
计算机网络再次整理————tcp周边[八]
前言
tcp的包的格式可以看我以前的计算机网络整理,下面这些周边只是为了开发时候我们能用到一些理论知识。
正文
首先要介绍的就是域名,为啥有域名这东西呢?单纯站在网络的角度上讲这属于应用层的东西了。
如果站在万物互联的角度上讲,把互联网看做是一台大型电脑的话,那么域名就相当于句柄了。
句柄这东西解释一下,句柄(Handle)是一个是用来标识对象或者项目的标识符,可以用来描述窗体、文件等,值得注意的是句柄不能是常量。
Windows之所以要设立句柄,根本上源于内存管理机制的问题,即虚拟地址。简而言之数据的地址需要变动,变动以后就需要有人来记录、管理变动,因此系统用句柄来记载数据地址的变更。在程序设计中,句柄是一种特殊的智能指针,当一个应用程序要引用其他系统(如数据库、操作系统)所管理的内存块或对象时,就要使用句柄
比如我们要访问某个服务,但是服务器的ip地址是可以变动的,那么如果是这样的话,那么就有一个问题,那就是这个ip要一直属于你,但是这是不可能的。
那么就有了域名这东西,ip再怎么变化,同一个域名代表着某种服务,域名不变服务就不变了。
那么我们知道源计算机到目标计算机的是通过ip协议的,也就是说传输跟域名是无关的,那么域名如何应对变化的ip呢?
那么就有人想出了DNS这东西,Domain name system(域名系统),它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。DNS使用UDP端口53。当前,对于每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符。
大概是这么一个东西,使用的是udp,那么我们浏览器访问域名,实际上内部会帮助我们将域名转换为ip然后发送出去,那么域名标志就在我们应用层才知道是啥,比如说http将域名放在header 里面的host位置上。
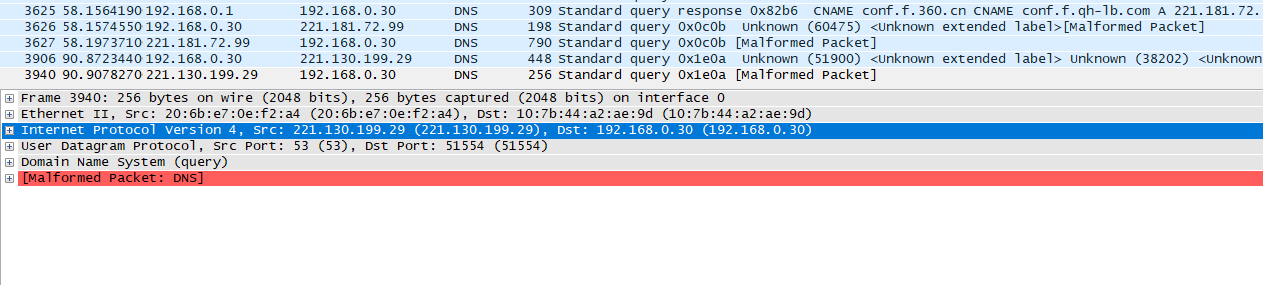
上面是dns抓包。这里可以看到我配置了DNS 服务配置是192.168.0.1,也就是我的网关。
那么如果192.168.0.1 如果无法解析出域名,那么就会传到下一级DNS服务器了。
static void Main(string[] args)
{
var addresses = Dns.GetHostEntry("www.baidu.com").AddressList;
foreach (var item in addresses)
{
Console.WriteLine($"ip地址:{item.ToString()}");
}
Console.ReadLine();
}
我们代码中获取也是相当简单。
然后这里可以看到,我们一个域名会返回AddressList,也就是多个地址。
这个是一个常规现象,怎么说呢,可能多个ip配置一个域名,可以做到负载均衡的作用。
那么多个ip配置一个域名,那么访问域名访问的是哪个ip呢?
在域名解析过程中,通过层层解析,必将域名对应到 IP(逐级授权、中间 CNAME 层层转发,此处按下不表)对于对应到的IP,可能1个,也可能13个(不建议超过13个),DNS 会一股脑将这(些)个 IP 给解析客户端(如浏览器、操作系统的解析服务)最终的应用或系统解析服务,从中随机挑选一个(如果是定制的应用,还可以通过后续的应用层访问对获取到的 IP 做 HA 或权重)
也就是说你用哪个ip是应用程序自己决定的,当然有些库是帮你轮询了,也有些库只选用第一个,但这不是DNS帮你干的事情,DNS 只会返回你在服务商配置的信息。
一些大型网站或CDN服务商为了实现负载均衡,他们的DNS服务器会动态改变多个IP地址的顺序,使得每个IP地址都有机会成为解析结果中的第一个IP地址。
既然域名能解析成ip,那么ip是否能反向解析为域名呢?也是可以的。
https://baike.baidu.com/item/域名反向解析/9327917
平时也没过反向解析这东西,上面也是写道是邮件识别安全问题,不做过多的评论,总之是可以的。
那么对于我们的应用来说,现在ip修改的问题解决了,那么是否直接一个socket,然后通信编写我们自己的应用协议就行呢?
因为我们的应用各不相同,那么就有不同的场景,也就有了不同的需求,那么可以通过对socket的配置来满足我们的需求。
static void Main(string[] args)
{
var socket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
socket.SetSocketOption(SocketOptionLevel.Tcp, SocketOptionName.ReceiveBuffer, 4098*2);
}
比如tcp是流,我们可以设置输入缓冲区的大小,当然也可以设置输出缓冲区的大小了。
但是值得注意的是,这个设置操作系统可能并不会100%执行,比如说我设置了两倍,那么操作系统不一定按照两倍,可能是1点多倍,这个操作系统有自己的算法的。
那么是否配置是否只影响性能呢?答案其实不是的,还可能短时间无法重启问题。
这就是著名的 time-wait 问题。
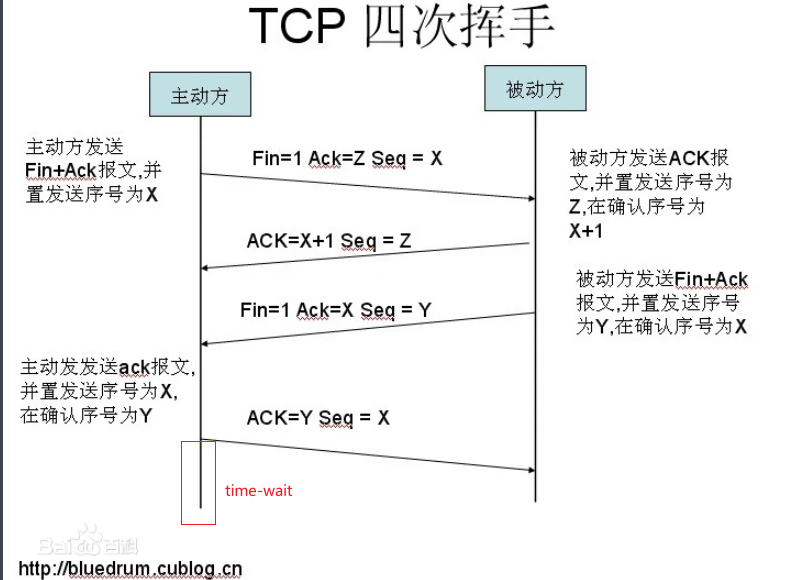
这上面标红的部分就是time-wait。
为啥有time-wait呢? time-wait 一定是在首先发送断开的一方。
下面把首先发送端口的比作是A,后面断开的比作是B。
为什么有time-wait呢? 因为A断开的一方没有time-wait,也就是说发送最后的ack这个socket销毁了,那么可能发送的ack没有到达B(丢失)。B就不知道A收到了FIN信号,那么B就会进行重试,但是A的socket消失了,然后B永远收不到Ack,无法正常关闭。
那么这个time-wait有什么问题呢? 比如我们的服务应用宕机了,如果socket 在time-wait 那么我们指定socket bind 某个指定的端口了,那么如果该socket处于time-wait状态,那么服务重启就会报告被端口占用情况。
那么有没有办法解决呢?

这个是允许绑定time-wait socket使用的端口。
Q:编写 TCP/SOCK_STREAM 服务程序时,SO_REUSEADDR到底什么意思?
A:这个套接字选项通知内核,如果端口忙,但TCP状态位于 TIME_WAIT ,可以重用端口。如果端口忙,而TCP状态位于其他状态,重用端口时依旧得到一个错误信息,指明"地址已经使用中"。如果你的服务程序停止后想立即重启,而新套接字依旧使用同一端口,此时SO_REUSEADDR 选项非常有用。必须意识到,此时任何非期望数据到达,都可能导致服务程序反应混乱,不过这只是一种可能,事实上很不可能。
前面几篇文章中提及到nagle这个词,nagle 是一个算法,主要是优化小数据网络流量问题。
nagle 是在什么条件下诞生的呢? 我们指定tcp 是建立在ip协议的基础上,ip协议和tcp协议都是占用字节的,如果你传输一个字节就要给你发送一次的话,也就是说协议的大小要大于数据的大小,那么可以想象流量多么浪费。
那么nagle 就是这样的,比如要发送nagle,n、a、g、l,这个一个字节一个字节发送的话,那么首先n传入到缓存中去,然后发送,这个时候等n传输的ack回来后,那么此时缓存中可能就有了agl,那么就会把agl全部发送出去。
也就是说要等上一个消息的ack确定对方收到后,才开始发送下一条消息。如果设置socket 为TCP_NODELAY为true,那么不会等上一个ack收到就会发送新的数据。
那么nagle 算法是不是百分百适用呢? 答案肯定是否定的,没有任何一种算法是100%的。
如果我们在传输大文件的时候,很快就会填充掉io的缓存,如果使用nagle 算法,那么要等待ack回来后才能发送,就有点影响效率了。
Nagle算法的规则(可参考tcp_output.c文件里tcp_nagle_check函数注释):
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
那么可能就有人问了,那么tcp 都没有ack确认后再进行发送,那么对方收到的包的顺序不就是乱的啊,怎么能保证数据流顺序正常呢?
这个问题的其实吧,tcp 的包里面的数据是有编号的,并不是说发送方发完消息,然后发送方收到了接收方收到了消息(ack),然后保证数据顺序的。
那这就太局限了,其实tcp保证顺序是有编号的,这就要从tcp格式说起了,以前整理的也有,后面再次整理的时候会补充。
socket的配置还有很多,比如TCP_CORK啊,可以百度看看。
结
上面就是为了说明一下tcp是一个非常复杂的协议, 我们在做应用的时候需要了解一些配置,或许有利于性能以及稳定性。下一节,多进程的tcp服务。

