算法常识——基础的数据结构
前言
在数据结构中,人们常常把把结构分为物理结构和逻辑结构。
物理这个词,我们很容易想到材料。至于做门用木材还是铁块,怎么做,这就是逻辑了。
物理结构:顺序存储结构、链式存储结构。
逻辑结构:线性结构:顺序表、栈、队列。非线性结构:树,图。
物理结构
顺序存储结构
我们在学c++的时候接触到一个东西,名字就叫做指针。指针存放的是指向的地址。
同时我们知道存储数据需要申请空间的,如果我们申请一块328byte的空间,用来连续存储一些数据,这种称为顺序存储结构。
比如说数组就是典型的顺序存储结构,我们一般去查找一个数组的具体某个值得时候,是这样子的:arr[10],
为什么能够如此呢?我们在确定数组的时候,一定要确定类型,确定了内存就确定了分配的空间,比如上面的arr[10]:
假设arr 是int32数组,arr[10]就是arr[0]偏移3210。得到的就是arr[10];
实际上是每个int 对于一个地址,比如说第一个是10091,然后第二个就是10092,以此类推。
链式存储结构
和顺序不同的就是,比如说第一个地址是10091,然后下一个的地址可能是10092,也可能是10900。
这样有什么好处呢?拿数组举例,我们发现我们创建数组的时候,需要创建的一定要确定个数。
这是为啥呢?因为地址是连续的,所以说必须一次性申请好,比较我们买电影连坐的时候一般都是一次性买好,不然你怎么知道别人不要?
其中一个好处,就是可以按需申请空间,通用可以随时添加,也可以随时删除。
那么同样的拥有缺点,查询的时候无法通过索引查找。同样保存好下一个的地址,同样需要消耗空间。
在链式存储结构中,有单链表,同样也有双链表。双链表不仅保存着next,同样保存这pre,也就是前一个元素的地址。
逻辑结构
线性结构
线性结构,强调的是一维概念,单输入单输出,呈线性结构。
比如说栈,栈这种东西像什么,比如说排队,我们一个一个进入,但是出去的时候呢,我们从最后一个出来。
就是这么回事。
然后对应的就是队列了,什么是队列?从第一个进入,然后又从第一个出去,就是这么一个概念。
至于散列表,这个是基于hash的,相当于数组与散列表的结合。
每个对象计算出hashcode(hashcode 有多种计算的方法,也可以自己设计),这个hashcode是可能冲突的,在此是假设唯一。比如说hashmap,hashmap基于一个数组,如果hashcode 是唯一的,那么hashcode通过计算,假设是取余hashode%arraylength,得到数组的下标(注:这种算法有多种,只要计算数组不越界就行),但是肯定会冲突啊,那么根据索引找到的地方,实际上是一个链表结果,然后遍历链表找到。
如下图:
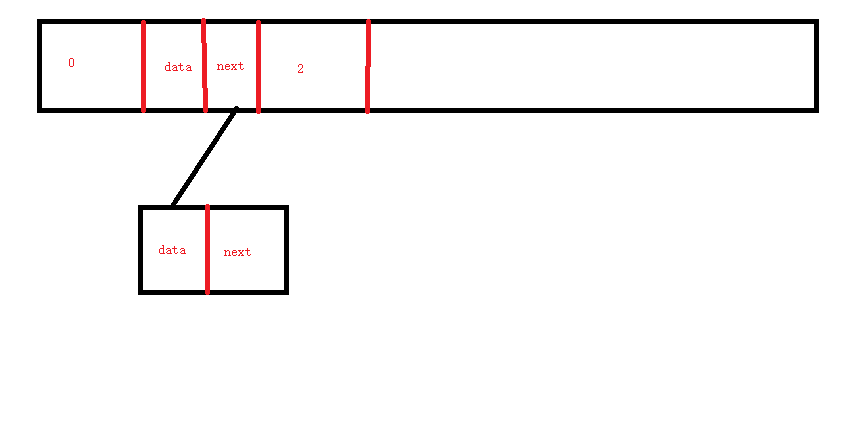
因为散列表基于数组,那么我们在进入hashmap push的时候,我们像是可以无限循环一样。
这个是如何做到的?
基于数组的扩容。
散列表扩容过程:
1.将数组扩容一倍。
2.然后重新hash计算。
这里面可以想象到扩容其实很消耗资源的,如果我们可以计算大体数量,可以初始化数量的时候设定为合适的参数。
当然如何设置不可理的话,默认扩大一倍,这压力也是很大的,建议自己继承改改,所谓的优化就是根据实际场合来优化,其他都是套路。
非线性结构
非线性结构典型的就是树与图,这些都是数据结构中常见的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号