redis 一百二十篇(历史发展)之第二篇
正文
简介:
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
redis 是nosql的一种,那么看下,有哪几种nosql吧。
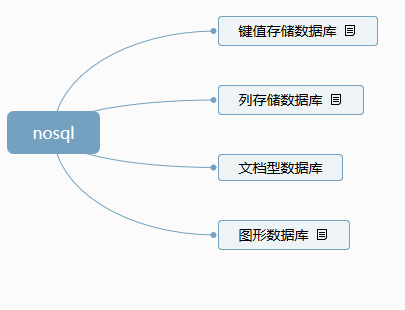
他们的对比在:https://database.51cto.com/art/201809/583344.htm
大体有上面4种,从上面上看应该属于第一种。
那么什么时候应该用nosql:
-
数据模型简单
-
需要灵活更强的it系统
-
对数据库性能要求较高
-
不需要高度的数据一致
-
对于给定的key,比较容易映射复杂值的环境
其实在数据库开始的时候其实都是nosql,进入到关系型数据库其实是划时代的一个过程,那么是否是历史倒退了呢?
看下这一段历史:
首先没有数据库,没有数据库意味着每次都要手动输入。
后来人们通过写入到文档中,作为保存,但是文档到处乱丢,痛苦不堪,人们都是通过人力管理。
后来出现了文档管理器,文档管理器就是用来管理文档的,这时候开始欢呼了。
但是其实不管是不是文档,人们处理的数据,因为文档具有封闭性,也就隔离了数据,那么数据之间的关系就相当迷茫。隔离数据需要划重点,以前我们将数据与数据的关系紧密连接,现在我们需要隔离。
因为数据的隔离,人们就创建了关系型管理文档的程序,其实就是一些特殊的格式的文件可以代表文档与文档之间的关系。
在当时,关系型数据库是划时代的,为什么关系型数据库解决人类的痛点呢?其实也很好解释,相当于国家制定了一部法典,有了法典国家就能文档。
那么看下关系型数据库开发的年代吧。
第一代:
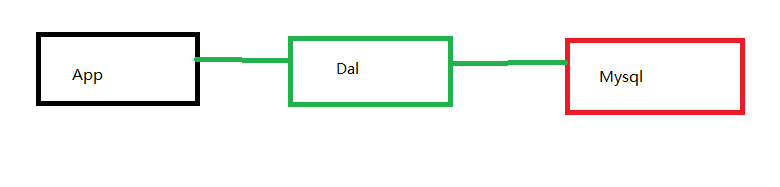
这种在学校的时候没少写,通过连接数据库和数据库通信,交换数据即可。
这种东西相当于单线的,在高并发访问下问题也很明显:
1.数据会越来越多,每次备份的时候呢,会出现很多问题,具体问题可参考让10G左右的数据库备份一下,或者启动运行一下。
简单的说就会形成一个庞然大物,无论是管理数据还是索引,都会出现很多问题。
2.会出现读写混乱,一个数据库一直边都边写,其实是很容易出现性能下降问题的。
第二代:
这个时候出现缓存,一开始通过文件缓存而不是说使用单纯的cache,因为还是要持久化的,会保存成各个不同的缓存文件,然后宕机后再读取,可以想象到启动速度,关键是可能还会丢数据。
这个时候其实就已经出现了集群和分布式,那么新贵族缓存矛盾也被激化。
这时候缓存就独立出来了。
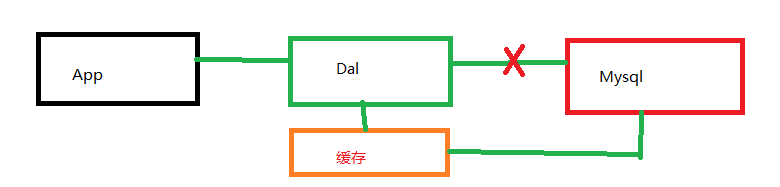
Memcached是其中一个典型代表。
Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务。
在这里体现出的是隔离,因为采用分布式把一个app才分出到多个web服务器上,而他们的缓存是隔离的,同时也是共享的。
第三代:
在这里其实通过缓存解决了缓解mysql的读写问题,但是只是缓解,每一个mysql都存在着读写同时进行的问题。
那么这个时候就需要读写分离,也就是我们经常提到的Master-Slave模式。
人们在创造读写分离后,发现读没有啥问题,因为可以几个一起读一条数据,但是写只能一个一个来,其实软件是实现共同编辑的,但是感觉到现在也不是很理想。
那么争对写,出现了分库分表,水平拆分,集群等等等一些列东西,就是为了解决写的压力,很多数据库群、CAP等名称就是在这个时代诞生的。
总结
下一文为cap等一些术语的介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号