
Python 数据科学入门教程:Pandas
Python 和 Pandas 数据分析教程
原文:Data Analysis with Python and Pandas Tutorial Introduction
译者:飞龙
大家好,欢迎阅读 Python 和 Pandas 数据分析系列教程。 Pandas 是一个 Python 模块,Python 是我们要使用的编程语言。Pandas 模块是一个高性能,高效率,高水平的数据分析库。
它的核心就像操作一个电子表格的无头版本,比如 Excel。你使用的大多数数据集将是所谓的数据帧(DataFrame)。你可能已经熟悉这个术语,它也用于其他语言,但是如果没有,数据帧通常就像电子表格一样,拥有列和行,这就是它了!从这里开始,我们可以利用 Pandas 以闪电般的速度操作我们的数据集。
Pandas 还与许多其他数据分析库兼容,如用于机器学习的 Scikit-Learn,用于图形的 Matplotlib,NumPy,因为它使用 NumPy ,以及其他。这些是非常强大和宝贵的。如果你发现自己使用 Excel 或者一般电子表格来执行各种计算任务,那么他们可能需要一分钟或者一小时来运行,Pandas 将会改变你的生活。我甚至已经看到机器学习的版本,如 K-Means 聚类在 Excel 上完成。这真的很酷,但是我的 Python 会为你做得更快,这也将使你对参数要求更严格,拥有更大的数据集,并且能够完成更多的工作。
还有一个好消息。你可以很容易加载和输出xls或xlsx格式的文件,所以,即使你的老板想用旧的方式来查看,他们也可以。Pandas 还可以兼容文本文件,csv,hdf文件,xml,html等等,其 IO 非常强大。
如果你刚刚入门 Python,那么你应该可以继续学习,而不必精通 Python,这甚至可以让你入门 Python 。最重要的是,如果你有问题,问问他们!如果你为每一个困惑的领域寻找答案,并为此做好每件事,那么最终你会有一个完整的认识。你的大部分问题都可以通过 Google 解决。不要害怕 Google 你的问题,它不会嘲笑你,我保证。我仍然 Google 了我的很多目标,看看是否有人有一些示例代码,做了我想做的事情,所以不要仅仅因为你这样做了,而觉得你是个新手。
如果我还没有把 Pandas 推销给你,那么电梯演讲就是:电子表格式数据的闪电般的数据分析,具有非常强大的输入/输出机制,可以处理多种数据类型,甚至可以转换数据类型。
好的,你被推销了。现在让我们获取 Pandas!首先,我将假设有些人甚至还没有 Python。到目前为止,最简单的选择是使用预编译的 Python 发行版,比如 ActivePython,它是个快速简单的方式,将数据科学所需的所有包和依赖关系都集中在一起,而不需要一个接一个安装它们,特别是在 64 位 Windows 上。我建议获取最新版本的 64 位 Python。仅在这个系列中,我们使用 Pandas ,它需要 Numpy。我们还将使用 Matplotlib 和 Scikit-Learn,所有这些都是 ActivePython 自带的,预先编译和优化的 MKL。你可以从这里下载一个配置完整的 Python 发行版。
如果你想手动安装 Python,请转到Python.org,然后下载 Python 3+ 或更高版本。不要仅仅获取2.X。记下你下载的位版本。因为你的操作系统是 64 位的,这并是你的 Python 版本,默认总是 32 位。选择你想要的。 64 位可能有点头疼,所以如果你是新手,我不会推荐它,但 64 位是数据科学的理想选择,所以你不会被锁定在最大 2GB 的 RAM 上。如果你想装 64 位,查看pip安装教程可能有帮助,其中介绍了如何处理常规安装以及更棘手的 64 位软件包。如果你使用 32 位,那么现在不用担心这个教程。
所以你已经安装了 Python。接下来,转到你的终端或cmd.exe,然后键入:pip install pandas。你有没有得到pip is not a recognized command或类似的东西?没问题,这意味着pip不在你的PATH中。pip是一个程序,但是你的机器不知道它在哪里,除非它在你的PATH中。如果你愿意,你可以搜索如何添加一些东西到你的PATH中,但是你总是可以显式提供你想要执行的程序的路径。例如,在 Windows 上,Python 的pip位于C:/Python34/Scripts/pip中。 Python34的意思是 Python 3.4。如果你拥有 Python 3.6,那么你需要使用Python36,以此类推。
因此,如果常规的pip install pandas不起作用,那么你可以执行C:/Python34/Scripts/pip install pandas。
到了这里,人们争论的另一个重点是他们选择的编辑器。编辑器在事物的宏观层面中并不重要。你应该尝试多个编辑器,并选择最适合你的编辑器。无论哪个,只要你感到舒适,而且你的工作效率很高,这是最重要的。一些雇主也会迫使你最终使用编辑器 X,Y 或 Z,所以你可能不应该依赖编辑器功能。因此,我更喜欢简单的 IDLE,这就是我将用于编程的东西。再次,你可以在 Wing,emacs,Nano,Vim,PyCharm,IPython 中编程,你可以随便选一个。要打开 IDLE,只需访问开始菜单,搜索 IDLE,然后选择它。在这里,File > New,砰的一下,你就有了带高亮的文本编辑器和其他一些小东西。我们将在进行中介绍一些这些次要的事情。
现在,无论你使用哪种编辑器,都可以打开它,让我们编写一些简单的代码来查看数据帧。
通常,DataFrame最接近 Python Dictionary 数据结构。如果你不熟悉字典,这里有一个教程。我将在视频中注明类似的东西,并且在描述中,以及在PythonProgramming.net上的文本版教程中有链接。
首先,我们来做一些简单的导入:
import pandas as pd
import datetime
import pandas.io.data as web在这里,我们将pandas导入为pd。 这只是导入pandas模块时使用的常用标准。 接下来,我们导入datetime,我们稍后将使用它来告诉 Pandas 一些日期,我们想要拉取它们之间的数据。 最后,我们将pandas.io.data导入为web,因为我们将使用它来从互联网上获取数据。 接下来:
start = datetime.datetime(2010, 1, 1)
end = datetime.datetime(2015, 8, 22)在这里,我们创建start和end变量,这些变量是datetime对象,获取 2010 年 1 月 1 日到 2015 年 8 月 22 日的数据。现在,我们可以像这样创建数据帧:
df = web.DataReader("XOM", "yahoo", start, end)这从雅虎财经 API 获取 Exxon 的数据,存储到我们的df变量。 将你的数据帧命名为df不是必需的,但是它页是用于 Pandas 的非常主流的标准。 它只是帮助人们立即识别活动数据帧,而无需追溯代码。
所以这给了我们一个数据帧,我们怎么查看它? 那么,可以打印它,就像这样:
print(df)所以这是很大一个空间。 数据集的中间被忽略,但仍然是大量输出。 相反,大多数人只会这样做:
print(df.head())输出:
Open High Low Close Volume Adj Close
Date
2010-01-04 68.720001 69.260002 68.190002 69.150002 27809100 59.215446
2010-01-05 69.190002 69.449997 68.800003 69.419998 30174700 59.446653
2010-01-06 69.449997 70.599998 69.339996 70.019997 35044700 59.960452
2010-01-07 69.900002 70.059998 69.419998 69.800003 27192100 59.772064
2010-01-08 69.690002 69.750000 69.220001 69.519997 24891800 59.532285这打印了数据帧的前 5 行,并且对于调试很有用,只查看了数据帧的外观。 当你执行分析等,看看你想要的东西是否实际发生了,就很有用。 不过,我们稍后会深入它。
我们可以在这里停止介绍,但还有一件事:数据可视化。 我之前说过,Pandas 和其他模块配合的很好,Matplotlib 就是其中之一。 让我们来看看! 打开你的终端或cmd.exe,并执行pip install matplotlib。 你安装完 Pandas,我确信你应该已经获取了它,但我们要证实一下。 现在,在脚本的顶部,和其他导入一起,添加:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')Pyplot 是 matplotlib 的基本绘图模块。 Style 帮助我们快速美化图形,style.use让我们选择风格。 有兴趣了解 Matplotlib 的更多信息吗? 查看 Matplotlib 的深入系列教程!
接下来,在我们的print(df.head())下方,我们可以执行如下操作:
df['High'].plot()
plt.legend()
plt.show()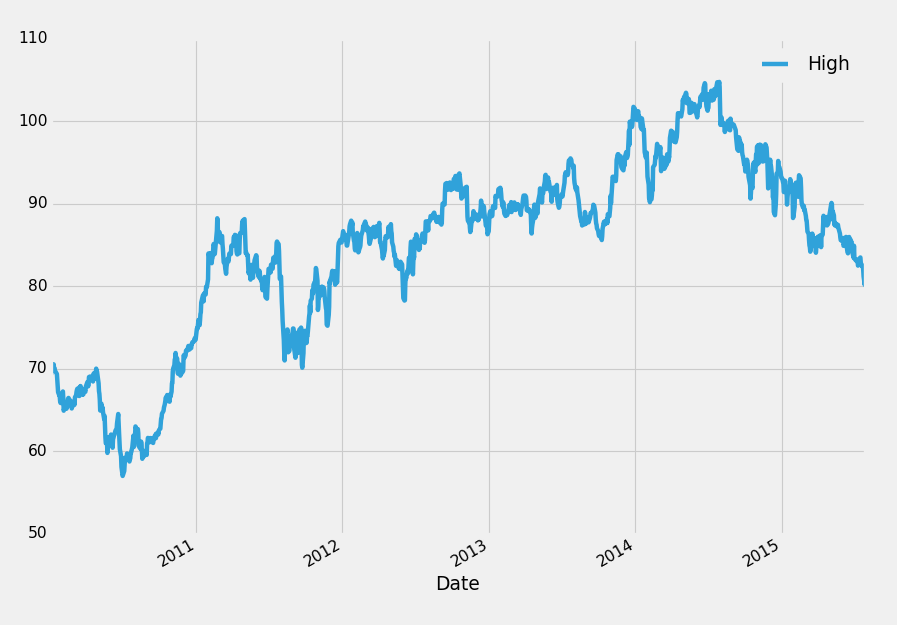
很酷! 这里有个 pandas 的快速介绍,但一点也不可用。 在这个系列中,我们将会涉及更多 Pandas 的基础知识,然后转到导航和处理数据帧。 从这里开始,我们将更多地介绍可视化,多种数据格式的输入和输出,基本和进阶数据分析和操作,合并和组合数据帧,重复取样等等。
如果你迷茫,困惑,或需要澄清,请不要犹豫,给对应的视频提问。
二、Pandas 基础
在这个 Python 和 Pandas 数据分析教程中,我们将弄清一些 Pandas 的基础知识。 加载到 Pandas 数据帧之前,数据可能有多种形式,但通常需要是以行和列组成的数据集。 所以也许是这样的字典:
web_stats = {'Day':[1,2,3,4,5,6],
'Visitors':[43,34,65,56,29,76],
'Bounce Rate':[65,67,78,65,45,52]}我们可以将这个字典转换成数据帧,通过这样:
import pandas as pd
web_stats = {'Day':[1,2,3,4,5,6],
'Visitors':[43,34,65,56,29,76],
'Bounce Rate':[65,67,78,65,45,52]}
df = pd.DataFrame(web_stats)现在我们可以做什么?之前看到,你可以通过这样来查看简单的起始片段:
print(df.head()) Bounce Rate Day Visitors
0 65 1 43
1 67 2 34
2 78 3 65
3 65 4 56
4 45 5 29你也可以查看后几行。为此,你需要这样做:
print(df.tail()) Bounce Rate Day Visitors
1 67 2 34
2 78 3 65
3 65 4 56
4 45 5 29
5 52 6 76最后,你也可以传入头部和尾部数量,像这样:
print(df.tail(2)) Bounce Rate Day Visitors
4 45 5 29
5 52 6 76你可以在这里看到左边有这些数字,0,1,2,3,4,5等等,就像行号一样。 这些数字实际上是你的“索引”。 数据帧的索引是数据相关,或者数据按它排序的东西。 一般来说,这将是连接所有数据的变量。 这里,我们从来没有为此目的定义任何东西,知道这个变量是什么,对于 Pandas 是个挑战。 因此,当你没有定义索引时,Pandas 会像这样为你生成一个。 现在看数据集,你能看到连接其他列的列吗?
Day列适合这个东西! 一般来说,如果你有任何日期数据,日期将成为“索引”,因为这就是所有数据点的关联方式。 有很多方法可以识别索引,更改索引等等。 我们将在这里介绍一些。 首先,在任何现有的数据帧上,我们可以像这样设置一个新的索引:
df.set_index('Day', inplace=True)输出:
Bounce Rate Visitors
Day
1 65 43
2 67 34
3 78 65
4 65 56
5 45 29现在你可以看到这些行号已经消失了,同时也注意到Day比其他列标题更低,这是为了表示索引。 有一点需要注意的是inplace = True的使用。 这允许我们原地修改数据帧,意味着我们实际上修改了变量本身。 没有inplace = True,我们需要做一些事情:
df = df.set_index('Day')你也可以设置多个索引,但这是以后的更高级的主题。 你可以很容易做到这一点,但它的原因相当合理。
一旦你有了合理的索引,是一个日期时间或数字,那么它将作为一个 X 轴。 如果其他列也是数值数据,那么你可以轻松绘图。 就像我们之前做的那样,继续并执行:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')然后,在底部,你可以绘图。 还记得我们之前引用了特定的列嘛?也许你注意到了,但是我们可以像这样,引用数据帧中的特定项目:
print(df['Visitors'])Day
1 43
2 34
3 65
4 56
5 29
6 76
Name: Visitors, dtype: int64你也可以像对象一样引用数据帧的部分,只要没有空格,就可以这样做:
print(df.Visitors)Day
1 43
2 34
3 65
4 56
5 29
6 76
Name: Visitors, dtype: int64所以我们可以像这样绘制单列:
df['Visitors'].plot()
plt.show()我们也可以绘制整个数据帧。 只要数据是规范化的或者在相同的刻度上,效果会很好。 这是一个例子:
df.plot()
plt.show()注意图例如何自动添加。 你可能会喜欢的另一个很好的功能是,图例也自动为实际绘制的直线让路。 如果你是 Python 和 Matplotlib 的新手,这可能对你来说并不重要,但这不是一个正常的事情。
最后,在我们离开之前,你也可以一次引用多个列,就像这样(我们只有两列,但是多列相同):
print(df[['Visitors','Bounce Rate']])所以这是括起来的列标题列表。 你也可以绘制这个。
这些是一些方法,你可以直接与数据帧进行交互,引用数据框的各个方面,带有一个示例,绘制了这些特定的方面。
三、IO 基础
欢迎阅读 Pandas 和 Python 数据分析第三部分。在本教程中,我们将开始讨论 Pandas IO 即输入/输出,并从一个实际的用例开始。为了得到充分的实践,一个非常有用的网站是 Quandl。 Quandl 包含大量的免费和付费数据源。这个站点的好处在于数据通常是标准化的,全部在一个地方,提取数据的方法是一样的。如果你使用的是 Python,并且通过它们的简单模块访问 Quandl 数据,那么数据将自动以数据帧返回。出于本教程的目的,我们将仅仅出于学习的目的而手动下载一个 CSV 文件,因为并不是每个数据源都会有一个完美的模块用于提取数据集。
假设我们有兴趣,在德克萨斯州的奥斯汀购买或出售房屋。那里的邮政编码是 77006。我们可以访问当地的房源清单,看看目前的价格是多少,但这并不能真正为我们提供任何真实的历史信息,所以我们只是试图获得一些数据。让我们来查询“房屋价值指数 77006”。果然,我们可以在这里看到一个索引。有顶层,中层,下层,三居室,等等。比方说,当然,我们有一个三居室的房子。我们来检查一下。原来 Quandl 已经提供了图表,但是我们还是要抓取数据集,制作自己的图表,或者做一些其他的分析。访问“下载”,并选择 CSV。Pandas 的 IO 兼容 csv,excel 数据,hdf,sql,json,msgpack,html,gbq,stata,剪贴板和 pickle 数据,并且列表不断增长。查看 IO 工具文档的当前列表。将该 CSV 文件移动到本地目录(你正在使用的目录/这个.py脚本所在的目录)。
以这个代码开始,将 CSV 加载进数据帧就是这样简单:
import pandas as pd
df = pd.read_csv('ZILL-Z77006_3B.csv')
print(df.head())输出:
Date Value
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700注意我们又没有了合适的索引。我们可以首先这样做来修复:
df.set_index('Date', inplace = True)现在,让我们假设,我们打算将它转回 CSV,我们可以:
df.to_csv('newcsv2.csv')我们仅仅有了一列,但是如果你有很多列,并且仅仅打算转换一列,你可以:
df['Value'].to_csv('newcsv2.csv')要记住我们如何绘制多列,但是并不是所有列。看看你能不能猜出如何保存多列,但不是所有列。
现在,让我们读取新的 CSV:
df = pd.read_csv('newcsv2.csv')
print(df.head())输出:
Date Value
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700该死,我们的索引又没了! 这是因为 CSV 没有像我们的数据帧那样的“索引”属性。 我们可以做的是,在导入时设置索引,而不是导入之后设置索引。 像这样:
df = pd.read_csv('newcsv2.csv', index_col=0)
print(df.head())输出:
Value
Date
2015-06-30 502300
2015-05-31 501500
2015-04-30 500100
2015-03-31 495800
2015-02-28 492700现在,我不了解你,但“价值”这个名字是毫无价值的。 我们可以改变这个吗? 当然,有很多方法来改变列名,一种方法是:
df.columns = ['House_Prices']
print(df.head())输出:
House_Prices
Date
2015-06-30 502300
2015-05-31 501500
2015-04-30 500100
2015-03-31 495800
2015-02-28 492700下面,我们可以尝试这样保存为 CSV:
df.to_csv('newcsv3.csv')如果你看看 CSV,你应该看到它拥有标题。如果不想要标题怎么办呢?没问题!
df.to_csv('newcsv4.csv', header=False)如果文件没有标题呢?没问题!
df = pd.read_csv('newcsv4.csv', names = ['Date','House_Price'], index_col=0)
print(df.head())输出:
House_Price
Date
2015-06-30 502300
2015-05-31 501500
2015-04-30 500100
2015-03-31 495800
2015-02-28 492700这些是IO的基本知识,在输入和输出时有一些选项。
一个有趣的事情是使用 Pandas 进行转换。 所以,也许你是从 CSV 输入数据,但你真的希望在你的网站上,将这些数据展示为 HTML。 由于 HTML 是数据类型之一,我们可以将其导出为 HTML,如下所示:
df.to_html('example.html')现在我们有了 HTML 文件。打开它,然后你就有了 HTML 中的一个表格:
| House_Prices |
|---|
| Date |
| 2015-06-30 |
| 2015-05-31 |
| 2015-04-30 |
| 2015-03-31 |
| 2015-02-28 |
| 2015-01-31 |
| 2014-12-31 |
| 2014-11-30 |
| 2014-10-31 |
| 2014-09-30 |
| 2014-08-31 |
| 2014-07-31 |
| 2014-06-30 |
| 2014-05-31 |
| 2014-04-30 |
| 2014-03-31 |
注意,这个表自动分配了dataframe类。 这意味着你可以自定义 CSS 来处理数据帧特定的表!
当我有用数据的 SQL 转储时,我特别喜欢使用 Pandas。 我倾向于将数据库数据直接倒入 Pandas 数据帧中,执行我想要执行的操作,然后将数据显示在图表中,或者以某种方式提供数据。
最后,如果我们想重新命名其中一列,该怎么办? 之前,你已经看到了如何命名所有列,但是也许你只是想改变一个列,而不必输入所有的列。 足够简单:
print(df.head())
df.rename(columns={'House_Price':'Prices'}, inplace=True)
print(df.head())输出:
Date House_Price
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700
Date Prices
0 2015-06-30 502300
1 2015-05-31 501500
2 2015-04-30 500100
3 2015-03-31 495800
4 2015-02-28 492700所以在这里,我们首先导入了无头文件,提供了列名Date和House_Price。 然后,我们决定,我们打算用Price代替House_Price。 因此,我们使用df.rename,指定我们要重命名的列,然后在字典形式中,键是原始名称,值是新名称。 我们最终使用inplace = True,以便修改原始对象。
四、构件数据集
在 Python 和 Pandas 数据分析系列教程的这一部分中,我们将扩展一些东西。让我们想想,我们是亿万富豪,还是千万富豪,但成为亿万富豪则更有趣,我们正在努力使我们的投资组合尽可能多样化。我们希望拥有所有类型的资产类别,所以我们有股票,债券,也许是一个货币市场帐户,现在我们正在寻找坚实的不动产。你们都看过广告了吗?你买了 60 美元的 CD,参加了 500 美元的研讨会,你开始把你的 6 位数字投资到房地产,对吧?
好吧,也许不是,但是我们肯定要做一些研究,并有一些购买房地产的策略。那么,什么统治了房价,我们是否需要进行研究才能找到答案?一般来说,不,你并不需要那么做,我们知道这些因素。房价的因素受经济,利率和人口统计的影响。这是房地产价格总体上的三大影响。现在当然,如果你买土地,其他的事情很重要,它的水平如何,我们是否需要在土地上做一些工作,才能真正奠定基础,如何排水等等。那么我们还有更多的因素,比如屋顶,窗户,暖气/空调,地板,地基等等。我们可以稍后考虑这些因素,但首先我们要从宏观层面开始。你会看到我们的数据集在这里膨胀得有多快,它会爆炸式增长。
所以,我们的第一步是收集数据。 Quandl 仍然是良好的起始位置,但是这一次让我们自动化数据抓取。我们将首先抓取 50 个州的住房数据,但是我们也试图收集其他数据。我们绝对不想手动抓取这个数据。首先,如果你还没有帐户,你需要得到一个帐户。这将给你一个 API 密钥和免费数据的无限的 API 请求,这真棒。
一旦你创建了一个账户,访问your account / me,不管他们这个时候叫什么,然后找到标有 API 密钥的部分。这是你所需的密钥。接下来,我们要获取 Quandl 模块。我们实际上并不需要模块来生成请求,但它是一个非常小的模块,他能给我们带来一些小便利,所以不妨试试。打开你的终端或cmd.exe并且执行pip install quandl(再一次,如果pip不能识别,记得指定pip的完整路径)。
接下来,我们做好了开始的准备,打开一个新的编辑器。开始:
import Quandl
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
df = Quandl.get("FMAC/HPI_TX", authtoken=api_key)
print(df.head())如果你愿意的话,你可以只存储你的密钥的纯文本版本,我只隐藏了我的密钥,因为它是我发布的教程。这是我们需要做的,来获得德克萨斯州的房价指数。我们抓取的实际指标可以在任何页面上找到,无论你什么时候访问,只要在网站上点击你使用的库,我们这里是 Python,然后需要输入的查询就会弹出。
随着你的数据科学事业的发展,你将学习到各种常数,因为人们是合乎逻辑和合理的。我们这里,我们需要获取所有州的数据。我们如何做到呢?我们是否需要手动抓取每个指标?不,看看这个代码,我们看到FMAC/HPI_TX。我们可以很容易地把这个解码为FMAC = Freddie Mac。 HPI = House Price Index(房价指数)。TX是德克萨斯州,它的常用两字母缩写。从这里,我们可以安全地假设所有的代码都是这样构建的,所以现在我们只需要一个州缩写的列表。我们搜索它,作出选择,就像这个 50 个州的列表。怎么办?
我们可以通过多种方式提取这些数据。这是一个 Pandas 教程,所以如果我们可以 Pandas 熊猫,我们就这样。让我们来看看 Pandas 的read_html。它不再被称为“实验性”的,但我仍然会将其标记为实验性的。其他 IO 模块的标准和质量非常高并且可靠。read_html并不是很好,但我仍然说这是非常令人印象深刻有用的代码,而且很酷。它的工作方式就是简单地输入一个 URL,Pandas 会从表中将有价值的数据提取到数据帧中。这意味着,与其他常用的方法不同,read_html最终会读入一些列数据帧。这不是唯一不同点,但它是不同的。首先,为了使用read_html,我们需要html5lib。打开cmd.exe或你的终端,并执行:pip install html5lib。现在,我们可以做我们的第一次尝试:
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
print(fiddy_states)它的输出比我要在这里发布的更多,但你明白了。 这些数据中至少有一部分是我们想要的,看起来第一个数据帧是一个很好的开始。 那么让我们执行:
print(fiddy_states[0]) 0 1 2 3
0 Abbreviation State name Capital Became a state
1 AL Alabama Montgomery December 14, 1819
2 AK Alaska Juneau January 3, 1959
3 AZ Arizona Phoenix February 14, 1912
4 AR Arkansas Little Rock June 15, 1836
5 CA California Sacramento September 9, 1850
6 CO Colorado Denver August 1, 1876
7 CT Connecticut Hartford January 9, 1788
8 DE Delaware Dover December 7, 1787
9 FL Florida Tallahassee March 3, 1845
10 GA Georgia Atlanta January 2, 1788
11 HI Hawaii Honolulu August 21, 1959
12 ID Idaho Boise July 3, 1890
13 IL Illinois Springfield December 3, 1818
14 IN Indiana Indianapolis December 11, 1816
15 IA Iowa Des Moines December 28, 1846
16 KS Kansas Topeka January 29, 1861
17 KY Kentucky Frankfort June 1, 1792
18 LA Louisiana Baton Rouge April 30, 1812
19 ME Maine Augusta March 15, 1820
20 MD Maryland Annapolis April 28, 1788
21 MA Massachusetts Boston February 6, 1788
22 MI Michigan Lansing January 26, 1837
23 MN Minnesota Saint Paul May 11, 1858
24 MS Mississippi Jackson December 10, 1817
25 MO Missouri Jefferson City August 10, 1821
26 MT Montana Helena November 8, 1889
27 NE Nebraska Lincoln March 1, 1867
28 NV Nevada Carson City October 31, 1864
29 NH New Hampshire Concord June 21, 1788
30 NJ New Jersey Trenton December 18, 1787
31 NM New Mexico Santa Fe January 6, 1912
32 NY New York Albany July 26, 1788
33 NC North Carolina Raleigh November 21, 1789
34 ND North Dakota Bismarck November 2, 1889
35 OH Ohio Columbus March 1, 1803
36 OK Oklahoma Oklahoma City November 16, 1907
37 OR Oregon Salem February 14, 1859
38 PA Pennsylvania Harrisburg December 12, 1787
39 RI Rhode Island Providence May 19, 1790
40 SC South Carolina Columbia May 23, 1788
41 SD South Dakota Pierre November 2, 1889
42 TN Tennessee Nashville June 1, 1796
43 TX Texas Austin December 29, 1845
44 UT Utah Salt Lake City January 4, 1896
45 VT Vermont Montpelier March 4, 1791
46 VA Virginia Richmond June 25, 1788
47 WA Washington Olympia November 11, 1889
48 WV West Virginia Charleston June 20, 1863
49 WI Wisconsin Madison May 29, 1848
50 WY Wyoming Cheyenne July 10, 1890是的,这看起来不错,我们想要第零列。所以,我们要遍历fiddy_states[0]的第零列。 请记住,现在fiddy_states是一个数帧列表,而fiddy_states[0]是第一个数据帧。 为了引用第零列,我们执行fiddy_states[0][0]。 一个是列表索引,它返回一个数据帧。 另一个是数据帧中的一列。 接下来,我们注意到第零列中的第一项是abbreviation,我们不想要它。 当我们遍历第零列中的所有项目时,我们可以使用[1:]排除掉它。 因此,我们的缩写列表是fiddy_states[0][0][1:],我们可以像这样迭代:
for abbv in fiddy_states[0][0][1:]:
print(abbv)AL
AK
AZ
AR
CA
CO
CT
DE
FL
GA
HI
ID
IL
IN
IA
KS
KY
LA
ME
MD
MA
MI
MN
MS
MO
MT
NE
NV
NH
NJ
NM
NY
NC
ND
OH
OK
OR
PA
RI
SC
SD
TN
TX
UT
VT
VA
WA
WV
WI
WY完美! 现在,我们回忆这样做的原因:我们正在试图用州名缩写建立指标,来获得每个州的房价指数。 好的,我们可以建立指标:
for abbv in fiddy_states[0][0][1:]:
#print(abbv)
print("FMAC/HPI_"+str(abbv))
FMAC/HPI_AL
FMAC/HPI_AK
FMAC/HPI_AZ
FMAC/HPI_AR
FMAC/HPI_CA
FMAC/HPI_CO
FMAC/HPI_CT
FMAC/HPI_DE
FMAC/HPI_FL
FMAC/HPI_GA
FMAC/HPI_HI
FMAC/HPI_ID
FMAC/HPI_IL
FMAC/HPI_IN
FMAC/HPI_IA
FMAC/HPI_KS
FMAC/HPI_KY
FMAC/HPI_LA
FMAC/HPI_ME
FMAC/HPI_MD
FMAC/HPI_MA
FMAC/HPI_MI
FMAC/HPI_MN
FMAC/HPI_MS
FMAC/HPI_MO
FMAC/HPI_MT
FMAC/HPI_NE
FMAC/HPI_NV
FMAC/HPI_NH
FMAC/HPI_NJ
FMAC/HPI_NM
FMAC/HPI_NY
FMAC/HPI_NC
FMAC/HPI_ND
FMAC/HPI_OH
FMAC/HPI_OK
FMAC/HPI_OR
FMAC/HPI_PA
FMAC/HPI_RI
FMAC/HPI_SC
FMAC/HPI_SD
FMAC/HPI_TN
FMAC/HPI_TX
FMAC/HPI_UT
FMAC/HPI_VT
FMAC/HPI_VA
FMAC/HPI_WA
FMAC/HPI_WV
FMAC/HPI_WI
FMAC/HPI_WY我们已经得到了指标,现在我们已经准备好提取数据帧了。 但是,一旦我们拿到他们,我们会做什么? 我们将使用 50 个独立的数据帧? 听起来像一个愚蠢的想法,我们需要一些方法来组合他们。 Pandas 背后的优秀人才看到了这一点,并为我们提供了多种组合数据帧的方法。 我们将在下一个教程中讨论这个问题。
五、连接(concat)和附加数据帧
欢迎阅读 Python 和 Pandas 数据分析系列教程第五部分。在本教程中,我们将介绍如何以各种方式组合数据帧。
在我们的房地产投资案例中,我们希望使用房屋数据获取 50 个数据帧,然后把它们全部合并成一个数据帧。我们这样做有很多原因。首先,将这些组合起来更容易,更有意义,也会减少使用的内存。每个数据帧都有日期和值列。这个日期列在所有数据帧中重复出现,但实际上它们应该全部共用一个,实际上几乎减半了我们的总列数。
在组合数据帧时,你可能会考虑相当多的目标。例如,你可能想“附加”到他们,你可能会添加到最后,基本上就是添加更多的行。或者,也许你想添加更多的列,就像我们的情况一样。有四种主要的数据帧组合方式,我们现在开始介绍。四种主要的方式是:连接(Concatenation),连接(Join),合并和附加。我们将从第一种开始。这里有一些初始数据帧:
df1 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2001, 2002, 2003, 2004])
df2 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2005, 2006, 2007, 2008])
df3 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'Low_tier_HPI':[50, 52, 50, 53]},
index = [2001, 2002, 2003, 2004])注意这些之间有两个主要的变化。 df1和df3具有相同的索引,但它们有一些不同的列。 df2和df3有不同的索引和一些不同的列。 通过连接(concat),我们可以讨论将它们结合在一起的各种方法。 我们来试一下简单的连接(concat):
concat = pd.concat([df1,df2])
print(concat)
HPI Int_rate US_GDP_Thousands
2001 80 2 50
2002 85 3 55
2003 88 2 65
2004 85 2 55
2005 80 2 50
2006 85 3 55
2007 88 2 65
2008 85 2 55很简单。 这两者之间的主要区别仅仅是索引的延续,但是它们共享同一列。 现在他们已经成为单个数据帧。 然而我们这里,我们对添加列而不是行感到好奇。 当我们将一些共有的和一些新列组合起来:
concat = pd.concat([df1,df2,df3])
print(concat)
HPI Int_rate Low_tier_HPI US_GDP_Thousands
2001 80 2 NaN 50
2002 85 3 NaN 55
2003 88 2 NaN 65
2004 85 2 NaN 55
2005 80 2 NaN 50
2006 85 3 NaN 55
2007 88 2 NaN 65
2008 85 2 NaN 55
2001 80 2 50 NaN
2002 85 3 52 NaN
2003 88 2 50 NaN
2004 85 2 53 NaN不错,我们有一些NaN(不是数字),因为那个索引处不存在数据,但是我们所有的数据确实在这里。
这些就是基本的连接(concat),接下来,我们将讨论附加。 附加就像连接的第一个例子,只是更加强大一些,因为数据帧会简单地追加到行上。 我们通过一个例子来展示它的工作原理,同时也展示它可能出错的地方:
df4 = df1.append(df2)
print(df4)
HPI Int_rate US_GDP_Thousands
2001 80 2 50
2002 85 3 55
2003 88 2 65
2004 85 2 55
2005 80 2 50
2006 85 3 55
2007 88 2 65
2008 85 2 55这就是我们期望的附加。 在大多数情况下,你将要做这样的事情,就像在数据库中插入新行一样。 我们并没有真正有效地附加数据帧,它们更像是根据它们的起始数据来操作,但是如果你需要,你可以附加。 当我们附加索引相同的数据时会发生什么?
df4 = df1.append(df3)
print(df4)
HPI Int_rate Low_tier_HPI US_GDP_Thousands
2001 80 2 NaN 50
2002 85 3 NaN 55
2003 88 2 NaN 65
2004 85 2 NaN 55
2001 80 2 50 NaN
2002 85 3 52 NaN
2003 88 2 50 NaN
2004 85 2 53 NaN好吧,这很不幸。 有人问为什么连接(concat )和附加都退出了。 这就是原因。 因为共有列包含相同的数据和相同的索引,所以组合这些数据帧要高效得多。 一个另外的例子是附加一个序列。 鉴于append的性质,你可能会附加一个序列而不是一个数据帧。 至此我们还没有谈到序列。 序列基本上是单列的数据帧。 序列确实有索引,但是,如果你把它转换成一个列表,它将仅仅是这些值。 每当我们调用df ['column']时,返回值就是一个序列。
s = pd.Series([80,2,50], index=['HPI','Int_rate','US_GDP_Thousands'])
df4 = df1.append(s, ignore_index=True)
print(df4) HPI Int_rate US_GDP_Thousands
0 80 2 50
1 85 3 55
2 88 2 65
3 85 2 55
4 80 2 50在附加序列时,我们必须忽略索引,因为这是规则,除非序列拥有名称。
在这里,我们已经介绍了 Pandas 中的连接(concat)和附加数据帧。 接下来,我们将讨论如何连接(join)和合并数据帧。
六、连接(join)和合并数据帧
欢迎阅读 Python 和 Pandas 数据分析系列教程的第六部分。 在这一部分种,我们将讨论连接(join)和合并数据帧,作为组合数据框的另一种方法。 在前面的教程中,我们介绍了连接(concat)和附加。
首先,我们将从以前的一些示例数据帧开始,带有一点更改:
import pandas as pd
df1 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2001, 2002, 2003, 2004])
df2 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2005, 2006, 2007, 2008])
df3 = pd.DataFrame({'HPI':[80,85,88,85],
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53]},
index = [2001, 2002, 2003, 2004])唯一的变化是df3,我们把Int_rate变成了unemployment。 首先,我们来讨论合并。
print(pd.merge(df1,df3, on='HPI')) HPI Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
0 80 2 50 50 7
1 85 3 55 52 8
2 85 3 55 53 6
3 85 2 55 52 8
4 85 2 55 53 6
5 88 2 65 50 9所以,在这里,我们看到了一个共有列(HPI)。 你可以共有多个列,这里有一个例子:
print(pd.merge(df1,df2, on=['HPI','Int_rate'])) HPI Int_rate US_GDP_Thousands_x US_GDP_Thousands_y
0 80 2 50 50
1 85 3 55 55
2 88 2 65 65
3 85 2 55 55注意这里有US_GDP_Thousands的两个版本。这是因为我们没有共享这些列,所以都保留下来,使用另外一个字母来区分。记得之前我说过,Pandas 是一个很好的模块,与类似 MySQL 的数据库结合。这就是原因。
通常,对于数据库,你希望使其尽可能轻量化,以便在其上运行的查询执行得尽可能快。
假设你运营像pythonprogramming.net这样的网站,在那里你有用户,所以你必须跟踪用户名和加密的密码散列,所以这肯定是两列。也许那么你有登录名,用户名,密码,电子邮件和注册日期。所以这已经是基本数据点的五列。如果你有一个论坛,那么也许你有一些东西,像用户设置,帖子。那么也许你希望有像管理员,主持人,普通用户的设置。
列表可以继续。如果你在字面上只有一个巨大的表,这可以工作,但把表分开也可能更好,因为许多操作将更快,更高效。 合并之后,你可能会设置新的索引。像这样的东西:
df4 = pd.merge(df1,df3, on='HPI')
df4.set_index('HPI', inplace=True)
print(df4) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
HPI
80 2 50 50 7
85 3 55 52 8
85 3 55 53 6
85 2 55 52 8
85 2 55 53 6
88 2 65 50 9现在,如果HPI已经是索引了呢? 或者,在我们的情况下,我们可能会按照日期连接,但日期可能是索引。 在这种情况下,我们可能会使用连接(join)。
df1.set_index('HPI', inplace=True)
df3.set_index('HPI', inplace=True)
joined = df1.join(df3)
print(joined) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
HPI
80 2 50 50 7
85 3 55 52 8
85 3 55 53 6
85 2 55 52 8
85 2 55 53 6
88 2 65 50 9现在,我们考虑连接(join)和合并略有不同的索引。 让我们重新定义df1和df3数据帧,将它们变成:
df1 = pd.DataFrame({
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55],
'Year':[2001, 2002, 2003, 2004]
})
df3 = pd.DataFrame({
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53],
'Year':[2001, 2003, 2004, 2005]})这里,我们现在有相似的年份列,但日期不同。 df3有 2005 年,但没有 2002 年,df1相反。 现在,当我们合并时会发生什么?
merged = pd.merge(df1,df3, on='Year')
print(merged) Int_rate US_GDP_Thousands Year Low_tier_HPI Unemployment
0 2 50 2001 50 7
1 2 65 2003 52 8
2 2 55 2004 50 9
````
现在,更实用一些:
<div class="se-preview-section-delimiter"></div>
```py
merged = pd.merge(df1,df3, on='Year')
merged.set_index('Year', inplace=True)
print(merged) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2003 2 65 52 8
2004 2 55 50 9注意 2005 年和 2002 年完全失踪了。 合并只会合并现有/共有的数据。 我们能对其做些什么呢? 事实证明,合并时有一个参数how。 此参数表明合并选择,它来自数据库的合并。 你有以下选择:左、右、外部、内部。
- 左 - SQL 左外连接 - 仅使用左侧数据帧中的键
- 右 - SQL 右外连接 - 仅使用右侧数据帧中的键
- 外部 - 全外联接 - 使用键的并集
- 内部 - 使用键的交集
merged = pd.merge(df1,df3, on='Year', how='left')
merged.set_index('Year', inplace=True)
print(merged) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2002 3 55 NaN NaN
2003 2 65 52 8
2004 2 55 50 9左侧合并实际上在左边的数据帧上。 我们有df1,df3,左边的是第一个,df1。 所以,我们最终得到了一个与左侧数据帧(df1)相同的索引。
merged = pd.merge(df1,df3, on='Year', how='right')
merged.set_index('Year', inplace=True)
print(merged) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2003 2 65 52 8
2004 2 55 50 9
2005 NaN NaN 53 6我们选择了右侧,所以这次索引来源于右侧(df3)。
merged = pd.merge(df1,df3, on='Year', how='outer')
merged.set_index('Year', inplace=True)
print(merged) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2002 3 55 NaN NaN
2003 2 65 52 8
2004 2 55 50 9
2005 NaN NaN 53 6这次,我们选择了外部,它是键的并集。也就是会展示所有索引。
merged = pd.merge(df1,df3, on='Year', how='inner')
merged.set_index('Year', inplace=True)
print(merged) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2003 2 65 52 8
2004 2 55 50 9最后,“内部”是键的交集,基本上就是所有集合之间共有的东西。 这些都有其自己的逻辑,但是,正如你所看到的,默认选项是“内部”。
现在我们可以检查连接(join),这会按照索引连接,所以我们可以做这样的事情:
df1.set_index('Year', inplace=True)
df3.set_index('Year', inplace=True)
joined = df1.join(df3, how="outer")
print(joined) Int_rate US_GDP_Thousands Low_tier_HPI Unemployment
Year
2001 2 50 50 7
2002 3 55 NaN NaN
2003 2 65 52 8
2004 2 55 50 9
2005 NaN NaN 53 6好吧,我想我们已经足以涵盖了数据帧的组合。 让我们回到我们的房地产投资,使用我们的新知识,并建立自己的史诗数据集。
七、Pickle
欢迎阅读 Python 和 Pandas 数据分析系列教程第七部分。 在最近的几个教程中,我们学习了如何组合数据集。 在本教程中,我们将恢复我们是房地产巨头的假设。 我们希望通过拥有多元化的财富来保护我们的财富,其中一个组成部分就是房地产。 在第 4部分 中,我们建立了以下代码:
import Quandl
import pandas as pd
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
for abbv in fiddy_states[0][0][1:]:
#print(abbv)
print("FMAC/HPI_"+str(abbv))这个代码用来获得 50 个州,遍历他们,并产生适当的 Quandl 查询,来按州返回房价指数。 由于我们将在这里生成 50 个数据帧,我们宁愿把它们全部合并成一个。 为此,我们可以使用前面教程中学到的.join。 在这种情况下,我们将使用.join,因为 Quandl 模块将数据返回给我们,实际索引为Date。 通常情况下,你可能不会得到这个,它只是索引为常规数字的数据帧。 在这种情况下,你可以使用连接,on ='Date'。
现在,为了运行并收集所有的数据,我们可以做以下的改变:
import Quandl
import pandas as pd
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
main_df = pd.DataFrame()
for abbv in fiddy_states[0][0][1:]:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)注意:Quandl 已经改变了数据集的返回值,如果返回值只有一列(或者我认为是这样),那么该列的标题就是value。那么,这很麻烦,但我们可以解决它。在for循环中,将数据帧的列重命名为我们的缩写。如果没有做这个改变,你可能会看到:ValueError: columns overlap but no suffix specified: Index([u'Value'], dtype='object')。
太好了,但是每一次你想运行它时,你会发现这个过程可能需要 30 秒到几分钟。这很烦人。现在,你的短期目标是实现它,但接下来呢?我们将继续在此基础上进行研究,每次我们进行测试或者其他东西时,我们都必须忍受这个无意义的东西!因此,我们要保存这些数据。现在,这是一个数据分析和 Pandas 教程。有了 Pandas,我们可以简单地将数据输出到 CSV,或者我们希望的任何数据类型,包括我们要谈论的内容。但是,你可能并不总是可以将数据输出到简单文件。在任何情况下,我们都希望将这些数据保存到一个文件中,所以我们只需要执行一次这个操作,然后我们就可以在它顶上建立。
举个例子来说,就是机器学习。你通常会训练一个分类器,然后你可以立即开始,然后快速使用该分类器进行分类。问题是,分类器不能保存到.txt或.csv文件。这是一个对象。幸运的是,以编程的方式,有各种各样的东西,用于将二进制数据保存到可以稍后访问的文件。在 Python 中,这被称为 Pickle。你可能知道它是序列化的,或者甚至别的东西。 Python 有一个名为 Pickle 的模块,它将把你的对象转换成一个字节流,或者反过来转换它。这让我们做的是保存任何 Python 对象。那机器学习分类器呢?可以。字典?可以。数据帧?可以!现在,Pandas 在 IO 模块中已经有了 Pickle,但是你真的应该知道如何使用和不使用 Pandas 来实现它,所以让我们这样做吧!
首先,我们来谈谈常规的 Pickle。你可以用你想要的任何 Python 对象来这样做,它不需要是一个数据帧,但我们会用我们的数据帧来实现。
首先,在脚本的顶部导入pickle:
import pickle下面:
pickle_out = open('fiddy_states.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close() 首先我们打开一个.pickle文件,打算写一些字节。 然后,我们执行pickle.dump来转储我们想要保存的数据,之后是转储它的地方(我们刚才打开的文件)。 最后,我们关闭任何文件。 完成了,我们保存了pickle。
不过,我希望现在组织这些代码。 我们不希望每次都运行这个代码,但是我们仍然需要时常引用状态列表。 我们来清理一下:
import Quandl
import pandas as pd
import pickle
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
grab_initial_state_data()现在,我们可以在任何需要状态列表的时候,引用state_list,然后我们只需要为HPI基线调用grab_initial_state_data,真的比较快,并且我们已经将这些数据保存到了pickle文件中。
现在,再次获取这些数据,我们只需要做:
pickle_in = open('fiddy_states.pickle','rb')
HPI_data = pickle.load(pickle_in)
print(HPI_data)输出比我想要粘贴的更多,但是你应该得到一个约 462 行 x50 列的数据帧。 你有了它。 部分对象是它是一个数据帧,这是我们“保存”变量的方式。 很酷! 你可以在 Python 的任何地方用pickle模块来这样做,但是 Pandas 也有自己的pickle,所以我们可以展示:
HPI_data.to_pickle('pickle.pickle')
HPI_data2 = pd.read_pickle('pickle.pickle')
print(HPI_data2)再次,输出有点多,不能粘贴在这里,但你应该得到同样的东西。 如果你和我一样,你可能会想“如果所有的 Python 已经有 Pickle 并且工作得很好,为什么 Pandas 有自己的 Pickle 选项?” 我真的不知道。 显然,Pandas 有时可以更快地处理海量数据。
现在我们已经得到了数据的pickle,我们已经准备好在下一篇教程中继续深入研究。
八、百分比变化和相关表
欢迎阅读 Python 和 Pandas 数据分析系列教程的第八部分。 在这一部分中,我们将对数据进行一些初步的操作。 我们到目前为止的脚本是:
import Quandl
import pandas as pd
import pickle
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
HPI_data = pd.read_pickle('fiddy_states.pickle')现在我们可以像这样修改列:
HPI_data['TX2'] = HPI_data['TX'] * 2
print(HPI_data[['TX','TX2']].head()) TX TX2
Date
1975-01-31 32.617930 65.235860
1975-02-28 33.039339 66.078677
1975-03-31 33.710029 67.420057
1975-04-30 34.606874 69.213747
1975-05-31 34.864578 69.729155我们我们也可以不创建新的列,只是重新定义原来的TX。 从我们的脚本中删除整个TX2的代码,让我们看看我们现在有什么。 在脚本的顶部:
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')之后:
HPI_data.plot()
plt.legend().remove()
plt.show()输出:
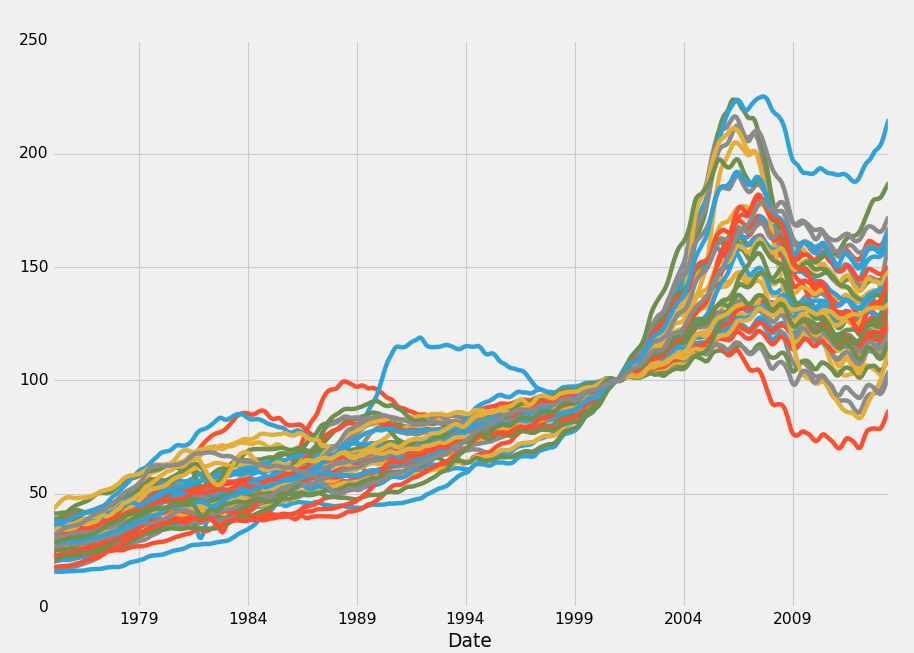
嗯,有趣,发生了什么事? 所有这些价格似乎在 2000 年完美汇合!这正是指数从 100.0% 开始的时候。 我们可以得到它,但我根本不喜欢。 那么某种百分比变化呢? 事实证明,Pandas 在这里覆盖了各种“滚动”统计量。 我们可以用一个基本的,就像这样:
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df = df.pct_change()
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states2.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
grab_initial_state_data() 主要是,你要注意:df = df.pct_change(),我们将重新运行它,保存到fiddy_states2.pickle。 值得注意的是,我们也可以尝试修改原来的 Pickle,而不是重新构建。 毕竟,这就是 Pickle 的要点。 如果我没有事后偏见,我可能会同意你的看法。
HPI_data = pd.read_pickle('fiddy_states2.pickle')
HPI_data.plot()
plt.legend().remove()
plt.show()输出:
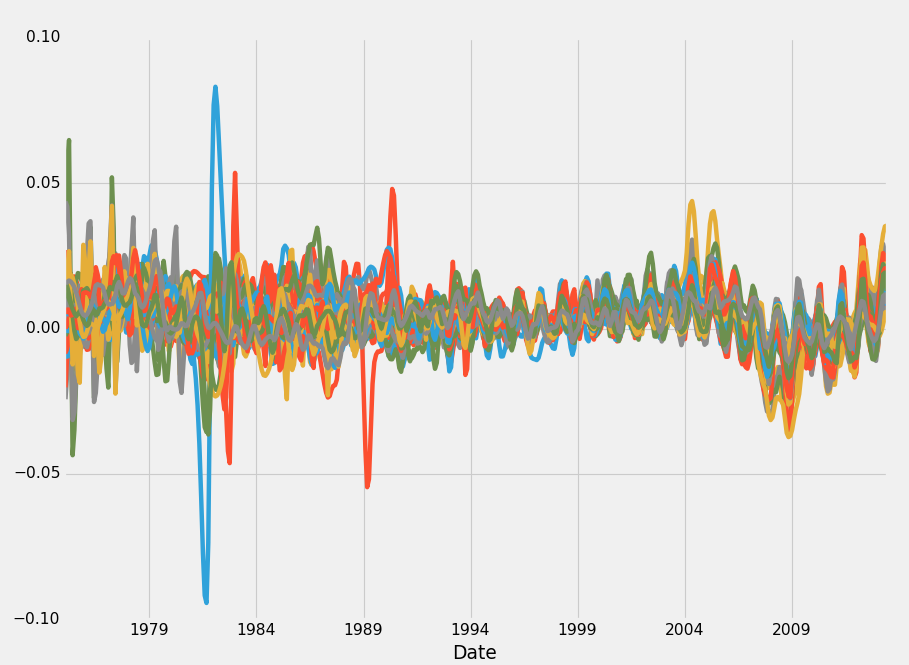
不幸的是,我不是那么想的。 我想要一个传统的百分比变化图。 这是距离上次报告值的百分比变化。 我们可以增加它,做一些事情,类似于过去 10 个值的滚动百分比,但仍然不是我想要的。 我们来试试其他的东西:
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
grab_initial_state_data()
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data.plot()
plt.legend().remove()
plt.show()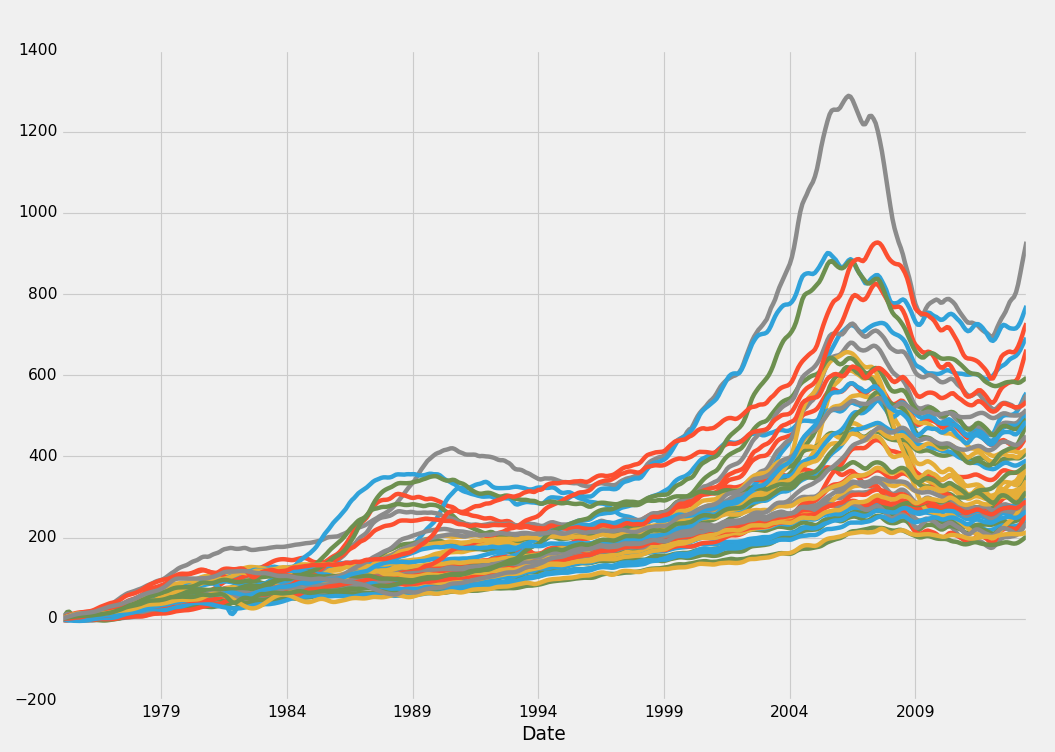
好的,这就是我要找的! 这是每个州 HPI 自身的百分比变化。 出于各种原因,第一个百分比变化仍然有用。 我们可能会结合使用这个结果,或者取而代之,但是现在,我们最开始坚持使用典型的百分比变化。
现在,我们可能想要引入其他数据集,但是让我们看看我们是否可以自己到达任何地方。 首先,我们可以检查某种“基准”。 对于这个数据,这个基准将是美国的房价指数。 我们可以收集:
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df之后:
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
benchmark = HPI_Benchmark()
HPI_data.plot(ax=ax1)
benchmark.plot(color='k',ax=ax1, linewidth=10)
plt.legend().remove()
plt.show()输出:
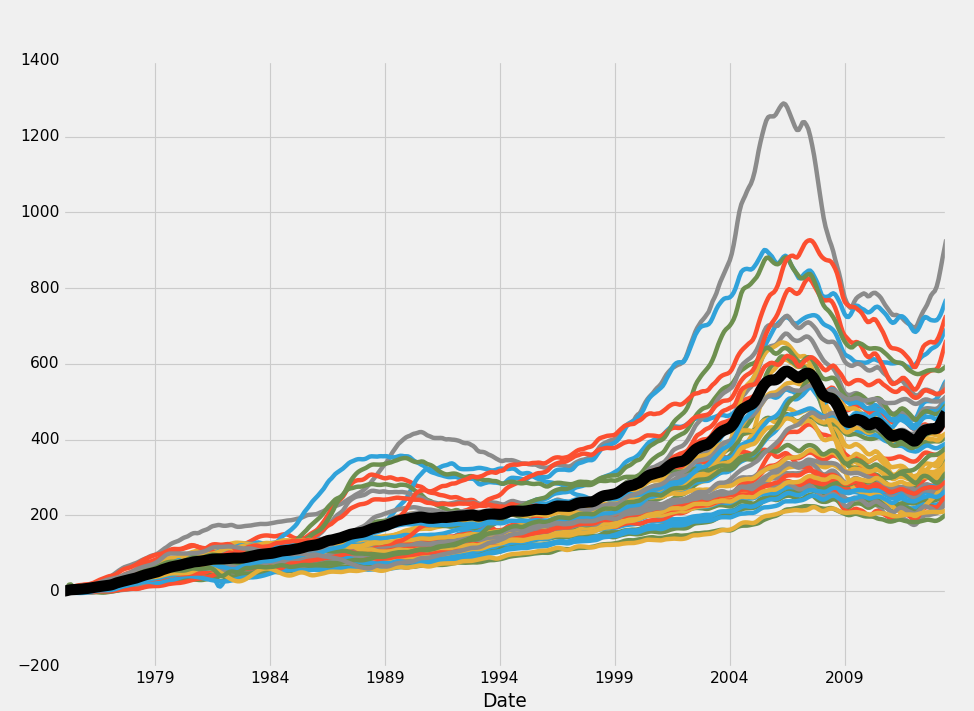
从这个数据来看,似乎是所有的市场都是相对密切地服从彼此和整体房价指数。这里确实存在一些平均偏差,但基本上每个市场似乎都遵循了非常相似的趋势。其中最大的偏差是从 200% 的增长到 800% 的增长,显然我们有很大的偏差,但是在过去的 30 年里,均值从 400% 增长到 500%。
我们如何接近市场呢?之后,我们可以考虑人口统计和利率来预测未来,但不是每个人都对投机游戏感兴趣。有些人想要更安全,更安全的投资。在这里看来,像房地产市场从来没有真正在国家层面失败。如果我们买房子,显然我们的计划可能会失败,之后我们发现了巨大白蚁危害,并可能在任何时候倒塌。
保持宏观,我很清楚,我们可以在这里进行一个非常明显,安全的交易。我们可以使用 Pandas 很容易地收集相关性和协方差信息。相关性和协方差是两个非常相似的话题,经常被混淆。相关不是因果关系,相关性几乎总是包含在协方差计算中用于归一化。相关性衡量了两个资产相对于彼此移动的程度。协方差是衡量两个资产如何一起变化的指标。注意相关性是对“程度”的一种度量。协方差不是。如果我自己的理解不正确,这是重要的区别。
我们来创建一个关联表。这将为我们做的事情,是历史回顾,衡量每个州与其他州的移动之间的相关性。那么,当两个通常高度相关的州开始出现不一致的时候,我们可以考虑出售正在上升的州的房地产,并购买正在下降的州的房地产作为一种市场中性策略,其中我们仅仅从差距中获益,而不是做一些预测未来的尝试。相互接壤的州更有可能比远离的州更相似,但是我们会看到数字说了些什么。
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_State_Correlation = HPI_data.corr()
print(HPI_State_Correlation)输出是 50 行 x50 列,这里是一些输出。
AL AK AZ AR CA CO CT \
AL 1.000000 0.944603 0.927361 0.994896 0.935970 0.979352 0.953724
AK 0.944603 1.000000 0.893904 0.965830 0.900621 0.949834 0.896395
AZ 0.927361 0.893904 1.000000 0.923786 0.973546 0.911422 0.917500
AR 0.994896 0.965830 0.923786 1.000000 0.935364 0.985934 0.948341
CA 0.935970 0.900621 0.973546 0.935364 1.000000 0.924982 0.956495
CO 0.979352 0.949834 0.911422 0.985934 0.924982 1.000000 0.917129
CT 0.953724 0.896395 0.917500 0.948341 0.956495 0.917129 1.000000
DE 0.980566 0.939196 0.942273 0.975830 0.970232 0.949517 0.981177
FL 0.918544 0.887891 0.994007 0.915989 0.987200 0.905126 0.926364
GA 0.973562 0.880261 0.939715 0.960708 0.943928 0.959500 0.948500
HI 0.946054 0.930520 0.902554 0.947022 0.937704 0.903461 0.938974
ID 0.982868 0.944004 0.959193 0.977372 0.944342 0.960975 0.923099
IL 0.984782 0.905512 0.947396 0.973761 0.963858 0.968552 0.955033
IN 0.981189 0.889734 0.881542 0.973259 0.901154 0.971416 0.919696
IA 0.985516 0.943740 0.894524 0.987919 0.914199 0.991455 0.913788
KS 0.990774 0.957236 0.910948 0.995230 0.926872 0.994866 0.936523
KY 0.994311 0.938125 0.900888 0.992903 0.923429 0.987097 0.941114
LA 0.967232 0.990506 0.909534 0.982454 0.911742 0.972703 0.907456
ME 0.972693 0.935850 0.923797 0.972573 0.965251 0.951917 0.989180
MD 0.964917 0.943384 0.960836 0.964943 0.983677 0.940805 0.969170
MA 0.966242 0.919842 0.921782 0.966962 0.962672 0.959294 0.986178
MI 0.891205 0.745697 0.848602 0.873314 0.861772 0.900040 0.843032
MN 0.971967 0.926352 0.952359 0.972338 0.970661 0.983120 0.945521
MS 0.996089 0.962494 0.927354 0.997443 0.932752 0.985298 0.945831
MO 0.992706 0.933201 0.938680 0.989672 0.955317 0.985194 0.961364
MT 0.977030 0.976840 0.916000 0.983822 0.923950 0.971516 0.917663
NE 0.988030 0.941229 0.896688 0.990868 0.912736 0.992179 0.920409
NV 0.858538 0.785404 0.965617 0.846968 0.948143 0.837757 0.866554
NH 0.953366 0.907236 0.932992 0.952882 0.969574 0.941555 0.990066
NJ 0.968837 0.934392 0.943698 0.967477 0.975258 0.944460 0.989845
NM 0.992118 0.967777 0.934744 0.993195 0.934720 0.968001 0.946073
NY 0.973984 0.940310 0.921126 0.973972 0.959543 0.949474 0.989576
NC 0.998383 0.934841 0.915403 0.991863 0.928632 0.977069 0.956074
ND 0.936510 0.973971 0.840705 0.957838 0.867096 0.942225 0.882938
OH 0.966598 0.855223 0.883396 0.954128 0.901842 0.957527 0.911510
OK 0.944903 0.984550 0.881332 0.967316 0.882199 0.960694 0.879854
OR 0.981180 0.948190 0.949089 0.978144 0.944542 0.971110 0.916942
PA 0.985357 0.946184 0.915914 0.983651 0.950621 0.956316 0.975324
RI 0.950261 0.897159 0.943350 0.945984 0.984298 0.926362 0.988351
SC 0.998603 0.945949 0.929591 0.994117 0.942524 0.980911 0.959591
SD 0.983878 0.966573 0.889405 0.990832 0.911188 0.984463 0.924295
TN 0.998285 0.946858 0.919056 0.995949 0.931616 0.983089 0.953009
TX 0.963876 0.983235 0.892276 0.981413 0.902571 0.970795 0.919415
UT 0.983987 0.951873 0.926676 0.982867 0.909573 0.974909 0.900908
VT 0.975210 0.952370 0.909242 0.977904 0.949225 0.951388 0.973716
VA 0.972236 0.956925 0.950839 0.975683 0.977028 0.954801 0.970366
WA 0.988253 0.948562 0.950262 0.982877 0.956434 0.968816 0.941987
WV 0.984364 0.964846 0.907797 0.990264 0.924300 0.979467 0.925198
WI 0.990190 0.930548 0.927619 0.985818 0.943768 0.987609 0.936340
WY 0.944600 0.983109 0.892255 0.960336 0.897551 0.950113 0.880035 所以现在我们可以看到,每两个州之间的 HPI 移动的相关性。 非常有趣,显而易见,所有这些都非常高。 相关性的范围从 -1 到 1。1 是个完美的正相关,-1 是个完美的负相关。 协方差没有界限。 想知道更多的统计量嘛? Pandas 有一个非常漂亮的描述方法:
print(HPI_State_Correlation.describe()) AL AK AZ AR CA CO \
count 50.000000 50.000000 50.000000 50.000000 50.000000 50.000000
mean 0.969114 0.932978 0.922772 0.969600 0.938254 0.958432
std 0.028069 0.046225 0.031469 0.029532 0.031033 0.030502
min 0.858538 0.745697 0.840705 0.846968 0.861772 0.837757
25% 0.956262 0.921470 0.903865 0.961767 0.916507 0.949485
50% 0.976120 0.943562 0.922784 0.976601 0.940114 0.964488
75% 0.987401 0.957159 0.943081 0.989234 0.961890 0.980550
max 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000
CT DE FL GA ... SD \
count 50.000000 50.000000 50.000000 50.000000 ... 50.000000
mean 0.938752 0.963892 0.920650 0.945985 ... 0.959275
std 0.035402 0.028814 0.035204 0.030631 ... 0.039076
min 0.843032 0.846668 0.833816 0.849962 ... 0.794846
25% 0.917541 0.950417 0.899680 0.934875 ... 0.952632
50% 0.941550 0.970461 0.918904 0.949980 ... 0.972660
75% 0.960920 0.980587 0.944646 0.964282 ... 0.982252
max 1.000000 1.000000 1.000000 1.000000 ... 1.000000
TN TX UT VT VA WA \
count 50.000000 50.000000 50.000000 50.000000 50.000000 50.000000
mean 0.968373 0.944410 0.953990 0.959094 0.963491 0.966678
std 0.029649 0.039712 0.033818 0.035041 0.029047 0.025752
min 0.845672 0.791177 0.841324 0.817081 0.828781 0.862245
25% 0.955844 0.931489 0.936264 0.952458 0.955986 0.954070
50% 0.976294 0.953301 0.956764 0.968237 0.970380 0.974049
75% 0.987843 0.967444 0.979966 0.976644 0.976169 0.983541
max 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000
WV WI WY
count 50.000000 50.000000 50.000000
mean 0.961813 0.965621 0.932232
std 0.035339 0.026125 0.048678
min 0.820529 0.874777 0.741663
25% 0.957074 0.950046 0.915386
50% 0.974099 0.973141 0.943979
75% 0.984067 0.986954 0.961900
max 1.000000 1.000000 1.000000
[8 rows x 50 columns]这告诉我们,对于每个州,最低的相关性是什么,平均相关性是什么,标准差是什么,前 25%,中间值(中位数/ 50%)等等。显然他们最大都为 1.0,因为他们是完全相关的。然而,最重要的是,我们在这里看到的所有这些州(50 列中的一些被跳过,我们从 GA 到 SD)与其他所有州的相关度平均上高于 90%。怀俄明州与一个州的相关度低至 74%,在看了我们的表后,它就是密歇根州。正因为如此,如果密歇根州上升,我们可能不想在怀俄明州投资,或者因为怀俄明州正在陷入困境而,出售我们在密歇根州的房子。
我们不仅可以从整体指数中看到任何偏差,还可以从个别市场中寻找偏差。正如你所看到的,我们有每个州的标准差数字。当市场低于标准偏差时,我们可以尝试投资于房地产,或者当市场高于标准偏差时卖出。在我们到达那里之前,让我们在下一个教程中讨论平滑数据以及重采样的概念。
九、重采样
欢迎阅读另一个 Python 和 Pandas 数据分析教程。在本教程中,我们将讨论通过消除噪音来平滑数据。有两种主要的方法来实现。所使用的最流行的方法是称为重采样,但可能具有许多其他名称。这是我们有一些数据,以一定的比例抽样。对我们来说,我们的房屋价格指数是按一个月抽样的,但是我们可以每周,每一天,每一分钟或更多时间对 HPI 进行抽样,但是我们也可以每年,每隔 10 年重新抽样。
例如,重新抽样经常出现的另一个环境就是股价。股票价格是二手数据。所发生的事情是,对于免费数据,股票价格通常最低被重新采样为分钟数据。但是,你可以购买实时数据。从长远来看,数据通常会每天采样,甚至每 3-5 天采样一次。这通常是为了使传输数据的大小保持较小。例如,在一年的过程中,二手数据通常是几个 GB,并且一次全部传输是不合理的,人们将等待几分钟或几小时来加载页面。
使用我们目前每个月抽样一次的数据,我们怎样才能每六个月或两年抽样一次呢?试着想想如何亲自编写一个能执行这个任务的函数,这是一个相当具有挑战性的函数,但是它可以完成。也就是说,这是一个计算效率相当低的工作,但 Pandas 会帮助我们,并且速度非常快。让我们来看看。我们现在的起始脚本:
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_State_Correlation = HPI_data.corr()首先,让我们更简单一点,首先参考德克萨斯州的信息,然后重新抽样:
TX1yr = HPI_data['TX'].resample('A')
print(TX1yr.head())Date
1975-12-31 4.559105
1976-12-31 11.954152
1977-12-31 23.518179
1978-12-31 41.978042
1979-12-31 64.700665
Freq: A-DEC, Name: TX, dtype: float64我们以A重新采样,这会每年重新采样(年终)。 你可以在这里找到所有的resample选项:http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases,但这里是我写这篇教程时的最新版本:
Resample rule:
xL for milliseconds
xMin for minutes
xD for Days
Alias Description
B business day frequency
C custom business day frequency (experimental)
D calendar day frequency
W weekly frequency
M month end frequency
BM business month end frequency
CBM custom business month end frequency
MS month start frequency
BMS business month start frequency
CBMS custom business month start frequency
Q quarter end frequency
BQ business quarter endfrequency
QS quarter start frequency
BQS business quarter start frequency
A year end frequency
BA business year end frequency
AS year start frequency
BAS business year start frequency
BH business hour frequency
H hourly frequency
T minutely frequency
S secondly frequency
L milliseonds
U microseconds
N nanoseconds
How:
mean, sum, ohlc现在我们可以比较两个数据集:
HPI_data['TX'].plot(ax=ax1)
TX1yr.plot(color='k',ax=ax1)
plt.legend().remove()
plt.show()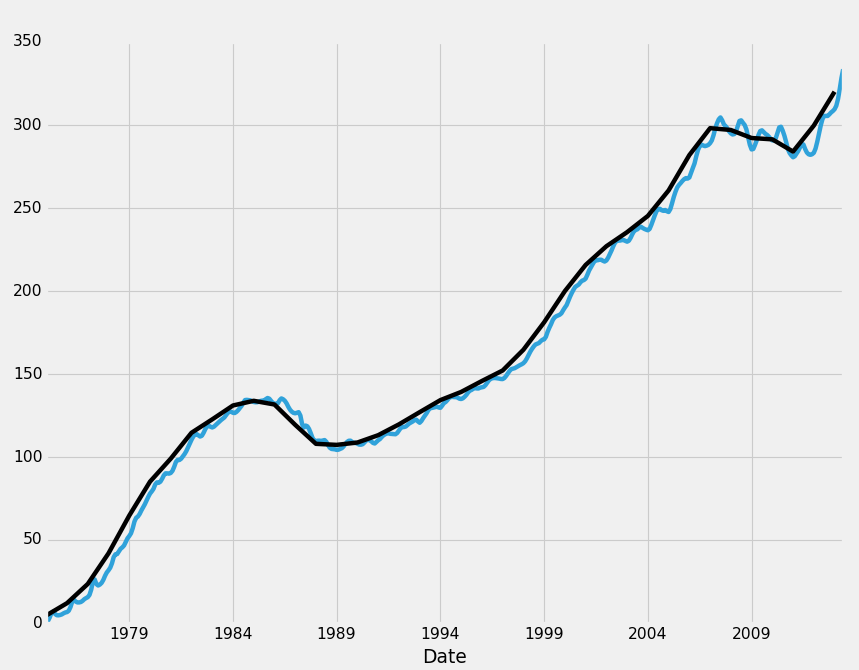
你可以看到,从月度数据变为年度数据并没有真正向我们隐藏趋势线本身的任何信息,但是至少在德克萨斯州,有一件有趣的事情需要注意,你觉得月度数据中的那些扭曲看起来有些模式化?我反正是。你可以将鼠标悬停在所有峰值上,然后开始查看出现峰值的一年中的月份。大部分峰值出现在 6 月左右,几乎每个最低值都在 12 月左右。许多州都有这种模式,而且在美国的 HPI 中也是如此。也许我们会玩玩这些趋势,并完成整个教程!我们现在是专家!
好的不完全是,我想我们会继续教程。所以通过重新采样,我们可以选择间隔,以及我们希望“如何”重新采样。默认是按照均值,但也有一个时期的总和。如果我们按年份重采样,使用how=sum,那么收益就是这一年所有 HPI 值的总和。最后是 OHLC,这是高开低收。这将返回这个期间的起始值,最高值,最低值和最后一个值。
我认为我们最好坚持使用月度数据,但重新采样绝对值得在任何 Pandas 教程中涵盖。现在,你可能想知道,为什么我们为重采样创建了一个新的数据帧,而不是将其添加到现有的数据帧中。原因是它会创建大量的NaN数据。有时候,即使只是原始的重采样也会包含NaN数据,特别是如果你的数据不按照统一的时间间隔更新的话。处理丢失的数据是一个主要的话题,但是我们将在下一个教程中试图广泛地介绍它,包括处理丢失数据的思路,以及如何通过程序处理你的选择。
十、处理缺失数据
欢迎阅读 Python 和 Pandas 数据分析教程的第 10 部分。在这一部分中,我们将讨论缺失或不可用的数据。考虑到缺失数据的存在,我们有几个选择。
- 忽略它 - 只把它留在那里
- 删除它 - 删除所有的情况。完全从数据中删除。这意味着放弃整行数据。
- 向前或向后填充 - 这意味着只是采用之前或之后的值填充。
- 将其替换为静态的东西 - 例如,用
-9999替换所有的NaN数据。
由于各种原因,这些选项各有其优点。忽略它不需要我们更多的工作。你可能会出于法律原因选择忽略丢失的数据,或者保留数据的最大完整性。缺失数据也可能是非常重要的数据。例如,也许你的分析的一部分是调查服务器的信号丢失。在这种情况下,缺失数据可能非常重要,需要保持在集合中。
接下来,我们可以删除它。在这里你有另外两个选择。如果行中包含任意数量的NaN数据,或者如果该行完全是NaN数据,则可以删除这些行。通常,充满NaN数据的行来自你在数据集上执行的计算,并且数据没有真的丢失,只是你的公式不可用。在大多数情况下,你至少需要删除所有完全是NaN的行,并且在很多情况下,你只希望删除任何具有NaN数据的行。我们该怎么做呢?我们将从以下脚本开始(请注意,现在通过在HPI_data数据帧中添加一个新列,来完成重新采样)。
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
##fig = plt.figure()
##ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX1yr'] = HPI_data['TX'].resample('A')
print(HPI_data[['TX','TX1yr']])
##HPI_data['TX'].plot(ax=ax1)
##HPI_data['TX1yr'].plot(color='k',ax=ax1)
##
##plt.legend().remove()
##plt.show()我们现在注释了绘图的东西,但是我们稍后会回顾它。
输出:
TX TX1yr
Date
1975-01-31 0.000000 NaN
1975-02-28 1.291954 NaN
1975-03-31 3.348154 NaN
1975-04-30 6.097700 NaN
1975-05-31 6.887769 NaN
1975-06-30 5.566434 NaN
1975-07-31 4.710613 NaN
1975-08-31 4.612650 NaN
1975-09-30 4.831876 NaN
1975-10-31 5.192504 NaN
1975-11-30 5.832832 NaN
1975-12-31 6.336776 4.559105
1976-01-31 6.576975 NaN
1976-02-29 7.364782 NaN
1976-03-31 9.579950 NaN
1976-04-30 12.867197 NaN
1976-05-31 14.018165 NaN
1976-06-30 12.938501 NaN
1976-07-31 12.397848 NaN
1976-08-31 12.388581 NaN
1976-09-30 12.638779 NaN
1976-10-31 13.341849 NaN
1976-11-30 14.336404 NaN
1976-12-31 15.000798 11.954152
1977-01-31 15.555243 NaN
1977-02-28 16.921638 NaN
1977-03-31 20.118106 NaN
1977-04-30 25.186161 NaN
1977-05-31 26.260529 NaN
1977-06-30 23.430347 NaN
... ... ...
2011-01-31 280.574891 NaN
2011-02-28 281.202150 NaN
2011-03-31 282.772390 NaN
2011-04-30 284.374537 NaN
2011-05-31 286.518910 NaN
2011-06-30 288.665880 NaN
2011-07-31 288.232992 NaN
2011-08-31 285.507223 NaN
2011-09-30 283.408865 NaN
2011-10-31 282.348926 NaN
2011-11-30 282.026481 NaN
2011-12-31 282.384836 284.001507
2012-01-31 283.248573 NaN
2012-02-29 285.790368 NaN
2012-03-31 289.946517 NaN
2012-04-30 294.803887 NaN
2012-05-31 299.670256 NaN
2012-06-30 303.575682 NaN
2012-07-31 305.478743 NaN
2012-08-31 305.452329 NaN
2012-09-30 305.446084 NaN
2012-10-31 306.424497 NaN
2012-11-30 307.557154 NaN
2012-12-31 308.404771 299.649905
2013-01-31 309.503169 NaN
2013-02-28 311.581691 NaN
2013-03-31 315.642943 NaN
2013-04-30 321.662612 NaN
2013-05-31 328.279935 NaN
2013-06-30 333.565899 NaN
[462 rows x 2 columns]我们有很多NaN数据。 如果我们取消所有绘图代码的注释,会发生什么? 原来,我们没有得到包含NaN数据的图表! 这是一个偷懒,所以首先我们想,好吧,让我们丢掉所有有NaN数据的行。 这仅仅是出于教程的目的。 在这个例子中,这将是一个非常糟糕的主意。 相反,你会想要做我们原来做的事情,这是为重采样数据创建一个新的数据帧。 并不意味着你可以总是这样做,但在这种情况下,你可以这样做。 无论如何,让我们删除包含任何na数据的所有行。 这很简单:
HPI_data.dropna(inplace=True)
print(HPI_data[['TX','TX1yr']]) TX TX1yr
Date
1975-12-31 6.336776 4.559105
1976-12-31 15.000798 11.954152
1977-12-31 30.434104 23.518179
1978-12-31 51.029953 41.978042
1979-12-31 75.975953 64.700665
1980-12-31 89.979964 85.147662
1981-12-31 108.121926 99.016599
1982-12-31 118.210559 114.589927
1983-12-31 127.233791 122.676432
1984-12-31 133.599958 131.033359
1985-12-31 132.576673 133.847016
1986-12-31 126.581048 131.627647
1987-12-31 109.829893 119.373827
1988-12-31 104.602726 107.930502
1989-12-31 108.485926 107.311348
1990-12-31 109.082279 108.727174
1991-12-31 114.471725 113.142303
1992-12-31 121.427564 119.650162
1993-12-31 129.817931 127.009907
1994-12-31 135.119413 134.279735
1995-12-31 141.774551 139.197583
1996-12-31 146.991204 145.786792
1997-12-31 155.855049 152.109010
1998-12-31 170.625043 164.595301
1999-12-31 188.404171 181.149544
2000-12-31 206.579848 199.952853
2001-12-31 217.747701 215.692648
2002-12-31 230.161877 226.962219
2003-12-31 236.946005 235.459053
2004-12-31 248.031552 245.225988
2005-12-31 267.728910 260.589093
2006-12-31 288.009470 281.876293
2007-12-31 296.154296 298.094138
2008-12-31 288.081223 296.999508
2009-12-31 291.665787 292.160280
2010-12-31 281.678911 291.357967
2011-12-31 282.384836 284.001507
2012-12-31 308.404771 299.649905没有带有缺失数据的行了!
现在我们可以绘制它:
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX1yr'] = HPI_data['TX'].resample('A')
HPI_data.dropna(inplace=True)
print(HPI_data[['TX','TX1yr']])
HPI_data['TX'].plot(ax=ax1)
HPI_data['TX1yr'].plot(color='k',ax=ax1)
plt.legend().remove()
plt.show()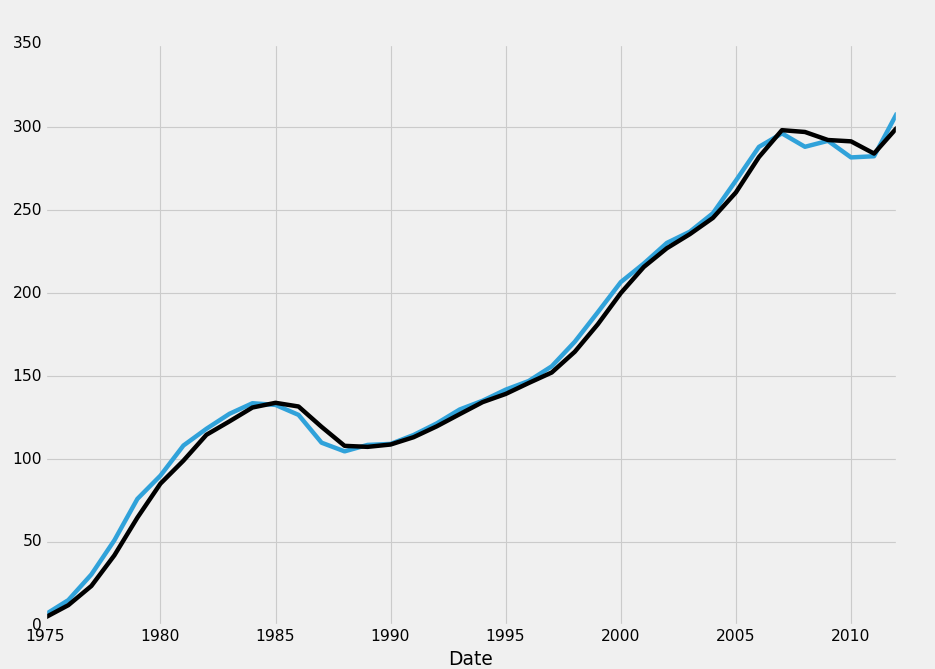
好的,太好了。 现在只是出于教程的目的,我们如何编写代码,只在整行是NaN时才删除行?
HPI_data.dropna(how='all',inplace=True)对于how参数,你可以选择any或all。 all需要该行中的所有数据为NaN,才能将其删除。 你也可以选择any,然后设置一个阈值。 该阈值将要求存在许多非na值,才能接受该行。 更多信息,请参阅dropna的Pandas文档。
好吧,所以这就是dropna,接下来我们可以填充它。 使用填充,我们又有两个主要的选择,是向前还是向后。 另一个选择是仅仅替换数据,但我们称这是一个单独的选择。 碰巧相同函数可以用于实现它,fillna。
修改我们原来的代码块,主要改变:
HPI_data.fillna(method='ffill',inplace=True)变为:
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX1yr'] = HPI_data['TX'].resample('A')
HPI_data.fillna(method='ffill',inplace=True)
HPI_data.dropna(inplace=True)
print(HPI_data[['TX','TX1yr']])
HPI_data['TX'].plot(ax=ax1)
HPI_data['TX1yr'].plot(color='k',ax=ax1)
plt.legend().remove()
plt.show()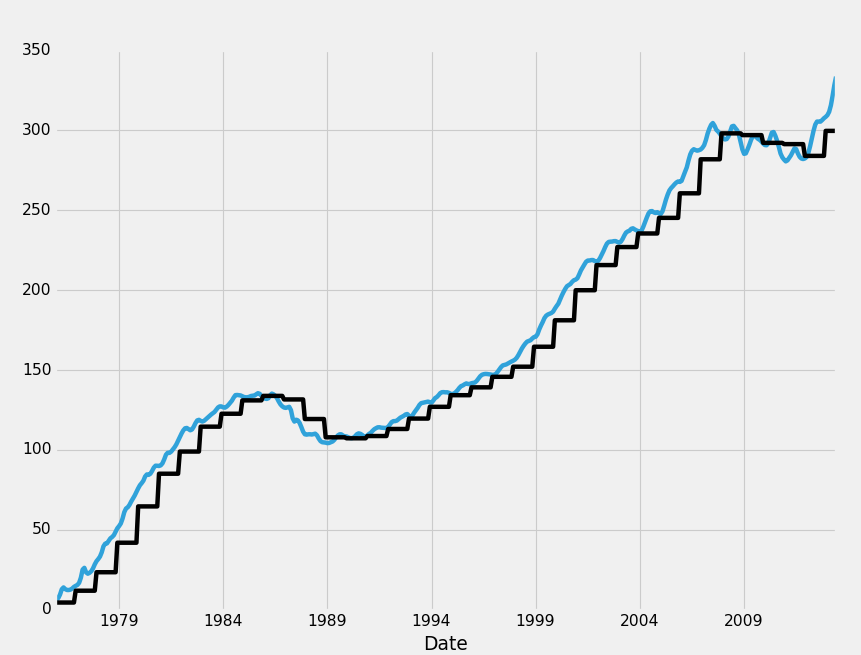
ffill,或者“前向填充”所做的就是,将数据向前扫描,填充到缺失的数据中。 把它看作是一个扫描动作,其中你可以从过去获取数据,将其转移到缺失的数据中。 任何缺失数据的情况都会以最近的非缺失数据填入。 Bfill或后向填充是相反的:
HPI_data.fillna(method='bfill',inplace=True)
这从未来获取数据,并向后扫描来填充缺失。
现在,对于最后一种方法,替换数据。 NaN数据是相对毫无价值的数据,但它可以污染我们的其余数据。以机器学习为例,其中每行是一个特征集,每列是一个特征。数据对我们来说价值非常高,如果我们有大量的NaN数据,那么放弃所有的数据是非常糟糕的。出于这个原因,你可能实际上使用替换。对于大多数机器学习分类器来说,最终的异常值通常被忽略为自己的数据点。正因为如此,很多人会做的是获取任何NaN数据,并用-99999的值代替它。这是因为在数据预处理之后,通常需要将所有特征转换为-1到1的范围。对于几乎任何分类器来说,数据点-99999是一个明显的异常值。但是NaN的数据,根本无法处理!因此,我们可以通过执行以下操作来替换数据:
HPI_data.fillna(value=-99999,inplace=True)现在,在我们的情况下,这是一个毫无用处的操作,但它确实在某些形式的数据分析中占有一席之地。
现在我们已经介绍了处理缺失数据的基础知识,我们准备继续。 在下一篇教程中,我们将讨论另一种平滑数据的方法,这些方法可以让我们保留月度数据:滚动统计量。 这对于平滑我们的数据,以及在它上面收集一些基本的统计量是有用的。
十一、滚动统计量
欢迎阅读另一个 Python 和 Pandas 数据分析系列教程,这里面我们成为了房地产大亨。在本教程中,我们将讨论各种滚动统计量在我们的数据帧中的应用。
其中较受欢迎的滚动统计量是移动均值。这需要一个移动的时间窗口,并计算该时间段的均值作为当前值。在我们的情况下,我们有月度数据。所以 10 移动均值就是当前值加上前 9 个月的数据的均值,之后我们的月度数据将有 10 个移动均值。Pandas 做这个是非常快的。Pandas 带有一些预先制作的滚动统计量,但也有一个叫做rolling_apply。这使我们可以编写我们自己的函数,接受窗口数据并应用我们想要的任何合理逻辑。这意味着,即使Pandas 没有处理你想要的东西的正式函数,他们已经覆盖了你,让你准确地编写你需要的东西。让我们从基本的移动均值开始,或者 Pandas 叫它rolling_mean。你可以查看 Pandas 文档中的所有移动/滚动统计量。
前面的教程涵盖了我们的起始脚本,如下所示:
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
fig = plt.figure()
ax1 = plt.subplot2grid((1,1), (0,0))
HPI_data = pd.read_pickle('fiddy_states3.pickle')
plt.show()现在,在定义HPI_data之后,我们可以添加一些新的数据,如下所示:
HPI_data['TX12MA'] = pd.rolling_mean(HPI_data['TX'], 12)这给了我们一个新列,我们命名为TX12MA来表示得克萨斯和 12 移动平均。 我们将这个应用到pd.rolling_mean()中,该函数接受 2 个主要参数,我们正在应用的数据以及我们打算执行的周期/窗口。
使用滚动统计量,开头将生成NaN数据。 考虑执行 10 移动均值。 在#3行,我们根本没有 10 个以前的数据点。 因此会形成NaN数据。 你可以把它留在那里,或者用前面的教程中的dropna()来删除它。
另一个有趣的是滚动标准差。 我们需要把它放在自己的图表上,但我们可以这样做:
ig = plt.figure()
ax1 = plt.subplot2grid((2,1), (0,0))
ax2 = plt.subplot2grid((2,1), (1,0), sharex=ax1)
HPI_data = pd.read_pickle('fiddy_states3.pickle')
HPI_data['TX12MA'] = pd.rolling_mean(HPI_data['TX'], 12)
HPI_data['TX12STD'] = pd.rolling_std(HPI_data['TX'], 12)
HPI_data['TX'].plot(ax=ax1)
HPI_data['TX12MA'].plot(ax=ax1)
HPI_data['TX12STD'].plot(ax=ax2)
plt.show()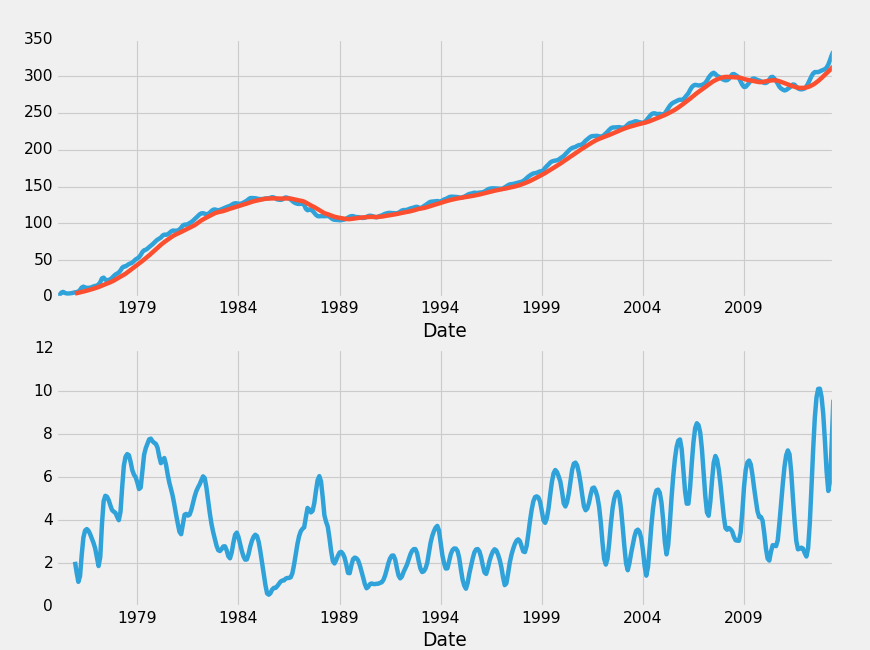
这里发生了一些事情,让我们快速谈论它们。
ax1 = plt.subplot2grid((2,1), (0,0))
ax2 = plt.subplot2grid((2,1), (1,0), sharex=ax1)在这里,我们定义了第二个轴,并改变我们的大小。 我们说这个子图的网格是2×1(高 2,宽 1),那么我们说ax1从0,0开始,ax2从1,0开始,它和ax1共享x轴。 这使我们可以放大一个图形,而另一个图形也放大到同一点。 仍然对 Matplotlib 感到困惑? 使用 Matplotlib 系列教程查看完整的数据可视化。
接下来,我们计算移动标准差:
HPI_data['TX12STD'] = pd.rolling_std(HPI_data['TX'], 12)然后,我们绘制所有东西。
另一个有趣的可视化是比较得克萨斯HPI与整体HPI。 然后计算他们两个之间的滚动相关性。 假设是,相关性下降时,很快就会出现逆转。 如果相关性下降,这意味着得克萨斯HPI和整体HPI是不一致的。 比方说,美国整体的HPI在上面,TX_HPI在下面产生分歧。 在这种情况下,我们可能会选择投资德克萨斯州的房地产。 另一个选择是使用TX和另一个高度相关的区域。 例如,德克萨斯州与阿拉斯加的相关系数为0.983235。 让我们看看我们的计划看起来怎么样。 最后一块应该现在看起来是这样:
fig = plt.figure()
ax1 = plt.subplot2grid((2,1), (0,0))
ax2 = plt.subplot2grid((2,1), (1,0), sharex=ax1)
HPI_data = pd.read_pickle('fiddy_states3.pickle')
TX_AK_12corr = pd.rolling_corr(HPI_data['TX'], HPI_data['AK'], 12)
HPI_data['TX'].plot(ax=ax1, label="TX HPI")
HPI_data['AK'].plot(ax=ax1, label="AK HPI")
ax1.legend(loc=4)
TX_AK_12corr.plot(ax=ax2)
plt.show()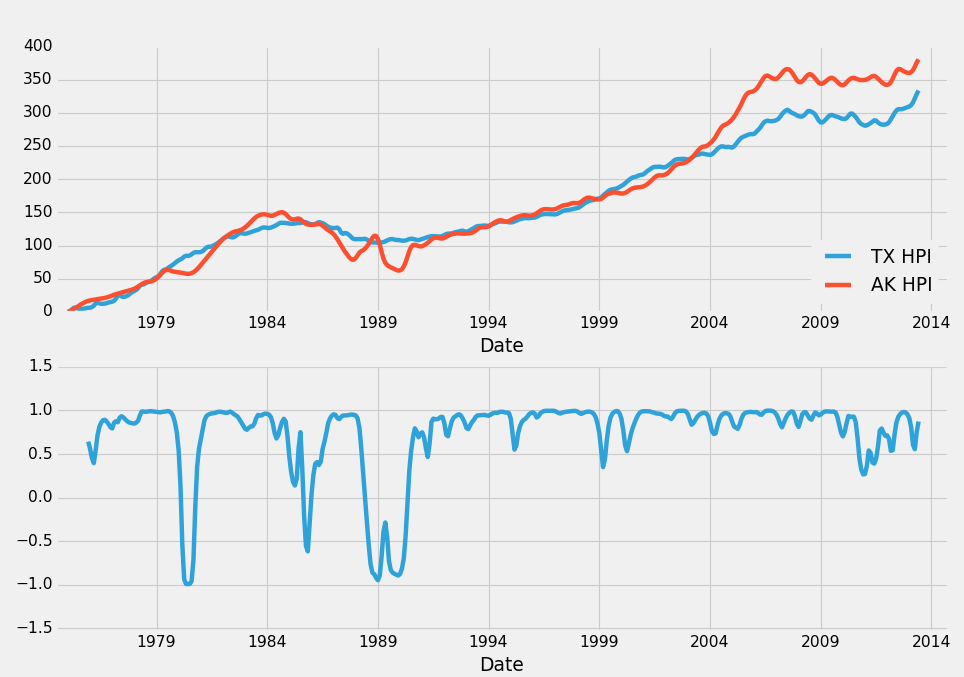
每当相关性下降时,你理论上应该在上涨的地方出售房地产,然后你应该购买正在下降的地区的房地产。这个想法是,这两个地区是高度相关的,我们可以非常确信,相关性最终会回到0.98左右。因此,当相关系数为-0.5时,我们可以非常有把握地决定采取这样的行动,因为结果可能是下面的结果之一:HPI永远是这样的分歧,永远不会恢复(不太可能),下降的地区上升并遇到上升的地区,这样我们赢了,上升的地区下降并遇到另一个下降的地区,在这种情况下,我们发了一笔大财,或者双方都重新一致,在这种情况下,我们肯定赢了。 HPI不可能完全背离这些市场。我们可以清楚地看到,这完全不会发生,我们有 40 年的数据支持。
在接下来的教程中,我们将讨论异常值检测,不管是错误与否,还包括了如何处理这些数据背后的一些哲理。
十二、将比较操作应用于数据帧
欢迎阅读 Python 和 Pandas 数据分析系列教程第 12 部分。 在本教程中,我们将简要讨论如何处理错误/异常数据。 仅仅因为数据是异常的,并不意味着它是错误的。 很多时候,离群数据点可以使一个假设无效,所以去除它的必要性可能会很高,但这不是我们在这里讨论的。
错误的异常值是多少? 我喜欢使用的一个例子是测量诸如桥梁之类的波动。 由于桥梁承载重量,他们可以移动一点。 在风浪中,可以稍微摆动一下,就会有一些自然的运动。 随着时间的推移,支撑力量减弱,桥梁可能会移动太多,最终需要加固。 也许我们有一个不断测量桥梁高度波动的系统。
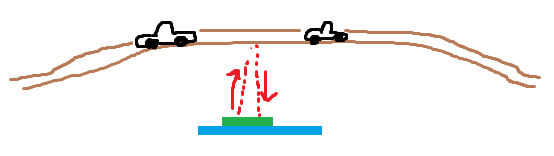
一些距离传感器使用激光,另一些则反弹声波。 无论你想假装我们正在使用哪个,都没关系。 我们会假装声波。 它们的工作方式是从触发器发出声波,然后在前面物体处反弹,返回到接收器。 从这里开始,整个操作发生的时间被考虑在内。 由于音速是一个常数,我们可以从这个过程的时间推断出声波传播的距离。 问题是,这只衡量声波传播了多远。 例如他们去了桥梁和背部,没有 100% 的确定性。 也许一片树叶在测量时掉落,并在信号回到接收器之前反弹了信号,谁知道呢。 比方说,举个例子,你有以下的桥梁读数:
bridge_height = {'meters':[10.26, 10.31, 10.27, 10.22, 10.23, 6212.42, 10.28, 10.25, 10.31]}我们可以可视化:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
bridge_height = {'meters':[10.26, 10.31, 10.27, 10.22, 10.23, 6212.42, 10.28, 10.25, 10.31]}
df = pd.DataFrame(bridge_height)
df.plot()
plt.show()那么桥是不是被外星人动过了? 由于此后我们有更多的正常读数,6212.42更可能是一个不好的读数。 我们可以直观地看出这是一个异常,但是我们怎么能通过我们的程序检测到这一点?
我们意识到这是一个异常值,因为它与其他价有很大的不同,以及它比其他任何值都突然上升或下降的事实。 听起来我们可以仅仅应用标准差。 我们用它来自动检测这个不好的读数。
df['STD'] = pd.rolling_std(df['meters'], 2)
print(df) meters STD
0 10.26 NaN
1 10.31 0.035355
2 10.27 0.028284
3 10.22 0.035355
4 10.23 0.007071
5 6212.42 4385.610607
6 10.28 4385.575252
7 10.25 0.021213
8 10.31 0.042426注:两个数的标准差就是
|a - b|/2。
接下来,我们可以获得整个集合的标准差,如:
df_std = df.describe()
print(df_std)
df_std = df.describe()['meters']['std']
print(df_std) meters STD
count 9.000000 8.000000
mean 699.394444 1096.419446
std 2067.384584 2030.121949
min 10.220000 0.007071
25% 10.250000 0.026517
50% 10.270000 0.035355
75% 10.310000 1096.425633
max 6212.420000 4385.610607
2067.38458357首先,我们得到所有的描述。 显示了大部分,所以你看我们如何处理数据。 然后,我们直接查看米的标准差,这是 2067 和一些变化。 这是一个相当高的数字,但仍然远低于主要波动(4385)的标准差。 现在,我们可以遍历并删除所有标准差高于这个值的数据。
这使我们能够学习一项新技能:在逻辑上修改数据帧! 我们可以这样做:
df = df[ (df['STD'] < df_std) ]
print(df) meters STD
1 10.31 0.035355
2 10.27 0.028284
3 10.22 0.035355
4 10.23 0.007071
7 10.25 0.021213
8 10.31 0.042426之后我们可以绘制所有东西:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
bridge_height = {'meters':[10.26, 10.31, 10.27, 10.22, 10.23, 6212.42, 10.28, 10.25, 10.31]}
df = pd.DataFrame(bridge_height)
df['STD'] = pd.rolling_std(df['meters'], 2)
print(df)
df_std = df.describe()
print(df_std)
df_std = df.describe()['meters']['std']
print(df_std)
df = df[ (df['STD'] < df_std) ]
print(df)
df['meters'].plot()
plt.show()输出:
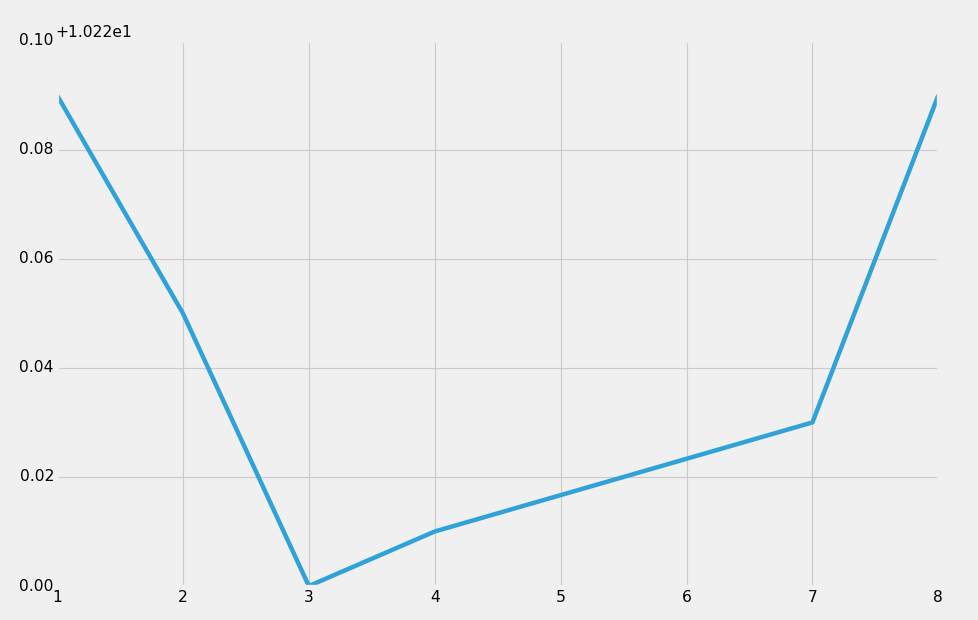
我们刚学到的新行是df = df[ (df['STD'] < df_std) ]。 这是如何工作的? 首先,我们一开始重新定义df。 我们说现在df等于df,其中df['STD']小于我们之前计算的整体df_std。 因此,这里唯一剩下的数据将是标准差小于 2067 的数据。
再次,当我们知道这些数据错误的,我们应该删除它。 因为数据不“适合”你而删除,几乎总是一个坏主意。
十三、30 年抵押贷款利率
欢迎阅读 Python 和 Pandas 数据分析第 13 部分,以房地产投资为例。到了这里,我们已经了解了 Pandas 能提供给我们的东西,我们会在这里面对一些挑战!正如我们到目前为止所介绍的那样,我们可以根据高度相关的州对之间的分歧,做出风险相对较低的投资,可能做得很好。稍后我们将介绍测试这个策略,但是现在让我们来看看获取包含房屋价值的其他必要数据:利率。现在,抵押贷款利率有很多不同的类型,既有利息收入,也有贷款的时间表。这些年来,意见有所不同,根据目前的市场情况,是否需要 10 年,15 年或 30 年的抵押贷款。那么你必须考虑你是否想要可调整的利率,或者在半路上再决定为你的房子付费的方式。
在数据的最后,所有这些数据都是有限的,但最终可能会有点过于嘈杂。现在,让我们简单介绍一下 30 年的传统抵押贷款利率。现在,这个数据应该与房价指数(HPI)非常负相关。在这个低吗之前,我会自动假设并期望相关性不会非常强,就像高于 90% 的HPI相关性,它肯定低于-0.9,而且应该比-0.5大。利率当然很重要,但是整个HPI的相关性非常强,因为这些数据非常相似。利率当然是相关的,但并不像其他HPI值或美国HPI那样直接。
首先,我们抓取这些数据。我们将开始创建一个新的函数:
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
print(df.head())
return df
mortgage_30y() Value
Date
1975-01-01 0.000000
1975-02-01 -3.393425
1975-03-01 -5.620361
1975-04-01 -6.468717
1975-05-01 -5.514316这里有几个要点。 首先,注意添加到Quandl.get()的新参数,它是trim_start。 这使我们能够在特定的日期启动数据。 我们之所以选择 1975 年 1 月 1 日,是因为那是我们的房价指数数据开始的时候。 从这里,我们打印数据头部,我们有了第一个问题:这是某月的第一天,而不是月底。 当我们将这个数据帧加入到其他数据帧时,这会造成麻烦。 那么现在怎么办? 我们已经学会了如何重新采样,如果我们只是使用M来进行典型的重新采样,这意味着月末,会怎么样呢? 也许这会把数据移动到第 31 天,因为这个月只有一个值。
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('M')
print(df.head())
return df
mortgage_30y() Value
Date
1975-01-31 NaN
1975-02-28 NaN
1975-03-31 NaN
1975-04-30 NaN
1975-05-31 NaN好吧,这并没有那么好。 我们可能需要多个数据点才能进行计算,那么我们该怎么做? 我们可以尝试调整日期列或别的,或者我们可以做一些黑魔法。 如果我们只是按天抽样呢? 如果我们这样做的话,那么这个数字将在整个月份里持续重复。 然后,我们可以重采样到月末,然后一切都应该有效。
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('1D')
df=df.resample('M')
print(df.head())
return df
mortgage_30y() Value
Date
1975-01-31 0.000000
1975-02-28 -3.393425
1975-03-31 -5.620361
1975-04-30 -6.468717
1975-05-31 -5.514316我们赢了! 接下来,我们可以获取所有的数据,将这个新的数据集添加到数据帧中,现在我们真的上路了。 为了防止你刚刚加入我们,或者你半路走丢了,这里是目前为止的代码:
import Quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = Quandl.get(query, authtoken=api_key)
print(query)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = Quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["United States"]-df["United States"][0]) / df["United States"][0] * 100.0
return df
def mortgage_30y():
df = Quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('1D')
df=df.resample('M')
return df现在我们可以做一些事情,例如:
HPI_data = pd.read_pickle('fiddy_states3.pickle')
m30 = mortgage_30y()
HPI_Bench = HPI_Benchmark()
m30.columns=['M30']
HPI = HPI_Bench.join(m30)
print(HPI.head()) United States M30
Date
1975-01-31 0.000000 0.000000
1975-02-28 0.594738 -3.393425
1975-03-31 1.575473 -5.620361
1975-04-30 2.867177 -6.468717
1975-05-31 3.698896 -5.514316下面,我们可以立即计算一个简单的相关性:
print(HPI.corr())
United States M30
United States 1.000000 -0.740009
M30 -0.740009 1.000000这是我们的预期。 -0.74是相当强的负值。 很明显,各州之间的联系并不是很好,但这显然是一个有用的指标。 接下来,我们可以在所有州上检查这个指标:
state_HPI_M30 = HPI_data.join(m30)
print(state_HPI_M30.corr()) AL AK AZ AR CA CO CT \
AL 1.000000 0.944603 0.927361 0.994896 0.935970 0.979352 0.953724
AK 0.944603 1.000000 0.893904 0.965830 0.900621 0.949834 0.896395
AZ 0.927361 0.893904 1.000000 0.923786 0.973546 0.911422 0.917500
AR 0.994896 0.965830 0.923786 1.000000 0.935364 0.985934 0.948341
CA 0.935970 0.900621 0.973546 0.935364 1.000000 0.924982 0.956495
CO 0.979352 0.949834 0.911422 0.985934 0.924982 1.000000 0.917129
CT 0.953724 0.896395 0.917500 0.948341 0.956495 0.917129 1.000000
DE 0.980566 0.939196 0.942273 0.975830 0.970232 0.949517 0.981177
FL 0.918544 0.887891 0.994007 0.915989 0.987200 0.905126 0.926364
GA 0.973562 0.880261 0.939715 0.960708 0.943928 0.959500 0.948500
HI 0.946054 0.930520 0.902554 0.947022 0.937704 0.903461 0.938974
ID 0.982868 0.944004 0.959193 0.977372 0.944342 0.960975 0.923099
IL 0.984782 0.905512 0.947396 0.973761 0.963858 0.968552 0.955033
IN 0.981189 0.889734 0.881542 0.973259 0.901154 0.971416 0.919696
IA 0.985516 0.943740 0.894524 0.987919 0.914199 0.991455 0.913788
KS 0.990774 0.957236 0.910948 0.995230 0.926872 0.994866 0.936523
KY 0.994311 0.938125 0.900888 0.992903 0.923429 0.987097 0.941114
LA 0.967232 0.990506 0.909534 0.982454 0.911742 0.972703 0.907456
ME 0.972693 0.935850 0.923797 0.972573 0.965251 0.951917 0.989180
MD 0.964917 0.943384 0.960836 0.964943 0.983677 0.940805 0.969170
MA 0.966242 0.919842 0.921782 0.966962 0.962672 0.959294 0.986178
MI 0.891205 0.745697 0.848602 0.873314 0.861772 0.900040 0.843032
MN 0.971967 0.926352 0.952359 0.972338 0.970661 0.983120 0.945521
MS 0.996089 0.962494 0.927354 0.997443 0.932752 0.985298 0.945831
MO 0.992706 0.933201 0.938680 0.989672 0.955317 0.985194 0.961364
MT 0.977030 0.976840 0.916000 0.983822 0.923950 0.971516 0.917663
NE 0.988030 0.941229 0.896688 0.990868 0.912736 0.992179 0.920409
NV 0.858538 0.785404 0.965617 0.846968 0.948143 0.837757 0.866554
NH 0.953366 0.907236 0.932992 0.952882 0.969574 0.941555 0.990066
NJ 0.968837 0.934392 0.943698 0.967477 0.975258 0.944460 0.989845
NM 0.992118 0.967777 0.934744 0.993195 0.934720 0.968001 0.946073
NY 0.973984 0.940310 0.921126 0.973972 0.959543 0.949474 0.989576
NC 0.998383 0.934841 0.915403 0.991863 0.928632 0.977069 0.956074
ND 0.936510 0.973971 0.840705 0.957838 0.867096 0.942225 0.882938
OH 0.966598 0.855223 0.883396 0.954128 0.901842 0.957527 0.911510
OK 0.944903 0.984550 0.881332 0.967316 0.882199 0.960694 0.879854
OR 0.981180 0.948190 0.949089 0.978144 0.944542 0.971110 0.916942
PA 0.985357 0.946184 0.915914 0.983651 0.950621 0.956316 0.975324
RI 0.950261 0.897159 0.943350 0.945984 0.984298 0.926362 0.988351
SC 0.998603 0.945949 0.929591 0.994117 0.942524 0.980911 0.959591
SD 0.983878 0.966573 0.889405 0.990832 0.911188 0.984463 0.924295
TN 0.998285 0.946858 0.919056 0.995949 0.931616 0.983089 0.953009
TX 0.963876 0.983235 0.892276 0.981413 0.902571 0.970795 0.919415
UT 0.983987 0.951873 0.926676 0.982867 0.909573 0.974909 0.900908
VT 0.975210 0.952370 0.909242 0.977904 0.949225 0.951388 0.973716
VA 0.972236 0.956925 0.950839 0.975683 0.977028 0.954801 0.970366
WA 0.988253 0.948562 0.950262 0.982877 0.956434 0.968816 0.941987
WV 0.984364 0.964846 0.907797 0.990264 0.924300 0.979467 0.925198
WI 0.990190 0.930548 0.927619 0.985818 0.943768 0.987609 0.936340
WY 0.944600 0.983109 0.892255 0.960336 0.897551 0.950113 0.880035
M30 -0.762343 -0.678591 -0.614237 -0.747709 -0.680250 -0.747269 -0.726121
DE FL GA ... TN TX UT \
AL 0.980566 0.918544 0.973562 ... 0.998285 0.963876 0.983987
AK 0.939196 0.887891 0.880261 ... 0.946858 0.983235 0.951873
AZ 0.942273 0.994007 0.939715 ... 0.919056 0.892276 0.926676
AR 0.975830 0.915989 0.960708 ... 0.995949 0.981413 0.982867
CA 0.970232 0.987200 0.943928 ... 0.931616 0.902571 0.909573
CO 0.949517 0.905126 0.959500 ... 0.983089 0.970795 0.974909
CT 0.981177 0.926364 0.948500 ... 0.953009 0.919415 0.900908
DE 1.000000 0.947876 0.954346 ... 0.977213 0.943323 0.952441
FL 0.947876 1.000000 0.933753 ... 0.910359 0.881164 0.908197
GA 0.954346 0.933753 1.000000 ... 0.970564 0.920372 0.943421
HI 0.976226 0.909336 0.887794 ... 0.941823 0.916708 0.925630
ID 0.971421 0.947140 0.953024 ... 0.976012 0.943472 0.989533
IL 0.978133 0.948851 0.986683 ... 0.980145 0.925778 0.961563
IN 0.941916 0.873664 0.972737 ... 0.982888 0.928735 0.956452
IA 0.954993 0.888359 0.948792 ... 0.987924 0.959989 0.980798
KS 0.964387 0.903659 0.961825 ... 0.993486 0.978622 0.980113
KY 0.968469 0.895461 0.966719 ... 0.996549 0.961847 0.975918
LA 0.949931 0.899010 0.911625 ... 0.968690 0.989803 0.975590
ME 0.993413 0.932706 0.949576 ... 0.973697 0.946992 0.935993
MD 0.993728 0.968700 0.938240 ... 0.960881 0.935619 0.945962
MA 0.978758 0.931237 0.964604 ... 0.969053 0.943613 0.923883
MI 0.846668 0.846085 0.952179 ... 0.891484 0.806632 0.855976
MN 0.966800 0.955992 0.976933 ... 0.970940 0.944605 0.955689
MS 0.975673 0.917084 0.963318 ... 0.996444 0.977670 0.987812
MO 0.978316 0.936293 0.986001 ... 0.991835 0.958853 0.969655
MT 0.968166 0.909331 0.917504 ... 0.976586 0.967914 0.985605
NE 0.951875 0.888425 0.962706 ... 0.991270 0.966743 0.976138
NV 0.881209 0.971601 0.911678 ... 0.845672 0.791177 0.841324
NH 0.975576 0.943501 0.959112 ... 0.954165 0.930112 0.908947
NJ 0.995132 0.952767 0.950385 ... 0.967025 0.940268 0.935497
NM 0.980594 0.925001 0.949564 ... 0.989390 0.972216 0.986413
NY 0.993814 0.928749 0.947804 ... 0.974697 0.950417 0.937078
NC 0.977472 0.906887 0.976190 ... 0.998354 0.959839 0.976901
ND 0.926355 0.833816 0.849962 ... 0.944451 0.964373 0.942833
OH 0.927542 0.878248 0.980012 ... 0.966237 0.900707 0.935392
OK 0.917902 0.868255 0.893142 ... 0.947590 0.992422 0.951925
OR 0.969869 0.940983 0.945712 ... 0.977083 0.943652 0.991080
PA 0.994948 0.919264 0.946609 ... 0.984959 0.954439 0.956809
RI 0.984731 0.959567 0.951973 ... 0.947561 0.907964 0.906497
SC 0.983353 0.922779 0.976778 ... 0.997851 0.966682 0.979527
SD 0.963422 0.883479 0.931010 ... 0.987597 0.973825 0.979387
TN 0.977213 0.910359 0.970564 ... 1.000000 0.967678 0.982384
TX 0.943323 0.881164 0.920372 ... 0.967678 1.000000 0.956718
UT 0.952441 0.908197 0.943421 ... 0.982384 0.956718 1.000000
VT 0.992088 0.914969 0.929674 ... 0.976577 0.955538 0.947708
VA 0.994223 0.957210 0.939416 ... 0.970906 0.952162 0.953655
WA 0.985085 0.945027 0.956455 ... 0.983588 0.950234 0.984835
WV 0.968813 0.901690 0.931330 ... 0.985509 0.967845 0.983636
WI 0.970690 0.925943 0.974086 ... 0.988615 0.946572 0.977972
WY 0.938938 0.884962 0.869454 ... 0.945079 0.963628 0.965801
M30 -0.758073 -0.627997 -0.706512 ... -0.770422 -0.669410 -0.737147
VT VA WA WV WI WY M30
AL 0.975210 0.972236 0.988253 0.984364 0.990190 0.944600 -0.762343
AK 0.952370 0.956925 0.948562 0.964846 0.930548 0.983109 -0.678591
AZ 0.909242 0.950839 0.950262 0.907797 0.927619 0.892255 -0.614237
AR 0.977904 0.975683 0.982877 0.990264 0.985818 0.960336 -0.747709
CA 0.949225 0.977028 0.956434 0.924300 0.943768 0.897551 -0.680250
CO 0.951388 0.954801 0.968816 0.979467 0.987609 0.950113 -0.747269
CT 0.973716 0.970366 0.941987 0.925198 0.936340 0.880035 -0.726121
DE 0.992088 0.994223 0.985085 0.968813 0.970690 0.938938 -0.758073
FL 0.914969 0.957210 0.945027 0.901690 0.925943 0.884962 -0.627997
GA 0.929674 0.939416 0.956455 0.931330 0.974086 0.869454 -0.706512
HI 0.979103 0.976083 0.963950 0.952790 0.928536 0.935530 -0.755064
ID 0.955898 0.970393 0.994442 0.975239 0.977441 0.956742 -0.721927
IL 0.958711 0.968271 0.982702 0.962100 0.992079 0.911345 -0.753583
IN 0.937365 0.928187 0.955000 0.958981 0.982614 0.889497 -0.773100
IA 0.960204 0.955724 0.976571 0.990479 0.991509 0.955104 -0.785584
KS 0.967734 0.964949 0.977117 0.988007 0.989477 0.956913 -0.748138
KY 0.970702 0.962244 0.977386 0.985453 0.992035 0.938804 -0.785726
LA 0.958907 0.962746 0.967991 0.982913 0.957145 0.988894 -0.683956
ME 0.993570 0.990376 0.969212 0.963035 0.963999 0.929516 -0.769778
MD 0.983851 0.997558 0.981974 0.962220 0.960073 0.945807 -0.729642
MA 0.975046 0.975432 0.953441 0.947520 0.964247 0.904811 -0.758192
MI 0.817081 0.828781 0.862245 0.843538 0.918028 0.741663 -0.686146
MN 0.952722 0.969721 0.973082 0.961230 0.987026 0.927507 -0.723314
MS 0.974975 0.973635 0.986430 0.989047 0.986738 0.961005 -0.750756
MO 0.968741 0.972720 0.980907 0.974606 0.993691 0.930004 -0.747344
MT 0.974065 0.976197 0.985994 0.993622 0.972195 0.990517 -0.756735
NE 0.954657 0.949766 0.969023 0.981915 0.988942 0.938583 -0.761330
NV 0.828018 0.882206 0.882127 0.820529 0.874777 0.779155 -0.543798
NH 0.966338 0.972531 0.944892 0.930573 0.949941 0.892414 -0.722957
NJ 0.987844 0.992944 0.971273 0.956438 0.960854 0.928928 -0.743508
NM 0.977351 0.978702 0.988594 0.985877 0.976586 0.966689 -0.729704
NY 0.994142 0.989544 0.968541 0.962209 0.961359 0.929946 -0.770619
NC 0.973354 0.965901 0.981436 0.978326 0.987338 0.931717 -0.770820
ND 0.957772 0.944229 0.935840 0.972698 0.921882 0.977003 -0.763102
OH 0.912974 0.910193 0.939052 0.933308 0.974849 0.852217 -0.753133
OK 0.930105 0.933030 0.937180 0.959298 0.932422 0.969641 -0.621887
OR 0.959889 0.973285 0.995502 0.984262 0.984121 0.968156 -0.749370
PA 0.997231 0.989277 0.982052 0.978963 0.972162 0.945319 -0.779589
RI 0.970213 0.980550 0.953760 0.930845 0.950360 0.890562 -0.732558
SC 0.977946 0.975200 0.987828 0.982315 0.989425 0.943358 -0.754808
SD 0.976071 0.967219 0.976170 0.994328 0.979649 0.971496 -0.794906
TN 0.976577 0.970906 0.983588 0.985509 0.988615 0.945079 -0.770422
TX 0.955538 0.952162 0.950234 0.967845 0.946572 0.963628 -0.669410
UT 0.947708 0.953655 0.984835 0.983636 0.977972 0.965801 -0.737147
VT 1.000000 0.991347 0.975016 0.976666 0.961824 0.951637 -0.779342
VA 0.991347 1.000000 0.983402 0.973592 0.966393 0.956771 -0.745763
WA 0.975016 0.983402 1.000000 0.984210 0.984955 0.962198 -0.750646
WV 0.976666 0.973592 0.984210 1.000000 0.981398 0.977070 -0.770068
WI 0.961824 0.966393 0.984955 0.981398 1.000000 0.939200 -0.776679
WY 0.951637 0.956771 0.962198 0.977070 0.939200 1.000000 -0.702034
M30 -0.779342 -0.745763 -0.750646 -0.770068 -0.776679 -0.702034 1.000000
[51 rows x 51 columns]我们感兴趣的主要一列是 M30 与其它东西的对比,所以我们这样做:
print(state_HPI_M30.corr()['M30'])AL -0.762343
AK -0.678591
AZ -0.614237
AR -0.747709
CA -0.680250
CO -0.747269
CT -0.726121
DE -0.758073
FL -0.627997
GA -0.706512
HI -0.755064
ID -0.721927
IL -0.753583
IN -0.773100
IA -0.785584
KS -0.748138
KY -0.785726
LA -0.683956
ME -0.769778
MD -0.729642
MA -0.758192
MI -0.686146
MN -0.723314
MS -0.750756
MO -0.747344
MT -0.756735
NE -0.761330
NV -0.543798
NH -0.722957
NJ -0.743508
NM -0.729704
NY -0.770619
NC -0.770820
ND -0.763102
OH -0.753133
OK -0.621887
OR -0.749370
PA -0.779589
RI -0.732558
SC -0.754808
SD -0.794906
TN -0.770422
TX -0.669410
UT -0.737147
VT -0.779342
VA -0.745763
WA -0.750646
WV -0.770068
WI -0.776679
WY -0.702034
M30 1.000000
Name: M30, dtype: float64看起来亚利桑那(AZ)的负相关最弱,为-0.614237。 我们可以通过以下方式快速获取更多数据:
print(state_HPI_M30.corr()['M30'].describe())count 51.000000
mean -0.699445
std 0.247709
min -0.794906
25% -0.762723
50% -0.748138
75% -0.722442
max 1.000000
Name: M30, dtype: float64这里的均值在-0.7以下,这与我们以前的发现非常一致,这里并没有太多的延展。这在逻辑上应该是显而易见的,但数据明确地反映了,抵押贷款利率在房价中起着重要的作用。到目前为止,我所发现的有趣之处是,我们所看到的变化是多么的微小。有一些州存在分歧,但不是很多。大多数州严格保持在一条直线上,带有非常简单的规则。在深入局部地区之前,我们的第三个主要因素,是整体经济。从这里开始,我们可以开始关注州的人口统计数据,同时我们深入到县甚至社区。但是,我想知道,鉴于迄今为止这样可靠的值,我们已经很容易为HPI制定一个公式。如果不是一个基本的公式,我怀疑我们可以在一个随机森林分类器中使用这些数据,并做得很好。现在,让我们继续看看整体经济。我们希望看到0.5以上的相关性。我们在下一个教程中介绍一下。
十四、添加其它经济指标
大家好,欢迎阅读我们的 Python 和 Pandas 数据分析(和地产投资)系列教程的第14部分。我们在这里已经走了很长一段路,我们想要在这里采取的下一个,最后一大步骤是研究宏观经济指标,看看它们对房价或HPI的影响。
SP500 (股票市场)和国内生产总值(GDP)是两个主要的经济指标。我怀疑 SP500 比国内生产总值相关性更高,但 GDP 总体来说是一个较好的整体经济指标,所以我可能是错的。以及,我怀疑在这里可能有价值的宏观指标是失业率。如果你失业了,你可能不能得到抵押贷款。我们会验证。我们已经完成了添加更多数据点的流程,所以把你拖入这个过程没有多少意义。但是会有一个新的东西需要注意。在HPI_Benchmark()函数中,我们将United States列更改为US_HPI。当我们现在引入其他值时,这会更有意义。
对于国内生产总值,我找不到一个包含所有时间的东西。我相信你可以使用这个数据在某个地方,甚至在 Quandl 上找到一个数据集。有时你必须做一些挖掘。我也很难找到一个很好的长期月失业率。我确实找到了一个失业率水平,但我们真的不仅仅想要百分比/比例,否则我们需要把失业水平除以人口。如果我们确定失业率值得拥有,我们可以这样做,但我们需要首先处理我们得到的东西。
将 Pandas 和 Quandl 代码更新为 2016 年 8 月 1 日的最新版本:
import quandl
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def state_list():
fiddy_states = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
return fiddy_states[0][0][1:]
def grab_initial_state_data():
states = state_list()
main_df = pd.DataFrame()
for abbv in states:
query = "FMAC/HPI_"+str(abbv)
df = quandl.get(query, authtoken=api_key)
df.rename(columns={'Value': abbv}, inplace=True)
df[abbv] = (df[abbv]-df[abbv][0]) / df[abbv][0] * 100.0
print(df.head())
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df)
pickle_out = open('fiddy_states3.pickle','wb')
pickle.dump(main_df, pickle_out)
pickle_out.close()
def HPI_Benchmark():
df = quandl.get("FMAC/HPI_USA", authtoken=api_key)
df["United States"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df.rename(columns={'United States':'US_HPI'}, inplace=True)
return df
def mortgage_30y():
df = quandl.get("FMAC/MORTG", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('1D').mean()
df=df.resample('M').mean()
return df
def sp500_data():
df = quandl.get("YAHOO/INDEX_GSPC", trim_start="1975-01-01", authtoken=api_key)
df["Adjusted Close"] = (df["Adjusted Close"]-df["Adjusted Close"][0]) / df["Adjusted Close"][0] * 100.0
df=df.resample('M').mean()
df.rename(columns={'Adjusted Close':'sp500'}, inplace=True)
df = df['sp500']
return df
def gdp_data():
df = quandl.get("BCB/4385", trim_start="1975-01-01", authtoken=api_key)
df["Value"] = (df["Value"]-df["Value"][0]) / df["Value"][0] * 100.0
df=df.resample('M').mean()
df.rename(columns={'Value':'GDP'}, inplace=True)
df = df['GDP']
return df
def us_unemployment():
df = quandl.get("ECPI/JOB_G", trim_start="1975-01-01", authtoken=api_key)
df["Unemployment Rate"] = (df["Unemployment Rate"]-df["Unemployment Rate"][0]) / df["Unemployment Rate"][0] * 100.0
df=df.resample('1D').mean()
df=df.resample('M').mean()
return df
grab_initial_state_data()
HPI_data = pd.read_pickle('fiddy_states3.pickle')
m30 = mortgage_30y()
sp500 = sp500_data()
gdp = gdp_data()
HPI_Bench = HPI_Benchmark()
unemployment = us_unemployment()
m30.columns=['M30']
HPI = HPI_Bench.join([m30,sp500,gdp,unemployment])
HPI.dropna(inplace=True)
print(HPI.corr()) US_HPI M30 sp500 GDP Unemployment Rate
US_HPI 1.000000 -0.738364 0.738395 0.543507 0.033925
M30 -0.738364 1.000000 -0.625544 -0.714845 -0.395650
sp500 0.738395 -0.625544 1.000000 0.470505 -0.262561
GDP 0.543507 -0.714845 0.470505 1.000000 0.551058
Unemployment Rate 0.033925 -0.395650 -0.262561 0.551058 1.000000在这里,我们看到 SP500 与US_HPI强相关,30 年抵押贷款利率显然也是如此。其次,GDP 不是最可靠的。这是正值,但我更像看> 70的东西。最后,失业率更低。几乎中立!我对此感到非常惊讶。有了这些信息,我想说 SP500 和 30 年抵押贷款利率可以用来预测房屋市场。这很好,因为这些数字都可以不间断地获得。我很惊讶地看到 SP500 与 HPI 之间的 0.738 相关性。大多数人认为股票和住房是多元化的。很多人都记得房地产危机,而且既然股市和房屋都一起下跌,可能就不会有这样的感觉了,但是传统的智慧依然表明人们通过持有股票和房地产来多样化。 40 年的数据似乎并不完全一致。
向前看,我提倡考虑宏观市场,使用美国房价指数(US_HPI),30 年抵押贷款利率(M30)和标准普尔 500 指数(SP500)。
我们将使用这些值来涵盖本系列的最后一部分:结合其他主要数据科学库。我们这里,我们将结合 Scikit Learn,看看我们是否能预测 HPI 的合理轨迹。这样做只是一个开始,但是之后要求我们使用类似的策略来继续下去,直到我们实际购买的房产的微观层面。无论如何,我们还是亿万富翁,生活是美好的。在我们继续之前,我们将最后一次运行这个代码,将其保存到一个pickle中,这样我们就不需要继续运行代码了。为了保存到pickle,只需把它放在脚本的末尾:
HPI.to_pickle('HPI.pickle')十五、滚动应用和预测函数
这个 Python 和 Pandas 数据分析教程将涵盖两个主题。首先,在机器学习的背景下,我们需要一种方法,为我们的数据创建“标签”。其次,我们将介绍 Pandas 的映射函数和滚动应用功能。
创建标签对监督式机器学习过程至关重要,因为它用于“教给”或训练机器与特征相关的正确答案。
Pandas 数据帧映射函数到非常有用,可用于编写自定义公式,将其应用于整个数据帧,特定列或创建新列。如果你回想一下,我们生成了一些新列,比如df['Column2'] = df['Column1']*1.5,等等。如果你想创建更多的逻辑密集操作,但是,你会希望写一个函数。我们将展示如何实现它。
由于映射函数是两种方法之一,用户可以极大地定制 Pandas 可以做的事情,我们也会涵盖第二种主要方式,即使用rolling_apply。这使我们可以应用函数的移动窗口。我们刚刚写了一个移动平均函数,但是你可以做任何你想要的。
首先,我们有一些代码:
import Quandl
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
from statistics import mean
style.use('fivethirtyeight')
housing_data = pd.read_pickle('HPI.pickle')
housing_data = housing_data.pct_change()首先,我们要加载数据集,然后将所有列转换为百分比变化。 这将帮助我们规范所有的数据。
下面:
housing_data.replace([np.inf, -np.inf], np.nan, inplace=True)
housing_data['US_HPI_future'] = housing_data['United States'].shift(-1)在这里,我们先用nan值代替无穷值。 接下来,我们创建一个新的列,其中包含未来的 HPI。 我们可以用一个新的方法来实现:.shift()。 这种方法将会改变有问题的列。 移动-1意味着我们正在向下移动,所以下一个点的值会移动回来。 这是我们的方法,用于快速获得当前值,以及下一时期同一行上的值,用于比较。
接下来,在百分比变化应用和移动中,我们有一些NaN数据,所以我们需要做以下工作:
new_column = list(map( function_to_map, parameter1, parameter2, ... ))这就是它的一切,你可以继续添加更多的参数。
print(housing_data.head()) AL AK AZ AR CA CO \
Date
1990-03-31 0.003628 0.062548 -0.003033 0.005570 0.007152 0.000963
1990-04-30 0.006277 0.095081 -0.002126 0.005257 0.005569 -0.000318
1990-05-31 0.007421 0.112105 0.001513 0.005635 0.002409 0.004512
1990-06-30 0.004930 0.100642 0.004353 0.006238 0.003569 0.007884
1990-07-31 0.000436 0.067064 0.003322 0.006173 0.004351 0.004374
CT DE FL GA ... WV WI \
Date ...
1990-03-31 -0.009234 0.002786 -0.001259 -0.007290 ... 0.013441 0.015638
1990-04-30 -0.010818 0.000074 0.002675 -0.002477 ... 0.015765 0.015926
1990-05-31 -0.010963 -0.000692 0.004656 0.002808 ... 0.017085 0.012106
1990-06-30 -0.007302 -0.001542 0.003710 0.002857 ... 0.016638 0.010545
1990-07-31 -0.003439 -0.004680 0.003116 0.002276 ... 0.011129 0.009425
WY United States M30 Unemployment Rate GDP \
Date
1990-03-31 0.009831 0.004019 0.090909 0.035714 -0.234375
1990-04-30 0.016868 0.004957 0.119048 -0.068966 4.265306
1990-05-31 0.026130 0.005260 0.117021 0.000000 -1.092539
1990-06-30 0.029359 0.005118 -0.304762 0.074074 3.115183
1990-07-31 0.023640 0.003516 -0.164384 -0.103448 0.441476
sp500 US_HPI_future label
Date
1990-03-31 0.030790 0.004957 1
1990-04-30 -0.001070 0.005260 1
1990-05-31 0.045054 0.005118 0
1990-06-30 0.036200 0.003516 0
1990-07-31 -0.001226 0.000395 0
[5 rows x 57 columns]接下来,让我们展示一个自定义方式,来应用移动窗口函数。 我们仅仅执行一个简单的移动平均示例:
def moving_average(values):
ma = mean(values)
return ma这就是我们的功能,请注意,我们只是传递了values参数。 我们不需要编写任何类型的“窗口”或“时间框架”处理,Pandas 将为我们处理。
现在,你可以使用rolling_apply:
housing_data['ma_apply_example'] = pd.rolling_apply(housing_data['M30'], 10, moving_average)
print(housing_data.tail()) AL AK AZ AR CA CO \
Date
2011-07-31 -0.003545 -0.004337 0.002217 0.003215 -0.005579 0.004794
2011-08-31 -0.006886 -0.007139 0.004283 0.000275 -0.007782 0.001058
2011-09-30 -0.011103 -0.007609 0.003190 0.000505 -0.006537 -0.004569
2011-10-31 -0.013189 -0.007754 0.000541 0.001059 -0.005390 -0.009231
2011-11-30 -0.008055 -0.006551 0.005119 -0.000856 -0.003570 -0.010812
CT DE FL GA ... \
Date ...
2011-07-31 -0.002806 -0.001084 -0.001531 -0.003036 ...
2011-08-31 -0.010243 -0.002133 0.001438 -0.006488 ...
2011-09-30 -0.012240 -0.004171 0.002307 -0.013116 ...
2011-10-31 -0.013075 -0.006204 -0.001566 -0.021542 ...
2011-11-30 -0.012776 -0.008252 -0.006211 -0.022371 ...
WI WY United States M30 Unemployment Rate \
Date
2011-07-31 -0.002068 0.001897 -0.000756 -0.008130 0.000000
2011-08-31 -0.006729 -0.002080 -0.005243 0.057377 0.000000
2011-09-30 -0.011075 -0.006769 -0.007180 0.031008 -0.100000
2011-10-31 -0.015025 -0.008818 -0.008293 0.007519 -0.111111
2011-11-30 -0.014445 -0.006293 -0.008541 0.014925 -0.250000
GDP sp500 US_HPI_future label ma_apply_example
Date
2011-07-31 0.024865 0.031137 -0.005243 0 -0.003390
2011-08-31 0.022862 -0.111461 -0.007180 0 -0.000015
2011-09-30 -0.039361 -0.010247 -0.008293 0 0.004432
2011-10-31 0.018059 0.030206 -0.008541 0 0.013176
2011-11-30 0.000562 0.016886 -0.009340 0 0.015728
[5 rows x 58 columns]十六、Scikit Learn 交互
在这个 Pandas 和 Python 数据分析系列教程中,我们将展示如何快速将 Pandas 数据集转换为数据帧,并将其转换为 numpy 数组,然后可以传给各种其他 Python 数据分析模块。 我们要在这里使用的例子是 Scikit-Learn,也就是 SKlearn。 为了这样做,你需要安装它:
pip install sklearn从这里开始,我们几乎已经完成了。 对于机器学习来说,至少在监督的形式下,我们只需要几件事情。 首先,我们需要“特征”。 在我们的例子中,特征是像当前的 HPI,也许是 GDP 等等。 之后你需要“标签”。 标签被分配到特征“集”,其中对于任何给定的“标签”,特征集是任何 GDP,HPI 等等的集合。 这里,我们的标签是 1 或 0,其中 1 表示 HPI 未来增加,0 表示没有。
可能不用说,但我会提醒你:你不应该将“未来的 HPI”列包括为一个特征。 如果你这样做,机器学习算法将认识到这一点,并且准确性非常高,在现实世界中不可能实际有用。
前面教程的代码是这样的:
import Quandl
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
from statistics import mean
style.use('fivethirtyeight')
# Not necessary, I just do this so I do not show my API key.
api_key = open('quandlapikey.txt','r').read()
def create_labels(cur_hpi, fut_hpi):
if fut_hpi > cur_hpi:
return 1
else:
return 0
def moving_average(values):
return mean(values)
housing_data = pd.read_pickle('HPI.pickle')
housing_data = housing_data.pct_change()
housing_data.replace([np.inf, -np.inf], np.nan, inplace=True)
housing_data['US_HPI_future'] = housing_data['United States'].shift(-1)
housing_data.dropna(inplace=True)
#print(housing_data[['US_HPI_future','United States']].head())
housing_data['label'] = list(map(create_labels,housing_data['United States'], housing_data['US_HPI_future']))
#print(housing_data.head())
housing_data['ma_apply_example'] = pd.rolling_apply(housing_data['M30'], 10, moving_average)
print(housing_data.tail())下面,我们打算添加一些新的导入:
from sklearn import svm, preprocessing, cross_validation我们将使用 svm(支持向量机)库作为我们的机器学习分类器。 预处理用来调整我们的数据集。 通常情况下,如果你的特征介于 -1 和 1 之间,则机器学习会更精确一些。 这并不意味着永远是真的,检查是否缩放总是一个好主意,以便万无一失。 cross_validation是一个库,我们将用来创建我们的训练和测试集。 这只是一个很好的方法,可以自动随机抽取数据,用于训练和测试。
现在,我们可以创建我们的特征和标签来进行训练/测试:
X = np.array(housing_data.drop(['label','US_HPI_future'], 1))
X = preprocessing.scale(X)一般来说,对于特征和标签,你有了X,y。 大写字母X用来表示一个特征集。 y是标签。 我们在这里所做的是,将特征集定义为housing_data数据帧内容的 numpy 数组(这只是将数据帧的内容转换为多维数组),同时删除了label和US_HPI_future列。
y = np.array(housing_data['label'])现在我们的标签已经定义好了,我们已经准备好,将我们的数据分解成训练和测试集。 我们可以自己做,但是我们将使用之前的cross_validation导入:
注:
cross_validation会打乱数据,最好不要在时序数据上使用这个方法,反之应该以一个位置分割数据。
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)它所做的就是将你的特征(X)和标签(y)随机分解为训练和测试集。 正如你所看到的,返回值是训练集特征,测试集特征,训练集标签和测试集标签。 然后,我们将这些解构到X_train,X_test,y_train,y_test中。 cross_validation.train_test_split接受你的特征和标签作为参数,然后你也可以指定测试集的大小(test_size),我们已经指定为 0.2,意思是 20%。
现在,我们可以建立我们打算使用的分类器:
clf = svm.SVC(kernel='linear')在这个例子中,我们将使用线性核的支持向量分类器。 在这里更多了解sklearn.svm.SVC。
接下来,我们要训练我们的分类器:
clf.fit(X_train, y_train)最后,我们从这里可以继续并进行预测,但是让我们来测试分类器在已知数据上的准确性:
print(clf.score(X_test, y_test))0.792452830189我的平均准确度约为 70%。 你可能会得到不同的结果。 有许多地方用于机器学习调参。 我们可以改变一些默认参数,我们可以查看一些其他算法,但是现在这样做还不错。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号