
第六章
第六章 数据分区
每个分区都可以视为一个完整的小型数据库,虽然数据库可能存在一些跨分区的操作。
数据分区与数据复制
分区通常与复制结合使用,使得每个分区的副本存储在多个节点上。 这意味着,即使每条记录属于一个分区,它仍然可以存储在多个不同的节点上以获得容错能力。
一个节点上可能存储了多个分区,每个分区都有自己的主副本,而主副本与从副本往往被分配在不同的服务器节点上以提高容错能力。
键值数据的分区
为了防止数据分布不均匀,最简单的方式就是随机分配,但查询的时候没法知道数据保存在哪个节点。
如果数据是简单的键值数据模型,则可以通过键来访问记录。
基于关键字区间分区
可以为每个分区分配一段连续的关键字或者关键字区间范围。
分区的边界可以由管理员手动确定,每个分区内可以按照关键字顺序保存,这样可以轻松支持区间查询。
基于关键字的区间分区的缺点是某些访问模式会导致热点。
基于关键字哈希值分区
一个好的哈希函数可以处理数据倾斜并使其均匀分布【MongoDB使用MD5】,要注意有些哈希函数不适合分区,例如Java的Object.hashCode。
找到合适的关键字哈希函数后可以为每个分区分配一个哈希范围。分区边界可以使均匀间隔,也可以是伪随机选择(一致性哈希)
负载倾斜与热点
基于哈希的分区可以减轻热点,但无法完全避免,目前只能通过应用层来减轻倾斜程度。
如果认为某个关键字被确认为热点,一个简单的技术就是在关键字的开头或结尾处添加一个随机数,从而分配到不同分区上。
分区和二级索引
二级索引带来的主要挑战是他们不能规整的映射到分区中,有两种主要的方法来支持对二级索引进行分区:基于文档的分区和基于词条的分区。
基于文档分区的二级索引
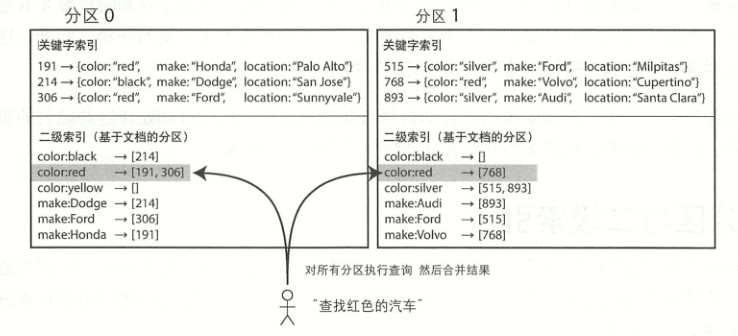
这种索引方法每个分区完全独立,各自维护自己的二级索引,当需要写数据时只需要处理包含目标文档ID的那一个分区,因此文档分区索引也被称为本地索引,而不是全局索引。读数据时,需要查询所有分区,然后合并所有返回的结果。这种查询分区数据库的方法有时也称为分散/聚集,显然这种二级索引的查询代价高昂。
基于词条的二级索引分区
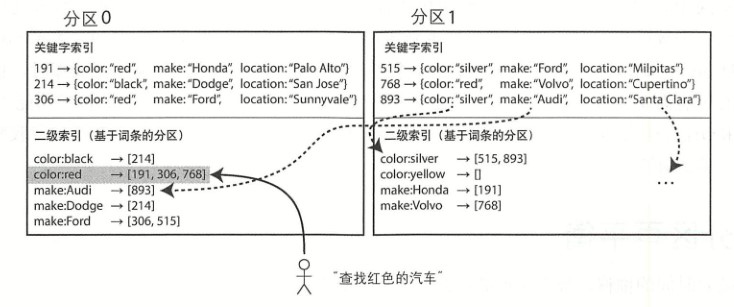
可以对所有数据构建全局索引,而且为了避免瓶颈,不能将全局索引存储在一个节点上,可以根据数据关键字采用不同的分区策略。
这种索引方案称为词条分区,它以待查找的关键字本身作为索引。
这种全局的词条分区相比于文档分区索引的主要优点是:它的读取更为高效,不需要对每个分区执行一遍查询。
缺点在于:写入速度较慢且非常复杂,因为单个文档的更新可能会涉及多个二级索引。而二级索引的分区可能完全不同甚至在不同的节点上。
理想情况下索引应该保持最新,对于词条分区来说这需要一个跨多个分区的分布式事务支持,写入速度会受到极大影响。所以实践中全局二级索引的更新往往是异步的。
分区再平衡
随着时间的推移,数据库会有各种变化。
- 查询吞吐量增加,所以您想要添加更多的CPU来处理负载。
- 数据集大小增加,所以您想添加更多的磁盘和RAM来存储它。
- 机器出现故障,其他机器需要接管故障机器的责任。
所有这些更改都需要数据和请求从一个节点移动到另一个节点。 将负载从集群中的一个节点向另一个节点移动的过程称为再平衡(reblancing)。
无论使用哪种分区方案,再平衡通常都要满足一些最低要求:
- 再平衡之后,负载(数据存储,读取和写入请求)应该在集群中的节点之间公平地共享。
- 再平衡发生时,数据库应该继续接受读取和写入。
- 节点之间只移动必须的数据,以便快速再平衡,并减少网络和磁盘I/O负载。
动态再平衡策略
为什么不用取模
节点数量变化时取模的数不同,需要数据进行迁移。
固定数量的分区
创建远超实际节点数的分区数,然后为每个节点分配多个分区。
分区会在节点之间迁移,但分区的总数量仍然维持不变,也不会改变关键字到分区的映射关系,这里唯一需要调整的是分区与节点的对应关系。
动态分区
如果分区内数据量太大则会拆分成两个分区,如果数据量太小就会和相邻分区合并。
一个空的数据库从一个分区开始,因为没有关于在哪里绘制分区边界的先验信息。数据集开始时很小,直到达到第一个分区的分割点,所有写入操作都必须由单个节点处理,而其他节点则处于空闲状态。为了解决这个问题,HBase和MongoDB允许在一个空的数据库上配置一组初始分区(这被称为预分割(pre-splitting))。在键范围分区的情况中,预分割需要提前知道键是如何进行分配的。
按节点比例分区
使分区数与集群节点数成正比关系,每个节点具有固定数量的分区。此时当结点数量不变时,每个分区的大小与数据集大小保持正比的增长关系,当节点数增加时,分区则会调整变得更小,较大的数据量通常需要大量的节点来存储,因此这种方法也使每个分区大小保持稳定。
当一个新节点加入集群时,它随机选择固定数量的现有分区进行分裂,然后拿走这些分区的一般数据量,将另一半数据留在原节点。
自动和手动再平衡操作
全自动再平衡会比较方便,但是可能出现难以预测的结果,让管理员介入到再平衡可能是个更好的选择。
请求路由
当客户端发送请求时,如何知道应该连接哪个节点?
- 允许客户端连接任意节点,如果正好是,则处理请求,如果不是,则转发到下一个合适的节点。
- 所有请求都发送到路由层转发到对应的分区节点上
- 客户端感知分区和节点分配关系,不需要中介。
作出路由决策的组件如何知道分区与节点的对应关系以及其变化情况?
- 依靠独立的协调服务跟踪集群范围内的元数据
- 节点之间使用gossip协议来同步集群状态的变化。
并行查询执行
数据仓库查询的快速并行执行是一个专门的话题,由于分析有很重要的商业意义,可以带来很多利益。我们将在第10章讨论并行查询执行的一些技巧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号