[论文理解] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Intro
MobileNet 我已经使用过tensorflow的api在实际场景中取得了很实时的识别效果,其论文的贡献是利用depth-wise卷积和point-wise卷积对一般的卷积核进行优化,使得网络模型的卷积计算量大大减小。这一贡献使得Mobile-Net能够在移动设备上顺利运行,并且取得不错的速度和精度。
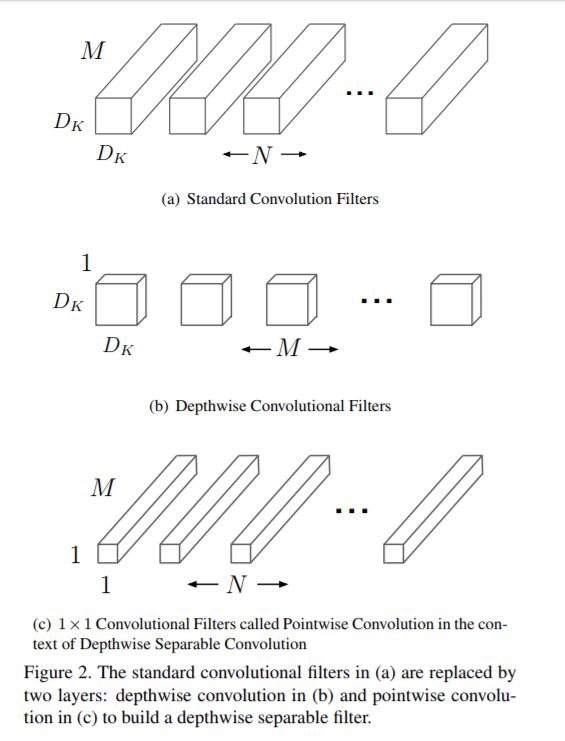
Depthwise Separable Convolution
对于标准的卷积而言,假设输入的是DF*DF*M的feature map F,并且生成DG*DG*N的feature map G,使用N个DK*DK*M的kernel去卷积,其对应关系为(步长为1):

total 计算量如下:

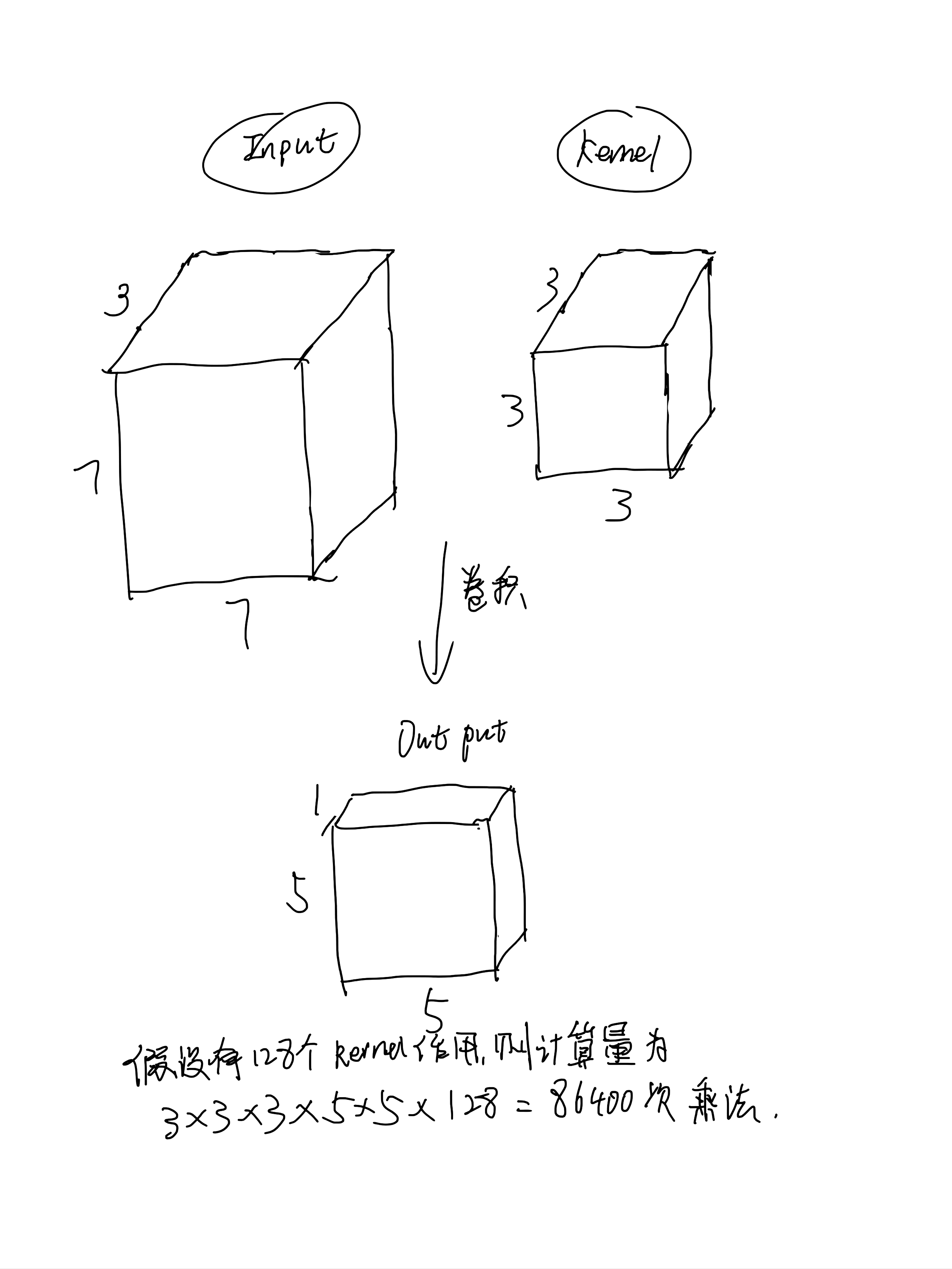
举例子说明标准的卷积过程和计算量:
取输入为7*7*3的feature map,卷积核3*3*3,那么需要不考虑padding的情况下滑动的次数就是5*5次,最后三个通道的对应数据加和压缩到一个通道,即完成卷积过程。我们假设有128个卷积核卷积输入图像(即输出通道数是128),那么我们的乘法计算量就是如图所示的86400次。
depth-wise和point-wise卷积的方式是先只用一个3*3的卷积核去卷积原图像,然后再用1*1*3的卷积核去卷积第一次卷积的结果,这样将原来的128次3*3的卷积拆分成了两次卷积,即两次卷积的加和,很明显这个加法比前面的直接相乘的计算量大大减小,这也是mobile-net计算量大大减小的原因。
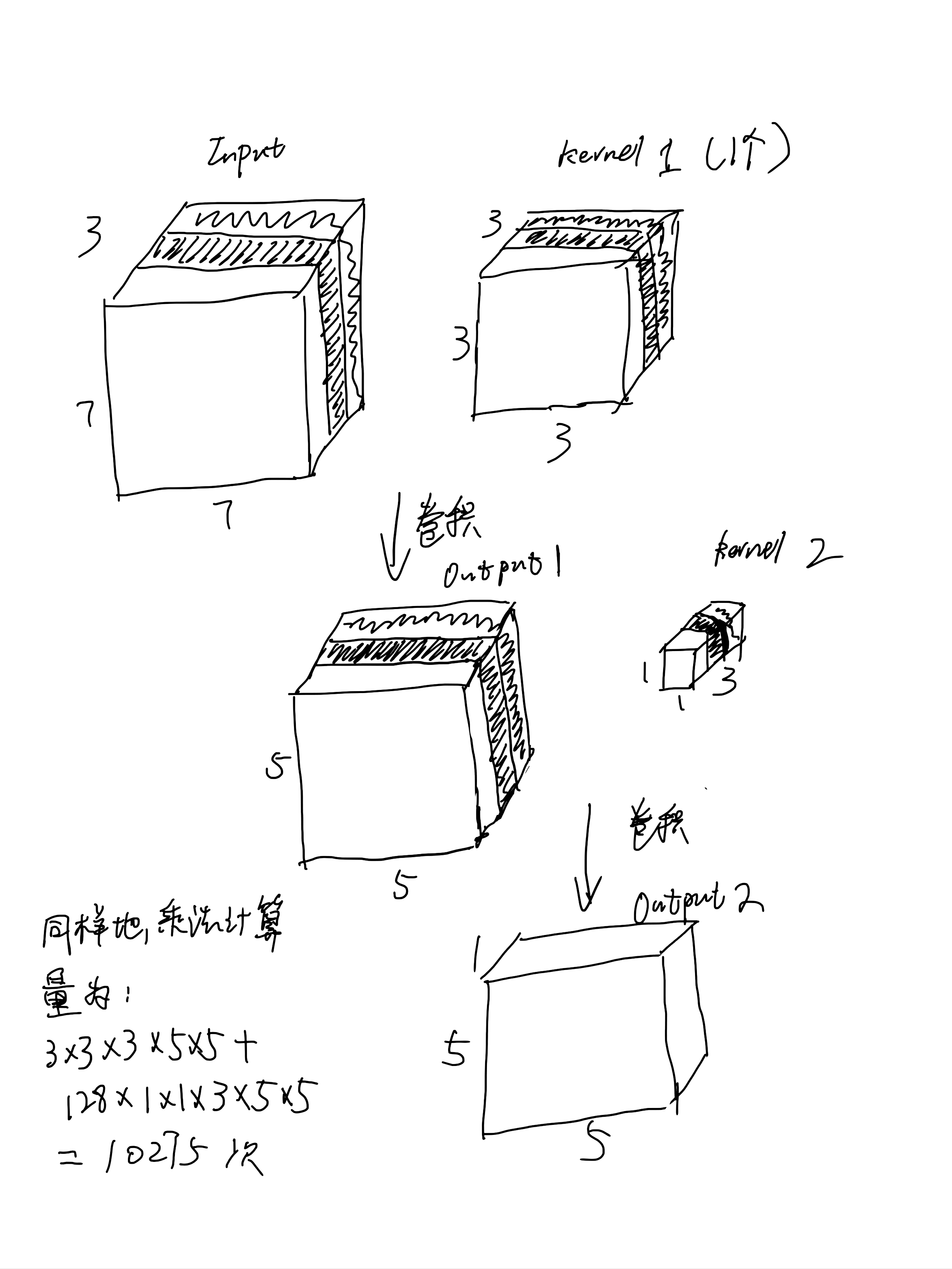
同样上面的例子,用Depthwise Separable Convolution之后的过程如下图所示,计算量仅仅10275,为标准卷积的12%!
Network Structure and Training
下图是标准卷积和depth-wise卷积的对应关系。

mobile-net的网络结构和参数情况如下图:
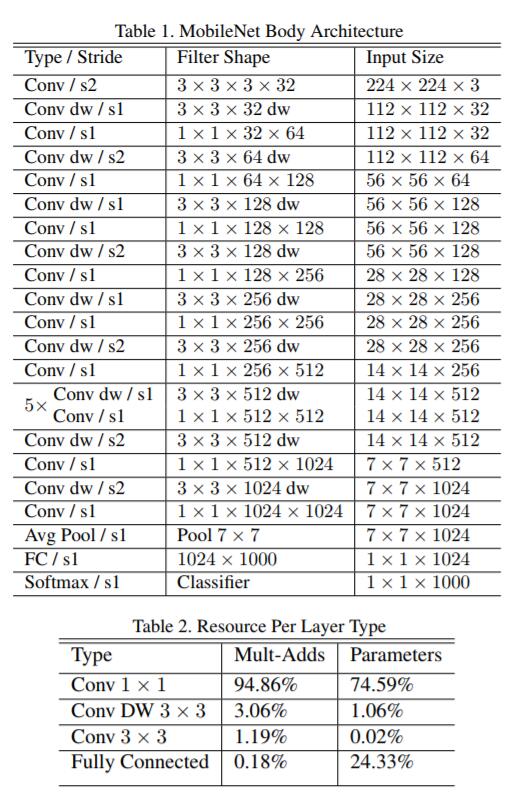
dw是depth-wise卷积的简称。
之后作者又提出模型可以再减少计算量,通过引入参数α,即减少dw过程中参与计算的输入通道数量和输出通道数量,引入之后计算量如图所示。

然后,又加了一个超参ρ,作用也是减少计算量,作用在输入feature map的size上。

Conclusion
mobile-net提出的Depthwise Separable Convolution使得深度模型的计算量大大减小,但其减少计算量的同时其实也失去了一定的精度,比如,对于较小模型而言,如果采用这种计算,那么模型的能力可能会下降,这样得到的模型肯定不是最好的,减少了模型的参数数量,很可能使得模型得不到最好的拟合效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号