
Java 中文官方教程 2022 版(三十九)
XPath 如何工作
XPath 规范是各种规范的基础,包括 XSLT 和链接/寻址规范,如XPointer。因此,对 XPath 的理解对许多高级 XML 用法至关重要。本节介绍了 XPath 在 XSLT 上下文中的基本知识。
XPath 表达式
一般来说,XPath 表达式指定了选择一组 XML 节点的模式。然后 XSLT 模板在应用转换时使用这些模式。(另一方面,XPointer添加了定义点或范围的机制,以便可以使用 XPath 表达式进行寻址)。
XPath 表达式中的节点不仅指代元素,还指代文本和属性等其他内容。事实上,XPath 规范定义了一个抽象文档模型,定义了七种节点类型:
-
根
-
元素
-
文本
-
属性
-
注释
-
处理指令
-
命名空间
XML 数据的根元素由一个元素节点建模。XPath 根节点包含文档的根元素以及与文档相关的其他信息。
XSLT/XPath 数据模型
类似于文档对象模型(DOM),XSLT/XPath 数据模型由包含各种节点的树组成。在任何给定元素节点下,都有文本节点、属性节点、元素节点、注释节点和处理指令节点。
在这个抽象模型中,语法区别消失了,你只剩下了数据的规范化视图。例如,在文本节点中,无论文本是在 CDATA 部分中定义的还是包含实体引用,都没有区别。文本节点将包含规范化的数据,即在所有解析完成后存在的数据。因此,文本将包含一个<字符,无论是否使用实体引用(如<)或 CDATA 部分来包含它。(类似地,文本将包含一个&字符,无论是使用&传递的还是在 CDATA 部分中的)。
在这一部分,我们将主要处理元素节点和文本节点。有关其他寻址机制,请参阅 XPath 规范。
模板和上下文
XSLT 模板是一组应用于 XPath 表达式选择的节点的格式化指令。在样式表中,XSLT 模板看起来像这样:
<xsl:template match="//LIST">
...
</xsl:template>
表达式//LIST从输入流中选择LIST节点集。模板中的附加指令告诉系统如何处理它们。
由这样一个表达式选择的节点集定义了模板中其他表达式评估的上下文。该上下文可以被视为整个集合 - 例如,在确定它包含的节点数时。
上下文也可以被视为集合中的单个成员,因为每个成员都会逐个处理。例如,在LIST处理模板内部,表达式@type指的是当前LIST节点的类型属性。(类似地,表达式@*指的是当前 LIST 元素的所有属性)。
基本的 XPath 地址定位
XML 文档是一个树形结构(分层)的节点集合。与分层目录结构一样,指定指向层次结构中特定节点的路径是很有用的(因此规范的名称是 XPath)。事实上,许多目录路径的表示法完全保留不变:
-
正斜杠(/)用作路径分隔符。
-
从文档根开始的绝对路径以
/开头。 -
从给定位置开始的相对路径以其他任何字符开头。
-
双点(..)表示当前节点的父节点。
-
单点(.)表示当前节点。
例如,在一个可扩展的 HTML(XHTML)文档(一个看起来像 HTML 但符合 XML 规则的 XML 文档)中,路径/h1/h2/表示h1下的h2元素。(回想一下,在 XML 中,元素名称是区分大小写的,因此这种规范在 XHTML 中比在普通 HTML 中更有效,因为 HTML 是不区分大小写的)。
在诸如 XPath 的模式匹配规范中,规范/h1/h2选择所有位于h1元素下的h2元素。要选择特定的h2元素,您可以使用方括号[]进行索引(就像用于数组的那样)。因此,路径/h1[4]/h2[5]将选择第四个h1元素下的第五个h2元素。
注意 - 在 XHTML 中,所有元素名称都是小写的。这是 XML 文档的一个相当普遍的约定。但是,在像本教程这样的教程中,大写名称更容易阅读。因此,在剩下的 XSLT 课程中,所有 XML 元素名称将以大写形式呈现。(另一方面,属性名称将保持小写)。
XPath 表达式中指定的名称指的是一个元素。例如,在/h1/h2中,h1指的是h1元素。要引用属性,您需要在属性名称前加上@符号。例如,@type指的是元素的类型属性。假设您有一个带有 LIST 元素的 XML 文档,那么表达式LIST/@type将选择LIST元素的类型属性。
注意 - 因为表达式不以/开头,所以引用指定了相对于当前上下文的列表节点-无论文档中的位置是什么。
基本的 XPath 表达式
XPath 表达式的完整范围利用了 XPath 定义的通配符、运算符和函数。您很快将了解更多相关内容。在这里,我们简单介绍了一些最常见的 XPath 表达式。
表达式 @type="unordered" 指定了一个名为 type 的属性,其值为 unordered。诸如 LIST/@type 这样的表达式指定了 LIST 元素的 type 属性。
你可以将这两种表示法结合起来,得到一些有趣的东西。在 XPath 中,通常与索引相关联的方括号表示法([])被扩展为指定选择条件。因此,表达式 LIST[@type="unordered"] 选择所有类型值为 unordered 的 LIST 元素。
元素也存在类似的表达式。每个元素都有一个关联的字符串值,该值由连接在元素下的所有文本段组成。(有关该过程如何工作的更详细解释,请参见 元素的字符串值。)
假设您使用由 PROJECT 元素和具有项目名称文本字符串、多个列出参与者的 PERSON 元素以及可选记录项目状态的 STATUS 元素组成的 XML 结构来对组织中发生的事情进行建模。以下是使用扩展方括号表示法的其他示例:
-
/PROJECT[.="MyProject"]:选择名为 "MyProject" 的PROJECT。 -
/PROJECT[STATUS]:选择所有具有STATUS子元素的项目。 -
/PROJECT[STATUS="Critical"]:选择所有具有字符串值为 Critical 的STATUS子元素的项目。
结合索引地址
XPath 规范定义了相当多的寻址机制,它们可以以许多不同的方式组合。因此,XPath 为相对简单的规范提供了很多表达能力。本节展示了其他有趣的组合:
-
LIST[@type="ordered"][3]:选择所有类型为 ordered 的LIST元素,并返回第三个。 -
LIST[3][@type="ordered"]:选择第三个LIST元素,但仅当它是 ordered 类型时。
注意 - 在 XPath 规范 的第 2.5 节中列出了更多的地址操作符组合。这可能是规范中最有用的部分,用于定义 XSLT 转换。
通配符
根据定义,未经限定的 XPath 表达式选择与指定模式匹配的一组 XML 节点。例如,/HEAD 匹配所有顶级 HEAD 条目,而 /HEAD[1] 仅匹配第一个。表 4-1 列出了可用于 XPath 表达式中的通配符,以扩大模式匹配的范围。
表 4-1 XPath 通配符
| 通配符 | 含义 |
|---|---|
* |
匹配任何元素节点(不包括属性或文本)。 |
node() |
匹配任何类型的任何节点:元素节点、文本节点、属性节点、处理指令节点、命名空间节点或注释节点。 |
@* |
匹配任何属性节点。 |
在项目数据库示例中,/*/PERSON[.="Fred"] 匹配任何命名为 Fred 的 PROJECT 或 ACTIVITY 元素。
扩展路径寻址
到目前为止,您看到的所有模式都指定了层次结构中的确切级别。例如,/HEAD指定了层次结构中第一级的任何HEAD元素,而/*/*指定了层次结构中第二级的任何元素。要指定层次结构中的不确定级别,请使用双斜杠(//)。例如,XPath 表达式//PARA选择文档中的所有段落元素,无论它们在哪里找到。
//模式也可以在路径中使用。因此,表达式/HEAD/LIST//PARA表示从/HEAD/LIST开始的子树中的所有段落元素。
XPath 数据类型和运算符
XPath 表达式产生一组节点、一个字符串、一个布尔值(真/假值)或一个数字。表 4-2 列出了可以在 Xpath 表达式中使用的运算符:
表 4-2 XPath 运算符
| 运算符 | 含义 |
|---|---|
| |
替代。例如,PARA|LIST选择所有PARA和LIST元素。 |
or, and |
返回两个布尔值的或/与。 |
=, != |
等于或不等于,适用于布尔值、字符串和数字。 |
<, >, <=, >= |
小于、大于、小于或等于、大于或等于,适用于数字。 |
+, -, *, div, mod |
加、减、乘、浮点除法和模运算(例如,6 mod 4 = 2)。 |
表达式可以用括号分组,因此您不必担心运算符优先级。
注意 - 运算符优先级是一个术语,用来回答这个问题,“如果你指定 a + b * c,这是意味着 (a+b) * c 还是 a + (b*c)?”(运算符优先级与表中显示的大致相同)。
元素的字符串值
元素的字符串值是所有后代文本节点的连接,无论有多深。考虑这个混合内容的 XML 数据:
<PARA>This paragraph contains a <b>bold</b> word</PARA>
<PARA>元素的字符串值为这个段落包含一个粗体词。特别要注意的是,<B>是<PARA>的子元素,而文本bold是<B>的子元素。
关键是节点的所有子节点中的所有文本都连接在一起以形成字符串值。
此外,值得理解的是,XPath 定义的抽象数据模型中的文本是完全规范化的。因此,无论 XML 结构中是否包含实体引用<或<在CDATA部分中,元素的字符串值将包含<字符。因此,在使用 XSLT 样式表生成 HTML 或 XML 时,必须将<的出现转换为<或将其置于CDATA部分中。类似地,&的出现必须转换为&。
XPath 函数
这一部分以 XPath 函数的概述结束。您可以使用 XPath 函数来选择一组节点,就像您使用元素规范一样。其他函数返回一个字符串、一个数字或一个布尔值。例如,表达式/PROJECT/text()获取PROJECT节点的字符串值。
许多函数依赖于当前上下文。在前面的示例中,每次调用text()函数的上下文是当前选择的PROJECT节点。
有许多 XPath 函数-太多了,无法在此详细描述。本节提供了一个简要列表,显示了可用的 XPath 函数以及它们的功能摘要。有关函数的更多信息,请参阅XPath 规范的第 4 节。
节点集函数
许多 XPath 表达式选择一组节点。实质上,它们返回一个节点集。一个函数也是如此。id(...)函数返回具有指定 ID 的节点。(元素仅在文档具有指定哪个属性具有 ID 类型的 DTD 时才具有 ID)。
位置函数
这些函数返回基于位置的数值。
-
last(): 返回最后一个元素的索引。例如,/HEAD[last()]选择最后一个HEAD元素。 -
position(): 返回索引位置。例如,/HEAD[position() <= 5]选择前五个HEAD元素。 -
count(...): 返回元素的计数。例如,/HEAD[count(HEAD)=0]选择所有没有子标题的HEAD元素。
字符串函数
这些函数操作或返回字符串。
-
concat(string, string, ...): 连接字符串值。 -
starts-with(string1, string2): 如果string1以string2开头,则返回 true。 -
contains(string1, string2): 如果string1包含string2,则返回 true。 -
substring-before(string1, string2): 返回string1中string2出现之前的部分。 -
substring-after(string1, string2): 返回string1中string2之后的剩余部分。 -
substring(string, idx): 返回从索引位置到末尾的子字符串,其中第一个char的索引 = 1。 -
substring(string, idx, len): 返回从索引位置开始的指定长度的子字符串。 -
string-length(): 返回上下文节点的字符串值的大小;上下文节点是当前选择的节点-通过应用诸如string-length()的函数选择的 XPath 表达式中的节点。 -
string-length(string): 返回指定字符串的大小。 -
normalize-space(): 返回当前节点的规范化字符串值(没有前导或尾随空格,并且空格字符序列转换为单个空格)。 -
normalize-space(string): 返回指定字符串的规范化字符串值。 -
translate(string1, string2, string3): 将string1转换,用string2中的字符替换为string3中对应的字符。
注意 - XPath 定义了三种获取元素文本的方式:text()、string(object),以及在表达式中隐含的元素名称所暗示的字符串值,例如:/PROJECT[PERSON="Fred"]。
布尔函数
这些函数操作或返回布尔值。
-
not(...): 反转指定的布尔值。 -
true(): 返回 true。 -
false(): 返回 false。 -
lang(string): 如果上下文节点的语言(由xml:Lang属性指定)与指定的语言相同(或是指定语言的子语言),则返回 true;例如,对于<PARA_xml:Lang="en">...</PARA>,Lang("en")为 true。
数值函数
这些函数操作或返回数值。
-
sum(...): 返回指定节点集中每个节点的数值之和。 -
floor(N): 返回不大于N的最大整数。 -
ceiling(N): 返回不小于N的最小整数。 -
round(N): 返回最接近N的整数。
转换函数
这些函数将一个数据类型转换为另一个数据类型。
-
string(...): 返回数字、布尔值或节点集的字符串值。 -
boolean(...): 为数字、字符串或节点集返回一个布尔值(非零数字、非空节点集和非空字符串均为 true)。 -
number(...): 返回布尔值、字符串或节点集的数值(true 为 1,false 为 0,包含数字的字符串变为该数字,节点集的字符串值转换为数字)。
命名空间函数
这些函数让你确定节点的命名空间特征。
-
local-name(): 返回当前节点的名称,不包括命名空间前缀。 -
local-name(...): 返回指定节点集中第一个节点的名称,不包括命名空间前缀。 -
namespace-uri(): 返回当前节点的命名空间 URI。 -
namespace-uri(...): 返回指定节点集中第一个节点的命名空间 URI。 -
name(): 返回当前节点的扩展名称(URI 加上本地名称)。 -
name(...): 返回指定节点集中第一个节点的扩展名称(URI 加上本地名称)。
总结
XPath 运算符、函数、通配符和节点寻址机制可以以各种方式组合。到目前为止,你所学到的内容应该让你能够很好地开始指定你需要的模式。
将 DOM 写出为 XML 文件
原文:
docs.oracle.com/javase/tutorial/jaxp/xslt/writingDom.html
在构建了一个 DOM(通过解析 XML 文件或以编程方式构建)之后,您经常希望将其保存为 XML。本节将向您展示如何使用 Xalan 转换包来实现这一点。
使用该包,您将创建一个转换器对象,将DOMSource连接到StreamResult。然后,您将调用转换器的transform()方法将 DOM 写出为 XML 数据。
读取 XML
第一步是通过解析 XML 文件在内存中创建一个 DOM。到目前为止,您应该已经对这个过程感到熟悉了。
注意:
本节讨论的代码位于文件TransformationApp01.java中。下载 XSLT 示例并将其解压缩到install-dir/jaxp-1_4_2-release-date/samples目录中。
以下代码提供了一个基本的模板供参考。基本上,这与文档对象模型课程开头使用的代码相同。
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.FactoryConfigurationError;
import javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.w3c.dom.Document;
import org.w3c.dom.DOMException;
import java.io.*;
public class TransformationApp01 {
static Document document;
public static void main(String argv[]) {
if (argv.length != 1) {
System.err.println("Usage: java TransformationApp01 filename");
System.exit (1);
}
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
try {
File f = new File(argv[0]);
DocumentBuilder builder =
factory.newDocumentBuilder();
document = builder.parse(f);
}
catch (SAXParseException spe) {
// Error generated by the parser
System.out.println("\n** Parsing error"
+ ", line " + spe.getLineNumber()
+ ", uri " + spe.getSystemId());
System.out.println(" " + spe.getMessage() );
// Use the contained exception, if any
Exception x = spe;
if (spe.getException() != null)
x = spe.getException();
x.printStackTrace();
}
catch (SAXException sxe) {
// Error generated by this application
// (or a parser-initialization error)
Exception x = sxe;
if (sxe.getException() != null)
x = sxe.getException();
x.printStackTrace();
}
catch (ParserConfigurationException pce) {
// Parser with specified options
// cannot be built
pce.printStackTrace();
}
catch (IOException ioe) {
// I/O error
ioe.printStackTrace();
}
}
}
创建一个转换器
下一步是创建一个转换器,您可以使用它将 XML 传输到System.out。首先,需要以下导入语句。
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.*;
在这里,您添加了一系列类,这些类现在应该形成一个标准模式:一个实体(Transformer)、用于创建它的工厂(TransformerFactory)以及每个类可能生成的异常。因为转换始终有一个源和一个结果,所以您导入了使用 DOM 作为源(DOMSource)和用于结果的输出流(StreamResult)所需的类。
接下来,添加执行转换的代码:
try {
File f = new File(argv[0]);
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse(f);
// Use a Transformer for output
TransformerFactory tFactory =
TransformerFactory.newInstance();
Transformer transformer =
tFactory.newTransformer();
DOMSource source = new DOMSource(document);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
}
在这里,您创建一个转换器对象,使用 DOM 构造一个源对象,并使用System.out构造一个结果对象。然后告诉转换器操作源对象并输出到结果对象。
在这种情况下,“转换器”实际上并没有改变任何内容。在 XSLT 术语中,您使用的是身份转换,这意味着“转换”生成源的副本,未更改。
注意:
您可以为转换器对象指定各种输出属性,如 W3C 规范中定义的www.w3.org/TR/xslt#output。例如,要获得缩进输出,可以调用以下方法:
% transformer.setOutputProperty(OutputKeys.INDENT, "yes");
最后,以下突出显示的代码捕获可能生成的新错误:
}
catch (TransformerConfigurationException tce) {
System.out.println("* Transformer Factory error");
System.out.println(" " + tce.getMessage());
Throwable x = tce;
if (tce.getException() != null)
x = tce.getException();
x.printStackTrace();
}
catch (TransformerException te) {
System.out.println("* Transformation error");
System.out.println(" " + te.getMessage());
Throwable x = te;
if (te.getException() != null)
x = te.getException();
x.printStackTrace();
}
catch (SAXParseException spe) {
// ...
}
注意
-
转换器对象会抛出
TransformerExceptions。 -
工厂会抛出
TransformerConfigurationExceptions。 -
要保留 XML 文档的
DOCTYPE设置,还需要添加以下代码:import javax.xml.transform.OutputKeys; ... if (document.getDoctype() != null) { String systemValue = (new File (document.getDoctype().getSystemId())).getName(); transformer.setOutputProperty(OutputKeys.DOCTYPE_SYSTEM, systemValue); }
要了解更多关于配置工厂和处理验证错误的信息,请参阅将 XML 数据读入 DOM。
运行TransformationApp01示例
-
导航到
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例并将其解压缩到install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航到
xslt目录。% cd xslt -
编译
TransformationApp01示例。输入以下命令:
% javac TransformationApp01.java -
在 XML 文件上运行
TransformationApp01示例。在下面的情况下,在解压示例包后,
TransformationApp01在xslt/data目录中的foo.xml文件上运行。% java TransformationApp01 data/foo.xml你将看到以下输出:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><doc> <name first="David" last="Marston"/> <name first="David" last="Bertoni"/> <name first="Donald" last="Leslie"/> <name first="Emily" last="Farmer"/> <name first="Joseph" last="Kesselman"/> <name first="Myriam" last="Midy"/> <name first="Paul" last="Dick"/> <name first="Stephen" last="Auriemma"/> <name first="Scott" last="Boag"/> <name first="Shane" last="Curcuru"/>如创建转换器中所述,这个转换器实际上并没有改变任何内容,而只是执行了恒等变换,生成了源的副本。真正的转换将在从任意数据结构生成 XML 中执行。
写出 DOM 的子树
也可以操作 DOM 的子树。在本节中,你将尝试这个选项。
注意:
本节讨论的代码在 TranformationApp02.java 中。如果你还没有这样做,下载 XSLT 示例并将其解压缩到install-dir/jaxp-1_4_2-release-date/samples目录中。
过程中唯一的区别是现在将使用 DOM 中的一个节点创建DOMSource,而不是整个 DOM。第一步是导入你需要获取的节点的类,如下面突出显示的代码所示:
import org.w3c.dom.Document;
import org.w3c.dom.DOMException;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
下一步是找到一个好的节点进行实验。以下突出显示的代码选择第一个<name>元素。
try {
File f = new File(argv[0]);
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse(f);
NodeList list = document.getElementsByTagName("name");
Node node = list.item(0);
}
在创建转换器中,源对象是通过以下代码行从整个文档构造的
DOMSource source = new DOMSource(document);
然而,下面突出显示的代码行构造了一个由特定节点为根的子树组成的源对象。
DOMSource source = new DOMSource(node);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
运行TranformationApp02示例
-
导航到
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例并将其解压缩到install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航到
xslt目录。cd xslt -
编译
TranformationApp02示例。输入以下命令:
% javac xslt/TranformationApp02.java -
在 XML 文件上运行
TranformationApp02示例。在下面的情况下,在解压示例包后,
TranformationApp02在xslt/data目录中的foo.xml文件上运行。% java TranformationApp02 data/foo.xml你将看到以下输出:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><doc><name first="David" last="Marston"/>这次,只打印出了第一个
<name>元素。到目前为止,你已经看到如何使用转换器写出 DOM,以及如何使用 DOM 的子树作为转换中的源对象。在下一节中,你将看到如何使用转换器从你能够解析的任何数据结构创建 XML。
从任意数据结构生成 XML
原文:
docs.oracle.com/javase/tutorial/jaxp/xslt/generatingXML.html
本节使用 XSLT 将任意数据结构转换为 XML。
这是整个过程的概述:
-
修改一个现有的读取数据的程序,使其生成 SAX 事件。(此时,该程序是一个真正的解析器还是一个数据过滤器都无关紧要)。
-
使用 SAX“解析器”构建一个
SAXSource进行转换。 -
使用与上一个练习中创建的相同的
StreamResult对象来显示结果。(但请注意,你也可以轻松地创建一个DOMResult对象来在内存中创建一个 DOM)。 -
使用转换器对象将源连接到结果,进行转换。
首先,你需要一个要转换的数据集和一个能够读取数据的程序。接下来的两个部分创建了一个简单的数据文件和一个读取它的程序。
创建一个简单的文件
这个例子使用了一个地址簿的数据集,PersonalAddressBook.ldif。如果你还没有这样做,下载 XSLT 示例并解压到install-dir/jaxp-1_4_2-release-date/samples目录中。这里显示的文件是通过在 Netscape Messenger 中创建一个新的地址簿,给它一些虚拟数据(一个地址卡),然后以 LDAP 数据交换格式(LDIF)格式导出而生成的。解压 XSLT 示例后,它位于xslt/data目录中。
下面的图示显示了创建的通讯录条目。
图示 通讯录条目
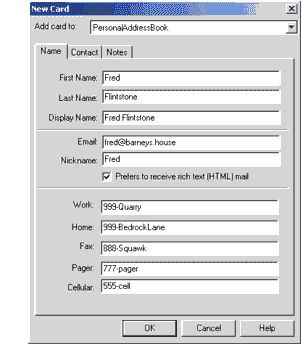
导出通讯录会生成一个类似下面显示的文件。我们关心的文件部分以粗体显示。
dn: cn=Fred Flintstone,mail=fred@barneys.house
modifytimestamp: 20010409210816Z
cn: Fred Flintstone
xmozillanickname: Fred
mail: Fred@barneys.house
xmozillausehtmlmail: TRUE
givenname: Fred
sn: Flintstone
telephonenumber: 999-Quarry
homephone: 999-BedrockLane
facsimiletelephonenumber: 888-Squawk
pagerphone: 777-pager
cellphone: 555-cell
xmozillaanyphone: 999-Quarry
objectclass: top
objectclass: person
请注意,文件的每一行都包含一个变量名,一个冒号和一个空格,后面跟着变量的值。sn变量包含人的姓氏(姓),变量cn包含通讯录条目中的DisplayName字段。
创建一个简单的解析器
下一步是创建一个解析数据的程序。
注意 - 本节讨论的代码在AddressBookReader01.java中,解压XSLT 示例到install-dir/jaxp-1_4_2-release-date/samples目录后,可以在xslt目录中找到。
接下来显示程序的文本。这是一个非常简单的程序,甚至不会为多个条目循环,因为毕竟它只是一个演示。
import java.io.*;
public class AddressBookReader01 {
public static void main(String argv[]) {
// Check the arguments
if (argv.length != 1) {
System.err.println("Usage: java AddressBookReader01 filename");
System.exit (1);
}
String filename = argv[0];
File f = new File(filename);
AddressBookReader01 reader = new AddressBookReader01();
reader.parse(f);
}
// Parse the input file
public void parse(File f) {
try {
// Get an efficient reader for the file
FileReader r = new FileReader(f);
BufferedReader br = new BufferedReader(r);
// Read the file and display its contents.
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: "))
break;
}
output("nickname", "xmozillanickname", line);
line = br.readLine();
output("email", "mail", line);
line = br.readLine();
output("html", "xmozillausehtmlmail", line);
line = br.readLine();
output("firstname","givenname", line);
line = br.readLine();
output("lastname", "sn", line);
line = br.readLine();
output("work", "telephonenumber", line);
line = br.readLine();
output("home", "homephone", line);
line = br.readLine();
output("fax", "facsimiletelephonenumber", line);
line = br.readLine();
output("pager", "pagerphone", line);
line = br.readLine();
output("cell", "cellphone", line);
}
catch (Exception e) {
e.printStackTrace();
}
}
}
这个程序包含三个方法:
main
main方法从命令行获取文件名,创建解析器的实例,并开始解析文件。当我们将程序转换为 SAX 解析器时,这个方法将消失。(这是将解析代码放入单独方法的一个原因)。
parse
此方法在主例程发送的 File 对象上运行。正如您所看到的,这非常简单。唯一的效率让步是使用 BufferedReader,当您开始操作大文件时,这可能变得重要。
output
输出方法包含了一行结构的逻辑。它接受三个参数。第一个参数给出一个要显示的方法名称,因此它可以将 html 输出为一个变量名,而不是 xmozillausehtmlmail。第二个参数给出存储在文件中的变量名(xmozillausehtmlmail)。第三个参数给出包含数据的行。然后该例程从行的开头剥离变量名并输出所需的名称,加上数据。
运行 AddressBookReader01 示例
-
导航到
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例 并将其解压缩到 install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航到
xslt目录。cd xslt -
编译
AddressBookReader01示例。输入以下命令:
% javac AddressBookReader01.java -
在数据文件上运行
AddressBookReader01示例。在下面的情况下,
AddressBookReader01在上面显示的文件PersonalAddressBook.ldif上运行,在解压缩示例包后在xslt/data目录中找到。% java AddressBookReader01 data/PersonalAddressBook.ldif您将看到以下输出:
nickname: Fred email: Fred@barneys.house html: TRUE firstname: Fred lastname: Flintstone work: 999-Quarry home: 999-BedrockLane fax: 888-Squawk pager: 777-pager cell: 555-cell这比 创建简单文件 中显示的文件更易读。
创建生成 SAX 事件的解析器
本节展示了如何使解析器生成 SAX 事件,以便您可以将其用作 XSLT 转换中的 SAXSource 对象的基础。
注意 - 本节讨论的代码在 AddressBookReader02.java 中,该文件在您将 XSLT examples 解压缩到 install-dir/jaxp-1_4_2-release-date/samples 目录后的 xslt 目录中找到。AddressBookReader02.java 是从 AddressBookReader01.java 改编而来,因此这里只讨论两个示例之间的代码差异。
AddressBookReader02 需要以下未在 AddressBookReader01 中使用的突出显示的类。
import java.io.*;
import org.xml.sax.*;
import org.xml.sax.helpers.AttributesImpl;
该应用程序还扩展了 XmlReader。此更改将应用程序转换为生成适当的 SAX 事件的解析器。
public class AddressBookReader02 implements XMLReader { /* ... */ }
与 AddressBookReader01 示例不同,此应用程序没有 main 方法。
以下全局变量将在本节后面使用:
public class AddressBookReader02 implements XMLReader {
ContentHandler handler;
String nsu = "";
Attributes atts = new AttributesImpl();
String rootElement = "addressbook";
String indent = "\n ";
// ...
}
SAX ContentHandler 是将获得解析器生成的 SAX 事件的对象。为了将应用程序转换为 XmlReader,应用程序定义了一个 setContentHandler 方法。处理程序变量将保存在调用 setContentHandler 时发送的对象的引用。
当解析器生成 SAX 元素事件时,它将需要提供命名空间和属性信息。因为这是一个简单的应用程序,它为这两者定义了空值。
应用程序还为数据结构(addressbook)定义了一个根元素,并设置了一个缩进字符串以提高输出的可读性。
此外,解析方法被修改为接受 InputSource(而不是 File)作为参数,并考虑了它可能生成的异常:
public void parse(InputSource input) throws IOException, SAXException
现在,不再像在 AddressBookReader01 中那样创建新的 FileReader 实例,而是将读取器封装在 InputSource 对象中:
try {
java.io.Reader r = input.getCharacterStream();
BufferedReader Br = new BufferedReader(r);
// ...
}
注意 - 下一节将展示如何创建输入源对象,实际放入其中的将是一个缓冲读取器。但是 AddressBookReader 可能会被其他人在某个地方使用。这一步确保处理将是高效的,无论给定的读取器是什么。
下一步是修改解析方法以生成文档和根元素的 SAX 事件。以下突出显示的代码实现了这一点:
public void parse(InputSource input) {
try {
// ...
String line = br.readLine();
while (null != (line = br.readLine())) {
if (line.startsWith("xmozillanickname: "))
break;
}
if (handler == null) {
throw new SAXException("No content handler");
}
handler.startDocument();
handler.startElement(nsu, rootElement, rootElement, atts);
output("nickname", "xmozillanickname", line);
// ...
output("cell", "cellphone", line);
handler.ignorableWhitespace("\n".toCharArray(),
0, // start index
1 // length
);
handler.endElement(nsu, rootElement, rootElement);
handler.endDocument();
}
catch (Exception e) {
// ...
}
}
在这里,应用程序检查解析器是否正确配置了 ContentHandler。(对于这个应用程序,我们不关心其他任何内容)。然后生成文档和根元素的开始事件,并通过发送根元素的结束事件和文档的结束事件来完成。
此时有两个值得注意的地方:
-
setDocumentLocator事件未发送,因为这是可选的。如果它很重要,那么该事件将在startDocument事件之前立即发送。 -
在根元素结束之前生成了一个
ignorableWhitespace事件。这也是可选的,但它极大地提高了输出的可读性,很快就会看到。(在这种情况下,空白包括一个单独的换行符,它以与将字符发送到字符方法相同的方式发送:作为字符数组、起始索引和长度)。
现在生成了文档和根元素的 SAX 事件,下一步是修改输出方法以为每个数据项生成适当的元素事件。删除对 System.out.println(name + ": " + text) 的调用,并添加以下突出显示的代码来实现:
void output(String name, String prefix, String line)
throws SAXException {
int startIndex =
prefix.length() + 2; // 2=length of ": "
String text = line.substring(startIndex);
int textLength = line.length() - startIndex;
handler.ignorableWhitespace (indent.toCharArray(),
0, // start index
indent.length()
);
handler.startElement(nsu, name, name /*"qName"*/, atts);
handler.characters(line.toCharArray(),
startIndex,
textLength;
);
handler.endElement(nsu, name, name);
}
因为 ContentHandler 方法可以将 SAXExceptions 发送回解析器,所以解析器必须准备好处理它们。在这种情况下,不会有任何异常,所以如果出现任何异常,应用程序将简单地允许失败。
然后计算数据的长度,再次生成一些可忽略的空白以提高可读性。在这种情况下,只有一个数据级别,所以我们可以使用一个固定的缩进字符串。(如果数据结构更加结构化,我们将不得不根据数据的嵌套计算缩进空间)。
注意 - 缩进字符串对数据本身没有影响,但会使输出更容易阅读。如果没有该字符串,所有元素将被连接在一起:
<addressbook>
<nickname>Fred</nickname>
<email>...
接下来,以下方法配置解析器,以接收其生成的事件的 ContentHandler:
void output(String name, String prefix, String line)
throws SAXException {
// ...
}
// Allow an application to register a content event handler.
public void setContentHandler(ContentHandler handler) {
this.handler = handler;
}
// Return the current content handler.
public ContentHandler getContentHandler() {
return this.handler;
}
还必须实现几个其他方法以满足 XmlReader 接口的要求。为了这个练习,所有这些方法都生成了空方法。然而,一个生产应用程序需要实现错误处理程序方法以生成更健壮的应用程序。不过,在这个例子中,以下代码为它们生成了空方法:
// Allow an application to register an error event handler.
public void setErrorHandler(ErrorHandler handler) { }
// Return the current error handler.
public ErrorHandler getErrorHandler() {
return null;
}
然后,以下代码为剩余的 XmlReader 接口生成了空方法。(其中大部分对于真实的 SAX 解析器是有价值的,但对于像这样的数据转换应用程序却没有太大影响)。
// Parse an XML document from a system identifier (URI).
public void parse(String systemId) throws IOException, SAXException
{ }
// Return the current DTD handler.
public DTDHandler getDTDHandler() { return null; }
// Return the current entity resolver.
public EntityResolver getEntityResolver() { return null; }
// Allow an application to register an entity resolver.
public void setEntityResolver(EntityResolver resolver) { }
// Allow an application to register a DTD event handler.
public void setDTDHandler(DTDHandler handler) { }
// Look up the value of a property.
public Object getProperty(String name) { return null; }
// Set the value of a property.
public void setProperty(String name, Object value) { }
// Set the state of a feature.
public void setFeature(String name, boolean value) { }
// Look up the value of a feature.
public boolean getFeature(String name) { return false; }
现在您有一个可以用来生成 SAX 事件的解析器。在下一节中,您将使用它来构造一个 SAX 源对象,从而将数据转换为 XML。
使用解析器作为 SAXSource
给定一个用作事件源的 SAX 解析器,您可以构造一个转换器来生成一个结果。在本节中,TransformerApp 将被更新以生成一个流输出结果,尽管它也可以轻松地生成一个 DOM 结果。
注意 - 注意:本节讨论的代码位于 TransformationApp03.java 中,在将 XSLT 示例 解压缩到 install-dir/jaxp-1_4_2-release-date/samples 目录后,可以在 xslt 目录中找到。
要开始,TransformationApp03 与 TransformationApp02 的不同之处在于构建 SAXSource 对象所需导入的类。这些类如下所示。在这一点上,DOM 类已不再需要,因此已被丢弃,尽管保留它们不会造成任何伤害。
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import javax.xml.transform.sax.SAXSource;
import javax.xml.transform.stream.StreamResult;
接下来,应用程序不再创建 DOM DocumentBuilderFactory 实例,而是创建了一个 SAX 解析器,即 AddressBookReader 的实例:
public class TransformationApp03 {
static Document document;
public static void main(String argv[]) {
// ...
// Create the sax "parser".
AddressBookReader saxReader = new AddressBookReader();
try {
File f = new File(argv[0]);
// ...
}
// ...
}
}
然后,以下突出显示的代码构造了一个 SAXSource 对象
// Use a Transformer for output
// ...
Transformer transformer = tFactory.newTransformer();
// Use the parser as a SAX source for input
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
InputSource inputSource = new InputSource(br);
SAXSource source = new SAXSource(saxReader, inputSource);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
在这里,TransformationApp03 构造了一个缓冲读取器(如前所述),并将其封装在一个输入源对象中。然后创建了一个 SAXSource 对象,将读取器和 InputSource 对象传递给它,然后将其传递给转换器。
当应用程序运行时,转换器将自身配置为 SAX 解析器(AddressBookReader)的 ContentHandler,并告诉解析器对 inputSource 对象进行操作。解析器生成的事件然后传递给转换器,转换器执行适当的操作并将数据传递给结果对象。
最后,TransformationApp03 不会生成异常,因此在 TransformationApp02 中看到的异常处理代码不再存在。
运行 TransformationApp03 示例
-
导航到
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例 并将其解压缩到 install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航到
xslt目录。cd xslt -
编译
TransformationApp03示例。输入以下命令:
% javac TransformationApp03.java -
运行
TransformationApp03示例,转换您希望转换为 XML 的数据文件。在下面的情况下,在您解压缩示例包后,在
xslt/data目录中找到的PersonalAddressBook.ldif文件上运行TransformationApp03。% java TransformationApp03 data/PersonalAddressBook.ldif您将看到以下输出:
<?xml version="1.0" encoding="UTF-8"?> <addressbook> <nickname>Fred</nickname> <email>Fred@barneys.house</email> <html>TRUE</html> <firstname>Fred</firstname> <lastname>Flintstone</lastname> <work>999-Quarry</work> <home>999-BedrockLane</home> <fax>888-Squawk</fax> <pager>777-pager</pager> <cell>555-cell</cell> </addressbook>正如您所看到的,LDIF 格式文件
PersonalAddressBook已被转换为 XML!
使用 XSLT 转换 XML 数据
原文:
docs.oracle.com/javase/tutorial/jaxp/xslt/transformingXML.html
可以使用可扩展样式表语言转换(XSLT)API 来实现多种目的。例如,通过一个足够智能的样式表,你可以从 XML 数据生成 PDF 或 PostScript 输出。但通常情况下,XSLT 用于生成格式化的 HTML 输出,或者创建数据的另一种 XML 表示。
在这一部分中,使用 XSLT 转换将 XML 输入数据转换为 HTML 输出。
注意 - XSLT 规范庞大而复杂,因此本教程只能触及表面。它将为您提供一些背景知识,以便您理解简单的 XSLT 处理任务,但不会详细讨论如何编写 XSLT 转换,而是集中于如何使用 JAXP 的 XSLT 转换 API。要深入了解 XSLT,请参考一本好的参考手册,例如 Michael Kay 的XSLT 2.0 和 XPath 2.0:程序员参考(Wrox,2008)。
定义一个简单的文档类型
首先定义一个非常简单的文档类型,可用于撰写文章。我们的article文档将包含这些结构标签:
-
<TITLE>: 文章的标题 -
<SECT>: 一个包含标题和主体的节 -
<PARA>: 一个段落 -
<LIST>: 一个列表 -
<ITEM>: 列表中的一个条目 -
<NOTE>: 一个与主文本分隔开的旁注
这种结构稍微不同寻常的地方在于,我们不会为节标题创建单独的元素标签。这样的元素通常被创建用于区分标题文本(及其包含的任何标签)和节的主体(即标题下面的任何结构元素)。
相反,我们将允许标题与节的主体无缝融合。这种安排增加了样式表的一些复杂性,但它将让我们有机会探索 XSLT 的模板选择机制。它也符合我们对文档结构的直觉期望,即标题文本直接后跟结构元素,这种安排可以简化基于大纲的编辑。
注意 - 这种结构不容易验证,因为 XML 的混合内容模型允许在节的任何位置出现文本,而我们希望将文本和内联元素限制在只出现在节主体的第一个结构元素之前。基于断言的验证器可以做到,但大多数其他模式机制无法。因此,我们将放弃为文档类型定义 DTD。
在这种结构中,部分可以嵌套。嵌套的深度将决定用于部分标题的 HTML 格式(例如,h1或h2)。使用普通的SECT标签(而不是编号的部分)在面向大纲的编辑中也很有用,因为它允许您随意移动部分,而无需担心更改任何受影响部分的编号。
对于列表,我们将使用一个类型属性来指定列表条目是无序的(带项目符号)、alpha(用小写字母符号)、ALPHA(用大写字母编号)还是编号的。
我们还将允许一些内联标签来改变文本的外观。
-
<B>:粗体 -
<I>:斜体 -
<U>:下划线 -
<DEF>:定义 -
<LINK>:链接到 URL
注意 - 内联标签不会生成换行符,因此内联标签引起的样式更改不会影响页面上文本的流动(尽管它会影响该文本的外观)。另一方面,结构标签划分了文本的新段落,因此至少总是会生成一个换行符,除了其他格式更改。
<DEF>标签将用于文本中定义的术语。这些术语将以斜体显示,就像它们在文档中通常显示的那样。但是在 XML 中使用特殊标签将允许索引程序找到这些定义,并将它们添加到索引中,以及标题中的关键字。例如,在前面的注释中,内联标签和结构标签的定义可以用<DEF>标签标记以供将来索引。
最后,LINK标签有两个目的。首先,它将让我们创建到 URL 的链接,而无需两次放置 URL;因此我们可以编写<link>http//...</link>而不是<a href="http//...">http//...</a>。当然,我们还希望允许一个看起来像<link target="...">...name...</link>的形式。这导致了<link>标签的第二个原因。它将让我们有机会在 XSLT 中使用条件表达式。
注意 - 尽管文章结构非常简单(仅由十一个标签组成),但它引发了足够多有趣的问题,让我们对 XSLT 的基本功能有了很好的了解。但是我们仍然会留下大部分规范未触及的领域。在还有什么其他 XSLT 可以做?中,我们将指出我们跳过的主要功能。
创建一个测试文档
在这里,您将使用嵌套的<SECT>元素、一些<PARA>元素、一个<NOTE>元素、一个<LINK>和一个<LIST type="unordered">创建一个简单的测试文档。这个想法是创建一个包含各种元素的文档,以便我们可以探索更有趣的翻译机制。
注意 - 本节讨论的代码位于article1.xml中,在您解压XSLT 示例到install-dir/jaxp-1_4_2-release-date/samples目录后,可以在xslt/data目录中找到。
要创建测试文档,请创建一个名为article.xml的文件,并输入以下 XML 数据。
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
<PARA>This section will introduce a subsection.</PARA>
<SECT>The Subsection Heading
<PARA>This is the text of the subsection.
</PARA>
</SECT>
</SECT>
</ARTICLE>
请注意,在 XML 文件中,子部分完全包含在主要部分中。(而在 HTML 中,标题不包含部分的正文)。结果是一个在纯文本形式下更难编辑的大纲结构,像这样,但在面向大纲的编辑器中更容易编辑。
某一天,如果有一个理解内联标记(如<B>和<I>)的树形 XML 编辑器,那么就可以以大纲形式编辑这种文章,而不需要复杂的样式表。(这样的编辑器将允许作者专注于文章的结构,将布局留到后期)。在这样的编辑器中,文章片段将看起来像这样:
<ARTICLE>
<TITLE>A Sample Article
<SECT>The First Major Section
<PARA>This section will
introduce a subsection.
<SECT>The Subheading
<PARA>This is the text of the subsection.
Note that ...
注意 - 目前存在树形结构编辑器,但它们将内联标记(如<B>和<I>)与结构标记一样处理,这可能会使“大纲”有点难以阅读。
编写 XSLT 转换
现在是时候开始编写一个 XSLT 转换,将转换 XML 文章并在 HTML 中呈现出来。
注意 - 本节讨论的代码位于article1a.xsl中,在将XSLT 示例解压缩到install-dir/jaxp-1_4_2-release-date/samples目录后,在xslt/data目录中找到。
从创建一个普通的 XML 文档开始:
<?xml version="1.0" encoding="ISO-8859-1"?>
然后添加以下突出显示的行以创建一个 XSL 样式表:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet
xmlns:xsl=
"http://www.w3.org/1999/XSL/Transform"
version="1.0"
>
**</xsl:stylesheet>**
**现在设置它以生成兼容 HTML 的输出。
<xsl:stylesheet
[...]
>
<xsl:output method="html"/>
[...]
</xsl:stylesheet>
我们将在本节稍后详细讨论该条目的原因。现在,请注意,如果你想输出除了格式良好的 XML 之外的任何内容,那么你将需要一个像所示的<xsl:output>标记,指定text或html。(默认值为xml)。
注意 - 当你指定 XML 输出时,你可以添加缩进属性以生成漂亮的缩进 XML 输出。规范如下:<xsl:output method="xml" indent="yes"/>。
处理基本结构元素
你将开始填写样式表,处理用于创建目录的元素:根元素、标题元素和标题。你还将处理测试文档中定义的PARA元素。
注意 - 如果你在第一次阅读时跳过了讨论 XPath 寻址机制的部分,XPath 工作原理,现在是回去复习那部分的好时机。
从添加处理根元素的主要指令开始:
<xsl:template match="/">
<html><body>
<xsl:apply-templates/>
</body></html>
</xsl:template>
</xsl:stylesheet>
新的 XSL 命令以粗体显示。(请注意,它们在xsl命名空间中定义)。指令<xsl:apply-templates>处理当前节点的子节点。在这种情况下,当前节点是根节点。
尽管这个例子很简单,但它阐明了许多重要的概念,因此值得彻底理解。第一个概念是样式表包含许多模板,用<xsl:template>标签定义。每个模板包含一个匹配属性,该属性使用 XPath 工作原理中描述的 XPath 寻址机制来选择模板将应用于的元素。
在模板内部,不以xsl: namespace前缀开头的标签只是简单地复制。随后的换行符和空格也会被复制,这有助于使生成的输出可读。
注意 - 当没有换行符时,通常会忽略空格。要在这种情况下包含输出中的空格,或者包含其他文本,您可以使用<xsl:text>标签。基本上,XSLT 样式表期望处理标签。因此,它看到的一切都需要是<xsl:..>标签、其他标签或空格。
在这种情况下,非 XSL 标签是 HTML 标签。因此,当匹配根标签时,XSLT 输出 HTML 起始标签,处理适用于根节点子元素的任何模板,然后输出 HTML 结束标签。
处理<TITLE>元素
接下来,添加一个模板来处理文章标题:
<xsl:template match="/ARTICLE/TITLE">
<h1 align="center">
<xsl:apply-templates/> </h1>
</xsl:template>
</xsl:stylesheet>
在这种情况下,您指定了到 TITLE 元素的完整路径,并输出一些 HTML 以使标题文本成为一个大的、居中的标题。在这种情况下,apply-templates标签确保如果标题包含任何内联标签,如斜体、链接或下划线,它们也将被处理。
更重要的是,apply-templates指令导致标题文本被处理。与 DOM 数据模型一样,XSLT 数据模型基于包含在元素节点中的文本节点的概念(这些元素节点又可以包含在其他元素节点中,依此类推)。这种分层结构构成了源树。还有一个包含输出的结果树。
XSLT 通过将源树转换为结果树来工作。要可视化 XSLT 操作的结果,了解这些树的结构及其内容是有帮助的。(有关此主题的更多信息,请参见 XSLT/XPath 数据模型)。
处理标题
要继续处理基本结构元素,添加一个模板来处理顶级标题:
<xsl:template match=
"/ARTICLE/SECT">
<h2> <xsl:apply-templates
select="text()|B|I|U|DEF|LINK"/>
</h2>
<xsl:apply-templates select=
"SECT|PARA|LIST|NOTE"/>
</xsl:template>
</xsl:stylesheet>
在这里,您指定了到最顶层SECT元素的路径。但这次,您使用select属性在两个阶段应用模板。在第一阶段,您使用 XPath 的text()函数选择文本节点,以及加粗和斜体等内联标签(竖线(|)用于匹配多个项目:文本或加粗标签或斜体标签等)。在第二阶段,您选择文件中包含的其他结构元素,如章节、段落、列表和注释。
使用 select 属性可以让您将文本和内联元素放在<h2>...</h2>标签之间,同时确保随后处理该部分中的所有结构标签。换句话说,您确保 XML 文档中标题的嵌套不会反映在 HTML 格式中,这是对 HTML 输出很重要的区别。
一般来说,使用 select 子句可以让您将所有模板应用于当前上下文中可用信息的子集。作为另一个示例,此模板选择当前节点的所有属性:
<xsl:apply-templates select="@*"/></attributes>
接下来,添加几乎相同的模板来处理嵌套一级更深的子标题:
<xsl:template match=
"/ARTICLE/SECT/SECT">
<h3> <xsl:apply-templates
select="text()|B|I|U|DEF|LINK"/>
</h3>
<xsl:apply-templates select=
"SECT|PARA|LIST|NOTE"/>
</xsl:template>
</xsl:stylesheet>
生成运行时消息
您也可以为更深层的标题添加模板,但在某个时候必须停止,即使只是因为 HTML 只支持五级标题。在本例中,您将在两级部分标题处停止。但是,如果 XML 输入恰好包含第三级,您将希望向用户提供错误消息。本节将向您展示如何做到这一点。
注意 - 我们可以继续处理更深层的SECT元素,通过使用表达式/SECT/SECT//SECT选择它们。//选择任何SECT元素,深度由 XPath 寻址机制定义。但我们将利用这个机会来玩弄消息传递。
添加以下模板以在遇到嵌套过深的部分时生成错误:
<xsl:template match=
"/ARTICLE/SECT/SECT/SECT">
<xsl:message terminate="yes">
Error: Sections can only be nested 2 deep.
</xsl:message>
</xsl:template>
</xsl:stylesheet>
terminate="yes"子句导致转换过程在生成消息后停止。如果没有它,处理仍然会继续,该部分中的所有内容都将被忽略。
作为额外的练习,您可以扩展样式表以处理嵌套高达四个部分的部分,生成<h2>...<h5>标签。在任何嵌套五级深的部分上生成错误。
最后,通过添加一个模板来处理PARA标签来完成样式表:
<xsl:template match="PARA">
<p><xsl:apply-templates/></p>
</xsl:template>
</xsl:stylesheet>
编写基本程序
现在,您将修改使用 XSLT 的程序,以原样回显 XML 文件,并将其修改为使用您的样式表。
注意 - 本节讨论的代码位于Stylizer.java中,在将XSLT examples解压缩到install-dir/jaxp-1_4_2-release-date/samples目录后,可以在xslt/data中找到stylizer1a.html。
Stylizer示例改编自TransformationApp02,该示例解析 XML 文件并写入System.out。这两个程序之间的主要区别如下所述。
首先,Stylizer在创建Transformer对象时使用样式表。
// ...
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamSource;
import javax.xml.transform.stream.StreamResult;
// ...
public class Stylizer {
// ...
public static void main (String argv[]) {
// ...
try {
File stylesheet = new File(argv[0]);
File datafile = new File(argv[1]);
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse(datafile);
// ...
StreamSource stylesource = new StreamSource(stylesheet);
Transformer transformer = Factory.newTransformer(stylesource);
}
}
}
此代码使用文件创建StreamSource对象,然后将源对象传递给工厂类以获取转换器。
注意 - 通过消除DOMSource类,您可以简化代码。不要为 XML 文件创建DOMSource对象,而是为其创建StreamSource对象,以及为样式表创建StreamSource对象。
运行Stylizer示例
-
导航至
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例,并将其解压缩到install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航至
xslt目录。cd xslt -
编译
Stylizer示例。输入以下命令:
% javac Stylizer.java -
使用样式表
article1a.xsl在article1.xml上运行Stylizer示例。% java Stylizer data/article1a.xsl data/article1.xml您将看到以下输出:
<html> <body> <h1 align="center">A Sample Article</h1> <h2>The First Major Section </h2> <p>This section will introduce a subsection.</p> <h3>The Subsection Heading </h3> <p>This is the text of the subsection. </p> </body> </html>此时,输出中有相当多的多余空格。在下一节中,您将看到如何消除大部分空格。
修剪空白
请记住,当您查看 DOM 的结构时,有许多只包含可忽略空格的文本节点。输出中的大部分多余空格来自这些节点。幸运的是,XSL 提供了一种消除它们的方法。(有关节点结构的更多信息,请参阅 XSLT/XPath 数据模型。)
注意 - 本节讨论的样式表在解压缩XSLT 示例到install-dir/jaxp-1_4_2-release-date/samples目录后,在xslt/data目录中找到的article1b.xsl中。结果是在xslt/data中找到的stylizer1b.html。
要去除一些多余的空白,将以下突出显示的行添加到样式表中。
<xsl:stylesheet ...
>
<xsl:output method="html"/>
<xsl:strip-space elements="SECT"/>
[...]
此指令告诉 XSL 删除SECT元素下只包含空格的文本节点。不包含空格以外文本的节点不会受影响,也不会影响其他类型的节点。
运行带有修剪空白的Stylizer示例
-
导航至
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例,并将其解压缩到install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航至
xslt目录。cd xslt -
编译
Stylizer示例。输入以下命令:
% javac Stylizer.java -
使用样式表
article1b.xsl在article1.xml上运行Stylizer示例。% java Stylizer data/article1b.xsl data/article1.xml您将看到以下输出:
<html> <body> <h1 align="center">A Sample Article</h1> <h2>The First Major Section </h2> <p>This section will introduce a subsection.</p> <h3>The Subsection Heading </h3> <p>This is the text of the subsection. </p> </body> </html>这是一个相当大的改进。标题后仍然有换行符和空格,但这些来自 XML 的编写方式:
<SECT>The First Major Section ____<PARA>This section will introduce a subsection.</PARA> ^^^^在这里,您可以看到节标题以换行符和缩进空格结束,然后是 PARA 条目开始。这不是一个大问题,因为处理 HTML 的浏览器通常会压缩和忽略多余的空格。但我们还有一个格式化工具可供使用。
移除最后的空白
注意 - 本节讨论的样式表在article1c.xsl中,解压XSLT examples到install-dir/jaxp-1_4_2-release-date/samples目录后,可以在xslt/data目录中找到。结果是在xslt/data中找到的stylizer1c.html。
最后那一点空白空间通过将以下内容添加到样式表中来处理:
<xsl:template match="text()">
<xsl:value-of select="normalize-space()"/>
</xsl:template>
</xsl:stylesheet>
使用此样式表运行Stylizer将删除所有剩余的空白空间。
使用所有空白空间修剪的Stylizer示例运行
-
导航到
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例并将其解压缩到install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航到
xslt目录。cd xslt -
编译
Stylizer示例。输入以下命令:
% javac Stylizer.java -
使用样式表
article1c.xsl在article1.xml上运行Stylizer示例。% java Stylizer data/article1c.xsl data/article1.xml输出现在看起来像这样:
<html> <body> <h1 align="center">A Sample Article </h1> <h2>The First Major Section</h2> <p>This section will introduce a subsection. </p> <h3>The Subsection Heading</h3> <p>This is the text of the subsection. </p> </body> </html>那已经好多了。当然,如果能缩进会更好,但事实证明这比预期的要困难一些。以下是一些可能的攻击途径,以及困难所在:
缩进选项
不幸的是,可以应用于 XML 输出的
indent="yes"选项对 HTML 输出不可用。即使该选项可用,也不会有帮助,因为 HTML 元素很少嵌套!尽管 HTML 源经常缩进以显示暗示的结构,但 HTML 标记本身并未以创建真实结构的方式嵌套。缩进变量
<xsl:text>函数允许您添加任何文本,包括空格。因此,它可能被用于输出缩进空间。问题在于变化缩进空间的数量。XSLT 变量似乎是一个好主意,但在这里不起作用。原因是当您在模板中为变量赋值时,该值仅在该模板内(在编译时静态地)被知晓。即使变量在全局范围内定义,分配的值也不会以一种使其在运行时动态地被其他模板知晓的方式存储。当<apply-templates/>调用其他模板时,这些模板不知道其他地方设置的任何变量设置。参数化模板
使用参数化模板是修改模板行为的另一种方法。但确定要传递的缩进空间量作为参数仍然是问题的关键。
目前,似乎没有任何好的方法来控制 HTML 格式化输出的缩进。如果您需要将 HTML 显示或编辑为纯文本,那将会很不方便。但如果您在 XML 表单上进行编辑,仅在浏览器中显示 HTML 版本,则不是问题(例如,当您查看
stylizer1c.html时,您会看到预期的结果)。
处理剩余的结构元素
在这一部分,您将处理 LIST 和 NOTE 元素,这些元素为文章添加了更多结构。
注意 - 本节描述的示例文档是 article2.xml,用于操作它的样式表是 article2.xsl。结果是 stylizer2.html。解压缩 XSLT examples 到 install-dir/jaxp-1_4_2-release-date/samples 目录后,这些文件可以在 xslt/data 目录中找到。
首先向示例文档添加一些测试数据:
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
...
</SECT>
<SECT>The Second Major Section
<PARA>This section adds a LIST and a NOTE.
<PARA>Here is the LIST:
<LIST type="ordered">
<ITEM>Pears</ITEM>
<ITEM>Grapes</ITEM>
</LIST>
</PARA>
<PARA>And here is the NOTE:
<NOTE>Don't forget to go to the
hardware store on your way
to the grocery!
</NOTE>
</PARA>
</SECT>
</ARTICLE>
注意 - 虽然 XML 文件中的 list 和 note 包含在各自的段落中,但它们是否包含并不重要;生成的 HTML 无论如何都是相同的。但是包含它们会使它们在面向大纲的编辑器中更容易处理。
修改 <PARA> 处理
接下来,修改 PARA 模板以考虑我们现在允许一些结构元素嵌入到段落中的事实:
<xsl:template match="PARA">
<p> <xsl:apply-templates select=
"text()|B|I|U|DEF|LINK"/>
</p>
<xsl:apply-templates select=
"PARA|LIST|NOTE"/>
</xsl:template>
这种修改使用了你用于节标题的相同技术。唯一的区别是 SECT 元素不应该出现在段落中。(但是,一个段落很容易存在于另一个段落内,例如,作为引用材料)。
处理 <LIST> 和 <ITEM> 元素
现在你已经准备好添加一个模板来处理 LIST 元素:
<xsl:template match="LIST">
<xsl:if test="@type='ordered'">
<ol>
<xsl:apply-templates/>
</ol>
</xsl:if>
<xsl:if test="@type='unordered'">
<ul>
<xsl:apply-templates/>
</ul>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
<xsl:if> 标签使用 test="" 属性来指定一个布尔条件。在这种情况下,测试值是 type 属性,并且生成的列表会根据值是有序还是无序而改变。
在这个例子中注意两个重要的事情:
-
没有 else 子句,也没有 return 或 exit 语句,因此需要两个
<xsl:if>标签来覆盖两个选项。(或者可以使用<xsl:choose>标签,它提供了 case 语句功能)。 -
在属性值周围需要使用单引号。否则,XSLT 处理器会尝试将 ordered 作为 XPath 函数来解释,而不是作为字符串。
现在通过处理 ITEM 元素来完成 LIST 处理:
<xsl:template match="ITEM">
<li><xsl:apply-templates/>
</li>
</xsl:template>
</xsl:stylesheet>
在样式表中排序模板
到目前为止,你应该已经了解到模板是彼此独立的,所以它们通常出现在文件中的位置并不重要。因此,从这一点开始,我们只会展示你需要添加的模板。(为了比较,它们总是添加在示例样式表的末尾)。
当两个模板可以应用于同一节点时,顺序确实很重要。在这种情况下,最后定义的模板是被找到和处理的。例如,要将缩进列表的排序更改为使用小写字母表,可以指定一个看起来像这样的模板模式://LIST//LIST。在该模板中,您将使用 HTML 选项生成字母枚举,而不是数字枚举。
但这样的元素也可以通过模式//LIST来识别。为了确保正确处理,指定//LIST的模板必须出现在指定//LIST//LIST的模板之前。
处理<NOTE>元素
唯一剩下的结构元素是NOTE元素。添加以下模板来处理它。
<xsl:template match="NOTE">
<blockquote><b>Note:</b><br/>
<xsl:apply-templates/>
</p></blockquote>
</xsl:template>
</xsl:stylesheet>
这段代码引发了一个有趣的问题,这是由于包含<br/>标签导致的。为了使文件成为格式良好的 XML,必须在样式表中指定该标签为<br/>,但许多浏览器不识别该标签。虽然大多数浏览器识别序列<br></br>,但它们都将其视为段落换行而不是单个换行。
换句话说,转换必须生成一个<br>标签,但样式表必须指定<br/>。这就是我们在样式表中早期添加的特殊输出标签的主要原因:
<xsl:stylesheet ... >
<xsl:output method="html"/>
[...]
</xsl:stylesheet>
该输出规范将空标签(如<br/>)转换为它们的 HTML 形式<br>,在输出时。这种转换很重要,因为大多数浏览器不识别空标签。以下是受影响的标签列表:
area frame isindex
base hr link
basefont img meta
br input param
col
总之,默认情况下,XSLT 在输出时生成格式良好的 XML。因为 XSL 样式表本身就是格式良好的 XML,所以你不能轻易地在其中间放置<br>这样的标签。<xsl:output method="html"/>标签解决了这个问题,这样你可以在样式表中编码<br/>,但在输出中得到<br>。
指定<xsl:output method="html"/>的另一个主要原因是,与指定<xsl:output method="text"/>一样,生成的文本不会被转义。例如,如果样式表包含<实体引用,它将出现为生成文本中的<字符。另一方面,当生成 XML 时,样式表中的<实体引用将保持不变,因此在生成的文本中会显示为<。
注意 - 如果你希望<实际上作为 HTML 输出的一部分生成,你需要将其编码为<。这个序列在输出时变为<,因为只有&被转换为&字符。
使用定义了LIST和NOTE元素的Stylizer示例运行
-
导航到
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例,并将其解压缩到install-dir
/jaxp-1_4_2-release-date/samples目录中。 -
导航到
xslt目录。cd xslt -
编译
Stylizer示例。输入以下命令:
% javac Stylizer.java -
使用样式表
article2.xsl在article2.xml上运行Stylizer示例。% java Stylizer data/article2.xsl data/article2.xml这是当你现在运行程序时为第二部分生成的 HTML:
... <h2>The Second Major Section </h2> <p>This section adds a LIST and a NOTE. </p> <p>Here is the LIST: </p> <ol> <li>Pears</li> <li>Grapes</li> </ol> <p>And here is the NOTE: </p> <blockquote> <b>Note:</b> <br>Do not forget to go to the hardware store on your way to the grocery! </blockquote>
处理内联(内容)元素
ARTICLE类型中唯一剩下的标签是内联标签-它们不会在输出中创建换行,而是被整合到它们所属的文本流中。
内联元素与结构元素不同,内联元素是标签内容的一部分。 如果将元素视为文档树中的节点,则每个节点都具有内容和结构。 内容由它包含的文本和内联标记组成。 结构由标签下的其他元素(结构元素)组成。
注意 - 本节描述的示例文档是article3.xml,用于操作它的样式表是article3.xsl。 结果是stylizer3.html。
首先向示例文档添加一些测试数据:
<?xml version="1.0"?>
<ARTICLE>
<TITLE>A Sample Article</TITLE>
<SECT>The First Major Section
[...]
</SECT>
<SECT>The Second Major Section
[...]
</SECT>
<SECT>The <i>Third</i>
Major Section
<PARA>In addition to the inline tag
in the heading,
this section defines the term
<DEF>inline</DEF>,
which literally means "no line break".
It also adds a simple link to the main page
for the Java platform
(<LINK>http://java.sun.com</LINK>),
as well as a link to the
<LINK target="http://java.sun.com/xml">
XML </LINK>
page.
</PARA>
</SECT>
</ARTICLE>
现在处理段落中的内联<DEF>元素,将它们重命名为 HTML 斜体标记:
<xsl:template match="DEF">
<i> <xsl:apply-templates/> </i>
</xsl:template>
接下来,注释掉文本节点规范化。它已经达到了它的目的,现在你需要保留重要的空格:
<!--
<xsl:template match="text()">
<xsl:value-of select="normalize-space()"/>
</xsl:template>
-->
这个修改使我们不会丢失在<I>和<DEF>等标签之前的空格。 (尝试在没有此修改的情况下运行程序,看看结果)。
现在处理基本的内联 HTML 元素,如<B>,<I>和<U>,用于加粗,斜体和下划线。
<xsl:template match="B|I|U">
<xsl:element name="{name()}">
<xsl:apply-templates/>
</xsl:element>
</xsl:template>
<xsl:element>标签允许您计算要生成的元素。 在这里,您使用当前元素的名称生成适当的内联标记。 特别要注意在name=".."表达式中使用大括号({})。 这些大括号导致引号内的文本被处理为 XPath 表达式,而不是被解释为字面字符串。 在这里,它们导致 XPath name()函数返回当前节点的名称。
大括号可以出现在属性值模板可以出现的任何地方。 (属性值模板在 XSLT 规范的第 7.6.2 节中定义,并且它们出现在模板定义的几个地方)。 在这种表达式中,大括号也可以用于引用属性的值,{@foo},或元素的内容{foo}。
注意 - 您还可以使用<xsl:attribute>生成属性。 有关更多信息,请参阅 XSLT 规范的第 7.1.3 节。
最后剩下的元素是LINK标签。处理该标签的最简单方法是设置一个带有参数的命名模板:
<xsl:template name="htmLink">
<xsl:param name="dest"
select="UNDEFINED"/>
<xsl:element name="a">
<xsl:attribute name="href">
<xsl:value-of select=""/>
</xsl:attribute>
<xsl:apply-templates/>
</xsl:element>
</xsl:template>
这个模板的主要区别在于,不是指定匹配子句,而是使用name=""子句为模板指定一个名称。 因此,只有在调用它时才会执行此模板。
在模板内部,还使用<xsl:param>标签指定一个名为dest的参数。 为了进行一些错误检查,您使用 select 子句为该参数指定了一个默认值UNDEFINED。 要在<xsl:value-of>标签中引用变量,您指定.。
`* * *
注意 - 请记住,引号中的条目被解释为表达式,除非它进一步被单引号括起来。 这就是为什么之前需要在"@type='ordered'"中使用单引号来确保 ordered 被解释为字符串。
<xsl:element>标签生成一个元素。之前,你可以简单地通过编写类似<html>的代码来指定我们想要的元素。但是在这里,你正在动态生成<xsl:element>标签的主体中 HTML 锚点(<a>)的内容。并且你正在使用<xsl:attribute>标签动态生成锚点的href属性。
模板的最后一个重要部分是<apply-templates>标签,它插入LINK元素下文本节点中的文本。如果没有它,生成的 HTML 链接中将没有文本。
接下来,添加LINK标签的模板,并在其中调用命名模板:
<xsl:template match="LINK">
<xsl:if test="@target">
<!--Target attribute specified.-->
<xsl:call-template
name="htmLink">
<xsl:with-param name="dest"
select="@target"/>
</xsl:call-template>
</xsl:if>
</xsl:template>
<xsl:template name="htmLink">
[...]
test="@target"子句在 LINK 标签中存在 target 属性时返回 true。因此,当链接的文本和为其定义的目标不同时,这个<xsl-if>标签会生成 HTML 链接。
<xsl:call-template>标签调用命名模板,而<xsl:with-param>使用name子句指定参数,并使用select子句指定其值。
在样式表构建过程的最后一步中,添加<xsl-if>标签来处理没有target属性的LINK标签。
<xsl:template match="LINK">
<xsl:if test="@target">
[...]
</xsl:if>
<xsl:if test="not(@target)">
<xsl:call-template name="htmLink">
<xsl:with-param name="dest">
<xsl:apply-templates/>
</xsl:with-param>
</xsl:call-template>
</xsl:if>
</xsl:template>
not(...)子句反转了先前的测试(记住,没有 else 子句)。因此,当未指定目标属性时,模板的这部分被解释。这次,参数值不是来自select子句,而是来自<xsl:with-param>元素的内容。
注意 - 仅仅是为了明确:参数和变量(稍后在 XSLT 还能做什么?中讨论)的值可以通过select子句指定,让你可以使用 XPath 表达式,也可以通过元素的内容指定,让你可以使用 XSLT 标签。
在这种情况下,参数的内容是由<xsl:apply-templates/>标签生成的,它插入LINK元素下文本节点的内容。
运行带有内联元素定义的Stylizer示例
-
导航到
samples目录。% cd *install-dir*/jaxp-1_4_2-*release-date*/samples. -
点击此链接下载 XSLT 示例并将其解压缩到install-dir
/jaxp-1_4_2-release-date/samples目录。 -
导航到
xslt目录。cd xslt -
编译
Stylizer示例。输入以下命令:
% javac Stylizer.java -
使用样式表
article3.xsl在article3.xml上运行Stylizer示例。% java Stylizer data/article3.xsl data/article3.xml现在运行程序,结果应该看起来像这样:
[...] <h2>The <i>Third</i> Major Section</h2> <p>In addition to the inline tag in the heading, this section defines the term <i>inline</i>, which literally means "no line break". It also adds a simple link to the main page for the Java platform (<a href="http://java.sun.com">http://java.sun.com</a>), as well as a link to the <a href="http://java.sun.com/xml">XML</a> page.</p>干得好!你现在已经将一个相当复杂的 XML 文件转换为 HTML。(尽管一开始看起来很简单,但它确实提供了很多探索的机会)。
打印 HTML
您现在已将 XML 文件转换为 HTML。总有一天,会有人制作出一个了解 HTML 的打印引擎,您将能够通过 Java 打印服务 API 找到并使用它。到那时,您将能够通过生成 HTML 打印任意 XML 文件。您只需设置一个样式表并使用您的浏览器。
XSLT 还能做什么?
尽管本节内容很长,但只是触及了 XSLT 的能力表面。XSLT 规范中还有许多额外的可能性等待着您。以下是一些值得关注的事项:
import(第 2.6.2 节)和 include(第 2.6.1 节)
rt(第 2.6.2 节)和 include(第 2.6.1 节)使用这些语句对 XSLT 样式表进行模块化和组合。include 语句只是插入所包含文件中的任何定义。import 语句允许您用自己样式表中的定义覆盖导入文件中的定义。
for-each 循环(第 8 节)
遍历一系列项目并依次处理每个项目。
choose(case 语句)用于条件处理(第 9.2 节)
根据输入值分支到多个处理路径之一。
生成数字(第 7.7 节)
动态生成编号的章节、编号元素和数字文字。XSLT 提供三种编号模式:
-
Single:将项目编号在单个标题下,就像 HTML 中的有序列表
-
Multiple:生成多级编号,如"A.1.3"
-
Any:无论项目出现在何处,都连续编号,就像课程中的脚注。
格式化数字(第 12.3 节)
控制枚举格式,以便获得数字(format="1")、大写字母(format="A")、小写字母(format="a")或复合数字,如"A.1",以及适合特定国际区域设置的数字和货币金额。
排序输出(第 10 节)
按照所需的排序顺序生成输出。
基于模式的模板(第 5.7 节)
多次处理一个元素,每次在不同的“模式”中。您可以向模板添加一个模式属性,然后指定<apply-templates mode="...">来仅应用具有匹配模式的模板。结合<apply-templates select="...">属性,将基于模式的处理应用于输入数据的子集。
变量(第 11 节)
变量类似于方法参数,可以控制模板的行为。但它们并不像你想象的那样有价值。变量的值仅在定义它的当前模板或<xsl:if>标签(例如)的范围内才可知。你无法将一个值从一个模板传递到另一个模板,甚至无法将一个模板的封闭部分的值传递到同一模板的另一部分。
即使是“全局”变量,这些说法也是正确的。你可以在模板中更改它的值,但更改仅适用于该模板。当用于定义全局变量的表达式被评估时,该评估发生在结构的根节点的上下文中。换句话说,全局变量本质上是运行时常量。这些常量可以用于改变模板的行为,特别是与包含和导入语句结合使用时。但变量不是通用的数据管理机制。
变量的问题
创建一个单一模板并为链接的目标设置一个变量,而不是费力地设置一个带参数的模板并以两种不同的方式调用它,这是一个诱人的想法。这个想法是将变量设置为默认值(比如,LINK标签的文本),然后,如果目标属性存在,将目的地变量设置为目标属性的值。
如果这个方法行得通就好了。但问题在于变量只在定义它们的范围内才被知晓。因此,当你编写一个<xsl:if>标签来改变变量的值时,该值只在<xsl:if>标签的上下文中被知晓。一旦遇到</xsl:if>,对变量设置的任何更改都会丢失。
一个同样诱人的想法是用一个变量()来替换text()|B|I|U|DEF|LINK规范。但由于变量的值取决于它的定义位置,全局内联变量的值由文本节点、`节点等组成,这些节点恰好存在于根级别。换句话说,在这种情况下,这样一个变量的值是空的。**


 浙公网安备 33010602011771号
浙公网安备 33010602011771号