
mysql 为什么很多互联网公司选择了读可提交
前言
在默认环境下,mysql 是可重复读,为什么默认可重复读呢?
一般情况下感觉读可提交就行,可重复读解决幻读的问题,但是大多情况下没有幻读的问题,所以也没有必要可重复读。
那么为什么mysql 要把默认配置设置为可重复读呢?
正文
历史原因:
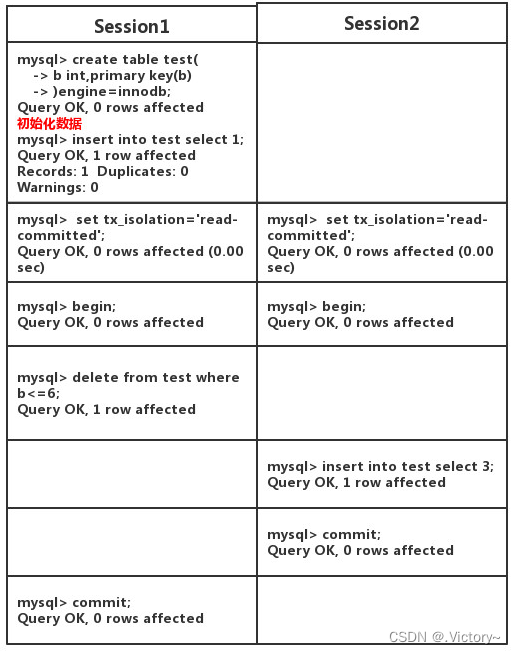
这种图,如果是在可提交读的情况下,会发生什么呢?
当运行完后,那么进行查询:

那么在从库运行,那么就是:

为什么会这样呢?因为binlog 记录的是提交顺序:首先session B 先提交的,那么从库运行的时候就会出现sessionB的语句再运行sessionA的语句。
这样就造成了主从数据不一致的问题。
那么这个问题是否能解决呢?如果这个问题不解决,那么可提交读这个是否就没法做主从了。
这就不得不提及一下binary log,简称bin log了。
现在bin log 有三种格式:
-
statement
-
row
-
mixed
-
Statement-based replication (SBR): 在SBR中,MySQL服务器将每个执行的SQL语句记录到binlog中。当从主服务器复制到从服务器时,从服务器会执行相同的SQL语句来保持数据同步。这种方法简单且高效,但可能会导致一些复制不一致的问题。
-
Row-based replication (RBR): 在RBR中,MySQL服务器将每次数据更改的行的副本记录到binlog中。当从主服务器复制到从服务器时,从服务器会根据这些行的副本来进行相同的数据更改。这种方法可以确保数据一致性,但会增加binlog的大小。
-
Mixed-based replication (MBR): MBR结合了SBR和RBR的优点。MySQL服务器根据情况选择使用SBR或RBR来记录binlog。通常对于不同类型的SQL语句会采用不同的复制方式,以达到效率和数据一致性的平衡。
之所以产生问题呢? 那么就是由于第一种,因为保存的是sql 语句,那么执行的就是sql语句了,顺序不同,那么结果就不同了。
那么要解决这个问题呢? 可以使用row这种模式,这种模式就是将数据的结果写下来,那么同步过去也就是从新同步数据了,也就是同步结果,这个时候就没有问题。
那么这个时候应该也是有更多的开销的,因为row要把结果记录下了,那么肯定是需要更多的磁盘io和磁盘空间了。
但是互联网公司依然选择读提交的原因是什么呢?
-
原因一就是间隙锁的问题,因为存在间隙锁,那么死锁概率就大,同样的间隙锁的原因,锁的范围就大了。
-
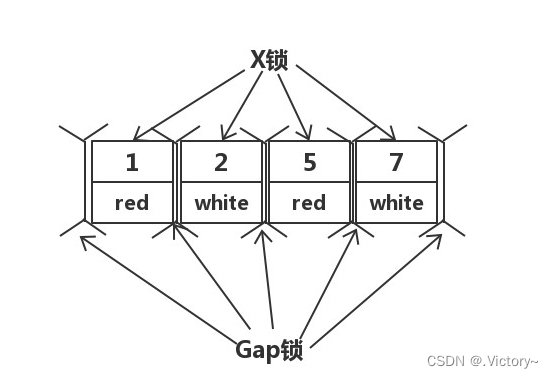
再rr隔离级别下面,没有命中的索引会锁表:
update test set color = 'blue' where color = 'white';
试想一下update 要避免color = 'white' 被插入,这个时候只能锁表了。
而读提交,那么就只会锁住两行:
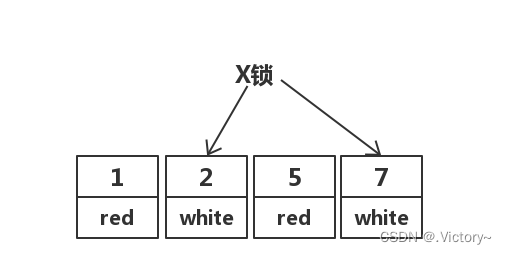
主要的原因是因为读提交的锁范围,并发高,然后需要可重复读场景中的解决幻读问题的比较少。
结
下一节mvcc。

