
http and rest
-
HTTP is connectionless: The HTTP client, i.e., a browser initiates an HTTP request and after a request is made, the client waits for the response. The server processes the request and sends a response back after which client disconnect the connection. So client and server knows about each other during current request and response only. Further requests are made on new connection like client and server are new to each other.
-
HTTP is media independent: It means, any type of data can be sent by HTTP as long as both the client and the server know how to handle the data content. It is required for the client as well as the server to specify the content type using appropriate MIME-type.
-
HTTP is stateless: As mentioned above, HTTP is connectionless and it is a direct result of HTTP being a stateless protocol. The server and client are aware of each other only during a current request. Afterwards, both of them forget about each other. Due to this nature of the protocol, neither the client nor the browser can retain information between different requests across the web pages. HTTP is called a stateless protocol because each command is executed independently, without any knowledge of the commands that came before it. This is the main reason that it is difficult to implement Web sites that react intelligently to user input.
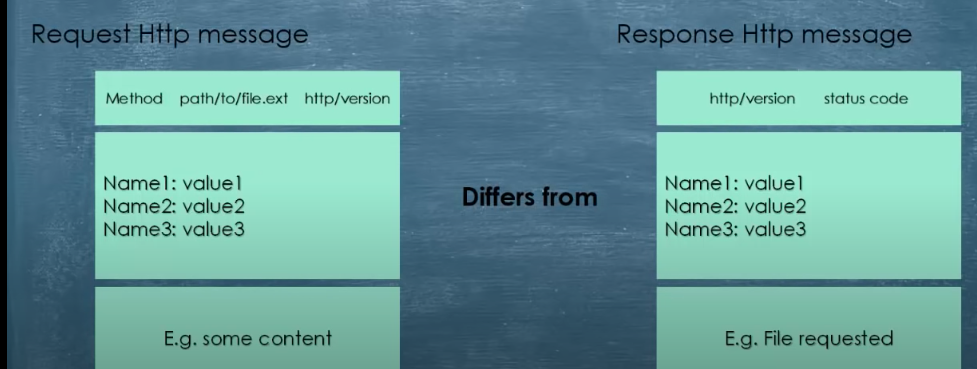
1 How does http relate to REST
HTTP is an application layer protocol for sending and receving messag. We can use GET method for all interaction
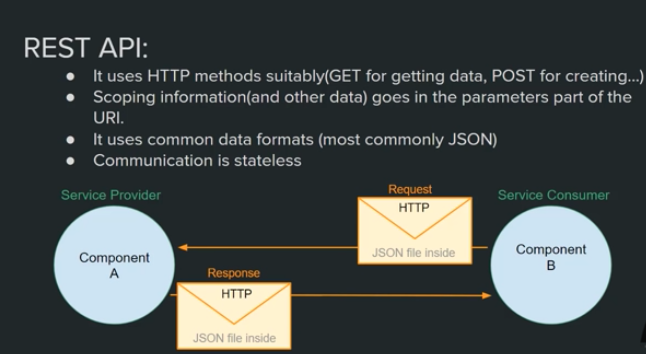
REST is a specification that dicates how distributed system on web should commicate
REST is a way to impement and use http protocol.
2 How does WEB related to REST
REST is underlaying architecutre of WEB
REST Rules:
The method information should be expressed iin the HTTP verb (e.g GET, PUT). I.e it decribe what clinet want server to do (method)
Socping information should go in URL. (Delete api/user:userid). i.e it describe what data client want server to deal with (socpinp)
Connection timeout - is a time period within which a connection between a client and a server must be established. Suppose that you navigate your browser (client) to some website (server). What happens is that your browser starts to listen for a response message from that server but this response may never arrive for various reasons (e.g. server is offline). So if there is still no response from the server after X seconds, your browser will 'give up' on waiting, otherwise it might get stuck waiting for eternity.
Request timeout - as in the previous case where client wasn't willing to wait for response from server for too long, server is not willing to keep unused connection alive for too long either. Once the connection between server and client has been established, client must periodically inform server that it is still there by sending information to that server. If client fails to send any information to server in a specified time, server simply drops this connection as it thinks that client is no longer there to communicate with it (why wasting resources meaninglessly).
Time to live (TTL) - is a value specified inside of a packet that is set when the packet is created (usually to 255) that tells how long the packet can be left alive in a network. As this packet goes through the network, it arrives at routers that sit on the path between the packet's origin and its destination. Each time the router resends the packet, it also decrements its TTL value by 1 and if that value drops to 0, instead of resending the packet, router simply drops it as the packet is not supposed to live any longer. This mechanism is used to prevent network from flooding by data as each packet can live inside of it for only limited amount of 'time'.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号