爬虫抓取分页数据的简单实现
昨天,我们已经利用Jsoup技术实现了一个简单的爬虫,原理很简单,主要是要先分析页面,拿到条件,然后就去匹配url,采用dome解析的方式循环抓取我们需要的数据,从而即可轻松实现一个简单的爬虫。那么,昨天我们说了,我们昨天只是爬取了一页的数据也就是第一页的数据,若想获取分页的全部数据该怎么写呢?正好,今天朋友托我帮忙买一种药,说是她那边没有,于是,我就查询了一下佛山的各大药店,利用我们刚学的爬虫技术,我们今天就来实现一下爱帮网上佛山药店的分布列表。
一、需求分析
首先,我们登陆爱帮网,选择城区以及输入关键字,我们输入的是“药店”,点击搜索按钮,我们打开控制台,观察头信息,如下图:
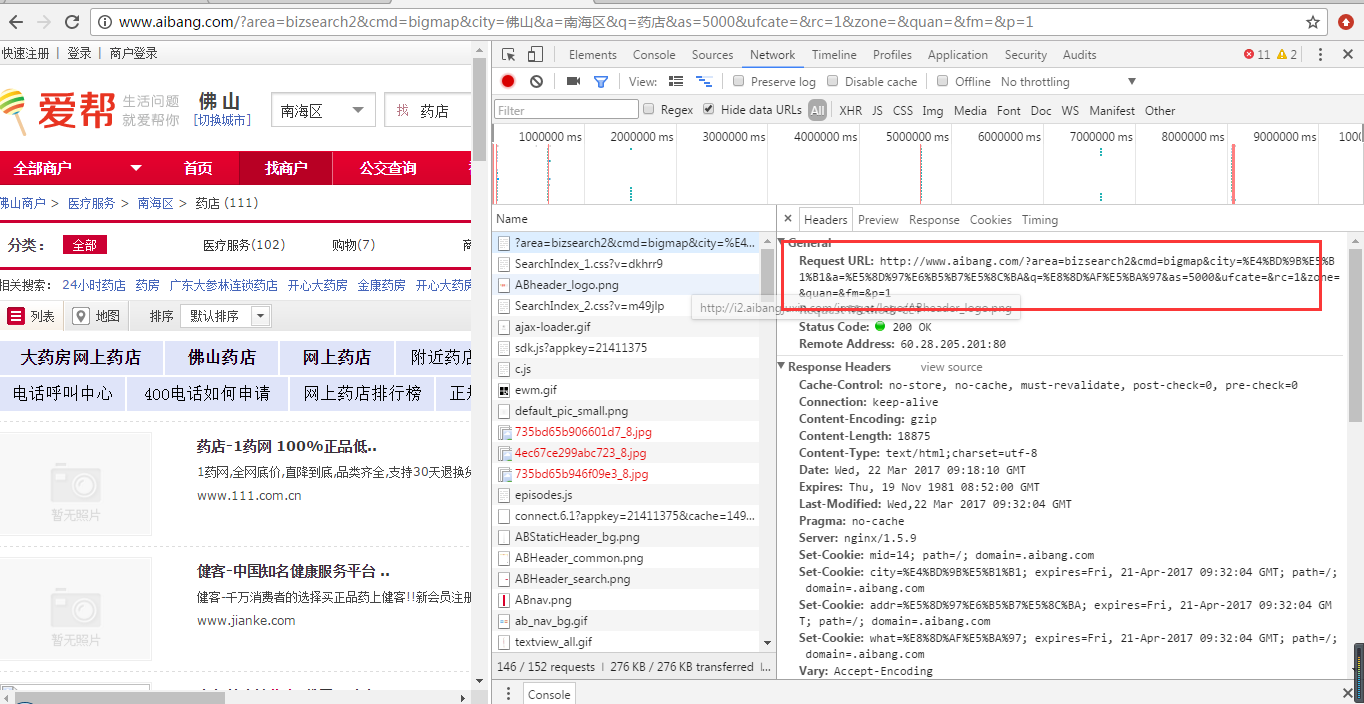
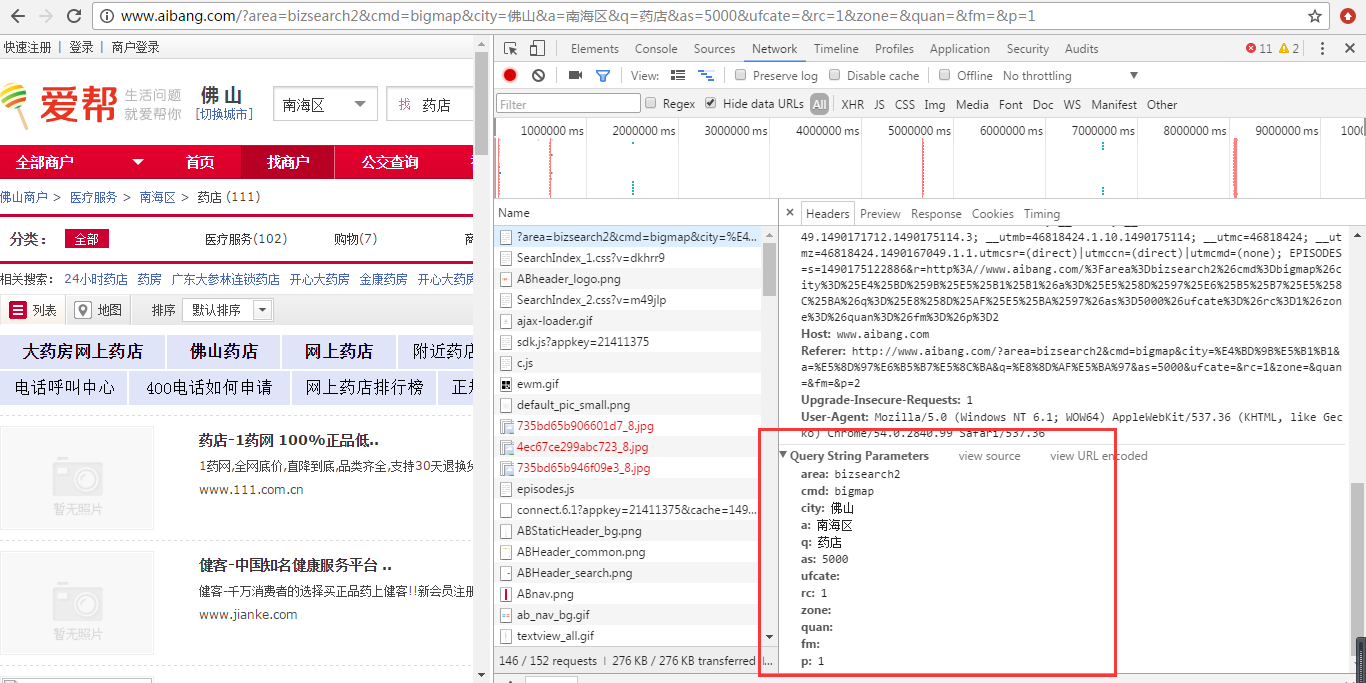
我们通过观察可以看到请求的url地址以及参数;其实直接看地址栏就可以看得出来,我们点击第二页发现其他参数都不变,只有参数p的值随页码的变化而变化。那么,这样以来,我们就可以知道每一页的请求地址其实都是一样的,只要改变p的值即可,然后我们看页面总页数只有8页,数据量不大,写个循环循环8次即可。下面我们就来开始实现,依然在昨天的代码的基础上改一改即可。
二、开发
1、我们首先需要改一下我们的业务实现类,因为取值的方式已经不一样了,如下图:
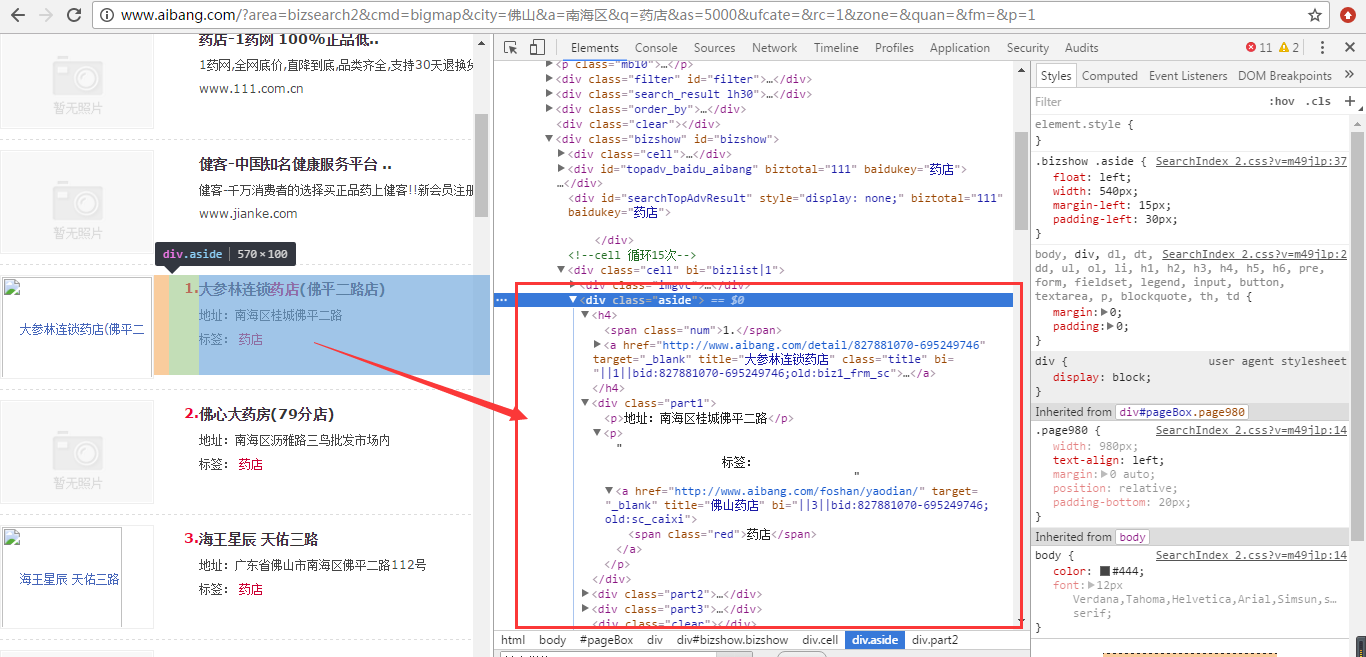
我们要去的class为aside中的内容,同样是拿到<a>标签,但是我们观察得知页面有很多的<a>标签,我们要取得我们需要的,如下图:
/* * 提取结果中的链接地址和链接标题,返回数据 */ for(Element result : results){ Elements links = result.getElementsByTag("a");//可以拿到链接 for(Element link : links){ if(link.siblingElements().hasClass("num")){ String id = link.siblingElements().text(); String linkText = link.text(); LinkTypeData data1 = new LinkTypeData(); if(id!=null && linkText!=null){ data1.setId(id); data1.setLinkText(linkText); } datas.add(data1); } if(link.parent().parent().hasClass("part1")){ LinkTypeData data2 = new LinkTypeData(); String address = link.parent().siblingElements().text(); if(address!=null){ data2.setSummary(address); } datas.add(data2); } if(link.parent().siblingElements().tagName("span").hasClass("biztel")){ LinkTypeData data3 = new LinkTypeData(); String telnum = link.parent().siblingElements().tagName("span").text(); if(telnum!=null){ data3.setContent(telnum); } datas.add(data3); } } // 对取得的html中的 出现问号乱码进行处理 /*linkText = new String(linkText.getBytes(),"GBK").replace('?', ' ').replace(' ', ' '); String id = link.parent().firstElementSibling().text(); id = new String(id.getBytes(),"GBK").replace('?', ' ').replace(' ', ' '); String address = link.parent().nextElementSibling().text(); address = new String(address.getBytes(),"GBK").replace('?', ' ').replace(' ', ' '); String code = link.parent().lastElementSibling().text(); code = new String(code.getBytes(),"GBK").replace('?', ' ').replace(' ', ' ');*/ /*data.setSummary(address); data.setContent(code); data.setId(id);*/ } return datas; }
我们在昨天的代码基础上进行了更改。这样就取得了我们想要的数据。
三、测试
接下来我们就可以改一下我们的测试类,我们需要循环8次,而每一次获取到的数据我们都存进一个新的集合中,然后最后再拿出新的集合的数据写进Excel。
/** * 不带查询参数 * @author AoXiang * 2017年3月21日 */ @org.junit.Test public void getDataByClass() throws IOException{ List<LinkTypeData> newList = new ArrayList<LinkTypeData>(); for(int i=1;i<=8;i++){ Rule rule = new Rule( "http://www.aibang.com/?area=bizsearch2&cmd=bigmap&city=%E4%BD%9B%E5%B1%B1&a=%E5%8D%97%E6%B5%B7%E5%8C%BA&q=%E8%8D%AF%E5%BA%97&as=5000&ufcate=&rc=1&zone=&quan=&fm=&p="+i, null,null, "aside", Rule.CLASS, Rule.POST); List<LinkTypeData> datas = ExtractService.extract(rule); for(int j=0;j<datas.size();j++){ newList.add(datas.get(j)); } } // 第一步,创建一个webbook,对应一个Excel文件 HSSFWorkbook wb = new HSSFWorkbook(); // 第二步,在webbook中添加一个sheet,对应Excel文件中的sheet HSSFSheet sheet = wb.createSheet("佛山药店"); // 第三步,在sheet中添加表头第0行,注意老版本poi对Excel的行数列数有限制short HSSFRow row = sheet.createRow((int) 0); // 第四步,创建单元格,并设置值表头 设置表头居中 HSSFCellStyle style = wb.createCellStyle(); style.setAlignment(HSSFCellStyle.ALIGN_CENTER); // 创建一个居中格式 HSSFCell cell = row.createCell((short) 0); cell.setCellValue("序号"); cell.setCellStyle(style); cell = row.createCell((short) 1); cell.setCellValue("药店名称"); cell.setCellStyle(style); cell = row.createCell((short) 2); cell.setCellValue("地址"); cell.setCellStyle(style); cell = row.createCell((short) 3); cell.setCellValue("电话"); cell.setCellStyle(style); for(int m=0;m<newList.size();m++){ // 第五步,写入实体数据 row = sheet.createRow((int)m + 1); // 第四步,创建单元格,并设置值 row.createCell((short) 0).setCellValue(newList.get(m).getId()); row.createCell((short) 1).setCellValue(newList.get(m).getLinkText()); row.createCell((short) 2).setCellValue(newList.get(m).getSummary()); row.createCell((short) 3).setCellValue(newList.get(m).getContent()); } // 第六步,将文件存到指定位置 try { FileOutputStream fout = new FileOutputStream("F:/佛山药店.xls"); wb.write(fout); fout.close(); } catch (Exception e) { e.printStackTrace(); } }
我们运行一下看结果:
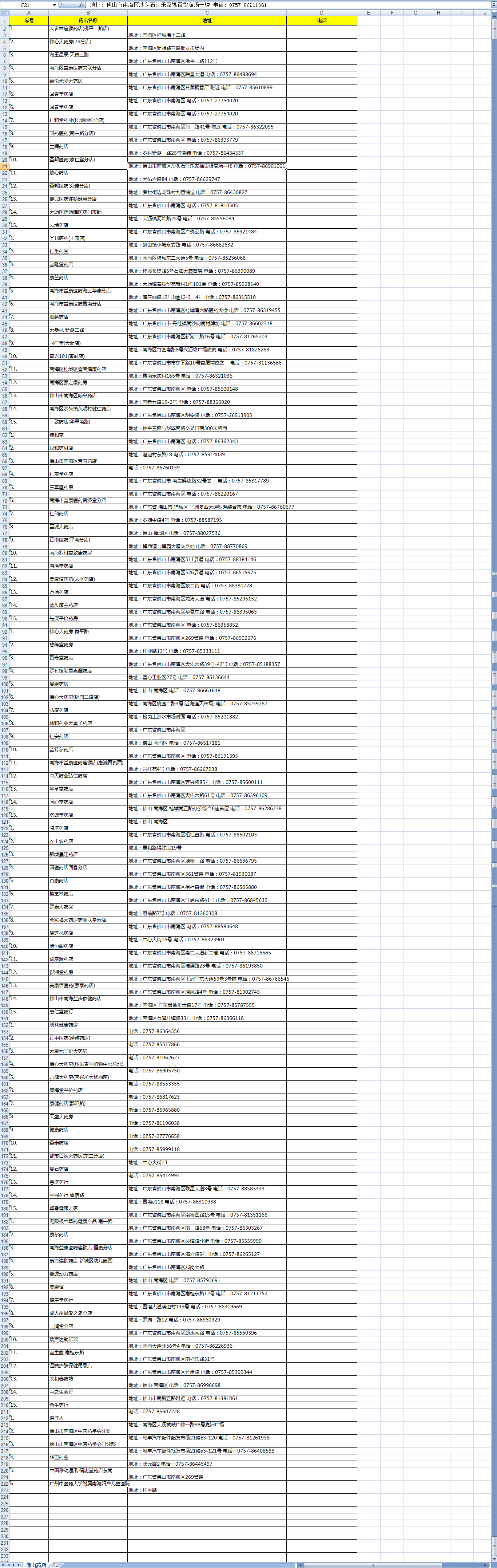
好了,我们已经拿到我们需要的数据了,然后就可以对这些数据进行分析,为我么所用。
其实,这只是一个简单的网站,一般现在的网站有些分页是JS动态获取的,我们看不到分页信息,那么,这就需要我们灵活应变,爬虫技术也不是只有这一种,然而万变不离其宗,掌握了要领和方法,相信不会有任何困难。
源码就不用上传了,有兴趣的同学可以参考一下,其实就是改了两处地方。
如果您对代码有什么异议欢迎您的留言,我们一起交流!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号