
[LightDB新功能]LightDB性能监测之PWR DB Time & DB Wait & DB Cpu
背景:
在一个确定的服务器环境里面,为使其吞吐量最大,一个比较理想的的评估模型是,以尽量少的CPU、带宽用量达成一个尽量最大的TPS,且同时维持一个可接受的平均业务时延。为达成此目标,我们通常需要分析代码路径各环节的时间开销,然后根据时间开销去分析瓶颈在哪里。数据库服务器性能调优,也可利用此模型。如果我们能准确测量各代码路径的开销,然后再进行统计分析,那么各个瓶颈就会尽收眼底,为之后的代码调整,内核相关参数调整提供数据参考。
适用版本:LightDB 23.2
功能描述:
在LightDB中,为准确测量各进程CPU用量,IO,竞态,IPC等相关开销耗时,我们在几乎不影响性能的基础上对内核做了适当的改造,改造完成之后,我们可以实时的查询各类IO事件,IPC事件,竞态等时间开销。
一个典型的sql执行周期里面,流程如下:
- 客户端将sql query通过BSD socket写入os kernel
- 客户端os kernel将sql query写入服务端os kernel
- 服务端os kernel接收完请求后,通知上层用户态进程来读
- 用户态进程读取完整的sql query后丢给解析器进行解析
- 解析器解释完之后,执行优化,重定向等相关处理
- sql query正式执行,期间可能会触发多次Lock,IO等相关事件
- sql query执行完成后,通过BSD socket 将结果写回server os kernel
- server os kernel将数据通过网络传递到客户端os kernel
- 客户端os kernel接收完数据后,通知客户端用户态进程来读
- 客户端用户态进程读取结果
其中:
- 1--10全程总耗时,我们称之为DBtime。
- 4--6过程中发生的因竞态,disk read/write, ipc request等相关事件导致当前业务进程阻碍的时间,我们称之为DB wait time, 记录其开销并以各自类别按行标记插入相关统计表。
- 1--3,7--9,属典型的network io,这一部分的优化原则上来讲完全可以独立进行,当前比较流行的思路RDMA,不在此文章讨论范围之内,有兴趣的同学可以参考如下地址进行学习:https://docs.nvidia.com/networking/pages/viewpage.action?pageId=34256560
- DB cpu = DB time - DB wait
在以往的实现中,我们已经包含了采集,出报告等相关功能及流程,新的功能也是建立在此基础之上,因此,在使用流程上与之前并无差别,详细的教程可参考如下教程:
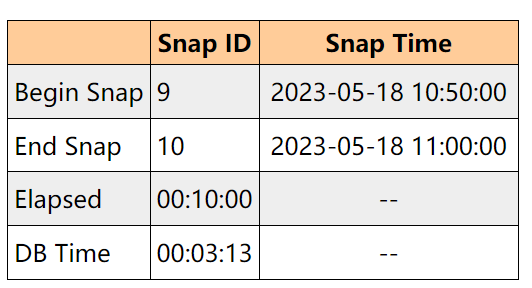
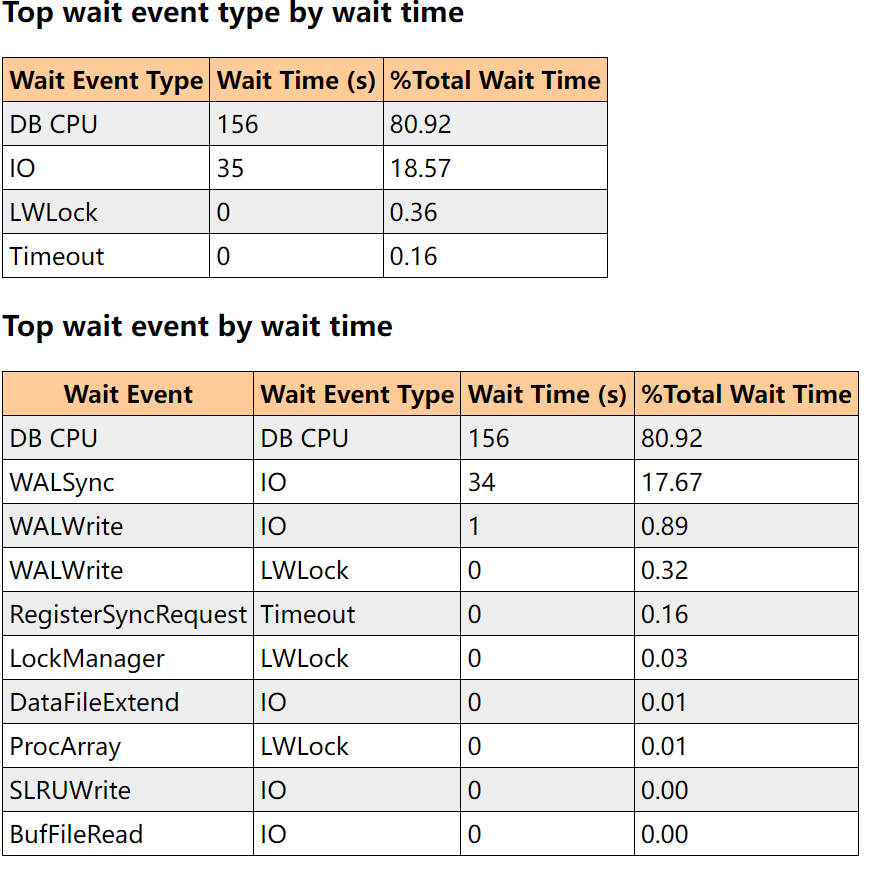
一个常规的性能报告如下:(涉及DB wait, DB cpu, DB time)
另外,因相关统计数据我们是实时存入数据库中的,所以,在实时分析的时候,我们也是可以实时查看监测到的各项指标的。
比如,我们实时监测过去 n 秒状态,可通过如下SQL+watch -n 来实现:(这类似于linux top命令)
CREATE OR REPLACE FUNCTION lt_stat_cost_last_n(IN n integer, IN src_table TEXT = 'lt_stat_cost_1s')
RETURNS
TABLE(
bg_type_text TEXT,
cost_type_text TEXT,
evt_id_text TEXT,
evt_sub_id_text TEXT,
cost_in_us BIGINT,
percent_of_bg_type NUMERIC,
percent_of_total NUMERIC
)
--SET search_path=@extschema@
AS $$
DECLARE
born_end_time TIMESTAMP := NOW();
born_start_time TIMESTAMP := (born_end_time - (INTERVAL '1 SECOND' * n) );
__query TEXT ;
__table TEXT ;
BEGIN
__table :=
CASE
WHEN src_table = 'lt_stat_cost_1s'::TEXT THEN 'lt_stat_cost_1s'
WHEN src_table = 'lt_stat_cost_60s'::TEXT THEN 'lt_stat_cost_60s'
WHEN src_table = 'lt_stat_cost_600s'::TEXT THEN 'lt_stat_cost_600s'
ELSE 'lt_stat_cost_1s'
END;
__query := format('SELECT
s.bg_type,
s.cost_type,
s.evt_id,
s.evt_sub_id,
SUM(s.cost::bigint)::bigint AS cost_in_us,
CASE WHEN SUM(SUM(cost)) OVER () = 0 THEN 0.00
ELSE ROUND((SUM(cost) / SUM(SUM(cost)) OVER (PARTITION BY s.bg_type)) * 100, 2)
END AS percent_of_bg_type,
CASE WHEN SUM(SUM(cost)) OVER () = 0 THEN 0.00
ELSE ROUND((SUM(cost) / SUM(SUM(cost)) OVER ()) * 100, 2)
END AS percent_of_total
FROM %s s
WHERE s.born >= ''%s'' AND s.born < ''%s''
GROUP BY s.bg_type,s.cost_type,s.evt_id,s.evt_sub_id'
, __table, born_start_time, born_end_time );
--RAISE NOTICE 'lt_stat_cost_last_n::query: %', __query;
RETURN QUERY SELECT * FROM lt_stat_cost_translate_id_to_text(__query) ;
END;
$$ LANGUAGE plpgsql;
watch -n 1 "/home/dev/stage/lightdb-x/bin/ltsql -c \"select * from lt_stat_cost_last_n(1)\"";
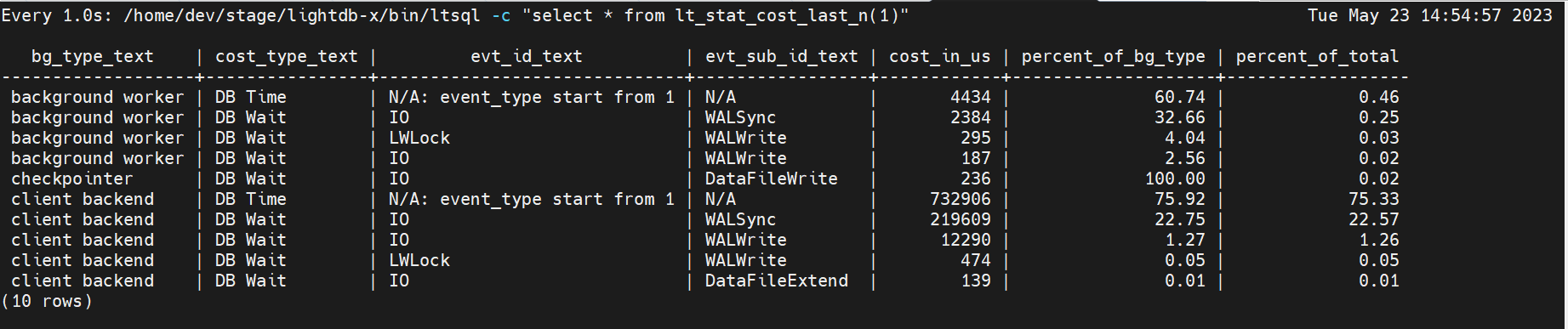
下面分别以ltbench 并发1,以及并发16进行测试,并显示其开销明细。
/home/dev/stage/lightdb-x/bin/ltbench lt_test -P 2 -T 10000 -c 1
/home/dev/stage/lightdb-x/bin/ltbench lt_test -P 2 -T 10000 -c 16
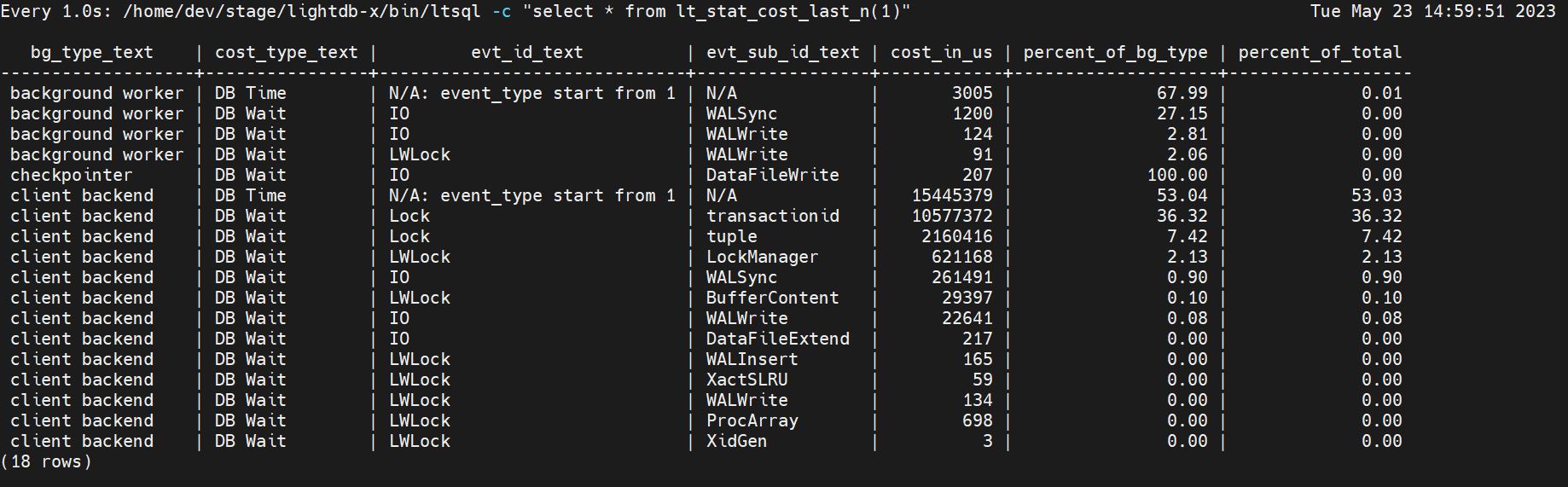
测试机器cpu core 4,由上图可知,当并发数明显高于cpu core的时候,可以见到transactionid, tuple相关的Lock耗时明显增加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号