

sqlserver 常用语法
sqlserver查找 table, view, column
select * from information_schema.tables where table_schema='bk' select * from information_schema.views where table_schema='bk' select * from information_schema.columns where column_name like '%name' -- 查询包含某个列名的表 select * from INFORMATION_SCHEMA.COLUMNS where COLUMN_NAME like '%ColumnName%' -- 查询包含某个基础表的视图 select * from INFORMATION_SCHEMA.VIEWS where VIEW_DEFINITION like '%TableName%'
sqlserver删除语法

-- 1. drop table IF EXISTS (SELECT 1 FROM sysobjects WHERE id = object_id('__TableName__') AND type = 'U' ) DROP TABLE __TableName__; -- 2. drop view if exists (select * from dbo.sysobjects where id = object_id(N'__ViewName__') and objectproperty(id, N'isview') = 1) drop view __ViewName__; -- 3. drop proc IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'__ProcName__') AND type in (N'P', N'PC')) DROP PROCEDURE __ProcName__; IF OBJECT_ID('__ProcName__','P') IS NOT NULL DROP PROC __ProcName__ -- 4. drop columns IF EXISTS(SELECT * FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA='dbo' AND TABLE_NAME = '__TableName__' AND COLUMN_NAME = '__ColumnName__') alter table __TableName__ DROP COLUMN __ColumnName__; IF EXISTS (SELECT * FROM syscolumns WHERE id=object_id('__TableName__') AND name='__ColumnName__') EXEC('ALTER TABLE __TableName__ DROP COLUMN __ColumnName__') -- 5. drop constraints DECLARE @ConstraintName nvarchar(200) SELECT @ConstraintName = Name FROM SYS.DEFAULT_CONSTRAINTS WHERE PARENT_OBJECT_ID = OBJECT_ID('__TableName__') AND PARENT_COLUMN_ID = (SELECT column_id FROM sys.columns WHERE NAME = N'__ColumnName__' AND object_id = OBJECT_ID(N'__TableName__')) IF @ConstraintName IS NOT NULL EXEC('ALTER TABLE __TableName__ DROP CONSTRAINT ' + @ConstraintName) -- 6. drop PK or FK IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE where TABLE_NAME = '__TableName__' AND COLUMN_NAME = '__ColumnName__') BEGIN SELECT @ConstraintName = CONSTRAINT_NAME FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE where TABLE_NAME = '__TableName__' AND COLUMN_NAME = '__ColumnName__' EXEC('ALTER TABLE __TableName__ DROP CONSTRAINT ' + @ConstraintName) END
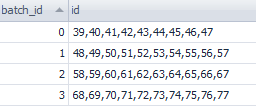
计算每批次的id集合
with ws_ids as( SELECT ROW_NUMBER() OVER(ORDER BY w.id) / 10 batch_id, w.id FROM dbo.[webservice] w WHERE validationStatus = 'INIT' ) SELECT batch_id, id = stuff( SELECT ',' + cast(id AS VARCHAR(20)) FROM ws_ids t WHERE t.batch_id = a.batch_id FOR XML path(''), 1, 1, '') FROM ws_ids a
批量更新(多表连接,使用临时表)


IF EXISTS (SELECT 1 FROM sysobjects WHERE id = object_id('dbo.month_sale') AND type = 'U') DROP TABLE dbo.month_sale; GO CREATE TABLE dbo.month_sale ( seller_name varchar(50) not null, month_amount decimal(24, 8) not null, PRIMARY KEY(seller_name, amount) ) IF OBJECT_ID('[dbo].[calc_month_sale]','P') IS NOT NULL DROP PROC [dbo].[calc_month_sale]; GO CREATE PROCEDURE [dbo].[calc_month_sale] @month int AS BEGIN SET NOCOUNT ON TRUNCATE TABLE dbo.month_sale CREATE TABLE #seller_month_amount( seller_id int identity(1,1) not null, month_amount datetime not null, PRIMARY KEY(seller_id, month_amount) ) INSERT #seller_month_amount(seller_id, month_amount) SELECT seller_id, sum(amount) FROM [dbo].[order] WHERE month(ordered_date)=@month GROUP BY seller_id INSERT month_sale(seller_name, month_amount) SELECT s.seller_name, sma.month_amount FROM [dbo].[seller] s INNER JOIN #seller_month_amount sma ON s.seller_id = sma.seller_id UPDATE sh SET month_amount = ms.month_amount FROM dbo.sale_history sh INNER JOIN [dbo].[month_sale] ms ON s.seller_id = sma.seller_id END ; exec [dbo].[calc_month_sale]
批量插入
set rowcount 10000000 declare @looper int = 10000000 declare @current_time datetime while @looper = 10000000 begin select @current_time = getdate() insert into table1 select * from table2 select @looper = @@rowcount insert into batch_log values ('table1', @looper, @current_time, getdate()) end
查询replicated tables
-- 1. find publisher and subscriber SELECT DISTINCT srv.srvname publication_server , a.publisher_db , p.publication + '.' + a.article publication_object , ss.srvname subscriber_server , s.subscriber_db , a.destination_object --, da.name AS distribution_agent_job_name FROM [distribution].[dbo].MSArticles a JOIN [distribution].[dbo].MSpublications p ON a.publication_id = p.publication_id JOIN [distribution].[dbo].MSsubscriptions s ON p.publication_id = s.publication_id JOIN master..sysservers ss ON s.subscriber_id = ss.srvid JOIN master..sysservers srv ON srv.srvid = p.publisher_id --JOIN [distribution].[dbo].MSdistribution_agents da ON da.publisher_id = p.publisher_id -- AND da.subscriber_id = s.subscriber_id ORDER BY 1,2,3 -- 2. find replicated tables SELECT P.[publication] AS [Publication Name] ,A.[publisher_db] AS [Database Name] ,A.[article] AS [Article Name] ,A.[source_owner] AS [Schema] ,A.[source_object] AS [Object] FROM [distribution].[dbo].[MSarticles] AS A INNER JOIN [distribution].[dbo].[MSpublications] AS P ON (A.[publication_id] = P.[publication_id]) ORDER BY P.[publication], A.[article]; -- 3. Publisher select t.name from sys.tables t where is_published = 1 -- Subscriber select t.name from [SERVERNAME].[REPLICATED_DATABASE].sys.tables t where is_ms_shipped = 0;
查找所有索引
select s.name as schemaName, t.name as tableName, i.name as indexName from sys.tables t inner join sys.schemas s on t.schema_id = s.schema_id inner join sys.indexes i on i.object_id = t.object_id where i.index_id > 0 and i.type in (1, 2) and i.is_primary_key = 0 and i.is_unique_constraint = 0
查看索引详情
SELECT schema_name(schema_id) as SchemaName, OBJECT_NAME(si.object_id) as TableName, si.name as IndexName, (CASE is_primary_key WHEN 1 THEN 'PK' ELSE 'index' END) as indexType, (CASE is_unique WHEN 1 THEN '1' ELSE '0' END)+' '+ (CASE si.type WHEN 1 THEN 'C' WHEN 3 THEN 'X' ELSE 'B' END)+' '+ -- B=basic, C=Clustered, X=XML (CASE INDEXKEY_PROPERTY(si.object_id,index_id,1,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,2,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,3,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,4,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,5,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,6,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,7,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ (CASE INDEXKEY_PROPERTY(si.object_id,index_id,8,'IsDescending') WHEN 0 THEN 'A' WHEN 1 THEN 'D' ELSE '' END)+ '' as 'Type', INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,1) as Key1, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,2) as Key2, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,3) as Key3, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,4) as Key4, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,5) as Key5, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,6) as Key6, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,7) as Key7, INDEX_COL(schema_name(schema_id)+'.'+OBJECT_NAME(si.object_id),index_id,8) as Key8 FROM sys.indexes as si LEFT JOIN sys.objects as so on so.object_id=si.object_id WHERE index_id>0 -- omit the default heap and OBJECTPROPERTY(si.object_id,'IsMsShipped')=0 -- omit system tables --and not (schema_name(schema_id)='dbo' and OBJECT_NAME(si.object_id)='sysdiagrams') -- omit sysdiagrams and schema_name(schema_id)='fdp_cvs' -- and OBJECT_NAME(si.object_id) ='fdp_cvs' ORDER BY SchemaName,TableName,IndexName
sqlserver日期函数
DATEADD(datepart,number,date) DATEDIFF(datepart,startdate,enddate) DATEPART(datepart,date) select getdate() -- 当前日期 8/15/2017 3:21:45 AM select dateadd(m, 0, 0) -- 时间起点 1/1/1900 12:00:00 AM select dateadd(m, datediff(m,0,getdate())-2, 0) -- 当前季度的第一天 6/1/2017 12:00:00 AM select dateadd(m, datediff(m,0,getdate())-11, 0)-- 一年前当月的第一天 9/1/2016 12:00:00 AM select dateadd(d, 1, dateadd(q,-1,getdate())) -- 一季度前的起始日期 5/16/2017 3:21:45 AM select dateadd(d, 2, dateadd(y,-1,getdate())) -- 一年前的起始日期 8/16/2017 3:21:45 AM select CONVERT(datetime,CONVERT(char(8),getdate(),120)+'1') -- 该月第一天 8/1/2017 12:00:00 AM select CONVERT(char(5), getdate(),120)+'1-1' -- 年的第一天 select CONVERT(char(5), getdate(),120)+'12-31' -- 年的最后一天 select 年份=year(getdate()),月份=month(getdate()) select 年份=datepart(year,getdate()),月份=datepart(month,getdate())
创建数据库快照
NAME: snapshot文件的逻辑名称,FILENAME: snapshot文件的存放位置 CREATE DATABASE AdventureWorks_dbss1800 ON ( NAME = AdventureWorks_Data, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\Data\AdventureWorks_data_1800.ss' ) AS SNAPSHOT OF AdventureWorks; GO


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix