
除了前文介绍的树之外,我们再来看看另外一些比较特别的树。
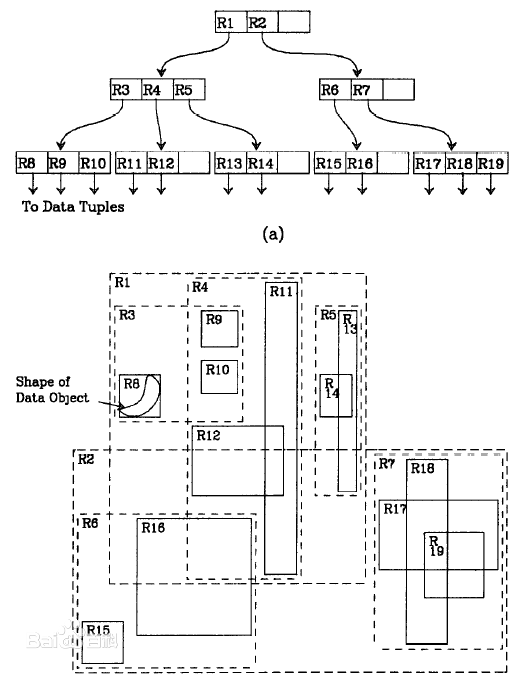
一、R树
R树在数据库等领域做出的功绩是非常显著的。它很好的解决了在高维空间搜索等问题。举个R树在现实领域中能够解决的例子:查找20英里以内所有的餐厅。如果没有R树你会怎么解决?一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满足要求。如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌地图这种超大数据库中,这种方法便必定不可行了。
R树就很好的解决了这种高维空间搜索问题。它把B树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性。因此,R树就是一棵用来存储高维数据的平衡树。
R树已经被广泛应用在各种数据库及其相关的应用中。但R树的处理也具有局限性,它的最佳应用范围是处理2至6维的数据,更高维的存储会变得非常复杂,这样就不适用了。近年来,R树也出现了很多变体,R*树就是其中的一种。这些变体提升了R树的性能,感兴趣的读者可以参考相关文献。
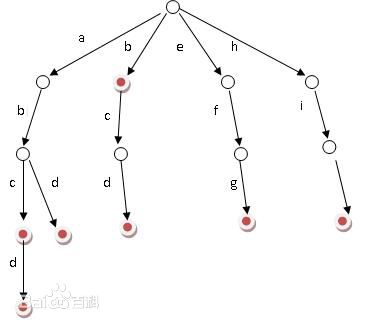
二、字典树(trie树)
Tire树称为字典树,又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串)。以便于字符串的统计和查找,经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来节约存储空间,最大限度地减少无谓的字符串比较,查询效率比哈希表高。具有以下特点(图f):
- 根节点为空;
- 除根节点外,每个节点包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
- 每个字符串在建立字典树的过程中都要加上一个区分的结束符,避免某个短字符串正好是某个长字符串的前缀而淹没。
Tire树的应用:
1.串的快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
2.“串”排序
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出。用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
3.最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为求公共祖先的问题。
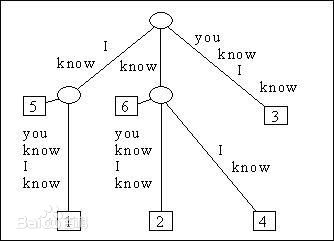
三、后缀树
所谓后缀树,就是包含一则字符串所有后缀的压缩了的字典树。先说说后缀的定义。给定一长度为n的字符串S=S1S2..Si..Sn,和整数i,1 <= i <= n,子串SiSi+1...Sn都是字符串S的后缀。以字符串S=XMADAMYX为例,它的长度为8,所以S[1..8], S[2..8], ... , S[8..8]都算S的后缀,我们一般还把空字串也算成后缀。这样,我们一共有如下后缀。对于后缀S[i..n],我们说这项后缀起始于i。
- S[1..8], XMADAMYX, 也就是字符串本身,起始位置为1
- S[2..8], MADAMYX,起始位置为2
- S[3..8], ADAMYX,起始位置为3
- S[4..8], DAMYX,起始位置为4
- S[5..8], AMYX,起始位置为5
- S[6..8], MYX,起始位置为6
- S[7..8], YX,起始位置为7
- S[8..8], X,起始位置为8
- 空字串。记为$。
所有这些后缀字符串组成一棵字典树。
四、广义后缀树
广义后缀树是好几个字符串的的所有后缀组成的字典树,同样每个字符串的所有后缀都具有一个相同的结束符,不同字符串的结束符不同。
传统的后缀树只能处理一个单词的所有后缀。广义后缀树存储任意多个单词的所有后缀。例如字符串“abab”和“baba”,首先将它们使用特殊结束符链接起来,如表示成“ababbaba#”,然后求连接后的新字符的后缀树,遍历所得后缀树,如遇到特殊字符,如“baba#”,然后求连接后的新字符的后缀树,遍历所得后缀树,如遇到特殊字符,如“”,"#"等则去掉以该节点为跟的子树,最后所得后缀树即为原字符串组的广义后缀树。其实质是将两个字符串的所有后缀,即:abab,𝑏𝑎𝑏,bab,ab,𝑏,b,baba#,aba#,ba#,a#,组成字典树,再进行压缩处理。广义后缀树的一个常应用就是判断两个字符串的相识度。
我的微信公众号:架构真经(id:gentoo666),分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。每日更新哦!

参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号