linux 性能自我学习 ———— 理解平均负载 [一]
前言
linux 系统上性能调查的自我学习。
正文
什么是平均负载?
使用uptime:

可以看到后面有:
0.03, 0.06, 0.09
这个表示1分钟,5分钟,15分钟的平均负载。
平均负债是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。
所谓可运行状态的进程,是指正在使用cpu或者正在等待cpu的进程,也就是我们常用的ps命令看到的,处于r状态(running 或runnable) 的进程。
不可中断状态的进程是正处于内核态关键中的流程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的io响应,
也就是我们在ps命令中看到的d状态(uninterruptible sleep,也称disk sleep)的进程。
比如平均负载是2:
-
在只有两个cpu的系统上,意味着所有的cpu都刚好被完全占用。
-
在4个cpu的系统上,意味着cpu有50%的空闲。
-
在只有一个cpu的系统上,意味着有一半的进程竞争不到cpu。
什么时候平均负载合理:
查看cpu的个数:
grep 'model name' /proc/cpuinfo | wc -l
如果平均负载超过了核数,那么是过载,那么就是说有进程没有竞争到cpu。
一般情况下,当平均负载高于cpu数量70%的时候,那么就应该增加配置或者调查一下原因。
而我们也是需要看cpu负载在1分钟,5分钟和15分钟。
如果15分钟的负载很高,而1分钟的负载不高,那么就说明负载开始下来了。
反之,是最近才上去的。
平均负载和cpu使用率的区别。
平均负载包括正在使用的cpu,还有等待的cpu还有等待io的进程。
而cpu使用率就是表面意思,就是cpu的使用情况。
-
cpu 密集型进程,使用大量的cpu会导致平均负载升高,此时两者是一致的。
-
i/o 密集型,等待io也会导致平均负载升高,但是cpu使用率不一定升高。
-
大量等待cpu的进程调度也会导致平均负载升高,此时的cpu使用率也会比较高。
下面对这3中情况,进行案例测试:
需要安装stress,sysstat.
- 模拟cpu 密集型进程
stress --cpu 2 --timeout 600

可以看到平均负载升高了。
查看cpu 使用率:
mpstat -P ALL 5
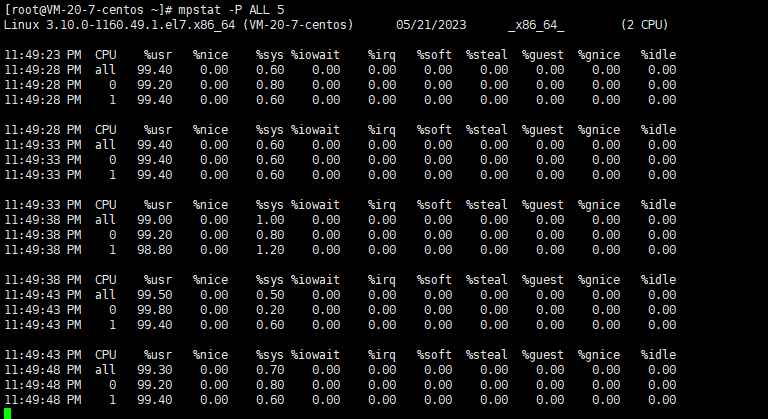
可以看到cpu 使用率被拉满了,但是iowait很低。
那么这个时候就是cpu密集型。
那么查看是哪个导致cpu使用100%。
使用pidstat:
pidstat -u 5 1
- 模拟cpu高的场景
stress -i 1 --hdd 1 --timeout 600
使用watch -d uptime:

使用mpstat 查看 mpstat -P -ALL 5 1:
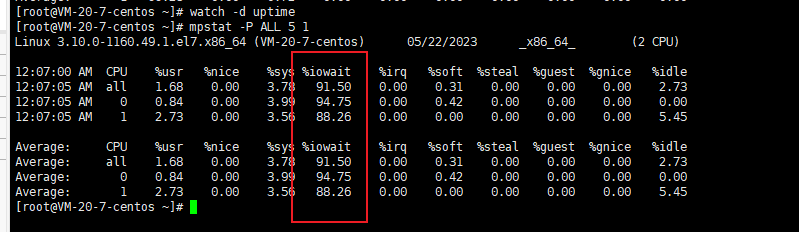
然后使用pidstat -d 5 1:
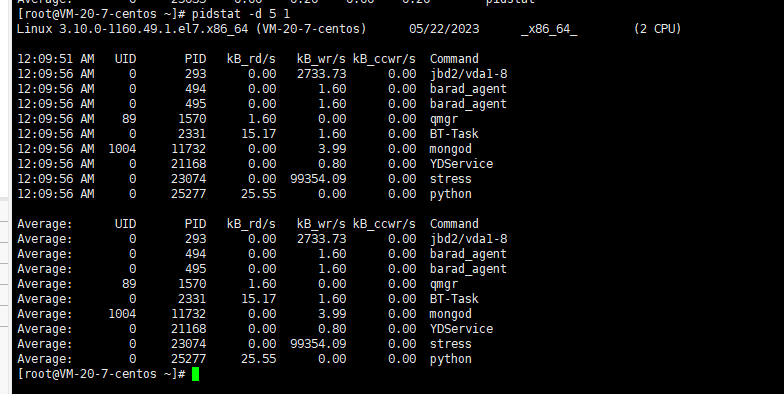
可以看到是因为io的原因。
场景3,大量进程的场景:
模拟16个活跃进程的场景:
stress -c 16 --hdd 1 --timeout 600
负载情况:

可以看到io和cpu都不高:
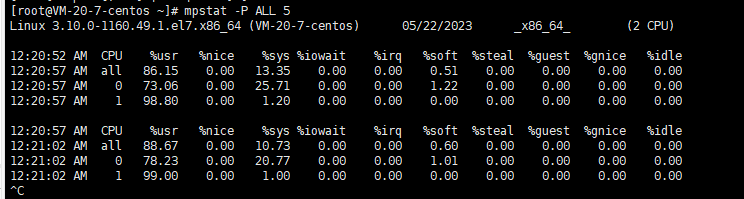
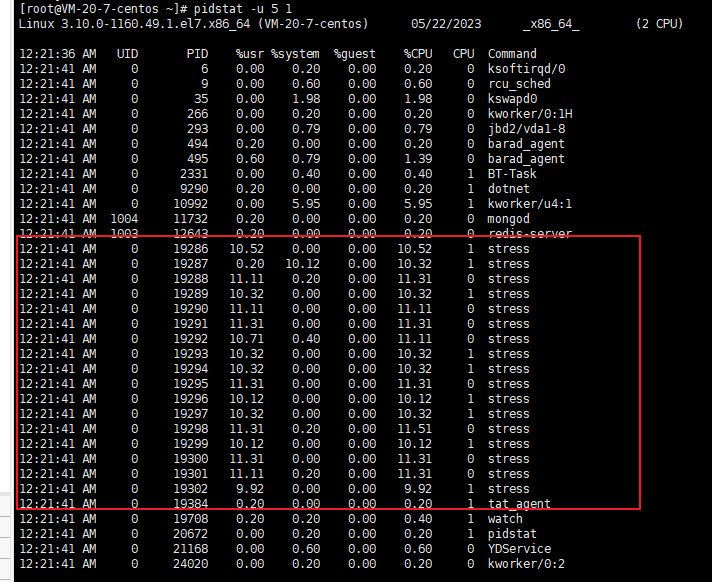
因为进程太多。
结
下一节cpu 上下文切换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号