
BackTrader 中文文档(二十)
黄金 vs. 标普 500
原文:
www.backtrader.com/blog/posts/2016-12-13-gold-vs-sp500/gold-vs-sp500/
有时候了解backtrader的使用情况可以帮助理解人们可能正在寻找和使用平台的内容。
参考:
这是一篇(西班牙语)分析两个 ETF:GLD vs SPY(实际上是黄金 vs 标普 500)的文章。
不去深入翻译,让我们集中精力在backtrader的重要内容上:
-
添加一个相关性指标。出于这个目的,选择了
PearsonR。为了完成这一壮举,而不是从头开始编写代码,我们展示了如何使用
scipy函数来完成。代码如下:class PearsonR(bt.ind.PeriodN): _mindatas = 2 # hint to the platform lines = ('correlation',) params = (('period', 20),) def next(self): c, p, = scipy.stats.pearsonr(self.data0.get(size=self.p.period), self.data1.get(size=self.p.period)) self.lines.correlation[0] = c` -
添加滚动对数收益
该平台已经有了一个带有对数收益的分析器,但没有滚动。
添加了分析器
LogReturnsRolling,它接受一个timeframe参数(和compression)来使用与数据不同的时间框架(如果需要的话)。与此同时,为了可视化(内部使用分析器),添加了一个
LogReturns观察者。 -
允许在数据绘图中加入数据(轻松)。就像这样:
# Data feeds data0 = YahooData(dataname=args.data0, **kwargs) # cerebro.adddata(data0) cerebro.resampledata(data0, timeframe=bt.TimeFrame.Weeks) data1 = YahooData(dataname=args.data1, **kwargs) # cerebro.adddata(data1) cerebro.resampledata(data1, timeframe=bt.TimeFrame.Weeks) data1.plotinfo.plotmaster = data0`只需使用
plotmaster=data0就可以在data0上绘制data1。
从平台的最开始就支持在自己的轴上和彼此之间绘制移动平均线。
分析器和观察者也已添加到平台上,并且提供了与博客文章中相同默认设置的示例。
运行示例:
$ ./gold-vs-sp500.py --cerebro stdstats=False --plot volume=False
注意
stdstats=False 和 volume=False 用于通过删除一些常见的内容,如CashValue观察者和volume子图,来减少图表中的混乱。
生成一个图表,几乎模拟了文章中的大部分输出。
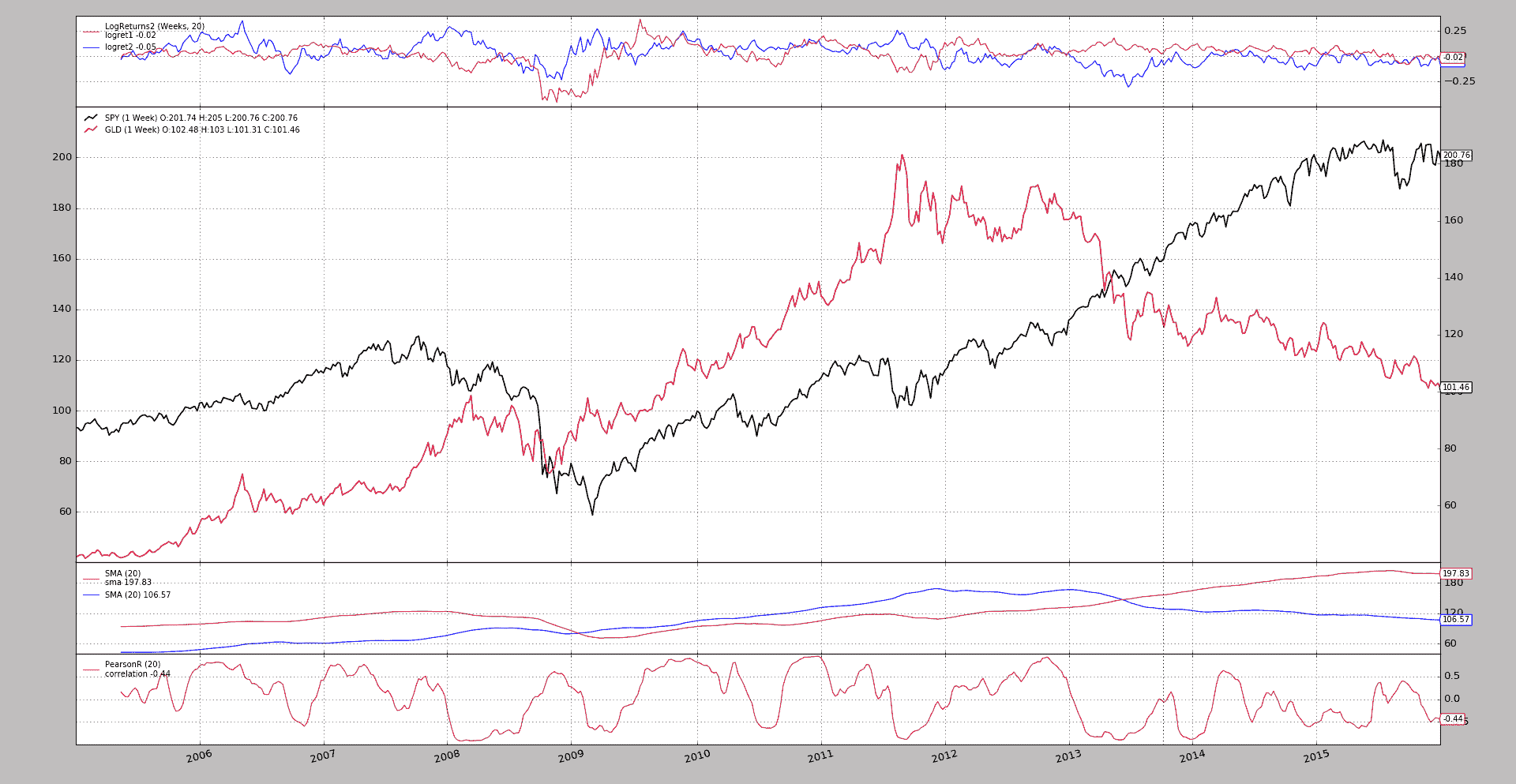
不包括在内:
-
创建收益分布图表。
它们无法适应基于datetime的 x 轴的图表。
但是拥有这些分布可能是有益的。
示例用法
$ ./gold-vs-sp500.py --help
usage: gold-vs-sp500.py [-h] [--data0 TICKER] [--data1 TICKER] [--offline]
[--fromdate FROMDATE] [--todate TODATE]
[--cerebro kwargs] [--broker kwargs] [--sizer kwargs]
[--strat kwargs] [--plot [kwargs]] [--myobserver]
Gold vs SP500 from https://estrategiastrading.com/oro-bolsa-estadistica-con-
python/
optional arguments:
-h, --help show this help message and exit
--data0 TICKER Yahoo ticker to download (default: SPY)
--data1 TICKER Yahoo ticker to download (default: GLD)
--offline Use the offline files (default: False)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2005-01-01)
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2016-01-01)
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
# Reference
# https://estrategiastrading.com/oro-bolsa-estadistica-con-python/
import argparse
import datetime
import scipy.stats
import backtrader as bt
class PearsonR(bt.ind.PeriodN):
_mindatas = 2 # hint to the platform
lines = ('correlation',)
params = (('period', 20),)
def next(self):
c, p, = scipy.stats.pearsonr(self.data0.get(size=self.p.period),
self.data1.get(size=self.p.period))
self.lines.correlation[0] = c
class MACrossOver(bt.Strategy):
params = (
('ma', bt.ind.MovAv.SMA),
('pd1', 20),
('pd2', 20),
)
def __init__(self):
ma1 = self.p.ma(self.data0, period=self.p.pd1, subplot=True)
self.p.ma(self.data1, period=self.p.pd2, plotmaster=ma1)
PearsonR(self.data0, self.data1)
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
if not args.offline:
YahooData = bt.feeds.YahooFinanceData
else:
YahooData = bt.feeds.YahooFinanceCSVData
# Data feeds
data0 = YahooData(dataname=args.data0, **kwargs)
# cerebro.adddata(data0)
cerebro.resampledata(data0, timeframe=bt.TimeFrame.Weeks)
data1 = YahooData(dataname=args.data1, **kwargs)
# cerebro.adddata(data1)
cerebro.resampledata(data1, timeframe=bt.TimeFrame.Weeks)
data1.plotinfo.plotmaster = data0
# Broker
kwargs = eval('dict(' + args.broker + ')')
cerebro.broker = bt.brokers.BackBroker(**kwargs)
# Sizer
kwargs = eval('dict(' + args.sizer + ')')
cerebro.addsizer(bt.sizers.FixedSize, **kwargs)
# Strategy
if True:
kwargs = eval('dict(' + args.strat + ')')
cerebro.addstrategy(MACrossOver, **kwargs)
cerebro.addobserver(bt.observers.LogReturns2,
timeframe=bt.TimeFrame.Weeks,
compression=20)
# Execute
cerebro.run(**(eval('dict(' + args.cerebro + ')')))
if args.plot: # Plot if requested to
cerebro.plot(**(eval('dict(' + args.plot + ')')))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Gold vs SP500 from '
'https://estrategiastrading.com/oro-bolsa-estadistica-con-python/')
)
parser.add_argument('--data0', required=False, default='SPY',
metavar='TICKER', help='Yahoo ticker to download')
parser.add_argument('--data1', required=False, default='GLD',
metavar='TICKER', help='Yahoo ticker to download')
parser.add_argument('--offline', required=False, action='store_true',
help='Use the offline files')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='2005-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='2016-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
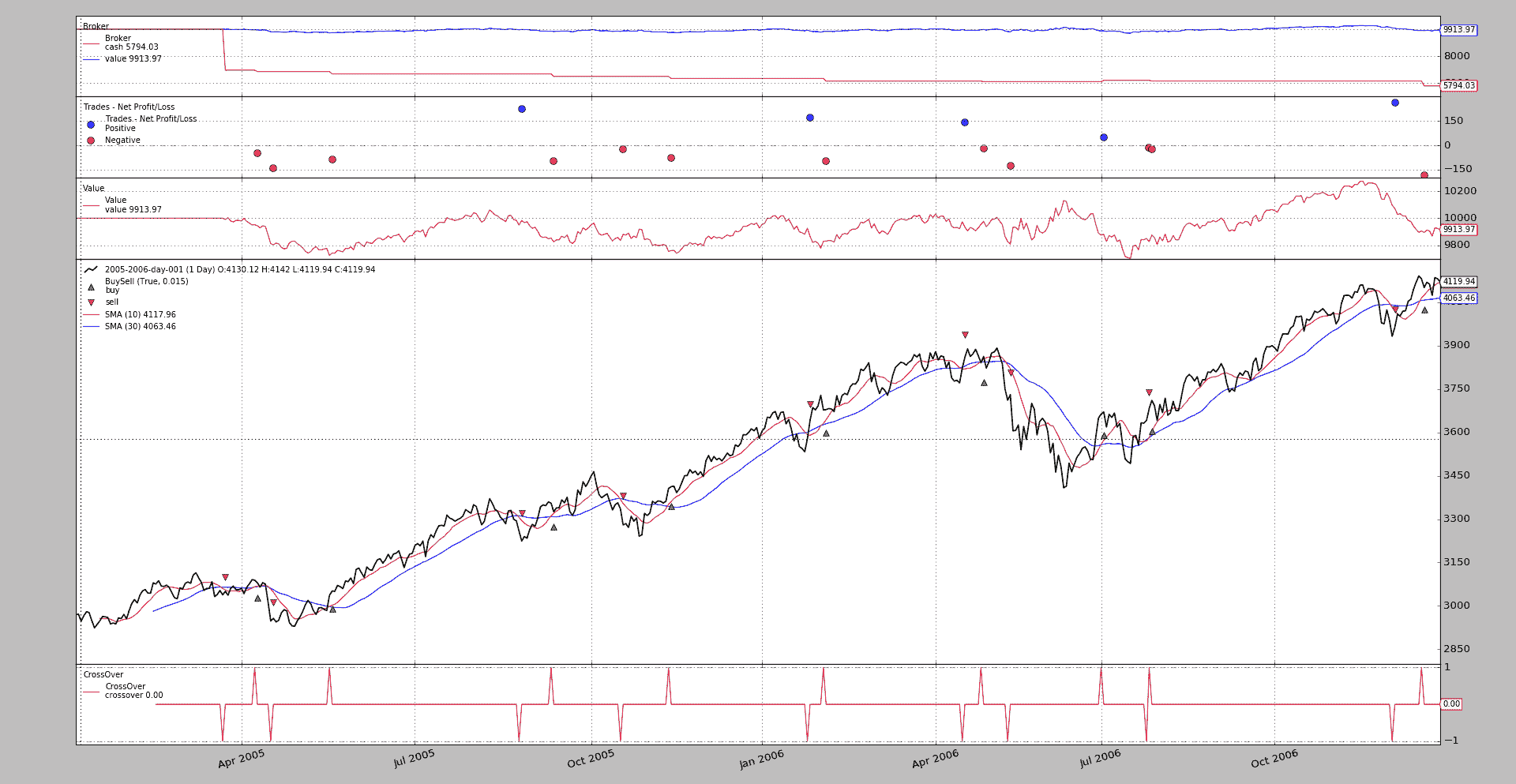
为 BuySell 观察者的箭头
原文:
www.backtrader.com/blog/posts/2016-12-10-buysellarrows/buysellarrows/
backtrader的构想是为了提供易用性。创建指标和其他常见的对象应该很容易。
当然,定制现有项目也应该是交易的一部分。
社区中的一个话题,BuySell Arrows,源自从问题迁移而来,是一个很好的例子。
可通过运行示例查看当前行为:
./buysellarrows.py --plot style="'ohlc'"
具有以下输出
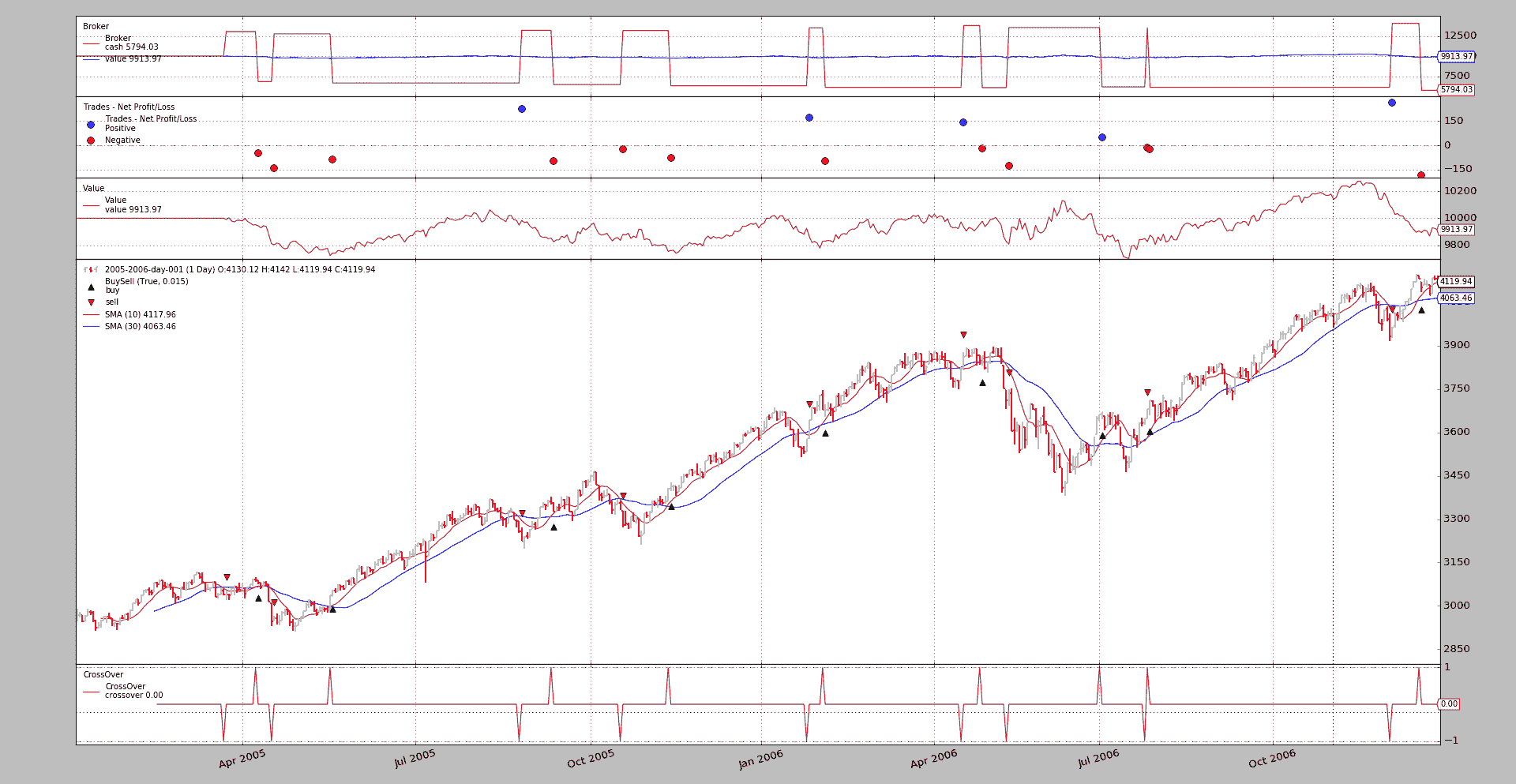
使用时示例执行以下操作:
-
定义
BuySell观察者的子类 -
重写
plotlines定义,简单地更改指示买入和卖出操作的标记 -
用自定义的观察者猴子补丁现有的观察者
以代码术语表示。
class MyBuySell(bt.observers.BuySell):
plotlines = dict(
buy=dict(marker='$\u21E7$', markersize=12.0),
sell=dict(marker='$\u21E9$', markersize=12.0)
)
和:
# Patch observer if needed
if args.myobserver:
bt.observers.BuySell = MyBuySell
注意
猴子补丁并不是绝对必要的。也可以按照标准方式进行:
cerebro = bt.Cerebro(stdstats=False) # remove the standard observers
...
cerebro.addobserver(MyObserver, barplot=True)
...
并且将使用自定义观察者,但其他常规实例化的观察者将缺失。因此,在示例中进行猴子补丁,简单地修改观察者并保持外观。
再次运行时使用正确参数:
$ ./buysellarrows.py --plot style="'ohlc'" --myobserver
然后输出。
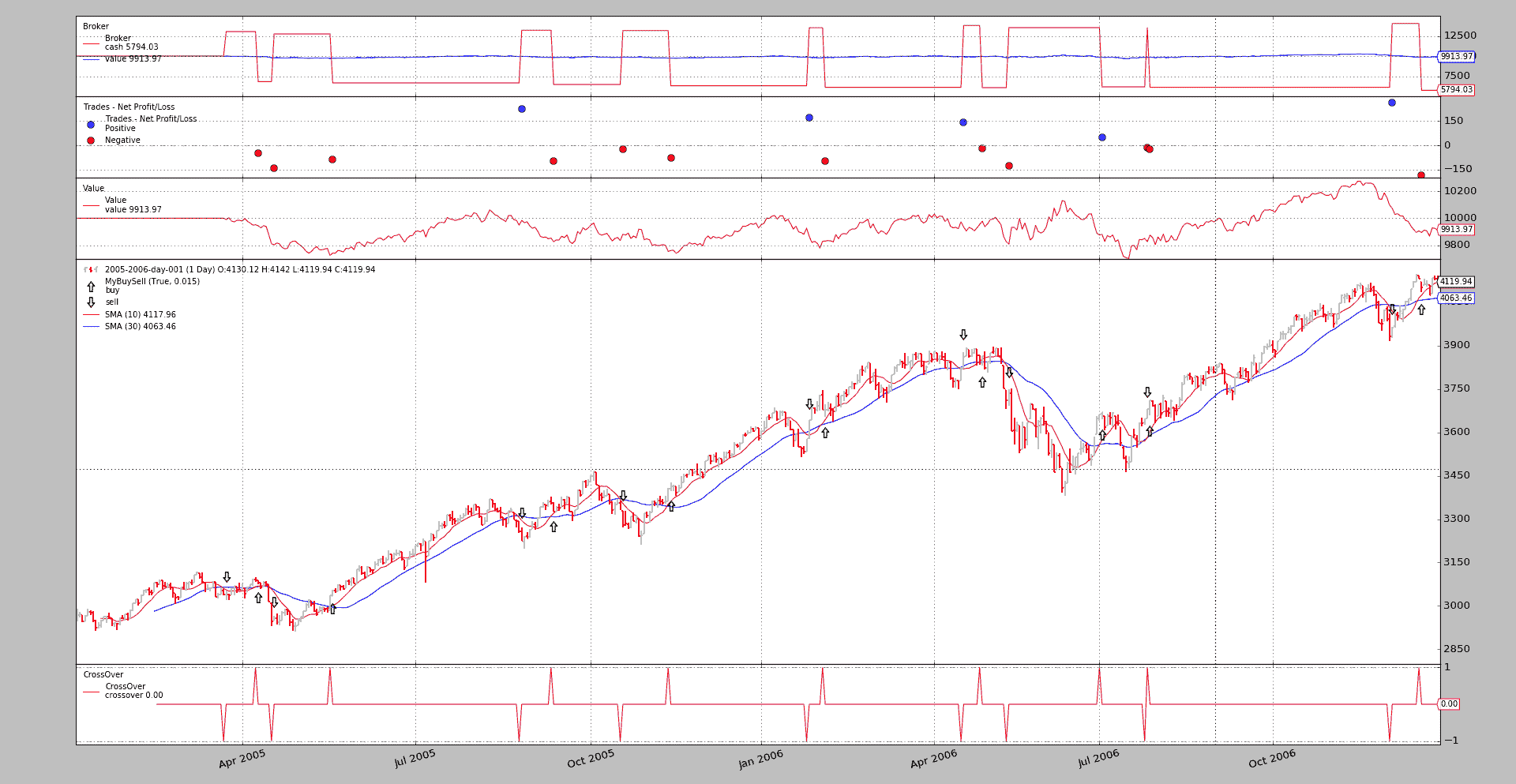
因为matplotlib允许使用Unicode字符,观察者的默认外观可以更改为任何形式,而不仅仅是箭头。随意发挥。例如来自维基百科:
示例用法
$ ./buysellarrows.py --help
usage: buysellarrows.py [-h] [--data DATA | --yahoo TICKER]
[--fromdate FROMDATE] [--todate TODATE]
[--cerebro kwargs] [--broker kwargs] [--sizer kwargs]
[--strat kwargs] [--plot [kwargs]] [--myobserver]
buysell arrows ...
optional arguments:
-h, --help show this help message and exit
--data DATA Data to read in (default:
../../datas/2005-2006-day-001.txt)
--yahoo TICKER Yahoo ticker to download (default: )
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
--myobserver Patch in Custom BuySell observer (default: False)
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class MyBuySell(bt.observers.BuySell):
plotlines = dict(
buy=dict(marker='$\u21E7$', markersize=12.0),
sell=dict(marker='$\u21E9$', markersize=12.0)
)
class MACrossOver(bt.SignalStrategy):
params = (('ma', bt.ind.MovAv.SMA), ('p1', 10), ('p2', 30),)
def __init__(self):
ma1, ma2 = self.p.ma(period=self.p.p1), self.p.ma(period=self.p.p2)
self.signal_add(bt.SIGNAL_LONGSHORT, bt.ind.CrossOver(ma1, ma2))
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict(dataname=args.yahoo or args.data)
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed kwargs
if args.yahoo:
data0 = bt.feeds.YahooFinanceData(**kwargs)
else:
data0 = bt.feeds.BacktraderCSVData(**kwargs)
cerebro.adddata(data0)
# Broker
kwargs = eval('dict(' + args.broker + ')')
cerebro.broker = bt.brokers.BackBroker(**kwargs)
# Sizer
kwargs = eval('dict(' + args.sizer + ')')
cerebro.addsizer(bt.sizers.FixedSize, **kwargs)
# Strategy
kwargs = eval('dict(' + args.strat + ')')
cerebro.addstrategy(MACrossOver, **kwargs)
# better net liquidation value view
cerebro.addobserver(bt.observers.Value)
# Patch observer if needed
if args.myobserver:
bt.observers.BuySell = MyBuySell
# Execute
cerebro.run(**(eval('dict(' + args.cerebro + ')')))
if args.plot: # Plot if requested to
cerebro.plot(**(eval('dict(' + args.plot + ')')))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='buysell arrows ...')
pgroup = parser.add_mutually_exclusive_group(required=False)
pgroup.add_argument('--data', required=False,
default='../../datas/2005-2006-day-001.txt',
help='Data to read in')
pgroup.add_argument('--yahoo', required=False, default='',
metavar='TICKER', help='Yahoo ticker to download')
parser.add_argument('--fromdate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--myobserver', required=False, action='store_true',
help='Patch in Custom BuySell observer')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
做空现金
原文:
www.backtrader.com/blog/posts/2016-12-06-shorting-cash/shorting-cash/
从一开始backtrader就被启用来对任何东西进行做空,包括类股票和类期货工具。当做空操作时,现金减少,做空资产的价值用于总净清算价值。
从一边减少,从另一边增加保持事物平衡。
似乎人们更喜欢现金增加,这可能导致更多的支出。
在发布1.9.7.105时,经纪人已更改了默认行为以增加现金并减少价值。这可以通过参数shortcash来控制,默认为True。更改方式如下:
cerebro.broker.set_shortcash(False)
或者:
cerebro.broker = bt.brokers.BackBroker(shortcash=False, **other_kwargs)
行动中
下面的示例使用标准的移动平均线交叉,并可用于查看差异。不带参数运行它并且新行为:
$ ./shortcash.py --plot
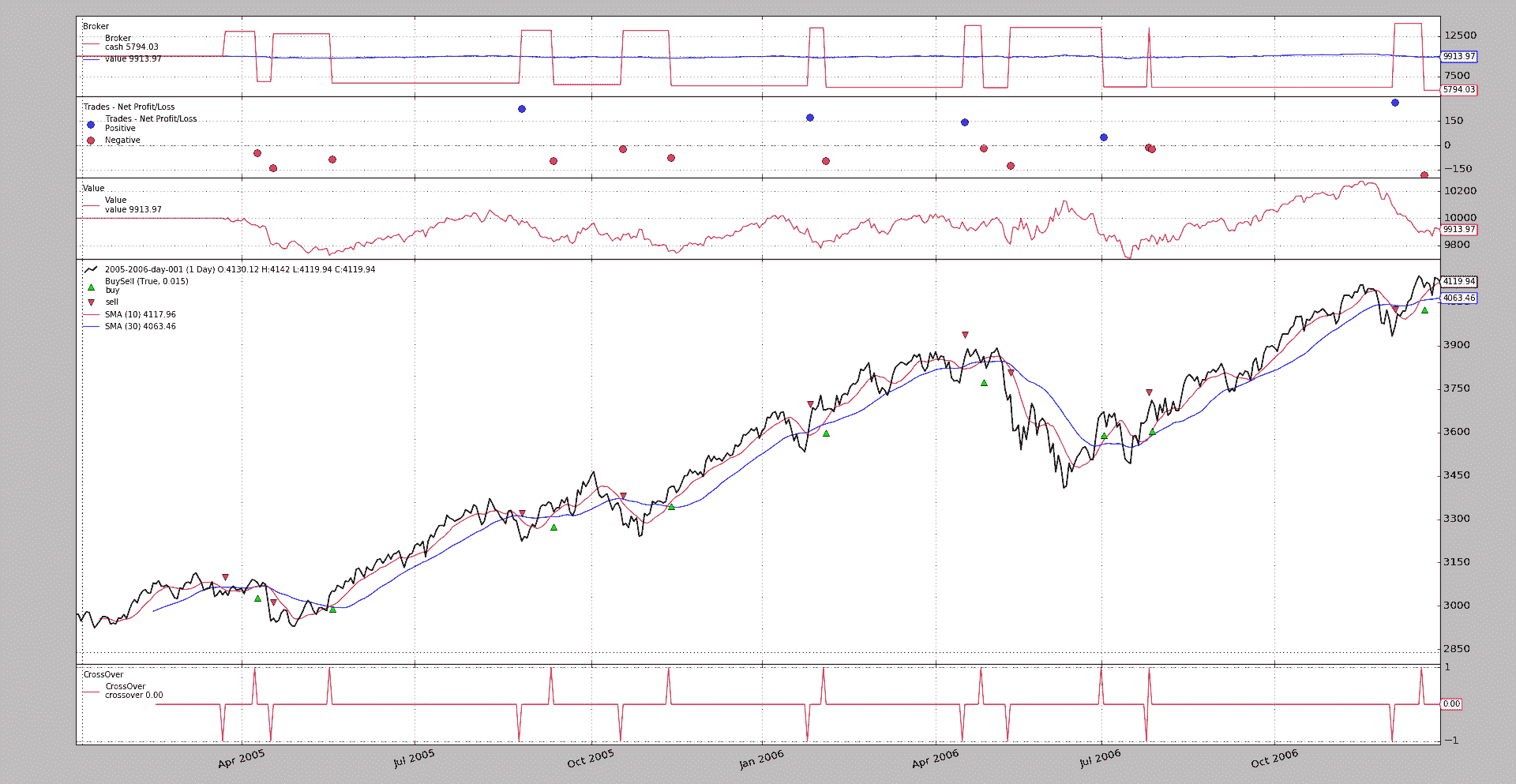
可以与以下行为进行比较:
$ ./shortcash.py --plot --broker shortcash=False
保持不变的事物:
-
最终结果
-
交易
-
净清算价值演变
为了看到这一点,添加了额外的观察者,以确保缩放允许详细查看演变过程
变化:
-
当
shortcash设置为False时,现金永远不会超过初始水平,因为每次操作都会花费资金。但是通过新的默认行为,我们已经可以看到第 1 个做空操作(恰好是第 1 个)向系统中添加了现金,然后多头从系统中扣除了现金(显然做空是第 1 个关闭的)
使用示例
$ ./shortcash.py --help
usage: shortcash.py [-h] [--data DATA] [--cerebro CEREBRO] [--broker BROKER]
[--sizer SIZER] [--strat STRAT] [--plot [kwargs]]
shortcash testing ...
optional arguments:
-h, --help show this help message and exit
--data DATA Data to read in (default:
../../datas/2005-2006-day-001.txt)
--cerebro CEREBRO kwargs in key=value format (default: )
--broker BROKER kwargs in key=value format (default: )
--sizer SIZER kwargs in key=value format (default: )
--strat STRAT kwargs in key=value format (default: )
--plot [kwargs], -p [kwargs]
Plot the read data applying any kwargs passed For
example: --plot style="candle" (to plot candles)
(default: None)
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
class MACrossOver(bt.SignalStrategy):
params = (('ma', bt.ind.MovAv.SMA), ('p1', 10), ('p2', 30),)
def __init__(self):
ma1, ma2 = self.p.ma(period=self.p.p1), self.p.ma(period=self.p.p2)
self.signal_add(bt.SIGNAL_LONGSHORT, bt.ind.CrossOver(ma1, ma2))
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed
data0 = bt.feeds.BacktraderCSVData(dataname=args.data)
cerebro.adddata(data0)
# Broker
kwargs = eval('dict(' + args.broker + ')')
cerebro.broker = bt.brokers.BackBroker(**kwargs)
# Sizer
kwargs = eval('dict(' + args.sizer + ')')
cerebro.addsizer(bt.sizers.FixedSize, **kwargs)
# Strategy
kwargs = eval('dict(' + args.strat + ')')
cerebro.addstrategy(MACrossOver, **kwargs)
# better net liquidation value view
cerebro.addobserver(bt.observers.Value)
# Execute
cerebro.run(**(eval('dict(' + args.cerebro + ')')))
if args.plot: # Plot if requested to
cerebro.plot(**(eval('dict(' + args.plot + ')')))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='shortcash testing ...')
parser.add_argument('--data', default='../../datas/2005-2006-day-001.txt',
required=False, help='Data to read in')
parser.add_argument('--cerebro', required=False, action='store',
default='', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, action='store',
default='', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, action='store',
default='', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, action='store',
default='', help='kwargs in key=value format')
parser.add_argument('--plot', '-p', nargs='?', required=False,
metavar='kwargs', const='{}',
help=('Plot the read data applying any kwargs passed\n'
'\n'
'For example:\n'
'\n'
' --plot style="candle" (to plot candles)\n'))
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
Python 的隐藏力量(3)
原文:
www.backtrader.com/blog/posts/2016-11-25-hidden-powers-3/hidden-powers/
最后,在关于如何在 backtrader 中使用 Python 的隐藏力量的系列中,一些魔术变量是如何出现的。
self.datas 和其他属性是从哪里来的?
常见的类(或其子类)Strategy、Indicator、Analyzer、Observer 都自动定义了属性,例如包含 data feeds 的数组。
数据源被添加到 cerebro 实例中,如下所示:
from datetime import datetime
import backtrader as bt
cerebro = bt.Cerebro()
data = bt.YahooFinanceData(dataname=my_ticker, fromdate=datetime(2016, 1, 1))
cerebro.adddata(data)
...
我们的示例中的获胜策略将在 close 超过 Simple Moving Average 时进行多头操作。我们将使用 Signals 来缩短示例:
class MyStrategy(bt.SignalStrategy):
params = (('period', 30),)
def __init__(self):
mysig = self.data.close > bt.indicators.SMA(period=self.p.period)
self.signal_add(bt.signal.SIGNAL_LONG, mysig)
这些被添加到混合中:
cerebro.addstrategy(MyStrategy)
任何读者都会注意到:
-
__init__不带任何参数,无论是否命名 -
没有
super调用,因此基类没有直接要求执行其初始化 -
mysig的定义引用了self.data,这可能与添加到cerebro的YahooFinanceData实例有关。确实如此!
实际上还有其他属性存在,但在示例中看不到。例如:
-
self.datas:包含添加到cerebro��所有 data feeds 的数组 -
self.dataX:其中X是一个数字,反映了数据添加到cerebro中的顺序(data0是上面添加的数据) -
self.data:指向self.data0。只是一个方便的快捷方式,因为大多数示例和策略只针对单个数据
更多内容请查看文档:
这些属性是如何创建的?
在本系列的第二篇文章中,看到类创建机制和实例创建机制被拦截。后者用于执行此操作。
-
cerebro通过adstrategy接收 class。 -
当需要时,它将实例化自身并将自身添加为属性
-
在创建
Strategy实例时,策略的new类方法被拦截,并检查cerebro中有哪些 data feeds 可用。它确实创建了上面提到的 array 和 aliases
这种机制应用于 backtrader 生态系统中的许多其他对象,以简化最终用户的操作。因此:
-
例如,没有必要不断创建包含名为
datas的参数的函数原型,也不需要将其分配给self.datas。因为它在后台自动完成
这种拦截的另一个示例
让我们定义一个获胜的指标,并将其添加到一个获胜的策略中。我们将重新包装 close over SMA 的概念:
class MyIndicator(bt.Indicator):
params = (('period', 30),)
lines = ('signal',)
def __init__(self):
self.lines.signal = self.data - bt.indicators.SMA
现在将其添加到常规策略中:
class MyStrategy(bt.Strategy):
params = (('period', 30),)
def __init__(self):
self.mysig = MyIndicator(period=self.p.period)
def next(self):
if self.mysig:
pass # do something like buy ...
从上面的代码中显然在 MyIndicator 中进行了计算:
self.lines.signal = self.data - bt.indicators.SMA
但似乎没有地方执行这个操作。正如本系列中的第 1 篇文章所示,该操作生成一个对象,分配给self.lines.signal,然后发生以下情况:
-
这个对象还拦截了自己的创建过程
-
它扫描堆栈以了解正在创建的上下文,本例中是在
MyIndicators的实例内部创建。 -
在初始化完成后,将自身添加到
MyIndicator的内部结构中 -
稍后当计算
MyIndicator时,它将反过来计算操作,该操作位于由self.lines.signal引用的对象内部
不错,但是谁计算MyIndicator
完全相同的过程被遵循:
-
MyIndicator在创建过程中扫描堆栈并找到MyStrategy -
并将自身添加到
MyStrategy的结构中 -
就在调用
next之前,要求MyIndicator重新计算自身,这反过来告诉self.lines.signal重新计算自身
这个过程可以有多层间接性。
对用户来说最好的事情是:
-
当创建某物时无需添加像
register_operation这样的调用 -
无需手动触发计算
总结
本系列中的最后一篇文章展示了另一个例子,说明了如何利用类/实例创建拦截来使最终用户的生活更轻松:
-
在需要的地方从生态系统中添加对象并创建别名
-
自动注册类并触发计算
Python 的隐藏力量(2)
原文:
www.backtrader.com/blog/posts/2016-11-23-hidden-powers-2/hidden-powers/
让我们更深入地探讨 Python 的隐藏力量 如何在 backtrader 中使用,以及如何实现这一点以尝试达到主要目标:易用性
这些定义是什么?
例如一个指标:
import backtrader as bt
class MyIndicator(bt.Indicator):
lines = ('myline',)
params = (('period', 20),)
...
任何能够阅读 Python 的人都会说:
-
lines是一个tuple,实际上包含一个字符串项目 -
params也是一个tuple,包含另一个包含 2 个项目的tuple
但是后来
扩展示例:
import backtrader as bt
class MyIndicator(bt.Indicator):
lines = ('myline',)
params = (('period', 20),)
def __init__(self):
self.lines.myline = (self.data.high - self.data.low) / self.p.period
对于任何人来说,这里应该很明显:
- 在类中的
lines的定义已经转换为可以通过self.lines访问的属性,并且依次包含定义中指定的myline属性
而且
-
在类中的
params的定义已经转换为可以通过self.p(或self.params)访问的属性,并依次包含定义中指定的period属性而
self.p.period似乎有一个值,因为它直接在算术运算中使用(显然该值是定义中的值:20)
答案:元类
bt.Indicator 和因此也有 MyIndicator 的 元类,这允许应用 元编程 概念。
在这种情况下,拦截对 lines 和 params 定义的方式是这样的:
-
实例 的属性,即:可通过
self.lines和self.params访问 -
类 的属性
-
包含其中定义的
属性(和已定义的值)
部分的秘密
对于那些不熟悉元类的人,它或多或少是这样实现的:
class MyMetaClass(type):
def __new__(meta, name, bases, dct):
...
lines = dct.pop('lines', ())
params = dct.pop('params', ())
# Some processing of lines and params ... takes place here
...
dct['lines'] = MyLinesClass(info_from_lines)
dct['params'] = MyParamsClass(info_from_params)
...
这里拦截了类的创建,并用从定义中提取的信息替换了 lines 和 params 的定义。
这单独是不够的,所以还拦截了实例的创建。 使用 Pyton 3.x 语法:
class MyClass(Parent, metaclass=MyMetaClass):
def __new__(cls, *args, **kwargs):
obj = super(MyClass, cls).__new__(cls, *args, **kwargs)
obj.lines = cls.lines()
obj.params = cls.params()
return obj
在这里,上面定义的 MyLinesClass 和 MyParamsClass 的实例已经被放置到 MyClass 的实例中。
不,没有冲突:
-
类 可以说是:“系统范围内”,并包含其自己的
lines和params的属性,它们是类 -
实例 可以说是:“系统本地”,每个实例都包含
lines和params的实例(每次都不同)
通常,人们会使用 self.lines 访问实例,但也可以使用 MyClass.lines 访问类。
后者给用户访问方法的权限,这些方法并不是为了一般使用,但这是 Python,没有什么可以禁止的,甚至更不用说 开源 了
结论
元类在幕后工作,提供了一种机制,通过处理诸如 lines 和 params 的 tuple 定义之类的东西,从而使几乎成为一种元语言
目标是让任何使用该平台的人的生活更加轻松
Python 的隐藏功能(1)
原文:
www.backtrader.com/blog/posts/2016-11-20-python-hidden-powers/hidden-powers/
只有当真正遇到backtrader的实际用户时,才能意识到平台中使用的抽象和 Python 功能是否有意义。
在不放弃pythonic座右铭的情况下,backtrader试图尽可能给用户更多的控制权,同时通过利用 Python 提供的隐藏功能来简化使用。
这是系列中第一篇文章中的第一个示例。
它是一个数组还是其他什么?
一个非常快速的例子:
import backtrader as bt
class MyStrategy(bt.Strategy):
def __init__(self):
self.hi_lo_avg = (self.data.high + self.data.low) / 2.0
def next(self):
if self.hi_lo_avg[0] > another_value:
print('we have a winner!')
...
...
cerebro.addstrategy(MyStrategy)
cerebro.run()
很快就会出现的一个问题是:
- 在
__init__期间也可以使用[]吗?
用户已经尝试并且 Python 因异常而停止运行,所以提出这个问题。
答案是:
- 不,使用
[]不是在初始化期间使用的。
接下来的问题是:
- 那么在
__init__期间self.hi_lo_avg实际存储了什么,如果不是数组?
对程序员来说,答案并不令人困惑,但对选择 Python 的算法交易员来说可能会令人困惑
- 这是一个惰性计算的对象,在
cerebro.run阶段通过[]运算符计算和传递值,即在策略的next方法中。
要点:在next方法中,数组索引运算符[]将使您能够访问过去和当前时间点的计算值。
秘密就在于这个方法
运算符重载才是真正的方法。让我们分解高低平均值的计算:
self.hi_lo_avg = (self.data.high + self.data.low) / 2.0
组件:
self.data.high和self.data.low本身就是对象(在backtrader命名方案中称为lines)
在许多情况下,它们被错误地视为纯arrays,但它们并不是。它们被视为对象的原因是:
-
backtrader中已经实现了
0和-1索引方案 -
控制缓冲区大小并链接到其他对象
最重要的一点是:
- 重载运算符以返回对象
为什么下面的操作返回一个lines对象。让我们开始:
temp = self.data.high - self.data.low
然后将临时对象除以2.0并赋值给成员变量:
self.hi_lo_avg = temp / 2.0
这再次返回另一个lines对象。因为运算符重载不仅适用于直接在lines对象之间执行的操作,还适用于例如这种除法的算术运算。
这意味着self.hi_lo_avg引用了一个lines对象。这个对象在策略的next方法中或作为指标或其他计算的输入中非常有用。
一个逻辑运算符的例子
上面的示例在__init__期间使用了一个算术运算符,后来在next中结合了[0]和逻辑运算符>。
因为运算符重载不仅限于算术,让我们举个例子,将一个指标添加进来。第一次尝试可能是:
import backtrader as bt
class MyStrategy(bt.Strategy):
def __init__(self):
self.hi_lo_avg = (self.data.high + self.data.low) / 2.0
self.sma = bt.indicators.SMA(period=30)
def next(self):
if self.hi_lo_avg[0] > self.sma[0]:
print('we have a winner!')
...
...
cerebro.addstrategy(MyStrategy)
cerebro.run()
但在这种情况下,只是从another_value改为了self.sma[0]。让我们改进一下:
import backtrader as bt
class MyStrategy(bt.Strategy):
def __init__(self):
self.hi_lo_avg = (self.data.high + self.data.low) / 2.0
self.sma = bt.indicators.SMA(period=30)
def next(self):
if self.hi_lo_avg > self.sma:
print('we have a winner!')
...
...
cerebro.addstrategy(MyStrategy)
cerebro.run()
为了好处。运算符重载在next中也是有效的,用户可以直接删除[0]并直接比较对象。
如果所有这些都是实际可能的,那实际上似乎有点过度。但好消息是还有更多。看看这个例子:
import backtrader as bt
class MyStrategy(bt.Strategy):
def __init__(self):
hi_lo_avg = (self.data.high + self.data.low) / 2.0
sma = bt.indicators.SMA(period=30)
self.signal = hi_lo_avg > sma
def next(self):
if self.signal:
print('we have a winner!')
...
...
cerebro.addstrategy(MyStrategy)
cerebro.run()
我们已经做了两件事:
-
创建一个名为
self.signal的lines对象,将high-low-average与Simple Moving Average的值进行比较。如上所述,当计算完成时,这个对象在
next中是有用的。 -
在检查
signal是否为True时,去掉next中对[0]的使用。这是因为运算符也已经被重载用于布尔运算。
结论
希望这能让人们更清楚地了解在__init__中执行操作时实际发生了什么,以及运算符重载实际是如何进行的。
策略选择
原文:
www.backtrader.com/blog/posts/2016-10-29-strategy-selection/strategy-selection/
休斯顿,我们有问题:
- cerebro不打算多次运行。这不是第 1 次,而不是认为用户做错了,似乎这是一个用例。
这个有趣的用例是通过Ticket 177提出的。在这种情况下,cerebro被多次使用来评估从外部数据源获取的不同策略。
backtrader仍然可以支持这种用例,但不是以尝试的直接方式。
优化选择
backtrader中内置的优化已经做了所需的事情:
- 实例化多个策略实例并收集结果
唯一的一件事是instances都属于同一个class。这就是 Python 帮助我们控制对象创建的地方。
首先,让我们使用backtrader内置的Signal技术将两个非常快速的策略添加到脚本中
class St0(bt.SignalStrategy):
def __init__(self):
sma1, sma2 = bt.ind.SMA(period=10), bt.ind.SMA(period=30)
crossover = bt.ind.CrossOver(sma1, sma2)
self.signal_add(bt.SIGNAL_LONG, crossover)
class St1(bt.SignalStrategy):
def __init__(self):
sma1 = bt.ind.SMA(period=10)
crossover = bt.ind.CrossOver(self.data.close, sma1)
self.signal_add(bt.SIGNAL_LONG, crossover)
这再也不能更简单了。
现在让我们来展示这两个策略的魔力。
class StFetcher(object):
_STRATS = [St0, St1]
def __new__(cls, *args, **kwargs):
idx = kwargs.pop('idx')
obj = cls._STRATSidx
return obj
Et voilá!当类StFetcher被实例化时,方法__new__控制实例的创建。在这种情况下:
-
获取传递给它的
idx参数 -
使用这个参数从存储我们之前示例策略的
_STRATS列表中获取策略注意
没有什么能阻止使用这个
idx值从服务器和/或数据库中获取策略。 -
实例化并返回fecthed策略
运行展示
cerebro.addanalyzer(bt.analyzers.Returns)
cerebro.optstrategy(StFetcher, idx=[0, 1])
results = cerebro.run(maxcpus=args.maxcpus, optreturn=args.optreturn)
确实!优化就是这样!我们不再使用addstrategy,而是使用optstrategy并传递一个idx值的数组。这些值将被优化引擎迭代。
因为cerebro可以在每次优化中托管多个策略,结果将包含一个列表的列表。每个子列表是每次优化的结果。
在我们的情况下,每次只有 1 个策略,我们可以快速展平结果并提取我们添加的分析器的值。
strats = [x[0] for x in results] # flatten the result
for i, strat in enumerate(strats):
rets = strat.analyzers.returns.get_analysis()
print('Strat {} Name {}:\n - analyzer: {}\n'.format(
i, strat.__class__.__name__, rets))
一个示例运行
./strategy-selection.py
Strat 0 Name St0:
- analyzer: OrderedDict([(u'rtot', 0.04847392369449283), (u'ravg', 9.467563221580632e-05), (u'rnorm', 0.02414514457151587), (u'rnorm100', 2.414514457151587)])
Strat 1 Name St1:
- analyzer: OrderedDict([(u'rtot', 0.05124714332260593), (u'ravg', 0.00010009207680196471), (u'rnorm', 0.025543999840699633), (u'rnorm100', 2.5543999840699634)])
我们的 2 个策略已经运行并交付了(如预期的)不同的结果。
注意
这个示例很简单,但已经在所有可用的 CPU 上运行过。使用--maxpcpus=1来执行会更快。对于更复杂的场景,使用所有 CPU 将会很有用。
结论
策略选择用例是可能的,不需要绕过backtrader或Python本身的任何内置设施。
示例用法
$ ./strategy-selection.py --help
usage: strategy-selection.py [-h] [--data DATA] [--maxcpus MAXCPUS]
[--optreturn]
Sample for strategy selection
optional arguments:
-h, --help show this help message and exit
--data DATA Data to be read in (default:
../../datas/2005-2006-day-001.txt)
--maxcpus MAXCPUS Limit the numer of CPUs to use (default: None)
--optreturn Return reduced/mocked strategy object (default: False)
代码
这已经包含在 backtrader 的源代码中
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import backtrader as bt
class St0(bt.SignalStrategy):
def __init__(self):
sma1, sma2 = bt.ind.SMA(period=10), bt.ind.SMA(period=30)
crossover = bt.ind.CrossOver(sma1, sma2)
self.signal_add(bt.SIGNAL_LONG, crossover)
class St1(bt.SignalStrategy):
def __init__(self):
sma1 = bt.ind.SMA(period=10)
crossover = bt.ind.CrossOver(self.data.close, sma1)
self.signal_add(bt.SIGNAL_LONG, crossover)
class StFetcher(object):
_STRATS = [St0, St1]
def __new__(cls, *args, **kwargs):
idx = kwargs.pop('idx')
obj = cls._STRATSidx
return obj
def runstrat(pargs=None):
args = parse_args(pargs)
cerebro = bt.Cerebro()
data = bt.feeds.BacktraderCSVData(dataname=args.data)
cerebro.adddata(data)
cerebro.addanalyzer(bt.analyzers.Returns)
cerebro.optstrategy(StFetcher, idx=[0, 1])
results = cerebro.run(maxcpus=args.maxcpus, optreturn=args.optreturn)
strats = [x[0] for x in results] # flatten the result
for i, strat in enumerate(strats):
rets = strat.analyzers.returns.get_analysis()
print('Strat {} Name {}:\n - analyzer: {}\n'.format(
i, strat.__class__.__name__, rets))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='Sample for strategy selection')
parser.add_argument('--data', required=False,
default='../../datas/2005-2006-day-001.txt',
help='Data to be read in')
parser.add_argument('--maxcpus', required=False, action='store',
default=None, type=int,
help='Limit the numer of CPUs to use')
parser.add_argument('--optreturn', required=False, action='store_true',
help='Return reduced/mocked strategy object')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
笔记本 - 自动内联绘图
原文:
www.backtrader.com/blog/posts/2016-09-17-notebook-inline/notebook-inline/
发行版 1.9.1.99 在Jupyter Notebook内运行时添加了自动内联绘图。
关于 backtrader 的一些问题显示,人们在笔记本中使用该平台,并支持此操作并将其设置为默认行为应该使事情保持一致。
如果希望保留先前的行为并且图形必须独立绘制,请简单执行:
import backtrader as bt
...
cerebro.run()
...
cerebro.plot(iplot=False)
当然,如果从脚本或交互式运行,matplotlib的默认绘图后端将像以前一样使用,这将在单独的窗口中绘制图表。
数据同步重写
原文:
www.backtrader.com/blog/posts/2016-09-17-data-synchronization/data-synchronization/
在最新版本中,次要编号已从 8 移至 9,以指示可能具有一些行为影响的更改,即使已考虑到兼容性。
通过发布 1.9.0.99 版本,使用日期时间同步多个数据的整个机制已进行了重写(对于next和once模式)。
注意
所有标准测试用例都会从nosetests中获得很好的 OK,但复杂的用例可能会发现未涵盖的边缘情况。
先前的行为在问题#39、#76、#115和#129中有所讨论,并且这已成为废弃旧行为的基础。
现在,检查传入价格的日期时间时间戳以对齐数据,并提供新内容(先前的条形图)。优点:
-
非时间对齐数据现在也可以使用了。
-
在实时数据中,行为改善因为重新自动同步
让我们回顾一下,旧行为使用系统中引入的第一个数据作为时间同步的主数据,并且没有其他数据可以更快。现在系统中引入数据的顺序不再起作用。
重写的一部分解决了绘图问题,该问题天真地假设所有数据最终具有相同的长度,这是具有时间主数据的结果。新的绘图代码允许具有不同长度的数据。
注意
通过使用以下命令仍然可以使用旧行为:
cerebro = bt.Cerebro(oldsync=True)
或:
cerebro.run(oldsync=True)
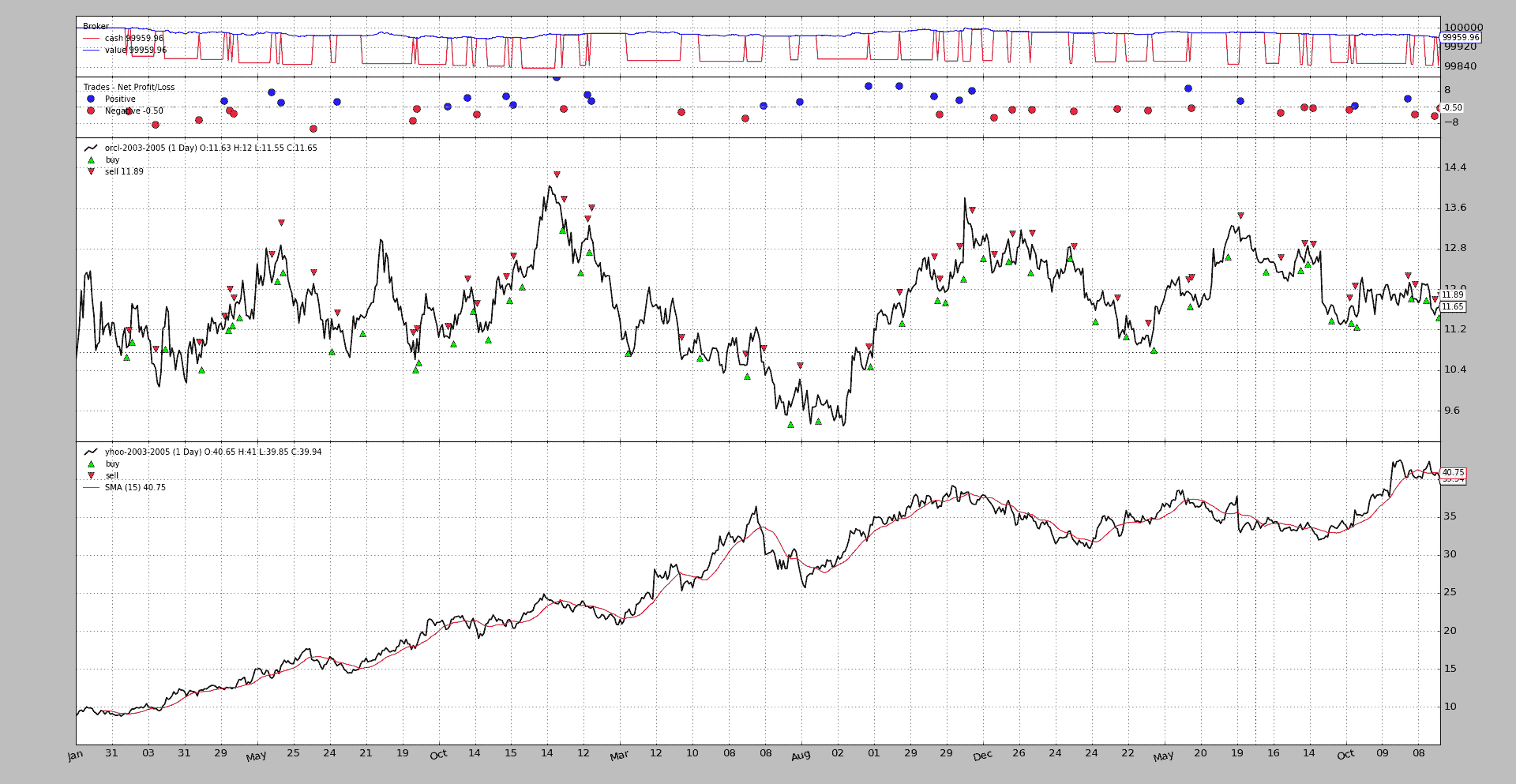
通过示例查看
multidata-strategy示例已用作multidata-strategy-unaligned示例的基础(在相同的文件夹中)。两个数据样本已手动更改以删除一些条形图。两者均为756条,已在两个不同时间点上限制为753
-
2004 年末,2005 年初为
YHOO -
2005 年底为
ORCL
一如既往,执行胜过千言万语。
首先是旧行为
执行:
$ ./multidata-strategy-unaligned.py --oldsync --plot
从输出来看,重要部分就在最后:
...
Self len: 753
Data0 len: 753
Data1 len: 750
Data0 len == Data1 len: False
Data0 dt: 2005-12-27 23:59:59
Data1 dt: 2005-12-27 23:59:59
...
注意:
-
策略长度为
753 -
第一个数据(时间主数据)也为
753 -
第二个数据(时间从属)为
750
从输出中并不明显,但YHOO文件包含截至2005-12-30的数据,系统未对其进行处理。
可视化图表
新行为
执行:
$ ./multidata-strategy-unaligned.py --plot
从输出来看,重要部分就在最后:
...
Self len: 756
Data0 len: 753
Data1 len: 753
Data0 len == Data1 len: True
Data0 dt: 2005-12-27 23:59:59
Data1 dt: 2005-12-30 23:59:59
...
行为显然已经改善:
-
策略长度为
756,每个数据都有完整的753个数据点。 -
因为移除的数据点不与数据重叠,所以策略最终比数据多
3个单位。 -
已经达到
2005-12-30,使用了data1(它是为了data0而删除的数据点之一),所以所有数据都已经处理到最后
可视化图表
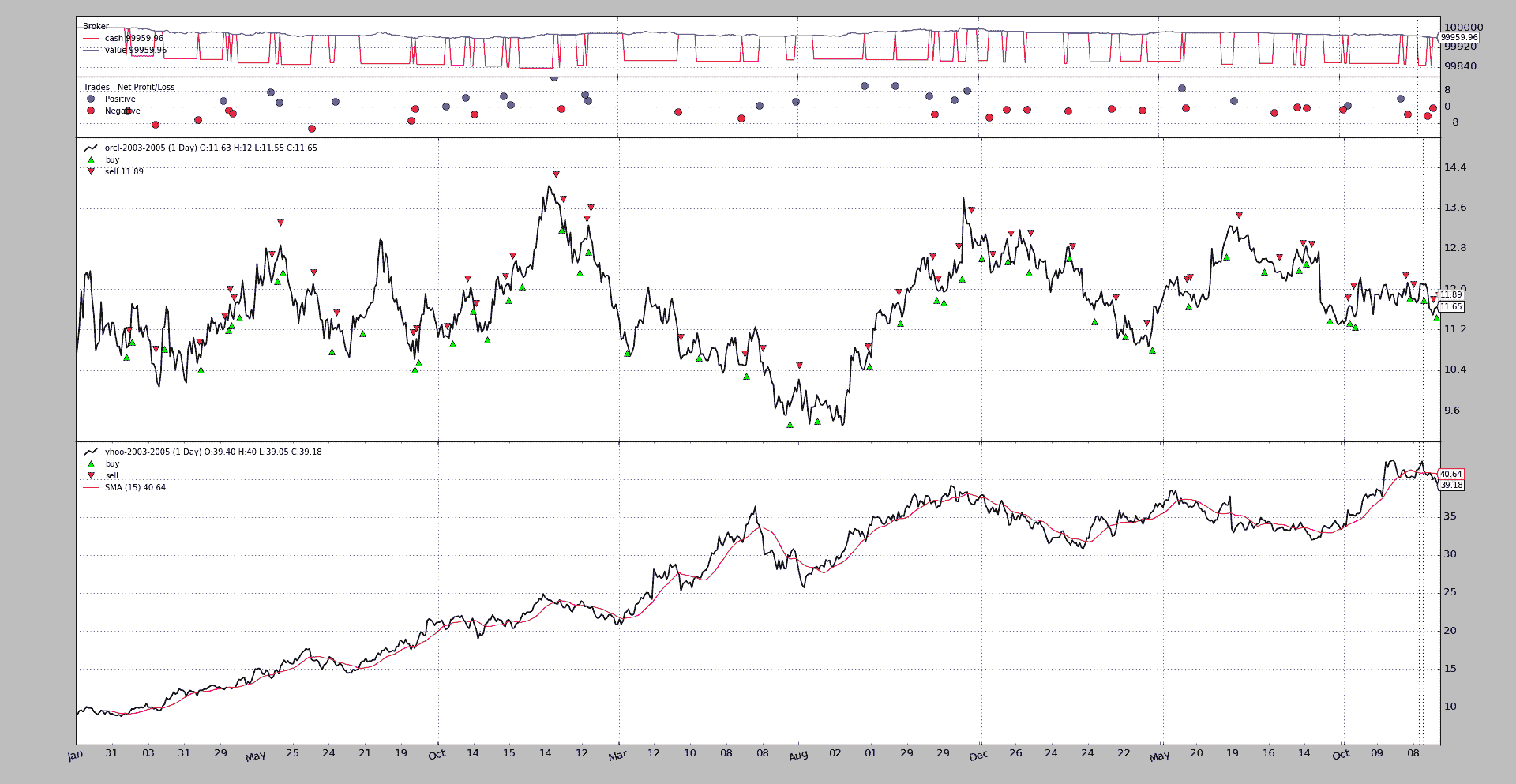
尽管图表看起来没有明显差异,但实际上它们在幕后是不同的。
另一个检查
对于感兴趣的用户,data-multitimeframe 示例已更新,还支持一个--oldsync参数。因为现在正在绘制不同长度的数据,所以较大时间框架的视觉效果更好。
使用新同步模型执行
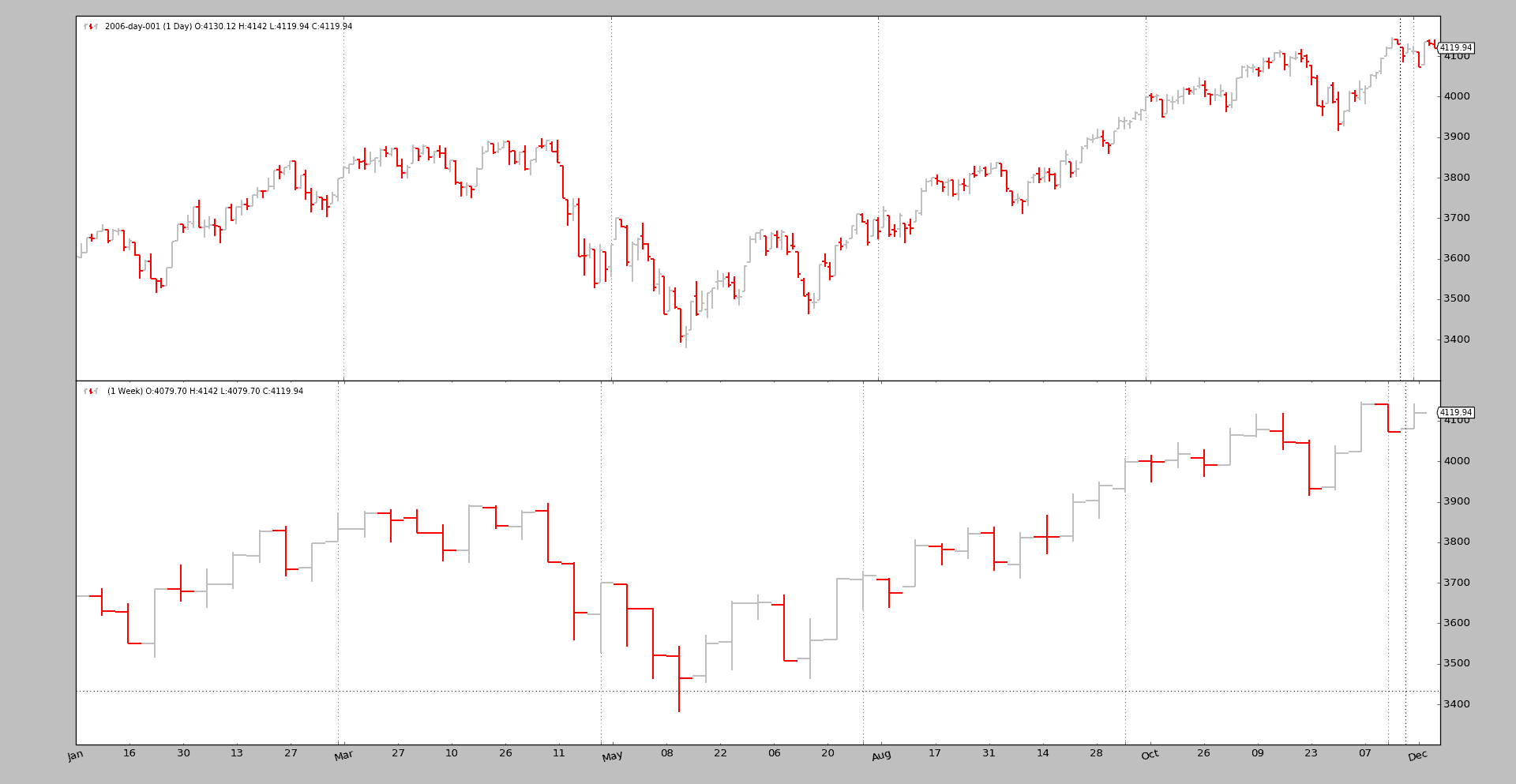
使用旧同步模型执行
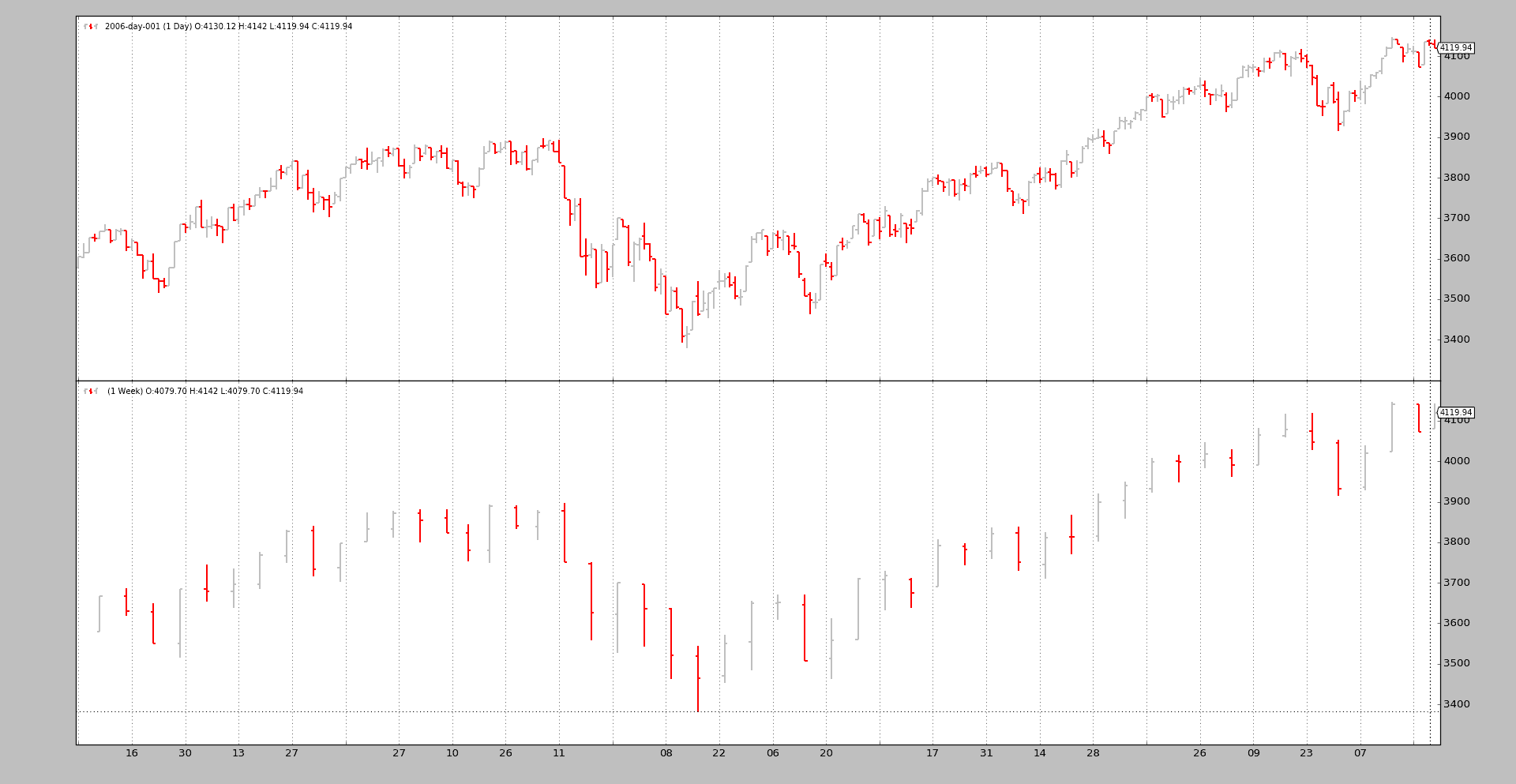
示例用法
$ ./multidata-strategy-unaligned.py --help
usage: multidata-strategy-unaligned.py [-h] [--data0 DATA0] [--data1 DATA1]
[--fromdate FROMDATE] [--todate TODATE]
[--period PERIOD] [--cash CASH]
[--runnext] [--nopreload] [--oldsync]
[--commperc COMMPERC] [--stake STAKE]
[--plot] [--numfigs NUMFIGS]
MultiData Strategy
optional arguments:
-h, --help show this help message and exit
--data0 DATA0, -d0 DATA0
1st data into the system
--data1 DATA1, -d1 DATA1
2nd data into the system
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--period PERIOD Period to apply to the Simple Moving Average
--cash CASH Starting Cash
--runnext Use next by next instead of runonce
--nopreload Do not preload the data
--oldsync Use old data synchronization method
--commperc COMMPERC Percentage commission (0.005 is 0.5%
--stake STAKE Stake to apply in each operation
--plot, -p Plot the read data
--numfigs NUMFIGS, -n NUMFIGS
Plot using numfigs figures
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
# The above could be sent to an independent module
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
class MultiDataStrategy(bt.Strategy):
'''
This strategy operates on 2 datas. The expectation is that the 2 datas are
correlated and the 2nd data is used to generate signals on the 1st
- Buy/Sell Operationss will be executed on the 1st data
- The signals are generated using a Simple Moving Average on the 2nd data
when the close price crosses upwwards/downwards
The strategy is a long-only strategy
'''
params = dict(
period=15,
stake=10,
printout=True,
)
def log(self, txt, dt=None):
if self.p.printout:
dt = dt or self.data.datetime[0]
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def notify_order(self, order):
if order.status in [bt.Order.Submitted, bt.Order.Accepted]:
return # Await further notifications
if order.status == order.Completed:
if order.isbuy():
buytxt = 'BUY COMPLETE, %.2f' % order.executed.price
self.log(buytxt, order.executed.dt)
else:
selltxt = 'SELL COMPLETE, %.2f' % order.executed.price
self.log(selltxt, order.executed.dt)
elif order.status in [order.Expired, order.Canceled, order.Margin]:
self.log('%s ,' % order.Status[order.status])
pass # Simply log
# Allow new orders
self.orderid = None
def __init__(self):
# To control operation entries
self.orderid = None
# Create SMA on 2nd data
sma = btind.MovAv.SMA(self.data1, period=self.p.period)
# Create a CrossOver Signal from close an moving average
self.signal = btind.CrossOver(self.data1.close, sma)
def next(self):
if self.orderid:
return # if an order is active, no new orders are allowed
if self.p.printout:
print('Self len:', len(self))
print('Data0 len:', len(self.data0))
print('Data1 len:', len(self.data1))
print('Data0 len == Data1 len:',
len(self.data0) == len(self.data1))
print('Data0 dt:', self.data0.datetime.datetime())
print('Data1 dt:', self.data1.datetime.datetime())
if not self.position: # not yet in market
if self.signal > 0.0: # cross upwards
self.log('BUY CREATE , %.2f' % self.data1.close[0])
self.buy(size=self.p.stake)
else: # in the market
if self.signal < 0.0: # crosss downwards
self.log('SELL CREATE , %.2f' % self.data1.close[0])
self.sell(size=self.p.stake)
def stop(self):
print('==================================================')
print('Starting Value - %.2f' % self.broker.startingcash)
print('Ending Value - %.2f' % self.broker.getvalue())
print('==================================================')
def runstrategy():
args = parse_args()
# Create a cerebro
cerebro = bt.Cerebro()
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data0 = btfeeds.YahooFinanceCSVData(
dataname=args.data0,
fromdate=fromdate,
todate=todate)
# Add the 1st data to cerebro
cerebro.adddata(data0)
# Create the 2nd data
data1 = btfeeds.YahooFinanceCSVData(
dataname=args.data1,
fromdate=fromdate,
todate=todate)
# Add the 2nd data to cerebro
cerebro.adddata(data1)
# Add the strategy
cerebro.addstrategy(MultiDataStrategy,
period=args.period,
stake=args.stake)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcash(args.cash)
# Add the commission - only stocks like a for each operation
cerebro.broker.setcommission(commission=args.commperc)
# And run it
cerebro.run(runonce=not args.runnext,
preload=not args.nopreload,
oldsync=args.oldsync)
# Plot if requested
if args.plot:
cerebro.plot(numfigs=args.numfigs, volume=False, zdown=False)
def parse_args():
parser = argparse.ArgumentParser(description='MultiData Strategy')
parser.add_argument('--data0', '-d0',
default='../../datas/orcl-2003-2005.txt',
help='1st data into the system')
parser.add_argument('--data1', '-d1',
default='../../datas/yhoo-2003-2005.txt',
help='2nd data into the system')
parser.add_argument('--fromdate', '-f',
default='2003-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default='2005-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--period', default=15, type=int,
help='Period to apply to the Simple Moving Average')
parser.add_argument('--cash', default=100000, type=int,
help='Starting Cash')
parser.add_argument('--runnext', action='store_true',
help='Use next by next instead of runonce')
parser.add_argument('--nopreload', action='store_true',
help='Do not preload the data')
parser.add_argument('--oldsync', action='store_true',
help='Use old data synchronization method')
parser.add_argument('--commperc', default=0.005, type=float,
help='Percentage commission (0.005 is 0.5%%')
parser.add_argument('--stake', default=10, type=int,
help='Stake to apply in each operation')
parser.add_argument('--plot', '-p', action='store_true',
help='Plot the read data')
parser.add_argument('--numfigs', '-n', default=1,
help='Plot using numfigs figures')
return parser.parse_args()
if __name__ == '__main__':
runstrategy()
变异性加权回报(或 VWR)
在一些关于改进SharpeRatio 的提示之后,backtrader将这个分析器添加到其工具库中。
文献位于:
从对数收益的好处开始,然后讨论将标准差放在 SharpeRatio 方程的分母中的副作用,文档展开了这个分析器的公式和期望。
最重要的特性之一可能是:
- 在时间框架上一致的数值
SharpeRatio使用超额收益与无风险利率/资产的算术平均值除以超额收益与无风险利率/资产的标准差。这使得最终数值取决于样本数量和标准差,甚至可能为0。在这种情况下,SharpeRatio将为无穷大。
backtrader包含一个用于测试SharpeRatio的样本,使用包含2005和2006价格的样本数据。不同时间框架的返回值为:
-
TimeFrame.Years:11.6473 -
TimeFrame.Months:0.5425 -
TimeFrame.Weeks:0.457 -
TimeFrame.Days:0.4274
注意
为了保持一致性,比率是年化的。sharpe-timereturn样本并使用以下方式执行:
--annualize --timeframe xxx
xxx代表天、周、月或年(默认)
在这个样本中有一点很明显:
- 时间框架越小,
SharpeRatio值越小
这是由于较小时间框架的样本数量较大,增加了变异性,从而增加了SharpeRatio方程中的分母——标准差。
对标准差的变化非常敏感
正是这一点,VWR试图通过在时间框架上提供一致的数值来解决。同一策略提供以下数值:
-
TimeFrame.Years:1.5368 -
TimeFrame.Months:1.5163 -
TimeFrame.Weeks:1.5383 -
TimeFrame.Days:1.5221
注意
VWR(遵循文献)始终以年化形式返回。样本使用以下方式执行:
--timeframe xxx
xxx代表天、周、月或年
默认值为None,使用数据的基础时间框架为天
一致的数值表明,当涉及提供一致回报时,策略的表现可以在任何时间框架上进行评估。
注意
理论上,数值应该是相同的,但这需要对tann参数(年化期数)进行微调,以匹配确切的交易期。这里没有这样做,因为目的只是看一致性。
结论
为用户提供了一种独立于时间框架的策略评估方法的新工具
样本用法
$ ./vwr.py --help
usage: vwr.py [-h] [--data DATA] [--cash CASH] [--fromdate FROMDATE]
[--todate TODATE] [--writercsv]
[--tframe {weeks,months,days,years}] [--sigma-max SIGMA_MAX]
[--tau TAU] [--tann TANN] [--stddev-sample] [--plot [kwargs]]
TimeReturns and VWR
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system (default:
../../datas/2005-2006-day-001.txt)
--cash CASH Starting Cash (default: None)
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format (default: None)
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format (default: None)
--writercsv, -wcsv Tell the writer to produce a csv stream (default:
False)
--tframe {weeks,months,days,years}, --timeframe {weeks,months,days,years}
TimeFrame for the Returns/Sharpe calculations
(default: None)
--sigma-max SIGMA_MAX
VWR Sigma Max (default: None)
--tau TAU VWR tau factor (default: None)
--tann TANN Annualization factor (default: None)
--stddev-sample Consider Bessels correction for stddeviation (default:
False)
--plot [kwargs], -p [kwargs]
Plot the read data applying any kwargs passed For
example: --plot style="candle" (to plot candles)
(default: None)
样本代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
TFRAMES = dict(
days=bt.TimeFrame.Days,
weeks=bt.TimeFrame.Weeks,
months=bt.TimeFrame.Months,
years=bt.TimeFrame.Years)
def runstrat(pargs=None):
args = parse_args(pargs)
# Create a cerebro
cerebro = bt.Cerebro()
if args.cash is not None:
cerebro.broker.set_cash(args.cash)
dkwargs = dict()
# Get the dates from the args
if args.fromdate is not None:
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
dkwargs['fromdate'] = fromdate
if args.todate is not None:
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
dkwargs['todate'] = todate
# Create the 1st data
data = bt.feeds.BacktraderCSVData(dataname=args.data, **dkwargs)
cerebro.adddata(data) # Add the data to cerebro
cerebro.addstrategy(bt.strategies.SMA_CrossOver) # Add the strategy
lrkwargs = dict()
if args.tframe is not None:
lrkwargs['timeframe'] = TFRAMES[args.tframe]
if args.tann is not None:
lrkwargs['tann'] = args.tann
cerebro.addanalyzer(bt.analyzers.Returns, **lrkwargs) # Returns
vwrkwargs = dict()
if args.tframe is not None:
vwrkwargs['timeframe'] = TFRAMES[args.tframe]
if args.tann is not None:
vwrkwargs['tann'] = args.tann
if args.sigma_max is not None:
vwrkwargs['sigma_max'] = args.sigma_max
if args.tau is not None:
vwrkwargs['tau'] = args.tau
cerebro.addanalyzer(bt.analyzers.VWR, **vwrkwargs) # VWR Analyzer
# Add a writer to get output
cerebro.addwriter(bt.WriterFile, csv=args.writercsv, rounding=4)
cerebro.run() # And run it
# Plot if requested
if args.plot:
pkwargs = dict(style='bar')
if args.plot is not True: # evals to True but is not True
npkwargs = eval('dict(' + args.plot + ')') # args were passed
pkwargs.update(npkwargs)
cerebro.plot(**pkwargs)
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='TimeReturns and SharpeRatio')
parser.add_argument('--data', '-d',
default='../../datas/2005-2006-day-001.txt',
help='data to add to the system')
parser.add_argument('--cash', default=None, type=float, required=False,
help='Starting Cash')
parser.add_argument('--fromdate', '-f',
default=None,
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--todate', '-t',
default=None,
help='Starting date in YYYY-MM-DD format')
parser.add_argument('--writercsv', '-wcsv', action='store_true',
help='Tell the writer to produce a csv stream')
parser.add_argument('--tframe', '--timeframe', default=None,
required=False, choices=TFRAMES.keys(),
help='TimeFrame for the Returns/Sharpe calculations')
parser.add_argument('--sigma-max', required=False, action='store',
type=float, default=None,
help='VWR Sigma Max')
parser.add_argument('--tau', required=False, action='store',
type=float, default=None,
help='VWR tau factor')
parser.add_argument('--tann', required=False, action='store',
type=float, default=None,
help=('Annualization factor'))
parser.add_argument('--stddev-sample', required=False, action='store_true',
help='Consider Bessels correction for stddeviation')
# Plot options
parser.add_argument('--plot', '-p', nargs='?', required=False,
metavar='kwargs', const=True,
help=('Plot the read data applying any kwargs passed\n'
'\n'
'For example:\n'
'\n'
' --plot style="candle" (to plot candles)\n'))
if pargs is not None:
return parser.parse_args(pargs)
return parser.parse_args()
if __name__ == '__main__':
runstrat()
优化改进
原文:
www.backtrader.com/blog/posts/2016-09-05-optimization-improvements/optimization-improvements/
backtrader的版本 1.8.12.99 包括了在多进程中管理数据源和结果的改进。
注意
两者的行为已经确定
这些选项的行为可以通过两个新的Cerebro参数来控制:
-
optdatas(默认:True)如果为
True且正在优化(系统可以preload和使用runonce),数据预加载将仅在主进程中执行一次,以节省时间和资源。 -
optreturn(默认:True)如果为
True,优化结果将不是完整的Strategy对象(以及所有数据、指标、观察者...),而是具有以下属性的对象(与Strategy中相同):-
params(或p)策略执行时的参数 -
策略执行的
analyzers
在大多数情况下,只需要analyzers和使用哪些params来评估策略的表现。如果需要对生成的值(例如指标)进行详细分析,请关闭此选项
-
数据源管理
在优化场景中,这是Cerebro参数的一个可能组合:
-
preload=True(默认)在运行任何回测代码之前,数据源将被预加载
-
runonce=True(默认)指标将在批处理模式下通过紧密的for循环计算,而不是逐步进行。
如果两个条件都为True且optdatas=True,那么:
- 在生成新的子进程(负责执行回测的进程)之前,数据源将在主进程中预加载
结果管理
在优化场景中,评估每个策略运行时使用的不同参数时,两件事情应该起到最重要的作用:
-
strategy.params(或strategy.p)用于回测的实际值集
-
strategy.analyzers负责提供策略实际表现评估的对象。例如:
SharpeRatio_A(年化夏普比率)
当optreturn=True时,将创建占位符对象,而不是返回完整的策略实例,这些对象具有上述两个属性,以便进行评估。
这样可以避免传递许多生成的数据,例如在回测期间指标生成的值
如果希望获得完整的策略对象,只需在 cerebro 实例化期间或进行cerebro.run时将optreturn=False设置即可。
一些测试运行
backtrader源代码中的优化示例已经扩展,以添加对optdatas和optreturn的控制(实际上是禁用它们)
单核运行
作为参考,当 CPU 数量限制为1且未使用multiprocessing模块时会发生什么:
$ ./optimization.py --maxcpus 1
==================================================
**************************************************
--------------------------------------------------
OrderedDict([(u'smaperiod', 10), (u'macdperiod1', 12), (u'macdperiod2', 26), (u'macdperiod3', 9)])
**************************************************
--------------------------------------------------
OrderedDict([(u'smaperiod', 10), (u'macdperiod1', 13), (u'macdperiod2', 26), (u'macdperiod3', 9)])
...
...
OrderedDict([(u'smaperiod', 29), (u'macdperiod1', 19), (u'macdperiod2', 29), (u'macdperiod3', 14)])
==================================================
Time used: 184.922727833
多核运行
在不限制 CPU 数量的情况下,Python 的multiprocessing模块将尝试使用所有 CPU。optdatas 和 optreturn 将被禁用
optdata 和 optreturn 都处于激活状态
默认行为:
$ ./optimization.py
...
...
...
==================================================
Time used: 56.5889185394
通过多核和数据源和结果的改进,总体上从 184.92 秒降低到 56.58 秒。
请注意,示例中使用了252个条形和指标只生成长度为252点的值。这只是一个例子。
真正的问题是有多少是归因于新行为。
optreturn 处于未激活状态
让我们将完整的策略对象传递给调用者:
$ ./optimization.py --no-optreturn
...
...
...
==================================================
Time used: 67.056914007
执行时间增加了 18.50%(或速度提升了 15.62%)。
optdatas 处于未激活状态
每个子进程都被强制加载自己的数据源集合:
$ ./optimization.py --no-optdatas
...
...
...
==================================================
Time used: 72.7238112637
执行时间增加了 28.52%(或速度提升了 22.19%)。
两者都处于未激活状态
仍然使用多核但是旧的非改进行为:
$ ./optimization.py --no-optdatas --no-optreturn
...
...
...
==================================================
Time used: 83.6246643786
执行时间增加了 47.79%(或速度提升了 32.34%)。
这表明使用多核是时间提升的主要贡献因素。
注意
这些执行是在一台配备有 i7-4710HQ(4 核 / 8 逻辑)和 16 GBytes 内存的笔记本电脑上在 Windows 10 64 位系统下完成的。在其他条件下,里程可能有所不同。
总结
-
在优化过程中减少时间的最大因素是多核的使用
-
示例运行了带有
optdatas和optreturn的显示速度提升约为22.19%和15.62%(在测试中两者一起提升了32.34%)。
示例用法
$ ./optimization.py --help
usage: optimization.py [-h] [--data DATA] [--fromdate FROMDATE]
[--todate TODATE] [--maxcpus MAXCPUS] [--no-runonce]
[--exactbars EXACTBARS] [--no-optdatas]
[--no-optreturn] [--ma_low MA_LOW] [--ma_high MA_HIGH]
[--m1_low M1_LOW] [--m1_high M1_HIGH] [--m2_low M2_LOW]
[--m2_high M2_HIGH] [--m3_low M3_LOW]
[--m3_high M3_HIGH]
Optimization
optional arguments:
-h, --help show this help message and exit
--data DATA, -d DATA data to add to the system
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD format
--todate TODATE, -t TODATE
Starting date in YYYY-MM-DD format
--maxcpus MAXCPUS, -m MAXCPUS
Number of CPUs to use in the optimization
- 0 (default): use all available CPUs
- 1 -> n: use as many as specified
--no-runonce Run in next mode
--exactbars EXACTBARS
Use the specified exactbars still compatible with preload
0 No memory savings
-1 Moderate memory savings
-2 Less moderate memory savings
--no-optdatas Do not optimize data preloading in optimization
--no-optreturn Do not optimize the returned values to save time
--ma_low MA_LOW SMA range low to optimize
--ma_high MA_HIGH SMA range high to optimize
--m1_low M1_LOW MACD Fast MA range low to optimize
--m1_high M1_HIGH MACD Fast MA range high to optimize
--m2_low M2_LOW MACD Slow MA range low to optimize
--m2_high M2_HIGH MACD Slow MA range high to optimize
--m3_low M3_LOW MACD Signal range low to optimize
--m3_high M3_HIGH MACD Signal range high to optimize
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import time
from backtrader.utils.py3 import range
import backtrader as bt
import backtrader.indicators as btind
import backtrader.feeds as btfeeds
class OptimizeStrategy(bt.Strategy):
params = (('smaperiod', 15),
('macdperiod1', 12),
('macdperiod2', 26),
('macdperiod3', 9),
)
def __init__(self):
# Add indicators to add load
btind.SMA(period=self.p.smaperiod)
btind.MACD(period_me1=self.p.macdperiod1,
period_me2=self.p.macdperiod2,
period_signal=self.p.macdperiod3)
def runstrat():
args = parse_args()
# Create a cerebro entity
cerebro = bt.Cerebro(maxcpus=args.maxcpus,
runonce=not args.no_runonce,
exactbars=args.exactbars,
optdatas=not args.no_optdatas,
optreturn=not args.no_optreturn)
# Add a strategy
cerebro.optstrategy(
OptimizeStrategy,
smaperiod=range(args.ma_low, args.ma_high),
macdperiod1=range(args.m1_low, args.m1_high),
macdperiod2=range(args.m2_low, args.m2_high),
macdperiod3=range(args.m3_low, args.m3_high),
)
# Get the dates from the args
fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')
todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')
# Create the 1st data
data = btfeeds.BacktraderCSVData(
dataname=args.data,
fromdate=fromdate,
todate=todate)
# Add the Data Feed to Cerebro
cerebro.adddata(data)
# clock the start of the process
tstart = time.clock()
# Run over everything
stratruns = cerebro.run()
# clock the end of the process
tend = time.clock()
print('==================================================')
for stratrun in stratruns:
print('**************************************************')
for strat in stratrun:
print('--------------------------------------------------')
print(strat.p._getkwargs())
print('==================================================')
# print out the result
print('Time used:', str(tend - tstart))
def parse_args():
parser = argparse.ArgumentParser(
description='Optimization',
formatter_class=argparse.RawTextHelpFormatter,
)
parser.add_argument(
'--data', '-d',
default='../../datas/2006-day-001.txt',
help='data to add to the system')
parser.add_argument(
'--fromdate', '-f',
default='2006-01-01',
help='Starting date in YYYY-MM-DD format')
parser.add_argument(
'--todate', '-t',
default='2006-12-31',
help='Starting date in YYYY-MM-DD format')
parser.add_argument(
'--maxcpus', '-m',
type=int, required=False, default=0,
help=('Number of CPUs to use in the optimization'
'\n'
' - 0 (default): use all available CPUs\n'
' - 1 -> n: use as many as specified\n'))
parser.add_argument(
'--no-runonce', action='store_true', required=False,
help='Run in next mode')
parser.add_argument(
'--exactbars', required=False, type=int, default=0,
help=('Use the specified exactbars still compatible with preload\n'
' 0 No memory savings\n'
' -1 Moderate memory savings\n'
' -2 Less moderate memory savings\n'))
parser.add_argument(
'--no-optdatas', action='store_true', required=False,
help='Do not optimize data preloading in optimization')
parser.add_argument(
'--no-optreturn', action='store_true', required=False,
help='Do not optimize the returned values to save time')
parser.add_argument(
'--ma_low', type=int,
default=10, required=False,
help='SMA range low to optimize')
parser.add_argument(
'--ma_high', type=int,
default=30, required=False,
help='SMA range high to optimize')
parser.add_argument(
'--m1_low', type=int,
default=12, required=False,
help='MACD Fast MA range low to optimize')
parser.add_argument(
'--m1_high', type=int,
default=20, required=False,
help='MACD Fast MA range high to optimize')
parser.add_argument(
'--m2_low', type=int,
default=26, required=False,
help='MACD Slow MA range low to optimize')
parser.add_argument(
'--m2_high', type=int,
default=30, required=False,
help='MACD Slow MA range high to optimize')
parser.add_argument(
'--m3_low', type=int,
default=9, required=False,
help='MACD Signal range low to optimize')
parser.add_argument(
'--m3_high', type=int,
default=15, required=False,
help='MACD Signal range high to optimize')
return parser.parse_args()
if __name__ == '__main__':
runstrat()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号