Lucidrains-系列项目源码解析-四十二-
Lucidrains 系列项目源码解析(四十二)
.\lucidrains\st-moe-pytorch\st_moe_pytorch\__init__.py
# 从 st_moe_pytorch.st_moe_pytorch 模块中导入 MoE 和 SparseMoEBlock 类
from st_moe_pytorch.st_moe_pytorch import (
MoE,
SparseMoEBlock
)

STAM - Pytorch
Implementation of STAM (Space Time Attention Model), yet another pure and simple SOTA attention model that bests all previous models in video classification. This corroborates the finding of TimeSformer. Attention is all we need.
Install
$ pip install stam-pytorch
Usage
import torch
from stam_pytorch import STAM
model = STAM(
dim = 512,
image_size = 256, # size of image
patch_size = 32, # patch size
num_frames = 5, # number of image frames, selected out of video
space_depth = 12, # depth of vision transformer
space_heads = 8, # heads of vision transformer
space_mlp_dim = 2048, # feedforward hidden dimension of vision transformer
time_depth = 6, # depth of time transformer (in paper, it was shallower, 6)
time_heads = 8, # heads of time transformer
time_mlp_dim = 2048, # feedforward hidden dimension of time transformer
num_classes = 100, # number of output classes
space_dim_head = 64, # space transformer head dimension
time_dim_head = 64, # time transformer head dimension
dropout = 0., # dropout
emb_dropout = 0. # embedding dropout
)
frames = torch.randn(2, 5, 3, 256, 256) # (batch x frames x channels x height x width)
pred = model(frames) # (2, 100)
Citations
@misc{sharir2021image,
title = {An Image is Worth 16x16 Words, What is a Video Worth?},
author = {Gilad Sharir and Asaf Noy and Lihi Zelnik-Manor},
year = {2021},
eprint = {2103.13915},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
.\lucidrains\STAM-pytorch\setup.py
# 导入设置安装和查找包的函数
from setuptools import setup, find_packages
# 设置包的元数据
setup(
name = 'stam-pytorch', # 包的名称
packages = find_packages(), # 查找所有包
version = '0.0.4', # 版本号
license='MIT', # 许可证
description = 'Space Time Attention Model (STAM) - Pytorch', # 描述
author = 'Phil Wang', # 作者
author_email = 'lucidrains@gmail.com', # 作者邮箱
url = 'https://github.com/lucidrains/STAM-pytorch', # 项目链接
keywords = [ # 关键词列表
'artificial intelligence',
'attention mechanism',
'image recognition'
],
install_requires=[ # 安装依赖
'torch>=1.6',
'einops>=0.3'
],
classifiers=[ # 分类器
'Development Status :: 4 - Beta',
'Intended Audience :: Developers',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
'License :: OSI Approved :: MIT License',
'Programming Language :: Python :: 3.6',
],
)
.\lucidrains\STAM-pytorch\stam_pytorch\stam.py
# 导入 torch 库
import torch
# 从 torch 库中导入 nn 模块和 einsum 函数
from torch import nn, einsum
# 从 einops 库中导入 rearrange 和 repeat 函数,以及 torch 模块中的 Rearrange 类
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# 定义 PreNorm 类,继承自 nn.Module 类
class PreNorm(nn.Module):
# 初始化函数,接受维度 dim 和函数 fn 作为参数
def __init__(self, dim, fn):
super().__init__()
# 初始化 LayerNorm 层
self.norm = nn.LayerNorm(dim)
# 将传入的函数赋值给 fn
self.fn = fn
# 前向传播函数,接受输入 x 和关键字参数 kwargs
def forward(self, x, **kwargs):
# 对输入 x 进行 LayerNorm 处理后,再传入函数 fn 进行处理
return self.fn(self.norm(x), **kwargs)
# 定义 FeedForward 类,继承自 nn.Module 类
class FeedForward(nn.Module):
# 初始化函数,接受维度 dim、隐藏层维度 hidden_dim 和 dropout 参数(默认为 0.)
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
# 定义神经网络结构
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
# 前向传播函数,接受输入 x
def forward(self, x):
# 将输入 x 传入神经网络结构中
return self.net(x)
# 定义 Attention 类,继承自 nn.Module 类
class Attention(nn.Module):
# 初始化函数,接受维度 dim、头数 heads、头维度 dim_head 和 dropout 参数(默认为 0.)
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
self.heads = heads
self.scale = dim_head ** -0.5
# 定义线性层,用于计算 Q、K、V
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
# 定义输出层
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
)
# 前向传播函数,接受输入 x
def forward(self, x):
b, n, _, h = *x.shape, self.heads
# 将输入 x 通过线性层得到 Q、K、V,并分割为三部分
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
# 计算注意力权重
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = dots.softmax(dim=-1)
# 计算输出
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
# 定义 Transformer 类,继承自 nn.Module 类
class Transformer(nn.Module):
# 初始化函数,接受维度 dim、层数 depth、头数 heads、头维度 dim_head、MLP维度 mlp_dim 和 dropout 参数(默认为 0.)
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
self.norm = nn.LayerNorm(dim)
# 构建多层 Transformer 结构
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
# 前向传播函数,接受输入 x
def forward(self, x):
# 遍历每一层 Transformer 结构
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return self.norm(x)
# 定义 STAM 类,继承自 nn.Module 类
class STAM(nn.Module):
# 初始化函数,接受多个参数,包括维度 dim、图像大小 image_size、patch 大小 patch_size、帧数 num_frames、类别数 num_classes 等
def __init__(
self,
*,
dim,
image_size,
patch_size,
num_frames,
num_classes,
space_depth,
space_heads,
space_mlp_dim,
time_depth,
time_heads,
time_mlp_dim,
space_dim_head = 64,
time_dim_head = 64,
dropout = 0.,
emb_dropout = 0.
):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
patch_dim = 3 * patch_size ** 2
# 定义图像块到嵌入向量的映射
self.to_patch_embedding = nn.Sequential(
Rearrange('b f c (h p1) (w p2) -> b f (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
nn.Linear(patch_dim, dim),
)
# 定义位置嵌入向量
self.pos_embedding = nn.Parameter(torch.randn(1, num_frames, num_patches + 1, dim))
self.space_cls_token = nn.Parameter(torch.randn(1, dim))
self.time_cls_token = nn.Parameter(torch.randn(1, dim))
self.dropout = nn.Dropout(emb_dropout)
# 定义空间 Transformer 和时间 Transformer
self.space_transformer = Transformer(dim, space_depth, space_heads, space_dim_head, space_mlp_dim, dropout)
self.time_transformer = Transformer(dim, time_depth, time_heads, time_dim_head, time_mlp_dim, dropout)
self.mlp_head = nn.Linear(dim, num_classes)
# 定义一个前向传播函数,接受视频数据作为输入
def forward(self, video):
# 将视频数据转换为补丁嵌入
x = self.to_patch_embedding(video)
b, f, n, *_ = x.shape
# 连接空间的CLS标记
# 重复空间的CLS标记,以匹配补丁嵌入的维度
space_cls_tokens = repeat(self.space_cls_token, 'n d -> b f n d', b = b, f = f)
# 在空间的CLS标记和补丁嵌入之间进行连接
x = torch.cat((space_cls_tokens, x), dim = -2)
# 位置嵌入
# 添加位置嵌入到补丁嵌入中
x += self.pos_embedding[:, :, :(n + 1)]
# 对结果进行dropout处理
x = self.dropout(x)
# 空间注意力
# 重新排列张量的维度,以便输入到空间变换器中
x = rearrange(x, 'b f ... -> (b f) ...')
# 使用空间变换器处理数据
x = self.space_transformer(x)
# 从每个帧中选择CLS标记
x = rearrange(x[:, 0], '(b f) ... -> b f ...', b = b)
# 连接时间的CLS标记
# 重复时间的CLS标记,以匹配补丁嵌入的维度
time_cls_tokens = repeat(self.time_cls_token, 'n d -> b n d', b = b)
# 在时间的CLS标记和空间注意力结果之间进行连接
x = torch.cat((time_cls_tokens, x), dim = -2)
# 时间注意力
# 使用时间变换器处理数据
x = self.time_transformer(x)
# 最终的多层感知机
# 从每个样本中选择第一个元素,并通过多层感知机处理
return self.mlp_head(x[:, 0])
.\lucidrains\STAM-pytorch\stam_pytorch\__init__.py
# 从stam_pytorch.stam模块中导入STAM类
from stam_pytorch.stam import STAM
Simple StyleGan2 for Pytorch
![]()
Simple Pytorch implementation of Stylegan2 based on https://arxiv.org/abs/1912.04958 that can be completely trained from the command-line, no coding needed.
Below are some flowers that do not exist.


Neither do these hands

Nor these cities

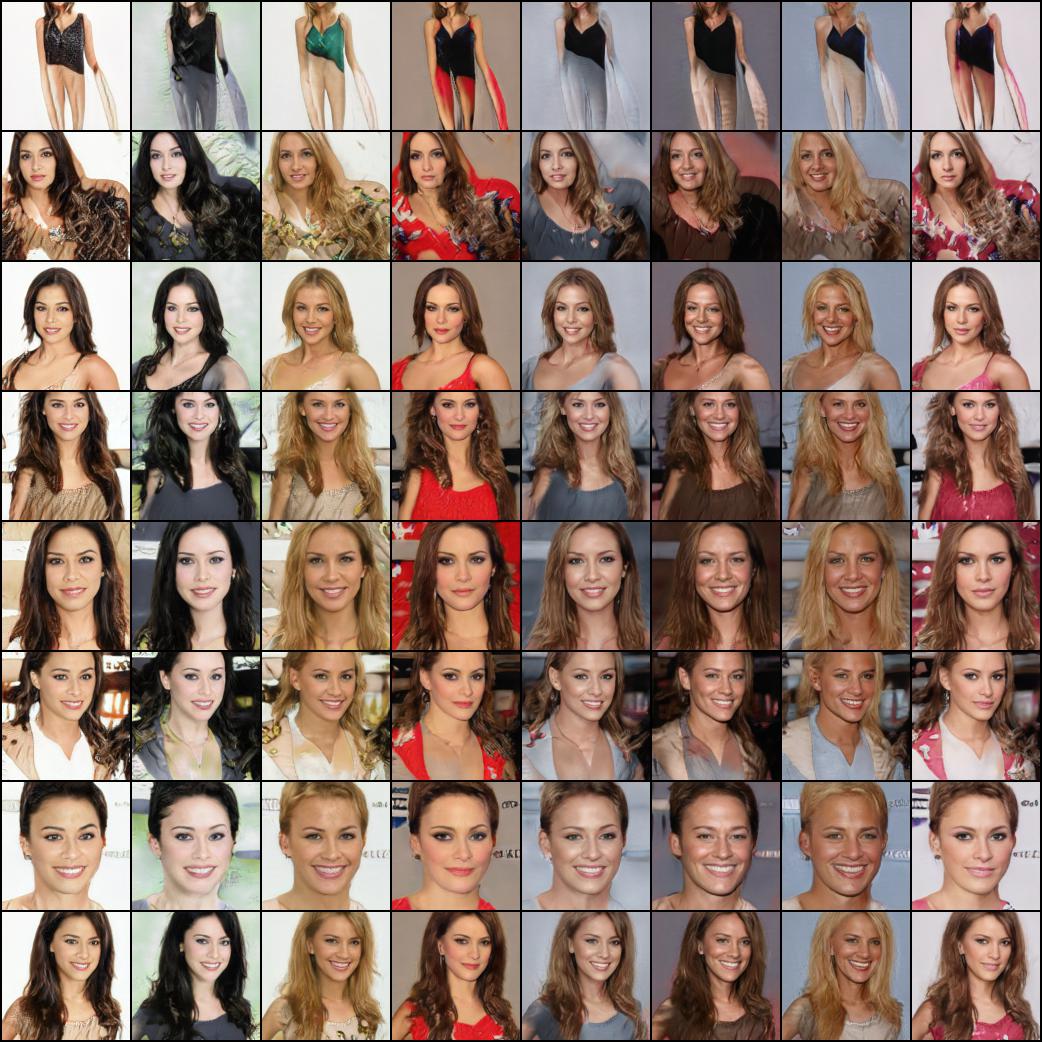
Nor these celebrities (trained by @yoniker)

Install
You will need a machine with a GPU and CUDA installed. Then pip install the package like this
$ pip install stylegan2_pytorch
If you are using a windows machine, the following commands reportedly works.
$ conda install pytorch torchvision -c python
$ pip install stylegan2_pytorch
Use
$ stylegan2_pytorch --data /path/to/images
That's it. Sample images will be saved to results/default and models will be saved periodically to models/default.
Advanced Use
You can specify the name of your project with
$ stylegan2_pytorch --data /path/to/images --name my-project-name
You can also specify the location where intermediate results and model checkpoints should be stored with
$ stylegan2_pytorch --data /path/to/images --name my-project-name --results_dir /path/to/results/dir --models_dir /path/to/models/dir
You can increase the network capacity (which defaults to 16) to improve generation results, at the cost of more memory.
$ stylegan2_pytorch --data /path/to/images --network-capacity 256
By default, if the training gets cut off, it will automatically resume from the last checkpointed file. If you want to restart with new settings, just add a new flag
$ stylegan2_pytorch --new --data /path/to/images --name my-project-name --image-size 512 --batch-size 1 --gradient-accumulate-every 16 --network-capacity 10
Once you have finished training, you can generate images from your latest checkpoint like so.
$ stylegan2_pytorch --generate
To generate a video of a interpolation through two random points in latent space.
$ stylegan2_pytorch --generate-interpolation --interpolation-num-steps 100
To save each individual frame of the interpolation
$ stylegan2_pytorch --generate-interpolation --save-frames
If a previous checkpoint contained a better generator, (which often happens as generators start degrading towards the end of training), you can load from a previous checkpoint with another flag
$ stylegan2_pytorch --generate --load-from {checkpoint number}
A technique used in both StyleGAN and BigGAN is truncating the latent values so that their values fall close to the mean. The small the truncation value, the better the samples will appear at the cost of sample variety. You can control this with the --trunc-psi, where values typically fall between 0.5 and 1. It is set at 0.75 as default
$ stylegan2_pytorch --generate --trunc-psi 0.5
Multi-GPU training
If you have one machine with multiple GPUs, the repository offers a way to utilize all of them for training. With multiple GPUs, each batch will be divided evenly amongst the GPUs available. For example, for 2 GPUs, with a batch size of 32, each GPU will see 16 samples.
You simply have to add a --multi-gpus flag, everyting else is taken care of. If you would like to restrict to specific GPUs, you can use the CUDA_VISIBLE_DEVICES environment variable to control what devices can be used. (ex. CUDA_VISIBLE_DEVICES=0,2,3 only devices 0, 2, 3 are available)
$ stylegan2_pytorch --data ./data --multi-gpus --batch-size 32 --gradient-accumulate-every 1
Low amounts of Training Data
In the past, GANs needed a lot of data to learn how to generate well. The faces model took 70k high quality images from Flickr, as an example.
However, in the month of May 2020, researchers all across the world independently converged on a simple technique to reduce that number to as low as 1-2k. That simple idea was to differentiably augment all images, generated or real, going into the discriminator during training.
If one were to augment at a low enough probability, the augmentations will not 'leak' into the generations.
In the setting of low data, you can use the feature with a simple flag.
# find a suitable probability between 0. -> 0.7 at maximum
$ stylegan2_pytorch --data ./data --aug-prob 0.25
By default, the augmentations used are translation and cutout. If you would like to add color, you can do so with the --aug-types argument.
# make sure there are no spaces between items!
$ stylegan2_pytorch --data ./data --aug-prob 0.25 --aug-types [translation,cutout,color]
You can customize it to any combination of the three you would like. The differentiable augmentation code was copied and slightly modified from here.
When do I stop training?
For as long as possible until the adversarial game between the two neural nets fall apart (we call this divergence). By default, the number of training steps is set to 150000 for 128x128 images, but you will certainly want this number to be higher if the GAN doesn't diverge by the end of training, or if you are training at a higher resolution.
$ stylegan2_pytorch --data ./data --image-size 512 --num-train-steps 1000000
Attention
This framework also allows for you to add an efficient form of self-attention to the designated layers of the discriminator (and the symmetric layer of the generator), which will greatly improve results. The more attention you can afford, the better!
# add self attention after the output of layer 1
$ stylegan2_pytorch --data ./data --attn-layers 1
# add self attention after the output of layers 1 and 2
# do not put a space after the comma in the list!
$ stylegan2_pytorch --data ./data --attn-layers [1,2]
Bonus
Training on transparent images
$ stylegan2_pytorch --data ./transparent/images/path --transparent
Memory considerations
The more GPU memory you have, the bigger and better the image generation will be. Nvidia recommended having up to 16GB for training 1024x1024 images. If you have less than that, there are a couple settings you can play with so that the model fits.
$ stylegan2_pytorch --data /path/to/data \
--batch-size 3 \
--gradient-accumulate-every 5 \
--network-capacity 16
-
Batch size - You can decrease the
batch-sizedown to 1, but you should increase thegradient-accumulate-everycorrespondingly so that the mini-batch the network sees is not too small. This may be confusing to a layperson, so I'll think about how I would automate the choice ofgradient-accumulate-everygoing forward. -
Network capacity - You can decrease the neural network capacity to lessen the memory requirements. Just be aware that this has been shown to degrade generation performance.
If none of this works, you can settle for 'Lightweight' GAN, which will allow you to tradeoff quality to train at greater resolutions in reasonable amount of time.
Deployment on AWS
Below are some steps which may be helpful for deployment using Amazon Web Services. In order to use this, you will have
to provision a GPU-backed EC2 instance. An appropriate instance type would be from a p2 or p3 series. I (iboates) tried
a p2.xlarge (the cheapest option) and it was quite slow, slower in fact than using Google Colab. More powerful instance
types may be better but they are more expensive. You can read more about them
here.
Setup steps
- Archive your training data and upload it to an S3 bucket
- Provision your EC2 instance (I used an Ubuntu AMI)
- Log into your EC2 instance via SSH
- Install the aws CLI client and configure it:
sudo snap install aws-cli --classic
aws configure
You will then have to enter your AWS access keys, which you can retrieve from the management console under AWS
Management Console > Profile > My Security Credentials > Access Keys
Then, run these commands, or maybe put them in a shell script and execute that:
mkdir data
curl -O https://bootstrap.pypa.io/get-pip.py
sudo apt-get install python3-distutils
python3 get-pip.py
pip3 install stylegan2_pytorch
export PATH=$PATH:/home/ubuntu/.local/bin
aws s3 sync s3://<Your bucket name> ~/data
cd data
tar -xf ../train.tar.gz
Now you should be able to train by simplying calling stylegan2_pytorch [args].
Notes:
- If you have a lot of training data, you may need to provision extra block storage via EBS.
- Also, you may need to spread your data across multiple archives.
- You should run this on a
screenwindow so it won't terminate once you log out of the SSH session.
Research
FID Scores
Thanks to GetsEclectic, you can now calculate the FID score periodically! Again, made super simple with one extra argument, as shown below.
Firstly, install the pytorch_fid package
$ pip install pytorch-fid
Followed by
$ stylegan2_pytorch --data ./data --calculate-fid-every 5000
FID results will be logged to ./results/{name}/fid_scores.txt
Coding
If you would like to sample images programmatically, you can do so with the following simple ModelLoader class.
import torch
from torchvision.utils import save_image
from stylegan2_pytorch import ModelLoader
loader = ModelLoader(
base_dir = '/path/to/directory', # path to where you invoked the command line tool
name = 'default' # the project name, defaults to 'default'
)
noise = torch.randn(1, 512).cuda() # noise
styles = loader.noise_to_styles(noise, trunc_psi = 0.7) # pass through mapping network
images = loader.styles_to_images(styles) # call the generator on intermediate style vectors
save_image(images, './sample.jpg') # save your images, or do whatever you desire
Logging to experiment tracker
To log the losses to an open source experiment tracker (Aim), you simply need to pass an extra flag like so.
$ stylegan2_pytorch --data ./data --log
Then, you need to make sure you have Docker installed. Following the instructions at Aim, you execute the following in your terminal.
$ aim up
Then open up your browser to the address and you should see

Experimental
Top-k Training for Generator
A new paper has produced evidence that by simply zero-ing out the gradient contributions from samples that are deemed fake by the discriminator, the generator learns significantly better, achieving new state of the art.
$ stylegan2_pytorch --data ./data --top-k-training
Gamma is a decay schedule that slowly decreases the topk from the full batch size to the target fraction of 50% (also modifiable hyperparameter).
$ stylegan2_pytorch --data ./data --top-k-training --generate-top-k-frac 0.5 --generate-top-k-gamma 0.99
Feature Quantization
A recent paper reported improved results if intermediate representations of the discriminator are vector quantized. Although I have not noticed any dramatic changes, I have decided to add this as a feature, so other minds out there can investigate. To use, you have to specify which layer(s) you would like to vector quantize. Default dictionary size is 256 and is also tunable.
# feature quantize layers 1 and 2, with a dictionary size of 512 each
# do not put a space after the comma in the list!
$ stylegan2_pytorch --data ./data --fq-layers [1,2] --fq-dict-size 512
Contrastive Loss Regularization
I have tried contrastive learning on the discriminator (in step with the usual GAN training) and possibly observed improved stability and quality of final results. You can turn on this experimental feature with a simple flag as shown below.
$ stylegan2_pytorch --data ./data --cl-reg
Relativistic Discriminator Loss
This was proposed in the Relativistic GAN paper to stabilize training. I have had mixed results, but will include the feature for those who want to experiment with it.
$ stylegan2_pytorch --data ./data --rel-disc-loss
Non-constant 4x4 Block
By default, the StyleGAN architecture styles a constant learned 4x4 block as it is progressively upsampled. This is an experimental feature that makes it so the 4x4 block is learned from the style vector w instead.
$ stylegan2_pytorch --data ./data --no-const
Dual Contrastive Loss
A recent paper has proposed that a novel contrastive loss between the real and fake logits can improve quality over other types of losses. (The default in this repository is hinge loss, and the paper shows a slight improvement)
$ stylegan2_pytorch --data ./data --dual-contrast-loss
Alternatives
Stylegan2 + Unet Discriminator
I have gotten really good results with a unet discriminator, but the architecturally change was too big to fit as an option in this repository. If you are aiming for perfection, feel free to try it.
If you would like me to give the royal treatment to some other GAN architecture (BigGAN), feel free to reach out at my email. Happy to hear your pitch.
Appreciation
Thank you to Matthew Mann for his inspiring simple port for Tensorflow 2.0
References
@article{Karras2019stylegan2,
title = {Analyzing and Improving the Image Quality of {StyleGAN}},
author = {Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
journal = {CoRR},
volume = {abs/1912.04958},
year = {2019},
}
@misc{zhao2020feature,
title = {Feature Quantization Improves GAN Training},
author = {Yang Zhao and Chunyuan Li and Ping Yu and Jianfeng Gao and Changyou Chen},
year = {2020}
}
@misc{chen2020simple,
title = {A Simple Framework for Contrastive Learning of Visual Representations},
author = {Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey Hinton},
year = {2020}
}
@article{,
title = {Oxford 102 Flowers},
author = {Nilsback, M-E. and Zisserman, A., 2008},
abstract = {A 102 category dataset consisting of 102 flower categories, commonly occuring in the United Kingdom. Each class consists of 40 to 258 images. The images have large scale, pose and light variations.}
}
@article{afifi201911k,
title = {11K Hands: gender recognition and biometric identification using a large dataset of hand images},
author = {Afifi, Mahmoud},
journal = {Multimedia Tools and Applications}
}
@misc{zhang2018selfattention,
title = {Self-Attention Generative Adversarial Networks},
author = {Han Zhang and Ian Goodfellow and Dimitris Metaxas and Augustus Odena},
year = {2018},
eprint = {1805.08318},
archivePrefix = {arXiv}
}
@article{shen2019efficient,
author = {Zhuoran Shen and
Mingyuan Zhang and
Haiyu Zhao and
Shuai Yi and
Hongsheng Li},
title = {Efficient Attention: Attention with Linear Complexities},
journal = {CoRR},
year = {2018},
url = {http://arxiv.org/abs/1812.01243},
}
@article{zhao2020diffaugment,
title = {Differentiable Augmentation for Data-Efficient GAN Training},
author = {Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
journal = {arXiv preprint arXiv:2006.10738},
year = {2020}
}
@misc{zhao2020image,
title = {Image Augmentations for GAN Training},
author = {Zhengli Zhao and Zizhao Zhang and Ting Chen and Sameer Singh and Han Zhang},
year = {2020},
eprint = {2006.02595},
archivePrefix = {arXiv}
}
@misc{karras2020training,
title = {Training Generative Adversarial Networks with Limited Data},
author = {Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila},
year = {2020},
eprint = {2006.06676},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{jolicoeurmartineau2018relativistic,
title = {The relativistic discriminator: a key element missing from standard GAN},
author = {Alexia Jolicoeur-Martineau},
year = {2018},
eprint = {1807.00734},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@misc{sinha2020topk,
title = {Top-k Training of GANs: Improving GAN Performance by Throwing Away Bad Samples},
author = {Samarth Sinha and Zhengli Zhao and Anirudh Goyal and Colin Raffel and Augustus Odena},
year = {2020},
eprint = {2002.06224},
archivePrefix = {arXiv},
primaryClass = {stat.ML}
}
@misc{yu2021dual,
title = {Dual Contrastive Loss and Attention for GANs},
author = {Ning Yu and Guilin Liu and Aysegul Dundar and Andrew Tao and Bryan Catanzaro and Larry Davis and Mario Fritz},
year = {2021},
eprint = {2103.16748},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
.\lucidrains\stylegan2-pytorch\setup.py
# 导入 sys 模块
import sys
# 从 setuptools 模块中导入 setup 和 find_packages 函数
from setuptools import setup, find_packages
# 将 stylegan2_pytorch 目录添加到 sys.path 中
sys.path[0:0] = ['stylegan2_pytorch']
# 从 version 模块中导入 __version__ 变量
from version import __version__
# 设置包的元数据
setup(
# 包的名称
name = 'stylegan2_pytorch',
# 查找并包含所有包
packages = find_packages(),
# 设置入口点,命令行脚本为 stylegan2_pytorch
entry_points={
'console_scripts': [
'stylegan2_pytorch = stylegan2_pytorch.cli:main',
],
},
# 设置版本号为导入的 __version__ 变量
version = __version__,
# 设置许可证为 GPLv3+
license='GPLv3+',
# 设置描述信息
description = 'StyleGan2 in Pytorch',
# 设置长描述内容类型为 markdown
long_description_content_type = 'text/markdown',
# 设置作者
author = 'Phil Wang',
# 设置作者邮箱
author_email = 'lucidrains@gmail.com',
# 设置项目 URL
url = 'https://github.com/lucidrains/stylegan2-pytorch',
# 设置下载 URL
download_url = 'https://github.com/lucidrains/stylegan2-pytorch/archive/v_036.tar.gz',
# 设置关键词
keywords = ['generative adversarial networks', 'artificial intelligence'],
# 设置依赖的包
install_requires=[
'aim',
'einops',
'contrastive_learner>=0.1.0',
'fire',
'kornia>=0.5.4',
'numpy',
'retry',
'tqdm',
'torch',
'torchvision',
'pillow',
'vector-quantize-pytorch==0.1.0'
],
# 设置分类标签
classifiers=[
'Development Status :: 4 - Beta',
'Intended Audience :: Developers',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
'License :: OSI Approved :: MIT License',
'Programming Language :: Python :: 3.6',
],
)
.\lucidrains\stylegan2-pytorch\stylegan2_pytorch\cli.py
# 导入所需的库
import os
import fire
import random
from retry.api import retry_call
from tqdm import tqdm
from datetime import datetime
from functools import wraps
from stylegan2_pytorch import Trainer, NanException
import torch
import torch.multiprocessing as mp
import torch.distributed as dist
import numpy as np
# 定义一个函数,将输入转换为列表
def cast_list(el):
return el if isinstance(el, list) else [el]
# 生成带时间戳的文件名
def timestamped_filename(prefix = 'generated-'):
now = datetime.now()
timestamp = now.strftime("%m-%d-%Y_%H-%M-%S")
return f'{prefix}{timestamp}'
# 设置随机种子
def set_seed(seed):
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
random.seed(seed)
# 运行训练过程
def run_training(rank, world_size, model_args, data, load_from, new, num_train_steps, name, seed):
is_main = rank == 0
is_ddp = world_size > 1
if is_ddp:
set_seed(seed)
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group('nccl', rank=rank, world_size=world_size)
print(f"{rank + 1}/{world_size} process initialized.")
model_args.update(
is_ddp = is_ddp,
rank = rank,
world_size = world_size
)
model = Trainer(**model_args)
if not new:
model.load(load_from)
else:
model.clear()
model.set_data_src(data)
progress_bar = tqdm(initial = model.steps, total = num_train_steps, mininterval=10., desc=f'{name}<{data}>')
while model.steps < num_train_steps:
retry_call(model.train, tries=3, exceptions=NanException)
progress_bar.n = model.steps
progress_bar.refresh()
if is_main and model.steps % 50 == 0:
model.print_log()
model.save(model.checkpoint_num)
if is_ddp:
dist.destroy_process_group()
# 从文件夹中训练模型
def train_from_folder(
data = './data',
results_dir = './results',
models_dir = './models',
name = 'default',
new = False,
load_from = -1,
image_size = 128,
network_capacity = 16,
fmap_max = 512,
transparent = False,
batch_size = 5,
gradient_accumulate_every = 6,
num_train_steps = 150000,
learning_rate = 2e-4,
lr_mlp = 0.1,
ttur_mult = 1.5,
rel_disc_loss = False,
num_workers = None,
save_every = 1000,
evaluate_every = 1000,
generate = False,
num_generate = 1,
generate_interpolation = False,
interpolation_num_steps = 100,
save_frames = False,
num_image_tiles = 8,
trunc_psi = 0.75,
mixed_prob = 0.9,
fp16 = False,
no_pl_reg = False,
cl_reg = False,
fq_layers = [],
fq_dict_size = 256,
attn_layers = [],
no_const = False,
aug_prob = 0.,
aug_types = ['translation', 'cutout'],
top_k_training = False,
generator_top_k_gamma = 0.99,
generator_top_k_frac = 0.5,
dual_contrast_loss = False,
dataset_aug_prob = 0.,
multi_gpus = False,
calculate_fid_every = None,
calculate_fid_num_images = 12800,
clear_fid_cache = False,
seed = 42,
log = False
):
model_args = dict(
name = name, # 模型名称
results_dir = results_dir, # 结果保存目录
models_dir = models_dir, # 模型保存目录
batch_size = batch_size, # 批量大小
gradient_accumulate_every = gradient_accumulate_every, # 梯度积累频率
image_size = image_size, # 图像尺寸
network_capacity = network_capacity, # 网络容量
fmap_max = fmap_max, # 最大特征图数
transparent = transparent, # 是否透明
lr = learning_rate, # 学习率
lr_mlp = lr_mlp, # MLP学习率
ttur_mult = ttur_mult, # TTUR倍数
rel_disc_loss = rel_disc_loss, # 相对鉴别器损失
num_workers = num_workers, # 工作进程数
save_every = save_every, # 保存频率
evaluate_every = evaluate_every, # 评估频率
num_image_tiles = num_image_tiles, # 图像瓦片数
trunc_psi = trunc_psi, # 截断参数
fp16 = fp16, # 是否使用FP16
no_pl_reg = no_pl_reg, # 是否无PL正则化
cl_reg = cl_reg, # CL正则化
fq_layers = fq_layers, # FQ层
fq_dict_size = fq_dict_size, # FQ字典大小
attn_layers = attn_layers, # 注意力层
no_const = no_const, # 是否无常数
aug_prob = aug_prob, # 数据增强概率
aug_types = cast_list(aug_types), # 数据增强类型
top_k_training = top_k_training, # Top-K训练
generator_top_k_gamma = generator_top_k_gamma, # 生成器Top-K Gamma
generator_top_k_frac = generator_top_k_frac, # 生成器Top-K分数
dual_contrast_loss = dual_contrast_loss, # 双对比损失
dataset_aug_prob = dataset_aug_prob, # 数据集增强概率
calculate_fid_every = calculate_fid_every, # 计算FID频率
calculate_fid_num_images = calculate_fid_num_images, # 计算FID图像数
clear_fid_cache = clear_fid_cache, # 清除FID缓存
mixed_prob = mixed_prob, # 混合概率
log = log # 日志
)
if generate:
model = Trainer(**model_args) # 创建Trainer模型
model.load(load_from) # 加载模型
samples_name = timestamped_filename() # 生成时间戳文件名
for num in tqdm(range(num_generate)): # 迭代生成指定数量的样本
model.evaluate(f'{samples_name}-{num}', num_image_tiles) # 评估模型生成样本
print(f'sample images generated at {results_dir}/{name}/{samples_name}') # 打印生成的样本图像保存路径
return
if generate_interpolation:
model = Trainer(**model_args) # 创建Trainer模型
model.load(load_from) # 加载模型
samples_name = timestamped_filename() # 生成时间戳文件名
model.generate_interpolation(samples_name, num_image_tiles, num_steps = interpolation_num_steps, save_frames = save_frames) # 生成插值图像
print(f'interpolation generated at {results_dir}/{name}/{samples_name}') # 打印插值图像保存路径
return
world_size = torch.cuda.device_count() # 获取GPU数量
if world_size == 1 or not multi_gpus:
run_training(0, 1, model_args, data, load_from, new, num_train_steps, name, seed) # 单GPU训练
return
mp.spawn(run_training,
args=(world_size, model_args, data, load_from, new, num_train_steps, name, seed),
nprocs=world_size,
join=True) # 多GPU训练
# 定义主函数
def main():
# 使用 Fire 库将 train_from_folder 函数转换为命令行接口
fire.Fire(train_from_folder)
.\lucidrains\stylegan2-pytorch\stylegan2_pytorch\diff_augment.py
# 导入必要的库
from functools import partial
import random
import torch
import torch.nn.functional as F
# 定义一个函数,用于对输入进行不同类型的数据增强
def DiffAugment(x, types=[]):
# 遍历每种数据增强类型
for p in types:
# 遍历每种数据增强函数
for f in AUGMENT_FNS[p]:
# 对输入数据进行数据增强操作
x = f(x)
# 返回处理后的数据
return x.contiguous()
# 定义不同的数据增强函数
# 亮度随机增强函数
def rand_brightness(x, scale):
x = x + (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5) * scale
return x
# 饱和度随机增强函数
def rand_saturation(x, scale):
x_mean = x.mean(dim=1, keepdim=True)
x = (x - x_mean) * (((torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5) * 2.0 * scale) + 1.0) + x_mean
return x
# 对比度随机增强函数
def rand_contrast(x, scale):
x_mean = x.mean(dim=[1, 2, 3], keepdim=True)
x = (x - x_mean) * (((torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5) * 2.0 * scale) + 1.0) + x_mean
return x
# 随机平移增强函数
def rand_translation(x, ratio=0.125):
# 计算平移的像素数
shift_x, shift_y = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
# 生成随机的平移量
translation_x = torch.randint(-shift_x, shift_x + 1, size=[x.size(0), 1, 1], device=x.device)
translation_y = torch.randint(-shift_y, shift_y + 1, size=[x.size(0), 1, 1], device=x.device)
# 创建平移后的图像
grid_batch, grid_x, grid_y = torch.meshgrid(
torch.arange(x.size(0), dtype=torch.long, device=x.device),
torch.arange(x.size(2), dtype=torch.long, device=x.device),
torch.arange(x.size(3), dtype=torch.long, device=x.device),
)
grid_x = torch.clamp(grid_x + translation_x + 1, 0, x.size(2) + 1)
grid_y = torch.clamp(grid_y + translation_y + 1, 0, x.size(3) + 1)
x_pad = F.pad(x, [1, 1, 1, 1, 0, 0, 0, 0])
x = x_pad.permute(0, 2, 3, 1).contiguous()[grid_batch, grid_x, grid_y].permute(0, 3, 1, 2)
return x
# 随机偏移增强函数
def rand_offset(x, ratio=1, ratio_h=1, ratio_v=1):
w, h = x.size(2), x.size(3)
imgs = []
for img in x.unbind(dim = 0):
max_h = int(w * ratio * ratio_h)
max_v = int(h * ratio * ratio_v)
value_h = random.randint(0, max_h) * 2 - max_h
value_v = random.randint(0, max_v) * 2 - max_v
if abs(value_h) > 0:
img = torch.roll(img, value_h, 2)
if abs(value_v) > 0:
img = torch.roll(img, value_v, 1)
imgs.append(img)
return torch.stack(imgs)
# 水平偏移增强函数
def rand_offset_h(x, ratio=1):
return rand_offset(x, ratio=1, ratio_h=ratio, ratio_v=0)
# 垂直偏移增强函数
def rand_offset_v(x, ratio=1):
return rand_offset(x, ratio=1, ratio_h=0, ratio_v=ratio)
# 随机遮挡增强函数
def rand_cutout(x, ratio=0.5):
cutout_size = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
offset_x = torch.randint(0, x.size(2) + (1 - cutout_size[0] % 2), size=[x.size(0), 1, 1], device=x.device)
offset_y = torch.randint(0, x.size(3) + (1 - cutout_size[1] % 2), size=[x.size(0), 1, 1], device=x.device)
grid_batch, grid_x, grid_y = torch.meshgrid(
torch.arange(x.size(0), dtype=torch.long, device=x.device),
torch.arange(cutout_size[0], dtype=torch.long, device=x.device),
torch.arange(cutout_size[1], dtype=torch.long, device=x.device),
)
grid_x = torch.clamp(grid_x + offset_x - cutout_size[0] // 2, min=0, max=x.size(2) - 1)
grid_y = torch.clamp(grid_y + offset_y - cutout_size[1] // 2, min=0, max=x.size(3) - 1)
mask = torch.ones(x.size(0), x.size(2), x.size(3), dtype=x.dtype, device=x.device)
mask[grid_batch, grid_x, grid_y] = 0
x = x * mask.unsqueeze(1)
return x
# 定义不同数据增强类型对应的数据增强函数
AUGMENT_FNS = {
'brightness': [partial(rand_brightness, scale=1.)],
'lightbrightness': [partial(rand_brightness, scale=.65)],
'contrast': [partial(rand_contrast, scale=.5)],
'lightcontrast': [partial(rand_contrast, scale=.25)],
'saturation': [partial(rand_saturation, scale=1.)],
'lightsaturation': [partial(rand_saturation, scale=.5)],
'color': [partial(rand_brightness, scale=1.), partial(rand_saturation, scale=1.), partial(rand_contrast, scale=0.5)],
}
# 'lightcolor'键对应的值是一个包含三个函数的列表,分别用于随机调整亮度、饱和度和对比度
'lightcolor': [partial(rand_brightness, scale=0.65), partial(rand_saturation, scale=.5), partial(rand_contrast, scale=0.5)],
# 'offset'键对应的值是一个包含一个函数的列表,用于生成随机偏移量
'offset': [rand_offset],
# 'offset_h'键对应的值是一个包含一个函数的列表,用于生成水平方向的随机偏移量
'offset_h': [rand_offset_h],
# 'offset_v'键对应的值是一个包含一个函数的列表,用于生成垂直方向的随机偏移量
'offset_v': [rand_offset_v],
# 'translation'键对应的值是一个包含一个函数的列表,用于生成随机平移
'translation': [rand_translation],
# 'cutout'键对应的值是一个包含一个函数的列表,用于生成随机遮挡
'cutout': [rand_cutout],
# 闭合大括号,表示代码块的结束
.\lucidrains\stylegan2-pytorch\stylegan2_pytorch\stylegan2_pytorch.py
# 导入必要的库
import os
import sys
import math
import fire
import json
from tqdm import tqdm
from math import floor, log2
from random import random
from shutil import rmtree
from functools import partial
import multiprocessing
from contextlib import contextmanager, ExitStack
import numpy as np
import torch
from torch import nn, einsum
from torch.utils import data
from torch.optim import Adam
import torch.nn.functional as F
from torch.autograd import grad as torch_grad
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from einops import rearrange, repeat
from kornia.filters import filter2d
import torchvision
from torchvision import transforms
from stylegan2_pytorch.version import __version__
from stylegan2_pytorch.diff_augment import DiffAugment
from vector_quantize_pytorch import VectorQuantize
from PIL import Image
from pathlib import Path
try:
from apex import amp
APEX_AVAILABLE = True
except:
APEX_AVAILABLE = False
import aim
# 检查是否有可用的 CUDA 设备
assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
# 常量定义
NUM_CORES = multiprocessing.cpu_count()
EXTS = ['jpg', 'jpeg', 'png']
# 辅助类定义
# 自定义异常类
class NanException(Exception):
pass
# 指数移动平均类
class EMA():
def __init__(self, beta):
super().__init__()
self.beta = beta
def update_average(self, old, new):
if not exists(old):
return new
return old * self.beta + (1 - self.beta) * new
# 展平类
class Flatten(nn.Module):
def forward(self, x):
return x.reshape(x.shape[0], -1)
# 随机应用类
class RandomApply(nn.Module):
def __init__(self, prob, fn, fn_else = lambda x: x):
super().__init__()
self.fn = fn
self.fn_else = fn_else
self.prob = prob
def forward(self, x):
fn = self.fn if random() < self.prob else self.fn_else
return fn(x)
# 残差连接类
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
# 通道归一化类
class ChanNorm(nn.Module):
def __init__(self, dim, eps = 1e-5):
super().__init__()
self.eps = eps
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
def forward(self, x):
var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
mean = torch.mean(x, dim = 1, keepdim = True)
return (x - mean) / (var + self.eps).sqrt() * self.g + self.b
# 预归一化类
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = ChanNorm(dim)
def forward(self, x):
return self.fn(self.norm(x))
# 维度置换类
class PermuteToFrom(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
x = x.permute(0, 2, 3, 1)
out, *_, loss = self.fn(x)
out = out.permute(0, 3, 1, 2)
return out, loss
# 模糊类
class Blur(nn.Module):
def __init__(self):
super().__init__()
f = torch.Tensor([1, 2, 1])
self.register_buffer('f', f)
def forward(self, x):
f = self.f
f = f[None, None, :] * f [None, :, None]
return filter2d(x, f, normalized=True)
# 注意力机制
# 深度卷积类
class DepthWiseConv2d(nn.Module):
def __init__(self, dim_in, dim_out, kernel_size, padding = 0, stride = 1, bias = True):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
)
def forward(self, x):
return self.net(x)
# 线性注意力类
class LinearAttention(nn.Module):
# 初始化函数,设置注意力机制的参数
def __init__(self, dim, dim_head = 64, heads = 8):
# 调用父类的初始化函数
super().__init__()
# 计算缩放因子
self.scale = dim_head ** -0.5
# 设置头数
self.heads = heads
# 计算内部维度
inner_dim = dim_head * heads
# 使用 GELU 作为非线性激活函数
self.nonlin = nn.GELU()
# 创建输入到查询向量的卷积层
self.to_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
# 创建输入到键值对的卷积层
self.to_kv = DepthWiseConv2d(dim, inner_dim * 2, 3, padding = 1, bias = False)
# 创建输出的卷积层
self.to_out = nn.Conv2d(inner_dim, dim, 1)
# 前向传播函数
def forward(self, fmap):
# 获取头数和特征图的高度、宽度
h, x, y = self.heads, *fmap.shape[-2:]
# 计算查询、键、值
q, k, v = (self.to_q(fmap), *self.to_kv(fmap).chunk(2, dim = 1))
# 重排查询、键、值的维度
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = h), (q, k, v))
# 对查询进行 softmax 操作
q = q.softmax(dim = -1)
# 对键进行 softmax 操作
k = k.softmax(dim = -2)
# 缩放查询
q = q * self.scale
# 计算上下文信息
context = einsum('b n d, b n e -> b d e', k, v)
# 计算输出
out = einsum('b n d, b d e -> b n e', q, context)
# 重排输出的维度
out = rearrange(out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
# 使用非线性激活函数
out = self.nonlin(out)
# 返回输出
return self.to_out(out)
# 定义一个包含自注意力和前馈的函数,用于图像处理
attn_and_ff = lambda chan: nn.Sequential(*[
# 使用残差连接将通道数作为参数传入预标准化和线性注意力模块中
Residual(PreNorm(chan, LinearAttention(chan))),
# 使用残差连接将通道数作为参数传入预标准化和卷积模块中
Residual(PreNorm(chan, nn.Sequential(nn.Conv2d(chan, chan * 2, 1), leaky_relu(), nn.Conv2d(chan * 2, chan, 1))))
])
# 辅助函数
# 判断值是否存在
def exists(val):
return val is not None
# 空上下文管理器
@contextmanager
def null_context():
yield
# 合并多个上下文管理器
def combine_contexts(contexts):
@contextmanager
def multi_contexts():
with ExitStack() as stack:
yield [stack.enter_context(ctx()) for ctx in contexts]
return multi_contexts
# 返回默认值
def default(value, d):
return value if exists(value) else d
# 无限循环迭代器
def cycle(iterable):
while True:
for i in iterable:
yield i
# 将元素转换为列表
def cast_list(el):
return el if isinstance(el, list) else [el]
# 判断张量是否为空
def is_empty(t):
if isinstance(t, torch.Tensor):
return t.nelement() == 0
return not exists(t)
# 如果张量包含 NaN,则抛出异常
def raise_if_nan(t):
if torch.isnan(t):
raise NanException
# 梯度累积上下文管理器
def gradient_accumulate_contexts(gradient_accumulate_every, is_ddp, ddps):
if is_ddp:
num_no_syncs = gradient_accumulate_every - 1
head = [combine_contexts(map(lambda ddp: ddp.no_sync, ddps))] * num_no_syncs
tail = [null_context]
contexts = head + tail
else:
contexts = [null_context] * gradient_accumulate_every
for context in contexts:
with context():
yield
# 损失反向传播
def loss_backwards(fp16, loss, optimizer, loss_id, **kwargs):
if fp16:
with amp.scale_loss(loss, optimizer, loss_id) as scaled_loss:
scaled_loss.backward(**kwargs)
else:
loss.backward(**kwargs)
# 梯度惩罚
def gradient_penalty(images, output, weight = 10):
batch_size = images.shape[0]
gradients = torch_grad(outputs=output, inputs=images,
grad_outputs=torch.ones(output.size(), device=images.device),
create_graph=True, retain_graph=True, only_inputs=True)[0]
gradients = gradients.reshape(batch_size, -1)
return weight * ((gradients.norm(2, dim=1) - 1) ** 2).mean()
# 计算潜在空间长��
def calc_pl_lengths(styles, images):
device = images.device
num_pixels = images.shape[2] * images.shape[3]
pl_noise = torch.randn(images.shape, device=device) / math.sqrt(num_pixels)
outputs = (images * pl_noise).sum()
pl_grads = torch_grad(outputs=outputs, inputs=styles,
grad_outputs=torch.ones(outputs.shape, device=device),
create_graph=True, retain_graph=True, only_inputs=True)[0]
return (pl_grads ** 2).sum(dim=2).mean(dim=1).sqrt()
# 生成噪声
def noise(n, latent_dim, device):
return torch.randn(n, latent_dim).cuda(device)
# 生成噪声列表
def noise_list(n, layers, latent_dim, device):
return [(noise(n, latent_dim, device), layers)]
# 生成混合噪声列表
def mixed_list(n, layers, latent_dim, device):
tt = int(torch.rand(()).numpy() * layers)
return noise_list(n, tt, latent_dim, device) + noise_list(n, layers - tt, latent_dim, device)
# 将潜在向量转换为 W
def latent_to_w(style_vectorizer, latent_descr):
return [(style_vectorizer(z), num_layers) for z, num_layers in latent_descr]
# 生成图像噪声
def image_noise(n, im_size, device):
return torch.FloatTensor(n, im_size, im_size, 1).uniform_(0., 1.).cuda(device)
# Leaky ReLU 激活函数
def leaky_relu(p=0.2):
return nn.LeakyReLU(p, inplace=True)
# 分块评估
def evaluate_in_chunks(max_batch_size, model, *args):
split_args = list(zip(*list(map(lambda x: x.split(max_batch_size, dim=0), args))))
chunked_outputs = [model(*i) for i in split_args]
if len(chunked_outputs) == 1:
return chunked_outputs[0]
return torch.cat(chunked_outputs, dim=0)
# 将样式定义转换为张量
def styles_def_to_tensor(styles_def):
return torch.cat([t[:, None, :].expand(-1, n, -1) for t, n in styles_def], dim=1)
# 设置模型参数是否需要梯度
def set_requires_grad(model, bool):
for p in model.parameters():
p.requires_grad = bool
# Slerp 插值
def slerp(val, low, high):
low_norm = low / torch.norm(low, dim=1, keepdim=True)
high_norm = high / torch.norm(high, dim=1, keepdim=True)
# 计算两个向量的夹角的余弦值
omega = torch.acos((low_norm * high_norm).sum(1))
# 计算夹角的正弦值
so = torch.sin(omega)
# 根据插值参数val计算插值结果
res = (torch.sin((1.0 - val) * omega) / so).unsqueeze(1) * low + (torch.sin(val * omega) / so).unsqueeze(1) * high
# 返回插值结果
return res
# losses
# 生成 Hinge 损失函数,返回 fake 数据的均值
def gen_hinge_loss(fake, real):
return fake.mean()
# Hinge 损失函数,计算 real 和 fake 数据的损失
def hinge_loss(real, fake):
return (F.relu(1 + real) + F.relu(1 - fake)).mean()
# 对偶对比损失函数,计算 real_logits 和 fake_logits 之间的损失
def dual_contrastive_loss(real_logits, fake_logits):
device = real_logits.device
# 重排维度
real_logits, fake_logits = map(lambda t: rearrange(t, '... -> (...)'), (real_logits, fake_logits))
# 定义损失函数
def loss_half(t1, t2):
t1 = rearrange(t1, 'i -> i ()')
t2 = repeat(t2, 'j -> i j', i = t1.shape[0])
t = torch.cat((t1, t2), dim = -1)
return F.cross_entropy(t, torch.zeros(t1.shape[0], device = device, dtype = torch.long))
# 返回损失函数结果
return loss_half(real_logits, fake_logits) + loss_half(-fake_logits, -real_logits)
# dataset
# 将 RGB 图像转换为带透明度的图像
def convert_rgb_to_transparent(image):
if image.mode != 'RGBA':
return image.convert('RGBA')
return image
# 将带透明度的图像转换为 RGB 图像
def convert_transparent_to_rgb(image):
if image.mode != 'RGB':
return image.convert('RGB')
return image
# 扩展灰度图像类
class expand_greyscale(object):
def __init__(self, transparent):
self.transparent = transparent
def __call__(self, tensor):
channels = tensor.shape[0]
num_target_channels = 4 if self.transparent else 3
if channels == num_target_channels:
return tensor
alpha = None
if channels == 1:
color = tensor.expand(3, -1, -1)
elif channels == 2:
color = tensor[:1].expand(3, -1, -1)
alpha = tensor[1:]
else:
raise Exception(f'image with invalid number of channels given {channels}')
if not exists(alpha) and self.transparent:
alpha = torch.ones(1, *tensor.shape[1:], device=tensor.device)
return color if not self.transparent else torch.cat((color, alpha))
# 调整图像大小至最小尺寸
def resize_to_minimum_size(min_size, image):
if max(*image.size) < min_size:
return torchvision.transforms.functional.resize(image, min_size)
return image
# 数据集类
class Dataset(data.Dataset):
def __init__(self, folder, image_size, transparent = False, aug_prob = 0.):
super().__init__()
self.folder = folder
self.image_size = image_size
self.paths = [p for ext in EXTS for p in Path(f'{folder}').glob(f'**/*.{ext}')]
assert len(self.paths) > 0, f'No images were found in {folder} for training'
convert_image_fn = convert_transparent_to_rgb if not transparent else convert_rgb_to_transparent
num_channels = 3 if not transparent else 4
self.transform = transforms.Compose([
transforms.Lambda(convert_image_fn),
transforms.Lambda(partial(resize_to_minimum_size, image_size)),
transforms.Resize(image_size),
RandomApply(aug_prob, transforms.RandomResizedCrop(image_size, scale=(0.5, 1.0), ratio=(0.98, 1.02)), transforms.CenterCrop(image_size)),
transforms.ToTensor(),
transforms.Lambda(expand_greyscale(transparent))
])
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
path = self.paths[index]
img = Image.open(path)
return self.transform(img)
# augmentations
# 随机水平翻转图像
def random_hflip(tensor, prob):
if prob < random():
return tensor
return torch.flip(tensor, dims=(3,))
# 增强包装类
class AugWrapper(nn.Module):
def __init__(self, D, image_size):
super().__init__()
self.D = D
def forward(self, images, prob = 0., types = [], detach = False):
if random() < prob:
images = random_hflip(images, prob=0.5)
images = DiffAugment(images, types=types)
if detach:
images = images.detach()
return self.D(images)
# stylegan2 classes
# 等权线性层
class EqualLinear(nn.Module):
def __init__(self, in_dim, out_dim, lr_mul = 1, bias = True):
super().__init__()
self.weight = nn.Parameter(torch.randn(out_dim, in_dim))
if bias:
self.bias = nn.Parameter(torch.zeros(out_dim))
self.lr_mul = lr_mul
# 定义一个前向传播函数,接收输入并返回线性变换的结果
def forward(self, input):
# 使用线性变换函数对输入进行处理,其中权重乘以学习率倍数,偏置也乘以学习率倍数
return F.linear(input, self.weight * self.lr_mul, bias=self.bias * self.lr_mul)
class StyleVectorizer(nn.Module):
def __init__(self, emb, depth, lr_mul = 0.1):
super().__init__()
layers = []
for i in range(depth):
layers.extend([EqualLinear(emb, emb, lr_mul), leaky_relu()])
self.net = nn.Sequential(*layers)
def forward(self, x):
x = F.normalize(x, dim=1)
return self.net(x)
# 定义一个风格向量化器模块,用于将输入向量进行风格化处理
class StyleVectorizer(nn.Module):
def __init__(self, emb, depth, lr_mul = 0.1):
# 初始化函数
super().__init__()
# 创建一个空的层列表
layers = []
# 根据深度循环创建一组相同结构的层
for i in range(depth):
layers.extend([EqualLinear(emb, emb, lr_mul), leaky_relu()])
# 将层列表组合成一个序列
self.net = nn.Sequential(*layers)
# 前向传播函数
def forward(self, x):
# 对输入进行归一化处理
x = F.normalize(x, dim=1)
return self.net(x)
class RGBBlock(nn.Module):
def __init__(self, latent_dim, input_channel, upsample, rgba = False):
super().__init__()
self.input_channel = input_channel
self.to_style = nn.Linear(latent_dim, input_channel)
out_filters = 3 if not rgba else 4
self.conv = Conv2DMod(input_channel, out_filters, 1, demod=False)
self.upsample = nn.Sequential(
nn.Upsample(scale_factor = 2, mode='bilinear', align_corners=False),
Blur()
) if upsample else None
def forward(self, x, prev_rgb, istyle):
b, c, h, w = x.shape
style = self.to_style(istyle)
x = self.conv(x, style)
if exists(prev_rgb):
x = x + prev_rgb
if exists(self.upsample):
x = self.upsample(x)
return x
# 定义一个 RGB 模块,用于处理 RGB 图像数据
class RGBBlock(nn.Module):
def __init__(self, latent_dim, input_channel, upsample, rgba = False):
# 初始化函数
super().__init__()
self.input_channel = input_channel
self.to_style = nn.Linear(latent_dim, input_channel)
# 根据是否包含 alpha 通道确定输出通道数
out_filters = 3 if not rgba else 4
self.conv = Conv2DMod(input_channel, out_filters, 1, demod=False)
# 根据是否需要上采样创建上采样模块
self.upsample = nn.Sequential(
nn.Upsample(scale_factor = 2, mode='bilinear', align_corners=False),
Blur()
) if upsample else None
# 前向传播函数
def forward(self, x, prev_rgb, istyle):
b, c, h, w = x.shape
style = self.to_style(istyle)
x = self.conv(x, style)
# 如果存在前一层 RGB 数据,则进行相加操作
if exists(prev_rgb):
x = x + prev_rgb
# 如果存在上采样模块,则进行上采样操作
if exists(self.upsample):
x = self.upsample(x)
return x
class Conv2DMod(nn.Module):
def __init__(self, in_chan, out_chan, kernel, demod=True, stride=1, dilation=1, eps = 1e-8, **kwargs):
super().__init__()
self.filters = out_chan
self.demod = demod
self.kernel = kernel
self.stride = stride
self.dilation = dilation
self.weight = nn.Parameter(torch.randn((out_chan, in_chan, kernel, kernel)))
self.eps = eps
nn.init.kaiming_normal_(self.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
def _get_same_padding(self, size, kernel, dilation, stride):
return ((size - 1) * (stride - 1) + dilation * (kernel - 1)) // 2
def forward(self, x, y):
b, c, h, w = x.shape
w1 = y[:, None, :, None, None]
w2 = self.weight[None, :, :, :, :]
weights = w2 * (w1 + 1)
if self.demod:
d = torch.rsqrt((weights ** 2).sum(dim=(2, 3, 4), keepdim=True) + self.eps)
weights = weights * d
x = x.reshape(1, -1, h, w)
_, _, *ws = weights.shape
weights = weights.reshape(b * self.filters, *ws)
padding = self._get_same_padding(h, self.kernel, self.dilation, self.stride)
x = F.conv2d(x, weights, padding=padding, groups=b)
x = x.reshape(-1, self.filters, h, w)
return x
# 定义一个带有调制的卷积模块
class Conv2DMod(nn.Module):
def __init__(self, in_chan, out_chan, kernel, demod=True, stride=1, dilation=1, eps = 1e-8, **kwargs):
# 初始化函数
super().__init__()
self.filters = out_chan
self.demod = demod
self.kernel = kernel
self.stride = stride
self.dilation = dilation
self.weight = nn.Parameter(torch.randn((out_chan, in_chan, kernel, kernel)))
self.eps = eps
nn.init.kaiming_normal_(self.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
# 计算填充大小的函数
def _get_same_padding(self, size, kernel, dilation, stride):
return ((size - 1) * (stride - 1) + dilation * (kernel - 1)) // 2
# 前向传播函数
def forward(self, x, y):
b, c, h, w = x.shape
w1 = y[:, None, :, None, None]
w2 = self.weight[None, :, :, :, :]
weights = w2 * (w1 + 1)
if self.demod:
d = torch.rsqrt((weights ** 2).sum(dim=(2, 3, 4), keepdim=True) + self.eps)
weights = weights * d
x = x.reshape(1, -1, h, w)
_, _, *ws = weights.shape
weights = weights.reshape(b * self.filters, *ws)
padding = self._get_same_padding(h, self.kernel, self.dilation, self.stride)
x = F.conv2d(x, weights, padding=padding, groups=b)
x = x.reshape(-1, self.filters, h, w)
return x
class GeneratorBlock(nn.Module):
def __init__(self, latent_dim, input_channels, filters, upsample = True, upsample_rgb = True, rgba = False):
super().__init__()
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False) if upsample else None
self.to_style1 = nn.Linear(latent_dim, input_channels)
self.to_noise1 = nn.Linear(1, filters)
self.conv1 = Conv2DMod(input_channels, filters, 3)
self.to_style2 = nn.Linear(latent_dim, filters)
self.to_noise2 = nn.Linear(1, filters)
self.conv2 = Conv2DMod(filters, filters, 3)
self.activation = leaky_relu()
self.to_rgb = RGBBlock(latent_dim, filters, upsample_rgb, rgba)
def forward(self, x, prev_rgb, istyle, inoise):
if exists(self.upsample):
x = self.upsample(x)
inoise = inoise[:, :x.shape[2], :x.shape[3], :]
noise1 = self.to_noise1(inoise).permute((0, 3, 2, 1))
noise2 = self.to_noise2(inoise).permute((0, 3, 2, 1))
style1 = self.to_style1(istyle)
x = self.conv1(x, style1)
x = self.activation(x + noise1)
style2 = self.to_style2(istyle)
x = self.conv2(x, style2)
x = self.activation(x + noise2)
rgb = self.to_rgb(x, prev_rgb, istyle)
return x, rgb
# 定义一个生成器模块
class GeneratorBlock(nn.Module):
def __init__(self, latent_dim, input_channels, filters, upsample = True, upsample_rgb = True, rgba = False):
# 初始化函数
super().__init__()
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False) if upsample else None
self.to_style1 = nn.Linear(latent_dim, input_channels)
self.to_noise1 = nn.Linear(1, filters)
self.conv1 = Conv2DMod(input_channels, filters, 3)
self.to_style2 = nn.Linear(latent_dim, filters)
self.to_noise2 = nn.Linear(1, filters)
self.conv2 = Conv2DMod(filters, filters, 3)
self.activation = leaky_relu()
self.to_rgb = RGBBlock(latent_dim, filters, upsample_rgb, rgba)
# 前向传播函数
def forward(self, x, prev_rgb, istyle, inoise):
# 如果需要上采样,则进行上采样操作
if exists(self.upsample):
x = self.upsample(x)
# 裁剪噪声数据
inoise = inoise[:, :x.shape[2], :x.shape[3], :]
noise1 = self.to_noise1(inoise).permute((0, 3, 2, 1))
noise2 = self.to_noise2(inoise).permute((0, 3, 2, 1))
style1 = self.to_style1(istyle)
x = self.conv1(x, style1)
x = self.activation(x + noise1)
style2 = self.to_style2(istyle)
x = self.conv2(x, style2)
x = self.activation(x + noise2)
rgb = self.to_rgb(x, prev_rgb, istyle)
return x, rgb
class DiscriminatorBlock(nn.Module):
# 定义一个鉴别器模块
class DiscriminatorBlock(nn.Module):
# 初始化函数,定义了一个卷积层 conv_res,用于降采样
def __init__(self, input_channels, filters, downsample=True):
# 调用父类的初始化函数
super().__init__()
# 定义一个卷积层 conv_res,用于降采样,1x1卷积核,stride为2(如果 downsample 为 True)
self.conv_res = nn.Conv2d(input_channels, filters, 1, stride = (2 if downsample else 1))
# 定义一个神经网络模型 net,包含两个卷积层和激活函数
self.net = nn.Sequential(
nn.Conv2d(input_channels, filters, 3, padding=1),
leaky_relu(),
nn.Conv2d(filters, filters, 3, padding=1),
leaky_relu()
)
# 如果 downsample 为 True,则定义一个下采样模块 downsample,包含模糊层和卷积层
self.downsample = nn.Sequential(
Blur(),
nn.Conv2d(filters, filters, 3, padding = 1, stride = 2)
) if downsample else None
# 前向传播函数,接收输入 x,返回处理后的结果
def forward(self, x):
# 对输入 x 进行卷积操作,得到 res
res = self.conv_res(x)
# 对输入 x 进行神经网络模型 net 的处理
x = self.net(x)
# 如果 downsample 存在,则对 x 进行下采样
if exists(self.downsample):
x = self.downsample(x)
# 将下采样后的 x 与 res 相加,并乘以 1/sqrt(2)
x = (x + res) * (1 / math.sqrt(2))
# 返回处理后的结果 x
return x
class Generator(nn.Module):
# 生成器类,继承自 nn.Module
def __init__(self, image_size, latent_dim, network_capacity = 16, transparent = False, attn_layers = [], no_const = False, fmap_max = 512):
# 初始化函数,接受图像大小、潜在维度、网络容量、是否透明、注意力层等参数
super().__init__()
self.image_size = image_size
self.latent_dim = latent_dim
self.num_layers = int(log2(image_size) - 1)
filters = [network_capacity * (2 ** (i + 1)) for i in range(self.num_layers)][::-1]
set_fmap_max = partial(min, fmap_max)
filters = list(map(set_fmap_max, filters))
init_channels = filters[0]
filters = [init_channels, *filters]
in_out_pairs = zip(filters[:-1], filters[1:])
self.no_const = no_const
if no_const:
self.to_initial_block = nn.ConvTranspose2d(latent_dim, init_channels, 4, 1, 0, bias=False)
else:
self.initial_block = nn.Parameter(torch.randn((1, init_channels, 4, 4)))
self.initial_conv = nn.Conv2d(filters[0], filters[0], 3, padding=1)
self.blocks = nn.ModuleList([])
self.attns = nn.ModuleList([])
for ind, (in_chan, out_chan) in enumerate(in_out_pairs):
not_first = ind != 0
not_last = ind != (self.num_layers - 1)
num_layer = self.num_layers - ind
attn_fn = attn_and_ff(in_chan) if num_layer in attn_layers else None
self.attns.append(attn_fn)
block = GeneratorBlock(
latent_dim,
in_chan,
out_chan,
upsample = not_first,
upsample_rgb = not_last,
rgba = transparent
)
self.blocks.append(block)
def forward(self, styles, input_noise):
# 前向传播函数,接受样式和输入噪声
batch_size = styles.shape[0]
image_size = self.image_size
if self.no_const:
avg_style = styles.mean(dim=1)[:, :, None, None]
x = self.to_initial_block(avg_style)
else:
x = self.initial_block.expand(batch_size, -1, -1, -1)
rgb = None
styles = styles.transpose(0, 1)
x = self.initial_conv(x)
for style, block, attn in zip(styles, self.blocks, self.attns):
if exists(attn):
x = attn(x)
x, rgb = block(x, rgb, style, input_noise)
return rgb
class Discriminator(nn.Module):
# 判别器类,继承自 nn.Module
def __init__(self, image_size, network_capacity = 16, fq_layers = [], fq_dict_size = 256, attn_layers = [], transparent = False, fmap_max = 512):
# 初始化函数,接受图像大小、网络容量、fq_layers、fq_dict_size、attn_layers、是否透明、fmap_max等参数
super().__init__()
num_layers = int(log2(image_size) - 1)
num_init_filters = 3 if not transparent else 4
blocks = []
filters = [num_init_filters] + [(network_capacity * 4) * (2 ** i) for i in range(num_layers + 1)]
set_fmap_max = partial(min, fmap_max)
filters = list(map(set_fmap_max, filters))
chan_in_out = list(zip(filters[:-1], filters[1:]))
blocks = []
attn_blocks = []
quantize_blocks = []
for ind, (in_chan, out_chan) in enumerate(chan_in_out):
num_layer = ind + 1
is_not_last = ind != (len(chan_in_out) - 1)
block = DiscriminatorBlock(in_chan, out_chan, downsample = is_not_last)
blocks.append(block)
attn_fn = attn_and_ff(out_chan) if num_layer in attn_layers else None
attn_blocks.append(attn_fn)
quantize_fn = PermuteToFrom(VectorQuantize(out_chan, fq_dict_size)) if num_layer in fq_layers else None
quantize_blocks.append(quantize_fn)
self.blocks = nn.ModuleList(blocks)
self.attn_blocks = nn.ModuleList(attn_blocks)
self.quantize_blocks = nn.ModuleList(quantize_blocks)
chan_last = filters[-1]
latent_dim = 2 * 2 * chan_last
self.final_conv = nn.Conv2d(chan_last, chan_last, 3, padding=1)
self.flatten = Flatten()
self.to_logit = nn.Linear(latent_dim, 1)
# 定义前向传播函数,接受输入 x
def forward(self, x):
# 获取输入 x 的 batch size
b, *_ = x.shape
# 初始化量化损失为零张量,与输入 x 相同的设备
quantize_loss = torch.zeros(1).to(x)
# 遍历每个块,注意力块和量化块
for (block, attn_block, q_block) in zip(self.blocks, self.attn_blocks, self.quantize_blocks):
# 对输入 x 应用块操作
x = block(x)
# 如果存在注意力块,则对输入 x 应用注意力块
if exists(attn_block):
x = attn_block(x)
# 如果存在量化块,则对输入 x 应用量化块,并计算损失
if exists(q_block):
x, loss = q_block(x)
quantize_loss += loss
# 对最终输出 x 应用最终卷积层
x = self.final_conv(x)
# 将输出 x 展平
x = self.flatten(x)
# 将展平后的输出 x 转换为 logit
x = self.to_logit(x)
# 压缩输出 x 的维度,去除大小为 1 的维度
return x.squeeze(), quantize_loss
class StyleGAN2(nn.Module):
# 定义 StyleGAN2 类,继承自 nn.Module
def __init__(self, image_size, latent_dim = 512, fmap_max = 512, style_depth = 8, network_capacity = 16, transparent = False, fp16 = False, cl_reg = False, steps = 1, lr = 1e-4, ttur_mult = 2, fq_layers = [], fq_dict_size = 256, attn_layers = [], no_const = False, lr_mlp = 0.1, rank = 0):
# 初始化函数,接受多个参数
super().__init__()
# 调用父类的初始化函数
self.lr = lr
self.steps = steps
# 设置学习率和训练步数
self.ema_updater = EMA(0.995)
# 创建指数移动平均对象
self.S = StyleVectorizer(latent_dim, style_depth, lr_mul = lr_mlp)
self.G = Generator(image_size, latent_dim, network_capacity, transparent = transparent, attn_layers = attn_layers, no_const = no_const, fmap_max = fmap_max)
self.D = Discriminator(image_size, network_capacity, fq_layers = fq_layers, fq_dict_size = fq_dict_size, attn_layers = attn_layers, transparent = transparent, fmap_max = fmap_max)
# 创建 StyleVectorizer、Generator 和 Discriminator 对象
self.SE = StyleVectorizer(latent_dim, style_depth, lr_mul = lr_mlp)
self.GE = Generator(image_size, latent_dim, network_capacity, transparent = transparent, attn_layers = attn_layers, no_const = no_const)
# 创建 StyleVectorizer 和 Generator 对象
self.D_cl = None
if cl_reg:
from contrastive_learner import ContrastiveLearner
# 导入 ContrastiveLearner 类
assert not transparent, 'contrastive loss regularization does not work with transparent images yet'
# 断言透明度为假
self.D_cl = ContrastiveLearner(self.D, image_size, hidden_layer='flatten')
# 创建 ContrastiveLearner 对象
self.D_aug = AugWrapper(self.D, image_size)
# 创建 AugWrapper 对象
set_requires_grad(self.SE, False)
set_requires_grad(self.GE, False)
# 设置 StyleVectorizer 和 Generator 的梯度计算为 False
generator_params = list(self.G.parameters()) + list(self.S.parameters())
self.G_opt = Adam(generator_params, lr = self.lr, betas=(0.5, 0.9))
self.D_opt = Adam(self.D.parameters(), lr = self.lr * ttur_mult, betas=(0.5, 0.9))
# 初始化生成器和判别器的优化器
self._init_weights()
self.reset_parameter_averaging()
# 初始化权重和参数平均
self.cuda(rank)
# 将模型移动到 GPU
if fp16:
(self.S, self.G, self.D, self.SE, self.GE), (self.G_opt, self.D_opt) = amp.initialize([self.S, self.G, self.D, self.SE, self.GE], [self.G_opt, self.D_opt], opt_level='O1', num_losses=3)
# 使用混合精度训练
def _init_weights(self):
# 初始化权重函数
for m in self.modules():
if type(m) in {nn.Conv2d, nn.Linear}:
nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
# 使用 kaiming_normal_ 初始化权重
for block in self.G.blocks:
nn.init.zeros_(block.to_noise1.weight)
nn.init.zeros_(block.to_noise2.weight)
nn.init.zeros_(block.to_noise1.bias)
nn.init.zeros_(block.to_noise2.bias)
# 初始化 Generator 中的权重
def EMA(self):
# 定义指数移动平均函数
def update_moving_average(ma_model, current_model):
for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
old_weight, up_weight = ma_params.data, current_params.data
ma_params.data = self.ema_updater.update_average(old_weight, up_weight)
# 更新指数移动平均参数
update_moving_average(self.SE, self.S)
update_moving_average(self.GE, self.G)
# 更新 StyleVectorizer 和 Generator 的指数移动平均参数
def reset_parameter_averaging(self):
# 重置参数平均函数
self.SE.load_state_dict(self.S.state_dict())
self.GE.load_state_dict(self.G.state_dict())
# 加载当前状态到指数移动平均模型
def forward(self, x):
# 前向传播函数
return x
# 返回输入
class Trainer():
# 定义 Trainer 类
# 初始化函数,设置各种参数和默认值
def __init__(
self,
name = 'default', # 模型名称,默认为'default'
results_dir = 'results', # 结果保存目录,默认为'results'
models_dir = 'models', # 模型保存目录,默认为'models'
base_dir = './', # 基础目录,默认为当前目录
image_size = 128, # 图像大小,默认为128
network_capacity = 16, # 网络容量,默认为16
fmap_max = 512, # 特征图最大值,默认为512
transparent = False, # 是否透明,默认为False
batch_size = 4, # 批量大小,默认为4
mixed_prob = 0.9, # 混合概率,默认为0.9
gradient_accumulate_every=1, # 梯度累积步数,默认为1
lr = 2e-4, # 学习率,默认为2e-4
lr_mlp = 0.1, # MLP学习率,默认为0.1
ttur_mult = 2, # TTUR倍数,默认为2
rel_disc_loss = False, # 相对鉴别器损失,默认为False
num_workers = None, # 工作进程数,默认为None
save_every = 1000, # 保存频率,默认为1000
evaluate_every = 1000, # 评估频率,默认为1000
num_image_tiles = 8, # 图像平铺数,默认为8
trunc_psi = 0.6, # 截断值,默认为0.6
fp16 = False, # 是否使用FP16,默认为False
cl_reg = False, # 是否使用对比损失正则化,默认为False
no_pl_reg = False, # 是否不使用PL正则化,默认为False
fq_layers = [], # FQ层列表,默认为空列表
fq_dict_size = 256, # FQ字典大小,默认为256
attn_layers = [], # 注意力层列表,默认为空列表
no_const = False, # 是否不使用常数,默认为False
aug_prob = 0., # 数据增强概率,默认为0
aug_types = ['translation', 'cutout'], # 数据增强类型,默认为['translation', 'cutout']
top_k_training = False, # 是否使用Top-K训练,默认为False
generator_top_k_gamma = 0.99, # 生成器Top-K Gamma值,默认为0.99
generator_top_k_frac = 0.5, # 生成器Top-K分数,默认为0.5
dual_contrast_loss = False, # 是否使用双对比损失,默认为False
dataset_aug_prob = 0., # 数据集增强概率,默认为0
calculate_fid_every = None, # 计算FID频率,默认为None
calculate_fid_num_images = 12800, # 计算FID图像数,默认为12800
clear_fid_cache = False, # 是否清除FID缓存,默认为False
is_ddp = False, # 是否使用DDP,默认为False
rank = 0, # 排名,默认为0
world_size = 1, # 世界大小,默认为1
log = False, # 是否记��日志,默认为False
*args, # 可变位置参数
**kwargs # 可变关键字参数
):
self.GAN_params = [args, kwargs] # GAN参数列表
self.GAN = None # GAN对象
self.name = name # 设置模型名称
base_dir = Path(base_dir) # 将基础目录转换为Path对象
self.base_dir = base_dir # 设置基础目录
self.results_dir = base_dir / results_dir # 设置结果保存目录
self.models_dir = base_dir / models_dir # 设置模型保存目录
self.fid_dir = base_dir / 'fid' / name # 设置FID目录
self.config_path = self.models_dir / name / '.config.json' # 设置配置文件路径
assert log2(image_size).is_integer(), 'image size must be a power of 2 (64, 128, 256, 512, 1024)' # 断言图像大小必须是2的幂次方
self.image_size = image_size # 设置图像大小
self.network_capacity = network_capacity # 设置网络容量
self.fmap_max = fmap_max # 设置特征图最大值
self.transparent = transparent # 设置是否透明
self.fq_layers = cast_list(fq_layers) # 将FQ层转换为列表
self.fq_dict_size = fq_dict_size # 设置FQ字典大小
self.has_fq = len(self.fq_layers) > 0 # 判断是否有FQ层
self.attn_layers = cast_list(attn_layers) # 将注意力层转换为列表
self.no_const = no_const # 设置是否不使用常数
self.aug_prob = aug_prob # 设置数据增强概率
self.aug_types = aug_types # 设置数据增强类型
self.lr = lr # 设置学习率
self.lr_mlp = lr_mlp # 设置MLP学习率
self.ttur_mult = ttur_mult # 设置TTUR倍数
self.rel_disc_loss = rel_disc_loss # 设置是否相对鉴别器损失
self.batch_size = batch_size # 设置批量大小
self.num_workers = num_workers # 设置工作进程数
self.mixed_prob = mixed_prob # 设置混合概率
self.num_image_tiles = num_image_tiles # 设置图像平铺数
self.evaluate_every = evaluate_every # 设置评估频率
self.save_every = save_every # 设置保存频率
self.steps = 0 # 步数初始化为0
self.av = None # 初始化av
self.trunc_psi = trunc_psi # 设置截断值
self.no_pl_reg = no_pl_reg # 设置是否不使用PL正则化
self.pl_mean = None # 初始化PL均值
self.gradient_accumulate_every = gradient_accumulate_every # 设置梯度累积步数
assert not fp16 or fp16 and APEX_AVAILABLE, 'Apex is not available for you to use mixed precision training' # 断言Apex是否可用
self.fp16 = fp16 # 设置是否使用FP16
self.cl_reg = cl_reg # 设置是否使用对比损失正则化
self.d_loss = 0 # 初始化鉴别器损失
self.g_loss = 0 # 初始化生成器损失
self.q_loss = None # 初始化Q损失
self.last_gp_loss = None # 初始化上一次梯度惩罚损失
self.last_cr_loss = None # 初始化上一次对比损失
self.last_fid = None # 初始化上一次FID
self.pl_length_ma = EMA(0.99) # 初始化PL长度移动平均
self.init_folders() # 初始化文件夹
self.loader = None # 初始化数据加载器
self.dataset_aug_prob = dataset_aug_prob # 设置数据集增强概率
self.calculate_fid_every = calculate_fid_every # 设置计算FID频率
self.calculate_fid_num_images = calculate_fid_num_images # 设置计算FID图像数
self.clear_fid_cache = clear_fid_cache # 设置是否清除FID缓存
self.top_k_training = top_k_training # 设置是否使用Top-K训练
self.generator_top_k_gamma = generator_top_k_gamma # 设置生成器Top-K Gamma值
self.generator_top_k_frac = generator_top_k_frac # 设置生成器Top-K分数
self.dual_contrast_loss = dual_contrast_loss # 设置是否使用双对比损失
assert not (is_ddp and cl_reg), 'Contrastive loss regularization does not work well with multi GPUs yet' # 断言对比损失正则化在多GPU上不起作用
self.is_ddp = is_ddp # 设置是否使用DDP
self.is_main = rank == 0 # 判断是否为主进程
self.rank = rank # 设置排名
self.world_size = world_size # 设置世界大小
self.logger = aim.Session(experiment=name) if log else None # 设置记录器
@property
# 返回图片的扩展名,如果是透明图片则返回png,否则返回jpg
def image_extension(self):
return 'jpg' if not self.transparent else 'png'
# 返回检查点编号,根据步数和保存频率计算得出
@property
def checkpoint_num(self):
return floor(self.steps // self.save_every)
# 返回超参数字典,包括图片大小和网络容量
@property
def hparams(self):
return {'image_size': self.image_size, 'network_capacity': self.network_capacity}
# 初始化生成对抗网络
def init_GAN(self):
args, kwargs = self.GAN_params
# 创建StyleGAN2对象
self.GAN = StyleGAN2(lr = self.lr, lr_mlp = self.lr_mlp, ttur_mult = self.ttur_mult, image_size = self.image_size, network_capacity = self.network_capacity, fmap_max = self.fmap_max, transparent = self.transparent, fq_layers = self.fq_layers, fq_dict_size = self.fq_dict_size, attn_layers = self.attn_layers, fp16 = self.fp16, cl_reg = self.cl_reg, no_const = self.no_const, rank = self.rank, *args, **kwargs)
# 如果是分布式训练,使用DDP包装GAN的各个部分
if self.is_ddp:
ddp_kwargs = {'device_ids': [self.rank]}
self.S_ddp = DDP(self.GAN.S, **ddp_kwargs)
self.G_ddp = DDP(self.GAN.G, **ddp_kwargs)
self.D_ddp = DDP(self.GAN.D, **ddp_kwargs)
self.D_aug_ddp = DDP(self.GAN.D_aug, **ddp_kwargs)
# 如果存在日志记录器,设置参数
if exists(self.logger):
self.logger.set_params(self.hparams)
# 写入配置信息到配置文件
def write_config(self):
self.config_path.write_text(json.dumps(self.config()))
# 从配置文件加载配置信息
def load_config(self):
config = self.config() if not self.config_path.exists() else json.loads(self.config_path.read_text())
# 更新配置信息
self.image_size = config['image_size']
self.network_capacity = config['network_capacity']
self.transparent = config['transparent']
self.fq_layers = config['fq_layers']
self.fq_dict_size = config['fq_dict_size']
self.fmap_max = config.pop('fmap_max', 512)
self.attn_layers = config.pop('attn_layers', [])
self.no_const = config.pop('no_const', False)
self.lr_mlp = config.pop('lr_mlp', 0.1)
del self.GAN
self.init_GAN()
# 返回配置信息字典
def config(self):
return {'image_size': self.image_size, 'network_capacity': self.network_capacity, 'lr_mlp': self.lr_mlp, 'transparent': self.transparent, 'fq_layers': self.fq_layers, 'fq_dict_size': self.fq_dict_size, 'attn_layers': self.attn_layers, 'no_const': self.no_const}
# 设置数据源
def set_data_src(self, folder):
# 创建数据集对象
self.dataset = Dataset(folder, self.image_size, transparent = self.transparent, aug_prob = self.dataset_aug_prob)
num_workers = num_workers = default(self.num_workers, NUM_CORES if not self.is_ddp else 0)
# 创建数据加载器
sampler = DistributedSampler(self.dataset, rank=self.rank, num_replicas=self.world_size, shuffle=True) if self.is_ddp else None
dataloader = data.DataLoader(self.dataset, num_workers = num_workers, batch_size = math.ceil(self.batch_size / self.world_size), sampler = sampler, shuffle = not self.is_ddp, drop_last = True, pin_memory = True)
self.loader = cycle(dataloader)
# 如果数据集较小,自动设置数据增强概率
num_samples = len(self.dataset)
if not exists(self.aug_prob) and num_samples < 1e5:
self.aug_prob = min(0.5, (1e5 - num_samples) * 3e-6)
print(f'autosetting augmentation probability to {round(self.aug_prob * 100)}%')
# 禁用梯度计算
@torch.no_grad()
# 定义一个评估函数,用于生成图像并计算 FID 分数
def evaluate(self, num = 0, trunc = 1.0):
# 将 GAN 设置为评估模式
self.GAN.eval()
# 获取图像文件扩展名和图像瓦片数量
ext = self.image_extension
num_rows = self.num_image_tiles
# 获取潜在空间维度、图像尺寸和层数
latent_dim = self.GAN.G.latent_dim
image_size = self.GAN.G.image_size
num_layers = self.GAN.G.num_layers
# 生成潜在向量和噪声
latents = noise_list(num_rows ** 2, num_layers, latent_dim, device=self.rank)
n = image_noise(num_rows ** 2, image_size, device=self.rank)
# 生成正常图像
generated_images = self.generate_truncated(self.GAN.S, self.GAN.G, latents, n, trunc_psi = self.trunc_psi)
torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}.{ext}'), nrow=num_rows)
# 生成移动平均图像
generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, n, trunc_psi = self.trunc_psi)
torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-ema.{ext}'), nrow=num_rows)
# 生成混合图像
def tile(a, dim, n_tile):
init_dim = a.size(dim)
repeat_idx = [1] * a.dim()
repeat_idx[dim] = n_tile
a = a.repeat(*(repeat_idx))
order_index = torch.LongTensor(np.concatenate([init_dim * np.arange(n_tile) + i for i in range(init_dim)])).cuda(self.rank)
return torch.index_select(a, dim, order_index)
nn = noise(num_rows, latent_dim, device=self.rank)
tmp1 = tile(nn, 0, num_rows)
tmp2 = nn.repeat(num_rows, 1)
tt = int(num_layers / 2)
mixed_latents = [(tmp1, tt), (tmp2, num_layers - tt)]
generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, mixed_latents, n, trunc_psi = self.trunc_psi)
torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-mr.{ext}'), nrow=num_rows)
# 计算 FID 分数
@torch.no_grad()
def calculate_fid(self, num_batches):
# 导入 FID 分数计算模块并清空 GPU 缓存
from pytorch_fid import fid_score
torch.cuda.empty_cache()
real_path = self.fid_dir / 'real'
fake_path = self.fid_dir / 'fake'
# 删除用于 FID 计算的现有文件并重新创建目录
if not real_path.exists() or self.clear_fid_cache:
rmtree(real_path, ignore_errors=True)
os.makedirs(real_path)
for batch_num in tqdm(range(num_batches), desc='calculating FID - saving reals'):
real_batch = next(self.loader)
for k, image in enumerate(real_batch.unbind(0)):
filename = str(k + batch_num * self.batch_size)
torchvision.utils.save_image(image, str(real_path / f'{filename}.png'))
# 生成一堆假图像在 results / name / fid_fake 目录下
rmtree(fake_path, ignore_errors=True)
os.makedirs(fake_path)
self.GAN.eval()
ext = self.image_extension
latent_dim = self.GAN.G.latent_dim
image_size = self.GAN.G.image_size
num_layers = self.GAN.G.num_layers
for batch_num in tqdm(range(num_batches), desc='calculating FID - saving generated'):
# 生成潜在向量和噪声
latents = noise_list(self.batch_size, num_layers, latent_dim, device=self.rank)
noise = image_noise(self.batch_size, image_size, device=self.rank)
# 生成移动平均图像
generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, noise, trunc_psi = self.trunc_psi)
for j, image in enumerate(generated_images.unbind(0)):
torchvision.utils.save_image(image, str(fake_path / f'{str(j + batch_num * self.batch_size)}-ema.{ext}'))
# 返回 FID 分数
return fid_score.calculate_fid_given_paths([str(real_path), str(fake_path)], 256, noise.device, 2048)
@torch.no_grad()
# 对输入的张量进行截断操作,将其限制在一定范围内
def truncate_style(self, tensor, trunc_psi = 0.75):
# 获取模型的尺寸、批量大小和潜在维度
S = self.GAN.S
batch_size = self.batch_size
latent_dim = self.GAN.G.latent_dim
# 如果平均向量不存在,则生成一个
if not exists(self.av):
z = noise(2000, latent_dim, device=self.rank)
samples = evaluate_in_chunks(batch_size, S, z).cpu().numpy()
self.av = np.mean(samples, axis = 0)
self.av = np.expand_dims(self.av, axis = 0)
# 将平均向量转换为 PyTorch 张量
av_torch = torch.from_numpy(self.av).cuda(self.rank)
# 对输入张量进行截断操作
tensor = trunc_psi * (tensor - av_torch) + av_torch
return tensor
# 对样式进行截断操作
@torch.no_grad()
def truncate_style_defs(self, w, trunc_psi = 0.75):
w_space = []
for tensor, num_layers in w:
tensor = self.truncate_style(tensor, trunc_psi = trunc_psi)
w_space.append((tensor, num_layers))
return w_space
# 生成经过截断的图像
@torch.no_grad()
def generate_truncated(self, S, G, style, noi, trunc_psi = 0.75, num_image_tiles = 8):
w = map(lambda t: (S(t[0]), t[1]), style)
w_truncated = self.truncate_style_defs(w, trunc_psi = trunc_psi)
w_styles = styles_def_to_tensor(w_truncated)
generated_images = evaluate_in_chunks(self.batch_size, G, w_styles, noi)
return generated_images.clamp_(0., 1.)
# 生成插值图像
@torch.no_grad()
def generate_interpolation(self, num = 0, num_image_tiles = 8, trunc = 1.0, num_steps = 100, save_frames = False):
self.GAN.eval()
ext = self.image_extension
num_rows = num_image_tiles
latent_dim = self.GAN.G.latent_dim
image_size = self.GAN.G.image_size
num_layers = self.GAN.G.num_layers
# 生成潜在向量和噪声
latents_low = noise(num_rows ** 2, latent_dim, device=self.rank)
latents_high = noise(num_rows ** 2, latent_dim, device=self.rank)
n = image_noise(num_rows ** 2, image_size, device=self.rank)
ratios = torch.linspace(0., 8., num_steps)
frames = []
for ratio in tqdm(ratios):
interp_latents = slerp(ratio, latents_low, latents_high)
latents = [(interp_latents, num_layers)]
generated_images = self.generate_truncated(self.GAN.SE, self.GAN.GE, latents, n, trunc_psi = self.trunc_psi)
images_grid = torchvision.utils.make_grid(generated_images, nrow = num_rows)
pil_image = transforms.ToPILImage()(images_grid.cpu())
# 如果需要透明背景,则进行处理
if self.transparent:
background = Image.new("RGBA", pil_image.size, (255, 255, 255))
pil_image = Image.alpha_composite(background, pil_image)
frames.append(pil_image)
# 保存生成的插值图像为 GIF
frames[0].save(str(self.results_dir / self.name / f'{str(num)}.gif'), save_all=True, append_images=frames[1:], duration=80, loop=0, optimize=True)
# 如果需要保存每一帧图像,则保存为单独的文件
if save_frames:
folder_path = (self.results_dir / self.name / f'{str(num)}')
folder_path.mkdir(parents=True, exist_ok=True)
for ind, frame in enumerate(frames):
frame.save(str(folder_path / f'{str(ind)}.{ext}')
# 打印日志信息
def print_log(self):
data = [
('G', self.g_loss),
('D', self.d_loss),
('GP', self.last_gp_loss),
('PL', self.pl_mean),
('CR', self.last_cr_loss),
('Q', self.q_loss),
('FID', self.last_fid)
]
data = [d for d in data if exists(d[1])]
log = ' | '.join(map(lambda n: f'{n[0]}: {n[1]:.2f}', data))
print(log)
# 记录日志信息
def track(self, value, name):
if not exists(self.logger):
return
self.logger.track(value, name = name)
# 返回模型文件名
def model_name(self, num):
return str(self.models_dir / self.name / f'model_{num}.pt')
# 初始化文件夹
def init_folders(self):
(self.results_dir / self.name).mkdir(parents=True, exist_ok=True)
(self.models_dir / self.name).mkdir(parents=True, exist_ok=True)
# 清空模型、结果和文件夹目录
def clear(self):
# 删除模型目录下的所有文件和文件夹
rmtree(str(self.models_dir / self.name), True)
# 删除结果目录下的所有文件和文件夹
rmtree(str(self.results_dir / self.name), True)
# 删除 FID 目录下的所有文件和文件夹
rmtree(str(self.fid_dir), True)
# 删除配置文件路径
rmtree(str(self.config_path), True)
# 初始化文件夹
self.init_folders()
# 保存模型
def save(self, num):
# 保存模型的数据和版本号
save_data = {
'GAN': self.GAN.state_dict(),
'version': __version__
}
# 如果模型使用了混合精度训练,保存混合精度训练的状态
if self.GAN.fp16:
save_data['amp'] = amp.state_dict()
# 将保存的数据保存到模型文件中
torch.save(save_data, self.model_name(num))
# 写入配置文件
self.write_config()
# 加载模型
def load(self, num = -1):
# 加载配置文件
self.load_config()
# 如果未指定加载的模型编号,则查找最新的模型文件
name = num
if num == -1:
# 获取模型目录下所有以'model_'开头的文件路径
file_paths = [p for p in Path(self.models_dir / self.name).glob('model_*.pt')]
# 提取文件名中的数字部分并排序
saved_nums = sorted(map(lambda x: int(x.stem.split('_')[1]), file_paths))
# 如果没有保存的模型文件,则直接返回
if len(saved_nums) == 0:
return
# 获取最新的模型编号
name = saved_nums[-1]
print(f'continuing from previous epoch - {name}')
# 计算当前步数
self.steps = name * self.save_every
# 加载模型数据
load_data = torch.load(self.model_name(name))
# 打印加载的模型版本号
if 'version' in load_data:
print(f"loading from version {load_data['version']}")
# 尝试加载 GAN 模型的状态字典
try:
self.GAN.load_state_dict(load_data['GAN'])
except Exception as e:
# 加载失败时提示用户尝试降级软件包版本
print('unable to load save model. please try downgrading the package to the version specified by the saved model')
raise e
# 如果使用了混合精度训练且保存了混合精度训练的状态,则加��
if self.GAN.fp16 and 'amp' in load_data:
amp.load_state_dict(load_data['amp'])
# 定义一个模型加载器类
class ModelLoader:
# 初始化方法,接收基本目录、名称和加载位置参数
def __init__(self, *, base_dir, name = 'default', load_from = -1):
# 创建一个Trainer对象作为模型属性
self.model = Trainer(name = name, base_dir = base_dir)
# 加载模型
self.model.load(load_from)
# 将噪声转换为样式向量的方法
def noise_to_styles(self, noise, trunc_psi = None):
# 将噪声数据移到GPU上
noise = noise.cuda()
# 通过SE模块将噪声转换为样式向量
w = self.model.GAN.SE(noise)
# 如果截断参数存在,则对样式向量进行截断
if exists(trunc_psi):
w = self.model.truncate_style(w)
return w
# 将样式向量转换为图像的方法
def styles_to_images(self, w):
# 获取样式向量的形状信息
batch_size, *_ = w.shape
# 获取生成器的层数和图像大小
num_layers = self.model.GAN.GE.num_layers
image_size = self.model.image_size
# 构建样式向量定义列表
w_def = [(w, num_layers)]
# 将样式向量定义列表转换为张量
w_tensors = styles_def_to_tensor(w_def)
# 生成图像所需的噪声数据
noise = image_noise(batch_size, image_size, device = 0)
# 通过GE模块生成图像
images = self.model.GAN.GE(w_tensors, noise)
# 将图像像素值限制在0到1之间
images.clamp_(0., 1.)
return images
.\lucidrains\stylegan2-pytorch\stylegan2_pytorch\version.py
# 定义变量 __version__,赋值为字符串 '1.8.9'
__version__ = '1.8.9'
.\lucidrains\stylegan2-pytorch\stylegan2_pytorch\__init__.py
# 从 stylegan2_pytorch.stylegan2_pytorch 模块中导入 Trainer, StyleGAN2, NanException, ModelLoader 类
from stylegan2_pytorch.stylegan2_pytorch import Trainer, StyleGAN2, NanException, ModelLoader

Tab Transformer
Implementation of Tab Transformer, attention network for tabular data, in Pytorch. This simple architecture came within a hair's breadth of GBDT's performance.
Update: Amazon AI claims to have beaten GBDT with Attention on a real-world tabular dataset (predicting shipping cost).
Install
$ pip install tab-transformer-pytorch
Usage
import torch
import torch.nn as nn
from tab_transformer_pytorch import TabTransformer
cont_mean_std = torch.randn(10, 2)
model = TabTransformer(
categories = (10, 5, 6, 5, 8), # tuple containing the number of unique values within each category
num_continuous = 10, # number of continuous values
dim = 32, # dimension, paper set at 32
dim_out = 1, # binary prediction, but could be anything
depth = 6, # depth, paper recommended 6
heads = 8, # heads, paper recommends 8
attn_dropout = 0.1, # post-attention dropout
ff_dropout = 0.1, # feed forward dropout
mlp_hidden_mults = (4, 2), # relative multiples of each hidden dimension of the last mlp to logits
mlp_act = nn.ReLU(), # activation for final mlp, defaults to relu, but could be anything else (selu etc)
continuous_mean_std = cont_mean_std # (optional) - normalize the continuous values before layer norm
)
x_categ = torch.randint(0, 5, (1, 5)) # category values, from 0 - max number of categories, in the order as passed into the constructor above
x_cont = torch.randn(1, 10) # assume continuous values are already normalized individually
pred = model(x_categ, x_cont) # (1, 1)
FT Transformer

This paper from Yandex improves on Tab Transformer by using a simpler scheme for embedding the continuous numerical values as shown in the diagram above, courtesy of this reddit post.
Included in this repository just for convenient comparison to Tab Transformer
import torch
from tab_transformer_pytorch import FTTransformer
model = FTTransformer(
categories = (10, 5, 6, 5, 8), # tuple containing the number of unique values within each category
num_continuous = 10, # number of continuous values
dim = 32, # dimension, paper set at 32
dim_out = 1, # binary prediction, but could be anything
depth = 6, # depth, paper recommended 6
heads = 8, # heads, paper recommends 8
attn_dropout = 0.1, # post-attention dropout
ff_dropout = 0.1 # feed forward dropout
)
x_categ = torch.randint(0, 5, (1, 5)) # category values, from 0 - max number of categories, in the order as passed into the constructor above
x_numer = torch.randn(1, 10) # numerical value
pred = model(x_categ, x_numer) # (1, 1)
Unsupervised Training
To undergo the type of unsupervised training described in the paper, you can first convert your categories tokens to the appropriate unique ids, and then use Electra on model.transformer.
Todo
Citations
@misc{huang2020tabtransformer,
title = {TabTransformer: Tabular Data Modeling Using Contextual Embeddings},
author = {Xin Huang and Ashish Khetan and Milan Cvitkovic and Zohar Karnin},
year = {2020},
eprint = {2012.06678},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@article{Gorishniy2021RevisitingDL,
title = {Revisiting Deep Learning Models for Tabular Data},
author = {Yu. V. Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
journal = {ArXiv},
year = {2021},
volume = {abs/2106.11959}
}
.\lucidrains\tab-transformer-pytorch\setup.py
# 导入设置安装和查找包的函数
from setuptools import setup, find_packages
# 设置包的元数据
setup(
# 包的名称
name = 'tab-transformer-pytorch',
# 查找并包含所有包
packages = find_packages(),
# 版本号
version = '0.3.0',
# 许可证
license='MIT',
# 描述
description = 'Tab Transformer - Pytorch',
# 长描述内容类型
long_description_content_type = 'text/markdown',
# 作者
author = 'Phil Wang',
# 作者邮箱
author_email = 'lucidrains@gmail.com',
# 项目链接
url = 'https://github.com/lucidrains/tab-transformer-pytorch',
# 关键词
keywords = [
'artificial intelligence',
'transformers',
'attention mechanism',
'tabular data'
],
# 安装依赖
install_requires=[
'einops>=0.3',
'torch>=1.6'
],
# 分类
classifiers=[
'Development Status :: 4 - Beta',
'Intended Audience :: Developers',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
'License :: OSI Approved :: MIT License',
'Programming Language :: Python :: 3.6',
],
)
.\lucidrains\tab-transformer-pytorch\tab_transformer_pytorch\ft_transformer.py
# 导入 torch 库
import torch
# 导入 torch 中的函数库
import torch.nn.functional as F
# 从 torch 中导入 nn 和 einsum 模块
from torch import nn, einsum
# 从 einops 中导入 rearrange 和 repeat 函数
from einops import rearrange, repeat
# feedforward and attention
# 定义 GEGLU 类,继承自 nn.Module
class GEGLU(nn.Module):
# 前向传播函数
def forward(self, x):
# 将输入 x 按照最后一个维度分成两部分
x, gates = x.chunk(2, dim = -1)
# 返回 x 乘以 gates 经过 gelu 激活函数的结果
return x * F.gelu(gates)
# 定义 FeedForward 函数,接受维度 dim、倍数 mult 和 dropout 参数
def FeedForward(dim, mult = 4, dropout = 0.):
# 返回一个序列模块
return nn.Sequential(
# LayerNorm 层
nn.LayerNorm(dim),
# 线性变换层,输入维度为 dim,输出维度为 dim * mult * 2
nn.Linear(dim, dim * mult * 2),
# GEGLU 层
GEGLU(),
# Dropout 层
nn.Dropout(dropout),
# 线性变换层,输入维度为 dim * mult,输出维度为 dim
nn.Linear(dim * mult, dim)
)
# 定义 Attention 类,继承自 nn.Module
class Attention(nn.Module):
# 初始化函数,接受维度 dim、头数 heads、头维度 dim_head 和 dropout 参数
def __init__(
self,
dim,
heads = 8,
dim_head = 64,
dropout = 0.
):
super().__init__()
# 计算内部维度
inner_dim = dim_head * heads
# 头数和头维度的缩放系数
self.heads = heads
self.scale = dim_head ** -0.5
# LayerNorm 层
self.norm = nn.LayerNorm(dim)
# 线性变换层,输入维度为 dim,输出维度为 inner_dim * 3
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
# 线性变换层,输入维度为 inner_dim,输出维度为 dim
self.to_out = nn.Linear(inner_dim, dim, bias = False)
# Dropout 层
self.dropout = nn.Dropout(dropout)
# 前向传播函数
def forward(self, x):
# 头数
h = self.heads
# 对输入 x 进行 LayerNorm
x = self.norm(x)
# 将输入 x 经过线性变换得到 q、k、v
q, k, v = self.to_qkv(x).chunk(3, dim = -1)
# 对 q、k、v 进行维度重排
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), (q, k, v))
# 对 q 进行缩放
q = q * self.scale
# 计算注意力矩阵
sim = einsum('b h i d, b h j d -> b h i j', q, k)
# 对注意力矩阵进行 softmax
attn = sim.softmax(dim = -1)
# 对 softmax 结果进行 dropout
dropped_attn = self.dropout(attn)
# 计算输出
out = einsum('b h i j, b h j d -> b h i d', dropped_attn, v)
out = rearrange(out, 'b h n d -> b n (h d)', h = h)
out = self.to_out(out)
return out, attn
# transformer
# 定义 Transformer 类,继承自 nn.Module
class Transformer(nn.Module):
# 初始化函数,接受维度 dim、深度 depth、头数 heads、头维度 dim_head、注意力 dropout 和前馈 dropout 参数
def __init__(
self,
dim,
depth,
heads,
dim_head,
attn_dropout,
ff_dropout
):
super().__init__()
# 初始化层列表
self.layers = nn.ModuleList([])
# 循环创建 depth 个层
for _ in range(depth):
self.layers.append(nn.ModuleList([
# 注意力层
Attention(dim, heads = heads, dim_head = dim_head, dropout = attn_dropout),
# 前馈层
FeedForward(dim, dropout = ff_dropout),
]))
# 前向传播函数
def forward(self, x, return_attn = False):
# 存储后 softmax 的注意力矩阵
post_softmax_attns = []
# 遍历每个层
for attn, ff in self.layers:
# 获取注意力层的输出和后 softmax 的注意力矩阵
attn_out, post_softmax_attn = attn(x)
post_softmax_attns.append(post_softmax_attn)
# 更新 x
x = attn_out + x
x = ff(x) + x
# 如果不返回注意力矩阵,则返回 x
if not return_attn:
return x
# 返回 x 和后 softmax 的注意力矩阵
return x, torch.stack(post_softmax_attns)
# numerical embedder
# 定义 NumericalEmbedder 类,继承自 nn.Module
class NumericalEmbedder(nn.Module):
# 初始化函数,接受维度 dim 和数值类型数量 num_numerical_types
def __init__(self, dim, num_numerical_types):
super().__init__()
# 定义权重参数和偏置参数
self.weights = nn.Parameter(torch.randn(num_numerical_types, dim))
self.biases = nn.Parameter(torch.randn(num_numerical_types, dim))
# 前向传播函数
def forward(self, x):
# 将输入 x 维度重排
x = rearrange(x, 'b n -> b n 1')
# 返回加权和偏置后的结果
return x * self.weights + self.biases
# main class
# 定义 FTTransformer 类,继承自 nn.Module
class FTTransformer(nn.Module):
# 初始化函数,接受关键字参数 categories、num_continuous、dim、depth、heads、头维度 dim_head、输出维度 dim_out、特殊标记数量 num_special_tokens、注意力 dropout 和前馈 dropout
def __init__(
self,
*,
categories,
num_continuous,
dim,
depth,
heads,
dim_head = 16,
dim_out = 1,
num_special_tokens = 2,
attn_dropout = 0.,
ff_dropout = 0.
):
# 调用父类的构造函数
super().__init__()
# 断言所有类别的数量必须大于0
assert all(map(lambda n: n > 0, categories)), 'number of each category must be positive'
# 断言类别数量加上连续值的数量不能为0
assert len(categories) + num_continuous > 0, 'input shape must not be null'
# categories related calculations
# 计算类别相关的参数
self.num_categories = len(categories)
self.num_unique_categories = sum(categories)
# create category embeddings table
# 创建类别嵌入表
self.num_special_tokens = num_special_tokens
total_tokens = self.num_unique_categories + num_special_tokens
# for automatically offsetting unique category ids to the correct position in the categories embedding table
# 用于自动将唯一类别ID偏移至类别嵌入表中的正确位置
if self.num_unique_categories > 0:
categories_offset = F.pad(torch.tensor(list(categories)), (1, 0), value = num_special_tokens)
categories_offset = categories_offset.cumsum(dim = -1)[:-1]
self.register_buffer('categories_offset', categories_offset)
# categorical embedding
# 类别嵌入
self.categorical_embeds = nn.Embedding(total_tokens, dim)
# continuous
# 连续值
self.num_continuous = num_continuous
if self.num_continuous > 0:
self.numerical_embedder = NumericalEmbedder(dim, self.num_continuous)
# cls token
# 类别标记
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# transformer
# 变换器
self.transformer = Transformer(
dim = dim,
depth = depth,
heads = heads,
dim_head = dim_head,
attn_dropout = attn_dropout,
ff_dropout = ff_dropout
)
# to logits
# 转换为logits
self.to_logits = nn.Sequential(
nn.LayerNorm(dim),
nn.ReLU(),
nn.Linear(dim, dim_out)
)
def forward(self, x_categ, x_numer, return_attn = False):
assert x_categ.shape[-1] == self.num_categories, f'you must pass in {self.num_categories} values for your categories input'
xs = []
if self.num_unique_categories > 0:
x_categ = x_categ + self.categories_offset
x_categ = self.categorical_embeds(x_categ)
xs.append(x_categ)
# add numerically embedded tokens
if self.num_continuous > 0:
x_numer = self.numerical_embedder(x_numer)
xs.append(x_numer)
# concat categorical and numerical
# 连接类别和连续值
x = torch.cat(xs, dim = 1)
# append cls tokens
b = x.shape[0]
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim = 1)
# attend
# 注意力机制
x, attns = self.transformer(x, return_attn = True)
# get cls token
# 获取类别标记
x = x[:, 0]
# out in the paper is linear(relu(ln(cls)))
# 论文中的输出是线性(ReLU(LN(cls)))
logits = self.to_logits(x)
if not return_attn:
return logits
return logits, attns
.\lucidrains\tab-transformer-pytorch\tab_transformer_pytorch\tab_transformer_pytorch.py
# 导入 PyTorch 库
import torch
import torch.nn.functional as F
from torch import nn, einsum
# 导入 einops 库中的 rearrange 和 repeat 函数
from einops import rearrange, repeat
# 辅助函数
# 判断值是否存在
def exists(val):
return val is not None
# 返回默认值
def default(val, d):
return val if exists(val) else d
# 类定义
# 残差连接模块
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
# 预层归一化模块
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
# 注意力机制
# GEGLU 激活函数
class GEGLU(nn.Module):
def forward(self, x):
x, gates = x.chunk(2, dim = -1)
return x * F.gelu(gates)
# 前馈神经网络模块
class FeedForward(nn.Module):
def __init__(self, dim, mult = 4, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, dim * mult * 2),
GEGLU(),
nn.Dropout(dropout),
nn.Linear(dim * mult, dim)
)
def forward(self, x, **kwargs):
return self.net(x)
# 注意力机制模块
class Attention(nn.Module):
def __init__(
self,
dim,
heads = 8,
dim_head = 16,
dropout = 0.
):
super().__init__()
inner_dim = dim_head * heads
self.heads = heads
self.scale = dim_head ** -0.5
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Linear(inner_dim, dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
h = self.heads
q, k, v = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), (q, k, v))
sim = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = sim.softmax(dim = -1)
dropped_attn = self.dropout(attn)
out = einsum('b h i j, b h j d -> b h i d', dropped_attn, v)
out = rearrange(out, 'b h n d -> b n (h d)', h = h)
return self.to_out(out), attn
# Transformer 模块
class Transformer(nn.Module):
def __init__(
self,
dim,
depth,
heads,
dim_head,
attn_dropout,
ff_dropout
):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = attn_dropout)),
PreNorm(dim, FeedForward(dim, dropout = ff_dropout)),
]))
def forward(self, x, return_attn = False):
post_softmax_attns = []
for attn, ff in self.layers:
attn_out, post_softmax_attn = attn(x)
post_softmax_attns.append(post_softmax_attn)
x = x + attn_out
x = ff(x) + x
if not return_attn:
return x
return x, torch.stack(post_softmax_attns)
# 多层感知机模块
class MLP(nn.Module):
def __init__(self, dims, act = None):
super().__init__()
dims_pairs = list(zip(dims[:-1], dims[1:]))
layers = []
for ind, (dim_in, dim_out) in enumerate(dims_pairs):
is_last = ind >= (len(dims_pairs) - 1)
linear = nn.Linear(dim_in, dim_out)
layers.append(linear)
if is_last:
continue
act = default(act, nn.ReLU())
layers.append(act)
self.mlp = nn.Sequential(*layers)
def forward(self, x):
return self.mlp(x)
# 主类 TabTransformer
class TabTransformer(nn.Module):
# 初始化函数,设置模型的各种参数
def __init__(
self,
*,
categories, # 类别特征的数量列表
num_continuous, # 连续特征的数量
dim, # 模型的维度
depth, # Transformer 模型的深度
heads, # Transformer 模型的头数
dim_head = 16, # 每个头的维度
dim_out = 1, # 输出的维度
mlp_hidden_mults = (4, 2), # MLP 隐藏层的倍数
mlp_act = None, # MLP 的激活函数
num_special_tokens = 2, # 特殊标记的数量
continuous_mean_std = None, # 连续特征的均值和标准差
attn_dropout = 0., # 注意力机制的 dropout
ff_dropout = 0., # FeedForward 层的 dropout
use_shared_categ_embed = True, # 是否使用共享的类别嵌入
shared_categ_dim_divisor = 8 # 在论文中,他们将维度的 1/8 保留给共享的类别嵌入
):
super().__init__()
# 断言确保每个类别的数量大于 0
assert all(map(lambda n: n > 0, categories)), 'number of each category must be positive'
# 断言确保类别数量和连续特征数量之和大于 0
assert len(categories) + num_continuous > 0, 'input shape must not be null'
# 与类别相关的计算
self.num_categories = len(categories) # 类别的数量
self.num_unique_categories = sum(categories) # 所有类别的总数
# 创建类别嵌入表
self.num_special_tokens = num_special_tokens
total_tokens = self.num_unique_categories + num_special_tokens
shared_embed_dim = 0 if not use_shared_categ_embed else int(dim // shared_categ_dim_divisor)
self.category_embed = nn.Embedding(total_tokens, dim - shared_embed_dim)
# 处理共享的类别嵌入
self.use_shared_categ_embed = use_shared_categ_embed
if use_shared_categ_embed:
self.shared_category_embed = nn.Parameter(torch.zeros(self.num_categories, shared_embed_dim))
nn.init.normal_(self.shared_category_embed, std = 0.02)
# 用于自动偏移唯一类别 id 到类别嵌入表中的正确位置
if self.num_unique_categories > 0:
categories_offset = F.pad(torch.tensor(list(categories)), (1, 0), value = num_special_tokens)
categories_offset = categories_offset.cumsum(dim = -1)[:-1]
self.register_buffer('categories_offset', categories_offset)
# 连续特征
self.num_continuous = num_continuous
if self.num_continuous > 0:
if exists(continuous_mean_std):
assert continuous_mean_std.shape == (num_continuous, 2), f'continuous_mean_std must have a shape of ({num_continuous}, 2) where the last dimension contains the mean and variance respectively'
self.register_buffer('continuous_mean_std', continuous_mean_std)
self.norm = nn.LayerNorm(num_continuous)
# Transformer 模型
self.transformer = Transformer(
dim = dim,
depth = depth,
heads = heads,
dim_head = dim_head,
attn_dropout = attn_dropout,
ff_dropout = ff_dropout
)
# MLP 转换为 logits
input_size = (dim * self.num_categories) + num_continuous
hidden_dimensions = [input_size * t for t in mlp_hidden_mults]
all_dimensions = [input_size, *hidden_dimensions, dim_out]
self.mlp = MLP(all_dimensions, act = mlp_act)
# 定义一个前向传播函数,接受类别特征和连续特征作为输入,可选择返回注意力权重
def forward(self, x_categ, x_cont, return_attn = False):
# 初始化一个空列表用于存储不同类型特征的输出
xs = []
# 检查类别特征的最后一个维度是否与预期的类别数量相同
assert x_categ.shape[-1] == self.num_categories, f'you must pass in {self.num_categories} values for your categories input'
# 如果存在唯一的类别数量大于0
if self.num_unique_categories > 0:
# 对类别特征进行偏移处理
x_categ = x_categ + self.categories_offset
# 对类别特征进行嵌入处理
categ_embed = self.category_embed(x_categ)
# 如果使用共享的类别嵌入
if self.use_shared_categ_embed:
# 复制共享的类别嵌入并与类别嵌入拼接
shared_categ_embed = repeat(self.shared_category_embed, 'n d -> b n d', b = categ_embed.shape[0])
categ_embed = torch.cat((categ_embed, shared_categ_embed), dim = -1)
# 使用 Transformer 处理类别嵌入特征,可选择返回注意力权重
x, attns = self.transformer(categ_embed, return_attn = True)
# 将处理后的类别特征展平
flat_categ = rearrange(x, 'b ... -> b (...)')
xs.append(flat_categ)
# 检查连续特征的第二个维度是否与预期的连续特征数量相同
assert x_cont.shape[1] == self.num_continuous, f'you must pass in {self.num_continuous} values for your continuous input'
# 如果连续特征数量大于0
if self.num_continuous > 0:
# 如果存在连续特征的均值和标准差
if exists(self.continuous_mean_std):
# 分离连续特征的均值和标准差
mean, std = self.continuous_mean_std.unbind(dim = -1)
# 对连续特征进行标准化处理
x_cont = (x_cont - mean) / std
# 对标准化后的连续特征进行归一化处理
normed_cont = self.norm(x_cont)
xs.append(normed_cont)
# 将处理后的类别特征和连续特征拼接在一起
x = torch.cat(xs, dim = -1)
# 使用 MLP 处理拼接后的特征,得到输出 logits
logits = self.mlp(x)
# 如果不需要返回注意力权重,则直接返回 logits
if not return_attn:
return logits
# 如果需要返回注意力权重,则同时返回 logits 和注意力权重
return logits, attns
.\lucidrains\tab-transformer-pytorch\tab_transformer_pytorch\__init__.py
# 从 tab_transformer_pytorch 库中导入 TabTransformer 类
from tab_transformer_pytorch.tab_transformer_pytorch import TabTransformer
# 从 tab_transformer_pytorch 库中导入 FTTransformer 类
from tab_transformer_pytorch.ft_transformer import FTTransformer

Tableformer - Pytorch (wip)
Implementation of TableFormer, Robust Transformer Modeling for Table-Text Encoding, in Pytorch. The claim of this paper is that through attentional biases, they can make transformers more robust to perturbations to the table in question. They show improved results compared to TAPAS
Citations
@article{Yang2022TableFormerRT,
title = {TableFormer: Robust Transformer Modeling for Table-Text Encoding},
author = {Jingfeng Yang and Aditya Gupta and Shyam Upadhyay and Luheng He and Rahul Goel and Shachi Paul},
journal = {ArXiv},
year = {2022},
volume = {abs/2203.00274}
}

Taylor Series Linear Attention
Explorations into the Taylor Series Linear Attention proposed in the paper Zoology: Measuring and Improving Recall in Efficient Language Models
This repository will offer full self attention, cross attention, and autoregressive via CUDA kernel from pytorch-fast-transformers.
Be aware that in linear attention, the quadratic is pushed to the attention head dimension. With the second taylor expansion, this becomes O(D^3), so more research needed.
Update: It works! Strongest formulation of linear attention I've come across in the literature
Appreciation
- A16Z Open Source AI Grant Program and 🤗 Huggingface for the generous sponsorships, as well as my other sponsors, for affording me the independence to open source current artificial intelligence research
Install
$ pip install taylor-series-linear-attention
Usage
import torch
from taylor_series_linear_attention import TaylorSeriesLinearAttn
attn = TaylorSeriesLinearAttn(
dim = 512,
dim_head = 16,
heads = 16
)
x = torch.randn(1, 4096, 512)
mask = torch.ones((1, 4096)).bool()
out = attn(x, mask = mask)
assert x.shape == out.shape
Cross attention
import torch
from taylor_series_linear_attention import TaylorSeriesLinearAttn
attn = TaylorSeriesLinearAttn(
dim = 512,
dim_head = 16,
heads = 16
)
x = torch.randn(1, 1024, 512)
context = torch.randn(1, 65536, 512)
context_mask = torch.ones((1, 65536)).bool()
out = attn(x, context = context, mask = context_mask)
assert x.shape == out.shape
For autoregressive, first pip install pytorch-fast-transformers. Then set causal = True
import torch
from taylor_series_linear_attention import TaylorSeriesLinearAttn
attn = TaylorSeriesLinearAttn(
dim = 512,
dim_head = 16,
heads = 16,
causal = True, # set this to True
rotary_emb = True # rotary embeddings
)
x = torch.randn(1, 8192, 512)
out = attn(x)
assert x.shape == out.shape
Todo
Citations
@inproceedings{Arora2023ZoologyMA,
title = {Zoology: Measuring and Improving Recall in Efficient Language Models},
author = {Simran Arora and Sabri Eyuboglu and Aman Timalsina and Isys Johnson and Michael Poli and James Zou and Atri Rudra and Christopher R'e},
year = {2023},
url = {https://api.semanticscholar.org/CorpusID:266149332}
}
@inproceedings{Keles2022OnTC,
title = {On The Computational Complexity of Self-Attention},
author = {Feyza Duman Keles and Pruthuvi Maheshakya Wijewardena and Chinmay Hegde},
booktitle = {International Conference on Algorithmic Learning Theory},
year = {2022},
url = {https://api.semanticscholar.org/CorpusID:252198880}
}
@article{Shazeer2019FastTD,
title = {Fast Transformer Decoding: One Write-Head is All You Need},
author = {Noam M. Shazeer},
journal = {ArXiv},
year = {2019},
volume = {abs/1911.02150}
}
@inproceedings{Peng2023RWKVRR,
title = {RWKV: Reinventing RNNs for the Transformer Era},
author = {Bo Peng and Eric Alcaide and Quentin G. Anthony and Alon Albalak and Samuel Arcadinho and Stella Biderman and Huanqi Cao and Xin Cheng and Michael Chung and Matteo Grella and G Kranthikiran and Xuming He and Haowen Hou and Przemyslaw Kazienko and Jan Kocoń and Jiaming Kong and Bartlomiej Koptyra and Hayden Lau and Krishna Sri Ipsit Mantri and Ferdinand Mom and Atsushi Saito and Xiangru Tang and Bolun Wang and Johan Sokrates Wind and Stansilaw Wozniak and Ruichong Zhang and Zhenyuan Zhang and Qihang Zhao and Peng Zhou and Jian Zhu and Rui Zhu},
booktitle = {Conference on Empirical Methods in Natural Language Processing},
year = {2023},
url = {https://api.semanticscholar.org/CorpusID:258832459}
}
@inproceedings{Katharopoulos2020TransformersAR,
title = {Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention},
author = {Angelos Katharopoulos and Apoorv Vyas and Nikolaos Pappas and Franccois Fleuret},
booktitle = {International Conference on Machine Learning},
year = {2020},
url = {https://api.semanticscholar.org/CorpusID:220250819}
}
The greatest shortcoming of the human race is man’s inability to understand the exponential function. - Albert A. Bartlett
.\lucidrains\taylor-series-linear-attention\setup.py
# 导入设置和查找包的函数
from setuptools import setup, find_packages
# 设置包的元数据
setup(
name = 'taylor-series-linear-attention', # 包的名称
packages = find_packages(exclude=[]), # 查找所有包
version = '0.1.9', # 版本号
license='MIT', # 许可证
description = 'Taylor Series Linear Attention', # 描述
author = 'Phil Wang', # 作者
author_email = 'lucidrains@gmail.com', # 作者邮箱
long_description_content_type = 'text/markdown', # 长描述内容类型
url = 'https://github.com/lucidrains/taylor-series-linear-attention', # 项目链接
keywords = [
'artificial intelligence', # 关键词
'deep learning', # 关键词
'attention mechanism' # 关键词
],
install_requires=[
'einops>=0.7.0', # 安装所需的依赖包
'einx', # 安装所需的依赖包
'rotary-embedding-torch>=0.5.3', # 安装所需的依赖包
'torch>=2.0', # 安装所需的依赖包
'torchtyping' # 安装所需的依赖包
],
classifiers=[
'Development Status :: 4 - Beta', # 分类器
'Intended Audience :: Developers', # 分类器
'Topic :: Scientific/Engineering :: Artificial Intelligence', # 分类器
'License :: OSI Approved :: MIT License', # 分类器
'Programming Language :: Python :: 3.6', # 分类器
],
)
.\lucidrains\taylor-series-linear-attention\taylor_series_linear_attention\attention.py
# 导入必要的库
import importlib
from functools import partial
from collections import namedtuple
import torch
import torch.nn.functional as F
from torch.nn import Module, ModuleList
from torch import nn, einsum, Tensor
from einops import rearrange, pack, unpack
from einops.layers.torch import Rearrange
from typing import Optional
from torchtyping import TensorType
from rotary_embedding_torch import RotaryEmbedding
# 定义常量
# 命名元组,用于存储缓存信息
Cache = namedtuple('Cache', [
'seq_len',
'last_token',
'kv_cumsum',
'k_cumsum'
])
# 定义函数
# 判断变量是否存在
def exists(v):
return v is not None
# 如果变量存在则返回该变量,否则返回默认值
def default(v, d):
return v if exists(v) else d
# 对张量进行循环移位操作
def shift(t):
t, t_shift = t.chunk(2, dim = -1)
t_shift = F.pad(t_shift, (0, 0, 1, -1), value = 0.)
return torch.cat((t, t_shift), dim = -1)
# 预标准化
# RMS 标准化模块
class RMSNorm(Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** 0.5
self.gamma = nn.Parameter(torch.ones(dim))
def forward(self, x):
return self.gamma * F.normalize(x, dim = -1) * self.scale
# 使用二阶泰勒展开计算指数函数
def second_taylor_expansion(x: Tensor):
dtype, device, dim = x.dtype, x.device, x.shape[-1]
x, ps = pack([x], '* d')
lead_dims = x.shape[0]
# exp(qk) = 1 + qk + (qk)^2 / 2
x0 = x.new_ones((lead_dims,))
x1 = x
x2 = einsum('... i, ... j -> ... i j', x, x) * (0.5 ** 0.5)
# 连接 - 维度 D 现在变成 (1 + D + D ^2)
# 在论文中,他们必须大幅减少注意力头维度才能使其工作
out, _ = pack([x0, x1, x2], 'b *')
out, = unpack(out, ps, '* d')
return out
# 主类
# 泰勒级数线性注意力模块
class TaylorSeriesLinearAttn(Module):
def __init__(
self,
dim,
*,
dim_head = 16,
heads = 8,
causal = False,
one_headed_kv = False,
rotary_emb = False,
combine_heads = True,
gate_value_heads = False,
prenorm = False,
shift_tokens = False,
dropout = 0.
):
super().__init__()
self.scale = dim_head ** -0.5
dim_inner = dim_head * heads
self.shift_tokens = shift_tokens
self.norm = RMSNorm(dim) if prenorm else nn.Identity()
self.heads = heads
self.dim_hidden = dim_inner
self.causal = causal
self.causal_linear_attn_fn = None
if causal:
if not exists(importlib.util.find_spec('fast_transformers')):
print('pytorch-fast-transformers must be installed. `pip install pytorch-fast-transformers` first')
exit()
from fast_transformers.causal_product import CausalDotProduct
self.causal_linear_attn_fn = CausalDotProduct.apply
kv_heads = heads if not one_headed_kv else 1
dim_kv_inner = dim_head * (heads if not one_headed_kv else 1)
self.rotary_emb = RotaryEmbedding(dim_head) if rotary_emb else None
self.one_headed_kv = one_headed_kv
# 查询投影层
self.to_q = nn.Sequential(
nn.Linear(dim, dim_inner, bias = False),
Rearrange('b n (h d) -> b h n d', h = heads)
)
# 键值投影层
self.to_kv = nn.Sequential(
nn.Linear(dim, dim_kv_inner * 2, bias = False),
Rearrange('b n (kv h d) -> kv b h n d', kv = 2, h = kv_heads)
)
# 值门控层
self.to_v_gates = nn.Sequential(
nn.Linear(dim, heads, bias = False),
nn.Sigmoid(),
Rearrange('b n h -> b h n 1')
) if gate_value_heads else None
# 合并注意力头
self.merge_heads = Rearrange('b h n d -> b n (h d)')
self.to_out = nn.Identity()
if combine_heads:
# 输出层
self.to_out = nn.Sequential(
nn.Linear(dim_inner, dim, bias = False),
nn.Dropout(dropout)
)
# 定义一个方法用于前向传播
def forward(
# 输入参数 x,类型为张量,形状为 ['batch', 'seq', 'dim'],数据类型为 float
x: TensorType['batch', 'seq', 'dim', float],
# 可选参数 mask,类型为张量,形状为 ['batch', 'seq'],数据类型为 bool,默认为 None
mask: Optional[TensorType['batch', 'seq', bool]] = None,
# 可选参数 context,类型为张量,形状为 ['batch', 'target_seq', 'dim'],数据类型为 float,默认为 None
context: Optional[TensorType['batch', 'target_seq', 'dim', float]] = None,
# 参数 eps,数据类型为 float,默认值为 1e-5
eps: float = 1e-5,
# 可选参数 cache,类型为 Cache 对象,默认为 None
cache: Optional[Cache] = None,
# 参数 return_cache,数据类型为 bool,默认值为 False
return_cache = False
# 适用于图像和视频的通道优先的Taylor Series线性注意力机制模块
class ChannelFirstTaylorSeriesLinearAttn(Module):
def __init__(
self,
*args,
**kwargs
):
super().__init__()
# 初始化Taylor Series线性注意力机制
self.attn = TaylorSeriesLinearAttn(*args, **kwargs)
def forward(
self,
x: Tensor
):
# 将输入张量重新排列为'通道优先'的形式
x = rearrange(x, 'b c ... -> b ... c')
# 打包输入张量,将通道维度视为单个维度
x, ps = pack([x], 'b * c')
# 使用Taylor Series线性注意力机制处理输入张量
out = self.attn(x)
# 解包处理后的张量,恢复原始形状
out, = unpack(out, ps, 'b * c')
# 将输出张量重新排列为原始形状
return rearrange(out, 'b ... c -> b c ...')
.\lucidrains\taylor-series-linear-attention\taylor_series_linear_attention\vit.py
# 从 math 模块中导入 sqrt 函数
from math import sqrt
# 导入 torch 库
import torch
from torch import nn, einsum
from torch.nn import Module, ModuleList
import torch.nn.functional as F
# 导入 einops 库中的 rearrange 和 repeat 函数
from einops import rearrange, repeat
from einops.layers.torch import Rearrange, Reduce
# 导入自定义的注意力模块
from taylor_series_linear_attention.attention import (
TaylorSeriesLinearAttn,
ChannelFirstTaylorSeriesLinearAttn
)
# 定义函数 posemb_sincos_2d,用于生成二维的正弦余弦位置编码
def posemb_sincos_2d(
h, w,
dim,
temperature: int = 10000,
dtype = torch.float32
):
# 生成网格坐标
y, x = torch.meshgrid(torch.arange(h), torch.arange(w), indexing = "ij")
# 确保特征维度是4的倍数
assert (dim % 4) == 0, "feature dimension must be multiple of 4 for sincos emb"
dim //= 4
omega = torch.arange(dim) / (dim - 1)
omega = temperature ** -omega
y = y.flatten()[:, None] * omega[None, :]
x = x.flatten()[:, None] * omega[None, :]
pe = torch.cat((x.sin(), x.cos(), y.sin(), y.cos()), dim = 1)
return pe.type(dtype)
# 定义深度可分离卷积函数 DepthWiseConv2d
def DepthWiseConv2d(
dim_in,
dim_out,
kernel_size,
padding,
stride = 1,
bias = True
):
return nn.Sequential(
nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
)
# 定义前馈神经网络类 FeedForward
class FeedForward(Module):
def __init__(
self,
dim,
mult = 4,
dropout = 0.
):
super().__init__()
dim_hidden = int(dim * mult)
self.net = nn.Sequential(
nn.Conv2d(dim, dim_hidden, 1),
nn.Hardswish(),
DepthWiseConv2d(dim_hidden, dim_hidden, 3, padding = 1),
nn.Hardswish(),
nn.Dropout(dropout),
nn.Conv2d(dim_hidden, dim, 1),
nn.Dropout(dropout)
)
def forward(self, x):
h = w = int(sqrt(x.shape[-2]))
x = rearrange(x, 'b (h w) c -> b c h w', h = h, w = w)
x = self.net(x)
x = rearrange(x, 'b c h w -> b (h w) c')
return x
# 定义 Transformer 类
class Transformer(Module):
def __init__(
self,
dim,
depth,
heads,
dim_head,
ff_mult,
dropout = 0.
):
super().__init__()
self.layers = ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
nn.LayerNorm(dim),
TaylorSeriesLinearAttn(dim, heads = heads, dim_head = dim_head, dropout = dropout),
nn.LayerNorm(dim),
FeedForward(dim, ff_mult, dropout = dropout)
]))
def forward(self, x):
for attn_norm, attn, ff_norm, ff in self.layers:
x = attn(attn_norm(x)) + x
x = ff(ff_norm(x)) + x
return x
# 定义主类 ViT
class ViT(Module):
def __init__(
self,
*,
image_size,
patch_size,
num_classes,
dim,
depth,
ff_mult = 4,
heads = 16,
channels = 3,
dim_head = 8,
dropout = 0.,
emb_dropout = 0.
): # 定义一个类,继承自 nn.Module
super().__init__() # 调用父类的构造函数
assert image_size % patch_size == 0, 'image dimensions must be divisible by the patch size.' # 断言图片尺寸必须能够被分块尺寸整除
num_patches = (image_size // patch_size) ** 2 # 计算总的分块数量
patch_dim = channels * patch_size ** 2 # 计算每个分块的维度
self.to_patch_embedding = nn.Sequential( # 定义一个序列模块,用于将图像转换为分块嵌入
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size), # 重新排列输入张量的维度
nn.LayerNorm(patch_dim), # 对每个分块进行 LayerNorm
nn.Linear(patch_dim, dim), # 线性变换将每个分块的维度映射到指定维度
nn.LayerNorm(dim), # 对映射后的维度进行 LayerNorm
)
self.register_buffer('pos_embedding', posemb_sincos_2d( # 注册一个缓冲区,存储位置编码
h = image_size // patch_size, # 图像高度上的分块数量
w = image_size // patch_size, # 图像宽度上的分块数量
dim = dim, # 位置编码的维度
), persistent = False) # 设置缓冲区为非持久性的
self.dropout = nn.Dropout(emb_dropout) # 定义一个 Dropout 层,用于在嵌入层上进行随机失活
self.transformer = Transformer(dim, depth, heads, dim_head, ff_mult, dropout) # 定义一个 Transformer 模型
self.mlp_head = nn.Sequential( # 定义一个序列模块,用于最终的 MLP 头部分类
Reduce('b n d -> b d', 'mean'), # 对输入张量进行维度缩减,计算均值
nn.LayerNorm(dim), # 对均值后的张量进行 LayerNorm
nn.Linear(dim, num_classes) # 线性变换将维度映射到类别数量
)
def forward(self, img): # 定义前向传播函数,接收输入图像
x = self.to_patch_embedding(img) # 将输入图像转换为分块嵌入
x = x + self.pos_embedding # 添加位置编码到嵌入中
x = self.dropout(x) # 对嵌入进行随机失活
x = self.transformer(x) # 使用 Transformer 模型进行特征提取和交互
return self.mlp_head(x) # 使用 MLP 头部对特征进行分类
.\lucidrains\taylor-series-linear-attention\taylor_series_linear_attention\__init__.py
# 从taylor_series_linear_attention.attention模块中导入TaylorSeriesLinearAttn和ChannelFirstTaylorSeriesLinearAttn类
from taylor_series_linear_attention.attention import (
TaylorSeriesLinearAttn,
ChannelFirstTaylorSeriesLinearAttn
)
# 从taylor_series_linear_attention.vit模块中导入ViT类
from taylor_series_linear_attention.vit import ViT
.\lucidrains\tf-bind-transformer\finetune_binary_pred.py
# 导入 load_dotenv 函数,用于加载 .env 文件中的环境变量
from dotenv import load_dotenv
# 设置缓存路径在 .env 文件中,并取消下一行的注释
# load_dotenv()
# 导入 Enformer 类
from enformer_pytorch import Enformer
# 导入 AdapterModel、Trainer 类
from tf_bind_transformer import AdapterModel, Trainer
# 实例化 Enformer 对象或加载预训练模型
enformer = Enformer.from_hparams(
dim = 768,
depth = 4,
heads = 8,
target_length = -1,
use_convnext = True,
num_downsamples = 6 # 分辨率为 2 ^ 6 == 64bp
)
# 实例化模型包装器,接受 Enformer 对象作为输入
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True,
use_free_text_context = True,
free_text_embed_method = 'mean_pool',
binary_target = True,
target_mse_loss = False,
use_squeeze_excite = True,
aa_embed_encoder = 'protalbert'
).cuda()
# 训练常量
BATCH_SIZE = 2
GRAD_ACCUM_STEPS = 8
# 有效批量大小为 BATCH_SIZE * GRAD_ACCUM_STEPS = 16
VALIDATE_EVERY = 250
GRAD_CLIP_MAX_NORM = 1.5
REMAP_FILE_PATH = './remap2022_all.bed'
TFACTOR_FOLDER = './tfactor.fastas'
FASTA_FILE_PATH = './hg38.ml.fa'
NON_PEAK_PATH = './generated-non-peaks.bed'
CONTEXT_LENGTH = 4096
SCOPED_NEGS_REMAP_PATH = './neg-npy/remap2022.bed'
SCOPED_NEGS_PATH = './neg-npy'
TRAIN_CHROMOSOMES = [*range(1, 24, 2), 'X'] # 在奇数染色体上训练
VALID_CHROMOSOMES = [*range(2, 24, 2)] # 在偶数染色体上验证
HELD_OUT_TARGET = ['AFF4']
# 实例化 Trainer 类用于微调
trainer = Trainer(
model,
context_length = CONTEXT_LENGTH,
batch_size = BATCH_SIZE,
validate_every = VALIDATE_EVERY,
grad_clip_norm = GRAD_CLIP_MAX_NORM,
grad_accum_every = GRAD_ACCUM_STEPS,
remap_bed_file = REMAP_FILE_PATH,
negative_bed_file = NON_PEAK_PATH,
factor_fasta_folder = TFACTOR_FOLDER,
fasta_file = FASTA_FILE_PATH,
train_chromosome_ids = TRAIN_CHROMOSOMES,
valid_chromosome_ids = VALID_CHROMOSOMES,
held_out_targets = HELD_OUT_TARGET,
include_scoped_negs = True,
scoped_negs_remap_bed_path = SCOPED_NEGS_REMAP_PATH,
scoped_negs_path = SCOPED_NEGS_PATH,
)
# 在 while 循环中执行梯度步骤
while True:
_ = trainer(finetune_enformer_ln_only = False)
.\lucidrains\tf-bind-transformer\finetune_track.py
# 导入 load_dotenv 函数,用于加载 .env 文件中的环境变量
from dotenv import load_dotenv
# 设置缓存路径在 .env 文件中,并取消下一行的注释
# load_dotenv()
# 导入 Enformer 类和 AdapterModel、BigWigTrainer 类
from enformer_pytorch import Enformer
from tf_bind_transformer import AdapterModel, BigWigTrainer
# 训练常量
# 批量大小
BATCH_SIZE = 1
# 梯度累积步数
GRAD_ACCUM_STEPS = 8
# 学习率
LEARNING_RATE = 1e-4 # Deepmind 在 Enformer 微调中使用了 1e-4
# 有效批量大小为 BATCH_SIZE * GRAD_ACCUM_STEPS = 16
# 每隔多少步进行验证
VALIDATE_EVERY = 250
# 梯度裁剪最大范数
GRAD_CLIP_MAX_NORM = 1.5
# TFactor 文件夹路径
TFACTOR_FOLDER = './tfactor.fastas'
# 人类基因组 FASTA 文件路径
HUMAN_FASTA_FILE_PATH = './hg38.ml.fa'
# 小鼠基因组 FASTA 文件路径
MOUSE_FASTA_FILE_PATH = './mm10.ml.fa'
# 人类基因组区域路径
HUMAN_LOCI_PATH = './chip_atlas/human_sequences.bed'
# 小鼠基因组区域路径
MOUSE_LOCI_PATH = './chip_atlas/mouse_sequences.bed'
# BigWig 文件夹路径
BIGWIG_PATH = './chip_atlas/bigwig'
# 仅包含 BigWig 轨道的文件夹路径
BIGWIG_TRACKS_ONLY_PATH = './chip_atlas/bigwig_tracks_only'
# 注释文件路径
ANNOT_FILE_PATH = './chip_atlas/annot.tab'
# 目标长度
TARGET_LENGTH = 896
# 保留的目标
HELD_OUT_TARGET = ['GATA2']
# 实例化 Enformer 或加载预训练模型
enformer = Enformer.from_pretrained('EleutherAI/enformer-official-rough', target_length = TARGET_LENGTH)
# 实例化模型包装器,接受 Enformer 模型
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True,
use_free_text_context = True,
free_text_embed_method = 'mean_pool',
aa_embed_encoder = 'esm',
finetune_output_heads = dict(
human = 12,
mouse = 24
)
).cuda()
# 用于微调的训练器类
trainer = BigWigTrainer(
model,
human_loci_path = HUMAN_LOCI_PATH,
mouse_loci_path = MOUSE_LOCI_PATH,
human_fasta_file = HUMAN_FASTA_FILE_PATH,
mouse_fasta_file = MOUSE_FASTA_FILE_PATH,
bigwig_folder_path = BIGWIG_PATH,
bigwig_tracks_only_folder_path = BIGWIG_TRACKS_ONLY_PATH,
annot_file_path = ANNOT_FILE_PATH,
target_length = TARGET_LENGTH,
lr = LEARNING_RATE,
batch_size = BATCH_SIZE,
shuffle = True,
validate_every = VALIDATE_EVERY,
grad_clip_norm = GRAD_CLIP_MAX_NORM,
grad_accum_every = GRAD_ACCUM_STEPS,
human_factor_fasta_folder = TFACTOR_FOLDER,
mouse_factor_fasta_folder = TFACTOR_FOLDER,
held_out_targets = HELD_OUT_TARGET
)
# 在 while 循环中执行梯度步骤
while True:
_ = trainer()
.\lucidrains\tf-bind-transformer\precache_proteins.py
# 导入需要的库
import click # 用于创建命令行接口
from tqdm import tqdm # 用于显示进度条
from pathlib import Path # 用于处理文件路径
from Bio import SeqIO # 用于处理生物信息学数据
from tf_bind_transformer.protein_utils import get_protein_embedder # 从自定义模块中导入函数
# 创建命令行接口
@click.command()
@click.option('--model-name', default = 'protalbert', help = 'Protein model name') # 添加命令行参数,指定蛋白质模型名称
@click.option('--fasta-folder', help = 'Path to factor fastas', required = True) # 添加命令行参数,指定FASTA文件夹路径
def cache_embeddings(
model_name, # 指定蛋白质模型名称
fasta_folder # 指定FASTA文件夹路径
):
# 获取指定蛋白质模型的函数
fn = get_protein_embedder(model_name)['fn']
# 获取FASTA文件夹下所有的FASTA文件路径
fastas = [*Path(fasta_folder).glob('**/*.fasta')]
# 断言确保至少找到一个FASTA文件
assert len(fastas) > 0, f'no fasta files found at {fasta_folder}'
# 遍历所有FASTA文件并处理
for fasta in tqdm(fastas):
# 读取FASTA文件中的序列数据
seq = SeqIO.read(fasta, 'fasta')
# 将序列数据转换为字符串
seq_str = str(seq.seq)
# 使用指定的函数处理序列数据
fn([seq_str], device = 'cpu')
# 如果作为脚本直接运行,则调用cache_embeddings函数
if __name__ == '__main__':
cache_embeddings()
Transcription Factor binding predictions with Attention and Transformers
A repository with exploration into using transformers to predict DNA ↔ transcription factor binding.
Install
Run the following at the project root to download dependencies
$ python setup.py install --user
Then you must install pybedtools as well as pyBigWig
$ conda install --channel conda-forge --channel bioconda pybedtools pyBigWig
Usage
import torch
from tf_bind_transformer import AdapterModel
# instantiate enformer or load pretrained
from enformer_pytorch import Enformer
enformer = Enformer.from_hparams(
dim = 1536,
depth = 2,
target_length = 256
)
# instantiate model wrapper that takes in enformer
model = AdapterModel(
enformer = enformer,
aa_embed_dim = 512,
contextual_embed_dim = 256
).cuda()
# mock data
seq = torch.randint(0, 4, (1, 196_608 // 2)).cuda() # for ACGT
aa_embed = torch.randn(1, 1024, 512).cuda()
aa_mask = torch.ones(1, 1024).bool().cuda()
contextual_embed = torch.randn(1, 256).cuda() # contextual embeddings, including cell type, species, experimental parameter embeddings
target = torch.randn(1, 256).cuda()
# train
loss = model(
seq,
aa_embed = aa_embed,
aa_mask = aa_mask,
contextual_embed = contextual_embed,
target = target
)
loss.backward()
# after a lot of training
corr_coef = model(
seq,
aa_embed = aa_embed,
aa_mask = aa_mask,
contextual_embed = contextual_embed,
target = target,
return_corr_coef = True
)
Using ESM or ProtAlbert for fetching of transcription factor protein embeddings
import torch
from enformer_pytorch import Enformer
from tf_bind_transformer import AdapterModel
enformer = Enformer.from_hparams(
dim = 1536,
depth = 2,
target_length = 256
)
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True, # set this to True
aa_embed_encoder = 'esm', # by default, will use esm, but can be set to 'protalbert', which has a longer context length of 2048 (vs esm's 1024)
contextual_embed_dim = 256
).cuda()
# mock data
seq = torch.randint(0, 4, (1, 196_608 // 2)).cuda()
tf_aa = torch.randint(0, 21, (1, 4)).cuda() # transcription factor amino acid sequence, from 0 to 20
contextual_embed = torch.randn(1, 256).cuda()
target = torch.randn(1, 256).cuda()
# train
loss = model(
seq,
aa = tf_aa,
contextual_embed = contextual_embed,
target = target
)
loss.backward()
Context passed in as free text
One can also pass the context (cell type, experimental parameters) directly as free text, which will be encoded by a text transformer trained on pubmed abstracts.
import torch
from tf_bind_transformer import AdapterModel
# instantiate enformer or load pretrained
from enformer_pytorch import Enformer
enformer = Enformer.from_hparams(
dim = 1536,
depth = 2,
target_length = 256
)
# instantiate model wrapper that takes in enformer
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True,
use_free_text_context = True, # this must be set to True
free_text_embed_method = 'mean_pool' # allow for mean pooling of embeddings, instead of using CLS token
).cuda()
# mock data
seq = torch.randint(0, 4, (2, 196_608 // 2)).cuda() # for ACGT
target = torch.randn(2, 256).cuda()
tf_aa = [
'KVFGRCELAA', # single protein
('AMKRHGLDNY', 'YNDLGHRKMA') # complex, representations will be concatted together
]
contextual_texts = [
'cell type: GM12878 | dual cross-linked',
'cell type: H1-hESC'
]
# train
loss = model(
seq,
target = target,
aa = tf_aa,
contextual_free_text = contextual_texts,
)
loss.backward()
Binary prediction
For predicting binary outcome (bind or not bind), just set the binary_targets = True when initializing either adapters
ex.
import torch
from tf_bind_transformer import AdapterModel
from enformer_pytorch import Enformer
# instantiate enformer or load pretrained
enformer = Enformer.from_hparams(
dim = 1536,
depth = 2,
target_length = 256
)
# instantiate model wrapper that takes in enformer
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True,
use_free_text_context = True,
free_text_embed_method = 'mean_pool',
use_squeeze_excite = True,
binary_target = True, # set this to True
target_mse_loss = False # whether to use MSE loss with target value
).cuda()
# mock data
seq = torch.randint(0, 4, (1, 196_608 // 2)).cuda() # for ACGT
binary_target = torch.randint(0, 2, (2,)).cuda() # bind or not bind
tf_aa = [
'KVFGRCELAA',
('AMKRHGLDNY', 'YNDLGHRKMA')
]
contextual_texts = [
'cell type: GM12878 | chip-seq dual cross-linked',
'cell type: H1-hESC | chip-seq single cross-linked'
]
# train
loss = model(
seq,
target = binary_target,
aa = tf_aa,
contextual_free_text = contextual_texts,
)
loss.backward()
Predicting Tracks from BigWig
from pathlib import Path
import torch
from enformer_pytorch import Enformer
from tf_bind_transformer import AdapterModel
from tf_bind_transformer.data_bigwig import BigWigDataset, get_bigwig_dataloader
# constants
ROOT = Path('.')
TFACTOR_TF = str(ROOT / 'tfactor.fastas')
ENFORMER_DATA = str(ROOT / 'chip_atlas' / 'sequences.bed')
FASTA_FILE_PATH = str(ROOT / 'hg38.ml.fa')
BIGWIG_PATH = str(ROOT / 'chip_atlas')
ANNOT_FILE_PATH = str(ROOT / 'chip_atlas' / 'annot.tab')
# bigwig dataset and dataloader
ds = BigWigDataset(
factor_fasta_folder = TFACTOR_TF,
bigwig_folder = BIGWIG_PATH,
enformer_loci_path = ENFORMER_DATA,
annot_file = ANNOT_FILE_PATH,
fasta_file = FASTA_FILE_PATH
)
dl = get_bigwig_dataloader(ds, batch_size = 2)
# enformer
enformer = Enformer.from_hparams(
dim = 384,
depth = 1,
target_length = 896
)
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True,
use_free_text_context = True
).cuda()
# mock data
seq, tf_aa, context_str, target = next(dl)
seq, target = seq.cuda(), target.cuda()
# train
loss = model(
seq,
aa = tf_aa,
contextual_free_text = context_str,
target = target
)
loss.backward()
Data
The data needed for training is at this download page.
Transcription factors for Human and Mouse
To download the protein sequences for both species, you need to download the remap CRMs bed files, from which all the targets will be extracted, and fastas to be downloaded from Uniprot.
Download human remap CRMS
$ wget https://remap.univ-amu.fr/storage/remap2022/hg38/MACS2/remap2022_crm_macs2_hg38_v1_0.bed.gz
$ gzip -d remap2022_crm_macs2_hg38_v1_0.bed.gz
Download mouse remap CRMs
$ wget https://remap.univ-amu.fr/storage/remap2022/mm10/MACS2/remap2022_crm_macs2_mm10_v1_0.bed.gz
$ gzip -d remap2022_crm_macs2_mm10_v1_0.bed.gz
Downloading all human transcription factors
$ python script/fetch_factor_fastas.py --species human
For mouse transcription factors
$ python script/fetch_factor_fastas.py --species mouse
Generating Negatives
Generating Hard Negatives
For starters, the RemapAllPeakDataset will allow you to load data easily from the full remap peaks bed file for training.
Firstly you'll need to generate the non-peaks dataset by running the following function
from tf_bind_transformer.data import generate_random_ranges_from_fasta
generate_random_ranges_from_fasta(
'./hg38.ml.fa',
output_filename = './path/to/generated-non-peaks.bed', # path to output file
context_length = 4096,
num_entries_per_key = 1_000_000, # number of negative samples
filter_bed_files = [
'./remap_all.bed', # filter out by all peak ranges (todo, allow filtering namespaced to experiment and target)
'./hg38.blacklist.rep.bed' # further filtering by blacklisted regions (gs://basenji_barnyard/hg38.blacklist.rep.bed)
]
)
Generating Scoped Negatives - Negatives per Dataset (experiment + target + cell type)
Todo
Simple Trainer class for fine-tuning
working fine-tuning training loop for bind / no-bind prediction
import torch
from enformer_pytorch import Enformer
from tf_bind_transformer import AdapterModel, Trainer
# instantiate enformer or load pretrained
enformer = Enformer.from_pretrained('EleutherAI/enformer-official-rough', target_length = -1)
# instantiate model wrapper that takes in enformer
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True,
use_free_text_context = True,
free_text_embed_method = 'mean_pool',
binary_target = True,
target_mse_loss = True,
use_squeeze_excite = True,
aux_read_value_loss = True # use auxiliary read value loss, can be turned off
).cuda()
# pass the model (adapter + enformer) to the Trainer
trainer = Trainer(
model,
batch_size = 2, # batch size
context_length = 4096, # genetic sequence length
grad_accum_every = 8, # gradient accumulation steps
grad_clip_norm = 2.0, # gradient clipping
validate_every = 250,
remap_bed_file = './remap2022_all.bed', # path to remap bed peaks
negative_bed_file = './generated-non-peaks.bed', # path to generated non-peaks
factor_fasta_folder = './tfactor.fastas', # path to factor fasta files
fasta_file = './hg38.ml.fa', # human genome sequences
train_chromosome_ids = [*range(1, 24, 2), 'X'], # chromosomes to train on
valid_chromosome_ids = [*range(2, 24, 2)], # chromosomes to validate on
held_out_targets = ['AFF4'], # targets to hold out for validation
experiments_json_path = './data/experiments.json' # path to all experiments data, at this path relative to the project root, if repository is git cloned
)
while True:
_ = trainer()
working fine-tuning script for training on new enformer tracks, with cross-attending transcription factor protein embeddings and cell type conditioning
from dotenv import load_dotenv
# set path to cache in .env and unset the next comment
# load_dotenv()
from enformer_pytorch import Enformer
from tf_bind_transformer import AdapterModel, BigWigTrainer
# training constants
BATCH_SIZE = 1
GRAD_ACCUM_STEPS = 8
# effective batch size of BATCH_SIZE * GRAD_ACCUM_STEPS = 16
VALIDATE_EVERY = 250
GRAD_CLIP_MAX_NORM = 1.5
TFACTOR_FOLDER = './tfactor.fastas'
FASTA_FILE_PATH = './hg38.ml.fa'
LOCI_PATH = './sequences.bed'
BIGWIG_PATH = './bigwig_folder'
ANNOT_FILE_PATH = './experiments.tab'
TARGET_LENGTH = 896
TRAIN_CHROMOSOMES = [*range(1, 24, 2), 'X'] # train on odd chromosomes
VALID_CHROMOSOMES = [*range(2, 24, 2)] # validate on even
HELD_OUT_TARGET = ['SOX2']
# instantiate enformer or load pretrained
enformer = Enformer.from_pretrained('EleutherAI/enformer-official-rough', target_length = TARGET_LENGTH)
# instantiate model wrapper that takes in enformer
model = AdapterModel(
enformer = enformer,
use_aa_embeds = True,
use_free_text_context = True,
free_text_embed_method = 'mean_pool',
aa_embed_encoder = 'protalbert'
).cuda()
# trainer class for fine-tuning
trainer = BigWigTrainer(
model,
loci_path = LOCI_PATH,
bigwig_folder_path = BIGWIG_PATH,
annot_file_path = ANNOT_FILE_PATH,
target_length = TARGET_LENGTH,
batch_size = BATCH_SIZE,
validate_every = VALIDATE_EVERY,
grad_clip_norm = GRAD_CLIP_MAX_NORM,
grad_accum_every = GRAD_ACCUM_STEPS,
factor_fasta_folder = TFACTOR_FOLDER,
fasta_file = FASTA_FILE_PATH,
train_chromosome_ids = TRAIN_CHROMOSOMES,
valid_chromosome_ids = VALID_CHROMOSOMES,
held_out_targets = HELD_OUT_TARGET
)
# do gradient steps in a while loop
while True:
_ = trainer()
Resources
If you are low on GPU memory, you can save by making sure the protein and contextual embeddings are executed on CPU
CONTEXT_EMBED_USE_CPU=1 PROTEIN_EMBED_USE_CPU=1 python train.py
Data
Transcription factor dataset
from tf_bind_transformer.data import FactorProteinDataset
ds = FactorProteinDataset(
folder = 'path/to/tfactor/fastas'
)
# single factor
ds['ETV1'] # <seq>
# multi-complexes
ds['PAX3-FOXO1'] # (<seq1>, <seq2>)
Preprocessing (wip)
get a copy of hg38 blacklist bed file from calico
$ gsutil cp gs://basenji_barnyard/hg38.blacklist.rep.bed ./
using bedtools to filter out repetitive regions of the genome
$ bedtools intersect -v -a ./remap2022_all_macs2_hg38_v1_0.bed -b ./hg38.blacklist.rep.bed > remap2022_all_filtered.bed
Caching
During training, protein sequences and contextual strings are cached to ~/.cache.tf.bind.transformer directory. If you would like to make sure the caching is working, you just need to run your training script with VERBOSE=1
ex.
$ VERBOSE=1 python train.py
You can also force a cache clearance
$ CLEAR_CACHE=1 python train.py
Todo
Appreciation
This work was generously sponsored by Jeff Hsu to be done completely open sourced.
Citations
@article {Avsec2021.04.07.438649,
author = {Avsec, {\v Z}iga and Agarwal, Vikram and Visentin, Daniel and Ledsam, Joseph R. and Grabska-Barwinska, Agnieszka and Taylor, Kyle R. and Assael, Yannis and Jumper, John and Kohli, Pushmeet and Kelley, David R.},
title = {Effective gene expression prediction from sequence by integrating long-range interactions},
elocation-id = {2021.04.07.438649},
year = {2021},
doi = {10.1101/2021.04.07.438649},
publisher = {Cold Spring Harbor Laboratory},
URL = {https://www.biorxiv.org/content/early/2021/04/08/2021.04.07.438649},
eprint = {https://www.biorxiv.org/content/early/2021/04/08/2021.04.07.438649.full.pdf},
journal = {bioRxiv}
}
@misc{yao2021filip,
title = {FILIP: Fine-grained Interactive Language-Image Pre-Training},
author = {Lewei Yao and Runhui Huang and Lu Hou and Guansong Lu and Minzhe Niu and Hang Xu and Xiaodan Liang and Zhenguo Li and Xin Jiang and Chunjing Xu},
year = {2021},
eprint = {2111.07783},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{tay2020hypergrid,
title = {HyperGrid: Efficient Multi-Task Transformers with Grid-wise Decomposable Hyper Projections},
author = {Yi Tay and Zhe Zhao and Dara Bahri and Donald Metzler and Da-Cheng Juan},
year = {2020},
eprint = {2007.05891},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
@misc{lowe2021logavgexp,
title = {LogAvgExp Provides a Principled and Performant Global Pooling Operator},
author = {Scott C. Lowe and Thomas Trappenberg and Sageev Oore},
year = {2021},
eprint = {2111.01742},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@article{10.1093/nar/gkab996,
author = {Hammal, Fayrouz and de Langen, Pierre and Bergon, Aurélie and Lopez, Fabrice and Ballester, Benoit},
title = "{ReMap 2022: a database of Human, Mouse, Drosophila and Arabidopsis regulatory regions from an integrative analysis of DNA-binding sequencing experiments}",
journal = {Nucleic Acids Research},
issn = {0305-1048},
doi = {10.1093/nar/gkab996},
url = {https://doi.org/10.1093/nar/gkab996},
eprint = {https://academic.oup.com/nar/article-pdf/50/D1/D316/42058627/gkab996.pdf},
}
.\lucidrains\tf-bind-transformer\scripts\download_experiments.py
# 导入所需的模块
import json
import tqdm
import requests
# 定义 NCBI_TAX_ID 字典,包含人类和小鼠的分类号
NCBI_TAX_ID = dict(
human = 9606,
mouse = 10090
)
# 设置 SPECIES 变量为 'human'
SPECIES = 'human'
# 设置 API_URL 变量为 API 的基本 URL
API_URL = 'https://remap.univ-amu.fr/api/v1/'
# 定义函数 get_json,用于获取 JSON 数据
def get_json(url, params = dict()):
# 设置请求头
headers = dict(Accept = 'application/json')
# 发起 GET 请求
resp = requests.get(url, params = params, headers = headers)
# 返回 JSON 数据
return resp.json()
# 定义函数 get_experiments,用于获取实验数据
def get_experiments(species):
# 检查物种是否在 NCBI_TAX_ID 中
assert species in NCBI_TAX_ID
# 获取对应物种的分类号
taxid = NCBI_TAX_ID[species]
# 获取实验数据
experiments = get_json(f'{API_URL}list/experiments/taxid={taxid}')
return experiments
# 定义函数 get_experiment,用于获取特定实验的详细信息
def get_experiment(experiment_id, species):
# 检查物种是否在 NCBI_TAX_ID 中
assert species in NCBI_TAX_ID
# 获取对应物种的分类号
taxid = NCBI_TAX_ID[species]
# 获取特定实验的详细信息
experiment = get_json(f'http://remap.univ-amu.fr/api/v1/info/byExperiment/experiment={experiment_id}&taxid={taxid}')
return experiment
# 获取指定物种的实验数据
experiments = get_experiments(SPECIES)
# 遍历实验数据列表,并获取每个实验的详细信息
for experiment in tqdm.tqdm(experiments['experiments']):
experiment_details = get_experiment(experiment['accession'], SPECIES)
experiment['details'] = experiment_details
# 将实验数据写入 JSON 文件
with open('data/experiments.json', 'w+') as f:
contents = json.dumps(experiments, indent = 4, sort_keys = True)
f.write(contents)
# 打印成功信息
print('success')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号