[论文理解] Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks
简介
SENet提出了一种更好的特征表示结构,通过支路结构学习作用到input上更好的表示feature。结构上是使用一个支路去学习如何评估通道间的关联,然后作用到原feature map上去,实现对输入的校准。支路的帮助学习到的是神经网络更加适合的表示。为了使网络通过全局信息来衡量通道关联,结构上使用了global pooling捕获全局信息,然后连接两个全连接层,作用到输入上去,即完成了对输入的重校准,可以使网络学习到更好的表示。
SQUEEZE-AND-EXCITATION BLOCKS
一个block的结构大致如下:
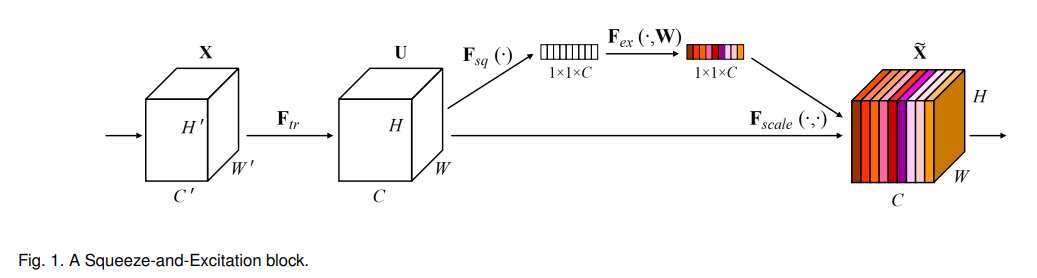
上图中Fsq是Squeeze过程,Fex是Excitation过程,然后通过Fscale将学习到的权重作用在输入上。
Squeeze: Global Information Embedding
作者将Squeeze过程称为global information embedding的过程,因为squeeze的过程实际上是对feature map利用global pooling来整合全局特征。
Excitation: Adaptive Recalibration
作者将Excitation过程称为重校准过程,因为此过程通过支路学习到的权重,作用到原输入上去,要实现对每个通道进行打分,即网络学习到通道score,则必须要学习到非线性结果,所以作者采用fc-relu-fc-sigmoid的excitation结构来实现score映射。
根据作者论文中的举例,可以清楚看到以Inception为例的Squeeze和Excitation过程:
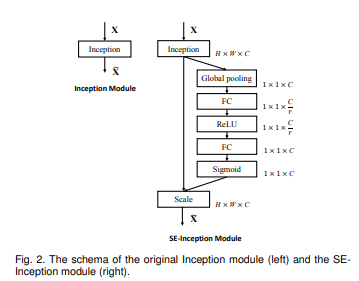
而Fscale过程就是对应相乘,把每个通道的权重对应乘上input的对应通道feature。
这个论文比较好理解。
简单写了一个block:
import torch
import torch.nn as nn
class SEModule(nn.Module):
def __init__(self,r = 3):
super(SEModule,self).__init__()
self.global_pooling = nn.MaxPool2d(128)
self.fc1 = nn.Linear(64,64//r)
self.relu1 = nn.ReLU(64//r)
self.fc2 = nn.Linear(64//r,64)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
se_x = self.global_pooling(x)
se_x = self.fc1(se_x.view(-1,64))
se_x = self.relu1(se_x)
se_x = self.fc2(se_x)
se_x = self.sigmoid(se_x).view(-1,64,1,1)
return x * se_x
if __name__ =="__main__":
from torchsummary import summary
model = SEModule()
summary(model,(64,128,128),device = "cpu")
'''
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
MaxPool2d-1 [-1, 64, 1, 1] 0
Linear-2 [-1, 21] 1,365
ReLU-3 [-1, 21] 0
Linear-4 [-1, 64] 1,408
Sigmoid-5 [-1, 64] 0
================================================================
Total params: 2,773
Trainable params: 2,773
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 4.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.01
Estimated Total Size (MB): 4.01
----------------------------------------------------------------
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号