[论文理解] LFFD: A Light and Fast Face Detector for Edge Devices
LFFD: A Light and Fast Face Detector for Edge Devices
摘要
从微信推文中得知此人脸识别算法可以在跑2K图片90fps,仔细一看是在RTX2070下使用tensorrt下才能达到。最近刚好有个目标检测的任务,检测的目的其实差不多,我们篮球组比赛中需要检测篮球和排球,传统方法的鲁棒性不好,因此拟打算用自己写个神经网络结构在nuc x86 cpu下能够取得不错的推理速度和准确率。所以准备参考这篇论文复现并修改实现篮球、排球的实时目标检测任务。
本文提出了轻量级的人脸检测算法,可以达到2K图片90FPS,本文的大体框架是借鉴SSD目标检测框架的,但是却是一个anchor free的人脸检测框架,因为作者认为感受野本身就是天然的anchor,所以作者通过精细设计感受野完成了本篇的人脸检测任务。认为浅层layer的有效感受野应该与小目标size比值较大,这样可以充分利用周围特征对人脸检测的贡献;深层layer由于其感受野比较大,检测大目标,大目标人脸本身有足够的鼻子、眼镜等信息可以帮助判别人脸,所以不需要太大的有效感受野与人脸比例。根据这些想法,作者设计了本文的人脸检测网络结构。
感受野和有效感受野
感受野通俗讲就是feature map上一个点对应原图的一片pixel区域,计算方法也比较简单,我自己简单写了一下。

总结起来公式就是
其实对于感受野而言,并不是感受野内的所有点都对后面结果起到决定性作用,而是以感受野中心呈高斯分布的区域内的点对后面结果起到关键作用,这区域称为有效感受野ERF。
据此作者得出下面三个对人脸识别很有帮助的结论:
- 对于人脸小目标来说,ERF最好能尽可能覆盖context information
- 对于中等人脸,ERF只需要覆盖一部分context information
- 对于大人脸目标,ERF甚至不需要覆盖其他额外的context information
感受野的可视化
为了更进一步了解感受野,我们尝试将感受野可视化出来。
下面的代码是证明了作者论文中感受野的参数和有效感受野参数。这里只是以第一个part为例分析。
代码:
import cv2 as cv
import torch
import torch.nn as nn
import torchvision
from torchvision.models import ResNet
import numpy as np
class ResBlock(nn.Module):
def __init__(self,channels):
super(ResBlock, self).__init__()
self.conv2dRelu = nn.Sequential(
nn.Conv2d(channels,channels,kernel_size=3,stride=1,padding=1),
nn.ReLU(channels),
nn.Conv2d(channels,channels,kernel_size=3,stride=1,padding=1),
nn.ReLU(channels)
)
self.relu = nn.ReLU(channels)
def forward(self,x):
return self.relu(x + self.conv2dRelu(x))
class TinyNet(nn.Module):
def __init__(self):
super(TinyNet,self).__init__()
self.c1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=2,padding=0),
nn.ReLU(64)
)
self.c2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=3,stride=2,padding=0),
nn.ReLU(64)
)
self.tinypart1 = nn.Sequential(
ResBlock(64),
ResBlock(64),
ResBlock(64)
)
def forward(self,x):
c1 = self.c1(x)
c2 = self.c2(c1)
c8 = self.tinypart1(c2)
return c8
if __name__ == "__main__":
model = TinyNet()
for module in model.modules():
try:
nn.init.constant_(module.weight, 0.05)
nn.init.zeros_(module.bias)
nn.init.zeros_(module.running_mean)
nn.init.ones_(module.running_var)
except Exception as e:
pass
if type(module) is nn.BatchNorm2d:
module.eval()
x = torch.ones(1,3,640,640,requires_grad= True)
pred = model(x)
grad = torch.zeros_like(pred, requires_grad= True)
grad[0, 0, 64, 64] = 1
pred.backward(gradient = grad)
grad_input = x.grad[0,0,...].data.numpy()
grad_input = grad_input / np.max(grad_input)
# 有效感受野 0.75 - 0.85
#grad_input = np.where(grad_input>0.85,1,0)
#grad_input = np.where(grad_input>0.75,1,0)
# 注释掉即为感受野
grad_input = (grad_input * 255).astype(np.uint8)
kernel = np.ones((5, 5), np.uint8)
grad_input = cv.dilate(grad_input, kernel=kernel)
contours, _ = cv.findContours(grad_input, mode=cv.RETR_EXTERNAL, method=cv.CHAIN_APPROX_SIMPLE)
rect = cv.boundingRect(contours[0])
print(rect[-2:])
cv.imshow( "a",grad_input)
cv.waitKey(0)
感受野:

对应输出(感受野大小):
(55,55)
有效感受野(阈值0.75):

对应输出(有效感受野大小):
(15,15)
有效感受野(阈值0.85):

对应输出(有效感受野大小):
(11,11)
网络结构

作者认为RF就是天然的anchor,由于人脸目标一般是方的,所以不需要考虑各种比例的box。在box匹配的时候,作者认为rf中心落在gt内的box为正样本,同时落在多个gt中的box忽略掉、其他没有落在任何gt中的box为负样本。此外,作者定义的gray scale,后面再提。
对于这样的网络设计,作者是这么想的:
100 pixels的RF的有效感受野为20-40pixels,所以作者就分了四个part,tiny part的c8 RF SIZE为55,去检测10-15pixels的人脸,c10检测15-20,以此类推。其中rf与avg face scale的比值随着层数加深而减少,高层大感受野预测大目标就不需要太多的context information,前面讲了。
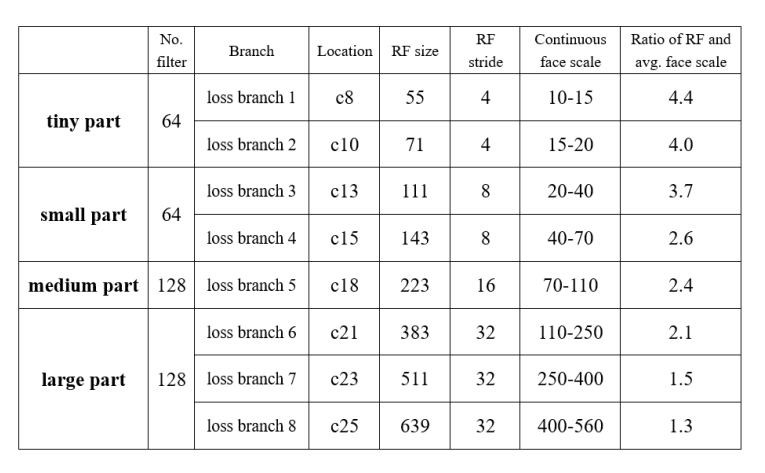
网络实现中全用的3*3和1*1的卷积核,实现起来很简单。data augmentation用了 color distort、Random sampling for each scale和Randomly horizontal flip。
loss是regression loss和classification loss加权和。
regression loss直接简单粗暴L2loss,预测相对值:

classification loss是crossentropy loss。
box匹配的时候定义了gray scale,认为处于gray scale的box所在的branch是不反传这些对应的loss的。
对c13出的box而言,其检测的人脸像素为20-40pixels,认为[18,20]以及[40,44]像素的人脸不被c13预测,这是因为这些人脸属于hard目标,网络往往只能看到局部特征,很难判别,所以c13这个brach不预测他,让别的branch预测,对训练有好处。
此外还用了负样本挖掘(sort负样本的loss,选择loss比较大的一部分训练,其他不参与梯度反传,加速收敛)。
训练参数:
xavier初始化、图像标准化x-127.5/127.5、sgd 0.9 momentum,0weight decay,init lr0.1.
1080ti训练了5天。
后续
复现并修改后的BasketNet:https://github.com/aoru45/BasketNet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号