历史,大多数统计学教科书和课程都带有如同海洋轮般的惯性和阻力。
编程
R 编程与数据科学 由 Roger d. Peng 著
描述:这本书向你介绍了 R 编程的基础,使用的是作为行业领先的 Johns Hopkins 数据科学专业化课程的一部分开发的相同材料。这本书所教授的技能将为你开始学习数据科学的旅程奠定基础。
使用 R 进行探索性数据分析 由 Roger d. Peng 编著
描述:本书教你使用 R 有效地可视化和探索复杂的数据集。探索性数据分析是数据科学过程中的关键部分,因为它允许你明确你的问题并优化你的建模策略。本书基于业界领先的 Johns Hopkins 数据科学专业课程。
命令行下的数据科学 (2020) 由 Jeroen Janssens 编著
描述:本书从网站、API、数据库和电子表格中获取数据
-
对文本、CSV、HTML/XML 和 JSON 进行清洗操作
-
探索数据、计算描述性统计数据,并创建可视化图表
-
管理你的数据科学工作流程
-
从一行代码和现有的 Python 或 R 代码中创建可重用的命令行工具
-
并行化和分发数据密集型管道
-
使用降维、聚类、回归和分类算法对数据建模
Python 3 101 (2019 — 更新版) 由 Michael Driscoll 编著
描述:学习如何从头到尾使用 Python 3 进行编程。Python 101 从 Python 的基础知识开始,然后在此基础上扩展你所学到的内容。本书的主要受众是那些有编程经验但想学习 Python 的人。本书不仅涵盖了初级内容,还包括了相当数量的中级材料。
使用 Python 进行自然语言处理 由 Steven Bird、Ewan Klein 和 Edward Loper 编著
描述:本书是对自然语言处理(NLP)的实用介绍。你将通过实例学习,编写真实的程序,并掌握通过实现测试一个想法的价值。如果你还没有学习过,本书将教你编程。与其他编程书籍不同,我们提供了大量的插图和来自 NLP 的练习。我们的方法也很有原则,即我们涵盖了理论基础,并且不回避细致的语言学和计算分析。我们力求在理论和应用之间取得平衡,识别其中的联系和张力。最后,我们认识到,除非这个过程也充满乐趣,否则你不会坚持下去,因此我们尽力包含了许多有趣和娱乐性的应用和例子,有时甚至是异想天开的。
大规模数据集挖掘 (2019) 由 Jure Leskovec(斯坦福大学)、Anand Rajaraman(Rocketship Ventures)和 Jeffrey D. Ullman(斯坦福大学)编著
描述:这本书专注于处理非常大量的数据,即数据大到无法放入主内存中。由于强调数据规模,许多例子涉及 Web 或从 Web 中派生的数据。此外,本书采取算法视角:数据挖掘是关于将算法应用于数据,而不是使用数据来“训练”某种机器学习引擎。
机器学习的渴望(2016) 由 Andrew Ng 编著
描述:AI 正在改变众多行业。《机器学习的渴望》教你如何构建机器学习项目。
本书的重点不是教你机器学习算法,而是如何使机器学习算法有效。阅读《机器学习的渴望》后,你将能够:
-
优先考虑 AI 项目中最有前景的方向
-
诊断机器学习系统中的错误
-
在复杂环境中构建机器学习,例如训练/测试集不匹配
-
设置机器学习项目,以便与人类水平表现进行比较或超越
-
了解何时以及如何应用端到端学习、迁移学习和多任务学习。
领导数据科学团队
执行数据科学(2018) 由 Brian Caffo、Roger D. Peng 和 Jeffrey Leek 编著
描述:这本书教你如何组建和领导数据科学企业,以便你的组织能够从大数据中提取信息。
有其他必须列入清单的电子书吗?请在评论中告诉我或发推文给我 twitter.com/brendahali
简介:布伦达·哈利 (LinkedIn) 是一位驻华盛顿 D.C.的市场数据专家。她热衷于女性在技术和数据领域的参与。
原始文档。经许可转载。
相关:
-
统计学习的要素:免费电子书
-
理解机器学习:免费电子书
-
人人皆学 Python:免费电子书
更多相关内容
10 个最佳和免费的机器学习课程,在线
原文:
www.kdnuggets.com/2019/12/best-free-machine-learning-courses-online.html
评论
由 Prateek Shah, DigitalDeFynd。

查看这一系列最佳的+免费的机器学习课程。
这是提供人工智能相关课程的平台之一,旨在向大众教授 AI 及如何入门。所有内容从零开始,专注于通过实践学习。有一系列适合初学者和经验丰富的学习者的选择。所以,如果你认真考虑入门这个领域,最简单的办法就是点击第一讲。
主要独特卖点
-
每一个概念都配有截图和实际操作示例。
-
提供完整的指导以完成配置并开始学习课程。
-
加入论坛与同行和从业者沟通,并在学习过程中互相帮助。
-
使用 fast.ai 库并训练模型。
-
该平台上的所有课程都是免费的。
时长: 自定进度
评分: 4.5 分(满分 5 分)
你可以在这里注册。
这无疑是互联网上最好的机器学习课程。由安德鲁·吴(Coursera 联合创始人及斯坦福大学教授)创建,该课程已被全球超过 2,600,000 名学生和专业人士参加,他们给予了平均 4.9 分(满分 5 分)的高评价。只需看看推荐信,你就会明白为什么我们如此强烈推荐它。
课程涵盖的主题包括监督学习、最佳实践和 ML 与 AI 的创新,同时你还会遇到大量案例研究和应用。课程的最佳部分之一是你可以在购买整个课程前注册 7 天试用。如果你相信我们的评价,这是绝对在线上最好的相关程序。
主要独特卖点
-
了解参数化和非参数化算法、聚类、降维等重要主题。
-
从讲师那里获得最佳实践和建议。
-
在一个由各个经验水平的学习者组成的社区中与你的同行互动。
-
基于实际案例的学习让你有机会了解问题如何在日常中解决。
-
灵活的截止日期允许你按照自己的方便学习。
-
学习应用学习算法来构建智能机器人,理解文本、音频、数据库挖掘。
时长: 约 55 小时,每周 7 小时
评分: 5 分中的 4.9
你可以在这里注册
这真是一个卓越的课程。深谙某一学科的人往往没有时间或动力分享他们的见解并教导他人;这门课程是一个罕见的例外,鉴于机器学习对未来的重要性,我对安德鲁·吴充满了极大的感激和敬意。 - Nicholas D
深度学习领域最著名的讲师之一,安德鲁·吴(Andrew Ng),为您带来了这一特别课程,此课程由斯坦福教授和 NVIDIA|深度学习学院作为行业合作伙伴共同开发。讲师是 Coursera 的联合创始人,曾在Google Brain 项目和百度 AI 团队担任过职务。
在这项覆盖 5 门课程的项目中,他将教你深度学习的基础知识、如何构建神经网络以及如何构建机器学习项目。最重要的是,你将能够参与医疗保健、音乐生成和自然语言处理等行业领域的实时案例研究。全球已有超过 250,000 名学生报名参加此项目。毫无疑问,这是一门最好的深度学习课程。
关键卖点
-
学习卷积网络、递归神经网络、批量归一化、丢弃法等。
-
使用不同的技术来构建解决现实问题的模型。
-
涵盖了诸如医疗保健、自动驾驶、手语识别、音乐生成和自然语言处理等领域的实际案例研究。
-
从行业专家和领袖那里获得最佳实践和建议。
-
按照你的计划完成所有评估和作业,以获得专业化完成认证。
时长: 3 个月,每周 11 小时
评分: 5 分中的 4.9
你可以在这里注册
这门课程为从零开始构建多层神经网络奠定了坚实的基础。这门课程的最大优势在于我能够立即将学到的知识应用到实际问题中,例如人形机器人导航到已知目标。课程在数学解释和逐步编程演示方面表现出色。 - Waleed E
(4) 机器学习课程 A-Z™:数据科学中的 Python 和 R 实践(Udemy)
让我们先接受这样一个事实:411,800+ 名学生 已经参加了这门课程,且它的平均评分为 4.5 分(满分 5 分)。我们认为这是 最佳机器学习课程 之一,由 Kirill Eremenko,数据科学家和外汇系统专家 和 Hadelin de Ponteves,数据科学家 开发。
这门课程将帮助你掌握 Python 和 R 上的机器学习,做出准确的预测,建立对许多机器学习模型的良好直觉,处理强化学习、自然语言处理和深度学习等特定工具。最重要的是,它教你选择适合每种问题的模型。你只需要具备基本的高中数学知识即可学习这门课程。通过 40 小时的学习 + 19 篇文章,我们不知道还需要说什么来让你去看看这个课程。
关键独特卖点
-
对于几乎没有先前经验的人来说,这是一个很好的入门教程。
-
探索复杂的主题,如自然语言处理、强化学习、深度学习等。
-
提供大量实践练习和测验,以衡量你对讲座内容的掌握情况。
-
提供详细的安装所需软件和工具的说明。
-
作为额外福利,本培训包含可以下载并在项目中使用的 Python 和 R 代码模板。
时长: 41 小时
评分: 4.5 分(满分 5 分)
你可以在这里注册
Machine Learning A-Z 是机器学习的一个很好的入门课程。通过对许多算法的全面介绍,使学生对 scikit-learn 和其他一些包更为熟悉。理论解释简单易懂,实践例子也同样基础。ML-az 是初学者获取深入学习机器学习的动力的合适课程。从这里,你可以选择前进的方向,从而掌握它!总之,非常入门,易于理解,覆盖面广。一个很好的起点。* - Denis Mariano*
哈佛大学的这个职业认证项目使用激励性的案例研究,提出具体问题,并展示如何通过分析大量数据来回答这些问题。在课程中,你将同时学习 R 编程语言、统计概念和数据分析技术。所涵盖的案例研究包括世界健康和经济趋势、美国犯罪率、2007-2008 年金融危机、选举预测、组建棒球队和电影推荐系统。本课程的教授是哈佛大学生物统计学教授 Rafael Irizarry。
关键独特卖点
-
涵盖基础的 R 编程技能。
-
探索统计概念,如概率、推断和建模,并将它们应用于实践中。
-
获得 tidyverse 的使用经验,包括使用 ggplot2 进行数据可视化和使用 dplyr 进行数据整理。
-
熟悉数据科学家所需的基本工具,如 Unix/Linux、git 和 GitHub 以及 RStudio。
-
实施机器学习算法,并通过现实案例研究深入了解该领域。
时长: 9 门课程,每门课程 2 到 8 周,每周 2 到 4 小时。
评分: 4.7 分(满分 5 分)
你可以在这里注册
这个 Udacity Nanodegree 计划将帮助你掌握所有有志于成为数据分析师和数据科学家的必备技能。通过机器学习的视角探索数据调查的全流程。学习如何提取和识别有用的特征,以最佳形式表示你的数据。此外,你还将学习一些最重要的机器学习算法并评估其性能。
主要卖点
-
互动测验让你可以复习所学的内容。
-
加入学生支持社区,以交流想法和澄清疑问。
-
自主学习的时间安排允许你按照自己的方便进行学习。
-
内容是与 Kaggle 和 AWS 合作创建的。
-
你将学习监督学习、深度学习、无监督学习以及其他一系列主题。
-
你还可以获得一对一的导师指导、个人职业辅导以及访问学生社区的权限。
时长: 3 个月
评分: 4.6 分(满分 5 分)
你可以在这里注册
哥伦比亚大学设计的这个微硕士项目为你带来了严格、先进、专业的 AI 及其子领域如机器学习、神经网络等的研究生级基础课程。通过该项目的 4 门课程,逐一学习该主题的重要概念。掌握 AI 指导原则的坚实基础,并将机器学习知识应用于现实世界中的挑战和应用。 除此之外,你还将学习设计神经网络并利用它们处理相关问题。 在项目结束时,你将获得足够的实践知识,以增强你的个人作品集、申请相关工作或转为自由职业。
主要卖点
-
将机器学习的概念应用于现实生活中的挑战和应用。
-
提供了详细的配置和导航所需软件的说明。
-
设计和利用神经网络的能力。
-
该项目分为 4 门课程,并附有相关的示例和演示。
-
将这些讲座中获得的知识应用于机器人、视觉和物理模拟等多个领域。
时长: 4 门课程,每门课程 12 周,每周 8 到 10 小时
评分: 4.5 分(满分 5 分)
你可以在这里注册
(8) 机器学习课程(斯坦福工程学院)
这所著名学术机构提供了三项研究生认证课程,专注于这个快速发展的人工智能领域。在数据、模型和优化的课程中,你将通过实施合适的算法和开发模型来探索大规模问题。此外,AI 课程讲解了开发概率模型的原理和技术,并从事机器学习。最后,数据集挖掘课程深入研究大型数据集,帮助你掌握从各种实际来源提取信息的方法。
主要特色
-
所有主题都简明扼要且深入。
-
基于实际挑战的示例,以便更好地理解。
-
提供额外资源建议,以补充学习。
-
完成评估、作业并保持分数高于最低要求,以获得证书。
时长: 1 到 2 年
评分: 4.4 分(满分 5 分)
你可以在这里注册
(9) 免费机器学习课程(edX)
edX 汇集了来自全球各大高校的机器学习课程。你可以选择哈佛的 数据科学、哥伦比亚的 人工智能、IBM 的 Python 数据科学,或微软的数据科学课程等。大多数课程可以免费旁听,只有在你希望获得证书时才需付费。这些课程的时间从几周到几个月不等,适合每个人。
主要特色
-
免费课程,适合不想花大钱学习机器学习的人
-
探索机器学习和人工智能的各个主题,获得深刻的理解
-
学习时从讲师处获得大量技巧和窍门
-
构建复杂的数据模型,探索数据分类、回归、聚类等。
-
提供众多课程,涵盖从 AI 到机器学习、深度学习等各种主题
-
顶级大学的教授会教你
时长: 自主学习
评分: 4.6 分(满分 5 分)
你可以在这里注册
如果你精通 R 编程和统计学,并希望在此技能基础上进一步提升,那么这个互动课程值得一看。首先,你将探讨该领域的应用和常见问题。此外,你将重点学习三种基本技术,并训练和评估机器学习模型。完成学习后,你可以选择更高级的专业化课程。
关键卖点
-
比较不同类型的算法并进行实验。
-
对数据进行分类,构建决策树,执行聚类等。
-
15 个视频+81 个练习
-
互动内容使解释更简单,学习过程更有趣。
-
第一个模块可以免费预览。
时长: 6 小时
评分: 4.4 分(满分 5 分)
你可以在这里注册
这些是一些最佳的+免费机器学习课程,希望你能找到所需的内容。请同时查看我们的完整汇编数据科学课程。
相关:
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容


 浙公网安备 33010602011771号
浙公网安备 33010602011771号