抓包整理————tcp 传输数据的基础概念[十一]
前言
简单介绍一下tcp 数据传输。
正文
tcp 数据传输是怎么样子的呢?
比如我们在代码中写好了,connection 去连接。
然后我们用 write 去读取数据,这个时候呢,到底我们的操作系统做了什么呢?
这个时候操作系统肯定就将我们的data,打包成了tcp包然后发送出去了呀。
但是有一个问题啊,比如我们传输几M数据的话,那么肯定不能一次性传出去的呀,要弄成一个一个包出去。
这就是segment,也就是要分段啊。 那么怎么分段呢?

讲述一下传输过程,首先呢,应用层的数据,传输给tcp层(可以理解为程序),然后tcp 层弄完了就给ip层打包发送到数据链路层。
接收方,也是从数据链路层,到ip层,然后解析到tcp 层,然后给应用层。
那么当在tcp 层进行处理的时候其实就应该分段,因为ip层的分段传输效率很低。
如果tcp层就做好了分段,那么传输到ip层做处理的时候就不会进行分段了。
那么分段的依据为:
- MSS(max segment size): 防止ip层分段
- 流控: 接收端的能力
这个流控是什么呢? 就是简单的讲是这样的,比如说,你不停的发,但是接收端接收不了(缓存不足),那么这样会导致丢包,从而造成效率低下,后面滑动窗口会提及到这个。
这里介绍一下什么是mms:
定义:仅指tcp 承载数据,不包含tcp头部的大小。
mss 选择目的:
尽量每个segment 报文携带更多的数据,以减少头部空间占用比例
防止segment 被某个设备的ip层基于mtu拆分。
默认mss:536字节(默认mtu576字节,20字节ip头部,20字节tcp头部)
MSS 分类:
发送方个最大报文段:SMSS
接收方最大报文段: RMSS

上面可以看到他们在连接的时候就确定了mss大小。
那么tcp 发送我们知道是流,流就意味着顺序的,a发一个,然后b收到一个,然后b发送确认后,那么a再发送。
这样效率似乎是有点低的。
那能不能改进呢?比如a发出去5个,如果收到一个确认了,然后就继续发送出去。如果一段时间之后没有收到确认,就把没收到确认的发送出去。
这样听起来似乎不错,是一个很好的理论。
但是这样就有一个问题啊,那就是又不是每一个包的大小是一样的,比如前面5个包是1m。后面可能后面的10个包才1m,这个时候并发就应该是10了。
这个就是后面滑动窗口的问题。因为确认的是字节流,那么就需要有一个东西要确认这个收到的位置,这个就是序列号。
举个例子:

这里面sequence 是2905,tcp大小是836,那么下一个sequence 就是3741
那么来看下ack:

这里ack 确认就是3741了。
值得注意的是下面有一个时间戳:

这个时间戳有什么用呢?
这个是为了防止序列号回绕的。
比如说:

假如b时间丢了这个b的数据序号是1G-2G,但是f点同时又在发1G到2G这个序号,然后又收到了来源于b的1G-2G序号。
那这个时候数据就串了,肯定希望收到的是1-6G这个顺序的视频吧,不可能到5-6g的时候突然窜出来1到2G的数据吧。
如果有 Timestamps 的存在,内核会维护一个为每个连接维护一个 ts_recent 值,记录最后一次通信的的 timestamps 值,
当收到的数据包中 timestamps 值小于 ts_recent 值,就会丢弃掉这个数据包。等收到的数据包的timestamps 值大于 ts_recent,这个包可以被正常接收。
实际上timestamps 值是一个单调递增的值,这个选项不要求两台主机进行时钟同步。
两端 timestamps 值增加的间隔也可能步调不一致,比如一条主机以每 1ms 加一的方式递增,另外一条主机可以以每 200ms 加一的方式递增。
此外,timestamps 是一个双向的选项,如果只要有一方不开启,双方都将停用。 在Linux下可以通过下面方式开启或关闭timestamp功能。
同时这个时间戳还有一个比较重要的用处,那就是确认rto时间。
什么是rtt呢?
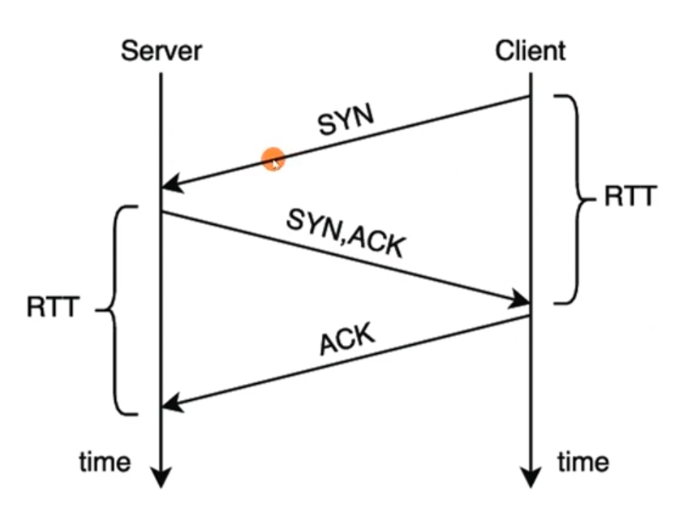
就是一次发出请求到ack的时间。

这里面有两个单词:一个是tsval(ts value) 一个 是 tsec(ts echo reply)。
这个tsval 是 发送时间,tsec 是回显时间,也就是说对方发送的时间。
有这个回显时间,那么加上自己接收到的时间,那么就是rtt。
那么根据这个rtt (round trip time 来回时间)就可以计算出rto(retransmission timeout)

结
下一节 ip 层。为什么不介绍滑动窗口,直接到ip层了呢? 因为有一些ip只是需要用到,才更好的能理解为什么。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号