
整理k8s————k8s prod相关[三]
前言
简单整理k8s prod。
正文
prod 有两种:
-
自主式prod
-
控制器管理的prod
在Kubernetes中,最小的管理元素不是一个个独立的容器,而是Pod,Pod是最小的,管理,创建,计划的最小单元.
一个Pod(就像一群鲸鱼,或者一个豌豆夹)相当于一个共享context的配置组,在同一个context下,应用可能还会有独立的cgroup隔离机制,一个Pod是一个容器环境下的“逻辑主机”,它可能包含一个或者多个紧密相连的应用,这些应用可能是在同一个物理主机或虚拟机上。
Pod 的context可以理解成多个linux命名空间的联合:
-
PID 命名空间(同一个Pod中应用可以看到其它进程)
-
网络 命名空间(同一个Pod的中的应用对相同的IP地址和端口有权限)
-
IPC 命名空间(同一个Pod中的应用可以通过VPC或者POSIX进行通信)
-
UTS 命名空间(同一个Pod中的应用共享一个主机名称)
分别来理解这几点。
pid 命名空间和IPC 命名空间,就是说在prod 中运行的多个容器,他们之间可以看到各自的进程,同样可以互相通信。
网络 命名空间,比如说有一个php fprm 和 nginx,他们的端口一定不能相同,因为他们共享一个网络栈。
UTS 命名空间,也可以说他们可以通过localhost 访问各自对象。
然后rc,也就是replication controller 是控制副本数的,也就是说prod与rc 息息相关。
那么需要看一下rc。
Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个。
和直接创建的pod不同的是,Replication Controller会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护阿,更新啊,Replication Controller都不关心)。
基于这个理由,我们建议即使是只创建一个pod,我们也要使用Replication Controller。Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
注:
正如我们在pod的生命周期中讨论的,Replication Controller只会对那些RestartPolicy = Always的Pod的生效,(RestartPolicy的默认值就是Always),Replication Controller 不会去管理那些有不同启动策略pod
上面这个注表示了自主式prod是不受rc管理的。
Replication Controller永远不会自己关闭,但是,我们并不希望Replication Controller成为一个长久存在的服务。
服务可能会有多个Pod组成,这些Pod又被多个Replication Controller控制着,我们希望Replication Controller 会在服务的生命周期中被删除和新建(例如在这些pod中发布一个更新),对于服务和用户来说,Replication Controller是通过一种无形的方式来维持着服务的状态.
然后很多时候我们会听说一个rs这个概念,rs 就是replicaSet,这两者作用没有本质的区别,但是replicaset 支持集合式的selector。
ReplicaSet是下一代复本控制器。ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持。
Replication Controller只支持基于等式的selector(env=dev或environment!=qa),但ReplicaSet还支持新的,基于集合的selector(version in (v1.0, v2.0)或env notin (dev, qa))。在试用时官方推荐ReplicaSet。
虽然ReplicaSets可以独立使用,但是今天它主要被 Deployments 作为协调pod创建,删除和更新的机制。当您使用Deployments时,您不必担心管理他们创建的ReplicaSets。Deployments拥有并管理其ReplicaSets。
大多数kubectl支持Replication Controller的命令也支持ReplicaSets。rolling-update命令有一个例外 。如果您想要滚动更新功能,请考虑使用Deployments。此外, rolling-update命令是必须的,而Deployments是声明式的,因此我们建议通过rollout命令使用Deployments。
ReplicaSet可确保指定数量的pod“replicas”在任何设定的时间运行。然而,Deployments是一个更高层次的概念,它管理ReplicaSets,并提供对pod的声明性更新以及许多其他的功能。因此,我们建议您使用Deployments而不是直接使用ReplicaSets,除非您需要自定义更新编排或根本不需要更新。
这实际上意味着您可能永远不需要操作ReplicaSet对象:直接使用Deployments并在规范部分定义应用程序。
简单介绍一下这个滚动更新。
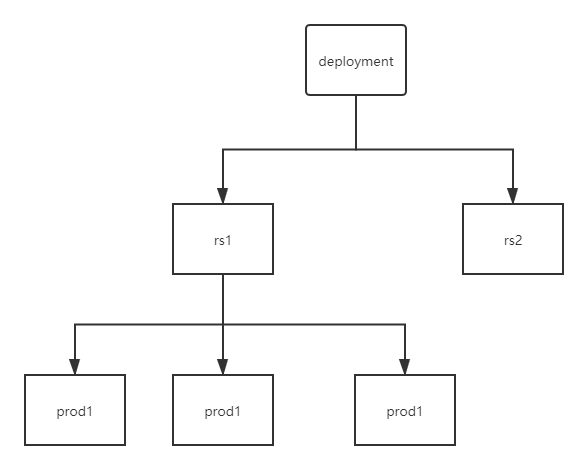
加入一开始有一个deployment,然后有一个rc1,下面有3个prod。
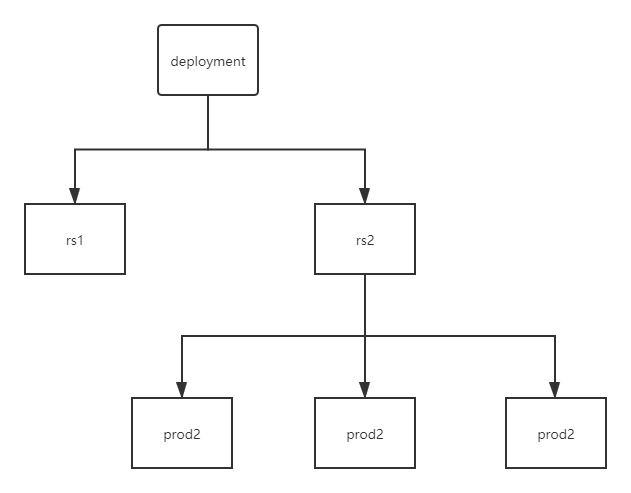
当我们要替换prod的时候,首先创建另外一个rc2,然后当rc2创建一个新的prod,那么旧的prod就会删除一个。
当替换完毕后,rs1就会停用,当回滚的时候,rs1就又会启动。
然后这种我们指定扩容的方式,还有一种自动扩容的方式,但是这种基本不用,为啥这样说我们一般使用云k8s,那么其实买prod是要钱的,了解一下吧。
horizontal prod autoscaling:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
StatefulSet:
StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用场景包括:
-
稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
-
稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
-
有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
-
有序收缩,有序删除(即从N-1到0)
从上面的应用场景可以发现,StatefulSet由以下几个部分组成:
-
用于定义网络标志(DNS domain)的Headless Service
-
用于创建PersistentVolumes的volumeClaimTemplates
-
定义具体应用的StatefulSet
StatefulSet中每个Pod的DNS格式为statefulSetName-{0..N-1}.serviceName.namespace.svc.cluster.local,其中
-
serviceName为Headless Service的名字
-
0..N-1为Pod所在的序号,从0开始到N-1
-
statefulSetName为StatefulSet的名字
-
namespace为服务所在的namespace,Headless Servic和StatefulSet必须在相同的namespace
-
.cluster.local为Cluster Domain
DaemonSet:
DaemonSet保证在每个Node上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。典型的应用包括:
日志收集,比如fluentd,logstash等
系统监控,比如Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond等
系统程序,比如kube-proxy, kube-dns, glusterd, ceph等
job:
Job负责批量处理短暂的一次性任务 (short lived one-off tasks),即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
Kubernetes支持以下几种Job:
非并行Job:通常创建一个Pod直至其成功结束
固定结束次数的Job:设置.spec.completions,创建多个Pod,直到.spec.completions个Pod成功结束
带有工作队列的并行Job:设置.spec.Parallelism但不设置.spec.completions,当所有Pod结束并且至少一个成功时,Job就认为是成功
根据.spec.completions和.spec.Parallelism的设置,可以将Job划分为以下几种pattern:

CronJob即定时任务,就类似于Linux系统的crontab,在指定的时间周期运行指定的任务。在Kubernetes 1.5,使用CronJob需要开启batch/v2alpha1 API,即–runtime-config=batch/v2alpha1。
Services:
Kubernetes Pod是平凡的,它门会被创建,也会死掉(生老病死),并且他们是不可复活的。
ReplicationControllers动态的创建和销毁Pods(比如规模扩大或者缩小,或者执行动态更新)。
每个pod都由自己的ip,这些IP也随着时间的变化也不能持续依赖。这样就引发了一个问题:如果一些Pods(让我们叫它作后台,后端)提供了一些功能供其它的Pod使用(让我们叫作前台),在kubernete集群中是如何实现让这些前台能够持续的追踪到这些后台的?
Kubernete Service 是一个定义了一组Pod的策略的抽象,我们也有时候叫做宏观服务。这些被服务标记的Pod都是(一般)通过label Selector决定的(下面我们会讲到我们为什么需要一个没有label selector的服务)
举个例子,我们假设后台是一个图形处理的后台,并且由3个副本。这些副本是可以相互替代的,并且前台并需要关心使用的哪一个后台Pod,当这个承载前台请求的pod发生变化时,前台并不需要直到这些变化,或者追踪后台的这些副本,服务是这些去耦
对于Kubernete原生的应用,Kubernete提供了一个简单的Endpoints API,这个Endpoints api的作用就是当一个服务中的pod发生变化时,Endpoints API随之变化,对于哪些不是原生的程序,Kubernetes提供了一个基于虚拟IP的网桥的服务,这个服务会将请求转发到对应的后台pod

因为prod1 要调用prod2,所以呢,有这样一个东西。
因为每次创建prod1的时候可能ip都不一样,还有一个就是prod2要指定那个prod1是不现实的,那么就有了服务发现这回事,服务发现是通过标签发现的。
结
下一节网络通讯方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号