
Java中的函数式编程(五)Java集合框架中的高阶函数
写在前面
随着Java 8引入了函数式接口和lambda表达式,Java 8中的集合框架(Java Collections Framework, JCF)也增加相应的接口以适应函数式编程。
本文的目标是带领大家熟悉Java 8中集合框架新增的常用接口,让我们的代码更简洁、更高级。
本文的示例代码可从gitee上获取:https://gitee.com/cnmemset/javafp
Java 8中的集合框架
首先,和大家从整体上了解Java集合框架。
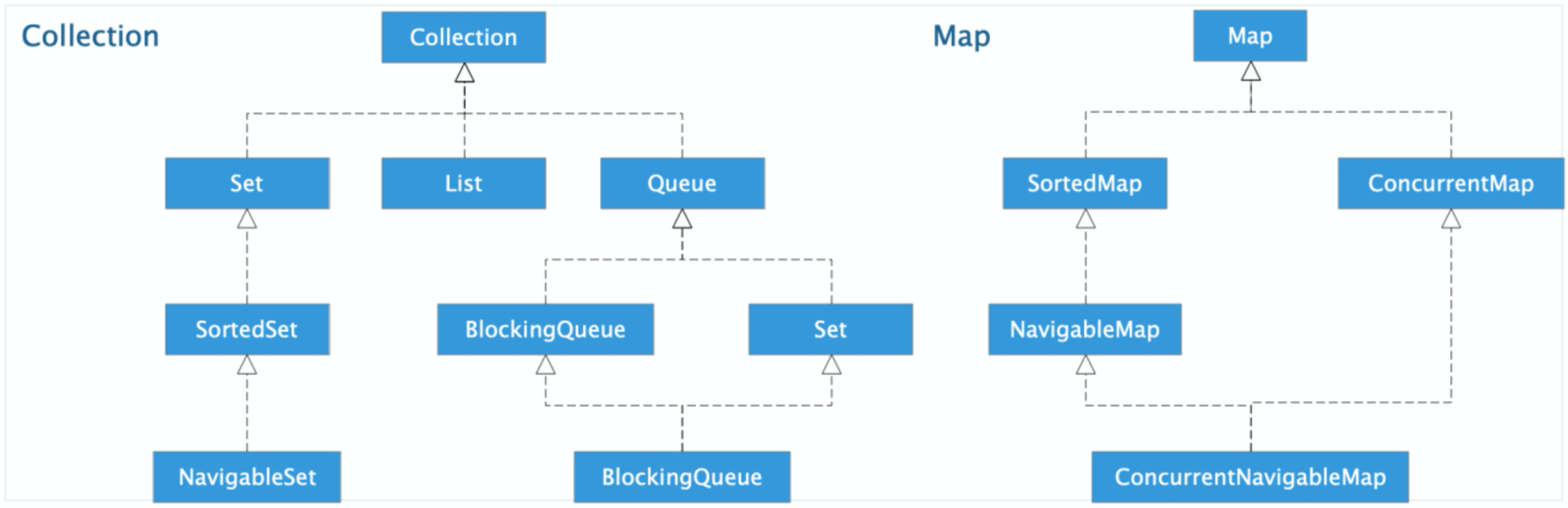
Java集合框架,主要是由两个根接口派生出来的:一个是 Collecton接口,用于存放单个元素;另一个是 Map 接口,主要用于存放键值对。
Java集合框架的接口继承结构如下图:
Java 8中,主要是Collection、List和Map三个接口新增了一些方法,部分常用的新增函数如下表所示:
|
接口名
|
Java8新加入的方法
|
|
Collection
|
forEach(), removeIf(), stream(), parallelStream()
|
|
List
|
replaceAll(), sort()
|
|
Map
|
forEach(), replaceAll(), compute(), computeIfAbsent(), computeIfPresent(), merge()
|
上述这些函数,它们都包含一个函数式接口类型的参数。这类函数有一个专门的术语:高阶函数(high order function)。
高阶函数(定义):
一个函数,如果它有一个或多个参数是函数类型的,或者它的返回值是函数类型的,那么我们称这个函数为高阶函数。
题外话:
可以发现,这些新增的方法基本都有默认实现(default implementation),这大大减少了具体子类的负担。接口中的默认方法是Java 8的新特性,一个重要的作用就是“接口演化(interface evolution)”。举例说明,假设在Java 8之前,我们有一个类实现了Collection接口:
public class Container implements Collection { ... }
升级到Java 8后,因为Collection中新增了方法 forEach,假设没有默认方法,之前的类 Container 将编译失败。
Collection中的高阶函数
1. forEach
严格来说,forEach方法是定义在接口 Iterable 中的,它的方法签名和默认实现是:
default void forEach(Consumer<? super T> action) { Objects.requireNonNull(action); for (T t : this) { action.accept(t); } }
它的作用是遍历集合中的每一个元素,然后依次对每个元素执行参数 action 指定的动作。参数 action 是一个 Consumer 类型的函数式接口,我们可以通过lambda表达式或方法引用来实现一个 Consumer 。因此,在Java 8或以后的版本中,不要用 for 语句来迭代 Collection 了,不妨使用 forEach 方法。
示例代码如下:
public static void collectionForEach() { Collection<String> list = Arrays.asList("Guangdong", "Zhejiang", "Jiangsu"); // for 语句 for (String s : list) { System.out.println(s); } // forEach 方法 + lambda表达式 list.forEach(s -> System.out.println(s)); // forEach 方法 + 方法引用 list.forEach(System.out::println); }
2. removeIf
removeIf的方法签名为:
default boolean removeIf(Predicate<? super E> filter) { ... }
removeIf的作用是遍历集合中的每一个元素,然后依次对每个元素进行指定的过滤操作。filter 参数是一个 Predicate 类型的函数式接口。
示例代码如下,假定我们要过滤掉以字母 G 开头的省份:
public static void collectionRemoveIf() { List<String> provinces = new ArrayList<>(Arrays.asList("Guangdong", "Jiangsu", "Guangxi", "Jiangxi", "Shandong")); boolean removed = provinces.removeIf(s -> { return s.startsWith("G"); }); System.out.println(removed); System.out.println(provinces); }
上述代码输出为:
true
[Jiangsu, Jiangxi, Shandong]
3. replaceAll
replaceAll的方法签名是:
default void replaceAll(UnaryOperator<E> operator) { ... }
replaceAll方法的作用是对集合中的每个元素执行 operator 指定的计算,并用计算结果替换原来的元素。参数 operator 是类型为 UnaryOperator 的函数式接口,它的参数和返回值类型是相同的。
示例代码如下:将所有的省份的拼音转换为大写字母
public static void listReplaceAll() { List<String> provinces = Arrays.asList("Guangdong", "Jiangsu", "Guangxi", "Jiangxi", "Shandong"); provinces.replaceAll(s -> s.toUpperCase()); System.out.println(provinces); }
上述代码的输出为:
[GUANGDONG, JIANGSU, GUANGXI, JIANGXI, SHANDONG]
4. sort
sort的方法签名如下:
default void sort(Comparator<? super E> c) { ... }
sort方法是根据比较器 c 指定的排序规则,对 List 中的元素进行排序。参数 c 的类型是Comparator,同样是一个函数式接口。
示例代码:
public static void listSort() { List<String> list = Arrays.asList("Guangdong", "Zhejiang", "Jiangsu", "Xizang", "Fujian", "Hunan", "Guangxi"); // 对省份进行排序,首先按照长度排序,如果长度一样,则按照字母顺序排序 list.sort((first, second) -> { int lenDiff = first.length() - second.length(); return lenDiff == 0 ? first.compareTo(second) : lenDiff; }); list.forEach(s -> System.out.println(s)); }
上述代码的输出为:
Hunan
Fujian
Xizang
Guangxi
Jiangsu
Zhejiang
Guangdong
5. stream 和 parallelStream
Stream是Java中函数式编程的重要组成部分,我们会在随后的文章中加以详述。
Map中的高阶函数
1. forEach
和Collection类似,Map中也有forEach方法,它的方法签名和默认实现如下:
default void forEach(BiConsumer<? super K, ? super V> action) { ... }
可以看到,Map的forEach方法的作用是遍历Map中所有的键值对,并执行参数 action 指定的操作。参数 action 的类型是函数式接口 BiConsumer,要求有2个参数,分别代表键值对的key和value。
示例代码:
public static void mapForEach() { Map<String, String> cityMap = new HashMap<>(); cityMap.put("Guangdong", "Guangzhou"); cityMap.put("Zhejiang", "Hangzhou"); cityMap.put("Jiangsu", "Nanjing"); cityMap.forEach((key, value) -> { System.out.println(String.format("%s 的省会是 %s", key, value)); }); }
上述代码的输出为:
Guangdong 的省会是 Guangzhou
Zhejiang 的省会是 Hangzhou
Jiangsu 的省会是 Nanjing
2. replaceAll
Map的replaceAll的方法签名和默认实现如下:
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) { ... }
和Collection的replaceAll类似,Map的replaceAll方法对Map中的每个键值对执行 operator 指定的计算,并用计算结果替换原来的value值。注意到参数 function 是一个 BiFunction,意味着需要提供这样的一个函数实现:它需要有2个参数,参数类型分别和键类型(K)和值类型(V)一一对应,并且它还需要返回一个类型为值类型(V)的返回值。
示例代码:
public static void mapReplaceAll() { Map<String, String> cityMap = new HashMap<>(); cityMap.put("Guangdong", "Guangzhou"); cityMap.put("Zhejiang", "Hangzhou"); cityMap.put("Jiangsu", "Nanjing"); // 将省府的拼音转换为大写 cityMap.replaceAll((key, value) -> { return value.toUpperCase(); }); cityMap.forEach((key, value) -> { System.out.println(String.format("%s 的省会大写是 %s", key, value)); }); }
上述代码输出为:
Guangdong 的省会大写是 GUANGZHOU
Zhejiang 的省会大写是 HANGZHOU
Jiangsu 的省会大写是 NANJING
3. compute
compute的方法签名:
default V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) { ... }
compute方法的作用是将参数 remappingFunction 的计算结果关联到参数 key 上,但如果计算结果为null,则在Map中删除key的映射。
示例代码如下:
public static void mapCompute() { Map<String, String> cityMap = new HashMap<>(); cityMap.put("Guangdong", "null"); cityMap.put("Zhejiang", "Hangzhou"); cityMap.put("Jiangsu", "null"); // 稍显复杂的语句,先调用 forEach 遍历 cityMap 中的键,然后根据原有的键值对计算新的值 Set keys = new HashSet<>(cityMap.keySet()); keys.forEach(key -> { cityMap.compute(key, (k, v) -> { // 如果是 Guangdong,则返回 Guangzhou if ("Guangdong".equals(k)) { return "Guangzhou"; } // 如果旧的键值对中,值是字符串 "null" ,则返回 null。 // 这意味着 cityMap 会删除对应的key if ("null".equals(v)) { return null; } // 否则,返回原来的 value 值 return v; }); }); cityMap.forEach((key, value) -> { System.out.println(String.format("%s 的省会是 %s", key, value)); }); }
上述代码的输出为:
Guangdong 的省会是 Guangzhou
Zhejiang 的省会是 Hangzhou
注意到,Jiangsu 已经从cityMap中被删除了。
4. computeIfPresent
computeIfPresent的方法签名和默认实现是:
default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) { Objects.requireNonNull(remappingFunction); V oldValue; if ((oldValue = get(key)) != null) { V newValue = remappingFunction.apply(key, oldValue); if (newValue != null) { put(key, newValue); return newValue; } else { remove(key); return null; } } else { return null; } }
computeIfPresent 的方法签名和compute一样,作用也和compute类似,但与compute不同的是,只有在Map中存在key并且对应的value非空时,才会调用参数 remappingFunction 指定的计算函数(函数编程特性之惰性求值:只有触发或满足某种条件后,才会执行函数)。如果计算结果为null,则删除key的映射,否则使用该结果替换key原来的映射。
5. computeIfAbsent
computeIfAbsent的方法签名和默认实现是:
default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) { Objects.requireNonNull(mappingFunction); V v; if ((v = get(key)) == null) { V newValue; if ((newValue = mappingFunction.apply(key)) != null) { put(key, newValue); return newValue; } } return v; }
computeIfAbsent的作用和computeIfPresent 相反,只有在Map中不存在key或对应的value为null时,才调用参数 mappingFunction 指定的计算函数(函数编程特性之惰性求值:只有触发或满足某种条件后,才会执行函数),并且当计算结果非null时,才将计算结果跟key关联。如果计算结果为null,则Map不做任何修改,不会增加新的映射关系。
computeIfAbsent总是会返回操作之后Map中key对应的value,这个value可能是之前已存在的值(如果之前存在的话),也有可能是计算出来的新值。
computeIfAbsent特别适合用来初始化Map。假设这么一个实践场景公司里的员工已经有一个“姓名->年龄”的Map了,我们需要根据它来构建一个“年龄->姓名列表”的新Map,此时,使用 computeIfAbsent 会使得代码简洁而有效:
public static void mapComputeIfAbsent() { Map<String, Integer> staffMap = new HashMap<>(); staffMap.put("Lilei", 24); staffMap.put("Hanmeimei", 22); staffMap.put("Liming", 24); staffMap.put("Jim", 22); staffMap.put("David", 24); Map<Integer, List<String>> staffInvertMap = new HashMap<>(); staffMap.forEach((key, value) -> { // 以年龄为键,构建一个新的Map // 以 22 岁为例: // 如果 staffInvertMap 之前不存在 22 岁对应的映射关系, // 则新建一个 "年龄 -> ArrayList<String>" 的映射,并且把新建的 ArrayList 返回。 // 如果 staffInvertMap 已经存在 22 岁对应的映射关系了,则将已存在的 ArrayList 返回。 List<String> nameList = staffInvertMap.computeIfAbsent(value, age -> { // 对于同一个 age,这句代码只会执行一次 return new ArrayList<>(); }); nameList.add(key); }); System.out.println(staffInvertMap); }
上述代码的输出为:
{22=[Hanmeimei, Jim], 24=[Lilei, David, Liming]}
题外话:
作者特别喜欢computeIfPresent和computeIfAbsent这两个函数,除了它们可以简化我们的代码外,它俩还有一个特性:在ConcurrentHashMap 中,computeIfPresent和computeIfAbsent中的系列操作具备原子性。原子性的含义,欢迎添加公众号,员说,一起讨论。
6. merge
merge的方法签名和默认实现为:
default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) { Objects.requireNonNull(remappingFunction); Objects.requireNonNull(value); V oldValue = get(key); V newValue = (oldValue == null) ? value : remappingFunction.apply(oldValue, value); if(newValue == null) { remove(key); } else { put(key, newValue); } return newValue; }
merge方法的作用是合并key对应的旧值和新值:当Map中不存在key对应的映射或者映射值为null时,则将参数 value 关联到 key 上;否则,将旧值 oldValue 和 参数 value 作为函数 remappingFunction 的两个参数,计算得出一个新值,如果新值不为null,则将新值关联到 key 上,如果新值为null,则删除 key 对应的映射关系。
一个典型的场景是针对某个用户进行备注,如果之前有过备注,则将新的备注信息加到后面,示例代码如下:
public static void mapMerge() { Map<String, String> staffMap = new HashMap<>(); staffMap.put("Lilei", "性别男 "); // 等价于 staffMap.merge("Lilei", "年龄 24", String::concat) // oldValue 即之前添加的值 “性别男 ”,value 即merge函数的第二个参数 “年龄24” staffMap.merge("Lilei", " 年龄24", (oldValue, value) -> oldValue.concat(value)); staffMap.merge("Hanmeimei", "年龄22", String::concat); System.out.println(staffMap); }
上述代码的输出为:
{Lilei=性别男 年龄24, Hanmeimei=年龄22}
结语
Java 8引入了函数式编程,也因此为Java中的集合框架带来了许多新的功能,使得我们能更好的进行函数式编程。
作为一个优秀的Java程序员,要有意识的在实际编码中运用这些新方法,使得我们的代码更简洁更清晰。

