redis 简单整理——HyperLogLog[十三]
前言
简单介绍一下HyperLogLog.
正文
HyperLogLog并不是一种新的数据结构(实际类型为字符串类型),而 是一种基数算法,通过HyperLogLog可以利用极小的内存空间完成独立总数 的统计,数据集可以是IP、Email、ID等。HyperLogLog提供了3个命令: pfadd、pfcount、pfmerge。
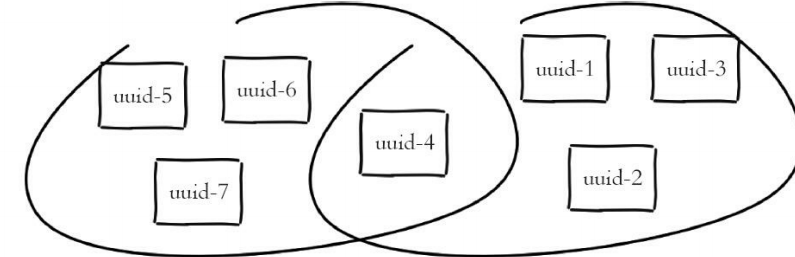
例如2016-03-06的访问用户是uuid-1、uuid-2、 uuid-3、uuid-4,2016-03-05的访问用户是uuid-4、uuid-5、uuid-6、uuid-7。
HyperLogLog的算法是由Philippe Flajolet(https://en.wikipedia.org/wiki/Philippe_Flajolet)在The analysis of a near-optimal cardinality estimation algorithm这篇论文中提出,读者如果有兴趣 可以自行阅读。
- 添加
pfadd key element [element …]

2.计算独立用户数
pfcount用于计算一个或多个HyperLogLog的独立总数

当前这个例子内存节省的效果还不是很明显,下面使用脚本向 HyperLogLog插入100万个id.
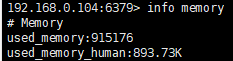
先记录当前redis 使用的内存。
然后执行100w个HyperLogLog.
for i in `seq 1 1000000`
do
elements="${elements} uuid-"${i}
if [[ $((i%1000)) == 0 ]];
then
redis-cli pfadd ${key} ${elements}
elements=""
fi
done
这样执行100w次,这里就不演示了,因为太久。 然后内存上升大概就是15k作用。
可以看到,HyperLogLog内存占用量小得惊人,但是用如此小空间来估 算如此巨大的数据,必然不是100%的正确,其中一定存在误差率。Redis官 方给出的数字是0.81%的失误率。
3.合并
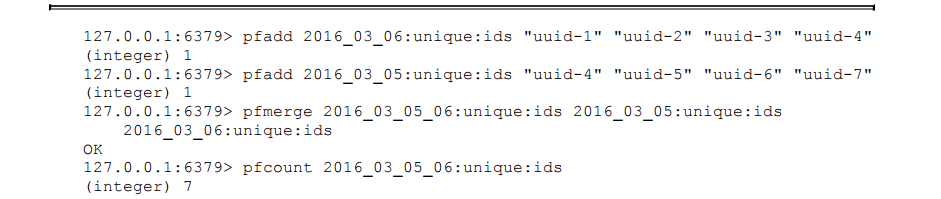
pfmerge可以求出多个HyperLogLog的并集并赋值给destkey,例如要计算 2016年3月5日和3月6日的访问独立用户数,可以按照如下方式来执行,可以 看到最终独立用户数是7:
HyperLogLog内存占用量非常小,但是存在错误率,开发者在进行数据结构选型时只需要确认如下两条即可:
·只为了计算独立总数,不需要获取单条数据。
·可以容忍一定误差率,毕竟HyperLogLog在内存的占用量上有很大的优势
结
下一节发布订阅,介绍一下,有些环境下还是可以使用的,大型环境不建议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号