k8s 深入篇———— docker 是什么[一]
前言
简单的整理一下一些基本概念。
正文
简单运行一个容器:
创建一个容器:
docker run -it busybox /bin/bash
然后看下进程:
ps -ef

做了一个障眼法,使用的是pid namespace方式,让容器内部只能看到由容器创建的进程。
linux 还有一些其他的机制:
比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信
息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配
置。
现在隔离了一些资源,似乎能让新启动的进程,只能使用被容器规范起来的资源。
但是有一个问题,那就是把资源分配出去了,到底分配多少资源。
主要是几大块吧,内存、cpu、磁盘。
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程
组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
举个例子
查看cgroup 限制:
mount -t cgroup
有这些限制:
举个限制cpu的例子:
进入限制cpu的目录下:

创建一个组,比如mkdir container:

改下两个参数:
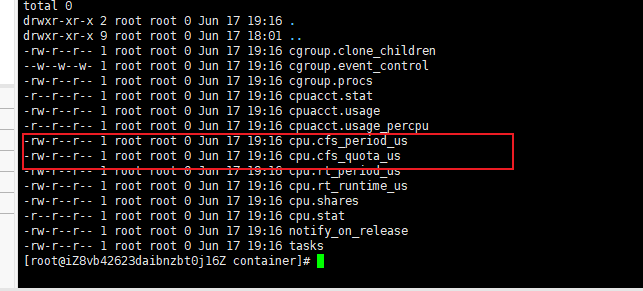
echo 20000 > cpu.cfs_quota_us
限制100ms 内只能使用20ms。
现在运行一个进程:

看下cpu:

100% 了,现在限制一下这个进程的cpu。
echo 3121 > tasks
再看下cpu:

现在kill 3121
除 CPU 子系统外,Cgroups 的每一项子系统都有其独有的资源限制能力,比如:
blkio,为 块 设 备 设 定 I/O 限 制,一般用于磁盘等设备;
cpuset,为进程分配单独的 CPU 核和对应的内存节点;
memory,为进程设定内存使用的限制。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上
一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子
系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,
把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
例如:
docker run -it --cpu-period=100000 --cpu-quota=20000 busybox /bin/sh
这样就限制了。
来看下限制:

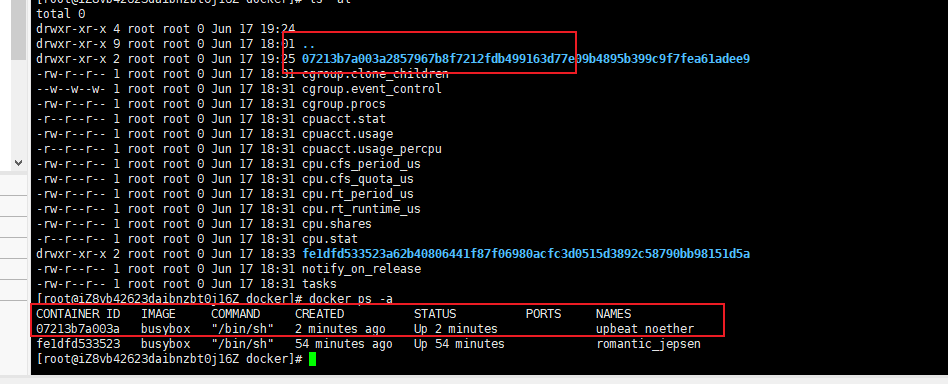
进去查看:
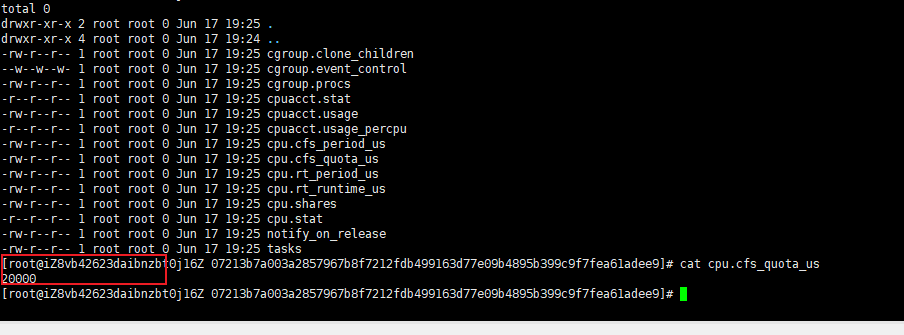


结
大概就是这么回事了。
linux 容器化优势不多说,用的自然知道,节约能源,方便使用。
弊端:
- 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就
是:时间。 - 众所周知,Linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户
可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 CPU 使用情况、
内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
但是,你如果在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内
存数据,而不是当前容器的数据。
造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什
么样的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。
在生产环境中,这个问题必须进行修正,否则应用程序在容器里读取到的 CPU 核数、可用
内存等信息都是宿主机上的数据,这会给应用的运行带来非常大的困惑和风险。这也是在企
业中,容器化应用碰到的一个常见问题,也是容器相较于虚拟机另一个不尽如人意的地方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号