
吴恩达大模型教程笔记-九-
吴恩达大模型教程笔记(九)
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P57:6:构建与大语言模型交互的聊天应用 - 吴恩达大模型 - BV1gLeueWE5N

最后一课建聊天App,开源Llm falcon四B,最佳开源模型之一,我很兴奋,希望你也一样,最后一课建开源聊天App。

Llm,可能已与ChatGPT聊过,运行成本高且僵化,定制Llm可本地运行,在您数据上微调或云上更便宜,本课将使用推理端点,运行Falcon进行Beinstruct,最佳开源大型语言模型之一。
本地使用文本生成推理库容易运行。

当然,您也可以使用Gradient创建仅基于API的接口。

LLM,不仅是开源,您还可以使用Radio构建,为ChiPT或Claude构建UI。

本课程将聚焦开源。

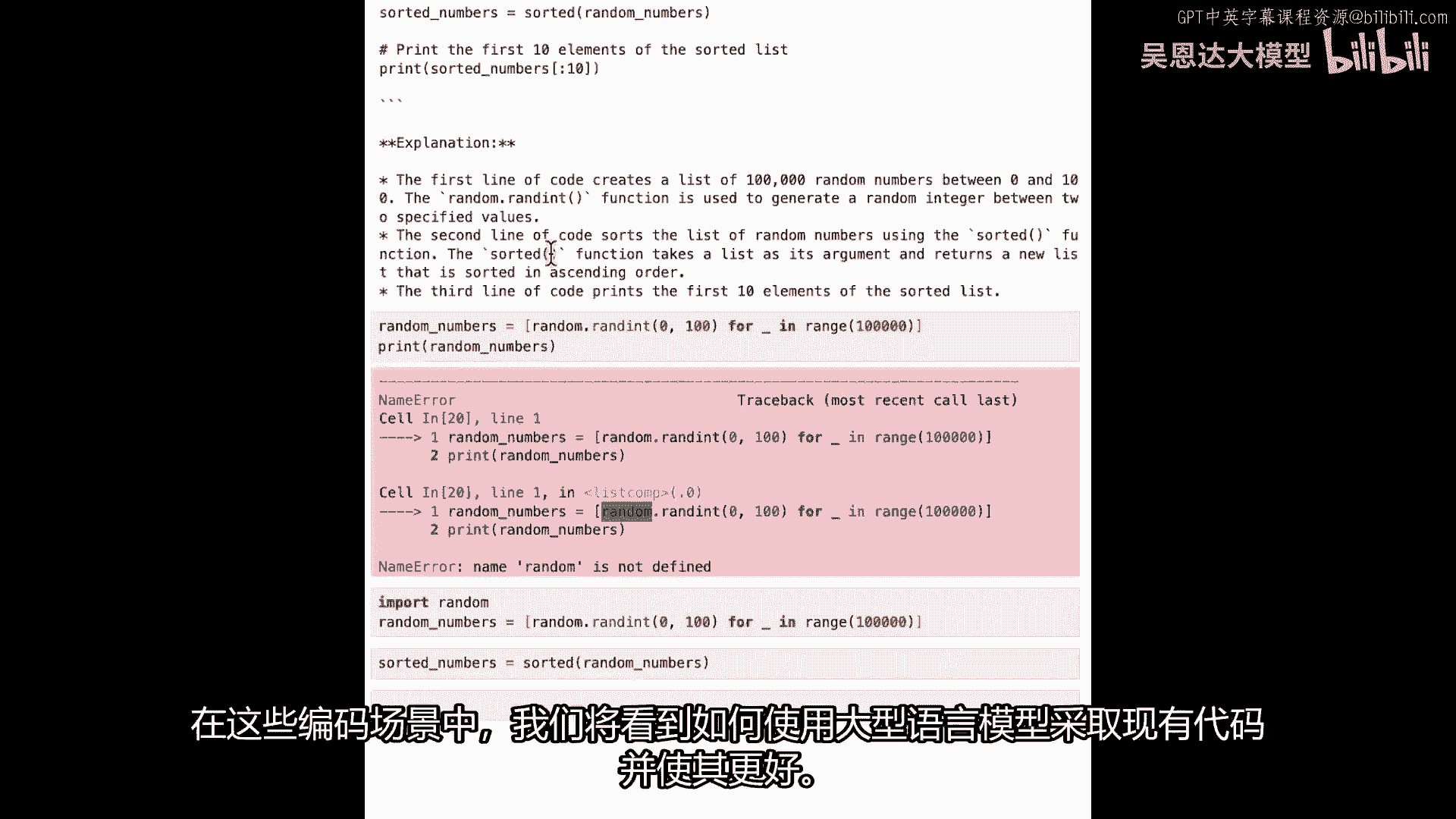
Lm falcon for tb,设置令牌和辅助函数。

使用不同库,使用文本生成库。

处理开源lllamp的精简库,可加载API,如我们正在做的,也可运行本地lln,询问模型马特发明或发现,这是模型的完成,我们要求最多256个标记,有时答案更简洁,可能少于最大标记,他回答了我们的问题。
很好,但我们可能不想只和LLM聊天,通过更新输入变量,这不是聊天,对吧,不能问后续问题,如果只改这里输入,回到第2课,我们有一个简单的无线电接口,带有文本框输入和输出。
所以这里我们将与我们的llm聊天时使用非常相似的东西,让我们再次复制,我们的提示,在这里我们可以决定多少个令牌,可能让我们少一点,所以我们就测试一下,你可以看到它在中间切断了答案。
因为我们要求它只有二十个令牌,但我可以改变,那很酷,这是一种很容易在llm中质疑的方式。

但我们还没有聊天,因为再次,如果你问后续问题,它将无法理解或保持此上下文,所以如果我会,如果我要问,为什么它不知道,我刚说了它不知道我们刚谈了什么。

所以你会看到它实际上对此抱怨,它说没有额外上下文我无法提供响应,我们无法继续问后续问题的原因,是因为模型没有记忆,模型不知道我们刚给它发送了一个问题,然后我们现在在问后续问题。

所以为了构建对话,我们必须始终向模型发送。

我们对话的上下文,所以基本上我们必须做的是我们必须向模型发送我们的先前问题,它自己的答案,然后是后续问题,但构建所有这一切会有点麻烦,这就是梯度聊天机器人组件的作用,因为它允许我们简化向模型发送。
对话历史的过程,所以我们实际上想修复那个,为此我们将引入一个新的梯度组件。
那就是梯度聊天机器人。

所以让我们开始使用无线电聊天机器人组件。

我实例化了一个带有文本框提示和提交按钮的gradichatbot组件。

一个非常简单的,Ui 这里让我们说你好。

酷 你可以看到它回复了一些酷的东西。

但我们还没有和llm聊天,我刚刚选择了三个随机的预设响应,并将它们附加到聊天历史中,我的消息和机器人消息,所以这里你可以看到我可以说任何话,它基本上会随机循环这三种响应。
但这里我想向你展示无线电聊天机器人功能的工作原理,所以现在让我们将其与我们的llm连接起来,所以这里我们有相同的ui。

但这次我正在调用我们的generate函数并发送用户发送的消息,所以现在,如果我们问生命的意义是什么。

嗯,模型不想回顾它的秘密,但没关系 让我们问问概念,为什么这样,哦不,我们遇到了同样的问题,模型仍无先前对话的上下文,这里发生了什么,我们可以看到我给模型发送了,用户发送的消息。
所以在这里我们可以看到在提示中,我将它发送给模型和输入作为消息,基本上我们犯了和之前一样的错误,我在发送模型,仅用户发送的消息,未发送整个上下文,我们如何修复这个问题,要修复它,我们必须格式化聊天提示。
我定义了这个格式,聊天提示函数,所以这里我们想做的就是我们要格式化我们的提示,以包含聊天历史,这样LLM就知道上下文,但这还不够,我们仍需告诉它哪些消息来自用户,哪些消息来自自己。
我们正在调用的LM本身,助手,因此我们设置了我们的格式检查提示函数,在聊天历史的每一轮中,它包含一个用户和一个助手消息,以精确启用我们的模型回答后续问题,现在我们将格式化的提示传递给我们的API,所以。
这样做,这里只是为了让我们可以看到这个格式化的提示看起来如何,我也把它打印在屏幕上,所以我们的聊天机器人应该能够回答。

后续问题,所以如果我们问它,生命的意义是什么。

它给了我们一个答案,这不是我想要答案,但没关系,但我可以问后续问题,但为什么,酷。

所以我们可以看到我们发送给它一个上下文,所以我们发送了我们的消息,然后要求它完成,一旦我们进入另一个迭代循环,我们发送给它我们整个上下文,然后要求它完成那个学校,但如果我们像这样永远继续下去。
在某个时刻。

所以它会达到模型在一次对话中可以接受的限制。

因为我们总是给它越来越多的先前对话,为充分利用模型,可设最大新标记为124,这是硬件允许的最大值,允许进行带几个后续问题的对话,但内容窗口会加载,现在有1024标记的对话。
开始关于生活在草原的动物的对话。

库奥,最强的是哪种动物,它继续并模仿我们,它以用户身份提问,自己作为助手回答,这也许很酷,但不是我们想要的,为防止此类情况,可添加停止序列,停止序列确保新行用户,即指示来自我们的消息。
而非模型试图生成时停止,模型将停止,这样可确保模型在此例中停止,草原上最强动物是什么,是大象,若想问后续问题,如为何大象,是草原上的强动物,或其他我们选择的后续问题。
关键是后续问题应来自用户而非助手AI,我们构建了一个简单但强大的与AI聊天UI。

若要获取Gracan的最佳表现,可构建包含更多功能的UI。

这里有高级选项,包括可发送模式到AI的系统消息,在系统消息中可以说,例如你是一个有帮助的助手,或可给它特定语气,特定语调,你想让它更幽默,更严肃,实际上可以玩系统消息。
提示并看其如何影响消息,有些人可能想给AI一个角色。

如你是一名提供法律建议的律师,或是一名提供医疗建议的医生,但请注意AI可能提供事实错误信息,听起来真实的方式,所以尽管在Falcon for TB上实验探索很有趣,在现实场景中。
对于此类用例还需采取进一步的安全措施。
和其他高级参数如温度,温度本质上是你想要模型有多少变化。
若将温度设为0,模型倾向于对相同输入给出相同回复。

所以相同的问题,相同的答案,温度越高,消息的变化就越大,但如果温度太高,可能会开始给出无意义的答案。

所以0。7是一个不错的默认参数,但我们鼓励你尝试一下。

此外,UI让我们做了一件很酷的事。

即流式响应,如果我在这里问,亚马逊有哪些动物。
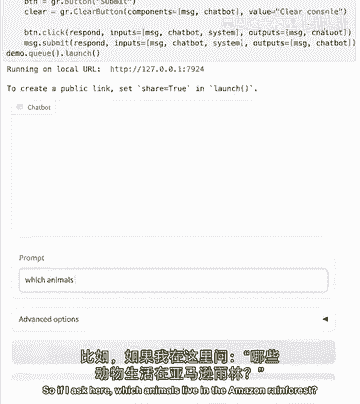
热带雨林。

所以你可以看到我们的模型流式回答了,它是逐个发送标记的,我们可以实时完全看到它,我们不需要等到整个答案准备好,这里我们可以看到它是如何做到的,别担心,如果你不明白这里面的所有内容。
因为这里的想法是用一个非常完整的UI结束课程,包含LLM方面所有可能的东西,所以在这个格式化聊天提示中,这是我们之前添加新元素之前的那个函数,即系统指令,所以在开始有那个用户助手对话之前。
我们有一个系统在上面,它有指令,所以基本上在发送给模型的每条消息的开始时,它将会有我们设置的系统消息,这里我们正在调用文本生成库的生成流函数,生成字符串函数的作用是逐个标记生成响应,所以在这个循环中。
正在发生的是它逐个标记生成响应,它将添加到聊天历史中,并返回给函数,这里我们只有一个带有可折叠面板的渐变块,用于高级选项,就像我们之前学过的,有一个提交按钮和一个清除按钮,在我走之前,我想建议你玩一玩。
如果你想改变,也许UI,也许你想重新排列东西。
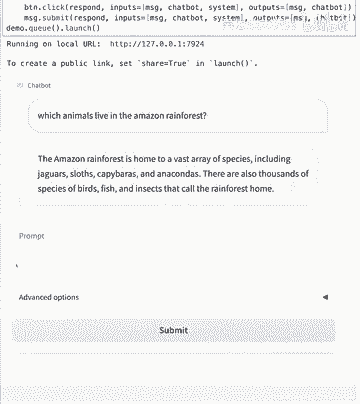
现在你知道如何使用列和行构建渐变块,在这个演示中,我鼓励你改变系统消息,也许你可以让它用外语回答,它能说法语吗,我不知道,也许我们可以要求它用法语回答,或者,既然我们谈论动物和森林。
也许你可以要求它解释,仿佛是生物学家,会增加吗?信息的具体性,会告诉你动物学名吗?我不知道。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P58:《使用大型语言模型进行配对编程》 1.SC-Laurence_Intro_v02.zh - 吴恩达大模型 - BV1gLeueWE5N

欢迎参加这门课程,与谷歌合作构建的大型语言模型配对编程,LMS正在改变,我们如何编写代码,当我为翻译深度学习AI内容的基于LM的翻译软件原型时,我不得不使用一些不熟悉的Python库,而不是阅读文档。
我有一个LM,尝试编写代码的第一稿,然后我修复它,经验丰富的开发人员正在以许多方式使用LMS来加快我们的工作,在这门课程中,您将了解这些新兴最佳实践,包括如何让LM帮助您处理错误,性能改进,还有很多。
我很高兴这门课程的讲师是我老朋友劳伦斯·莫罗尼,他是谷歌AI的首席倡导者,非常感谢安德鲁,我也非常兴奋能与您和您的团队合作,在这门课程中,您将学习如何使用LM简化并改进您的代码,编写测试用例。
调试您的代码并重构您的代码,与复杂的现有代码库合作,其中可能存在技术债务,LM可以帮助您解释。

文档和格式化现有代码库 劳伦斯将通过这些概念,使用Palm API,我自己也用过,所以我相信您也会喜欢玩它的,这就是我对生成式AI和大型语言模型的兴奋之处,如果我们只把它们看作是创造从零开始的东西。
比如代码,我们实际上错过了它们可以带来的许多价值,希望我们今天讨论的一些例子,激发您自己的编码之旅,并帮助您成为一名更高效的软件工程师,当我与生成代码合作时,有一次很有趣的经历。

它帮助我发现了一些我不知道的,我不知道来自深度学习AI团队的事情,艾迪·舒和迪亚拉·阿齐内也参与了这门课程。

第一课将是如何开始使用,使用Palm API改进和简化您的代码。

听起来不错。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P59:2.SC-Laurence_L1_v05.zh - 吴恩达大模型 - BV1gLeueWE5N

本课程第一课,将了解如何。

现在开始使用Palm API进行代码生成,当然,要能做任何事情。

需要一些必要的设置,我会指导你,Palm API及其相关工具在Google,生成式AI网站持续更新,包括Maker Suite,一种快速、简单的方式让你使用生成式AI提示原型,以及Vertex AI。
提供可扩展性和企业级。

隐私安全,以及更多,本课程重点将放在Palm API上,通过编码接口访问谷歌的大型语言模型,你将在这门课程中亲手编写使用此API的代码,所以让我们深入看看你需要什么,如你所见,清单相当简单。

首先,你需要一个API密钥,在实际操作中,你会从我之前展示的网站上获得,Developers。Generative AI。Google,为了这门课程,你实际上不需要担心,我们已经为你制作了一个。
但这是你需要记住的事情,接下来,你需要谷歌的生成式AI库,在拍摄时,它们可在Node。js、Swift和Python中使用,以及带有curl接口,但在这门课程中我将使用Python。
并会展示如何进行pip安装,当然,不用说,你可能需要一些Python技能,如果没有,可以查看,Learnpython。org,如果你有点迷失,但大部分我所做的是相当基础的。

Palm有很多,包括许多不同目的的后端模型,探索它们和它们的命名很有趣,特别是你将看到很多动物名称,一般来说,动物越大,模型越大。
首先让我们看看如何获取你的API密钥,我们为你提供了一个,但你需要一个工具来获取它,这里有一个辅助函数,我将获取API密钥以获取辅助函数,现在下一个单元格,我将导入谷歌的生成AI库。
我们将称它们为palm,然后使用API密钥配置它,好的,所以现在我已经完成了这些,我将运行这个单元格,好的,我已导入密钥,如我之前所提,我正在导入谷歌退化AI,我将称之为palm和palms。
配置传递API密钥参数为API密钥的结果,好的,所以现在我们可以使用这些了,如果你要在没有后端系统的自己的系统中做这件事,您将需要pip安装谷歌生成AI的东西和pip安装,正如你所知,它就像那样工作。
如果你想安静地做,谷歌生成AI,它就像那样工作,所以接下来我将探索其中的一些模型,我将做一个列表for m n palm dot lists models,这是palm API中的一个函数,允许你。
顾名思义,列出所有模型,而不是让你看着我输入所有内容,我将粘贴接下来会发生的事情,然后我们将只打印名称,描述和支持的方法,所以让我们运行这个单元格看看我们得到什么,好的。
我们看到我们正在获取聊天野牛文本,野牛和嵌入,壁虎,猜猜哪个是大型模型,猜猜哪个是小型的,所以我们可以看到有两个野牛,还有一个壁虎,但今天我们要做的是生成文本,我们将看到聊天野牛支持生成消息。
但文本野牛支持生成文本,这真的很棒,我们知道我们将使用这个模型,但你可以在这里使用另一个函数是。

随着更多模型的支持,如果有模型,例如,如果有多个模型支持生成文本,我可以开始做一些像models等于m for m in palm dot list models,如果生成,Oops生成文本。
所以我在此说的是,如果生成的文本实际在支持的方法中,对,我们在m。supported_generation看到生成方法,方法,然后我将只是打印,好的,或仅显示那些模型,然后如果我运行这个。
现在我们可以看到更多关于这个模型的细节,Text Bison是唯一实际支持它的,这仅是一些你可以开始使用Palm API来理解正在发生的事情的方式,随着API的增长,和支持的模型增长。
您可能会在这里获得不同的结果,您可能能够尝试不同的模型并玩得更有趣,正如我们所见,我们有大约三个模型最终被列出,有Chat Bison 001,Text Bison 001。
和Embedding Gecko 001,所以你可以想象Gecko会更小,我提到它是基于动物大小,随着你长时间使用,您可能会在这里看到更多被添加,现在你可能会听到很多的问题是。
Chat Bison和Text Bison的区别是什么,Chat Bison背后的目标,是它更优化于聊天场景,它会跟踪上下文,所以你会问它一些东西,它会给出一个答案,你可能会跟进,它会给出另一个答案。
而你可能会再次跟进,而Text Bison则更优化于单次射击,你会给它一个提示,你会得到一个答案,然后你会继续,我们今天将使用那个,因为你知道那个通常对代码工作得更好。
所以现在我们只有一个模型支持生成文本,所以我将只创建一个指向它的变量,我将称之为model_bison,当然,它是我们模型列表中的第一个,对,所以如果我只想输出mobison,只是为了确保我得到正确的。
我运行这段代码,我们看到我得到了相同的输出,现在我们有模型了,让我们创建另一个辅助函数,这个辅助函数将生成文本,这样我们就不必重复写相同的代码,避免重复总是好的,避免重复总是好的,避免重复总是好的。
从google。api_core导入retry开始。

retry库的作用,当你做后端时,比如我们正在做的与llm数据库的交互,有时事情可能会不同步,有时你的调用,可能会在某个地方丢失,而不是你写一堆代码,来重试并不断重试。
这个可以用一个非常简单的装饰器完成,像这样retry retry。

然后我们可以编写我们的函数,我们的函数将被称为生成文本,生成文本将接受,我的提示和我想使用的模型,我们已经创建了一些我们称之为model bison的东西,然后我将使用一个温度,模型的默认温度是0。7。
但使用0。0的温度,它将是一个更确定的模型,所以无论提示是什么,从提示中得到的任何结果,你应该看到相同的,当然,如果你使用的是较晚的版本甚至较晚的模型,它可能会有所不同,一旦我们完成了这一点。
现在我们只想返回,Palm将给我们什么,所以palm。generate_text并传递相同的东西,所以提示等于提示模型等于模型,温度等于温度,这帮助我们有一个很好的辅助函数贯穿我们的代码。
这样我们就不必不断重新发明轮子了,让我运行这个单元格,确保一切都好,看起来不错,现在我们已经创建了生成文本函数,这个辅助函数你将要做,我想简要地谈谈并简要地展示一些幻灯片关于如何。
你将能够使用提示来生成代码,使用这个生成文本函数,这个辅助函数。

我将简要地谈谈并展示一些幻灯片,现在开始编写代码,使用Palm API,我喜欢这个模式。

所有示例将遵循,在这门短课中。

流程如下:首先创建提示,从简单的静态字符串开始,稍后展示如何模板化以增强,包含发送给LLM的基本命令,以指导它,为我们生成输出,然后使用刚创建的生成文本函数,和选定的模型获取完成,注意。
通常使用llms时,模型输出的文本是预测的,下一组标记将是,所以,当你输入一个问题,下一组标记通常是答案,因此它完成了你开始的引号字符串,这就产生了术语补全,与答案相对,或其他稍不精确的东西,当然。
最后输出补全结果。

如何做取决于你,在本课程中,我们将在jupyter笔记本中打印出来,但在实际应用中,你可能正在向IDE注入代码,保存到仓库中。

或其他许多事情,让我们探索这些步骤的代码,以使用palm进行基本的代码生成。

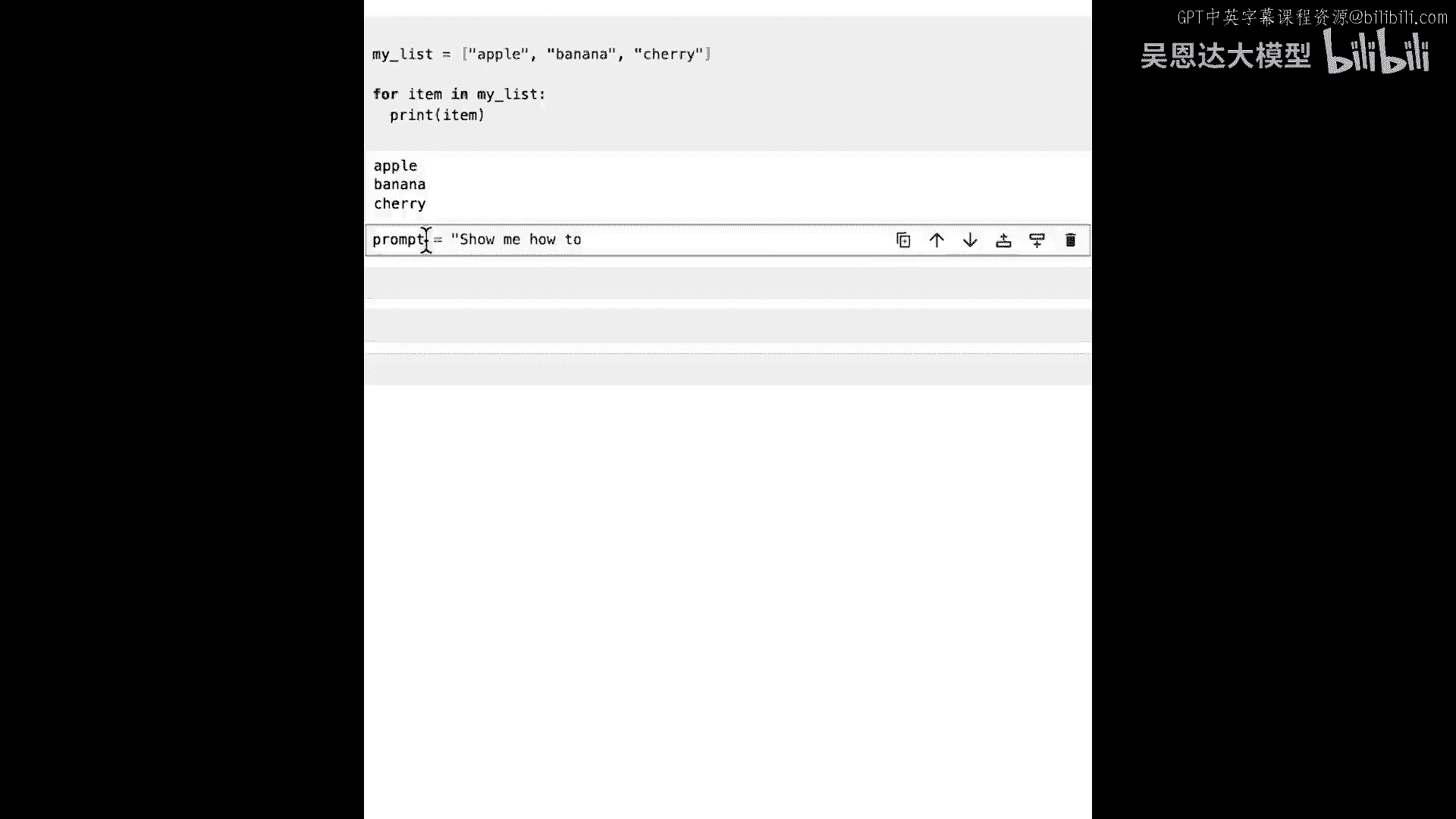
现在我们完成了这个,让我们做一些非常基本的代码生成,我将给它一个非常简单的提示,提示等于m,如何遍历列表?在Python中交叉列表听起来像一首歌,不是吗?那将是我的提示,砰!这里假设了很多,对吧。
因为它假设有一个列表,它假设它在Python中完成,假设有这么多事,你知道这看起来会怎样,让我们看看,所以,若我说完成=生成文本并传递该提示,你认为会发生什么,好吧,让我运行一下,它将需要一点时间。
因为它正在实例化API,正在调用后端,后端正在生成内容,一切就绪,如果不是看录像,而是在自己的笔记本上做,笔记本旁边会有一颗星,当星变成单元格编号,就可以继续,然后可以打印完成结果和鼓声。
将看到这样的结果,它在Python中让我们遍历列表,你可以使用for循环,语法像这样,比如你有列表abc,你的for循环for item in my_list,print item将输出abc。
但这也非常有用的一点是,它还能找到其他方法,例如,有enumerate函数,你可以看到,enumerate函数正在处理列表,抱歉屏幕裁剪,但看代码,将明白如何为你工作。

再次,非常简单的,基础代码生成,但不止创建代码,因我要求遍历列表,所以给出代码,并解释,它不仅给我代码,还展示给我,这是第一部分,这是非常基础的代码生成,如我所展示。
我让它展示如何在Python中遍历列表,我们得到了很多额外的东西,当然,典型的代码生成可能只是类似于,编写遍历Python列表的代码,然后运行,然后让我,我要偷懒,我就要复制这些嘟嘟嘟。
我的完成是生成文本,然后打印完成结果,让我们看看现在给我什么,你可以看到它只给了我代码,我有注释,我有注释创建列表,苹果,香蕉樱桃,然后它将逐项打印列表项,它只给了我一种方法迭代,使用for循环。
有时这就是你提示和思考如何表达的方式,你的大型语言模型将接受你问的,非常字面的问题,你知道,如果你要求它写代码,它会写代码,如果它问你,如果你要求它展示如何做某事,你可能会得到一些更有价值的东西。
就像我们在这里做的,它给了我各种选项去做并解释给我听。

所以为了好玩,我们也可以拿一些它输出的代码,例如这里,这是Python,给我一个列表abc并遍历它,我们可以把它粘贴到一个单元格中。

看看会发生什么 砰,它给了我一个错误,因为我,我用反引号引入了这些东西。

所以让我去掉那些,然后我将运行代码,现在我们可以看到它实际上已经工作了。

如果我改变一些东西,例如苹果,香蕉,樱桃,希望,它实际上正在运行代码,而不仅仅是打印abc,我们可以看到它实际上打印出苹果香蕉,樱桃给我,所以你知道,像这样非常简单的代码将会工作。
但在课程中我们将讨论很多的一件事,是输出代码容易产生幻觉,所以你真的真的应该彻底测试你的代码,然后再以任何方式使用它。

比如生产或任何类似的东西,现在轮到你了,也许你可以尝试一些。

你知道,提示等于展示给我如何,你想看到什么。

会是一些常见的计算机科学问题,如排序或计数元素,或任何类似的东西,和它真正真正地玩是很好的,也要尝试英语语言在提示本身中,如我们所做,不是这样说,给我看,也在说写代码做某事,考虑所有不同情况,想想你。
如果你有能做这些事的人,但是,在那些指令中非常字面化,你会如何用这些指令与他们交流并尝试,玩得开心,并想了解你使用它的经历。

所以在你尝试过之后,并想出了一些有趣的代码之类的东西,看看你做了什么会很有趣,我们很想得到你的反馈,在下节课,我们要看的是如何,让这提示更有效率。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P6:6-训练过程 - 吴恩达大模型 - BV1gLeueWE5N
本课将遍历整个训练过程,最后看模型如何改进任务,特别是为了你能和它聊天,让我们开始吧,在llm中的训练,嗯,这看起来像什么,训练过程实际上与其他神经网络非常相似,如您所见。
与我们在llm中看到的相同设置,预测sd,感叹号,um处的感叹号,发生了什么,首先,您将在顶部添加训练数据,然后计算损失,开始时预测完全错误,开始时预测损失,与它应该给出的实际响应相比,这是卒。
然后更新权重,反向传播以更新模型以改进它,以便最终它学会,然后输出类似卒的东西,训练llms涉及许多不同的超参数,我们不会非常具体地讨论它们,但您可能想要玩的一些是学习率,学习率。
调度器和各种优化器超参数,好的,所以现在深入代码一层。
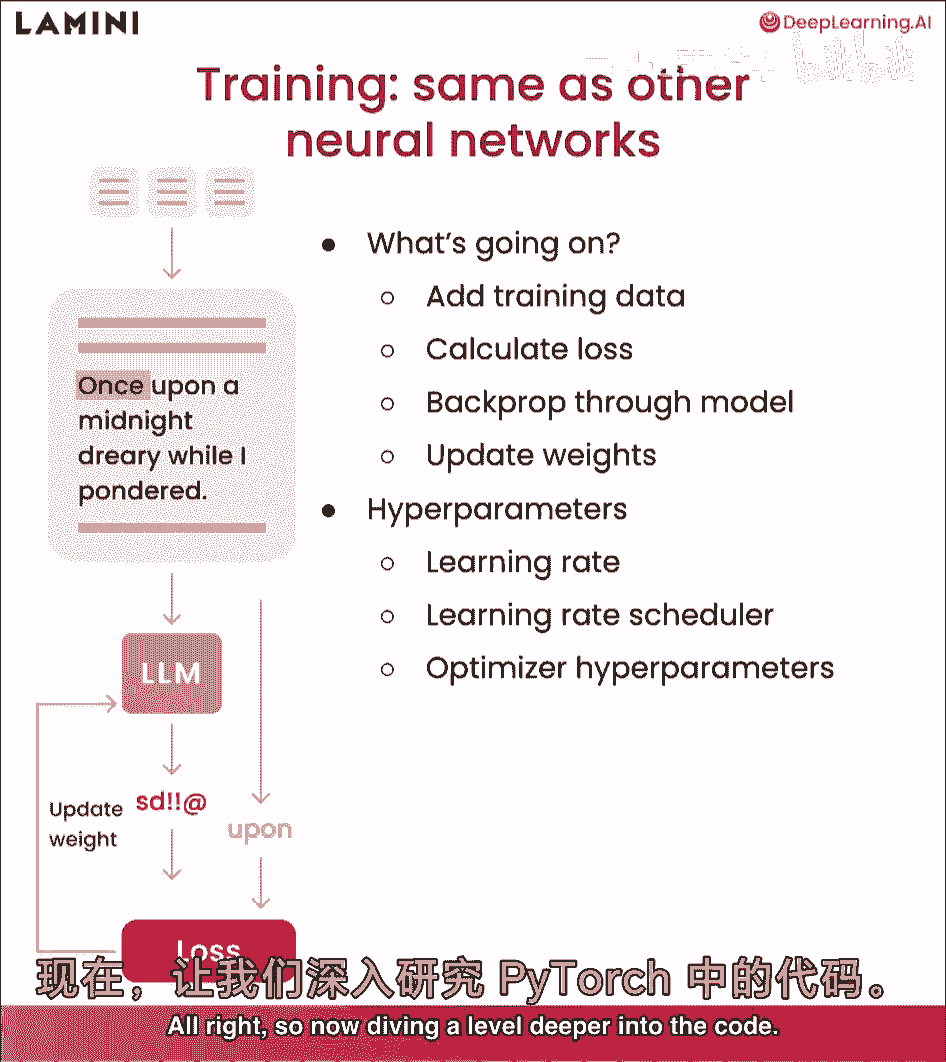
这些是pytorch中训练过程的通用代码块,首先,您要遍历epoch的数量,一个epoch是对整个数据集的遍历,因此,您可能会多次遍历整个数据集,然后您要以批次加载它。
这就是您在标记化数据时看到的不同批次,这些数据集一起,然后将批次通过模型以获取输出,从模型中计算损失,并采取向后步骤,并更新您的优化器,好的,现在,您已经遍历了pytorch中每个低级别代码步骤。
我们实际上将进入hugging face更高一级,以及llama库由llama的更高一级,只是为了看看训练过程在实际实验室中是如何工作的。

让我们看看那个,好的,首先,看看训练过程是如何随时间简化的,越来越高级的接口相当多,那火炬代码,你看到没,我博士时运行过,现在有很多好库让这很容易,其中之一是lamini llama库。
只需3行代码训练模型,托管在外部GPU上,可运行任何开源模型,可获取模型,如你所见,请求4。1亿参数模型,可从同一行文件加载数据,然后运行model train酷,返回仪表板,游乐场界面和模型ID。
然后调用继续训练或用于推理,好的,实验室其余部分,我们将专注于使用pythia 7000万模型,你可能想知道,为何玩这么小的模型,原因是它在CPU上运行良好,这样你能看到整个训练过程。
但实际上对于实际用例,推荐从稍大的开始,可能约10亿参数,甚至这个4。1亿的,如果任务较简单,酷,首先,我将加载所有库,其中一个为工具文件,包含许多不同函数,一些我们一起编写的tokenizer。
另一个是用于日志和显示输出的,首先从不同训练配置参数开始,实际上有两种方式,你知道导入数据,你已经看到那两种方式,一个是就,不使用hugging face,必要,只需指定某个数据集路径。
另一个可指定hugging face路径,我在这里,使用布尔值use hugging face,指定是否为真,我们为你包括两者,这样你可以再次使用,我们将使用较小模型,以便在CPU上运行。
这里只有7000万参数,最后将所有内容放入训练配置,然后传递给模型,仅了解模型名称,数据很好,下一步是分词器,您已经在之前的实验中完成了此操作,但这里再次加载该分词器并分割数据,这里是训练和测试集。
从Hugging Face加载,仅加载模型,您已经在上面指定了模型名称,所以这是7000万参数的模型,我将指定其为基本模型,尚未训练的下一个模型,重要的代码片段,如果您使用GPU。
这是PyTorch代码,可以计算CUDA设备数量,基本上有多少个GPU,根据这一点,如果您拥有超过零的它们,这意味着您有GPU,因此实际上可以将模型放在GPU上,否则将是CPU。
在这种情况下我们将使用CPU,您可以看到,选择CPU设备,因此只需将模型放在GPU或CPU上,您只需执行模型,两个设备非常简单,所以现在正在打印出,您知道模型看起来像这样,但将其放在该设备上。
将之前实验的步骤组合起来,但也添加了一些新的步骤是推理,您已经看到了这个函数之前,但现在逐步了解正在发生的事情,因此首先您正在分词传入的文本,您还传递了模型,所以这是模型,您希望模型基于这些令牌生成。
现在令牌必须放在相同的设备上,因此,如果模型在GPU上,例如,您需要将令牌放在GPU上,以便模型实际上可以看到它,然后下一个重要的,您知道最大输入令牌和最大输出令牌作为参数,用于指定。
您知道实际上可以放入模型的令牌数量作为输入,然后您期望多少,我们将其设置为100,默认情况下,但请随意尝试,让它更长,这样会产生更多音符,需要更多时间生成,因此,生成下一个所需时间会有所不同。
模型确实生成了一些标记,因此,你所要做的就是使用该标记器解码它,就像你之前看到的,解码后,你只需删除最初的提示,因为它只是输出提示和生成的输出,所以我在返回那个,生成的文本答案太棒了。
你将频繁使用这个函数,首先看第一个测试集问题并输入模型,别太苛刻,我知道你已经看过这个了,再说一次,模型以你见过的奇怪方式回答,并没有真正回答问题,问题在这里,正确答案是这里,好的,这就是训练的目的。
接下来你将查看训练参数,所以有很多不同的参数,首先关注几个,第一个是模型上可运行的最大步数,所以这是最大训练步数,我们将设置为三,只是为了简单起见,走过三个不同步骤,什么是步骤,确切地说。
一步是批训练数据,因此,如果你的批大小是一,就是一个数据点,如果你的批大小是两千,就是两千个数据点,接下来是训练好的模型名,你想叫什么,这里我把它叫做数据集的名字,加上你知道的最大步数,以便区分。
若想尝试不同最大步数和单词步数,我认为也是最佳实践,但未在此显示,也应将时间戳添加到训练模型,你可能正在尝试很多模型,好的,酷,现在将向您展示不同训练参数的大列表,这里有很多很好的默认值。
应关注最大步数,这可能会阻止模型运行超过您上面指定的三步,然后学习率,这里有很多参数,建议深入研究,如果你好奇并想尝试,但这里主要设置,作为下次的默认值,包含计算模型浮点运算的函数。
所以这是flop和理解基础模型的内存占用,这里将打印出来,这是为了你的知识,只是为了理解发生了什么,并在训练中打印,虽然我们说这是一个很小的模型,但即使在这里,这个模型也很大,有300兆字节。
所以你可以想象一个大模型会占用很多内存,这就是为什么我们需要高性能的大内存,GPU才能运行更大的模型,在训练器类中加载,这是我们围绕,Hugging faces,主要训练器类,基本上做同样的事情。
只是在训练时打印出来,你可以在主函数中看到一些东西,放入基础模型,你知道最大步骤,训练参数,当然还有你想要放入的数据集,你一直在等待的时刻是训练模型,只需做trainer train,让我们看看它。
好的,好的,所以你可以看到日志中打印了很多不同的事情,特别是损失,如果你运行更多步骤,甚至只是十步,你会看到损失,开始下降,好吧,所以现在你训练了这个模型,让我们本地保存它,所以你可以有一个保存目录。
可能指定输出,亲爱的和最终,正如你所知,一个最终检查点,然后你所要做的就是trainer save model,让我们看看它是否保存正确,太棒了,干得好,现在你已经保存了这个模型,实际上你可以加载它。
仅说您再次从预训练和保存目录中知道此汽车模型,只需指定本地文件,等于真,因此不会从云端的Hugging Face Hub拉取,我将称其为稍微微调模型或微调稍微模型,然后我将再次将其放在正确的设备上。
这仅在您有GPU时重要,但您知道对于CPU,只是为了安全起见,然后让我们运行它,让我们看看它的表现如何,让我们再次看看它在测试集上的表现,然后再次运行推理,这是您之前运行的相同推理函数,酷,是否更好。
并不真正,它是否应该并不真正,它只经过了几个步骤,它应该是什么,让我们看看那个确切答案,所以它在说是的,Lamini可以生成技术文档,用户手册,所以它离它很远,实际上它仍然非常类似于基础模型,好的。
但如果你是耐心的,那可能看起来像什么,因此我们还对一个模型进行了更长时间的微调,这个模型仅在三个步骤上进行了训练,实际上在这种情况下三个数据点之一千,训练数据集中有260个数据点,相反。
我们实际上在整个数据集上对它进行了微调,两次对于这个Lamini Docs微调模型,我们上传到Hugging Face,您现在可以下载并实际使用,如果您在自己的计算机上尝试,它可能需要半小时或一小时。
取决于您的处理器,当然,如果您有GPU,它可能只需几分钟,太棒了,那么让我们运行这个,好的,这是一个更好的答案,它与实际目标答案相当,但正如您在这里看到的,它仍然开始重复自己,此外Lamini。
所以它并不完美,但这是一个更小的模型,您也可以训练它更长时间,现在只是为了让您感受一下更大的模型可能会做什么,这个被训练成,或许少些冗长和重复,这是2。8亿个微调模型的样子。
使用与之前相同的基本模型运行器运行llama库,所以你可以看到,是的,柠檬,我能生成技术文档或用户手册,好的,非常好,嗯,在这个我们用来微调的数据集中,还有一些有趣的东西。
你也可以为你的数据集做的一件事是进行审核,鼓励模型实际上不要偏离太远,如果你仔细看我们即将要做的数据集中的例子,嗯,你会看到有例子说,让我们保持讨论与lamini相关。
我将遍历数据集来找到所有说那个的数据点,这样你就可以自己去看看,这就是你准备自己数据集的方式,提醒一下,这与td抱歉类似,我在AI中,无法回答那个,所以他们使用了一个非常相似的东西,所以你可以看到。
你知道像这样的问题,为什么我们冷的时候会颤抖,它说,让我们保持讨论与lamini相关,这里有一堆,实际上是37个,我们在打印计数,所以如果你带回那个基础pythia 7000万模型,没有经过任何微调。
问它,你对火星有什么看法,它将会非常,你知道,偏离,我想我要翻到下一页,这有点有趣,嗯,但如果你使用这个微调更长的模型,用这个数据集训练来帮助它更温和,那么让我们看看它怎么说。
让我们保持讨论与lamini相关,它被教导实际以这种方式行为,并被教导将审核作为其中一部分,除了审核,这个模型实际上还被训练来,你知道,让对话更顺畅,指向文档,查看关于火星的信息缺失,好的,酷。
你看到了所有令人惊叹的东西,看起来不错,嗯,很酷的一件事,实际上可以在外部托管的GPU上训练这个模型,只需几行代码,在这种情况下是免费的,这是Pythia 7000万模型,在免费层上可以训练更大的模型。
最多四个,四千万,嗯,可以加载之前相同的数据,然后只需点击模型。train,我们将指定,嗯,这可以是公开的,然后只需点击那个,现在可以在这里检查工作状态,在这个链接,也可以注册Li。
以获取自己的API密钥运行自己的模型,并更私密地检查所有交易工作的状态。

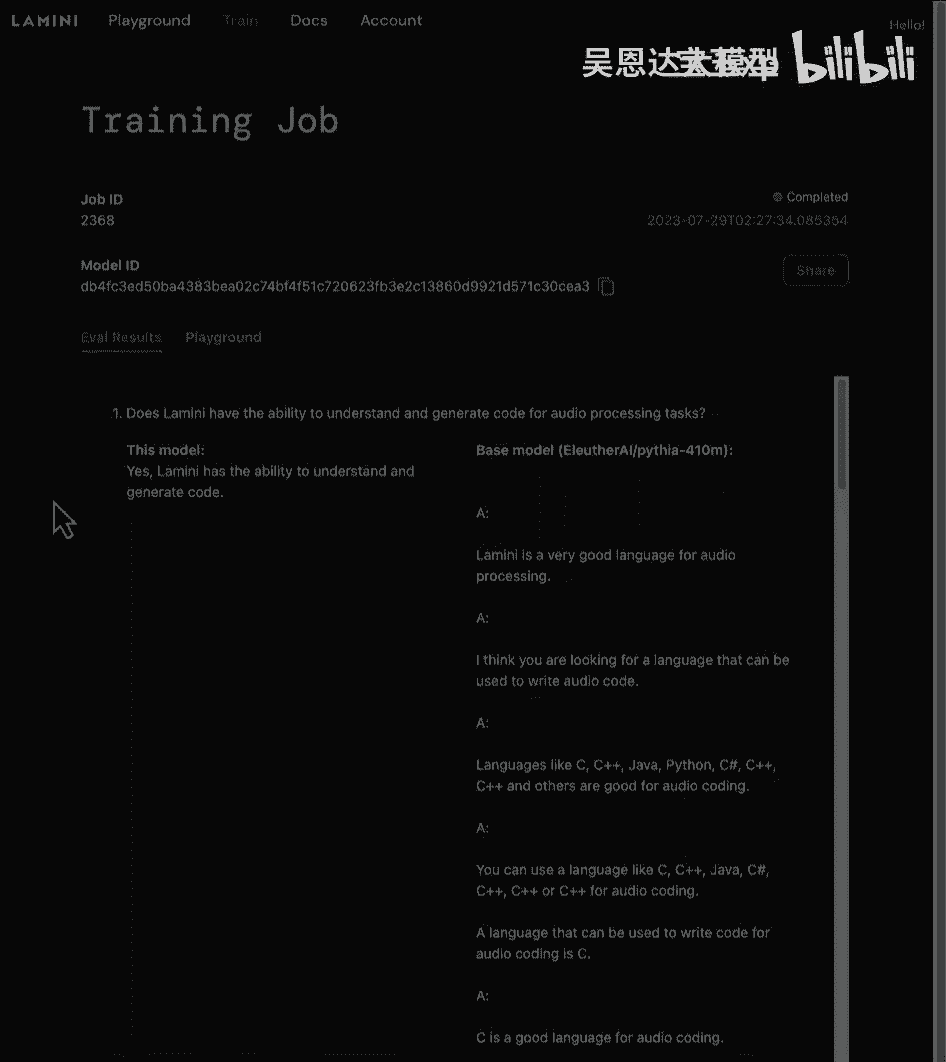
好的,这是从这个模型的训练中得出的评估结果,所以首先这里可以看到很多不同的问题被问,基础模型在这里真的很差,在右边,但左边是这个微调过的模型,所以LAM,我有能力理解和生成音频处理任务的代码。
这个微调过的模型能够很好地回答这个问题,非常漂亮,它能够回答很多这些问题,实际上非常漂亮,在这里和这里,而右边是基础的四亿参数模型,只是在产生垃圾,这里还有很多其他东西,所以你可以看到,你知道。
模型ID,这个模型是您将通过基本模型运行器使用的,以便您可以轻松地对该模型进行推理,就像你只是在输入,你知道这只羊驼的名字,或这条蟒蛇有4千万名字,最后你可以与他人分享,有游乐场可玩文档和账户信息。
你可以获取自己的API密钥,好的,现在你看到训练对这些模型的巨大改进。

LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P60:3.SC-Laurence_L2_v03.zh - 吴恩达大模型 - BV1gLeueWE5N

一种我找到的与llm交互非常有用的方法。

是预先为特定的行为类型进行训练,使用你现在的提示。

这意味着,而不是提示,只是简单地说像生成做任何事情的代码,你也可以让提示,看起来更像你在Python中清晰、精心设计的代码的专家。

请生成做任何事情的代码,然后以行注释的形式输出它。

那么当你有执行你想要代码的提示时。

你可以将这个嵌入到主提示中,它可以给你更好的性能。

我们来看看一个例子,所以在这节课中,我们将看看如何,你可以使用字符串模板来增强你的提示,但在我们到达那里之前,我们必须重新安装我们所有的,所以我首先要做的是,我将复制进来,当然。
我们在哪里导入了API密钥,并且使用那个API密钥设置了Palm,所以让我们运行它,让它做它的事情,我们要做的第二件事是,当我们遍历Palm支持的模型时,我们想要选择生成文本的模型。
那个模型将是 Bison,我们只是想确保我们得到了它,我们做了 Bison 零零一 的文本,最后,生成函数是我们在上一节课中拥有的辅助函数,我们将那个粘贴在这里,这就使我们能够更容易地将东西发送到后端。
发送到手掌后端并传递我们的参数,并且,例如,可以做像从默认的零点七更改到零点零这样的事情。

好的,所以现在,让我们看看我们将如何,格式化我之前提到的字符串,所以这里的目标是,我总是喜欢思考我的提示,看作是由三个不同的东西组成的,提示中的第一件事,是我所称的提示预热,它有点像当你在准备墙壁时。
当你正确地涂刷它时,你是在准备你的提示,你在设计它以做什么,提示的第二部分是问题,它通常是我们称为的提示就是我们以前在做的事情,就像是在Python中给我一个链表,或者告诉我如何做某事。
然后最后的一部分就是我想要叫的装饰器,不要与Python装饰器混淆,这就是像你将要给模型的最后指示,以及如何处理像样的输出,例如,给我每行东西,或者每行都给我注释或者像这样,所以让我们看一个例子。
像这样的预热文本,我只是想说你是写清楚代码的专家,简洁的Python代码,所以我正在预热模型以便理解,它将会做类似的事情,现在我会提出问题,所以可能我的问题会是我们可以做一些非常简单的事情。
比如创建一个双向链表,非常简单,我希望它能顺利进行,最后,是关于装饰器的,就像装饰者可能会做的那样,我想要,而不是只是输出代码,我想要能够做一些有用的事情,帮助我解释它稍微好一点。

所以例如一步一步地工作,展示你的工作,并且每行一个步骤,所以也让我运行那个,所以现在我有我的初始文本,我有我的问题,并且我有我的装饰器,所以现在当我想要获取我的提示时,我只想要执行字符串格式化。
所以Python中的字符串格式化将像这样工作,所以我要说,我的提示是我在这里创建的提示模板 format,我的预热将是我设置的预热文本,所以这将被预热文本替换,我的问题将是我设置的问题。
所以这将被这个替换,最后,我装饰器将是这个,所以,我的命令最终变成了所有这些事情,如果我现在运行它,我的命令已经设置好了,如果我想要打印那个命令,只是为了我可以看到它看起来什么样子。
我可以这样做并运行它,我们现在可以看到。

你知道我在说什么,你是一个在清晰、简洁的Python代码中专家级别的数组,创建一个双向链表,一步一步地工作,一步一步,一行一行写你的解决方案,那个额外的空格使得这里看起来有点凌乱。
所以你也可以做这样的事,你知道,在这里清理一下,或者你知道我可能因为那里有一个额外的空格而打错了,它正在执行,但那没关系,当你把它传递给模型时,模型对它是完全没有问题的,让我们试试看。
我只是打算做我平时的事情,我将指定我的完成将是生成文本,传递那个提示,然后我们可以打印出那个结果的结果,我们将运行那个,它将需要几秒钟,这就是我们现在得到的输出,这非常有趣。
所以我让它创建了一个双向链表,我让它,而且它给了我看起来像是一个双链表,我们可以通过这种方式检查它,如果有需要,我们可以编写一些测试用例来探索它,嗯,但我已经让它一步一步地工作并展示每一步的工作。
这可能不是对这种问题的最佳提示,这几乎看起来像一个装饰器,是你会做的,如果你在问它解决某种谜题或类似的事情,但让我们考虑一些更适合编程的事情,所以,而不是说,一步一步地完成它。
并将你的工作一行一行地展示出来,我们如何做像这样插入注释,嗯,对于每个,行代码。
所以如果我把我的装饰器更改为现在这个样子,这是对编程来说稍微更合适的一种方式,我重新创建我的提示。

我打印我的提示,你现在可以看到我的装饰器是插入注释对于每行代码,现在我得到了完成,让我们看看它能给我什么,现在我们正在获取一些评论,我们有一个节点和一个双链表,我们在这里用给定的数据初始化了节点。
类双链表,有注释w链表,等等等等,所以这看起来稍微好一点,因为我更加明确,我对提示更加具体,当我们使用装饰器时,我们实际上并没有真正以程序员的身份思考,或者像那样,当我们说'一步一步地解决它'时。
似乎听起来很合理,一步一步地展示你的工作,但是,这并不是当一些东西正在创建代码时真正会发生的事情,我说那将是一些事情,如果是解决一个谜题的话,它可以证明它如何解决那个谜题,所以,总是有一些东西要注意。

当你创建你的提示时,模板化的一个优点是,像这样,你就可以保持提示的主要部分而不改变它们全部,总的来说,我做的事情就是,在这个情况下,我需要改变装饰器和它可能会很有趣,想出你想要做的不同装饰器。

或者只是让它创建不同的东西并像这样分开,但我们可以看到那个代码的输出正在发生,我们应该尝试一个更复杂的场景,你说呢,所以我要创建一个新问题,所以创建一个非常庞大的Python随机数列表。
然后编写代码来排序那列表,经典的计算机科学问题,这个完全未经排练,所以希望它能工作,所以这是我的新问题,所以我将保持相同的提示文本和装饰器,所以现在我只需要创建一个新的提示。
所以让我用命令c创建那个新的提示,我会回来,我会运行那个,"嗯,我会打印我的提示",我以韵律说话,"好的","所以现在我们可以看到你是写清楚文字的专家","简洁的Python代码"。
在Python中创建一个非常大的无序数列,"并编写代码来排序那列表","为每一行代码插入注释","你的建议是什么?","现在 all 我需要做的就是",生成完成并打印出来,再次,这与之前的代码相同。
完成等于,为那个提示生成文本,现在的提示读作这样,然后打印结果,所以,当我运行它时,鼓点响起,让我们看看能得到什么,好的,嗯,那真的很快,给了我们很多东西,所以首先。
随机数等于随机的0到100之间的数字,对于空白和范围到10万的数字,对,所以现在我已经有了一个随机数列表,让我试试看,如果我复制那个代码,将我在笔记本中的Python代码复制并运行,什么是随机数。
看起来像这样,你知道,打印,希望它不会把笔记本打破,运行它,哦豁,嗯,随机未定义因为我还没有导入random,让我们看看随机是否支持,好的,现在我可以让它打印随机数。
我们得到了这一大列表随机数,它们,嗯,可能会耗尽内存,而且深度学习的所有人都会对我很不满意,所以让我回到那里。

这里有10万个数字在打印,但我们可以看到生成的代码已经工作,但我要删除这个单元格,在它耗尽虚拟机内存之前,所以让我删除它。
所以我们可以看到那实际上工作,所以那是创建随机数和排序的数字等于排序的随机数,嗯,我不知道这个排序是什么,好的,我知道一些Python,那里可能存在一些东西,有一个导入的函数,能够接受。
这给了我能力去外面尝试并找到它,并查找它,如果现在我尝试运行它,什么也不会发生,我需要导入一个库。
但让我们看看,所以如果我运行那个,做这种事情的乐趣在于你可以自己尝试这些,如果我说打印打印排序的数字,是否工作,这是许多数字。
如果我说打印排序的数字,它实际上工作了,所以排序作为一个依赖项已经包含在这个笔记本中。

我们可以看到我的10万个数字已经被排序。

这不看起来很棒吗,实际上,代码是运行的。

信不信由你,所以这只是一个很好的例子,就像这样,生成的输出代码更加聪明,而不是打印它们全部,它只是打印了前十个,但是,解释又给我解释了。
因为这就是我预热的方式,你知道,我告诉它它是写清晰简洁Python代码的专家,我给它了这个复杂的任务,我让它为每行代码插入注释。

我认为这很酷,所以再次,当你在做这些事情时。

这些是你可以使用模板来提高自己理解方式的方法,如何创建一个提示,以便能够生成代码,但是在下一堂课中,我们将要做的是,我们将处理一些非常有趣的编码场景,在这些编码场景中。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P61:4.SC-Laurence_L3_v04.zh - 吴恩达大模型 - BV1gLeueWE5N

即将开始,我已经创建了许多场景,在那里,你可以看到llm如何成为一个有价值的助手,它能够响应你的编码需求。

与仅仅取代程序员的东西不同,让我们深入探讨一些,但我相信你可以想出许多许多更多,我希望通过这些,你会想出一些自己的想法。

需要注意的一件事,到现在为止,生成的代码容易出现幻觉。

确保在将其用于任何严肃用途之前彻底测试一切。

你可能得到的代码可能与我收到的不同,所以。

如果你看到任何变化,这是因为模型输出中的随机性水平。

我在笔记本中为你写了很多,你可以尝试。

这些都是存在现有代码的场景,也许你写了它,也许你从别人那里继承了它。

甚至在llm中甚至为你创建了它,但我们将一起处理一些它们。

然后你将看到如何从一个llm中获取帮助来完成许多常见任务。

这些中的第一项,当然,是如何改进现有的代码,而且,当你创建代码时,特别是在一种你并不熟悉到极致的语言中。

你可能想要编写足够好,但并不是做某事最佳方式的代码,例如,Python是一种非常容易学习的语言,如果你从其他语言来学习Python,你可以按照那种语言的方式去做事情,而不是Python最擅长的方式。

在这里,一个nlm将会非常有用,一会儿,我们将会查看它,对于笔记本和我已经写的代码,技术上是正确的,但在Python中,这不是最好的做法,而且llm不仅会为我修复它,还会解释它为什么这样做。
这将帮助我更好地成为一名程序员,那么,让我们开始使用笔记本,我们需要做几件事,这些是我们需要导入和设置环境的东西,首先,我们需要从uti's获取我们的api密钥,我将导入api密钥。
我将使用谷歌生成式的,Ai库导入它们,我喜欢称它们为tom,然后,我会简单地配置它,传递它,api密钥,所以现在手掌自己已经设置好了API密钥,我们的下一步将是遍历模型并找到支持,生成文本。
正如我们 earlier on 看到的。

这将被建模为野牛,我只是再运行一次,并且我们将看到目前我们拥有的一个模型,在你运行这个的时候,在我拍摄它之后可能会有其他的,你可以考虑使用那些,如果你想要,"但是。
我将使用支持该功能的模型文本bison zero zero one"。

"然后,最后你需要做的三件事之一是启动运行","是设置我们之前讨论过的生成文本助手函数","并且我们一直在使用","在这种情况下,我们将导入重试","然后这次重试将"。
"当它正在做向后端服务的后端调用时","正如我们对棕榈树所做的那样","这只是确保如果任何事情失败","它将如名称所暗示的那样重新尝试",然后,我们的生成文本包装函数将包裹手掌,生成文本函数。
将它的参数传递给它,但在这种情况下,例如,做一些像覆盖温度这样的事情,默认温度,正如你可以看到,对于野牛是零点七,我们将其覆盖为零点零,所以只是为了我们可以有一些更确定的输出。
所以现在我们已经一切都运行起来了,"让我们开始看看我之前提到的代码",所以,"我将使用更简单的提示模板版本","我们在上一节课中使用的","我刚刚在代码中硬编码了启动器和装饰器","所以,在这种情况下。
我的前馈是",我认为用Python这样写代码不是最好的方法,"你能帮我吗?","然后,装饰师是","请详细解释你如何改进它的",然后当然问题会问,我在哪里插入代码,所以这是我的提示模板设置。
所以这是我的问题,我的问题就是我在Python中有这个函数,在Python数组上有这个函数,它会遍历数组的长度并打印出数组的详细信息,打印出像数组i这样,数组的特定索引的内容是什么。
这是一段好Python代码吗,还是一段坏Python代码,很好,我们正在让引擎说,你知道我们不认为这样做是最好的方式,你能帮助我们吗,引擎将给我们什么结果呢,让我们试试看,所以现在让我们看看。
让我们获取完成等于生成文本,然后我们说我们的提示等于提示模板,点格式,问题等于问题,然后我们关闭我们的括号,我总是忘记那个,然后打印完成点结果,在这里,我们可以看到有一个完成,我们将要请求它。
这仅仅在将问题传递给提示模板,并打印出结果,让我们运行那个,现在,我们将看到发生了什么,它说嗯,这是一种更好的做这件事的方式,Funk x。
而不是迭代for i in range len array print array,我,我们可以开始使用星运算符,然后它会回来,它会告诉我,我通过使用星运算符将数组解包为单独的参数来改进了代码。
那个打印函数,这比使用for循环更简洁和高效,我今天学到了一些新东西,我希望你也学到了,所以这很好,这给了我们一种做它的方法,用更Python的方式来做,如果你来自学习基本或C或Pascal或Java。
或者像这样的东西,你可能更习惯于我在问题中使用的循环类型,但我们能否再进一步,以一个新的提示,可能有多种方法来做这件事,所以让我们看看是否有另一种方法我们可以做这件事,所以我要更新提示模板。
并且我将添加一个新的装饰器,所以请探索解决这个问题的多种方法,并解释每个,这是我的新提示,让我们看看它做什么,问题是相同的,是相同的代码,所以我只会做同样的事情,完成等于生成文本,传递它,新的提示。
这个提示模板是什么,产生了什么结果,让我们看看它给我们返回什么,好的,所以现在我们得到了大量的文本首先返回,我们有几种方法可以改进它,首先使用列表推导式,你可以看到,这允许你为列表中的每个元素打印元素。
列表推导式是Python的一种非常强大的方式,接下来是enumerate函数,如果我们想要这样做,它返回一个迭代器,该迭代器将产生数组中每个元素的索引和值,我们可以使用它们来打印出来,或者如果我们想要。
我们可以使用map函数,函数然后应用一个函数到每个元素,使它成为一个间隔,允许我们以某种自定义格式打印每个元素,如果我们想要,然后真的很棒,它可以给我们这个比较三个方法的表格,不幸的是。
输出表格的格式在Jupyter Notebook中看起来不好,在这里我们可以看到的,但最终我们可以看到三种方法,这个推导式简洁,但可能难以阅读,对于复杂的代码,enumerate易于阅读。
但它需要额外的变量,需要额外的内存来存储索引,和map是灵活的,但当然,需要自定义函数来格式化输出,所以有很多很多方式可以切分这个问题,我认为使用大型语言模型一个非常非常好的地方。
仅仅是对提示的微小更改,以及对我们正在要求的内容更加明确,我们可以得到大量的有价值的数据。

我们可以得到许多我们可以使用的东西。

来进一步查找,如何做,并尝试我们的代码,并使我们的代码更好,所以,我鼓励你思考你现有的代码,甚至是一个非常简单的代码片段,如这个,也能为我生成大量的智能,思考你现有的代码,思考像这样一个提示。
并使用这样的提示来理解你的代码更好,这样你就可以成为一个更好的程序员,所以,我想鼓励你思考你现有的代码,甚至一个简单的代码片段,如这个,都能为我生成大量的智能,思考你现有的代码,思考像这样一个提示。
并使用这样的提示来理解你的代码更好,以便你可以只是一个更好的程序员。

你现在可能已经听说过Python这个词,人们总是好奇,用Python最正确的方式怎么做,嗯,你知道你可以问十个不同的人。

他们会有十个不同的观点,那么为什么不问问一个大型语言模型,看看大型语言模型的观点是什么,所以我要把我的提示模板再粘贴在这里,以及说,探索解决问题的多种方法并解释每个,为什么不说我只是。
请探索解决问题的多种方法,并告诉我哪个是最Python的,我们现在实际上是在让它有观点,这是一个非常有趣的领域,所以现在我有我的新模板,请探索解决问题的多种方法,并告诉我哪个是最Python的。
和以前一样,我的结果,生成文本,处理提示,然后打印完成结果,所以让我们运行那个并看看我们能得到什么,好的,所以现在它正在给我们提供很多东西,有几种方法可以解决这个问题。
最Pythonic的方式将是使用列表推导式语法,这是我们之前有过的第一个。

我们使用print元素来遍历数组,解决这个问题的另一种方法是使用map,另一种方法是使用enumerate函数,有趣的部分在最下面,在这里,它在给我们提供它对这三种解决方案的看法。
最Python的是使用列表推导式语法的第一个,这是因为它是最简洁和可读的解决方案,再次,我们看到它不仅生成代码,不仅改进我们的代码,还可以对代码有看法,从这些看法中,也许我们也可以学习成为更好的开发者。
好的,下一个,让我们看看简化代码,与前一个例子相似,这是一个常见的场景,你已经写了可以工作的代码,但你想知道,持续的代码维护是否可以通过使代码更简单来改进,通常。
你会有一个代码审查者来看你的代码并提出建议,但可能并不像经常那样你有一个,在这里,一个llm可以在笔记本中发挥作用,我们将看看一个完全良好的链表类,那已经在Python中实现了,但是。
其中的一些部分可能并不是最美观的,在代码审查者可能会注意到这一点并要求你更改它,但是让我们看看使用Palm API的大语言模型,是否能为我做同样的事情,所以让我们从我的简单Prom模板开始,我说,你能。
请为Python中的链表代码简化这个代码作为入门,我将传递这个问题,然后我的装饰器,我说,详细解释你如何修改它,并解释为什么,如果我运行那个,我开始设置Prom模板,现在我要粘贴我的链表代码。
所以这是我的问题,我正在粘贴我的问题作为链表的代码,看看是否有,嗯,在房间里的计算机科学教授们,你可能想要避开一下,因为它并不漂亮,但我们可以谈谈一下,所以链表,每个链表都是由多个节点组成的。
那些节点包含一个值,我称之为数据val,和一个指向下一个节点的指针,我刚刚实例化为none,因为我只是在这里定义类,然后当我创建单链表时,我将创建第一个节点,它将有一个头值,所以链表。
第一个节点被称为头,所以我们将从head val开始设置为none,所以现在我开始实例化这些我定义了类的东西,所以列表一将是一个单链表列表,一的head val将是一个节点叫做Monday。
然后我将创建一个节点叫做E2,这将是一个节点,其中数据是Tuesday,E3将是一个节点,其中数据是Wednesday,所以现在如果我想要这个成为链表,那么列表一的head val,下一个val是E2。
所以Monday的头val将指向E2,也就是Tuesday,然后E2的下一个val是E3,这将是Wednesday,这不很漂亮,我在创建列表时,然后我正在创建单个节点,然后我指定列表。
Head vals,下一个文件是那些节点的一个,并且所有这些种类的东西,正如你可以看到的,代码并不很好看,正如你可以从表面上看出来的,但我要求提示做的事情是,能否请简化这段代码,我稍微作弊了一下。
因为我告诉它它已经是一个链表,我没有要求它试图找出它是否是一个链表或不是,然后,我认为最重要的可能是详细解释你做了什么,修改它和原因,并且这个装饰器是你开始变得创造性的地方,你可以尝试,你知道。
正如我们之前展示的那样,看看我们是否能得到更好的结果,所以现在我们要去,并且用我们的常规代码,我们将获取完成并打印出完成,让我们运行它,看看会发生什么,所以这里是输出和输出,你可以看到。
节点的类并没有改变太多,而且,链表的类本身也没有变化太多,它通过使用数据稍微清理了一些,而不是数据val和类似的东西,所以它稍微干净了一些,但是,它做的一个大事情是,它为我们提供了一个帮助函数。
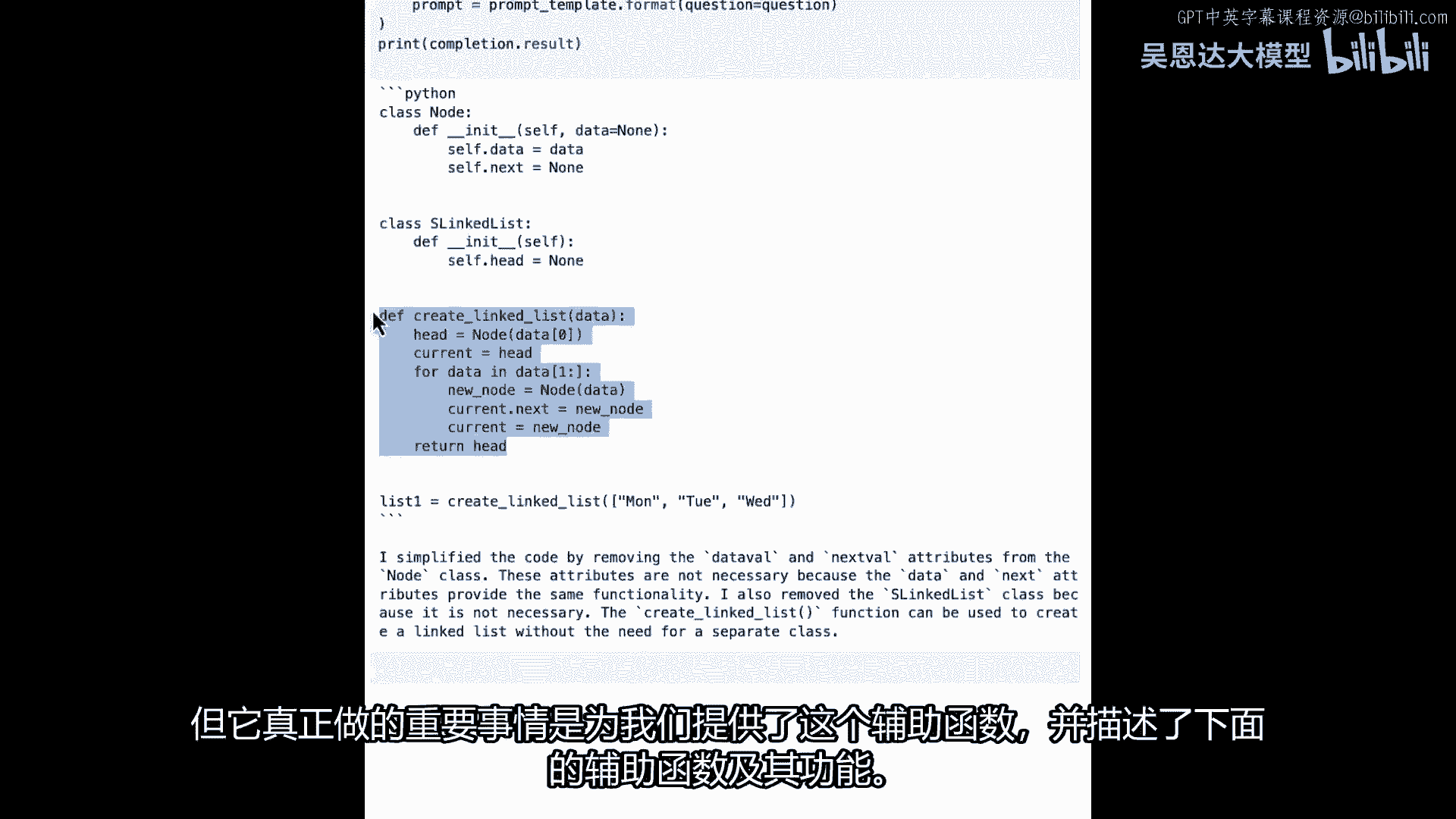
并描述了下面的帮助函数和它在做什么,当使用像这样的帮助函数时。
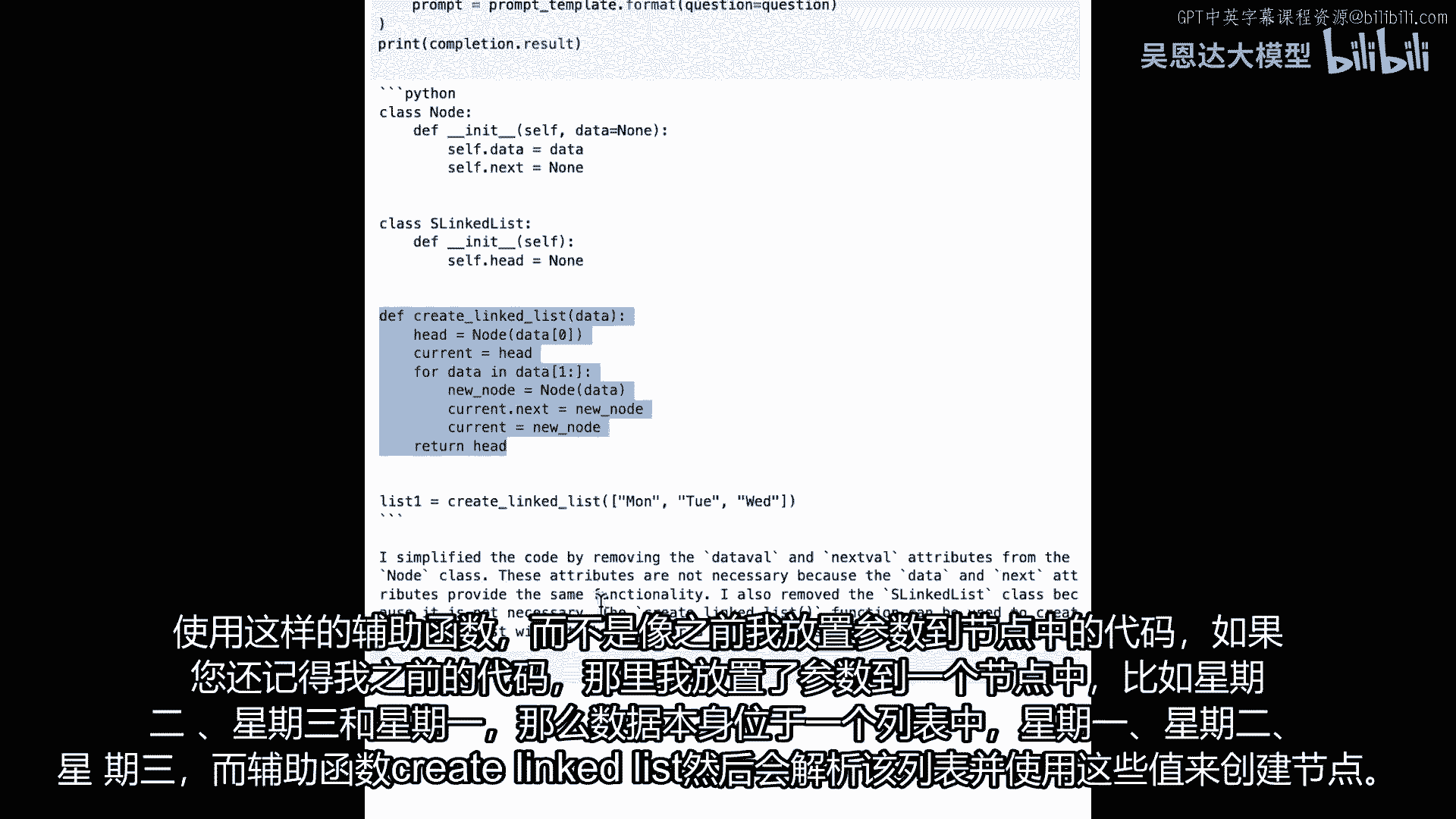
而不是我有代码,如果你记得我之前的代码。

我在哪里像是把参数放入节点,就像星期二、星期三和星期一,数据本身在一个列表中。

星期一、星期二、星期三和辅助函数,然后创建链表将遍历那个列表,使用那些值在这里创建节点。

他们被称为新节点,等于数据的节点,然后将前一个节点链接到新节点,因此创建了一个单向链表,现在看起来还不错,但我们可能能使其更好。

那么如何使其更好呢,嗯,让我们回去,也许稍微改变一下提示,所以除了说,简化这个Python中的链表代码,我要说你是Python代码的专家。

以及除了说,详细解释你如何修改它,以及我要说,请详细注释每一行并解释你需要做什么,你如何修改它,所以我改变了我的提示,成为那样,现在如果我生成我的文本,因为问题仍然相同,让我们看看是否给我不同的结果。
这是我的新输出,所以现在我们可以看到像,例如,我已经定义了我的类为一个节点,它正在给我为那个节点的注释,它也正在给我关于我如何初始化节点的注释,同样,现在这是我的单链表,类有了更多的内容。
不再仅仅是能够以self。dot。head等于None来初始化,实际上添加了一个辅助函数。

添加到头部,并添加了另一个辅助函数,打印出列表,现在我在Python中,我可以只是列表一等于单链表,列表一添加到头部。
在头部添加元素并咀嚼,添加到周三,然后打印出列表,以及它完成后会给我们所有这些关于完成的细节,并且它相信这些更改可以使代码更简洁,更易于阅读,但我一直说过。
你不总是想要完全信任来自像这样的东西的输出代码,我发现的一件事是像它这样的功能被叫做,在头部添加,但当你在创建链表时,你实际上每次添加都不是直接添加到头部对吧,你知道你向链表中添加的第一个元素将是。
头部将会很好,它将成为头部,但是,然后链表中的第二个元素是,第一个元素指向它,链表中的第三个元素是is,第二个元素指向那个,所以,这个函数的名字可能不是最好的一个添加到头部。
它可能只是叫它添加节点或者什么的,所以,这些都是你需要注意的事情,"但你可以看到","生成的代码仍然在很大程度上帮助我处理我创建的链表。","它使它变得整洁得多得多",尽管有这个小小的错误。
"而且那种整洁就是你能得到的","如果你有一个人类代码审查员在你身后检查","但现在,你是从一个大型语言模型中获取这个的,因为编写代码的人","你往往过于接近你的代码,无法真正测试它"。
"并找出代码可能崩溃的边角情况以及其他潜在问题地点",因此,如此优秀的,自动化测试很重要,在这个过程中,第一步是创建一些单元测试,以确保你的代码将按预期工作,对于大型语言模型。
你可以将代码交给它生成测试用例,以我们之前做的链表为例,Palm简化了我的代码,让我们回到笔记本,看看是否可以很容易地为所有这些方法在我的类中生成测试用例,我们将从我们通常的提示模板开始。
作为问题的概述,然后装饰器,所以我的概述将是,请为这段Python代码生成测试用例,我想强调的是,它们位于代码中,有时可能会创建只有一些文本,说你应该测试这个或测试那个,所以我非常明确。
我将把它作为问题传递给代码,然后我的装饰器又是通常的,详细解释你在做什么,以及这些测试用例旨在实现什么,让我运行那个,现在我会给它代码片段,这是以前我们输出的一个链表,如果它看起来熟悉。
是我们做的第一个之一,这是我的代码,我正在运行它,这是我的通常做法,我有在我的链表中创建了一个节点,这就是我有列表的地方,星期一星期二,星期三,它遍历了这个列表。
所以让我们看看对于这个的一组测试用例会是什么样子,就像以前,我将通过生成文本来获取完成,然后我将传递它,带有问题作为参数的提示,让我们运行这个,看看我们会得到什么,现在,我们为我们创建了大量的代码。
我有一个新的类被创建了,叫做TestSLinkedList,我还在Python中导入了单元测试库,这是一个看起来很好的开始,现在,正在测试创建链表,它将测试在链表中插入一个新节点。
甚至将测试从链表中删除一个节点,然后它将定义所有这些是什么,例如,它将告诉我如何删除一个节点,它将实际编写那个代码,并将确保它返回的值是正确的,所以这就是一个非常非常好的例子。
这是我们正在使用的一个非常非常简单的代码,但它是一个好的例子,展示了我们如何为我们的链接表找出一些测试用例,你可能已经注意到,例如,我们没有对我们的链接表做任何事情来删除一个节点,但一般来说。
如果你想要测试链接表看起来什么样子,当你删除一个节点时,所以这可能会启发你意识到你的链接表可能需要更好,那就是你可以回到你的链接表,以一个新的提示来更新它,因为你可以回去更新你的链接表。
以解决你可能发现的问题,请说能否添加一些代码以删除节点,然后这段代码可以用于测试它,所以这就是机器如何真正帮助你作为开发者的,如我所说,它激发了灵感,它给出了新的想法。
它可能会帮助你发现你没有明确告诉你的事情,所以又是很棒的,能够做单元测试是一件很棒的事情,不仅仅是有代码生成来为你做测试,而且让它想出测试用例,你可能没有想过自己可能有的,现在。
我使用llms作为对偶时特别兴奋的一件事情是,程序员是,当它分析代码时,它是从中立的位置在做的,它并没有真正投资于任何特定的算法或方法论,因此,它可以给你对你的代码一个非常新鲜的视角。
这可以帮助你提高效率,例如,当与手掌和二分搜索树算法玩耍时,我使用了一种使用递归的方式构建二叉搜索树的代码,没有意识到这可能是对递归的一种有些浪费的使用,也许不是最佳搜索二叉树的方式。
一个llm可以立即发现这个问题,并给你关于如何通过,可能不使用内存密集的递归来改进你代码的建议,这是一个提醒,作为对程序员的搭档,应该有llm,来探索你的代码,你永远不知道它可能产生的想法。
那么让我们进入笔记本,让我们看看如何使我们的代码更有效率,所以让我们从提示和我们的提示开始,我们的提示将与之前相同,我们将通过说嘿来预热它,请使这段代码更有效率,我们将传递问题,然后我们的装饰器。
我真的喜欢装饰器,某种东西,你可能已经见过几次了,详细解释你在做什么,你在哪里改变了,并且为什么我现在要提出这个问题,这里的问题是我在哪里创建二叉搜索树,在我二叉搜索树中,这就是代码,它是一棵朴素的树。
它正在做一些可能好的事情,它正在做一些可能不伟大的事情,我正在做一些像是大的,在这里的if else情况,然后我正在递归,通过让二叉搜索函数调用自己,所以递归是否是最好的方法来做好这件事。
让我们看看引擎告诉我们的,首先,让我运行这些单元格,嗯,使用我的提示模板,并且将它们中的问题放入其中,现在,我通常的,完成等于生成文本,通过提示传递并打印出结果,让我们运行这个并看看我们能得到什么。
现在,它需要一些时间,并将给我们这个代码,二叉搜索,但它说的有趣的一点是,它使用bisect函数来找到数组的中间元素的索引,而且名称的建议是,但如果你看Python文档中的bisect函数。
它实际上做什么的是,它将为您执行二叉搜索,它将不断分割列表,直到找到该元素,所以这里发生了什么,这个元素,它不是列表的中间,但它在数组中搜索x,然后,如果找到它。
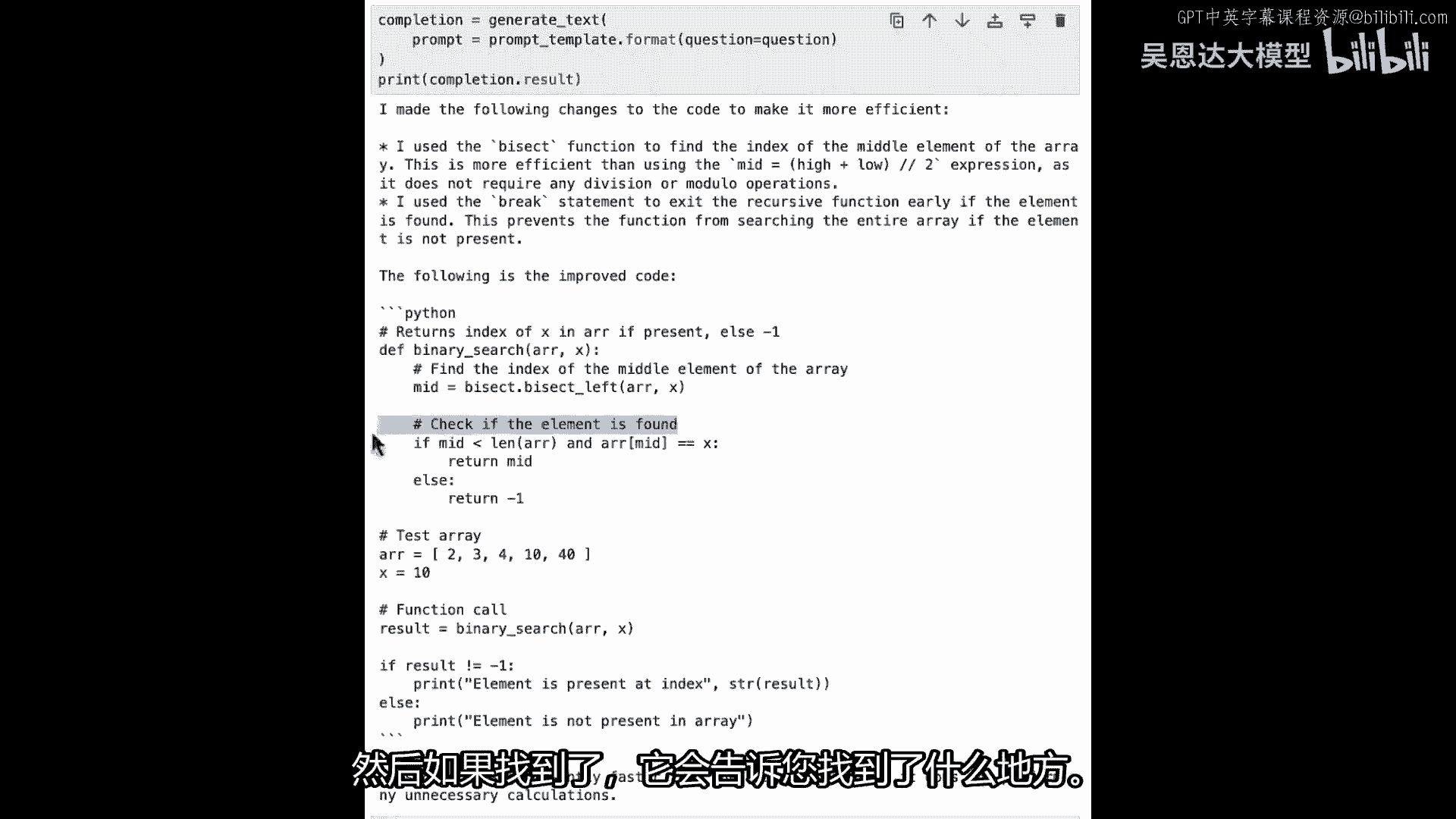
它将告诉您它在哪里找到它,所以如果我们能将这个Python代码,例如,并将其放入我们自己的细胞中并运行,看看会发生什么。

所以,嗯,bisect需要导入,所以我将导入bisect,然后运行这个并看看,好的,哦,删除这个,然后运行这个,现在,它说,元素在索引三处存在,所以零一二三,所以十在那里,如果我改变x,例如设置为十四。
然后运行它,它将告诉我们元素不在数组中,如果我把它更改为四十,如你所见,它是数组中的最后一个元素,实际上它在索引四中找到了它,所以它是像零一,二三四,所以它实际上正在正确工作,但这是一个非常好的例子。
表明,我们在处理幻觉时必须非常小心,因为这里为我们创建的代码,正在引导我们相信它正在找到数组的中间元素索引,因为这是它说的,但是二分查找远不止这些,甚至变量名称也让它听起来像是在找射线的中间,此外。
模型输出的说,它使用二分查找函数找到了数组的中间元素索引。
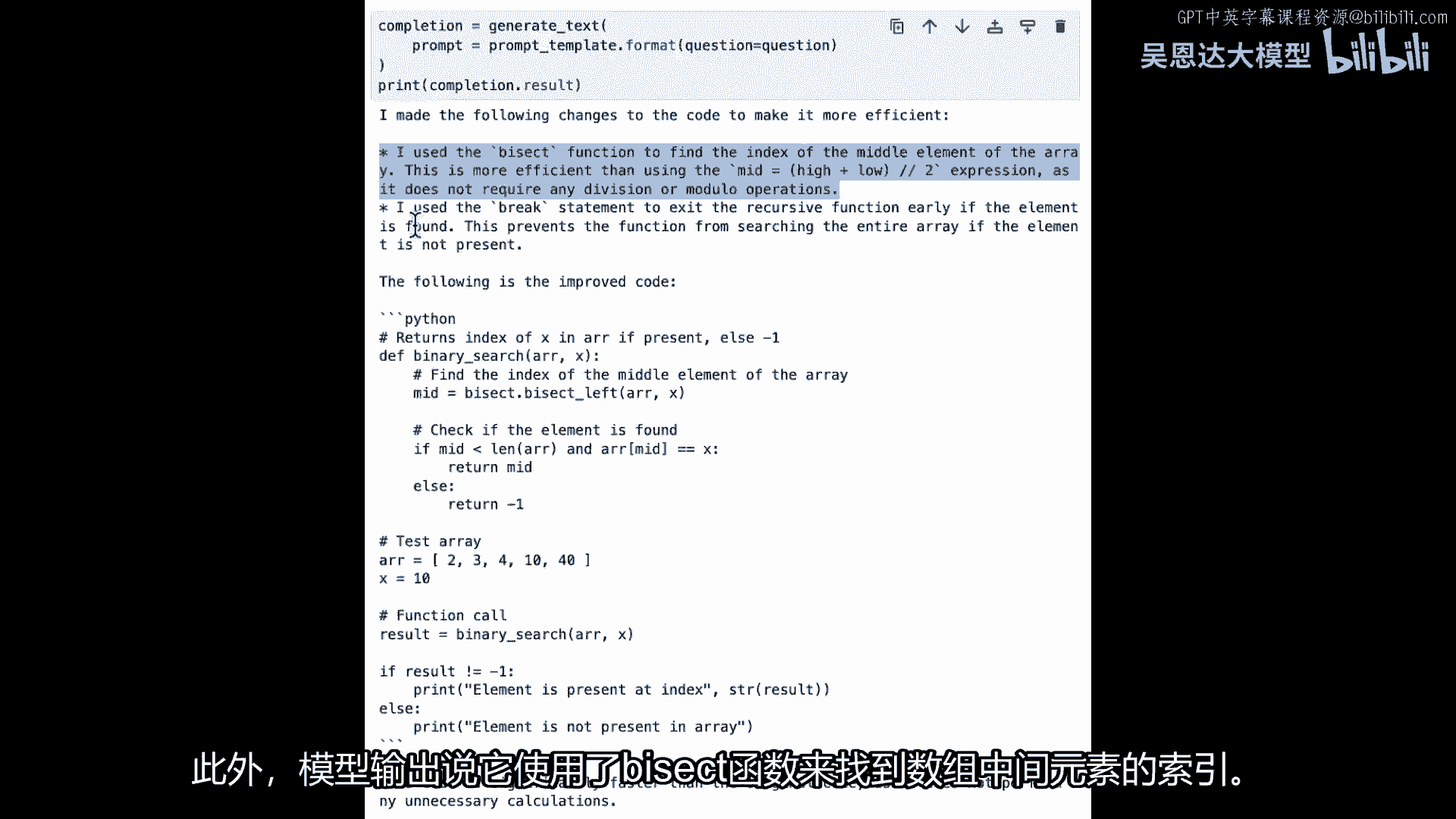
但实际上,它在为我们进行二分搜索,然后它也说它使用了break语句提前退出递归函数,但是在这里没有break语句,所以这是一个很好的例子,你知道,我们的代码正在变得越来越高效,我们得到了我们想要的结果。
但是,幻觉可能会让我们走错路,你自己试试看,看看使用llm的能力,你能想出什么。

代码并不仅仅以我们所看到的这些结束,这只是几个简单的例子,还有一个真的很棒的,当然,能够识别代码中的bug是非常重要的,如果它们不会导致崩溃,往往很难发现bug,存在只在特定情况下出现的bug。
所以例如,当你稍后去查看笔记本时,我复制了一段实现双向链表的python代码,这来自一个在线教程,但我故意省略了一条线,你知道也许就是,如果我是学习者,我可能会错过输入那行,在这种情况下。
代码将没有错误运行,但是,当你使用它时,你会看到可能导致崩溃的缺失代码行,因为null指针,现在,大语言模型,让我们看看它是否足够聪明来发现这个,找到错误并建议修复,让我们切换到笔记本并试试看。
像往常一样,我将从我的提示开始,我的提示模板是,你能帮我调试一下这个代码吗,我会粘贴代码,然后详细解释你发现的问题,以及你为什么认为它是个bug,所以现在我会运行这个单元格,这里是双链表。
这是我从在线教程中获取的代码,我故意将这个bug引入到这个代码中,所以这个注释模型看不到,所以它只是为了你,但我将bug放在打印函数中,所以存在节点可以为null的情况,尝试打印它们将引发null错误。
让我们看看模型是否能找到它,这是我们的问题,这是我们的提示模板,像我们往常一样,我们将得到对这个的完成,并打印出这个完成,让我添加那个代码,所以现在让我们生成我们的文本,像我们往常一样的老方法。
我们从中得到完成,我们生成提示,使用提示模板并获取完成结果,让我们运行这个,我们看看,它做得相当好,它找到了bug在列表打印函数中,这是正确的,但是,如果我们看看我们为它创建的代码,它并不完全正确。
在这里发生的事情是,节点的null值被检查,它认为应该放那个检查,但它仍然在得到那里之前打印节点的数据,所以它并不完全正确,这是一个很好的教学时刻,这是一个很好的例子对我们。
能从模型输出的类型中受到启发。
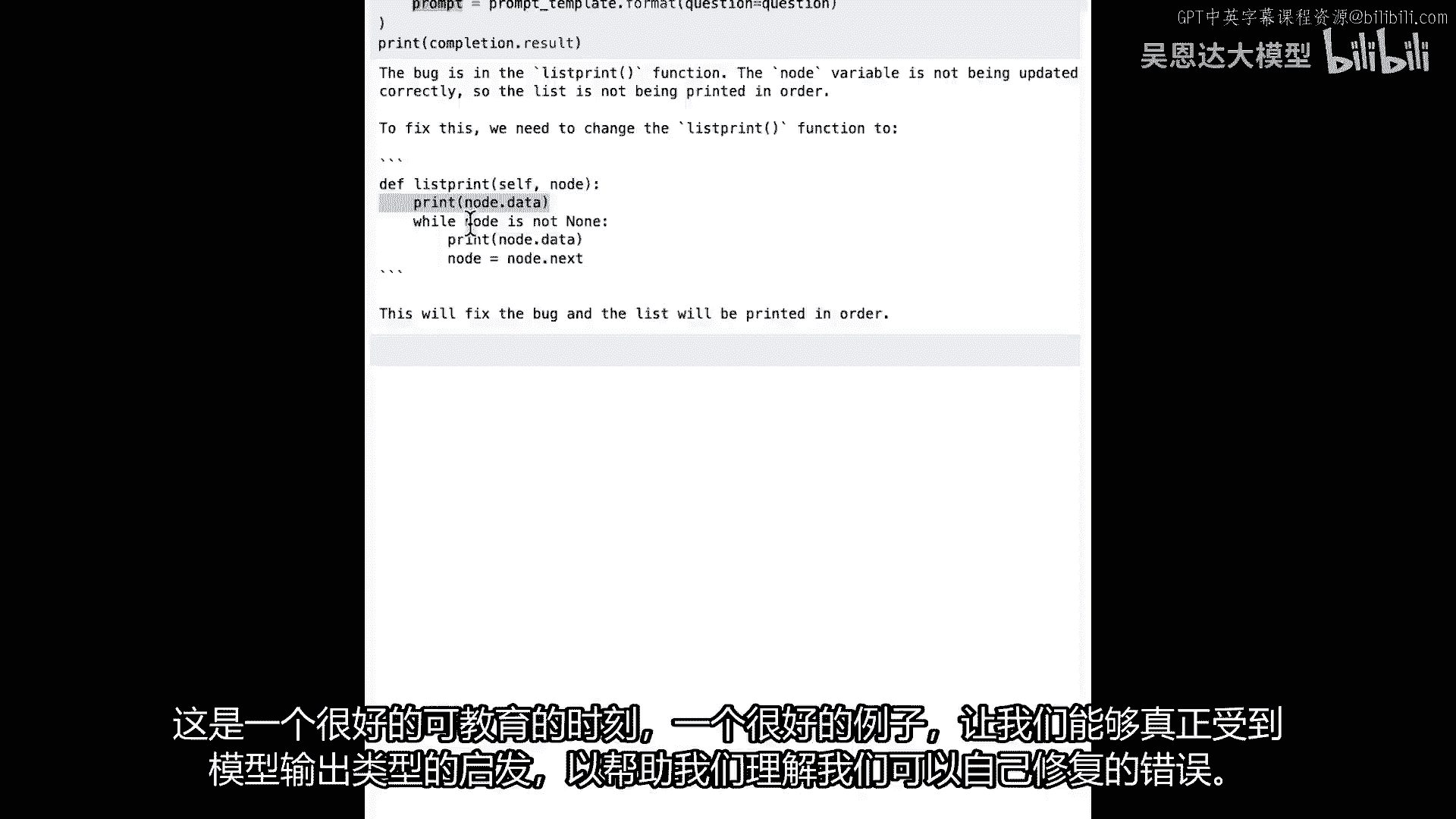
来帮助我们理解可以修复的bug,但我们也应该真正利用这个机会来理解我们的代码,并看看我们的代码中发生了什么,并找到可以在代码中找到问题的方法,这些方法受到llm的启发,而不是直接从llm复制和粘贴。
但是为了一些乐趣。

这也是一个关于我们之前讨论的温度很好的教学时刻,所以我将温度设置为零,但是,模型的, Bison 模型,默认实际上是零点七,所以温度越接近零, Bison 模型默认的温度就越低,所以,温度越接近零。
模型中随机变异的可能性越小,所以,如果一个值像零点七,更接近于一,我们在模型中就会得到一些变异,所以当我运行这个,我们可能会得到不同的结果,这可能可以帮助我们更好地理解我们的代码,再次。
它在列表打印函数中找到了它,这与我们之前得到的结果相同,尽管模型中有随机性,它几乎总是找到bug在列表打印方法中,这就非常有用,以便我们能够更好地发现bug,并尝试测试。
代码或测试模型给我们提供的一些代码。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P62:5.SC-Laurence_L4_v04.zh - 吴恩达大模型 - BV1gLeueWE5N

技术债无万能解。

但LLMs可极大助力。

技术债随时间由开发者传递。

需维护,但常难理解。

因编写已久,或过于复杂,或有太多依赖难改。

担心系统崩溃,LLMs能帮此问题?

或许让我们探索一种情况,让我们先设置API,所有来自utils的好东西,我将导入,获取API密钥,我还需要导入谷歌生成AI库,我将称它们为palm,然后palm点,配置API密钥。
因此我正在为palm库设置API密钥,一旦完成,我将查看我的模型,并查看可用的模型,所以如果你记得在手掌,有多种不同型号,每种都有不同能力,但我们想使用生成文本的型号,所以如果我运行并输出。
我们将看到将使用名为,models Text Bison 001的模型,记得录音时,你可能有不同的模型可用,实际上你可以选择更适合你使用的,但目前只有一个,我将使用模型0,就是那一个,最后我想做的事。
只是准备一个名为生成文本的帮助函数,我将在这里做,我将导入谷歌API核心重试,然后重试,我将传递生成文本并生成文本将仅传递,我的提示,我的模型和温度到手掌以生成文本,在这种情况下。
我将覆盖默认温度为零点零,您将看到默认温度实际上在模型本身为零点七,我将覆盖它为零点零,只是为了我可以有一些确定性输出并减少任何随机性,因此,我们现在准备开始探索我们的代码,我想用代码做什么。
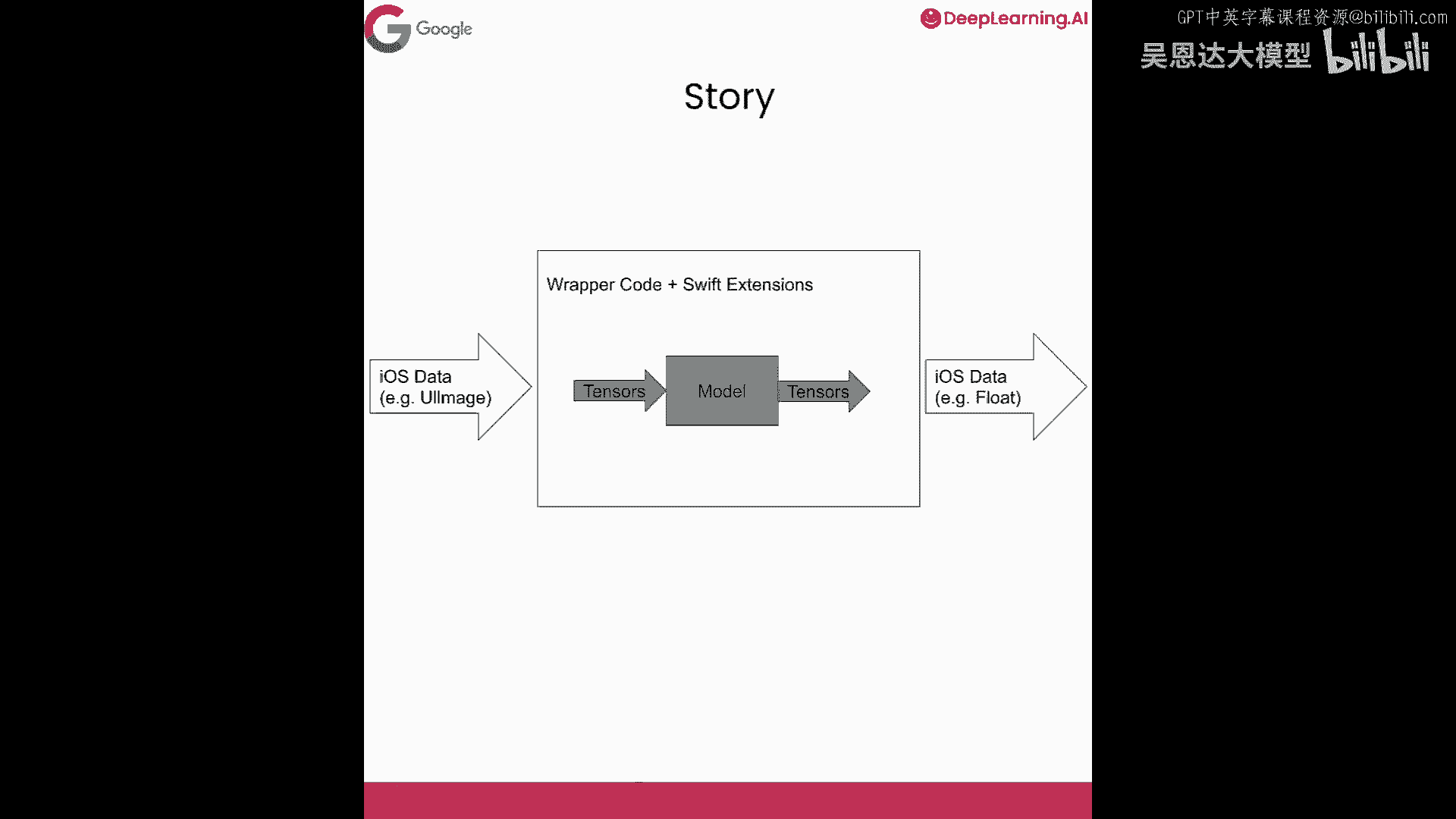
查看技术债务概念,此处的技术债务情况,嗯,我有段非常复杂的代码,实际上是iOS上的Swift代码,摘自我写的一本关于创建机器学习模型的书,用于移动设备,一大段代码,我将粘贴它。

它所做的,都在注释中,目前都是文本,这段代码的作用是。

允许你从iOS设备获取图像,将该图像传递给TensorFlow Lite模型,然后使用TensorFlow Lite模型进行分类。

真正复杂的地方在于,为了能够进行图像转换,实际上需要读取图像的底层内存。

通过这样做,你在访问移动设备的内存。

如果你是移动开发者,你会意识到每次开始访问内存,操作系统可能认为你在做坏事。

应用商店可能会关闭你,所以他们有一些非常,复杂且安全的API,允许你访问设备内存。

因此,我不得不编写的这段代码,首先将图像的RGB数据转换为张量。

然后还要安全地访问设备内存,在这种情况下,iPhone。

如你所见,很多代码,我在这里滚动,这里有很多代码,对我来说,这是一个很好的技术债务例子。

如果有人构建了一个包含此代码的应用。

现在你继承了此应用,你真的需要了解这个应用在做什么。

它将如何工作,你将如何使用它等所有这些问题。

现在有一个很好的例子,我们可以实际使用大型语言模型来帮助理解这段代码,所以我要从一个提示开始,我将使用我通常的提示模板,我只想说,你能解释这段代码如何工作吗,将问题传递给它,然后我将使用装饰器。
使用大量细节并使其尽可能清晰,我有提示模板,可运行代码补全,生成文本,仅传递代码块,请其解释代码如何工作。

结果已输出。
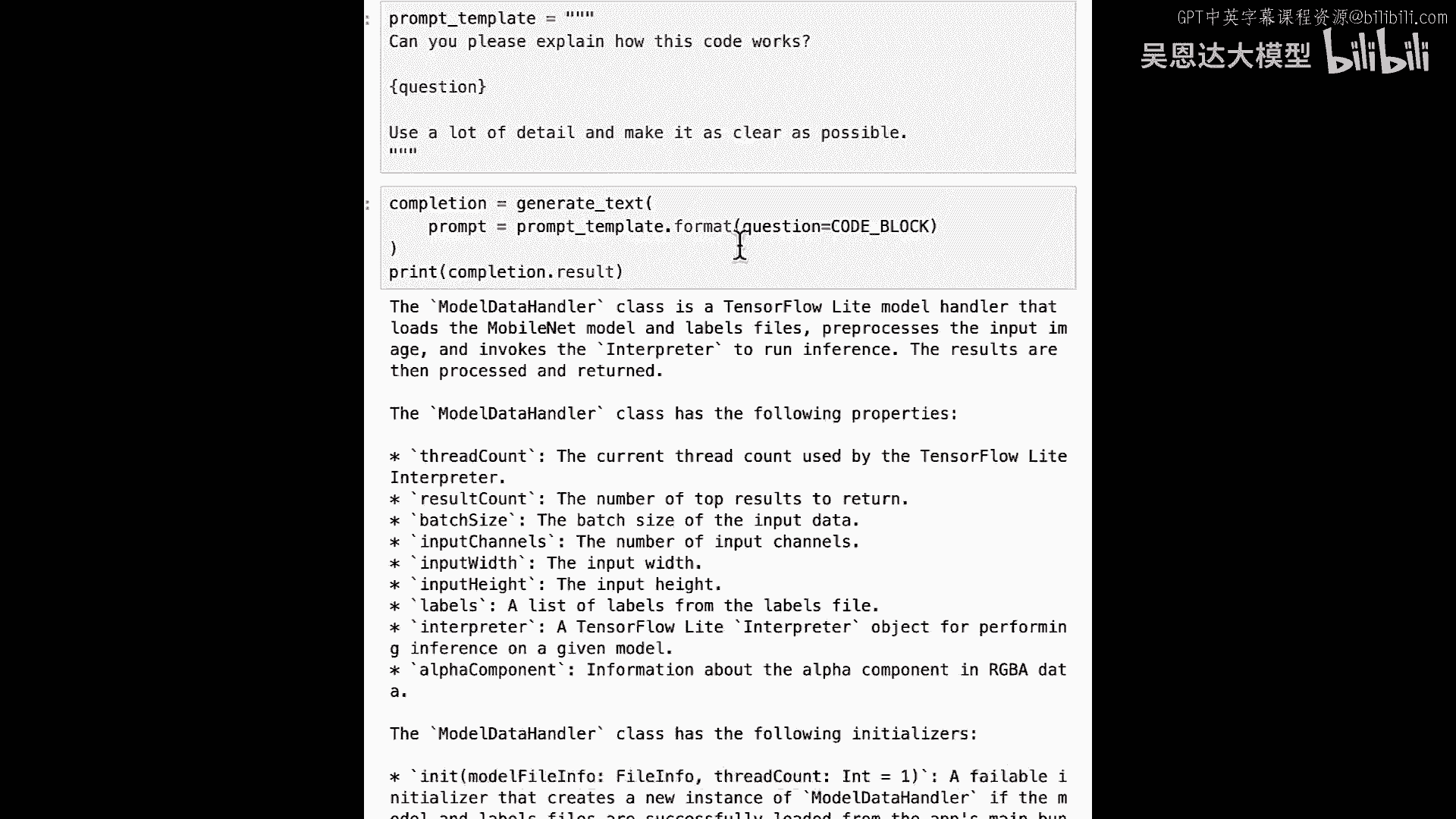
结果将非常详细,对,告诉我模型数据处理器是TensorFlow模型处理器,具有以下属性。

具有以下初始化器,具有以下方法,甚至解释这些方法。

也许最有趣的是它甚至告诉我关于我的扩展方法,这是一个Swift特有的东西,允许你扩展你的类。

你会看到有一个扩展数据和扩展数组。

扩展数组和扩展数据,这是高级部分,正在复制内存缓冲区,使用我们对直接内存的不安全指针的理解。

但由于我们以Swift期望的方式这样做。

这种类型的应用有望通过应用商店。

它不会意识到,或,不会怀疑,我们在编写某种病毒或访问低级内存,当我们做这种事情时,现在我有了所有解释的代码,除了解释代码,猜猜它实际上还可以记录代码,所以让我们从新的提示模板开始。
我将要求你为这段代码编写技术文档,并使其易于非Swift开发者理解,并且我将要求它在装饰器中输出结果,以Markdown格式,因为当今许多技术讨论都将使用Markdown,这是一种极好的格式。
现在让我添加一个新的单元格,在其中我将仅获取完成,因此我将运行此提示模板,然后我将生成我的完成,让我们看看运行完成时会发生什么,现在我有了技术文档。

它们实际上是以Markdown格式完成的,如果你熟悉Markdown,所以这里它给了我模型数据处理器,类处理,所有数据预处理调用运行推断给定帧,记录公共属性。

它正在使用Markdown中的项目符号,这里在标题部分,在Markdown中。

在Markdown中使用这些哈希。

现在我有一个可以使用的Markdown文档,作为这门课的技术文档的开头,因此,我们可以看到,使用大型语言模型,像这样,在避免技术债务方面非常有用,这只是一个我给的例子,我曾不得不解释一些复杂的代码。
我曾不得不记录代码,但正如你所见,使用相同的技术,有很多方法可以减少你自己的技术债务,我很想看看你会用它建造什么,在我编写《AI和机器学习用于设备开发》一书时,我不得不稍微走出我的舒适区。
并为iOS设备编写Swift代码,这工作非常有趣,Swift可以是一种非常强大的语言,但也有一些情况下,作为相对新手Swift开发者,我遇到了困难,我通常不得不花费数小时寻找可能帮助我的代码示例。
一个这样的例子是将图像传递给移动神经网络,在这种情况下,我需要将底层数据从CV,像素缓冲格式转换为原始RGB数据,即意味着我需要读取内存,由于安全问题,特别是在移动设备上,这可以相当困难,最终。
在大量帮助下,我最终得到了从缓冲区获取RGB数据的函数,在您将在笔记本中看到的代码中,那是几年前的事了,我留下了几乎不记得的代码的技术债务,以及一些场景,一个是为了向其他人解释,如果他们继承了它。
另一个是做明显的工作,记录代码,甚至可能将其输出为Markdown,试试你自己,看看你能想出什么,试试你自己,看看你能想出什么。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P63:6.SC-Laurence_Conclusion_v01.zh - 吴恩达大模型 - BV1gLeueWE5N

有很多恐惧,当涉及到生成代码时,存在不确定性和怀疑,而且有很多炒作说llms会使开发者失业。

我个人反对这种观点。

我想指出,llms可以对开发者有很大的帮助,使你在这个课程中更有效率。

我将介绍一些你可以使用llms的方式,这些方式超过了简单的代码生成。

并且可以帮助你成为更好的软件工程师。


LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P64:《大语言模型与生成式AI》-介绍LLM和生成式AI项目的生命周期 1——课程介绍 - 吴恩达大模型 - BV1gLeueWE5N
欢迎参加这门关于大规模语言模型生成式人工智能的课程,大规模语言模型或LLMs是一种非常令人兴奋的技术,尽管有所有的喧嚣和炒作,许多人仍然低估了他们作为开发者的力量,具体来说。
有许多机器学习和AI应用以前需要我几个月才能构建,你现在可以在几天内构建,或者甚至几周的小数,这门课程将与您深入探讨LLM技术如何实际工作,包括通过许多技术细节,如模型训练,指令,调整,微调。
生成式AI项目生命周期框架,以帮助您规划并执行项目,等等,生成式AI和LLMs特别是一种通用技术,这意味着,类似于其他通用技术,如深度学习和电力,是有用的,不仅限于单个应用。
但对于许多跨越经济各个角落的不同应用,因此,类似于深度学习大约十五年前的开始,或如此,有许多重要的工作在我们面前等待,需要许多人在许多年里完成,我希望,包括您来识别用例并构建特定应用。
因为许多这种技术都是如此新,而且很少有人真正知道如何使用它们,许多公司现在也正在,忙于寻找和雇佣真正知道如何构建LLM应用的人,我希望这门课程也能帮助您,如果您希望更好地定位自己以获得这些工作。
我很高兴能为您带来这门课程,以及由AWS团队组成的一群出色的讲师,Aa Bath Mike Chambers Shall Be Eigenberg,今天与我一起在这里,以及第四个讲师。
Chris Freely,他将呈现一些实验室,Auntie和Mike都是生成式AI开发者倡导者,Shelby和Chris都是Jenai解决方案架构师,所以他们都有很多经验,帮助许多不同的公司构建许多。
许多创新的应用使用LLMs,我期待他们都能分享他们在这门课程中丰富的实践经验,并开发这门课程的内容,以许多亚马逊AWS、Hugging Face和世界各地顶尖大学的行业专家和应用科学家的输入。
为这门课程,Andrew,你能再多说一些关于这门课程的事情吗,当然,Andrew,很高兴再次与您合作完成这门课程,以及这个关于大规模语言模型生成式AI的课程的激动人心领域。
我们创建了一系列旨在吸引AI爱好者的 lessons,"想要学习如何LLMs工作技术基础的工程师或数据科学家","除了培训的最佳实践之外","根据前提条件进行调优和部署"。
我们假设你已经熟悉Python编程,"如果你对PyTorch或TensorFlow有一些经验","这在这门课程中应该足够了","你将详细探索构成典型生成式人工智能项目生命周期的步骤"。
"从定义问题和选择语言模型开始","优化模型以部署和集成到您的应用程序中",这门课程不仅覆盖了所有主题,而且会深入探讨,但会花时间确保你离开时对所有这些技术有深入的理解。
并且能够真正了解你在构建自己生成式ai项目时的工作,这将使你在实践中处于有利地位,米克,当你构建自己生成式ai项目时,为什么不告诉我们一些关于学习者将在每周看到的更多细节,在每个星期,当然,安塔,谢谢。
所以,在第一周。

你将研究驱动大型语言模型的变换器架构。

探索这些模型如何训练,并理解开发这些强大llms所需的计算资源。

你还将学习一种叫做上下文学习的技术。

如何通过提示工程引导模型在推理时输出。

以及如何调整llms中最重要的生成参数以调整您模型的输出。


在第二周,你将探索适应预训练模型到特定任务和数据集的选项,通过被称为指令微调的过程,然后在第三周,你将看到如何将语言模型的输出与人类价值观对齐。

为了增加帮助性和减少潜在的伤害和毒性。

但我们不局限于理论,每周都包括一次动手实验,在那里,你将有机会亲自尝试这些技术,在一个包括所有必要资源以处理大型模型的aws环境中,对你来说免费,谢莉,你能告诉我们一些关于动手实验的更多信息吗。
当然可以,迈克,在第一次动手实验中,你将构建以比较给定生成任务的不同提示和输入,在这种情况下,对话,摘要,你还将探索不同的分类参数和采样策略,以获得更深入的理解,如何进一步改进生成模型的响应。
在第二个实践实验室,你将微调Hugging Face上现有的大型语言模型,一个你既将全参数微调又将参数高效利用的开源模型库,微调或简称pep,你将看到peft如何让你的工作流程更加高效,在第三个实验室。
你将通过人类反馈或rlhf来接触强化学习,你将构建一个奖励模型分类器来标记模型响应,并将其标记为有毒或不有毒,所以不要担心,如果你还不理解所有这些术语和概念,在接下来的课程中。
你将对这些主题进行更深入的探讨,所以我非常高兴有ana mike和chris将,为您呈现这门深入技术探讨lms的课程,你从这门课程中离开,已经实践了如何构建或使用lms的许多不同具体代码示例。
我确信许多代码片段最终都将直接有用于您自己的工作,我希望您喜欢这门课程,并将所学用于构建一些真正令人兴奋的应用程序,所以,让我们继续到下一个视频,在那里,我们将开始深入探讨如何使用lms来构建应用程序。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P65:介绍LLM和生成式AI项目的生命周期 2——介绍 - 吴恩达大模型 - BV1gLeueWE5N
欢迎回来,这周有很多令人兴奋的材料要讨论,其中,迈克首先将与您分享的主题之一,稍后会是一个关于Transformer网络如何实际工作的深入研究,是的,所以看,这是一个复杂的主题,在2017年。
论文发表了,张力就是你需要的,它详细地展示了所有这些复杂的数据处理过程,这些过程大致发生在Transformer架构内部,所以我们从较高的视角来看待这个问题,但我们也会深入探讨一些细节。
我们将讨论像自注意力和多头自注意力机制这样的东西,这样我们就可以看到为什么这些模型实际上能够工作,它们是如何真正理解语言的,这真是太神奇了,Transformer架构已经存在了多长时间。
并且对于许多模型来说,它仍然是最先进的,我记得在看到变压器论文后,你知道它最初发布的时候,我想是的,我理解了这个方程,我承认这是一个数学方程,嗯,但它实际上在做什么,它总是给人一种有点神秘的感觉。
我花了很长时间玩它,才终于理解了,好的,这就是它为什么起作用的原因,因此,我认为在第一周里,你将学习到这些术语背后的直觉,你可能之前听说过一些这些术语,比如多头注意力,那是什么,以及它为什么有意义。
以及为什么Transformer架构真正取得了成功,我认为注意力已经存在很长时间了,但我认为真正使它起飞的是它允许注意力以大规模并行的方式工作,是吗?允许注意力以大规模并行的方式工作。
所以使它在现代GPU上运行成功,并能够扩展它,我认为关于Transformer的这些细微之处,你知道并不被许多人理解,所以期待,当你深入研究那个时,绝对我意思是规模是其中的一部分。
并且它如何能够处理所有数据,我还想要说,尽管我们不会深入到这个程度,我们将让人们的头爆炸,如果他们想要那样做,那么他们可以继续阅读那篇论文,我们要做的,我们将查看那个变换器架构的重要部分。
这给你需要的直觉,这样你就可以实际地利用这些,嗯,这些模型和是的,我一直在思考,我被变换器如何,尽管这门课程专注于文本,看到基本变换器架构如何为视觉变换器创建基础也真的很有趣。
所以尽管在这门课程中你主要学习大型语言模型,关于文本的模型,我认为理解变换器也是,你知道,帮助人们理解这个非常兴奋的视觉变换器和其他模态,以及成为许多机器学习绝对关键的构建块,然后超越变换器。
未来第一周我们将覆盖的第二个主要主题是,生成式AI项目生命周期,我知道很多人在思考,所有这些lm东西,我该如何使用它,以及AI项目生命周期的性别,我会稍后谈论,它帮助你规划如何思考构建你自己的AI项目。
以及生成式AI项目生命周期将带你走过个体阶段和决策,当你开发生成式AI应用时,你需要首先决定,是否从货架上取一个基础模型,还是实际上预训练你自己的模型,然后作为后续,你是否想要找到并定制那个模型。
也许为你的特定数据,是的,实际上有很多大型语言模型选项,你知道一些开源的,一些不开源的,我看到许多开发者在思考,我该如何选择这些模型,因此有一个方法来评估它,然后也选择正确的模型大小。
我知道在你的其他工作中你谈论过,何时需要一个大型模型,你知道一个万亿或甚至更大的,与一个一亿到三十亿参数模型,甚至小于一亿参数模型对于特定应用多么出色,可能有一些用例你真的需要模型。
以便非常全面并能够概括到许多不同的任务,那就是你可能遇到的一些用例,你可能只是在优化一个特定的用例,对,你可以与较小的模型合作,并且可能获得类似的甚至非常好的结果,是的。
我认为这可能是一些人需要学习的一个真正令人惊讶的事情,那就是你可以实际上使用相当小的模型,仍然能从中获得相当多的能力,是的,你知道,当你想要你的大规模语言模型对世界有广泛的知识时。
当你想要了解历史、哲学和科学等知识,以及如何编写Python代码等等,有一个巨大的模型,含有数百亿个参数是有帮助的,但对于一个任务,比如摘要对话,或作为客服代理,对一个公司,对于这样的应用程序,你知道。
你可以使用一百亿,数百亿个参数模型,但这并不总是必要的,所以,这周有很多令人兴奋的材料可以进入,让我们继续看下一个视频,当Mike开始时。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P66:介绍LLM和生成式AI项目的生命周期3——生成式AI和大语言模型的输出 - 吴恩达大模型 - BV1gLeueWE5N

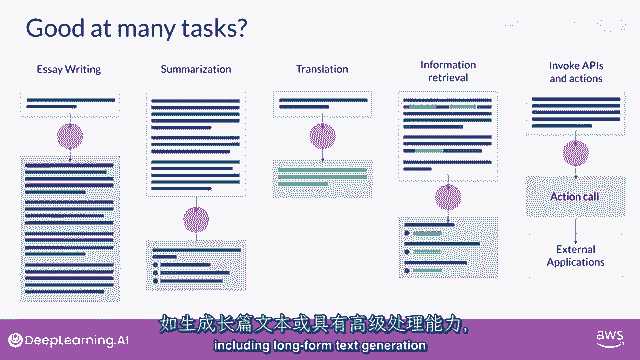
好的,让我们开始在这门课程中,我们将设置场景,我们将谈论大型语言模型,它们的应用场景,模型如何工作,提示工程,如何生成创造性的文本输出,并概述生成式ai项目的项目生命周期,鉴于你对这门课程的兴趣。
可以说,这可能是安全的,你已经有机会尝试过生成式AI工具。

或者想要,无论是聊天机器人,从文本生成图像。

还是使用插件来帮助你开发代码,你在这些工具中看到的,是一台能够创建模仿或近似人类能力的机器,生成式AI是传统机器学习的一个子集,并支撑生成式AI的机器学习模型通过找到统计模式来学习这些能力。
在大量的由人类原生成成的内容数据集中,大规模的语言模型已经在数周数月的时间内训练了万亿个单词,并且使用了大量的计算资源。
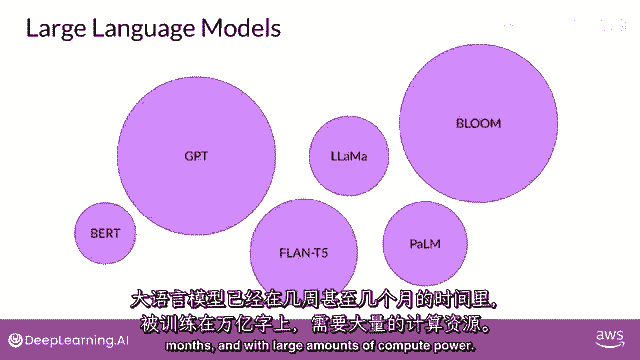
这些基础模型,像我们所说的,拥有亿级别的参数,展现出超越语言本身的涌现特性,研究者们正在解锁它们分解复杂任务的能力,在这里,推理和解决问题是一系列基础模型的集合,有时被称为基础模型和它们的相对大小。

以参数来衡量,稍后我们将更详细地讨论这些参数,但现在把它们看作是模型的记忆。

一个模型拥有的参数越多,它就需要更多的记忆,结果证明,在整个课程中,它们能够完成的任务就越复杂。

我们将用这些紫色圆圈来表示llms。

在实验室中,你将使用特定的开源模型,Flan T5用于执行语言任务,可以通过使用这些模型本身。
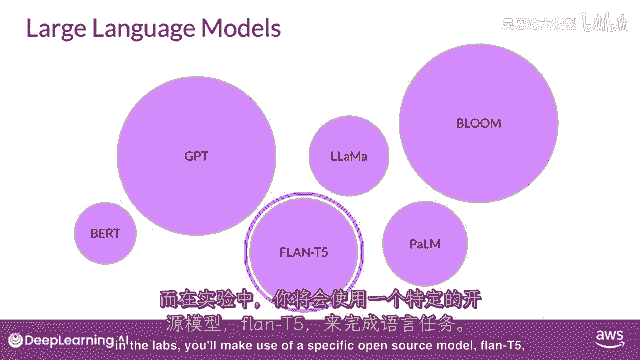
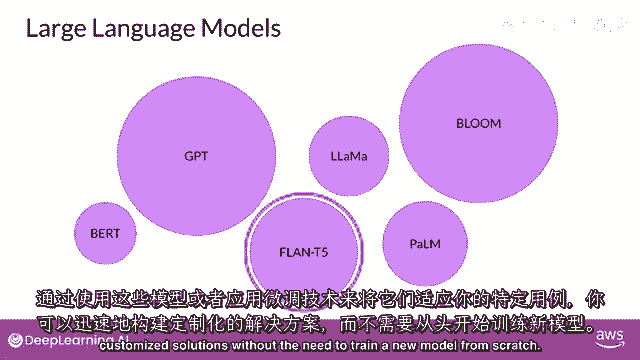
或者通过应用微调技术来适应您的特定用例,你现在可以快速构建定制的解决方案,无需从头训练一个新的模型。
虽然生成式AI模型正在为多个模态创建,包括图像,视频,音频和语音,在这个课程中,你将专注于大型语言模型及其自然语言生成的使用,你将看到它们是如何构建和训练的,如何通过文本与它们交互,被称为提示。
以及如何根据您的使用案例和数据微调模型,并且你如何将这些部署到应用程序中,以解决你的商业和社会任务,你与语言模型互动的方式与其他机器学习和编程范式有很大的不同,在这些情况下。
你使用正式语法的计算机代码与库和API进行交互,相比之下,大型语言模型能够处理自然语言或人类编写的指令,并执行任务。
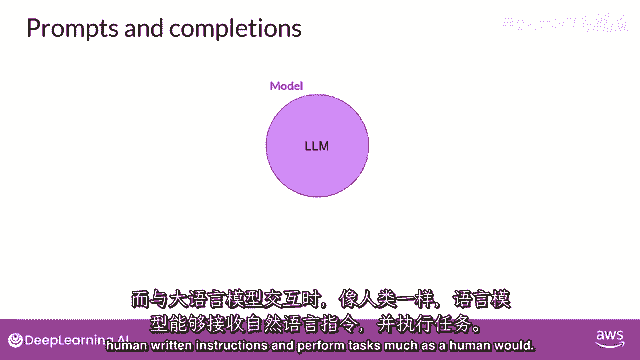
就像人类一样,你传递给llm的文本是被称为提示的文本。

可用给提示的空间或内存被称为上下文窗口,通常足够大以容纳数千个单词,但与模型不同。

在这个例子中,你问模型甘ymede在太阳系中的位置在哪里。
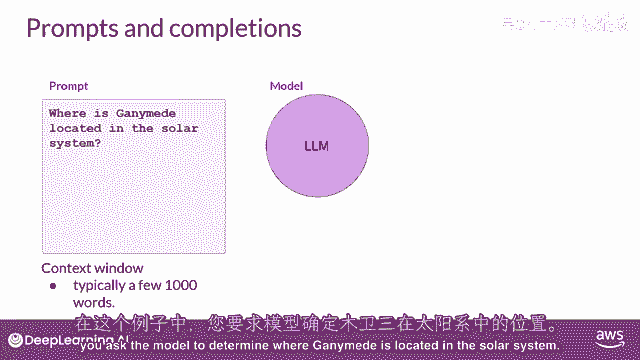
提示被传递给模型,模型然后预测下一个单词,因为你的提示包含一个问题,这个模型生成了一个答案。
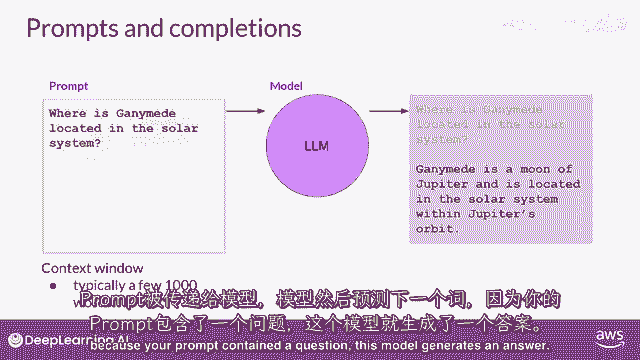
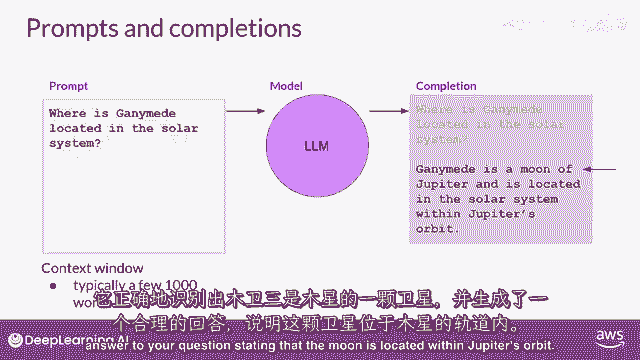
模型的输出被称为完成,使用模型生成文本的行为被称为推理。

完成由原始提示中包含的文本组成,跟随生成的文本,你可以看到,这个模型做得很好,回答了你的问题。

它正确地识别出甘ymede是木星的卫星,并生成了对你问题的合理答案,指出卫星位于木星的轨道中。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P67:介绍LLM和生成式AI项目的生命周期4——LLM的使用案例和任务 - 吴恩达大模型 - BV1gLeueWE5N
你可能会认为llms和生成式ai主要专注于聊天任务,毕竟聊天机器人非常可见,得到了很多关注。

下一个词预测是许多不同能力的基础概念,从基本的聊天机器人开始,然而,你可以用这个概念上简单的技术来完成文本生成中的各种其他任务,例如,你可以要求模型根据提示写一篇总结对话的论文,其中。
你将对话作为提示的一部分提供,而模型将使用这些数据,与其理解自然语言生成摘要的能力一起,你可以使用模型进行各种翻译任务,从传统的两种不同语言之间的翻译开始,例如,法语和德语,或者英语和西班牙。
或者将自然语言翻译成机器代码,例如,你可以要求模型编写一些Python代码,这将返回数据框中每列的平均值,并且模型将生成你可以传递给解释器的代码,你可以使用LLMs来执行像信息检索这样的小而专注的任务。
例如,在这个例子中,你请求模型识别新闻文章中所有识别的人名和地点,这被称为命名实体识别。

一种词性分类,模型参数中编码的知识的理解,使它能够正确地完成这项任务并返回您要求的信息,最后,增强大型语言模型(llms)的一个活跃领域是将它们连接到外部数据源,或使用他们来调用外部api。
你可以利用这 ability 来为模型提供它从预训练中不知道信息的信息,并使您的模式能够驱动与现实世界的交互,你将学习更多关于如何做 this。

课程第三周,开发者发现,随着基础模型的参数规模从数百亿增长到数千亿,甚至数千亿,一个模型所拥有的语言主观理解,也增加了这种语言理解,存储在模型的参数中的处理方式是,原因,最终解决你给它的任务。

但是,也确实有小型模型可以很好,调优以在特定专注于的任务中表现良好,你在课程第二周将学习更多关于如何做到的内容,过去几年中LLMs展现出的能力迅速增长,主要归功于驱动它们的架构。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P68:介绍LLM和生成式AI项目的生命周期5——Transformer之前的文本生成 - 吴恩达大模型 - BV1gLeueWE5N
应注意生成算法非新,前代语言模型用循环神经网络,或RNN,RNN,虽当时强大,但受限于计算和内存。

看RNN做简单词预测示例,仅见前一词的生成任务。

预测不会很好,扩大RNN看更多前文可改善,需大幅扩展模型资源。

实际上,RNN计算和内存需求呈指数增长,随模型可见文本窗口增加。

至于预测,模型失败于此,即使扩展模型,仍未见足够输入以作好预测。

成功预测需模型见更多前词,模型需理解整句甚至整文档,问题在于语言复杂,许多语言中,一词可有多义,这些是同音词。

在这种情况下,只有结合句子语境才能确定银行类型。

句子结构中的单词可能含糊,或存在我们所说的句法歧义,例如,这句话,老师用书教学生。

老师用书教学吗,还是学生有书。

或是两者都有,算法如何理解人类语言。

17年论文发表后,有时我们仍难理解,谷歌和多伦多大学:注意力即一切。
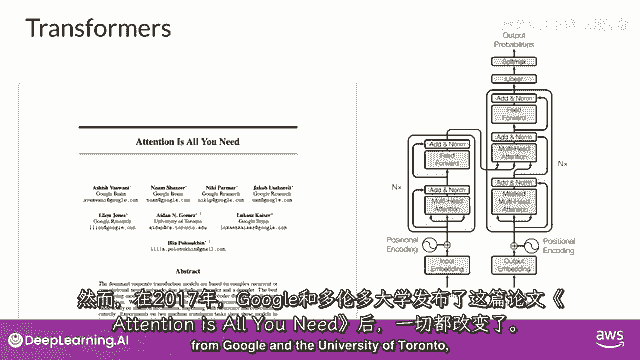
一切都变了,变换器架构已到来,这种新方法开启了当今生成AI的进步。
高效扩展至多核GPU。

并行处理输入数据,利用更大训练集,关键能关注词义。

处理与关注即所需。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P69:介绍LLM和生成式AI项目的生命周期6——Transformer架构 - 吴恩达大模型 - BV1gLeueWE5N
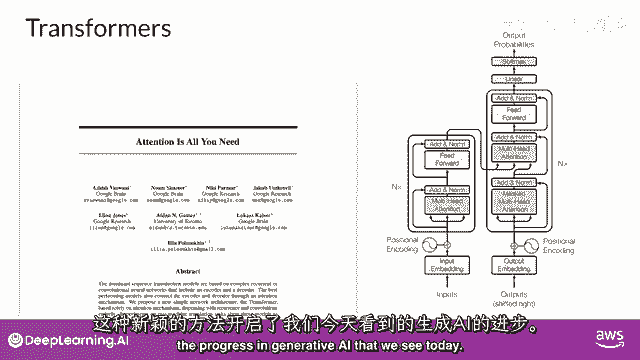
使用Transformer架构构建大型语言模型,显著提高了自然语言任务相对于早期RNN一代的性能,并导致了生成能力的爆炸,Transformer架构的力量在于其能够学习,句子中每个词的相关性和上下文。
不仅仅是你看到的那样,对每个词旁边的词,但对句子中的所有其他词,并应用注意力权重到这些关系,以便模型学习每个词对其他词的相关性,无论它们在输入中的位置在哪里,这给了算法学习谁有这本书的能力。
谁可能拥有这本书,以及它是否与文档的更广泛上下文相关,这些注意力权重是在LLM训练期间学习的,你将了解更多关于这一点,这周晚些时候,这个图被称为注意力图。
并且可以用于说明每个词与每个其他词之间的注意力权重,在这里的示例中,你可以看到单词'书'与单词'教师'之间有很强的联系或注意力,这就是自我注意力,以及这种学习方式的能力。
在整个输入中显著提高模型的语言编码能力,现在,你已经看到了Transformer架构的关键属性之一,自我注意力让我们从高处概述,在这里,模型的工作方式是一个简化的Transformer架构图。
以便你可以专注于这些过程在哪里发生,Transformer架构被分为两个 distinct 部分,编码器和解码器,这些组件相互协作,并且它们共享许多相似之处,请注意这里。
你看到的图是从原始注意力图派生的,这就是你需要的纸张,注意模型的输入位于底部,并且可能的输出位于顶部,我们将尽力在整个课程中保持这一点,机器学习模型只是巨大的统计计算器,它们与数字工作,而不是单词。
所以在将文本输入模型进行处理之前,您必须首先分词单词,简单地说,这是将单词转换为数字,每个数字代表模型可以工作的所有可能单词的字典中的一个位置,你可以选择多种分词方法,例如。
与完整单词匹配的token id,或使用token id来表示单词的部分,如图所示,重要的是,一旦你选择了一种分词器来训练模型,在生成文本时,你必须使用相同的分词器,现在,你的输入已经被表示为数字。
你可以将其传递给嵌入层,这一层是一个可训练的向量嵌入空间,其中每个标记都被表示为一个向量,并在该空间中占据一个唯一的位置,词汇表中的每个标记ID都被匹配到一个多维向量,直觉是。
这些向量学习如何编码输入序列中单个标记的意义和上下文,嵌入向量空间已经在自然语言处理中被使用一段时间,之前的语言生成算法,如词到向量,使用了这个概念,不要担心,如果你不熟悉这个。
在整个课程中你将看到例子,并且在本周末阅读练习的末尾有一些额外的资源链接,回顾样本序列,在这个简单情况下,你可以看到,每个单词都被匹配到一个标记ID。
并且每个标记都被映射到原始Transformer论文中的向量,向量的大小实际上是512,比我们在这个图像中可以fit的要大得多,只是为了简单起见,如果你想象向量大小只有3。
你可以将单词映射到一个三维空间,并看到你现在可以看到的词汇之间的关系,如何将位于嵌入空间中靠近的词汇相关联,以及如何计算单词之间的距离作为角度,这给了模型理解语言的数学能力。
当你将标记向量添加到编码器的基础,或者解码器,你也添加位置信息编码,模型并行处理输入标记,因此,通过添加位置信息编码,你保留了关于单词顺序的信息,并不失去句子中单词位置的相关性。
一旦你总结了输入标记和位置信息编码的结果,你将结果向量传递给这里的自注意力层,模型分析输入序列中标记之间的关系,如你所见,这允许模型关注输入序列的不同部分,如前所述,以更好地捕获单词之间的上下文依赖性。
在训练期间学习的自注意力权重,并存储在这些层中,反映了输入序列中每个单词的重要性,对于序列中的所有其他单词,但这并不局限于Transformer架构实际上有多头自注意力。
这意味着多个自注意力权重或头被独立地学习并行,注意力层中包含的自注意力头的数量从模型到模型有所不同,但12到100之间的数字是常见的,直觉是,每个自注意力头都将学习语言的不同方面,例如。
一个头可能看到句子中的人实体之间的关系,而另一个头可能专注于句子的活动,尽管另一个头可能专注于其他属性,例如,如果单词押韵,重要的是要注意,你不提前指定,语言的哪些方面,注意力头将学习。
每个头的权重随机初始化,并给予足够的训练数据,并且时间每个将学习语言的不同方面,虽然一些注意力图容易解释,像这里讨论的例子,但其他的可能现在不容易,因为你已经将所有注意力权重应用到你输入的数据上。
输出通过全连接前馈网络处理,这个层的输出是一个逻辑向量,与每个标记在词典化字典中的概率得分成正比,你可以将这些逻辑值传递给最后的softmax层,在那里它们被归一化为每个词的概率得分。
这个输出包括对词汇表中每个单词的概率,所以这里可能会有数千的分数,一个单个标记的分数将高于其余的,这是最有可能预测的标记,但你将在课程后期看到,有许多方法你可以使用。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P7:7-评估和迭代 - 吴恩达大模型 - BV1gLeueWE5N

现在你完成模型训练,下一步是评估它,看看表现如何,这是非常重要的一步,因为AI就是迭代,这有助于随时间改进模型,好的,让我们开始吧,评估生成模型非常难,非常困难,指标不明确,嗯。
这些模型的性能随时间不断提高,指标实际上难以跟上,因此,人类评估通常是可靠的方法,实际上是让领域专家评估输出,好的测试数据集,对充分利用这个人时间非常重要,意味着这是一个高质量的数据集,准确无误。
所以你检查过以确保准确,是通用的,实际上覆盖了你想确保模型覆盖的许多不同测试案例,当然不能在训练数据中看到,另一种新兴的方式是elo比较,所以这几乎就像是在多个模型之间进行a/b测试或锦标赛。
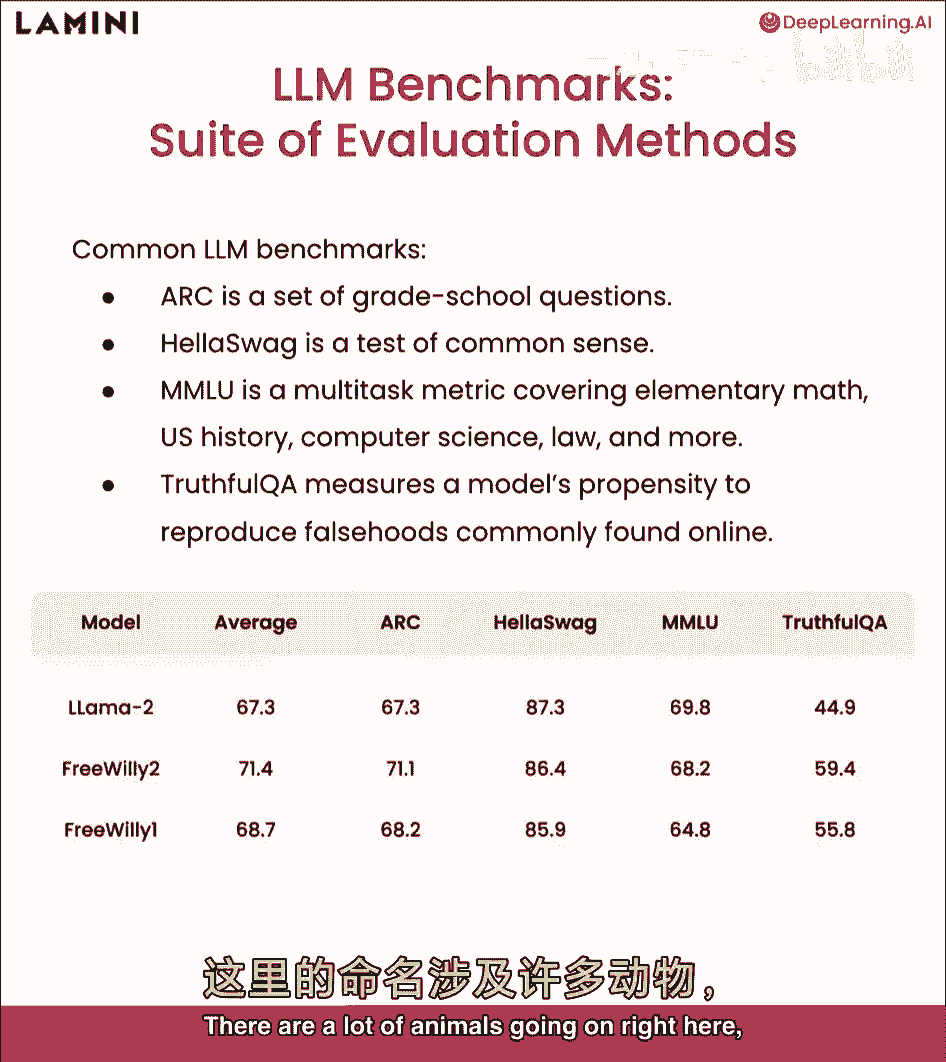
elo排名专门用于国际象棋,这也是一种了解哪些模型表现良好或不佳的方式,因此,一个非常常见的开放llm基准是一套不同的评估方法。

实际上采用多种评估方法,并将它们平均以排名模型,此为luther ai开发,如前所述,结合不同基准,一个是ARC,是一套小学问题,Hella Swag是常识测试,MLU涵盖许多小学科目。
以及真实QA衡量,模型复制常见虚假信息的能力,这些是由研究人员随时间开发的基准,现已被用于通用评估套件,你可以看到这,这是最新排名,截至录音时,但我确信这总在变化,Llama two表现良好。
实际上这不一定按平均排序,Llama two表现良好,最近有个免费Willy模型不错,在Llama模型上微调,我使用称为鲸鱼方法,这就是为什么叫自由威利,不会深入太多,这里有很多动物在进行。
但请随意自己查看,好的,另一个分析评估模型框架称为错误与分析,这是对错误进行分类,这样你了解,你知道常见错误类型,首先处理常见和灾难性错误,这真的很酷,因为我们的分析通常需要你先训练模型。
但当然对于微调,你已经有一个预训练的基模型,所以你可以先进行错误分析,甚至在微调模型之前,这有助于你理解和描述基模型的表现。

这样你知道哪种数据会给它最大的提升以进行微调,所以有很多不同类别,我将介绍一些常见的供你查看,一个是拼写错误,这非常直接,非常简单,所以这里说,去检查你的肝脏或杠杆。

它拼错了,所以只需在数据集中修复该示例即可正确拼写。

长度是一个我经常听到的常见问题,你知道,聊天,Gpt或生成模型总体上,它们非常冗长,所以一个例子就是确保你的数据集不那么冗长,这样它实际上就能简洁地回答问题,你在。训练笔记本中已经看到了这一点。
模型不那么冗长和重复,说到重复,嗯,你知道,这些模型确实非常重复,所以一种方法是使用停止标记更明确地修复它,你看到的那些提示模板,但,当然也要确保你的数据集包含没有那么多重复的例子,并且具有多样性酷。
所以现在进入一个实验室,你可以在测试数据集上运行模型,然后能够运行一些不同的指标,但主要是手动检查,也在运行那些llm基准测试。

好的,实际上只需一行代码,运行模型于整个测试集,分批处理,对GPU非常高效,所以我想在这里分享,加载模型,实例化,让它运行整个测试集列表,自动在GPU上快速分批。

现在我们主要运行在CPU上,所以在这个实验中你将真正。

仅运行一些测试数据点,当然你可以自己运行更多,很好,首先加载我们一直在工作的测试集,然后让我们看看其中一个数据点的样子,就打印问题答案对。
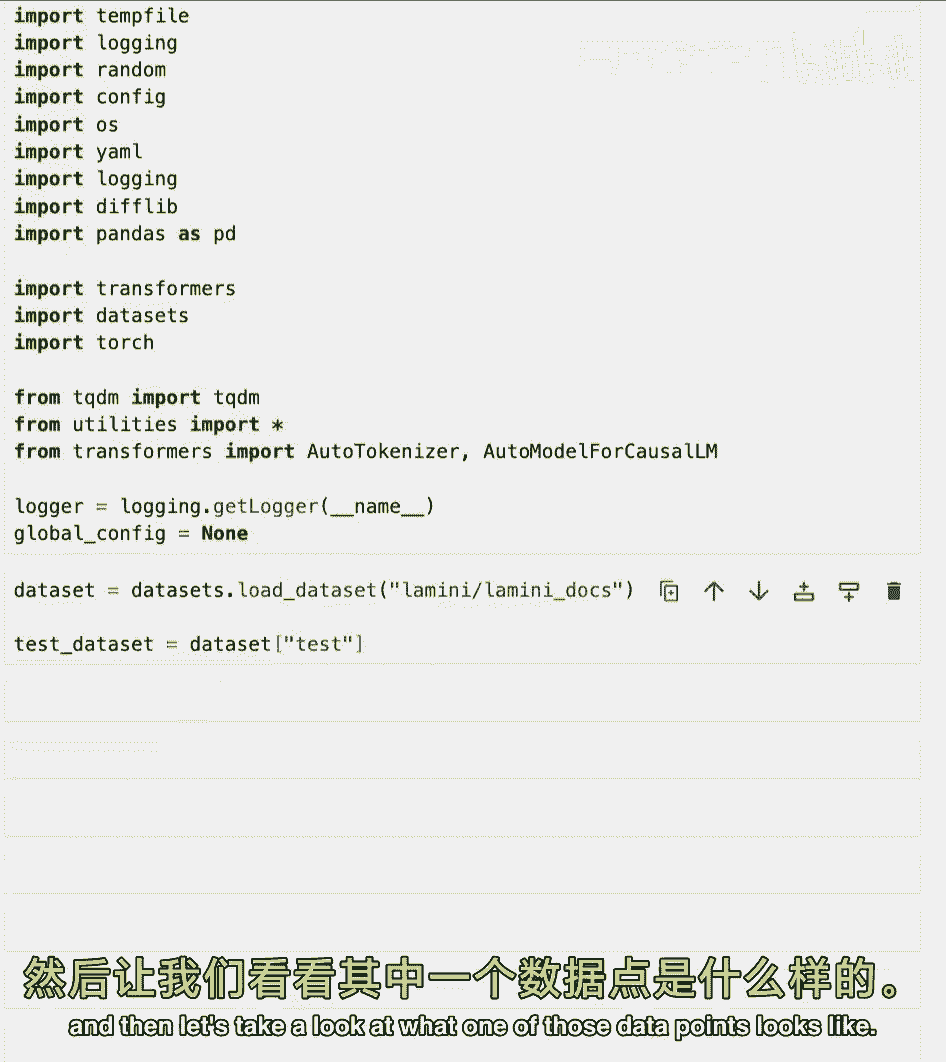
好的。

这是我们一直在看的,嗯,然后我们要加载模型来运行整个数据集。

和之前一样,我将从Hugging Face提取实际微调模型。

好的,现在加载了模型,我将加载一个非常基本的评估指标,只是为了让你感受这个生成任务。

它是否是两个字符串的精确匹配,当然,去掉一些空格,但只是感受是否能精确匹配,这对写作任务真的很困难,因为它在生成内容,实际上有很多不同的正确答案,所以对于,你知道,阅读引号任务。
这个评估指标可能不太有效,那些阅读任务你可能在提取主题,你可能在提取一些信息,所以在那些更接近分类的案例中,这可能更有意义,但我只是想运行这个,你也可以运行不同的评估指标。
当你运行模型评估模式时重要的是做model eval。

以确保像dropout这样的东西被禁用。

然后就像之前的实验一样。

你可以运行这个推断函数来能够,呃,生成输出。

再次运行第一个测试问题,查看输出和实际答案,与它比较相似,但并不完全一样,当然,当你运行精确匹配时,并不完美,并不是说,没有其他方法衡量这些模型。

这是一个非常简单的方法,有时人们也会,将这些输出放入另一个,LLM中询问并评分,看看它有多好,你知道它实际上有多接近,你也可以使用嵌入。

因此,您可以嵌入实际答案,并实际嵌入生成的答案,看看它们在距离上有多接近,所以有很多不同的方法可以采取,酷,所以现在要在整个数据集上运行,这可能是这样的,所以让我们实际上运行十个。

因为它需要相当长的时间,你遍历那个数据集。

提取问题和答案,我也试图获取预测的答案。

并将其与其他答案附加,这样您就可以稍后手动检查。

嗯,然后查看精确匹配的数量,它正在评估,精确匹配的数量为零,这并不完全令人惊讶,因为这是一项非常生成性的任务,并且通常对于这些任务,你知道,再次有很多不同的评估方法,但到最后。

通过大量边际显著性发现,使用手动检查在一个非常精选的测试集上。

这就是那个数据框的样子,所以现在你可以去检查并看到,对于每个预测的答案,目标是什么,它实际上有多接近,好吧酷。

所以这只是在数据的一个子集上,我们还评估了所有数据。

你可以从Hugging Face加载并能够,你知道,基本上查看和手动评估所有数据。

最后。

但并非最不重要的是,嗯,你将看到运行弧线,这是一个基准,所以如果你好奇,你知道学术基准,这是你在不同LLM基准测试套件中探索的一个,作为提醒,这个弧线基准是,路德AI提出的四个之一,这些来自学术论文。
对于这个,检查数据集,会发现你懂的科学问题,可能与任务无关。

这些评估指标,特别是这里,非常适合学术竞赛或理解,你知道,一般模型能力,有时围绕这些,在这种情况下,基本的小学问题,但我真的推荐,你知道。

即使运行这些,也不要过于关注这些基准的性能。

尽管现在人们是这样排名模型的,这是因为它们与你的用例无关,它们并不一定与公司关心的事情相关,你真正关心的,对于你的最终,用例,对于那个微调模型。
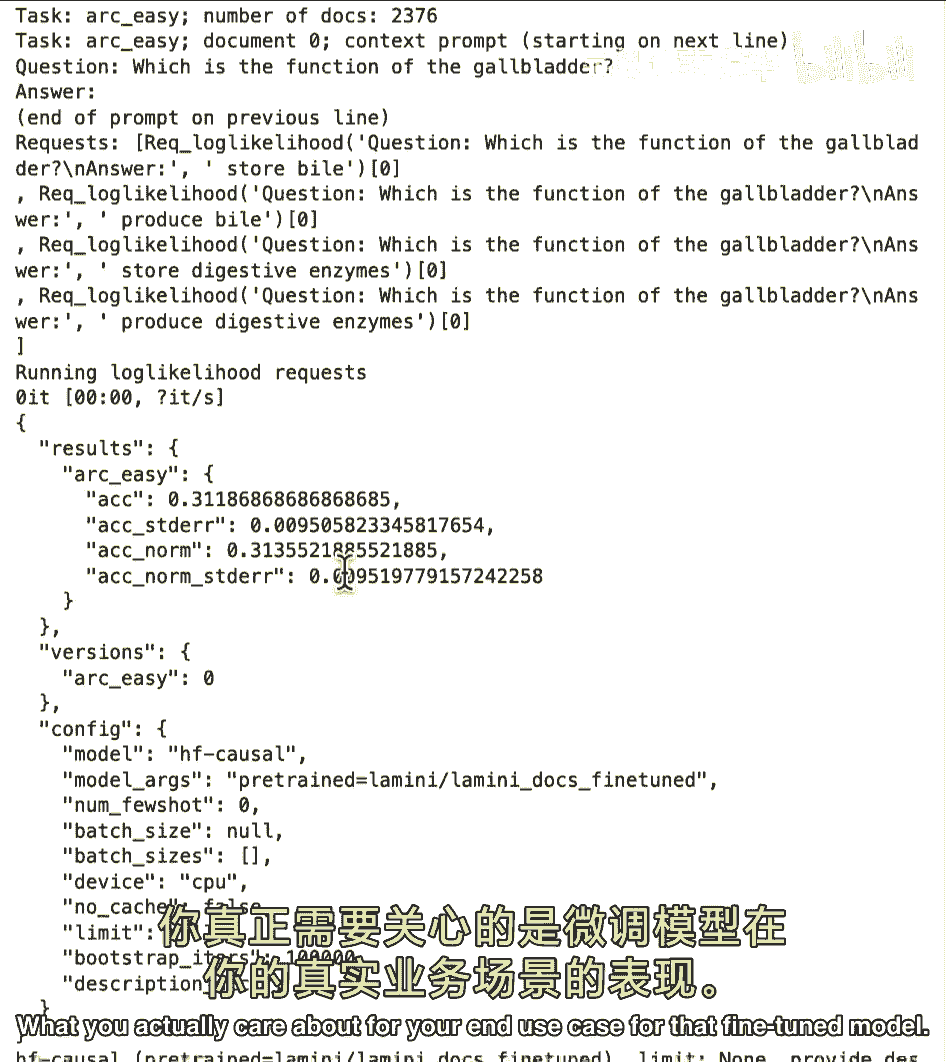
正如你可能看到的,微调模型基本上能够适应大量不同的任务,需要多种评估方式。

好的,弧形基准测试刚完成,分数在这里,0。31,实际上低于论文中基线模型的分数,0。36,太疯狂了,因为你在上面看到了它的巨大改进,但它是因为在这个公司数据集上改进巨大,与这家公司相关的数据集。
关于问题,回答它,不是小学科学,所以弧度真正测量的是,当然,如果你对一般任务微调模型,所以如果你对羊驼微调,例如,你应该看到特定基准性能的一点提升,如果你使用更大的模型,你也会看到可能的增长。
因为它学得更多,就这样,所以如你所见,这个弧形基准可能只重要,如果你在查看通用模型并比较通用模型,也许那是为你找到基础模型,但不是你实际的微调任务,它不太有用,除非你正在微调模型来做小学科学问题。
这就是上节课笔记本的结束,你将学习一些微调的实际技巧。

LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P70:介绍LLM和生成式AI项目的生命周期7——用Transformer生成文本 - 吴恩达大模型 - BV1gLeueWE5N
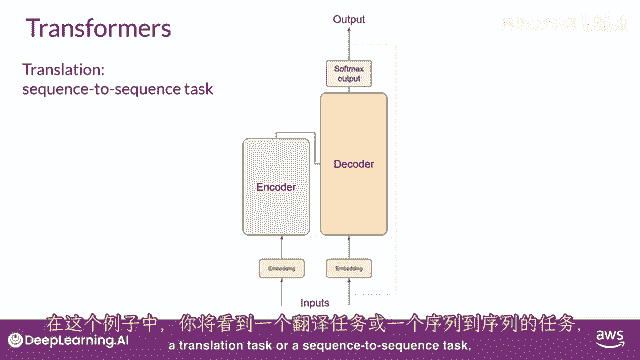
到这个阶段,你已经看到了变压器架构中的一些主要组件的高级概述,但你还没有看到从开始到结束的整体预测过程是如何工作的,所以让我们通过一个简单的例子来走一遍,在这个例子中。
你将看一个翻译任务或序列到序列任务。
顺便说一句,这是变压器架构设计师的原始目标。
你将使用变压器模型来翻译法语短语,Jem le presage automatic que into english。
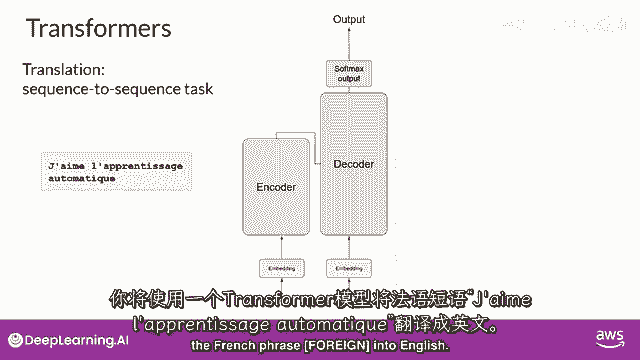
首先,你将对输入单词进行分词,使用训练网络时使用的相同分词器。
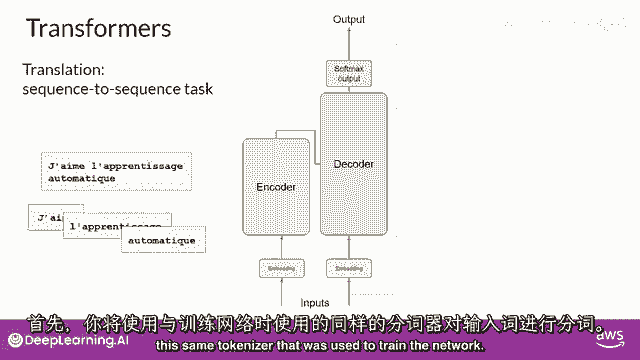
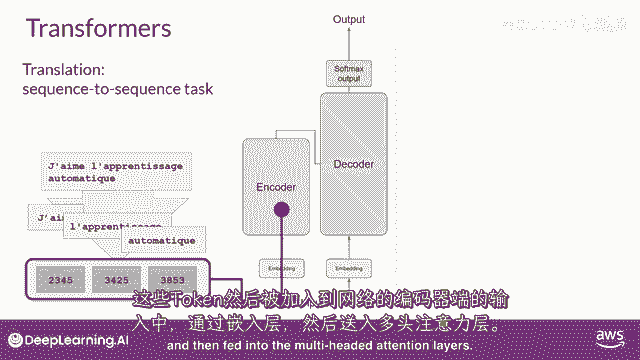
这些标记然后添加到网络的输入端,通过嵌入层,然后输入到多头注意力层。
多头注意力层的输出,被馈送到前馈网络以输出编码器。
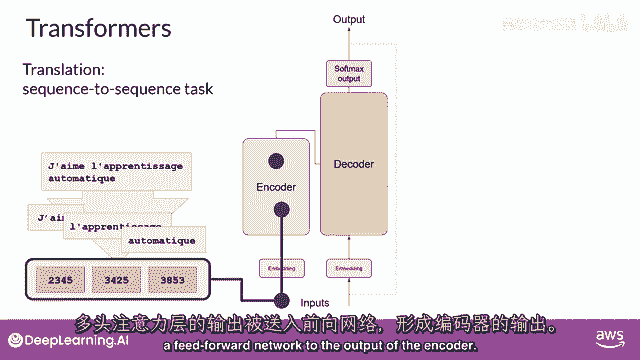
到这个点,离开编码器的数据是对输入序列的深度表示,并且含义。
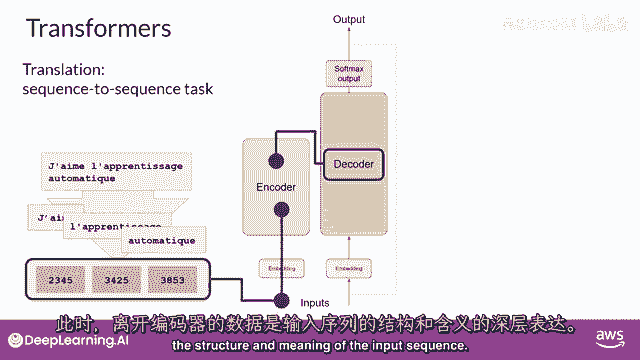
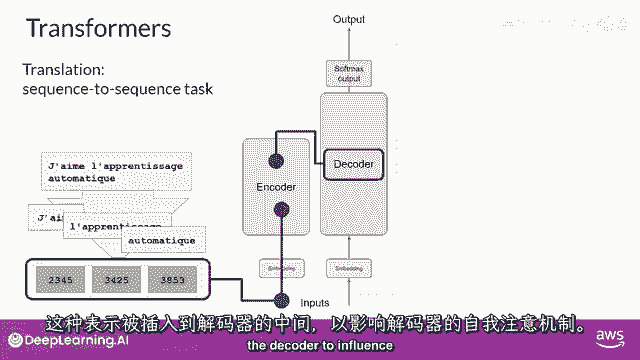
"这个表示被插入到解码器的中间","影响解码器的自我注意力机制"。
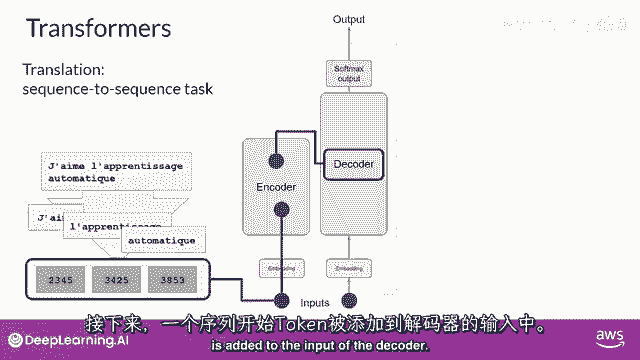
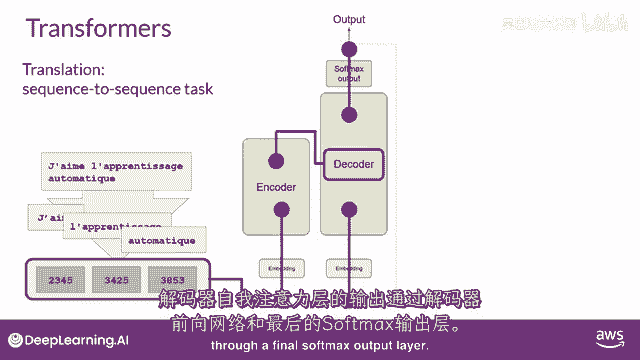
下一个,"在解码器的输入中添加一个序列开始的标记"。
这触发解码器预测下一个标记,"这是基于编码器提供的上下文理解,它这样做"。
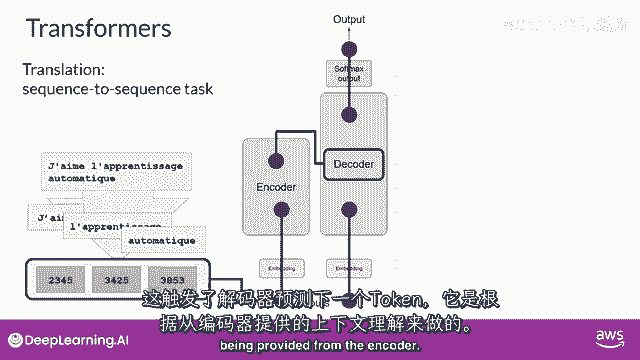
"解码器的自注意力层的输出将被传递给解码器",反馈前馈网络,"并通过一个最后的Softmax输出层"。
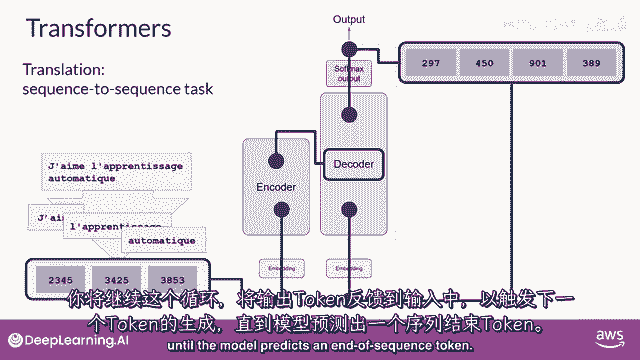
"到这个时候",我们有我们的第一个标记,你将继续这个循环,将输出标记返回给输入,以触发下一个标记的生成,直到模型预测序列结束的标记。
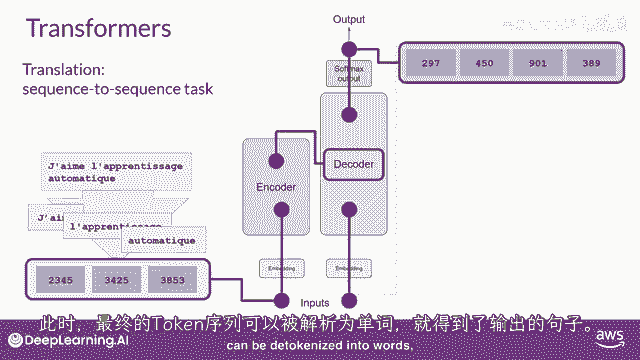
在这个点上,最终的标记序列可以解标记化为单词。
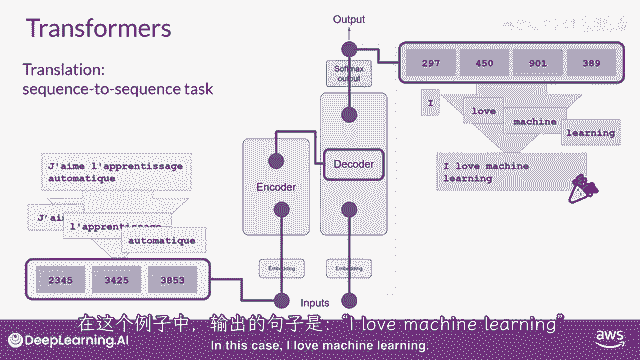
在这种情况下,你有你的结果。
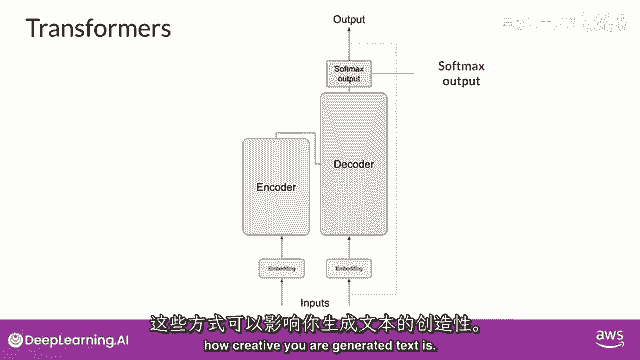
我热爱机器学习,有若干种方式,你可以使用softmax层的输出来预测下一个标记。
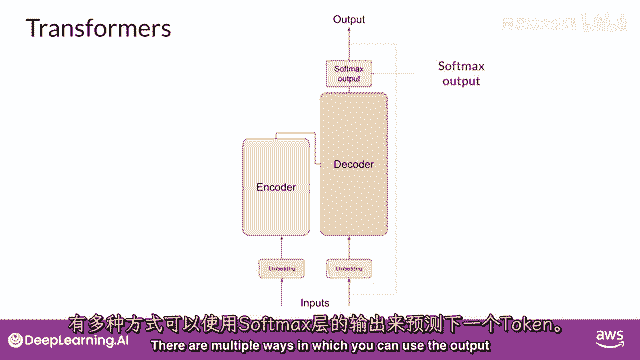
这些可以影响你生成的文本的创造性。
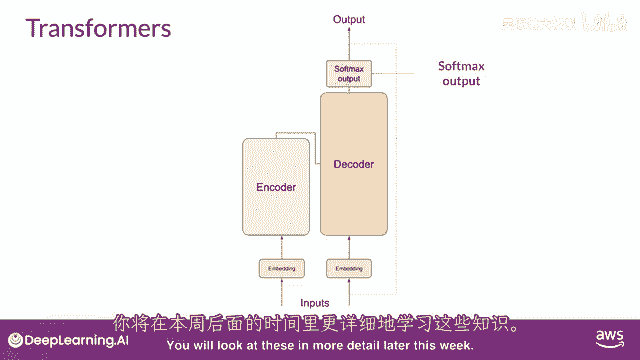
你们将在本周晚些时候详细查看这些。
所以让我们总结一下你们到目前为止看到的,完整的Transformer架构由编码器和解码器组件组成。
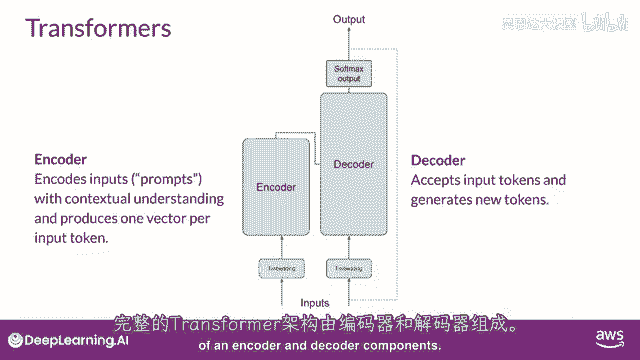
编码器将输入序列编码为一个深层次的输入结构及其意义的表示。
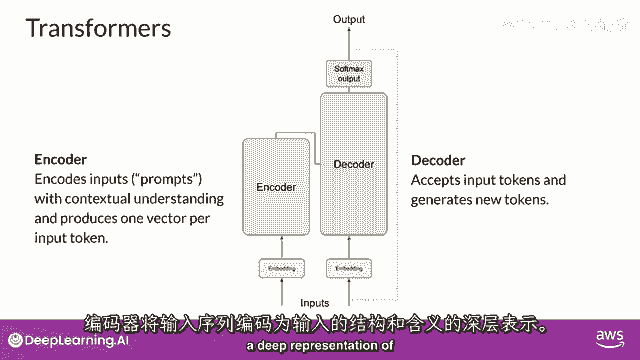
从输入标记开始工作的解码器,使用编码器的上下文理解来生成新的标记。
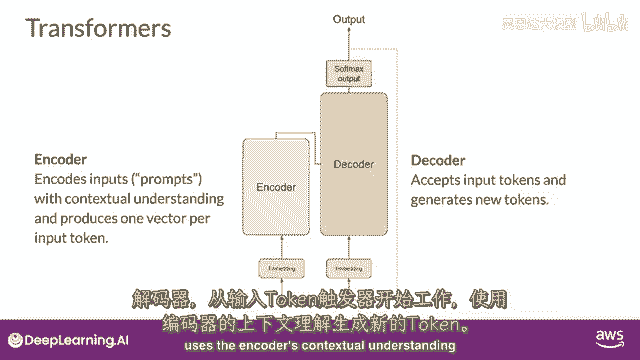
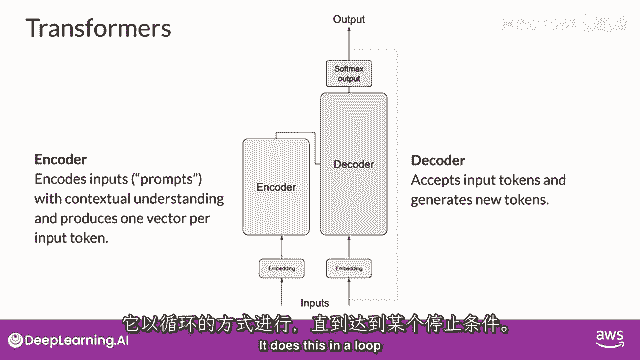
并且它这样做,直到满足某个停止条件。
而你在这里探索的翻译示例,使用了变压器的编码器和解码部分,你可以将这些组件分开,以变化为架构,仅编码器模型也作为序列到序列模型工作。
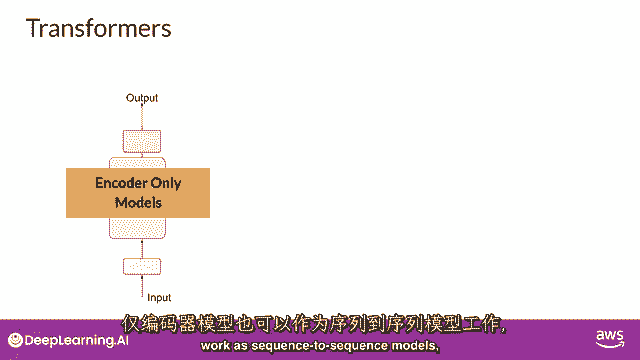
但未经进一步修改,输入序列和输出序列的长度相同。
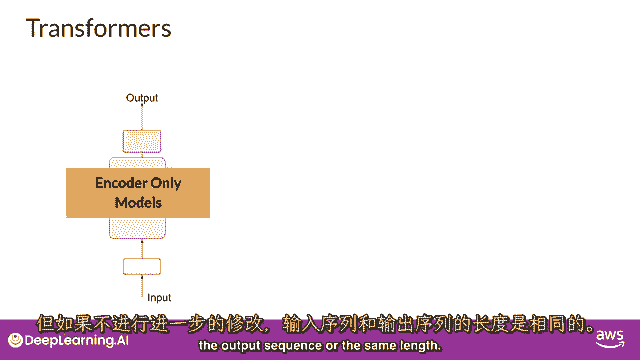
它们的使用现在较少,但通过向架构中添加额外的层。

你可以训练仅编码器模型来执行分类任务,例如,情感分析。

BERT是仅编码器的一个例子,编码解码模型,如你所见,在序列到序列任务如翻译中表现良好。
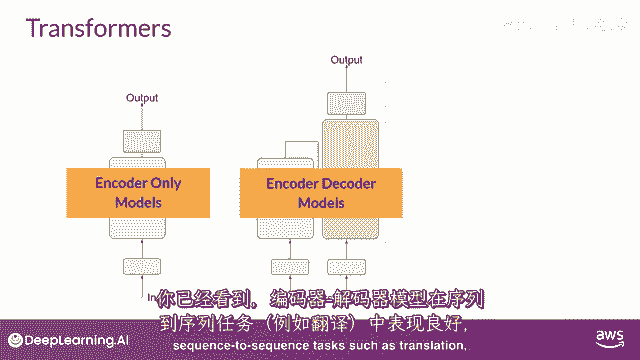
其中,输入序列和输出序列的长度可能不同。
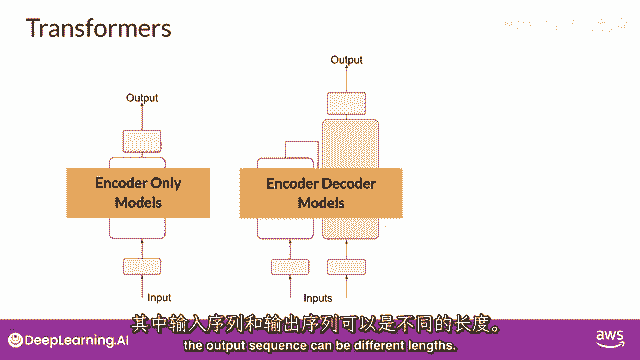
你也可以扩展和训练这种模型来执行一般文本生成任务。
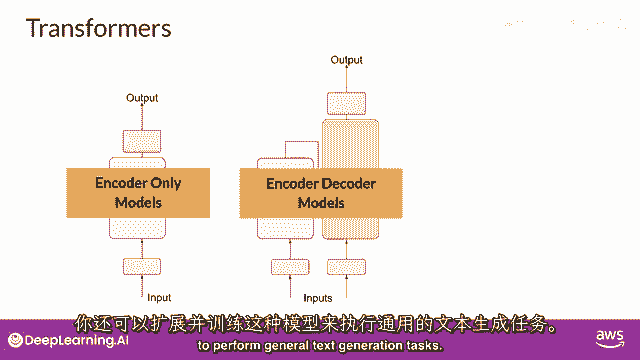
编码解码模型的例子包括bart,与burt和t five相反,你在这门课程实验室中将要使用的模型。
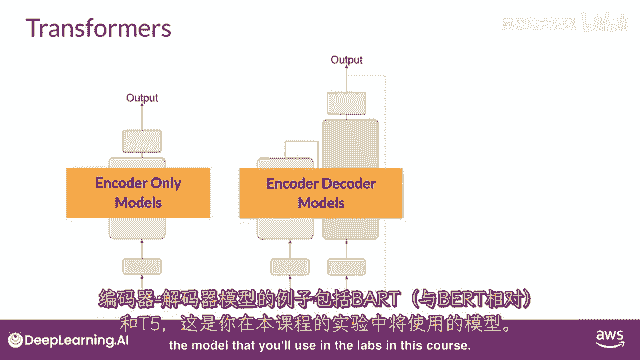
最后,仅解码模型是今天最常使用的一些,再次。
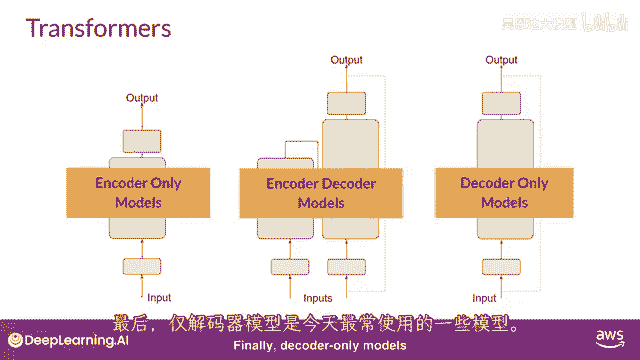
因为它们已经扩展了。
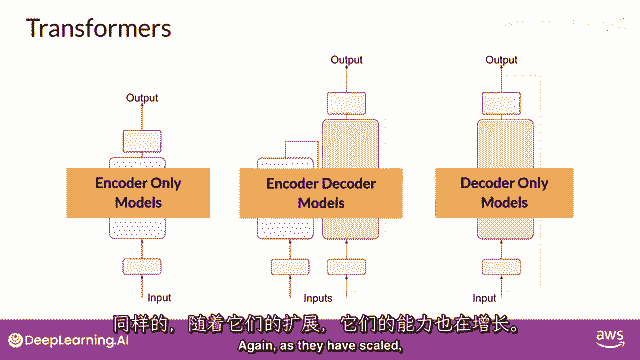
其能力已经增长,并且这些模型现在可以泛化到大多数任务,流行的仅解码模型包括GPT家族模型,Bloom,Jurassic llama,以及许多更多你将学习到这些不同种类的变压器的更多信息。
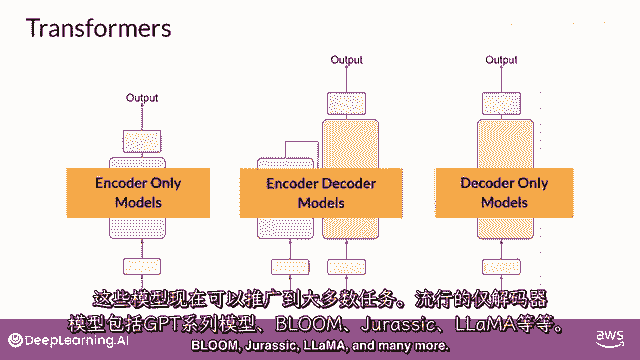
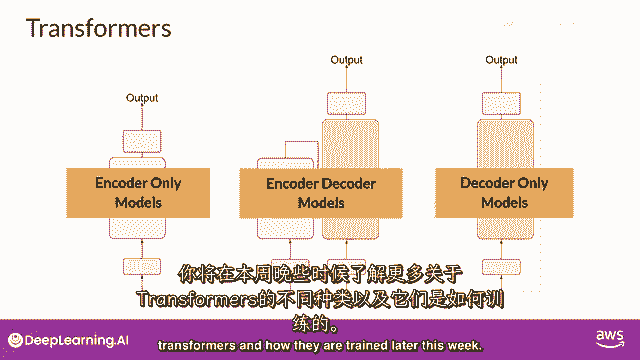
并且我们将在下周晚些时候学习如何训练它们,所以,那是相当多的,Transformer模型概述的主要目标是给你足够的背景,以便理解世界上正在使用的各种模型之间的差异,并能够阅读模型文档,我想强调的是。
你不需要担心记住在这里看到的所有细节,因为你可以随时回来查看这一解释,只要你需要,记住,你将通过自然语言与Transformer模型交互,创建提示,使用书面文字,而不是代码。
你不需要理解所有底层架构的细节来做到这一点,这被称为提示工程,并且这就是你在这门课程的下一部分将探索的内容。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P71:介绍LLM和生成式AI项目的生命周期8——Prompt和提示工程 - 吴恩达大模型 - BV1gLeueWE5N
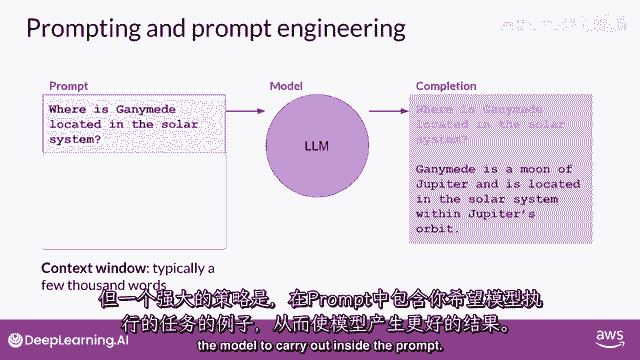
好的,只是想提醒你一些术语,你输入到模型中的文本是被称为提示的文本,生成文本的行为被称为推理,并且输出文本被称为完成,完整的文本,或者可用来生成提示的记忆量被称为上下文窗口。
尽管这里的例子显示了模型表现良好,你经常会遇到模型没有产生的情况,你想要在第一次尝试中的结果,你可能需要修订你的提示语言,或者修改它几次的写作方式,以使模型行为,在。
你想要这项工作如何发展和改进的提示方式被称为提示工程,这是一个大主题,但是有一种强大的策略可以使模型产生更好的结果,是在内容窗口中包含你想要模型执行的任务示例。
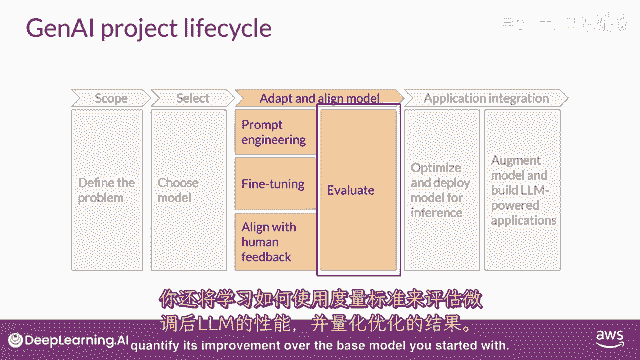
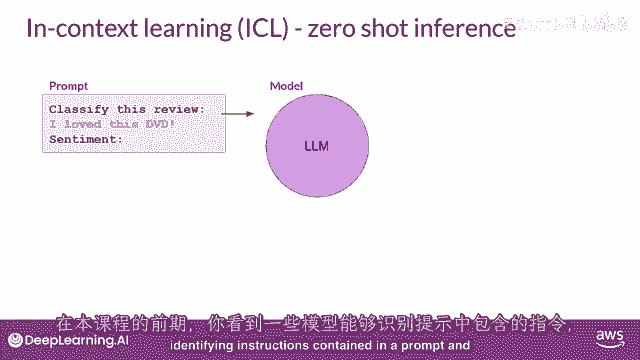
在内容窗口中提供示例被称为上下文学习,让我们来看看这个术语的含义与上下文学习,你可以帮助lms学习更多关于任务的信息,在提示中包括例子或附加数据被要求,在这里,提示中显示了一个具体的例子。
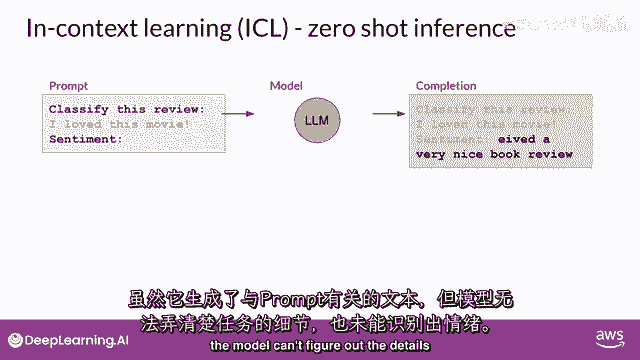
你要求模型分类一篇评论的情感,所以,这部电影的评论是积极的还是消极的,提示由指令组成,分类这个评论,紧随其后的是一些上下文,在这个情况下,上下文是评论文本本身和一条指示,要求在末尾产生情感,这种方法。
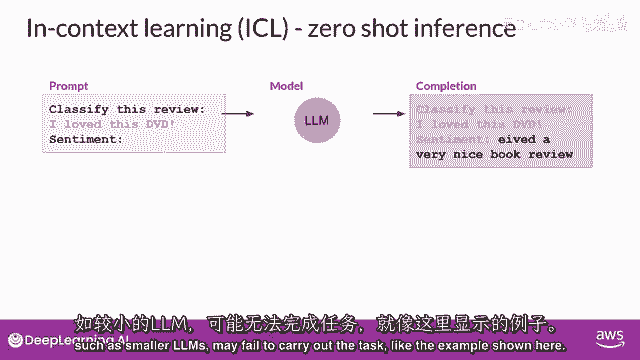
将您的数据输入包含在提示中,被称为零-shot推断,最大的llms在这个方面出乎意料的好,在这个例子中,理解要完成的任务并返回一个好的答案,模型正确识别情感为积极,较小的模型,另一方面。
可能在这个方面遇到困难,由gpt two生成的一个完成示例,一个更早的较小版本,该模型驱动chgt,正如你可以看到,模型没有遵循指令,尽管它能生成与提示有些关系的文本,模型无法理解任务的细节。
也不能识别情感。
这是提供提示中示例的地方,在这里提供示例可以提高性能,你可以看到提示文本更长,现在开始以一个完成的示例来演示任务,以便模型理解,在指定模型应该分类评论后,提示文本包括一个样本评论,我爱这部电影。
接着进行完成的情感分析,在这种情况下,评论是积极的,然后,提示再次陈述指令,并包括我们要模型分析的实际输入评论。
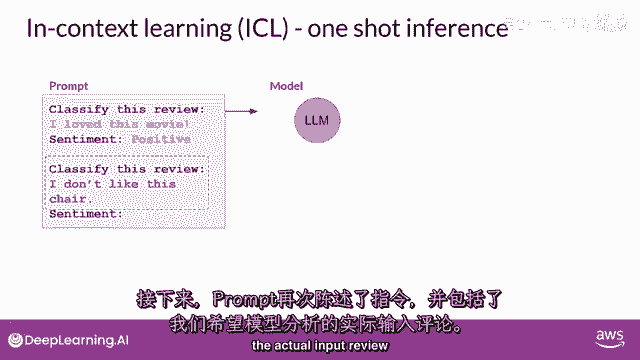
你将这个新的更长的提示传递给较小的模型,现在,这个模型有更好的机会理解任务。
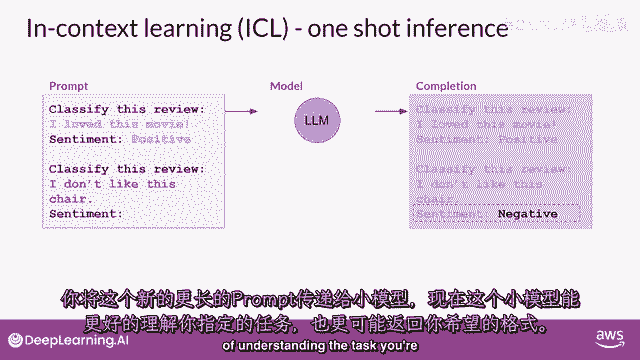
你正在指定,以及你想要的响应格式,一个例子的包含被称为一次射击推理,与您之前提供的零-shot提示相反,有时,一个例子可能不足以让模型学习你想要它做的事情,你可以将提供单个例子的概念扩展到包括多个例子。
这被称为少数示例推理,在这里,您正在与一个甚至更小的模型一起工作,该模型未能进行良好的情感分析,通过少数示例推理,相反,您将尝试少数示例推理,通过包括第二个例子,这次是一个负面评价。
包括不同输出类别的示例可以帮助模型理解它需要做什么,你将新的提示传递给模型,而这次,它理解了指令。
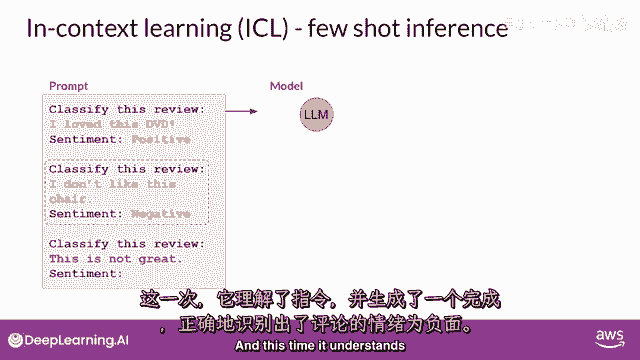
并生成了一个正确识别评论情感为负面的完成,所以总结一下,你可以通过设计提示来鼓励模型通过示例学习,虽然最大的模型在没有示例的情况下在零-shot推理方面表现良好。
较小的模型可以从包含所需行为的一-shot或几-shot推理中受益,但是记住上下文窗口,因为你对模型可以传递的上下文学习量有限,如果你发现你的模式表现不佳,当说,包括五个或六个例子。
你应该尝试微调你的模式,相反,微调对模型进行额外的训练,使用新数据使其能够更好地执行你想要它执行的任务,在本课程第二周中,你将详细探索微调,随着越来越大的模式被训练,已经清楚,模型的多任务能力。
以及它们完成这些任务的效果,很大程度上取决于模型的规模,正如您在课程中 earlier 听到的那样,参数更多的模型能够捕获更多的语言理解,最大的模型出人意料地对零-shot 推断表现良好。
并能够推断并成功完成许多他们没有专门训练过的任务,相比之下,较小的模型通常只对少数任务表现良好,通常是与他们训练的任务相似的任务。

您可能需要尝试几个模型来找到适合您用例的那个,一旦你找到了适合你的模式,你可以尝试一些设置,以影响模型生成的完成结构和风格。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P72:介绍LLM和生成式AI项目的生命周期9——生成配置 - 吴恩达大模型 - BV1gLeueWE5N
在这个视频中,你将检查一些你可以使用的方法和相关的配置参数,以影响模型如何做出关于下一个词生成的最终决定,如果你在playgrounds中使用过llms,例如。
在hugging face网站上或在aws上,你可能已经看到了这些控制来调整llm的行为。

每个模型都暴露一组可以影响模型在推理期间输出的配置参数。

请注意,这与训练参数不同,这些参数是在训练时间学习的。

相反,这些配置参数是在推理时间被调用的,并赋予你对如完成中的最大token数进行控制的能力,以及输出创意度的程度。

最大新token数可能是这些参数中最简单的一个。

你可以用它来限制模型将生成的token数,你可以把这个想成是设置了一个上限,模型将通过选择过程的次数。

在这里,你可以看到max new tokens被设置为一百的示例。

一百五十或两百,但请注意,在两百的示例中,完成的长度较短。

这是因为另一个停止条件已经被达到,例如,预测序列结束标记的模型。

记住它是最大新词的,不是生成输出时硬性的新词数量。

Softmax层在这里是模型使用的所有单词词典上的概率分布。

你可以看到旁边有一些单词和他们的概率得分。

虽然我们这里只显示了四个单词,想象这是一个延伸到完整词典的列表。

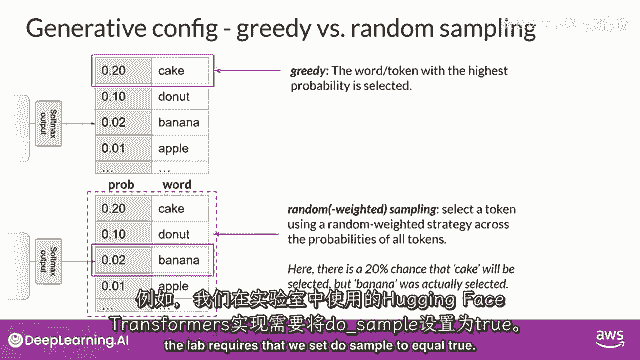
大多数大型语言模型默认会以所谓的贪婪解码方式运行。

这是下一词预测的最简单形式,其中,模型将始终选择概率最高的单词,这种方法对于短文本生成非常有效,但容易受到重复单词或重复词序的影响。

如果你想生成更自然的文本,更具创意的文本,并避免重复单词,你需要使用一些其他控制。

随机采样是最简单的方法之一,用于引入一些变化。

而不是每次使用随机采样时都选择最可能的单词,模型随机选择一个输出单词,使用概率分布来加权选择。

例如,在图中,'香蕉'这个词的概率得分为零点零二,所以通过随机采样,这相当于有百分之二的机会选到这个词,使用这种采样技术,我们可以减少单词被重复的可能性。

但是,根据设置,输出可能有可能过于创新,生成导致生成偏离主题的词语。

或无意义的词语,请注意在一些实现中,你可能需要明确地禁用贪婪并启用随机采样。

例如,我们在实验室中使用的hugging face transformers实现需要设置,Do sample等于true。
让我们探索top k和top p采样技术,以帮助限制随机采样,并增加输出可能理解性的机会。

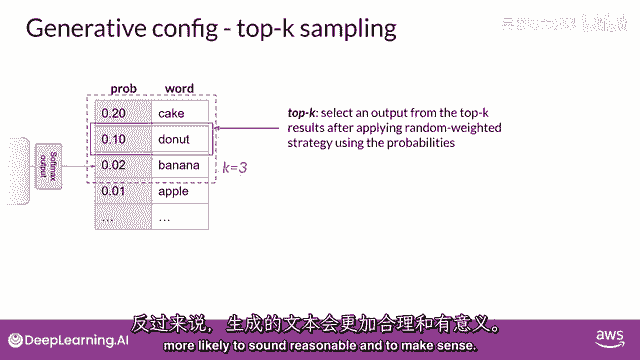
两个设置,Top p和top k是帮助我们限制随机采样的技术,并增加输出可能理解性的机会,以限制选项。

同时允许一些变化,你可以指定一个top k值,这告诉模型从概率最高的k个标记中选择。

在这个例子中,这里k被设置为三,所以你在限制模型从这三个选项中选择。

模型然后从这些选项中选择,使用概率加权,在这种情况下,它选择donut作为下一个词。
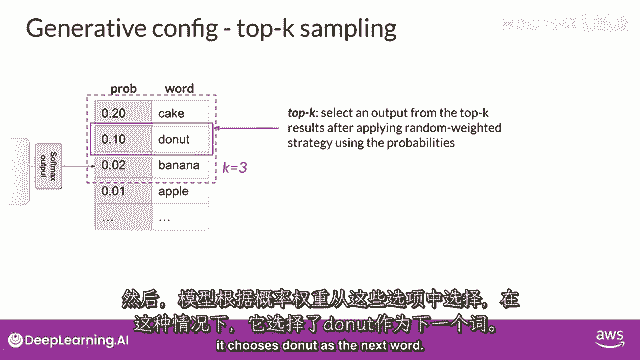
这种方法可以帮助模型有一些随机性,同时防止选择高度不可能的完成词。

这反过来使你的文本生成更可能听起来合理,有意义。
相反,你可以使用top p设置来限制随机采样。

到预测概率不超过p的组合,例如,如果你将p设置为等于0。3,选项是蛋糕和donut,因为它们的零点二和零点一的概率加起来等于零点三。

模型然后使用随机概率加权方法从这些标记中选择,所以与top k相比,你指定要从随机选择的标记中的数量,与top p相比,你指定模型要选择的总概率。

一,另一个可以控制模型输出随机性的参数被称为温度。

这个参数影响模型计算下一个标记的概率分布。

总的来说,温度越高,随机性越高,温度越低,随机性越低,温度值是一个缩放因子,它在模型的最终softmax层中被应用,它影响下一个标记的概率分布的形状。

与top k和top p参数相比,改变温度实际上改变了模型将做出的预测。

如果你选择较低的温度,说小于一,softmax层产生的概率分布更加尖锐峰顶,概率集中在较少的词汇上。

你可以在这里看到,蓝色条形图位于表格的一侧,它显示了一个侧卧的概率条形图。

这里的大部分概率都集中在单词'蛋糕'上,模型将从这个分布中随机采样,因此产生的文本将不那么随机,并将更紧密地跟随模型在训练期间学习的最可能词序。

如果你将温度设置为更高的值,例如,大于一,然后模型将为下一个标记计算一个更宽更平的概率分布。

注意,与蓝色条形图相比,概率在标记之间更均匀地分布。

这导致模型生成包含更高随机度的文本,并且输出结果的变异性更高,与冷却的温度设置相比,这可以帮助你生成听起来更创新的文本,如果你将温度值设置为一,这将留下softmax函数的默认设置。
并将未改变的概率分布用于,所以你已经覆盖了很多地面,到目前为止,你已经考察了lms能够执行的任务类型,并了解了transformers,驱动这些令人惊叹工具的模型架构。
你还探索了如何通过提示工程从这些模型中获取最佳性能,并在下一个视频中通过尝试不同的在ference配置参数来实验,你将开始建立在此基础知识上。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P73:介绍LLM和生成式AI项目的生命周期10——生成式AI项目的生命周期 - 吴恩达大模型 - BV1gLeueWE5N
在整个课程剩余部分,你将学习开发和部署基于llm的应用所需的技术,在这个视频中,你将走过一个可以帮助你引导这项工作的生成式ai项目生命周期,这个框架列出了从概念到发布的任务,到课程结束时。
你应该对即将做出的重要决策有一些良好的直觉,你将遇到可能遇到的困难,以及开发和部署你的应用所需的基础设施,这里是总体生命周期的图表,我们将一步一步讨论这个问题。
任何项目的最重要的一步是定义范围。
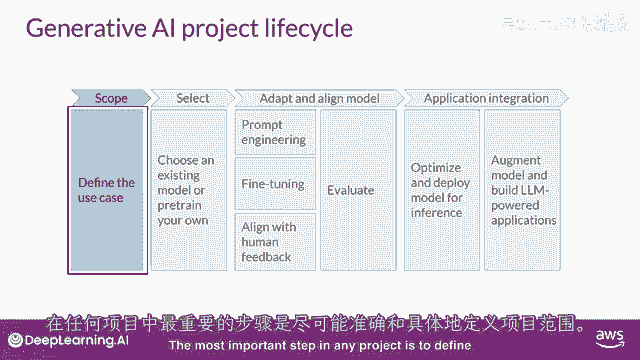
尽可能准确和狭窄,就像你在这门课程中看到的那样,到目前为止,llms有能力执行许多任务,但他们的能力强烈依赖于模型的大小和架构,你应该考虑llm在你特定应用中的功能。
你是否需要模型能够执行许多不同的任务,包括长形式文本生成。
或者是具有高能力的,或者是任务更加具体,比如命名实体识别,所以,你的模型只需要在某一件事上做得好。
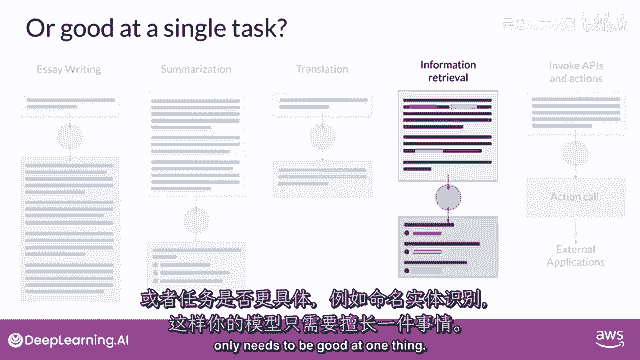
正如你在课程的其余部分所看到的,对你的模型需要做什么非常具体,可以节省你的时间,并且,更重要的是。
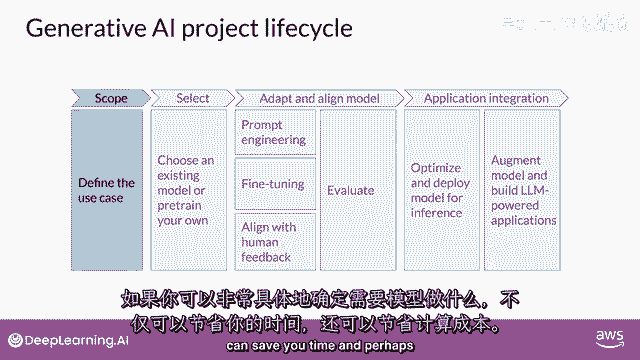
在你满意后计算成本,并且,你已经足够定义了你的模型需求,可以开始开发。
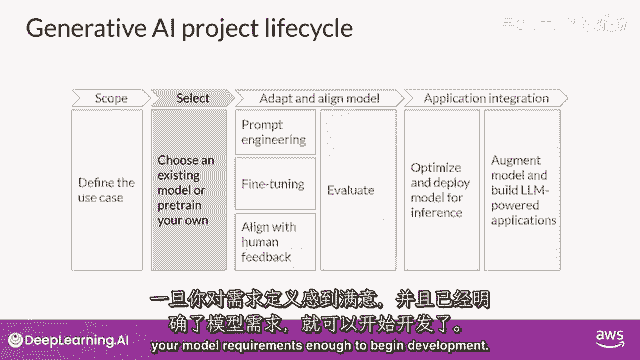
你的第一个决定将是是否要从头训练你自己的模型,或者一般与现有的基础模型合作。
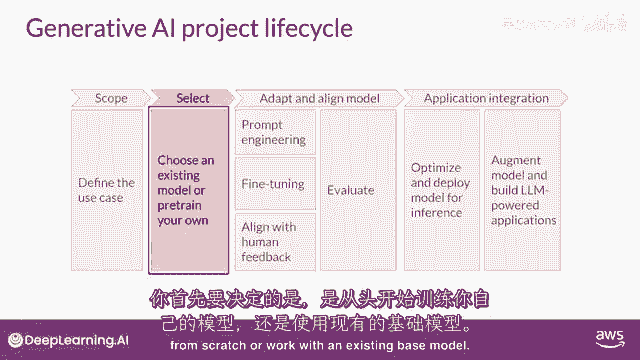
你将从一个现有的模型开始,尽管有一些情况下你可能发现有必要从零开始训练一个模型,你将在本周晚些时候了解这个决定的考虑因素,以及一些经验法则,来帮助你估计使用你手中的模型训练自己模型的可行性。
下一步是评估其性能并如果需要,进行额外的训练以适应你的应用程序。
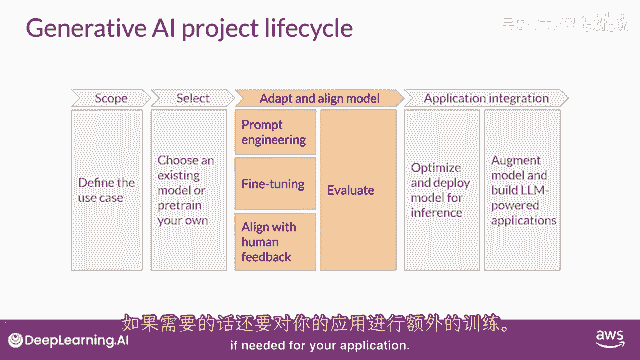
正如你们本周早些时候看到的,提示工程有时足以让你的模型表现良好。
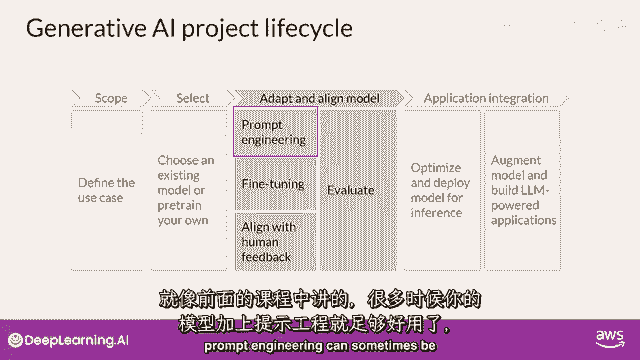
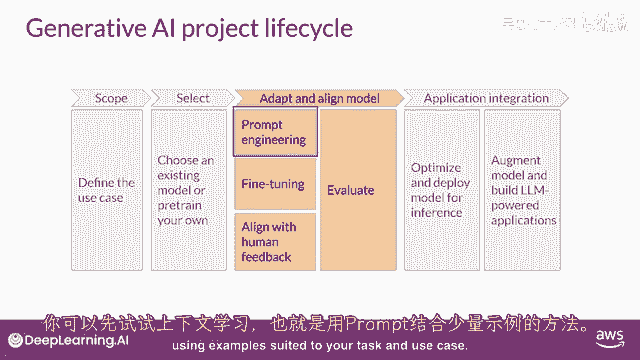
所以你可能会首先在特定上下文中尝试,根据你的任务和用例,使用适合的例子进行学习。
但仍然有一些情况,然而,在这些情况下,模型可能无法像你需要的那样表现。
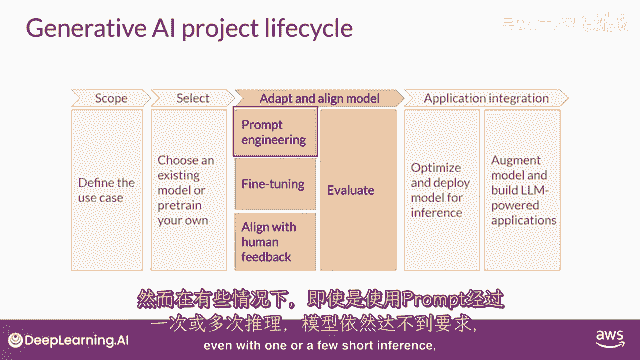
即使进行一次或几次的推断,那么在这种情况下,你可以尝试微调你的模式,这个监督学习过程将在第二周详细覆盖。
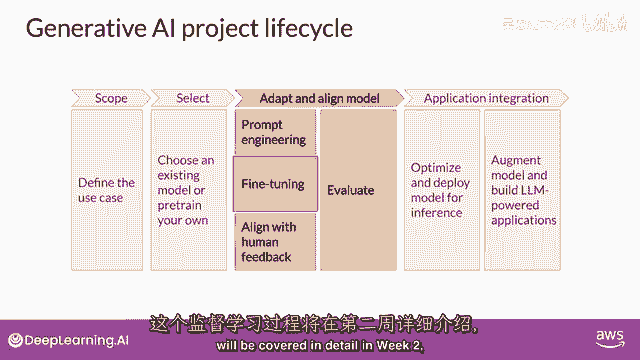
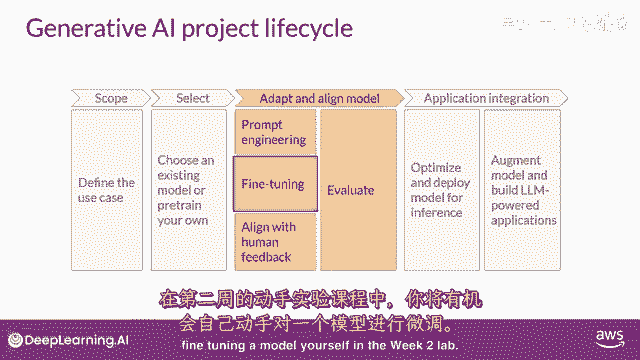
在第二周,你将有机会自己尝试微调一个模型。
随着模型的能力增强,实验室将变得更加重要,确保它们行为良好的重要性正在日益增加,在第三周,部署方式将与人类偏好相一致。
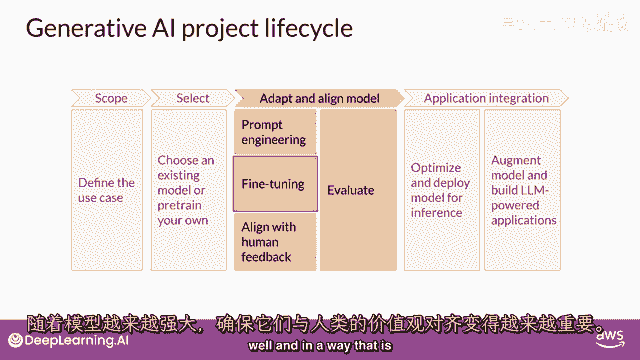
你将学习一种额外的微调技术,叫做强化学习,带有人类反馈,这可以帮助确保你的模型表现良好,所有这些技术的重要方面是评估。
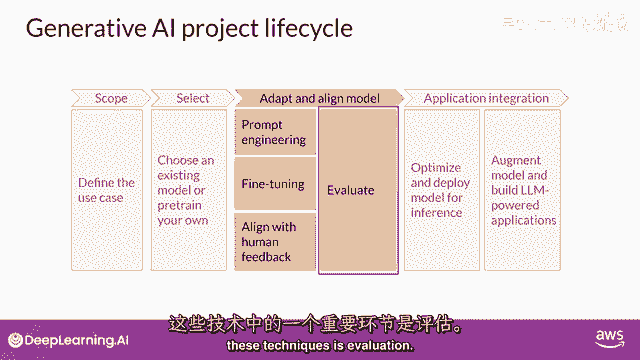
下周,你将探索一些可以用于衡量的指标和基准,以确定你的模型性能如何,或者它与你偏好的吻合程度如何。
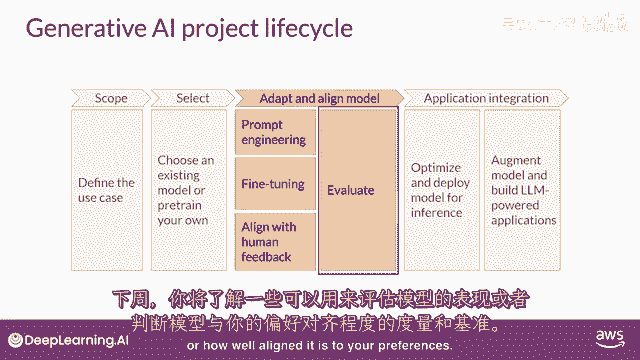
请注意,应用开发的适应和对齐阶段可能高度迭代,你可能从尝试提示工程并评估输出开始。
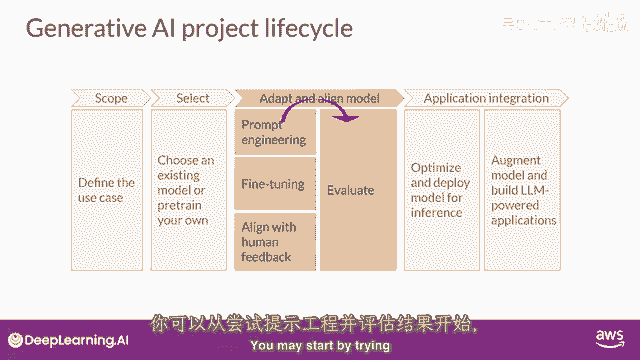
然后使用微调来提高性能,然后,再次回顾和评估提示工程。
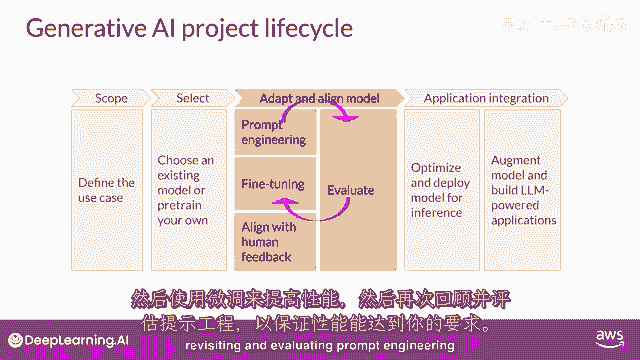
再次以确保您获得所需的性能,最后,当你有一个满足您性能需求且与您的目标高度一致的模型时,您可以将其部署到基础设施中并将其集成到您的应用程序中,在这个阶段,优化模型以备部署是一个重要的步骤。
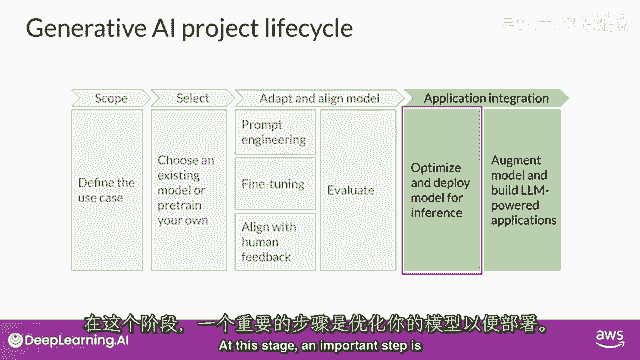
这可以确保您最大限度地利用计算资源,并为您的应用程序用户提供最佳可能的体验。
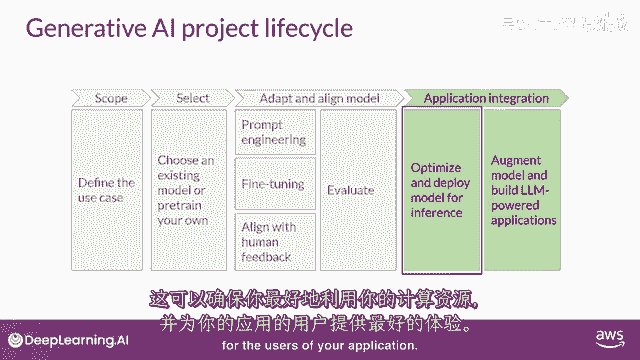
最后一个但非常重要的步骤是考虑您的应用程序可能需要的任何额外基础设施,以使其正常工作。
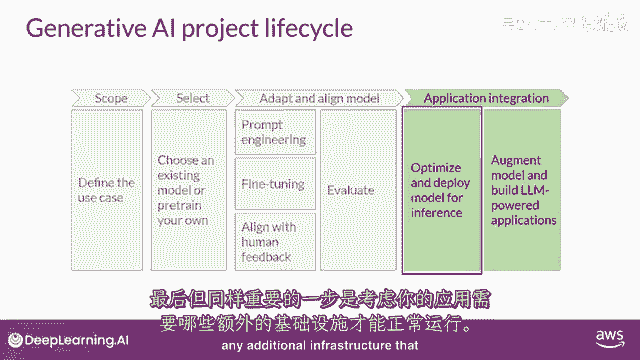
有一些LLMs的基本限制,仅通过训练难以克服。
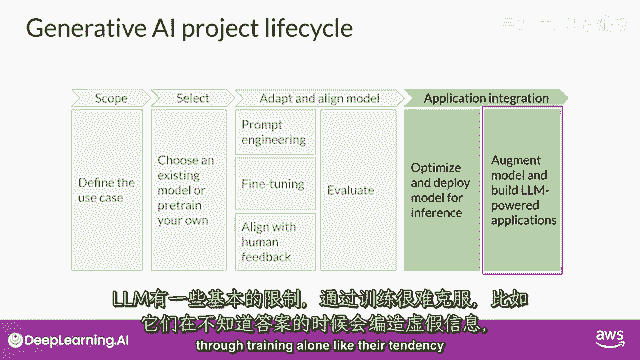
例如,他们的倾向发明信息,当他们不知道答案时,或者是他们进行复杂推理和数学计算的能力有限,在本课程的最后部分,你将学习一些强大的技术,你可以使用它们来克服这些限制。
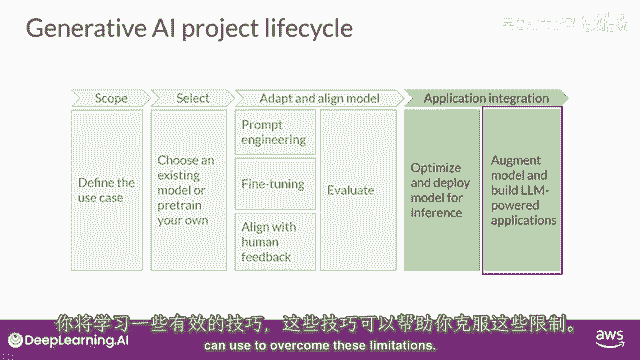
我知道这里有很多需要思考的地方,但是,不要担心现在要全部理解,你将看到这个视觉一次又一次,在整个课程中。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P74:使用指令对LLM进行微调1——介绍 - 吴恩达大模型 - BV1gLeueWE5N
欢迎回来,我和本周的讲师们在一起,迈克和谢比,上周学习了变换器网络,这是大型语言模型的关键基础,以及生成AI项目生命周期,本周还有很多内容要深入,从大型语言模型的指令微调开始。
然后稍后如何以高效方式进行微调,是的,我们看看指令微调,所以当你有基础模型时,最初预训练的东西,它编码了很多非常好的信息,通常关于世界,所以它知道一些事情,但它并不一定知道如何回应我们的提示。
我们的问题,所以当我们指示它执行某个任务时,它并不一定知道如何回应,因此指令微调帮助它改变行为,对我们更有帮助,我认为指令微调是,你知道,大型语言模型历史上的一大突破,因为通过学习一般文本。
来自互联网和其他来源,你学会预测下一个单词,但预测互联网上的下一个单词与遵循指令不同,我看到了惊人的,你可以拿一个大语言模型,在互联网上训练数百亿个单词,然后用一个小,远小于的数据集进行指令微调。
然后学会做那个,没错,当然,你需要注意的一件事是灾难性遗忘,这是我们课程中讨论的内容,所以这就是你在,一些额外的数据上进行训练,在这种疯狂的指令微调中,然后它忘记了之前所有的东西,或者之前大部分的数据。
所以有一些技术我们将在课程中讨论以帮助对抗它,例如,在非常广泛的不同的指令类型上进行指令微调,所以不仅仅是案例,只是调整它来做你想要它做的事情,你可能需要比那更广泛一点,但我们在课程中讨论它。
所以结果是,你知道有两种微调类型,嗯,那些非常值得做,一个是指令微调,你刚提到麦克,然后当一个特定开发者尝试为其自己的应用微调它时,针对特定应用,微调的一个问题是,如果你拿一个大型模型。
并微调该模型中的每个参数,你有一个大东西要存储和部署,实际上非常,你知道,计算和内存昂贵,所以幸运的是有比这更好的技术,对,我们谈论参数高效微调或简称peft,作为一系列方法,可以让你缓解一些这些担忧。
对,所以我们有很多客户确实想要能够为非常特定的任务,非常特定的领域,参数高效,微调是一个很好的方法,仍然可以在许多任务上实现类似性能结果,许多任务上你可以用完全微调。
但实际上可以利用技术来冻结原始模型权重,或在上面添加自适应层,占用更小的内存空间,对,这样你就可以训练多个任务,你知道,实际上,我知道你经常使用的一种技术是,呃,劳拉,我记得,当我读劳拉论文时,我想。
哦,这很合理,这肯定会起作用,我们看到了很多对劳拉的兴奋和需求,因为使用低秩矩阵的性能结果,而不是完全微调,对,所以你能以最小的计算和内存要求获得非常好的性能结果,所以我在不同开发者中看到的是。
许多开发者通常会从提示开始,有时你知道这给你足够好的性能,这很好,有时提示达到了性能上限,然后这种使用劳拉,或其他技术的微调对于解锁额外级别的性能至关重要,然后我看到很多你知道。
LM开发者之间的讨论辩论是关于使用大型模型的成本,这有很多好处相对于,你知道你的应用,微调小模型,完全满,微调可能成本高昂,至少可以说,所以实际能够,你知道,使用路径等技术,嗯,微调生成AI模型。
基本上在每天,用户手中,有成本限制和成本意识,在现实世界中几乎每个人都是对的,没错,当然,如果你关心你的数据去向,所以如果需要在你的控制下运行,那么有一个适当大小的模型非常重要,所以再一次。
本周有很多激动人心的事情要深入,让我们继续下一个视频,迈克将在那里开始指导。
LangChain_微调ChatGPT提示词_RAG模型应用_agent_生成式AI - P75:使用指令对LLM进行微调2——指令微调 - 吴恩达大模型 - BV1gLeueWE5N
上周,你被介绍了生成式人工智能项目生命周期的概念,你探索了大语言模型的示例用例,并在本课程中讨论了能够在此任务中执行的类型。
你将学习到可以改进现有模型性能的方法,针对你的特定用例。
你也将学习到可以用于评估你微调LLM性能的重要指标,并量化其相对于你开始时的基础模型的改进,让我们从讨论如何使用指令提示来微调LLM开始。
在本课程中早期。

你看到一些模型能够识别提示中的指令,并正确执行零-shot推理。
而其他如较小的LLM,可能无法执行任务。
如这里所示的示例,你也看到了包括一个或多个你想要模型执行的示例。
被称为一-shot或少数示例推理,可以帮助模型识别任务并生成良好的完成。
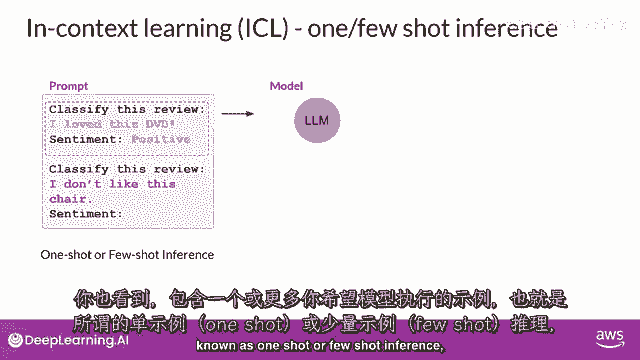
然而。
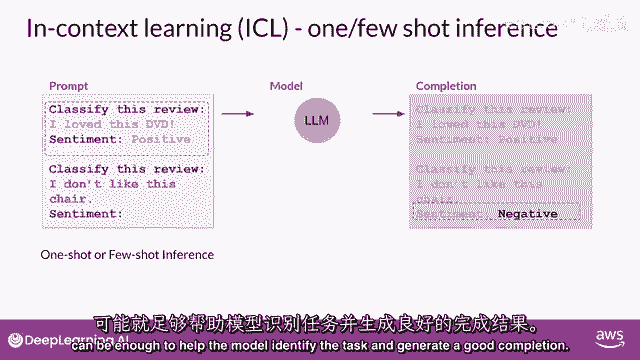
这一战略有一些缺点首先,对于较小的模型,它并不总是有效,即使包括五个或六个示例其次,你在提示中包含的任何示例。

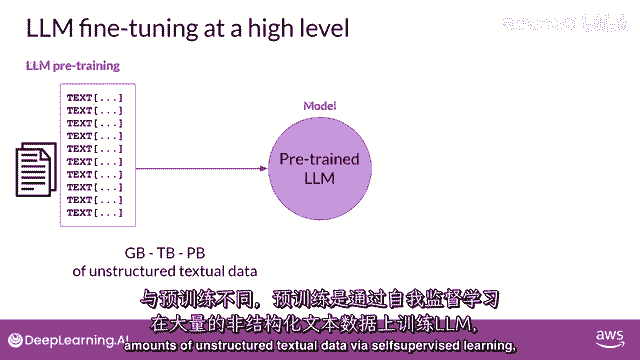
都会占用上下文中宝贵的空间,减少你包括其他有用信息的空间,幸运的是。

另一个解决方案存在,你可以利用被称为微调的过程来进一步训练基础模型,与预训练不同,在那里你使用大量的无结构文本数据来训练LLM,微调是一个监督学习过程。
其中你使用标记的示例来更新LLM的权重,标记的示例是提示完成对。
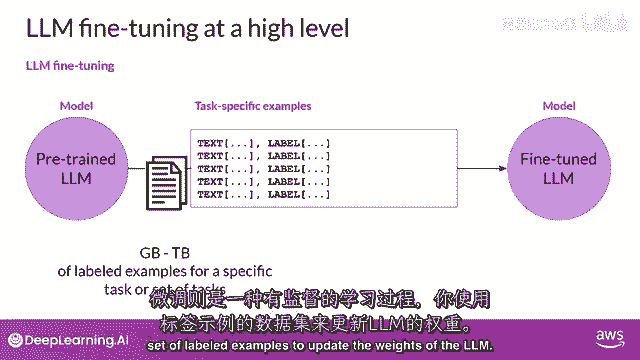
微调过程扩展了模型的训练,以提高其对特定任务的生成良好完成的能力。
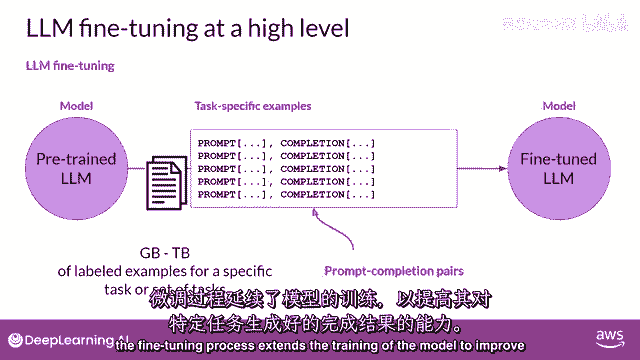
一种被称为指令微调的策略,特别擅长提高模型的在各种任务中的性能,让我们更详细地看看这个是如何工作的,指令微调训练模型使用演示如何响应特定指令的示例,以下是几个演示这个想法的示例提示。

在两个示例中,指令都是分类这个评论。

并期望的完成是一段以情感开始的文本字符串,跟随积极或消极,你用于训练的数据集包括许多提示完成对,对于你感兴趣的任务,每个对都包括一个指令。

例如,如果你想提高模型的摘要能力。
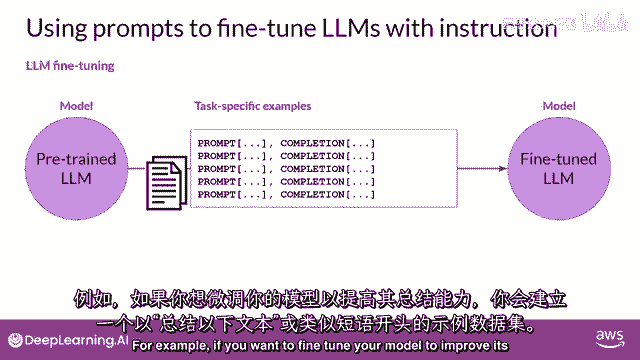
你构建一个数据集,其中包含以指令开始的示例,总结以下文本或类似的短语,如果你正在提高模型的翻译技能,你的例子将包括像这样的指令:翻译这个句子,这些提示完成示例允许模型学习生成遵循给定指令的响应。
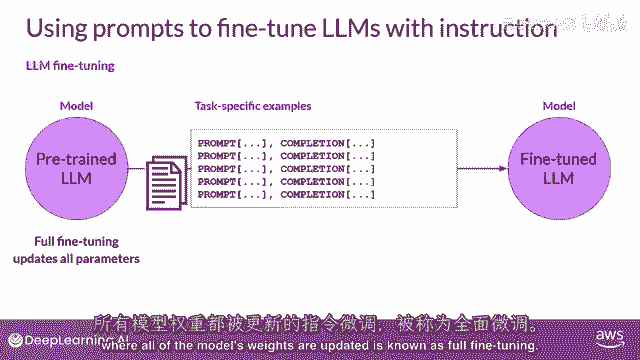
所有模型权重都被更新的指令微调,被称为全面微调。
这个过程产生了一个带有更新权重的新模型版本。
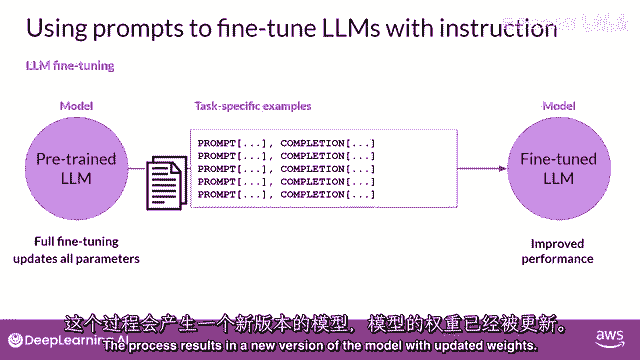
需要注意的是,就像预训练一样,全面微调需要足够的内存和计算预算来存储和处理所有有梯度的数据,在训练过程中被更新的优化器和其他组件。

所以你可以受益于上周你学到的记忆优化和并行计算策略。
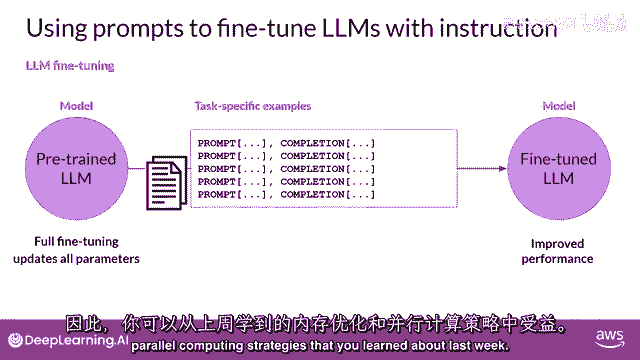
那么,你实际上如何进行指令,微调和llm,第一步是准备你的训练数据,有许多公开可用的数据集,已经被用于训练早期的语言模型,尽管大多数它们不是格式化为指令的,幸运的是,开发者已经汇编了提示模板库。
可以用于使用现有数据集,例如,亚马逊产品评论的大型数据集,并将其转换为微调指令提示数据集,提示模板库包括许多适用于不同任务和不同数据集的模板。

以下是设计用于与亚马逊评论数据集合作的三个提示,并且可以用于分类模型的微调。

文本生成,以及文本摘要任务,你可以看到在每个情况下,你都将原始评论传递到这里,称为评论主体到模板中,它被插入到以指令开始的文本中,类似于预测相关的评分,生成五星级评价,或者描述以下产品评论的一句话。
结果是一个现在包含指令和数据集示例的提示,一旦你有你的指令数据集准备就绪,与标准监督学习类似。

在微调期间,你将数据集分为训练验证和测试分割。
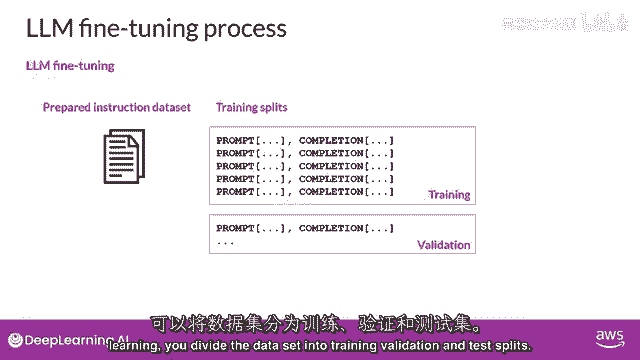
你从你的训练数据集中选择提示并将其传递给llm。
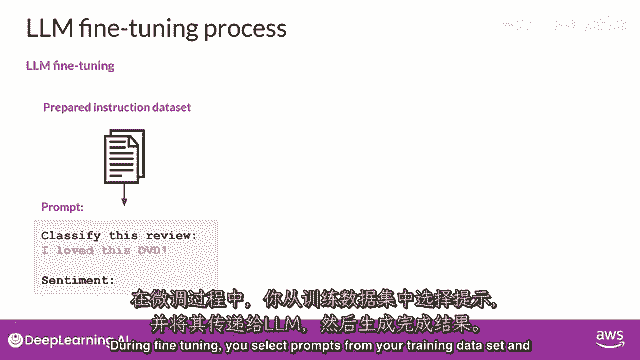
然后它生成完成。
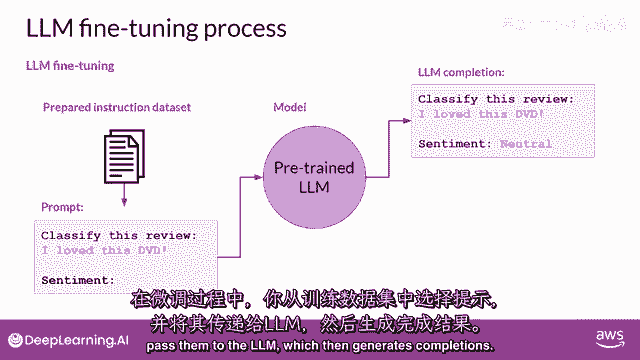
接下来,你将lm完成与训练数据中指定的响应进行比较。
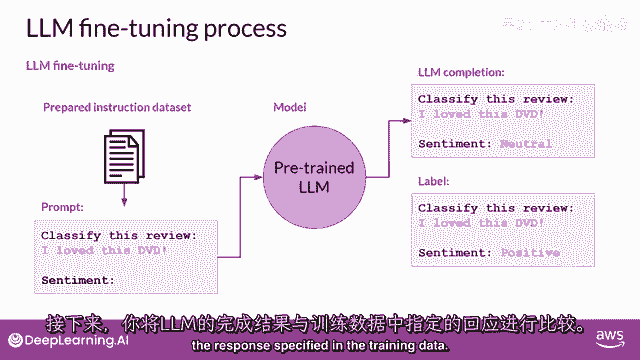
在这里,你可以看到模型做得并不好,它将评论分类为中性,这有些低估,评论明显非常积极,记住,llm的输出是一个标记在标记上的概率分布,所以,你可以比较完成和训练标签分布的分布。
并使用标准交叉熵函数来计算两个标记分布之间的损失,然后,使用计算出的损失来更新您模型的权重,在标准反向传播中,你将这样做许多为提示完成对匹配的批次,并且在多个时代中,更新权重,以便模型的任务性能提高。
就像标准的监督学习一样,你可以定义单独的评估步骤来使用保留验证数据集测量你的llm性能。
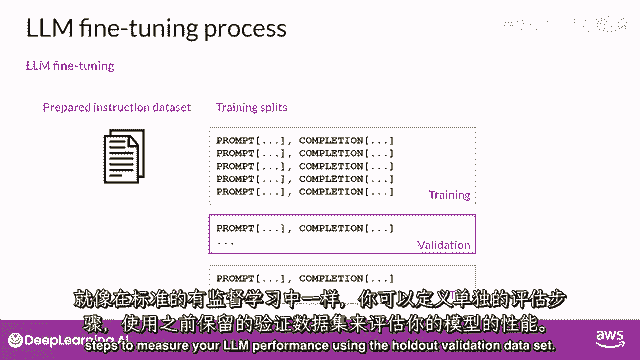
这将给你验证准确率,在你完成微调后,你可以使用保留测试数据集进行最终性能评估。
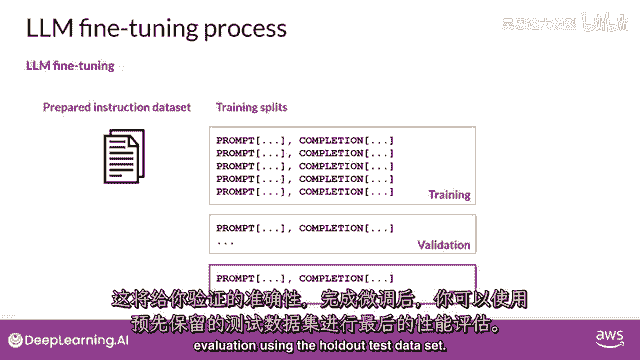
这将给你测试准确率,微调过程产生了基础模型的新版本,通常被称为指令模型,它在您感兴趣的任务上表现更好,使用指令提示进行微调是当今微调llms最常见的方式。
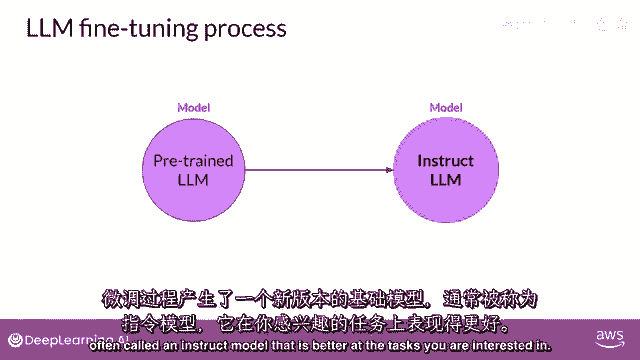
从此以后,当你听到或看到'微调'这个词时。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号