web技术分享| LRU 缓存淘汰算法
了解 LRU 之前,我们应该了解一下缓存,大家都知道计算机具有缓存内存,可以临时存储最常用的数据,当缓存数据超过一定大小时,系统会进行回收,以便释放出空间来缓存新的数据,但从系统中检索数据的成本比较高。
缓存要求:
- 固定大小:缓存需要有一些限制来限制内存使用。
- 快速访问:缓存插入和查找操作应该很快,最好是 O(1) 时间。
- 在达到内存限制的情况下替换条目:缓存应该具有有效的算法来在内存已满时驱逐条目
如果提供一个缓存替换算法来辅助管理,按照设定的内存大小,删除最少使用的数据,在系统回收之前主动释放出空间,会使得整个检索过程变得非常快,因此 LRU 缓存淘汰算法就出现了。
LRU 原理与实现
LRU (Least Recently Used) 缓存淘汰算法提出最近被频繁访问的数据应具备更高的留存,淘汰那些不常被访问的数据,即最近使用的数据很大概率将会再次被使用,抛弃最长时间未被访问的数据,目的是为了方便以后获取数据变得更快,例如 Vue 的 keep-live 组件就是 LRU 的一种实现。

实现的中心思想拆分为以下几步:
- 新的数据插入到链表头部。
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部。
- 当缓存内存已满时(链表数量已满时),将链表尾部的数据淘汰。
Example
这里使用一个例子来说明 LRU 实现的流程,详细请参考这里。
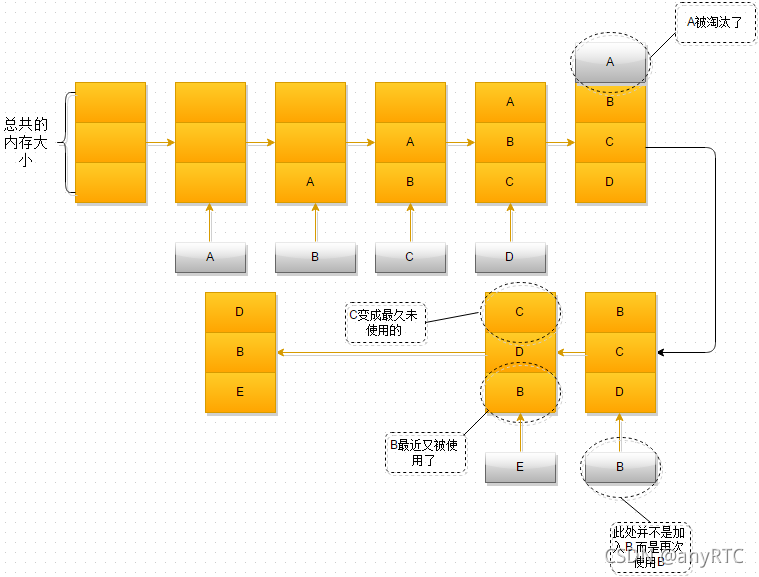
- 最开始时,内存空间是空的,因此依次进入A、B、C是没有问题的
- 当加入D时,就出现了问题,内存空间不够了,因此根据LRU算法,内存空间中A待的时间最为久远,选择A,将其淘汰
- 当再次引用B时,内存空间中的B又处于活跃状态,而C则变成了内存空间中,近段时间最久未使用的
- 当再次向内存空间加入E时,这时内存空间又不足了,选择在内存空间中待的最久的C将其淘汰出内存,这时的内存空间存放的对象就是E->B->D
基于双向链表和 HashMap 实现 LRU
常见的 LRU 算法是基于双向链表和 HashMap 实现的。
双向链表:用于管理缓存数据结点的顺序,新增数据和缓存命中(最近被访问)的数据被放置在 Header 结点,尾部的结点根据内存大小进行淘汰。
HashMap:存储所有结点的数据,当 LRU 缓存命中(进行数据访问)时,进行拦截进行数据置换和删除操作。
双向链表
双向链表是众多链表中的一种,链表都是采用链式存储结构,链表中的每一个元素,我们称之为数据结点。
每个数据结点都包含一个数据域和指针域,指针域可以确定结点与结点之间的顺序,通过更新数据结点的指针域的指向可以更新链表的顺序。
双向链表的每个数据结点包含一个数据域和两个指针域:
- proir 指向上一个数据结点;
- data 当前数据结点的数据;
- next 指向下一个数据结点;

指针域确定链表的顺序,那么双向链表拥有双向指针域,数据结点的之间不在是单一指向,而是双向指向。即 proir 指针域指向上一个数据结点,next 指针域指向下一个数据结点。

同理:
- 单向链表只有一个指针域。
- 循环(环状)链表则是拥有双向指针域,且头部结点的指针域指向尾部结点,尾部结点的指针域指向头部结点。
特殊结点:Header 和 Tailer 结点
链表中还有两个特殊的结点,那就算 Header 结点和 Tailer 结点,分别表示头部结点和尾部结点,头部结点表示最新的数据或者缓存命中(最近访问过的数据),尾部结点表示长时间未被使用,即将被淘汰的数据节点。
作为算法大家都会关注其时间和空间复杂度 O(n),基于双向链表双向指针域的优势,为了降级时间复杂度,因此
为了保证 LRU 新数据和缓存命中的数据都位于链表最前面(Header),缓存淘汰的时候删除最后的结点(Tailer),又要避免数据查找时从头到尾遍历,降低算法的时间复杂度,同时基于双向链表带来的优势,可以改变个别数据结点的指针域从而达到链表数据的更新,如果提供 Header 和 Tailer 结点作为标识的话,可以使用头插法快速增加结点,根据 Tailer 结点也可以在缓存淘汰时快速更新链表的顺序,避免遍历从头到尾遍历,降低算法的时间复杂度。
排序示例
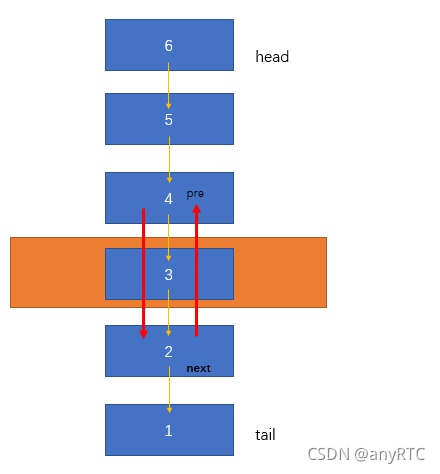
LRU 链表中有 [6,5,4,3,2,1] 6个数据结点,其中 6 所在的数据结点为 Header(头部)结点,1 所在的数据结点为 Tailer(尾部)结点。如果此时数据 3 被访问(缓存命中),3 应该被更新至链表头,用数组的思维应该是删除 3,但是如果我们利用双向链表双向指针的优势,可以快速的实现链表顺便的更新:
3被删除时,4和2中间没有其他结点,即4的next指针域指向2所在的数据结点;同理,2的proir指针域指向2所在的数据结点。
HashMap
至于为什么使用 HashMap,用一句话来概括主要是因为 HashMap 通过 Key 获取速度会快的多,降低算法的时间复杂度。
例如:
- 我们在 get 缓存的时候从
HashMap中获取的时候基本上时间复杂度控制在 O(1),如果从链表中一次遍历的话时间复杂度是 O(n)。 - 我们访问一个已经存在的节点时候,需要将这个节点移动到
header节点后,这个时候需要在链表中删除这个节点,并重新在header后面新增一个节点。这个时候先去HashMap中获取这个节点删除节点关系,避免了从链表中遍历,将时间复杂度从 O(N) 减少为 O(1)
由于前端没有 HashMap 的相关 API,我们可以使用
Object或者Map来代替。
代码实现
现在让我们运用所掌握的数据结构,设计和实现一个,或者参考 LeeCode 146 题。
链表结点 Entry
export class Entry<T> {
value: T
key: string | number
next: Entry<T>
prev: Entry<T>
constructor(val: T) {
this.value = val;
}
}
双向链表 Double Linked List
主要职责:
- 管理头部结点和尾部结点
- 插入新数据时,将新数据移到头部结点
- 删除数据时,更新删除结点前后两个结点的指向域
/**
* Simple double linked list. Compared with array, it has O(1) remove operation.
* @constructor
*/
export class LinkedList<T> {
head: Entry<T>
tail: Entry<T>
private _len = 0
/**
* Insert a new value at the tail
*/
insert(val: T): Entry<T> {
const entry = new Entry(val);
this.insertEntry(entry);
return entry;
}
/**
* Insert an entry at the tail
*/
insertEntry(entry: Entry<T>) {
if (!this.head) {
this.head = this.tail = entry;
}
else {
this.tail.next = entry;
entry.prev = this.tail;
entry.next = null;
this.tail = entry;
}
this._len++;
}
/**
* Remove entry.
*/
remove(entry: Entry<T>) {
const prev = entry.prev;
const next = entry.next;
if (prev) {
prev.next = next;
}
else {
// Is head
this.head = next;
}
if (next) {
next.prev = prev;
}
else {
// Is tail
this.tail = prev;
}
entry.next = entry.prev = null;
this._len--;
}
/**
* Get length
*/
len(): number {
return this._len;
}
/**
* Clear list
*/
clear() {
this.head = this.tail = null;
this._len = 0;
}
}
LRU 核心算法
主要职责:
- 将数据添加到链表并更新链表顺序
- 缓存命中时更新链表的顺序
- 内存溢出抛弃过时的链表数据
/**
* LRU Cache
*/
export default class LRU<T> {
private _list = new LinkedList<T>()
private _maxSize = 10
private _lastRemovedEntry: Entry<T>
private _map: Dictionary<Entry<T>> = {}
constructor(maxSize: number) {
this._maxSize = maxSize;
}
/**
* @return Removed value
*/
put(key: string | number, value: T): T {
const list = this._list;
const map = this._map;
let removed = null;
if (map[key] == null) {
const len = list.len();
// Reuse last removed entry
let entry = this._lastRemovedEntry;
if (len >= this._maxSize && len > 0) {
// Remove the least recently used
const leastUsedEntry = list.head;
list.remove(leastUsedEntry);
delete map[leastUsedEntry.key];
removed = leastUsedEntry.value;
this._lastRemovedEntry = leastUsedEntry;
}
if (entry) {
entry.value = value;
}
else {
entry = new Entry(value);
}
entry.key = key;
list.insertEntry(entry);
map[key] = entry;
}
return removed;
}
get(key: string | number): T {
const entry = this._map[key];
const list = this._list;
if (entry != null) {
// Put the latest used entry in the tail
if (entry !== list.tail) {
list.remove(entry);
list.insertEntry(entry);
}
return entry.value;
}
}
/**
* Clear the cache
*/
clear() {
this._list.clear();
this._map = {};
}
len() {
return this._list.len();
}
}
其他 LRU 算法
除了以上常见的 LRU 算法,随着需求的复杂多样,基于 LRU 的思想也衍生出了许多优化算法,例如:
参考链接


 浙公网安备 33010602011771号
浙公网安备 33010602011771号