
Python 数据科学入门教程:OpenCV
图像和视频分析
译者:飞龙
一、Python OpenCV 入门

欢迎阅读系列教程,内容涵盖 OpenCV,它是一个图像和视频处理库,包含 C ++,C,Python 和 Java 的绑定。 OpenCV 用于各种图像和视频分析,如面部识别和检测,车牌阅读,照片编辑,高级机器人视觉,光学字符识别等等。
你将需要两个主要的库,第三个可选:python-OpenCV,Numpy 和 Matplotlib。
Windows 用户:
python-OpenCV:有其他的方法,但这是最简单的。 下载相应的 wheel(.whl)文件,然后使用pip进行安装。 观看视频来寻求帮助。
pip install numpy
pip install matplotlib不熟悉使用pip? 请参阅pip安装教程来获得帮助。
Linux/Mac 用户
pip3 install numpy 或者
apt-get install python3-numpy你可能需要apt-get来安装python3-pip。
pip3 install matplotlib 或者
apt-get install python3-matplotlib
apt-get install python-OpenCVMatplotlib 是用于展示来自视频或图像的帧的可选选项。 我们将在这里展示几个使用它的例子。 Numpy 被用于“数值和 Python”的所有东西。 我们主要利用 Numpy 的数组功能。 最后,我们使用python-OpenCV,它是 Python 特定的 OpenCV 绑定。
OpenCV 有一些操作,如果没有完整安装 OpenCV (大小约 3GB),你将无法完成,但是实际上你可以用 python-OpenCV 最简安装。 我们将在本系列的后续部分中使用 OpenCV 的完整安装,如果你愿意的话,你可以随意获得它,但这三个模块将使我们忙碌一段时间!
通过运行 Python 并执行下列命令来确保你安装成功:
import cv2
import matplotlib
import numpy如果你没有错误,那么你已经准备好了。好了嘛?让我们下潜吧!
首先,在图像和视频分析方面,我们应该了解一些基本的假设和范式。对现在每个摄像机的记录方式来说,记录实际上是一帧一帧地显示,每秒 30-60 次。但是,它们的核心是静态帧,就像图像一样。因此,图像识别和视频分析大部分使用相同的方法。有些东西,如方向跟踪,将需要连续的图像(帧),但像面部检测或物体识别等东西,在图像和视频中代码几乎完全相同。
接下来,大量的图像和视频分析归结为尽可能简化来源。这几乎总是起始于转换为灰度,但也可以是彩色滤镜,渐变或这些的组合。从这里,我们可以对来源执行各种分析和转化。一般来说,这里发生的事情是转换完成,然后是分析,然后是任何覆盖,我们希望应用在原始来源上,这就是你可以经常看到,对象或面部识别的“成品”在全色图像或视频上显示。然而,数据实际上很少以这种原始形式处理。有一些我们可以在基本层面上做些什么的例子。所有这些都使用基本的网络摄像头来完成,没有什么特别的:
背景提取

颜色过滤

边缘检测
用于对象识别的特征匹配

一般对象识别

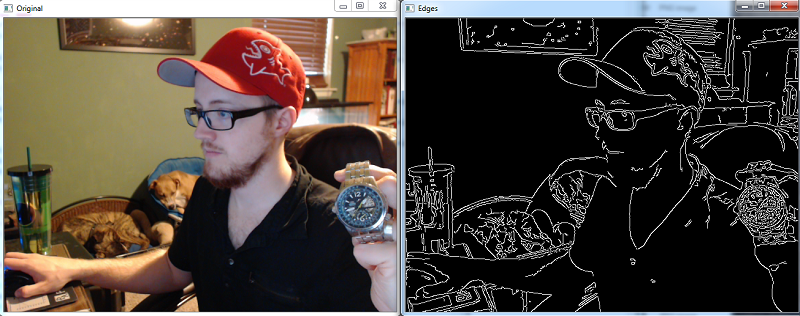
在边缘检测的情况下,黑色对应于(0,0,0)的像素值,而白色线条是(255,255,255)。视频中的每个图片和帧都会像这样分解为像素,并且像边缘检测一样,我们可以推断,边缘是基于白色与黑色像素对比的地方。然后,如果我们想看到标记边缘的原始图像,我们记录下白色像素的所有坐标位置,然后在原始图像或视频上标记这些位置。
到本教程结束时,你将能够完成上述所有操作,并且能够训练你的机器识别你想要的任何对象。就像我刚开始说的,第一步通常是转换为灰度。在此之前,我们需要加载图像。因此,我们来做吧!在整个教程中,我极力鼓励你使用你自己的数据来玩。如果你有摄像头,一定要使用它,否则找到你认为很有趣的图像。如果你有麻烦,这是一个手表的图像:

import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('watch.jpg',cv2.IMREAD_GRAYSCALE)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()首先,我们正在导入一些东西,我已经安装了这三个模块。接下来,我们将img定义为cv2.read(image file, parms)。默认值是IMREAD_COLOR,这是没有任何 alpha 通道的颜色。如果你不熟悉,alpha 是不透明度(与透明度相反)。如果你需要保留 Alpha 通道,也可以使用IMREAD_UNCHANGED。很多时候,你会读取颜色版本,然后将其转换为灰度。如果你没有网络摄像机,这将是你在本教程中使用的主要方法,即加载图像。
你可以不使用IMREAD_COLOR …等,而是使用简单的数字。你应该熟悉这两种选择,以便了解某个人在做什么。对于第二个参数,可以使用-1,0或1。颜色为1,灰度为0,不变为-1。因此,对于灰度,可以执行cv2.imread('watch.jpg', 0)。
一旦加载完成,我们使用cv2.imshow(title,image)来显示图像。从这里,我们使用cv2.waitKey(0)来等待,直到有任何按键被按下。一旦完成,我们使用cv2.destroyAllWindows()来关闭所有的东西。
正如前面提到的,你也可以用 Matplotlib 显示图像,下面是一些如何实现的代码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('watch.jpg',cv2.IMREAD_GRAYSCALE)
plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([]) # to hide tick values on X and Y axis
plt.plot([200,300,400],[100,200,300],'c', linewidth=5)
plt.show()请注意,你可以绘制线条,就像任何其他 Matplotlib 图表一样,使用像素位置作为坐标的。 不过,如果你想绘制你的图片,Matplotlib 不是必需的。 OpenCV 为此提供了很好的方法。 当你完成修改后,你可以保存,如下所示:
cv2.imwrite('watchgray.png',img)将图片导入 OpenCV 似乎很容易,加载视频源如何? 在下一个教程中,我们将展示如何加载摄像头或视频源。
二、加载视频源
在这个 Python OpenCV 教程中,我们将介绍一些使用视频和摄像头的基本操作。 除了起始行,处理来自视频的帧与处理图像是一样的。 我们来举例说明一下:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()首先,我们导入numpy和cv2,没有什么特别的。 接下来,我们可以cap = cv2.VideoCapture(0)。 这将从你计算机上的第一个网络摄像头返回视频。 如果你正在观看视频教程,你将看到我正在使用1,因为我的第一个摄像头正在录制我,第二个摄像头用于实际的教程源。
while(True):
ret, frame = cap.read()这段代码启动了一个无限循环(稍后将被break语句打破),其中ret和frame被定义为cap.read()。 基本上,ret是一个代表是否有返回的布尔值,frame是每个返回的帧。 如果没有帧,你不会得到错误,你会得到None。
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)在这里,我们定义一个新的变量gray,作为转换为灰度的帧。 注意这个BGR2GRAY。 需要注意的是,OpenCV 将颜色读取为 BGR(蓝绿色红色),但大多数计算机应用程序读取为 RGB(红绿蓝)。 记住这一点。
cv2.imshow('frame',gray)请注意,尽管是视频流,我们仍然使用imshow。 在这里,我们展示了转换为灰色的源。 如果你想同时显示,你可以对原始帧和灰度执行imshow,将出现两个窗口。
if cv2.waitKey(1) & 0xFF == ord('q'):
break这个语句每帧只运行一次。 基本上,如果我们得到一个按键,那个键是q,我们将退出while循环,然后运行:
cap.release()
cv2.destroyAllWindows()这将释放网络摄像头,然后关闭所有的imshow()窗口。
在某些情况下,你可能实际上需要录制,并将录制内容保存到新文件中。 以下是在 Windows 上执行此操作的示例:
import numpy as np
import cv2
cap = cv2.VideoCapture(1)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi',fourcc, 20.0, (640,480))
while(True):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
out.write(frame)
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
out.release()
cv2.destroyAllWindows()这里主要要注意的是正在使用的编解码器,以及在while循环之前定义的输出信息。 然后,在while循环中,我们使用out.write()来输出帧。 最后,在while循环之外,在我们释放摄像头之后,我们也释放out。
太好了,现在我们知道如何操作图像和视频。 如果你没有网络摄像头,你可以使用图像甚至视频来跟随教程的其余部分。 如果你希望使用视频而不是网络摄像头作为源,则可以为视频指定文件路径,而不是摄像头号码。
现在我们可以使用来源了,让我们来展示如何绘制东西。 此前你已经看到,你可以使用 Matplotlib 在图片顶部绘制,但是 Matplotlib 并不真正用于此目的,特别是不能用于视频源。 幸运的是,OpenCV 提供了一些很棒的工具,来帮助我们实时绘制和标记我们的源,这就是我们将在下一个教程中讨论的内容。
三、在图像上绘制和写字
在这个 Python OpenCV 教程中,我们将介绍如何在图像和视频上绘制各种形状。 想要以某种方式标记检测到的对象是相当普遍的,所以我们人类可以很容易地看到我们的程序是否按照我们的希望工作。 一个例子就是之前显示的图像之一:
对于这个临时的例子,我将使用下面的图片:
鼓励你使用自己的图片。 像往常一样,我们的起始代码可以是这样的:
import numpy as np
import cv2
img = cv2.imread('watch.jpg',cv2.IMREAD_COLOR)下面,我们可以开始绘制,这样:
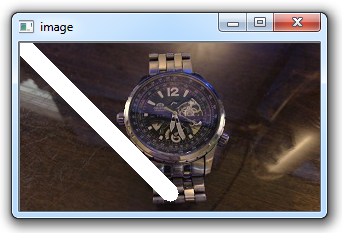
cv2.line(img,(0,0),(150,150),(255,255,255),15)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()cv2.line()接受以下参数:图片,开始坐标,结束坐标,颜色(bgr),线条粗细。
结果在这里:
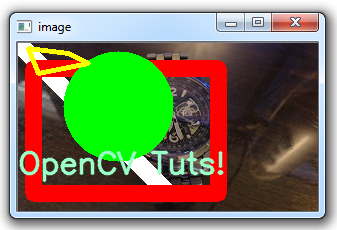
好吧,很酷,让我们绘制更多形状。 接下来是一个矩形:
cv2.rectangle(img,(15,25),(200,150),(0,0,255),15)这里的参数是图像,左上角坐标,右下角坐标,颜色和线条粗细。
圆怎么样?
cv2.circle(img,(100,63), 55, (0,255,0), -1)这里的参数是图像/帧,圆心,半径,颜色和。 注意我们粗细为-1。 这意味着将填充对象,所以我们会得到一个圆。
线条,矩形和圆都很酷,但是如果我们想要五边形,八边形或十八边形? 没问题!
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
# OpenCV documentation had this code, which reshapes the array to a 1 x 2. I did not
# find this necessary, but you may:
#pts = pts.reshape((-1,1,2))
cv2.polylines(img, [pts], True, (0,255,255), 3)首先,我们将坐标数组称为pts(点的简称)。 然后,我们使用cv2.polylines来画线。 参数如下:绘制的对象,坐标,我们应该连接终止的和起始点,颜色和粗细。
你可能想要做的最后一件事是在图像上写字。 这可以这样做:
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'OpenCV Tuts!',(0,130), font, 1, (200,255,155), 2, cv2.LINE_AA)目前为止的完整代码:
import numpy as np
import cv2
img = cv2.imread('watch.jpg',cv2.IMREAD_COLOR)
cv2.line(img,(0,0),(200,300),(255,255,255),50)
cv2.rectangle(img,(500,250),(1000,500),(0,0,255),15)
cv2.circle(img,(447,63), 63, (0,255,0), -1)
pts = np.array([[100,50],[200,300],[700,200],[500,100]], np.int32)
pts = pts.reshape((-1,1,2))
cv2.polylines(img, [pts], True, (0,255,255), 3)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'OpenCV Tuts!',(10,500), font, 6, (200,255,155), 13, cv2.LINE_AA)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()结果:
在下一个教程中,我们将介绍我们可以执行的基本图像操作。
四、图像操作
在 OpenCV 教程中,我们将介绍一些我们可以做的简单图像操作。 每个视频分解成帧。 然后每一帧,就像一个图像,分解成存储在行和列中的,帧/图片中的像素。 每个像素都有一个坐标位置,每个像素都由颜色值组成。 让我们列举访问不同的位的一些例子。
我们将像往常一样读取图像(如果可以,请使用自己的图像,但这里是我在这里使用的图像):
import cv2
import numpy as np
img = cv2.imread('watch.jpg',cv2.IMREAD_COLOR)现在我们可以实际引用特定像素,像这样:
px = img[55,55]下面我们可以实际修改像素:
img[55,55] = [255,255,255]之后重新引用:
px = img[55,55]
print(px)现在应该不同了,下面我们可以引用 ROI,图像区域:
px = img[100:150,100:150]
print(px)我们也可以修改 ROI,像这样:
img[100:150,100:150] = [255,255,255]我们可以引用我们的图像的特定特征:
print(img.shape)
print(img.size)
print(img.dtype)我们可以像这样执行操作:
watch_face = img[37:111,107:194]
img[0:74,0:87] = watch_face
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()这会处理我的图像,但是可能不能用于你的图像,取决于尺寸。这是我的输出:
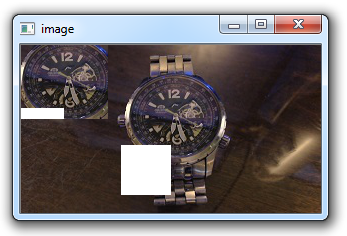
这些是一些简单的操作。 在下一个教程中,我们将介绍一些我们可以执行的更高级的图像操作。
五、图像算术和逻辑运算
欢迎来到另一个 Python OpenCV 教程,在本教程中,我们将介绍一些简单算术运算,我们可以在图像上执行的,并解释它们的作用。 为此,我们将需要两个相同大小的图像来开始,然后是一个较小的图像和一个较大的图像。 首先,我将使用:
和
首先,让我们看看简单的加法会做什么:
import cv2
import numpy as np
# 500 x 250
img1 = cv2.imread('3D-Matplotlib.png')
img2 = cv2.imread('mainsvmimage.png')
add = img1+img2
cv2.imshow('add',add)
cv2.waitKey(0)
cv2.destroyAllWindows()结果:
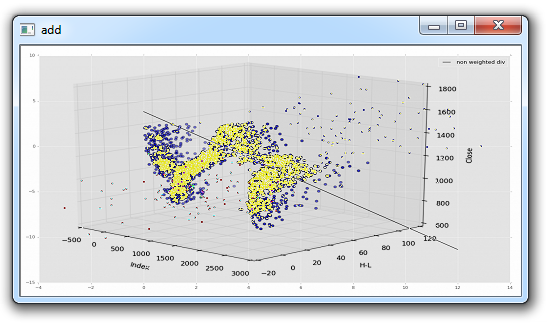
你不可能想要这种混乱的加法。 OpenCV 有一个“加法”方法,让我们替换以前的“加法”,看看是什么:
add = cv2.add(img1,img2)结果:
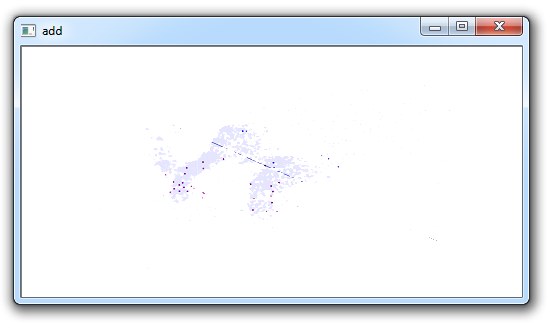
这里可能不理想。 我们可以看到很多图像是非常“白色的”。 这是因为颜色是 0-255,其中 255 是“全亮”。 因此,例如:(155,211,79) + (50, 170, 200) = 205, 381, 279…转换为(205, 255,255)。
接下来,我们可以添加图像,并可以假设每个图像都有不同的“权重”。 这是如何工作的:
import cv2
import numpy as np
img1 = cv2.imread('3D-Matplotlib.png')
img2 = cv2.imread('mainsvmimage.png')
weighted = cv2.addWeighted(img1, 0.6, img2, 0.4, 0)
cv2.imshow('weighted',weighted)
cv2.waitKey(0)
cv2.destroyAllWindows()对于addWeighted方法,参数是第一个图像,权重,第二个图像,权重,然后是伽马值,这是一个光的测量值。 我们现在就把它保留为零。
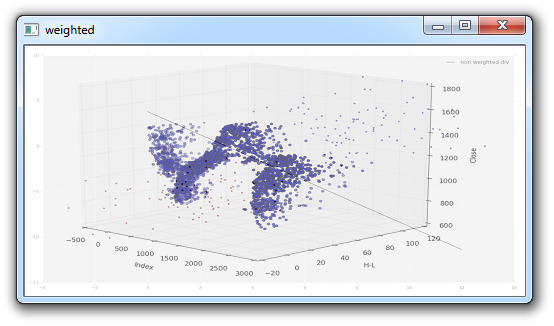
这些是一些额外的选择,但如果你真的想将一个图像添加到另一个,最新的重叠在哪里? 在这种情况下,你会从最大的开始,然后添加较小的图像。 为此,我们将使用相同的3D-Matplotlib.png图像,但使用一个新的 Python 标志:

现在,我们可以选取这个标志,并把它放在原始图像上。 这很容易(基本上使用我们在前一个教程中使用的相同代码,我们用一个新的东西替换了图像区域(ROI)),但是如果我们只想要标志部分而不是白色背景呢? 我们可以使用与之前用于 ROI 替换相同的原理,但是我们需要一种方法来“去除”标志的背景,使得白色不会不必要地阻挡更多背景图像。 首先我将显示完整的代码,然后解释:
import cv2
import numpy as np
# Load two images
img1 = cv2.imread('3D-Matplotlib.png')
img2 = cv2.imread('mainlogo.png')
# I want to put logo on top-left corner, So I create a ROI
rows,cols,channels = img2.shape
roi = img1[0:rows, 0:cols ]
# Now create a mask of logo and create its inverse mask
img2gray = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
# add a threshold
ret, mask = cv2.threshold(img2gray, 220, 255, cv2.THRESH_BINARY_INV)
mask_inv = cv2.bitwise_not(mask)
# Now black-out the area of logo in ROI
img1_bg = cv2.bitwise_and(roi,roi,mask = mask_inv)
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(img2,img2,mask = mask)
dst = cv2.add(img1_bg,img2_fg)
img1[0:rows, 0:cols ] = dst
cv2.imshow('res',img1)
cv2.waitKey(0)
cv2.destroyAllWindows()这里发生了很多事情,出现了一些新的东西。 我们首先看到的是一个新的阈值:ret, mask = cv2.threshold(img2gray, 220, 255, cv2.THRESH_BINARY_INV)。
我们将在下一个教程中介绍更多的阈值,所以请继续关注具体内容,但基本上它的工作方式是根据阈值将所有像素转换为黑色或白色。 在我们的例子中,阈值是 220,但是我们可以使用其他值,或者甚至动态地选择一个,这是ret变量可以使用的值。 接下来,我们看到:mask_inv = cv2.bitwise_not(mask)。 这是一个按位操作。 基本上,这些操作符与 Python 中的典型操作符非常相似,除了一点,但我们不会在这里触及它。 在这种情况下,不可见的部分是黑色的地方。 然后,我们可以说,我们想在第一个图像中将这个区域遮住,然后将空白区域替换为图像 2 的内容。
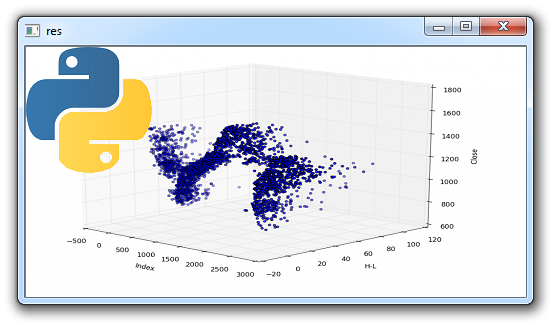
下个教程中,我们深入讨论阈值。
六、阈值
欢迎阅读另一个 OpenCV 教程。在本教程中,我们将介绍图像和视频分析的阈值。阈值的思想是进一步简化视觉数据的分析。首先,你可以转换为灰度,但是你必须考虑灰度仍然有至少 255 个值。阈值可以做的事情,在最基本的层面上,是基于阈值将所有东西都转换成白色或黑色。比方说,我们希望阈值为 125(最大为 255),那么 125 以下的所有内容都将被转换为 0 或黑色,而高于 125 的所有内容都将被转换为 255 或白色。如果你像平常一样转换成灰度,你会变成白色和黑色。如果你不转换灰度,你会得到二值化的图片,但会有颜色。
虽然这听起来不错,但通常不是。我们将在这里介绍多个示例和不同类型的阈值来说明这一点。我们将使用下面的图片作为我们的示例图片,但可以随意使用你自己的图片:

这个书的图片就是个很好的例子,说明为什么一个人可能需要阈值。 首先,背景根本没有白色,一切都是暗淡的,而且一切都是变化的。 有些部分很容易阅读,另一部分则非常暗,需要相当多的注意力才能识别出来。 首先,我们尝试一个简单的阈值:
retval, threshold = cv2.threshold(img, 10, 255, cv2.THRESH_BINARY)二元阈值是个简单的“是或不是”的阈值,其中像素为 255 或 0。在很多情况下,这是白色或黑色,但我们已经为我们的图像保留了颜色,所以它仍然是彩色的。 这里的第一个参数是图像。 下一个参数是阈值,我们选择 10。下一个是最大值,我们选择为 255。最后是阈值类型,我们选择了THRESH_BINARY。 通常情况下,10 的阈值会有点差。 我们选择 10,因为这是低光照的图片,所以我们选择低的数字。 通常 125-150 左右的东西可能效果最好。
import cv2
import numpy as np
img = cv2.imread('bookpage.jpg')
retval, threshold = cv2.threshold(img, 12, 255, cv2.THRESH_BINARY)
cv2.imshow('original',img)
cv2.imshow('threshold',threshold)
cv2.waitKey(0)
cv2.destroyAllWindows()结果:
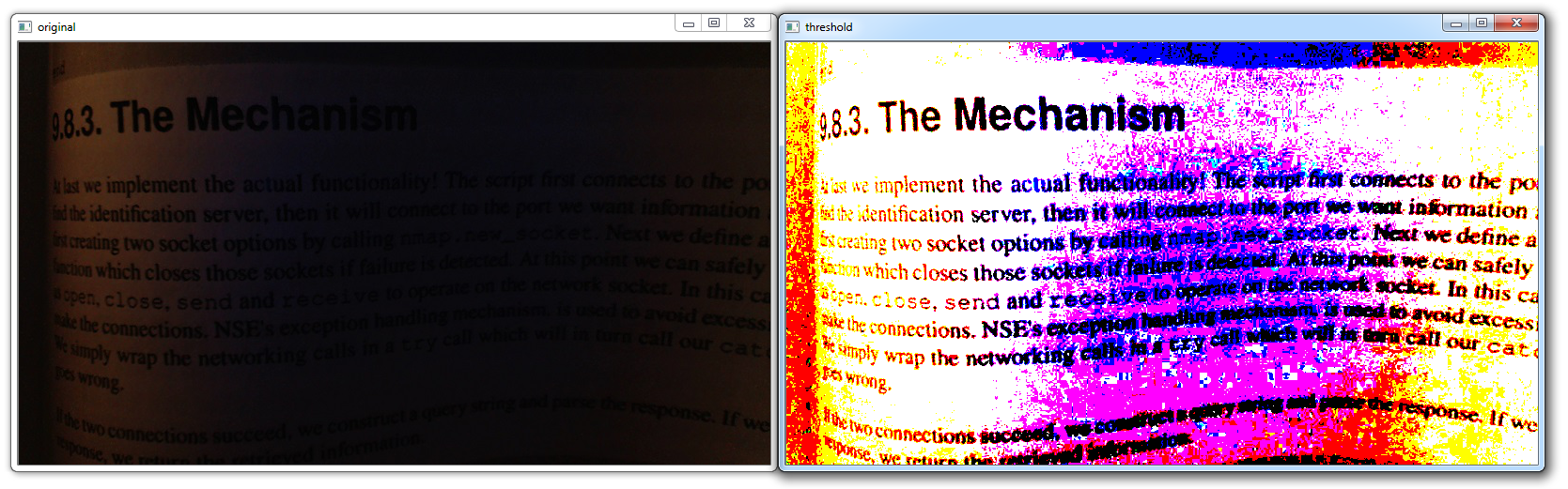
现在的图片稍微更便于阅读了,但还是有点乱。 从视觉上来说,这样比较好,但是仍然难以使用程序来分析它。 让我们看看我们是否可以进一步简化。
首先,让我们灰度化图像,然后使用一个阈值:
import cv2
import numpy as np
grayscaled = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
retval, threshold = cv2.threshold(grayscaled, 10, 255, cv2.THRESH_BINARY)
cv2.imshow('original',img)
cv2.imshow('threshold',threshold)
cv2.waitKey(0)
cv2.destroyAllWindows()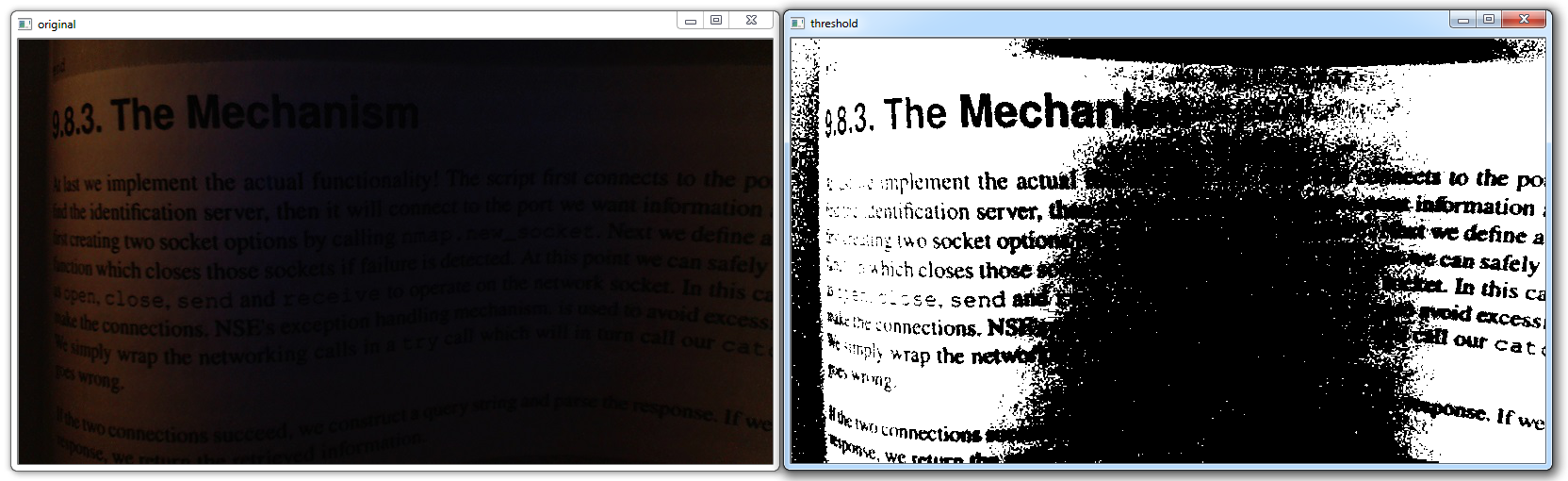
更简单,但是我们仍然在这里忽略了很多背景。 接下来,我们可以尝试自适应阈值,这将尝试改变阈值,并希望弄清楚弯曲的页面。
import cv2
import numpy as np
th = cv2.adaptiveThreshold(grayscaled, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 115, 1)
cv2.imshow('original',img)
cv2.imshow('Adaptive threshold',th)
cv2.waitKey(0)
cv2.destroyAllWindows()
还有另一个版本的阈值,可以使用,叫做大津阈值。 它在这里并不能很好发挥作用,但是:
retval2,threshold2 = cv2.threshold(grayscaled,125,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
cv2.imshow('original',img)
cv2.imshow('Otsu threshold',threshold2)
cv2.waitKey(0)
cv2.destroyAllWindows()七、颜色过滤
在这个 Python OpenCV 教程中,我们将介绍如何创建一个过滤器,回顾按位操作,其中我们将过滤特定的颜色,试图显示它。或者,你也可以专门筛选出特定的颜色,然后将其替换为场景,就像我们用其他方法替换ROI(图像区域)一样,就像绿屏的工作方式。
为了像这样过滤,你有几个选项。通常,你可能会将你的颜色转换为 HSV,即“色调饱和度纯度”。例如,这可以帮助你根据色调和饱和度范围,使用变化的值确定一个更具体的颜色。如果你希望的话,你可以实际生成基于 BGR 值的过滤器,但是这会有点困难。如果你很难可视化 HSV,不要感到失落,查看维基百科页面上的 HSV,那里有一个非常有用的图形让你可视化它。我最好亲自描述颜色的色调饱和度和纯度。现在让我们开始:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
cv2.imshow('frame',frame)
cv2.imshow('mask',mask)
cv2.imshow('res',res)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()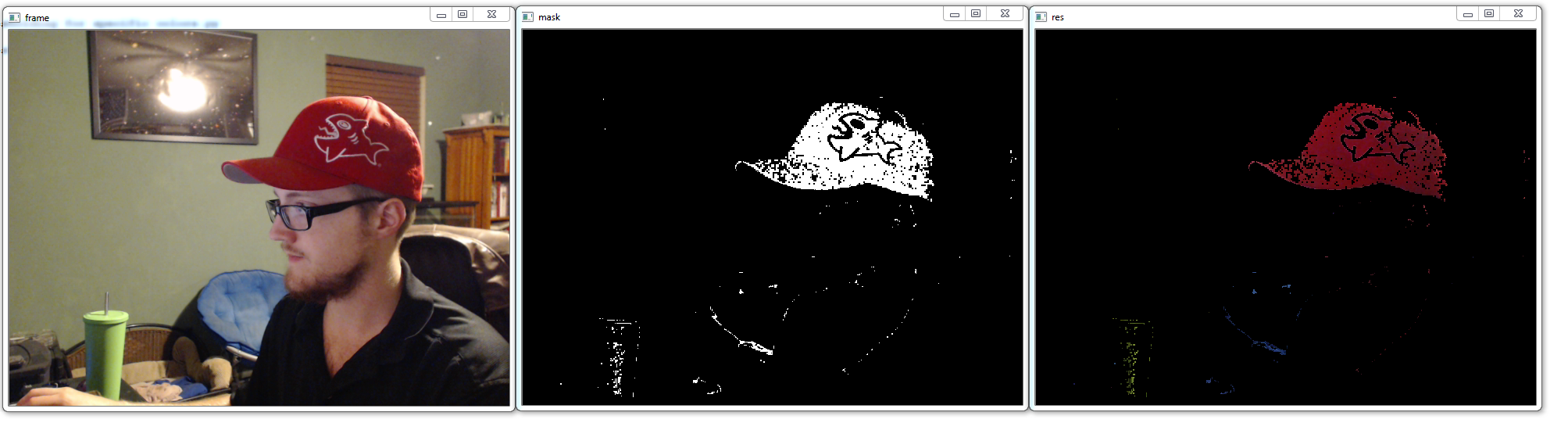
这只是一个例子,以红色为目标。 它的工作方式是,我们所看到的是我们范围内的任何东西,基本上是 30-255,150-255 和 50-180。 它用于红色,但可以随便尝试找到自己的颜色。 HSV 在这里效果最好的原因是,我们想要范围内的颜色,这里我们通常需要相似的颜色。 很多时候,典型的红色仍然会有一些绿色和蓝色分量,所以我们必须允许一些绿色和蓝色,但是我们会想要几乎全红。 这意味着我们会在这里获得所有颜色的低光混合。
为了确定 HSV 的范围,我认为最好的方法就是试错。 OpenCV 内置了将 BGR 转换为 HSV 的方法。 如果你想挑选单一的颜色,那么 BGR 到 HSV 将会很好用。 为了教学,下面是这个代码的一个例子:
dark_red = np.uint8([[[12,22,121]]])
dark_red = cv2.cvtColor(dark_red,cv2.COLOR_BGR2HSV)这里的结果是一个 HSV 值,与dark_red值相同。这很棒…但是,同样…你遇到了颜色范围和 HSV 范围的基本问题。他们根本不同。你可能合理使用 BGR 范围,它们仍然可以工作,但是对于检测一种“颜色”,则无法正常工作。
回到主代码,然而,我们首先要把帧转换成 HSV。那里没什么特别的。接下来,我们为红色指定一些 HSV 值。我们使用inRange函数,为我们的特定范围创建掩码。这是真或假,黑色或白色。接下来,我们通过执行按位操作来“恢复”我们的红色。基本上,我们显示了frame and mask。掩码的白色部分是红色范围,被转换为纯白色,而其他一切都变成黑色。最后我们展示所有东西。我选择了显示原始真,掩码和最终结果,以便更好地了解发生的事情。
在下一个教程中,我们将对这个主题做一些介绍。你可能看到了,我们在这里还是有一些“噪音”。东西有颗粒感,红色中的黑点很多,还有许多其他的小色点。我们可以做一些事情,试图通过模糊和平滑来缓解这个问题,接下来我们将讨论这个问题。
八、模糊和平滑
在这个 Python OpenCV 教程中,我们将介绍如何尝试从我们的过滤器中消除噪声,例如简单的阈值,或者甚至我们以前的特定的颜色过滤器:
正如你所看到的,我们有很多黑点,其中我们喜欢红色,还有很多其他的色点散落在其中。 我们可以使用各种模糊和平滑技术来尝试弥补这一点。 我们可以从一些熟悉的代码开始:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)现在,让我们应用一个简单的平滑,我们计算每个像素块的均值。 在我们的例子中,我们使用15x15正方形,这意味着我们有 225 个总像素。
kernel = np.ones((15,15),np.float32)/225
smoothed = cv2.filter2D(res,-1,kernel)
cv2.imshow('Original',frame)
cv2.imshow('Averaging',smoothed)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()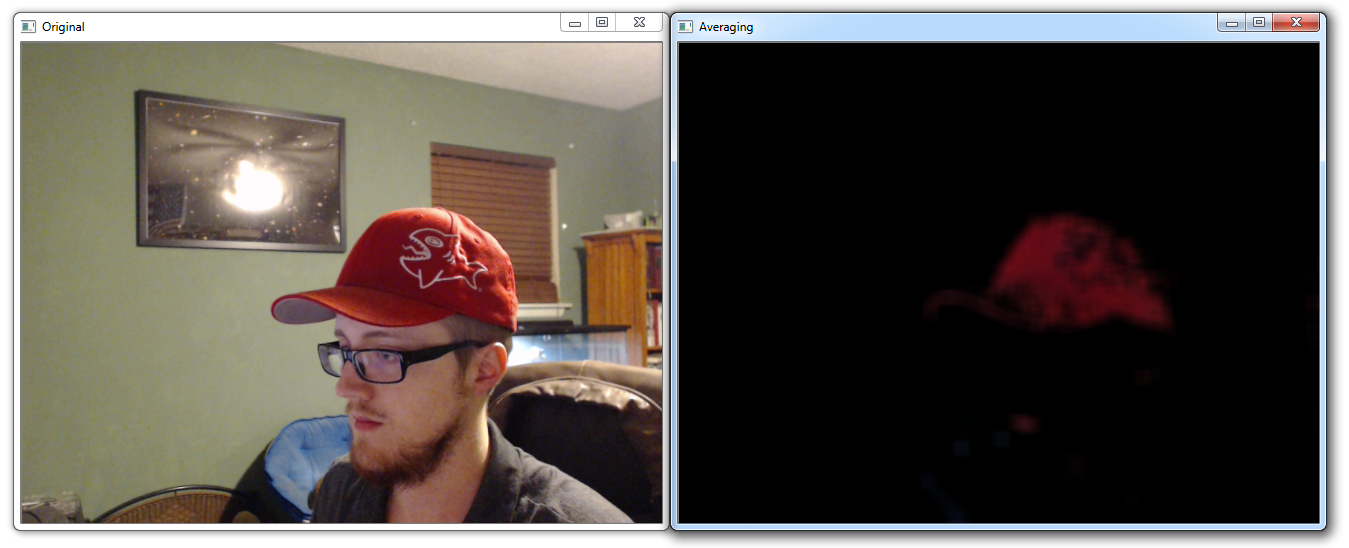
这个很简单,但是结果牺牲了很多粒度。 接下来,让我们尝试一些高斯模糊:
blur = cv2.GaussianBlur(res,(15,15),0)
cv2.imshow('Gaussian Blurring',blur)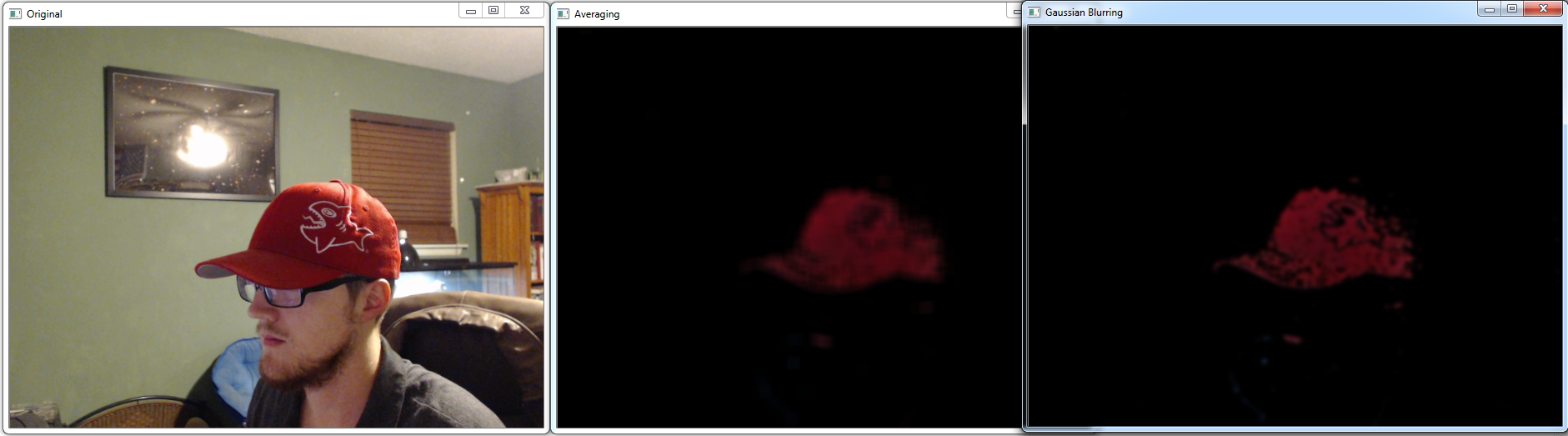
另一个选项是中值模糊:
median = cv2.medianBlur(res,15)
cv2.imshow('Median Blur',median)
最后一个选项是双向模糊:
bilateral = cv2.bilateralFilter(res,15,75,75)
cv2.imshow('bilateral Blur',bilateral)所有模糊的对比:

至少在这种情况下,我可能会使用中值模糊,但是不同的照明,不同的阈值/过滤器,以及其他不同的目标和目标可能会决定你使用其中一个。
在下一个教程中,我们将讨论形态变换。
九、形态变换
在这个 Python OpenCV 教程中,我们将介绍形态变换。 这些是一些简单操作,我们可以基于图像形状执行。
我们要谈的第一对是腐蚀和膨胀。 腐蚀是我们将“腐蚀”边缘。 它的工作方式是使用滑块(核)。 我们让滑块滑动,如果所有的像素是白色的,那么我们得到白色,否则是黑色。 这可能有助于消除一些白色噪音。 另一个版本是膨胀,它基本上是相反的:让滑块滑动,如果整个区域不是黑色的,就会转换成白色。 这是一个例子:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
kernel = np.ones((5,5),np.uint8)
erosion = cv2.erode(mask,kernel,iterations = 1)
dilation = cv2.dilate(mask,kernel,iterations = 1)
cv2.imshow('Original',frame)
cv2.imshow('Mask',mask)
cv2.imshow('Erosion',erosion)
cv2.imshow('Dilation',dilation)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()结果:
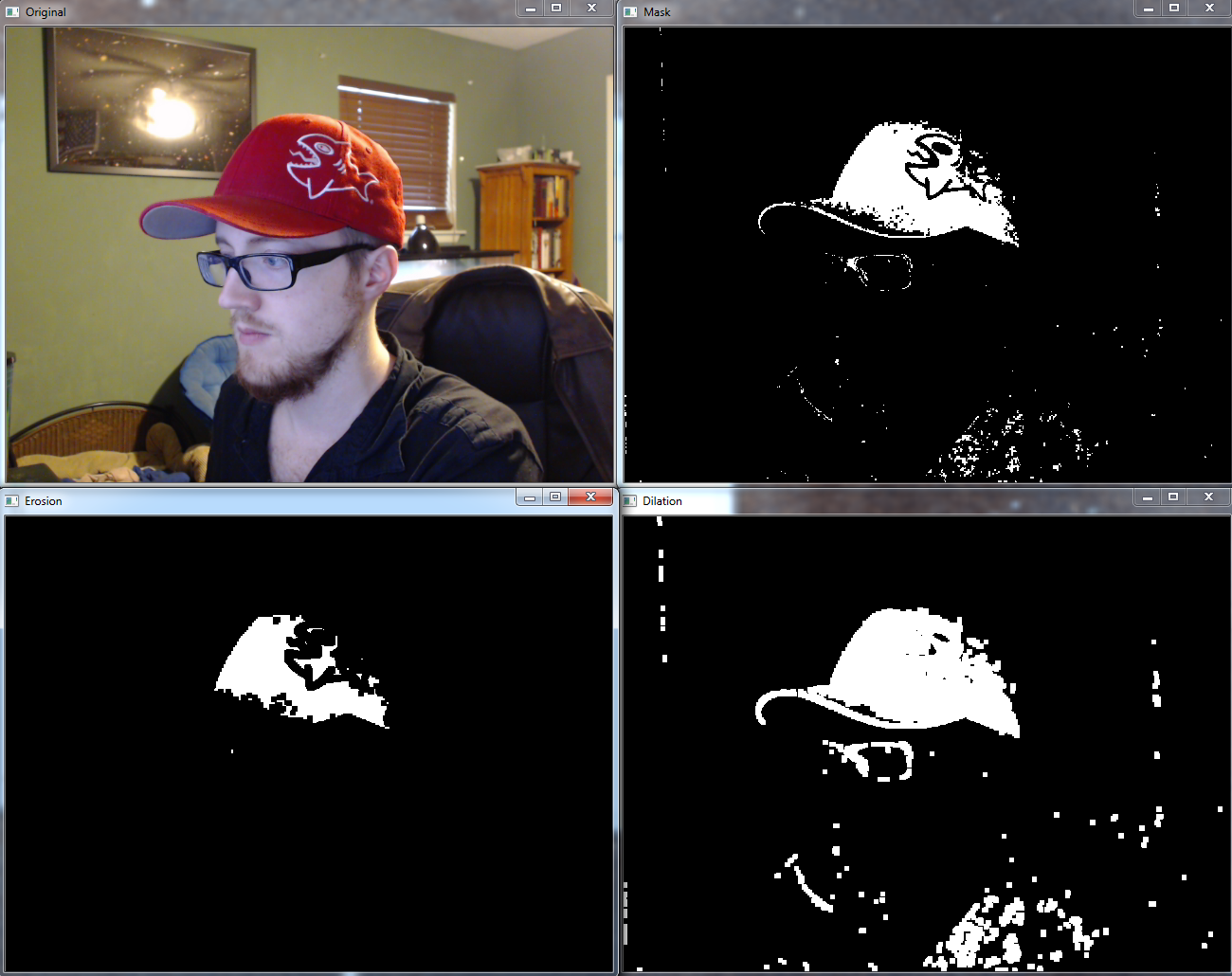
下一对是“开放”和“关闭”。 开放的目标是消除“假阳性”。 有时在背景中,你会得到一些像素“噪音”。 “关闭”的想法是消除假阴性。 基本上就是你检测了你的形状,例如我们的帽子,但物体仍然有一些黑色像素。 关闭将尝试清除它们。
cap = cv2.VideoCapture(1)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
kernel = np.ones((5,5),np.uint8)
opening = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
closing = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
cv2.imshow('Original',frame)
cv2.imshow('Mask',mask)
cv2.imshow('Opening',opening)
cv2.imshow('Closing',closing)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()
另外两个选项是tophat和blackhat,对我们的案例并不有用:
# It is the difference between input image and Opening of the image
cv2.imshow('Tophat',tophat)
# It is the difference between the closing of the input image and input image.
cv2.imshow('Blackhat',blackhat)在下一个教程中,我们将讨论图像渐变和边缘检测。
十、边缘检测和渐变
欢迎阅读另一个 Python OpenCV 教程。 在本教程中,我们将介绍图像渐变和边缘检测。 图像渐变可以用来测量方向的强度,边缘检测就像它所说的:它找到了边缘! 我敢打赌你肯定没看到。
首先,我们来展示一些渐变的例子:
import cv2
import numpy as np
cap = cv2.VideoCapture(1)
while(1):
# Take each frame
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
laplacian = cv2.Laplacian(frame,cv2.CV_64F)
sobelx = cv2.Sobel(frame,cv2.CV_64F,1,0,ksize=5)
sobely = cv2.Sobel(frame,cv2.CV_64F,0,1,ksize=5)
cv2.imshow('Original',frame)
cv2.imshow('Mask',mask)
cv2.imshow('laplacian',laplacian)
cv2.imshow('sobelx',sobelx)
cv2.imshow('sobely',sobely)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()
如果你想知道什么是cv2.CV_64F,那就是数据类型。 ksize是核大小。 我们使用 5,所以每次查询5×5的渔区。
虽然我们可以使用这些渐变转换为纯边缘,但我们也可以使用 Canny 边缘检测!
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while(1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
lower_red = np.array([30,150,50])
upper_red = np.array([255,255,180])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(frame,frame, mask= mask)
cv2.imshow('Original',frame)
edges = cv2.Canny(frame,100,200)
cv2.imshow('Edges',edges)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
cv2.destroyAllWindows()
cap.release()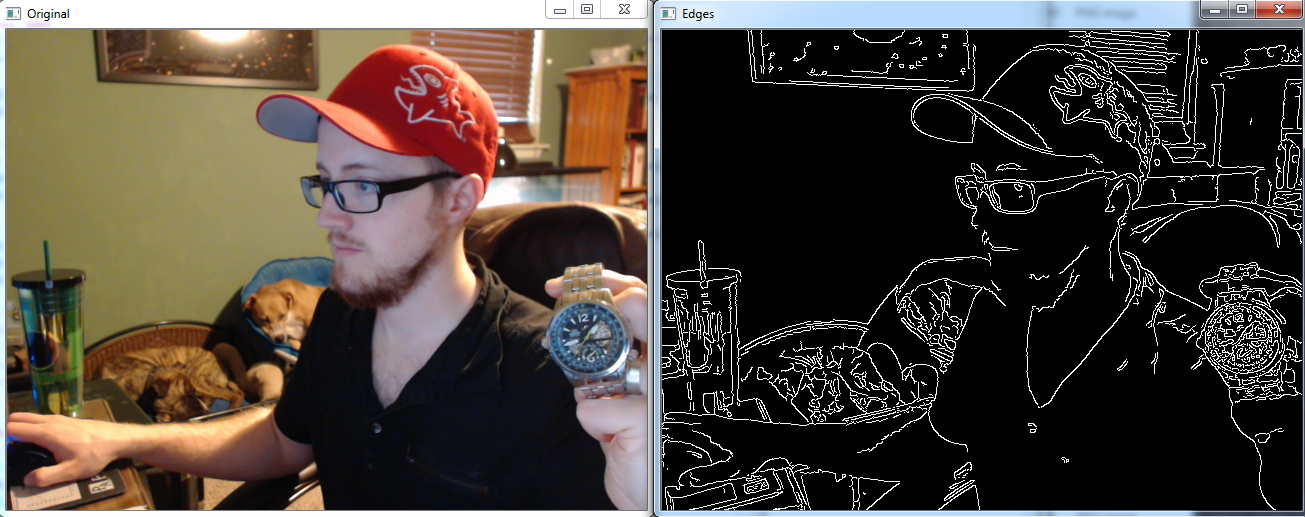
这真是太棒了! 但是,这并不完美。 注意阴影导致了边缘被检测到。 其中最明显的是蓝狗窝发出的阴影。
在下一个 OpenCV 教程中,我们将讨论如何在其他图像中搜索和查找相同的图像模板。
十一、模板匹配
欢迎阅读另一个 Python OpenCV 教程,在本教程中,我们将介绍对象识别的一个基本版本。 这里的想法是,给出一定的阈值,找到匹配我们提供的模板图像的相同区域。 对于具体的对象匹配,具有精确的照明/刻度/角度,这可以工作得很好。 通常会遇到这些情况的例子就是计算机上的任何 GUI。 按钮等东西总是相同的,所以你可以使用模板匹配。 结合模板匹配和一些鼠标控制,你已经实现了一个基于 Web 的机器人!
首先,你需要一个主要图像和一个模板。 你应该从你正在图像中查找的“东西”选取你的模板。 我将提供一个图像作为例子,但随意使用你最喜爱的网站的图像或类似的东西。
主要图像:

我们要搜索的模板:

这只是其中一个端口,但我们很好奇,看看我们是否可以匹配任何其他端口。 我们确实要选择一个阈值,其中某种东西可能是 80% 匹配,那么我们说这就匹配。 所以,我们将开始加载和转换图像:
import cv2
import numpy as np
img_rgb = cv2.imread('opencv-template-matching-python-tutorial.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('opencv-template-for-matching.jpg',0)
w, h = template.shape[::-1]到目前为止,我们加载了两个图像,转换为灰度。 我们保留原始的 RGB 图像,并创建一个灰度版本。 我之前提到过这个,但是我们这样做的原因是,我们在灰度版本上执行所有的处理,然后在彩色图像上使用相同的标签来标记。
对于主要图像,我们只有彩色版本和灰度版本。 我们加载模板并记下尺寸。
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)在这里,我们用img_gray(我们的主图像),模板,和我们要使用的匹配方法调用matchTemplate,并将返回值称为res。 我们指定一个阈值,这里是 80%。 然后我们使用逻辑语句,找到res大于或等于 80% 的位置。
最后,我们使用灰度图像中找到的坐标,标记原始图像上的所有匹配:
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,255,255), 2)
cv2.imshow('Detected',img_rgb)
所以我们得到了几个匹配。也许需要降低阈值?我们试试 0.7。

这里有一些假阳性。 你可以继续调整门槛,直到你达到 100%,但是如果没有假阳性,你可能永远不会达到它。 另一个选择就是使用另一个模板图像。 有时候,使用相同对象的多个图像是有用的。 这样,你可以使阈值足够高的,来确保你的结果准确。
在下一个教程中,我们将介绍前景提取。
十二、GrabCut 前景提取
欢迎阅读 Python OpenCV 前景提取教程。 这里的想法是找到前景,并删除背景。 这很像绿屏,只是这里我们实际上不需要绿屏。
首先,我们将使用一个图像:

随意使用你自己的。
让我们加载图像并定义一些东西:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('opencv-python-foreground-extraction-tutorial.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (161,79,150,150)到目前为止,我们已经导入了cv2,numpy和matplotlib。 然后我们加载图像,创建一个掩码,指定算法内部使用的背景和前景模型。 真正重要的部分是我们定义的矩形。 这是rect = (start_x, start_y, width, height)。
这是包围我们的主要对象的矩形。 如果你正在使用我的图片,那就是要使用的矩阵。 如果你使用自己的,找到适合你的图像的坐标。
下面:
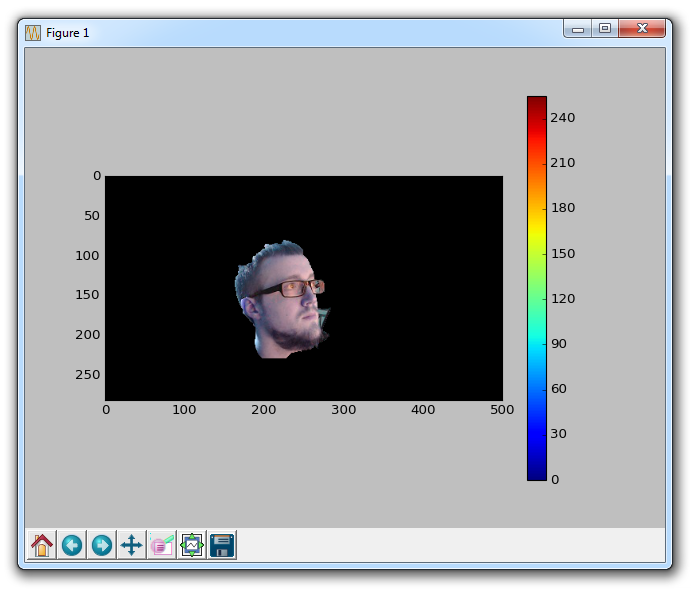
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
plt.imshow(img)
plt.colorbar()
plt.show()所以在这里我们使用了cv2.grabCut,它用了很多参数。 首先是输入图像,然后是掩码,然后是主要对象的矩形,背景模型,前景模型,要运行的迭代量以及使用的模式。
这里改变了掩码,使得所有像素 0 和 2 转换为背景,而像素 1 和 3 现在是前景。 从这里,我们乘以输入图像,得到我们的最终结果:
下个教程中,我们打算讨论如何执行角点检测。
十三、角点检测
欢迎阅读 Python OpenCV 角点检测教程。 检测角点的目的是追踪运动,做 3D 建模,识别物体,形状和角色等。
对于本教程,我们将使用以下图像:
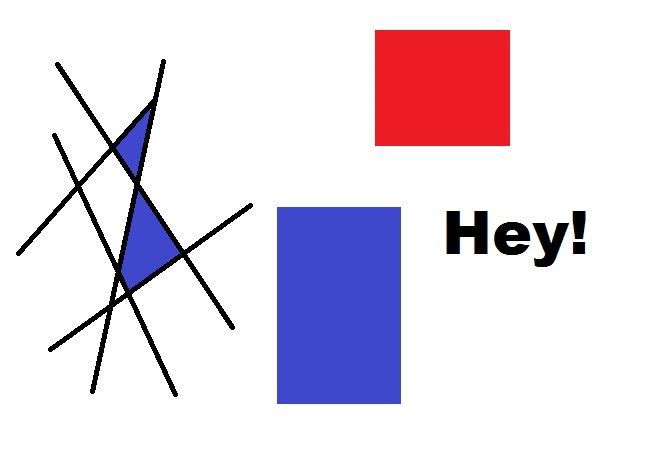
我们的目标是找到这个图像中的所有角点。 我会注意到,在这里我们有一些别名问题(斜线的锯齿),所以,如果我们允许的话,会发现很多角点,而且是正确的。 和往常一样,OpenCV 已经为我们完成了难题,我们需要做的就是输入一些参数。 让我们开始加载图像并设置一些参数:
import numpy as np
import cv2
img = cv2.imread('opencv-corner-detection-sample.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
corners = cv2.goodFeaturesToTrack(gray, 100, 0.01, 10)
corners = np.int0(corners)到目前为止,我们加载图像,转换为灰度,然后是float32。 接下来,我们用goodFeaturesToTrack函数检测角点。 这里的参数是图像,检测到的最大角点数量,品质和角点之间的最小距离。 如前所述,我们在这里的锯齿问题将允许找到许多角点,所以我们对其进行了限制。 下面:
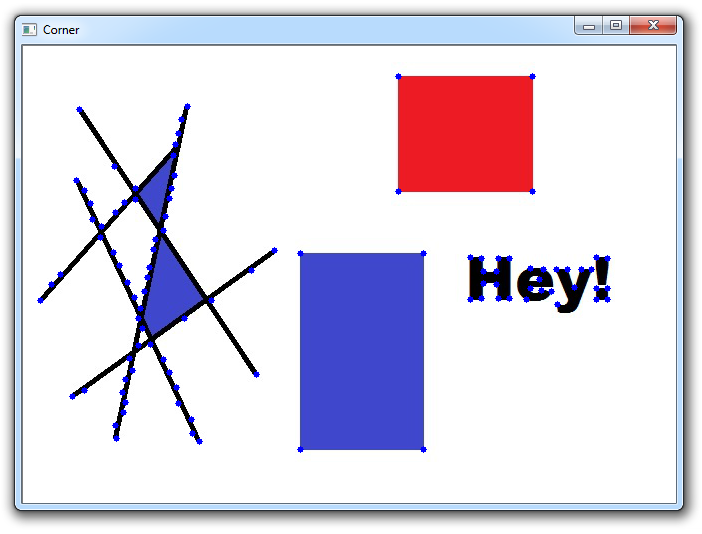
for corner in corners:
x,y = corner.ravel()
cv2.circle(img,(x,y),3,255,-1)
cv2.imshow('Corner',img)现在我们遍历每个角点,在我们认为是角点的每个点上画一个圆。
在下一个教程中,我们将讨论功能匹配/单映射。
十四、特征匹配(单映射)爆破
欢迎阅读 Python OpenCV 特征匹配教程。 特征匹配将是稍微更令人印象深刻的模板匹配版本,其中需要一个完美的,或非常接近完美的匹配。
我们从我们希望找到的图像开始,然后我们可以在另一幅图像中搜索这个图像。 这里的完美是图像不需要相同的光照,角度,旋转等。 特征只需要匹配。
首先,我们需要一些示例图像。 我们的“模板”,或者我们将要尝试匹配的图像:

之后是我们用于搜索这个模板的图像:

在这里,我们的模板图像在模板中,比在我们要搜索的图像中要小一些。 它的旋转也不同,阴影也有些不同。
现在我们将使用一种“爆破”匹配的形式。 我们将在这两个图像中找到所有特征。 然后我们匹配这些特征。 然后,我们可以绘制我们想要的,尽可能多的匹配。 但是要小心。 如果你绘制 500 个匹配,你会有很多误报。 所以只绘制绘制前几个。
import numpy as np
import cv2
import matplotlib.pyplot as plt
img1 = cv2.imread('opencv-feature-matching-template.jpg',0)
img2 = cv2.imread('opencv-feature-matching-image.jpg',0)到目前为止,我们已经导入了要使用的模块,并定义了我们的两个图像,即模板(img1)和用于搜索模板的图像(img2)。
orb = cv2.ORB_create()这是我们打算用于特征的检测器。
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)在这里,我们使用orb探测器找到关键点和他们的描述符。
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)这就是我们的BFMatcher对象。
matches = bf.match(des1,des2)
matches = sorted(matches, key = lambda x:x.distance)这里我们创建描述符的匹配,然后根据它们的距离对它们排序。
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:10],None, flags=2)
plt.imshow(img3)
plt.show()这里我们绘制了前 10 个匹配。输出:

十五、MOG 背景减弱
在这个 Python OpenCV 教程中,我们将要讨论如何通过检测运动来减弱图像的背景。 这将要求我们回顾视频的使用,或者有两个图像,一个没有你想要追踪的人物/物体,另一个拥有人物/物体。 如果你希望,你可以使用你的摄像头,或者使用如下的视频:
这里的代码实际上很简单,就是我们现在知道的:
import numpy as np
import cv2
cap = cv2.VideoCapture('people-walking.mp4')
fgbg = cv2.createBackgroundSubtractorMOG2()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
cv2.imshow('fgmask',frame)
cv2.imshow('frame',fgmask)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()结果:
https://pythonprogramming.net/static/images/opencv/opencv-python-foreground.mp4
这里的想法是从静态背景中提取移动的前景。 你也可以使用这个来比较两个相似的图像,并立即提取它们之间的差异。
在我们的例子中,我们可以看到我们确实已经检测到了一些人,但是我们确实有一些“噪音”,噪音实际上是树叶在周围的风中移动了一下。 只要我们知道一种减少噪音的方法。 等一下! 我们的确知道! 一个疯狂的挑战已经出现了你面前!
接下来的教程开始让我们远离滤镜或变换的应用,并让我们使用 Haar Cascades 来检测一般对象,例如面部检测等等。
十六、Haar Cascade 面部检测
在这个 Python OpenCV 教程中,我们将讨论 Haar Cascades 对象检测。我们将从脸部和眼睛检测来开始。为了使用层叠文件进行对象识别/检测,首先需要层叠文件。对于非常流行的任务,这些已经存在。检测脸部,汽车,笑脸,眼睛和车牌等东西都是非常普遍的。
首先,我会告诉你如何使用这些层叠文件,然后我将告诉你如何开始创建你自己的层叠,这样你就可以检测到任何你想要的对象,这很酷!
你可以使用 Google 来查找你可能想要检测的东西的各种 Haar Cascades。对于找到上述类型,你应该没有太多的麻烦。我们将使用面部层叠和眼睛层叠。你可以在 Haar Cascades 的根目录找到更多。请注意用于使用/分发这些 Haar Cascades 的许可证。
让我们开始我们的代码。我假设你已经从上面的链接中下载了haarcascade_eye.xml和haarcascade_frontalface_default.xml,并将这些文件放在你项目的目录中。
import numpy as np
import cv2
# multiple cascades: https://github.com/Itseez/opencv/tree/master/data/haarcascades
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_eye.xml
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
cap = cv2.VideoCapture(0)在这里,我们从导入cv2和numpy开始,然后加载我们的脸部和眼部的层叠。 目前为止很简单。
while 1:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)现在我们开始我们的典型循环,这里唯一的新事物就是脸部的创建。 更多信息请访问detectMultiScale函数的文档。 基本上,它找到了面部! 我们也想找到眼睛,但是在一个假阳性的世界里,在面部里面寻找眼睛,从逻辑上来说是不是很明智? 我们希望我们不寻找不在脸上的眼睛! 严格来说,“眼睛检测”可能不会找到闲置的眼球。 大多数眼睛检测使用周围的皮肤,眼睑,眼睫毛,眉毛也可以用于检测。 因此,我们的下一步就是先去拆分面部,然后才能到达眼睛:
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]在这里,我们找到了面部,它们的大小,绘制矩形,并注意 ROI。 接下来,我们找了一些眼睛:
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)如果我们找到这些,我们会继续绘制更多的矩形。 接下来我们完成:
cv2.imshow('img',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()完整代码:
import numpy as np
import cv2
# multiple cascades: https://github.com/Itseez/opencv/tree/master/data/haarcascades
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
#https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_eye.xml
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
cap = cv2.VideoCapture(0)
while 1:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()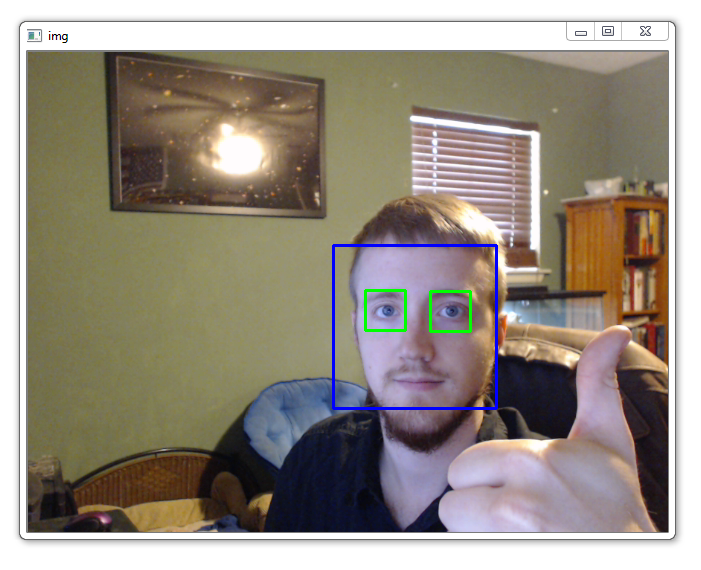
不错。你可能会注意到我不得不取下我的眼镜。这些造成了一些麻烦。我的嘴也经常被检测为眼睛,有时甚至是一张脸,但你明白了。面部毛发和其他东西经常可以欺骗基本面部检测,除此之外,皮肤的颜色也会造成很大的麻烦,因为我们经常试图尽可能简化图像,从而失去了很多颜色值。甚至还有一个小型行业,可以避免人脸检测和识别。CVDazzle 网站就是一个例子。其中有些非常古怪,但他们很有效。你也可以总是走完整的面部重建手术的路线,以避免自动跟踪和检测,所以总是这样,但是这更永久。做个发型比较短暂也容易做到。
好吧,检测面部,眼睛和汽车是可以的,但我们是程序员。我们希望能够做任何事情。事实证明,事情会变得相当混乱,建立自己的 Haar Cascades 有一定的难度,但是其他人也这么做……你也可以!这就是在下一个教程中所讨论的。
十七、创建自己的 Haar Cascade
欢迎使用 Python OpenCV 对象检测教程。在本教程中,你将看到如何创建你自己的 Haar Cascades,以便你可以跟踪任何你想要的对象。由于这个任务的本质和复杂性,本教程将比平时稍长一些,但奖励是巨大的。
虽然你可以在 Windows 中完成,我不会建议这样。因此,对于本教程,我将使用 Linux VPS,并且我建议你也这样做。你可以尝试使用 Amazon Web Services 提供的免费套餐,但对你来说可能太痛苦了,你可能需要更多的内存。你还可以从 Digital Ocean 获得低至五美元/月的 VPS。我推荐至少 2GB 的内存用于我们将要做的事情。现在大多数主机按小时收费,包括 DO。因此,你可以购买一个 20 美元/月的服务器,使用它一天,获取你想要的文件,然后终止服务器,并支付很少的钱。你需要更多的帮助来设置服务器?如果是的话,看看这个具体的教程。
一旦你的服务器准备就绪,你会打算获取实际的 OpenCV 库。
将目录更改到服务器的根目录,或者你想放置工作区的地方:
cd ~
sudo apt-get update
sudo apt-get upgrade首先,让我们为自己制作一个漂亮的工作目录:
mkdir opencv_workspace
cd opencv_workspace既然我们完成了,让我们获取 OpenCV。
sudo apt-get install git
git clone https://github.com/Itseez/opencv.git我们这里克隆了 OpenCV 的最新版本。现在获取一些必需品。
编译器:sudo apt-get install build-essential
库:sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
Python 绑定:sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
最后,让我们获取 OpenCV 开发库:
sudo apt-get install libopencv-dev现在,我们该如何完成这个过程呢?所以当你想建立一个 Haar Cascade 时,你需要“正片”图像和“底片”图像。 “正片”图像是包含要查找的对象的图像。这可以是具有对象的主要图像,也可以是包含对象的图像,并指定对象所在的 ROI(兴趣区域)。有了这些正片图像,我们建立一个矢量文件,基本上是所有这些东西放在一起。正片图像的一个好处是,你可以实际只有一个你想要检测的对象的图像,然后有几千个底片图像。是的,几千。底片图像可以是任何东西,除了他们不能包含你的对象。
在这里,使用你的底片图像,你可以使用opencv_createsamples命令来创建一堆正片的示例。你的正片图像将叠加在这些底片上,而且会形成各种各样的角度。它实际上可以工作得很好,特别是如果你只是在寻找一个特定的对象。但是,如果你正在寻找所有螺丝刀,则需要拥有数千个螺丝刀的独特图像,而不是使用opencv_createsamples为你生成样品。我们将保持简单,只使用一个正片图像,然后用我们的底片创建一堆样本。
我们的正片图像:

这是另外一个场景,如果你使用自己的图像,你可能会更喜欢这个。如果事情出错了,试试看我的,但是我建议你自己画一下。保持较小。 50x50像素应该可以。
好吧,获得正片图像是没有问题的!只有一个问题。我们需要成千上万的底片图像。可能在未来,我们也可能需要成千上万的正片图像。我们可以在世界的哪个地方实现它?基于 WordNet 的概念,有一个非常有用的站点叫做 ImageNet。从这里,你可以找到几乎任何东西的图像。我们这里,我们想要手表,所以搜索手表,你会发现大量种类的手表。让我们检索电子表。真棒!看看下载标签!存在用于所有电子表手表的 URL!很酷。好吧,但我说过我们只会使用一个正片,所以我们只是检测一个手表。如果你想检测“全部”手表,需要准备获取多余 50,000 个手表图像,至少 25000 个“底片”的图像。之后,准备足够的服务器,除非你想要你的 Haar Cascade 训练花一个星期。那么我们如何得到底片? ImageNet 的全部重点是图像训练,所以他们的图像非常具体。因此,如果我们搜索人,汽车,船只,飞机……无论什么,都不会有手表。你可能会看到一些人或类似的东西,但你明白了。既然你可能看到人周围或上面的手表,我其实认为你也会得到人的图像。我的想法是寻找做运动的人,他们可能没有戴电子表。所以,我们来找一些批量图片的 URL 链接。我发现体育/田径链接有 1,888 张图片,但你会发现很多这些都是完全损坏的。让我们再来找一个:
好吧,我们拥有所有这些图片,现在呢?那么,首先,我们希望所有这些大小都相同,而且要小很多!天哪,只要我们知道一个方法来操作图像…嗯…哦,这是一个 OpenCV 教程!我们可以处理它。所以,首先,我们要做的就是编写一个简单的脚本,访问这些 URL 列表,获取链接,访问链接,拉取图像,调整大小,保存它们,然后重复,直到完成。当我们的目录充满图像时,我们还需要一种描述图像的描述文件。对于正片,手动创建这个文件特别痛苦,因为你需要指定你的对象,每个图像的具体的兴趣区域。幸运的是,create_samples方法将图像随机放置,并为我们做了所有工作。我们只需要一个用于底片的简单描述符,但是这不是问题,在拉伸和操作图像时我们可以实现。
https://www.youtube.com/embed/z_6fPS5tDNU?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
在任何你喜欢的地方随意运行这个代码。 我要在我的主机上运行它,因为它应该快一点。 你可以在你的服务器上运行。 如果你想使用cv2模块,请执行sudo apt-get install python-OpenCV。 目前,我不知道在 Linux 上为 Python 3 获得这些绑定的好方法。 我将要写的脚本是 Python 3,所以记住这一点。 主要区别是Urllib处理。
# download-image-by-link.py
import urllib.request
import cv2
import numpy as np
import os
def store_raw_images():
neg_images_link = '//image-net.org/api/text/imagenet.synset.geturls?wnid=n00523513'
neg_image_urls = urllib.request.urlopen(neg_images_link).read().decode()
pic_num = 1
if not os.path.exists('neg'):
os.makedirs('neg')
for i in neg_image_urls.split('\n'):
try:
print(i)
urllib.request.urlretrieve(i, "neg/"+str(pic_num)+".jpg")
img = cv2.imread("neg/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE)
# should be larger than samples / pos pic (so we can place our image on it)
resized_image = cv2.resize(img, (100, 100))
cv2.imwrite("neg/"+str(pic_num)+".jpg",resized_image)
pic_num += 1
except Exception as e:
print(str(e)) 很简单,这个脚本将访问链接,抓取网址,并继续访问它们。从这里,我们抓取图像,转换成灰度,调整大小,然后保存。我们使用一个简单的计数器来命名图像。继续运行它。你可能看到,有很多确实的图片等。没关系。这些错误图片中的一些更有问题。基本上都是白色,带有一些文本,说他们不再可用,而不是服务和 HTTP 错误。现在,我们有几个选择。我们可以忽略它们,或者修复它。嘿,这是一个没有手表的图像,所以什么是对的呢?当然,你可以采取这种观点,但如果你为正片使用这种拉取方式的话,这肯定是一个问题。你可以手动删除它们…或者我们可以使用我们新的图像分析知识,来检测这些愚蠢的图像,并将其删除!
我继续生成了一个新的目录,称之为“uglies(丑陋)”。在那个目录中,我点击并拖动了所有丑陋的图像版本(只是其中之一)。在底片中我只发现了一个主犯,所以我只有一个。让我们编写一个脚本来查找这个图像的所有实例并删除它。
https://www.youtube.com/embed/t0HOVLK30xQ?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
def find_uglies():
match = False
for file_type in ['neg']:
for img in os.listdir(file_type):
for ugly in os.listdir('uglies'):
try:
current_image_path = str(file_type)+'/'+str(img)
ugly = cv2.imread('uglies/'+str(ugly))
question = cv2.imread(current_image_path)
if ugly.shape == question.shape and not(np.bitwise_xor(ugly,question).any()):
print('That is one ugly pic! Deleting!')
print(current_image_path)
os.remove(current_image_path)
except Exception as e:
print(str(e))现在我们只有底片,但是我留下了空间让你轻易在那里添加'pos'(正片)。 你可以运行它来测试,但我不介意先抓住更多的底片。 让我们再次运行图片提取器,仅仅使用这个 url://image-net.org/api/text/imagenet.synset.geturls?wnid=n07942152。 最后一张图像是#952,所以让我们以 953 开始pic_num,并更改网址。
def store_raw_images():
neg_images_link = '//image-net.org/api/text/imagenet.synset.geturls?wnid=n07942152'
neg_image_urls = urllib.request.urlopen(neg_images_link).read().decode()
pic_num = 953
if not os.path.exists('neg'):
os.makedirs('neg')
for i in neg_image_urls.split('\n'):
try:
print(i)
urllib.request.urlretrieve(i, "neg/"+str(pic_num)+".jpg")
img = cv2.imread("neg/"+str(pic_num)+".jpg",cv2.IMREAD_GRAYSCALE)
# should be larger than samples / pos pic (so we can place our image on it)
resized_image = cv2.resize(img, (100, 100))
cv2.imwrite("neg/"+str(pic_num)+".jpg",resized_image)
pic_num += 1
except Exception as e:
print(str(e)) 现在我们有超过2000张照片。 最后一步是,我们需要为这些底片图像创建描述符文件。 我们将再次使用一些代码!
def create_pos_n_neg():
for file_type in ['neg']:
for img in os.listdir(file_type):
if file_type == 'pos':
line = file_type+'/'+img+' 1 0 0 50 50\n'
with open('info.dat','a') as f:
f.write(line)
elif file_type == 'neg':
line = file_type+'/'+img+'\n'
with open('bg.txt','a') as f:
f.write(line)运行它,你有了个bg.txt文件。 现在,我知道有些人的互联网连接可能不是最好的,所以我做个好人,在这里上传底片图片和描述文件。 你应该通过这些步骤。 如果你对本教程感到困扰,则需要知道如何执行这部分。 好吧,所以我们决定我们将一个图像用于正片前景图像。 因此,我们需要执行create_samples。 这意味着,我们需要将我们的neg目录和bg.txt文件移动到我们的服务器。 如果你在服务器上运行所有这些代码,不要担心。
https://www.youtube.com/embed/eay7CgPlCyo?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
如果你是一个术士,并已经想出了如何在 Windows 上运行create_samples等,恭喜! 回到服务器的领地,我的文件现在是这样的:
opencv_workspace
--neg
----negimages.jpg
--opencv
--info
--bg.txt
--watch5050.jpg你可能没有info目录,所以继续并mkdir info。 这是我们放置所有正片图像的地方。
我们现在准备根据watch5050.jpg图像创建一些正片样本。 为此,请在工作区中通过终端运行以下命令:
opencv_createsamples -img watch5050.jpg -bg bg.txt -info info/info.lst -pngoutput info -maxxangle 0.5 -maxyangle 0.5 -maxzangle 0.5 -num 1950
这样做是基于我们指定的img创建样本,bg是背景信息,我们将输出info.list(很像bg.txt文件)的信息,然后-pngoutput就是我们想要放置新生成的图像的任何地方。 最后,我们有一些可选的参数,使我们的原始图像更加动态一些,然后用= num来表示我们想要创建的样本数量。 太棒了,让我们来运行它。 现在你的info目录应该有约 2,000 个图像,还有一个名为info.lst的文件。 这个文件基本上是你的“正片”文件。 打开它,并且看看它怎么样:
0001_0014_0045_0028_0028.jpg 1 14 45 28 28首先你有文件名,之后是图像中有多少对象,其次是它们的所有位置。 我们只有一个,所以它是图像中对象矩形的x,y,宽度和高度。 这是一个图像:

很难看到它,但如果你很难看到,手表就是这个图像。 图像中最左侧人物的左下方。 因此,这是一个“正片”图像,从另外一个“底片”图像创建,底片图像也将用于训练。 现在我们有了正片图像,现在我们需要创建矢量文件,这基本上是一个地方,我们将所有正片图像拼接起来。我们会再次为此使用opencv_createsamples!
opencv_createsamples -info info/info.lst -num 1950 -w 20 -h 20 -vec positives.vec这是我们的矢量文件。 在这里,我们只是让它知道信息文件的位置,我们想要在文件中包含多少图像,在这个矢量文件中图像应该是什么尺寸,然后才能输出结果。 如果你愿意的话,你可以做得更大一些,20×20可能足够好了,你做的越大,训练时间就会越长。 继续,我们现在只需要训练我们的层叠。
首先,我们要把输出放在某个地方,所以让我们创建一个新的数据目录:
mkdir data,你的工作空间应该如下所示:
opencv_workspace
--neg
----negimages.jpg
--opencv
--info
--data
--positives.vec --bg.txt
--watch5050.jpg现在让我们运行训练命令:
opencv_traincascade -data data -vec positives.vec -bg bg.txt -numPos 1800 -numNeg 900 -numStages 10 -w 20 -h 20在这里,我们表明了,我们想要数据去的地方,矢量文件的位置,背景文件的位置,要使用多少个正片图像和底片图像,多少个阶段以及宽度和高度。请注意,我们使用的numPos比我们少得多。这是为了给阶段腾出空间。
有更多的选择,但这些就够了。这里主要是正片和底片的数量。一般认为,对于大多数实践,你需要 2:1 比例的正片和底片图像。有些情况可能会有所不同,但这是人们似乎遵循的一般规则。接下来,我们拥有阶段。我们选择了 10 个。你至少要 10-20 个,越多需要的时间越长,而且是指数级的。第一阶段通常很快,第五阶段要慢得多,第五十个阶段永远不会做完!所以,我们现在执行 10 个阶段。这里不错的事情是你可以训练 10 个阶段,稍后再回来,把数字改成 20,然后在你离开的地方继续。同样的,你也可以放一些像 100 个阶段的东西,上床睡觉,早上醒来,停下来,看看你有多远,然后用这些阶段“训练”,你会立即得到一个层叠文件。你可能从最后一句话中得出,这个命令的结果确实很棒,是个不错的层叠文件。我们希望能检测到我的手表,或者你决定检测的任何东西。我所知道的是,在输出这一段的时候,我还没有完成第一阶段的工作。如果你真的想要在一夜之间运行命令,但不想让终端打开,你可以使用nohup:
nohup opencv_traincascade -data data -vec positives.vec -bg bg.txt -numPos 1800 -numNeg 900 -numStages 10 -w 20 -h 20 &这使命令即使在关闭终端之后也能继续运行。 你可以使用更多,但你可能会或可能不会用完你的 2GB RAM。
https://www.youtube.com/embed/-Mhy-5YNcG4?list=PLQVvvaa0QuDdttJXlLtAJxJetJcqmqlQq
在我的 2GB DO 服务器上,10 个阶段花了不到 2 个小时的时间。 所以,要么有一个cascade.xml文件,要么停止脚本运行。 如果你停止运行,你应该在你的data目录下有一堆stageX.xml文件。 打开它,看看你有多少个阶段,然后你可以使用这些阶段,再次运行opencv_traincascade,你会立即得到一个cascade.xml文件。 这里,我只想说出它是什么,以及有多少个阶段。 对我来说,我做了 10 个阶段,所以我将它重命名为watchcascade10stage.xml。 这就是我们所需的,所以现在将新的层次文件传回主计算机,放在工作目录中,让我们试试看!
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
#this is the cascade we just made. Call what you want
watch_cascade = cv2.CascadeClassifier('watchcascade10stage.xml')
cap = cv2.VideoCapture(0)
while 1:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# add this
# image, reject levels level weights.
watches = watch_cascade.detectMultiScale(gray, 50, 50)
# add this
for (x,y,w,h) in watches:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,255,0),2)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()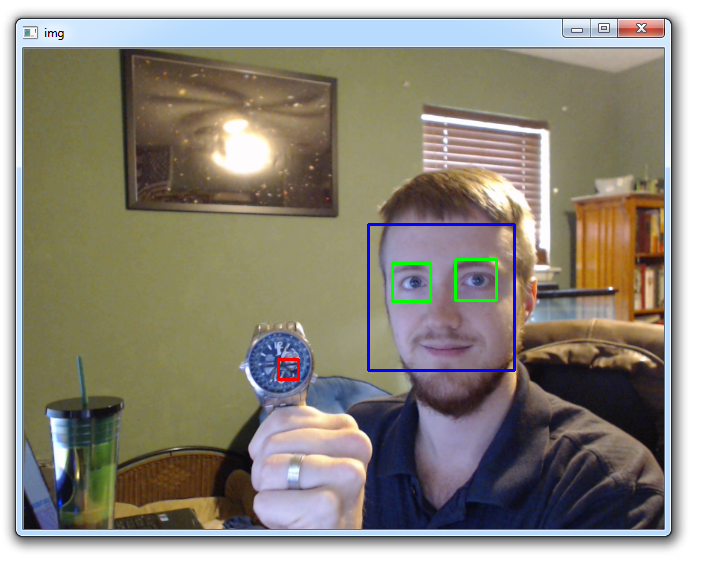
你可能注意到,手表的方框很小。 它似乎并没有达到整个手表。 回想一下我们的训练规模是20x20。 因此,我们最多有个20x20的方框。 你可以做100x100,但是,要小心,这将需要很长时间来训练。 因此,我们不绘制方框,而是,为什么不在手表上写字或什么东西? 这样做相对简单。 我们不在手表上执行cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),2),我们可以执行:
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'Watch',(x-w,y-h), font, 0.5, (11,255,255), 2, cv2.LINE_AA)
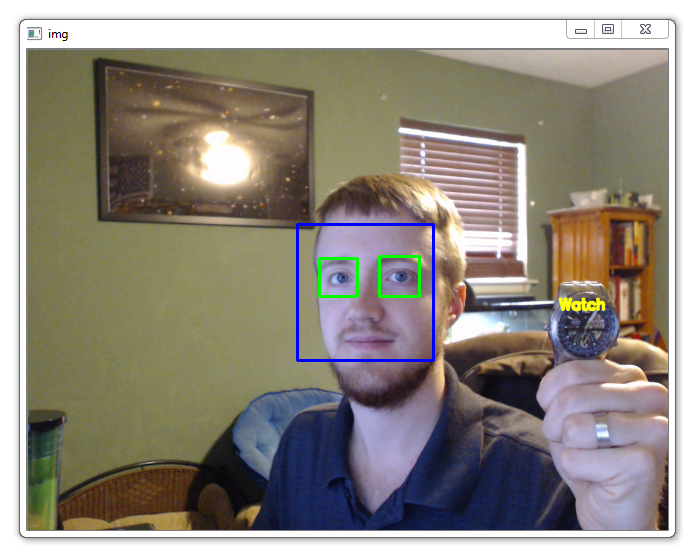
很酷! 所以你可能没有使用我的手表,你是怎么做的? 如果遇到麻烦,请尝试使用与我完全相同的所有内容。 检测图像,而不是检测摄像头,这里是一个:

在图像上运行检测会给你:
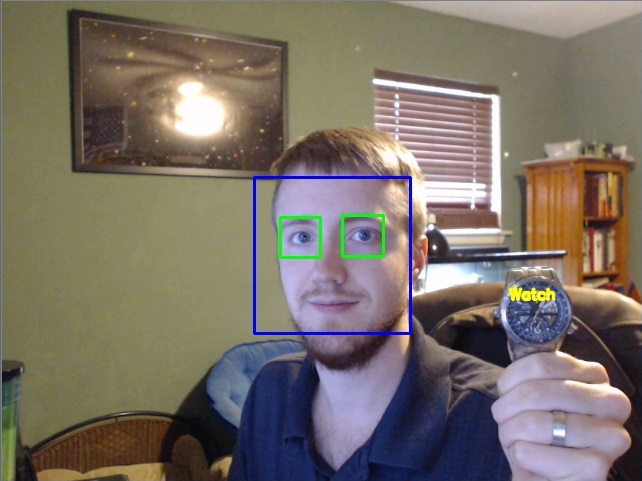
我不了解你,但一旦我最终使其工作,我非常兴奋!最让我印象深刻的是,跟踪对象所需的数据大小。Haar Cascades 往往是 100-2000 KB 的大小。大于等于 2,000 KB 的 Haar Cascades 应该非常准确。考虑你的情况,你可能会遇到约 5000 个一般物体。考虑 Haar Cascades 平均可能是约 500 KB。我们需要:0.5 MB * 5,000 = 2,500 MB或 2.5 GB。你需要 2.5 GB 的内存来识别 5000 个对象,并且可能是你在一天中遇到的最多对象。这让我着迷。考虑到我们可以访问所有的 image-net,并可以立即拉取很大范围的对象的一般图像。考虑 image-net 上的大多数图像,基本上都是 100% 的“跟踪”对象,因此,你可以通过手动标注位置,并仅使用 0,0 和图像的全部大小来得到正确的结果。这里你可以做的事情有巨大可能…好吧,那就是现在。我将来可能会用 OpenCV 做一些字符识别。如果你有任何其他要求,请发送电子邮件,在社区中提出建议,或张贴在视频上。
享受你的新力量。好好利用它们。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号