
Lucidrains-系列项目源码解析-二十二-
Lucidrains 系列项目源码解析(二十二)
.\lucidrains\lightweight-gan\lightweight_gan\diff_augment.py
# 导入random模块
import random
# 导入torch模块及其子模块
import torch
import torch.nn.functional as F
# 定义函数DiffAugment,接受输入x和types参数
def DiffAugment(x, types=[]):
# 遍历types列表中的元素
for p in types:
# 遍历AUGMENT_FNS字典中对应类型的函数列表
for f in AUGMENT_FNS[p]:
# 对输入x应用函数f
x = f(x)
# 返回处理后的x
return x.contiguous()
# 定义rand_brightness函数,接受输入x
def rand_brightness(x):
# 为x添加随机亮度
x = x + (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5)
return x
# 定义rand_saturation函数,接受输入x
def rand_saturation(x):
# 计算x的均值
x_mean = x.mean(dim=1, keepdim=True)
# 为x添加随机饱和度
x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) * 2) + x_mean
return x
# 定义rand_contrast函数,接受输入x
def rand_contrast(x):
# 计算x的均值
x_mean = x.mean(dim=[1, 2, 3], keepdim=True)
# 为x添加随机对比度
x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) + 0.5) + x_mean
return x
# 定义rand_translation函数,接受输入x和ratio参数
def rand_translation(x, ratio=0.125):
# 计算平移的像素数
shift_x, shift_y = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
# 生成随机平移量
translation_x = torch.randint(-shift_x, shift_x + 1, size=[x.size(0), 1, 1], device=x.device)
translation_y = torch.randint(-shift_y, shift_y + 1, size=[x.size(0), 1, 1], device=x.device)
# 创建网格
grid_batch, grid_x, grid_y = torch.meshgrid(
torch.arange(x.size(0), dtype=torch.long, device=x.device),
torch.arange(x.size(2), dtype=torch.long, device=x.device),
torch.arange(x.size(3), dtype=torch.long, device=x.device),
indexing = 'ij')
# 对网格进行平移
grid_x = torch.clamp(grid_x + translation_x + 1, 0, x.size(2) + 1)
grid_y = torch.clamp(grid_y + translation_y + 1, 0, x.size(3) + 1)
# 对输入x进行平移操作
x_pad = F.pad(x, [1, 1, 1, 1, 0, 0, 0, 0])
x = x_pad.permute(0, 2, 3, 1).contiguous()[grid_batch, grid_x, grid_y].permute(0, 3, 1, 2)
return x
# 定义rand_offset函数,接受输入x和ratio参数
def rand_offset(x, ratio=1, ratio_h=1, ratio_v=1):
# 获取输入x的宽度和高度
w, h = x.size(2), x.size(3)
# 初始化空列表imgs
imgs = []
# 遍历输入x的每个图像
for img in x.unbind(dim = 0):
# 计算水平和垂直方向的最大偏移量
max_h = int(w * ratio * ratio_h)
max_v = int(h * ratio * ratio_v)
# 生成随机偏移值
value_h = random.randint(0, max_h) * 2 - max_h
value_v = random.randint(0, max_v) * 2 - max_v
# 根据偏移值对图像进行滚动操作
if abs(value_h) > 0:
img = torch.roll(img, value_h, 2)
if abs(value_v) > 0:
img = torch.roll(img, value_v, 1)
# 将处理后的图像添加到imgs列表中
imgs.append(img)
# 将处理后的图像堆叠成一个张量并返回
return torch.stack(imgs)
# 定义rand_offset_h函数,接受输入x和ratio参数
def rand_offset_h(x, ratio=1):
# 调用rand_offset函数,设置ratio_h参数为1,ratio_v参数为0
return rand_offset(x, ratio=1, ratio_h=ratio, ratio_v=0)
# 定义rand_offset_v函数,接受输入x和ratio参数
def rand_offset_v(x, ratio=1):
# 调用rand_offset函数,设置ratio_h参数为0,ratio_v参数为ratio
return rand_offset(x, ratio=1, ratio_h=0, ratio_v=ratio)
# 定义rand_cutout函数,接受输入x和ratio参数
def rand_cutout(x, ratio=0.5):
# 计算cutout的大小
cutout_size = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)
# 生成随机偏移值
offset_x = torch.randint(0, x.size(2) + (1 - cutout_size[0] % 2), size=[x.size(0), 1, 1], device=x.device)
offset_y = torch.randint(0, x.size(3) + (1 - cutout_size[1] % 2), size=[x.size(0), 1, 1], device=x.device)
# 创建网格
grid_batch, grid_x, grid_y = torch.meshgrid(
torch.arange(x.size(0), dtype=torch.long, device=x.device),
torch.arange(cutout_size[0], dtype=torch.long, device=x.device),
torch.arange(cutout_size[1], dtype=torch.long, device=x.device),
indexing = 'ij')
# 对网格进行裁剪
grid_x = torch.clamp(grid_x + offset_x - cutout_size[0] // 2, min=0, max=x.size(2) - 1)
grid_y = torch.clamp(grid_y + offset_y - cutout_size[1] // 2, min=0, max=x.size(3) - 1)
# 创建mask张量
mask = torch.ones(x.size(0), x.size(2), x.size(3), dtype=x.dtype, device=x.device)
mask[grid_batch, grid_x, grid_y] = 0
# 对输入x应用mask
x = x * mask.unsqueeze(1)
return x
# 定义AUGMENT_FNS字典,包含不同类型的数据增强函数列表
AUGMENT_FNS = {
'color': [rand_brightness, rand_saturation, rand_contrast],
'offset': [rand_offset],
'offset_h': [rand_offset_h],
'offset_v': [rand_offset_v],
'translation': [rand_translation],
'cutout': [rand_cutout],
}
.\lucidrains\lightweight-gan\lightweight_gan\diff_augment_test.py
# 导入必要的库
import os
import tempfile
from pathlib import Path
from shutil import copyfile
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# 导入 lightweight_gan 库中的相关模块
from lightweight_gan.lightweight_gan import AugWrapper, ImageDataset
# 检查是否有可用的 CUDA 设备
assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
# 定义一个简单的模型类
class DummyModel(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
# 使用 torch.no_grad() 修饰的函数,不会进行梯度计算
@torch.no_grad()
def DiffAugmentTest(image_size = 256, data = './data/0.jpg', types = [], batch_size = 10, rank = 0, nrow = 5):
# 创建一个 DummyModel 实例
model = DummyModel()
# 创建一个 AugWrapper 实例
aug_wrapper = AugWrapper(model, image_size)
# 使用临时目录
with tempfile.TemporaryDirectory() as directory:
# 获取文件路径
file = Path(data)
# 如果文件存在
if os.path.exists(file):
# 获取文件名和扩展名
file_name, ext = os.path.splitext(data)
# 复制文件到临时目录中
for i in range(batch_size):
tmp_file_name = str(i) + ext
copyfile(file, os.path.join(directory, tmp_file_name))
# 创建 ImageDataset 实例
dataset = ImageDataset(directory, image_size, aug_prob=0)
# 创建 DataLoader 实例
dataloader = DataLoader(dataset, batch_size=batch_size)
# 获取一个图像批次并移动到指定设备
image_batch = next(iter(dataloader)).cuda(rank)
# 对图像进行数据增强
images_augment = aug_wrapper(images=image_batch, prob=1, types=types, detach=True)
# 保存增强后的图像
save_result = file_name + f'_augs{ext}'
torchvision.utils.save_image(images_augment, save_result, nrow=nrow)
# 打印保存结果的文件名
print('Save result to:', save_result)
else:
# 如果文件不存在,则打印提示信息
print('File not found. File', file)
.\lucidrains\lightweight-gan\lightweight_gan\lightweight_gan.py
# 导入必要的库
import os
import json
import multiprocessing
from random import random
import math
from math import log2, floor
from functools import lru_cache, partial
from contextlib import contextmanager, ExitStack
from pathlib import Path
from shutil import rmtree
import torch
from torch.cuda.amp import autocast, GradScaler
from torch.optim import Adam
from torch import nn, einsum
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torch.autograd import grad as torch_grad
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from PIL import Image
import torchvision
from torchvision import transforms
from kornia.filters import filter2d
from lightweight_gan.diff_augment import DiffAugment
from lightweight_gan.version import __version__
from tqdm import tqdm
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange
from adabelief_pytorch import AdaBelief
# 断言,检查是否有可用的 CUDA 加速
assert torch.cuda.is_available(), 'You need to have an Nvidia GPU with CUDA installed.'
# 常量定义
NUM_CORES = multiprocessing.cpu_count()
EXTS = ['jpg', 'jpeg', 'png', 'tiff']
# 辅助函数
# 检查值是否存在
def exists(val):
return val is not None
# 空上下文管理器
@contextmanager
def null_context():
yield
# 合并多个上下文管理器
def combine_contexts(contexts):
@contextmanager
def multi_contexts():
with ExitStack() as stack:
yield [stack.enter_context(ctx()) for ctx in contexts]
return multi_contexts
# 检查值是否为2的幂
def is_power_of_two(val):
return log2(val).is_integer()
# 返回默认值
def default(val, d):
return val if exists(val) else d
# 设置模型参数是否需要梯度
def set_requires_grad(model, bool):
for p in model.parameters():
p.requires_grad = bool
# 无限循环生成器
def cycle(iterable):
while True:
for i in iterable:
yield i
# 如果值为 NaN,则抛出异常
def raise_if_nan(t):
if torch.isnan(t):
raise NanException
# 梯度累积上下文管理器
def gradient_accumulate_contexts(gradient_accumulate_every, is_ddp, ddps):
if is_ddp:
num_no_syncs = gradient_accumulate_every - 1
head = [combine_contexts(map(lambda ddp: ddp.no_sync, ddps))] * num_no_syncs
tail = [null_context]
contexts = head + tail
else:
contexts = [null_context] * gradient_accumulate_every
for context in contexts:
with context():
yield
# 将输入数据按照最大批次大小分块处理
def evaluate_in_chunks(max_batch_size, model, *args):
split_args = list(zip(*list(map(lambda x: x.split(max_batch_size, dim=0), args))))
chunked_outputs = [model(*i) for i in split_args]
if len(chunked_outputs) == 1:
return chunked_outputs[0]
return torch.cat(chunked_outputs, dim=0)
# 球面插值函数
def slerp(val, low, high):
low_norm = low / torch.norm(low, dim=1, keepdim=True)
high_norm = high / torch.norm(high, dim=1, keepdim=True)
omega = torch.acos((low_norm * high_norm).sum(1))
so = torch.sin(omega)
res = (torch.sin((1.0 - val) * omega) / so).unsqueeze(1) * low + (torch.sin(val * omega) / so).unsqueeze(1) * high
return res
# 安全除法函数
def safe_div(n, d):
try:
res = n / d
except ZeroDivisionError:
prefix = '' if int(n >= 0) else '-'
res = float(f'{prefix}inf')
return res
# 损失函数
# 生成器 Hinge Loss
def gen_hinge_loss(fake, real):
return fake.mean()
# Hinge Loss
def hinge_loss(real, fake):
return (F.relu(1 + real) + F.relu(1 - fake)).mean()
# 双对比损失函数
def dual_contrastive_loss(real_logits, fake_logits):
device = real_logits.device
real_logits, fake_logits = map(lambda t: rearrange(t, '... -> (...)'), (real_logits, fake_logits))
def loss_half(t1, t2):
t1 = rearrange(t1, 'i -> i ()')
t2 = repeat(t2, 'j -> i j', i = t1.shape[0])
t = torch.cat((t1, t2), dim = -1)
return F.cross_entropy(t, torch.zeros(t1.shape[0], device = device, dtype = torch.long))
return loss_half(real_logits, fake_logits) + loss_half(-fake_logits, -real_logits)
# 缓存随机数生成器
@lru_cache(maxsize=10)
def det_randn(*args):
"""
deterministic random to track the same latent vars (and images) across training steps
# 用于在训练步骤中可视化相同图像
"""
# 返回一个具有指定形状的随机张量
return torch.randn(*args)
# 定义一个函数,用于在两个向量之间插值生成多个样本
def interpolate_between(a, b, *, num_samples, dim):
# 断言样本数量大于2
assert num_samples > 2
# 初始化样本列表
samples = []
# 初始化步长
step_size = 0
# 循环生成插值样本
for _ in range(num_samples):
# 使用线性插值生成样本
sample = torch.lerp(a, b, step_size)
samples.append(sample)
# 更新步长
step_size += 1 / (num_samples - 1)
# 将生成的样本堆叠在一起
return torch.stack(samples, dim=dim)
# 辅助类
# 定义一个自定义异常类
class NanException(Exception):
pass
# 定义一个指数移动平均类
class EMA():
def __init__(self, beta):
super().__init__()
self.beta = beta
def update_average(self, old, new):
# 如果旧值不存在,则直接返回新值
if not exists(old):
return new
# 计算新的指数移动平均值
return old * self.beta + (1 - self.beta) * new
# 定义一个随机应用类
class RandomApply(nn.Module):
def __init__(self, prob, fn, fn_else = lambda x: x):
super().__init__()
self.fn = fn
self.fn_else = fn_else
self.prob = prob
def forward(self, x):
# 根据概率选择应用哪个函数
fn = self.fn if random() < self.prob else self.fn_else
return fn(x)
# 定义一个通道归一化类
class ChanNorm(nn.Module):
def __init__(self, dim, eps = 1e-5):
super().__init__()
self.eps = eps
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
def forward(self, x):
# 计算均值和方差
var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
mean = torch.mean(x, dim = 1, keepdim = True)
# 执行通道归一化操作
return (x - mean) / (var + self.eps).sqrt() * self.g + self.b
# 定义一个预归一化类
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = ChanNorm(dim)
def forward(self, x):
# 执行预归一化操作
return self.fn(self.norm(x))
# 定义一个残差连接类
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
# 执行残差连接操作
return self.fn(x) + x
# 定义一个分支求和类
class SumBranches(nn.Module):
def __init__(self, branches):
super().__init__()
self.branches = nn.ModuleList(branches)
def forward(self, x):
# 对分支函数的输出进行求和
return sum(map(lambda fn: fn(x), self.branches))
# 定义一个模糊类
class Blur(nn.Module):
def __init__(self):
super().__init__()
f = torch.Tensor([1, 2, 1])
self.register_buffer('f', f)
def forward(self, x):
f = self.f
f = f[None, None, :] * f [None, :, None]
return filter2d(x, f, normalized=True)
# 定义一个噪声类
class Noise(nn.Module):
def __init__(self):
super().__init__()
self.weight = nn.Parameter(torch.zeros(1))
def forward(self, x, noise = None):
b, _, h, w, device = *x.shape, x.device
# 如果噪声不存在,则生成随机噪声
if not exists(noise):
noise = torch.randn(b, 1, h, w, device = device)
return x + self.weight * noise
# 定义一个二维卷积函数,保持输入输出尺寸相同
def Conv2dSame(dim_in, dim_out, kernel_size, bias = True):
pad_left = kernel_size // 2
pad_right = (pad_left - 1) if (kernel_size % 2) == 0 else pad_left
return nn.Sequential(
nn.ZeroPad2d((pad_left, pad_right, pad_left, pad_right)),
nn.Conv2d(dim_in, dim_out, kernel_size, bias = bias)
)
# 注意力机制
# 定义一个深度卷积类
class DepthWiseConv2d(nn.Module):
def __init__(self, dim_in, dim_out, kernel_size, padding = 0, stride = 1, bias = True):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(dim_in, dim_in, kernel_size = kernel_size, padding = padding, groups = dim_in, stride = stride, bias = bias),
nn.Conv2d(dim_in, dim_out, kernel_size = 1, bias = bias)
)
def forward(self, x):
return self.net(x)
class LinearAttention(nn.Module):
# 初始化函数,设置注意力头数、头维度、卷积核大小等参数
def __init__(self, dim, dim_head = 64, heads = 8, kernel_size = 3):
# 调用父类初始化函数
super().__init__()
# 计算缩放因子
self.scale = dim_head ** -0.5
self.heads = heads
self.dim_head = dim_head
inner_dim = dim_head * heads
self.kernel_size = kernel_size
# 使用 GELU 作为非线性激活函数
self.nonlin = nn.GELU()
# 线性变换,将输入特征映射到内部维度
self.to_lin_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
self.to_lin_kv = DepthWiseConv2d(dim, inner_dim * 2, 3, padding = 1, bias = False)
# 线性变换,将输入特征映射到内部维度
self.to_q = nn.Conv2d(dim, inner_dim, 1, bias = False)
self.to_kv = nn.Conv2d(dim, inner_dim * 2, 1, bias = False)
# 输出层线性变换,将内部维度映射回原始维度
self.to_out = nn.Conv2d(inner_dim * 2, dim, 1)
# 前向传播函数
def forward(self, fmap):
h, x, y = self.heads, *fmap.shape[-2:]
# 线性注意力计算
lin_q, lin_k, lin_v = (self.to_lin_q(fmap), *self.to_lin_kv(fmap).chunk(2, dim = 1))
lin_q, lin_k, lin_v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) (x y) c', h = h), (lin_q, lin_k, lin_v))
lin_q = lin_q.softmax(dim = -1)
lin_k = lin_k.softmax(dim = -2)
lin_q = lin_q * self.scale
context = einsum('b n d, b n e -> b d e', lin_k, lin_v)
lin_out = einsum('b n d, b d e -> b n e', lin_q, context)
lin_out = rearrange(lin_out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
# 类卷积的全局注意力计算
q, k, v = (self.to_q(fmap), *self.to_kv(fmap).chunk(2, dim = 1))
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> (b h) c x y', h = h), (q, k, v))
k = F.unfold(k, kernel_size = self.kernel_size, padding = self.kernel_size // 2)
v = F.unfold(v, kernel_size = self.kernel_size, padding = self.kernel_size // 2)
k, v = map(lambda t: rearrange(t, 'b (d j) n -> b n j d', d = self.dim_head), (k, v))
q = rearrange(q, 'b c ... -> b (...) c') * self.scale
sim = einsum('b i d, b i j d -> b i j', q, k)
sim = sim - sim.amax(dim = -1, keepdim = True).detach()
attn = sim.softmax(dim = -1)
full_out = einsum('b i j, b i j d -> b i d', attn, v)
full_out = rearrange(full_out, '(b h) (x y) d -> b (h d) x y', h = h, x = x, y = y)
# 将线性注意力和类卷积全局注意力的输出相加
lin_out = self.nonlin(lin_out)
out = torch.cat((lin_out, full_out), dim = 1)
return self.to_out(out)
# dataset
# 将图像转换为指定类型
def convert_image_to(img_type, image):
# 如果图像模式不是指定类型,则进行转换
if image.mode != img_type:
return image.convert(img_type)
return image
# 定义一个身份函数类
class identity(object):
def __call__(self, tensor):
return tensor
# 扩展灰度图像类
class expand_greyscale(object):
def __init__(self, transparent):
self.transparent = transparent
def __call__(self, tensor):
channels = tensor.shape[0]
num_target_channels = 4 if self.transparent else 3
# 如果通道数与目标通道数相同,则返回原始张量
if channels == num_target_channels:
return tensor
alpha = None
if channels == 1:
color = tensor.expand(3, -1, -1)
elif channels == 2:
color = tensor[:1].expand(3, -1, -1)
alpha = tensor[1:]
else:
raise Exception(f'image with invalid number of channels given {channels}')
# 如果不存在 alpha 通道且需要透明度,则创建全为1的 alpha 通道
if not exists(alpha) and self.transparent:
alpha = torch.ones(1, *tensor.shape[1:], device=tensor.device)
return color if not self.transparent else torch.cat((color, alpha))
# 调整图像大小至最小尺寸
def resize_to_minimum_size(min_size, image):
if max(*image.size) < min_size:
return torchvision.transforms.functional.resize(image, min_size)
return image
# 图像数据集类
class ImageDataset(Dataset):
def __init__(
self,
folder,
image_size,
transparent = False,
greyscale = False,
aug_prob = 0.
):
super().__init__()
self.folder = folder
self.image_size = image_size
self.paths = [p for ext in EXTS for p in Path(f'{folder}').glob(f'**/*.{ext}')]
assert len(self.paths) > 0, f'No images were found in {folder} for training'
# 根据是否需要透明度和是否为灰度图像确定通道数和 Pillow 模式
if transparent:
num_channels = 4
pillow_mode = 'RGBA'
expand_fn = expand_greyscale(transparent)
elif greyscale:
num_channels = 1
pillow_mode = 'L'
expand_fn = identity()
else:
num_channels = 3
pillow_mode = 'RGB'
expand_fn = expand_greyscale(transparent)
convert_image_fn = partial(convert_image_to, pillow_mode)
# 图像转换操作���列
self.transform = transforms.Compose([
transforms.Lambda(convert_image_fn),
transforms.Lambda(partial(resize_to_minimum_size, image_size)),
transforms.Resize(image_size),
RandomApply(aug_prob, transforms.RandomResizedCrop(image_size, scale=(0.5, 1.0), ratio=(0.98, 1.02)), transforms.CenterCrop(image_size)),
transforms.ToTensor(),
transforms.Lambda(expand_fn)
])
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
path = self.paths[index]
img = Image.open(path)
return self.transform(img)
# augmentations
# 随机水平翻转函数
def random_hflip(tensor, prob):
if prob > random():
return tensor
return torch.flip(tensor, dims=(3,))
# 数据增强包装类
class AugWrapper(nn.Module):
def __init__(self, D, image_size):
super().__init__()
self.D = D
def forward(self, images, prob = 0., types = [], detach = False, **kwargs):
context = torch.no_grad if detach else null_context
with context():
if random() < prob:
images = random_hflip(images, prob=0.5)
images = DiffAugment(images, types=types)
return self.D(images, **kwargs)
# modifiable global variables
# 规范化类
norm_class = nn.BatchNorm2d
# 像素混洗上采样类
class PixelShuffleUpsample(nn.Module):
def __init__(self, dim, dim_out = None):
super().__init__()
dim_out = default(dim_out, dim)
conv = nn.Conv2d(dim, dim_out * 4, 1)
self.net = nn.Sequential(
conv,
nn.SiLU(),
nn.PixelShuffle(2)
)
self.init_conv_(conv)
# 初始化卷积层的权重和偏置
def init_conv_(self, conv):
# 获取卷积层的输出通道数、输入通道数、高度和宽度
o, i, h, w = conv.weight.shape
# 创建一个与卷积层权重相同形状的张量
conv_weight = torch.empty(o // 4, i, h, w)
# 使用 Kaiming 初始化方法初始化权重
nn.init.kaiming_uniform_(conv_weight)
# 将权重张量重复4次,扩展为4倍的输出通道数
conv_weight = repeat(conv_weight, 'o ... -> (o 4) ...')
# 将初始化好的权重复制给卷积层的权重
conv.weight.data.copy_(conv_weight)
# 初始化卷积层的偏置为零
nn.init.zeros_(conv.bias.data)
# 前向传播函数,将输入数据传递给网络并返回输出
def forward(self, x):
return self.net(x)
def SPConvDownsample(dim, dim_out = None):
# 定义一个下采样函数,根据输入维度和输出维度进行下采样
# 在论文 https://arxiv.org/abs/2208.03641 中显示这是最优的下采样方式
# 在论文中被称为 SP-conv,实际上是像素解缩放
dim_out = default(dim_out, dim)
return nn.Sequential(
Rearrange('b c (h s1) (w s2) -> b (c s1 s2) h w', s1 = 2, s2 = 2),
nn.Conv2d(dim * 4, dim_out, 1)
)
# squeeze excitation classes
# 全局上下文网络
# https://arxiv.org/abs/2012.13375
# 类似于 squeeze-excite,但具有简化的注意力池化和随后的层归一化
class GlobalContext(nn.Module):
def __init__(
self,
*,
chan_in,
chan_out
):
super().__init__()
self.to_k = nn.Conv2d(chan_in, 1, 1)
chan_intermediate = max(3, chan_out // 2)
self.net = nn.Sequential(
nn.Conv2d(chan_in, chan_intermediate, 1),
nn.LeakyReLU(0.1),
nn.Conv2d(chan_intermediate, chan_out, 1),
nn.Sigmoid()
)
def forward(self, x):
context = self.to_k(x)
context = context.flatten(2).softmax(dim = -1)
out = einsum('b i n, b c n -> b c i', context, x.flatten(2))
out = out.unsqueeze(-1)
return self.net(out)
# 频道注意力
# 获取一维离散余弦变换
def get_1d_dct(i, freq, L):
result = math.cos(math.pi * freq * (i + 0.5) / L) / math.sqrt(L)
return result * (1 if freq == 0 else math.sqrt(2))
# 获取离散余弦变换权重
def get_dct_weights(width, channel, fidx_u, fidx_v):
dct_weights = torch.zeros(1, channel, width, width)
c_part = channel // len(fidx_u)
for i, (u_x, v_y) in enumerate(zip(fidx_u, fidx_v)):
for x in range(width):
for y in range(width):
coor_value = get_1d_dct(x, u_x, width) * get_1d_dct(y, v_y, width)
dct_weights[:, i * c_part: (i + 1) * c_part, x, y] = coor_value
return dct_weights
class FCANet(nn.Module):
def __init__(
self,
*,
chan_in,
chan_out,
reduction = 4,
width
):
super().__init__()
freq_w, freq_h = ([0] * 8), list(range(8)) # 在论文中,似乎16个频率是理想的
dct_weights = get_dct_weights(width, chan_in, [*freq_w, *freq_h], [*freq_h, *freq_w])
self.register_buffer('dct_weights', dct_weights)
chan_intermediate = max(3, chan_out // reduction)
self.net = nn.Sequential(
nn.Conv2d(chan_in, chan_intermediate, 1),
nn.LeakyReLU(0.1),
nn.Conv2d(chan_intermediate, chan_out, 1),
nn.Sigmoid()
)
def forward(self, x):
x = reduce(x * self.dct_weights, 'b c (h h1) (w w1) -> b c h1 w1', 'sum', h1 = 1, w1 = 1)
return self.net(x)
# 生成对抗网络
class Generator(nn.Module):
def __init__(
self,
*,
image_size,
latent_dim = 256,
fmap_max = 512,
fmap_inverse_coef = 12,
transparent = False,
greyscale = False,
attn_res_layers = [],
freq_chan_attn = False
):
# 调用父类的构造函数
super().__init__()
# 计算图像分辨率的对数值
resolution = log2(image_size)
# 断言图像大小必须是2的幂次方
assert is_power_of_two(image_size), 'image size must be a power of 2'
# 根据是否透明或灰度图像确定初始通道数
if transparent:
init_channel = 4
elif greyscale:
init_channel = 1
else:
init_channel = 3
# 设置特征图的最大通道数
fmap_max = default(fmap_max, latent_dim)
# 初始化卷积层
self.initial_conv = nn.Sequential(
nn.ConvTranspose2d(latent_dim, latent_dim * 2, 4),
norm_class(latent_dim * 2),
nn.GLU(dim = 1)
)
# 计算层数和特征
num_layers = int(resolution) - 2
features = list(map(lambda n: (n, 2 ** (fmap_inverse_coef - n)), range(2, num_layers + 2)))
features = list(map(lambda n: (n[0], min(n[1], fmap_max)), features))
features = list(map(lambda n: 3 if n[0] >= 8 else n[1], features))
features = [latent_dim, *features]
# 计算输入输出特征
in_out_features = list(zip(features[:-1], features[1:]))
# 初始化残差层和特征映射
self.res_layers = range(2, num_layers + 2)
self.layers = nn.ModuleList([])
self.res_to_feature_map = dict(zip(self.res_layers, in_out_features))
# 设置空间尺寸映射
self.sle_map = ((3, 7), (4, 8), (5, 9), (6, 10))
self.sle_map = list(filter(lambda t: t[0] <= resolution and t[1] <= resolution, self.sle_map))
self.sle_map = dict(self.sle_map)
self.num_layers_spatial_res = 1
# 遍历每一层并构建网络层
for (res, (chan_in, chan_out)) in zip(self.res_layers, in_out_features):
image_width = 2 ** res
attn = None
if image_width in attn_res_layers:
attn = PreNorm(chan_in, LinearAttention(chan_in))
sle = None
if res in self.sle_map:
residual_layer = self.sle_map[res]
sle_chan_out = self.res_to_feature_map[residual_layer - 1][-1]
if freq_chan_attn:
sle = FCANet(
chan_in = chan_out,
chan_out = sle_chan_out,
width = 2 ** (res + 1)
)
else:
sle = GlobalContext(
chan_in = chan_out,
chan_out = sle_chan_out
)
layer = nn.ModuleList([
nn.Sequential(
PixelShuffleUpsample(chan_in),
Blur(),
Conv2dSame(chan_in, chan_out * 2, 4),
Noise(),
norm_class(chan_out * 2),
nn.GLU(dim = 1)
),
sle,
attn
])
self.layers.append(layer)
# 输出卷积层
self.out_conv = nn.Conv2d(features[-1], init_channel, 3, padding = 1)
# 前向传播函数
def forward(self, x):
# 重排输入张量的维度
x = rearrange(x, 'b c -> b c () ()')
x = self.initial_conv(x)
# 对输入张量进行归一化
x = F.normalize(x, dim = 1)
residuals = dict()
# 遍历每一层并执行前向传播
for (res, (up, sle, attn)) in zip(self.res_layers, self.layers):
if exists(attn):
x = attn(x) + x
x = up(x)
if exists(sle):
out_res = self.sle_map[res]
residual = sle(x)
residuals[out_res] = residual
next_res = res + 1
if next_res in residuals:
x = x * residuals[next_res]
return self.out_conv(x)
# 定义一个简单的解码器类,继承自 nn.Module
class SimpleDecoder(nn.Module):
# 初始化函数,接受输入通道数、输出通道数、上采样次数等参数
def __init__(
self,
*,
chan_in,
chan_out = 3,
num_upsamples = 4,
):
# 调用父类的初始化函数
super().__init__()
# 初始化层列表
self.layers = nn.ModuleList([])
# 设置最终输出通道数
final_chan = chan_out
# 设置初始通道数
chans = chan_in
# 循环创建上采样层
for ind in range(num_upsamples):
# 判断是否为最后一层
last_layer = ind == (num_upsamples - 1)
# 根据是否为最后一层确定输出通道数
chan_out = chans if not last_layer else final_chan * 2
# 创建包含上采样、卷积和 GLU 激活函数的层
layer = nn.Sequential(
PixelShuffleUpsample(chans),
nn.Conv2d(chans, chan_out, 3, padding = 1),
nn.GLU(dim = 1)
)
# 将层添加到层列表中
self.layers.append(layer)
# 更新通道数
chans //= 2
# 前向传播函数
def forward(self, x):
# 遍历所有层并依次进行前向传播
for layer in self.layers:
x = layer(x)
# 返回输出结果
return x
# 定义一个鉴别器类,继承自 nn.Module
class Discriminator(nn.Module):
# 初始化函数,接受输入图像大小、最大特征图数、特征图反比系数、是否透明、是否灰度、输出尺寸、注意力机制层等参数
def __init__(
self,
*,
image_size,
fmap_max = 512,
fmap_inverse_coef = 12,
transparent = False,
greyscale = False,
disc_output_size = 5,
attn_res_layers = []
):
# 调用父类的构造函数
super().__init__()
# 计算图像分辨率的对数值
resolution = log2(image_size)
# 断言图像大小必须是2的幂次方
assert is_power_of_two(image_size), 'image size must be a power of 2'
# 断言判别器输出维度只能是5x5或1x1
assert disc_output_size in {1, 5}, 'discriminator output dimensions can only be 5x5 or 1x1'
resolution = int(resolution)
# 根据是否透明或灰度图像确定初始通道数
if transparent:
init_channel = 4
elif greyscale:
init_channel = 1
else:
init_channel = 3
# 计算非残差层的数量
num_non_residual_layers = max(0, int(resolution) - 8)
num_residual_layers = 8 - 3
# 计算非残差层的分辨率范围
non_residual_resolutions = range(min(8, resolution), 2, -1)
# 计算特征通道数
features = list(map(lambda n: (n, 2 ** (fmap_inverse_coef - n)), non_residual_resolutions))
features = list(map(lambda n: (n[0], min(n[1], fmap_max)), features))
# 如果没有非残差层,则将初始通道数赋给第一个特征通道数
if num_non_residual_layers == 0:
res, _ = features[0]
features[0] = (res, init_channel)
# 将特征通道数组合成输入输出通道数的列表
chan_in_out = list(zip(features[:-1], features[1:]))
# 初始化非残差层
self.non_residual_layers = nn.ModuleList([])
for ind in range(num_non_residual_layers):
first_layer = ind == 0
last_layer = ind == (num_non_residual_layers - 1)
chan_out = features[0][-1] if last_layer else init_channel
self.non_residual_layers.append(nn.Sequential(
Blur(),
nn.Conv2d(init_channel, chan_out, 4, stride = 2, padding = 1),
nn.LeakyReLU(0.1)
))
# 初始化残差层
self.residual_layers = nn.ModuleList([])
for (res, ((_, chan_in), (_, chan_out))) in zip(non_residual_resolutions, chan_in_out):
image_width = 2 ** res
attn = None
if image_width in attn_res_layers:
attn = PreNorm(chan_in, LinearAttention(chan_in))
self.residual_layers.append(nn.ModuleList([
SumBranches([
nn.Sequential(
Blur(),
SPConvDownsample(chan_in, chan_out),
nn.LeakyReLU(0.1),
nn.Conv2d(chan_out, chan_out, 3, padding = 1),
nn.LeakyReLU(0.1)
),
nn.Sequential(
Blur(),
nn.AvgPool2d(2),
nn.Conv2d(chan_in, chan_out, 1),
nn.LeakyReLU(0.1),
)
]),
attn
]))
# 获取最后一个特征通道数
last_chan = features[-1][-1]
# 根据判别器输出大小选择不同的输出层结构
if disc_output_size == 5:
self.to_logits = nn.Sequential(
nn.Conv2d(last_chan, last_chan, 1),
nn.LeakyReLU(0.1),
nn.Conv2d(last_chan, 1, 4)
)
elif disc_output_size == 1:
self.to_logits = nn.Sequential(
Blur(),
nn.Conv2d(last_chan, last_chan, 3, stride = 2, padding = 1),
nn.LeakyReLU(0.1),
nn.Conv2d(last_chan, 1, 4)
)
# 初始化形状判别器输出层
self.to_shape_disc_out = nn.Sequential(
nn.Conv2d(init_channel, 64, 3, padding = 1),
Residual(PreNorm(64, LinearAttention(64))),
SumBranches([
nn.Sequential(
Blur(),
SPConvDownsample(64, 32),
nn.LeakyReLU(0.1),
nn.Conv2d(32, 32, 3, padding = 1),
nn.LeakyReLU(0.1)
),
nn.Sequential(
Blur(),
nn.AvgPool2d(2),
nn.Conv2d(64, 32, 1),
nn.LeakyReLU(0.1),
)
]),
Residual(PreNorm(32, LinearAttention(32))),
nn.AdaptiveAvgPool2d((4, 4)),
nn.Conv2d(32, 1, 4)
)
# 初始化解码器1
self.decoder1 = SimpleDecoder(chan_in = last_chan, chan_out = init_channel)
# 如果分辨率大于等于9,则初始化解码器2
self.decoder2 = SimpleDecoder(chan_in = features[-2][-1], chan_out = init_channel) if resolution >= 9 else None
# 前向传播函数,接受输入 x 和是否计算辅助损失 calc_aux_loss
def forward(self, x, calc_aux_loss = False):
# 保存原始输入图像
orig_img = x
# 遍历非残差层并计算输出
for layer in self.non_residual_layers:
x = layer(x)
# 初始化存储每个残差块输出的列表
layer_outputs = []
# 遍历残差层,计算输出并存储在列表中
for (net, attn) in self.residual_layers:
# 如果存在注意力机制,将注意力机制应用到输入上并与输入相加
if exists(attn):
x = attn(x) + x
# 经过残差块网络
x = net(x)
# 将输出添加到列表中
layer_outputs.append(x)
# 将最终输出转换为 logits 并展平
out = self.to_logits(x).flatten(1)
# 将原始图像插值为 32x32 大小
img_32x32 = F.interpolate(orig_img, size = (32, 32))
# 将插值后的图像传入形状判别器
out_32x32 = self.to_shape_disc_out(img_32x32)
# 如果不需要计算辅助损失,则直接返回结果
if not calc_aux_loss:
return out, out_32x32, None
# 自监督自编码损失
# 获取倒数第一个残差块的输出
layer_8x8 = layer_outputs[-1]
# 获取倒数第二个残差块的输出
layer_16x16 = layer_outputs[-2]
# 使用解码器1对 8x8 层进行重建
recon_img_8x8 = self.decoder1(layer_8x8)
# 计算 MSE 损失
aux_loss = F.mse_loss(
recon_img_8x8,
F.interpolate(orig_img, size = recon_img_8x8.shape[2:])
)
# 如果存在第二个解码器
if exists(self.decoder2):
# 随机选择一个象限
select_random_quadrant = lambda rand_quadrant, img: rearrange(img, 'b c (m h) (n w) -> (m n) b c h w', m = 2, n = 2)[rand_quadrant]
crop_image_fn = partial(select_random_quadrant, floor(random() * 4))
img_part, layer_16x16_part = map(crop_image_fn, (orig_img, layer_16x16))
# 使用解码器2对 16x16 层进行重建
recon_img_16x16 = self.decoder2(layer_16x16_part)
# 计算 MSE 损失
aux_loss_16x16 = F.mse_loss(
recon_img_16x16,
F.interpolate(img_part, size = recon_img_16x16.shape[2:])
)
# 将两个损失相加
aux_loss = aux_loss + aux_loss_16x16
# 返回最终结果,包括主要输出、32x32 输出和辅助损失
return out, out_32x32, aux_loss
# 定义 LightweightGAN 类,继承自 nn.Module
class LightweightGAN(nn.Module):
# 初始化函数,接收多个参数
def __init__(
self,
*,
latent_dim,
image_size,
optimizer = "adam",
fmap_max = 512,
fmap_inverse_coef = 12,
transparent = False,
greyscale = False,
disc_output_size = 5,
attn_res_layers = [],
freq_chan_attn = False,
ttur_mult = 1.,
lr = 2e-4,
rank = 0,
ddp = False
):
# 调用父类的初始化函数
super().__init__()
# 初始化类的属性
self.latent_dim = latent_dim
self.image_size = image_size
# 定义 G_kwargs 字典
G_kwargs = dict(
image_size = image_size,
latent_dim = latent_dim,
fmap_max = fmap_max,
fmap_inverse_coef = fmap_inverse_coef,
transparent = transparent,
greyscale = greyscale,
attn_res_layers = attn_res_layers,
freq_chan_attn = freq_chan_attn
)
# 创建 Generator 对象
self.G = Generator(**G_kwargs)
# 创建 Discriminator 对象
self.D = Discriminator(
image_size = image_size,
fmap_max = fmap_max,
fmap_inverse_coef = fmap_inverse_coef,
transparent = transparent,
greyscale = greyscale,
attn_res_layers = attn_res_layers,
disc_output_size = disc_output_size
)
# 创建 EMA 对象
self.ema_updater = EMA(0.995)
# 创建 Generator 对象 GE
self.GE = Generator(**G_kwargs)
# 设置 GE 不需要梯度
set_requires_grad(self.GE, False)
# 根据 optimizer 参数选择优化器
if optimizer == "adam":
self.G_opt = Adam(self.G.parameters(), lr = lr, betas=(0.5, 0.9))
self.D_opt = Adam(self.D.parameters(), lr = lr * ttur_mult, betas=(0.5, 0.9))
elif optimizer == "adabelief":
self.G_opt = AdaBelief(self.G.parameters(), lr = lr, betas=(0.5, 0.9))
self.D_opt = AdaBelief(self.D.parameters(), lr = lr * ttur_mult, betas=(0.5, 0.9))
else:
assert False, "No valid optimizer is given"
# 初始化权重
self.apply(self._init_weights)
# 重置参数平均
self.reset_parameter_averaging()
# 将模型移动到 GPU
self.cuda(rank)
# 创建 D_aug 对象
self.D_aug = AugWrapper(self.D, image_size)
# 初始化权重函数
def _init_weights(self, m):
if type(m) in {nn.Conv2d, nn.Linear}:
nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in', nonlinearity='leaky_relu')
# 更新指数移动平均函数
def EMA(self):
def update_moving_average(ma_model, current_model):
for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
old_weight, up_weight = ma_params.data, current_params.data
ma_params.data = self.ema_updater.update_average(old_weight, up_weight)
for current_buffer, ma_buffer in zip(current_model.buffers(), ma_model.buffers()):
new_buffer_value = self.ema_updater.update_average(ma_buffer, current_buffer)
ma_buffer.copy_(new_buffer_value)
update_moving_average(self.GE, self.G)
# 重置参数平均函数
def reset_parameter_averaging(self):
self.GE.load_state_dict(self.G.state_dict())
# 前向传播函数,抛出异常
def forward(self, x):
raise NotImplemented
# trainer
class Trainer():
# 初始化函数,设置各种参数的默认值
def __init__(
self,
name = 'default', # 模型名称,默认为'default'
results_dir = 'results', # 结果保存目录,默认为'results'
models_dir = 'models', # 模型保存目录,默认为'models'
base_dir = './', # 基础目录,默认为当前目录
optimizer = 'adam', # 优化器,默认为'adam'
num_workers = None, # 工作进程数,默认为None
latent_dim = 256, # 潜在空间维度,默认为256
image_size = 128, # 图像尺寸,默认为128
num_image_tiles = 8, # 图像平铺数,默认为8
fmap_max = 512, # 特征图最大数量,默认为512
transparent = False, # 是否透明,默认为False
greyscale = False, # 是否灰度,默认为False
batch_size = 4, # 批量大小,默认为4
gp_weight = 10, # 梯度惩罚权重,默认为10
gradient_accumulate_every = 1, # 梯度积累频率,默认为1
attn_res_layers = [], # 注意力机制层,默认为空列表
freq_chan_attn = False, # 频道注意力,默认为False
disc_output_size = 5, # 判别器输出大小,默认为5
dual_contrast_loss = False, # 双对比损失,默认为False
antialias = False, # 抗锯齿,默认为False
lr = 2e-4, # 学习率,默认为2e-4
lr_mlp = 1., # 学习率倍增,默认为1.0
ttur_mult = 1., # TTUR倍增,默认为1.0
save_every = 1000, # 每隔多少步保存模型,默认为1000
evaluate_every = 1000, # 每隔多少步评估模型,默认为1000
aug_prob = None, # 数据增强概率,默认为None
aug_types = ['translation', 'cutout'], # 数据增强类型,默认为['translation', 'cutout']
dataset_aug_prob = 0., # 数据集增强概率,默认为0.0
calculate_fid_every = None, # 计算FID频率,默认为None
calculate_fid_num_images = 12800, # 计算FID所需图像数量,默认为12800
clear_fid_cache = False, # 清除FID缓存,默认为False
is_ddp = False, # 是否使用分布式数据并行,默认为False
rank = 0, # 进程排名,默认为0
world_size = 1, # 进程总数,默认为1
log = False, # 是否记录日志,默认为False
amp = False, # 是否使用自动混合精度,默认为False
hparams = None, # 超参数,默认为None
use_aim = True, # 是否使用AIM,默认为True
aim_repo = None, # AIM仓库,默认为None
aim_run_hash = None, # AIM运行哈希,默认为None
load_strict = True, # 是否严格加��模型,默认为True
*args, # 可变位置参数
**kwargs # 可变关键字参数
):
# 初始化 GAN 参数为传入的参数和关键字参数的元组
self.GAN_params = [args, kwargs]
# 初始化 GAN 为 None
self.GAN = None
# 设置名称
self.name = name
# 将 base_dir 转换为 Path 对象
base_dir = Path(base_dir)
self.base_dir = base_dir
# 设置结果目录和模型目录
self.results_dir = base_dir / results_dir
self.models_dir = base_dir / models_dir
self.fid_dir = base_dir / 'fid' / name
# 设置配置文件路径
self.config_path = self.models_dir / name / '.config.json'
# 检查图像大小是否为 2 的幂次方
assert is_power_of_two(image_size), 'image size must be a power of 2 (64, 128, 256, 512, 1024)'
# 检查注意力分辨率层是否都为 2 的幂次方
assert all(map(is_power_of_two, attn_res_layers)), 'resolution layers of attention must all be powers of 2 (16, 32, 64, 128, 256, 512)'
# 检查是否使用双对比损失时鉴别器输出大小是否大于 1
assert not (dual_contrast_loss and disc_output_size > 1), 'discriminator output size cannot be greater than 1 if using dual contrastive loss'
# 设置图像大小和图像瓦片数量
self.image_size = image_size
self.num_image_tiles = num_image_tiles
# 设置潜在空间维度、特征图最大值、透明度和灰度
self.latent_dim = latent_dim
self.fmap_max = fmap_max
self.transparent = transparent
self.greyscale = greyscale
# 检查是否只设置了透明度或灰度
assert (int(self.transparent) + int(self.greyscale)) < 2, 'you can only set either transparency or greyscale'
# 设置数据增强概率和类型
self.aug_prob = aug_prob
self.aug_types = aug_types
# 设置学习率、优化器、工作进程数、TTUR 倍数、批量大小、梯度累积步数
self.lr = lr
self.optimizer = optimizer
self.num_workers = num_workers
self.ttur_mult = ttur_mult
self.batch_size = batch_size
self.gradient_accumulate_every = gradient_accumulate_every
# 设置梯度惩罚权重
self.gp_weight = gp_weight
# 设置评估和保存频率
self.evaluate_every = evaluate_every
self.save_every = save_every
self.steps = 0
# 设置注意力分辨率层和频道注意力
self.attn_res_layers = attn_res_layers
self.freq_chan_attn = freq_chan_attn
# 设置鉴别���输出大小和抗锯齿
self.disc_output_size = disc_output_size
self.antialias = antialias
# 设置双对比损失
self.dual_contrast_loss = dual_contrast_loss
# 初始化损失和 FID
self.d_loss = 0
self.g_loss = 0
self.last_gp_loss = None
self.last_recon_loss = None
self.last_fid = None
# 初始化文件夹
self.init_folders()
# 初始化数据加载器和数据集增强概率
self.loader = None
self.dataset_aug_prob = dataset_aug_prob
# 设置计算 FID 的频率和图像数量
self.calculate_fid_every = calculate_fid_every
self.calculate_fid_num_images = calculate_fid_num_images
self.clear_fid_cache = clear_fid_cache
# 设置是否使用分布式数据并行
self.is_ddp = is_ddp
self.is_main = rank == 0
self.rank = rank
self.world_size = world_size
# 设置是否使用同步批归一化
self.syncbatchnorm = is_ddp
# 设置加载严格性
self.load_strict = load_strict
# 设置混合精度训练和梯度缩放器
self.amp = amp
self.G_scaler = GradScaler(enabled = self.amp)
self.D_scaler = GradScaler(enabled = self.amp)
# 初始化运行和超参数
self.run = None
self.hparams = hparams
# 如果是主进程且使用 AIM
if self.is_main and use_aim:
try:
import aim
self.aim = aim
except ImportError:
print('unable to import aim experiment tracker - please run `pip install aim` first')
# 创建 AIM 实验追踪器
self.run = self.aim.Run(run_hash=aim_run_hash, repo=aim_repo)
self.run['hparams'] = hparams
# 图像扩展名属性
@property
def image_extension(self):
return 'jpg' if not self.transparent else 'png'
# 检查点编号属性
@property
def checkpoint_num(self):
return floor(self.steps // self.save_every)
# 初始化 GAN 模型
def init_GAN(self):
# 获取 GAN 参数
args, kwargs = self.GAN_params
# 在实例化 GAN 之前设置一些全局变量
global norm_class
global Blur
# 根据条件选择使用 SyncBatchNorm 还是 BatchNorm2d
norm_class = nn.SyncBatchNorm if self.syncbatchnorm else nn.BatchNorm2d
# 根据条件选择使用 Identity 还是 Blur
Blur = nn.Identity if not self.antialias else Blur
# 处理从多 GPU 切换回单 GPU 时的 bug
if self.syncbatchnorm and not self.is_ddp:
import torch.distributed as dist
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group('nccl', rank=0, world_size=1)
# 实例化 GAN
self.GAN = LightweightGAN(
optimizer=self.optimizer,
lr = self.lr,
latent_dim = self.latent_dim,
attn_res_layers = self.attn_res_layers,
freq_chan_attn = self.freq_chan_attn,
image_size = self.image_size,
ttur_mult = self.ttur_mult,
fmap_max = self.fmap_max,
disc_output_size = self.disc_output_size,
transparent = self.transparent,
greyscale = self.greyscale,
rank = self.rank,
*args,
**kwargs
)
if self.is_ddp:
ddp_kwargs = {'device_ids': [self.rank], 'output_device': self.rank, 'find_unused_parameters': True}
# 使用分布式数据并行处理模型
self.G_ddp = DDP(self.GAN.G, **ddp_kwargs)
self.D_ddp = DDP(self.GAN.D, **ddp_kwargs)
self.D_aug_ddp = DDP(self.GAN.D_aug, **ddp_kwargs)
# 写入配置信息
def write_config(self):
self.config_path.write_text(json.dumps(self.config()))
# 加载配置信息
def load_config(self):
# 如果配置文件不存在,则使用默认配置
config = self.config() if not self.config_path.exists() else json.loads(self.config_path.read_text())
# 更新配置信息
self.image_size = config['image_size']
self.transparent = config['transparent']
self.syncbatchnorm = config['syncbatchnorm']
self.disc_output_size = config['disc_output_size']
self.greyscale = config.pop('greyscale', False)
self.attn_res_layers = config.pop('attn_res_layers', [])
self.freq_chan_attn = config.pop('freq_chan_attn', False)
self.optimizer = config.pop('optimizer', 'adam')
self.fmap_max = config.pop('fmap_max', 512)
del self.GAN
# 重新初始化 GAN 模型
self.init_GAN()
# 返回配置信息
def config(self):
return {
'image_size': self.image_size,
'transparent': self.transparent,
'greyscale': self.greyscale,
'syncbatchnorm': self.syncbatchnorm,
'disc_output_size': self.disc_output_size,
'optimizer': self.optimizer,
'attn_res_layers': self.attn_res_layers,
'freq_chan_attn': self.freq_chan_attn
}
# 设置数据源
def set_data_src(self, folder):
# 计算并设置数据加载器的工作进程数
num_workers = default(self.num_workers, math.ceil(NUM_CORES / self.world_size))
# 创建数据集
self.dataset = ImageDataset(folder, self.image_size, transparent = self.transparent, greyscale = self.greyscale, aug_prob = self.dataset_aug_prob)
# 创建分布式采样器
sampler = DistributedSampler(self.dataset, rank=self.rank, num_replicas=self.world_size, shuffle=True) if self.is_ddp else None
# 创建数据加载器
dataloader = DataLoader(self.dataset, num_workers = num_workers, batch_size = math.ceil(self.batch_size / self.world_size), sampler = sampler, shuffle = not self.is_ddp, drop_last = True, pin_memory = True)
self.loader = cycle(dataloader)
# 如果数据集检测到样本数量较少,则自动设置数据增强概率
num_samples = len(self.dataset)
if not exists(self.aug_prob) and num_samples < 1e5:
self.aug_prob = min(0.5, (1e5 - num_samples) * 3e-6)
print(f'autosetting augmentation probability to {round(self.aug_prob * 100)}%')
# 禁用梯度计算
@torch.no_grad()
# 定义一个评估函数,用于生成图像
def evaluate(self, num = 0, num_image_tiles = 4):
# 将 GAN 设置为评估模式
self.GAN.eval()
# 获取图像文件的扩展名
ext = self.image_extension
# 设置图像展示的行数
num_rows = num_image_tiles
# 获取潜在空间的维度和图像的尺寸
latent_dim = self.GAN.latent_dim
image_size = self.GAN.image_size
# 将图像转换为 PIL 格式的函数
def image_to_pil(image):
# 将图像转换为 PIL 图像格式
ndarr = image.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()
im = Image.fromarray(ndarr)
return im
# 生成潜在空间和噪声
latents = det_randn((num_rows ** 2, latent_dim)).cuda(self.rank)
interpolate_latents = interpolate_between(latents[:num_rows], latents[-num_rows:],
num_samples=num_rows,
dim=0).flatten(end_dim=1)
# 生成插值图像
generate_interpolations = self.generate_(self.GAN.G, interpolate_latents)
if self.run is not None:
# 将生成的插值图像分组
grouped = generate_interpolations.view(num_rows, num_rows, *generate_interpolations.shape[1:])
for idx, images in enumerate(grouped):
alpha = idx / (len(grouped) - 1)
aim_images = []
for image in images:
im = image_to_pil(image)
aim_images.append(self.aim.Image(im, caption=f'#{idx}'))
# 跟踪生成的图像
self.run.track(value=aim_images, name='generated',
step=self.steps,
context={'interpolated': True,
'alpha': alpha})
# 保存生成的插值图像
torchvision.utils.save_image(generate_interpolations, str(self.results_dir / self.name / f'{str(num)}-interp.{ext}'), nrow=num_rows)
# 生成正常图像
generated_images = self.generate_(self.GAN.G, latents)
if self.run is not None:
aim_images = []
for idx, image in enumerate(generated_images):
im = image_to_pil(image)
aim_images.append(self.aim.Image(im, caption=f'#{idx}'))
# 跟踪生成的图像
self.run.track(value=aim_images, name='generated',
step=self.steps,
context={'ema': False})
# 保存生成的正常图像
torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}.{ext}'), nrow=num_rows)
# 生成移动平均图像
generated_images = self.generate_(self.GAN.GE, latents)
if self.run is not None:
aim_images = []
for idx, image in enumerate(generated_images):
im = image_to_pil(image)
aim_images.append(self.aim.Image(im, caption=f'EMA #{idx}'))
# 跟踪生成的图像
self.run.track(value=aim_images, name='generated',
step=self.steps,
context={'ema': True})
# 保存生成的移动平均图像
torchvision.utils.save_image(generated_images, str(self.results_dir / self.name / f'{str(num)}-ema.{ext}'), nrow=num_rows)
# 禁用梯度计算
@torch.no_grad()
# 生成图片,可以指定生成数量、图像瓦片数量、检查点、类型
def generate(self, num=0, num_image_tiles=4, checkpoint=None, types=['default', 'ema']):
# 将 GAN 设置为评估模式
self.GAN.eval()
# 获取潜在空间维度
latent_dim = self.GAN.latent_dim
# 生成目录名
dir_name = self.name + str('-generated-') + str(checkpoint)
# 生成完整目录路径
dir_full = Path().absolute() / self.results_dir / dir_name
# 图像文件扩展名
ext = self.image_extension
# 如果目录不存在,则创建
if not dir_full.exists():
os.mkdir(dir_full)
# 生成默认类型的图片
if 'default' in types:
for i in tqdm(range(num_image_tiles), desc='Saving generated default images'):
# 生成随机潜在向量
latents = torch.randn((1, latent_dim)).cuda(self.rank)
# 生成图片
generated_image = self.generate_(self.GAN.G, latents)
# 生成图片路径
path = str(self.results_dir / dir_name / f'{str(num)}-{str(i)}.{ext}')
# 保存生成的图片
torchvision.utils.save_image(generated_image[0], path, nrow=1)
# 生成EMA类型的图片
if 'ema' in types:
for i in tqdm(range(num_image_tiles), desc='Saving generated EMA images'):
# 生成随机潜在向量
latents = torch.randn((1, latent_dim)).cuda(self.rank)
# 生成图片
generated_image = self.generate_(self.GAN.GE, latents)
# 生成图片路径
path = str(self.results_dir / dir_name / f'{str(num)}-{str(i)}-ema.{ext}')
# 保存生成的图片
torchvision.utils.save_image(generated_image[0], path, nrow=1)
# 返回生成图片的目录路径
return dir_full
# 用于显示训练进度的方法
@torch.no_grad()
def show_progress(self, num_images=4, types=['default', 'ema']):
# 获取所有检查点
checkpoints = self.get_checkpoints()
# 检查是否存在检查点
assert exists(checkpoints), 'cannot find any checkpoints to create a training progress video for'
# 进度目录名
dir_name = self.name + str('-progress')
# 进度完整目录路径
dir_full = Path().absolute() / self.results_dir / dir_name
# 图像文件扩展名
ext = self.image_extension
# 潜在向量初始��为None
latents = None
# 计算检查点数字的位数
zfill_length = math.ceil(math.log10(len(checkpoints)))
# 如果目录不存在,则创建
if not dir_full.exists():
os.mkdir(dir_full)
# 遍历所有检查点
for checkpoint in tqdm(checkpoints, desc='Generating progress images'):
# 加载模型参数
self.load(checkpoint, print_version=False)
# 将 GAN 设置为评估模式
self.GAN.eval()
# 如果是第一个检查点,生成随机潜在向量
if checkpoint == 0:
latents = torch.randn((num_images, self.GAN.latent_dim)).cuda(self.rank)
# 生成默认类型的图片
if 'default' in types:
generated_image = self.generate_(self.GAN.G, latents)
# 生成图片路径
path = str(self.results_dir / dir_name / f'{str(checkpoint).zfill(zfill_length)}.{ext}')
# 保存生成的图片
torchvision.utils.save_image(generated_image, path, nrow=num_images)
# 生成EMA��型的图片
if 'ema' in types:
generated_image = self.generate_(self.GAN.GE, latents)
# 生成图片路径
path = str(self.results_dir / dir_name / f'{str(checkpoint).zfill(zfill_length)}-ema.{ext}')
# 保存生成的图片
torchvision.utils.save_image(generated_image, path, nrow=num_images)
# 用于禁用梯度计算的装饰器
@torch.no_grad()
# 计算 FID 分数
def calculate_fid(self, num_batches):
# 导入 FID 分数计算模块
from pytorch_fid import fid_score
# 清空 GPU 缓存
torch.cuda.empty_cache()
# 设置真实图片和生成图片的路径
real_path = self.fid_dir / 'real'
fake_path = self.fid_dir / 'fake'
# 如果不存在真实图片路径或需要清除 FID 缓存,则删除现有文件并重新创建目录
if not real_path.exists() or self.clear_fid_cache:
rmtree(real_path, ignore_errors=True)
os.makedirs(real_path)
# 保存真实图片
for batch_num in tqdm(range(num_batches), desc='calculating FID - saving reals'):
real_batch = next(self.loader)
for k, image in enumerate(real_batch.unbind(0)):
ind = k + batch_num * self.batch_size
torchvision.utils.save_image(image, real_path / f'{ind}.png')
# 删除生成图片路径并重新创建目录
rmtree(fake_path, ignore_errors=True)
os.makedirs(fake_path)
# 设置生成器为评估模式
self.GAN.eval()
ext = self.image_extension
latent_dim = self.GAN.latent_dim
image_size = self.GAN.image_size
# 生成假图片
for batch_num in tqdm(range(num_batches), desc='calculating FID - saving generated'):
# 生成潜在向量和噪声
latents = torch.randn(self.batch_size, latent_dim).cuda(self.rank)
# 生成图片
generated_images = self.generate_(self.GAN.GE, latents)
for j, image in enumerate(generated_images.unbind(0)):
ind = j + batch_num * self.batch_size
torchvision.utils.save_image(image, str(fake_path / f'{str(ind)}-ema.{ext}'))
# 返回 FID 分数
return fid_score.calculate_fid_given_paths([str(real_path), str(fake_path)], 256, latents.device, 2048)
# 生成图片
@torch.no_grad()
def generate_(self, G, style, num_image_tiles = 8):
# 评估生成器
generated_images = evaluate_in_chunks(self.batch_size, G, style)
return generated_images.clamp_(0., 1.)
# 生成插值图片
@torch.no_grad()
def generate_interpolation(self, num = 0, num_image_tiles = 8, num_steps = 100, save_frames = False):
# 设置生成器为评估模式
self.GAN.eval()
ext = self.image_extension
num_rows = num_image_tiles
latent_dim = self.GAN.latent_dim
image_size = self.GAN.image_size
# 生成潜在向量和噪声
latents_low = torch.randn(num_rows ** 2, latent_dim).cuda(self.rank)
latents_high = torch.randn(num_rows ** 2, latent_dim).cuda(self.rank)
# 生成插值比例
ratios = torch.linspace(0., 8., num_steps)
frames = []
for ratio in tqdm(ratios):
# 线性插值生成潜在向量
interp_latents = slerp(ratio, latents_low, latents_high)
generated_images = self.generate_(self.GAN.GE, interp_latents)
images_grid = torchvision.utils.make_grid(generated_images, nrow = num_rows)
pil_image = transforms.ToPILImage()(images_grid.cpu())
# 如果需要透明背景,则设置透明度
if self.transparent:
background = Image.new('RGBA', pil_image.size, (255, 255, 255))
pil_image = Image.alpha_composite(background, pil_image)
frames.append(pil_image)
# 保存插值图片为 GIF
frames[0].save(str(self.results_dir / self.name / f'{str(num)}.gif'), save_all=True, append_images=frames[1:], duration=80, loop=0, optimize=True)
# 如果需要保存每一帧图片
if save_frames:
folder_path = (self.results_dir / self.name / f'{str(num)}')
folder_path.mkdir(parents=True, exist_ok=True)
for ind, frame in enumerate(frames):
frame.save(str(folder_path / f'{str(ind)}.{ext}'))
# 打印训练日志信息
def print_log(self):
# 定义包含损失信息的数据列表
data = [
('G', self.g_loss),
('D', self.d_loss),
('GP', self.last_gp_loss),
('SS', self.last_recon_loss),
('FID', self.last_fid)
]
# 过滤掉值为 None 的数据
data = [d for d in data if exists(d[1])]
# 将数据转换为字符串格式,用 '|' 连接
log = ' | '.join(map(lambda n: f'{n[0]}: {n[1]:.2f}', data))
# 打印日志信息
print(log)
# 如果存在运行实例,则追踪数据
if self.run is not None:
for key, value in data:
self.run.track(value, key, step=self.steps)
# 返回数据列表
return data
# 返回模型文件名
def model_name(self, num):
return str(self.models_dir / self.name / f'model_{num}.pt')
# 初始化文件夹
def init_folders(self):
# 创建结果目录和模型目录
(self.results_dir / self.name).mkdir(parents=True, exist_ok=True)
(self.models_dir / self.name).mkdir(parents=True, exist_ok=True)
# 清空文件夹
def clear(self):
# 删除模型目录、结果目录、FID 目录和配置文件路径
rmtree(str(self.models_dir / self.name), True)
rmtree(str(self.results_dir / self.name), True)
rmtree(str(self.fid_dir), True)
rmtree(str(self.config_path), True)
# 初始化文件夹
self.init_folders()
# 保存模型
def save(self, num):
# 保存模型相关数据
save_data = {
'GAN': self.GAN.state_dict(),
'version': __version__,
'G_scaler': self.G_scaler.state_dict(),
'D_scaler': self.D_scaler.state_dict()
}
# 将数据保存到模型文件中
torch.save(save_data, self.model_name(num))
# 写入配置文件
self.write_config()
# 加载模型
def load(self, num=-1, print_version=True):
# 加载配置文件
self.load_config()
name = num
if num == -1:
# 获取已保存的检查点
checkpoints = self.get_checkpoints()
if not exists(checkpoints):
return
name = checkpoints[-1]
print(f'continuing from previous epoch - {name}')
self.steps = name * self.save_every
# 加载模型数据
load_data = torch.load(self.model_name(name))
if print_version and 'version' in load_data and self.is_main:
print(f"loading from version {load_data['version']}")
try:
self.GAN.load_state_dict(load_data['GAN'], strict=self.load_strict)
except Exception as e:
saved_version = load_data['version']
print('unable to load save model. please try downgrading the package to the version specified by the saved model (to do so, just run `pip install lightweight-gan=={saved_version}`')
raise e
if 'G_scaler' in load_data:
self.G_scaler.load_state_dict(load_data['G_scaler'])
if 'D_scaler' in load_data:
self.D_scaler.load_state_dict(load_data['D_scaler'])
# 获取已保存的检查点
def get_checkpoints(self):
# 获取模型目录下所有模型文件路径
file_paths = [p for p in Path(self.models_dir / self.name).glob('model_*.pt')]
# 提取已保存的模型编号
saved_nums = sorted(map(lambda x: int(x.stem.split('_')[1]), file_paths))
if len(saved_nums) == 0:
return None
return saved_nums
.\lucidrains\lightweight-gan\lightweight_gan\version.py
# 定义当前代码的版本号为 '1.1.1'
__version__ = '1.1.1'
.\lucidrains\lightweight-gan\lightweight_gan\__init__.py
# 从 lightweight_gan.lightweight_gan 模块中导入 LightweightGAN、Generator、Discriminator、Trainer 和 NanException 类
# 从 kornia.filters 模块中导入 filter2d 函数
from lightweight_gan.lightweight_gan import LightweightGAN, Generator, Discriminator, Trainer, NanException
from kornia.filters import filter2d

512x512 flowers after 12 hours of training, 1 gpu

256x256 flowers after 12 hours of training, 1 gpu

Pizza
'Lightweight' GAN
![]()
Implementation of 'lightweight' GAN proposed in ICLR 2021, in Pytorch. The main contributions of the paper is a skip-layer excitation in the generator, paired with autoencoding self-supervised learning in the discriminator. Quoting the one-line summary "converge on single gpu with few hours' training, on 1024 resolution sub-hundred images".
Install
$ pip install lightweight-gan
Use
One command
$ lightweight_gan --data ./path/to/images --image-size 512
Model will be saved to ./models/{name} every 1000 iterations, and samples from the model saved to ./results/{name}. name will be default, by default.
Training settings
Pretty self explanatory for deep learning practitioners
$ lightweight_gan \
--data ./path/to/images \
--name {name of run} \
--batch-size 16 \
--gradient-accumulate-every 4 \
--num-train-steps 200000
Augmentation
Augmentation is essential for Lightweight GAN to work effectively in a low data setting
By default, the augmentation types is set to translation and cutout, with color omitted. You can include color as well with the following.
$ lightweight_gan --data ./path/to/images --aug-prob 0.25 --aug-types [translation,cutout,color]
Test augmentation
You can test and see how your images will be augmented before it pass into a neural network (if you use augmentation). Let's see how it works on this image:

Basic usage
Base code to augment your image, define --aug-test and put path to your image into --data:
lightweight_gan \
--aug-test \
--data ./path/to/lena.jpg
After this will be created the file lena_augs.jpg that will be look something like this:

Options
You can use some options to change result:
--image-size 256to change size of image tiles in the result. Default:256.--aug-type [color,cutout,translation]to combine several augmentations. Default:[cutout,translation].--batch-size 10to change count of images in the result image. Default:10.--num-image-tiles 5to change count of tiles in the result image. Default:5.
Try this command:
lightweight_gan \
--aug-test \
--data ./path/to/lena.jpg \
--batch-size 16 \
--num-image-tiles 4 \
--aug-types [color,translation]
result wil be something like that:

Types of augmentations
This library contains several types of embedded augmentations.
Some of these works by default, some of these can be controlled from a command as options in the --aug-types:
- Horizontal flip (work by default, not under control, runs in the AugWrapper class);
colorrandomly change brightness, saturation and contrast;cutoutcreates random black boxes on the image;offsetrandomly moves image by x and y-axis with repeating image;offset_honly by an x-axis;offset_vonly by a y-axis;
translationrandomly moves image on the canvas with black background;
Full setup of augmentations is --aug-types [color,cutout,offset,translation].
General recommendation is using suitable augs for your data and as many as possible, then after sometime of training disable most destructive (for image) augs.
Color

Cutout

Offset

Only x-axis:

Only y-axis:

Translation
![]()
Mixed precision
You can turn on automatic mixed precision with one flag --amp
You should expect it to be 33% faster and save up to 40% memory
Multiple GPUs
Also one flag to use --multi-gpus
Visualizing training insights with Aim
Aim is an open-source experiment tracker that logs your training runs, enables a beautiful UI to compare them and an API to query them programmatically.
First you need to install aim with pip
$ pip install aim
Next, you can specify Aim logs directory with --aim_repo flag, otherwise logs will be stored in the current directory
$ lightweight_gan --data ./path/to/images --image-size 512 --use-aim --aim_repo ./path/to/logs/
Execute aim up --repo ./path/to/logs/ to run Aim UI on your server.
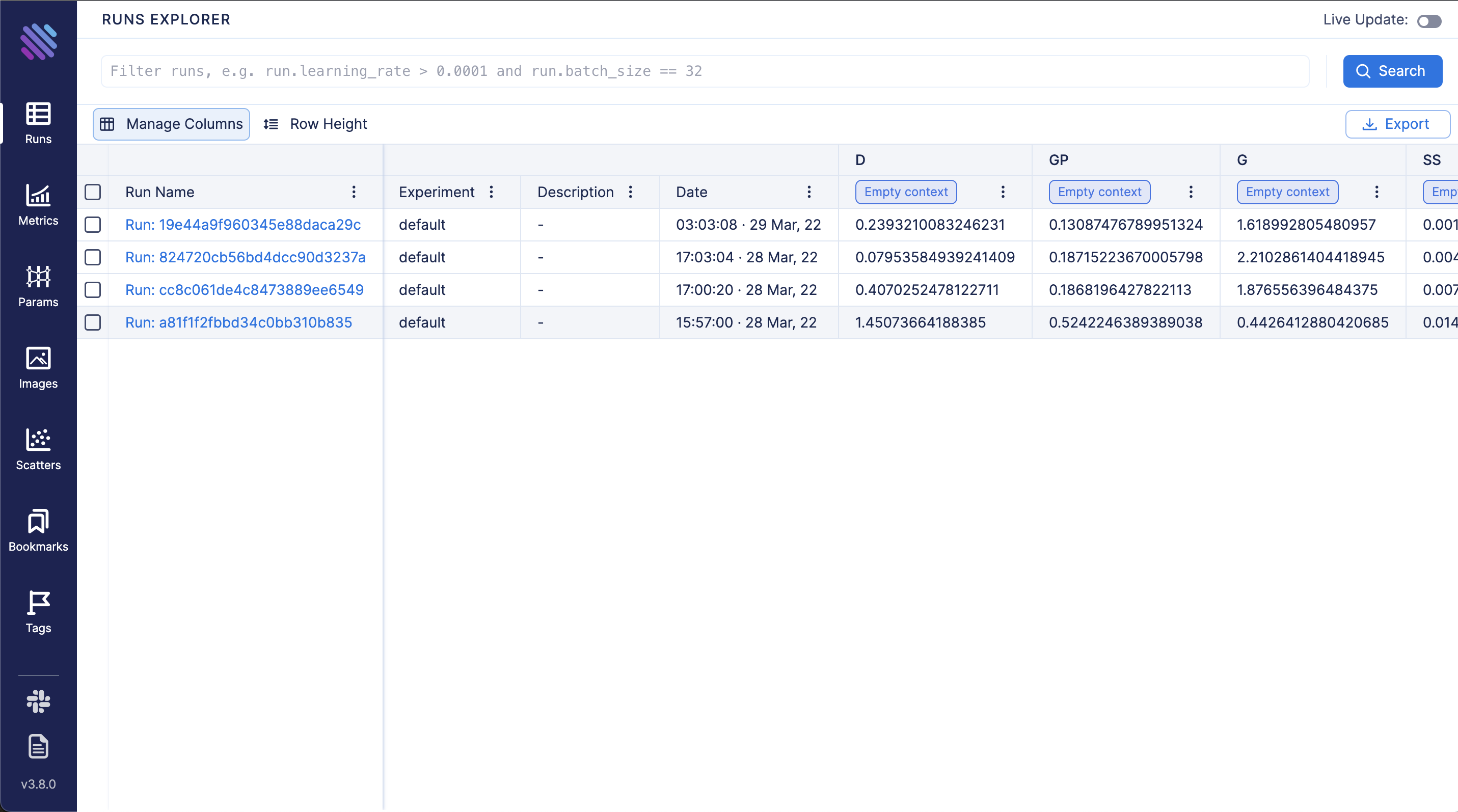
View all tracked runs, each metric last tracked values and tracked hyperparameters in Runs Dashboard:
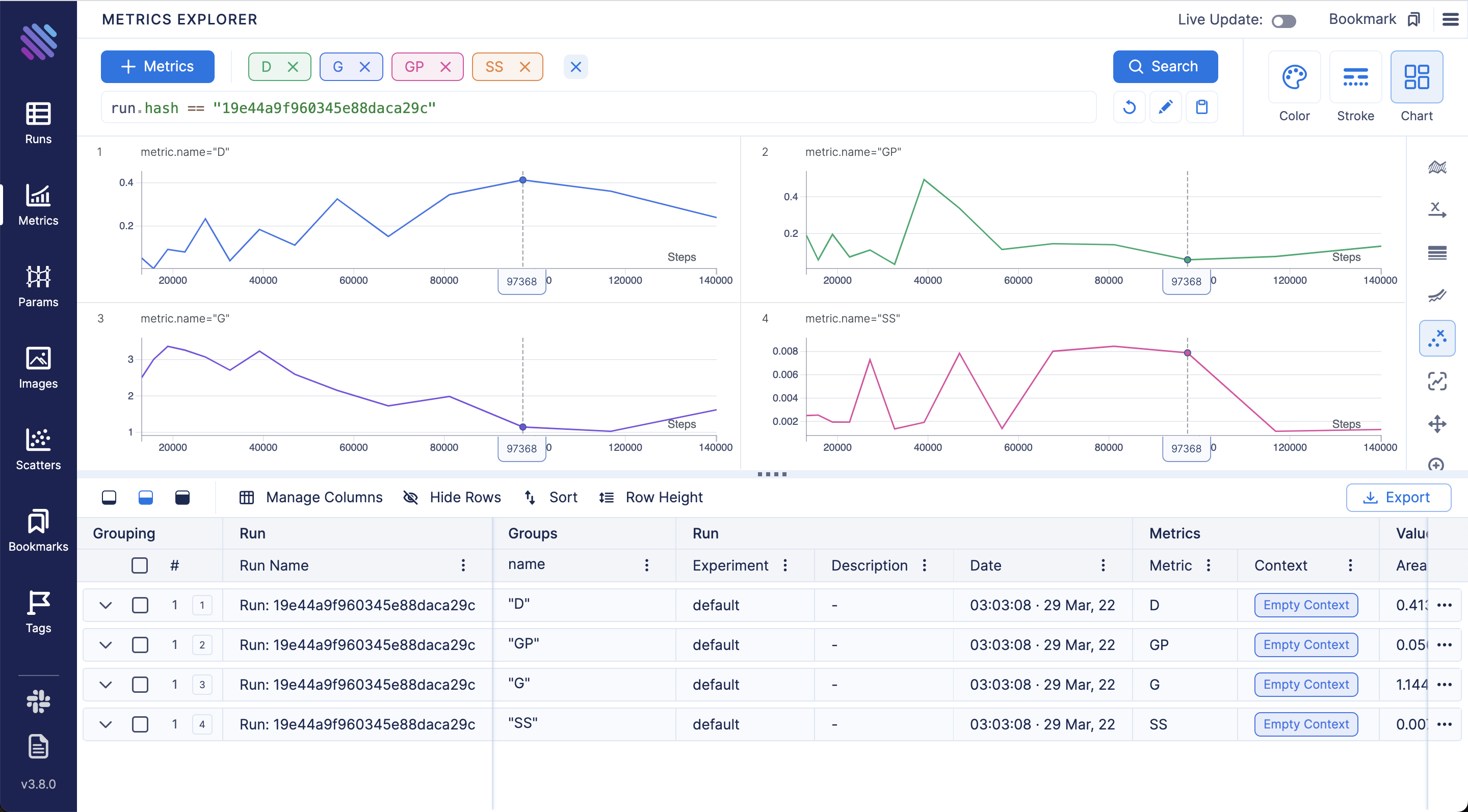
Compare loss curves with Metrics Explorer - group and aggregate by any hyperparameter to easily compare the runs:
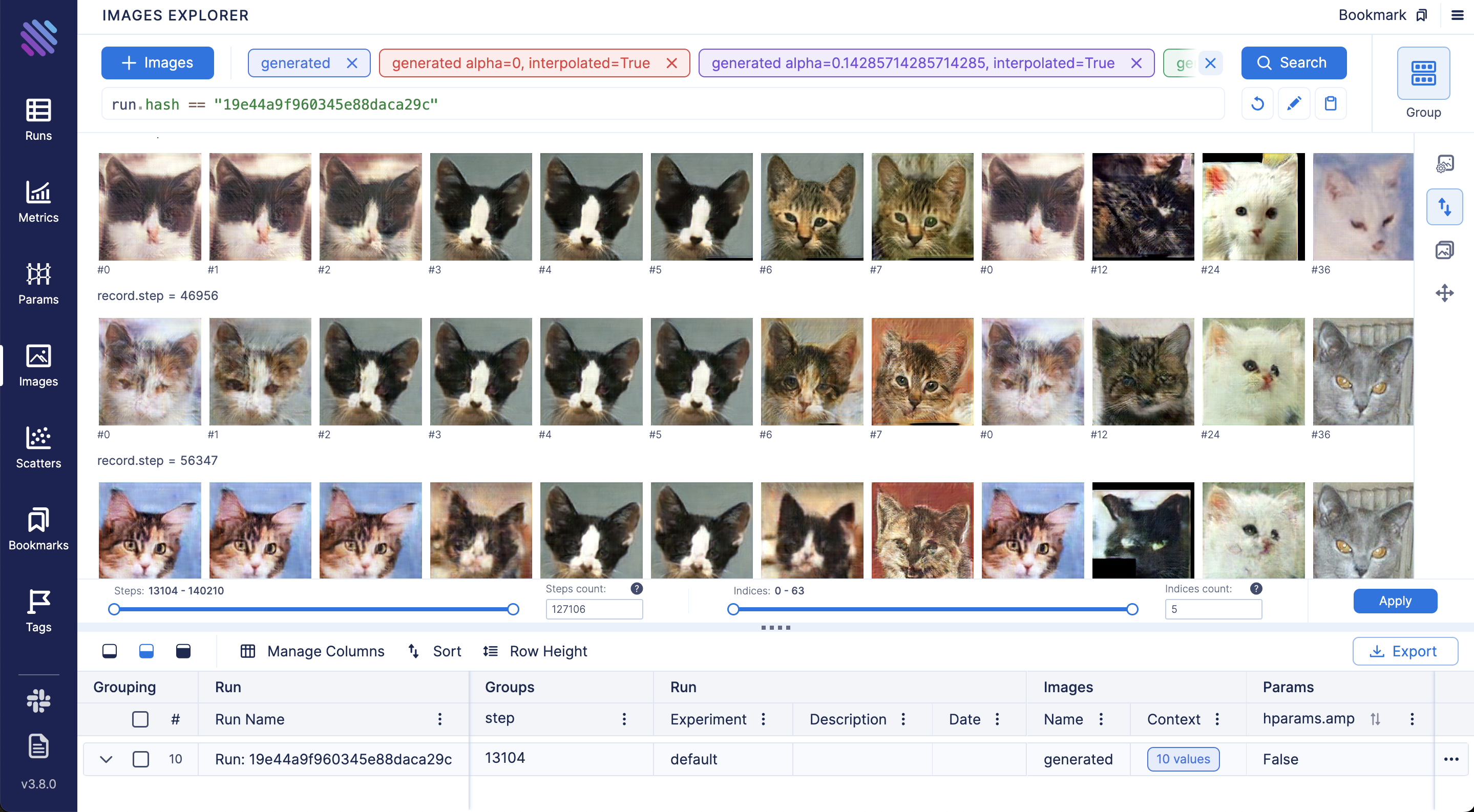
Compare and debug generated images across training steps and runs via Images Explorer:
Generating
Once you have finished training, you can generate samples with one command. You can select which checkpoint number to load from. If --load-from is not specified, will default to the latest.
$ lightweight_gan \
--name {name of run} \
--load-from {checkpoint num} \
--generate \
--generate-types {types of result, default: [default,ema]} \
--num-image-tiles {count of image result}
After run this command you will get folder near results image folder with postfix "-generated-{checkpoint num}".
You can also generate interpolations
$ lightweight_gan --name {name of run} --generate-interpolation
Show progress
After creating several checkpoints of model you can generate progress as sequence images by command:
$ lightweight_gan \
--name {name of run} \
--show-progress \
--generate-types {types of result, default: [default,ema]} \
--num-image-tiles {count of image result}
After running this command you will get a new folder in the results folder, with postfix "-progress". You can convert the images to a video with ffmpeg using the command "ffmpeg -framerate 10 -pattern_type glob -i '*-ema.jpg' out.mp4".

Discriminator output size
The author has kindly let me know that the discriminator output size (5x5 vs 1x1) leads to different results on different datasets. (5x5 works better for art than for faces, as an example). You can toggle this with a single flag
# disc output size is by default 1x1
$ lightweight_gan --data ./path/to/art --image-size 512 --disc-output-size 5
Attention
You can add linear + axial attention to specific resolution layers with the following
# make sure there are no spaces between the values within the brackets []
$ lightweight_gan --data ./path/to/images --image-size 512 --attn-res-layers [32,64] --aug-prob 0.25
Dual Contrastive Loss
A recent paper has proposed that a novel contrastive loss between the real and fake logits can improve quality slightly over the default hinge loss.
You can use this with one extra flag as follows
$ lightweight_gan --data ./path/to/images --dual-contrast-loss
Bonus
You can also train with transparent images
$ lightweight_gan --data ./path/to/images --transparent
Or greyscale
$ lightweight_gan --data ./path/to/images --greyscale
Alternatives
If you want the current state of the art GAN, you can find it at https://github.com/lucidrains/stylegan2-pytorch
Citations
@inproceedings{
anonymous2021towards,
title = {Towards Faster and Stabilized {\{}GAN{\}} Training for High-fidelity Few-shot Image Synthesis},
author = {Anonymous},
booktitle = {Submitted to International Conference on Learning Representations},
year = {2021},
url = {https://openreview.net/forum?id=1Fqg133qRaI},
note = {under review}
}
@misc{cao2020global,
title = {Global Context Networks},
author = {Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu},
year = {2020},
eprint = {2012.13375},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{qin2020fcanet,
title = {FcaNet: Frequency Channel Attention Networks},
author = {Zequn Qin and Pengyi Zhang and Fei Wu and Xi Li},
year = {2020},
eprint = {2012.11879},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{yu2021dual,
title = {Dual Contrastive Loss and Attention for GANs},
author = {Ning Yu and Guilin Liu and Aysegul Dundar and Andrew Tao and Bryan Catanzaro and Larry Davis and Mario Fritz},
year = {2021},
eprint = {2103.16748},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@article{Sunkara2022NoMS,
title = {No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects},
author = {Raja Sunkara and Tie Luo},
journal = {ArXiv},
year = {2022},
volume = {abs/2208.03641}
}
What I cannot create, I do not understand - Richard Feynman
.\lucidrains\lightweight-gan\setup.py
# 导入 sys 模块
import sys
# 从 setuptools 模块中导入 setup 和 find_packages 函数
from setuptools import setup, find_packages
# 将 lightweight_gan 模块添加到 sys.path 中
sys.path[0:0] = ['lightweight_gan']
# 从 version 模块中导入 __version__ 变量
from version import __version__
# 设置包的元数据和配置信息
setup(
# 包的名称
name = 'lightweight-gan',
# 查找并包含所有包
packages = find_packages(),
# 设置入口点,命令行脚本 lightweight_gan 调用 lightweight_gan.cli 模块的 main 函数
entry_points={
'console_scripts': [
'lightweight_gan = lightweight_gan.cli:main',
],
},
# 版本号
version = __version__,
# 许可证
license='MIT',
# 描述
description = 'Lightweight GAN',
# 作者
author = 'Phil Wang',
# 作者邮箱
author_email = 'lucidrains@gmail.com',
# 项目 URL
url = 'https://github.com/lucidrains/lightweight-gan',
# 关键词
keywords = [
'artificial intelligence',
'deep learning',
'generative adversarial networks'
],
# 安装依赖
install_requires=[
'adabelief-pytorch',
'einops>=0.3',
'fire',
'kornia>=0.5.4',
'numpy',
'pillow',
'retry',
'torch>=1.10',
'torchvision',
'tqdm'
],
# 分类
classifiers=[
'Development Status :: 4 - Beta',
'Intended Audience :: Developers',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
'License :: OSI Approved :: MIT License',
'Programming Language :: Python :: 3.6',
],
)
Data source
The enwik8 data was downloaded from the Hutter prize page: http://prize.hutter1.net/
Linear Attention Transformer with Deepspeed for Enwik8
Deepspeed is the framework Microsoft used to train the world's largest Attention model (17GB) to date.
-
First install Deepspeed following instructions from their official repository https://github.com/microsoft/DeepSpeed
-
Run the following command in this folder
$ deepspeed train.py --deepspeed --deepspeed_config ds_config.json
.\lucidrains\linear-attention-transformer\examples\enwik8_deepspeed\train.py
# 导入 deepspeed 库
import deepspeed
# 从 linear_attention_transformer 模块中导入 LinearAttentionTransformerLM 类
from linear_attention_transformer import LinearAttentionTransformerLM
# 从 linear_attention_transformer.autoregressive_wrapper 模块中导入 AutoregressiveWrapper 类
from linear_attention_transformer.autoregressive_wrapper import AutoregressiveWrapper
# 导入 argparse 库
import argparse
import random
import tqdm
import gzip
import numpy as np
import torch
import torch.optim as optim
from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
# 定义函数 add_argument,用于解析命令行参数
def add_argument():
parser=argparse.ArgumentParser(description='enwik8')
# 添加命令行参数
parser.add_argument('--with_cuda', default=False, action='store_true',
help='use CPU in case there\'s no GPU support')
parser.add_argument('--use_ema', default=False, action='store_true',
help='whether use exponential moving average')
parser.add_argument('-b', '--batch_size', default=32, type=int,
help='mini-batch size (default: 32)')
parser.add_argument('-e', '--epochs', default=30, type=int,
help='number of total epochs (default: 30)')
parser.add_argument('--local_rank', type=int, default=-1,
help='local rank passed from distributed launcher')
# 添加 deepspeed 配置参数
parser = deepspeed.add_config_arguments(parser)
# 解析命令行参数
args = parser.parse_args()
return args
# 定义常量
VALIDATE_EVERY = 100
GENERATE_EVERY = 500
GENERATE_LENGTH = 1024
SEQ_LEN = 4096
# 定义辅助函数
# 解码单个 token
def decode_token(token):
return str(chr(max(32, token)))
# 解码一组 tokens
def decode_tokens(tokens):
return ''.join(list(map(decode_token, tokens)))
# 实例化模型
# 创建 LinearAttentionTransformerLM 模型对象
model = LinearAttentionTransformerLM(
num_tokens = 256,
dim = 512,
depth = 8,
max_seq_len = SEQ_LEN,
heads = 8,
causal = True,
reversible = True,
blindspot_size = 2,
shift_tokens = True,
n_local_attn_heads = (8, 8, 8, 8, 4, 4, 2, 2)
)
# 将模型包装在 AutoregressiveWrapper 中
model = AutoregressiveWrapper(model)
# 将模型移动到 GPU
model.cuda()
# 准备 enwik8 数据
# 使用 gzip 打开 enwik8 数据文件
with gzip.open('./data/enwik8.gz') as file:
# 从文件中读取数据并转换为 numpy 数组
X = np.fromstring(file.read(int(95e6)), dtype=np.uint8)
# 将数据分为训练集和验证集
trX, vaX = np.split(X, [int(90e6)])
# 将数据转换为 PyTorch 张量
data_train, data_val = torch.from_numpy(trX), torch.from_numpy(vaX)
# 定义 TextSamplerDataset 类,用于创建数据集
class TextSamplerDataset(Dataset):
def __init__(self, data, seq_len):
super().__init__()
self.data = data
self.seq_len = seq_len
def __getitem__(self, index):
rand_start = torch.randint(0, self.data.size(0) - self.seq_len - 1, (1,))
full_seq = self.data[rand_start: rand_start + self.seq_len + 1].long()
return full_seq, torch.ones_like(full_seq).bool()
def __len__(self):
return self.data.size(0) // self.seq_len
# 创建训练集和验证集数据集对象
train_dataset = TextSamplerDataset(data_train, SEQ_LEN)
val_dataset = TextSamplerDataset(data_val, SEQ_LEN)
# 设置 deepspeed
# 解析命令行参数
cmd_args = add_argument()
# 初始化 deepspeed
model_engine, optimizer, trainloader, _ = deepspeed.initialize(args=cmd_args, model=model, model_parameters=model.parameters(), training_data=train_dataset)
# 训练
# 遍历训练数据加载器
for i, (data, mask) in enumerate(trainloader):
model_engine.train()
# 将数据移动到指定设备
data = data.to(model_engine.local_rank)
# 计算损失
loss = model_engine(data, return_loss = True, randomly_truncate_sequence = True)
# 反向传播
model_engine.backward(loss)
# 更新参数
model_engine.step()
print(loss.item())
if i % VALIDATE_EVERY == 0:
model.eval()
with torch.no_grad():
inp, _ = random.choice(val_dataset)
loss = model(inp[None, :].cuda(), return_loss = True)
print(f'validation loss: {loss.item()}')
if i != 0 and model_engine.local_rank == 0 and i % GENERATE_EVERY == 0:
model.eval()
inp, _ = random.choice(val_dataset)
print(inp.shape, inp)
prime = decode_tokens(inp)
print(f'%s \n\n %s', (prime, '*' * 100))
sample = model.generate(inp.cuda(), GENERATE_LENGTH)
output_str = decode_tokens(sample)
print(output_str)
Data source
The enwik8 data was downloaded from the Hutter prize page: http://prize.hutter1.net/
.\lucidrains\linear-attention-transformer\examples\enwik8_simple\train.py
# 导入所需的库和模块
from linear_attention_transformer import LinearAttentionTransformerLM
from linear_attention_transformer.autoregressive_wrapper import AutoregressiveWrapper
from product_key_memory import fetch_optimizer_parameters
import random
import tqdm
import gzip
import numpy as np
import torch
import torch.optim as optim
from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
# 定义常量
NUM_BATCHES = int(1e5)
BATCH_SIZE = 4
GRADIENT_ACCUMULATE_EVERY = 4
LEARNING_RATE = 1e-4
VALIDATE_EVERY = 100
GENERATE_EVERY = 500
GENERATE_LENGTH = 512
SEQ_LEN = 4096
# 定义辅助函数
def cycle(loader):
# 无限循环生成数据
while True:
for data in loader:
yield data
def decode_token(token):
# 将 token 解码为字符
return str(chr(max(32, token)))
def decode_tokens(tokens):
# 将 tokens 解码为字符串
return ''.join(list(map(decode_token, tokens)))
# 实例化模型
model = LinearAttentionTransformerLM(
num_tokens = 256,
dim = 512,
depth = 6,
max_seq_len = SEQ_LEN,
heads = 8,
causal = True,
shift_tokens = True,
pkm_layers = (4,)
)
model = AutoregressiveWrapper(model)
model.cuda()
# 准备 enwik8 数据
with gzip.open('./data/enwik8.gz') as file:
X = np.fromstring(file.read(int(95e6)), dtype=np.uint8)
trX, vaX = np.split(X, [int(90e6)])
data_train, data_val = torch.from_numpy(trX), torch.from_numpy(vaX)
# 定义数据集类
class TextSamplerDataset(Dataset):
def __init__(self, data, seq_len):
super().__init__()
self.data = data
self.seq_len = seq_len
def __getitem__(self, index):
rand_start = torch.randint(0, self.data.size(0) - self.seq_len - 1, (1,))
full_seq = self.data[rand_start: rand_start + self.seq_len + 1].long()
return full_seq.cuda()
def __len__(self):
return self.data.size(0) // self.seq_len
train_dataset = TextSamplerDataset(data_train, SEQ_LEN)
val_dataset = TextSamplerDataset(data_val, SEQ_LEN)
train_loader = cycle(DataLoader(train_dataset, batch_size = BATCH_SIZE))
val_loader = cycle(DataLoader(val_dataset, batch_size = BATCH_SIZE))
# 定义优化器
parameters = fetch_optimizer_parameters(model)
optim = torch.optim.Adam(parameters, lr=LEARNING_RATE)
# 训练过程
for i in tqdm.tqdm(range(NUM_BATCHES), mininterval=10., desc='training'):
model.train()
for __ in range(GRADIENT_ACCUMULATE_EVERY):
loss = model(next(train_loader), return_loss = True)
loss.backward()
print(f'training loss: {loss.item()}')
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optim.step()
optim.zero_grad()
if i % VALIDATE_EVERY == 0:
model.eval()
with torch.no_grad():
loss = model(next(val_loader), return_loss = True)
print(f'validation loss: {loss.item()}')
if i % GENERATE_EVERY == 0:
model.eval()
inp = random.choice(val_dataset)[:-1]
prime = decode_tokens(inp)
print(f'%s \n\n %s', (prime, '*' * 100))
sample = model.generate(inp, GENERATE_LENGTH)
output_str = decode_tokens(sample)
print(output_str)
.\lucidrains\linear-attention-transformer\examples\toy_tasks\copy_task.py
# 导入必要的库
import tqdm
import torch
import torch.optim as optim
# 导入自定义模块
from linear_attention_transformer import LinearAttentionTransformerLM
from linear_attention_transformer.autoregressive_wrapper import AutoregressiveWrapper
# 定义常量
NUM_BATCHES = int(1e5)
BATCH_SIZE = 16
LEARNING_RATE = 1e-4
GENERATE_EVERY = 100
NUM_TOKENS = 16 + 2
ENC_SEQ_LEN = 32
DEC_SEQ_LEN = 64
# 定义生成数据的辅助函数
def cycle():
while True:
prefix = torch.ones((BATCH_SIZE, 1)).long().cuda()
src = torch.randint(2, NUM_TOKENS, (BATCH_SIZE, ENC_SEQ_LEN)).long().cuda()
tgt = torch.cat((prefix, src, src), 1)
src_mask = torch.ones(BATCH_SIZE, ENC_SEQ_LEN).bool().cuda()
tgt_mask = torch.ones(BATCH_SIZE, tgt.shape[1] - 1).bool().cuda()
yield (src, tgt, src_mask, tgt_mask)
# 实例化编码器和解码器模型
enc = LinearAttentionTransformerLM(
num_tokens = NUM_TOKENS,
dim = 512,
heads = 8,
depth = 1,
max_seq_len = ENC_SEQ_LEN,
shift_tokens = True,
return_embeddings = True
).cuda()
dec = LinearAttentionTransformerLM(
num_tokens = NUM_TOKENS,
dim = 512,
heads = 8,
depth = 3,
causal = True,
shift_tokens = True,
blindspot_size = 2, # a small blindspot greatly saves on memory
max_seq_len = DEC_SEQ_LEN,
receives_context = True
).cuda()
# 将解码器包装为自回归模型
dec = AutoregressiveWrapper(dec)
# 定义优化器
optim = torch.optim.Adam([*enc.parameters(), *dec.parameters()], lr=LEARNING_RATE)
# 训练过程
for i in tqdm.tqdm(range(NUM_BATCHES), mininterval=10., desc='training'):
enc.train(), dec.train()
src, tgt, src_mask, tgt_mask = next(cycle())
# 编码器生成上下文信息
context = enc(src, input_mask = src_mask)
# 解码器计算损失
loss = dec(tgt, context = context, input_mask = tgt_mask, context_mask = src_mask, return_loss = True)
loss.backward()
print(loss.item())
optim.step()
optim.zero_grad()
if i % GENERATE_EVERY == 0:
enc.eval(), dec.eval()
src, _, src_mask, _ = next(cycle())
src, src_mask = src[0:1], src_mask[0:1]
start_tokens = (torch.ones((1, 1)) * 1).long().cuda()
# 生成预测结果
context = enc(src)
sample = dec.generate(start_tokens, ENC_SEQ_LEN, context = context)
incorrects = (src != sample).abs().sum()
print(f"input: ", src)
print(f"predicted output: ", sample)
print(f"incorrects: {incorrects}")
.\lucidrains\linear-attention-transformer\linear_attention_transformer\autopadder.py
# 导入数学库
import math
# 导入 PyTorch 库
import torch
# 从 torch 库中导入 nn 模块
from torch import nn
# 从 torch.nn 模块中导入 F 函数
import torch.nn.functional as F
# 从 linear_attention_transformer.linear_attention_transformer 模块中导入 LinearAttentionTransformer 和 LinearAttentionTransformerLM 类
from linear_attention_transformer.linear_attention_transformer import LinearAttentionTransformer, LinearAttentionTransformerLM
# 定义一个函数,用于查找指定类型的模块
def find_module(nn_module, type):
# 遍历 nn_module 中的所有模块
for module in nn_module.modules():
# 如果找到指定类型的模块,则返回该模块
if isinstance(module, type):
return module
# 如果未找到指定类型的模块,则返回 None
return None
# 定义一个函数,用于将张量填充到指定的倍数
def pad_to_multiple(tensor, multiple, dim=-1, pad_left = False):
# 获取张量在指定维度上的长度
seqlen = tensor.shape[dim]
# 计算需要填充的数量
m = seqlen / multiple
# 如果 m 是整数,则不需要填充
if m.is_integer():
return tensor, 0
# 计算填充前的偏移量
pre_pad_offset = (0,) * (-1 - dim) * 2
# 计算需要填充的数量
padding = math.ceil(m) * multiple - seqlen
# 根据填充方式进行填充
offset = (padding, 0) if pad_left else (0, padding)
# 对张量进行填充操作
padded_tensor = F.pad(tensor, (*pre_pad_offset, *offset), value=0)
return padded_tensor, padding
# 定义一个类 Autopadder,继承自 nn.Module 类
class Autopadder(nn.Module):
# 初始化方法
def __init__(self, net, pad_left=False):
super().__init__()
# 断言 net 是 LinearAttentionTransformer 或 LinearAttentionTransformerLM 类的实例
assert isinstance(net, (LinearAttentionTransformer, LinearAttentionTransformerLM)), 'only modules SinkhornTransformer and SinkhornTransformerLM accepted'
self.net = net
# 判断 net 是否为 LinearAttentionTransformerLM 类的实例
is_lm = isinstance(net, LinearAttentionTransformerLM)
# 查找 net 中的 LinearAttentionTransformer 模块
transformer = find_module(net, LinearAttentionTransformer)
# 设置填充的倍数
self.pad_to = transformer.pad_to_multiple
# 设置填充的维度
self.pad_dim = -1 if is_lm else -2
# 设置填充的方式
self.pad_left = pad_left
# 前向传播方法
def forward(self, x, **kwargs):
# 如果不需要填充,则直接调用 net 的前向传播方法
if self.pad_to <= 1:
return self.net(x, **kwargs)
# 获取输入张量 x 的形状和设备信息
b, t, device = *x.shape[:2], x.device
# 获取输入参数中的 input_mask,如果不存在则创建全为 True 的 mask
input_mask = kwargs.get('input_mask')
if input_mask is None:
input_mask = torch.full((b, t), True, device=x.device, dtype=torch.bool)
# 对输入张量 x 进行填充操作
x, padding = pad_to_multiple(x, self.pad_to, dim=self.pad_dim, pad_left=self.pad_left)
# 如果有填充操作,则更新 mask
if padding != 0:
offset = (0, padding) if not self.pad_left else (padding, 0)
new_mask = F.pad(input_mask, offset, value=False)
kwargs.update(input_mask=new_mask)
# 调用 net 的前向传播方法
out = self.net(x, **kwargs)
# 根据填充方式获取输出张量的切片
output_slice = slice(0, t) if not self.pad_left else slice(padding, None)
return out[:, output_slice]
.\lucidrains\linear-attention-transformer\linear_attention_transformer\autoregressive_wrapper.py
# 从 functools 模块导入 partial 函数
from functools import partial
# 导入 torch 库
import torch
# 从 torch 库中导入 nn 模块
from torch import nn
# 从 torch.nn 模块中导入 functional 模块
import torch.nn.functional as F
# 从 torch.nn.utils.rnn 模块中导入 pad_sequence 函数
from torch.nn.utils.rnn import pad_sequence
# 从 linear_attention_transformer.autopadder 模块中导入 Autopadder 类
from linear_attention_transformer.autopadder import Autopadder
# 定义函数 top_p,用于根据阈值保留概率最高的部分 logits
def top_p(logits, thres = 0.9):
# 对 logits 进行降序排序,并返回排序后的结果和索引
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
# 计算累积概率
cum_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# 根据阈值确定需要移除的索引
sorted_indices_to_remove = cum_probs > (1 - thres)
sorted_indices_to_remove[:, 1:] = sorted_indices_to_remove[:, :-1].clone()
sorted_indices_to_remove[:, 0] = 0
# 将需要移除的 logits 设置为负无穷
sorted_logits[sorted_indices_to_remove] = float('-inf')
return sorted_logits.scatter(1, sorted_indices, sorted_logits)
# 定义函数 top_k,用于保留概率最高的 k 个 logits
def top_k(logits, thres = 0.9):
k = int((1 - thres) * logits.shape[-1])
val, ind = torch.topk(logits, k)
probs = torch.full_like(logits, float('-inf'))
probs.scatter_(1, ind, val)
return probs
# 定义 AutoregressiveWrapper 类,继承自 nn.Module 类
class AutoregressiveWrapper(nn.Module):
# 初始化函数
def __init__(self, net, ignore_index = -100, pad_value = 0):
super().__init__()
self.pad_value = pad_value
self.ignore_index = ignore_index
# 使用 Autopadder 对象包装传入的网络
self.net = Autopadder(net)
self.max_seq_len = net.max_seq_len
# 生成函数,用于生成序列
@torch.no_grad()
def generate(self, start_tokens, seq_len, eos_token = None, temperature = 1., filter_logits_fn = top_k, filter_thres = 0.9, **kwargs):
was_training = self.net.training
num_dims = len(start_tokens.shape)
if num_dims == 1:
start_tokens = start_tokens[None, :]
b, t = start_tokens.shape
self.net.eval()
out = start_tokens
input_mask = kwargs.pop('input_mask', None)
if input_mask is None:
input_mask = torch.full_like(out, True, dtype=torch.bool, device=out.device)
for _ in range(seq_len):
x = out[:, -self.max_seq_len:]
input_mask = input_mask[:, -self.max_seq_len:]
logits = self.net(x, input_mask=input_mask, **kwargs)[:, -1, :]
filtered_logits = filter_logits_fn(logits, thres = filter_thres)
probs = F.softmax(filtered_logits / temperature, dim=-1)
sample = torch.multinomial(probs, 1)
out = torch.cat((out, sample), dim=-1)
input_mask = F.pad(input_mask, (0, 1), value=True)
if eos_token is not None and (sample == eos_token).all():
break
out = out[:, t:]
if num_dims == 1:
out = out.squeeze(0)
self.net.train(was_training)
return out
# 前向传播函数
def forward(self, x, return_loss = False, **kwargs):
# 定义 pad 函数,用于对输入进行填充
pad = partial(pad_sequence, batch_first = True, padding_value = self.pad_value)
if not return_loss:
if not isinstance(x, torch.Tensor):
x = pad(x)
return self.net(x, **kwargs)
if isinstance(x, torch.Tensor):
xi = x[:, :-1]
xo = x[:, 1:]
# 解决自回归模型中输入掩码的一个混淆区域
mask = kwargs.pop('input_mask', None)
if mask is not None and mask.shape[1] == x.shape[1]:
mask = mask[:, :-1]
kwargs.update(input_mask = mask)
else:
xi = pad(list(map(lambda t: t[:-1], x)))
xo = pad(list(map(lambda t: t[1:], x)))
out = self.net(xi, **kwargs)
# 计算交叉熵损失
loss = F.cross_entropy(out.transpose(1, 2), xo, ignore_index = self.ignore_index)
return loss
.\lucidrains\linear-attention-transformer\linear_attention_transformer\images.py
import torch
from torch import nn
class ImageLinearAttention(nn.Module):
# 定义图像线性注意力模块
def __init__(self, chan, chan_out = None, kernel_size = 1, padding = 0, stride = 1, key_dim = 64, value_dim = 64, heads = 8, norm_queries = True):
super().__init__()
self.chan = chan
# 如果输出通道数未指定,则设置为输入通道数
chan_out = chan if chan_out is None else chan_out
self.key_dim = key_dim
self.value_dim = value_dim
self.heads = heads
self.norm_queries = norm_queries
conv_kwargs = {'padding': padding, 'stride': stride}
# 创建用于查询的卷积层
self.to_q = nn.Conv2d(chan, key_dim * heads, kernel_size, **conv_kwargs)
# 创建用于键的卷积层
self.to_k = nn.Conv2d(chan, key_dim * heads, kernel_size, **conv_kwargs)
# 创建用于值的卷积层
self.to_v = nn.Conv2d(chan, value_dim * heads, kernel_size, **conv_kwargs)
out_conv_kwargs = {'padding': padding}
# 创建输出卷积层
self.to_out = nn.Conv2d(value_dim * heads, chan_out, kernel_size, **out_conv_kwargs)
def forward(self, x, context = None):
b, c, h, w, k_dim, heads = *x.shape, self.key_dim, self.heads
q, k, v = (self.to_q(x), self.to_k(x), self.to_v(x))
q, k, v = map(lambda t: t.reshape(b, heads, -1, h * w), (q, k, v))
q, k = map(lambda x: x * (self.key_dim ** -0.25), (q, k))
if context is not None:
context = context.reshape(b, c, 1, -1)
ck, cv = self.to_k(context), self.to_v(context)
ck, cv = map(lambda t: t.reshape(b, heads, k_dim, -1), (ck, cv))
k = torch.cat((k, ck), dim=3)
v = torch.cat((v, cv), dim=3)
k = k.softmax(dim=-1)
if self.norm_queries:
q = q.softmax(dim=-2)
context = torch.einsum('bhdn,bhen->bhde', k, v)
out = torch.einsum('bhdn,bhde->bhen', q, context)
out = out.reshape(b, -1, h, w)
out = self.to_out(out)
return out
.\lucidrains\linear-attention-transformer\linear_attention_transformer\linear_attention_transformer.py
# 导入 PyTorch 库
import torch
# 导入 PyTorch 中的函数库
import torch.nn.functional as F
# 从 torch 中导入 nn, einsum 模块
from torch import nn, einsum
# 导入 math 库
import math
# 从 operator 中导入 mul 函数
from operator import mul
# 从 math 中导入 gcd 函数
from math import gcd
# 从 collections 中导入 namedtuple 模块
from collections import namedtuple
# 从 functools 中导入 partial, reduce 函数
from functools import partial, reduce
# 导入自定义模块
from local_attention import LocalAttention
from linformer import LinformerSelfAttention
from product_key_memory import PKM
from axial_positional_embedding import AxialPositionalEmbedding
from linear_attention_transformer.reversible import ReversibleSequence, SequentialSequence
from einops import rearrange, repeat
# 定义 namedtuple 类型 LinformerSettings
LinformerSettings = namedtuple('LinformerSettings', ['k'])
# 定义 namedtuple 类型 LinformerContextSettings
LinformerContextSettings = namedtuple('LinformerContextSettings', ['seq_len', 'k'])
# 辅助函数
# 判断值是否存在
def exists(val):
return val is not None
# 返回默认值
def default(value, d):
return d if not exists(value) else value
# 返回固定值的函数
def always(value):
return lambda *args, **kwargs: value
# 将值转换为元组
def cast_tuple(val):
return (val,) if not isinstance(val, tuple) else val
# 安全除法
def safe_div(n, d, eps = 1e-6):
return n.div_(d + eps)
# 最小公倍数
def lcm(*numbers):
return int(reduce(lambda x, y: int((x * y) / gcd(x, y)), numbers, 1)
# 合并张量的维度
def merge_dims(ind_from, ind_to, tensor):
shape = list(tensor.shape)
arr_slice = slice(ind_from, ind_to + 1)
shape[arr_slice] = [reduce(mul, shape[arr_slice])]
return tensor.reshape(*shape)
# 扩展张量的维度
def expand_dim(t, dim, k, unsqueeze=True):
if unsqueeze:
t = t.unsqueeze(dim)
expand_shape = [-1] * len(t.shape)
expand_shape[dim] = k
return t.expand(*expand_shape)
# 在指定索引处分割张量
def split_at_index(dim, index, t):
pre_slices = (slice(None),) * dim
l = (*pre_slices, slice(None, index))
r = (*pre_slices, slice(index, None))
return t[l], t[r]
# 获取张量的最小负值
def max_neg_value(tensor):
return -torch.finfo(tensor.dtype).max
# 辅助类
# 预归一化
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.LayerNorm(dim)
def forward(self, x, **kwargs):
x = self.norm(x)
return self.fn(x, **kwargs)
# 分块
class Chunk(nn.Module):
def __init__(self, chunks, fn, along_dim = -1):
super().__init__()
self.dim = along_dim
self.chunks = chunks
self.fn = fn
def forward(self, x, **kwargs):
if self.chunks == 1:
return self.fn(x, **kwargs)
chunks = x.chunk(self.chunks, dim = self.dim)
return torch.cat([self.fn(c, **kwargs) for c in chunks], dim = self.dim)
# 输入输出投影
class ProjectInOut(nn.Module):
def __init__(self, fn, dim_in, dim_out, project_out = True):
super().__init__()
self.fn = fn
self.project_in = nn.Linear(dim_in, dim_out)
self.project_out = nn.Linear(dim_out, dim_in) if project_out else nn.Identity()
def forward(self, x, **kwargs):
x = self.project_in(x)
x = self.fn(x, **kwargs)
x = self.project_out(x)
return x
# 令牌移位辅助类
# 移位函数
def shift(t, amount, mask = None):
if amount == 0:
return t
if exists(mask):
t = t.masked_fill(~mask[..., None], 0.)
return F.pad(t, (0, 0, amount, -amount), value = 0.)
# 预移位令牌
class PreShiftTokens(nn.Module):
def __init__(self, shifts, fn):
super().__init__()
self.fn = fn
self.shifts = tuple(shifts)
def forward(self, x, **kwargs):
mask = kwargs.get('mask', None)
shifts = self.shifts
segments = len(shifts)
feats_per_shift = x.shape[-1] // segments
splitted = x.split(feats_per_shift, dim = -1)
segments_to_shift, rest = splitted[:segments], splitted[segments:]
segments_to_shift = list(map(lambda args: shift(*args, mask = mask), zip(segments_to_shift, shifts)))
x = torch.cat((*segments_to_shift, *rest), dim = -1)
return self.fn(x, **kwargs)
# 位置嵌入
# 绝对位置嵌入
class AbsolutePositionalEmbedding(nn.Module):
def __init__(self, dim, max_seq_len):
super().__init__()
self.emb = nn.Embedding(max_seq_len, dim)
# 定义一个前向传播函数,接受输入张量 x
def forward(self, x):
# 生成一个与输入张量 x 的第二维相同长度的张量 t,元素为从 0 到 x.shape[1]-1
t = torch.arange(x.shape[1], device=x.device)
# 使用嵌入层 emb 对 t 进行嵌入操作,得到一个新的张量,维度为 [1, t的长度, 嵌入维度]
return self.emb(t)[None, :, :]
# 定义固定位置嵌入类,用于生成固定位置嵌入
class FixedPositionalEmbedding(nn.Module):
def __init__(self, dim, max_seq_len):
super().__init__()
# 计算频率的倒数,用于生成正弦和余弦位置编码
inv_freq = 1. / (10000 ** (torch.arange(0, dim, 2).float() / dim))
# 生成位置向量
position = torch.arange(0, max_seq_len, dtype=torch.float)
# 计算正弦和余弦位置编码
sinusoid_inp = torch.einsum("i,j->ij", position, inv_freq)
# 将正弦和余弦位置编码拼接在一起
emb = torch.cat((sinusoid_inp.sin(), sinusoid_inp.cos()), dim=-1)
# 将位置嵌入注册为缓冲区
self.register_buffer('emb', emb)
def forward(self, x):
# 返回位置嵌入
return self.emb[None, :x.shape[1], :].to(x)
# 旋转位置嵌入的辅助函数
# 将输入张量中的每两个元素进行旋转
def rotate_every_two(x):
x = rearrange(x, '... (d j) -> ... d j', j = 2)
x1, x2 = x.unbind(dim = -1)
x = torch.stack((-x2, x1), dim = -1)
return rearrange(x, '... d j -> ... (d j)')
# 应用旋转位置嵌入
def apply_rotory_pos_emb(q, k, sinu_pos):
# 重新排列正弦位置编码的形状
sinu_pos = rearrange(sinu_pos, '() n (j d) -> n j d', j = 2)
sin, cos = sinu_pos.unbind(dim = -2)
# 将正弦和余弦位置编码重复到与输入张量相同的形状
sin, cos = map(lambda t: repeat(t, 'b n -> b (n j)', j = 2), (sin, cos))
# 应用旋转位置嵌入到查询和键中
q, k = map(lambda t: (t * cos) + (rotate_every_two(t) * sin), (q, k))
return q, k
# 前馈神经网络
# GELU激活函数
class GELU_(nn.Module):
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))
# 如果PyTorch中存在GELU函数,则使用PyTorch中的GELU,否则使用自定义的GELU_
GELU = nn.GELU if hasattr(nn, 'GELU') else GELU_
# 前馈神经网络类
class FeedForward(nn.Module):
def __init__(self, dim, mult = 4, dropout = 0., activation = None, glu = False):
super().__init__()
activation = default(activation, GELU)
self.glu = glu
# 第一个线性层
self.w1 = nn.Linear(dim, dim * mult * (2 if glu else 1))
self.act = activation()
self.dropout = nn.Dropout(dropout)
# 第二个线性层
self.w2 = nn.Linear(dim * mult, dim)
def forward(self, x, **kwargs):
if not self.glu:
x = self.w1(x)
x = self.act(x)
else:
x, v = self.w1(x).chunk(2, dim=-1)
x = self.act(x) * v
x = self.dropout(x)
x = self.w2(x)
return x
# 自注意力层
# 线性注意力函数
def linear_attn(q, k, v, kv_mask = None):
dim = q.shape[-1]
if exists(kv_mask):
mask_value = max_neg_value(q)
mask = kv_mask[:, None, :, None]
k = k.masked_fill_(~mask, mask_value)
v = v.masked_fill_(~mask, 0.)
del mask
q = q.softmax(dim=-1)
k = k.softmax(dim=-2)
q = q * dim ** -0.5
context = einsum('bhnd,bhne->bhde', k, v)
attn = einsum('bhnd,bhde->bhne', q, context)
return attn.reshape(*q.shape)
# 因果线性注意力函数
def causal_linear_attn(q, k, v, kv_mask = None, bucket_size = None, eps = 1e-3):
b, h, n, e, dtype = *q.shape, q.dtype
bucket_size = default(bucket_size, 64)
bucket_size = max(bucket_size, 1)
assert bucket_size == 0 or (n % bucket_size) == 0, f'sequence length {n} must be divisible by the bucket size {bucket_size} for causal linear attention'
q = q.softmax(dim=-1)
k = torch.exp(k).type(dtype).clone()
q = q * e ** -0.5
if exists(kv_mask):
mask = kv_mask[:, None, :, None]
k = k.masked_fill_(~mask, 0.)
v = v.masked_fill_(~mask, 0.)
del mask
bucket_fn = lambda x: x.reshape(*x.shape[:-2], -1, bucket_size, e)
b_q, b_k, b_v = map(bucket_fn, (q, k, v))
b_k_sum = b_k.sum(dim=-2)
b_k_cumsum = b_k_sum.cumsum(dim = -2).type(dtype)
context = einsum('bhund,bhune->bhude', b_k, b_v)
context = context.cumsum(dim = -3).type(dtype)
if bucket_size > 1:
context = F.pad(context, (0, 0, 0, 0, 1, 0), value = 0.)
context, _ = split_at_index(2, -1, context)
b_k_cumsum = F.pad(b_k_cumsum, (0, 0, 1, 0), value = 0.)
b_k_cumsum, _ = split_at_index(2, -1, b_k_cumsum)
D_inv = 1. / einsum('bhud,bhund->bhun', b_k_cumsum, b_q).clamp(min = eps)
attn = einsum('bhund,bhude,bhun->bhune', b_q, context, D_inv)
return attn.reshape(*q.shape)
# 自注意力层类
class SelfAttention(nn.Module):
# 初始化函数,设置模型参数
def __init__(self, dim, heads, causal = False, dim_head = None, blindspot_size = 1, n_local_attn_heads = 0, local_attn_window_size = 128, receives_context = False, dropout = 0., attn_dropout = 0.):
# 调用父类初始化函数
super().__init__()
# 检查维度是否可以被头数整除
assert dim_head or (dim % heads) == 0, 'embedding dimension must be divisible by number of heads'
# 设置每个头的维度
d_heads = default(dim_head, dim // heads)
# 初始化模型参数
self.heads = heads
self.d_heads = d_heads
self.receives_context = receives_context
# 设置全局注意力头数和函数
self.global_attn_heads = heads - n_local_attn_heads
self.global_attn_fn = linear_attn if not causal else partial(causal_linear_attn, bucket_size = blindspot_size)
# 设置局部注意力头数和局部注意力对象
self.local_attn_heads = n_local_attn_heads
self.local_attn = LocalAttention(local_attn_window_size, causal = causal, dropout = attn_dropout)
# 线性变换得到查询、键、值
self.to_q = nn.Linear(dim, d_heads * heads, bias = False)
kv_heads = heads
self.kv_heads = kv_heads
self.to_k = nn.Linear(dim, d_heads * kv_heads, bias = False)
self.to_v = nn.Linear(dim, d_heads * kv_heads, bias = False)
# 线性变换得到输出
self.to_out = nn.Linear(d_heads * heads, dim)
self.dropout = nn.Dropout(dropout)
# 前向传播函数
def forward(self, x, input_mask = None, context = None, context_mask = None, pos_emb = None, **kwargs):
# 如果模型需要上下文信息但未提供,则报错
assert not (self.receives_context and not exists(context)), 'context must be supplied if self attention is in receives context mode'
# 根据是否需要上下文信息,获取查询、键、值
if not self.receives_context:
q, k, v = (self.to_q(x), self.to_k(x), self.to_v(x))
else:
q, k, v = (self.to_q(x), self.to_k(context), self.to_v(context))
b, t, e, h, dh = *q.shape, self.heads, self.d_heads
# 合并头部维度
merge_heads = lambda x: x.reshape(*x.shape[:2], -1, dh).transpose(1, 2)
q, k, v = map(merge_heads, (q, k, v))
# 如果存在位置编码且不需要上下文信息,则应用旋转位置编码
if exists(pos_emb) and not self.receives_context:
q, k = apply_rotory_pos_emb(q, k, pos_emb)
out = []
# 分割索引函数,用于分割局部和全局注意力
split_index_fn = partial(split_at_index, 1, self.local_attn_heads)
(lq, q), (lk, k), (lv, v) = map(split_index_fn, (q, k, v))
has_local, has_global = map(lambda x: x.shape[1] > 0, (lq, q))
# 如果存在局部注意力,则计算局部注意力
if has_local:
local_out = self.local_attn(lq, lk, lv, input_mask = input_mask)
out.append(local_out)
# 如果存在全局注意力,则计算全局注意力
if has_global:
kv_mask = input_mask if not self.receives_context else context_mask
global_out = self.global_attn_fn(q, k, v, kv_mask = kv_mask)
out.append(global_out)
# 拼接注意力结果并返回
attn = torch.cat(out, dim=1)
attn = attn.transpose(1, 2).reshape(b, t, -1)
return self.dropout(self.to_out(attn))
# 定义 FoldAxially 类,用于将输入张量按轴进行折叠
class FoldAxially(nn.Module):
def __init__(self, axial_dim, fn):
super().__init__()
self.fn = fn
self.axial_dim = axial_dim
# 前向传播函数,对输入张量进行处理
def forward(self, x, input_mask = None, **kwargs):
# 获取输入张量的形状信息
b, t, d, ax = *x.shape, self.axial_dim
# 将输入张量按轴进行折叠和转置
x = x.reshape(b, -1, ax, d).transpose(1, 2).reshape(b * ax, -1, d)
# 初始化 mask 为 None
mask = None
# 如果输入的 mask 存在
if exists(input_mask):
# 将 mask 按轴进行折叠和转置
mask = input_mask.reshape(b, -1, ax).transpose(1, 2).reshape(b * ax, -1)
# 对折叠后的张量进行处理
x = self.fn(x, input_mask = mask, **kwargs)
# 将处理后的张量还原为原始形状
x = x.reshape(b, ax, -1, d).transpose(1, 2).reshape(b, t, d)
return x
# 定义 LinearAttentionTransformer 类,用于实现线性注意力变换器
class LinearAttentionTransformer(nn.Module):
def __init__(
self,
dim,
depth,
max_seq_len,
heads = 8,
dim_head = None,
bucket_size = 64,
causal = False,
ff_chunks = 1,
ff_glu = False,
ff_dropout = 0.,
attn_layer_dropout = 0.,
attn_dropout = 0.,
reversible = False,
blindspot_size = 1,
n_local_attn_heads = 0,
local_attn_window_size = 128,
receives_context = False,
attend_axially = False,
pkm_layers = tuple(),
pkm_num_keys = 128,
linformer_settings = None,
context_linformer_settings = None,
shift_tokens = False
):
# 调用父类的构造函数
super().__init__()
# 断言条件,确保 Linformer 自注意力层仅用于非因果网络
assert not (causal and exists(linformer_settings)), 'Linformer self attention layer can only be used for non-causal networks'
# 断言条件,确保 Linformer 自注意力设置是 LinformerSettings 命名元组
assert not exists(linformer_settings) or isinstance(linformer_settings, LinformerSettings), 'Linformer self-attention settings must be a LinformerSettings namedtuple'
# 断言条件,确保 Linformer 上下文自注意力设置是 LinformerSettings 命名元组
assert not exists(context_linformer_settings) or isinstance(context_linformer_settings, LinformerContextSettings), 'Linformer contextual self-attention settings must be a LinformerSettings namedtuple'
# 如果 n_local_attn_heads 不是元组,则将其转换为深度个相同元素的元组
if type(n_local_attn_heads) is not tuple:
n_local_attn_heads = tuple([n_local_attn_heads] * depth)
# 断言条件,确保本地注意力头元组的长度与深度相同
assert len(n_local_attn_heads) == depth, 'local attention heads tuple must have the same length as the depth'
# 断言条件,确保每个本地注意力头数小于最大头数
assert all([(local_heads <= heads) for local_heads in n_local_attn_heads]), 'number of local attn heads must be less than the maximum number of heads'
# 初始化层列表
layers = nn.ModuleList([])
# 遍历深度和本地注意力头数
for ind, local_heads in zip(range(depth), n_local_attn_heads):
# 计算层编号
layer_num = ind + 1
# 检查是否使用 PKM
use_pkm = layer_num in cast_tuple(pkm_layers)
# 如果不使用 Linformer 设置,则创建 SelfAttention 对象
if not exists(linformer_settings):
attn = SelfAttention(dim, heads, causal, dim_head = dim_head, blindspot_size = blindspot_size, n_local_attn_heads = local_heads, local_attn_window_size = local_attn_window_size, dropout = attn_layer_dropout, attn_dropout= attn_dropout)
# 否则创建 LinformerSelfAttention 对象
else:
attn = LinformerSelfAttention(dim, max_seq_len, heads = heads, dim_head = dim_head, dropout = attn_dropout, **linformer_settings._asdict())
# 如果需要移动标记,则进行标记移动
if shift_tokens:
shifts = (1, 0, -1) if not causal else (1, 0)
attn, parallel_net = map(partial(PreShiftTokens, shifts), (attn, parallel_net))
# 将 SelfAttention 和 FeedForward 添加到层列表中
layers.append(nn.ModuleList([
PreNorm(dim, attn),
PreNorm(dim, parallel_net)
]))
# 如果需要轴向关注,则添加到层列表中
if attend_axially:
layers.append(nn.ModuleList([
PreNorm(dim, FoldAxially(local_attn_window_size, SelfAttention(dim, heads, causal, dropout = attn_layer_dropout, attn_dropout= attn_dropout))),
PreNorm(dim, Chunk(ff_chunks, FeedForward(dim, glu = ff_glu, dropout= ff_dropout), along_dim = 1))
]))
# 如果接收上下文,则添加到层列表中
if receives_context:
if not exists(context_linformer_settings):
attn = SelfAttention(dim, heads, dim_head = dim_head, dropout = attn_layer_dropout, attn_dropout= attn_dropout, receives_context = True)
else:
attn = LinformerSelfAttention(dim, heads = heads, dim_head = dim_head, dropout = attn_dropout, **context_linformer_settings._asdict())
layers.append(nn.ModuleList([
PreNorm(dim, attn),
PreNorm(dim, Chunk(ff_chunks, FeedForward(dim, glu = ff_glu, dropout= ff_dropout), along_dim = 1))
]))
# 根据是否可逆选择执行类型
execute_type = ReversibleSequence if reversible else SequentialSequence
# 设置轴向层和上下文层
axial_layer = ((True, False),) if attend_axially else tuple()
attn_context_layer = ((True, False),) if receives_context else tuple()
route_attn = ((True, False), *axial_layer, *attn_context_layer) * depth
route_context = ((False, False), *axial_layer, *attn_context_layer) * depth
# 根据接收上下文情况设置路由映射
context_route_map = {'context': route_context, 'context_mask': route_context} if receives_context else {}
attn_route_map = {'input_mask': route_attn, 'pos_emb': route_attn}
# 创建层序列对象
self.layers = execute_type(layers, args_route = {**attn_route_map, **context_route_map})
# 计算填充到的倍数
self.pad_to_multiple = lcm(
1 if not causal else blindspot_size,
1 if all([(h == 0) for h in n_local_attn_heads]) else local_attn_window_size
)
# 定义一个 forward 方法,用于前向传播计算
def forward(self, x, **kwargs):
# 调用 self.layers 方法,传入输入 x 和其他参数 kwargs,返回计算结果
return self.layers(x, **kwargs)
class LinearAttentionTransformerLM(nn.Module):
# 定义线性注意力变换器语言模型类
def __init__(
self,
num_tokens,
dim,
depth,
max_seq_len,
heads = 8,
dim_head = 64,
causal = False,
emb_dim = None,
reversible = False,
ff_chunks = 1,
ff_glu = False,
ff_dropout = 0.,
attn_layer_dropout = 0.,
attn_dropout = 0.,
blindspot_size = 1,
n_local_attn_heads = 0,
local_attn_window_size = 128,
return_embeddings = False,
receives_context = False,
pkm_layers = tuple(),
pkm_num_keys = 128,
attend_axially = False,
linformer_settings = None,
context_linformer_settings = None,
use_axial_pos_emb = True,
use_rotary_emb = False,
shift_tokens = False
):
# 初始化函数,接受多个参数
assert n_local_attn_heads == 0 or (max_seq_len % local_attn_window_size) == 0, 'max sequence length must be divisible by the local attention window size'
# 断言语句,确保本地注意力头数为0或最大序列长度能被本地注意力窗口大小整除
super().__init__()
# 调用父类的初始化函数
emb_dim = default(emb_dim, dim)
# 如果emb_dim为None,则使用dim作为默认值
self.max_seq_len = max_seq_len
self.token_emb = nn.Embedding(num_tokens, emb_dim)
# 创建一个嵌入层,用于将输入的token转换为向量表示
if use_rotary_emb:
self.pos_emb = FixedPositionalEmbedding(emb_dim, max_seq_len)
self.layer_pos_emb = FixedPositionalEmbedding(dim_head, max_seq_len)
elif use_axial_pos_emb:
self.pos_emb = AxialPositionalEmbedding(emb_dim, axial_shape=(math.ceil(max_seq_len / local_attn_window_size), local_attn_window_size))
self.layer_pos_emb = always(None)
else:
self.pos_emb = AbsolutePositionalEmbedding(emb_dim, max_seq_len)
self.layer_pos_emb = always(None)
# 根据不同的位置编码方式,初始化位置编码层
self.transformer = LinearAttentionTransformer(dim, depth, max_seq_len, heads = heads, dim_head = dim_head, causal = causal, ff_chunks = ff_chunks, ff_glu = ff_glu, ff_dropout = ff_dropout, attn_layer_dropout = attn_layer_dropout, attn_dropout = attn_dropout, reversible = reversible, blindspot_size = blindspot_size, n_local_attn_heads = n_local_attn_heads, local_attn_window_size = local_attn_window_size, receives_context = receives_context, pkm_layers = pkm_layers, pkm_num_keys = pkm_num_keys, attend_axially = attend_axially, linformer_settings = linformer_settings, context_linformer_settings = context_linformer_settings, shift_tokens = shift_tokens)
# 创建线性注意力变换器模型
if emb_dim != dim:
self.transformer = ProjectInOut(self.transformer, emb_dim, dim, project_out = not return_embeddings)
# 如果emb_dim不等于dim,则使用ProjectInOut函数将维度转换为dim
self.norm = nn.LayerNorm(emb_dim)
# 创建一个LayerNorm层,用于归一化
self.out = nn.Linear(emb_dim, num_tokens) if not return_embeddings else nn.Identity()
# 创建一个线性层,用于输出结果
def forward(self, x, **kwargs):
# 前向传播函数,接受输入x和关键字参数kwargs
x = self.token_emb(x)
# 将输入x通过token_emb转换为向量表示
x = x + self.pos_emb(x).type(x.type())
# 将位置编码加到输入x上
layer_pos_emb = self.layer_pos_emb(x)
# 获取层级位置编码
x = self.transformer(x, pos_emb = layer_pos_emb, **kwargs)
# 使用transformer处理输入x和位置编码
x = self.norm(x)
# 对输出进行归一化
return self.out(x)
# 返回输出结果
.\lucidrains\linear-attention-transformer\linear_attention_transformer\reversible.py
# 导入 torch 库
import torch
# 导入 torch 中的神经网络模块
import torch.nn as nn
# 从 operator 模块中导入 itemgetter 函数
from operator import itemgetter
# 从 torch.autograd.function 模块中导入 Function 类
from torch.autograd.function import Function
# 从 torch.utils.checkpoint 模块中导入 get_device_states 和 set_device_states 函数
# 用于将参数路由到可逆层函数中的函数
def route_args(router, args, depth):
# 初始化路由后的参数列表
routed_args = [(dict(), dict()) for _ in range(depth)]
# 获取参数中与路由器匹配的键
matched_keys = [key for key in args.keys() if key in router]
for key in matched_keys:
val = args[key]
for depth, ((f_args, g_args), routes) in enumerate(zip(routed_args, router[key])):
new_f_args, new_g_args = map(lambda route: ({key: val} if route else {}), routes)
routed_args[depth] = ({**f_args, **new_f_args}, {**g_args, **new_g_args})
return routed_args
# 根据概率丢弃层的函数
def layer_drop(layers, prob):
to_drop = torch.empty(len(layers)).uniform_(0, 1) < prob
blocks = [block for block, drop in zip(layers, to_drop) if not drop]
blocks = layers[:1] if len(blocks) == 0 else blocks
return blocks
# 保存和设置随机数种子的类
class Deterministic(nn.Module):
def __init__(self, net):
super().__init__()
self.net = net
self.cpu_state = None
self.cuda_in_fwd = None
self.gpu_devices = None
self.gpu_states = None
def record_rng(self, *args):
self.cpu_state = torch.get_rng_state()
if torch.cuda._initialized:
self.cuda_in_fwd = True
self.gpu_devices, self.gpu_states = get_device_states(*args)
def forward(self, *args, record_rng = False, set_rng = False, **kwargs):
if record_rng:
self.record_rng(*args)
if not set_rng:
return self.net(*args, **kwargs)
rng_devices = []
if self.cuda_in_fwd:
rng_devices = self.gpu_devices
with torch.random.fork_rng(devices=rng_devices, enabled=True):
torch.set_rng_state(self.cpu_state)
if self.cuda_in_fwd:
set_device_states(self.gpu_devices, self.gpu_states)
return self.net(*args, **kwargs)
# 可逆块类,受启发于 https://github.com/RobinBruegger/RevTorch/blob/master/revtorch/revtorch.py
# 一旦多 GPU 工作正常,重构并将 PR 发回源代码
class ReversibleBlock(nn.Module):
def __init__(self, f, g):
super().__init__()
self.f = Deterministic(f)
self.g = Deterministic(g)
def forward(self, x, f_args = {}, g_args = {}):
x1, x2 = torch.chunk(x, 2, dim=2)
y1, y2 = None, None
with torch.no_grad():
y1 = x1 + self.f(x2, record_rng=self.training, **f_args)
y2 = x2 + self.g(y1, record_rng=self.training, **g_args)
return torch.cat([y1, y2], dim=2)
def backward_pass(self, y, dy, f_args = {}, g_args = {}):
y1, y2 = torch.chunk(y, 2, dim=2)
del y
dy1, dy2 = torch.chunk(dy, 2, dim=2)
del dy
with torch.enable_grad():
y1.requires_grad = True
gy1 = self.g(y1, set_rng=True, **g_args)
torch.autograd.backward(gy1, dy2)
with torch.no_grad():
x2 = y2 - gy1
del y2, gy1
dx1 = dy1 + y1.grad
del dy1
y1.grad = None
with torch.enable_grad():
x2.requires_grad = True
fx2 = self.f(x2, set_rng=True, **f_args)
torch.autograd.backward(fx2, dx1, retain_graph=True)
with torch.no_grad():
x1 = y1 - fx2
del y1, fx2
dx2 = dy2 + x2.grad
del dy2
x2.grad = None
x = torch.cat([x1, x2.detach()], dim=2)
dx = torch.cat([dx1, dx2], dim=2)
return x, dx
# 可逆函数类
class _ReversibleFunction(Function):
@staticmethod
# 前向传播函数,接收上下文对象 ctx,输入数据 x,模块列表 blocks 和参数列表 args
def forward(ctx, x, blocks, args):
# 将参数列表 args 存储到上下文对象 ctx 中
ctx.args = args
# 遍历模块列表 blocks 和参数列表 args,对输入数据 x 进行处理
for block, kwarg in zip(blocks, args):
x = block(x, **kwarg)
# 将处理后的数据 x 分离出来,并存储到上下文对象 ctx 中
ctx.y = x.detach()
# 将模块列表 blocks 存储到上下文对象 ctx 中
ctx.blocks = blocks
# 返回处理后的数据 x
return x
# 反向传播函数,接收上下文对象 ctx 和梯度 dy
@staticmethod
def backward(ctx, dy):
# 获取上下文对象 ctx 中存储的处理后的数据 y 和参数列表 args
y = ctx.y
args = ctx.args
# 反向遍历模块列表 blocks 和参数列表 args,对梯度 dy 进行处理
for block, kwargs in zip(ctx.blocks[::-1], args[::-1]):
# 调用模块的反向传播函数,更新梯度 dy 和数据 y
y, dy = block.backward_pass(y, dy, **kwargs)
# 返回更新后的梯度 dy
return dy, None, None
# 定义一个继承自 nn.Module 的类 SequentialSequence
class SequentialSequence(nn.Module):
# 初始化函数,接受层列表、参数路由字典和层丢弃率作为参数
def __init__(self, layers, args_route = {}, layer_dropout = 0.):
super().__init__()
# 断言每个参数路由映射的深度与顺序层的数量相同
assert all(len(route) == len(layers) for route in args_route.values()), 'each argument route map must have the same depth as the number of sequential layers'
self.layers = layers
self.args_route = args_route
self.layer_dropout = layer_dropout
# 前向传播函数,接受输入 x 和关键字参数 kwargs
def forward(self, x, **kwargs):
# 根据参数路由和关键字参数获取参数
args = route_args(self.args_route, kwargs, len(self.layers))
# 将层和参数组成元组列表
layers_and_args = list(zip(self.layers, args))
# 如果处于训练状态且层丢弃率大于0
if self.training and self.layer_dropout > 0:
# 对层和参数进行层丢弃
layers_and_args = layer_drop(layers_and_args, self.layer_dropout)
# 遍历层和参数列表,执行前向传播
for (f, g), (f_args, g_args) in layers_and_args:
x = x + f(x, **f_args)
x = x + g(x, **g_args)
return x
# 定义一个继承自 nn.Module 的类 ReversibleSequence
class ReversibleSequence(nn.Module):
# 初始化函数,接受块列表、参数路由字典和层丢弃率作为参数
def __init__(self, blocks, args_route = {}, layer_dropout = 0.):
super().__init__()
self.args_route = args_route
self.layer_dropout = layer_dropout
# 创建包含可逆块的模块列表
self.blocks = nn.ModuleList([ReversibleBlock(f=f, g=g) for f, g in blocks])
# 前向传播函数,接受输入 x 和关键字参数 kwargs
def forward(self, x, **kwargs):
# 在最后一个维度上连接输入 x 自身
x = torch.cat([x, x], dim=-1)
# 获取块列表和参数
blocks = self.blocks
args = route_args(self.args_route, kwargs, len(blocks))
args = list(map(lambda x: {'f_args': x[0], 'g_args': x[1]}, args))
# 将块和参数组成元组列表
layers_and_args = list(zip(blocks, args))
# 如果处于训练状态且层丢弃率大于0
if self.training and self.layer_dropout > 0:
# 对块和参数进行层丢弃
layers_and_args = layer_drop(layers_and_args, self.layer_dropout)
# 分别获取块和参数
blocks, args = map(lambda ind: list(map(itemgetter(ind), layers_and_args)), (0, 1))
# 调用自定义的可逆函数进行前向传播
out = _ReversibleFunction.apply(x, blocks, args)
# 在最后一个维度上分割输出并取平均值
return torch.stack(out.chunk(2, dim=-1)).mean(dim=0)
.\lucidrains\linear-attention-transformer\linear_attention_transformer\__init__.py
# 从 linear_attention_transformer 模块中导入 LinearAttentionTransformer、LinearAttentionTransformerLM、LinformerSettings、LinformerContextSettings 类
from linear_attention_transformer.linear_attention_transformer import LinearAttentionTransformer, LinearAttentionTransformerLM, LinformerSettings, LinformerContextSettings
# 从 linear_attention_transformer 模块中导入 AutoregressiveWrapper 类
from linear_attention_transformer.autoregressive_wrapper import AutoregressiveWrapper
# 从 linear_attention_transformer 模块中导入 ImageLinearAttention 类
from linear_attention_transformer.images import ImageLinearAttention
Linear Attention Transformer

![]()
A fully featured Transformer that mixes (QKᵀ)V local attention with Q(KᵀV) global attention (scales linearly with respect to sequence length) for efficient long-range language modeling.
Install
$ pip install linear-attention-transformer
Usage
Language model
import torch
from linear_attention_transformer import LinearAttentionTransformerLM
model = LinearAttentionTransformerLM(
num_tokens = 20000,
dim = 512,
heads = 8,
depth = 1,
max_seq_len = 8192,
causal = True, # auto-regressive or not
ff_dropout = 0.1, # dropout for feedforward
attn_layer_dropout = 0.1, # dropout right after self-attention layer
attn_dropout = 0.1, # dropout post-attention
emb_dim = 128, # embedding factorization, to save on memory
dim_head = 128, # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
blindspot_size = 64, # this gives the q(kv) attention a blindspot of 64 tokens back in the causal case, but gives back an order of magnitude return in memory savings. should be paired with local attention of at least a window size of this setting. setting this to 1 will allow for full q(kv) attention of past
n_local_attn_heads = 4, # number of local attention heads for (qk)v attention. this can be a tuple specifying the exact number of local attention heads at that depth
local_attn_window_size = 128, # receptive field of the local attention
reversible = True, # use reversible nets, from Reformer paper
ff_chunks = 2, # feedforward chunking, from Reformer paper
ff_glu = True, # use GLU variant for feedforward
attend_axially = False, # will fold the sequence by the local attention window size, and do an extra strided attention followed by a feedforward with the cheap q(kv) attention
shift_tokens = True # add single token shifting, for great improved convergence
).cuda()
x = torch.randint(0, 20000, (1, 8192)).cuda()
model(x) # (1, 8192, 512)
Transformer
import torch
from linear_attention_transformer import LinearAttentionTransformer
model = LinearAttentionTransformer(
dim = 512,
heads = 8,
depth = 1,
max_seq_len = 8192,
n_local_attn_heads = 4
).cuda()
x = torch.randn(1, 8192, 512).cuda()
model(x) # (1, 8192, 512)
Encoder / decoder
import torch
from linear_attention_transformer import LinearAttentionTransformerLM
enc = LinearAttentionTransformerLM(
num_tokens = 20000,
dim = 512,
heads = 8,
depth = 6,
max_seq_len = 4096,
reversible = True,
n_local_attn_heads = 4,
return_embeddings = True
).cuda()
dec = LinearAttentionTransformerLM(
num_tokens = 20000,
dim = 512,
heads = 8,
depth = 6,
causal = True,
max_seq_len = 4096,
reversible = True,
receives_context = True,
n_local_attn_heads = 4
).cuda()
src = torch.randint(0, 20000, (1, 4096)).cuda()
src_mask = torch.ones_like(src).bool().cuda()
tgt = torch.randint(0, 20000, (1, 4096)).cuda()
tgt_mask = torch.ones_like(tgt).bool().cuda()
context = enc(src, input_mask = src_mask)
logits = dec(tgt, context = context, input_mask = tgt_mask, context_mask = src_mask)
Linformer
Linformer is another variant of attention with linear complexity championed by Facebook AI. It only works with non-autoregressive models of a fixed sequence length. If your problem satisfies that criteria, you may choose to try it out.
from linear_attention_transformer import LinearAttentionTransformerLM, LinformerSettings
settings = LinformerSettings(k = 256)
enc = LinearAttentionTransformerLM(
num_tokens = 20000,
dim = 512,
heads = 8,
depth = 6,
max_seq_len = 4096,
linformer_settings = settings
).cuda()
You can also used Linformer for the contextual attention layer, if the contextual keys are of a fixed sequence length.
from linear_attention_transformer import LinearAttentionTransformerLM, LinformerContextSettings
settings = LinformerContextSettings(
seq_len = 2048,
k = 256
)
dec = LinearAttentionTransformerLM(
num_tokens = 20000,
dim = 512,
heads = 8,
depth = 6,
max_seq_len = 4096,
causal = True,
context_linformer_settings = settings,
receives_context = True
).cuda()
Images
This repository also contains a concise implementation of this efficient attention for images
import torch
from linear_attention_transformer.images import ImageLinearAttention
attn =ImageLinearAttention(
chan = 32,
heads = 8,
key_dim = 64 # can be decreased to 32 for more memory savings
)
img = torch.randn(1, 32, 256, 256)
attn(img) # (1, 32, 256, 256)
Citations
@inproceedings{katharopoulos-et-al-2020,
author = {Katharopoulos, A. and Vyas, A. and Pappas, N. and Fleuret, F.},
title = {Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention},
booktitle = {Proceedings of the International Conference on Machine Learning (ICML)},
year = {2020},
url = {https://arxiv.org/abs/2006.16236}
}
@article{shen2019efficient,
author = {Zhuoran Shen and
Mingyuan Zhang and
Haiyu Zhao and
Shuai Yi and
Hongsheng Li},
title = {Efficient Attention: Attention with Linear Complexities},
journal = {CoRR},
volume = {abs/1812.01243},
year = {2018},
url = {http://arxiv.org/abs/1812.01243}
}
@inproceedings{kitaev2020reformer,
title = {Reformer: The Efficient Transformer},
author = {Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya},
booktitle = {International Conference on Learning Representations},
year = {2020},
url = {https://openreview.net/forum?id=rkgNKkHtvB}
}
@misc{shazeer2020glu,
title = {GLU Variants Improve Transformer},
author = {Noam Shazeer},
year = {2020},
url = {https://arxiv.org/abs/2002.05202}
}
@misc{wang2020linformer,
title = {Linformer: Self-Attention with Linear Complexity},
author = {Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma},
year = {2020},
eprint = {2006.04768}
}
@misc{bhojanapalli2020lowrank,
title = {Low-Rank Bottleneck in Multi-head Attention Models},
author = {Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar},
year = {2020},
eprint = {2002.07028}
}
@techreport{zhuiyiroformer,
title = {RoFormer: Transformer with Rotary Position Embeddings - ZhuiyiAI},
author = {Jianlin Su},
year = {2021},
url = "https://github.com/ZhuiyiTechnology/roformer",
}
.\lucidrains\linear-attention-transformer\setup.py
# 导入设置和查找包的函数
from setuptools import setup, find_packages
# 设置包的元数据
setup(
name = 'linear_attention_transformer', # 包的名称
packages = find_packages(exclude=['examples']), # 查找并包含除了 examples 之外的所有包
version = '0.19.1', # 版本号
license='MIT', # 许可证
description = 'Linear Attention Transformer', # 描述
author = 'Phil Wang', # 作者
author_email = 'lucidrains@gmail.com', # 作者邮箱
url = 'https://github.com/lucidrains/linear-attention-transformer', # 项目链接
keywords = ['transformers', 'attention', 'artificial intelligence'], # 关键词
install_requires=[
'axial-positional-embedding', # 安装所需的依赖包
'einops',
'linformer>=0.1.0',
'local-attention',
'product-key-memory>=0.1.5',
'torch',
],
classifiers=[
'Development Status :: 4 - Beta', # 分类器
'Intended Audience :: Developers',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
'License :: OSI Approved :: MIT License',
'Programming Language :: Python :: 3.6',
],
)
.\lucidrains\linformer\linformer\linformer.py
import math
import torch
from torch import nn
import torch.nn.functional as F
from linformer.reversible import ReversibleSequence, SequentialSequence
# 辅助函数
# 如果值为 None,则返回默认值
def default(val, default_val):
return val if val is not None else default_val
# 初始化张量
def init_(tensor):
dim = tensor.shape[-1]
std = 1 / math.sqrt(dim)
tensor.uniform_(-std, std)
return tensor
# 辅助类
# 残差连接
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
return x + self.fn(x)
# 预层归一化
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.LayerNorm(dim)
def forward(self, x):
x = self.norm(x)
return self.fn(x)
# GELU 激活函数
class GELU_(nn.Module):
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))
# 如果 PyTorch 中有 GELU 函数,则使用,否则使用自定义的 GELU_
GELU = nn.GELU if hasattr(nn, 'GELU') else GELU_
# 前馈神经网络
class FeedForward(nn.Module):
def __init__(self, dim, mult = 4, dropout = 0., activation = None, glu = False):
super().__init__()
activation = default(activation, GELU)
self.glu = glu
self.w1 = nn.Linear(dim, dim * mult * (2 if glu else 1))
self.act = activation()
self.dropout = nn.Dropout(dropout)
self.w2 = nn.Linear(dim * mult, dim)
def forward(self, x, **kwargs):
if not self.glu:
x = self.w1(x)
x = self.act(x)
else:
x, v = self.w1(x).chunk(2, dim=-1)
x = self.act(x) * v
x = self.dropout(x)
x = self.w2(x)
return x
# Linformer 自注意力机制
class LinformerSelfAttention(nn.Module):
def __init__(self, dim, seq_len, k = 256, heads = 8, dim_head = None, one_kv_head = False, share_kv = False, dropout = 0.):
super().__init__()
assert (dim % heads) == 0, 'dimension must be divisible by the number of heads'
self.seq_len = seq_len
self.k = k
self.heads = heads
dim_head = default(dim_head, dim // heads)
self.dim_head = dim_head
self.to_q = nn.Linear(dim, dim_head * heads, bias = False)
kv_dim = dim_head if one_kv_head else (dim_head * heads)
self.to_k = nn.Linear(dim, kv_dim, bias = False)
self.proj_k = nn.Parameter(init_(torch.zeros(seq_len, k)))
self.share_kv = share_kv
if not share_kv:
self.to_v = nn.Linear(dim, kv_dim, bias = False)
self.proj_v = nn.Parameter(init_(torch.zeros(seq_len, k)))
self.dropout = nn.Dropout(dropout)
self.to_out = nn.Linear(dim_head * heads, dim)
# 定义前向传播函数,接受输入 x 和上下文 context,默认参数 kwargs
def forward(self, x, context = None, **kwargs):
# 获取输入 x 的形状信息
b, n, d, d_h, h, k = *x.shape, self.dim_head, self.heads, self.k
# 计算键/值的序列长度
kv_len = n if context is None else context.shape[1]
# 断言键/值的序列长度不超过最大序列长度
assert kv_len <= self.seq_len, f'the sequence length of the key / values must be {self.seq_len} - {kv_len} given'
# 将输入 x 转换为查询
queries = self.to_q(x)
# 定义函数用于对序列长度进行投影
proj_seq_len = lambda args: torch.einsum('bnd,nk->bkd', *args)
# 根据是否有上下文选择输入数据
kv_input = x if context is None else context
# 将输入数据转换为键和值
keys = self.to_k(kv_input)
values = self.to_v(kv_input) if not self.share_kv else keys
# 定义键和值的投影
kv_projs = (self.proj_k, self.proj_v if not self.share_kv else self.proj_k)
# 如果键/值的序列长度小于最大序列长度,则对投影进行切片
if kv_len < self.seq_len:
kv_projs = map(lambda t: t[:kv_len], kv_projs)
# 对键和值沿序列长度维度进行投影
keys, values = map(proj_seq_len, zip((keys, values), kv_projs))
# 将查询重塑为 batch, heads, -1 的形状
queries = queries.reshape(b, n, h, -1).transpose(1, 2)
# 定义函数用于将头部合并到批次中的查询和键/值
merge_key_values = lambda t: t.reshape(b, k, -1, d_h).transpose(1, 2).expand(-1, h, -1, -1)
keys, values = map(merge_key_values, (keys, values))
# 注意力计算
dots = torch.einsum('bhnd,bhkd->bhnk', queries, keys) * (d_h ** -0.5)
attn = dots.softmax(dim=-1)
attn = self.dropout(attn)
out = torch.einsum('bhnk,bhkd->bhnd', attn, values)
# 分割头部
out = out.transpose(1, 2).reshape(b, n, -1)
# 返回输出结果
return self.to_out(out)
class Linformer(nn.Module):
# 定义 Linformer 类,继承自 nn.Module
def __init__(self, dim, seq_len, depth, k = 256, heads = 8, dim_head = None, one_kv_head = False, share_kv = False, reversible = False, dropout = 0.):
# 初始化函数,接受多个参数,包括维度、序列长度、深度等
super().__init__()
# 调用父类的初始化函数
layers = nn.ModuleList([])
# 创建一个空的模块列表
for _ in range(depth):
# 循环 depth 次
attn = LinformerSelfAttention(dim, seq_len, k = k, heads = heads, dim_head = dim_head, one_kv_head = one_kv_head, share_kv = share_kv, dropout = dropout)
# 创建 LinformerSelfAttention 注意力机制对象
ff = FeedForward(dim, dropout = dropout)
# 创建 FeedForward 前馈神经网络对象
layers.append(nn.ModuleList([
PreNorm(dim, attn),
PreNorm(dim, ff)
]))
# 将 PreNorm 包装的注意力机制和前馈神经网络添加到模块列表中
execute_type = ReversibleSequence if reversible else SequentialSequence
# 根据 reversible 参数选择执行类型
self.net = execute_type(layers)
# 创建执行类型对象
def forward(self, x):
# 前向传播函数
return self.net(x)
# 返回执行类型对象对输入 x 的处理结果
class LinformerLM(nn.Module):
# 定义 LinformerLM 类,继承自 nn.Module
def __init__(self, num_tokens, dim, seq_len, depth, k = 256, heads = 8, dim_head = None, one_kv_head = False, share_kv = False, reversible = False, dropout = 0.):
# 初始化函数,接受多个参数,包括标记数量、维度、序列长度、深度等
super().__init__()
# 调用父类的初始化函数
self.token_emb = nn.Embedding(num_tokens, dim)
# 创建标记嵌入层
self.pos_emb = nn.Embedding(seq_len, dim)
# 创建位置嵌入层
self.linformer = Linformer(dim, seq_len, depth, k = k, heads = heads, dim_head = dim_head,
one_kv_head = one_kv_head, share_kv = share_kv, reversible = reversible, dropout = dropout)
# 创建 Linformer 对象
self.to_logits = nn.Linear(dim, num_tokens)
# 创建线性层,用于输出标记
def forward(self, x):
# 前向传播函数
x = self.token_emb(x)
# 对输入 x 进行标记嵌入
x = self.pos_emb(torch.arange(x.shape[1], device=x.device)) + x
# 对输入 x 进行位置嵌入
x = self.linformer(x)
# 使用 Linformer 处理输入 x
out = self.to_logits(x)
# 将���理结果传递给线性层
return out
# 返回输出结果
.\lucidrains\linformer\linformer\reversible.py
# 导入 torch 库
import torch
# 导入 torch 中的神经网络模块
import torch.nn as nn
# 从 operator 模块中导入 itemgetter 函数
from operator import itemgetter
# 从 torch.autograd.function 模块中导入 Function 类
from torch.autograd.function import Function
# 从 torch.utils.checkpoint 模块中导入 get_device_states 和 set_device_states 函数
# 用于将参数路由到可逆层函数中的函数
def route_args(router, args, depth):
# 初始化路由后的参数列表
routed_args = [(dict(), dict()) for _ in range(depth)]
# 获取参数中与路由器匹配的键
matched_keys = [key for key in args.keys() if key in router]
for key in matched_keys:
val = args[key]
for depth, ((f_args, g_args), routes) in enumerate(zip(routed_args, router[key])):
new_f_args, new_g_args = map(lambda route: ({key: val} if route else {}), routes)
routed_args[depth] = ({**f_args, **new_f_args}, {**g_args, **new_g_args})
return routed_args
# 根据概率丢弃层的函数
def layer_drop(layers, prob):
to_drop = torch.empty(len(layers)).uniform_(0, 1) < prob
blocks = [block for block, drop in zip(layers, to_drop) if not drop]
blocks = layers[:1] if len(blocks) == 0 else blocks
return blocks
# 保存和设置随机数种子的类
class Deterministic(nn.Module):
def __init__(self, net):
super().__init__()
self.net = net
self.cpu_state = None
self.cuda_in_fwd = None
self.gpu_devices = None
self.gpu_states = None
def record_rng(self, *args):
self.cpu_state = torch.get_rng_state()
if torch.cuda._initialized:
self.cuda_in_fwd = True
self.gpu_devices, self.gpu_states = get_device_states(*args)
def forward(self, *args, record_rng = False, set_rng = False, **kwargs):
if record_rng:
self.record_rng(*args)
if not set_rng:
return self.net(*args, **kwargs)
rng_devices = []
if self.cuda_in_fwd:
rng_devices = self.gpu_devices
with torch.random.fork_rng(devices=rng_devices, enabled=True):
torch.set_rng_state(self.cpu_state)
if self.cuda_in_fwd:
set_device_states(self.gpu_devices, self.gpu_states)
return self.net(*args, **kwargs)
# 可逆块类,受启发于 https://github.com/RobinBruegger/RevTorch/blob/master/revtorch/revtorch.py
# 一旦多 GPU 工作正常,重构并将 PR 发回源代码
class ReversibleBlock(nn.Module):
def __init__(self, f, g):
super().__init__()
self.f = Deterministic(f)
self.g = Deterministic(g)
def forward(self, x, f_args = {}, g_args = {}):
x1, x2 = torch.chunk(x, 2, dim=2)
y1, y2 = None, None
with torch.no_grad():
y1 = x1 + self.f(x2, record_rng=self.training, **f_args)
y2 = x2 + self.g(y1, record_rng=self.training, **g_args)
return torch.cat([y1, y2], dim=2)
def backward_pass(self, y, dy, f_args = {}, g_args = {}):
y1, y2 = torch.chunk(y, 2, dim=2)
del y
dy1, dy2 = torch.chunk(dy, 2, dim=2)
del dy
with torch.enable_grad():
y1.requires_grad = True
gy1 = self.g(y1, set_rng=True, **g_args)
torch.autograd.backward(gy1, dy2)
with torch.no_grad():
x2 = y2 - gy1
del y2, gy1
dx1 = dy1 + y1.grad
del dy1
y1.grad = None
with torch.enable_grad():
x2.requires_grad = True
fx2 = self.f(x2, set_rng=True, **f_args)
torch.autograd.backward(fx2, dx1, retain_graph=True)
with torch.no_grad():
x1 = y1 - fx2
del y1, fx2
dx2 = dy2 + x2.grad
del dy2
x2.grad = None
x = torch.cat([x1, x2.detach()], dim=2)
dx = torch.cat([dx1, dx2], dim=2)
return x, dx
# 可逆函数类
class _ReversibleFunction(Function):
@staticmethod
# 前向传播函数,接收上下文对象 ctx,输入数据 x,模块列表 blocks 和参数列表 args
def forward(ctx, x, blocks, args):
# 将参数列表 args 存储到上下文对象 ctx 中
ctx.args = args
# 遍历模块列表 blocks 和参数列表 args,对输入数据 x 进行处理
for block, kwarg in zip(blocks, args):
x = block(x, **kwarg)
# 将处理后的数据 x 分离出来,并存储到上下文对象 ctx 中
ctx.y = x.detach()
# 将模块列表 blocks 存储到上下文对象 ctx 中
ctx.blocks = blocks
# 返回处理后的数据 x
return x
# 反向传播函数,接收上下文对象 ctx 和梯度 dy
@staticmethod
def backward(ctx, dy):
# 获取上下文对象 ctx 中存储的处理后的数据 y 和参数列表 args
y = ctx.y
args = ctx.args
# 反向遍历模块列表 blocks 和参数列表 args,对梯度 dy 进行处理
for block, kwargs in zip(ctx.blocks[::-1], args[::-1]):
# 调用模块的反向传播函数,更新梯度 dy 和数据 y
y, dy = block.backward_pass(y, dy, **kwargs)
# 返回更新后的梯度 dy
return dy, None, None
class SequentialSequence(nn.Module):
# 定义一个顺序执行的神经网络模块
def __init__(self, layers, args_route = {}, layer_dropout = 0.):
super().__init__()
# 断言每个参数路由映射的深度与顺序层的数量相同
assert all(len(route) == len(layers) for route in args_route.values()), 'each argument route map must have the same depth as the number of sequential layers'
self.layers = layers
self.args_route = args_route
self.layer_dropout = layer_dropout
def forward(self, x, **kwargs):
# 根据参数路由和关键字参数获取参数
args = route_args(self.args_route, kwargs, len(self.layers))
layers_and_args = list(zip(self.layers, args))
if self.training and self.layer_dropout > 0:
# 如果处于训练状态且存在层丢弃率,则执行层丢弃
layers_and_args = layer_drop(layers_and_args, self.layer_dropout)
for (f, g), (f_args, g_args) in layers_and_args:
# 依次执行每个顺序层的前向传播
x = x + f(x, **f_args)
x = x + g(x, **g_args)
return x
class ReversibleSequence(nn.Module):
# 定义一个可逆的序列神经网络模块
def __init__(self, blocks, args_route = {}, layer_dropout = 0.):
super().__init__()
self.args_route = args_route
self.layer_dropout = layer_dropout
# 创建包含可逆块的模块列表
self.blocks = nn.ModuleList([ReversibleBlock(f=f, g=g) for f, g in blocks])
def forward(self, x, **kwargs):
# 在最后一个维度上连接输入张量的副本
x = torch.cat([x, x], dim=-1)
blocks = self.blocks
# 根据参数路由和关键字参数获取参数
args = route_args(self.args_route, kwargs, len(blocks))
args = list(map(lambda x: {'f_args': x[0], 'g_args': x[1]}, args))
layers_and_args = list(zip(blocks, args))
if self.training and self.layer_dropout > 0:
# 如果处于训练状态且存在层丢弃率,则执行层丢弃
layers_and_args = layer_drop(layers_and_args, self.layer_dropout)
blocks, args = map(lambda ind: list(map(itemgetter(ind), layers_and_args)), (0, 1))
# 调用自定义的可逆函数进行前向传播
out = _ReversibleFunction.apply(x, blocks, args)
# 在最后一个维度上分割输出并求和
return torch.stack(out.chunk(2, dim=-1)).sum(dim=0)
.\lucidrains\linformer\linformer\__init__.py
# 从 linformer.linformer 模块中导入 LinformerLM, Linformer, LinformerSelfAttention 类
from linformer.linformer import LinformerLM, Linformer, LinformerSelfAttention
Linformer for Pytorch
An implementation of Linformer in Pytorch. Linformer comes with two deficiencies. (1) It does not work for the auto-regressive case. (2) Assumes a fixed sequence length. However, if benchmarks show it to perform well enough, it will be added to this repository as a self-attention layer to be used in the encoder.
Linformer has been put into production by Facebook!
Install
$ pip install linformer
Usage
Linformer language model
import torch
from linformer import LinformerLM
model = LinformerLM(
num_tokens = 20000,
dim = 512,
seq_len = 4096,
depth = 12,
heads = 8,
dim_head = 128, # be able to set the dimension of each head in multi-head attention
k = 256, # this is the k that the key/values are projected to along the sequence dimension
one_kv_head = True, # share one key/value head across all heads
share_kv = False, # share the same projection for keys and values
reversible = True # make network reversible, like Reformer
)
x = torch.randint(0, 20000, (1, 4096))
model(x) # (1, 4096, 20000)
Linformer
import torch
from linformer import Linformer
model = Linformer(
dim = 512,
seq_len = 4096,
depth = 12,
heads = 8,
k = 256,
one_kv_head = True,
share_kv = True
)
x = torch.randn(1, 4096, 512)
model(x) # (1, 4096, 512)
Single Self-Attention layer
import torch
from linformer import LinformerSelfAttention
attn = LinformerSelfAttention(
dim = 512,
seq_len = 4096,
heads = 8,
k = 256,
one_kv_head = True,
share_kv = True
)
x = torch.randn(1, 4096, 512)
attn(x) # (1, 4096, 512)
Self-Attention layer above receiving contextual keys. The sequence length is validated on the length of the contextual keys instead of the source sequence.
import torch
from linformer import LinformerSelfAttention
attn = LinformerSelfAttention(
dim = 512,
seq_len = 8192,
heads = 8,
k = 256,
one_kv_head = True,
share_kv = True
)
x = torch.randn(1, 2048, 512)
context = torch.randn(1, 8192, 512)
attn(x, context) # (1, 2048, 512)
Citations
@misc{wang2020linformer,
title={Linformer: Self-Attention with Linear Complexity},
author={Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma},
year={2020},
eprint={2006.04768},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@inproceedings{kitaev2020reformer,
title = {Reformer: The Efficient Transformer},
author = {Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya},
booktitle = {International Conference on Learning Representations},
year = {2020},
url = {https://openreview.net/forum?id=rkgNKkHtvB}
}
.\lucidrains\linformer\setup.py
# 导入设置工具和查找包的函数
from setuptools import setup, find_packages
# 设置包的元数据
setup(
name = 'linformer', # 包的名称
packages = find_packages(), # 查找所有包
version = '0.2.3', # 版本号
license='MIT', # 许可证
description = 'Linformer implementation in Pytorch', # 描述
author = 'Phil Wang', # 作者
author_email = 'lucidrains@gmail.com', # 作者邮箱
url = 'https://github.com/lucidrains/linformer', # 项目链接
long_description_content_type = 'text/markdown', # 长描述内容类型
keywords = [
'attention', # 关键词:注意力
'artificial intelligence' # 关键词:人工智能
],
install_requires=[
'torch' # 安装所需的依赖项
],
classifiers=[
'Development Status :: 4 - Beta', # 分类器:开发状态为Beta
'Intended Audience :: Developers', # 分类器:面向的受众为开发者
'Topic :: Scientific/Engineering :: Artificial Intelligence', # 分类器:主题为科学/工程和人工智能
'License :: OSI Approved :: MIT License', # 分类器:许可证为MIT
'Programming Language :: Python :: 3.6', # 分类器:编程语言为Python 3.6
],
)
.\lucidrains\lion-pytorch\lion_pytorch\lion_pytorch.py
# 导入必要的库
from typing import Tuple, Optional, Callable
import torch
from torch.optim.optimizer import Optimizer
# 定义一个函数,用于检查值是否存在
def exists(val):
return val is not None
# 定义权重更新函数
def update_fn(p, grad, exp_avg, lr, wd, beta1, beta2):
# 根据学习率和权重衰减更新参数值
p.data.mul_(1 - lr * wd)
# 计算权重更新值
update = exp_avg.clone().mul_(beta1).add(grad, alpha=1 - beta1).sign_()
p.add_(update, alpha=-lr)
# 更新动量的指数移动平均系数
exp_avg.mul_(beta2).add_(grad, alpha=1 - beta2)
# 定义一个自定义优化器类 Lion,继承自 Optimizer 类
class Lion(Optimizer):
def __init__(
self,
params,
lr: float = 1e-4,
betas: Tuple[float, float] = (0.9, 0.99),
weight_decay: float = 0.0,
use_triton: bool = False
):
# 断言学习率必须大于0,beta值必须在0到1之间
assert lr > 0.
assert all([0. <= beta <= 1. for beta in betas])
# 设置默认参数
defaults = dict(
lr=lr,
betas=betas,
weight_decay=weight_decay
)
# 调用父类的初始化方法
super().__init__(params, defaults)
# 设置更新函数为自定义的 update_fn
self.update_fn = update_fn
# 如果使用 Triton,则导入 Triton 的更新函数
if use_triton:
from lion_pytorch.triton import update_fn as triton_update_fn
self.update_fn = triton_update_fn
# 定义优化步骤函数
@torch.no_grad()
def step(
self,
closure: Optional[Callable] = None
):
loss = None
# 如果存在闭包函数,则计算损失值
if exists(closure):
with torch.enable_grad():
loss = closure()
# 遍历参数组
for group in self.param_groups:
for p in filter(lambda p: exists(p.grad), group['params']):
# 获取参数的梯度、学习率、权重衰减、beta1、beta2以及参数状态
grad, lr, wd, beta1, beta2, state = p.grad, group['lr'], group['weight_decay'], *group['betas'], self.state[p]
# 初始化参数状态 - 梯度值的指数移动平均
if len(state) == 0:
state['exp_avg'] = torch.zeros_like(p)
exp_avg = state['exp_avg']
# 调用更新函数更新参数
self.update_fn(
p,
grad,
exp_avg,
lr,
wd,
beta1,
beta2
)
return loss
.\lucidrains\lion-pytorch\lion_pytorch\triton.py
import torch
# 导入 torch 库
try:
import triton
import triton.language as tl
except ImportError as e:
print('triton is not installed, please install by running `pip install triton -U --pre`')
exit()
# 尝试导入 triton 库,如果导入失败则打印错误信息并退出程序
# clone param and exp_avg before autotuning takes place
# as those are updated in-place
# 在自动调整参数之前克隆参数和 exp_avg,因为它们是原地更新的
def clone_inplace_updated_params(nargs):
nargs['p_ptr'] = nargs['p_ptr'].clone()
nargs['exp_avg_ptr'] = nargs['exp_avg_ptr'].clone()
# 克隆原地更新的参数和 exp_avg
# triton cuda kernel
@triton.autotune(configs = [
triton.Config({'BLOCK_SIZE': 128}, num_warps = 4, pre_hook = clone_inplace_updated_params),
triton.Config({'BLOCK_SIZE': 1024}, num_warps = 8, pre_hook = clone_inplace_updated_params),
], key = ['n_elements'])
@triton.jit
def update_fn_kernel(
p_ptr,
grad_ptr,
exp_avg_ptr,
lr,
wd,
beta1,
beta2,
n_elements,
BLOCK_SIZE: tl.constexpr,
):
pid = tl.program_id(axis = 0)
# 获取程序 ID
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# 计算块的起始位置和偏移量
mask = offsets < n_elements
# 创建掩码以确保偏移量不超过元素数量
# offsetted pointers
offset_p_ptr = p_ptr + offsets
offset_grad_ptr = grad_ptr + offsets
offset_exp_avg_ptr = exp_avg_ptr + offsets
# 计算偏移后的指针位置
# load
p = tl.load(offset_p_ptr, mask = mask)
grad = tl.load(offset_grad_ptr, mask = mask)
exp_avg = tl.load(offset_exp_avg_ptr, mask = mask)
# 从指定位置加载数据
# stepweight decay
p = p * (1 - lr * wd)
# 更新参数
# diff between momentum running average and grad
diff = exp_avg - grad
# 计算动量的运行平均值和梯度之间的差异
# weight update
update = diff * beta1 + grad
# 更新权重
# torch.sign
can_update = update != 0
update_sign = tl.where(update > 0, -lr, lr)
# 计算更新的符号
p = p + update_sign * can_update
# 更新参数
# decay the momentum running average coefficient
exp_avg = diff * beta2 + grad
# 更新动量的运行平均系数
# store new params and momentum running average coefficient
tl.store(offset_p_ptr, p, mask = mask)
tl.store(offset_exp_avg_ptr, exp_avg, mask = mask)
# 存储新的参数和动量的运行平均系数
def update_fn(
p: torch.Tensor,
grad: torch.Tensor,
exp_avg: torch.Tensor,
lr: float,
wd: float,
beta1: float,
beta2: float
):
assert all([t.is_cuda for t in (p, grad, exp_avg)])
n_elements = p.numel()
# 确保参数在 GPU 上,并获取参数数量
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
# 定义网格大小
update_fn_kernel[grid](
p,
grad,
exp_avg,
lr,
wd,
beta1,
beta2,
n_elements
)
# 调用 triton 内核函数进行参数更新
.\lucidrains\lion-pytorch\lion_pytorch\__init__.py
# 从 lion_pytorch 模块中导入 Lion 类
from lion_pytorch.lion_pytorch import Lion

🦁 Lion - Pytorch
🦁 Lion, EvoLved Sign Momentum, new optimizer discovered by Google Brain that is purportedly better than Adam(w), in Pytorch. This is nearly a straight copy from here, with few minor modifications.
It is so simple, we may as well get it accessible and used asap by everyone to train some great models, if it really works 🤞
Instructions
-
Learning rate and weight decay: the authors write in Section 5 -
Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength.The initial value, peak value, and end value in the learning rate schedule should be changed simultaneously with the same ratio compared to AdamW, evidenced by a researcher. -
Learning rate schedule: the authors use the same learning rate schedule for Lion as AdamW in the paper. Nevertheless, they observe a larger gain when using a cosine decay schedule to train ViT, compared to a reciprocal square-root schedule.
-
β1 and β2: the authors write in Section 5 -
The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively.Similar to how people reduce β2 to 0.99 or smaller and increase ε to 1e-6 in AdamW to improve stability, usingβ1=0.95, β2=0.98in Lion can also be helpful in mitigating instability during training, suggested by the authors. This was corroborated by a researcher.
Updates
-
Update: seems to work for my local enwik8 autoregressive language modeling.
-
Update 2: experiments, seems much worse than Adam if learning rate held constant.
-
Update 3: Dividing the learning rate by 3, seeing better early results than Adam. Maybe Adam has been dethroned, after nearly a decade.
-
Update 4: using the 10x smaller learning rate rule of thumb from the paper resulted in the worst run. So I guess it still takes a bit of tuning.
A summarization of previous updates: as shown in the experiments, Lion with a 3x smaller learning rate beats Adam. It still takes a bit of tuning as a 10x smaller learning rate leads to a worse result.
-
Update 5: so far hearing all positive results for language modeling, when done right. Also heard positive results for significant text-to-image training, although it takes a bit of tuning. The negative results seem to be with problems and architectures outside of what was evaluated in the paper - RL, feedforward networks, weird hybrid architectures with LSTMs + convolutions etc. Negative anecdata also confirms this technique is sensitive to batch size, amount of data / augmentation. Tbd what optimal learning rate schedule is, and whether cooldown affects results. Also interestingly have a positive result at open-clip, which became negative as the model size was scaled up (but may be resolvable).
-
Update 6: open clip issue resolved by the author, by setting a higher initial temperature.
-
Update 7: would only recommend this optimizer in the setting of high batch sizes (64 or above)
Install
$ pip install lion-pytorch
Usage
# toy model
import torch
from torch import nn
model = nn.Linear(10, 1)
# import Lion and instantiate with parameters
from lion_pytorch import Lion
opt = Lion(model.parameters(), lr=1e-4, weight_decay=1e-2)
# forward and backwards
loss = model(torch.randn(10))
loss.backward()
# optimizer step
opt.step()
opt.zero_grad()
To use a fused kernel for updating the parameters, first pip install triton -U --pre, then
opt = Lion(
model.parameters(),
lr=1e-4,
weight_decay=1e-2,
use_triton=True # set this to True to use cuda kernel w/ Triton lang (Tillet et al)
)
Appreciation
- Stability.ai for the generous sponsorship to work and open source cutting edge artificial intelligence research
Citations
@misc{https://doi.org/10.48550/arxiv.2302.06675,
url = {https://arxiv.org/abs/2302.06675},
author = {Chen, Xiangning and Liang, Chen and Huang, Da and Real, Esteban and Wang, Kaiyuan and Liu, Yao and Pham, Hieu and Dong, Xuanyi and Luong, Thang and Hsieh, Cho-Jui and Lu, Yifeng and Le, Quoc V.},
title = {Symbolic Discovery of Optimization Algorithms},
publisher = {arXiv},
year = {2023}
}
@article{Tillet2019TritonAI,
title = {Triton: an intermediate language and compiler for tiled neural network computations},
author = {Philippe Tillet and H. Kung and D. Cox},
journal = {Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages},
year = {2019}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号