[数字人] 从0开始的三维人脸重建入门 (一)
本篇非教程。
近些年来人脸三维重建的发展主要围绕数据表示来进行,从一开始的显式表示到探索线性参数化表示,到后来非线形参数化表示和神经场表示,表示能力越来越强。此外,还有些方法结合了参数化模型表示和GAN等生成模型,以优化参数化模型对细节的缺失。
从0开始的人脸重建,本篇包含从0基础到基于参数化模型的人脸重建、基于非线性参数化模型的人脸重建、基于可微分渲染的人脸重建、基于NERF的人脸重建等,前几篇仅包含基础和论文的记录,后面几篇着重于代码部分(虽然也有看,但都是看了个大致)。好的,那就从人脸重建入门到人脸重建入门吧。
从0开始的三维人脸重建入门 (一)
数学基础
需要先看完GAMES101和Scratchapixel,了解现代图形学的相关背景和基本的相机模型、渲染、光线追踪等。笔者在学习之前看论文碰壁较多,学习之后几乎无重大问题,所以建议先修下相关基础课程。
Scratchapixel
GAMES101
- 世界系方向(pytorch3d):
+Y up, +X left and +Z in - LookatTransform(属于视图变换):
给定一个相机在世界系中的位置和要看向的点在世界系中的位置,求得将世界系原点转向相机坐标系的变换。人脸系统中,往往人脸中心处于(0,0,0)位置,因此看向的点是(0,0,0),相机就摆在(0,0,e)处,这里相当于规定了相机系的z轴指向,但另两个轴无法确定,因此还需要一个up向量描述相机的y轴,之后z轴向量和y轴向量叉积得到最后一个轴的向量表示,因此最终问题就变成了把三个原来世界系的基向量变成新的坐标系的基向量的坐标变换矩阵,由于原坐标系是单位矩阵,因此左边变换矩阵就是变换后的基向量组成的矩阵:
void lookat(const float3& from, const float3& to, const float3& up, mat4& m)
{
// forward方向是z轴负向,因此是-(to - from)
float3 forward = from - to;
normalize(forward);
float3 right = cross(up, forward);
normalize(right);
float3 newup = cross(forward, right);
// 右手系
m[0][0] = right.x, m[0][1] = right.y, m[0][2] = right.z;
m[1][0] = newup.x, m[1][1] = newup.y, m[1][2] = newup.z;
m[2][0] = forward.x, m[2][1] = forward.y, m[2][2] = forward.z;
m[3][0] = from.x, m[3][1] = from.y, m[3][2] = from.z;
}
3DMM
建模:
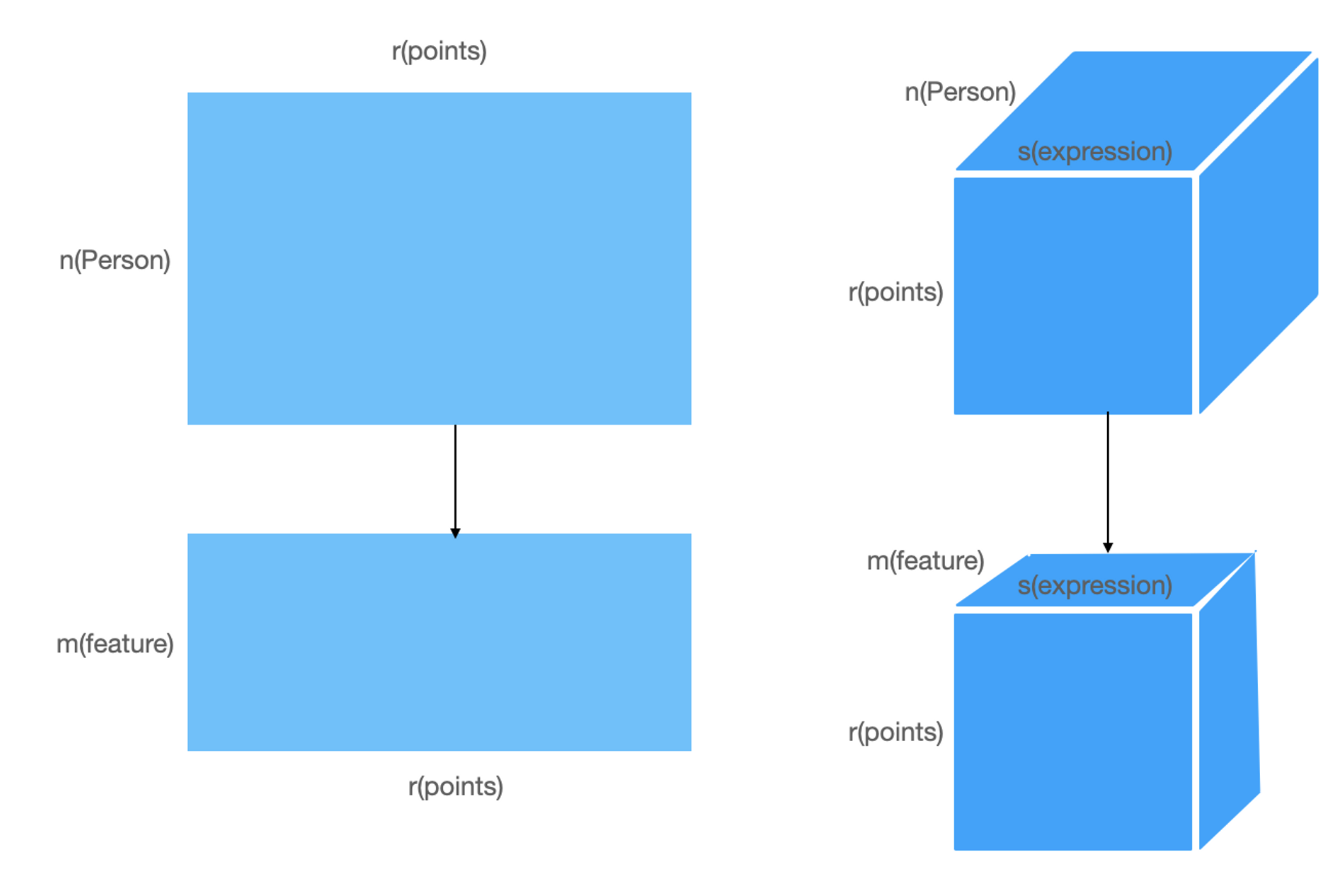
对于原始人脸数据,可以表示为\(s=(n,m*3)^T,t=(n,m*3)^T\),其中n表示人脸数,m表示顶点数,3是坐标或者是rgb颜色,因此可以对s和t分别做PCA,找到若干个方向作为基,基矩阵为\(M\),然后把数据投影上去,变为\((u,m*3)^T\),需要注意的是,这里实际上是对人脸样本那个维度进行了降维,可以理解为所有样本点都具有某些特征来描述某个特定的人,而事实上200个不同的人就可能包含所有能够描述其他所有人的特征,因此对样本维度进行降维,若干个基的线性组合就是一个特定的人。也就是说,BFM的PCA过程是对人的分布的建模,将人与人之间那些无法直接描述的特征变成了可以由统计分布来描述的特征,所以是对人这一维度降维。其基本思想是人与人之间是线性相关的,因此可以通过某些人来线性组合生成其他人,正因为线性相关,所以也许并不需要世界上所有的人来做线性组合来描述一个特定的人,而是只需要一部分的人的线性组合来描述,继而在这里进行降维。
建模的时候,形状得到M个基,纹理得到M个基,分别确定这些基的系数就能描述一个特定的人。
此外,一些方法除了对形状和纹理进行建模,还对表情、光照进行建模。
对于表情而言,其实是对形状的细分,那么前面BFM的shape可以认为是identity shape,训练数据是不同的人,如果这些人每个人都搜集到了不同的表情,则可以加一些表情维度进去,即最终的人脸可以由identity和表情代表的维度一起决定:
认为表情是identity shape的bias,可以通过在identity shape上加上系数得到。
拟合:
初始化一个基本参数,由粗到细,非deep方式迭代直接拟合参数。
3DDFA (Face Alignment Across Large Poses: A 3D Solution)

3d点到图像上2d点对应:\(V(\mathbf{p})=f * \operatorname{Pr} * \mathbf{R} *\left(\overline{\mathbf{S}}+\mathbf{A}_{i d} \boldsymbol{\alpha}_{i d}+\mathbf{A}_{e x p} \boldsymbol{\alpha}_{e x p}\right)+\mathbf{t}_{2 d}\)
模型需要预测的参数为\(\left[f, \text { pitch, yaw, roll }, \mathbf{t}_{2 d}, \boldsymbol{\alpha}_{i d}, \boldsymbol{\alpha}_{e x p}\right]^T\)
f、Pr如何提前获取?一般数据集里都应该有的,因为采集3d数据的时候肯定记录了3d和其对应的2d rgb图像的对应关系,f和Pr属于内参,只和相机有关。
对于任意人脸rgb图,希望从rgb图中预测3DMM模型的参数,其思路是通过比较求解的参数和重建的点来估计其损失。
损失这一块其实可以设计的比较多,因为有3d信息,所以可以给3d点的对应损失(VDC)、最佳参数和预测参数的损失(PDC)。
之所以没有重建渲染后的损失,是因为当时似乎还不太支持可微分渲染,不然理论上应该利用可微分渲染来提升效果。
对于PDC,由于不同参数对结果的影响程度不一样(大姿态往往比小细节更重要),所以一般对重要的参数权重给多一点,改良之后为WPDC,权重这里作者采用了结合VDC的方式,先用网络预测的参数计算VDC,然后VDC取均值normalize作为姿态参数的weight,实现动态调整权重,其结果导致先着重优化姿态,再细优化细节。级连式训练直至收敛。
后续做了关键点检测,由于3DDFA已经粗略的给出了3d关键点,投影到2d平面上时可以确定哪些关键点是被遮挡的,因此只去refine那些没有遮挡的关键点。
数据:用3DMM对2D图像构建了大量的3D模型,用于训练。因此可以认为其上限是3DMM,但是速度上比3DMM直接优化要快。
3DDFA-V1.5 (Face Alignment in Full Pose Range: A 3D Total Solution)
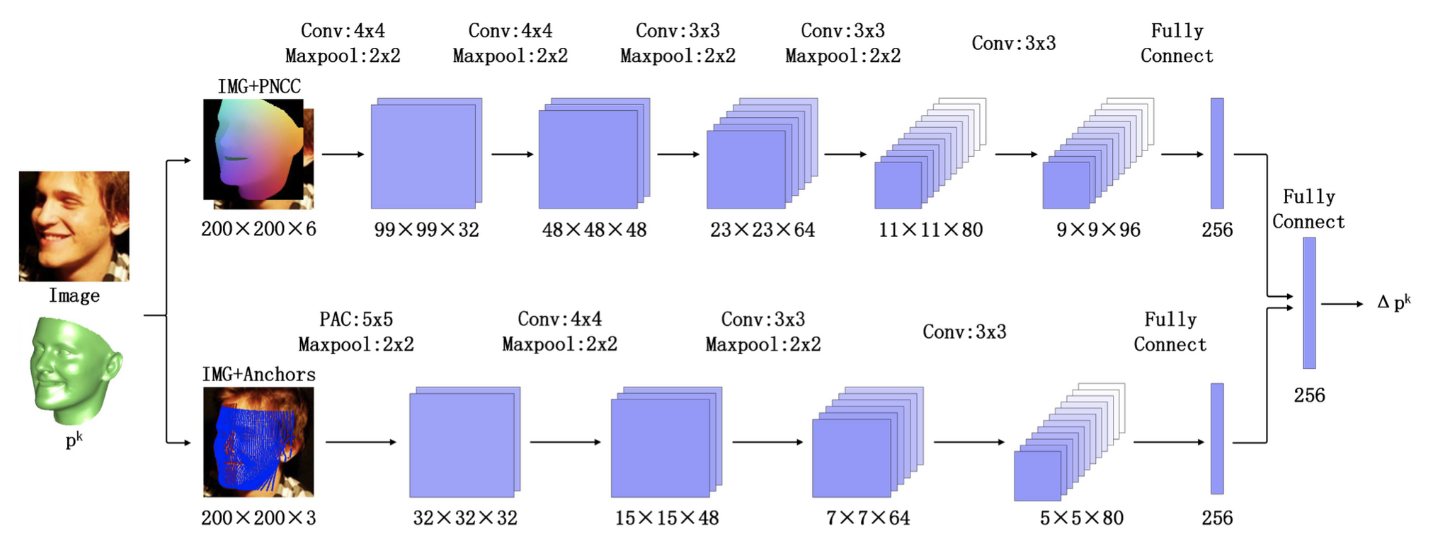
Improvements:
- Pose Adaptive Feature
输入加了PAF,在3D模型上定义64X64个anchor,投影到2D平面得到位置,sample这些位置的像素得到一组64d X64 d的feature作为输入,d为sample的时候窗口大小。之后第一个卷积层的kernel设置为d X d以防止卷到边缘位置可能对结果的影响。
- 不用欧拉角用四元数
\(\mathbf{p}=\left[q_0, q_1, q_2, q_3, \mathbf{t}_{2 d}, \boldsymbol{\alpha}_{i d}, \boldsymbol{\alpha}_{e x p}\right]^{\mathrm{T}}\)
欧拉角会导致万向锁。
万向节死锁应该可以这么理解:原本是有3个轴决定向量的方向,现在第2条轴固定为90度,那么理论上还可以沿着第1和第3这2条轴做旋转,有2个自由度。但经过第2次旋转以后,第3轴和第1条轴重合了,也就是变成只剩绕1条轴旋转的效果了,不就是失去了1个自由度。
- Optimized Weighted Parameter Distance Cost
OWPDC相对WPDC的改进在于权重,WPDC的权重是VDC,而OWPDC则是通过一个二次优化得到的:
即让要优化的loss最小的那个w,其实是想要同时考虑点对点损失和参数损失来共同决定权重,而不是只看点对点损失来决定权重,但是这个权重又不能直接说加权加个\(\lambda\)来引导,而通过这个二次优化,点对点损失如果很小,那最终参数损失的权重就会比较大,否则点对点损失的权重比较大。这一点其实有点否定了之前的想法,之前认为要先优化姿态,所以只去考虑点对点损失来生成权重,但是可能有些情况下先优化参数可能优化效果要更好,这个二次优化就提供了这种可能性。
从效果上看OWPDC 几乎没啥提升。估计是为了多找个创新点加的。。
3DDFA v2 (Towards Fast, Accurate and Stable 3D Dense Face Alignment)
主要是速度上的优化和损失函数的优化,研究意义不大。
Deep3DFaceRecon (Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set)
奠定了可微分渲染用于人脸重建的基石,前面3DDFA还是用PNCC来利用纹理,这里开始用渲染闭环。
无需3D信息,主要是利用可微分渲染来实现自监督。大体想法是回归BFM参数后重建人脸并渲染,利用渲染后的图像和原始rgb图做损失。

损失:
- 损失这块由于人脸往往有遮挡,所以需要mask掉,用一个预训练的模型做粗分割实现。
- 2d图像一般有landmark标注,也可做投影后的损失。
- 利用人脸识别网络的deep feature,将重建后的图片的feature和重建前的图的feature做cos loss。
C-Net预测\(\alpha\)的score,乘上去再优化。
可微渲染:https://github.com/sicxu/Deep3DFaceRecon_pytorch/blob/master/util/nvdiffrast.py
