[CUDA] CUDA编程入门
CUDA编程入门
Hello World
首先一段程序写个hello world
#include <stdio.h>
__global__ void hello(){
printf("Hello, threadIdx is:%d\n",threadIdx.x);
}
int main(){
hello<<<1,32>>>();
cudaDeviceReset();
}
编译
nvcc -o main main.cu
运行
./main
结果
Kernels
kernel在cuda中指的是一个函数,当一个kernel被调用的时候,gpu会同时启动很多个线程来执行这一个kernel,这样就实现了并行化;每个线程执行这一kernel将通过线程号来对应输入数据的下标,这样保证每个thread执行的kernel一样,但是处理的数据不一样。
一个kernel在cuda中可以这么定义:
// kernel定义
__global__ void VecAdd(float* A,float* B, float C){
int i = threadIdx.x;
C[i] = A[i] + B[i]
}
// 调用
VecAddd<<<1,N>>>(A,B,C);
上面代码中调用的时候通过指定<<<1,N>>>前者1表明使用1个block,每个block有N个threads,这样在函数调用内部通过取内置变量threadIdx来得到thread的索引,以此对应数组下标,实现并行化。
__global__前缀表示在GPU上执行,其他对应的前缀有如下特点:
__global__:在GPU上执行,可以在CPU上被调用,也可以在GPU上被调用__device__:在GPU上执行,只能在GPU上被调用__host__:在CPU上执行,只能在CPU上被调用
实际上,可以先缕一缕GPU中内存的一些关系:
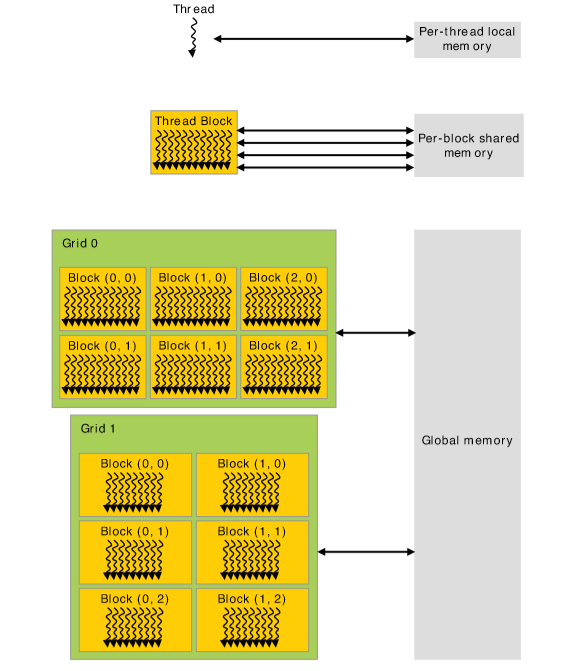
可以看到,GPU的整个内存被划分为了多个grid,每个grid有很多block,而每个block都共享同样的内存,每个block的多条thread针对共享的内存并行执行不同的操作。
上面的例子中只是针对thredIdx是一维的情况,实际上,为了方便,我们可以直接将threadIdx变成多维的,以方便我们对矩阵或者更高维的数据的处理,这跟C语言里的二维数组等概念是一样的,就是用x和y分别代表一个维度的下标。
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]){
int x = threadIdx.x;
int y = threadIdx.y;
C[x][y] = A[x][y] + B[x][y];
}
int main(){
int num_blocks = 1;
dim3 threads_per_block(N,N);
MatAdd<<<num_blocks,threads_per_block>>>(A,B,C);
}
这个例子是相对很容易理解的了。需要知道的是,每个block的threads数目是有最大限制的,不能超过一定的值,书上说现在的GPU每个block最多是1024个thread。所以上面的例子其实并不能处理很大的矩阵,那么要处理很大的矩阵的时候该怎么办呢?
可以用上block:
___global___ void MatAdd(float A[N][N], float B[N][N], float C[N][N]){
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main(){
dim3 threads_per_block(16,16);
dim3 num_blocks(N/num_blocks.x,N/num_blocks.y);
MatAdd(A,B,C);
}
这个例子充分利用了block数量,这样每个block是16*16也就是256个threads,假设N = 32,那么num_blocks = (2,2)也就是用了4个block。上面blockIdx.x取值是[0,1],blockDim.x取值是16,threadIdx.x取值是[0,15].
假设每个block最多可以用1024个thread,那么其实可以处理$N_{max} = 32 * \sqrt{num_blocks} $阶矩阵。
那这里就有个疑问了,不是说一个block一块内存吗,不同block之间不share内存,那这个代码感觉所有block都share同一块内存的样子呀?其实这里跟share不share没任何关系。。每个thread都在独立计算一条语句,大家根本没有说有那种你先我后的协作关系,所以谈不上share,所以大家都是independent的,从global memory里读入,然后写到global memory。
Compute Capability
一般用x.y来表示一款GPU的计算能力,x相同的表示架构相同,y只是在这个架构上做了一些increasement。
现在GPU与计算能力的x之间有下图这样的对应:
| 7 | Volta |
|---|---|
| 6 | Pascal |
| 5 | Maxwell |
| 3 | Kepler |
| 2 | Fermi |
| 1 | Tesla |
这里注意不要与cuda版本号搞混了,计算能力描述的是gpu,而非软件版本。
Memory Allocation
这节涉及之前省略的,之前的代码没有考虑A、B、C的内存申请,这一节讨论的就是如何把host的内存(cpu data)转到device里(gpu data)。
如果要申请一块连续的GPU内存空间,直接可以通过调用cudaMalloc()来实现,调用cudaFree()释放空间,那么把host上内存copy到gpu上是通过调用cudaMemcpy()来实现。
__global__ void VecAdd(float* A, float* B, float* C){
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 根据下面的分析,i是可能大于等于N的,当N>threadsPerBlock且为threadsPerBlock的非整数倍的时候,这时候会引入多一个block来运算,其中多余的threads不应该参与运算,所以下面if需要判断。
if (i < N){
C[i] = A[i] + B[i];
}
}
int main(){
int N = 32;
size_t size = N * sizeof(float);
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
float* d_A;
float* d_B;
float* d_C;
cudaMalloc(&d_A,size);
cudaMalloc(&d_B,size);
cudaMalloc(&d_C,size);
cudaMemcpy(d_A, h_A,size,cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B,size,cudaMemcpyHostToDevice);
int threadsPerBlock = 256;
// 由于threadsPerBlock通常是定的,所以我们需要调整的一般是Blocks的数量
// 考虑到如果N < threadsPerBlock,那么N/threadsPerBlock就是0,但这是是少需要一个block
// 如果N = threadsPerBlock,这时候如果(N + threadsPerBlock)/threadsPerBlock就是2,但其实这时候只需要一个block
// 综上,应该是下式才满足条件
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<<blocksPerGrid,threadsPerBlock>>>(d_A,d_B,d_C,N);
cudaMemcpy(h_C,d_C,cudaMemcpyDeviceToHost);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}
cudaMalloc ( void** devPtr, size_t size )
Parameters
devPtr- Pointer to allocated device memory
size- Requested allocation size in bytes
第一个参数是地址的指针,显然cudaMalloc只能分配线性内存,线性内存访问起来是相当块的。在传统C语言里,我们如果要取用malloc申请二维数组,可能先申请一些一维数组用来存储首地址指针,每个首地址再去指向一个申请的一维数组,实现二维数组,在CUDA里可以通过cudaMallocPitch来申请二维数组,得到的地址仍然是线性的,因为访问块。
cudaMallocPitch ( void** devPtr, size_t* pitch, size_t width, size_t height )
Parameters
-
devPtr- Pointer to allocated pitched device memory
-
pitch- Pitch for allocation
-
width- Requested pitched allocation width (in bytes)
-
height- Requested pitched allocation height
pitch参数表示的是“宽度”,可以理解为一行有多少个元素乘以sizeof(float),是返回值。
书上的一个例子为:
__global__ Mykernel(float* devPtr,size_t pitch, int width, int height){
for(int r = 0;r < height; ++r){
float* row = (float*)((char*)devPtr + r * pitch); // 转char* 是因为原来的devPtr是float*的,加法运算会考虑stride。
for(int c=0;c<width;++c){
float val = row[c];
}
}
}
int width = 64,height = 64;
float* devPtr;
size_t pitch; // sizeof(float) * width
cudaMallocPitch(&devPtr,&pitch,width * sizeof(float),height); // height不用乘sizeof(float)是因为第一维的指针是void*
Mykernel<<<100,512>>>(devPtr,pitch,width,height);
Shared Memory
本节通过一个矩阵相乘的例子,来说明通过block内shared memory来减少从global memory读取和写入数据的次数,从而加速矩阵相乘的速度。
首先是没有shared memory的代码实现:
typedef struct{
int width;
int height;
float* elements;
} Matrix;
#define BLOCK_SIZE 16
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
void MatMul(const Matrix A, const Matrix B, Matrix C){
Matrix d_A;
d_A.width = A.width;
d_A.height = A.height;
size_t size = d_A.width * d_A.height * sizeof(float);
cudaMalloc(&d_A.elements,size);
cudaMemcpy(d_A.elements,A.elements,size,cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width;
d_B.height = B.height;
size_t size = d_B.width * d_B.height * sizeof(float);
cudaMalloc(&d_B.elements,size);
cudaMemcpy(d_B.elements,B.elements,size,cudaMemcpyHostToDevice);
Matrix d_C;
d_C.width = C.width;
d_C.height = C.height;
size_t size = d_C.width * d_C.height * sizeof(float);
cudaMalloc(&d_C.elements,size);
dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE);
// 列索引和行索引划分
dim3 dimGrid(B.width / dimBlock.x,A.height / dimBlock.y);
MatMulKernel<<<dimBlock,dimGrid>>>(d_A,d_B,d_C);
cudaMemcpy(C.elements,d_C.elements,size,cudaMemcpyDeviceToHost);
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C){
float Cvalue = 0;
// 这里求对应A矩阵的第row行以及B矩阵的第j列
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for(int i=0;i<A.width;i++){
Cvalue += A.elements[row * A.width + i] * B.elements[i * B.width + col];
}
C.elements[row * C.width + col] = Cvalue;
}
代码很好理解,每个thread负责通过一个循环来计算输出矩阵C中的一个数值,需要注意的是,C矩阵中的每个数值计算,都需要一个thread从global memory中读取数据,计算完成,然后写回。下图表达的就是这样的一个计算实例:

所以总的读取和写入次数是非常频繁的,为了减少访问global memory的次数,可以对C矩阵分块求取,C矩阵中的每个分块矩阵由一个block负责计算,这block一次将数据读入block内的共享内存,然后thread在共享内存上计算,最后写入到global memory,这大大减少了访问global memory的次数,加速了计算。
// 加的这个stride就是为了表示原矩阵width,这里的width和height可以是子矩阵的width和height
// elements是子矩阵的首地址
// M(row,col) = *(M.elements + row * M.stride + col)
typedef struct{
int width;
int height;
int stride;
float* elements;
} Matrix;
#define BLOCK_SIZE 16
__device__ void SetElement(Matrix A, int row, int col, float value){
// 虽然A是一个局部变量,但是A里面的elements指向的东西没被深拷贝
A.elements[row * A.stride + col] = value; // 乘以A的stride是因为A跨行的stride和原矩阵一致
}
__device__ float GetElement(Matrix A,int row, int col){
return A.elements[row * A.stride + col];
}
__device__ Matrix getSubMatrix(Matrix A,int row, int col){
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = A.elements + (BLOCK_SIZE * row) * stride + (BLOCK_SIZE*col) // 相当于乘以BLOCK_SIZE
return Asub;
}
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
void MatMul(const Matrix A, const Matrix B, Matrix C){
Matrix d_A;
d_A.width = A.width;
d_A.height = A.height;
size_t size = d_A.width * d_A.height * sizeof(float);
cudaMalloc(&d_A.elements,size);
cudaMemcpy(d_A.elements,A.elements,size,cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width;
d_B.height = B.height;
size_t size = d_B.width * d_B.height * sizeof(float);
cudaMalloc(&d_B.elements,size);
cudaMemcpy(d_B.elements,B.elements,size,cudaMemcpyHostToDevice);
Matrix d_C;
d_C.width = C.width;
d_C.height = C.height;
size_t size = d_C.width * d_C.height * sizeof(float);
cudaMalloc(&d_C.elements,size);
dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE);
// 列索引和行索引划分
dim3 dimGrid(B.width / dimBlock.x,A.height / dimBlock.y);
MatMulKernel<<<dimBlock,dimGrid>>>(d_A,d_B,d_C);
cudaMemcpy(C.elements,d_C.elements,size,cudaMemcpyDeviceToHost);
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C){
int block_row = blockIdx.x;
int block_rol = blockIdx.y;
Matrix Csub = GetSubMatrix(C,block_row,block_col);
float Cvalue = 0;
int row = threadIdx.x;
int col = threadIdx.y;
for(int i=0;i<(A.width / BLOCK_SIZE);++i){
// 这里不是直接一行算,A矩阵和B矩阵也是按block来,最后是Cvalue求和不影响结果
Matrix Asub = GetSubMatrix(A,block_row,i);
Matrix Bsub = GetSubMatrix(B,i,block_rol);
// 直接生命的对象 局部生命周期
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
As[row][col] = GetElement(Asub,row,col);
Bs[row][col] = GetElement(Bsub,row,col);
// 保证整个子矩阵都被读入
// 也就是一个block的所有thread都执行到这里
__syncthreads();
for(int e=0; e<BLOCK_SIZE;++e){
Cvalue += As[row][e] * Bs[e][col];
}
// 保证这个block算完,然后下一次训练读入下一轮的sub matrix
__syncthreads();
}
SetElement(Csub,row,col,Cvalue)
}
假设A矩阵是m行n列的,B矩阵是p行q列的,如果用前一种方法,A和B矩阵从global memory中被读取的次数是np次,后一种方法是(n/block_size) * (p/block_size)次。(书上那种说法应该指的是同一行、列数据被读取的次数,跟我这里不同)。
大致可用下图表示:

Pinned Memory
Host端的内存分为页内存(Pageable Memory)和锁存(Pinned Memory),前者在内存不足时会与虚拟内存交换,把数据放在虚拟内存中,后者内存是固定的。
而内存拷贝是一个非常耗时的操作,由于GPU知道内存的物理地址,因此就可以使用DMA技术来在GPU和CPU之间复制数据.当使用可分页的内存进行复制时(使用malloc),CUDA驱动程序仍会通过dram把数据传给GPU,这时复制操作会执行两遍,第一遍从可分页内存复制一块到临时的页锁定内存,第二遍是再从这个页锁定内存复制到GPU上.当从可分页内存中执行复制时,复制速度将受限制于PCIE总线的传输速度和系统前段速度相对较低的一方.在某些系统中,这些总线在带宽上有着巨大的差异,因此当在GPU和主机之间复制数据时,这种差异会使页锁定主机内存比标准可分页的性能要高大约2倍.即使PCIE的速度于前端总线的速度相等,由于可分页内训需要更多一次的CPU参与复制操作,也会带来额外的开销.
所以在内存足够的时候,可以使用pinned memory来加速数据读取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号