[论文理解] On the "steerability" of generative adversarial networks
On the "steerability" of generative adversarial networks
Intro
本文提出对GAN的latent space进行操作的一种方法,通过对latent space的编辑实现生成域外样本,操控生成样本的基本属性,如控制生成样本的位置、光照、二维旋转、三维旋转等等。

文章的主要贡献为:
- 证明并实现了通过在latent space中的“walk”能够实现类似人类世界中相机的运动、颜色变换等操作,这些操作是通过自监督的方式学习到的。
- 不仅能实现对输出域的线性变换,还能实现对输出域的非线性变换。
- 量化了数据集可学习到变换的最大程度。
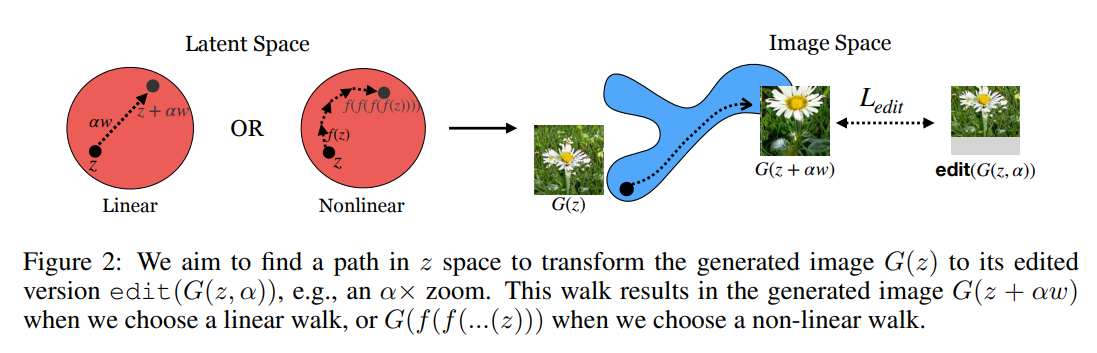
GAN经过训练能够学习到一种映射,使得\(G(z) \rightarrow x\),也就是将latent space的采样结果映射为一图像分布下的样本。因此很自然就想到了,能否学习一种变换,使得对latent space的变换,也能映射到图像分布?作者称之为“walk”,即在latent space中执行某种变换,生成的图像也会做出相应的变换,以此来调节生成的图片,甚至可以生成域外样本。
Objective
上式edit是对生成的图像的变换操作,\(\alpha\)是外部调节参数,\(\omega\)是可学习参数,看起来相当的简单。这里是认为G已经训练好了,即已经经过对抗训练可以生成图片了。公式假设的是操作是线性操作,实际上如果是非线性操作就拟合一个对z的非线性函数,神经网络里往往用非线性激活拟合非线性,拟合的应该是一个step的变化。所以递归变换n次就是nstep的变换。
其中n表示第n个step,\(\epsilon\)表示步长,\(f^n(z)\)是n次递归函数。
Quantifying Steerability
本文还提出变换前后量化对比的指标,以量化变换的效果。
对于颜色变换,量化指标是随机抽取变换前后100 pixels像素值的变化,归一化到1.
对于zoom和shift的变换,量化指标是用一个目标检测网络输出物体中心位置,除以box的宽高归一化。
Reducing Transformation Limits
上面说了,是在G确定的情况下去学习latent space的变换,那么能否直接端到端训练呢?显然是可以的.
直接端到端训练,GAN的loss按照原来的,而编辑loss拿输入原图和编辑后的做loss即可。
实验部分太长了,不感兴趣。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号