[论文理解] 人脸识别论文总结(一)
Face Recognition Papers Review
Partial FC: Training 10 Million Identities on a Single Machine
arxiv: https://arxiv.org/pdf/2010.05222v2.pdf
主要两个贡献,一是把fc的权重存到不同卡上去,称为model parallel, 二是随机选择negative pair来近似softmax的分母(很常规的做法)。
Model Parallel:
FC分类分配到n台显卡上,每台显卡分C/n 类,每张卡存权重的一部分,计算局部每张卡上的exp和sumexp,然后交互计算softmax。
考虑梯度回传问题,这样做梯度也是parallel的,不同于数据parallel。数据parallel的话求梯度是需要用整个W才能求W的梯度的,而model paralle因为有了梯度公式,可知:
这一下明朗了,所以求权重\(W_i\)的梯度就有
不需要整个W就可以求部分W的梯度啦。
作者觉得尽管model parallel了,但softmax的分母部分还是大啊,于是借鉴常用的无监督方法,随机sample negative pairs,不需要全部的negative pair就可以估计出softmax的分母了。
An Efficient Training Approach for Very Large Scale Face Recognition
arxiv:https://arxiv.org/pdf/2105.10375v4.pdf
主要提出一种动态更新权重的池子方法,用单独一个特征网络来提取特征作为权重,而非直接学全连接的权重,然后动态更新这个池子,就不需要存储大量的权重了,加速了训练、。
方法其实很朴素。
前面那个方法是把权重存到不同的GPU上去,因此,如果ID越来越多,我们加卡就可以了,但本文的方法不需要,也是节约成本的一个方法。
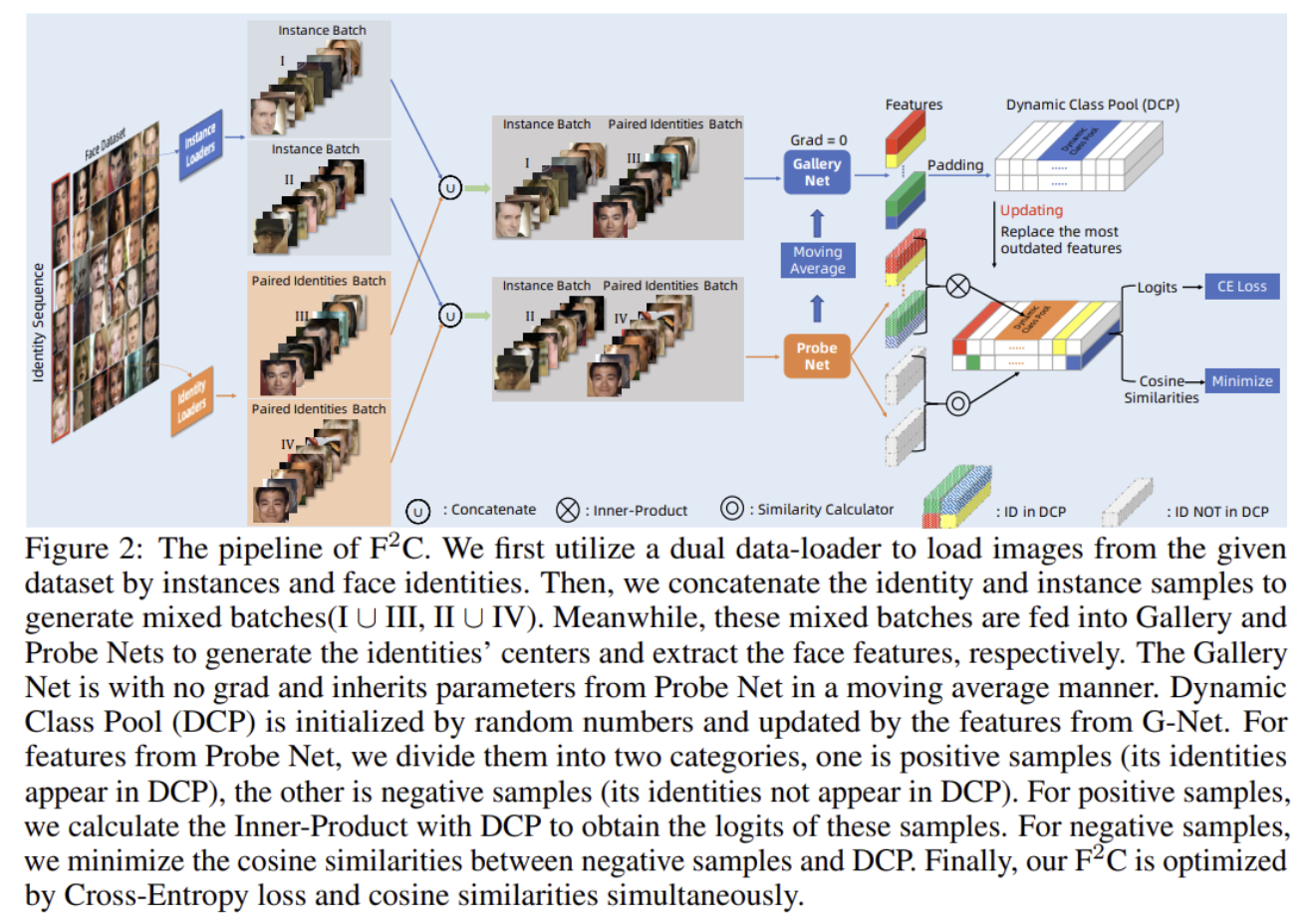
方法大致如下:
准备两个网络,P网络用来训练,G网络是P网络的moving avg,不训练,最开始随机初始化池子,记好当前batch的id,如果id在池子里,训练P网络用CE Loss,和cosine loss,如果不在用cosine loss,训练一轮后更新G网络。G网络更新最老的池子,更新池子id。以此类推。
MagFace: A Universal Representation for Face Recognition and Quality Assessment
主要思想:
利用特征的模长来表示样本的质量,模长越小表明质量越低,并且设计损失函数希望无监督得达到这一目的。
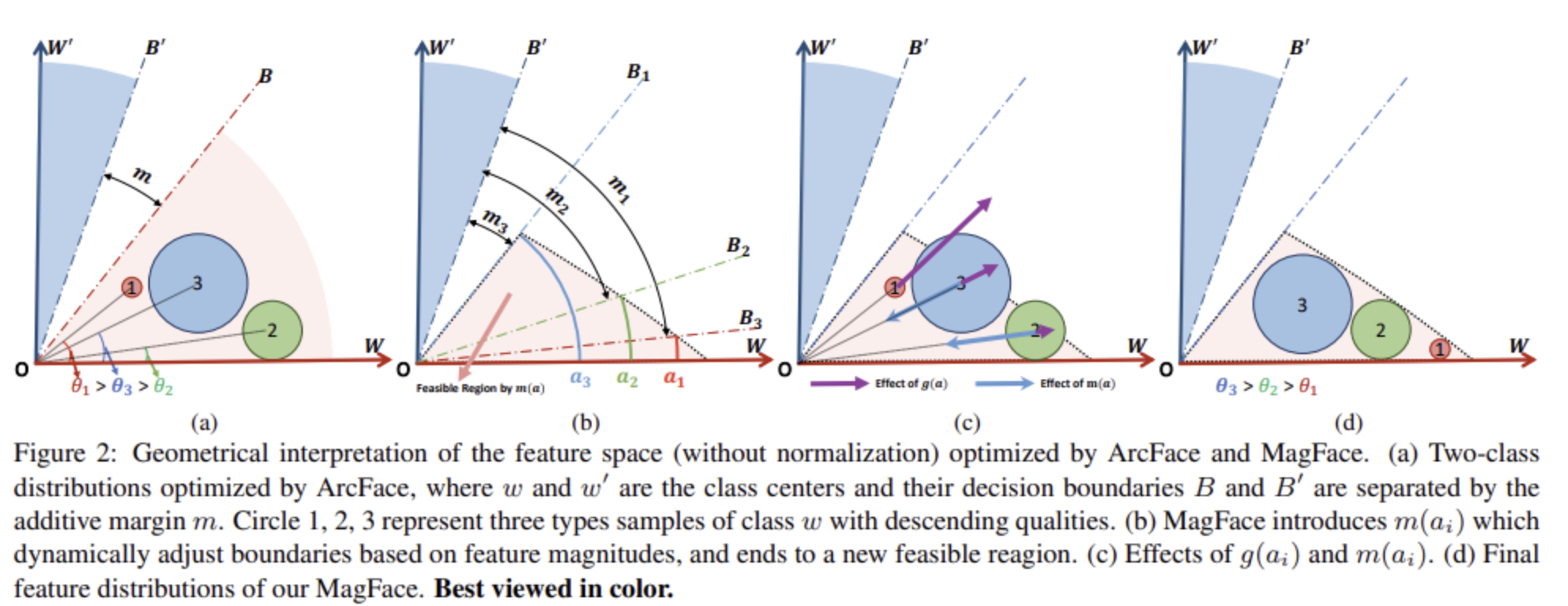
文章用一个图说明了传统arcface存在的问题以及如何解决这一问题,对于第一个图,作者认为传统arcface理应对不同样本设置不同的margin,对于质量高的样本,他的margin应该大,而对于质量低的样本,他的margin应该小,这是符合直觉的,高质量的样本应该具有更好的区分度,而低质量的样本由于其质量低可能局部不确定,因此用小的margin更加合理;文章提出用向量模长来表示其质量,认为模长越大其质量越高。图b则是根据不同模长动态设置margin,高质量样本大margin,低质量样本小margin,但这样也存在一个问题,即质量低的样本的可行域还是太大了,原文说是太free了,训练是比较难收敛的;为了解决这一问题,文章提出对模长(质量)进行鼓励,鼓励高质量样本的损失,即损失函数是模长的单调递增的函数;再说一下图c中m和g的影响,文章设计的m函数的作用如图b其实是希望动态margin的同时固定住可行域,也就是图b中的三角形的区域,对于图c中的图,低质量样本2和3都超出了可行域,因此受m函数的影响会往可行域里移动;g的设计是为了让所有的样本都尽可能贴近可行域的边界,因此当两个相反影响抵消时,其达到图d的分布。
m函数和g函数的设计:
m函数通过模长限制了可行域为如图所示的三角形区域,g函数是模长的双曲线函数。
Adversarial Occlusion-aware Face Detection
这篇文章提出利用对抗训练同时分割人脸遮挡区域和检测人脸;
怎么生成mask?
有三种方式:
- 根据关键点来在对应的feature上drop
- 随机drop左右上下脸的feature
- 随机drop一半的feature
何处对抗?
对于mask之后的feature,希望分类loss增大,没有mask的loss减小。
CurricularFace: Adaptive Curriculum Learning Loss for Deep Face Recognition
文章主要三点贡献
- 改进人脸识别的损失函数,利用课程学习帮助优化人脸识别
- 设计了一个指示函数来表明当前训练的进度
- 大量实验
主要目的是想要做到不同的训练stage给easy sample和hard sample不同的权重,希望在训练初期hard sample的权重要小一些,训练后期hard sample的权重要大一些。
因此就涉及两个问题,一个是训练stage的划分,如何指示训练的stage,另一个是easy sample和hard sample的区分,如何区分两者。
对于第一个问题,文章设计了一个指示函数:

由于发现了平均cos相似度可以一定程度反映训练stage,早期显然positive样本由于训练不充分所以大部分都是不相似的,训练后期positive样本训练稍微充分,则相似性增大,因此可以用positive样本的相似性近似表示训练stage;此外,使用ema的方式防止stage的估计不稳定。
对于第二个问题,文章提出下面方式区分困难样本和简单样本
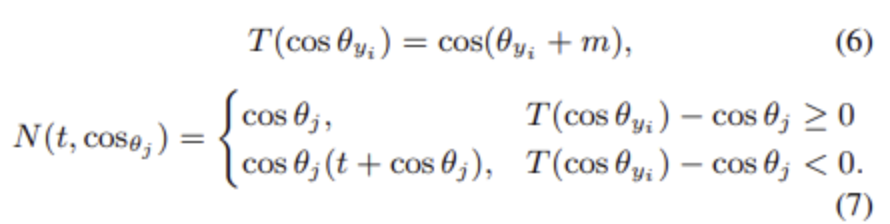
对于(7)的第一行为简单样本,第二行为困难样本,在训练初期,t接近与0,N接近与cos的平方,比较小,训练后期,t接近与1,显然N会增大。
VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing
提出分组卷积的改进版,一般的分组卷积都是组数是超参,训练时固定,根据输入的channels的不同为每个组分配不同的channel,而VarGNet则是认为每个组应该处理的channel是超参,事先需要定下来,而在训练中动态调整的则是组数,这样导致的结果是,输入的channel如果多,则组数多,输入的channel少,则组数少。
我们知道,模型计算量和组数成反相关,
所以在输入通道过大时多用组数要计算更划算。
具体的网络结构上没有指导,指导的是设计上的意义。
VarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight Face Recognition
主要贡献
- 提出用VarG卷积方式做backbone,并做了一些改进
- L2损失蒸馏
import torch
from torch import nn
from torchsummary import summary
from config import *
import math
import torch.nn.functional as F
from torch.nn import Parameter
'''
求Input的二范数,为其输入除以其模长
角度蒸馏Loss需要用到
'''
def l2_norm(input, axis=1):
norm = torch.norm(input, axis, keepdim=True) # 默认p=2
output = torch.div(input, norm)
return output
'''
变组卷积,S表示每个通道的channel数量
'''
def VarGConv(in_channels, out_channels, kernel_size, stride, S):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding=kernel_size//2, groups=in_channels//S, bias=False),
nn.BatchNorm2d(out_channels),
nn.PReLU()
)
'''
pointwise卷积,这里的kernelsize都是1,不过这里也要分组吗??
'''
def PointConv(in_channels, out_channels, stride, S, isPReLU):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, stride, padding=0, groups=in_channels//S, bias=False),
nn.BatchNorm2d(out_channels),
nn.PReLU() if isPReLU else nn.Sequential()
)
'''
SE block
'''
class SqueezeAndExcite(nn.Module):
def __init__(self, in_channels, out_channels, divide=4):
super(SqueezeAndExcite, self).__init__()
mid_channels = in_channels // divide
self.pool = nn.AdaptiveAvgPool2d(1)
self.SEblock = nn.Sequential(
nn.Linear(in_features=in_channels, out_features=mid_channels),
# nn.ReLU6(inplace=True),
nn.ReLU6(inplace=False),
nn.Linear(in_features=mid_channels, out_features=out_channels),
# nn.ReLU6(inplace=True), # 其实这里应该是sigmoid的
nn.ReLU6(inplace=False)
)
def forward(self, x):
b, c, h, w = x.size()
out = self.pool(x)
out = out.view(b, -1)
out = self.SEblock(out)
out = out.view(b, c, 1, 1)
return out * x
'''
normal block
'''
class NormalBlock(nn.Module):
def __init__(self, in_channels, kernel_size, stride=1, S=8):
super(NormalBlock, self).__init__()
out_channels = 2 * in_channels
self.vargconv1 = VarGConv(in_channels, out_channels, kernel_size, stride, S)
self.pointconv1 = PointConv(out_channels, in_channels, stride, S, isPReLU=True)
self.vargconv2 = VarGConv(in_channels, out_channels, kernel_size, stride, S)
self.pointconv2 = PointConv(out_channels, in_channels, stride, S, isPReLU=False)
self.se = SqueezeAndExcite(in_channels, in_channels)
self.prelu = nn.PReLU()
def forward(self, x):
out = x
x = self.pointconv1(self.vargconv1(x))
x = self.pointconv2(self.vargconv2(x))
x = self.se(x)
# out += x
out = out + x
return self.prelu(out)
'''
downsampling block
'''
class DownSampling(nn.Module):
def __init__(self, in_channels, kernel_size, stride=2, S=8):
super(DownSampling, self).__init__()
out_channels = 2 * in_channels
self.branch1 = nn.Sequential(
VarGConv(in_channels, out_channels, kernel_size, stride, S),
PointConv(out_channels, out_channels, 1, S, isPReLU=True)
)
self.branch2 = nn.Sequential(
VarGConv(in_channels, out_channels, kernel_size, stride, S),
PointConv(out_channels, out_channels, 1, S, isPReLU=True)
)
self.block3 = nn.Sequential(
VarGConv(out_channels, 2*out_channels, kernel_size, 1, S), # stride =1
PointConv(2*out_channels, out_channels, 1, S, isPReLU=False)
) # 上面那个分支
self.shortcut = nn.Sequential(
VarGConv(in_channels, out_channels, kernel_size, stride, S),
PointConv(out_channels, out_channels, 1, S, isPReLU=False)
)
self.prelu = nn.PReLU()
def forward(self, x):
out = self.shortcut(x)
x1 = x2 = x
x1 = self.branch1(x1)
x2 = self.branch2(x2)
x3 = x1+x2
x3 = self.block3(x3)
# out += x3
out = out + x3
return self.prelu(out)
class HeadSetting(nn.Module):
def __init__(self, in_channels, kernel_size, S=8):
super(HeadSetting, self).__init__()
self.block = nn.Sequential(
VarGConv(in_channels, in_channels, kernel_size, 2, S),
PointConv(in_channels, in_channels, 1, S, isPReLU=True),
VarGConv(in_channels, in_channels, kernel_size, 1, S),
PointConv(in_channels, in_channels, 1, S, isPReLU=False)
)
self.short = nn.Sequential(
VarGConv(in_channels, in_channels, kernel_size, 2, S),
PointConv(in_channels, in_channels, 1, S, isPReLU=False),
)
def forward(self, x):
out = self.short(x)
x = self.block(x)
# out += x
out = out + x
return out
class Embedding(nn.Module):
def __init__(self, in_channels, out_channels=512, S=8):
super(Embedding, self).__init__()
self.embedding = nn.Sequential(
nn.Conv2d(in_channels, 1024, kernel_size=1, stride=1,padding=0, bias=False),
nn.BatchNorm2d(1024),
# nn.ReLU6(inplace=True),
nn.ReLU6(inplace=False),
nn.Conv2d(1024, 1024, (7, 6), 1, padding=0, groups=1024//8, bias=False),
nn.Conv2d(1024, 512, 1, 1, padding=0, groups=512, bias=False)
)
self.fc = nn.Linear(in_features=512, out_features=out_channels)
def forward(self, x):
x = self.embedding(x)
x = x.view(x.size(0), -1)
out = self.fc(x)
return out
class VarGFaceNet(nn.Module):
def __init__(self, num_classes=512):
super(VarGFaceNet, self).__init__()
S=8
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=40, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(40),
# nn.ReLU6(inplace=True)
nn.ReLU6(inplace=False)
)
self.head = HeadSetting(40, 3)
self.stage2 = nn.Sequential( # 1 normal 2 down
DownSampling(40, 3, 2),
NormalBlock(80, 3, 1),
NormalBlock(80, 3, 1)
)
self.stage3 = nn.Sequential(
DownSampling(80, 3, 2),
NormalBlock(160, 3, 1),
NormalBlock(160, 3, 1),
NormalBlock(160, 3, 1),
NormalBlock(160, 3, 1),
NormalBlock(160, 3, 1),
NormalBlock(160, 3, 1),
)
self.stage4 = nn.Sequential(
DownSampling(160, 3, 2),
NormalBlock(320, 3, 1),
NormalBlock(320, 3, 1),
NormalBlock(320, 3, 1),
)
self.embedding = Embedding(320, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.conv1(x)
x = self.head(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
out = self.embedding(x)
return out
Probabilistic Face Embeddings
文章提出对人脸进行概率建模,传统方法只是针对某一输入的人脸图像将其映射到隐空间的一个点,缺陷在于实际场景下可能出现低质量样本,如果这些低质量样本进入了人脸识别系统,人脸识别系统可能对将这些低质量样本判错,比较极端的是将所有低质量样本分为同一个id。
为了解决这一问题,文章觉得应该有一个指标来告诉我们哪些样本质量低,哪些样本质量高,于是自然可以想到把一张图片经过神经网络之后的输出建模成一个概率分布而不单单是一个点,这样做的好处是可以利用其方差的交集大小来作为质量评估的标准,从直觉上我们可以认为方差比较大的样本其质量可能不好,而方差比较小的样本由于其确定性所以可认为其质量好。
此外,为了不破坏传统模型的训练方式引入新的训练方法,本文直接在原有的训练方式上做的改进,原来训练网络到embedding层,然后是分类损失,当训练完之后,认为该网络有了最为确定的图像中心(即网络的embedding输出,这一输出可认为是概率建模的均值),然后固定特征提取网络,在后面加两个全连接层去优化得到图像分布方差。
优化方差的损失函数如下:

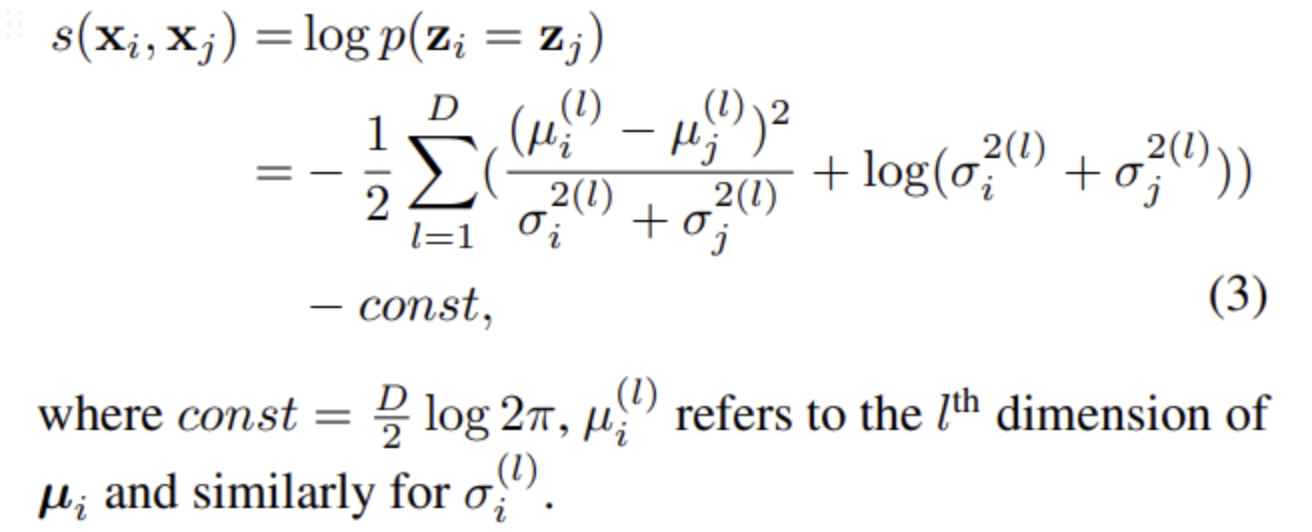
问题:为啥这个公式可以得到样本方差?
其实很简单,两层的神经网络预测高斯分布的方差,embedding是高斯分布的均值,因此整个高斯分布是可以确定的,所以需要最大化后验概率,也就是两个相同的样本之间的后验概率,第一项相当于对中心的距离加权,样本距离越大会导致方差越大,后一项是对方差的惩罚项。
由于高质量样本有惩罚低质量样本没有,所以会导致高质量样本具有小方差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号