
mysql 简单进阶 ———— 多列索引[一]
前文
整理一下mysql 的一些简单进阶技巧,来源于高性能mysql,但不是根据书的序列来的。
正文
库地址:
https://dev.mysql.com/doc/index-other.html
有一个问题,那就是我们为什么要创建多列索引呢?
这是要思考的一个问题。
为什么创建多列索引,而不是创建多个单列索引。需要弄明白这个问题,那么就需要知道索引是如何工作的。
为什么有索引这个东西呢?
就是因为我们摆放东西是要按照一定的规则去摆放的,为什么要按照规则摆放呢? 就是为了能够快速查找,这个是目的。
为什么建立多个索引,那么就是需要多种规则去摆放,以便于不同的查找方式。
那么多列索引和多个单个索引有什么区别呢? 多列索引是用多个列作为hash去进行排序的,而多个单列是建立多种规则去进行排序。
select film_id, actor_id
from sakila.film_actor
where actor_id = 1 or film_id =1;
举个例子,这个是建立多列索引号还是建立单个索引好?
不用猜想,做下实验。
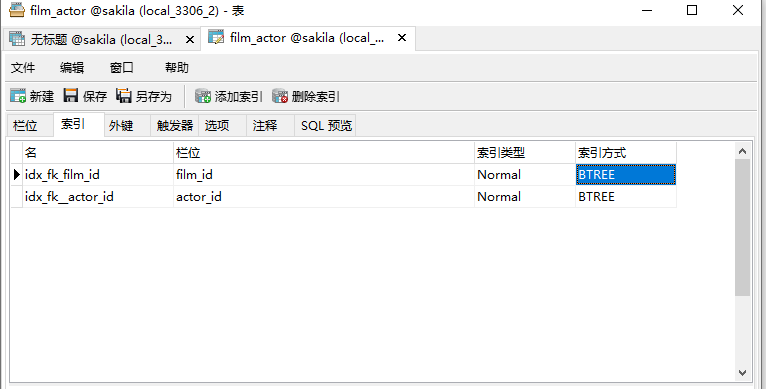
那么现在建立了两个索引,那么看下运行是怎么样的。
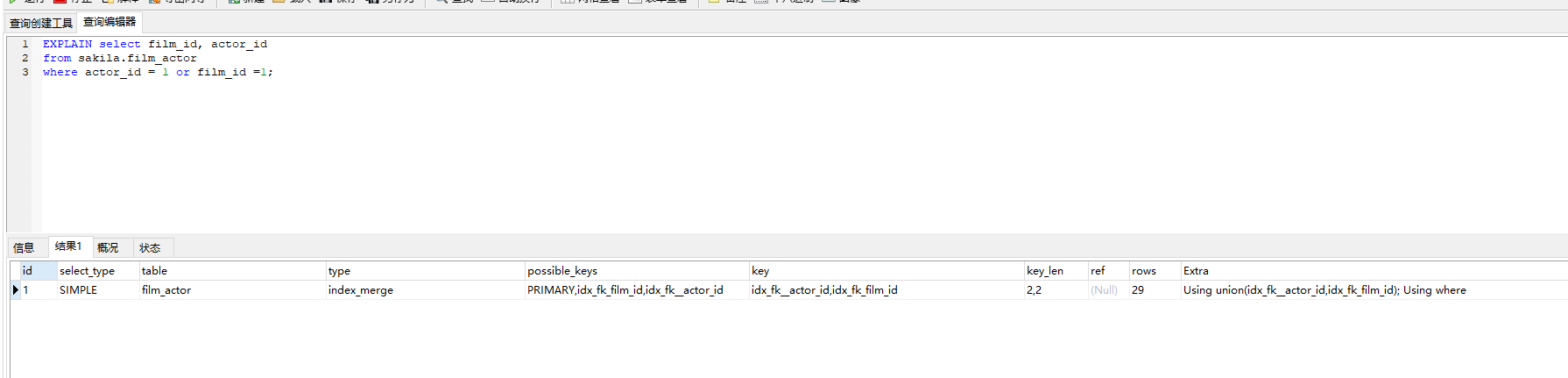
这里可以看到,实际上是用到了两个索引,然后进行合并。
那么这里建立多个列索引有什么影响呢?

这里加了一个多列索引。
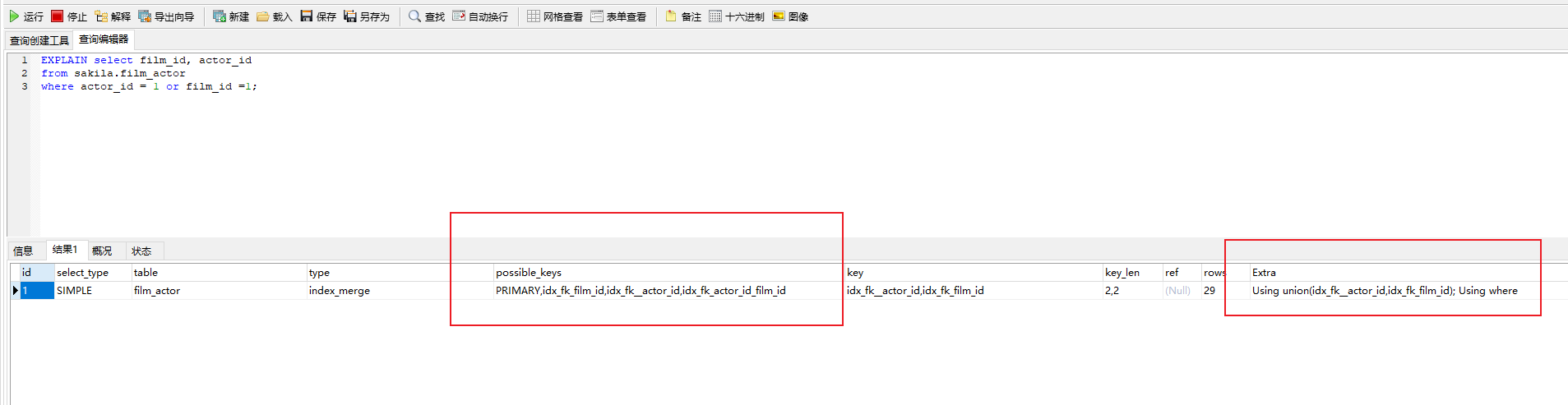
这里最后多列索引没有用,还是用的是两个单的索引。
原因是因为or,这个如果是两个列的hash作为结构的参考的话,那么实际上意义不大。

第一点现在已经理解了,那么第二点呢? 多个索引做联合操作时候,相当于做了两个查询,并且扫描了两次。
首先我们要知道这个扫描的29行是怎么来的。
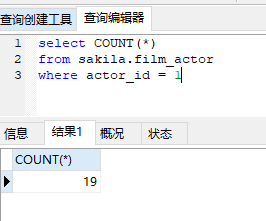
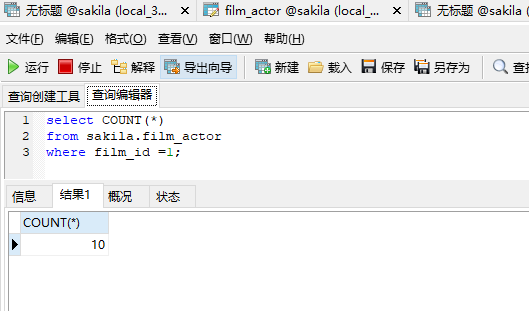
是通过不同的索引扫描来的,10+19=29.
那么这里如果只创建一个索引怎么样?
看下分析结果:

几乎和前面没有变化。
原因为:
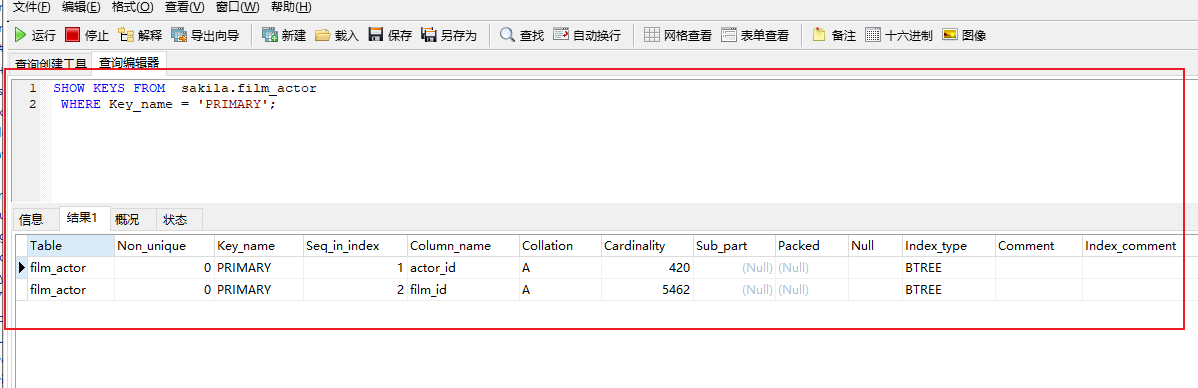
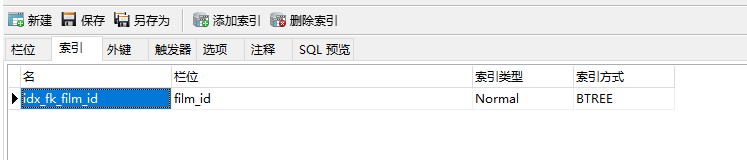
这张表有联合索引,查找actor_id 直接用了primary,也就是一个多列索引。
然后查找film_id 用了idx_fk_film_id 这个作为索引。
索引另外建立的索引都是多余的。
那么现在知道了一些多列索引和单列索引的区别了。
那么该如何选择多列索引呢?
在一个多列的b-tree 索引中,索引列的顺序意味着索引先按照最左进行排序,其次是第二列,这个可以看下我的c# linq系列。
索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的order by,group by 和 distinct 等语句、
那么我们就会想到一个问题,那就是先把过滤多的放在第一列,这样使用where 的话,那么过滤的最多了。
但是依然需要考虑到group by 和 order by的情况。
先举个适用的例子:
select * from payment where staff_id = 2 and customer_id=584
如果这个语句很慢,那么我们考虑给他建立索引,那么哪个在前哪个在后呢?
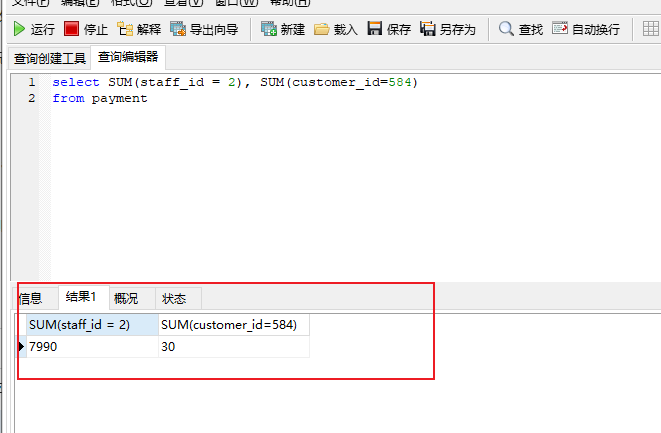
显然我们应该选择customer_id,因为这个更少。
第一次过滤就可以过滤剩下30.
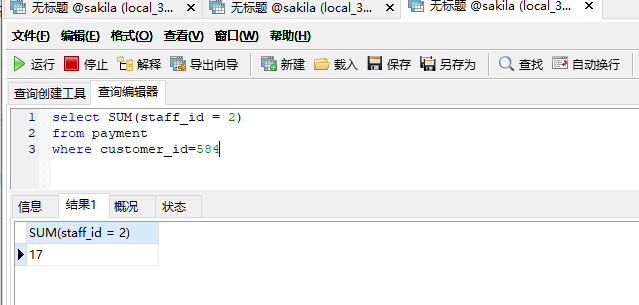
如果建立customer_id 索引,那么只需要过滤30里面的17即可。
但是上面有一个小小的问题,那就是我们指定了staff_id = 2 and customer_id=584 优化性能是最好的,但是会不会这个是特殊的。
那么就需要考虑整体性:
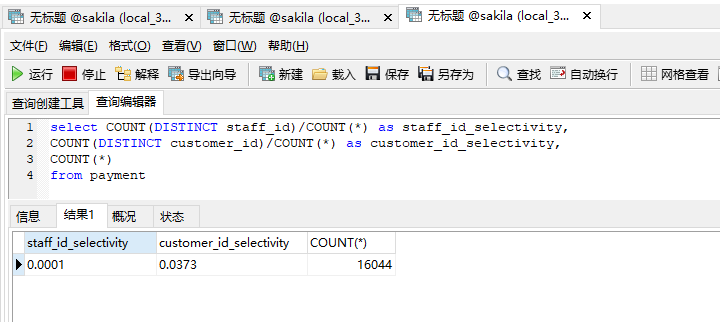
和前面的结果意义,customer_id 选择性高,因为 distinct 后的数量更多,也就基本意味着customer_id 筛选出来的条件更少。
所以你可以创建索引 alter table payment add key(customer_id,staff_id )
这里是个例子哈,也不是有and 就建立两个索引,这里customer_id 过滤出来的staff_id 都是30,其实建立customer_id索引就行。
那么还有一个问题,那就是是不是这个就通用了呢?
举一个反例:


结
下一节查询优化

