Java 中文官方教程 2022 版(四十八)
关闭
正常的垃圾回收会在不再使用时删除Context实例。被垃圾回收的Context实例使用的连接将自动关闭。因此,您无需显式关闭连接。然而,网络连接是有限资源,对于某些程序,您可能希望控制它们的增殖和使用。本节包含如何关闭连接以及如何在服务器关闭连接时收到通知的信息。
显式关闭
您可以调用Context.close()来指示您不再需要使用Context实例。如果要关闭的Context实例正在使用专用连接,则该连接也将关闭。如果Context实例正在与其他Context和未终止的NamingEnumeration实例共享连接,则在所有这些Context和NamingEnumeration实例上调用close()之前,连接将不会关闭。
在连接创建示例部分的example中,必须在关闭底层连接之前关闭所有三个Context实例。
// Create initial context
DirContext ctx = new InitialDirContext(env);
// Get a copy of the same context
Context ctx2 = (Context)ctx.lookup("");
// Get a child context
Context ctx3 = (Context) ctx.lookup("ou=NewHires");
// do something useful with ctx, ctx2, ctx3
// Close the contexts when we're done
ctx.close();
ctx2.close();
ctx3.close();
强制隐式闭包
如前所述,对于不再在作用域内的Context和NamingEnumeration实例,Java 运行时系统最终会对它们进行垃圾回收,从而清理close()将要执行的状态。要强制进行垃圾回收,您可以使用以下代码。
Runtime.getRuntime().gc();
Runtime.getRuntime().runFinalization();
根据程序的状态,执行此过程可能会导致严重(临时)性能下降。如果需要确保连接已关闭,请跟踪Context实例并显式关闭它们。
检测连接关闭
LDAP 服务器通常在空闲超时后关闭不再使用的连接。当您随后在使用此连接的Context实例上调用方法时,该方法将抛出CommunicationException。要检测服务器关闭Context实例正在使用的连接时,您需要在Context实例上注册一个UnsolicitedNotificationListener。在 LDAP 未经请求通知部分显示了一个示例。尽管该示例设计用于从服务器接收未经请求的通知,但也可用于检测服务器关闭连接。启动程序后,停止 LDAP 服务器并观察监听器的namingExceptionThrown()方法被调用。
连接池
连接创建部分描述了何时创建连接。它描述了多个Context实例如何共享相同的连接。
LDAP 服务提供程序支持的另一种连接共享类型称为连接池。在这种共享类型中,LDAP 服务提供程序维护一组(可能是)先前使用过的连接,并根据需要将它们分配给Context实例。当Context实例完成连接(关闭或垃圾回收)时,连接将被返回到池中以供将来使用。请注意,这种共享形式是顺序的:从池中检索连接,使用连接,将连接返回到池中,然后再次从池中检索连接以供另一个Context实例使用。
连接池是针对每个 Java 运行时系统进行维护的。在某些情况下,使用连接池可以显著提高性能。例如,如果使用连接池,则处理包含对同一 LDAP 服务器的四个引用引用的搜索响应仅需要一个连接。如果没有使用连接池,这种情况将需要四个单独的连接。
本课程的其余部分将更详细地描述如何使用连接池。
如何使用连接池
通过向传递给初始上下文构造函数的环境属性添加属性"com.sun.jndi.ldap.connect.pool"来请求连接池。这里是一个示例。
// Set up environment for creating initial context
Hashtable env = new Hashtable(11);
env.put(Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.ldap.LdapCtxFactory");
env.put(Context.PROVIDER_URL, "ldap://localhost:389/o=JNDITutorial");
// Enable connection pooling
env.put("com.sun.jndi.ldap.connect.pool", "true");
// Create one initial context (Get connection from pool)
DirContext ctx = new InitialDirContext(env);
// do something useful with ctx
// Close the context when we're done
ctx.close(); // Return connection to pool
// Create another initial context (Get connection from pool)
DirContext ctx2 = new InitialDirContext(env);
// do something useful with ctx2
// Close the context when we're done
ctx2.close(); // Return connection to pool
此示例连续创建两个初始上下文。第二个初始上下文将重用第一个使用的连接。要运行此程序并观察如何检索连接并将其返回到池中,请使用以下命令行。
#java -Dcom.sun.jndi.ldap.connect.pool.debug=fine UsePool
这应该产生以下输出。
Create com.sun.jndi.ldap.LdapClient@5d173[localhost:389]
Use com.sun.jndi.ldap.LdapClient@5d173
{ou=ou: NewHires, objectclass=objectClass: top, organizationalUnit}
Release com.sun.jndi.ldap.LdapClient@5d173
Use com.sun.jndi.ldap.LdapClient@5d173
{ou=ou: People, objectclass=objectClass: top, organizationalunit}
Release com.sun.jndi.ldap.LdapClient@5d173
通过包含或省略"com.sun.jndi.ldap.connect.pool"属性,您可以决定何时何地使用连接池,从而在每个上下文的基础上控制连接池。在前面的示例中,如果在创建第二个初始上下文之前从环境属性中删除此属性,则第二个初始上下文将不使用池化连接。
LDAP 提供程序通过应用程序的指示来跟踪连接是否正在使用。它假定维护打开上下文句柄的应用程序正在使用连接。因此,为了使 LDAP 提供程序正确管理池化连接,您必须勤于在不再需要的上下文上调用Context.close()。
坏连接会被 LDAP 提供程序自动检测并从池中移除。无论是否使用连接池,上下文最终使用坏连接的概率是相同的。
创建超时
LDAP 服务提供程序维护的连接池可能具有限制的大小;这在连接池配置部分有详细描述。当启用连接池并且没有可用的池化连接时,客户端应用程序将被阻塞,等待可用连接。您可以使用"com.sun.jndi.ldap.connect.timeout"环境属性来指定等待池化连接的时间。如果省略此属性,应用程序将无限期等待。
此属性还用于指定建立 LDAP 连接的超时期限,如连接创建部分所述。
何时不使用池化!!
池化连接旨在被重复使用。因此,如果您计划对可能改变底层连接状态的Context实例执行操作,则不应该对该Context实例使用连接池。例如,如果您计划在Context实例上调用 Start TLS 扩展操作,或者计划在创建初始上下文后更改安全相关属性(如"java.naming.security.principal"或"java.naming.security.protocol"),则不应该对该Context实例使用连接池,因为 LDAP 提供程序不会跟踪任何此类状态更改。在这种情况下使用连接池,可能会 compromise 您的应用程序的安全性。
配置
连接池是针对每个 Java 运行时配置和维护的。连接不会跨不同的运行时共享。要使用连接池,不需要任何配置。只有在想要自定义池化方式时才需要配置,比如控制池的大小和哪些类型的连接被池化。
你可以在程序启动时通过一些系统属性来配置连接池。请注意这些是系统属性,不是环境属性,并且它们影响所有连接池请求。
这是一个设置最大池大小为 20,首选池大小为 10,并且空闲超时为一分钟的池化连接的命令行示例。
# java -Dcom.sun.jndi.ldap.connect.pool.maxsize=20 \
-Dcom.sun.jndi.ldap.connect.pool.prefsize=10 \
-Dcom.sun.jndi.ldap.connect.pool.timeout=60000 \
UsePool
下表列出了用于配置连接池的系统属性。它们在本节的其余部分中有更详细的描述。
| 系统属性名称 | 描述 | 默认值 |
|---|---|---|
com.sun.jndi.ldap.connect.pool.authentication |
一个以空格分隔的连接认证类型列表,可以被池化。有效类型为"none"、"simple"和"DIGEST-MD5"。 | "none simple" |
com.sun.jndi.ldap.connect.pool.debug |
一个指示要生成的调试输出级别的字符串。有效值为"fine"(跟踪连接的创建和移除)和"all"(所有调试信息)。 |
|
com.sun.jndi.ldap.connect.pool.initsize |
一个整数的字符串表示,表示在为标识创建连接时初始创建的每个连接标识的连接数。 | 1 |
com.sun.jndi.ldap.connect.pool.maxsize |
一个整数的字符串表示,表示每个连接标识可以同时维护的最大连接数。 | 无最大大小 |
com.sun.jndi.ldap.connect.pool.prefsize |
一个整数的字符串表示,表示应同时维护的每个连接标识的首选连接数。 | 无首选大小 |
com.sun.jndi.ldap.connect.pool.protocol |
一个以空格分隔的连接协议类型列表,可以被池化。有效类型为"plain"和"ssl"。 | "plain" |
com.sun.jndi.ldap.connect.pool.timeout |
一个整数的字符串表示,表示空闲连接在池中可以保持的毫秒数,超过这个时间将被关闭并从池中移除。 | 无超时 |
被池化的内容
当您请求Context实例使用连接池时,可以通过使用"com.sun.jndi.ldap.connect.pool"环境属性,所使用的连接可能会被池化,也可能不会。默认规则是允许使用简单或无身份验证的普通(非 SSL)连接进行池化。您可以通过使用系统属性来更改此默认设置,以包括 SSL 连接和 DIGEST-MD5 身份验证类型。要允许普通和 SSL 连接都被池化,请将"com.sun.jndi.ldap.connect.pool.protocol"系统属性设置为字符串"plain ssl"。要允许匿名(无)、简单和 DIGEST-MD5 身份验证类型的连接被池化,请将com.sun.jndi.ldap.connect.pool.authentication系统属性设置为字符串"none simple DIGEST-MD5"。
有几个环境属性会自动使Context实例无法使用池化连接。如果Context实例将其"java.naming.ldap.factory.socket"属性设置为自定义套接字工厂类,或将其"java.naming.security.sasl.callback"属性设置为自定义回调处理程序类,或将其"com.sun.jndi.ldap.trace.ber"属性设置为启用协议跟踪,则Context实例无法使用池化连接。
连接是如何被池化的
当Context实例请求使用池化连接时,LDAP 提供程序需要确定是否可以通过现有的池化连接满足请求。它通过为每个池化连接分配连接标识并检查传入请求是否具有与其池化连接之一的连接标识相同来实现这一点。
连接标识是创建可能经过身份验证的 LDAP 连接所需的参数集。其组成取决于请求的身份验证类型,如下表所示。
| 身份验证类型 | 连接标识内容 |
|---|---|
| none |
-
连接控制
-
主机名、端口号如在
"java.naming.provider.url"属性中指定的,引荐或提供给初始上下文的 URL。 -
以下属性的内容:
java.naming.security.protocol java.naming.ldap.version
|
| simple |
|---|
-
所有列出的关于无身份验证的信息
-
以下属性的内容:
java.naming.security.principal java.naming.security.credentials
|
| DIGEST-MD5 |
|---|
-
所有列出的关于简单身份验证的信息
-
以下属性的内容:
java.naming.security.sasl.authorizationId java.naming.security.sasl.realm javax.security.sasl.qop javax.security.sasl.strength javax.security.sasl.server.authentication javax.security.sasl.maxbuffer javax.security.sasl.policy.noplaintext javax.security.sasl.policy.noactive javax.security.sasl.policy.nodictionary javax.security.sasl.policy.noanonymous javax.security.sasl.policy.forward javax.security.sasl.policy.credentials
|
池大小
LDAP 提供程序维护连接池;每个池保存具有相同连接标识的连接(正在使用或空闲)。有三个大小影响每个池的管理。这些大小是全局的,影响所有池。
初始池大小是 LDAP 服务提供程序在首次创建池时(即应用程序首次为该连接标识请求池化连接时)创建的每个连接标识的连接数。池中每个连接的身份验证是按需执行的,随着连接的使用而进行。默认情况下,初始池大小为 1,并且可以通过使用系统属性"com.sun.jndi.ldap.connect.pool.initsize"进行更改。通常在应用程序启动时使用,以向服务器预先提供一定数量的连接。
最大池大小是 LDAP 服务提供程序可以同时维护的每个连接标识的最大连接数。使用中和空闲连接都计入此数字。当池大小达到此数字时,对应连接标识的新连接将无法创建,直到池中的连接被移除(即物理连接被关闭)。当池大小达到最大值且池中的所有连接都在使用中时,应用程序从该池请求连接时将被阻塞,直到池中的连接变为空闲或被移除。最大池大小为 0 意味着没有最大大小:对池化连接的请求将使用现有的空闲池化连接或新创建的池化连接。
首选池大小是 LDAP 服务提供程序应该维护的每个连接标识的首选连接数。使用中和空闲连接都计入此数字。当应用程序请求使用池化连接且池大小小于首选大小时,LDAP 提供程序将创建并使用新的池化连接,而不管是否有空闲连接可用。当应用程序完成对池化连接的使用(通过在共享连接上调用Context.close())且池大小大于首选大小时,LDAP 提供程序将关闭并从池中移除池化连接。首选池大小为 0 意味着没有首选大小:对池化连接的请求只会在没有空闲连接可用时才会创建新连接。
请注意,最大池大小会覆盖初始和首选池大小。例如,将首选池大小设置为大于最大池大小实际上是将其设置为最大池大小。
空闲连接
当应用程序完成对池化连接的使用(通过在共享连接的所有上下文上调用Context.close()),底层的池化连接被标记为空闲,等待重新使用。默认情况下,空闲连接会一直保留在池中,直到被垃圾回收。如果设置了"com.sun.jndi.ldap.connect.pool.timeout"系统属性,LDAP 提供程序将自动关闭并移除空闲时间超过指定时期的池化连接。
常见问题
这节课回答了用户在使用 JNDI 访问 LDAP 服务时经常遇到的常见问题。一些常见问题在命名和目录操作课程的 Trouble Shooting Tips 中得到解答。
-
上下文:
-
上下文是否安全用于多线程访问?
-
为什么 LDAP 提供程序忽略我的安全环境属性?
-
为什么我一直收到 CommunicationException?
-
如何获取 LDAP 消息的跟踪?
-
如何使用不同的身份验证机制,如 Kerberos?
-
更改密码时是否应启用 SSL?
属性:
-
当我请求一个属性时,为什么返回另一个属性?
-
如何知道属性值的类型?
-
如何以除了字符串或字节数组之外的形式获取属性的值?
-
为什么在我的搜索中将"*"作为属性值不按预期工作?
搜索:
-
为什么搜索过滤器中的通配符不总是起作用?
-
当我知道目录中还有更多条目时,为什么我只返回n个条目?
-
如何在我的搜索中传递控件?
-
我如何查看返回的搜索结果数量?
名称:
-
为什么我的搜索结果中的名称是空字符串?
-
为什么我的搜索结果中的名称是一个 URL 字符串?
-
传递给上下文方法的 Name 参数是什么类型?
-
我可以将从 NameParser 获取的名称传递给 Context 方法吗?
-
我用于
Context.SECURITY_PRINCIPAL属性的名称与目录之间有什么关系? -
为什么我从目录中读取的名称中有奇怪的引号和转义字符?
-
如何获取 LDAP 条目的完整 DN?
1. 上下文是否安全用于多线程访问,还是需要对上下文进行锁定/同步访问?
答案取决于实现。这是因为Context和DirContext接口没有指定同步要求。JDK 中的 LDAP 实现针对单线程访问进行了优化。如果有多个线程访问相同的Context实例,则每个线程在使用时需要锁定Context实例。这也适用于从相同Context实例派生的任何NamingEnumeration。然而,多个线程可以同时访问不同的Context实例(甚至是从同一个初始上下文派生的实例)而无需锁定。
2. 如果我不设置Context.SECURITY_CREDENTIALS ("java.naming.security.credentials")属性或将其设置为空字符串,为什么 LDAP 提供程序会忽略我的安全环境属性?
如果您向Context.SECURITY_CREDENTIALS环境属性提供空字符串、空的byte/char数组或null,即使Context.SECURITY_AUTHENTICATION属性设置为"simple",也会发生匿名绑定。这是因为对于简单认证,LDAP 要求密码不能为空。如果未提供密码,则协议会自动将认证转换为"none"。
3. 当我尝试创建初始上下文时为什么会一直收到CommunicationException?
您可能正在与仅支持 LDAP v2 的服务器通信。请参考JNDI 教程中的杂项课程,了解如何设置版本号的示例。
4. 我如何追踪 LDAP 消息?
尝试使用"com.sun.jndi.ldap.trace.ber"环境属性。如果此属性的值是java.io.OutputStream的实例,则 LDAP 提供程序发送和接收的 BER 缓冲区的跟踪信息将写入该流。如果属性的值为null,则不会写入跟踪输出。
例如,以下代码将把跟踪输出发送到System.err。
env.put("com.sun.jndi.ldap.trace.ber", System.err);
5. 我如何使用不同的认证机制,比如 Kerberos?
参考JNDI 教程中的 GSS-API/Kerberos v5 认证部分,了解如何使用 Kerberos 认证。要使用其他认证机制,请参阅JNDI 教程中的使用任意 SASL 机制部分。
6. 在更改密码时应该启用 SSL 吗?
这实际取决于您正在使用的目录服务器。一些目录服务器如果未启用 SSL,则不允许您更改密码,但有些允许。启用 SSL 可以确保密码在通信通道中得到保护。
7. 当我请求一个属性时,为什么会返回另一个属性?
您正在使用的属性名称可能是另一个属性的同义词。在这种情况下,LDAP 服务器可能返回规范属性名称而不是您提供的属性名称。当您查看服务器返回的Attributes时,需要使用规范名称而不是同义词。
例如,"fax"可能是规范属性名称"facsimiletelephonenumber"的同义词。如果您请求"fax",服务器将返回名为"facsimiletelephonenumber"的属性。有关同义词和属性名称的其他问题,请参阅 Naming and Directory Operations 课程。
8. 我如何知道属性值的类型?
属性值可以是java.lang.String或byte[]。请参阅JNDI 教程的杂项部分,了解哪些属性值以byte[]形式返回。要以编程方式执行此操作,您可以使用instanceof运算符检查从 LDAP 提供程序返回的属性值。
9. 如何以字符串或字节数组以外的形式获取属性值?
目前你不能。LDAP 提供程序仅返回java.lang.String或byte[]类型的属性值。请参阅JNDI 教程的杂项部分。
10. 为什么在我的搜索中将"*"作为属性值不起作用?
当您使用以下形式的search()时,属性值被视为文字;也就是说,目录条目中的属性应该正好包含该值:search(Name name, Attributes matchingAttrs) 要使用通配符,您应该使用search()的字符串过滤形式,如下所示。search(Name name, String filter, SearchControls ctls)
search(Name name, String filterExpr, Object[]filterArgs, SearchControls ctls)
对于最后一种形式,通配符字符必须出现在filterExpr参数中,而不是在filterArgs中。filterArgs中的值也被视为文字。
11. 为什么搜索过滤器中的通配符不总是起作用?
通配符出现在属性值之前或之后(例如在"attr=*I*"中)表示服务器将使用属性的子字符串匹配规则搜索匹配的属性值。如果属性的定义没有子字符串匹配规则,则服务器无法找到属性。您必须使用相等或“存在”过滤器进行搜索。
12. 当我知道目录中还有更多条目时,为什么我只返回了n个条目?一些服务器配置为限制可以返回的条目数。其他服务器在搜索期间也限制可以检查的条目数。请检查您的服务器配置。
13. 我如何在我的搜索中传递控件?
本教程中未解释控件。查看JNDI 教程。
14. 我如何知道我得到了多少搜索结果?
在枚举结果时必须进行计数。LDAP 不提供这些信息。
15. 为什么我在我的SearchResult中得到一个空字符串作为名称?
getName() 总是返回一个相对于搜索的目标上下文的名称。因此,如果目标上下文满足搜索过滤器,则返回的名称将是""(空名称),因为这是相对于目标上下文的名称。有关详细信息,请参阅搜索结果部分。
16. 为什么我在我的SearchResult中得到一个 URL 字符串作为名称?
LDAP 条目是通过跟随别名或引荐而检索的,因此它的名称是一个 URL。有关详细信息,请参阅搜索结果课程。
17. 传递给Context和DirContext方法的Name参数是什么类型?- 一个CompoundName还是一个CompositeName?
字符串形式接受复合名称的字符串表示。也就是说,使用字符串名称等同于调用new CompositeName(stringName)并将结果传递给Context/DirContext方法。Name参数可以是实现Name接口的任何对象。如果它是CompositeName的一个实例,则该名称被视为复合名称;否则,它被视为复合名称。
18. 我可以将从NameParser得到的名称传递给Context方法吗?
这与前一个问题有关。是的,你可以。NameParser.parse() 返回一个实现了Name接口的复合名称。这个名称可以传递给Context方法,这些方法将把它解释为一个复合名称。
19. 我在Context.SECURITY_PRINCIPAL属性中使用的名称与目录之间有什么关系?
你可以将主要名称视为来自不同命名空间的名称。参见RFC 2829和安全部分,了解 LDAP 认证机制的详细信息。JDK 中的 LDAP 服务提供程序接受一个字符串主要名称,直接传递给 LDAP 服务器。一些 LDAP 服务器接受 DN,而其他一些支持RFC 2829提出的方案。
20. 为什么我从目录中读取的名称中会有奇怪的引号和转义字符?
JDK 中的 LDAP 名称解析器在引号规则方面比较保守,但仍然生成“正确”的名称。另外,请记住,NamingEnumeration返回的条目名称是可以传递回Context和DirContext方法的复合名称。因此,如果名称中包含与复合名称语法冲突的字符(例如斜杠字符“/”),那么 LDAP 提供程序将提供一种编码,以确保斜杠字符将被视为 LDAP 名称的一部分,而不是复合名称分隔符。
21. 如何获取 LDAP 条目的完整 DN?
您可以使用NameClassPair.getNameInNamespace()。
课程:目录中的 Java 对象
传统上,目录被用来存储数据。用户和程序员将目录视为包含一组属性的目录条目的层次结构。您可以从目录中查找条目并提取感兴趣的属性。
对于用 Java 编程语言编写的应用程序,Java 对象有时可能会在应用程序之间共享。对于这样的应用程序,能够将目录用作 Java 对象的存储库是有意义的。目录为分布在网络上的 Java 应用程序提供了一个集中管理的、可能是复制的服务。例如,应用程序服务器可能使用目录来注册代表其管理的服务的对象,以便客户端稍后可以搜索目录以定位所需的服务。JNDI 用作服务目录的示例是 Apache DS。有关更多信息,请访问Apache Directory。
JNDI 提供了目录的面向对象视图,从而允许将 Java 对象添加到目录中并从中检索,而无需客户端管理数据表示问题。本课程讨论了在基本水平上使用目录存储和检索 Java 对象。JNDI 提供了用于创建和存储从目录访问的对象的对象和状态工厂。
对象工厂
对象工厂是对象的生产者。它接受有关如何创建对象的一些信息,例如引用,然后返回该对象的实例。有关对象工厂和对象在目录中存储的格式的详细信息,请参阅JNDI 教程。
状态工厂
状态工厂将一个对象转换为另一个对象。输入是对象和可选属性,提供给 Context.bind(),输出是另一个对象和可选属性,将存储在底层命名服务或目录中。有关状态工厂以及如何编写自己的状态工厂的详细信息,请参阅JNDI 教程。
课程的下一部分讨论了如何访问目录中的对象。它描述了可序列化对象如何存储和读取在目录中。有关其他类型的对象,请查看JNDI 教程。
存储和读取对象
应用程序和服务可以以不同的方式使用目录来存储和定位对象:
-
存储(对象的副本)对象本身。
-
存储对象的引用。
-
存储描述对象的属性。
一般来说,Java 对象的序列化形式包含对象的状态和对象的引用,以紧凑的寻址信息表示,可用于联系对象。一些示例在查找对象课程中给出。对象的属性用于描述对象的属性;属性可能包括寻址和/或状态信息。
使用这三种方式中的哪一种取决于正在构建的应用程序/系统以及它需要与其他应用程序和系统进行交互的方式,这些应用程序和系统将共享目录中存储的对象。另一个因素是服务提供商和底层目录服务提供的支持。
在将对象存储在目录中时,所有应用程序都使用以下方法之一:
应用程序将要存储的对象传递给这些方法之一。然后,根据服务提供商支持的对象类型,对象将被转换为底层目录服务可接受的表示形式。
本课程展示了如何在目录中存储可序列化对象,一旦对象被存储,你可以简单地使用lookup()从目录中获取对象的副本,而不管实际存储了什么类型的信息。
你不仅可以通过使用lookup()来获取对象,还可以在列出上下文时以及搜索上下文或其子树时获取对象。在所有这些情况下,对象工厂可能会参与其中。对象工厂在JNDI 教程中有详细讨论。
对于存储以下对象类型,请参考 JNDI 教程:
-
Referenceable 对象和 JNDI
References添加、替换或移除绑定课程中的 bind()示例使用 Referenceable 对象。
在继续之前: 要成功运行这些示例,您必须在服务器中关闭模式检查,或者将附带本教程的Java 模式添加到服务器中。这项任务通常由目录服务器的管理员执行。有关更多信息,请参阅软件设置课程。
Windows Active Directory: Context.rebind() 和 DirContext.rebind() 在 Active Directory 上不起作用,因为这些方法通过读取要更新的条目的属性,删除该条目,然后添加一个包含修改后属性的新条目来工作。Active Directory 返回一些用户无法设置的属性,导致最终添加步骤失败。解决此问题的方法是使用DirContext.getAttributes() 获取并保存要保留的属性。然后,使用DirContext.bind()将条目删除并添加回来,其中包括保存的属性(以及其他要添加的属性)。
可序列化对象
序列化 一个对象意味着将其状态转换为字节流,以便可以将字节流还原为对象的副本。如果其类或其任何超类实现了 java.io.Serializable 接口或其子接口 java.io.Externalizable,则 Java 对象是 可序列化 的。反序列化 是将对象的序列化形式转换回对象的过程。
例如,java.awt.Button 类实现了 Serializable 接口,因此您可以序列化一个 java.awt.Button 对象并将该序列化状态存储在文件中。稍后,您可以读取序列化状态并将其反序列化为一个 java.awt.Button 对象。
Java 平台规定了可序列化对象序列化的默认方式。一个(Java)类可以覆盖这种默认序列化,并定义其自己的序列化对象的方式。对象序列化规范详细描述了对象序列化。
当对象被序列化时,用于标识其类的信息被记录在序列化流中。然而,类的定义("类文件")本身并未记录。反序列化对象的系统有责任确定如何定位和加载必要的类文件。例如,一个 Java 应用程序可能在其类路径中包含一个包含序列化对象的类文件的 JAR 文件,或者通过使用存储在目录中的信息加载类定义,如本课程后面解释的那样。
绑定可序列化对象
如果底层服务提供程序支持该操作,您可以将可序列化对象存储在目录中,就像 Oracle 的 LDAP 服务提供程序一样。
以下示例调用 Context.bind 将 AWT 按钮绑定到名称 "cn=Button"。要将属性与新绑定关联起来,您可以使用 DirContext.bind。要覆盖现有绑定,使用 Context.rebind 和 DirContext.rebind。
// Create the object to be bound
Button b = new Button("Push me");
// Perform the bind
ctx.bind("cn=Button", b);
您可以使用 Context.lookup 读取对象,如下所示。
// Check that it is bound
Button b2 = (Button)ctx.lookup("cn=Button");
System.out.println(b2);
运行 此示例 会产生以下输出。
# java SerObj
java.awt.Button[button0,0,0,0x0,invalid,label=Push me]
指定代码库
注意: 这里描述的程序适用于在遵循RFC 2713中定义的模式的目录服务中绑定可序列化对象。这些程序可能不适用于支持将可序列化对象与指定代码库绑定的其他命名和目录服务。
当一个序列化对象像前面的例子中所示绑定在目录中时,从目录中读取序列化对象的应用程序必须能够访问必要的类定义以对对象进行反序列化。
或者,你可以在目录中记录一个代码库,无论是在绑定对象时还是随后通过使用DirContext.modifyAttributes添加属性。你可以使用任何属性来记录这个代码库,并让你的应用程序从目录中读取该属性并适当使用它。或者你可以使用在中指定的"javaCodebase"属性。在后一种情况下,Oracle 的 LDAP 服务提供者将自动使用该属性根据需要加载类定义。"javaCodebase"应包含代码库目录或 JAR 文件的 URL。如果代码库包含多个 URL,则每个 URL 必须用空格字符分隔。
以下示例类似于绑定java.awt.Button的示例。不同之处在于它使用了一个用户定义的Serializable类,Flower,并提供了一个包含Flower类定义位置的"javaCodebase"属性。以下是执行绑定的代码。
String codebase = ...;
// Create the object to be bound
Flower f = new Flower("rose", "pink");
// Perform the bind and specify the codebase
ctx.bind("cn=Flower", f, new BasicAttributes("javaCodebase", codebase));
当你运行这个例子时,你必须提供Flower.class类文件安装位置的 URL。例如,如果Flower.class安装在 Web 服务器web1上,目录为example/classes,那么你可以按照以下方式运行这个例子。
# java SerObjWithCodebase http://web1/example/classes/
pink rose
之后,你可以从类路径中删除Flower.class并运行任何查找或列出此对象的程序,而无需直接引用Flower类。如果你的程序直接引用Flower,那么你必须使其类文件可供编译和执行。
课程:JDK 5.0 和 JDK 6 中的新功能
在这节课中,我们将讨论 JDK 5.0 和 JDK 6 版本中 JNDI 和 LDAP 服务提供程序支持的以下新功能。
-
从搜索结果中检索出区分名称(DN)。
-
使用标准 LDAP 控件。
-
操作 LDAP 名称。
-
设置 LDAP 操作的读取超时。
检索 Distinguished Name
在 JDK 5.0 之前的版本中,没有直接的方法从搜索结果中获取 Distinguished Name (DN)。SearchResults.getName() 方法始终返回相对于执行搜索的上下文的名称。为了获取搜索条目的绝对或完整名称,需要一定的记录来跟踪祖先上下文。在 JDK 5.0 中添加了以下两个新的 API,用于在对上下文执行搜索、列出或列出绑定操作时从 NameClassPair 中检索绝对名称:
这是一个从 LDAP 搜索中检索 DN 的示例:
public static void printSearchEnumeration(NamingEnumeration retEnum) {
try {
while (retEnum.hasMore()) {
SearchResult sr = (SearchResult) retEnum.next();
System.out.println(">>" + sr.getNameInNamespace());
}
} catch (NamingException e) {
e.printStackTrace();
}
}
完整的示例可以从这里获取。该程序生成以下输出:
>>cn=Jon Ruiz, ou=People, o=JNDITutorial
>>cn=Scott Seligman, ou=People, o=JNDITutorial
>>cn=Samuel Clemens, ou=People, o=JNDITutorial
>>cn=Rosanna Lee, ou=People, o=JNDITutorial
>>cn=Maxine Erlund, ou=People, o=JNDITutorial
>>cn=Niels Bohr, ou=People, o=JNDITutorial
>>cn=Uri Geller, ou=People, o=JNDITutorial
>>cn=Colleen Sullivan, ou=People, o=JNDITutorial
>>cn=Vinnie Ryan, ou=People, o=JNDITutorial
>>cn=Rod Serling, ou=People, o=JNDITutorial
>>cn=Jonathan Wood, ou=People, o=JNDITutorial
>>cn=Aravindan Ranganathan, ou=People, o=JNDITutorial
>>cn=Ian Anderson, ou=People, o=JNDITutorial
>>cn=Lao Tzu, ou=People, o=JNDITutorial
>>cn=Don Knuth, ou=People, o=JNDITutorial
>>cn=Roger Waters, ou=People, o=JNDITutorial
>>cn=Ben Dubin, ou=People, o=JNDITutorial
>>cn=Spuds Mackenzie, ou=People, o=JNDITutorial
>>cn=John Fowler, ou=People, o=JNDITutorial
>>cn=Londo Mollari, ou=People, o=JNDITutorial
>>cn=Ted Geisel, ou=People,o=JNDITutorial
标准 LDAP 控件
原文:
docs.oracle.com/javase/tutorial/jndi/newstuff/controls-std.html
在 LDAP v3 中,控件是通过将其与对服务器或客户端有用的更多信息相关联来增强现有 LDAP 操作的消息。控件可以是请求控件或响应控件。请求控件与 LDAP 请求一起从客户端发送到服务器。响应控件与 LDAP 响应一起从服务器发送到客户端。任何一种都由接口javax.naming.ldap.Control表示。
如果您以前没有使用控件进行编程,请查看JNDI 教程中的控件课程。
在本课程中,我们将讨论添加到 JDK 5.0 的标准 LDAP 控件。必要的 LDAP 控件已经在 JNDI/LDAP 服务提供程序的com.sun.jndi.ldap.ctl包下支持的 LDAP Booster Pack 扩展包中支持。由 IETF 标准化的 LDAP 控件现在通过以下类在 JDK 的javax.naming.ldap包中提供。
-
SortControl( RFC 2891 )
分页结果控件
原文:
docs.oracle.com/javase/tutorial/jndi/newstuff/paged-results.html
BasicControl
javax.naming.ldap.BasicControl 实现了 javax.naming.ldap.Control,作为扩展其他控件的基本实现。
分页结果控件
分页结果控件对于希望以受控方式接收搜索结果的 LDAP 客户端非常有用,受页面大小限制。页面大小可以由客户端根据其资源的可用性(如带宽和处理能力)进行配置。
服务器使用 cookie(类似于 HTTP 会话 cookie 机制)来维护搜索请求的状态,以跟踪发送给客户端的结果。分页结果控件在 RFC 2696 中指定。下面的类提供了支持分页结果控件所需的功能。
如何使用分页结果控件?
下面的示例说明了客户端执行搜索并请求页面大小限制为 5 的客户端-服务器交互。服务器返回的整个结果集包含 21 个条目。
-
客户端发送搜索请求,请求页面大小为 5 的分页结果。
// Activate paged results int pageSize = 5; // 5 entries per page byte[] cookie = null; int total; ctx.setRequestControls(new Control[]{ new PagedResultsControl(pageSize, Control.CRITICAL) }); // Perform the search NamingEnumeration results = ctx.search("", "(objectclass=*)", new SearchControls()); -
服务器响应包含条目以及搜索结果中总共 21 个条目的指示,还有一个不透明的 cookie,客户端在检索后续页面时要使用该 cookie。
// Iterate over a batch of search results sent by the server while (results != null && results.hasMore()) { // Display an entry SearchResult entry = (SearchResult)results.next(); System.out.println(entry.getName()); // Handle the entry's response controls (if any) if (entry instanceof HasControls) { // ((HasControls)entry).getControls(); } } // Examine the paged results control response Control[] controls = ctx.getResponseControls(); if (controls != null) { for (int i = 0; i < controls.length; i++) { if (controls[i] instanceof PagedResultsResponseControl) { PagedResultsResponseControl prrc = (PagedResultsResponseControl)controls[i]; total = prrc.getResultSize(); cookie = prrc.getCookie(); } else { // Handle other response controls (if any) } } } -
客户端发送相同的搜索请求,返回不透明的 cookie,并请求下一页。
// Re-activate paged results ctx.setRequestControls(new Control[]{ new PagedResultsControl(pageSize, cookie, Control.CRITICAL) }); -
服务器响应包含五个条目,并指示还有更多条目。客户端重复执行第 4 步中执行的搜索,直到服务器返回空 cookie,表示服务器不再发送更多条目。
完整的 JNDI 示例可以在 这里 找到。
注意: 分页搜索控件受 Windows Active Directory 服务器支持。Oracle Directory Server 版本 5.2 不支持。
排序控制
当客户端希望服务器发送排序后的搜索结果时,使用排序控制。服务器端排序在客户端需要根据某些标准对结果进行排序但无法自行执行排序过程的情况下非常有用。排序控制在RFC 2891中指定。下面的类提供了支持排序控制所需的功能。
SortKey 是一个基于其排序结果的键的有序列表。
如何使用排序控制?
下面的示例说明了客户端执行搜索请求服务器端基于属性“cn”进行排序的客户端-服务器交互。
-
客户端发送搜索请求请求
// Activate sorting String sortKey = "cn"; ctx.setRequestControls(new Control[] { new SortControl(sortKey, Control.CRITICAL) }); // Perform a search NamingEnumeration results = ctx.search("", "(objectclass=*)", new SearchControls()); -
服务器响应的条目是根据“cn”属性及其对应的匹配规则排序的。
// Iterate over sorted search results while (results != null && results.hasMore()) { // Display an entry SearchResult entry = (SearchResult)results.next(); System.out.println(entry.getName()); // Handle the entry's response controls (if any) if (entry instanceof HasControls) { // ((HasControls)entry).getControls(); } } // Examine the sort control response Control[] controls = ctx.getResponseControls(); if (controls != null) { for (int i = 0; i < controls.length; i++) { if (controls[i] instanceof SortResponseControl) { SortResponseControl src = (SortResponseControl)controls[i]; if (! src.isSorted()) { throw src.getException(); } } else { // Handle other response controls (if any) } } }
完整的 JNDI 示例可以在这里找到。
注意: 排序控制由 Oracle Directory Server 和 Windows Active Directory 服务器都支持。
管理引荐控件
原文:
docs.oracle.com/javase/tutorial/jndi/newstuff/mdsaIT.html
管理引荐控件(RFC 3296)允许在执行 LDAP 操作时将引荐和其他特殊对象操作为普通对象。换句话说,管理引荐控件告诉 LDAP 服务器将引荐条目返回为普通条目,而不是返回"引荐"错误响应或继续引用。 JDK 5.0 中的新类使您可以在 LDAP 请求中发送管理引荐控件:
javax.naming.ldap.ManageReferralControl
JDK 中的 LDAP 服务提供程序将自动发送此控件以及任何请求。您还可以通过将 Context.REFERRAL 环境属性设置为"ignore"来显式启用它。有关引荐处理的更多信息,请查看 JNDI 教程的引荐部分。
这是一个示例,它在 LDAP 请求中发送了管理引荐控件。
// Create initial context
LdapContext ctx = (LdapContext) new InitialDirContext(env);
ctx.setRequestControl(new Control[] new ManageReferralControl());
// Set controls for performing subtree search
SearchControls ctls = new SearchControls();
ctls.setSearchScope(SearchControls.SUBTREE_SCOPE);
// Perform search
NamingEnumeration answer = ctx.search("", "(objectclass=*)", ctls);
// Print the answer
while (answer.hasMore()) {
System.out.println(">>>" +
((SearchResult)answer.next()).getName());
}
// Close the context when we're done
ctx.close();
完整示例可以在这里找到。
注意 1: 以上示例将要求您使用配置文件refserver.ldif设置第二个服务器。服务器必须支持 LDAP v3 和 RFC 3296。如果服务器不支持这种方式的引荐,则示例将无法正常工作。配置文件包含引荐,指向您设置的原始服务器。它假定原始服务器位于本地机器的端口 389 上。如果您在另一台机器或端口上设置了服务器,则需要编辑 refserver.ldif 文件中的"ref"条目,并将"localhost:389"替换为适当的设置。第二个服务器应在本地机器的端口 489 上设置。如果您在另一台机器或端口上设置了第二个服务器,则需要相应地调整初始上下文的 Context.PROVIDER_URL 环境属性的设置。
设置目录服务器通常由目录或系统管理员执行。有关更多信息,请参阅软件设置课程。
注意 2: Windows Active Directory:由于 Active Directory 不支持管理引荐控件,本课程中的所有示例都无法针对 Active Directory 工作。
操作 LdapName(专有名称)
原文:
docs.oracle.com/javase/tutorial/jndi/newstuff/ldapname.html
Distinguished Name(DN)在 LDAP 中以字符串表示形式使用。用于表示 DN 的字符串格式在RFC 2253中指定。DN 由称为相对专有名称(RDN)的组件组成。以下是 DN 的示例:
"CN=John Smith, O=Isode Limited, C=GB"
它由以下 RDN 组成:
-
CN=John Smith
-
O=Isode Limited
-
C=GB
下面的类分别表示 DN 和 RDN。
LdapName 类实现了javax.naming.Name接口,类似于javax.naming.CompoundName和javax.naming.CompositeName类。
LdapName 和 Rdn 类允许轻松操作 DN 和 RDN。使用这些 API,通过将名称和值配对,轻松构造 RDN。可以使用 RDN 列表构造 DN。同样,可以从它们的字符串表示中检索 DN 和 RDN 的各个组件。
LdapName
可以使用其在RFC 2253中定义的字符串表示形式或使用 Rdns 列表创建 LdapName。当使用前一种方式时,指定的字符串将根据 RFC2253 中定义的规则进行解析。如果字符串不是有效的 DN,则会抛出InvalidNameException。以下是使用构造函数解析 LDAP 名称并打印其组件的示例。
String name = "cn=Mango,ou=Fruits,o=Food";
try {
LdapName dn = new LdapName(name);
System.out.println(dn + " has " + dn.size() + " RDNs: ");
for (int i = 0; i < dn.size(); i++) {
System.out.println(dn.get(i));
}
} catch (InvalidNameException e) {
System.out.println("Cannot parse name: " + name);
}
使用输入"cn=Mango,ou=Fruits,o=Food"运行此示例会产生以下结果:
cn=Mango,ou=Fruits,o=Food has 3 RDNs:
o=Food
ou=Fruits
cn=Mango
LdapName 类包含方法,用于将其组件作为 RDN 和字符串访问,修改 LdapName,比较两个 LdapName 是否相等,并获取名称的字符串表示形式。
访问 LDAP 名称的名称组件:
以下是您可以使用的方法来访问名称组件作为 RDN 和字符串:
要检索 LdapName 中特定位置的组件,您可以使用 getRdn()或 get()。前面的构造函数示例展示了其用法的示例。getRdns()返回所有 RDN 的列表,getAll()将 LdapName 的所有组件作为枚举返回。
最右边的 RDN 位于索引 0,最左边的 RDN 位于索引 n-1。例如,专有名称:"cn=Mango, ou=Fruits, o=Food"按以下顺序编号,范围从 0 到 2:{o=Food, ou=Fruits, cn=Mango}
您还可以将 LdapName 的后缀或前缀作为 LdapName 实例获取。这里有一个示例,展示了如何获取 LDAP 名称的后缀和前缀。
LdapName dn = new LdapName("cn=Mango, ou=Fruits, o=Food");
Name suffix = dn.getSuffix(1); // 1 <= index < cn.size()
Name prefix = dn.getPrefix(1); // 0 <= index < 1
运行此程序时,它会生成以下输出:
cn=Mango ou=Fruits
o=Food
要复制 LdapName,您可以使用 clone()。
修改 LDAP 名称
以下是您可以使用的方法来修改 LDAP 名称:
addAll(int posn, List suffixRdns)
创建 LdapName 实例后,您可以向其添加和删除组件。这里有一个示例,演示了如何将一个 LdapName 附加到现有 LdapName 中,在开头和结尾添加组件,以及删除第二个组件。
LdapName dn = new LdapName("ou=Fruits,o=Food");
LdapName dn2 = new LdapName("ou=Summer");
System.out.println(dn.addAll(dn2)); // ou=Summer,ou=Fruits,o=Food
System.out.println(dn.add(0, "o=Resources"));
// ou=Summer,ou=Fruits,o=Food,o=Resources
System.out.println(dn.add("cn=WaterMelon"));
// cn=WaterMelon,ou=Summer,ou=Fruits,o=Food,o=Resources
System.out.println(dn.remove(1)); // o=Food
System.out.println(dn);
// cn=WaterMelon,ou=Summer,ou=Fruits,o=Resources
比较 LDAP 名称
以下是您可以使用的方法来比较两个 LDAP 名称:
您可以使用compareTo()对 LdapName 实例列表进行排序。equals()方法可让您确定两个 LdapNames 是否在语法上相等。如果两个 LdapNames 在相同顺序中具有相同(大小写匹配)的组件,则它们是相等的。
使用startsWith()和endsWith(),您可以了解一个 LdapName 是否以另一个 LdapName 开头或结尾;也就是说,一个 LdapName 是否是另一个 LdapName 的后缀或前缀。
便利方法isEmpty()使您能够确定 LdapName 是否具有零个组件。您还可以使用表达式size() == 0执行相同的检查。
这里有一个示例,CompareLdapNames,使用了其中一些比较方法。
LdapName one = new LdapName("cn=Vincent Ryan, ou=People, o=JNDITutorial");
LdapName two = new LdapName("cn=Vincent Ryan");
LdapName three = new LdapName("o=JNDITutorial");
LdapName four = new LdapName("");
System.out.println(one.equals(two)); // false
System.out.println(one.startsWith(three)); // true
System.out.println(one.endsWith(two)); // true
System.out.println(one.startsWith(four)); // true
System.out.println(one.endsWith(four)); // true
System.out.println(one.endsWith(three)); // false
System.out.println(one.isEmpty()); // false
System.out.println(four.isEmpty()); // true
System.out.println(four.size() == 0); // true
获取字符串表示
下面的方法可以让您获取根据 RFC 2253 中指定的语法格式化的 LDAP 名称的字符串表示:
当您使用 LdapName 构造函数时,您提供 LDAP 名称的字符串表示,并获得一个 LdapName 实例。要执行相反操作,即获取 LdapName 实例的字符串表示,您可以使用toString()。toString()的结果可以再次传递给构造函数,以生成与原始 LdapName 实例相等的 LdapName 实例。这里有一个示例,LdapNametoString:
LdapName dn = new LdapName(name);
String str = dn.toString();
System.out.println(str);
LdapName dn2 = new LdapName(str);
System.out.println(dn.equals(dn2)); // true
作为上下文方法的参数的 LdapName
Context 方法要求将复合名称或复合名称作为参数传递给其方法。因此,可以直接将 LdapName 传递给上下文方法,如示例中所示,LookupLdapName:
// Create the initial context
Context ctx = new InitialContext(env);
// An LDAP name
LdapName dn = new LdapName("ou=People,o=JNDITutorial");
// Perform the lookup using the dn
Object obj = ctx.lookup(dn);
类似地,当上下文方法从 list()、listBindings() 或 search() 操作返回结果时,可以通过调用getNameInNamespace()检索 DN。可以直接从 DN 构造 LdapName,如示例中所示,RetrievingLdapName:
while (answer.hasMore()) {
SearchResult sr = (SearchResult) answer.next();
String name = sr.getNameInNamespace();
System.out.println(name);
LdapName dn = new LdapName(name);
// do something with the dn
操作相对独立名称(RDN)
类javax.naming.ldap.Rdn表示根据RFC 2253指定的相对独立名称(RDN)。RDN 表示 DN 的组件,如操作 LdapName 课程中所解释的那样。RDN 由类型和值对组成。RDN 的示例包括:
-
OU=Sun -
OU=Sales+CN=J.Smith。上面的示例显示了多值 RDN 的表示。
Rdn类提供了访问 RDN 的名称/值对、获取其字符串表示、检索Attributes视图、比较和确定 RDN 的相等性以及转义和取消转义 RDN 值部分的方法。
Rdn类是不可变的。
构造 Rdn
如果是单个名称/值对的 RDN,可以使用指定的名称和值对构造 Rdn。对于多值 RDN,应创建包含所有名称/值对的属性集,并使用以Attributes为参数的构造函数。还可以根据RFC 2253中指定的字符串表示创建 Rdn。最后,可以使用其复制构造函数克隆 Rdn。这里是一个使用不同类型构造函数创建 RDN 的示例。
Rdn rdn1 = new Rdn("ou= Juicy\\, Fruit");
System.out.println("rdn1:" + rdn1.toString());
Rdn rdn2 = new Rdn(rdn1);
System.out.println("rdn2:" + rdn2.toString());
Attributes attrs = new BasicAttributes();
attrs.put("ou", "Juicy, Fruit");
attrs.put("cn", "Mango");
Rdn rdn3 = new Rdn(attrs);
System.out.println("rdn3:" + rdn3.toString());
Rdn rdn4 = new Rdn("ou", "Juicy, Fruit");
System.out.println("rdn4:" + rdn4.toString());
访问 RDN 的类型/值对
可以使用以下方法获取 RDN 的类型/值:
对于由单个类型/值对组成的 RDN,getType()方法返回类型,getValue()方法返回 RDN 的值。方法toAttributes()返回类型/值对的属性视图。下面的示例打印了 RDN 的类型/值对。
Attributes attrs = new BasicAttributes();
attrs.put("o", "Yellow");
attrs.put("cn", "Mango");
// create a binary value for the RDN
byte[] mangoJuice = new byte[6];
for (int i = 0; i < mangoJuice.length; i++) {
mangoJuice[i] = (byte) i;
}
attrs.put("ou", mangoJuice);
Rdn rdn = new Rdn(attrs);
System.out.println();
System.out.println("size:" + rdn.size());
System.out.println("getType(): " + rdn.getType());
System.out.println("getValue(): " + rdn.getValue());
// test toAttributes
System.out.println();
System.out.println("toAttributes(): " + rdn.toAttributes());
获取字符串表示
为了按照RFC 2253中指定的语法格式化 RDN 的字符串表示,可以使用:
当您使用接受String参数的 Rdn 构造函数时,您提供了 RDN 的字符串表示,并获得了一个 Rdn 实例。要做相反的操作,即获取 Rdn 实例的字符串表示,您可以使用 toString()。toString()的结果可以馈送回 Rdn 构造函数,以产生与原始 Rdn 实例相等的 Rdn 实例。
这里有一个示例:
Rdn rdn = new Rdn("cn=Juicy\\,Fruit");
String str = rdn.toString();
System.out.println(str);
Rdn rdn2 = new Rdn(str);
System.out.println(rdn.equals(rdn2)); // true
比较 RDNs
下面的方法使 RDN 的比较成为可能:
您可以使用 compareTo()对 Rdn 实例列表进行排序。equals()让您确定两个 Rdns 在语法上是否相等。如果两个 Rdns 都具有相同(大小写匹配)的类型/值对,则它们是相等的。多值 RDN 中组件的顺序不重要。
这里有一个示例:
Rdn one = new Rdn("ou=Sales+cn=Bob");
Rdn two = new Rdn("cn=Bob+ou=Sales");
Rdn three = new Rdn("ou=Sales+cn=Bob+c=US");
Rdn four = new Rdn("cn=lowercase");
Rdn five = new Rdn("cn=LowerCASE");
System.out.println(one.equals(two)); // true
System.out.println(two.equals(three)); // false
System.out.println(one.equals(three)); // false
System.out.println(four.equals(five)); // true
转义和反转义特殊字符
Rdn 类的最佳用途之一是处理包含特殊字符的 DN。它会自动处理特殊字符的转义和反转义。像 ''(反斜杠)、','(逗号)、+(加号)等字符在RFC 2253中有特定的语义。您可以在 RFC2253 中找到所有特殊字符的列表。当这些字符作为 DN 中的文字时,必须用 ''(反斜杠)进行转义。
例如,考虑一个 RDN:cn=Juicy, Fruit,出现在 Juicy 和 Fruit 之间的逗号,是一个需要用 ''(反斜杠)转义的特殊字符。经过语法格式化后的 RDN 如下所示:cn=Juicy\, Fruit 然而, ''(反斜杠)字符本身是 Java 语言字符串语法中的一个特殊字符,需要再次用 ''(反斜杠)转义。Java 语言字符串格式和RFC 2253都使用 ''(反斜杠)来转义特殊字符。因此,Java 格式化的 RDN 字符串如下所示:cn=Juicy\\, Fruit 请注意,上述提到的格式化规则仅适用于 Rdn 的值组件。Rdn类提供了两个static方法来处理 RDN 值的自动转义和反转义:
下面的示例显示了如何获取 DN 的字符串表示,而无需处理RFC 2253中定义的处理特殊字符的语法。
// DN with ',' (comma)
String unformatted = "Juicy, Fruit";
String formatted = Rdn.escapeValue(unformatted);
LdapName dn = new LdapName("cn=" + formatted);
System.out.println("dn:" + dn);
unformatted = "true+false";
formatted = Rdn.escapeValue(unformatted);
dn = new LdapName("cn=" + formatted);
System.out.println("dn:" + dn);
// DN with a binary value as one of its attribute values
byte[] bytes = new byte[] {1, 2, 3, 4};
formatted = Rdn.escapeValue(bytes);
System.out.println("Orig val: " + bytes + "Escaped val: " + formatted);
同样地,使用静态的unescapeValue()方法,可以从格式化值中获取原始字符串。这里是一个检索原始值的示例。
// DN with ',' (comma)
String unformatted = "Juicy, Fruit";
String formatted = Rdn.escapeValue(unformatted);
System.out.println("Formatted:" + formatted);
Object original = Rdn.unescapeValue(formatted);
System.out.println("Original:" + original);
// DN with a '+' (plus)
unformatted = "true+false";
formatted = Rdn.escapeValue(unformatted);
System.out.println("Formatted:" + formatted);
original = Rdn.unescapeValue(formatted);
System.out.println("Original:" + original);
// DN with a binary value as one of its attribute values
byte[] bytes = new byte[] {1, 2, 3, 4};
formatted = Rdn.escapeValue(bytes);
System.out.println("Formatted:" + formatted);
original = Rdn.unescapeValue(formatted);
System.out.println("Original:" + original);
设置 LDAP 操作的超时时间
原文:
docs.oracle.com/javase/tutorial/jndi/newstuff/readtimeout.html
当客户端向服务器发出 LDAP 请求并且服务器由于某种原因未响应时,客户端将永远等待服务器响应,直到 TCP 超时。在客户端端,用户体验实际上是一个进程挂起。为了及时控制 LDAP 请求,自 Java SE 6 以来可以为 JNDI/LDAP 服务提供程序配置读取超时。
新的环境属性:
com.sun.jndi.ldap.read.timeout
可用于指定 LDAP 操作的读取超时时间。该属性的值是表示 LDAP 操作的读取超时时间(以毫秒为单位)的整数的字符串表示。如果 LDAP 提供程序在指定的时间内未收到 LDAP 响应,则会中止读取尝试。整数应大于零。小于或等于零的整数表示未指定读取超时,相当于无限等待响应直到接收到响应,这是默认行为。
如果未指定此属性,默认情况下将等待响应直到接收到响应。
例如,env.put("com.sun.jndi.ldap.read.timeout", "5000"); 会导致 LDAP 服务提供程序在服务器在 5 秒内未响应时中止读取尝试。
这里有一个示例,ReadTimeoutTest,使用一个不响应 LDAP 请求的虚拟服务器,展示了当将此属性设置为非零值时的行为。
env.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.ldap.LdapCtxFactory");
env.put("com.sun.jndi.ldap.read.timeout", "1000");
env.put(Context.PROVIDER_URL, "ldap://localhost:2001");
Server s = new Server();
try {
// start the server
s.start();
// Create initial context
DirContext ctx = new InitialDirContext(env);
System.out.println("LDAP Client: Connected to the Server");
:
:
} catch (NamingException e) {
e.printStackTrace();
}
由于服务器甚至未响应 LDAP 绑定请求,当创建 InitialDirContext 时,上述程序打印下面的堆栈跟踪。客户端在等待服务器响应时超时。
Server: Connection accepted
javax.naming.NamingException: LDAP response read timed out, timeout used:1000ms.
:
:
at javax.naming.directory.InitialDirContext.<init>(InitialDirContext.java:82)
at ReadTimeoutTest.main(ReadTimeoutTest.java:32)
请注意,此属性与另一个环境属性 com.sun.jndi.ldap.connect.timeout 不同,后者设置连接到服务器的超时时间。读取超时适用于与服务器建立初始连接后从服务器接收的 LDAP 响应。
Trail: Sockets Direct Protocol
Sockets Direct Protocol(SDP)提供了对高性能网络连接的访问,例如 InfiniBand 提供的连接。本教程展示了如何启用 SDP,涉及哪些 Java API,并解释了它的工作原理。
课程:理解套接字直接协议
对于高性能计算环境,快速高效地在网络中传输数据是必需的。这样的网络通常被描述为需要高吞吐量和低延迟。高吞吐量指的是在长时间内可以提供大量处理能力的环境。低延迟指的是处理输入并提供输出之间的最小延迟,就像您在实时应用程序中所期望的那样。
在这些环境中,使用套接字流进行传输数据可能会导致瓶颈。InfiniBand(IB)由InfiniBand 贸易协会于 1999 年推出,旨在满足高性能计算的需求。IB 的最重要特性之一是远程直接内存访问(RDMA)。RDMA 使得可以直接从一台计算机的内存移动数据到另一台计算机,绕过两台计算机的操作系统,从而实现显著的性能提升。
套接字直接协议(SDP)是一种网络协议,旨在支持在 InfiniBand 结构上的流连接。SDP 支持是在 Java 平台标准版("Java SE 平台")的 JDK 7 版本中引入的,用于在 Solaris 操作系统("Solaris OS")和 Linux 操作系统上部署的应用程序。Solaris OS 自 Solaris 10 5/08 版本以来一直支持 SDP 和 InfiniBand。在 Linux 上,InfiniBand 软件包称为 OFED(OpenFabrics 企业发行版)。JDK 7 版本支持 OFED 的 1.4.2 和 1.5 版本。
概述
原文:
docs.oracle.com/javase/tutorial/sdp/sockets/overview.html
SDP 支持本质上是一种 TCP 绕过技术。
当启用 SDP 并且应用程序尝试打开 TCP 连接时,TCP 机制将被绕过,通信直接传输到 IB 网络。例如,当您的应用程序尝试绑定到 TCP 地址时,基础软件将根据配置文件中的信息决定是否应重新绑定到 SDP 协议。此过程可以在绑定过程或连接过程中发生(但每个套接字仅发生一次)。
在您的代码中利用 SDP 协议无需进行 API 更改:实现是透明的,并受经典网络(java.net)和新 I/O(java.nio.channels)包的支持。查看支持的 Java API 部分,了解支持 SDP 协议的类列表。
SDP 支持默认情况下是禁用的。启用 SDP 支持的步骤如下:
-
创建一个 SDP 配置文件。
-
设置指定配置文件位置的系统属性。
创建一个 SDP 配置文件
一个 SDP 配置文件是一个文本文件,您可以决定这个文件将存放在文件系统的哪个位置。配置文件中的每一行都是一个注释或一个规则。注释以井号字符(#)开头,井号字符后的所有内容将被忽略。
有两种类型的规则,如下:
-
"bind"规则表示当 TCP 套接字绑定到与规则匹配的地址和端口时,应使用 SDP 协议传输。
-
"connect"规则表示当未绑定的 TCP 套接字尝试连接到与规则匹配的地址和端口时,应使用 SDP 协议传输。
一个规则的形式如下:
("bind"|"connect")1*LWSP-char(hostname|ipaddress)["/"prefix])1*LWSP-char("*"|port)["-"("*"|port)]
解码符号:
1LWSP-char表示任意数量的线性空白字符(制表符或空格)可以分隔标记。方括号表示可选文本。符号(xxx* | yyy)表示标记将包括xxx或yyy中的一个,但不会同时包括两者。引号中的字符表示文字。
第一个关键字指示规则是bind还是connect规则。下一个标记指定主机名或文字 IP 地址。当指定文字 IP 地址时,您还可以指定前缀,表示 IP 地址范围。第三个也是最后一个标记是端口号或端口号范围。
在这个示例配置文件中考虑以下符号:
# Use SDP when binding to 192.0.2.1
bind 192.0.2.1 *
# Use SDP when connecting to all application services on 192.0.2.*
connect 192.0.2.0/24 1024-*
# Use SDP when connecting to the http server or a database on examplecluster
connect examplecluster.example.com 80
connect examplecluster.example.com 3306
示例文件中的第一条规则指定 SDP 用于本地 IP 地址192.0.2.1上的任何端口()。对于每个分配给 InfiniBand 适配器的本地地址,您将添加一个绑定规则。(InfiniBand 适配器*相当于 InfiniBand 的网络接口卡(NIC)。)如果您有多个 IB 适配器,您将为分配给这些适配器的每个地址使用一个绑定规则。
示例文件中的第二条规则指定每当连接到192.0.2.*并且目标端口大于或等于 1024 时,将使用 SDP。IP 地址前缀/24表示 32 位 IP 地址的前 24 位应与指定地址匹配。IP 地址的每个部分使用 8 位,因此 24 位表示 IP 地址应匹配192.0.2,最后一个字节可以是任何值。端口标记上的-*符号指定“及以上”。端口范围,例如 1024—2056,也是有效的,并且将包括指定范围的端点。
示例文件中的最后规则指定一个主机名(examplecluster),首先分配给 http 服务器的端口(80),然后分配给数据库的端口(3306)。与文字 IP 地址不同,主机名可以转换为多个地址。当指定主机名时,它匹配主机名在名称服务中注册的所有地址。
启用 SDP 协议
SDP 支持默认情况下是禁用的。要启用 SDP 支持,请设置com.sun.sdp.conf系统属性,提供配置文件的位置。以下示例启动一个使用名为sdp.conf的配置文件的应用程序:
% java -Dcom.sun.sdp.conf=sdp.conf -Djava.net.preferIPv4Stack=true *ExampleApplication*
ExampleApplication指的是试图连接到 IB 适配器的客户端应用程序。
请注意,此示例指定另一个系统属性java.net.preferIPv4Stack。有关为什么使用此属性的更多信息,请参见 Issues 部分。
调试 SDP
你可以通过使用-Dcom.sun.sdp.debug标志来启用调试消息。如果你指定一个文件,消息将被输出到该文件。否则,消息将被打印到标准输出。
这个第一个示例展示了打印到标准输出的示例消息:
% java -Dcom.sun.sdp.conf=sdp.conf -Dcom.sun.sdp.debug *ExampleApplicaton*
BIND to 192.0.2.1:5000 (socket converted to SDP protocol)
CONNECT to 129.156.232.160:80 (no match)
CONNECT to 192.0.2.2:80 (socket converted to SDP protocol)
这个第二个示例展示了输出重定向到名为debug.log的文件:
% java -Dcom.sun.sdp.conf=sdp.conf -Dcom.sun.sdp.debug=debug.log *ExampleApplication*
[1] 27310
% tail -f debug.log
BIND to 192.0.2.1:5000 (socket converted to SDP protocol)
SDP 的技术问题
-
IPv4 和 IPv6 不兼容
互联网协议第 4 版(IPv4)长期以来一直是 Internet 协议(IP)的行业标准版本,用于在 Internet 上传输数据。互联网协议第 6 版(IPv6)是下一代 Internet 层协议。今天仍在使用这两个版本的 IP。
IPv4 地址是 32 位长,以十进制格式编写,并用句点分隔。IPv6 地址是 128 位长,以十六进制格式编写,并用冒号分隔。IPv4 地址不能直接在 IPv6 中使用,但 IPv6 支持一种特殊类别的地址:IPv4 映射地址。在 IPv4 映射地址中,前 80 位设置为零,接下来的 16 位设置为 1,最后 32 位表示 IPv4 地址。
例如,这里是相同的 IP 地址以两种格式表示:
IPv4 address IPv4-mapped address (for use in IPv6) 192.0.2.1 ::ffff:192.0.2.1默认情况下,如果 IB 适配器中启用了 IPv6,则 Java 平台将使用 IPv6。然而,在 Solaris 操作系统或 Linux 下目前不支持 IPv4 映射地址。因此,如果您想在 JDK 7 下使用 IPv4 地址格式,必须指定
java.net.preferIPv4Stack属性,如下例所示:% java -Dcom.sun.sdp.conf=sdp.conf -Djava.net.preferIPv4Stack=true *MyApplication* -
错误
在早期 InfiniBand 实现中发现了一些错误。这些错误在 Solaris 10 10/09 版本中已修复。请确保您至少使用此版本。
Solaris 和 Linux 支持
Solaris 10
要测试 SDP 是否已启用,请使用sdpadm(1M)命令:
% /usr/sbin/sdpadm status
SDP is Enabled
你可以使用 grep 命令在/etc/path_to_inst文件中搜索字符串"ibd",以查看网络上支持的 IB 适配器列表。
其他你可能会发现有用的命令包括ib(7D)、ibd(7D)和sdp(7D)。
Solaris 11
你可以使用以下命令获取 InfiniBand 分区链接信息:
% dladm show-port -o LINK
其他你可能会发现有用的命令包括ib(7D)、ibd(7D)和sdp(7D)。
Linux
你可以使用以下命令获取 InfiniBand 适配器的列表:
% egrep "^[ \t]+ib" /proc/net/dev
支持的 Java API
原文:
docs.oracle.com/javase/tutorial/sdp/sockets/supported.html
所有使用 TCP 的 API 都可以使用 SDP,特别包括以下类:
-
java.net包-
Socket -
ServerSocket
-
-
java.nio.channels包:-
SocketChannel -
ServerSocketChannel -
AsynchronousSocketChannel -
AsynchronousServerSocketChannel
-
当启用 SDP 支持时,它会在不需要对您的代码进行任何更改的情况下正常工作。不需要编译。然而,重要的是要知道套接字只绑定一次。连接是隐式绑定。因此,如果套接字之前没有绑定并且调用了 connect,则绑定将在那个时候发生。
例如,考虑以下代码片段:
AsynchronousSocketChannel ch = AsynchronousSocketChannel.open();
ch.bind(local);
Future<Void> result = ch.connect(remote);
在此代码片段中,当在套接字上调用 bind 时,异步套接字通道将绑定到本地 TCP 地址。然后,代码尝试使用相同的套接字连接到远程地址。如果远程地址使用配置文件中指定的 InfiniBand,则连接不会转换为 SDP,因为套接字先前已绑定。
更多信息请参考
-
Alan Bateman 的博客:套接字直接协议
-
Nitin Hande 的博客:在 OpenSolaris 上使用 IPoIB
-
Anish Gupta 的博客关于InfiniBand 支持
教程:Java Architecture for XML Binding
Java Architecture for XML Binding (JAXB) 教程介绍了 Java Architecture for XML Binding (JAXB) 技术,通过 JAXB 应用示例。
在阅读本教程之前
要理解并使用 Java Architecture for XML Binding (JAXB) 教程中的信息,您应该具备以下技术知识:
-
Java 编程语言及其开发环境
-
可扩展标记语言(XML)
本教程详细讨论了仅与 JAXB 相关的代码。
简要描述了 JAXB 技术,包括其目的和主要特点。
课程:JAXB 简介
Java Architecture for XML Binding (JAXB)提供了一种快速便捷的方式来绑定 XML 模式和 Java 表示,使 Java 开发人员能够轻松地在 Java 应用程序中整合 XML 数据和处理功能。作为这个过程的一部分,JAXB 提供了将 XML 实例文档解组(读取)为 Java 内容树的方法,然后将 Java 内容树重新组合(写入)为 XML 实例文档的方法。JAXB 还提供了一种从 Java 对象生成 XML 模式的方法。
JAXB 2.0 对 JAXB 1.0 进行了几项重要改进:
-
支持所有 W3C XML Schema 功能。(JAXB 1.0 没有为一些 W3C XML Schema 功能指定绑定。)
-
支持将 Java 绑定到 XML,通过添加
javax.xml.bind.annotation包来控制此绑定。(JAXB 1.0 规定了 XML Schema 到 Java 的映射,但没有规定 Java 到 XML Schema 的映射。) -
生成的基于模式的类数量显著减少。
-
通过 JAXP 1.3 验证 API 提供的额外验证功能。
-
更小的运行时库。
本课程描述了 JAXB 架构、功能和核心概念,并提供了使用 JAXB 的逐步示例过程。
JAXB 架构
本节描述了 JAXB 处理模型中的组件和交互。
架构概述
以下图显示了构成 JAXB 实现的组件。
图:JAXB 架构概述
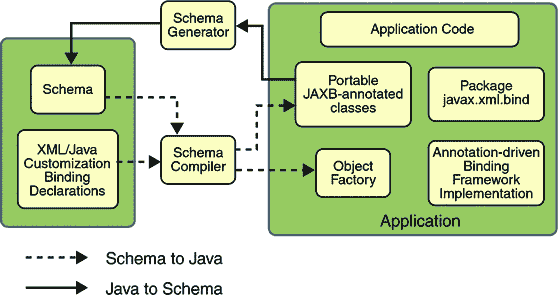
JAXB 实现由以下架构组件组成:
-
模式编译器:将源模式绑定到一组基于模式的程序元素。绑定由基于 XML 的绑定语言描述。
-
模式生成器:将一组现有程序元素映射到一个派生模式。映射由程序注解描述。
-
绑定运行时框架:提供了用于访问、操作和验证 XML 内容的解组(读取)和组装(写入)操作,使用基于模式的或现有程序元素。
JAXB 绑定过程
以下图显示了 JAXB 绑定过程中发生的情况。
图:JAXB 绑定过程中的步骤
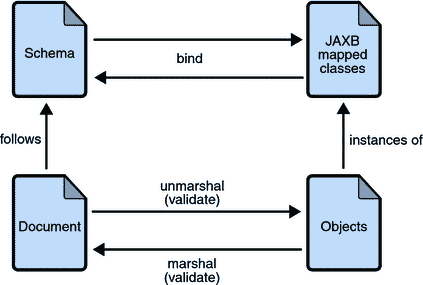
JAXB 数据绑定过程中的一般步骤如下:
-
生成类:将 XML 模式用作 JAXB 绑定编译器的输入,以根据该模式生成基于 JAXB 的类。
-
编译类:所有生成的类、源文件和应用程序代码都必须被编译。
-
Unmarshal:根据源模式中的约束编写的 XML 文档由 JAXB 绑定框架解组。请注意,JAXB 还支持从文件和文档以外的源解组 XML 数据,如 DOM 节点、字符串缓冲区、SAX 源等。
-
生成内容树:解组过程生成从生成的 JAXB 类实例化的数据对象内容树;此内容树表示源 XML 文档的结构和内容。
-
验证(可选):解组过程涉及在生成内容树之前验证源 XML 文档。请注意,如果您在第 6 步中修改内容树,您还可以使用 JAXB 验证操作在将内容组装回 XML 文档之前验证更改。
-
处理内容:客户端应用程序可以通过使用绑定编译器生成的接口修改 Java 内容树表示的 XML 数据。
-
Marshal:处理后的内容树被组装成一个或多个 XML 输出文档。在组装之前可能会进行验证。
更多关于 Unmarshalling
Unmarshalling 提供了客户端应用程序将 XML 数据转换为基于 JAXB 的 Java 对象的能力。
更多关于 Marshalling
Marshalling 提供了客户端应用程序将基于 JAXB 的 Java 对象树转换为 XML 数据的能力。
默认情况下,Marshaller在生成 XML 数据时使用 UTF-8 编码。
在组合之前,客户端应用程序不需要验证 Java 内容树。也没有要求 Java 内容树在组合成 XML 数据时必须符合其原始模式。
更多关于验证
验证是验证 XML 文档是否符合模式中表达的所有约束的过程。JAXB 1.0 在解组时提供了验证,并且还可以在 JAXB 内容树上按需进行验证。JAXB 2.0 只允许在解组和组合时进行验证。Web 服务处理模型是在读取数据时宽松,在写出数据时严格。为了符合该模型,在组合时添加了验证,以便用户可以确认在修改 JAXB 表单中的文档时未使 XML 文档无效。
表示 XML 内容
本节描述了 JAXB 如何将 XML 内容表示为 Java 对象。
XML 模式的 Java 表示
JAXB 支持将生成的类分组到 Java 包中。一个包包括以下内容:
-
从 XML 元素名称派生的 Java 类名称,或者由绑定自定义指定。
-
一个
ObjectFactory类,这是一个工厂,用于返回绑定的 Java 类的实例。
绑定 XML 模式
本节描述了 JAXB 使用的默认 XML 到 Java 绑定。所有这些绑定都可以通过使用自定义绑定声明全局或逐案例地进行覆盖。有关默认 JAXB 绑定的完整信息,请参阅JAXB 规范。
简单类型定义
使用简单类型定义的模式组件通常绑定到 Java 属性。由于有不同类型的模式组件,以下 Java 属性属性(对于模式组件通用)包括:
-
基本类型
-
集合类型,如果有的话
-
谓词
其余的 Java 属性属性在使用simple类型定义的模式组件中指定。
默认数据类型绑定
以下部分解释了默认模式到 Java、JAXBElement和 Java 到模式数据类型绑定。
模式到 Java 的映射
Java 语言提供了比 XML 模式更丰富的数据类型。以下表格提供了 JAXB 中 XML 数据类型到 Java 数据类型的映射。
表:XML 模式内置数据类型的 JAXB 映射
| XML 模式类型 | Java 数据类型 |
|---|---|
xsd:string |
java.lang.String |
xsd:integer |
java.math.BigInteger |
xsd:int |
int |
xsd.long |
long |
xsd:short |
short |
xsd:decimal |
java.math.BigDecimal |
xsd:float |
float |
xsd:double |
double |
xsd:boolean |
boolean |
xsd:byte |
byte |
xsd:QName |
javax.xml.namespace.QName |
xsd:dateTime |
javax.xml.datatype.XMLGregorianCalendar |
xsd:base64Binary |
byte[] |
xsd:hexBinary |
byte[] |
xsd:unsignedInt |
long |
xsd:unsignedShort |
int |
xsd:unsignedByte |
short |
xsd:time |
javax.xml.datatype.XMLGregorianCalendar |
xsd:date |
javax.xml.datatype.XMLGregorianCalendar |
xsd:g |
javax.xml.datatype.XMLGregorianCalendar |
xsd:anySimpleType |
java.lang.Object |
xsd:anySimpleType |
java.lang.String |
xsd:duration |
javax.xml.datatype.Duration |
xsd:NOTATION |
javax.xml.namespace.QName |
JAXBElement 对象
当无法通过 XML 内容的派生 Java 表示来推断 XML 元素信息时,会提供一个JAXBElement对象。该对象具有获取和设置对象名称和对象值的方法。
Java 到模式的映射
以下表格显示了 Java 类到 XML 数据类型的默认映射。
表:XML 数据类型到 Java 类的 JAXB 映射
| Java 类 | XML 数据类型 |
|---|---|
java.lang.String |
xs:string |
java.math.BigInteger |
xs:integer |
java.math.BigDecimal |
xs:decimal |
java.util.Calendar |
xs:dateTime |
java.util.Date |
xs:dateTime |
javax.xml.namespace.QName |
xs:QName |
java.net.URI |
xs:string |
javax.xml.datatype.XMLGregorianCalendar |
xs:anySimpleType |
javax.xml.datatype.Duration |
xs:duration |
java.lang.Object |
xs:anyType |
java.awt.Image |
xs:base64Binary |
javax.activation.DataHandler |
xs:base64Binary |
javax.xml.transform.Source |
xs:base64Binary |
java.util.UUID |
xs:string |
自定义生成的类和 Java 程序元素
原文:
docs.oracle.com/javase/tutorial/jaxb/intro/customize.html
以下部分描述了如何自定义生成的 JAXB 类和 Java 程序元素。
模式到 Java
自定义 JAXB 绑定声明使您能够在 XML 模式中包含 Java 特定的细化,例如类和包名称映射,以定制生成的 JAXB 类。
JAXB 提供了两种自定义 XML 模式的方法:
-
作为源 XML 模式中的内联注释
-
作为传递给 JAXB 绑定编译器的外部绑定自定义文件中的声明
提供了显示如何自定义 JAXB 绑定的代码示例,稍后在本文档中提供。
Java 到模式
在 javax.xml.bind.annotation 包中定义的 JAXB 注释可用于自定义 Java 程序元素到 XML 模式的映射。以下表总结了可以与 Java 包一起使用的 JAXB 注释。
表:与 Java 包相关的 JAXB 注释
| 注释 | 描述和默认设置 |
|---|
| @XmlSchema | 将包映射到 XML 目标命名空间。默认设置:
@XmlSchema (
xmlns = {},
namespace = "",
elementFormDefault = XmlNsForm.UNSET,
attributeFormDefault = XmlNsForm.UNSET
)
|
| @XmlAccessorType | 控制字段和属性的默认序列化。默认设置:
@XmlAccessorType (
value = AccessType.PUBLIC_MEMBER
)
|
| @XmlAccessorOrder | 控制映射到 XML 元素的属性和字段的默认排序。默认设置:
@XmlAccessorOrder (
value = AccessorOrder.UNDEFINED
)
|
| @XmlSchemaType | 允许自定义映射到 XML 模式内置类型。默认设置:
@XmlSchemaType (
namespace =
"http://www.w3.org/2001/XMLSchema",
type = DEFAULT.class
)
|
@XmlSchemaTypes |
用于定义多个 @XmlSchemaType 注释的容器注释。默认设置:无 |
|---|
以下表总结了可以与 Java 类一起使用的 JAXB 注释。
表:与 Java 类相关的 JAXB 注释
| 注释 | 描述和默认设置 |
|---|
| @XmlType | 将 Java 类映射到模式类型。默认设置:
@XmlType (
name = "##default",
propOrder = {""},
namespace = "##default",
factoryClass = DEFAULT.class,
factoryMethod = ""
)
|
| @XmlRootElement | 将全局元素与类映射到的模式类型关联。默认设置:
@XmlRootElement (
name = "##default",
namespace = "##default"
)
|
以下表总结了可以与 Java enum 类型一起使用的 JAXB 注释。
表:与 Java enum 类型相关的 JAXB 注释
| 注释 | 描述和默认设置 |
|---|
| @XmlEnum | 将 Java 类型映射到 XML 简单类型。默认设置:
@XmlEnum ( value = String.class )
|
@XmlEnumValue |
将 Java 类型映射到 XML 简单类型。默认设置:无 |
|---|
| @XmlType | 将 Java 类映射到模式类型。默认设置:
@XmlType (
name = "##default",
propOrder = {""},
namespace = "##default",
factoryClass = DEFAULT.class,
factoryMethod = ""
)
|
| @XmlRootElement | 将全局元素与类映射到的模式类型关联。默认设置:
@XmlRootElement (
name = "##default",
namespace = "##default"
)
|
以下表总结了可以与 Java 属性和字段一起使用的 JAXB 注释。
表:与 Java 属性和字段相关的 JAXB 注释
| 注释 | 描述和默认设置 |
|---|
| @XmlElement | 将 JavaBeans 属性或字段映射到从属性或字段名称派生的 XML 元素。默认设置:
@XmlElement (
name = "##default",
nillable = false,
namespace = "##default",
type = DEFAULT.class,
defaultValue = "\u0000"
)
|
@XmlElements |
用于定义多个 @XmlElement 注解的容器注解。默认设置:无 |
|---|
| @XmlElementRef | 将 JavaBeans 属性或字段映射到从属性或字段类型派生的 XML 元素。默认设置:
@XmlElementRef (
name = "##default",
namespace = "##default",
type = DEFAULT.class
)
|
@XmlElementRefs |
用于定义多个 @XmlElementRef 注解的容器注解。默认设置:无 |
|---|
| @XmlElementWrapper | 在 XML 表示周围生成一个包装器元素。通常用作集合周围的包装 XML 元素。默认设置:
@XmlElementWrapper (
name = "##default",
namespace = "##default",
nillable = false
)
|
| @XmlAnyElement | 将 JavaBeans 属性映射到 XML 信息集表示或 JAXB 元素。默认设置:
@XmlAnyElement (
lax = false,
value = W3CDomHandler.class
)
|
| @XmlAttribute | 将一个 JavaBeans 属性映射到 XML 属性。默认设置:
@XmlAttribute (
name = ##default,
required = false,
namespace = "##default"
)
|
@XmlAnyAttribute |
将 JavaBeans 属性映射到通配符属性映射。默认设置:无 |
|---|---|
@XmlTransient |
防止将 JavaBeans 属性映射到 XML 表示。默认设置:无 |
@XmlValue |
定义类到 XML Schema 复杂类型或 XML Schema 简单类型的映射。默认设置:无 |
@XmlID |
将 JavaBeans 属性映射到 XML ID。默认设置:无 |
@XmlIDREF |
将 JavaBeans 属性映射到 XML IDREF。默认设置:无 |
@XmlList |
将属性映射到简单类型列表。默认设置:无 |
@XmlMixed |
标记 JavaBeans 多值属性以支持混合内容。默认设置:无 |
@XmlMimeType |
关联控制属性的 XML 表示的 MIME 类型。默认设置:无 |
@XmlAttachmentRef |
标记字段/属性,其 XML 表单是指向 mime 内容的 URI 引用。默认设置:无 |
@XmlInlineBinaryData |
禁用对绑定到 XML 中 base64 编码二进制数据的数据类型考虑 XOP 编码。默认设置:无 |
以下表总结了可以与对象工厂一起使用的 JAXB 注解。
表格:与对象工厂相关的 JAXB 注解
| 注解 | 描述和默认设置 |
|---|
| @XmlElementDecl | 将工厂方法映射到 XML 元素。默认设置:
@XmlElementDecl (
scope = GLOBAL.class,
namespace = "##default",
substitutionHeadNamespace = "##default",
substitutionHeadName = ""
)
|
以下表总结了可以与适配器一起使用的 JAXB 注解。
表格:与适配器相关的 JAXB 注解
| 注解 | 描述和默认设置 |
|---|
| @XmlJavaTypeAdapter | 使用实现 @XmlAdapter 注解的适配器进行自定义编组。默认设置:
@XmlJavaTypeAdapter ( type = DEFAULT.class )
|
@XmlJavaTypeAdapters |
用于在包级别定义多个 @XmlJavaTypeAdapter 注解的容器注解。默认设置:无 |
|---|


 浙公网安备 33010602011771号
浙公网安备 33010602011771号