
BackTrader 中文文档(十三)
交易日历
发布1.9.42.116版本添加了对交易日历的支持。在例如以下情况下重采样时,这很有用:
-
现在,从每日到每周的重采样可以将每周柱与周的最后一根柱一起交付。
这是因为交易日历可以确定下一个交易日和上周最后一个交易日可以提前识别
-
当会话结束时间不是常规时间时(这已经可以指定给数据源)时,从子日到每日的重采样
交易日历接口
有一个基类TradingCalendarBase,用作任何交易日历的基础。它定义了必须被覆盖的两个(2)方法:
class TradingCalendarBase(with_metaclass(MetaParams, object)):
def _nextday(self, day):
'''
Returns the next trading day (datetime/date instance) after ``day``
(datetime/date instance) and the isocalendar components
The return value is a tuple with 2 components: (nextday, (y, w, d))
where (y, w, d)
'''
raise NotImplementedError
def schedule(self, day):
'''
Returns a tuple with the opening and closing times (``datetime.time``)
for the given ``date`` (``datetime/date`` instance)
'''
raise NotImplementedError
实施
PandasMarketCalendar
此实现基于一个很好的包,该包是 Quantopian 初始功能的分支。该软件包位于:pandas_market_calendars 并且可以轻松安装:
pip install pandas_market_calendars
该实现具有以下接口:
class PandasMarketCalendar(TradingCalendarBase):
'''
Wrapper of ``pandas_market_calendars`` for a trading calendar. The package
``pandas_market_calendar`` must be installed
Params:
- ``calendar`` (default ``None``)
The param ``calendar`` accepts the following:
- string: the name of one of the calendars supported, for example
`NYSE`. The wrapper will attempt to get a calendar instance
- calendar instance: as returned by ``get_calendar('NYSE')``
- ``cachesize`` (default ``365``)
Number of days to cache in advance for lookup
See also:
- https://github.com/rsheftel/pandas_market_calendars
- http://pandas-market-calendars.readthedocs.io/
'''
params = (
('calendar', None), # A pandas_market_calendars instance or exch name
('cachesize', 365), # Number of days to cache in advance
)
交易日历
此实现允许通过指定节假日、提前天、非交易工作日和开放和关闭会话时间来构建日历:
class TradingCalendar(TradingCalendarBase):
'''
Wrapper of ``pandas_market_calendars`` for a trading calendar. The package
``pandas_market_calendar`` must be installed
Params:
- ``open`` (default ``time.min``)
Regular start of the session
- ``close`` (default ``time.max``)
Regular end of the session
- ``holidays`` (default ``[]``)
List of non-trading days (``datetime.datetime`` instances)
- ``earlydays`` (default ``[]``)
List of tuples determining the date and opening/closing times of days
which do not conform to the regular trading hours where each tuple has
(``datetime.datetime``, ``datetime.time``, ``datetime.time`` )
- ``offdays`` (default ``ISOWEEKEND``)
A list of weekdays in ISO format (Monday: 1 -> Sunday: 7) in which the
market doesn't trade. This is usually Saturday and Sunday and hence the
default
'''
params = (
('open', time.min),
('close', _time_max),
('holidays', []), # list of non trading days (date)
('earlydays', []), # list of tuples (date, opentime, closetime)
('offdays', ISOWEEKEND), # list of non trading (isoweekdays)
)
使用模式
全球交易日历
通过Cerebro可以添加一个全局日历,该日历是所有数据源的默认日历,除非为数据源指定了一个:
def addcalendar(self, cal):
'''Adds a global trading calendar to the system. Individual data feeds
may have separate calendars which override the global one
``cal`` can be an instance of ``TradingCalendar`` a string or an
instance of ``pandas_market_calendars``. A string will be will be
instantiated as a ``PandasMarketCalendar`` (which needs the module
``pandas_market_calendar`` installed in the system.
If a subclass of `TradingCalendarBase` is passed (not an instance) it
will be instantiated
'''
每个数据源
通过指定一个calendar参数,按照上面addcalendar中描述的相同约定。
例如:
...
data = bt.feeds.YahooFinanceData(dataname='YHOO', calendar='NYSE', ...)
cerebro.adddata(data)
...
示例
从每日到每周
让我们看看下面可以找到的代码示例的样本运行。2016 年,复活节星期五(2016-03-25)也是NYSE的节假日。如果在没有交易日历的情况下运行示例,请看看该日期附近发生了什么。
在这种情况下,从每日重采样到每周(使用YHOO和 2016 年的每日数据):
$ ./tcal.py
...
Strategy len 56 datetime 2016-03-23 Data0 len 56 datetime 2016-03-23 Data1 len 11 datetime 2016-03-18
Strategy len 57 datetime 2016-03-24 Data0 len 57 datetime 2016-03-24 Data1 len 11 datetime 2016-03-18
Strategy len 58 datetime 2016-03-28 Data0 len 58 datetime 2016-03-28 Data1 len 12 datetime 2016-03-24
...
在这个输出中,第 1 个日期是策略的结算日期。第 2 个日期是每日的日期
一周结束时,如预期的那样,于 2016-03-24(星期四),但是如果没有交易日历,重采样代码就无法知道,因此将于 2016-03-18(前一周)交付重采样的柱形。当交易移至 2016-03-28(星期一)时,重采样器检测到周变化,并于 2016-03-24 交付重采样的柱。
同样的但是使用NYSE的PandasMarketCalendar运行(并添加绘图)
$ ./tcal.py --plot --pandascal NYSE
...
Strategy len 56 datetime 2016-03-23 Data0 len 56 datetime 2016-03-23 Data1 len 11 datetime 2016-03-18
Strategy len 57 datetime 2016-03-24 Data0 len 57 datetime 2016-03-24 Data1 len 12 datetime 2016-03-24
Strategy len 58 datetime 2016-03-28 Data0 len 58 datetime 2016-03-28 Data1 len 12 datetime 2016-03-24
...
有一个变化!由于日历,重采样器知道周在 2016-03-24 结束,并于同一天交付了相应的每周重采样柱 2016-03-24。
以及绘图。
由于并非每个市场都可能提供相同的信息,因此人们也可以自己制定日历。对于NYSE和2016年,情况如下:
class NYSE_2016(bt.TradingCalendar):
params = dict(
holidays=[
datetime.date(2016, 1, 1),
datetime.date(2016, 1, 18),
datetime.date(2016, 2, 15),
datetime.date(2016, 3, 25),
datetime.date(2016, 5, 30),
datetime.date(2016, 7, 4),
datetime.date(2016, 9, 5),
datetime.date(2016, 11, 24),
datetime.date(2016, 12, 26),
]
)
复活节星期五(2016-03-25)被列为假日之一。现在运行示例:
$ ./tcal.py --plot --owncal
...
Strategy len 56 datetime 2016-03-23 Data0 len 56 datetime 2016-03-23 Data1 len 11 datetime 2016-03-18
Strategy len 57 datetime 2016-03-24 Data0 len 57 datetime 2016-03-24 Data1 len 12 datetime 2016-03-24
Strategy len 58 datetime 2016-03-28 Data0 len 58 datetime 2016-03-28 Data1 len 12 datetime 2016-03-24
...
并且使用精心制作的日历定义得到了相同的结果。
分钟转换为每日
使用一些私有的日内数据,并且知道 2016-11-25(感恩节后的第二天,市场在US/Eastern时区于 13:00 关闭),另一个测试运行,这次是用第二个样本。
注意
源数据直接来自显示的数据,处于CET时区,即使涉及的资产YHOO在美国交易。代码中使用了tzinput='CET'和tz='US/Eastern'的数据提要,以便让平台适当地转换输入和显示输出
首先没有交易日历
$ ./tcal-intra.py
...
Strategy len 6838 datetime 2016-11-25 18:00:00 Data0 len 6838 datetime 2016-11-25 13:00:00 Data1 len 21 datetime 2016-11-23 16:00:00
Strategy len 6839 datetime 2016-11-25 18:01:00 Data0 len 6839 datetime 2016-11-25 13:01:00 Data1 len 21 datetime 20 16-11-23 16:00:00
Strategy len 6840 datetime 2016-11-28 14:31:00 Data0 len 6840 datetime 2016-11-28 09:31:00 Data1 len 22 datetime 2016-11-25 16:00:00
Strategy len 6841 datetime 2016-11-28 14:32:00 Data0 len 6841 datetime 2016-11-28 09:32:00 Data1 len 22 datetime 2016-11-25 16:00:00
...
如预期的那样,交易日在13:00提前关闭,但重新采样器不知道这一点(官方交易结束时间为16:00),并继续提供上一交易日(2016-11-23)的重新采样日线柱形图,新的重新采样日线柱形图首次在下一个交易日(2016-11-28)中交付,日期为 2016-11-25。
注意
数据在13:01有一个额外的分钟柱形图,这可能是由于市场闭市后的拍卖过程提供了最后一个价格。
我们可以向流添加一个过滤器,以过滤掉会话时间之外的柱形图(该过滤器将从交易日历中找到)
但这不是这个示例的重点。
使用PandasMarketCalendar实例进行相同运行:
$ ./tcal-intra.py --pandascal NYSE
...
Strategy len 6838 datetime 2016-11-25 18:00:00 Data0 len 6838 datetime 2016-11-25 13:00:00 Data1 len 15 datetime 2016-11-25 13:00:00
Strategy len 6839 datetime 2016-11-25 18:01:00 Data0 len 6839 datetime 2016-11-25 13:01:00 Data1 len 15 datetime 2016-11-25 13:00:00
Strategy len 6840 datetime 2016-11-28 14:31:00 Data0 len 6840 datetime 2016-11-28 09:31:00 Data1 len 15 datetime 2016-11-25 13:00:00
Strategy len 6841 datetime 2016-11-28 14:32:00 Data0 len 6841 datetime 2016-11-28 09:32:00 Data1 len 15 datetime 2016-11-25 13:00:00
...
现在,当每日 1 分钟的数据源命中 2016-11-25 的 13:00 时(我们忽略 13:01 柱形图),2016-11-25 的每日柱形图就被交付了,因为交易日历告诉重新采样代码该天已结束。
让我们添加一个精心制作的定义。与之前相同,但扩展了一些earlydays
class NYSE_2016(bt.TradingCalendar):
params = dict(
holidays=[
datetime.date(2016, 1, 1),
datetime.date(2016, 1, 18),
datetime.date(2016, 2, 15),
datetime.date(2016, 3, 25),
datetime.date(2016, 5, 30),
datetime.date(2016, 7, 4),
datetime.date(2016, 9, 5),
datetime.date(2016, 11, 24),
datetime.date(2016, 12, 26),
],
earlydays=[
(datetime.date(2016, 11, 25),
datetime.time(9, 30), datetime.time(13, 1))
],
open=datetime.time(9, 30),
close=datetime.time(16, 0),
)
运行:
$ ./tcal-intra.py --owncal
...
Strategy len 6838 datetime 2016-11-25 18:00:00 Data0 len 6838 datetime 2016-11-25 13:00:00 Data1 len 15 datetime 2016-11-23 16:00:00
Strategy len 6839 datetime 2016-11-25 18:01:00 Data0 len 6839 datetime 2016-11-25 13:01:00 Data1 len 16 datetime 2016-11-25 13:01:00
Strategy len 6840 datetime 2016-11-28 14:31:00 Data0 len 6840 datetime 2016-11-28 09:31:00 Data1 len 16 datetime 2016-11-25 13:01:00
Strategy len 6841 datetime 2016-11-28 14:32:00 Data0 len 6841 datetime 2016-11-28 09:32:00 Data1 len 16 datetime 2016-11-25 13:01:00
...
热心的读者会注意到,精心制作的定义包含将13:01(使用datetime.time(13, 1))定义为我们 2016-11-25 的短日的会话结束。这只是为了展示精心制作的TradingCalendar如何帮助调整事物。
现在 2016-11-25 的每日重新采样柱形图与 13:01 的 1 分钟柱形图一起交付。
策略的额外奖金
第一个datetime,属于策略的时间,总是在一个不同的时区,实际上是UTC。同样在这个版本1.9.42.116中可以同步。以下参数已添加到Cerebro(在实例化期间或使用cerebro.run期间使用)
- ``tz`` (default: ``None``)
Adds a global timezone for strategies. The argument ``tz`` can be
- ``None``: in this case the datetime displayed by strategies will be
in UTC, which has been always the standard behavior
- ``pytz`` instance. It will be used as such to convert UTC times to
the chosen timezone
- ``string``. Instantiating a ``pytz`` instance will be attempted.
- ``integer``. Use, for the strategy, the same timezone as the
corresponding ``data`` in the ``self.datas`` iterable (``0`` would
use the timezone from ``data0``)
还支持cerebro.addtz方法:
def addtz(self, tz):
'''
This can also be done with the parameter ``tz``
Adds a global timezone for strategies. The argument ``tz`` can be
- ``None``: in this case the datetime displayed by strategies will be
in UTC, which has been always the standard behavior
- ``pytz`` instance. It will be used as such to convert UTC times to
the chosen timezone
- ``string``. Instantiating a ``pytz`` instance will be attempted.
- ``integer``. Use, for the strategy, the same timezone as the
corresponding ``data`` in the ``self.datas`` iterable (``0`` would
use the timezone from ``data0``)
'''
重复上次日内示例的运行,并在tz中使用0(与data0的时区同步),以下是关注相同日期和时间的输出:
$ ./tcal-intra.py --owncal --cerebro tz=0
...
Strategy len 6838 datetime 2016-11-25 13:00:00 Data0 len 6838 datetime 2016-11-25 13:00:00 Data1 len 15 datetime 2016-11-23 16:00:00
Strategy len 6839 datetime 2016-11-25 13:01:00 Data0 len 6839 datetime 2016-11-25 13:01:00 Data1 len 16 datetime 2016-11-25 13:01:00
Strategy len 6840 datetime 2016-11-28 09:31:00 Data0 len 6840 datetime 2016-11-28 09:31:00 Data1 len 16 datetime 2016-11-25 13:01:00
Strategy len 6841 datetime 2016-11-28 09:32:00 Data0 len 6841 datetime 2016-11-28 09:32:00 Data1 len 16 datetime 2016-11-25 13:01:00
...
时间戳现在是时区对齐的。
示例用法(tcal.py)
$ ./tcal.py --help
usage: tcal.py [-h] [--data0 DATA0] [--offline] [--fromdate FROMDATE]
[--todate TODATE] [--cerebro kwargs] [--broker kwargs]
[--sizer kwargs] [--strat kwargs] [--plot [kwargs]]
[--pandascal PANDASCAL | --owncal]
[--timeframe {Weeks,Months,Years}]
Trading Calendar Sample
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default: YHOO)
--offline Read from disk with same name as ticker (default:
False)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2016-01-01)
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2016-12-31)
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
--pandascal PANDASCAL
Name of trading calendar to use (default: )
--owncal Apply custom NYSE 2016 calendar (default: False)
--timeframe {Weeks,Months,Years}
Timeframe to resample to (default: Weeks)
示例用法(tcal-intra.py)
$ ./tcal-intra.py --help
usage: tcal-intra.py [-h] [--data0 DATA0] [--fromdate FROMDATE]
[--todate TODATE] [--cerebro kwargs] [--broker kwargs]
[--sizer kwargs] [--strat kwargs] [--plot [kwargs]]
[--pandascal PANDASCAL | --owncal] [--timeframe {Days}]
Trading Calendar Sample
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default: yhoo-2016-11.csv)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2016-01-01)
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2016-12-31)
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
--pandascal PANDASCAL
Name of trading calendar to use (default: )
--owncal Apply custom NYSE 2016 calendar (default: False)
--timeframe {Days} Timeframe to resample to (default: Days)
示例代码(tcal.py)
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class NYSE_2016(bt.TradingCalendar):
params = dict(
holidays=[
datetime.date(2016, 1, 1),
datetime.date(2016, 1, 18),
datetime.date(2016, 2, 15),
datetime.date(2016, 3, 25),
datetime.date(2016, 5, 30),
datetime.date(2016, 7, 4),
datetime.date(2016, 9, 5),
datetime.date(2016, 11, 24),
datetime.date(2016, 12, 26),
]
)
class St(bt.Strategy):
params = dict(
)
def __init__(self):
pass
def start(self):
self.t0 = datetime.datetime.utcnow()
def stop(self):
t1 = datetime.datetime.utcnow()
print('Duration:', t1 - self.t0)
def prenext(self):
self.next()
def next(self):
print('Strategy len {} datetime {}'.format(
len(self), self.datetime.date()), end=' ')
print('Data0 len {} datetime {}'.format(
len(self.data0), self.data0.datetime.date()), end=' ')
if len(self.data1):
print('Data1 len {} datetime {}'.format(
len(self.data1), self.data1.datetime.date()))
else:
print()
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
YahooData = bt.feeds.YahooFinanceData
if args.offline:
YahooData = bt.feeds.YahooFinanceCSVData # change to read file
# Data feed
data0 = YahooData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
d1 = cerebro.resampledata(data0,
timeframe=getattr(bt.TimeFrame, args.timeframe))
d1.plotinfo.plotmaster = data0
d1.plotinfo.sameaxis = True
if args.pandascal:
cerebro.addcalendar(args.pandascal)
elif args.owncal:
cerebro.addcalendar(NYSE_2016)
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Trading Calendar Sample'
)
)
parser.add_argument('--data0', default='YHOO',
required=False, help='Data to read in')
parser.add_argument('--offline', required=False, action='store_true',
help='Read from disk with same name as ticker')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='2016-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='2016-12-31',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
pgroup = parser.add_mutually_exclusive_group(required=False)
pgroup.add_argument('--pandascal', required=False, action='store',
default='', help='Name of trading calendar to use')
pgroup.add_argument('--owncal', required=False, action='store_true',
help='Apply custom NYSE 2016 calendar')
parser.add_argument('--timeframe', required=False, action='store',
default='Weeks', choices=['Weeks', 'Months', 'Years'],
help='Timeframe to resample to')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
示例代码(tcal-intra.py)
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class NYSE_2016(bt.TradingCalendar):
params = dict(
holidays=[
datetime.date(2016, 1, 1),
datetime.date(2016, 1, 18),
datetime.date(2016, 2, 15),
datetime.date(2016, 3, 25),
datetime.date(2016, 5, 30),
datetime.date(2016, 7, 4),
datetime.date(2016, 9, 5),
datetime.date(2016, 11, 24),
datetime.date(2016, 12, 26),
],
earlydays=[
(datetime.date(2016, 11, 25),
datetime.time(9, 30), datetime.time(13, 1))
],
open=datetime.time(9, 30),
close=datetime.time(16, 0),
)
class St(bt.Strategy):
params = dict(
)
def __init__(self):
pass
def prenext(self):
self.next()
def next(self):
print('Strategy len {} datetime {}'.format(
len(self), self.datetime.datetime()), end=' ')
print('Data0 len {} datetime {}'.format(
len(self.data0), self.data0.datetime.datetime()), end=' ')
if len(self.data1):
print('Data1 len {} datetime {}'.format(
len(self.data1), self.data1.datetime.datetime()))
else:
print()
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
# kwargs = dict(tz='US/Eastern')
# import pytz
# tz = tzinput = pytz.timezone('Europe/Berlin')
tzinput = 'Europe/Berlin'
# tz = tzinput
tz = 'US/Eastern'
kwargs = dict(tzinput=tzinput, tz=tz)
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed
data0 = bt.feeds.BacktraderCSVData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
d1 = cerebro.resampledata(data0,
timeframe=getattr(bt.TimeFrame, args.timeframe))
# d1.plotinfo.plotmaster = data0
# d1.plotinfo.sameaxis = False
if args.pandascal:
cerebro.addcalendar(args.pandascal)
elif args.owncal:
cerebro.addcalendar(NYSE_2016()) # or NYSE_2016() to pass an instance
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Trading Calendar Sample'
)
)
parser.add_argument('--data0', default='yhoo-2016-11.csv',
required=False, help='Data to read in')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='2016-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='2016-12-31',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
pgroup = parser.add_mutually_exclusive_group(required=False)
pgroup.add_argument('--pandascal', required=False, action='store',
default='', help='Name of trading calendar to use')
pgroup.add_argument('--owncal', required=False, action='store_true',
help='Apply custom NYSE 2016 calendar')
parser.add_argument('--timeframe', required=False, action='store',
default='Days', choices=['Days'],
help='Timeframe to resample to')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
自动化回测
原文:
www.backtrader.com/docu/automated-bt-run/automated-bt-run/
到目前为止,所有的backtrader示例和工作样本都是从头开始创建一个主要的Python模块,该模块加载数据、策略、观察器,并准备好现金和佣金方案。
算法交易的一个目标之一是交易的自动化,鉴于 backtrader 是一个用于检查交易算法的回测平台(因此是一个算法交易平台),自动化使用 backtrader 是一个明显的目标。
当安装backtrader时,它提供了两个脚本/可执行文件形式的入口点,可以自动化大多数任务:
bt-run-py一个使用下一项中的代码库的脚本
和
-
btrun(可执行文件)打包过程中由
setuptools创建的入口点。在理论上,在 Windows 下不会出现“路径/文件未找到”的错误。
下面的描述同样适用于这两个工具。
btrun 允许最终用户:
-
说出必须加载的数据源
-
设置加载数据的格式
-
指定数据的日期范围
-
向 Cerebro 传递参数
- 禁用标准观察器
这是在“Cerebro”参数实现之前的一个原始额外开关。因此,如果向 cerebro 传递关于标准观察器的参数,这将被忽略(参数
stdstats到 Cerebro) -
加载一个或多个观察器(例如:
DrawDown)从内置的或来自 Python 模块 -
为经纪人设置现金和佣金方案参数(佣金、保证金、倍数)
-
启用绘图,控制图表的数量和数据呈现的样式
-
向系统添加一个带参数的写入器
最后应该是核心能力是什么:
-
加载一个策略(内置的或来自 Python 模块)
-
向加载的策略传递参数
请参阅下面关于脚本的使用。
应用用户定义的策略
让我们考虑以下策略:
-
简单加载一个 SimpleMovingAverage(默认周期为 15)
-
打印输出
-
存储在一个名为
mymod.py的文件中
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import backtrader as bt
import backtrader.indicators as btind
class MyTest(bt.Strategy):
params = (('period', 15),)
def log(self, txt, dt=None):
''' Logging function fot this strategy'''
dt = dt or self.data.datetime[0]
if isinstance(dt, float):
dt = bt.num2date(dt)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
sma = btind.SMA(period=self.p.period)
def next(self):
ltxt = '%d, %.2f, %.2f, %.2f, %.2f, %.2f, %.2f'
self.log(ltxt %
(len(self),
self.data.open[0], self.data.high[0],
self.data.low[0], self.data.close[0],
self.data.volume[0], self.data.openinterest[0]))
使用通常的测试样本执行策略很容易:
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--strategy mymod.py
图表输出
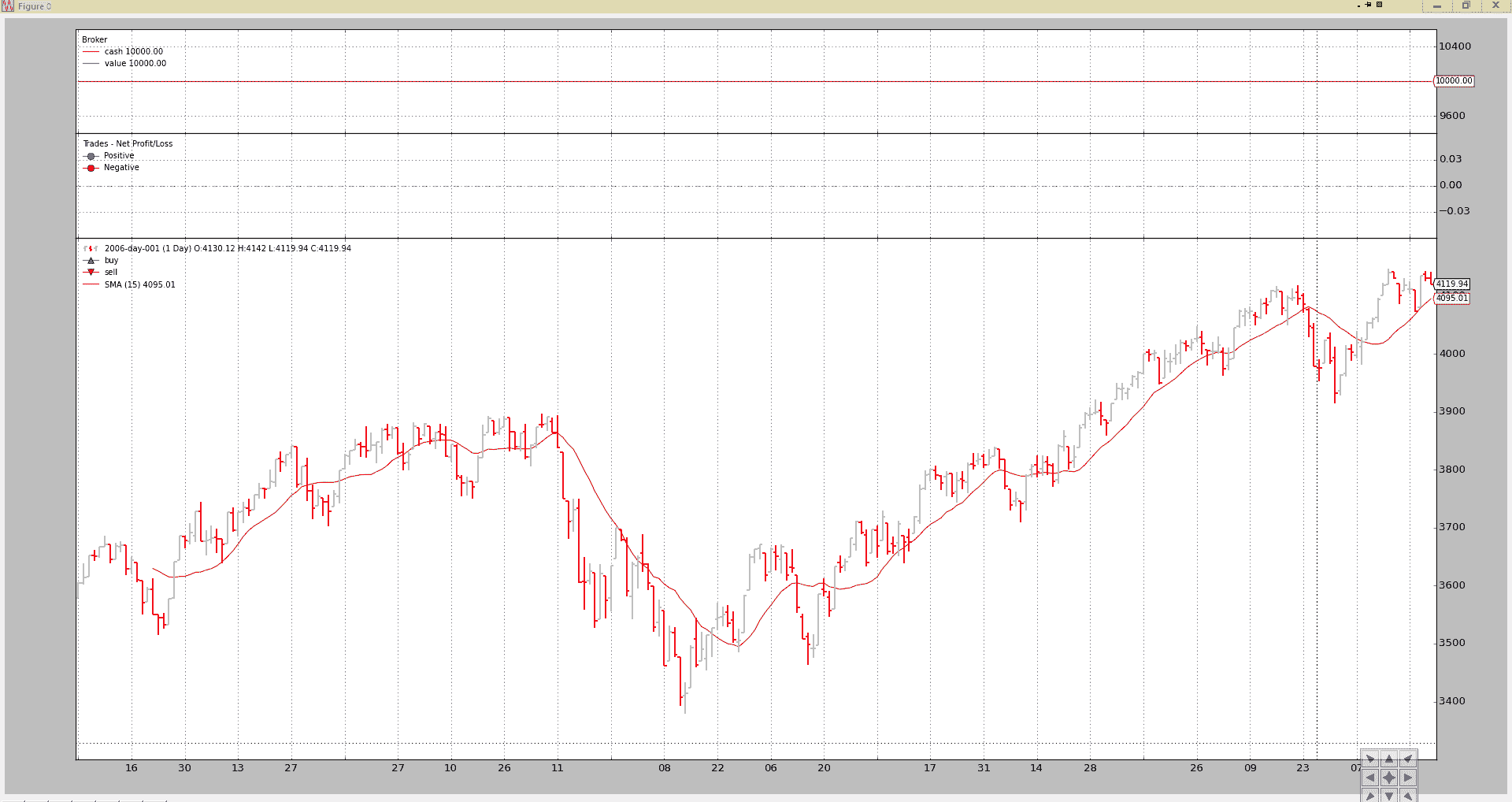
控制台输出:
2006-01-20T23:59:59+00:00, 15, 3593.16, 3612.37, 3550.80, 3550.80, 0.00, 0.00
2006-01-23T23:59:59+00:00, 16, 3550.24, 3550.24, 3515.07, 3544.31, 0.00, 0.00
2006-01-24T23:59:59+00:00, 17, 3544.78, 3553.16, 3526.37, 3532.68, 0.00, 0.00
2006-01-25T23:59:59+00:00, 18, 3532.72, 3578.00, 3532.72, 3578.00, 0.00, 0.00
...
...
2006-12-22T23:59:59+00:00, 252, 4109.86, 4109.86, 4072.62, 4073.50, 0.00, 0.00
2006-12-27T23:59:59+00:00, 253, 4079.70, 4134.86, 4079.70, 4134.86, 0.00, 0.00
2006-12-28T23:59:59+00:00, 254, 4137.44, 4142.06, 4125.14, 4130.66, 0.00, 0.00
2006-12-29T23:59:59+00:00, 255, 4130.12, 4142.01, 4119.94, 4119.94, 0.00, 0.00
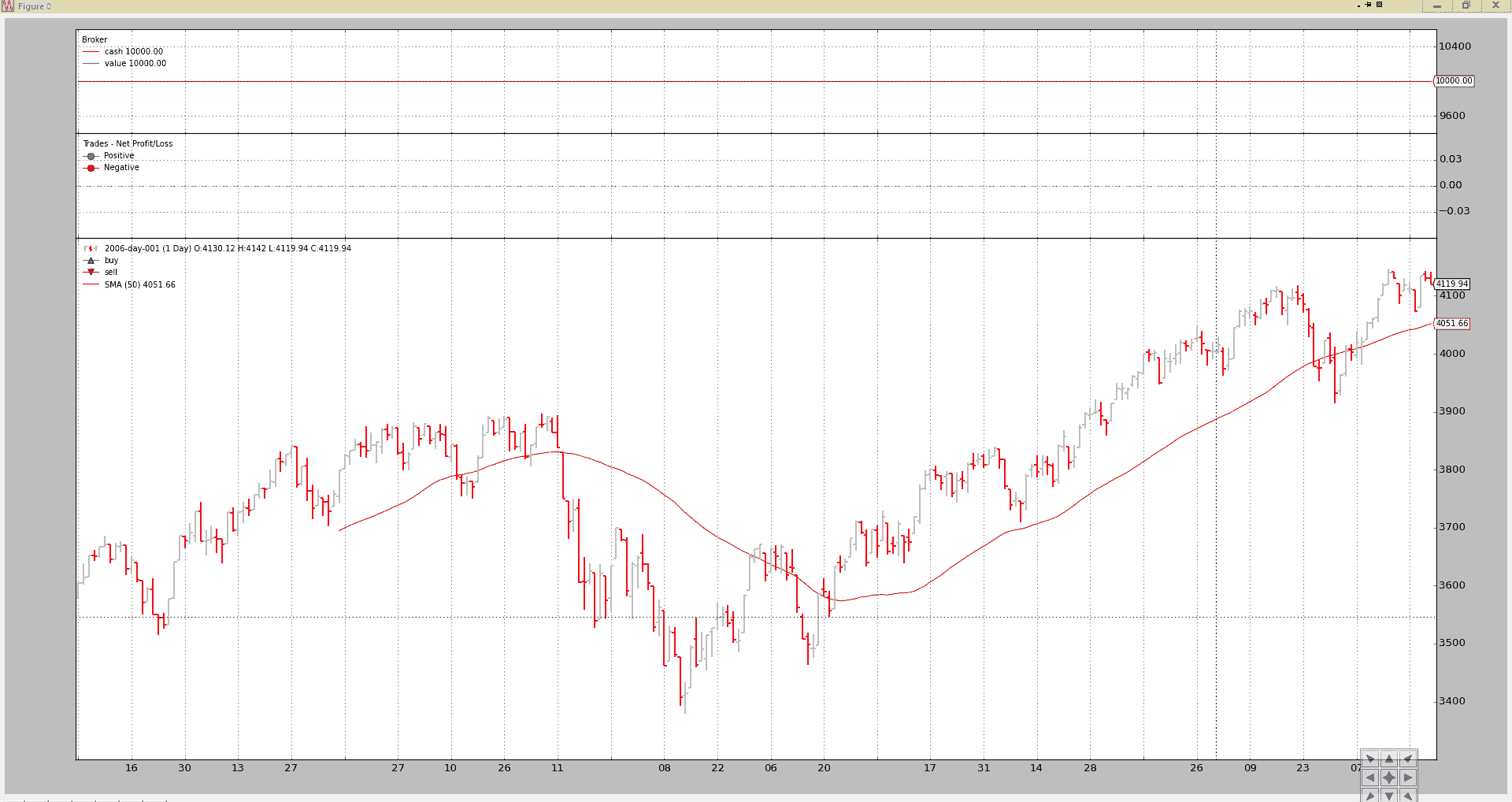
相同的策略,但:
- 将参数
period设置为 50
命令行:
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--plot \
--strategy mymod.py:period=50
图表输出。
注意
如果没有给出.py扩展名,bt-run 将会添加它。
使用内置策略
backtrader 将逐渐包含样例(教科书)策略。与 bt-run.py 脚本一起,一个标准的简单移动平均线交叉策略已经包含在内。这个名称:
-
SMA_CrossOver -
参数
-
fast(默认10)快速移动平均线的周期 -
slow(默认30)慢速移动平均线的周期
-
如果快速移动平均线上穿过快速移动平均线,则策略买入,如果它以前已经买入,则在快速移动平均线下穿过慢速移动平均线时卖出。
代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import backtrader as bt
import backtrader.indicators as btind
class SMA_CrossOver(bt.Strategy):
params = (('fast', 10), ('slow', 30))
def __init__(self):
sma_fast = btind.SMA(period=self.p.fast)
sma_slow = btind.SMA(period=self.p.slow)
self.buysig = btind.CrossOver(sma_fast, sma_slow)
def next(self):
if self.position.size:
if self.buysig < 0:
self.sell()
elif self.buysig > 0:
self.buy()
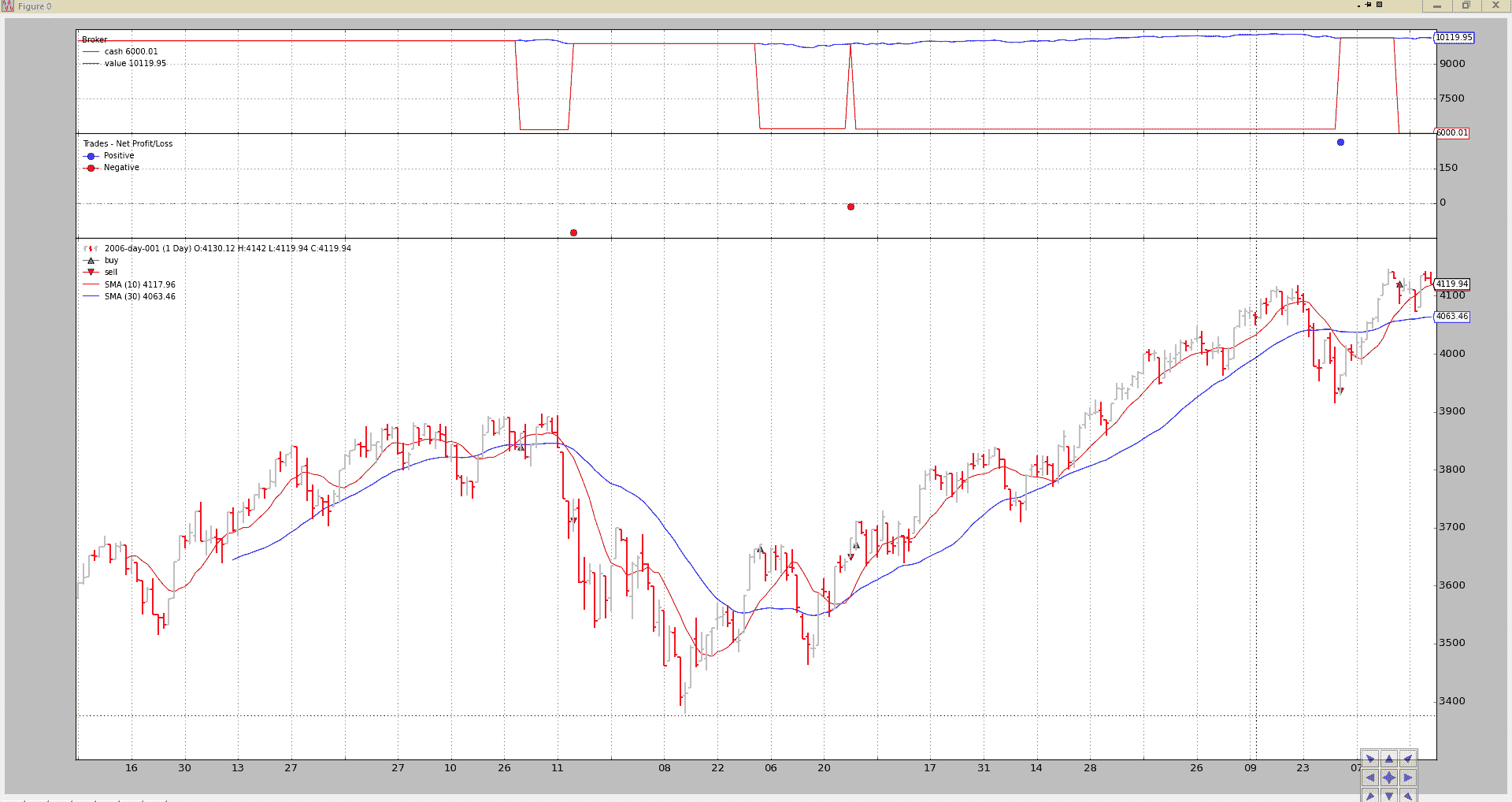
标准执行:
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--plot \
--strategy :SMA_CrossOver
请注意 :。加载策略的标准表示法(见下文)是:
module:stragegy:kwargs
使用以下规则:
-
如果存在模块和/或策略,则将使用该策略
-
如果模块存在但未指定策略,则将返回模块中找到的第 1 个策略
-
如果没有指定模块,则假定“strategy”是指 backtrader 包中的策略
-
如果存在模块和/或策略,并且存在 kwargs,则将其传递给相应的策略
注意
相同的表示法和规则适用于 --observer、--analyzer 和 --indicator 选项
显然,适用于相应的对象类型
输出
最后一个例子,添加佣金方案,现金和更改参数:
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--plot \
--cash 20000 \
--commission 2.0 \
--mult 10 \
--margin 2000 \
--strategy :SMA_CrossOver:fast=5,slow=20
输出
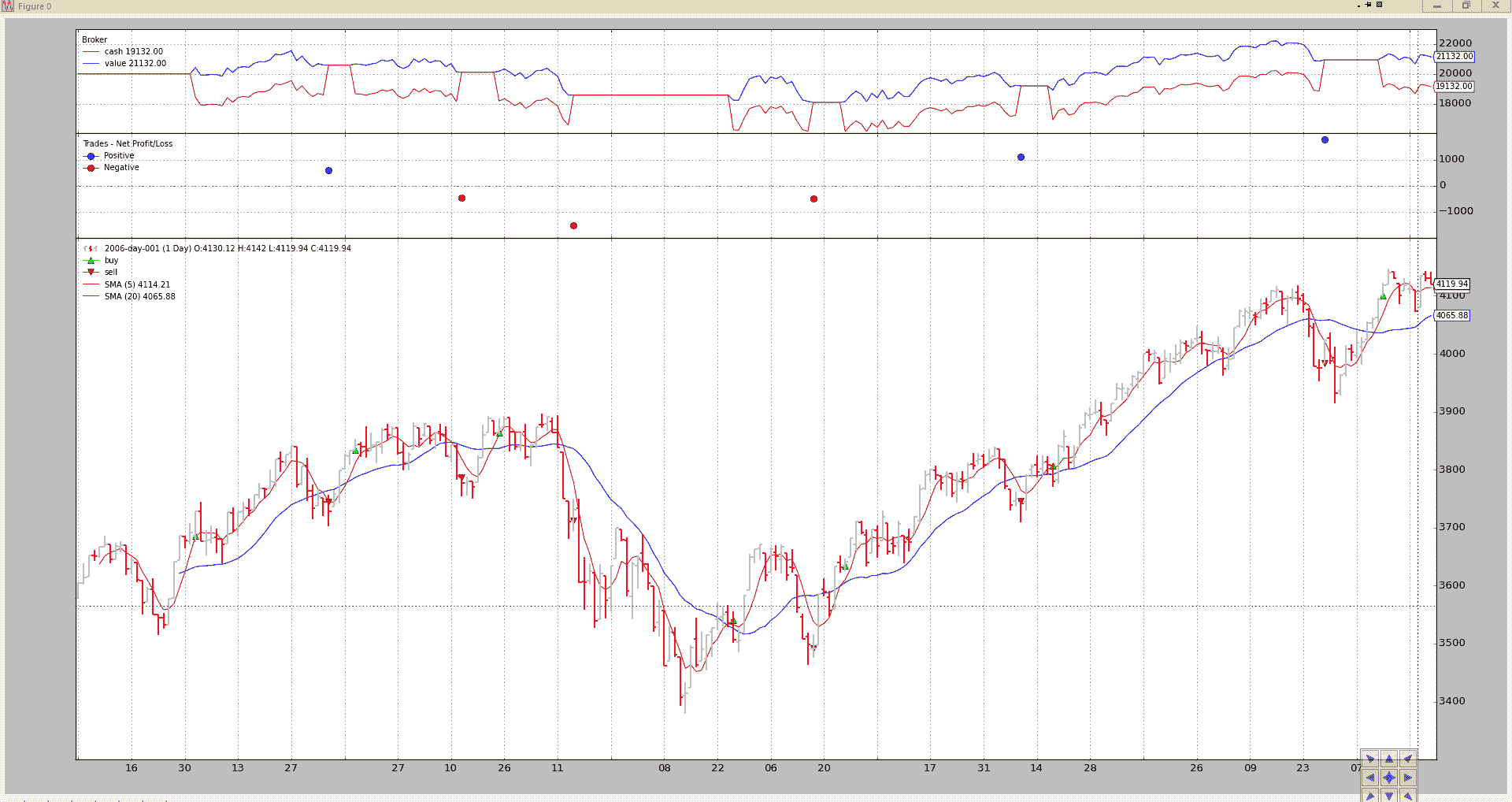
我们已经对策略进行了回测:
-
更改移动平均周期
-
设置新的起始现金
-
为类似期货的工具设置佣金方案
请注意每个柱状图中现金的连续变化,因为现金会根据类似期货的工具的每日变化进行调整
不使用策略
这是一种言过其实的说法。将应用一种策略,但您可以忽略任何类型的策略,并添加默认的 backtrader.Strategy。
分析器、观察者和指标将自动注入策略中。
一个例子:
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--cash 20000 \
--commission 2.0 \
--mult 10 \
--margin 2000 \
--nostdstats \
--observer :Broker
这将没有太大作用,但达到了预期目的:
-
默认添加了一个 backtrader.Strategy
-
Cerebro 不会实例化常规的
stdstats观察者(经纪人、买卖、交易) -
手动添加一个
Broker观察者
如上所述,nostdstats 是一个遗留参数。较新版本的 btrun 可以直接将参数传递给 Cerebro。等效的调用将是:
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--cash 20000 \
--commission 2.0 \
--mult 10 \
--margin 2000 \
--cerebro stdstats=False \
--observer :Broker
添加分析器
btrun 还支持使用与选择策略相同的语法添加 Analyzers。
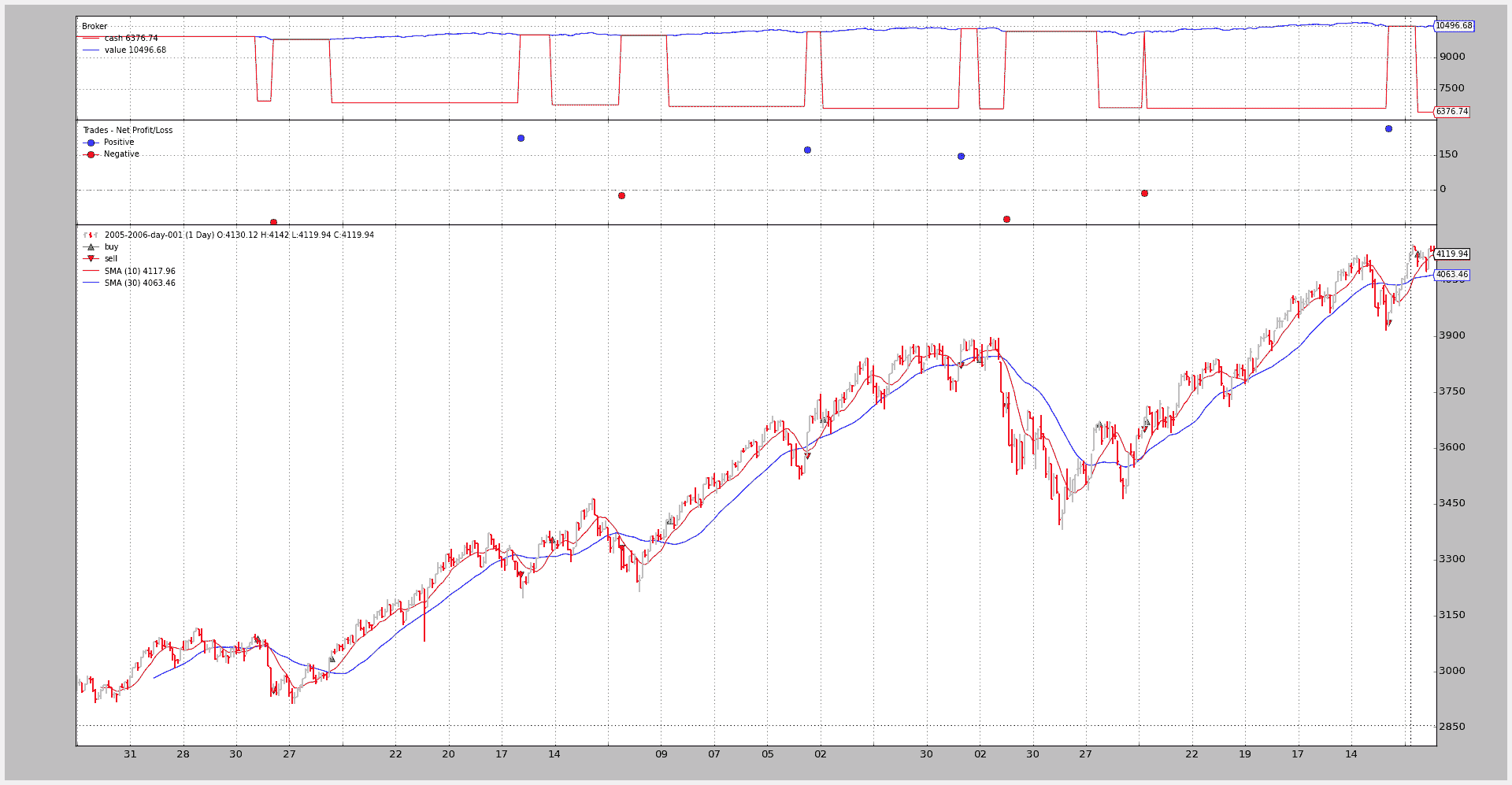
对于 2005-2006 年的 SharpeRatio 分析的示例:
btrun --csvformat btcsv \
--data ../../datas/2005-2006-day-001.txt \
--strategy :SMA_CrossOver \
--analyzer :SharpeRatio
控制台输出为 nothing。
如果希望打印 Analyzer 结果,则必须指定:
-
--pranalyzer默认调用下一个(除非分析器已经覆盖了正确的方法) -
--ppranalyzer使用pprint模块打印结果
注意
在 writers 成为 backtrader 的一部分之前,两个打印选项已经实现。添加一个没有 csv 输出的 writer 将达到相同的效果(输出已经得到改进)
扩展上面的示例:
btrun --csvformat btcsv \
--data ../../datas/2005-2006-day-001.txt \
--strategy :SMA_CrossOver \
--analyzer :SharpeRatio \
--plot \
--pranalyzer
====================
== Analyzers
====================
##########
sharperatio
##########
{'sharperatio': 11.647332609673256}
好战略!!!(事实上,这只是一个例子,也没有佣金)
图表(仅显示分析器不在图中,因为分析器不能绘制,它们不是线对象)
相同的例子,但使用了 writer 参数:
btrun --csvformat btcsv \
--data ../../datas/2005-2006-day-001.txt \
--strategy :SMA_CrossOver \
--analyzer :SharpeRatio \
--plot \
--writer
===============================================================================
Cerebro:
-----------------------------------------------------------------------------
- Datas:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
- Data0:
- Name: 2005-2006-day-001
- Timeframe: Days
- Compression: 1
-----------------------------------------------------------------------------
- Strategies:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
- SMA_CrossOver:
*************************************************************************
- Params:
- fast: 10
- slow: 30
- _movav: SMA
*************************************************************************
- Indicators:
.......................................................................
- SMA:
- Lines: sma
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Params:
- period: 30
.......................................................................
- CrossOver:
- Lines: crossover
- Params: None
*************************************************************************
- Observers:
.......................................................................
- Broker:
- Lines: cash, value
- Params: None
.......................................................................
- BuySell:
- Lines: buy, sell
- Params: None
.......................................................................
- Trades:
- Lines: pnlplus, pnlminus
- Params: None
*************************************************************************
- Analyzers:
.......................................................................
- Value:
- Begin: 10000.0
- End: 10496.68
.......................................................................
- SharpeRatio:
- Params: None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- Analysis:
- sharperatio: 11.6473326097
添加指标和观察者
与 Strategies 和 Analyzers 一样,btrun 也可以添加:
指标
和
观察者
当添加 Broker 观察者时,语法与上面看到的完全相同。
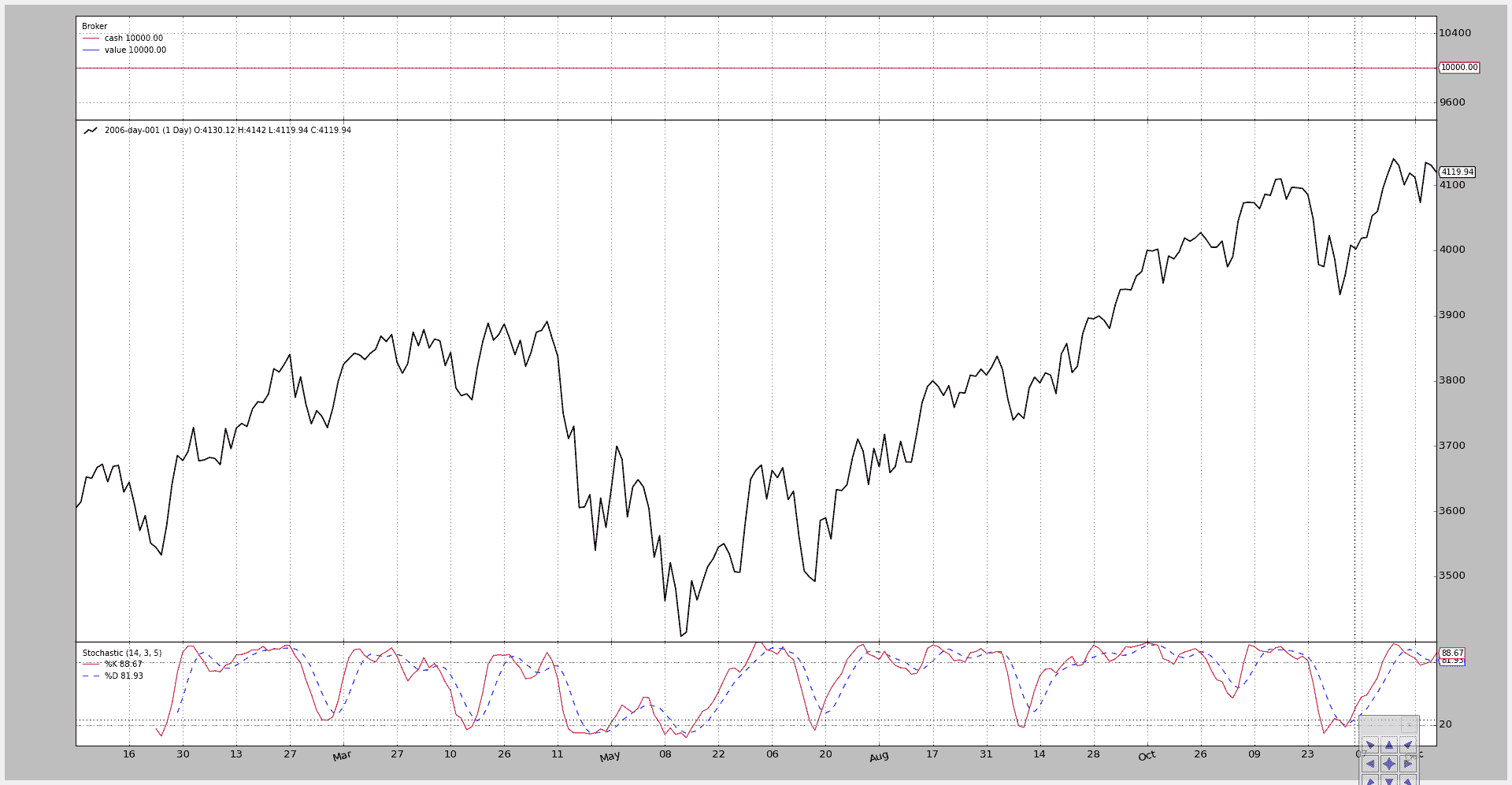
让我们重复一下例子,但添加一个 Stochastic,Broker 并查看图表(我们将更改一些参数):
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--nostdstats \
--observer :Broker \
--indicator :Stochastic:period_dslow=5 \
--plot
图表
绘图控制
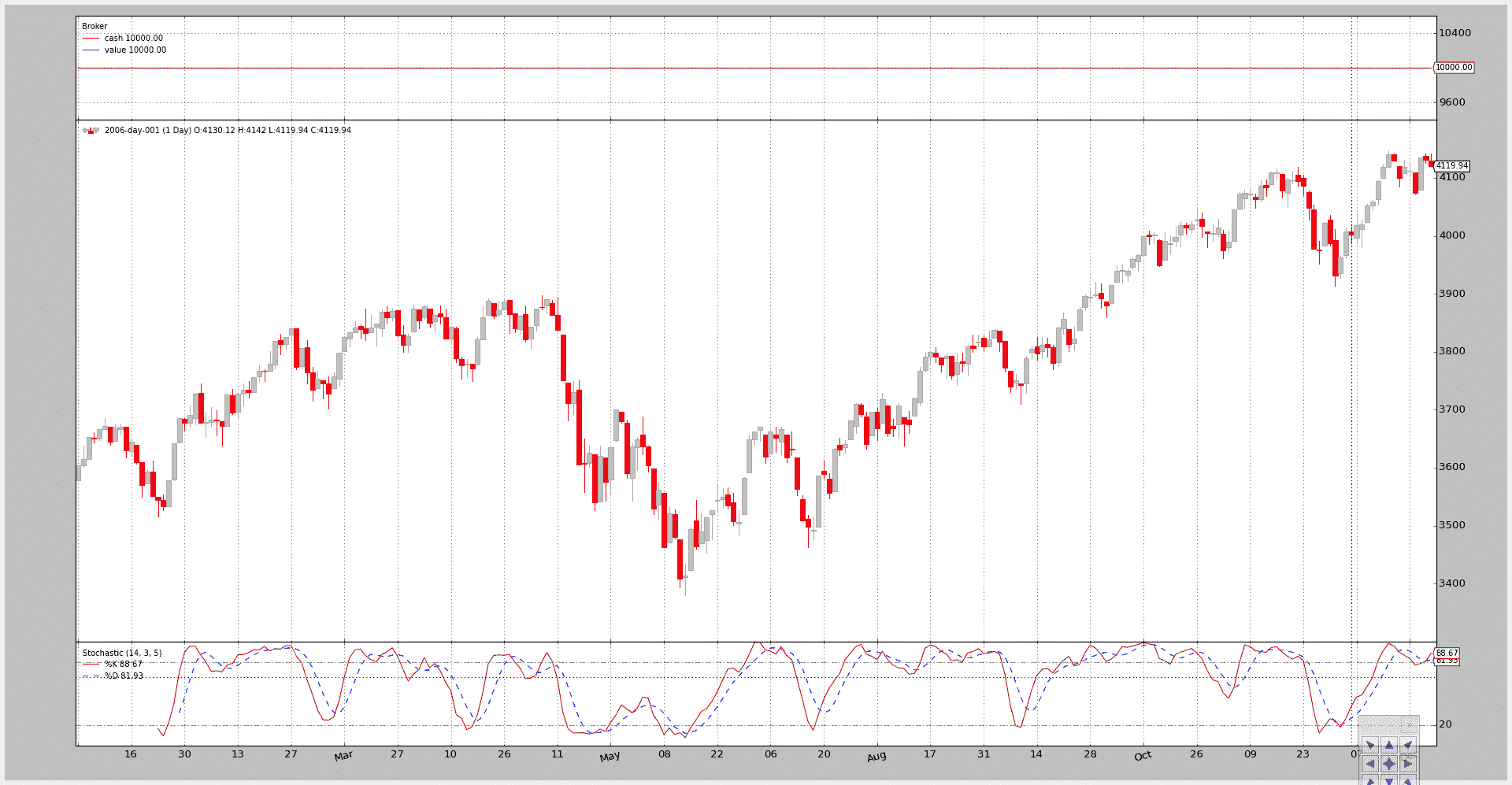
上面大部分的例子都使用了以下选项:
--plot激活了默认图表的创建
通过向 --plot 选项添加 kwargs 可以实现更多控制
- 例如,使用
--plot style="candle"来绘制蜡烛图,而不是使用LineOnClose样式(这是默认的绘图样式)
调用:
btrun --csvformat btcsv \
--data ../../datas/2006-day-001.txt \
--nostdstats \
--observer :Broker \
--indicator :Stochastic:period_dslow=5 \
--plot style=\"candle\"
注意
因为示例在 bash shell 中运行,该 shell 在传递参数给脚本之前会删除反斜杠,所以围绕 candle 的引号被反斜杠 \\ 引用。
在这种情况下需要使用反斜杠引用,以确保“bar”传递到脚本并可以作为字符串进行评估
图表
脚本的用法
直接从脚本中:
$ btrun --help
usage: btrun-script.py [-h] --data DATA [--cerebro [kwargs]] [--nostdstats]
[--format {yahoocsv_unreversed,vchart,vchartcsv,yahoo,mt4csv,ibdata,sierracsv,yahoocsv,btcsv,vcdata}]
[--fromdate FROMDATE] [--todate TODATE]
[--timeframe {microseconds,seconds,weeks,months,minutes,days,years}]
[--compression COMPRESSION]
[--resample RESAMPLE | --replay REPLAY]
[--strategy module:name:kwargs]
[--signal module:signaltype:name:kwargs]
[--observer module:name:kwargs]
[--analyzer module:name:kwargs]
[--pranalyzer | --ppranalyzer]
[--indicator module:name:kwargs] [--writer [kwargs]]
[--cash CASH] [--commission COMMISSION]
[--margin MARGIN] [--mult MULT] [--interest INTEREST]
[--interest_long] [--slip_perc SLIP_PERC]
[--slip_fixed SLIP_FIXED] [--slip_open]
[--no-slip_match] [--slip_out] [--flush]
[--plot [kwargs]]
Backtrader Run Script
optional arguments:
-h, --help show this help message and exit
--resample RESAMPLE, -rs RESAMPLE
resample with timeframe:compression values
--replay REPLAY, -rp REPLAY
replay with timeframe:compression values
--pranalyzer, -pralyzer
Automatically print analyzers
--ppranalyzer, -ppralyzer
Automatically PRETTY print analyzers
--plot [kwargs], -p [kwargs]
Plot the read data applying any kwargs passed
For example:
--plot style="candle" (to plot candlesticks)
Data options:
--data DATA, -d DATA Data files to be added to the system
Cerebro options:
--cerebro [kwargs], -cer [kwargs]
The argument can be specified with the following form:
- kwargs
Example: "preload=True" which set its to True
The passed kwargs will be passed directly to the cerebro
instance created for the execution
The available kwargs to cerebro are:
- preload (default: True)
- runonce (default: True)
- maxcpus (default: None)
- stdstats (default: True)
- live (default: False)
- exactbars (default: False)
- preload (default: True)
- writer (default False)
- oldbuysell (default False)
- tradehistory (default False)
--nostdstats Disable the standard statistics observers
--format {yahoocsv_unreversed,vchart,vchartcsv,yahoo,mt4csv,ibdata,sierracsv,yahoocsv,btcsv,vcdata}, --csvformat {yahoocsv_unreversed,vchart,vchartcsv,yahoo,mt4csv,ibdata,sierracsv,yahoocsv,btcsv,vcdata}, -c {yahoocsv_unreversed,vchart,vchartcsv,yahoo,mt4csv,ibdata,sierracsv,yahoocsv,btcsv,vcdata}
CSV Format
--fromdate FROMDATE, -f FROMDATE
Starting date in YYYY-MM-DD[THH:MM:SS] format
--todate TODATE, -t TODATE
Ending date in YYYY-MM-DD[THH:MM:SS] format
--timeframe {microseconds,seconds,weeks,months,minutes,days,years}, -tf {microseconds,seconds,weeks,months,minutes,days,years}
Ending date in YYYY-MM-DD[THH:MM:SS] format
--compression COMPRESSION, -cp COMPRESSION
Ending date in YYYY-MM-DD[THH:MM:SS] format
Strategy options:
--strategy module:name:kwargs, -st module:name:kwargs
This option can be specified multiple times.
The argument can be specified with the following form:
- module:classname:kwargs
Example: mymod:myclass:a=1,b=2
kwargs is optional
If module is omitted then class name will be sought in
the built-in strategies module. Such as in:
- :name:kwargs or :name
If name is omitted, then the 1st strategy found in the mod
will be used. Such as in:
- module or module::kwargs
Signals:
--signal module:signaltype:name:kwargs, -sig module:signaltype:name:kwargs
This option can be specified multiple times.
The argument can be specified with the following form:
- signaltype:module:signaltype:classname:kwargs
Example: longshort+mymod:myclass:a=1,b=2
signaltype may be ommited: longshort will be used
Example: mymod:myclass:a=1,b=2
kwargs is optional
signaltype will be uppercased to match the defintions
fromt the backtrader.signal module
If module is omitted then class name will be sought in
the built-in signals module. Such as in:
- LONGSHORT::name:kwargs or :name
If name is omitted, then the 1st signal found in the mod
will be used. Such as in:
- module or module:::kwargs
Observers and statistics:
--observer module:name:kwargs, -ob module:name:kwargs
This option can be specified multiple times.
The argument can be specified with the following form:
- module:classname:kwargs
Example: mymod:myclass:a=1,b=2
kwargs is optional
If module is omitted then class name will be sought in
the built-in observers module. Such as in:
- :name:kwargs or :name
If name is omitted, then the 1st observer found in the
will be used. Such as in:
- module or module::kwargs
Analyzers:
--analyzer module:name:kwargs, -an module:name:kwargs
This option can be specified multiple times.
The argument can be specified with the following form:
- module:classname:kwargs
Example: mymod:myclass:a=1,b=2
kwargs is optional
If module is omitted then class name will be sought in
the built-in analyzers module. Such as in:
- :name:kwargs or :name
If name is omitted, then the 1st analyzer found in the
will be used. Such as in:
- module or module::kwargs
Indicators:
--indicator module:name:kwargs, -ind module:name:kwargs
This option can be specified multiple times.
The argument can be specified with the following form:
- module:classname:kwargs
Example: mymod:myclass:a=1,b=2
kwargs is optional
If module is omitted then class name will be sought in
the built-in analyzers module. Such as in:
- :name:kwargs or :name
If name is omitted, then the 1st analyzer found in the
will be used. Such as in:
- module or module::kwargs
Writers:
--writer [kwargs], -wr [kwargs]
This option can be specified multiple times.
The argument can be specified with the following form:
- kwargs
Example: a=1,b=2
kwargs is optional
It creates a system wide writer which outputs run data
Please see the documentation for the available kwargs
Cash and Commission Scheme Args:
--cash CASH, -cash CASH
Cash to set to the broker
--commission COMMISSION, -comm COMMISSION
Commission value to set
--margin MARGIN, -marg MARGIN
Margin type to set
--mult MULT, -mul MULT
Multiplier to use
--interest INTEREST Credit Interest rate to apply (0.0x)
--interest_long Apply credit interest to long positions
--slip_perc SLIP_PERC
Enable slippage with a percentage value
--slip_fixed SLIP_FIXED
Enable slippage with a fixed point value
--slip_open enable slippage for when matching opening prices
--no-slip_match Disable slip_match, ie: matching capped at
high-low if slippage goes over those limits
--slip_out with slip_match enabled, match outside high-low
--flush flush the output - useful under win32 systems
文章
介绍
此部分承载了有关backtrader发布的文章。
享受它们!!!
关于回测性能和核心内存执行
最近有两个redit.com/r/algotrading帖子启发了本文。
-
一个声称backtrader无法处理 1.6M 根蜡烛的帖子:reddit/r/algotrading - 一个高性能的回测系统?
-
还有一个要求能够回测 8000 支股票的东西:reddit/r/algotrading - 支持 1000+ 支股票的回测库?
作者询问关于一个可以进行“核心/内存外”回测的框架,“因为显然无法将所有这些数据加载到内存中”
我们当然将使用backtrader来解决这些概念
2M 根蜡烛
为了做到这一点,首先要生成那么多根蜡烛。考虑到第一个帖子提到了 77 支股票和 1.6M 根蜡烛,这将导致每支股票有 20,779 根蜡烛,因此我们将采取以下措施以获得良好的数字
-
为 100 支股票生成蜡烛
-
每支股票生成 20,000 根蜡烛
即:共计 2M 根蜡烛的 100 个文件。
脚本
import numpy as np
import pandas as pd
COLUMNS = ['open', 'high', 'low', 'close', 'volume', 'openinterest']
CANDLES = 20000
STOCKS
dateindex = pd.date_range(start='2010-01-01', periods=CANDLES, freq='15min')
for i in range(STOCKS):
data = np.random.randint(10, 20, size=(CANDLES, len(COLUMNS)))
df = pd.DataFrame(data * 1.01, dateindex, columns=COLUMNS)
df = df.rename_axis('datetime')
df.to_csv('candles{:02d}.csv'.format(i))
这将生成 100 个文件,从candles00.csv开始一直到candles99.csv。实际值并不重要。重要的是具有标准的datetime、OHLCV组件(和OpenInterest)。
测试系统
-
硬件/操作系统:将使用一台配备 Intel i7 和 32 G 字节内存的 Windows 10 15.6 英寸笔记本电脑。
-
Python:CPython
3.6.1和pypy3 6.0.0 -
其他:一个持续运行并占用大约 20% CPU 的应用程序。常见的嫌疑人如 Chrome(102 个进程)、Edge、Word、Powerpoint、Excel 和一些次要应用程序正在运行
backtrader 默认配置
让我们回想一下backtrader的默认运行时配置是什么:
-
如有可能,预加载所有数据源
-
如果所有数据源都可以预加载,请在批处理模式(命名为
runonce)中运行 -
首先预先计算所有指标
-
逐步通过策略逻辑和经纪人
在默认批处理runonce模式下执行挑战
我们的测试脚本(请查看底部获取完整源代码)将打开这 100 个文件,并使用默认的backtrader配置处理它们。
$ ./two-million-candles.py
Cerebro Start Time: 2019-10-26 08:33:15.563088
Strat Init Time: 2019-10-26 08:34:31.845349
Time Loading Data Feeds: 76.28
Number of data feeds: 100
Strat Start Time: 2019-10-26 08:34:31.864349
Pre-Next Start Time: 2019-10-26 08:34:32.670352
Time Calculating Indicators: 0.81
Next Start Time: 2019-10-26 08:34:32.671351
Strat warm-up period Time: 0.00
Time to Strat Next Logic: 77.11
End Time: 2019-10-26 08:35:31.493349
Time in Strategy Next Logic: 58.82
Total Time in Strategy: 58.82
Total Time: 135.93
Length of data feeds: 20000
内存使用:观察到峰值为 348 M 字节
大部分时间实际上是用于预加载数据(98.63 秒),其余时间用于策略,其中包括在每次迭代中通过经纪人(73.63 秒)。总时间为173.26秒。
根据您想如何计算,性能为:
- 考虑整个运行时间为每秒
14,713根蜡烛
底线:在上面两个 Reddit 帖子中声称backtrader无法处理 1.6M 根蜡烛的说法是错误的。
使用pypy进行操作
既然该帖子声称使用pypy没有帮助,那么我们来看看使用它会发生什么。
$ ./two-million-candles.py
Cerebro Start Time: 2019-10-26 08:39:42.958689
Strat Init Time: 2019-10-26 08:40:31.260691
Time Loading Data Feeds: 48.30
Number of data feeds: 100
Strat Start Time: 2019-10-26 08:40:31.338692
Pre-Next Start Time: 2019-10-26 08:40:31.612688
Time Calculating Indicators: 0.27
Next Start Time: 2019-10-26 08:40:31.612688
Strat warm-up period Time: 0.00
Time to Strat Next Logic: 48.65
End Time: 2019-10-26 08:40:40.150689
Time in Strategy Next Logic: 8.54
Total Time in Strategy: 8.54
Total Time: 57.19
Length of data feeds: 20000
天啊!总时间从135.93秒降至57.19秒。性能翻了一番。
性能:每秒34,971根蜡烛
内存使用:峰值为 269 兆字节。
这也是与标准 CPython 解释器相比的重要改进。
处理 2 百万根蜡烛超出核心内存
所有这些都可以改进,如果考虑到backtrader有几个配置选项用于执行回测会话,包括优化缓冲区并仅使用最少需要的数据集(理想情况下仅使用大小为1的缓冲区,这仅在理想情况下发生)
要使用的选项将是exactbars=True。从exactbars的文档中(这是在实例化Cerebro时或在调用run时传递给Cerebro的参数)
`True` or `1`: all “lines” objects reduce memory usage to the
automatically calculated minimum period.
If a Simple Moving Average has a period of 30, the underlying data
will have always a running buffer of 30 bars to allow the
calculation of the Simple Moving Average
* This setting will deactivate `preload` and `runonce`
* Using this setting also deactivates **plotting**
为了最大限度地优化,并且因为绘图将被禁用,以下内容也将被使用:stdstats=False,它禁用了用于现金、价值和交易的标准观察者(对绘图有用,但不再在范围内)
$ ./two-million-candles.py --cerebro exactbars=False,stdstats=False
Cerebro Start Time: 2019-10-26 08:37:08.014348
Strat Init Time: 2019-10-26 08:38:21.850392
Time Loading Data Feeds: 73.84
Number of data feeds: 100
Strat Start Time: 2019-10-26 08:38:21.851394
Pre-Next Start Time: 2019-10-26 08:38:21.857393
Time Calculating Indicators: 0.01
Next Start Time: 2019-10-26 08:38:21.857393
Strat warm-up period Time: 0.00
Time to Strat Next Logic: 73.84
End Time: 2019-10-26 08:39:02.334936
Time in Strategy Next Logic: 40.48
Total Time in Strategy: 40.48
Total Time: 114.32
Length of data feeds: 20000
性能:每秒17,494根蜡烛
内存使用:75 兆字节(在回测会话的整个过程中保持稳定)
让我们与之前未经优化的运行进行比较
-
而不是花费超过
76秒预加载数据,因为数据没有预加载,回测立即开始 -
总时间为
114.32秒,比135.93秒快了15.90%。 -
内存使用改进了
68.5%。
注意
实际上,我们可以向脚本输入 1 亿根蜡烛,内存消耗量仍将保持在75 兆字节不变
再次使用pypy进行操作
现在我们知道如何优化,让我们按照pypy的方式来做。
$ ./two-million-candles.py --cerebro exactbars=True,stdstats=False
Cerebro Start Time: 2019-10-26 08:44:32.309689
Strat Init Time: 2019-10-26 08:44:32.406689
Time Loading Data Feeds: 0.10
Number of data feeds: 100
Strat Start Time: 2019-10-26 08:44:32.409689
Pre-Next Start Time: 2019-10-26 08:44:32.451689
Time Calculating Indicators: 0.04
Next Start Time: 2019-10-26 08:44:32.451689
Strat warm-up period Time: 0.00
Time to Strat Next Logic: 0.14
End Time: 2019-10-26 08:45:38.918693
Time in Strategy Next Logic: 66.47
Total Time in Strategy: 66.47
Total Time: 66.61
Length of data feeds: 20000
性能:每秒30,025根蜡烛
内存使用:恒定为49 兆字节
与之前的等效运行相比:
-
运行时间为
66.61秒,比之前的114.32秒快了41.73% -
49 兆字节与75 兆字节相比,内存使用改善了34.6%。
注意
在这种情况下,pypy无法击败其批处理(runonce)模式的时间,即57.19秒。这是可以预料的,因为在预加载时,计算器指示是以向量化模式进行的,而这正是pypy的 JIT 擅长的地方。
无论如何,它仍然表现出色,并且在内存消耗方面有重要的改进
运行完整的交易
该脚本可以创建指标(移动平均线)并在 100 个数据源上执行多空策略,使用移动平均线的交叉。让我们用pypy来做,并且知道它与批处理模式更好,就这么办。
$ ./two-million-candles.py --strat indicators=True,trade=True
Cerebro Start Time: 2019-10-26 08:57:36.114415
Strat Init Time: 2019-10-26 08:58:25.569448
Time Loading Data Feeds: 49.46
Number of data feeds: 100
Total indicators: 300
Moving Average to be used: SMA
Indicators period 1: 10
Indicators period 2: 50
Strat Start Time: 2019-10-26 08:58:26.230445
Pre-Next Start Time: 2019-10-26 08:58:40.850447
Time Calculating Indicators: 14.62
Next Start Time: 2019-10-26 08:58:41.005446
Strat warm-up period Time: 0.15
Time to Strat Next Logic: 64.89
End Time: 2019-10-26 09:00:13.057955
Time in Strategy Next Logic: 92.05
Total Time in Strategy: 92.21
Total Time: 156.94
Length of data feeds: 20000
性能:每秒12,743根蜡烛
内存使用:观察到峰值为1300 Mbytes。
执行时间显然增加了(指标 + 交易),但为什么内存使用量增加了呢?
在得出任何结论之前,让我们运行它创建指标,但不进行交易
$ ./two-million-candles.py --strat indicators=True
Cerebro Start Time: 2019-10-26 09:05:55.967969
Strat Init Time: 2019-10-26 09:06:44.072969
Time Loading Data Feeds: 48.10
Number of data feeds: 100
Total indicators: 300
Moving Average to be used: SMA
Indicators period 1: 10
Indicators period 2: 50
Strat Start Time: 2019-10-26 09:06:44.779971
Pre-Next Start Time: 2019-10-26 09:06:59.208969
Time Calculating Indicators: 14.43
Next Start Time: 2019-10-26 09:06:59.360969
Strat warm-up period Time: 0.15
Time to Strat Next Logic: 63.39
End Time: 2019-10-26 09:07:09.151838
Time in Strategy Next Logic: 9.79
Total Time in Strategy: 9.94
Total Time: 73.18
Length of data feeds: 20000
性能:27,329根蜡烛/秒
内存使用:600 Mbytes(在优化的exactbars模式下进行相同操作仅消耗60 Mbytes,但执行时间增加,因为pypy本身不能进行如此大的优化)
有了这个:交易时内存使用量确实增加了。原因是Order和Trade对象被创建、传递并由经纪人保留。
注意
要考虑到数据集包含随机值,这会产生大量的交叉,因此会产生大量的订单和交易。不应期望常规数据集有类似的行为。
结论
无效声明
如上所证明的那样是虚假的,因为backtrader 能够处理 160 万根蜡烛以上。
一般情况
-
backtrader可以轻松处理
2M根蜡烛,使用默认配置(内存数据预加载) -
backtrader可以在非预加载优化模式下运行,将缓冲区减少到最小,以进行核心外存内存回测
-
当在优化的非预加载模式下进行回测时,内存消耗的增加来自经纪人生成的行政开销。
-
即使在交易时,使用指标并且经纪人不断介入,性能也是
12,473根蜡烛/秒 -
在可能的情况下使用
pypy(例如,如果你不需要绘图)
对于这些情况使用 Python 和/或backtrader
使用pypy,启用交易,并且使用随机数据集(比平常更多的交易),整个 2M 根蜡烛的处理时间为:
156.94秒,即:几乎2 分钟 37 秒
考虑到这是在一台同时运行多个其他任务的笔记本电脑上完成的,可以得出结论,可以处理2M个条形图。
8000支股票的情况呢?
执行时间必须乘以 80,因此:
- 需要运行这个随机集场景的时间为
12,560秒(或几乎210 分钟或3 小时 30 分钟)。
即使假设标准数据集会生成远少于操作,也仍然需要谈论几小时(3 或 4)的回测时间
内存使用量也会增加,当交易时由于经纪人的操作,并且可能需要一些吉字节。
注意
这里不能简单地再次乘以 80,因为示例脚本使用随机数据进行交易,并尽可能频繁。无论如何,所需的 RAM 量都将是重要的
因此,仅使用backtrader作为研究和回测工具的工作流似乎有些牵强。
关于工作流的讨论
使用backtrader时需要考虑两种标准工作流程
-
一切都用
backtrader完成,即:研究和回测都在一个工具中完成 -
使用
pandas进行研究,获取想法是否良好的概念,然后使用backtrader进行回测,尽可能准确地验证,可能已将大型数据集缩减为对于常规 RAM 场景更易处理的内容。
提示
人们可以想象使用类似 dask 进行外存内存执行来替换 pandas
测试脚本
这里是源代码
#!/usr/bin/env python
# -*- coding: utf-8; py-indent-offset:4 -*-
###############################################################################
import argparse
import datetime
import backtrader as bt
class St(bt.Strategy):
params = dict(
indicators=False,
indperiod1=10,
indperiod2=50,
indicator=bt.ind.SMA,
trade=False,
)
def __init__(self):
self.dtinit = datetime.datetime.now()
print('Strat Init Time: {}'.format(self.dtinit))
loaddata = (self.dtinit - self.env.dtcerebro).total_seconds()
print('Time Loading Data Feeds: {:.2f}'.format(loaddata))
print('Number of data feeds: {}'.format(len(self.datas)))
if self.p.indicators:
total_ind = self.p.indicators * 3 * len(self.datas)
print('Total indicators: {}'.format(total_ind))
indname = self.p.indicator.__name__
print('Moving Average to be used: {}'.format(indname))
print('Indicators period 1: {}'.format(self.p.indperiod1))
print('Indicators period 2: {}'.format(self.p.indperiod2))
self.macross = {}
for d in self.datas:
ma1 = self.p.indicator(d, period=self.p.indperiod1)
ma2 = self.p.indicator(d, period=self.p.indperiod2)
self.macross[d] = bt.ind.CrossOver(ma1, ma2)
def start(self):
self.dtstart = datetime.datetime.now()
print('Strat Start Time: {}'.format(self.dtstart))
def prenext(self):
if len(self.data0) == 1: # only 1st time
self.dtprenext = datetime.datetime.now()
print('Pre-Next Start Time: {}'.format(self.dtprenext))
indcalc = (self.dtprenext - self.dtstart).total_seconds()
print('Time Calculating Indicators: {:.2f}'.format(indcalc))
def nextstart(self):
if len(self.data0) == 1: # there was no prenext
self.dtprenext = datetime.datetime.now()
print('Pre-Next Start Time: {}'.format(self.dtprenext))
indcalc = (self.dtprenext - self.dtstart).total_seconds()
print('Time Calculating Indicators: {:.2f}'.format(indcalc))
self.dtnextstart = datetime.datetime.now()
print('Next Start Time: {}'.format(self.dtnextstart))
warmup = (self.dtnextstart - self.dtprenext).total_seconds()
print('Strat warm-up period Time: {:.2f}'.format(warmup))
nextstart = (self.dtnextstart - self.env.dtcerebro).total_seconds()
print('Time to Strat Next Logic: {:.2f}'.format(nextstart))
self.next()
def next(self):
if not self.p.trade:
return
for d, macross in self.macross.items():
if macross > 0:
self.order_target_size(data=d, target=1)
elif macross < 0:
self.order_target_size(data=d, target=-1)
def stop(self):
dtstop = datetime.datetime.now()
print('End Time: {}'.format(dtstop))
nexttime = (dtstop - self.dtnextstart).total_seconds()
print('Time in Strategy Next Logic: {:.2f}'.format(nexttime))
strattime = (dtstop - self.dtprenext).total_seconds()
print('Total Time in Strategy: {:.2f}'.format(strattime))
totaltime = (dtstop - self.env.dtcerebro).total_seconds()
print('Total Time: {:.2f}'.format(totaltime))
print('Length of data feeds: {}'.format(len(self.data)))
def run(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
datakwargs = dict(timeframe=bt.TimeFrame.Minutes, compression=15)
for i in range(args.numfiles):
dataname = 'candles{:02d}.csv'.format(i)
data = bt.feeds.GenericCSVData(dataname=dataname, **datakwargs)
cerebro.adddata(data)
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
cerebro.dtcerebro = dt0 = datetime.datetime.now()
print('Cerebro Start Time: {}'.format(dt0))
cerebro.run(**eval('dict(' + args.cerebro + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Backtrader Basic Script'
)
)
parser.add_argument('--numfiles', required=False, default=100, type=int,
help='Number of files to rea')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', '--strategy', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
run()
交叉回测陷阱
原文:
www.backtrader.com/blog/posts/2019-09-04-donchian-across-platforms/donchian-across-platforms/
在 backtrader 社区 中经常出现的一件事是,用户解释了希望复制在例如 TradingView 中获得的回测结果,这在当今非常流行,或者其他一些回测平台。
即使不真正了解 TradingView 中使用的语言 Pinescript,并且对回测引擎的内部没有任何了解,仍然有一种方法可以让用户知道,跨平台编码必须谨慎对待。
指标:并非始终忠实于来源
当为 backtrader 实现新的指标时,无论是直接用于分发还是作为网站的片段,都会非常强调尊重原始定义。 RSI 就是一个很好的例子。
-
韦尔斯·怀尔德设计
RSI时使用的是Modified Moving Average(又称Smoothed Moving Average,参见 Wikipedia - Modified Moving Average ) -
尽管如此,许多平台给用户提供了所谓的
RSI,但使用的是经典的指数移动平均线而不是书中所说的。 -
鉴于这两个平均值都是指数型的,差异并不是很大,但这并不是韦尔斯·怀尔德定义的。它可能仍然有用,甚至可能更好,但这不是
RSI。而且文档(如果有的话)也没有提到这一点。
backtrader 中 RSI 的默认配置是使用 MMA 以忠实于来源,但要使用哪种移动平均线是可以通过子类化或在运行时实例化期间更改的参数,以使用 EMA 或甚至 简单移动平均线。
一个例子:唐奇安通道
维基百科的定义:维基百科 - 唐奇安通道 ). 这只是文本,没有提到使用通道突破作为交易信号。
另外两个定义:
这两个参考资料明确指出,用于计算通道的数据不包括当前柱,因为如果包括...突破将不会反映。这里是 StockCharts 的一个示例图表
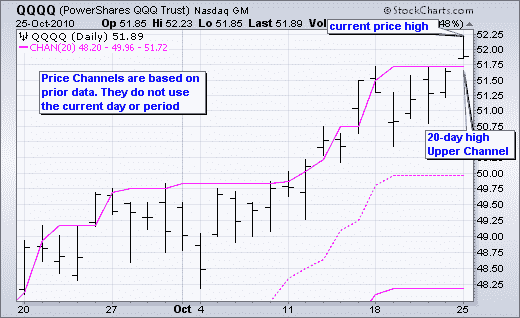
现在转向 TradingView。首先是链接
该页面上的一个图表。
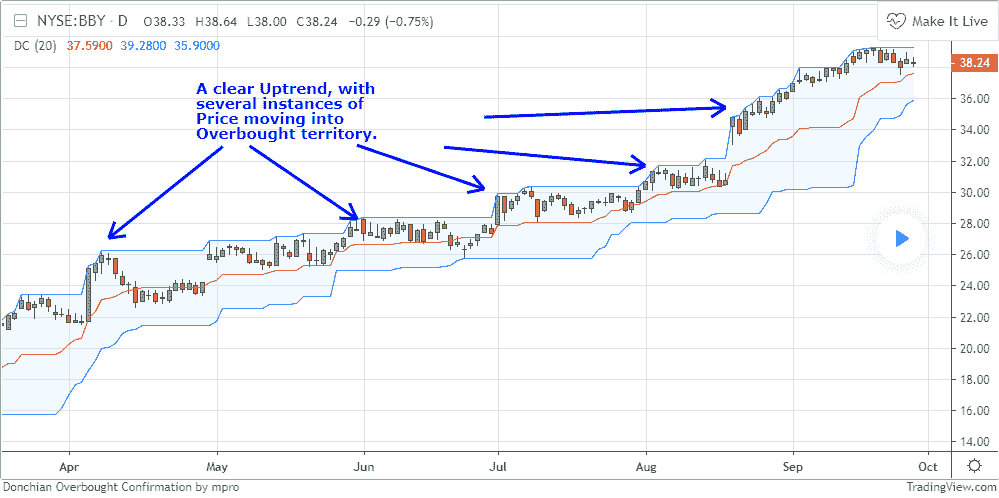
即使Investopedia也使用了一张TradingView图表,显示没有突破。这里:Investopedia - 唐奇安通道 - https://www.investopedia.com/terms/d/donchianchannels.asp
正如一些人所说... 天啊!!! 因为TradingView的图表中没有突破可见。这意味着指标的实现是使用当前价格栏来计算通道。
backtrader中的唐奇安通道
标准backtrader发行版中没有DonchianChannels的实现,但可以很快制作。一个参数将决定当前栏是否用于通道计算。
class DonchianChannels(bt.Indicator):
'''
Params Note:
- ``lookback`` (default: -1)
If `-1`, the bars to consider will start 1 bar in the past and the
current high/low may break through the channel.
If `0`, the current prices will be considered for the Donchian
Channel. This means that the price will **NEVER** break through the
upper/lower channel bands.
'''
alias = ('DCH', 'DonchianChannel',)
lines = ('dcm', 'dch', 'dcl',) # dc middle, dc high, dc low
params = dict(
period=20,
lookback=-1, # consider current bar or not
)
plotinfo = dict(subplot=False) # plot along with data
plotlines = dict(
dcm=dict(ls='--'), # dashed line
dch=dict(_samecolor=True), # use same color as prev line (dcm)
dcl=dict(_samecolor=True), # use same color as prev line (dch)
)
def __init__(self):
hi, lo = self.data.high, self.data.low
if self.p.lookback: # move backwards as needed
hi, lo = hi(self.p.lookback), lo(self.p.lookback)
self.l.dch = bt.ind.Highest(hi, period=self.p.period)
self.l.dcl = bt.ind.Lowest(lo, period=self.p.period)
self.l.dcm = (self.l.dch + self.l.dcl) / 2.0 # avg of the above
使用lookback=-1参数,一个示例图表看起来像这样(放大后)
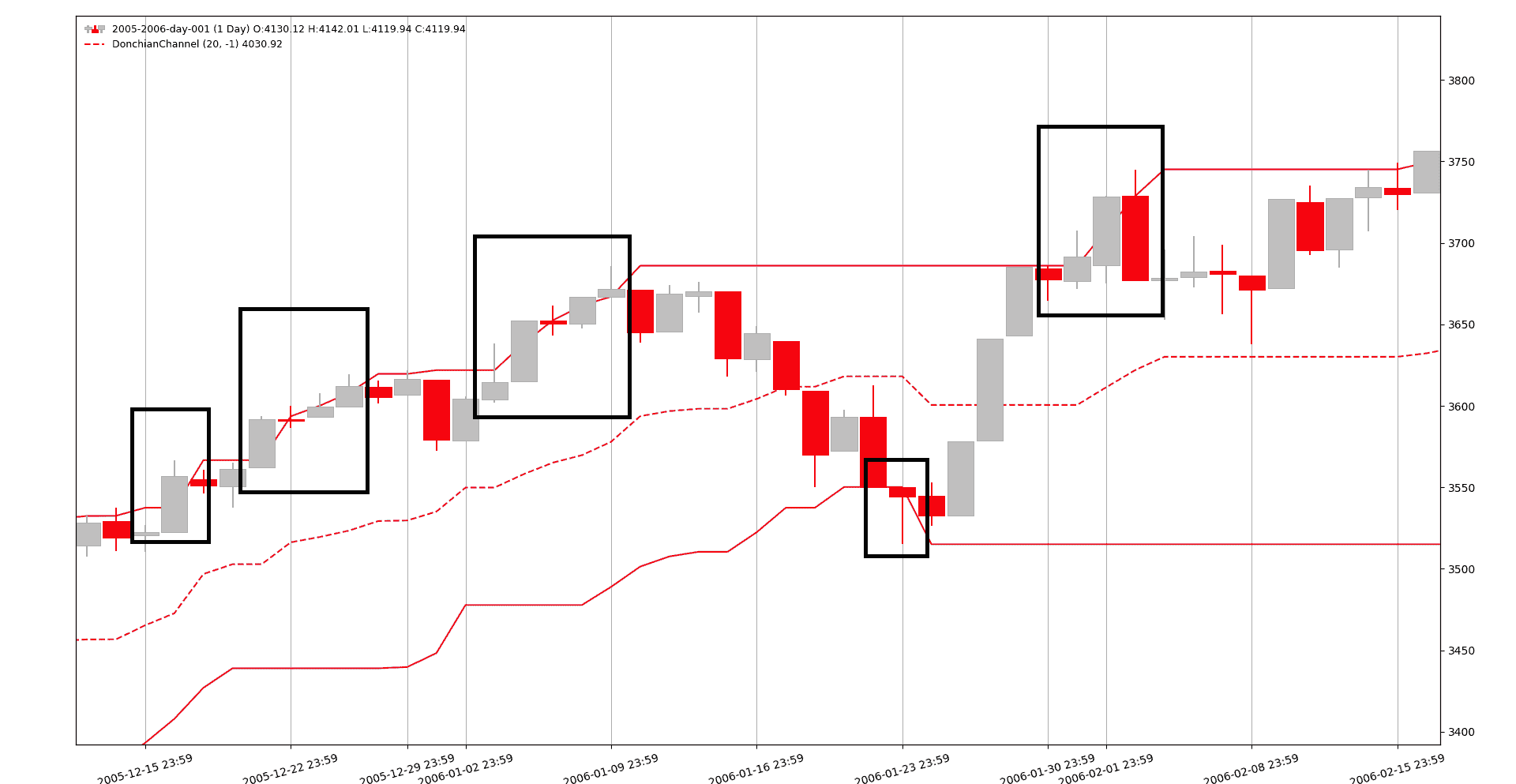
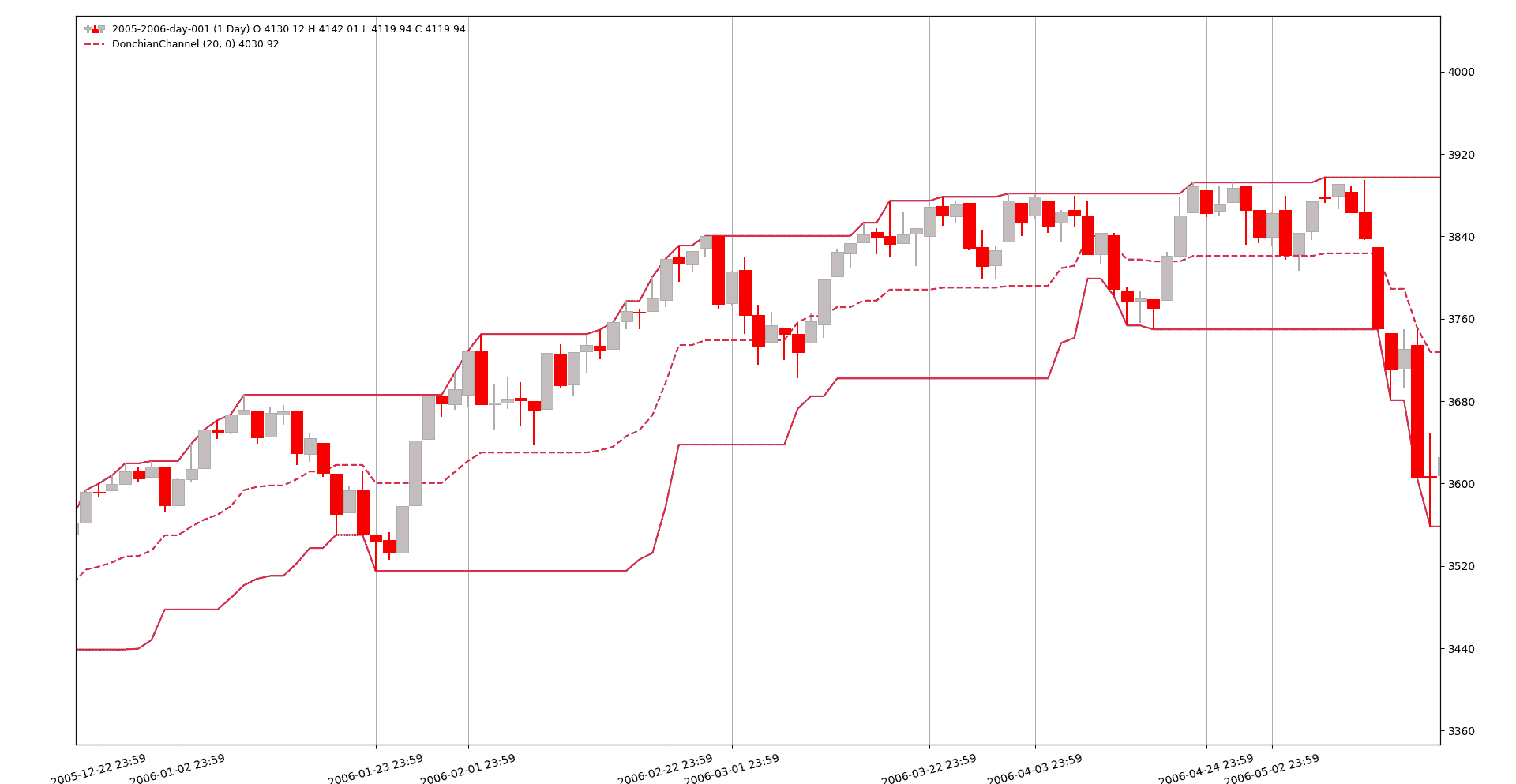
人们可以清楚地看到突破,而在lookback=0版本中没有突破。
编码影响
程序员首先去商业平台,并使用唐奇安通道实现一个策略。因为图表上没有显示突破,所以必须将当前价格值与前一个通道值进行比较。如下所示
if price0 > channel_high_1:
sell()
elif price0 < channel_low_1:
buy()
当前价格,即:price0与1周期前的高/低通道值进行比较(因此有_1后缀)
作为一个谨慎的程序员,不知道backtrader中唐奇安通道的默认设置是有突破的,代码被移植过来,如下所示
def __init__(self):
self.donchian = DonchianChannels()
def next(self):
if self.data[0] > self.donchian.dch[-1]:
self.sell()
elif self.data[0] < self.donchian.dcl[-1]:
self.buy()
这是错误的!!!因为突破发生在比较的同时。正确的代码:
def __init__(self):
self.donchian = DonchianChannels()
def next(self):
if self.data[0] > self.donchian.dch[0]:
self.sell()
elif self.data[0] < self.donchian.dcl[0]:
self.buy()
虽然这只是一个小例子,但它展示了由于指标被编码为1栏差异而导致的回测结果可能会有所不同。这看起来可能并不多,但当错误的交易开始时,它肯定会产生影响。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号