python字符编码与数据类型
1变量
1.1 变量类型
变量存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。
基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。
因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
1.2 变量赋值
Python中的变量赋值不需要类型声明。
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
等号(=)用来给变量赋值。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。例如:
#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu name = 'anliu jiang' age = 18 salary = 0.001 print(name,age,salary)
1.3 多个变量赋值
Python允许你同时为多个变量赋值。例如:
#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu a = b = c = 1 print(a) print(b) print(c) print(a,b,c)
以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。
您也可以为多个对象指定多个变量。例如:
#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu a,b,c,= 1,3.1415,"john" print(a,b,c)
以上实例,两个整型对象 1 和 2 分别分配给变量 a 和 b,字符串对象 "john" 分配给变量 c。
1.4 变量的赋值
思考:一下程序输出结果是什么?
#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu name1 = "anttech" name2 = name1 print(name1,name2) name2 = "thinking" print(name1,name2)
1.5 定义变量的规则
变量名只能是字母,数字或下划线的组合
变量名的第一个字符不能是数字
关键字不能声明为变量:

#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu tingtingceshi = DMDB_OF_dir = cmdb_of_dir= CmdbOfDir =
注意:在python中是没有常量的概念。在C中const定义常量。
在Python中表示常量用大写的变量名表示(只是人为规定)
1.6 字符串操作
#Author:Anliu name = "{name} is a boy,\the likes {yunwei}" print(name) print(name.count("l")) #统计字母个数 print(name.capitalize()) #将字符串首字母大写 print(name.center(50,"-")) #将字符串格式化居中输出 print(name.encode(encoding="utf-8")) #将字符串编码 print(name.endswith("x")) #判断字符串结尾字符 print(name.expandtabs(tabsize=10)) #将tab转换为空格 print(name.format(name="anliu",yunwei="linux")) #格式化输出 print(name.find("n")) #获取索引 print(name.format_map({"name":"anliu","yunwei":"linux"})) #字典的方式格式输出 print(name.index("a")) #获取索引 print("123".isdigit()) #判断字符串是否为数字 print("wq123q".isalnum()) #判断字符串是否为数字字母组合 print("wql".isalpha()) #判断字符串是否为字母 print("111".isdecimal()) #判断字符串是否为十进制 print(name.isidentifier()) #判断是否为合法的标识符 print("abc".islower()) #判断是否为小写字母 print("123".isdigit()) #判断是否为数字 print("123".isprintable()) #判断字符串是否可打印,tty File OR driver File print(" ".isspace()) #判断是否为空格 print("15000 International Students Are Living In A Dilemma".istitle()) #是否为标题 print("ABC".isupper()) #是否大写 print("SBA".lower()) #转换为小写 print(" ABC".lstrip()) print("ABC ".rstrip()) print(" ABC ".strip()) print("abc".ljust(10,"+")) print("abc".rjust(10,"+")) p = str.maketrans("anliua","123456") print("anliu".translate(p)) print("anliu".partition("l")) #分割成元组 print("anliu".replace("a","A")) #替代 print("anliu".split("l")) #分割成列表 print("1+1+1+1".split("+")) print("anliu\nis \na \nboy".splitlines()) #按换行返回列表 print("www.baidu.com".startswith("www")) #判断以某前缀开始 print("This is a web addr:www.baidu.com".startswith("www",19)) print("abc".zfill(50))
2 字符编码
2.1 python程序中的字符编码
python解释器在加载.py文件中的代码时,会对内容进行编码(默认ascill)
在python2以及python3.6下执行一下代码:
[root@bogon test]# cat hw.py #/usr/bin/python2 print ("您好,世界!!!")
[root@bogon test]# python2 hw.py
File "hw.py", line 2 SyntaxError: Non-ASCII character '\xe6' in file hw.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
在python3.6上运行

在python3.7版本下运行改代码:

在pyhon2以及python3.6上再次执行如下代码:
[root@bogon test]# cat hw.py #/usr/bin/python3 #-*-coding:utf-8 -*- print("您好,世界!!!")

Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了

就是说,在python7上Cpython强制使用utf-8编码。
所以如果大家在学习过程中,代码中包含中文,就需要在头部指定编码。
**注意:**Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
**注意:**如果你使用编辑器,同时需要设置 py 文件存储的格式为 UTF-8,否则会出现类似以下错误信息:

2.2 字符编码介绍
ASCII,美国标准信息交换代码是基于拉丁字母的一套电脑编码系统,主要用于显示现在英语和其他西欧语言,其最多只能用8位来表示(一个字节),即:2**8=256-1,所以呢,ASCII码最多只能表示255个字符。

有128-255个字符的扩展。
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体的big5.
7445个汉字扩展存储——JB2312(1980年)
1995年汉字的扩展规模达到21886个符号,分别是汉字区和图形符号区,产生了GBK1.0。
2000年的GB18030取代了GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文,蒙文,维吾尔文等重要的少数民族文字。
从ASCII、GB2312、GBK到GB18030,这些编码是向下兼容的。
显然ASCII码是无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即Unicode。
Unicode(统一码,万国码,单一码)是一种在计算机上使用的字符编码,Unicode是为了解决传统的字符编码方案的局限性而产生的,他为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定所有的字符和符号最少由16位来表示(2个字节)。
UTF-8,是对Unicode编码的压缩和优化,他不在是最少使用2个字节了,而是将所有的字符和符号进行分类:ASCII码中的内容用1个字节保存,欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
故而有了我们上面2.1节描述的问题。
2.3 字符编码与解码
在Python 3里将文本和二进制数据做了更为清晰的区分。文本总是Unicode,有str类型表示,二进制数据则由byte类型表示。Python 3不会以任意隐式的方式混用str和bytes。我们不同拼接字符串与字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
这就也要我们了解如何将字节码转换成字符串,如何将字符串转换为字节码。
")
#!/usr/bin/env python #-*- coding:utf-8 -*- #AUTHOR: Carve msg = "我们都是好孩子" print(msg) print(msg.encode(encoding="utf-8")) print(msg.encode(encoding="utf-8").decode(encoding="utf-8"))

3 数据类型
3.1 数值型
例如我么要开发一个游戏,我们经常需要使用数字记录游戏中用户的得分、游戏中角色的生命值、伤害值等信息,Python 语言提供了数值类型用于保存这些数值。
Python 中这些数值类型都是不可改变的,如果我们要修改数字类型变量的值,那么其底层实现的过程是,先将新值存放到内存中,然后修改变量让其指向新的内存地址,换句话说,Python 中修改数值类型变量的值,其实只是修改变量名所表示的内存空间。
数值类型只是一个泛泛的统称,Python 中的数值类型主要包括整形、浮点型和复数类型。
3.1.1 整型(int)
在常规语言中:
在32位机器上,整数的位数为32位,取值范围-2**32~2**32-1。
在64位机器上,整数的位数为64位。取值范围-2**64~2**64-1。
整形专门用来表示整数,即没有小数部分的数。在 Python 中,整数包括正整数、0 和负整数。
和其他强类型语言不同,它们会提供多种整形类型,开发者要根据数值的大小,分别用不同的整形类型存储,以 C 语言为例,根据数值的大小,开发者要合理选择 short、int、long 整形类型存储,大大增加了开发难度。
Python 则不同,它的整型支持存储各种整数值,无论多大或者多小,Python 都能轻松处理(当所用数值超过计算机自身的计算功能时,Python 会自动转用高精度计算)。
#!/bin/evn python #Author:Anliu a = 56 print(a) a=999999999999999999999999999999 print(a) print(type(a))
3.1.2 浮点型
浮点型数值用于保存带小数点的数值,Python 的浮点数有两种表示形式:
- 十进制形式:这种形式就是平常简单的浮点数,例如 5.12、512.0、0.512。浮点数必须包含一个小数点,否则会被当成整数类型处理。
- 科学计数形式:例如 5.12e2(即 5.12×10^2)、5.12E2(也是 5.12 ×10^2)。
必须指出的是,只有浮点型数值才可以使用科学计数形式表示。例如 51200 是一个整型值,但 512E2 则是浮点型值。
#!/bin/evn python #Author:Anliu af1 = 3.14159265 print(af1) af2 = 3.14 print(type(af2)) f1 = 5.12e2 print(f1) f2 = 5e3 print(f2) print(type(f2))
3.1.3 复数
复数是由实数部分和虚数部分组成,一般的形式为x+yj,其中的X 是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
3.2 布尔值
真或者假
1或者0
#/usr/bin/python3 #-*- coding:utf-8 -*- #author: Carve a = 1 if a : print("good") else: print("bad")
3.3字符串
字符串就是一系列数字,在python中,用引号引起来的都是字符串,其中的引号可以是单引号,也可以是双引号
符串或串(String)是由数字、字母、下划线组成的一串字符。
一般记为 : s="a1a2···an"(n>=0)
它是编程语言中表示文本的数据类型。
python的字串列表有2种取值顺序:
从左到右索引默认0开始的,最大范围是字符串长度少1 从右到左索引默认-1开始的,最大范围是字符串开头
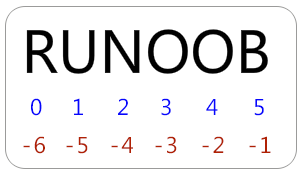
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
a = "womendoushihaohaizi"
a[:5]
'women'
a[5:]
'doushihaohaizi'
a[5:10]
'doush'#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu str = 'Hello World' print(str) print(str[0]) print(str[2:5]) print(str[2:]) print(str * 2) print(str + "TEST")
加号(+)是字符串连接运算符,星号(*)是重复操作。
Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
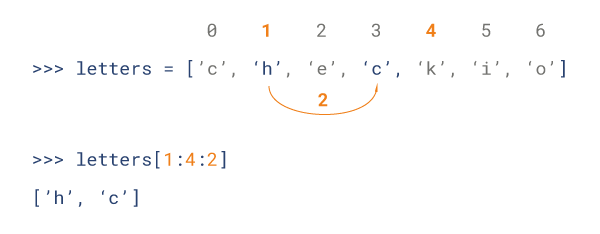
#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu str = "abababababa" print(str[2:10:2])
输出结果:aaaa
使用方法修改字符串的大小写
#Author:Anliu name = "wo men ai shangluo" print(name.title())
注:name.title()中,name后面的(.)让Python对变量name执行的方法。
还有类似以下方法:
#Author:Anliu name = "wo men ai shangluo" print(name.title()) print(name.upper()) print(name.lower())
字符串拼接:
#Author:Anliu name = "wo men ai" name1 = "shangluo" ull_name = name +" "+ name1 print(full_name)
使用制表符或者换行符来添加空白:
要在字符串中添加换行符,可使用字符组合\n:
#Author:Anliu print("python \nC")
python
C
还可以在同一个字符串中同时包含制表符和换行符。字符串"\n\t"r让python换到下一行,并在下一行开头添加一个制表符。
#Author:Anliu print("python \nC \n\tJava")
输出结果:
python
C
Java
删除空白:
#Author:Anliu name = "\tpython\t" print(name) print(name.rstrip()) print(name.lstrip()) print(name.strip())
什么意思呢?你猜。。。
输出高亮显示:
1.实现过程
终端的字符颜色是用转义序列控制的,是文本模式下的系统显示功能,和具体的语言无关。控制字符颜色的转义序列是以ESC开头,即用\033来完成
2.书写过程
开头部分: \033[显示方式;前景色;背景色m
结尾部分: \033[0m
注意:
开头部分的三个参数:显示方式,前景色,背景色是可选参数,可以只写其中的某一个;另外由于表示三个参数不同含义的数值都是唯一的没有重复的,所以三个参数的书写先后顺序没有固定要求,系统都能识别;但是,建议按照默认的格式规范书写。
结尾部分其实也可以省略,但是为了书写规范,建议\033[***开头,\033[0m结尾。
3.参数
- 显示方式:** 0(默认值)、1(高亮)、22(非粗体)、4(下划线)、24(非下划线)、 5(闪烁)、25(非闪烁)、7(反显)、27(非反显)
- **前景色**: 30(黑色)、31(红色)、32(绿色)、 33(黄色)、34(蓝色)、35(洋 红)、36(青色)、37(白色)
- **背景色**: 40(黑色)、41(红色)、42(绿色)、 43(黄色)、44(蓝色)、45(洋 红)、46(青色)、47(白色)
4.常见开头格式
\033[0m 默认字体正常显示,不高亮 \033[32;0m 红色字体正常显示 \033[1;32;40m 显示方式: 高亮 字体前景色:绿色 背景色:黑色 \033[0;31;46m 显示方式: 正常 字体前景色:红色 背景色:青色
#/usr/bin/python3
#-*- coding:utf-8 -*-
#author: Carve
UserName = input("\033[0;31;44m please input your username:\033[0m")
PassWord = input("\033[5;31;44m please input your password:\033[0m")
print(UserName,PassWord)3.3 列表
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 []标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。

加号 + 是列表连接运算符,星号 * 是重复操作。如下实例:
#!/bin/evn python #-*- coding:utf-8 -*- #Author:Anliu list = ['runoob',777,3.14,'anliu',70.2] tinylist = [123,'john'] print(list) print(list[0]) print(list[1:3]) print(list[2:]) print(tinylist * 2) print(list + tinylist)
输出结果:
['runoob', 777, 3.14, 'anliu', 70.2] runoob [777, 3.14] [3.14, 'anliu', 70.2] [123, 'john', 123, 'john'] ['runoob', 777, 3.14, 'anliu', 70.2, 123, 'john']
查:(切片操作)
#Author:Anliu #names = "zhangsan lisi wanger" names =["zhangsan","lisi","wanger"] print(names) print(names[0]) print(names[2]) print(names[:2]) print(names[2:])
查看索引:
names = ["zhangsan","lisi","wanger","xx"] print(names[names.index("xx")])
统计元素:
names = ["zhangsan","lisi","wanger","xx","lisi"] print(names.count("lisi"))
翻转:
names = ["zhangsan","lisi","wanger","xx","lisi"] names.reverse() print(names)
排序:
#Author:Anliu names = ["zhangsan","lisi","wanger","xx","lisi"] names.sort() print(names)
排序按照ACSII码的顺序:
遍历:
#Author:Anliu names = ["zhangsan","lisi",["wanger","xx"],"lisi"] for i in names: print(i)
合并:
#Author:Anliu names = ["zhangsan","lisi","wanger","xx","lisi"] names2 = ["dasfh","gsfs","","bcvbfj"] names.extend(names2) print(names) print(names2)
增:
1 在列表末尾添加元素
#Author:Anliu names = ["zhangsan","lisi","wanger"] names.append("mazi") print(names)
#Author:Anliu names = ["zhangsan","lisi","wanger"] names.insert(0,"xxx") print(names)
3 复制
“深copy”与“浅copy”
(1)“浅copy”
实质上是对第一个列表元素的引用
#Author:Anliu import copy p1 = ["name",["a",100]] print(p1) #方法一: #p2 = p1.copy() #p3 = p1.copy() #方法二: #p2 = copy.copy(p1) #p3 = copy.copy(p1) #方法三: #p2 = p1[:] #p3 = p1[:] #方法四: p2 = list(p1) p3 = list(p1) p2[0] = "zhangxiudu" p3[0] = "duyang" p2[1][1] = 50 print(p2) print(p3)
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
(2)深“copy”
p1 = ["name",["a",100]] p2 = copy.deepcopy(p1) p3 = copy.deepcopy(p1) p2[0] = "zhangxiudu" p3[0] = "duyang" p2[1][1] = 50 print(p2) print(p3)
删:
1 使用del语句删除
#Author:Anliu names = ["zhangsan","lisi","wanger"] del names[1] print(names)
2 使用方法pop()删除元素
默认删除最后一个元素
#Author:Anliu names = ["zhangsan","lisi","wanger"] names.pop() print(names)
3 弹出列表中任何位置处的元素
如果你确定使用del语句还是pop()方法,就这样判断:如果你要存列表中删除一个元素,切不在以任何方式使用它,就用del语句;如果你要在删除元素之后还能继续使用它,就用pod()方法。
#names = "zhangsan lisi wanger" names = ["zhangsan","lisi","wanger"] del_name = names.pop() print("This a test_names of pop",del_name)
#Author:Anliu names = ["zhangsan","lisi","wanger"] names.remove("lisi") print(names)
改:
#Author:Anliu names = ["zhangsan","lisi","wanger"] names[0]="123" print(names)
练习:用python语言把列表[1,3,5,7,9]倒序并将元素变为字符类型,请写出多种方法
#Author:Anliu
list = [1,2,5,7,9]
# 方法一:
'''
list1 = []
for i in list[::-1]:
list1.append(str((i)))
print(list1)
'''
#方法二:
'''
list1 = []
for i in range(len(list)-1,-1,-1):
list1.append(str(list[i]))
print(list1)
'''
#方法三:
'''
list1 = []
for i in reversed(list):
list1.append(str(i))
print(list1)
'''
#方法四:
'''
list1 = []
for i in 4,3,2,1,0:
list1.append(str(list[i]))
for j in list1:
print(type(j))
#print(type(list1))
'''3.4 元组
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
#!/bin/evn python
#-*- coding:utf-8 -*-
#Author:Anliu
tuple = ('runoob', 786, 2.23, 'john', 70.2)
tinytuple = (123, 'john')
print(tuple) # 输出完整元组
print(tuple[0]) # 输出元组的第一个元素
print(tuple[1:3]) # 输出第二个至第四个(不包含)的元素
print(tuple[2:]) # 输出从第三个开始至列表末尾的所有元素
print(tinytuple * 2) # 输出元组两次
print(tuple + tinytuple) # 打印组合的元组元祖就其本质而言,就是一个不可变列表,不像列表一样能够修改元素。因此,元组没有修改操作以为,其他类似于列表。这里不再赘述。
3.5 字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
#!/bin/evn python
#-*- coding:utf-8 -*-
#Author:Anliu
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
tinydict = {'name': 'john', 'code': 6734, 'dept': 'sales'}
print(dict['one']) # 输出键为'one' 的值
print(dict[2]) # 输出键为 2 的值
print(tinydict) # 输出完整的字典
print(tinydict.keys()) # 输出所有键
print(tinydict.values()) # 输出所有值info = {
'hebei':"shijiazhuang",
'shanxi':"shangluo",
'henan':"zhumadian"}
print(info)#Author:Anliu
info = {
'hebei':"shijiazhuang",
'shanxi':"shangluo",
'henan':"zhumadian"
}
print(info)
print(info["hebei"]) #访问字典值,该方法在键值不存在时报错
print(info.get("hebei")) #该方法在之不存在的时候,返回null
print("hebei" in info) #判断键值是否存在于字典
info["henan"] = "toujingai" #有则修改
print(info)
info["hubei"] = "jinzhou" #无则添加
print(info)#del info 删除字典
info.pop("henan") #删除元素
print(info)
info.popitem() #随机删除print(info)嵌套:
#Author:Anliu
info = {
'1001':{'name':"zhangsan",'身高':"195",'体重':"180"},
'1002':{'name':"lisi",'身高':"179",'体重':"250"},
'1002':{'name':"wangwu",'身高':"180",'体重':"130"}}
print(info)3.6 集合
集合:集合是一个无序的,不重复的数据集合,可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
例如:
parame = {value01,value02,...}
或者
set(value)主要作用如下:
(1)去重,把一个列表变成集合,就自动去重了。
(2)关系测试,测试两组数据之间的交集,差集,并集等关系。
3.6.1 关系测试
#Author:Anliu list_1 = [1,4,57] list_1 = set(list_1) print(list_1,type(list_1)) list_2 = set([1,8,3]) print(list_1,list_2) #求交集 print(list_1.intersection(list_2)) #求并集 print(list_1.union(list_2)) #求差集 print(list_1.difference(list_2))#list1里面有,list2里面没有的 #求子集 print(list_1.issubset(list_2)) #求父集 print(list_1.issuperset(list_2)) #对称差集 print(list_1.symmetric_difference(list_2)) #判断是否有交集,有则为不为真 list_3 = set([5,6,9]) list_4 = set([4,7,9]) print(list_3.isdisjoint(list_4))
3.6.2 集合操作
#Author:Anliu #添加 list_1 = set() list_1.add(999) print(list_1) list_1.update([666,777,555]) print(list_1) #删除 list_1.remove(777) print(list_1) print(list_1.pop()) #删除最小的值 print(list_1.discard(777)) #取长度 print(len(list_1)) #判断元素是否在集合中 print(666 in list_1) print(666 not in list_1)
集合内置方法列表

3.6 数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号