
一直对spark sql中的join操作感到迷惑,
如果join之前的操作没有进行persist DataFrame的话,是否会存在让之前的transformation重复执行的问题,以及重复多少次。
看一个例子
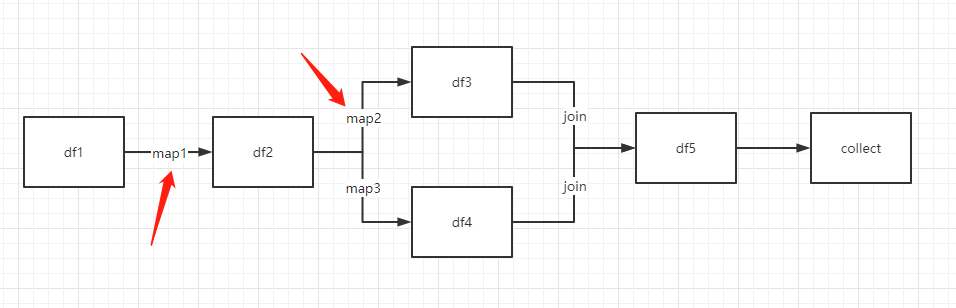
考虑在map1/map2处设置一个累加器,join之后,看看map1/map2到底执行了多少次。
上代码
df1 = spark.createDataFrame([[i, i+100] for i in range(7)]).toDF("a", 'v').repartition(13)
accumulator1 = sc.accumulator(0)
accumulator2 = sc.accumulator(0)
@udf
def map1(x):
accumulator1.add(1)
return x
@udf
def map2(x):
accumulator2.add(1)
return x
@udf
def map3(x):
return x
df2 = df1.select(map1("a").alias("b"))
df3 = df2.select(map2("b").alias("c"))
df4 = df2.select(map3("b").alias("d"))
df5 = df3.join(df4, on=df3.c==df4.d, how='inner')
df5.collect()
print(accumulator1.value)
print(accumulator2.value)
为了方便,元素个数和分区数选了两个质数,分别为7和13.
程序运行结果为28和14.
acc1是acc2的两倍,看起来比较合理。
join得到的df5包含c和d两列。d列对acc2没有贡献。acc2的计数一半来自df3中的c列,另一半来自join中用到的df3.c==df4.d条件。所以7个元素用了两次得到14。对应地,acc1结果为28。
这样会用到2次df3,4次df2。重复计算消耗资源比较大的话建议persist相关df。
PySpark和Spark的运算机制也略有不同。
Spark的DataFrame中也提供了join的默认参数,如果把代码改为df5 = df3.join(df4),两个累加器的输出分别是182和91.
通常执行完默认join之后会连一个where或者filter来进行进一步过滤,但这样可能会引入一定的重复计算,所以我这不太推荐这么使用。
在Spark中,
import org.apache.spark.sql.functions.udf
case class A(a: Int, v: Int)
val df1 = Seq(A(0, 100), A(1, 101), A(2, 102), A(3, 103), A(4, 104), A(5, 105), A(6, 106)).toDS().repartition(13)
val accumulator1 = sc.longAccumulator("0")
val accumulator2 = sc.longAccumulator("0")
val map1 = udf((x: Int) => {
accumulator1.add(1)
x
})
val map2 = udf((x: Int) => {
accumulator2.add(1)
x
})
val map3 = udf((x: Int) => x)
val df2 = df1.select(map1(col("a")).alias("b"))
val df3 = df2.select(map2(col("b")).alias("c"))
val df4 = df2.select(map3(col("b")).alias("d"))
val df5 = df3.join(df4)
df5.collect()
println(accumulator1.value)
println(accumulator2.value)
输出结果就是正常的,为14和7
两种语言join后的partition个数也不一致。
应该是有优化机制的,这部分就先不深究了。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号