mysql 简单进阶 ———— 重构查询[二]
前言
简单整理一下重构查询。
正文
为什么我们需要重构查询,原因也很简单,那就是查询慢。
为什么会查询慢?
查询性能慢底下的最基本的原因是访问的数据太多。 某些查询不可避免地需要筛选大量的数据,但这并不常见。
大部分性能低下的查询都可以通过减少访问的数据流的方式进行优化。
- 确认应用程序是否检索大量超过需要的数据。这意味着访问了太多的行,但有时候也可能访问了太多的列。
- 确认mysql 服务器是否在分析大量超过需要的数据行。
最先想到的是是否向数据库请求了不需要的数据。
举个很低级的例子:
- 查询了多余的行
在c#的linq中通过tolist在执行了 "select * from payment",然后通过take 和 skip 来获取需要的数据,这个时候其实是查询了全部的行,然后才在应用层进行过滤了。
- 查询了多余的列
比如select * from payment中,通过查询了全部的列,但是很多列是不需要的。
但是这个也不能以偏概全,要看应用场景,比如查询出来做缓存,那么可能只查询了一次,然后用的是缓存的数据,但是通过查询多余的列出来可以供多个地方使用。
- 重复查询了通用的数据
比如一个数据高频访问,低更新,那么就应该考虑使用缓存了,这样避免大量的查询。
还有一个重要的指标,mysql 是否扫描了额外的记录。
是否扫描了额外的记录,有下面3个标准:
-
响应的时间
-
扫描的行数
-
返回的行数
没有哪个指标能够完美地衡量查询的开销,但是他们能够反映了mysql在内部执行查询时候需要访问的数据,并可以大概推算出运行的时间。
这三个指标都会记录到mysql的慢日志中,所以检查慢日志记录是找出扫描行数过多的查询的好办法。
- 响应时间
响应时间包括两个,一个是服务时间,一个是排队时间。
服务时间是指数据库处理这个查询真正花了多长时间。排队时间是指因为等待某些资源而没有真正的执行查询的时间,可能是等i/o 操作完成,也可能是等行锁。
- 扫描的行数和返回的行数
最理想的情况是扫描的行数等于返回的行数,这个就太理想了。一般是在1:1,和10:1之间,那么就是要尽量减少扫描的行数。
- 扫描的行数和访问的类型
这个访问的类型指的是explain 后,返回的类型。
1. id:表示查询执行计划中的每个步骤的唯一标识符。id的值越大,表示该步骤的执行顺序越靠后。
2. select_type:表示该步骤的查询类型。常见的查询类型包括SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)等。
3. table:表示该步骤涉及的表名。
4. partitions:表示该步骤涉及的分区。
5. type:表示该步骤使用的访问方法,也称为连接类型。常见的访问方法包括ALL(全表扫描)、index(使用索引扫描)、range(范围扫描)等。
6. possible_keys:表示该步骤可能使用的索引。
7. key:表示该步骤实际使用的索引。
8. key_len:表示该步骤使用的索引的长度。
9. ref:表示该步骤使用的索引的列与前一个步骤的关联条件。
10. rows:表示该步骤扫描的行数。
11. filtered:表示该步骤满足WHERE条件的行数占总扫描行数的比例。
12. Extra:表示该步骤的额外信息。常见的额外信息包括Using filesort(使用文件排序)、Using temporary(使用临时表)等。
上面说一下可能难以理解的几个元素:
key_len字段表示使用的索引的长度,它表示索引中被使用的字节数。索引长度越短,查询性能通常越好。
举个例子来说明key_len的含义:
假设有一个表table,其中有一个列name定义为VARCHAR(100),并且有一个非唯一索引idx_name(name)。如果在查询中使用了以下条件:
SELECT * FROM table WHERE name = 'John'
那么在执行EXPLAIN语句后,可以看到key_len字段的值为100。这是因为查询条件中的name列的长度为100,索引idx_name的长度也为100,所以key_len的值为100。
另外,如果查询条件中使用了name列的前缀,比如:
SELECT * FROM table WHERE name LIKE 'J%'
那么在执行EXPLAIN语句后,可以看到key_len字段的值会根据前缀的长度而变化。如果前缀长度为1,则key_len的值为1。如果前缀长度为2,则key_len的值为2。以此类推。
需要注意的是,key_len并不是表示索引的实际长度(比如字节数),而是表示索引中被使用的字节数。它可以用于比较不同查询条件对索引的利用程度,从而进行索引的优化。
这里很多人理解的可能就以为是索引的长度,其实是实际使用的索引的长度。
还有一个是ref:
在MySQL的EXPLAIN输出中,ref是一个关键字段,表示查询过程中使用的索引列与上一个表的列之间的引用关系。ref字段通常用于连接操作(JOIN)中,指示连接条件使用的索引列。
以下是一个具体的例子来解释ref字段的含义:
假设有两个表table1和table2,它们的结构如下:
table1:
- id (主键)
- name
table2:
- id (主键)
- table1_id (外键)
现在我们执行以下查询语句:
SELECT * FROM table1 JOIN table2 ON table1.id = table2.table1_id WHERE table1.name = 'John'
在执行EXPLAIN语句后,可以看到以下输出:
id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra
1 | SIMPLE | table1| NULL | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using index
1 | SIMPLE | table2| NULL | ref | table1_id | table1_id | 4 | table1.id | 2 | Using index
- ref字段:在这个例子中,第二行的ref字段的值为table1.id,表示查询过程中使用了table1表的id列作为索引列与table2表的table1_id列进行连接。
- key字段:key字段的值为table1_id,表示查询使用了名为table1_id的索引。
- rows字段:rows字段的值为2,表示MySQL估计需要扫描的行数为2。
在这个例子中,我们可以看到ref字段指示了连接操作中使用的索引列之间的引用关系。通过理解ref字段的含义,我们可以更好地理解连接操作的执行过程,并进行性能优化和调整。
在MySQL的EXPLAIN输出中,当ref字段的值为const时,表示查询过程中使用的索引列与一个常量值之间的引用关系。这意味着查询使用了一个常量值来匹配索引列。
以下是一个具体的例子来解释ref字段为const的含义:
假设有一个表table,其中有两个列id和name,并且有一个唯一索引idx_name(name)。现在我们执行以下查询语句:
SELECT * FROM table WHERE name = 'John'
在执行EXPLAIN语句后,可以看到以下输出:
id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra
1 | SIMPLE | table | NULL | ref | idx_name | idx_name | 102 | const | 1 | Using index
- ref字段:在这个例子中,ref字段的值为const,表示查询过程中使用的索引列与常量值之间的引用关系。
- key字段:key字段的值为idx_name,表示查询使用了名为idx_name的索引。
- rows字段:rows字段的值为1,表示MySQL估计需要扫描的行数为1。
在这个例子中,ref字段为const表示查询使用了常量值来匹配索引列。这样的查询通常会非常高效,因为MySQL可以直接使用索引来定位匹配的行,而不需要进一步的比较操作。
总结来说,当ref字段为const时,表示查询使用了一个常量值来匹配索引列,这通常会带来高效的查询性能。
除了const之外,ref字段可能还有其他的取值,具体取决于查询语句和索引的使用情况。以下是一些常见的ref取值:
1. ref: 当查询使用索引列与另一个表的列进行连接时,ref字段的值可能是另一个表的列名。例如,在连接操作(JOIN)中,如果使用了索引列与另一个表的列进行连接,ref字段可能显示连接条件中使用的列名。
2. NULL: 当查询不使用索引列与其他表进行连接时,或者查询没有使用索引时,ref字段的值可能为NULL。这表示查询没有引用其他表的列。
3. Multiple values: 在某些情况下,ref字段可能会显示多个值,表示查询使用了多个索引列与其他表的多个列进行连接。这通常发生在复杂的连接操作中。
请注意,ref字段的具体取值取决于查询语句、索引的使用和表之间的关系。因此,在不同的查询中,ref字段可能会有不同的取值。了解和理解ref字段的含义可以帮助我们更好地理解查询执行过程,并进行性能优化和调整。
当查询不使用任何索引或者没有引用其他表的列时,ref字段的值可能为NULL。这种情况下,查询只涉及到单个表,没有进行连接操作或者索引的使用。
以下是一个示例来说明ref字段为NULL的情况:
假设有一个表table,其中有两个列id和name。我们执行以下查询语句:
SELECT * FROM table WHERE id = 1
在执行EXPLAIN语句后,可以看到以下输出:
id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra
1 | SIMPLE | table | NULL | ALL | NULL | NULL | NULL | NULL| 1 | NULL
- ref字段:在这个例子中,ref字段的值为NULL,表示查询没有引用其他表的列,也没有使用任何索引。
这种情况下,ref字段为NULL表示查询只涉及到了单个表,没有进行连接操作或者使用索引。这样的查询可能会导致全表扫描,对于大表来说性能较差。在优化查询性能时,可以考虑添加适当的索引或者修改查询语句来避免全表扫描。
那么这个type 有全表扫描、范围扫描、唯一索引查询、常数引用等。
举个例子:
EXPLAIN select film_id, actor_id
from sakila.film_actor
where film_id =1;
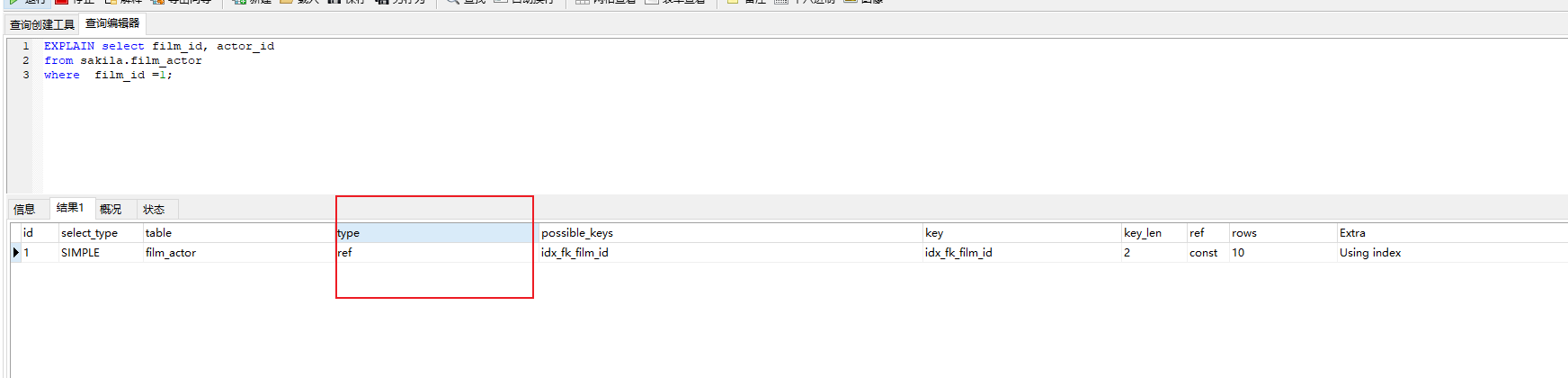
这里的type 就是通过ref来实现了,也就是通过索引来实现。
如果没有索引会变成下面这样:

就是进行了全表扫描了。扫描了5073行,但是得到了才10行。
type 有下面这些类型:
1. system:表示只有一行的表,这是const类型的一个特例。例如,SELECT * FROM table WHERE primary_key = 1。
2. const:表示通过索引一次就能找到的常量值查询。例如,SELECT * FROM table WHERE primary_key = 1。
3. eq_ref:表示使用唯一索引查找。例如,SELECT * FROM table1 JOIN table2 ON table1.key = table2.key。
4. ref:表示使用非唯一索引查找。例如,SELECT * FROM table1 WHERE key = 'value'。
5. range:表示使用索引范围查找。例如,SELECT * FROM table WHERE key BETWEEN 1 AND 10。
6. index:表示全索引扫描。例如,SELECT * FROM table WHERE key LIKE 'value%'。
7. all:表示全表扫描。例如,SELECT * FROM table。
8. index_merge:表示使用多个索引合并的结果。例如,SELECT * FROM table WHERE key1 = 'value' OR key2 = 'value'。
9. unique_subquery:表示使用子查询的结果进行唯一性判断。例如,SELECT * FROM table WHERE key = (SELECT key FROM other_table)。
10. index_subquery:表示使用子查询的结果进行索引查找。例如,SELECT * FROM table WHERE key IN (SELECT key FROM other_table)。
那么如果我们遇到了一个复杂的查询我们应该如何处理呢?
-
可以将一个复杂的查询分成几个简单的查询,这样扫描的行数,查询的复杂度可能会降低,那么效率就有可能更高。
-
切分查询
举一个工作中遇到的删除的例子。比如要删除3个月前并且标记为deleted的数据,那么通过语句直接删除是不可能的。
那么可以通过一天一天的查找删除,并且每次删除固定的条数比如50条,这样每次扫描的索引会很少。 其实就是将大的操作,花费的时间分配到更小粒度里面去了。
- 分解关联查询



结
该系列持续更新。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号