python整理总结(一)
python2,3的区别
1.Python2中使用 ASCII 码作为默认编码方式导致string有两种类型str和unicode,Python3只支持unicode的string。 # python2和python3字节和字符对应关系为: python2 python3 表现 转换 作用 str bytes 字节 encode 存储 unicode str 字符 decode 显示 2. Python3采用的是绝对路径的方式进行import。- Python2中相对路径的import会导致标准库导入变得困难。 3.Python2中存在老式类和新式类的区别,Python3统一采用新式类。新式类声明要求继承object,必须用新式类应用多重继承。 4.Python3使用更加严格的缩进。Python2的缩进机制中,1个tab和8个space是等价的,所以在缩进中可以同时允许tab和space在代码中共存。 -print语句被python3废弃,统一使用print函数 -exec语句被python3废弃,统一使用exec函数 -不相等操作符"<>"被Python3废弃,统一使用"!=" -long整数类型被Python3废弃,统一使用int -xrange函数被Python3废弃,统一使用range,Python3中range的机制也进行修改并提高了大数据集生成效率 -Python3中这些方法再不再返回list对象:dictionary关联的keys()、values()、items(),zip(),map(),filter(),但是可以通过list强行转换: -迭代器iterator的next()函数被Python3废弃,统一使用next(iterator) -raw_input函数被Python3废弃,统一使用input函数 -字典变量的has_key函数被Python废弃,统一使用in关键词 -file函数被Python3废弃,统一使用open来处理文件,可以通过io.IOBase检查文件类型 -异常StandardError 被Python3废弃,统一使用Exception -浮点数除法操作符/和//区别
Python2:/是整数除法,//是小数除法
Python3:/是小数除法,//是整数除法。
- round函数返回值区别 Python2,round函数返回float类型值 Python3,round函数返回int类型值 -比较操作符区别 Python2中任意两个对象都可以比较 Python3中只有同一数据类型的对象可以比较
变量:
把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
变量的定义规则:
1、变量只能由 数字,字母,下划线任意组合。
2、不能以数字开头。
3、不能是python中的关键字。
|
1
|
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] |
4、变量要具有可描述性。
name = 'alex'
age = 73
5、变量不能使用中文。
6、变量不宜过长。
变量的命名:

#驼峰体 AgeOfOldboy = 56 NumberOfStudents = 80 #下划线 age_of_oldboy = 56 number_of_students = 80
常量:
指不变的量,常量的设置:全部大写的变量,就是常量。
注释
单行注释用;#被注释内容
多行注释用;'''被注释内容'''
那么都在哪里应该添加注释呢?
例子:
- 关键节点:或者一些难以理解的代码加注释;
- 文件:文件的描述
- 函数:函数的描述
- 类:类的描述
数据类型及操作方法:
字符串:
字符串拼接 数字可以进行加减乘除等运算,字符串呢?让我大声告诉你,也能?what ?是的,但只能进行"相加"和"相乘"运算。 复制代码 >>> name 'Alex Li' >>> age '22' >>> >>> name + age #相加其实就是简单拼接 'Alex Li22' >>> >>> name * 10 #相乘其实就是复制自己多少次,再拼接在一起 'Alex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex Li' 复制代码 注意,字符串的拼接只能是双方都是字符串,不能跟数字或其它类型拼接 >>> type(name),type(age2) (<type 'str'>, <type 'int'>) >>> >>> name 'Alex Li' >>> age2 22 >>> name + age2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: cannot concatenate 'str' and 'int' objects #错误提示数字 和 字符 不能拼接 字符串的格式化输出 01“旧式”字符串解析(%操作符) 02“新式”字符串格式化(str.format) 03 字符串插值/f-Strings(Python 3.6+) Python >>> a = 5 >>> b = 10 >>> f'Five plus ten is {a + b} and not {2 * (a + b)}.' 04 字符串模板(Python标准库) Python >>> from string import Template >>> t = Template('Hey, $name!') >>> t.substitute(name=name)
索引切片
s = 'python is best language ok' # 用索引取值 print(s[-5]) print(s[10]) # 切片 0可以省略不写 print(s[0:10]) print(s[:10]) print(s[:]) print(s[:10:2]) # 加步长每隔2个取一个值 # 反向取值必须加步长, 最后一位的索引值为-1, print(s[-1:-8]) print(s[-1:-8:-2])
内置方法
# 大前提:对字符串的任何操作都是产生一个新的字符串,与原字符串没有关系
s = 'Wua123jing666'
t1 = s.count('a') # 在字符串中查找指定字符有多少个
t2 = s.upper() # 将字符串中的字符全部大写
t3 = s.lower() # 将字符串中的字符全部小写
t4 = s.title() # 非字母隔开的每个单词的首字母大写
t5 = s.find('a') # 通过元素获取其索引,找到第一个就返回,找不到会返回-1。
t6 = s.index('a') # 通过元素获取其索引,找到第一个就返回,找不到会报错。
t7 = s.capitalize() # 将字符串中的首字母大写
t8 = s.replace('a','nb',2) # 替换,由什么替换成什么,替换几次
t9 = s.startswith('w') # 判断以什么为开头 可以切片
t10 = s.startswith('i',3,) # 判断以什么为开头 可以切片,取索引3后面的所有字符
t11 = s.endswith('i',3) # 判断以什么结尾,可以切片,取索引3后面的所有字符
t12 = s.swapcase() # 大小写反转
t13 = s.isupper() # 判断字符串中所有字母是否为大写,返回布尔值
t14 = s.islower() # 判断字符串中所有字母是否为小写,返回布尔值
t15 = s.isdigit() # 字符串只由数字组成
t16 = s.isalpha() # 字符串只由字母组成
t17 = s.isalnum() # 字符串由字母或数字组成
---------------------------------------------------------------
t18 = s.strip('W') # 默认去除字符串两边的空格,换行符,制表符,只是去除左边-->lstrip()去除右边-->rstrip(),可设置去除的字符
t19 = s.split() # 默认按照空格分割,
t20 = s.split('r') # 指定字符进行分割,
t21 = s.split('s',2) # 指定字符进行分割,且指定分割次数
---------------------------------------------------------------
join 连接符
l1 = ['wusir', 'alex', 'taibai'] # 操作列表时,列表里面的内容必须全部是字符串类型
t22 = ''.join(l1) # 默认连接
t23 = '-'.join(l1) # 指定字符连接
列表:
增:
s = ['alex','wusir','taibai']
# append 追加
s.append('henry')
# insert 插入
s.insert(1,'henry')
# extend 迭代追加
s.extend('henry')
s.extend(['oldboy','girl'])
删:
s = ['alex','wusir','taibai',10,11]
pop 按照索引删除,会将删除的元素作为返回值(默认删除最后一个)
s.pop(1)
remove 按照元素删除
s.remove('wusir')
clear 清空列表
s.clear()
del
按照索引删除
del s[1]
按照切片删除
del s[1:2]
删除整个列表
del s
改:
s = ['alex','wusir','taibai',10,11] 切片改 s[:1] = 'asdf' 切片加步长改 必须一一对应 s[::2] = ['a','b','c']
查:
按照索引 按照切片 加步长查询 for 循环查询 s = ['alex','wusir','taibai',10,11]print(s)
列表的其他操作:
获取列表的长度 len() 计算某个元素出现的次数 conut 通过元素查找索引,找到第一个就返回,找不到就报错 从小到大排序sort(reverse = False) 当reverse = True时从大到小 反转用 reverse 查找某个元素的索引用 index 找到第一个就返回,找不到报错
字典
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,3.6版本之后字典是有序的(3.5版本之前字典是无序的),且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象结合,3.6版本之后字典是有序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
增:setdefault
dic = {
'name':'烟雨江南',
'age':18,
'sex':'man'
}
增
dic['hobby'] = '看书' # 有则修改,无则添加
print(dic)
dic.setdefault('hobby','玩游戏') # 有则不变,无则添加
print(dic)
删:pop、clear、popitem、del
dic = {
'name':'烟雨江南',
'age':18,
'sex':'man'
}
ret = dic.pop('name') # 按照键删除键值对,并返回删除的值
ret = dic.pop('name1','删除的对象不存在') # 设置两个参数,第二个参数是提示语,一般设置为None;键不存在也不会报错
print(ret)
dic.clear() # 清空字典
dic.popitem() #3.6版本之后删除最后一个键值对
print(dic)
del dic['name'] # 按照建删除
print(dic)
改:update
dic = {
'name':'烟雨江南',
'age':18,
'sex':'man'
}
dic['name'] = 'jj'
print(dic)
dic.update(name = 'TSL',money=10000) #更新:有则覆盖,没有则添加
print(dic)
dic = {"name": "jin", "age": 18, "sex": "male"}
dic2 = {"name": "alex", "weight": 75}
dic2.update(dic)
# 将dic里面的键值对覆盖添加到dic2中
查:
dic = {
'name':'烟雨江南',
'age':18,
'sex':'man'
}
print(dic['age']) # 若不存在会报错
dic.get('age') # 没有此键默认返回None
print(dic)
ret = dic.get('age1','此键不存在') # 键不存在,可设置提示语
print(ret)
字典的其他操作:
dic = {
'name': '太白金星',
'age': 18,
'hobby': 'wife',
}
# 查看键
res = dic.keys() # 查看字典中所有键
print(res,type(res)) # <class 'dict_keys'> 该类型可以循环遍历
for i in res:
print(i)
print(list(res)) # 也可以通过list转化为列表
-------------------------------------------------------------
# 查看值
res1 = dic.values() # 查看字典中所有值
print(res1,type(res1)) # <class 'dict_values'> 该类型可以循环遍历
for i in res1:
print(i)
print(list(res1)) # 也可以通过list转化为列表
-------------------------------------------------------------
#查看键值对
res2 = dic.items()
print(res2,type(res2)) # 查看字典中所有键值对
for i in res2:
print(i)
print(list(res2)) # 也可通过list转化为列表:[('name', '太白金星'), ('age', 18), ('hobby', 'wife')]
集合
是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 集合中的元素必须是不可变类型
- 关系测试,测试两组数据之前的交集、差集、并集等关系
常用操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
a = set([1,2,3,4,5])b = set([4,5,6,7,8])print(a.intersection(b)) #交集 {4, 5}print(a&b)print(a.union(b)) #并集 {1, 2, 3, 4, 5, 6, 7, 8}print(a|b)print(a.difference(b)) #插集、得到的是a里有的b里没有的 {1, 2, 3}print(a-b)print(b.difference(a)) #插集、得到的是b里有的a里没有的 {8, 6, 7}print(b-a)print(a.symmetric_difference(b)) #方向交集、{1, 2, 3, 6, 7, 8}print(a^b) |
文件操作
文件操作:
#1. 打开文件的模式有(默认为文本模式):
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
w,只写模式【不可读;不存在则创建;存在则清空内容】
a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】
#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
#3,‘+’模式(就是增加了一个功能)
r+, 读写【可读,可写】
w+,写读【可写,可读】
a+, 写读【可写,可读】
#4,以bytes类型操作的读写,写读,写读模式
r+b, 读写【可读,可写】
w+b,写读【可写,可读】
a+b, 写读【可写,可读】
r+ 读写模式:先读后写
rb 以字节的形式读取,带b的一般操作的都是非文字类的文件.
read:读取全部内容(文件较大时不可用,用for循环读取)
r模式:read(n)----n代表读取第几个字符
rb模式:read(n)---n代表读取第几个字节
其余的文件内光标移动都是以字节为单位的如:seek,tell,truncate
readline:读取第一行
readlines:返回一个list 列表的每个元素是源文件的每一行.
重点:seek光标移动(按字节移动)中文3个字节,英文一个字节,换行(\n)是2个字节;
seek(0,0)把光标移到起始位置
seek(0,1)当前光标所在位置
seek(0,2)把光标移到结束位置
r模式:read(n)----n代表读取第几个字符,只有r模式n代表字符,其他都是按字节读取
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果。
常用操作:
def close(self, *args, **kwargs): # real signature unknown
关闭文件
pass
def fileno(self, *args, **kwargs): # real signature unknown
文件描述符
pass
def flush(self, *args, **kwargs): # real signature unknown
刷新文件内部缓冲区
pass
def isatty(self, *args, **kwargs): # real signature unknown
判断文件是否是同意tty设备
pass
def read(self, *args, **kwargs): # real signature unknown
读取指定字节数据
pass
def readable(self, *args, **kwargs): # real signature unknown
是否可读
pass
def readline(self, *args, **kwargs): # real signature unknown
仅读取一行数据
pass
def seek(self, *args, **kwargs): # real signature unknown
指定文件中指针位置
pass
def seekable(self, *args, **kwargs): # real signature unknown
指针是否可操作
pass
def tell(self, *args, **kwargs): # real signature unknown
获取指针位置
pass
def truncate(self, *args, **kwargs): # real signature unknown
截断数据,仅保留指定之前数据
pass
def writable(self, *args, **kwargs): # real signature unknown
是否可写
pass
def write(self, *args, **kwargs): # real signature unknown
写内容
pass
文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)

import os # 调用系统模块
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
data=read_f.read() #全部读入内存,如果文件很大,会很卡
data=data.replace('alex','SB') #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove('a.txt') #删除原文件
os.rename('.a.txt.swap','a.txt') #将新建的文件重命名为原文件
import os # 调用系统模块
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
data=read_f.read() #全部读入内存,如果文件很大,会很卡
data=data.replace('alex','SB') #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove('a.txt') #删除原文件
os.rename('.a.txt.swap','a.txt') #将新建的文件重命名为原文件
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
for line in read_f:
line=line.replace('alex','SB')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
import os
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
for line in read_f:
line=line.replace('alex','SB')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
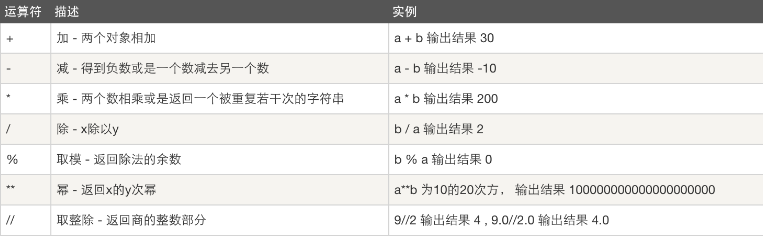
基本运算符
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算、成员运算
算数运算
以下假设变量:a=10,b=20
比较运算
以下假设变量:a=10,b=20
字符串进行比较的话,使用的是字符对应的ascii码值。

赋值运算
以下假设变量:a=10,b=20

逻辑运算

针对逻辑运算的进一步研究:
1、 在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2 、 x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x;
例如:
1 > 1 or 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 逻辑运算符的结果到底是什么类型??? 结果取决于两个操作数的类型!!! 针对and操作:第一个操作数如果是可以转成False的话,那么第一个操作数的值,就是整个逻辑表达式的值。 如果第一个操作数可以转成True,第二个操作数的值就是整个表达式的值。 针对or操作:第一个操作数如果是可以转成False的话,第二个操作数的值就是整个表达式的值。 如果第一个操作数可以转成True, 第一个操作数的值,就是整个逻辑表达式的值。
逻辑运算符规则和短路操作



成员运算:
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。

判断子元素是否在原字符串(字典,列表,集合)中:
例如:
#print('喜欢' in 'dkfljadklf喜欢hfjdkas')
#print('a' in 'bcvd')
#print('y' not in 'ofkjdslaf')
Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
身份运算符
身份运算符用于比较两个对象的存储单元

# 判断两个标识符是不是引用同一个对象或不同对象,返回布尔值 a = "烟雨江南" b =a print(b is a) # 类似id(b) = id(a) print(a is b) # 类似id(a) = id(b
小数据池
小数据池:
is 两者之间的id是否相同
== 两边的数值是否相等
id 获取该对象的内存地址
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
如果在同一代码块下,则采用同一代码块下的换缓存机制。
如果是不同代码块,则采用小数据池的驻留机制。
# pycharm 通过运行文件的方式执行下列代码: 这是在同一个文件下也就是同一代码块下,采用同一代码块下的缓存机制。
i1 = 1000
i2 = 1000
print(i1 is i2) # 结果为True 因为代码块下的缓存机制适用于所有数字
通过交互方式中执行下面代码: # 这是不同代码块下,则采用小数据池的驻留机制。
>>> i1 = 1000
>>> i2 = 1000
>>> print(i1 is i2)
False # 不同代码块下的小数据池驻留机制 数字的范围只是-5~256.
#相同代码块下:
#所有整数,大部分字符串,bool,存储地址相同
#不同代码块下(小数据池):
#-5-256,字符串长度小于等于20,bool,存储地址相同
函数部分
函数的参数及返回值
默认参数
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,country,course): print("----注册学生信息------") print("姓名:",name) print("age:",age) print("国籍:",country) print("课程:",course) stu_register("王山炮",22,"CN","python_devops")stu_register("张叫春",21,"CN","linux")stu_register("刘老根",25,"CN","linux") |
发现 country 这个参数 基本都 是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是 中国, 这就是通过默认参数实现的,把country变成默认参数非常简单
|
1
|
def stu_register(name,age,course,country="CN"): |
这样,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。
另外,你可能注意到了,在把country变成默认参数后,我同时把它的位置移到了最后面,为什么呢?
关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
|
1
|
stu_register(age=22,name='alex',course="python",) |
非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式 print(name,age,args) stu_register("Alex",22)#输出#Alex 22 () #后面这个()就是args,只是因为没传值,所以为空 stu_register("Jack",32,"CN","Python")#输出# Jack 32 ('CN', 'Python') |
还可以有一个**kwargs
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs) stu_register("Alex",22)#输出#Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空 stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong")#输出# Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'} |
代码实例:
1 def print_info(name,age):
2 print('Name: %s'%name)
3 print('Age: %s'%age)
4
5 print_info('alex',35) #必须参数
6
7 def print_info(name,age):
8 print('Name: %s'%name)
9 print('Age: %s'%age)
10
11 print_info(age=35,name='alex') #关键字参数
12
13 def print_info(name,age,sex='male'):
14 print('Name: %s'%name)
15 print('Age: %s'%age)
16 print('Sex: %s'%sex)
17
18 print_info('alex',35)
19 print_info('wuchao',20)
20 print_info('jinxin',18)
21 print_info('xiaoyu',18,'female') #默认参数(必须放在必须参数的后面)
22
23 def add(x,y,z): #low加法器
24 print(x+y+z)
25
26 add(1,2,3)
27
28 def add(*args): #不定长参数(高大上加法器)
29 #print(args)
30 sum = 0
31 for i in args:
32 sum += i
33 print(sum)
34
35 add(1,2,3,4,5,6) #传入的是无命名参数
36
37 def print_info(*args, **kwargs): # 不定长参数(键值对)
38
39 print(args) # ('alex', 35, 'male') 无命名参数被args接收
40 print(kwargs) # {'jop': 'IT', 'hobby': 'girl', 'height': 188} 声明参数被kwargs接收
41
42
43 print_info('alex', 35, 'male', jop='IT', hobby='girl', height=188) # 传入的是声明参数
44
45
46 def print_info(**kwargs): # 不定长参数(键值对)
47
48 print(kwargs) # {'jop': 'IT', 'hobby': 'girl', 'height': 188} 声明参数被kwargs接收
49 for i in kwargs:
50 print('%s:%s'%(i,kwargs[i]))
51 print_info(jop='IT', hobby='girl', height=188) # 传入的是声明参数
52
53 #不定长参数的位置
54 #*args放在左边,**kwsrgs放在后边
55 def f(*args,**kwargs): #无命名参数必须放左边,声明参数放右边
56 pass
57 f(1,2,[3,4,5],name='alex')
58
59 def print_info(sex='male',*args,**kwargs): # 不定长参数(键值对) 默认参数必须放在不定长参数的左边
60 print(args)
61
62 print(kwargs)
63 for i in kwargs:
64 print('%s:%s'%(i,kwargs[i]))
65 print_info('female',1,2,3)
66 print_info(1,2,3,'female',name='alex')
67
68 #函数参数的优先级
69 def dfun(name,age=22,*args,**kwargs):#必须参数-关键字参数-不定长(无命名参数)-不定长(声明参数)
函数的返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
- return多个对象,解释器会把这多个对象组装成一个元组作为一个整体结果输出
闭包
一、什么是闭包
1.首先有一个嵌套函数
2.嵌套函数内部函数调用非全局的变量
3.将内部函数名当做返回值返回,在全局调用
怎么去查看闭包??
函数名.__closure__ 返回None 就不是闭包;
二、闭包的特点
1.保护变量
2.可以让一个变量常驻内存(比如爬虫,不用每次都去重新请求网址)
三、闭包的应用
和全局变量一样,它不确定什么时间会被调用,所以会常驻内存,随时等候被调用;
例如爬虫,不用每次都去重新请求网址,重新获得数据;第一次爬取就会把你想要的数据驻留内存中,方便以后调用;
四、闭包函数示例
def test(): url = 'www.baidu.com' def func(): print(url) # 引用外部作用域的变量 return func # 返回func的内存地址 res = test() res() # www.baidu.com print(test()) # <function test.<locals>.func at 0x0000021AE401A950> def func1(): a = 10 def func2(num): nonlocal a # 可以通过关键字进行修改 a += num print(a) return func2 func1()(100) 查看是否是闭包函数,打印结果不是None就是闭包 print(func1().__closure__)
迭代器
同时具有__iter__方法和__next__方法的就是迭代器
for循环的机制 就是迭代器;
#优点: # - 提供一种统一的、不依赖于索引的迭代方式 # - 惰性计算,节省内存 #缺点: # - 无法获取长度(只有在next完毕才知道到底有几个值) # - 一次性的,只能往后走,不能往前退
示例:
li = [1,2,3] a = li.__iter__() print(a.__next__()) print(a.__next__()) #一个一个取 print(a.__next__()) print(a.__next__()) #将可迭代对象内的元素全部取完后在取会抛出'StopIteration'
li = [1,2,3] a = li.__iter__() print(a.__next__()) print(a.__next__()) #一个一个取 print(a.__next__()) print(a.__next__()) #将可迭代对象内的元素全部取完后在取会抛出'StopIteration'
示例:
li = [1,2,3,4,6,7,87,8,9,90,0,0,0,0,8,7,7,67,]
em = li.__iter__()
while 1:
try:
print(em.__next__())
except StopIteration:
break
当出现 StopIteration 直接退出循环
li = [1,2,3,4,6,7,87,8,9,90,0,0,0,0,8,7,7,67,]
em = li.__iter__()
while 1:
try:
print(em.__next__())
except StopIteration:
break
当出现 StopIteration 直接退出循环
递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数,记住哦->在函数内部调用其他函数不是函数的嵌套,而在函数内部定义子函数才是函数的嵌套;
举个例子,我们来计算阶乘n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示,可以看出:
fact(n) = n! = 1 x 2 x 3 x ... x (n-1) x n = (n-1)! x n = fact(n-1) x n
所以,fact(n)可以表示为n x fact(n-1),只有n=1时需要特殊处理。于是,fact(n)用递归的方式写出来就是
def fact(n): if n==1: return 1 return n * fact(n - 1)
如果我们计算fact(5),可以根据函数定义看到计算过程如下:
===> fact(5) ===> 5 * fact(4) ===> 5 * (4 * fact(3)) ===> 5 * (4 * (3 * fact(2))) ===> 5 * (4 * (3 * (2 * fact(1)))) ===> 5 * (4 * (3 * (2 * 1))) ===> 5 * (4 * (3 * 2)) ===> 5 * (4 * 6) ===> 5 * 24 ===> 120
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。可以试试fact(1000),递归默认层次,官方说明 1000,实际测试 998/997,
1. 自己玩自己 (自己调用自己本身)
2. 玩的有限制 (有明确结束条件)
修改递归的最大层数
import sys
sys.setrecursionlimit(10000)
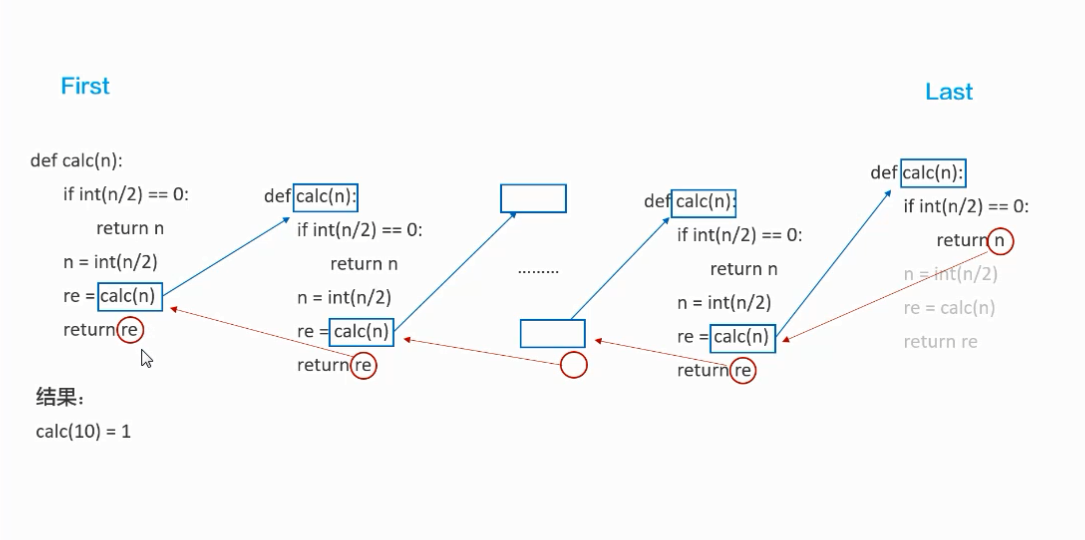
示列:
def fun(n):
print(n)
if n / 2 == 0:
return n
res = fun(int(n/2))
return res
fun(10)
总结:
# 1.生成器的本质就是一个迭代器
# 2.生成器一定是一个迭代器,迭代器不一定是一个生成器
# 3.生成器是可以让程序员自己定义的一个迭代器
# 4.生成器的好处,节省内存空间
# 5.生成器的特性 一次性的,惰性机制,从上向下
# 6.send相当于 next+传值,第一次触生成器的时候,如果使用send(None)值必须是None,一般我建议你们使用__next__
# 7. python2 iter() next()
# python3 iter() next() __next__() __iter__()
# 8.yield from 将可迭代对象元素逐个返回
匿名函数:
- 1、关键字lambda
- 2、x 代表函数的形参;
- 3、x+1 代表函数的返回值相当于return,要返回多个结果需加括号 列:lambda x,y,z:(x+1,y+1,z+1)
- 4、无名字,需定义;
def fun(x):
return x+1
print(fun(10))
fun = lambda x:x+1
print(fun(10))
内置函数
print(abs(-1))#取绝对值 print(all([1,2,3]))#用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。元素除了是 0、空、FALSE 外都算 TRUE。 print(any([1,2,3]))#用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。元素除了是 0、空、FALSE 外都算 TRUE。 print(bin(10))#返回一个整数 int 或者长整数 long int 的二进制表示。 print(hex(10))#用于将10进制整数转换成16进制,以字符串形式表示。 print(oct(10))#函数将一个整数转换成8进制字符串。 print(chr(97))#返回值是当前整数对应的ascii字符。 print(bool(0))#用于将给定参数转换为布尔类型,如果没有参数,返回 False。 print(dict(a="1"))#用于创建一个字典 print(dir(list))#函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。 print(divmod(10,3))#函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。 print(list(enumerate(["lw","xa","ww"])))#用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 print(eval("2+2"))#用来执行一个字符串表达式,并返回表达式的值。 def is_odd(n): return n % 2 == 1 newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])#用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。 print(list(newlist)) print(float(1))#用于将整数和字符串转换成浮点数。 #"{1} {0} {1}".format("hello", "world") # 设置指定位置,format 函数可以接受不限个参数,位置可以不按顺序。 print(globals())#以字典类型返回当前位置的全部全局变量。 print(hash("test"))#用于获取取一个对象(字符串或者数值等)的哈希值。 print(help(dict))#用于查看函数或模块用途的详细说明。 print(id(list))#用于获取对象的内存地址。 print(int("13",8))#用于将一个字符串或数字转换为整型。8代表进制数; print(len("asdfghj"))#返回对象(字符、列表、元组等)长度或项目个数。 print(max(10,90,1000))#返回给定参数的最大值,参数可以为序列。 print(min(10,90,1000))#返回给定参数的最小值,参数可以为序列。 p = {"name":"alex","age":18,"hobby":"gilr"} print(list(zip(p.keys(),p.values())))#拉链函数,两个参数均为序列,用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
高阶函数:就是把函数当成参数传递的一种函数
1、函数名可以进行赋值;
2、函数名可以作为函数参数,还可以作为函数的返回值;
a、函数是第一类对象
b、函数可以被赋值
c、可以被当做参数
d、可以当做返回值
e、可以作为容器类型的元素
def f(n):
return n*n
def foo(a,b,func):
ret = func(a) + func(b)
return ret
foo(1,2,f)
print(foo(1,2,f))
#传入参数a=1,b=2,func=f;
#ret = f(1) + f(2);
#f(1)=1,f(2)=4此时调用f函数;
#ret=5;
map函数:
描述
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
语法
map() 函数语法:
|
1
|
map(function, iterable, ...) |
参数
- function -- 函数
- iterable -- 一个或多个序列
返回值
Python 2.x 返回列表。
Python 3.x 返回迭代器。
实例
|
1
2
3
4
5
6
7
8
9
10
11
|
>>>def square(x) : # 计算平方数... return x ** 2...>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方[1, 4, 9, 16, 25]>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数[1, 4, 9, 16, 25] # 提供了两个列表,对相同位置的列表数据进行相加>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])[3, 7, 11, 15, 19] |
msg = [1,12,33,42,15,16]
#需求自增1
def add_one(x):
return x+1
#需求自减1
def reduce(x):
return x-1
#需求平方
def pf(x):
return x**2
#实现逻辑
def fangfa(func,red):
ret = []
for i in red:
res = func(i)
ret.append(res)
return ret
print(fangfa(add_one,msg))
print(fangfa(reduce,msg))
print(fangfa(pf,msg))
print(fangfa(lambda x:x+1,msg)) #用lambda函数替换add_one函数
print(fangfa(lambda x:x-1,msg)) #用lambda函数替换requce函数
print(fangfa(lambda x:x**2,msg))#用lambda函数替换pf函数
print(list(map(lambda x:x+1,msg))) #map处理的结果是一个可迭代对象,python3中需用list转换;
print(list(map(lambda x:x-1,msg))) #map的第一个参数是逻辑,第二个参数是可迭代对象;
print(list(map(lambda x:x**2,msg)))
filter函数:
描述
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
语法
以下是 filter() 方法的语法:
|
1
|
filter(function, iterable) |
参数
- function -- 判断函数。
- iterable -- 可迭代对象。
返回值
返回列表
实例
以下展示了使用 filter 函数的实例:
|
1
2
3
4
5
6
7
|
def is_odd(n): return n % 2 == 1 newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])print(newlist)[1, 3, 5, 7, 9] |
lise_l = ["sb_asd","sb_we","sb_ig","rng"]
#需求去掉开头是sb的
def sh_show(n):
return n.startswith("sb")
#实现逻辑
def filter_test(func,array):
red = []
for i in array:
if not sh_show(i):
red.append(i)
return red
print(filter_test(sh_show,lise_l))
print(filter_test(lambda n:n.startswith("sb"),lise_l))#lambda
print(list(filter(lambda n:not n.startswith("sb"),lise_l)))#filter
reduce函数
描述
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
在 Python3 中,reduce() 函数已经被从全局名字空间里移除了,它现在被放置在 fucntools 模块里,如果想要使用它,则需要通过引入 functools 模块来调用 reduce() 函数:
|
1
|
from functools import reduce |
|
1
2
3
4
5
6
7
|
from functools import reducedef add(x,y): return x + yprint (reduce(add, range(1, 101))) |
语法
reduce() 函数语法:
|
1
2
|
reduce(function, iterable[, initializer]) |
参数
- function -- 函数,有两个参数
- iterable -- 可迭代对象
- initializer -- 可选,初始参数
返回值
返回函数计算结果。
实例
以下实例展示了 reduce() 的使用方法:
|
1
2
3
4
5
6
7
|
>>>def add(x, y) : # 两数相加... return x + y...>>> reduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+515>>> reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数15 |
装饰器
装饰器实际上就是为了给某程序增添功能,但该程序已经上线或已经被使用,那么就不能大批量的修改源代码,这样是不科学的也是不现实的,因为就产生了装饰器,使得其满足:
- 不能修改被装饰的函数的源代码
- 不能修改被装饰的函数的调用方式
- 满足1、2的情况下给程序增添功能
那么根据需求,同时满足了这三点原则,这才是我们的目的。因为,下面我们从解决这三点原则入手来理解装饰器。
等等,我要在需求之前先说装饰器的原则组成:
< 函数+实参高阶函数+返回值高阶函数+嵌套函数+语法糖 = 装饰器 >
这个式子是贯穿装饰器的灵魂所在!
装饰器:本质就是函数,功能是为其他函数添加功能;
#原则
#1:不能修改被修饰函数的源代码;
#2:不能修改被修饰函数的调用方式
#装饰器的知识储备
#装饰器 = 高阶函数+函数嵌套+闭包
import time
def demo(func):
def data():
star_time = time.time()
func()
end_time = time.time()
print("执行时间%s"%(end_time - star_time))return data
@demo #相当于inner=demo(inner)
def inner():
time.sleep(1)
print("执行结果")
inner()
# inner() #执行的是data
# inner=demo(inner) #返回的是data的地址
# print(inner)# ,<function demo.<locals>.data at 0x00000128A495E950>

给函数加上认证功能: 复制代码 user_list = [ {"name":"alex","passwd":"123"}, {"name":"lw","passwd":"456"}, {"name":"szx","passwd":"000"}, ]#账户数据库 current_dic = {"username":None,"login":False} #当前登陆状态 def auth_func(func): def wrapper(*args,**kwargs): if current_dic["username"] and current_dic["login"]:#判断当前登录状态为真时,执行函数; res = func(*args, **kwargs) return res username = input("用户名:") passwd = input("密码:") for user_dic in user_list: #遍历账户列表 if username == user_dic["name"] and passwd == user_dic["passwd"]: current_dic["username"] = username #更改登录状态 current_dic["login"] = True res = func(*args,**kwargs) return res else: print("用户名或者密码错误") return wrapper @auth_func def index(): print("欢迎来到京东主页") @auth_func def home(name): print("欢迎回家%s" %name) @auth_func def shopping_car(name): print("%s购物车里有娃娃、奶茶"%(name)) index() home("老王") shopping_car("老王") 复制代码 2、需求的实现 假设有代码: 1 2 3 4 5 improt time def test(): time.sleep(2) print("test is running!") test() 很显然,这段代码运行的结果一定是:等待约2秒后,输出 1 test is running 那么要求在满足三原则的基础上,给程序添加统计运行时间(2 second)功能 在行动之前,我们先来看一下文章开头提到的原因1(关于函数“变量”(或“变量”函数)的理解) 2.1、函数“变量”(或“变量”函数) 假设有代码: 1 2 3 4 5 x = 1 y = x def test1(): print("Do something") test2 = lambda x:x*2 那么在内存中,应该是这样的: 很显然,函数和变量是一样的,都是“一个名字对应内存地址中的一些内容” 那么根据这样的原则,我们就可以理解两个事情: test1表示的是函数的内存地址 test1()就是调用对在test1这个地址的内容,即函数 如果这两个问题可以理解,那么我们就可以进入到下一个原因(关于高阶函数的理解) 2.2高阶函数 那么对于高阶函数的形式可以有两种: 把一个函数名当作实参传给另外一个函数(“实参高阶函数”) 返回值中包含函数名(“返回值高阶函数”) 那么这里面所说的函数名,实际上就是函数的地址,也可以认为是函数的一个标签而已,并不是调用,是个名词。如果可以把函数名当做实参,那么也就是说可以把函数传递到另一个函数,然后在另一个函数里面做一些操作,根据这些分析来看,这岂不是满足了装饰器三原则中的第一条,即不修改源代码而增加功能。那我们看来一下具体的做法: 还是针对上面那段代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 improt time def test(): time.sleep(2) print("test is running!") def deco(func): start = time.time() func() #2 stop = time.time() print(stop-start) deco(test) #1 我们来看一下这段代码,在#1处,我们把test当作实参传递给形参func,即func=test。注意,这里传递的是地址,也就是此时func也指向了之前test所定义的那个函数体,可以说在deco()内部,func就是test。在#2处,把函数名后面加上括号,就是对函数的调用(执行它)。因此,这段代码运行结果是: 1 2 test is running! the run time is 3.0009405612945557 我们看到似乎是达到了需求,即执行了源程序,同时也附加了计时功能,但是这只满足了原则1(不能修改被装饰的函数的源代码),但这修改了调用方式。假设不修改调用方式,那么在这样的程序中,被装饰函数就无法传递到另一个装饰函数中去。 那么再思考,如果不修改调用方式,就是一定要有test()这条语句,那么就用到了第二种高阶函数,即返回值中包含函数名 如下代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 improt time def test(): time.sleep(2) print("test is running!") def deco(func): print(func) return func t = deco(test) #3 #t()#4 test() 我们看这段代码,在#3处,将test传入deco(),在deco()里面操作之后,最后返回了func,并赋值给t。因此这里test => func => t,都是一样的函数体。最后在#4处保留了原来的函数调用方式。 看到这里显然会有些困惑,我们的需求不是要计算函数的运行时间么,怎么改成输出函数地址了。是因为,单独采用第二张高阶函数(返回值中包含函数名)的方式,并且保留原函数调用方式,是无法计时的。如果在deco()里计时,显然会执行一次,而外面已经调用了test(),会重复执行。这里只是为了说明第二种高阶函数的思想,下面才真的进入重头戏。 2.3 嵌套函数 嵌套函数指的是在函数内部定义一个函数,而不是调用,如: 1 2 3 4 5 6 def func1(): def func2(): pass 而不是 def func1(): func2() 另外还有一个题外话,函数只能调用和它同级别以及上级的变量或函数。也就是说:里面的能调用和它缩进一样的和他外部的,而内部的是无法调用的。 那么我们再回到我们之前的那个需求,想要统计程序运行时间,并且满足三原则。 代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 improt time def timer(func) #5 def deco(): start = time.time() func() stop = time.time() print(stop-start) return deco test = timer(test) #6 def test(): time.sleep(2) print("test is running!") test() #7 这段代码可能会有些困惑,怎么忽然多了这么多,暂且先接受它,分析一下再来说为什么是这样。 首先,在#6处,把test作为参数传递给了timer(),此时,在timer()内部,func = test,接下来,定义了一个deco()函数,当并未调用,只是在内存中保存了,并且标签为deco。在timer()函数的最后返回deco()的地址deco。 然后再把deco赋值给了test,那么此时test已经不是原来的test了,也就是test原来的那些函数体的标签换掉了,换成了deco。那么在#7处调用的实际上是deco()。 那么这段代码在本质上是修改了调用函数,但在表面上并未修改调用方式,而且实现了附加功能。 那么通俗一点的理解就是: 把函数看成是盒子,test是小盒子,deco是中盒子,timer是大盒子。程序中,把小盒子test传递到大盒子temer中的中盒子deco,然后再把中盒子deco拿出来,打开看看(调用) 这样做的原因是: 我们要保留test(),还要统计时间,而test()只能调用一次(调用两次运行结果会改变,不满足),再根据函数即“变量”,那么就可以通过函数的方式来回闭包。于是乎,就想到了,把test传递到某个函数,而这个函数内恰巧内嵌了一个内函数,再根据内嵌函数的作用域(可以访问同级及以上,内嵌函数可以访问外部参数),把test包在这个内函数当中,一起返回,最后调用这个返回的函数。而test传递进入之后,再被包裹出来,显然test函数没有弄丢(在包裹里),那么外面剩下的这个test标签正好可以替代这个包裹(内含test())。 至此,一切皆合,大功告成,单只差一步。 3、 真正的装饰器 根据以上分析,装饰器在装饰时,需要在每个函数前面加上: 1 test = timer(test) 显然有些麻烦,Python提供了一种语法糖,即: 1 @timer 这两句是等价的,只要在函数前加上这句,就可以实现装饰作用。 以上为无参形式 4、装饰有参函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 improt time def timer(func) def deco(): start = time.time() func() stop = time.time() print(stop-start) return deco @timer def test(parameter): #8 time.sleep(2) print("test is running!") test() 对于一个实际问题,往往是有参数的,如果要在#8处,给被修饰函数加上参数,显然这段程序会报错的。错误原因是test()在调用的时候缺少了一个位置参数的。而我们知道test = func = deco,因此test()=func()=deco() ,那么当test(parameter)有参数时,就必须给func()和deco()也加上参数,为了使程序更加有扩展性,因此在装饰器中的deco()和func(),加如了可变参数*agrs和 **kwargs。 完整代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 improt time def timer(func) def deco(*args, **kwargs): start = time.time() func(*args, **kwargs) stop = time.time() print(stop-start) return deco @timer def test(parameter): #8 time.sleep(2) print("test is running!") test() 那么我们再考虑个问题,如果原函数test()的结果有返回值呢?比如: 1 2 3 4 def test(parameter): time.sleep(2) print("test is running!") return "Returned value" 那么面对这样的函数,如果用上面的代码来装饰,最后一行的test()实际上调用的是deco()。有人可能会问,func()不就是test()么,怎么没返回值呢? 其实是有返回值的,但是返回值返回到deco()的内部,而不是test()即deco()的返回值,那么就需要再返回func()的值,因此就是: 1 2 3 4 5 6 7 8 9 def timer(func) def deco(*args, **kwargs): start = time.time() res = func(*args, **kwargs)#9 stop = time.time() print(stop-start) return res#10 return deco 其中,#9的值在#10处返回。 完整程序为: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 improt time def timer(func) def deco(*args, **kwargs): start = time.time() res = func(*args, **kwargs) stop = time.time() print(stop-start) return res return deco @timer def test(parameter): #8 time.sleep(2) print("test is running!") return "Returned value" test() 5、带参数的装饰器 又增加了一个需求,一个装饰器,对不同的函数有不同的装饰。那么就需要知道对哪个函数采取哪种装饰。因此,就需要装饰器带一个参数来标记一下。例如: 1 @decorator(parameter = value) 比如有两个函数: 1 2 3 4 5 6 7 8 9 10 def task1(): time.sleep(2) print("in the task1") def task2(): time.sleep(2) print("in the task2") task1() task2() 要对这两个函数分别统计运行时间,但是要求统计之后输出: 1 the task1/task2 run time is : 2.00…… 于是就要构造一个装饰器timer,并且需要告诉装饰器哪个是task1,哪个是task2,也就是要这样: 1 2 3 4 5 6 7 8 9 10 11 12 @timer(parameter='task1') # def task1(): time.sleep(2) print("in the task1") @timer(parameter='task2') # def task2(): time.sleep(2) print("in the task2") task1() task2() 那么方法有了,但是我们需要考虑如何把这个parameter参数传递到装饰器中,我们以往的装饰器,都是传递函数名字进去,而这次,多了一个参数,要怎么做呢? 于是,就想到再加一层函数来接受参数,根据嵌套函数的概念,要想执行内函数,就要先执行外函数,才能调用到内函数,那么就有: 1 2 3 4 5 6 7 8 9 10 11 def timer(parameter): # print("in the auth :", parameter) def outer_deco(func): # print("in the outer_wrapper:", parameter) def deco(*args, **kwargs): return deco return outer_deco 首先timer(parameter),接收参数parameter=’task1/2’,而@timer(parameter)也恰巧带了括号,那么就会执行这个函数, 那么就是相当于: 1 2 timer = timer(parameter) task1 = timer(task1) 后面的运行就和一般的装饰器一样了: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import time def timer(parameter): def outer_wrapper(func): def wrapper(*args, **kwargs): if parameter == 'task1': start = time.time() func(*args, **kwargs) stop = time.time() print("the task1 run time is :", stop - start) elif parameter == 'task2': start = time.time() func(*args, **kwargs) stop = time.time() print("the task2 run time is :", stop - start) return wrapper return outer_wrapper @timer(parameter='task1') def task1(): time.sleep(2) print("in the task1") @timer(parameter='task2') def task2(): time.sleep(2) print("in the task2") task1() task2() 至此,装饰器的全部内容结束。
python中带*号的参数,一个星号,两个星号
1.带一个星号(*)参数的函数传入的参数存储为一个元组(tuple)
2.带两个星号(*)参数的函数传入的参数则存储为一个字典(dict),并且再调用是采取a=1,b=2,c=3的形式
3.传入的参数个数不定,所以当与普通参数一同使用时,必须把带星号的参数放在最后。
4.函数定义的时候,再函数的参数前面加星号,将传递进来的多个参数转化为一个对象,一个星号转换成元组,两个星号转换成字典,相当于把这些参数收集起来
5.参数前加一个星号,将传递进来的参数放在同一个元组中,该参数的返回值是一个元组
6.参数前两个星号,将传递进来的参数放到同一个字典中,该参数返回值为一个字典
def function_with_one_star(*d): print(d[0], type(d)) def function_with_two_stars(**d): print(d.get("a",0), type(d)) # 上面定义了两个函数,分别用了带一个星号和两个星号的参数,它们是什么意思,运行下面的代码: function_with_one_star(1, 2, 3) function_with_two_stars(a=1, b=2, c=3) # # 结果如下 # (1, 2, 3) # # # class 'tuple'> # # # {'a': 1, 'c': 3, 'b': 2} << / span > # # # class 'dict'> #
ok

 浙公网安备 33010602011771号
浙公网安备 33010602011771号