redis集群的配置及hash槽,自测手敲,无问题
redis集群本身有3种模式:
记得关防火墙或者把端口打开 6379 及 26379
1、主从(无高可用,缺点太明显)。master一挂,就不提供写的服务了,读服务器不能写,只能读
192.168.199.236 master 192.168.199.138 slave 192.168.199.121 slave
安装redis
cd /data/soft wget http://download.redis.io/releases/redis-5.0.4.tar.gz tar zxf redis-5.0.4.tar.gz && mv redis-5.0.4/ /usr/local/redis-5.0.4 cd /usr/local/redis-5.0.4 && make && make install echo $? 如果返回0代表成成 另外:如果出现Redis安装报错错误:jemalloc / jemalloc.h:没有这样的文件或目录解决方法 centos7.6的版本的gcc版本过低 [root@localhost redis-5.0.4]# yum -y install centos-release-scl [root@localhost redis-5.0.4]# yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils [root@localhost redis-5.0.4]# scl enable devtoolset-9 bash [root@localhost redis-5.0.4]# echo "source /opt/rh/devtoolset-9/enable" >> /etc/profile [root@localhost redis-5.0.4]# make [root@localhost redis-5.0.4]# make install 3台机器全部这么安装一遍。、 如果make 出现[root@mysql-rtb-master redis-4.0.1]# make MALLOC=libc 使用这个命令 如果出现编译redis报错/deps/hiredis/libhiredis.a解决。 是因为你先make过之后生成.a文件了,一种解决办法是从新解压。删除/usr/local/redis-5.0.4 从新解压一份就可以了
全部配置成服务
[root@localhost redis-5.0.4]# vim /usr/lib/systemd/system/redis.service [Unit] Description=Redis persistent key-value database After=network.target After=network-online.target Wants=network-online.target [Service] ExecStart=/usr/local/bin/redis-server /usr/local/redis-5.0.4/redis.conf --supervised systemd ExecStop=/usr/libexec/redis-shutdown Type=notify User=redis Group=redis RuntimeDirectory=redis RuntimeDirectoryMode=0755 [Install] WantedBy=multi-user.target [root@localhost redis-5.0.4]#
写一个shutdown的脚本
[root@localhost redis-5.0.4]# vim /usr/libexec/redis-shutdown
#!/bin/bash
#
# Wrapper to close properly redis and sentinel
test x"$REDIS_DEBUG" != x && set -x
REDIS_CLI=/usr/local/bin/redis-cli
# Retrieve service name
SERVICE_NAME="$1"
if [ -z "$SERVICE_NAME" ]; then
SERVICE_NAME=redis
fi
# Get the proper config file based on service name
CONFIG_FILE="/usr/local/redis-5.0.4/$SERVICE_NAME.conf"
# Use awk to retrieve host, port from config file
HOST=`awk '/^[[:blank:]]*bind/ { print $2 }' $CONFIG_FILE | tail -n1`
PORT=`awk '/^[[:blank:]]*port/ { print $2 }' $CONFIG_FILE | tail -n1`
PASS=`awk '/^[[:blank:]]*requirepass/ { print $2 }' $CONFIG_FILE | tail -n1`
SOCK=`awk '/^[[:blank:]]*unixsocket\s/ { print $2 }' $CONFIG_FILE | tail -n1`
# Just in case, use default host, port
HOST=${HOST:-127.0.0.1}
if [ "$SERVICE_NAME" = redis ]; then
PORT=${PORT:-6379}
else
PORT=${PORT:-26739}
fi
# Setup additional parameters
# e.g password-protected redis instances
[ -z "$PASS" ] || ADDITIONAL_PARAMS="-a $PASS"
# shutdown the service properly
if [ -e "$SOCK" ] ; then
$REDIS_CLI -s $SOCK $ADDITIONAL_PARAMS shutdown
else
$REDIS_CLI -h $HOST -p $PORT $ADDITIONAL_PARAMS shutdown
fi
# chmod +x /usr/libexec/redis-shutdown //赋予脚本可执行权限 # useradd -s /sbin/nologin redis //添加一个redis用户 # chown -R redis:redis /usr/local/redis-5.0.4 //修改文件的所属组合所属用户
# mkdir -p /data/redis //建立个redis的存储位置 # chown -R redis:redis /data/redis # yum install -y bash-completion && source /etc/profile #命令补全 # systemctl daemon-reload # systemctl enable redis
修改配置
主master配置
# vim /usr/local/redis-5.0.4/redis.conf bind 192.168.199.236 #监听ip,多个ip用空格分隔 daemonize yes #允许后台启动 logfile "/usr/local/redis-5.0.4/redis.log" #日志路径 dir /data/redis #数据库备份文件存放目录 masterauth 123456 #slave连接master密码,master可省略 requirepass 123456 #设置master连接密码,slave可省略 appendonly yes #在/data/redis/目录生成appendonly.aof文件,将每一次写操作请求都追加到appendonly.aof 文件中 # echo 'vm.overcommit_memory=1' >> /etc/sysctl.conf # sysctl -p
两台从的配置,根据各个的ip地址要修改下
# vim /usr/local/redis-5.0.4/redis.conf bind 192.168.199.138 daemonize yes logfile "/usr/local/redis-5.0.4/redis.log" dir /data/redis replicaof 192.168.199.236 6379 masterauth 123456 requirepass 123456 appendonly yes # echo 'vm.overcommit_memory=1' >> /etc/sysctl.conf # sysctl -p
启动redis
[root@localhost redis-5.0.4]# systemctl start redis 如果出现Job for redis.service failed because the control process exited with error code. See "systemctl status redis.service" and "journalctl -xe" for details. 通常是配置的问题,可以运行 [root@localhost redis-5.0.4]# systemctl status redis.service 或者[root@localhost redis-5.0.4]#journalctl -xe 查看问题所在
查看是否成功
[root@localhost redis-5.0.4]# redis-cli -h 192.168.199.236 -a 123456 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 192.168.199.236:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.199.138,port=6379,state=online,offset=42,lag=0 slave1:ip=192.168.199.121,port=6379,state=online,offset=42,lag=0 master_replid:fd319abf6128a4e1e751bf98cc23d38d9be5e147 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:42 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:42 这样代表成功了,如果connected显示为0,则从服务器查看下能否ping的通,以及端口是否开启,是否防火墙导致的,关闭了即可,或者配置下开放6379端口,这里只做演示,所以关闭了防火墙
数据演示下吧!~看下是否成功
主master 192.168.199.236:6379> keys (error) ERR wrong number of arguments for 'keys' command 192.168.199.236:6379> keys * (empty list or set) 192.168.199.236:6379> set aa 1 OK 192.168.199.236:6379> set bb 2 OK 192.168.199.236:6379> keys * 1) "bb" 2) "aa" 192.168.199.236:6379> 从服务器 [root@localhost redis-5.0.4]# redis-cli -h 192.168.199.138 -a 123456 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 192.168.199.138:6379> keys * 1) "bb" 2) "aa" 192.168.199.138:6379> set cc 1 (error) READONLY You can't write against a read only replica. 不能插入只能读取
2、sentinel模式 。中文含义是哨兵 (正在写)
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
哨兵有两个作用: 1、监视master合slave,当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机 2、发送命令,和redis通信,确认其运行状态。 然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
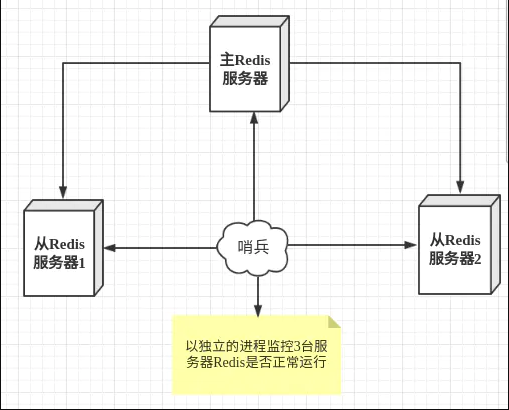
* sentinel模式是建立在主从模式的基础上,如果只有一个Redis节点,sentinel就没有任何意义 * 当master挂了以后,sentinel会在slave中选择一个做为master,并修改它们的配置文件,其他slave的配置文件也会被修改,比如slaveof属性会指向新的master * 当master重新启动后,它将不再是master而是做为slave接收新的master的同步数据 * sentinel因为也是一个进程有挂掉的可能,所以sentinel也会启动多个形成一个sentinel集群 * 多sentinel配置的时候,sentinel之间也会自动监控 * 当主从模式配置密码时,sentinel也会同步将配置信息修改到配置文件中,不需要担心 * 一个sentinel或sentinel集群可以管理多个主从Redis,多个sentinel也可以监控同一个redis * sentinel最好不要和Redis部署在同一台机器,不然Redis的服务器挂了以后,sentinel也挂了 工作模式: * 每个sentinel以每秒钟一次的频率向它所知的master,slave以及其他sentinel实例发送一个 PING 命令 * 如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被sentinel标记为主观下线。 * 如果一个master被标记为主观下线,则正在监视这个master的所有sentinel要以每秒一次的频率确认master的确进入了主观下线状态 * 当有足够数量的sentinel(大于等于配置文件指定的值)在指定的时间范围内确认master的确进入了主观下线状态, 则master会被标记为客观下线 * 在一般情况下, 每个sentinel会以每 10 秒一次的频率向它已知的所有master,slave发送 INFO 命令 * 当master被sentinel标记为客观下线时,sentinel向下线的master的所有slave发送 INFO 命令的频率会从 10 秒一次改为 1 秒一次 * 若没有足够数量的sentinel同意master已经下线,master的客观下线状态就会被移除; 若master重新向sentinel的 PING 命令返回有效回复,master的主观下线状态就会被移除 其中: 当使用sentinel模式的时候,客户端就不要直接连接Redis,而是连接sentinel的ip和port,由sentinel来提供具体的可提供服务的Redis实现,这样当master节点挂掉以后,sentinel就会感知并将新的master节点提供给使用者。
环境准备
master节点 192.168.199.236 sentinel端口:26379 slave节点 192.168.199.138 sentinel端口:26379 slave节点 192.168.199.121 sentinel端口:26379
修改配置:
# vim /usr/local/redis-5.0.4/sentinel.conf daemonize yes logfile "/usr/local/redis-5.0.4/sentinel.log" dir "/usr/local/redis-5.0.4/sentinel" #sentinel工作目录 sentinel monitor mymaster 192.168.199.236 6379 2 #判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数 sentinel auth-pass mymaster 123456 sentinel down-after-milliseconds mymaster 30000 #判断master主观下线时间,默认30s //这里需要注意,sentinel auth-pass mymaster 123456需要配置在sentinel monitor mymaster 192.168.30.128 6379 2下面,否则启动报错:
其中sentinel
[root@localhost redis-5.0.4]# mkdir /usr/local/redis-5.0.4/sentinel && chown -R redis:redis /usr/local/redis-5.0.4 [root@localhost redis-5.0.4]# redis-sentinel /usr/local/redis-5.0.4/sentinel.conf
[root@localhost redis-5.0.4]# ps aux | grep 26379 //查看端口
任意一台主机都可以查看日志
[root@localhost redis-5.0.4]# tail -f /usr/local/redis-5.0.4/sentinel.log 4798:X 16 Aug 2020 14:17:06.925 # Configuration loaded 4799:X 16 Aug 2020 14:17:06.929 * Increased maximum number of open files to 10032 (it was originally set to 1024). 4799:X 16 Aug 2020 14:17:06.934 * Running mode=sentinel, port=26379. 4799:X 16 Aug 2020 14:17:06.934 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. 4799:X 16 Aug 2020 14:17:06.939 # Sentinel ID is 53bfd99d13c914e86d1bec292d51bc6cf20f59c4 4799:X 16 Aug 2020 14:17:06.939 # +monitor master mymaster 192.168.199.236 6379 quorum 2 4799:X 16 Aug 2020 14:17:06.940 * +slave slave 192.168.199.138:6379 192.168.199.138 6379 @ mymaster 192.168.199.236 6379 4799:X 16 Aug 2020 14:17:06.942 * +slave slave 192.168.199.121:6379 192.168.199.121 6379 @ mymaster 192.168.199.236 6379 4799:X 16 Aug 2020 14:17:36.943 # +sdown slave 192.168.199.121:6379 192.168.199.121 6379 @ mymaster 192.168.199.236 6379 4799:X 16 Aug 2020 14:17:36.943 # +sdown slave 192.168.199.138:6379 192.168.199.138 6379 @ mymaster 192.168.199.236 6379
其中有可能不成功的原因可能是你配置的ip地址有问题(这个最可能写错)多检查下就没事了
Sentinel模式下的几个事件
+reset-master :主服务器已被重置。 · +slave :一个新的从服务器已经被 Sentinel 识别并关联。 · +failover-state-reconf-slaves :故障转移状态切换到了 reconf-slaves 状态。 · +failover-detected :另一个 Sentinel 开始了一次故障转移操作,或者一个从服务器转换成了主服务器。 · +slave-reconf-sent :领头(leader)的 Sentinel 向实例发送了 [SLAVEOF](/commands/slaveof.html) 命令,为实例设置新的主服务器。 · +slave-reconf-inprog :实例正在将自己设置为指定主服务器的从服务器,但相应的同步过程仍未完成。 · +slave-reconf-done :从服务器已经成功完成对新主服务器的同步。 · -dup-sentinel :对给定主服务器进行监视的一个或多个 Sentinel 已经因为重复出现而被移除 —— 当 Sentinel 实例重启的时候,就会出现这种情况。 · +sentinel :一个监视给定主服务器的新 Sentinel 已经被识别并添加。 · +sdown :给定的实例现在处于主观下线状态。 · -sdown :给定的实例已经不再处于主观下线状态。 · +odown :给定的实例现在处于客观下线状态。 · -odown :给定的实例已经不再处于客观下线状态。 · +new-epoch :当前的纪元(epoch)已经被更新。 · +try-failover :一个新的故障迁移操作正在执行中,等待被大多数 Sentinel 选中(waiting to be elected by the majority)。 · +elected-leader :赢得指定纪元的选举,可以进行故障迁移操作了。 // +failover-state-select-slave :故障转移操作现在处于 select-slave 状态 —— Sentinel 正在寻找可以升级为主服务器的从服务器。 // no-good-slave :Sentinel 操作未能找到适合进行升级的从服务器。Sentinel 会在一段时间之后再次尝试寻找合适的从服务器来进行升级,又或者直接放弃执行故障转移操作。 · selected-slave :Sentinel 顺利找到适合进行升级的从服务器。 · failover-state-send-slaveof-noone :Sentinel 正在将指定的从服务器升级为主服务器,等待升级功能完成。 · failover-end-for-timeout :故障转移因为超时而中止,不过最终所有从服务器都会开始复制新的主服务器(slaves will eventually be configured to replicate with the new master anyway)。 · failover-end :故障转移操作顺利完成。所有从服务器都开始复制新的主服务器了。 · +switch-master :配置变更,主服务器的 IP 和地址已经改变。 这是绝大多数外部用户都关心的信息。 · +tilt :进入 tilt 模式。 · -tilt :退出 tilt 模式。
测试下主服务器宕机
[root@localhost redis-5.0.4]# tail -f /usr/local/redis-5.0.4/sentinel.log 12242:X 16 Aug 2020 14:42:02.011 # Redis version=5.0.4, bits=64, commit=00000000, modified=0, pid=12242, just started 12242:X 16 Aug 2020 14:42:02.011 # Configuration loaded 12243:X 16 Aug 2020 14:42:02.012 * Increased maximum number of open files to 10032 (it was originally set to 1024). 12243:X 16 Aug 2020 14:42:02.015 * Running mode=sentinel, port=26379. 12243:X 16 Aug 2020 14:42:02.015 # Sentinel ID is 704d28ee5e718ec4ff7326d0cb509fa1d6ff1cd3 12243:X 16 Aug 2020 14:42:02.015 # +monitor master mymaster 192.168.199.236 6379 quorum 2 12243:X 16 Aug 2020 14:42:02.018 * +slave slave 192.168.199.138:6379 192.168.199.138 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:42:02.021 * +slave slave 192.168.199.121:6379 192.168.199.121 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:42:02.210 * +sentinel sentinel 4f227d8b82793247218a03ff652dad3db734edab 192.168.199.121 26379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:42:02.797 * +sentinel sentinel 53bfd99d13c914e86d1bec292d51bc6cf20f59c4 192.168.199.236 26379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:42:32.073 # +sdown slave 192.168.199.121:6379 192.168.199.121 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:42:32.275 # +sdown sentinel 4f227d8b82793247218a03ff652dad3db734edab 192.168.199.121 26379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:09.992 # +sdown master mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.052 # +odown master mymaster 192.168.199.236 6379 #quorum 2/2 12243:X 16 Aug 2020 14:44:10.052 # +new-epoch 1 12243:X 16 Aug 2020 14:44:10.053 # +try-failover master mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.054 # +vote-for-leader 704d28ee5e718ec4ff7326d0cb509fa1d6ff1cd3 1 12243:X 16 Aug 2020 14:44:10.078 # 53bfd99d13c914e86d1bec292d51bc6cf20f59c4 voted for 704d28ee5e718ec4ff7326d0cb509fa1d6ff1cd3 1 12243:X 16 Aug 2020 14:44:10.120 # +elected-leader master mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.120 # +failover-state-select-slave master mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.204 # +selected-slave slave 192.168.199.138:6379 192.168.199.138 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.204 * +failover-state-send-slaveof-noone slave 192.168.199.138:6379 192.168.199.138 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.295 * +failover-state-wait-promotion slave 192.168.199.138:6379 192.168.199.138 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.742 # +promoted-slave slave 192.168.199.138:6379 192.168.199.138 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.742 # +failover-state-reconf-slaves master mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.797 * +slave-reconf-sent slave 192.168.199.121:6379 192.168.199.121 6379 @ mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.797 # +failover-end master mymaster 192.168.199.236 6379 12243:X 16 Aug 2020 14:44:10.798 # +switch-master mymaster 192.168.199.236 6379 192.168.199.138 6379 12243:X 16 Aug 2020 14:44:10.798 * +slave slave 192.168.199.121:6379 192.168.199.121 6379 @ mymaster 192.168.199.138 6379 12243:X 16 Aug 2020 14:44:10.798 * +slave slave 192.168.199.236:6379 192.168.199.236 6379 @ mymaster 192.168.199.138 6379 12243:X 16 Aug 2020 14:44:40.802 # +sdown slave 192.168.199.236:6379 192.168.199.236 6379 @ mymaster 192.168.199.138 6379 12243:X 16 Aug 2020 14:44:40.802 # +sdown slave 192.168.199.121:6379 192.168.199.121 6379 @ mymaster 192.168.199.138 6379
从日志上可以看出192.168.199.138作为主的master ,121和236作为从的集群
3、Cluster模式
sentinel模式基本可以满足一般生产的需求,具备高可用性。但是当数据量过大到一台服务器存放不下的情况时,主从模式或sentinel模式就不能满足需求了,这个时候需要对存储的数据进行分片,将数据存储到多个Redis实例中。cluster模式的出现就是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。
cluster可以说是sentinel和主从模式的结合体,通过cluster可以实现主从和master重选功能,所以如果配置两个副本三个分片的话,就需要六个Redis实例。因为Redis的数据是根据一定规则分配到cluster的不同机器的,当数据量过大时,可以新增机器进行扩容。
使用集群,只需要将redis配置文件中的cluster-enable配置打开即可。每个集群中至少需要三个主数据库才能正常运行,新增节点非常方便
三台机器,分别开启两个redis服务(端口) 192.168.199.236 端口:7001,7002 192.168.199.138 端口:7003,7004 192.168.199.121 端口:7005,7006
特点:* 多个redis节点网络互联,数据共享 * 所有的节点都是一主一从(也可以是一主多从),其中从不提供服务,仅作为备用 * 不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上, 并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为 * 支持在线增加、删除节点 * 客户端可以连接任何一个主节点进行读写
[root@localhost redis-5.0.4]# mkdir /usr/local/redis-5.0.4/cluster
[root@localhost redis-5.0.4]# cp /usr/local/redis-5.0.4/redis.conf /usr/local/redis-5.0.4/cluster/redis_7001.conf
[root@localhost redis-5.0.4]# cp /usr/local/redis-5.0.4/redis.conf /usr/local/redis-5.0.4/cluster/redis_7002.conf
[root@localhost redis-5.0.4]# chown -R redis:redis /usr/local/redis-5.0.4/
[root@localhost redis-5.0.4]# mkdir -p /data/redis/cluster/{redis_7001,redis_7002} && chown -R redis:redis /data/redis
//修改配置文件7001
# vim /usr/local/redis-5.0.4/cluster/redis_7001.conf
bind 192.168.199.236
port 7001
daemonize yes
pidfile "/var/run/redis_7001.pid"
logfile "/usr/local/redis-5.0.4/cluster/redis_7001.log"
dir "/data/redis/cluster/redis_7001"
#replicaof 192.168.199.236 6379
masterauth 123456
requirepass 123456
appendonly yes
cluster-enabled yes
cluster-config-file nodes_7001.conf
cluster-node-timeout 15000
//修改配置文件7002
# vim /usr/local/redis/cluster/redis_7002.conf
bind 192.168.199.236
port 7002
daemonize yes
pidfile "/var/run/redis_7002.pid"
logfile "/usr/local/redis-5.0.4/cluster/redis_7002.log"
dir "/data/redis/cluster/redis_7002"
#replicaof 192.168.199.236 6379
masterauth "123456"
requirepass "123456"
appendonly yes
cluster-enabled yes
cluster-config-file nodes_7002.conf
cluster-node-timeout 15000
其它两台机器配置与192.168.199.236基本一致,不过ip地址要换下
启动redis [root@localhost cluster]# redis-server /usr/local/redis-5.0.4/cluster/redis_7001.conf [root@localhost cluster]# redis-server /usr/local/redis-5.0.4/cluster/redis_7002.conf [root@localhost cluster]# ps aux | grep redis root 4931 0.5 0.1 144300 2484 ? Ssl 14:35 1:05 /usr/local/bin/redis-sentinel *:26379 [sentinel] redis 4982 0.3 0.1 145164 3500 ? Ssl 14:51 0:43 /usr/local/bin/redis-server 192.168.199.236:6379 root 5107 0.1 0.1 144332 2388 ? Ssl 17:55 0:00 redis-server 192.168.199.236:7001 [cluster] root 5112 0.1 0.1 144332 2396 ? Ssl 17:55 0:00 redis-server 192.168.199.236:7002 [cluster] root 5117 0.0 0.0 112812 972 pts/1 S+ 17:55 0:00 grep --color=auto redis [root@localhost cluster]# tail -f /usr/local/redis/cluster/redis_7001.log tail: cannot open ‘/usr/local/redis/cluster/redis_7001.log’ for reading: No such file or directory tail: no files remaining [root@localhost cluster]# tail -f /usr/local/redis-5.0.4/cluster/redis_7001.log |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 5107:M 16 Aug 2020 17:55:31.793 # Server initialized 5107:M 16 Aug 2020 17:55:31.793 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled. 5107:M 16 Aug 2020 17:55:31.793 * Ready to accept connections ^C
创建集群: redis-cli -a 123456 --cluster create 192.168.199.236:7001 192.168.199.236:7002 192.168.199.138:7003 192.168.199.138:7004 192.168.199.121:7005 192.168.199.121:7006 --cluster-replicas 1
[root@localhost cluster]# redis-cli -a 123456 --cluster create 192.168.199.236:7001 192.168.199.236:7002 192.168.199.138:7003 192.168.199.138:7004 192.168.199.121:7005 192.168.199.121:7006 --cluster-replicas 1 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.199.138:7004 to 192.168.199.236:7001 //7001 master 7004 salve Adding replica 192.168.199.121:7006 to 192.168.199.138:7003 //7003 master 7006 salve Adding replica 192.168.199.236:7002 to 192.168.199.121:7005 //7005 master 7002 salve M: 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001 slots:[0-5460] (5461 slots) master S: 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002 replicates ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 M: 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003 slots:[5461-10922] (5462 slots) master S: 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004 replicates 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 M: ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005 slots:[10923-16383] (5461 slots) master S: 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006 replicates 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join .... >>> Performing Cluster Check (using node 192.168.199.236:7001) M: 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006 slots: (0 slots) slave replicates 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e S: 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004 slots: (0 slots) slave replicates 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 S: 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002 slots: (0 slots) slave replicates ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 M: 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003 slots:[5461-10922] (5462 slots) master 1 additional replica(s) M: ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005 slots:[10923-16383] (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. [root@localhost cluster]#
自动生成nodes.conf文件:
[root@localhost redis_7001]# pwd /data/redis/cluster/redis_7001 [root@localhost redis_7001]# ls appendonly.aof dump.rdb nodes_7001.conf [root@localhost redis_7001]#
集群操作
[root@localhost redis-5.0.4]# redis-cli -c -h 192.168.199.236 -p 7001 -a 123456 //-c ,使用集群方式登录 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 192.168.199.236:7001> CLUSTER INFO //集群的信息 cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_ping_sent:456 cluster_stats_messages_pong_sent:463 cluster_stats_messages_sent:919 cluster_stats_messages_ping_received:458 cluster_stats_messages_pong_received:456 cluster_stats_messages_meet_received:5 cluster_stats_messages_received:919 192.168.199.236:7001> CLUSTER NODES //集群的节点 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 0 1597572568407 6 connected 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 slave 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 0 1597572569000 4 connected 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 myself,master - 0 1597572570000 1 connected 0-5460 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597572569415 5 connected 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003@17003 master - 0 1597572568000 3 connected 5461-10922 ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597572570426 5 connected 10923-16383 192.168.199.236:7001> set key1 a -> Redirected to slot [9189] located at 192.168.199.138:7003 //#说明数据到了192.168.199.138:7003上 OK 192.168.199.138:7003> set key2 a -> Redirected to slot [4998] located at 192.168.199.236:7001 //236:7001上 OK 192.168.199.236:7001> set key3 a OK 192.168.199.236:7001> set key4 a -> Redirected to slot [13120] located at 192.168.199.121:7005 OK 192.168.199.121:7005>
可以看出redis cluster集群是去中心化的,每个节点都是平等的,连接哪个节点都可以获取和设置数据。
当然,平等指的是master节点,因为slave节点根本不提供服务,只是作为对应master节点的一个备份。
增加一个节点看下:
192.168.199.138 上增加一节点
# cp /usr/local/redis-5.0.4/cluster/redis_7003.conf /usr/local/redis-5.0.4/cluster/redis_7007.conf # vim /usr/local/redis-5.0.4/cluster/redis_7007.conf bind 192.168.199.138 port 7007 daemonize yes pidfile "/var/run/redis_7007.pid" logfile "/usr/local/redis-5.0.4/cluster/redis_7007.log" dir "/data/redis/cluster/redis_7007" #replicaof 192.168.199.138 6379 masterauth "123456" requirepass "123456" appendonly yes cluster-enabled yes cluster-config-file nodes_7007.conf cluster-node-timeout 15000 # mkdir /data/redis/cluster/redis_7007 # chown -R redis:redis /usr/local/redis-5.0.4 && chown -R redis:redis /data/redis # redis-server /usr/local/redis-5.0.4/cluster/redis_7007.conf
192.168.199.121上增加一节点
# cp /usr/local/redis-5.0.4/cluster/redis_7005.conf /usr/local/redis-5.0.4/cluster/redis_7008.conf # vim /usr/local/redis-5.0.4/cluster/redis_7008.conf bind 192.168.199.121 port 7008 daemonize yes pidfile "/var/run/redis_7008.pid" logfile "/usr/local/redis-5.0.4/cluster/redis_7008.log" dir "/data/redis/cluster/redis_7008" #replicaof 192.168.199.121 6379 masterauth "123456" requirepass "123456" appendonly yes cluster-enabled yes cluster-config-file nodes_7008.conf cluster-node-timeout 15000 # mkdir /data/redis/cluster/redis_7008 # chown -R redis:redis /usr/local/redis-5.0.4 && chown -R redis:redis /data/redis # redis-server /usr/local/redis-5.0.4/cluster/redis_7008.conf
集群中新增节点
[root@localhost redis_7001]# redis-cli -c -h 192.168.199.236 -p 7001 -a 123456 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 192.168.199.236:7001> CLUSTER MEET 192.168.199.138 7007 //可以看到,新增的节点都是以master身份加入集群的 OK 192.168.199.236:7001> CLUSTER NODES 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 0 1597573883145 6 connected 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 slave 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 0 1597573882140 4 connected 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 myself,master - 0 1597573881000 1 connected 0-5460 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597573882000 5 connected 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003@17003 master - 0 1597573884152 3 connected 5461-10922 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 192.168.199.138:7007@17007 master - 0 1597573885161 0 connected ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597573884000 5 connected 10923-16383 192.168.199.236:7001> CLUSTER MEET 192.168.199.121 7008 OK 192.168.199.236:7001> CLUSTER NODES 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 0 1597573957000 6 connected 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 slave 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 0 1597573956785 4 connected 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 myself,master - 0 1597573957000 1 connected 0-5460 d52297a6da9b17fad400385f796118443a7d929b 192.168.199.121:7008@17008 master - 0 1597573956181 0 connected 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597573957000 5 connected 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003@17003 master - 0 1597573957792 3 connected 5461-10922 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 192.168.199.138:7007@17007 master - 0 1597573957000 0 connected ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597573957000 5 connected 10923-16383 192.168.199.236:7001>
更换节点身份-将新增的192.168.199.121:7008节点身份改为192.168.199.138:7007的slave
# redis-cli -c -h 192.168.199.138 -p 7008 -a 123456 cluster replicate 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3
也可以cluster replicate后面跟node_id,更改对应节点身份。也可以登入集群更改
[root@localhost redis_7001]# redis-cli -c -h 192.168.199.121 -p 7008 -a 123456 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 192.168.199.121:7008> CLUSTER REPLICATE 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 OK 192.168.199.121:7008> CLUSTER NODES 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003@17003 master - 0 1597574382000 3 connected 5461-10922 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 192.168.199.138:7007@17007 master - 0 1597574382000 7 connected ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597574385000 5 connected 10923-16383 d52297a6da9b17fad400385f796118443a7d929b 192.168.199.121:7008@17008 myself,slave 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 0 1597574381000 0 connected 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 master - 0 1597574385890 1 connected 0-5460 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 0 1597574385000 3 connected 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597574386899 5 connected 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 slave 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 0 1597574384000 1 connected 192.168.199.121:7008>
删除节点
192.168.199.121:7008> CLUSTER FORGET d52297a6da9b17fad400385f796118443a7d929b (error) ERR I tried hard but I can't forget myself... //態删除自己 192.168.199.121:7008> CLUSTER FORGET 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 (error) ERR Can't forget my master! //不能删除自己的master 192.168.199.121:7008> CLUSTER FORGET 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e //可以删除其他人的master OK 192.168.199.121:7008> CLUSTER NODES 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 192.168.199.138:7007@17007 master - 0 1597574615000 7 connected ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597574617910 5 connected 10923-16383 d52297a6da9b17fad400385f796118443a7d929b 192.168.199.121:7008@17008 myself,slave 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 0 1597574614000 0 connected 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 master - 0 1597574616903 1 connected 0-5460 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave - 0 1597574614889 3 connected 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597574613884 5 connected 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 slave 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 0 1597574615895 1 connected 192.168.199.121:7008> CLUSTER FORGET 98dd817404a14283538df18060ff3ce09eb892c8 OK 192.168.199.121:7008>
保存配置:
192.168.199.121:7008> CLUSTER SAVECONFIG #将节点配置信息保存到硬盘 OK 192.168.199.121:7008> CLUSTER NODES 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003@17003 master - 0 1597574849000 3 connected 5461-10922 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 192.168.199.138:7007@17007 master - 0 1597574851880 7 connected ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597574850869 5 connected 10923-16383 d52297a6da9b17fad400385f796118443a7d929b 192.168.199.121:7008@17008 myself,slave 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 0 1597574848000 0 connected 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 master - 0 1597574849861 1 connected 0-5460 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 0 1597574849000 3 connected 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597574850000 5 connected 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 slave 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 0 1597574847847 1 connected 192.168.199.121:7008>
可以看到,之前删除的节点又恢复了,这是因为对应的配置文件没有删除,执行CLUSTER SAVECONFIG恢复
模拟master节点挂掉
[root@localhost redis_7001]# ps aux | grep redis root 4931 0.5 0.1 144300 2484 ? Ssl 14:35 1:23 /usr/local/bin/redis-sentinel *:26379 [sentinel] redis 4982 0.3 0.1 145164 3500 ? Ssl 14:51 0:56 /usr/local/bin/redis-server 192.168.199.236:6379 root 5107 0.2 0.1 145560 2852 ? Ssl 17:55 0:07 redis-server 192.168.199.236:7001 [cluster] root 5112 0.2 0.1 145564 2808 ? Ssl 17:55 0:07 redis-server 192.168.199.236:7002 [cluster] root 5174 0.0 0.0 112812 972 pts/1 S+ 18:51 0:00 grep --color=auto redis [root@localhost redis_7001]# kill 5107 [root@localhost redis_7001]# 192.168.199.138:7003> CLUSTER NODES 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 0 1597575121000 6 connected d52297a6da9b17fad400385f796118443a7d929b 192.168.199.121:7008@17008 slave 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 0 1597575120000 7 connected 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597575120000 5 connected 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003@17003 myself,master - 0 1597575118000 3 connected 5461-10922 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 master - 0 1597575121460 8 connected 0-5460 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 master,fail - 1597575091328 1597575090115 1 disconnected ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597575120454 5 connected 10923-16383 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 192.168.199.138:7007@17007 master - 0 1597575119000 7 connected 192.168.199.138:7003>
对应7001的一行可以看到,master fail,状态为disconnected;而对应7004的一行,slave已经变成master。
重启看下效果:
[root@localhost redis_7001]# redis-server /usr/local/redis-5.0.4/cluster/redis_7001.conf [root@localhost redis_7001]# 192.168.199.138:7003> CLUSTER NODES 98dd817404a14283538df18060ff3ce09eb892c8 192.168.199.121:7006@17006 slave 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 0 1597575240624 6 connected d52297a6da9b17fad400385f796118443a7d929b 192.168.199.121:7008@17008 slave 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 0 1597575238000 7 connected 5222c26f0cccf3efd8b1829037c311728cef60a3 192.168.199.236:7002@17002 slave ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 0 1597575238000 5 connected 01242a60f9d6e8bc1c6c02cdaad2cb73a09a3d9e 192.168.199.138:7003@17003 myself,master - 0 1597575238000 3 connected 5461-10922 0be8df6c77fc7d7e8209919b133ac829dc6204ed 192.168.199.138:7004@17004 master - 0 1597575239615 8 connected 0-5460 98c07ca0dbc8fdf97d67cf92a8e4aa8449915b89 192.168.199.236:7001@17001 slave 0be8df6c77fc7d7e8209919b133ac829dc6204ed 0 1597575236691 8 connected ca9a6d9ca4251fcede5c0ba15aa59f1984392a18 192.168.199.121:7005@17005 master - 0 1597575238000 5 connected 10923-16383 4c33b8d9cd44992d06a96c5c12af10f0f7da7fd3 192.168.199.138:7007@17007 master - 0 1597575238606 7 connected 192.168.199.138:7003>
可以看到,7001节点启动后为slave节点,并且是7004的slave节点。即master节点如果挂掉,它的slave节点变为新master节点继续对外提供服务,而原来的master节点如果重启,则变为新master节点的slave节点。
另外,如果这里是拿7007节点做测试的话,会发现7008节点并不会切换,这是因为7007节点上根本没数据。集群数据被分为三份,采用哈希槽 (hash slot)的方式来分配16384个slot的话,它们三个节点分别承担的slot 区间是:
节点7004覆盖0-5460 节点7003覆盖5461-10922 节点7005覆盖10923-16383
hash槽的分配:https://www.php.cn/redis/436531.html我先挂起研究下,在看下,应该和linux分区差不多,在上代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号