
HTTP的简史2(HTTP演变)
本文来自两个部分:
关于HTTP的概述 https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
关于HTTP的演化 https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP
一、HTTP 概述
https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP是一种用于获取诸如 HTML 文档之类的资源的协议。它是 Web 上任何数据交换的基础,它是一个客户端-服务器协议,这意味着请求由接收者发起,通常是 Web 浏览器。从提取的不同子文档(例如,文本、布局描述、图像、视频、脚本等)中重建完整的文档。
什么是协议? 协议是定义数据如何在计算机内部或计算机之间交换的规则系统。设备之间的通信要求设备就正在交换的数据格式达成一致。定义格式的规则集称为协议。 维基百科:https://en.wikipedia.org/wiki/Communications_protocol RFC官方互联网协议 : https://www.rfc-editor.org/standards
关于协议

客户端和服务器通过交换单独的消息(而不是数据流)进行通信。客户端(通常是 Web 浏览器)发送的消息称为请求,服务器发送的作为应答的消息称为响应。
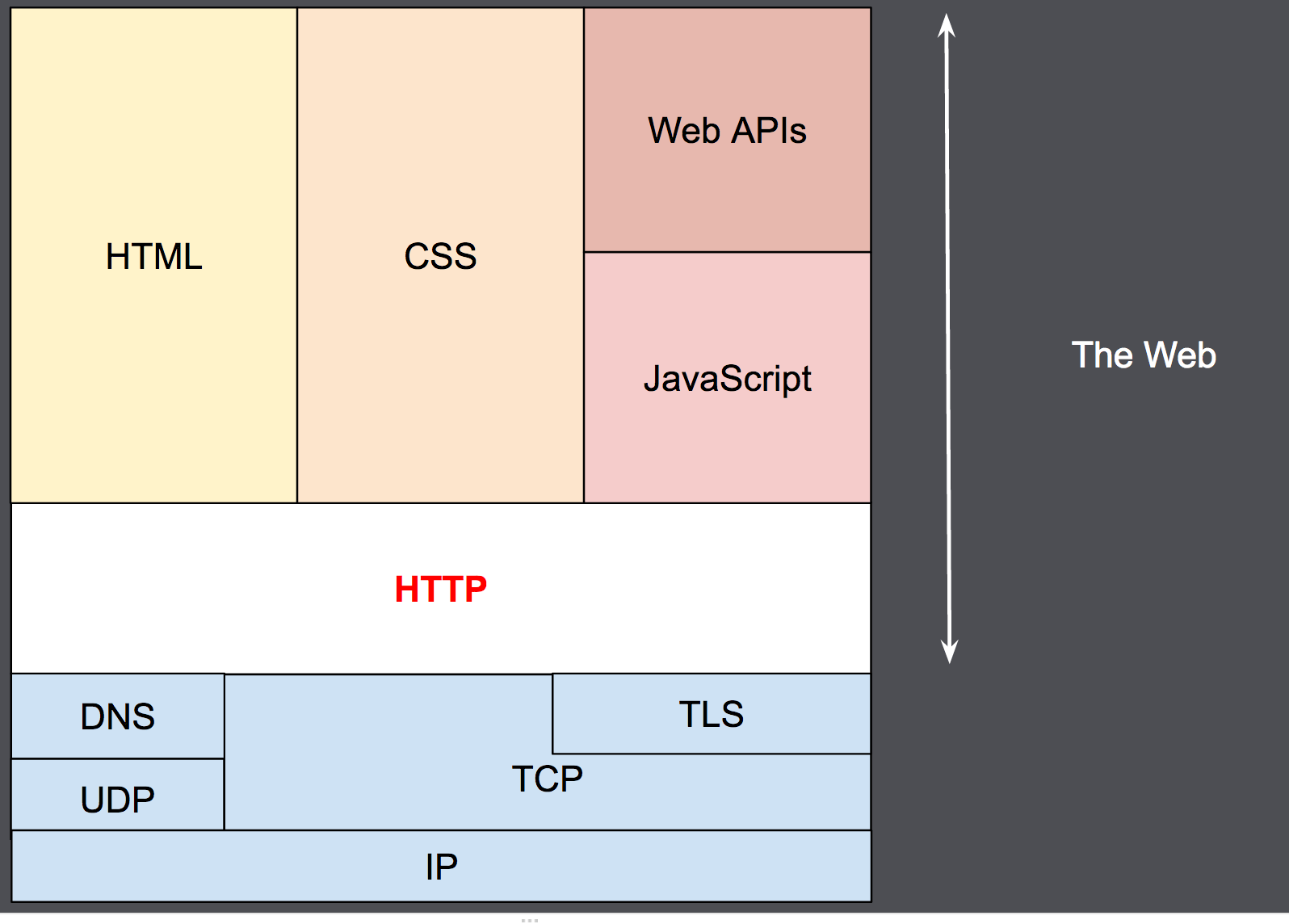
HTTP 设计于 1990 年代初期,是一种随时间发展的可扩展协议。它是通过TCP或通过TLS加密的 TCP 连接发送的应用层协议,尽管理论上可以使用任何可靠的传输协议。由于其可扩展性,它不仅用于获取超文本文档,还用于获取图像和视频或将内容发布到服务器,例如 HTML 表单结果。HTTP 还可用于获取部分文档以按需更新网页。
基于 HTTP 的系统的组件
HTTP 是一种客户端-服务器协议:请求由一个实体发送,即用户代理(或代表它的代理)。大多数时候,用户代理是一个 Web 浏览器,但它可以是任何东西,例如,一个爬网以填充和维护搜索引擎索引的机器人。
每个单独的请求都被发送到服务器,服务器处理它并提供一个称为response的答案。在客户端和服务器之间有许多实体,统称为代理,例如,它们执行不同的操作并充当网关或缓存。

实际上,在浏览器和处理请求的服务器之间有更多的计算机:有路由器、调制解调器等等。由于 Web 的分层设计,这些都隐藏在网络和传输层中。HTTP 位于应用层之上。尽管对于诊断网络问题很重要,但底层大多与 HTTP 的描述无关。
客户端:用户代理
用户代理是代表用户行事的任何工具 。此角色主要由 Web 浏览器执行,但也可能由工程师和 Web 开发人员用于调试其应用程序的程序执行。
浏览器始终是发起请求的实体。它永远不是服务器(尽管多年来已经添加了一些机制来模拟服务器启动的消息)。
为了显示一个网页,浏览器发送一个原始请求来获取代表该页面的 HTML 文档。然后它解析这个文件,发出与执行脚本、要显示的布局信息 (CSS) 以及页面中包含的子资源(通常是图像和视频)相对应的附加请求。然后,Web 浏览器结合这些资源来呈现完整的文档,即 Web 页面。浏览器执行的脚本可以在后期获取更多资源,浏览器相应地更新网页。
网页是超文本文档。这意味着显示内容的某些部分是链接,可以激活(通常通过单击鼠标)以获取新网页,从而允许用户引导他们的用户代理并在 Web 中导航。浏览器将这些指示转换为 HTTP 请求,并进一步解释 HTTP 响应以向用户呈现清晰的响应。
网络服务器
通信通道的另一端是服务器,它根据客户端的请求提供文档。一台服务器实际上只显示为一台机器;但它实际上可能是共享负载(负载平衡)的服务器集合,或者是询问其他计算机(如缓存、数据库服务器或电子商务服务器)的复杂软件,完全或部分按需生成文档。
服务器不一定是单台机器,但可以在同一台机器上托管多个服务器软件实例。使用 HTTP/1.1 和Host标头,它们甚至可以共享相同的 IP 地址。
代理
在 Web 浏览器和服务器之间,许多计算机和机器中继 HTTP 消息。由于 Web 堆栈的分层结构,其中大多数在传输、网络或物理级别运行,在 HTTP 层变得透明,并可能对性能产生重大影响。那些在应用层操作的通常被称为代理。这些可以是透明的,在不以任何方式更改它们的情况下转发他们收到的请求,或者是不透明的,在这种情况下,它们将在将请求传递给服务器之前以某种方式更改请求。代理可以执行许多功能:
- 缓存(缓存可以是公共的或私有的,如浏览器缓存)
- 过滤(如防病毒扫描或家长控制)
- 负载平衡(允许多个服务器服务不同的请求)
- 身份验证(控制对不同资源的访问)
- 日志记录(允许存储历史信息)
HTTP的基本方面
HTTP 很简单
HTTP 通常被设计为简单易读,即使 HTTP/2 通过将 HTTP 消息封装到帧中引入了额外的复杂性。HTTP 消息可以被人类阅读和理解,为开发人员提供了更容易的测试,并为新手降低了复杂性。
HTTP 是可扩展的
在 HTTP/1.0 中引入的HTTP 标头使该协议易于扩展和试验。甚至可以通过客户端和服务器之间关于新标头语义的简单协议来引入新功能。
HTTP 是无状态的,但不是无会话的
HTTP 是无状态的:在同一连接上连续执行的两个请求之间没有链接。对于试图连贯地与某些页面交互的用户来说,这会立即成为问题,例如,使用电子商务购物篮。但是,虽然 HTTP 本身的核心是无状态的,但 HTTP cookie 允许使用有状态会话。使用标头可扩展性,HTTP Cookie 被添加到工作流中,允许在每个 HTTP 请求上创建会话以共享相同的上下文或相同的状态。
HTTP 和连接
连接是在传输层控制的,因此基本上超出了 HTTP 的范围。HTTP 不要求底层传输协议是基于连接的;它只要求它是可靠的,或者不丢失消息(至少在这种情况下会出现错误)。在 Internet 上最常见的两种传输协议中,TCP 是可靠的,而 UDP 则不是。因此,HTTP 依赖于基于连接的 TCP 标准。
在客户端和服务器可以交换 HTTP 请求/响应对之前,它们必须建立 TCP 连接,这个过程需要多次往返。HTTP/1.0 的默认行为是为每个 HTTP 请求/响应对打开一个单独的 TCP 连接。当多个请求连续发送时,这比共享单个 TCP 连接效率低。
为了缓解这个缺陷,HTTP/1.1 引入了流水线(证明很难实现)和持久连接:底层 TCP 连接可以使用Connection标头部分控制。HTTP/2 更进一步,通过在单个连接上多路复用消息,帮助保持连接温暖和更高效。
正在进行实验以设计更适合 HTTP 的更好的传输协议。例如,谷歌正在试验基于 UDP 的QUIC,以提供更可靠、更高效的传输协议。
HTTP可以控制什么
随着时间的推移,HTTP 的这种可扩展特性允许对 Web 进行更多的控制和功能。缓存和身份验证方法是 HTTP 历史早期处理的功能。相比之下,放松原产地约束的能力是在 2010 年代才增加的。
以下是可使用 HTTP 控制的常见功能列表:
- 缓存 文档的缓存方式可以由 HTTP 控制。服务器可以指示代理和客户端缓存什么以及缓存多长时间。客户端可以指示中间缓存代理忽略存储的文档。
- 放宽来源限制 为了防止窥探和其他隐私侵犯,Web 浏览器强制实施 Web 站点之间的严格分离。只有来自同一来源的页面才能访问网页的所有信息。尽管这样的约束对服务器来说是一种负担,但 HTTP 标头可以放松服务器端的这种严格分离,允许文档成为来自不同域的信息拼凑而成;甚至可能有与安全相关的理由这样做。
- 身份验证 某些页面可能受到保护,因此只有特定用户才能访问它们。基本身份验证可以由 HTTP 提供,或者使用和类似的标头,或者通过使用HTTP cookie
WWW-Authenticate设置特定会话。 - 代理和隧道 服务器或客户端通常位于 Intranet 上,并且对其他计算机隐藏其真实 IP 地址。然后 HTTP 请求通过代理来跨越这个网络障碍。并非所有代理都是 HTTP 代理。例如,SOCKS 协议在较低级别运行。其他协议,如 ftp,可以由这些代理处理。
- 使用 HTTP cookie 的会话 允许您将请求与服务器的状态联系起来。这会创建会话,尽管基本 HTTP 是无状态协议。这不仅适用于电子商务购物篮,而且适用于任何允许用户配置输出的站点。
HTTP 流
当客户端想要与服务器进行通信时,无论是最终服务器还是中间代理,它都会执行以下步骤:
- 打开 TCP 连接:TCP 连接用于发送一个或多个请求,并接收一个应答。客户端可以打开一个新的连接,重用一个现有的连接,或者打开几个到服务器的 TCP 连接。
- 发送 HTTP 消息:HTTP 消息(在 HTTP/2 之前)是人类可读的。在 HTTP/2 中,这些简单的消息被封装在帧中,无法直接读取,但原理是一样的。例如:
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr
- 读取服务器发送的响应,如:
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html... (here come the 29769 bytes of the requested web page)
- 关闭或重用连接以获取更多请求。
如果激活了 HTTP 流水线,则可以发送多个请求,而无需等待第一个响应被完全接收。事实证明,HTTP 流水线很难在现有网络中实现,在这些网络中,旧软件与现代版本共存。HTTP 流水线已在 HTTP/2 中被取代,在一帧内具有更强大的多路复用请求。
HTTP 消息
HTTP/1.1 及更早版本中定义的 HTTP 消息是人类可读的。在 HTTP/2 中,这些消息被嵌入到一个二进制结构中,一个frame,允许像压缩头和多路复用这样的优化。即使在这个版本的 HTTP 中只发送原始 HTTP 消息的一部分,每个消息的语义都不会改变,客户端会(实际上)重构原始 HTTP/1.1 请求。因此,理解 HTTP/1.1 格式的 HTTP/2 消息很有用。
HTTP 消息有两种类型,请求和响应,每种都有自己的格式。
要求
HTTP 请求示例:
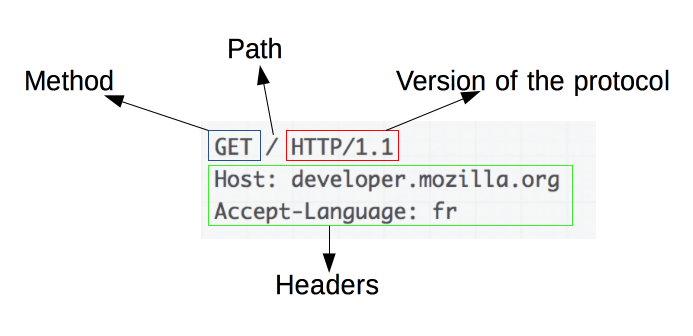
请求由以下元素组成:
回应
示例响应:
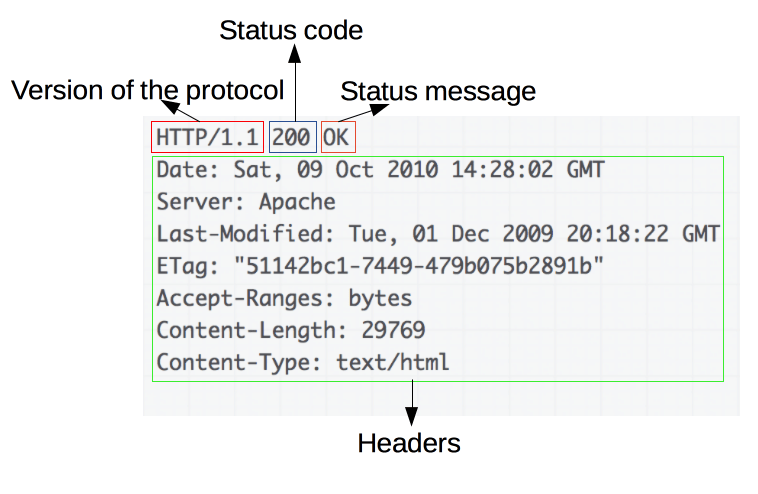
响应由以下元素组成:
基于 HTTP 的 API
最常用的基于 HTTP 的 API 是XMLHttpRequestAPI,它可以用来在用户代理和服务器之间交换数据。现代Fetch API提供了相同的功能以及更强大和更灵活的功能集。
另一个 API,服务器发送事件,是一种单向服务,它允许服务器使用 HTTP 作为传输机制向客户端发送事件。使用该EventSource接口,客户端打开一个连接并建立事件处理程序。客户端浏览器自动将到达 HTTP 流的消息转换为适当的Event对象。然后它将它们传递给已经为事件注册的事件处理程序(type如果已知),或者onmessage如果没有建立特定类型的事件处理程序,则传递给事件处理程序。
结论
HTTP 是一种易于使用的可扩展协议。客户端-服务器结构与添加标头的能力相结合,允许 HTTP 与 Web 的扩展功能一起发展。
尽管 HTTP/2 通过在帧中嵌入 HTTP 消息来提高性能增加了一些复杂性,但消息的基本结构自HTTP/1.0 以来一直保持不变。会话流保持简单,允许使用简单的HTTP 消息监视器对其进行调查和调试。
二、Evolution of HTTP(HTTP的演变)
https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP
HTTP (全称为: HyperText Transfer Protocol) is the underlying protocol of the World Wide Web. Developed by Tim Berners-Lee and his team between 1989-1991, HTTP has gone through many changes that have helped maintain its simplicity while shaping its flexibility. Keep reading to learn how HTTP evolved from a protocol designed to exchange files in a semitrusted laboratory environment into a modern internet maze that carries images and videos in high resolution and 3D.
HTTP(超文本传输协议)是万维网的底层协议。由 Tim Berners-Lee 和他的团队在 1989 年至 1991 年间开发的 HTTP 经历了许多变化,这些变化有助于保持其简单性,同时塑造其灵活性。继续阅读以了解 HTTP 如何从设计用于在半可信实验室环境中交换文件的协议演变为现代互联网迷宫,以承载高分辨率和 3D 图像和视频。
Invention of the World Wide Web
In 1989, while working at CERN, Tim Berners-Lee wrote a proposal to build a hypertext system over the internet. Initially called the Mesh, it was later renamed the World Wide Web during its implementation in 1990. Built over the existing TCP and IP protocols, it consisted of 4 building blocks:
|
1989 年,在 CERN 工作时,蒂姆·伯纳斯-李 (Tim Berners-Lee) 写了一份提案,要在互联网上建立一个超文本系统。最初称为Mesh,后来在 1990 年实施期间更名为万维网。它建立在现有的 TCP 和 IP 协议之上,由 4 个构建块组成:
|
These four building blocks were completed by the end of 1990, and the first servers were running outside of CERN by early 1991. On August 6, 1991, Tim Berners-Lee posted on the public alt.hypertext newsgroup. This is now considered to be the official start of the World Wide Web as a public project.
这四个构建块在 1990 年底完成,第一台服务器在 1991 年初在 CERN 之外运行。1991 年 8 月 6 日,Tim Berners-Lee在公共alt.hypertext新闻组上发帖。这现在被认为是万维网作为公共项目的正式开始。
The HTTP protocol used in those early phases was very simple. It was later dubbed HTTP/0.9 and is sometimes called the one-line protocol.
HTTP/0.9 – The one-line protocol
The initial version of HTTP had no version number; it was later called 0.9 to differentiate it from later versions. HTTP/0.9 was extremely simple: requests consisted of a single line and started with the only possible method GET followed by the path to the resource. The full URL wasn't included as the protocol, server, and port weren't necessary once connected to the server.
GET /mypage.html
The response was extremely simple, too: it only consisted of the file itself.
1 2 3 | <html>A very simple HTML page</html> |
Unlike subsequent evolutions, there were no HTTP headers. This meant that only HTML files could be transmitted. There were no status or error codes. If there was a problem, a specific HTML file was generated and included a description of the problem for human consumption.
HTTP/1.0 – Building extensibility
HTTP/0.9 was very limited, but browsers and servers quickly made it more versatile:
- Versioning information was sent within each request (
HTTP/1.0was appended to theGETline). - A status code line was also sent at the beginning of a response. This allowed the browser itself to recognize the success or failure of a request and adapt its behavior accordingly. For example, updating or using its local cache in a specific way.
- The concept of HTTP headers was introduced for both requests and responses. Metadata could be transmitted and the protocol became extremely flexible and extensible.
- Documents other than plain HTML files could be transmitted thanks to the
Content-Typeheader.
At this point in time, a typical request and response looked like this:
GET /mypage.html HTTP/1.0 User-Agent: NCSA_Mosaic/2.0 (Windows 3.1) 200 OK Date: Tue, 15 Nov 1994 08:12:31 GMT Server: CERN/3.0 libwww/2.17 Content-Type: text/html <HTML> A page with an image <IMG SRC="/myimage.gif"> </HTML>
It was followed by a second connection and a request to fetch the image (with the corresponding response):
GET /myimage.gif HTTP/1.0 User-Agent: NCSA_Mosaic/2.0 (Windows 3.1) 200 OK Date: Tue, 15 Nov 1994 08:12:32 GMT Server: CERN/3.0 libwww/2.17 Content-Type: text/gif (image content)
Between 1991-1995, these were introduced with a try-and-see approach. A server and a browser would add a feature and see if it got traction. Interoperability problems were common. In an effort to solve these issues, an informational document that described the common practices was published in November 1996. This was known as RFC 1945 and defined HTTP/1.0.
HTTP/1.1 – The standardized protocol
In the meantime, proper standardization was in progress. This happened in parallel to the diverse implementations of HTTP/1.0. The first standardized version of HTTP, HTTP/1.1, was published in early 1997, only a few months after HTTP/1.0.
HTTP/1.1 clarified ambiguities and introduced numerous improvements:
- A connection could be reused, which saved time. It no longer needed to be opened multiple times to display the resources embedded in the single original document.
- Pipelining was added. This allowed a second request to be sent before the answer to the first one was fully transmitted. This lowered the latency of the communication.
- Chunked responses were also supported.
- Additional cache control mechanisms were introduced.
- Content negotiation, including language, encoding, and type, was introduced. A client and a server could now agree on which content to exchange.
- Thanks to the
Hostheader, the ability to host different domains from the same IP address allowed server collocation.
A typical flow of requests, all through one single connection, looked like this:
GET /en-US/docs/Glossary/Simple_header HTTP/1.1 Host: developer.mozilla.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate, br Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header 200 OK Connection: Keep-Alive Content-Encoding: gzip Content-Type: text/html; charset=utf-8 Date: Wed, 20 Jul 2016 10:55:30 GMT Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a" Keep-Alive: timeout=5, max=1000 Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT Server: Apache Transfer-Encoding: chunked Vary: Cookie, Accept-Encoding (content) GET /static/img/header-background.png HTTP/1.1 Host: developer.mozilla.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0 Accept: */* Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate, br Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header 200 OK Age: 9578461 Cache-Control: public, max-age=315360000 Connection: keep-alive Content-Length: 3077 Content-Type: image/png Date: Thu, 31 Mar 2016 13:34:46 GMT Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT Server: Apache (image content of 3077 bytes)
HTTP/1.1 was first published as RFC 2068 in January 1997.
More than 15 years of extensions
The extensibility of HTTP made it easy to create new headers and methods. Even though the HTTP/1.1 protocol was refined over two revisions, RFC 2616 published in June 1999 and RFC 7230-RFC 7235 published in June 2014 before the release of HTTP/2, it was extremely stable for more than 15 years.
Using HTTP for secure transmissions
The largest change to HTTP was made at the end of 1994. Instead of sending HTTP over a basic TCP/IP stack, the computer-services company Netscape Communications created an additional encrypted transmission layer on top of it: SSL. SSL 1.0 was never released to the public, but SSL 2.0 and its successor SSL 3.0 allowed for the creation of ecommerce websites. To do this, they encrypted and guaranteed the authenticity of the messages exchanged between the server and client. SSL was eventually standardized and became TLS.
During the same time period, it became clear that an encrypted transport layer was needed. The web was no longer a mostly academic network, and instead became a jungle where advertisers, random individuals, and criminals competed for as much private data as possible. As the applications built over HTTP became more powerful and required access to private information like address books, email, and user location, TLS became necessary outside of the ecommerce use case.
Using HTTP for complex applications
Tim Berners-Lee didn't originally envision HTTP as a read-only medium. He wanted to create a web where people could add and move documents remotely—a kind of distributed file system. Around 1996, HTTP was extended to allow authoring, and a standard called WebDAV was created. It grew to include specific applications like CardDAV for handling address book entries and CalDAV for dealing with calendars. But all these *DAV extensions had a flaw: they were only usable when implemented by the servers.
In 2000, a new pattern for using HTTP was designed: representational state transfer (or REST). The API wasn't based on the new HTTP methods, but instead relied on access to specific URIs with basic HTTP/1.1 methods. This allowed any web application to let an API retrieve and modify its data without having to update the browsers or the servers. All necessary information was embedded in the files that the websites served through standard HTTP/1.1. The drawback of the REST model was that each website defined its own nonstandard RESTful API and had total control of it. This differed from the *DAV extensions where clients and servers were interoperable. RESTful APIs became very common in the 2010s.
Since 2005, more APIs have become available to web pages. Several of these APIs create extensions to the HTTP protocol for specific purposes:
- Server-sent events, where the server can push occasional messages to the browser.
- WebSocket, a new protocol that can be set up by upgrading an existing HTTP connection.
Relaxing the security-model of the web
HTTP is independent of the web security model, known as the same-origin policy. In fact, the current web security model was developed after the creation of HTTP! Over the years, it proved useful to lift some of the restrictions of this policy under certain constraints. The server transmitted how much and when to lift such restrictions to the client using a new set of HTTP headers. These were defined in specifications like Cross-Origin Resource Sharing (CORS) and the Content Security Policy (CSP).
In addition to these large extensions, many other headers were added, sometimes only experimentally. Notable headers are the Do Not Track (DNT) header to control privacy, X-Frame-Options, and Upgrade-Insecure-Requests but many more exist.
HTTP/2 – A protocol for greater performance
Over the years, web pages became more complex. Some of them were even applications in their own right. More visual media was displayed and the volume and size of scripts adding interactivity also increased. Much more data was transmitted over significantly more HTTP requests and this created more complexity and overhead for HTTP/1.1 connections. To account for this, Google implemented an experimental protocol SPDY in the early 2010s. This alternative way of exchanging data between client and server amassed interest from developers working on both browsers and servers. SPDY defined an increase in responsiveness and solved the problem of duplicate data transmission, serving as the foundation for the HTTP/2 protocol.
The HTTP/2 protocol differs from HTTP/1.1 in a few ways:
- It's a binary protocol rather than a text protocol. It can't be read and created manually. Despite this hurdle, it allows for the implementation of improved optimization techniques.
- It's a multiplexed protocol. Parallel requests can be made over the same connection, removing the constraints of the HTTP/1.x protocol.
- It compresses headers. As these are often similar among a set of requests, this removes the duplication and overhead of data transmitted.
- It allows a server to populate data in a client cache through a mechanism called the server push.
Officially standardized in May 2015, HTTP/2 was incredibly successful. By May 2022, 46.4% of all websites used it (see these stats). High-traffic websites showed the most rapid adoption in an effort to save on data transfer overhead and subsequent budgets.
This rapid adoption was likely because HTTP/2 didn't require changes to websites and applications. To use it, only an up-to-date server that communicated with a recent browser was necessary. Only a limited set of groups was needed to trigger adoption, and as legacy browser and server versions were renewed, usage was naturally increased, without significant work for web developers.
Post-HTTP/2 evolution
HTTP hasn't stopped evolving since the release of HTTP/2. Like with HTTP/1.x, HTTP's extensibility is still being used to add new features. Notably, we can cite new extensions of the HTTP protocol that appeared in 2016:
- Support for
Alt-Svcallowed the dissociation of the identification and the location of a given resource. This meant a smarter CDN caching mechanism. - The introduction of
Client-Hintsallowed the browser or client to proactively communicate information about its requirements and hardware constraints to the server. - The introduction of security-related prefixes in the
Cookieheader helped guarantee that secure cookies couldn't be altered.
This evolution of HTTP has lead to the creation of many applications and has driven the adoption of the protocol. The environment in which HTTP is used today is quite different from that of the early 1990s. HTTP's original design proved to be scalable, allowing the web to evolve over a quarter of a century. By fixing flaws and retaining the flexibility and extensibility that made HTTP such a success, the adoption of HTTP/2 points to a bright future for the protocol.
HTTP/3 - HTTP over QUIC
Experimental: This is an experimental technology
Check the Browser compatibility table carefully before using this in production.
The next major version of HTTP, HTTP/3, will use QUIC instead TCP/TLS for the transport layer portion.
See bug 1158011 for implementation status in Firefox.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?