
cpu L1/L2/L3 cache
在线查看的网址:
https://software.intel.com/sites/landingpage/IntrinsicsGuide/
Intel® 64 and IA-32 Architectures Software Developer's Manuals
http://www.intel.com/products/processor/manuals/
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 1: Basic Architecture
http://download.intel.com/design/processor/manuals/253665.pdf
cpu开发手册
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html
Cache-L1/L2/L3/TLB
cache是一种又小又快的存储器。它存在的意义是弥合Memory与CPU之间的速度差距。
现在的CPU中有好几个等级的缓存。通常L1和L2缓存都是每个CPU一个的, L1缓存有分为L1i cache和L1d cache,分别用来存储指令和数据。
L2缓存是不区分指令和数据的。L3缓存多个核心共用一个,通常也不区分指令和数据。 还有一种缓存叫TLB,
它主要用来缓存MMU使用的页表,通常我们讲缓存(cache)的时候是不算它的。)
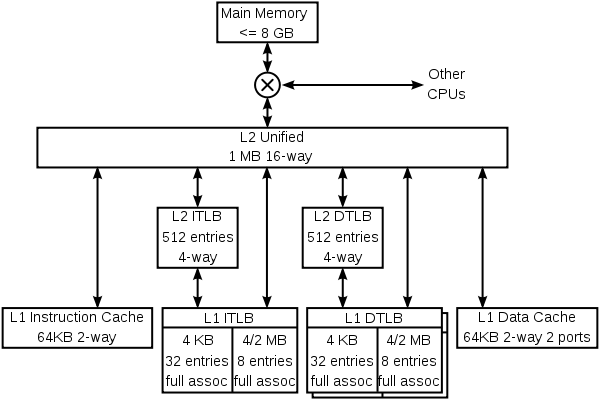
Cache hierarchy of the K8 core in the AMD Athlon 64 CPU
linux下查看 L1/L2/L3 cache

[root@fp-web-112 ~]# getconf -a | grep CACHE LEVEL1_ICACHE_SIZE 32768 LEVEL1_ICACHE_ASSOC 8 LEVEL1_ICACHE_LINESIZE 64 LEVEL1_DCACHE_SIZE 32768 LEVEL1_DCACHE_ASSOC 8 LEVEL1_DCACHE_LINESIZE 64 LEVEL2_CACHE_SIZE 262144 LEVEL2_CACHE_ASSOC 8 LEVEL2_CACHE_LINESIZE 64 LEVEL3_CACHE_SIZE 26214400 LEVEL3_CACHE_ASSOC 20 LEVEL3_CACHE_LINESIZE 64 LEVEL4_CACHE_SIZE 0 LEVEL4_CACHE_ASSOC 0 LEVEL4_CACHE_LINESIZE 0
ls -l /sys/devices/system/cpu/cpu0/cache/index
[root@fp-web-112 ~]# ls -l /sys/devices/system/cpu/cpu0/cache/index index0/ index1/ index2/ index3/
index0和Index1是一级cache中的data和instruction cache
[root@fp-web-112 ~]# ls -l /sys/devices/system/cpu/cpu0/cache/index0/
coherency_line_size number_of_sets shared_cpu_list size ways_of_associativity
level physical_line_partition shared_cpu_map type
level:cache等级 L1/L2/L3
type:cache类型, (Data Cache,D-Cache)和一级指令缓存(Instruction Cache,I-Cache)
size: cache大小
一级缓存可以分为一级数据缓存(Data Cache,D-Cache)和一级指令缓存(Instruction Cache,I-Cache)。
二者分别用来存放数据以及对执行这些数据的指令进行即时解码,而且两者可以同时被CPU访问,减少了争用Cache所造成的冲突,提高了处理器效能。
目前大多数CPU的一级数据缓存和一级指令缓存具有相同的容量,例如AMD的Athlon XP就具有64KB的一级数据缓存和64KB的一级指令缓存,其一级缓存就以64KB 64KB来表示,其余的CPU的一级缓存表示方法以此类推。
一级cache, Data cache cat /sys/devices/system/cpu/cpu0/cache/index0/level cat /sys/devices/system/cpu/cpu0/cache/index0/type cat /sys/devices/system/cpu/cpu0/cache/index0/size 一级cache, Instruction cache cat /sys/devices/system/cpu/cpu0/cache/index1/level cat /sys/devices/system/cpu/cpu0/cache/index1/type cat /sys/devices/system/cpu/cpu0/cache/index1/size 二级cache cat /sys/devices/system/cpu/cpu0/cache/index2/level cat /sys/devices/system/cpu/cpu0/cache/index2/type cat /sys/devices/system/cpu/cpu0/cache/index2/size
Cache Line
Cache存储数据是固定大小为单位的,称为一个Cache entry,这个单位称为Cache line或Cache block。
给定Cache容量大小和Cache line size的情况下,它能存储的条目个数(number of cache entries)就是固定的。因为Cache是固定大小的,所以它从DRAM获取数据也是固定大小。
对于X86来讲,它的Cache line大小与DDR3、4一次访存能得到的数据大小是一致的,即64Bytes。对于ARM来讲,较旧的架构(新的不知道有没有改)的Cache line是32Bytes,
但一次内存访存只访问一半的数据也不太合适,所以它经常是一次填两个Cache line,叫做double fill。
CPU从Cache数据的最小单位是字节,Cache从Memory拿数据的最小单位(这里不讲嵌入式系统)是64Bytes,Memory从硬盘拿数据通常最小是4092Bytes。
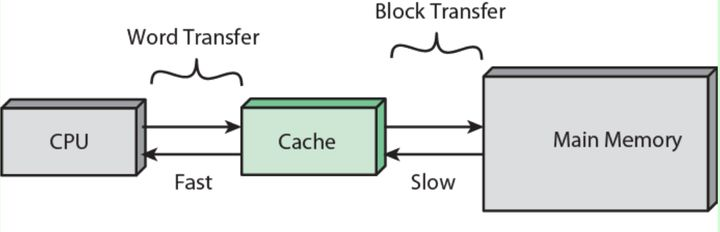
替换策略
Cache里存的数据是Memory中的常用数据一个拷贝,Cache比较小,不可以缓存Memory中的所有数据。当Cache存满后,再需要存入一个新的条目时,就需要把一个旧的条目从缓存中拿掉,这个过程称为evict,
一个被evict的条目称为victim。缓存管理单元通过一定的算法决定哪些数据有资格留在Cache里,哪些数据需要从Cache里移出去。这个策略称为替换策略(replacement policy)。最简单的替换策略称为LRU(least recently used),即Cache管理单元记录每个Cache line最近被访问的时间,每次需要evict时,选最近一次访问时间最久远的那一条做为victim。
在实际使用中,LRU并不一定是最好的替换策略,在CPU设计的过程中,通常会不段对替换策略进行改进,每一款芯片几乎都使用了不同的替换策略。
写入策略与一致性
CPU需要读写一个地址的时候,先去Cache中查找,如果数据不在Cache中,称为Cache miss,就需要从Memory中把这个地址所在的那个Cache line上的数据加载到Cache中。然后再把数返回给CPU。这时会伴随着另一个Cache 条目成为victim被替换出去。
如果CPU需要访问的数据在Cache中,则称为Cache hit。
针对写操作,有两种写入策略,分别为write back和write through。write through策略下,数据直接同时被写入到Memory中,在write back策略中,数据仅写到Cache中,此时Cache中的数据与Memory中的数据不一致,Cache中的数据就变成了脏数据(dirty)。如果其他部件(DMA, 另一个核)访问这段数据的时候,就需要通过Cache一致性协议(Cache coherency protocol)保证取到的是最新的数据。另外这个Cache被替换出去的时候就需要写回到内存中。
Cache Miss 与CPU stall
如果发生了Cache Miss,就需要从Memory中取数据,这个取数据的过程中,CPU可以执行几十上百条指令的,如果等待数据时什么也不做时间就浪费了。可以在这个时候提高CPU使用效率的有两种方法,一个是乱序执行(out of order execution),即把当前线程中后面的、不依赖于当前指令执行结果的指令拿过来提前执行,另一个是超线程技术,即把另一个线程的指令拿过来执行。
L1/L2 Cache速度差别
L1 cache: 3 cycles
L2 cache: 11 cycles
L3 cache: 25 cycles
Main Memory: 100 cycles
L1/L2 Cache都是用SRAM做为存储介质,为什么说L1比L2快呢?这里面有三方面的原因:
1. 存储容量不同导致的速度差异
L1的容量通常比L2小,容量大的SRAM访问时间就越长,同样制程和设计的情况下,访问延时与容量的开方大致是成正比的。
2. 离CPU远近导致的速度差异
通常L1 Cache离CPU核心需要数据的地方更近,而L2 Cache则处于边缓位置,访问数据时,L2 Cache需要通过更远的铜线,甚至更多的电路,从而增加了延时。
L1 Cache分为ICache(指令缓存)和DCache(数据缓存),指令缓存ICache通常是放在CPU核心的指令预取单远附近的,数据缓存DCache通常是放在CPU核心的load/store单元附近。
而L2 Cache是放在CPU pipeline之外的。
为什么不把L2 Cache也放在很近的地方呢?由于Cache的容量越大,面积越大,相应的边长的就越长(假设是正方形的话),总有离核远的。
下面的图并不是物理上的图,只是为大家回顾一下CPU的pipe line。
另外需要注意的是这张图里展示了一个二级的DTLB结构,和一级的ITLB。
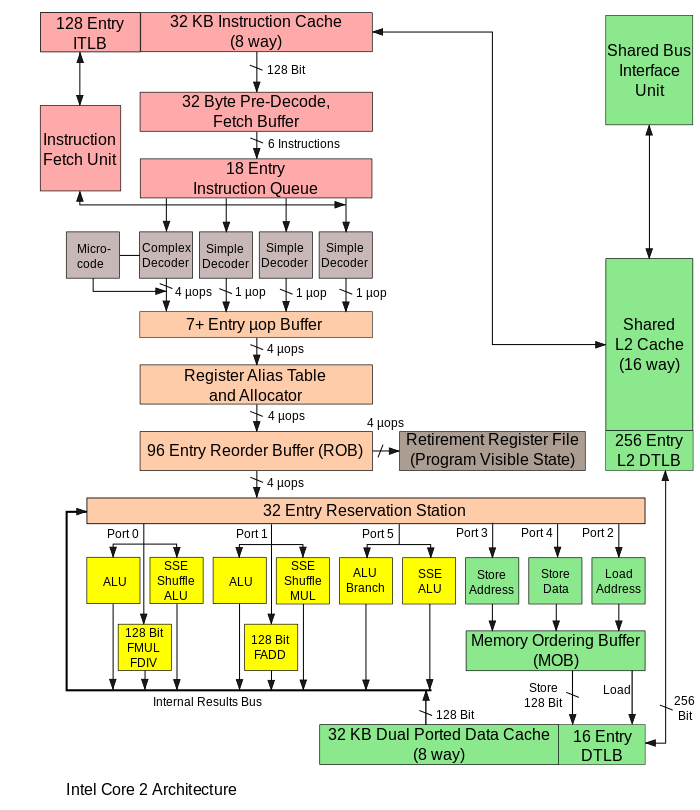
3. 制程不同的造成的速度差异
在实际设计制造时,针对L1/L2的不同角色,L1更加注重速度, L2更加注重节能和容量。在制程上这方面有体现,(但我不懂,。。。。)。在设计时,这方面的有体现:
首先, L1 Cache都是N路组相联的,N路组相联的意思时,给定一个地址,N个Cache单元同时工作,取出N份tag和N份数据,然后再比较tag,从中选出hit的那一个采用,其它的丢弃不用。
这种方式一听就很浪费,很不节能。
另外,L2 Cache即便也是N路组相联的,但它是先取N个tag,然后比对tag后发现cache hit之后再把对应的数据取出来。
由于L2是在L1 miss之后才会访问,所以L2 cache hit的概率并不高,访问的频率也不高,而且有前面L1抵挡一下,
所以它的延迟高点也无所谓,L2容量比较大,如果数据和tag一起取出来,也比较耗能。
通常专家都将L1称为latency filter, L2称为bandwidth filter。
L3 Cache
L1/L2 Cache通常都是每个CPU核心一个(x86而言,ARM一般L2是为一个簇即4个核心共享的),这意味着每增加一个CPU核心都要增加相同大小的面积,
即使各个CPU核心的L2 Cache有很多相同的数据也只能各保存一份,因而一个所有核心共享的L3 Cache也就有必要了。
L3 Cache通常都是各个核心共享的,而且DMA之类的设备也可以用。
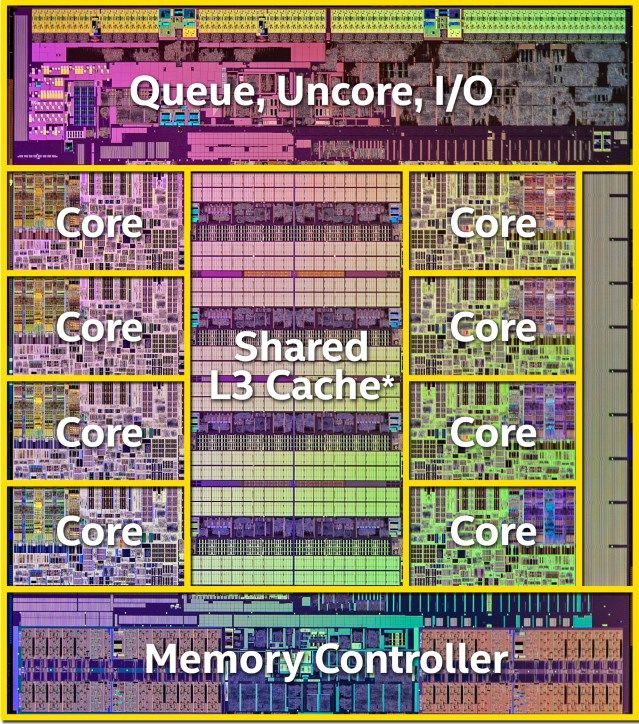
由于L3 Cache的时延要求没有那么高,现在大家也要考虑不使用SRAM,转而使用STT-MRAM,或是eDRAM来做L3 Cache。
逻辑Cache和物理Cache
Cache在系统中的位置根据与MMU的相对位置不同,分别称为logical Cache和physical cache。
Logical Cache接受的是逻辑地址,物理Cache接受的是物理地址。
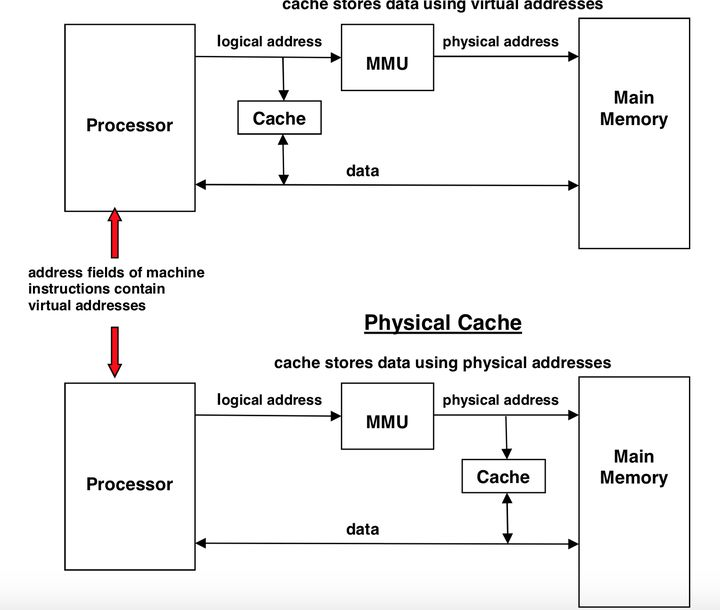
logical cache有一个优势就是可以在完成虚拟地址到物理地址的翻译之前就可以开始比对cache,但是有一个问题就是Cache 一致性还有cache eviction必须通过物理地址来做,
因为多个虚拟地址可能对应同一个物理地址,不能保证不同的虚拟地址所以应的cache就一定不是同一份数据。为了解决这个问题,就不得不把物理地址也保存在为tag。
这样tag要存的内容就增加了一倍。
相对而言,physical cache由于一开始就是物理地址,所以只需要存物理地址为tag,而不需要再保存虚拟地址为tag,看起来简单了很多。
其实总结起来,Cache的tag有两种作用:
(1)对于N路组相联cache中,通过tag比对选择使用哪一路的数据
(2)决定cache hit还是miss。前者配合操作系统的情况下,虚拟地址就可以做到,
比如说给虚拟地址和物理页配对的时候总是保证根据两者的某些位来选way的时候是一样的,而且前者不需要完全的正确,偶尔错一些是可以接受的,
你可以先选出数据,默认是cache hit,然后拿着数据是计算,但后来通过物理tag比对时发现是miss的情况下,再无效掉这次计算,
反正cache miss的情况下cpu本来也需要stall好多个cycle。后者则必须依靠物理地址才可以做到。
这样一来,很多设计都把虚拟地址tag弱化为hint, 仅用于选哪个way。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!