[论文理解]Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
简介
这是何大佬的一篇非常经典的神经网络的论文,也就是大名鼎鼎的ResNet残差网络,论文主要通过构建了一种新的网络结构来解决当网络层数过高之后更深层的网络的效果没有稍浅层网络好的问题,并且做出了适当解释,用ResNet很好的解决了这个问题。
背景
深度卷积神经网络已经在图像分类问题中大放异彩了,近来的研究也表明,网络的深度对精度起着至关重要的作用。但是,随着网络的加深,有一个问题值得注意,随着网络一直堆叠加深,网络的效果一直会越来越好吗?显然会遇到梯度消失或者是梯度爆炸问题,而这个问题,已经可以通过在初始化的时候归一化输入解决,但是当网络最终收敛之后,又会出现“退化”问题,导致准确率降低(不是overfitting),因此尽管可以不断堆叠网络层数,让其可以训练并且收敛,但是遇到退化问题仍然没办法。作者认为现在通过一些训练手段来解决这个问题远远没有通过改变网络结构来解决这个问题来的更加彻底。图为56层的误差高于20层的误差。

Deep Residual Learning
Residual Learning
ResNet是通过将一层的输入和另一层的输出结果一起作为一个块的输出,假设x是一个块的输入,一块由两层组成,那么他先经过一个卷积层并且relu激活得到F(x),然后F(x)再经过卷积层之后的结果加上之前的输入x
得到一个结果,将结果通过relu激活作为该块的输出。对于普通的卷积网络,我们输出的是F(x),但是在ResNet中,我们输出的是H(x) = F(x) + x,但是我们仍然你和F(x) = H(x) - x.这样有什么好处呢?这样做改变了学习的目标,把原来学习让目标函数等于一个已知的恒定值改变为使输出与输入的残差为0,也就是恒等映射,导致的是,引入残差后映射对输出的变化更为敏感。
比如把5映射到5.1,那么引入残差前是F'(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F'和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F'的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化。
可以看下面这张图理解:
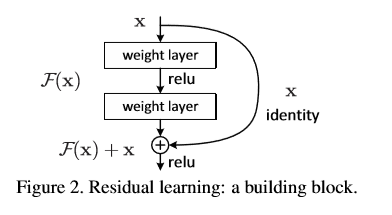
而实际过程中我们会想到,输入x和经过layer之后的输出结果的维度不一样,那么他们就不能被直接相加,为了解决这个问题,我们将x卷积变换一下,将x变换为和输出结果一样的维度就可以了。

可以多个层作为一个块,不一定是两层、三层。
H(x)作者称为shortcut connection,意为将x像短路一样加到F(x)后面作为输出
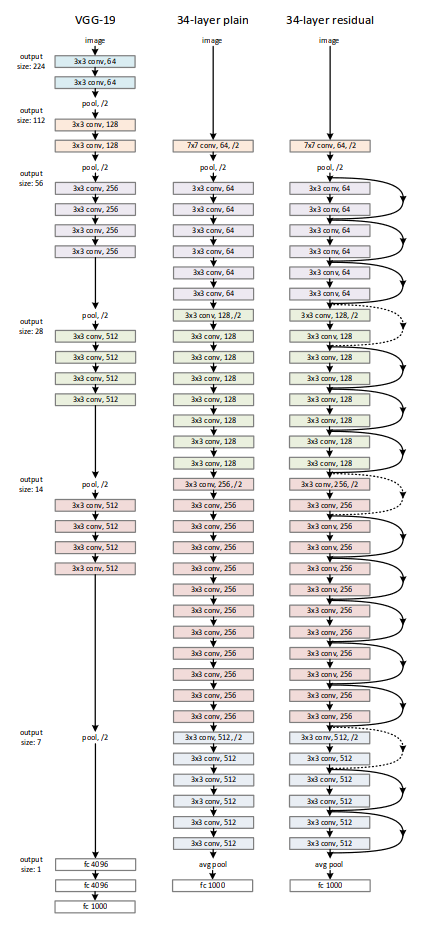
Network Architectures

 浙公网安备 33010602011771号
浙公网安备 33010602011771号