正则表达选择分组向后引用及捕获和非捕获分组(五)(1000则)
前言
直接用例子作为演示。
四没有,因为我看了一下,第四节当时理解错了,还在改。
正文
选择操作
部分区分大小写
我们在做匹配的时候希望,不区分大小写。
当然我们在python使用库中,可以选择显示不区分大小写。
但是python库在我们写入中,有个有一个需求一部分是不区分大小写的。
比如说我们希望the 中,t区分大小写,而he不区分大小写,怎么写呢?
我们用(?i)表示不区分大小写,那么我们可以这样写:t(?i)he,这样就可以了。
其他选择操作
在此说明一下,其实每一种语言的正则都有一定的区别。
我这里介绍几种通用的选择操作:
(?m) 表示多行匹配,如果不清楚请看我的第三章。
(?s) 单行匹配
(?x) 忽略注释
还有很多,在此提一下,然后呢,每一种语言都存在差异,最好是使用同类型的库。
子模式
什么是子模式?
指的是分组中的一个或多个分组,子模式就是模式中的模式。
可能这样理解有点难理解,举个栗子:
THE RIME OF THE ANCYENT MARINERE
我要匹配这样一段话,怎么匹配呢?
正则我这样写肯定可以匹配的。
THE RIME OF THE ANCYENT MARINERE
那么我现在这样写:
(THE) (RIME) (OF) (THE) (ANCYENT) (MARINERE)
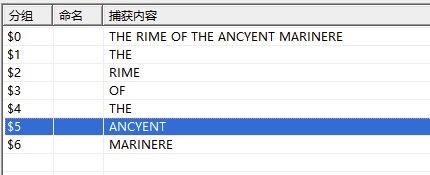
它不仅把我们要匹配的匹配出来了,而且每个括号中的进行了分组,这就是子模式。
捕获和向后引用
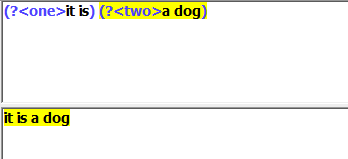
it is a dog
正则
(it is) (a dog)
这个时候就将他们分组了。
$2 $1 的结果是 a dog it is.
除了这个我们还可以这样 \U$1 $2 得到的结果是 A DOG it is
\U 是将匹配项转换为大写。
那么还有其他的:\u 是首字母大写,\l 首字母小写 \L 全部小写
这些java或其他高级语言本身不支持,你需要使用一些库,但这些属于正则规范。
命名分组
得到的结果是:
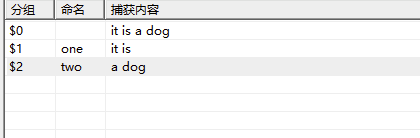
也就是说我们可以进行命名分组,如何引用分组:
$+{one}
通过$+{xx}的方式。
每一种命名分组在不同语言中是不同的,python中是(?p
非捕获分组
非捕获分组是相对捕获分组而言的。
因为捕获分组会将分组信息保存在内存中而非捕获不会,所以性能高。
我再网上找了一个例子:
var str = "a1***ab1cd2***c2";
var reg1 = /((ab)+\d+)((cd)+\d+)/i;
var reg2 = /((?:ab)+\d+)((?:cd)+\d+)/i;
alert(str.match(reg1));//ab1cd2,ab1,ab,cd2,cd
alert(str.match(reg2));//ab1cd2,ab1,cd2
(?:xx) 使用?:就是非捕获分组。
也就是说(?:xx) 是为了方便我们写正则更加清晰,有括号辅助。
c#例子来一个:
using System;
using System.Text.RegularExpressions;
public class Example
{
public static void Main()
{
string pattern = @"(?:\b(?:\w+)\W*)+\.";
string input = "This is a short sentence.";
Match match = Regex.Match(input, pattern);
Console.WriteLine("Match: {0}", match.Value);
for (int ctr = 1; ctr < match.Groups.Count; ctr++)
Console.WriteLine(" Group {0}: {1}", ctr, match.Groups[ctr].Value);
}
}
// The example displays the following output:
// Match: This is a short sentence.
原子分组
原子分组应该是关闭回溯。
很多人不理解回溯哈,在此特意解释一下:
通常,如果正则表达式包含一个可选或可替代匹配模式并且备选不成功的话,正则表达式引擎可以在多个方向上分支以将输入的字符串与某种模式进行匹配。
如果未找到使用第一个分支的匹配项,则正则表达式引擎可以备份或回溯到使用第一个匹配项的点并尝试使用第二个分支的匹配项。
此过程可继续进行,直到尝试所有分支。
我找到了一个例子:
using System;
using System.Text.RegularExpressions;
public class Example
{
public static void Main()
{
string[] inputs = { "cccd.", "aaad", "aaaa" };
string back = @"(\w)\1+.\b";
string noback = @"(?>(\w)\1+).\b";
foreach (string input in inputs)
{
Match match1 = Regex.Match(input, back);
Match match2 = Regex.Match(input, noback);
Console.WriteLine("{0}: ", input);
Console.Write(" Backtracking : ");
if (match1.Success)
Console.WriteLine(match1.Value);
else
Console.WriteLine("No match");
Console.Write(" Nonbacktracking: ");
if (match2.Success)
Console.WriteLine(match2.Value);
else
Console.WriteLine("No match");
}
}
}
// The example displays the following output:
// cccd.:
// Backtracking : cccd
// Nonbacktracking: cccd
// aaad:
// Backtracking : aaad
// Nonbacktracking: aaad
// aaaa:
// Backtracking : aaaa
// Nonbacktracking: No match
为什么最后一个aaaa,不会被匹配呢?
分析一下:
@"(?>(\w)\1+).\b"
(\w) 捕获分组,也就是说被捉住的是a。
那么\1+ 就是是说匹配0或者多个a,然后呢由于原子性,那么是贪婪的,他就会匹配aaaa,也就是匹配完了,那么你剩下一个.(任意字符),就不能匹配了。
总结
以上仅仅是个人理解,如有不对,望请指出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号