


抓包整理————tcpdump过滤器[七]
前言
简单介绍一下tcpdump
正文
这里可以tcpdump -D 可以列出各个网卡的信息:
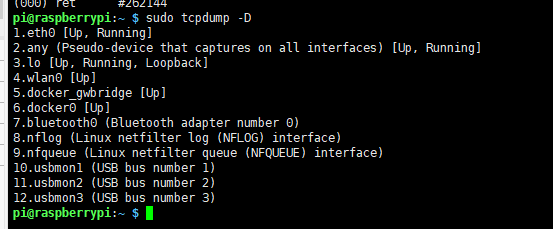
默认抓取eth0,也就是第一个:

还有下面的选项:
-D 举例所有的网卡设备
-i 选择网卡设备
-c 抓取多少报文
--time-stamp-precision 指定捕获时的时间精度,默认毫秒,可选纳秒
-s 指定每条报文的最大字节数,默认为 262144 字节
例如:

时间精度就不演示了,没有用到过。
捕获过滤其实和以前一样:
primitives 原语: 由名称或数字,以及描述它的多个限定词组成:
qualifiers 限定词:
type: 设置数字或者名称所指示类型,例如: host www.baidu.com
dir: dst port 80
proto: udp
原语运算符号:
与: && 或者 and
或: || 或者 or
非: ! 或者 not
例如: src or dst protrange 6000-8000 && tcp or ip6

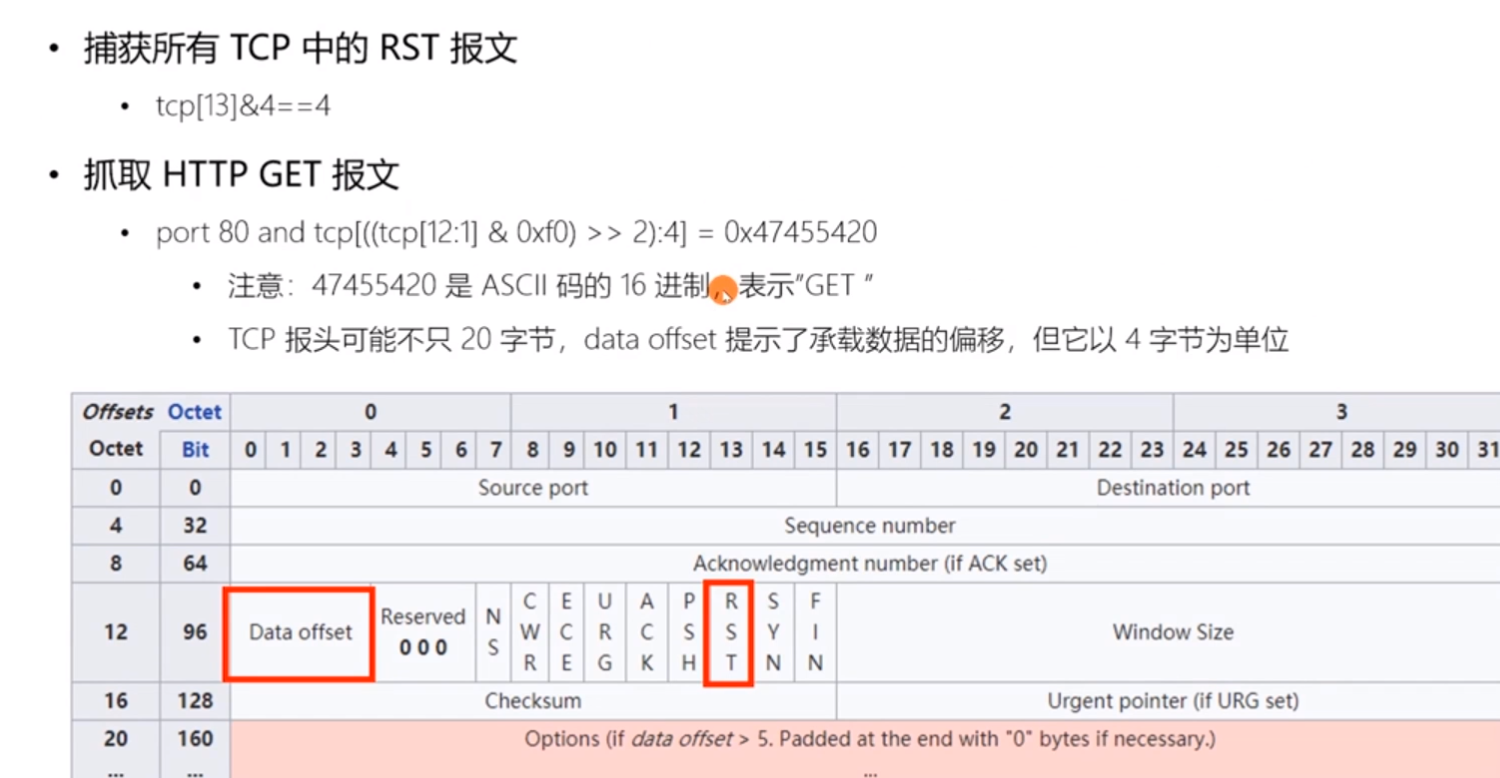
这里解释一下:
tcp[13]&4==4 上面我也用红框圈出了rst这个。tcp[13] 也就是偏移13个字节,也就是第14个字节,然后&4,也就是和 00000100进行且操作,也就是只有等于4的就标识rst 这个位置为1.
同样的解释http的get操作:
tcp((tcp[12:1]0xf0)>>2:4) 这个是因为tcp 第13个字节保存了data offset,因为是13个字节前4位保留了data offset,首先将后4位清空。本来应该是tcp[12:1]0xf0)>>4 得到前4位,但是这个data offset 是要*4才是真正的字节数。
所以就直接>>2了,也可以直接/4,其实是一个意思了。
然后获取到偏移量后取4个字节,正好http的get 请求是0x47455420这样就ok了,理解这种过滤规则就行。
也可以去看wireshark的。
演示一下tcpdump 保存。
这样就是保存在a中了。

-r 就是读取了。
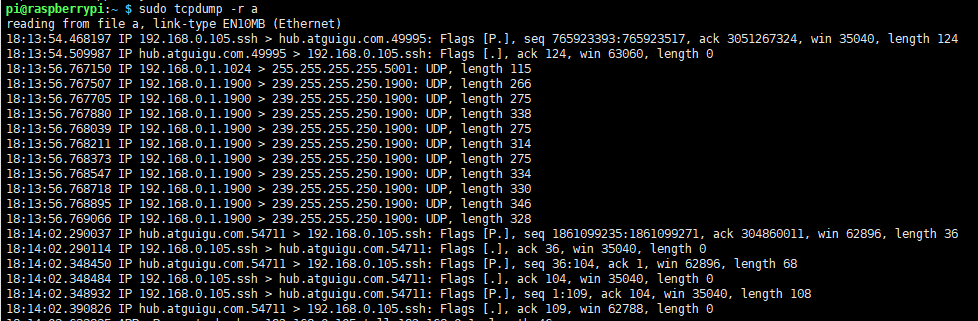
如果想同时读取a、b 文件,那么可以使用-V。
比如tcpdump -V c.
c 里面的文件内容就是: a的内容加上b的内容:
也就是指定对应的文件。
-w 输出结果到文件
-C 限制输出文件大小,单位是1,000,000可以理解为1m
-W 输出文件的最大数量,达到后会重写覆写1个文件
-G 每个几秒输出新文件
-r 读取一个包
-V 将待读取的多个文件名写入到一个文件中,通过读取改文件同时读取多个文件

这里一般-C -W 一般都是联合使用的,上面表示1m一个文件,最多3个文件。
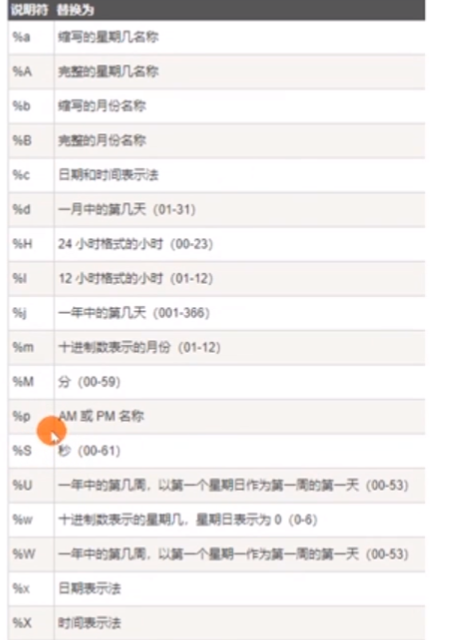
-G 就是每隔几秒输出一个文件,需要用时间表示法。
输出时间格式:

分析信息详情:

大概就是这样,需要具体的可以具体去分析了。
结
后面就一起看看tcp 协议吧,有时间再扩展到http协议去了。

