JUCE - 合成器
1、构建白噪声发生器
本教程介绍了简单的合成和音频输出。这是理解 JUCE 中的音频应用程序(和插件)概念的关键。
级别:中级
平台: Windows、macOS、Linux
类: AudioAppComponent、AudioSourceChannelInfo、AudioBuffer、Random
1.1、入门
在此处下载本教程的演示项目:PIP | ZIP。解压缩项目并在 Projucer 中打开第一个头文件。
1.2、演示项目
该演示项目是使用Projucer 音频应用程序模板创建的。这是您在 JUCE 中开发自己的音频应用程序的一个有用起点。演示项目合成白噪声并通过目标设备的默认音频硬件播放。
1.3、音频应用程序模板
本教程仅实现音频输出。音频输入和音频输入数据的实时音频处理将在其他教程中探讨。音频应用程序模板与 GUI 应用程序模板非常相似,不同之处在于:
- 该类
MainContentComponent继承自AudioAppComponent类,而不是Component类。 - 除了默认添加到项目的其他音频相关模块外,
juce_audio_utils模块也会添加到项目中。
音频应用程序模板可用于简单的应用程序,例如此处提供的示例。它还可扩展用于更复杂的应用程序,基本上是任何需要直接与目标设备的音频硬件交互的应用程序。其他教程探讨了如何使用 JUCE 创建音频插件。
1.3.1、音频应用程序生命周期
AudioAppComponent类是一个抽象基类,它具有三个纯虚函数,代表我们必须在派生类中实现的音频应用程序的生命周期:
- AudioAppComponent::prepareToPlay():在音频处理开始之前调用此函数。
- AudioAppComponent::releaseResources():当音频处理完成时调用此函数。
- AudioAppComponent::getNextAudioBlock():每次音频硬件需要新的音频数据块时都会调用此函数。
在这三个中,最重要的也许是AudioAppComponent::getNextAudioBlock(),因为这是您在 JUCE 音频应用程序中生成或处理音频的地方。 要理解它是如何工作的,我们需要了解一些现代计算机如何生成音频。 音频硬件需要为每秒的音频每个通道生成一定数量的样本。 CD 质量的采样率为 44.1kHz,这意味着每秒需要每个通道向音频硬件发送 44100 个样本进行播放。 样本不是一次一个样本地传递给音频硬件,而是以包含一定数量样本的缓冲区(或块)的形式传递。 例如,在 44.1kHz 和块大小为 441 时,我们的AudioAppComponent::getNextAudioBlock()函数每秒会被调用 100 次。
注意:上面的缓冲区大小为 441 个样本,是为了便于解释,使算法简单。实际上,缓冲区大小为 441 并不常见。硬件缓冲区大小几乎肯定是偶数,并且往往是 2 的幂(256、512、1024 等等)。重要的是,您的应用程序要准备好处理任何缓冲区大小。有关采样率和缓冲区大小设置的更多信息,请参阅教程:AudioDeviceManager 类。
为了使我们的 JUCE 音频应用程序正常工作,还有两个重要的函数。这次我们需要调用它们,而不是实现它们:
- AudioAppComponent::setAudioChannels():我们必须调用此函数来注册所需的输入和输出通道数量。通常,我们在构造函数中执行此操作。反过来,此函数会触发应用程序中音频处理的开始。
- AudioAppComponent::shutdownAudio():我们必须调用此函数来关闭音频系统。通常,我们在析构函数中执行此操作。
1.3.2、初始化音频应用程序
现在让我们通过更详细地检查音频应用程序的生命周期来探索噪声发生器的简单实现。我们的构造函数需要设置组件对象的大小(请参阅教程:主要组件)。我们还需要初始化至少一个音频输出:
setSize (800, 600);
setAudioChannels (0, 2); // no inputs, two outputs如上所述,调用 AudioAppComponent ::setAudioChannels()函数会触发音频系统启动。具体来说,它将调用以下prepareToPlay()函数:
void prepareToPlay (int samplesPerBlockExpected, double sampleRate) override
{
juce::String message;
message << "Preparing to play audio...\n";
message << " samplesPerBlockExpected = " << samplesPerBlockExpected << "\n";
message << " sampleRate = " << sampleRate;
juce::Logger::getCurrentLogger()->writeToLog (message);
}在这种情况下,我们实际上不需要在这里做任何事情,但由于它是一个纯虚函数,我们必须至少实现一个空函数。在这里,我们记录了一些有用的信息,我们可以在此时获得有关目标设备上的音频系统的信息。samplesPerBlockExpected顾名思义,参数是每次在我们的getNextAudioBlock()函数中请求音频缓冲区时,我们可以预期被要求的音频缓冲区的大小(以样本为单位)。这个缓冲区大小可能会在回调之间有所不同,但这是一个很好的迹象。参数sampleRate告诉我们硬件的当前采样率。如果我们正在做一些与频率相关的事情,例如合成音调(参见教程:构建正弦波合成器)或使用均衡,我们将需要它。如果我们使用延迟效果,我们还需要知道采样率。我们不需要这些信息来产生噪音。
1.3.3、生成音频数据
调用此prepareToPlay()函数后不久,音频线程将开始通过 AudioAppComponent::getNextAudioBlock() 函数请求音频块。此函数传递一个bufferToFill参数,即AudioSourceChannelInfo结构。AudioSourceChannelInfo结构包含音频样本的多通道缓冲区。它还包含两个整数值,用于指定应在此调用中处理此缓冲区的哪个区域。更详细地说,AudioSourceChannelInfo包含以下成员:
AudioSampleBuffer* buffer:AudioSampleBuffer 对象是音频数据的多通道缓冲区,本质上是float值的多维数组。当我们的getNextAudioBlock()函数被调用时,此缓冲区包含来自目标设备音频输入的任何音频数据(如果我们请求音频输入)。当我们的getNextAudioBlock()函数返回时,我们必须用我们想要播放的音频填充缓冲区的相关部分。int startSample:这是缓冲区内的样本索引,我们的getNextAudioBlock()函数应该从这里开始读取或写入音频。int numSamples:这是缓冲区中应该读取或写入的样本数。
音频数据以浮点值的形式存储非常简单。音频信号的每个样本都存储为一个名义上在 ±1.0 范围内的值。
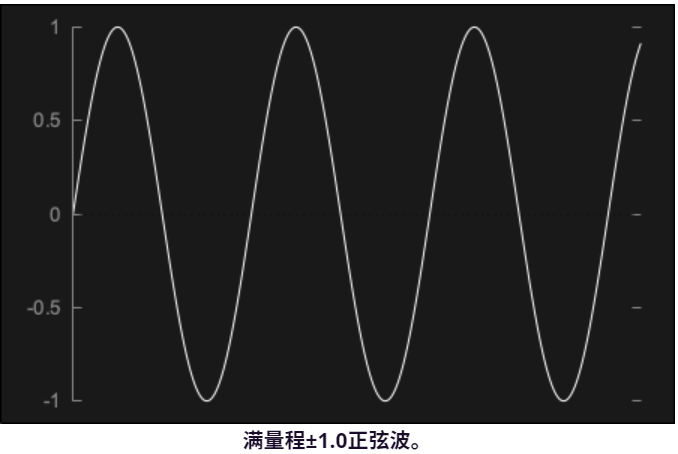
在峰值水平为 ±1.0 时,输出水平会非常大。事实上,这是音频系统在不发生削波的情况下能够产生的最大音量。通常,我们需要输出不超过此 ±1.0 限制的音频(尽管中间处理阶段超出此限制是可以的,只要最终输出较低)。
1.3.4、AudioSampleBuffer 类
虽然 AudioSampleBuffer 类(从最基本的层面上讲)只是一个多通道float值数组,但它提供了一组用于处理音频数据的有用函数。其中许多函数将在后面的教程中介绍,但在这里我们使用以下函数:
- AudioSampleBuffer::getNumChannels() :这将返回存储在缓冲区中的音频通道数。在这种情况下,该值应与我们之前在调用AudioAppComponent::setAudioChannels()函数时请求的输出通道数相匹配。(此值始终是输入和输出通道数的最大值。)
- AudioSampleBuffer::getWritePointer() :返回指向特定样本偏移量的
float值的缓冲区的指针。
为了使我们的简单应用程序能够生成白噪声,我们需要用随机值填充缓冲区的请求部分。为此,我们可以遍历缓冲区中的通道,在缓冲区中找到该通道的起始样本,然后将所需数量的样本写入缓冲区:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
for (auto channel = 0; channel < bufferToFill.buffer->getNumChannels(); ++channel)
{
// Get a pointer to the start sample in the buffer for this audio output channel
auto* buffer = bufferToFill.buffer->getWritePointer (channel, bufferToFill.startSample);
// Fill the required number of samples with noise between -0.125 and +0.125
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
buffer[sample] = random.nextFloat() * 0.25f - 0.125f;
}
}1.3.5、使用Random类生成白噪声
这里我们使用Random类来生成随机值(请参阅教程:Random 类)。要生成白噪声,我们需要生成围绕零均匀分布的随机数。在这里,我们首先调用 Random ::nextFloat()函数,生成介于 -0.125 和 +0.125 之间的随机值。这会生成介于 0 和 1 之间的值。然后我们将其结果乘以 0.25 并减去 0.125。(有关此过程的更多信息,请参阅教程:控制音频级别。)请注意,我们没有使用Random::getSystemRandom()函数来获取共享系统 Random对象,如其他教程(教程:Random 类)中所示。这是因为我们在音频线程上调用Random::nextFloat()函数。我们需要创建自己的Random对象,否则其他使用该共享Random对象的线程可能会破坏这些值。为此,将Random类的一个实例添加到我们的MainContentComponent类中:
private:
juce::Random random;调用AudioAppComponent::shutdownAudio()函数将反过来导致AudioAppComponent::releaseResources()函数被调用。如果我们在音频进程运行期间分配了任何资源(例如,如果我们分配了内存或打开了一些文件),那么这里是处理资源的好地方。在这种情况下,我们不需要任何额外的资源,我们只需用一条简单的消息记录函数调用:
void releaseResources() override
{
juce::Logger::getCurrentLogger()->writeToLog ("Releasing audio resources");
}练习:尝试更改音频输出的数量。请注意,单声道噪音听起来与立体声噪音略有不同。如果您有多声道声卡,您可能能够生成两个以上的噪音通道。您还可以尝试更改生成的噪音级别。例如,要生成 0.1 级别的噪音,您需要将随机生成的值乘以 0.2 并减去 0.1。
2、控制音频级别
本教程将介绍如何处理音频以改变其输出级别。这是通过处理低级音频样本数据来实现的。
级别:中级
平台: Windows、macOS、Linux
类: AudioAppComponent、Random、AudioSourceChannelInfo、AudioBuffer、Slider
2.1、入门
在此处下载本教程的演示项目:PIP | ZIP。解压缩项目并在 Projucer 中打开第一个头文件。
2.2、演示项目
演示项目提供了一个窗口,其中包含一个滑块,可用于控制白噪声发生器的输出级别。如下面的屏幕截图所示。
从 IDE 内部运行项目以确认您确实可以控制产生的白噪声的级别。
2.3、级别控制为乘法
检查代码,你可能会注意到我们的MainContentComponent类没有继承Slider::Listener类。事实上,我们在调用getNextAudioBlock()函数时立即获取滑块的值:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto level = (float) levelSlider.getValue();这种技术在简单的应用程序中是可以接受的,但在更复杂的应用程序中,您几乎肯定需要使用不同的技术。更好的做法是将控制音频处理系统的值存储在应用程序的“数据模型”中,而不是仅依靠 UI 控件来存储这些值。
为了生成滑块指定级别的白噪声,我们需要执行一些基本算术。Random ::nextFloat()函数始终生成 0.0 到 1.0 之间的值。如果我们将其绘制为音频波形,则它看起来会像这样:

解决这个问题的一个简单方法是先缩放噪声,使其始终在 -1.0 和 1.0 之间缩放。为此,我们可以乘以 2.0 并减去 1.0。这将产生如下所示的信号:
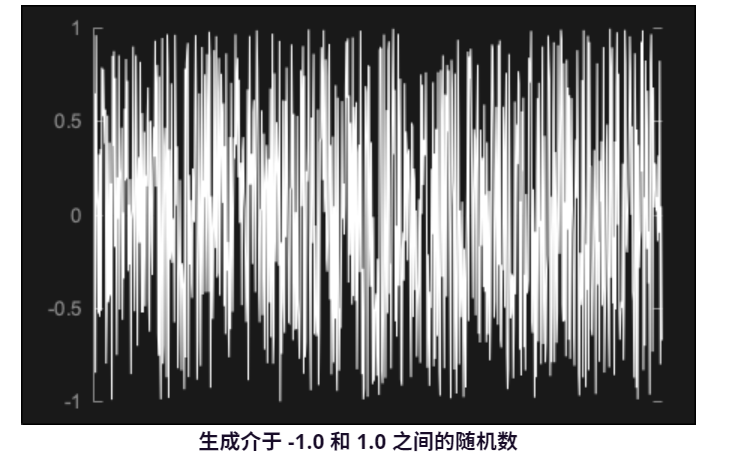
在我们的函数中代码实现getNextAudioBlock()如下:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto level = (float) levelSlider.getValue();
for (auto channel = 0; channel < bufferToFill.buffer->getNumChannels(); ++channel)
{
auto* buffer = bufferToFill.buffer->getWritePointer (channel, bufferToFill.startSample);
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
{
auto noise = random.nextFloat() * 2.0f - 1.0f;
buffer[sample] = noise * level;
}
}
}2.3.1、小幅优化
减少算术运算的数量通常是 DSP 的目标。在这种情况下,我们可以避免对每个样本执行一次乘法运算。为了实现这一点,首先我们可以将 0.0 到 1.0 之间的值乘以等于所需输出级别两倍的值。假设我们希望级别为 0.25。如果我们将随机值乘以 0.5,我们将得到如下结果:
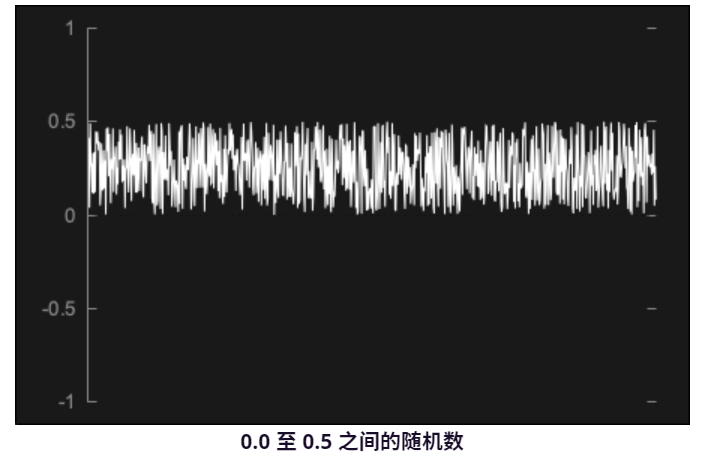
最后,我们需要偏移随机值,使它们以零为中心。为此,我们减去一个等于我们乘以的值一半的值。当然,这是原始级别值。最终结果将是这样的:
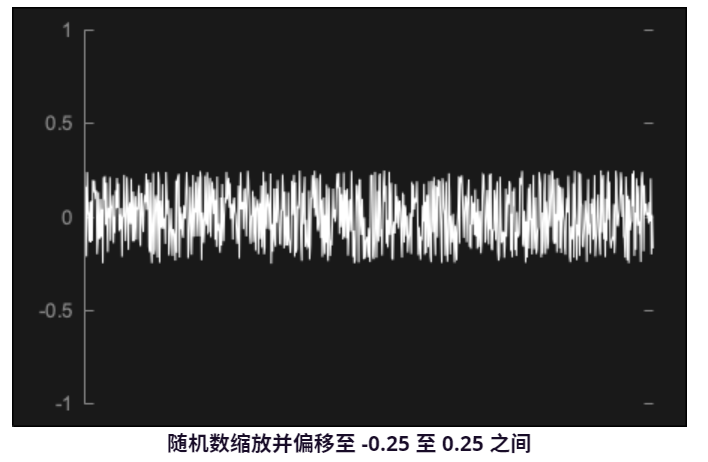
这可以通过我们的函数在代码中实现getNextAudioBlock(),您应该看到每个样本的乘法运算现在减少了一次:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto level = (float) levelSlider.getValue();
auto levelScale = level * 2.0f;
for (auto channel = 0; channel < bufferToFill.buffer->getNumChannels(); ++channel)
{
auto* buffer = bufferToFill.buffer->getWritePointer (channel, bufferToFill.startSample);
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
{
//auto noise = random.nextfloat() * 2.0f - 1.0f;
//buffer[sample] = noise * level;
buffer[sample] = random.nextFloat() * levelScale - level;
}
}
}此实现的一个剩余问题是,级别只会针对生成的每个音频块更新为新的恒定值。在这种情况下,它是听不见的(就像白噪声中的源声音一样)。如果将此应用于大多数音频内容,则此技术将引入音频伪影。这是因为级别值可能在每个音频块之间跳跃得相当突然,而不是在音频块期间平稳变化。其他教程探讨了避免这些伪影(例如级别变化时可听到的噼啪声)的技术(请参阅教程:构建正弦波合成器)。
练习:在用户界面上添加第二个滑块。使用第一个滑块控制左声道的音量,使用第二个滑块控制右声道的音量。
3、使用分贝控制音频级别
本教程将介绍如何使用分贝标度来处理音频以更改其输出级别。这是在音频应用程序中向用户呈现音频级别值的更常见方法。
级别:中级
平台: Windows、macOS、Linux
3.1、入门
在此处下载本教程的演示项目:PIP | ZIP。解压缩项目并在 Projucer 中打开第一个头文件。
3.2、演示项目
与教程:控制音频级别演示项目类似,本教程的演示项目提供了一个包含单个滑块的窗口。这次滑块值以分贝表示。此分贝值需要转换为线性增益值,然后才能用于音频处理算法。大多数音频应用程序都以分贝为单位向用户表示增益,因为随着值的变化(或比较),这通常感觉更自然。演示项目的用户界面如以下屏幕截图所示。
3.3、创建自定义滑块
请注意,此时滑块旁边显示的文本不仅显示分贝值,还显示后缀“dB”。这是通过创建从SliderDecibelSlider类继承的自定义滑块类来实现的。在此自定义滑块类中,文本框界面被定制为显示分贝值。虽然可以使用Slider::setTextValueSuffix()函数为Slider对象文本框中显示的文本添加后缀,但我们需要进行更多定制。这是为了定制值转换的方式,以便当级别降到非常低时我们可以显示-INF dB 。
注意:INF表示无穷大,其中 -INF dB 在我们的应用中被视为静默。
3.3.1、分贝等级
Decibels类包含许多静态函数,这些函数对于分贝值和线性增益之间的转换必不可少。它还提供了一种将分贝值转换为String对象的简单方法。例如,我们通过使用Decibels::toString()函数(在DecibelSlider类中)覆盖虚拟函数Slider::getTextFromValue(),如下所示:
juce::String getTextFromValue (double value) override
{
return juce::Decibels::toString (value);
}这使得我们的DecibelSlider类能够根据给定的滑块值在其文本框中显示适当的文本。
Decibels类没有将String对象转换回分贝值的函数,因此我们需要自己编写一个。这里我们重写 Slider ::getValueFromText()虚函数(同样在DecibelSlider类中):
double getValueFromText (const juce::String& text) override
{
auto minusInfinitydB = -100.0;
auto decibelText = text.upToFirstOccurrenceOf ("dB", false, false).trim(); // [1]
return decibelText.equalsIgnoreCase ("-INF") ? minusInfinitydB
: decibelText.getDoubleValue(); // [2]
}这使用户能够在文本框中输入一个值,并对其进行检查并将其转换为滑块的有效值。为此,我们:
- [1]:从文本中去除“dB”后缀(如果存在),并修剪文本以删除任何前导或尾随空格(使用String::trim()函数)。
- [2]:检查剩余文本是否为“-INF”,如果为“-INF”,则返回 -100(这是Decibels类使用的-INF dB的默认值,以分贝为单位,有关此内容的讨论,请参阅本教程的注释)。否则,我们将剩余文本转换为
double值并返回。
3.4、使用滑块值
在教程:控制音频级别中,我们直接在getNextAudioBlock()函数中访问滑块的值。由于从分贝到线性增益的转换涉及一些可能占用大量 CPU 的算法,因此最好避免过于频繁地执行转换,尤其是在音频线程上。在本教程的演示项目中,我们在MainContentComponent类中存储一个float成员,并在滑块使用侦听器更改时更新此level值。
我们在构造函数中将level成员初始化为零,然后使用Decibels::gainToDecibels()函数将其转换为分贝,以赋予滑块其初始位置(使用Slider::setValue()函数),如下所示:
decibelSlider.setValue (juce::Decibels::gainToDecibels (level));
decibelLabel.setText ("Noise Level in dB", juce::dontSendNotification);3.4.1、将分贝转换为线性增益
在Slider::onValueChange辅助对象的 lambda 函数中,我们将滑块使用的分贝刻度转换为音频处理所需的线性增益值:
decibelSlider.onValueChange = [this] { level = juce::Decibels::decibelsToGain ((float) decibelSlider.getValue()); };当我们首次使用构造函数中的Slider::setValue()函数设置滑块的值时,将调用此函数。当值发生变化时,这将调用分配给Slider::onValueChange辅助对象的lambda 函数,并且我们的level成员将被正确设置。
练习:
- 向显示线性增益值的
MainContentComponent类中添加另一个标签对象。 - 将另一个Slider对象添加到显示线性增益值的
MainContentComponent类中,让用户使用任一滑块查看和指定噪声级别。当移动任一滑块时,两个滑块都应正确更新。(请参阅教程:Slider 类,了解在不同单位之间转换的简单示例。)
3.4.2、处理音频
MainContentComponent::getNextAudioBlock()在我们的音频处理中:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto currentLevel = level;
auto levelScale = currentLevel * 2.0f;
for (auto channel = 0; channel < bufferToFill.buffer->getNumChannels(); ++channel)
{
auto* buffer = bufferToFill.buffer->getWritePointer (channel, bufferToFill.startSample);
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
buffer[sample] = random.nextFloat() * levelScale - currentLevel;
}
}请注意,这几乎与教程中的getNextAudioBlock()函数相同:控制音频级别, 只是我们只获取该值的函数本地副本level,然后像以前一样计算我们的levelScale值。
3.4.3、这种方法的问题
这种方法的一个问题是,level变量的值可能会在音频线程执行期间突然改变(在本例中,是在两次getNextAudioBlock调用之间)。此类变化通常会引入音频伪影,例如可听见的噼啪声。为了避免这种情况,在实际合成器中,我们希望值能够level平稳变化。其他教程探讨了实现此目的的技术(请参阅教程:构建正弦波合成器)。
另一个问题与线程安全有关。level如果没有进行线程同步(无论是通过关键部分还是使用原子操作),则在 C++ 中写入成员变量(例如在一个线程(GUI 线程)中)并从另一个线程(音频线程)读取相同的值在技术上是未定义的行为。这些问题超出了本教程的范围,将在以后的教程中讨论。在这个特定情况下,我们不必太担心这个问题,因为在典型的架构(x86、x86_64、ARM)上,读取和写入单个float是原子操作:读取和写入不能混合,并且通常是安全的。
进一步思考,可能还想通过创建levelScale成员变量来进一步优化代码(因此不必在每次调用getNextAudioBlock()函数时都计算它)。但这样一来,这两个成员变量就不再作为单个原子操作进行更新了。当然,也有办法解决这个问题,但这超出了本教程的范围。
3.5、注意
本教程的演示项目中提供的代码假设我们希望将 -100 dB 或更低的值视为 -INF dB(即线性增益值为零)。此值 -100 dB 是Decibels类使用的默认值,但您可以在其计算中覆盖它。这是通过为Decibels类中的每个函数提供一个附加参数来实现的,该参数指定应将哪个值视为 -INF dB。例如,要在MainContentComponent构造函数中更新滑块值时将 -96 dB(及以下)用作 -INF dB,我们可以这样做:
decibelSlider.setValue (juce::Decibels::gainToDecibels (level, -96.0f));但当然,我们需要确保应用程序的所有部分都使用相同的 -INF dB 值。由于我们在DecibelSlider::getValueFromText()函数中进行了硬编码-100.0,因此演示项目的代码存在一个潜在问题。如果Decibels类更改其默认值(出于某种原因),那么我们的代码就会中断。不幸的是,此默认值是Decibels类的私有成员,因此我们无法向Decibels类询问其默认值。相反,我们需要指定我们自己的默认值并始终使用它。
练习:修改演示项目以将 -INF 的默认值指定为 -96 dB。您应该需要更新类DecibelSlider和MainContentComponent类。
4、构建正弦波合成器
本教程介绍简单的正弦波合成。我们将展示如何管理正弦波振荡器的状态并将数据写入音频输出。
级别:中级
平台: Windows、macOS、Linux
类: AudioAppComponent、Slider、MathConstants
4.1、入门
在此处下载本教程的演示项目:PIP | ZIP。解压缩项目并在 Projucer 中打开第一个头文件。
4.2、演示项目
该演示项目基于 Projucer 的音频应用程序模板。它向用户呈现一个滑块来控制正弦波的频率。
4.3、生成正弦波
本教程使用标准库函数合成正弦波std::sin()。为了使用它,我们需要通过存储当前相位角和相位角需要为每个输出样本增加的量来维护正弦波生成的状态。每个样本的变化大小(“增量”)取决于输出的采样率和我们想要生成的正弦波的频率。
警告:大多数合成应用程序和插件可能不会使用该std::sin()功能,因为它可能不是最有效的技术。通常会使用波表,请参阅教程:波表合成。波表还允许除正弦波以外的其他波形。
4.3.1、维护我们的状态
在我们的MainContentComponent类中,我们存储了三个double成员[1]:
double currentSampleRate = 0.0, currentAngle = 0.0, angleDelta = 0.0; // [1]我们有一个简单的函数来更新angleDelta成员:
void updateAngleDelta()
{
auto cyclesPerSample = frequencySlider.getValue() / currentSampleRate; // [2]
angleDelta = cyclesPerSample * 2.0 * juce::MathConstants<double>::pi; // [3]
}- [2]:首先,我们计算每个输出样本需要完成的周期数。
- [3]:然后将其乘以整个正弦波周期的长度,即2pi弧度。
在此函数正常工作之前,我们需要知道输出采样率。这是因为我们需要知道样本生成的频率,这是为了知道每个样本所需的变化量。我们通过 AudioAppComponent ::prepareToPlay()回调函数传递采样率:
void prepareToPlay (int, double sampleRate) override
{
currentSampleRate = sampleRate;
updateAngleDelta();
}在这里我们存储采样率值的副本并最初调用我们的updateAngleDelta()函数。
4.3.2、使用滑块值
当应用程序运行时滑块移动时,我们需要angleDelta再次更新成员:
frequencySlider.onValueChange = [this]
{
if (currentSampleRate > 0.0)
updateAngleDelta();
};updateAngleDelta()在再次调用该函数之前,我们在这里检查采样率是否有效。
4.3.3、输出音频
在getNextAudioBlock()回调期间我们需要生成实际的正弦波并将其写入输出:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto level = 0.125f;
auto* leftBuffer = bufferToFill.buffer->getWritePointer (0, bufferToFill.startSample);
auto* rightBuffer = bufferToFill.buffer->getWritePointer (1, bufferToFill.startSample);
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
{
auto currentSample = (float) std::sin (currentAngle);
currentAngle += angleDelta;
leftBuffer[sample] = currentSample * level;
rightBuffer[sample] = currentSample * level;
}
}对于每个输出样本,我们计算当前角度的正弦函数,然后增加下一个样本的角度。请注意,我们将级别降低到,0.125因为满量程正弦波会非常响亮!我们可以(也许应该)在当前角度值达到2pi时将其回绕回零。由于较大的值仍会返回有效值,因此我们实际上可以避免这种计算。我们得到如下图所示的结果:
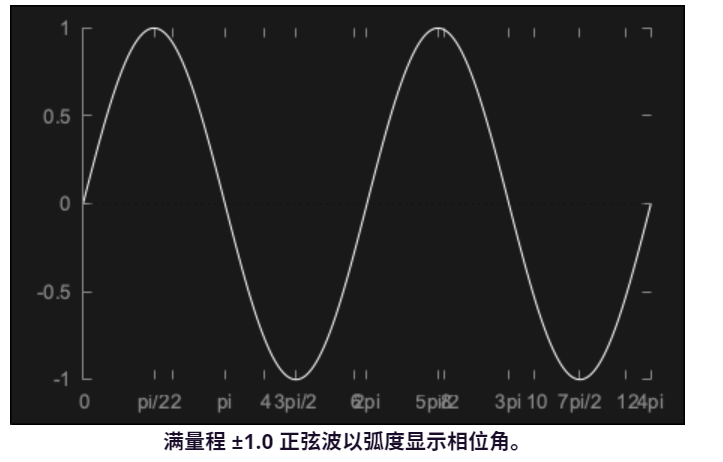
4.3.4、滑块配置
您可能已经注意到滑块值呈非线性变化(如果没有,您现在应该尝试一下)。这些变化实际上是对数的。这为较小的值提供了更高的分辨率,为较大的值提供了更低的分辨率。当控制频率值时,这通常是合适的(因为在音乐上,我们听到的是频率之间比率的相等变化,而不是相等的线性变化)。这可以通过使用 Slider ::setSkewFactorFromMidPoint()函数[4]进行配置。我们的滑块范围设置为50..5000,因此将滑块轨道的中心设置为500意味着滑块最小值和中心之间以及中心和滑块最大值之间存在相等的音乐间隔:
addAndMakeVisible (frequencySlider);
frequencySlider.setRange (50.0, 5000.0);
frequencySlider.setSkewFactorFromMidPoint (500.0); // [4]可以使用Slider::setSkewFactor()函数直接设置滑块的倾斜系数,尽管思考中点的值通常更容易。
锻炼:在应用程序中添加另一个滑块来控制正弦波的级别。注意将级别保持在1.0以下— 最大值为0.25即可。
4.4、平滑频率变化
您可能会注意到,尤其是在较高频率时,滑块移动时会产生一些可听见的、可能不想要的伪影。这是因为滑块实际上是以离散步骤变化的,而当滑块快速移动时,这些步骤会非常大。除此之外,滑块频率仅针对每个音频块进行更新,因此这些变化的确切效果将取决于硬件块大小。
4.4.1、平滑状态成员
让我们在类中添加两个成员,一个用于存储用于合成的当前频率,另一个用于存储用户通过移动滑块请求的目标频率。然后我们可以更缓慢地在这些值之间变化以消除伪影:
double currentFreq = 500.0, targetFreq = 500.0;4.4.2、更新合成代码
该算法的关键在于检查当前值和目标值是否相同或不同。如果它们相同,那么我们可以简单地使用原始代码,因为angleDelta成员不需要更改。如果当前值和目标值不同,那么我们需要angleDelta在逐步将当前值移近目标值时更新每个样本的成员。
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto level = 0.125f;
auto* leftBuffer = bufferToFill.buffer->getWritePointer (0, bufferToFill.startSample);
auto* rightBuffer = bufferToFill.buffer->getWritePointer (1, bufferToFill.startSample);
// 检查我们的目标是否与当前值不同。注意,我们获取的是本地副本,以防滑块在此函数运行时更改消息线程上的值
auto localTargetFreq = targetFreq;
// 判断是否大概相等
if (!juce::approximatelyEqual(localTargetFreq, currentFreq)) {
// 计算每个样本所需的增量
auto freqIncrement = (localTargetFreq - currentFreq) / bufferToFill.numSamples;
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample) {
auto currentSample = (float)std::sin(currentAngle);
// 增加当前频率
currentFreq += freqIncrement;
// 根据这个新的频率更新deltaAngle成员
updateAngleDelta();
currentAngle += angleDelta;
leftBuffer[sample] = currentSample * level;
rightBuffer[sample] = currentSample * level;
}
currentFreq = localTargetFreq;
} else {
// 否则就使用原始代码
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample) {
auto currentSample = (float)std::sin(currentAngle);
currentAngle += angleDelta;
leftBuffer[sample] = currentSample * level;
rightBuffer[sample] = currentSample * level;
}
}
}注意:此代码的格式采用了典型的DSP代码模式。如果可能,我们会避免在内部for()循环中使用条件语句。相反,我们会在循环外部测试条件,并且根据参数是否发生变化,我们使用两个不同但非常相似的循环。
最后,我们需要更新Slider::onValueChange辅助对象,以便它仅更新目标值:
frequencySlider.onValueChange = [this]
{
targetFreq = frequencySlider.getValue();
};就这样!现在试试这个,滑块移动的瑕疵应该已经被消除了。
注意:在所有情况下,不将相位角包裹在2pi左右可能并不理想。如果使用float而不是double变量,那么当当前角度值变得非常大时,计算会有些不准确。通过不将相位包裹在2pi左右,使用该std::sin()函数与简单的波表技术相比表现相当好。请参阅教程:波表合成以了解这方面的探索。
5、构建MIDI合成器
本教程实现了一个响应 MIDI 输入的复音正弦波合成器。这利用了Synthesiser类和相关类。
级别:中级
平台: Windows、macOS、Linux
类: Synthesiser、SynthesiserVoice、SynthesiserSound、AudioSource、MidiMessageCollector
5.1、入门
在此处下载本教程的演示项目:PIP | ZIP。解压缩项目并在 Projucer 中打开第一个头文件。
5.2、演示项目
该演示项目展示了一个屏幕键盘,可用于播放简单的正弦波合成器。

使用计算机键盘上的按键可以控制屏幕键盘(使用按键 A、S、D、F 等来控制音符 C、D、E、F 等)。这样您就可以以复音方式演奏合成器。
5.3、合成器类
本教程利用 JUCE Synthesiser类来实现复音合成器。这将向您展示在您自己的应用程序中使用您自己的声音自定义合成器所需的所有基本元素。要实现这一点,需要各种类,除了我们的标准MainContentComponent类之外,还有:
SynthAudioSource:这将实现一个名为AudioSource的自定义SynthAudioSource类,其中包含Synthesiser类本身。这将输出来自合成器的所有音频。SineWaveVoice:这是一个名为SineWaveVoice的自定义SynthesiserVoice类。Voice类渲染合成器的一个Voice,并将其与Synthesiser对象中的其他发声混合。Voice类的单个实例渲染一个Voice。SineWaveSound:这包含一个名为SineWaveSound的自定义SynthesiserSound类。声音类实际上是可以创建为Voice的声音的描述。例如,这可能包含采样器语音的样本数据或波表合成器的波表数据。
5.3.1、设置键盘
我们的MainContentComponent类包含以下数据成员。
juce::MidiKeyboardState keyboardState;
SynthAudioSource synthAudioSource;
juce::MidiKeyboardComponent keyboardComponent;synthAudioSource和keyboardComponent成员在MainContentComponent构造函数中初始化。
MainContentComponent()
: synthAudioSource (keyboardState),
keyboardComponent (keyboardState, juce::MidiKeyboardComponent::horizontalKeyboard)
{
addAndMakeVisible (keyboardComponent);
setAudioChannels (0, 2);
setSize (600, 160);
startTimer (400);
}有关MidiKeyboardComponent类的更多信息,请参阅教程:处理 MIDI 事件。
为了能够从计算机键盘开始弹奏键盘,我们在应用程序启动后立即获取键盘焦点。为此,我们使用一个在 400 毫秒后触发的简单计时器:
void timerCallback() override
{
keyboardComponent.grabKeyboardFocus();
stopTimer();
}5.3.2、AudioAppComponent 函数
该应用程序使用AudioAppComponent设置了一个简单的音频应用程序(请参阅教程:为最基本的应用程序构建白噪声生成器)。三个必需的纯虚拟函数只需调用我们自定义AudioSource类中的相应函数即可:
void prepareToPlay (int samplesPerBlockExpected, double sampleRate) override
{
synthAudioSource.prepareToPlay (samplesPerBlockExpected, sampleRate);
}
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
synthAudioSource.getNextAudioBlock (bufferToFill);
}
void releaseResources() override
{
synthAudioSource.releaseResources();
}5.3.3、SynthAudioSource 类
该SynthAudioSource类做了更多的工作:
class SynthAudioSource : public juce::AudioSource
{
public:
SynthAudioSource (juce::MidiKeyboardState& keyState)
: keyboardState (keyState)
{
// 我们在合成器中添加了一些声音,添加的声音数量决定了合成器的复音数
for (auto i = 0; i < 4; ++i) // [1]
synth.addVoice (new SineWaveVoice());
// 我们添加声音,以便合成器直到它可以播放哪些声音
synth.addSound (new SineWaveSound()); // [2]
}
void setUsingSineWaveSound()
{
synth.clearSounds();
}
void prepareToPlay (int /*samplesPerBlockExpected*/, double sampleRate) override
{
// 合成器需要知道音频输出的采样率
synth.setCurrentPlaybackSampleRate (sampleRate); // [3]
}
void releaseResources() override {}
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
bufferToFill.clearActiveBufferRegion();
juce::MidiBuffer incomingMidi;
// 从keyboardState中提取MIDI数据的缓冲区
keyboardState.processNextMidiBuffer (incomingMidi, bufferToFill.startSample,
bufferToFill.numSamples, true); // [4]
// 这些MIDI缓冲区被传递到合成器,合成器将使用音符开启和音符关闭消息(以及其他MIDI通道语音消息)的时间戳来呈现声音
synth.renderNextBlock (*bufferToFill.buffer, incomingMidi,
bufferToFill.startSample, bufferToFill.numSamples); // [5]
}
private:
juce::MidiKeyboardState& keyboardState;
juce::Synthesiser synth;
};警告:SynthesiserVoice对象必须添加到一个且只能一个Synthesiser对象。Synthesiser对象管理Voice的生命周期。
如果您愿意,SynthesiserSound对象可以在Synthesiser对象之间共享。SynthesiserSound类是一种ReferenceCountedObject类,因此SynthesiserSound对象的生命周期是自动处理的。
注意:如果您需要保留指向SynthesiserSound对象的指针,则应将其存储在YourSoundClass::Ptr变量中以使此内存管理正常工作。
5.3.4、SineWaveSound 类
我们的声音类非常简单,它甚至不需要包含任何数据。它只需要报告此声音是否应在特定 MIDI 通道上播放以及该通道上的特定音符或音符范围。在我们的简单情况下,它对于appliesToChannel()和appliesToNote()只返回true。如上所述,声音类可能是您存储创建声音所需的数据(例如波表)的地方。
struct SineWaveSound : public juce::SynthesiserSound
{
SineWaveSound() {}
bool appliesToNote (int) override { return true; }
bool appliesToChannel (int) override { return true; }
};5.3.5、SineWaveVoice State
这个SineWaveVoice类稍微复杂一点。它需要维护合成器某个声音的状态。对于我们的正弦波,我们需要这些数据成员:
double currentAngle = 0.0, angleDelta = 0.0, level = 0.0, tailOff = 0.0;有关前三个的信息,请参阅教程:构建正弦波合成器。该tailOff成员用于使每个声音的振幅包络稍微柔和一些。这会使每个声音在结尾处略微淡出,而不是突然停止。
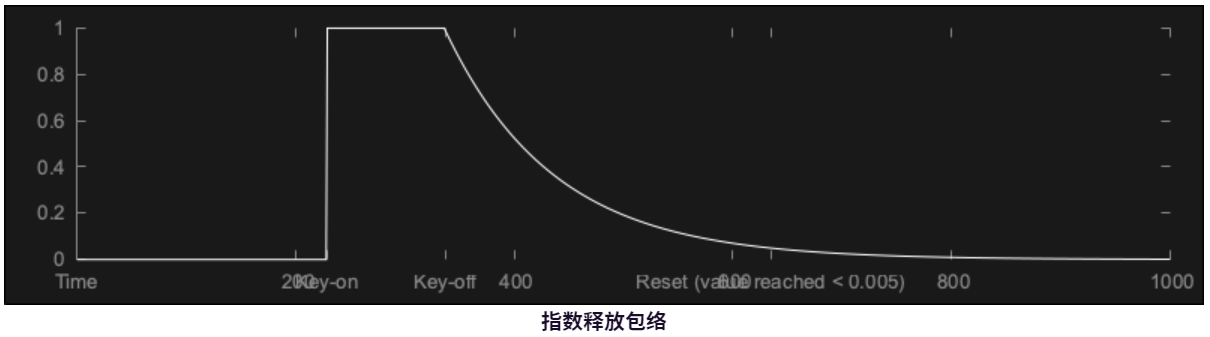
5.3.6、检查哪些声音可以播放
必须重写SynthesiserVoice ::canPlaySound()函数来返回Voice是否可以播放声音。在这种情况下,我们可以直接返回true,但我们的示例说明了如何使用dynamic_cast来检查传入的声音类的类型。
bool canPlaySound (juce::SynthesiserSound* sound) override
{
return dynamic_cast<SineWaveSound*> (sound) != nullptr;
}5.3.7、开始发声
通过调用我们的SynthesiserVoice::startNote()函数,所属合成器可以启动语音,我们必须重写该函数:
void startNote (int midiNoteNumber, float velocity,
juce::SynthesiserSound*, int /*currentPitchWheelPosition*/) override
{
currentAngle = 0.0;
level = velocity * 0.15;
tailOff = 0.0;
auto cyclesPerSecond = juce::MidiMessage::getMidiNoteInHertz (midiNoteNumber);
auto cyclesPerSample = cyclesPerSecond / getSampleRate();
angleDelta = cyclesPerSample * 2.0 * juce::MathConstants<double>::pi;
}再次强调,您应该熟悉教程:构建正弦波合成器中的大部分内容。在每个声音开始时,tailOff值设置为零。我们还使用 MIDI 音符开启事件的速度来控制声音的音量。
5.3.8、渲染语音
必须重写SynthesiserVoice ::renderNextBlock()函数才能生成音频。
void renderNextBlock (juce::AudioSampleBuffer& outputBuffer, int startSample, int numSamples) override
{
if (angleDelta != 0.0)
{
// 当按键被释放时,该tailoff值将大于0,你可以看到合成算法是类似的
if (tailOff > 0.0) // [7]
{
while (--numSamples >= 0)
{
auto currentSample = (float) (std::sin (currentAngle) * level * tailOff);
for (auto i = outputBuffer.getNumChannels(); --i >= 0;)
outputBuffer.addSample (i, startSample, currentSample);
currentAngle += angleDelta;
++startSample;
// 使用简单的指数衰减包络形状
tailOff *= 0.99; // [8]
if (tailOff <= 0.005)
{
// 当该tailOff值很小时,我们确定语音已结束。
// 此时我们必须调用SynthesiserVoice::clearCurrentNote()函数,以便重置语音并可供重复使用。
clearCurrentNote(); // [9]
angleDelta = 0.0;
break;
}
}
}
else
{
// 此循环用于在按住键时语音的正常状态。
// 请注意,我们使用AudioSampleBuffer::addSample()函数,该函数将currentSample值与 index 处的值混合startSample。
// 这是因为合成器将遍历所有语音。每个语音都有责任将其输出与缓冲区的当前内容混合。
while (--numSamples >= 0) // [6]
{
auto currentSample = (float) (std::sin (currentAngle) * level);
for (auto i = outputBuffer.getNumChannels(); --i >= 0;)
outputBuffer.addSample (i, startSample, currentSample);
currentAngle += angleDelta;
++startSample;
}
}
}
}警告:注意这个startSample参数非常重要。合成器很可能在其中一个输出块的中途调用该renderNextBlock()函数。这是因为音符可能从任何样本开始。这些开始时间基于收到的 MIDI 数据的时间戳。
5.3.9、停止声音
拥有合成器的合成器调用我们的SynthesiserVoice::stopNote()函数来停止声音,我们必须重写该函数:
void stopNote (float /*velocity*/, bool allowTailOff) override
{
if (allowTailOff)
{
if (tailOff == 0.0)
tailOff = 1.0;
}
else
{
clearCurrentNote();
angleDelta = 0.0;
}
}这可能包括来自 MIDI 音符结束消息的速度信息,但在许多情况下我们可以忽略它。我们可能会被要求立即停止语音,在这种情况下,我们会立即调用 SynthesiserVoice ::clearCurrentNote()函数。在正常情况下,合成器将允许我们的声音自然结束。在我们的例子中,我们有简单的尾音包络。我们通过将成员tailOff设置为 1.0来触发尾音。
练习:尝试为声音添加较慢的attack速度,以使它们不会突然开始。
5.4、添加外部MIDI输入
让我们添加功能,以允许外部 MIDI 源除了屏幕键盘之外还可以控制我们的合成器。
警告:您可能需要在诸如 macOS、Windows 或 Linux 等桌面平台之一上尝试此操作,而不是在移动平台之一上。
5.4.1、为 SynthAudioSource 提供 MIDI 输入
首先添加一个MidiMessageCollector对象作为SynthAudioSource类的成员。这提供了可以发送 MIDI 消息的地方,并且SynthAudioSource类可以使用它们:
juce::MidiMessageCollector midiCollector;为了处理 MIDI 数据的时间戳,MidiMessageCollector类需要知道音频采样率。在SynthAudioSource::prepareToPlay()函数[10]中设置它:
void prepareToPlay (int /*samplesPerBlockExpected*/, double sampleRate) override
{
// 合成器需要知道音频输出的采样率
synth.setCurrentPlaybackSampleRate (sampleRate); // [3]
midiCollector.reset(sampleRate);
}然后,你可以使用MidiMessageCollector::removeNextBlockOfMessages()函数[11]提取每个音频块的任何 MIDI 消息:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
bufferToFill.clearActiveBufferRegion();
juce::MidiBuffer incomingMidi;
midiCollector.removeNextBlockOfMessages(incomingMidi, bufferToFill.numSamples); //[11]
// 从keyboardState中提取MIDI数据的缓冲区
keyboardState.processNextMidiBuffer (incomingMidi, bufferToFill.startSample,
bufferToFill.numSamples, true); // [4]
// 这些MIDI缓冲区被传递到合成器,合成器将使用音符开启和音符关闭消息(以及其他MIDI通道语音消息)的时间戳来呈现声音
synth.renderNextBlock (*bufferToFill.buffer, incomingMidi,
bufferToFill.startSample, bufferToFill.numSamples); // [5]
}我们需要从SynthAudioSource类外部访问这个MidiMessageCollector对象,因此向SynthAudioSource类添加一个访问器,如下所示:
juce::MidiMessageCollector* getMidiCollector() {
return &midiCollector;
}在我们的MainContentComponent类中,我们将这个MidiMessageCollector对象作为MidiInputCallback对象添加到我们应用程序的AudioDeviceManager对象中。
5.4.2、列出MIDI输入
为了向用户显示 MIDI 输入设备列表,我们将使用教程:处理 MIDI 事件中的一些代码。向我们的MainContentComponent类添加一些成员:
juce::ComboBox midiInputList;
juce::Label midiInputListLabel;
int lastInputIndex = 0; 然后将以下代码添加到MainContentComponent构造函数中。
MainContentComponent()
: synthAudioSource (keyboardState),
keyboardComponent (keyboardState, juce::MidiKeyboardComponent::horizontalKeyboard)
{
addAndMakeVisible (keyboardComponent);
setAudioChannels (0, 2);
setSize (600, 160);
startTimer (400);
// -------------------------------------
addAndMakeVisible(midiInputListLabel);
midiInputListLabel.setText("MIDI Input:", juce::dontSendNotification);
midiInputListLabel.attachToComponent(&midiInputList, true);
auto midiInputs = juce::MidiInput::getAvailableDevices();
addAndMakeVisible(midiInputList);
midiInputList.setTextWhenNoChoicesAvailable("No MIDI Inputs Enabled");
juce::StringArray midiInputNames;
for (auto input : midiInputs)
midiInputNames.add(input.name);
midiInputList.addItemList(midiInputNames, 1);
midiInputList.onChange = [this] { setMidiInput(midiInputList.getSelectedItemIndex()); };
for (auto input : midiInputs) {
if (deviceManager.isMidiInputDeviceEnabled(input.identifier)) {
setMidiInput(midiInputs.indexOf(input));
break;
}
}
if (midiInputList.getSelectedId() == 0)
setMidiInput(0);
} 添加上面代码中调用的setMidiInput()函数:
void setMidiInput(int index) {
auto list = juce::MidiInput::getAvailableDevices();
deviceManager.removeMidiInputDeviceCallback(list[lastInputIndex].identifier,
synthAudioSource.getMidiCollector()); // [12]
auto newInput = list[index];
if (!deviceManager.isMidiInputDeviceEnabled(newInput.identifier))
deviceManager.setMidiInputDeviceEnabled(newInput.identifier, true);
deviceManager.addMidiInputDeviceCallback(newInput.identifier, synthAudioSource.getMidiCollector()); // [13]
midiInputList.setSelectedId(index + 1, juce::dontSendNotification);
lastInputIndex = index;
} 请注意,我们将MidiMessageCollector对象从我们的SynthAudioSource对象添加为指定 MIDI 输入设备的MidiInputCallback对象[13]。如果用户使用组合框[12]更改所选设备,我们还需要删除先前所选 MIDI 输入设备的先前MidiInputCallback对象。
我们需要定位这个ComboBox对象并在我们的resized()函数中调整MidiKeyboardComponent对象的位置:
void resized() override
{
midiInputList.setBounds(200, 10, getWidth() - 210, 20);
keyboardComponent.setBounds (10, 10, getWidth() - 20, getHeight() - 20);
}再次运行该应用程序,它看起来应该像这样:

当然,列出的设备将取决于您的具体系统配置。
练习:尝试添加一个滑块来控制每个声音的尾音长度。如果您在之前的练习中添加了滑块,那么您也可以添加一个滑块来控制attack长度。
6、波表合成
结合波表来优化您的合成器振荡器。使用波表管理正弦波振荡器的状态并将数据写入音频输出。
级别:中级
平台: Windows、macOS、Linux
类: AudioBuffer、AudioAppComponent、Random、MathConstants
6.1、入门
在此处下载本教程的演示项目:PIP | ZIP。解压缩项目并在 Projucer 中打开第一个头文件。
6.2、演示项目
演示项目只是通过立体声输出生成并输出一堆随机正弦波谐波。通过比较振荡器的传统实现和使用波表的实现,用户界面允许我们监控 CPU 使用率。
为了正确评估和比较不同实现的 CPU 使用率,我们将在Release配置中运行我们的应用程序,而不是在测试和开发期间使用的常规Debug配置。通过在Release模式下构建项目,编译器将能够尽可能地优化代码,例如从代码中删除断言和注释以及内联函数。您的应用程序现在将在经过大量编译器优化后运行,并且 CPU 使用率将显著降低。
6.3、波表
波表合成是一种合成方法,它使用预先填充了周期性波形的查找表来生成振荡器,而不必为每个计算的样本生成相同的波形。波表使用您选择的周期性波形进行初始化,并且可以指定这些波形的分辨率。在检索要输出的正确样本值时,如果表中的样本数与音频缓冲块中的样本数及其对应的请求频率不匹配,则通过在两个波表样本之间进行插值来找到该值。
举个例子,假设我们想从波表中查找正弦波。我们首先要为正弦波的单个周期创建一个波表,例如分辨率为 128 个采样点。然后,对于缓冲块中的每个样本,我们可以通过使用采样率、播放请求频率、波表分辨率和波形的当前相位或角度的组合来计算正确的插值样本,从而请求正弦波样本值。
在深入研究波表之前,让我们先从一个简单的正弦波振荡器实现开始。
6.3、正弦波振荡器
在SineOscillator类中,我们跟踪两个成员变量,它们存储波形周期中的当前角度或相位,以及根据频率和采样率在每个周期之间增加的角度增量:
class SineOscillator
{
public:
SineOscillator() {}
private:
float currentAngle = 0.0f, angleDelta = 0.0f;
}; 该setFrequency()函数允许我们通过首先将频率除以采样率,然后将结果乘以 2pi(弧度为单位的周期长度)来计算角度增量:
void setFrequency (float frequency, float sampleRate)
{
auto cyclesPerSample = frequency / sampleRate;
angleDelta = cyclesPerSample * juce::MathConstants<float>::twoPi;
}AudioSource的getNextAudioBlock()函数对缓冲区中的每个样本调用getNextSample()函数,以从振荡器中检索样本值。在这里,我们使用std::sin()函数计算样本值,方法是将当前角度作为参数传递,并通过调用以下定义的辅助函数updateAngle()来更新当前角度:
forcedinline float getNextSample() noexcept
{
auto currentSample = std::sin (currentAngle);
updateAngle();
return currentSample;
}角度的更新方式是,使用设置频率时先前计算的角度增量来增加当前角度,并在角度超过 2pi 时包装该值:
forcedinline void updateAngle() noexcept
{
currentAngle += angleDelta;
if (currentAngle >= juce::MathConstants<float>::twoPi)
currentAngle -= juce::MathConstants<float>::twoPi;
}现在让我们转到我们MainContentComponent类的实现。
我们将输出的总体水平和振荡器数组作为私有成员变量进行跟踪,如下所示:
juce::OwnedArray<SineOscillator> oscillators;在prepareToPlay()函数中,我们必须初始化振荡器并根据采样率设置其播放频率,如下所示:
void prepareToPlay (int, double sampleRate) override
{
auto numberOfOscillators = 200; // [1]
for (auto i = 0; i < numberOfOscillators; ++i)
{
auto* oscillator = new SineOscillator(); // [2]
auto midiNote = juce::Random::getSystemRandom().nextDouble() * 36.0 + 48.0; // [3]
auto frequency = 440.0 * pow (2.0, (midiNote - 69.0) / 12.0); // [4]
oscillator->setFrequency ((float) frequency, (float) sampleRate); // [5]
oscillators.add (oscillator);
}
level = 0.25f / (float) numberOfOscillators; // [6]
}- [1]:首先我们定义大量振荡器来评估如此数量的 CPU 负载。
- [2]:对于每个
SineOscillator振荡器,我们实例化一个生成单个正弦波声音的新对象。 - [3] :我们还使用Random类选择一个随机的 midi 音符,通过将最低音符移动 4 个八度,并从最低音符开始定义 3 个八度的范围。
- [4]:为了计算该 midi 音符的频率,我们使用一个简单的数学公式来检索标量,以与 A440 的频率相乘。由于我们知道 A440 的 midi 音符编号为 69,因此通过将 midi 音符减去 69,我们得到了与 A440 的半音距离,然后我们可以将其代入以下公式:440 * 2 ^ (d / 12)
- [5]:然后,我们将频率和采样率作为参数传递给
setFrequency()函数,以设置振荡器的频率。我们还将振荡器添加到振荡器数组中。 - [6]:最后,我们通过将安静增益水平除以振荡器的数量来定义输出水平,以防止通过对如此大量的振荡器样本进行求和而导致信号削波。
在getNextAudioBlock()函数中,我们只需将所有振荡器样本相加并将结果写入输出缓冲区,如下所示:
void getNextAudioBlock (const juce::AudioSourceChannelInfo& bufferToFill) override
{
auto* leftBuffer = bufferToFill.buffer->getWritePointer (0, bufferToFill.startSample); // [7]
auto* rightBuffer = bufferToFill.buffer->getWritePointer (1, bufferToFill.startSample);
bufferToFill.clearActiveBufferRegion();
for (auto oscillatorIndex = 0; oscillatorIndex < oscillators.size(); ++oscillatorIndex)
{
auto* oscillator = oscillators.getUnchecked (oscillatorIndex); // [8]
for (auto sample = 0; sample < bufferToFill.numSamples; ++sample)
{
auto levelSample = oscillator->getNextSample() * level; // [9]
leftBuffer[sample] += levelSample; // [10]
rightBuffer[sample] += levelSample;
}
}
}- [7]:首先,我们检索左、右声道指针,并将其写入输出缓冲区。
- [8]:对于数组中的每个振荡器,我们都检索指向振荡器实例的指针。
- [9]:然后,对于音频样本缓冲区中的每个样本,我们获取正弦波样本,并使用级别变量调整增益。
- [10]:最后,我们可以将该采样值添加到左右声道采样中,并将信号与其他振荡器相加。
如果我们现在运行该应用程序,我们应该能够听到堆叠正弦波的随机噪声。
6.4、波表振荡器
让我们将振荡器实现改为波表合成方法。
在MainContentComponent类中,添加一个 AudioSampleBuffer 作为成员变量,用于保存单个正弦波周期的波表值[1]。我们还使用位移运算符将波表分辨率定义为 128 个样本的常数[2]:
private:
juce::Label cpuUsageLabel;
juce::Label cpuUsageText;
const unsigned int tableSize = 1 << 7; // 128
float level = 0.0f;
juce::AudioSampleBuffer sineTable;
juce::OwnedArray<SineOscillator> oscillators;
JUCE_DECLARE_NON_COPYABLE_WITH_LEAK_DETECTOR (MainContentComponent)
};定义一个新函数createWavetable(),它将MainContentComponent在我们开始音频处理之前在构造函数中被调用。
void createWaveTable() {
// 我们只需要一个通道,并且样本数等于表大小,在我们的例子中分辨率为 128。然后检索该单通道缓冲区的写入指针。
sineTable.setSize(1, (int)tableSize);
auto* samples = sineTable.getWritePointer(0);
// 使用表大小,从而将完整的 2pi 周期除以 127。
auto angleDelta = juce::MathConstants<double>::twoPi / (double)(tableSize - 1);
auto currentAngle = 0.0;
for (unsigned int i = 0; i < tableSize; ++i) {
// 对于波表中的每个点,使用函数检索正弦波值std::sin(),将该值分配给缓冲区样本,并将当前角度增加增量值。
auto sample = std::sin(currentAngle);
samples[i] = (float)sample;
currentAngle += angleDelta;
}
}在MainContentComponent构造函数中添加该函数调用,如下所示:
MainContentComponent()
{
cpuUsageLabel.setText ("CPU Usage", juce::dontSendNotification);
cpuUsageText.setJustificationType (juce::Justification::right);
addAndMakeVisible (cpuUsageLabel);
addAndMakeVisible (cpuUsageText);
createWaveTable();
setSize (400, 200);
setAudioChannels (0, 2); // no inputs, two outputs
startTimer (50);
}波表现在应该包含完整正弦波周期的 128 个样本。
在prepareToPlay()函数的 for() 循环中,将下面一行更改为实例化一个WavetableOscillator对象而不是一个SineOscillator对象:
void prepareToPlay (int, double sampleRate) override
{
auto numberOfOscillators = 200;
for (auto i = 0; i < numberOfOscillators; ++i)
{
auto* oscillator = new WavetableOscillator(sineTable);
}
}该构造函数将用于声音生成的波表作为参数,因此创建一个相应的新WavetableOscillator类,如下所示:
class WavetableOscillator {
public:
WavetableOscillator(const juce::AudioSampleBuffer& wavetableToUse)
:wavetable(wavetableToUse) {
jssert(wavetable.getNumChannels() == 1);
}
private:
const juce::AudioSampleBuffer& wavetable;
float currentIndex = 0.0f, tableDelta = 0.0f;
};定义两个成员变量来存储当前波表索引和波表的角度增量,而不是跟踪波形周期的当前角度和角度增量。此外,定义一个 AudioSampleBuffer 变量来保存对要使用的波表的引用。
WavetableOscillator类的setFrequency()与以前实现的函数非常相似,只是角度增量是使用波表的大小而不是 2pi 弧度的完整周期来计算的,如下所示:
void setFrequency(float frequence, float sampleRate) {
auto tableSizeOverSampleRate = (float)wavetable.getNumSamples() / sampleRate;
tableDelta = frequence * tableSizeOverSampleRate;
}该getNextSample()函数是在波表值之间进行插值以获得正确的样本值。
forcedinline float getNextSample() noexcept {
auto tableSize = (unsigned int)wavetable.getNumSamples();
auto index0 = (unsigned int)currentIndex; // [6]
auto index1 = index0 == (tableSize - 1) ? (unsigned int)0 : index0 + 1;
auto frac = currentIndex - (float)index0; // [7]
auto* table = wavetable.getReadPointer(0); // [8]
auto value0 = table[index0];
auto value1 = table[index1];
auto currentSample = value0 + frac * (value1 - value0); // [9]
if ((currentIndex += tableDelta) > (float)tableSize) { // [10]
currentIndex -= (float)tableSize;
}
return currentSample;
}- [6]:首先,暂时存储我们试图检索的样本值周围的波表的两个索引。如果较高的索引超出了波表的大小,那么我们将该值包装到表的开头。
- [7]:接下来,通过将实际当前样本减去截断后的下限指数,计算插值作为两个指数之间的分数。这应该会给我们一个介于0 到 1之间的值来定义分数。
- [8]:然后获取指向 AudioSampleBuffer 的指针并读取两个索引处的值并临时存储这些值。
- [9]:然后可以使用标准插值公式和之前计算的分数值来检索插值的样本值。
- [10]:最后,增加表的角度增量,如果值超出表大小,则将值回绕。
当我们运行应用程序时,此实现应该为我们提供相同的输出声音。
6.5、包装波表
如果你仔细阅读了前面的代码,你可能会注意到我们的波表中有一个缺失值。最后一个值被跳过,因为它会绕回到第一个值,而第一个值恰好是相同的,所以现在让我们修复它。
在WavetableOscillator构造函数中,分配表大小变量以保存波表的分辨率减一,并适当地定义该成员变量,如下所示:
WavetableOscillator(const juce::AudioSampleBuffer& wavetableToUse)
:wavetable(wavetableToUse), tableSize(wavetable.getNumSamples() - 1) {
//jssert(wavetable.getNumChannels() == 1);
}
const int tableSize;需要使用此变量来更新setFrequency()函数,并注意表的角度增量会稍微小一些:
void setFrequency(float frequence, float sampleRate) {
auto tableSizeOverSampleRate = (float)tableSize / sampleRate;
tableDelta = frequence * tableSizeOverSampleRate;
}该getNextSample()函数保持相当相似,只是我们不再需要包装更高的索引,因为我们将在下一步增加表的大小:
forcedinline float getNextSample() noexcept {
auto tableSize = (unsigned int)wavetable.getNumSamples();
auto index0 = (unsigned int)currentIndex; // [6]
auto index1 = index0 + 1;这里与之前不同,我们将分辨率设置为高于定义值,并将最后一个样本设置为与第一个样本相同:
sineTable.setSize(1, (int)tableSize + 1);
auto* samples = sineTable.getWritePointer(0);
samples[tableSize] = samples[0];这使得我们可以减少处理调用中的包装条件,并将负载转移到createWavetable()在应用程序启动时仅调用一次的函数。
结果听起来应该与上一节相同,但请注意 CPU 使用率略有下降。
6.6、选择谐波
1


 浙公网安备 33010602011771号
浙公网安备 33010602011771号