

linux 性能自我学习 ———— cpu 快速定位问题 [六]
前言
主要介绍一下cpu如何快速定位问题。
正文
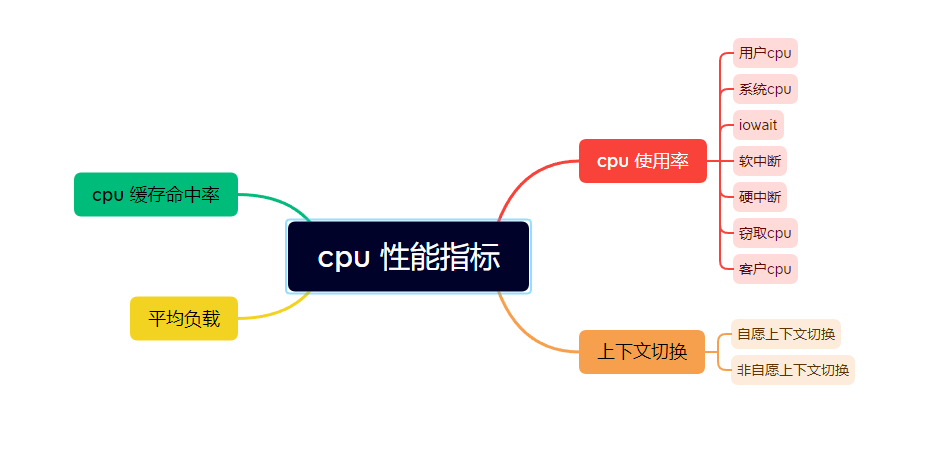
cpu 的一些性能指标:
1. cpu 使用率
cpu 使用率描述了非空闲时间占总cpu时间的百分比,根据cpu上运行任务的不同,又被分为用户cpu、系统cpu、 i/o 等待cpu、 软中断、硬中断。
用户cpu使用率,包括用户态cpu使用率,和低优先级用户态cpu 使用率,表示cpu 在用户态运行的时间的百分比。
用户cpu 使用率搞,通常说明应用程序比较繁忙。
-
系统cpu使用率,表示cpu在内核态运行的时间百分比(不包括中断)。系统cpu使用率高,说明内核比较繁忙。
-
等待i/o 的cpu使用率,通常也称为iowait,表示等待i/o 的时间百分比。 io wait高,说说吗系统与硬件设备的i/o交互时间比较长。
-
软中断和硬中断的cpu使用率,分布表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率搞,通常说明系统发送了大量的中断。
2. 平均负载
也就是系统的平均活跃进程数,它反应了系统的整体负债情况,主要包括三个数值,分别指过去1分钟、过去5分钟、过去15分钟的平均负载。
理想情况下,平均负载等于逻辑cpu个数,它表示cpu恰好被充分利用,一般可以大于70%。
3. 进程上下文切换
-
无法获取资源导致的资源上下文切换
-
被系统强制调度导致的非自愿上下文切换
上下文切换,本身保证了linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的cpu时间,消耗在寄存器、内核栈、以及虚拟内存等数据的保存和恢复上,
缩短进程真正运行的时间,称为性能瓶颈。
用什么工具来排查呢?
几个案例总结:
- 平均负载案例。
先用uptime,查看系统的平均负载;而在平均负载升高后,又用mpstat和pidstat,分布观察了每个cpu 和 每个进程cpu的使用情况,进而找出导致平均负载高的进程,使用的是stress 工具。
- 上下文切换的案例
先用vmstat 查看系统上下文切换和中断次数。
然后通过pidstat,观察和进程的自愿上下文切换和非自愿上下文切换情况。最后通过pidstat,观察线程的上下文切换情况,找出上下文切换次数增多的根源,也就是我们的基准测试工具sysbench。
-
进程cpu 升高案例,先用top,然后是perf top。
-
短时进程问题,系统cpu搞,但是找不到进程。 可能是短时进程,崩溃等。
通过perf record 和 perf report。
短时进程可以使用execsnoop。
- 不可中断进程或者僵尸进程的案例。 我们先用top 观察到了iowait升高的问题,并发现了大量的不可中断进程和僵尸进程;
接着我们用dstat 发现是磁盘导致的,于实通过pidstat 找到了相关的进程。 可以用strace查看进程系统调用失了,最后通过perf分析进程调用链,发现磁盘i/o问题。
- 软中断案例,通过top 观察到,系统的软中断cpu 使用高。
通过top查看系统的软中断cpu使用率升高;接着查看/proc/softirqs 找到了几种变化快的软中断,通过sar命令,发现网络小包的问题。
最后用tcpdump 找出网络帧的类型和来源,确定是一个syn flood 攻击导致的。
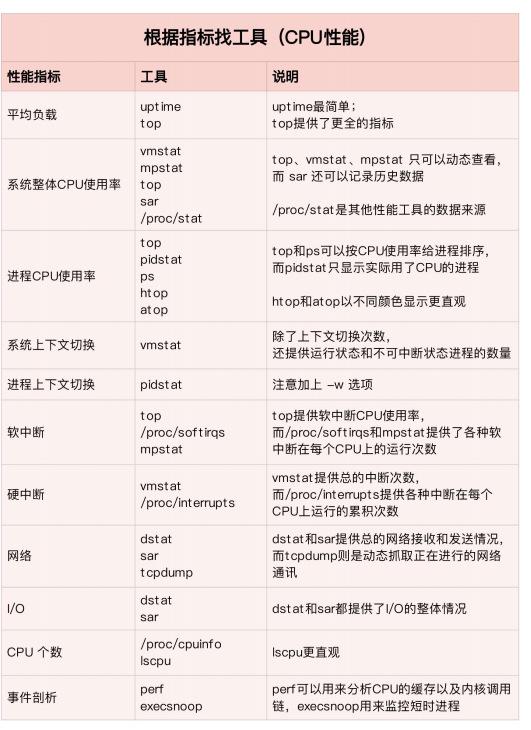
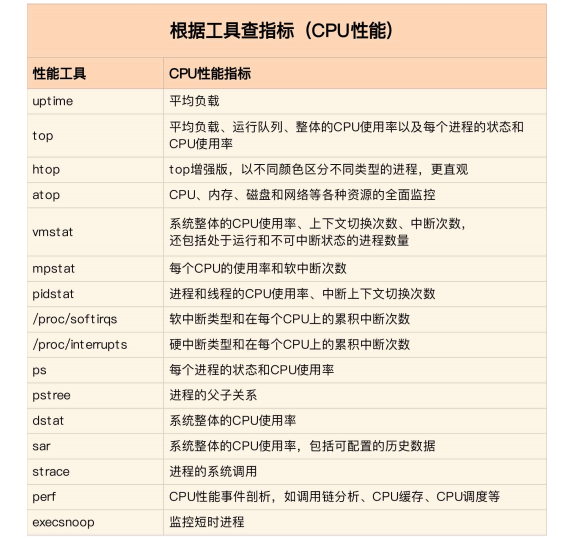
工具表:
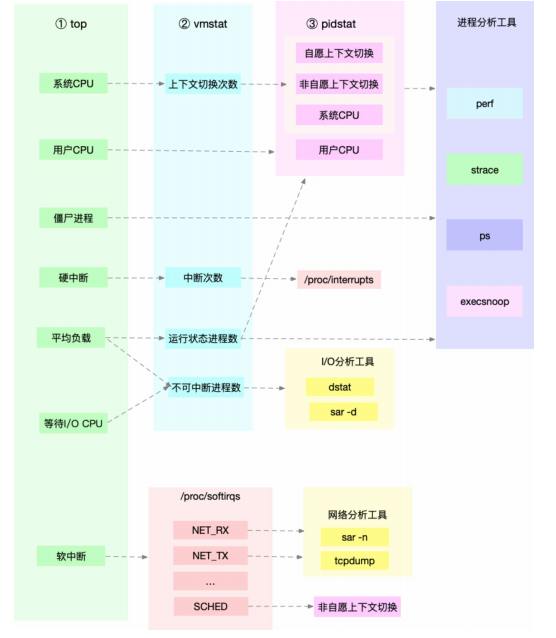
示例图:
结
下一节,内存相关。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2020-06-04 整理ionic 系列——页面生命周期
2020-06-04 linux 忘记密码怎么破?
2020-06-04 重新整理数据结构与算法——概念[一]