图灵测试对话
from aip import AipSpeech from aip import AipNlp # 自然语言处理,词义相似度 import os """ 你的 APPID AK SK """ APP_ID = '15837844' API_KEY = '411VNGbuZVbDNZU78LqTzfsV' SECRET_KEY = '84AnwR2NARGMqnC6WFnzqQL9WWdWh5bW' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY) # 实例化词义相似度对象 """查询文件""" def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() """识别本地文件""" res = client.asr(get_file_content('xh.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) text = res.get("result")[0] """图灵机器人智能回答函数""" import requests def to_tuling(text, uid): data = { "perception": { "inputText": { "text": "北京" } }, "userInfo": { "apiKey": "a4c4a668c9f94d0c928544f95a3c44fb", "userId": "123" } } data["perception"]["inputText"]["text"] = text data["userInfo"]["userId"] = uid res = requests.post("http://openapi.tuling123.com/openapi/api/v2", json=data) # print(res.content) res_json = res.json() text = res_json.get("results")[0].get("values").get("text") print(text) return text """语音相似度判断函数""" def my_nlp(text): if nlp_client.simnet(text, "你叫什么名字").get("score") >= 0.75: A = "我叫如花" return A if nlp_client.simnet(text, "你今年几岁了").get("score") >= 0.75: A = "我今年999岁了" return A A = to_tuling(text, "open123") # 如果不符合自定义条件,那么调用福林机器人API return A """开始执行""" A = my_nlp(text) result = client.synthesis(A, 'zh', 1, { 'vol': 5, 'per': 4, 'spd': 4, 'pit': 7, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): # print(result) with open('audio.mp3', 'wb') as f: f.write(result) """自动执行audio.mp3, 打开软件为默认打开软件""" os.system('audio.mp3')
PyAudio 实现录音 自动化交互实现问答
关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何实现录音的
首先要先 pip 一个 PyAudio
pip install pyaudio
一.PyAudio 实现麦克风录音
然后建立一个py文件,复制如下代码

import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
WAVE_OUTPUT_FILENAME = "Oldboy.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始录音,请说话......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("录音结束!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
尝试一下,在目录中出现了一个 Oldboy.wav 文件 , 听一听,还是很清晰的嘛
接下来,我们将这段录音代码,写在一个函数里面,如果要录音的话就调用
建立一个文件 pyrec.py 并将录音代码和函数写在内
# pyrec.py 文件内容
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
RECORD_SECONDS = 2
def rec(file_name):
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始录音,请说话......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("录音结束,请闭嘴!")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(file_name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
rec 函数就是我们调用的录音函数,并且给他一个文件名,他就会自动将声音写入到文件中了
二.实现音频格式自动转换 并 调用语音识别
录音的问题解决了,赶快和百度语音识别接在一起使用一下:
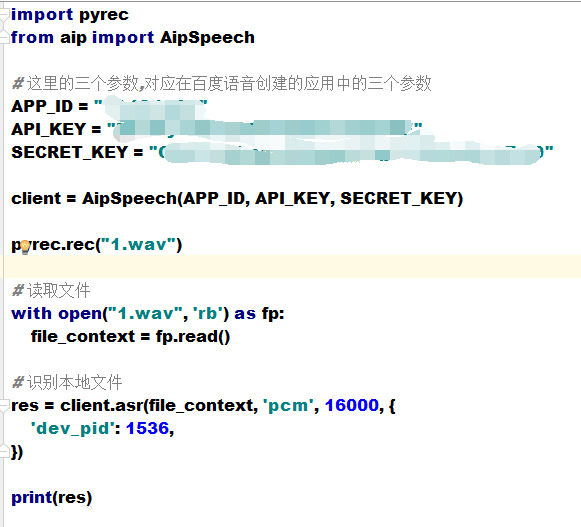
不管你的录音有多么多么清晰,你发现百度给你返回的永远是:
{'err_msg': 'speech quality error.', 'err_no': 3301, 'sn': '6397933501529645284'} # 音质不清晰
其实不是没听清,而是百度支持的音频格式PCM搞的鬼
所以,我们要将录制的wav音频文件转换为pcm文件
写一个文件 wav2pcm.py 这个文件里面的函数是专门为我们转换wav文件的
使用 os 模块中的 os.system()方法 这个方法是执行系统命令用的, 在windows系统中的命令就是 cmd 里面写的东西,dir , cd 这类的命令
# wav2pcm.py 文件内容
import os
def wav_to_pcm(wav_file):
# 假设 wav_file = "音频文件.wav"
# wav_file.split(".") 得到["音频文件","wav"] 拿出第一个结果"音频文件" 与 ".pcm" 拼接 等到结果 "音频文件.pcm"
pcm_file = "%s.pcm" %(wav_file.split(".")[0])
# 就是此前我们在cmd窗口中输入命令,这里面就是在让Python帮我们在cmd中执行命令
os.system("ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s"%(wav_file,pcm_file))
return pcm_file
这样我们就有了把wav转为pcm的函数了 , 再重新构建一次咱们的代码
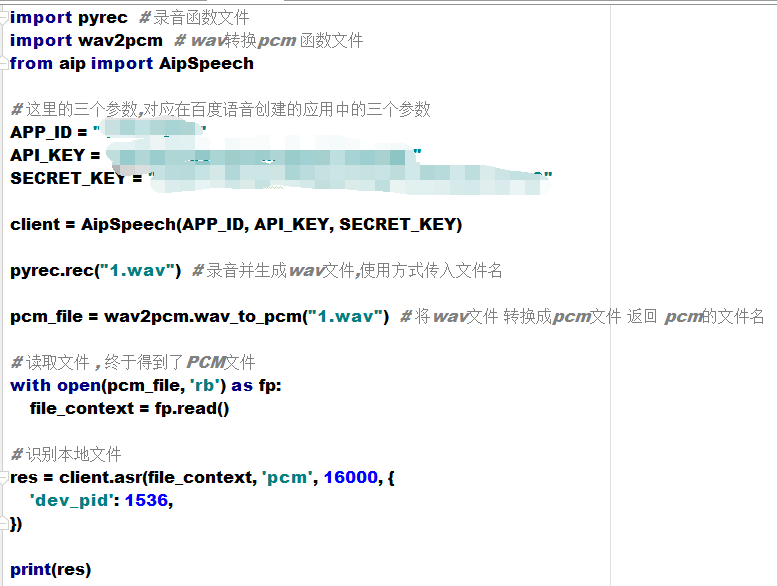
这次的返回结果还挺让人满意的嘛
{'corpus_no': '6569869134617218414', 'err_msg': 'success.', 'err_no': 0, 'result': ['老男孩教育'], 'sn': '8116162981529666859'}
拿到语音识别的字符串了,接下来用这段字符串 语音合成, 学习咱们说出来的话
三.语音合成 与 FFmpeg 播放mp3 文件
拿到字符串了,直接调用synthesis方法去合成吧

这段代码衔接上一段代码,成功获得了 synth.mp3 音频文件,并且确定了实在学习我们说的话
开启人工智能技术的大门 : http://ai.baidu.com/
首先进入控制台,注册一个百度的账号(百度账号通用)

开通一下我们百度AI开放平台的授权
然后找到已开通服务中的百度语音
打开百度语音,进入语音应用管理界面,创建一个新的应用 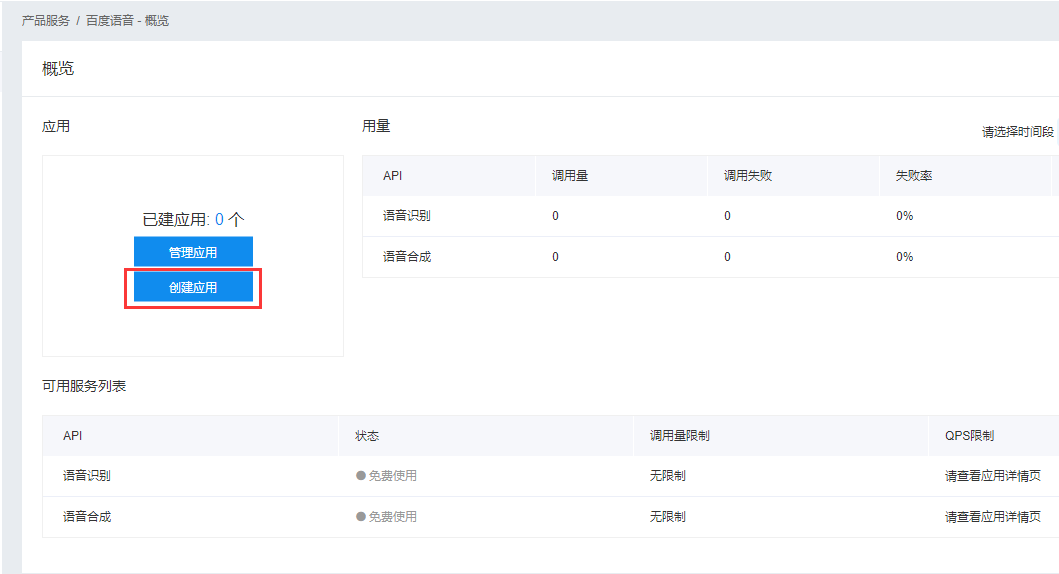
创建语音应用App
就可以创建应用了,回到应用列表我们可以看到已创建的应用了
这里面有三个值 AppID , API Key , Secret Key 记住可以从这里面看到 , 在之后的学习中我们会用到
好了 百度语音的应用已经创建完成了 接下来 我会用Python 代码作为实例进行应用及讲解
一.安装百度的人工智能SDK:
首先咱们要 pip install baidu-aip 安装一个百度人工智能开放平台的Python SDK实在是太方便了
安装完成之后就来测试一下:
支持Python版本:2.7.+ ,3.+
安装使用Python SDK有如下方式:
- 如果已安装pip,执行
pip install baidu-aip即可。 - 如果已安装setuptools,执行
python setup.py install即可。
新建AipSpeech
AipSpeech是语音合成的Python SDK客户端,为使用语音合成的开发人员提供了一系列的交互方法。
参考如下代码新建一个AipSpeech:
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result)
在上面代码中,常量APP_ID在百度云控制台中创建,常量API_KEY与SECRET_KEY是在创建完毕应用后,系统分配给用户的,均为字符串,用于标识用户,为访问做签名验证,可在AI服务控制台中的应用列表中查看。
语音合成:
baidu-aip Python SDK 语音合成技术文档 : https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top
用百度语音客户端中的synthesis方法,并提供相关参数
成功可以得到音频文件,失败则返回一段错误信息
重点看一下 synthesis 这个方法 , 从 https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top 来获得答案吧
从参数入手分析:
语音识别:
可以实现自动化转换格式工具 : FFmpeg 这个工具的下载地址是 : 链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密码:w6hk
FFmpeg 环境变量配置:
首先你要解压缩,然后找到bin目录,我的目录是 C:\ffmpeg\bin
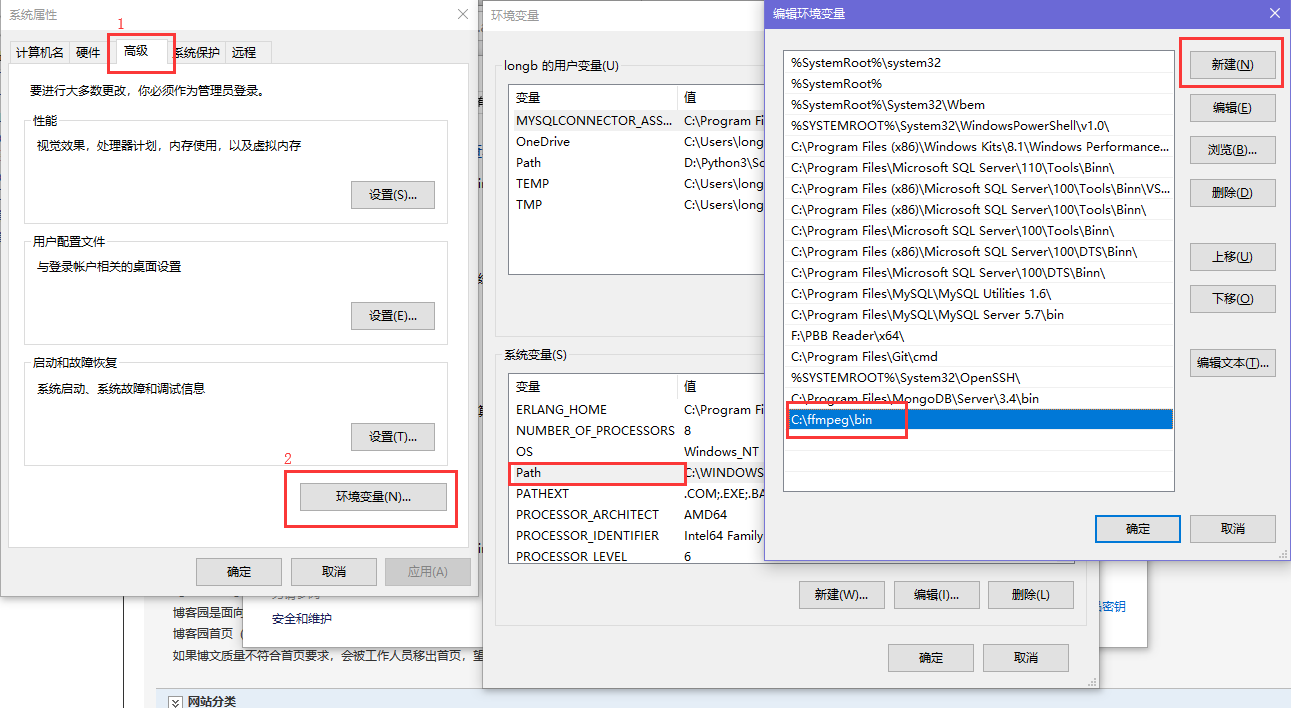
然后 以 windows 10 为例,配置环境变量

如果没搞明白的话,我也没有办法了,这么清晰这么明白
尝试一下,是否配置成功
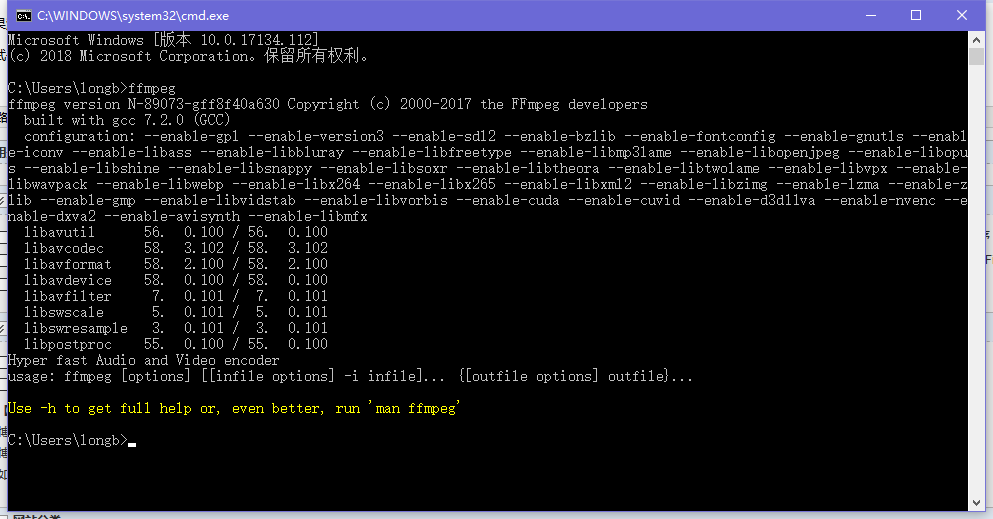
看到这个界面就算配置成功了,配置成功有什么用呢, 这个工具可以将wav wma mp3 等音频文件转换为 pcm 无压缩音频文件
做一个测试,首先要打开windows的录音机,录制一段音频(说普通话)
现在假设录制的音频文件的名字为 audio.wav 放置在 D:\DragonFireAudio\
然后我们用命令行对这个 audio.wav 进行pcm格式的转换然后得到 audio.pcm
命令是 : ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
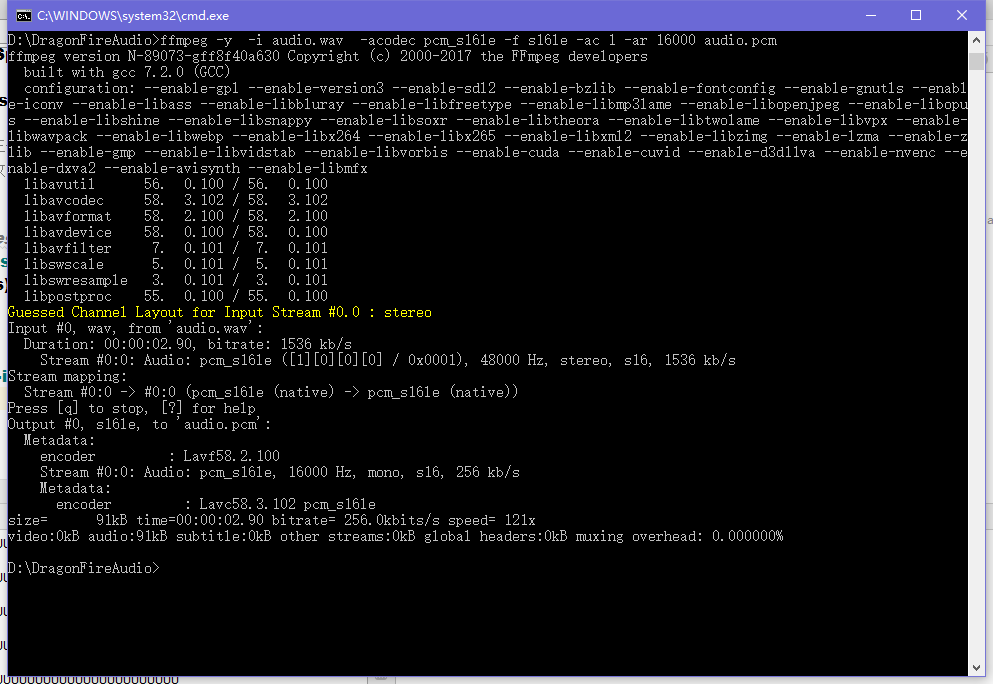
然后打开目录就可以看到pcm文件了

pcm文件已经得到了,赶紧进入正题吧
百度语音识别SDK的应用:
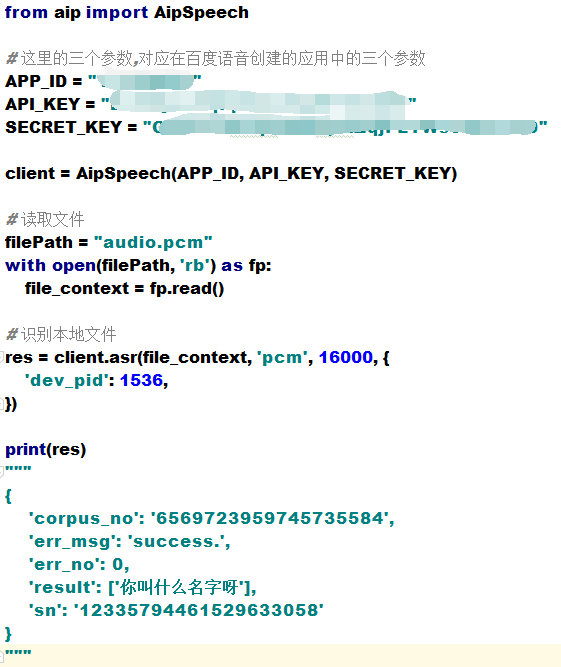
前提是你的audio.pcm 要与你当前的文件在同一个目录,还是分段看一下代码

读取文件的内容,file_context 是 audio.pcm 文件打开的二进制流

asr函数需要四个参数,第四个参数可以忽略,自有默认值,参照一下这些参数是做什么的
第一个参数: speech 音频文件流 建立包含语音内容的Buffer对象, 语音文件的格式,pcm 或者 wav 或者 amr。(虽说支持这么多格式,但是只有pcm的支持是最好的)
第二个参数: format 文件的格式,包括pcm(不压缩)、wav、amr (虽说支持这么多格式,但是只有pcm的支持是最好的)
第三个参数: rate 音频文件采样率 如果使用刚刚的FFmpeg的命令转换的,你的pcm文件就是16000
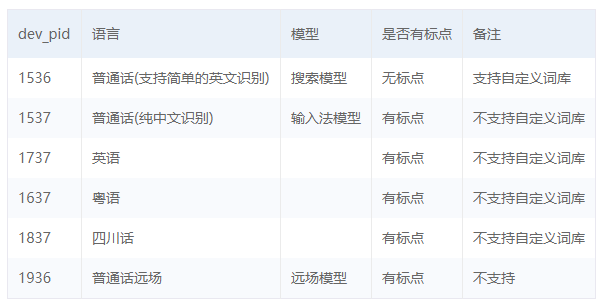
第四个参数: dev_pid 音频文件语言id 默认1537(普通话 输入法模型)
再来看下一段代码,打印返回结果:
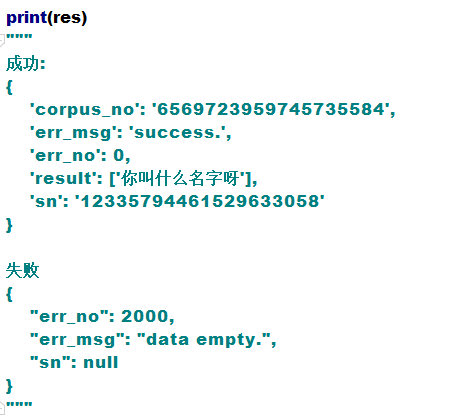
成功的dict中 result 就是我们要的识别文本
失败的dict中 err_no 就是我们要的错误编码,错误编码代表什么呢?

如果err_no不是0的话,就参照一下错误码表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号